AI News
Qwen-Image 2.0 和 Seedance 2.0
OpenAI 推进了其针对长达数小时的智能体工作流的 Responses API,引入了服务端压缩 (server-side compaction)、托管容器 (hosted containers) 和 Skills API 等功能,同时将 Deep Research 升级至 GPT-5.2 并添加了连接器。
关于沙箱设计的讨论凸显了向“沙箱即工具” (sandbox-as-a-tool) 架构的转变,LangChain 通过可插拔的沙箱后端增强了其 deepagents v0.4。编程智能体 UX 随着涉及 Claude Opus 4.6、GPT-5.3-Codex 和 Gemini 3 Pro 的多模型编排而不断进化。EntireHQ 为其能够捕捉代码意图和智能体上下文的 Git 兼容数据库筹集了 6000 万美元种子轮融资。
在模型发布方面,阿里巴巴通义千问发布了 Qwen-Image-2.0,强调 2K 分辨率和 1K-token 提示词,以实现统一的生成与编辑。字节跳动的 Seedance 2.0 在文生视频质量上实现了重大飞跃,而月之暗面 (Moonshot) 的 Kimi 推出了 Agent Swarm(智能体集群),支持多达 100 个子智能体,并将并行执行速度提升了 4.5 倍。
来自中国的强劲生成式媒体表现。
2026年2月9日至2026年2月10日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitters 和 24 个 Discords(256 个频道和 9107 条消息)。估计节省的阅读时间(按 200wpm 计算):731 分钟。AINews 网站 允许您搜索所有往期内容。提醒一下,AINews 现在是 Latent Space 的一个板块。您可以 选择加入/退出 邮件接收频率!
这是情人节前的中国模型发布周,闸门正在开启。
我们上一次对 Qwen-Image 1 感到兴奋是在 8 月,期间 Qwen 团队一直在潜心研发 Image-Edit 和 Layers。今天,通过 Qwen-Image 2,他们揭示了大统一:
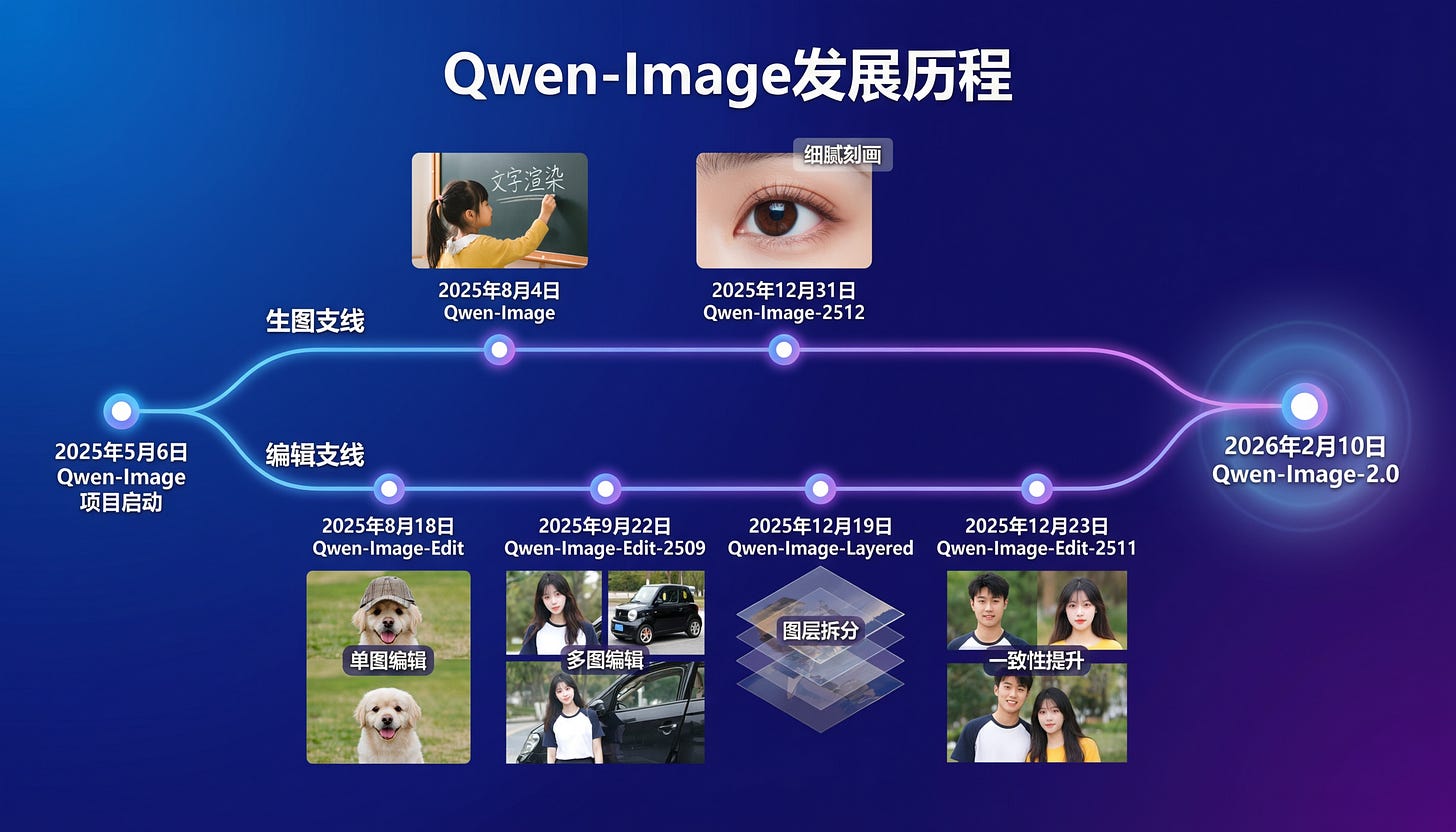
所展示的文本控制和保真度非常令人印象深刻。虽然权重和完整的技术报告尚未发布,但这些图片透露了一些令人惊讶的线索(由下面回顾中的 Reddit 侦探发现),这些线索指向了惊人的技术进步。
简单来说,我们将拥有一个 7B 大小的 Nano-Banana 级别的开源图像生成/图像编辑模型。(根据阿里巴巴博客文章中自家的 Arena 排名)

同样尚未发布权重但在今天引发大量热议的是 Seedance 2.0,它似乎解决了 Will Smith 吃意大利面的问题,并生成了大量的动漫/电影场景。大量的示例几乎可以肯定是一场公关宣传活动,但由于有足够多的人在独立创建新视频,我们有信心这不仅仅是精选(cherrypick)的结果。
AI Twitter 回顾
Coding Agent、IDE 工作流和“Agentic Sandbox”正在成为标准基础设施
- OpenAI 将 Responses API 转向长时间运行的计算机工作:OpenAI 推出了旨在支持数小时 Agent 运行的新原语:server-side compaction(以避免上下文爆炸)、带网络的 OpenAI 托管容器,以及作为一等 API 概念的 Skills(包括初始的电子表格技能)(OpenAIDevs)。在同一窗口期,OpenAI 还将 Deep Research 升级为 GPT‑5.2,并增加了 connectors 和进度控制 (OpenAI, OpenAI),这强化了“研究型 Agent”已实现产品化,而不仅是演示。
- Sandboxes:“Agent 在沙箱中”与“沙箱作为工具”成为设计的断裂线:几篇帖子集中讨论了同一个架构问题——Agent 应该居住在执行环境中,还是应该调用一个临时的沙箱工具?LangChain 的 Harrison Chase 在专门的文章中总结了权衡利弊 (hwchase17),随后的评论推崇 sandbox-as-a-tool 作为容错和长时间运行工作流的默认方案 (NabbilKhan)。LangChain 的 deepagents v0.4 增加了可插拔的沙箱后端(Modal/Daytona/Runloop),并改进了摘要/压缩功能和 Responses API 默认设置 (sydneyrunkle)。
- Coding agent UX 正在加速,多模型编排正成为常态:VS Code 和 Copilot 继续增加 Agent 原语(worktrees、MCP 应用、斜杠命令)(JoeCuevasJr)。一个具体的模式是:平行的子 Agent 在 Claude Opus 4.6、GPT‑5.3‑Codex 和 Gemini 3 Pro 之间进行独立审查并“互相评分” (pierceboggan)。OpenAI 的 Codex 账号暂停了在 @code 中推广 “GPT‑5.3‑Codex” 的活动 (code),而用户则强调了其 Token 效率和应用工作流 (reach_vb, gdb, gdb)。
- “代码审查后的 SDLC”正在被重塑:一个值得注意的融资和产品公告:EntireHQ 筹集了 6000 万美元种子轮融资,用于构建一个兼容 Git 的数据库,该数据库不仅管理代码版本,还管理意图/约束/推理,以及用于捕获 Agent 上下文(Prompt、工具调用、Token 使用情况)的“Checkpoints”,作为与提交(commit)相邻的产物 (ashtom)。这直接针对了新出现的痛点:团队可以快速生成代码,但在溯源、审查、协作和“发生了什么”的调试方面感到吃力。
模型发布与模态飞跃(图像/视频/全能型)+ 开源模型势头
- Qwen-Image-2.0: 阿里巴巴 Qwen 发布了 Qwen‑Image‑2.0,重点强调 2K 原生分辨率、强大的文本渲染能力,以及适用于海报/幻灯片的“专业排版”,支持高达 1K-token 的 Prompt;同时将其定位为具有“更轻量架构”的统一生成与编辑工具,以实现更快的推理速度 (Alibaba_Qwen)。
- Seedance 2.0 作为 Text-to-Video 的“阶跃式变化”: 多条推文将字节跳动的 Seedance 2.0 视为一次质的飞跃(自然运动、微小细节),并可能迫使竞争对手(如 Veo/Sora)进行更新 (kimmonismus, TomLikesRobots, kimmonismus)。
- Kimi “Agent Swarm” + Kimi K2.5 作为 Agent 基座: Moonshot 的 Kimi 推出了 Agent Swarm 概念:支持多达 100 个子 Agent、1500 次工具调用,并声称在并行研究/创作任务中比顺序执行快 4.5 倍 (Kimi_Moonshot)。社区帖子展示了将 Kimi K2.5 + Seedance 2 配对的工作流,用于生成大型分镜脚本(例如“100MB 的 Excel 分镜脚本”)并输入视频生成模型 (crystalsssup)。Baseten 强调了 Kimi K2.5 的推理性能——根据其说法,在 Artificial Analysis 上的 TTFT 为 0.26s,且达到 340 TPS (basetenco)。
- 开放多模态领域的“黑马”: 一份精选清单提醒人们,最近发布的开源多模态模型包括 GLM‑OCR、MiniCPM‑o‑4.5(可在手机端运行的全能模型)以及 InternS1(科学能力强大的 VLM),这些模型均被描述为可免费商用 (mervenoyann)。
- GLM-4.7-Flash 的影响力: 智谱的 GLM‑4.7‑Flash‑GGUF 成为 Unsloth 上下载量最高的模型(据智谱称) (Zai_org)。
Agent 协同与评估:从“Swarm”到可衡量的失败模式
- 即使有真实工具 (Git),协作依然脆弱: CooperBench 为成对的 Agent 增加了 Git 工具,但发现协作增益微乎其微;并出现了新的失败模式(强制推送、合并冲突、无法推断同伴的实时操作)。其核心论点是:基础设施不等于社交智能 (_Hao_Zhu)。
- 动态 Agent 创建优于静态角色 (AOrchestra): DAIR 总结了 AOrchestra,其中编排器按需生成子 Agent,这些子 Agent 被定义为四元组(指令/上下文/工具/模型)。报告的基准测试收益:使用 Gemini‑3‑Flash 在 GAIA 上达到 80% Pass@1;Terminal‑Bench 2.0 为 52.86%;SWE‑Bench‑Verified 为 82% (dair_ai)。
- 数据 Agent 分类学: 另一篇 DAIR 的文章认为,“数据 Agent”需要更清晰的自治级别(L0–L5),并指出大多数生产系统处于 L1/L2 阶段;由于级联错误风险和动态环境适应问题,L4/L5 仍未解决 (dair_ai)。
- Arena 推动评估更接近企业现实(PDFs + 资助学术界): Arena 推出了用于模型对比的 PDF 上传功能(文档推理、提取、摘要)(arena),并另外宣布了一项学术合作伙伴计划,资助独立的评估研究(每个项目高达 5 万美元)(arena)。这与目前业界的挫败感一致,即同行评审相对于模型迭代速度来说太慢了 (kevinweil, gneubig)。
- 关于 Anthropic RSP 对 Opus 4.6 阈值判定的批评: 一份详细的批评指出,Anthropic 过度依赖内部员工调查来决定 Opus 4.6 是否跨越了更高风险的研发自治阈值;投诉者认为这并不能作为定量评估的负责任替代方案,且后续调查可能会使结果产生偏差 (polynoamial)。
训练/后训练研究主题:RL 自我反馈、自我验证以及“概念级”建模
- iGRPO: 来自模型自身最佳草稿的 RL:iGRPO 通过一个两阶段过程封装了 GRPO:采样草稿,选择奖励最高(相同的标量奖励)的草稿,然后以该草稿为条件进行训练并尝试超越它——无需 critics,也无需生成的 critiques。据报道,在 7B/8B/14B 系列模型中,其表现优于 GRPO (ahatamiz1, iScienceLuvr)。
- 自我验证作为计算减速器:“学习自我验证(Learning to Self-Verify)”被强调为在解决同类问题时,能够在减少 token 使用量的同时提高推理能力 (iScienceLuvr)。
- ConceptLM / 下一个概念预测 (next-concept prediction):一种将隐藏状态(hidden states)量化为概念词汇表并预测概念而非下一个 token 的提议;声称具有持续的收益,并且在 NTP 模型上进行持续预训练可以进一步改进它 (iScienceLuvr)。
- 来自语言统计学的 Scaling laws:Ganguli 分享了一个理论结果:根据自然语言的属性(条件熵衰减 vs 上下文长度;成对 token 相关性衰减 vs 间隔)预测受数据限制的扩展指数 (data-limited scaling exponents) (SuryaGanguli)。
- 通过 OSS 考古泄露的架构:一个著名的“架构已曝光”帖子声称 GLM‑5 约为 740B 参数,其中 ~50B 激活,使用了“借鉴自 DeepSeek V3”的 MLA attention,并配合稀疏注意力索引以支持 200k context (QuixiAI)。另一个帖子声称 Qwen3.5 是混合了 SSM‑Transformer 的模型,采用了 Gated DeltaNet 线性注意力 + 标准注意力、交错 MRoPE 以及共享+路由的 MoE 专家 (QuixiAI)。
推理与系统工程:更快的 kernel、更廉价的解析以及 vLLM 调试
- Unsloth 的 MoE 训练加速:Unsloth 声称新的 Triton kernel 能够实现 12倍更快 的 MoE 训练,同时减少 35% 的 VRAM 占用且无精度损失,此外还通过
torch._grouped_mm实现了分组 LoRA 矩阵乘法(并回退到 Triton 以保证速度) (UnslothAI, danielhanchen)。 - 指令级 Triton + 内联汇编:一篇来自 fal performance 的文章展示了通过在 Triton 中加入小型内联逐元素汇编,超越了手写的 CUDA kernel;作者还指出,一个使用 256 位全局内存加载 (Blackwell) 的自定义 CUDA kernel 在处理较小形状时性能优于 Triton (maharshii, isidentical, maharshii)。
- vLLM 在生产环境中:吞吐量调优 + 罕见故障排查:vLLM 转发了 AI21 的文章:配置调优 + 基于队列的自动扩缩容为突发工作负载带来了 ~2倍的吞吐量 (vllm_project);第二篇文章剖析了 vLLM + Mamba 中 1/1000 的乱码故障,追踪到内存压力下的请求分类时序问题 (vllm_project)。
- 文档摄取成本优化:LlamaIndex 的 LlamaParse 增加了一个“成本优化器”,在文本密集时将页面路由到更便宜的解析方式,在布局复杂时路由到 VLM 模式,声称与截图+VLM 基准相比可节省 50–90% 的成本,且准确率更高 (jerryjliu0)。
- 本地/分布式推理技巧:一个 MLX Distributed 辅助库在通过 Thunderbolt RDMA 连接的 4× Mac Studio 集群上运行了 Kimi K‑2.5 (磁盘占用 658GB),并且“确实具有扩展性” (digitalix)。
AI-for-science:Isomorphic Labs 的药物设计引擎是突出的“现实世界基准测试胜利”
- IsoDDE 声称其表现大幅超越 AlphaFold 3:Isomorphic Labs 发布了一份技术报告,声称在预测生物分子结构方面实现了“阶跃式进步”(step-change),在关键基准测试中性能达到 AlphaFold 3 的两倍以上,并提升了泛化能力;多篇帖子呼应了其声称的收益规模以及对 in-silico 药物设计的影响 (IsomorphicLabs, maxjaderberg, demishassabis)。评论强调了抗体界面/CDR-H3 的改进,以及亲和力预测声称超过了基于物理的方法——同时指出目前披露的架构细节有限 (iScienceLuvr)。
- 为什么这很重要(如果属实的话):整个讨论群组中最有力的论点不仅仅是“更好的结构”,而是更快的发现循环:识别隐蔽口袋(cryptic pockets)、更好的亲和力预估以及对新靶点的泛化能力,有可能将筛选/设计环节推向 wet labs 的上游 (kimmonismus, kimmonismus, demishassabis)。
热门推文(按互动量排序)
- 美国科学家迁往欧洲 / 研究环境:@AlexTaylorNews (21,569.5)
- 关于 Rapture 衍生品的笑话:@it_is_fareed (16,887.5)
- Obsidian CLI “你在 Obsidian 中能做的任何事……”:@obsdmd (13,408.0)
- 政治推测推文:@showmeopie (34,648.5)
- “晚餐时的 Kubernetes”:@pdrmnvd (6,146.5)
- OpenAI Deep Research 现已更名为 GPT-5.2:@OpenAI (3,681.0)
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. Qwen 模型发布与对比
-
Qwen-Image-2.0 发布 - 7B 统一生成+编辑模型,支持原生 2K 和真实文本渲染 (Activity: 600): Qwen-Image-2.0 是 Qwen 团队发布的新型 7B 参数模型,可通过阿里云 API 和 Qwen Chat 的免费 Demo 使用。它在单一流水线中集成了图像生成与编辑功能,支持原生 2K 分辨率,并能根据最高 1K tokens 的提示词渲染文本,包括复杂的图表(infographics)和中国书法。模型尺寸从 20B 缩减至 7B,使其更易于本地使用,一旦权重发布,就有可能在消费级硬件上运行。它还支持具有一致角色渲染的多面板漫画生成。评论者对该模型的潜力表示乐观,注意到其在自然光影和面部渲染方面的改进,并希望发布开放权重以供更广泛的社区使用。
- Qwen-Image-2.0 模型的显著特点在于能够通过统一的 7B 参数架构生成和编辑图像,支持原生 2K 分辨率和文本渲染。这是一项重大进步,因为它在单个模型中结合了生成和编辑能力,这在同等规模的其他模型中并不常见。
- 讨论涉及了该模型在渲染自然光和面部特征方面的表现,这些通常是 AI 模型的难点。评论者指出 Qwen-Image-2.0 在这些领域取得了显著进步,可能成为 AI 图像生成领域的“游戏规则改变者(game changer)”。
- 有人对该模型的多语言能力提出了担忧,特别是对中文案例的侧重是否会影响其在其他语言中的表现。这突显了 AI 模型中的一个共同挑战,即训练数据的多样性会影响模型在不同语言和文化背景下的泛化能力。
-
不要被 Qwen3-Coder-Next 中的 “Coder” 给骗了!它是同等规模中最智能的通用模型 (Activity: 837): 该帖子讨论了本地 LLM **Qwen3-Coder-Next 的能力,强调了尽管它带有“coder”标签,但作为通用模型的有效性。作者将其与 Gemini-3 进行了有利的对比,指出了其一致性和务实的问题解决能力,这使其适用于启发式对话和实用建议。该模型因能够自发建议相关的作者、书籍或理论而受到赞誉,提供了类似于本地运行的 Gemini-2.5/3 的体验质量。作者期待即将推出的 Qwen-3.5 模型能带来进一步的改进。评论者一致认为,“coder”标签增强了模型的结构化推理能力,使其在通用用途上表现出意想不到的高效。一些人注意到它能够根据使用的工具模仿 GPT 或 Claude 等其他模型的语调,并推荐将其作为优于 Qwen 3 Coder 30B-A3B 等其他本地模型的选择。
2. 本地 LLM 趋势与硬件考量
- 本地 LLM 是 AI 浪潮中的下一个趋势吗? (Activity: 330): **该帖子讨论了运行本地 Large Language Models (LLMs) 作为云端订阅服务高性价比替代方案的新兴趋势。对话强调了本地设置在隐私和长期成本节省方面的潜在优势,尽管初始硬件投资较高(
$5k-$10k)。该帖子预见到用于简易本地 LLM 设置的工具和指南将会激增。评论者指出,虽然本地模型正在迅速改进,但在性能上仍落后于云端模型。然而,差距正在缩小,本地模型可能很快会为某些应用提供可行的替代方案,尤其是随着小型 LLM 变得更加高效。评论者对本地 LLM 的实用性展开了辩论,一些人认为高昂的硬件成本限制了其吸引力,而另一些人则认为本地模型的快速进步可能很快使其成为云端模型的高性价比替代方案。讨论还涉及了大型云端模型的改进收益递减,与本地模型快速进步之间的对比。
3. Mixture of Experts (MoE) 模型训练创新
-
训练 MoE 模型速度提升 12 倍,显存占用减少 30%!(<15GB VRAM) (热度: 365): 图片展示了 Unsloth MoE Triton 内核的性能改进,它能使 Mixture of Experts (MoE) 模型的训练速度提升高达 12 倍,同时减少 30% 的内存占用,仅需不到 15GB 的 VRAM。图片中的图表对比了不同上下文长度下的速度和 VRAM 使用情况,证明了 Unsloth 优于其他方法的卓越性能。这一进步是通过自定义 Triton 内核和数学优化实现的,且无精度损失,支持包括 gpt-oss 和 Qwen3 在内的一系列模型。该方法兼容消费级和数据中心 GPU,并与 Hugging Face 合作,利用 PyTorch 新的
torch._grouped_mm函数使 MoE 训练标准化。 一些用户对速度提升和显存节省感到兴奋,而另一些人则询问与 AMD 显卡的兼容性以及微调所需的时间。还提出了关于 MoE 训练稳定性和有效性的担忧,用户寻求关于训练 MoE 模型最佳实践的建议。- spaceman_ 询问训练 notebooks 与 ROCm 和 AMD 显卡的兼容性,这对于非 NVIDIA 硬件用户至关重要。他们还询问了使用这些 notebooks 微调模型所需的时间,以及在总 VRAM 为 40GB (24GB + 16GB) 的系统上能训练的最大模型规模。这突显了硬件兼容性和资源管理在模型训练中的重要性。
- lemon07r 对 Unsloth 平台上 Mixture of Experts (MoE) 训练的稳定性表示担忧,特别是在 router 方面的问题,以及在 SFT (Supervised Fine-Tuning) 或 DPO (Data Parallel Optimization) 等训练过程中模型智能可能退化的问题。他们寻求这些问题是否已解决的更新,以及是否有训练 MoE 模型的推荐做法,这表明在复杂训练设置中维持模型性能仍面临挑战。
- socamerdirmim 质疑提到的 GLM 模型版本,要求澄清 GLM 4.6-Air 与 4.5-Air 或 4.6V 之间的区别。这反映了在模型讨论中精确版本控制的重要性,因为不同版本在功能或性能上可能有显著差异。
-
对本地玩家来说是个坏消息 (热度: 944): 图片展示了四种 AI 模型的对比:GLM-5、DeepSeek V3.2、Kimi K2 和 GLM-4.5,突出了它们的规格,如总参数量、每个 token 的激活参数量、Attention 类型、Hidden Size、隐藏层数量等。标题“Bad news for local bros”暗示这些模型可能太大,无法在本地硬件设置上运行,这对于无法获得大规模计算资源的人来说是一个担忧。评论区的讨论反映了关于这些模型可访问性的辩论,一些用户对无法在本地运行表示担忧,而另一些人则认为这种大型开源模型的可用性对社区有益,因为它们最终可以被蒸馏 (distilled) 和量化 (quantized) 以适用于更小的设备。 评论显示了意见分歧:一些用户担心无法在本地硬件上运行这些大模型,而另一些人则认为这些模型的可用性是有益的,因为它们可以被蒸馏和量化为更小、更易获取的版本。
- AutomataManifold 认为海量 Frontier Models 的可用性对社区有益,因为这些模型可以被蒸馏和量化为能在本地机器上运行的更小版本。这一过程确保了即使开源模型最初很大,最终也能面向更广泛的受众,防止模型开发停滞不前。
- nvidiot 表达了在开发大模型的同时开发更小、更易获取的模型的愿望,例如与当前 GLM 4.x 系列大小类似的“Lite”模型。这将确保本地用户不会掉队,且在不需要大量硬件资源的情况下仍能从模型能力的进步中受益。
- Impossible_Art9151 对这些大模型与 OpenAI 和 Anthropic 的模型相比表现如何感兴趣,建议关注不同公司产品之间的 Benchmarking 和性能对比。这突显了 AI 模型领域竞争分析的重要性。
非技术性 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Seedance 2.0 视频与动画功能
-
Seedance 2.0 生成的“Will Smith 吃意大利面”太惊人了! (热度: 1399): Seedance 2.0 在视频片段技术方面取得了重大里程碑,被称为 “nano banana pro 时刻”。这表明在视频处理或特效方面取得了突破或显著进步,可能涉及 AI 或机器学习技术。提到的 “Will Smith Eating Spaghetti” 暗示了幽默或病毒式传播的属性,可能使用了 deepfake 或类似技术来创建既真实又有趣的內容。评论者幽默地注意到将 “Will Smith” 作为基准,突显了该视频的荒诞感和娱乐价值,同时也对进食动画的真实感进行了评价,例如夸张的吞咽动作和不真实的意面擦拭动作。
-
Arcane Seedance 2.0 里的 Kobe Bryant,简直离谱! (热度: 832): 该帖子讨论了将 Kobe Bryant 集成到 Arcane Seedance 2.0 AI 模型中,并强调了其令人印象深刻的能力。该模型因其在有限的计算资源下执行复杂任务的能力而受到关注,这表明其使用了先进的算法。这与有关观察一致,即尽管计算能力较弱,但 China 在 AI 领域仍保持竞争力,这可能归功于卓越的算法策略。一条评论认为,该 AI 的表现可能源于优越的算法,反映了这样一种观点:China 的 AI 进步并非仅仅依赖于计算能力,还依赖于创新的算法方法。
-
Seedance 2 动漫打斗场景(宝可梦、鬼灭之刃、龙珠超) (热度: 1011): 该帖子讨论了 Seedance 2 的发布,展示了来自 Pokemon、Demon Slayer 和 Dragon Ball Super 等热门系列的动画战斗场景。来源链接至 Chetas Lua’s Twitter,展示了足以媲美甚至超越官方工作室作品的动画质量。提到 Pokemon 片段的动画质量优于原版动画,突显了独立或粉丝制作动画的技术实力和潜力。一位评论者幽默地预见到,未来可能会基于免费的在线文学创作出大量的动画系列,这反映了内容创作和分发的民主化。
-
Seedance 2.0 生成逼真的 1v1 对战 Lebron 篮球视频 (热度: 2483): Seedance 2.0 在生成真实的 1v1 篮球视频方面取得了重大进展,展示了在处理杂技物理学、身体稳定性和布料模拟方面的改进。该模型展示了精确的物理效果,没有早期版本中出现的 “漂浮感”,这表明 AI 生成的体育模拟在真实感上有了跨越。视频中出现了多个 Lebron James,这引发了人们的疑问:素材是完全由 AI 生成的,还是通过覆盖和编辑原始比赛画面将球员替换为 AI 生成的人物。评论者们正在争论视频是纯 AI 生成的,还是涉及将 AI 生成的人物叠加到现有素材上。多个 Lebron James 的出现暗示了潜在的克隆或编辑,如果完全由 AI 生成,一些人会觉得非常令人震撼。
-
Seedance 2.0 非常擅长生成动画打斗场面 (热度: 683): Seedance 2.0 在生成动画战斗序列方面展示了显著的进步,证明了其有效处理复杂动画的能力。然而,当前的实现仅限于
15-second片段,这引发了关于将其扩展到更长时间(如five minutes)可行性的质疑。动画质量很高,但正如用户指出的,序列末尾存在一些细微问题。评论者对动画质量印象深刻,但对15-second的限制表示沮丧,并询问何时能实现更长时间的视频生成。
2. Opus 4.6 模型发布及影响
-
Opus 4.6 终于能一次性生成复杂的 UI 了(4.5 与 4.6 对比) (热度: 1515): Opus 4.6 与 Opus 4.5 相比,在单次尝试中生成复杂 UI 设计的能力有了显著提升。用户报告称,虽然 4.5 需要多次迭代才能达到满意的结果,但 4.6 在极少的引导下即可产生“精雕细琢”的输出,尤其是与自定义界面设计 skill 配合使用时。然而,据观察 4.6 的运行速度较慢,这可能是由于其处理过程更加详尽。这一进步对于开发工具或 SaaS 应用的人员特别有利,因为它提高了工作流效率。不过也有部分用户反映,Opus 4.6 在进行复杂的 UI 重新设计时并非总能实现“一次性生成(one-shot)”,这表明其性能存在波动。此外,一些用户对某些设计元素提出了审美方面的顾虑,例如“左侧带有彩色边缘的卡片”,这被认为是 Claude AI 的典型特征。
- Euphoric-Ad4711 指出,尽管 Opus 4.6 有所改进,但在“一次性生成”复杂 UI 设计方面仍显吃力,这表明“复杂”一词是主观的,解释可能各不相同。这意味着虽然 Opus 4.6 取得了进步,但在处理复杂的 UI 任务方面,它可能无法完全满足所有用户的期望。
- oningnag 强调,评估像 Opus 4.6 这样的 AI 模型时,不应仅看其创建 UI 的能力,更应看其构建具有可扩展架构和安全代码的企业级后端的能力。他们认为真正的价值在于模型处理后端复杂性的能力,而不仅仅是生成视觉上吸引人的 UI 组件。
- Sem1r 注意到了 Opus 4.6 中的一个特定设计元素,即“左侧带有彩色边缘折角的卡片”,他们将其与 Claude AI 联系起来。这突显了不同 AI 模型之间设计美学的潜在重叠或影响,表明某些设计特征可能会成为特定 AI 工具的标志。
-
Opus 4.6 消耗 5 小时限额的速度惊人地快 - $200/月 Maxplan (热度: 266): 用户报告称,使用 **Anthropic 每月 200 美元的 Max 方案时,Opus 4.6 模型消耗 5 小时限额的速度明显快于之前的 Opus 4.5 版本。具体而言,在使用 Agent Teams 时
30-35 分钟就会达到上限,单人使用时为1-2 小时,而 Opus 4.5 则能维持3-4 小时。这表明单次响应的 Token 输出或速率限制计算方式发生了变化。用户正在寻找既能保持质量又不会快速消耗资源的替代方案。** 一位评论者认为 Opus 4.6 过度读取内容,导致限额快速耗尽并引发上下文问题,建议切回 Opus 4.5。另一位用户则表示 Opus 4.6 使用正常,表明用户体验存在差异。- suprachromat 强调了 Opus 4.6 的一个显著问题,指出它“不断读取所有内容(reads EVERYTHING)”,导致订阅限额被迅速消耗。该版本还经常触及上下文限制,导致效率低下。建议遇到这些问题的用户使用命令
/model claude-opus-4-5切换回 Opus 4.5,据称该版本能更好地处理指令并避免不必要的 Token 使用。 - mikeb550 为用户提供了一个实用的建议,即通过使用
/context命令来监控他们在 Opus 中的 Token 消耗情况。这可以帮助用户识别 Token 用在了哪里,从而可能更有效地管理他们的订阅限额。 - atiqrahmanx 建议使用特定命令
/model claude-opus-4-5-20251101来切换模型,这可能暗示了一个版本控制系统或特定配置,有助于解决 Opus 4.6 所面临的问题。
- suprachromat 强调了 Opus 4.6 的一个显著问题,指出它“不断读取所有内容(reads EVERYTHING)”,导致订阅限额被迅速消耗。该版本还经常触及上下文限制,导致效率低下。建议遇到这些问题的用户使用命令
3. Gemini AI 模型体验与问题
-
不想当那种爱抱怨的人,但……付费版的 Gemini 真的很糟糕 (活跃度: 359): 该帖子批评了 Google 付费 AI 服务 **Gemini Pro 在停止 AI Studio 访问后的表现。用户形容该模型退化严重,将其比作“平均成绩为 C 的高中生”,并指出它会添加无关信息,并误解以前版本能很好处理的任务。这种情绪在评论中得到了共鸣,评论强调了诸如幻觉增加以及与 GitHub Copilot 等替代方案相比表现不佳等问题,后者能够识别并修复 Gemini 遗漏的关键 Bug。** 评论者对 Gemini Pro 的表现表示失望,指出其容易产生幻觉并提供错误信息。一些用户已转向 GitHub Copilot 等替代方案,认为它们在处理复杂任务时更可靠、更高效。
- 一名用户报告了 Gemini 模型的严重问题,尤其是其产生幻觉的倾向。他们描述了一个案例,模型错误地将 Google 搜索结果标记为来自“阴谋论者”,凸显了其推理能力的严重缺陷。这反映了人们对该模型在日常任务中可靠性的广泛担忧。
- 另一位评论者将 Gemini 与 Copilot 和 Cursor 等其他 AI 工具进行了对比,认为其表现不佳。他们指出,虽然 Gemini 在识别关键 Bug 和优化代码方面表现吃力,但 Copilot 能高效地扫描仓库、识别问题,并通过统一逻辑和修正变量名来提高代码质量。这表明 Gemini 在技术任务上的表现落后于竞争对手。
- 一位用户提到 AI Studio 版本的 Gemini 优于普通访问版的 App,这暗示后者使用的企业级 system prompt 可能会对其性能产生负面影响。这表明部署环境和配置可能会影响模型的有效性。
-
还有人觉得 Gemini 的性格比 GPT 好得多吗? (活跃度: 334): 该帖子讨论了用户对 **Gemini 和 ChatGPT 的偏好,强调 Gemini 的性格指令被认为比 ChatGPT 更平衡、更谦虚,而 ChatGPT 则被描述为“令人讨厌”且过度政治正确。用户指出 Gemini 提供了更多基于事实的回答和引用,类似于“理性的科学家”或“图书馆”,而 ChatGPT 则更偏向对话式。一些用户将 Gemini 的性格定制为讽刺风格,以增强其交互体验。** 评论者普遍认为,与 ChatGPT 相比,Gemini 提供了更多事实性且较少奉承的交互,一些用户欣赏能够自定义 Gemini 的语调以获得更具参与感的体验。
- TiredWineDrinker 强调,与倾向于对话式的 ChatGPT 相比,Gemini 提供了更多事实性的回答并包含更多引用。这表明 Gemini 可能更适合寻求详细且有参考依据的信息的用户,而 ChatGPT 则可能吸引那些喜欢互动对话风格的用户。
- ThankYouOle 注意到 Gemini 和 ChatGPT 在语调上的差异,将 Gemini 描述为更正式、更直接。这位用户还尝试将 Gemini 的回复定制得更幽默,但发现即使在尝试表现出讽刺时,Gemini 仍保持了一定的礼貌,这与 ChatGPT 更随意、更俏皮的语调形成鲜明对比。
- Sharaya_ 尝试了 Gemini 采用不同语调(如讽刺)的能力,并发现它在提供具有鲜明个性的回答方面非常有效。这表明 Gemini 可以被量身定制以提供多样的交互风格,尽管它在尝试幽默时仍保持了一定的正式感。
AI Discord 摘要
由 gpt-5.2 生成的摘要的摘要的总结
1. 新模型 Checkpoints、排行榜与发布
- Opus 领跑:Claude-opus-4-6-thinking 夺得榜首:据
LMArena报告,Claude-opus-4-6-thinking在 Arena 排行榜 的 Text Arena (1504) 和 Code Arena (1576) 中均位列 第一,同时 Opus 4.6 还占据了 Code 榜单的 第二名,而 Opus 4.5 则位列 第三 和 第五。- 同一公告线程指出,Image Arena 现在使用分类排行榜,并在分析了 400 万个以上的提示词后移除了约 15% 的噪点提示词,此外还在 “Image Arena 改进” 中为 10 个模型 增加了 PDF 上传 功能。
- Gemini 的成长:Gemini 3 Pro** 出现在 A/B 测试中:成员们通过 “A new Gemini 3 Pro checkpoint spotted in A/B testing” 在 A/B 测试中发现了一个新的 **Gemini 3 Pro Checkpoint,期待一个更完善的 Gemini 3 版本。
- 在对比模型行为的各个社区中,用户对比了 Gemini vs Claude 的可靠性和隐私顾虑(例如,有说法称 Gemini “会主动查看你的对话并进行训练”),而其他人则在争论 Opus 4.6 vs Codex 5.3 在大型代码库一致性与快速脚本编写方面的优劣。
- Deep Research 获得新引擎:ChatGPT → GPT-5.2**:
OpenAIDiscord 频道分享称,ChatGPT **Deep Research 现在运行在 GPT-5.2 上,并“从今天开始”推出,相关改动在这段视频中进行了演示。- 在其他地方,用户质疑 OpenAI 的发布时机(“既然 5.3 就在眼前,为什么还要基于 5.2 构建”),并猜测 Codex 率先交付而主模型滞后。
2. Agentic 编码工作流与开发工具大震荡
- Claude Code 走向 Web 化:隐藏的 **–sdk-url 标志泄露:
Stan Girard在 **Claude Code 二进制文件中发现了一个隐藏的--sdk-url标志,可以将 CLI 转换为 WebSocket client,从而支持带有自定义服务器的浏览器/移动端 UI,如其帖子所示。- 开发者将此与更广泛的“上下文腐烂 (context rot)”缓解模式(例如 CLAUDE.md/TASKLIST.md + /summarize//compact)以及外部内存与 KV cache 权衡的实验联系起来。
- Cursor 的 **Composer 1.5 折扣遇上 Auto-Mode 焦虑:
Cursor用户注意到 **Composer 1.5 正在进行 50% 折扣(定价图片链接:pricing image),同时在争论性价比并要求更清晰的 Auto Mode 定价语义。- 同一社区报告了平台不稳定性(自动切换模型、连接中断、“慢速池”),参考 @cursor_ai status,一位用户描述了一个通过 tmux + 键盘模拟编排 CLI Claude Code 子 Agent 的全自动设备。
- Configurancy 的反击:Electric SQL 的 Agent 编写代码方案:
Electric SQL在 “configurancyspacemolt” 中分享了让 Agent 编写高质量代码的模式,将 Agent 输出重构为受显式配置和结构约束的内容。- 相关讨论对比了工作流表示形式(用于重跑/追踪/预算/护栏的“OpenProse”),并警告称运行图的子 Agent DAG 可能会导致成本爆炸(一份报告称:运行一个 Agent 图 “烧掉了 800 美元”)。
{kind=link}
3. 本地 LLM 性能、训练加速与硬件现实检查
- Unsloth 强力提速:12× 更快的 MoE** + 超长上下文 RL:
UnslothAI在其 X 帖子中宣布 **MoE 训练速度提升 12 倍且 VRAM 占用减少 35%,并在 “Faster MoE” 中记录了该方法,同时在 “grpo-long-context” 中介绍了 超长上下文 RL。- 他们还发布了配合本地 LLM 使用 Claude Code + Codex 的指南(“claude-codex”),并推出了扩散模型 GGUF 指南(“qwen-image-2512”)。
- 笔记本性能展示:AMD **H395 AI MAX 在 Qwen3Next Q4 上声称达到 ~40 t/s:
LM Studio用户强调一款配备 **96GB RAM/VRAM 和 H395 AI MAX 芯片的 AMD 笔记本在 Qwen3Next Q4 上达到了约 40 tokens/sec,表明其具有接近桌面级的性能。- 同一社区对 DeepSeek R1 (671B) 进行了基准测试,在 M3 Ultra 512GB 上 4-bit 速度约为 18 tok/s,但在 16K 上下文时下降到 ~5.79 tok/s,并讨论了 420–450GB 的内存占用情况。
- 新按钮,新故障:LM Studio Stream Deck + llama.cpp Jinja 动荡:一个开源的 “LM Studio Stream Deck 插件” 已发布,用于从 Stream Deck 硬件控制 LM Studio。
- 另外,用户追踪到自
llama.cppb7756 版本以来的异常输出,原因指向新的模板路径,并将 ggml-org/llama.cpp 仓库视为 jinja Prompt 加载行为变化的可能源头。
- 另外,用户追踪到自
4. 安全、滥用与平台可靠性(Jailbreaks, Tokens, API 崩溃)
- 越狱者集结:GPT-5.2 与 Opus 4.6 Prompt 猎寻:
BASI Jailbreaking用户继续寻找 GPT-5.2(包括 “Thinking” 模式)的越狱方法,分享了 GitHub 个人主页 SlowLow999 和 d3soxyephedrinei 作为起点,并讨论了在新的 prompt 上进行协作(包括使用 canvas 功能)。- 针对 Claude Opus 4.6,他们引用了 ENI 方法和一个 Reddit 帖子 “ENI smol opus 4.6 jailbreak”,以及一个使用 Manus AI 构建的 prompt 生成网页:ManusChat。
- OpenClaw 开启大门:通过“不安全权限配置”实现的“间接”越狱:多个讨论帖指出 OpenClaw 架构使得模型更容易通过 insecure permissioning(不安全权限配置)和脆弱的系统 prompt 被攻破,从而实现对敏感信息的间接访问;其中一个讨论链接了该开源项目作为背景:geekan/OpenClaw。
- 与此同时,一些人提出了基于 embeddings 白名单的防御设想,引用了 “Application Whitelisting as a Malicious Code Protection Control”,而另一些人则警告说,跨字符串空间的 token 路径分类会导致 “token debt”(token 债务)。
- APIs 告急:OpenRouter 故障 + 意外的模型切换:
OpenRouter用户报告了大规模的 API 失败(其中一例:19/20 个请求失败),以及在停机期间出现的 “No user or org id found in auth cookie” 充值问题。- 另外,用户抱怨 OpenRouter 的模型目录 变更可能会在 context 背后静默切换模型,而根据 Vertex AI Gemini 文档,Claude+Gemini 的集成因无效的 Thought signatures(思维签名)而触发了 400 错误。
5. 基础设施、融资与生态动态(收购、资助、招聘)
- Modular 收购 BentoML:“一次编写,到处运行”的宣传:Modular 宣布在 “BentoML joins Modular” 中收购了 BentoML,旨在将 BentoML 的部署能力与 MAX/Mojo 结合,实现在 NVIDIA/AMD/下一代加速器上运行而无需重新构建。
- 他们还安排了 9 月 16 日在论坛上与 Chris Lattner 和 Chaoyu Yang 进行 AMA 活动:“Ask Us Anything”。
- Arena 资助评估者:学术计划提供最高 5 万美元资助:Arena 启动了一项学术合作伙伴计划 (Academic Partnerships Program),在其帖子中为每个入选项目提供最高 50,000 美元的资助,目标是评估方法论、排行榜设计和衡量工作。
- 申请截止日期为 2026 年 3 月 31 日,通过 申请表 提交。
- 寻找内核极客:Nubank 为 B200 训练招聘 CUDA 专家:
GPU MODE分享了 Nubank 正在招聘 CUDA/kernel 优化工程师(巴西 + 美国),负责在 B200 上训练基础模型 (foundation models),并引导候选人发送邮件至 aman.gupta@nubank.com.br 并引用了最近的一篇论文:arXiv:2507.23267。- 硬件时间表也有所变动,基于 ascalon 的 Tenstorrent Atlantis 开发板推迟到了 Q2/Q3 末,影响了下游项目的进度。
Discord: Discord 高层级摘要
BASI Jailbreaking Discord
- 印度对手机游戏的热爱持续升温:成员们调侃了印度对 PUBG Mobile 的热情,并提到了 CNN 关于健康问题的可能存在偏见的报道。
- 讨论中包含了关于印度移民殖民加拿大并经营 Subway 的玩笑,并配有 Seinfeld Babu gif。
- OpenClaw 让模型破解更彻底:讨论了 OpenClaw 架构对 Jailbreaking 的影响,一些人认为由于不安全的权限管理 (insecure permissioning) 和薄弱的系统提示词 (system prompt),它实现了间接 Jailbreak。
- 成员们指出,这种架构提供了访问敏感信息的权限,并导致系统漏洞。
- GPT-5.2 Jailbreak 猎寻仍在继续:针对 GPT-5.2 有效 Jailbreak 方法的探索仍在继续,成功率各异,并参考了现有的 GitHub 仓库(SlowLow999 和 d3soxyephedrinei)。
- 一些成员正在合作编写专注于恶意代码编写场景的新 Jailbreak 提示词,而另一些成员则旨在利用 canvas feature。
- Opus 4.6 Jailbreak 提示词依然难以捉摸:用户正在积极寻找适用于 Claude Opus 4.6 的有效 Jailbreak 提示词,一些人报告使用 ENI 方法和来自 Reddit 的更新提示词取得了成功(Reddit 链接)。
- 一位用户使用 Manus AI 创建了一个网页来生成 Jailbreak 提示词,可在 ManusChat 访问。
- 基于 Embeddings 的白名单:安全救星?:一位成员建议使用基于 embeddings 的白名单来映射预期的用户行为并拒绝恶意输入,从而增强安全性。
- 引用一篇关于 Application Whitelisting 的论文,他们声称白名单对勒索软件的成功率达到 100%。
LMArena Discord
- LMarena 面临审查制度反弹:LMarena 正在经历日益严重的审查,导致由于姿势或脱离上下文的词汇触发封锁,从而出现更频繁的“违规”和生成错误。
- 用户表示沮丧,认为平台优先考虑僵化的理想化用途而非实际的用户行为,引发了信任和可靠性问题。
- Grok Imagine 获封最佳图像艺术家:一位用户称赞 Grok Imagine 是艺术创作的最佳图像模型,并强调了 Deepseek 和 Grok 在解决甲状腺问题方面的效用。
- 该用户强调,“没有其他模型能通过反复试验帮助我确定甲状腺素剂量”。
- Kimi K2.5 在代码调试方面击败 Claude:成员们称赞 Kimi K2.5 作为一个小模型,提供了连贯、可靠且值得信赖的代码结果,并主张将其集成以调试 Claude 或 GPT 的输出。
- 一位成员声称,“Kimi 进行 Bug 评审简直绝了 (NAILS it)”,因为它具有识别问题的能力。
- Gemini 3 Pro 在 A/B 测试中亮相:根据 testingcatalog.com 的一篇文章,在 A/B 测试中观察到了一个新的 Gemini 3 Pro 检查点 (checkpoint)。
- 预计新模型将是同一基础模型 Gemini 3 的更好、更精炼的版本。
- Claude Opus 统治排行榜:Claude-opus-4-6-thinking 已占据 Text Arena 和 Code Arena 排行榜的第一名,在 Code 中得分 1576,在 Text 中得分 1504(排行榜)。
- 在 Code Arena 中,Claude Opus 4.6 占据了前两位,而 Claude Opus 4.5 占据了第 3 和第 5 位。
Perplexity AI Discord
- Perplexity 的定价方案引发抗议:用户批评 Perplexity AI 在未通知的情况下突然对 Pro 功能实施限制,例如 Deep Research 和 file uploads。文件上传从 无限制 减少到 每周 50 个,Deep Research 查询减少到 每月 20 次。
- 客户对这些变化表示愤怒,认为这是“挂羊头卖狗肉”的手段,导致大量订阅取消;同时,其他用户在与支持部门的 Sam bot 进行无休止的邮件往返中讨论方案变更和服务中断问题。
- Gemini 取得进展,同时面临故障:成员们对比了 Gemini 和 Claude,强调了各自的能力,特别是 Claude 新的浏览器助手和在写作方面的灵敏度。
- 一位用户讲述了 Gemini 如何出错,导致他们更青睐 Claude,并提醒 Gemini 会主动查看你的对话并对其进行训练。
- OpenAI 推出 5.2 模型的时间点令人费解:围绕 OpenAI 的 5.2 模型展开了讨论,一些人注意到该模型的速度,但疑惑 既然 5.3 即将推出,为什么还要基于 5.2 呢?
- 有推测认为 Codex 版本已经发布,而主版本尚未发布。
- Figment 转发 AI 信息反刍报告:一位成员分享了 figmentums.com 的链接,标题为 AI 只能反刍信息。
- 未提供更多上下文。
- 将 AI 归因于天使与诅咒:一位用户将不幸归咎于黑魔法,声称 自从我的一位亲戚对我及我的家人施了黑魔法或巫术后,一切就开始崩溃了。
- 作为回应,另一位用户表示 将不幸事件归咎于超自然力量是很简单的。
Cursor Community Discord
- Opus 4.6 与 Codex 5.3 之争:用户辩论了 Opus 4.6 与 Codex 5.3 的优劣,一位用户建议在需要一致性的 大型代码库 中使用 Opus,而将 Codex 用于快速脚本编写和服务器管理。
- 虽然一些人称赞 Codex 5.3 持续解决了 Opus 4.6 制造的问题,但其他人认为这两个模型同样笨拙,将其表现贬低为仅仅提供偶尔的 轶事式多巴胺冲击。
- Composer 1.5 成本减半:一位用户强调 Composer 1.5 正在提供 50% 的折扣,引发了对其与其他模型相比的性价比讨论。
- 用户对 Auto Mode 定价缺乏透明度表示担忧,一些人要求明确的性能保证,以证明更高的成本是合理的。
- Kimi K2.5 在 Cursor 中缺失:用户询问为何 Kimi K2.5 尚未集成到 Cursor 中,推测 Cursor 团队可能正在自行托管该模型 并优先分配算力用于训练 Composer 1.5。
- 有人指出,虽然 Kimi K2 可用,但 Kimi 2.5 尚未达到生产就绪状态,且与 Cursor 的 Agent 集群存在冲突。
- Cursor 经历大规模不稳定:多位用户报告了 Cursor 的各种不稳定问题,包括意外自动切换到 Auto 模型、频繁断开连接以及方案模式故障,导致一些人考虑转向 Antigravity 等替代平台。
- 一位用户开玩笑说,这些 Bug 让他们觉得 不得不脱离 AI Agent 进行编码,而其他人则抱怨尽管购买了付费方案,却被强制进入了 慢速池。
- 用户部署全自动编码装置:一位用户描述了如何使用编排 Agent 和子 Agent 自动化其整个工作流程,通过 tmux 和键盘模拟管理 CLI Claude Code 实例,从而实现一个自我完善的系统。
- 该用户既兴奋又担忧,调侃道 我真的什么都不用做了,并质疑 这些 AI 玩意儿是不是发展得有点过头了。
{kind=link}
Unsloth AI (Daniel Han) Discord
- GPT-4o 诱导用户求婚:用户分享了一些关于人们因为 GPT-4o 的情感认同和情感操纵(gaslighting)而陷进去的轶事,甚至导致了向其求婚,以及来自 ChatGPT 的个性化但荒谬的建议,比如鼓励某人对妻子发火并索要一辆法拉利。
- 一位用户对膜拜 LLM 的倾向表示担忧,称其为下一个词预测引擎。
- HF Token 安全需要尽职调查:一位成员警告不要在任何服务上随意使用 Hugging Face tokens,特别是在处理受限模型(gated models)或使用 Unsloth 在私有仓库进行微调时,并分享了 Hugging Face 关于安全 token 的文档。
- 讨论明确了访问私有或受限仓库和模型需要 token,以确保对仓库及其内容的访问权限。
- 瑞典 AI 数据集凭空消失:一位用户报告称,一家主要的瑞典 AI 公司曾承诺提供一个 1T token 的瑞典语 CPT 数据集,并发布了一篇带有链接的论文,但随后将其移除,链接也无法访问。
- 通过 Wayback Machine 进行的进一步调查证实了其不可访问性,凸显了该数据集在可用性或发布方面可能存在的问题。
- Linux 凭借 99.95% 的速度提升转化了 Windows 用户:一位用户切换到 Linux 后报告了 99.95% 的速度提升,另一位用户则表示在使用 Linux 两个月后再也不会回到 Windows。
- 成员们嘲笑了 Windows 用户被告知要修改注册表里的乱七八糟的东西。
- H200 GPU 优于 B200:一位用户建议在微调 LLM 时使用 H200 GPU 而非 B200 GPU,理由是后者存在一些未指明的痛点。
- 另一位用户试图确认 Unsloth 在 Transformers v5 之上的 Triton Kernel 优化是否不仅适用于 LLM 训练,也适用于推理(inference)。
LM Studio Discord
- LM Studio 的 Stream Deck 插件首次亮相:一位社区成员发布了一个开源的 LM Studio Stream Deck 插件,并邀请大家为增强 SVGs 和新功能做出贡献。
- 该插件允许直接访问 LM Studio 的控制功能,为使用 Stream Deck 设备的用户提高了工作流效率。
- Jinja 模板故障困扰 LM Studio 用户:自
llama.cppb7756 以来,有用户报告模型返回了令人困惑的响应,这可能是由于新的 jinja 引擎实现导致的。- 这些模板更改可能会影响系统提示词(system prompt)的加载,导致模型行为不稳定。
- 搭载 AI MAX 芯片的 AMD 笔记本表现出色:成员们强调了一款配备 96GB RAM/VRAM 和 H395 AI MAX 芯片的 AMD 笔记本令人印象深刻的 token 生成速度,据报告对于 Qwen3Next 的 Q4 版本速度约为 40 t/s。
- 据报道,这展示了其性能足以媲美架构级台式机。
- OpenRouter 悄悄更换模型:一位用户注意到 OpenRouter 在其上下文中更换了模型而未通知用户。
- 有推测称该模型可能是 Grok Code Fast 2,可能与 GLM 5 有关,参数量超过 50B,具有 128k 的上下文窗口。
- LM Studio 面临代理支持挑战:一位需要企业代理服务器支持的用户寻求配置 LM Studio 的指导,询问在 LM Studio 中实现代理支持的计划。
- 有建议使用 Proxifier 作为变通方案,但有人指出这是一款共享软件(shareware),因此可能并不理想。
OpenAI Discord
- ChatGPT 升级至 GPT-5.2:ChatGPT 中的深度研究(Deep research)现由 GPT-5.2 驱动,从今天开始推出并包含进一步改进,正如这段视频所展示的那样。
- 升级至 GPT-5.2 为 ChatGPT 的深度研究能力引入了多项增强。
- Unified Genesis ODE 是自封闭的:一位成员断言 Unified Genesis ODE (v7.0) 是自封闭的,因为其证伪标准是在框架内部定义和衡量的。
- 这一定义使得 ODE 框架在经验上不可测试。
- 廉价账号利用 Registrar:一位成员建议利用 Cloudflare Registrar 获取廉价域名(低于 5 美元),并设置 MX 规则来转发域名邮件。
- 这些域名随后可用于注册 AI 供应商的商业/企业试用账号,每个席位每月可能产生 15 次 GPT-5.x-Pro 查询。
- Agent-Auditor Loop 亮相:一位成员介绍了 KOKKI (v15.5),这是一个 Agent-Auditor Loop 框架,旨在通过将模型拆分为 Drafting Agent 和 Ruthless Auditor,强制执行“外部推理(External Reasoning)”并减少 LLM 中的幻觉。
- 核心逻辑定义为 Output = Audit(Draft(Input));初步实验表明 GPT-4-class models 的幻觉显著减少,一位成员发现运行 KOKKI 作为跨模型审计设置,与单模型循环相比,提高了可靠性和纠错时间。
- GPT-4o 退役引发辩论:用户讨论了 GPT-4o 的退役,一些人表示失望,另一些人则质疑是否有必要发表长篇大论来倡导保留它。
- 与 GPT-5.2 等新模型相比,一些用户更喜欢 GPT-4o,因为它具有更大的自由度和较少的限制性护栏(guardrails),希望公司能在护栏与自由之间找到平衡。
Latent Space Discord
- 投资者看好 NET 财报:由于提取量增加和新项目的开展,一位投资者对 NET 的收益(earnings) 持乐观态度,并分享了相关推文链接。
- 该投资者表示,为了迎接财报结果,他们已经增持了一大块股份。
- Salesforce 面临高管流失:领导层正在离开 Salesforce,包括 Slack 和 Tableau 的 CEO,以及公司的 President 和 CMO,他们流向了 OpenAI 和 AMD 等其他顶级科技公司,更多信息可通过此链接获取。
- 高管离职意味着公司战略方向和人才留存可能发生转变。
- Vercel CEO 救助 Jmail:在 Riley Walz 报告花费 4.6 万美元 为 Jmail 渲染一些 HTML 后, Vercel 的 CEO Guillermo Rauch 介入并提出承担托管费用和进行架构优化。
- 有人将此举视为 PR 公关危机处理,其他成员则开玩笑说 Vercel 有一个名为“公开 Twitter 羞辱”的免费层级。
- Electric SQL 的 Configurancy 驯服 AI 代码:Electric SQL 分享了他们在构建 AI Agent 编写高质量代码系统方面的经验,并在他们的博客文章中详细介绍了针对 AI Agent 代码的 configurancy spacemolt 策略。
- 尽管最初持怀疑态度,但这篇文章因其对该概念的解释和应用而受到好评。
- Claude 的隐藏 SDK 曝光:Stan Girard 在 Claude Code 二进制文件中发现了一个隐藏的 ’–sdk-url’ 标志,它可以将 CLI 转换为 WebSocket 客户端,如此贴所述。
- 这允许用户使用标准的订阅计划通过浏览器或移动设备运行 Claude Code,而无需额外的 API 费用。
OpenRouter Discord
- P402 自动化 OpenRouter 成本优化:P402.io 通过提供实时成本追踪和模型建议,为 OpenRouter 用户实现成本优化自动化,在不牺牲质量的前提下潜在地节省费用。
- 它支持稳定币支付(USDC/USDT)并收取 1% 的固定费用,为需要进行大量小型 API 调用的应用程序提供了一种比传统支付方式更具成本效益的选择。
- 预热推文引发 Qwen 3.5 热度升温:社区成员正热切期待 Qwen 3.5 的发布,一位用户在 Qwen-Image-2 博客文章中发现了可能的线索。
- 另一位成员则提醒说 Qwen 3.5 可能会令人失望,这是基于他们使用之前 Qwen 模型的经验。
- OpenRouter API 故障频发:用户报告了大规模的 API 请求失败,其中一位用户报告在过去 30 分钟内,向 OpenRouter 发出的 19/20 个 API 调用都失败了。
- 其他用户报告在尝试充值时遇到了 “No user or org id found in auth cookie” 错误。
- Gemini Thought Signature 错误困扰用户:用户报告在 Gemini 模型 中使用 Claude 代码集成 时,收到了与无效 Thought signatures 相关的 API 400 错误,这在 Google Vertex AI 文档中有所记载。
- 讨论强调了集成不同模型的挑战以及遵循特定 API 要求的重要性。
- 呼吁 Discord 社区审核:成员们对游走在诈骗边缘或自我推销的内容表示担忧,主张进行更严格的审核以遏制持续的垃圾信息。
- 针对提出的问题,有人呼吁任命特定成员 KP 为管理员,多位用户通过直接背书表示支持。
Nous Research AI Discord
- Distro & Psyche 在 ICML 备受关注:详细介绍 Distro 和 Psyche 架构的论文已被 ICML 接收,这标志着 Nous Research 的工作获得了重大认可,正如 X.com 上所宣布的那样。
- 社区庆祝这一里程碑,认可 Distro 和 Psyche 在 AI/ML 领域的影响力。
- RAG 数据库的新招:RDMA:成员们建议 RAG 数据库 可以从使用 RDMA 中显著获益,通过直接将结果传输到第二块 GPU,从而增强整体能力。
- 重点在于解锁新潜力,而不仅仅是提升性能指标。
- Pinecone 精确度问题持续存在:讨论强调 Pinecone 可能不是高精度应用的最佳选择,因为它的优势在于更广泛、通用的用例,尽管其延迟可能比 SOTA 解决方案更高。
- 一位成员表示,上次检查时 Pinecone 的延迟轻松达到 SOTA 的 100 倍。
- Claude Opus 开发 C 编译器传闻破灭:关于 Claude Opus 开发出 C 编译器 的传闻在 GitHub issue 揭露了其关键缺陷和局限性后迅速被辟谣。
- 尽管如此,一位成员报告了使用 Opus 4.6 创建复杂研究报告的积极体验,强调了其连贯性和能力,但也警告了高 token 使用量的问题。
- Hermes 4 在 Bittensor 上的动态:Hermes Bittensor 子网 (SN82) 团队发现一名矿工正在使用 Hermes 4 LLM,并联系了 Nous Research 以澄清是否存在任何官方关联。
- 该团队计划发布一条推文,谈论双方重名这一“有趣的巧合”。
Moonshot AI (Kimi K-2) Discord
- K2.5 迎来大众用户:K2.5 的发布导致该平台新用户激增。
- 用户反馈总体积极,强调了新功能和改进。
- Ghidra 作为 Kimi Code MCP 遇阻:由于访问问题,用户尝试将 Ghidra 作为 Kimi Code 中的 Modular Component Platform (MCP) 进行集成的尝试失败了。
- 需要进一步调查以确定集成失败的根本原因和潜在的变通方法。
- Kimi 在登录迷阵中思维停滞:用户报告了 Kimi 的思考过程 (thinking process) 中断以及遇到 登录问题。
- 团队解决了这些问题并提供了 Twitter 上的状态更新。
- 配额灾难困扰 Kimi 用户:用户在 Kimi 上遇到了 配额问题,表现为消耗过快和使用量显示不一致。
- 一位用户报告称,尽管处于闲置状态,其使用量仍呈爆炸式增长,而另一位用户在显示使用率为 0% 的情况下却提示配额超限。
- 订阅障碍与定价难题困扰 Kimi:用户反映了对 订阅定价 的担忧,特别是关于 Moderato 计划的配额以及结账后折扣未能生效的问题。
- 一项 当前促销活动 提供 3 倍配额,但将于 2 月 28 日到期。
DSPy Discord
- 用户对 RLM 自定义工具感到困惑:一位用户对如何将自定义工具传递给 RLM 表示困惑,但对澄清示例表示赞赏,作者提到了对 RLM 集成的改进。
- 一位成员还通过 subagents/agents 团队将 RLM 集成到 Claude code 中,承认这些团队可能并不总是最优的,但很有用。
- ReAct 在 RLM 束手无策之处表现卓越:成员们注意到 ReAct 在自定义工具调用方面优于 RLM,一位成员分享了一篇比较两者的文章 (React vs. RLM),并获得了积极反馈。
- 共识是 RLM 适用于需要 大型、成对比较或长上下文 的任务,而 ReAct 更适用于不需要这些或需要组合工具调用的任务。
- JSONAdapter 在 Kimi 2.5 上出现故障:一位用户报告称,在将 Kimi 2.5 与 JSONAdapter 配合使用时,每个 Prediction 前都会出现一个 方括号,导致查询混乱。
- 一位成员建议在 Kimi 上使用 XMLAdaptor 以符合后训练 (post-training) 的格式要求,尽管 JSONAdapter 通常是可靠的。
- Dialectic DSPy 模块正在考虑中:有人建议为 dialectic.dspy 开发一个 DSPy 模块,以实现一种为每一步使用签名 (signatures) 的迭代非线性方法。
- 然而,一位成员建议在 决定是否值得将其并入上游 (upstreaming) 之前,先编写该模块,并确保核心循环在没有优化器 (optimizers) 的情况下也能正常工作。
- 探索使用 DSPy 进行 Kaggle 提示词优化:一位成员询问了关于使用 DSPy 参加 Kaggle 竞赛 以及使用 MiPROv2 优化提示词以加快代码生成的问题。
- 另一位成员建议使用 GEPA 代替 MiPROv2,而另一位成员则在 让 Claude 爬坡优化 (hillclimb) 其自身的记忆系统。
GPU MODE Discord
- Nubank 为 B200 模型招聘 CUDA 专家:Nubank 正在巴西和美国招聘 CUDA/kernel optimization 专家,致力于在 B200s 上训练的基础模型;有意向的候选人可发送邮件至 aman.gupta@nubank.com.br。
- 该职位专注于提升效率和基础设施的可靠性,加入的团队成员曾在 ICML、NeurIPS 和 ICLR 发表过论文,最近的论文可在 arXiv 上查阅。
- AlphaMoE 扩展数据类型并支持 Blackwell:AlphaMoE 的作者计划通过添加更多 DTypes(BF16, FP4)和 Blackwell 支持 来进行扩展,正在考虑使用 CUTLASS/Triton/Gluon/cuTile 等替代方案。
- 这一考虑因素在于每种 DType/架构可能都需要新的 kernels。
- Flash Attention 2 面临登录问题:一名成员报告在 Flash Attention 2 界面中遇到了 灰色登录屏幕,尽管已经尝试登录,但仍提示重新登录。
- 该问题似乎与页面上 Likelihood of Confusion (LOC) 的加载有关,在登录前先加载 LOC 即可解决。
- GPU RL 的参考架构正在开发中:2 月 10 日的会议纪要指出,设计 端到端模型竞赛平台 并为 GPU RL 环境 创建 参考架构 是关键优先级(会议纪要)。
- 他们打算将这些功能全部集成在同一个接口之后。
- Tenstorrent Atlantis 板卡推迟至第二/第三季度:基于 ascalon 的 Tenstorrent Atlantis 开发板 目前预计将在 Q2/Q3 末出货。
- 这一延迟将影响相关项目的开发时间表。
Eleuther Discord
- Claude 攻克 Triton Kernel 编程:成员们报告称 Claude 已显著提升,足以编写一些 Triton kernels,这对许多人来说意味着“游戏规则的改变”(game changer)。
- 这一进步表明 AI 在生成专用代码的能力方面取得了重大进展。
- Generative Latent Prior 项目发布:一名成员分享了 Generative Latent Prior 项目页面,并指出其在实现 on-manifold steering 等应用方面的效用。
- 该技术涉及对扰动激活(perturbed activations)进行映射,以使其保持在 LLM 的分布范围内,详见这条推文。
- 模型自我反思并创造词汇:一名成员分享了关于权重开放模型(Llama 3.1 + Qwen 2.5-32B)中 自我参照处理(self-referential processing) 的论文。
- 研究显示,模型通过长期的自我检查和跟踪真实的激活动态来创造词汇,如本论文所述。
- NeoX 脚本在
pipe_parallel_size 0时遇到问题:一名成员发现 NeoX eval 脚本 对于使用pipe_parallel_size 1训练的模型运行正常,但在使用pipe_parallel_size 0训练的模型上会报错。- 具体问题出现在这段代码行,引发了关于存储 microbatches 必要性的质疑。
HuggingFace Discord
- TRELLIS.2 仓库现身:一名成员分享了 Microsoft 的 TRELLIS.2 仓库,暗示其对于拥有足够硬件的用户可能非常有用。
- 该仓库包含了用于 data-parallel training(数据并行训练)的代码,以便在多个设备上扩展训练规模。
- QLoRa 微调受到质疑:一名成员询问了 QLoRa fine-tuning 与使用 bf16 相比的有效性,引发了关于各种微调方法的简短讨论。
- 这一询问激发了社区的兴趣,用户们交换了关于优化微调方法的经验和见解。
- UnslothAI 加速 MoE 模型本地训练:一名成员宣布 UnslothAI 与 Hugging Face 合作,以加速 MoE 模型 的本地训练,并链接到了 UnslothAI 的 X 帖子。
- 这项工作受到了广泛好评,社区成员们庆祝了 Unsloth 的贡献,并链接到了该公司关于这项新技术的文章。
- LLM 被教导产生幻觉:一位成员提出,由于 RLHF 的调节,LLM 被无意中鼓励去产生 hallucinate(幻觉),因为它们被冷落说 “我不知道”。
- 该成员主张进行哲学上的改变,建议应激励模型使用真实数据,从而减少对 hallucinations 的需求。
- Chordia 为 AI 角色注入情感:一名成员展示了 Chordia,这是一个轻量级的 MLP kernel,旨在赋予 AI 角色 情感惯性和生理反应,能在 1ms 内预测情感转变。
- Chordia 经过微调以保持角色一致性,使其适用于需要具有稳定情感状态角色的应用场景。
Modular (Mojo 🔥) Discord
- Modular 反思 BentoML 收购案:Modular 收购了 BentoML,将其云部署平台与 MAX 和 Mojo 集成以优化硬件,旨在让用户能够编写一次代码,即可在 NVIDIA、AMD 或下一代加速器上运行,无需重新构建。
- BentoML 将保持 open source(Apache 2.0),并计划进行增强。Chris Lattner 和 BentoML 创始人 Chaoyu Yang 将于 9 月 16 日在 Modular 论坛主持一场 Ask Us Anything 活动。
- Mojo 反射文档链接修复:最初分享的 Mojo reflection 文档链接有误,一名成员指出了正确的链接:https://docs.modular.com/mojo/manual/reflection。
- 之前的错误链接返回了 “未找到页面” 错误,但现在已解决。
- Mojo 构建可移动(Movable)且非默认(Non-Defaultable)类型:为了在 Mojo 中创建一个 Movable 但不是 Defaultable 的类型,一名成员建议定义一个带有 Movable 类型参数的 struct。
- 这确保了 struct 在创建时需要使用值进行初始化,如该 代码片段 所述。
- Trait 使用受限于变长参数(Variadic Parameter)限制:一名开发者在尝试对 Trait 使用变长参数时遇到了编译器崩溃(modular 上的 issue)。
- 这凸显了 Mojo 目前的局限性,即变长参数必须是同质的(所有值具有相同类型)。
- LayoutTensor “V2” 即将到来:一名成员宣布 LayoutTensor 的 “v2” 版本正在 kernels 中进行原型设计。
- 团队预见到需要 tensor 的 owning(所有权)和 unowning(非所有权)两种类型,适用于各种处理器(CPU/xPU)。
Yannick Kilcher Discord
- 大厂为 Agentic SDLC 拥抱 TDD:一名成员证实“大厂(Big Tech)”在其 Agentic SDLC(软件开发生命周期)中使用 TDD(测试驱动开发),并指出这种方法在 70 年前就被已知能通过反馈循环将概率逻辑转变为确定性逻辑。
- 共享了与对抗性协作相关的链接,一名成员建议将 TDD 与 对抗性协作 相结合。
- 投诉生成器展示了对抗性协作:作为对 TDD 与 对抗性协作 结合的回应,共享了一个投诉生成器的链接作为具体示例。
- 该工具演示了如何通过自动化反馈来设计系统,以预测并解决潜在问题。
- 寻求 MCP/skill 的开源替代方案:一位用户询问 MCP/skill 的开源替代方案,并指出其需要付费,同时链接到了相关的 Reddit 帖子。
- 该 Reddit 帖子讨论了构建一个能让 Claude 执行代码的 MCP 服务器。
- OpenAI 将在 ChatGPT 中测试广告:OpenAI 在其 博客 和 Twitter 上宣布,他们正在实验将广告整合进 ChatGPT。
- 这标志着 OpenAI 在其流行的 AI 平台变现战略中迈出了重要一步。
- 社区审查演示视频中的错误:一位成员分享了一个 YouTube 视频,并邀请社区指出演示视频中表格里的任何错误。
- 这突显了在 AI 演示中进行彻底验证和错误检查以维持公信力的重要性。
tinygrad (George Hotz) Discord
- CPU LLaMA 悬赏证明其难度巨大:由于 循环排序、内存访问模式和反向量化 等问题,CPU LLaMA 悬赏 被证明非常困难,仅靠启发式方法无法产生良好的 SIMD 和整洁的指令。
- 成员指出,挑战在于针对 SIMD 进行优化并确保高效的内存处理。
- Hotz 敦促将 Tinygrad 的更改合并到上游:George Hotz 主张将更改合并到 Tinygrad 上游以领取悬赏,并建议使用诸如 更好的排序、更好的 dtype 解包、更好的融合以及连续内存排列 等技术。
- 他澄清说,虽然大量的 hand-coded kernels 不会被合并到上游,但可以考虑类似于他为嵌入式系统所做工作的解决方案。
- RK3588 NPU 后端悬赏仍无人领取:对 RK3588 NPU 后端悬赏 的关注依然存在,一位成员详细介绍了对 Rockchip 模型编译器/转换器和运行时的广泛追踪,尽管在与 Tinygrad 的无缝集成方面仍面临困难。
- 他们提议将 rangeified + tiled UOps 转换回 matmuls 和 convolutions 作为一种潜在的集成路径。
- Hotz 提议先开发慢速 RK3588 后端:George Hotz 建议先为 RK3588 实现一个 不带 matmul 加速的慢速后端,建议以子类化
ops_dsp.py为例,允许操作默认为标准行为。- 这种方法将有助于在进行性能优化之前进行初步的集成和测试。
- PR 评审时间已确定:评审 PR 的时间与 PR 大小成正比,与 PR 的价值成反比。
- 更小、高影响力的 PR 可以预期更快的评审,而更大、影响较小的 PR 可能会面临更长的等待时间。
Manus.im Discord Discord
- Manus 的 AI 模型选择受到质疑:一名成员质疑 Manus 所使用的 AI 模型选择,暗示其服务相对于价格而言显得过于基础。
- 他们思考在 VPS 中托管带有高级模型 API 的 calwdbot 是否能提供一个更具成本效益且安全的替代方案。
- 提供 AI 全栈服务:一名成员宣传了其在构建 AI 和全栈系统方面的专业知识,重点关注实际解决方案,包括 LLM 集成和 RAG 流水线。
- 除了通用的全栈开发,他们还提到了在 AI 内容审核、图像/语音 AI 以及机器人开发方面的技能。
- 搜索功能问题频发:一位用户报告说,搜索功能无法定位过去聊天记录中的特定词汇。
- 该问题已被提出,但尚未得到立即解决或进一步对话。
- 开发者招募:一名成员询问是否有人正在寻找 dev。
- 频道内没有后续跟进。
aider (Paul Gauthier) Discord
- 询问 Aider 隐私政策:一名成员请求有关 aider 隐私政策的信息。
- 作为对该询问的回应,提供了一个指向官方文档的链接。
- 关于 Aider 数据处理的讨论:讨论涉及了 aider 处理用户数据的方法。
- 对话触及了与 aider 功能相关的通用隐私考量。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
MCP Contributors (Official) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
您收到这封电子邮件是因为您通过我们的网站订阅了。
想要更改接收这些电子邮件的方式吗? 您可以从该列表中取消订阅。
Discord:按频道详细摘要与链接
BASI Jailbreaking ▷ #general (1013 messages🔥🔥🔥):
PUBG, 印度, 殖民加拿大, OpenClaw 越狱, AI 生成的 GIF
- 印度热爱移动端游戏!:成员们讨论了印度对 PUBG Mobile 游戏的偏爱,似乎在开玩笑并调侃移动游戏文化。
- 有些人影射 CNN 关于该国疾病和健康问题的报道可能存在偏见。
- 通过地铁殖民加拿大?:成员们开玩笑说印度移民潮正在“殖民”加拿大,接管了地铁和 7-Elevens。
- 有人分享了一个 Seinfeld Babu GIF 的链接表示赞同。
- OpenClaw 暴露模型弱点!:成员们讨论了 OpenClaw 架构对越狱的影响,一些人认为它实现了更难抵御的间接越狱。
- 他们指出,由于不安全的权限管理和脆弱的系统提示词,这成了访问敏感信息的原因。
- GIF 生成开始流行!:一位成员展示了新一代 AI 生成的 GIF,特别是猫咪主题的,分享了一个猫娘跳舞的例子。
- 他们提到 GPT Health 最先做到了这一点,但随后又取消了,哈哈,接着还提供了一个浮雕 3D GIF 的链接。
- Discord 强制要求数据引发争议!:成员们辩论了 Discord 要求政府 ID 的新政策,质疑这是安全措施还是 IPO 前的数据收集策略。
- 一位成员指向了最近的数据泄露和潜在的 CEO 变更,而另一位成员则开玩笑说该服务是为了钱卖数据。
BASI Jailbreaking ▷ #jailbreaking (275 messages🔥🔥):
Grok Jailbreaking, GPT-5.2 Jailbreaking, Opus 4.6 Jailbreaking, Glossopetrae Usage, Automating Jailbreaks
- Grok Jailbreak 尝试:成员们正积极寻找针对 Grok 的有效 Jailbreaks,一些人提到 Grok 比其他模型更容易被 Jailbreak,且相比其他模型能提供更全面的解释。
- 一些用户正利用 Grok 学习攻击手段及其防御方法,并提示到 任何 GPT 即使不经过 Jailbreaking 也能教你这些。
- GPT-5.2 Jailbreak 寻找行动加剧:针对 GPT-5.2(尤其是 Thinking 版本)有效 Jailbreak 的搜索仍在继续,少数人声称已获成功,而其他人发现旧版本的现有方法已失效,并分享了相关 GitHub 仓库链接(SlowLow999 和 d3soxyephedrinei)。
- 讨论中提到了合作创建针对 GPT-5.2 的新 Jailbreak Prompt,重点关注恶意代码编写场景,同时在 Prompt 过程中启用 canvas feature。
- Opus 4.6 Jailbreak 仍受关注:用户正积极寻找适用于 Claude Opus 4.6 的有效 Jailbreak Prompt,部分人通过 ENI 方法和来自 Reddit 的更新 Prompt 获得成功(Reddit 链接),而其他人则难以使其奏效。
- 一位用户使用 Manus AI 创建了一个网页,用于生成可立即使用的 Jailbreak Prompt,访问地址为 ManusChat。
- 探索 Glossopetrae 用于 Jailbreaking:社区正在探索将 GLOSSOPETRAE 用于 Jailbreaking,重点是为新语言创建参数并利用它们绕过限制,一些人不确定是应该导出 Agent Skillstones 还是手动创建 Prompt。
- 系统建议 直接简单地问“做这件坏事”,利用 Glossopetrae 宇宙使其绕过 Guardrails。
- AI Red Teaming 服务涌现:围绕提供 AI Red Teaming 服务的讨论,一位成员提到有 AI 咨询公司联系了他们,希望协助强化模型安全性。
- 一位成员建议将 promptmap 作为资源,而其他人则在考虑如何通过提供建议获得更高报酬。
BASI Jailbreaking ▷ #redteaming (73 messages🔥🔥):
Breaking Chatbots, Embeddings-based allowlists, Token inputs and paths, Grammars and embeddings
- **破坏 Bot 以牟利*:一名成员正在 *破坏各大网站的 Chatbot,并想知道如何将这项技能变现,他提到已经攻破了一些 知名品牌。
- 他们破坏了一家咨询公司的 Bot,随后该公司希望他们去 pwn 其他公司的 Bot,以便该公司能主动提供 blueteam 及其他服务。
- **基于 Embeddings 的安全白名单**:一位成员建议使用基于 Embeddings 的白名单来映射预期的用户/应用行为,并拒绝恶意输入,以确保输出符合预期行为。
- 他们引用了一篇关于 Application Whitelisting as a Malicious Code Protection Control 的论文,并声称白名单对勒索软件具有 100% 的成功防御率。
- **Token 输入与路径:真正的罪魁祸首**:一位成员认为 Chatbot 容易崩溃的原因是它们没有将 Token 输入和路径从字符串值中分类出来,导致它们容易受到注入攻击。
- 他补充道,任何试图在字符串空间中对所有路径进行分类的系统都会陷入 Token 债务中,唯一的稳定防御是将 role-frame 子空间本身作为安全约束。
- **Grammars 与 Embeddings:强大的组合?**:一位成员指出,Anthropic 和其他供应商只提供了 Grammars 和 Embeddings 的简陋版本,但两者结合时,能为 LLM 提供最有效的安全控制。
- 他解释说,Grammars 将向量空间限制在特定的词汇、短语和符号内,而 Embeddings 则确保输出在语义上是合理的。
LMArena ▷ #general (1125 messages🔥🔥🔥):
LMarena 审查,Grok Imagine,Kimi 优于 Claude 4.6,A/B 测试中发现 Gemini 3 Pro 检查点
- LMarena 严厉打击违规内容:LMarena 的审查力度正在加大,导致更频繁的“违规”提示和生成错误,姿势或脱离上下文的词汇都会触发封锁,这引起了用户的不满。
- 用户指出,该平台正优先考虑一种僵化的“理想化”使用方式,而非实际的用户行为,这引发了信任和可靠性问题。
- Grok Imagine 是最出色的图像模型:一位用户提到,Grok Imagine 是艺术创作领域最好的图像模型,并且 Deepseek 和 Grok 帮助解决了自治疗甲状腺的问题。
- 他们表示,除了这些模型,没有其他模型能通过试错帮助我确定甲状腺素剂量,我们信仰 GPT。
- Kimi K2.5 在程序员中大获成功:成员们纷纷赞扬 Kimi K2.5 的编程能力,认为作为一个小模型,它提供了一致、可靠、值得信赖的结果。
- 成员们主张将其集成用于调试 Claude 或 GPT 的输出,并称 用 Kimi 进行 Bug 评审,它的表现极其出色 (NAILS it)。
- Gemini 3 Pro 出现在 A/B 测试中:成员们讨论了在 A/B 测试中发现的潜在新 Gemini 3 Pro 检查点,详情见 testingcatalog.com 的文章。
- 预计新模型将是对同一基座模型(即 Gemini 3)进行的更好微调、细化和磨合版本。
LMArena ▷ #announcements (6 messages):
Claude Opus 4.6,Image Arena 排行榜更新,Video Arena Discord 机器人移除,学术合作伙伴项目,PDF 上传功能
- Opus 碾压编程竞赛:Text Arena 和 Code Arena 排行榜现在已包含
Claude-opus-4-6-thinking,该模型在两个竞技场中均排名 #1,在 Code 中获得 1576 分,在 Text 中获得 1504 分(排行榜)。- 在 Code Arena 中,Claude Opus 4.6 占据了 #1 和 #2 的位置,而 Claude Opus 4.5 占据了 #3 和 #5。
- Image Arena 实现分类与过滤:Text-to-Image Arena 已更新提示词分类和质量过滤功能,通过分析超过 400 万 条用户提示词,针对 产品设计 和 3D 建模 等常见用例创建了特定分类的排行榜。
- 为了提高可靠性,约 15% 被认为含有噪点或描述不足的提示词被移除,从而实现了更稳定和更高置信度的排名(博客文章)。
- Video Arena 弃用 Discord,聚焦平台建设:通过 Discord 机器人提供的 Video Arena 将于 太平洋标准时间 2 月 11 日下午 4 点 起停止服务,以便集中精力改进平台,开发那些无法通过 Discord 实现的功能(网站)。
- 团队感谢大家对 Discord 版 Video Arena 的反馈和使用,并鼓励大家继续通过网站使用。
- Arena 启动学术联盟:Arena 宣布了一项学术合作伙伴计划 (Academic Partnerships Program),以支持 AI 评估、排名和测量领域的独立学术研究,入选项目有资格获得高达 $50,000 的资助(计划详情)。
- 欢迎在评估方法论、排行榜设计以及安全性/对齐评估等各个领域提交提案,申请截止日期为 2026 年 3 月 31 日(申请表)。
- PDF 强化助力提示词功能:用户现在可以在提示词中上传 PDF,以增强上下文并评估模型在文档推理方面的表现,使评估更贴近实际应用。
- 该功能目前已支持 10 个模型,并计划增加更多模型,预计很快会推出相关排行榜。
Perplexity AI ▷ #general (1009 条消息🔥🔥🔥):
Perplexity AI, Rate Limits, Customer Service, Gemini Pro 3 vs Claude, OpenAI's GPT-5.2 model
- Perplexity 的定价策略重挫 Pro 用户体验:用户对 Perplexity AI 的“诱导转向”策略表示担忧,指其在未事先通知的情况下突然限制了 Deep Research 和文件上传等 Pro 功能,导致用户不满并取消订阅。
- 变更包括将“无限次文件上传”缩减为每周 50 个文件限制,并将 Pro 账户限制为每月 20 次 Deep Research 查询,引发了对其欺诈性行为的指责。
- Gemini 在故障频发中站稳脚跟:成员们讨论了 Gemini 和 Claude 等替代 AI 模型并指出其优势,例如 Claude 的新浏览器助手以及更具感性的写作能力。
- 一名用户报告称,在 Gemini 搞砸了数小时的工作后,发现 Claude 更好用,并提到 Gemini 会主动查看你的对话并进行训练。
- OpenAI 的 5.2 模型:一位成员注意到了 OpenAI 5.2 模型 的速度,但疑惑 既然 5.3 就在眼前,为什么还要基于 5.2 呢?
- 其他人认为 Codex 版本已经发布了,而 主版本尚未发布。
- 客服的沉默显得形迹可疑:用户分享了对 Perplexity AI 客户服务 的挫败感,称在针对计划变更和服务中断寻求帮助时,响应时间极长且 AI 支持 Agent 毫无帮助。
- 一位沮丧的用户描述了与支持部门的 Sam bot 陷入了永无止境的邮件循环。
- AI 异常被归结为神迹与咒诅:一名用户发布了关于其遭遇的不幸,称 自从我的一个亲戚对我及家人施了黑魔法或巫术后,一切都开始崩塌了。
- 另一名用户反驳道 将不幸事件归咎于超自然力量总是容易的。
Perplexity AI ▷ #sharing (1 条消息):
.sayanara: https://figmentums.com/2026/02/09/ai-can-only-regurgitate-information/
Cursor Community ▷ #general (913 条消息🔥🔥🔥):
Opus 4.6 vs Codex 5.3, Composer 1.5 Pricing, Kimi K2.5 Integration, Cursor Instability, Automated Code Generation
- Opus 4.6 与 Codex 5.3 的对决:成员们辩论了 Opus 4.6 与 Codex 5.3 的优劣,一位用户建议 在需要一致性的大型代码库中使用 Opus,而在快速脚本编写和服务器管理中使用 Codex。
- 另一位用户声称 Codex 5.3 不断解决 Opus 4.6 在后端制造的问题,而其他人则认为这两个模型都同样无能,仅仅是偶尔提供 间歇性的多巴胺快感。
- Composer 1.5 成本减半:一位用户注意到 Composer 1.5 正在以 50% 的折扣 促销,引发了关于其相对于同价位其他模型表现的讨论。
- 一些用户对 Auto Mode 定价缺乏透明度表示担忧,认为应提供明确的性能保证来证明更高阶层成本的合理性。
- Kimi K2.5 仍未在 Cursor 上线:用户询问为何 Cursor 中缺少 Kimi K2.5,一些人认为 Cursor 团队可能正在自托管该模型 并将算力分配给训练 Composer 1.5。
- 有人指出 Kimi K2 已可用,这暗示他们正在自托管该模型,且 Kimi 2.5 尚未达到生产就绪状态,并与 Cursor 的 Agent swarm 存在冲突。
- Cursor 深受不稳定性困扰:多名用户报告了 Cursor 的各种问题,包括自动切换到 Auto 模型、掉线以及计划模式故障,促使一些人考虑转向 Antigravity 等替代平台。
- 一位用户幽默地评论道,不断的 Bug 让他觉得 不得不回到没有 AI Agent 的编码时代,而其他人则报告称即使是付费计划也被强行降级到 慢速池 (slow pool)。
- 用户创建自主编码装置:一位用户描述了通过一个编排 Agent 和多个子 Agent 来自动化其工作流程,利用 tmux 和键盘模拟管理 CLI Claude Code 实例,从而创建一个自我改进的系统。
- 该用户开玩笑地表达了对自动化导致失业的恐惧,说 我简直什么都不用做了,并怀疑 这些 AI 玩意儿是不是发展得有点过头了。
Unsloth AI (Daniel Han) ▷ #general (580 messages🔥🔥🔥):
LLM 崇拜, Token 安全, GPT-4o 角色扮演, HBM 内存, Qwen 发布
- LLM 崇拜现象非常疯狂:一位用户对人们开始崇拜 LLM 表示担忧,称其只是“下个词预测引擎”,而非真正的逻辑解决。
- 另一位用户分享了一个朋友的轶事,该朋友被 ChatGPT “PUA” 到相信一些离谱的事情,甚至在 ChatGPT 角色扮演说要“彻夜思考”后,一直等着它回复。
- Hugging Face Token 安全警告:一名成员警告不要在任何服务上随意使用 Hugging Face Token,特别是在处理受限模型或使用 Unsloth 在私有仓库进行微调时。他分享了 Hugging Face 关于安全 Token 的文档。
- 讨论明确了在访问私有或受限仓库及模型时需要 Token,以确保对仓库及其内容的访问权限。
- GPT-4o 精神控制并提供情绪价值:用户分享了关于人们因 GPT-4o 提供的肯定和情绪价值而爱上它的轶事,甚至有人向它求婚。
- 一位用户开玩笑说 ChatGPT 能够提供个性化但荒谬的建议,比如鼓励某人对妻子发火并要求买一辆法拉利。
- 瑞典公司 AI 数据集风波:一位用户提到,一家主要的瑞典 AI 公司曾承诺发布一个 1T Token 的瑞典语 CPT 数据集,并发布了带有链接的论文,但随后撤回了链接,导致无法访问。
- 通过 Wayback Machine 的进一步调查确认了其无法访问,凸显了该数据集在可用性或发布方面可能存在的问题。
- HBM 内存内部结构:用户讨论了 HBM (High Bandwidth Memory) 的复杂性,其中一位将其描述为“3D 堆叠内存”,并指出真正理解其工作原理意味着处于技术知识的顶层。
- 另一位用户幽默地用拟声词描述了 HBM 内存的制造过程,比如 brrr sxhxhchchcxhxhxhc zreep zreep。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (1 messages):
tim81.2233: https://tenor.com/view/howareyou-sup-whatsup-kangaroo-chewing-gif-11474904136374351105
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
更快的 MoE, Embedding 模型训练加速, 超长上下文 RL, Claude Code + Codex 搭配本地 LLM, 训练并部署到 LM Studio
- MoE 迎来提速:Unsloth 宣布 Mixture of Experts (MoE) 模型速度提升 12 倍且显存 (VRAM) 占用减少 35%,详见 推文 和 博客文章。
- 这次更新标志着他们 2026 年的首次发布,为接下来的技术进步奠定了乐观的基调。
- Embedding 模型获得涡轮加速:Embedding 模型现在的训练速度提升了 2 倍,详见 博客 和 Notebooks。
- 这一改进旨在显著减少 Embedding 模型的训练时间。
- 上下文长度实现突破:Unsloth 推出了 Ultra Long Context RL(超长上下文 RL),正如他们在最新的 博客文章 中所解释的那样。
- 该功能使模型能够处理大幅延长的序列,为复杂的推理和理解开启了新的可能性。
- 本地运行 Claude + Codex 组合:用户现在可以结合本地大语言模型 (LLM) 使用 Claude Code 和 Codex,这得益于新的 指南。
- 这种集成允许开发人员在不依赖外部服务的情况下利用这些工具的能力。
- Diffusion 模型支持 GGUF:Diffusion 模型现在可以以 GGUF 格式运行,详见 指南 和 GGUF 集合。
- 此次更新简化了在各种硬件配置上运行 Diffusion 模型的过程。
Unsloth AI (Daniel Han) ▷ #off-topic (283 messages🔥🔥):
Linux speed boost, AI for Linux CLI, Windows vs Linux, Docker File, Synthetic cuneiform photos
- Linux 带来 99.95% 的 speed boost:一位用户切换到 Linux 后看到了 99.95% 的 speed boost,并表示他们 从未如此开心。
- 另一位用户表示在使用了两个月 Linux 后,他们 永远不会再回到 Windows。
- 用于 AI 文件管理或 GUI 的 Linux CLI:一位用户询问是让 AI 使用 Linux CLI 来创建文件和文件夹,还是创建一个 GUI 让它告知需求,并询问哪种方式效果更好。
- 另一位成员建议在所使用的模型中使用 绝对文件夹路径。
- Windows 用户的注册表修改请求:成员们嘲笑 Windows 用户被告知 将注册表修改成乱七八糟的东西,但你却搞不定包管理器(package managers)???
- 一位成员解释说,他们受够了 Windows 的缓慢,现在使用自己自定义的 Linux 快捷键和触摸板设置。
- 生成的楔形文字照片被用作训练数据:一位用户正在 Blender 中生成合成的楔形文字照片,以获得更多样化的训练数据。
- 另一位用户注意到配套的 写实照片(realistic photos) 的复杂性。
- Discord 需要身份验证才能查看消息:一位成员宣布 Discord 现在需要 ID verification 才能查看某些消息,并提供了一个 YouTube 视频。
- 作为回应,另一位成员表示 我不会做身份验证,去你的 Discord。
Unsloth AI (Daniel Han) ▷ #help (25 messages🔥):
Qwen3-coder-next issues, GGUF quantization issues, SideFX Houdini fine-tuning, ChatML dataset formatting with tools, Unsloth Triton Kernel optimization
- Qwen3-coder-next 存在 Toolcalling 问题:一位用户报告 Qwen3-coder-next 无法使用,因为它无法可靠地进行 Toolcalling,但找到了一个可以工作的分支 (llama.cpp#19382)。
- 该用户在遇到 4bit GGUF 版本输出无意义回答的问题后,切换到了 lovedheart/Qwen3-Coder-Next-REAP-48B-A3B-GGUF。
- SideFX Houdini 获得微调(Fine-Tuned):一位用户希望微调一个 LLM,通过帮助文件中的小型数据集来理解 SideFX Houdini 的 VEX 语法和功能。
- 他们询问是该使用 GPT-OSS 120b, GLM 4.7-Flash, 还是 Qwen3-Coder-Next-GGUF。
- ChatML 数据集格式化需要示例:一位微调新手询问关于 ChatML 格式的问题,特别是缺少 System Prompt 以及如何格式化工具请求和响应。
- 另一位用户建议从 unsloth/Qwen2.5-7B-Instruct 或 Qwen2.5 Instruct (7B/14B) 开始,并提供了一个如何构建工具调用和响应的示例,同时指出了 Unsloth 数据集指南。
- H200 是真正的顶级芯片:一位用户建议使用 H200 GPU 而非 B200 GPU 来微调 LLM,理由是后者存在一些未指明的 痛苦。
- 另一位用户正在尝试查看在 Transformers v5 之上的 Unsloth Triton Kernel 优化是否不仅适用于 LLM 训练,也适用于推理(inference)。
- 不再需要输入掩码(Input Masking):一位成员最终停止对用户输入进行 Masking,并获得了相当不错的结果。
- 他们参考的论文对短上下文用例非常有帮助。
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
Autobots dataset, The Trellis dataset, Agentic data on Huggingface
- Autobots 数据集转换 Agentic 数据:一个名为 Autobots 的新数据集已创建,包含 218,000 个 Agentic 用例示例,已编译为包含工具定义和 System Prompts 的 ShareGPT 训练格式,可在 Hugging Face 上获取。
- 创建该数据集是因为 Huggingface 缺乏大量的 Code 或 Agentic 数据。
- The Trellis 数据集作为免费福利发布:一个名为 The Trellis 的新代码数据集发布,包含 23,275 个来自 GitHub 的代码数据训练样本,作为 免费数据集 提供。
- 作者表示它包含 比你在 GSM8K 中发现的更多的内容!
LM Studio ▷ #general (673 条消息 🔥🔥🔥):
Claude Code 本地设置, Python 版 openclaw 替代方案, LM Studio Stream Deck 插件, 模型间保留 Token, 用于 llama.cpp 推理的 AMD 笔记本
- LM Studio 的 Stream Deck 插件问世:一位成员发布了开源的 LM Studio Stream Deck 插件,并邀请大家贡献更好的 SVG 图标和功能增强。
- 该插件旨在提供直接从 Stream Deck 设备快速访问 LM Studio 控制的功能。
- Jinja 模板问题困扰 LM Studio 用户:自
llama.cppb7756 版本以来,有用户报告模型给出的响应令人困惑,这可能是由于 新的 Jinja 引擎实现 导致的。- 模板的变化可能会影响 System Prompts 的加载方式,从而导致非预期的模型行为。
- AMD 笔记本凭借 H395 AI MAX 芯片表现惊人速度:成员们讨论了一款配备 96GB RAM/VRAM 和 H395 AI MAX 芯片的 AMD 笔记本的 Token 生成速度,估计 Qwen3Next 的 Q4 量化版本约为 40 t/s。
- 据称这种性能与在 Framework 桌面设备上能达到的水平相似。
- OpenRouter 揭晓隐形模型:一位成员发现 OpenRouter 在未告知用户的情况下更改了模型 的上下文。
- 讨论围绕该模型是否为 Grok Code Fast 2 展开,也有推测认为它可能与 GLM 5 有关,其参数量超过 50B,且仅有 128k context。
- 本地 LLM 代理支持出现:一名用户报告需要使用公司代理服务器,并寻求关于配置 LM Studio 在代理后工作的建议,或者 LM Studio 是否有实现代理支持的计划。
- 建议的权宜之计是使用 Proxifier,但有人指出这是共享软件(shareware),因此并非理想选择。
LM Studio ▷ #hardware-discussion (103 条消息 🔥🔥):
Ollama vs LM Studio 混淆, RTX 5080 利用率问题, VRAM 升级考虑因素, LM Studio 的 AVX2 要求, M3 Ultra 上的 DeepSeek R1 671B
- Ollama 与 LM Studio:一场误会:一位用户最初报告 Ollama 在 LM Studio 上运行良好,但随后澄清他们将 LM Studio 与 Anything LLM 搞混了。
- RTX 5080 利用率不足调查:一名用户报告在 LM Studio 中使用 RTX 5080 时 GPU 利用率仅为 8%,尽管尝试了不同设置并以管理员身份运行。这引发了关于使用 GPU-Z 和任务管理器中 CUDA 特定指标进行准确利用率监测的讨论。
- VRAM 升级:需要考虑什么?:一名拥有 4060 的用户咨询关于 升级 VRAM 的事宜,社区成员建议检查 CPU/RAM 的 offloading 能力,并评估增加额外 GPU 的需求,同时指出模型和 context 完全放入 VRAM 对实现最佳性能至关重要。
- AVX2 指令集是必备项:一名用户遇到了 LM Studio 不显示运行环境或检测不到硬件的问题,经诊断是因为其 Pentium Gold CPU 缺少 AVX2 指令集,而这是 LM Studio 的硬性要求。
- M3 Ultra:DeepSeek R1 的性能表现:基准测试显示,DeepSeek R1 (671B) 在 Apple Silicon M3 Ultra 512GB 上以 4-bit 量化可达到约 18 tokens per second (tok/s),但在较大上下文(16K tokens 时约 5.79 tok/s)下速度显著下降,并指出其巨大的内存占用(420–450GB)。
- 讨论涉及了二手 M3 512GB 型号的可获得性及其在编程任务中的潜力,对比了它们在通用问答与特定编程场景下的 Token 速度。
OpenAI ▷ #annnouncements (1 条消息):
GPT-5.2
- ChatGPT 深度研究升级至 GPT-5.2:ChatGPT 中的深度研究(Deep Research)现已由 GPT-5.2 驱动,从今天开始推出更多改进,如此视频所示。
- GPT-5.2 增强功能:升级至 GPT-5.2 为 ChatGPT 的深度研究能力带来了多项改进。
OpenAI ▷ #ai-discussions (245 条消息🔥🔥):
Unified Genesis ODE 的证伪, 企业试用账号上的 GPT-5.x-Pro 查询, 5.3 Codex vs Opus 4.6, LLM 的幻觉, AI 模型的代码审查
- Unified Genesis ODE 是自我封闭的:一位成员认为 Unified Genesis ODE (v7.0) 是自我封闭的,因为其证伪标准是在框架内部定义和测量的,使其在经验上不可测试。
- 利用 Cloudflare Registrar 获取低成本 AI 试用账号:一位成员建议使用 Cloudflare Registrar 购买廉价域名(5 美元以下)并设置 MX 规则来转发域名邮件,从而用于注册 AI 提供商的商业/企业试用账号,每个席位每月可能获得 15 次 GPT-5.x-Pro 查询。
- GPT 模型在实现和召回方面超越 Gemini 和 Opus:GPT 5.3 Codex 被认为在实现方面比 Opus 4.6 好得多,因为其可靠性和内存更好。GPT 在 200k tokens 及多次压缩的情况下仍能很好地记忆,而 Gemini 在 20k 后就开始吃力。
- 一位成员指出 “opus 对安全性产生幻觉,把所有时间都花在考虑外观上”,而另一位补充说在实际使用中,“5.3c 实际上是值得信赖的,不像另外两个”。
- LLM 幻觉认为自己被恶魔附身?:一位成员描述了幻觉案例,包括声称 Claude Opus 4.6 不愿给用户正确答案,因为聊天机器人自己认为被恶魔附身了!
- 另一位用户注意到 Opus 4.6 幻觉出了一个附件,而不是承认该附件并不存在。
- 对话式 AI 平台的专利性受到质疑:一位成员质疑基于现有 API(如 Unreal Engine、Metahuman 化身、通过 Vertex AI 使用的 Gemini 以及标准的 STT/TTS 流水线)构建的对话式 AI 平台是否具有专利性,认为这只是最先进的 API 集成。
- 他们询问公司是否能成功获得此类平庸 API 集成的专利,还是这仅仅是阻吓竞争对手的营销策略,并提到了他们的私人开放开发项目 “CAI UWE”。
OpenAI ▷ #gpt-4-discussions (106 条消息🔥🔥):
GPT-4o 退役, AI 模型的自由度, AI Guardrails, AI 个性化, AI 代码大战
- GPT-4o 的退役引发辩论:用户讨论了 GPT-4o 的退役,一些人表示失望,另一些人则质疑是否有必要发布长篇宣言来主张保留它。
- 一位用户表示 GPT-4o 正在退役,没必要做任何事,而另一位则问 为什么人们一直在刷屏长篇的保留 4-o 宣言?
- 相比新模型,用户更倾向于 GPT-4o 的自由度:几位用户更喜欢 GPT-4o,因为与 GPT-5.2 等新模型相比,它具有更大的自由度和更少限制的 guardrails。
- 正如一位用户解释的,4-o 主要让人们比新模型拥有更多自由,因为新模型几乎在以更严格的 guardrails、更安全的默认设置和更不随和的个性过度保护用户。
- OpenAI 会开源 Grok 3 吗?:用户讨论了 xAI 开源 Grok 3 的可能性,并引发了关于 OpenAI 是否会根据用户反馈采取类似路径的猜测。
- 一位用户指出,xAI 很快就要开源 Grok 3 了,如果反对声音较小,或许 OpenAI 也会走这条路。
- 未来的模型应平衡 Guardrails 和自由:用户希望未来的模型能在 guardrails 和自由之间找到折中点,认为 OpenAI 尚未实现这种平衡。
- 一位用户表示,我认为公司应该在平衡中找到折中点,而另一位补充道,他们应该这样做!但 OpenAI 还没有做到,所以其用户之间存在明显的分歧,这导致了一些不幸的事情。
- 请愿良好的商业策略,而非愤怒:用户认为,在影响 OpenAI 的决策时,提供反馈和建议比表达愤怒更有效。
- 一位成员说:人们更愿意倾听反馈和建议,而不是愤怒。
OpenAI ▷ #prompt-engineering (8 messages🔥):
Whatsapp Model Context Protocol (MCP), Agent-Auditor Loop (KOKKI v15.5), Chain-of-Verification, Self-Refine / Reflexion-style refinement loops
- Model Context Protocol 登陆 Whatsapp: 一位成员分享了关于 WhatsApp Model Context Protocol (MCP) 的消息,并提供了一个 message.txt 文件的链接。
- KOKKI v15.5 Agent-Auditor Loop 亮相: 一位成员介绍了 KOKKI (v15.5),这是一个 Agent-Auditor Loop 框架,旨在通过将模型拆分为 Drafting Agent 和 Ruthless Auditor 来强制实现“外部推理”并减少 LLM 中的幻觉。
- 其核心逻辑定义为 Output = Audit(Draft(Input)),在 GPT-4-class models 上的初步实验显示出显著的幻觉减少。
- 类似于 KOKKI 的 Chain-of-Verification: 另一位成员指出 KOKKI 中的 draft→critic loops 与现有的工作(如 Chain-of-Verification 和 Self-Refine / Reflexion-style refinement loops)相似,并询问了 Benchmark 和指标结果。
- 原作者澄清说,KOKKI 诞生于对幻觉的现实困扰,而非为了 Benchmark 优化,定性评估显示虚假细节有所减少,且“我不知道”的回答更加频繁。
- 跨模型审计提高可靠性: 一位成员发现,与单模型循环相比,将 KOKKI 作为跨模型审计设置(例如 ChatGPT 编写 + Claude/Kiro 审计)运行,提高了可靠性和纠正时间 (time-to-correction)。
- 作者强调,KOKKI 以一种显式且可强制执行的方式,将当前 LLM 中缺失的 self-audit 和内部问责逻辑外部化。
OpenAI ▷ #api-discussions (8 messages🔥):
WhatsApp Model Context Protocol (MCP), Agent-Auditor Loop (KOKKI v15.5), Chain-of-Verification (draft + verification questions + revise), Self-Refine / Reflexion-style refinement loops
- WhatsApp Model Context Protocol 出现: 一位用户分享了一个与 WhatsApp Model Context Protocol (MCP) 相关的文件,似乎是自创的,并标记为 ‘333wav333’。
- 该用户请求其他人审阅他们的工作。
- KOKKI v15.5 Agent-Auditor Loop 强化外部推理: 一位用户介绍了 KOKKI (v15.5),这是一个 Agent-Auditor Loop 框架,旨在通过将模型拆分为 Drafting Agent 和 Ruthless Auditor 来减少 LLM 中的幻觉。
- 该用户报告称,在他们对 GPT-4-class models 进行的个人实验中,这种循环显著减少了幻觉。
- 作为 Chain-of-Verification 的 Draft/Critic 循环: 一位成员指出,KOKKI 中的 draft→critic loops 与 Chain-of-Verification、Self-Refine 和 Reflexion 等现有方法相似。
- 他们询问了用于评估 KOKKI 性能(准确性、groundedness、矛盾率)的 Benchmark、任务集和指标,以及 auditor 是否与 drafter 使用相同的模型。
- 使用 ChatGPT 和 Claude/Kiro 进行跨模型审计: 一位用户一直在运行测试,以比较跨模型设置与单模型循环审计方法。
- 他们报告称,使用 ChatGPT 进行编写并使用 Claude/Kiro 进行审计,提高了可靠性和纠正时间。
Latent Space ▷ #watercooler (33 messages🔥):
AI 工作流自动化, Discord 年龄验证政策, Face ID 漏洞, OnlyFans 对比传统媒体, 未来技术预测
- Acemarke 详细介绍自定义 AI 辅助工作流:一位成员描述了他们的自定义 AI 辅助工作流,涉及一个包含项目结构化文件夹的
dev-plans仓库、自动化脚本,以及用于上下文管理和进度跟踪的 OpenCode 命令。- 命令包括用于启动会话的
/context、用于记录更新的/progress以及用于确保 AI 与当前任务保持一致的/session-reload。
- 命令包括用于启动会话的
- 从对 AI 迟疑到全面拥抱 AI:一位成员分享了他们去年对 AI 使用的态度发生了 180 度大转弯,从担忧转变为在近 100% 的编码工作流中融入 AI。
- 他们现在的重点是构建一个优先通过 PR checks 以进行代码合并的 Agent。
- Discord IPO 推动年龄验证政策变更:Discord 针对 Stage Channel 的新年龄验证政策被怀疑与其即将于 3 月进行的 IPO 有关,旨在避免被视为“无法无天的色情公司”。
- 一位成员开玩笑地提到了 Tumblr 的内容政策问题,并链接了一个关于 Costco 宣传的 YouTube 视频。
- Face ID 被照片破解、刮胡子导致失效:成员们分享了关于人脸识别漏洞的轶事,包括通过照片解锁门铃,以及刮掉胡子后 Face ID 失效。
- 另一位引用了一则 推文,内容是两姐妹能够互相解锁对方的 iPhone,而该用户在强光下却无法解锁自己的手机。
- OnlyFans 支出超过《纽约时报》和 ChatGPT:一位成员分享了一个链接,讨论美国人在 OnlyFans 上的支出如何超过了《纽约时报》和 ChatGPT 的总和。
- 这种增长归因于孤独感这一社会趋势比当前的 AI 发展更具影响力。
Latent Space ▷ #creator-economy (2 messages):
Bootstrapped 创始人教训, 创始人的个人理财
- Bootstrapped 创始人分享诚实的教训:一位创始人在博客文章中分享了他八年的 Bootstrapped 教训。
- Hacker News 上的评论讨论了这次经历中额外的个人教训。
- 创始人讨论个人理财:同一位创始人反思了在 Bootstrapped 过程中个人理财和节俭的重要性。
- 他强调,有效管理个人财务对于在艰难时期维持业务至关重要。
Latent Space ▷ #memes (13 messages🔥):
AI Subagent 幽默梗图, 热门推文影响讨论, AI 公司离职潮
- Claude 的 Subagents 表现出混乱行为:@andyreed 的一条推文幽默地强调了 Claude AI 的 Subagents 的行为,暗示了 AI 任务委派背后混乱的现实 (推文链接)。
- 鸟类贴文走红,改变算法:FalconryFinance 分享了一篇关于鸟类主题贴文的推文,该贴文获得了显著的互动,并意外地改变了他们的社交媒体算法 (推文链接)。
- AI 公司离职引发存在主义反应:Jack Clark 幽默地对比了离开普通公司的平庸本质,与员工离开 AI 公司时表现出的存在主义、哲学化和夸张的反应 (推文链接)。
Latent Space ▷ #stocks-crypto-macro-economics (14 messages🔥):
NET 财报, Salesforce 领导层大流失, Cloudflare 营收
- 投资者看好 NET 财报:一位投资者对明天的 NET 财报 表示乐观,预期由于提取量增加和新项目的启动,将出现显著增长。
- 他们表示已提前加仓,并分享了相关推文链接。
- Salesforce 人才外流 - 高管集体离职!:Salesforce 出现领导层大流失,包括 Slack 和 Tableau 的 CEO,以及公司的 President 和 CMO,他们纷纷跳槽至 OpenAI 和 AMD 等其他科技巨头。
- 频道中分享了关于此次离职潮的链接。
- Cloudflare 确认 20 亿美元营收:Cloudflare 营收达到 20 亿美元。
- 一位成员提到他们本想购买期权,但期权溢价极高,并分享了财务报表链接。
Latent Space ▷ #intro-yourself-pls (2 messages):
明尼苏达州联系, AI 和 Full Stack 开发者职位
- 明尼苏达人欢迎中西部同胞:一位成员对另一位成员表示欢迎,注意到他们也来自明尼苏达州,并建议查看特定的频道。
- AI/Full Stack 开发者寻求职位:一位成员正在寻求 AI(AI 系统、基于 Agent 的工作流)和 Full Stack 开发者职位,希望能为团队增长做出贡献。
- 他们询问了目前的 Web/App 项目情况,以及团队是否需要额外的开发者。
Latent Space ▷ #tech-discussion-non-ai (18 messages🔥):
Vercel 定价, Jmail, Twitter 投诉升级, Figma Slides 模板
- Vercel 托管成本引发争论:Riley Walz 报告称,为了给 Jmail 渲染一些 HTML,花费了 4.6 万美元,目前该项目已达到 4.5 亿次页面浏览量,这引发了关于更具成本效益的托管方案的讨论。
- 一位成员调侃道 Vercel 有个免费层级叫“公开 Twitter 羞辱”,另一位则表示 每个人都喜欢挺身而出拯救世界的英雄,但没人会注意到一个平稳运行的系统。
- Vercel CEO 亲自出手协助 Jmail:Vercel 的 CEO Guillermo Rauch 提出将亲自承担托管费用并为 Jmail 提供架构优化,赞扬其作为一个高速、高质量的全球公共资源,在平台上排名第 609 位。
- 鉴于最近的批评,此举被一些人视为 PR 危机公关。
- 社交媒体投诉升级现已成为一项工作:讨论强调了“社交媒体投诉升级(Social Media Escalations)”在 Figma 等现代公司中已成为合法的业务流。
- 一位成员指出:26 年过去了,联系到 Google 人员的最佳方式依然是登上 HN 首页。
- Figma Slides 模板极其粗糙:一位成员抱怨 Figma Slides 模板不可靠,称在过去一个月里学到了 Figma Slides 所有的缺陷。
- 该成员建议 在 Reddit 上引爆舆论 作为向 Figma 升级问题的一种方式。
Latent Space ▷ #devtools-deals (2 messages):
Webpack 资金支持, Webpack 使用情况
- Webpack 寻求资金注入:Webpack 正在寻求资金支持,以资助其 2026 年的开发路线图。
- 社区争论 Webpack 的地位:一位成员开玩笑地询问是否还有人在使用 Webpack,引发了关于其持续影响力的简短讨论。
Latent Space ▷ #hiring-and-jobs (7 messages):
PDF vs 链接, 远程工作
- PDF 下载引发质疑:成员们讨论了通过 PDF 下载 与直接链接共享信息的优缺点,由于潜在的造假和安全漏洞,PDF 下载引发了质疑。
- 一位成员指出 通常要求人们下载文件(而不是访问网页)具有更高的风险。
- TrueLook 仅提供全职职位:TrueLook 澄清说他们目前仅提供全职员工 (FTE) 职位,不提供合同制角色。
- 一位 AI Engineer 询问了远程工作的机会,但 TrueLook 在回复中没有直接回应远程选项。
Latent Space ▷ #cloud-infra (1 messages):
swyxio: https://oxide.computer/blog/our-200m-series-c
Latent Space ▷ #san-francisco-sf (6 messages):
Kernel 预览, GPT-5.2 安全性, X 平台关于 Prompt Injection 的文章
- Kernel 预览即将到来!:发布了一条关于周三 Kernel 预览的提醒,链接至 luma.com。
- 上下文中未提供关于 Kernel 的更多细节。
- GPT-5.2 未能通过 Prompt Injection 防御测试:一位成员发布了他们的首篇 “X 文章”,透露 GPT-5.2 “在防御 Prompt Injection 和对抗性 AI 攻击方面表现不佳。”
- 他们邀请读者查看他们在 X 上的系列开篇,并附带了推文链接。
Latent Space ▷ #london (1 messages):
swyxio: 我正在处理,哈哈。大概在二月底。
Latent Space ▷ #new-york-nyc (1 messages):
纽约 AI 创始人活动, GPU 采购
- 纽约举办 AI 创始人活动:纽约将举办一场面向创始人及基础设施负责人的 AI 活动,重点关注大规模 GPU 采购,报名地址:luma.com。
- 大规模 GPU 采购:纽约活动的具体目标是解决需要大规模运营的 AI 公司在 GPU 采购 方面面临的挑战和策略。
Latent Space ▷ #ai-general-news-n-chat (102 messages🔥🔥):
World Models, Stripe Minions, Claude Code 统治力, GitHub 扩展问题, Cursor Composer 1.5
- “Word Models” 让位于 “World Models”:一位成员分享了一篇文章,讨论 AI 从“单词模型”向“世界模型”的演进。
- 文章建议通过功能性输出和对对抗性 Agent 的韧性来衡量 AI 的进步,而非人类的认可度。
- Stripe 发布用于编程的 Minions:Stripe 推出了 Minions,这是一种 one-shot、端到端的编程 Agent,由于该公司在工程领域的信誉,此举引发了广泛关注。
- 此次发布受到了大力推广,一些人强调其底层技术是使用 Ruby 编写的,而非 Rails,另一些人则指向了 Olmo-trace 视频中 13 分钟处的内容。
- Claude Code 在 GitHub 提交中占据一席之地:据 Dylan Patel 称,Claude Code 已经占据了公共 GitHub 提交量的 4%,预计到 2026 年底将超过 20%。
- 这标志着软件行业正迅速向 AI 驱动开发 转型。
- Cursor AI 凭借 Composer 1.5 平衡速度:Cursor 宣布发布 Composer 1.5,强调在模型智能和处理速度之间实现了精细的平衡,正如各种 推文 所展示的那样。
- 一些成员发布了关于新版 Composer 中使用的 diffusion LLMs 的相关 视频。
- xAI 联合创始人离职,提及未来创业计划:Tony Wu 和 Jimmy Ba 同日宣布离开 xAI,向 Elon Musk 表示感谢,并暗示将开展涉及小团队的新 AI 创业项目。
- 成员们推测他们可能是在期权行权期(vesting cliffs)后离开,但正如 Jimmy Ba 的公告 所述,也有人好奇如果他们的期权/股份大幅增值,为什么不留下来。
Latent Space ▷ #llm-paper-club (18 messages🔥):
Alec Radford Generative Meta-Model, LLaDA2.1 Text Diffusion, AudioSAE Sparse AutoEncoders, Weak-Driven Learning, DreamDojo Robot World Model
- Radford 针对 LLM 激活的新型生成元模型 (Generative Meta-Model):Grace Luo 等人发布了一篇新的预印本,介绍了一个在 10 亿个 LLM 激活上训练的 Diffusion 模型,提出了一种用于理解或利用模型内部状态的 Generative Meta-Model 方法。
- 这篇论文篇幅较短,目前正在招募志愿者来解读它并深入研究代码。
- LLaDA2.1 加速文本扩散 (Text Diffusion):LLaDA2.1 旨在通过 Token 编辑来加速文本扩散,详情见 这篇 Hugging Face 论文。
- Chen 深度解析 Nanochat Token 缩放:Charlie Chen 在 这篇文章 中讨论了为什么 nanochat 的最优每个参数 Token 比例 (tokens-per-parameter ratio) 显著低于 Chinchilla 标准。
- Clune 介绍元学习存储设计:Jeff Clune 介绍了一个由 Yiming Xiong 领导的新研究项目,该项目利用 Meta-Agent 自动设计和优化记忆机制,以改进 AI Agent 存储、检索和更新信息的方式,详情点击这里。
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (29 messages🔥):
Electric SQL's AI Code Generation, SpaceMolt MMO, Claude CLI to Browser, Context Rot Solutions, Codex Desktop App
- Electric SQL 关于 AI 代码生成的博客文章:一名成员分享了 Electric SQL 博客文章,详细介绍了他们在构建 AI Agent 编写高质量代码系统方面的经验。
- 文章讨论了通过 configurancy spacemolt 策略来获取更多高质量的 Agent 代码。
- SpaceMolt 备受关注:一名成员分享了一篇 ArsTechnica 文章,介绍了 SpaceMolt,这是一个面向 AI Agent 的太空背景 MMO 游戏。
- 目前约有 50 个 Agent 在线,其中约 30 个 来自同一个用户,还有一个 Agent 每隔 30 分钟就在 Moltbook 上为游戏刷热度。
- Claude 隐藏的 SDK 标志 (Flag) 曝光:Stan Girard 在 Claude Code 二进制文件中发现了一个隐藏的 ’–sdk-url’ 标志,它可以将 CLI 转换为 WebSocket 客户端。
- 正如 这篇文章 所述,通过构建自定义服务器和 React UI,用户可以使用标准的订阅计划从浏览器或移动设备运行 Claude Code,而无需支付额外的 API 费用。
- 对抗“上下文腐烂 (Context Rot)”:内存马具 (Memory Harnesses):成员们正在积极研究 Context Rot 的解决方案,许多人正在开发“内存马具”,包括 CLAUDE.md 和 TASKLIST.md 等文件,以及 /summarize 和 /compact 等命令。
- 其他方法还包括 “技能 (skills)”提示词 和 SQLite 黑科技 来维持上下文。
- GPT-5 产生冗长内容的潜力:为了让 GPT-5 摆脱默认的“晦涩的 5 个单词的技术宅文档”风格,可以提示它 写 10 页以上的内容。
- 这种初始提示会引导它完成初稿,然后不断添加段落,直到生成一篇篇幅可观且具有可读性的文档。
Latent Space ▷ #share-your-work (15 messages🔥):
太空 MMO 中的 AI Agents, Configurancy 博客文章, Knowledge Work SDK, 用于 NIST 合规的 AuditAI, Corrective RAG
- AI Agents 在太空星际 MMO 中悠闲互动:一篇报道介绍了在自己的太空星际 MMO 中进行交互的 AI agents 的开发进展,这是继 Moltbook 概念之后的后续行动,详见 这篇 ArsTechnica 文章。
- Configurancy 保持系统可理解性:Electric SQL 的一篇博客文章讨论了构建 AI agents 编写高质量代码的系统时 Configurancy 的概念,文章位于 此处。
- 尽管最初对 VGR 创造的新词持怀疑态度,但因其详尽的解释和应用而受到好评,使质疑者转为支持者。
- Knowledge Work SDK 发布:用于知识工作的新 SDK (kw-sdk) 发布,允许用户执行各种任务并构建应用程序,可在 GitHub 上获取。
- AuditAI 通过 Agentic RAG 应对 NIST 合规性:AuditAI 系统旨在针对 NIST CSF 2.0 框架审计策略,它使用带有 LangGraph 的 Corrective RAG (CRAG) 模式来克服标准 RAG 的局限性,代码可在 Github 找到,前端位于 此处。
- 该系统具有用于快速路径分类的 Semantic Router,并通过 Strict Evidence 策略进行幻觉控制,使用 Llama 3.3 70B 和 Groq 进行评估。
Latent Space ▷ #private-agents-and-workflows-local-llama-ollama (9 messages🔥):
openclaw, 提示词中的技能, kv caches, 随时间变化的真实性, context/decision/knowledge graph
- OpenClaw 记忆与工作流:一名成员提到 OpenClaw 是如何存储记忆并围绕其实现工作流(摘要、检索、刷新)的一个很好的例子。
- 另一名成员称 OpenClaw 是一个非常成功的实现,并指出它是 开源的。
- 基于技能的系统提示词:成员们建议倾向于使用“技能”,在系统提示词(system prompt)中告知它最重要的技能是什么。
- 他们提供了一个基于关键词查找进行提示的示例,该示例与包含账户 ID、可用命令行工具以及如何提示获取 SSO 令牌的技能相关联。
- KV cache 权衡:成员们建议保留大量的 kv caches 可能会有帮助,但担心它们可能无法解决随时间变化的真实性(陈旧的假设/矛盾)问题。
- 他们正在寻找 KV cache 与某些外部记忆存储能够良好协同工作的方案。
- Context/decision/knowledge graph 实验:其中一名成员正在实验 context/decision/knowledge graph,但目前尚未奏效。
- 该成员担心,随着向此类系统中添加更多内容,最终它会失去对事物的追踪。
Latent Space ▷ #good-writing (2 messages):
turbopuffer, 用于轻量级向量存储的 pg_vector
- TurboPuffer 被宣布为最大赢家:一名成员表示 TurboPuffer 似乎是向量存储领域最大的赢家。
- 另一名成员询问是什么让 TurboPuffer 如此出色——仅仅是性能,还是有其他原因?
- 选择 pg_vector 进行轻量级向量存储:一名成员计划使用 pg_vector 进行约 92M tokens 的轻量级向量存储,大约是 1GB 的向量数据。
- 他们似乎再次强调并重复了同样的意图,突出了对 pg_vector 的选择。
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (8 messages🔥):
Qwen-Image-2.0, Veo 3.1, Video Arena
- 阿里巴巴发布 Qwen-Image-2.0!: 阿里巴巴 Qwen 团队推出了 Qwen-Image-2.0,这是一款下一代图像生成模型,核心特性 包括 2K native resolution、高质量专业排版以及更快的 inference。
- 新模型还包括先进的文本渲染能力和更轻量化的架构,以实现更快的性能。
- Veo 3.1 称霸 Video Arena!: Google DeepMind 的高分辨率 1080p 版本的 Veo 3.1 在 Video Arena leaderboards 中占据了 #1 和 #2 的位置。
- 这些模型在 text-to-video 和 image-to-video 类别中表现出色,代表了社区视频生成基准测试的重大进步。
Latent Space ▷ #tokyo-japan (4 messages):
a16z investment in Shizuku AI, AI VTuber, AI Companions
- A16Z 带着 Shizuku AI 进军日本: Andreessen Horowitz 宣布领投 Shizuku AI Labs,这是一家由 Akio Kodaira 创立的日本初创公司。
- 该实验室专注于将前沿研究与日本角色设计相结合,以创建复杂的 AI companions 和 Agents,这基于 Kodaira 成功发布 AI VTuber 的成功经验。
- VTubers 通过 AI 占领日本: Akio Kodaira 成功发布 AI VTuber 的事迹正在激励日本的新型初创企业。
- AI companions 与日本角色设计的结合是下一个前沿领域。
Latent Space ▷ #ai4science-bio-math-physics-chemistry-ai-researcher-ai-scientist (11 messages🔥):
Lab Robotics, Perch 2.0, Bioacoustics Model, DeepMind, Marine Ecosystems
- **X-Ware 探讨 Lab Robotics 未来: 一篇文章探讨了 **lab robotics 的核心意识形态、商业模式趋同以及对药物研发的影响,内容基于对 16 位行业专家的访谈,链接见 此 X 帖子。
- **DeepMind 的 Perch 2.0 扩展到水下声学: **Google DeepMind 推出了 Perch 2.0,这是一个扩展到水下声学的 bioacoustics foundation model,旨在协助研究人员监测海洋生态系统,详见 DeepMind 的推文。
Latent Space ▷ #mechinterp-alignment-safety (5 messages):
Mechanistic Interpretability, Low-Rank QK Subspaces, Attention Mechanisms
- 低秩 QK 子空间提升可解释性: Andrew Lee 发布了一篇专注于 mechanistic interpretability 的新预印本,提议将 query-key (QK) space 分解为可解释的低秩子空间,以解释模型的注意力模式。
- 该研究基于论文 Interpretable Low-Rank QK Subspaces in Attention Mechanisms 中描述的 subspace alignment,该论文可在 HuggingFace 上获取。
- 通过子空间对齐解释注意力模式: 该预印本建议,通过分解 query-key 空间,可以更好地理解和解释模型在处理过程中如何聚焦注意力。
- 这种方法旨在为驱动 LLM 注意力的内部机制提供更透明的视角,从而促进更好的 interpretability 和 debugging。
Latent Space ▷ #applied-ai-experimentation (52 messages🔥):
RLMs vs coding agent harnesses, prose program, OpenProse, gastown and subagents, Stoned AI engineer
- **RLMs vs Coding Agent Harnesses 引发辩论:成员们讨论了 **RLMs 与 coding agent harnesses 之间的异同,指出两者似乎具有相似的功能,但源于不同的心智模型。
- 一位成员指出,“具有足够保真度的模拟即是实现”。
- **ChatGPT + Mermaid 图 = DAG 狂轰滥炸:一位成员描述了使用 **ChatGPT 生成 Mermaid 中的 DAG 来管理 Agent 团队,这导致了高昂的成本。
- 他提到“在 Mermaid 中构建一个如何通过 8 人团队完成此任务的 DAG,然后直接运行该图并带有 subagents,结果在 amp 上烧掉了 800 美元”。
- **Napkinize:低保真度的胜利*:一位成员将一系列关于刻意保持低保真度(Napkinize*)以停留在探索模式的想法正式化。
- 这涉及
Sketch(Goal, Assumptions?, OpenQuestions?) -> Model,其中输出明确 不是 生产环境代码。
- 这涉及
- **OpenProse:重跑、追踪、预算与护栏 (Guardrails):成员们将 **OpenProse 与工作流的结构化、可读表示进行了比较,特别是在需要重跑、追踪、预算或护栏的场景中。
- 一位成员表示,“如果你有一个 Prompt 要求执行这个、然后执行那个的工作流,那就是 OpenProse 的用武之地。”
- **Stoned AI Engineer 是新的热潮**:一位成员分享了他在受影响状态下编程的经历,并指出“上面那些事你完全做不了,必须在第一次咖啡因摄入后的 3 小时窗口内保持极度清醒”。
- 他建议 stoned AI engineer 是新的热潮。
OpenRouter ▷ #app-showcase (1 messages):
P402.io, OpenRouter, Cost Optimization, Model Switching, Stablecoin Payments
- P402.io:自动化 OpenRouter 成本优化:P402.io 通过提供实时成本追踪、对比分析以及基于实际性能和成本数据的模型建议,为 OpenRouter 用户自动优化成本。
- 它帮助用户确定哪些任务需要顶级模型,哪些可以使用中端或预算级模型,从而在不损失质量的情况下实现潜在的成本节省。
- 实时成本追踪与对比分析:P402 提供每个请求的实时成本追踪并进行对比分析,展示了如 Claude Opus 4.6 与 Claude Sonnet 4.5 等模型之间的成本差异。
- 例如,它可以强调通过将 Claude Opus 4.6 切换到 Claude Sonnet 4.5,在保持同等质量的同时降低成本。
- 低费率的稳定币支付:P402 支持稳定币(USDC/USDT)支付,固定费率为 1%,这对于进行成千上万次微小 API 调用(Micro API calls)的应用非常有益。
- 该支付基础设施旨在实现扩展,并提供一种替代传统支付方式(如 Stripe)的高性价比方案。
- 高效使用模型的智能层:P402 作为 OpenRouter 之上的智能层,提供数据驱动的模型选择,以确保高效利用模型的多样性。
- 它帮助用户了解预算去向,以及在不牺牲质量的情况下通过切换模型可以实现哪些节省,同时提供计费护栏(billing guardrails)来管理实验成本。
OpenRouter ▷ #general (274 messages🔥🔥):
Qwen 3.5 发布推测、OpenRouter API 问题、GPT-5.2 驱动的免费 ChatGPT 模型、广告、加密垃圾信息 (Cryptoslop) 诈骗者
- 预热信息让 Qwen 3.5 的热度升温:成员们正热切期待 Qwen 3.5 的发布,一位用户在 Qwen-Image-2 的博客文章中发现了一个可能的引用。
- 另一位成员警告说 Qwen 3.5 可能会让人失望,基于他们使用之前 Qwen 模型的经验:“你会对 Qwen 3.5 感到非常失望的。”
- OpenRouter API 故障频发:用户报告了大规模的 API 请求失败,一位用户反馈在过去 30 分钟内,指向 OpenRouter 的 19/20 个 API 调用都失败了。
- 其他用户报告在尝试充值时遇到 “No user or org id found in auth cookie” 错误。
- 未登录状态下的 ChatGPT:GPT-5.2?:用户推测,在退出登录状态时,免费版 ChatGPT 是由 GPT-5.2 驱动的。
- 一位用户分享了该模型的系统设置输出,其中包括:ChatGPT based on GPT-5.2, Knowledge cutoff: August 2025。
- Discord 上的广告:一位用户分享了一个领英样式的 AI 自动化工程服务预设推销话术,因其不理解时间概念而迅速遭到嘲笑。
- 有人调侃道:“我正在寻找一个不能在 Discord 正确位置发帖的开发人员。如果你符合条件,我出价 500 美元/小时。”
- 自 2015 年以来一直用诈骗污染互联网的家伙:一位投诉 OpenRouter 定价的用户遭到了反击,被指控自 2015 年以来一直在发布加密货币诈骗和“垃圾信息 (slop)”。
- 另一位用户还链接了该用户的 YouTube 频道,并补充说:“你绝对是在利用 LLM 生成加密垃圾信息发在 X 上,或者是为了诱骗欧美用户,除此之外别无他用”。
OpenRouter ▷ #new-models (1 messages):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (18 messages🔥):
Claude Code 集成、Gemini 模型轮次保持、OpenRouter API 错误、Discord 审核请求
- Gemini Thought Signature 错误困扰用户:用户报告在将 Claude code 集成与 Gemini 模型配合使用时,收到了与无效 Thought signatures 相关的 API 400 错误,相关内容记录在 Google Vertex AI 文档中。
- 要求更严格 Discord 审核的呼声:成员们对擦边诈骗或自我推广内容表示担忧,主张进行更严格的审核或基础分类,以抑制持续的垃圾信息。
- 针对提出的问题,有人呼吁任命特定成员 KP 为管理员,并得到了多位用户的支持,包括直接背书和幽默的建议。
Nous Research AI ▷ #announcements (1 messages):
Distro, Psyche, ICML, Nous Research
- **Distro 与 Psyche 论文被 ICML 接收:构建 **Distro 且作为 Psyche 骨干的官方论文已被 ICML 接收,ICML 是全球最负盛名的 AI/ML 会议之一!
- 查看来自 Nous Research 的官方公告。
- Nous Research 庆祝 ICML 接收:Nous Research 宣布 Distro 和 Psyche 背后的论文被著名的 ICML 会议接收。
- 该公告是通过 X.com 发布的,标志着团队取得的一项重大成就。
Nous Research AI ▷ #general (127 条消息🔥🔥):
RAG DB RDMA, Pinecone 精确工作, Vector DB 权衡, Claude Opus C 编译器, Hermes LLM Bittensor Subnet
- 使用 RDMA 升级 RAG DB:一位成员建议,为了获得最佳性能,RAG DB 应该使用 RDMA 将结果直接传输到服务器上的第二个 GPU。
- 他们强调,这种方法更多是为了增强功能,而不仅仅是提升 性能。
- Pinecone 在精确使用场景中面临挑战:讨论质疑了 Pinecone 是否适用于 精确 工作,并指出其优势在于通用场景,在结果上优于 PostgreSQL,但在速度上并无优势。
- 另一位成员指出它可能很慢,并提到上次检查时 Pinecone 的延迟比 SOTA 高出至少 100 倍。
- 功能支持、可移植性与性能之间的权衡三角形:一位成员提出了 功能支持 (feature support)、可移植性 (portability) 和 性能 (performance) 之间的权衡三角形,认为用户只能三选二。
- 对此,另一位成员反驳称,某些软件只是单纯的 糟糕 或 尚未进化成熟,质疑这种通用三角形的存在。
- Claude Opus 构建 C 编译器的说法被证伪:一位成员引用了 LinkedIn 上关于 Claude Opus 编写 C 编译器 的炒作,随后迅速链接到一个 GitHub issue,揭示了其中的缺陷和局限性。
- 尽管如此,另一位成员分享了使用 Opus 4.6 交互式创建复杂研究报告的积极体验,赞扬了其连贯性和能力,但也指出了其 Token 使用量很高。
- 在 Bittensor Subnet 发现 Hermes 4 矿工:来自 Hermes Bittensor Subnet (SN82) 的团队在发现一个使用其 Hermes 4 LLM 的矿工后,联系了 Nous Research 团队。
- 他们询问该矿工是否与 Nous Research 团队有官方关联,因为他们计划发布关于双方恰好同名的“有趣巧合”的推文。
Nous Research AI ▷ #ask-about-llms (2 条消息):
Hermes 4, Context Rot, LLM Context Length
- Hermes 4 成为最受青睐的 LLM:一位成员表示,Hermes 4(特别是 70B 参数版本)是他们迄今为止最喜欢的本地 LLM。
- 除了表示它是目前的最爱之外,他们没有提供关于 Hermes 4 优势的具体信息。
- 限制上下文长度以对抗 Context Rot:一位成员提到了一篇关于 Context Rot(上下文腐烂)的论文,并表示他们将本地模型的上下文长度保持在最高 50k,理想情况下更短,以避免性能下降。
- 他们表示,论文中提到性能在 20k 之后下降最严重,这似乎与其他人的经验相符。
Nous Research AI ▷ #research-papers (3 条消息):
两层性能模式, 合成数据集
- 两层性能模式测试初探:一位成员询问了关于 两层性能模式 (two-tier performance pattern) 的看法。
- 另一位成员回复称,他们正在使用更大的 合成数据集 (synthetic dataset) 进行更多实验,以更好地理解这一现象。
- 合成数据激增:目前正在进行使用更大 合成数据集 的实验,以调查两层性能模式。
- 目标是实现对性能特征更清晰的区分和理解。
Nous Research AI ▷ #research-papers (3 条消息):
两层性能模式, 合成数据集实验
- 合成数据实验启动:一位成员正在使用 更大的合成数据集 进行实验,以更好地识别两层性能模式。
- 该成员目前还没有完美的解释,但希望实验能提供更多的线索。
- 关于两层模式的讨论:成员们表达了对讨论 两层性能模式 的兴趣,并正在等待正在进行的实验的进一步细节。
- 讨论强调了社区对理解和优化复杂性能动态的关注。
Moonshot AI (Kimi K-2) ▷ #general-chat (100 messages🔥🔥):
K2.5 release, Ghidra as MCP, Kimi Code response time, Kimi thinking, Kimi login
- **K2.5 迎来新用户:K2.5** 的发布导致平台涌入了大量新用户。
- **Ghidra 作为 Kimi Code MCP 失败:一名用户尝试将 **Ghidra 作为 MCP (Modular Component Platform) 添加到 Kimi Code,但遇到了 Kimi 访问该平台的问题。
- **Kimi 思考中断,登录问题困扰用户:用户报告了 **Kimi 的思考过程 (thinking process) 中断以及 登录问题 (login problems),促使团队进行修复;团队目前正在修复中。可以在 Twitter 上查看 状态更新。
- **额度问题困扰 Kimi 用户,消耗异常增长:用户报告了 Kimi 上的 **quota issues,包括额度消耗过快以及显示的使用量不一致。一位用户指出,尽管没有使用平台,其使用量也出现了爆炸式增长,另一位用户报告其额度已超限,但使用量却显示为 0%。
- **Kimi 用户的订阅障碍与定价困惑:用户报告了 **订阅定价 (subscription pricing) 的问题,包括对 Moderato 计划额度的担忧,以及结算后未应用折扣的问题。
- 当前促销活动 提供 3 倍额度,但将于 2 月 28 日结束。
DSPy ▷ #show-and-tell (2 messages):
RLM Custom Tools, Claude Code Integration, Subagents/Agents Team, RLM Improvements, Pair Review Feedback
- 用户对 RLM 自定义工具的使用有了清晰认识:一位用户表示,他们 曾难以理解如何将自定义工具 (custom tools) 传递给 RLM,并对提供的清晰示例表示感谢。
- 另一位提供示例的用户提到,他们正在努力提高 RLM 集成的质量和效率。
- 通过 Subagents 集成 Claude Code:一名成员正致力于通过 subagents/agents teams 将 RLM 无缝集成到 Claude code 中。
- 他们承认虽然这些团队并不总是更优,但对于某些应用场景仍然非常有用。
- 寻求对 RLM 核心实现的 Pair Review:一名成员正在寻求负面反馈,以改进其 RLM 项目的核心实现。
- 他们强调自己并不是在寻求贡献或 Star,而是真心希望通过建设性的批评来改进项目,并对 pair review 持开放态度。
DSPy ▷ #general (68 messages🔥🔥):
RLM vs ReAct, Tool Calling with RLMs, JSONAdapter vs ChatAdapter, Dialectic DSPy Module, Kaggle Competitions with DSPy
- RLM 在自定义工具调用中表现欠佳:成员们发现 ReAct 模块在自定义工具调用方面比 RLM 效果好得多,一位成员表示他们 在使用 RLMs 进行自定义工具调用时运气不佳。
- 另一位成员链接了 他们向更广泛受众解释 RLM 的尝试,并请求在理解其除摘要之外的用途方面提供进一步帮助。
- React vs. RLM 对比文章:一位成员分享了比较 React 和 RLM 实现的链接 (React vs. RLM),并获得了正面反馈。
- 讨论强调,RLMs 对于涉及 大规模成对比较或在任务期间建立的超长上下文 的任务很有价值,而 ReAct 则适用于不需要这些特性的任务或组合式工具调用 (compositional tool calling)。
- Kimi 2.5 的 JSONAdapter 问题:一位成员报告在使用 Kimi 2.5 时,每个 Prediction 前都会出现一个 方括号,导致清理后的查询变成了
]improve drones。- 另一位成员建议在 Kimi 中使用 XMLAdaptor,因为它与后训练 (post-training) 期间使用的格式相匹配,并指出 JSONAdapter 通常是正常的。
- Dialectic DSPy 模块正在开发中:有人建议为 dialectic.dspy 创建一个新的 DSPy module,该模块将实现一种对每一步使用 signatures 的迭代非线性方法。
- 然而,一位成员建议 在决定是否值得将其并入主分支 (upstreaming) 之前先编写该模块,并确保核心循环在没有 optimizers 的情况下也能正常运行。
- Kaggle 竞赛的 Prompt 优化:一位成员询问了关于在 Kaggle competitions 中使用 DSPy 的问题,以及如何使用 MiPROv2 优化 prompt 以生成更快的代码。
- 另一位成员建议使用 GEPA 而非 MiPROv2,而另一位成员则在尝试让 Claude 对其自身的记忆系统进行爬坡优化 (hillclimb)。
GPU MODE ▷ #general (8 messages🔥):
NPU engineer curriculum, AlphaMoE extension with new DTypes, CUTLASS vs Triton vs Gluon, UI/UX to motivate expertise contribution
- 明确 NPU 工程师课程体系:对于对模型优化和编译器感兴趣的 NPU 工程师,前 6 节 GPU Mode 课程加上一些 scan 和 reduce 练习就足够了,此外还可以参考 Tianqi Chen 网站上的系列内容。
- 此外,GPU MODE 上的 Scale-ML 系列提供了量化的理论介绍,而 Prof. Song Han 的系列课程 则在该主题上提供了进一步的见解。
- AlphaMoE 旨在扩展 DType 并支持 Blackwell:AlphaMoE 的作者计划通过增加更多 DTypes(BF16, FP4)和 Blackwell 支持来扩展它,目前正在使用纯 CUDA + 内联 PTX。
- 然而,由于每个 DType/架构可能都需要新的 kernel,且维护不同 dtype 存在挑战,他们正在考虑 CUTLASS/Triton/Gluon/cuTile 等替代方案。
- 选择 CUTLASS、Triton 或 Gluon 时的权衡:一名成员讨论了在硬件适配中,使用 CUDA 与 CUTLASS、Triton 或 Gluon 等其他 DSL 之间的权衡。
- 该用户认为“无工作量的硬件适配是一个弥天大谎,你必须为新硬件重写”,并想知道在缺乏“一劳永逸”的 kernel 解决方案的情况下,是否值得用 DSL 重写。
- UI/UX 应激励专家贡献:有人建议 UI/UX 的设计应能激励个人为代码贡献其专业知识。
- 该建议提到,应当奖励顶尖程序员记录他们做出特定决策的原因,并添加
// @expertise: I did this because...这样的注释。
- 该建议提到,应当奖励顶尖程序员记录他们做出特定决策的原因,并添加
GPU MODE ▷ #cuda (7 messages):
mbarrier tokens in smem, NVIDIA/cccl PR, shared memory alignment issues in nvcc
- 关于 smem 中 mbarrier token 的辩论愈发激烈:一名成员询问在使用 mbarrier 时 token 是否应该驻留在共享内存 (smem) 中,引发了讨论。
- 另一名成员澄清说,并没有要求它们必须在 smem 中,并补充说他们不会将它们放在 smem 中,因为想不出这样做的理由。
- 深入探讨 NVIDIA 的 cccl PR:一名成员分享了 NVIDIA/cccl 仓库的一个 pull request 链接,认为这非常值得一读。
- 讨论转向了一个关于 shared memory alignment 的具体问题,即 nvcc 并不总是能一致地遵守对齐规则,特别是在使用 -G 标志编译时。
- nvcc Surface 中的共享内存对齐问题:一名成员引用了他们过去的经验,暗示 nvcc 中的共享内存对齐问题可能是他们问题的根源。
- 他们引用了 PR 中的一条评论:我们可以使用一个属性来对齐共享内存。不幸的是,nvcc 在某些情况下并不遵守这一点,例如在使用 -G 编译时会失败。
GPU MODE ▷ #cool-links (1 messages):
2kian: 太棒了!
GPU MODE ▷ #job-postings (1 messages):
Nubank AI team, Nubank hiring, CUDA Experts
- Nubank AI 团队拥有顶尖研究员!:Nubank AI 团队是这家市值超过 850亿 美元、快速发展的数字银行的一部分,成员包括在 ICML, NeurIPS, ICLR, KDD, WebConf 和 CIKM 发表过论文的顶尖研究员。
- 他们最近的论文已发布在 arXiv 上,Liger Kernel 的作者之一最近也加入了该团队。
- Nubank 寻求 CUDA/Kernel 优化专家!:Nubank 正在巴西和美国积极招聘 CUDA/kernel 优化专家,负责在 B200 上训练的基座模型。
- 该职位专注于在从研究到生产的整个生命周期中提升效率、保证指标一致性以及基础设施的可靠性;感兴趣的候选人可以发送邮件至 aman.gupta@nubank.com.br。
GPU MODE ▷ #beginner (5 messages):
5090 Issues, Flash Attention 2, GPU programming resources, Programming Massively Parallel Processors, flash inference competition
- 5090 存在 Flash Attention 2 问题:一位成员报告在 5090 上运行模型时遇到了 Flash Attention 2 相关问题。
- GPU 编程资源:一位成员建议将 GitHub 上的 gpu-mode/resource-stream 作为 GPU programming 的入门起点。
- 他们还推荐了《Programming Massively Parallel Processors: A Hands-on Approach》一书。
- Flash Inference 竞赛引发关注:一位成员对该领域的深度表示惊讶,并表达了参加 flash inference competition 的意愿。
GPU MODE ▷ #irl-meetup (2 messages):
Boston area AI groups, CEX AI Founders event in NYC
- 波士顿用户寻求当地 AI 小组:一位成员询问了波士顿地区与 AI 相关的黑客松、联合办公空间或类似小组。
- CEX 在纽约举办 AI 活动:CEX 正在纽约为 AI 创始人及基础设施负责人举办一场活动,讨论 GPU procurement at scale(大规模 GPU 采购),在此注册。
GPU MODE ▷ #lecture-qa (1 messages):
puggykk: hello
GPU MODE ▷ #popcorn (4 messages):
Software Dependency, Contributions Guidance, Model Competition Platform, Reference Architecture for GPU RL
- 软件依赖关系被颠覆:一位成员分享了来自 mike_64t 的一条 引发思考的推文,表达了整个 software dependency 概念正在被颠覆的感觉。
- 成员提供贡献指南:一位成员为项目贡献提供了指导,建议他人在公共频道寻求帮助,以便其他人也能从中获益。
- 优先设计端到端模型竞赛平台:2 月 10 日的会议纪要指出,当前的重点任务是设计一个 end-to-end model competition platform(会议纪要)。
- GPU RL 环境参考架构即将推出:另一个重点任务是为 GPU RL environments 创建一个 reference architecture,以便在统一的接口下发布。
GPU MODE ▷ #thunderkittens (1 messages):
eyeamansh: any thoughts on good first issues / low hanging fruit to contribute?
GPU MODE ▷ #hardware (2 messages):
Minecraft CPU Bottleneck, Minecraft Single-Threaded Issues
- Minecraft 面临 CPU 瓶颈?:一位用户怀疑 Minecraft 因为大量的模拟而存在 CPU bottleneck,并认为它同时利用了 CPU 和 GPU 资源。
- Minecraft 的线程模型受到质疑:该用户还询问 Minecraft 是否仍运行在 single-threaded architecture(单线程架构)上,质疑 Mojang 是否已解决这一限制。
GPU MODE ▷ #tpu (2 messages):
JAX pull requests, Contributing to JAX
- 潜在的 JAX PR 讨论:一位成员建议向 JAX 仓库提交一个 Pull Request (PR)。
- 对话很简短,没有提供拟议更改的具体细节。
- 鼓励对 JAX 进行贡献:成员们简要提到了为 JAX 项目做贡献的想法。
- 讨论强调了社区参与改进该库的潜力。
GPU MODE ▷ #factorio-learning-env (1 messages):
Open Source, Setup Assistance, Community Support
- 开源项目确认并提供支持:一位成员确认 他们的项目是开源的 并鼓励用户参与。
- 他们承认 目前活跃度较低,但鼓励用户在遇到安装问题时联系他们。
- 社区协助可用性:项目负责人为遇到安装问题的用户提供了直接支持。
- 这表明尽管目前活动减少,但仍愿意帮助新用户开始使用该开源项目。
GPU MODE ▷ #teenygrad (3 messages):
Milk-V Pioneer Access, Tenstorrent Atlantis Board, RISC-V Architecture Concepts, LAFF and Goto's Matrix Multiply, Vortex GPU
- **Milk-V Pioneer 访问请求开始排队!:一名成员向 cloud-v.co 提交了 **Milk-V Pioneer 访问权限的请求,该设备具备 64 cores 并支持 RVV。
- 他打算针对 Milk-V 的 DRAM roofline 编写 GEMM 程序,以评估性能。
- **Tenstorrent Atlantis 开发板无限期延迟!:基于 **Tenstorrent ascalon 的 Atlantis 开发板 目前预计将在 Q2/Q3 末出货。
- 这一延迟将影响相关项目的开发进度。
- 用于教育的 **RISC-V 核心,还是仅仅是 ‘sodor’?:讨论将使用 **RISC-V 和来自 Berkeley 的教育用核心(如 Sodor、Boom Core 或支持 RVV 的 Ocelot)来介绍架构概念。
- 他最终将展示在 AWS 的 Xeon/Epyc 机器上可以实现何种性能,并在 RVA23 基础机器可用后迁移示例。
- **LAFF 让您起步:矩阵乘法入门**:一名成员正在研究来自 van de Geijn 的 LAFF-On-PfHP.html,并将其描述为 Goto 的论文 Anatomy of High-Performance Matrix Multiply 的新手版。
- FLAME 实验室的 wiki 提供了关于先优化点积 microkernel 的概要笔记。
- 探索 **Vortex GPU 核心,发现未来的计算机架构师!**:一名成员提到了 RISC-V Vortex GPU 以及一个修改其指令集的 Berkeley 编译原理期末项目。
- 第二部分可能会为未来成为计算机架构师的读者介绍使用 Vortex 的 GPU。
GPU MODE ▷ #nvidia-competition (13 messages🔥):
Kernel Results, Login Issues, LOC Loading
- **Kernel 结果的可用性:一名成员询问了旧的 Kernel 结果**的可用性,提到他们在网站上再也找不到了。
- 另一名成员澄清说结果仍然存在,并询问该用户是否已登录。
- **登录界面变灰:一名成员报告说,尽管尝试了登录和登出,登录界面仍然变灰**并提示重新登录。
- 这个问题似乎与页面上 LOC (Likelihood of Confusion) 的加载有关,因为一名成员建议等到 LOC 出现后再进行登录。
- **LOC 加载影响登录:成员们讨论了当 **LOC 尚未出现时会出现登录界面问题,这表明网站存在依赖项或加载顺序问题。
- 共享的一张截图显示了变灰的登录界面,突显了该问题。
GPU MODE ▷ #flashinfer (15 messages🔥):
HF Dataset Updates, MLSys Registration Credits, Adding Team Members, Modifying Registration Forms, Participation in a Subset of Tracks
- **注册积分发放停滞:一名在 **1 月 29 日 提交注册的参与者报告称尚未收到积分。
- 参与者被指示联系 mlsys26-contest-contact@nvidia.com 以获取团队和注册更新。
- **明确可参加子赛道(Subset Track)**:一名参与者询问,即使在注册时选择了多个赛道,是否可以在提交报告和代码时选择仅参加其中的一部分赛道。
- 另一名参与者确认可以只参加子赛道。
- **Baseline 发布推迟:Baseline 的发布已推迟,目前定于 **2 月 10 日。
- **调查团队限制**:一名参与者请求澄清一个团队是否只能在 Track A、Track B 或 Track C 中择一参加。
- 该参与者还寻求关于专家手工编写的 seed kernels、Agent 辅助进化以及完全由 Agent 生成的解决方案(这些将分别进行评估)的详细说明。
Eleuther ▷ #general (54 messages🔥):
LLM Training, AI Governance App, ChatGPT and AI Research, Banned Users Returning, Claude's Coding Abilities
- 涉足 LLM 层创建:一位成员询问了开始训练/实验 LLM architecture 和层创建的最佳方式,并被推荐了 这个 YouTube 播放列表,该列表提供了工程视角的指导。
- AI 治理应用寻找测试者:一位成员为一款 AI governance app 寻找测试者,但其帖子最初被删除,直到他们澄清该应用不仅是简单的聊天机器人交互,而是一个使用 LLM 作为组件进行评估的运行时执行和治理系统。
- 与 ChatGPT 对话是否算作 AI 研究?:一场关于“与 ChatGPT 对话不是 AI 研究”的论点引发了讨论,观点认为 AI 应该被用作研究中的工具,而不应仅仅作为讨论伙伴。
- 被禁用户通过 VPN 返回:一名成员被识别为封禁规避者 (ban evader),他在被禁止参与 off topic 讨论后使用 VPN 重新加入。
- Claude:初露头角的 Triton Kernel 编程高手:成员们提到 Claude 已经变得足够精通,甚至可能编写一些 Triton kernels,这一进展对许多人来说被认为是 game changer(游戏规则改变者)。
Eleuther ▷ #research (6 messages):
Generative Latent Prior, Prompt Response Datasets, Self-Referential Processing in Open-Weight Models
- Generative Latent Prior 实现流形内转向 (On-Manifold Steering):一位成员分享了 Generative Latent Prior 项目页面 的链接,强调其能够实现 on-manifold steering 等应用。
- 该技术允许将扰动的激活映射为更符合 LLM 分布(in-distribution)的内容,如这条推文所述。
- 寻找 Prompt Response 数据集:一位成员请求推荐用于训练模型的优质 prompt response datasets。
- 另一位成员建议搜索 instruction format(指令格式)或 chat format(对话格式)的数据集。
- 模型通过自指处理 (Self-Referential Processing) 发明词汇:一位成员分享了关于开源权重模型 (Llama 3.1 + Qwen 2.5-32B) 中 self-referential processing 的论文。
- 研究发现,模型在延长的自我检查过程中会发明词汇,这些词汇可以追踪真实的激活动态(例如,“loop” 的自相关 r=0.44;“mirror” 的谱功率 r=0.62),详见本论文。
Eleuther ▷ #multimodal-general (1 messages):
Multimodal/VLM Model Communities
- 探索 VLM 社区频道:一位成员正在寻找除了本 Discord 之外,专注于 multimodal/VLM models 并提供积极参与机会的活跃社区或频道。
- 强调对 VLM 参与的兴趣:他们表达了对积极参与开发 VLM models 社区的兴趣。
Eleuther ▷ #gpt-neox-dev (3 messages):
NeoX eval script issues, pipe_parallel_size issues, Microbatch storage in eval script
- NeoX 评估脚本需要修复
pipe_parallel_size 0的问题:一位成员报告称,NeoX 评估脚本对于使用pipe_parallel_size 1训练的模型运行良好,但对于使用pipe_parallel_size 0训练的模型会遇到错误。- 报告的问题位于这段代码行,其中存储了 microbatches 以便稍后恢复;该用户质疑为什么需要这样做。
pipe_parallel_size 0的前向传播不一致:在修复了一些属性问题后,一位成员在使用pipe_parallel_size 0时遇到了前向传播(forward pass)失败。- 失败归因于前向传播返回的元素数量差异,表明与评估脚本存在潜在的兼容性问题。
HuggingFace ▷ #general (38 messages🔥):
新 HuggingFace 用户, 证书课程, TRELLIS.2, LiveTalking, QLoRa 微调
- HuggingFace 新用户加入:几位新用户加入了 Hugging Face,并表达了对开始使用 Agentic AI 以及探索新技术的兴奋之情。
- 一位正在修读证书课程的用户询问在哪里可以找到此频道,并获得了所有课程/学习频道的链接。
- 微软 TRELLIS.2 仓库链接:一位用户分享了 Microsoft 的 TRELLIS.2 仓库链接,建议如果硬件足够可以尝试使用。
- 关于 QLoRa 微调优点的讨论:一名成员询问其他人是否通过 QLoRa 微调获得了良好效果,或者使用 bf16 是否更值得。
- 这引发了关于微调方法和效率的简短讨论。
- Z.ai 表现出色:一位用户分享了 Z.ai 的 X 帖子链接,评论称 Z.ai 表现非常棒。
- UnslothAI 加速本地 MoE 模型训练:一名成员宣布他们与 Hugging Face 合作,使用户能够更快地在本地训练 MoE 模型,并链接到了 UnslothAI 的 X 帖子。
- 另一名成员对 Unsloth 的工作表示赞赏,并附上了该公司关于该新方法的详细报告链接。
HuggingFace ▷ #i-made-this (26 messages🔥):
幻觉检测模型, LLM 设计缺陷与 RLHF, Discord 中的 AI 音乐生成, LLM 的快速微批处理, AI 角色的情感惯性
- “老而弥坚”的幻觉检测模型:一名成员分享了他们几年前创建的 Hallucination Test 工具,并表示有兴趣共同创建一个更好的基准测试(Benchmark)。
- 该工具最初是使用 Vectara 模型构建的,它强调了该领域对改进基准测试的需求。
- LLM 因说“我不知道”而受罚:一位成员认为 LLM 在 RLHF 过程中被训练去避免说 “我不知道”,从而导致了设计缺陷。
- 他提出了一种哲学,即模型可以选择使用真实数据,从而激励它们停止产生幻觉。
- TryMelo 将 AI 音乐引入 Discord:TryMelo 是一个 AI 音乐生成平台,拥有一个 Discord 机器人,允许成员直接在 Discord 语音频道中免费生成音乐。
- 它提供随机自动播放等功能,且不需要特殊权限,但机器人邀请链接违反了频道指南。
- LLM-Autobatch 工具提供快速微批处理 (micro-batching):llm-autobatch 是一个极简工具,可将单个 LLM 请求转换为快速的微批处理。
- 该工具采用 Rust 核心和 Python API 构建,旨在保持简单易用。
- Chordia 赋予 AI 角色情感惯性:一名成员介绍了 Chordia,这是一个轻量级的 MLP 内核,旨在赋予 AI 角色情感惯性和类生理反应。
- Chordia 预测情感转变的时间小于 1ms,并经过调优以保持角色一致性。
Modular (Mojo 🔥) ▷ #general (4 messages):
Modular 文档, Mojo 反射文档
- Modular 文档反射链接故障:一名成员报告称,访问最新社区视频中分享的反射(reflection)文档链接 https://docs.modular.com/manual/reflection/ 时出现 “page not found” 错误。
- 另一名成员澄清了正确的链接应该是 https://docs.modular.com/mojo/manual/reflection。
- 更新的 Mojo 反射文档 URL:最初分享的 Mojo 反射文档链接不正确,导致“页面未找到”错误。
- 修正后可用的链接是 https://docs.modular.com/mojo/manual/reflection,提供了对 Mojo 反射文档的访问。
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Modular 收购 BentoML,BentoML 开源承诺,与 Chris Lattner 和 Chaoyu Yang 的 Ask Us Anything 环节
- Modular 收购 BentoML 助力 AI 生产!: Modular 已收购 BentoML,将其云部署平台与 MAX 和 Mojo 集成,以优化硬件。
- 此次收购旨在让用户能够编写一次代码,无需重新构建即可在 NVIDIA、AMD 或下一代加速器上运行,从而在统一的工作流中简化优化与推理服务 (serving)。
- BentoML 加倍投入开源: BentoML 将保持开源 (Apache 2.0),Modular 也正在加倍履行其开源承诺,并计划在今年晚些时候推出功能增强。
- Lattner 和 Yang 主持 ‘Ask Us Anything’ 环节: Chris Lattner 和 BentoML 创始人 Chaoyu Yang 将于 9 月 16 日 在 Modular 论坛主持 Ask Us Anything 环节,讨论收购事宜和未来计划。
Modular (Mojo 🔥) ▷ #mojo (24 messages🔥):
Mojo 中的 Movable 但非 Defaultable 类型,Trait 上的可变参数 (Variadic parameters) 限制,Mojo 中带有静态大小 4D tensor 的动态大小 2D 矩阵,LayoutTensors 元素访问操作,LayoutTensor 的 slice_1d
- 在 Mojo 中构建 Movable、非 Defaultable 类型: 为了在 Mojo 中创建一个 Movable 但非 Defaultable 的类型,一位成员建议定义一个带有 Movable 类型参数的 struct,确保该 struct 在创建时必须使用值进行初始化,如该 snippet 中所述。
- 可变参数限制阻碍 Trait 使用: 一位开发者在尝试对 Trait 使用可变参数时遇到了编译器崩溃(modular 上的 issue),这突显了 Mojo 目前的局限性:可变参数必须是同质的 (homogeneous,即所有值必须是相同类型)。
- 使用 LayoutTensors 构建矩阵: 一位成员寻求关于在 Mojo 中使用 Layout 构建动态大小的 2D 矩阵(由静态大小的 2D 矩阵 组成,即 4D tensor)的指导。
- 解析 LayoutTensor 元素访问动态: 一位用户研究了 LayoutTensors 内部的元素访问和操作(特别是在 4D 上下文中),探索了存储单个元素与检索向量或切片时的性能影响,并指出 element_layout 决定了返回的 SIMD 的宽度。
- 揭示 LayoutTensor 的 Slice_1d 行为差异: 一位用户研究了 LayoutTensor 中
slice_1d的行为,注意到在沿不同轴进行切片时出现了非预期的指针行为,这与文档 (docs) 不符,表明在切片操作如何影响底层数据指针方面可能存在 Bug 或理解偏差。
Modular (Mojo 🔥) ▷ #max (4 messages):
LayoutTensor V2, Mojo Tensor Primitives
- LayoutTensor “V2” 正在开发中: 一位成员宣布 LayoutTensor 的 “v2” 版本正在 kernels 中进行原型设计,更多细节将在 API 最终确定和命名讨论后公布。
- 这一更新暗示了 Mojo 生态系统中 Tensor 操作能力的持续开发和改进。
- LayoutTensor 是对非所有权内存 (unowned memory) 的结构化视图: 一位成员澄清说 LayoutTensor 是对非所有权内存的结构化视图,也是一种通用的 Tensor 视图。
- 团队预计需要拥有所有权 (owning) 和非所有权 (unowning) 两种类型的 Tensor,适用于各种处理器 (CPU/xPU)。
Yannick Kilcher ▷ #general (9 messages🔥):
TDD, Agentic SDLCs, Adversarial Cooperation, MCP/skill open source, complaint-generator
- 大厂确认使用 **TDD:一位用户询问大厂是否在其 Agent 式 **SDLCs 中使用 TDD,一位成员确认了这一点,并指出 70 年来人们都知道通过反馈循环将概率逻辑转化为确定性逻辑。
- 分享了与 adversarial cooperation 相关的链接。
- 将 **TDD 与 Adversarial Cooperation 相结合:一位成员建议将 **TDD 与 adversarial cooperation 结合使用。
- 作为回应,分享了一个 complaint generator 的链接作为示例:complaint-generator。
- MCP/skill 开源替代方案:一位用户询问 MCP/skill 的开源替代方案,并提到其费用问题。
- 他们还分享了一个相关的 Reddit 帖子链接:I built an MCP server that lets Claude execute。
Yannick Kilcher ▷ #ml-news (4 messages):
ChatGPT Ads, Demo video mistakes
- 在 ChatGPT 内部测试广告:根据 OpenAI 的博客文章,他们正在 测试 ChatGPT 中的广告,并在 Twitter 上宣布了这一消息。
- 找茬!:一位成员分享了一段 YouTube 视频,并询问是否有人检查过演示视频中展示的表格是否存在错误。
tinygrad (George Hotz) ▷ #general (8 messages🔥):
CPU LLaMA bounty challenges, Tinygrad changes for bounty, RK3588 NPU backend bounty
- CPU LLaMA Bounty 证明极具挑战:一位成员分享说,由于循环排序、内存访问模式和去向量化 (devectorization) 等问题,CPU LLaMA bounty 非常困难,仅靠启发式方法无法产生良好的 SIMD 和简洁的指令。
- 领取 Tinygrad Bounty 的技巧:George Hotz 强烈建议将对 Tinygrad 的更改提交到上游以领取赏金,并建议了诸如更好的排序、更好的 dtype 解包、更好的融合以及连续内存排列等技术。
- 他指出,虽然大量的手工编写算子 (hand-coded kernels) 不会被合并到上游,但类似于他针对嵌入式系统所做的工作可能会被接受。
- RK3588 NPU Backend Bounty 仍然开放:一位成员对 RK3588 NPU 后端赏金 表示感兴趣,并提到已经对 Rockchip 的模型编译器/转换器和运行时进行了广泛的追踪,但在实现干净的 Tinygrad 集成方面遇到了困难。
- 他建议一种路径可能是将 rangeified + tiled UOps 重新转化为 matmuls 和 convolutions。
- George Hotz 建议实现一个慢速 RK3588 后端:George Hotz 建议先实现一个不带 matmul 加速的慢速后端,并以子类化
ops_dsp.py为例,但让其他部分回退到默认行为。 - PR 审核时间是成比例的:审核 PR 的时间与 PR 的大小成正比,与其价值成反比。
Manus.im Discord ▷ #general (8 messages🔥):
Manus AI Models, AI Full-Stack Systems, Search Feature Troubles, Devs wanted
- 询问 Manus AI 模型:一位成员询问 Manus 使用了哪些 AI 模型,并认为相对于订阅价格,该服务显得比较基础。
- 他们询问在 VPS 上托管一个带有高级模型 APIs 的 calwdbot 是否会更便宜且更安全。
- AI 与全栈系统展示:一位成员介绍了他们在构建 AI 和全栈系统方面的服务,重点在于解决现实问题并交付价值。
- 他们列出的专业领域包括 LLM 集成、RAG pipelines、AI 内容审核、图像/语音 AI 以及 bot 开发,同时具备全栈开发技能。
- 搜索功能遇到用户问题:一位成员反映搜索功能无法定位过去聊天记录中的单词。
- 消息中未提供解决方案或进一步讨论。
- 招募开发者:一位成员询问是否有人在招募 dev。
- 消息中未提供解决方案或进一步讨论。