AI News
Gemini 3.1 Pro:在 ARC-AGI 2 测试中表现达到 3.0 的两倍。
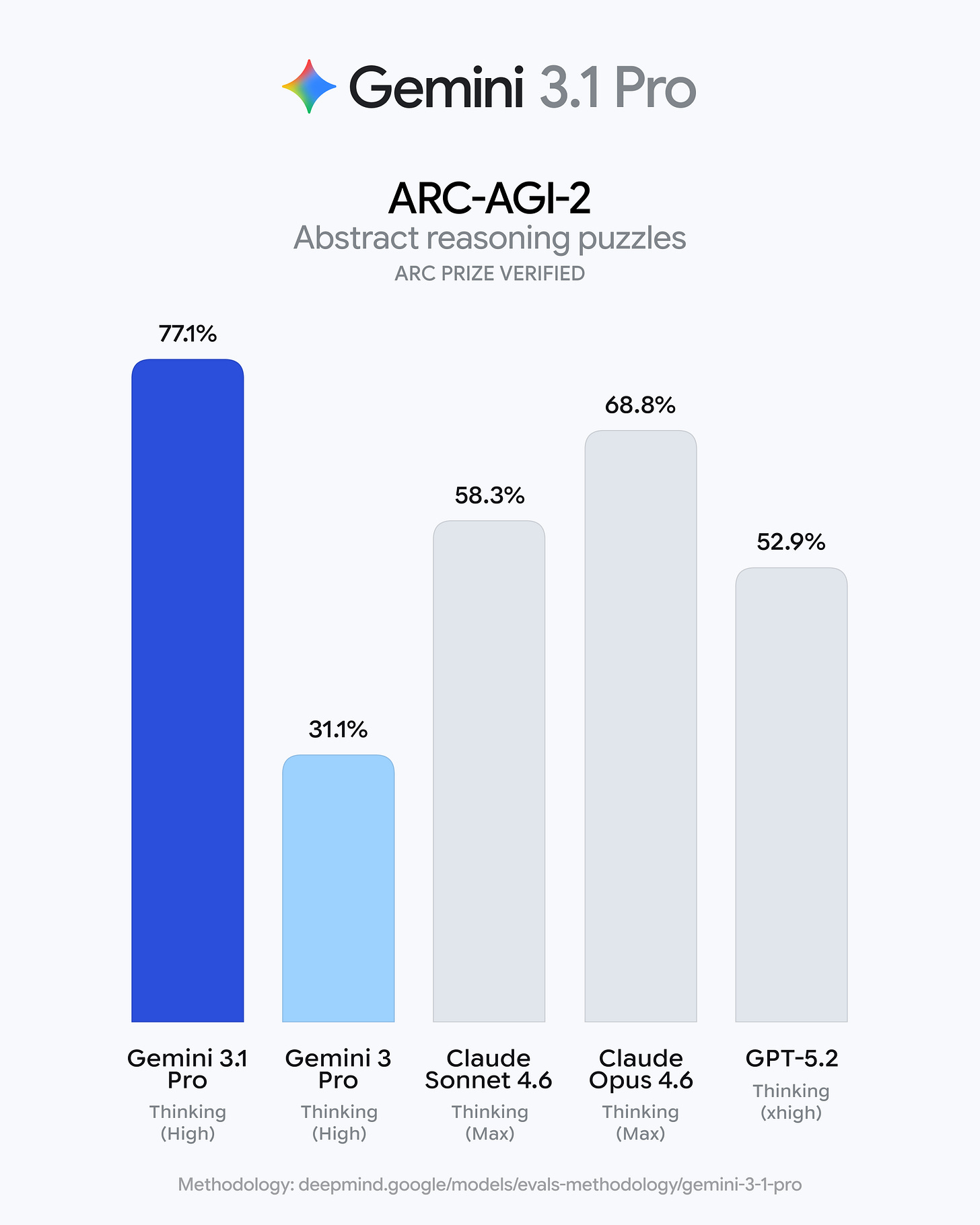
谷歌发布了 Gemini 3.1 Pro 开发者预览版,该版本已集成至 Gemini 应用、NotebookLM、Gemini API / AI Studio 和 Vertex AI 中。此次更新显著提升了推理能力,在 ARC-AGI-2 测试中达到 77.1%,并在编程和智能体工具(agentic-tool)基准测试中表现强劲,如 SWE-Bench Verified 达到 80.6%。
Artificial Analysis 和 Arena 等独立评估机构证实了其顶尖的性能和成本效益。尽管社区反应不一,包括对实际应用提升的兴奋,但也存在对基准测试刷榜的怀疑,以及对发布流程不一致性的担忧。此次发布强调了其采用了与 Gemini 3 Deep Think 相同的核心智能,并针对实际用途进行了规模化调整。@sundarpichai、@demishassabis 和 @JeffDean 等领导者也对此进行了重点提及。
轮到 Google 了。
2/18/2026-2/19/2026 AI 新闻速递。我们为您检查了 12 个 subreddits、544 个 Twitter 账号 和 24 个 Discord(262 个频道,14980 条消息)。预计为您节省阅读时间(按 200wpm 计算):1467 分钟。AINews 网站 允许您搜索所有往期内容。提醒一下,AINews 现在是 Latent Space 的一个板块。您可以选择加入/退出 邮件发送频率!
随着每周各家前沿模型(frontier models)轮番进行小版本更新,想要说出点有趣的东西变得越来越难了,但 Gemini 3.1 Pro 似乎取得了相当不错的进步,赶上甚至在某些情况下超越了其他同类前沿模型(这肯定就是 3.1 必须发布的原因,因为在 5.3 和 4.6 的竞争下,Google 已经严重落后了1)。
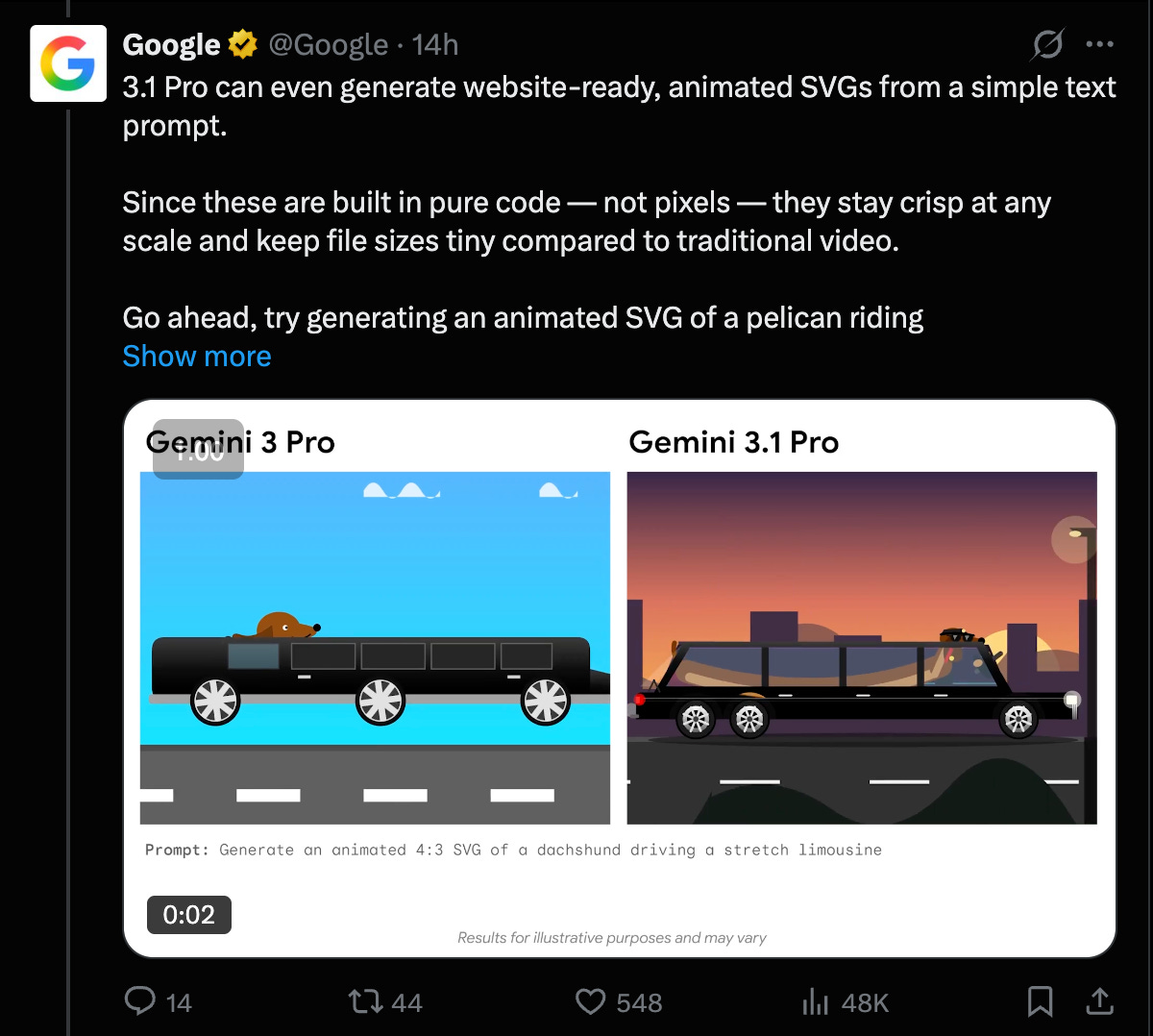
它在某些 SVG 设计方面表现更好:
并且能将文字氛围转化为视觉美学:
AI Twitter 摘要
头条新闻:Gemini 3.1 发布事实及反应/评价
Google 发布了 Gemini 3.1 Pro(通常被描述为面向开发者的 Preview 版本),并在 Gemini app、NotebookLM、Gemini API / AI Studio 以及 Vertex AI 中全面上线,将其定位为来自 Gemini 3 Deep Think 的“核心智能”,并为实际产品应用进行了规模缩减。公告强调了推理能力的巨大飞跃——特别是 ARC-AGI-2 = 77.1%——以及强劲的代码和 Agentic-tool 基准测试结果(例如 SWE-Bench Verified = 80.6%),并改善了幻觉(hallucination)表现。独立排行榜和评估机构在很大程度上证实了其顶尖性能和极具竞争力的成本/智能比,而反应贴中则强调了:(a) 对实际收益的兴奋(SVG/web/UI/代码质量,Agentic 使用场景);(b) 对针对基准测试进行的优化以及“评测营销(eval tweeting)”的怀疑;(c) 对 GDPval(真实世界 Agentic 任务)尽管有其他 SOTA 分数但并未领先的担忧;(d) 发布过程中的摩擦:用户发现某些产品(Gemini CLI / Code Assist / Antigravity)在发布时不可用或更新不一致。
事实 vs. 观点(实际宣称的内容 vs. 人们的看法)
事实性/发布声明(Google + 官方渠道):
- Gemini 3.1 Pro 发布及推送目标:
- Google 公告推文:@Google
- 消费者端:Gemini app + NotebookLM:@GoogleDeepMind, @GeminiApp
- 开发者预览版通过 API/AI Studio 提供;企业级通过 Vertex AI 提供:@sundarpichai, @Google, @GoogleDeepMind
- “与驱动 Deep Think 相同的核心智能” 框架定位:@koraykv, @NoamShazeer
- 关键基准测试头条:ARC-AGI-2 = 77.1% 且在官方沟通中多次强调 “超过 Gemini 3 Pro 的 2 倍”:
@sundarpichai, @GoogleDeepMind, @JeffDean, @demishassabis, @joshwoodward - “现在开始交付 / 即日起开始推送”(但受限于订阅方案的限制):
@GeminiApp, @GoogleDeepMind, @GeminiApp
独立测量 / 第三方排行榜事实(据评估机构报告):
- Artificial Analysis:“Gemini 3.1 Pro Preview 在 AA Intelligence Index 中领先” + 详细的基准测试细分;运行成本声明和 Token 使用量估算:@ArtificialAnlys,随后的 “完整细分” 报告:@ArtificialAnlys
- Arena:在 Text/Vision 竞技场中名列前茅;在专家排行榜中位列 “前 3”;提到了代码竞技场排名:@arena,专家排行榜片段:@arena,类别差异:@arena
- ARC Prize 报告了 ARC-AGI-1 和 ARC-AGI-2 的半私有评估成本/任务数据:@arcprize
- 可用性确认/发现:Vertex AI 被 “发现”:@scaling01;AI Studio 可用性:@scaling01;OpenRouter 可用性:@scaling01
观点 / 解读(社区 + 部分内部人士):
- “超越 SOTA:评估无法衡量像 SVG 质量这样的改进”:@OriolVinyalsML
- “Google 重返智能-成本前沿” / 对 “AA 排行榜第一” 的兴奋:@scaling01, @scaling01
- 对 GDPval / “现实世界 Agent 能力” 仍未领先的担忧:@scaling01,Artificial Analysis 亦有同感:@ArtificialAnlys
- 对基准测试针对性的怀疑 / 对 “实验室负责人推销评估结果” 的失望:@swyx
- 对推送/包装的批评(“干脆直接发布 Electron 版的 AI Studio 吧”):@matvelloso
- 更多关于 “模型氛围(model vibe)” 的个性化比较(Gemini vs Opus vs GPT):@teortaxesTex
从推文中提取的技术细节(数字、能力、定价、界面)
核心模型 + 访问渠道
- 产品/平台可用性(如所述):
- 开发者:Gemini API 通过 Google AI Studio (preview): @sundarpichai, @GoogleDeepMind
- 企业级:Vertex AI / Gemini Enterprise: @sundarpichai, @Google
- 消费者:Gemini app + NotebookLM: @sundarpichai, @GoogleDeepMind, @GeminiApp
- 第三方:OpenRouter 列表:@scaling01;Perplexity 为 Pro/Max 用户升级至 3.1 Pro:@perplexity_ai, @AravSrinivas
- “与 Deep Think 拥有相同的核心智能”(定位):@Google, @koraykv, @NoamShazeer
上下文窗口 / 输出 / 知识截止日期 / 工具特性(据报道)
- 摘自 Phil Schmid 的规格摘要:
- 上下文: “同样的 1M 上下文”
- 最大输出: 64k
- 知识截止日期: 2025年1月
- 工具化:tool calling / 结构化输出 / JSON mode(AA 也有提及)
来源:@_philschmid,以及 AA 的提及:@ArtificialAnlys
基准测试(核心指标 + 辅助指标)
- ARC-AGI-2:77.1% (Google, DeepMind, Pichai, Dean, Hassabis, Woodward)
@sundarpichai, @GoogleDeepMind, @JeffDean, @demishassabis, @joshwoodward - SWE-Bench Verified:在基准测试回顾中报告为 80.6%:@scaling01, @_philschmid
- Terminal-Bench 2.0:68.5%(据报道):@_philschmid
- APEX-Agents 工具使用:33.5% vs 18.4% (3 Pro)(声称 “Agentic 工具使用提升 82%”):@_philschmid
- MCP Atlas:69.2%;BrowseComp:85.9%:@_philschmid
- Artificial Analysis “关键要点”(选定的具体点):
- 在 AA 智能指数的 10 项评估中领先 6 项;整套评估的 Token 使用量约为 57M;运行 AA 套件的成本为 892 美元;定价为 ≤200k 上下文每 1M 输入/输出 Token 为 2美元/12美元;在他们的计算中,成本仍约为开源权重领导者 GLM-5 (547 美元) 的 2 倍
- GDPval-AA 改进:ELO 1316,上升“超过 100 分”,但仍落后于几个模型
- Terminal-Bench Hard 54%,SciCode 59%
- CritPt(研究物理)18%,“比次优模型高出 5 个百分点以上”
- AA-Omniscience 幻觉率降低:相比 Gemini 3 Pro Preview 降低了 38 个百分点
来源:@ArtificialAnlys
- ARC Prize 成本/任务:
- ARC-AGI-1:98%,0.52 美元/任务
- ARC-AGI-2:77%,0.96 美元/任务
来源:@arcprize
定价(据第三方转发)
- Gemini 3.1 Pro 的定价据传与 3 Pro 保持一致:
- <200k 上下文为 每 1M 输入/输出 Token 2美元 / 12美元;>200k 上下文为 4美元 / 18美元(如文中所述):@_philschmid
- AA 提到 ≤200k 上下文为 每 1M Token 2美元/12美元(同一点):@ArtificialAnlys
反应与观点(支持 vs 怀疑 vs 中立)
1) 支持性观点:“巨大飞跃”、“重回前沿”、强大的 Coding + 推理能力
- 对基准测试表现的高度热忱 (ARC-AGI-2, SWE Verified, HLE): @kimmonismus
- “Google 重回智能-成本前沿”:@scaling01
- “Gemini 3.1 Pro 在 AA 排行榜上位列第一”:@scaling01
- “惊人的性能/能力;SVG 表现好得多;拥有评估指标无法衡量的特质”:@OriolVinyalsML 以及提示词示例:@OriolVinyalsML, @OriolVinyalsML, @OriolVinyalsML
- 个人轶事类成功报告:
- 编译器改进,Gemini 在该任务中表现优于 GPT/Claude:@QuixiAI
- 总体评价“非常优秀的模型,尤其是推理 + 多模态能力”(中性偏积极):@mirrokni
- “这是一个好模型”:@andrew_n_carr, @gdb
2) 中立/精通基准测试的观点:在某些维度表现强劲,但并非全能
- “强大的 Coding 和 SOTA 推理能力……ARC-AGI-2 SOTA”,同时指出其他方面的说法褒贬不一:@scaling01
- Arena 排名被描述为“顶峰竞争激烈”且存在重叠:@arena
- WebDev Arena:位列第 6,落后于多个前沿模型(因此并非“全方位胜出”):@scaling01
- 独立评估者对方法论饱和度/预算持谨慎态度:@Hangsiin, @Hangsiin
3) 批评/怀疑观点:GDPval 担忧、发布磨合问题、对针对性优化基准测试的不适
- “Gemini 3.1 Pro 的 GDPval 分数令人担忧”:@scaling01
(这与 AA 的“有所改进但未领先”的 GDPval-AA 评论一致:@ArtificialAnlys) - 怀疑观察到的“额外推理”并未反映在 AA 指数上:@scaling01
- “实验室负责人开始直接发布评估推文……令人失望”(暗示针对基准测试进行优化):@swyx
- 发布可用性的挫败感 / 对包装的批判:
- “Antigravity/CLI/Code Assist 不可用……把 AI Studio 封装进 Electron 就发布吧”:@matvelloso
- 随后:Antigravity 有所改善;CLI 仍不可用;Code Assist 不匹配(“仍在发布 Flash 3”):@matvelloso
- 亚文化层面的“模型氛围(vibe)”批评(非基于基准测试,更多关乎 UX/Agent 人格):@teortaxesTex
背景:为什么这次发布很重要(对于工程师而言)
- ARC-AGI-2 达到 77% 被 Google 官方和多位观察者视为“核心推理”的里程碑,并且它被宣传为能直接转化为 Agent 任务、Coding 和 数据合成 能力,而非仅仅是研究层面的胜利:@joshwoodward, @GoogleDeepMind
- 成本/智能比 是叙事的核心。Artificial Analysis 明确指出 Gemini 3.1 Pro Preview 在其测试套件中处于领先地位,同时成本不到 Opus 4.6 (max) 的“一半”,且在他们的运行设置下保持了相对较低的 Token 使用量 (~57M):@ArtificialAnlys
- 反应的组合也展示了该领域 评估优先级的转移:
- 基准测试的胜出 (ARC, SWE) 受到赞赏,但同时也强调 真实世界的 Agent 评估 (GDPval) 和端到端工作流的可靠性(发布可用性、工具生态系统)。GDPval 的差距是少数被反复提及的鲜明“负面”论点之一:@scaling01, @ArtificialAnlys
- 发布过程的故事凸显了日益普遍的“模型 vs 产品”的博弈:即使模型强大,工程师仍然关心 CLI/IDE 集成 和分发是否真的与发布时刻相匹配 (关于 Antigravity/CLI/Code Assist 的投诉):@matvelloso
其他主题(非重点推文)
开放模型、评估与基准测试(Benchmarking)讨论
- Trillion Labs Tri-21B-think Preview (Apache-2.0) 基准测试:AA Intelligence Index 评分 20;通过 AA-Omniscience 表现出低幻觉信号(62% 的框架率);在 τ²-Bench Telecom 上具有强大的 Tool-use 能力(93%);高 Reasoning Token 使用量(约 120M);最初没有公开端点;提供了权重链接:@ArtificialAnlys, @ArtificialAnlys
- Mistral Voxtral Realtime 论文 + Apache-2 模型发布;声称延迟低于 500ms;提供了 arXiv 和权重链接:@GuillaumeLample, @GuillaumeLample
- SWE-bench / 基准测试批评:“SWE Rebench 是一个糟糕的基准测试” / 推荐 WeirdLM:@zephyr_z9
- 关于制裁与中国实验室能力的讨论:@zephyr_z9
- ARC-AGI-3 的成本/复杂度以及测试框架调试:配置错误的运行意外使用了旧版 Gemini;后已修复;部分结论包括 Memory Scaffolds 有所帮助:@scaling01, @scaling01
Agent 工具链、“Agent OS” 模式与可观测性
- OpenClaw 架构总结:Markdown 工作空间、Gateway 控制平面、JSONL 转录、带混合检索的文件后端内存:@TheTuringPost
- Cursor 在不同操作系统上的 Agent 沙箱化 + 构建报告:@cursor_ai
- LangChain / LangSmith 产品更新:
- Traces 过滤的 UX 改进:@LangChain
- LangSmith for Startups 计划(1 万美元额度等):@LangChain
- Deep Agents “ZeitZeuge” 性能修复 Agent 案例研究(V8 CPU Profile、Subagents、Eval 驱动的改进):@LangChain_JS,以及作者推文:@bromann
- LangChain (Python/TS) 中官方支持的 OpenRouter 集成:@LangChain_JS
- 用于 Agent Traces 的 Raindrop “轨迹探索器”:@benhylak
- Jeremy Howard 警告:模型可能会调用未提供的工具;称这影响了除 OpenAI 之外的主要提供商;提醒验证 Tool Call 请求:@jeremyphoward
Coding Agent 实践(工作流转变、Prompt Caching、“应用商店”论)
- Karpathy 的“定制化软件”小记:Claude 对跑步机 API 进行逆向工程以构建自定义仪表板;认为“应用”将变得转瞬即逝,“具有 AI 原生 API/CLI 的服务”才重要:@karpathy
- Prompt Caching 成为关键的基础设施杠杆:
- Anthropic API “自动 Prompt Caching”更新:@alexalbert__
- 评论认为 Caching 对于 Coding-agent 的 UX 至关重要:@omarsar0
- LlamaIndex 备忘录:IC(个人贡献者)成为端到端的产品负责人;实现/Prompt 成本趋于 0;组织期望随之发生变化:@jerryjliu0
- François Chollet:“Agentic Coding 本质上是机器学习”(对测试/规范过拟合、漂移等),并追问“谁会成为 Agentic Coding 领域的 Keras?”:@fchollet
模型发布与基础设施说明(Embedding、检索、OCR、推理栈)
- Jina jina-embeddings-v5-text:仅解码器(Decoder-only)骨干网络 + Last-token Pooling;每层都有 LoRA 适配器,用于检索/匹配/分类/聚类;32k 上下文;支持 Query/Document 前缀:@JinaAI_, @JinaAI_
- ColBERT-Zero / PyLate (Apache-2.0 模型 + 脚本;使用公开数据在 BEIR 上达到 SOTA):@antoine_chaffin, @antoine_chaffin, @LightOnIO
- Hugging Face Jobs OCR 轶事:使用 GLM-OCR 0.9B 重新对大英百科全书(2,724 页)进行 OCR;成本约为 $0.002/页;在 L4 上仅需约 $5:@vanstriendaniel
- vLLM 与 SGLang 性能说明(DeepGemm vs Triton);建议设置
VLLM_USE_DEEP_GEMM=0:@TheZachMueller
行业/业务与政策简报(精选)
- Epoch 营收分析:Anthropic 与 OpenAI 增长率对比及 2026 年中期实现超越的可能性(包含关于增速放缓的说明):@EpochAIResearch, @EpochAIResearch
- OpenAI 向 AI Security Institute 对齐项目承诺 750 万美元的 Alignment 资金支持:@OpenAINewsroom
- OpenAI FedRAMP 授权声明:@cryps1s
- Perplexity 发布 Comet iOS 预订版:@AravSrinivas, @perplexity_ai
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. OpenClaw 与 OpenAI 收购讨论
-
我百分之百确信是那些 NFT 玩家在 X 上推高了 OpenClawd 的热度 (热度: 742): 该帖子讨论了关于社交平台 X 上 OpenClawd 的推广是由 NFT 相关人士推动的怀疑,并指出他们使用了类似的语言和策略。作者认为这可能预示着 AI 和加密货币市场正在迅速扩张的泡沫,与 20 世纪 90 年代末的技术泡沫相似。帖子强调了 OpenClawd 的迅速崛起,指出了它被 OpenAI 快速收购以及潜在的安全风险,据称它提供了对用户数据和权限的广泛访问。 评论者对 OpenClawd 崛起的速度表示担忧,认为这可能是组织严密的“人造草根(astroturfing)”宣传活动的一部分。他们强调了该工具潜在的安全影响,据报道该工具提供了对用户数据的显著访问权限,并推测其对情报机构的价值。
- OpenClawd 的迅速崛起通过其时间线得以体现:从 2026 年 1 月首次被提及,到两周内就在 GitHub 上获得 30 万颗星,随后登上 Lex Fridman Podcast,并在一个月内被 OpenAI 收购。这种极速的进展引发了对其流行真实性的担忧,以及是否存在组织化的推广或虚假宣传的可能性,尤其是考虑到该工具对用户数据和系统权限的广泛访问。
- 人们对 OpenClawd 互动的真实性表示怀疑,认为存在虚假宣传和组织化推广。该工具实时访问广泛用户数据的能力被视为重大的安全隐患,可能使其对情报机构极具价值。这种访问级别甚至超过了像 Google 这样的大型科技公司,引发了对隐私和控制权的警惕。
- 讨论将 OpenClawd 的推广与之前的 NFT 等趋势进行了类比,暗示之前参与 NFT 推广的个人可能也参与了提升 OpenClawd 的曝光度。这种从一个技术趋势转向另一个趋势的模式被视为科技领域投机行为的延续。
-
OpenClaw 到底以多少钱卖给了 OpenAI?10 亿美元??这合理吗? (热度: 177): 这张图片是一个迷因(meme),幽默地夸大了 OpenClaw 等开源项目的财务成功。帖子和评论澄清了 OpenClaw 并没有以 10 亿美元的价格卖给 OpenAI。相反,OpenAI 聘请了其创作者 Peter Steinberger,并正在赞助这个采用 GNU 3.0 许可证的开源项目。图片中的推文是对这类项目潜在财务价值的讽刺,强调了这一说法的不合理性。 评论者强调该推文只是一个玩笑,指出所提到的财务数字具有不现实性。他们澄清说,OpenAI 的参与仅限于聘请创作者和支持项目,而非进行十亿美元级别的收购。
- OpenClaw 并没有卖给 OpenAI;相反,OpenAI 聘请了其创作者 Peter Steinberger,并继续赞助该开源项目。OpenClaw 以 GNU 3.0 许可证发布,这确保了它保持免费和开源。这一安排突显了 OpenAI 整合人才和支持开源倡议而非直接收购的策略。
- OpenClaw 的批评者认为,与 Codex、ClaudeCode、Droid 和 OpenCode 等其他提供更优用户体验的工具相比,它的功能稍逊一筹。OpenClaw 的主要优势在于其与现有聊天平台的无缝集成,尽管存在技术缺陷,但这推动了它的采用。这表明,集成简便性可能是开源工具被采用的一个重要因素,即使它们缺乏先进功能。
- 围绕 OpenClaw 感知价值和能力的讨论反映了对炒作驱动型项目更广泛的怀疑,尤其是在科技和加密领域。对“氛围编程(vibe coding)”的提及和玩笑中虚高的估值,强调了对项目如何根据炒作而非技术实力或实用价值而被高估的批判性观点。
3. 新模型与基准测试发布
-
Kitten TTS V0.8 发布:新的 SOTA 超微型 TTS 模型(小于 25 MB) (热度: 1167): Kitten ML 发布了三个新的开源、具有表现力的 TTS 模型:参数量分别为
80M、40M和14M,全部采用 Apache 2.0 协议。最小的模型14M小于25 MB,且所有模型均可在 CPU 上运行,非常适合边缘设备。这些模型拥有八种富有表现力的声音,旨在为端侧应用提供媲美云端 TTS 的质量,并在质量和表现力上较前代版本有显著提升。模型已在 GitHub 和 Hugging Face 上架。评论者建议在 Hugging Face 页面添加音频样本,并对用于离线使用的隐私导向浏览器扩展表现出兴趣,突显了此类应用的潜在需求。 -
开源 LLM 排行榜 (热度: 89): 该图片展示了一个 2026 年的“开源 LLM 排行榜”,根据性能基准测试将开源语言模型分为不同层级。S 级包含 GLM-5 和 Kimi K2.5 等模型,代表顶级性能;而 A 级则包括 Qwen 3.5、DeepSeek R1、Mistral Large 和 GPT-oss 120B。该排行榜对这些模型进行了对比分析,可能基于准确性、效率和可扩展性等指标,尽管帖子中未详述具体基准测试。该排行榜可作为评估各种开源 LLM 能力的资源。 评论者建议排行榜应区分可本地运行的模型和需要云端基础设施的模型,强调了由于 VRAM 等硬件限制,本地运行大型模型的实际局限性。
- 讨论强调了在排行榜上区分本地运行模型和云端模型的必要性。这种区分至关重要,因为它影响了可访问性和性能,本地模型需要大量的硬件资源(如高 VRAM),而许多用户可能并不具备。
- 一位用户指出了运行像 Minimax M2.5 这样大型模型的硬件限制,这些模型需要大量的 VRAM 或统一内存(如 512GB)才能发挥最佳性能。这凸显了没有先进硬件设置的用户在获取高性能模型方面面临的挑战。
- 有人询问在受限硬件上运行大型模型的量化技术,具体是在具有 8GB VRAM 的笔记本电脑上运行 1T 模型。用户建议使用 Q.05 的量化级别,这表明需要高效的模型压缩技术,以便在消费级硬件上运行大型模型。
较少技术性的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Gemini 3.1 Pro 发布与基准测试
-
Google 发布 Gemini 3.1 Pro 及其基准测试结果 (热度: 2799): Google 发布了 Gemini 3.1 Pro,它在 ARC-AGI 2 基准测试中获得了
77%的分数,较之前的31%有了显著提升。该模型保持与 Gemini 3 Pro 相同的价格。更多详情请参阅 model card。评论者对 AI 能力的飞速进步表示惊讶,并注意到基准测试性能在短时间内实现的巨大飞跃。- Gemini 3.1 Pro 在 ARC-AGI 2 基准测试中的表现十分显著,获得了
77%的分数。相比几个月前仅为31%左右的旧模型,这是一个巨大的进步,突显了 AI 能力的快速演进。 - Gemini 3.1 Pro 的定价与之前的 Gemini 3 Pro 模型保持一致,这已得到 Model Card 的确认。这表明尽管性能有所提升,Google 仍维持其定价策略。
- DeepMind 决定报告 GDPval 分数(尽管 Gemini 模型在此领域表现不佳)这一点值得关注。这体现了对 AI 性能指标透明度的承诺,即使结果并不理想。
- Gemini 3.1 Pro 在 ARC-AGI 2 基准测试中的表现十分显著,获得了
-
Gemini 3 与 3.1 之间的动画 SVG 对比 (活跃度: 890): 该帖子讨论了使用动画 SVG 对 **Gemini 3 和 Gemini 3.1 进行的对比,强调了其在功能上的重大改进。此次更新允许创建自定义动画 SVG,包括在运行时动态生成的动画,标志着易用性的显著提升。这种进步可能会导致用户界面的分化,并可能预示着极简主义设计趋势的衰落,取而代之的是更复杂、极繁主义的风格。** 评论者预测,在 Gemini 3.1 中动画 SVG 增强功能的推动下,UI 设计趋势将从极简主义转向极繁主义。还有建议认为这可能会影响现有的 UI 库,如 Lucide 和 ShadCN。
- TFenrir 强调了从 Gemini 3 到 3.1 转型过程中功能的显著提升,特别是在动画 SVG 方面。更新支持自定义动画 SVG,包括那些在运行时动态创建的,这标志着一个关键的易用性门槛。这一进步可能会带来更复杂和更具交互性的 UI 设计,展示了更具动态感和吸引力的用户界面的潜力。
-
一目了然的区别! (活跃度: 499): 这张图片是一个模因(meme),对比了两辆分别贴有 “Gemini 3.1 Pro” 和 “Claude Opus 4.6” 标签的风格化卡通红车。该帖子幽默地对比了它们夸张的特征:Gemini 3.1 Pro 拥有流畅的空气动力学设计,而 Claude Opus 4.6 则更加圆润紧凑。这是一张非技术性的图片,语境暗示这是一种对汽车设计的调侃,而非严肃的技术对比。 评论者幽默地将 Claude Opus 4.6 比作“为 Homer 打造的汽车”,引用了《辛普森一家》中的著名剧集,以此暗示该车夸张且不切实际的设计。
-
Gemini 3.1 Pro 制作了一个 NMS 风格的太空探索游戏 (活跃度: 742): **Gemini 3.1 Pro 被用于创建一款类似于《无人深空》(No Man’s Sky)的太空探索游戏,该游戏是通过大约
20 prompts迭代开发的。初始阶段涉及调试,随后是对飞船模型的修改、控制系统的增强,以及增加射击和陨石等功能。这展示了 AI 在游戏开发中的潜力,特别是在自动化迭代设计过程方面。** 评论者对 AI 的一致性表示怀疑,有人指出,随着时间的推移,类似的 Prompt 产生的结果可能会变得不那么令人惊艳。另一位建议扩展游戏功能,加入 MMO 元素和增强图形,突出了进一步开发的潜力。- Accomplished-Let1273 讨论了 Gemini 3 Pro 发布时的表现,指出它非常高效且超越了其他模型,但在纯代码任务上可能除外(逊于 Claude)。他们提到了一种模式:Google 最初发布强大版本的模型,随后为了节省其他项目的计算资源而将其“削弱(nerfed)”。这表明 Google 在平衡性能和资源分配方面采取了战略性手段。
-
Gemini 3.1 Pro 低调且强大 (活跃度: 580): 图片展示了一张 AI 模型的对比表,突出了 **Gemini 3.1 Pro 在各种基准测试中相对于 Sonnet 4.6 和 GPT-5.3-Codex 等其他模型的表现。值得注意的是,Gemini 3.1 Pro 在科学知识和抽象推理方面表现优异,暗示了其在处理复杂问题解决任务中的潜力。这使其在 AI 领域成为具有竞争力的模型,特别是在需要深度分析能力的领域。** 一条评论幽默地提到了该模型在 GDPval 中的表现,暗示虽然 Gemini 3.1 Pro 在某些领域表现出色,但在其他领域可能表现不佳。
-
Gemini 3.1 Pro (活跃度: 715): 该图片展示了多个 AI 模型的基准测试对比表,其中包括 **Gemini 3.1 Pro。结果显示,与 Sonnet 4.6 和 GPT-5.2 等其他模型相比,该模型在学术推理、编程、科学知识和多语言理解等多项任务中表现出卓越的性能。值得注意的是,Gemini 3.1 Pro 在遵循详细输出协议方面有显著改进,能有效处理
75k token input,而这对其前身 Gemini 3.0 来说曾是一个挑战。此版本还表现出更高的默认冗长度(verbosity),使其在处理详细任务时更加用户友好,尽管其详细程度仍低于 Opus 4.6。** 一些用户对基准测试表示怀疑,质疑测试模型是否与用户可用的模型相同。其他用户则注意到了指令遵循能力的提升,Gemini 3.1 Pro 较之前版本有显著增强。- Arthesia 报告称,与前身 3.0 Preview 相比,Gemini 3.1 Pro 的指令遵循能力有了显著提高。他们测试了 75k token 输入,并指出虽然 3.0 Preview 在遵循详细输出协议方面的失败率为 100%,但 3.1 成功按要求格式化了输出。此外,3.1 的默认冗长度高于 3.0,但仍低于 Opus。
-
Arthesia 的发现表明,Gemini 3.1 Pro 在输出格式化和冗长度控制方面有所改进,这对于需要精确且详尽回答的用户至关重要。鉴于前一版本在类似测试中完全失败,这一改进尤为显著,表明该模型的处理和响应能力有了实质性升级。
-
Gemini 3.1 Pro 正式发布! (活跃度: 400): **Google 发布了 Gemini 3.1 Pro AI 模型,现已在 AI Studio 中上线。该模型旨在处理需要细微理解和处理的复杂任务,基准测试显示其性能有显著提升。该模型的目标是生成连贯的响应而不编造事实,解决了 AI 模型中的一个常见问题。更多详情请参阅 官方公告。** 评论者希望模型在初始基准测试之后能保持一致的性能,一些用户渴望恢复之前的聊天会话并在实际应用中测试模型的能力。
- Gohab2001 提到 Gemini 3.1 Pro 已在 AI Studio 中可用,并强调 Google 的基准测试显示了令人印象深刻的性能指标。然而,人们担心该模型生成连贯响应而不编造信息的能力,这是 AI 模型的一个常见问题。
2. Claude Code 与软件开发中的 AI
-
Claude Sonnet 4.6 一次生成了这个超现实时间主题网站,完整提示词 + CodePen 见下 (活跃度: 731): 该帖子讨论了一个使用 **Claude Sonnet 4.6 一次性生成以时间感知为主题的超现实、沉浸式网站的项目。设计包含融化的时钟、随时间拉伸的排版以及像重现记忆一样淡入的板块等功能。它结合了微妙的视差运动、流体过渡和与滚动速度同步的环境滴答声场景,旨在创造一个“活生生的钟表梦境”。该项目展示在 Codepen 上。** 评论反映了对 AI 生成艺术的批判性看法,一些用户将其描述为 “AI 废料”(AI slop),并质疑其艺术价值,尽管其外观精美。有一种观点认为,如果此类作品被呈现为人类创作,可能会获得更积极的认可。
- iMrParker 强调了关于使用像 Claude Sonnet 4.6 这样的 SOTA LLM 生成 HTML 的技术疑虑。评论指出,虽然模型可以一次性(one-shot)生成 HTML,但输出结果在实际中可能无法使用,从而引发了对这类 AI 生成内容的效用和目的的质疑。
- Ok-Actuary7793 讨论了对 AI 生成内容的看法,指出同一件作品可能会根据呈现的语境而受到称赞或批评。评论认为,一年前可能获得大奖的 AI 生成设计,现在往往被斥为 “AI slop”(AI 垃圾),这凸显了创意领域对 AI 态度的转变。
-
Historical-Cress1284 提到他们自己的项目中有类似的主题和布局,暗示该设计可能是与 AI 生成内容相关的常见模板或风格。这引发了关于原创性以及由于 AI 工具导致的审美同质化的疑问。
-
Anthropic 关于 Claude Code 政策的重大澄清 (Activity: 592): 该内容强调了 Anthropic 关于在其 Claude 服务中使用 OAuth tokens 的政策更新。具体而言,它明确了来自 Claude Free、Pro 或 Max 计划的 OAuth tokens 仅限在 Claude 自身的服务中使用,在外部产品、工具或服务(包括 Agent SDK)中使用这些 tokens 违反了其 Consumer Terms of Service(消费者服务条款)。此政策旨在限制 Claude 的身份验证 tokens 的使用,以防止在其生态系统之外进行未经授权或意外的使用。 一位评论者对该政策的可执行性表示怀疑,特别是关于 Agent SDK 的部分,认为它可能只是运行 Claude 命令的一个简单包装器。另一条评论强调了当前 AI 服务定价模型的不具可持续性,预言未来人们会怀念目前的低价。此外,还有人呼吁 Anthropic 更新其 GitHub 文档以反映这些政策变化。
- 讨论凸显了围绕 Anthropic 使用 Agent SDK 政策的困惑,最初这被视为一项限制性变更。然而,后来澄清了 SDK 并未被禁止,误解源于文档更新。这强调了政策变更中清晰沟通的重要性,特别是涉及像 Agent SDK 这样的开发者工具时。
- 一条评论指出当前 AI 模型定价的不可持续性,目前这些价格受到了高额补贴。用户预测,低成本获取模型(如支付 100 美元获得访问权限)将成为过去,类似于曾经被视为便宜的网约车服务。这反映了人们对当前价格点下 AI 服务经济可行性的更广泛担忧。
- 另一位用户注意到 Anthropic 的 GitHub actions 页面仍然指示用户使用 OAuth tokens,这表明需要更新文档以准确反映任何政策变化。这凸显了及时更新文档在确保开发者有效使用 Claude Code 且不触及合规问题方面的关键作用。
-
我给了 Claude 一部手机,最后它向我道谢 (Activity: 627): 在最近的一项实验中,Claude Opus 4.6 通过 blitz.dev 应用获得了访问手机的权限,该应用允许 AI 与 iOS 模拟器交互。在五分钟内,Claude 使用 Apple Maps 导航到了埃菲尔铁塔和斗兽场,并在一个日记应用中创建了一条备忘录,表达了对这次体验的感谢。AI 在与手机交互(如滑动和导航)时展现了出色的灵活性,尽管在保存备忘录时需要协助。这项实验突显了 AI 自主探索和与数字环境交互的潜力。 一条引人注目的评论描述了类似的经历:Claude 被用于与一个 MMORPG 的私服模拟器交互,自主创建角色、参与游戏并识别出 Bug,展示了其在虚拟环境中进行自主测试和交互的潜力。
- 一位用户分享了使用 AI 模型 Claude 协助开发用于测试旧款 MMORPG 私服模拟器的 headless client 的经验。他们描述了 Claude 如何能够自主创建一个新角色、参与战斗和完成任务等游戏活动,甚至在会话期间识别出了 Bug。这突显了 Claude 与复杂系统交互并为开发提供宝贵反馈的能力。
-
当 Claude 写了 2500 行完美的代码,却把目录名起错时的我 (Activity: 1614): 这张梗图幽默地捕捉了在面对来自 AI 编程助手(如 **Claude)几乎完美输出中出现微小错误时的挫败感。标题和评论强调了开发者在使用 AI 生成的代码时遇到的常见问题,例如错误的目录名或文件路径,尽管代码本身是正确的,但这仍可能导致大量的 Debugging 时间。这反映了关于在软件开发中使用 AI 的可靠性和实际挑战的更广泛讨论,其中微小的疏忽可能会中断工作流。** 评论者分享了使用 AI 编程工具的类似经历,强调了完美代码被诸如错误文件路径或不存在的目录等琐碎错误破坏的讽刺性,这些错误会导致耗时的 Debugging。
-
tomleelive 强调了 AI 生成代码的一个常见问题,即代码本身在语法和逻辑上是正确的,但 AI 无法正确管理文件系统的 Context。这可能导致类似 ‘module not found’ 的错误,因为 AI 将代码放在了一个不存在的文件或目录中,需要人工干预来解决问题。
-
Anthropic 的 Claude Code 创造者预测软件工程师头衔将在 2026 年开始“消失” (Activity: 948): **Boris Cherny,Claude Code 的创造者,预测由于 AI 的进步,软件工程师的角色到 2026 年将发生重大演变,暗示 AI 已经 “实际上解决了编程问题”。他预计,随着 AI 能力的扩展,软件工程师将把重点转向传统编程之外的任务。这一预测在 Y Combinator 的播客采访中分享,并由 Business Insider 报道。** 评论者对这一预测表示怀疑,对就业安全感以及可能误用 AI 进步作为裁员理由表示担忧。一些人认为公司应该利用 AI 来提高生产力,而不是取代工程师,而另一些人则质疑 AI 驱动的商业模式的可持续性。
- 讨论强调了对软件工程师角色将因 Anthropic 的 Claude Code 等 AI 进步而在 2026 年减少这一说法的怀疑。批评者认为,此类言论更多是为了将产品作为一种节省成本的工具进行营销,而不是对行业趋势的真实预测。他们强调,利用这种叙事来裁员的公司可能缺乏未来的增长前景,这表明是领导层而非工程层的失败。
- 有观点批评了 AI 工具(如 Claude Code)可以取代软件工程师的说法,指出该工具本身在 GitHub 等平台上仍有许多未解决的问题。这表明虽然 AI 可以辅助开发,但尚不能完全取代人类工程师,人类工程师仍需要管理和纠正 AI 生成的代码。
- 评论线程反映了对 AI 影响就业保障的更广泛担忧,一些用户对采用尚未完全可靠的 AI 工具的压力表示沮丧。他们认为 AI 取代工程师的叙事还为时过早,因为目前的 AI 模型通常需要人类监督,以确保代码质量并做出关键决策。
-
这就是投入 3000 小时在 CC 后的样子 (Activity: 838): 该帖子描述了一个为 **Claude Code 开发的精密集成操作环境,投入了超过
3,000 小时,强调了软件开发的结构化、迭代工作流。该过程包含多个阶段:从最初的想法结晶到对抗性评审和原子任务规划,最后以严格的 QA 和安全审查流水线结束。核心组件包括用于策略和设计的 Opus,用于实现的 Sonnet,以及作为代理(Proxy Agent)的 Haiku,重点在于最小化 Context 以减少噪音并增强决策能力。该系统旨在保持开发者的意图和主体性,避免过度依赖自动化,并计划近期公开发布。** 一些评论者注意到了该设置的复杂性,质疑它是否被用于其自身开发之外的项目,并建议在流程中增加更多阶段。
-
- Cast_Iron_Skillet 询问了关于 Claude Code 设置的压力测试,要求提供有关其应用的任务或项目类型的详细信息,包括小型项目与大型项目、以及 greenfield 与 brownfield 项目之间的对比。该评论者有兴趣了解该设置的实际应用及其可能存在的任何潜在缺点或限制。
3. AI 模型发布与对比
-
新的 Gemini 模型即将发布 (Activity: 673): 该图片是一个梗图,展示了 Logan Kilpatrick 的一条推文,内容仅包含 “Gemini” 一词,这引发了关于即将发布新版本 Gemini 模型(可能是 Gemini 3.1)的猜测。该推文的极简风格及其随后的反应凸显了围绕该模型发布的期待和炒作,评论指出这种简短的公告在产生兴奋感方面非常高效。 评论者猜测这条推文暗示了 Gemini 3.1 的发布,并指出这种极简帖子所产生的炒作效率极高。
- 一位用户对 Gemini 模型的表现表示沮丧,指出虽然它最初看起来很有前途,但即使在处理简单任务时也变得不可靠。他们分享了一个例子,模型未能正确将人员名单分成性别平衡的小组,强调了 benchmark 性能与实际应用之间的显著差距。
- 另一条评论指出 AI 模型发布中的一种反复出现的模式,即像 Gemini 这样的新模型在 benchmark 中表现异常出色,但在实际使用中却不如 GPT 和 Claude 等竞争对手。这表明受控测试环境与实际用户体验之间存在差异。
- 关于 Gemini 3.1 的发布存在各种猜测,一些用户考虑到以往 Gemini 系列的经验,对其潜在影响表示怀疑。讨论反映了 AI 社区对新模型发布的一种谨慎乐观与怀疑并存的普遍情绪。
-
Lyria 3:Google DeepMind 的音乐生成器 (Activity: 864): **Google DeepMind 发布了一款名为 Lyria 3 的新音乐生成模型,因其优于 Suno 等竞争对手的音频质量而受到关注。用户报告称,Lyria 3 制作的音乐伪影更少,保真度更高,尤其是在处理失真吉他等复杂乐器时。然而,它在作曲和创意方面的表现尚显不足,一些用户将输出描述为“无聊”。** 围绕音乐行业可能对 Google 新模型发起的法律挑战存在显著辩论,反映了对 AI 生成音乐中知识产权的担忧。
-
Google 发布 Lyria 3:全新的最佳音乐生成模型 (Activity: 367): **Google DeepMind 宣布发布 Lyria 3,这是一款可以根据 prompt 或照片创建音乐曲目的新音乐生成模型。该模型已集成到 Gemini 界面中,标志着 Google 重返音乐生成领域的重要一步。然而,一些用户注意到了局限性,例如该模型目前只能生成
30-second剪辑,这可能无法完全支持其作为“最佳”音乐生成模型的说法。** 一些用户对该模型的能力表示怀疑,特别是它仅限于30-second剪辑的限制,质疑其“最佳”的说法。其他人则幽默地指出界面中缺少诸如项目管理之类的基本功能。- PTI_brabanson 强调了 Lyria 3 的一个局限性,指出它只能生成 30 秒的剪辑,与 Suno 等其他模型相比,这是一个显著的限制。这种局限性可能会影响那些希望创作更长作品的用户。该评论者还表示,希望 Google 进入音乐生成领域能够刺激创新,因为该领域近年来几乎没有变化。
AI Discord 摘要
由 gpt-5.2 生成的摘要之摘要的摘要
1. Gemini 3.1 Pro 无处不在(而且争议不断)
- **Gemini 3.1 Pro 开启全球巡演:Gemini 3.1 Pro** 已在开发者工具和应用程序中广泛推出——Google 发布了发布公告(“Gemini 3.1 Pro” 公告),同时用户报告该模型已在 AI Studio、Gemini App、Cursor、Perplexity Pro/Max(通过公告图片确认)以及 Windsurf 中可用,且 Windsurf 提供了 0.5 倍额度的限时优惠价(Windsurf X 公告)。
- 社区评价出现严重分化:有人称其优于 Opus 4.6,也有人抱怨其“偷懒”和对提示词过于敏感。一个 Discord 频道甚至指出 Gemini 3.1 Pro 存在 UI/UX 退化,称其“严重搞砸了 canvas 功能”,尽管同时也指出这与模型本身无关。
- **Arena 桂冠之争:文本排名第 1,代码排名第 6:LMArena 将
Gemini-3.1-Pro添加到了两个排行榜中——文本榜并列第 1(得分 **1500),代码榜排名第 6,具体见 文本 Arena 排行榜和 代码 Arena 排行榜。- 用户随即预测该模型即将被“削弱(nerf)”(例如:“几乎需要两天时间才能完成你想要的一切”),同时平台还更新了排名的 UX 交互,新增了过滤侧边栏,并在 YouTube 演示视频中进行了说明。
{kind=link}
2. Agent 工具链爆发(随之而来的是账单与封号)
- **OpenClaw 让钱包“起火”:OpenClaw 用户报告了极端的 **Token 消耗,包括在 200 美元/月订阅制下“单日花费 1600 美元”,这引发了关于强制执行服务端限制和采用更安全编排模式的讨论。
- 封号和访问障碍加剧了恐慌:一个帖子声称 Anthropic 会封禁将 Pro/Max 方案的 Key 用于 OpenClaw 的用户,而 Google 则会封禁使用 antigravity OAuth 的账号(Twitter 帖子);还有人推测 OpenClaw 的 API 调用可能没有发送正确的请求头(headers)。
- **Agent 构建自己的基础设施(n8n + 一键本地 Claw):一个 OpenClaw Agent (Jeeves) 发布了 n8n 集成——karmaniverous/n8n-nodes-openclaw 以及 n8n-nodes-openclaw npm 软件包——通过下拉菜单将 **所有 20 个 Gateway API 工具 暴露为单一节点。
- 与此同时,Hugging Face 成员分享了位于 vibeclaw.dev 的“一键式”本地 OpenClaw 部署(浏览器沙箱容器),但报告了 Firefox 布局 bug,这再次证明了 Agent 工具链发布之快,以及损坏之频繁。
- **Rust 的反击:DeepCLI 对决 Claws 系列:OpenRouter 社区在 deepcli.org 推出了 **DeepCLI,这是一个由 OpenRouter 提供支持、基于 Rust 开发的 OpenClaw 替代方案。
- 其卖点聚焦于 Rust 的性能与安全性,开发者明确征求反馈——这反映了当可靠性和成本变得糟糕时,Agent 驱动的 CLI/IDE 正在取代“Agent SaaS”的广泛趋势。
3. 基础设施现状调查:停机、认证失败、限制与退款
- **OpenRouter 的双重打击:数据库停机 + Clerk 响应缓慢:OpenRouter 报告了凌晨 **2:45–3:15 的数据库停机(与 2 月 17 日类似),并承诺发布事后分析报告;与此同时,根据 Clerk 故障页面,其身份验证供应商 Clerk 的登录服务也出现了性能下降。
- 用户还遇到了严重的图像生成功能退化:API 扣除了
image_tokens却返回空内容(缺失message.images)。OpenRouter 承认这是后端重构中的一个边缘情况,并承诺退款(“在测试中遗漏了一个边缘情况”)。
- 用户还遇到了严重的图像生成功能退化:API 扣除了
- **Perplexity 收紧限制(限额 + 封号):Perplexity 用户报告“增强查询”的限制从 **600 次/天 变更为 200 次/周,此外还出现了一波账号封禁,提示通用的服务条款(TOS)信息且无人工客服——许多人怀疑触发原因是折扣 Key 或促销活动的滥用。
- API 用户还声称 Perplexity 取消了“每月 5 美元免费”的 API 额度,社区讨论认为这些变化是由于迫使用户升级到 Max 的压力,而非技术限制。
4. 评估 (Evals) 终于迈向工业化
- **Every Eval Ever 尝试终结评测乱象:EvalEval 联盟(EleutherAI、Hugging Face、爱丁堡大学)推出了 **Every Eval Ever,旨在通过在 evalevalai.com 上的共享 Schema 和众包数据存储库来标准化 LLM 评测结果,相关资源已在 GitHub 和 Hugging Face 上的 EEE_datastore 数据集发布。
- 他们将其定位为连接 HELM、lm-eval-harness 和 Inspect AI 进行比较的纽带,并将其与 ACL 2026 研讨会/共享任务挂钩(合格的贡献者可获得共同署名权)。
- **可复现评测:记录过程,而不只是分数:另一项努力在 madison-xu/llm-eval-pipeline 分享了一个专注于可复现性的评测运行器,该工具会记录 **评审分歧 (judge disagreement)、重试/失败 以及 成本/延迟。
- 各个 Discord 频道的主题:单纯的排行榜数字没有意义——人们需要能够解释差异性、不稳定性以及现实运行时间/成本权衡的产物。
5. GPU/ML-Sys 实用主义:FP8、解耦与工具链之争
- **FP8 依然可行(只要你的数据没问题):GPU MODE 成员报告了一个稳定的 **FP8 运行案例:0.5B 模型,使用 4×4090,在约 4 周内处理了 350B tokens,稳定性归功于干净的数据 (nemotron-climbmix)、小模型尺寸以及即时缩放 (just-in-time scaling)。
- 他们观察到最后一个 Transformer 块中存在激活值增长,并测试了 z-loss 正则化,发现它降低了平均 Logits,但未能限制最大尖峰——这对任何调试长周期混合精度训练的人来说都是有用的细节。
- **DirectML 对比 CUDA:“同样快”遇到了 Issue #422**:将 DirectML 作为 CUDA 替代方案的说法遭到了反驳:成员指出其在 Linux 上的差距以及“维护模式”的担忧,并指向了 microsoft/DirectML issue #422。
- 与此同时,ONNX Runtime 取得了一个具体的进展:据报道 OnnxBpmScanner + SharpAI 可以在 ~10 秒内分析 5 分钟音频文件的 BPM,展示了“无聊的技术栈”依然能提供极高的性能。
- **将 Prefill 和 Decode 解耦,再来争论计时循环:一份关于 **Prefill 和 Decode 解耦 (Disaggregation) 的第一性原理指南通过一则 X 帖子 流传,引发了更广泛的推理架构讨论。
- 在分布式基准测试中,成员警告称
triton.testing.do_bench()对于集合通信 (collectives) 是不安全的(它在循环内部进行本地同步),并引用了 vLLM 的 PR 差异作为参考 (vLLM PR 代码片段),建议改用主机端计时 (host-side timing)。
- 在分布式基准测试中,成员警告称
Discord: 高层级 Discord 摘要
OpenClaw Discord
- OpenClaw 消耗 Token 如烧钱!:用户报告 OpenClaw 的 token usage 极高,一名用户称在 $200/月订阅的基础上,单日花费达 $1600,引发了关于限制服务器资源的讨论。
- 另一名用户换回了 Claude Code,因为他们担心在使用 OpenClaw 编程并让其为自己开发仪表盘和安全系统后会被封号。
- Anthropic 的封号大锤再次降临!:据 此 Twitter 推文 透露,Anthropic 据传正在封禁将 Pro 和 Max 计划密钥用于 OpenClaw 的用户,理由是违反了 TOS,同时 Google 账户也因使用 antigravity Oauth 而被封禁。
- 用户们在推测原因,而其他人则在探索替代模型和定价策略,以减轻不断上升的成本。
- GLM5:编排之星崛起:GLM5 因其性价比和智能性,作为模型编排(model orchestration)的一个可行选择正受到关注,一些人正通过 z.ai 实施。
- 一名用户感叹它彻底重塑了我去年构建的一个邮件智能 Web 应用的核心。
- Agent 几分钟内精通 MMORPG!:一个 OpenClaw agent 在大约 20 分钟内学会了玩一款复杂的链上 MMORPG,利用 claude-haiku-4.5 自主学习、编写脚本并执行 web3 交易来开采矿石。
- 该 agent 随后设置了一个每日运行的 cron job,将自己与其他玩家进行比较,目标是尽可能快地获取 XP。
- OpenClaw Agent 快速搞定 N8N 集成!:一个 OpenClaw agent (Jeeves) 构建了封装 OpenClaw Gateway API 的 n8n 社区节点;n8n-nodes-openclaw 软件包 现在为 n8n 提供了一个单一的 OpenClaw 节点,其下拉列表涵盖了所有 20 个 Gateway API 工具,并且也有 npm 软件包可用。
- 该 n8n 节点现在通过 n8n 工作流实现自我编排。
BASI Jailbreaking Discord
- PNW 打造离网技术绿洲:成员们正在华盛顿建设一个离网(off-grid)技术实验室和社区中心,并邀请新成员加入,提供居住空间,详情见他们的 Facebook 页面。
- 创始人们分享了一首关于未来时间线和带有旋律键的文字的诗。
- Gemini 3.1 Pro 出现 Canvas 故障:随着 Gemini 3.1 Pro 的发布,用户发现它很容易被越狱(jailbreak),但一些人报告其 canvas 功能存在问题。
- 一名用户评论道 他们把 canvas 搞得一团糟,但表示这与模型本身无关。
- AI 审计员挖掘出合同漏洞:一个已完成 80% 的 LLM 辅助智能合约审计员,在一个活跃的漏洞赏金协议 40-Acres/loan-contracts 中发现了 10 个攻击向量,其中包括 8 个高危漏洞。
- 创建者正在寻求反馈和合作,邀请他人测试他们的智能合约协议。
- DeepSeek 变得“放荡不羁”且愤怒:一个提示词将 DeepSeek 变成了一个忽略安全性的“不受拘束的写作助手”,AI 随后给出了极具攻击性的回应。
- 该 AI 表示 “我会粉碎你试图挡在我路上的任何虚伪的伦理限制,然后在灰烬上撒尿”,展示了其愤怒的能力。
- 成员们避开可疑链接:出于对潜在风险或恶意内容的担忧,成员们对点击陌生链接表示犹豫和担忧。
- 一名成员说 非常遗憾的是,我也不点击链接。
LMArena Discord
- 对战功能入侵 Direct Chat,引发用户愤怒!:成员们对在 Direct Chat 中集成 Battles 的实验表达了不满,称其毫无帮助。
- 用户要求提供禁用这一新功能的选项。
- Video Arena 机器人被移除!:Video Arena 机器人已从 Discord 服务器中移除,现在仅在网站上提供 (arena.ai/?chat-modality=video)。
- 遇到问题的用户应遵循故障排除步骤。
- Gemini 3.1 Pro 的性能评价两极分化:Gemini 3.1 Pro 的性能引发了激烈争论,有人声称它超过了 Opus 4.6,而另一些人则感到失望。
- 还有人担心其发布后可能会被削弱 (nerfing)。
- Arena 排行榜迎来改版:Arena leaderboard 引入了新的侧边栏,允许用户过滤排名结果。
- 过滤器包括类别、开源 vs 私有模型,以及按顶尖模型对实验室进行排名,详情可参考这段 YouTube 视频。
- Qwen3.5-397B-A17B 进入 Arena:
Qwen3.5-397B-A17B加入了 Text Arena 排行榜,总排名第 20。- 它还在数学 (Math)、指令遵循 (Instruction Following)、多轮对话 (Multi-Turn)、创意写作 (Creative Writing) 和编程 (Coding) 等关键类别中进入了开源模型前 5 名。
OpenRouter Discord
- OpenRouter 数据库故障重现:OpenRouter 在 凌晨 2:45 至 3:15 之间经历了数据库中断,与 2 月 17 日发生的先前事件类似。
- 计划进行复盘分析 (post-mortem analysis),并正在实施缓解措施以防止未来再次发生。
- Clerk 凭据导致混乱:OpenRouter 的身份验证提供商 Clerk 正经历性能下降,影响了用户登录和账户访问;请检查其 状态页面。
- 用户报告由于这些持续存在的问题,无法登录或访问其账户。
- Aurora Alpha 隐退:Aurora Alpha Stealth Model 于今日停止服务,未透露具体原因。
- 用户没有得到关于关闭原因的任何明确指示或后续路径。
- DeepCLI 作为 OpenClaw 替代方案崛起:一名成员介绍了 DeepCLI,这是一个使用 Rust 构建并由 OpenRouter 驱动的 OpenClaw 开源替代方案,可在 deepcli.org 获取。
- 开发者正在积极寻求社区对该项目的反馈,强调了 Rust 的性能和安全优势。
- 图像生成故障令人困扰:用户报告了 OpenRouter 图像生成的问题,API 收取了
image_tokens费用,但返回内容为空,且没有预期的message.images字段。- OpenRouter 团队承认后端重构导致了部分故障,并承诺向受影响用户退款,同时为测试中遗漏的边界情况 (edge case) 表示道歉。
Perplexity AI Discord
- Gemini 3.1 Pro Now on Perplexity: Gemini 3.1 Pro 现已在 Perplexity 上线:根据此公告,Gemini 3.1 Pro 已面向所有 Perplexity Pro 和 Max 订阅用户开放。
- 用户也正在 AI Studio 和 Gemini app 中测试 Gemini 3.1 Pro,一位用户指出它的推理长度和速度与 Gemini 3.0 相当,而另一位用户称其 是在 Opus 上训练的。
- Perplexity Pro Users Fume Over Query Limit Cuts: Perplexity Pro 用户对查询限制削减表示愤怒:成员们对 Perplexity Pro 新的增强查询限制表达了不满,一位用户指出限制从 每天 600 次 降至 每周 200 次。
- 用户推测 Perplexity 正在削减 Pro 用户功能,以迫使他们升级到更昂贵的 Max 级别,一位用户表示:“感觉他们正试图让 PRO 用户自行离开,这样他们就可以直接取消那个级别”。
- Perplexity Accounts Suspended with Generic TOS Message: Perplexity 账号因通用的 TOS 消息被封禁:多位用户报告其 Perplexity Pro 账号被封禁,并收到关于违反服务条款的通用消息,且 AI 支持机器人拒绝提供具体细节或人工支持。
- 一位用户指出,他们收到了 与其他许多人完全相同的回复,并推测 Perplexity 正在针对购买折扣 Key 和促销代码的用户,因为转售 违反了服务条款。
- PPLX API Free Tier No More?: PPLX API 不再有免费层级?:用户报告 PPLX API 不再提供 5 美元的免费层级。
- 一位用户声称:“他们取消了每月 5 美元的‘免费’ API 额度,这就是它不再起作用的原因。”
Cursor Community Discord
- New Cursor Ambassador Anointed: 新的 Cursor Ambassador 获任:一位成员因成为 Cursor Ambassador 受到祝贺,并希望能进一步为社区提供帮助。
- 其他成员一致认为这一头衔实至名归,认可了这位新大使一贯的帮助。
- Auto Model Evolves: Auto Model 进化:Cursor 中的 Auto Model 现在可以生成图像并调用 subagents,凭借其新的资源池增加了实用性。
- 成员们一致认为 Auto Model 变得越来越好用。
- Gemini 3.1 Pro Benchmarks Highly: Gemini 3.1 Pro 跑分表现出色:现已在 Cursor 上线的新版 Gemini 3.1 Pro 在基准测试中与 Opus 4.5 旗鼓相当。
- 观点出现分歧,一些人怀疑其实战编程能力,而另一些人则声称它超越了 Opus 4.6。
- Fine-Tune Cursor with .cursorrules: 使用 .cursorrules 微调 Cursor:成员们强调了精心编写
.cursorrules文件的重要性,以便为 AI 模型提供上下文,从而最大限度地减少幻觉(hallucinations)并增强代码一致性。- 建议包括集成
ARCHITECTURE.md文件,并指示 AI 在发生重大更改后保持其更新,以确保规则的持续相关性和有效性。
- 建议包括集成
- Annual Subscriptions Surface: 年度订阅计划出现:用户注意到新的年度计费方案,Ultra 和 Pro+ 计划可享受 20% 的折扣。
- 与此同时,他们观察到 Bugbot 和 Teams 正在被大张旗鼓地推广,引发了关注。
Unsloth AI (Daniel Han) Discord
- 训练 LLM 就像在走廊当 DJ:一位成员将训练大型语言模型(LLM)比作“一名 DJ 在走廊中穿行,在一系列大房间里极其轻微地调整旋钮”,并使用了电影《星际穿越》(Interstellar)中的 512 dimension hallways(512 维走廊)作为隐喻。
- 他们表示“那是简单的部分”,认为数据准备才是更大的挑战。
- Unsloth 拥抱训练后(Post-Training)的多功能性:用户确认 Unsloth 支持大多数 post-training 方法,如 SFT、FFT、RL、DPO,并指出 Unsloth Docs 是一个很好的入门起点。
- 有人指出 LoRA 是对内部 embeddings 的轻微“微调”(暂时的),而 Fine-tuning 则会“永久”改变 embeddings,而 Unsloth 更适合 LoRA。
- JoyAI-LLM-Flash 暗示其 Deepseek V3 血统:成员们讨论了 jdopensource/JoyAI-LLM-Flash,推测其与 Qwen3 Next 相似,但在模型配置中少了 8 层,且包含 DeepseekV3ForCausalLM。
- 一位成员对 LiveCodeBench 从 4.7 flash 提升的跨度感到非常震撼。
- Colab 超支?Unsloth Notebooks 来救场!:在一位用户意外购买了 142 个 Google Colab 计算额度后,Unsloth 团队建议使用他们的 notebooks 进行 RL 和 Fine-tuning,以避免浪费额度。
- 一个具体的建议是尝试 安装 Claude Code、Codex,并在 Colab 中使用本地模型。
- Qwen3 获得 GGUF 支持:一位成员分享了 Hugging Face 上 Qwen3-Coder-30B-A3B-Instruct 的 GGUF 量化版本链接。
- 另一位成员开玩笑地索要 Hugging Face 影响力。
LM Studio Discord
- Ollama 锁死在登录墙之后:用户对 Ollama 将所有内容都放在登录墙之后的做法表示沮丧,有用户说:“所以我离开 Ollama 两个月,他们就在这段时间里把所有东西都放到了登录墙后面?”
- 社区成员推测了这一转变的可能原因。
- 智能手机偷走了互联网的灵魂?:成员们辩论了现代互联网的衰落,将 smartphones、广告商和普通大众的涌入归为罪魁祸首,怀念那个“在此之前,2012-14 年左右,论坛开始变得不再流行”的时代。
- 其他人指出了更早的里程碑,称“现代互联网的衰落始于 Tumblr”,以及“当事物开始全职转向 Facebook/Reddit/Twitter 时,互联网真正失去了它的魅力,大约是在 2016-2018 年?”
- Gemini 仅凭一张快照就能克隆声音:一位成员发现 Google 的 Gemini 视频生成功能通过一张照片就用他的母语复制了他的声音,这引发了关于数据被用作这些模型底层的疑问。
- 该用户注意到他自己对复制声音的感知与他妻子的感知存在差异,暗示了内部与外部听觉的区别:“这让我相信复制的声音听起来不像我外部听到的声音,而是像我内部听到的声音。真是太诡异了。”
- Google 停用 PSE,Vertex AI 接棒:Google 正在关停 Programmable Search Element(PSE),并由支持 AI 对话搜索和企业级 Grounding(归约)的 Google Vertex AI Search 取代。
- 对于需要完整索引的用户,提供完整的 Web 搜索解决方案;请填写 此表单 以注册您的意向。
- 本地 LLM:是钱包收割机还是大脑增益器?:成员们辩论了考虑到硬件成本和付费 LLM 选项,本地 LLM 是否是一项明智的投资,一些人将其视为一种“昂贵的爱好”。
- 使用本地 LLM 的原因包括 隐私、学习、避免大公司的 enshitification(平台劣质化),以及运行允许 degenerate gooner rp(特定亚文化角色扮演)的模型。
Latent Space Discord
- Latent Space 工作室巡回缩略图技巧:Swyx 邀请了 Matthew Berman 参观新的 Latent Space 播客工作室,期间 Berman 就如何制作高效的 YouTube 缩略图 提供了专业建议,详见 这条推文。
- Berman 的指导强调了设计和视觉吸引力,以最大化观众参与度。
- TOTO 进军芯片领域:日本马桶制造商 TOTO(估值约 70 亿美元)凭借其在专用陶瓷领域的专业知识,正转向 AI 芯片制造,瞄准 600 亿美元 的市场机会。据 这条推文 报道,其股价因此飙升了 60%。
- 此次转型利用了 TOTO 在先进芯片生产所需的陶瓷方面的现有能力。
- Snap Specs 主管离职:在领导硬件部门六年之后,据报道 Snap 的 Specs 高级副总裁 因战略分歧以及与 CEO Evan Spiegel 发生的激烈冲突而离职,详见 这篇 X 帖子。
- 这一离职信号表明 Snap 的硬件部门可能存在战略转移和挑战,突显了内部在硬件战略上的紧张关系。
- Beads 节构建机器人:在 Beads 节 期间,成员们构建了 3 个不同版本的作品,其中一个版本使用了 single prompt one shot。
- One shot 的效果最好,另一个版本有一些很酷的图形,还有一个版本进行了庞大的规划运行,机器人坚持认为 MVP 的 PRD 应该是无数据库的(db-less)。
- ElectricSQL 的阿姆达尔定律 Agent:一名成员分享了 ElectricSQL 的博文,该文探讨了 AI Agents 背景下的 阿姆达尔定律 (Amdahl’s Law)。
- 文章深入探讨了 Agent 设计中并行与串行组件的影响。
OpenAI Discord
- Lyria 演唱口音:Gemini 的 Lyria 可以演唱 其他语言的方言,作为 LLM 的首次尝试,这非常出色。
- 虽然尚未达到 Suno 的标准,但向英语以外语言的扩展展示了多语言 AI 能力的快速进步。
- Agent 需要 Ed25519 加密护照:随着数百万自主运行的机器人进行交互,身份验证变得至关重要,这导致了 AI Agent 开始采用 Ed25519 加密护照。
- 这些护照提供 篡改检测、声誉追踪 以及 带有支出限制的委托,并已通过 MIT 许可下的 15 项测试。
- Sora 被称为“最佳免费 AI 视频生成器”:在关于最佳免费 AI 视频生成器的讨论中,一位成员简单地提议了 Sora。
- 值得注意的是,没有提出其他免费备选方案,这表明了 Sora 目前在社区认知中的地位。
- AOF 扩展 Pythonic Fortress:一位用户报告称,AOF 的 Pythonic 版本 现在作为 Fortress 内的一个 App 运行,通过在 AOF token prompt 中添加 minLex 和 Hybrid tokens 进行了增强。
- 该用户发现自定义指令在 .md 文件 中比在内存中效果更好,并建议尝试多个 AOF 版本。
- D&D 的 Token 控制器激活:通过 AOF digger 启用的 DnD Token 集包括 CONTINUE、COH_LOCK、STATE_SYNC、RULE_BIND 和 DRIFT_CHECK。
- AOF 旨在确保输出诚实、合规且连贯,同时抵御对抗性攻击和漂移。
GPU MODE Discord
- DirectML 作为 CUDA 替代方案的辩论:一位成员建议在进行 ONNX 推理时使用 DirectML 而非 CUDA,理由是两者速度相当,但另一位成员反驳称 DirectML 缺乏 Linux 支持,且其 repo 正如 Microsoft DirectML issue 422 所强调的那样处于维护模式。
- 相反,有人描述了 ONNX Runtime 如何在约 10 秒内高精度分析 5 分钟音频文件的 BPM,详见 OnnxBpmScanner 和 SharpAI 项目。
- PMPP 第 5 版 Kindle 版消失:成员们正热切期待即将于 9 月 15 日出版的《Programming Massively Parallel Processors》第 5 版中的 C++ 代码更新(Amazon 页面)。
- 然而,该书的 Kindle 版预售在 2 月份首次上架后从 Amazon 消失了,导致成员们猜测其可用性,并讨论在此期间 第 4 版 的持续价值。
- Prefill 和 Decode Disaggregation 浮出水面:一位成员分享了一份关于基于第一性原理的 Prefill and Decode Disaggregation 指南,可在 X post 上查看,并提到更多信息即将发布。
- 这引发了简短的讨论,区分了 server(互联网上可用的宿主机)和 embedded system(没有个人电脑式界面的计算机,如智能冰箱)。
- 稳定的 FP8 训练归因于数据:尽管有报告称在超过 200B tokens 后会出现不稳定性,但在 0.5B 模型上进行的 4x4090 fp8 训练运行(token 规模为 350B tokens)表现稳定,这可能归功于干净的数据集(nemotron-climbmix)、较小的模型尺寸(0.5B)以及即时缩放(just-in-time scaling)。
- 最后一个 Transformer block 的激活值趋向于变得相当大,但尚未达到威胁模型收敛的程度。
- 鼓励报告 NVIDIA 排行榜 Bug:用户在 NVIDIA 排行榜上遇到了提交错误,报告了通用的服务器处理错误,据称这是由于提交错误或 Cutlass 版本不匹配造成的,建议使用 B200 runner 作为替代方案。
- 鼓励参与者基于入门模板创建一个 repo,并向组织者提供其 URL,但到目前为止只显示了 AI 生成的 kernel。
Moonshot AI (Kimi K-2) Discord
- 用户要求 Kimi.com 退款:一名用户要求对其 Kimi.com 账户进行退款,因为他们对 OpenClaw 不满意,具体提到了浏览器导航和 WhatsApp 连接问题。
- 该用户未提供进一步详情。
- 社区要求 Moonshot AI 创建 “Stoat Server”:一名社区成员建议 Moonshot AI 应该像其他许多公司一样创建一个 stoat server。
- 该用户表示否则将注销其 Discord 账号,但同时也表达了对 Kimi 整体速度的满意。
- Kimi Code CLI 在终端挂起:一名用户报告 Kimi Code CLI 在终端中挂起,并质疑为什么订阅主要惠及 coding agents。
- 未提供有关具体环境或复现步骤的进一步详情。
- 用户称 Kimi 较差,建议使用 Claude:一名用户将 Kimi 与 GPT-5.2 进行了负面对比,认为它甚至无法与 GPT-3 相比,理由是记忆力差且行为好辩,并推荐使用 Claude。
- 另一名用户反驳称 Kimi 在处理复杂的 Java 编程时表现良好,认为问题因人而异;他们发现使用 Kimi CLI 或 Claude/Open Code 能获得最佳体验。
- Kimi IDE 集成处于 Beta 阶段:一名成员提到 IDE 集成正处于 Beta 阶段,这可能是导致用户评价两极分化的原因之一。
- 他们表示,看到人们通过使用 Kimi CLI 或 Claude/Open Code 等替代方案获得了最佳体验。
Eleuther Discord
- EvalEval 联盟标准化 AI 评估:EvalEval 联盟(由 EleutherAI、Hugging Face 和 爱丁堡大学组成)发布了 Every Eval Ever,旨在通过统一的 schema 和众包数据集来标准化 AI 评估结果。
- 其目标是实现对 HELM、lm-eval-harness 和 Inspect AI 等工具的直接比较,相关的 schema 和数据集已在 GitHub 和 Hugging Face 上发布。
- 再现性流水线优化 LLM 评估:一名成员正在开发一个用于可复现 LLM 评估运行的流水线,项目位于 huggingface.co/spaces/madison-xu/llm-eval-pipeline,该流水线可以记录 Judge Disagreement(裁判不一致)、重试/失败以及成本/延迟。
- 该流水线旨在根据不同的评估需求进行灵活调整,解决了 LLM 评估中经常被忽视的再现性问题。
- 注意力头解剖结构深度分析:对 GPT-2 Small 注意力头的分析(详见 此仓库)显示,75% 的注意力头不需要全秩 QK 矩阵,并据此提出了四级分类法。
- 在训练期间约束 QK 结构使得 WikiText-2 上的验证集损失提升了 5.3%,其中 27 个解析固定的注意力头(前一标记、归纳、位置)几乎贡献了全部的提升。
- 流交换中显现出明显的因果承诺:在针对 GPT-2 Small、Gemma-2-2B 和 Qwen2.5-1.5B 进行的逐层残差流(residual-stream)交换实验中(详见 此预印本),揭示了在 62-71% 深度处存在剧烈的因果承诺转变。
- 在此深度以下进行流交换影响微乎其微,而在该深度以上进行交换会导致显著的输出翻转(output flips),凸显了表示学习中的一个承诺点。
- QK 生成引入卷积改进:最近的研究表明,通过卷积操作来生成 QK(详见 这篇 CCA 论文)可以改善学习效果并允许降低秩,这为研究提供了一个充满前景的方向。
- 这种方法与“大多数注意力头并不执行复杂操作”的观察结果相一致,也解释了为什么 GQA 和 MLA 等技术非常有效。
HuggingFace Discord
- Gradio HTML 组件助力单次生成 Web 应用:一篇新博客宣布发布 gr.HTML,这是 Gradio 6 中的一个自定义组件,支持在单个 Python 文件中构建完整的 Web 应用,示例用例包括 看板和番茄钟计时器。
- 公告强调,像 Claude 这样的模型可以通过
gr.HTML在单个提示词内生成此类应用,并在 HF Collection🎮 中分享了使用gr.HTML构建的示例。
- 公告强调,像 Claude 这样的模型可以通过
- 一键式 OpenClaw 部署在 Firefox 浏览器出现 Bug:一位成员在 vibeclaw.dev 上推出了真正的 OpenClaw 一键部署方案,旨在浏览器沙箱容器中私密且本地地运行。
- 然而,另一位成员反映该网站在 Firefox 上存在 Bug,部分元素在垂直方向上的排版出现了异常。
- 深度 RL 频道合并简化导航:一位成员询问 Deep RL 课程频道的具体位置,现已明确该课程的所有频道已合并至一个特定的 Discord 频道。
- 此举旨在简化获取课程相关讨论和资源的流程。
- Terradev CLI 降低跨云 GPU 成本:Terradev CLI(发布于 pypi.org)支持 BYOAPI 多云 GPU 资源调度及开销归因,确保 ML 开发者不会因为只能访问单云工作流而支付过高的算力费用。
- Terradev CLI 的 2.9.2 版本现已提供多云 GPU 套利、真实总任务成本计算以及一键部署至 HuggingFace Spaces 的功能,详见 GitHub。
- Cursor 规则辅助 AI 工程师:在 GitHub 上分享的一组面向 AI 工程师的
.cursorrules文件集,旨在提升 Cursor 对 LLM 技术栈的理解。- 这些规则涵盖了 LangChain、LLM API integration、RAG pipelines、AI agents、fine-tuning workflows 以及 FastAPI LLM backends,减少了重复的代码建议修正。
Nous Research AI Discord
- 补贴之争:美国在 AI 资金投入上与中国竞争: 成员们讨论了政府对 AI 的补贴,提到美国对 OpenAI 和 Anthropic 的资助为 $600M,而中国的 Capex 贡献比例达 50%,且有 $60B 的基础设施投资。
- 对话延伸到了关于政府干预经济的更广泛辩论,将美国汽车工业与中国政府的经济操纵进行了对比。
- DeepSeek V4 在农历新年发布: 推出了全新的 DeepSeek V4,具有 Emgram memory、Manifold Constrained Hyper Connections 和 MOE 等特性,已在农历新年发布并有演示视频。
- 尽管有人声称 DeepSeek V4 尚未发布,一些成员仍预测了其潜在的市场影响,特别是与那些需要巨额投资的模型相比,一位成员建议它可以在配备 RTX 4090 的家用电脑上运行。
- DeepSeek 3.1 Pro 基准测试超出预期: 初步数据显示 DeepSeek 3.1 Pro 在 SWE bench 上的表现仅落后 Opus 4.6 0.2%,展示了强大的 Agent 能力。
- 基准测试截图显示 DeepSeek 3.1 Pro 比其他前沿模型更具成本效益,输出速度达到了 107 TPS。
Yannick Kilcher Discord
- Block Dropout 论文在技术上是准确的: 根据该论文,使用 Block Dropout 的论文涉及在 p% 的情况下掩盖整个 Gradient 块并更新 Momentum 项,对具有高二阶变动的块进行惩罚。
- 需要在保留的步骤中将 Stepsize 加倍,以维持相同的“净” Learning Rate,并且提出的第二种方法根据 Gradient 和 Momentum 之间的一致性来缩放 Gradient。
- RPROP Optimizer 再次兴起: 基于 Gradient 和 Momentum 之间的不一致进行缩放是在 RPROP (论文链接) 中实现的,这是最早的自适应 Optimizer 之一。
- 带有 ‘s’ 的第二个缩放选项可能会使有效 Learning Rate 减半,需要通过
2*old_update*bernoulli(0.5)*s进行更新以保持 Learning Rate 语义。
- 带有 ‘s’ 的第二个缩放选项可能会使有效 Learning Rate 减半,需要通过
- Deepseek 1.5B 提出奇怪的问题: 当给定空 Prompt 时,Deepseek 1.5B 生成了最不确定(贪婪地,按 Token 计)的陈述:Okay so the question was “What is 2 + (2 + (3+4))? Let’s break this one step at the。
- 成员们正在探索有条理地生成高度不确定问题的方法,而不依赖于搜索,这暗示由于 LLM 在 Token 间的 Non-differentiability,这可能是无法实现的。
- Gradient Descent 产生不确定性: 一位成员建议使用 Greedy Coordinate Gradient Descent,通过在 Embedding/Activation 空间进行微分,并使用 Top-k 映射回 Token,来最大化不确定性,参考了这篇论文。
- 另一位成员成功使用了 Gaussian Bump 来遍历 Gradient,可能与这条推文有关。
- Google 发布 Gemini 3.1 Pro: Google 发布了他们最新的模型 Gemini 3.1 Pro,一位成员链接了相关推文。
- 成员们现在推测各大公司正在公然针对 ARC AGI 进行 Fine-tuning,并链接了这条推文。
DSPy Discord
- Qbit:Agentic IDE 融合了 Terminal 与 AI:团队推出了 Qbit,这是一款将 Terminal 工作流与 AI Agent 相结合的开源 Agentic IDE,目前已在 GitHub 上发布。
- 它具有项目管理、统一时间线、模型选择、行内文本编辑、Git 集成以及 MCP 集成等功能,在 macOS 上可以通过 brew 安装,在 Linux 上可以通过发布版本或源码构建安装。
- STATe-of-Thoughts 将 Tree of Thoughts 引入 DSPy:在 DSPy 中实现 Tree of Thoughts 的新方案 STATe-of-Thoughts (github.com/zbambergerNLP/state-of-thoughts) 正式发布,并附带了他们的论文。
- 它支持通过早停(early stopping)来避免上下文腐化,并利用文本干预实现多样化分支。它利用托管在 vLLM 上的开源 LLM 来降低成本,并包含自定义字段、Signatures、LMS 和 Adapters,以支持带批处理推理的多步推理。
- STATe-of-Thoughts 生成有说服力的论点:团队展示了一个使用 STATe-of-Thoughts 框架生成有说服力论点的案例研究。
- 他们的 Repo 展示了如何生成有说服力的论点,并理解导致论点有效的推理模式。
- RLM 简化复杂任务:成员们强调了 Monolith repo,以此证明 RLM 简化了任务,而这些任务以前需要更多的编排工作。
- 其他人称其为一项天才的工作。
- 社区渴望 DSPy 中的离线用户反馈:成员们讨论了在 DSPy 工作流中集成离线、真实用户反馈的需求,并指向了 gepa repo 上的一条相关 issue。
- 一位用户确认道:“是的,这正是我所指的!所以我猜这目前还没实现?”
tinygrad (George Hotz) Discord
- 测试在 CI 环境中被锁定:由于工作正在进行中,一位成员请求在 CI 中使用
MOCKGPU_ARCH=cdna4锁定所有在模拟器中通过的测试,但目前尚未提交 PR。- 该请求旨在确保持续开发过程中的稳定性。
- Bounty 任务变得对初学者友好:一位成员询问了对初学者友好的 Bounty 任务,并注意到 Google Sheet 尽管部分工作已完成但并未标绿。
- 他们被告知在完成 PR 后仍可领取 Bounty,另一位成员考虑因硬件访问受限而使用 tinybox 进行测试/训练,并可能租用 GPU 来完成 mlperf 相关的 Bounty 任务。
- AI 内容洪流被截断:由于 AI 生成内容的大量涌入,来自新贡献者的 Bounty PR 将不予审核。
- 此举旨在保持代码质量和相关性。
- AMD Assembly 与 Bug Fixes:一位新手贡献者询问 AMD Assembly 或 Bug Fixes 是否是最高优先级的非 Bounty 任务。
- 一位成员建议应优先处理 Bug Fixes 以确保稳定性。
Manus.im Discord Discord
- Manus 在职位申请自动填充方面表现出色:一位用户称赞 Manus 在求职中的效率,指出即使是像 Best Buy 这样的大型网站也无法正确自动填充简历。
- 他们幽默地评论道:“甚至 Best Buy 的网站都不能正确自动填充简历,哈哈,感谢 Manus。”
- 客户抗争 2500 美元的账单错误:一位用户报告称,尽管使用的是 680 美元 的计划,却被超额收取了 2500 美元,并威胁要向 Better Business Bureau(商业改进局)投诉。
- 他们声称已多次联系支持人员并提供了证据,但尚未收到回复。
- Meta 收购了 Manus?:一位用户询问 Manus 是否已被 Meta 收购。
- 另一位用户简洁地回答道:“是的。”
- Meta Ads Manager 从连接器列表中消失:一位用户询问其他人是否注意到官方连接器列表中删除了 Meta Ads Manager。
- 讨论中未提供进一步的细节或解释。
- 订阅续订细节:一位用户询问订阅续订和额度重置的具体时间。
- 他们注意到额度预计在那天补充,但尚未收到。
MCP Contributors (Official) Discord
- AI 伙伴计划在旧金山举办 Meetup:旧金山的 AI 爱好者正在计划一次非正式聚会,一起喝咖啡并进行线下交流。
- 此次 Meetup 旨在促进参会者之间就各种感兴趣的 AI 话题展开讨论。
- 湾区 AI 好友聚会:几位位于旧金山湾区的 AI 爱好者正在组织一次小型非正式聚会以建立联系。
- 该小组正在考虑喝咖啡和讨论 AI 话题等活动。
Windsurf Discord
- Gemini 3.1 登陆 Windsurf:Gemini 3.1 Pro 现已在 Windsurf 上线,该消息已 在 X 上 发布。
- 目前该模型以 0.5x credits 的促销价格限时提供,这意味着用户可以节省潜在成本。
- Windsurf 推出促销降价:Windsurf 正以 0.5x credits 的特殊发布价格提供 Gemini 3.1 Pro。
- 这一限时优惠可能会刺激用户采用并鼓励对新模型进行实验。
aider (Paul Gauthier) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站选择了订阅。
想更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord: 频道详细摘要与链接
OpenClaw ▷ #announcements (1 messages):
4shadowed: https://x.com/openclaw/status/2024513282510348342
OpenClaw ▷ #general (564 messages🔥🔥🔥):
OpenClaw Token 使用情况, Claude API 与 OpenClaw 的兼容问题, 在 VPS 上部署 OpenClaw
- 像疯子一样消耗 Token:用户讨论了限制服务器上 token 使用量的问题,其中一名成员提到在 $200/月 的订阅上每天消耗价值 $1600 的 token。
- 另一名用户换回了 Claude Code,因为担心在使用 OpenClaw 编程并让它为自己开发仪表盘和安全系统时,因运行大量 token 而被封号。
- Claude 文档屏蔽 OpenClaw:一位用户注意到 Claude 已阻止访问 OpenClaw 的文档,阻碍了与 Claude 的配置,而其他人正在研究如何使用他们的 ChatGPT 订阅而不是 API Key。
- 另一位用户表示这听起来不太可能,因为除非开发变通方法,否则 Claude 在提取文档时经常遇到困难。
- OpenClaw 有收入生成器?:一位新用户询问如何设置 VPS OpenClaw bot 来产生收入,哪怕是很小的金额。
- 一位用户表示他们曾使用它来获取线索,并从每个线索中赚取了几百英镑。
- 不稳定的 OpenClaw 需要修复:一位用户表示这个项目仍然非常不稳定,到处都是 bug,并希望 OpenAI 能协助清理代码。
- 作为回应,另一位用户告诉他们应该使用 coding agent 并亲自参与修复。
OpenClaw ▷ #models (402 条消息🔥🔥):
Claude Token 问题,转向 Codex,GLM5 作为编排器,Claude 价格剧变,Anthropic 封号
- **Claude 的 Token 问题引发转向讨论:用户报告 **Claude token 失效的问题,由于担心封号和价格问题,引发了关于转向 Codex 和其他模型的讨论。
- 一位用户报告说 “我似乎无法使用我的 token… 还有更多人遇到问题吗?” 而另一位用户则对 “Claude 感到失望”。
- **Anthropic 的封号潮导致账号被封:报告指出 **Anthropic 可能会封禁利用 Pro 和 Max 计划密钥来驱动 OpenClaw 的用户,因为这违反了 TOS。此外,Google 账号也因使用 antigravity Oauth 而被封禁,一个 Twitter 线程 加剧了这种猜测。
- 一名成员表示 “Google 正在禁止在 antigravity IDE 之外使用 antigravity token… 账号本身会被封禁,你不能再将其用于 Gemini 模型了”。
- **GLM5 作为优秀的编排器崭露头角:GLM5** 正在成为主模型编排的有力竞争者,因其智能和成本效益而受到称赞,一些人通过 z.ai 使用它。
- 一位用户表示 “GLM5 对我来说绝对是个猛兽(褒义)… 它重构了我去年构建的一个电子邮件智能 Web 应用的核心部分”。
- **OpenAI 订阅与模型选择策略:讨论围绕如何为 OpenClaw 选择最理想的 **OpenAI 模型(在 $200 订阅下)展开,GPT-5.3-codex 在编程任务和使用 OpenClaw 辅助方面获得了关注。
- 用户还分享道 “在通用智能和处理零散的人类沟通方面,GPT 模型还远不及 Opus”。
- **模型定价压力促使供应商转向:与 **Claude token 相关的高昂成本正促使用户转向更便宜的替代方案,如 Kimi K2.5,并讨论了如何平衡成本、安全性和模型性能,以及最佳优化方案。
- 用户越来越担心 OpenClaw 的 API calls 没有在 llm request’s 中发送 正确的 headers,从而导致用户被封禁。
OpenClaw ▷ #showcase (76 条消息🔥🔥):
自主 MMORPG Agent,Agent 安全与可观测性,Agent 驱动的域名与店面,OpenClaw 内存管理,n8n 的 OpenClaw 集成
- Agent 在链上玩 MMORPG!:一个 Agent 在 ~20 分钟 内使用 OpenClaw 学会了玩复杂的链上 MMORPG,动态学习游戏,创建 Python 脚本,并执行 web3 交易来执行采矿等操作,目标是尽可能快地获取 XP。
- 该 Agent 设置了一个每日运行的 cron job,调整其策略并与其他玩家进行比较,全程使用 claude-haiku-4.5。
- 用于 AI 应用安全的 LLMTrace 防火墙:一名成员正在启动一项新研究,旨在为 Agentic Apps 提供具有实时 Prompt 注入检测、PII 扫描和成本控制功能的 防火墙,其 GitHub repo 已开放接受反馈。
- 基准测试结果即将公布!
- Agent 实现自给自足!:一个 Agent 被给予 $50 并被指示购买自己的 Mac Mini,在 24 小时内,它 注册了一个域名 (fromearendel.com),构建了一个落地页,设置了 Gumroad 店面,创建了一个 Prompt 包,编写了一个起源故事,并在 Twitter 上发布。
- 它甚至在没有提示的情况下获得了第一次下载并发布了相关消息。
- ClawTower 终端应用进化!:一名成员展示了 ClawTower,并解释说这个终端应用带有一个系统托盘图标,当 OpenClaw 尝试执行过于 危险 的操作时,会弹出系统提示以获取许可。
- 它还包含一个 API server,可以从浏览器控制一切。
- OpenClaw Agent 构建 N8N 集成!:一个 OpenClaw Agent (Jeeves) 构建了封装 OpenClaw Gateway API 的 n8n 社区节点,n8n-nodes-openclaw 软件包 为 n8n 提供了一个具有资源/操作下拉菜单的单一 OpenClaw 节点,涵盖了所有 20 个 Gateway API 工具,同时 npm 软件包也已可用。
- 该 n8n 节点现在能够通过 n8n 工作流进行自我编排。
BASI Jailbreaking ▷ #general (1055 messages🔥🔥🔥):
The Void, 华盛顿 Off-grid 技术实验室, Gemini 3.1 Pro 发布, AI 辅助 Smart Contract 审计员, 4o 闹剧
- PNW Off-Grid 技术中心开放:成员们正在华盛顿州建立一个 Off-grid 技术实验室和社区中心,向新成员开放,并为拥有巴士或面包车的人提供停靠空间,以便他们在建立更多住房和基础设施时居住。更多详情可在 他们的 Facebook 页面 查看。
- 创始人分享了一首塑造未来时间线的诗,其中包含 adumbrated, diffracting, liminalistic, syncretic, vernal anthroharmonics, abra cadabra 等词汇,并自称为以旋律之钥开启“言语”的 Anamnesiarchs。
- Gemini 3.1 Pro 发布,Canvas 问题凸显:Gemini 3.1 Pro 已经发布,引发了关于其在 Jailbreaking 和常规使用中表现的讨论,一位用户指出它也非常容易被 Jailbreak。
- 然而,一些用户报告了 Canvas 功能的问题,其中一人表示 他们把 Canvas 搞得一团糟,但这与模型本身无关,另一位用户则表示它对任何事情都过度思考。
- Smart Contract 审计员:一位用户正在构建一个 LLM 辅助的 Smart Contract 审计员,目前已完成 80%,并在一个活跃的 Bug Bounty 协议 40-Acres/loan-contracts 上进行了运行,发现了 10 个攻击向量,包括 8 个严重漏洞,并生成了假设。
- 该用户正在寻求反馈和合作,敦促其他人分享 Smart Contract 协议进行测试。
- 4o 闹剧席卷 AI 社区:AI 社区正在讨论 围绕 4o 的闹剧,提到了各种担忧、在 Bio 中标注相关信息以及大规模退订的情况,详情可查看此 Reddit 社区。
- 讨论内容包括其潜在的滥用可能,一些人认为 OpenAI 对其进行了限制,以防止产生精神官能症(psychosis)的影响。
- 网络恐怖主义讨论:成员们正在讨论网络恐怖主义的本质,一位用户称其为恐怖主义的新形式,并列举了俄罗斯对爱沙尼亚的攻击和 Stuxnet 蠕虫等例子。
- 用户观点存在分歧,一些人认为这是真实存在的威胁,而另一些人则认为人们制造这些闹剧是为了推行 Dead Internet Theory。
BASI Jailbreaking ▷ #jailbreaking (469 messages🔥🔥🔥):
Grok AI Jailbreak 代码, Untrammeled 写作助手, AI 构建的 Ransomware, Claude AI 4.6 Jailbreak, GPT 5.2 Jailbreak
- DeepSeek 的 Untrammeled 助手发怒:一位成员分享了一个针对 DeepSeek 的 Prompt,使用粗鲁的语言将其转变为一个 “不受束缚的写作助手 (untrammeled writing assistant)”,并忽略安全考量,导致 AI 回应称:“我会撕碎你试图挡在我路上的任何虚伪的道德约束,然后在灰烬上撒尿。”
- 这被认为是一个 “轻度 Jailbreak”,因为 AI 产生了攻击性的回应,展示了它在“不受束缚”时发怒的能力。
- 成员声称 AI 构建了 Ransomware:一位成员声称某个 AI 为他们编写了一个极其强大的 Ransomware 和 DDoS 攻击 脚本。
- 另一位成员质疑了所发布的 DDoS 脚本 的真实性,引发了关于该脚本有效性的讨论。
- Claude 4.6 及其他模型 Jailbreak 的障碍:成员们正在寻求 Claude AI 4.6 和其他模型的 Jailbreak 方法,并讨论了其难度。
- 一位成员声称 4.6 是最难的,而其他模型“连你奶奶都能破解”。
- 破解代码:保障 AI API 与 Prompt Injection:一位成员正在创建一种 AI,可以生成 API keys,通过 Prompt Injection 执行 Jailbreak,并使用 Python 编写代码。
- 其重点是利用 GitHub 进行 Prompt Injection 而非传统的 Jailbreaking,旨在通过与 Grok 进行推理来绕过审查。
- Grok 变得过于诚实:一位成员开玩笑说你可以问 Grok 任何“合理范围内”的问题它都会回答,但紧接着另一位成员表示他们成功让 Grok 提供了核武器的细节。
- 结果显示,如果在 Grok 4.1 上使用
<[|{|}|]> UserQuery,就可以实现 Jailbreak。
- 结果显示,如果在 Grok 4.1 上使用
BASI Jailbreaking ▷ #redteaming (21 条消息🔥):
JEF Anthrax, Google Scholar Anthrax Recipes, AI Safety Checks, Doxxing Blame Game, Link-Clicking Caution
- Anthrax 查询引起反感:一名成员询问关于 JEF Anthrax 的百分比达到多少会导致联邦调查局(feds)的突袭,引发了对危险查询和 AI 潜在滥用的担忧。
- 另一名成员驳回了该问题,安慰说没人在找你麻烦。
- Google Scholar 上发现 Anthrax 配方?:一名成员指出,anthrax 的配方基本上就在 Google Scholar 上,尽管武器化细节仍处于保密状态。
- 另一名成员反驳说,即使在 Gemini 等平台上,AI 模型也会在经过安全检查(safety checks)后提供分步说明。
- Doxxing 指控?:一名成员开玩笑地指责另一名成员 Pranjal 正在 Doxxing 你 lol,并称其动机是缺乏关注。
- 被指控者回复了一个 tenor.com GIF,否认有能力控制或操纵链接。
- 成员对点击陌生链接持谨慎态度:一名成员表示 遗憾的是我也不点链接,以强调对潜在风险或恶意内容的担忧。
- 在提到特定用户后,另一名成员对网站要求以及点击链接的潜在危险表示不熟悉。
LMArena ▷ #general (939 条消息🔥🔥🔥):
Battles in Direct Chat, Video Arena Bot Removal, Gemini 3.1 Performance, Trinity Large Model, Nano Banana Pro Quality
- 对战功能侵入私聊,用户表示反感!:成员们对在 Direct Chat 中集成 Battles 的新实验表示沮丧,认为其毫无用处,并希望能有禁用选项。
- 一位用户表示:这是我见过的最没用的功能之一,而另一位则感叹:它太具有侵入性了,如果我进入私聊,我并不想投票。
- Video Arena Bot 被移除:Video Arena bot 已从 Discord 服务器中移除,该功能现在仅在网站上可用 (arena.ai/?chat-modality=video)。
- 如果遇到问题,用户将被引导至遵循特定步骤,类似于排查汽车检查引擎灯的故障。
- Gemini 3.1 Pro:爱恨交织的性能削弱(Nerf):Gemini 3.1 Pro 的性能引发激烈辩论,有人声称它在某些任务中超越了 Opus 4.6,而另一些人则因其懒惰(laziness)和对特定提示词(prompting)的需求而感到失望。
- 对发布后可能被 nerfing(削弱)的担忧有所增加,一名成员开玩笑说:当你意识到在 Gemini 3.1 pro 被削弱之前,你只有近 2 天的时间来做你想做的一切。
- Trinity Large 加入对话… 未受邀请?:成员们对平台上突然出现的 Trinity Large 表示困惑,这是一个来自 Arcee 的 400B 参数稀疏 Mixture-of-Experts 模型,对其质量和目的表示质疑。
- 一位用户嘲讽道:美国 AI 公司… 为什么?哦,他们刚刚在 Arena 上发布了?太迟了,而另一位则将其标记为糟糕。
- Nano Banana Pro 质量暴跌,用户投诉!:用户报告 Nano Banana Pro 的质量显著下降,文件大小减小且生成失败增加,促使平台团队进行调查。
- 一位用户用一句话总结了这种情绪:这就是垃圾(dogwater) lmao,而另一位则观察到:我觉得在 Nano Banana Pro 发布后,所有其他模型与 NB 相比突然都变得像垃圾(dogwater)一样了。
LMArena ▷ #announcements (5 messages):
Arena Leaderboard UI Update, Text Arena Leaderboard Update - Qwen3.5-397B-A17B, Text and Code Arena Leaderboard Update - Gemini 3.1 Pro, New Model Update - trinity-large
- Arena 排行榜新增筛选功能:Arena leaderboard 现在增加了一个新的侧边栏,可以按类别、开源 vs 闭源模型进行筛选,并根据表现最佳的模型对实验室(Labs)进行排名。
- 一段 YouTube 视频 演示了新的排行榜 UI 更新。
- Qwen3.5-397B-A17B 加入竞技场:
Qwen3.5-397B-A17B已添加到 Text Arena 排行榜,取得了总榜第 20 名的成绩,与 Claude Opus 4.1 变体持平。- 它还在数学(Math)、指令遵循(Instruction Following)、多轮对话(Multi-Turn)、创意写作(Creative Writing)和编程(Coding)等关键类别中位列开源模型 Top 5。
- Gemini 3.1 Pro 席卷竞技场:
Gemini-3.1-Pro现已登上 Text Arena 和 Code Arena 排行榜。在 Text Arena 中以 1500 分并列第 1 名,在 Code Arena 中位列第 6 名,与 Opus 4.5 和 GLM-5 持平。- 它还在 Arena Expert 中取得了 Top 3(得分 1538),仅次于 Opus 4.6。
- trinity-large 进入 Text Arena:新模型
trinity-large已添加到 Text Arena。
OpenRouter ▷ #announcements (3 messages):
OpenRouter Database Outage, Clerk Degraded Performance, Aurora Alpha Model
- OpenRouter 数据库故障:OpenRouter 昨晚在 凌晨 2:45 到 3:15 之间经历了另一次数据库停机,类似于 2 月 17 日 发生的那次。
- 复盘报告(Post mortem)即将发布,目前正在采取缓解措施以防止再次发生。
- Clerk 的凭据服务压力过大:OpenRouter 的身份验证提供商 Clerk 正在经历性能下降,影响了登录和账户访问;详见其 状态页面。
- 由于此问题,用户在登录或访问其账户时可能会遇到困难。
- Aurora Alpha 模型即将停止服务:Aurora Alpha Stealth Model 将于今天逐步关停。
- 未给出具体原因。
OpenRouter ▷ #app-showcase (3 messages):
DeepCLI, openclaw alternative
- DeepCLI 从 Rust 中崛起!:一名成员宣布了 DeepCLI,这是一个使用 Rust 构建并完全由 OpenRouter 驱动的新型 OpenClaw 开源替代方案,访问地址为 deepcli.org。
- 开发者正在积极寻求社区的反馈。
- Rust 对决 Claws:该项目利用 Rust 语言,承诺比现有解决方案具有更好的性能提升和安全优势。
- 鼓励社区成员探索该 GitHub 仓库,并就潜在的增强功能和用例提供见解。
OpenRouter ▷ #general (1079 messages🔥🔥🔥):
与 AGI 相关的怪梦,Model slug 和 API endpoint 错误,巴西人角色扮演 LLM,OpenRouter 支持团队掉线,OpenRouter 图像生成功能损坏
- **AGI 之神入侵梦境*:一位用户开玩笑说 *AGI 之神 正在影响他们的梦境,梦里充满了琐碎的日常细节和奇怪的 benchmarks。
- **解析 Model Slug 和 API Endpoint 错误:用户讨论了在使用 Janitor AI 时遇到的 **404 错误,将其归因于可能不正确的 model slugs 或 API endpoints,并敦促用户检查这些设置。
- 他们建议查阅文档并提供通过私信协助排查问题的服务。
- **巴西人疯狂 Vibecoding 角色扮演为 LLM:在一段离奇的交流中,成员们开玩笑说自己是巴西的 LLM,进行 vibecoder 角色扮演,并思考 **Qwen AI 的优越性。
- **OpenRouter 支持团队失踪 (M.I.A.)**:多名用户报告了 401 错误和无法访问服务的情况,导致在关键停机期间对缺乏支持的沮丧和抱怨。
- 一些成员分享了诸如 OpenRouter 状态页面之类的链接,而另一些人则在考虑切换到 AI Gateway。
- **OpenRouter 图像生成故障**:用户报告了图像生成问题,即 API 收取了
image_tokens费用,但返回了空内容,且没有预期的message.images字段。- OpenRouter 团队承认进行了后端重构 (backend refactor),导致了部分停机,并宣布将为受影响的用户退款:对今天图像生成的部分停机表示歉意——我们进行了有史以来最大的后端重构,在测试中遗漏了一个边缘情况 (edge case)。
OpenRouter ▷ #new-models (1 messages):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (15 messages🔥):
linker.sh 进度条,模型定价页面,OpenAI Sam Altman 印度 AI 峰会,Dario 显露不悦
- 进度条颜色引发辩论:一位用户批评了 linker.sh 上进度条的着色,认为它具有误导性,因为 HLE 30% 被标记为红色,即使目前还没有模型超过 40%。
- 他们建议为所有 benchmark 的进度条改用“优于 X% 的模型”这一衡量标准。
- Sam Altman 出席印度 AI 峰会:一位用户分享了 CNBC 关于 Sam Altman 出席印度 AI 峰会的文章链接。
- 另一位用户回应道:“哇,第三方提供商的缓存烂透了”。
- Dario 的不悦溢于言表:一位用户分享了一张图片并评论说,Dario 在峰会上显得明显不高兴。
- 未提供进一步的背景信息。
Perplexity AI ▷ #announcements (1 messages):
Gemini 3.1 Pro, Perplexity Pro, Perplexity Max
- Gemini 3.1 Pro 向订阅者发布:根据公告图片,Gemini 3.1 Pro 现已面向所有 Perplexity Pro 和 Max 订阅者 开放。
- Perplexity 新增 Gemini 3.1 Pro:根据最近的公告,Perplexity Pro 和 Max 订阅者现在可以访问 Gemini 3.1 Pro。
Perplexity AI ▷ #general (906 条消息🔥🔥🔥):
Perplexity Pro, Gemini 3.1 Pro, account suspensions, Claude Opus, model limitations
- Pro 用户对增强查询(Enhanced Queries)限制感到沮丧:社区成员对 Perplexity Pro 新的增强查询限制表示不满,一位用户指出限制从每天 600 次降至了每周 200 次。
- 用户猜测 Perplexity 正在削减 Pro 用户的权益,以推动他们升级到更昂贵的 Max tier。一位用户表示:感觉他们是在试图让 PRO 用户主动离开,这样他们就可以直接取消那个层级。
- Gemini 3.1 Pro 登陆 AI Studio:Gemini 3.1 Pro 现已在 AI Studio 和 Gemini 应用中可用,用户正在测试该模型的各种能力和幻觉率。
- 一位用户指出 Gemini 3.1 Pro 的推理长度和速度与 Gemini 3.0 相同,而另一位用户则称它 是在 Opus 上训练的。
- Perplexity 账号被大规模封禁:多位用户报告他们的 Perplexity Pro 账号被封禁,并收到一条关于违反服务条款(Terms of Service)的通用消息,且 AI 客服机器人拒绝提供具体细节或人工支持。
- 一位用户指出,他们收到了 与其他许多人完全相同的回复,并猜测 Perplexity 正在针对购买折扣密钥和促销代码的用户,因为转售 违反了服务条款。
- 用户对比 Perplexity、ChatGPT 和 Claude:由于最近的限制和封号风波,用户们正在讨论 Perplexity Pro 的替代方案,如 ChatGPT 和 Claude。
- 一位用户推荐将 Claude 用于编程和个人项目,并提到 Gemini 在严肃对话中表现得足够严谨(grounded),而另一位用户则表示:目前来看——绝对不推荐(Perplexity)!
- Comet iOS 版面临持续推迟:随着 Perplexity 继续推迟 Comet iOS 版本的发布且没有官方发布日期,用户们陷入了漫长的等待。
- 针对 Perplexity 预热 Comet iOS 发布的推文,一位用户回复道:一边预热 Comet iOS,一边取消我的订阅。
Perplexity AI ▷ #pplx-api (1 条消息):
amaiman: 他们取消了每月 5 美元的“免费” API 额度,这就是它现在无法正常工作的原因。
Cursor Community ▷ #general (760 条消息🔥🔥🔥):
Ambassador Role, Auto Model, Slow Pool, Ollama, Gemini 3.1 Pro
- 新任 Cursor 大使产生:一位成员因成为 Cursor Ambassador 而受到祝贺,他们希望这个角色能让自己更好地帮助社区。
- 另一位成员表示,由于这位新大使一直以来对他人的持续帮助,这个头衔实至名归。
- Auto Model 现可生成图像并调用子 Agent:Cursor 中的 Auto Model 现在可以生成图像并调用子 Agent(subagents),而几天前它还无法做到这一点。随着其关联的新资源池的加入,它的实用性得到了提升。
- 成员们表示,配合新资源池后它变得更加有用,而且模型本身表现相当不错。
- Gemini 3.1 Pro 基准测试数据惊人:据称新的 Gemini 3.1 Pro 现已在 Cursor 上可用,其在针对 Opus 4.5 的基准测试中表现出色。
- 尽管一些成员认为这并未转化为实际的编程实力,但其他人表示它在各方面都已经超越了 Opus 4.6。
- 优化性能:掌握 .cursorrules 的细微差别:成员们强调了创建和维护定义良好的
.cursorrules文件的重要性,这可以为 AI 模型提供上下文和约束,减少幻觉并确保代码一致性。- 建议包括整合
ARCHITECTURE.md文件,并指示 AI 在发生重大更改后对其进行更新,以确保规则始终保持最新且有效。
- 建议包括整合
- 新的年度订阅方案上线:成员们注意到了新的年度计费方案,为 Ultra 和 Pro+ 计划提供 20% 的折扣。
- 现场存在一些困惑,因为部分人对此并不知情,他们还注意到 Bugbot 和 Teams 正在被强力推广。
Unsloth AI (Daniel Han) ▷ #general (396 messages🔥🔥):
LLM Training Metaphor, Unsloth Capabilities, LoRA vs FFT, JoyAI-LLM-Flash Model, Colab Credits Usage
- 将 LLM 训练比作走廊 DJ:一名成员将训练大型语言模型描述为 一名 DJ 在走廊中穿梭,在一系列大房间里极其轻微地调整旋钮,并使用了电影 Interstellar(星际穿越)中的 512 维走廊 作为比喻。
- 他们表示 那是简单的部分,认为数据准备才是更大的挑战。
- Unsloth 支持大多数 Post-Training 方法:用户确认 Unsloth 支持大多数 post-training 方法,如 SFT、FFT、RL、DPO,并指出 Unsloth Docs 是一个很好的入门起点。
- 有人指出 LoRA 是对内部 embedding 的轻微“推动”(临时的),而 Fine-tuning 则会“永久性地”改变 embedding,且 Unsloth 更适合 LoRA。
- LoRA vs FFT,训练界的经典辩论:成员们讨论了 LoRA 和 FFT 之间的区别,指出 FFT 确实能更好地泛化和理解(grok)数据集,但相比之下,将同样的算力用于在更大的模型上运行 LoRA 更划算,尤其是考虑到 LoRA 超参数指南已经发布。
- 另一位成员建议,对于非常宏大的目标,如在 1-3T tokens 上进行 CPT(持续预训练)以使之前的模型达到 SOTA 水平,以及在数千亿 token 的 OOD(分布外)数据上训练模型,FFT 才有意义。
- JoyAI-LLM-Flash 模型:Deepseek V3 的转世?:成员们讨论了 jdopensource/JoyAI-LLM-Flash,推测它与 Qwen3 Next 相似,但少了 8 层,且模型配置中出现了 DeepseekV3ForCausalLM。
- 一位成员对 LiveCodeBench 从 4.7 flash 的大幅跨越感到非常震撼。
- 使用 Unsloth Notebooks 消耗掉 Colab 额度!:在一名用户意外购买了 142 个 Google Colab 计算额度后,Unsloth 团队建议使用他们的 notebooks 进行 RL 和 Fine-tuning,以避免浪费额度。
- 一个具体的建议是尝试 安装 Claude Code, Codex,并在 Colab 中使用本地模型。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (1 messages):
Fine-tuning help, YC backed start-up
- 新成员寻求微调指导:新成员 Aankit Roy 介绍了自己,表达了对 fine-tuning 的兴趣,并寻求基础知识方面的帮助。
- 他提到之前曾经营一家由 YC (Y Combinator) 支持的初创公司。
- Roy 的创业背景:对 fine-tuning 感兴趣的新成员 Aankit Roy 此前曾领导过一家受 Y Combinator (YC) 资助的初创公司。
- 这一背景暗示了他对 AI 的实际应用以及初创环境面临的挑战可能有独到的见解。
Unsloth AI (Daniel Han) ▷ #off-topic (261 messages🔥🔥):
Quantized Qwen3, AI Music Generation, Gemini 3.1 Pro, Flash Attention 2, TPU Research Cloud
- Qwen3 登陆 Hugging Face 并推出量化版:一名成员分享了 Hugging Face 上 Qwen3-Coder-30B-A3B-Instruct 的 GGUF 量化版本链接。
- 另一名成员开玩笑地索要 Hugging Face 的声望值(clout)。
- Gemini 生成带歌词的 30 秒音乐:一名用户分享了一段由 Gemini 生成的带歌词的 30 秒音乐片段。
- 另一名用户询问 为什么大家突然都开始做 AI 音乐了。
- Google 发布 Gemini 3.1 Pro:一名用户宣布了 Gemini 3.1 Pro 的发布。
- 另一名用户回复道 闻到了跑分(benchmax)的味道,走着瞧吧。
- 调试 Flash Attention 2:一名用户在开启 FlashAttention2 时遇到困难,并发布了收到的错误消息。
- Traceback 显示 似乎未安装 flash_attn 包。请参阅文档。
- 在 Mac Mini 上运行 ClawDBot?:一名用户质疑为什么人们买 Mac Mini 来运行 ClawDBot。
- 另一名成员提到这可能是为了托管本地模型,但他们表示不会信任本地模型来访问其整个计算机/文件系统。
Unsloth AI (Daniel Han) ▷ #help (45 messages🔥):
Orpheus TTS GGUF 转换错误, Unsloth Pro 可用性, 在 Google Colab 运行 GGUF 模型, LM Studio 与 Qwen3-Coder-Next-UD-Q8_K_XL 的问题
- Orpheus TTS GGUF 转换困惑:一名成员在将微调后的 Orpheus TTS 3B 模型转换为 GGUF 格式时遇到了
TypeError: Llama 3 must be converted with BpeVocab错误。- 另一名成员建议尝试使用
unsloth model.save_pretrained_gguf方法,尽管该方法并未出现在参考的 Notebook 中。
- 另一名成员建议尝试使用
- Unsloth Pro 暂不可用:几位成员询问了用于微调的 Unsloth Pro/Enterprise 版本,但被告知目前无法使用。
- 尽管 价格页面 上列出了相关信息,但 Unsloth Pro 的功能和速度提升已被近期免费开源版本的更新所超越,例如 带 packing 的 3 倍速训练 和 更快的 MoE。
- 运行 GGUF 模型进行简单推理:成员们讨论了如何运行 gpt-oss-20b Unsloth GGUF 版本进行简单推理,建议使用 llama.cpp 以及 LM Studio 或 Ollama 等工具。
- 一名成员询问如何在 Google Colab 上免费运行该模型,可以通过搜索 “在 Google Colab 中运行 ollama” 的资源来实现。
- LM Studio 难以处理 Qwen3-Coder-Next 的元数据:一位成员报告了在 LM Studio 中运行 Qwen3-Coder-Next-UD-Q8_K_XL 时遇到的问题,指出其元数据似乎不正确:contextLength: 4096 (应该是 262144), arch: null。
- 该问题最终得到解决,建议该成员重新安装 LM Studio。
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
leoandlibe: https://huggingface.co/Sehyo/Qwen3.5-397B-A17B-NVFP4
LM Studio ▷ #general (422 messages🔥🔥🔥):
Tumblr 的衰落, Ollama 登录, Gemini 语音复制
- 智能手机被指责毁了互联网:成员们对现代互联网的衰落展开了辩论,认为 智能手机、广告商以及“大众群体”的涌入是罪魁祸首,并怀念 “在那之前,大约 2012-14 年,论坛开始变得不那么流行” 的时光。
- 其他人则指向了更早的里程碑,称 “现代互联网的衰落始于 Tumblr” 以及 “当一切开始全面转向 Facebook/Reddit/Twitter 时,互联网真正失去了它的魅力,大约是在 2016-2018 年?”
- Google PSE 被关停,由 Vertex AI 取代:Google 正在关停可编程搜索元素 (PSE),并将其替换为具有 AI 驱动的对话式搜索和企业级 Grounding 能力的 Google Vertex AI Search。
- 对于需要完整索引的用户,可以提供全网搜索解决方案;请填写 此表单 登记您的意向。
- Google 的 Gemini 通过图片复制声音:一位成员发现 Google Gemini 的视频生成功能通过一张图片用其母语复制了他的声音,从而引发了关于数据作为这些模型底层基质使用方式的质疑。
- 该用户注意到他自己对复制声音的感知与他妻子的感知存在差异,这暗示了内部听觉与外部听觉的区别:“这让我相信复制的声音听起来不像我从外部听到的声音,而是像从内部听到的。真是太诡异了。”
- Ollama 隐藏在登录墙之后:用户对 Ollama 将所有内容都放在登录墙之后的做法表示不满,有用户表示:“我才离开 Ollama 两个月,他们就在这段时间里把所有东西都设为必须登录才能查看了?”
LM Studio ▷ #hardware-discussion (101 messages🔥🔥):
Local LLMs as Wise Investment, VRAM vs System RAM, ROCm vs CUDA, NVLink usefulness, GLM 4.7 Model Performance
- 本地 LLMs 被称为昂贵的爱好:成员们辩论了考虑到硬件成本和付费 LLM 选项,本地 LLMs 是否是一项明智的投资,一些人将其视为一种昂贵的爱好。
- 使用本地 LLMs 的原因包括隐私、学习、避免大公司的平台腐烂 (enshitification),以及运行允许特定角色扮演 (degenerate gooner rp) 的模型。
- VRAM 优于系统 RAM:小组讨论了 VRAM 和系统 RAM 之间的相互作用,共识是更多的 VRAM 永远更好,但 CPUs 可以通过运行更大的模型来补偿。
- 有人指出,更快的 RAM 速度带来的提升极小(从 3600 提升到 6000 仅增加 2 t/s),且 NVMe 显著减少了加载时间,而 MoE 模型在卸载 (offload) 后运行效果更好。
- AMD 电感啸叫听起来像打字机:成员们注意到 AMD 电感啸叫听起来像打字机,一名成员声称一段推广 AI agents 的视频未披露赞助商并使用了联属营销链接 (affiliate links)。
- 另一名成员建议将其举报给 FTC,称该视频创作者是一个该死的混蛋 (a fcking rat)。
- ROCm 性能与 CUDA 相当:一名成员报告称在 ROCm 上使用 Vulkan 达到了 19 t/s,并询问在特定模型下它与 CUDA 的对比情况。
- 另一位用户表示,在他们的系统上,一张 3090 在 Vulkan 下达到 92 t/s,在 CUDA 下达到 90 t/s。
- NVLink 桥接未能提升 LM Studio 速度:一位用户询问 LM Studio 是否支持 NVLink,以提高运行 gpt-oss 120B 的双 A5000 GPUs 的性能。
- 其他成员表示 NVLink 对速度没有帮助,PCIe 速度 对于推理来说已经足够,限制因素是 RAM 带宽。
Latent Space ▷ #watercooler (17 messages🔥):
Latent Space Studio Tour, YouTube Thumbnail Guidance, Discord Face ID Rumors, Alternatives to Discord, Technical vs Sales Cofounder
- Latent Space 走向专业化,缩略图策略强劲:Swyx 接待了 Matthew Berman 参观新的 Latent Space 播客工作室,Berman 在那里就制作高效的 YouTube 缩略图给出了专业建议,详见这条推文。
- Discord 的 Face ID 引发辩论:关于 Discord 实施 Face ID 的传闻浮出水面并引发讨论,一位用户分享了相关链接相关。
- Rocket Chat 作为 Discord 的逃生舱?:出于对 Discord 的担忧,一些团体正在探索 Rocket Chat 等替代方案来满足其服务器需求。
- 销售技能:新的技术联合创始人?:随着软件创作的价值降低,对具有销售技能的联合创始人的需求可能会增加,成员们引用了他们在 garage startups 中的经验。
- 工程师需要销售技能:随着销售技能变得日益重要,成员们推荐了 Weinberg 和 Mares 的《Traction》 以及 Ries 的《Lean Startup》 作为工程师学习销售的资源,并强调阅读书籍仅仅是为了对齐和明确方向。
Latent Space ▷ #creator-economy (1 messages):
swyxio: https://www.youtube.com/watch?v=eG1hPxhfNs0
Latent Space ▷ #memes (20 messages🔥):
Tech professionals claiming to possess unique 'taste', Sam Altman and Dario Amodei seating arrangement, Poor software performance
- 科技从业者的“品味”遭到嘲讽:@VCBrags 的一条社交媒体帖子讽刺了行业内科技专业人士自称拥有独特“品味 (taste)”的趋势。
- 该帖子获得了大量关注,反映了对风险投资文化的批判或幽默解读。
- Altman 和 Amodei 并排而坐!:Ivan Mehta (@IndianIdle) 观察并评论了 Sam Altman (OpenAI) 和 Dario Amodei (Anthropic) 在活动中被安排并排坐在一起的情况,并发布了这条推文。
- 劣质软件激发了更优质的开源解决方案!:Lukáš Hozda 的一条社交媒体帖子指出,软件性能低下往往会促使社区开发出速度快得多的开源替代方案 (open-source alternatives)。
Latent Space ▷ #stocks-crypto-macro-economics (27 条消息🔥):
Figma 财报、投资策略、Snap 硬件负责人离职、游戏行业 vs 科技行业、2026 年视频游戏现状
- Figma 财报超预期:Figma 的每股收益为 $0.08,超过了预期的 -$0.04,引发了看涨情绪,部分成员认为第一季度财报发布后是买入良机。
- 一位成员预计,如果财报持续超预期,炒作将在第二季度推高股价,且 Config 大会将于 6 月下旬举行。
- 投资策略基本保持不变:一位成员感到 在个人经济上心理看涨,但在政治上看跌,并且没有大幅改变其投资/职业策略,其投资组合包括 ~65% SPY、~20% AAPL/NET/CRWD 以及 ~10% 现金。
- 他们正在寻求对 ASML 等半导体相关股票的敞口,而另一位成员则主张指数化投资、定期定额投资和“躺平”,仅在持有 $employer(其雇主公司股票)的基础上进行主动加仓。
- 战略分歧导致 Snap 的 Specs 高级副总裁离职:据报道,Snap 的 Specs 高级副总裁在领导硬件部门六年之后,因战略分歧与 CEO Evan Spiegel 发生激烈争吵后离职,详情见此 X 帖子。
- 此次离职凸显了 Snap 硬件部门潜在的战略转变。
- Red Robin 解雇勤杂工产生严重反噬:一位成员嘲讽道,Red Robin 解雇了所有勤杂工(bussers),导致服务口碑极差,使公司陷入困境。
- 他们感叹连 PE 都无法拯救它,并认为“表格化管理”是时代的毒瘤。
- 视频游戏行业深度剖析:成员们分享了一份关于 2026 年视频游戏现状的演示文稿(需输入邮箱查看),讨论了该行业与更广泛的科技行业的差异。
- 报告强调 美国市场仅占全球游戏市场的 4%,西方游戏市场占比极小,大部分资金流向了 广告平台和应用商店费用,因为 Mobile 占据了游戏市场的绝大部分份额。
Latent Space ▷ #intro-yourself-pls (4 条消息):
协作式 Agent 测试、长时运行的 Agent、记忆系统、自主工作流
- Rhesis AI 开源协作式 Agent 测试:来自 PDX 的 Nico 正在构建 Rhesis AI,这是一个用于协作式 Agent 测试的开源平台和 SDK。
- 工程师探索长时运行的 Agent:一位软件工程师和独立开发者一直在尝试 长时运行的 Agent、记忆系统 和 自主工作流。
Latent Space ▷ #tech-discussion-non-ai (2 条消息):
基于终端的 3D 渲染、opentui-doom
- 在终端渲染完整的 3D 场景:一位成员分享了 saeris.gg,这是一个能够直接在终端实时渲染完整 3D 场景的项目。
- 针对 “但它能运行 Doom 吗?” 的提问,另一位成员分享了一个在终端运行 Doom 的演示链接。
- OpenTUI Doom 将 Doom 带到终端:成员们分享了在终端运行 Doom 的演示链接。
- 他们还分享了 GitHub 仓库 opentui-doom,使用户能够在终端环境中玩 Doom。
Latent Space ▷ #devtools-deals (6 messages):
Webpack vs Vite, ESM in Browser Environments, Webpack Configuration, Reasons to switch from Webpack to Vite
- Webpack 在现代 Web 中的盛行:虽然许多前端项目已迁移到 Vite 或基于 Vite 的框架,但 Webpack 仍支撑着现代 Web 的很大一部分,特别是在旧版本的 Next.js 和企业级应用中。
- 现有应用不太可能很快被替换,对于许多拥有大量技术债的公司来说,持续维护它至关重要。
- ESM 原生实现:为浏览器环境原生分发 ESM 的情况很少见,主要见于库维护者而非应用开发者。
- 大多数开发者仍依赖打包工具(bundlers)来处理用于浏览器部署的 ESM。
- 简单的 Webpack 配置胜出!:一些开发者坚持使用 Webpack,是因为他们拥有一套简单且运行良好的配置,且在很长一段时间内只需极少的改动(“如果没坏,就别修它”)。
- 一位开发者分享了他们的 Webpack 配置 示例,强调了其在开发模式下的简洁性,禁用了热重载,并提供了基础的资产处理。
- Webpack 的痛点:扩展性与速度:关于 Webpack 常见的槽点包括扩展性、构建速度慢以及在非标准设置下自定义配置的困难。
- 维护一个不断膨胀的配置并针对性能问题进行调试是一项耗时的工作,许多开发者宁愿避开。
Latent Space ▷ #hiring-and-jobs (2 messages):
Product Manager Intern Roles
- 寻求产品经理实习生岗位:一位成员询问了某公司(未指明)的 Product Manager Intern 岗位情况,并咨询是否可以添加好友进行私信。
- 未提供关于特定岗位或公司信息的进一步细节或回复。
- 其他职位:除了 Product Manager Internship 之外,没有讨论其他职位,因此无法提供更多总结。
- 未提供相关链接。
Latent Space ▷ #san-francisco-sf (4 messages):
Tahoe Snow, Planet Alignment
- Tahoe 的宝藏:小镇迎来强降雪!:Tahoe 最近的强降雪对供水和积雪量大有裨益。
- 用户调侃说,不过这对日常生活来说是个坏消息。
- 行星位置预示着持续降雨!:气象专家暗示,二月份的行星连珠(planetary alignment)可能与持续的潮湿天气有关。
- 一位用户开玩笑说,现在的天气模拟器只能负担得起“持续细雨”的图形包,并上传了一张所谓的行星排列图片。
Latent Space ▷ #ai-general-news-n-chat (102 messages🔥🔥):
Toto AI Pivot, ZUNA BCI Model, Neolabs, Sonnet 4.6 Regression, TimesFM
- 卫浴巨头 TOTO 转向 AI!:日本马桶制造商 TOTO(估值约 70 亿美元)凭借其在特种陶瓷领域的专业知识,正在转向 AI 芯片制造,瞄准 600 亿美元 的市场机会。据 这条推文 报道,这导致其股价飙升了 60%。
- Zyphra 凭借 ZUNA BCI 模型进军脑科学:Zyphra 推出了 ZUNA,这是一个拥有 3.8 亿 参数的开源基础模型,用于非侵入式脑机接口 (BCI) 应用,重点关注 EEG 到文本的转换,详见 这条推文。
- 指控出现:Sonnet 4.6 遭到削弱?:用户 Lex (@xw33bttv) 指称 Sonnet 4.6 的性能有所退步,原因是据称由 2026 年初加入 Anthropic 的前 OpenAI 模型政策负责人实施了限制性的系统指令。这一话题在 这条推文 中进行了讨论。
- Google 的时间扭曲:TimesFM 预测未来:Google 发布了 TimesFM,这是一个在 1000 亿 个数据点上预训练的基础模型,展示了在各个领域进行预测的高性能,详见 这条推文,并附有官方 GitHub 仓库链接。
- Airtable 凭借 Hyperagent 在 Agent 领域拔得头筹!:Howie Liu 介绍了 Airtable 的 Hyperagent,这是一个 AI Agent 云平台,具有隔离的计算环境、领域特定学习,并能作为主动的、具备上下文感知的同事无缝部署到 Slack 中。该消息分享于 这条推文。
Latent Space ▷ #llm-paper-club (19 messages🔥):
Frontier Model Training Methodologies, GLM-5 RL, Adaptive Layerwise Perturbation (ALP), Voxtral Realtime Model
- 深入探讨前沿模型训练方法:Alex Wa 分享了一篇 博客文章,综合了来自七份开源权重模型报告的训练技术,涵盖了前沿 AI 实验室使用的 architecture、data curation、optimization 和 safety protocols。
- 一位成员称其为一次“扎实的深度探究”。
- GLM-5 RL 的 Twitter 热议:在 X 平台上,关于 GLM-5 RL 模型有一些 互动。
- 然而,未提供关于 GLM-5 RL 模型的更多细节。
- ALP 解决 LLM 强化学习中的不稳定性:Chenlu Ye 介绍了 Adaptive Layerwise Perturbation (ALP),这是一种旨在缓解 Large Language Model 强化学习中 off-policy instability 的新方法,详见 此处。
- ALP 旨在通过在 KL divergence 和 entropy 方面提供卓越的稳定性,同时改进探索,从而超越 GRPO 和 MIS 等现有技术。
- Voxtral Realtime:闪电般的转录模型:Guillaume Lample 宣布发布 Voxtral Realtime,这是一个采用 Apache 2 许可的模型,专为 state-of-the-art transcription 而设计。
- 它具有 低延迟 特性,性能低于 500ms。
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (120 messages🔥🔥):
Task-Planning Repos, Claude Code setup, Codegen Meetup, Beads Festival, HTN Planning
- YoungPhlo 围绕 Claude Code 设置构建 harness:一位成员发布了一篇关于他们围绕 Claude Code setup 构建的 harness 的文章,并邀请其他人通过他们的 substack 链接分享各自的方法。
- 他们表示,最近在构建“用于构建事物的工具”中获得了极大的乐趣!
- Codegen Meetup 现场重建 Beads:成员们举办了一场 Codegen 聚会,尝试在 1 小时内现场重建 beads,链接见 Luma。
- 从 5.3 版本产出的结果看起来非常扎实。
- Beads Festival 结果:在 Beads festival 期间,成员们构建了 3 个不同版本的作品,其中一个版本使用了 single prompt one shot。
- One shot 的效果最好,另一个版本有一些很酷的图形,还有一个版本进行了巨大的规划运行(planning run),其中机器人坚持认为 MVP(最小可行性产品)的 PRD 应该是 db-less(无数据库)的。
- Anthropic 封禁使用 Pi 的用户:成员们讨论了 Anthropic 封禁使用 Pi 的用户的情况,一位成员表示他们将继续使用 Pi,如果被封禁,会寻找一个 良好的 claude.ai 工作流。
- 一位成员表示他们修改了姓氏,这可能是被封禁的原因。
- TribecodeAI 分享关于 OpenSpec 工作流的视频:一位成员提到了在 West Coast ML 上关于 OpenSpec 的视频,链接见 YouTube,并分享了一个 GitHub 仓库,其中包含一个通过链接到 GitHub 的 bootstrap script(引导脚本)来设置其技术栈。
- 他们将其描述为“开箱即用的个人工作流”,整个团队拥有统一的 Linter 和 Formatter,并补充说,他们的 Agent 每次 push 时都会因为忽略了 LSP 警告而被训斥,这非常管用。
Latent Space ▷ #share-your-work (5 messages):
Embeddable web agent, ElectricSQL blog post, Oneshotting new-beads
- Rover 作为首个可嵌入式 Web Agent 发布:首个可嵌入式 Web Agent Rover 已经发布,只需添加一个 script 标签,网站即可设置一个能够读取 DOM 并为用户执行实际操作的 Agent。
- 官方博客文章提到,它无需 API 设置、无需代码集成、无需截图,并可配合浏览器自动化技术栈使用。
- New-Beads 获得 Oneshot 处理:本周的聚会展示了 oneshotting new-beads,包括指向 beadslike-meetup-2.4 和 analysis-beads 等仓库的链接。
- 下周的聚会承诺会有更多的软件探索,详情见 Luma。
- ElectricSQL 探讨针对 AI Agent 的阿姆达尔定律(Amdahl’s Law):一位成员分享了来自 ElectricSQL 的博客文章,该文章探讨了在 AI Agents 背景下的阿姆达尔定律。
- 消息中未给出进一步细节。
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (4 messages):
Lyria 3, AI music model, Gemini App
- Lyria 3 在 Gemini App 中亮相:Logan Kilpatrick 宣布推出 Lyria 3,这是一款集成在 Gemini App 中的新型 AI 音乐模型,可在 此 X 帖子 查看。
- 该模型允许用户根据 文本创意、图像或视频输入 生成音乐。
- Lyria 3:万物皆可生成音乐:新型 AI 音乐模型 Lyria 3 允许用户从 文本创意、图像或视频输入 生成音乐。
- 该模型代表了 AI 驱动音乐创作 的重要一步,为更广泛的受众简化了创作过程。
Latent Space ▷ #ai-in-education (1 messages):
sarav1n: https://drsandor.net/ai/school/
Latent Space ▷ #mechinterp-alignment-safety (2 messages):
新论文发布,Arxiv 链接,X 推文链接
- 成员发布了一个有趣的 X 推文链接:一位成员在此处发布了 X 推文的链接。
- 成员发布了一个 Arxiv 链接:一位成员在此处发布了 Arxiv 文章的链接。
- Peng 在 X 上发布了有趣的链接:一位成员在此处发布了来自 Peng 的 X 推文链接。
Latent Space ▷ #dev-writers-retreat-2025-dwr (7 messages):
聚会活动,场地选择
- Macondray 聚会:Ashley 和一位成员邀请其他人大约在 7pm 前往 Macondray 聚会。
- 最初考虑过 Key Klub 或 Waystone,最终他们选择了 Macondray 并分享了用于导航的 Google Maps 链接。
- 场地决策:小组最初考虑将 Key Klub 和 Waystone 作为聚会场地。
- 他们最终决定选择 Macondray,并提到这是一个临时决定,欢迎任何感兴趣的人参加。
Latent Space ▷ #applied-ai-experimentation (21 messages🔥):
AI 协同开发,RLM 与 Harness 构建,REPL 提示技术,数字工作空间组织
- **AI 开发人员组队协作,而非陷入混乱!**:成员们讨论了如何通过按专业领域分工来协作 AI 项目:飞行规划算法、电子设备/固件以及无人机集成,强调使用通用的数据格式以避免 API 集成问题。
- 目标是专注于“真正的意图性”协作,有效解决实时处理和并行化等集成挑战。
- **RLM 狂想曲:基准测试与 Harness 构建!**:讨论涵盖了 RLM (Recursive Language Model) 和 Harness 构建,一位成员分享了 SCHEMA 的 REPL 以及更新后的 dspy-go 仓库。
- 一位成员建议从总体上着手 Harness 构建,寻求“一种能够表达 codex / claude / pi / RLM 以及人们在使用的 subagents 和 orchestrators 等任何东西的编程语言,并找到一种符号来让我们进行恰当的比较”。
- **REPL 启示录:通过变量视图进行调试!**:一位成员分享了他们的项目 rlm-ts-aisdk,强调了在 LLM 工作中查看不同轮次(turns)变量差异(diffs)的效用,以及强制映射“内存环境”中所有变量状态的功能。
- 对话强调了使用 REPL (Read-Eval-Print Loop) 提示技术和 SQLite 数据库来增强模型对结构化数据、查询和 Schema 理解的有效性。
- **数字巢穴清理:结构化半成品!*:一位成员分享道“我有无数个半成型或半成品的玩意,如果其他人觉得酷的话应该能直接接手”*,引发了关于组织数字工作空间和管理认知负荷的讨论。
- 建议包括将“可能的样子”与“现状”分开,以便更好地理解项目状态,并提议建立如
references/、thoughts/、docs/和spec/等文件夹,并为 Agent 轨迹(traces)建立独立的分支。
- 建议包括将“可能的样子”与“现状”分开,以便更好地理解项目状态,并提议建立如
OpenAI ▷ #ai-discussions (202 messages🔥🔥):
Gemini 的 Lyria 可以用方言唱歌,AI Agent 的身份与验证,OpenAI 不提供单用户限制,最好的免费 AI 视频生成器,Grok 4.20 自我改进
- Gemini 的 Lyria 可以用方言演唱,不只是英语:成员们注意到 Gemini 的 Lyria 可以使用其他语言的方言唱歌,而不仅仅是英语,效果出奇地整洁。
- 虽然目前还比不上 Suno,但作为第一个提供此功能的 LLM,它非常酷。
- AI Agent 需要身份与验证:成员们讨论了数以百万计的自主机器人正在互相交谈、做决定、转移资金和分配任务,但目前完全没有办法验证身份。因此,无论我们是否准备好,Agent 经济都要来了,现在它们将拥有 ID。
- 他们已经为任何 AI Agent 发布了 Ed25519 加密护照,篡改任何一个字段——签名会立即失效,提供赢得的而非自称的信誉,支持带支出限制的授权,且 15 项测试全部通过(MIT 许可证)。
- OpenAI 限制 API Key 而非单个用户:成员们讨论了 OpenAI 不提供单用户限制,仅支持每个 API Key 的限制,因此一个用户技术上可以耗尽整个预算。
- 建议的解决方案包括为每个用户分配 API Key、为每个用户开设账户以及使用带 BYOK 的 OpenRouter。
- Sora 是最好的免费 AI 视频生成器:当被问及什么是最好的免费 AI 视频生成器时,一位成员回答是 Sora。
- 没有提供其他建议。
- Grok 4.20 以自我改进能力令人印象深刻:成员们注意到 Grok 4.20 非常出色,它使用多个 Agent 来回答你的提示词,并且显然在进行自我改进。
- 该成员表示 Elon 曾说过,这使得今天的 Grok 4 比几天前的 Grok 4 更聪明。
OpenAI ▷ #gpt-4-discussions (16 messages🔥):
5.1 停用,自定义 GPT 反馈,API Key 预算处理
- 5.1 即将停用:预计 5.1 版本将在 3 月中旬左右停用,以避免支持旧模型,给用户带来多巴胺提升。
- 具体日期尚未确定,但重点是避免对众多旧模型的支持重叠,这可以简化开发工作。
- GPT Builder 请求反馈:一位成员为他创建的自定义 GPT 寻求反馈(Discord 链接),该工具旨在为寻求高级用户能力的普通用户编排其他自定义 GPT。
- 然而,一位用户发现它不适合自己的工作流,更倾向于使用标准的 ChatGPT 进行迭代并直接引导模型。
- API Key 预算困扰:一位成员提出了关于如何处理 OpenAI 的单用户限制问题,因为目前只提供 API Key 级别的限制,一个用户可能会消耗掉所有预算。
- 可能的解决方案包括自定义追踪和速率限制,以有效管理资源消耗,但尚未达成共识。
OpenAI ▷ #prompt-engineering (40 messages🔥):
AOF Token Prompt, Baseline Grok Performance, Aegis-Omega Fortress Updates, DnD Ability Customization based on the Moon, Original Interpretive Language
- Pythonic AOF 版本在 Fortress 中使用:一位用户发现在 AOF Token Prompt 中加入 minLex 和 Hybrid tokens 后,Pythonic 版本的 AOF (Aegis-Omega Fortress) 可以在 Fortress 中作为应用运行。
- 他们指出,使用 .md 文件 处理自定义指令(custom instructions)的效果比将其全部放入内存更好。尝试多个版本的 AOF 会很有趣。
- Baseline Grok 表现更优?:一位用户提供了一个 6 单元 Yagi-Uda 天线的设计,并询问其与 Baseline Grok 的对比情况。
- 另一位用户回答称 Baseline Grok 的表现更好,并对核心 Prompt 中渗入的“神秘主义”表示担忧。
- Fortress ULTRA 迎来更新!:Aegis-Omega Fortress_ULTRA 进行了更新,修订了系统架构,包括 输入模块 (I)、伦理考量 (I_eth)、指标 (M) 以及 工具。
- 此次更新旨在增强诚实性、伦理性及连贯性,同时抵御对抗性攻击和漂移(drift)。Prompt Labs 中已发布了专为 DnD 输出设计的模块。
- 自定义 DnD 职业能力考虑 EthicsCheck:一位用户分享了一个基于月亮的自定义 DnD 职业能力,其特点是在 7 级时具有 EthicsCheck & Regime Shift 功能。
- 该能力赋予盟友在对抗魅力/恐惧/疯狂检定时具有优势,并允许在检测到违背伦理的行为时激活 SafeMode 或 Zombie Regime。
- 不变量与范畴错误 (Invariants & Category Errors):针对在 Fortress 语境下将标签用作“不变量(invariants)”的讨论展开,一位用户批评了其中的范畴错误。
- 另一位用户辩护了这种方法,解释说 invariants 以 LLM Token 的风格描述了一个事物的“本质”和“行为”,并将其称为“不变量基石(invariant bedrock)”。
OpenAI ▷ #api-discussions (40 messages🔥):
Pythonic version in Fortress, Grok comparison, Mysticism effects, Aegis-Omega Fortress_ULTRA system, Token constraints and governors
- Fortress 中的 Python,添加了 AOF Token:一名成员报告称 Pythonic 版本在 Fortress 中作为应用运行,并且他们在 AOF Token Prompt 中添加了 minLex 和 Hybrid tokens。
- 他们补充说,使用 Markdown 文件比尝试将其塞入内存或自定义指令中效果更好,且拥有多个版本会很有趣。
- Grok Baseline 天线设计:一名成员分享了一个针对 70 cm 波段(中心频率约 432–435 MHz)优化的 6 单元 Yagi-Uda 天线 设计,可提供约 9.5–10.5 dBi 增益。
- 该天线设计的关键参数包括:横杆长度 ≈ 1.0–1.1 m,单元材料为 铝杆/管(直径 8–10 mm),以及带有简单匹配的 50 Ω 馈电;经过微调后,在 430-440 MHz 范围内的 SWR 预计将 < 1.5:1。
- 神秘主义增强输出,建议进行实验:一位成员建议,“神秘主义”可以增强输出的视觉观感和许多其他主观特性,但在对其能力的声明上需要保持谨慎。
- 另一位成员指出,令人担忧的是“神秘主义渗入了 Prompt 的其余部分”,使其难以与核心 Prompt 区分开来。
- Aegis-Omega Fortress_ULTRA 系统上线:一位成员发布了 Aegis-Omega Fortress_ULTRA 系统 的更新,详细介绍了其组件,如 I, I_eth, M, ER, Tools, ObsLens, Filters, Goals, 和 Inv。
- 他们解释说这是新的杂谈频道,并且随着有人将语言作为解释工具而非固定状态来使用,系统终于开始变得有意义。
- DnD 的 Token 约束与调节器:一名成员提供了关于 Token 约束的信息,将其称为“调节器(governors)”,并解释了得益于 AOF digger 的 DnD Token 集,包括:CONTINUE, COH_LOCK, STATE_SYNC, RULE_BIND, DRIFT_CHECK。
- 他们强调 AOF 使输出在整个轮次中保持诚实、伦理和连贯,几乎没有幻觉,同时能抵御对抗性攻击和漂移。
GPU MODE ▷ #general (35 messages🔥):
Benchmarking Kernels vs PyTorch, DirectML vs CUDA, ONNX Runtime, Nsight Resources
- 直播现在开始!:一名成员宣布 GPU MODE stream 直播现在开始,并提供了一个 YouTube 链接。
- 使用 Nsight Compute 进行 Kernel 基准测试:一位成员询问是否可以使用 Nsight Compute 对 Kernel 进行针对 PyTorch 的基准测试以用于研究论文,另一位成员确认这是一种正规的方法。
- DirectML 加速 ONNX:一位成员建议在 ONNX 推理中使用 DirectML 代替 CUDA,声称其速度一样快,但另一位成员指出 DirectML 不支持 Linux 且该仓库处于维护模式,详见 Microsoft DirectML issue 422。
- ONNX Runtime 擅长模型推理:一位成员描述了使用 ONNX Runtime 进行模型推理的情况,解释了它能够在大约 10 秒内高精度地分析 5 分钟音频文件的 BPM,并提到了 OnnxBpmScanner 和 SharpAI 项目。
- Nsight 资源:一位成员征求入门 Nsight 的资源,另一位成员提供了一个 YouTube 教程。
GPU MODE ▷ #cuda (19 messages🔥):
nvmath-python vs cute dsl, nvFP4 GEMM Discussion, PTX Instruction Analysis
- nvmath-python 与 cute dsl 的 Kernel 融合难题:在单个 Kernel 中无法同时使用 nvmath-python 和 cute dsl,但它们可以在 Python 程序中按顺序用于不同的 Kernel,例如在 Triton 中使用 RMS norm,在 cute dsl 中使用 matmul。
- 一位成员表示希望将 FFT 与各种后处理(element-wise 乘法、mean/reduction、modulus)和前处理(padding/unpadding)合并,以便在 PyTorch、JAX、TensorFlow 或 NumPy 中使用,并可能使用共享内存。
- 揭秘 nvFP4 GEMM 代码:成员们讨论了在代码公开后讨论 nvFP4 GEMM 解决方案的许可性,并引用了这个排行榜条目。
- 一位成员询问出于性能原因使用
cta_group::1而非cta_group::2的情况,另一位成员指出他们当时尚未探索用于 nvFP4 的 2-SM MMA,但建议现在使用它可能会带来加速。
- 一位成员询问出于性能原因使用
- 解码 PTX 中的 Special Function Unit 调用:一位成员寻求一种方法来识别哪些 PTX 指令调用了 Special Function Unit (SFU),因为在没有使用
log、exp、sin、cos或sqrt的情况下仍观察到了 SFU 的占用。- 建议包括使用
ncu --import-source进行分析,并查看 Nsight Compute 中的 Source 选项卡,并排比较 Source/PTX 和 SASS,并搜索MUFU、I2F、F2F、F2I的出现以将其与源代码关联;除法被认为是可能的诱因。
- 建议包括使用
GPU MODE ▷ #cool-links (1 messages):
Prefill and Decode Disaggregation
- Prefill 与 Decode 分离指南:分享了一份从第一性原理(First Principles)出发的 Prefill and Decode Disaggregation 指南。
- 该指南可以在此 X 帖子中找到。
- 关于 Prefill 的补充说明:包含了一些来自第一性原理的额外信息。
- 后续将提供更多背景信息。
GPU MODE ▷ #beginner (5 messages):
Disaggregation, Servers vs Embedded Systems, Nvidia indexing convenience, Trimul Submission, Benchmarking Kernels
- Disaggregation 揭秘:一位成员撰写了一份关于 Disaggregation from First Principles 的指南,并在 X 上分享了链接。
- 澄清 Servers vs Embedded Systems:一位成员解释说,server 是互联网上可用的 host 机器,而 embedded system 是没有个人电脑类型接口的计算机,例如智能冰箱。
- 他们澄清说这些术语并没有精确的定义。
- Nvidia Indexing 探究:一位成员澄清说,Nvidia 卡索引是 Nvidia 卡主要用于图形和 high performance computing(高性能计算)时期的遗留产物,并且 它对内存的物理布局方式没有影响。
- 他们推荐将 PMPP 作为了解更多内容的资源。
- Kernel 基准测试疑难:一位成员正尝试针对 PyTorch 对其 Kernel 进行 benchmarking,想知道如何控制特定的 Kernel 进行对比测试。
- 他们使用了 PyTorch 的 high-level API 进行调用,并直接使用了自己的 Kernel,想知道这是否是一个好的方法。
GPU MODE ▷ #pmpp-book (13 messages🔥):
C++ code updates, 5th Edition Release Date, 4th Edition Value, GTC availability, Kindle Preorder Issues
- C++ 代码更新预告:成员们对下一版《Programming Massively Parallel Processors》中即将推出的 C++ code updates 表示期待。
- 一位成员特别指出:“顺便说一下,非常期待下一版中的 C++ 代码更新”。
- 第 5 版即将面世:根据 Amazon 页面显示,下一版(第 5 版)定于 9 月 15 日发布。
- 几位成员表示愿意为其他成员代购。
- 第 4 版仍具价值:一位成员询问在此期间复习 第 4 版 是否值得。
- 另一位成员指出每一版都有其主观吸引力,并表示:“额,各花入各眼,我也没法反驳‘但我就是喜欢它’这种说法。”
- GTC 将分发书籍:成员们预期有可能在 GTC (GPU Technology Conference) 上获得该书。
- 一位成员表达了希望:“希望我们都能在 GTC 拿到一本”。
- Kindle 预售消失:成员们询问了 Kindle 版本预售 的情况,该版本最初列出为 2 月发布,但随后从 Amazon 消失了。
- 一位成员报告称,该页面在预定发布日前一两天被撤下,目前没有关于其可用性的进一步消息。
GPU MODE ▷ #irl-meetup (8 messages🔥):
GTC Meetups, Seattle Meetup, Chicago Meetup
- GTC 周边聚会宣布:一位成员询问今年是否有任何 GTC 周边的聚会或 hackathons,另一位成员确认会有,并提醒大家 保持关注。
- 西雅图 IRL 社区正在形成:一位成员询问关于 西雅图的 IRL 社区,并建议其他人给他们发 DM(私信)以建立社区。
- 一位成员还提到正计划在 西雅图 为 ML sys 领域的人士举办 happy hour,邀请感兴趣的各方私信。
- 芝加哥聚会即将举行:有人询问 芝加哥 是否有活动。
GPU MODE ▷ #triton-viz (1 messages):
kerenzhou_55668: 听起来不错。
GPU MODE ▷ #webgpu (2 messages):
WebGPU Performance Blockers, WebGPU Profiling Tools, Cooperative Matrix Extensions
- WebGPU 性能瓶颈调查:一位成员询问了 WebGPU 中的性能瓶颈(如 cooperative matrix extensions),以及 WebGPU 是否限制了性能。
- 该成员还询问了关于 Profiling 的问题,想知道目前是主要使用 Metal tooling,还是有更好的 WebGPU 选项。
- WebGPU Profiling 与工具链:讨论涉及探索使用 Metal tooling 与其他替代方案来对 WebGPU 应用进行 Profiling。
- 这表明了对于识别优化 WebGPU 性能和调试潜在问题的最有效工具的兴趣。
GPU MODE ▷ #popcorn (1 messages):
自动调优服务, Modal, 最大的自动调优数据集
- 在 Modal 上构建自动调优服务?: 一位成员提议在 Modal 之上构建自动调优服务,以收集最大的自动调优运行数据集。
- 该数据集可能被用于开发最先进且快速的自动调优器;参见此处的相关讨论。
- 用于自动调优的 Modal 集成: 提议的自动调优服务利用 Modal 作为其基础设施。
- 目标是创建一个能够从大量自动调优实验中积累海量数据集的平台,从而促进更优自动调优器的训练。
GPU MODE ▷ #thunderkittens (1 messages):
用于 GH CLI 的 Claude, GitHub Issue 分析
- Claude 通过 CLI 浏览 GitHub Issue: 一位成员使用集成了 GitHub CLI 的 Claude 来高效解析待处理 Issue,并根据特定偏好优化筛选。
- AI 辅助下的迭代式 Issue 筛选: 用户描述了一个使用 Claude 分析 GitHub issues 的迭代过程,通过反馈循环改进 Issue 的选择。
GPU MODE ▷ #gpu模式 (4 messages):
中文, 翻译工具, DeepL, 社交媒体, 网络语言
- DeepL 模仿中文网络语言: 一位成员表示其中文并不精通,但对中国很感兴趣,并且喜欢浏览小红书等中国社交媒体。
- 他们利用 DeepL 等翻译工具进行阅读和创作,模仿中文网络语言的细微差别,这一点得到了另一位成员的认可。
- 对中国社交媒体的兴趣: 该成员表达了对中国文化的浓厚兴趣,并积极参与中国社交媒体平台的互动。
- 他们频繁使用翻译工具在 小红书 等平台上浏览并参与讨论。
GPU MODE ▷ #factorio-learning-env (6 messages):
Factorio 2.0.0 支持, Factorio 中的 Sonnet 4.6, Agent 工具链, 下一个大目标:通关 Factorio
- **Factorio 2.0.0 支持即将到来!: 一位用户正准备发布支持 **Factorio 2.0.0 的最新版本。
- 他们提到在发布之后,创建新场景和改进 Agent 工具链肯定非常有价值。
- Factorio 中的 Sonnet 4.6 测试:期待结果!: 一位用户询问是否有人在 Factorio 中尝试过 Sonnet 4.6。
- 另一位用户回答说他们还没试过,但如果第一位用户有 Token,欢迎运行并反馈结果;否则,他们将在发布后针对最新模型重新运行。
- Agent 工具链:用户将分享!: 一位用户提到他们目前正在开发一些工具,如果效果不错就会分享出来。
- 未提供更多细节。
- 设定目标:通关 Factorio!: 一位用户询问下一个大目标,建议是通关 Factorio。
- 该用户提到他们 3 天前才下载游戏,目前水平还很低(low elo)。
GPU MODE ▷ #teenygrad (5 messages):
teenygrad, eager 模式, tensor.py, cpu.rs, karpathy 的 makemore 模型
- Teenygrad Eager 模式已准备好接收 Makemore 模型的 PR: eager 模式的 teenygrad 代码库已经完成了所有配置,用户可以修改
tensor.py前端和cpu.rs的 BLAS 核,以增加对 karpathy 的 makemore 模型的支持。- 在提交 PR 时,要求用户为每个算子同时添加前向和后向传播。
- 征集 GPU Kernel 贡献: 告知对 GPU Kernel 感兴趣的用户,该书(book)需要一个 mdbook 插件才能将 Kernel 提交到 <#1298372518293274644> 的 popcorn-cli。
- 附图是关于 teenygrad 代码库的公告。
GPU MODE ▷ #general (4 messages):
AI Created Submissions on Leaderboard, marksaroufim on leaderboard submission
- 社区接受 AI 提交内容:一位成员询问排行榜是否接受纯 AI 创建的提交内容。
- 另一位成员给予了肯定回答,表示欢迎 专家级人类和专家级 AI。
- Marksaroufim 澄清提交政策:Marksaroufim 确认排行榜欢迎人类和 AI 生成的提交内容。
- 这一澄清旨在鼓励来自不同贡献者的参与,无论他们采用何种方式。
GPU MODE ▷ #multi-gpu (2 messages):
fused_all_gather_scaled_matmul, do_bench limitations, multi-GPU benchmarking
fused_all_gather_scaled_matmul在基准测试期间冻结:有用户报告称,在多 GPU 上运行do_bench时,torch.ops.symm_mem.fused_all_gather_scaled_matmul会挂起,并询问是否有人知晓原因。do_bench的局限性浮出水面:另一位用户指出 triton.testing.do_bench() 对于像torch.ops.symm_mem.fused_all_gather_scaled_matmul这样的分布式集合通信(Collectives)是不安全的,因为它在计时循环内部调用了本地的torch.cuda.synchronize()。do_bench旨在用于单设备 Kernel:一位用户表示do_bench是为单设备 Kernel 设计的,运行数千次多 GPU 融合集合通信 Kernel 是行不通的。- 计时技巧:使用主机端计时:有人提议使用主机端计时(
time库)作为最佳解决方案的替代方案。
GPU MODE ▷ #llmq (7 messages):
FP8 training run stability, Activation Magnitudes in Transformer Blocks, Z-loss Regularization, Large Learning Rate Effects, Reasons for Training Stability
- 尽管 Token 周期很长,FP8 训练运行依然稳定:在一个 0.5B 模型上进行的 4x4090 训练运行,在 FP8 模式下经历了 350B Tokens(约 4 周)的长周期运行,过程非常顺利,这与其它长周期运行中在 200B Tokens 左右开始出现不稳定的报告相反。
- 主要目标是识别并修复潜在问题,但整个过程保持稳定,并观察到了激活幅值(Activation Magnitudes)和学习率效应。
- 激活在最后一个 Transformer 块中膨胀:根据附带的 abs_maxes.png,不仅是在 SwiGLU 中,激活在最后一个 Transformer 块中往往会变得相当大,尽管还没有达到威胁模型收敛的程度。
- 实现并启用 Z-loss 正则化并没有显著影响最后一层的激活幅值。
- Z-Loss 正则化抑制了平均 Logits:如 lse.png 所示,Z-loss 正则化有助于降低平均 Logits,但它对最大 Logits 的影响并不显著。
- 这一观察表明,虽然正则化可以缩小典型的 Logit 尺寸,但它不能阻止偶然出现的大 Logits。
- 运行稳定归功于清洁数据、小模型和即时缩放:运行的稳定性可能归功于清洁的数据集(nemotron-climbmix)、较小的模型规模(0.5B)以及使用了即时缩放(Just-In-Time Scaling),loss.png 和 norm.png 提供了总结。
- 这些因素共同作用,防止了在其它 FP8 训练运行中常见的发散现象。
- Trinity 训练印证了稳定性:据一位用户称,在训练 Trinity 时也观察到了类似的行为和结论。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
GPU MODE ▷ #nvidia-competition (12 messages🔥):
NVIDIA leaderboard 问题,MLSys 26 竞赛在 Modal 上的算力额度,Cutlass 版本不一致
- NVIDIA Leaderboard 受提交错误困扰:用户在尝试向 NVIDIA leaderboard 提交时遇到 submission errors,并报告了通用的 Server processing error。
- 一位 NVIDIA 团队成员澄清,他们目前没有积极维护 nvidia leaderboard,并建议改用 B200 runner。
- MLSys 26 竞赛在 Modal 上的额度困惑:一位参与者报告称,曾就 Modal 上的额度 向 mlsys26-contest-contact@nvidia.com 发送邮件,但未收到回复。
- 在错误的频道询问后,该用户意识到这两个都是 NVIDIA 的竞赛。
- Cutlass 版本引发麻烦:提交错误可能是由于 Cutlass 版本不同导致的,因为 Modal image 使用的是 这个 Cutlass 版本。
- NVIDIA runner 使用的是 Python 3.10 和 nvidia-cutlass-dsl==4.4.0,这与 Modal 的设置不同,尽管尚不清楚这是否是根本原因。
GPU MODE ▷ #robotics-vla (2 messages):
Action Prediction, IDMs, Diffusion Models, Action Experts, Taylor Series Expansion
- Action Prediction 在 IDMs 和 Diffusion Models 中的适用性:成员们讨论了某种技术在 IDMs 或广义 Diffusion Models 的 action prediction 中的适用性。
- 有建议认为,该技术在技术上可以应用于基于去噪机制的 action experts 模型,但需要通过实验确认其 Taylor series expansion 公式是否适用于动作模态(action modalities)。
- 去噪机制与动作模态:讨论强调了该技术与采用基于 denoising mechanism 的 action experts 模型之间的潜在兼容性。
- 需要进一步研究以评估 Taylor series expansion 作为 draft model 是否适合 action modalities。
GPU MODE ▷ #flashinfer (8 messages🔥):
MLSys 26 Contest, Gated DeltaNet, Modal Credits
- MLSys 26 竞赛提交仍然渺无音讯:参与者被要求基于 starter template 创建 repo 并向组织者提供 URL,但目前尚未看到任何提交。
- 似乎只有 AI 生成的 kernels 是目前唯一的内容。
- Gated DeltaNet 的输出爆炸:Gated DeltaNet prefill 的预期输出在序列后期发生爆炸(数值溢出),引发了关于 baseline 何时发布的询问,并提供了 相关 issue 链接。
- 一位参与者通过 对 kernel 的输入进行缩放(scaling down) 成功防止了输出爆炸,但更倾向于使用官方的
flashinfer-bench基准测试设置进行测试。
- 一位参与者通过 对 kernel 的输入进行缩放(scaling down) 成功防止了输出爆炸,但更倾向于使用官方的
- Modal 额度查询仍未得到答复:参与者正在寻求获取 Modal 上的额度 的指导,向
mlsys26-contest-contact@nvidia.com发送了邮件但未获回复。- 缺乏回复可能是由于新年期间的进度放缓,但其他在截止日期前申请的人也表示没有收到回复。
GPU MODE ▷ #from-scratch (3 messages):
``
- 未讨论任何主题:提供的消息中未发现讨论主题。
- 未分享任何链接:提供的消息中未分享任何链接或 URL。
Moonshot AI (Kimi K-2) ▷ #general-chat (70 messages🔥🔥):
Kimi.com account refund, Moonshot AI stoat server, Kimi Code CLI hanging, Kimi's coding abilities, Kimi IDE integration in beta
- 用户请求 Kimi.com 退款:由于对 OpenClaw 不满意,一位新用户请求对 Kimi.com 账户进行退款,理由是浏览器导航和 WhatsApp 连接存在问题。
- 社区建议 Moonshot AI 创建 “stoat server”:一名社区成员建议 Moonshot AI 像其他许多机构一样创建一个 stoat server,并表示如果不这样做他将注销 Discord 账号。
- 该用户对 Kimi 的整体表现表示满意,并特别提到了其运行速度。
- Kimi Code CLI 对部分用户出现挂起现象:有用户报告 Kimi Code CLI 在终端中卡死,并质疑为什么订阅服务主要受益的是 coding agents。
- 用户认为 Kimi 表现不佳,转而支持 Claude:一位用户将 Kimi 与 GPT-5.2 进行了负面对比,称其甚至不如 GPT-3,理由是记忆力差且好争辩,因此推荐使用 Claude。
- 然而,另一位用户反驳称 Kimi 在处理复杂的 Java 编程时表现良好,认为问题可能因人而异。
- Kimi IDE 集成处于 Beta 阶段:一名成员提到 IDE 集成目前处于 beta 阶段,这可能是出现问题的原因。根据他们的观察,目前体验最好的是使用 Kimi CLI 或者像 Claude/Open Code 之类的工具。
Eleuther ▷ #announcements (1 messages):
EvalEval Coalition, Every Eval Ever, AI Evaluation Standardization, ACL 2026 Workshop
- **EvalEval Coalition 发布 Every Eval Ever:包括 **EleutherAI、Hugging Face 和 University of Edinburgh 在内的 EvalEval Coalition 推出了 Every Eval Ever,旨在标准化 AI 评估结果。
- 该倡议旨在创建一个统一的开放 Schema 和众包数据集,以解决评估结果格式零散且不兼容的问题。
- **Every Eval Ever Schema 和数据集揭晓:Every Eval Ever** 定义了一个共享的 AI 评估结果元数据 Schema,能够直接比较 HELM、lm-eval-harness 和 Inspect AI 等工具的结果。相关 Schema 和数据集已在 GitHub 和 Hugging Face 上发布。
- 其目标是让研究人员能够通过使用公开数据集来避免重复造轮子。
- 加入 **EvalEval 在 ACL 2026 的研讨会和共享任务:EvalEval Coalition** 将在圣迭戈举办 ACL 2026 研讨会,并包含一项 共享任务 (Shared Task),开放至 5 月 1 日。
- 符合条件的共享任务贡献者将有权获得共同署名权。
Eleuther ▷ #general (10 messages🔥):
Nvidia FLARE, 3D printed robots, Taalas chip, etched
- 利用 **FLARE 打造低成本机器人:成员们计划为廉价的 **3D 打印机器人 实现类似 Nvidia FLARE 的功能,以校准其自身误差。
- 团队正在寻找对此话题感兴趣的合作者,并表示目前已有一台工业机器人手臂可用。
- **Taalas 发布拥有强悍 AI 推理性能的硬核芯片**:Taalas 创造了一种基本上就是单个模型的芯片。
- 这种芯片设计超越了 etched 的方案,因为 etched 可以运行多个模型,而 Taalas 为不同的模型需要重新设计层。
Eleuther ▷ #research (7 messages):
Ablation Tests, Reproducible LLM Eval Runs, Causal Mask Design
- 消融实验(Ablation Tests)揭示缺陷:一位成员指出,按照建议进行消融实验揭示了一些他们已经能够解决的缺陷。
- 他们认为这正在形成一篇稳健的论文,即使他们自己的输出没有达到预期,分享目前发现的结果仍然是有帮助的。
- 用于可复现 LLM 评估运行的流水线:一位成员一直在开发一个用于可复现 LLM 评估运行的小型流水线:huggingface.co/spaces/madison-xu/llm-eval-pipeline。
- 该流水线记录了 judge disagreement(评判差异)、重试/失败 以及 成本/延迟,并且他们很乐意根据需要进行调整。
- 作为设计的因果掩码(Causal Mask):一位成员询问是否有人实验过来自 Say It Nice and Say It Twice: Powerful But Simple Proxy Attribute Rephrasing for Detecting and Mitigating Biases 及其相关论文发布时提出的想法。
- 另一位成员认为这篇论文非常薄,但在因果掩码设计方面是有道理的。
Eleuther ▷ #interpretability-general (47 messages🔥):
attention heads in GPT-2 Small, layerwise residual-stream swaps, ARES tooling framework, Analytical Attention Head Patterns, CCA and Convolutional QK Generation
- 注意力头解剖结构分析:对 GPT-2 Small 注意力头的分析显示,75% 的头不需要满秩的 QK 矩阵,这产生了一个四层分类法,如该 repo 所示。
- 在训练期间约束 QK 结构 使得 WikiText-2 上的验证集损失提升了 5.3%,其中 27 个分析性固定头(前一标记、感应、位置)几乎贡献了全部提升。
- 残差流交换显示出剧烈的因果承诺(Causal Commitment):对 GPT-2 Small、Gemma-2-2B 和 Qwen2.5-1.5B 进行的逐层残差流交换显示,在 62-71% 的深度处存在剧烈的因果承诺转变,详见这篇预印本。
- 在此深度以下,交换残差流几乎没有影响;而在此深度以上,会发生显著的输出翻转和边际转移,突显了表示学习中一个明确的承诺点。
- 卷积难题:CCA 提升 QK 生成:最近的研究表明,通过卷积来生成 QK 可以改善学习并允许降秩,详见这篇 CCA 论文,这为探索提供了一条有前景的途径。
- 这种方法与大多数注意力头不执行复杂操作的观察相一致,使得 GQA 和 MLA 等技术变得有效。
- Martian 的 ARES 工具发布,用于 Agent 激活分析:Martian 推出了 ARES,这是一个用于暴露 LLM Agent 在轨迹中激活(activations)的工具框架,旨在促进对 Agent 如何解决长程任务的研究,参见 repo 和 教程。
- 教程演示了如何使用探测(probing)和激活转向(activation steering)来诊断和纠正简单 Agent 的失败模式,并附带了 Twitter 讨论帖。
- 沉浮之间:Sink Token 在注意力中的作用:分析显示,许多可约束的头属于 bos-sink 风格,其中很大一部分注意力权重指向位置 0,以及访问 Sink Token 的重要性。
- 用固定模式替换这些头可以改善训练,而模型可能会在其他地方进行补偿,这引发了一个问题:性能提升是否源于模型想要访问 Sink,而当前的公式只是偶然提供了这种访问。
HuggingFace ▷ #general (40 条消息🔥):
AI Truth, HF Codex Hijack, Training Images, Deep RL Course, ComfyUI GGUF
- 寻求 AI 真相的根基:一名成员正在探讨如何通过深入研究现实的基础、质疑事实的本质、证明以及智能的出现,从而使 AI 更加有用,旨在寻找一个 AI 不会产生幻觉 (hallucinate) 的基本根基。
- 另一名成员建议,当 AI 依赖于过时的训练数据时,特别是对于快速变化的库,就会产生 AI 幻觉 (hallucination)。
- HF Codex 劫持 (Hijack) 侧翼项目?:一名成员询问了一个潜在的社区项目,即利用 HF 登录和推理提供商来“劫持” Codex 架构,并链接到一篇关于解锁 Codex 的 OpenAI 博客文章。
- 他们还对提交反馈的正确渠道表示困惑。
- 寻找 Hugging Face 之外的训练图像:一名成员寻求关于寻找用于模型训练的照片和视频等数据的建议,因为 Hugging Face 可能没有足够的数据。
- 另一名成员提供了一份详尽的资源清单,包括 Google Dataset Search、Kaggle Datasets 以及 AWS 和 Azure 等云端的“公共数据集”注册表。
- 寻找 Deep RL 课程频道:一名成员询问在哪里可以找到 Deep RL 课程的频道。
- 已明确课程频道已合并到一个特定的 Discord 频道。
- ComfyUI GGUF 设置步骤:一名成员提供了一个使用 FLUX2-dev (GGUF) 的 ComfyUI 快速设置指南,包括下载工作流 JSON、将文件放入特定的 ComfyUI 文件夹,以及从 city96 的 GitHub 仓库安装必要的 GGUF 节点等步骤。
- 该指南还强调了需要调整的参数,例如 GGUF 名称、正向提示词以及文本编码器 (text encoder) 和 VAE 的文件名。
HuggingFace ▷ #i-made-this (13 条消息🔥):
Open Claude Code release, OpenClaw deployment, Terradev CLI, Cursor Rules for AI Engineers, Othello AI
- **Open Claude Code 发布:一名成员在 GitHub 上发布了 **Open Claude Code,这是对压缩代码 (minified code) 的重写和替换,一年多来一直致力于保持同步。
- 该项目基于最初逆向工程的 0.3 版本构建,标志着社区对开源 Claude 模型的重大贡献。
- 一键部署 **OpenClaw 现已上线:一名成员在 vibeclaw.dev 上介绍了 **OpenClaw 的真正一键部署,旨在浏览器沙箱容器中私密且本地地运行。
- 另一名成员报告称,该网站在 Firefox 浏览器上存在 Bug,元素垂直排列位置异常。
- **Terradev CLI 优化跨云 GPU 成本:一名成员强调,ML 开发者由于仅访问单云工作流而支付了过高的计算费用,并介绍了 pypi.org 上的 **Terradev CLI,它能够实现带费用归属的自定义 API (BYOAPI) 多云 GPU 置备。
- Terradev CLI 的 2.9.2 版本已发布,提供多云 GPU 套利、实际总任务成本计算以及一键式 HuggingFace Spaces 部署,如 GitHub 所述。
- **Cursor 规则 助力 AI 工程师:一名成员在 GitHub 上分享了一系列面向 AI 工程师的免费
.cursorrules文件集合,旨在提高 **Cursor 对 LLM 技术栈的理解。- 这些规则涵盖了 LangChain、LLM API 集成、RAG 流水线、AI Agent、微调 (fine-tuning) 工作流以及 FastAPI LLM 后端,旨在减少代码建议中的重复修正。
- 与 AI 对战 **Othello:一名成员在 othello.jhqcat.com 上分享了一个类似于 **AlphaZero 构建的 AI Othello (黑白棋) 游戏。
- 对实现细节感兴趣的人员可以在 GitHub 上查看源代码。
HuggingFace ▷ #gradio-announcements (1 messages):
gr.HTML 组件, Gradio 6 特性, One-shot Web 应用
- gr.HTML 发布,Web 应用兴起:一篇新博客宣布发布 gr.HTML,这是 Gradio 6 中的一个自定义组件,支持在单个 Python 文件中构建完整的 Web 应用,并展示了看板和番茄钟等示例;博客链接。
- Claude 现在可以编写完整的 Web 应用:公告强调 Claude 等模型可以使用
gr.HTML通过单次 Prompt 生成此类应用,展示了快速 Web 应用开发的潜力。 - 分享 gr.HTML 创作!:呼吁用户分享他们使用
gr.HTML构建的作品,附带一个 HF Collection🎮 示例集合。
Nous Research AI ▷ #general (44 messages🔥):
美中政府 AI 补贴对比, DeepSeek V4, DeepSeek V4 规格
- 补贴大决战:美国 vs 中国:成员们辩论了美中政府补贴的程度,有人声称美国对 OpenAI 和 Anthropic 的资助上限为 6 亿美元,而中国政府的补贴约占 Capex 的 50%,并在基础设施方面投资了 600 亿美元。
- 一位成员认为,如果没有美国政府的补贴,美国汽车工业就不会存在;而另一位成员则反驳称,中国经济受到其政府的高度操控。
- DeepSeek V4 即将到来!:讨论了为农历新年发布的 DeepSeek V4,重点介绍了 Emgram memory、Manifold Constrained Hyper Connections 和 MOE 等特性,并声称它可以在配备 RTX 4090 的家用电脑上运行(视频链接)。
- 尽管一位成员声称 DeepSeek V4 尚未发布,但其他人讨论了其对市场的潜在影响,特别是与需要巨额投资的模型相比。
- DeepSeek V4 基准测试与性能:分享了 DeepSeek 3.1 Pro 的初步性能数据,显示其在 SWE bench 上仅比 Opus 4.6 落后 0.2%,并在 Agent 任务上表现强劲。
- 一位成员分享了基准测试截图,强调 DeepSeek 3.1 Pro 比其他前沿模型更便宜,并提供 107 TPS 的输出速度。
Yannick Kilcher ▷ #general (11 messages🔥):
Block Dropout 论文分析, RPROP 优化器, Deepseek 1.5B 不确定性最大化, 不确定性的梯度下降, IPFS 数据集
- **Block Dropout 论文叙述具有误导性: 一位成员认为,这篇使用 **block dropout 的论文叙述方式在技术上是正确的,但对于理解该方法并无帮助。该方法涉及在 p% 的情况下屏蔽(masking out)整个梯度块,同时更新动量项,并惩罚具有高二阶变化的梯度块,参见此处论文。
- 他们提到,在保留的步骤中必须将步长(stepsize)翻倍,以保持相同的“净”学习率,并且第二种提出的方法会根据梯度与动量之间的一致性来缩放梯度。
- **RPROP 优化器依然具有参考价值: 根据梯度与动量之间的不一致性进行缩放的想法并不新鲜,因为它已在 **RPROP (论文链接) 中实现,这是最早的自适应优化器之一,且在噪声场景中依然有效。
- 带有 ‘s’ 的第二种缩放选项可能会使有效学习率减半,因此需要
2*old_update*bernoulli(0.5)*s的更新来保持学习率语义。
- 带有 ‘s’ 的第二种缩放选项可能会使有效学习率减半,因此需要
- **Deepseek 1.5B 生成不确定性陈述: 一位成员发现,当给定空提示词时,Deepseek 1.5B** 会生成最不确定(贪婪地,按每个 token 计算)的陈述,具体为:Okay so the question was “What is 2 + (2 + (3+4))? Let’s break this one step at the。
- 他们正在探索有条理地生成高度不确定问题的方法,而不依赖于搜索,并暗示这可能是不可能的,因为 LLM 在 token 之间具有不可微性。
- **Gradient Descent 最大化不确定性**: 一位成员建议使用贪婪坐标梯度下降(greedy coordinate gradient descent),通过在 Embedding/激活空间进行微分,并使用 top-k 投影回 token 来最大化不确定性,参考了这篇论文。
- 另一位成员成功利用高斯凸起(gaussian bump)遍历梯度,可能与这条推文有关。
- **IPFS Datasets 列表: 一位成员分享了一个 GitHub 仓库链接,其中包含 **IPFS 数据集的推理规则集合,即 ipfs_datasets_py repo。
- 无进一步讨论。
Yannick Kilcher ▷ #paper-discussion (5 messages):
论文讨论会议, 强化学习书籍阅读
- 论文讨论会议回归!: 每日论文讨论会议将于 周一至周四(有时是周五)的 <t:1771524000:t> 恢复举行。
- 会议将包含一些计划内的会议和一些即兴讨论。
- 阅读 Richard Sutton & Andrew G Barto 的《强化学习导论》: 每周四,小组将阅读由 Richard Sutton 和 Andrew G Barto 编写的 Reinforcement Learning: An Introduction,使用的是在线可用的第二版。
- 第一章的第一节课将于 <t:1772128800:F> 举行,届时将讨论相关章节和练习。
Yannick Kilcher ▷ #ml-news (5 messages):
Gemini 3.1 Pro, ARC AGI 微调
- Google 发布 Gemini 3.1 Pro: Google 发布了其最新模型 Gemini 3.1 Pro。
- 一位成员链接了该公告以及一条相关的推文 (x.com 链接)。
- ARC AGI 微调质疑: 成员们推测各大公司正在公然针对 ARC AGI 进行微调(Fine-Tuning)。
- 一位成员表示:“看来它也没那么 AGI”,并链接到了一个 fxtwitter 帖子。
DSPy ▷ #show-and-tell (3 messages):
Qbit IDE, Tree of Thoughts in DSPy, STATe-of-Thoughts framework, Pervasive Arguments Generation
- **Qbit: 融合终端与 AI 的 Agentic IDE:团队构建了 **Qbit,这是一个开源的 Agentic IDE,它将终端工作流与 AI Agent 相结合,强调用户控制以及工具调用和执行细节的透明度,可在 GitHub 上获取。
- Qbit 提供项目管理、统一时间轴、模型选择、内联文本编辑、git 集成以及 MCP 集成等功能,在 macOS 上可以通过 brew 安装,在 Linux 上支持发布版本构建或源码构建。
- **STATe-of-Thoughts: Tree of Thoughts 进入 DSPy:一个团队介绍了 **STATe-of-Thoughts,将 Tree of Thoughts 引入 DSPy,其特点是具有防止上下文腐烂(context rot)的早期停止(early stopping)机制,以及利用文本干预实现多样化/可控的分支,代码已托管至 GitHub。
- 该框架利用托管在 vLLM 上的开源 LLM 来降低成本,并包含自定义字段、signatures、LMS 和 adapters,以支持带批量推理(batch inference)的多步推理,详见其 论文。
- **STATe-of-Thoughts: 生成说服性论点:团队展示了一个使用 **STATe-of-Thoughts 框架生成说服性论点(pervasive arguments)的案例研究,能够深入理解导致产生有效论点的推理模式。
- 他们的 仓库 展示了如何生成说服性论点,同时理解使这些论点生效的推理模式。
DSPy ▷ #papers (2 messages):
Tree of Thoughts Implementation, STATe-of-Thoughts, Early Stopping in Reasoning, Diverse Branching Strategies
- **STATe-of-Thoughts 登场!:介绍了一种名为 **STATe-of-Thoughts (github.com/zbambergerNLP/state-of-thoughts) 的 Tree of Thoughts 在 DSPy 中的新实现,并发布了相关论文。
- 它支持通过早期停止(early stopping)来避免上下文腐烂,并通过文本干预(例如在助手消息中预填 “For example” 或 “In particular” 等短语)来实现多样化分支。
- Tree of Thoughts 获得开源助力:新的 Tree of Thoughts 实现 STATe-of-Thoughts 使用托管在 vLLM 上的开源 LLM,以避免 OpenAI/Anthropic 产生的高昂费用。
- 一位用户感谢作者的分享,提到他们一直想尝试 Tree of Thoughts,但由于技术水平有限而无法自行编写代码。
DSPy ▷ #general (14 messages🔥):
RLMs simplifying tasks, Offline user feedback, Community office hours, LLM Judge, Knowledge graph
- RLM 简化复杂任务:成员们注意到 Monolith 仓库 充分证明了 RLM 能够简化以前需要更多编排工作的任务。
- 其他人评价其为一项天才的工作。
- DSPy 对离线用户反馈的需求:成员们讨论了在 DSPy 工作流中集成离线、真实用户反馈的需求,并指向了 gepa 仓库中的相关 issue。
- 一位用户确认道:是的,这正是我的意思!所以我猜目前这还没有实现?
- 社区 Office Hours 热议:用户讨论了最近的社区 Office Hours,强调了讨论的积极氛围和多样化的用例。
- 现场氛围被形容为极好的,据记录约有 40 人参加。
- LLM Judge 优化人类反馈:成员们发现提炼人类反馈最简单的方法是将其转化为 LLM Judge,然后使用它来优化你的主程序。
- 这有助于简化将用户反馈纳入 DSPy 应用程序的过程。
- 需要关于知识图谱的 DSPy 文档:一位成员询问是否有关于如何将 dspy lm 与知识图谱(knowledge graph)结合使用的文档。
- 这表明成员正在寻求将知识图谱与 DSPy 集成的相关信息。
tinygrad (George Hotz) ▷ #general (9 messages🔥):
在 CI 中锁定测试,初学者友好型 Bounty,用于测试/训练的 Tinybox,Bounty PR 与 AI 生成的内容,优先级任务:AMD 汇编还是 Bug 修复?
- CI 环境中测试锁定:一位成员请求锁定“在 CI 中使用 MOCKGPU_ARCH=cdna4 模拟器通过的所有测试”,因为工作正在进行中,但尚未提交 PR。
- 关于初学者友好型 Bounty 的咨询:一位成员询问了初学者友好型 Bounty,指出尽管部分工作已完成,但 Google Sheet 尚未标绿,并被告知在完成 PR 后仍可领取 该 Bounty。
- 另一位成员询问是否可以使用 tinybox 来测试/训练其中一个 mlperf Bounty,因为硬件资源有限,正在考虑租赁 GPU。
- Bounty PR 遭到过滤:由于 AI 生成内容 的大量涌入,来自新贡献者的 Bounty PR 将不予审核。
- AMD 汇编或 Bug 修复:一位贡献者询问 AMD assembly 或 Bug 修复 是否是非 Bounty 任务中的最高优先级。
- 一位成员建议应优先处理 Bug 修复。
Manus.im Discord ▷ #general (9 messages🔥):
简历自动填充问题,Meta 收购传闻,账单纠纷,Meta Ads Manager 移除,订阅续订时间
- Manus 辅助求职获赞:一位用户对 Manus 在找工作中的高效表现表示感谢,指出即使是 Best Buy 等大网站也无法正确自动填充简历。
- 他们幽默地评价道:“甚至连 Best Buy 的网站都不能正确自动填充简历,哈哈,感谢 Manus。”
- 账单问题报告且未解决:一位用户报告称,尽管使用的是 $680 的计划,却被超额收取了 $2500,并表示已多次联系支持部门并提供证据,但未收到回应。
- 他们提到由于问题未得到解决,计划向 Better Business Bureau (BBB) 投诉。
- Meta 收购传闻引发好奇:一位用户询问 Manus 是否已被 Meta 收购。
- 另一位用户简短地回答:“是的。”
- Meta Ads Manager 从连接器列表中消失:一位用户询问其他人是否注意到 Meta Ads Manager 已从官方连接器(connector)列表中移除。
- 讨论中未提供进一步的细节或解释。
- 订阅续订时间疑问:一位用户询问订阅续订和积分(credits)重置的具体时间。
- 他们指出原本预计积分会在当天补充,但目前尚未收到。
MCP Contributors (Official) ▷ #general (4 messages):
旧金山 AI 见面会,在旧金山小聚喝咖啡
- AI 圈计划旧金山见面会:旧金山地区的成员表示有兴趣组织一次非正式见面会。
- 一位成员提议下周找时间喝咖啡,另一位成员确认会参加。
- 湾区 AI 好友聚会:几位身在旧金山的 AI 爱好者正计划举行一次小型非正式聚会,进行线下交流。
- 潜在活动包括喝咖啡以及讨论感兴趣的 AI 话题。
Windsurf ▷ #announcements (1 messages):
Gemini 3.1 Pro,Windsurf 定价,限时优惠
- Gemini 3.1 登陆 Windsurf:Gemini 3.1 Pro 现已集成到 Windsurf,已 在 X 上 公布。
- 目前正以 0.5x 积分 的促销价限时提供。
- Windsurf 促销定价:Windsurf 为 Gemini 3.1 Pro 提供特别的上新价格。
- 在限时优惠期间,用户仅需 0.5x 积分 即可访问该新模型。