ainews-12122023-towards-langchain-01
2023年12月12日:迈向 LangChain 0.1
Langchain 架构重构已完成,通过拆分代码库提升了可维护性和可扩展性,同时保持了向后兼容。Mistral 推出了新的 Discord 社区,传闻 Anthropic 正在筹集另外 30 亿美元的资金。
在 OpenAI Discord 上,讨论内容涉及 AI 训练中的信息泄露、混合专家模型 (MoE)(如 mixtral 8x7b)、高级提示工程技术,以及 ChatGPT 性能和 API 访问的问题。用户还探讨了 AI 在 Logo 生成、教育和游戏领域的应用,并分享了 Oauth2 身份验证问题的解决方案。此外,文中还提到了来自微软的一个名为 Phi-2 的新型小语言模型。
Langchain 的重大架构重组似乎已经完成:
这将 Langchain 仓库进行了拆分,以提高可维护性和可扩展性,这是每个重度集成的开源框架必然经历的过程:
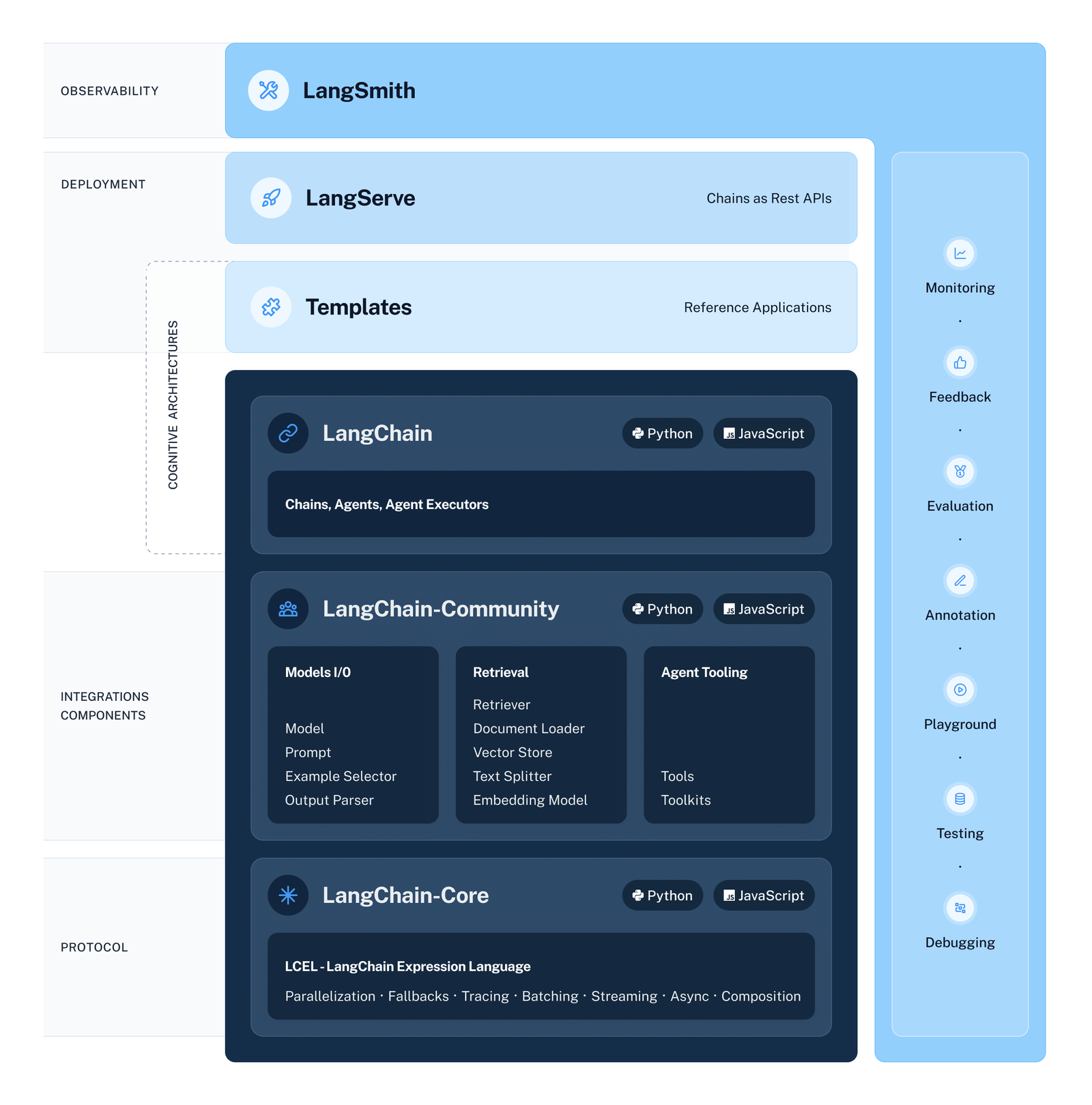
这一切都是向后兼容的,所以不必着急。
在其他消息方面,Mistral 推出了新的 Discord(我们将把它添加到我们的追踪器中),传闻 Anthropic 正在筹集另外 30 亿美元。
[TOC]
OpenAI Discord 总结
- 关于 AI 训练中的信息泄露和 Mixture of Experts 模型的讨论:
@moonkingyt询问了 AI 对话过程中的信息泄露问题,并对名为 “mixtral 8x7b” 的模型表示好奇。会议澄清了该模型是一种 Mixture of Experts (MoE) 模型。 - AI 的高级用例:用户探索了各种潜在的 AI 用例,例如为特定活动修改公司 Logo,在大学的大型班级中解释复杂概念,以及本地语言模型的潜在应用。
- OpenAI 的技术挑战:多位用户分享了他们在 ChatGPT 中遇到的问题,如服务器无响应、响应时间慢以及图片上传困难。用户还讨论了利用 Discord 服务器和 HTML 文本文件训练 AI 模型的可行性以及具体操作方法。
- 对 ChatGPT 性能和行为的担忧:用户的挫败感包括感知到的响应质量/细微差别的下降、记忆力变差以及客户支持不力。一些用户反映 GPT 不再像以前那样回答问题,而是提供在互联网上搜索答案的参考资料。
- 关于访问 OpenAI GPT-4 API 的讨论:用户讨论了 GPT-4 API 的访问权限和成本、ChatGPT Plus 的使用限制、如何获取访问权限以及联系人工支持的流程。发现并报告了一个关于 diff markdowns 中高亮显示错误的问题。
- Prompt Engineering 技术:用户讨论了各种高级 Prompt Engineering 策略,强调通过清晰的 Prompt 设置来获得理想的输出。提出了诸如针对较长文本输出的提纲法、迭代校对以及动态模型系统的实现等技术。
- Oauth2 问题及解决方案:用户协作解决了 Oauth2 身份验证问题。还讨论了细微的 Bug 及其报告流程。
- 将 AI 用于游戏:用户分享了他们尝试让 AI 玩猜单词(hangman)等游戏的经历。提出了一个可以在此类交互界面中切换 Python 显示的功能建议。
- 详细 2D 插图请求:一位用户请求详细的 2D 插图,并被引导在 Bing 的图像生成器上使用 DALL·E 3,或通过 ChatGPT Plus 使用!此外,还报告了一个无法编辑自定义 GPTs 的问题。
OpenAI 频道总结
▷ #ai-discussions (42 条消息🔥):
- AI 训练中的信息泄露:
@moonkingyt询问了聊天机器人在对话过程中泄露信息的案例。@xiaoqianwx给予了肯定回答,但未进一步阐述具体背景。 - 关于 Mixture of Experts 模型的讨论:
@moonkingyt对 “mixtral 8x7b” 这个术语表示好奇。@xiaoqianwx澄清这是一种 Mixture of Experts (MoE) 模型。 - 使用 AI 生成 Logo:
@julien1310寻求指导,询问 AI 是否可以为 20 周年庆典等特殊活动修改公司现有的 Logo。@elektronisade建议使用 StyleGAN 或其衍生模型中的 inpainting 等特定功能。 - AI 在教育机构中的使用:
@offline提到一些大学不允许使用 AI 辅助,并暗示了像 GPT-3 这样的 AI 在解释复杂概念方面的潜力,其详细程度往往超过了大班授课的讲师。 - 关于本地语言模型的问题:
@Shunrai向小组征求优秀的本地语言模型(Local Language Models)推荐。这引发了随后的讨论,但未推荐具体的模型。 - Microsoft 的新语言模型:
@【penultimate】分享了 Microsoft 发布名为 Phi-2 的小型语言模型的消息。未提供进一步的细节或相关链接。 - AGI (Artificial General Intelligence) 辩论:
@chief_executive质疑如果 AGI 在每一步都不断被“削弱 (nerfed)”,那么这个术语还有什么意义,由此引发了一场侧面讨论。同时,@【penultimate】批评了 AGI 标准(goalpost)的不断移动。
▷ #openai-chatter (337 条消息🔥🔥):
- OpenAI ChatGPT 的问题:用户
@ruhi9194,@stupididiotguylol,@rjkmelb,@yyc_,@eskcanta,@toutclaquer,@gingerai,@ivy7k,@millicom,@ayymoss,@knightalfa,@loschess,@primordialblanc报告了 ChatGPT 的多个技术问题,包括服务器无响应、响应时间慢、图片上传困难以及“Hmm…something seems to have gone wrong”等错误消息。 - 关于使用自定义 GPT 文件的讨论:用户
@maxdipper询问了是否可以基于 Discord 服务器训练模型,以及是否可以使用 HTML 文本文件为模型提供数据。 - 对 ChatGPT 图像分析的困惑:用户
@toutclaquer分享了一个 ChatGPT 图像分析无法工作的问题。在尝试分析图像时显示了错误消息。 - 对 ChatGPT 行为和性能的担忧:用户
@prncsgateau,@the_time_being,@.nasalspray,@one_too_many_griz,@fefe_95868分享了他们对 ChatGPT 行为变化、感知的响应质量/细微差别下降、记忆力变差以及客户支持不力的沮丧。 - 关于访问 GPT-4 API 的问题:用户
@moonkingyt询问了 GPT-4 API 的访问权限和成本。@elektronisade提供了 OpenAI 文档的链接,概述了访问条件,@offline进一步澄清了需要成为 Pay-As-You-Go 客户且最低消费为 $1 的要求。@DawidM对高级用户的服务降级表示担忧。
▷ #openai-questions (170 条消息🔥🔥):
- ChatGPT 故障排除与问题:许多用户(如
@mustard1978、@yyc_、@blinko0440、@jonsnov等)报告了平台的各种问题,常见的挑战包括回答不一致、错误消息、图片上传问题以及系统达到使用限制时的问题。@solbus提供了详尽的故障排除建议,建议的解决方案包括检查 VPN 状态、尝试不同的浏览器以及清除浏览器缓存和 cookies。 - 访问终止问题:用户
@mouse9005分享了关于账号被封禁的问题并寻求帮助。@rjkmelb建议他们通过 help center 联系 OpenAI 支持团队。 - ChatGPT Plus 订阅与使用限制:围绕 ChatGPT Plus 的使用限制展开了讨论,涉及用户
@lunaticspirit、@rjkmelb和@DkBoss。ChatGPT Plus 的限制是每 3 小时 40 条消息。该讨论的参考资料见此 链接。 - 在新版 ChatGPT Plus UI 中访问工具和插件:
@_.gojo询问了如何通过 ChatGPT Plus 订阅在 playground 中访问新的 GPT-4 模型和插件。@solbus提供了一个关于如何访问 GPT-4 API 的 链接,并解释了如何在账号设置中启用插件。 - 支付问题:
@Ugibugi、@michaelyungkk和@tardis77b等用户在订阅服务的支付过程中遇到了困难。@solbus和@eskcanta建议联系 OpenAI help center 寻求帮助。
▷ #gpt-4-discussions (74 条消息🔥🔥):
- Oauth2 问题与解决方案:用户
@jdo300和@draennir讨论了他们在 API 服务器上遇到的 Oauth2 身份验证问题。他们协作解决了这些问题,@draennir最终通过在 Express 的解析器中添加application/x-www-form-urlencoded解决了他的问题。 - GPT 动态模型建议:用户
@offline建议实现一个动态模型系统,根据用户请求的需求来决定使用哪个 GPT 模型。该想法得到了@solbus的进一步讨论和支持。 - 次要 Bug 与 Bug 报告:用户
@offline发现并报告了 diff markdowns 中高亮显示错误的问题。他们与@solbus讨论了 Bug 报告流程。 - GPT 行为问题:用户
@maypride报告了 GPT 不再像以前那样回答问题,而是提供在互联网上搜索答案的参考资料。@cris_cezar报告无法编辑其自定义 GPT 之一,即使尝试了多个浏览器并清除了缓存。 - 用户界面与支持:
@cris_cezar对 Discord 界面表示困惑,将其比作飞机驾驶舱。该用户被引导通过 help.openai.com 聊天窗口联系 OpenAI 工作人员支持。@solbus和@eskcanta讨论了通过 help.openai.com 聊天界面联系人工支持的流程。
▷ #prompt-engineering (32 messages🔥):
-
ChatGPT 与特定字数写作:
@davidmajoulian提到,当要求 ChatGPT 撰写特定长度的文章时,它生成的字数往往达不到要求。@rjkmelb对此回应称,ChatGPT 并不懂得如何计算字数,期望它生成特定长度的文章是不现实的。两位用户还讨论了使用能为 OpenAI 模型添加此类功能的工具的可能性。 -
高级 Prompt Engineering 的探索:
@yautja_cetanu发起了关于高级 Prompt Engineering 的讨论,以及在寻找能显著提高模型性能的提示词调整前后对比案例时遇到的挑战。几位用户确认,鉴于 ChatGPT 等模型的进步,许多传统的 Prompt Engineering 技术似乎变得不再那么重要,输出质量很大程度上取决于给 AI 指令的清晰度和具体性。 -
Prompt Engineering 技术:
@eskcanta和@cat.hemlock强调了清晰、具体且无误的提示词设置对于从 AI 获取理想结果的重要性,后者建议针对较长的写作输出使用大纲法并进行迭代校对。 -
将 AI 用于游戏:
@eskcanta分享了一次让 AI 玩猜单词游戏(hangman)的失败尝试,@thepitviper则回应了一个成功案例,他们成功让 AI 生成了一个可运行的 Python 猜单词游戏。还有人建议在这种互动中增加切换 Python 显示开关的功能。 -
详细 2D 插图请求:
@yolimorr请求一个详细的 2D 插图,@solbus提到该服务器不支持图像生成,并引导用户在 Bing 的图像创建器或通过 ChatGPT Plus 使用 DALL·E 3。
▷ #api-discussions (32 messages🔥):
-
ChatGPT 的提示词长度问题:
@davidmajoulian询问了 ChatGPT 生成内容少于提示词要求的问题。他表示当要求一篇 1,500 字的文章时,它只返回了大约 800 字。@rjkmelb澄清说 ChatGPT 不知道如何计算字数,并建议利用该工具协助构建文章,而不是期望固定的字数长度。@rjkmelb还暗示可以使用 OpenAI GPT-4 API 构建其他工具来实现高级功能。 -
高级 Prompt Engineering:
@yautja_cetanu发起了关于高级 Prompt Engineering 的讨论,表示由于 ChatGPT 已经非常出色,很难为他的见面会演讲提供调整前后的对比示例。@tryharder0569建议更多地关注特定提示词如何增强应用程序的功能。@madame_architect建议考虑 Step-back prompting,或者从更高价值或更有帮助的角度思考输出质量,而不是简单的“有效 vs 无效”二分法。 -
提示词输出质量控制:
@cat.hemlock强调了在指导 AI 时保持具体和审慎的重要性,以避免生成“AI slop”(垃圾输出)。他们建议先使用 ChatGPT 生成文章大纲并进行完善,然后再将其扩展为完整内容,最后进行终审校对。 -
ChatGPT 能力局限性:还提到了 ChatGPT 的某些局限性。
@eskcanta提供了一个模型无法正确玩猜单词游戏的例子,即使已知单词、字母顺序、对话中纠错并遵循分步示例。@thepitviper展示了在 ChatGPT 中使用 Python 来运行一个运行缓慢但准确的猜单词游戏。 -
Python 工具显示切换:
@thepitviper和@eskcanta讨论了在界面中切换 Python 显示的潜在功能,这可以改善用户体验,尽管这需要妥善处理系统正在执行操作以防止意外结果的情况。
Nous Research AI Discord 总结
- 多个频道对 SOLAR 10.7B AI 模型进行了广泛讨论,涉及基准测试结果、性能对比以及对其超越其他模型声明的有效性分析。该模型在 AGIEval 中表现出显著提升,引发了有趣的质疑并最终获得了对其性能的认可。
- “初看之下,它是个失败之作” -
@teknium - “太长不看:不错,但不值得这么多关注” -
@artificialguybr
- “初看之下,它是个失败之作” -
- 针对各领域技术挑战的互动:基础 AI 模型被描述为“未驯服的野兽”;关于 GPU 性能的咨询引发了对 Lambda 的 Vector One 工作站冷却方法的讨论;以及关于使用 HuggingFace Transformers 优化推理速度的咨询。
- 关于 OpenHermes 2.5 的函数调用(function calling)能力以及涉及共享经验和资源的复杂性的对话。提到了 Microsoft 的 Phi-2,据报道其在基准测试中优于 Mistral 7b 和 Llama 7b。
- 关于各种 Mistral 模型 的持续讨论,以及在 Apple Silicon 上微调模型的潜力。分享了用于进一步探索的资源和讨论线程。
- 社区协作与寻求帮助:包括需要前端界面开发的 AI 仓库、关于开发基于 LLM 应用的编排库(orchestration library)选择建议,推荐不使用 LangChain 而倾向于 Llama-Index 或自定义平台。
- 发布了 UNA-Neural-Chat-v3-3-Phase 1 模型的公告,据描述在初步测试中优于原始版本。
- 其他杂项:关于在 Microsoft 工作的幽默观察、参与基因编辑技术、使用机器人解决语法和拼写问题,以及通过推文和视频链接在不同频道分享感兴趣的内容。
Nous Research AI 频道总结
▷ #ctx-length-research (1 条消息):
teknium: https://fxtwitter.com/abacaj/status/1734353703031673200
▷ #off-topic (18 条消息🔥):
- 对基础模型的担忧:
@nagaraj_arvind将基础 AI 模型描述为“未驯服的野兽”,表达了在使用中遇到的一些挑战或困难。 - AI 仓库协助:
@httpslinus寻求任何需要前端界面构建或扩展帮助的 AI 相关仓库,打算利用现有技能提供帮助。 - 职场烦恼:
@airpods69分享了因对高级开发人员的做法不满和压力而离职的经历。 - DeciLM-7B 讨论:
@pradeep1148分享了一个关于 DeciLM-7B(一个 70 亿参数的语言模型)的 YouTube 视频。然而,@teknium表达了失望,称 DeciLM-7B 的性能是由其 GSM8K 分数驱动的,且在 MMLU 上的表现比 Mistral 差。 - Vector One 工作站分析:
@erichallahan分享了一篇 Twitter 帖子,提供了对 Lambda 的 Vector One 工作站的分析。这引发了关于冷却方法的讨论,@fullstack6209表达了对风冷系统的偏好,@erichallahan表示赞同。 - GPU 利用率查询:
@everyoneisgross询问了在 GPU VRAM 上运行 LLM、同时使用 Python 跑满 CPU 并多屏播放 YouTube 视频时的 GPU 性能表现,并暗示可能出现了视觉闪烁或伪影。
▷ #benchmarks-log (15 条消息🔥):
- 分享 SOLAR 10.7B 基准测试:
@teknium发布了 SOLAR 10.7B AI 模型在各项任务中的基准测试分数,包括:truthfulqa_mc:数值:0.3182 (mc1), 0.4565 (mc2) 以及arc_challenge:数值:0.5247 (acc), 0.5708 (acc_norm)。 - 与其他模型的对比评估:
@teknium将 SOLAR 10.7B 的性能与 Mistral 7b 进行了对比。SOLAR 10.7B 似乎在 AGIEval 中取得了显著提升(39% 对比 30.65%),但在其他评估中表现相似(GPT4All 为 72% 对比 71.16%,TruthfulQA 为 45% 对比 42.5%)。 - 对 SOLAR 10.7B 性能的评论:尽管最初认为 SOLAR 10.7B 的表现并不令人印象深刻(“初看之下,它是个失败之作”以及“不错,但可能不像它声称的那样比 Yi 好”),但对比结果促使
@teknium重新评估了该模型的性能,特别是在 AGIEval 方面。 - 关于 SOLAR 10.7B 的最终想法:
@artificialguybr总结了讨论,认为虽然 SOLAR 10.7B 性能尚可,但似乎不值得引起如此大的关注(“太长不看:不错,但不值得这么多关注”)。
▷ #interesting-links (42 messages🔥):
- SOLAR-10.7B 模型讨论:
@metaldragon01链接到了 一个 Hugging Face 帖子,该帖子介绍了首个 107 亿参数模型 SOLAR-10.7B。 - 声称性能超越其他模型:SOLAR 团队声称他们的模型优于包括 Mixtral 在内的其他模型。用户
@n8programs和@teknium对此说法表示怀疑。 - 评估 SOLAR-10.7B 模型:
@teknium开始对新的 SOLAR 模型进行 Benchmarking,并计划将其结果与 Mixtral 的得分进行对比。 - SOLAR-10.7B 特性分析:在讨论中,用户根据 SOLAR 与之前一个非 Base Model 版本的相似性得出结论,认为 SOLAR 可能是经过 Pre-trained 的,但可能不是一个 Base Model。
- 关于 Mixtral 和 3090 配置的推文:
@fullstack6209询问了 Mixtral 和 3090 的最佳配置,@lightningralf回复了一个可能包含答案的 Twitter 链接。
▷ #bots (48 messages🔥):
- 基因编辑技术:用户
@nagaraj_arvind询问了 2015 年以来基因编辑技术的进展。Bot 进行了回复,但消息中未详述具体细节。 - 倒序句子补全:
@crainmaker寻求 Bot 完成一段倒序句子的字符串。 - 葡萄牙语提问:
@f3l1p3_lv用葡萄牙语提出了一系列问题,大部分涉及基础数学题、星期计算、类比构思以及句子中合适的代词选择。Bot@gpt4和@compbot协助解决了大部分问题。 - 语法和拼写问题:
@f3l1p3_lv还发布了多个拼写和语法问题供 Bot 解决,例如用特定字母或字母组填空、为句子选择代词以及选择书写正确的句子。Bot@gpt4提供了解决方案和解释。
▷ #general (337 messages🔥🔥):
-
关于 Function Calling 能力的讨论:用户
@realsedlyf询问了 OpenHermes 2.5 执行 Function Calling 的能力,包括@.beowulfbr和@tobowers在内的其他用户分享了他们在不同模型上使用 Function Calling 的经验。@.beowulfbr分享了一个具有 Function Calling 能力的 HuggingFace 模型 链接,而@tobowers分享了他使用来自 GitHub 的 SocialAGI 代码实现的 Function Calling。 -
UNA-Neural-Chat-v3-3-Phase 1 发布公告:用户
@fblgit宣布发布 UNA-Neural-Chat-v3-3-Phase 1,初步测试显示其性能优于原始模型。 -
关于使用 hf transformers 优化推理速度的讨论:
@lhl分享了他在优化 HuggingFace transformers 推理速度方面的经验,详细说明了他是如何获得更好结果的。 -
小规模模型的实用性与性能讨论:
@a.asif询问了可以在笔记本电脑上运行的小规模模型中表现最好的是哪些。Plugyy 提出了关于在有限硬件上借助 Quantization 和 llama.cpp 运行 Mixtral MoE 模型可能性的问题。 -
分享的链接:
▷ #ask-about-llms (63 条消息🔥🔥):
- Mistral 模型讨论:用户
@agcobra1、@teknium、@gabriel_syme和@giftedgummybee讨论了各种 Mistral 模型,包括 Base 和 Instruct 版本。 - 基于 LLM 的应用开发库:用户
@coco.py就在开发基于 LLM 的应用时如何选择编排库(LangChain、Haystack 或 Llama-Index)寻求建议。用户@.beowulfbr和@decruz表达了他们在使用 LangChain 时遇到的问题,并建议尝试 Llama-Index 或构建自己的平台。 -
微调讨论:用户
@n8programs、@teknium、@youngphlo和@eas2535讨论了在 Apple Silicon 上微调模型的潜力,并提供了一些资源,包括 GitHub 讨论帖 https://github.com/ggerganov/llama.cpp/issues/466 以及 Reddit 帖子 Fine tuning on Apple Silicon 和 Fine tuning with GGML and Quantization。 - 模型基准测试:
@brace1征求针对特定文本提取任务的开源模型基准测试建议。@night_w0lf推荐了 Mamba、Mistral0.2、Mixtral、OpenHermes 等模型,并引导至 Hugging Face 上的排行榜。@n8programs提醒注意基准测试的局限性,并建议在另一个排行榜上查看模型的 ELO 评分。 - 参数对速度的影响:用户
@n8programs提出了一个疑问,即为什么拥有约 30 亿参数的 Stable Diffusion 比同样 30 亿参数的 LLM 慢得多。
▷ #memes (1 条消息):
- 关于微软描绘的讨论:用户
@fullstack6209分享了一个关于在微软工作的幽默观察,并质疑其代表性中缺失了某个特定群体。
DiscoResearch Discord 摘要
-
Mixtral 发布与模型优化:Mistral 发布了 Mixtral 8x7B,这是一个具有开放权重的高性能 SMoE 模型。该模型的效率和速度受到称赞,
@aortega_cyberg强调它比Goliath快 4 倍,且在 Coding 方面表现更好。用户还注意到Hermes 2.5相较于Hermes 2的改进。此外还提到了Mistral-Medium模型的可用性和用法。在 Mistral 的博客文章中阅读完整的发布细节和定价。 -
量化、软件集成与挑战:
@vince62s和@casper_ai重点讨论了包括"INT3 quantization"和"AWQ"在内的量化方法。还提到了 exllamav2 对超过 4k 上下文的支持需求,@aiui提出了 LM Studio 和 exllama 中的软件限制。 -
模型效率与 Function-Calling:根据
@fernando.fernandes的理论,该模型的效率源于其 Experts 的“正交性”。有人建议使用 minimum-p 路由系统进行 Expert 评估,这可以实现可扩展的速度优化。针对减轻类似问题和丰富 Mixtral 训练数据的策略(如包含 Function-Calling 示例)进行了讨论,并分享了相关资源,其中包括 HuggingFace 上的 Glaive Function-Calling v2 数据集。 -
基准测试、评分模型与情感智能:
@.calytrix引入了一个专注于 LLM 情感智能的新基准测试 EQ-Bench,并声称它与其他基准测试有很强的相关性。讨论了由于使用 GPT-4 可能导致的偏差问题以及潜在的改进。GSM8K 被推荐为 SOTA 数学基准测试。Mixtral Instruct 与其他模型在 EQ-Bench 上的得分差异引发了关于潜在原因的讨论。 -
资源与新进展:分享了来自 Hugging Face 关于 Mixture of Experts (MoEs) 模型的解释文章,链接见此处。介绍了 Minami-su 在 HuggingFace 上发布的新模型 “Yi_34B_Chat_2bit”,链接见此处。修正后的定价页面链接分享在此处,Mistral 的 Discord 服务器链接在此处。
DiscoResearch 频道摘要
▷ #mixtral_implementation (170 条消息🔥🔥):
-
Mixtral 模型性能与优化:用户对 Mixtral 模型的性能和效率给予了积极评价。
@Makya表示,在添加了代码指令示例后,"Hermes 2.5"的表现优于"Hermes 2"。关于Mixtral-Instruct模型,@aortega_cyberg强调虽然Goliath在创意写作方面更好,但 Mixtral 在编程方面表现更佳,且速度快 4 倍。@goldkron指出了 Poe 的 Mixtral 实现中存在重复循环的问题。 -
量化与软件集成:参与者讨论了不同的量化方法,包括 1-bit 和 3-bit 选项。
@vince62s讨论了对"AWQ"进行"INT3 quantization"的需求。@casper_ai回应称 Mixtral 尚未准备好支持"AWQ",但预计一旦支持,其性能应能超过每秒 12 个 tokens。与此同时,@vince62s建议通过 6 个激活专家(active experts)进行微调,可能使 Mixtral 模型在单张 24GB 显卡上运行。此外,用户讨论了 exllamav2 对超过 4k 上下文支持的需求,@aiui指出了目前 LM Studio 和 exllama 的局限性。 -
专家在模型效率中的重要性:
@fernando.fernandes理论化地认为,Mixtral 的效率可能源于其专家的“正交性(orthogonality)”,从而实现了最大化的知识压缩。@someone13574提出了一种 minimum-p 路由系统,根据专家与顶级专家相比的 softmax 分数来评估专家。通过控制 minimum-p 水平,这可能实现可扩展的速度优化。 -
在训练中使用函数调用示例:
@fernando.fernandes建议用函数调用(function-calling)示例来丰富 Mixtral 的训练数据,以增加多样性并缓解类似问题。他在 HuggingFace 上分享了 Glaive Function-Calling v2 数据集作为潜在资源。用户还分享了用于此目的的其他潜在数据集。 -
Mistral-Medium 模型的可用性:用户提到
Mistral-Medium模型现在可以通过 Mistral API 获取。他们推测该版本可能约为 700 亿参数,尽管模型的具体大小尚未得到确认。
▷ #general (9 条消息🔥):
- Mixtral 发布与定价:
@bjoernp分享了 Mistral 官方关于发布 Mixtral 8x7B 的公告,这是一个具有开放权重的优质稀疏混合专家模型(SMoE)。他指出,该模型在 Together Inference Platform 上以最低的价格提供最快的性能——每 1K token 仅需 0.0006 美元,速度高达 100 tokens/s。其优化版本已可在 Together 平台进行推理。完整详情见 Mistral 博客文章。 - 混合专家模型解析:
@nembal分享了来自 HuggingFace 的关于混合专家模型(MoEs)的解析链接。该文章深入探讨了 MoEs 的构建模块、训练方法以及推理时需要考虑的权衡。点击此处查看完整解析。 - 定价页面问题:
@peterg0093报告称 Mistral 的定价页面链接返回 404 错误。不过,@_jp1_提供了 Mistral 定价信息的正确链接。 - Mistral Discord 链接:
@le_mess询问 Mistral 的 Discord 服务器链接,@nembal成功提供。点击此处加入他们的服务器。 - Minami-su 发布的新模型:
@2012456373在 HuggingFace 上分享了 Minami-su 的新模型 “Yi_34B_Chat_2bit”。该模型经过优化,可在 11GB 显存的 GPU 上运行,采用名为 QuIP# 的仅权重(weights-only)量化方法,仅用每权重 2 bit 即可实现接近 fp16 的性能。详细信息可以在此处找到。
▷ #benchmark_dev (15 messages🔥):
- EQ-Bench 用于情感智能:
@.calytrix介绍了关于 LLMs 情感智能的论文和基准测试 EQ-Bench,声称它与其他基准测试有很强的相关性(例如与 MMLU 的相关性为 r=0.97)。他提到 EQ-Bench 似乎对为了在其他基准测试中获得高分而进行的 Fine-tuning 不太敏感。值得注意的是,Parameter size 似乎更重要,因为情感智能所需的细微理解和解释在更大的参数规模下表现出更强的 Emergent 特性。他还分享了 论文链接 和 GitHub 仓库。 - EQ-Bench 的潜在改进和局限性:
@onuralp.提出了潜在的改进建议,包括引入项目反应理论(Item Response Theory)和报告每个主题的 MMLU 分数相关性。还建议探索模型在涉及宜人性和谈判的结构化场景中的响应。有人提出了由于选择 GPT-4 作为生成器而可能产生偏见的担忧。 - EQ-Bench 创建者的回应:
@.calytrix分享说,使用 GPT-4 的决定是基于资源限制,但确认它没有生成问题和答案。在为 EQ-Bench 辩护时,他认为它真实地衡量了认知能力的某些深层方面,并提供了有用的区分能力。 - 数学基准测试查询:针对
@mr.userbox020关于 SOTA 数学基准测试参考资料的请求,@.calytrix推荐了 GSM8K,因为它专注于推理而非原始计算。他还分享了一篇 论文链接,探讨了将推理空间作为 Scratchpad,利用从左到右的启发式方法来解决问题。 - EQ-Bench 上模型间的分数差异:用户
@bjoernp、@rtyax和@.calytrix讨论了 Mixtral Instruct 在 EQ-Bench 上的得分低于其在其他基准测试中得分的原因。他们对这种差异表示好奇,并提出了可能的原因,包括快速且粗糙的 Fine-tuning,以及使用 7b 模型作为 MoE 基础模型的固有局限性。
OpenAccess AI Collective (axolotl) Discord Summary
-
围绕 Mixtral 展开了热烈讨论,涉及 通过 vLLM 加载 Mixtral 时的 TypeError、使用 QLoRA 在单张 A100 上进行训练、LM Studio 的支持,以及包括 支持 Mixtral 在内的代码更新。
@le_mess在此处分享了一个展示可能训练设置的 WandB 项目。 -
技术对话围绕 Axolotl 展开,包括在模型配置中激活 “output_router_logits” 设置以实现辅助平衡损失(Auxiliary Balancing Loss),以及加载带有连字符名称的多个数据集时的问题。
-
关于当前量化技术的咨询引出了对 Hugging Face API、GenUtils 和用于基于选择的推理的 AutoGPTQ 的提及。
-
关于训练模型的积极互动,特别是围绕训练和 Fine-tuning AI 模型的 VRAM 最低要求、与卡住的 Mixtral 训练 相关的问题和解决方案、发现并分享 WandB 项目 结果。用户分享了在 Axolotl 设置和使用 Docker 调试时的经验,并讨论了与 huggingface/Transformers 相关的 Axolotl 训练问题的观点和解决方法。关于预训练中 Loss 尖峰(Loss Spikes)的问题仍然悬而未决,尚未达成共识。
-
特定数据集的聊天涉及在 YouTube 辩论转录文本上训练 AI 的潜力和缺点、对本地搜索仓库的兴趣、将 PDF 转换为 Markdown 工具的个人推荐和经验,特别提到了 Marker。讨论扩展到了文档处理的替代方案,但预算限制使得某些用户无法使用这些方案。
OpenAccess AI Collective (axolotl) Channel Summaries
▷ #general (48 条消息🔥):
- 通过 vLLM 加载 Mixtral 的问题:
@papr_airplane报告了在使用 “pt” 格式尝试通过 vLLM 加载 Mixtral 时出现 TypeError。@caseus_宣布官方发布的 Mixtral 建模代码现在已支持 Mixtral。 - RoPE 对训练的影响:用户
@kaltcit发起了关于启用 RoPE 对 VRAM 占用和训练序列影响的讨论。@nanobitz澄清说 RoPE 本身不影响 VRAM,但增加序列长度会影响。 - 在 LM Studio 上加载 Mixtral GGUF:
@papr_airplane询问是否有人在 LM Studio 上加载了 Mixtral GGUF,但@nruaif回复称 LM Studio 尚不支持,而@faldore声称使用 Ollama 实现了这一点。 - 在单张 A100 上使用 QLoRA 训练 Mixtral:
@le_mess分享了在单张 A100 上使用 QLoRA 训练 Mixtral 似乎是可行的,并链接到了一个 W&B 项目。 - Docker 镜像的使用体验改进:
@caseus_宣布了一项新更新,增加了evals_per_epoch和saves_per_epoch参数,很快将在 Docker 镜像中提供。该更新旨在通过消除计算总步数或从总 Epoch 数反推的需求来提升使用体验。
▷ #axolotl-dev (11 条消息🔥):
- 更新的建模代码:
@bjoernp提到 Mixtral 的更新建模代码已经推送。 - Router 的辅助平衡损失:
@bjoernp询问了如何激活 Router 的辅助平衡损失(Auxiliary Balancing Loss)。据@caseus_称,可以通过配置启用此功能。@caseus_提供了一个示例代码片段,表明在 Axolotl 中可以通过在model_config下添加"output_router_logits: true"来启用此功能。 - 加载多个数据集:
@le_mess报告了加载名称中包含-的多个数据集时出现的问题,并询问是否有人遇到过类似情况。根据@nanobitz和@noobmaster29的说法,如果使用引号,或者尚未更新到 Axolotl 最新的 Mixtral 更新,加载应该可以正常工作。
▷ #other-llms (3 条消息):
- 量化技术讨论:用户
@jovial_lynx_74856询问了目前用于量化和推理的技术,并提到了 Hugging Face 的 API 和 GenUtils。作为回应,@nanobitz提到了用于量化的 AutoGPTQ,并建议采用基于选择的推理。
▷ #general-help (70 条消息🔥🔥):
-
不同 VRAM 下的模型训练:用户讨论了训练 AI 模型的最低 VRAM 要求。
@nruaif提到最低要求是 1 张 A6000,相当于 48 GB VRAM。@gameveloster询问 24 GB 或 48 GB VRAM 是否足以微调 34B 模型,@le_mess确认 48 GB 应该足够,但 24 GB 可能会有问题。 -
Mixtral 训练:
@le_mess分享了 Mixtral 训练卡住且 Loss 没有下降的问题。其他用户建议启用output_router_logits,将学习率提高 10 倍,并提供了类似训练问题的参考资料。@le_mess使用 Weights & Biases 追踪了他的实验。结果 1 链接,结果 2 链接。@caseus_建议参考使用更高学习率的训练 链接 -
使用 Docker 进行 Axolotl 设置和调试:
@jovial_lynx_74856发布了在 80 GB A100 服务器上使用 CUDA 12.0 版本设置 Axolotl 并运行示例命令时遇到的问题。@le_mess建议在 Ubuntu 和 CentOS 的 Docker 环境中运行设置。 -
Axolotl 训练问题:
@jovial_lynx_74856报告了在 Axolotl 训练期间遇到的错误。@caseus_提供了一些见解,并分享了关于 Hugging Face/Transformers 引入的相关更改的参考链接 链接。问题似乎归结为回退到了 SDPA (Scaled Dot Product Attention) 而不是 Eager 版本,@jovial_lynx_74856通过在 YML 文件中将sample_packing设置为false找到了解决方法。 -
预训练中的 Loss 突刺:
@jinwon_k询问了预训练中 Loss 突刺(Loss Spike)的问题。用户未提供解决方案或指引。该问题仍处于开放状态。
▷ #datasets (20 messages🔥):
- 在辩论 YouTube 转录文本上训练 AI:
@papr_airplane建议在辩论比赛的 YouTube 转录文本上训练 AI,以提高其推理能力。然而,@faldore反驳称,这可能会导致 AI 总是倾向于与用户争论。 - 访问本地搜索仓库:在
@papr_airplane表达兴趣后,@emrgnt_cmplxty提议提供一个新 repository 的早期访问权限。 - 关于 PDF 转 Markdown 转换工具的讨论:
@visuallyadequate分享了使用多种 PDF 转 Markdown 转换工具和库的个人经验。他们推荐 Marker 作为一个强有力的候选工具,但也指出了它在处理表格和目录方面的局限性。他们总结道,某些 PDF 在转换时的效果比其他 PDF 更好。 - 文档处理的替代方案:其他用户建议了文档处理的替代方案。
@lightningralf提到使用 Llama Index Hub,而@joshuasundance提到将 Azure Document Intelligence 与 Langchain 结合使用。然而,考虑到预算限制,这些替代方案对@visuallyadequate来说并不太合适。
HuggingFace Discord Discord 摘要
- 技术故障:用户
@harrison_2k确认了一个关于所有模型均无法工作的报告问题。 - 关于开始学习 NLP 的咨询,建议将探索 Transformer 模型作为第一步。
- 关于在土耳其语问答数据集上微调 BERT 模型以获得更好性能和准确性的问题。
- 关于为 XM 标准账户创建用于 FX 自动化交易的 EA 的对话及相关推测。
- 用户参与了关于 神经网络蒸馏论文 的讨论,general 和 reading group 频道均提供了论文链接,支持了思想交流和进一步理解。
- 围绕 Nougat Transformers 空间中的运行时错误 展开讨论,用户
@osanseviero建议尝试在不同的空间运行。 - 用户
@databoosee_55130介绍了一个新模型 “Deepsex-34b”,并分享了多个与该模型相关的链接。 - 共同关注 对象、属性、值列表 (OPV) 在数字领域的价值。
- 对该领域研究论文所需的 数据集布局 表示关注。
- 分享了一篇关于 模拟完整人脑的神经形态超级计算机 将于 2024 年启动的 文章。
- 推广 Learning Machine Learning for Mathematicians 论文,旨在让更多数学家应用机器学习技术。
- 展示了各种教育视频和文章,包括 检索增强生成 (RAG) 视频、XTTS2 安装指南视频 以及 语言模型的突破 - MOE-8x7b。
- 分享了在 HuggingFace 上新创建的模型,例如使用 sentence-transformers/paraphrase-mpnet-base-v2 的 SetFit Polarity Model 和 Go Bruins V2 Model,并征求关于如何创建类似 ABSA Model 的指南。
- 讨论主要在周三的 Reading Group 频道进行,此外还介绍了论文 Distilling the Knowledge in a Neural Network。
- 询问关于 为报纸中的每篇新闻文章创建单独的边界框 的问题。
- 围绕 RAG 系统的最佳编码器/解码器 (Encoder/Decoder) 展开讨论,目前使用的模型是 BERT,并且对了解更多关于多语言或特定代码用例的模型排名表现出浓厚兴趣。Palm 模型被频繁推荐。
HuggingFace Discord 频道摘要
▷ #general (21 messages🔥):
- 模型故障:
@noone346报告所有模型似乎都已宕机,@harrison_2k确认了这一问题。 - 启动 NLP 学习:
@bonashio寻求开始学习 NLP 的建议,他已经具备 Deep Learning 的基础知识。@jskafer建议先从探索 Transformer 模型开始。 - 在土耳其语问答任务上微调 BERT 模型:
@emirdagli.询问关于在土耳其语问答任务上微调可变 BERT 模型的建议,数据集包含约 800 个问题和 60-70 个答案。 - 关于 MT4 和外汇自动化交易的咨询:
@ronny28717797提到他们打算为 XM 的标准账户创建一个 EA,并详细说明了具体的性能预期和偏好。 - 关于蒸馏论文的讨论:
@murtazanazir发起了关于一篇蒸馏论文的讨论,并提供了该论文在 arXiv 上的链接。 - Nougat Transformers Space 运行时错误:
@pier1337报告了@697163495170375891的 Nougat Transformers Space 出现运行时错误,询问是否可以在仅有 16GB RAM 的 CPU 上运行。@osanseviero提供了一个链接,建议在另一个 Space 中尝试。 - 介绍 Deepsex-34b 模型:
@databoosee_55130介绍了一个新模型 “Deepsex-34b” 并分享了多个相关链接。 - 对象、属性、值 (OPV) 列表:
@noonething通过质疑该领域中对象、属性、值列表的价值引发了讨论。 - 数据集布局查询:
@largedick询问了某篇论文所需的数据集布局。 - 类脑超级计算机文章分享:
@bread browser分享了一篇 New Scientist 文章,内容关于一台模拟整个人类大脑的超级计算机将于 2024 年启用。
▷ #today-im-learning (1 messages):
- 面向数学家的机器学习:
@alexmath分享了一篇 arXiv 论文 链接,鼓励更多数学家学习应用机器学习技术。
▷ #cool-finds (3 messages):
- 检索增强生成 (RAG) 视频:用户
@abelcorreadias分享了来自 Umar Jamil 的一段视频,该视频解释了整个 Retrieval Augmented Generation 流水线。 - XTTS 安装指南:
@devspot发布了一个 YouTube 视频 链接,讲解如何使用 Python 在本地安装热门的 Text-To-Speech AI 模型 XTTS2。 - 语言模型的突破 - MOE-8x7b:
@tokey72420分享了 MarkTechPost 上的一篇文章链接,内容关于 Mistral AI 发布 MOE-8x7b 在语言模型方面取得的新突破。
▷ #i-made-this (5 messages):
- 创建 SetFit 极性模型:
@andysingal分享了他最近在 HuggingFace 上创建的模型链接:基于 sentence-transformers/paraphrase-mpnet-base-v2 的 SetFit 极性模型,并鼓励其他人尝试使用它进行基于方面的情感分析 (ABSA)。 - 指南请求:
@fredipy询问是否有关于如何创建类似于@andysingal的 ABSA 模型的指南。 - Go Bruins V2 模型展示:
@rwitz_在 HuggingFace 平台上展示了他微调的语言模型 Go Bruins V2。
▷ #reading-group (3 messages):
- 会议安排:
@chad_in_the_house确认会议通常在周三举行,并且通常在专门的线程中进行。 - 关于蒸馏论文的讨论:
@murtazanazir发起了对论文 Distilling the Knowledge in a Neural Network 的讨论,邀请其他人加入以进行深入理解。
▷ #computer-vision (2 messages):
- 报纸分割的边界框:用户
@navinaananthan寻求关于模型或方法论的建议,以便在上传报纸时为每篇新闻文章创建独立的边界框。该用户目前尚未收到回复。
▷ #NLP (5 messages):
- RAG 系统最佳 Encoder/Decoder:用户
@woodenrobot询问了最适合 RAG 系统的 Encoder/Decoder。他们目前使用 BERT,但对其他建议持开放态度,因为他们不确定 BERT 在数据随时间增长时的扩展能力。 - 多语言/代码排名:
@woodenrobot表示有兴趣查看专门针对多语言/代码用例的模型排名。 - Palm 作为顶级模型建议:
@woodenrobot指出,根据与 Bard 的互动,Palm 经常作为推荐模型出现。
LangChain AI Discord 总结
@hwchase17介绍了 LangChain 的新架构,即langchain-core和langchain-community。这一更新后的架构将促进使用 LLM 开发上下文感知推理应用。欢迎就此变化提出疑问。- 各种技术咨询和问题:
- 社区请求了用于追踪每次 LLM 调用 Token 消耗以及改进 SQL 查询结果摘要的新技术。
- 有报告称 LangSmith API 在维护过去 45 分钟的 LLM 调用日志时存在问题。
- 社区成员寻求关于使用 LangChain 完成特定任务、使用开源替代方案替换 OpenAIEmbeddings 以及增强聊天机器人以显示数据库中相似记录的建议。
- 关于使用 LangChain 改进 Azure Search Service 的多查询检索和 Fusion RAG 功能的讨论。
- 在 langserve 频道中:
- 用户在 Llama.cpp 的回调管理器以及 langserve、langchain 和 Hugging Face pipelines 的集成方面面临挑战。
- 有人提议创建一个关于 Langserve 挑战的 Issue,并可能调整为使用 RunnableGenerators 而非 RunnableLambdas。
- 请求在 langserve 中暴露
agent_executor。
- 分享了一个关于使用 OpenAI 和 LangChain 构建 AI 系统的免费 9 部分动手实践系列课程。第一部分专门涵盖了使用 GPT 和 LangChain 进行情感分析、MRKL prompts 以及构建一个简单的 AI Agent。课程可以通过此链接找到,同时也有相应的 YouTube 视频。
LangChain AI 频道总结
▷ #announcements (1 messages):
- LangChain 新架构:
@hwchase17分享了一篇博客文章,详细介绍了新的langchain-core和langchain-community。此次架构重组的目标是简化使用 LLM 开发上下文感知推理应用的过程。这一变化是对 LangChain 增长和社区反馈的回应,并以完全向后兼容的方式实施。@hwchase17还表示愿意回答有关此变化的任何问题。
▷ #general (12 messages🔥):
-
追踪每次 LLM 调用的 Token 消耗:
@daii3696询问了在 JavaScript 中追踪每次 LLM 调用 Token 消耗的方法。作为回应,@pferioli建议使用回调函数并提供了一段代码片段,专门处理handleLLMEnd回调,用于记录 Token 使用详情。 -
改进 SQL 查询结果摘要:
@jose_55264询问了加快 SQL 查询执行结果摘要生成的可能方法。在给定的消息中未提供具体解决方案。 -
使用 LangChain 完成任务:
@sampson7786表示希望利用 LangChain 通过特定流程完成任务,并在平台上寻求相关帮助。 -
LangSmith API 问题:
@daii3696对 LangSmith API 的明显问题表示担忧,因为他们在过去 45 分钟内无法追踪其 LLM 调用。 -
YouTube 助手项目中 OpenAIEmbeddings 的开源替代方案:
@infinityexists.正在开发一个 YouTube 助手项目,并询问如何使用 HuggingFace 作为 OpenAIEmbeddings 的开源替代方案。他们提供了项目中使用的 GitHub 代码链接。 -
增加向量搜索的成功率:
@rez0询问了一个函数的名称,该函数在向量搜索中将检索拆分为三个查询,以提高获取所需结果的几率。 -
增强聊天机器人的搜索能力:
@hamza_sarwar_有兴趣增强其聊天机器人的功能,以便在没有精确匹配用户查询时显示数据库中的相似记录(例如车辆信息)。 -
使用 LangChain 实现 Azure Search Service 的多查询检索/融合 RAG:
@hyder7605正在使用 Azure Search Service,并希望通过 LangChain 将多查询检索或融合 RAG 功能与 Azure Cognitive Search 集成。他们还旨在查询过程中包含混合搜索和语义搜索等高级功能,但不确定如何使用 LangChain 定义过滤器和搜索参数。
▷ #langserve (5 messages):
- Llama.cpp 中回调管理器的问题:用户
@jbdzd在使用 langserve 期间提出了 Llama.cpp 中回调管理器的挑战。他们收到了一个 RuntimeWarning,指出协程 ‘AsyncCallbackManagerForLLMRun.on_llm_new_token’ 未被 await。 - 在 Langserve 中实现流式传输的困扰:
@fortune1813表达了在集成 langserve、langchain 和 hugging face pipelines 时遇到的困难,特别是在流式传输方面。他们研究了 notebook,但请求进一步澄清正确的流式传输实现。 - 建议在 Langserve 中创建 Issue:
@veryboldbagel建议@fortune1813在 Langserve 中创建一个关于其挑战的 issue,并分享完整的服务器脚本。他们还提醒注意,对于常见操作应使用 RunnableGenerators 而非 RunnableLambdas,并指出这方面的文档较少。 - 在 Langserve 中暴露 Agent Executor 的请求:
@robertoshimizu询问了在 langserve 中暴露agent_executor的问题,并分享了一个示例代码片段。然而,他们遇到了困难,因为在 Python 脚本中调用时输入似乎有所不同。
▷ #tutorials (1 messages):
- AI 实战系列:用户
@datarhys分享了由 DataCamp 发布的免费 9 部分 AI 实战系列,重点是“使用 OpenAI 和 LangChain 构建 AI 系统”。该系列旨在引导学习者从基础到更高级的 AI 和 LangChain 主题。- 第一个实战涵盖:
- 使用 GPT 和 LangChain 进行情感分析
- 了解用于帮助 LLM 推理的 MRKL 提示词
- 构建一个简单的 AI Agent
- 第一个实战涵盖:
- 讲师 Olivier Mertens 因其能够以通俗易懂的方式讲解复杂主题而受到赞誉。
- 要开始此实战,请点击提供的链接:Code Along
- 该实战的 YouTube 课程也可观看:YouTube Session
Alignment Lab AI Discord 摘要
- 由
@lightningralf发起的关于基于 Mixtral 的 OpenOrca 测试的对话,并引用了来自 OpenOrca 开发团队的相关 fxtwitter 帖子。 - 对 Machine Learning 过程速度的推测,提出的解决方案包括使用 72 台 8h100 服务器来增强性能。
@teknium声明正在测试一个未识别的模型,并表示需要对该模型进行进一步澄清。@mister_poodle询问扩展或微调 Mistral-OpenOrca 以执行特定任务的方法,即利用其数据集提升 NER 任务性能并生成 JSON 输出。
Alignment Lab AI 频道摘要
▷ #oo (5 条消息):
- 关于基于 Mixtral 的 OpenOrca 测试的讨论:
@lightningralf询问@387972437901312000是否测试了基于 OpenOrca 的 Mixtral,并链接了一个 fxtwitter 帖子。 - 关于处理速度的问题:
@nanobitz对处理速度表示惊讶,@lightningralf建议使用 72 台 8h100 服务器。 - 未识别模型测试:
@teknium提到正在测试某个模型,但不确定是哪一个。
▷ #open-orca-community-chat (1 条消息):
- 针对特定任务扩展/微调 Mistral-OpenOrca:用户
@mister_poodle表示有兴趣使用其数据集来提升 Mistral-OpenOrca 在带有 JSON 输出的 NER 任务上的性能。他们寻求扩展或微调 Mistral-OpenOrca 以实现此目标的示例或建议。
Latent Space Discord 摘要
- 关于微调开源模型的讨论,
@henriqueln7推荐了 Replicate.ai 等平台,该平台能够通过单行代码运行模型。 @swizec介绍了一个全栈 LLMOps 解决方案 Agenta-AI,包括 Prompt 管理、评估、人类反馈和部署。@swyxio分享了 Andrej Karpathy 的一条 Twitter 帖子,强调了每日 AI Newsletter 的普及程度。@henriqueln7询问了用于 RAG 应用的语言模型的理想尺寸,辩论焦点在于平衡世界知识和推理能力。-
@stealthgnome分享了一个 YouTube 视频,题为 “AI and Everything Else - Benedict EvansSlush 2023”,展示了对 AI 未来的见解。 @yikesawjeez请求访问 Smol Newsletter Discord 文本和 API,目标是将内容显示为 Embeds 或创建每日摘要。@yikesawjeez更新了 SK 插件的开发进度,计划在处理积压项目之前完成此项工作。
Latent Space 频道摘要
▷ #ai-general-chat (11 条消息🔥):
-
微调开源模型:用户
@henriqueln7征求微调开源模型的平台建议,并推荐了 https://replicate.ai/。该平台允许用户通过单行代码运行开源模型。 -
全栈 LLMOps 平台:用户
@swizec分享了 Agenta-AI 的 GitHub 仓库链接。该平台提供全栈 LLMOps 解决方案,包括 Prompt 管理、评估、人类反馈和部署。 -
每日 AI Newsletter:
@swyxio评论了每日 AI Newsletter 的流行程度,并以 Andrej Karpathy 的一条 Twitter 帖子 为例。 -
用于 RAG 应用的语言模型尺寸:
@henriqueln7提出了一个关于 RAG 应用中语言模型理想尺寸的问题。该问题旨在澄清在考虑较小模型有限的世界知识与较大模型卓越的推理能力时,哪种模型更好。 -
2023 年 AI 概览:用户 @stealthgnome分享了 ‘AI and Everything Else - Benedict EvansSlush 2023’ 视频的 YouTube 链接,提供了对 AI 未来的见解。
▷ #llm-paper-club (2 条消息):
- 请求访问 Smol Newsletter Discord 文本和 API:用户
@yikesawjeez向@272654283919458306请求一个 API,以便访问 Smol Newsletter Discord 的原始文本或 .md 文件。该 API 将使他们能够通过另一个用户 Red 将内容显示为嵌入内容,或创建每日摘要。 - SK Plugin 的开发:
@yikesawjeez目前正在开发一个 SK Plugin,并计划在处理积压工作之前完成它。
LLM Perf Enthusiasts AI Discord 总结
- 关于 Anthropic 融资 的对话:用户
@res6969提到一个关于 Anthropic 额外筹集 30 亿美元的传闻,并戏称 Function Calling 问题 或许可以通过更多资金来解决。 - 关于 用于邮件解析的 Fine-tuning 的讨论:由
@robhaisfield发起,涉及创建 JSONL 文件以将邮件字符串解析为结构化对象所需的示例数量。 @robotums分享了 Microsoft Research 博客的一篇文章,主题为 Phi 2: The Surprising Power of Small Language Models。- 用户
@lhl分享了他们在 推理引擎性能 方面的经验,声称在将部分代码替换为 vLLM 后,性能提升了 50 倍。他们还将 Transformers 与其他引擎进行了对比,并分享了一个包含详细结果的 GitHub 仓库。 - 关于 Prompting 技术 的对话:包括 MedPrompt 方法和 DeepMind 的 Uncertainty Routed CoT (Cooperative Output Transformations)。讨论还涉及了 OCR (Optical Character Recognition) 的使用和 MS Research 的成就。所有话题均由用户
@robotums和@dhruv1引入并讨论。
LLM Perf Enthusiasts AI 频道总结
▷ #claude (3 条消息):
- Anthropic 融资:用户
@res6969评论了关于 Anthropic 正在额外筹集 30 亿美元的传闻。 - Function Calling 问题:
@res6969戏称,也许再多花几十亿美元就能让 Function Calling 正常工作了。
▷ #finetuning (2 条消息):
- 用于邮件解析的 Fine-tuning:用户
@robhaisfield询问了创建 JSONL 文件以 Fine-tune 模型将邮件字符串解析为带有嵌套回复的结构化对象所需的示例数量。他询问 30 个示例是否足够。
▷ #opensource (1 条消息):
- Phi 2: The Surprising Power of Small Language Models:
@robotums分享了 Microsoft Research 博客文章的链接,探讨了小型语言模型的潜力,并附上了内容贡献者名单。
▷ #speed (1 条消息):
- 推理引擎性能:用户
@lhl详细介绍了他们在不同推理引擎上的经验。他们指出,在将现有代码替换为 vLLM 后,观察到了 50 倍的性能提升。他们还将 Transformers 的各种推理选项与其他引擎进行了对比,并通过 GitHub 仓库分享了发现。该仓库包含了推理测试的详细结果。
▷ #prompting (5 条消息):
- 了解何时使用 OCR:
@robotums对如何确定页面何时需要 OCR (Optical Character Recognition) 表示好奇,询问是否有人知道 ChatDOC 是如何实现这一点的。 - 询问 MedPrompt 技术:
@dhruv1询问是否有人在他们的应用中使用了 MedPrompt 技术。 - MS Research 使用 MedPrompt 取得的成就:
@dhruv1分享了 MS Research 发布的一篇帖子,介绍如何使用 MedPrompt 技术在 MMLU(明尼苏达大学多项选择机器学习数据集)上超越 Gemini 的表现。 - DeepMind 的 Uncertainty Routed CoT 技术:
@dhruv1告知频道,DeepMind 披露了一种名为 Uncertainty Routed CoT (Cooperative Output Transformations) 的新技术,其在 MMLU 上的表现优于 GPT。 - 分享 CoT 技术:
@dhruv1承诺将分享更多关于 CoT 技术的内容。
AI Engineer Foundation Discord 摘要
只有一个频道有活动,因此无需总结…
- 活动时间混淆:
@yikesawjeez询问活动时间被标记为 9:30 PM 的问题,他们原本预期是在 8:00 AM。@._z澄清说活动实际安排在 9:30 AM PST。由于时间被错误地标记为 PM 而非 AM,导致了轻微的混乱。
Skunkworks AI Discord 摘要
- 在 #moe-main 频道中提到了某人对 Mistral licensing 的影响,用户 “.mrfoo” 评论道:“看来在影响 Mistral licensing。不错!”。
- 在 #off-topic 频道中,用户 “pradeep1148” 分享了一个 YouTube 链接:https://www.youtube.com/watch?v=wjBsjcgsjGg。视频内容未被讨论。
Skunkworks AI 频道摘要
▷ #moe-main (1 条消息):
.mrfoo: <@1117586410774470818> : Influencing mistral licensing I see. Nice!
▷ #off-topic (1 条消息):
pradeep1148: https://www.youtube.com/watch?v=wjBsjcgsjGg
MLOps @Chipro Discord 摘要
只有一个频道有活动,因此无需总结…
- 完整的数据产品生命周期 (Data Product Lifecycle):
@viv2668分享了一个关于实用 Data Products 的增强型端到端指南的两个部分的链接。
Ontocord (MDEL discord) Discord 没有新消息。如果该服务器长期处于静默状态,请告知我们,我们将予以移除。
Perplexity AI Discord 没有新消息。如果该服务器长期处于静默状态,请告知我们,我们将予以移除。
YAIG (a16z Infra) Discord 没有新消息。如果该服务器长期处于静默状态,请告知我们,我们将予以移除。