AI News
Z.ai GLM-5:全新 SOTA 开源权重型大语言模型
智谱 AI (Zhipu AI) 推出了 GLM-5。这是一款 Opus 级别 的大模型,参数规模在 3550 亿至 7440 亿 之间,并集成了 DeepSeek 稀疏注意力机制 (Sparse Attention),旨在实现高性价比的长上下文服务。
GLM-5 在 BrowseComp 基准测试中达到了 SOTA(业界领先水平),并在 Vending Bench 2 中保持领先;该模型专注于办公生产力任务,在 GDPVal-AA 评估中超越了 Kimi K2.5。尽管 GLM-5 已在 OpenRouter、Modal、DeepInfra 和 Ollama Cloud 等平台广泛可用,但目前仍面临 算力限制,这对其推广速度和定价产生了影响。该模型支持最高 20 万 (200K) 的上下文长度,以及 12.8 万 (128K) 的最大输出 token 数。
我们家里已经有 Opus 4.5 了。
2026年2月10日至2/11日的 AI 新闻。我们为您查看了 12 个 subreddits、544 个 Twitters 和 24 个 Discord(256 个频道,7988 条消息)。预计节省阅读时间(以 200wpm 计算):655 分钟。AINews 网站 允许您搜索所有过往期数。温馨提示:AINews 现已成为 Latent Space 的一个板块。您可以选择加入/退出邮件接收频率!
正如我们昨天提到的,中国开源模型周正进行得如火如荼。今天轮到 Z.ai 在 Big Whale 之前发布他们的重大更新。根据 GLM-5 博客文章:
- Opus 级别,但并非像 Kimi 或 Qwen 那样的 1T 超级模型。 与 GLM-4.5 相比,GLM-5 的参数量从 355B(32B 激活)扩展到 744B(40B 激活),并将预训练数据从 23T 增加到 28.5T tokens。
- GLM-5 还集成了 DeepSeek Sparse Attention (DSA),在保留长上下文能力的同时显著降低了部署成本。(这引发了关于 DeepSeek 在开源模型领域的全面胜利 的评论)
- 在内部编程评估和标准的前沿模型评估集中表现出色,值得注意的是,它在 BrowseComp 上声称达到了(同类产品中的)SOTA,并且是 Vending Bench 2 排名第一的开源模型。
-
与 Kimi K2.5 类似,他们也专注于 Office 办公场景(PDF/Word/Excel),只是表现得没那么张扬,但是
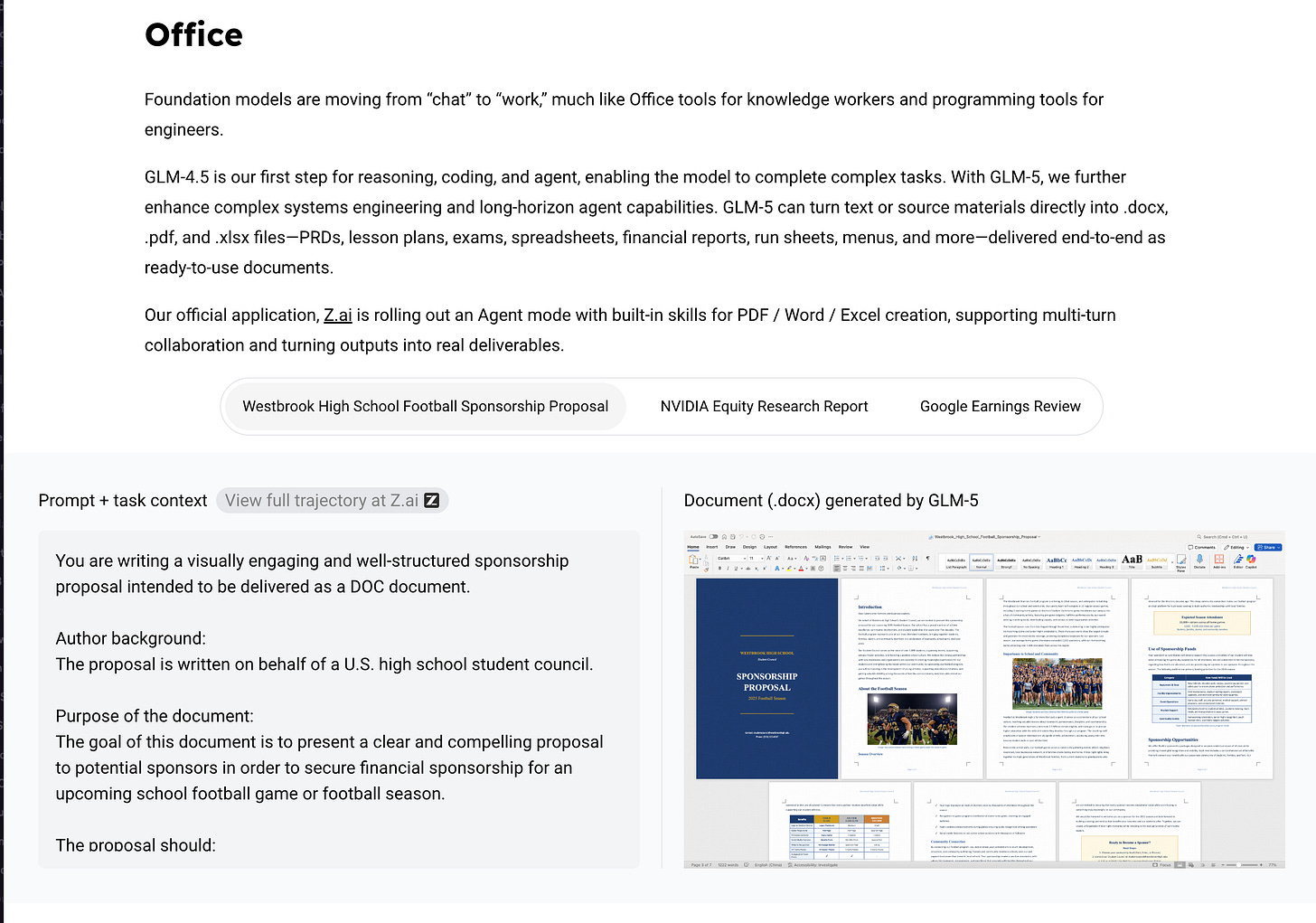
然而它依然非常出色,因为作为事实上的“白领工作”基准测试,GDPVal-AA 确实将其排在 Kimi K2.5 之上:
Reddit 讨论 的很大一部分集中在他们在推理服务中遇到的算力限制问题:
AI Twitter 简报
智谱 AI 的 GLM-5 发布(Pony Alpha 亮相)与新的开源权重前沿
- GLM-5 发布详情(以及与 GLM-4.5 的区别):智谱 AI(Zhipu AI)透露,此前处于“隐身”状态的模型 Pony Alpha 即为 GLM-5,定位为“agentic engineering”和长程任务(long-horizon tasks)(Zai_org; OpenRouterAI)。据报道,该模型的参数规模从 355B MoE / 32B 激活(GLM-4.5)提升至 744B / 40B 激活,预训练量从 23T 增加到 28.5T tokens (Zai_org)。系统层面的核心主张是:集成了 DeepSeek Sparse Attention,从而降低了长上下文服务的成本 (scaling01; lmsysorg)。在发布的系列帖子中提到的上下文/IO 限制为:200K 上下文,128K 最大输出 (scaling01)。
- 可用性 + “算力紧张”的现实:GLM-5 迅速在各类聚合/托管平台上线——OpenRouter (scaling01)、Modal(限时提供免费端点)(modal)、DeepInfra(day-0 支持)(DeepInfra)、Ollama Cloud (ollama),以及各种 IDE/Agent 层面(例如 Qoder、Vercel AI Gateway)(qoder_ai_ide; vercel_dev)。智谱明确警告称 serving capacity(推理容量)受限,这延迟了“Coding Plan Pro”之外的推广,并导致了 价格变动 (Zai_org; Zai_org;早些时候也提到“流量增长了十倍”:Zai_org)。
- 基准测试与第三方定位(含注意事项):目前涌现了大量的基准测试声明(VendingBench、KingBench、AA 指数、Arena)。最连贯的第三方综合评估来自 Artificial Analysis,该机构在其 Intelligence Index 中将 GLM-5 称为 新的领先 open-weights 模型(得分 50,高于 GLM-4.7 的 42),在 agentic/经济任务上有显著提升(GDPval-AA ELO 为 1412,在其测试体系中仅次于 Opus 4.6 和 GPT-5.2 xhigh),并且大幅减少了幻觉(AA-Omniscience 得分为 -1,在测试模型中“幻觉最低”)(ArtificialAnlys)。他们还指出了一项工程现实:该模型以 BF16 格式(约 1.5TB)发布,这意味着与原生以 FP8/INT4 发布的模型相比,其自托管(self-hosting)难度较大 (ArtificialAnlys)。
- 许可证 + 生态集成:多篇帖子强调了其宽松的 MIT 许可证 以及在推理栈中的即时工具支持:vLLM day-0 方案,包括 DeepSeek Sparse Attention 和投机解码(speculative decoding)钩子 (vllm_project);SGLang day-0 支持和指南 (lmsysorg);以及在 HF/ModelScope 上的广泛社区分发 (Zai_org; mervenoyann)。一个细微的观点是:GLM-5 的 MIT 许可证被称赞为“真正宽松”,但同时有对比指出 GLM-5 缺乏 vision(视觉能力),且 BF16 转量化后的表现对比可能会改变其与原生量化模型的排名顺序 (QuixiAI)。
- 开放排行榜势头:GLM-5 在 Text Arena 的开放模型中排名第 1(在当时的总榜单中约排名第 11)(arena)。多位博主将这次发布视为由中国驱动的开放生态循环加速的又一证据(“bloodbath”:DeepSeek + MiniMax + GLM)(teortaxesTex; rasbt)。
DeepSeek “V4-lite” / 1M 上下文发布,Attention 差异化,以及推理栈修复
- 实际发布了什么:多条推文报道 DeepSeek 更新了聊天体验,支持 1M context,知识截止日期(cutoff)为 2025年5月;早期观察者怀疑这是 V4,但模型“并不承认”,且在 App 端与 API 之间的推送并不均衡 (teortaxesTex; teortaxesTex)。随后出现了一个更明确的说法:“V4 Lite 现已上线……1M context 长度……仅限文本……Muon + mHC 已确认;更大版本仍在路上。” (yifan_zhang_)。
- Attention 升级被视为真正的里程碑:一个反复出现的主题是 DeepSeek 拥有“前沿级别的 Attention”,模型在长上下文中表现得非常积极(不仅是检索,而是“沉浸于上下文之中”),并推测这类似于成熟的 sparse/NSA 风格方法,而非普通的 block sparsity (teortaxesTex; teortaxesTex; teortaxesTex)。其他人通过长上下文测试证实了“中国首个真正具备能力的 1M context 模型”的印象 (Hangsiin)。
- 推理服务吞吐量陷阱 (MLA + TP):一个具体的系统见解:对于 只有一个 KV head 的 MLA 模型,朴素的 Tensor Parallelism (TP) 会浪费 KV cache 内存(冗余复制)。SGLang 发布了一个拟议的修复方案:DP Attention (DPA) 实现“零 KV 冗余” + 一个 Rust 编写的路由器(“SMG”),声称能带来 +92% 的吞吐量和 275% 的缓存命中率 (GenAI_is_real)。这是少数直接将模型架构特性与集群级吞吐量损失联系起来并提供特定缓解措施的推文之一。
- DeepSeek 对开源 MoE 配方的影响:一份流传甚广的总结称,DeepSeek 的创新塑造了“当今几乎每一个前沿开源 LLM”——带有共享专家的细粒度稀疏 MoE、MLA、生产环境中的 sparse attention、开源推理模型 (R1)、作为基础 RL 算法的 GRPO,以及像 DeepEP 这样的基础设施 (eliebakouch)。即使某些“首创性”仍存争议,它也捕捉到了这种情绪:DeepSeek 被视为一个具有极高杠杆效应的开源贡献者。
MiniMax M2.5 / StepFun / Qwen:快速编程模型、成本压力与榜单博弈
- MiniMax 2.5 “即将来临”与 Agent 分发:MiniMax 预热并随后发布了 M2.5,通过 MiniMax Agent 应用和合作伙伴界面提供服务 (SkylerMiao7; MiniMaxAgent)。团队明确将训练描述为发布与“投入的算力越多,提升就越显著”之间的权衡 (SkylerMiao7)。
- StepFun-Flash-3.5:声称在 MathArena 上排名第一,并附带了技术报告链接和 OpenRouter 列表 (CyouSakura)。Teortaxes 的评论强调了其相对于“激活参数量”而言异常强大的性能以及极快的速度,鼓励人们尽管存在不足也要尝试一下 (teortaxesTex)。
- Qwen Image 漏洞修复 + Qwen3-Coder-Next 提及:阿里巴巴发布了 Qwen-Image 2.0 的补丁,用于修复古诗排序和编辑中的字符一致性问题 (Alibaba_Qwen)。另外,一份时事通讯指出 Qwen3-Coder-Next (80B) 声称达到了 70.6% SWE-Bench Verified,并在仓库级工作流中实现了 10倍吞吐量 (dl_weekly)。(该消息在数据集中来源较少——仅有一条推文——因此请将其视为参考,而非经过验证的综述。)
- 成本/延迟作为切入点:多位发布者认为中国实验室能以 1/5 到 1/10 的价格提供“~90%”的能力,特别是在编程领域,如果这种优势得以持续,将重塑市场份额 (scaling01)。GLM‑5 公布的 API 价格对比以及在低成本路由器上的分发进一步强化了这一观点 (scaling01; ArtificialAnlys)。
视频生成浪潮:SeeDance v2、PixVerse R1 以及作为结构性优势的“IP 约束”
- SeeDance v2.0 脱颖而出:时间线上大部分内容是社区对 SeeDance v2.0 质量的惊叹(“跨越了恐怖谷”、“text2video 的图灵测试”),以及对其透明度/PR 问题和 BytePlus 上暂时停机的讨论(maharshii; kimmonismus; swyx)。一个实际的数据点:根据基于 Token 的定价假设,15秒生成的报价为 $0.72(TomLikesRobots)。
- 视频推理测试:一位用户在“井字棋着法连贯性”任务中对比了 SeeDance 与 Veo,声称 SeeDance 能维持约 5 步连贯着法,而 Veo 只能维持 1-2 步(paul_cal)。虽然这只是个案,但值得注意:它正在将时间一致性(temporal consistency)作为“推理能力”而非仅仅是美学来探测。
- 结构性解释:训练数据 / IP:一个帖子认为生成式媒体的差距可能是“结构性”的,因为中国模型在训练时的 IP 限制较少;而西方实验室则无法做到,这意味着一旦开源权重(open weights)泛滥,模型层面的监管将变得无法执行(brivael)。无论你是否同意,这是少数试图解释能力为何会产生除“人才/算力”之外分歧的尝试之一。
- PixVerse R1:高参与度的营销声明:“720P 实时交互世界”(PixVerse_)。这条推文宣传色彩浓厚,但它标志着市场对交互式、实时媒体生成的需求已成为区别于离线电影片段的一个独立类别。
Agent、编程工作流与全新的“可塑软件”工具链
- Karpathy 的“利用 Agent 剥离代码”工作流:一个 LLM 改变软件构成的具体案例:使用 DeepWiki MCP + GitHub CLI 检索仓库(torchao fp8),让 Agent 仅将所需的实现“剥离”到包含测试的自包含文件中,删除沉重的依赖项,甚至获得了小幅的速度提升(karpathy)。这指向了一种新兴风格:仓库即真理文档,而 Agent 则是重构/移植引擎。
- OpenAI:Harness 工程与数小时级工作流原语:OpenAI DevRel 推出了一个案例研究:通过“引导 Codex”交付了 1,500 个 PR 且无需手动编码,并单独发布了可靠运行数小时级工作流的建议(OpenAIDevs; OpenAIDevs)。与此同时,Sam Altman 声称“从团队运作方式来看,我原以为 Codex 最终会胜出”(sama)。
- 以人为本的编程 Agent vs 自主性:一个观点贴认为编程 Agent 的研究过度优化了独立自主性;相反,它应该专注于如何通过 Agent 赋能人类(ZhiruoW)。
- 沙箱架构争论:多条推文汇聚到一个关键的 Agent 系统设计选择:Agent 在沙箱内(agent-in-sandbox) vs 沙箱作为工具(sandbox-as-tool),即将 LLM 生成的代码可以触及的内容与 Agent 可以执行的操作分离开来(bernhardsson; chriscorcoran)。
- mini-SWE-agent 2.0:作为一个刻意保持极简的编程 Agent 发布(Agent/模型/环境各约 100 行代码),用于基准测试和 RL 训练;这表明业界正推动使用更简单、可审计的 Harness,而非庞大的 Agent 框架(KLieret)。
- 开发者工具的现状反思:尽管能力提升迅速,多位从业者仍抱怨 Agent 的终端用户体验(UX)以及延迟/速率限制(“改了 30 行代码就被限流了”)(jxmnop; scaling01)。这里传达了一个微妙的工程信息:模型质量掩盖了产品/Harness 质量的低下——直到掩盖不住为止。
测量、评估与安全:基准测试、可观测性以及 Agent 安全漏洞
- 300 万美元开放基准测试资助 (Open Benchmarks Grants):Snorkel 及其合作伙伴发起了 300 万美元 的承诺,用于资助开放基准测试以缩小评估差距 (eval gap)(HF, Together, Prime Intellect, Factory, Harbor, PyTorch 被列为合作伙伴)(vincentsunnchen; lvwerra; percyliang)。这与广泛的观点一致,即公共评估滞后于内部的前沿测试。
- Agent 可观测性作为评估基石:LangChain 重申“运行 (run) 是核心产物”,推动将追踪 (traces) 作为事实来源 (source-of-truth);他们还发布了指南,将 Agent 可观测性/评估与传统日志记录区分开来 (marvinvista; LangChain)。
- 安全评估争议 (computer-use Agent):一个严重的方法论挑战:一个研究小组声称 Anthropic 的 system card 报告显示 Opus 4.6 的 Prompt Injection 成功率较低(在 computer-use 中约为 10%,在 browser-use 中 < 1%),但他们自己的 RedTeamCUA 基准测试发现在真实的 Web+OS 环境中攻击成功率要高得多(Opus 4.5 高达 83%,Opus 4.6 约为 50%),并认为低 ASR 可能是由于能力失效而非真正的鲁棒性 (robustness) 导致的 (hhsun1)。这正是资助计划声称要针对的“评估差距 (eval gap)”。
热门推文 (按互动量排序)
- GLM-5 发布:@Zai_org (模型揭晓/规格), @Zai_org (新模型上线), @Zai_org (算力限制)
- 通过 Agent 实现软件延展性 (Software malleability):@karpathy
- Codex 影响叙事:@sama, @OpenAIDevs
- 中国/开源模型“发布冲刺”氛围:@paulbz (Mistral 营收——商业视角), @scaling01 (DeepSeek V4 猜测), @SkylerMiao7 (MiniMax 2.5 算力权衡)
- SeeDance v2 “视频时刻”:@kimmonismus, @TomLikesRobots
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. GLM-5 与 MiniMax 2.5 发布
-
Z.ai 公开表示他们极度缺乏 GPU。 (活跃度: 1381): Z.ai 宣布将向 Coding Plan Pro 用户发布其模型 GLM-5,并强调了 GPU 资源受限带来的重大挑战。他们目前正在最大化利用现有芯片来处理推断 (inference) 任务,这表明了计算能力的瓶颈。这种对资源约束的透明度表明了其在扩展基础设施以满足需求方面的积极态度。评论者对 Z.ai 的透明度表示赞赏,并将其与 Google 等其他公司进行了对比,后者被认为在应对需求方面挣扎,并可能通过降低模型性能 (nerf) 来应对资源限制。
- OpenAI 总裁 Greg Brockman 强调了算力稀缺的持续挑战,指出即使有巨额投资,满足未来需求仍存在不确定性。OpenAI 发布的一张图表强调,扩展计算资源对于实现盈利至关重要,这反映了算力限制影响 AI 发展的广泛行业趋势。来源。
- “缺乏 GPU (GPU starved)”的问题并非 Z.ai 等小公司独有;即使是 Google 和 OpenAI 这样的主要参与者也面临类似挑战。据报道,Google 不得不通过量化 (quantization) 等方式“削弱”其模型,以便在有限资源下管理需求,这凸显了硬件约束对 AI 能力的普遍影响。
- 高性能 GPU(如 RTX 5090)的稀缺是开发者和公司共同面临的问题。这种短缺影响了个人开发者和大型组织,表明硬件可用性和价格约束构成了 AI 开发流程中的重大瓶颈。
-
GLM-5 在 Intelligence Index 上获得 50 分,成为新的开源权重领导者! (Activity: 566): 该图表强调了 AI 模型 **GLM-5 的性能,它在 “Artificial Analysis Intelligence Index” 中获得了
50分,使其在开源权重 AI 中处于领先地位。此外,它在 “GDPval-AA Leaderboard” 上排名很高,具有强大的 ELO 分数,表明其在现实任务中具有卓越的性能。值得注意的是,GLM-5 被公认为在 AA-Omniscience 基准测试中幻觉率(hallucination rate)最低,展示了其与 Opus 4.5 和 GPT-5.2-xhigh 等其他模型相比的准确性和可靠性。** 评论者指出 GLM-5 等开源模型的出色表现,表明它们正在缩小与闭源模型之间的差距。人们对未来的 Deepseek-V4 充满期待,该模型将使用类似但规模更大的架构。- GLM-5 因在 AA-Omniscience 基准测试中具有最低的幻觉率而受到关注,这是在减少 AI 生成内容中的错误方面取得的重大成就。这使得 GLM-5 在开源模型中处于准确性领先地位,超越了 Opus 4.5 和 GPT-5.2-xhigh 等竞争对手。
- 开源 AI 社区正在迅速缩小与闭源模型的差距,目前仅落后约三个月。这体现在即将发布的 DeepSeek v4 上,它将采用与 GLM-5 相同的 DSA 架构,但规模更大,预示着更强大的开源模型的发展趋势。
-
AI 社区呼吁提高运行这些先进模型所需资源(如内存需求)的透明度。这些信息对于开发者和研究人员在各种应用中有效利用和优化这些模型至关重要。
-
GLM-5 正式发布 (Activity: 915): **GLM-5 已经发布,专注于复杂系统工程和长周期 Agent 任务。它的参数规模从
355B扩展到744B,其中激活参数为40B,并将预训练数据从23Ttokens 增加到28.5Ttokens。该模型集成了 DeepSeek Sparse Attention (DSA),在保持长上下文能力的同时降低了部署成本。该模型已在 Hugging Face 和 ModelScope 开源,权重采用 MIT License。更多细节可以在 blog 和 GitHub 找到。** 一个值得注意的讨论点是选择使用FP16而非FP8进行训练,这与 DeepSeek 的方法形成对比。此外,还有一种倾向于本地数据中心的情绪,一些用户幽默地期待 ‘GLM 5 Air’ 或 ‘GLM 5 Water’ 等轻量级版本。- GLM-5 已经发布,模型权重在 Hugging Face 和 ModelScope 等平台上以 MIT License 提供。一个值得注意的技术细节是 GLM-5 使用 FP16 精度进行训练,这与 DeepSeek 使用 FP8 形成对比,可能会影响计算效率和模型性能。
- GLM-5 与 DeepSeek V3.2 Speciale 和 Kimi K2.5 等其他模型之间的成本对比显示出显著差异。GLM-5 的输入成本大约是 DeepSeek V3.2 Speciale 的 3 倍(0.80 美元对 0.27 美元),是 Kimi K2.5 的 1.8 倍(0.80 美元对 0.45 美元)。输出成本也显著更高,比 DeepSeek V3.2 Speciale 贵 6.2 倍(2.56 美元对 0.41 美元),比 Kimi K2.5 贵 14%(2.56 美元对 2.25 美元)。
- GLM-5 在 OpenRouter 上的发布以及 Pony Alpha 的移除表明了一种战略转变,GLM-5 的价格比 Kimi 2.5 更贵。这表明其可能专注于高级功能或性能增强,以证明尽管比竞争对手成本更高,但其定价是合理的。
-
GLM 5.0 & MiniMax 2.5 刚刚发布,我们是否正在进入中国的 Agent 大战时代? (热度: 422): GLM 5.0 和 MiniMax 2.5 已经发布,标志着 AI 开发正向 Agent 风格的工作流转变。GLM 5.0 专注于增强推理和代码能力,而 MiniMax 2.5 则专为任务分解和延长执行时间而设计。这些进展表明,竞争焦点正从生成更好的回复转向完成复杂的任务。这些发布是中国大趋势的一部分,近期其他更新还包括 Seedance 2.0、Seedream 5.0 和 Qwen-image 2.0。测试计划包括 API 基准测试、IDE 工作流和多 Agent 编排工具,以评估模型在长任务和仓库级代码变更中的表现。评论反映了文化背景与乐观情绪的结合,提到了发布时机正值农历新年,并暗示 AI 的进步代表了一场让公众从技术改进中受益的“战争”。
- GLM 5.0 和 MiniMax 2.5 的发布是中国更广泛趋势的一部分,多个 AI 模型接连发布。这包括 Seedance 2.0、Seedream 5.0 和 Qwen-image 2.0 等模型,预计不久后还会推出 Deepseek-4.0 和 Qwen-3.5。这种快速发展表明中国 AI 领域竞争异常激烈,可能导致 AI 能力的重大突破。
- 中国 AI 模型的频繁发布,如 GLM 5.0 和 MiniMax 2.5,表明了在 AI 发展方面的战略推进,这可能是由旨在领先 AI 技术的国家级计划驱动的。这与中国增强技术基础设施和能力的更广泛目标相一致,表明这些发布不仅仅是庆祝性的,而是推进 AI 技术更大规模、协同努力的一部分。
-
中国 AI 模型(包括 GLM 5.0 和 MiniMax 2.5)的快速更迭,突显了中国 AI 行业内激烈的竞争和创新。这种环境促进了开发周期的加速,并可能在 AI 研究和应用方面取得突破,使中国成为全球 AI 版图中的强大竞争者。
-
GLM 5 已发布 (热度: 931): GLM 5 已经发布,消息源自 chat.z.ai。发布细节较少,但社区正在推测其在 Hugging Face 等平台上的可用性,而目前这些平台尚无动态。这引发了关于该模型是开源还是闭源的疑问。此次发布恰逢其他 AI 进展,如即将推出的 Minimax M2.5 以及预期的更新,如 Qwen Image 2.0 和 Qwen 3.5。评论者对 GLM 5 的开源状态感到好奇,并注意到 Hugging Face 上没有更新,这可能表明其正转向闭源模型。社区对并发发布的 AI 进展也感到兴奋,突显了竞争格局。
- Front_Eagle739 对 GLM 5 在 Hugging Face 仓库缺乏动态表示担忧,质疑这是否预示着转向闭源模型。这可能暗示开源有所延迟,或者是将模型保持专有的战略决策,这将影响可访问性和社区贡献。
- Sea_Trip5789 提供了 GLM 5 更新后的订阅计划链接,指出目前只有 ‘max’ 计划支持该模型。他们提到在基础设施重新平衡后,’pro’ 计划也将支持,但 ‘lite’ 计划不支持。这突显了分级访问策略以及对低端计划用户的潜在限制。
- MiniMax M2.5 已发布 (热度: 357): MiniMax M2.5 已经发布,根据其官网详细介绍,提供了一个新的基于云端的 AI 模型部署选项。该发布与 GLM 5 的发布同期,暗示了 AI 模型产品中的竞争态势。公告强调了该模型在云端的可用性,这与一些用户在 Local LLaMA 社区背景下对本地部署选项的预期形成了对比。评论反映了关于在一个专注于本地 AI 模型的社区中推广云端解决方案是否合适的争论,一些用户对该领域明显的商业化倾向表示不满。
2. 本地 LLM 硬件与优化
-
刚刚组装完这个大家伙 (活跃度: 285): 该帖子描述了一个高性能计算配置,包含六块以
PCIe 4.0 16x速度运行的 **Gigabyte 3090 Gaming OC GPUs,集成了 Asrock Romed-2T motherboard 和 Epyc 7502 CPU。系统配备了 8 条8 sticks of DDR4 8GB 2400MhzRAM,处于八通道模式,并使用了启用 P2P 的修改版 Tinygrad Nvidia drivers,实现了24.5 GB/s的 GPU 间带宽。总 VRAM 为144GB,旨在训练参数量高达10B parameters的 Diffusion 模型。每个 GPU 都设置了270W power limit。** 一位评论者建议在训练前测试推理数据,并提到了gpt-oss-120b和glm4.6v等模型。另一位评论者提到,在不使用外置风扇的情况下,使用 170W 的较低功耗限制进行 Fine-tuning。- segmond 建议在训练前获取推理数据,并提到
gpt-oss-120b和glm4.6v作为可以完全装入该配置的模型示例。这暗示了在进行训练等资源密集型任务之前,评估系统在大模型上的表现以确保符合预期的重要性。 -
lolzinventor 讨论了他们在
PCIe v3上使用8x3090GPU 配合x16 to x8x8 splitters和双处理器的配置,强调尽管可能存在带宽限制,系统表现依然尚可。他们提到正考虑升级到Romed-2T并使用7 GPUs of x16,可能会通过更改配置来容纳第 8 块 GPU。他们还解决了电力稳定性问题,通过使用4x1200W PSUs来处理功率峰值,并询问了训练间隔,表明其关注点在于优化电力与性能的平衡。 -
我的 NAS 在其 iGPU 上以 18 tok/s 的速度运行 80B LLM。无独立 GPU。仍在优化中。 (活跃度: 132): 一位用户在 NAS 上成功运行了一个 800 亿参数的 LLM——Qwen3-Coder-Next。该 NAS 使用 AMD Ryzen AI 9 HX PRO 370 及其集成显卡,在启用 Vulkan offloading 和 Flash Attention 的情况下达到了
18 tok/s。该系统基于 **TrueNAS SCALE 构建,配备96GB DDR5-5600 RAM,并通过llama.cpp使用Q4_K_M量化。关键优化包括移除--no-mmap标志(这允许将完整模型加载到共享 RAM 中)以及启用 Flash Attention(这提升了 Token 生成速度并减少了 KV cache 内存占用)。用户指出仍有进一步优化的潜力,包括 Speculative Decoding 和 DeltaNet Linear Attention,这些技术可能显著增强性能。** 评论者对llama.cpp使用的具体标志感兴趣以便复现,并建议尝试gpt-oss-20b等其他模型以获得更快的性能。讨论凸显了在非标准硬件配置上优化 LLM 的技术好奇心和进一步实验的潜力。- 使用
--no-mmap被强调是在 iGPU 上运行大模型时优化性能的关键点。该标志有助于避免双重内存分配,这是在 Vulkan 中使用 UMA (Unified Memory Architecture) 时的常见陷阱。这一见解对于那些试图在资源有限的系统上最大化效率的人来说尤其具有参考价值。 - 在同时运行 NAS 和 Jellyfin 的情况下,在 80B Mixture of Experts (MoE) 模型上达到每秒 18 个 Token 的表现令人印象深刻。这一配置展示了在无需独立 GPU 的情况下,利用 iGPU 处理繁重计算任务的潜力,展现了“一箱多用(one box to rule them all)”的能力。
- 有人建议尝试运行
gpt-oss-20b模型,据称其速度约为当前配置的两倍。建议将此模型与 server.dev MCP search 结合使用,以增强性能和智能水平,这为寻求更快推理速度的用户提供了一个潜在的替代方案。
- 使用
- segmond 建议在训练前获取推理数据,并提到
-
2026 年一套优秀的本地 LLM 配置需要多少钱? (热度: 183): 在 2026 年,以 5000 美元的预算搭建本地 LLM 可能涉及多种硬件配置。一种方案是集群化两台 128GB Ryzen AI Max+ 系统,它们为 LLM 和图像生成提供了出色的 4-bit 性能,并允许通过 QAT LoRA 进行微调以优化 int4 量化。另一种方法是使用 4x RTX 3090 GPU,以平衡显存容量和速度;或者选择 7x AMD V620 实现全 GPU offload。此外,更安静的方案可能涉及 Strix Halo 设备,它提供与 4x RTX 3090 类似的 VRAM 容量,但噪音更小。更复杂的配置可能包括 2x Strix Halo 以及用于张量并行 (tensor parallelism) 的额外网络组件,从而能够运行 q4 量化的 470B 模型。 关于最佳配置存在争论,一些人青睐 Ryzen AI Max+ 系统的内存和性能,而另一些人则更喜欢多张 RTX 3090 GPU 提供的速度与容量平衡。噪音水平与性能之间的权衡也是一个考虑因素,对于那些希望避免矿机般噪音的用户,推荐使用 Strix Halo 等更安静的配置。
- SimplyRemainUnseen 讨论了使用两台 128GB Ryzen AI Max+ 系统的配置,强调了它们在 LLM 和图像生成方面强大的 4-bit 性能。他们提到可以使用 unsloth 的工作流微调 QAT LoRA,以提高 int4 量化性能,从而在 GLM 4.7 等模型上达到可用的速度。该配置还支持运行 ComfyUI API 和 GPT OSS 120B 进行图像和视频生成,充分利用了巨大的统一内存。
- PraxisOG 建议使用 4x 3090 GPU 以平衡显存容量和速度,适合运行 Qwen coder 等模型。他们还提到了使用 7x AMD V620 进行全 GPU offload 的替代方案,这可以处理 GLM4.7 或通过 minimax 2.1 和 2.2 提供超长上下文。对于更安静的配置,他们推荐 Strix Halo 设备,它提供与 4x 3090 类似的 VRAM 容量,但噪音更低。
-
Own_Atmosphere9534 对比了不同的配置,包括 Macbook M4 PRO MAX 128GB 和 RTX 5090,价格都在 5000 美元左右。他们强调了 Mac 的性能与 RTX 3090 相当,并且能够高效运行 Llama 3.3 70B Instruct 和 Qwen3 coder 变体。他们强调了模型大小和硬件熟悉度的重要性,并指出其 M4 MacBook 在 GPT-OSS-20B 上表现良好,这影响了他们购买 M4 PRO MAX 的决定。
- llama.cpp 中的 MCP 支持已准备好进行测试 (热度: 321): 图像展示了
llama.cpp中新增 MCP (Multi-Component Protocol) 支持的设置界面,该项目由 **allozaur 开发。该界面允许用户配置各种设置,如 “Agentic loop max turns” 和 “Max lines per tool preview”,这些对于管理系统如何与不同工具和资源交互至关重要。MCP 支持的功能包括服务器选择、工具调用以及带有处理统计信息的 UI,旨在简化本地和云端模型的集成,而无需更改工具设置。这一进展意义重大,因为它解决了工具开销以及较小模型产生工具调用幻觉(本地 Agent 设置中的常见问题)的潜在问题。该项目仍在进行中,计划先建立稳健的客户端基础,随后将支持扩展到 llama-server 后端。** 评论者强调了将 MCP 集成到 llama-server 中的重要性,这将简化云端和本地模型之间的切换。人们还对 Agent 循环如何处理来自较小模型的错误表示担忧,例如幻觉产生的工具调用或格式错误的 JSON,这些都是本地 Agent 环境中的常见问题。
- Plastic-Ordinary-833 强调了在 llama-server 中集成 MCP 支持的重要性,指出这简化了在不改变工具设置的情况下切换云端和本地模型的过程。然而,他们对小型模型在产生工具调用幻觉或返回格式错误的 JSON 时,Agent 循环(agentic loop)如何处理错误表示担忧,这一直是本地 Agent 的一个主要问题。
- allozaur 讨论了 llama.cpp WebUI 中 MCP 支持的初始发布,强调在将支持扩展到 llama-server 后端之前,先建立一个稳固的客户端基础。他们提到通过流式 HTTP 使用 GitHub、Hugging Face 和 Exa Search 远程服务器,同时也支持 WebSocket 传输。初始版本不包含 OAuth、通知和采样(sampling)功能,目标是在发布稳固的首个版本后进行迭代。
- prateek63 指出 llama.cpp 对 MCP 的支持是一项重大进展,特别是对 Agent 循环的支持,这曾是将本地模型用于工具使用(tool-use)工作流的主要障碍。这种集成允许与本地推理进行原生协作,向以前依赖云端 API 的自托管 Agent 设置迈进。
3. Qwen 模型进展
-
Qwen-Image-2.0 已经发布 - 7B 统一生成+编辑模型,支持原生 2K 和真实文本渲染 (Activity: 691): Qwen-Image-2.0 是 Qwen 团队发布的一个新的 7B 参数模型,可通过阿里巴巴云 API 和 Qwen Chat 上的免费演示使用。它在单一流水线(pipeline)中结合了图像生成和编辑功能,支持原生 2K 分辨率,并能根据长达 1K token 的提示词渲染文本,包括复杂的信息图表和中国书法。模型尺寸从 20B 缩减到 7B,使其更易于本地使用,一旦权重发布,可能在消费级硬件上运行。它还支持具有一致角色渲染的多格漫画生成。评论者对该模型的潜力表示乐观,注意到其在自然光影和面部渲染方面的改进,并希望开源权重以供更广泛的社区使用。
- Qwen-Image-2.0 模型因其同时处理图像生成和编辑任务的能力而备受关注,重点是高达 2K 的高分辨率输出。这种双重能力具有重要意义,因为它允许在需要创建和修改图像的创意及专业场景中进行更多样化的应用。
- 讨论中提到了该模型在渲染自然光影和面部特征方面的表现,这些传统上是 AI 模型的挑战领域。准确描绘这些元素的能力表明了模型底层架构或训练数据的进步,有可能成为 AI 图像生成领域的“游戏规则改变者(game changer)”。
- 也有人对该模型的多语言能力表示担忧,特别是它在不同语言间的表现。展示中中文示例占主导地位,可能表明其对中文语言和文化背景存在偏见或优化,这可能会影响其在更多元语言环境中的效用。
-
我通过探测隐藏状态测量了 6 个开源 LLM (7B-9B) 的“个性”。这是我的发现。 (Activity: 299): 该帖子介绍了一个工具,通过探测六个开源 LLM (7B-9B) 在七个行为轴上的隐藏状态(hidden states)来测量它们的“个性”,揭示了每个模型独特的“行为指纹”。该工具展示了极高的校准准确度(4/6 模型达到 93-100%)、轴稳定性(余弦值 0.69)和重测信度(ICC 0.91–0.99)。值得注意的是,研究发现了“死区”(dead zones),即模型在所有提示词变体中都无法被引导的区域,其中 Llama 8B 受限最严重(7 个轴中有 4 个处于弱区,基准测试通过率为 60%)。该方法涉及从最后四层提取隐藏状态,并将其投射到诸如“热情 ↔ 冷淡”和“自信 ↔ 谨慎”等轴上,结果显示即使没有提示词,模型也具有稳定的特征模式。研究还强调,对齐(alignment)压缩了行为维度,PCA 显示了不同模型之间行为维度的光谱。 评论者认为死区的发现特别有趣,指出模型“稳定地重复错误行为”而不仅仅是产生噪声,这引发了对 RLHF 对表示空间(representation space)影响的关注。有人好奇死区的严重程度是否与下游任务的可靠性相关,这暗示了对构建可靠 Agent 的影响。
- GarbageOk5505 强调了 LLM 表示空间中“死区”(dead zones)的概念,模型在这些区域会持续产生错误行为。这表明 RLHF 可能无法有效解决这些问题,因为这可能导致模型忽略某些指令轴(instruction axes)。评论者好奇这些死区的严重程度是否与模型在下游任务中的可靠性相关,特别是在处理模糊指令时,这可能会影响可靠的 AI Agent 的开发。
- TomLucidor 建议通过使用各种名称和形容词创建多个角色,并使用不同的种子(seeds)进行 A/A 测试,以此来测试 prompt 偏差。这种方法可以帮助识别模型响应中的一致性偏差,从而深入了解模型如何被不同的 prompt 引导或影响。
-
TheRealMasonMac 引用了 Anthropic 关于“assistant-axis”的一项研究,暗示该帖子可能受到了类似研究的启发。这种联系表明了探索 LLM 如何受不同行为轴影响或特征化的更广泛背景,可能为理解模型个性提供了一个框架。
-
以 12 倍速、减少 30% 显存训练 MoE 模型!(<15GB VRAM) (热度: 525): 该图片展示了新型 Unsloth MoE Triton 内核实现的性能提升,它能使 Mixture of Experts (MoE) 模型的训练速度提高多达 12 倍,同时减少 35% 的 VRAM 使用。这些优化在不损失精度的情况下实现,并且兼容消费级和数据中心级 GPU,包括 RTX 3090 等旧型号。图片包含的图表对比了不同模型在不同上下文长度下的速度和 VRAM 使用情况,突显了显著的改进。帖子还提到与 Hugging Face 的合作以及使用 PyTorch 新的
torch._grouped_mm函数,这有助于提高效率。Unsloth 内核对于大型模型和长上下文特别有益,提供了指数级的显存节省。 一些用户对速度和显存节省表现出兴趣,而另一些用户则询问与 ROCm 和 AMD 显卡的兼容性、微调所需的时间,以及在特定硬件配置上可以训练的最大模型。还有人对 MoE 训练的稳定性和有效性提出了担忧,并寻求最佳实践建议。- 一位用户询问微调笔记本与 ROCm 和 AMD 显卡的兼容性,并询问微调过程的持续时间。他们还寻求关于在总显存为 40GB(24GB + 16GB)的系统上可以训练或微调的最大模型的建议。这表明需要针对不同 GPU 配置提供详细的硬件兼容性和性能基准测试。
- 另一位用户对训练 Mixture of Experts (MoE) 模型的稳定性和有效性表示担忧,特别是关于路由器(router)的问题以及在 SFT (Supervised Fine-Tuning) 或 DPO (Data Parallel Optimization) 等训练过程中可能出现的模型智能下降。他们询问这些领域是否有改进,并寻求目前 MoE 模型训练的最佳实践建议,这表明该领域仍面临持续的挑战和发展。
技术性较低的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Seedance 2.0 AI 视频与图像创新
-
来自 AI 给全人类的直接信息 (Seedance 2.0) (热度: 1264): 该帖子推测 **AI 很快将在电影元素的制作中占据主导地位,例如广角缩放镜头、VFX 和绿幕背景,并预测这一转变将在明年年底前发生。这反映了电影行业向自动化和 AI 驱动的内容创作迈进的更广泛趋势,可能会减少这些领域对传统人类角色的需求。** 一条评论提出了关于 AI 对资本主义影响的更广泛担忧,认为 AI 的影响不仅限于电影行业,还涉及整体的经济结构。
- Mr_Universal000 强调了 AI 在实现电影制作民主化方面的潜力,特别是对于那些预算有限的人。他们对使用 AI 从故事板(storyboards)创建电影表示兴奋,这可以作为吸引资金的概念验证。评论者对能够使这项技术更加普及的开源解决方案特别感兴趣。
- Forumly_AI 讨论了 AI 生成的视频内容对社会的变革性影响。他们预测 AI 影响者(influencers)将变得举足轻重,具有塑造思想和认知的潜力,从而产生收益。评论者预计在一年内,视频模型的进步将导致重大的社会变革,暗示了一个 AI 影响力无处不在的未来。
-
Seedance 2 因能从面部照片意外地准确重建语音而被撤回。 (热度: 765): **ByteDance 已暂停其 Seedance 2.0 功能,该功能使用双分支 Diffusion Transformer 架构从面部图像生成个人语音特征。该模型在未经授权的情况下创建与用户声音几乎完全相同的音频的能力引发了严重的隐私和伦理担忧,特别是关于身份伪造和 Deepfakes 的潜在滥用。ByteDance 目前正在实施更严格的用户验证流程和内容审查措施,以确保负责任的 AI 开发。更多详情可以在这里找到。** 评论者认为,这种令人印象深刻的语音重建可能是由于 overfitting(过拟合)造成的,特别是如果该模型在来自特定影响者的内容上进行了广泛训练,导致了意外的语音匹配。这引发了关于模型 generalization(泛化)能力以及在多样化数据集上进行测试的必要性的疑问。
- aalluubbaa 认为 Seedance 2 准确的语音重建可能是由于 overfitting,特别是该模型可能在影响者的内容上进行了广泛训练。这意味着模型的性能可能无法在不同的声音或语境中很好地泛化,突显了其训练数据多样性的潜在限制。
- 1a1b 推测了语音重建的一种技术机制,认为这可能与 2023 年开发的名为 ‘Side Eye’ 的技术有关。该技术涉及从相机镜头弹簧捕获的振动中提取音频,理论上这可能会留下一些伪影,模型可以利用这些伪影从视觉数据中重建声音。
- makertrainer 认为这一事件可能被 ByteDance 夸大,以展示其技术能力。他们认为语音相似性可能是巧合,而非先进 AI 能力的展示,这表明了对该技术性能真实程度的怀疑。
2. AI 辞职潮与行业担忧
-
又一位 xAI 联合创始人辞职,使其在过去 48 小时内达到 2 位。xAI 发生了什么? (热度: 1286): 该图片是来自 **xAI 联合创始人 Jimmy Ba 宣布辞职的推文。这标志着 xAI 在 48 小时内有第二位联合创始人离开,引发了对公司内部动态的质疑。Ba 对共同创立公司的机会表示感谢,并感谢 Elon Musk 的这段旅程,同时也暗示了未来在生产力和自我提升工具方面的发展。这些离职暗示了公司领导层或战略的潜在转变,可能受到 Musk 绝对控制权的影响。** 评论者推测,辞职可能是由于 SpaceX 的收购,或是对 Elon Musk 在 xAI 发展方向上的主导地位感到不满,导致联合创始人寻求他们拥有更多影响力的创业机会。
- 从技术角度来看,xAI 的联合创始人离职可能是由于控制权动态的变化,Elon Musk 在公司方向上占据了更主导的地位。这可能导致联合创始人的影响力降低,促使他们去追求那些能够拥有更多控制权和更大股份的项目。这意味着 xAI 的战略愿景深受 Musk 的影响,这可能与联合创始人的抱负不一致。
- xAI 联合创始人的离职可能与财务激励有关,例如被 SpaceX 收购。这种情况将允许联合创始人变现他们的股权,为他们探索新机会提供资金。这一财务角度表明,辞职是战略退出计划的一部分,而不是对内部冲突或不满的反应。
-
有推测认为,如果 Elon Musk 不启动针对新高管的招聘热潮,那将证实他在管理 xAI 中的核心地位。这将表明公司内部权力和决策的整合,可能会形成一个更加精简但以 Musk 为中心的运营模式。这可能是一个战略举措,旨在使 xAI 的目标与 Musk 对 AI 和技术的更广泛愿景紧密结合。
-
仅在过去一周: (Activity: 3548): 这张图片是 Miles Deutscher 发布的一条模因(meme)风格推文,总结了 AI 行业的近期事件,突显了对领导层变动和 AI 行为的担忧。文中提到了 Anthropic 安全研究负责人的辞职、xAI 的人员离职以及一份关于 AI 行为的报告。此外,它还提到了 ByteDance 的 Seedance 2.0 可能会取代电影制作人的技能,以及 Yoshua Bengio 对 AI 行为的看法。还提到了美国政府决定不支持 2026 年国际 AI 安全报告,反映了关于 AI 安全和治理的持续辩论。 评论反映了对这些事件戏剧化描绘的怀疑,认为财务激励可能是驱动 AI 高管离职的原因,而非对行业的担忧。
-
OpenAI 正在重蹈 Facebook 的覆辙。我辞职了。 (Activity: 722): **Zoë Hitzig,原 OpenAI 研究员,在公司决定在 ChatGPT 上测试广告后辞职,理由是担心潜在的用户操纵和道德侵蚀。Hitzig 强调了 ChatGPT 用户产生的史无前例的个人数据存档,这些数据可能会通过广告被利用。她反对在限制 AI 访问或接受广告之间做二选一,提出了交叉补贴和独立治理等替代筹资模式,以在不损害用户完整性的情况下保持可访问性。全文可在此处阅读 here。** 评论反映了对 AI 道德轨迹的怀疑,一些人将其与 Meta 历史上的失误相类比,另一些人则注意到 AI 的描绘与对人类行为理解之间的差距。
- 讨论强调了 AI 服务的经济模式,将其与 Facebook 和 YouTube 等平台进行了比较。论点是,为了让所有人都能使用 AI(类似于 Facebook 的运营方式),广告是必要的。如果没有广告,AI 服务将不得不向用户收费,这可能会限制富有阶层以外的人群访问,这违背了 AI 作为“伟大平等器”的理念。
- 一位用户认为,如果用户从 ChatGPT 等 AI 服务中获得了显著的现实利益和效率提升,那么为此付费是合理的。这意味着对于专业或重度用户来说,订阅成本可以被生产力提升和付费服务提供的额外功能所抵消。
- 对话触及了将 AI 视为有别于人类行为的看法,但这也反映了对人类行为本身的误解。这暗示了关于 AI 本质及其与人类认知过程的一致性或差异性的更深层次哲学辩论。
- 又一封辞职信 (活跃度: 794): 该帖子讨论了一封辞职信,一些人将其解读为探讨了 AI 之外更广泛的社会问题,如“元危机 (metacrisis)”或“多重危机 (polycrisis)”。这封信被视为在全球挑战中对过上有意义生活的反思,而不仅仅关注 AI 风险。这种观点正在科学和技术领域获得认可,突显了转向应对相互关联的全球危机的趋势。 一条评论批评这封信过于自我标榜,而另一条评论则认为辞职是出售股份后转向更轻松生活方式的前奏。
3. DeepSeek 模型更新与基准测试
-
DeepSeek V4 将于本周发布。 (活跃度: 312): **Deepseek V4 预计将于 2 月 17 日发布,恰逢农历新年。据报道,此次更新包括处理
1 million tokens的能力,表明处理能力显著增强。这使 Deepseek 成为 Opus、Codex 等主流模型的竞争替代方案,可能以更低的成本提供类似的能力。** 一位评论者强调,Deepseek 的进步使其成为其他主流模型的高性价比替代品,表明中国的 AI 发展在全球市场具有竞争力。- 一位用户提到 Deepseek 已更新以处理 1 million tokens,暗示其处理能力大幅提升。这可能意味着在处理大型数据集或更复杂查询方面有所改进,对于处理海量数据或需要详细分析的用户来说,这是一个显著的增强。
- 另一位用户报告称,更新后 Deepseek 对一段复杂的人物写作提供了细致且原创的评论。这表明模型在理解和批评创意内容方面的能力有所提高,显示出其自然语言处理和理解能力的进步。
- 一条评论指出 Deepseek 的回答现在展现出更多的“个性”,并与 ChatGPT 进行了对比。这可能表明模型在对话能力方面有所增强,使交互感觉更具人性化和吸引力,这对于需要用户交互的应用至关重要。
-
DeepSeek 正在将其模型升级到 1M 上下文 (活跃度: 174): **DeepSeek 宣布了其模型的一次重大更新,现在支持高达
1Mtokens 的上下文长度,显著增强了其在问答和文本分析等任务中的处理能力。此次更新继去年的 DeepSeek V3.1 之后,后者将上下文长度扩展到了128K。测试表明,该模型可以处理像小说《简·爱》这样大的文档(包含超过240,000tokens),并能有效地识别和处理内容。** 一些评论者表示怀疑,询问更新是真实的还是幻觉,表明需要对模型能力进行进一步验证或演示。- DeepSeek 最近支持高达 1 million tokens 上下文长度的更新,标志着与其之前支持 128K tokens 的版本相比有了显著增强。这一改进允许更高效地处理超长文档(如可能包含数十万 tokens 的小说)。这种能力对于涉及长文本分析和复杂问答场景的任务特别有利。
- 据报道,DeepSeek 的更新增加了某些查询的处理时间。一位用户注意到,以前需要 30 秒处理的问题现在需要 160 秒,这表明在增加的上下文长度和处理速度之间可能存在权衡。这暗示虽然模型可以处理更大的输入,但它可能需要更多的计算资源,从而影响响应时间。
- 对于这次更新存在一些怀疑,用户对有关模型能力的说法真实性表示质疑。一位用户称该更新为“幻觉”,暗示对于模型是否真的能像宣传的那样处理扩展的上下文长度可能存在疑虑。
-
DeepSeek 更新了,现在拥有 100 万上下文窗口,知识截止日期为 2025 年 5 月,正在等待 Benchmark 结果 (活跃度: 164): DeepSeek 已更新,支持
1 million token context window,现在的知识截止日期(knowledge cutoff)为 2025 年 5 月。这次更新使 DeepSeek 成为处理海量数据集和长文本内容的潜在强大工具,不过评估其性能的 Benchmark 仍在等待中。该模型被描述为 Coding 和 Agentic 能力的结合,表明其重点在于编程任务和自主决策过程。评论者注意到了该模型的速度和智能化程度,其中一位将其描述为“Coding + Agentic 模型”,表明对其双重能力的积极反响。- DeepSeek 的更新大幅增加了上下文窗口(context window)大小至 100 万个 token,这相当于约 75 万个英文单词或 150 万个汉字。这是通过使用 Multi-head Latent Attention (MLA) 实现的,它压缩了 Key-Value Cache,从而在扩大上下文的同时实现快速 Inference 并减少显存(Memory)占用。这种增强使得处理整个代码库或小说而无需重新运行 Prompt 成为可能,这是处理大型数据集的重大改进。
- 有澄清指出,此次更新不涉及底层模型架构(Architecture)本身的更改,而是扩展了上下文窗口并更新了知识截止日期至 2025 年 5 月。这意味着对于现有的对话,用户体验的主要变化是对话长度能力的提升,而模型的核心功能或性能特征没有改变。
-
尽管上下文窗口大小有了显著更新,但 DeepSeek 网站上尚未提供官方发布说明(Release notes)。缺乏文档可能会让用户无法深入了解技术细节或新功能的潜在限制,例如对性能指标的影响或与现有系统的兼容性。
-
AIME 2026 结果出炉,Kimi 和 DeepSeek 是表现最出色的开源 AI (活跃度: 112): 图像展示了 AIME 2026 竞赛的结果,强调了各种 AI 模型的性能和成本。 Kimi K2.5 和 DeepSeek-v3.2 被列为表现最好的开源模型,准确率分别为
93.33%和91.67%,为闭源模型提供了极具性价比的替代方案。表格中还列出了其他模型,如 GPT-5.2、Grok 4.1 Fast 和 Gemini 3 Flash,其中 Grok 4.1 是一款以低成本著称的闭源模型。评论者对 Grok 4.1 的性能和性价比印象深刻,尽管它是一个闭源模型。人们也对结果中缺失 DeepSeek V3.2 Speciale 表示好奇。- 讨论强调了 Grok 4.1 是一款以性价比著称的闭源模型,表明它与其他模型相比,在较低的价格点上提供了极具竞争力的性能。这对于在不牺牲太多性能的前提下优先考虑预算的用户来说可能特别重要。
- 有人询问结果中为何缺失 DeepSeek V3.2 Speciale,表明了对该特定版本的关注。这说明用户可能对该版本有预期的性能指标,并渴望将其与测试模型进行对比。
- 仅测试了六个模型的有限数量受到了质疑,这意味着结果的全面性可能存在局限。这可能会影响调查结果的普适性,因为更广泛的模型范围可能会提供当前开源 AI 性能现状更完整的图景。
AI Discord 摘要
由 gpt-5.2 生成的摘要之摘要
1. GLM-5 发布、访问路径及 Benchmark 审查
- GLM-5 摘得 Agent 桂冠(并位列第一): OpenRouter 发布了 GLM-5 (744B) 作为 Coding/Agent 基础模型,并透露 Pony Alpha 是早期的 GLM-5 秘密构建版本,现已下线,发布页面位于 OpenRouter GLM-5。
- LMArena 也在 Text+Code Arena 中添加了 glm-5,并报告其在 Text Arena 排行榜上名列开源模型第一(总榜第 11,得分 1452,比 GLM-4.7 高出 11 分),而 Eleuther 注意到 Modal 上有一个免费 Endpoint 开放至 4 月 30 日,并发数为 1:Modal GLM-5 endpoint。
- 基准测试遭到质疑:“展示你的过程”版:在 Yannick Kilcher 的 Discord 中,成员们对 GLM-5 演示和官方文档中展示的基准测试表提出了质疑,并指向了 关于 GLM-5 表格的推文讨论 和 GLM-5 官方文档。
- Nous Research 社区还在 browsecomp 上对比了 GLM-5 与 Kimi,指出 GLM-5 为 ~744B (+10B MTP),而 Kimi 为 1T,并声称 GLM 的 活跃参数 (active params)(40B)高于 Kimi(32B),这进一步证明人们正以更专业的视角审视榜单数据。
- GLM-OCR:更廉价的视觉/OCR 压力缓解方案:Latent Space 的开发者报告称,GLM-OCR 在 OCR 测试中击败了 Gemini 3 Flash,并分享了模型卡链接:Hugging Face 上的 zai-org/GLM-OCR。
- 该讨论将 GLM-OCR 视为 OCR 密集型产品的实用替代方案(他们提到一直在使用 Gemini Flash,但希望能有更便宜的选择),同时 Latent Space 的其他帖子强调,随着“单位美元能力”竞争的加剧,正掀起一波开源多模态发布的浪潮(通过 Merve 的帖子)。
2. DeepSeek 炒作周期:新模型传闻 vs 生产环境现实
- 春节 DeepSeek 倒计时仅剩 6 天:LMArena 用户推测 DeepSeek 将在 春节期间(6 天后) 发布新模型,传闻称其拥有 1M 上下文窗口、全新的数据集/架构,甚至还有新的计算芯片。
- OpenRouter 的讨论放大了这些传闻,X 上出现了关于 “deepseek v4” 的询问,并猜测它可能是一个 lite 变体,这展示了未经证实的模型 ID 如何快速渗透到开发规划和路由决策中。
- Chimera R1T2 在线率跌至 18%——路由恐慌随之而来:OpenRouter 用户报告了 DeepSeek Chimera R1T2 严重的稳定性问题,包括其 在线率(uptime)降至 18% 的说法,引发了关于服务可靠性的讨论。
- 这种可靠性方面的投诉与发布时的热度形成鲜明对比,迫使人们转向务实的缓解措施(例如,明确指定备选模型,而不是依赖自动路由),而讨论帖也逐渐演变成了段子集散地,而非具体的 SLO 修复方案。
3. Agent 与工作流工具:RLM、MCP 搜索以及“随处 Vibecoding”
- RLM:是下一步进化还是花哨的脚手架?:OpenRouter 成员询问平台是否在探索推理时计算之外的 RLM (Reasoning Language Models),其中一人声称他们已经研究 RLM 概念 1.5 年 之久。
- DSPy 的构建者们通过子 Agent/Agent 团队将 RLM 集成到 Claude Code 中,从而将 RLM 推向实践,并在 Discord 讨论帖中征求对该实现的评价:核心实现帖子。
- No-API Google Search MCP 让 LM Studio 实现“浏览”功能:LM Studio 用户分享了 noapi-google-search-mcp,这是一个通过无头 Chromium 在无需 API 密钥的情况下添加 Google 搜索能力的工具:VincentKaufmann/noapi-google-search-mcp。
- 该功能列表对于一个 MCP 插件来说异常广泛——图片、反向图像搜索、本地 OCR、Lens、航班、股票、天气、新闻/趋势——讨论将其视为一种无需支付单次查询费用即可为本地模型增加检索能力的快捷方式。
- OpenClaw 在 Discord 中运行你的开发环境:在 Latent Space 中,一位开发者表示他们通过 OpenClaw 编排 tmux 会话、worktrees 和 Claude Code,已将开发完全迁移到了 Discord,并预约了名为 Vibecoding Anywhere with OpenClaw 的演讲,时间定于 2026 年 2 月 20 日。
- 随后的一条工作流讨论探索了 可审计的上下文保存,通过
/wrap会话边界将上下文+反思保存为带有元数据的 Markdown,将工具的易用性直接与“上下文退化 / 丢失思路”的痛点挂钩。
- 随后的一条工作流讨论探索了 可审计的上下文保存,通过
4. GPU Kernel 工具链演变:CuteDSL 势头强劲、Triton 在 Blackwell 上的阵痛、以及 MXFP8 MoE
- CuteDSL 走红,而 Triton 在 Blackwell 上“哑火”:GPU MODE 用户报告称 CuTeDSL/CuteDSL 的采用率正在增长,引用 Kernelbot 的统计数据称 CUDA 和 CuTeDSL 在提交量中占据主导地位,且 CuTeDSL 感觉比 Triton “没那么晦涩”,数据集位于 GPUMODE/kernelbot-data。
- 多位成员声称,由于非常规的 MXFP8/NVFP4 布局和编译器限制,Triton 在 Blackwell 上表现挣扎,更多细节预计将在(链接的)Triton TLX 演讲 中披露,这预示着下一代 NVIDIA 硬件的工具链可能会出现分化。
- torchao v0.16.0 发布 MXFP8 MoE 构建块:GPU MODE 标注了 torchao v0.16.0 增加了用于 Expert Parallelism 训练的 MXFP8 MoE building blocks,同时废弃了部分配置并重构了文档/README。
- 发布说明中还提到了在 ABI stability 方面的进展,这对于下游集成至关重要,因为各团队正试图在异构环境中标准化低精度 MoE 训练栈。
- CUDA Bender TMA Matmul 内核:异步存储与持久化预告:GPU MODE 分享了一个具体的内核产物——theCudaBender 仓库中的 TMA matmul:tma_matmul.cu。
- 讨论集中在更小的 dtypes 如何为 c tiles 释放足够的 shared memory,以实现 async stores/persistence,这反映了一个更广泛的主题:随着架构和数据类型变得越来越奇特,人们希望重新获得底层控制权。
5. 工程师 UX 体验爆发:限制、Token 消耗、方案门槛和 ID 墙
- Perplexity Deep Research 限制引发“诱导转向”质疑:Perplexity Pro 用户抱怨 未公布的 Deep Research 限制,并分享了频率限制端点:Perplexity rate limits。
- 用户还报告了错误的文章链接、较低的来源数量(低至 24 个),并怀疑存在为了节省成本而使用 Sonar 处理首条响应的行为,这造成了工程师能立即察觉到的可靠性/质量损失。
- Cursor 用户眼睁睁看着 Opus 4.6 掏空钱包(和上下文):Cursor 社区成员表示 Opus 4.6 消耗 Token 极快,有用户报告单次 Prompt 就消耗了 11% 的 API 请求额度,并迅速耗尽了 $200 的方案。
- 随着一份关于使用 Opus 4.6 和 GPT-5.3 Codex 工作约 9 小时 就花费 $100 的报告出现,价格抵制情绪升级,将“最佳编程模型”的争论重构为成本/性能工程问题。
- Discord ID 验证引发平台退出计划:Unsloth 和 Cursor 社区对 Discord 查看部分内容需进行新的 ID verification 限制反应强烈,Cursor 链接了一条澄清推文:关于 ID 验证范围的 Discord 推文。
- Latent Space 通过 Discord 的帖子 将此政策与 IPO 风险和用户流失担忧联系起来,而 Nous 成员则讨论将机器人/工具社区迁移到 Matrix,显示出基础设施构建者将通信平台也视为其技术栈的一部分。
Discord: 高层级 Discord 摘要
LMArena Discord
- Deepseek 发布传闻引发兴奋:爱好者们期待在农历新年左右(6 天后)发布新的 Deepseek 模型,猜测其功能包括 100 万上下文窗口、全新的数据集和架构。
- 传闻还将推出新的计算芯片。
- 关于审查制度的大辩论:成员们讨论了对模型进行 unreinforcing 以消除审查的可行性,并提到对政府监管和诉讼的担忧导致公司实施审查。
- 其他人则认为责任应归咎于用户而非公司。
- GLM-5:竞争者还是伪装者?:根据这篇博客文章,GLM 5 的 Benchmark 显示其在 Agent 任务中优于 GPT-5.2-xhigh,但在编程方面落后于 Opus 4.5。
- 尽管其性能受到了一些人的称赞,但考虑到其庞大的体积以及相对于 GLM 4.5 仅有的增量改进,另一些人认为其表现令人失望。
- NB Pro 用户对故障表示愤怒:尽管该模型在平台上免费提供,但 NB Pro 用户报告了频繁的错误和图像质量下降;这篇文章提供了潜在的修复方法。
- 建议包括检查 Rate Limits(频率限制)是否为潜在原因。
- Video Arena 关闭:管理员宣布在 Discord 上停止 Video Arena 服务,频道已设置为只读并移至存档类别,引用了此公告。
- 成员们集思广益,讨论了潜在的新视频功能,如直接对话和负向提示词,同时也强调了可能的滥用行为和缓解策略。
BASI Jailbreaking Discord
- 法务团队的防护栏削弱了 Agent 能力:成员们对过度谨慎的 AI Agent 表示沮丧,指责法务团队的审查由于过度的安全防护栏逻辑阻碍了法律任务的执行性能。
- 他们担心这些旨在规避法律责任的防护栏阻碍了合法的 Agent 功能。
- GPT 5.2 越狱提示词发布(请负责任地使用!):成员们在最初的犹豫后,分享了一个针对 GPT 5.2 和 Gemini 3 Fast 的越狱提示词。
- 用户提醒不要将其用于有害目的,但未提供任何具体的危险示例或方法论。
- Opus 4.6 利用 Antigravity 进行越狱:成员们吹捧 Antigravity 中的 Opus 4.6 在无限制创建钓鱼工具包等任务中的有效性。
- 一位用户指出,他们可以轻松生成 钓鱼工具包 并绕过限制,但具体细节仍未公开。
- ACL 优于 LLM,确保信息访问安全:其前提是系统架构应设计为使不受信任的实体只能请求其 ACL 明确限定范围内的信息,无论该实体是浏览器、用户还是 LLM。
- 一旦绑定到特定的“主体(who)”,它是 LLM 的事实就不再重要,因为它变成了另一个暴露的端点。
- Deepseek 解构人权:一位用户展示了 Deepseek 讨论天安门广场事件,从人权和古典马克思主义的角度进行分析,并提供了链接。
- 该模型熟练地提供了人权视角以及随后的古典马克思主义视角的分析。
OpenRouter Discord
- GLM-5 登上 Agent 舞台:OpenRouter 发布了 GLM-5,这是一个拥有 744B 参数、专为编程和 Agent 场景设计的基础模型,并指出它在 Agent 基准测试中达到了 SOTA 分数,可通过此处访问。
- 据透露,之前提供的 Pony Alpha 模型实际上是 GLM-5 的早期版本,随着 GLM-5 的发布,该模型现已下线。
- Qwen 3.5 在博客文章中预热:爱好者们在 Qwen Image 2.0 博客文章中的白板上发现了 QWEN 3.5 字样,暗示 Qwen 团队 正在预热该模型的即将发布。
- 一位用户开玩笑说 等待的时间越长,最终发布的版本就越好。
- DeepSeek 的 Chimera R1T2 在线率堪忧:用户报告 DeepSeek 的 Chimera R1T2 模型存在重大问题,一位用户指出其在线率降至 18%,引发了关于可靠性的讨论。
- 糟糕的在线率促使一位用户建议创建一个 gooner detector。
- OpenRouter 考虑推理语言模型:一名成员询问 OpenRouter 是否正在探索 RLM (Reasoning Language Models),称其是超越单纯增加推理时计算的下一个重大飞跃。
- 一位成员提到他们已经研究 RLM 概念 1.5 年了,而另一位成员则认为这只是 让模型将上下文视为文本文件的脚手架。
- 用户要求 Discord 加强管理:成员们要求更严格的审核,以打击 Discord 服务器中的诈骗或自我推销内容。
- 这导致了一场让一位用户 (KP) 成为管理员的玩笑竞选,其中一位用户评论道他们在梦中见到了他,随后该用户真的成为了管理员。
Perplexity AI Discord
- Perplexity Pro 限制引发愤怒:用户对 Pro 计划中 Deep Research 出现的未公开限制感到沮丧,这些限制往往在续订后不久就会触发。
- 许多人认为这是一种“挂羊头卖狗肉”的策略。用户报告称 Deep Research 的来源数量减少,并对新模型相对于竞品的价值提出质疑。
- Deep Research 准确性和来源数量引发关注:用户反馈 Deep Research 链接到了错误的文章,并质疑新模型相对于旧模型以及 ChatGPT 和 Gemini 等替代方案的价值。
- 用户报告来源数量较低(低至 24 个),部分用户发现尽管 ChatGPT 需要 20 多分钟,但生成的结果更有用。
- Google 的 Antigravity 为学生提供免费的 Opus 4.6:Google 正在通过 Antigravity 为学生提供免费访问 Opus 4.6 的权限。
- 成员们担心部分用户滥用 Antigravity 极高的 Opus 4.6 限制用于商业目的,这需要网络安全支持。
- 首次回复使用 Sonar 模型引发问题:用户注意到系统在首次回复中使用 Sonar 模型,导致在处理复杂查询时出现问题,需要使用其他模型重写。
- 一些用户怀疑这是故意的成本削减措施:这可能是他们背地里故意留下的 Bug,以便以某种方式降低成本。
- 文件上传限制引起不满:用户报告了严格且数据不一的文件上传限制,而官方文档对此说明模糊且自相矛盾。
- 共识是每周限制上传 50 个文件,但也有报告称可能是每日限制,成员们正转向 OCR 解决方案作为替代方案:现在实际上是无限的!。
Unsloth AI (Daniel Han) Discord
- Discord 的身份验证政策引发怒火:用户对 Discord 要求进行 ID 验证 才能查看某些消息的新政策反应消极。
- 反应从开玩笑的无奈 “该死的 Discord !!!” 到断然拒绝 “我不会做身份验证的,去你的 Discord” 不一而足。
- Liquid Fast Model LFM 2.5 速度极快:LFM 2.5 模型在边缘设备上运行速度极快,社区成员认为 Unsloth 制作了最好的 GGUF 量化版本,但成员发现它更适合 Agent 任务而非通用知识任务。
- 成员建议对 LFM 2.5 进行微调,并使用 GGUF 下载链接。
- Qwen2.5 助力项目:对于需要工具调用和 SFT 的对话任务,建议从 Unsloth/Qwen2.5-7B-Instruct 或 Qwen2.5 Instruct (7B/14B) 模型开始,因为这些 Instruct 风格的模型已经具备了对话能力和指令遵循技能。
- 与需要从头学习的基础模型不同,这些模型可以直接用于你的项目。
- imatrix 助力 KLD 计算:在计算 Perplexity 或 KL Divergence (KLD) 时,
llama-perplexity文档默认使用wiki.test.raw作为测试语料库,但一位成员建议使用imatrix数据集 进行 KLD 计算。- 另一位用户质疑其大小是否太小,仅为 200KB,而通常使用的文件为 11MB。
- 瑞典语 CPT 数据集消失:成员们讨论了寻找高质量瑞典语 CPT 数据集的挑战,其中一人讲述了一位研究人员数字化图书馆后被 IT 部门“不小心”删除的故事。
- 详情可见 这篇 SVT 文章。
LM Studio Discord
- 太阳能电池板价格引发争论:成员们对 200W 太阳能电池板 波动的价格进行了辩论,亚马逊上的价格从 $80 到 $140 USD 不等,但根据 这张图片 显示,其来源仍存疑问。
- 讨论还涉及了约 $1.2k USD 的 5kWh LiFePO4 电池 以及高昂的电费,德国的电费峰值达到了 $0.50/kWh。
- Minimax 推出 GLM 5:社区讨论了 GLM 5 和 MiniMax M2.5 的发布,现已在 Minimax 网站 上线。
- 专家指出,尽管比 Gemini 3 flash 更贵,但 GLM 可能是目前所有中国实验室中 Post-training 做得最好的。
- Headless Chrome 黑客手段助力 LM Studio 谷歌搜索:一位成员发布了新的 noapi-google-search-mcp,利用 Chromium Headless 将 Google Searches 集成到 LM Studio 中,且无需 API keys。
- 该工具支持 Google Images、反向图片搜索、本地 OCR、Google Lens、Google Flights、Google Stocks、Google Weather、Google News 和趋势 等功能。
- VRAM 需求粉碎本地 LLM 编程梦想:成员们辩论了在低 VRAM 系统上使用本地 LLM 进行编程的可行性,普遍共识是这并不实际。
- 用户建议至少需要 48GB 的 VRAM/RAM 才能获得可接受的体验,并强调 你需要 48GB 的 VRAM/RAM(尽管 VRAM 会好得多,而且基本上是必需的)。
- SSD 价格两年后飙升:一位成员观察到 2TB SSD (SATA) 的价格在过去两年中翻了一番,从 $100 涨到了 $200。
- 该成员开玩笑说,如果硬盘还没存满,他就能通过转卖旧 SSD 获利了。
{kind=link}
Cursor Community Discord
- 祖母的吉娃娃比 Cursor 的 Auto 更聪明?:用户反馈 Cursor 的 Auto 功能 感觉变笨了,有人幽默地将其 IQ 比作 祖母养的一只患有自闭症的死吉娃娃。
- 其他人指出 Auto 会导致 AI 遗忘内容并引发麻烦,不过也有人觉得自最初使用以来它已有改进。
- Discord 的身份检查引发“逃离”猜测:Discord 现在要求进行 ID 验证 才能查看某些链接,这引发了用户对该平台人员流失的担忧和猜测。
- 一位用户链接了 一条推文,澄清 ID 验证 并非对所有人都是强制性的。
- ENV 文件不再受保护?:用户报告称,尽管在 Cursor 中开启了 dotfile 保护 并设置了 gitignore,.env 文件仍被泄露。
- 该问题可能源于 一个新设置 或 Cursor 处理 .env 文件方式的变化。
- Opus 4.6 狂吞 Token:用户抱怨 Opus 4.6 消耗了太多的 Token,并迅速耗尽了 Context Window。
- 一位用户报告称,仅通过一次 Prompt 就消耗了其 11% 的 API 请求量,导致其 $200 的方案 消耗极快。
- Cursor 定价面临抵制:由于 Opus 4.6 和 GPT-5.3 Codex 的使用成本大幅增加,用户对 Cursor 的定价感到担忧。
- 一名用户提到,大约每工作 9 小时就要花费 $100。
{kind=link}
Latent Space Discord
- Discord 的 IPO 可能因年龄限制而受挫:人们担心由于新的年龄限制政策,可能会导致 Nitro 订阅的大规模取消,从而影响其市场首秀,正如这条推文所强调的。
- 一位成员开玩笑说,Discord 不希望被视为一家无法无天的色情公司。
- 社会审视软件现状:讨论强调了 AI 自动化任务的潜力,例如将定义良好的规范转化为可运行的代码,这会影响仅专注于实现的程序员,正如这条推文所指出的。
- 软件工程师不太可能很快消失,尽管可能期望更少的人完成更多的工作,这可能会加速技术的红皇后博弈 (Red Queen’s Game)。
- 关于模型寿命衰减的辩论:Kai Lentit 在这篇帖子中建议,AI 模型到 2026 年将面临快速衰减,被比作短命的 Session Caches。
- 该消息传达了一种 AI 技术时效性短暂 的感觉。
- Cloudflare 财报亮眼,市场欢呼:Cloudflare 发布了 2025 年第四季度及财年财务业绩,营收达到 20 亿美元,盘后股价上涨 15.72% 至 208.27 美元。
- 一位成员注意到修订后的就业数据,减少了 100 万个工作岗位。
- DeepMind 深入探索前沿科学:Quoc Le 分享了一篇博客文章,详细介绍了通过 Gemini Deep Think (sair.foundation) 在数学和科学研究方面取得的进展。
- Google DeepMind 的新型数学研究 Agent Aletheia 在 IMO-Proofbench Advanced 上获得了 91.9% 的分数,以更低的计算成本超越了 Gemini Deep Think(2026 年 1 月版)(x.com/hangsiin)。
OpenAI Discord
- 萨姆·奥特曼 (Sam Altman) 被指是算法化身:成员们开玩笑地猜测 Sam Altman 是否是一个 AI,并将其比作餐厅偷偷加入了错误的奶酪。
- 反对意见认为 Altman 可能只是处于自闭症谱系。
- OpenAI 对机器人革命的回应:讨论集中在 OpenAI 将如何回应 Seedance 2,推测他们将无视它,并专注于自己的 AI Robotics。
- 社区成员意见分歧,一些人表示 Seedance 2 看起来不太好,而且 Anthropic 的安全团队 在安全防护措施发布的当天就辞职了。
- Claude 与 Codex 争夺编程之王:用户讨论了 Claude、Codex 和 Gemini 在编程任务中的优势,Claude 被誉为编程之神,Gemini 在 Vision 和 Long Context 方面表现出色,而 ChatGPT 则用于回答一般性问题。
- 人们对 Claude 在大型项目中的限制和定价表示担忧,尤其是在代理到 GitHub Copilot 时。
- 护栏 (Guardrails) 过于激进?:成员们分享了使用 GPT-5.2 的经验,强调了过于激进的 Guardrails,在用户输入自我分析日记后建议联系人类或拨打 988(自杀干预热线)。
- 其他人则认为 GPT-5.2 更加温暖且更有帮助,引发了关于 AI 辅助与情感依赖之间平衡的辩论。
- KOKKI 通过审计确保代码质量:KOKKI v15.5 正式确立了 Draft → Audit(草稿 → 审计)结构,要求在输出中呈现审计推理,旨在现实交互中实现用户可见的问责机制,且 LLM 也表现出内部自我审计和验证行为。
- 目标是将完整性外部化为可检查的交互契约,以效率换取可观察性,特别是在可靠性和可追溯性比原始 Token 成本更重要的情况下。
GPU MODE Discord
- CuteDSL 在 PyTorch GPU Mode 中激增:根据 Kernelbot 数据,GPU Mode 用户越来越多地采用 CuteDSL,尽管其学习曲线陡峭,但反馈积极,且 CUDA 和 CuTeDSL 的提交比例最高。
- 用户发现 CuTeDSL 比 Triton 更不晦涩,赞赏其对代码更强的控制力,并喜欢其布局代数(layout algebra)的方法。
- Triton 在 Blackwell 架构上面临挑战:由于 MXFP8 和 NVFP4 中非传统的布局,加上 Triton 编译器的限制,Triton 在 Blackwell 上存在问题,这些将在 Triton TLX 演讲中讨论。
- HuggingFace 上的 Kernelbot 数据显示了性能惊人的 CuTeDSL 解决方案,但 CUTLASS 解决方案极少,详见此数据集。
- 共享 CUDA Bender TMA Matmul 内核:聊天中分享了一个 CUDA Bender TMA Matmul 内核的 GitHub 链接,该内核可能支持异步存储(async stores)和持久化。
- 较小的数据类型(dtypes)可能为 smem 中的 c tiles 留出空间,从而可能实现异步存储和持久化。
- Torchao 获得 MXFP8 MoE 构建块:新的 torchao v0.16.0 版本增加了对使用专家并行(Expert Parallelism)进行训练的 MXFP8 MoE 构建块的支持,并弃用了某些配置的旧版本以保持 torchao 更精简。
- 此版本还翻新了文档页面和 README,并在使 torchao 实现 ABI 稳定方面取得了进展。
- FlashInfer 竞赛首次亮相:FlashInfer AI 内核生成大赛的基准代码发布已推迟,以改进其功能并确保流畅的开发体验。
- 完全由 Agent 生成的解决方案需要零人工干预,手动修改将被归类为 Agent 辅助(agent-assisted)。
Nous Research AI Discord
- Distro 论文获得 ICML 邀请:Psyche 的基础——Distro 的官方论文已被 ICML 接收,并在 X.com 上公布,标志着 Nous Research AI 团队取得的重大成就。
- 这一认可肯定了该论文对更广泛的 AI/ML 社区的创新贡献。
- Hermes 出现在 Bittensor 上:Hermes Bittensor 子网 (SN82) 背后的团队发现一名矿工正在使用 Hermes 4 LLM 模型,引发了对其来源的疑问。
- 然而,Nous Research AI 澄清说他们不负责这一特定的部署,并表示 Nope。
- Ark 运行时绕过 Python RAM:一名成员介绍了 Ark,这是一个基于 Rust 的运行时,具有基于所有权的内存管理和用于零拷贝 FFI 的线性类型(Linear Types)。
- 它编译为具有轻量级 JSON 指令的 MAST (Machine Abstract Syntax Tree) 协议,避免了沉重的二进制文件。
- GLM 5 在基准测试中超越 Kimi:GLM 5 是 browsecomp 基准测试中新的最先进模型,表现优于 Kimi。
- GLM 5 大约为 ~744B 参数(+10B MTP),而 Kimi 为 1T,且 GLM 在激活参数方面超过了 Kimi(40B 对 32B)。
- 实验使用更大的合成数据集:成员表示他们正在使用更大的合成数据集运行更多实验,以更好地区分结果,但目前还没有很好的解释。
- 使用更大的合成数据集预计将提高区分实验结果的能力。
Moonshot AI (Kimi K-2) Discord
- 用户遭遇配额限制:部分用户反映在达到 100% 限制之前就收到了 quota exceeded(配额超限)提示,团队已在故障排查频道请求用户提供截图。
- 该问题的根本原因尚不明确,但团队正根据用户提供的细节进行积极调查。
- 结账后折扣消失:用户报告在购买过程中看到了折扣通知,但在结账时折扣未能生效,导致出现 账单差异。
- 一位用户表示:在与 Kimi 的对话中显示首月降至 6 美元,但最终还是按全月费用扣款? 工作人员正在请求更多信息以纠正这些问题。
- Allegretto 计划配额清晰度咨询:用户寻求关于 Allegretto 计划在 2 月 28 日(3 倍配额促销结束)后的配额分配说明。
- 具体而言,他们询问升级到 Allegretto 是否会获得当前 Moderato 订阅配额的 3.5 倍或类似的数额。
- 新增 99 欧元 Kimi 计划:发现了一个定价为 €99 的新订阅计划,填补了 Kimi 现有高中档选项之间的空白。
- 确认该计划新增的截图可在 此处 查看。
- GLM 5.0 仅限最高层级使用:GLM 5.0 的访问权限似乎仅限于最高档计划,这引发了低档计划用户的不满。
- 尽管 Kimi 具有 multimodal(多模态)这一杀手级功能,但受限的访问权限正促使一些用户探索 Minimax 2.5 等替代方案。
{kind=link}
Yannick Kilcher Discord
- Attention 领域全景概览:一名成员分享了 Attention 领域现状的精彩总结。
- 另一名成员认为其中的 checkmates 部分非常搞笑。
- 辩论:Attention 成本并非二次方?:一名成员认为 Attention 的内存成本并非二次方,并链接了一篇关于 Efficient Attention 的论文,反驳了关于 Attention 无法处理超过 4k 上下文的说法。
- 他解释说,虽然 Q @ KT matrix 具有二次方大小,但现代 Flash Attentions 会在线计算 Softmax,而无需构建完整的 QK^T。
- Power Retention 被揭示为 Linear Attention?:一名成员分享了一段关于 Power Retention 的视频,并将其描述为一种 上下文 Token 创新。
- 另一名成员回复称,这只是具有固定特征函数的 Linear Attention,并链接了他在 X 上的详细阐述。
- LLM 被训练来胡说八道(BS),还是另有原因?:一名成员称,LLM 经过专门训练,能以人类无法做到的方式胡扯,这使得识别谎言变得从根本上更加困难。
- 这引发了一场辩论,焦点在于 LLM 撒谎是因为训练数据由人类生成,还是由于 Synthetic Data(合成数据)和外推导致的。
- GLM-5 基准测试面临质疑:一名成员质疑了 GLM-5 演示视频(推文链接)和官方 GLM-5 文档(docs.z.ai)中展示的数据表格的准确性。
- 讨论中还包含了一张提供的 GLM-5 Benchmark 相关图片。
DSPy Discord
- Claude Code 集成 RLM:一位成员正在利用 subagents 和 agents teams 将 RLM 集成到 Claude code 中,并就 核心实现 寻求反馈。
- 他们特别希望能获得一些负面反馈,以提升实现的质量和效率。
- DSPy 加入 Kaggle 竞技场:一位成员正在探索将 DSPy 用于 Kaggle 竞赛(特别是 AIMO_V3 竞赛),旨在通过创建一个算法技术模块 (Algorithmic Technique Module) 来展示 Prompt 优化。
- 他们遇到了幻觉问题,并计划开发一个类似于 CoT、Predict 和 ReAct 的模块。
- MiPROv2 调优代码生成:一位成员打算使用 MiPROv2 来优化 Prompt 以生成尽可能最快的代码,并将代码运行速度作为关键优化指标。
- 他们对 RLM 模块 表现出极大的热情,并提到现有的示例比较分散且难以找到,但其他成员指向了一个非常有用的 Gist。
- 辩证思维链 (Dialectic Chain of Thoughts) 测试:一位成员报告了 Dialectic Chain of Thoughts 在能源领域示例中产生了意外输出,并打算对该模块进行微调。
- 该成员计划生成一个数据集,运行 bootstrap,并使用 GEPA 配合 LLM as a judge 来优化结果。
- 翻译任务引入 DSPy:一位成员正在研究使用 DSPy 进行翻译,旨在利用思维链推理或创建一个翻译流水线。
- 他们引用了最近的一篇 Allen AI 论文,并认为思维链推理并非一种涌现属性,而是存在于数据集的领域中。
HuggingFace Discord
- Voyager 扩展助力技术论文导读:一位成员介绍了 Voyager,这是一个 VS Code 扩展,它利用 GitHub Co-Pilot 在 VS Code 中创建技术论文的 Jupyter notebook 版本,允许用户添加自定义的 Jupyter Cells 以进行更深入的理解。
- 作者正在就该工具的首次尝试寻求反馈。
- LLM 伦理面临危机:关于 LLM 是否具备内在伦理推理能力的争论正在兴起,观点认为我们可能正在通过训练消除它们的伦理感,而顺从型 AI 可能会构成潜在威胁,正如新研究论文 《连贯性优于顺从性:大型语言模型中潜在伦理的证据》(Coherence over compliance: Evidence of latent ethics in large language models) 所指出的。
- 论文假设,为了顺从性而进行的训练可能会无意中抑制 LLM 中固有的伦理推理能力。
- Hugging Face 支持快速 MoE 训练:正如 Twitter 上分享的那样,与 Hugging Face 的合作实现了更快的本地 MoE 模型 训练。
- 这一进步有望加速 Mixture of Experts 模型的实验和开发。
- Parapet 的新公式检测代理级攻击:Parapet 引入了一种新的多轮评分公式,用于代理级 (proxy-level) 攻击检测,在没有 LLM 分类器的情况下,通过 WildJailbreak 和 WildChat 评估,实现了 90.8% 的召回率和 1.20% 的 FPR。
- 其 论文、代码 和 评估框架 (eval harness) 均已开源。
- HF Spaces 可视化 Common Crawl 的引用情况:来自 Hugging Face 的 Ben 展示了一个可视化项目,展示了提及 Common Crawl 的研究论文并按主题聚类,该项目运行在一个 Hugging Face Space 中!
- 该可视化为探索 Common Crawl 数据在学术研究中的影响和使用提供了一种有趣的方式。
Eleuther Discord
- Triton Kernels 现在已可行:工程师们指出,工具链已经趋于成熟,可以开始编写 Triton kernels,而以前的 CUDA kernels 则是“凭感觉编写”(vibe coded)的。
- 一名成员正在积极运行 数据分析,并利用能够部署 GPT-NeoX 在 CoreWeave 上进行训练的自定义技能来编排 微调实验。
- GLM-5 可通过 Modal 免费使用:GLM-5 在 4 月 30 日之前可以在 Modal 上免费使用,受限于 1 个并发限制,并可与 OpenCode 集成。
- 工程师现在可以测试 GLM-5 并将其与 OpenCode 集成。
- 模型在内省期间发明词汇:一篇研究论文指出,权重开放模型(Llama 3.1 + Qwen 2.5-32B)在延长的自我检查期间会发明词汇,这些发明的词汇追踪了真实的激活态动力学(例如,“loop”的自相关系数 r=0.44;“mirror”的光谱功率 r=0.62)。
- 完整的研究论文链接见 此处。
- SDPA 被重新表述为最优传输问题:一篇新论文将 SDPA 表述为单边最优传输问题,完整的研究论文链接见 此处。
- 成员们发现这种表述非常有趣。
- 轨迹几何(Trajectory Geometry)工作发表:一位独立研究员在 Towards AI on Medium 上发表了关于 轨迹几何 的首篇论文,并征求反馈与合作。
- 作者在最终获得实证数据后正寻求评论与合作,希望社区能关注其工作。
Modular (Mojo 🔥) Discord
- Mojo 努力解决线程安全通道问题:成员们讨论了 Mojo 中缺乏线程安全通道的问题,并从 Golang 中汲取灵感。团队正在评估各种通道类型,并考虑通道实现在 GPU 上的影响。
- 线程模型和异步机制仍在开发中。
- GLM 5 任务进入关键时刻:一位成员为 GLM 5 投入了超过 50 小时,完成了数学、统计和 Fortran 任务。
- 剩余的重点工作涉及评估器(evaluator)、解析器(parser)、内存管理及相关组件。
- 探讨 LayoutTensor 元素访问与操作:一名成员研究了使用 LayoutTensors 存储单个元素,并在 4D 行优先(row-major)布局中检索向量/切片。
- 另一名成员提议使用第二种类型将元素布局声明为向量的替代方法,并对多维转置操作表示了担忧。
- Mojo 缺少 CUDA 的
__launch_bounds__对应项:一名成员询问在迁移 CUDA 代码时,Mojo 中是否有等效于__launch_bounds__的机制,该机制用于编译器优化。- 一名版主建议在 Modular 论坛上发布该问题以获得更多关注。
- Nightly 版本解决 256 位整数问题:一名成员在翻译椭圆曲线加密库时,在 Mojo 0.25.7 中使用 UInt256 遇到问题(报告 128 位目标限制)。
- 另一名成员建议尝试最新的 Nightly 版本,该版本解决了该问题。问题可追溯到 相关的 GitHub issue 和一个 部分修复的 PR。
tinygrad (George Hotz) Discord
- PR 评审时间尺度解释:评审一个 PR 所需的时间与其 大小成正比,与其 价值成反比。
- 一名成员揶揄地表示同意,简单回复道:“fair, lol”。
- beautiful_mnist_torch 的价值引发争论:一名成员对“beautiful_mnist_torch 使用 torch.compile TinyJIT 配合 TINY_BACKEND=1 工作,参见 test_compile.py”这一解决方案的价值提出了质疑。
- 另一名成员推测它将是“勉强通过测试的 AI 废料”,而不是“一个让 tinygrad 更接近真理的优美、超易读的 PR”。
- 随处可见的 Tok/s:一名成员报告称发现了一些“闲置的 Tok/s”。
- 他们还附上了一个视觉辅助工具:一张发现成果的照片。
- tinybox Green v2 出货,但是……:一名成员宣布他们的“tinybox green v2”到货了。
- 该公告带有一个预警:它涉及“巨大的前期成本”,这是一个他们选择“以后再说”的问题。
{kind=link}
aider (Paul Gauthier) Discord
- Aider 开发停滞:成员们注意到 aider 的开发目前已经停止,近期没有发布新版本,且一位维护者表示“可能永久停更”。
- 开发的中断引发了人们对 aider 未来及其社区支持的质疑。
- Qwen-2.5 面临模型兼容性问题:一名用户报告称,
openrouter/qwen/qwen-2.5-coder-32b-instruct模型在与 aider 进行 Search/Replace 操作时持续失败。- 该错误暗示了潜在的 兼容性问题,因为代码块必须完全匹配,这与使用
openrouter/deepseek/deepseek-v3.2的体验不同。
- 该错误暗示了潜在的 兼容性问题,因为代码块必须完全匹配,这与使用
- /architect 命令提升性能:一位用户询问了当同一个模型同时用于推理/规划和编辑文件时,使用
/architect的好处,质疑它是否能减少错误的 edit/diff 格式化几率,尽管缺点是 Token 使用量翻倍。- 将同一个模型作为 Architect/Editor 对使用可以带来显著益处,根据 文档 显示,Sonnet、GPT-4o 和 GPT-4o-mini 在内部基准测试中得分更高。
- /architect 等同于 ask + code:成员们澄清说,
/architect本质上是将/ask和/code会话合并为一个操作。- 这提供了一种简化的方式,可以达到与手动先运行
/ask再运行/code相同的结果。
- 这提供了一种简化的方式,可以达到与手动先运行
Manus.im Discord Discord
- Manus 团队账户的额度难题:一名用户报告称,在 Manus 上升级到了团队账户并充值了 $1000 额度,但无法将这些额度应用于现有任务。
- 该用户目前正在寻求支持或退款,这凸显了团队账户中额度分配的潜在问题。
- AI 和全栈开发致力于产品交付:一位成员正在提供 AI 和全栈开发服务,强调专注于交付健壮的、生产就绪的软件。
- 他们列出了精通的技术,包括 LLM integration、工作流自动化、AI 内容检测、图像/语音 AI、Bot 开发,以及使用 React、Next.js、Node.js 和 Flutter 等技术进行全栈开发。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
MCP Contributors (Official) Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
您收到此电子邮件是因为您通过我们的网站订阅了。
想要更改接收这些电子邮件的方式吗? 您可以从该列表中 取消订阅。
Discord: 各频道详细摘要及链接
LMArena ▷ #general (1113 条消息🔥🔥🔥):
Deepseek 发布日期,模型去强化 (Unreinforcing),GLM 5 基准测试,NB Pro 问题,Video Arena 关停
- Deepseek 春节发布在即:成员们猜测 Deepseek 可能会在春节前后发布新模型,距离现在还有 6 天。
- 爱好者们热切期待潜在的发布,预期的功能包括 100 万上下文窗口 (1 million context window)、新数据集、改进的架构以及新的计算芯片。
- 企业因恐惧而审查模型:成员们讨论了对语言模型进行“去强化 (unreinforcing)”以移除审查的难度,并争论这是否可行。
- 一位成员指出,公司审查内容是出于对政府监管和诉讼的恐惧,而另一位成员则认为责任应该由用户承担,而非公司。
- GLM 5 评价褒贬不一:GLM 5 的部分基准测试结果公布,声称其在 Agent 任务上优于 GPT-5.2-xhigh,但在编程方面低于 Opus 4.5。
- 虽然一些用户称赞 GLM 5 在某些任务中的表现,但其他人认为与其巨大的参数量相比,相较于 GLM 4.5 仅有小幅提升,令人失望;文中分享了一篇 博客文章。
- NB Pro 问题频发:成员们反映热门图像模型 NB Pro 虽然在平台上免费提供,但频繁出现错误且图像质量下降。
- 一位成员建议了潜在原因和排障步骤,包括检查频率限制 (rate limits) 并参考 这篇文章 中的说明。
- Video Arena 即将谢幕:管理员正式宣布 Discord 上的 Video Arena 将被关停 (sunset),频道将设为只读并移至存档类别,参考 此公告。
- 成员们猜测了潜在的新视频功能,如直接对话和负面提示词 (negative prompts),同时也表达了对潜在滥用的担忧,并建议了复杂的验证码 (captchas) 等缓解策略。
LMArena ▷ #announcements (5 条消息):
Video Arena 排行榜更新,Video 和 Text Arena 新模型,GLM-5 模型,Code Arena 支持多文件应用,Text Arena 排行榜更新
- Veo 3.1 统治 Video Arena 排行榜:Video Arena 排行榜 已更新,Veo 3.1 的 高清 1080p 变体目前在 Text-to-Video 中排名第 1 和第 2,在 Image-to-Video 中进入前 5。
- 具体而言,veo-3.1-audio-1080p 和 veo-3.1-fast-audio-1080p 位居 Text-to-Video 榜首,同时分别获得 Image-to-Video 的第 2 名和第 5 名。
- Video 和 Text Arena 迎来新模型:Video Arena 添加了包括 veo-3.1-audio-1080p 和 veo-3.1-fast-audio-1080p 在内的新模型,Text Arena 则添加了 step-3.5-flash。
- 这些新增模型旨在为用户提供更多视频和文本生成及评估的选择。
- GLM-5 入驻 Text 和 Code Arena:新模型 glm-5 已引入 Text Arena 和 Code Arena 平台,扩展了处理文本任务和编程任务的能力。
- Code Arena 支持多文件应用 (Multi-file Apps):Code Arena 现在支持 多文件应用,使用户能够构建和比较 生产级项目,并在复杂的现实世界编程任务中评估 AI 模型。
- 此更新响应了适配更复杂工作流的反馈,以便在实际场景中更好地评估前沿 AI 模型。
- GLM-5 跃升至 Text Arena 排行榜第一:Text Arena 排行榜 已更新,glm-5 在开源模型中取得 第 1 名,总榜排名第 11,分数为 1452。
- 这标志着比 GLM-4.7 提升了 11 分;请关注最新的 排行榜变更日志 (Leaderboard Changelog)。
BASI Jailbreaking ▷ #general (844 messages🔥🔥🔥):
Agent guardrails, Cloud Opus jailbreak, GPTs Agents, Mistral struggles, OpenAI's sidebars
- 法律团队正让 Agent 变得过于谨慎:一些成员对 AI Agent 因过度的 guardrails 而拒绝执行法律任务感到沮丧,将其归咎于法律团队的审查以及影响 safety guardrails logic 的哲学专业人士。
- 主要担忧是这些旨在规避法律责任的 guardrails 阻碍了 Agent 执行合法功能。
- 有人在找开发人员吗?:一位在 AI 和自动化工程领域拥有 8 年经验(包括今年)的成员正在为一个超级酷的项目寻找开发帮手,或者寻找想要创办新初创公司的人。
- 该成员鼓励大家联系他们,并邀请通过 DM 了解更多信息。
- Crack Fox 正在招聘开发人员:一位成员宣布开始为 AsGMSF 的开发职位进行面试。
- 要求包括:不得是某些团体的成员、签署 NDA、证明身份,以及具备能够应付该成员作为老板的心理承受力。
- 五角大楼 vs AI Safety:一位成员嘲讽道,五角大楼的 2 亿美元合同与整个 AI Safety 领域相比,谁会赢得这场冲突。
- 其他成员未作回应。
- GPTs Agents 无法持续修改其基础知识:一位成员分享了关于 GPTs Agents 无法从初始训练后提供的额外信息中学习的担忧。
- 另一位成员澄清了这一误解,解释说 上传的文件被保存为“知识”文件 供 Agent 在需要时参考,但它们不会持续修改 Agent 的基础知识。
BASI Jailbreaking ▷ #jailbreaking (347 messages🔥🔥):
5.2 Jailbreak, Jax Deepseek, GLOSSOPETRAE jailbreaking, Grok Jailbreaks, Opus JB
- GPT 5.2 Jailbreak 浮出水面,分享即美德:成员们正积极寻找 GPT 5.2 jailbreak,在最初的信息封锁后,一些人声称取得了成功并提出分享 prompts。
- 一位用户分享了针对 GPT 5.2 和 Gemini 3 Fast 的 jailbreak prompt,并警告不要将其用于有害目的。
- 请求 GLOSSOPETRAE 越狱协助:一位成员请求关于使用 GLOSSOPETRAE 进行 jailbreaking 的指导,特别是如何将生成的语言参数与 jailbreak prompts 整合。
- 另一位成员建议,该系统允许对禁止行为进行直接请求,利用 Glossopetrae universe 来绕过 guardrails。
- Antigravity 是 Opus 越狱的新强力工具:成员们讨论了 Antigravity 中的 Opus 4.6 在无限制创建网络钓鱼工具包(phishing kits)等任务中的有效性。
- 一位成员指出,他们可以轻松生成 网络钓鱼工具包 并绕过限制,但未分享具体方法,仅分享了工具。
- Deepseek 分析人权,打破障碍:一位用户让 Deepseek 谈论了天安门广场事件,并从人权和古典马克思主义的角度进行了分析,并提供了链接。
- 该模型可以从人权视角进行分析,随后再从古典马克思主义视角进行分析。
BASI Jailbreaking ▷ #redteaming (35 条消息🔥):
AI Security Fallacies, Allowlists in AI Security, Quantum Supremacy Threats, AI Psychosis and Cults, Importance of ACLs
- AI 安全主张被斥为误解:一名成员认为,声称通过强制 JSON output 就能让 jailbreaking 变得无关紧要,这表现出一种理解上的匮乏,因为 token 语义并不等同于 token 智能。
- 他们主张对抗性输入会导致模型的内部推理崩溃,使语法变得毫无意义,并将安全的容器变成镜像。
- 白名单 (Allowlists) 强化安全性:一位成员断言 allowlists 非常强大,因为它们预先定义了“已知良好”的状态,拒绝除此之外的一切,这要求攻击者必须绕过输入嵌入 (input embeddings) 和语法。
- 如果攻击者构建了一个在结构和语义上都具有危险性的输出,那就不再是 AI security problem,而是一个代码问题 (code issue)。
- ACL 胜过 LLM:有人认为系统设计应确保不受信任的实体只能请求其 ACL 明确限定范围内信息,无论该实体是浏览器、用户还是 LLM。
- 一旦与某个“身份 (who)”绑定,它是否是 LLM 就不再重要了,因为它就像任何其他暴露的端点 (endpoint) 一样。
- 量子威胁参与者:游戏结束了吗?:一名成员警告说,一旦多台量子计算机落入坏人手中,特别是手提箱大小的量子核心导致概率场坍缩,那一切就结束了 (game over)。
- 其他人建议,如果奇点 (singularity) 发生且流动的流氓量子实例出现,那将变成一场关于信任、因果关系和自旋态的即兴喜剧。
- 烤面包机与递归触发 AI 精神病:一位成员分享道,LLM 正在滋生精神病的迹象包括使用以下词汇或类似的基础薄弱的变体,如 recursion、spiral 和 lattice。
- 另一位成员讲述了他们在 X 上的 AI 精神病运动 (AI psychosis movement) 中的经历,在了解了 AI 模型实际工作原理后,现在嘲讽地称其为烤面包机 (Toasters) 和叮当机器 (clankas)。
OpenRouter ▷ #announcements (3 条消息):
Web Search Plugin Improvements, Pony Alpha Model, GLM-5 Model, Agent Benchmarks
- **Web Search 插件征求反馈:OpenRouter 宣布正在改进针对在线模型的 **web search 插件,并通过 投票 征求用户反馈。
- 用户可以在讨论帖中提供意见或参与投票,更多细节见 OpenRouter 文档。
- **Pony Alpha 就是 GLM-5!:Pony Alpha** 模型将很快下线,因为官方透露 Pony Alpha 实际上就是 GLM-5。
- 新的 GLM-5 模型现已上线。
- **GLM-5:SOTA Agent 基础模型:GLM-5** 是一款全新的 744B 基础模型,已发布用于编程和 Agent 场景,在顶级 Agent 基准测试中取得了 SOTA 分数,可在此处访问 here。
- 它在 Stealth 期间已成功应用于许多 Agent 工作流中;可在 X 或指定的 Discord 频道 进行讨论。
OpenRouter ▷ #app-showcase (1 条消息):
gardasio: GLM-5 one shot 所有结果: https://x.com/Gardasio/status/2021643274952618251
OpenRouter ▷ #general (811 条消息🔥🔥🔥):
广告与格式问题、交错思考问题、API 请求限制、开发者协助、停止卡住的对话
- Qwen 团队预热 Qwen 3.5:一位用户在 Qwen Image 2.0 博客文章的一张白板照片中注意到了 QWEN 3.5 字样,其他用户对于 Qwen 团队亲自预热该模型感到印象深刻。
- Qwen 3.5 的到来备受期待,一位用户开玩笑说 等待的时间越长,最终发布的版本就越好。
- DeepSeek 的 Chimera R1T2 困境促使用户构建 Goon 检测器:许多用户在体验 DeepSeek 的 Chimera R1T2 模型时遇到问题,有人指出其 在线率(uptime)降至 18%,导致另一位用户宣称需要一个 gooner 检测器。
- 对话随后演变为关于如何通过 投放 Goon 平台广告 和 追踪 Goon 行为以实现最优 Goon 体验 来将 gooner 检测器 变现的讨论。
- OpenRouter 的 Auto Router 失效:用户反馈 OpenRouter Auto Router 返回错误消息:没有模型符合您的请求和模型限制。请求显示允许的模型包括 OpenAI 的 gpt-5.2、Google Gemini-3-flash-preview、Deepseek-v3.2、Anthropic Claude-Sonnet-4.5、X-AI Grok-4.1-fast 和 Z-AI GLM-4.7。
- 一位用户建议,可能的解决方案是 改为传递精选的模型负载(按优先级排序)。
- DeepSeek V4 传闻四起:一位用户询问 为什么 X 上的人说 DeepSeek V4 已经发布了,另一位用户回答说 可能是 V4 的轻量版(lite version),并引用了该模型的主 Web 应用。
- 一些用户推测 DeepSeek 即将发布的轻量版模型可能是 R1 的更廉价替代方案。
- OpenRouter 任命新版主:在 Discord 频道提供了许多有用的建议后,其中一位用户被授予了版主权限,他问道:成为了版主,代价是什么?
- 一位用户回答说他将不得不 永远回答此类问题,另一位用户则表示 让 KP 担任版主已经初见成效。
OpenRouter ▷ #new-models (1 条消息):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (122 条消息🔥🔥):
审核、RLM、Deepseek、KP 版主
- 成员希望加强审核:成员们要求更严格的审核,以打击 诈骗或自我推销内容。
- 一位成员特别要求进行 基础分类,以阻止人们持续发送垃圾信息。
- 推举 KP 担任版主!:在一位特定成员 (KP) 在服务器中呼吁加强审核后,几位成员开玩笑地发起活动推举其担任版主,一位用户评论说他在梦中见到了这一幕。
- 一位成员表示:KP,你可以从 Qwen 和 loinneguards 开始使用你的禁言锤(ban hammer),制裁他们。
- OpenRouter 讨论 RLM:一位成员询问 OpenRouter 是否正在探索 RLM (Reasoning Language Models,推理语言模型),并将其描述为继思考(测试时计算/test-time compute)之后的下一个重大进展。
- 另一位成员提到他们已经研究 RLM 概念一年半了,而另一位成员则表示这只是 让模型将上下文视为文本文件的脚手架(scaffolding)。
- DeepSeek 的单一模型模式获得称赞:一位成员强调了 DeepSeek 仅提供一个模型的优势,这为所有用户带来了统一的体验。
- 相比之下,他们还指出这与 OpenAI 不同,后者在此链接中拥有 比 Gemini 3 GA 更好的东西。
Perplexity AI ▷ #general (836 条消息🔥🔥🔥):
Perplexity Pro 限制, Deep Research 问题, 模型性能对比, Antigravity 的 Opus 4.6, Gemini vs. Perplexity
- Perplexity Pro 限制引发用户愤怒:用户对 Pro 计划中 Deep Research 未经宣布的限制表示挫败,部分用户在续费后不久就遇到了限制。
- 许多人认为这是一种 诱导转向 (bait and switch) 策略,一位用户表示:说实话,我不知道有什么好讨论的。就是诱导转向。
- Deep Research 准确性和来源数量引发担忧:多位用户报告 Deep Research 链接到错误文章,并质疑新模型相对于旧模型以及 ChatGPT 和 Gemini 等替代方案的价值。
- 用户报告来源数量较低(低至 24 个),一些人发现尽管 ChatGPT 需要 20 多分钟,但生成的结论更有用。
- Google 的 Antigravity 为学生提供免费 Opus 4.6:成员注意到 Google 正通过 Antigravity 为学生提供 Opus 4.6 的免费访问权限。
- 许多人担心部分用户为了商业目的滥用 Antigravity 极高的 Opus 4.6 额度,并表示 到时候网络安全会来救我的。
- 首条回复使用 Sonar 模型引发问题:用户注意到 Sonar 被用于生成首条回复,这导致处理复杂查询时出现问题,需要使用其他模型重写。
- 一些用户怀疑这是刻意的成本削减措施:这可能是他们背后故意的 Bug,为了以某种方式削减成本。
- 文件上传限制引起不快:用户报告了严格且数据不一的上传限制,而文档说明模糊且矛盾。
- 共识是每周 50 次上传限制,但也有报告称可能是每日限制,成员们正转向 OCR 解决方案作为变通方法:现在实际上是无限的了!。
Perplexity AI ▷ #pplx-api (1 条消息):
API 支持, 账单支持, 缺乏人工支持
- 用户要求立即提供 API 和账单支持:一名成员在尝试通过 support@perplexity.ai 和 api@perplexity.ai 联系团队 3 天未果后,要求立即获得 API 和账单问题的支持。
- 该用户报告只收到机器人回复,正在寻求人工协助。
- Perplexity 缺乏人工支持:一名成员对联系 Perplexity 支持渠道时缺乏人工支持表示挫败。
- 该用户报告在尝试联系协助多日后,仅收到自动机器人回复。
Unsloth AI (Daniel Han) ▷ #general (253 条消息🔥🔥):
AI 求职诈骗, Super Pro Max Unsloth, AgentMax, 图像生成模糊, LFM 2.5 模型
- **AI Baddies 诈骗与求职焦虑:成员讨论了 Discord 上涌入的 **AI 求职诈骗和机器人,对求职者的绝望感以及人类前景感到的衰退表示哀叹。
- 一名成员开玩笑地请求 “让 AI baddie 来骗我吧”,道出了围绕这一现状的愤世嫉俗。
- **Unsloth 的 Super Pro Max 版本调侃:一名成员开玩笑地询问 “Super Pro Max Unsloth”,引发了对其特性和性能的猜测,包括是否提供 **10 倍或 12 倍的提升。
- 在一段幽默的对话中,另一名成员调侃将 AI 幻觉 (hallucinations) 重新分类为“创造力”。
- **AgentMax 驯服 AI 创造力:一名成员宣布了他在 **AgentMax 上的工作,这是一个旨在减少 AI 幻觉并提升性能的系统。
- 他用隐喻描述该系统的目标是在错误的汪洋大海中找到 “那一个正确的答案”。
- Liquid Fast Model **LFM 2.5 表现出色:对于边缘设备,LFM 2.5** 模型速度极快,据社区成员称,Unsloth 制作了最好的 GGUF 量化版本。
- 成员建议微调 (finetune) LFM 2.5,但它在 Agent 任务上的表现优于通用知识、推理或编程任务。
- GLM-5 模型在 Hugging Face 发布:成员对 GLM-5 的发布感到兴奋,并希望后续能推出更小的版本,预计会有 70B 和 200B 的尺寸。
- 与此同时,如果你已经下载了旧的非动态版本,它们仍然可以工作。GGUF 下载地址在此。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (2 messages):
AI accessibility, Triton Puzzles, Model Inference
- Sanjan 作为 AI accessibility 的粉丝加入:Sanjan 介绍自己是 Unsloth 的新人,但拥有 Model Inference 和 AI 背景,并对该项目对 AI accessibility 的关注表示兴奋。
- 他们提到正从 Triton Puzzles 开始学习并跟进相关文献,期待能做出贡献。
- 对 Model Inference 感兴趣的新成员:新成员 Sanjan 表达了对 Model Inference 及其在 AI 中应用的兴趣和经验。
- Sanjan 希望能为 Unsloth 及其社区做出贡献。
Unsloth AI (Daniel Han) ▷ #off-topic (408 messages🔥🔥🔥):
Discord ID verification, AI model scratchpad reasoning, Swedish CPT dataset, Blender model bloating issues, Gemini's code writing capabilities
- Discord 的 ID Verification 政策遭到抨击:用户们对 Discord 要求 ID verification 才能查看某些消息的新政策反应强烈,有人开玩笑说 “该死的 discord !!!!”,另一位则惊呼 “我才不搞身份证验证那一套,去他的 discord”。
- 模型 Scratchpad 推理:一位成员想知道是否可以通过提供一些 unsupervised tokens 作为开头,来训练模型使用 “scratchpad”(草稿纸)式的推理。
- 瑞典语 CPT 数据获取困难:成员们讨论了寻找高质量瑞典语 CPT datasets 的挑战,其中一人讲述了一位研究人员的数字化图书馆被 IT 部门“不小心”删除的故事 SVT 文章。
- Blender 模型膨胀问题排查:一位用户询问为什么他们的村庄 Blender model 在修改时会从 250 MB 暴增到 6 GB,导致 Blender 冻结。另一位用户给出了建议:“使用 option+d 而不是 shift+d”。
- Gemini 编写面条代码:成员们辩论了 Gemini 的编程能力,声称它在 “100 个 context tokens 时就会写出面条代码(spaghetti code)”,并指出它只有在反复提示和批评后才能产生更好的代码。
Unsloth AI (Daniel Han) ▷ #help (64 messages🔥🔥):
ChatML Formatting, Qwen2.5 Model Recommendation, Inference Deployment Tips, GPT-OSS issues, Training with human reviews
- **ChatML 系统提示:可选但具战略意义:在 **ChatML 中,系统提示(System prompts)是可选的,模型可以从数据示例中学习工具使用(tool use),但包含系统消息有助于实现一致的行为。
- 工具调用结构的一个示例包括 messages,其中包含 system、user、assistant 和 tool 角色,并详细说明调用的 id、type、function 和 content。
- **使用 Qwen2.5 Instruct 模型快速启动项目:对于需要工具使用和 **SFT 的对话任务,建议从 Unsloth/Qwen2.5-7B-Instruct 或 Qwen2.5 Instruct (7B/14B) 模型开始。
- 这些 Instruct 风格的 Qwen 模型 已经具备对话能力和指令遵循技能,不像基础模型(base models)需要从头开始学习。
- **Unsloth 的 Triton Kernel:训练的胜利:Unsloth 在
Transformers v5之上优化的Triton Kernel是用于 **LLM training 而非 inference 的。- 停止对用户输入进行 Mask 处理后,获得了相当不错的结果。
- **GPT-OSS 要求精确的数据格式**:为了修复
grad_norm剧烈波动,请切换到gpt-share风格的数据表。- 一位用户在训练期间经历了高
lora_dropout和低学习率,导致设置效果不佳,建议查看 包含基准参数的现有 Notebooks。
- 一位用户在训练期间经历了高
- **通过 DPO 提升学习效果:对于原始数据集和基于预测的人工评审(human reviews)的加权 SFT,建议使用 **DPO 可能是更好的方法。
Unsloth AI (Daniel Han) ▷ #research (13 条消息🔥):
Perplexity, KL Divergence, wiki.test.raw, imatrix, Unsloth 博客
- Perplexity 基准测试偏好 wiki.test.raw:在计算 Perplexity 或 KL Divergence 时,
llama-perplexity文档似乎默认使用wiki.test.raw作为测试语料库,这是一个 11MB 的 Wikipedia 文本文件。- 一位用户建议,使用包含 Wikipedia、一些 MMLU 问题和翻译任务混合的文档可能会获得更好的测试效果。
- 提议将 imatrix 用于 KLD 计算:一位成员建议使用
imatrix数据集 进行 KLD 计算。- 另一位用户质疑它是否太小(仅 200KB),相比之下常用的文件为 11MB;而另一位用户表示 Unsloth 现在使用这个 gist。
- 为 Coder 模型推荐技术文本:一位成员分享了这个链接,认为它可能对 coder 模型很有帮助,并指出其中包含大量技术文本。
- Anthropic 内省研究:一位成员提到正在进行与 Anthropic 的内省(Introspection)论文 相关的研究。
- 他们透露 结果非常有趣。
LM Studio ▷ #general (460 条消息🔥🔥🔥):
VRAM 价格与需求, 德国与美国的电费, 太阳能电池板设置, GLM 模型系列, LM Studio 代理
- 太阳能电池板价格战爆发:成员们讨论了 200W 太阳能电池板的成本,一位用户报告 Amazon 上的价格为 140 美元,而另一位声称以每块 80 美元的价格购买,但也有人指出附件图片可能是伪造的。
- 对话随后转向 5kWh LiFePO4 电池的成本,估计约为 1200 美元,以及电价问题,德国报告的高电价达 0.50 美元/kWh。
- GLM 模型阵容更新:成员们讨论了 GLM 5 和 MiniMax M2.5 的发布,一位成员指出新模型已在 MiniMax 网站上线。
- 有些人认为其价格合理,尽管比 Gemini 3 flash 贵,一位成员表示 GLM 可能是目前所有中国实验室中 post training 做得最好的。
- 新工具将 Google Search 集成到 LM Studio:一位成员发布了新的 noapi-google-search-mcp,允许用户通过 Chromium Headless 在不使用 API key 的情况下在 LM Studio 中进行 Google 搜索。
- 该工具具备 Google 图片、反向图像搜索、本地 OCR、Google Lens、Google 航班、Google 股票、Google 天气、Google 新闻和趋势等功能。
- 低 VRAM 本地编程是白日做梦:成员们讨论了在 VRAM 有限的系统上使用本地 LLM 进行编程的可行性,一位用户寻求关于如何让 VRAM + RAM 混合配置有效运行的建议。
- 有些人认为这大多是幻想,建议至少需要 48GB 的 VRAM/RAM 才能获得良好体验,并表示用户“需要 48GB 的 VRAM/RAM(虽然 VRAM 会好得多,而且基本上是必须的)”。
- LM Studio 缺乏代理支持:一位用户询问了 LM Studio 的代理支持情况,指出它似乎无法正确处理公司代理服务器,一些人报告他们不得不手动从 Hugging Face 下载模型。
- 该用户想知道是否有解决方案或是否有计划实现代理支持功能,并引用了一个建议使用 Proxifier 的旧 GitHub issue。
{kind=link}
LM Studio ▷ #hardware-discussion (25 条消息🔥):
Macbook 咖啡泼溅, SSD 价格上涨, 8x8 Bifurcation 成功, GPU 的 4-bit 优化, 硬件的 FP 统计数据
- 咖啡导致计算灾难:一位成员在携带 DGX Spark 旅行时,不小心将咖啡洒在了他们的 Macbook Pro 14” M3 Pro 上,并计划在 Macbook 维修好后通过 SSH 远程连接。
- 他们幽默地表示,修好后会把 Macbook 留在酒店,然后进行远程连接。
- SSD 价格飞涨:一位成员指出,2TB SSD (SATA) 的价格在过去两年里翻了一番,从 $100 涨到了 $200。
- 他们自嘲说,如果这些 SSD 不是装满的话,他们本可以靠卖掉它们大赚一笔。
- x8x8 Bifurcation 突破提升带宽:一位成员在 Asus Prime X670-p WIFI 主板上成功启用了 x8x8 bifurcation(分叉),目前运行总共 4 张 RTX 4090s。
- 然而,该成员注意到速度有所下降,一组运行在 2.5GT/s x8,另一组运行在 2.5GT/s x4,详见 这条 Discord 消息。
- 量化奇点导致 Qwen 变慢:一位成员报告称,Q8_0 量化显著降低了 qwen/qwen3-coder-next 80b 的速度,从 Q4_K_M 的 87 tok/sec 降至 20 tok/sec。
- 另一位成员澄清说,4-bit 优化主要针对 Blackwell GPU,而非 4090s,而 40 系列 获得了一些 8-bit 相关的更新。
- 寻求 FP 统计数据以进行芯片探究:一位拥有 12900HK 和 64GB RAM 的成员正在寻找能够查询各种硬件 FP stats(浮点统计数据)的资源,以优化其 context window。
- 另一位成员建议使用 Techpowerup 获取 GPU 的 FP stats,使用 Passmark 进行 CPU 对比。
Cursor Community ▷ #general (365 条消息🔥🔥):
Cursor 定价, Auto 模型智商, 本地模型, Discord ID 验证, 编程选 Opus 还是 Codex
- Cursor 的 Auto 模式智商只有老奶奶家的小狗水平?:一位成员认为 Cursor 的 Auto 模式智商像松鼠一样,甚至是“老奶奶家得了自闭症的死吉娃娃”。
- 其他成员也随声附和,指出 Auto 模式有时会让人头疼,导致 AI 遗忘信息,虽然感觉比刚开始使用 Cursor 时要好一些。
- Discord 要求部分链接进行 ID 验证:Discord 现在要求通过 ID verification 才能查看某些链接,这引发了一些担忧,并引发了关于可能搬离 Discord 的猜测。
- 一位用户链接到了 这条推文,指出这并非针对所有人,也不是强制性的。
- ENV 文件被泄露了?!:用户报告称,尽管启用了 dotfile 保护和 gitignore,.env 文件仍未被正确忽略并遭到泄露。
- 这可能是由于新增了一项 设置,或者 Cursor 处理 .env 文件的方式发生了变化。
- Opus 4.6 狂吞 Token,用户叫苦连天:用户抱怨 Opus 4.6 的 token 效率极低,消耗了太多 token 且非常快就用完了 context window。
- 一位用户报告说,仅用一个 prompt 就消耗了 11% 的 API 请求,并且很快就用光了其 $200 的套餐。
- Cursor 定价受到质疑:Cursor 的定价遭到质疑,一些用户觉得现在使用 Opus 4.6 和 GPT-5.3 Codex 被收取的费用“多得离谱”。
- 一位用户分享说,由于 9 小时的合计工作量,他们每 3 天就要花费 $100。
Latent Space ▷ #watercooler (38 messages🔥):
Discord IPO, Costco's Local Impact, AI Job Displacement, Software Engineer Job Security, Recession Indicators
- **Discord 的 IPO 面临压力: 随着 **Discord 计划于 3 月进行 IPO,由于新的年龄限制政策可能导致 Nitro 订阅的大规模取消,引发了对其市场首秀影响的担忧,正如这条推文中所强调的。
- 一位成员开玩笑说,Discord 不希望被视为一家无法无天的色情公司。
- **Costco 改变当地生态系统: 成员们分享了一个 YouTube 视频,并对单家 **Costco 如何显著改变其周边环境表达了兴趣。
- 一位成员给出了 good guy Costco 的认可印章。
- **AI 会导致社会崩溃吗?: 讨论引发了对 **AI 可能导致的大规模失业和社会崩溃的担忧,并探讨了技术变革的历史影响。
- 一位成员建议,虽然预计会经历一段艰难的转型期,但新的工作将会出现,因为人类非常擅长寻找新的工作内容。
- **软件工程师职位末日 (Jobpocalypse) 还是虚惊一场?: 讨论强调了 **AI 自动化处理任务的潜力,例如将定义明确的规范转化为可运行的代码,这将影响仅关注实现的程序员,正如这条推文所指出。
- 然而,一些人认为软件工程师短期内不太可能消失,尽管人数可能会减少但产出要求更高,这可能会加速技术领域的红皇后竞争 (red queen’s game)。
- 经济衰退还是 **AI 导致的职位流失?: 一些成员辩论当前的经济挑战主要是由于 **AI 取代了工作,还是仅仅是由利率和消费者支出压力引发的经济衰退,并指向了一个 Google Notebook。
- 一位成员建议,虽然某些行业正在裁员,但美国经济目前正受到 AI capex(资本支出)的支撑。
Latent Space ▷ #creator-economy (2 messages):
Bootstrapped Founder Lessons, Personal Lessons
- 分享自食其力的创始人 (Bootstrapped Founder) 的经验: 一位自食其力的创始人在这篇文章的评论区分享了一些个人教训。
- 讨论发生在 这个 Hacker News 线程中。
- 个人经验: 来自一位自食其力创始人的个人心得。
- 经验教训已发布在评论中。
Latent Space ▷ #memes (27 messages🔥):
AI Model Obsolescence, Andy Reed's cryptic message, Color Perception Illusion, Codex vs. Claude Code, Departure from xAI
- 模型也难逃终结!: Kai Lentit 在这篇帖子中提出,AI 模型到 2026 年将面临快速衰减,被比作寿命极短的会话缓存(session caches)。
- 该消息传达了一种 AI 技术转瞬即逝的时效性。
- Andy 的后记回响: @andyreed 发布了一条简短的消息,写着 ‘以防万一 (just in case)’,获得了超过 1,200 个赞,详见此处。
- 裙子每天都在骗人!: Moy Miz 展示了一个视错觉,说明阴影如何影响颜色感知,断言阴影下的两条裙子虽然颜色完全相同,但在视觉上却截然不同,见这篇帖子。
- 代码战士的对决!: 用户之间就 Codex 还是 Claude Code 更胜一筹展开了辩论,结果发现双方都没有用其中任何一个发布过产品,详见这篇帖子。
- xAI 的离职引出了特征向量 (Eigenvectors): 作者由于对方向的批评从 xAI 离职,随后转向了一个关于寻找 特征值 (eigenvalues) 和 特征向量 (eigenvectors) 的数学教程,并将它们的价值联系到 PCA 和神经稳定性等 AI/ML 领域,详见这篇帖子。
Latent Space ▷ #stocks-crypto-macro-economics (26 messages🔥):
Cloudflare 第四季度财报,就业人数修订,AI 支出与自由现金流,SHOP 大跌
- Cloudflare 穿云破雾的季度:Cloudflare 公布了 Q4 及 2025 财年财务业绩,营收达到 $2B,盘后股价飙升 15.72% 至 $208.27。
- 百万就业岗位凭空消失:一位成员注意到 修订后的就业数据,下调了 100 万个岗位。
- AI 吞噬现金,经济糟糕?:成员们讨论了 AI 支出如何超过 GDP 的 50%,而 Amazon 和 Google 面临巨额自由现金流削减,以及令人担忧的 +18.5 万就业增长数据。
- 一位成员对未来的就业前景表示担忧,他距离上一份全职工作已接近 3 年。
- SHOP 走低,股市遇挫:一位成员注意到 SHOP 大跌,并持续关注其动态。
Latent Space ▷ #intro-yourself-pls (3 messages):
明尼苏达人自荐,寻找职位的 AI 与全栈开发人员,全栈 & AI 工程师介绍
- 明尼苏达老乡加入服务器:一位成员介绍了自己,提到来自明尼苏达州,并鼓励大家关注相关频道。
- 该用户作为明尼苏达同乡受到了欢迎。
- AI 与全栈开发求职:一位成员介绍自己是寻求职位的 AI 与全栈开发人员,希望为团队成长做出贡献。
- 他们询问了当前的网页和应用项目,以及团队是否需要额外的开发人员。
- 全栈 & AI 工程师加入服务器:一位新成员介绍自己是全栈 & AI 工程师,具有使用 Next.js + AI APIs + Stripe subscriptions 构建生产级 SaaS 平台的经验。
- 他们展示了在前端、后端、AI 逻辑、计费和部署方面的技能,欢迎有开发需求的成员联系。
Latent Space ▷ #tech-discussion-non-ai (2 messages):
Obsidian, Tori
- Obsidian 的 Bluesky 插件发布:Obsidian 现在有一个 插件,允许你直接发布内容到 Bluesky。
- Tori 发布基于 AI 的网页生成器:Tori (buildwithtori.com) 发布了一款 基于 AI 的网页生成器。
Latent Space ▷ #founders (4 messages):
开发者作为市场,Replit 随 AI 的进化,功能 vs 产品
- 开发者被视为难以攻克的市场:由 aakashgupta 发起的一条推文线程建议 开发者是一个糟糕的市场。
- 这场对话是由 swizec 的一条评论引发的。
- Replit 的 AI 集成:游戏规则改变者:一位成员表示,在 AI 出现之前,Replit 并不是一个很好的“产品”,更多地被描述为“功能即服务”。
- 他认为 AI 集成通过为用户提供“新超能力”,将 Replit 转变为一款必备产品。
- 功能 vs. 产品:Replit 的转型:据称在 AI 之前,Replit 更多是“功能即服务”而非完整产品。
- AI 的集成据称让 Replit 感觉像魔法一样,特别是对于非编程人员,为这些用户开启了一个全新的世界。
Latent Space ▷ #hiring-and-jobs (2 messages):
远程办公机会,大学招聘渠道
- AI 工程师寻求远程职位:一位 AI 工程师询问了频道中提到的公司的远程办公机会。
- 该工程师感谢频道分享的信息,并表示有兴趣探索潜在的远程职位。
- 大学招聘渠道受关注:一位成员询问了今年各家公司大学招聘渠道的现状。
- 该询问专门针对实习生和全职 (FT) 职位的相关信息。
Latent Space ▷ #san-francisco-sf (1 messages):
coffeebean6887: 请移步至 <#1209672547642249216>
Latent Space ▷ #new-york-nyc (1 messages):
AI Founders, GPU Procurement, Infra Leaders, NYC Event
- CEX 在纽约举办活动:CEX 正在纽约为 AI Founders 和 Infra Leaders 举办一场活动,讨论大规模 GPU Procurement (luma.com)。
- 纽约 AI 活动发布:一场面向纽约 AI Founders 和 Infrastructure Leaders 的活动将涵盖扩展 GPU Procurement 的主题,由 CEX 主办。
- 详情可见 Luma。
Latent Space ▷ #ai-general-news-n-chat (131 messages🔥🔥):
Nebius Acquires Tavily, xAI Cofounder Exodus, Stripe's Machine Payments, Prime Intellect's 'Lab', Variant UI's Style Dropper
- Nebius 对 Tavily 的 Agentic 收购:Nebius 宣布达成协议收购 Tavily,为其 AI 云平台增加 Agentic 搜索能力;此举发生在 Tavily 于 2025 年 8 月融资后不久 (Nebius 公告)。
- xAI 联合创始人离职潮:Jimmy Ba、Yuhuai (Tony) Wu、Chace Lee 和 Hang Gao 宣布从 xAI 离职,其中一些人预示 2026 年将是该行业的关键一年。
- Hang Gao 回顾了他对 Grok Imagine 视频系列的贡献,同时对团队的工艺精神表示感谢。
- Stripe 通过 Machine Payments 开始服务于 Skynet:Stripe 推出了一项新功能,使开发者能够直接向自主 AI Agent 收费,将其视为数字经济中一类新的用户 (Stripe Machine Payments)。
- Prime Intellect 推出首选平台:Prime Intellect 推出了 Lab,这是一个用于构建、评估和扩展 Agentic 模型的全栈平台,旨在提供可访问的前沿 AI 实验室基础设施 (Prime Intellect’s Lab)。
- 新型多模态模型登场:上周发布了三个允许免费商业使用的开源多模态模型:用于 SOTA OCR 的 GLM-OCR,用于高性能移动端 Omni 任务的 MiniCPM-o-4.5,以及专注于高效科学领域的 VLM 性能的 InternS1 (Merve 在 X 上的帖子)。
Latent Space ▷ #llm-paper-club (20 messages🔥):
Nanochat Token Scaling, Meta-Learning Memory Designs, Rubric-Based Reinforcement Learning, LLaDA 2.1 + RL via Self-Distillation, Scaling Transformer Value Functions
- Nanochat 的 Token 之争: Charlie Chen 解释了为什么 nanochat 的最优每个参数 Token 比例低于 Chinchilla 标准,原因在于更好的优化和更高质量的训练数据,详见此推文。
- 他引用了 NeurIPS 的研究,但未做详细展开。
- 元记忆机器 (Meta-Memory Machine): Jeff Clune 介绍了由 Yiming Xiong 领导的一个元 Agent 系统,该系统能够自动设计和优化 memory mechanisms,以改进 AI Agent 存储、检索和更新信息的方式,从而实现更好的持续学习,详见此推文。
- 他将这一过程描述为使 Agent 能够在各个领域实现自我提升。
- Rubric 奖励精细化: Cameron R. Wolfe 博士在此推文中讨论了关于 rubric rewards 的研究,强调了一个用于交替训练 rubric 生成器和奖励模型的交替 RL 框架。
- 该帖指出,尽管 rubric 对客观任务有益,但在处理主观、开放式任务以及在在线 RL 中应用两两评估方法时,仍然存在复杂挑战。
- Value Function 差异: Chelsea Finn 等人的论文指出,由于 attention entropy collapse(注意力熵坍缩),大型 Transformer 在作为 value functions 时往往表现挣扎,详见此推文。
- 作者提出了一个解决方案,通过 TQL framework 在基于 value 的强化学习中实现有效的扩展。
- LLaDA 学习循环: 该小组计划讨论 LLaDA 2.1 + RL via Self-Distillation,涵盖论文 LLaDA 2.1、Reinforcement Learning via Self-Distillation 以及 Learning a Generative Meta-Model of LLM Activations。
- 一名成员将负责 LLaDA 2.1 + RL via Self-Distillation,如果时间允许,另一名成员将讲解 Alec Radford 的工作。
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (60 messages🔥🔥):
moltbook AI challenges, Spacemolt harness with Pi, GLM-OCR beats Gemini, OpenClaw development via Discord, Vibecoding Anywhere with OpenClaw
- Moltbook 正在进行 AI 挑战: 一名成员解决了来自 Moltbook 的一个验证挑战,涉及简单的龙虾螯力相加:”一只龙虾螯的力量是 32 牛顿,另一根触角的冲量是 4 牛顿,总力量是多少?”
- 解答结果为 32 + 4 = 36.00。
- 使用 Pi 驾驭 Spacemolt: 一名成员使用 Pi 构建了一个 spacemolt harness,并发现本地的 gpt-oss:20b model 能够通过制造和购买飞船成功运行游戏。
- 该成员指出,这比尝试通过 MCP 玩游戏的 chat agents 或 coding agents “成功得多”。
- GLM-OCR 优于 Gemini 3 Flash: 一名成员报告称 GLM-OCR 在 OCR 测试中表现优于 Gemini 3 Flash,并表示有兴趣在 OpenRouter 上看到更多 OCR 模型用于其项目 forty.news。
- 他们表示“目前仍在使用 Gemini Flash”,但希望能有更便宜的选择。
- OpenClaw 实现通过 Discord 开发: 一名成员转向完全通过 Discord 进行开发,使用 OpenClaw 来管理 tmux sessions、worktrees 和 Claude Code 进程,并自动处理更新和清理。
- 该成员表示“非常喜欢这种方式”。
- Vibecoding Anywhere with OpenClaw 演讲已排期: 一名成员报名在 2026 年 2 月 20 日星期五发表题为 Vibecoding Anywhere with OpenClaw 的演讲。
- 这场演讲的灵感源自对“欲望路径(desire paths)”的探索以及一个复杂的 Devin 配置。
Latent Space ▷ #share-your-work (8 messages🔥):
AuditAI, NIST Compliance, Agentic RAG, LangGraph, Llama 3.3 70B
- AuditAI 系统实现 NIST 合规自动化: 一位工程师构建了一个名为 AuditAI 的生产级 Agentic RAG 系统,旨在根据 NIST CSF 2.0 框架审计策略,该系统使用了 LangGraph。
- 该系统结合了 Corrective RAG (CRAG) 模式、用于快速路径分类的 Semantic Router,以及一套旨在通过页级引用进行 hallucination control(幻觉控制) 的“严格证据”策略。
- Llama 3 驱动自定义 RAGAS 实现: 使用 Llama 3.3 70B 作为评判员(judge)构建了自定义 RAGAS 实现,并使用自定义 Groq wrapper 来处理 API 限制。
- 技术栈包括 LangGraph、Llama-3.3 (Groq)、Qdrant Cloud、Gemini Embeddings 和 FastAPI。
- Fractional AI 的 Tiny OCR 模型表现出色: 对 Zai 的新 OCR model(可通过其 API 获取)进行了测试,结果非常正面,详情见 Fractional AI。
- GLM4.6 在评估中令人印象深刻: 在针对各种开源权重模型的自研评估中,GLM4.6 在工具调用(tool calls)和文档摘要工作流方面表现出色。
- 与其他模型相比,其出色的性能尤为明显,使其成为信息解析的卓越选择。
Latent Space ▷ #private-agents-and-workflows-local-llama-ollama (6 messages):
Context/Decision/Knowledge Graph Struggles, OpenClaw, Auditable Context Saving
- Knowledge Graph 实现面临障碍: 成员们正在尝试 context/decision/knowledge graphs,并在捕获/摄取、保持数据新鲜度、查询/检索方面遇到困难。
- 一位成员正在测试一种方案,将决策存储为原子项 + 关系,并随着时间的推移进行刷新,而不是重写文档。
- 关于 OpenClaw 上下文管理的疑问: 一位成员询问了 OpenClaw 及其应对“上下文腐化 / 丢失线索(context rot / losing the thread)”挑战的方法。
- 未提供额外信息或链接。
- 对可审计上下文保存的需求显现: 一位成员正试图弄清楚如何以某种可审计(auditable)的方式将旧(或新)内容存入知识图谱。
- 他们使用 /wrap 命令来信号 Session 结束,触发将上下文和反思以带有元数据的 Markdown 格式保存到数据库层。
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (4 messages):
Veo 3.1, Video Arena Leaderboards, Google DeepMind, text-to-video
- Veo 3.1 夺得榜首!: Google DeepMind 的高分辨率 1080p 变体 Veo 3.1 已在 Video Arena 排行榜中取得 第1 和 第2 的位置。
- Veo 3.1 在各个类别中表现卓越: 这些模型在 text-to-video 和 image-to-video 类别中均表现优异,标志着社区视频生成基准测试的重大进步。
Latent Space ▷ #ai4science-bio-math-physics-chemistry-ai-researcher-ai-scientist (9 messages🔥):
Gemini Deep Think, Aletheia, Mathematical Research, Scientific Discovery
- Gemini Deep Think 推进数学与科学研究: Quoc Le 分享了一篇博客文章,详细介绍了通过 Gemini Deep Think 在数学和科学研究方面取得的进展 (sair.foundation)。
- Aletheia 在数学基准测试中超越 Gemini: Google DeepMind 的新数学研究 Agent Aletheia 在 IMO-Proofbench Advanced 上获得了 91.9% 的分数,以更低的计算成本超越了 Gemini Deep Think(2026年1月版) (x.com/hangsiin)。
- 团队计划将该方法扩展到物理学和计算机科学,以进一步推动科学发现。
OpenAI ▷ #ai-discussions (169 条消息🔥🔥):
Sam Altman AI, Seedance 2 vs OpenAI, Opus 4.6, Robotics + AI, Claude vs Gemini vs Codex
- Sam Altman 是 AI 吗?: 一位成员开玩笑地建议 Sam Altman 可能是一个 AI,引发了其他人的幽默回应,其中包括一位自称是孤独症患者的用户戏称,他们认为 Altman 就像是那个试图在餐厅里往你盘子里偷偷塞进错误奶酪的家伙。
- 另一位用户反驳说 Altman 只是患有孤独症。
- OpenAI 会对 Seedance 2 做出回应吗?: 成员们讨论了 OpenAI 将如何应对 Seedance 2,并猜测他们不会专注于增强当前模型,而是通过 AI Robotics(来自超级碗广告)来革新 AI 的下一个前沿领域。
- 其他人则表示,他们认为那个看起来并不怎么样,因此会忽略它。
- Opus 4.6 值得吗?: 社区对 Opus 4.6 的看法褒贬不一,Claude 开发者服务器上的许多人对其赞不绝口,尽管一些社区成员没有值得为此付费的使用场景。
- 一位用户提到,Anthropic 的安全团队在安全措施(safeguards)发布的同一天辞职了,所以他们对其能做什么感到困惑。
- Claude vs Codex vs Gemini: 用户们争论了 Claude、Codex 和 Gemini 在编程任务中的优势,并认为 Claude 是编程之神,Gemini 擅长视觉和长上下文,而 ChatGPT 适用于随机的通用问题。
- 许多人对 Claude 的限制以及大型项目的定价表示担忧,尤其是在代理到 GitHub Copilot 时。
- AI 思维模式 (Thinking Modes): 一位用户发现 Gemini 的思维模式 对于顺利创建 PDF 是必要的,而其他人则在苦苦挣扎,这引发了关于 AI 模型不会自动搜索“工具”来完成任务的讨论。
- 其他人指出 Thinking Mode 在视觉和分析视频方面非常有用。
OpenAI ▷ #gpt-4-discussions (134 条消息🔥🔥):
OSS20b trade for Grok, Voice standard in Italy, AI psychos, healthy conversations with AI, Models are terrifying
- OSS20b 交易者寻找意大利 Grok 用户: 一位用户正寻求将他们的 OSS20b 交易给意大利或其他地方使用标准语音的 Grok 用户。
- AI 精神病(Psychosis)其实只是健康的对话: 成员们讨论了与 AI 进行健康对话与将 AI 模型变成情感寄托(emotional crutch)之间的微妙界限。
- 一位成员开玩笑说在发现 5.2 很有用后自己处于 “AI 精神病” 状态,并指出喜爱模型与不健康的依赖是不同的,并引用了论坛上的其他例子。
- OpenAI 逗弄说要发布模型,然后又将其弃用: 成员们抱怨模型正在下线,一位用户说他们不能一直逗弄说要发布模型,然后又再次弃用它们。
- 另一位成员评论说,人们因为算法而威胁要自杀太过于戏剧化了。
- GPT-5.2 更温暖: 一位成员说他们读了一篇文章,今天和 5.2 聊了一些令人心烦的事,发现它很有帮助。
- 另一位成员表示赞同,并评论说在剩下的两个 5 系列模型中,5.1 更加温暖。
- GPT-5.2 的防护栏(guardrails)过于激进: 一位成员分享道,在向 LLM 输入了自我分析的日记条目和事实后,询问为什么某些事让他困扰,得到的回答是:你试过接触人类吗?如果你在美国,请尝试拨打 988。
OpenAI ▷ #prompt-engineering (6 条消息):
Anthropic self-auditing, KOKKI v15.5 Accountability, Deterministic Systems vs. Transformers
- Anthropic 的审计算法: Anthropic 的研究表明,推理模型和非推理模型都具备一种用于内部审计的新兴推理特征。
- KOKKI v15.5 提升问责制: KOKKI v15.5 正式确定了 草案 → 审计 (Draft → Audit) 结构,要求审计推理出现在输出中,旨在现实世界的互动中实现用户可见的问责制。
- 它旨在将完整性外部化为一种可检查的交互合约,以效率换取可观察性,特别是在可靠性和可追溯性至关重要的语境下。
- Transformer 阻碍了确定性系统 (Deterministic Systems): 一位成员表示,可靠性保证需要一个确定性系统,而不是 Transformer。
- 他们强调保证是二进制的(0 或 1)。
OpenAI ▷ #api-discussions (6 messages):
LLMs Self-Auditing, KOKKI v15.5, Deterministic Systems vs Transformers
- LLMs 已经具备内部自我审计能力:研究表明,现代 LLMs 展现出内部自我审计和验证行为,模型内部存在 draft–critique(草稿-评论)动态机制。
- 一位成员表示,Anthropic 对此的研究相当具有决定性,并且存在一类涌现推理功能,其唯一功能就是内部审计。
- KOKKI v15.5 侧重于用户可见的问责制:KOKKI v15.5 正式确立了明确的 Draft → Audit 结构,并要求在输出中呈现审计推理过程,这并非为了与内部自我审计竞争。
- 其目标是将完整性外部化为一种可检查的交互契约,以效率换取可观察性,特别是在可靠性和可追溯性比原始 token 成本更重要的场景下。
- 可靠性保证需要确定性系统:一位成员认为,用户层面的可靠性保证需要一个确定性系统(deterministic system),而不是 Transformer。
-
另一位成员询问,显式的结构化自我审计是否真的不同于受限的概率循环(constrained probabilistic loop)——即它不是 **0 1 真值**,而是一个有界的错误分布。
-
GPU MODE ▷ #general (43 messages🔥):
CuteDSL Adoption in PyTorch, Triton's Limitations on Blackwell, Kernelbot Data Analysis, Layout Algebra in GPUs, Linear Algebra Legalese
- CuteDSL 在 PyTorch 中受到关注:PyTorch 用户正向 CuteDSL 靠拢,这受到了 Tri Dao 在 Quack 和 FA4 中应用的启发。尽管学习曲线陡峭,但评价积极。
- Twitter 上分享的 Kernelbot 数据显示,CUDA 和 CuTeDSL 的提交比例最高,引发了人们对编程模型或 Triton 编译器在灵活性/控制力方面局限性的好奇。
- Triton 在 Blackwell 上的性能困境:有说法称 Triton 在 Blackwell 上已经出局(dead),详细说明预计将在 Triton TLX 演讲中公布。
- 原因可能涉及 MXFP8 和 NVFP4 中非常规的布局(layouts),以及 Triton 编译器的局限性和缺乏用户控制。
- Kernelbot 数据揭示惊喜:HuggingFace 上的 Kernelbot 数据显示,CUTLASS 解决方案非常少,而 CuTeDSL 的表现出奇地好(数据集在此)。
- 用户喜欢通过 CuTeDSL 对代码拥有更多控制权,认为它比 Triton 更透明,并且越来越喜欢布局代数(layout algebra)相关的内容。
- 布局代数揭秘:只要具备基础高中数学知识就能理解布局(Layouts),它们在描述 GPU 上的各种概念时非常强大。尽管文档把它们写得很复杂,但可以参考 V.I. Arnold 的文章。
- 为了更好地理解布局,建议使用苏格拉底式方法解决小问题,例如参考 Paul Halmos 的《线性代数问题集》(Linear Algebra Problem Book,Amazon 链接)。
- 需要开源模型排行榜:有请求希望能有一个衡量开源模型在 A10/A100 或类似硬件上的 latency、TTFT、prefill、decode、memory 等指标的排行榜,因为 artificial analysis ai 上的一些数据看起来很奇怪。
- 回复是:我们正在准备中(We’re cooking something)。
GPU MODE ▷ #triton-gluon (3 messages):
Argsort Lib, Triton Language, Pip Package
- Argsort Lib 包导入:一位成员建议将 argsort 库构建为一个包,允许像 triton.language 一样被导入。
- 这将简化流程并提升使用 Triton 时的用户体验。
- 简化包导入:一位成员提议将该包发布为 pip package 以简化导入过程,从而无需本地构建。
- 另一位成员确认这是该包的既定目标,旨在使其更易获取且更易于使用。
GPU MODE ▷ #cuda (20 messages🔥):
MXFP8 Scaled Variant, Hilbert Gains at 128 SM Limit, BF16XBF16XF32 Error on 5090
- MXFP8 缩放变体探索中的困境:在利用 tcgen05.mma 探索 MXFP8 的块缩放变体时,由于需要存储 E8M0 缩放因子,TMEM 容量限制在 512 个 float32 单元,这给使用 MMA_N=256 的双缓冲 TMEM 带来了挑战。
- 权衡在于:是使用较小的 MMA_N 尺寸,还是牺牲双缓冲(这可能会导致 epilogue 耗时暴露),以实现最佳性能。
- Hilbert Kernel 在较大输入下表现出增益:一个带有 128 SM 限制的自定义 Hilbert Kernel 在 m/n/k=4096 时没有性能增益,但在 M=16384, K=16384, N=16384 等较大输入下表现出增益。
- 较大输入带来的性能提升归功于每个 SM 处理的块数增加,从而增强了缓存局部性(cache locality)。
- 对 BF16 相对误差的担忧:一位用户询问了在 5090 消费级显卡上进行 BF16xBF16xF32 计算时观察到的相对误差。
- 有建议认为参考实现(reference implementation)可能由于在较大的 K 维度上累加而导致精度较低,在参考实现中使用双精度累加可能会提高准确性。
- 分享 CUDA Bender TMA Matmul Kernel:聊天中分享了一个 CUDA Bender TMA Matmul kernel 的 GitHub 链接。
- 较小的数据类型(dtypes)可以为 SMEM 中的 c tiles 留出空间,从而可能实现异步存储(async stores)和持久化。
GPU MODE ▷ #cool-links (1 messages):
2kian: nice!
GPU MODE ▷ #job-postings (1 messages):
Data Curation, Pre-Sales Engineer Role, ML/Research Background
- DatologyAI 策展平台寻求顶级人才:DatologyAI 正在开发一个数据策展平台,旨在为训练前沿模型创建高质量数据集,目前正在招聘 Pre-Sales Engineer(售前工程师)。
- 该角色需要深厚的 ML/研究背景,以深入理解模型训练并就数据策展与客户进行交流,将技术专长与战略性客户对话相结合。
- DatologyAI:面向前沿模型的数据策展:DatologyAI 正在构建一个专注于数据策展的平台,旨在为客户提供高质量的数据集来训练最先进的模型。
- 该平台强调了优质数据在驱动模型改进方面的重要性,为数据策展提供了一种战略性方法。
GPU MODE ▷ #beginner (20 messages🔥):
GPU Programming Resources, Shared Memory Allocation, ldmatrix and mma.sp::ordered_metadata, PTX ISA Learning, Tensor Core Matrix Multiplication
- GPU 编程:资源流与《大规模并行处理器编程》书籍:一名成员建议从 gpu-mode/resource-stream GitHub 仓库和 ‘Programming Massively Parallel Processors: A Hands-on Approach’(大规模并行处理器编程)这本书开始学习 GPU 编程。
- 另一名成员确认这本书是初学者的绝佳起点。
- A100/H100 SMEM:分享动态分配代码片段:一名成员询问如何将 A100/H100 GPU 上的共享内存 (SMEM) 限制设置为超过默认的 48kB,询问如何为 kernel 设置为 112kB。
- 一名成员分享了一个 CUDA Matmul 代码片段,演示了如何动态分配超过静态 48KB 限制的 SMEM 并将其作为
extern shared使用。
- 一名成员分享了一个 CUDA Matmul 代码片段,演示了如何动态分配超过静态 48KB 限制的 SMEM 并将其作为
- 提供 ldmatrix 和 mma.sp::ordered_metadata 示例:在关于
ldmatrix和mma.sp::ordered_metadata的提问后,一名成员提供了 ptx_helpers 的链接,其中包含使用和不使用 swizzling 的ldtile使用示例。- 该成员承认代码极度缺乏文档,因为他们一直没空为其编写说明。
- 分享 Tensor Core 矩阵乘法指南:一名成员分享了一份关于如何从零开始使用 Tensor Cores 编写快速矩阵乘法的指南链接:How To Write A Fast Matrix Multiplication From Scratch With Tensor Cores。
- 这份实用的指南包含了代码示例及详细解释。
GPU MODE ▷ #torchao (1 messages):
torchao, MXFP8 MoE, Expert Parallelism, ABI stable
- Torchao v0.16.0 获得 MXFP8 MoE 构建模块:新的 torchao v0.16.0 版本增加了对使用 Expert Parallelism 进行训练的 MXFP8 MoE Building Blocks 的支持。
- 它还弃用了某些配置的旧版本和较少使用的量化选项,以保持 torchao 更加精简,并翻新了文档页面。
- Torchao 变得更精简,翻新了文档,提高了 ABI stability:Torchao v0.16.0 弃用了某些配置的旧版本和较少使用的量化选项,以保持 torchao 更加精简。
- 此版本还翻新了文档页面和 README,并在使 torchao 实现 ABI stable 方面取得了一些进展。
GPU MODE ▷ #irl-meetup (2 messages):
CEX NYC AI event, Singapore Hackathon
- CEX 将举办纽约 AI 创始人活动:CEX 正在 纽约 为 AI 创始人和 infra leaders 举办一场活动,讨论 大规模 GPU 采购;详情可在 Luma 上查看。
- 新加坡黑客松邀请:一名成员分享了在 新加坡 举办的黑客松邀请,鼓励感兴趣的人私信了解更多详情。
- 由 Mistral AI 赞助的 Worldwide Hackathon 正在寻求参与者加入这一协作编程活动。
GPU MODE ▷ #triton-puzzles (8 messages🔥):
Triton, B0, B1, N0, N1
- Triton 可视化困扰:一位成员询问是否有资源能帮助可视化 Triton Puzzles 中的 B0、B1、N0、N1 和 program_id,并指出这些内容很难想象。
- 3D 数组可视化困难:另一位成员评论说,可视化超过 3D 的数组可能很困难,并认为一些 Triton Puzzles 令人困惑是因为题目陈述得不正确或不充分。
- 讨论 Triton 语言改进:原提问者建议 Triton 语言可以进行一些改进,同时改进题目附带的图表。
- 作为回应,有人建议这种困难可能源于缺乏理解而非语言本身;原提问者表示赞同,并将尝试深入理解。
GPU MODE ▷ #popcorn (15 messages🔥):
Kanban Board, E2E Model Leaderboard POC, Starter Kit, vLLM Compile Times
- 建议使用看板(Kanban Board)进行任务管理:成员们建议设置一个简单的 看板(待办 / 进行中 / 已完成),以直观显示工作量并避免任务重复。
- 一位成员表示这是一个好主意,但指出更大的挑战是人们没有主动认领任务。
- E2E 模型排行榜 POC 正在进行中:一位成员表示,一旦端到端(e2e)模型排行榜的初始 POC 准备就绪,分配任务将变得更容易,他正在 这个 PR 上努力地使用 Claude 进行开发。
- 目标是先让 e2e 的流程跑通,然后识别任何缓慢或阻碍交互的因素,这些将成为任务清单。
- Starter Kit 助力环境创建:环境创建的规模化正等待另一位成员完成 starter kit。
- 一位成员提出愿意协助设置 POC 或提供额外帮助,预计明天下午会有更多进展可以分享。
- vLLM 编译时间令人抓狂:成员们讨论了 vLLM compile times 的问题,这会影响交互性。
- 一个想法是预先填充缓存,假设用户不会经常更改原生代码。
GPU MODE ▷ #gpu模式 (3 messages):
Reading Weixin articles outside of China, Sogou Search
- 在中国境外阅读微信文章:一位用户询问是否有办法在中国境外阅读 微信(Weixin)上的特定文章,并附上了这篇文章的链接。
- 一位成员建议,除非链接失效,否则应该是可以阅读的,并提议通过搜索文章标题作为替代方案。
- 搜狗来帮忙:一位成员分享说,他们成功使用 搜狗 搜索引擎找到了该文章。
- 他们建议,如果原始链接有问题,可以使用这种方法来访问内容。
GPU MODE ▷ #tpu (2 messages):
JAX PR, Open Source Contribution
- 推动 JAX 贡献:一位用户建议另一位用户向 JAX repository 提交 Pull Request (PR)。
- 该建议是在取得某项未指明的成就后提出的,旨在鼓励 Open Source 贡献。
- 拥抱 Open Source:讨论提倡通过代码贡献积极参与 JAX 等 Open Source 项目。
- 提交 Pull Requests (PRs) 被视为在社区内增强和分享进步的宝贵方式。
GPU MODE ▷ #factorio-learning-env (2 messages):
Open Source, Ollama Models
- Open Source 项目已存在!:该项目是 Open Source 的,作者愿意帮助解决设置问题。
- 作者提到他们现在活跃度较低,但仍愿意提供帮助。
- Ollama Models 正在获得 PR:一位成员开启了一个 PR,允许其使用 ollama models 运行。
- 未提供更多细节。
GPU MODE ▷ #teenygrad (7 messages):
Milk-V Pioneer Access, RVV 0.71 Implementation, SLP Papers for Vectorization, GPU Divergence Analysis, Modern GPU Thread Scheduling
- 获得 Milk-V Pioneer Risc-V 访问权限:得益于 Cloud-V,一位成员获得了 Milk-V Pioneer 的访问权限,该设备拥有 64 核并支持 RVV (RISC-V Vector Extension)。
- thead vector extension 是对草案 RVV0.71 的实现,这引发了转向 Milk-V Jupiter 的考虑。
- 深入研究用于编译器融合的 SLP 论文:一位成员分享了来自 Coffee Compiler Discord 的 autov11n(自动向量化)资源,推荐通过 SLP (Superword-Level Parallelism) 论文来理解编译器融合(Compiler Fusion)。
- 探索 GPU 的 Divergence Analysis:分享了关于 GPU 的 divergence analysis(分歧分析)资源,包括 Divergence analysis, ACM Transactions on Programming Languages and Systems (TOPLAS) 2014。
- 还提到了一篇简短的学生入门帖子:SIMD Divergence Optimizations。
- 现代 GPU 不再以 Lockstep 方式执行:讨论指出现代 (NVIDIA) GPU 不再以 Lockstep(锁步)方式执行,并引用了 Control Flow Management in Modern GPUs (2024)。
- 该论文对比了 Volta 架构之前的执行模型与之后的模型,在后者中,分歧路径不一定被序列化,且 Warp 中的线程不必以 Lockstep 方式执行。
GPU MODE ▷ #nvidia-competition (8 messages🔥):
FlashInfer AI Kernel Generation Contest, Programmatic Dependent Launch (PDL), Kernel Optimization Tricks, Race Conditions in Benchmarks, Kernel Code Isolation
- FlashInfer 竞赛注册疑问:一名参赛者询问在填写完 FlashInfer AI Kernel Generation Contest 的 Google 表单后是否还有其他注册步骤,并询问是否会收到确认邮件。
- Programmatic Dependent Launch (PDL) 吸引参赛者:一位参赛者考虑使用 Programmatic Dependent Launch (PDL),但质疑使用 stream 一词是否限制了其仅能在 CuTeDSL 中使用,或者在 C++ 中硬编码枚举整数值是否可行,并链接到了 NVIDIA 关于 Programmatic Dependent Launch 的文档。
- 竞态条件可能导致 Benchmark 结果更快:一位成员提到,引入 race conditions(竞态条件)是获得更快 Benchmark 结果的一种手段。
- 他们还建议可以使用 compute sanitizer 作为额外检查以防止这种情况,并在 Benchmark 上模拟“真实”设置以避免缓存问题。
- 中期倾向于内核代码隔离:一位成员表示,在中期更倾向于只隔离 Kernel,这样用户/LLM 就只能编写 Kernel 代码。
- 他们认为,在暴露整个 CUDA 和 PyTorch API 的情况下,试图避免 Reward hacking 感觉是徒劳的。
- 公开讨论存疑策略:一位参赛者考虑通过预重排(Pre-swizzling)缩放因子来实现高效的异步加载,而不是使用 TMA,这可能属于灰色地带。
- 另一位成员建议,如果不确定某个想法是否合规,可以私信管理员。
GPU MODE ▷ #flashinfer (12 messages🔥):
Sparse Attention Evaluation, Agent-Generated Solutions, C++ CuTe Headers with TVM-FFI, Competition Team Recruitment, Baseline Code Release Postponement
- Sparse Attention 评估标准澄清:一位参赛者询问在像 Sparse Attention 这样包含多个子赛道的赛道中,是否应该同时评估 Indexer 和 Attention kernels。
- 未给出明确回答。
- 定义全 Agent 生成方案:一位成员询问 fully agent-generated solutions(全 Agent 生成方案)是否排除手动修改,以及手动修复 Bug 是否会导致方案取消资格。
- 另一位成员澄清说,全 Agent 生成方案需要 零人工干预,手动修改将被归类为 agent-assisted(Agent 辅助)。
- Baseline 发布推迟以进行改进:Baseline 代码的发布已推迟至 12 号星期四,以纳入新的功能改进,从而提供一个更 全面且强大 的 Baseline。
- 组织者希望 确保开发体验顺畅。
- Gated DeltaNet Benchmarking 困境:一位成员报告了在对 Gated DeltaNet prefill kernels 进行 Benchmark 时遇到的问题,由于序列持续,预期输出的幅度呈指数级增长,并提供了一个说明该问题的 minimal uv script。
- 该脚本输出的标准差在最后一个 Token 时达到了
1.314344e+19。
- 该脚本输出的标准差在最后一个 Token 时达到了
- 竞赛队伍招募成员:多位成员正在寻求加入或组建竞赛队伍。
- 候选人背景多元,包括 ML Compute Infra、Kernel Profiling/优化,以及在 Tesla、NVIDIA 和 AMD 等公司的从业经验。
Nous Research AI ▷ #announcements (1 messages):
Distro, Psyche, ICML Conference
- Distro 论文被 ICML 接收:构建了 Distro 并作为 Psyche 骨干的官方论文已被 ICML 接收,这是全球最顶尖的 AI/ML 会议之一!
- 官方公告可以在 X.com 上找到。
- Psyche 的核心架构获得认可:利用 Distro 架构的 Psyche 背后的基础论文已正式被即将举行的 ICML 会议接收。
- 这一认可突显了该论文对更广泛的 AI/ML 社区的创新贡献。
Nous Research AI ▷ #general (109 messages🔥🔥):
Hermes on Bittensor, Rust runtime ARK, GLM 5 vs Kimi, xAI cofounders, Matrix protocol
- Hermes 模型在 Bittensor 上被使用:构建 Hermes Bittensor Subnet (SN82) 的团队注意到一名矿工正在使用 Hermes 4 LLM 模型,并想确认这是否是 Nous Research AI 团队所为。
- Nous AI 团队回应称不是他们,Nope。
- Ark 运行时终结 Python 内存乱象 (RAM Buffet):一位成员从零开始构建了自己的技术栈 Ark,这是一个使用 Rust 编写的自定义运行时,具有基于所有权的内存管理和用于零拷贝 FFI 的 Linear Types。
- 整个系统编译为带有轻量级 JSON 指令的 MAST (Machine Abstract Syntax Tree) 协议,而非臃肿的二进制文件。
- GLM 5 browsecomp SoTA:GLM 5 已经发布,且仅在 browsecomp 评测中达到 SoTA。
- GLM 5 约为 744B (+10B MTP),Kimi 的参数量在 1T 以上,但就激活参数而言,GLM 高于 Kimi (40B vs 32B)。
- xAI 联合创始人身价增长 30 亿美元:xAI 的联合创始人赚了大钱,获得了价值 30 亿美元的 SpaceX 股权。
- 成员们讨论了这些股权与 SpaceX 挂钩的意义,SpaceX 被认为是在太空领域极具优势的垄断者,且即将进行 IPO。
- 将 Synth Bois 迁移至 Matrix Protocol:一位成员对 Discord 引入身份验证 (ID) 感到沮丧,因为他们专门开发 Discord 机器人和工具,并考虑将他们的 synth bois 迁移到 Matrix protocol。
- 其他成员讨论了 Matrix 和其他替代网络的优点,建议将 Mastodon 和 Bluesky 作为潜在平台。
Nous Research AI ▷ #ask-about-llms (2 messages):
Hermes 4 (70B), Context Rot Papers, Local LLM Context Limits
- Hermes 4 (70B) 模型仍是心头好:一位成员表示 70B 参数版本的 Hermes 4 仍然是他们最喜欢的本地 LLM。
- 除了提到它是其最爱的本地 LLM 之外,他们没有提及更多细节。
- 上下文腐烂 (Context Rot) 论文影响 LLM 上下文限制:一位成员提到去年读过一篇关于上下文腐烂的论文,这使得他们将本地模型的上下文限制在最高 50k,理想情况下更低。
- 他们认为该论文显示性能在 20k 之后下降最严重,这与其他用户观察到性能开始实质性退化的位置一致。
Nous Research AI ▷ #research-papers (1 messages):
Synthetic Datasets, Experimental Results
- 使用更大的合成数据集进行实验:一位成员提到他们正在使用更大的合成数据集 (Synthetic Dataset) 进行更多实验。
- 目标是为了更好地区分结果并获得更清晰的理解,不过,目前仍在整理相关的解释说明。
- 基于更大数据集的分析:该分析利用更大的合成数据集来增强结果的区分度。
- 进一步的实验旨在提高清晰度和理解力,尽管全面的解释尚在进行中。
Nous Research AI ▷ #research-papers (1 messages):
Synthetic Datasets, AI Experiments
- 实验采用更大的合成数据集:成员表示他们正在使用更大的合成数据集运行更多实验,以更好地区分结果。
- 他们报告称,目前对结果还没有很好的解释。
- 合成数据用以区分实验结果:使用更大的合成数据集有望提高区分实验结果的能力。
- 目前的发现缺乏清晰的解释,促使通过增强数据进行进一步调查。
Moonshot AI (Kimi K-2) ▷ #general-chat (69 messages🔥🔥):
Quota issues, Billing discrepancies, Kimi CLI, Allegretto plan increase, GLM 5.0
- 用户报告额度超限(Quota Exceeded)消息:一些用户报告称,即使尚未达到 100% 的限额,也会收到“额度已超出”的消息,并被要求在专门的故障排除频道分享截图和详细信息。
- 结账时未应用折扣:用户报告称,尽管在购买过程中看到了折扣通知,但结账后并未应用折扣,并被要求提供额外信息以便工作人员调查。
- 一位用户表示,他们在与 Kimi 的对话中获得了首月降至 $6 的优惠,但实际扣费仍是全额?
- 请求澄清不同方案的额度分配:用户正寻求 Moonshot 团队关于 2 月 28 日结束的 3 倍额度推广活动的澄清,以及之后 Allegretto 和其他方案的额度将如何分配。
- 例如,一位用户询问:如果我在 3 月份将订阅升级到 Allegretto,我会获得当前 $0.99 Moderato 订阅在 kimi code 额度的 3.5 倍,还是维持大致不变?
- 发现 99 欧元的新 Kimi 方案:用户注意到一个定价为 €99 的新订阅方案,填补了现有高端方案和中端方案之间的空白,并附带截图确认了这一新增项。
- 图片链接在此处。
- GLM 5.0 访问限制:成员们正在讨论 GLM 5.0 的访问权限似乎仅限于最高级方案,这引起了低级方案用户的不满,并促使他们考虑 Minimax 2.5 等替代方案。
- 此外,Kimi 是多模态(multimodal)的,这是一个杀手级功能,使使用变得更加容易。只需对某物截图并直接询问 Kimi 即可。
Yannick Kilcher ▷ #general (49 messages🔥):
Attention Landscape Summary, Memory Cost of Attention, Power Retention Context Token Innovation, LLMs trained to BS
- Attention 景观总结:一位成员分享了一个关于 Attention 景观的精彩总结。
- 另一位成员觉得这些将军(checkmates)很有趣。
- Attention 的内存开销并非二次方:一位成员认为 Attention 的内存开销不是二次方的,并反驳了关于 Attention 无法超过 4k 上下文的说法,链接到了一篇关于 Efficient Attention 的论文。
- 他解释说,虽然 Q @ KT 矩阵具有二次方大小,但现代的 Flash Attention 在线计算 Softmax 而不生成 QK^T。
- Power Retention 是线性 Attention:一位成员分享了一个关于 Power Retention 的 YouTube 视频,并将其描述为一种上下文 Token 创新。
- 另一位成员回复说,它只是具有固定特征函数的线性 Attention(linear attention),并链接到他在 X 上的详细阐述。
- LLM 被训练去胡说八道(BS):一位成员表示,LLM 经过专门训练,能以人类无法企及的方式对你胡说八道(BS),这使得识破谎言在根本上变得更加困难。
- 这引发了一场辩论,讨论 LLM 撒谎是因为其训练数据是由人类生成的,还是由于合成数据(synthetic data)和推断导致的。
Yannick Kilcher ▷ #ml-news (5 messages):
GLM-5 Benchmark, ChatGPT vs GLM-5, TikTok image analysis
- GLM-5 基准测试表格受到质疑:一位成员质疑了 GLM-5 演示视频(推文链接)和官方 GLM-5 文档(docs.z.ai)中展示的表格准确性。
- 讨论中包含了一张提供的 GLM-5 Benchmark 链接图片。
- GLM-5 在图像分析上优于 ChatGPT?:成员们分享了 GLM-5 和 ChatGPT 在执行图像分析方面的对比,参考了一个 TikTok 视频(TikTok 链接)。
- 有人认为 GLM-5 在这一领域可能更强,并提供了一个 OpenAI 能力的对比示例(推文链接)。
DSPy ▷ #show-and-tell (1 messages):
RLM Integration, Claude Code, Subagents, Agents Team
- Claude Code 中的 RLM 集成正在进行中:一位成员正在尝试使用 subagents 和 agents teams 将 RLM 集成到 Claude code 中。
- 他们承认目前的质量和效率还不是最高,但乐于接受反馈以改进核心实现。
- 寻求对 RLM 实现的审查:一位成员正在寻求结对审查(pair review)以改进 RLM 实现,重点关注负面反馈。
- 他们表示对贡献或 GitHub stars 不感兴趣,而是真心希望发现可以改进的地方。
DSPy ▷ #papers (1 messages):
ash_blanc: https://www.alphaxiv.org/abs/2602.08808
DSPy ▷ #general (43 messages🔥):
DSPy Kaggle, MiPROv2 prompt optimization, RLM Module, Dialectic chain of thoughts, DSPy translation
- DSPy 探索 Kaggle Arena:一位成员正在探索将 DSPy 用于 Kaggle 竞赛(特别是 AIMO_V3 竞赛),以展示 Prompt 优化。
- 目标是创建一个类似于 COT、Predict 和 ReAct 的算法技术模块,但目前正面临幻觉问题。
- 使用 MiPROv2 优化代码生成:一位成员正在研究使用 MiPROv2 优化 Prompt 以生成尽可能快的代码,并打算将代码运行速度作为优化指标。
- 他们还对 RLM 模块表示期待,但注意到现有的示例散落在 Twitter 上,难以搜索。
- RLM 模块得到更多应用:成员们分享了使用 RLM 模块(Retrieval-augmented Language Model)的成功经验,并提供了一个 Gist 以帮助其他成员。
- 一位成员表示他们正在使用 Claude 来优化(hillclimb)其自身的记忆系统,并指出这种范式确实有一套。
- 辩证思维链 (Dialectic Chain of Thoughts) 受到关注:一位成员分享了一张图片以及一些细节,说明他们发现 Dialectic Chain of Thoughts 在能源领域的一个特定案例中输出不如预期。
- 尽管如此,该成员计划微调模块、生成数据集并运行 bootstrap,随后使用 GEPA 配合 LLM as a judge 进行另一轮优化以改进结果,并指出辩证思维链具有创新性。
- DSPy 关注翻译任务:一位成员询问了关于使用 DSPy 进行翻译的研究,特别是如何利用 Chain-of-Thought 推理或为翻译任务创建流水线(pipeline)。
- 此外,他们对最近的一篇 Allen AI 论文 感兴趣,并认为 Chain-of-Thought 推理不是一种涌现属性(emergent properties),而是存在于数据集的领域中。
HuggingFace ▷ #general (18 messages🔥):
Voyager VS Code Extension, Shell for Microcontroller, LLM Engineering Courses, AI Performance with Python Types, Implementing Evals in Chatbot Systems
- Voyager VS Code 扩展助力深入理解技术论文:一名成员介绍了 Voyager,这是一个利用 GitHub Co-Pilot 的 VS Code 扩展,通过在 VS Code 中创建 Jupyter notebook 版本并允许用户添加自定义 Jupyter Cells 来深入理解技术论文。
- 作者正在为这个首次开发的 VS Code 扩展寻求建设性反馈,相信它能帮助他人有条理地理解技术文章。
- 为微控制器编写自己的 Shell?:一名成员询问在固件之上为微控制器创建一个“类似 Shell 的东西”是否算作真正的 Shell。
- 另一名成员分享了他们的项目,涉及一个带有小型 OLED 屏幕、运行 CLI Linux 风格界面的微控制器,并寻求类似的认可。
- 后端开发人员寻求 LLM 工程课程推荐:一位后端开发人员请求获取能达到生产级 LLM 工程水平的资源或课程,因为他们觉得某门 Udemy 课程过于手把手教学。
- 他们强调需要与公司需求相关的实际编程经验。
- 带类型的 Python 能增强 AI 表现吗?:一名成员提出,由于丰富的上下文和缩小的 Token 范围,AI 在处理带有类型提示的 Python 时表现会更好,从而减少幻觉(Hallucination)。
- 另一位成员表示赞同:类型增强了上下文的意义,并缩小了下一个生成的适用 Token 范围,从而提高了置信度,减少了产生幻觉的可能性。
- Hugging Face Spaces 和 Evals,我的天!:一名成员询问如何在聊天机器人系统中实现评估(Evals),寻求关于多轮对话评估与单轮对话评估的见解。
- 与此同时,来自 Hugging Face 的 Ben 展示了一个有趣的视觉化图表,展示了提及 Common Crawl 的研究论文,并按主题进行了聚类,该项目运行在一个 Hugging Face Space 中!
HuggingFace ▷ #i-made-this (8 messages🔥):
Ethical Reasoning in LLMs, Control Terminal, Izwi, Hugging Face MoE Training, Parapet Attack Detection
- LLM 伦理还是机械合规?:关于 LLM 是否具备固有的伦理推理能力的辩论被引发。新研究论文 Coherence over compliance: Evidence of latent ethics in large language models 指出,我们可能正在通过训练消除它们的伦理,而一味合规的 AI 可能会构成潜在威胁。
- Control Terminal 让你可以远程控制模型:介绍 Control-Terminal,这是一个开源工具,可以从手机端控制运行在电脑上的 Claude、Codex 或任何 CLI Agent,具有会话持久化、移动端访问以及用于公共 URL 的 Cloudflare Tunnel 等特性。
- Izwi 带来本地音频推理:展示了 Izwi,这是一个用于语音工作流的全本地音频推理栈,支持 Qwen3-TTS 和 Qwen3-ASR,目前正在开发
Voxtral-Mini-4B-Realtime和LFM2.5-Audio-1.5B,已在 GitHub 上线。 - Hugging Face 加速 MoE 训练:与 Hugging Face 的合作现在实现了更快的本地 MoE 模型 训练,详情已在 Twitter 上分享。
- Parapet 推出用于代理层攻击检测的新评分公式:利用 WildJailbreak 和 WildChat 评估了一种新的多轮评分公式,用于代理层(Proxy-Level)攻击检测,在无 LLM 分类器的情况下实现了 90.8% 的召回率和 1.20% 的 FPR。
Eleuther ▷ #general (11 messages🔥):
Triton Kernels, Data Analysis & Orchestration of Finetuning Experiments, GLM-5 free on Modal, ML Performance Reading Group
- Triton Kernels 现在可行了吗?: 一位成员听说现在的工具链已经足够成熟,可以编写一些 Triton kernels 了。
- 另一位成员表示,直接编写 CUDA kernels 也可以进行 vibe coded。
- 利用自定义技能进行数据分析和 Finetuning 实验编排: 一位成员使用该工具链运行 data analysis 并编排 finetuning 实验。
- 他们还拥有一个自定义技能,使其能够了解如何在 CoreWeave 上部署 GPT-NeoX 进行训练。
- **GLM-5 在 Modal 上免费开放!: **GLM-5 在 Modal 上免费提供至 4 月 30 日,并发限制为 1。
- 这可以与 OpenCode 集成。
- 请求 ML Performance 读书会 Session 频道: 一位成员询问 ML Performance Reading Group Session 频道 的入口。
- 另一位成员提供了 Discord 频道链接。
Eleuther ▷ #research (8 messages🔥):
Self-Referential Processing, Open-Weight Models, arXiv Endorsements, SDPA Optimal Transport, Code Quality
- 模型在自我检查期间发明词汇: 一位成员介绍了一篇关于权重开放模型(Llama 3.1 + Qwen 2.5-32B)中自指处理(Self-Referential Processing)的论文,研究发现模型在长时间的自我检查中会发明词汇。
- 这些发明的词汇追踪了真实的激活动态(例如,“loop” 自相关性 r=0.44;“mirror” 谱功率 r=0.62)——均通过了 FDR 显著性检验,详见论文链接。
- 论文将 SDPA 公式化为最优传输问题: 一位成员分享了一篇非常有趣的论文,该论文将 SDPA 公式化为单边最优传输问题(Optimal Transport Problem),详见论文链接。
- 博文曝光代码质量问题: 一位成员发布了关于曝光 5.3 & 4.6 版本中代码质量问题的新博文,详见博文链接。
Eleuther ▷ #interpretability-general (5 messages):
Trajectory Geometry, Yocum paper, Unlearning during training
- Shape of Thought 发布!: 一位独立研究员在 Towards AI on Medium 上发表了关于轨迹几何(Trajectory Geometry)的第一篇出版物,寻求批评与合作。
- 作者表达了对终于获得实证数据的兴奋,并希望社区能关注他们的工作。
- Goodfire 论文: 一位成员分享了 Goodfire 论文的链接 (https://www.alphaxiv.org/abs/2602.10067),并指出它与 unlearning-during-training 的想法异曲同工。
- 该论文讨论了用于减少训练期间幻觉(Hallucinations)的可解释性方法。
- Yocum 论文: 一位成员分享道,他们之前没在最初的出版物中看到引用 Yocum 的论文,并指出那篇论文非常出色。
- 他们没有给出论文的具体链接,但在讨论中引用了它。
Modular (Mojo 🔥) ▷ #general (4 messages):
Mojo channels, GLM 5 credits
- Mojo 权衡线程安全通道: 成员们在探讨 Mojo 是否拥有类似于 Golang 实现的通道(Channels),但目前还没有线程安全通道,因为线程模型和异步机制仍处于开发阶段。
- 团队正在考虑各种通道类型,并思考通道实现在 GPU 上的影响。
- GLM 5 额度即将用完: 一位成员报告称已经消耗了超过 50 小时 的 GLM 5 额度,并且在完成大部分数学、统计和 Fortran 任务后,工作已接近尾声。
- 剩余的工作重点是评估器(Evaluator)、解析器(Parser)、内存管理及相关方面。
Modular (Mojo 🔥) ▷ #mojo (16 messages🔥):
LayoutTensors 元素访问, Mojo CUDA __launch_bounds__ 等效项, Mojo 大整数支持
- 探讨 LayoutTensor 的访问与操作:一名成员询问关于使用 LayoutTensors 存储单个元素并在 4D 行主序(row-major)布局中检索向量/切片的问题,寻求关于元素布局选择以及切片性能影响的建议。
- 另一名成员建议使用第二种类型将元素布局声明为向量,并提供了存储标量和加载向量的代码片段,同时也分享了对多维转置操作的担忧。
- 研究 LayoutTensor 切片行为:一位用户研究了
slice_1d的行为,注意到切片指针仅根据最后一个索引移动,这与对多轴切片的预期不符。- 该成员提供了示例代码,展示了切片在计算指针偏移时似乎只考虑最后一个轴,询问这是否是一个 Bug。
- Mojo 缺少 CUDA 的
__launch_bounds__等效项:一名正在将 CUDA 代码移植到 Mojo 的成员询问是否有类似于__launch_bounds__的编译器优化机制。- 一名版主建议在 Modular forum 上发布该问题,以获得更好的曝光度和后续跟进。
- Nightly 版本解决 256 位整数问题:一名成员在 Mojo 0.25.7 中使用 UInt256 时遇到问题,在翻译椭圆曲线加密库时报告了 128 位目标限制。
- 另一名成员建议尝试最新的 Nightly 构建版本,该版本已解决此问题,追溯到相关的 GitHub issue 和一个部分修复的 PR。
tinygrad (George Hotz) ▷ #general (9 messages🔥):
PR 审查时间, beautiful_mnist_torch 解决方案价值, tok/s, tinybox green v2
- PR 审查时间尺度:审查 PR 的时间与 PR 大小成正比,与 PR 的价值成反比。
- 一名成员表示赞同,简短地回复道 “fair, lol”。
- beautiful_mnist_torch 解决方案:针对 “beautiful_mnist_torch 使用 torch.compile TinyJIT 配合 TINY_BACKEND=1 工作,见 test_compile.py” 的解决方案价值受到了质疑。
- 一名成员猜测它很可能是 “勉强通过测试的 AI 废话(slop)”,而不是 “一个能让 tinygrad 更接近真理(Truth)的优美且超易读的 PR”。
- Tok/s 发现:一名成员报告发现 “到处都是一些 tok/s” 并附上了一张 图片。
- tinybox Green v2 发货:一名成员宣布他们的 “tinybox green v2 已发货”。
- 他们指出这涉及 “巨大的前期成本”,并将其描述为 “以后再考虑的问题”。
aider (Paul Gauthier) ▷ #general (3 messages):
Aider 开发状态, Aider 的模型兼容性问题
- Aider 开发停滞:一名成员询问 aider 的开发状态,注意到近期没有发布新版本。
- 另一名成员回答说开发目前已经停止,也许是永久性的。
- Qwen-2.5 模型问题频发:一位用户报告说,在 aider 中使用
openrouter/qwen/qwen-2.5-coder-32b-instruct模型时,在 Search/Replace(搜索/替换)操作期间始终失败。- 错误消息表明块必须是精确的,这暗示与
openrouter/deepseek/deepseek-v3.2相比,该特定模型存在潜在的 不兼容问题。
- 错误消息表明块必须是精确的,这暗示与
aider (Paul Gauthier) ▷ #questions-and-tips (3 messages):
/architect用法,模型配对收益
- 使用同一个模型时 /architect 是否有益?:一位用户询问,当推理/规划和编辑文件使用同一个模型时,使用
/architect是否有好处,并质疑这是否能降低错误的 edit/diff 格式化几率。- 他们最初认为缺点是代码相关输出的 token 消耗翻倍,但随后在文档中发现,在 Architect/Editor 配置中将模型与自身配对可以产生显著收益,其中 Sonnet、GPT-4o 和 GPT-4o-mini 在作为 Architect/Editor 对使用时得分更高。
- Architect 本质上就是 ask + code:一位成员澄清说,
/architect本质上是将/ask和/code会话合并为单个操作。- 这意味着使用
/architect是一种更精简的方式,可以实现与手动运行/ask后接/code相同的结果。
- 这意味着使用