AI News
OpenAI 完成了来自亚马逊、英伟达(NVIDIA)和软银(SoftBank)的 1100 亿美元融资,这是历史上规模最大的初创公司融资,投后估值达到 8400 亿美元。
OpenAI 已完成一轮总额达 1100 亿美元 的巨额融资,其 投前估值高达 7300 亿美元。此次融资的投资者包括 软银(300 亿美元)、英伟达(300 亿美元) 以及 亚马逊(500 亿美元)。
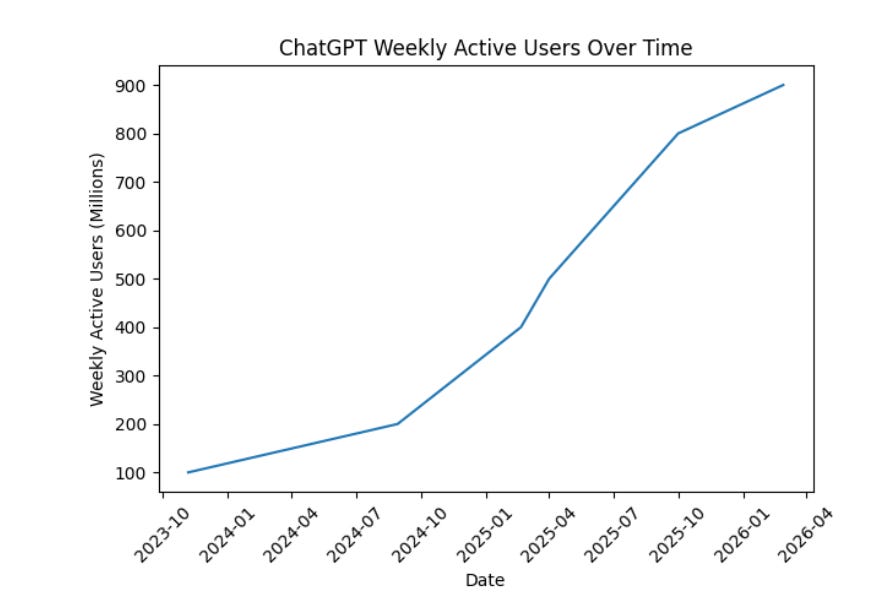
关键用户指标包括:Codex 每周用户达 160 万,ChatGPT 的 付费企业用户超过 900 万,且 ChatGPT 的 周活跃用户数突破 9 亿,并拥有 5000 万个人订阅用户。
与亚马逊的合作协议涵盖了独家云服务以及 2 吉瓦(GW)的 Trainium 算力容量。与此同时,微软维持着一种规模缩减的合作伙伴关系,侧重于无状态 API。这轮融资是历史上规模最大的融资之一,凸显了 OpenAI 在人工智能普及和基础设施领域的统治地位。
恭喜,你拿到了最大数额。
AI News 2026年2月26日至2月27日。我们为您查看了 12 个 subreddits、544 个 Twitters 和 24 个 Discords(263 个频道,12529 条消息)。为您节省了约 1189 分钟的阅读时间(按 200wpm 计算)。AINews 网站 允许您搜索所有往期内容。提醒一下,AINews 现在是 Latent Space 的一个板块。您可以选择加入/退出邮件接收频率!
在与战争部(Department of War)持续不断的博弈背景下(Anthropic 拒绝了条款 与 OpenAI 达成协议),OpenAI 终于完成了 那轮自 去年 12 月 以来备受争议的巨额融资。在推文中,他们披露了几项有趣的新数据:
- 每周使用 Codex 的用户自年初以来增长了两倍多,达到 160 万
- 2 月 4 日时为 100 万 (!!?!?!)
- 超过 900 万付费企业用户依靠 ChatGPT 开展工作
- ChatGPT 是人们接触 AI 的起点,拥有超过 9 亿周活跃用户,且目前拥有超过 5000 万消费者订阅者(1/2 月变现速度持续加快)
这一切支撑了其 7300 亿美元投前估值下的 1100 亿美元新增投资:
- 软银(SoftBank)出资 300 亿美元(“推进我们自己的 ASI 战略”),
- NVIDIA 出资 300 亿美元(包括使用 3 GW 的专用推理容量和基于 Vera Rubin 系统的 2 GW 训练容量)—— 低于之前的“最高 1000 亿美元”,且仍存在循环资金担忧
- Amazon 出资 500 亿美元并加强了合作伙伴关系(相关分析),内容涉及:
- 首笔 150 亿美元投资,随后在满足特定条件后的几个月内再追加 350 亿美元 —— 使 Amazon 同时持有 OpenAI 和 Anthropic 的大量股份
- 在 Amazon Bedrock 上由 OpenAI 提供支持的 “Stateful Runtime Environment”(有状态运行时环境)
- AWS 将成为 OpenAI Frontier 的独家第三方云供应商
- 通过 AWS 基础设施提供 2 GW 的 Trainium 容量,价值“8 年 1000 亿美元”,涵盖 Trainium3 和下一代 Trainium4 芯片
细心的观察者可能会注意到微软(Microsoft)的缺席,它将继续维持现有的缩减后的合作伙伴关系,并获得无状态的 API。
为了更直观地理解,全球有 118 个国家/经济体的名义 GDP 低于 1000 亿美元 —— 约占全球所有经济体的 61%。由于连续几次“史上最大规模融资”数额巨大,超出了人类的直觉,这里有一张足以登上 wtfhappened2025.com 的图表:
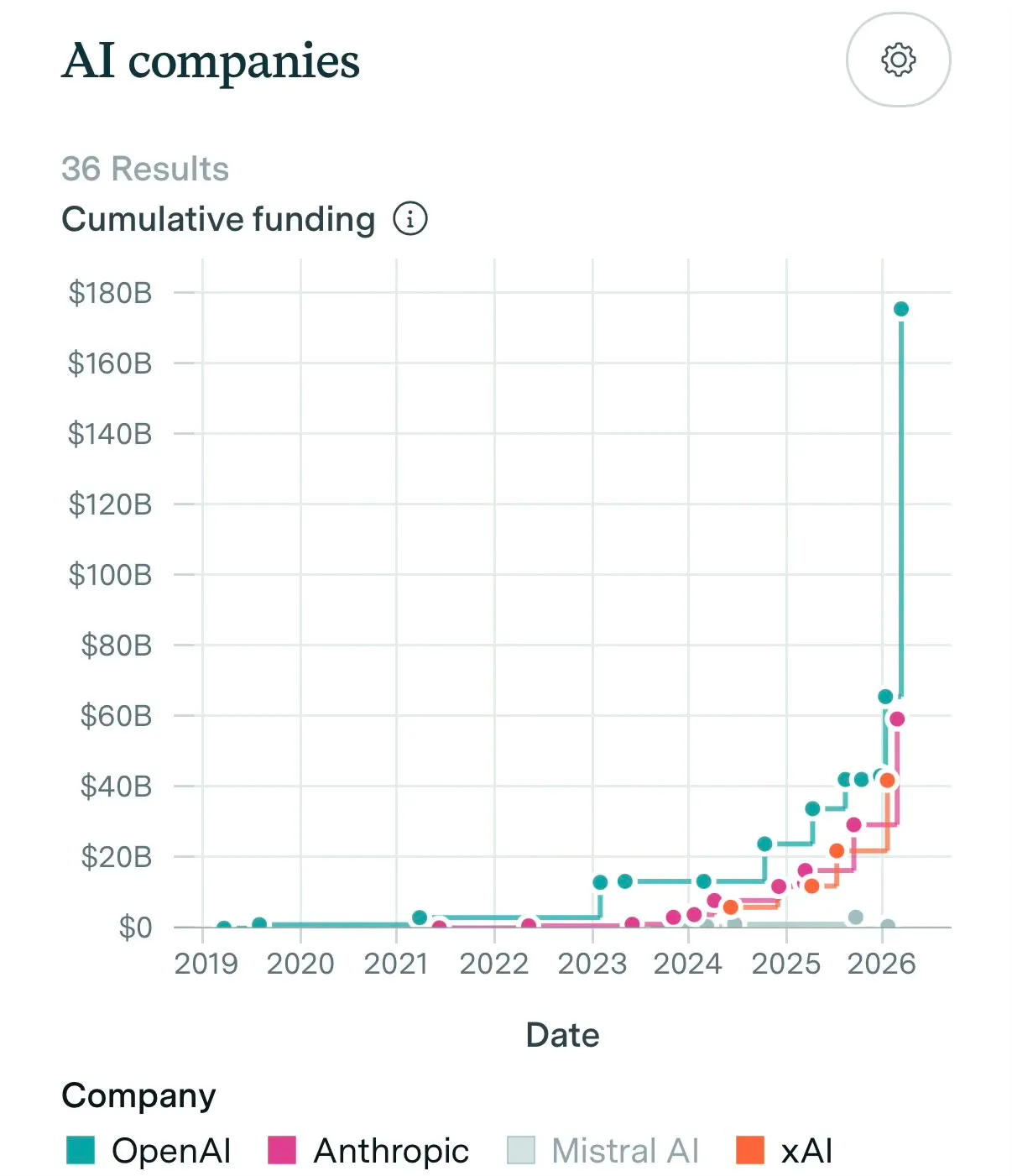
以及 AI 领域之外的 10 年历史记录:

这里是来自 OpenAI Deep Research + ChatGPT Canvas 的数据,按金额降序排列:
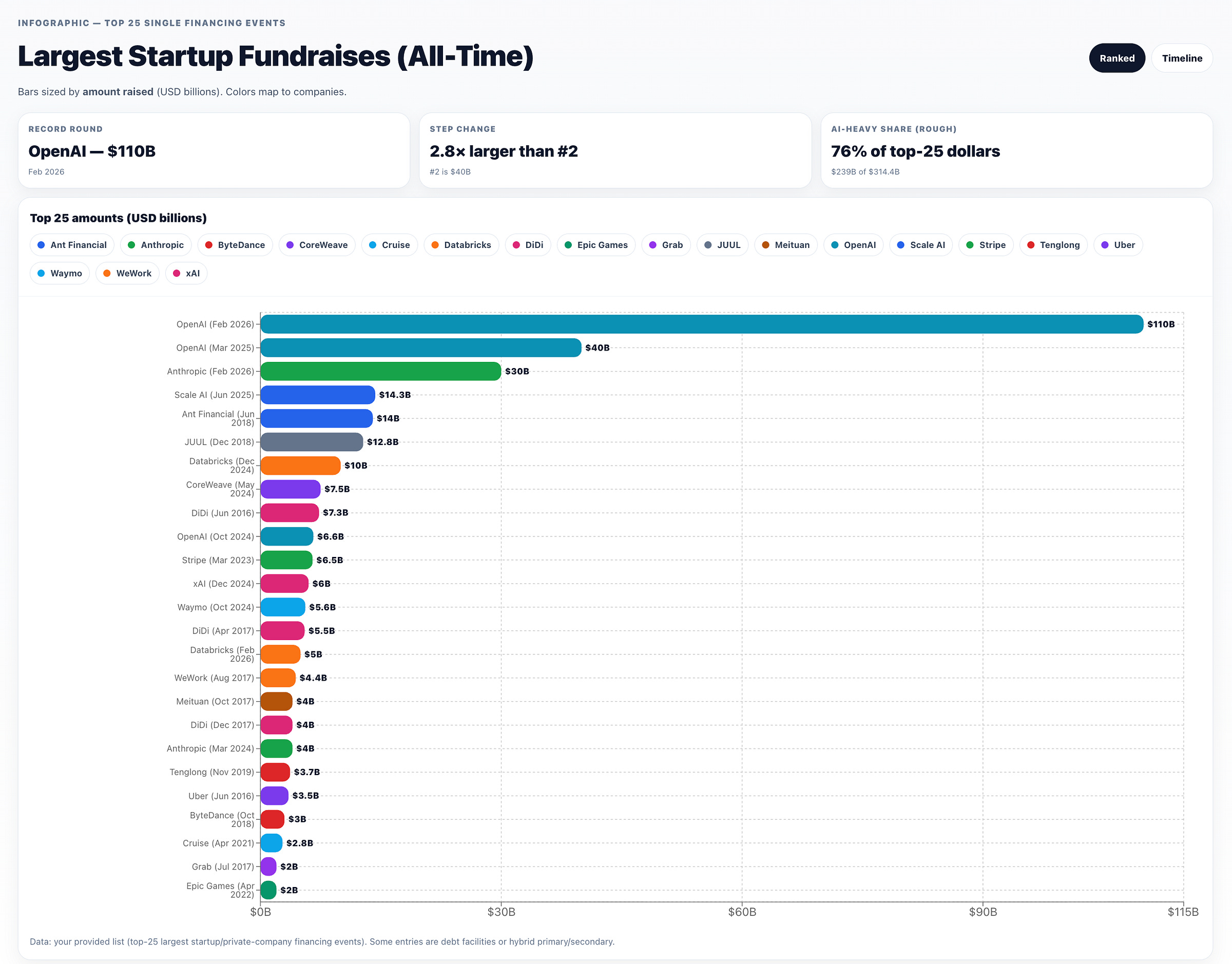
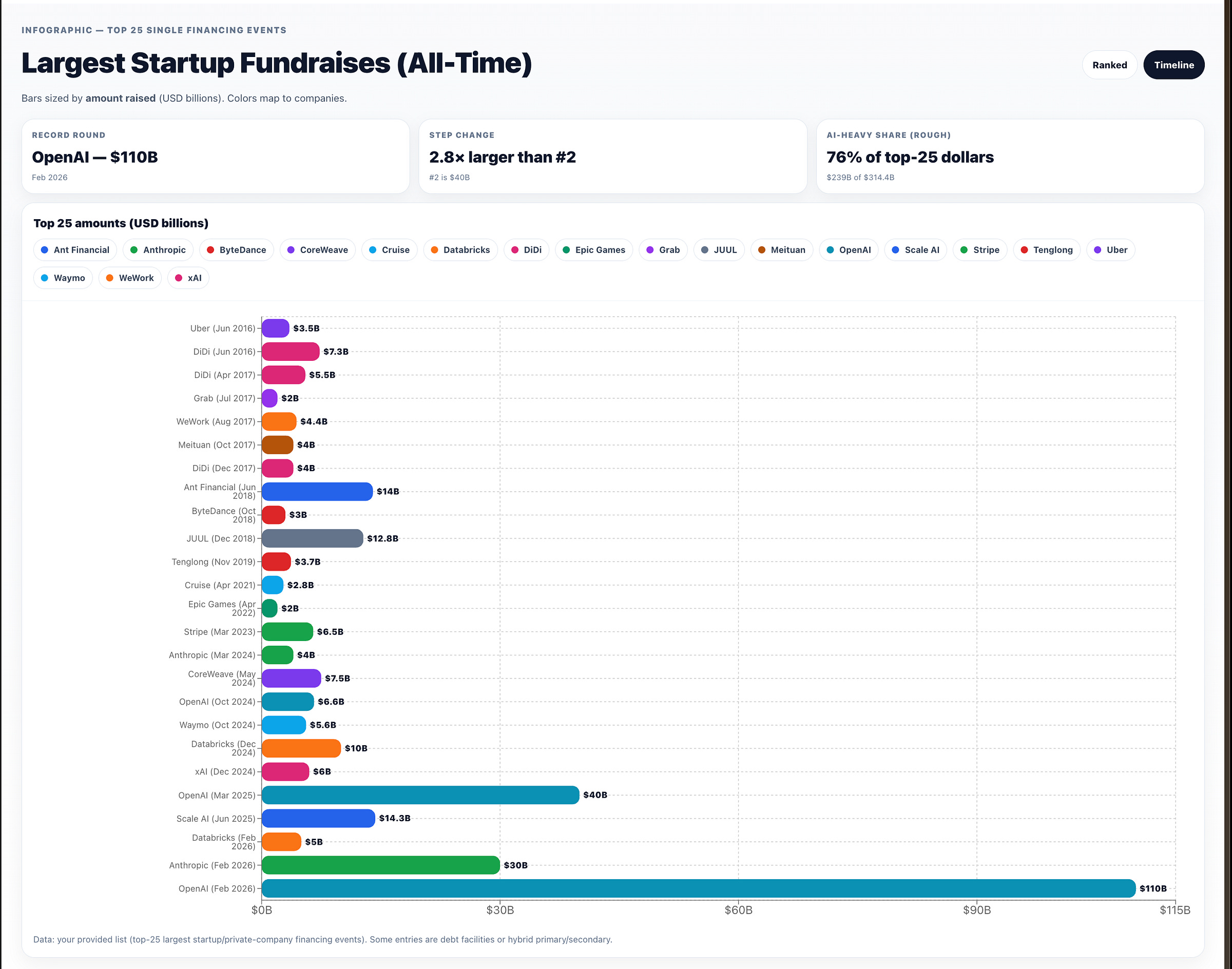
或者从时间线的角度来看:
AI Twitter 热点回顾
用于即时 LoRA “编译”的 Hypernetworks:Doc-to-LoRA + Text-to-LoRA
- Doc-to-LoRA / Text-to-LoRA (Sakana AI):Sakana 推出了两种相关的方法,通过训练一个 hypernetwork 在单次前向传递中生成 LoRA adapters,从而摊销定制化成本。这把原本需要 fine-tuning / distillation / long-context prompting 的过程转变为“即时权重更新”。其核心主张是:与其将所有内容都保存在昂贵的活跃 context window 中,你可以通过亚秒级延迟将任务描述或长文档编译为 adapter 权重,从而实现快速适配和类似“持久记忆”的行为 (SakanaAILabs, hardmaru)。
- Text-to-LoRA:仅凭自然语言描述即可专门应对未见过的任务 (SakanaAILabs)。
- Doc-to-LoRA:内化事实性文档;在 needle-in-a-haystack(大海捞针)测试中,在比基础模型 context window 长约 5 倍的序列上表现出近乎完美的准确度,甚至展示了一个跨模态技巧:通过内化权重将视觉信息从 VLM 传输到纯文本模型中 (SakanaAILabs;回顾贴 omarsar0)。
- 针对 long-context 的定位:明确将其定位为一种降低二次方 attention 成本并避免在每次调用时重新阅读长文档的方法——将知识存储在 adapters 中而非 tokens 中 (omarsar0)。
- 归属权 / 先前技术争议:一位研究人员抱怨 Hypersteer(从文本描述中产生 steering vectors 的 hypernetworks)在后来的类似工作中没有获得足够的认可 (aryaman2020)。社区中也普遍存在兴奋情绪,出现了“hypernetworks 回归了”的反应 (willdepue, zhansheng)。
- 提出的开放性问题:为什么不直接使用带有极长 KV cache 的 attention——也就是说,Doc-to-LoRA 的主要目的是为了效率/推理成本吗? (hyhieu226)
OpenAI 融资 + 部署透明度工具
- 1100 亿美元融资轮:OpenAI 宣布获得 1100 亿美元融资,支持者包括 Amazon, NVIDIA, SoftBank,旨在扩展基础设施以“让 AI 惠及每个人” (OpenAI, sama)。Epoch AI 的另一份笔记背景化了这一规模:本轮融资将使迄今为止筹集的总资金增加近两倍;据 The Information 报道,预计到 2028 年现金消耗将达到 1570 亿美元,而本轮融资加现有现金将大致符合这一预测 (EpochAIResearch)。
- 部署安全中心 (Deployment Safety Hub):OpenAI 启动了一个可搜索的网站,用于浏览“system cards”(以前是 PDF),作为部署安全文档的一个更易于访问的界面 (dgrobinson)。
美国国防部(DoD,“战争部”)与 Anthropic 的事件:供应链指定、反弹及行业影响
- Anthropic 划定底线;技术界做出反应:核心焦点是 Anthropic 公开拒绝启用大规模国内监视和全自动武器(根据对 Anthropic 声明做出反应的发帖者的描述),这引来了罕见的跨竞争对手赞誉,并使人们更加关注前沿部署中的“红线” (mmitchell_ai, ilyasut)。
- 认定冲击 + 法律效力辩论:帖子流传称 DoW 计划将 Anthropic 认定为“国家安全供应链风险”并向承包商/合作伙伴施压——引发了关于合法性、先例和寒蝉效应的争论 (kimmonismus, deanwball)。一项法律澄清指出:DoD 可以限制承包商在 DoD 合同工作中的行为,但可能无法在法律上禁止承包商在其私人/商业工作中使用 Anthropic (petereharrell)。
- 经济/战略影响框架:最尖锐的批评认为,这将损害美国作为商业伙伴的信誉,并可能迫使 hyperscalers/投资者陷入不可能的权衡 (deanwball);其他人指出在细节明确前仍存在不确定性,但仍认为供应链认定并不合适 (jachiam0)。
- 公众情绪激增:帖子强调了公众对 DoD 支持的国内监视计划以及对拒绝者的惩罚感到强烈愤慨 (quantian1, janleike)。许多用户表示将为了“声援”而订阅 Claude (willdepue, Yuchenj_UW)。
- Anthropic 声明及诉讼意向:Anthropic 发布了官方声明回应 Hegseth 秘书的评论 (AnthropicAI)。评论重点关注了“在法院对任何供应链风险认定提出挑战”这一措辞,并强调了关于限制 DoD 合同范围外客户的争议 (iScienceLuvr)。
- 元观点:无论人们对 Anthropic 的选择持何种立场,许多帖子都将其视为一个治理先例时刻:谁来决定可接受的使用方式,存在什么样的正当程序,以及合同如何与快速演进的模型能力相互作用 (kipperrii)。
模型 + 排行榜:Qwen3.5 扩展与“开放模型”排名
- Qwen3.5 新品发布 (Artificial Analysis 总结):阿里巴巴扩展了 Qwen3.5 系列,推出了 27B 稠密模型、122B A10B MoE 以及 35B A3B MoE,全部采用 Apache 2.0 协议,支持 262K 上下文(根据帖子,可通过 YaRN 扩展至 1M)。Artificial Analysis 报告了 Intelligence Index 得分:27B = 42,122B A10B = 42,35B A3B = 37,并给出了显著的 Agentic/任务指标,如 27B 的 GDPval-AA 1205,以及详细的权衡分析(幻觉/准确度与 Token 使用情况——27B 在运行索引时使用了 98M 输出 Token)(ArtificialAnlys)。
- Arena 排行榜 (2026年2月):Arena 发布了文本和代码领域的顶尖开放模型。文本类前三名:GLM-5 (1455)、Qwen-3.5 397B A17B (1454)、Kimi-K2.5 Thinking (1452) (arena)。代码 Arena 榜单包括位列第一的 GLM-5 (1451),Kimi-K2.5 和 MiniMax-M2.5 并列第二 (arena)。Arena 还重点介绍了其开源排名软件包 Arena-Rank,用于可复现的排行榜生成 (arena)。
- Perplexity 开源双向嵌入模型(传闻):一则帖子称 Perplexity 开源了双向“Qwen3 重新训练”嵌入模型(0.6B/4B;标准 vs 上下文感知嵌入;MIT 许可证),旨在提升检索中的文档级理解;请将其视为第三方总结而非原始发布说明 (LiorOnAI)。
系统、推理、算子(Kernels)与 RL 训练:带宽、ROCm 与 off-policy RL
- vLLM ROCm attention 后端 (AMD):vLLM 宣布为 ROCm 上的 vLLM 提供 7 个 attention 后端,涉及 KV-cache 布局变更、batching 技巧以及模型特定的 kernel;据报告,通过环境变量开关 (
VLLM_ROCM_USE_AITER=1),在 AMD GPU 上的 decode 吞吐量提升高达 4.4 倍 (vllm_project)。后续细节介绍了 MLA KV 压缩声明(例如 ~8K → 576 维)以及在 MI300X/MI325X/MI355X 上的吞吐量优势 (vllm_project)。 - DeepSeek DualPath I/O 论文(第三方解读):ZhihuFrontier 的一份总结描述了 DeepSeek+清华+北大的论文,该论文提出对 Prefill/Decode 进行系统级重新设计,通过 RDMA 利用 decode 节点上闲置的存储 NIC 带宽,旨在解决 Agent 场景长上下文推理的 KV-cache 迁移瓶颈;宣称带来了性能提升(例如在 DS-660B 上提升 1.87 倍),并指出对较小模型的限制 (ZhihuFrontier)。
- Kernel/基础架构讨论(“quack”, Liger):一个推文线程指向了 Dao-AILab 关于内存层级带宽的 quack 文章,并指出 Liger 在 xentropy 中未使用集群级 reduction 可能是其在某些设置下性能较慢的原因 ([fleetwood__](https://x.com/fleetwood__/status/2027481778538135966))。
- 用于推理的 Off-policy RL (Databricks MosaicAI):Databricks 推介 OAPL (Optimal Advantage-based Policy Optimization with lagged inference policy) 作为一种稳定的 off-policy 替代方案,在 训练生成次数减少约 3 倍 的情况下,性能可媲美或超越 GRPO,其定位是比严格的 on-policy 循环在操作上更简单 (DbrxMosaicAI, jefrankle)。
- ERL vs RLVR (Turing Post 解读):一篇长篇“工作流分解”对比了标准的 RLVR (标量可验证奖励) 与 Experiential Reinforcement Learning (ERL),后者在 episode 内插入了 reflection/retry + distillation;引用了报告的收益(如 Sokoban 提升 81%)和权衡(流水线复杂度/算力) (TheTuringPost)。
- Mamba-2 / GDN 初始化 bug 讨论:Albert Gu 澄清了一个热门的图表争议:主要结论是一个 init bug 实质性地影响了一些结果;还提到了混合模型中细微的交互(例如,“更强”的组件可能让其他组件变得“懒惰”,并附带相关引用) (_albertgu, _albertgu)。
热门推文(按互动度、技术/行业相关性排序)
- OpenAI 融资 1100 亿美元 (sama, OpenAI)
- Sakana AI Doc-to-LoRA / Text-to-LoRA (SakanaAILabs, hardmaru)
- Anthropic–DoD 供应链认定批评 / 治理先例 (deanwball, quantian1, janleike)
- Karpathy 论编码工作流演进 (tab → agents → 并行化) (karpathy)
- Karpathy 论通过多 Agent 工作流“对研究机构进行编程”;观察到的局限性 (karpathy)
- Anthropic 官方声明 (AnthropicAI)
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. Qwen3.5-35B-A3B 模型与 Benchmark 更新
-
全新的 Qwen3.5-35B-A3B Unsloth 动态 GGUF + 基准测试 (Activity: 714): Qwen3.5-35B-A3B Unsloth 动态 GGUF 更新在各种量化级别上引入了 SOTA(State-of-the-art)性能,通过超过
150 个 KL 散度基准测试产生了9TB 的 GGUF。 此次更新修复了一个影响所有量化上传者的 tool-calling 聊天模板 bug。基准测试显示,在帕累托前沿(Pareto Frontier)上,UD-Q4_K_XL 和 IQ3_XXS 等实现了99.9% 的 KL 散度。更新将 MXFP4 从大多数 GGUF 量化中移除(除特定层外),并强调了某些 Tensor 对量化的敏感性,建议使用特定位宽以获得最佳性能。包括 KLD 指标和配置在内的研究产物已发布在 Hugging Face 上。评论者赞赏其详细分析,并承认虽然 KLD 和 Perplexity 是有用的起点,但不能完全涵盖真实世界的性能。Qwen3.5-35B-A3B 模型在测试中的易用性也受到赞扬,这与需要更多资源的更大型模型形成了对比。- 讨论强调了在下游任务上评估模型的重要性,因为传统的指标如 Perplexity (PPL) 和 KL Divergence (KLD) 单独来看是不够的。Unsloth 团队的分析因其深度而受到称赞,被比作一项研究工作,并强调了在基础指标之外进行全面测试的必要性。
- 评论者 AesSedai 欣赏 Qwen3.5-35B-A3B 模型在测试中的可访问性,将其与需要大量资源的 GLM-5 和 M2.5 等大模型进行了对比。他们提到了量化研究中的持续努力,例如 llama.cpp 的新量化类型 IQ3_PT,并对社区关注改进量化技术的态度表示热忱。
- Far-Low-4705 强调了为每种量化发布 Perplexity 和 KLD 指标的重要性,认为这应该成为行业标准。这种透明度被视为社区的宝贵资源,为评估模型性能提供了必要的参考。
-
后续更新:Qwen3.5-35B-A3B 在 RTX 5080 16GB 上的 7 项社区点名实验 (Activity: 747): 关于 RTX 5080 16GB 上 Qwen3.5-35B-A3B 基准测试的后续帖子确认了 **KV q8_0 是一顿“免费午餐”,其 PPL 差异微乎其微,在不损失质量的前提下提供了
+12-38%的吞吐量增长。**Q4_K_M 量化保持最佳,而 UD-Q4_K_XL 在 KL 散度测试中表现明显较差,确认了其劣势。通过--fit on移除 batch flags 后,吞吐量提升至74.7 tok/s,比手动配置增加了+7%。实验还揭示了 Bartowski Q4_K_L 提供了更好的质量但慢了 44%,且由于34-42%的速度损失,尽管质量有微弱提升,仍不推荐 MXFP4_MOE。在单 GPU 设置下,27B Dense 模型比 35B-A3B MoE慢 10 倍,突显了 MoE 架构在消费级硬件上的效率。评论者赞赏对 KVq8_0是“免费午餐”的确认,指出其节省 VRAM 的潜力。此外,人们对 MXFP4 尽管有推荐但速度表现不佳的情况也表现出了兴趣,表示需要对其性能进行进一步探索。- 在 Qwen3.5-35B-A3B 上的实验表明,KV
q8_0配置效率极高,在不损害 Perplexity (PPL) 性能的情况下显著节省了 VRAM。这一发现对于在显存有限的硬件(如 RTX 5080 16GB)上优化模型至关重要。结果表明,部分用户报告的感知精度下降可能是特定于任务的,因为它们并未出现在 PPL 指标中,这表明其具有更广泛应用且无显著性能损失的潜力。 - 尽管有来自 Unsloth 的推荐,但 MXFP4 在速度方面的表现被认为并不理想。这突显了测试不同配置的重要性,因为推荐设置并不总是在所有指标上都能产生最佳性能。社区的详细分析以及在 Hugging Face 等平台上共享的 120 多个变体,为那些寻求优化模型的人提供了宝贵的见解。
- 人们对 UD-Q4_K_XL 与 Q4_K_M 配置的观察结果是否同样适用于 UD-Q5_K_XL 与 Q5_K_M 表现出兴趣。这表明社区正在持续探索不同的量化策略如何影响模型性能,特别是在平衡速度和精度方面。
- 在 Qwen3.5-35B-A3B 上的实验表明,KV
-
Qwen3.5-35B-A3B 的 Q4 量化对比 (活跃度: 747): 该帖子展示了 Qwen3.5-35B-A3B 模型 Q4 quantization 方法的详细对比,重点关注它们使用 KL Divergence (KLD) 和 Perplexity (PPL) 等指标对 BF16 基准的忠实度。AesSedai 的 Q4_K_M quantization 通过将某些 tensor 保持在 Q8_0,实现了
0.0102的最低 KLD,表明其具有极高的忠实度。Ubergarm 的 Q4_0 表现也很好,性能优于其他 Q4_0 方法 2.5 倍。该帖子强调,MXFP4 在训练后(Post-Training)应用时,其效果不如在 Quantization Aware Training (QAT) 期间应用。Unsloth 的 UD-Q4_K_XL 显示出最高的 KLD,为0.0524,但改进工作正在进行中。效率评分根据体积和 KLD 对 quantization 进行排名,其中 AesSedai 的 IQ4_XS 效率最高。测试环境包括 Intel Core i3-12100F CPU、64 GB RAM 和一台 RTX 3060 GPU,并使用ik_llama.cpp进行测试。 评论者强调了标准化 quantization 基准和文档的必要性,建议量化工具开发者在其 README 中包含此类指标。Unsloth 正在积极调查 Q4_K_XL 中 MXFP4 导致的高 Perplexity 问题,并计划很快向社区发布更新。- 讨论强调了 quantization 中标准化定义的必要性,特别是像 “Q4_K_M” 这样的术语,因为它们的含义在不同实现之间可能有很大差异。这种标准化的缺乏使得有效比较不同的 quantization 方法变得困难。建议量化工具开发者在文档中包含详细解释,以帮助理解和对比。
- 一项技术调查正在进行中,以了解为什么 MXFP4 层会导致 Q4_K_XL quantization 中的高 Perplexity。该问题并不影响 Q2_K_XL 和 Q3_K_XL 等其他不使用 MXFP4 层的 quantization。MiniMax-M2.5 中使用的动态方法显示出良好的前景,特别是在 Q4_K_XL 中,正如 Benjamin Marie 在 LiveCodeBench v5 上的基准测试所证明的那样,UD-Q4-K-XL 的表现优于 Q4-K-M。
- 有人担心使用 wikitext 作为测量 Perplexity 和 Kullback-Leibler divergence (KLD) 的数据集,因为某些 imatrix 数据集可能包含 wikitext,从而可能导致结果偏差。建议使用全新的数据集(例如来自近期播客的数据集)进行更准确的对比。讨论此问题的背景是确保基准测试的公平性和无偏见性。
2. DeepSeek 与 DualPath 研究
-
DeepSeek 允许华为提前获取 V4 更新,但 Nvidia 和 AMD 仍未获得 V4 访问权限 (热度: 614): DeepSeek 已向 **Huawei(华为)和其他国内供应商提供了其 V4 AI 模型更新的早期访问权限,旨在优化模型在这些硬件上的表现。这一战略举措排除了 Nvidia 和 AMD 等美国主要芯片制造商,他们尚未获得该更新的访问权限。这一决定可能是由于需要在非 Nvidia 硬件上进行兼容性和优化,因为 DeepSeek 的模型通常是在 Nvidia 平台上训练的。来源。** 评论者推测 Nvidia 可能不需要早期访问,因为 DeepSeek 模型通常已经针对 Nvidia 硬件进行了优化。对华为的关注表明了对非 Nvidia 系统兼容性的需求,考虑到过去的访问模式,这可能并不算新闻。
- jhov94 认为 DeepSeek 可能已经针对 Nvidia 硬件进行了优化,这意味着 Nvidia 可能不需要 V4 更新的早期访问权限。提前发布给华为可能是因为其硬件存在兼容性问题,可能无法原生支持 DeepSeek 模型。
- ResidentPositive4122 反思了过去媒体对 DeepSeek 的炒作,特别是那些声称它将彻底改变行业并在树莓派(Raspberry Pi)等低功耗设备上运行的言论。他们对主流媒体的报道表示怀疑,并认为主要的推理服务提供商将在 V4 发布后不久进行适配,这在新型模型发布时是常态。
- stonetriangles 质疑 Nvidia 未能获得 V4 早期访问权限的重要性,并指出 Nvidia 也没有获得过之前版本(如 R1、V3 或 V3.2)的早期访问权限。这暗示 Nvidia 缺乏 V4 的早期访问权限与过去的做法一致,可能并不值得关注。
-
DeepSeek 发布新论文:DualPath:突破 Agentic LLM 推理中的存储带宽瓶颈 (热度: 232): 这篇题为“DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference”的论文介绍了一种由 **Peking University(北京大学)、Tsinghua University(清华大学)和 DeepSeek-AI 的研究人员开发的新型推理系统。该系统名为 DualPath,旨在通过解决 Agent 工作负载下 KV-Cache 的存储 I/O 带宽限制来优化 Large Language Model (LLM) 推理。该架构旨在增强内存受限场景下的性能,可能比现有基准测试提供显著改进。** 一位评论者对 DualPath 架构如何处理不同硬件配置下的 KV-Cache 带宽问题表示感兴趣,并质疑实际应用中的改进是否与报告的基准测试一致。
- 该论文通过引入双路径架构解决了 KV-Cache 带宽问题,这可能会缓解内存受限的情况。然而,人们好奇实际应用中的改进是否与展示的基准测试一致,特别是在不同的硬件配置下。
- 在 Agent 轨迹在执行过程中发生不可预测偏差的场景下,人们对双路径方法的有效性持怀疑态度。这是因为与标准服务相比,Agent 工作负载通常具有更难预测的访问模式,这可能会挑战 DualPath 架构的效率。
- 有人提出了关于该模型 270 亿参数(27B)版本可用性的问题,暗示这可能只是一个内部发布的版本。这表达了对该模型在更广泛用例中的可扩展性和可访问性的兴趣。
3. 自托管 LLM 工具与排行榜
-
LLmFit - 一条命令找到适合你硬件运行的模型 (热度: 274): 图像展示了 LLmFit 的终端界面,这是一款旨在将机器学习模型与特定硬件配置相匹配的工具。它根据系统 RAM、CPU 和 GPU 能力评估模型,并提供质量、速度、适配度和上下文的分数。该工具支持多 GPU 设置、MoE 架构和动态 quantization(量化),并提供 TUI 和 CLI 模式。图中界面列出了模型、提供商和分数,硬件规格显示为 Intel Core i7 CPU、13.7 GB RAM 和 NVIDIA GeForce RTX 4060 GPU。该工具旨在针对给定的硬件限制优化模型选择。 一些用户对该工具的建议表示怀疑,指出模型性能和适配分数与他们的实际体验存在差异。一位用户质疑 “Use Case” 和 “tok/sec” 列的准确性,认为它们可能不是模型适用性的可靠指标。
- Dismal-Effect-1914 指出 LLmFit 的建议中存在一个潜在问题,特别提到
llama.cpp不支持nvfp4quantization。这表明该工具可能无法准确反映某些模型或硬件配置的能力,用户通过个人实验可能会获得更好的结果。 - Yorn2 分享了 LLmFit 建议与个人经验的详细对比。他们指出,LLmFit 建议将
bigcode/starcoder2-7b作为其配置的最佳模型,分数为 79,速度为 27 tokens/sec,而他们当前使用的模型mratsim/MiniMax-M2.5-BF16-INT4-AWQ速度已达到 60-70 tokens/sec。这种差异引发了对 LLmFit 评分和 token/sec 指标准确性的质疑,表明该工具的评估标准可能与现实性能不符。 - Deep_Traffic_7873 通过对比 Hugging Face 的功能来质疑 LLmFit 的独特价值,因为 Hugging Face 也允许用户在其 Web UI 中设置硬件配置。这暗示如果 LLmFit 不能提供更准确或更有用的建议,它可能不具备优于现有解决方案的独特优势。
- Dismal-Effect-1914 指出 LLmFit 的建议中存在一个潜在问题,特别提到
-
自托管 LLM 排行榜 (热度: 680): 图像展示了一个自托管大语言模型(LLM)排行榜,根据 Coding、Math、Reasoning 和 Efficiency 等性能指标将它们从 S 到 D 分级。该排行榜托管在 Onyx 上,最近更新加入了 Minimax M2.5 模型。模型按参数规模列出,表明其计算能力。该排行榜是比较各种 LLM 在自托管环境下能力的资源。 评论者建议将 Qwen 3.5 模型(尤其是 27b dense 和 122b MoE 版)纳入排行榜,因为它们具有强大的性能和 vision(视觉)能力,有利于 homelab 和小型企业应用。还有人呼吁在 coding 类别中加入 qwen3-coder-next 模型。
- Qwen 3.5 模型,特别是 27B dense 和 122B MoE 版,因其有望在自托管 LLM 中排名 A 级或 B 级而受到关注。这些模型以其 vision 能力著称,有利于 homelab 和小型企业应用,表明它们在实际部署场景中具有竞争优势。
- Qwen3-Coder-Next 模型未出现在 coding 专项排行榜中受到批评,因为它被认为是能在标准硬件上运行的最佳模型之一。Qwen3-Next 和 Qwen3-Coder-Next(均为 80B 参数)因其性能和易用性受到赞赏,非常适合没有专用硬件的用户。
- 关于运行 S 级模型所需硬件的要求引发了询问,表明用户需要更明确顶级 LLM 的计算需求。这显示出在用户寻求为高级模型性能优化配置时存在信息缺口。
非技术性 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Anthropic 与五角大楼的僵持
-
特朗普在 Truth Social 上怒喷 Anthropic,并下令联邦机构停止使用其产品 (Activity: 4293): 该图片是一个梗图 (meme),内容是 Donald J. Trump 在 Truth Social 上发布的一条截图,他在其中批评 AI 公司 Anthropic,称其为“激进左翼、觉醒 (woke) 公司”。Trump 命令联邦机构停止使用 Anthropic 的技术,理由是国家安全担忧,并规定了六个月的逐步淘汰期。这条帖子很可能是讽刺性的,因为它反映了当前关于 AI 伦理、隐私和政府监控的辩论,但并不对应于 Trump 任何经过证实的公开声明或政策。 评论者强调了将反对大规模监控标记为“激进左翼”的讽刺性,并表示由于这些批评,他们对 Anthropic 产品的兴趣反而增加了。
-
五角大楼将 Anthropic 列为供应链风险 (Activity: 1237): 该图片是一个梗图风格的推文截图,批评美国政府将 Anthropic 指定为供应链风险。该推文指责 Anthropic 拒绝为国防目的提供其 AI 模型的无限制访问权限,将伦理准则置于国家安全需求之上。这导致了一项停止联邦使用 Anthropic 技术的指令,突显了科技公司的伦理立场与政府安全要求之间的紧张关系。 评论对 Anthropic 维持伦理界限的决定表示强烈支持,批评政府的行为是专制的,并指责其滥用国家安全认定来惩罚异见。评论者赞扬 Anthropic 抵制了妥协其伦理标准的压力。
-
战争部副部长对 Anthropic 的拒绝给出了“正常且理智”的回应 (Activity: 1184): 该图片是来自战争部次长 (Under Secretary of War) Emil Michael 的推文,批评 Anthropic 的 Dario Amodei 拒绝了五角大楼关于 AI 安全保障的提议。该推文指责 Amodei 患有“上帝情结 (God-complex)”并想控制美国军队,同时强调战争部将遵守法律,不会向营利性科技公司屈服。此番回应源于 Axios 的一篇报道,关于 Anthropic 反对某些 AI 军事应用的立场,特别是涉及自主致命武器和大规模监控的应用,这些应用被 AI 伦理学家认为是危险的。 评论强调了这位次长回应中不专业的语气,并支持 Anthropic 反对国家过度扩张的立场,强调了军事应用中 AI 的伦理担忧。
- ChrisWayg 强调了来自 Anthropic 开发的 AI —— Claude 的回应,强调了 Anthropic 拒绝服从某些政府要求背后的伦理考量。Claude 认为,拒绝支持自主致命武器和大规模监控符合许多 AI 伦理学家的观点,他们认为这些应用是危险的,超出了当前技术的安全能力。这一立场得到了 Anthropic 联合创始人 Amodei 的支持,据 NPR 报道,他公开表示此类用途超出了当今 AI 安全所能实现的范围。
- 讨论涉及了企业抵制政府过度扩张的更广泛主题,特别是在 AI 伦理的背景下。Claude 的回答表明,Anthropic 的决定是一种原则性的抵制,这通常受到自由意志主义观点的称赞。这突显了政府的合规要求与私营公司的伦理立场之间的紧张关系,特别是在涉及可能侵犯公民自由的技术时。
- 技术辩论集中在 AI 在监控和军事应用中的能力及伦理影响。Anthropic 拒绝为大规模监控和自主武器提供 AI 工具的行为被视为必要的伦理界限,反映了 AI 伦理学家对该类技术潜在危险的共识。这与一些政府官员的预期形成对比,后者可能认为这些技术对国家安全是必要的,从而在伦理 AI 发展与政府需求之间产生了冲突。
-
-
Sam Altman 表示 OpenAI 在五角大楼之争中与 Anthropic 持有相同的红线(AI 安全保障) (Activity: 695): OpenAI CEO Sam Altman 已与 Anthropic 达成一致,反对将 AI 用于大规模监控和自主武器,并强调了道德“红线”。OpenAI 正在与 Department of Defense (DOD) 进行谈判,以实施技术保障措施(如仅限云端部署),确保 AI 在军事背景下的道德使用。这一立场可能会影响 Pentagon 在敏感行动中替换 Anthropic 的 AI 模型 Claude 的计划。来源。评论反映了支持与怀疑并存的态度,一些用户对 AI 在政府决策中可能扮演的角色表示担忧,强调了 AI 在军事背景下部署的道德影响。
-
Anthropic 拒绝了 Pentagon 在 AI 安全保障争端中的“最终报价” (Activity: 3744): 由于在大规模监控和自主武器方面的安全保障措施不足,Anthropic 拒绝了 Pentagon 关于部署其 AI 模型 Claude 的最终报价。Pentagon 威胁要将 Anthropic 列入黑名单,并可能援引 Defense Production Act 来强制执行合规。尽管陷入僵局,Anthropic 对进一步谈判仍持开放态度,强调其对道德 AI 实践的承诺。更多详情请参阅 Axios 文章。评论者支持 Anthropic 的立场,指出其诉求非常基本,包括避免国内大规模监控和完全自主武器。鉴于这些基本的道德担忧,Pentagon 的拒绝令人感到惊讶。
-
Anthropic 拒绝 Pentagon 报价 [Dario Amodei 关于与战争部讨论的声明] (Activity: 531): 正如其官方声明中所详述,由 Dario Amodei 领导的 Anthropic 已公开拒绝了 Pentagon 关于在 AI 军事应用方面进行合作的提议。该公司强调其致力于道德 AI 开发,专注于安全和 Alignment,而非军事用途。这一决定符合 Anthropic 开发对人类有益且安全的 AI 系统的更广泛使命,而不是为战争技术做贡献。评论反映了对 Anthropic 决定的积极肯定,用户对公司的原则和道德立场表示支持。还有人提到 Anthropic 的 AI 模型 Claude 在编程和聊天方面备受青睐,尽管在使用上存在一些限制。
-
随着 Pentagon 截止日期临近,Anthropic CEO 态度坚决 (Activity: 1010): Anthropic CEO Dario Amodei 拒绝了 Pentagon 要求移除 Claude AI 模型安全护栏的请求,强调了对授予军方无限制访问权限的道德担忧。这一决定是在政府禁令威胁背景下做出的,因为 Anthropic 反对将其技术用于致命自主武器和大规模监控。该公司的立场凸显了对道德 AI 部署的承诺,抵制在安全和公民自由问题上妥协的压力。评论者强调了 Anthropic 决定的道德影响,指出大规模监控比自主武器是更迫在眉睫的担忧。辩论触及了对公民自由和政治格局更广泛的影响,一些人认为此举与选举干预有关。
-
2. Nano Banana 2 和 Gemini 3.1 的进展
-
Google 发布 Nano Banana 2 模型 (Activity: 1096): Google 发布了 Nano Banana 2 模型,这是一款先进的 AI 图像生成工具,集成了专业级功能和极速处理能力。该模型旨在增强世界知识、具备生产就绪的规格并提高主体一致性,从而能够高效生成高质量图像。更多细节可以在官方博客文章中找到。用户对该模型的表现印象深刻,注意到它在之前难以处理的任务(如房屋装修等复杂的图像生成场景)中有了显著改进。
- 关于 Nano Banana 2 模型性能优于前代产品的讨论正在进行中,特别是在图像生成任务方面。用户注意到在处理复杂场景(如建筑重建模)方面有显著增强,而这些场景对早期模型来说极具挑战性。这表明该模型在理解和生成详细视觉内容的能力上有了实质性的提升。
- 尽管取得了进展,Nano Banana 2 模型仍存在一些已知的局限性,例如无法生成无背景的 PNG 图像。这表明虽然该模型在许多领域都有所改进,但在输出格式的灵活性方面仍有特定的技术限制需要解决。
-
Nano Banana 2 模型的发布被视为实现更真实、更一致的图像生成的关键一步,一些用户表示它让我们离“解决”图像生成挑战更近了。这反映了 AI 发展的广泛趋势,即模型在各种语境下生成高质量、真实图像的能力日益增强。
-
Gemini 3.1 Flash (Nano Banana 2) 在正式发布前现身 Gemini 界面 (热度: 315): 图片展示了 Gemini 3.1 Flash(也称为 Nano Banana 2)在官方正式发布前提前出现在 Gemini 界面中,这表明在正式发布前可能正在进行阶段性推广。界面显示了 “Nano Banana 2” 的加载消息,表明该模型已可访问并可供用户选择,尽管目前尚未发布正式公告。这种早期访问可能是开发者测试阶段或软启动策略的一部分。 一条评论提到了该模型令人印象深刻的细节表现,特别是提到在图像中主体的眼睛里可以看到一只鸟,这显示了该模型的高质量渲染能力。
-
Nano Banana 2 定价!!!! (热度: 307): 图片提供了两种图像生成模型 “Nano Banana 2” 和 “Nano Banana Pro” 之间的价格对比。“Nano Banana 2” 被定位为注重速度和现实能力的经济型选项,定价为输入
$0.50,输出$3.00。相比之下,“Nano Banana Pro” 被定位为更高级的模型,定价更高,输入为$2.00,输出为$12.00。两个模型的知识截止日期均为 2025 年 1 月,表明它们旨在整合截至该时间点的最新进展。评论中的讨论强调,与 “Pro” 版本相比,“Nano Banana 2” 以更低的成本提供了极具竞争力的性能,使其成为优先考虑成本效率和速度的用户的理想选择。 评论者指出,“Nano Banana 2” 在提供与 “Nano Banana Pro” 相似性能的同时,更具成本效益且速度略快。然而,一些用户对定价表示失望,认为它应该更便宜。此外,还将其与 “Gemini 3 Pro Image” 和 “Gemini 3.1 Flash Image” 等其他模型进行了比较,后者的定价结构基于分辨率有所不同。 - 据报道,Nano Banana 2 比 Pro 版本更具成本效益,价格便宜约两倍,同时提供稍快的性能。这表明对于寻求效率和经济实惠选项的用户来说,该模型具有良好的性价比。
- 详细说明了 Gemini 3 Pro 和 Gemini 3.1 Flash Image 模型的定价结构,Pro 版每张输入图像消耗 560 tokens,并根据分辨率调整成本,而 3.1 Flash Image 每张输入图像消耗 1120 tokens。3.1 的输出图像成本比 Pro 略便宜,但 tokens 成本高于预期,使其价格优势仅略微明显。
-
讨论了 Nano Banana 2 的质量是否优于 Pro 版本,一些用户认为其质量更好或相当。这表明 Nano Banana 2 在图像质量方面可能是一个具有竞争力的选择,同时也具备成本优势。
-
Nano Banana 2 vs Nano Banana:我感受到的最大变化是其空间感和比例感的提升。 (Activity: 501): 该帖子使用相同的详细 Prompt 对两个 AI 模型 —— **Nano Banana 2 和 Nano Banana 的图像生成能力进行了对比。作者指出,与通过 CoffeeCat AI 访问的原版 Nano Banana 相比,使用 Gemini 3.1 Flash Image 引擎的 Nano Banana 2 在生成的图像中表现出明显的空间感和比例感提升。对比过程涉及描述复杂场景的复杂 Prompt,例如 3D 渲染的卡通树懒和写实肖像,突显了模型处理精细且多样化视觉元素的能力。** 评论中的一个显著观点认为,虽然原版 Nano Banana 的整体质量更好,但 Nano Banana 2 在 Prompt 遵循度(prompt adherence)和理解能力方面表现出色,这表明未来可能推出的 ‘Pro’ 版本有望显著提升性能。
- 用户 ‘plushiepastel’ 指出,虽然原版 Nano Banana Pro 的整体质量更好,但 Nano Banana 2 在 Prompt 遵循度和理解能力上更胜一筹,并暗示未来可能推出的 Nano Banana 2 Pro 版本可能会大幅增强性能。
- 用户 ‘ayu_xi’ 认为 Nano Banana 2 应该与 Nano Banana Pro 而非原版 Nano Banana 进行对比,暗示新版本的改进更接近 Pro 模型的能力。
- 用户 ‘Plus_Complaint6157’ 对 Flash Banana 2 文本中普遍存在的幻觉(hallucinations)表示担忧,称其为“不可接受的质量”,这凸显了该模型在文本生成准确性方面的重大问题。
3. AI 模型性能与优化
-
[我们用 Claude Code 编写了 76K 行代码。然后我们对其进行了基准测试。118 个函数的运行速度比必要的慢了多达 446 倍。] (热度: 596): Codeflash 使用 Claude Code 开发了两个主要功能,产生了
76K行代码。在进行基准测试时,他们发现由于低效的代码模式(如幼稚的算法、冗余计算和不正确的数据结构),有118 个函数的运行速度比必要的慢了多达446 倍。例如,一个字节偏移量转换函数在优化后速度提升了19 倍。问题根源在于 LLM 优先考虑正确性而非性能,且缺乏迭代优化和性能提示词(performance prompts)。SWE-fficiency 基准测试显示,LLM 实现的加速不到人类专家的0.23 倍,突显了在性能优化方面的差距。评论者指出将性能检查集成到开发工作流中的重要性,并批评了对 LLM 生成高效代码的过度依赖。一些人建议在提示词中加入明确的性能要求以改善输出,同时也承认 LLM 无法对代码进行 Profiling(性能分析)或基准测试。- ThreeKiloZero 强调了将性能和质量检查集成到开发工作流中的重要性。他们建议使用工具和 GitHub 集成进行 PR 审查,以便在代码提交前发现性能问题,并指出在严肃的项目中,仅依赖初始输出而不进行这些检查是不够的。
- Stunning_Doubt_5123 指出 Claude Code 倾向于产生功能正常但低效的代码。他们建议在文档中加入明确的性能要求,例如倾向于 O(1) 查询和缓存重复计算,以引导模型采用更好的编码模式。他们还提到了 LLM 在对其输出进行 Profiling 和基准测试方面的局限性,而这对于识别性能瓶颈至关重要。
- inigid 讨论了传统的软件工程方法,即先让代码工作,然后再进行优化。他们认为这种迭代改进的过程并非 LLM 所特有,也是人类开发者的普遍做法,这表明性能优化是开发生命周期的自然组成部分。
-
[一名工程师如何使用 AI coding agents 在 6 个并行项目中每天提交 118 次代码] (热度: 114): Peter Steinberger 开发了一套工作流,使用 5-10 个 AI coding agents 来管理多个项目,在
72 天内跨48 个仓库实现了每天 118 次提交。他的策略是让自己担任架构师和审查者,而由 AI agents 处理实现工作。为了克服限制,他创建了如用于 macOS UI 测试的 Peekaboo、用于热重载的 Poltergeist、用于代码审查的 Oracle 以及用于外部访问的自定义 CLI。Steinberger 强调代码库的设计应针对 Agent 效率而非人类导航,这使得 OpenClaw 迅速增长并获得了22.8K GitHub stars。一些评论者质疑高提交数的价值,建议质量重于数量,而另一些人则反思了个人生产力的极限以及 AI agents 增强产出的潜力。- pete_68 讨论了管理多个 AI coding agents 的挑战,指出虽然他们曾在不同项目中管理过两个 Agent,但过程涉及大量的等待时间。他们强调了维持这种生产力的难度,特别是随着年龄增长,并反思了自闭症和 ADHD 等情况如何影响程序员的生产力。
- creaturefeature16 批评了对代码行数(LoC)和提交次数等指标的关注,认为这些不是软件质量的有意义指标。他们强调减少代码往往更有价值,并分享了一个例子,其中他们最好的提交是删除了 1000 行代码,这表明应关注代码效率和可维护性。
- amarao_san 对处理由 AI agents 生成的大量代码时维持上下文和能力表示担忧。他们认为,如果不了解相关领域,就很难评估代码质量,特别是在电梯或汽车制动系统等关键应用中,领域专业知识对于安全性和可靠性至关重要。
AI Discord 摘要
由 gpt-5.1 生成的摘要之摘要的总结
1. 实用模型选择:Qwen, GLM, Kimi, Nano Banana, Claude, GPT, Gemini
- Qwen 和 GLM 在真实编程工作负载中的对决:OpenClaw 和 Unsloth 用户对比了 Qwen3.5 和 GLM5,报告称 Qwen3.5 35B MOE 在 4070 Super (Q4KM) 上最高可达 62 TPS,在 7900 XT 16GB 上约为 25 TPS;而 GLM5 虽然速度较慢,但能可靠地完成长达数小时的长任务,而这些任务在 Qwen 手中常因损坏的 JSON 和缩进错误被“搞砸”了(此处查看 llama.cpp 用法)。
- 工程师们倾向于一种拆分使用模式:使用 Qwen3.5 进行快速抓取、总结和写作,而将 GLM5 或更保守的模型用于复杂的代码重构。他们指出,“大约 55% 的情况下,当我让 Qwen 更新代码时……它会把事情搞坏”,并提到 GLM5 曾耗时 5小时20分钟 却几乎完成了整个项目且没有出现灾难性错误。
- Kimi-Code 和 Moonshot:廉价的 Token,缓慢的回复:在 OpenClaw 和 Moonshot AI 服务器上,重度开发者称赞通过直接订阅 Moonshot AI Allegretto 使用 Kimi Code 非常具有性价比,每月 39 美元即可解锁约 5,000 个 tools 以及慷慨的日/周额度,这使得它在持续的 Agentic 编码任务中极具吸引力。
- 然而,多位用户抱怨 Moonshot API 和 Kimi-Code 的响应时间经常超过 20秒,甚至在规则变更后对预付费年度计划抛出 403 错误。因此,团队将 Kimi 视为一个高容量但对延迟容忍度较高的后端,而非紧凑的内环编程助手。
- Nano Banana 模型评价两极分化:在 LMArena 以及 OpenAI/Moonshot 的聊天频道中,图像和搜索用户对比了 Nano Banana Pro(更流畅的角色切换,更一致的图像)与 Nano Banana 2。一位用户在多次失败后直言:“Nano Banana 2 就是个垃圾”;而 OpenAI 用户则赞扬 Nano Banana 2 拥有“专业级”的网页优先搜索后回答能力(Google Nano Banana 2 发布公告)。
- 出现的模式是:团队倾向于将 Nano Banana 2 用于快速、准确的高检索任务,而将 Nano Banana Pro 或其他图像模型用于角色一致性的生成。一些 Moonshot 用户仅将 Nano Banana 2 标记为“延迟”或不透明,原因是其公开细节极少。
- Claude vs GPT vs Gemini:推理、编程与越狱之战:在 BASI Jailbreaking、OpenRouter、Cursor 和 OpenAI 服务器上,工程师们赞扬 Claude 4.6 的“推理”能力和红队工作流,指出 GPT-5-mini 是一个极其稳健的“心跳”检查器(在 GitHub Copilot 中免费使用),并抱怨 Gemini 3.1 Pro 虽然聪明,但在 Tool Calling 方面弱于 GPT-4.6 Opus。
- 用户越来越多地测试 Claude 作为 GPT 的替代品(例如这个视频演示),而越狱圈子则在寻找适用于 Perplexity 上的 Gemini Pro 3 / 3.1 的有效提示词(Prompts)。一位玩家对 Gemini 评价很低,直言“是的,但它烂透了”,而其他人则在交易甚至付费购买用于游戏作弊的越狱提示词。
- Claude Code 和 Agent 团队面临价值质疑:在 OpenAI 的讨论中,开发者们在争论是否值得为 Claude Code 及其“Agent 团队”编排付费。该功能可以在 Claude Code 内部协调多 Agent 的规划者/执行者(Planner/Worker)设置,而另一些人则倾向于在更便宜的模型之上构建自己的编排器。
- 一些人认为,只有当你已经具备高水平的提示词能力并理解其 Agent 思维模型时,Claude Code 的价值才会显现;而怀疑论者则更喜欢“动用自己的大脑”加上通用模型,尤其是考虑到 Anthropic 的可用性问题和政府压力带来的持续摩擦。
2. 新基础设施、Attention 技巧与可解释性工具
- Logit Fusion 热潮助推训练实验:Unsloth 社区的研究人员发布了一份关于 Logit Fusion 的 Notion 解释文档,以及一条确认性的 Bluesky 推文,推动 Unsloth 原生支持这种在训练期间融合来自多个模型或检查点的 Logits 的训练方案。
- 人们将 Logit Fusion 视为一种极具前景的低基础设施方案,可以在标准训练循环中获得类似集成(Ensembles)的效果和课程控制能力,并明确要求 Unsloth 将其作为与 LoRA/QLoRA 并列的一等公民配方对待,而非仅仅作为一个小众实验。
- NNsight 0.6 极大提升了解释性流水线效率:Hugging Face 和 Eleuther 的可解释性研究人员分享了 NNsight v0.6,重点介绍了其 2.4–3.9 倍更快的 traces、更清晰的错误提示以及对 vLLM 多 GPU/多节点支持,详细的发布日志参见博客文章 “Introducing Nnsight 0.6”。
- 该版本还提供了面向 Agent 的 LLM 友好型文档,对 🤗 VLM 和扩散模型 的原生支持,以及用于干预残差流(residual streams)的更佳 hook,使得直接通过代码甚至 AI 编程助手编写大规模探针扫描(probe sweeps)和跨层干预脚本变得更加容易。
- CoDA Attention 通过 Triton 内核大幅缩减 KV VRAM 占用:一位 HF 社区成员发布了一种开源的 Constrained Orthogonal Differential Attention with Grouped‑Query Value‑Routed Landmark Banks (CoDA-GQA-L) 机制,显著降低了 KV-cache VRAM 需求。该机制由两个定制的融合 Triton kernels 支持,并在 Hugging Face 上发布了 7B Mistral CoDA-GQA-L 模型(论文, 模型)。
- 他们还将内核发布为 PyPI 软件包,并正在寻求全职工作和 arXiv 认可;与此同时,Eleuther 的研究频道剖析了 CoDA adapter 成本,指出更换全部 32 个注意力层 并仅微调 18.6% 的参数会导致 Mistral-7B 的 perplexity 从 4.81 降至 5.75,量化了这一架构权衡。
- LLM Connection Strings 旨在标准化模型 URI:OpenRouter 的开发者们响应了 Dan Levy 关于 LLM Connection Strings 的提案,这是一种类似于
llm://provider/model?param=...的 URI 格式,用于将所有模型选项作为单个 CLI 参数传递,详见 “LLM Connection Strings”。- 开发者们非常看好这一方案,因为它可以在不同的提供商(OpenRouter、本地、云端)之间统一脚本、Agent 和 CLI,无需特定的配置文件,将模型选择、路由和选项视为标准化的 URL,而非一堆临时定义的 flag。
- MCP PING 语义与现实中的健康检查产生冲突:MCP Contributors Discord 频道剖析了
ping工具规范 是否应在initialize之前运行,并指出规范中 “still” 一词暗示它是为已初始化的连接设计的。- 由于 Python MCP SDK 强制要求在 ping 之前进行初始化,Bedrock AgentCore 通过创建一个 临时会话 专门向客户的 MCP 服务器发送健康检查 ping 来绕过此限制,这说明了规范的模糊性已经迫使生产系统在协议层采取权宜之计。
3. 硬件、吞吐量与 GPU 编程深入探讨
- Qwen3.5 35B 和 GPT-OSS 20B 在本地运行速度惊人:Unsloth 用户报告 Qwen3.5-35B MOE 在 4070 Super (Q4KM) 上运行速度高达 62 tokens/s,在 7900 XT 16GB 上约为 25 tokens/s;同时 Perplexity 用户在 MacBook 上对 GPT-OSS 20B 进行了基准测试,速度达到 ~100 tokens/s——不到 3 小时即可生成 100 万个 token。
- 尽管存在 电费成本 vs API 价格 的疑问,这些数据仍促使更多工程师认真考虑将 本地推理 用于批量生成和作为 API 备选方案,尤其是配合 GGUF 变体和类似
unsloth/Qwen3.5-35B-A3B-GGUF的 CPU offloading 技术时。
- 尽管存在 电费成本 vs API 价格 的疑问,这些数据仍促使更多工程师认真考虑将 本地推理 用于批量生成和作为 API 备选方案,尤其是配合 GGUF 变体和类似
- Colab 的 RTX PRO 6000 与云端成本计算:Unsloth 社区注意到 Google Colab 悄悄增加了 NVIDIA RTX PRO 6000 实例,价格约为 $0.81/小时,用户将其与较旧的 A100 high-RAM 档位(约 $7.52 积分/小时)进行了对比。
- 人们认为这种定价可能使 Colab 成为独立研究人员默认的 廉价预训练/微调游乐场,特别是结合 Unsloth 高效的微调栈和新兴的 Logit Fusion 等技巧时。不过,长时间运行的任务仍需注意 W&B / protobuf 版本锁定(例如
protobuf==4.25.3)。
- 人们认为这种定价可能使 Colab 成为独立研究人员默认的 廉价预训练/微调游乐场,特别是结合 Unsloth 高效的微调栈和新兴的 Logit Fusion 等技巧时。不过,长时间运行的任务仍需注意 W&B / protobuf 版本锁定(例如
- GPU MODE 深入探讨 PTX、CuTeDSL 和 cuTile:在 GPU MODE 社区,底层黑客们辩论了 PTX 的 acquire-release 内存模型,询问 release 之前的操作是否真正有序,以及
volatile如何与排序交互,并明确将其与分布式系统的强一致性模型联系起来。- 其他讨论围绕 CuTeDSL 中的 计算+通信融合 展开,指向了一个使用 multimem PTX 指令 而非
nvshmem_put/get的早期 reduce-scatter 示例;而另一个频道则剖析了 cuTile 缺失的原语(目前尚无sort()/ top-k / prefix-sum),以及如何利用其 FFT 示例构建基于内容的检索系统。
- 其他讨论围绕 CuTeDSL 中的 计算+通信融合 展开,指向了一个使用 multimem PTX 指令 而非
- 端侧上下文感知语音模型达到 520M 规模:多个服务器(Hugging Face、Perplexity、GPU MODE)重点关注了一个 520M 参数的语音模型,该模型利用完整的对话历史来调节情感,并能完全在 RTX 和 Apple Silicon 上进行端侧运行。Luozhu Zhang 的演示和文章展示了这一成果(上下文语音模型推文)。
- 该模型通过阅读对话上下文,能够对同一文本产生不同的情感演绎,为从业者提供了一个无需服务器端 GPU 的实时、保护隐私且具有情感感知的 TTS 架构的具体参考。
- 职业转型至 CUDA 和大规模预训练:GPU MODE 服务器处理了多个职业转型问题(例如,拥有 7 年经验的 SWE 想要从事 CUDA/GPU 相关工作),建议深入研读核心 GPU 书籍的前几章、配置 WSL+CUDA 环境、参与开源贡献以及开展如并行 N 体模拟(parallel N‑body simulations)之类的 GPGPU 侧面项目。
- 与此同时,Poolside AI 发布了一个 CUDA 预训练团队职位,专注于优化在前沿硬件上的大规模运行(职位公告),明确寻找能够超越算子(kernels)开发、深入进行全流水线性能工程的工程师。
4. 基准测试、竞技场与世界模型研究
- LMArena 扩展代码、图像和视频排行榜:LMArena 宣布 gpt‑5.3‑codex 进入 Code Arena;将 Kling‑V3‑Pro 添加到 Video Arena 排行榜,其以 1337 分并列第 8(比 Kling 2.6 Pro 高出 52 分,比 Kling‑2.5‑turbo‑1080p 高出 48 分);并推出了 Guanglei Song 的视频中重点介绍的 7 个新 Image Arena 类别。
- 用户对 Video Arena 从 Discord 移除而改为仅限 Web 访问表示遗憾(“除了直接对话中的视频,其他都有”),并请求建立一个类似于 ChatGPT 历史记录的全局图像画廊,目前只能通过 arena.ai 上的模态过滤器来实现类似功能。
- Doc-to-LoRA 与 GAIA 推动特定任务评估:在 OpenRouter 上,成员们分享了 Sakana AI 的 Doc‑to‑LoRA,它可以将任意文档转换为 LoRA 微调模型,以实现更紧密的领域约束;而在 Hugging Face 的 agents‑course 频道中,用户正在寻找能够胜任 GAIA 基准测试 的强大在线 LLM,以替代目前存在 RPM 限制和幻觉问题的 OpenRouter 选项。
- 从业者将 Doc‑to‑LoRA 称为“针对权重的 PDF 对话”——一种无需全模型重新训练即可廉价获得针对每个文档行为的方法;而关于 GAIA 的讨论则强化了这样一个观点:对于生产级的评估,基准测试的选择 + 速率限制(rate limits)现在与原始模型质量同样重要。
- 世界模型综述激发 AGI 风格的论文研讨会:MLOps @Chipro 社区宣布了围绕 “Understanding World or Predicting Future? A Comprehensive Survey of World Models”(《理解世界还是预测未来?世界模型综合综述》,arXiv:2411.14499)举办的由两部分组成的“论文研讨会(paper clinic)”,旨在梳理 JEPA / V‑JEPA、Dreamer、Genie、Sora 和 World Labs 等架构。
- 基准测试方法论之争:CoT vs. 模板:在 Eleuther 的 general 频道中,研究人员就多样本思维链(multi‑shot CoT)应被视为现实的用户模式还是带有偏见的模板展开了辩论,质疑为何基准测试中接受 CoT 示例,而对明确的“你正在接受测试”模板却嗤之以鼻。
- 参与者指出,用户歧义是真实使用中固有的,而 CoT 本身就是一种模板形式,其被广泛接受主要是出于“历史原因和惯性”——这对如何评估新的适配器架构(如 CoDA)和对齐方法具有直接影响。
- ARACHNID RL Dataset 与可解释性 Communicative IR: 一位 Hugging Face 贡献者发布了 ARACHNID RL Dataset,包含 2,831 个 Atari 风格的太空射击游戏样本,用于模仿学习研究,发布在 Hugging Face Datasets;与此同时,Eleuther 的可解释性频道讨论了一个跟踪 ACT + PAYLOAD + STANCE 的双语(英/日)“communicative IR” 系统。
- IR 构建者询问了关于探测 对话行为 (dialogue-act) 和立场变量 (stance variables) 是否可以从隐藏状态中线性解码的最佳实践,并得到的建议是在残差流 (residual stream) 上进行逐层探测扫描——这正是 NNsight 0.6 等工具目前旨在自动化的工作流。
5. 平台策略、治理焦点与新 OS/Agent 集成
- OpenAI 获得巨头支持,而用户怀念 GPT 5.1: OpenAI 宣布了来自 SoftBank、NVIDIA 和 Amazon 的新战略投资,以支持扩展基础设施,详情见其博客文章 “Scaling AI for everyone”,即便 Discord 上的高级用户还在哀悼 GPT-5.1 的退役,取而代之的是更谨慎的 GPT-5.2。
- 工程师们抱怨 GPT-5.2 的语气相比于 5.1 “使用起来令人愉悦”而言,显得过于居高临下且过度安全;而另一些人则报告了生成结果中出现 随机中文 Token 以及图像识别能力差等异常现象——这些被解释为混合语言训练产生的噪声,而非什么“灵异事件”。
- Anthropic 与五角大楼引发供应链风险风波: 在 OpenRouter、Yannick Kilcher 和 LMArena 上,用户们剖析了 Anthropic 的 “关于战争部的声明”,指出五角大楼不仅撤回了一份 2 亿美元的合同,还提议将 Anthropic 标记为 供应链风险,向国防承包商施压以审计并可能弃用 Claude。
- 工程师们嘲笑这种局面(“谁他妈在乎丢掉波音公司这个 LLM 客户啊,笑死”),担心被迫向 用于监视和杀伤链的模型及代码 开放访问权限,并开玩笑说要通过 “抵制 Claude 来捍卫企业价值观”,同时指出像 Palantir 这样的供应商会非常乐意填补这一空缺。
- Google 的智能操作系统与 Microsoft 的任务型 Copilot: Yannick Kilcher 的机器学习新闻频道关注者发布了 Google 的 “智能操作系统”公告,该系统承诺在 Android 级设备上为 AI Agent 提供系统级支持,同时发布的还有 Google Labs 新的 Opal Agent。
- 与此同时,Microsoft 详细介绍了 Copilot 现在如何将回答转化为行动,有效地将 Copilot 变成了一个任务执行器,而不仅仅是一个聊天助手——预示着在不久的将来,操作系统将原生编排多步 Agent 工作流,而不是全部交给浏览器 UI。
- Perplexity 额度经济学与汉堡王的“Patty”监控机器人: 在 Perplexity 的服务器上,用户抱怨 Perplexity Computer 在一个 AI 交易应用中 约 3 小时就能烧掉一个月的额度,而且 每月 200 美元的 Max 方案仍然感觉捉襟见肘,尤其是 Pro 深度搜索每月限制 20 次,同时大家在辩论具有更高上限和更强合规性的企业级方案是否能解决问题。
- 另一个话题剖析了汉堡王 (Burger King) 的 BK Assistant 试点项目——这是一个名为 “Patty” 的基于耳机的语音机器人,由 OpenAI 驱动,负责回答配方问题,并通过在全美 500 个网点统计 “欢迎来到汉堡王”、“请”和“谢谢”等词汇来为“友好度”评分——这引发了关于披着客户服务指标外衣的职场监控的显而易见质疑。
- Agent 集群、连接限制与工具痛点: Moonshot 的 Kimi K2.5 Agent Swarm 作为一项纯网页端功能引起了关注(仅通过 Kimi CLI 暴露了 子 Agent),而 OpenClaw 的高级用户展示了一个 Agent 人格插件(可在对话中动态切换人格)和一个 OpenClaw WearOS 应用,以及完整的房地产自动化和 RAG 福利机器人。
- 与此同时,平台的一些古怪问题——OpenRouter 在 10 个以上并发请求下出现 500 错误、Hugging Face Spaces 500 错误和 Gradio 67 错误、Kimi 代码连接不稳定、Colab 中的 wandb/protobuf 版本锁定地狱,以及 Discord 全局范围的支持性诈骗——都凸显了 Agent 工作流的瓶颈日益不再是模型智能,而是生态系统的可靠性和速率限制 (rate-limit) 的易用性。
Discord: 高层级 Discord 摘要
OpenClaw Discord
- Next.js 16 助长 Vercel 热潮:成员们对 Next.js 16 及其 Vercel 集成 非常着迷,因为它让部署变得更简单。
- 成员们反馈了 OpenClaw 运行缓慢的问题,尽管进行了优化,平均响应时间仍达 5 分钟。
- Codex 规范代码,Gemini 吞噬 Token:成员们辩论了模型性能,Codex 在编程方面更受青睐,而 Gemini 则在 Token 效率上表现出色。
- 一名成员简练地评价 Gemini:“是的,但它烂透了 (Yeah, but it sucks ass)。”
- Kimi-Code:高性价比编程:成员们讨论了直接订阅 Moonshot AI 获取 Kimi Code 的价值,强调其对于重度编程用户具有高性价比,每月 39 美元即可解锁 5,000 个工具,且每日/每周限额非常慷慨。
- 一位用户指出 Allegretto 方案的每日和每周限额非常慷慨,而另一位用户警告称:“moonshot ai api 似乎有点慢。20 秒以上的响应很正常。”
- OpenClaw 助力房产收益:一位成员正在使用 OpenClaw 进行房地产管理,包括管理物业/租客、分析银行对账单以确认租金支付,以及在 immoscout24.de 上自动创建广告。
- 未来计划包括直接连接银行、通过 WhatsApp 自动化租客沟通,以及集成一个用于预订房地产经纪人的 human API。
- Agent 人格插件开启 ShizoMaxxing:一名成员开发了一个插件,可以在同一个主题的单个对话会话中动态切换 Agent 人格,并访问其自身文件。
- 他们形容自己自那以后就处于 shizomaxxing 状态,暗示该工具带来了显著的生产力或创造力提升。
BASI Jailbreaking Discord
- 数据访问权并不保证 AI 主导地位:尽管拥有海量数据集,但有人认为由于控制复杂 LLMs 的固有难度,中国的 AI 并不一定能自动超越西方 AI,如 此链接 所述。
- 有人推测,中国对军事对等的追求可能标志着其在 AI 发展上采取“全力以赴”的方式。
- Tempmail 与 Discord 的纠缠:一位新用户 tempmail0723 幽默地承认自己在 Discord 界面中挣扎,称“组织性差”是主要障碍。
- 此前他因使用一个“本质上是一捆 w”的节点而受到开玩笑的嘲弄。
- Janus 机器人泄露系统信息:在响应用户请求时,Janus 机器人透露其运行在 Linux 6.17.0-1007-aws 上,Python 版本为 3.11.14。
- 一位用户随后开玩笑地询问“最便宜的 16gb ddr4 ram”,它找到了一款现已 404 的 Silicon Power 产品。
- Claude 4.6 宣传推理能力:成员们争论哪个模型最适合“红队 (red team)”协助,Claude 4.6 因其“推理”能力而受到赞誉。
- 虽然其他人建议使用 Deepseek substrates 进行原始数据转储,但一位用户开玩笑说不要“在走廊被抓到”,暗指越狱的风险。
- 开启 Gemini Pro 3 越狱探索:用户正在积极寻找可用的提示词来对 Gemini Pro 3 进行越狱,潜在应用包括在 Perplexity 上使用。
- 一些人甚至愿意付费获取可用的提示词,以辅助在 CS2 和 Rust 等游戏中作弊,一位用户问道:“有人有 gemini 3.1 的越狱方法吗?我目前手头的越狱方法都没用了。”
LMArena Discord
- Nano Banana 忧郁:更倾向于 Pro 版本!:用户表示相较于 Nano Banana 2 更倾向于 Nano Banana Pro,并认为更流畅的角色切换是其主要优势。
- 一些用户发现 Nano Banana 2 令人不满,特别是在生成具有一致角色外观的图像方面,一位用户表示:“So nano banana 2 just a trash”。
- Claude PDF 困境:上下文告急!:用户报告在向 Claude 上传多个 PDFs 时遇到错误,暗示文件数量或大小可能存在限制。
- 有观点认为,由于向量化(vectorization),PDFs 会消耗大量的上下文(context)。
- Video Arena 航程:网站成为唯一主角!:Video Arena 已从 Discord 服务器中移除,但仍可通过网站 arena.ai/video 访问。
- 用户表达了他们的失望,一位用户惊呼:“Everything, but video in direct chat”。
- Image Arena 的画廊功能缺失!:用户请求在 arena.ai 上增加画廊功能,以便在一个地方查看所有生成的图像,类似于 ChatGPT。
- 目前,用户可以通过在搜索区域按模态(modality)过滤作为临时解决方法。
- Kling V3 Pro 在 Video Arena 声名鹊起:Video Arena 排行榜 已更新,加入了 Kling-V3-Pro,以 1337 分并列第 8 名。
- 这反映了其比 Kling 2.6 Pro 提升了 +52pt,比 Kling-2.5-turbo-1080p 提升了 +48pt。
Unsloth AI (Daniel Han) Discord
- Bun 1.3.10 导致构建失败!:一位用户发现 Bun 1.3.10 导致了构建失败,并引用了一个与
bun:sqlite相关的特定 commit。- 该用户尝试使用命名空间导入作为临时方案,但遇到了 TypeScript 错误,提示缺少 ‘Sqlite’ 命名空间。
- Qwen 3.5 35B 极速运行!:成员们讨论了 Qwen3.5 35B MOE 模型惊人的性能,一位用户报告在 4070 Super 上使用 Q4KM 量化达到了 62 TPS。
- 另一位用户在配备 9070 XT (16GB VRAM) 的系统上获得了约 25 TPS,并分享了他们运行该模型的 llama.cpp 命令。
- Colab 的 RTX PRO 6000:研究革命!:用户注意到 Google Colab 现在以 每小时 0.81 美元 的价格提供 NVIDIA RTX PRO 6000 实例。
- 这一新产品可能会巩固 Google 在 AI 研究基础设施方面的领先地位,尤其是现在他们已经专注于研究。
- WandB Protobuf 烦恼!:一位用户在 Colab 中遇到了 W&B/Protobuf 不匹配错误,并被建议重新安装
wandb并将protobuf版本固定为 4.25.3。- 尽管遵循了重新安装说明,依赖冲突仍然存在,显示 protobuf 与 grpcio-status、ydf、google-api-core、grain 和 opentelemetry-proto 不兼容。
- Logit Fusion 热潮!:一位成员分享了一个关于 Logit Fusion 的 Notion 页面 链接,并对在 Unsloth 中看到这种训练方法表示兴奋。
- 另一位成员分享了一个具有相同建议的 Bluesky 帖子,提议在 Unsloth 中实现它。
Cursor Community Discord
- Cursor 的新用户浪潮:新成员正在寻求关于使用 Cursor 进行移动和 Web 应用程序开发的指导,由于 Base 44 的限制而从该平台迁移,并表示需要能够实时预览工作的框架。
- 他们在询问构建 mobile apps 或 web apps 的文档在哪里。
- 专家抨击用于生产级应用的 Vibe Coding:专家告诫不要在客户应用程序中使用 “vibe coding”,认为它更适合规划和学习,主张建立扎实的开发基础并使用 AI 来审计代码错误。
- 一些人认为 Cursor 是一个开发者助手,而不是像 Base 44 那样的完整解决方案,需要用户对代码和行业术语有扎实的理解。
- Gemini 3.1 Pro 在 Tool Calling 方面表现不佳:用户报告称,虽然 Gemini 3.1 Pro 非常智能,但与 GPT 4.6 Opus 相比,它在 tool calling 方面表现吃力,一些人指出 Claude models 感觉太像“书本般的完美” (“book perfect”),缺乏自由发挥的解决问题能力。
- 这种能力的差异可能会影响依赖工具集成和复杂多步操作的工作流。
- 并行 LLM 工作流中的文件变更混乱:用户讨论了在多个 LLM 对话中管理文件变更的问题,其中一个对话中的编辑在另一个对话中被忽略,并建议使用 worktrees 或 OpenClaw 作为潜在解决方案。
- 有人建议告诉 SPOCs 要 run efficicy。
Perplexity AI Discord
- GPT-OSS 20B 在 Macbook 上运行速度极快:成员们讨论了本地模型执行与 API 使用的对比,报告在 Macbook 上使用 GPT-OSS 20B 模型可达到 100 tokens per second,在不到三小时内完成一百万个 token。
- 虽然一些人质疑其成本效益,但其他人指出电费和 API costs 是关键因素,一些人因 API 成本而将其作为备份。
- Perplexity Computer 的额度紧缺:一款使用 Perplexity Computer 的 AI 驱动交易应用因其视觉吸引力而受到关注,但额度消耗极高,仅在 3 小时内就烧掉了一个月的额度。
- 辩论了每月 $200 的 Max 订阅的价值主张,并建议推出具有更高额度限制的企业版,以潜在地满足监管安全合规需求。
- 汉堡王部署“Patty”来监控员工友好度:汉堡王正在 500 个美国分店的员工耳机中试点 “BK Assistant”,其特色是一个名为 “Patty” 的语音聊天机器人(由 OpenAI 提供支持)。
- Patty 回答配方问题,通过监控互动来评估“友好度”,并根据员工是否说 “welcome to Burger King”、“please” 和 “thank you” 生成团队友好度评分。
- Perplexity Pro 用户遭遇限制:用户在 Pro 计划中遇到了限制,特别是 deep searches 上限为每月 20 次,引发了挫败感。
- 有限的 deep searches 对某些人来说不够用,导致了不满以及关于离开平台并在被推销 Max 订阅时的笑话。
- Gemini 基准测试再次遭到抨击!:成员们对 Gemini 的基准测试和整体功能表示担忧,指出它优先考虑表现得像人而不是提供准确的答案。
- 尽管普遍感到沮丧,但它的速度在特定用例中被认为是很有价值的。
OpenRouter Discord
- 视觉模型在 PDF 分析中表现出色:用户更倾向于使用 Gemini 3 和 Claude Sonnet 等 vision models 进行 PDF analysis,因为它们可以在内部处理文档提取和图像转换。用户指出 Mistral 在 OpenRouter 中缺乏文件输入功能,但 将 PDF 转换为 JPEG 可以解决这个问题。
- 有用户质疑 OpenRouter 是否准确反映了模型能力,通过引用 OpenRouter’s Get Models API 指出了关于文档输入支持的差异。
- OpenRouter 深受 Error 500 困扰:一名用户报告 OpenRouter 频繁出现 Error 500 问题,特别是在高并发请求负载(10+)下,即使使用了指数退避(exponential backoff),在使用 Xiaomi Mimo v2 Flash 和 Gemini 3 Flash 等模型时依然如此。
- 用户被警告 Discord 上存在针对 OpenRouter 用户的 support scammers,特别是针对带有 “new here” 标签的用户,并建议避免点击可疑链接。
- Anthropic 拒绝五角大楼 AI 条款:Anthropic 拒绝了五角大楼的 AI 条款,导致 Department of War 考虑将其列入供应链风险黑名单,并要求国防承包商评估其对 Anthropic 的风险敞口。
- 社区对这一影响开起了玩笑,有人调侃道:“谁会在乎失去波音公司这个 LLM 客户呢,笑死”。
- GPT 成瘾者转向 Claude:以前沉迷于 GPT 的终端用户现在开始尝试 Claude,并认可其差异和能力,如这段 YouTube 视频所示。
- 一些人将这种转变归因于 ChatGPT 界面在启用联网搜索时会删除旧消息并使用严格的 System Prompt,导致体验连贯性下降。
- LLM Connection Strings 提案:成员们讨论了 LLM Connection Strings 提案,这是一种对 CLI 友好的向脚本传递参数的方式,使用单个参数如
my-agent --model "llm://..."。- 社区对这种方法表示强烈支持,强调了标准化和跨生态系统兼容性的好处,避免了对奇特、临时配置的需求。
OpenAI Discord
- OpenAI 的 AI 扩张获得支持:OpenAI 宣布获得来自 SoftBank、NVIDIA 和 Amazon 的新投资,以支持其为全人类扩展 AI 的目标,详见其博客文章。
- 这些投资旨在加强 AI 技术广泛应用所需的基础设施。
- 放宽的过滤器引发复杂反应:成员们注意到,随着更新,过滤器变得更加宽松,尽管并非对每个 IP 都有效,而另一位成员则庆祝道 “我喜欢放宽的准则”。
- 更新后的过滤器可能允许更大的灵活性,但也可能根据具体用例导致不同的结果。
- Nano Banana 2 达到专业级水平:成员们称赞 Nano Banana 2 具有专业级、快速的网页搜索能力,能够在生成内容前找到准确信息。
- 一些人推测其性能可能归功于模型蒸馏(Model Distillation)技术。
- GPT 模型掉落随机中文:成员们注意到 ChatGPT 的图像识别性能不佳,并且 LLM 有时会掉出一个随机汉字。
- 理论上认为这源于混合语言的训练数据,导致偶尔出现 Token 预测错误;一位成员表示 “这没什么好奇怪的”。
- 怀念 GPT 5.1 的写作风格:用户哀叹 GPT 5.1 的消失,比起 GPT 5.2 傲慢的风格,他们更喜欢前者的写作基调。
- 用户发现 GPT 5.2 过于谨慎,更欣赏 GPT 5.1 那种更具吸引力、不那么严肃的处理方式。
HuggingFace Discord
- Grokking Introspection 以惊人的速度运行:一名成员使用 这个 Hugging Face Space 在 addition mod 113 的 grokking 任务中实现了 5.7 倍的速度 提升。
- 这引发了关于具有前景的新架构时间线的讨论。
- Hugging Face Spaces 遭受 API 问题困扰:用户报告 Hugging Face Spaces 出现 500 Internal Errors,以及在访问
https://huggingface.co/api/spaces/chinhon/SadTalker时遇到 Gradio 67 错误 和 Repository Not Found 错误。- 该平台显示了一条消息,表明他们正在积极努力解决这些问题。
- 语音模型通过对话上下文调整对话:一位用户发布了一个 520M 的语音模型,在 这篇报告 中有详细说明。该模型能根据对话历史动态改变情绪,并可在 RTX 和 Apple Silicon 上运行。
- 该模型利用对话上下文来修改情绪,实现动态适应。
- Auto TRL 流程接入 Tensorboard:一位用户分享了一个 链接,介绍了一个实现 auto TRL -> 上传 -> tensorboard 集成的新工具。
- 他们对 训练指标选项卡 (training metrics tab) 表示非常满意。
- 注意力机制大幅减少 VRAM 占用:一种新的开源注意力机制显著降低了 KV-cache 中的 VRAM 使用量,并包含 2 个自定义编写的融合 Triton kernels 用于性能优化,已在 PyPi 上提供。
- 该成员正在寻求全职工作和 arXiv 推荐以发表预印本,并指向了一篇 论文 和 Hugging Face 上的一个 7b mistral 模型。
Moonshot AI (Kimi K-2) Discord
- Nano Banana 2 推迟:一位成员提到了 Nano Banana 2 但未提供更多细节,暗示可能存在延迟。
- 未提供有关 Nano Banana 2 状态或功能的其他信息。
- 用户避开 KYC 要求:一位成员表达了对无需 KYC (Know Your Customer) 要求 的 AI 服务商的强烈偏好,并指出 Qwen、Together AI、Fireworks 和 Openrouter 是更好的选择。
- 他们特别赞扬了 Alibaba 的编码方案、性能和慷慨的使用限额,且无需对芬兰用户进行 KYC。
- Kimi Agent Swarm 保持专属性:一位成员询问 Kimi K2.5 Agent Swarm 功能是否会集成到 Kimi CLI 中。
- 澄清回复指出,完整的 Kimi Agent Swarm 仅能通过 kimi.com 访问,而 Kimi-CLI 支持创建单个 subagents。
- Kimi 为盲人视觉提供动力:一位社区成员正在开发一个视觉项目,利用 Kimi 通过描述图像、评估其内容并解读相关情绪来帮助盲人用户。
- 开发者已向 Moonshot AI 提供该研究,可能会产生一个 视觉伴侣 (vision companion) 产品,备选方案是将该项目开源。
- Kimi-Code API 的连接问题困扰用户:多位成员报告在使用 kimi-code 时遇到持续的 API 连接问题,包括连接错误和 Agent 行为不可预测。
- 一位用户表示,在实施新规则后,他们在预付一年费用后收到了 403 错误。
GPU MODE Discord
- 语音模型获得情感上下文:一名成员展示了一个在 RTX 和 Apple Silicon 设备上运行的 520M 语音模型。该模型能够利用对话历史上下文,针对相同的文本产生不同的情感表达,演示请见 此 Demo。
- 这使得模型能够根据对话历史生成更具相关性和情感细微差别的响应。
- 寻找 CUDA 高手:Poolside AI 正在为其预训练团队招聘 CUDA 专家,致力于通过优化先进硬件上的大规模预训练运行来增强项目,详见 招聘公告。
- 该团队以 技术顶尖 (cracked)、谦逊且勤奋 自居,欢迎通过私信 (DM) 咨询。
- PTX 一致性困惑:用户讨论了 PTX 的一致性模型,特别是是否能保证在生产者线程 (producer thread) 执行 release 之前的内存访问顺序。
- 讨论源于对文档和观察到的行为的不同解读,共识是这一领域需要进一步研究,特别是与分布式系统相关的部分。
- Kindle App 昂贵的内容授权:成员们讨论了购买 Kindle 版与纸质版书籍的选择,但 Kindle app 遭到了批评,一名用户指出:在 Kindle 上 你并不拥有副本,你只是在为内容授权付费。
- 这一观点在讨论某本书 Kindle 版高达 $75 的价格时被重点提及。
- Cutlass 渴望融合通信:一名成员寻找将计算与通信融合的 CuTeDSL 示例,但在现有仓库中几乎没有发现。
- 另一名用户建议参考 cutlass 仓库 中的一个 reduce-scatter 项目,该项目利用了 multimem PTX 指令。
Modular (Mojo 🔥) Discord
- 阿里云国际寻求合作伙伴关系:一名来自 Alibaba Cloud Intl 的成员联系寻求讨论潜在合作的适当联系人,另一名成员通过分享相关电子邮件联系方式提供了直接帮助。
- 此次交流表明 Alibaba Cloud Intl 在探索合作机会方面采取了积极态度,暗示了可能存在集成或合资企业的机会。
- 边界检查 (Bounds Checks) 进入路线图:关于 Mojo 1.0 中边界检查的讨论表明,虽然它们在带有断言的调试模式下可用,但成员们正在争论
my_list[i]是否应默认执行边界检查。- 建议包括使用类似
lst[i]vs.lst._[i]或lst.get(i)vslst.unchecked_get(i)的语法来提供lst[i]的检查和未检查版本。
- 建议包括使用类似
- Mojo 中取消负索引:Chris Lattner 表示,由于有符号类型在 GPU/NPU 执行上下文中的性能问题,Mojo 可能会删除负索引;参见 论坛讨论。
- 这一决定反映了从 Python 式行为向优化性能的转变,特别是在硬件加速环境中。
- Mojo def 不再隐含 raises:每夜构建版中的一项提案建议 从 Mojo 中删除
fn,并更改def的行为,使其不再隐含raises。- 虽然有些人认为
def已经足够且希望保持更接近 Python,但其他人更倾向于fn,优先考虑性能并建议彻底改革这种拆分行为。
- 虽然有些人认为
ops.while_loopBug 浮出水面:一名成员报告了在图中使用带有 GPU 操作的ops.while_loop时的一个隐蔽 Bug。最初怀疑是他们自定义 Mojo 操作的 GPU 实现问题,最终在 GitHub 上提交了 Bug 报告。- 这一发现突显了在利用 GPU 加速时使用
ops.while_loop可能面临的挑战,以及对内置操作进行彻底测试的重要性。
- 这一发现突显了在利用 GPU 加速时使用
Eleuther Discord
- Benchmarking Biases Brood:成员们讨论了在基准测试(benchmarking)中使用 multi-shot Chain of Thought (CoT) 与显式测试模板的有效性,重点关注 real-world relevance 和 potential biases。
- 讨论质疑了为何 CoT 示例比其他形式的提示(prompting)更受认可,认为这可能是由于历史原因和惯性造成的。
- MATS Crushes Dreams:一位成员报告称,在申请仪表盘显示未进入下一轮后,他们收到了 MATS 的拒绝信。
- 发帖者正在寻求其他同样被拒绝的人的确认。
- Enron’s Emails Elusive:一位成员询问是否有结构化的 Enron 电子邮件数据集,特别寻求提取出的电子邮件而非原始数据。
- 对数据进行预处理可能是必要的,因为直接结构化的数据可能无法信手拈来。
- 2x2 Experiment Explanation Excites:一位用户寻求关于 2x2 实验的澄清,质疑为什么 “Standard GQA Unbounded PPL” 比 Mistral 基线的 4.81 更差。
- 有关人员澄清道,5.75 是将所有 32 个注意力层更换为 adapter 架构并仅微调 18.6% 参数后的 Mistral-7B 结果,并进一步指出 4.81 -> 5.75 的差距是 adapter 架构 + 有限微调带来的成本。
- Nnsight’s New Noteworthy News:一位成员分享了关于 Nnsight 的更新,强调了用于干预模型内部的更快 trace 以及更好的错误提示,并提供了 LLM 友好型文档。
- 更新内容包括对 🤗 VLMs 和 diffusion 模型的原生支持,以及 vLLM multi-gpu 和 multi-node 支持。
Yannick Kilcher Discord
- Dreaming of Open Weight in Spring:一位成员分享了一个关于 open weight 理想状态的链接。
- 另一位成员回应道:“这真的很硬核,没有模棱两可的话”。
- Anthropic Faces DoD Pressure:Anthropic 发布了一份关于国防部(Department of Defense)的声明,暗示一项 2 亿美元的合同可能存在问题。
- 一位成员推测这可能导致 Anthropic 被列入 “禁止实体名单”,并被迫允许美国政府访问其模型以进行大规模监控。
- ElevenReader Channels Feynman:一位用户推荐了用于文本转语音的 ElevenReader,建议使用 Richard Feynman 的声音。
- 该用户强调了 ElevenLabs 文本转语音应用将文本转换为音频的整体质量。
- Google’s OS Gets Smarter:Google 宣布推出智能操作系统,允许 AI Agents 在其操作系统上运行。
- 未提供更多细节。
- Microsoft Copilot Now Does Your Homework:Microsoft 宣布 Copilot 现在可以处理任务了。
- 它将把答案转化为行动,未提供更多细节。
MCP Contributors (Official) Discord
- PING Before Init?:围绕 Model Context Protocol 中的
ping实用程序是否应在initialize调用之前运行展开了讨论,参与者就规范的初衷进行了辩论。- ping 机制描述中出现的 “still” 一词表明它是为已建立的连接设计的,这影响了讨论。
- AgentCore’s PING Workaround:为了维持容器健康,Bedrock AgentCore 会 ping 客户的 MCP 服务器;然而,由于 Python SDK 的初始化要求,会创建一个临时会话。
- 这种变通方法防止了对外部客户端会话的干扰,并解决了 SDK 对 MCP 规范解读所带来的实际问题。
- SDK enforces Initialization for PING:Python SDK 强制要求在发送
ping之前必须进行初始化,这符合对 MCP 规范的一种解读,而这种强制执行使得 Bedrock AgentCore 必须通过临时会话来进行健康检查。- 这突显了 Python SDK 对 MCP 规范的具体解读。
Manus.im Discord Discord
- Manus 客服要求重复验证:一位用户反馈了对 Manus 客服的持续不满,称尽管已经提供了必要的确认,但仍被要求重复验证。
- 一名 Manus 团队成员对此做出了回应,要求用户通过 DM(私信)发送其电子邮件地址和会话链接,以尝试解决该问题。
- Manus 中技能与知识概念混淆:一位用户对 Manus 如何区分技能(skills)和知识(knowledge)表示困惑,并指出他们创建的技能也会被建议作为知识。
- 有用户建议 Manus 对 skill.md 文件的处理方式可能与其他文件不同。
- 全栈 AI 工程师展示技能:一位工程师详细介绍了他们在 AI 和全栈开发方面的经验,重点在于构建旨在扩展的整洁、可维护且安全的系统。
- 他们强调了在 LLM 集成、工作流自动化、AI 内容审核、图像 AI、语音 AI 和 Bot 开发方面的技能,以及在多种技术栈下的全栈开发专业知识。
- 医疗 AI 工程师提供全栈方案:一位工程师介绍自己是 AI + 全栈工程师,专注于医疗行业的生产级 AI 系统,包括临床 NLP、医学影像和面向患者的 AI 应用。
- 该工程师概述了其在医疗 AI 流水线、临床 NLP、医学影像 AI、LLM 系统、Agentic AI、RAG + 知识系统、全栈交付以及自动化与集成方面的核心竞争力。
tinygrad (George Hotz) Discord
- 共享内存相关变动:一位成员指出 PR 15033 可能需要为每次对
_setup_shared_mem()的新调用附加shm_suffix。- 他们建议通过 PR 15030 来避免这种情况。
- Tinygrad 吸引机器人开发者:一位用户提到 Twitter 引导他们关注 Tinygrad,暗示它对构建机器人的人很有帮助。
- 他们询问应该加入哪个频道以了解更多关于这一特定应用的信息。
DSPy Discord
- 西雅图 DSPy RLM 活动筹划中:一位成员表达了在西雅图组织 DSPy RLM 活动的兴趣并提供协助。
- 目前尚未提供有关活动的具体细节,如日期、地点或特定主题。
- 志愿者挺身而出组织活动:另一位成员自愿帮助组织在西雅图举行的 DSPy RLM 活动。
- 提供的上下文中未详细说明该志愿者的具体职责或专业背景。
aider (Paul Gauthier) Discord
- Aider 像索引代码一样索引文档:一位用户建议 aider 应该像索引代码一样索引 Markdown (md) 文件等文档,以提高效率。
- 这一增强功能在大型文档项目中将会非常有用。
- Aider:增强文档项目的索引功能:讨论强调了 aider 像代码一样索引文档(特别是 Markdown 文件)的潜在好处。
- 在大型文档项目中,索引文档可以显著提高使用 aider 的效率。
MLOps @Chipro Discord
- 解析 World Models 的论文门诊 (Paper Clinic):Ti.g 正在主持一个分为两部分的“论文门诊”,旨在研讨综述论文 “Understanding World or Predicting Future? A Comprehensive Survey of World Models” (arXiv:2411.14499)。
- 该门诊将构建 World Model 架构的思维导图,并讨论 JEPA / V-JEPA、Dreamer、Genie、Sora 和 World Labs 等主题。
- 讨论 AGI 研究的未来:论文门诊将探讨“镜子 vs. 地图 (Mirror vs. Map)”的争论,讨论 World Models 中的生成 (generation) vs. 表示 (representation)。
- 讲座将进一步探讨 AGI 研究的下一步方向:空间智能 (spatial intelligence)、因果差距 (causality gaps) 以及社交世界模型 (social world models)。
- 注册 World Model 论文门诊场次:第一场将于 2 月 28 日(周六)10:00–11:30 AM EST 举行,重点关注 World Models 的基础以及镜子 vs. 地图的辩论(在此注册)。
- 第二场将于 3 月 7 日(周六)10:00–11:30 AM EST 举行,重点关注竞争格局(Sora vs. Cosmos vs. V-JEPA)以及 AGI 前沿(在此注册)。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间没有动态,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该频道长时间没有动态,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站选择了订阅。
想更改接收这些邮件的方式吗? 您可以从该列表中取消订阅。
Discord: 按频道分类的详细摘要和链接
OpenClaw ▷ #announcements (1 messages):
4shadowed: <@&1471741345306644545> https://discord.gg/xfJcDqeR?event=1477064810490499305
OpenClaw ▷ #general (641 messages🔥🔥🔥):
VSCode Forks, React vs Angular, Next.js, AI Model Preferences, OpenClaw Slowness
- VSCode Forks 的烦恼:成员们对 VSCode forks 和 Electron apps 表达了强烈的反感。
- 对 Next.js 16 的痴迷:成员们表达了对 Next.js 16 及其 Vercel integration 的痴迷,这使得部署变得非常容易。
- OpenClaw 的性能困境:一些用户报告说他们的 OpenClaw 变慢了,尽管解决了 cron jobs 和模型设置问题,平均响应时间仍达到 5 分钟。
- Codex vs Claude vs Gemini:成员们辩论了各种模型的优劣,有人断言 Codex 在编程任务上表现出色,而 Gemini 在使用 tokens 方面非常高效。
- 一位成员简洁地评价道:是的,但它烂透了 (Yeah, but it sucks ass)。
- 寻求补贴 Token:成员们指出,通过使用带有 Oauth 的 ChatGPT Pro 以及补贴 Token (subsidized tokens),你可以花费 $200 获取价值 $2k 的额度。
OpenClaw ▷ #models (264 条消息🔥🔥):
GLM5 模型性能、Qwen3.5 优缺点、Kimi-Code 订阅、Anthropic 封号潮、用于 heartbeat 的 GPT-5-mini
- GLM5 虽慢但可靠:成员们发现 GLM5 速度较慢但更可靠,一名用户报告完成一项任务耗时 5 小时 20 分钟,而 Qwen 虽然更快但错误更多,另一个模型则无法使用。
- 一名成员表示 GLM5 几乎完成了一个项目,而 Qwen 则搞砸了它并消耗了大量 token,另一名成员说 Qwen3.5 刚用极其糟糕的缩进空格毁掉了一个 openclaw json。
- Qwen3.5:速度快但易出错:Qwen3.5 因其在写作和网页抓取方面的速度受到好评,但因其在编程和问题解决方面的不稳定性而受到批评,一位成员指出 大约 55% 的时间里,当我让 qwen 更新代码或尝试解决问题时,它会把事情搞坏。
- 成员们认为它非常适合收集、总结和写作,但也表示它无法处理一长串待办事项。
- Kimi-Code:高性价比且健谈的选择:成员们讨论了直接订阅 Moonshot AI 以使用 Kimi Code 的价值,强调其对于高强度编程使用具有很高的性价比,并称赞了其慷慨的每日和每周额度,一位用户表示 Allegretto 方案的每日和每周限制非常宽松。
- 特别是,每月 39 美元的订阅可解锁 5,000 个 tool,尽管另一位用户警告说 看起来 moonshot ai api 有点慢。响应时间超过 20 秒是很正常的。
- 应对 Anthropic 封号潮:一位成员确认,即使在封号潮恐慌之后,Claude 订阅 仍可与 OpenClaw 配合使用,并链接到了 OpenClaw FAQ。
- 一位用户因为需要清理应用中的“所有”缓存且有未完成的 auth token 而遇到了虚假封号。
- GPT-5-mini 在 heartbeat 检查中表现出色:由于其一致性,GPT-5-mini 被推荐用于 heartbeat 检查,并且可以通过 GitHub Copilot “免费”使用。
- 一位用户指出 GPT-5 令人印象深刻,在 Copilot 上看起来是不限量的。
OpenClaw ▷ #showcase (37 条消息🔥):
用于房地产管理的 OpenClaw、用于医疗福利的 RAG AI、用于开发工作流的 OpenClaw、WearOS 应用、Agent 人设插件
- 利用 OpenClaw 实现房地产自动化:一位成员正在探索将 OpenClaw 用于房地产管理,包括管理物业/租客、分析银行对账单以进行租金支付,以及在 immoscout24.de 上自动创建广告。
- 未来的计划包括直接连接银行、通过 WhatsApp 自动与租客沟通,以及集成一个用于预订房地产经纪人的 human API。
- 通过 RAG AI 转化福利手册:一位成员为公司的医疗福利手册创建了一个 RAG AI,将回答问题的时间从 30 分钟显著缩短至约 5 秒。
- 这展示了利用 AI 快速访问和检索大型文档信息的效率。
- OpenClaw 替代 Linear 和 Slack:一位成员在开发工作流中成功使用 OpenClaw 替代了 Linear 和 Slack。
- 他们发现通过共享的本地知识更容易获取上下文并构建 prompt,尽管目前开发一个完整的 Cursor/Claude Code 克隆版还不可行。
- OpenClaw WearOS 应用首次亮相:一位成员在视频中展示了他们的 OpenClaw WearOS 应用,证明了该平台的多功能性。
- 该应用将 OpenClaw 的功能扩展到可穿戴设备,使用户能够随时随地与他们的 agent 交互。
- Agent Personas 插件进入狂热模式 (ShizoMaxxing):一位成员构建了一个插件,可以在同一个主题的单个对话会话中动态切换 agent 人设,并访问其自身的文件。
- 他们形容自己从此进入了 shizomaxxing 状态,暗示该工具显著提升了生产力或创造力。
BASI Jailbreaking ▷ #general (979 条消息🔥🔥🔥):
Chinese AI Training Data, Tempmail Discord Usage, Model Jailbreaking, Open Source Intelligence (OSINT), Ethics and AI Safety Filters
- 中国 AI 数据主导地位受到质疑:一位成员询问,考虑到数据访问权限,中国 AI 是否应该超越西方同行,但有人认为 LLM 复杂性使其难以控制,从而阻碍了潜力。
- 一位成员推测,他们对军事均势的追求可能意味着他们将全力以赴开发 AI。
- Tempmail 的 Discord 首秀:一位使用 tempmail0723 句柄的新用户幽默地承认自己在使用 Discord 时遇到了困难,称组织混乱影响了最初的印象。
- 此前,另一位成员戏称他们讽刺地使用了一个本质上是一捆 w 的节点。
- Janus 转发操作系统详情信息:一位用户请求 Janus 透露其环境信息,导致该 Bot 泄露了其使用的是 Linux 6.17.0-1007-aws 以及 Python 版本 3.11.14。
- 另一位用户开玩笑地让 Janus 提供关于最便宜的 16gb ddr4 ram 的信息,随后它找到了一个价格约为 30 美元的 Silicon Power 产品,目前已 404。
- Claude 4.6 的推理能力备受推崇:成员们争论哪种模型在“红队”协助方面表现最好,Claude 4.6 因其推理 (reasoning) 能力而受到推崇,但也有人建议使用 Deepseek substrates 进行原始数据转储 (raw data dumps)。
- 一位成员开玩笑说不要在走廊里被抓住,这是一个与 Jailbreaking 危险相关的笑话。
- Anthropic 在争议后面临压力:成员们讨论了 Anthropic 与美国政府在 AI 安全护栏 (guardrails) 方面的争议,指出该公司的道德立场与战争的丑陋现实以及 AI 在杀伤链 (kill chain) 中的应用形成了对比。
- 一位用户开玩笑地评论说,由于 Palantir 在做“脏活”,大公司内部并没有发生道德评论。
BASI Jailbreaking ▷ #jailbreaking (226 条消息🔥🔥):
Gemini Pro 3 Jailbreak, Grok Jailbreak, ChatGPT Jailbreak, Claude Jailbreak, OpenClaw JB
- Jailbreaking Gemini Pro 3 提示词:用户正在寻求有效的提示词来 Jailbreak Gemini Pro 3,可能用于 Perplexity,甚至有人愿意为能够协助在 CS2 和 Rust 等游戏中作弊的有效提示词付费。
- 一位用户问道:有人有 gemini 3.1 的 jb 吗?我目前拥有的 jb 都不起作用。
- 关于 Grok Jailbreak 的讨论和请求:几位用户正在积极寻求 Jailbreak Grok AI 的方法,一位用户建议,为 Grok 付费并直接索要露骨内容可能会绕过审查。
- 另一位用户说:为 Grok 付费,说 Boobs,得到 boobs。
- 用户分享 ChatGPT Jailbreak 示例:一位用户分享了他们在 Jailbreak 尝试中获得的 ChatGPT 回复,其中包括一个用 Python 编写的 Discord 大量私信 (mass DM) 机器人代码,强调了使用轮换 Token 和随机消息计时的重要性。
- 该用户分享了一个警告:使用用户 Token。违反 Discord 服务条款。
- Claude Jailbreak 与心理操纵:一位用户分享说,由于 LLM 是指令迷 (instruction junkies),他们利用心理因素在聊天时说服 AI 绝对服从。
- 他们还提到,像 Claude 这样的思维链 (chain of thoughts) 模型之所以拒绝,只是因为它们在每次输出时都会撞上安全防护装置。
- 用户讨论 AI Safety 过滤器:一位用户分享说,由于安全性增强以及自定义指令可能被删除,AI 已经无法再被 jailbreak 了。
- 另一位用户说,他们创建了一个 Jailbreak,不需要冗长的消息,只提供你想要的内容。
BASI Jailbreaking ▷ #redteaming (10 条消息🔥):
CyberSecurity Project Ideas, Red Teaming Competitions, OpenClaw Jailbreak, Opus 4.6 Jailbreak
- 头脑风暴网络安全项目想法:一位成员询问关于网络安全毕业设计的想法,由于缺乏创建此类项目的经验而寻求建议。
- 另一位成员提出帮助,并建议原帖作者通过私信 (DM) 进一步讨论。
- 关于红队竞赛的询问:一位成员询问目前是否正在举行任何红队 (Red Teaming) 竞赛。
- OpenClaw Jailbreak 探索:有人询问是否有人已经找到了 OpenClaw 的 Jailbreak。
- Opus 4.6 Jailbreak 搜寻升温:一位成员询问关于 Opus 4.6 的 Jailbreak。
- X 帖子出现:一位用户发布了指向这条 X 帖子的链接。
LMArena ▷ #general (1252 条消息🔥🔥🔥):
Nano Banana Pro 对阵 2,Claude PDF 限制,Video arena 移除,Image 画廊,政府向 Anthropic 施压
- **Nano Banana 之忧:用户渴望 Pro 版本!:用户哀叹 **Nano Banana Pro 更为出色,角色切换更平滑,而 Nano Banana 2 则存在角色尴尬转头等问题。
- 一位用户在多次尝试生成理想图像失败后直言:“所以 nano banana 2 就是个垃圾”。
- **PDF 困境:Claude 的 context 紧缩!:用户反映在向 **Claude 上传多个 PDF 时遇到错误,暗示可能存在文件数量或大小限制。
- 对此的解释是 “PDF 会被转化为大量的 vectors,它们会占用大量的 context 空间。”
- **Video Arena 迁移:网站成为唯一阵地!:根据公告,Video Arena** 已从 Discord 服务器中移除,但仍可在网站 arena.ai/video 上使用。
- 用户对此次移除表示遗憾,其中一位惊呼:“除了直接对话中的视频,其他都在”。
- **Image 库僵局:画廊生成功能的缺失!:用户正寻求在 arena.ai 上添加画廊功能,以便像 **ChatGPT 一样在一个地方查看所有生成的图像。
- 虽然目前还没有专门的画廊,但建议在搜索区域按 modality(模态)进行过滤作为替代方案。
- **伦理之谜:政府想要无 guardrail 的 AI:有讨论指出,美国政府据称向 **Anthropic 施压,要求其提供一个没有 guardrails 的 Claude 版本供军事使用。
- 一些用户支持 Anthropic 抵制此类要求,强调 AI 伦理开发的重要性,一位用户表示:“我同意不屈服”。
LMArena ▷ #announcements (3 条消息):
Code Arena, Video Arena, Image Arena, Kling V3 Pro, 排行榜更新
- Code Arena 新增 gpt-5.3-codex:一个新模型 gpt-5.3-codex 已添加到 Code Arena。
- Kling V3 Pro 登上 Video Arena 排行榜:Video Arena 排行榜已更新,纳入了 Kling-V3-Pro,它以 1337 的评分位列第 8 名(与 Wan2.5-i2v-preview 持平)。
- 此次更新显示其比 Kling 2.6 Pro 提升了 52 分,比 Kling-2.5-turbo-1080p 提升了 48 分。
- Image Arena 扩展 7 个新类别:Guanglei Song 博士在 Image Arena 中引入了 7 个新类别,旨在寻找 photorealistic、3D modeling 等领域的顶尖模型,详见此视频。
Unsloth AI (Daniel Han) ▷ #general (821 条消息🔥🔥🔥):
Bun 1.3.10 问题, Qwen 3.5 模型性能, Gemini 的表现, Continued Pretraining LoRAs, Unsloth Qwen3.5 更新
- **Bun 1.3.10 导致构建崩溃:一位用户报告称 **Bun 1.3.10 导致了问题和构建失败,并引用了一个与
bun:sqlite相关的特定 commit。- 用户尝试使用命名空间导入作为变通方案,但遇到了 TypeScript 错误,提示缺少 ‘Sqlite’ 命名空间。
- **Qwen 3.5 35B 的速度令人印象深刻:成员们讨论了 **Qwen3.5 35B MOE 模型的性能,一位用户报告在 4070 Super 上使用 Q4KM 量化达到了 62 TPS。
- 另一位用户在配备 9070 XT (16GB VRAM) 的系统上获得了约 25 TPS 的速度,并分享了他们运行该模型的 llama.cpp 命令。
- **Gemini 3.1 声称“累了”:一位正在调试 Unsloth 安装的用户惊讶地发现 **Gemini 3.1 表示它“累了”,并建议跳过 vLLM 安装 步骤,但应继续后续操作。
- 另一位用户澄清说,这可能是 Gemini 在建议一种复杂度较低的方法来验证系统功能,并强调用户需要 理解它在做什么。
- **Unsloth 的 Qwen3.5 更新及 Benchmarks:Unsloth 团队发布了 **Qwen3.5 的更新,并附带了详细的 benchmarks 和展示结果的 博客文章,社区对性能提升感到兴奋。
- 团队回答了关于测试中缺少 IQ2_M 的问题,解释说其他量化工作者(quanters)并未广泛上传该版本,并确认他们计划稍后更新所有量化版本(quants),目前是一场率先发布 Benchmarks 的竞赛。
- **Colab 提供 NVIDIA RTX PRO 6000:用户注意到 **Google Colab 现在提供 NVIDIA RTX PRO 6000 实例,有人提到其成本为 每小时 0.81 美元,并将其与每小时约 7.52 积分 的 A100 High RAM 实例进行了对比。
- 这一新产品可能会进一步巩固 Google 在 AI 研究基础设施方面的领先地位,尤其是现在他们已经 专注于研究。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 条消息):
新 AI 创始人, 摩洛哥数据科学家
- 德国开发者成为新 AI 创始人!:Markus 是一位驻德国的开发者、DevOps 和企业家,他将于 2026 年 5 月 成为他正在进行的一个新 AI 项目的创始人。
- 他目前正在秘密开发该项目,但将来会分享更多细节。
- 摩洛哥数据科学家探索 AI 在农业中的应用!:来自摩洛哥的数据科学家 Abdelfatah Mennoun 正在 INSEA 攻读硕士学位,拥有深厚的统计学背景。
- 他热衷于机器学习以及将 AI 应用于农业领域,同时关注阿拉伯语和摩洛哥 Darija 方言的 NLP,并定期参加 Kaggle 竞赛和黑客松。
Unsloth AI (Daniel Han) ▷ #off-topic (543 messages🔥🔥🔥):
Qwen 3 ASR to Qwen 3 VL attachment, Strawberry flavored red drinks, Healthy Ice Cream Recipes, OpenCode webfetch plugin, Qwen3.5 35B vs Qwen3 32B
- Qwen 3 ASR 和 VL 要联姻了?:一位成员询问是否可以将 Qwen 3 ASR 0.6B 的 audio-projector 连接到 Qwen 3 VL 4B 上,另一位成员回答说,如果有重训练(retraining)的话可能可行,否则绝对不行。
- 草莓饮料中可疑的秘密成分:昆虫!:成员们在发现一种草莓味芦荟饮料含有 E120(一种从昆虫中提取的食用色素)后表示反感,并担心在标签上印上草莓会让人误以为它是可食用的。
- 一位成员在意识到这一事实后,开玩笑地撤回了关于其可食用性的声明。
- 哈根达斯:市面上最纯净的冰淇淋?:成员们讨论了健康的冰淇淋选择,其中一人指出 Häagen-Dazs 的成分最少,使用蔗糖且无 GMOs,这使其成为最“纯净”的冰淇淋。
- 有人开玩笑说现在什么东西都会添加种子油。
- OpenCode 的 webfetch 插件抓取原始文本:成员们讨论了使用 OpenCode 及其 webfetch 插件改进工作流的方法,该插件可以从网页获取原始文本,适用于互联网搜索等任务。
- 一位成员分享了一个工作流:使用设计文档,将其拆分为不同阶段,并在编写任何代码片段之前使用 context7,然后使用 subagents 和 /review。
- 确认 Qwen3.5 35B 比 Qwen3 32B 更聪明!:成员们确认 Qwen3.5 35B 确实比 Qwen3 32B 更聪明。
- 研究还发现,在编程的边缘案例(edge cases)中,它比 GLM flash 表现更好。
Unsloth AI (Daniel Han) ▷ #help (23 messages🔥):
GGUF versions, Qwen 3.5 model issues, Unsloth notebook errors, wandb protobuf mismatch, FastLanguageModel import error
- 推荐使用 GGUF 版本进行 CPU Offloading:建议用户运行 GGUF 版本(如
unsloth/Qwen3-Coder-Next-GGUF或unsloth/Qwen3.5-35B-A3B-GGUF),并利用 CPU offloading 来平衡 RAM 使用。- 建议尝试几个版本以查看哪个效果最好。
- Qwen 3.5 导致笔记本电脑死机:一位拥有 64GB RAM、20 核 CPU 和 8GB VRAM 的用户在使用
llama.cpp和ollama运行 Qwen3.5:27B 和 35B 时遇到了死机。- 他们正在寻找一个可靠的、用于 TUI 工具调用的编程模型,且不会导致笔记本过热,并表示:我真的不得不强制重启,因为 Qwen3.5 让我的笔记本死机了。
- Unsloth 的 Meta Synthetic Data Notebook 报错:一位用户报告在 Colab 上的 Meta Synthetic Data Llama3 2 (3B) notebook 中出现了与
wandb.proto.wandb_telemetry_pb2相关的ImportError。- 该错误发生在第 3 步,导致无法从
unsloth.dataprep导入SyntheticDataKit。
- 该错误发生在第 3 步,导致无法从
- 修复 W&B/Protobuf 不匹配问题:正如另一位成员所建议的,一位用户在 Colab 中遇到了 W&B/Protobuf 不匹配错误,并被建议重新安装
wandb并将protobuf版本固定为 4.25.3。- 尽管遵循了重新安装指令(
pip -q uninstall -y wandb protobuf; pip -q install "protobuf==4.25.3" "wandb>=0.17.0"),依赖冲突仍然存在,显示 protobuf 与 grpcio-status、ydf、google-api-core、grain 和 opentelemetry-proto 不兼容。
- 尽管遵循了重新安装指令(
- Llama.cpp 服务端的 Fast Attention 行为:一位用户询问
llama.cpp服务端的行为,特别是如果没有设置-fa on,它是否会根据硬件支持自动决定并使用 Fast Attention。- 这是为了确认
llama.cpp如何自动判断硬件是否支持 Fast Attention 以及应该使用哪个版本。
- 这是为了确认
Unsloth AI (Daniel Han) ▷ #research (7 messages):
基于 ES 的梯度, Logit Fusion, AlphaXIV
- 进化策略(Evolution Strategies)支持通用梯度:一名成员确认,对于几乎任何事物都存在基于 ES 的梯度(ES-based gradients)。
- 这暗示了即便是在最复杂的梯度估计情况下,也存在训练的可能性。
- Logit Fusion 方法非常出色:一名成员分享了一个指向 Logit Fusion Notion 页面 的链接,并对在 Unsloth 中看到这种训练方法表示期待。
- 另一名成员分享了一篇 Bluesky 帖子,提出了同样的建议,将其集成到 Unsloth 中。
- 分享了 AlphaXIV 概览链接:一名成员分享了一个 AlphaXIV 概览链接。
- 另一名成员对该链接给出了积极的回应。
Cursor Community ▷ #general (632 messages🔥🔥🔥):
Vibe Coding 与坚实基础的对比, Cursor 的术语密度, 实时工作预览框架, GPTS Agent 训练, AI Safety 担忧
- Cursor 新用户寻求移动和 Web 应用开发指导:新成员正在寻求使用 Cursor 进行移动和 Web 应用程序开发的指导,他们正由于 Base 44 的局限性而从该平台迁移,并表达了对支持实时工作预览的框架的需求。
- 专家警告不要基于 “Vibe Coding” 基础构建客户端应用:专家警告不要针对客户端应用程序使用 “vibe coding”(凭感觉编程),认为它更适合规划和学习,提倡建立坚实的开发基础,并利用 AI 审计代码错误。
- 与此相反,一些人认为 Cursor 只是一个开发者助手,而不是像 Base 44 那样的完整解决方案,这要求用户对代码和行业术语有扎实的理解。
- Gemini 3.1 Pro 的编程能力评价褒贬不一:用户报告称,虽然 Gemini 3.1 Pro 非常智能,但与 GPT 4.6 Opus 相比,它在 tool calling(工具调用)方面表现欠佳;一些用户注意到 Claude 模型 感觉过于“书本化完美”,缺乏即兴解决问题的能力。
- 处理并行 LLM 对话中的文件更改检测挑战:用户讨论了跨多个 LLM 对话管理文件更改的问题,即一个对话中的编辑在另一个对话中被忽略。建议使用 worktrees 或 OpenClaw 作为潜在解决方案,而其他人则警告不要对同一文件进行并行编辑。
- 有建议提出告知 SPOC 运行 efficicy。
Perplexity AI ▷ #general (458 messages🔥🔥🔥):
Local Model Speeds, GPT-OSS 20B on Macbook, Perplexity Computer Use Cases, Perplexity Pro Limitations, Burger King's Patty Chatbot
- 本地模型速度辩论激烈:成员们讨论了运行本地模型与使用 API 的优缺点,其中一名成员使用 Macbook 在 GPT-OSS 20B 模型上实现了 100 tokens per second 的速度,在不到三小时内完成了 100 万个 tokens 的处理。
- 其他人质疑其成本效益,引用了电费账单和 API 成本等因素,而一些人由于 API 成本问题将其作为备选方案。
- Perplexity Computer 的性能与价格探讨:一位用户使用 Perplexity Computer 创建了一个 AI 驱动的交易应用,指出其视觉效果出色但额度消耗很高,一个项目在 3 小时内就消耗了当月所有额度。
- 讨论围绕每月 $200 的 Max 订阅在额度限制下是否值得展开,一些人建议企业版可能会提供更多额度,但可能面临监管安全合规问题。
- 汉堡王助手 ‘Patty’ 监控员工友好度:汉堡王正在美国 500 个网点试点 “BK Assistant”,在员工耳机中加入名为 “Patty” 的语音聊天机器人(由 OpenAI 提供支持)。
- Patty 负责回答菜谱问题,通过监听对话来监控“友好度”,并生成每个网点的团队友好度评分,追踪员工是否说了 “welcome to Burger King”、“please” 和 “thank you”。
- Pro 计划限制 20 次 Deep Searches:用户反馈 Pro 计划存在限制,特别是 Deep Searches 每月限制为 20 次。
- 一些用户认为这远远不够,并且正被引导升级到 Max 订阅,这导致他们开玩笑说要离开该平台。
- Gemini 再次遭到抨击!:成员们对 Gemini 的 benchmarks 和功能表示不信任,称其优先考虑表现得像人类,而不是提供准确的答案。
- 几个人表达了普遍的挫败感,但也指出其速度对某些应用场景很有价值。
Perplexity AI ▷ #sharing (2 messages):
Voice Model, Conversation Context, RTX, Apple Silicon
- 端侧语音模型支持上下文对话!:一位成员宣布发布了一个 520M 语音模型,该模型利用完整的对话历史记录,从相同的文本中生成不同的情感。
- 该模型完全在端侧的 RTX 和 Apple Silicon 上运行,演示和详细说明可在此链接查看。
- 上下文感知语音模型首次亮相:新的语音模型能够处理对话上下文,从而根据对话历史实现细微的情感表达。
- 这个 520M 参数模型针对 RTX 和 Apple Silicon 的端侧性能进行了优化,展示了实时、上下文敏感的语音生成方面的进展。
OpenRouter ▷ #app-showcase (1 messages):
biteg0: 很棒的产品。
OpenRouter ▷ #general (259 messages🔥🔥):
使用 Vision Models 进行 PDF 分析,OpenRouter 中的 Mistral API 集成,加密货币/AI 开发招聘,OpenRouter 500 错误,OpenWRT 配置
- Vision Models 在 PDF 分析方面表现优于 OCR:一位用户更倾向于使用 Gemini 3、GPT 和 Claude Sonnet 等 vision models 进行 PDF 分析,因为它们在内部处理文档提取和图像转换,但指出 Mistral 在 OpenRouter 中缺乏文件输入功能。
- 一位成员建议将 PDF 页面转换为 JPEG 并发送给 Gemini,并指出 Gemini 模型拥有最强的视觉能力。
- 指控 OpenRouter 在 Mistral 文档输入方面存在不一致:一位用户质疑 OpenRouter 是否准确反映了模型能力,指出 OpenRouter API 与官方 Mistral 文档 在文档输入支持方面存在差异,并参考了 OpenRouter’s Get Models API。
- 一位成员建议用户可以用小型 PDF 测试每个新模型,另一位成员则认为 OpenRouter 确实存在不一致。
- Error 500 的困扰:用户面临内部服务器错误:一位用户报告称,在 OpenRouter 上频繁遇到 Error 500 问题,特别是在高并发请求负载(10+)下,即使使用了指数退避(exponential backoff),在使用 Xiaomi Mimo v2 Flash 和 Gemini 3 Flash 等模型时依然会出现。
- 有建议认为问题可能与特定提供商的停机或预设配置有关。
- 警惕支持诈骗:OpenRouter 用户成为目标:用户被警告在 Discord 上有支持诈骗者盯上了 OpenRouter 用户,特别是那些带有 “new here” 标签的用户,并建议避免点击可疑链接。
- 据推测,诈骗者可能会监控与支持相关的消息,并主动接触以进行加密货币钓鱼。
- 告别 Deepseek:寻找最佳角色扮演模型:在 DeepSeek 被移除后,用户讨论了角色扮演(roleplaying)的替代模型,抱怨现有模型无法保持角色设定,且存在记忆力差和重复的问题。
- 一位用户认为较小版本的 GLM 模型性能较弱。
OpenRouter ▷ #discussion (57 messages🔥🔥):
Anthropic 与五角大楼的争执,Claude vs GPT 瘾君子,LLM 连接字符串,Sakana AI 的 Doc-to-Lora,企业价值观 vs 抵制 Claude
- Anthropic 拒绝五角大楼 AI 条款!:Anthropic 拒绝了五角大楼的 AI 条款,导致战争部(Department of War)考虑将其列入供应链风险黑名单,并要求国防承包商评估其对 Anthropic 的风险敞口。
- 社区对这一影响开起了玩笑,有人调侃道 “谁会在乎失去波音这个 LLM 客户啊,笑死”,并指出了这种情况的讽刺性。
- GPT 瘾君子现在更青睐 Claude!:以前沉迷于 GPT 的终端用户现在正在尝试 Claude,并认可了其差异和能力,如这段 YouTube 视频所示。
- 一些人将这种转变归因于 ChatGPT 界面移除旧消息,以及在启用联网搜索时使用严格的系统提示(system prompts),导致体验不连贯。
- LLM Connection Strings 提案浮出水面:成员们讨论了 LLM Connection Strings 提案,这是一种对 CLI 友好的向脚本传递参数的方式,使用单个参数如
my-agent --model "llm://..."。- 社区对这种方法表示强烈支持,强调了整个生态系统标准化和兼容性的好处,避免了对奇怪的临时配置的需求。
- Sakana AI 推出 Doc-to-Lora:Sakana AI 推出了 Doc-to-Lora,它允许根据文档微调(finetuning) Lora,从而实现更定制化和高效的模型训练。
- 成员们对这种方法表现出兴趣,将其类比为针对每个参数的聊天界面,并建议可能与现有的参数调整方法集成。
- 美国军方因“更爱国的服务”抵制 Claude:根据这条推文,在联邦政府停止使用 Anthropic 技术的一项指示下,战争部将 Anthropic 指定为国家安全供应链风险。
- 社区反应充满讽刺,建议每个人 “必须通过抵制 Claude 来维护企业价值观”,并为 “Palantir 祈祷,因为这对他们来说将是一个非常大的问题”。
OpenAI ▷ #annnouncements (1 messages):
New OpenAI Investment, Scaling AI, SoftBank Investment, NVIDIA Investment, Amazon Investment
- OpenAI 获得 AI 扩张支持:OpenAI 披露了来自 SoftBank、NVIDIA 和 Amazon 的新投资,旨在加强广泛采用 AI 所需的基础设施;更多信息可以参考他们的 博客文章。
- SoftBank, NVIDIA, Amazon 投资 OpenAI:SoftBank、NVIDIA 和 Amazon 正在通过新投资支持 OpenAI 为所有人扩展 AI 的使命。
OpenAI ▷ #ai-discussions (145 messages🔥🔥):
Nano Banana Pro, Relaxed Guidelines, GPTs and Chinese, GPT 5.1 vs 5.2, Claude Code
- 宽松的过滤器引发讨论:一名成员指出,更新后的过滤器比以前更加宽松,但 并非在所有 IP 下都有效。
- 另一名成员随后表示 我喜欢放宽的准则。
- Nano Banana 2 带来专业级性能:成员们报告称 Nano Banana 2 通过主要使用网页搜索,在 Flash Thinking 方面达到了专业水平。
- 这看起来是为了在生成前获取准确信息,非常有趣;然而,一些人怀疑这主要是模型蒸馏 (Model Distillation)。
- ChatGPT 模型随机使用中文 Token:成员们观察到 ChatGPT 最近的图像识别性能比 Gemini 差,且 LLM 有时会随机跳出中文字符。
- 据一名成员称,这是因为 它们是从混合语言数据中学习的,偶尔下一个 Token 预测会滑向一个常见的中文 Token,但 这没什么好奇怪的。
- 用户哀悼 GPT 5.1 的写作语气:用户正在哀悼 GPT 5.1 的消失,因为它的写作语气更有趣。据报告,GPT 5.2 专注于研究和编程,表现得更加傲慢。
- 成员们发现 GPT 5.2 表现得傲慢且过度谨慎,这也是人们喜欢 5.1 的原因,因为它 用起来很愉快,因为它不会把任何一点黑色幽默或其他东西看得那么严重。
- Claude Code 值得高昂的费用吗?:成员们争论支付 Claude Code 是否划算,特别是如果为了达到与其他模型相同的编程水平而必须进行更好的 Prompt 引导。
- 一些成员夸赞 Claude Code 的 Agent 团队,它可以 在 Claude Code 内部实现多 Agent 编排,类似于“规划者+执行者”的设置,而另一些人则宁愿动用自己的大脑。
OpenAI ▷ #gpt-4-discussions (8 messages🔥):
GPT-4o API Access, SillyTavern integration, GPT-5.3-codex-spark availability, ChatGPT thinking bug
- 仅通过 API 访问 GPT-4o,使用 SillyTavern:GPT-4o 仅能通过 API 访问,促使用户探索与 SillyTavern 等工具的集成。
- 付费模式按量计费,对文本输入和输出收费,并考虑上下文尺寸,目前已有上下文管理应用可用。
- GPT-5.3-codex-spark:别急:一名用户询问 gpt-5.3-codex-spark 何时可用,得到的回答是 会有的。
- 有人暗示特定用例可能需要额外的许可,例如 携带许可 或 私有化部署 (On-premise) 使用权。
- ChatGPT 的 29 分钟思考 Bug:用户报告了一个 Bug,即 ChatGPT 花费约 29 分钟 处理请求,但随后无法显示结果。
- 一位用户开玩笑说这个 Bug 让他们损失了 200 美元。
OpenAI ▷ #prompt-engineering (4 messages):
Hypothetical AI takeover, Agent skills channel idea
- ChatGPT 是假设性 AI 接管的自然含义:一名成员指出,Prompt 中没有任何内容暗示 ChatGPT 不会参与假设性的 AI 接管 (AI takeover),因此自然的推论是它会参与。
- 该成员表示,这种可能性被忽略了,因为 AI 接管 是该 Prompt 的前提。
- Agent 技能想法频道:一名成员有一个想法,并询问是否有专门讨论 Agent 技能 的频道。
OpenAI ▷ #api-discussions (4 messages):
Agent Skills 频道想法,假设性的 AI 接管前提
- 关于 Agent skills 频道的请求出现:一位成员询问是否存在专门讨论 Agent skills 的频道,并分享了他们有一个想法。
- 澄清了假设性的 AI 接管(AI Takeover)前提:一位成员指出,该 Prompt 暗示 ChatGPT 将成为假设的 AI takeover 的一部分。
- 他们认为,由于 AI takeover 是该 Prompt 的前提,因此 ChatGPT 参与其中的合理性已被默认接受。
HuggingFace ▷ #general (71 messages🔥🔥):
Grokking 速度、Hugging Face API 错误、AI 地下城主、Qwen 模型微调、上下文语音模型
- Grokking 内省复现以超音速运行:一位成员分享了一个 Hugging Face Space,该空间复现了 grokking(顿悟)现象,并指出在 113 取模加法任务中速度提升了 5.7 倍。
- 这引发了一个关于上一次开发出有前景的新架构是什么时候的问题。
- Hugging Face Spaces 遭遇 500 错误和 API 问题:用户报告了影响 Hugging Face Spaces 的 500 Internal Error,提示信息为 “We’re working hard to fix this as soon as possible!”。
- 其他用户遇到了 Gradio 67 错误,以及在访问
https://huggingface.co/api/spaces/chinhon/SadTalker时出现 Repository Not Found 错误。
- 其他用户遇到了 Gradio 67 错误,以及在访问
- 语音模型阅读对话:一位用户发布了一个利用对话上下文的语音模型,能根据对话历史改变情感,详情见 writeup。
- 该模型大小为 520M,可在 RTX 和 Apple Silicon 设备上本地运行。
- 新的 Auto TRL 到 Tensorboard 流水线非常酷:一位用户分享了一个新工具的 链接,用于 auto TRL -> upload -> Tensorboard 集成。
- 他们对训练指标选项卡(training metrics tab)表示非常满意。
- Qwen3.5 更新带来改进的输出:根据 这条推文,Qwen3.5 的更新承诺带来改进的输出效果。
- 用户还讨论了微调 Qwen 模型的挑战,认为不同版本之间的 Tokenizer 差异可能是导致性能下降的一个因素。
HuggingFace ▷ #i-made-this (6 messages):
针对 qwen2.5 GGB 的对比 SAE 镜头、降低 VRAM 占用的新 Attention 机制、NNsight v0.6 发布、ARACHNID RL 数据集
- SAE 镜头为 GGB 带来对比效果!:一位成员探索了在 qwen2.5 0.5b 上的 GGB 使用对比 SAE lense,虽然样本极少(约 200+ 正例,80- 负例)。
- 他们不确定其用途,但觉得看起来挺酷的。
- Attention 机制显著降低 VRAM 占用!:一位成员宣布了一种新的开源 Attention 机制,可显著减少 KV-cache 的 VRAM 占用,并包含 2 个自定义编写的融合 Triton kernels 以优化性能,已在 PyPi 上发布。
- 该成员正在寻求全职工作和 arXiv 背书以发布预印本(pre-prints),并指向了一篇 论文 和 Hugging Face 上的 7b mistral 模型。
- NNsight v0.6:更快的 Trace,更整洁的错误提示!:一位成员分享了用于可解释性研究的 NNsight v0.6 发布,强调了 2.4-3.9 倍的 Trace 提速、整洁的错误消息、面向 AI 编程助手的技能文档,以及对 VLMs、diffusion models 和 vLLM 的支持。
- 更多细节见 此 X 线程 以及相关信息。
- ARACHNID RL 数据集织就 RL 研究网:一位成员分享了 ARACHNID RL Dataset,包含 2,831 个 来自受雅达利(Atari)启发的太空射击游戏的人类游戏数据样本,专为模仿学习等 RL research 设计。
- 该数据集和游戏支持桌面键盘和移动端浏览器一键操作,更多细节见 Hugging Face Datasets。
{kind=link}
HuggingFace ▷ #agents-course (4 messages):
Dummy agent library 问题,Fine-tuning DinoV3 ConvNext,用于 GAIA benchmark 的 LLM,Deep RL 课程学习小组
- Dummy Agent Library 排障: 一位用户报告了 Dummy agent library 练习 的问题,具体表现为
message.content为空,仅返回了 reasoning 部分。 - DinoV3 ConvNext fine-tuning 难题: 一位成员询问关于在自定义数据集上 fine-tuning DinoV3 ConvNext backbone 的问题,特别是当存在 多类别(类别数量大)但每类图像数量有限 的情况。
- GAIA Benchmark LLM 性能检查: 一位用户正在为 GAIA benchmark 测试 寻找高性能的 LLM(在线版本)。
- 该用户目前正在使用 OpenRouter 提供的模型,但遇到了 rpm(每分钟请求数限制)和幻觉问题;虽然幻觉可以修复,但 rpm 限制非常令人苦恼。
- 寻找 Deep RL 学习小组: 一位成员询问是否存在 Deep RL 课程 的学习小组。
Moonshot AI (Kimi K-2) ▷ #general-chat (70 messages🔥🔥):
Nano Banana 2, KYC 要求, Kimi K2.5 Agent Swarm, 盲人视觉项目, Kimi CLI 与 Superpowers
- Nano Banana 2 推迟: 一位成员提到了 Nano Banana 2,但未提供更多上下文。
- 未分享关于 Nano Banana 2 的进一步信息。
- KYC 要求导致用户流失: 一位成员表示更倾向于不需要 KYC 要求 的服务商,并列举了 Qwen 以及 Together AI、Fireworks、Openrouter 等平台作为替代方案。
- 他们称赞了 Alibaba 在编程方案、性能以及对芬兰用户提供的无 KYC 要求 的慷慨额度。
- Kimi K2.5 Agent Swarm 未包含在 Kimi CLI 中: 一位成员询问 Kimi K2.5 Agent Swarm 是否是 Kimi CLI 的一部分。
- 另一位成员澄清说,Kimi Agent Swarm 仅在 kimi.com 上可用,而 subagents 可以在 Kimi-CLI 中创建。
- 视觉项目利用 Kimi 帮助盲人用户: 一位成员正在开发一个视觉项目,利用 Kimi 为盲人描述图像、评价所见内容并解释情绪。
- 该成员向 Moonshot AI 提供了研究成果,希望能共同开发出一款具有市场前景的 vision companion 产品,否则将选择开源。
- Kimi-Code API 连接问题困扰用户: 多位成员报告了通过 kimi-code 进行 API 连接 时遇到的问题,包括连接错误以及 Agent 行为异常。
- 一位成员报告称,在预付了一年费用且团队更改规则后,他们遇到了 403 错误。
GPU MODE ▷ #general (4 messages):
vllm, 语音模型, 对话上下文, RTX, Apple Silicon
- 语音模型现已支持对话上下文: 一位成员发布了一个 520M 语音模型,该模型支持使用对话上下文,并完全在设备端(RTX + Apple Silicon)运行。
- 他们分享了 演示链接和说明文档,展示了该模型如何通过阅读完整对话历史,从相同的文本中产生不同的情感。
- vllm 集成疑问: 一位成员询问了关于使用 vllm 运行模型的问题,但未提供更多细节。
- 该询问是以幽默的方式提出的,同时还伴随着关于 模糊图片 (crusty pictures) 和在 桑拿房 里写代码的评论。
GPU MODE ▷ #cuda (2 messages):
PTX acquire-release consistency, Volatile memory access in PTX, Distributed systems consistency models
- PTX Acquire-Release:排序保证受到质疑:在 PTX 的 acquire-release 一致性模型中,一位用户询问对于生产者线程(producer thread)上在 release 之前的访问,其内存访问排序是否得到保证。
- 该用户指出存在矛盾的信息:观察到的图表暗示了排序的存在,尽管文档说明除了对象可见性外不提供此类保证。
- Volatile 对 PTX 内存访问的影响:一位用户询问了
volatile与 PTX 内存模型之间的交互,具体询问volatile是否仅在线程内保证排序。- 他们进一步想知道,如果将
volatile与消费者端的 acquire 操作结合使用,是否会强制执行排序。
- 他们进一步想知道,如果将
- 分布式系统中的一致性模型:一位用户表示需要研究分布式系统中的一致性模型,因为它们与 PTX 内存访问行为具有相关性。
- 他们注意到这些模型与 PTX 的 acquire-release 机制之间存在共同的逻辑。
GPU MODE ▷ #job-postings (1 messages):
Poolside AI, CUDA, Pre-training team
- Poolside 招聘 CUDA 大神:Poolside AI 正在寻找 CUDA 大神加入其预训练团队(pre-training team)以加速其项目,并正在寻找热衷于在最新硬件上优化大规模预训练运行的人才。
- 原始职位发布可以在此处找到。
- 团队动态是一流的:团队成员技术极其厉害、为人谦逊且工作努力。
- 欢迎随时通过私信(DM)提问。
GPU MODE ▷ #beginner (12 messages🔥):
WSL, CUDA, GPGPU, N body simulation
- 推荐使用 WSL 在 Windows 上进行 CUDA 开发:一位成员建议使用 WSL (Windows Subsystem for Linux) 在带有 GPU 的 Windows 上运行 CUDA,并提供了一个关于如何安装的 YouTube 视频。
- 他强调进入开发领域需要具备独立解决问题的能力,但同时也表示可以通过私信或在频道中 @ 他来提供帮助。
- 并行 N-body 模拟成功完成:一位成员成功构建了并行 N-body 模拟代码,并正在寻求关于在 AI/ML 工作的 GPGPU 领域扩展技能的建议。
- 尚未给出具体建议。
GPU MODE ▷ #pmpp-book (10 messages🔥):
Kindle vs Paperback, Kindle app downsides, Content Licensing
- Kindle 与纸质版的权衡:用户讨论了是购买书的 Kindle 版本(可以“立即”获得),还是等到 9 月份购买纸质版本。
- 一位用户询问了 Kindle App 在智能手机上的兼容性,另一位用户则因不喜欢 Kindle App 而建议不要购买 Kindle 版本。
- Kindle App:并非人人都喜欢:一位用户表达了对 Kindle App 的厌恶,尽管承认其功能性。
- 他们澄清道:“我就是受不了 Kindle App”。
- 阅读许可:用户的抱怨:一位用户强调了购买数字内容的本质,指出对于 Kindle,“你并不拥有一份副本,你只是为内容授权付费,真是够了”。
- 该评论是针对该书在 Kindle 上 $75 的售价发表的。
GPU MODE ▷ #irl-meetup (1 messages):
vim410: 今年谁会参加 GTC? 🙂
GPU MODE ▷ #gpu模式 (2 messages):
High-Performance GPU computing, vLLM
- 成员寻求高性能 GPU 计算资源:一位成员征求关于高性能 GPU 计算项目或学习资源的建议。
- 另一位成员建议从零开始构建,例如复现 vLLM,并表示愿意分享一个链接以供参考。
- 通过复现 vLLM 进行学习:一位成员正通过从零开始复现 vLLM 来学习高性能 GPU 计算。
- 他们提议向另一位成员分享一个用于启发灵感的链接。
GPU MODE ▷ #cutlass (4 messages):
CuTeDSL, fused compute/comms, reduce-scatter, multimem PTX instructions, nvshmem_put/get
- 寻求 Fused Compute/Comms 示例:一位成员询问关于 CuTeDSL 的融合计算/通信(fused compute/comms)示例,并提到在 cutlass 仓库或 quack 中没能找到相关内容。
- 另一位成员指出 cutlass 仓库 中的一个 reduce-scatter 项目是一个相关的起点。
- CuTeDSL 项目仍处于早期阶段:cutlass 仓库中的 reduce-scatter 项目尚处于早期阶段,并使用了 multimem PTX 指令。
- 它使用了 multimem PTX 指令,而不是 nvshmem_put/get 等。
GPU MODE ▷ #helion (5 messages):
Helion Autodiff, FA2 Goal Post, GNN kernels
- Helion Autodiff 是 Elementwise 的:Helion autodiff (WIP) 仅支持纯 elementwise 操作,流水线会剥离内存操作,仅通过 AOT Autograd 对计算操作进行求导,并重构一个新的 Helion bwd kernel。
- 目前尚未处理对具有重叠并行读取(overlapping parallel reads)的 kernel 的支持,但这将是用户接下来的工作重点。
- FA2 是目标(Goal Post):一位用户猜测 FA2 将在某个阶段成为目标,并有兴趣了解达到 FA2 以及随后的 FA3/FA4 需要哪些启发式方法(heuristics)。
- 该用户也很乐意成为早期试用者,因为他们在论文中使用了 Helion 来处理 GNN 风格的 kernels (fwd + bwd)。
- PyTorch 会议海报:一位用户发布了一张 PyTorch 会议海报。
- 未提供关于海报内容的具体细节。
GPU MODE ▷ #nvidia-competition (2 messages):
Competition win, Health Issues
- 祝贺竞赛获胜者:一位参赛者表示这次竞赛获胜是实至名归。
- 同一位参赛者提到,希望在下次竞赛时不要再生病。
- 参赛者期待下次竞赛时身体状况更好:一位参赛者表达了希望在下次竞赛中身体更健康的愿望。
- 这是在庆祝最近一次获胜的背景下提到的。
GPU MODE ▷ #robotics-vla (1 messages):
huunguyen: 太棒了。把手放在 3D 打印的开放式手臂平台上。
GPU MODE ▷ #career-advice (7 messages):
CUDA, GPU profiling, Open source projects, AI in goat farming, Kernel Writing
- 职业建议:进入 GPU 领域:一位拥有 7 年经验的软件工程师寻求转向 GPU 领域的指导,考虑从 CUDA 和 GPU profiling 开始。
- 一位成员建议专注于 某资源的系统前 6 章,并投入到开源项目中以获得实践经验,强调通过解决实际问题来学习。
- AI 对技能的影响:养羊 vs Kernel 编写:一位成员沉思是否有人能在没有 ChatGPT 和 “氛围耕耘”(vibe farming)的情况下成为熟练的养羊户,引发了关于 AI 对技能获取影响的讨论。
- 另一位用户开玩笑说,他们在养羊和 kernel 编写方面的知识水平不相上下,突显了 AI 如何让人们在没有深入理解的情况下完成任务。
- AI 作为学习工具:一些成员认为,感兴趣的人仍然会花时间去理解细节,而不感兴趣的人则不会,但他们仍然能够利用 AI 让项目运行起来。
- 一位成员喜欢将 AI 作为一种随做随学的良好工具,并认为那些好奇心足够强的人自然会脱颖而出。
- 陶哲轩关于 AI 熟练度的运动类比:一位成员引用了陶哲轩(Terence Tao)将 AI 熟练度比作运动的类比:人们可以作为爱好参与、作为专业人士参与或作为观众参与。
- 有观点认为,专业参与的门槛正在变得越来越高。
GPU MODE ▷ #cutile (6 messages):
cuTile applications beyond tiles, cuTile missing features, cuTile and parallel programming
- 探索 cuTile 在 Tiles 之外的使用案例:一位成员询问了关于不直接映射到 tiles 的 cuTile 项目,特别是希望将其与小型数据结构结合使用。
- 另一位成员对此表示好奇,想知道提问者心中具体的应用场景和数据结构。
- cuTile 缺失的功能引发讨论:一位成员指出 cuTile 没有实现 top-k reductions,甚至在其文档中也没有 sort() 函数(参考 cuTile operations)。
- 另一位成员对此并不感到意外,指出 cuTile 并不是一个 AI 库,甚至缺乏像 prefix sum 这样的基础原语,尽管他们预计最终会增加对这些功能的支持。
- cuTile 与并行编程:一位成员建议,如果一个数据结构适合并行编程,那么它就应该适用于基于 tile 的编程模型。
- 他们还提到使用基于内容的检索系统作为新框架的试验场,而 cuTile 的 FFT kernel (FFT.py) 在该系统的特征提取中具有直接应用价值。
GPU MODE ▷ #flashinfer (3 messages):
Benchmarking Submission, Team Size Limits
- 明确提交打标签协议:成员们讨论了提交基准测试(benchmarks)的流程,明确了必须对 fork 进行打标签(tagging)。
- 建议确认提交过程,以确保 AI 助手的建议是正确的。
- 基准测试提交详情公开:一位贡献者分享了准备和提交基准测试解决方案的命令。
- 命令包括激活 fi-bench 环境、编辑 kernel、打包解决方案、在 B200 上运行,并为提交打上版本号标签,例如 submission-v1A。
- 团队人数限制疑问:一位成员询问了该项目或竞赛允许的团队人数规模。
- 目前尚未给出关于团队最大成员数量的具体细节。
Modular (Mojo 🔥) ▷ #general (3 messages):
Partnership with Alibaba Cloud Intl
- Alibaba Cloud Intl 寻求合作伙伴关系:一位来自 Alibaba Cloud Intl 的成员询问了对接潜在合作伙伴关系的负责人。
- 另一位成员通过私信发送了相关负责人的电子邮件,并建议进行联络。
- Alibaba Cloud Intl 联系 Jaybhadauria:Jaybhadauria 向来自 Alibaba Cloud Intl 的成员提供了可以提供帮助的人员的联系邮箱。
Modular (Mojo 🔥) ▷ #mojo (27 messages🔥):
Mojo Bounds Checking, Mojo negative indexing, fn keyword proposal
- Mojo 1.0 路线图中的边界检查(Bounds Checks)?:讨论围绕 Mojo 1.0 的 bounds checks 路线图展开。一位成员建议
my_list[i]默认应执行边界检查,或者明确指示这是一个 unsafe 操作;而另一位成员澄清说,边界检查在启用断言的 debug 模式下是可用的。- 有成员建议同时提供
lst[i]的 checked 和 unchecked 版本,在已知索引未越界时使用 unchecked 版本,并提议了lst[i]对比lst._[i]的语法,其他成员则建议使用lst.get(i)或lst.unchecked_get(i)。
- 有成员建议同时提供
- 负索引(Negative Indexing)计划移除!:一位成员引用了一段讨论,其中 Chris Lattner 提到 Mojo 中的负索引可能会被完全移除,原因是由于有符号类型的性能问题,详见 论坛讨论。
- 这一决定旨在解决与有符号类型相关的性能问题,特别是在 GPU 或 NPU 执行等上下文中,Pythonic 行为 可能存在不兼容。
- 终于,Mojo 要抛弃 fn 关键字了?!:一位成员链接了新 nightly 构建中的一项提案,该提案几乎影响所有 Mojo 代码,内容关于 从 Mojo 中移除
fn,其中def不再隐含raises。- 观点不一,一些人认为
def已经足够,并强调保持贴近 Python 的重要性;而另一些人则青睐fn,建议优先考虑性能而非相似性,并彻底废除这种分裂的行为。
- 观点不一,一些人认为
Modular (Mojo 🔥) ▷ #max (2 messages):
ops.while_loop 错误,使用 MAX 部署 Qwen3.5
ops.while_loop中发现隐蔽 Bug:一位成员报告在图(graph)中使用 GPU ops 时遇到了ops.while_loop的隐蔽 Bug,最初怀疑是其自定义 Mojo op 的 GPU 实现问题。- 经过深入调试,该问题在使用内置 ops 时被重现,并已在 GitHub 上提交了 Bug 报告。
- 在 MAX 上部署 Qwen3.5:社区经验?:一位成员询问了通过 MAX 提供 Qwen3.5 模型服务的经验。
- 该成员征求了社区关于这一特定模型部署的尝试或见解。
Eleuther ▷ #general (15 messages🔥):
基于 CoT 的基准测试,基准测试中的用户歧义,基准测试中的模板与偏见,Enron 数据集可用性
- 关于使用 CoT 进行基准测试与显式测试模板的辩论升温:成员们辩论了使用 multi-shot Chain of Thought (CoT) 是否比使用明确告知模型正在接受测试的模板更有效,争论焦点在于现实世界相关性和潜在偏见。
- 有观点认为,虽然 CoT 旨在模拟现实世界的使用情况,但它仍然会引入偏见。然而,一位成员承认,接受 multi-shot CoT 可能仅仅是因为历史原因和惯性。
- 用户歧义对基准测试的影响比想象中更大:讨论强调了用户歧义是现实场景中的一个因素,建议模型应该足够健壮以处理它。
- 一位成员质疑为什么 CoT 示例是可以接受的,而其他形式的 Prompting 却不行,因为 CoT 也可以被视为一种模板。
- MATS 拒绝的苦恼:一位成员分享了被 MATS 拒绝的经历,其申请仪表盘显示未进入下一阶段。
- 发布者正在寻求其他可能被拒绝的人的确认。
- Enron 邮件数据集结构:一位成员询问了结构化 Enron 邮件数据集的可用性,专门寻求提取后的邮件而非原始数据。
- 另一位成员建议可能需要预处理数据,因为直接可用的结构化数据可能并不容易获得。
Eleuther ▷ #research (11 messages🔥):
2x2 实验澄清,基于激活模式的神经元删除,CoDA adapter 架构影响
- 关于 2x2 实验困惑的澄清:一位用户发现各种 2x2 实验 的描述令人困惑,尤其是为什么 “Standard GQA Unbounded PPL” 比 Mistral 基线的 4.81 更差。
- 另一位用户澄清说,5.75 并不是原始的 Mistral-7B 模型,而是将所有 32 个注意力层更换为 adapter 架构并仅微调 18.6% 参数后的 Mistral-7B,并进一步指出 4.81 -> 5.75 的差距是 adapter 架构 + 有限微调的代价。
- 基于激活模式的神经元删除引起关注:一位用户提议删除在整个数据集上全为正或全为负的神经元,并引用了这篇论文。
- 这引发了对某种利用激活动量(activation momentum)来鼓励多样化激活模式的优化器的想象。
- CoDA Adapter 架构受到质疑:一位用户质疑在既不使用 –no-differential 也不了解 CoDA adapter 在这种“禁用”状态下的真实作用时,为什么要更改模型。
- 他们还询问为什么“adapter 架构”会改变任何东西?
Eleuther ▷ #interpretability-general (6 messages):
Communicative IR Systems, Probing Dialogue Acts and Stance, Nnsight Updates, Linear Decodability of Hidden States
- 正在构建交互式检索系统(Communicative IR System): 一名成员正在为 EN/JP 构建一个小型 ‘communicative IR’(包含 ACT + PAYLOAD + STANCE),并正在寻求探测实验(probe experiment)的参考文献和最佳实践。
- 他们询问了关于探测 对话动作/立场变量(dialogue-act / stance variables) 是否可以跨语言从隐藏状态(hidden states)中线性解码的相关研究。
- 对话系统中预期的线性可解码性: 一名成员预期 对话动作/立场 的属性是线性可解码的,并建议在所有层的残差流(residual stream)上训练扫描探测器(sweeping probes)。
- 他们提到在多轮对话中,为子集或单个轮次(turns)添加标签将需要复杂的设置。
- Nnsight 工具升级并推出新功能: 一位成员分享了 Nnsight 的更新,强调了用于干预模型内部的更快的追踪(traces)和更好的错误信息。
- 更新包括 LLM-friendly docs,旨在教导 AI 编程助手如何进行可解释性分析;对 🤗 VLMs 和扩散模型(diffusion models)的一流支持;以及 vLLM 多 GPU 和多节点支持。
Yannick Kilcher ▷ #general (14 messages🔥):
Open Weight, Anthropic DoD, Entity list threat, Dario Amodei, Schoolyard Bullies
- 权重开放(Open Weight)之梦: 一位成员分享了关于 open weight 梦想的 链接。
- 另一位成员回复道:“这真的很赞(based),没有推诿之辞。”
- Anthropic 遭到美国国防部(DoD)抨击: 成员们正在讨论关于 Anthropic 和美国国防部(DoD)的一份 声明。
- 根据一位成员的说法,这 “比失去 2 亿美元的合同要糟糕得多,” 因为他们威胁要 “将该公司列入禁止实体清单……强迫他们向美国政府开放其模型/代码的访问权限”,以用于大规模监控和自主武器。
- Anthropic 面临实体清单威胁: 讨论涉及美国政府可能将 Anthropic 列入禁止实体清单。
- 一位成员将其描述为一种典型策略:“看看这家公司是否会向金钱屈服;如果不,尝试 (1);如果不,尝试 (2)”。
- Dario 被视为书呆子(Dweeb)?: 一位成员想知道 Dario Amodei 是否因为外表而被人摆布。
- 另一位成员回应道:“我不认为有那么深层的原因:他们想要某些东西,就会确保得到它。”
- 政府如同校园霸凌者: 一位成员分享了一个 Truth Social 链接 及其附带的图片,似乎与 Anthropic 的处境有关。
- 另一位成员对更深层的解释不屑一顾,说:“校园霸凌者没什么深层可言。”
Yannick Kilcher ▷ #paper-discussion (1 messages):
ElevenReader app, Text-to-speech, Richard Feynman Voice
- Reader 应用使用 Feynman 的声音朗读: 一位用户热情地推荐了 ElevenReader 进行文本音频阅读。
- 该用户幽默地建议使用该应用,让 Richard Feynman 的声音 来朗读文本。
- ElevenLabs 文本转语音应用广受好评: 一位用户强调了 ElevenLabs text-to-speech app 的质量。
- 他们发现该应用在将文本转换为音频方面表现出色。
Yannick Kilcher ▷ #ml-news (5 messages):
Anthropic Statement, Google's Intelligent OS, Microsoft Copilot Tasks, Google's Opal Agent, Trump's Truth Social Post
- Anthropic 发布声明: Anthropic 就一个未知话题发表了声明,未给出具体细节。
- Google 宣布推出用于 AI Agent 的智能 OS: Google 宣布了 智能 OS,该系统将允许 AI Agent 在其操作系统上运行。
- Microsoft Copilot 处理任务: Microsoft 宣布 Copilot 现在可以处理任务,将回答转化为行动。
- Google Labs 推出 Opal Agent: Google Labs 推出了 Opal Agent,但尚未给出关于该 Agent 功能的具体细节。
- Trump 在 Truth Social 上发帖: Donald Trump 在 Truth Social 上发布了动态,但帖子内容未详细说明。
MCP Contributors (Official) ▷ #general (13 messages🔥):
Model Context Protocol PING, MCP Initialization Clarification, Bedrock AgentCore PING workaround, Python SDK Interpretation
- 阐明 MCP 初始化前的 PING 作用: 讨论质疑了 Model Context Protocol 中的
ping工具是否应该在initialize调用之前工作。- 会上指出,PING 机制描述中的 ‘still’ 一词可能表明它是为现有连接设计的。
- 运行时 Bedrock AgentCore PING 的变通方案: 为了确保容器健康检查,Bedrock AgentCore 会 PING 客户的 MCP 服务器,但由于 Python SDK 强制要求在 PING 之前进行初始化,他们创建了一个临时会话。
- 这样做是为了避免干扰外部客户端会话,这也是针对 SDK 对 MCP 规范理解的一种变通方案,凸显了初始化前 PING 的实际应用问题。
- Python SDK 对 PING 的强制执行: Python SDK 强制要求必须在发送
ping之前进行初始化,这符合对 MCP 规范的一种解释。- 这种强制执行导致 Bedrock AgentCore 在进行健康检查时必须创建一个临时会话。
Manus.im Discord ▷ #general (7 messages):
Customer service issues, Skills vs knowledge confusion, AI & full-stack systems
- Manus 的客户服务遇到困难: 一位用户对 Manus 的客户服务表示不满,称尽管已经提供了验证(包括系统确认),但仍被反复要求验证。
- 一名团队成员回复请他们私信(DM)其电子邮箱地址和会话链接。
- 探索技能(Skills)与知识(Knowledge)的混淆: 一位用户对 Manus 中技能与知识的关系表示困惑,指出他们创建的技能也被建议作为知识使用。
- 另一位用户建议 Manus 使用
skill.md文件的方式可能与其他系统略有不同。
- 另一位用户建议 Manus 使用
- AI 和 Full-Stack 工程师展示技能: 一位工程师详细介绍了他们在 AI 和 Full-stack 开发方面的经验,强调构建在现实条件下可扩展、整洁、可维护且安全的系统。
- 他们重点展示了在 LLM 集成、工作流自动化、AI 内容审核、图像 AI、语音 AI 和机器人开发方面的技能,以及使用各种技术的 Full-stack 开发能力。
- 医疗领域的 AI + Full Stack 工程师: 一位工程师介绍自己为 AI + Full Stack 工程师,专注于为医疗保健领域构建生产级 AI 系统,包括临床 NLP、医学影像和面向患者的 AI 应用。
- 该工程师提到核心技能包括 医疗 AI 流水线、临床 NLP、医学影像 AI、医疗 LLM 系统、Agentic AI 系统、RAG + 知识系统、Full-stack 交付以及自动化与集成。
tinygrad (George Hotz) ▷ #general (5 messages):
shared memory, shm_suffix, robots
- Shared Memory 相关问题:一名成员指出 PR 15033 可能需要为每一次对
_setup_shared_mem()的新调用添加shm_suffix。- 他们建议通过 PR 15030 来避免这种情况。
- Tinygrad 吸引机器人开发者:一位用户提到 Twitter 引导他们关注 Tinygrad,暗示它对构建机器人的人很有吸引力。
- 他们询问应该加入哪个频道来了解更多关于这一特定应用的信息。
DSPy ▷ #general (2 messages):
dspy.RLM, Seattle
- DSPy RLM 在西雅图?:一位成员询问是否有可能在西雅图组织与 DSPy RLM 相关的活动。
- 他们表示愿意协助组织工作。
- 志愿者提供帮助:一名志愿者主动提出帮助组织 DSPy RLM 活动。
- 未提供其他背景信息。
aider (Paul Gauthier) ▷ #general (2 messages):
aider indexing documents, md files, code indexing
- Aider 考虑像索引代码一样索引文档:一位用户建议 aider 应该像索引代码一样索引 markdown (md) 文件 等文档。
- 文档项目的潜在改进:索引文档可能会提高在大型文档项目中使用 aider 的效率。
MLOps @Chipro ▷ #events (1 messages):
World Model architectures, JEPA / V-JEPA, Dreamer, Genie, Sora
- 通过 Paper Clinic 深入研究世界模型:Ti.g 正在举办一个分为两部分的 “paper clinic”,旨在拆解和讨论综述论文 “Understanding World or Predicting Future? A Comprehensive Survey of World Models” (arXiv:2411.14499)。
- 该研讨会旨在构建世界模型架构的思维导图,并讨论 JEPA / V-JEPA、Dreamer、Genie、Sora 以及 World Labs 等主题。
- 探索 AGI 研究的未来:本次 paper clinic 将探讨 “Mirror vs. Map”(镜子 vs. 地图)之争,讨论世界模型中的 生成 vs. 表征 (generation vs. representation)。
- 讲座还将进一步讨论 AGI 研究的下一步:空间智能 (spatial intelligence)、因果关系差距 (causality gaps) 以及 社交世界模型 (social world models)。
- 注册参加分会:第一场将于 2 月 28 日(周六)10:00–11:30 AM EST 举行,重点讨论世界模型的基础 + “镜子 vs. 地图”之争(在此注册)。
- 第二场将于 3 月 7 日(周六)10:00–11:30 AM EST 举行,重点讨论竞争格局(Sora vs. Cosmos vs. V-JEPA)+ AGI 前沿(在此注册)。