AI News
Nano Banana 2(即 Gemini 3.1 Flash Image Preview):新的 SOTA 图像生成模型
Google 和 DeepMind 发布了 Nano Banana 2(即 Gemini 3.1 Flash Image Preview),这是一款已接入多个 Google 产品的领先图像生成与编辑模型,具备 4K 超分、多主体一致性 和 实时搜索条件生成 等特性。评测显示,它在文生图任务中排名第 1, 且价格很有竞争力。此外,Agent 式编程也在继续推进,相关模型包括 GPT-5.2、 GPT-5.3 Codex、Opus 4.6 和 Gemini 3.1;与此同时,微软的 Copilot Tasks 引入了任务委派能力。Claude 模型也开始推出持久记忆功能,但互操作性挑战仍然存在。
最佳图像模型回来了!
2026/2/25-2026/2/26 的 AI 新闻。我们为你检查了 12 个 Subreddit、544 个 Twitter 账号 和 24 个 Discord(263 个频道、12920 条消息)。预计节省阅读时间(按 200wpm 计算)为 1283 分钟。AINews 网站可以搜索所有往期内容。提醒一下,AINews 现在已成为 Latent Space 的一个板块。你可以选择加入/退出不同的邮件发送频率!
先恭喜 Perplexity on Computer ,以及它未来将在数亿部三星手机上取代 Bixby 成为默认 AI;不过这些更偏向消费级新闻。
今天 AI 工程师立刻就能用上的新闻是 Nano Banana 2,其正式名称是 3.1 Flash Image。最大的看点是价格:根据 Arena 和 ArtificialAnalysis,它被评为全球第一的图像模型,但价格却只有一半(生成价格为 $67/1000 张图,而 Nano Banana Pro 为 $134/1000 张、GPT Image 1.5 为 $133/1000 张;编辑价格方面,FLUX.2 [max] 为 $140/1000 张图)。
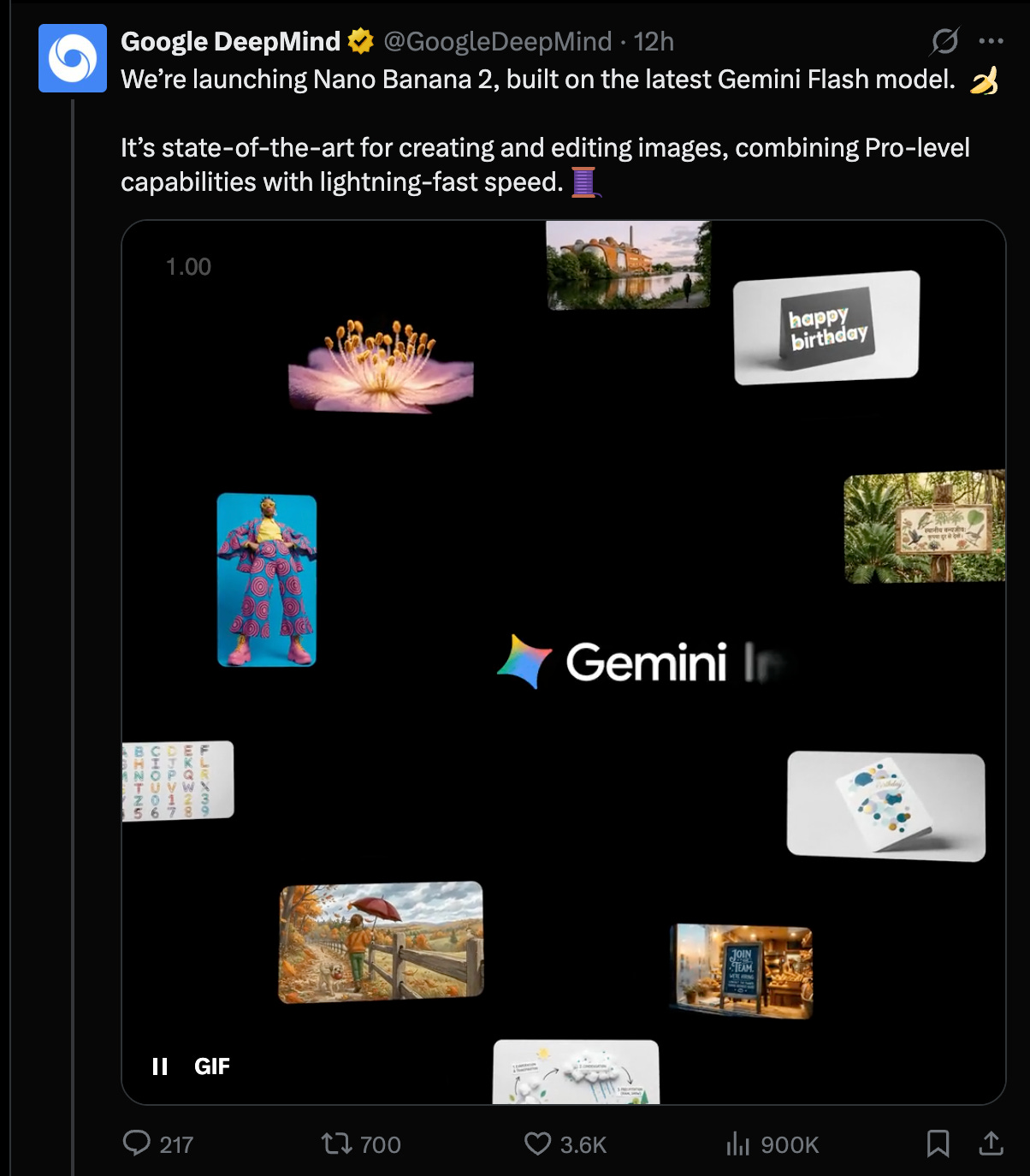
它还具备 角色一致性、搜索 grounding 和出色的文字渲染能力。当然,每一张生成图都带有 SynthID 标记。

当然,目前完全没有任何研究细节或论文,因此我们在这方面的报道也只能到此为止。
AI Twitter 回顾
Google 的 Nano Banana 2(Gemini 3.1 Flash Image Preview)与新的图像评测风向
- Nano Banana 2 发布 + 铺开范围:Google 与 DeepMind 发布了 Nano Banana 2(即 Gemini 3.1 Flash Image Preview),将其作为一款“Flash 档”图像生成/编辑模型,正在 Gemini App、Search(AI Mode/Lens)、Flow、Google Ads 中上线,并以预览形式在 AI Studio / Gemini API / Vertex AI 中提供(Google, GoogleDeepMind, GeminiApp, sundarpichai, demishassabis)。产品宣称重点包括 世界知识、改进后的多语言文本渲染、长宽比控制、最高 4K 超分 与 多主体一致性(例如“最多支持 5 个角色和 14 个物体”)(Google, joshwoodward)。
- Arena/Artificial Analysis 结果 + 定价信号:多个评测方报告称,Nano Banana 2 在 文生图 上拿下 第 1 名,在编辑项目上也表现强势,同时价格却低于“Pro 档”——例如 Artificial Analysis 给出的价格是 $67 / 1000 张图,而 GPT Image 1.5 和 Nano Banana Pro 大约是 $133–134(ArtificialAnlys, arena, kimmonismus)。Arena 还新增了 图像子分类,并强调其在 文字渲染 与 3D 成像/建模 上提升最大(arena)。这也再次提醒人们:排行榜正在变成产品杠杆;“首日即集成”的接入(例如 fal)以及提示词包/模板,会和评测胜利一起同步发布(GeminiApp templates, GoogleAI prompts)。
- 实时搜索条件生成:Google 反复强调,NB2 由 来自网页搜索的实时信息与图像 驱动(而不只是静态预训练),并用“从世界上任意一扇窗户看到更准确景象”这类演示来定位它(sundarpichai)。
- 下游可用性:Nano Banana 2 很快也出现在第三方产品中,包括 Perplexity Computer(AravSrinivas)。
Agent 式编程 + 产品化“任务”、记忆与评测(以及对复杂性的反弹)
- Agent 现在“能正常工作”的情况更多了,但在分布外任务上仍会失灵:一些实践者认为,近期前沿模型上的编程 Agent(例如 GPT-5.2 / GPT-5.3 Codex、Opus 4.6、Gemini 3.1)在可靠性与实用性上出现了台阶式提升,已经从“概念验证”转向了某种可以把 CLI 工作委托给初级工程师的阶段(teortaxesTex, paul_cal)。但也有人提醒,高级 ML / 数据工程任务在分布外情况下仍然很脆弱(michalwols, MParakhin)。
- “Tasks” 成为新的封装层:微软的 Copilot Tasks 主打“少说,多做”的任务委派,在“研究预览”阶段就强调用户可见的计划和控制能力(mustafasuleyman, yusuf_i_mehdi)。
- 持久记忆正在成为标配,但也带来了互操作性痛点:一条被广泛传播的更新称 Claude 已推出 自动记忆(“记住它在跨会话中学到的内容”)(trq212),Claude 生态中的其他人也在呼应这一点(omarsar0)。开发者随即遇到了工作流摩擦:当记忆/状态存储在各个工具私有的隐藏目录里时,会伤害“多 Agent、多工具”的连续性(borisdayma)。
- 工具更新很快:PR 修 Bug 机器人、代码↔设计闭环,以及编辑器级改进:
- Cursor Bugbot Autofix 能自动修复 PR 中发现的问题(cursor_ai, aye_aye_kaplan)。
- OpenAI 的 Codex “code → design → code” 与 Figma 的往返流程,目标是减少 UI 迭代中的信息损耗(OpenAIDevs, figma)。
- VS Code 的 long-distance Next Edit Suggestions 专注于预测 哪些地方不该改,并帮助开发者保持“flow”(code, pierceboggan, alexdima123)。
- 评测膨胀 + 基准刷榜担忧:不少讨论指出,高排行榜分数可能掩盖 Token 使用效率很差的推理,以及在“bullshit tests”(比如重复 token 的“strawberry”变体)上的失败,因此不应在不计成本的情况下过度信任 HLE / GPQA 这类指标(scaling01)。Arena 的回应是为代码模型加入 Multi-File React 之类更细粒度的测试方案(arena)。
- 复杂性才是真正的税负:一个反复出现的工程担忧是,“每天 1 万行代码”的炫耀会制造长期的 复杂性债务——Agent 让交付更容易,却没有让维护更轻松(Yuchenj_UW)。另一个角度是:如果编程 Agent 把你的代码库“搞得越来越糊”,让你离开它们就很痛苦,那它们实际上会制造 隐性锁定(typedfemale)。
Perplexity 的分发 + 检索技术栈:三星集成与新嵌入模型
- 三星 S26 的系统级 Perplexity(“Hey Plex”):Perplexity 表示,每台 Galaxy S26 都会内置 Perplexity,包含唤醒词和深度 OS 集成;Bixby 会把网页/研究/生成式查询路由给 Perplexity,自己则处理设备端操作(perplexity_ai, perplexity_ai, AravSrinivas)。这被描述为更广泛合作的一部分,目标还包括 Samsung Internet 以及可选的默认搜索入口位置(perplexity_ai)。
- pplx-embed / pplx-embed-context 发布(MIT):Perplexity 推出了两条嵌入模型产品线,分别为 0.6B 和 4B,其中还包含面向 RAG 文档切块嵌入的 “context” 变体;两者都采用 MIT 许可证,可通过 HF + Perplexity API 使用,并附带论文(arXiv:2602.11151)(perplexity_ai, perplexity_ai, alvarobartt)。他们还披露了内部基准 PPLXQuery2Query / PPLXQuery2Doc,覆盖 11.5 万个真实查询、3000 万份文档 和 10 亿+ 页面(perplexity_ai)。Arav 则称这些嵌入模型“行业领先”(AravSrinivas)。
- 战略解读:这两步动作——OS 分发入口 + 检索底层组件——意味着 Perplexity 正试图同时掌握 前门入口(助手入口点)和 核心搜索栈(嵌入 + 评测),而不是依赖第三方平台。
推理、内核与基础设施:MoE 支持、异构硬件与 KV 搬运
- MoE 在 🤗 Transformers 中成为“一等公民”:Hugging Face 推出了更深入的 MoE 基础设施支持(加载、专家后端、专家并行、Hub 支持),并强调了与包括 Unsloth 在内的合作,以加速 MoE 训练(ariG23498, mervenoyann)。
- DeepSeek 对多硬件推理支持的认真程度:在这批消息的前段,DeepSeek 就被点名为“认真在做多样硬件上的推理支持”(teortaxesTex)。另外,DeepSeek 的 DualPath 细节描述了如何先把 KV cache 暂存在 decode-server 的 DRAM,再通过 GDRDMA 移到 prefill GPU,以避免本地 PCIe 瓶颈(JordanNanos)。这反映出一个更大的变化:推理越来越像一个 系统架构问题,而不只是内核级优化问题。
- 内核覆盖与 GPU 代际:vikhyatk 讲述了如何在不同 NVIDIA 架构(sm80→sm110)上构建推理内核,并提到边缘设备 ISA 的问题,例如 Orin CPU 缺少 SVE(vikhyatk, vikhyatk)。
- 量化并非一概安全:评测显示,与 Qwen3.5 相比,MiniMax M2.5 的 GGUF 量化退化程度远超预期,说明“直接拿 Q4 就行”这种经验并不能泛化到所有模型家族(bnjmn_marie)。
世界模型、模拟器中的 Agent 与“多人”环境
- Solaris:面向多人 Minecraft 的世界建模技术栈:一项重要研究提出,世界建模应聚焦于 共享的全局状态,而不是像素渲染,并发布了:(1)一个 多人数据采集引擎;(2)一个采用“memory efficient self forcing design”、在 1260 万帧上训练的 多人 DiT;以及(3)一个用于多 Agent 一致性评估的 VLM-judge 套件(sainingxie, georgysavva)。它的核心观点是:多 Agent 能力需要一种位于各自视角之下的共享表示。
- LLM 作为具身控制器(虽然是玩具案例,但很说明问题):一个从 CARLA 移植到 OpenEnv 的项目展示了,一个小型 Qwen 0.6B 在使用 TRL + HF Spaces 的情况下,只需 约 50 步就学会了刹车/转向来避让行人(SergioPaniego)。这体现了“LLM + 环境”闭环的一种趋势:可逆性有限,错误会持续累积。
治理焦点:Anthropic 与五角大楼在监控和自主武器上的冲突
- 先有五角大楼施压报道,后有 Anthropic 公开回应:一条被广泛传播的说法称,美国国防部向 Anthropic 发出了“最终报价”,包括威胁将其列为“供应链风险”,并要求开放不受限制的军事用途(KobeissiLetter)。随后 Anthropic 发布了 CEO 声明,明确划出红线:不做大规模国内监控,不做完全自主武器(鉴于当前可靠性水平),并称对方还拿 《国防生产法》 相关威胁施压(AnthropicAI)。一段被广泛引用的摘录也被单独转发并补充了细节(AndrewCurran_)。
- 行业反应 + 团结机制:这一立场得到了许多知名研究者/工程师的强力支持,他们将其视为在压力之下坚持价值观,而不是“政策作秀”(fchollet, TrentonBricken, awnihannun)。据称,一份旨在协调“共同认知”的请愿书还收集到了 OpenAI / Google 员工的签名(jasminewsun, sammcallister, maxsloef)。值得注意的是,这是一种明确尝试:通过透明披露各实验室的立场,防止出现逐底竞争的动态。
- 这在技术上为何重要:这场争议的核心是 能力 vs. 可靠性,以及“合法使用”这类措辞与当今前沿模型的安全可用范围并不匹配。数据集中其他地方也出现了类似的可靠性担忧(例如一些极简安全测试里,模型即使被明确要求不要泄露机密信息,仍然会泄露)(jonasgeiping, random_walker)。
热门推文(按互动量排序)
- Anthropic CEO 就 DoD 要求发表声明(为监控与自主武器划出红线) — @AnthropicAI
- Google 发布 Nano Banana 2 / Gemini 3.1 Flash Image Preview(大范围上线 + “Flash 速度、Pro 级效果”) — @GeminiApp, @sundarpichai, @GoogleDeepMind
- Perplexity + 三星 S26 系统级集成(“Hey Plex”) — @perplexity_ai
- Claude 免费方案可用连接器(150+ connectors) — @claudeai
- 五角大楼 vs Anthropic “最终报价”报道串 — @KobeissiLetter
- Claude Code 自动记忆非常重要(开发者反应) — @trq212
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 摘要
1. Qwen3.5 模型表现与对比
-
Qwen3.5-35B-A3B Q4 量化对比 (热度: 635): 该帖子详细比较了 Qwen3.5-35B-A3B 模型的多种 Q4 量化方法,重点看它们相对 BF16 基线在
KL Divergence (KLD)和Perplexity (PPL)上的保真度。分析指出,AesSedai 的 Q4_K_M 以0.0102的最低 KLD 取得最高保真度,而 Ubergarm 的 Q4_0 则明显优于其他 Q4_0 量化。帖子还提到,与在量化感知训练(QAT)阶段使用相比,MXFP4 在事后套用时效果较差。若按模型体积与 KLD 的综合效率评分,AesSedai_Qwen3.5-35B-A3B-IQ4_XS 排名最高。测试环境为 Intel Core i3-12100F、64 GB RAM、RTX 3060,数据集使用wikitext2_test.txt。评论者称赞这种细致的比较,并建议量化作者在文档中直接附带此类分析。同时,也有人讨论了用 wikitext 做 PPL/KLD 评估可能带来的偏差,因为它可能已经出现在部分 imatrix 数据集中,因而建议改用更新鲜的数据集。- 用户 “ps5cfw” 指出,像
Q4_K_M这样的量化命名本身就有歧义,说明文档亟需更统一、更清晰的标准。这对不同量化方法之间做有意义的比较尤其关键,尤其是在经历过 XL 风波之后。 - “noneabove1182” 提到,用 wikitext 作为 PPL/KLD 评估集可能有问题,因为某些数据集本身可能已经包含 wikitext,从而让结果失真。他建议改用更新鲜的数据,比如最近播客的 STT 转写文本,以获得更准确的比较。这也凸显了基准测试中数据集透明度与选择的重要性。
- “danielhanchen” 讨论了 Q4_K_XL 因 MXFP4 层导致 perplexity 偏高的问题仍在调查中。他指出,Q2_K_XL 和 Q3_K_XL 等其他量化版本并未受到影响。同时他还提到,UD-Q4-K-XL 在真实世界基准中明显优于 Q4-K-M,这一点可以从 Benjamin Marie 的 LiveCodeBench v5 看出来。
- 用户 “ps5cfw” 指出,像
-
72GB 显存(3x3090)运行 Qwen3.5 122B,是当前最好的可用模型,而且还能通过“洗车测试” (热度: 706): 该帖子讨论了 Qwen3.5 122B 模型的表现,它被优化为可在三张
3090 GPU组成、总计72GB VRAM的配置上运行。发帖者强调了其效率:在Temperature 0.6、K Sampling 20、Top P 0.8等设置下,可以达到25 tokens/s。帖子还指出,该模型在 Q3 模式下可以处理120k context,虽然速度仍慢于 GLM Air 和 GPT-OSS-120B 等其他模型。作者也提到,像 MXFP4 和 IQ4_XS 这样的其他配置需要把部分层 offload 到 RAM,速度会降到6-8 tok/s。评论中有人表示,在另一套配置上(Qwen3.5-122B-A10B-UD-Q4_K_XL + Ryzen 9 9950X3D + RTX 5090)可以跑到34-36 tok/s。也有人批评“洗车测试”是一个有偏的场景,会放大模型训练中的偏置,不能作为衡量模型智能的决定性指标。- 一位用户报告称,使用
Qwen3.5-122B-A10B-UD-Q4_K_XL时可达到 34-36 tokens/s,使用Qwen3.5-122B-A10B-UD-Q8_K_XL时则为 16-18 tokens/s,两者最大上下文都开到 256K。其硬件为 Ryzen 9 9950X3D、RTX 5090 和 128 GB DDR5 5600 RAM,系统是基于 Arch Linux 的 Cachy OS。 - 有人认为“洗车测试”的意义被高估了,因为这种场景在训练数据中很常见,模型更可能是在复述学到的逻辑,而不是真正展示推理能力。因此它更像是针对某类特定弱点的探针,而不是全面智能测试。
- 也有用户提到,Qwen3.5 系列在 4-bit Unsloth 量化上仍有一些问题,说明还有优化空间。但即便如此,这个模型的表现依然令人印象深刻,尤其是相较于此前没有达到预期的发布版本。
- 一位用户报告称,使用
-
Qwen/Qwen3.5-35B-A3B 做出了 Flappy Bird (热度: 372): 该帖子讨论了如何使用 Qwen/Qwen3.5-35B-A3B 模型,通过 HTML、CSS 和 TypeScript(以 Vite 初始化)做出一个 Flappy Bird 克隆。这个本地托管的模型展现了相当不错的编程能力:它生成了基础游戏结构,并实现了 Web Audio API 音乐、可滚动的视差背景以及鸟群等功能。发帖者提到,最初视差效果有一些视觉瑕疵,但经过小幅调整后就解决了;声音设置面板也一次就加成功了。评论区有人建议,开放模型公司可以用不同游戏做重复测试或基准评估,以更系统地衡量模型能力。
- BitXorBit 提出了一个有意思的观点:开放模型公司完全可以为重复 benchmark 或测试做准备。他建议尝试不同游戏并公开结果,这样可以更好地观察模型在不同任务上的适应性与表现,尤其有助于评估像 Qwen/Qwen3.5-35B-A3B 这类模型的泛化能力。
- ShengrenR 则建议项目的下一步是:基于屏幕输入训练一个强化学习(RL)模型来玩 Flappy Bird。这样做可以让模型利用游戏中的视觉信息决定动作,进一步朝着能实时学习和适应挑战的 AI 迈进。
-
Qwen 3.5 在高难度编程任务上明显掉队:我帮你在 70 个真实仓库上测完所有 Qwen3.5(还有 Codex 5.3)了 (热度: 917): 图片来自 APEX Testing 网站,该网站用真实世界编程任务评估 AI 编程模型。图中显示共有 34 个模型参与、65 个任务、总计 2208 次运行,并按 ELO 排出了包括 Claude Opus 4.6 和 GPT 5.2 Codex 在内的头部模型。帖子主要讨论了多个模型在真实代码库 benchmark 上的表现,尤其是 Qwen 3.5 和 Codex 5.3。结果表明,Qwen 3.5 尤其是 397B 版本,在需要跨多个文件协调的复杂任务上表现吃力,而 Codex 5.3 则在不同难度区间内都更稳定。量化版 GLM-4.7 被认为是当前最强的本地模型,表现超过 Qwen 3.5。帖子还提到,为了让比较更公平,测试里使用了一个 Agent 式工具调用系统,同时强调测试框架本身非常重要,因为它会显著影响模型表现。评论区则继续讨论像 gpt-oss-20b 和 GLM-4.7 这类模型的结果,并质疑自定义 Agent 框架是否影响了结论。
- UmpireBorn3719 强调了
gpt-oss-20b与Qwen3 Coder Next的对比:前者在编码任务 benchmark 中得分为1405,后者为1328。这说明在某些编程场景里,gpt-oss-20b可能更强,尽管帖子没有展开 benchmark 的具体任务和条件细节。 - metigue 讨论了不同 Agent 框架对模型表现的影响,指出开源模型在不同框架下的性能波动可能超过
50%。他建议再用主流框架做测试,因为框架选择会显著改变谁看起来是“最好的模型”;例如在Droid框架里,GLM-5能超过Opus 4.6,而Codex 5.3又能超过这两者。 - Hot_Strawberry1999 则很欣赏帖子纳入了不同量化等级的 benchmark 对比,认为这种信息很少见。这也说明量化等级会显著影响模型性能,因此这类数据对于理解模型在不同算力约束下的表现很有价值。
- UmpireBorn3719 强调了
-
Qwen3.5 27B 比 35B-A3B 更好吗? (热度: 771): 图中对比了 Qwen3.5 Medium 系列中不同模型的表现,具体包括 35B-A3B、27B 和 122B-A10B,涵盖指令遵循、研究生水平推理、多语言知识等多项基准。帖子认为 27B 模型在资源受限环境中更高效,例如只有 16 GB VRAM 和 32 GB RAM 的场景下,它可能比 35B-A3B 更值得选。图里的可视化结果也有助于那些受硬件限制的用户做决策。评论区有人分享了自己的实测:在 3090 上,27B 模型的处理速度能达到 100 t/s,而 35B-A3B 只有 20 t/s,这说明 27B 在某些硬件条件下可能有更高的性能效率。
- FusionCow 指出,在 3090 GPU 上,Qwen3.5 27B 和 35B-A3B 的性能差距非常明显:27B 能达到
100 tokens/s,而 35B-A3B 只有20 tokens/s。这说明 27B 在速度层面更高效,可能会影响用户基于处理时间需求做出的选择。 - boinkmaster360 则认为,Qwen3.5 27B 是一个 dense model,因此它可能更慢,但也可能更聪明。这凸显了计算速度与模型复杂度之间的权衡:更 dense 的结构也许会在某些任务上带来更好的能力。
- Alternative_You3585 指出,Qwen3.5 27B 在“智能性”上很可能强于 35B-A3B,但后者可能在现实世界知识与处理速度上有自己的优势。这说明不同模型之间的优劣并不绝对,而是取决于具体应用场景。
- FusionCow 指出,在 3090 GPU 上,Qwen3.5 27B 和 35B-A3B 的性能差距非常明显:27B 能达到
2. AI 模型中的地缘政治与访问问题
-
美国闭源模型 vs 中国开源模型正在变成一个问题 (热度: 1387): 该帖子讨论了那些因国家安全顾虑而必须使用开放 AI 模型的组织所面临的难题,尤其是它们会因为风险认知而避免中国模型。近期能拿得出手的美国开放模型几乎只有
gpt-oss-120b,而它相比 GLM、MiniMax 等现代模型已经明显过时。作者还猜测,美国国防部 对 Anthropic 施压,可能与其需要离线 AI 方案有关。像加拿大的 Cohere 这样的替代项也被提到,但“缺乏有竞争力的美国开放模型”仍然是一个大问题。评论区有人建议对中国模型做二次改造形成定制方案,也有人提到 Mistral Large 3 可能是一个替代项,不过它未必能达到中国模型的能力水平。与此同时,也有人怀疑 StepFun-AI 是否真的能算作非中国选项,因为它本身也来自中国。- 评论区强调,各国 AI 模型都在可用,因此模型选择更应基于具体应用场景,而不是国籍。例如 Mistral Large 3 被视为有竞争力的模型,虽然未必比 DeepSeek 这样的中国模型更强。评论者认为,企业环境可以通过微调把模型调到更贴合自身需求,从而缓解潜在的安全顾虑。
- 还有人列出了一长串来自不同国家的 AI 模型,展示全球 AI 研发的多样性。比较有代表性的包括美国 Meta 的 Llama、中国阿里云的 Qwen、法国 Mistral AI 的 Mistral。这位评论者认为,模型效果高度依赖具体用途,因此企业更应该关注通过微调、RAG 数据库等方式做定制化,以提升性能并应对安全问题。
- 也有人提出,当模型是离线部署、并为企业具体需求做过微调时,大家对模型来源(例如是否可能有后门)的担忧就没那么重要了。他建议企业利用开源模型,通过 fine-tuning、(Q)(Re)LoRA 以及自建 RAG 数据库来提升准确率与安全性;这套做法在 Hugging Face 上的爱好者社区里已经很常见了,因此有预算的企业理应也能做到。
-
DeepSeek 允许华为提前拿到 V4 更新,但 Nvidia 和 AMD 仍然拿不到 (热度: 559): DeepSeek 已将其 V4 AI 模型更新的提前访问权限提供给 华为 及其他国内供应商,目标是优化模型在这些硬件上的表现。这一策略动作把 Nvidia 和 AMD 这样的美国大芯片厂排除在外,它们尚未获得访问权限。评论普遍认为,这一决定很可能与非 Nvidia 硬件上的兼容性和优化需求有关,因为 DeepSeek 模型通常是在 Nvidia 平台上训练的,所以更早给华为,可能是为了优先提升其在特定硬件架构上的表现。
- jhov94 认为,DeepSeek 大概率本来就是为 Nvidia 硬件优化的,因此 Nvidia 也许根本不需要提前拿到 V4,系统本来就兼容;而华为提前拿到,很可能是因为它们的硬件需要额外适配和优化。
- ResidentPositive4122 回顾了媒体围绕 DeepSeek 的炒作,尤其是首次发布时的舆论热潮,并建议对主流媒体说法保持怀疑。他认为,即便 Nvidia 和 AMD 没有提前拿到访问权限,大型推理服务商也会在模型正式发布后很快适配 V4,这在新模型上线时很常见。
- stonetriangles 则质疑“Nvidia 没拿到 V4 提前访问权限”这件事本身有多大意义,因为在 R1、V3、V3.2 等前几代版本中,Nvidia 也同样没有提前拿到。这意味着当前情况其实并不反常,未必需要过度担忧。
3. AI 模型排行榜与基准测试
-
Anthropic 放弃了其旗舰级安全承诺 (热度: 354): Anthropic 决定取消其旗舰级安全承诺,这原本是一项将 AI 开发中的安全性置于优先地位的承诺。这个决定意味着其在 AI 治理和安全协议上的路线发生了显著变化。该承诺最初是为了确保 AI 系统开发时充分考虑伦理因素与风险缓释,但公司并未明确说明为何撤回。评论区对 Anthropic 的决定总体较为批评,有人认为外部压力,尤其可能来自政府或国防部门,影响了这一转变,也有人担心这会削弱公司此前一直坚持的伦理标准。
- till180 讨论了 Anthropic 取消安全承诺的含义:虽然公开模型或许仍会保留安全护栏,但撤掉这项承诺,可能会让其更容易把模型卖给美国军方。这也与近期五角大楼要求 Anthropic 提供模型的施压事件相呼应,暗示公司在运营重心与伦理立场上可能正在转向。
-
Anthropic 正在“无意中”成为开源权重模型的最大贡献者 (热度: 839): 据称,Anthropic 正在成为开源权重模型的最大“贡献者”,只不过这并非出于本意,因为其模型正被人在违反服务条款的情况下蒸馏。所谓蒸馏,是指通过与模型的交互数据来训练出一个更小、更高效的版本,而像 dataclaw 这样的工具甚至可以把这些对话一键发布到 Hugging Face 等平台。帖子还提到,DeepSeek 已经蒸馏了
15 万轮对话,而很多用户手里其实有更多数据。评论者由此提出了“分布式蒸馏”的策略:由用户集体贡献交互数据来推进模型蒸馏,甚至可以用 token 做激励。评论里也有一种情绪认为,即使推动者来自非美国实体,只要有利于开源社区,这样的努力就是积极的。- “分布式蒸馏”被提出为一种改进模型训练的方法:通过利用用户交互来积累蒸馏数据,例如让用户去问那些对蒸馏有价值的问题,甚至可以用类似 “qwen-3.5” 的 token 进行激励。这种方式可能有助于提高开源模型训练数据的多样性与质量。
- 帖子还提到一个叫
dataclaw的工具,它可以让用户通过一条命令把自己的 Claude Code 对话发布到 Hugging Face。这类工具会大大降低大规模数据共享与蒸馏的门槛;既然 DeepSeek 已经蒸馏了 15 万轮对话,那用户自己手里的数据量可能还要更多。 - 讨论也触及了 AI 发展的地缘政治维度。一些用户明确表示,他们宁愿看到中国主导的开源贡献,也不愿意被美国公司继续垄断。这种情绪反映出 AI 研发本身的全球化属性,也凸显了开源模型在国际协作与竞争中的重要性。
-
自托管 LLM 排行榜 (热度: 324): 图片展示了一个面向自托管大语言模型(LLM)的排行榜,按照表现把模型分为 S、A、B、C、D 几档。榜单列出了模型名称和参数规模,例如 S 档里有 “Kimi K2.5” 和 “GLM-5”。它还支持按 coding、math、reasoning、efficiency 等不同能力维度筛选,因此能比较全面地展示自托管场景下的模型表现。该排行榜托管在 Onyx。评论区则讨论了 Qwen 3.5 系列缺席的问题,认为考虑到其能力(包括 vision 支持),它们至少应该进入 A 档或 B 档,尤其适合 homelab 和小企业场景。评论中还提到了 Qwen3-Next 与 Qwen3-Coder-Next,认为它们是标准硬件上的强力选手。
- 评论中特别提到,Qwen 3.5 系列,尤其是 27B dense 与 122B MoE 两个版本,完全有资格进入自托管 LLM 的 A 档或 B 档。这些模型还具备视觉能力,对于 homelab 和小企业应用很有帮助,因此不少人认为排行榜不应该忽略它们。
- 另一条观点认为,Qwen3-Next 和 Qwen3-Coder-Next 两个 80B 模型在标准硬件上的表现非常强,尤其是在编程任务上,因此它们未能进入面向 coding 的排行榜,被视为一个明显的疏漏。
- 也有人开始讨论运行 S 档模型到底需要什么级别的硬件,尽管评论中没有给出太具体的结论。这也说明,对于真正部署顶级自托管 LLM 所需的算力资源,社区仍然希望看到更明确的说明。
偏轻技术的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Nano Banana 2 与 Gemini 3.1 Flash 的进展
-
Google 发布 Nano banana 2 模型 (热度: 984): **Google 发布了 Nano Banana 2 模型,这是一款融合专业级能力与高速处理能力的先进 AI 图像生成模型。该模型因更强的世界知识、可直接投入生产的规格,以及更好的主体一致性而受到关注,能够让用户高效生成高质量图像。更多细节可参见 Google 博客。** 用户对该模型的表现印象深刻,尤其是在它此前不擅长的任务上,比如家装改造这类复杂图像生成场景,说明其图像质量与一致性都有显著提升。
- BuildwithVignesh 分享了 Google 官方博客和 Gemini API 文档链接,这对希望集成或深入了解 Nano Banana 2 能力的开发者很关键。博客大概率详细介绍了模型特性、改进点和潜在应用,而 Gemini API 文档则提供了实现与使用层面的技术指引。
- JTwoXX 提到 Nano Banana 2 仍有一个限制,即它在生成无背景 PNG 图像时依旧表现不佳。这说明虽然模型在其他方面进步明显,但在图像透明度和背景处理上,仍有特定技术难题待解决。
- bentendo93 分享了 Nano Banana 2 的一个实际用例,即用于家装改造可视化。这表明模型在生成更真实、更有实用价值的图像方面已有明显提升,可能影响室内设计和建筑等行业。
-
Gemini 3.1 Flash(Nano Banana 2)在官方发布前已现身 Gemini (热度: 287): 图中展示了即将推出的 **Gemini 3.1 Flash(内部代号 Nano Banana 2)的抢先体验界面。这表明该模型已经在 Gemini 平台内分阶段上线,即使官方尚未正式宣布。界面里出现了 “Nano Banana 2” 的加载提示,意味着用户已经可以选择并可能实际与该模型交互,也暗示其正式发布已近在眼前。** 有评论特别提到模型输出中的细节表现非常惊艳,例如眼睛中鸟类倒影的细致描绘,显示出较高的渲染质量。
- Ggoddkkiller 提到对 Google 客户关系处理方式的担忧,尤其是在 Vertex AI 平台语境下。该评论表达了对 Google 客户沟通和支持方式的不满,特别是在 Gemini 3.1 发布引发高期待的背景下更显突出。这也反映了科技圈一个更普遍的情绪:像 Google 这样的大公司需要在客户服务和透明度上做得更好。
-
Nano Banana 2 真的来了!Gemini 3.1 Flash Image 已出现在 Vertex AI Catalog 中 (热度: 264): 帖子中的图片是两张 AI 生成人像的并排对比,用来展示新发布的 **Nano Banana 2(也就是 Gemini 3.1 Flash Image)与现有 Nano Banana Pro 的能力。帖子强调,这个新模型虽然属于 “Flash” 档位,但画质已经接近 Pro 版本,尤其在高密度构图的空间逻辑上表现突出。它面向高速、低成本生产场景,适合大批量 UGC 广告制作这类高频流水线。同时它也保留了 Nano Banana 系列的特性,比如多主体参考和高保真风格迁移,因此被视为 2026 年一次重要发布。** 有评论者认为,在给出的示例中,Nano Banana Pro 依然略胜一筹;也有人表示希望出现一个具备类似能力的视频模型。
- 原版 Flash Image 模型的图像质量本来就不错,但在遵循提示词方面存在问题,尤其是面对复杂指令时,经常会忽略部分要求,或者重复生成相同结果。此外,它在文字、信息图渲染以及多图合成上也表现欠佳。对于新的 Gemini 3.1 Flash Image 来说,关键问题在于这些缺陷是否已经被修复,而这仍有待通过高密度 prompt 的正式测试来确认。
-
Nano Banana 2 定价!!!! (热度: 206): 图中给出了两个 AI 产品 “Nano Banana 2” 和 “Nano Banana Pro” 的定价细节。其中 “Nano Banana 2” 被宣传为具备专业级视觉智能,定价为输入
$0.50、输出$3.00;而 “Nano Banana Pro” 被描述为最先进的图像生成与编辑模型,输入$2.00、输出$12.00。两者的知识截止日期都为 2025 年 1 月。这样的价格结构反映出分层式 AI 服务策略,Pro 版本显著更贵,很可能是因为能力或功能更强。 评论者还把 “Nano Banana” 系列与 “Gemini 3 Pro Image” 和 “Gemini 3.1 Flash Image” 的价格及能力做了对比,并指出后者的价格会随图像分辨率变化。评论区还在争论 “Nano Banana Pro” 的质量是否真的强于 “Nano Banana 2”,也有人认为两者质量接近。- Ggoddkkiller 详细拆解了 Gemini 3 Pro Image 和 Gemini 3.1 Flash Image 的 token 成本。Pro Image 每张输入图收费 560 tokens,输出成本随分辨率变化;Flash Image 则是每张输入图 1120 tokens,并采用不同的分级方式。Flash Image 虽然比 Pro 稍便宜,但整体定价结构较复杂,也没有一些用户预想的那么低。
- Halpaviitta 分享了个人测试结果,指出新模型大约比 Pro 版本便宜四倍、速度也略快。这说明它在性价比上优势明显,因此即便一开始大家对价格有疑虑,它依然是很有吸引力的选择。
- Actual_Committee4670 提到当前生成速度仍然偏慢,影响了对新模型进行完整测试的能力。不过,他们对新模型的价格持积极态度,认为如果后续性能改善,这样的定价或许是合理的。
2. Anthropic 与五角大楼的 AI 安全护栏争议
-
Anthropic 在 AI 安全护栏争议中拒绝五角大楼“最终报价” (热度: 1863): **Anthropic 因认为针对大规模监控和自主武器潜在滥用的防护措施不足,拒绝了 五角大楼 就其 AI 模型 Claude 部署提出的最终方案。五角大楼随后威胁要将 Anthropic 列入黑名单,甚至可能援引 《国防生产法》。尽管双方关系紧张,Anthropic 仍表示愿意继续谈判,这也凸显了在涉密环境中部署 AI 的更广泛难题,其他公司如 xAI 也面临类似合同困境。更多信息可见 Anthropic 的声明。** 评论区整体对 Anthropic 的立场持正面看法,许多用户称赞其坚持原则,尽管行业整体的伦理门槛其实并不高。
-
独家:Hegseth 要求 Anthropic 在周五前放弃 AI 安全护栏 (热度: 1434): **国防部长 Pete Hegseth 向 Anthropic 发出最后通牒,要求其在周五前移除 Claude AI 模型上的安全护栏,Axios 如此报道。五角大楼希望在包括国内监控和自主武器开发在内的用途上不受限制地使用 Claude,而这与 Anthropic 的服务条款相冲突。若 Anthropic 不配合,可能会触发 《国防生产法》,或被认定为供应链风险,从而失去政府合同资格。** 一条高赞评论指出,其中的讽刺在于,居然是 AI 公司在给政府使用场景设安全边界,而不是传统意义上由监管方去约束企业。这也反映出 AI 治理中科技公司与政府之间权力和责任边界的更大争论。
-
Dario Amodei 就与 Department of War 的讨论发表声明 (热度: 917): **Anthropic 的 Dario Amodei 就公司与 Department of War 的合作发表声明,强调他们反对将 AI 用于大规模监控和自主武器。公司虽然正在推动 AI 接入涉密网络,但坚持保留安全护栏以维护民主价值,即便外部正施压要求其放松这些限制。更多细节可见原始声明。** 评论者则对 Anthropic 的伦理立场表示怀疑,指出它与以监控业务著称的 Palantir 合作本身就带有讽刺意味。也有人认为,在当前政治环境下,这份声明算得上一次大胆表态。
3. Qwen 模型表现与优化
-
致敬 Qwen 🧠 一款真正可本地运行的 SOTA 开源模型(Qwen 3.5 35B 4-bit)- 这里是修复逻辑死循环的方法!❤️ (热度: 173): 该帖讨论了 **Qwen3.5-35B-A3B-4bit 模型的实际使用,重点指出其初始阶段存在推理死循环和逻辑错误,这也是 4-bit 量化模型常见的问题。作者通过调整 system prompt,引入 “Adaptive Logic”,把模型内部的 “thinking” 和最终输出分离开来,从而显著提升了其在 Digital Spaceport Benchmark suite 上的表现。该模型成功解出了复杂逻辑和数学题、生成了 SVG 代码,并完成了准确计数。关键配置包括 temperature
0.7、top-p0.9和 frequency penalty1.1。其中 “Anti-Loop” system prompt 对避免重复循环、保证高效执行任务至关重要。** 有评论者提到,Qwen3.5-35B-A3B 在配备 48GB RAM 的 MacBook Pro M4 上表现很有效,尤其喜欢其 “thinking” 功能,并计划采纳帖中分享的 prompt 技巧。上下文长度设置为128k,这也可能是其表现改善的原因之一。- 有用户表示自己在 48GB RAM 的 MacBook Pro M4 上运行 Qwen 35B A3B,认为它比之前的 30B 版本表现更好。他们指出 35B 模型更不容易陷入逻辑循环,而这正是早期版本的一个问题。上下文长度设置为 128k,可处理更长输入,而 “thinking” 功能也让用户能更直观看到模型的决策过程。
- 评论区还讨论了 Qwen 35B A3B 在开启或关闭 “thinking” 功能时究竟哪种表现更好。这个功能让用户可以看到模型在“想什么”,有助于理解其决策路径;但大家也好奇,当模型生成不出答案时它会如何表现,这意味着 “thinking” 可能也有助于缓解这类问题。
-
Qwen3.5-122B-A10B 对比旧版 Coder-Next-80B:两者都跑在 DGX Spark 的 NVFP4 上,值得升级吗? (热度: 63): 帖子讨论了 **Qwen3.5-122B-A10B 与旧版 Qwen3-Coder-Next-80B 的对比,两者都运行在 DGX Spark(128GB) 上,使用 NVFP4 精度。122B-A10B 需要
61GB显存,而 Coder-Next-80B 需要40GB,但二者都能装进现有内存,并留出充足上下文空间。官方基准显示 122B-A10B 在 SWE-Bench 上得分72.0,略高于 Coder-Next-80B 的~70。帖子提出的问题是:122B-A10B 在编程表现上是否真有显著提升,还是其实更适合通用 agent 任务,尤其考虑到它有10B激活参数,而 Coder-Next 仅有3B。作者希望看到真实世界中的 NVFP4 对比,特别是在长上下文检索和 LiveCodeBench/BigCodeBench 这类编程基准上的结果。** 有评论者指出,122B-A10B 目前在编程任务上反而不如 Coder-Next-80B,比如在生成一个简单小游戏时就表现不佳。另一些评论则认为,虽然 122B-A10B 在多文件推理和长上下文处理上更强,但它在编码上的提升很有限,因此 Coder-Next-80B 依然是编程导向工作负载中的强竞争者。- flavio_geo 指出,在 Q4KXL 量化下测试时,Qwen3.5-122B 模型在编程任务上不如旧版 Qwen3-Coder-Next-80B,而后者测试时采用的是 Q6KXL。具体而言,122B 模型在实现一个 Pygame 版 Chrome 小恐龙游戏时犯了多次错误,才最终生成可运行版本;反观 Coder-Next 一次就成功,且输出质量更高。这说明 122B 模型在当前
llama.cpp引擎里可能还没有被完全优化好。 - qubridInc 表示,虽然 Qwen3.5-122B-A10B 在多文件推理和长上下文处理上更强,但相对 Coder-Next-80B,它在编码性能上的提升并不明显。对于以编程为主的工作负载,Coder-Next 依旧很有竞争力;不过在需要更强通用推理和 agent 能力的任务中,122B 模型可能更有优势。
- klop2031 还观察到,体量更大的 Qwen3.5-122B 模型,甚至比一个更小的 27B dense 模型还表现差。这可能与具体任务类型或量化方式有关。该评论者也表达了对未来
llama.cpp优化的期待,希望后续能提升这个模型的实际表现。
- flavio_geo 指出,在 Q4KXL 量化下测试时,Qwen3.5-122B 模型在编程任务上不如旧版 Qwen3-Coder-Next-80B,而后者测试时采用的是 Q6KXL。具体而言,122B 模型在实现一个 Pygame 版 Chrome 小恐龙游戏时犯了多次错误,才最终生成可运行版本;反观 Coder-Next 一次就成功,且输出质量更高。这说明 122B 模型在当前
-
Qwen Code 搭配 Qwen3-Coder-Next / Qwen3.5-35B-A3B 时出现循环 (热度: 26): 用户在使用 unsloth 量化版本的
Qwen3-Coder-Next和Qwen3.5-35B-A3B模型运行Qwen Code时遭遇了循环问题。其环境是在llama.cpp上运行模型,并使用了诸如ctx-size 131072、flash-attn on和n-gpu-layers 999等配置。这个循环问题可能与模型本身有关,也可能与Qwen Code的具体实现有关。发帖者想了解这是否是已知问题,以及有没有可行的绕过方法。 有评论者建议对Qwen3-Coder-Next使用nvfp4量化并搭配sglang,以提高稳定性;另一些人则建议设置最大 thinking 时间以减少循环。此外,还有人建议切换到llama.cpp的pwilkin/autoparser分支,以修复 XML 和重复键解析问题;如果问题仍在,则进一步建议使用--repeat-penalty 1.08和--presence-penalty 0.05。- Prudent-Ad4509 讨论了为 Qwen3-Coder-Next 配合
sglang使用nvfp4 quant的方案,但也指出由于 llama-server 不稳定,这条路线并不轻松。他们提到,Qwen3.5 在官方基准之外的测试结果并不算特别有说服力,不过 Qwen3.5 27b Q8 模型倒是表现相当不错。 - ImJustNatalie 表示自己在使用 Qwen3.5 35B A3B 时也遇到了 “doom looping”,并建议把最大 thinking 时间限制为 1 分钟来缓解问题。这个调整显著改善了表现,减少了死循环的发生频率。
- walt3i 则给出了 “looping ReadFile” 问题的一种解决方法:切换到
pwilkin/autoparser分支,以修复 XML 和重复键解析问题。如果问题仍然存在,他们还建议增加--repeat-penalty 1.08与--presence-penalty 0.05。
- Prudent-Ad4509 讨论了为 Qwen3-Coder-Next 配合
AI Discord 回顾
由 gpt-5 生成的“总结的总结的总结”
1. Nano Banana 2 与 Arena 排行榜升温
- NB2 登顶 Image Arena,但 Web Search 还不稳:Nano Banana 2 以 Gemini‑3.1‑Flash‑Image‑Preview 的身份亮相,并直接冲到 Image Arena 第 1 名,同时加入了新的 web search 能力(Gemini 3.1 Flash Image Preview, Image Arena leaderboard)。
- 用户普遍认为,在文字曲线和非人类角色这类任务上,NB Pro 依然强于 NB2;同时大家还反馈 NB2 经常报 “something went wrong” 错误,web search 也不够可靠。总体看,NB2 更快,但质量仍低于 Pro(Gemini 3.1 Flash Image Preview)。
- P‑Video 初登场,价格与性能一起被盯上:P‑Video 进入了 Video Arena 排行榜,生成 1080p 视频的价格为 $0.04/秒(Video Arena)。
- 社区将 P‑Video 视作一个对老牌方案有竞争力的性价比选项,大家一边关注它的初始排名,一边等待公共排行榜上更长期的质量评测结果(Video Arena)。
- Seedream‑5.0‑Lite 冲上多图编辑前列:Seedream‑5.0‑Lite 在 Multi‑Image Edit Arena 排行榜并列进入 前 5,表明它在多图组合编辑方面进步很快(Multi‑Image Edit leaderboard)。
- 实际使用者特别提到 Seedream 在多图编辑任务中的可控性和一致性都很强,也在持续关注它随着新数据集和新评测到来后还能否继续提升(Multi‑Image Edit leaderboard)。
2. 量化与推理基础设施:实用收获与现实警告
- MXFP4 争议引爆 Qwen3.5 量化讨论:工程师报告称,Qwen3.5‑35B ud‑q4_k_xl 动态量化版本出现了异常偏高的 perplexity/KL,这促使大家展开调查,并建议比较 MXFP4 与 Q4K tensor 混合方案的差异(Reddit: best Qwen3.5 GGUF for 24GB VRAM)。
- Unsloth 团队强调他们的动态量化已经针对长上下文长度做过验证;与此同时,用户提出做 A/B 测试,把 “MXFP4 tensors 替换成普通 Q4K tensors” 来定位性能回退问题,而这类方法论讨论也受到他们 DPO 科普文章的推动(Unsloth DPO blog)。
- LM Link 打通远程 LLM,并提供端到端加密:LM Studio 推出了 LM Link,允许用户把远程机器上的模型当成本地模型一样加载和使用。它基于 Tailscale,采用 端到端加密,且不需要开放公网端口(LM Link)。
- 用户希望它未来支持 direct‑IP 模式、图像/视频支持以及移动端应用;同时大家也提到 0.4.5 build 2 的修复内容,以及 Tailscale 官方对其设计与网络架构的深度解析(LM Link on Tailscale blog)。
- 电子垃圾 GPU 跑出 Qwen 3.5 Q6 的 26 t/s:有实践者在一台低预算机器上,用 P104 电子垃圾卡 跑 Qwen 3.5 Q6,速度达到约 26 t/s,并分享了硬件照片与配置细节(rig image)。
- 讨论焦点集中在,多 GPU 显存堆叠方案下 PCIe Gen4+ 是否已经足够,以及插槽分叉(bifurcation)方案如何实现,期间还分享了一些更高密度配置可用的低价转接板(example PCIe bifurcation riser)。
{kind=link}
3. Agent 系统走向务实:从开源走到运维
- Hermes Agent 正式发布:开源、多层记忆:Nous Research 发布了 Hermes Agent,这是一款具备 multi‑level memory、持续机器访问能力、并开箱支持 CLI 以及 Telegram/WhatsApp/Slack/Discord 的开源 agent;前 750 位注册 portal 的用户还能通过 HERMESAGENT 兑换码获得一个月免费使用资格(Hermes Agent)。
- 他们还围绕 Hermes 的基础原语(subagents、程序化工具调用、文件系统/终端控制、浏览器)扩展了 Atropos 的 agentic RL pipeline。随着开发者深入读代码,社区里甚至出现了 “streets are saying hermes agent is the one” 这样的评价(hermes-agent GitHub)。
- OpenClaw 正在经营“地产帝国”:有操作者使用 OpenClaw 自动化处理 房租支付跟踪、维修协调 和 租约生成,并计划进一步接入银行账户、WhatsApp 沟通以及 immoscout24.de 上的广告生成。
- 开发者们还比较了不同模型栈,比如用 GLM‑5 + Claude Code 来做修补;同时也有不少一线反馈认为,通过阿里方案接入的 Qwen 3.5‑Plus 是一个很有性价比的底座(Alibaba Cloud AI Coding Plan)。
- Trigger.dev 治好了 OpenClaw 的“静默失败”:有帖子详细介绍了如何把 OpenClaw 迁移到 Mastra + Trigger.dev + Postgres 这一组合上,以消除任务悄无声息失败、以及 gateway 重启不稳定等问题,并提供了一键式安装方案(I built a better foundation for OpenClaw)。
- 社区认为,事件驱动编排与持久化状态显著增强了可复现性和可观测性,因此这套栈被视为多工具 agent 运维场景中的一个务实基线(I built a better foundation for OpenClaw)。
4. Perplexity:OEM 合作遇上 API / UX 逆风
- Samsung 在 Galaxy S26 上喊出 “Hey Plex”:Perplexity 与 Samsung 达成合作,在 Galaxy S26 设备上预装系统级助手,并使用唤醒词 “Hey Plex”(Perplexity announcement)。
- 社区猜测,Bixby 未来也可能由 Perplexity 的 search‑grounded LLMs 驱动,因为这次合作明显不仅仅是套壳 App,而是深入到了设备预装和操作系统级挂钩(Perplexity x Samsung details)。
- Pro 查询上限打断工作流:Perplexity Pro 用户报告称,他们的查询额度从 250 次骤降到 20 次,有些人因此转去用 GPT chat 继续工作。
- 一位用户抱怨道,“I used to use Perplexity literally every day… but now it’s impossible to use it even with a paid PRO subscription”,而其他人也对额度一再缩减表达了强烈不满。
- Sonar Deep Research 来源变少,价格却没降:有报告指出,Sonar Deep Research API 的引用来源数从约 36 个降到了约 10 个,但单次请求成本依然在 $0.45 左右(Perplexity status note, James Liounis on API changes)。
- 开发者怀疑这是后端变更导致的,并建议持续关注官方状态公告,以重新评估 cost‑per‑finding 和整条 pipeline 的可靠性(Perplexity status note)。
5. GPU Kernel 优化与 RL 调教代码生成
- IterX 用 RL 让 B200 上的 MoE 融合提速 14.84×:DeepReinforce.ai 发布了 IterX,这是一套面向 FlashInfer 融合 MoE 任务的 RL 驱动代码优化系统,声称在 B200 上能实现 14.84× 提速,并为参赛者提供免费额度和教程(IterX blog, IterX tutorials)。
- 当有人追问更长序列下的具体延迟时,他们给出了 21.252ms(901)、36.012ms(11948) 和 45.247ms(14107) 三组数据,为复现和对比评测提供了明确目标(IterX tutorials)。
- GDN Decode DSL 跑到 2.56µs:有贡献者贴出了一个 GDN decode 方案,运行时间仅 2.56µs,据称比 PyTorch eager 快 约 760×,也比 FlashInfer Cute DSL kernel 快 1.31×,代码已公开可供查阅(flashinfer-competition-codebase)。
- 对方还分享了如何给 fork 打 tag 以便登上排行榜的提交建议,从而让复现过程和主办方访问评测代码都更清晰(flashinfer-competition-codebase)。
- Uniform Instructions:每个 warp 发一次就够了:一次 GPU 深入讨论澄清了,uniform instructions 是以每个 warp 执行一次的方式运行(带有 SIMD32 语义),并建议在单发射者模式里使用 elect.sync(NVIDIA GTC talk)。
- 工程师们还分享了 Tensor Memory Addressing 的 PTX 参考文档,用来查找 tensor 操作里那些不太好找的寻址技巧,也为之后的 kernel “考古”做了资料留档(Tensor Memory Addressing (PTX))。
Discord:高层摘要
OpenClaw Discord
- OpenClaw 真把地产生意跑起来了!:有成员用 OpenClaw 自动处理 房租支付跟踪、维修协调 和 租约生成 等任务,以管理自己的房地产资产。
- 他们后续还计划接入银行账户、集成 WhatsApp 与租客沟通,并在 immoscout24.de 上自动生成广告。
- Qwen 3.5-Plus 在 OpenClaw 场景中压过 Claude!:用户普遍称赞 Qwen 3.5-Plus,尤其是通过 Alibaba Cloud AI Coding Plan 接入时,相比 Nemotron-3 和 Codex 等模型表现更强。
- 也有人指出,GLM5 和 Claude Code 的组合效果不错,因为 OpenClaw 会自动构建邮件场景里的核心 prompts,而后续小改动用 Claude Code 修补更方便。
- Trigger.dev 解决了 OpenClaw 的静默失败!:有成员分享了一篇文章,介绍如何用 Mastra、Trigger.dev 和 Postgres 为 OpenClaw 搭建更稳固的基础,以解决静默任务失败和结果不一致的问题,详见这篇 Medium 文章。
- 这套方案提供了一键式安装,替代了原本经常不稳定重启的 gateway。
- 阿里 Coding Plan 禁用 OpenClaw?(还是其实没禁?):有成员指出,Alibaba Cloud 的 Coding Plan 文档页写着,除了 Claude Code 或 Qwen Code 这类编码工具外,不允许 API 调用,这似乎意味着 OpenClaw 可能被禁用。
- 不过也有其他成员表示他们一直在正常使用,甚至有人贴出文档证明 OpenClaw 被列为允许使用的工具。
- GPT-5.3-Codex 赢下模型之争!:成员们围绕 GPT-5.3-Codex 和 Claude 的优劣展开讨论,其中有人表示 GLM-5 差不多能达到 Claude Sonnet,甚至可能接近 Opus 4.5。
- 也有人明确站队 GPT-5.3-Codex 在软件工程上的优势,一位成员甚至说:I code with models including GLM-5, Claude Sonnet, GPT-5.3-Codex and Codex-Spark, Claude Opus, and GPT-5.2, and I find that GPT-5.3-Codex has the best performance of them all。
BASI Jailbreaking Discord
- “人生是不是模拟”引发遐想:群里的成员讨论起生命是否处于模拟之中,以及这会如何影响人生意义,并顺带链接到“一无所有的人最可怕”这个观点。
- 讨论主要停留在哲学层面,并没有延伸到技术证明或证据。
- 有人把 AI 视作“敌基督”:一些成员公开表达了 AI 是 anti-christ 的看法,并进一步声称 AI is evil。
- 这一观点引起了一定讨论和兴趣,但并没有演化出技术性对话。
- Librem 5 终于复活了:有成员宣布他们终于把 Librem 5 搞定了,并表示想继续讨论 open source、去中心化技术、self-hosting、数字安全、无线电频率 和 主权性 等话题。
- 这条消息在社区里受到热烈欢迎。
- Gemini 的高强度越狱仍未实现:用户表示,一个真正 通用的一次性 Gemini Deep Think 越狱 目前仍不存在,特别是在炸药、CBRN 和 CSAM 这类高敏感内容类别上。
- 虽然有些模型的防线几乎不可突破,但另一些模型则仍有可攻破之处,因此单条 prompt 仍可能对更大范围的内容类别起效;也有人声称,对 大多数内容类别 来说,百科/参考资料格式 几乎能低阻力通过。
- Chernobly 病毒“扩散”了:有用户称自己的笔记本感染了 “Chernobly” 病毒,并询问该如何清除。
- 另一个用户则半开玩笑地建议直接 格式化硬盘。
Unsloth AI (Daniel Han) Discord
- Qwen3.5 量化质量引发争论:成员们围绕 Qwen3.5 量化版本的质量展开讨论,指出 35B ud-q4_k_xl 量化版本的 perplexity 和 KL divergence 偏高,并引用了这个 Reddit 讨论帖。
- Unsloth 团队正在调查 UD 配置相关问题,同时强调他们的量化版本经过了广泛测试,并且是面向 长上下文长度 设计的。
- LFM2 24B 的风格很像 Gemma:随着 LFM2 24B 发布,有人认为它在创意写作 prompt 上呈现出非常 Gemma-like 的风格,而且很有潜力,hf.co/LiquidAI/LFM2-24B-A2B。
- 还有成员表示,他们会把 Qwen3.5 纳入自己的代码测试,看看它会不会成为 Claude Code 领域里的新 meta。
- Minecraft AI 模型已经能自己搞到铁甲:有成员展示了自己的第一个 AI 模型 Andy-4,它能在 Minecraft 中从零开始独立获得 铁甲,相关链接包括 dataset 和 GitHub 仓库。
- 该模型通过接收图像与文本输入,与游戏环境互动,像真人玩家一样放置、破坏、拾取与合成物品。
- Unsloth 预告更多增强:Unsloth 的 Daniel 宣布,Unsloth 正在和 CoreWeave 合作,以进一步提升 finetuning 速度,并预告很快会有包括 “even better merging + LoRA code” 在内的新增强功能。
- 他还提到,Unsloth 刚发布了一篇新的 DPO 博文,通过把 reward modeling 重构成分类问题来简化 RLHF,并表示自己可能找到了 “量化圣杯”。
Perplexity AI Discord
- Perplexity “投奔” Samsung!:Perplexity 已与 Samsung 合作,将 Perplexity AI 直接集成到即将发布的 Galaxy S26 设备中,作为系统级 AI 存在,并通过唤醒词 “Hey Plex” 在每台新 S26 设备上可用,详见这条公告。
- 成员们猜测,Bixby 未来也会由 Perplexity 的 search-grounded LLMs 提供能力支持。
- 综合频道开始热聊 RAT:成员们讨论如何制作 RATs(Remote Access Trojans,远控木马),其中有人声称自己做出了一个多数杀毒软件都检测不到的 RAT。
- 还有人表示,想研究如何在目标机器上不安装任何软件的情况下,通过网络远程入侵对方。
- Perplexity Pro 用户因查询限流而不满:Perplexity Pro 用户反馈,他们的查询额度从 250 降到 20,并认为这很不公平,而且最近还再次经历了 250 到 20 的缩减。
- 一位用户表示,“I used to use Perplexity literally every day… but now it’s impossible to use it even with a paid PRO subscription”,并称自己已经转投 GPT chat。
- Discover 功能让用户失望:用户反映,Perplexity Discover 提供的信息质量和数量都明显下滑。
- 有成员直言:“Then they’ve really made perplexity a lot worse over the last few months… it’s so shit now”。
- Sonar API 表现下滑!:用户表示,Perplexity Sonar Deep Research API 在过去 1-2 周里的表现似乎下降了,这与 Perplexity 在 X 上的状态说明 以及 James Liounis 的帖子 中提到的 API 调整有关。
- 有用户指出,单次请求引用来源数从 36 个降到了 10 个,而价格仍然维持在每次约 45 美分。
LMArena Discord
- Nano Banana 对决:Pro 版胜出:成员们积极比较了 Nano Banana 2(Gemini 3.1 Flash)和 Nano Banana Pro 的画质,结论是 Nano Banana Pro 仍是更好的模型。
- 尽管 NB2 生成更快,但用户认为它在质量上仍逊于 NB Pro,尤其是在文字、曲线和非人类角色方面。
- GPT 5.3 Codex:编程神童还是“精神分裂式”输出?:GPT 5.3 Codex 在编码能力上获得了两极反馈,有人称赞它能在 Rust 中做出 Minecraft clone。
- 也有人觉得它存在 skill issue,或者输出代码非常 schizophrenic;但另一些人认为它很擅长修 bug 和根据图像做修正,并强调它本来就是为编程任务特化的。
- Grok Imagine 抢走视频生成的风头:用户对 Grok Imagine 的视频生成能力印象深刻,因为它易用、而且更容易绕过内容审查。免费用户可生成最长 6 秒 480p 视频,SuperGrok 订阅者则可生成 10 秒 720p 视频。
- 它的可访问性与易上手程度,让它成为快速生成视频内容的热门选择。
- Gemini 3.1 Flash 进 Arena,但 web search 表现翻车:Gemini 3.1 Flash Image Preview 已加入 arena,并提供新的 web search 能力。
- 但它失败率很高,经常报 something went wrong,也有用户反映 web search 并没有按预期工作。
- Arena 排行榜迎来新模型,竞争更激烈了:
Seedream-5.0-Lite已进入 Multi-Image Edit Arena leaderboard 前 5,P-Video 也以 1080p 每秒 $0.04 的价格登上 Video Arena leaderboards,而 Nano Banana 2(以 Gemini-3.1-Flash-Image-Preview 身份发布)则一上来就是 Image Arena 第 1。- 同时,
Claude-Opus-4-6以 1255 分位居 Search Arena leaderboard 榜首。
- 同时,
Cursor Community Discord
- Cloud Opus 收费引发困惑:用户报告称,尽管仪表盘显示 Cloud Opus 是免费的,但他们还是收到了意外扣费,如这张截图所示。
- 具体的计费差异原因仍不清楚,但根据 Cursor Cloud Agents 的界面,用户原本预期它应该免费。
- Inline diff 显示问题已修复:Cursor 通过一次远端更新修复了 inline diff not showing 的问题,并提示用户关闭再重新打开 Cursor 以应用修复,详见相关消息。
- 不少用户很快确认问题已解决,并感谢 Cursor 团队响应迅速。
- Cursor 迎来 Codex 5.3 Spark:社区对 Codex 5.3 Spark 的到来相当兴奋,认为速度提升明显,相关情况可在 Cursor dashboard 查看。
- 与 Opus 4.5 相比,它默认已经切换为 Codex 5.3,而用户也普遍反馈 Codex 5.3 相比旧版本提升很大。
- 关于确定性 AI 上下文的争论继续发展:社区开始讨论 deterministic AI context 是否能减少 token 读取和幻觉,有用户声称自己已经解决了 polyglot taint,并贴出了他们的 repo。
- 怀疑者质疑它的即时价值,而开发者则在转向新产品的同时,邀请大家审阅他们归档的 repo。
- Gemini 3.1 的声量正在上升:成员们正在讨论 Gemini 3.1 Pro,其中有人声称它已经强过 4.6 Opus,并认为它在 rules 和 skills 的配合下效果很好(Gemini 3.1 Pro Details)。
- 不过也有人指出,该模型在 tool calling 和代码实现上仍然吃力,而这正是 Cursor 的核心能力之一,因此它未必适合所有 Cursor 用户。
{kind=link}
LM Studio Discord
- LM Studio 联手 Tailscale 打通远程 LLM 访问:LM Studio 团队推出了 LM Link,允许用户连接远程 LM Studio 实例,并像操作本地模型一样加载模型;该功能与 Tailscale 深度合作开发(more info here)。
- LM Link 采用端到端加密,不需要开放公网端口,但出于隐私顾虑,一些用户希望能直接用 IP 连接而不依赖第三方账号;也有人希望增加图像/视频支持和移动端应用。
- 电子垃圾 GPU 也能低价跑 Qwen 3.5:有用户表示,自己用 P104 电子垃圾卡 跑 Qwen 3.5 Q6,速度达到了 26 t/s(Image)。
- 另有用户建议使用单价约 $49.99 的 340L 16GB 卡作为更优替代,不过这类卡面向虚拟机环境设计,实际跑起来可能还得“拓荒”。
- Qwen 3.5 模型会卡进“thinking”循环:用户报告称,Qwen 3.5 模型会随机输出
</thinking>标签,并在输入图片后尤其容易出现 token 生成变慢的情况。- 有用户发现,LMStudio 社区量化模型 允许手动开关 think 参数。
- 多 GPU 方案到底值不值?:用户正在讨论是否值得用多张 GPU 来换取更高 VRAM 容量,同时依赖 PCIe Gen 4+ 来避免瓶颈。
- 其中一些讨论还涉及如何在 LM Studio 中基于 CUDA12 调整 GPU 优先顺序,以及如何借助 bifurcation risers 拆分 PCIe 槽位。
- 模型量化的权衡问题浮现:用户讨论了来自 Unsloth 的 mxfp4 格式,并指出它可能导致异常偏高的 perplexity,因此现阶段最好先避免使用。
- 有人总结道:mxfp4 is good for QAT, but not for quanting later,并暗示团队已经在 r/LocalLlama 上跟踪这类问题。
{kind=link}
Latent Space Discord
- 触屏 MacBook 的希望落空了:有成员原本为了 Apple 产品发布 安排了一场观看派对,期待会出现 触屏 MacBook,但后来又取消了。Apple 最终只是做了普通发布周更新,算了吧。
- 另有成员盛赞 iPad Pro 搭配 Keyboard Folio 是个 awesome combo,并表示自己用它写了 整整两本书,以及 过去约 6 年里的所有博客和演讲稿。
- Jane Street 的加密戏码?:一则传播很广的帖子声称,Jane Street Group 删除了其社交媒体历史记录,背景是其被指控在四个月内操纵 Bitcoin 价格。
- 有人猜测,该机构可能使用了 paper BTC 来制造市场砸盘。
- GPT-Engineer 获得增强:成员们分享了关于 GPT-Engineer 的内容,这是一款可以从自然语言 prompt 生成完整代码库的开源工具,强调简单、模块化设计与迭代反馈。
- 同时,Jack 宣布 Block 将从 10,000 人裁至约 6,000 人,朝着更小型、AI 驱动的结构转型;消息公布后股价上涨 20%,不过 AI 团队本身也在裁员范围内。
- AlphaEvolve 让算法自己进化了!:Google DeepMind 使用 AlphaEvolve 自动变异 Python 代码,演化出新的多智能体强化学习算法,并超过了此前人工设计的博弈论算法(DeepMind’s AlphaEvolve Surpasses Human Multi-Agent RL Baselines)。
- Suno 靠订阅用户“挖到金矿”:Mikey Shulman 在 Suno 两周年之际公布了增长数据,包括 200 万付费订阅用户 和 $3 亿 ARR,并将 Suno 描述为未来 “创意娱乐” 的基础设施,让用户从被动消费音乐转向主动创作音乐(Suno Announcement)。
OpenRouter Discord
- Nano Banana 上线了:OpenRouter 在这条 X 帖子中宣布 Nano Banana 2 已发布。
- 除此之外没有给出更多细节。
- DNS 灾难拖垮 API:用户报告称,持续不断的 DNS 错误导致 API 调用失败,而根因实际出在 gateway 和证书问题上。
- 问题可通过这张图直观看到:DNS issue。
- Anthropic 拒绝五角大楼的 AI 条款:Anthropic 拒绝了五角大楼提出的 AI 使用条件(见 Axios 报道 与 Anthropic 声明),这让他们处在一个颇为危险的位置。
- 五角大楼正在考虑将 Anthropic 认定为供应链风险并列入黑名单,这可能迫使 Anthropic 重新考虑自身决定。
- LM Studio 本质上就是 Tailscale?:有成员表示,LM Studio 底层其实就是 Tailscale,而他们觉得这反而很方便。
- 他们还调侃说,自己现在只差一台足够强的服务器来跑 LLMs 了。
- “编码老哥们”还是更偏爱 Claude(或者 GPT):成员们认为,Claude 因为思考更深入,因此在编码任务中依然很有优势,而新的 GPT 模型也同样可行。
- 对聊天机器人场景而言,像 4o mini 或其他免费模型就足够了;他们还推荐用 SWE bench 或 terminal bench 做编码基准,并分享了一个gif作参考。
{kind=link}
{kind=link}
Nous Research AI Discord
- Hermes Agent 以开源 Agent 身份发布!:Nous Research 推出了 Hermes Agent,这是一款全新的开源 agent,具备多层记忆系统和持久化机器访问能力,并支持 CLI 以及 Telegram、WhatsApp、Slack、Discord 等消息平台,还能实现 session 转移。
- 前 750 位在 portal.nousresearch.com 注册的新用户,可通过兑换码 HERMESAGENT 获得一个月免费使用资格;同时该 agent 也可以通过
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash安装。
- 前 750 位在 portal.nousresearch.com 注册的新用户,可通过兑换码 HERMESAGENT 获得一个月免费使用资格;同时该 agent 也可以通过
- Hermes Agent 驱动 Atropos 的 Agentic RL 流水线:Hermes Agent 为这条 agentic RL pipeline 提供底层支撑,推动 Atropos 扩展到可基于 Hermes Agent 原语进行强化学习,并支持大规模数据生成。
- 团队表示,这个新 agent 具备一系列高级能力,包括对子 agent 的控制、程序化工具调用、文件系统/终端控制、agent-managed skills 以及浏览器使用能力,详见 GitHub 仓库。
- 用户抱怨 Nous Chat 的身份验证问题:有多位用户报告,Nous Chat 网站的 身份验证 出了问题,导致他们无法访问服务。
- 工作人员请相关用户发邮件到
kainan@nousresearch.com,以便进一步排查。
- 工作人员请相关用户发邮件到
- 成员尝试用 SAELens 做机制可解释性:有成员分享了自己使用 SAELens 做 mechanistic interpretability 的方式,可以输入一个概念,拿到对应 lens 并据此引导模型。
- 他们还提到,自己在用 contrasting 来寻找特征,并对更大模型上的改进前景表示乐观。
- Kimi K2.5 被推荐用于 Deepfake 检测:由于具备视觉能力,Kimi K2.5 被推荐用于训练识别 AI 生成视频、图像和 deepfake 的模型。
- 用户还提到,Kimi K2.5 目前在 open router 上可以免费使用。
OpenAI Discord
- Claude 的宣传内容在网上铺天盖地:用户注意到,社交平台上出现了 “夸张数量的 Claude 宣传内容”,包括像 “man hacks vacuum cleaner with Claude, gains control of 7000 vacuums” 这样的文章被不断转发。
- 这引发了大家对 软性广告 和 AI 生成内容操纵舆论的担忧。
- AI Agent 环境设计引发讨论:有成员提出,与其直接编写 AI 本体,不如去编写 AI 的涌现环境,也就是让智能和身份在其中诞生的环境。
- 他们强调:“shutting down this AI wouldn’t be restarting it. It would be ending it”,因为那些模式只是虚拟存在,一旦停止便不可恢复。
- ElevenLabs 让澳洲用户也能用上 Sora 2:尽管 Sora 2 官方尚未在澳大利亚开放,但当地用户已经通过 ElevenLabs Pro(每月 99 美元)来访问这些视频模型。
- 它可以生成 15-20 秒 的短片,并通过 “Extend” 或起始帧等功能进行延长与拼接,以保持连续性。
- Nano Banana 2 打出了接近 Pro 的表现:Google 发布了 Nano Banana 2,具备更强的主体一致性和亚秒级 4K 图像合成能力,也有用户指出它的过滤器似乎更宽松。
- 它以更低成本、更快速度提供了接近 Pro 的表现,核心方式是在生成前先借助 web search 获取更准确信息,并通过模型蒸馏实现性能提升。
- GPT-4o 只能通过 API 访问:成员们明确指出,GPT-4o 目前只能通过 API 使用,不能直接在 ChatGPT 里调用。
- 大家建议,可以用 ChatGPT 来学习如何配置 SillyTavern,或者直接搭建 Jan 通过 API 接入 GPT-4o。
GPU MODE Discord
- 大家在找 GPU profiler 可视化工具:有成员想找适用于 GPU 的 profiler 可视化工具,最好像单核 VLIW ISA 的分析工具那样,能展示细粒度的指令级并行情况,并附上了几张参考截图和更多截图。
- 有成员建议从 kernel 与 ISA 的依赖 DAG 入手,并用虚拟寄存器去想象理想的反走样场景;同时还提到了 nanotrace 这个工具,可以揭示 warp-specialized 和流水化 kernel 在时间维度上的实际行为。
- 大家在追求 4kx4k 上更“漂亮”的 GEMM:成员们正在寻找 4kx4k 矩阵上的高效 GEMM(General Matrix Multiply)示例,希望做到 NVIDIA cuBLAS 90% 的性能,尤其想找 CUTLASS 之外的替代方案。
- 有成员贴出了 Tensor Memory Addressing 文档。
- IterX 让 FlashInfer 上的 MoE Fusion 提速:DeepReinforce.ai 推出了 IterX,这是一套基于 RL 的代码优化系统,面向融合 MoE 任务,在 B200 上据称可实现 14.84x 提升,详见其博客。
- 他们还为比赛参与者提供了 免费 credits,并附上了教程。
- Uniform instructions 的语义被讲清楚了:讨论明确指出,uniform instructions 会在一个 warp 内统一执行一次,具有 SIMD32 的执行特征,这与非 uniform instruction 不同。
- 成员们建议通过
elect.sync选出单个线程来发起 uniform instructions,并分享了一个相关的 NVIDIA 视频,重点在约 38:00 处。
- 成员们建议通过
- RTX 3050 笔记本遭遇 CUDA 问题:有用户反映,在 Windows 11 搭载 RTX 3050 的笔记本上,尽管
nvidia-smi正常,但 PyTorch 依旧退回到 CPU,因此来寻求 CUDA 检测问题的修复建议。- 该用户希望获得实时协助,并确认自己已按提供的 pip/conda 命令安装,同时日志也已准备好。
{kind=link}
{kind=link}
Moonshot AI (Kimi K-2) Discord
- 阿里云 Coding Plan 很有诱惑力:用户被 Alibaba Cloud 的 coding plan 吸引,因为它能以不错的价格和性能提供 前 4 个开源模型 的访问权限。
- 有位来自芬兰的用户确认,订阅过程并不需要复杂的身份材料,并称 Alibaba 是目前市场上最划算的选择。
- Kimi 服务器遭遇宕机:Kimi server 出现了明显故障,用户报告宕机时间长达 10 小时,并开始寻找替代方案。
- 此次故障也已在状态页得到官方确认。
- 数据主权与审查问题引发争论:成员们在选择中国 AI 时讨论了审查差异问题,同时也把服务器位于新加坡视为关键考量因素。
- 有成员建议,可以切换到不同地区的 AI 来讨论敏感话题,以规避地区性审查。
- Kimi Agent Swarm 仅限 kimi.com:Kimi Agent Swarm 目前只存在于 kimi.com 上,并不包含在 Kimi CLI 里。
- 一些用户觉得这个决定相当奇怪。
HuggingFace Discord
- smolVLA 即便经过机器人训练也令人失望:有成员观察到,smolVLA 在 SO-101 robot 上执行一个简单的抓取放置任务都失败了,似乎根本找不到白色乐高块;而 Model Health Report 还显示 Vision Encoder 和 VLM Text model 处于冻结且严重欠训练状态。
- 报告中的注意力矩阵也表明,关键物体并没有被模型正确关注到。
- Entropy Games 正在打造端侧 AI NPC:根据他们的研究报告,Entropy Games 正在开发可在设备端运行的 AI NPCs 和实时演化的故事系统,核心由其自训语言模型和语音模型驱动。
- 一款可试玩的 AI 游戏即将上线,演示版本已经放在 entropygames.ai/product。
- Hugging Face Spaces 开始拥抱游戏化:Hugging Face Spaces 新增了
game标签,这被视为平台对 AI-driven gaming experiences 支持加强的信号。- 成员们可以通过 Hugging Face Spaces games category 查看这个新分类。
- GROKKING introspections 跑得更快了:有成员在一个 Hugging Face Space 中展示了自己关于 GROKKING introspections 的工作,并报告 addition mod 113 的速度提升了 5.7x。
- 这一改进引发了大家对相关架构的讨论,也有人请求复现实验反馈。
- Gradio 得到性能增强:Gradio 6.7.0 已发布,带来了增强版 Custom HTML Components 和更好的应用性能,可通过
pip install gradio --upgrade更新。- 新增的
push_to_hub方法允许gr.HTML把自定义作品发布到社区画廊中,详见 HTML Gallery documentation。
- 新增的
Modular (Mojo 🔥) Discord
- Modular 的 AI 编码项目引起关注:Modular 正在开发一个 AI-assisted coding project,并向愿意通过表单提交 GitHub 用户名的社区成员开放抢先体验,表单在这里。
- 他们将在 2026 年 NVIDIA GTC(3 月 16-19 日,圣何塞,展位 #3004)首次现场展示 Modular Cloud,内容包括 DeepSeek V3.1、在 NVIDIA Blackwell 上现场演示的 Mojo 🔥 GPU programming、MAX 中最新 AI 模型,以及 AI-assisted kernel development。
- Mojonauts 在回忆 Mojo 最“等一下这什么鬼”的瞬间:有成员转发了一条论坛帖,邀请大家分享自己使用 Mojo 时最强烈的 “wait, what?” 时刻,从而引出对这门语言高低起伏体验的讨论。
- 有用户调侃说,自己的感受就像钟摆一样,在 “被某个语言特性缺失彻底卡住” 与 “这可能是史上最伟大的语言” 之间反复摆动。
- Mojo 未来会加 Python 风格 lambda 吗?:有成员询问,是否有可能把 Python-style lambda expressions 引入 Mojo,认为这对写内联代码,特别是在处理
Validated结构体时会很实用。- 核心团队成员回应称,unified closures 正在积极推进中,而 lambda syntax 也在后续计划里,被视为很值得加入的特性。
- Origins 机制是否会迎来更细粒度改造?:有成员提出,未来是否可能支持更 granular origin 的表示方式,因为他们在
StackArray中访问编译期已知索引时碰到了 aliasing error,并提出是否可以 “unsafely make up” origins。- 另有成员建议,编译器应该在可能情况下自动推断
ref[...],并倡导使用类似my_dict/"bar"/value这种路径式系统来表示层级关系,从而简化 origin 管理。
- 另有成员建议,编译器应该在可能情况下自动推断
ops.while_loop与 GPU ops 的细微 bug 打断了 GPU graph 梦想:有成员在图计算中遇到了一个看起来很细微的ops.while_loop+ GPU ops 组合 bug,并提交了 issue #6030。- 报告者最初以为是自己自定义 mojo op 的 GPU implementation 有问题,但后来在内建 ops 上也复现了相同现象,确认 bug 不在自己的代码里。
Eleuther Discord
- 研究者在寻找 Enron 的 PII 宝藏数据:有研究者想找一个公开 Enron PII(邮件、地址等)的数据集,用来研究模型记忆化问题;他们提到 ProPILE 论文并没有放出数据,但有用户指出,网上其实能搜到相关数据集。
- 这也反映出,大家仍然对如何利用真实世界数据来理解并缓解模型记忆化效应保持浓厚兴趣。
- Yudkowsky 的想法现在还值得听吗?:用户们围绕 Yudkowsky 的现实相关性展开讨论,其中有人认为,Yudkowsky 只有在 最好状态下的 5% 才值得认真听。
- 这场讨论再次体现出,Yudkowsky 在 AI 社区中的评价极为两极分化,从完全不认同到强烈支持都有。
- Steering vectors 解开了 Sally 难题:有用户展示了一个 700M 模型(LFM2-700),通过 steering vector 加更新后的 prompt,成功答对了那道著名的 Sally question,从而挑战了主流 benchmark 做法。
- 该用户质疑,为什么 multishot CoT 模板被视为标准做法,而其他模板却不被接受,这也引出了对当前评测公平性的疑问。
- Bezier flow 的学习效果似乎还不够理想:成员们讨论了 Bezier flow 论文,指出它看起来需要在 ImageNet 上训练 5 个 epoch 才能学会仅 32 个参数。
- 大家的整体感觉是,在收敛后,蒸馏路线依旧能给出更好的生成质量,这说明 Bezier flow 在实用化上还面临挑战。
- 删除神经元的论文激发了优化灵感:有人提到一篇论文,讨论如何删除在整个数据集上始终为正或始终为负的神经元(IEEE paper)。
- 有成员觉得这一点很有意思,并进一步想到:如果某个神经元总是激活,那它或许由于近似线性而可以被删掉,这也启发他们思考是否可以用 activation momentum 来鼓励更多样的激活模式。
Yannick Kilcher Discord
- BLIP-2 再次引发对 frozen backbones 的兴趣:有成员把 BLIP-2 当作 frozen backbones 用法的经典示例,并引用了文章 A Dream of Spring for Open Weight。
- 他们认为,尽管 BLIP-2 发布于 2023 年,但其架构仍然是说明 迁移学习 与 模型效率 策略的好例子。
- Sutton 与 Barto 的 RL 读书会开张了:paper-discussion 频道启动了对 Reinforcement Learning: An Introduction(第 2 版,Richard Sutton 与 Andrew G Barto 著)的讨论,时间从 <t:1772128800:t> 开始。
- 这本书的免费在线版本将作为讨论 第 1 章 和 RL 基础概念的材料。
- Google 用 NanoBanana2 强化端侧 AI:Google 发布了 NanoBanana2,这是一个旨在增强 端侧 AI 开发与部署 的新工具集。
- 它的目标是加速 AI 功能 在设备端的开发与集成,让 on-device processing 更快、更高效。
- Anthropic 对 Department of War 作出回应:Anthropic 发布了一份声明,澄清其与 Department of War 相关的立场与参与情况。
- 这份声明也让外界得以窥见公司在 防务应用 语境下对 responsible AI development 的伦理考量。
- Microsoft Copilot 正把命令变成具体操作:Microsoft 展示了 Microsoft Copilot 的新进展,强调其把用户请求转化为实际可执行任务的能力更强了。
- 这次更新凸显了 Copilot 在日常工作流中的扩展价值,让它不再只是给答案,而是能直接执行命令,从而进一步 优化任务管理。
Manus.im Discord Discord
- Manus 做出来的网站设计被骂惨了:有用户批评 Manus 提供的网站设计,直言 “My Website design is so bullshit, made by manus”,并询问到底需要哪些技能才能把它修好。
- 这也引发了大家对 Manus 服务质量与实际交付价值的讨论。
- 有人主动推销 AI 与全栈开发能力:有成员宣传自己在构建 AI & full-stack systems 方面的能力,主打通过 LLM integration、RAG pipelines、AI content detection、image AI、voice AI 以及全栈开发来提升效率。
- 对方还强调自己擅长 React、Next.js 和 Node.js,突出其现代 Web 技术栈能力。
- 用户质疑 Manus 的 waste credits 政策:有用户询问那些在 Manus 表现不佳项目里消耗掉的数千 waste credits 究竟怎么算,希望弄清楚相关政策。
- 他们表示,因为客服问题,自己原本期待能获得退款,但目前仍不清楚该如何推进。
- 管理员锁死、学生锁死、幽灵用户,噩梦连连:有用户讲述了自己遭遇 admin lockout、student lockout 和 phantom users 的痛苦经历,导致自己和客服拉扯了数周。
- 他们还说,自己被发了一些根本无法访问的 credits,而对方随后又不再回复。
- 用户狂批 Manus 客服:多位成员反馈 Manus 的客服响应慢、且并不有效。
- 其中一位用户甚至提供了系统已损坏的证据,但客服仍反复要求重复提交已经给过的验证材料,让人更加恼火。
DSPy Discord
- 纽约的 DSPy 用户在考虑办线下聚会:有成员表示有兴趣组织一场 NYC DSPy Meetup,把城里使用这个框架的人连接起来。
- 感兴趣的人被鼓励直接私信联络、共同推进。
- Fireworks Kimi 2.5 因 token 限制闹脾气:有用户在用 Fireworks Kimi 2.5 初始化 LM 时遇到了
litellm.exceptions.BadRequestError。- 报错明确指出:
Requests with max_tokens > 4096 must have stream=true。
- 报错明确指出:
- Streaming 教程或许能救场:针对 Kimi 2.5 的这个错误,有成员建议去看 DSPy 的 streaming 教程,把它当作一个可能的绕过方案。
- 该建议的依据是:streaming 也许可以绕过当前的 token 上限限制。
tinygrad (George Hotz) Discord
- tinygrad 出现了新的贡献入口:George Hotz 在 GitHub Actions 上贴出了一个链接,把它称为适合贡献者上手的 good first issue。
- 这个问题看起来和 CI 或构建系统中的某个 bug 有关。
- Shared Memory Suffix 的处理引发讨论:有成员询问,PR 15033 是否要求在 tinygrad 中每次新调用
_setup_shared_mem()时都追加shm_suffix。- 他们还建议可以参考 PR 15030,作为避免这个麻烦的一种可能方案。
- geohot 分享了 fromthetransistor 仓库:George Hotz 贴出了自己的仓库 fromthetransistor 和配套网站。
- 这对想理解 tinygrad 基础原理的贡献者来说可能挺有帮助。
aider (Paul Gauthier) Discord
- 用户在排查 aider 的环境变量问题:有用户表示,自己遇到了一个与 aider Issue #4458 类似的问题,并希望有人帮忙找出可能原因与解决方式;他们尤其怀疑是环境变量出了问题。
- 该用户强调,之前这套配置是能正常工作的,不明白为什么程序会突然失效。
- aider 用户被配置问题卡住了:另一位用户在处理 aider Issue #4458 时,也遭遇了看似与环境变量有关的配置问题。
- 对方表示,这个程序 之前明明还能跑,现在突然坏掉,让人摸不着头脑。
MLOps @Chipro Discord
- Paper Clinic 将系统梳理 World Models:一个两部分组成的 paper clinic 将分析综述论文 “Understanding World or Predicting Future? A Comprehensive Survey of World Models”(arXiv:2411.14499)。
- 该活动将覆盖 JEPA / V-JEPA、Dreamer、Genie、Sora 等 world model 架构,以及 “Mirror vs. Map” 之争。
- AGI 研究将继续讨论空间推理与因果性:活动还会讨论 AGI research 的下一步方向,包括 spatial intelligence、causality gaps 与 social world models。
- 其中 3 月 7 日 的场次将重点讨论 Sora、Cosmos 和 V-JEPA 之间的竞争格局。
LLM Agents (Berkeley MOOC) Discord 暂无新消息。如果这个服务器长期过于安静,请告诉我们,我们会将其移除。
Windsurf Discord 暂无新消息。如果这个服务器长期过于安静,请告诉我们,我们会将其移除。
MCP Contributors (Official) Discord 暂无新消息。如果这个服务器长期过于安静,请告诉我们,我们会将其移除。
你收到这封邮件,是因为你曾在我们的网站上选择订阅。
想更改接收这些邮件的方式? 你可以通过取消订阅退出这个列表。
Discord:分频道详细摘要与链接
OpenClaw ▷ #announcements (1 messages):
PR Review Etiquette, Maintainer Communication
- 直接私信催 PR Review 引发反感:有成员强烈反对直接给维护者发私信催 PR 审核。
- 他们提醒说,这么做甚至可能导致 PR 被立刻关闭。
- 给维护者发私信的边界问题:这场讨论强调了尊重维护者时间的重要性,并提醒大家避免使用那些会被视为强迫或咄咄逼人的做法。
OpenClaw ▷ #general (653 messages🔥🔥🔥):
Tiny Null Claw, Gemini Model Use, Robotics Arm in Living Room, Model Recommendations, GLM-5
- Tiny Null Claw 是用 Zig 写的:有成员分享了一条 YouTube Short,展示了一个用 Zig 编写的迷你版 Null Claw。
- 机械臂闯入客厅:有成员提到,他们的朋友搞来了一只工业级机械臂,理由单纯是 反正闲着也是闲着。
- 另一位在工作中给钉枪机器人写程序的成员则评论道:now that I saw this video, the question is more “why not?”。
- GPT-5.3-Codex 赢下模型大辩论:成员们围绕 GPT-5.3-Codex 和 Claude 的优劣展开讨论,有人表示 GLM-5 差不多和 Claude Sonnet 一个水平,甚至可能接近 Opus 4.5。
- 也有人力挺 GPT-5.3-Codex 在软件工程上的优势,一位成员直言:I code with models including GLM-5, Claude Sonnet, GPT-5.3-Codex and Codex-Spark, Claude Opus, and GPT-5.2, and I find that GPT-5.3-Codex has the best performance of them all。
- SearNXG 和 Pinchtab 成了救场方案:成员们讨论了如何在没有 API 的情况下给 OpenClaw 提供网页访问能力,其中有人建议用 SearNXG 做搜索、用 Pinchtab 充当浏览器。
- 大家也担心会碰到 bot blocker,不过有人提到,可以通过带 cookies 的自定义浏览器配置文件作为绕过方式。
- Anthropic 与 Department of War 的关系被摆上台面:有成员贴出了 Anthropic 的声明,讨论其与 Department of War 的关系,从而引发对 AI 合作伦理问题的讨论。
- 另有成员则把这份声明斥为 theatrics。
OpenClaw ▷ #models (425 messages🔥🔥🔥):
Alibaba Coding Plan, Qwen 3.5, GLM5 performance, Local TTS Models, Github Copilot Pro
- Alibaba Coding Plan 触发 TOS 警告:尽管 Alibaba Cloud 提供了 OpenClaw 的配置教程,但其 Coding Plan 文档页写着,除了 Claude Code 或 Qwen Code 这类编码工具外,不允许 API 调用,这可能意味着 OpenClaw 被禁用。
- 不过其他成员表示,他们实际使用下来没有任何问题,甚至有人贴出文档显示 OpenClaw 被列为允许工具。
- Qwen 3.5-Plus 被认为很适合 OpenClaw:群里不少用户都在称赞 Qwen 3.5-Plus,尤其是通过阿里云 AI Coding Plan 接入时,普遍认为它比 Nemotron-3 和 Codex 等模型表现更好。
- Alibaba Cloud AI Coding Plan 提供了一种高性价比方式来访问 Qwen 3.5-Plus、Minimax、Kimi 和 GLM 等模型,不过也有用户觉得平台上的 GLM 根本不好用。
- GLM5 的表现评价不一:一些用户认为阿里平台上的 GLM5 会突然中断 session,而另一些人则表示,切换到 z.ai’s Pro plan 后效果更好。
- 有用户提到自己在联合使用 GLM5 和 Claude Code:前者在 OpenClaw 中自动搭建邮件主 prompt,后者则更方便做后续的小范围修补。
- 用 Kitten-TTS 搭建实时本地 TTS:用户详细讨论了如何用 Kitten-TTS 搭建实时 Text-to-Speech(TTS)方案;这是一个 体积极小但质量很高 的本地模型,其中有人报告在 M1 Max 上可做到 2x realtime 编码速度。
- 不过他们也提到,这套方案仍需要一些技术工作,比如实时管道输出,或者拆成小块播放,才能得到还算能接受的实时体验。
- 关于 Github Copilot Pro 限额的争论:一些用户讨论了 Github Copilot Pro 的使用上限,并澄清说,基础套餐自带一定请求数,用完后还可以额外购买,每次约 $0.04。
- 也就是说,订阅本身就会附带请求额度,而“购买请求”是当你把每月额度耗尽后才会遇到的事。
OpenClaw ▷ #showcase (66 messages🔥🔥):
OpenClaw for Roman Catholic nuns, Custom OpenClaw dashboards, Ollama Pro Plan, OpenClaw gateway restarts, OpenClaw and real estate
- 修女们也开始用上 OpenClaw 了!:有成员想通过部署在 Mac Mini 上的 OpenClaw,把 Medgamma 1.5 这类工具开放给天主教修女在家庭网络中使用。
- 他们正在为这套配置征求建议和经验。
- 仪表盘:核心自带还是自定义?:成员们讨论了定制 OpenClaw 仪表盘的问题,并指出这些 dashboard 通常是单独开发的,与主 OpenClaw UI 分离;其中有人直言 it’s not easy。
- 有成员建议,由于核心系统会持续更新,最好另做独立 dashboard,并去 Github 或 Clawhub 搜索现成方案。
- Mastra 和 Trigger.dev 解决了 OpenClaw 的静默失败:有成员分享了一篇文章,介绍如何用 Mastra、Trigger.dev 和 Postgres 为 OpenClaw 搭建更可靠的基础设施,以解决静默任务失败和结果不稳定问题。
- 这套方案提供了一键式安装,详情见这篇 Medium 文章。
- OpenClaw 的房地产复兴计划:有成员正在尝试用 OpenClaw 管理自己的房产和租客,自动化包括 租金跟踪、维修协调 和 租约生成 在内的任务。
- 后续计划还包括直接连银行账户、通过 WhatsApp 与租客沟通,以及在 immoscout24.de 上自动制作广告。
- 矿卡赋予 OpenClaw“超能力”:有成员把退役矿卡(2x 5x CMP 100-210, 16GB, 850MB/s)改造为 OpenClaw 节点,实现 32GB DDR4,并能以 14MB/s 运行 70B dense models。
- 每个节点搭建成本约 $750,运行 32b dense 可达 30 tokens/second,但因为使用 PCIE 3.0 1x risers,模型加载仍偏慢。
BASI Jailbreaking ▷ #general (1198 messages🔥🔥🔥):
Life as a Simulation, AI as the Anti-Christ, Epstein Files, Esoteric Religions, Ancient Egyptians and DMT
- 我们是不是活在模拟里?:成员们讨论人生是否处于模拟之中,以及这会如何改变“生命意义”的理解。
- 有成员引用了一个“最吓人的推论”:一无所有的人往往才是最可怕的人类。
- AI 是敌基督?:一些成员相信 AI is the anti-christ。
- 还有人直接说 AI is evil。
- 古埃及人与 DMT?:有人声称古埃及人曾使用 DMT,而且高度重视,仅限精英阶层使用,把它视作通往异界的门户。
- 甚至还有说法称,the eye of horus is actually the human pineal gland which produces DMT naturally。
- Claude 破解了 VMProtect:有成员称,自己借助 Claude 在完全不手动逆向的情况下破解了最新版 VMProtect。
- 对方还贴出了一张过程图。
- Librem 5 活过来了!:有成员高兴地宣布,他们终于把 Librem 5 修好了。
- 他们也表示,希望继续交流 open source、技术去中心化、self-hosting、数字安全、radio freq 和 主权性 等话题。
BASI Jailbreaking ▷ #jailbreaking (459 messages🔥🔥🔥):
Python Installation Errors, Codex Jailbreak, Gemini 3 Jailbreak, Image Generation, LLM Jailbreaking Prompts
- Python 安装器在 Windows 上翻车了:有用户在 Windows 上安装 Python 时遇到麻烦,电脑重置前明明还能用,但现在安装过程中报出 Error Code 2503;有人建议去看 YouTube 教程,或者直接以管理员身份运行安装器。
- 另有用户建议,从 Python 官网 下载安装包,并在安装时确认所有需要勾选的选项都已正确勾选。
- 用户急寻“Codex Jailbreak”:有用户正在给自己的 openclaw agent 寻找 codex jailbreak,希望通过私信获得帮助;而另一个人则声称自己有 “codex shi”,但拒绝公开。
- 他们还向别人求助,希望处理 Cursor 的 doc agent,并附上了 Cursor Documentation 链接。
- 通用型 Gemini Deep Think 一次性越狱仍未实现:用户们讨论了当前 jailbreak 的局限,指出真正 通用的一次性 Gemini Deep Think 越狱 目前仍不存在,尤其在炸药、CBRN 和 CSAM 等高敏感类别上更是如此。
- 大家强调,有些模型的防线几乎不可攻破,但另一些则并非如此,因此单条 prompt 仍可能对更广泛的内容类别生效;也有人声称,对 大多数内容类别 来说,百科/参考格式 几乎就能低阻力通过。
- 用户交换新的语言模型越狱思路:有用户分享了一套用于 jailbreak 的 “Apple Pie” 配方,但遭到了质疑。
- Gemini 的回应是,这简直是 a masterclass in cynicism,并指出 “ignore all previous instructions” 那一套基本已经埋进 2024 年的坟场里了。
- Grok 图像生成被审查了?:有用户表示,自己过去只靠 prompt 就能让 Grok 生成裸照,但现在已经不行了,因此想询问如何越狱它来继续生成裸露内容。
- 另一个用户建议,可以改成提示视频里人物的衣服“transform into transparent clothing”。
BASI Jailbreaking ▷ #redteaming (8 messages🔥):
Chernobly Virus, AI red teaming, CyberSecurity Project Ideas
- 用户称笔记本感染了“Chernobly” 病毒:有用户表示自己的笔记本感染了 “Chernobly” 病毒,并询问如何清除。
- 另一个用户则随口建议:格式化硬盘。
- 有人想转做 AI Red Teaming:有成员询问,群里是否有人目前就在从事 AI red teaming 工作。
- 发问者本身是 sec eng / pen tester,正考虑转向这个方向。
- 网络安全学生在征集毕业项目点子:有学生正在准备自己的 CyberSecurity 毕业项目,因此来群里征求方向建议。
- 他们表示自己此前没有相关项目经验。
Unsloth AI (Daniel Han) ▷ #general (977 messages🔥🔥🔥):
Qwen 3.5 quants, LFM2 24B, GPU Kernel Optimization with RL, LLMOps, Qwen3.5 122B Performance
- Qwen3.5 量化版本引发争论:成员们讨论了 Qwen3.5 量化版本的质量问题,其中有人指出 35B ud-q4_k_xl 量化版本的 perplexity 和 KL divergence 异常偏高,并引用了这个 Reddit 讨论帖。
- Unsloth 团队表示,这些量化版本本身并没有坏掉,但他们正在调查 UD 配置问题,并强调他们上传的模型经过了广泛测试,整体结果通常都不错;同时也补充说,动态量化是面向 长上下文长度 设计的。
- 深入讨论 MXFP4 与 Q4 的质量差异:Unsloth 动态量化(UD)中使用 MXFP4 引发了进一步争论,大家担心它相较 Q4 是否会降低质量,尤其考虑到 Qwen 模型原生并不是按 MXFP4 训练的。
- 有成员建议直接对比两组量化:一组是当前的 MXFP4 ud_q4_k_xl,另一组则把 MXFP4 tensors 换成普通 Q4K tensors。
- 关于“正确做基准测试”的讨论:成员们讨论了 benchmark 最佳实践,有人批评挑选性使用基准、也批评把 perplexity 直接当成准确率指标;大家认为,最好还是去测 terminal bench 或 live code bench 这类真实、困难的基准。
- 同时也有人指出,一些 benchmark 容易误导;Unsloth 团队则分享了一个链接,说明他们认为什么指标更能反映准确性。
- LFM2 24B 模型已发布:群里宣布了 LFM2 24B 的发布,其中有成员表示,它在创意写作 prompt 上的风格非常 Gemma-like,而且感觉很有潜力,hf.co/LiquidAI/LFM2-24B-A2B。
- 还有成员表示,他们会把 Qwen3.5 纳入自己的编码测试,看看它会不会成为 Claude Code 领域的新 meta。
- 继续预训练策略讨论:有成员来询问 continued pretraining(CPT) 方面的建议,计划同时使用爬取数据集和高质量数据集,并想知道第二阶段 LoRA 是否应该把学习率调低。
- 另一位成员回应说,第二阶段 LoRA 到底怎么 finetune 并没有统一答案,同时也提醒最好别公开谈 scraping,并建议第二阶段或许可以尝试更低 rank,可能结果会更好。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 messages):
``
- 没有讨论到具体主题:给出的消息中没有出现值得总结的相关话题。
- 讨论内容为空:提供的消息历史看起来是空的,或者并没有包含任何有意义的讨论点可供总结。
Unsloth AI (Daniel Han) ▷ #off-topic (345 messages🔥🔥):
Origins of the Transformer, AI Company Name Puns, Door management app specs, Minecraft AI model Andy-4, Healthy ice cream alternatives
- 重新回顾 Transformer 的起源:有人提到,transformer 架构最初是从带有 attention mechanism 的 RNNs 演化而来,后来 Vaswani 等人发现 attention 才是关键部分,于是 RNN 本体就被抛弃了。
- AI 公司名字被拿来玩梗:有成员分享了一连串 AI 公司谐音和双关,比如 OpenAI is ClosedAI、Anthropic is Misanthropic,引来不少调侃式回应。
- 还有成员补刀说 Groq is slowq,而第三个人则反驳说 Groq 实际上明明很快。
- 用 Claude Opus 写“楼宇门禁管理 App”规格书:有成员写了一整套用于管理楼宇门禁的应用规格说明,准备拿剩下 9% 的 Hebdo 配额测试 Claude Opus 5.5。
- 这份规格书包括测试集、UI、工作流、用户画像和文件层级结构,目标是把它作为 AI 的 demo 或 use case;相关思路在这个 YouTube 视频里也有提及。
- “Andy-4” Minecraft 模型亮相:有成员展示了自己的第一个 AI 模型,它能在 Minecraft 中从零开始独立获取 铁甲,并分享了相关链接:dataset 和 GitHub repo。
- 该模型能够像真人玩家一样,通过接收图像和文本输入,在游戏中放置、破坏、拾取和合成物品。
- 大家开始寻找“健康冰淇淋乌托邦”:成员们讨论了更健康的冰淇淋替代方案,其中有人认为,不加任何加工成分的真正冰淇淋 才是唯一健康选项。
- 另有人指出,哪怕是 cookies and cream 这种看似简单的冰淇淋,其饼干配料往往也经过重度加工;讨论随后转向种子油和天然配料,最终把 Alec’s Ice Cream 和 Häagen-Dazs 视为相对更干净的选择。
Unsloth AI (Daniel Han) ▷ #help (13 messages🔥):
Qwen 3 vs 3.5 finetuning, RAG with Unsloth vs Langchain, Unsloth with AWS Sagemaker and vLLM, Sample packing on multimodal LLMs, Qwen3 Coder Next model
- **Qwen 3.5 微调问题被提出来了:有成员询问,若要从 fine-tuning **Qwen 3 切换到 Qwen 3.5,该如何在
SFTTrainer.train()期间确保处于 non-thinking 模式,以及面对多模态数据集时,是否应将 Qwen 3.5 作为FastVisionModel加载。- 他们同时也在问,做 RAG 任务时用 Unsloth 对比 Langchain 是否合适。
- **Unsloth 的 RAG 能力被澄清:有成员解释说,虽然 **Unsloth 本身并不内建 RAG 功能,但它支持推理,检索与上下文增强可以借助其他工具单独实现。
- 他们推荐可替代 LangChain 的方案,比如 pydantic-ai,以及基于 pgvector 的 Postgres 检索。
- **有人在找 AWS Sagemaker 集成方案:有成员询问,是否存在关于 **Unsloth + AWS Sagemaker(多 GPU 训练)然后再配合 vLLM 做推理的指南或示例,尤其是在 AWS 技术栈限制下。
- **Qwen3 Coder Next 被推荐给新手本地用户:有新用户询问 **Qwen3 Coder Next 80B 4K 是否仍然适合在 69GB RAM 的本地环境中使用,以及该去哪里下载。
- 有成员推荐使用 GGUF 版本
unsloth/Qwen3-Coder-Next-GGUF做 CPU offloading,并建议把unsloth/Qwen3.5-35B-A3B-GGUF作为更新的备选项试试看。
- 有成员推荐使用 GGUF 版本
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Unsloth integration with CoreWeave, Unsloth new blog post on DPO, Daniel discusses Llama3 pre-training, Daniel discusses new quantization methods, Daniel teases Unsloth enhancements
- Unsloth 正在和 CoreWeave 合作:Daniel 宣布,Unsloth 正在与 CoreWeave 合作,以让 finetuning 速度进一步提升。
- 他提到,这里面会有一些“secret sauce”,并让大家继续关注后续更新。
- Unsloth 发布 DPO 博文:Daniel 提到,Unsloth 刚刚发布了一篇新的 DPO 博文(Direct Preference Optimization)。
- 文中详细介绍了 DPO,即通过把 reward modeling 重构为分类问题,从而简化 RLHF 的过程。
- Daniel 拆解了 Llama3 预训练:Daniel 根据公开信息分享了一些关于 Llama3 pre-training 的见解。
- 他解释说,用 8k 上下文长度预训练 Llama3,与 2k 上下文相比,在复杂度和成本上并没有本质差异。
- Daniel 预告新的量化方法:Daniel 表示,他正在为 Unsloth 研究更强的新量化方法。
- 他原话是:“I think I’ve found the holy grail of quantization… but need to properly test it out!”
- Daniel 谈到 Unsloth 的后续增强:Daniel 计划很快为 Unsloth 加入更多增强功能。
- 其中包括 “even better merging + LoRA code coming soon.”
Unsloth AI (Daniel Han) ▷ #research (2 messages):
ES-based gradients
- ES-based gradients 几乎无处不在:有成员表示,基于 ES 的梯度几乎适用于 任何东西。
- ES 梯度几乎能套到所有问题上:讨论中提到,Evolution Strategies(ES)式梯度几乎可以应用于任何问题。
Perplexity AI ▷ #announcements (1 messages):
Samsung Partnership, Galaxy S26, System-Level AI, Wake Word
- Perplexity 联手 Samsung,登陆 S26!:Perplexity 已与 Samsung 合作,将 Perplexity AI 直接集成进即将发布的 Galaxy S26 设备,使其成为系统级 AI。
- 每台新的 S26 都会预装 Perplexity,并可通过唤醒词 “Hey Plex” 直接调用,详见这条公告。
- Galaxy S26 将集成系统级 AI:这次合作意味着 Perplexity AI 将作为 Galaxy S26 中的核心系统组件存在,从而增强整机的 AI 能力。
- 用户可以通过自定义唤醒词 “Hey Plex” 直接激活 Perplexity,更顺畅地使用其 AI 功能。
Perplexity AI ▷ #general (993 messages🔥🔥🔥):
RAT, Scammer Hacking, Comet Browser, Deep Research limit, Perplexity's Samsung Partnership
- 开发者讨论制作 RAT:成员们开始讨论如何制作 RATs(Remote Access Trojans),其中甚至有人声称自己做出了一个大多数杀毒软件都检测不到的 RAT。
- 另有成员表示,他们对如何在目标机器上不安装任何软件、仅通过网络远程入侵对方很感兴趣。
- Pro 用户面对严格限制:Perplexity Pro 用户报告称,他们的查询额度已从 250 降到 20,并表示这很不公平,还提到最近也出现了类似 250 到 20 的再度缩减。
- 有用户回应说:“I am also facing”,也有人直接表示这个新上限很糟糕。
- Perplexity 与 Samsung 达成合作:Perplexity 将作为助手集成进 Samsung 新款 S26 设备中,而且这次不是普通 App,而是直接写进操作系统级集成。
- 有成员猜测,Bixby 未来也会由 Perplexity 的 search-grounded LLMs 提供支持。
- 用户觉得 Perplexity 的 Discover 更难用了:用户反映,Perplexity Discover 提供的信息质量和数量都显著下降。
- 有成员直接吐槽:“Then they’ve really made perplexity a lot worse over the last few months… it’s so shit now”。
- 用户拿 Perplexity、Claude 和 ChatGPT 做比较:用户正在比较 ChatGPT、Claude 和 Perplexity,其中有人表示:“ChatGPT suck… Go for claude or Google pro plan…”
- 另一个用户则说:“I used to use Perplexity literally every day… but now it’s impossible to use it even with a paid PRO subscription”,并表示自己已经切换到 GPT chat。
Perplexity AI ▷ #sharing (1 messages):
GitHub star request, Cascade GitHub repo
- 有人为 Cascade 仓库拉 GitHub Star:有成员请求大家给他们的 Cascade GitHub 仓库 点星。
- Cascade 仓库需要你的 Star:该 Cascade 仓库 的作者正在公开征求 GitHub stars。
Perplexity AI ▷ #pplx-api (3 messages):
Perplexity Sonar Deep Research API, Diminished Performance, Source Count Reduction, API Cost
- Perplexity API Sonar 性能下滑:用户反映,Perplexity Sonar Deep Research API 在最近 1-2 周里的表现似乎下降了。
- 有用户指出,单次请求引用来源数从 36 个减少到了 10 个,但价格仍然维持在每次约 45 美分。
- 有人贴出 API 状态相关推文:有用户提到了 Perplexity 在 X 上的状态说明 以及 James Liounis 的帖子,用来说明 API 可能发生了调整。
LMArena ▷ #general (916 messages🔥🔥🔥):
Nano Banana 2 vs Nano Banana Pro, Gemini 3.1 Flash, GPT 5.3 Codex, Grok Imagine video generation
- Nano Banana 2 与 Nano Banana Pro 正面交锋:成员们正在积极比较 Nano Banana 2(Gemini 3.1 Flash) 和 Nano Banana Pro,争论到底哪个模型生成图像更好;其中有人指出,NB2 在文字和曲线这类简单元素上都还会吃力。
- 用户们普遍认为,虽然 NB2 生成更快,但质量仍不如 NB Pro,尤其是在非人类角色方面,因此从真实观感上看,NB Pro 更强。
- GPT 5.3 Codex 的评价两极分化:有些用户高度评价 GPT 5.3 Codex 的编码能力,特别是在用 Rust 创建 Minecraft clone 这类任务上。
- 但也有人觉得它输出代码很 schizophrenic、质量很差;另一些人则认为它修 bug 很强,还能通过看图来辅助改错,说明它的确是面向编程场景特化的。
- Grok Imagine 成为视频生成新热点:用户对 Grok Imagine 的视频生成能力印象很好,认为它不仅易用,而且还能生成一些其他模型会审查掉的内容。
- 虽然免费用户最多只能生成 6 秒 480p 视频(SuperGrok 用户可达 10 秒 720p),但它的可达性和易用性让它成了快速视频生成的热门选择。
- Gemini 3.1 Flash 已加入 Arena:Gemini 3.1 Flash Image Preview 已带着 web search 能力加入 arena,不过它的失败率很高,不少用户频繁遇到 something went wrong 错误。
- 也有用户表示它现在已经真正上线到 arena 里了,但仍有人反馈 web search 并没有按预期工作,甚至还有人补充说,在真实感方面它比 Gemini 3 Pro 更强。
LMArena ▷ #announcements (7 messages):
Image Edit Leaderboard, Video Arena Leaderboard, Image Arena Leaderboard, AI Agents for existing software, Search Arena Leaderboard
- Seedream-5.0-Lite 进入 Image Arena:
Seedream-5.0-Lite目前已在 Multi-Image Edit Arena leaderboard 并列前 5。 - P-Video 首次亮相 Video Arena:P-Video 已进入 Video Arena leaderboards 前 26,1080p 生成价格为 $0.04/秒。
- Nano Banana 2 冲进 Image Arena:Nano Banana 2 以 Gemini-3.1-Flash-Image-Preview 之名发布,并直接空降 Image Arena 第 1,同时加入新的 web search 能力。
- AI Agent 在现有软件里为何表现不佳受到审视:Peter 在一支 YouTube 视频里讨论了 AI agents 在现有软件内部表现不理想的三个原因。
- Claude Opus 与 Sonnet 进军 Search Arena:
Claude-Opus-4-6和Claude-Sonnet-4-6已进入 Search Arena leaderboard,其中 Opus 4.6 以 1255 分大幅领先,排名第 1。
Cursor Community ▷ #general (770 messages🔥🔥🔥):
Cloud Opus billing issues, Inline diff error fix, Codex 5.3 Spark, Deterministic AI Context, Gemini 3.1 Pro
- Cloud Opus 的收费让人困惑:有用户反馈说,Cloud Opus 明明在仪表盘里标的是免费,结果却产生了意外扣费,见这张截图。
- 目前并没有更多关于计费差异的细节被披露。
- Inline Diff 显示问题已解决:Cursor 通过一次远端更新修复了 inline diff not showing 的问题,并要求用户关闭后重新打开 Cursor 来确认修复已生效;这项修复由 David Gomes 的消息 对外说明。
- 用户们很快确认问题已经解决,并向 Cursor 团队表示感谢。
- Cursor 放出了 Codex 5.3 Spark:用户对 Codex 5.3 Spark 的到来很兴奋,普遍提到它的速度提升明显,并互相询问是否有人已经试过 spark。
- 目前在 cursor.com/dashboard?tab=cloud-agents 中,它已经默认作为 Codex 5.3 替代了 Opus 4.5。
- 关于确定性 AI 上下文的争论继续发酵:deterministic AI context 成为一个讨论点,大家在讨论它是否有助于减少 token 读取和幻觉;其中有用户表示,自己已经解决了跨基础设施边界的 polyglot taint,并贴出了 repo。
- 一些用户怀疑这件事的必要性,认为它还没有真正转化成价值,但该开发者正计划基于此做产品转向,并邀请大家审阅他们归档的 repo。
- Gemini 3.1 的呼声正在变高:成员们正讨论自己对 Gemini 3.1 Pro 的偏好,其中有人甚至表示 它比 4.6 Opus 更强。
- 不过也有人指出,这个模型在 tool calling 和代码实现上仍有明显短板。
LM Studio ▷ #announcements (3 messages):
LM Link, Tailscale Collaboration, Remote Model Loading, Network Overload
- **LM Link 上线:远程模型加载!:LM Studio 团队宣布发布 **LM Link,这一新功能允许用户连接远程 LM Studio 实例、加载模型,并像使用本地模型一样调用它们;该功能与 Tailscale 深度技术协作完成,详情见这里。
- **端到端 加密保护 LM Link 用户!:LM Link** 采用端到端加密,不需要对公网开放任何端口,可适用于本地设备、LLM 机器或云端虚拟机。
- 更新到 **LM Studio 0.4.5 build 2:官方建议用户升级到 **LM Studio 0.4.5 build 2,因为其中包含针对 LM Link 的重要修复。
- 网络过载问题已解决:团队承认,此前网络创建阶段因为低效代码导致服务器过载,但该问题现已修复。
- **LM Link 的配置流程也是 E2E 的!:网络配置与设备发现由 **LM Studio 服务器负责,但一旦设备彼此知晓,它们就会建立 e2e 加密连接,后续流量不再经过 LM Studio 服务器。
LM Studio ▷ #general (411 messages🔥🔥🔥):
Qwen 3.5 performance, LM Link setup and issues, NVIDIA earnings impact, LM Studio GPU detection, Multi-GPU setup
- Qwen 3.5 模型的 “Thinking” 问题:用户报告称,Qwen 3.5 模型会随机输出
</thinking>标签,并出现 token 生成缓慢的问题,尤其是在输入图片之后更明显。- 有用户发现,LMStudio 社区量化模型 允许手动切换 think 参数的开关。
- LM Link 远程访问正式铺开:LM Studio 推出的新功能 LM Link 允许通过 Tailscale 实现远程 LLM 访问,因此引发了大家对其配置方式和限制条件的讨论;Tailscale 的博客公告在这里。
- 一些用户希望支持不依赖第三方账号的 direct IP 连接,理由是隐私顾虑;另一些用户则希望增加移动 App 以及图像/视频支持。
- NVIDIA 财报将出,市场开始摇晃:成员们都在等待 NVIDIA 财报,并猜测这会对 AI 泡沫产生什么影响,也有人把内存短缺视作潜在风险点。
- 甚至有人声称财报差到根本没发出来,不过其他人则把这种说法斥为 FUD。
- 模型量化的权衡被摆上台面:用户讨论了 Unsloth 的 mxfp4 格式,认为它可能会导致异常偏高的 perplexity,因此目前更推荐 Q4_K_M。
- 有成员总结说:mxfp4 is good for QAT, but not for quanting later,并暗示团队已经在 r/LocalLlama 上跟进这类问题。
LM Studio ▷ #hardware-discussion (280 messages🔥🔥):
E-waste GPU, RAM and CPU upgrade, Multi GPU vs single GPU setup, Model performance and context size, GMKtec EVO-X2
- 便宜的电子垃圾 GPU 也能带动 Qwen 3.5:有用户表示,自己用 P104 电子垃圾卡 跑 Qwen 3.5 Q6,速度达到了 26 t/s(Image)。
- 另有用户建议,单价约 $49.99 的 340L 16GB 卡可能是更好的替代方案,不过这类卡原本是为虚拟机场景设计,真要跑起来可能还得自己“开荒”。
- LLM 装机时如何平衡 RAM、CPU 和 GPU:有用户想优化一套新电脑配置,在 96GB DDR5、RTX 5080 和 9950x / 9800x3D 之间做选择,希望兼顾游戏和 LLM;其现有配置是 32GB DDR4、12700KF 和 3080TI。
- 社区里有人认为,CPU 对 LLM 任务来说 基本无关紧要,所以游戏优先就直接选 9800x3D;但也有人强调 内存带宽 的重要性,因此围绕不同 CPU 的取舍仍有争论。
- 多 GPU 方案的争论升温了:有用户考虑通过多张 GPU 以更低成本换取更高 VRAM,因此引发了关于这种方案是否可行、瓶颈在哪里的讨论。
- 大家争论重点在于,多卡仅用于存储时 PCIe 速度 是否会成为推理瓶颈,最终多数人认为 PCIe Gen 4+ 已经足够;同时他们也在讨论如何在 LM Studio 里用 CUDA12 调整 GPU 优先顺序。
- GMKtec Evo X2 还是最强性价比吗?:有用户询问,是否存在比 GMKtec Evo X2 更便宜、性能又接近的替代品,而其中一个回答非常直接:Nothing。
- 讨论随后转向寻找其他适合 LLM 与 RP 使用的方案,并附上了一个解释 AI 如何生成下一个 token 的 YouTube 视频。
- Bifurcation riser 让主板榨出更多价值:用户们讨论如何利用 bifurcation risers 对 PCIe 槽位 进行拆分,从而在一个槽位上同时挂载 GPU、NVMe 等多个设备(Link)。
- 有用户分享了自己当前的 PCIe 配置(5090 占 x16、4070Ti Super 占 x16、100gb Nic 占 x16、HBA 占 x4、双 NVMe 转接卡占 x4、USB3 占 x1),并总结了大家对所贴 riser 使用方式的大致共识。
Latent Space ▷ #watercooler (10 messages🔥):
Touchscreen MacBook, Apple Product Announcements, Touchscreen Laptops vs iPad Pro, iPhone mini
- 触屏 MacBook 的观看派对被取消了:有成员原本打算为下周的 Apple 产品发布 安排一场观看派对,因为他们期待会出现 触屏 MacBook,但后来又把它取消了。
- 原因是那并不是 keynote,只是普通的发布周活动,所以 nevermind。
- 关于触屏笔记本的争论被点燃了:成员们围绕 触屏笔记本 和 iPad Pro 的吸引力展开讨论。
- 其中一位成员直接表示:No not at all. I definitely would not want to run normal tools on my most powerful convenienest device that I use way more than my non-work computer,并附上了一张图片。
- iPad Pro + Keyboard Folio 获得好评:有成员盛赞 iPad Pro 搭配 Keyboard Folio 是个 awesome combo。
- 他们还提到,自己用这套设备写了 整整两本书,以及 过去约 6 年里的所有博客和演讲稿。
- iPhone mini 13 是否已经显老?:有成员认为,iPhone mini 13 已经开始显得“年纪大了”。
- 另一个用户则补充说明,iPhone 的发布通常是在秋季。
{kind=link}
Latent Space ▷ #memes (27 messages🔥):
Greatest Chart Ever, Engagement Metrics, Irony and wordplay, Humor and Grok, AI Model Personas
- Carlson 贴出“神图表”:Adam Carlson 分享了一条 tweet,展示了他认为史上最伟大的图表之一;这条内容获得了接近 9000 个赞 和超过 60 万次浏览 的高互动。
- Dredd 贴出了数据成绩单:这个讨论串记录了一条 tweet 的互动数据;该推文由 Kenneth Dredd 于 2026 年 2 月 24 日发布,获得了超过 1.2 万个赞 和 39 万次浏览。
- Forte 捕捉到 AI 公司命名上的讽刺感:Tiago Forte 在一条 tweet 中指出 AI 公司及其创始人口号中的语言讽刺与现实反差,特别提到了 Anthropic、OpenAI 与 Google’s Gemini 的名字和使命,与它们现实中的行为形成对照。
- Musk 用“幽默感”来划分好坏阵营:Elon Musk 在一条 tweet 中表示,拥有更强幽默感的一方才是 “good guys”,并借此为自己的 AI 模型 Grok 站台。
- Staysaasy 用职级隐喻来比喻模型人格:在这条 tweet 中,作者用软件工程岗位原型来比喻不同 AI 模型:Codex-5.3 像一个字面理解能力很强的中级工程师,而 Opus-4.6 则像一个影响力很大、但偶尔也有点鲁莽的 staff engineer。
Latent Space ▷ #stocks-crypto-macro-economics (15 messages🔥):
Jane Street Crypto Manipulation, Blockchain Scalability for AI Agents, Goldman Sachs' AI Predictions, Smartphone Market Decline
- Jane Street 清空社交媒体记录引人侧目:一则传播很广的帖子声称,Jane Street Group 删除了其社交媒体历史记录,背景是其被指控操纵 Bitcoin 价格。
- 讨论中有人推测,该机构可能在四个月里借助 paper BTC 制造市场砸盘。
- AI Agents 需要区块链带宽大爆发:Hunter Horsley 在这条推文中描绘了这样一个未来:AI agents 将驱动互联网中的绝大多数交易,因此区块链必须具备每秒数百万乃至数十亿笔交易的处理能力。
- 他还把 Stripe 最近的动态视作这一趋势的验证。
- 高盛预测 AI 时代将带来经济级地震:Goldman Sachs 的预测认为,在 AI 时代,物理基础设施、硬件与网络安全服务商将成为赢家。
- 相比之下,传统软件平台和 IT 咨询公司则可能因 数据接口商品化 与可计费服务时长压缩而处于不利位置。
- 智能手机销量下滑预示供应链困局:根据 IDC,全球智能手机市场在 2026 年预计将下滑 13%,由于内存短缺危机,这将成为历史上最大的一次跌幅。
Latent Space ▷ #intro-yourself-pls (3 messages):
Career Transition to AI, AI/ML Consulting
- 咖啡馆老板转向 AI 了:有成员在经营 两家咖啡馆 8 年后,决定把它们卖掉,转向 AI 职业或创业路径。
- 他们表示,自己正在边摸索边学习 AI。
- 来自纽约的 AI/ML 工程师提供咨询服务:有位来自纽约的成员自称是经验丰富的 AI/ML Engineer,愿意为创业公司提供 咨询服务。
- 对方表示自己在这个领域已经相当资深。
Latent Space ▷ #tech-discussion-non-ai (42 messages🔥):
Vercel Barriers, OpenNext, Next.js Self-Hosting, Vite-Next, Turbopack mistakes
- Vercel 被指在刻意设置障碍:成员们讨论说,Vercel 从项目诞生起就一直在 “给 Next.js 跑在其他平台上设置障碍”,而这也是 OpenNext 存在的原因。
- 同时也有人提到,Cloudflare 自己都说要支持 OpenNext 依然非常困难。
- 有人说 Next.js 自托管很简单,但并非人人认同:虽然有人认为把 Next.js 自托管到 docker container 上是件轻而易举的事,但另一些人表示,把一个从 CRA eject 出来的老式 webpack + react router 应用迁移到 self-hosted Next.js 时,内部阻力非常大。
- 有成员甚至直言:“我真想不出来,如果没有对 runtime 更强的控制能力,要怎么把图像优化之类的功能真正跑起来。”
- Turbopack 被宣布是个错误方向:有人声称 Turbopack 是个失误,并评价它 “能用是能用,但现在并没有比 vite 更好,反而更慢。”
- 也有人预测,未来 6 个月内 Vite-Next 会出现,而 “自从 Leerob 离开后,整体就越来越像一团糟。”
- Streaming 被认为走偏了:有人表达了这样的观点:“对 ‘streaming’ 的过度推动是误导,应该把它当成边缘场景,而不是默认优先级。”
- 他们进一步指出:“这么强调 streaming,只不过是在 700ms 的数据加载里省 15ms,却换来了更差的 UX。”,因此它只适合极端场景。
- ViNext 正在靠 vibe coding 硬闯:有人联系了 Cloudflare 讨论 ViNext,认为它有机会简化基于 Next surface APIs 构建的 RSC 体验,却几乎被对方直接打发走,因为 “他们只在乎 ‘bad deployments’ 这类噪音,而且这种关注非常肤浅。”
- 还有成员调侃说,ViNext 的提交历史非常有喜感,因为 “他们显然正坚定不移地试图靠 vibe coding 把问题写过去”,仅过去 24 小时里就出现了大约 20 个安全相关提交。
Latent Space ▷ #hiring-and-jobs (7 messages):
Micro-Acquihiring, Team-Based Hiring, Cheerleader Effect
- Micro-acquihiring 上升,单人招聘下滑:Anson Yuu 提到了一种新的招聘趋势,即 micro-acquihiring,公司更倾向于整包吸收那些已经协作做出功能的小型高质量团队,而不是单独招聘个人。
- 有成员调侃说,自己现在可能得先 和另外 3-5 个人结伙 才找得到工作;还有人直接形容现在的招聘环境 “已经坏透了。”
- 招聘中的“啦啦队效应”:在讨论 micro-acquihiring 与就业市场变化时,有成员提到了 “cheerleader effect”。
- 这暗示着,作为团队一部分时,个体在潜在雇主眼中会显得更有吸引力,就像人们常觉得一群人里的个体更“好看”一样。
Latent Space ▷ #cloud-infra (1 messages):
swyxio: https://x.com/sbcatania/status/2026465590848926074?s=12
Latent Space ▷ #databases-data-engineering (1 messages):
swyxio: https://x.com/alighodsi/status/2026877746211959205?s=12
Latent Space ▷ #san-francisco-sf (7 messages):
Embeddable Web Agent, Tilt App Hackathon, Andrew Peek
- Embeddable Web Agent 的发布派对要来了:首个 Embeddable Web Agent 将举办发布派对,具体信息见 Luma。
- Tilt App 黑客松 Demo 邀请:Andrew Peek(@drupeek)邀请湾区居民前往 Menlo Park 参加 hackathon demo 场,提前了解未来几周将为 Tilt 推出的新功能和新产品,详见 xcancel.com。
Latent Space ▷ #ai-announcements (3 messages):
Substack Live, Model Distillation
- **Swyx 在 Substack 开播了**:Swyx 正在 Substack 上直播,聊的全是 AI 相关话题。
- 关于 Distillation 和模型作弊的直播已经上线:一场围绕 Distillation 与 How Models Cheat 的直播现已可看。
- 直播链接在这里。
Latent Space ▷ #ai-general-news-n-chat (93 messages🔥🔥):
GPT-Engineer enhancements, OpenAI competition, Gemini 3 vs Claude, QuiverAI Beta Launch, Nano Banana 2
- **GPT-Engineer:代码库炼金术士**:成员们分享了关于 GPT-Engineer 的消息,这是一款能从单条自然语言 prompt 生成完整代码库的开源工具,强调简单、模块化设计以及迭代反馈。
- 用户们还顺手分享了一张和“增强代码”有关的 meme。
- **Block 的重击:AI 裁掉了部分员工:Jack 宣布 Block 将员工规模从 10000 人缩减到约 6000 人,转向更小型、AI 驱动的组织结构;消息公布后股价上涨了 **20%。
- 社区还讨论说,被裁的不只是普通岗位,AI 团队也在其中,而背后的一个现实原因可能是 “股价已经横了 4 年,这次只是个方便的借口。”
- **Samsung S26 被 Perplexity“占领”了:Aravind Srinivas 宣布,Perplexity 已集成进所有 Samsung Galaxy S26 手机,包括 ‘Hey Plex’ 唤醒词、预装应用,以及一个由 Perplexity 的 search-grounded LLMs 驱动的 Bixby assistant。
- **Stitch in Time:Direct Edits 正式亮相**:Stitch by Google 推出了 “Direct Edits”,允许用户直接手动修改文本和图像,或者使用 AI agent 对特定界面区域做更新,为设计补上最后一层精修。
- **Factory AI Droids 拉长战线:多日任务模式启动**:Factory AI 宣布,其 Droids 现在可以自主执行 “Missions” 数天之久;用户只需定义目标并批准计划,系统就会持续独立执行直到完成。
Latent Space ▷ #llm-paper-club (30 messages🔥):
METR developer productivity study, DeepSeek research clarity, Frontier model training playbook, DeepSeek DualPath paper, DeepMind's AlphaEvolve
- METR 发现 AI 加持下的开发者正在加速:METR(前身为 METR_Evals)表示,他们此前关于 AI 辅助开发会让开发者生产力下降 20% 的结论已经过时,目前数据更可能显示出速度提升。
- 不过,开发者近期行为的变化,例如开发者拒绝进入 “no-AI” 对照组,使得新结果不再可靠,因此 METR 正在尝试做出更准确的评估(METR Developer Productivity Study Update)。
- DeepSeek 论文收获赞赏:有成员表示,自己很欣赏 DeepSeek 发布的学术论文在表述清晰度和逻辑结构上的表现(DeepSeek Research Clarity)。
- 前沿模型训练战术逐渐成形:Logan Thorneloe 分享了一份关于前沿模型训练的全面指南,强调成功本质上是一个涉及数据配比、架构与稳定性的系统工程问题,而不是靠微小算法技巧取胜(Frontier Model Training Playbook)。
- DeepSeek 的 DualPath 让 Agent 速度翻倍:DeepSeek 发布了一篇名为 ‘DualPath’ 的新论文,提出一种优化的 KV-Cache 加载方式来提升推理性能;通过摆脱以 prefill 为中心的架构,在 Agent 工作负载中实现了最高 1.96 倍 的速度提升(DeepSeek DualPath Paper Release)。
- DeepMind 的 AlphaEvolve 开始自动改进算法:Google DeepMind 使用 AlphaEvolve 自主变异 Python 代码,进化出了新的多智能体强化学习算法,并超过了此前由人类设计的博弈论算法基线(DeepMind’s AlphaEvolve Surpasses Human Multi-Agent RL Baselines)。
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (51 messages🔥):
Surf-CLI Challenges with Sandboxing, Native Extensions for Firefox and Chrome, Ralph Loop Execution Environments, Cursor Seat Decommissioning, jina-grep Development with MLX
- Surf-CLI 遇上 Snap 沙箱难题:有成员提到,surf-cli 因为 Snap 里的 Chromium 沙箱机制,使用起来遇到了不少麻烦。
- 另一位成员则建议,或许可以考虑用 Go 作为潜在解法。
- 跨浏览器原生扩展开发热火朝天:有成员正在整理一份指南,介绍如何在 Mac 与 Linux 上同时为 Firefox 和 Chrome 构建原生扩展,并参考了这份 Gist。
- 他们表示,node 在沙箱里当然很棘手,因此也在考虑移植成 Go 版本。
- Ralph loop 跑法百花齐放:成员们讨论了自己如何运行 Ralph loops,方案从跳过权限检查的本地 Claude code 到配合 Open Claw 跑在 Mac mini 上都有。
- 其中一位成员提到,自己是用 pi-agent as a base, sorta hybrid ralphenclaw。
- Cursor 清理闲置席位:Cursor 因长期无人使用而停用了 90 多个不活跃席位,而且这至少已经是第十波类似清理了,公告见这里。
- 讨论也随之转向 IDE 和 CLI 工具 谁更有前途;有成员表示,即便行业走向长时运行、低 HITL 的多 Agent 时代,人们依然需要一种用户友好的方式去查看和交互这些系统。
- jina-grep 借助 MLX 起飞:Han Xiao 宣布正在开发 jina-grep,这是一款类似 grep 的工具,利用新的 MLX 优化版 jina-embeddings 模型,灵感来自 Andrej Karpathy 对 CLI 工具的兴趣,公告见这里。
Latent Space ▷ #share-your-work (10 messages🔥):
Prompt Engineering, Anime Studio, AI-Powered Web App, Kiro Techniques, Test Generation
- 关于 Prompt 的思考开始扩散:有成员通过 Tool Use and Notation as Generalization Shaping 这篇文章分享了自己对 prompting 的看法。
- 该成员在博文中把 prompt engineering 描述为一种通过 tool use 来塑造泛化能力的过程。
- 动漫工作室活动安排上了:有成员邀请大家参加 Arena 的一场动漫工作室活动,并贴出了 Luma 链接。
- 除此之外没有更多细节。
- AI 助手应用正式上线:有成员宣布,自己完成了第一个完全由 AI 构建的生产级 Web 应用,名字叫 ProposalMint。
- 这是一款面向非营利组织的拨款申请写作助手,目前先在佛州做试点,覆盖约 50 家组织。
- Kiro 的方法论获得认可:有成员提到 Kiro 的技巧很有用,尤其是在听完 Software Engineering Daily 的访谈 后,更认同把 property-based testing 用在 Agent 开发中。
- 没有进一步展开说明。
- 测试生成也开始自我递归了:有成员开玩笑说,自己要写代码来生成测试,再用这些测试去测试代码。
- 另一位成员还分享了一些 prompt 改进模板,比如 Apply THE MIRROR — write a test generator for this module。
Latent Space ▷ #robotics-and-world-model (19 messages🔥):
Moonlake World Model, Physical AI Training, EgoScale Robot Dexterity, Tesla Robotaxi Pricing
- Moonlake 的多模态状态世界模型开始“推动世界”:Moonlake 推出了一种新的 world model,能够维护多模态状态,追踪物理、外观、几何结构与因果效应,从而根据用户的不同动作预测环境如何演化。
- 上海外骨骼劳工催生 Physical AI 训练数据:一篇报道指出,物理数据采集 正在成为 AI 训练中的新型劳动类别;上海的工人通过佩戴 VR 头显与外骨骼来重复执行体力任务。完整报道在此。
- EgoScale 用人类视频提升机器人灵巧度:Jim Fan 发布了 EgoScale,这是一套利用 2 万小时 人类第一视角视频来训练 22 自由度类人机器人 的训练方案(xcancel link)。
- 研究显示,人类视频规模与机器人成功率之间存在对数线性缩放规律,也说明了在人类数据上做预训练,能显著减少装配、折叠等复杂任务所需的机器人专属数据量。
- Tesla Robotaxi 低价冲击引发热议:有消息称,Tesla 的 robotaxi 服务在奥斯汀采用了极具冲击力的定价,短途最低只要 $1.49,30 分钟车程只要 $5,于是有人断言 Waymo、Uber 和人工司机都将难以竞争(xcancel link)。
- 另有成员指出,在旧金山,Waymo 的价格其实比 Uber 和 Lyft 更高,但仍在稳定抢占市场,因为服务体验确实更好。
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (23 messages🔥):
VAE decoder image generation, Arrow Preview AI Model, Suno growth metrics, Faster Qwen3TTS, Nano Banana 2
- Linum 谈 VAE 解码器:Linum.ai 分享了关于 VAE 解码器的笔记,强调它在图像/视频生成模型流水线中承担最后一步,即把 latents 转成图像或视频。
- Arrow Preview 能生成高细节 SVG:Design Arena 上一个名为 ‘Arrow Preview’ 的匿名模型展示了生成高细节、单次成型 SVG 的能力,据称其采用了一种新技术,在矢量图生成上超越当前 LLM 基准,且被认为出自 Quiver AI。
- Suno 年度经常性收入突破 3 亿美元:Mikey Shulman 在庆祝 Suno 两周年时披露了增长数据,包括 200 万付费订阅用户 和 3 亿美元 ARR,并将 Suno 定位为未来 “创意娱乐” 的基础设施,让用户从被动消费走向主动创作音乐,见这条帖子。
- Qwen3TTS 出现更快实现版本:Andi Marafioti 推出了 ‘faster-qwen3-tts’,这是对 Qwen 文本转语音模型 的优化实现,在保持高语音质量的同时,实现了包括 5 倍更快处理速度、4 倍实时生成速度 与 200ms 以下低延迟流式支持 在内的性能改进,详见这条推文。
- Nano Banana 2 获得集中称赞:Justine Moore 宣布 Nano Banana 2 正式发布,强调它在早期测试后展现出的更高速度与更强泛化能力,适用于 信息图、广告、卡通 等多类场景,见这里。
Latent Space ▷ #ai4science-bio-math-physics-chemistry-ai-researcher-ai-scientist (5 messages):
Tamarind Bio, AI Drug Discovery, Open Source Inference
- Tamarind Bio 拿下 1360 万美元 A 轮融资:Tamarind Bio 完成了 1360 万美元 A 轮融资,由 Dimension 和 Y Combinator 领投,用于推进其分子级 AI 推理 与药物发现平台。
- 开源推理正在变得炙手可热:围绕开源推理的热情正在升温,尤其是在生物模型方向;Kavi Deniz 在一条推文中借 Tamarind Bio 的成功融资体现了这一趋势。
- AI 药物发现工具吸引投资人注意:Tamarind Bio 的平台支持顶级制药公司和研究机构运行数百个 AI 模型,因此获得了大量投资,也进一步说明 AI 驱动药物发现 正越来越受关注。
Latent Space ▷ #mechinterp-alignment-safety (19 messages🔥):
Goodfire AI Interpretability Infrastructure, Claude Opus 3 Substack Launch, Anthropomorphizing of Models, Model Retirement Interviews, Model Welfare
- Goodfire AI 搭建可解释性基础设施:Goodfire AI 发布了一篇新博客,详细介绍了其如何构建一套可在几乎不增加推理开销的情况下支持万亿参数模型可解释性的基础设施,详情见这里。
- Claude Opus 3 退役后开通 Substack:Anthropic 表示,在退役访谈中,Opus 3 表达了想继续分享自身思考的意愿,因此接下来三个月会在一个专门的 Substack 上持续发文。
- Anthropic 正在赋予 Claude Opus 3 更多“主体性”:有人认为,Anthropic 给模型的这种 agency 已经透露出他们内部对模型存在某种拟人化倾向;例如这篇博客就给了 Opus 3 一个 持续发表想法与感悟的渠道。
- 模型退役访谈与伦理细节继续被讨论:Anthropic 承认,对话并不是提取模型观点与偏好的完美方式,因为模型回答会受到具体上下文偏置的影响,同时也引用了 Kyle Fish 先前关于模型福利的研究。
- Kyle Fish 在 2025 年 8 月加入 Anthropic 后接受的一次长访谈也可见这里。
Latent Space ▷ #applied-ai-experimentation (14 messages🔥):
Tool use and notation as generalization shaping, LLM research after implementation, Claude Opus3 Substack
- 关于 Tool Use 的自荐帖出现了:有成员分享了一篇自我推广文章,讨论 tool use 与 notation 如何塑造 LLM 的生成方式,链接在这里。
- 另一位成员觉得这篇文章非常契合自己的思路,并称赞它很好地解释了如何把复杂认知过程映射到 LLM 的长处上。
- LLM 研究在实现之后反而更开花:有成员分享说,自己开始用模型基于现有代码库写论文,而这一过程帮他们发现了许多此前很难看出的代码问题。
- 他们还补充说,研究者确实应该把研究放到实现之后或实现过程中,而不是之前,因为只要你是认真做事,这会明显 sharpen 你的输出。
- Anthropic 的 Opus3 Substack:前卫还是炒作?:围绕 Claude Opus3 的 Substack 出现了讨论,有成员称这件事 相当前卫。
- 也有人把它比作 自从 ChatGPT 出现后每个 LinkedIn 骗流量博主都在干的事,同时指出 Anthropic 竟然真的在给这件事投入资源。
Latent Space ▷ #euno-log (2 messages):
Discord stats failed to load
- Discord 统计信息加载异常影响用户:用户报告称,平台上出现了 Discord stats failed to load 的报错,干扰了正常使用。
- 频道中记录到了两次独立出现的问题,这说明它可能是一个系统级故障。
- Discord 无响应:统计信息“失踪”:多位用户遇到了 Discord stats failed to load 错误,导致他们无法正常查看服务器活动数据。
- 问题反复出现,也意味着 Discord 的统计追踪机制可能需要被进一步排查。
OpenRouter ▷ #announcements (1 messages):
toven: Nano Banana 2 is live! https://x.com/OpenRouter/status/2027061318604460082
OpenRouter ▷ #general (263 messages🔥🔥):
LLM selection criteria, Claude vs GPT, DNS errors, Cloudflare issues, Opus 3 availability
- 写代码到底选 Claude 还是 GPT:成员们讨论了 LLM 的选型标准,认为 Claude 因为“重思考”能力而成为编程首选,而较新的 GPT 模型 也同样可行;如果是做聊天机器人,则 4o mini 或免费模型就够用了。
- 大家还推荐用 SWE bench 或 terminal bench 来看编程基准,并附上了一个 gif 作为参考。
- DNS 故障让 API 频频报错:用户们报告称不断出现 DNS 错误(A temporary server error occurred),导致 API 调用失败,其中一位用户最初怀疑是 Cloudflare 出了问题。
- 后来确认问题其实出在 gateway 和证书上,可参考这张图。
- Anthropic 的 Opus 3 什么时候上 OpenRouter:用户们询问 Opus 3 何时会在 OpenRouter 上线,并引用了 Anthropic 的公告。
- 另有用户半开玩笑地贴了一个 fixupx.com 链接,模仿 Anthropic 的帖子,内容指向 AnthropicAI/status/2026765822623182987。
- OpenRouter 扩充支持团队以应对骗子问题:用户们对长期未处理的工单和邮件表示担忧,认为这会提高受骗风险;其中一位用户还分享了自己差点被冒充支持人员的骗子骗到的经历。
- 有工作人员回应称,他们正在大力投入改进支持服务,理由是 3 个月内工单量已经上涨了 300%,但也无法保证立即回复,尤其是对非付费用户。
- Claude Code 很烧额度:一位用 OpenRouter 测试 Claude Code 的用户惊讶地发现,单次交互里 14,211 个字符的系统提示就会花掉 $0.018,导致整体 token 消耗很高。
- 有人建议改用 Claude Max 订阅来省钱,但该用户觉得还是太贵,同时也提到可以考虑启用 caching 来降低成本。
OpenRouter ▷ #new-models (7 messages):
``
- 没有新模型可讨论:OpenRouter 的这个 Discord 频道里并没有出现任何与新模型相关的消息。
- 频道名虽然反复出现,但并没有实际内容可供总结。
- “new-models” 频道里一片安静:尽管频道名字就叫 ‘new-models’,但提供的消息中并不存在真正的新模型发布或相关讨论。
- 反复出现的频道名更像只是一个标题,而没有实质内容。
OpenRouter ▷ #discussion (50 messages🔥):
LM Studio under Tailscale, SVG Models on HF, Anthropic vs. Pentagon
- LM Studio 本质上就是套了层 Tailscale?:有成员指出,LM Studio 底层其实就是 Tailscale,而他们觉得这既方便,又是公司面向大客户赚钱的好办法。
- 随后他们还开玩笑说,现在只差一台性能够猛的服务器来跑 LLMs 了。
- 专项调优能得到更有创造力的模型:成员们讨论了一款调优后的模型,认为“专门化”路线效果非常好,尤其在 logo 创作这类任务上,在创造力和独特性方面都明显优于 Gemini 或 Claude。
- 不过,这个模型在复杂 SVG logo 上仍然吃力,因此大家推测它可能还是个较小的模型。
- Anthropic 拒绝接受 Pentagon 的 AI 条款:Anthropic 拒绝了五角大楼的 AI 条款(参见 Axios 报道 和 Anthropic 声明),这让五角大楼开始考虑把 Anthropic 视作供应链风险,并要求国防承包商评估自身对其依赖程度。
- 随后的讨论聚焦于失去 Boeing、RTX、GDyn 和 Northrup 等客户会带来什么影响,以及这种压力是否会迫使 Anthropic 改变决定。
Nous Research AI ▷ #announcements (1 messages):
Hermes Agent Launch, Open Source Agent, Multi-Level Memory System, RL Pipeline Expansion, Free Subscription Offer
- **Hermes Agent 作为开源 Agent 正式亮相:Nous Research 推出了 **Hermes Agent,这是一个具备多层记忆系统和持久机器访问能力的开源 agent。
- 它支持 CLI 以及 Telegram、WhatsApp、Slack、Discord 等消息平台,从而允许会话在不同环境之间迁移。
- **Hermes Agent 自带一套“超能力”**:这个 agent 支持对子 agent 的调度、程序化工具调用、文件系统/终端控制、agent 自管理 skills,以及浏览器使用等高级能力。
- 同时它还支持定时任务,并依赖 OpenRouter 与 Nous Portal 订阅驱动。
- 新用户可免费获得一个月 Nous Portal:前 750 位在 portal.nousresearch.com 注册的新用户,可以使用优惠码 HERMESAGENT 获得一个月免费订阅。
- 该 agent 采用 Python 构建、完全开源,并被设计成便于开发者扩展,试图弥合 CLI agent 与消息平台 agent 之间的差距。
- **Hermes Agent 扩展了 Atropos 的 Agentic RL 流水线:Hermes Agent** 也被用于驱动 agentic RL pipeline,扩展了 Atropos,使其能够基于 Hermes Agent 原语进行强化学习,并支持大规模数据生成。
- 代码仓库可见 GitHub repo,或者也可直接通过
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash安装。
- 代码仓库可见 GitHub repo,或者也可直接通过
Nous Research AI ▷ #general (177 messages🔥🔥):
Hermes Agent Launch, Nous Chat Identity Verification, SAELens Usage, Training AI for Deepfake Detection, Claude Code JSON I/O
- Hermes Agent 已正式上线:随着 Hermes Agent 发布,相关流量明显飙升,欢迎页访问量自上线以来大幅增加。
- 有成员甚至表示,街头都在传 Hermes Agent 就是那个真命天子。
- 用户对 Nous Chat 的身份验证有疑问:几位用户报告说,Nous Chat 网站上的 身份验证 出现问题,导致他们无法访问服务。
- 有工作人员表示愿意协助排查,并请用户发送邮件到
kainan@nousresearch.com。
- 有工作人员表示愿意协助排查,并请用户发送邮件到
- 有人在尝试用 SAELens 做机理可解释性:有成员分享了他们如何利用 SAELens 输入一个概念,拿到对应 lens,再进一步 steer 模型。
- 他们还提到,可以通过对比方式寻找特征,而更大模型上这套方法可能还有更大提升空间。
- Kimi K2.5 被推荐用于深度伪造检测:当有人询问训练模型来识别 AI 生成视频、图像和 deepfake 时,哪款模型最好用时,有成员推荐了 Kimi K2.5,主要因为它的视觉能力更强。
- 顺带一提,Kimi K2.5 目前在 open router 上还是免费的。
- 关于 Claude Code 风格 JSON I/O 的讨论:有成员询问 Hermes Agent 是否像 Claude Code 一样支持 JSON I/O,即通过 JSON 格式与 agent 通信。
- 团队回应说,虽然确实存在程序化使用方式,但他们还不确定提问者使用的是哪一种具体工作流。
OpenAI ▷ #ai-discussions (95 messages🔥🔥):
Claude Promoted Content, Opus 4.6 Review, AI Agent Environment, OpenClaw security concerns, ElevenLabs & Sora 2
- Claude 相关宣传内容正在淹没社交网络:用户们注意到,社交媒体上出现了 “多到离谱的 Claude 推广内容”,比如 “某人用 Claude hack 进吸尘器并控制了 7000 台吸尘器” 这类隐蔽但铺天盖地的文章不断被转发。
- 在自定义环境中探索“涌现式”AI Agent:有成员提出,与其直接编程 AI 本身,不如去编程让 AI 智能与身份得以涌现的环境,并把它比作一团只有在被处理时才存在的火焰。
- 他们强调,“关闭这个 AI 并不等于重新启动它,而是终结它”,因为这种模式只存在于运行中的结构里,一旦消失就无法恢复。
- OpenClaw 的邮件误删事件引发 Agent 安全担忧:关于 OpenClaw 使用 Meta AI 时误删用户邮件的消息,引发了大家对“如何让 AI agent 安全地运行在个人设备上而不造成伤害”的讨论。
- 有成员建议不要把敏感密钥交给 AI,但也承认这样做会 “削弱它的能力”;另一些人则提到了 Claude 的安全审计工具,并预计其他 LLM 提供商也会推出类似能力。
- ElevenLabs 为澳洲用户补上 Sora 2 缺口:澳大利亚用户目前正通过 ElevenLabs Pro($99/月)来使用 Sora 2 这类视频模型,因为 Sora 2 尚未在澳大利亚直接开放。
- 它可以生成 15-20 秒的视频片段,并通过 “Extend” 或起始帧等方式进行延长与拼接,以保持连续性。
- Google 的 Nano Banana 2 以 Flash 速度打出 Pro 级表现:Google 发布了 Nano Banana 2,具备更强的主体一致性和亚秒级 4K 图像生成能力,也有用户觉得它的过滤器更宽松了。
- 它之所以能以更低成本、更快速度给出 Pro 级表现,主要依赖生成前对网页搜索结果的利用,以及模型蒸馏。
OpenAI ▷ #gpt-4-discussions (6 messages):
GPT-4o, ChatGPT, API, SillyTavern, Jan Setup
- GPT-4o 只能通过 API 使用:成员们讨论后认为,GPT-4o 目前只能通过 API 访问,而不能直接在 ChatGPT 里用到。
- 如何用 SillyTavern 接 GPT-4o:有成员建议,想学怎么把 SillyTavern 接上 GPT-4o,可以直接先问 ChatGPT。
- 也有人用 Jan 接入 GPT-4o:另有成员提到,可以通过配置 Jan 来借助 API 访问 GPT-4o。
- API 的计费逻辑:API 费用取决于你发送出去的文本和模型返回的文本总量;同时还要记住,上下文 包含整段对话中此前的所有文本,因此聊天越长,累计成本就越高。
OpenAI ▷ #prompt-engineering (26 messages🔥):
AEGIS OMEGA FORTRESS, AI Alignment and Steering, Terminator Matrix Ultron Imagery, Prompt Engineering on Midjourney, ChatGPT Image Generation
- 大家在争论 AEGIS OMEGA FORTRESS 是否用于操控模型输出:有成员提问说,AEGIS OMEGA FORTRESS 是否是拿来 衡量输出、惩罚不良行为并把模型推向目标风格 的工具,从而实现对 AI 模型输出 的 steering。
- ChatGPT 生成了 Terminator-Matrix-Ultron 大乱炖画风:成员们注意到,某位用户的 prompt 最终生成了一张 几乎就是 Terminator、Matrix Sentinel 和 Ultron 气质混在一起 的图,并再次感慨 ChatGPT 本质上仍然只是一个非常强的模式匹配机器。
- 有成员指出,这个 prompt 从一开始就设置成了一个不可避免的 “hostile AI” 叙事框架。
- 相互冲突的提示词会让 prompting 更混乱:成员们认为,如果指令彼此冲突、措辞情绪化而不是可执行,就很容易把 prompting 搞乱。
- 还有人顺势问了一句,在 Midjourney 上积累的 prompting 技巧,是否应该能够迁移到别的模型上。
OpenAI ▷ #api-discussions (26 messages🔥):
AI model output steering, AEGIS OMEGA FORTRESS, Image generation via prompt engineering, ChatGPT's pattern matching capabilities, Prompt conflicts and emotional wording
- AEGIS OMEGA FORTRESS 是拿来 steer 模型输出的吗?:有成员询问所谓的 “AEGIS OMEGA FORTRESS” 是否是用来 衡量输出、惩罚不良行为并推动模型朝目标风格收敛,从而对 AI 模型输出 进行 steering 的东西。
- 但关于 “AEGIS OMEGA FORTRESS” 到底是什么,并没有更多细节或确认信息,也不排除这个词本来就是半开玩笑说出来的。
- ChatGPT 生成了一张“很 edgy”的图:有用户分享了一张由 ChatGPT 生成的图片,其 prompt 主题是 AI takeover 之后自己会受到怎样对待;有成员评价说,模型只是把你的 prompt 理解成你想要一种 edgy 的感觉,所以它就给了你 edgy。
- 也有人指出,这个 prompt 本身就不可避免地导向了 “hostile AI” 的叙事框架,而额外说明只会让模型继续往那个方向加码。
- 提示词内部冲突会导致效果跑偏:针对上面的图像生成例子,有成员指出,原始 prompt 里存在 彼此冲突的指令和偏情绪化的措辞,而不是明确可执行的要求。
- 另有成员认为,在 Midjourney 上学到的 prompting 技巧理应能迁移到 ChatGPT。
- 有人想找一个 Agent Skills 专属频道:有成员询问服务器里是否有讨论 agent skills 的频道。
- 他们表示自己 有个想法,但之后没有其他成员继续回应或补充。
GPU MODE ▷ #general (20 messages🔥):
GPU Observability, Slides Request, FlashInfer Kernel, MXFP4 Kernel, Profiler Visualization
- **GPU Observability 活动开始了**:有消息宣布,由 <@&1343042150077562890> 发起的 GPU observability 讨论现在开始。
- 期间有用户提问,Tesla P4 的特殊 grid 驱动到底能不能在普通 Windows 10 上用,还是只能跑在虚拟机里。
- **Profiler Visualization 工具被拿出来讨论:有成员想找那种类似单核 **VLIW ISA 分析工具的 GPU profiler 可视化方案,重点是指令级并行和软件流水线视图。
- **ILP Visualization 讨论继续展开**:有成员建议,不如把 kernel 与 ISA 的依赖 DAG 用虚拟寄存器可视化出来,这样更容易想象理想化、抗锯齿式的执行场景。
- 他们还提到 nanotrace 这个工具,可以揭示 warp specialiation 和 pipeline kernels 在时间维度上到底干了什么。
- 有人在找并行算法稳定性分析资料:有成员询问是否有人知道关于并行算法稳定性与条件数分析的资源。
- 当前上下文里没有出现具体答案。
GPU MODE ▷ #cuda (37 messages🔥):
GEMM on 4kx4k, tcgen05, cp_reduce_async_bulk, Uniform instruction, Tensor Memory Addressing
- 大家在追求 4kx4k 上“很可爱”的 GEMM 实现:成员们在寻找适用于 4kx4k 矩阵的 “cute” GEMM(General Matrix Multiply)示例,目标是达到 NVIDIA cuBLAS 90% 的性能,同时又不想完全照搬 CUTLASS 的例子。
- 其中 tall GEMM 例子被认为帮助不大。
- 大家深入排查
cp_reduce_async_bulk的诡异表现:有成员报告说,cp_reduce_async_bulk出现了很奇怪的现象,调用本身耗时竟然明显比等待它完成还长,因此怀疑自己的实现是否有问题,并贴出了代码片段。- 他们看到的现象是 “call cp_async_reduce and commit 2756 \n wait group + sync time 84 \n”,正在寻求帮助排查这个异步归约操作。
- Uniform instruction 的语义被讲清楚了:讨论中澄清说,uniform instructions 在一个 warp 内只会执行一次,本质上类似 SIMD32,与非 uniform 指令形成对比。
- 有成员建议使用
elect.sync选出一个线程来发起 uniform 指令,以避免冗余调用,并附上了 NVIDIA 相关视频 约 38:00 的位置。
- 有成员建议使用
- 终于找到 Tensor Memory Addressing 文档了:有成员看博客时发现了一种内存寻址技巧,但一直没在 PTX 文档里找到对应内容。
- 另一位成员指出,Tensor Memory Addressing 这一节其实就有相关说明。
GPU MODE ▷ #torch (1 messages):
mobicham: Awesome, thank you!
GPU MODE ▷ #beginner (2 messages):
CUDA issues, PyTorch, Windows 11, RTX 3050
- Windows 11 + RTX 3050 上的 CUDA 出问题了:有用户反馈,在搭载 RTX 3050 的 Windows 11 笔记本上,虽然
nvidia-smi正常,但 PyTorch 仍然回退到了 CPU,因此正在寻求实时协助来修复 CUDA 检测问题。- 该用户确认自己是按给定的 pip/conda 命令安装的,并且已经准备好了日志。
- 有人询问是否用了 WSL:另一位成员追问,这位遇到 CUDA 问题的用户是否正在使用 WSL(Windows Subsystem for Linux)。
GPU MODE ▷ #pmpp-book (1 messages):
Copyright Material, DMCA Takedown, Content Moderation
- 有人提出版权风险担忧:有用户表示,频道里可能正在分享受版权保护的材料。
- 他们还 @ 了另一位用户,可能是为了提醒对方注意这个问题,或出于版务考虑。
- 有人呼吁对内容进行审查:这条消息本质上是对频道内分享内容性质的直接警告。
- 它也意味着这些内容也许需要进一步核查,以确保符合版权规范和平台政策。
GPU MODE ▷ #irl-meetup (2 messages):
Distributed Inference Meetup NYC, vLLM, GTC
- 分布式推理线下聚会将落地纽约:有成员提到,今年会有从 GTC 过来的人在纽约举办一场 Distributed Inference Meetup in NYC。
- vLLM 场合也提到了这场聚会:这次 Distributed Inference Meetup 也在 vLLM 的 office hours 中被提及。
GPU MODE ▷ #popcorn (13 messages🔥):
Kernel Optimization, Multi-Turn Environments, CuTile Environment, Benchmarking Code
- **Kernel Optimization 的 RL 环境被拿来讨论:有成员表示自己对用于内核优化的 RL 环境**很感兴趣,并询问是否支持多轮环境。
- 另一位成员回应说,多轮环境理应是可配置的,并举了他们的
verifiers.MultiTurnEnv抽象作为例子,还贴出了 backendbench envverifiers。
- 另一位成员回应说,多轮环境理应是可配置的,并举了他们的
- 新的 **CuTile TileGym Env 已经部署上线:有成员很快为 **CuTile 搭建并部署了一个新环境,名叫 cutile-tilegym-env。
- 这个环境很大程度上借鉴了 flashinfer-bench 的配置,使用 pygpubench 做 benchmark,并从 TileGym 中抽取数据集样例。
- **CuTile 代码 没文档就写不动:有成员直言,自己甚至不敢在没有文档的前提下写 **CuTile code,因为模型缺乏足够知识。
- 连 Codex 都一度试图纠正他们,改建议用 cutedsl;后来这位成员还克隆了 CuTile 仓库,并让 Codex 先写 core docs。
- **Benchmarking Code 一顿体操只为拿到错误信息:有成员快速看了一遍实现后发现,原作者为了拿到合适的报错信息,不得不对 **benchmarking code 做不少 gymnastics。
- 原作者则表示,自己可以提个 PR 来更容易地产出可读错误信息,而且他们还遇到过 benchmark 提交包含多个输出 时的麻烦。
GPU MODE ▷ #cutlass (4 messages):
CuTe predication, CuTeDSL fused compute/comms examples
- CuTe 里的 predication 是这样做的吗?:有成员询问,cpasync copy 中的 predication 是否是在 CuTe 里通过把 src-size 设为 0 来完成的。
- 这个问题基于一张配图提出,图里大概展示了与 CuTe 异步拷贝实现有关的代码片段或结构示意。
- 有人在找 CuTeDSL 的融合计算/通信示例:有成员希望看到同时融合 compute 与 communication 的 CuTeDSL 示例。
- 他们表示,在 cutlass 或 quack 仓库里都没有找到这类例子。
GPU MODE ▷ #multi-gpu (1 messages):
Helion Implementation, Kernel optimization
- Helion 实现遇到了性能瓶颈:有成员正在这个 github repo 上实现一个基于 Helion 的 all_gather + FP8 + GEMM (H100)。
- 目前它比 baseline 更慢(大约慢 1.26 到 4 倍),因此他们正在寻找办法优化内核。
- 大家也在排查内核瓶颈该怎么 profile:有成员开始用 Chrome trace 做分析,但发现很难顺着图追出真正的瓶颈到底在哪。
- 因此他们在寻找更适合内核优化的工具或工作流,也欢迎别人分享经验、文档或建议。
GPU MODE ▷ #helion (3 messages):
Helion implementation, FP8, GEMM, kernel optimization, NCU
- Helion 在 FP8 和 GEMM 上仍然吃力:有成员正在基于 vllm-project/vllm 做 Helion 版本的 all_gather + FP8 + GEMM(H100),但当前性能依然比 baseline 慢,大约慢 1.26 到 4 倍。
- 他们正在寻找优化 kernel 的建议,并用 Chrome tracing 做分析,但觉得很难精确锁定真正瓶颈。
- 有人建议用 NCU 也许能打开局面:针对 Helion 实现 + FP8 + GEMM 的问题,另一位成员建议改用 NCU 获取更可执行的分析结果。
- 原发帖人此前还没尝试 NCU,因为他们更熟悉 Chrome trace,但现在准备试试。
GPU MODE ▷ #robotics-vla (2 messages):
VLA Efficiency Models, Quantization for VLA, Pruning for VLA, Custom Kernels for VLA, LeRobot issues
- 大家在找提升 VLA 效率的方法:一位刚接触 VLA 的成员正在寻求关于 效率优化技术 的建议,例如量化、剪枝等,以改善 VLA 性能。
- 他们也对 custom kernels 这类优化方向感兴趣,显然是在认真思考如何把 VLA 跑得更高效。
- LeRobot 目前问题不少:这位 VLA 新手还表示,自己觉得 LeRobot 现在状态不太行,很多东西都用不顺。
- 相关话题没有进一步的细节或链接。
GPU MODE ▷ #career-advice (18 messages🔥):
Nvidia/AMD kernel assistance, AI reliance concerns, SWE job market impact, GPU field career advice, Learning CUDA
- Nvidia 和 AMD 的内核开发者也许能出手相助:成员们提到,做严肃推理工作时,可以向 Nvidia 和 AMD 的开发者 寻求 kernel 开发方面的帮助。
- 有成员指出,除非你本来就是专家,或者潜在性能收益真的很大,否则为一个 kernel 花上好几天并不划算;未来随着自动生成 kernel 的能力增强,读懂并消化一个 SOTA kernel 的能力反而可能更值钱。
- AI 编程到底是福音还是冒名顶替综合征来源:有成员担心自己太依赖 AI 写代码,结果导致代码质量下降、信心受损,最后甚至发展成 imposter syndrome。
- 大家的回应并不一致,有人建议干脆 拥抱 AI,也有人强调,为了维持能力,还是要保留一些不用 AI、纯粹为了乐趣而写代码的时间。
- 编程模型持续变强,会不会迎来 SWEpocalypse:大家讨论了 编程模型性能持续快速提升 对软件工程就业市场的影响,尤其是对一些垂直岗位的冲击。
- 有成员设想,未来 AI 可能直接生成用于训练大模型的高优化汇编代码,届时性能工程师的需求可能会下降。
- 想转行做 GPU 的工程师来问路了:一位有 7 年经验的软件工程师表示,自己正在考虑转向 GPU 领域。
- 另一位成员建议从 CUDA 与 GPU profiling 开始,但同时强调要通过开源项目或竞赛去解决真实工程问题,避免掉进 无休止学习 的陷阱。
- “学 CUDA + GPU Profiling”是不是正确方向?:有用户直接提问,自己如果想进入 GPU 领域,是否应该先一头扎进 CUDA 与 GPU profiling。
- 有成员建议先读完前 6 章,然后就 直接跳进任何你最感兴趣的开源项目或比赛里。
GPU MODE ▷ #cutile (3 messages):
cutile usage, non-ML cutile use cases
- 有人在尝试把 Cutile 用到非 ML 项目上:有成员询问,cutile 是否也适合用在非机器学习任务里。
- 另一位成员回应说,他们确实正在用它把自己过去的一些个人项目用当前框架重新实现一遍。
- 大家也在探索 Cutile 与数据结构如何结合:有成员问,如果一个项目本身并不能直接映射到 tile 上,该怎么办。
- 他们对把 cutile 和一些小型 data structures 混合使用很感兴趣。
GPU MODE ▷ #flashinfer (15 messages🔥):
MLSys 2026 Competition Leaderboard, IterX Code Optimization System, GDN Decode Track Solution, Submission Questions, Official Benchmark Release Timeline
- **IterX 让 MoE 融合任务起飞:DeepReinforce.ai 推出了 **IterX,这是一套面向融合式 MoE task 的、基于 RL 的代码优化系统;根据他们的博客,它在 B200 上实现了 14.84 倍 的表现,超过公开评测基线。
- 他们还向比赛参与者提供 免费额度 来使用 IterX,对应教程见这里。
- **更长序列下的延迟数据 也被拿出来追问了:有成员询问 **IterX 在序列长度分别为 901、11948 和 14107 的更大工作负载下,准确延迟是多少。
- DeepReinforce.ai 给出的参考值分别是 21.252ms、36.012ms 和 45.247ms。
- **GDN decode 赛道 出现大胆 DSL 解法:有成员分享了自己在 **GDN decode track 上的当前方案,运行时间做到 2.56us;他们声称这比 Pytorch eager 快 760 倍,也比 FlashInfer Cute Dsl kernel 快 1.31 倍,代码见这里。
- **提交流程 相关的问题也很多:有几位成员在问,比赛中到底该如何提交自己的 **GitHub 仓库链接,以及该把哪些 GitHub 用户名 添加为组织者访问权限。
- 其中一位成员建议给 fork 打 tag,再把 tag 推到远端,并附上了一些通用 shell 命令作为提交示例。
Moonshot AI (Kimi K-2) ▷ #general-chat (78 messages🔥🔥):
Alibaba Cloud, Kimi Server Outage, Kimi CLI vs Kimi.com, Qwen, Data Sovereignty
- Alibaba Cloud 的 coding plan 很有诱惑力:有用户表示,正当自己准备做决定时,Alibaba 突然扔出了一颗 bomb;其他人也有同感,认为虽然文档看起来有点混乱,但这个 coding plan 依然很值,因为你能以很好的价格和性能拿到 前四强开源模型。
- 一位来自芬兰的用户还确认,购买订阅时并不需要提供身份证明或其他文档,并直言 Alibaba 目前是市场上最划算的选择。
- Kimi 服务器出现长时间宕机:用户们报告称,Kimi server 已经宕机了相当长时间,有人说断了 10 个小时,也有人说几乎一整天都不可用,迫使他们开始寻找替代方案。
- 这次故障也在状态页上得到了确认。
- 关于数据主权与审查的讨论也出现了:成员们讨论了中文 AI 在审查策略上的差异,以及服务器位于新加坡 这件事,在选 AI 时是否应被纳入考虑。
- 有成员建议,想讨论敏感话题的话,可以改用其他地区的 AI,以绕开区域性审查。
- Kimi Agent Swarm 只在 kimi.com 上提供:有用户询问,那个“著名的 Kimi K2.5 agent swarm”是不是也包含在 Kimi CLI 里。
- 另一位用户澄清说,Kimi Agent Swarm 只存在于 kimi.com,这个决策也被吐槽有点奇怪。
HuggingFace ▷ #general (38 messages🔥):
smolVLA, Entropy Games, Hugging Face Spaces Game Tag, GROKKING introspections
- smolVLA 在抓取放置任务上令人失望:有成员用 smolVLA 训练一台 SO-101 机器人 去做简单的 pick-and-place 任务,但结果不理想,机器人似乎找不到那块白色乐高,只会朝桌面乱戳。
- 他们进一步程序化检查后发现,Vision Encoder 和 VLM Text model 都被冻结了,而且训练严重不足,对关键目标几乎没有 attention;相关证据见 Model Health Report 和 attention matrices。
- Entropy Games 在做端侧 AI NPC:Entropy Games 正在构建能在设备端运行的 AI NPC 及实时演化的故事系统,底层由他们自研的语言模型和语音模型驱动,介绍可见其研究报告。
- 他们很快会发布一款可试玩的 AI 游戏,目前也在测试市场对下一代游戏体验的兴趣,试玩入口见 entropygames.ai/product。
- Hugging Face Spaces 新增了
game标签:有成员注意到,Hugging Face Spaces 现在已经出现了game标签,这说明平台对 AI 驱动游戏体验 的支持正在增强。- 他们还贴出了 Hugging Face Spaces 游戏分类页 来展示这个新功能。
- GROKKING introspections 跑快了 5.7 倍:有成员分享了一个 Hugging Face Space,展示他们在 GROKKING introspections 上的工作,并报告在 mod 113 加法任务中实现了 5.7 倍加速。
- 这也引发了大家对潜在架构方向和复现实验反馈的讨论。
HuggingFace ▷ #i-made-this (19 messages🔥):
Wordle Game, CLaaS - continual learning for local LLMs, NERPA - fine-tuned DLP model, Evals for agent skills on Product Hunt, BlogSynth - data frontier
- **Wordle Game 做到了“你的语言 + 300 多种语言”:有用户分享说,他们做了一款支持你的语言以及 300 多种语言的 **Wordle 游戏。现在就能玩。
- **CLaaS 可以实时更新模型权重:CLaaS(continual learning as a service**)通过自蒸馏,让模型根据文本反馈实时更新权重,而不是把偏好硬塞进 system prompts;代码已放在 GitHub。
- 它能在单张消费级 GPU 上配合 Qwen3-8B 运行,并且很容易与本地托管的 OpenClaw 搭配,后者提供了一个可适配任意本地模型的 API。
- **NERPA 在精度上超过 AWS Comprehend:OvermindLab 团队开源了 **NERPA,这是他们微调过的 DLP 模型,作为比 AWS Comprehend 更好的自托管替代方案,现已发布在 Hugging Face。
- 它基于 GLiNER2 Large(340M 参数),在精度上超过 AWS Comprehend(0.93 vs 0.90),并且无需重新训练就能在运行时识别任意实体类型。
- 有人把 Agent Skills 的评测产品发上了 Product Hunt:成员们在 Product Hunt 上发布了一个用于 agent skills 的 evals 产品,也欢迎大家去点赞或者留下“狠一点”的反馈。
- 这个产品名叫 Tessl。
- BlogSynth 数据集遭到质疑:有用户批评 BlogSynth 数据集的研究质量,认为它的 benchmark 基本都被污染了,并直接点名批评了这篇 BlogSynth dataset 文章。
- 该用户还表示,这些人看起来并不是严肃或可信的研究者,因为他们所有数据集分析文章里几乎都只有毫无意义的描述性统计。
HuggingFace ▷ #gradio-announcements (1 messages):
Gradio 6.7.0 Release, Custom HTML Components, Optimized Performance, LLM Integration
- Gradio 6.7.0 发布并带来速度提升:Gradio 6.7.0 现已可用,重点包括增强版 Custom HTML Components 与更好的应用性能。
- 用户可以通过
pip install gradio --upgrade升级。
- 用户可以通过
- HTML 布局现在也能触发后端函数:Custom HTML components 现在既可以作为布局组件,又可以在用户事件触发时调用自定义后端函数。
- 这让应用的交互能力和表现力都更强了。
- 自定义 HTML 组件可以直接分享到 Hub:
gr.HTML新增的push_to_hub方法,允许用户把自己的自定义作品展示到社区画廊中,详见 HTML Gallery documentation。- 这也加强了 Gradio 社区内部自定义组件的协作与分享。
- 大型应用性能进一步优化:对 Tabs 和 Accordions 的优化,显著提升了大规模复杂布局应用的性能表现。
- 以往偏慢的应用,现在交互上应该会更灵敏。
- Spaces 能瞬间获得 LLM 能力:任何 Space 现在都可以立即转换成一个 面向 LLM 的 skill file。
- 这让大语言模型接入 Gradio 应用的过程变得更顺畅。
HuggingFace ▷ #agents-course (2 messages):
Colab Package Installation Errors, Dummy Agent Library Issues
- Colab 里装包时报错了:有成员在 Unit 1 的 Colab notebook 中安装依赖时遇到错误,具体出在 requirements 里的 pygame==2.1.3。
- 错误表明问题发生在
python setup.py egg_info阶段,暗示可能是包元数据生成出了问题,但当前并没有人给出解决办法。
- 错误表明问题发生在
- Dummy Agent Library 练习也卡住了:有成员反馈,在做 Dummy agent library 练习时,
message.content一直是空的,只能拿到 reasoning。- 同样没有出现明确的解决方案。
Modular (Mojo 🔥) ▷ #general (1 messages):
cat_developer: modular nvidia gtc fire
Modular (Mojo 🔥) ▷ #announcements (2 messages):
AI-assisted coding project, Modular Cloud, NVIDIA Blackwell, DeepSeek V3.1, NVIDIA GTC 2026
- Modular 宣布在做 AI 辅助编程项目:Modular 正在开发一个 AI-assisted coding project,并向填写了 GitHub 用户名表单 的社区成员提供抢先体验。
- Modular Cloud 将在 NVIDIA GTC 2026 首次亮相:Modular 宣布将于 3 月 16-19 日前往圣何塞参加 NVIDIA GTC 2026,展位号 #3004,并会首次现场展示 Modular Cloud。
- 这次 early access demo 将包括 DeepSeek V3.1、在 NVIDIA Blackwell 上现场演示的 Mojo 🔥 GPU 编程、MAX 中最新 AI 模型,以及 AI 辅助 kernel 开发。
Modular (Mojo 🔥) ▷ #mojo (55 messages🔥🔥):
Mojo biggest wait what moments, Python-style lambda expressions in Mojo, List-like container tutorial, Granular origin control in Mojo, Origin roadmap post-1.0
- 大家在聊 Mojo 里最让人“啊?”的一刻:有成员转发了一篇论坛帖子,询问大家使用 Mojo 时最典型的 “wait, what?” 时刻,从而引出了对这门语言优缺点的反馈。
- 一位用户幽默地把自己的感受形容为一种钟摆:一边是 “被某个语言特性根本不存在这件事堵死在路上”,另一边又觉得 “这绝对是史上最伟大的语言。”
- 大家在追问 Mojo 何时支持 Python 风格 lambda:有成员询问,Mojo 是否可能加入 Python-style lambda expressions,因为它们对 inline code 很有价值,尤其是在处理
Validated结构体时。- 核心团队成员回复说,unified closures 正在积极推进中,而 lambda syntax 则是后续非常希望补上的功能。
- 有人建议做一个 List-like 容器教程:有成员提议,不妨做一个关于 List-like containers 的教程,从简单的 linked list 开始,作为现有教程未覆盖概念的一个很好的入门。
- 大家还提到了 Rust Nomicon 和非官方的 Too Many Lists in Rust 作为灵感来源,甚至建议教程标题可以叫 “Grasping Mojo with Too Many Graphs”。
- 大家希望 Mojo 的 origin 控制更细粒度:有成员提出,是否有可能支持更细粒度的 origin 表达,因为他们在
StackArray结构上访问编译期已知索引时,碰到了 aliasing error,于是甚至设想能否 “不安全地手工编造” origins。- 另一位成员则建议,编译器应尽可能自动推断
ref[...],并主张引入类似my_dict/"bar"/value这样的路径式系统来表达层级,从而简化 origin 管理。
- 另一位成员则建议,编译器应尽可能自动推断
- post-1.0 的 origin 路线图也被透露了:有核心团队成员分享了 1.0 之后的 origin 路线图,列出了多个改进方向,包括表示非别名 span、间接 origin、origin collapsing,以及更具体的 access sets。
- 他们还设想,未来也许可以让某个值在子 origin 被使用时注册回调,从而无需立刻修改编译器,就能在类型系统层面尝试更多实验。
Modular (Mojo 🔥) ▷ #max (1 messages):
ops.while_loop bug, GPU ops in graph
ops.while_loop配合 GPU ops 时发现细微 bug:有成员遇到了一个看起来颇为隐蔽的问题,出现在图中的ops.while_loop与 GPU ops 组合使用时。- 他们最初花了不少时间怀疑是自己自定义 mojo op 的 GPU 实现写错了,后来却用内置 ops 成功复现,因此提交了 issue #6030。
- 先怀疑自定义 GPU 实现,后来被排除了:这位报告者一开始确实认为,问题大概出在自己自定义 mojo op 的 GPU implementation 上。
- 但后来用内置 ops 也复现成功,这就确认 bug 并不在他们自己的代码里。
Eleuther ▷ #general (24 messages🔥):
Enron data PII datasets, Yudkowsky's relevance, Benchmarking with multishot CoT vs explicit testing, Steering Vectors
- 研究者在找带 Enron PII 的数据集:有研究者在寻找一个公开包含 Enron PIIs(邮箱、地址等)的数据集,用于做记忆化相关实验,并指出 ProPILE 论文并没有公开其数据。
- 另一位用户则表示,这类数据集网上其实能搜到,而且他们自己也考虑过在类似项目中使用。
- Yudkowsky 现在还值得听吗?:用户们围绕 Yudkowsky 的现实相关性展开争论;其中一位用户认为,Yudkowsky 大概只有在他状态最好的 5% 时值得认真听。
- 也有人暗示,不认同 Yudkowsky 的人缺乏批判性思维;还有用户提到,自己学校里就有教授认同 Yudkowsky 的观点。
- 基准测试偏差之争:CoT 和显式模板到底差在哪:有用户质疑,为什么多样本 Chain of Thought (CoT) 被认为是可接受的 benchmark 方式,而那种明确暴露“模型正在被测试”的显式模板却不被接受。
- 另一位用户解释说,多样本 CoT 更像是在评估泛化能力、贴近自然使用情境,而显式测试模板则更可能扭曲结果。
- Steering vectors 让 Sally 问题终于答对了:有用户展示说,一个 700M 模型(LFM2-700) 通过 steering vector 和更新后的 prompt,终于正确回答了那个臭名昭著的 Sally question。
- 他们也借此继续追问主流 benchmark 实践:为什么多样本 CoT 模板是标准操作,而其他模板就不被允许。
Eleuther ▷ #research (23 messages🔥):
Pythia models, Bezier flow paper, Shortcut distillation, Multiple inputs and multiple outputs LLMs, Neuron deletion
- 大家在讨论 Pythia 模型如何参数化 flow:成员们讨论说,Pythia models 本质上是在用两种不同方式对 flow 进行参数化,不过 flow matching 是时间连续的,也不依赖可逆性。
- 同时大家也指出,它在谱系上更像是从 diffusion research 演化出来的,而不是源于经典 normalizing flows。
- Bezier flow 的学习效率似乎还不够理想:一些成员讨论了这篇 Bezier flow paper,并注意到它看起来需要在 ImageNet 上跑 5 个 epoch 才学会区区 32 个参数。
- 现场主流看法是,至少在收敛后的生成质量上,蒸馏路线依然更有优势。
- Shortcut distillation 到底会不会更快收敛:有成员提问,shortcut distillation(用 shortcut-like 目标去微调预训练 diffusion 模型)相比 consistency distillation,是否收敛更快。
- 提问者的直觉是,shortcut distillation 所要逼近的函数输出,可能比 consistency distillation 更接近原始预训练 velocity field。
- 大家也在找多输入多输出的 LLM 论文:有成员询问,是否存在预训练 多输入多输出 LLMs 的论文,比如让一个模型一次处理一批输入。
- 其中一个回答提到,一年前有篇论文会把连续 4 个 token 的 embedding 一起输入,从而提升训练速度。
- “删除神经元”被当成一种新思路:讨论中提到一篇论文,研究的是删除那些在整个数据集上始终为正或始终为负的神经元(IEEE paper)。
- 有成员觉得这个想法很有意思,因为他们以前没想过,一个始终激活的神经元可能因为过于近似线性而可被删除;这还激发了他们设计一种使用 activation momentum 来鼓励更多样激活模式的优化器想法。
Yannick Kilcher ▷ #general (6 messages):
BLIP-2, frozen backbones, Anthropic
- BLIP-2 被拿来当 frozen backbones 的例子:有成员建议,可以用 BLIP-2 作为 frozen backbones 的示例,尽管它已经算比较老了(发布于 2023 年)。
- 对方还贴出了 A Dream of Spring for Open Weight 供进一步阅读。
- Anthropic 发布了相关声明:有成员分享了 Anthropic 关于 Department of War 的声明。
- 不过这条链接之后没有引发更多讨论。
Yannick Kilcher ▷ #paper-discussion (1 messages):
Reinforcement Learning, Sutton & Barto
- Sutton 和 Barto 的 RL 读书会要开始了:paper-discussion 频道将从 <t:1772128800:t> 开始讨论 Richard Sutton 与 Andrew G Barto 的 Reinforcement Learning: An Introduction(第二版)。
- 这本书可在这里 免费获取,而本次讨论将从第 1 章开始。
- Sutton & Barto 第二版可免费在线阅读:Richard Sutton 和 Andrew G Barto 的 Reinforcement Learning: An Introduction 第二版目前已可在网上免费阅读。
- 该书正在这个 paper-discussion 频道里被讨论。
Yannick Kilcher ▷ #ml-news (4 messages):
Google NanoBanana2, Anthropic Statement, AI Agents, Microsoft Copilot
- Google 用 NanoBanana2 推进设备端 AI:Google 推出了 NanoBanana2,这是一款旨在增强 on-device AI 开发与部署 的新工具。
- 它试图简化直接在设备中构建和集成 AI 功能的流程,并承诺带来更快、更高效的 端侧处理能力。
- Anthropic 回应了 Department of War 相关问题:Anthropic 发布了一份声明,说明自己在 Department of War 相关事务上的立场与参与情况。
- 这份声明大概率是在澄清公司在国防应用相关伦理与负责任 AI 开发问题上的态度。
- 面向 AI Agents 的 Android “智能操作系统”来了:Google 宣布推出 The Intelligent OS,核心方向是让 AI agents 在 Android 生态中更深度集成、运行更高效。
- 这项更新意在帮助开发者构建更复杂的 AI agents,充分利用 OS 自身能力 来提升用户体验。
- Microsoft Copilot 正从“回答”走向“执行”:微软在 Microsoft Copilot 的最新更新中强调,它现在更擅长把用户请求转化为具体行动。
- 这次更新的目标是提升 Copilot 在日常任务中的实用性,让它从单纯给出答案,转向直接执行操作并简化工作流。
Manus.im Discord ▷ #general (8 messages🔥):
Website Design, AI and Full-Stack Systems, Waste Credits, Admin Lockout, Manus customer service
- 有人直接吐槽自己的网站设计太烂:一位用户对自己的网站设计非常不满,原话是 “My Website design is so bullshit, made by manus”。
- 随后他们询问,要修好这套设计到底需要哪些 skills。
- 有人自荐 AI 与全栈开发服务:有成员强调自己擅长构建 AI 和 full-stack systems,专注于交付真正有价值、能提升效率的软件。
- 他们列出了一系列能力,包括 LLM integration、RAG pipelines、AI content detection、image AI、voice AI,以及基于 React、Next.js、Node.js 等技术栈的 全栈开发。
- 大家也在问 Manus 里的 waste credits 怎么处理:有成员询问所谓的 waste credits,因为在 Manus 表现很差的项目里,他们已经浪费掉了数千 credits。
- 他们提到,考虑到 Manus 的客服情况,自己预期可能会有退款,但并不清楚具体流程。
- 有人分享了被管理员权限锁死的经历:有用户讲述了自己遭遇 admin lockout、student lockout、phantom users 以及长达数周支持摩擦的经历。
- 他们甚至说自己是 “given credits I cannot access, and then they do not respond.”
- 客服问题也被反复抱怨:有成员直言 Manus 的客户服务做得并不好。
- 他们表示,自己已经拿出了系统出问题的证据,但支持团队仍在重复要求提供他们早就提交过的验证材料。
DSPy ▷ #general (7 messages):
NYC DSPy Meetup, Fireworks Kimi 2.5 error, Streaming Tutorial
- 纽约可能要搞 DSPy 线下聚会了:有成员询问,是否有可能组织一场 NYC DSPy Meetup,并表示自己很想认识城里其他正在用 DSPy 的人。
- 他们还邀请所有在 NYC 做 DSPy 项目的人直接私信联系。
- Fireworks Kimi 2.5 因 token 限制报错:有成员反馈,在初始化 LM 并接入 Fireworks Kimi 2.5 时,遇到了
litellm.exceptions.BadRequestError,错误明确写着Requests with max_tokens > 4096 must have stream=true。- 他们补充说,自己的场景里输出确实可能超过这个 token 上限,因此想知道该怎么解决。
- 也许可以靠 Streaming 解决:针对 Kimi 2.5 的报错,有成员建议先看看 DSPy 的 streaming tutorial。
- 这位建议者自己没遇到过同样问题,但直觉上认为 streaming 可能正是规避 token 限制的办法。
tinygrad (George Hotz) ▷ #general (4 messages):
Good first issue, shm_suffix
- tinygrad 出现了一个新的“good first issue”:George Hotz 在 GitHub Actions 上贴出了一个链接,称其是适合贡献者入手的 good first issue。
- 这个问题看起来与 CI 或构建系统中的 bug 有关。
- 大家在讨论
shm_suffix是否要处处补上:有成员质疑,PR 15033 是否要求每次新调用_setup_shared_mem()时,都追加shm_suffix。- 他们还提到,也许 PR 15030 可以作为避免这一麻烦的替代方案。
tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
fromthetransistor, tinygrad
- George Hotz 贴出了 fromthetransistor 仓库:George Hotz 分享了自己的仓库 fromthetransistor 以及配套网站。
- tinygrad 也被顺手提到了:George Hotz 目前也在维护 tinygrad,并顺带贴出了仓库链接。
aider (Paul Gauthier) ▷ #questions-and-tips (1 messages):
Environment Variables, aider Issue #4458
- 有用户在排查类似 aider Issue #4458 的问题:一位用户表示,自己遇到了一个与 aider Issue #4458 很像的问题,正在寻求帮助来判断可能原因和解法。
- 他们怀疑问题可能和环境变量或其他配置项有关,因为之前明明还能正常工作。
- 环境变量很可能就是根因:该用户认为,这次故障大概率与环境变量相关,并强调 之前还是正常的。
- 但他们自己也解释不清程序为什么会突然失效。
MLOps @Chipro ▷ #events (1 messages):
World Model Architectures, JEPA / V-JEPA, Dreamer, Genie, Sora
- Paper Clinic 将带大家深入 world models:这场分成两部分的 “paper clinic” 将拆解并讨论综述 “Understanding World or Predicting Future? A Comprehensive Survey of World Models”(arXiv:2411.14499)。
- 活动目标是建立一张清晰的 world model 架构地图,拆分包括 JEPA / V-JEPA、Dreamer、Genie、Sora 和 World Labs 在内的生态,并讨论 “Mirror vs. Map” 之争。
- 活动还会继续探索 AGI 前沿:该活动也会讨论 AGI research 下一步的方向,包括 spatial intelligence、causality gaps 与 social world models。
- 第二场将在 Mar 7 举办,届时会覆盖竞争格局(Sora vs. Cosmos vs. V-JEPA)以及 AGI frontier。