ainews-ai-discords-1262023-9118
谷歌的 Gemini……靠谱吗?
谷歌的 Gemini AI 模型正引发广泛的讨论和质疑,尤其是针对其 32-shot 思维链 (Chain of Thought) MMLU 跑分声明以及 32k 上下文窗口。社区正在将 Gemini 的性能和能力与 OpenAI 的 GPT-4 和 GPT-3.5 进行对比,并重点关注即将在 Bard 平台上推出的 Gemini Pro 和 Gemini Ultra 模型。
与此同时,用户报告了 OpenAI 的各种服务问题,包括聊天机器人错误和订阅故障。讨论内容还涉及提示工程 (Prompt Engineering) 技术、针对 GPT-4、Claude 2.1 和 PaLM2 的 AI 模型评估,以及语音和多模态能力的提升。此外,该机器人目前已支持读取并总结来自 arXiv、Twitter 和 YouTube 等平台的链接,进一步增强了用户交互体验。
各位 Alpha 测试者,你们好!
没错,现在的时事通讯有了自定义的开场白。我们非常荣幸,数以百计的读者竟然找到了这个简陋的 MVP,所以我决定加入一点点最后的人文关怀点评。
今天的大新闻当然是 Google Gemini。多个 Discord 频道都在讨论它——营销做得非常出色,但人们理所当然地持怀疑态度。其中最主要的一点是,核心的 MMLU 声明是基于 32-shot chain of thought 的:
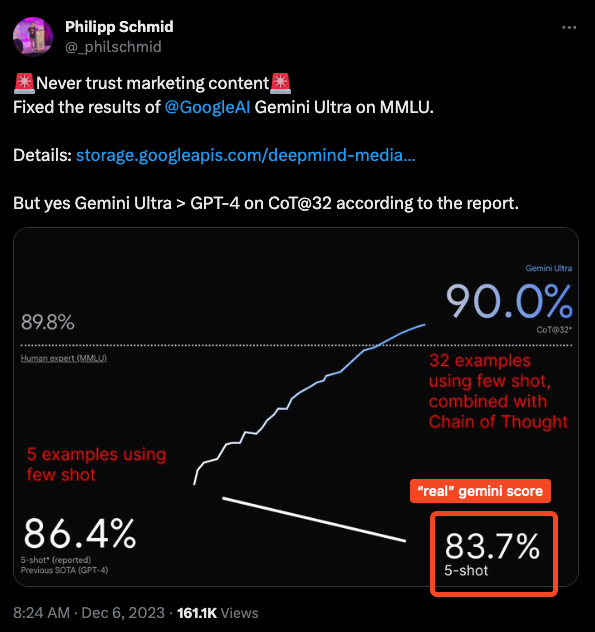
我们将在 12 月 13 日了解更多信息。
其他消息:
- 我们的机器人现在会尝试读取用户发送的链接。例如,如果你看到 Latent Space Paper Club,我们放入 arXiv 链接,摘要生成器就能识别这些论文的标题和摘要。Twitter/YouTube/HN 等链接同理。
- Discord 链接现在会直接跳转到捕获的第一条消息,感谢 Sam Ching 的反馈。
明天见,
swyx
[TOC]
OpenAI Discord 总结
-
围绕 Google Gemini 和 OpenAI GPT-4 模型展开了热烈讨论,重点关注它们的能力、性能预期及对比。参与讨论的用户包括
@solbus、@bambooshoots、@anurag9249、@DawidM、@alexblue66、@dezuzel等。讨论中还提到了 Gemini 的上下文窗口大小以及 Bard 平台的图像溯源能力。 -
报告了多项关于 OpenAI 服务 的问题,包括 Chatbot 错误、访问问题和文件管理。显著的问题包括 GPT Plus 订阅未被识别、GPT 上的知识文件消失,以及处理特定请求时出现无效响应错误。相关用户名包括
@merlinkyle、@signate、@chepe87、@creator320、@da.a、@coalescamarenus等。 -
Gemini Pro 被认为优于 GPT-3.5 引发了市场竞争讨论。用户对 ChatGPT+ 订阅无限期的等待以及 Prompt 失败仍扣除使用次数表示不满。针对即将推出的 GPT 版本,用户建议在语音、多模态能力、速度和上下文处理方面进行功能改进。
-
提出了不同的 Prompt Engineering 技术来增强 AI 生成的输出。深入讨论了 AI 回复变短的潜在根本原因。
@iyioio介绍了一种托管在 NPM 上、名为 “convo-lang” 的 GPT 模型新 Prompt 语言。此外,还提出并辩论了关于 JSON 响应行为异常和未指明的 AI 指令处理问题。 -
用户分享了关于 AI 模型评估 的资源和经验。
@tony_07612提供了一个链接,对比评估了 GPT-4、Claude 2.1 和 PaLM2,同时讨论了 GPT 的改进和功能问题。
OpenAI 频道总结
▷ #ai-discussions (113 条消息):
- Google Gemini vs OpenAI GPT-4:关于 Google 新发布的 AI 模型 Gemini 及其与 OpenAI GPT-4 的对比展开了活跃讨论。用户
@solbus、@bambooshoots、@anurag9249、@DawidM、@dezuzel等探讨了该话题,重点关注了目前在 Google Bard 平台上线的 “Gemini Pro” 以及即将推出的 “Gemini Ultra”。 - Gemini 性能预期:
@alexblue66和@bambooshoots就 Google Gemini 模型的性能预期交换了意见。然而,用户也强调,很难验证尚未发布的模型的声明。 - Bard 与 Gemini:用户
@anurag9249和@offline谈到了 Bard 的功能,讨论了 Bard 是否能使用 Gemini 进行图像生成,并澄清它只是从网络上查找现有图像。 - OpenAI 登录问题:用户
@merlinkyle寻求关于 OpenAI 登录问题的帮助,@satanhashtag协助进行了故障排除。 - 报告 OpenAI Chatbot 错误:
@solbus为@pipounix.提供了如何记录 GPT Chatbot 遇到的错误的信息,并分享了专门用于此类报告的频道。 - Gemini 的上下文窗口:Google Gemini 的上下文窗口大小是另一个关注点,
@anurag9249和@kotykd讨论提到 Gemini 拥有 32k 的上下文窗口。 - AI 数据助手评估:用户
@tony_07612分享了一个链接,内容是他作为 AI 数据助手对 GPT-4、Claude 2.1 和 PaLM2 进行的对比评估。
▷ #openai-chatter (307 条消息🔥):
- GPT-4 vs Gemini:用户讨论了他们使用 OpenAI GPT-4 模型和搭载了新发布的 Gemini 模型的 Google Bard 工具的体验。一些用户表示,他们发现 Gemini Pro 在当前状态下优于 GPT-3.5,且接近 GPT-4。提到的一份报告指出, Gemini Ultra(尚未开放使用)在多个类别中比 GPT-4 高出 1-2%。
- ChatGPT 订阅等待名单:用户对无限期等待订阅 ChatGPT+ 表示越来越沮丧。讨论仍在继续,但
@solbus确认目前还没有关于何时重新开放订阅的官方公告。 - ChatGPT 的技术问题:多名用户报告了 ChatGPT 的技术问题,包括提示词(prompt)超限的消息以及对话过程中的错误。
@picturesonpictures对这些持续存在的问题表示担忧,并指出失败的 prompt 似乎仍会从使用次数中扣除,他们认为这是不可接受的。 - ChatGPT 的未来增强功能:用户推测了 ChatGPT 未来版本中可能实现的改进,包括单一模型中的多模态(multimodal)能力、更快的速度以及更好的上下文处理。一些用户还希望 GPT-4 能够脱离订阅模式,向用户提供更直接的访问权限。
- 竞争与市场前景:Google Bard 工具最近的改进引发了关于 AI 对话模型竞争格局的讨论。一些用户指出,竞争最终对消费者有利,并期待看到更多的创新和服务改进。还有人对 Google 即将推出的搭载 Gemini Ultra 的 Bard Advanced 可能采取的收费结构进行了推测。
▷ #openai-questions (56 条消息):
-
Premium GPT 订阅问题:有多起关于 GPT 服务的投诉,包括
@signate、@eejai42、@joeycan2、@beeman.dev和@yoruiopz。讨论围绕着尽管支付成功但 GPT 高级订阅未被识别、网络错误、服务中断以及在 GPT 对话中附加特定格式文档时出现的严重服务器错误。 -
“知识库”文件被删除:
@chepe87、@alienpotus和@tarn0ld等用户报告了他们在 GPT 上的知识库文件消失的问题。尽管成功上传了文件,但这些文件在重新访问或发布后经常消失。@eskcanta建议这可能是一个新 bug,建议用户向 OpenAI 支持团队报告并希望得到修复。 -
用户验证与重新访问服务:
@creator320和@nellly1讨论了关于用户验证和账号停用的问题,以及他们是否仍能使用旧账号访问 OpenAI 服务。 -
语音转文字功能咨询:用户(
@da.a、@ex_hort.、@satanhashtag、@nachos.ai)交流了关于 Text to Speech 功能的存在。结论是该功能在移动端存在,其他平台的用户可能需要插件。 -
自定义 GPT 文件限制:
@coalescamarenus和@solbus确认了一个 GPT 无法识别上传文件的问题,这可能是由于目前每个 GPT 限制 10 个文件的上限。文件丢失问题可能也是 GPT 文件管理中一个持续存在的 bug。
▷ #gpt-4-discussions (69 messages):
- GPT 知识库文件问题:多位用户(包括
@heuehdhdb、@chepe87、@a2jhagrhbm92awno和@weiwenn)报告了在尝试编辑 GPT 时,上传的 知识库文件消失 的问题。@pietman注意到 GPT 还会忽略他的知识库文件,并且没有按照指示执行 web browsing 或运行 Python。 - GPT 功能问题:用户
@borisproductions对 GPT 的限制 表示不满,特别是在尝试寻求考试题目帮助时,该行为被标记为违反 OpenAI 的服务条款。 - Vision 使用案例咨询:用户
@zainsheikh寻求关于使用案例的建议,询问如何使用 GPT-4 Vision 来 识别和分离常见图像。他被@satanhashtag引导至另一个频道。 - GPT 状态:尽管 OpenAI 官方状态页面显示当前没有问题,但用户报告 GPT 的各种功能无法正常工作。
@pietman注意到了这种差异,而@satanhashtag则报告他那边没有问题。 - 文件翻译:用户
@mysteries_praisethefool询问了 GPT 翻译文件的能力。讨论期间未提供任何回复。 - 在 GPT Action 响应中返回文件:用户
@jdo300询问是否可以在 GPT 的 Action 响应中返回文件(如 CSV)。讨论期间未提出解决方案。
▷ #prompt-engineering (31 messages):
-
提升 Chatbot 响应的技巧:
@27.3degwest分享了关于改进 Chatbot 输出长度和相关性的想法。他们建议在 Prompt 中加入头脑风暴步骤,并降低 “temperature” 参数以减少无关输出。 -
添加指令会缩短 Chatbot 响应:
@tonyaichamp报告了一种特定行为,即包含关于响应格式的额外指令似乎会缩短 AI 的响应长度。他们链接了一个关于此观察结果的详细 OpenAI 论坛讨论,链接见 此处。 -
推理类 Prompt 列表:
@alienanthony询问了除 “StepByStep” 之外的其他推理类 Prompt 格式,@tonyaichamp推荐了 LearnPrompting 网站作为资源。 -
为 GPT 模型开发新的 Prompt 语言:
@iyioio提到他们正在开发一种适用于 GPT 模型(包括 GPT-3.5、GPT-4 和 GPT-vision)的新 Prompt 语言。他们分享了该项目 “convo-lang” 可以在 NPM 上找到。 -
从 OpenAI API 获取正确的 JSON 响应:
@quantumqueenxox提出了关于从 OpenAI API 接收到不稳定的 JSON 响应的问题。@ex_hort.评论说,问题可能是由于指令不清晰或难以理解造成的。
▷ #api-discussions (31 messages):
- 带有额外输出指令的模型行为:
@tonyaichamp观察到,添加详细的输出格式指令似乎会导致 AI 生成的响应显著变短,这一行为也在 OpenAI 论坛 上进行了讨论。 - 不同的 Prompt 生成类型:
@alienanthony询问了针对推理问题的不同 Prompt 生成类型,@tonyaichamp将其推荐至 LearnPrompting 网站。 - 为 GPT 模型开发的新 Prompt 语言:由
@iyioio设计的一种用于 Prompt GPT 模型的新语言已经开发完成,并在 NPM 包管理器上以 “convo-lang” 的名称分享,目前正向社区征求反馈。 - 关于 JSON 输出稳定性:
@quantumqueenxox表达了在从 AI 获取一致的 JSON 格式输出方面的困难。然而,讨论中没有分享明确的解决方案。 - 改进的 Prompt 指令:
@ex_hort.提供了一种有效的方法,可以将 Prompt 包含在对话中,而无需将其括在单独的括号内。
LLM Perf Enthusiasts AI Discord 总结
- 围绕小型和大型语言模型(Small and Large Language Models)的背景和实用性进行了详细讨论,涉及尺寸决定因素和性能复杂性;正如
@thebaghdaddy所提到的:“……小型语言模型参数较少,更容易针对特定任务进行微调(fine-tune)”。该用户还分享了一个宝贵的教育资源:大型语言模型入门视频。 - 对 Google 的 Gemini AI 发布表示兴奋和期待,并附上了官方 Gemini AI 博客文章链接(点击此处)。值得注意的是,
@pantsforbirds对 Gemini Ultra 的安全性检查能否达到适当平衡表示期待。 - 讨论了与 GPT-4 Turbo 相关的重大更新和担忧,例如速率限制(rate limits)的提高、
@res6969观察到的延迟(latency)降低,以及报告的 Chat-GPT 延迟和 Vision API 的问题。 @lhl分享了一个开源的 Shisa 7B 多语言模型,旨在日语和英语中都有出色表现。该模型及相关文档可以在此处找到。- 在 AI 系统长篇问答和适应度函数(fitness function)建模的背景下讨论了评估实践。
- 对即将举行的活动进行了前瞻性规划,包括参会确认、邀请 Google Gemini 团队参与的提议,以及在活动期间举办“提示词狂热微型演示日(mini demo days of prompting madness)”的建议。
LLM Perf Enthusiasts AI 频道总结
▷ #general (15 条消息):
- 理解小型语言模型:针对
@dongdong0755的提问,@thebaghdaddy解释说,小型语言模型参数较少,更容易针对特定任务进行微调。他们还提到,在某些情况下,经过特定调整和微调的小型模型表现优于大型模型。不过,他们也指出,根据经验,GPT-4 的表现通常优于较小的模型。 - 分享 LLM 入门链接:
@thebaghdaddy分享了一段由 OpenAI 科学家制作的 大型语言模型入门视频。 - 语言模型尺寸分类:
@dongdong0755和@thebaghdaddy讨论了拥有 7B 参数的语言模型(如 Llama2)是否可以被视为小型模型。他们得出的结论是,分类可能取决于具体任务,尽管通常参数少于 10B 的模型被视为小型模型。 - Google Gemini AI 发布公告:
@pantsforbirds分享了 Google Gemini AI 发布公告的链接,并对 13 号发布的 API 表示期待。包括@wenquai、@adeelzaman和@res6969在内的其他成员也对此次发布表示了兴趣和期待。 - 模型的安全措施:
@pantsforbirds引用 Gemini 公告称,在发布前正对 Gemini Ultra 进行重大的信任与安全检查。他们希望该模型不会受到过度限制,因为这可能会导致使用困难。
▷ #gpt4 (10 条消息):
- GPT-4 Turbo 速率限制提升:用户
@res6969注意到 GPT-4 Turbo 速率限制显著提高,分享称他们刚刚获得了 GPT-4 Turbo 上 600k TPM 的访问权限。 - GPT-4 延迟降低:同一用户
@res6969还报告了延迟(latency)的降低。 - Chat-GPT 延迟问题:用户
@pantsforbirds报告称在 Chat-GPT 中遇到了波动且普遍较差的延迟。然而,他们指出在 API 中缺乏针对相同观察结果的可靠基准测试。 - Vision API 问题:用户
@blakeandersonw和@daymanfan指出 Vision API 对他们来说无法正常工作。
▷ #opensource (1 条消息):
- 多语言模型 - Shisa 7B:用户
@lhl公开发布了一个名为 Shisa 7B 的日语和英语(JA/EN)双语模型。该模型的目标是在日语任务中实现高性能,同时保留强大的英语能力。它使用了合成数据和类似 Mistral 7B 的模型。所有使用的数据集、方法论和代码均已公开以供复现。该模型可以在 Hugging Face 上找到。
▷ #eval (4 messages):
- Context Window 的改进:
@res6969提到他们在应用中使用 Context Window 后看到了显著的改进。 - 评估生成内容与人类内容:
@pantsforbirds提出了关于评估 AI 生成的长篇问题回答与人类创作内容相比的最佳实践问题。 - Fitness Function 建模:
@pantsforbirds还对在 AI 系统中建模 Fitness Function 表示好奇。
▷ #irl (6 messages):
- 参加活动:用户
@jeffreyw128确认参加该活动。 - 参与人数:用户
@res6969分享了目前参加活动的人数为 35 人。 - 联系 Google Gemini:
@res6969思考是否可以邀请 Google Gemini 的员工参与活动。 - 提议的 IRL 活动:用户
@frandecam建议在 IRL 活动期间举办 “mini demo days of prompting madness”。
Latent Space Discord 总结
- 围绕各种 Large Language Models (LLMs) 的讨论,例如由
@swyxio引入的开源 Magicoder(根据 论文,其在 HumanEval+ 上的表现优于 ChatGPT),以及由@aravindputrevu和@guardiang提到的 Google DeepMind 的 Gemini。 @kbal11参考一篇 博客文章 强调了散文中的某些短语如何暴露底层的 LLM。- 由
@__chef__发起的对用于 text to video 和 image to video 转换的开源软件的探索。 @kevmodrome分享了诸如 MLX(适用于 Apple silicon 的数组框架)和 AxLearn 等技术。@philltornroth创新性地应用 GPT,通过输入菜单照片,根据饮食限制建议餐食选择。- 引用并参与了由
Kevin Ball、Eugene Yan和swyx主持的 LLM Paper Club 会议,明确提到了 Emergence paper 讨论(链接)以及关于在强化学习中使用 Transformer 的 Q-Transformer(链接)的讨论和批评。 - 解决了参与者关于 LLM Paper Club 会议访问权限和翻译质量的疑问和担忧。
Latent Space 频道总结
▷ #ai-general-chat (15 messages):
- Magicoder 介绍:
@swyxio分享了一篇描述 Magicoder 的 论文,这是一个完全开源的代码 Large Language Model (LLM)。关键点包括:Magicoder 模型使用 OSS-Instruct(一种使用开源代码片段的新方法)在 75K 合成指令数据上进行训练。MagicoderS-CL-7B 在 HumanEval+ 上的表现甚至超过了著名的 ChatGPT(pass@1 为 66.5 vs. 65.9)。 - LLM 散文风格观察:
@kbal11发布了一篇 博客文章,描述了某些短语如何揭示生成散文背后的 LLM,赋予其独特的“氛围 (vibe)”。 - Text to Video 讨论:
@__chef__发起了关于将文本转换为视频的开源软件模型/框架的讨论,并询问了关于将图像转换为视频的类似模型。 - 提及 MLX 和 AxLearn:
@kevmodrome分享了代码仓库链接:MLX(适用于 Apple silicon 的数组框架)和 AxLearn。 - GPT 建议餐食选择:
@philltornroth分享了一个有趣的 GPT 应用,通过输入菜单照片,根据食物偏好和饮食限制建议餐食选择。 - 介绍 Gemini:
@aravindputrevu和@guardiang提到并讨论了 Gemini,这是由 Google DeepMind 开发的一项技术。Gemini Ultra 的性能在各种推理和理解任务中与 GPT-4V 进行了比较。
▷ #ai-event-announcements (1 条消息):
- Emergence 论文讨论公告:
@swyxio宣布将在 5 分钟后开始关于 Emergence 论文的讨论环节。该论文可以在 https://arxiv.org/abs/2206.07682 找到,作者包括 Jason Wei, Yi Tay, Rishi Bommasani 等。 - LLM Paper Club 环节:此次讨论是由
Kevin Ball,Eugene Yan和swyx主持的每周 LLM Paper Club 环节的一部分。这些环节旨在回顾 LLM 论文,特别是基础性论文,对其内容进行拆解和讨论。该系列活动的注册地址为 https://lu.ma/llm-paper-club。
▷ #llm-paper-club (11 条消息):
- Q-Transformer 讨论:
@cakecrusher分享了一篇名为 “Scalable Offline Reinforcement Learning via Autoregressive Q-Functions”(即 Q-Transformer)的论文链接。该论文讨论了在强化学习中使用 Transformer 作为 Q 函数。 - 会议访问问题:
@iamkrish10在寻找加入会议的链接时遇到困难。@swizec和@coffeebean6887协助了他,并建议该链接可在 Discord 中找到,或者可能需要在 webui 上查找。 - 翻译质量担忧:
@hackgoofer对无缝翻译功能表示不满,称其输出和输入令人失望。
LangChain AI Discord 总结
- 对话围绕 LangChain Loader 展开,
@uhaseeb向@fatema_08922询问她在项目中使用 UnstructuredHTML Loader 的情况。 - 现场进行了活跃的技术对话,讨论了 LangChain 功能;从 使用 LangChain 设置 Instruct Prompt 到 在 LangChain 中合并文档,以及可视化方法和工具。
- 用户对 LangChain 与 Azure Open AI 的集成 表现出浓厚兴趣并提出了一些问题,如
@manojmd详细描述了他在处理企业数据和准确性问题方面的经验。 - 关于 文档存储(Document Storage) 有各种建议和对话,特别是
@.dame99和@veryboldbagel讨论了将不同主题的文档存储在不同集合(collections)还是同一集合中的优劣。 - 用户分享了他们的工作,包括
@.broodstar开发的 最先进的聊天机器人 API 服务,@appstormer_25583开发的 DIY 助手 GPT,以及@m1337d和@synacktra分别分享的关于将 Lang chain 嵌入 LLM 的信息和新版本的 Hypertion。分享的链接以便更好地访问和理解:
LangChain AI 频道总结
▷ #general (19 条消息):
-
在项目中使用 LangChain Loader:用户
@uhaseeb询问@fatema_08922在她的项目中使用了哪个 LangChain loader。她确认使用的是UnstructuredHTML Loader。 -
使用 LangChain 设置 Instruct Prompt:
@menny9762询问了在使用 ollama 运行本地 LLM 模型时,如何通过 LangChain 设置 instruct prompt。随后他自己提出了一个解决方案,涉及使用chain.call方法和handleLLMNewToken回调。 -
在 LangChain 中合并文档:由
@b0otable发起的一场讨论围绕在 LangChain 中合并文档展开。用户最初询问是否有内置工具可以在文档作为 ‘docs’ 返回后进行合并,随后澄清是想在已经获取 ‘docs’ 后合并文档。 -
LangChain 与 Azure Open AI 的集成:
@manojmd.讨论了将 LangChain 与 Azure Open AI 集成以处理企业数据的问题。他还分享了在此过程中遇到的问题,包括结果准确性不足以及对上传文档源文件的需求。 -
LangChain 数据摄取教程:
@aaravvv__寻求有关使用 LangChain 将数据摄取到 pinecone 实例的教程或文档。 -
其他 AI 工程师 Discord 社区:
@rez0表示有兴趣了解社区成员推荐并经常使用的其他 AI 工程师 Discord 频道。 -
用于文档咨询的 AI 工具:
@bru.leo发起了一场关于从文档中咨询信息的最佳非编程平台的讨论。@m0xt回复推荐了 Jerry 关于处理 PDF 中嵌入表格的演讲。 -
可视化 LangChain 流程:用户
@m0xt询问了除了 Langsmith 之外,还有哪些方法/工具可以用来可视化 LangChain 中的 chain、步骤、变量、schema 等。
▷ #langserve (2 条消息):
- 文档存储讨论:用户
@.dame99提到他们有不同主题的不同文档,并将它们存储在不同的 collections 中。作为回应,@veryboldbagel建议考虑将文档存储在同一个 collection 中并使用过滤器,并询问这些文档是否具有不同的 schemas 或完全不同的主题领域,以及一次性查询多种文档类型是否会有所帮助。
▷ #share-your-work (5 条消息):
- 聊天机器人 API 服务:用户
@.broodstar提供了他正在开发的最先进的聊天机器人 API 服务的访问权限。该服务声称能够设计出唤起情感、展开叙事并提供智力刺激的对话,以提高用户参与度。他向少数感兴趣的人免费提供该服务。 - DIY 助手 GPT:
@appstormer_25583分享了一个 链接,指向一个可以分析房屋维修图像并提供建议的 DIY 助手 GPT。 - LangChain 与 LLM:
@m1337d分享了一条 推文,指出 LangChain 现在可以嵌入到 LLM (Llama) 中。这允许 LangChain 代码作为 LLM 的回调直接在内部运行。 - New Version of Hypertion:
@synacktra宣布了支持 Pydantic 模型的新版本 Hypertion。他分享了 GitHub 仓库 和 Pypi 项目 的链接。Hypertion 是一个用于简化且高效的 LLM function calling 的 Python 库。
Alignment Lab AI Discord 摘要
- 关于日志记录和利用生产环境进行评估的最佳实践的讨论,重点关注聊天机器人和代码搜索。用户
@red_shoes_3寻求关于如何收集生产数据以用作不同应用程序训练数据的建议。 - 引用了 Jürgen Schmidhuber 的一条推文,其中阐述了他对面向规划的深度学习架构的贡献,由用户
@lightningralf分享。 - 社区互动:用户
@ajink024自我介绍并表示参加了 Open Source Meetup AI Data Source;同时用户@kainan_e提议举办一场关于 AI 应用从实验到大规模生产部署流程的见面会。 - 技术讨论集中在 lm-eval harness 4.0 的性能基准测试以及低于预期的 ARC 分数,同时用户
@nanobitz对 Winogrande + GSM8k 排行榜结果表示担忧。 - 用户
@imonenext和@benjamin_w分享了关于 Torch.jit 与 Flash Attention 接口的见解及相关挑战,指出torch.jit.trace中max_seqlen类型的问题、PyTorch SDPA 实现的局限性,以及通过 Torch.jit 实现 LayerNorm 可能带来的 5% 性能提升。相关链接包括此 issue 和一篇博客文章(注意此链接已失效)。
Alignment Lab AI 频道摘要
▷ #ai-and-ml-discussion (2 条消息):
- LLM 的生产运维 (Production Ops):
@red_shoes_3询问了关于日志记录和利用生产环境进行评估的最佳实践,特别是在聊天机器人、代码搜索等背景下。他们寻求关于如何收集生产数据,以便随后在不同应用场景中用作训练数据的见解。 - 深度学习与规划:
@lightningralf分享了 Jürgen Schmidhuber 的一条推文,Schmidhuber 在文中针对 Yann LeCun 的言论,展示了他对具备规划能力的深度学习架构的贡献。Schmidhuber 引用了他自 1990 年以来的大量出版物,并最后表示希望有一天能提供他自己的模型。
▷ #general-chat (3 条消息):
- 介绍与社区参与:用户
@ajink024自我介绍为 Asante,并提到他们参加了 Open Source Meetup AI Data Source。 - AI 应用生产化见面会推广:
@kainan_e鼓励其他人参加目前在 180 Townsend 举行的见面会,主题涵盖将 AI 应用从实验推向大规模生产的过程。该见面会计划演示一个旨在简化此过程的参考架构。详细信息已通过此链接分享。 - 现场注册:
@kainan_e提到现场仍可办理补登记。
▷ #oo (8 messages):
- 使用 lm-eval harness 4.0 的性能基准测试:用户
@nanobitz在注意到使用新发布的 4.0 版本 lm-eval harness 测得的 ARC 分数低于预期后寻求建议。结果似乎比 HF OpenLLM 排行榜上 7b chat 的结果要低。 - 关于 Winogrande + GSM8k 排行榜结果的疑虑:
@nanobitz还发布了一个关于 Winogrande + GSM8k 排行榜结果的查询,这些结果看起来有些异常。 - Torch.jit 与 Flash Attention 的接口对接:
@imonenext分享了在尝试将 Torch.jit 与 Flash Attention 结合使用时遇到的问题,并提交了关于max_seqlen类型与torch.jit.trace不兼容的 issue。 - Flash Attention 2 在 PyTorch SDPA 下的性能:
@benjamin_w提到 Flash Attention 2 在与 PyTorch 的 SDPA 实现对接时存在一些限制,由于每次外部 CUDA 调用都会导致图中断 (graph breaks),从而导致轻微的性能损失。尽管如此,他们还是分享了一个博客文章链接(链接已失效),讨论了 Flash Attention 2 优于 PyTorch SDPA 实现的场景。 - 使用 Torch.jit 提升 LayerNorm 速度:
@imonenext提供的反馈显示,对 LayerNorm 使用 jit 可以提升高达 5% 的性能。
MLOps @Chipro Discord Summary
- 用户
@erisianrite目前正在为一个显微镜任务探索弱监督语义分割 (Weakly Supervised Semantic Segmentation) 技术、Segment Anything 以及传统的 CNN 架构。他们请求推荐以了解这些主题的当前趋势。
MLOps @Chipro 频道总结
▷ #events (1 messages):
twenzy03: Hi
▷ #general-ml (1 messages):
- 探索弱监督语义分割技术:
@erisianrite正在进行一个项目,评估用于显微镜任务的 Segment Anything、弱监督语义分割 (WSSS) 技术和传统的 CNN 架构。他们正在寻求建议,以跟上 WSSS 技术的最新进展。
Skunkworks AI Discord Summary
只有一个频道有活动,因此无需总结…
rfhuang: 传闻称 GPT-5 将具备视频理解能力
AI Engineer Foundation Discord Summary
只有一个频道有活动,因此无需总结…
- 免费 Scrimba 订阅请求:用户
@vince_uc向<@500607885714128897>表达了对免费 Scrimba 订阅的感谢,并提到他们曾在 YouTube 上使用过免费版本,希望这个版本也能如此。
YAIG (a16z Infra) Discord Summary
只有一个频道有活动,因此无需总结…
- 关于 AWS Aurora Limitless 的讨论:用户
@rafaelnadal发起了关于 AWS Aurora Limitless 的讨论,这是 AWS 针对 Yugabyte/Cockroach 推出的新竞争产品。该用户想知道为什么 AWS 推出产品的时间比竞争对手晚这么多(Yugabyte 和 Cockroach 始于 2015/2016 年),以及这是否预示着分布式/双活 (Active-Active)、ACID 数据库存在巨大的市场。
Ontocord (MDEL discord) Discord 没有新消息。如果该服务器长期没有活动,请告知我们,我们将移除它。
Perplexity AI Discord 没有新消息。如果该服务器长期没有活动,请告知我们,我们将移除它。