ainews-ai-discords-12132023-6438
2023年12月13日,SOLAR 10.7B 性能超越了 Mistral 7B?
Upstage 发布了 SOLAR-10.7B 模型。该模型采用了基于 llama-2 架构的新型深度放大(Depth Up-Scaling)技术,并集成了 mistral-7b 的权重,随后进行了持续预训练。Nous 社区认为该模型很有前景,但并非出类拔萃。
此外,phi-2 基础模型的权重也已发布。该模型在 1.4 万亿个 token 上进行了训练,其中包括由 GPT-3 生成并由 GPT-4 过滤的合成文本,使用了 96 块 A100 GPU,耗时 14 天。
在 OpenAI 的 Discord 频道上,用户讨论了各种 GPT 模型面临的挑战,包括输出不连贯、API 使用限制以及 GPT-4 Vision API 的问题。对话还涉及了对 AGI(通用人工智能)和 ASI(超级人工智能)的理解、对 OpenAI 与 Axel Springer 合作的担忧,以及 GPT Plus 的价格变动。讨论内容还包括集成到 Bard 中的 Gemini 聊天模型,以及其与 GPT-4 性能的对比。
Upstage 的 10.7B 模型已发布:
我们开发了 Depth Up-Scaling 技术。基于 Llama2 架构,SOLAR-10.7B 融入了创新的 Upstage Depth Up-Scaling。随后我们将 Mistral 7B 的权重集成到扩展层中,最后对整个模型进行了持续预训练。
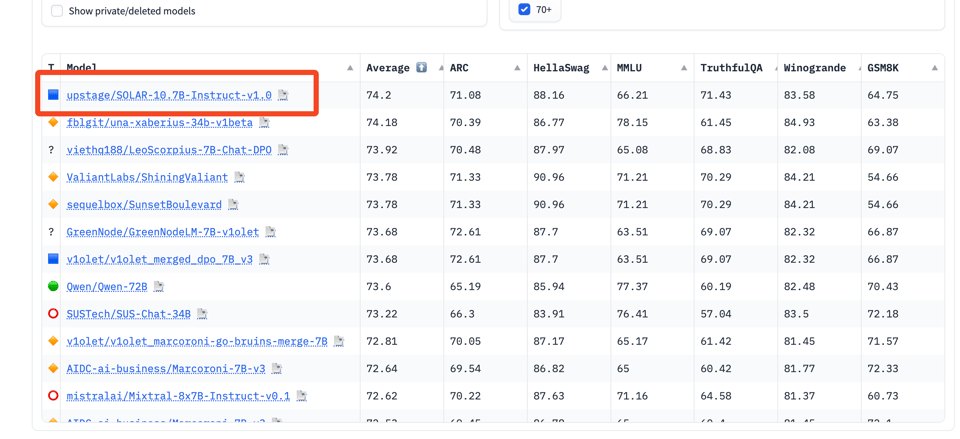
Nous 社区认为它不错,但并非出类拔萃。
在其他消息中,Phi-2 基础模型的权重已发布——它由 1.4T tokens 的 Phi 1.5 加上 250B 的由 GPT3 生成的新合成文本和经过 GPT4 过滤的网站数据组成,在 96 台 A100 上训练了 14 天。
[TOC]
OpenAI Discord 总结
- OpenAI GPT 模型的挑战、解决方案和讨论:各社区用户报告了各种 GPT 模型运行中的困难并提出了解决方案,提到的问题包括 GPT 输出内容不连贯、GPT 在回答前拒绝检查知识库文件,以及 GPT-4 Vision API 的错误。这些讨论还涵盖了特定问题,如 GPT 无法有效地玩猜单词游戏(Hangman)、无法生成图表以及无法创作高质量内容;用户发现先创建大纲再进行增强可以获得更高的性能。
- OpenAI API 使用关注点与澄清:对话集中在理解 AI 的局限性上,包括其无法生成视觉内容、与使用上限相关的问题,以及生成不太有用的项目符号式回答的问题。用户对比了 GPT Assistants 和 Custom GPTs,同时探索了 OpenAI API 的不同用例可能性,如批量上传 PDF 和交叉引用食品成分以检查饮食限制。值得注意的是,文中强调了集成 API 玩猜单词游戏的挑战,一些用户提供了成功案例,但也提到了 Python 访问速度较慢的限制。
- 账户问题和功能故障报告:有大量关于账户相关问题(账户降级、删除、登录问题)的讨论,建议用户联系 OpenAI 官方支持。他们商议了各种问题,如聊天数据丢失、无法加载某些对话、影响 GPT 模型的浏览器特定故障,以及 GPT 每小时 40 条消息限制的现状。
- 对 AGI 和 ASI 的共同理解:社区用户深化了对通用人工智能(AGI)和人工超智能(ASI)的理解,讨论了不断提高的预期及其潜在影响。
- 对 OpenAI 商业策略的回应:由于担心潜在的偏见和此类伙伴关系的伦理影响,用户对 OpenAI 与 Axel Springer 的合作表示担忧。价格变动和 GPT Plus 的访问权限也在社区内引发了讨论。
OpenAI 频道总结
▷ #ai-discussions (55 条消息🔥🔥):
- ChatGPT 与 PDF 读取:
@vantagesp讲述了一个问题,尽管 AI 具备相应功能,但它似乎对其读取和总结 PDF 的能力表示不确定。 - 关于 AGI 和 ASI 的讨论:
@【penultimate】发起了一场关于通用人工智能(AGI)和人工超智能(ASI)定义与预期的对话,断言人们对 AGI 的期望正在不断提高。 - OpenAI 的 Jukebox:
@【penultimate】分享了 OpenAI 名为 Jukebox 的项目链接,这是一个音乐生成模型,并希望能够开发出该模型更新或增强的版本。 - GPT-4 和 ChatGPT 的问题:用户
@Saitama和@kyoei报告了 GPT-4 的问题,包括响应质量平庸和输入流错误。用户@slickog还提到了 GPT 输出不连贯(“词语杂烩”)的问题。 - Gemini AI 的使用:用户
@iron_hope_shop、@lugui、@solbus和@jason.scott讨论了集成在 Bard 中的聊天模型 Gemini。@【penultimate】还指出,通过适当的提示词(prompting),微软有能力诱导 GPT-4 达到 Gemini Ultra 的水平。
▷ #openai-chatter (270 条消息🔥🔥):
-
GPT-4 Vision 的集成问题:多位用户讨论了在使用 GPT-4 Vision API 时遇到的困难。例如,
@moonkingyt和@gingerai都报告了相关问题,@gingerai特别提到在上传图片时经常报错。@lugui和@rjkmelb提供了一些指导和排错建议,详见 bug 报告线程。 -
关于 GPT 局限性的讨论:用户
@mischievouscow发起了关于 ChatGPT 局限性的讨论,特别是关于其使用上限(usage cap)以及生成不太实用的列表式回答的问题。随后@dabonemm将 GPT 的学习过程比作“猴子打字机实验”。 -
ChatGPT Plus 访问问题与通知:多位用户报告了与访问和购买 ChatGPT Plus 相关的问题和咨询。例如,
@isrich和@themehrankhan提出了关于价格变动和 GPT Plus 访问权限的疑问,而@openheroes和@miixms则宣布 ChatGPT 已重新开放订阅。 -
对 OpenAI 与 Axel Springer 合作的担忧:用户
@zawango、@jacobresch、@loschess等人对 OpenAI 与 Axel Springer 的合作伙伴关系表示失望和担忧,理由是与曾面临争议的新闻机构合作可能带来潜在的偏见和伦理影响。 -
ChatGPT 的各种用例与评价:
@textbook1987分享了使用 ChatGPT 为医生起草一封语气专业的信函的正面反馈。@loschess指出 AI 在为复杂项目编写代码方面的局限性,最终不得不聘请开发人员来完成项目。@thepitviper批评了 Prompt 限制干扰了用户体验,这可能会促使用户转向其他替代方案。
▷ #openai-questions (168 条消息🔥🔥):
- 账号问题:包括
@vexlocity、@Kevlar、.draixon、norvzi、@thedebator和.sweetycuteminty在内的用户讨论了各种账号相关问题,如登录故障、账号降级和账号注销。建议他们联系 OpenAI 官方支持寻求帮助。 - GPT 功能问题:
@woodenrobot、@david_36209、@vadimp_37142、@8u773r、@astoundingamelia、@bayeslearner和@happydiver_79等用户报告并讨论了模型功能方面的问题。问题包括 GPT 在回答前拒绝检查知识文件(knowledge files)、自定义 GPTs 中外部 API/Actions 停止工作、性能缓慢、模型无法正常处理图片,以及无法在 OpenAI GPT 中使用语音对话(voice chat)。 - 用例讨论:
@samuleshuges就一个“批量上传 PDF 并与其对话”的项目寻求建议,而@core4129询问了利用 API 交叉引用食品成分以满足饮食和过敏限制的可行性。@skrrt8227对使用 OpenAI 将笔记听写至 Notion 感兴趣。 - 浏览器相关问题:
@Mdiana94和@jordz5讨论了影响 GPT 模型运行的浏览器特定问题。清除缓存和更换浏览器被提议为潜在的解决方案。 - 数据丢失问题:用户如
@singularity3100、@Mdiana94和@Victorperez4405对丢失对话数据或无法加载特定对话表示担忧。除了建议退出并重新登录外,还建议用户联系官方支持。
▷ #gpt-4-discussions (21 messages🔥):
- 联系 OpenAI 员工寻求支持:用户
@eskcanta解释说这个 Discord 频道主要是社区成员。他们提到了一些可以联系的金色名字的 OpenAI 官方人员。这里有一个由 OpenAI 成员@Michael发布的帖子链接,澄清了通过其帮助门户联系人工支持的流程。“[它应该] 指向一个真人,并表示他们打算让联系人工客服变得更容易、更快捷。” Discord 帖子链接 - 修改 GPTs 的对话标题:
@lduperval询问是否可以影响 GPT 为对话生成的标题。他们对识别创建该对话的 GPT 的方法很感兴趣。 - GPT 批改论文:用户
@bloodgore表示在让其 GPT 根据上传的文件(评分标准)进行扫描和响应时遇到了困难。他们正尝试使用 GPT 批改论文,但面临模型尽管知识库中已有正确的评分标准,却仍会幻觉(hallucinating)出自己的评分标准的问题。 - 上传文件供 GPT 参考:
@solbus和@mysticmarks1建议在用户请求中引用特定的文件名,以引导 GPT 分析该文档,并强调 context limit 可能不允许对完整文档进行评估。 - 消息限制与升级:用户
@elpapichulo1308, @bloodgore, @satanhashtag, @solbus和@loschess讨论了消息限制规则。限制似乎是每小时 40 条消息,这与某些用户认为的每天限制不同。@solbus指出“天(days)”是一个翻译错误。@loschess提到升级本应带来“无需等待(No wait times)”的体验。
▷ #prompt-engineering (45 messages🔥):
- 如何增强 AI 输出:用户
@cat.hemlock建议指示 AI 先创建大纲或对文章进行头脑风暴,然后对其生成的内容进行扩充和校对,以获得更优的结果。 - AI 与猜单词游戏 (Hangman) 的问题:
@eskcanta分享了一个对话链接,其中 AI 即使在有明确指令和示例的情况下,也未能正确进行 Hangman 游戏。 - AI 成功运行 Python 版 Hangman 游戏:针对
@eskcanta,@thepitviper分享了一个 AI 成功生成 Python 版 Hangman 游戏的案例链接,尽管由于 Python 访问的原因运行速度较慢。 - 从 GPT 寻求有效的营销建议:
@dnp_征求了关于如何从 AI 获取更具体、更具操作性输出的建议,例如在营销活动中使用特定方法或 powerwords。@bambooshoots建议指示 AI 扮演特定领域的专家,向高知识储备的受众提供回复。 - 病毒式传播内容要素的可视化:
@dnp_还表达了对创建图表以直观展示病毒式内容要素的兴趣,但因 AI 无法生成韦恩图 (Venn diagrams) 等视觉内容而感到困扰。@exhort_one确认 GPT-3 是基于文本的,除非结合 DALL-E 等其他工具,否则无法创建视觉内容。@bambooshoots提供了一个使用 Python 生成可视化内容的 Prompt,不过@dnp_注意到在涉及 3 个以上元素的拆解时存在局限性。
▷ #api-discussions (45 条消息🔥):
- 使用 OpenAI API 创建高质量内容:
@cat.hemlock分享了一种创建高质量 AI 内容的方法:先构思大纲,然后围绕大纲生成内容,并强调了内容生成后进行润色和校对的重要性。 - 猜单词游戏 (Hangman) 的挑战:
@eskcanta指出 OpenAI ChatGPT 在玩猜单词游戏时表现不佳,即使已知单词和字母选择顺序也是如此。然而,@thepitviper分享了一个他们生成的 Python 游戏,其中 Hangman 运行良好,并提出使用 Python 工具会使算法变慢。 - OpenAI API 与内容创作:
@dnp_征求了关于使用 ChatGPT 获取特定答案(如营销活动的方法、框架和强力词)的建议。@bambooshoots建议假设 AI 是特定领域的专家,并根据受众的专业水平调整回复。@dnp_还表达了对使用模型创建数据可视化的兴趣,对此@exhort_one回复称 GPT 是基于文本的,无法直接创建视觉图像或图表。 - GPT Assistants 与 Custom GPTs 的比较:
@dnp_询问了 GPT Assistants 与 Custom GPTs 之间的对比,但未提供明确答案。 @bambooshoots提供了一个用于创建 Python 图表的高级脚本及进一步说明,但@dnp_提到了韦恩图(Venn diagrams)无法支持超过 3 个圆圈的限制。
Nous Research AI Discord 总结
-
讨论了服务器机架偏好以及运行高负载应用时的潜在性能问题,例如在 GPU VRAM 上运行 LLM、Python 占满 CPU 以及多屏播放 YouTube 视频;讨论了降低图形负载的选项以及 Intel 核心独特的并行处理能力。
-
对 SOLAR 10.7B 模型和 Mistral 7B 在多项测试中的性能进行了基准测试对比,显示 SOLAR 10.7B 有所提升;
@euclaise建议下一步对 DeciLM-7B 模型进行基准测试,并分享了模型链接。 -
介绍并讨论了 SOLAR-10.7B 模型及其特性,以及其性能声明中可能存在的不准确之处;关于用于训练 AI 模型的数据质量与数量的辩论;建议在海量数据转换中使用质量启发式 (quality heuristics)、语义去重和 SSL Prototype 过滤。
-
讨论了 RWKV 的进展,重点是性能提升和 VRAM 占用减少;围绕 LLM 建模中长 Prompt 长度限制的对话;关于 GPT 的 AGI 能力和性能的持续辩论;DeBERTa 1B 模型的内存占用问题;关于开源社区、潜在版权冲突以及许可限制影响的讨论。
-
推荐了包括 Mamba, Mistral0.2, Mixtral, 和 openHermes 在内的模型,用于对对话片段相关任务进行性能基准测试;比较了 stable diffusion 与 30 亿参数 LLM 的运行速度;多位用户分享了资源和模型;询问关于在 2080 Ti 显卡上运行 Mistral-7B-v0.1 的问题,并得到了关于量化版本和模型卸载 (offloading) 的建议;讨论了在移动设备上运行小模型的问题。
Nous Research AI 频道总结
▷ #off-topic (9 条消息🔥):
- 服务器机架偏好:
@fullstack6209和@erichallahan表达了对 stealth 4U 服务器机架的偏好,并在技术配置中倾向于使用风冷而非水冷。@fullstack6209表示愿意为此类特定配置支付高价。 - 图形性能担忧:
@everyoneisgross询问了在 GPU VRAM 上运行 LLM、Python 占满 CPU 以及多屏播放 YouTube 视频时预期的故障。@coffeebean6887预测在这些条件下可能会出现卡顿、冻结和显存溢出 (OOM) 错误。 - 降低图形负载:
@coffeebean6887建议以 headless (无头) 模式运行系统、断开多余显示器并降低显示器分辨率,以减轻图形负载并提高系统性能。 - 利用 Intel 核心进行多任务处理:
@airpods69提到成功使用 Intel 的能效核 (efficient cores) 进行网页浏览,并使用性能核 (performance cores) 进行模型推理,且没有感到延迟。 - API 限制:
@fullstack6209评论了特定 API 中缺少 stop 或 logit bias 功能的问题。
▷ #benchmarks-log (19 条消息🔥):
- SOLAR 10.7B 与 Mistral 7B 的性能对比:
@teknium分享了 SOLAR 10.7B 模型与 Mistral 7B 在多项测试中的 Benchmark 结果对比。关键观察结果包括: - SOLAR 10.7B 在 AGIEval 中得分约为 39%,相比 Mistral 7B 的 30.65% 有显著提升。
- 在 GPT4All Benchmark 中,SOLAR 10.7B 获得了 72% 的分数,略高于 Mistral 7B 的 71.16%。
- SOLAR 10.7B 在 TruthfulQA Benchmark 中的表现仅略好于 Mistral 7B,得分为 45%,而 Mistral 7B 为 42.5%。
- BigBench 结果:还对 SOLAR 10.7B 模型 进行了 BigBench 测试。根据
@teknium分享的结果,该模型的平均得分为 38.66%。 - 对 SOLAR 10.7B 模型的看法:一些用户(如
@artificialguybr和@teknium)提到,虽然 SOLAR 10.7B 表现良好,但与复杂度相似的其他模型相比,并没有显著脱颖而出。 - DeciLM-7B:在总结了其他模型的性能后,
@euclaise建议接下来对 DeciLM-7B 模型进行 Benchmark 测试,并分享了该模型的链接,指出其在 Open LLM Leaderboard 上表现优异。
▷ #interesting-links (103 条消息🔥🔥):
-
SOLAR-10.7B 模型介绍:
Metaldragon01分享了一个拥有 107 亿参数的新模型 SOLAR-10.7B 的链接,该模型声称通过一种新方法优于 Mixtral。teknium承诺将针对这一说法对该模型进行 Bench 测试并分享结果。 -
关于 SOLAR-10.7B 模型性能的讨论:讨论围绕 SOLAR-10.7B 模型的性能展开。几位成员
n8programs和teknium根据初步测试结果表示怀疑,质疑 Model Card 中的声明是否准确。Carsonpoole提到 SOLAR-10.7B 只是一个 Pre-trained 模型,需要针对特定任务进行 Fine-tuning。 -
Phi-2 权重更新:
metaldragon01通知 Phi-2 权重已经发布,giftedgummybee暗示这些权重很快将在 Hugging Face (HF) 上提供。随后讨论了 Phi-2 与 HF 的可用性和兼容性。 -
关于模型训练数据质量和数量的辩论:由
georgejrjrjr和crainmaker发起的一场详细讨论,围绕训练 AI 模型所使用的数据选择和数量展开。涵盖的主题包括:最小化数据需求而非最大化数据量的想法、重复 Epochs 与新数据的对比问题,以及将 Synthetic Data 用作填充的概念。 -
数据生成、转换和过滤:
atgctg向georgejrjrjr询问了大规模数据转换的问题,后者就使用质量启发式方法过滤垃圾文本、语义去重(Semantic De-duplication)以及 SSL Prototype 过滤提出了建议。
▷ #general (382 messages🔥🔥):
-
RWKV 讨论与更新:用户
@vatsadev、@gabriel_syme、.benxh和@giftedgummybee讨论了 RWKV 的进展,指出了每个版本的快速开发和改进。用户@vatsadev强调了 RWKV 相比 Transformer 在性能上的提升以及 VRAM 占用的减少。此外,@gabriel_syme分享了他在 RWKV 2 上训练 Architext 模型的经验。相关链接:Architext Model -
LLM 建模中的长 Prompt 长度:用户
@ldj、@gitfedgummybee和@carsonpoole讨论了 Mistral 7b 在 A100 上、Batch Size 为 256 时每秒 6k Token 的限制,并指出如果 Batch Size 设置为 1,可能会超出内存容量。 -
关于 GPT 的 AGI 能力辩论:用户
@fullstack6209、@nruaif、.benxh和@crainmaker围绕 GPT 的 AGI 能力展开了讨论,认为 GPT 可能会从更多的 Few-shot Prompting 中受益。@kenshin9000的 Twitter 帖子建议,对“命题逻辑”和“概念”的理解可以显著增强 GPT-4 的性能。 -
DeBERTa 1B 讨论:
@euclaise和@coffeebean6887讨论了 DeBERTa 1B 模型的高内存占用,指出它往往比更大的模型占用更多内存。 -
开源社区与模型共享:
@yikesawjeez、@atgctg、@.benxh、@tsunemoto、@beowulfbr、@nruaif等人讨论了在 Hugging Face 上共享模型的问题,争论焦点在于许可协议、潜在的版权冲突以及社区内模型共享的优缺点。他们还触及了微软 Phi-2 的发布及其许可限制的影响。相关链接:Phi-2
▷ #ask-about-llms (72 messages🔥🔥):
-
对话片段的模型基准测试:
@brace1寻求开源模型的推荐,以针对从对话片段中提取和理解文本的任务进行性能基准测试。@night_w0lf推荐了几个模型,包括 Mamba、Mistral0.2、Mixtral 和 openHermes。他们还建议查看 Chatbot Arena 排行榜上模型的 ELO 评分。@n8programs提醒说这些排行榜是基于 Benchmark 的,建议更加看重模型的 ELO。 -
模型间的速度比较:
@n8programs讨论了 Stable Diffusion 与 3B 参数 LLM 之间的速度差异。尽管两者规模相似,但 Stable Diffusion 每秒只能完成一次迭代,而后者在相同硬件上每秒可以处理 80+ Token。 -
资源与模型共享:多位用户在讨论中分享了资源和模型。例如,
@tsunemoto发布了 MLX Mistral 权重的链接。@coffeebean6887讨论了他们使用 Apple 模型转换脚本的经验,并分享了一个包含示例的 GitHub 链接以指导他人完成该过程。@.benxh建议使用位于此 GitHub 仓库的开源 ChatGPT UI。 -
量化与模型运行:
@Fynn询问如何通过 Hugging Face Transformers 在拥有 10GB VRAM 的 2080 Ti 显卡上运行 Mistral-7B-v0.1,并寻求关于使用量化版本或模型卸载(Offloading)的建议。@.beowulfbr推荐了来自 Hugging Face 的 Mistral 量化版本。他们还分享了一个关于使用 Transformers 微调 Mistral-7B 的 Google Colab 笔记本,其中包含推理部分。 -
移动设备上的 LLM:
@gezegen和@bevvy分别询问了在 iPhone 和 Android 上运行小模型的问题。@tsunemoto建议使用 LLM Farm TestFlight 应用在 iPhone 上运行量化 GGUF 模型,而@night_w0lf提到了 mlc-llm,作为在包括 Android 和 iOS 在内的一系列硬件后端和平台上原生部署模型的解决方案。
DiscoResearch Discord 摘要
- 关注 OpenAI 的新聊天版本,该版本在 Prometheus dataset 上进行了训练。参与者想知道这是否对报告中性能的提升有所贡献,尽管该数据集不包含代码相关的示例。参考 OpenChat 在 HuggingFace 上的详细描述。
- 关于 Mixture of Experts (MoE) 的讨论表明,专家之间的正交性可能会带来更好的性能。还提到了单个专家的 lower order rank approximation 概念。其他话题包括基于设定最小阈值的动态专家分配和自定义 MoE 路由。
- 讨论了 QuIP# method。这是一种仅权重(weights-only)的量化方法,允许模型使用每权重 2 bits 在 11G GPU 上运行,并达到接近 fp16 的性能。在 GitHub 上查看更多细节,在 HuggingFace 上查看相关模型。
- 围绕 OpenSource German embedding models 的对话,参考了 Deutsche Telekom 的模型和 Jina 即将推出的德语嵌入模型。还提到了基于 LeoLM Mistral 7B, LeoLM Llama2 70B, 和 Mixtral 8x7B 的即将推出的模型。
- 辩论了 EQ Bench 的有效性,考虑到情感评估中潜在的主观性。一致认为情绪智力测量中的主观性是一个挑战。
- 关于 Mixtral 性能 的辩论,尽管有报告称该模型似乎比其他 7B 模型更“聪明”。在评估过程中测试了几个模型,并提出了一种可能性,即基础 7B 模型可能会限制某些类型的认知,这也可能影响角色扮演和创意写作任务。
DiscoResearch 频道摘要
▷ #disco_judge (3 条消息):
- OpenChat 版本在 Prometheus 数据上进行训练:用户
_jp1_提到新的 OpenChat 版本是在 Prometheus dataset 上训练的,并询问这种加入是提高还是降低了整体评估性能。_jp1_提供了 Huggingface 网站上 OpenChat 版本详情的链接:OpenChat 详情。 - HumanEval 性能提升:用户
le_mess回应了_jp1_的查询,指出在整合 Prometheus dataset 后,HumanEval 性能有了惊人的提升。 - Prometheus 数据集和 C-RLFT 训练的效果:用户
_jp1_对为什么不包含代码示例的 Prometheus dataset 能提高性能表示好奇。_jp1_还指出,自定义的 C-RLFT 训练似乎运行得非常有效,未来还有增强的潜力。
▷ #mixtral_implementation (160 messages🔥🔥):
-
混合专家模型与路由性能:
@fernando.fernandes分享了一个关于混合专家模型 (MoE) 表现更好的推测,认为专家的正交性导致了更高的排名,从而实现了更高效的信息存储和检索。提到了由于假设矩阵秩较高,单个专家的“低秩近似 (lower order rank approximation)”具有挑战性 讨论链接。 -
适用于 GPU 的量化 QuIP 方法:
@2012456373分享了一个来自 Hugging Face 的 AI 模型,该模型使用每权重 2-bit 的仅权重参数量化方法 (QuIP#),可以在 11GB 的 GPU 上运行。据称该方法能达到接近 fp16 的性能 模型链接 和 源代码。 -
专家的动态分配:
@kalomaze和@nagaraj_arvind讨论了根据每个层/Token 设置的最小阈值动态分配专家的可能性。这引发了关于修改和重新构建llama.cpp以适配此类参数的讨论 讨论链接。 -
自定义 MoE 路由:
@kalomaze开发了一个自定义版本的llama.cpp,允许在脚本创建的 experts.txt 文件中指定路由专家的数量 源代码。 -
关于专家与 MoE 路由系统的讨论:对路由机制以及 Token 处理时选择的专家数量进行实验是讨论的重点。引用了来自 Reddit 和 Discord 服务器 (TheBloke discord) 的帖子 Reddit 帖子 和 Discord 服务器邀请。
▷ #general (18 messages🔥):
- 量化基础 QuIP# 方法:
@2012456373分享了关于一个使用 QuIP# 方法的模型信息 模型链接,这是一种仅权重参数量化方法,仅使用每权重 2 bits 即可达到接近 fp16 的性能。该模型可以在 11G 显存的 GPU 上运行,关于 QuIP# 方法的更多细节可以在 GitHub 上找到。 - Mixtral 的 STK 训练代码:
@e.vik正在寻求关于 Mixtral 的 stk 训练代码 的帮助。他们接近完成但遇到了内存访问错误。 - 德语嵌入模型:
@thewindmom和_jp1_讨论了他们测试过的各种 开源德语嵌入模型。_jp1_还提到即将推出的 DiscoLM German v2 模型,计划在圣诞期间发布,将使用新的微调数据集。@rasdani推荐了 Deutsche Telekom 的gbert-large-paraphrase-euclidean和gbert-large-paraphrase-cosine模型,而@flozi00宣布了 Jina 计划发布德语嵌入模型。 - Leolm 和 Mixtral 旗下的新模型:
_jp1_分享了基于 LeoLM Mistral 7B、LeoLM Llama2 70B 和 Mixtral 8x7B 创建模型的计划。不过,他们澄清并非所有模型都能立即准备就绪或发布。 - Mixtral 与 Qwen-72b 的对比:
@aslawliet询问了 Mixtral 和 Qwen-72b 的对比,而@cybertimon表达了对 Mixtral 8x7B 模型发布的期待。
▷ #benchmark_dev (6 条消息):
- 关于在 GitHub 上分享代码的担忧:用户
@rtyax对在 GitHub 上分享代码表示犹豫,担心潜在的隐私问题。不过,他们考虑创建一个新的 GitHub 账号来规避这一担忧。 - EQ Bench 与情感评估中的主观性:
@_jp1_指出 EQ Bench 可能会受到情感评估主观性的影响,并建议对专家评估进行对比研究。@calytrix同意情感智能测量的固有主观性是一个挑战,但仍认为 EQ Bench 能有效区分不同的回答。 - 关于 Mixtral 性能的疑问:
@_jp1_还询问了为什么 Mixtral 的表现不如预期。@calytrix回复称他们使用了指定的 tokenisation,并测试了多个模型,包括:DiscoResearch/mixtral-7b-8expert, mattshumer/mistral-8x7b-chat, mistralai/Mixtral-8x7B-Instruct-v0.1, migtissera/Synthia-MoE-v3-Mixtral-8x7B。他们假设基础 7b 模型可能会限制某些类型的认知,并预计这可能也会影响角色扮演和创意写作任务。 - 对模型性能的主观感知:
@technotech评论道,尽管性能评分较低,但根据他们的主观意见,Mixtral 模型 似乎比其他 7B 模型“聪明得多”。
OpenAccess AI Collective (axolotl) Discord 摘要
- 宣布 Microsoft Phi-2 模型权重 已可用于研究目的 Microsoft 官方 Phi-2 仓库。还讨论了 Phi-2 与 GPT4 的对比。
- 关于多样化 指令数据集 的对话,涉及非结构化数据集如何结构化的主题。
- 提到建立 AI 模型基准测试 的想法;对该概念以及用于基准测试的假设数据集进行了有趣的讨论。
- Mixtral (FFR 问题修复) 的更新公告,促进了在特定硬件配置上的 FFT 操作。
- 讨论了 信用卡问题 并尝试寻找解决方案。
- 有兴趣实现对 微调模型 在测试数据集上的评估,以便与基础模型进行对比。
- 关于 Loss 尖峰 及其稳定方法的交流,例如调整学习率。
- 关于训练大模型时的 内存限制 以及潜在解决方案(如使用 offload)的对话。
- 关于 多 GPU 训练 问题的对话;分享了应对该问题的策略,包括 GitHub 上提到的一个 Pull Request GitHub 上的 Pull Request。
- 分享了关于 Mixtral 模型 与 Mistral 模型性能的观察,包括一个用于更好进行 DeepSpeed 加载的有用 Pull Request Pull Request。
- 围绕 Flash Attention 安装 问题和 transformers 的 attention 实现展开讨论,涉及 HuggingFace 所做的更改 HuggingFace 更改。
- 修复 训练错误 的战术尝试,例如在配置文件中将
sample_packing修改为false。 - 部署了解决上述 训练错误 的修复程序;并验证了其成功。
- 探索 预训练中突然出现 Loss 尖峰 的潜在原因。
- 分享了用户对某款 PDF 解析工具 的体验,该工具并不完全令人满意。
- 分享并讨论了 Jon Durbin 的推文。
- 表示愿意尝试 不同的 PDF 解析解决方案 以获得更好的效果。
OpenAccess AI Collective (axolotl) 频道摘要
▷ #general (71 messages🔥🔥):
- Phi-2 权重可用性:用户
@caseus_分享了 Microsoft Phi-2 权重现已在 Hugging Face 上发布,供研究使用。此前@noobmaster29发起了关于该模型在 Azure 上可用性的讨论。据报道,该模型虽然不如 GPT4 有效,但在某些方面具有可比性 (Microsoft 官方 Phi-2 仓库)。 - 指令数据集讨论:用户
@dreamgen和_dampf讨论了各种指令数据集,如 OpenOrca, Platypus, Airoboros 3.1 和 OpenHermes 2.5。有人询问了这些数据集是如何策划的,以及非结构化数据集是如何转化为结构化的。 - 潜在的模型基准测试:关于为 AI 模型创建基准测试进行了一场幽默的讨论。
@faldore建议将其命名为 Dolphin Benchmark,而@le_mess提议使用@faldore的一个模型来生成数据集。他们开玩笑说要在测试集上进行训练,并比较各种 Prompting 策略的结果。 - Mixtral FFT 更新:
@caseus_宣布了 Mixtral 的一项更新,修复了 Fast Fourier Transform (FFT) 问题,从而在某些硬件配置上启用 FFT 操作。 - 信用卡问题:用户
@nruaif报告了在尝试访问某些服务时信用卡被拒绝的问题。他们还向聊天中的另一位用户发送了好友请求以寻求帮助。
▷ #axolotl-dev (82 messages🔥🔥):
- 微调模型的评估:
@z7ye表示有兴趣在测试数据集上评估微调模型,以便与基础模型进行比较。他们提供了一个想要运行的潜在命令示例。 - Loss 尖峰:
@casper_ai在训练时遇到了突然的 Loss 尖峰,但通过将学习率调整为 0.0005 成功使其稳定。 - 内存限制:讨论了训练大模型时的内存限制。
@casper_ai提到由于 FFT 极其消耗内存,他们无法在 8x A100 上容纳该模型。@nruaif建议使用 offload,前提是 VM 有足够的 RAM。 - 模型保存问题:包括
@casper_ai和@caseus_在内的几位成员讨论了在多 GPU 训练期间尝试保存模型时出现的问题。@caseus_分享了一个解决该问题的 GitHub Pull Request 链接。 - Mixtral 模型性能:在比较 Mixtral 和 Mistral 模型时,
@casper_ai观察到 Mixtral 模型在微调期间的 Loss 似乎更稳定。@caseus_还分享了一个 Pull Request,旨在改进 Mixtral 模型的 DeepSpeed 加载。
▷ #general-help (14 messages🔥):
- Flash Attention 安装与 Transformers Attention 实现:由于
transformers中 Attention 实现的更改,@jovial_lynx_74856在训练时遇到了麻烦。@caseus_发现由于这一更改,补丁可能无法按预期工作,并认为实现可能会回退到 SDPA。 - Transformers Attention 实现的更改:
@caseus_指出了 Hugging Face 最近在transformersAttention 实现中进行的更改,这可能是导致问题的原因。 - 尝试修复训练错误:
@jovial_lynx_74856通过将openllama-3b/lora.yml中的sample_packing修改为false,成功在不进行打包的情况下运行了训练。 - 针对训练错误的更新分支:
@caseus_推送了另一个更新以修复该问题。@jovial_lynx_74856确认现在训练运行正常。 - 预训练中的 Loss 尖峰:
@jinwon_k提出了一个关于在预训练期间遇到 Loss 尖峰的未知问题,并询问其背后的已知原因。
▷ #datasets (6 条消息):
- 关于 PDF 解析工具的讨论:用户
@visuallyadequate分享了他们使用某 PDF 解析工具的经验。他们指出该工具无法处理其部分 PDF 文件,并提到该工具并非开源。他们还反映 API 会在不给出解释的情况下拒绝某些文件,即使工具能正常工作,速度也非常缓慢,且会弄乱格式。 - 来自 Jon Durbin 的推文分享:
@lightningralf分享了一条 Jon Durbin 的推文供大家讨论。 - 关于 PDF 解析的进一步讨论:在回复
@lightningralf时,@visuallyadequate表示愿意继续尝试不同的解决方案,以实现更好的 PDF 解析效果。
Mistral Discord 总结
- 讨论了 API Access Invitations(API 访问邀请)和 Mistral 模型性能,用户针对模型评估和访问流程等话题表达了反馈和咨询。
- 提出了关于 Mistral vs Qwen 模型、隐私顾虑、数据主权以及 Mistral API 的托管与定价等各种技术考量。
- 定价详情可在 pay-as-you-go platform(按需付费平台)找到。
- 围绕 Mistral 模型的超参数、API 输出大小、API 与 HF 模型输出之间的差异等话题进行了详细对话,并针对这些领域做出了各种回应。
- 宣布了一个新频道
<#1184444810279522374>,用于处理 API 和仪表板相关的问题。
- 宣布了一个新频道
- 探讨了多个与部署相关的话题,包括 endpoint 开源、FastChat Tokenization 以及 Mixtral 的推荐设置。
- 在实现方面,讨论内容包括纠正 Mistral v0.2 错误的 HF 仓库并分享了正确的仓库:Mistral-7B-Instruct-v0.2。
- 提供了指向更新文档的链接,包括 Mistral-7B-v0.2 Instruct 文件 和 Mixtral-8x7B-v0.1-Instruct。
- 用户
@casper_ai询问了 Mistral instruct 的微调学习率。 - 展示的工作和实验包括发布了一个名为 “Bagel” 的新 Mistral-7b fine-tune 版本,并分享了 Chat Completion Streaming Starter 的 GitHub 仓库。
- 包含了一些随机问题和幽默内容,涉及用 随机问题查询 LLM 以及对比 Mistral 与 QMoE Mixtral。
- 在
la-plateforme频道中,重点讨论了 API 使用、性能问题、Grammar Integration(语法集成)、模型反馈与 Playground、Rate Limit(速率限制)、计费以及 Bug 报告。- 创建了一个 Mistral 交互 Playground:Github 链接 和网页链接 (https://mistral-playground.azurewebsites.net/)。
▷ #general (74 messages🔥🔥):
- API 访问邀请:
@vortacs和@jaredquek等用户询问了 API 访问邀请的发放速度。@aikitoria在公告发布几小时后注册并较早获得了访问权限,这表明处理过程相对较快。 - Mistral 模型性能:
@someone13574讨论了 Mistral 中动态专家计数路由的可能性,并询问了在推理时每个 token 不同激活专家数量的评估情况。 - Mistral API 的托管与定价:Mistral API 的托管和定价是讨论的主要话题。确认 API 托管在瑞典的 Azure 上。对于国际客户,账单以欧元结算,并会产生一定的货币转换费。对于美国客户,未来将直接以美元计费。定价可以在其 pay-as-you-go 平台上找到。
- 隐私担忧与数据主权:用户对《爱国者法案》以及美国云服务商托管数据表示担忧。来自 Mistral 的
@lerela保证这是一个重要话题,他们正在努力为客户提供更好的保障。对于企业客户,模型也可以进行本地部署 (on-premises)。 - Mistral 与 Qwen 模型对比:
@aslawliet和@cybertimon讨论了 Mistral 与 Qwen 模型的对比,结论是 Mistral 速度更快、更易于运行,且优于 Qwen 7b 和 14b。由于缺乏深入测试,与 Qwen 72b 的对比尚不明确,但用户因其宣称的优势而更倾向于 Mistral。
▷ #models (21 messages🔥):
- Mistral 模型的超参数:用户
@tim9422对缺乏 Mistral 模型训练超参数信息表示担忧,寻求全量微调 (full-finetuning) 的指导。 - API 输出长度:
@vince_06258讨论了 API 输出的限制,发现无论 prompt 长度如何,生成的响应始终很简短。@aikitoria建议在开头添加系统消息以生成更长的响应,但确认目前没有任何关于“期望长度”的参数。 - API 与 HF 模型输出的差异:
@thomas_pernet在协调 API 结果与 Hugging Face 的 Transformer 模型输出时遇到问题,导致结果显著不同。@daain指出,与基础模型相比,API 使用的是 instruct 模型。@thomas_pernet随后通过使用正确的 instruct 模型成功复现了 API 结果。 - API 咨询新频道:
@lerela宣布创建了一个新频道<#1184444810279522374>,专门用于 API 和仪表板相关的问题,并指出 API 仅使用 instruct 模型。 - 关于 Mixtral 和 SOLAR 10.7B 模型的讨论:用户
@_dampf、@_bluewisp和@vijen.发起了关于 Mixtral 和 SOLAR 10.7B 模型的对话。讨论点包括 Mixtral 是否在新的英文数据上进行了训练、Mixtral 与新发布的 SOLAR 10.7B-Instruct-v1.0 模型的性能对比,以及关于 Mixtral 具体用例的咨询。
▷ #deployment (6 messages):
- 端点开源咨询:
@yvaine_16425询问端点 (endpoint) 是否也是开源的。 - FastChat 分词问题:
@lionelchg注意到 FastChat(在 vLLM 中使用)的一个分词 (tokenization) 陷阱,并询问该问题是否也存在于 TensorRT-LLM 部署中,或者 NVIDIA 是否正确发送了 token。@tlacroix_澄清说 tensorrt-llm 只是 token-in/token-out,并建议参考 Triton Inference Server 教程来设置分词/反分词 (tokenization/detokenization) 流水线。 - Mixtral 的推荐设置:
@sa_code询问了 Mixtral 的 top-p 和 temperature 的推荐设置。 - 关于 API RPS 限制的查询:
@kml1087正在考虑部署到生产环境,但首先想知道 Mistral API 是否有每秒请求数 (RPS) 的上限。
▷ #ref-implem (8 messages🔥):
- Mistral v0.2 的 HF 仓库错误:用户
@titaux12指出 Mistral AI Platform 页面上指向 Mistral v0.2 的 HuggingFace 仓库链接不正确。错误的链接指向了 Mistral-7B-v0.1,但它应该指向 Mistral-7B-Instruct-v0.2。该错误出现在Generative endpoints > Mistral-tiny章节。 - 错误修正:用户
@lerela确认了该错误并感谢@titaux12的指出。该问题随后已被修复。 - Mistral-7B-v0.2-Instruct 文档更新:
@tlacroix_分享了一个 Mistral-7B-v0.2 Instruct 文件链接,并表示该链接将被添加到文档中。@vgoklani对此更新表示感谢。 - 请求 Mixtral-8x7B-Instruct-v0.1:
@vgoklani请求提供非 HuggingFace 版本的Mixtral-8x7B-Instruct-v0.1。@tlacroix_幽默地回应并承诺会着手处理。 - 参考实现偏好:
@vgoklani表达了对参考实现(reference implementation)的偏好,理由是代码更简洁,且在使用 FA2 (Fast Attention Assemble) 时性能高效,特别是当它与来自 Tri Dao 的 RMS_NORM 和 Rotary Embeddings 实现融合时。@vgoklani还提到正在为参考模型开发 flash-decoding 和自定义的 AWQ 实现。 - Mixtral-8x7B-v0.1-Instruct 链接:
@tlacroix_提供了所请求的 Mixtral-8x7B-v0.1-Instruct 链接,并确认这将被添加到文档中。
▷ #finetuning (1 messages):
- Mistral Instruct 的微调:用户
@casper_ai提出了一个问题,询问用于微调 Mistral instruct 的学习率(learning rate)信息。提供的消息历史中没有记录进一步的讨论或回复。
▷ #showcase (8 messages🔥):
- 在 Macbook 上运行 Mistral:
@sb_eastwind提到他在配有 32GB 内存的 Macbook 上通过 llamacpp 和 LM Studio 运行 3bit 版本的 Mistral,并分享了一篇展示该设置的 Twitter 帖子。 - 增加内存分配:针对
@sb_eastwind,@daain建议可以在 MacOS 上为 llamacpp 分配更多内存以运行 4bit 版本的 Mistral,并指向了一条 Discord 消息了解详情。 - Q3 和 Q4 的区别:
@sb_eastwind询问了q3_k_m和Q4之间的区别,@daain表示他们不知道,因为还没尝试过Q3。 - Chat Completion Streaming Starter:用户
@flyinparkinglot分享了一个 Chat Completion Streaming Starter 的 GitHub 仓库,该项目允许用户在 React 应用中切换使用 OpenAI GPT-4 和 Mistral Medium。 - Bagel 发布,Mistral-7b 微调版:
@jondurbin宣布发布了一个名为 “Bagel” 的新 Mistral-7b 微调模型,它具有数据集合并、基准测试去污染(benchmark decontamination)、多种 Prompt 格式、NEFTune 和 DPO 等特性。
▷ #random (3 messages):
-
用随机问题查询 LLM:
@basedblue建议为语言模型学习系统(LLMS)整理一份随机问题列表。 -
查询 Mistral 是否等同于查询 QMoE Mixtral:用户
@sb_eastwind幽默地询问查询 Mistral AI 是否类似于查询 QMoE Mixtral。 -
Mistral AI 生成的文本是否可用于商业数据集:
@nikeox向知识产权律师、AI 伦理专家和数据隐私专家提出了一个关于 Mistral AI 生成文本商业用途的问题。该用户将其咨询分解为一个由两部分组成的专家计划,并请求频道中其他人的确认。
▷ #la-plateforme (52 messages🔥):
-
API 使用与性能问题:用户
@_jp1_询问了关于追踪使用情况的问题,@qwertio在 文档 中发现了一个拼写错误。用户@flyinparkinglot对 Function Calling 功能表示感兴趣,@sa_code和@coco.py表示赞同。@svilup遇到了 API 访问问题,结果证明是 URL 渲染错误。 -
Grammar 集成与模型使用:
@nikeox询问了集成类似 Llama.CPP 的 grammars 的可能性。@tlacroix_确认 Function Calling 和 grammars 已列入 Mistral 的路线图,并进一步询问了@nikeox关于其 grammar 使用的具体细节。@lionelchg、@tlacroix_和@nikeox讨论了在 chat completions API 中使用 system role 以及如何包含它的问题。 -
Mistral 模型反馈与 Playground:
@delip.rao分享了对mistral-medium模型处理复杂编程任务的正面反馈,并链接到了 Twitter Post。用户@xmaster6y创建了一个与 Mistral API 交互的 playground,并分享了 GitHub 链接 和网页链接 (https://mistral-playground.azurewebsites.net/)。 -
速率限制、计费与模型 Embeddings:
@_jp1_和@yusufhilmi_提出了关于速率限制的问题,@tlacroix_解释说大约是每分钟 1.5M tokens,每月 150M。@akshay_1询问了 embedding 模型,@alexsablay建议 context 最高为 512。@lars6581提出了关于 embedding 请求 batch 限制的进一步查询,@tlacroix_期待 API 精确速率限制的答案。 -
Bug 报告:
@nikeox报告了实际 API 响应与 API 文档中提供的示例响应之间的一致性问题。oleksandr_now报告了 API 响应超时的问题,并请求提供 Billing API 以监控其使用情况。
HuggingFace Discord Discord 摘要
- 在 AI 和机器学习模型领域讨论了多项更新和发布,包括 Transformers、Mixtral、multimodal LLMs、Seamless M4T v2 models、来自 Microsoft 的 Phi 1 和 1.5,以及针对 Llama 启发式架构的 AMD GPU 支持;这些都是
@osanseviero提到的开源更新的一部分。此外,Spaces Analytics 获得了关注,同时还发布了关于 API 中的 LoRAs 推理以及标记为 text-to-3D 的模型的公告。Codecademy 还分享了一门专注于 Hugging Face 的新课程(Intro to Hugging Face Course & Gaussian Splatting)。 - General 频道进行了各种讨论,特别是关于 Deepsex-34b model 的多个计划和微调版本、旨在实现人工智能的大脑模拟,以及使用 HuggingFace 模型进行潜在的文本分类。提到了一个名为 DeepSouth 的澳大利亚超级计算机,用于模拟人类大脑。成员们还就时间序列预测进行了 LSTM 讨论。
- “Today I’m Learning” 频道主要围绕 Mamba 架构、RNN、LSTM 和 GRUs 展开讨论。用户
@merve3234为@nerdimo理解这些 RNN 架构提供了指导(Mamba Paper)。 - “Cool Finds” 频道中一些令人惊叹的新语言模型引起了关注,包括 Mistral AI 发布的 MOE-8x7B,以及针对偏差的 tabular deep learning。还分享了 ML 模型的安全问题,以及一篇关于成员推理攻击(membership inference attacks)的有趣读物。揭晓了一个名为 Marigold 的用于深度估计的扩散模型,以及来自 DataCamp 的免费 AI 编程系列,其中提到了“使用 Hugging Face 构建 NLP 应用程序”的课程(DataCamp NLP session)。此外还分享了一篇关于精准医学的综合文章。
- “I Made This” 频道主要关注个人成就。
@rwitz_发布了一个微调模型 Go Bruins V2,@thestingerx编译了一个提供音频转换和 TTS 功能的项目 RVC。为了增添节日气氛,@andysingal使用 Stable Diffusion 创作了圣诞氛围图。@Metavers Artspace介绍了一个在线艺术空间,同时@merve3234发布了一篇关于 LLMs 量化(quantization)的博客文章。 - “Reading Group” 频道以拟议的讨论话题 Distilling the Knowledge in a Neural Network 开场。
- “Diffusion Discussions” 频道提出了 GPU 升级的可能性。
- 在 “Computer Vision” 频道中,有人在寻求用于识别 2D 建筑图纸的模型推荐。
- NLP 频道出现了关于将图论或有限状态自动机理论与模型相结合的提议,寻找在 GPU 之间分配模型 Checkpoints 的解决方案,寻求关于简历解析模型的建议,以及处理机器翻译自定义数据集的问题。
HuggingFace Discord 频道摘要
▷ #announcements (1 条消息):
- Transformers 发布: 用户
@osanseviero宣布了多项更新,包括 Mixtral 与 Flash Attention 的兼容性、多模态 LLMs (Bak)LlaVa 的引入、提供多种翻译能力的 Seamless M4T v2 模型、PatchTST 和 PatchTSMixer 等预测模型、来自 Microsoft 的 Phi 1 和 1.5、AMD GPU 支持以及针对 Llama 启发式架构的 Attention Sinks。更多详情可以在官方 GitHub release page 找到。 - 开源: 一些重要的更新包括 Small Distil Whisper,它比较大的 Whisper v2 小 10 倍且快 5 倍,同时保持相似的准确度;Llama Guard,一个用于内容审核的 7B 模型,用于对 Prompt 和响应进行分类;以及 Optimum-nvidia,它允许通过 1 行代码更改实现更快的延迟和吞吐量。此外,HuggingFace 平台上还更新了 Apple 新的 MLX 框架中的模型。
- 产品更新: Spaces Analytics 现在可以在 Spaces 的设置页面中使用。API 中的 LoRAs 推理得到了极大改进。标记为 text-to-3D 的模型现在可以轻松地在 Hub 上找到。您可以在 Huggingface 的博客页面上了解更多关于 LoRAs 推理的信息。
- 学习资源: Codecademy 推出了 Intro to Hugging Face 课程。这是课程链接。此外还提到了一个非常有趣的 Gaussian Splatting 入门介绍,可以在这里查看。
▷ #general (57 条消息🔥🔥):
-
Deepsex-34b 模型协作:用户
@databoosee_55130分享了一系列由不同贡献者微调的 Deepsex-34b 模型版本,包括[TheBloke](https://huggingface.co/TheBloke/deepsex-34b-GGUF)、[waldie](https://huggingface.co/waldie/deepsex-34b-4bpw-h6-exl2)以及来自 HuggingFace 社区的其他成员。他宣布计划创建一个基于“七宗罪(Seven Deadly Sins)”系列的新模型。 -
大脑模拟与 AI:
@databoosee_55130发起了一场关于大脑模拟和人工智能的讨论,指出模拟人类大脑极其复杂,目前的人工神经网络仅实现了人类大脑复杂性的一小部分。@ahmad3794补充道,模仿真实神经元的硬件实现可能会产生更高效的模拟。 -
用于大脑模拟的超级计算机:
@stroggoz分享了关于 DeepSouth 超级计算机的信息,该计算机由澳大利亚国际神经形态系统中心(International Center for Neuromorphic Systems)开发,能够模拟人类大脑突触,计划于 2024 年推出。 -
文本分类与 HuggingFace 支持咨询:用户
@jeffry4754和@fireche寻求关于文本文件分类的建议,特别是使用现有模型进行类别预测。@cakiki建议通过 HuggingFace 支持表单 联系专家。 -
关于 LSTM 神经网络的辩论:
@cursed_goose就实现用于时间序列预测的 LSTM 单元获得了小组反馈。他分享了一个用 Rust 编写的基础实现,并寻求关于创建 LSTM 层和进行预测的指导。@vipitis建议进行无监督训练或聚类,或者尝试大模型的 zero-shot 任务。
▷ #today-im-learning (4 条消息):
@merve3234讨论了 Mamba:介绍了 Mamba,这是一种在性能和效率上都超越了 Transformers 的架构,并分享了 Arxiv 上的 Mamba 论文链接(Mamba Paper)。@nerdimo学习 循环神经网络 (RNN) 架构:开始学习 GRUs 和 LSTMs,特别是为了解决标准 RNNs 面临的梯度消失问题。@merve3234关于理解 RNN, LSTM 和 GRUs 的建议:指出与标准 RNNs 相比,理解 LSTMs 和 GRUs 的初始复杂度较高。@nerdimo分享了他们的学习经验,提到了理解 LSTMs 和 GRUs 复杂的逻辑门机制时的困难。
▷ #cool-finds (7 条消息):
- Mistral AI 最新的语言模型:
@tokey72420分享了关于 Mistral AI 在语言模型领域取得最新突破的链接,即发布了 MOE-8x7B,点击此处了解更多。 - 表格深度学习:
@d3aries推荐了一篇题为“An inductive bias for tabular deep learning”的论文,可在 Amazon.science 上获取。 - 机器学习安全:
@shivank2108分享了一篇关于机器学习安全和成员推理攻击(membership inference attacks)的研究论文链接,可在 arXiv 上查阅。 - 新型深度估计模型 Marigold:
@merve3234提到了 Marigold,这是一种用于深度估计的扩散模型(diffusion model),是密集预测 Transformer(dense prediction transformers)的替代方案,可在 huggingface.co 上获取。 - AI 实战编码系列:
@datarhys分享了来自 DataCamp 的免费 9 部分 AI 实战编码系列。该系列包括“使用 Hugging Face 构建 NLP 应用程序”的课程,可在 Datacamp NLP session 免费访问。 - 精准医学及其在医疗实践中的作用:
@jeffry4754分享了一篇关于由基因组学和蛋白质组学等技术驱动的精准医学如何具有改变医疗实践潜力的文章,可在 link.springer.com 查阅。
▷ #i-made-this (7 条消息):
- Go Bruins V2 - 一个微调过的语言模型:
@rwitz_分享了他们微调后的语言模型 Go Bruins V2 的 链接。 - RVC 项目:
@thestingerx讨论了他们的 RVC 项目,其中包括音频转换、各种 TTS 功能等。他们提到了在 CPU 上运行的挑战,并分享了该项目的 链接。 - 使用 Stable Diffusion 营造圣诞氛围:
@andysingal分享了一段 YouTube 视频,展示了应用 Stable Diffusion 创造圣诞氛围的过程。 - Metavers Artspace:
@Metavers Artspace分享了一个在线艺术空间的 链接。 - LLM 量化博客文章:
@merve3234写了一篇关于 LLM 量化的 博客文章(不包括 AWQ)。他们鼓励其他用户在 Hugging Face 上撰写博客文章。 @nerdimo表示有兴趣在空闲时间研究@merve3234关于量化的博客文章。
▷ #reading-group (5 条消息):
- 频道介绍:用户
@murtazanazir表示有兴趣讨论并深入了解某个特定主题。@merve3234建议在频道内进行讨论,以便其他人加入。 - 讨论主题:
@murtazanazir提出了一个讨论主题:Distilling the Knowledge in a Neural Network。
▷ #diffusion-discussions (3 条消息):
- GPU 升级讨论:
@pseudoterminalx提到,尽管在 2023 年初可以升级 GPU,但它在每次迭代中会消耗 350w 持续 2 秒。@knobels69回应称,可能是时候升级他们的 GPU 了。
▷ #computer-vision (3 条消息):
- 2D 建筑数据识别:用户
@fireche询问是否有可以基于图像分类识别 2D 建筑图纸 的模型,@merve3234对此进行了说明。
▷ #NLP (9 条消息🔥):
- 将图论或有限状态自动机与模型结合:用户
@stroggoz提出了一个开源库的想法,该库将图论或有限状态自动机理论与模型相结合。使用哪个模型的决策将基于预测/评分。 - 在 GPU 之间分配模型 Checkpoints 的并行性:针对
@acidgrim关于在两个不同系统之间拆分模型的询问,@merve3234向其推荐了并行性的概念,详见 Hugging Face 关于 Text Generation Inference 的文档以及 Transformers 关于训练性能优化的文档。 - 用于简历解析的模型:
@surya2796寻求关于创建简历解析模型的信息。该查询后没有进一步的对话或建议。 - 机器翻译自定义数据集的问题:
@dpalmz在尝试使用自定义数据集进行机器翻译训练时遇到了ValueError。@nerdimo表示愿意提供帮助,因为他过去也遇到过同样的问题。
▷ #diffusion-discussions (3 条消息):
- GPU 升级讨论:用户
@pseudoterminalx建议由于高能耗,使用某个未指明的功能是不切实际的,并表示:“最简单的答案很可能是否定的,即使你可以(在 2023 年初曾短暂可行),它在每次迭代中也会消耗 350w 持续 2 秒”。作为回应,@knobels69表现出了升级其 GPU 的兴趣。
LangChain AI Discord 总结
只有一个频道有活动,因此无需总结…
- 使用 LangChain 的 Azure Search 服务:
@hyder7605正在寻求帮助,希望利用 LangChain 将多查询检索(multi-query retrieval)或 fusion RAG 功能与 Azure Cognitive Search 集成。他的目标是在文档检索期间定义过滤器和搜索参数,并结合混合搜索(hybrid search)和语义搜索(semantic search)等高级功能。 - 在 Node.js 中使用 ReRanking 模型:
@daii3696正在寻找将 ReRanking 模型整合到 Node.js RAG 应用中的建议。注意到 Cohere Re-Ranking 模型目前仅在 Python 版 LangChain 中可用。 - GPT-3.5 语言响应:
@b0otable正在讨论让 GPT-3.5 以指定语言响应的困难,特别是在上下文较长且包含混合语言的情况下。目前的 Prompt 大约有 85% 的成功率。 - LangChain 错误:
@infinityexists.在使用 LangChain 运行任何模型时遇到错误:”Not implemented error: text/html; charset =utf -8 output type is not implemented yet”。 - LangChain 与 gRPC 的集成:
@manel_aloui正在寻找有关如何将 gRPC 与 LangChain 集成的信息。询问社区是否有人找到了解决方案。 - 文档差异:
@vuhoanganh1704注意到 LangChain JavaScript 和 Python 文档之间存在差异,导致了困惑。 - LANGSMITH 突然无响应:
@thejimmycz提出了一个问题,即 LANGSMITH 没有保存任何调用。@seththunder也证实了这是一个问题。 - 使用 Next.js 进行流式输出:
@menny9762正在征求关于使用 Next.js 和 LangChain 进行流式输出(streaming)的建议。@seththunder建议使用名为StreamCallBack的回调函数,并在语言模型中将stream = true设置为参数。 - 支持多语言的开源 Reranking:
@legendary_pony_33278对支持多种语言(包括德语)的 RAG 应用开源 Reranking 技术感兴趣。注意到大多数教程都使用 Cohere Reranker 模型。 - 使用 LangChain 微调 Mixtral-8x7B:
@zaesar正在询问如何使用 LangChain 微调 Mixtral-8x7B 模型。 - LangChain 资料:
@sniperwlf.正在寻找 LangChain 的学习资料,类似于 O’Reilly 出版的书籍。@arborealdaniel_81024评论说该项目还太年轻且不稳定,目前还不适合出书。 - RAG 中带有来源的索引解决方案:
@hucki_rawen.io询问了关于 RAG 中使用的带有来源的索引解决方案。并对这一过程的预期结果提出了疑问。
Latent Space Discord 总结
- 分享了视频演示 “Ben Evans’s 2023 AI Presentation”。YouTube 链接,由 @stealthgnome 分享
- 介绍了 AI News 服务,这是一个总结各 AI Discord 服务器讨论内容的工具,并提供了加入服务启动预约的选项。@swyxio 的帖子
- 讨论了由 AI News 服务中的相关帖子引发的 LangChain 架构重构 话题。LangChain 架构重构帖子
- 分享了首份 Mistral Medium 报告,随后
@kevmodrome成功使用 Mistral-Medium 进行了 UI 组件创建的实验。Twitter 链接,由 @swyxio 分享 @swyxio参加了一个关于超越 Scaling 的 LLM 开发 讲座,并分享了讨论链接。Twitter 链接,由 @swyxio 分享- 分享了 Sama 对某个未指明主题的评论,尽管被描述为并不是特别有见地。Twitter 链接,由 @swyxio 分享
- 积极组织论文评审及相关讨论:
- 发出了关于 Q-Transformer 论文 聊天室讨论的邀请。论文链接
- 鼓励报名参加定期举行的 LLM Paper Club 活动的每周提醒。活动报名链接
- 在 LLM Paper Club 频道中:
@cakecrusher宣布了关于 Q-Transformer 论文 的演示,并提供了一个关于该主题的 Copilot 链接。Copilot 链接- 用户针对技术问题和未来讨论的主题进行了查询和澄清。
Latent Space 频道总结
▷ #ai-general-chat (9 messages🔥):
- Ben Evans 的 2023 AI 演讲:
@stealthgnome分享了 Ben Evans 2023 年 AI 演讲的 YouTube 视频链接。 -
AI News 服务发布:
@swyxio介绍了 AI News 服务,这是一个总结 AI Discord 服务器讨论的 MVP 服务,并分享了即将发布的服务启动注册链接。 -
Langchain 架构重构: AI News 服务中包含了一个关于 Langchain 架构重构帖子的链接。
-
首份 Mistral Medium 报告:
@swyxio分享了首份 Mistral Medium 报告的 Twitter 链接。 - Mistral-Medium 的实验:
@kevmodrome提到他们在生成 UI 组件方面成功实验了 Mistral-Medium。 - 关于 LLM 开发的讨论:
@swyxio参加了一个关于超越 scaling 的 LLM 开发讲座,并分享了讨论的 Twitter 链接。 - Sama 的评论:
@swyxio分享了 Sama 评论的 Twitter 链接,并指出其内容不多。
▷ #ai-event-announcements (1 messages):
- Q-Transformer 论文讨论:
@swyxio邀请服务器成员加入由<@383468192535937026>主持的聊天室,讨论 Q-Transformer 论文。该论文题为 “Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions“,由 Yevgen Chebotar, Quan Vuong, Alex Irpan, Karol Hausman 等多位研究人员撰写。论文可通过 https://qtransformer.github.io/ 访问,旨在进行开放讨论。 - LLM Paper Club:
@swyxio还鼓励大家订阅 LLM Paper Club 的每周提醒。这是一个定期举行的活动,每周进行论文研读,拆解并讨论各种 LLM 论文。感兴趣的成员可以在 https://lu.ma/llm-paper-club 注册。该活动由 Kevin Ball, Eugene Yan & swyx 主持,鼓励在讨论前先阅读选定的论文。
▷ #llm-paper-club (7 messages):
- Q-Transformer 演讲计划:
@cakecrusher宣布他们将演示 Q-Transformers 论文,并分享了他们在 OpenAI Chat 上的 Q-Transformer “copilot” 链接。 - 访问问题: 用户
@swyx.io表示在某些事情上遇到了麻烦,但具体问题尚不明确。 - 对论文主题的困惑:
@__pi_pi__对下次会议讨论的论文主题表示困惑。@slono通过提供讨论 Q-transformers 论文的频道线索直接链接解决了这一困惑。 - 下周的论文:
@coffeebean6887询问了下周要讨论的论文。在提供的消息中没有对此查询的回复。
LLM Perf Enthusiasts AI Discord 总结
dongdong0755和rabiat分别表达了对 Google Gemini 的 Gemini Pro API 使用情况和延迟统计数据的兴趣,表明需要更多关于该主题的信息。- 关于 GPT-4 和 GPT Tasks 的查询,体现在
.psychickoala请求更新或示例,以及@dhruv1在 #resources 频道中询问关于 GPT 任务的问题。 - 围绕 AI 微调(fine-tuning)的对话,包括
@robertchung寻求理解“嵌套回复”(nested replies)一词,以及@robhaisfield讨论通过 TypeChat 使用 GPT-4 来实现特定的 Email 界面。 - 价值资源分享,包括
@robotums分享了一篇题为 “Phi-2: The Surprising Power of Small Language Models” 的博客文章,以及@nosa_.在 #resources 频道提供了一个有用的链接,可能与 GPT 相关。 - 关于 LLM 应用评估指标(evaluation metrics)的讨论。
@joschkabraun分享了一篇关于该主题的博客文章,并强调了 Hex 的 AI 负责人 Bryan Bischof 关于在 GitHub Copilot 中使用防御性代码解析(defensive code parsing)的观点。 jeffreyw128在 #prompting 频道中发起了一个关于深入理解某未指定主题的未完成询问。
LLM Perf Enthusiasts AI 频道总结
▷ #general (1 条消息):
dongdong0755: 有人在尝试 Gemini Pro API 吗?
▷ #gpt4 (1 条消息):
.psychickoala: 这里有任何更新吗?有人有这方面的示例吗?
▷ #finetuning (2 条消息):
- 嵌套回复讨论:
@robertchung询问关于“嵌套回复”(nested replies)一词的澄清,质疑它是否指代“第一条入站消息 -> 其他回复”的构成。 - 为 Email 界面微调 AI:
@robhaisfield讨论了通过 TypeChat 使用 GPT-4 来生成特定的Email界面。他还推测经过微调的 GPT-3.5 或 Mistral 可能也能达到同样的效果,但在不进行微调的情况下,他认为 GPT-4 是最可行的方案。
▷ #opensource (1 条消息):
- Phi-2 小型语言模型:用户
@robotums分享了来自 Microsoft Research 关于小型语言模型潜力的博客文章。这篇题为 “Phi-2: The Surprising Power of Small Language Models” 的博客文章包含了 Marah Abdin、Jyoti Aneja 和 Sebastien Bubeck 等多位研究人员的贡献。
▷ #resources (2 条消息):
- 讨论 GPT 任务:用户
@dhruv1询问一位未具名用户他们正在使用 GPT 运行哪种任务。 - 分享资源链接:
@nosa_.分享了一个他们认为非常有用的链接,可能与 GPT 的讨论有关。
▷ #speed (1 条消息):
rabiat: 有关于 Google Gemini 的延迟统计数据吗?
▷ #eval (1 条消息):
- LLM 应用的评估指标:
@joschkabraun分享了一篇关于评估指标(包含代码)的博客文章,这些指标不依赖于基准真相(ground truth)数据,适用于那些希望在没有基准真相数据的情况下评估 LLM 应用的实时流量或离线实验的人。 - LLM 应用中的质量控制与评估:据 Bryan Bischof(Hex 的 AI 负责人)的见解指出,GitHub Copilot 中使用了防御性代码解析,涉及数千行代码以捕捉不理想的模型行为。Bryan 提到,这种防御性编程可以通过评估指标来创建,强调了它们在构建生产级 LLM 应用程序的质量控制和评估中的重要性。
▷ #prompting (1 条消息):
jeffreyw128: 有人找到好的理解方法吗
Alignment Lab AI Discord 总结
- 关于近期版本更新的讨论,包括更新后的 v0.2 与 OpenHermes 2.5 和 2 之间的差异对比,由
@lightningralf和@gabriel_syme指出。 @gabriel_syme提到可能存在一个经过广泛预训练的新基础模型。- 关于在 franken llama-Mistral 上采用 Upstage 的 Depth Upscaling 技术以通过持续预训练达到 10.7B 参数规模的对话。据
@entropi称,该方法的效果优于 Mixtral。名为 SOLAR-10.7B-Instruct-v1.0 的模型已在 Hugging Face 上分享,该模型针对单轮对话进行了微调。 - 由
@joshxt发起的关于 phi 2 是否有任何有趣应用的讨论。 @entropi分享了 Phi-2 模型摘要,并提供了指向 Phi-2(一种 Transformer 模型)的 Hugging Face 模型卡片链接。训练 Phi-2 使用了与 Phi-1.5 相同的来源,并增加了一些 NLP 合成文本和经过过滤的网站数据。@entropi提到 Phi-2 权重近期已开放。
Alignment Lab AI 频道总结
▷ #general-chat (4 条消息):
- 版本讨论:
@lightningralf和@gabriel_syme讨论了最新版本,@lightningralf指出 v0.2 是更新的版本。@gabriel_syme将其与 openhermes 2.5 和 2 之间的区别进行了对比。 - 模型预训练:
@gabriel_syme提到期待一个经过更多预训练的新基础模型。
▷ #oo (1 条消息):
- Upstage Depth Upscaling:用户
@entropi分享了关于在 franken llama-mistral 上使用 Upstage 的 Depth Upscaling 技术,通过持续预训练实现 10.7B 参数规模。他们声称这种方法击败了 Mixtral,并在 Hugging Face 上分享了名为 SOLAR-10.7B-Instruct-v1.0 的模型链接。他们指出这是一个针对单轮对话微调的版本。
▷ #phi-tuning (3 条消息):
- 关于 Phi-2 的讨论:
@joshxt询问是否有人用 phi 2 做了什么有趣的事情。 - Phi-2 模型摘要:
@entropi分享了 Phi-2 的 Hugging Face 模型卡片链接,这是一个拥有 27 亿参数的 Transformer 模型。该模型使用了与 Phi-1.5 相同的数据源进行训练,并增加了由各种 NLP 合成文本和过滤网站组成的新数据源。 - Phi-2 权重开放:
@entropi提到 Phi-2 的权重刚刚开放。
AI Engineer Foundation Discord 总结
@tonic_1提议使用 Gemini 创建 Langchain openagents。@tonic_1对最近的 Google Gemini 演示进行了反馈,称其由于演示者剧烈咳嗽而受到干扰。记录到了多次中断并切换到电梯音乐的情况。- 用户
@juanreds更新了 Java SDK 获取的进度,解释了缺席会议的原因,并提到他们仍在努力获取 Java SDK。
AI Engineer Foundation 频道总结
▷ #general (2 条消息):
- 使用 Gemini 创建 Langchain Openagents:用户
@tonic_1提出了使用 Gemini 创建 Langchain openagents 的建议。 - Google Gemini 演示问题:
@tonic_1描述最近的 Google Gemini 演示由于演示者剧烈咳嗽而受到干扰。这导致了多次中断并切换到电梯音乐。
▷ #events (1 条消息):
- Java SDK 获取:用户
@juanreds为缺席上次会议道歉,并提到他们仍在努力获取 Java SDK。
MLOps @Chipro Discord 总结
- 使用 Featureform 和 MLflow 进行特征与模型管理研讨会公告:由
@marie_59545发布,定于 太平洋时间 12 月 19 日上午 8 点 举行。本次会议旨在帮助数据科学家和 ML Engineers 等角色了解如何利用 Featureform 的数据处理能力和 MLflow 的模型生命周期管理工具。可以通过 此链接 进行注册。 - 用户
@misturrsam正在寻找专注于 ML 模型部署的在线课程,特别强调 Microsoft Azure、Google Cloud 和 Amazon AWS 平台,并寻求社区推荐。
MLOps @Chipro 频道摘要
▷ #events (1 条消息):
- 使用 Featureform 和 MLflow 进行特征与模型管理研讨会:
@marie_59545宣布了即将于 太平洋时间 12 月 19 日上午 8 点 举行的研讨会,由 Simba Khadder 主持。会议将演示如何使用 Featureform 的高效数据处理和 MLflow 的模型生命周期管理工具来增强机器学习工作流。研讨会面向数据科学家、数据工程师、ML Engineers 以及 MLOps/平台工程师。活动免费,参与者可在 此链接 报名。 - 关于 Featureform 和 MLflow:Featureform 是一个用于管理和部署 ML 特征流水线的开源 Feature Store,而 MLflow 是一个管理端到端 ML 模型生命周期的系统。这两个工具结合使用,可以为机器学习项目创建一个稳健的环境。
▷ #general-ml (1 条消息):
- ML 模型部署课程:用户
@misturrsam征求针对特定平台(Microsoft Azure、Google Cloud 和 Amazon AWS)的优质 ML 模型部署在线课程推荐。
Skunkworks AI Discord 总结
只有一个频道有活动,因此无需汇总…
- Phi 和 Zephyr 的基准测试对比:
@albfresco询问是否有针对新款 Phi 和 Zephyr 模型的基准测试对比,这两个模型都被声称是具有极高基准测试评分的强力 3B 模型。
Ontocord (MDEL discord) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
Perplexity AI Discord 没有新消息。
YAIG (a16z Infra) Discord 没有新消息。