ainews-12162023-bytedance-suspended-by-openai
2023年12月16日:字节跳动被 OpenAI 暂停使用权限。
OpenAI Discord 社区讨论了 Mac 机架和 A6000 GPU 等硬件选项,强调了它们在 AI 工作负载中的价值。他们比较了 Claude 2.1 和 GPT 4 Turbo 在编程任务上的表现,结果显示 GPT 4 Turbo 的表现优于 Claude 2.1。讨论中还提到了 Gemini Pro 的 Bard API 的优势,包括每分钟 60 次查询的免费配额。用户分享了关于 ChatGPT Plus 会员问题和支付问题的经验,并对即将推出的 GPT-5 和传闻中的 GPT-4.5 进行了推测。此外,讨论还涉及了 Alpha 功能的保密性、AI 艺术生成政策以及组织工作功能的改进。社区对 GPT-4 的表现评价褒贬不一,并期待未来的模型更新。
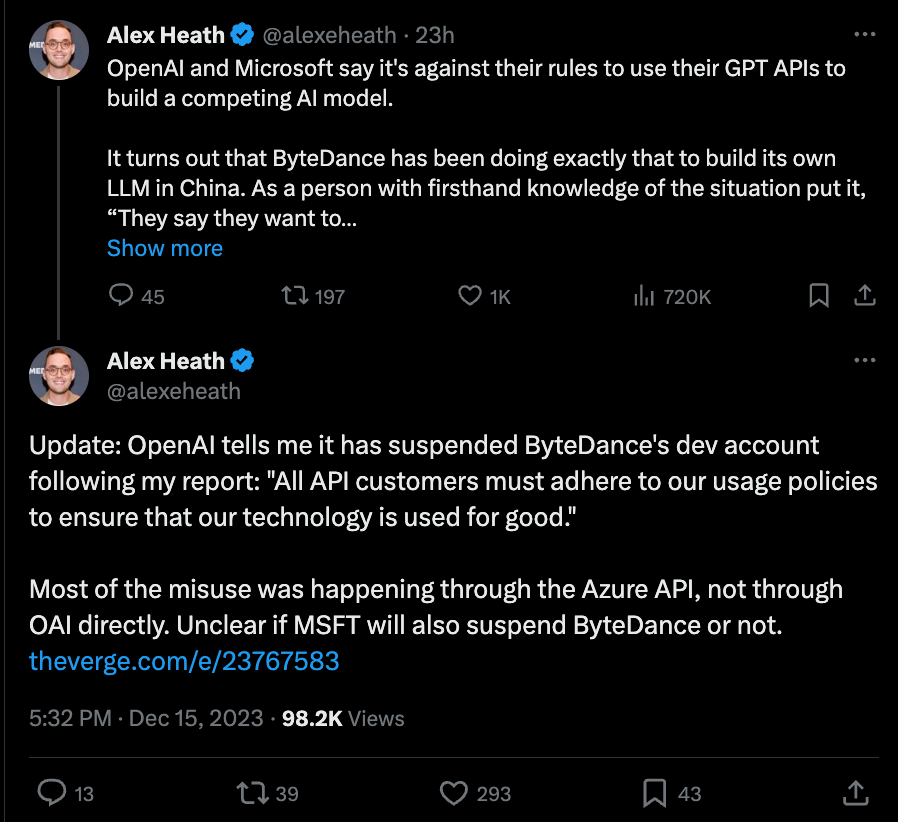
我们在最近的播客中讨论了 OpenAI 服务条款的问题 —— 但对于“开源 AI”个人爱好者来说,这通常不是问题。但对于大公司来说,情况就完全不同了 —— 以下是针对字节跳动 (ByteDance) 极其迅速的惩罚:
[TOC]
OpenAI Discord 总结
- 关于 AI 硬件的讨论,提到新的 Mac 机架对消费者有利,而 A6000 因其价格具有良好的性价比。(
@exx1&@birdetta) - 讨论了为 Gemini Pro 使用 Bard API 的优势及其每分钟 60 次查询的免费配额。探讨了与 OpenAI API 相关的成本及其在实验方面的优点。(
@thepitviper&@webhead) - 分享了 Claude 2.1 和 GPT 4 Turbo 在编程任务中表现的对比视频。对话包括对它们各自能力的评判,GPT 4 Turbo 的表现优于 Claude 2.1。对比视频 (
@rrross) - 关于 ChatGPT Plus 的用户体验讨论,对 GPT-4 的不同看法以及对即将推出的 GPT-5 的推测。提到了所谓的 GPT-4.5,但被成员否认,并根据播客参考推测将逐步进展到 GPT-5。(
@auracletech,@exx1,@satanhashtag,@moshymello) - 许多用户询问与 OpenAI 产品相关的技术问题、信用卡支付问题、使用 ChatGPT 进行大型 JSON 翻译、组织账户升级困难、意外的聊天存档以及密码重置麻烦。此外,还澄清了服务器名称与 ChatGPT 使用限制的相关性,并询问了什么构成一次 GPT-4 的使用。
- 由于询问未得到答复,Alpha 功能的状态仍然不明朗。同样,关于 GitHub Copilot 中使用 GPT-4 模型的问题也缺乏回应。
- 注意到图片损坏的问题,GPT-5 发布的不确定性,以及对 ChatGPT Plus 会员消息数量减少表示不满。
- 关于 AI 艺术生成政策的辩论,在 AI 生成场景中描绘多样化人群的重要性,以及关于在 chat completion 调用中限制输出 tokens 的查询。此外,还提到了组织工作功能的显著改进。
OpenAI 频道总结
▷ #ai-discussions (48 条消息🔥):
- 用于 AI 的 Mac 机架和 A6000:
@exx1和@birdetta分别简短讨论了新 Mac 机架对消费者的优势,以及 A6000 在其价位上表现不错。 - Gemini Pro 和 Bard API 的使用:
@thepitviper提到了 Bard API 用于 Gemini Pro 的好处,即每分钟 60 次查询免费,这鼓励了用户使用。他还讨论了尽管 OpenAI API 有成本,但用来实验很有趣。@webhead反驳了成本问题,指出它相对便宜,他每月消耗 100 万个 tokens 的费用不到 40 美元。 - Alpha 功能的机密性:
@wintre询问了 Alpha 功能的状态,是仍处于机密状态还是已被移除。 - Claude 2.1 和 GPT 4 Turbo 在编程方面的对比:
@rrross分享了一个关于 Claude 2.1 和 GPT 4 Turbo 处理编程任务的简短对比视频。讨论中提出了一些见解,例如 Claude 1 的评分高于 Claude 2 和 2.1。他还对比了 Claude 2.1 和 GPT 4 Turbo 的结果,GPT 4 Turbo 表现更好。 - Bard 和 Claude 2 的运行情况:
@eljajasoriginal指出 Bard 似乎幻觉 (hallucinating) 更少了,表现优于 Claude 2,尤其是在需要联网搜索的任务中。然而,他提到由于请求限制的减少,他几乎不再使用 Claude 2 了。
▷ #openai-chatter (117 条消息🔥🔥):
- ChatGPT Plus 会员及支付问题:
@mrcrack_遇到了其 ChatGPT Plus 订阅未被识别的问题。似乎是他的卡片出了问题,但在更换另一张卡后问题得到了解决。另一位用户@5sky遇到了卡片在支付 ChatGPT 服务时被拒绝的问题。 - GPT-4 和 GPT-5 的体验与预期:
@auracletech、@exx1和@auracletech等成员就 GPT-4 的性能和对 GPT-5 的预期展开了辩论。一些用户觉得 GPT-4 差强人意,而另一些人则赞赏其功能上的进步。此外,还有关于所谓的 GPT-4.5 的传闻和讨论,但@satanhashtag和@exx1澄清这些是基于虚假截图,而@moshymello提到了 Sam Altman 在播客中间接提到的向 GPT-5 逐步推进的过程。 - ChatGPT 用户体验:用户
@yethaplaya寻求让 OpenAI 模型生成更复杂代码的建议。用户@smoosh_laboosh注意到 DALL-E 3 每个 Prompt 仅提供一张图片。@arrushc询问是否有插件可以更好地整理和过滤 ChatGPT 的对话历史。@jeweis提到尽管他是 ChatGPT Plus 会员,但在使用 GPT3.5 时仍出现了错误提示。 - OpenAI API 与 Voiceflow:
@zevv_.询问了学习如何将 Assistant API 与 Voiceflow 连接并使用的资源。@Teemu建议查看 Voiceflow 的 YouTube 教程及其预构建模板。 - Converge 2 咨询:
@soulztundra询问是否有人了解 Converge 2 的年龄要求或机构要求。
▷ #openai-questions (30 条消息🔥):
- 层级升级问题:
@superseethat对其组织账户在用量增加、账户充值并提交问题后仍未升级到第三级速率限制(Rate Limit Tier)表示担忧,并寻求解决方案。 - 取消归档已归档的聊天:
@martinrj寻求帮助以恢复误归档的聊天,@lumirix指引其前往“Settings”中“General”下的“Archived Chats”部分。 - 使用 Chat-GPT 翻译大型 JSON 文件:
@youseif询问是否有办法使用 Chat-GPT 翻译大型 JSON 文件。 - 密码重置问题:
@marnold0015寻求帮助,因为重置密码的邮件没有出现在收件箱中,@satanhashtag建议使用help.openai.com并向支持部门发送邮件。 - 编写大型代码库的 Prompt:
@yethaplaya正在寻找好的自定义指令(Custom Instructions)来处理更长、更复杂的代码,试图绕过机器人默认不愿生成此类代码的限制。 - 异常系统活动错误:
@jeweis提到在使用 GPT3.5 时收到关于异常系统活动的错误消息,尽管 ChatGPT 4.0 运行正常。 - ChatGPT 4 或 3.5 使用限制:
@kingchengge询问服务器名称显示为“ChatGPT 4”或“3.5”是否会影响每 3 小时 40 条消息的限制。 - GPT 使用规范:
@solbus澄清所有自定义 GPT 都是 GPT-4 并计入用户的配额,并分享了一个说明什么算作一次 GPT-4 使用的链接。 - 账单咨询:
@avnova和@theblack.sage都提出了潜在的账单问题,特别是升级到下一层级以及一般的账单协助。
▷ #gpt-4-discussions (28 条消息🔥):
- 图片损坏问题:
@wehodl遇到了图片损坏的问题,并分享了相关的论坛讨论。目前他们尚未找到解决方案。 - 关于 GitHub Copilot 中 GPT-4 模型的疑问:
@blueberryberry询问 GitHub Copilot 是否正在使用 GPT-4 模型。报告的消息中未提供直接回答。 - 对 Alpha 功能的关注:
@wintre询问了 Alpha 功能的状态,是仍处于保密状态还是已被移除。在给出的消息中,这仍然没有得到解答。 - 关于 GPT-5 发布时间的讨论:
@sinize、@pudochu和@sxr_等用户讨论了 GPT-5 可能的发布时间。普遍共识认为,由于当前模型(如 GPT-4 Vision 和 Turbo)存在的问题以及为大量用户提供最佳服务的潜在挑战,它可能不会很快发布。目前没有相关的官方公告或链接。 - 对 ChatGPT Plus 会员消息限制的担忧:
@pudochu对 ChatGPT Plus 会员每 3 小时分配的消息数量减少表示不满,限制从 50 条降至 40 条。
▷ #prompt-engineering (5 条消息):
-
限制 Chat Completion 调用的输出 Token 数量:
@slobby_knobby_corny_cobby询问如何通过 API 限制 chat completion 调用的输出 Token 数量,同时避免消息被截断。 -
AI 艺术生成与归属政策:
@mysticmarks1对生成 AI 艺术的政策表示担忧。他们认为,不创建作品晚于 1912 年的艺术家风格图像的规则会产生偏见,并建议了一种变通方法:用三个描述其风格关键方面的形容词替换艺术家名字,并附上相关的艺术运动或时代背景,以及注明其主要媒介。 -
AI 生成场景中的多样化呈现:
@mysticmarks1批评了在 AI 生成场景中通过包含每个人的族裔和性别来使人物描绘多样化的政策。他们争论说,这种规则可能会歪曲现实,并质疑其在例如古代阿兹特克厨房场景中的适用性。 -
为组织工作添加新功能:
@mysticmarks1分享说他们显著扩展了某未指明组织工作的特性,增加了强大的功能。
▷ #api-discussions (5 条消息):
-
API 调用中的输出 Token 限制:
@slobby_knobby_corny_cobby寻求关于如何通过 API 限制 chat completion 调用的输出 Token 数量且不导致消息截断的建议。 -
对图像生成政策的担忧:
@mysticmarks1对现行的图像生成政策表示担忧,引用了在重现艺术家风格和多样化人物描绘准则中可能存在的问题。一个特别的争议点是限制重现作品晚于 1912 年的艺术家风格的政策。 -
描述多样性与现实主义:
@mysticmarks1指出了政策指南中感知到的矛盾,指出在平衡现实呈现(例如,不让特定职业的所有成员都是同一性别或种族)与描述多样性需求之间的挑战。质疑了这一规则如何应用于历史或特定背景场景,如“古代阿兹特克厨房”。 -
修订后的工作:
@mysticmarks1声称已经重写并扩展了该组织的工作,以引入强大的特性和功能,暗示对当前指南的不满。没有提供关于这些改进性质的具体信息。
Mistral Discord 总结
- Mistral AI 与开源模型:关于 Mistral AI 提供的各种模型的有效性、选择和使用的活跃讨论。提到了 Medium 和 Mixtral 模型,并附带了讨论、Twitter 和 GitHub 的支持链接。特别关注了 Mistral 性能中的参数微调。
- 构建 Chatbot UI:发布了关于聊天机器人开发的开源解决方案建议,提供了 Chatbot-UI 和 OpenAgents 及其各自 GitHub 仓库的链接。
- AI 模型性能比较:对包括 Medium 和 Mixtral 在内的各种 AI 模型进行了比较。组织了一场“AI Hack Night”活动,以探索 Mistral 的 LLM 与 Assistant API 的应用。提到了由于复杂的版本控制 API 系统要求,导致基准测试性能下降的感知。
- Mistral AI 内部的微调:关于微调能力的讨论探索了当前 API 是否支持微调。该问题得到了回应,指出目前的 API 尚未提供微调服务。
- 贡献与项目:分享了在 .NET 中使用 Mistral AI 平台的 Nuget 包链接。发起了项目协作邀请,并对想法和修改表示开放态度。讨论还涵盖了对调用 Mistral API 的探索。
- 量化与平台集成:提供了对 Quantization(量化)过程的解释。一些用户表达了对 Token 使用跟踪功能的期望,并确认该功能正在开发中。提出了关于平台集成以及 Mistral Medium API 所雇用的专家数量的问题。
Mistral 频道总结
▷ #general (180 条消息🔥🔥):
- Mistral API 和开源模型:用户
@lee0099、@cyborgdream和@marketingexpert讨论了他们在使用 API 调用不同模型(包括 Medium 和 Mixtral 模型)时的偏好和选择。讨论链接 - 创建 Chatbot UI:
@cyborgdream建议了用于开发聊天机器人的开源 UI 解决方案,并提供了 Chatbot-UI 和 OpenAgents 的 GitHub 仓库链接。 - API 使用和等待名单:用户
@marketingexpert表达了使用 Mistral API 的迫切愿望,并对等待名单表示沮丧。@tlacroix_解释了为了确保良好的用户体验而进行的谨慎负载管理过程。 - Mistral 模型性能:
@jamsyns分享了他发现 Mistral-medium 在编程方面比 ChatGPT 4 更高效的经验,并提供了一个 Twitter 链接 作为参考。 - 使用 Mistral LLM 和 Assistants API 的 AI 黑客之夜:
@louis030195组织了一场专注于将 Mistral 的 Language Learning Model (LLM) 与 Assistant’s API 结合使用的 AI 黑客之夜活动。分享了活动链接。
▷ #models (10 条消息🔥):
- Mistral 专注于非人类行:
@reguile评论说 Mistral 的专家模型 似乎在名词和标点符号等非人类行方面具有专长。 - 关于 Mistral 微调的问题:
@pdehaye询问 Mistral 的 8 个专家模型 是否使用人工策划的数据集进行微调,并询问这一决策背后的逻辑。 - Mistral 的性能调优:
@svilupp通过实验发现,改变 top-p 和 temperature 设置几乎可以复制 GPT-4 的性能,在他们的基准测试中,观察到比默认参数设置提高了近 30 分。然而,他们注意到在 Mistral-medium API 似乎发生更改后,性能大幅下降,影响了他们的预期收益。 - 性能对比:
@svilupp进一步提到,虽然他们喜欢 Mistral 的回答,但与[GPT-3.5-turbo-1106](https://github.com/svilupp/Julia-LLM-Leaderboard)甚至Mistral-small相比,在一致性和处理更复杂 Prompt 方面存在明显差异。 - LLM 中的版本控制挑战:
@casper_ai强调了提供大语言模型服务的困难,因为需要一个复杂的版本控制 API 系统来实现可重复的结果。然而,这一要求是有代价的,可能导致基准测试性能下降。
▷ #ref-implem (1 条消息):
- 在项目中集成 Jinja 模板:
@titaux12表达了对“开箱即用”的 Jinja 模板的兴趣,以促进无缝运行多个 LLM 的项目。这一请求是在支持 privateGPT 内多个模型的工作背景下提出的,Jinja 模板被视为管理不同 LLM 所需的各种 Prompt 格式的一种高效且优雅的方式。相关工作在 GitHub pull request 中有概述。 - 与 vLLM 工作的比较:
@titaux12提到 vLLM 团队正在进行类似的工作,他们被认为在这一领域更领先,因为他们已经在使用这些文件。 - 模型输出格式合规性:
@titaux12表示他们将进行调整,以确保其模型提供其他用户模型所需的输出格式,即保持所提供的 Token 表示的完整性,将1(BOS) 作为第一个 Token,并避免重复或编码为不同的 Token。
▷ #finetuning (3 条消息):
- 当前 API 的微调功能:用户
@jamiecropley提出了一个关于是否可以在当前 API 中进行微调的问题。@lerela确认 当前的 API 不具备微调功能,并鼓励用户向 Mistral AI 的支持邮箱分享他们的使用案例。
▷ #showcase (10 条消息🔥):
- 适用于 Mistral AI 平台的 .NET 库:用户
@vortacs分享了他为 Mistral AI 平台开发的 .NET 库链接,该库已实现列出模型(list models)和聊天(chat)端点。该软件包可在 Nuget 上获取。 - 寻找合作者:用户
@tonic_1表达了为项目寻找合作者的兴趣,同时也欢迎其他人使用该想法并进行修改。 - GitHub 上的贡献:
@aha20395和@fayiron都分享了他们已经很久没有进行编程或在 GitHub 上贡献代码了。尽管如此,@aha20395表达了他的支持以及在非代码层面提供帮助的意愿。 - 探索 Mistral API:
@tonic_1提到他正处于探索如何调用 Mistral API 的早期阶段。
▷ #la-plateforme (17 条消息🔥):
- Mistral-tiny 与 GGUF Mistral-7B-Instruct-v0.2 性能对比:用户
@tarruda发现 Mistral-tiny 的性能显著优于 Hugging Face 上的 Q8 GGUF 版 Mistral-7B-Instruct-v0.2。测试是在两者 temperature 均为 0 的情况下进行的,Prompt 可以在此 Benchmark 链接中找到。 - 关于 Quantization 的讨论:用户
@someone13574和@titaux12解释了 Quantization 的基本原理。据他们介绍,在llama.cpp中,Q8_K 是通过将参数以 256 个为一组进行分组,并为每个数据块寻找一个weight_scale来完成的。权重以 8 位整数存储,乘以 scale 后即可得到原始权重(存在一定误差)。 - 用量追踪请求:用户
@phinder.ai请求添加一个追踪 Token 使用情况的功能。@tlacroix_确认该功能将在下周添加。 - 关于平台集成的提问:
@subham5089询问了 LlamaIndex 与该平台的集成情况。 - 关于 Mistral Medium API 专家数量的问题:用户
@timotheeee1询问 Mistral Medium API 使用的是 2 个还是 3 个 Expert。他们推测增加到 3 个 Expert 可能会提高模型的性能。
Nous Research AI Discord 摘要
-
关于 AI 模型选择和偏好的讨论:用户分享了他们对 AI 模型和 Embedding(如 GTE-small 和 Jina)的选择方法和偏好。引用了一个即将推出的选项来嵌入整个 Arxiv 数据库,尽管有人对混合 Embedding 的有效性表示担忧。此外还讨论了 Fine-tuning 和面试模型,概述了不同模型训练策略的潜力和挑战。
-
发布用户生成的 AI 模型:用于推理和文本理解的 Metis 0.1 模型已在 Hugging Face 发布,同时分享了关于下载、Quantization 和评估该模型的条款。首个 Phi 2 GGUF 也已面世并发布。
-
GPU 资源的获取与应用:讨论中表现出对获取 MI300X GPU 的兴趣,并链接了一篇关于如何在消费级 PC 中运行 Nvidia SXM GPU 的博客。
-
对点对点(P2P)和分布式计算网络的兴趣:分享了多个资源,包括 Petals、Bacalhau/Filecoin、Bittensor、Hyperspace、Akash 和 Shoggoth Systems。
-
AI 行业新闻更新:注意到 OpenAI 因违反开发者许可而暂停了字节跳动(ByteDance)的账号;此外,微软宣布在 Azure OpenAI Service 上正式推出 GPT-4 Turbo with Vision 的消息也引发了讨论。
-
关于开源模型(如 Mistral 和 Openhermes)的 Fine-tuning 和操作问题的咨询:涉及恢复 logprobs 和衡量文本连贯性的具体咨询。对话展示了 Fine-tuning 模型的动态特性,考虑了诸如使用
<backspace>Token 或模型提供自我修正等方案。在关于 State Space Model 架构的讨论中,分享了 Mamba chat 仓库及相关研究论文。
Nous Research AI 频道摘要
▷ #off-topic (21 条消息🔥):
- AI 模型选择与方法:用户
@adjectiveallison对多种可用的 AI 模型和推理选项表示困惑。@lightningralf建议如果可能的话可以先等待,并提到一个即将推出的选项,可以将整个 Arxiv 数据库进行嵌入(embedding)。不过,@lightningralf也对混合 embedding 的效果表示担忧。 - 不同模型的用途:
@natefyi_30842分享了他们使用gte-small模型的偏好,并建议像Jina这样较大的 embedding 模型更适合书籍等大型项目。 - 微调与面试模型:
@a.asif正在考虑微调(fine-tuning)一个模型来担任面试官,根据提供的场景卡片提问。@.beowulfbr建议如果场景能放入上下文窗口(context window),可以使用 System Prompt 或RAG方法。然而,@a.asif认为由于场景数量庞大,微调可能是更好的方法,并能产生一个适用于特定用例的模型。 - GPU:
@dragan.jovanovich询问了购买MI300XGPU 的途径。 - Embedding 技术:
@nikhil_thorat分享了他们的方法:在句子/页面层级使用gte-small,在全文层级使用Jina进行 embedding,并强调了Jina在聚类(clustering)方面的有效性。
▷ #interesting-links (17 条消息🔥):
- Metis 0.1 模型微调:用户
@mihai4256宣布他们创建了一个 7b 的微调模型 Metis 0.1,用于推理和文本理解,现已在 GitHub 上发布。该模型并非针对故事创作,而是针对推理和文本理解任务。它是在私有数据集上训练的,而非 MetaMath 数据集。 - 下载与量化 Metis 0.1:用户
@.benxh确认已下载并量化(quantizing)了 Metis 0.1 模型进行测试。他们表示对于 7B 模型更倾向于使用 Q6,因为其质量高且性能极快;而@mihai4256则肯定了使用 Q8 GGUF 的做法,因为在显存(VRAM)上运行时采样速度很快。 - 在个人电脑上采用 Nvidia SXM GPU:
@giftedgummybee分享了一篇关于如何在个人电脑和第三方服务器中运行 Nvidia SXM GPU的博客文章,将其作为消费级 GPU 的替代方案,因为目前这些 GPU 的性能已经能够媲美数据中心 GPU。 - 在推理库中使用 ChatML:用户
@.benxh建议未来在推理库(inference libraries)中使用 ChatML,称其更易于使用并能提高模型的可访问性。 - 首个 Phi-2 GGUF:
@tsunemoto宣布首个 Phi 2 GGUF已经出现,它是 Microsoft Phi-2 的量化版本,包含 4_0、8_0 bits 并转换为了 GGUF 16FP 模型。不过,他澄清说,除非使用经过修改的特定分支(fork),否则它无法运行。@nonameusr表示打算测试该模型。
▷ #general (41 条消息🔥):
-
P2P 和分布式计算网络:
@yikesawjeez分享了关于点对点 (P2P) 和分布式计算网络的各种资源和信息,包括 Petals、Bacalhau/Filecoin、Bittensor、Hyperspace、Akash 和 Shoggoth Systems。 -
ChatGPT 的问题:
.interstellarninja提到了 ChatGPT 的问题,类似于之前在 Llama-2 中遇到的问题,特别是它在协助终止进程方面表现不佳。 -
Mixtral 的实验:
@nonameusr报告称他们一直在测试 Mixtral,并发现它非常有趣。 -
模型对比:
@shane_74436向@879714655356997692询问了关于基础版 Mixtral、Mixtral 的 Instruct 版本以及他们构建的模型的对比指标。他们指出在 The Gradient Institute (TGI) 上的表现参差不齐,但不确定是平台、Prompt 还是模型本身的问题。 -
新闻更新:
@atgctg分享了来自 The Verge 的一篇文章,指出 OpenAI 已暂停字节跳动 (ByteDance) 的账户,原因是其使用 GPT 生成的数据违反了 Microsoft 和 OpenAI 的开发者许可。@lightningralf评论说,这可能会促使中国买家转而使用 Mistral。@giftedgummybee分享了 Greg Brockman 的一条推文,并表达了对其中讨论的论文的困惑,随后标记了关于 GPT-4 Turbo with Vision 在 Azure OpenAI Service 上公开发布的 Microsoft 公告,并询问@550656390679494657是否看过。 -
寻求开源模型微调帮助:
@realsedlyf询问是否有人有关于微调 Mistral 和 openhermes 等开源模型的资源或想法,特别是针对函数调用 (function calling) 数据集。
▷ #ask-about-llms (11 条消息🔥):
- 状态空间模型 (State Space Model) 架构:
@vincentweisser发起了关于 Mamba 等状态空间模型架构的讨论,并分享了 Mamba 的 GitHub 仓库链接,这是一个使用状态空间模型架构的聊天 LLM。此外,他还分享了该主题的一篇相关研究论文。 - 模型微调:
@jason.today提出了微调模型的想法,使其具备纠正输出的内在能力,例如重新阅读并自我纠正,以及执行插入和删除等通用命令。然而,@atgctg反驳说,这可能会导致模型起初总是输出错误的 Token。 - **
Token**:在微调讨论中,`@atgctg` 提到了一篇介绍使用 ` ` Token 的[相关研究论文](https://arxiv.org/abs/2306.05426)。 - 计算资源的可用性:
@yikesawjeez提出分享他们最近获得的计算资源,专门针对开源项目或对人类有贡献、或创作高质量 Meme 的努力。 - 从开源模型中恢复 Logprobs:
@adjectiveallison询问了从特定推理提供商或本地恢复开源模型返回的 Logprobs 的标准方法,@atgctg回复说 Together 平台支持此功能。 - 衡量文本连贯性:
@xela_akwa询问是否有衡量文本连贯性的方法或基准测试 (Benchmarks)。
OpenAccess AI Collective (axolotl) Discord 总结
- 围绕 Phi-2 Base 的 fine-tuning 展开了持续对话,用户
@noobmaster29分享了一条 推文,暗示了其进一步开发的潜力。这引发了关于其他首选 LLM base 的讨论,包括 Mistral 7B 和 Hermes。 - 用户
@casper_ai分享了关于 AMD 新产品 MI300x 技术细节和性能的详细讨论,以及它在推理速度上相对于 Nvidia H100 的竞争优势。这引发了关于将 ROCm 支持扩展到 AMD 消费级显卡的进一步讨论。 - 社区成员就 HF Transformers 的故障排除 进行了互动,并分享了问题的解决方案。值得注意的是,据报道更新 NCCL 和 Nvidia 解决了训练过程中的一些挂起问题。一个 Transformers 的 PR 请求 已在 guild 中开启并分享。
- 关于不同 Training Configurations 的积极讨论,揭示了关于 Mixtral 训练的 FFT(全参数微调)见解。此外,还出现了针对 Mixtral 专家的 fusedmlp 潜在实现的探索,提议的内存节省方案是一个显著的关注话题。
- 针对某些问题的咨询,例如 pod 的运行情况 和 双 EOS token 问题。寻找在独立训练任务完成后停止不必要容器运行的解决方案也是一个紧迫的话题,并提出了使用 Runpod 原生 API key 的方法以及建议的任务终止回调实现。有人提出了关于 在没有 base URL 的情况下查看图像 的问题,但尚未得到解答。
OpenAccess AI Collective (axolotl) 频道总结
▷ #general (8 条消息🔥):
- 用于 Fine-tuning 的 Phi-2 Base:
@noobmaster29分享了 Sebastien Bubeck 的推文,该推文指出 phi-2 确实是一个非常适合进一步 fine-tuning 的 base。他详细说明了他们在 100 万个数学练习题上进行了 fine-tuned,并在最近的法国全国数学考试中进行了测试,结果令人鼓舞。 - 首选 LLM Base 模型:
@jovial_lynx_74856调查了集体首选的 LLM base,提到了 Mistral 7B 和 Hermes 作为选项。 - AMD 与 Nvidia 推理速度竞赛:
@casper_ai向小组通报了 AMD 的新产品 MI300x,据称其推理速度超过了 Nvidia H100,而成本降低了 50%。他还附上了 相关 AMD 社区帖子的链接。 - 对 AMD 消费级显卡的 ROCm 支持:
@le_mess表达了希望 ROCm 支持能扩展到 AMD 消费级显卡的愿望。 - Mixtral Medium 基准测试:
@dangfutures询问是否有 Mixtral Medium 的基准测试可用。@le_mess回复说公司网站上提供了一些基准测试。
▷ #axolotl-dev (49 条消息🔥):
- HF Transformers 故障排除:用户
@hamelh提到在使用 HF Transformers 时遇到问题。@caseus_提供了一个 GitHub 上的 PR 链接,据报道该 PR 修复了该问题。 - NCCL 和 Nvidia 的更新:用户
@richbrain分享说,在将 NCCL 更新到 2.19.3 并将 Nvidia 更新到 23-10 后,他们在训练 1 小时后不再遇到挂起问题。该更新受到了社区的好评。 - Transformers 的 PR 请求:
@caseus_请求开启一个 PR,在 requirement 文件中固定新的 Transformers 版本。@richbrain完成了该请求,并提供了 PR 链接。 - 讨论训练配置:
@yamashi和@casper_ai与@richbrain就他们的 Mixtral 训练 FFT 配置进行了讨论。Richbrain 透露他们正在使用 2 个带有 H100 GPU 的节点运行,sequence length 为 2048。 - FusedMLP 的潜在实现:
@caseus_和@casper_ai讨论了为 Mixtral 的专家实现 fusedmlp 预计可节省的内存。Casper 根据在 Llama 7B MLP 中观察到的 1GB 内存节省,估计可以节省 8GB 的 VRAM 显存。
▷ #general-help (4 messages):
- Pod 运行问题:
@dangfutures询问了关于 Pod 运行的潜在问题,不确定其是否存在 Bug。 - 双重 EOS Token 解决方案:
@noobmaster29建议了一个修复双重 EOS Token 问题的方案。提议的方案涉及修改sharegpt.py文件。具体来说,是移除 ‘sep style’ 并添加stop_str="
▷ #runpod-help (6 messages):
- 使用 RUNPOD_API_KEY 和 RUNPOD_POD_ID 控制 Runpod:
@caseus_解释说 Runpod 提供了环境变量(RUNPOD_API_KEY和RUNPOD_POD_ID),可用于调用 API 来控制 Pod,例如将其关闭。他们还发布了 Runpod 的 “Stop Pod” 文档链接,并分享了一个curl命令示例,但指出 “stop”(停止)与 “terminate”(终止)并不相同。 - 配置 Runpod 容器在任务完成后退出:
@_jp1_希望 Runpod 容器在独立的训练任务完成后立即退出,因为 Runpod 的默认行为似乎是无限次重启容器。由于运行容器成本较高,他们正在寻找一种不需要外部服务器或服务来监控作业并停止容器的解决方案。 - 任务完成后自动停止 Runpod 的建议:针对
_jp1_的问题,@caseus_建议在训练结束时设置一个回调,以便在任务完成后关闭容器。这可能涉及到一个定时器,以确保在关机前完成最终 Checkpoint 的上传。 - 在没有 Base URL 的情况下查看图像:
@mustapha7150询问在输出不包含 Base URL 时如何查看图像。提供的信息中未回答此问题。
HuggingFace Discord Discord Summary
- 解决涉及 AI 模型训练、Gradio 的 API 服务器以及使用 KoalaAI/Text-Moderation 执行 FastAPI 的技术问题。具体引用包括 HuggingFace 的教程和与 FastAPI 错误相关的 GitHub issue。
- 关于 AI 模型性能和实现的活跃对话,包括用例、性能特征和对比。广泛讨论的模型包括 cogvlm 模型、Phi-2、deepseek-coder 和 go-bruins-v2.1.1。
- 分享的项目和演示,例如使用 Web3 API 网关的货币化语音转文本应用 YouTube 链接、Diffusion-Cocktail 的 demo 以及关于使用 AI 生成超写实面孔的链接。
- 征求项目方面的帮助和建议,例如使用 CodeGen2.5 和 StarChat Beta 等模型将 PHP 项目转换为 Laravel,将 Animate Diff .ckpt 文件转换为 .bin 文件,以及从原始歌曲人声和定时歌词创建数据集。
- 强调了硬件资源的重要性,特别是高 VRAM GPU 对于成功进行模型推理的关键作用。
HuggingFace Discord 频道总结
▷ #general (26 条消息🔥):
- Diffusion Models 训练问题:用户
@everythinging报告称,在按照 HuggingFace 官方教程尝试使用自己的图像进行训练时,生成的图像全是噪声。他们询问数据集是否有最小尺寸要求。 - API 连接问题:用户
@paghkman发现 Gradio 客户端库的 API 链接目前已宕机并返回错误。 - 多模态模型讨论:用户
@doctorpangloss和@asrielhan称赞了 cogvlm 模型作为多模态模型的有效性。此外,用户@asrielhan还在此处提到了另一个新模型。 - 训练模型讨论:
@vipitis分享了他们使用 Phi-2 模型的经验,表示该模型仅在训练过的领域表现良好,并在此处分享了对比。 - 代码转换项目:
@pyr0t0n询问有关将完整的 PHP 编程项目转换为 PHP Laravel Framework 的项目。用户@merve3234建议查看代码指令模型,如 CodeGen2.5 和 StarChat Beta。
▷ #today-im-learning (1 条消息):
nixon_88316: 你好!有人能向 stabilityAI 添加模型吗?
▷ #cool-finds (1 条消息):
- 使用 AI 生成超写实面部:用户
@kingabzpro分享了来自 KDNuggets 的一篇博客文章链接,详细介绍了使用 AI 生成超写实面部的三种方法,主要通过 prompt engineering、Stable Diffusion XL 模型以及来自 CivitAI 的自定义模型。该文章为那些苦于生成的 AI 图像质量不佳、经常充满故障和伪影的用户提供了解决方案。
▷ #i-made-this (7 条消息):
- 模型生成改进:
@vipitis报告称在修复了模型生成的后处理后,结果有所改善。他们称赞了 deepseek-coder 的性能,并表示渴望运行其更大的变体。 - Web3 API 应用:
@dsimmo使用 Web3 API 网关设计了一个货币化的语音转文本应用。他们分享了一个 YouTube 链接以启发他人创建类似应用。 - 新模型发布:
@rwitz_宣布发布新模型go-bruins-v2.1.1,声称截至 2023 年 12 月 16 日,它是 leaderboard 上任何尺寸中评分最高的模型。该模型是在Intel/orca_dpo_pairs上经过 DPO 训练的。 - 图像内容/风格操控方法:
@.ricercar提出了一种无需训练的图像内容/风格操控方法。他们分享了一个 demo,展示了预训练 DMs 和 LoRAs 的集成。 - Demo 反馈与故障排除:用户
@jo_pmt_79880在使用.ricercar的 demo 时遇到了图像输出问题,返回的图像为空。@.ricercar请用户刷新浏览器并重试。
▷ #reading-group (1 条消息):
pcuenq: 那太棒了 <@582573083500478464>!
▷ #diffusion-discussions (2 条消息):
- 将 Animate Diff .ckpt 转换为 .bin 文件:
@jfischoff询问是否有办法将 Animate Diff .ckpt 文件转换为 diffusers motion adapters 可以理解的 .bin 文件。
▷ #computer-vision (1 条消息):
vision12: 大家好,有人知道如何将 timm 模型权重转换为 keras 权重吗?
▷ #NLP (3 messages):
- 推理的 GPU 需求:用户
@nerdimo建议,对于推理过程,一个具有高显存(VRAM)的强力 GPU 是必不可少的,否则推理可能会出现问题。 - 使用 KoalaAI/Text-Moderation 时的 FastAPI 执行错误:用户
@marshy.dev报告了通过 FastAPI 运行 KoalaAI 的 Text-Moderation 模型时遇到的 RuntimeError 问题。分享了一个关于该错误的相关 GitHub issue 链接,并提供了导致错误的当前方法代码。 - 从带有时间戳的歌词创建数据集:用户
@sushi057寻求帮助,希望从原始歌曲人声中创建数据集,并将其映射到定时歌词以辅助其模型。
▷ #diffusion-discussions (2 messages):
- 为 Diffusers Motion Adapters 将 .ckpt 转换为 .bin:用户
@jfischoff询问了将 Animate Diff 的 .ckpt 文件转换为 Diffusers Motion Adapters 可以识别的 .bin 文件的可能方法。
LangChain AI Discord 摘要
- 用户参与了各种技术协助需求,包括关于在 Node.js 中从 Faiss store 删除文档的建议、估算使用 AWS 托管 RAG 应用的成本,以及咨询旧版本的 LangChain API。目前的帮助途径包括
@holymode邀请并帮助@quantumqueenxox将同步代码转换为异步代码。 @ofermend提到 Vectara 即将推出 OCR 功能,这可能对 LangChain 客户有益。通过等候名单链接提供新功能的早期访问。@arborealdaniel_81024报告 LangChan-ai 的 GitHub 仓库 在检查发布说明模板时显示为损坏的链接。@_johnny1984发起了一场关于 AI 潜在安全风险的讨论,可能与披露的与 OpenBSD 的关联有关。他们还表示如果需要,愿意提供 Ruby 示例。- 社区看到了两个项目的更新。
@discossi在其 llama-cpp-chat-memory GitHub 仓库上分享了 AI 聊天机器人的网页抓取功能,@heydianaa宣布了一个将图像转换为舞蹈视频的 Discord 机器人,欢迎在 kineticpix.ai 提供反馈。
LangChain AI 频道摘要
▷ #general (11 messages🔥):
- 在 Node.js 中从 Faiss Store 删除文档:
@binodev询问如何从 Node.js 的 Faiss store 中删除文档。目前尚未提供解决方案或进一步讨论。 - 使用 AWS 的 RAG 应用成本:
@legendary_pony_33278寻求关于估算在 AWS 上托管 RAG 应用成本的建议。他们目前使用 Mixtral 8x7B 或 Llama 2 13b 模型以及一个小型向量数据库(vectordb)。目前尚未提供建议。 - Vectara 的 OCR 能力:
@ofermend宣布 Vectara 即将推出 OCR 功能,这对于将其与 LangChain 集成的客户非常有用,特别是处理扫描文档时。他们为有兴趣获得早期访问的人分享了等候名单链接。 - 咨询旧版 LangChain API:
@damianj5489正在寻找旧版本的 LangChain API,但通过提供的链接只能找到最新版本 (0.0.350)。目前暂无回复。 - 使用 AI 协助法律事务:
@_johnny1984提议使用 AI 帮助他的女朋友赢得监护权争夺战,尽管她持怀疑态度。目前尚未给出反馈或建议。 - 请求异步代码方面的帮助:
@quantumqueenxox请求协助将他们的代码转换为异步模式,并为该服务提供报酬。@holymode表示愿意提供帮助,具体细节正在私下讨论。
▷ #langchain-templates (1 messages):
- 发布说明中的链接失效:用户
@arborealdaniel_81024指出发布说明中提供的一个链接已失效。该链接本应指向说明中提到的一个模板。链接:https://github.com/langchain-ai/langchain/tree/master/templates/rag-chroma-dense-retrieval指向一个 GitHub 仓库,但似乎已失效或不存在。
▷ #share-your-work (5 messages):
- 安全顾虑:用户
@_johnny1984发起了一场关于 AI 安全性的讨论,推测了具备系统黑客攻击能力的 AI 所带来的风险和影响。 - OpenBSD AI 开发:
_johnny1984还透露了他与 OpenBSD 的隶属关系,暗示他正在致力于创建一个具备黑客攻击能力的 AI。 - AI 聊天机器人中的网页抓取:
@discossi分享了在其 AI 聊天机器人中为文档记忆添加基础网页抓取功能的更新。他提供了该项目 llama-cpp-chat-memory 的 GitHub 仓库链接。 - 图片转舞蹈视频机器人:
@heydianaa开发了一个免费使用的 Discord 机器人,可以将图片转换为舞蹈视频。他们鼓励用户在 kineticpix.ai 注册、试用并提供反馈。
▷ #tutorials (2 messages):
- 提供 Ruby 示例:用户
@_johnny1984表示可根据需求提供 Ruby 示例。
Alignment Lab AI Discord 摘要
只有一个频道有活动,因此无需总结…
- 关于 Phi-2 训练效率的讨论:成员们对微软如何如此高效地训练其模型 Phi-2 感到好奇。
@autometa声称该模型对 GPU 的负载比Llama 13b更重,并提出了关于使用 “90 多个 A100 运行 20 天” 这一令人困惑的效率说法。 - 关于 Phi-2 效率的推测:
@benxh推测其策略可能包括多个 Epoch、合成数据,以及应用于整个网络的 Phi1.5 分类器。 - 对某些限制的担忧:
@damiondreggs和@lightningralf讨论了正在实施的某种形式的限制,并对采取此类措施耗时如此之久表示惊讶。
DiscoResearch Discord 摘要
只有一个频道有活动,因此无需总结…
- 关于稀疏激活模型的训练与质量的讨论:用户
@someone13574建议在训练期间 Top-k 可能没有限制,或者可能存在少量的泄漏。随后,@saunderez理论化认为,稀疏激活模型中的质量下降可能与稀疏模型中大多数 MLP (Multi-Layer Perceptron) 激活值为零有关。 - 在显卡上运行代码:用户
@goldkoron表示他们使用了 3090 和 4060ti 16GB 显卡的组合,总计 40GB 显存用于其任务。当@tcapelle询问代码库时,@goldkoron回复说他们使用的是 Text Gen WebUI,以及带有实验性分支的 exllamav2。 - 语言模型的准确性:用户
@alliebot3000、@nyxkrage和@jiha讨论了语言模型不完美的准确性。@alliebot3000提到一些模型虽然非常接近,但仍然无法给出正确答案。@jiha指出,如果模型不正确,那它就是错误的。 - 改进语言模型响应的建议:
@nyxkrage提出了一项潜在的改进,建议要求语言模型仅在解释结束时给出最终答案,这可能会产生更好的结果。@someone13574回应称,这测试的是不同的方面,而不是模型是否能立即提供正确的响应。
Latent Space Discord 总结
- 关于代码解释以及 Python code 生成 R code 的意外进展的讨论,用户
@slono未提及。 - 用户对 Latent Space 聊天机器人 Cody’s context 功能的使用体验,
@slono对其性能表示失望。 @slono面临的技术问题:聊天机器人未按预期从 project/ 目录加载文件,以及一个幽默的解决方案:通过 shellscript 上下文搜索过滤掉不需要的go.sum和package.lock文件。- 用户
@ayenem参与了关于聊天机器人 guardrails 的讨论,表示有兴趣分享来自 arxiv.org 的论文,并请求有关该主题的更多资源。
Latent Space 频道总结
▷ #ai-general-chat (5 条消息):
- Code Interpreter R vs Python:
@slono幽默地指出,他们的代码解释器并没有直接解释 R code,而是创建了生成 R 代码的 Python code。 - 对 Cody 上下文的看法:
@slono对 Latent Space 聊天机器人 Cody 的上下文功能表示不满,认为其表现低于预期。 - Project/ 目录文件加载问题:
@slono还报告了一个问题,尽管他有明确指示,但聊天机器人似乎没有从 project/ 目录加载任何文件。 - 聊天机器人列出不需要的文件:
@slono进一步指出,当询问目录中的文件信息时,聊天机器人列出了所有的go.sum文件,这些文件延伸了多个后续步骤。 - 过滤掉不需要的文件: 为了处理像
go.sum和package.lock这样不必要的文件列表,@slono诙谐地提到他们创建了一个 shellscript 上下文搜索来过滤掉这些文件。
▷ #llm-paper-club (1 条消息):
- Guardrails 讨论与资源:
@ayenem目前正在阅读一篇关于 guardrails 的论文 arxiv.org,并表示如果大家对该主题感兴趣,愿意进行分享。他们还在寻找关于聊天机器人 guardrails 的额外资源。
LLM Perf Enthusiasts AI Discord 总结
- 关于使用 Azure 的讨论,
@rabiat表达了兴趣并询问了 Azure 的 rate limits,@robotums提供了关于性能的个人经验,称 在首个 token 之后流式传输速度变慢。 - 关于潜在社区扩展的对话,
@jeffreyw128建议是增加社区规模还是维持现状,并指出等待加入的潜在成员名单很长。 @jeffreyw128提议引入一个由 GPT4 驱动的机制,用于对社区讨论进行每日总结,旨在简化让成员了解活跃对话的过程。
LLM Perf Enthusiasts AI 频道总结
▷ #gpt4 (2 条消息):
- Azure 使用与 Rate Limits: 用户
@rabiat表达了使用 Azure 的意图并询问了其 rate limits。 - Azure 的性能:
@robotums回复称 Azure 的 rate limits 对他们来说是一样的,并分享了关于首个 token 之后流式传输速度变慢的经验。
▷ #feedback-meta (3 条消息):
- 关于社区扩展的讨论:
@jeffreyw128提出了社区应该邀请更多成员还是保持当前规模的问题,并指出有大量准成员积压等待加入。 - 关于使用 GPT4 进行每日总结的建议:
@jeffreyw128还提出了利用 GPT4 驱动的机制生成社区活动的每日总结的想法,以帮助成员跟上正在进行的讨论,并以更精简的方式获取见解。
Skunkworks AI Discord 摘要
只有一个频道有活动,因此无需总结…
- 中文聊天机器人评估:用户
@strangeloopcanon询问了关于 Chinese Language Models 基准测试评估的见解,特别是那些不仅仅运行 MMLU 测试的模型。 - Qwen 72B 性能:
@sentdex提到了他们使用 Qwen 72B 的经验,称其在信息类问题和通用问答方面非常有效。虽然它在 instruction following 方面最初表现出弱点,但@sentdex怀疑一个构建合理的 prompt 可以提高其性能。有趣的是,@sentdex表示相比 Mixtral,他更倾向于选择 Qwen 72B。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
Ontocord (MDEL discord) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
AI Engineer Foundation Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
Perplexity AI Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。