ainews-12112023-mixtral-beats-gpt35-and-llama2-70b
2023年12月11日:Mixtral 击败了 GPT3.5 和 Llama2-70B。
Mistral AI 发布了 Mixtral 8x7B 模型,该模型采用了稀疏混合专家(SMoE)架构,引发了关于其是否有潜力抗衡 GPT-4 的热烈讨论。社区针对用于训练和微调 Transformer 模型的 GPU 硬件选择展开了辩论,涉及 RTX 4070、A4500、带有 nvlink 的 RTX 3090 以及 A100 GPU。此外,人们对微调 Mixtral、生成量化版本以及策划高质量代码数据集表现出了浓厚兴趣。分享的资源包括一段关于开源模型部署的 YouTube 视频、一篇 Arxiv 论文、GitHub 仓库以及一篇关于混合专家(MoE)的博客文章。讨论还涉及了 GPT-3.5 Turbo 和 Llama-3 可能的开源发布,以及在 Mac M3 Pro 上运行 OpenHermes 2.5 时的显存(VRAM)考量。
以下是来自 Mixtral 博客文章 的关键结果:
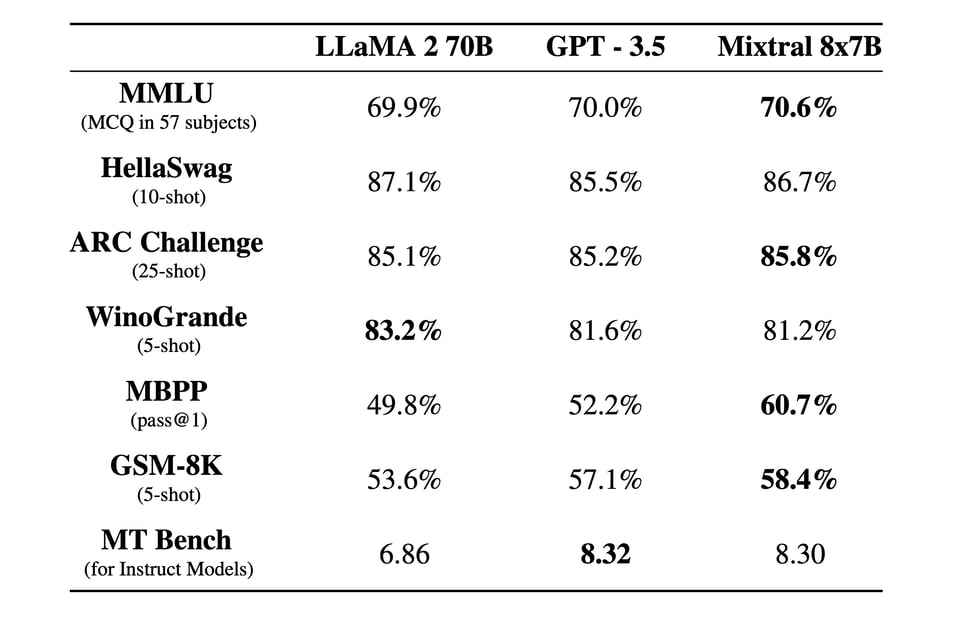
人们理所当然地在欢呼。他们今天还宣布了 他们的 API 平台。
[TOC]
Nous Research AI Discord 总结
- 公会讨论了用于训练 Transformer 模型和微调语言模型的 GPU 硬件 选项,考虑了如两块 RTX 4070、单块 A4500 或带有 nvlink 的 RTX 3090 等方案,并分享了一个在 A100 GPU 上运行 Mistral 8x7B LLM 的 YouTube 视频。
- 进行了关于 Mistral AI 的 Mixtral 模型 是否能因其高质量的 Sparse Mixture of Experts (SMoE) 输出而与 GPT-4 竞争的关键对话,并讨论了微调 Mixtral 以及生成该模型的 Quantized(量化)版本。
- 表达了对 策划高质量代码数据集 的兴趣,潜在任务范围包括生成代码、调试、翻译、注释、解释以及扩展/清理/转换代码。
- 公会成员分享并讨论了关键资源:一个讨论开源模型部署的 YouTube 视频、一篇 Arxiv 论文、GitHub 资源、一篇关于 Mixture-of-Experts (MoE) 的 博客文章,以及指向 Mistral 的 Mixtral 8X7B v0.1 的 GGUF 格式模型文件的 链接。
- 讨论了关于未来可能发布的版本,如 OpenAI 的开源版 GPT-3.5 Turbo 和 LLama-3,并分享了暗示此类进展的消息源,例如 (@futuristflower) 的推文、(@apples_jimmy) 的推文 以及 The Information 的文章。
- 澄清了关于在 Mac M3 Pro 上微调运行 OpenHermes 2.5 的问题,以及运行 Mixtral 8x7b 的 VRAM 需求,同时分享了 Llava v1.5 13B - GPTQ 模型的 HuggingFace 链接。
Nous Research AI 频道总结
▷ #off-topic (13 条消息🔥):
- 硬件讨论:用户
@airpods69向社区咨询选择用于训练 Transformer 模型和微调语言模型的 GPU 硬件建议。讨论围绕选择 两块 RTX 4070 还是单块 A4500 展开,前者是因为担心 A4500 价格过高。@giftedgummybee还提出了采购 RTX 4090 的想法。 - 替代 GPU 方案:
@giftedgummybee建议将两块带有 nvlink 的 RTX 3090 作为替代方案,并指出 A4500 与这些选项相比似乎溢价过高。 - Nvidia 的 EULA:用户
@kazamimichiru提到 Nvidia 的 EULA 限制在数据中心使用 RTX 系列 GPU,但这一点被@airpods69反驳,他澄清说该设置将用于家庭环境,而非要求更严格的数据中心环境。 - 在 A100 上运行 Mistral:
@pradeep1148分享了一个 YouTube 视频,展示了在 A100 GPU 上运行 Mistral 8x7B LLM 的过程。 - 开源 AI 网页开发:
@.plot提议帮助社区建立网站,表现出对开源 AI 领域的兴趣,并提到了之前的项目,如 open-neuromorphic.org 和 aimodels.org。
▷ #interesting-links (13 条消息🔥):
- 你是否应该使用开源大语言模型?:
@teknium分享了一个 YouTube 视频,讨论了在 WatsonX 上部署开源模型的话题。 - Arxiv 论文:
@euclaise分享了一篇 研究论文 的链接,不过未对其具体内容展开讨论。 - Awesome-llm-role-playing-with-persona:
@kazamimichiru指出了一个 GitHub 仓库,该仓库提供了使用大语言模型进行带有设定人格的角色扮演的相关资源。 - Mixture-of-Experts 讨论:
@.beowulfbr分享了他们的 博客文章,讨论了 Mixture-of-Experts (MoE) 作为 Large Language Models 未来发展的趋势。 - Mistral 的 Mixtral 8X7B v0.1 - GGUF:
@cyborgdream分享了 Mistral 的 Mixtral 8X7B v0.1 的 GGUF 格式模型文件 链接。他们提到 该模型可以在单张 3090 或任何具有 32GB 内存的 CPU 上运行。
▷ #general (545 条消息🔥🔥🔥):
- 目前正在进行关于 Mixtral 模型性能和潜力的讨论,这是 Mistral AI 最近发布的高质量 Sparse Mixture of Experts (SMoE) 模型。用户对其 微调能力、多语言支持 以及在性能上抗衡 GPT-4 的潜力表现出浓厚兴趣。
- 多位用户表达了尝试 微调 Mixtral 并生成量化版本 模型的意图。提到了关于量化的挑战和问题,特别关注于理解 Mixtral 的 VRAM 需求。
@nagaraj_arvind讨论了 Mixture-of-Experts 模型中的 router auxiliary loss(路由辅助损失),并指向了 HuggingFace Transformers 中最近添加 Mixtral MoE 支持的一个 PR。据报道,该 PR 包含一个自动计算辅助损失的设置,据@euclaise称,这有助于平衡 MoE 模型中专家(experts)的使用。@wlrd提出了 策划高质量编程数据集 的想法。@teknium支持这一想法,并概述了此类数据集可能包含的任务类型,包括生成代码、将代码翻译成其他编程语言、调试代码、注释代码、解释代码以及扩展/清理/转换代码。- 讨论了 Kenshin9000 关于 GPT-4 击败 Stockfish(最强国际象棋引擎) 的帖子。该用户表示将在两周内发布这一主张的证据。
▷ #ask-about-llms (50 条消息🔥):
- GPT-3.5 Turbo 未来的开源计划: 用户
@cyborgdream分享了几个泄露消息,暗示 OpenAI 可能发布 GPT-3.5 Turbo 的开源版本。来源包括 (@futuristflower) 的推文、(@apples_jimmy) 的推文 以及 The Information 的文章。讨论指出,此类发布可能会提升 OpenAI 在开发者中的声誉。 - LLama-3: 用户
@cyborgdream提到了 LLama-3,该模型预计将超越 GPT-4 并且是多模态的。据报道,该模型定于 2 月发布。 - 在 Mac M3 Pro 上进行推理和微调: 用户
@teknium和@night_w0lf回答了@httpslinus关于 M3 Pro 机器是否能运行 OpenHermes 2.5 的问题。两人都建议该电脑可以通过推理运行,但无法进行微调。 - 使用 Mixtral 和 Llava 13B 进行推理: 用户
@chhillee询问了 Mixtral 达到的最佳 tokens/sec。@papr_airplane在讨论运行 Llava 13B 模型推理时,分享了一个 Llava v1.5 13B - GPTQ 模型的 HuggingFace 链接。 - Mixtral 8x7b 的 VRAM 需求: 用户
@gerred询问 96GB VRAM 是否足以运行 Mixtral 8x7b。对话未提供具体答案。
OpenAI Discord 总结
- 围绕科学界真理哲学、公平性指标以及 AI 方法论中算法偏见的广泛讨论。辩论由
@light.grey.labs发起,@whynot66k20ni、@lhc1921、@solbus等人参与了贡献。 - 针对 OpenAI 服务性能和功能的共同担忧与问题,包括 ChatGPT 消息限制、GPT-4 订阅以及视频调色。用户
@robg2718、@rjkmelb、@lyrionex、@marcelaze、@lumirix、@croc_cosmos、@null_of_gehenna、@thunder9289、@prncsgateau、@solbus、@gd2x、@elektronisade、@swedikplay和@lugui参与了这些讨论。 - 关于 GPT-4 的各种担忧,包括漫长的等待名单、上下文理解问题以及性能不一致。
@kyper、@eveiw、@Rock、@.pywiz、@drcapyahhbara、@pietman、@solbus、@chotes、@napoleonbonaparte0396加入了讨论。 - 与提示词工程 (Prompt Engineering) 相关的广泛咨询和问题,重点在于提升模型性能、指令理解、审查问题、对标记语言的理解以及衡量提示词工程成功的指标。此番讨论得到了
@m0bsta、@cat.hemlock、@tp1910、@you.wish、@madame_architect、@exhort_one、@pfakanator和@bambooshoots的贡献。 - 报告了与 GPT-4 相关的各种技术问题,包括访问权限捐赠问题、网络问题、对性能和功能的不满、可能的账号封禁以及创建自定义 GPTs 时的挫败感,涉及用户包括
@strange073、@inspectorux、@lucianah、@slo_it_down、@kurailabs、@lumirix、@michaelyungkk、@rjkmelb、@maledizioni、@panospro、@maticboncina、@chealol、@digitallywired和@mfer.pirx。 - AI 艺术是一个显著的讨论话题,涉及修改规则的辩论、对
Bard和Gemini Pro等 AI 艺术工具的评估,以及由@rchap92、@lugui、@fluffy_dog__、@staniscraft、@avalani、@thunder9289和@julien1310等用户建议的 AI 新闻资源。 @swedikplay提出了对潜在版权侵权的担忧,@lugui确认 OpenAI 已意识到该问题并敦促转发更多相关信息。- 围绕提示词风格、DALL-E 政策、AI 性能、扩展的 AI 上下文等事项的激烈辩论和多样化观点,导致频道间产生大量互动,
@m0bsta、@cat.hemlock、@pfakanator、@mysticmarks1、@fluffy_dog__、@bambooshoots、@madame_architect、@eskcanta等人参与了讨论。
OpenAI 频道总结
▷ #ai-discussions (69 条消息🔥🔥):
- 科学中的真理哲学:对话由
@light.grey.labs发起,质疑科学界追求真理背后的动机。对话随后演变为关于现实、可观测性和量子物理本质的更广泛讨论,贡献者包括@whynot66k20ni、@lhc1921、@solbus等。 - 公平性指标与算法偏见:
@whynot66k20ni发表了关于算法公平性和偏见的随性评论,未对此话题进行详细讨论。 - AI 艺术修改规则:
@rchap92和@lugui之间关于使用 AI 工具生成真人图像指南的简短讨论,提到了 BING AI 和 Krea.ai 等多个平台。 - AI 艺术工具评估:
@fluffy_dog__和@staniscraft分别对Bard和Gemini Pro给出正面评价,此外@avalani、@lugui和@thunder9289之间就 Grok AI 进行了简短互动。 - AI 新闻资源:
@julien1310询问获取 AI 新闻的最佳资源,多位用户推荐了 Ycombinator、Perplexity 和 arXiv 等来源。特别是@shadowoftheturing分享了 arXiv 上计算语言学 (cs.CL) 和人工智能 (cs.AI) 领域近期提交论文的直接链接。 - AI 艺术放大 (Upscaling):以
@sgsd_发起的关于 AI 艺术放大的讨论结束,@elektronisade提供了多项建议,包括 Stable Diffusion、Magnific AI 和 Topaz 等免费及付费服务。
▷ #openai-chatter (131 条消息🔥🔥):
-
Android 上的语音功能:用户
@gd2x询问了 Android 设备上 ChatGPT 缺失语音功能的问题。@elektronisade建议可能是广告拦截 DNS 或服务在干扰,禁用后@gd2x确认问题已解决。 -
关于 OpenAI 的各种问题和讨论:许多用户提出了他们对 OpenAI 服务各方面的担忧和讨论。主题包括关于 ChatGPT 随时间变化的消息限制 信息不明确(
@robg2718,@rjkmelb,@lyrionex)、GPT-4 订阅 的等待名单和可用性(@marcelaze,@lumirix,@satanhashtag)、使用 GPT-4 进行视频调色 的可能性(@croc_cosmos,@null_of_gehenna,@thunder9289),以及 iOS 应用上针对旁白(voiceover)用户的 无障碍访问问题(@prncsgateau,@solbus)。在这些讨论中,包括@lugui、@offline和@mrcrack_在内的多位用户提供了信息或参考了相应的帮助资源。 -
潜在的版权侵权:
@swedikplay讨论了他们对 Discord 上一个可能侵犯 OpenAI 身份的第三方机器人的担忧。@lugui确认 OpenAI 已知晓此问题,并鼓励@swedikplay通过 DM 传递任何支持信息。 -
OpenAI 的功能和更新:多位用户询问了传闻中的 即将发布的公告(
@merpnderp)、通过 iOS 升级到 ChatGPT Plus 的能力(@alpha33589)以及期待已久的 GPT store 发布(@emiliaaaaa_)。然而,目前还没有确切的答复。 -
对 GPT 使用和性能的困惑与投诉:用户
@becausereasons、@mrcrack_和@Meme Popperz对 GPT 服务的性能表示不满,提出了 指令遵循、创造力下降、限制消息配额 以及使用过程中 网站卡顿 等问题。
▷ #openai-questions (97 条消息🔥🔥):
- 访问 GPT-4:
@strange073和@inspectorux讨论了访问 GPT-4 的捐赠标准。然而,聊天中并未明确说明如何通过捐赠 1 美元来获取访问权限。 - 性能问题:
@lucianah和@inspectorux对网络错误和处理时间缓慢表示沮丧,@lucianah怀疑由于 Plus 用户数量过多可能存在使用限制(throttling)。@slo_it_down也提到了反复出现的错误消息,尤其是在文件输入之后。聊天社区提供的故障排除建议极少。 - 使用 Custom GPT 处理复杂任务:
@kurailabs对 GPT-4 不愿根据特定指令完整生成法律论文表示沮丧,而 GPT-3.5 则愿意这样做。@lumirix提供了一些解释,并分享了 OpenAI 关于高风险政府决策的使用政策。 - 订阅问题:
@michaelyungkk报告了在尝试订阅时多次信用卡被拒的问题。@rjkmelb建议通过 iPhone App 订阅,并在该方法无效时建议通过官网联系 OpenAI 支持。 - 账号停用:
@maledizioni因误报年龄验证错误请求紧急恢复账号,但被@rjkmelb引导至 OpenAI 支持。 - 创建 Custom GPT:
@panospro、@maticboncina、@chealol、@digitallywired和@mfer.pirx提出了关于创建自定义 GPT 的问题和疑难。@mysticmarks1提供了帮助。 - 损坏且过长的聊天线程:
@maf2829讨论了一个提示“对话中的消息未找到”错误的问题。@elektronisade建议可能是线程损坏,并询问@maf2829是否使用了任何非官方的 ChatGPT 浏览器扩展。该问题仍未解决。
▷ #gpt-4-discussions (69 条消息🔥🔥):
- Custom GPT 的工具限制:
@kyper提出了关于 Custom GPT 可处理的函数数量限制以及包含工具是否消耗 Token 的问题。 - GPT-4 的问题: 包括
@eveiw、@Rock、@.pywiz和@drcapyahhbara在内的多位用户对 GPT-4 的性能表示担忧,包括难以记住上下文、性能不稳定以及漫长的等待名单。 - Custom GPT 中的指令: 讨论了将指令包含在 Custom GPT 的配置中还是放在知识库(Knowledge)文件中更好,
@smilebeda和@offline提出了建议策略。 - 在 GPT 中创建变量:
@pietman征求关于在 GPT 中创建变量以便在指令中引用的建议。@solbus和@chotes提供了实现此目标的策略和阅读资源。 - 创建 GPT 的限制:
@napoleonbonaparte0396询问了可以创建多少个 GPT 的限制。
▷ #prompt-engineering (93 条消息🔥🔥):
-
Prompt 与模型性能:
@mysticmarks1分享了对 DALLE3 模型偏差和问题的担忧,并表示他们调整了某些代码以提高其性能。然而,并非所有人都同意他们的观点。@pfakanator和@bambooshoots讨论了如何修改指令 Prompt 以获得更准确的结果。@cat.hemlock还分享了一份关于指导模型的 Markdown 格式详细指南。 -
GPT 对指令的理解:
@tp1910询问了在 Custom GPT 的配置部分或知识库部分添加指令的区别。聊天中没有给出明确答案。 -
OpenAI GPT 的游戏查询:
@you.wish寻求关于调整被 OpenAI 审查的游戏相关查询(Dead by Daylight)的建议。@madame_architect提供了一个似乎符合用户需求的建议。 -
标记语言咨询:
@exhort_one寻求关于 Markdown(一种标记语言)的澄清。 -
Prompt Engineering 成功衡量标准:
@madame_architect发起了关于衡量 Prompt Engineering 成功指标的讨论,重点是将语言的定性方面转换为定量指标。@cat.hemlock建议通过评估一致性来衡量成功。
▷ #api-discussions (93 条消息🔥🔥):
- 关于 Prompt 风格的讨论:
@m0bsta表示由于理解问题,在创建有效 Prompt 方面存在困难,而@cat.hemlock提供了如何使用 Markdown 创建有效 Prompt 的示例,并建议不要推迟这一过程。 - DALLE 政策:
@cat.hemlock分享了 DALLE(一种图像生成工具)使用政策的详细说明。这些说明涵盖了多个要点,例如其图像生成限制以及上下文限制和伦理准则。@cat.hemlock进一步提供了一个用 TypeScript 编写的 DALLE 默认 Prompt 示例,并询问了用户@215370453945024513的看法。 - 关于 AI 性能的反馈与互动:
@pfakanator分享说,指示 Agent 以“合乎逻辑的方式理解事物”可以改善回答。@mysticmarks1对当前的 Prompt 设置表示不满,并分享了一个改进版本。@fluffy_dog__询问了关于 Bard 与 ChatGPT 性能对比的看法,@eskcanta将其重定向到了另一个频道。 - 扩展 AI 上下文:
@bambooshoots讨论了跨对话上下文管理的实现,以便与 AI 进行更连贯和更长时间的对话。 - 激烈的个人互动:
@bambooshoots和@mysticmarks1进行了激烈的辩论,对代码贡献和性格特征表达了不同的观点。 - Prompt Engineering 的定量衡量:
@madame_architect试图了解如何将语言的定性方面转换为定量指标,以衡量 Prompt Engineering 的成功,并征求了他人的建议/意见。
DiscoResearch Discord 总结
- 讨论主要围绕 Mixtral 模型的实现、性能和未来预期展开,涉及各种技术问题和建议的解决方案。关键主题包括输出问题、VRAM 需求、多 GPU 兼容性、模型 quantization(量化)以及 auxiliary losses(辅助损失),详见 Huggingface 上的 Mixtral。”
@nagaraj_arvind指出基础 MoE 模型使用标准的 language model loss 函数…” - 用户分享了关于 Mixtral 性能的不同体验,共识是它能够出色地处理长 context(上下文),尽管其翻译能力稍逊一筹。”
@goldkoron提到该模型的翻译能力不如 GPT-3.5 等其他模型。” - 技术更新包括 Huggingface 通过一个 pull request 增加了对 Mixtral 模型支持,以及在 #benchmark_dev 频道中报告的来自 Mistral 侧 正在进行的 vllm pull-request。
- #general 频道的成员讨论了 LeoLM 70b Chat 和 DiscoLM 70b 之间的区别。”
@bjoernp澄清说 Leo 70b chat 仅在德语 instruction 数据上进行微调,而 DiscoLM 则主要包含英语 instructions。” - 发现了一个名为 “Mistral-7B-v0.2” 的 Mistral-7B 模型 改进版本,引起了社区的兴趣。“
_jp1_在 Mistral AI 模型页面 上发现了 “Mistral-7B-v0.2”…” @tarikoctapm发起了一项呼吁,寻求 分布式计算项目 的潜在合作伙伴,该项目专注于在空闲期间训练 LLM。- 社区还参与了一些更轻松的讨论,例如在 #mixtral_implementation 频道中庆祝
@fernando.fernandes的生日。
DiscoResearch 频道总结
▷ #disco_judge (1 条消息):
nagaraj_arvind: 它们是一样的
▷ #mixtral_implementation (322 条消息🔥🔥):
-
Mixtral 实现问题与解决方案:频道中的用户在实现 Mixtral 模型时遇到了各种问题。部分问题涉及模型性能、VRAM 需求、多 GPU 兼容性以及模型量化(quantization)。为了解决这些问题,提出了几种方案,包括使用特定版本的库以及引入辅助损失(auxiliary losses)。
-
@goldkoron表示运行 DiscoLM Mixtral 模型时出现了输出问题,但发现禁用exllama可能会解决该问题。@goldkoron还报告了有关内存分配的 ErrorResponse 问题。 -
@nagaraj_arvind指出基础 MoE 模型使用标准语言模型损失函数,如果设置output_router_logits = True,则会自动计算 aux loss。如果你想添加自定义损失,可以从 switch transformer 导入并使用返回的 logits 来计算,参考 Huggingface 仓库中 Mixtral 模型的这一部分。 -
@datarevised注意到 Mixtral 目前在推理(inference)方面缺乏多 GPU 支持,但正如 这个 pull request 所示,该问题正在解决中。 -
@armifer91表示他们正尝试使用 此处提供的 LLaMa 实现来运行 Mixtral。 -
@fernando.fernandes建议 Mixtral v0.1 可以在 8k 等低 RAM 环境下通过 4-bit 量化运行,详见 此处,其中可以安装带有 ‘python -m venv venv’ 等指令的 GGUF 格式模型文件。
-
-
Mixtral 性能评估:用户分享了他们对 Mixtral 性能的体验,
@goldkoron提到该模型的翻译能力逊于 GPT-3.5 等其他模型。该模型处理更广泛上下文的能力受到了@goldkoron和@fernando.fernandes等用户的重视。 -
Huggingface Transformers 上的 Mixtral:
@flozi00分享了关于 Huggingface 上 Mixtral pull request 的讨论。该 PR 为 Transformers 添加了对 Mixtral 模型的支持。据@le_mess报告,该 PR 已合并到 Transformers 中。 -
生日庆祝:
@fernando.fernandes表示这是他的生日周,频道成员如@datarevised和.grey_向他表达了生日祝福。 -
Mixtral 模型尺寸推测与未来预期:
@dyngnosis发起了关于未来发布的 Mixtral 模型中专家(experts)尺寸的讨论。用户推测尺寸可能在 30 到 70 之间。@fernando.fernandes提到,像 Mixtral 7B 这样的“全能型”模型对于特定任务可能非常有益。
▷ #general (15 条消息🔥):
- DiscoResearch Discord 链接修复:
@philpax报告称 HuggingFace 上 DiscoResearch 页面上的 Discord 邀请链接已过期。该问题已由_jp1_解决。 - LeoLM 70b Chat 与 DiscoLM 70b 的区别:
@apepper询问了 LeoLM 70b Chat 和 DiscoLM 70b 之间的区别。@bjoernp澄清说,Leo 70b chat 仅针对德语指令数据进行微调(finetuned),而 DiscoLM 主要包含英语指令。 - 翻译模型推荐:
@apepper询问哪种模型适合英译德。@bjoernp建议 LeoLM 和 DiscoLM 可能都不是最佳选择,因为翻译数据并未明确包含在数据集中。不过,@noobmaster29分享了一个 GitHub 资源链接,这可能对微调翻译功能有所帮助。 - 发现 Mistral-7B-v0.2:
_jp1_在 Mistral AI 模型页面 上发现了 “Mistral-7B-v0.2”,并指出虽然这并不是一个改进的 7b base,但它是对初始 Mistral-7B 更好的微调(fine-tuning)。 - 协作咨询:
@tarikoctapm在其分布式计算项目中寻求潜在合作伙伴,他们计划在节点空闲且未被租用时训练 LLM。
▷ #benchmark_dev (2 messages):
- 为 llama.cpp 添加后端:
@rtyax报告称,为 llama.cpp 添加运行模型的后端非常直接,但与其他后端集成面临挑战,因为它们利用了 Hugging Face 的 configuration 和 tokenizer 特性。 - vllm PR 的进展:根据文档,
@flozi00提到 Mistral 侧 正在进行 vllm pull request 的相关工作。
HuggingFace Discord Discord 总结
- 使用 Fuyu 进行图表扩展:用户
@heumas在扩展图表时遇到挑战。@doctorpangloss建议使用Fuyu并通过 Google Colab 链接 提供了演示。 - 音频分类模型:针对
@vara2096的咨询,@doctorpangloss推荐了audioclip和wav2vec用于音频分类。 - Mistral 上的 Accelerate 框架:
@ghimiresunil分享了在 Mistral 模型上使用 Accelerate 框架时遇到的错误,并通过 GitHub Gist 分享了错误信息和代码示例。 - 去中心化预训练:用户 ‘neuralink’ 分享了实现 0.01% 的 DiLoCo 去中心化预训练的相关内容。
- 关于基于 LLM 的应用及其风险的网络研讨会:
@kizzy_kay宣布了由 Philip Tannor 主讲的“评估基于 LLM 的应用并降低其风险”的网络研讨会。分享了 注册链接。 - HuggingFace 摘要模型:用户
@kaycebasques通过 博客文章 分享了为 Sphinx 站点页面使用 HuggingFace 摘要模型的经验。 - 电视剧台词抓取:’joshuasundance’ 分享了一个可在 HuggingFace 上获取的电视剧台词数据集 链接在此。
- AI 模型徽章系统:用户
@.plot建议为 AI 模型建立一个开源徽章系统,详见此处。 - 读书小组讨论重点关注了 Magvit2、Eliciting Latent Knowledge (ELK) 论文链接 以及 Text-to-image (T2I) diffusion models 论文链接。
- 在 Animatediff 中运行 mm_sdxl_v10_beta.ckpt 的困难:
@happy.j报告了运行该实现时的困难,不得不转而使用 animatediff GitHub 仓库的实现。 - 计算机视觉讨论:主题包括从 bounding boxes 中提取过多文本、摄影测量(photogrammetry)和网格提取(mesh extraction)Sugar 项目链接。
- 聊天机器人架构、Amazon EC2 G5g 上的 LLM 以及情感分析 是 NLP 频道 的主要话题。会议解决了 CUDA 不兼容和内存错误等问题。
HuggingFace Discord 频道总结
▷ #general (70 messages🔥🔥):
- 使用 Fuyu 进行图表扩展:用户
@heumas在使用 AI 模型扩展或创建图表时遇到问题。@doctorpangloss建议使用Fuyu从图表中提取数据,尽管它不具备连贯地向图表添加新图像数据的能力。他还通过 Google Colab 提供了演示。 - 关于音频分类模型的讨论:用户
@vara2096寻求一个能有效使用原始人声音频作为输入,旨在对大量音频文件进行分类的开源模型。@doctorpangloss建议尝试audioclip或wav2vec。 - Mistral 模型上 Accelerate 框架的问题:用户
@ghimiresunil发布了在使用 Accelerate 框架在 7 张 A100 GPU 上训练 Mistral 模型时遇到的错误,寻求修复帮助。错误和代码示例已通过 GitHub Gist 分享。 - 大数据集压缩:用户
@guactheguac就使用 ML/DL 压缩从 LiDAR、大格式摄影测量和多光谱采集的大型数据集寻求建议。@doctorpangloss回复称对神经方法的期望应保持适度,但未提供具体的建议或资源。 - 使用 PPO 微调 Llama-2:用户
@harrison_2k提到他正在使用 PPO 微调Llama-2,并正在寻找关于此过程中合适奖励范围(reward range)的建议或文档。
▷ #today-im-learning (1 messages):
neuralink:过去三天我学到的:实现了 0.01% 的 DiLoCo 去中心化预训练。
▷ #cool-finds (1 messages):
- 关于基于 LLM 的应用及其风险缓解的即将举行的网络研讨会:来自 Data Phoenix 团队的
@kizzy_kay宣布了一场名为 “GPT on a Leash: Evaluating LLM-based Apps & Mitigating Their Risks” 的免费网络研讨会。本次研讨会的演讲者是 Philip Tannor,Deepchecks 的联合创始人兼 CEO。 - 研讨会日期和时间:活动定于 12 月 12 日太平洋标准时间(PST)上午 10 点举行。
- 学习机会:参与者可以期待学习如何评估和缓解基于 LLM 的应用程序中的风险、测试涉及文本和非结构化数据的 AI 系统,以及如何应对提供上下文相关响应的复杂性。
- 注册:鼓励感兴趣的人员在活动前注册以预留名额。
- 问答环节:研讨会还将包括一个问答环节,供参与者探讨与该主题相关的特定问题。
▷ #i-made-this (6 messages):
- Sphinx 站点的页面摘要:
@kaycebasques分享了他使用 HuggingFace 摘要模型为 Sphinx 站点页面生成摘要的探索。根据他的实验,这项尝试看起来很有前景,但尚未定论。这篇博客文章解释了在技术文档网站上实现页面摘要的潜在优势。 - 电视剧引用抓取:
@joshuasundance从 wikiquote.org 抓取了电视剧的引用。这些引用已作为数据集joshuasundance/wikiquote_tv在 HuggingFace 上发布,包含 103,886 行数据,点击此处获取。 - AI 模型徽章系统:用户
@.plot建议为 AI 模型建立一个类似于 Creative Commons 徽章的徽章式开源信息系统,并寻求公众反馈。提议的系统由Open Model (OM)和Open Model - Open Weights (OM-OW)等徽章组成,旨在促进透明度和协作。 - 积极反响:AI 模型徽章系统收到了来自
@tonic_1的积极反馈。 - 电视剧引用的应用可能性:
@joshuasundance和@tonic_1集思广益,探讨了抓取引用的潜在应用,例如微调语言模型或创建一个可以扮演任何电视剧角色的 RAG 类型机器人。
▷ #reading-group (2 messages):
- Magvit2 讨论:
@chad_in_the_house建议对 Magvit2 进行演示,并在此分享了论文链接 here。 - ELK 研究:
@chad_in_the_house还考虑讨论一篇关于 Eliciting Latent Knowledge (ELK) 的论文。摘要指出该研究针对“古怪的”语言模型,论文可在 here 查阅。 - 文本生成图像 Diffusion 模型:最后,
@chad_in_the_house对一篇关于 Text-to-image (T2I) diffusion models 的论文表现出兴趣,该论文讨论了这些模型的计算成本。论文可在 here 查阅。
▷ #diffusion-discussions (1 messages):
- 使用 Animatediff 运行 mm_sdxl_v10_beta.ckpt 遇到困难:
@happy.j报告了在使用 diffusers 的 animatediff 实现运行 mm_sdxl_v10_beta.ckpt 时遇到困难,不得不转而使用来自 animatediff GitHub 仓库的实现。
▷ #computer-vision (15 messages🔥):
-
从边界框中提取文本:
@navinaananthan询问如何从一组边界框中提取文本,特别是针对报纸。@boriselanimal7建议使用 Optical Character Recognition (OCR) 并提供了一篇 Medium 文章 作为资源。@merve3234也强调文本提取是目标,并推荐@947993236755054633提供专业指导。 -
摄影测量与网格提取:
@n278jm和@individualkex讨论了将摄影测量(Photogrammetry)用于 3D 建模,特别是针对异地或有预算限制客户的室内设计应用。@n278jm对在没有 Lidar 的情况下能达到的精度水平表示担忧。随后他们分享了一个名为 Sugar 的项目链接,该项目专注于从 3D Gaussian Splatting 中进行精确且快速的网格提取(Mesh Extraction)。 -
计算机视觉中的机器学习/深度学习:
@guactheguac询问是否有人在 Computer Vision 中使用 Machine Learning/Deep Learning,引发了频道内潜在的进一步讨论。
▷ #NLP (34 messages🔥):
- 关于聊天机器人架构的讨论:
@ppros666和@vipitis讨论了 Chatbot 实现中的 Transformer。@ppros666澄清说,他们提到的论文中指的是带有某些修改的 Transformer,而不是像许多 Chatbot 应用那样“舍弃 Encoder”。 - 在 Amazon EC2 G5g 实例上运行 LLM 应用:
@lokendra_71926询问关于使用 auto-gptq 在 Amazon EC2 G5g 实例上运行 LLM 应用的问题。@merve3234澄清说,如果模型太大无法放入 EC2 实例,可以使用 auto-gptq 对模型进行量化(Quantize)。 - 排查 Torch 中的 GPU 可用性问题:
@lokendra_71926遇到了一个问题,尽管使用nvidia-smi命令可以看到 GPU,但torch.cuda.is_available()却返回 false。@merve3234建议可能是 CUDA 相关包与 GPU 需求不匹配,或者 GPU 不兼容 CUDA。 - 使用 TinyBERT 模型进行情感分析:
@blood_bender64就使用 TinyBERT 模型的情感分析问题寻求建议,尽管进行了各种学习率(Learning Rate)调整,该模型在验证集上的表现仍然很差。@merve3234和@9alx建议检查验证集和测试集中的数据分布,调查类别噪声(Class Noise),并监控每一轮(Epoch)的 Loss 变化,以了解模型是否处于欠拟合(Underfitting)状态。 - RuntimeError: CUDA out of memory:
@blood_bender64在训练期间遇到了 CUDA 显存不足的问题。@vipitis建议检查 Optimizer States 是否保留在 GPU 上,并询问了 Batch 数量和梯度累积(Gradient Accumulation)步数。
▷ #diffusion-discussions (1 messages):
- 在 animatediff 中运行 mm_sdxl_v10_beta.ckpt:用户
@happy.j询问了在diffusers的 animatediff 实现中运行mm_sdxl_v10_beta.ckpt时遇到的困难。他们提到多次尝试均未成功,最终不得不换回使用 animatediff GitHub 仓库中的实现。
OpenAccess AI Collective (axolotl) Discord 摘要
- 关于 Axolotl 项目,
@caseus_分享了一个专注于 Mixtral Sharded 的开发中分支。查看该分支的详情请点击这里。 - 提出了围绕 Distributed Policy Optimization (DPO) 和 Reinforcement Learning with Human Feedback (RLHF) 的问题。引用了 Hugging Face TRL DPO Trainer 文档作为两者密切相关的证据。
- 讨论了在服务器或 VLLM 上托管 LLava 13b 模型的问题,在尝试通过 Python 请求将图像传递给 API 时遇到了困难。
- 辩论了在单个 24GB GPU 上使用 qLora 从 Axolotl 训练 Mixtral-MoE 模型的可行性,指出在 4-bit 模式下进行推理就需要约 27GB 的显存。
- 对 V100 和 3080 进行了比较,评估在单个 GPU 上微调 opt-350m 的表现:3080 约为每秒 3.5 次迭代 (it/s),而 V100 为 2 it/s。
- 分享了使用 tinygrad 训练 Mixtral 的脚本,以及关于在 3xA40 上使用 openorca 训练 Mixtral 的相关对话,特别是使用 DiscoResearch 模型。
- 提到了 Mistral 的 Mixtral 8x7B 发布更新,这是一个具有开放权重的优质稀疏混合专家模型 (SMoE),详情见这里。
- 回答了关于 Mixtral 高 VRAM 需求的问题,并分享了在适当的量化和优化下,其资源需求应与运行 12B 模型相当。
- Transformers 现在原生支持 llava,简化了集成流程。
- 提出了关于 multipack 使用以及与 token packing、positional encoding、loss computation 相关的疑问——并提供了文档页面供参考。
- 成员在涉及 checkpoints 的 mixtral 训练运行中遇到了 FileNotFoundError 问题——对此分享了一个潜在的解决方案 mgan,并建议对虚拟环境中的本地文件进行 monkeypatch。
- 最后,
@joshuasundance创建了一个包含 超过 103,886 行 各种电视节目引言的数据集,可在此处访问:Hugging Face 数据集。
OpenAccess AI Collective (axolotl) 频道摘要
▷ #general (64 条消息🔥🔥):
- Axolotl 开发中分支:
@caseus_分享了 GitHub 上 Axolotl 项目中与 Mixtral Sharded 相关的开发中分支链接。分支详情可通过此链接查看。 - DPO 与 RLHF:
@noobmaster29好奇 DPO 是否是 RLHF 的一种形式。@nanobitz指向了 Hugging Face TRL DPO Trainer 文档作为两者可能属于同一事物的证明。 - 在服务器上托管 LLava 13b 模型:回应
@papr_airplane关于在服务器或 VLLM 上托管 LLava 13b 模型的咨询,该用户在通过 Python 请求向 API 传递图像时遇到困难。 - Axolotl 训练 Mixtral-MoE:
@gururise想知道是否可以在单个 24GB GPU 上使用 qLora 训练 Axolotl 的 Mixtral-MoE 模型。@whiskeywhiskey怀疑这是否可行,因为 4-bit 推理就需要约 27GB。 - V100 训练速度:在与
@gururise讨论训练速度时,@whiskeywhiskey提到在单个 GPU 上微调 opt-350m,3080 的速度约为 3.5 it/s,而 V100 为 2 it/s。
▷ #axolotl-dev (16 messages🔥):
- Mixtral 与 Tinygrad:
@caseus_分享了使用 tinygrad 训练 Mixtral 的脚本,该脚本源自其官方 GitHub 页面 mixtral.py at mixtral · tinygrad/tinygrad。 - 使用 Openorca 训练 Mixtral:
@whiskeywhiskey讨论了在 3xA40 上使用 openorca 训练 mixtral。他进一步提到他使用了与 transformers@main 兼容的 DiscoResearch model。 - Mistral Mixtral 发布:
@jaredquek和@nanobitz讨论了 Mistral 发布的 Mixtral 8x7B,这是一个具有开放权重的优质稀疏混合专家模型 (SMoE) Mixtral of Experts。 - VRAM 需求与优化:
@jaredquek对高 VRAM 需求表示担忧(根据 Lelio 的数据约为 28GB)。@_dampf保证通过量化和优化,所需资源将更接近处理 12B 模型,如果用户能够运行 13B 模型,就应该能够运行 Mixtral。 - Transformers 原生支持 Llava:
@caseus_告知 transformers 现在已原生支持 llava,这可能会使集成变得更容易。
▷ #general-help (9 messages🔥):
- 理解 Multipack:
@tim9422询问了关于 multipack 在 token packing、positional encoding 和 loss computation 方面如何工作的进一步说明,并引用了该主题的 文档页面。 - Mixtral 训练问题:
@colejhunter在涉及 checkpoints 的 mixtral training 运行过程中遇到了 FileNotFoundError。@nanobitz提到另一位用户之前也遇到过类似问题。 - FileNotFoundError 的可能解决方案:
@caseus_针对 FileNotFoundError 提出了一个潜在的解决方案,引用了一个 GitHub issue,并建议用户在其虚拟环境中对本地文件进行 monkeypatch。@colejhunter和@whiskeywhiskey对此建议表示感谢。
▷ #datasets (1 messages):
- 电视剧引用数据集:
@joshuasundance从 wikiquote.org 抓取了电视剧引用并将其汇编成一个数据集,该数据集已在 Hugging Face 上公开,名称为 ‘wikiquote_tv’。该数据集包含来自各种电视剧的引用,由超过 103,886 行数据组成。数据集链接:huggingface.co/datasets/joshuasundance/wikiquote_tv。
LangChain AI Discord 总结
- 在 pandas 中实现 kork 包:用户
@xstepz参与了关于如何引入 kork 包以限制机器人访问的 pandas 函数的讨论。 - LangChain 与 React.js 和 Python 的集成:探讨了在使用 LangChain 和 React.js 进行 AI 开发时 Python 的重要性,并讨论了一个关于农业技术中诊断植物病害的活跃项目。推荐的学习 Python LangChain 的资源:deeplearning.ai 课程。
- 对使用 LangChain 的批评:用户
@philipsman分享了一个 Reddit 帖子,展示了对 LangChain 实现的批评,并建议谨慎使用。 ChatOpenAIAPI 的问题:@a404.eth表达了在结合自定义Tools使用ConversationalChatAgent.from_llm_and_tools时,调用ChatOpenAIAPI 遇到的困难。- 模型性能测量方法论:
@martinmueller.dev发起了关于衡量模型性能变化及特定代码的方法论讨论,并考虑了自动化实现。 Chroma.from_documents()API 的连接超时:@wei5519报告了在使用Chroma.from_documents()API 时出现的连接超时错误。- 避免 RAG 响应中的冗余:
@b0otable讨论了如何消除 RAG 响应中重复短语的方法,并建议将提示词暗示(prompt hints)作为潜在解决方案。 - 理解
AgentExecutor的运行机制:@egeres寻求理解AgentExecutor的运作方式——动作是提前规划好的还是实时选择的。 - 在 LangChain 中使用 Tracers:
@lhc1921建议在 LangChain 中使用像 LangSmith 和 Langfuse 这样的 Tracers,以便比控制台日志更清晰地理解运行情况。 - 模型性能对比:
@_egeres提出了一个关于 7B 模型在何时能超越更大型模型(34B/70B)的问题,询问这是由于规避了评估流程还是由于独特的微调技术。 - 为深度学习抓取电视剧台词:
@joshuasundance分享了为深度学习抓取电视剧台词的经历,并将包含约 103,886 行数据的数据集发布在 Hugging Face 上,其中包含电视剧《我恨你的十件事》的样本。
LangChain AI 频道总结
▷ #general (69 条消息🔥🔥):
- 实现 kork 包以限制 pandas 函数:用户
@xstepz请求关于如何实现 kork 包以限制机器人访问的 pandas 函数的示例。 - 关于结合 React.js 使用 LangChain 的讨论:
@yasuke007提出了在使用 LangChain 和 React.js 进行 AI 开发时 Python 是否必要的问题。讨论延伸到了一个利用 AI 诊断植物病害的农业技术项目。@lhc1921推荐了学习 Python LangChain 的资源:deeplearning.ai 课程。 - Reddit 上的 LangChain 批评:
@philipsman分享了一个 Reddit 帖子,批评了 LangChain 的实现并建议谨慎对待。 ChatOpenAIAPI 的问题:@a404.eth对结合自定义Tools使用ChatOpenAIAPI 和ConversationalChatAgent.from_llm_and_tools表示困惑。- Bedrock API 调用与模型性能测量:
@martinmueller.dev询问了随着模型和特定代码的演进,如何衡量其性能的方法论,旨在实现过程自动化。 Chroma.from_documents()API 错误:@wei5519在使用Chroma.from_documents()API 时遇到了与连接超时相关的错误。- 消除 RAG 响应中的冗余:
@b0otable讨论了 RAG 工作流响应中短语冗余的问题,并分享了一个潜在的提示词暗示解决方案。 - 理解
AgentExecutor的运作:@egeres寻求澄清AgentExecutor的运作方式——是先制定行动计划,还是边执行边选择行动。 - 在 LangChain 中利用 Tracers:
@lhc1921建议在 LangChain 中使用 LangSmith 和 Langfuse 等 Tracers 以获得比控制台日志更好的理解。 - 关于模型性能的讨论:
@_egeres提出了一个关于 7B 模型在某些情况下击败 34B/70B 等更大型模型的问题,询问这是否归功于欺骗评估过程或创新的微调方法。
▷ #share-your-work (1 messages):
- 为深度学习抓取电视剧台词:用户
@joshuasundance分享了他们从 wikiquote.org 抓取的电视剧台词。该数据集包含约 103,886 行,已在 Hugging Face 上发布。他们提供了电视剧 “10 Things I Hate About You” 中的几个示例。
Latent Space Discord 总结
- 关于 AI 领域各种话题的讨论,包括 NeurIPS Expo Day 上热门的效率主题,由
@swyxio在回顾中分享。 @aristokratic.eth提出了一个关于创建个人数据集以微调 ML 模型的问题,但目前没有明显的回复。@swyxio分享了一篇 Twitter 帖子,提供了关于 Mixtral 的见解,引发了讨论。@kaycebasques对 Latent Space Benchmarks 101 的实用性给予了正面反馈,并询问了未来的 101 系列。@fanahova回复表示 Algorithms 101 可能是下一个主题。@swyxio分享了一条关于 11 月 AI 事件回顾的 推文。@swyxio在不明确的上下文中提到了 Humanloop,引发了讨论但缺乏具体细节。
Latent Space 频道总结
▷ #ai-general-chat (8 messages🔥):
- NeurIPS Expo Day 回顾:用户
@swyxio分享了 NeurIPS expo day 0 的回顾,强调了活动期间热门的效率主题。 - Humanloop 咨询:用户
@swyxio发起了关于 Humanloop 的讨论,但未提供具体问题或背景。 - 创建自己的数据集:
@aristokratic.eth向社区提出了一个关于创建自己的数据集以微调 ML 模型的问题。 - Mixtral 详解:
@swyxio分享了来自 Guillaume Lample 的 Twitter 帖子,提供了 Mixtral 的详细拆解。 - Latent Space Benchmarks 101 反馈及未来的 101 系列:
@kaycebasques认为 Latent Space Benchmarks 101 非常有用,并询问了未来 101 系列的发布计划。@fanahova回复称他们将发送一份关于 101 系列需求的调查问卷,并考虑将 Algorithms 101 作为下一个主题。
▷ #ai-event-announcements (1 messages):
swyxio: 11 月回顾看这里!https://fxtwitter.com/latentspacepod/status/1734245367817093479
Alignment Lab AI Discord 总结
- 由
@lightningralf发起的关于 基于 Mixtral 的 OpenOrca 测试 的对话,并引用了 OpenOrca 开发团队的相关 fxtwitter 帖子。 - 对 机器学习过程速度 的推测,提出的解决方案包括使用 server 72 8h100 来提升性能。
@teknium声明正在 测试一个未识别的模型,并需要对该模型进行进一步澄清。@mister_poodle询问 如何为特定任务扩展或微调 Mistral-OpenOrca,即利用他们的数据集提升 NER 任务性能并生成 JSON 输出。
Alignment Lab AI 频道总结
▷ #oo (5 messages):
- 关于基于 Mixtral 的 OpenOrca 测试的讨论:
@lightningralf询问@387972437901312000是否测试了基于 OpenOrca 的 Mixtral,并附上了 fxtwitter 帖子 链接。 - 关于处理速度的问题:
@nanobitz对处理速度表示惊讶,@lightningralf建议使用 server 72 8h100。 - 未识别的模型测试:
@teknium提到正在测试某个模型,但不确定是哪一个。
▷ #open-orca-community-chat (1 messages):
- 为特定任务扩展/微调 Mistral-OpenOrca:用户
@mister_poodle表示有兴趣使用他们的数据集来提升 Mistral-OpenOrca 在带有 JSON 输出的 NER 任务上的性能。他们正在寻求扩展或微调 Mistral-OpenOrca 以实现该目标的示例或建议。
Skunkworks AI Discord 摘要
- zq_dev 提到了关于对 Mixtral 进行指令微调(instruction tune)的潜在探索讨论。
- @lightningralf 分享了一条 推文,内容是关于基于 slim openorca 构建的微调聊天版本的开发。
- pradeep1148 分享了一个 YouTube 链接,但未提供额外的背景信息。
Skunkworks AI 频道摘要
▷ #finetune-experts (1 条消息):
zq_dev: 有人尝试对 Mixtral 进行指令微调了吗?
▷ #moe-main (1 条消息):
- 基于 Slim openorca 的微调聊天版本:
@lightningralf分享了一条关于基于 slim openorca 的微调聊天版本的 推文。
▷ #off-topic (1 条消息):
pradeep1148: https://www.youtube.com/watch?v=yKwRf8IwTNI
MLOps @Chipro Discord 摘要
- 用户 ty.x.202. 在 #events 频道分享了一个活动通知,并附带了邀请链接:https://discord.gg/FKYww6Fn?event=1183435830711296032
- 用户 fehir 在 #general-ml 频道提到了新的欧盟立法,但未提供进一步的细节或背景。由于提供的背景不足,该话题将被忽略。
MLOps @Chipro 频道摘要
▷ #events (1 条消息):
ty.x.202.: @everyone https://discord.gg/FKYww6Fn?event=1183435830711296032
▷ #general-ml (1 条消息):
fehir: 简而言之的欧盟新立法
Ontocord (MDEL discord) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
AI Engineer Foundation Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
Perplexity AI Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。