ainews-12212023-the-state-of-ai-according-to
2023年12月21日:AI 现状(LangChain 视角)
LangChain 发布了基于 LangSmith 统计数据的首份报告,揭示了市场关注度(mindshare)的排行榜。在 OpenAI 的 Discord 社区中,用户提出了关于 Mixtral 模型 的问题,指出其表现不一致,并将其与 Poe 平台上的 Mixtral 进行了对比。有报告称 GPT-4 和 ChatGPT 的输出质量有所下降且行为不可预测,同时用户还讨论了 Playground 版 GPT-4 与 ChatGPT 版 GPT-4 之间的差异。用户还报告了 Bing 和 Bard AI 模型的异常行为,包括产生幻觉和发表奇怪的言论。用户的各种担忧还包括:GPT-4 的消息限制、响应完成错误、聊天延迟、语音设置无法访问、密码重置失败、双重身份验证(2FA)问题以及订阅限制。此外,用户还讨论了引导 GPT-4 输出的技巧以及 DALL-E 的创意用法。用户还强调了影响订阅的经济限制,并咨询了关于如何利用 ChatGPT 赚钱以及 Token 成本的问题。
LangChain 发布了 他们的第一份基于 LangSmith 统计数据的报告:
顶部的图表对于了解市场占有率(mindshare)很有帮助:


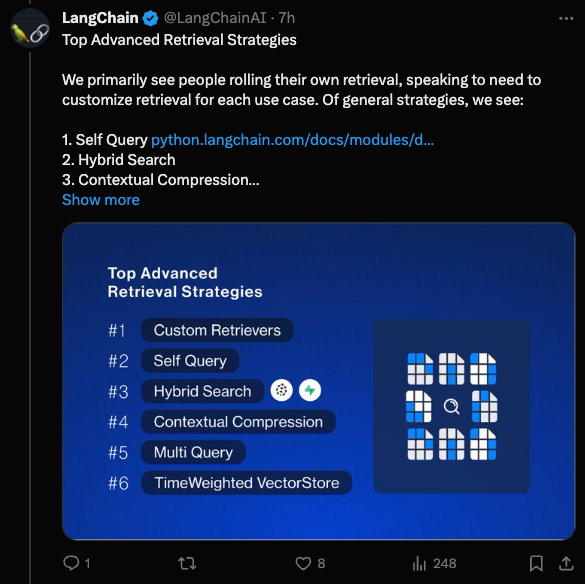
[TOC]
OpenAI Discord 总结
@eljajasoriginal提出了关于使用 Mixtral model 的问题,包括回复的不一致性以及与 Poe’s Mixtral 的对比。- 根据用户
@eljajasoriginal和@felly007的反馈,GPT-4 和 ChatGPT 的输出质量明显下降,且 OpenAI 披露了其行为的不可预测性。 @eljajasoriginal指出了 Playground GPT-4 与 ChatGPT GPT-4 的性能对比。@odasso.最初报告了 Bing 在回复一致性方面的异常行为,以及用户对幻觉(hallucination)或缓存信息使用的担忧。- 讨论了 ChatGPT 平台的用户问题和性能:包括消息数量限制、完成复杂回复、打字机式的回复延迟、使用 GPT-4 编写代码,以及由
@superiornickson5312、@sieventer、@afayt、@the_boss7044和@clockrelativity2003分别提出的影响订阅的财务限制。 - 用户报告的 OpenAI 平台问题和查询:包括聊天延迟、Android 上无法访问语音设置、密码重置失败、2FA 激活问题、ChatGPT4 中不可点击的链接、GPT 对对称性的误解、文件上传失败、GPT-3.5 侧边栏访问问题以及重复模式错误。
@nicky_83270讨论了对 ChatGPT Subscription Gear 的访问限制。@.cymer和@satanhashtag观察到了 OpenAI 服务器限制,@.cymer提到内容政策和审查可能影响 ChatGPT 性能。@Rock和@cat.hemlock关于在 GPT 中使用“知识”(Knowledge)的询问和对话。@eskcanta、@stealth2077、@jeziboi、@rendo1和@seldomstatic分享了在 GPT-4 中引导输出以满足特定要求的技巧和方法。@neurophin寻求关于使用 GPT-4 创建角色全身视角的建议,@errorsource和@seldomstatic探讨了使用 DALL-E 和 ChatGPT-4 创建极简主义艺术风格。@antonioguak强调了关于 ChatGPT 获利机会以及使用 GPT token 成本的查询。
OpenAI 频道总结
▷ #ai-discussions (52 messages🔥):
-
Mixtral 输出的一致性:
@eljajasoriginal注意到,无论在 Perplexity AI playground 中重新生成多少次回复,Mixtral model 对相同的 prompts 都会给出相同的回复。该用户还对比发现 Poe’s Mixtral 的回复一致性较低。 -
GPT-4 和 ChatGPT 的问题:
@eljajasoriginal和@felly007等用户讨论了 GPT-4 和 ChatGPT 明显的质量下降。@eljajasoriginal引用了 OpenAI 的一份声明,称模型行为可能不可预测,他们正在研究修复该问题。 -
Playground 中的 GPT-4 与 ChatGPT 中的 GPT-4 对比:
@eljajasoriginal分享了一个观点,认为 Playground GPT-4 可能会提供更好的结果,因为它没有 ChatGPT 模型中存在的内部指令。这一点在安全措施和 context length 等方面被进一步讨论。 -
Bing 的异常行为:
@odasso.分享了关于 Bing 在不同对话中保持查询上下文能力的异常体验。包括@brokearsebillionaire和@lugui在内的一些用户认为这是 hallucination 或使用了缓存信息。 -
Bard AI 模型中的奇怪设置:
@eljajasoriginal报告在 Bard 的回复中发现了奇怪的断言,例如它提到了过去不存在的对话,并包含了不必要的地点详情。
▷ #openai-chatter (115 条消息🔥🔥):
-
GPT4 消息限制:用户
@superiornickson5312对发送给 GPT4 的消息数量限制表示担忧,随后@toror澄清说,用户每小时发送的消息数量确实有限制。 -
GPT4 错误与生成完成度:用户
@sieventer对 GPT-4 因提示词复杂或错误而无法完成回复感到沮丧,对此@z3wins建议使用更短的提示词并一次只问一个步骤。 -
清理延迟的 ChatGPT 响应:用户
@afayt抱怨 PC 端 ChatGPT 的打字动画出现问题,最终断定这是由于对话历史记录过长导致的。 -
使用 ChatGPT 编写代码:用户
@the_boss7044询问如何使用 GPT-4 编写实际代码。用户_@jonpo建议直接告诉它编写代码,并注明不要说太多废话。 -
订阅与性能问题:一些用户对 ChatGPT 的性能表示不满,理由是频繁出现网络错误 (
@fanger0ck)。然而,其他人为系统辩护,认为这些是由于服务器负载导致的暂时性问题 (@aminelg)。@loschess尽管遇到了一些小问题,但对服务表示满意,而@clockrelativity2003则分享了因财务困难需要取消订阅的情况。
▷ #openai-questions (66 条消息🔥🔥):
-
长对话问题:用户
@imythd询问当对话变得太长并出现卡顿时该如何解决。@solbus建议在新对话中总结关键信息,或者如果用户拥有 Plus 订阅,可以创建一个自定义 GPT 来存储关键上下文。 -
Android 应用上的语音设置问题:
@davidssp.在 ChatGPT 的 Android 应用上访问语音设置时遇到问题。@solbus澄清说语音功能仅在应用中可用,并建议检查 Android 应用或从 Play Store 下载。 -
无法重置密码:
@vijaykaravadra报告了未收到重置密码邮件的问题。所提供的消息中未讨论此问题的解决方案。 -
2FA 激活问题:用户
@palindrom_报告了在停用双重身份验证(2FA)后无法重新激活的问题。@satanhashtag链接到了一篇 OpenAI 的文章,解释说 2FA 可能会被暂时暂停。 -
ChatGPT4 中不可点击的链接:
@mouad_benardi_98遇到了 ChatGPT4 提供不可点击链接的问题。@satanhashtag建议尝试在不使用自定义指令和插件的情况下开启新的 GPT4 对话,或者在单独的频道中寻求解决方案。 -
GPT 误解对称性:
@neonn3mesis报告说 GPT 混淆了水平对称和垂直对称。所提供的消息中未讨论此问题的解决方案。 -
无法上传文件:
@askwho报告了无法向 ChatGPT4 上传任何文件的问题。所提供的消息中未讨论此问题的解决方案。 -
桌面版 GPT-3.5 侧边栏访问问题:
@d_smoov77在访问桌面版 GPT-3.5 的左侧选项卡时遇到困难。@solbus指引他们查看页面左侧正中间的小箭头。 -
重复模式错误:
@slip1244报告了在多次调用相同的系统消息和函数时出现BadRequestError: 400错误。所提供的消息中未讨论此问题的解决方案。 -
Gemini 测试:
@ttmor报告了测试 Gemini 的情况,虽然遇到了一些 Bug,但总体认为还可以。给出的消息中没有关于此的进一步讨论。
▷ #gpt-4-discussions (33 条消息🔥):
- ChatGPT 订阅问题:
@nicky_83270报告了一个问题,即在支付订阅费用后仍无法访问 ChatGPT 4,@solbus对此提供了故障排除协助。建议的选项包括检查订阅续订是否成功,以及尝试不同的浏览器/设备。 - 关于 OpenAI 服务器限制的讨论:
@.cymer和@satanhashtag讨论了 GPT 在高峰时段变慢的潜在原因,包括服务器限制以及对更多服务器或优化的需求。 - 内容策略与 ChatGPT 性能:
@.cymer提出一个理论,认为 ChatGPT 的策略更新和内容审查(content censors)可能导致其随着时间的推移变得更慢且效率更低。 - Custom GPT 中知识文件的使用:
@jobydorr询问了 Custom GPT 中知识文件(knowledge files)的行为,寻求明确模型是仅在特定提示时搜索文件,还是会在开放式查询中使用文件。@solbus澄清说,知识文件是作为 GPT 的参考文档存在的,而不是永久的上下文数据。它们可以被查询并返回与特定查询相关的数据。 - GPT 模型消失:
@redash999对其 GPT 模型在没有任何通知或邮件的情况下消失表示担忧。@Rock建议加载之前可能与该 GPT 进行过的任何测试对话,这可能会恢复它。
▷ #prompt-engineering (62 条消息🔥🔥):
- 利用 GPT-4 创作详细场景和特定请求:
@eskcanta使用 GPT-4 创作了一个涉及复杂人物关系和争论的详细场景。他们展示了如何通过提供叙述的具体细节和指令来引导模型 Prompt,强调了在模型舒适范围内提供清晰引导以及避免负面提示(negative prompting)的必要性。文中提供了一个 对话示例链接。 - 关于 ChatGPT 输出和污染上下文的担忧:
@stealth2077对输出中可能污染上下文的不必要部分表示担忧。@brokearsebillionaire提到,提供更多上下文会减少可用于输出的 Token,从而导致回复变短,这个问题可以通过使用更大的模型、有针对性的上下文或检索(retrieval)来解决。 - 生成特定脚本风格:
@jeziboi寻求生成特定风格脚本的帮助,并提供了参考示例。@alienpotus建议采用一种结构化方法,重点关注叙事结构、角色发展、上下文以及生成示例中此类脚本所需的其他关键要素。 - 负面指令处理与输出不匹配:
@rendo1建议要求 GPT 严格遵守 Prompt,并提醒 GPT 可能会略微修改 Prompt。@seldomstatic分享了一种利用 GPT-4 根据艺术风格(artstyle)创建定制化输出的方法,这引发了与@errorsource关于 Bing 和 GPT-4 之间输出不一致的讨论。 - 利用 GPT 中的“知识”:
@Rock和@cat.hemlock讨论了如何最好地利用 GPT 中的“知识”(Knowledge)。他们讨论了 2M Token 的限制,以及 GPT 倾向于总结、跳过和推断所带来的挑战。
▷ #api-discussions (62 条消息🔥🔥):
- 使用 GPT-4 生成剧本:
@jeziboi寻求帮助,希望使用 GPT-4 创作具有特定叙事风格的剧本。这些剧本包含清晰的叙事结构、丰满的角色发展、情感深度、详尽的细节描述以及出人意料的结局(如他粘贴的示例)。@alienpotus提出了一种结构化的方法来创作此类剧本。 - 使用 GPT-4 构建角色视角:
@neurophin寻求协助,通过 GPT-4 创建角色的全身视角(full-body perspective)。这得到了关于如何引导 AI 模型更紧密地遵循给定 Prompt 的回复。 - 使用 DALL-E 和 ChatGPT-4 生成艺术风格:
@errorsource、@seldomstatic等人就如何使用 ChatGPT-4 中的 DALL-E 重现某种极简且富有细节的风景生成艺术风格进行了讨论。不同模型之间的结果有所差异。 - 从 ChatGPT 获利与 Token 成本:
@antonioguak想了解如何通过 ChatGPT 赚钱,并对使用 GPT Token 的成本发表了评论。 - 关于 Knowledge 功能的研究:
@Rock分享了他们对 GPT 模型中Knowledge功能使用的研究发现。他们提到 Knowledge 的使用有 200 万 Token 的限制,且 GPT 结果的推理过程可能令人沮丧。@cat.hemlock还补充说,要求 GPT 同时从多个 Knowledge 文件中提取信息是一个挑战,他们尚未找到解决方法。 - 感兴趣的链接:
@eskcanta分享了一个 ChatGPT Prompt 示例链接:链接;@cat.hemlock分享了一个关于 Guidance Teacher 的研究链接:链接
Nous Research AI Discord 总结
- 讨论了各种 AI Models 的潜力和能力。围绕 BAAI 的 Emu2 模型和 UNA Solar 尚未发布的模型进行了深入交流。社区还见证了由
datarevised开发的新 AI 模型 OpenDalle 的发布。 - 关于提高 AI 模型性能的详细对话。提出了在 OpenChat 模型上应用 “Starling” 方法以及合并多个 Mistral LoRAs 等策略。
- 社交媒体联系方式:
@pogpunk询问@764914453731868685是否有 Twitter。@maxwellandrews进行了回复,确认其 Twitter 账号为 madmaxbr5。 - 资源共享与推荐非常普遍,链接涵盖了从 Tri Dao 和 Michael Poli 等研究人员的访谈,到免费 Discord Nitro 等促销活动,以及像 CursorAI 这样的 API 相关资源。
- 出现了几个与 AI 相关的查询,包括寻求支持模糊图像 Prompt 的工具、系统化的 Prompt Engineering,以及提高 NLP 中的延迟效率。此外,还围绕本地运行和 Fine-tuning 语言模型的前景展开了讨论。
@plbjt提出了 “Free the Compute” 的声明,但未透露任何背景信息。
Nous Research AI 频道总结
▷ #ctx-length-research (2 条消息):
- 社交媒体联系方式:
@pogpunk询问@764914453731868685是否有 Twitter。@maxwellandrews确认他们拥有 Twitter 账号, ID 为 madmaxbr5。
▷ #off-topic (3 条消息):
- 图像 Prompt 工具咨询:
@elmsfeuer询问是否存在一种工具,允许图像 Prompt 具有模糊性,从而在不同的光学分辨率下允许不同的解释(例如,在低分辨率下将图像视为一棵树,但在高分辨率下看到的是一名潜水员)。 - Free the Compute:
@plbjt发表了一个简短的声明:”free the compute“。消息历史中未提供该声明的背景和含义。
▷ #interesting-links (55 条消息🔥🔥):
- 面试分享:
@atgctg分享了与研究员 Michael Poli 和 Tri Dao 的访谈链接,指出从 AI 领域的研究人员那里获取第一手见解的价值。 - Emu2 模型讨论:包括
@yorth_night和@coffeebean6887在内的多位成员围绕 BAAI 的 Emu2 多模态模型的性能进行了长时间对话,讨论了其能力、局限性和潜在用途。 - 免费 Discord Nitro 优惠:
@jockeyjoe分享了一个面向 Opera GX 浏览器用户的免费一个月 Discord Nitro 促销链接,尽管这引发了关于其合法性的激烈辩论。 - 订阅 vs API Key:
@.beowulfbr和@night_w0lf讨论了使用像 CursorAI 这样的订阅服务与直接使用 API Key 的优缺点,后者推荐了 DIY 替代方案,例如使用在 GitHub 和 Unsaged 上找到的开源 UI 工具。 - 文档推荐:
@night_w0lf推荐阅读 Emu2 模型的文档,尽管它最初看起来并不吸引人,并提供了关于如何使用它的见解。
▷ #general (128 条消息🔥🔥):
- 对 UNA 性能的期待:用户讨论了对 UNA(”UNA Solar”)性能的期待,其中
n8programs、nonameusr和yorth_night提到了数值预期以及对初步测试结果的反馈。 - 关于使用 LoRAs 进行模型合并的讨论:
ldj和carsonpoole讨论了合并多个 Mistral LoRAs 的想法。ldj建议将每个微调后的 Mistral 模型与基础模型之间的权重差异保存为 “delta”,然后合并这些 delta。他担心carsonpoole在合并前将全量微调转换为 LoRAs 的方法可能会导致信息丢失。 - OpenChat 模型测试和改进建议:
.beowulfbr在尝试使用自己的配置和数据集(其中一个属于tokenbender)改进 OpenChat 模型性能失败后寻求建议。tokenbender建议他在新的 OpenChat 模型上应用 “Starling” 方法,因为该方法之前取得了成功。 - DataRevised 发布 OpenDalle:
datarevised宣布了他的新模型 OpenDalle,这是他通过将自定义的 slerp 方法应用于 SDXL 开发的。他请求反馈并在 HuggingFace 上分享了该模型的两个版本(v1.0 和 v1.1)(OpenDalle 和 OpenDalleV1.1)。 - 对多模态 AI 的期待:
ldj和yorth_night在多模态背景下讨论了 LLMs 的未来。ldj对端到端多模态音频 AI 表示兴奋,认为其重要性可能超过基于图像的多模态 AI。还探讨了基于图像的 AI 辅助设计任务的想法。
▷ #ask-about-llms (9 条消息🔥):
- 系统化 Prompt Engineering:
@flow_love询问是否有人以前做过系统化的 Prompt Engineering,以及是否有相关的基准测试或库。 - 本地运行语言模型:
@leuyann询问在本地运行语言模型是否也意味着能够对它们进行微调。 - 微调和 QLoRA:
@atgctg提到微调是计算密集型的,并介绍了可以在消费级显卡上运行的 QLoRA (Quantum Language of Resonating Actions)。分享了一个关于该话题的相关 Reddit 帖子。 - NLP 中的延迟效率:
@pogpunk询问在构建搜索产品时,是否有更具延迟效率的 NLP 方法。
Mistral Discord 总结
- 集成 Autogen 和更新的聊天模板,由
@cyb3rward0g主导关于实现、可能性和挑战的讨论 (HuggingFace Blog Post)。 - 区分 Mixtral-8x7B-v0.1 和 Mixtral-8x7B-Instruct-v0.1,以及由
@netapy和@cuzitzso澄清的专门用例。 @asgnosi剖析了基准测试和模型性能比较,指出了微调的作用以及 GPT-4 的预期性能。@michaelwechner询问了 Mistral API 中的速率和限制,以及实现最大利用率的潜在解决方案。- 关于 Mistral 中 stopwords 实现的讨论,包括使用 [END] Token 的替代方案。
@dutchellie和@nootums分享了关于模型训练的 GPU 要求和内存需求的多次对话。值得注意的是,有人请求 Mistral 7B v2 Model 的基准测试指标。- 详细讨论了 Mixtral 在不同系统上的性能,特别是 Apple M2 Max 系统,
@sublimatorniq质疑了 Prompt 处理阶段的潜在改进;而@Epoc_(herp/derp) 分享了其 Windows 系统上的具体性能细节。 - Mistral API 的查询在 #finetuning 频道中持续存在,主要由
@expectopatronum6269和@lerela推动。重点主要集中在速率限制、Context Window、超时限制以及 API 参数指导。 - 微调关注点和技术也涌入了
#ref-implem频道;涉及使用 qlora (@mjak) 进行微调,对实现过程和必要组件的困惑 (@duck),以及利用来自 HuggingFace 的选定模型 (@daain)。 #la-plateforme频道专注于解决 API rate limit 问题,@robhaisfield、@d012394和@lerela讨论了 Token 输出计算错误的可能,以及随后 Mistral 员工的调查。#showcase频道展示了由@bam4d开发的 Mistral Playground,尽管没有进一步的细节或上下文。
Mistral 频道总结
▷ #general (35 messages🔥):
- Mistral API 结合 Autogen 和更新的聊天模板:
@cyb3rward0g讨论了使用 Mistral 的特定实现,并链接了 HuggingFace 上的博客文章,同时考虑更新聊天模板以包含 “SYSTEM” 角色。Cyb3rward0g 还就这种更新的聊天模板对于在创建过程中需要 “SYSTEM” Prompt 的 Agent 是否可行寻求建议。 - Mixtral-8x7B-v0.1 和 Mixtral-8x7B-Instruct-v0.1 的区别:针对
@hasanurrahevy的提问,@netapy和@cuzitzso澄清了区别。Instruction-tuned 模型被描述为针对分析给定指令并制定适当回答而进行的微调。 - 基准测试和模型比较:
@asgnosi分享了对不同模型在各种测试(难题和奇才问题)中表现的观察。进一步的讨论强调了微调的作用和 GPT-4 的性能。 - Mistral API 的速率和限制:
@michaelwechner引用了 Mistral API 文档,其中提到每分钟 2M Token 的速率限制,并承认可以通过并行化请求来充分利用这一速率限制。其他用户肯定了这一解决方案。 - Mistral 中的 Stopword 实现:
@tomaspsenicka提出了关于在 Mistral 中使用 stopwords 的查询,并讨论了在每条消息后使用 [END] Token 作为替代方法。 - 获取 API Key:
@harvey_77132询问了获取 API Key 的流程以及如何联系客户成功团队。@brokearsebillionaire提供了通常可以找到 Key 的 Mistral 控制台链接。 - Autogen 错误:
@aha20395报告了使用 Autogen 时的错误。@brokearsebillionaire对此事提供了一些见解,并建议利用 LiteLLM 转换器进行 Mistral API 调用,并链接了相关文档。 - Mixtral Instruct 的性能:最后,
@ldj报告称,根据 LMSys Arena 评定的用户偏好,Mixtral Instruct 的表现优于包括 Claude 2.1、Gemini Pro 和所有版本的 GPT-3.5-turbo 在内的其他模型。
▷ #models (2 条消息):
- 模型训练的 GPU 需求:
@dutchellie建议 24GB 的 VRAM 可能不足以进行模型训练,并建议考虑二手 Nvidia P40,因为它们具有性价比且拥有 24GB VRAM。 - Mistral 7B v2 模型的基准测试指标请求:
@nootums询问是否有基准测试指标来对比 Mistral 7B instruct 模型 v1 和 v2 的性能,因为他们正考虑将自托管的 v1 模型升级到 v2。
▷ #deployment (5 条消息):
- Mixtral 在不同系统上的性能:
@sublimatorniq分享了 Mixtral 在不同系统上的性能细节,并评论说系统在 Prompt 处理阶段似乎反应迟钝,尤其是在他们的 Apple M2 Max 系统上。他们提到:“我获得的 eval rate 确实足够快。只是希望前者(prompt eval rate)能够得到改进!”。 - Mistral 性能指标:
@Epoc_(herp/derp) 透露:“在我的系统上(Windows, LM Studio),Mixtral 8x7B Q8_0 使用 47.5GB VRAM 和 50.5GB RAM,运行速度约为 17t/s。配置为 13900k, 64GB DDR4, A6000 48GB”。 - Jetson Orin 64B 上的 Mixtral 性能查询:
@romillyc询问是否有人在 Jetson Orin 64B 上使用 Mixtral 8x7B Q4_K_M 或 Q6-K,并提到虽然 “llama.cpp 在较小的 Jetson 设备上运行良好”,但他们的 Jetson Xavier 的 16GB 内存似乎是一个限制因素。 @derpsteb似乎开始了一个问题或讨论,但在提供的对话中尚未完成。
▷ #ref-implem (4 条消息):
- 使用叙事数据微调 Mistral:
@mjak提到他们正尝试使用 QLoRA 和叙事数据来微调 Mistral。他们补充说,不确定是否所有数据都应格式化为 QA-pairs(问答对)。 - 参考实现与部署步骤:
@duck询问参考实现是否依赖于仓库 README 中提到的部署步骤。他们对 Python 脚本是否与容器服务交互表示困惑,并寻求在不使用 LM Studio 和 Ollama 等工具的情况下运行的方法。 - 从 HuggingFace 挑选模型:
@daain分享说,他们一直在从 HuggingFace 挑选相关的模型,如 Dolphin 2.1、Open Hermes 2.5、Neural Chat 等,而不是自己进行微调。
▷ #finetuning (4 条消息):
- 最大 API 超时查询:用户
@expectopatronum6269分享了他们的计划,准备将其由 Mistral API 驱动的新应用扩展到 1 小时内处理 10,000 个请求。他们请求了解更多关于使用 Mistral medium 时的最大 API 超时、最大 Context Window(上下文窗口)以及请求速率限制(Rate Limit)的细节。 - Mistral API 参数指导:
@lerela回答了该查询,说明了文档中概述的 Context Window(32k)和速率限制(2M tokens/minute)。提到超时设置是很全面的。由于缺乏专门的 API,还敦促用户设置max_tokens并利用响应头(Response Headers)来跟踪 Token 使用情况。 - 关于 System Prompt 和 Chat Template 的咨询:
@caseus_征求关于在 Chat Template 中实现 System Prompt 的建议,并提供了一个特定 Tokenizer 配置的 链接 作为参考。 - 关于函数调用微调的问题:
@krissayrose询问是否有人进行过针对 Function Calling(函数调用)的微调。
▷ #showcase (1 条消息):
bam4d: Mistral Playground
▷ #la-plateforme (14 条消息🔥):
- API Rate Limit 问题:包括
@robhaisfield和@d012394在内的多位用户遇到了速率限制错误,尽管根据他们的仪表板显示,其 Token 使用量并未接近每分钟 200 万个 Token 的限制。@robhaisfield推测问题可能出在速率限制器计算 Token 输出的方式上(展示该问题的视频)。 - Mistral 员工的调查:
@lerela请求受影响的用户私信(DM)他们的 Profile ID 以便进一步调查,随后宣布他们已经推送了更改以提高 API 的可靠性。 - Litellm 对 la-platforme 的支持:
@brokearsebillionaire询问了 Litellm 对 la-platforme 的支持情况,@ved_ikke通过分享 Litellm 关于 Mistral AI API 的文档 予以确认。@brokearsebillionaire随后确认已成功运行。
OpenAccess AI Collective (axolotl) Discord 总结
- 各频道针对 fine-tuning models(模型微调) 展开了积极讨论,涵盖了较短上下文长度下的模型性能(由
@noobmaster29提出)以及个人聊天数据的处理流程(由@enima提出)。此外,@yamashi分享了他们在特定数据上训练 Mixtral Moe 的计划。 - Huggingface/transformers PR 是一个讨论重点,涉及其对代码调整的潜在影响、有效使用 Flash Attention 2 的必要性,以及 PEFT 中对 LoftQ 的支持。文中分享了 Pull Request 和 LoftQ arXiv 论文 的直接链接。
@nanobitz介绍了一个新的多模态模型,并链接到了相关源码。此外,还讨论了与 Half-Quadratic Quantization (HQQ) 相关的资源,但缺乏实质性的用户反馈。- 提出了一系列关于不同方法和工具的技术问题,包括 LLama.cpp 内部机制的使用、土耳其语文本的分词(Tokenizing)、LLM 推理的处理以及使用 axolotl 进行 训练的滑动窗口(Sliding Windows)。
- 针对 Axolotl 的功能改进和未来项目提出了多项建议。值得注意的是,用户讨论了引入 Prompt Gisting 以及在微调后向 Tokenizer 添加聊天模板(Chat Templates)。还提到了正在进行的实验,如冻结
*.gate.weight,预计很快会分享结果。
OpenAccess AI Collective (axolotl) 频道总结
▷ #general (24 条消息🔥):
- 使用较短上下文长度微调模型:用户
@noobmaster29提出了关于在比基座模型更短的上下文长度下微调模型的影响。@nanobitz推测模型在全长下仍能工作,但性能可能不佳。 - 最大模型序列长度:
@noobmaster29进一步询问了在4096而不是其最大长度8192下调整Mistral的问题,@nanobitz安慰说这完全没问题。 - 新的多模态模型资源:
@nanobitz分享了一个由北京人工智能研究院(BAAI)、清华大学和北京大学开发的新多模态模型链接。 - 在特定数据上训练 Mixtral Moe:
@yamashi提到计划在 1 月份根据他们的数据训练Mixtral Moe,希望在medqa上达到 85% 的准确率,通过在 Prompt 中嵌入答案可能达到 90%。 - Half-Quadratic Quantization (HQQ) 资源:
@dangfutures询问是否有人使用过 Half-Quadratic Quantization (HQQ) 的官方实现,但未收到反馈。 - Axolotl 中的 Prompt Gisting:用户
@lightningralf提出了在Axolotl中加入 Prompt Gisting 的观点,@caseus_回复说虽然可能有用,但由于 Token Gisting 的 Attention Masking 运作方式,训练可能会很慢。 - 微调后向 Tokenizer 添加聊天模板:
@touristc询问axolotl是否能在微调后向 Tokenizer 添加聊天模板,@caseus_认为这是一个非常有益的功能。
▷ #axolotl-dev (13 条消息🔥):
-
huggingface/transformers PR 的影响:用户
@nanobitz提醒用户注意 huggingface/transformers GitHub 上的一个新 pull request。该 PR 修复了 FA2 的集成问题,@nanobitz指出他们的代码可能需要进行相应调整。@caseus_承认了这一变化可能产生的影响,并计划着手解决。 -
Flash Attention 2 的使用:在上述 PR 的背景下,
@nanobitz提供了关于如何使用 Flash Attention 2 的建议,主要建议在使用 Flash Attention 2 时不要将torch_dtype传递给from_pretrained类方法,并确保使用 Automatic Mixed-Precision 训练。 -
在 PEFT 中增加对 LoftQ 的支持:用户
@nruaif提到了对 LoftQ 的支持,这是一种可以改进 Large Language Models (LLMs) 微调的量化方法。@nruaif表示 PEFT 自 0.7 版本起已支持 LoftQ,并提供了相应的 arXiv 论文链接。 -
LoftQ 与 LoRA 的结合使用:
@caseus_暗示了 LoftQ 与 LoRA 的结合使用非常直接,并提供了一个示例代码片段。 -
正在进行的实验:
@theobjectivedad询问@faldore关于冻结*.gate.weight后是否有任何重大发现。@faldore表示现在分享结果还为时过早,但承诺在第二天提供结果。
▷ #general-help (22 条消息🔥):
- 模型微调:用户
@enima正在考虑使用个人聊天数据微调模型,类似于 Minotaur/Mistral-Dolphin 项目中使用的方法。他们意识到需要在一个小样本规模上重新构建其数据集。 - llama.cpp 内部机制帮助:
@_awill正在寻求熟悉 llama.cpp 内部机制的人员进行讨论。 - 土耳其语文本分词:用户
@emperor在使用 HF Tokenizers 训练土耳其语文本分词器时遇到了问题。尽管使用的是没有中文文本的土耳其语数据集,但生成的词表(vocabulary)中却含有大量的汉字。在从另一个数据集中激进地过滤掉所有汉字和表情符号后,该问题显著减少。用户仍然质疑为什么不到 1% 的非土耳其语字符会对分词器产生如此大的影响。 - LLM 推理处理:
@JK$询问了 LLM 推理的处理方式。根据@nruaif的说法,并行处理(加快速度但需要更多 VRAM)和队列方式都可以使用,尽管后者会有更大的延迟(latency)。 - 训练中的滑动窗口:
@marijnfs询问 axolotl 是否支持训练中的滑动窗口(sliding windows),@le_mess回复称 Mistral 支持。在被问及为什么该功能不是所有 LLM 的标准配置时,@le_mess提到只有 Mistral 是用它训练的。该选项默认启用,且可能没有禁用的选项。
Latent Space Discord 总结
- 关于 Probabilistic Programming 的深入讨论,涉及管理模糊输出(fuzzy outputs)以及 Lambda Learning Machines (LLMs) 与 DBs 的并行演进。值得注意的引用包括:“…概率编程的挑战…”,“…LLM 应该被设计在需要概率输出的领域…”。
- 关于 AI 演进的深入对话,强调了微调 GPT-4 以创建 OpenAI Functions 的关键作用,以及预言了上下文管理模式(context management patterns)在未来 AI 开发中的重要性。
- 关于 LLM 潜在功能的详尽讨论,包括根据特定 Schema 生成和验证 JSON,以及相比于语法受限采样(grammar constrained sampling)方法,更倾向于有效 Token 采样。
@slono提供了关于 Grammar Constrained Sampling 的 Perplexity.ai 引用,供进一步学习。- 分享了多个与 AI 发展相关的资源,包括 LangChainAI “State of AI” 报告、GPT engineer 的托管服务公告,以及 《时代》杂志对 2023 年重大 AI 创新的回顾。
- 发布了 NeurIPS 回顾章节的预览,并征求反馈,内容详见此处。
Latent Space 频道总结
▷ #ai-general-chat (29 条消息🔥):
- 概率编程讨论:
@swizec发起了关于概率编程挑战以及对具有 fuzzy outputs(模糊输出)的程序进行推理的讨论,并对误差条(error bars)快速堆叠导致系统混沌表示担忧。@slono回应称,与不可预测的分布式系统所需的高可靠性不同,LLMs 应该被设计在概率输出和受限概率表现良好的领域。@optimus9973将 LLMs 的发展与 DBs 进行了比较,提到期待类似的成熟过程。 - AI 演进对话:
@optimus9973强调了微调 GPT-4 以创建 OpenAI Functions 的重要性,将其定义为 2023 年被低估的一大进步,在概念工具链中几乎与 RAG 并驾齐驱。@slono预测了 context management patterns(上下文管理模式)在未来发展中的重要性。 - Json Schema 讨论:
@optimus9973提议了一种未来的 LLM 功能,即在请求具有特定 Schema 的 JSON 时,LLM 会反复尝试生成,直到符合验证并可供用户使用。@slono提到 grammar constrained sampling(语法受限采样)是更优的方法,因为它只允许采样有效的 Token。 - 语法受限采样参考:应
@swizec关于 grammar constrained sampling 进一步阅读的要求,@slono提供了 Perplexity.ai 的链接。 - AI 动态分享:
@swyxio分享了多个链接,包括 LangChainAI “State of AI” 报告,GPT engineer 托管服务发布公告,以及 《时代》杂志对 2023 年主要 AI 创新的回顾。
▷ #ai-event-announcements (1 条消息):
- NeurIPS 回顾集预览:
@swyxio提供了他们第一集 NeurIPS 回顾节目的预览,并正在征求反馈。预览可以通过 这里 访问。
LangChain AI Discord 总结
- 关于在 Vector stores 中使用 from_documents 类进行 batch upsert 的深入讨论。用户
@kingkkaktus寻求实现指导。 - 集中讨论了 backend image management(后端图像管理),特别是管理 Web 应用后端用户上传图像缓存的方法。
@tameflame探索了包括随机服务器文件夹、Redis 等内存缓存以及其他可能的方案。 - 用户
@vivek_13452在使用FAISS.from_documents()方法时遇到了 Vectorstore error,并寻求排查见解。 @shrinitg提到了 ChatVertexAI 模型中的 streaming limitation(流式传输限制)实例。该用户强调了这一点并在 Pull Request 中提出了解决方案。- 征求关于能够对大型数据集进行计算的 chatbot 架构建议。
@shivam51给出的具体例子是计算庞大产品目录中棉质衬衫的实例。 @rodralez展示了 ConversationBufferMemory 的显著用法,展示了输出定义在促进特定 Playground 显示方面的能力。@cosmicserendipity展示了关于 Web AI 应用的 server-side running and testing(服务端运行与测试)的精彩工作,提供了一个 GitHub 解决方案,用于在标准化设置中比较和测试新旧模型。GitHub 链接。@shving90发布了一个 ProductHunt 页面链接 AI4Fire。但消息中未提供详细说明或上下文,难以判断其重要性。@emrgnt_cmplxty发布了 AgentSearch,这是一个雄心勃勃的 Open-core 项目,旨在通过嵌入 Wikipedia、Arxiv、过滤后的 Common Crawl 等资源,为 LLM Agent 提供人类知识的主要部分。鼓励用户在 AgentSearch 尝试该搜索引擎,并在该 Twitter 帖子中查看更多细节。
LangChain AI 频道总结
▷ #general (19 messages🔥):
- 使用 from_documents 类进行批量更新 (Batch upsert):用户
@kingkkaktus询问如何在 vector stores 中使用from_documents类进行批量更新。 - 后端图像管理:
@tameflame正在寻找在 Web 应用后端管理用户上传图像缓存的最佳方式,并询问使用随机服务器文件夹、Redis 等内存缓存或其他方法哪种效率最高。 - Vectorstore 错误:
@vivek_13452在尝试使用FAISS.from_documents()方法并传入texts和embeddings参数时遇到错误。他们请求帮助理解为什么会收到ValueError: not enough values to unpack (expected 2, got 1)。 - ChatVertexAI 模型中的流式传输限制实例:
@shrinitg报告称 ChatVertexAI 模型目前不支持流式传输 (streaming),并分享了一个尝试修复该问题的 Pull Request 链接。 - 用于大数据查询的聊天机器人:
@shivam51寻求关于构建聊天机器人架构的建议,该机器人能够基于大型数据集进行计算,例如确定大型产品目录中有多少件衬衫是棉制的。
▷ #langserve (1 messages):
- 在输出定义中使用 ConversationBufferMemory:用户
@rodralez指出,通过如下所示修改chain.py,可以在输出定义中使用ConversationBufferMemory,从而仅在 Playground 上显示输出。chain = agent().with_types(input_type=AgentInput) | (lambda x: x["output"])
▷ #share-your-work (3 messages):
- 服务端 Web AI 测试:用户
@cosmicserendipity分享了关于利用 NVIDIA T4 GPU 以无头模式运行和测试 Web AI 应用(如 TensorFlow.js、Onnx Runtime Web)的更新。该方案涉及通过 headless Chrome 在真实的 Chrome 浏览器中运行应用。这有助于在标准化的服务器环境中测试和对比新旧 Web AI 模型。用户在此分享了 GitHub 链接。 - AI4Fire:用户
@shving90分享了一个 ProductHunt 页面链接:AI4Fire。但消息中未提供更多上下文或讨论。 - AgentSearch - 为 LLM Agent 提供知识获取能力:用户
@emrgnt_cmplxty介绍了 AgentSearch,这是一个旨在让人类知识可供 LLM Agent 获取的开源核心项目。用户已经嵌入了整个 Wikipedia、Arxiv、过滤后的 Common Crawl 等内容,总计超过 10 亿个嵌入向量 (embedding vectors)。可以在此处尝试搜索。更多详情见此 Twitter 帖子。
Alignment Lab AI Discord 摘要
@entropi宣布了 Text-to-CAD 的 Alpha 发布,这是一项允许将文本转换为 CAD 模型的新技术,而非更常见的 Text-to-3D 模型。该消息分享于上述 URL。@entropi介绍了 OpenPipe,一个“为开发者提供的全托管微调 (fine-tuning) 平台”。据报道,该平台已为用户节省了超过 200 万美元,自发布以来一直推荐 Mistral 7B 作为其推荐模型。更多细节可从 OpenPipe 获取。@entropi还透露 OpenPipe 是基于 Open Hermes 2.5 和基于 Intel SlimOrca 的 Neural-Chat-v3-3 技术的结合。- 用户
@emrgnt_cmplxty分享了他们的项目 AgentSearch 的发布,这是一个为 LLM Agent 策划人类知识的开源核心项目,包含来自互联网各处的数据库。正如这条推文所述,search.sciphi.ai 显然提供了总计超过 10 亿个嵌入向量。 @neverendingtoast提出了一个关于 AgentSearch 项目中向量搜索数据如何分段的问题,但摘要中未包含回复。@imonenext询问公会中是否有人认识来自 Megatron 或 Pytorch 的人。@neverendingtoast寻求关于实验模型合并 (model merges) 的优质仓库建议。
Alignment Lab AI 频道摘要
▷ #ai-and-ml-discussion (3 messages):
- Text-to-CAD 介绍:用户
@entropi分享了 Text-to-CAD 的 Alpha 发布,这是一项能够将文本转换为 CAD 模型的技术创新,区别于主要用于游戏资产的传统文本转 3D 模型。 - 微调平台 - OpenPipe:
@entropi介绍了 OpenPipe,这是一个面向开发者的全托管微调平台,已为用户节省了超过 200 万美元。自 9 月发布以来,Mistral 7B 一直是推荐模型。 - Open Hermes 2.5 与基于 Intel SlimOrca 的 Neural-Chat-v3-3 合并:
@entropi评论称该平台构建于 Open Hermes 2.5 与基于 Intel SlimOrca 的 Neural-Chat-v3-3 的合并版本之上。
▷ #general-chat (2 messages):
- AgentSearch 项目发布:用户
@emrgnt_cmplxty分享了他们一直在开发的项目 AgentSearch,这是一个旨在为 LLM Agent 嵌入人类知识的核心开源项目,涵盖了全部 Wikipedia、Arxiv、经过过滤的 Common Crawl 等。该项目产生了超过 10 亿个 embedding vectors,可在 search.sciphi.ai 获取 —— 引用自其 推文。 - 关于数据分段的询问:用户
@neverendingtoast询问了 AgentSearch 项目中用于向量搜索的数据是如何进行分段的。
▷ #oo (2 messages):
@imonenext询问是否有人认识 Megatron 或 Pytorch 团队的人。@neverendingtoast寻求进行 model merges 的优秀仓库推荐,并表示有兴趣进行相关实验。
Skunkworks AI Discord Summary
- 指令格式的反馈与代码:用户
@far_el分享了对建设性反馈的感谢,并提到在 #general 中出现了大量使用 instruct format 的代码。 - 成功的模型应用:用户
@far_el在 #general 中表示,他们的 AI 模型有效地满足了用户的专门应用需求,对此感到满意。 - 用户
lightningralf在 #finetune-experts 中询问是否有人在组内尝试过 ‘prompt gisting’。
Skunkworks AI 频道摘要
▷ #general (3 messages):
- 指令格式的反馈与代码:
@far_el对收到的反馈表示感谢,并指出存在大量使用 instruct format 的代码。 - 成功的模型应用:
@far_el对其 AI 模型在用户特定用例中的有效运行表示高兴。
▷ #finetune-experts (1 messages):
lightningralf: 这个组里有人尝试过 prompt gisting 吗?
LLM Perf Enthusiasts AI Discord Summary
- 关于 检索策略探索 的讨论,
@daymanfan分享了尽管面临类似问题但响应质量有所提高的经验。 - 关于 跨模型 Prompt 功能 的对话,
@dongdong0755询问了相同 Prompt 在不同模型中结果的一致性,并好奇是否存在潜在差异。
LLM Perf Enthusiasts AI 频道摘要
▷ #openai (1 messages):
- 检索策略探索:
@daymanfan询问是否有人在探索自己的检索策略,并表示他们遇到了类似的问题,但其 响应质量 优于其他选项。
▷ #prompting (1 messages):
- 跨模型 Prompt 功能:用户
@dongdong0755提出了关于 相同 Prompt 在 不同模型 间性能一致性的查询。该用户想知道 Prompt 结果的差异是否明显。
DiscoResearch Discord Summary
-
关于 模型差异 的对话,特别关注潜在原因。
@calytrix建议 router layers 的变化可能是一个因素,并建议采用针对 router layers 使用不同参数的两步微调过程。 -
@datarevised请求对其 OpenDalle model 提供反馈,该模型包含一种应用于 SDXL 的自定义 Slerp 方法。该用户对正面和负面评论均持开放态度。
DiscoResearch 频道摘要
▷ #mixtral_implementation (1 条消息):
- 模型差异的可能原因:
@calytrix认为最近模型中观察到的差异可能是由于早期版本中不存在的因素导致的,其中 router layers 被认为是可能的原因。他们建议采用两阶段 fine-tuning 过程,在第二阶段使用不同的参数对 router layers 进行 fine-tuning。
▷ #general (1 条消息):
- OpenDalle 模型反馈请求:
@datarevised请求对其使用应用于 SDXL 的自定义 slerp 方法创建的 OpenDalle model 提供反馈。该用户欢迎正面和负面的评价。
MLOps @Chipro Discord 摘要
只有一个频道有活动,因此无需汇总…
- True ML Talks 剧集 - 在 Twilio 部署 ML 和 GenAI 模型:用户
@Nikunjb讨论了与 Twilio 资深数据科学家 Pruthvi 合作的一集 True ML Talks。主题包括 X-GPT concept、Twilio 增强 Rack flow 的努力,以及 Twilio 正在开发的 GenAI 之外 的不同模型。 - 讨论还涉及了用于 vector database 的各种 embeddings 的复杂性,以及 Twilio 如何管理 Open AI rate limits。
- 该剧集因其对 Twilio 生态系统内 Machine Learning 及其基础设施各方面的深入见解而受到称赞。
- 剧集链接:YouTube - Deploying ML and GenAI models at Twilio
AI Engineer Foundation Discord 摘要
只有一个频道有活动,因此无需汇总…
- ML 与 AI 的介绍与兴趣:用户
@paradoxical_traveller09介绍了自己,并表达了希望与对 Machine Learning (ML) 和 Artificial Intelligence (AI) 感兴趣的其他用户建立联系。他们乐于讨论以 ML 为核心的话题。
YAIG (a16z Infra) Discord 没有新消息。如果该公会长时间没有活动,请告知我们,我们将将其移除。