ainews-12152023-mixtral-instruct-beats-gemini-pro
2023年12月15日:Mixtral-Instruct 击败了 Gemini Pro(并与 GPT3.5 持平)
由于 karpathy 的推荐,lmsys 现在拥有足够的数据来对 mixtral 和 gemini pro 进行排名。讨论强调了这些可以在笔记本电脑上运行的最先进开源模型的出色性能。
在 openai 的 Discord 频道中,用户对比了 perplexity 和 chatgpt 的联网浏览工具等 AI 工具,并因其卓越的数据收集能力、定价和使用限制而更青睐 Perplexity。人们对 AI 转换大型代码文件的能力表现出浓厚兴趣,并推荐了 deepseek coder。
关于 AI 进步对隐私的影响,以及在本地和云端 GPU 上运行大语言模型(LLM)所面临的挑战,也是讨论的重点。用户报告了 chatgpt 的一些问题,包括性能下降、无法访问自定义 GPT 以及未经授权的访问。讨论还涉及了针对大上下文窗口的提示工程(prompt engineering),以及对 gpt-4.5 和 gpt-4 未来发展的推测。
感谢 Karpathy 的推荐,Lmsys 现在已有足够的数据为 Mixtral 和 Gemini Pro 排名:
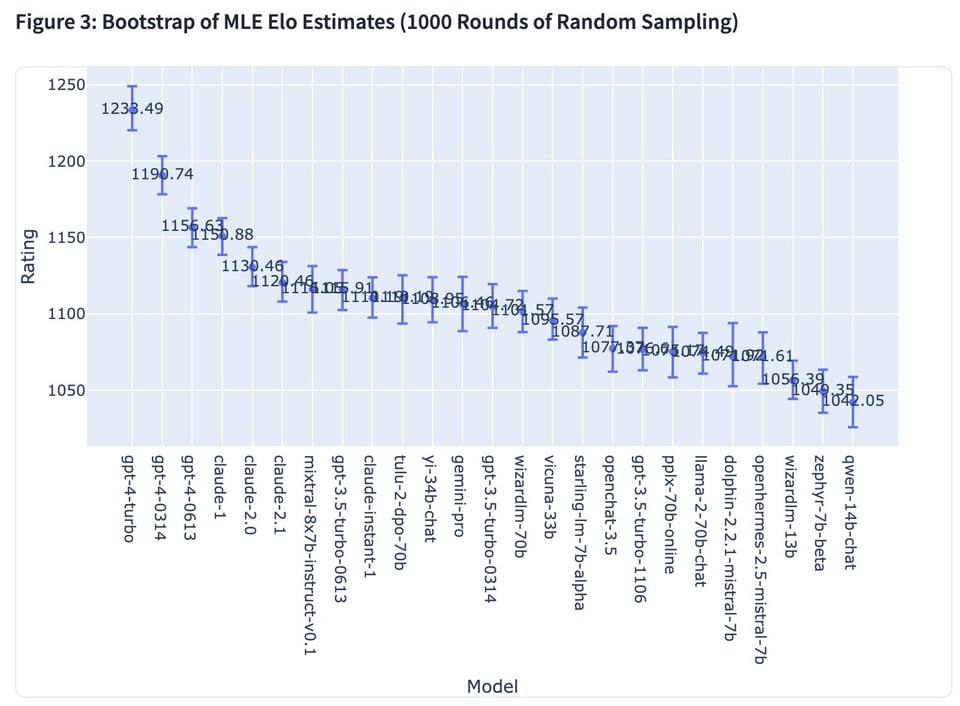
对于一个可以在笔记本电脑上运行的 SOTA 开源模型来说,这非常令人印象深刻。Discord 社区对 Mistral-medium 的评价也很积极,但对 Le Platforme API 感到困惑。
[TOC]
OpenAI Discord 总结
- 围绕各种 AI 模型和工具展开了激烈的讨论,用户对比了 Perplexity 和 ChatGPT 的浏览工具;
@chief_executive更青睐 Perplexity,因为与 ChatGPT 相比,它具有更出色的数据收集能力、定价和使用限制。Gemini Pro 和 Mistral 也因其独特的功能被提及。 - 用户对 AI 将大型代码文件转换为另一种编程语言的能力表现出兴趣,并推荐使用 DeepSeek Coder 来完成此类任务。讨论了与大型模型相关的 context window 大小问题。
@【penultimate】和@qpdv领导了一场关于为了 AI 进步而消除隐私的潜在影响的激烈辩论。- 关于在本地和云端 GPU 上处理 LLM 的几个要点——
@afterst0rm和@lugui等用户详细介绍了成本效益、复杂性以及合适 GPU 的选择。 - 用户还报告了有关 OpenAI 服务的多个问题,包括 ChatGPT 的性能问题、自定义 GPTs 的访问权限丢失、未经授权的访问,以及多位参与者报告的发布 GPT 为公开状态时遇到的问题。ChatGPT 中新的存档按钮功能也是讨论的话题。
- 对 AI 未来发展的关注被激发,包括对 GPT 4.5 和 GPT 4 的讨论和推测,以及各种 AI 模型在不同任务中的表现。
- OpenAI Questions 频道处理了关于 ChatGPT Discord 机器人和 Assistant API 错误增加的查询。
- 在 prompt-engineering 和 api-discussions 频道中,还就为具有大 context window 的 LLM 编写 Prompt 以及处理大上下文进行了咨询和建议交流。
注:所有用户名和直接引用均以斜体提及。
OpenAI 频道总结
▷ #ai-discussions (154 messages🔥🔥):
- 各种 AI 模型和工具的性能:
@chief_executive对比了 Perplexity 和 ChatGPT 的浏览工具的信息获取能力,指出 Perplexity 表现更优,且不像 ChatGPT 那样耗时。@chief_executive和@pietman还讨论了 Perplexity 的定价和使用限制。@chief_executive提到 Perplexity 每天有超过 300 次 GPT-4 和 Copilot 使用额度,因其强大的浏览能力,这笔费用花得很值。
- 通过 AI 转换编程语言:
@Joakim询问是否有 AI 模型可以将大型代码文件转换为另一种编程语言。@rjkmelb建议尝试使用 DeepSeek Coder 来完成此类任务,而@afterst0rm指出了大型模型中与上下文窗口(context window)大小相关的问题,并建议将大型任务拆分以获得更好的效果。
- 关于隐私和 AI 的讨论:
@【penultimate】和@qpdv讨论并推测为了 AI 的进步可能会完全丧失隐私。讨论转向了互联互通与隐私的潜在影响。
- AI 模型的使用:
@chief_executive分享了他们使用 Gemini Pro 的经验,提到了它的视频分析能力和多模态语言模型(LLM)的潜力。@afterst0rm分享称他们的工作中使用 Mistral 进行分类(准确率约 80%),并使用 GPT-3.5 处理生成式任务。他们还提到了 Cloudflare 和 Poe 等支持 Mistral 的服务,这些服务提供更低的延迟。
- 在本地 GPU 和云端 GPU 上运行 LLM:
@afterst0rm和@lugui讨论了在当前市场环境下在本地 GPU 上运行 LLM 的复杂性和成本,以及像 HuggingFace 或 Cloudflare 这样低成本的替代方案如何发挥作用。@lugui提到 Cloudflare 的免费层级选项是一个非常有益的特性。@millymox就如何为他们的使用场景选择云端 GPU 寻求建议,并对比了 24GB VRAM 的 RTX 3090 和 48GB VRAM 的 A6000 的价格与规格。多位用户建议以最优价格购买显存(VRAM)更大的型号,并表示拥有更多内存可能比拥有更多张量核心(tensor cores)更有利。
▷ #openai-chatter (546 messages🔥🔥🔥):
- ChatGPT 新功能:
@klenak、@thecroug和@dr.quantum讨论了 ChatGPT 历史记录界面中三点菜单旁新增的存档按钮。新按钮可以将对话存档并从历史记录中移除。用户表示很难找到访问已存档对话的选项。 - 关于 GPT 4.5 的虚假信息:
@DawidM和@satanhashtag就关于 GPT 4.5 泄露消息的可信度进行了辩论。他们注意到传闻源自 Reddit,并一致认为未来的公告只有直接来自 OpenAI 或经过验证的渠道才应被视为可靠。 - AI 在不同任务中的表现:在关于 AI 能力的讨论中,
@cynicalcola询问在总结和解读 PDF 方面,Claude Pro 和带有 GPT 4 Advanced Data Analysis 的 ChatGPT Plus 哪个模型更好。@rjkmelb和@australiaball支持 ChatGPT,称 Claude 在处理复杂/长文档时似乎会丢失上下文,而 ChatGPT 能够专注于细节并讨论用户要求的任何内容,但选择取决于处理速度和所考虑数据的复杂性。 - ChatGPT 性能问题:包括
@jcrabtree410和@.australiaball在内的多位用户报告称,ChatGPT 服务的浏览速度变慢且存在延迟。他们指出这些问题已经持续了几天。有人建议这可能是服务器问题导致的。 - GPT 对比:在讨论不同版本 GPT 模型的性能时,
@arigatos和@barret一致认为 Python 语言往往最适合 GPT 模型,因为它与英语在语言学上具有相似性,这使得翻译更加准确可靠。
▷ #openai-questions (102 条消息🔥🔥):
-
服务器上的 ChatGPT Discord 机器人:一位用户 (
@jah777) 询问是否有可以用于其服务器的 Discord 版 ChatGPT 机器人。@satanhashtag回复称可以通过 API 实现,但并非免费。 -
Assistant API 错误增加:
@sweatprints报告在过去几小时内看到 Assistant API 的请求失败,表明错误率有所上升。 -
无法访问 ChatGPT:包括
@sharo98、@s1ynergy和@crafty.chaos在内的许多用户报告在电脑上访问 ChatGPT 时遇到问题。@solbus提出了各种可能的解决方案(例如尝试不同的浏览器以及检查网络设置),但目前似乎尚未找到确定的解决办法。 -
失去对自定义 GPT 的访问权限:
@milwaukeeres对失去花费大量时间构建的自定义 GPT 的访问权限表示担忧。@fulgrim.alpha询问是否可以在没有 Plus 订阅的情况下共享自定义 GPT 的访问权限,但@solbus解释说目前这是不可能的。 -
账号未经授权的访问:
@babbalanja报告其账号被盗用,出现了新的未经授权的对话。@solbus建议他们更改账号密码,并前往 help.openai.com 寻求帮助。
▷ #gpt-4-discussions (48 条消息🔥):
- 将 GPT 发布为公开时遇到的问题:包括
@franck.bl、@optimalcreativity和.parkerrex在内的用户报告称,将 GPT 发布为公开(Public)的选项显示为灰色或被禁用。尽管之前发布过 GPT,但现在无法操作,怀疑是系统故障。@elektronisade也确认确认按钮似乎在延迟或点击后变为禁用状态。@optimalcreativity报告在浏览器控制台中看到了错误。 - 关于归档按钮的问题:
@imdaniel__、@rjkmelb和@gare_62933分享了他们使用“归档(Archive)”按钮的经历。对话线程从菜单中消失了,他们只能通过浏览器历史记录找回。 - ChatGPT 延迟/卡顿问题:用户
@.australiaball遇到了 ChatGPT 卡顿的问题。虽然对话可以显示,但用户只能滚动侧边栏,或者在与界面交互时遇到困难。.australiaball请遇到同样问题的用户点赞回应。 - 对 GPT-4 开发的兴趣:
@lyraaaa_开玩笑说,如果有 8xA100 实例可用,他想以初级开发人员的身份使用 GPT-4。 - 不同 AI 的工作表现:
@drcapyahhbara分享了他们的看法,认为虽然 Gemini 看起来被过度炒作且表现不及预期,但 GPT-4 和 Bing AI 表现良好,其中 Bing AI 有显著进步。
▷ #prompt-engineering (9 条消息🔥):
- 针对 RAG 系统的 LLM 系统提示词技术:用户
@jungle_jo正在询问如何为具有接收大量信息的上下文窗口的 LLM 编写提示词。该用户提供了一个提示词的示例风格。 - 在 ChatGPT 中处理长上下文:
@eskcanta分享了他们使用 secretkeeper 的经验,其中包括从上传的知识文件中提取多达 30 万个字符的数据。他们指出,虽然 ChatGPT 可以处理这种规模的数据,但在处理更大、更复杂的输入时可能效果不佳。 - 标记参考文本:
@knb8761询问是否仍有必要使用三引号来标记参考文本,并引用了 OpenAI 平台文档。目前的做法通常是直接插入一个空行并粘贴参考文本。
▷ #api-discussions (9 条消息🔥):
- RAG 系统的 LLM System Prompt 技术:
@jungle_jo寻求关于 RAG 系统中 LLM System Prompt 技术的建议,并详细说明了问题在于 LLM 如何处理其 Context Window 中的大量信息,以最佳方式回答用户查询。他们提供了一个 Prompt 风格示例来阐述自己的观点。 - 上传的知识文件:
@eskcanta分享了他们从上传的知识文件中提取数据的经验。他们提到已经使用了多达 30 万字符的纯文本,但尚未超过这个限制。 - 使用三引号标记参考文本:
@knb8761询问是否仍需要使用三引号来标记参考文本,并引用了建议使用它们的 OpenAI 文档。他们指出,自己通常在问题后的空行之后粘贴参考文本。
Nous Research AI Discord 摘要
-
关于 AI 模型性能的广泛讨论,包括对 SOLAR-10.7B、GPT-3.5、Tulu、Qwen 72B、Hermes 2.5、PHI-2b 和 OpenChat 3.5 的具体提及。值得注意的是,
@nemoia认为 SOLAR-10.7B 的表现优于所有 13B 模型,而@agcobra1则怀疑其能否超越像 Qwen 72B 这样更大的模型。此外,@n8programs报告了 PHI-2b 的运行时间慢于预期。 -
Discord 社区就 Embeddings 和向量存储的最佳模型进行了对话。建议包括 Quadrant 的 fast embed 和 gte-small。
@lightningralf分享了一条警示性的 推文,内容是关于使用 ada-002 对 ArXiv 上的科学论文进行未经修改的 Embedding 从而生成合成数据。 -
关于模型混合(Blending)和合并(Merging)所需功能和性能的对话引发了对 mergekit 等工具的兴趣。参与者比较了运行模型的不同基础设施,如 MLX、Ollama 和 LM Studio。
-
辩论了 AI 训练的 GPU 需求,并对行业进展(如即将推出的 nVidia H200)进行了辅助讨论。有人提出了关于租用 GPU 需求的问题,并建议了接受加密货币的服务。
-
关于潜在 Benchmark 污染的对话,特别是与在 metamath 数据集上训练的模型有关。
@nonameusr表达了担忧,@tokenbender链接到了 Huggingface 上类似的讨论。 -
提供了关于构建 定制化评估(Tailored Evaluations) AI 模型过程的详细指导。
@giftedgummybee提出了一个六步策略,其中包括确定评估范围和汇编结果数据等组件。 -
用户
@mihai4256宣布了一个新模型 “Metis-0.1”,该模型是推理和文本理解的结果。强调了其在 GSM8K 上的强劲表现,并使用私有数据集进行训练。 -
分享了 YouTube 视频链接,包括 “Viper - Crack 4 Tha First Time” 和 “Stanford CS25: V3 I Recipe for Training Helpful Chatbots”,以及关于带有外部验证器的开放式搜索强度、Phi-2 更新以及 FunSearch 与 openELM 比较的讨论。
-
@vincentweisser发起了一场关于 State-space Model 架构 Mamba 的 GitHub 讨论。分享了相关的 GitHub 链接 和关于该主题的 Arxiv 论文。 -
关于 Benchmark 性能重要性的讨论,
@gabriel_syme认为 74 分的分数非常可观,前提是社区可以进行 Fine-tune 以获得更好的结果。 -
@dragan.jovanovich提出了一个关于在 Mixtral 模型中用另一个预训练专家替换其中一个专家的经验问题。@crainmaker提出了一个类似的主题,关于 Character-level Transformers 达到与 BPE-based Transformers 相当性能所需的参数差异。
Nous Research AI 频道摘要
▷ #ctx-length-research (1 条消息):
nonameusr: 这非常有道理
▷ #off-topic (8 条消息🔥):
- 关于 Embeddings 和 Vector Storage 的讨论:
@adjectiveallison发起了关于 Embeddings 和 Vector Storage 最佳模型的讨论,并特别询问了 Jina 8k 的性能。 - 来自 Quadrant 的 Fast Embed:
@lightningralf建议如果正在使用该方案,可以考虑使用 Quadrant 的 Fast Embed。他提醒在采用特定模型时要谨慎,因为可能需要对整个 Arxiv 数据库进行 Embedding。 - 引用一条 Twitter 帖子:
@lightningralf分享了一个推文链接,该推文涉及从 ArXiv 上每篇科学论文的原始 Embedding 中生成合成数据。这一过程显然使用了 ada-002。 - 偏好 gte-small:
@natefyi_30842分享了他们在工作中更倾向于使用 gte-small,并认为像 Jina 这样较大的 Embeddings 更适合涉及大量数据(如书籍)的项目。
▷ #benchmarks-log (2 条消息):
- 基准测试性能讨论: 用户
@artificialguybr提到另一位用户已经进行了 Benchmark 测试,并表示提升并不明显。作为回应,@gabriel_syme认为 74 分可以被视为实质性的进步,并假设社区可以通过 fine-tune 获得更显著的结果。
▷ #interesting-links (11 条消息🔥):
- 带有外部验证器的开放式搜索:用户
@gabriel_syme对关于带有外部验证器的开放式搜索强度的讨论发表了评论。 - Phi-2 咨询:用户
@huunguyen征求关于 Phi-2 的意见或更新。 - FunSearch 和 ELM:
@gabriel_syme将 FunSearch 与 openELM in-context 进行了比较,并提到他将研究 islands 方法。他将其与 Quality-Diversity 算法进行了对比,但指出它们并不相同。 -
分享 YouTube 链接: @nonameusr分享了一个名为 “Viper - Crack 4 Tha First Time” 的音乐视频,@atgctg分享了来自 YouTube 的 [“Stanford CS25: V3Recipe for Training Helpful Chatbots”](https://www.youtube.com/watch?v=mcep6W8oB1I)。 - Metis-0.1 模型发布:
@mihai4256介绍了一个名为 “Metis-0.1” 的 7b fine-tuned 模型,用于推理和文本理解,并表示该模型在 GSM8K 上得分较高,建议在使用时采用 few-shot prompting。他强调该模型是在私有数据集上训练的,而非 MetaMath 数据集。
▷ #general (189 条消息🔥🔥):
- 对 Benchmark Contamination 的担忧:几位用户讨论了在 Benchmark 数据集(特别是 metamath)上训练模型的问题。
@nonameusr表示担心任何使用 metamath 的模型都可能存在污染,@tokenbender链接了 Huggingface 上关于同一问题的讨论。有人呼吁大家在模型混合(blends)中避免使用 metamath。 - 不同模型的性能表现:讨论了不同 AI 模型的性能和实用性,包括 Hermes 2.5、PHI-2b 和 OpenChat 3.5。
@tsunemoto表示可以根据要求提供 Mistral medium 的 Prompt 回复。@n8programs报告称,在 M3 Max 上使用 MLX 运行 PHI-2b 时,速度仅为 35 tokens/second(混合精度),低于预期。 - 对合并 AI 模型的兴趣:多位用户表达了对合并不同模型以增强性能的兴趣。建议使用
@datarevised开发的工具包 mergekit,并讨论了合并 Open Hermes 2.5 Mistral 的可能性,因为它具有良好的基础属性。 - 不同推理引擎的使用:讨论了运行模型的不同基础设施,如 MLX、Ollama 和 LM Studio。
@n8programs报告了 MLX 的效果不佳,而@coffeebean6887指出 Ollama 可能会更快,即使精度高于默认的 4 bit。 - 神经架构搜索 (Neural Architecture Search):
@euclaise提出了使用 Neural Architecture Search 代替参数合并的想法,并简要讨论了将其应用于不同模型合并相关的搜索空间子集的潜在可能性。 - AI 的 GPU 需求:引发了关于 AI 训练中 GPU 资源需求的辩论,以及集中式或去中心化计算哪个更有效。讨论还涉及行业进展和未来可能推出的 GPU 资源,特别是 NVIDIA H200。
- AI 服务的潜在问题:用户
@realsedlyf询问了租用 GPU 的要求,特别是是否需要信用卡,对此@qasb和@thepok建议了一些接受加密货币的服务。 - 神经模型混合 (Neural Model Blending):用户
@dragan.jovanovich提出了一个关于在 Mixtral 模型中用另一个预训练专家替换其中一个专家的经验问题。 - 模型性能对比:用户
@artificialguybr分享了来自 LMSysOrg 的 Twitter 帖子,对比了不同模型的性能。@zakkor和@adjectiveallison分别建议将 Mixtral-Medium 和 Mistral-Medium 加入对比。
▷ #ask-about-llms (45 条消息🔥):
-
关于模型性能的讨论:用户对各种模型的性能进行了辩论。
@nemoia提到 SOLAR-10.7B 的表现优于所有 13B 模型,@n8programs分享了实验 Tulu 的非正式测试结果,称其几乎与 GPT-3.5 持平。然而,@agcobra1对 SOLAR-10.7B 能否超越 Qwen 72B 等更大型模型表示怀疑。 -
模型评估策略:引发了关于构建定制化评估的讨论。
@natefyi_30842分享了他需要评估多个使用场景,@giftedgummybee提供了一个详细的 6 步指南,包括确定评估范围、整理 Ground Truth 示例列表、验证它们不在通用数据集中、构建测试模型的结构以及将结果汇编为数据。 -
Llava API 问题:
@papr_airplane报告在处理 Llava 的 API 时遇到 ValueError,原因是<image>Token 的数量与实际图像数量不匹配。 -
字符级 Transformer 与基于 BPE 的 Transformer:
@crainmaker询问了字符级 Transformer (Character-Level Transformer) 要达到与基于 BPE 的 Transformer 相当的性能所需的参数差异。 -
状态空间模型 (State-Space Model) 架构:
@vincentweisser发起了关于名为 Mamba 的状态空间模型架构的讨论。分享了相关的 GitHub 链接和 Arxiv 论文。
Mistral Discord 总结
- Mixtral 配置与使用:讨论了 Mixtral 配置中的问题,
@dizee通过调整config.json文件解决了这些问题。此外,@tlacroix_进一步讨论了在 Mixtral 模型中不使用 sliding window 的情况,并指导将 context length 设置为 32768。 - 使用 Mistral 构建聊天机器人和文档分类:用户
@.akatony和@naveenbachkethi_57471发起了关于构建聊天机器人以及使用 Mistral 进行文档分类的讨论。针对 Mistral API 的使用,提供了多种 Web UI 推荐,包括@cyborgdream建议的 OpenAgents 项目。 - 模型性能与优化:一系列消息(主要来自
@ex3ndr和@choltha)表达了对模型无法准确回答基于规则的问题的沮丧,并提出了优化 MoE 架构的潜在解决方案。 - SillyTavern 角色扮演与 API 修改:由
@aikitoria发起的对话,建议@xilex.如何在 SillyTavern 后端修改 OpenAI API URL,以适应角色扮演/故事设定。 - 库更新、输入数据与微调:
@cpxjj发布了 LLaMA2-Accessory 的新版本,并进行了关于微调参数和正确数据输入格式的技术讨论。@geedspeed注意到示例资源与原始指令之间存在差异。此外,还针对 Mixtral 微调的 learning rates 提出了建议。 - 新进展展示:用户分享了新项目,包括
@thesealman开源的用于 Mistral 与 .NET 集成的库,以及@cpxjj提供的最新版 LLaMA2-Accessory。 - la-plateforme 功能讨论与请求:用户询问并讨论了 Mistral 平台的功能,包括 API rate limits、Mistral-Medium 模型的开源、关于 function calling 和 VPC Deployment 能力的潜在功能请求、不同 Mistral 版本的对比与反馈,以及 Stripe 验证问题。
Mistral 频道总结
▷ #general (90 条消息🔥🔥):
-
Mixtral 配置问题:用户
@dizee讨论了在 llama.cpp 上运行 Mixtral 的一些问题,指出问题出在 config.json 文件上。他们成功运行了 Mixtral 分支,但指出 llama.cpp 的主仓库会导致错误。 -
使用 Mistral 进行文档分类:用户
@naveenbachkethi_57471询问是否可以像使用 Amazon Bedrock 一样使用 Mistral 进行文档分类。用户@potatooff建议为此使用 few shot prompts。 -
Mixtral 模型中的 Sliding Window:用户
@tlacroix_澄清说,对于 Mixtral 模型,不应使用 sliding window。这些模型的 context length 保持在 32768。 -
聊天机器人集成讨论:用户
@.akatony发起了关于构建聊天机器人的讨论,@.dontriskit建议将 Rocketchat(配合 live chat 插件)与 N8N 及 LLM 结合使用。 -
Mixtral Context 与配置问题:在关于 Mixtral 的 context 和配置的对话中,
@tlacroix_解释说 Mixtral 的 context length 是 32768,并提到了 sliding_window 设置。 -
适用于 Mistral API 的聊天机器人 UI:
@cyborgdream征求支持特定功能的 Mistral API Web UI 推荐。@lee0099建议使用 Chatbot UI,而@cyborgdream找到了符合要求的 OpenAgents。 -
Streamlit 聊天应用介绍:
@jamsyns分享了一个与 Mistral API 交互的 Streamlit 聊天应用。
▷ #models (9 messages🔥):
- 模型在默认参数下的性能:
@svilupp正在考虑通过调整参数来测试模型,但不确定这是否是一个公平的比较,因为通常模型都是在默认设置下进行测试的。 - 模型回答基于规则的问题的能力:
@ex3ndr对当前模型无法正确回答有关空当接龙(FreeCell)游戏规则的问题表示沮丧。 - MoE 架构的潜在修改:
@choltha提出了一个优化 MoE 架构的想法,即增加一个“前向传播终止(forward-pass-termination)”专家,如果模型只需处理“简单”的下一个 token,则强制模型跳过后续步骤。 - 本地运行 Mistral-Embed:
@talon1337询问了关于 Mistral-Embed 的信息,表示想了解推荐的距离函数(distance function)以及如何本地运行它。 - Mixtral 模型训练数据集详情:
@pdehaye和@petet6971都对 Mixtral 数据集的细节提出了疑问——@pdehaye对 Mixtral 中的 8 个专家分别擅长什么感兴趣,而@petet6971则在寻求与训练 Mixtral-8x7B 和 Mixtral-8x7B-Instruct 所用数据集相关的详细信息或许可证。
▷ #deployment (5 messages):
- 在 SillyTavern 中使用角色扮演/故事功能:
@aikitoria建议@xilex.使用 SillyTavern 来进行角色扮演/故事设定,并提到虽然它官方并不支持 Mistral API,但可以通过在后端替换 OpenAI API URL 来实现变通。 - 在 SillyTavern 中替换 API URL:
@aikitoria提供了在 SillyTavern 后端修改 API URL 的指导——具体在server.js文件中进行。
▷ #ref-implem (2 messages):
- 关于不同项目中 Jinja 模板的讨论:用户
@saullu询问为什么@titaux12认为 Jinja 模板必须被固定。@saullu澄清说没有人说它是错的,但强调他们只保证参考实现。他们还指出在vllm中使用聊天模板(chat template)会导致 Bug,并提供了 Issue 链接。 - Jinja 模板在支持多个 LLM 方面的效用:
@titaux12回应称,对于那些需要无缝运行多个 LLM 的项目来说,一个可用的 Jinja 模板非常有用。他们还提到正在为privateGPT开发多模型支持。 - 遵守模型输出的建议:
@titaux12表示他们将尽力遵守其模型所需的输出格式,并强调了 token 表示(1(BOS))在首位的重要性,且不能有重复或被编码为其他 token。
▷ #finetuning (13 messages🔥):
- 使用 mlx / mlx-examples 在 Apple Metal 上进行微调:
@cogbuji询问来自 mlx-examples 的 Mistral 模型是否适用于在 Apple Metal 上进行问答指令(Q/A instructions)的微调。他们还询问是否应该为此目的使用单独的“指令(instruction)”模型。 - 微调 Mixtral 的推荐学习率:
@ludis___和@remek1972分别建议,在微调 Mixtral 时,1e-4 和 0.0002 左右的学习率(learning rates)效果较好。 - 新版 LLaMA2-Accessory 及微调参数:
@cpxjj宣布了最新版本的 LLaMA2-Accessory,该版本支持 mixtral-8x7b 的推理和指令微调,并分享了详细文档。他们还提供了全量微调设置和 PEFT 设置的链接。 - 关于格式化输入数据的困惑:
@geedspeed对如何格式化 mistral-7b-instruct 的微调输入数据表示困惑,并引用了来自 AI makerspace 的一个 Colab 笔记本示例。他们注意到示例笔记本与 Mistral 关于使用 [INST] token 的指令之间存在差异。 - 用于微调的 API:
@robhaisfield建议实现一个用于微调的 API,特别提到需要微调 “medium” 模型。@jamiecropley附议了这一观点,并指出目前尚不清楚当前的 API 是否支持微调。
▷ #showcase (6 条消息):
- Mistral 与 .NET: 用户
@thesealman完成了一个用于在 .NET 中使用 Mistral 的开源库。该用户欢迎任何反馈,并已发布了一个 NuGet 包。GitHub 仓库地址为 https://github.com/tghamm/Mistral.SDK。 - 为语言学习应用理解 Mistral: 新社区成员
@webcreationpastor正在寻求资源以了解 AI,特别是 Mistral,以便将其应用于语言学习应用中。 - 理解 Mistral 的博客文章: 针对
@webcreationpastor的提问,@daain分享了一系列用于理解 Mistral 的博客。已发布的文章包括 Understanding embeddings and how to use them for semantic search 以及 What are large language models and how to run open ones on your device。 - LLaMA2-Accessory 支持 mixtral-8x7b: 用户
@cpxjj宣布了其最新版本的 LLaMA2-Accessory,现在支持在 mixtral-8x7b 模型上进行推理(inference)和指令微调(instruction finetuning)。详细文档请见 https://llama2-accessory.readthedocs.io/en/latest/projects/mixtral-8x7b.html。 - Microsoft Autogen 支持 Mistral AI API:
@tonic_1分享了一个 GitHub issue 链接,讨论在 Microsoft 的 Autogen 中添加对 Mistral AI API(以及 Mixtral2)的支持。
▷ #random (1 条消息):
balala: Привет
▷ #la-plateforme (68 条消息🔥🔥):
-
速率限制与 API 访问: 用户
@robhaisfield询问了 API 的速率限制(rate limits),@tlacroix_提供的回答是每分钟 2M tokens,每月 200M tokens。对话还建议将 JavaScript 客户端开源,以便接受 PR 以获得更好的兼容性。 -
关于开源 Mistral Medium 的讨论: 由
@netbsd发起的讨论提出了关于开源 Mistral-Medium 模型的问题。社区对于这样做(开源)的可行性和影响持有不同看法。 -
潜在的 Mistral 平台功能需求: 用户对函数调用(function calling)、VPC 部署能力以及 Mistral Large 表现出兴趣,
@lukasgutwinski、@pierre_ru和@casper_ai分别表达了对这些功能的关注。@tlacroix_确认 VPC 部署功能正在开发中。 -
Mistral Medium 反馈与对比:
@rad3vv、@lukasgutwinski和@flyinparkinglot等多位用户分享了关于 Mistral Medium 性能的正面反馈。@tarruda还指出,他发现 Mistral Tiny 的性能优于 Huggingface 上的 Mistral 量化版本。 -
Stripe 验证问题: 用户
@phantine在订阅时遇到了 Stripe 手机号验证问题,但通过使用邮箱验证选项解决了该问题。
OpenAccess AI Collective (axolotl) Discord 总结
- 详细讨论了微调 Mistral 的相关问题,涉及处理显存不足(OOM)错误、qLoRA Mixtral 训练的 GPU VRAM 需求,以及使用 deepspeed 或 Data parallel 在多 GPU 上进行模型分布。提到了 Sebastien Bubeck 的一条 Twitter 帖子,内容关于在数学练习上微调 phi-2 取得的积极结果。
- 在 Axolotl 开发方面,探讨了对 GPU 显存错误的理解和处理,并分享了一篇富有资源价值的 PyTorch 博客文章。此外,还尝试解决了与 DeepSpeed PyTorch 扩展相关的导入错误、随后的 TypeError 问题,以及针对该问题可能的 GitHub PR 热修复。
- 在常规帮助中讨论了关于 ChatML template 和 Axolotl 推理能力的持续性问题,特别是关注模型无法正确学习的问题。
- 在数据集方面,分享了一个泛化语言模型工具学习的 ToolAlpaca GitHub 仓库。
- 披露了关于在 Runpod 上进行推理的显著问题,特别是与 HuggingFace 平台相比,推理时间较长且无法完成。此外,还咨询了如何在训练后自动停止 Runpod 实例(pods),而不是默认的重启行为。
OpenAccess AI Collective (axolotl) 频道总结
▷ #general (16 条消息🔥):
- Mistral 微调中的样本打包问题:用户
@dirisala提到,在尝试启用样本打包(sample packing)微调 Mistral(非最新版本)时遇到了显存不足错误。通过禁用样本打包解决了该错误。 - qLoRA Mixtral 训练的 VRAM 需求:
@jaredquek询问了训练 qLoRA Mixtral 的 VRAM 需求。@faldore回复称训练使用了 4 张 A100。 - 多 GPU 模型分布:用户
@kaltcit询问 axolotl 是否支持将模型分布在多个 GPU 上进行训练。@nruaif确认这是可行的,可以通过使用 deepspeed 或普通的 Data parallel 来实现。他们还补充说,如果单个 GPU 无法容纳模型,可以使用 deepspeed 3。 - 关于 Phi-2 微调的推文:
@noobmaster29分享了 Sebastien Bubeck 的 Twitter 链接,讨论了在 100 万个类似于 CodeExercises 的数学练习上微调 phi-2 并在最近的法国数学考试中进行测试的显著成果。
▷ #axolotl-dev (20 条消息🔥):
-
志愿者参与训练模板工作:用户
.tostino表示愿意参与使聊天模板(chat templates)在训练中生效的工作,并指出主要任务是让训练数据通过模板运行,并对训练数据的某些部分进行正确的 tokenization/masking。 -
GPU 显存问题:
@tmm1分享了一篇关于处理和理解 GPU 显存错误的 PyTorch 博客文章,涉及错误信息:torch.cuda.OutOfMemoryError: CUDA out of memory。 -
尝试解决 ImportError:用户
@hamelh正在协助@teknium解决一个 ImportError,特别是涉及共享库文件:/home/nous/.cache/torch_extensions/py310_cu117/fused_adam/fused_adam.so。推测这可能是由于安装不当或与 DeepSpeed PyTorch 扩展中的 flash attention 有关。 -
PyTorch 修复后遇到 TypeError:在修复 PyTorch 问题后,
@hamelh遇到了一个与LlamaSdpaAttention.forward()函数相关的 TypeError。提供了一个 YAML 文件和完整的 traceback 以协助排查。 -
潜在的热修复:
@caseus_提到 Axolotl 仓库中的一个 PR 可能会修复@hamelh遇到的 TypeError。该 PR 旨在解决由最新版本的 Transformers 引起的问题,该版本在不使用 flash attention 时更改了 SDPA 的注意力机制使用方式,从而破坏了所有的猴子补丁(monkey patches)。你可以在这里找到该 PR。
▷ #general-help (84 条消息🔥🔥):
- 模型训练与模板问题:
@noobmaster29和@self.1讨论了 ChatML 模板以及 Axolotl 的推理能力问题。核心关注点似乎是模型未能正确学习 `
▷ #datasets (2 条消息):
- ToolAlpaca 仓库:用户
@visuallyadequate分享了一个指向 ToolAlpaca 的 GitHub 链接,该项目通过 3000 个模拟案例实现了语言模型的通用工具学习。
▷ #runpod-help (2 条消息):
- Runpod 上的推理问题:
@mustapha7150在 Runpod(1x A100 80G)上运行一个 HuggingFace Space,遇到了推理时间极长(将近一小时且从未完成)的问题,尽管在 HuggingFace 平台上仅需几秒钟。他们还尝试了使用 A40,但没有显著改善。 - 关于训练后自动停止 Pod 的咨询:
@_jp1_询问如何让 Pod 在训练结束后自动停止,而不是默认的重启行为。除了通过 API 手动停止外,他们没能找到其他更改此行为的方法。
HuggingFace Discord Discord 总结
- 围绕 GPU 性能等级分类展开了一场热烈对话,起因是
@nerdimo询问 RTX 4080 的排名。@osanseviero建议,任何没有 10,000+ GPU 的配置都可以被视为 “GPU poor“。 - 几位用户遇到并提供了技术问题的解决方案。例如,
@vishyouluck在使用autotrain_advanced函数时遇到问题,@abhi1thakur建议他们在 GitHub 上发布问题以获得更彻底的帮助。 - 一场深入的对话围绕 模型托管与推理速度 展开。
@sagar___寻求托管 TensorRT-LLM 模型的技巧,他与@acidgrim讨论了推理过程中的显存使用挑战,以及针对大型模型采用多服务器部署的概念。 - 多位用户对循环神经网络表现出好奇并分享了发现,触发点是关于 GRU vs. RNN、LSTM 偏好以及 TD Lambda 算法 的讨论。在此背景下,
@nerdimo提到他们正在使用 Andrew Mg ML 规范作为学习资源。 - 用户分享并展示了他们的作品,例如
@not_lain基于 RAG 的 PDF 搜索 Space,@aabbhishekk0804使用 Zephyr 7B 模型 构建的 PdfChat Hugging Face Space,以及@vipitis为微调模型开发的新指标。 - 阅读小组 计划研读一篇关于扩散模型的论文,题为 “On the Importance of the Final Time Step in Training Diffusion Models“。
@chad_in_the_house还对常见的扩散噪声调度(noise schedules)和采样器(sampler)实现中的问题提出了见解。 - 社区宣布部署 Diffusers 基准测试,用于跟踪
diffusers中常见流水线的性能,自动报告由 GitHub 仓库中的benchmark.yml文件管理。 - 各种用户提出了疑问,分享了关于使用成对数据训练扩散模型、Segformer 预训练权重差异、Llama-2 模型的上下文长度、微调语言模型的过程,以及 Mixtral-8x7B 模型的大小和下载时间 等方面的资源和指导。
- 在分享的酷炫发现中,值得关注的有关于 Flipper Zero 的 AI 生成脚本的 Reddit 讨论,以及一篇关于使用深度学习技术训练的端到端音乐生成器的 HuggingFace 论文。
HuggingFace Discord 频道总结
▷ #general (56 条消息🔥🔥):
- GPU 等级与性能:
@nerdimo和@osanseviero讨论了 GPU 的等级和性能。@nerdimo询问 RTX 4080 应被归类为中端还是低端 GPU,@osanseviero引用了一篇文章作为回应,该文章幽默地声称任何没有 1 万块以上 GPU 的人都是 “GPU poor”(贫 GPU 阶层)。 - autotrain_advanced 的问题:
@vishyouluck在使用autotrain_advanced微调模型时遇到了问题。@abhi1thakur回复称需要更多信息才能提供帮助,并建议在 GitHub 上发布该 Issue。 - LLM 工具使用调查:
@jay_wooow分享了一份调查问卷,旨在了解在使用 LLM(大语言模型)进行构建时的动机和挑战。 - Segformer 性能疑虑:
@shamik6766表达了对 Hugging Face 上预训练 Segformer 模型的担忧,认为其表现与论文中提到的官方 mIOU(平均交并比)数值不符。 - 模型托管与推理速度:
@sagar___征求关于如何永久托管 TensorRT-LLM 模型的建议,并观察到推理过程中内存占用会升高。@acidgrim也讨论了在 mpirun 上运行 stablediffusion 和 Llama,考虑为大型模型使用多台服务器。
▷ #today-im-learning (6 条消息):
- GRU vs. RNN:用户
@nerdimo提到,他们的直觉是门控机制的加入使得 GRU 比标准 RNN 更复杂。他们还表示正在学习 Andrew Ng ML(吴恩达机器学习)课程,并计划通过侧边项目来补充学习。 - 对 LSTM 的偏好:
@nerdimo表达了对 LSTM 的偏好,理由是它提供了更多的过滤机制和参数。 - TD Lambda 算法:用户
@d97tum分享说他们正在尝试从零开始编写 TD Lambda 算法 的代码。 - GRU vs. LSTM:
@merve3234澄清说他们是在将 GRU 与 LSTM 进行比较,而不是 RNN,这与@nerdimo之前的评论一致。 - 向 stabilityAI 添加模型:
@nixon_88316询问是否有人可以协助向 StabilityAI 添加模型。
▷ #cool-finds (4 条消息):
- 为 Flipper Zero 生成的 AI 代码:用户
@_user_b分享了一个 Reddit 讨论链接,关于为 Flipper Zero 生成脚本的可能性。Flipper Zero 是一款面向渗透测试人员和极客的完全开源、可定制的便携式多功能工具。 - TensorRT-LLM 模型托管:
@sagar___征求关于如何使用 TensorRT-LLM 保持模型持续加载的建议。 - 利用 AI 进行音乐流媒体传输:
@not_lain分享了一篇关于端到端音乐生成器的 HuggingFace 论文,该生成器采用深度学习技术训练,能够进行响应式聆听并创作音乐,非常适合电台或 Discord 机器人等项目。该用户对模型一致的性能以及无需等待 AI 完成处理即可流式传输音乐的能力印象深刻。 - 对音乐 AI 的反馈:用户
@osanseviero对分享的 HuggingFace 论文做出了积极回应,评论道“非常酷”。
▷ #i-made-this (3 条消息):
- 基于 RAG 的搜索 Space:
@not_lain完成了一个基于 RAG 的 Space 构建,专为 PDF 搜索设计,使用了facebook/dpr-ctx_encoder-single-nq-base模型。模型及其相关代码可以通过此链接访问。 - PdfChat Space:
@aabbhishekk0804宣布在 Hugging Face 上创建了一个用于 PdfChat 的 Space。该项目使用 zephyr 7b model 作为 LLM,可以在此处查看。 - 指标开发:
@vipitis分享了他们正在开发的指标的初步结果。这包括一个需要解决的后处理问题,该问题是在微调模型中发现的。
▷ #reading-group (4 messages):
- 阅读小组的下一篇论文:
@chad_in_the_house建议阅读小组的下一篇论文为 “On the Importance of the Final Time Step in Training Diffusion Models“,因其在该领域的重要性和影响力。此外,他提到@636706883859906562在这方面做了大量工作,并分享了他的实现的 Colab notebook 链接。 - 关于 Diffusion Models 的讨论:
@chad_in_the_house强调了常见 Diffusion 噪声调度(noise schedules)未强制最后一步时间步具有零信噪比(SNR)的问题,以及一些采样器实现未从最后一步开始的问题,指出这些设计存在缺陷,并导致训练与推理之间出现偏差。 - 实现论文时的问题:
@chad_in_the_house发现 Stability 未能实现这篇研究论文的内容,这很有趣,并邀请对此话题进行进一步讨论。 - Epsilon Loss 问题:
@pseudoterminalx指出,由于 Epsilon Loss 的问题,实现效果未达预期。
▷ #core-announcements (1 messages):
- 引入 Diffusers Benchmarks:用户
@sayakpaul宣布引入 Diffusers benchmarks,以追踪diffusers中最常用 Pipelines 的性能。在此处访问 Benchmarks。 - 自动报告工作流由名为
benchmark.yml的文件管理,该文件位于diffusersGitHub 仓库的.github/workflows目录下。在此处查看工作流文件。 - Benchmarks 包含多个配置,例如使用 TencentARC 模型的
StableDiffusionXLAdapterPipeline、StableDiffusionAdapterPipeline和StableDiffusionXLControlNetPipeline,如t2i-adapter-canny-sdxl-1.0和t2iadapter_canny_sd14v1。
▷ #diffusion-discussions (2 messages):
- 关于 Diffusion Model 训练的讨论:用户
@guinan_16875询问是否可以使用成对数据训练 Diffusion Models,并举了孩子照片和对应父亲照片的例子。他们质疑使用相同风格图像训练 Diffusion Models 的做法是否可以被视为一种风格迁移。 - Diffusion Models 与成对数据训练:针对
@guinan_16875的提问,@asrielhan建议研究 Instructpix2pix 和 InstructDiffusion,并表示这些可能涉及与提议方法类似的过程。
▷ #computer-vision (1 messages):
- Segformer 预训练权重差异:
@shamik6766提出了关于 Segformer b4 或 b5 模型在 cityscape 或 ADE20k 数据集上的 mIOU 值不匹配的问题,即论文中引用的值与 Hugging Face 上可用的值不符。该用户请求协助获取正确的预训练权重。他们还提到了使用#nvidia。
▷ #NLP (8 messages🔥):
-
模型的上下文长度:用户
@ppros666询问了 Llama 2 的上下文长度,特别是它是 4000 还是 4096。@Cubie | Tom澄清是 4096,此信息可以在 HuggingFace 上的 模型配置 中找到。此外,@Cubie | Tom分享了在 Python 中可以通过model.config.max_position_embeddings访问该值。 -
微调语言模型:
@ppros666还表达了他们第一次微调语言模型的意图。他们找到了一个名为 “Llama-2 4bit fine-tune with dolly-15k on Colab” 的教程,并询问鉴于该领域发展迅速,这是否是一个值得参考的资源。 -
模型下载大小和时间:
@vikas8715询问了 Mixtral-8x7B 模型的下载大小和时间。@vipitis报告称大小约为 56GB。@nerdimo建议使用具有高 VRAM 的强大 GPU 来处理此类大型模型。
▷ #diffusion-discussions (2 messages):
- 关于 Diffusion Models 训练数据的讨论:用户
@guinan_16875发起了关于现有 Diffusion Models 所用训练数据的讨论。他们指出当前模型使用相同风格的图像,使得任务本质上变成了风格迁移。该用户提出了一种替代的 paired data training method(成对数据训练方法),并以一次训练会话中使用孩子的照片和对应的父亲照片为例。其目标是利用训练好的模型根据孩子的照片生成预测的父亲照片。 - 作为回应,
@asrielhan提到了 Instructpix2pix 和 InstructDiffusion 是可以执行类似任务的潜在模型。
LangChain AI Discord Summary
- Gemini-Pro 流式查询:
@fullstackeric询问了 Gemini-Pro 的流式传输(streaming)功能,收到了 Google 对话式 AI Nodejs 教程的参考,并探讨了与 LangChain 库兼容的可能性。 - 社区互动 - 用户调查与公告:
@jay_wooow通过 tally.so 链接 分享了一项以开发者为中心的开源调查,而@ofermend通过 google form 宣布了 Vectara 中光学字符识别 (OCR) 功能的早期预览注册。 - 关于在 Prompt 中处理 JSON 输入的讨论:
@infinityexists.询问了在 PromptTemplate 中加入 JSON 的可行性,根据@seththunder的说法,这可以通过使用 Pydantic Output Parser 来实现。 - AI 工作流工具的使用经验,特别是 Aiflows 和 LangChain:
@tohrnii征求了用户关于使用 Aiflows 的反馈,并将其与 LangChain 进行了对比。 - 技术问题报告:用户
@ackeem_wm报告了在使用 Langserve 与 Pydantic v1 时出现 “422 Unprocessable Entity” 错误。同时,@arborealdaniel_81024指出了 LangChain 发布说明中的一个失效链接。
LangChain AI 频道摘要
▷ #general (42 messages🔥):
- Gemini-Pro 流式传输查询:
@fullstackeric询问 Gemini-Pro 是否支持流式传输,@holymode确认了这一点,并提供了 Python 和 Javascript 的代码片段。此外,建议参考 Google 的对话式 AI Nodejs 教程。然而,@fullstackeric正在寻求通过 LangChain 库实现的解决方案,据@holymode称,目前似乎尚未支持。 - 调查通知:用户
@jay_wooow分享了一个 tally.so 链接,鼓励社区参与一项开源调查,以帮助了解开发者在处理底层模型(LLMs)时的动机和挑战。调查结果也将以开源形式发布。 - Prompt 接收 JSON 输入的查询:
@infinityexists.询问是否可以在 PromptTemplate 中传递 JSON,@seththunder建议这可以通过使用 Pydantic Output Parser 来实现。 - AI 工作流工具讨论:
@tohrnii询问了社区关于 Aiflows(一个用于协作式 AI 工作流的工具包)的使用经验,并将其与 LangChain 进行了对比。该工具可以在此 GitHub 链接 中找到。 - Vectara OCR 功能公告:
@ofermend宣布了 Vectara 的光学字符识别 (OCR) 功能,该功能将允许用户从图像中提取文本。有兴趣参与早期预览的用户被引导通过提供的 google form 进行注册。
▷ #langserve (1 messages):
- POST /openai-functions-agent/invoke HTTP/1.1” 422 Unprocessable Entity 错误:用户
@ackeem_wm报告称,在使用 Langserve 与 Pydantic v1 时收到 “422 Unprocessable Entity” 错误,尽管 Playground 在处理其请求时运行正常。
▷ #langchain-templates (1 messages):
- 发布说明中的失效链接:用户
@arborealdaniel_81024报告了发布说明中的一个失效链接,该链接本应指向相关的模板。指定的 URL 为https://github.com/langchain-ai/langchain/tree/master/templates/rag-chroma-dense-retrieval。用户已标记此问题以便修复。
DiscoResearch Discord 摘要
- 用户
@bjoernp和_jp1_就评估模型与基准测试 (Benchmarks) 展开了深入讨论,探讨了评分准确率的概率以及创建有效基准测试的潜在方法,包括使用评估模型训练集的测试集。 - 围绕 Mixtral 实现的技术细节,用户
@huunguyen、@tcapelle、@goldkoron、@dyngnosis、@bjoernp和@someone13574进行了交流。话题涵盖了从线性专家 (Linear Experts) 的训练和路由重训练 (Router Retraining) 到在特定 GPU 上执行 Mixtral 以及通过 Top-k 门的反向传播技术。 @rtyax、@bjoernp和@.calytrix广泛讨论了 Llama-cpp-python 问题、调试策略以及其他潜在的推理方法。针对 Llama-cpp-python 报告的静默失败 (Silent Failure) 问题,建议使用 VLLM 等替代模型,并提出了包含 Ooba 在内的统一 API 的想法。此外,@rtyax和@bjoernp分享了不同的高效模型下载方法。
DiscoResearch 频道摘要
▷ #disco_judge (6 条消息):
- 评估模型与基准测试讨论:用户
@bjoernp和_jp1_讨论了评估模型和基准测试的使用。@bjoernp解释说,评估模型用于对其他模型进行评分,并展示了实际基准测试分数与评分模型分数之间的正相关性,表明高概率的正确评分。另一方面,_jp1_认为评估模型的能力应该几乎等同于测量评估模型自身的 MMLU。 - 测试集作为基准测试:
_jp1_建议可以将评估模型训练集的测试集用作评估模型的基准测试,而@bjoernp同意留出测试集 (Held-out Test Set) 确实可以作为有效的基准测试,尤其是在数据集创建者值得信赖的情况下。 - 合作邀请:
_jp1_邀请其他人基于他们现有的德语数据评估模型,共同开发更好的英语模型。
▷ #mixtral_implementation (8 条消息🔥):
- 训练中的专家副本:用户
@huunguyen询问专家是原始线性层的副本并继续训练,还是完全端到端训练的新线性层。 - 在 40GB A100 上运行 Mixtral:
@tcapelle询问是否有人成功在 40GB 显存的 A100 GPU 上运行 Mixtral。作为回应,@goldkoron提到他们在 3090 和 4060ti 16GB GPU 的组合上运行,理论上等同于 40GB。 - 新专家的路由重训练:
@dyngnosis推论路由部分可能需要重新训练,以便将 Token 正确路由到新专家。 - 通过 Top-k 门的反向传播:
@bjoernp对反向传播如何通过 Top-k 门工作表示不确定,并建议进一步研究路由输出可能会提供见解。 - 带或不带 Top-k 的训练:
@someone13574推测在训练期间是否使用了 Top-k,或者是否允许少量“泄漏”通过 Top-k。
▷ #benchmark_dev (20 条消息🔥):
- Llama-cpp-python 问题:
@rtyax报告称 Llama-cpp-python 在 generate / chat_completion 期间发生静默失败,即使使用低级 API 示例代码也是如此。这种行为是在为 Mixtral 重新构建 Llama-cpp-python 后观察到的,目前尚不清楚问题是否是局部性的。尽管存在这些问题,据报告 Oobabooga 使用相同的 Llama-cpp-python wheel 可以正常工作。 - 调试建议:
@bjoernp建议先调试更简单的模型,如 Mistral-7b。他还指出可以尝试调整fasteval/evaluation/constants.py中的线程设置,这可能有助于解决问题。 - 替代模型和推理方法:
@bjoernp推荐 VLLM 作为替代模型,因为它像 Llama-cpp-python 一样支持min_p。然而,@rtyax表现出继续深入探索 Llama-cpp-python 的兴趣。@.calytrix和@bjoernp都主张采用统一 API 的方法,.calytrix特别提到将 Ooba 作为推理引擎对于增加灵活性非常有价值。 - 模型下载技术:
@rtyax和@bjoernp分享了他们首选的模型下载方法。@rtyax使用 Hugging Face 的download_snapshot,而@bjoernp使用huggingface-cli download并开启HF_HUB_ENABLE_HF_TRANSFER=1选项以优化下载速度。@.calytrix承认后者的有效性,并表示最近的改进使其更加可靠。
Latent Space Discord 摘要
- 围绕 AI 模型托管与定价 的讨论;@dimfeld 对不同服务器上的 Anyscale 性能 进行了对比,报告称在 Mistral 8x7b 上其性能逊于 Fireworks 和 DeepInfra。
- 随后强调了 Anyscale 的性能增强 努力,展示了他们对这些性能问题的认可,以及 ‘@coffeebean6887’ 通过 Twitter 帖子 分享的后续解决工作。
- 一份更新描述了 Anyscale 在基准测试(benchmarking)中的改进,提到实现了 4-5 倍更低的端到端延迟。
- AI 行业中一个较少为人知的方面浮出水面:AI 模型托管/推理服务中激烈的价格竞争。
- 社区的资源丰富性得到体现,‘@guardiang’ 分享了指向 OpenAI API 文档 的 链接,以造福频道成员。
- ‘@swyxio’ 在 #llm-paper-club 频道简要提到了术语 “Qtransformers”,但没有任何随附的上下文或讨论。
Latent Space 频道摘要
▷ #ai-general-chat (13 条消息🔥):
- Anyscale 在 Mistral 8x7b 上的性能:
@dimfeld报告称,与 Fireworks 和 DeepInfra 相比,在 Mistral 8x7b 上尝试使用 Anyscale 时速度明显较慢。 - Anyscale 的性能增强努力:针对上述情况,
@coffeebean6887分享了一个 Twitter 帖子,表明 Anyscale 已意识到性能问题并正在积极改进。 - 基准测试改进:在后续跟进中,
@coffeebean6887指出,一个 PR 显示 Anyscale 在基准测试中实现了 4-5 倍更低的端到端延迟。 - 托管/推理服务中的价格竞争:
@coffeebean6887和@dimfeld讨论了 AI 模型托管和服务提供商之间明显的价格竞争。 - OpenAI API 文档链接:
@guardiang发布了指向 OpenAI 平台上新 Twitter/OpenAIDevs 账号的 链接。
▷ #llm-paper-club (1 条消息):
swyxio: Qtransformers
LLM Perf Enthusiasts AI Discord 摘要
- 关于在生产环境中使用 GPT-4 Turbo API 及其性能的讨论。用户
@evan_04487寻求关于尽管该 API 处于预览状态但仍进行操作的澄清,并询问了任何初始的间歇性问题,@res6969保证在他们的经验中不存在这些问题。 - 用户
@ayenem询问关于扩展合成表格数据生成的 MLOps 资源,特别是相关的书籍和博客。 @thebaghdaddy询问了 MedPalm2 在 kNN 用途上与他们当前使用的模型以及 GPT4 相比的有效性,并计划很快进行对比试验。
LLM Perf Enthusiasts AI 频道摘要
▷ #gpt4 (3 条消息):
- 在生产环境中使用 GPT-4 Turbo API:用户
@evan_04487提出了一个关于在生产环境中使用 GPT-4 Turbo API 的问题,尽管它仍处于预览状态。提到虽然每分钟事务数 (TPM) 的限制提高到了 600k(是 GPT-4 容量的两倍),且每分钟请求数 (RPM) 与 GPT-4 持平(为 10,000),但技术上它仍属于预览版。 @res6969给予了积极回应,表示他们正在积极使用且表现良好。@evan_04487进一步询问了系统初始的间歇性问题是否已得到解决。
▷ #resources (1 条消息):
- 用于扩展合成表格数据生成的 MLOps 资源:用户
@ayenem询问是否有人知道专门讨论在生产中扩展合成表格数据生成的 MLOps 主题书籍或博客。
▷ #prompting (1 条消息):
- 模型的使用与对比:
@thebaghdaddy目前正在使用一个未指明的模型,并觉得效果令人满意。他们还没有使用过 MedPalm2,因此无法对比两者。他们还在思考 MedPalm2 是否能比 GPT4 更有效地为 kNN 提供 CoT,并计划很快进行测试。
Skunkworks AI Discord 总结
只有一个频道有活动,因此无需总结…
- LLM 开发者调查:
@jay_wooow正在进行一项开源调查,旨在了解那些基于 LLM (Language Models) 进行构建的人员的动机、挑战和工具偏好。他希望收集能够帮助更广泛开发者社区的数据。调查结果(包括原始数据)将在达到目标参与人数后公布。其目标是影响产品开发,并为其他 AI 开发者提供有用的数据。
YAIG (a16z Infra) Discord 总结
只有一个频道有活动,因此无需总结…
- 针对 AI 工作负载的 DC 优化:一位用户讨论道,由于经济因素不同,大多数现有的 Data Centers (DCs) 并没有针对 AI 工作负载进行良好的优化。
- 边缘推理与训练:该用户认为在边缘进行推理并在电力更便宜的地方进行训练的概念是一个有趣的方法。
Alignment Lab AI Discord 没有新消息。如果该公会长期处于沉寂状态,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会长期处于沉寂状态,请告知我们,我们将将其移除。
Ontocord (MDEL discord) Discord 没有新消息。如果该公会长期处于沉寂状态,请告知我们,我们将将其移除。
AI Engineer Foundation Discord 没有新消息。如果该公会长期处于沉寂状态,请告知我们,我们将将其移除。
Perplexity AI Discord 没有新消息。如果该公会长期处于沉寂状态,请告知我们,我们将将其移除。