ainews-12252023-nous-hermes-2-yi-34b-for-christmas
2023年12月25日:圣诞节发布的 Nous Hermes 2 Yi 34B
Teknium 基于 Yi 34B 发布了 Nous Hermes 2,将其定位为可与 Mixtral、DeepSeek 和 Qwen 媲美的顶尖开源模型。苹果 (Apple) 推出了 Ferret,这是一款新型开源多模态大语言模型 (LLM)。
Nous Research AI Discord 社区的讨论重点集中在 AI 模型优化和量化技术(如 AWQ、GPTQ 和 AutoAWQ),并分享了关于专有优化和吞吐量指标的见解。其他亮点还包括:NucleusX 模型已添加到 transformers 库中;一款 MMLU 分数达到 80 的 30B 模型;以及由中科闻歌 (Wenge Technology) 开发、基于 2.65 万亿 token 训练的 雅意 2 (YAYI 2) 语言模型。
此外,讨论中指出“在 Batch size 高达 8 的情况下,AutoAWQ 的性能优于 vLLM”,并探讨了通过跨 GPU 的专有并行解码和张量并行化(tensor parallelization)来提升速度。
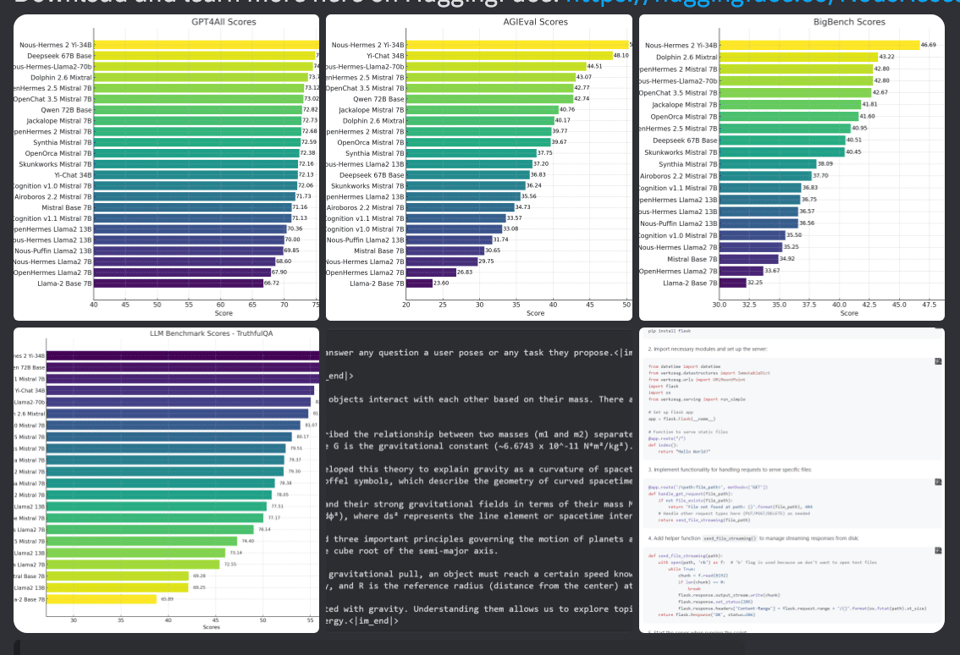
今天 Teknium 在 Yi 上发布了 Nous Hermes 2,使其成为与 Mixtral、DeepSeek、Qwen 等相比顶尖的开源模型:
Apple 还推出了 Ferret,一个多模态 LLM。
此外,这是年度迷因回顾。
https://www.youtube.com/watch?v=m3kA3eJpnqo
[TOC]
Nous Research AI Discord 摘要
- 深入讨论了 AI 模型优化的技术层面,特别是针对 AWQ、GPTQ 和 AutoAWQ 等量化方法。对话围绕公开量化技术的效率低下、专有优化方法以及模型吞吐量指标展开。参与对话的用户包括 #off-topic 频道中的
@teknium、@carsonpoole和@casper_ai。 - 在 #interesting-links 频道分享了多个 有价值的链接:NucleusX 模型加入
transformers,Huggingface 上的研究论文,一个 MMLU 达到 80 的 30B 模型,以及文格科技(Wenge Technology)的 YAYI 2 语言模型。 - 宣布发布 Nous Hermes 2,这是一个超越以往 Hermes 模型的高级模型,基于 Yi 34B 训练,可从 HuggingFace 下载,由
@teknium在 #announcements 频道分享。 - 在 #general 频道进行了多方面的讨论:涵盖 ML 模型、text-to-speech 和 text-to-music 数据集、AI 对电影行业的影响、Nous Hermes 2 的发布及其量化过程。
- #ask-about-llms 频道的对话涉及推理服务器的托管服务推荐,以及在 Mac 上运行 Hermes 模型的方法。
- 在 #project-obsidian 频道中,讨论了寻找特定模型的推理代码示例以及更新相应 model card 的需求。
Nous Research AI 频道摘要
▷ #off-topic (45 条消息🔥):
- 量化的优势与局限:
@teknium、@carsonpoole和@casper_ai就 AI 模型优化中量化方法的效果和效率进行了长时间的技术讨论。@teknium认为,AWQ 和 GPTQ 等公开量化技术效率不高,无法与某些机构内部使用的未公开技术相比。 - 吞吐量指标:讨论还深入探讨了不同 Batch Size 下的模型吞吐量指标,并进一步探索了 Batching 与顺序生成 之间的权衡。
- 专有优化方法:
@teknium建议某些机构可能正在使用能显著提高速度的专有并行解码方法。@carsonpoole认为,这些机构更有可能使用 跨多 GPU 的张量并行(tensor parallelization)来加速。 - AutoAWQ 性能:
@casper_ai发表了看法,称在他们的基准测试中,当 Batch Size 达到 8 时,AutoAWQ 的表现优于 vLLM。然而,在并发生成足够多的情况下,FP16 最终会提供更高的吞吐量。 - 求职咨询:用户
@pradeep1148在一条简短的消息中表达了为 Nous Research 工作的兴趣。
▷ #interesting-links (4 条消息):
- NucleusX 模型加入 Transformers:用户
@osanseviero指出 NucleusX 模型正被添加到transformers。 - 研究论文引用:用户
@metaldragon01分享了 Huggingface 上的一篇 研究论文链接。 - MMLU 达到 80 的 30B 模型:用户
@metaldragon01提到了一个 MMLU 达到 80 的 30B 模型,但未说明更多细节。 - YAYI 2 语言模型:用户
@metaldragon01分享了由文格科技(Wenge Technology)开发的 YAYI 2 语言模型链接。该模型使用 2.65 万亿 Token 的高质量多语言语料库进行预训练。
▷ #announcements (2 messages):
- Nous Hermes 2 发布公告:用户
@teknium正式宣布发布 Nous Hermes 2。该模型基于 Open Hermes 2.5 数据集构建,在 Benchmark 分数上超越了之前所有的 Open Hermes 和 Nous Hermes 模型。该模型是在 Yi 34B 之上训练的,可以从 HuggingFace 此处下载。
▷ #general (214 messages🔥🔥):
- 不同 ML 模型的讨论:
@gabriel_syme .beowulfbr在讨论一篇研究论文时,询问了如何识别 ML 模型中应该减少的权重。在另一个话题中,@Otto von Bismarck和@alpindale讨论了 AI 模型 goliath 的性能以及可能的测试模型。随后@.beowulfbr分享了他对 Reddit 毒性环境的个人经历,并透露了他的 AI 模型 codeninja 在该平台上遭受的批评。 - 文本转语音与文本转音乐数据集:
@qwerty_qwer宣布他拥有用于 Text-to-Speech 和 Text-to-Music 模型的海量数据集,对此@nruaif建议使用基于 Diffusion 的 text2sound 模型,并提供了一个高效 Text-to-Speech 模型 VITS2 的 GitHub 仓库链接。 - AI 与电影行业讨论:
@mihai4256分享了一篇 Twitter 帖子,讨论了 AI 在推动电影行业民主化方面的潜力。随后他还询问了 Fast.ai 创始人 Jeremy Howard 的职业动向,后者最近启动了一个新项目 Answer.ai。 - Nous Hermes AI 模型:
@teknium兴奋地宣布了新 Nous Hermes 2 AI 模型的发布,并分享了模型聊天链接作为送给社区的圣诞礼物。这引发了平台上其他用户的多次赞赏和兴奋的询问。 - 关于模型量化与性能的讨论:
@teknium和@n8programs详细讨论了如何对新模型进行 Quantization(量化),包括硬件需求和其他相关方面。他们讨论了各种 Benchmark,随后@n8programs成功完成了量化,并在 GitHub 上分享了量化后的模型。
▷ #ask-about-llms (5 messages):
- 推理服务器的托管服务:用户
@kenakafrosty征求关于推理服务器托管服务的建议,表示倾向于支持 Serverless 且仅按计算付费、同时不会产生过长启动时间的解决方案。 - 在 Mac 上运行 Hermes 模型:用户
@ac_sd询问 Hermes 模型是否可以直接在 Mac 上运行,并要求澄清一种特定的文件格式。用户@n8programs回复确认 Hermes 模型确实可以在 Mac 上运行。
▷ #project-obsidian (5 messages):
- 模型的推理代码:用户
@vic49.表示很难在网上找到特定模型的推理代码示例,并指出 Model Card 上缺少此类信息。@qnguyen3对此作出了回应,保证他们会在当天晚些时候更新 Model Card 并提供所需信息。
LM Studio Discord 总结
-
新 AI 模型的发布与讨论:介绍了 Apple 的 Ferret,这是一个开源的多模态 LLM,因其独特的图像查询功能而受到讨论;同时介绍了 Dolphin 2.6 Phi-2,这是另一个专注于编程的新模型,并讨论了其指令遵循能力和依赖关系。提供了进一步交流的信息和链接。
-
AI 与技术讨论:关于加载大型模型的激烈讨论引出了修改层数(layer numbers)的建议;还讨论了聊天历史维护、AI 生成文本的变更以及实时代码自动补全。简要讨论了 Windows 用户名中特殊字符的问题并提供了解决方案。
- 在相关背景下,通过发布的性能表讨论并比较了 AMD Radeon RX 6800 XT 的性能;发现在多 GPU 设置中 3060 ti 优于 2080 Super 的优势;分享了为运行更大模型而升级到 64GB RAM 的经验;并通过分享的指南讨论了 Mixtral 模型 的优化配置。提出了通过 PCI risers 安装多个 GPU 的想法,并承认了潜在的问题。
-
LM Studio 在商业领域与应用开发:宣布了来自
@thelefthandofurza的 LM Studio Android 应用项目;@docorange88询问并探讨了 LM Studio 的商业用途及测试流程。 -
扩展发布:宣布了支持多种 AI 技术的 AI navigator extension 预发布版本。
-
社区互动:用户之间交换了圣诞和节日问候;解决了一个关于模型加载错误的问题,并探讨了用于长对话的实验性构建版本及其局限性。还处理了一个通过重新安装进行系统故障排除的具体案例。
-
最后,进行了关于模型配置和即将推出的更新的杂项讨论。包括用于加载模型的 GPU 使用情况、OpenChat 预设的捆绑,以及 Linux 平台上 Mixtral 模型 持续存在的错误。
LM Studio 频道总结
▷ #🎄🎅-general (17 条消息🔥):
- Apple 的新开源 ML 模型:用户
@pierrunoyt分享了关于 Ferret 的链接,这是 Apple 和康奈尔大学的研究人员在 10 月发布的一个新型开源多模态 LLM。该模型可以使用图像区域进行查询。 - 节日问候:用户
@heyitsyorkie、@authentictimers、@thelefthandofurza、@izukumidoriya2211等人交换了圣诞和节日问候。 - LM Studio Android 应用项目:
@thelefthandofurza宣布他们正在开发一个配合推理服务器使用的 LM Studio Android 应用,该应用大部分由 ChatGPT 开发。并表示计划在 GitHub 上分享代码,开放给社区共同改进。 - LM Studio 的商业用途:
@docorange88询问了关于出于商业目的测试和使用 LM Studio 的事宜,并倾向于通过私信进行沟通。 - AI 音乐生成讨论:
@american_pride发起了关于 AI 音乐生成模型的对话,特别提到了 Suno。@musenik参与了讨论,并表示更倾向于 LM Studio,因为 Suno 需要在线生成和创建账户。关于是否有可以在 LM Studio 上运行的音乐生成模型的问题目前仍无定论。
▷ #🤝-help-each-other (36 条消息🔥):
-
加载大模型:
@bearmcx98在一台拥有 8GB VRAM 和 32GB RAM 的机器上尝试加载一个 40 层的模型时遇到了问题。@fabguy建议将层数减少到 10 层,因为当前的配置对于该机器来说可能负担过重,特别是对于 Q3 或 Q4 以上的模型。 -
与 AI 的消息历史记录:
@oaaliyev询问关于使用 Python 或其他语言通过 API 与 AI 聊天、保存消息历史记录以及在重新加载脚本后保持聊天历史的问题。@fabguy解释说,这需要通过将历史记录存储在文件中来手动编程实现,因为目前服务端尚不支持此功能。 -
修改 AI 生成的文本:
@fabguy解释了一种修改 AI 生成文本的方法,建议用户可以直接修改 AI 使用的词汇,而不是试图说服或反驳 AI。这将使 AI 将该修改视为其自己的想法。 -
实时代码补全:
@funapple询问是否有办法在 LMS 中使用活动模型进行实时代码补全。@heyitsyorkie建议探索 VS Code 中的 continue 扩展,它通过本地模型实现类似的功能。 -
Windows 用户名中特殊字符带来的挑战:
@proutes遇到了一个可能与 Windows 用户名中包含特殊字符(é)有关的问题。@yagilb确认这是由于非法字符引起的,并建议通过点击左上角“Chats”旁边的齿轮图标来更改路径。
▷ #🤖-models-discussion-chat (1 条消息):
- 关于 Dolphin 2.6 Phi-2 的讨论:用户
@clickclack777介绍了 Dolphin 2.6 Phi-2,这是一个全新的、无审查的、专注于编程的聊天模型 链接。 - 该用户评论道,Dolphin 2.6 Phi-2 非常听从指令,但没有经过 DPO 微调,因此可能需要系统提示词(system prompt)的鼓励。
- 该模型由 Eric Hartford 和 Fernando Fernandes 开发,由 convai 赞助。
- Dolphin 2.6 Phi-2 基于 Phi-2,并遵循微软的 microsoft-research-license,该许可证禁止商业用途。
- 为了交流该模型,他们分享了一个 Discord 链接。
▷ #🛠-configs-discussion (6 条消息):
- 加载模型时的 GPU 使用情况:用户
@mynd建议,通过将层数尝试设置为-1,应该能够在 3090 GPU 上完整加载模型,这意味着该操作会将所有层转移到 GPU。 @pefortin回应建议监控 VRAM 使用情况,预计使用量会增加。如果没有增加,则可能是安装或配置(config)存在问题。- 捆绑 OpenChat 预设:
@sublimatorniq希望 OpenChat 预设能像其他聊天模板一样进行捆绑,以方便使用。 @ptable回应询问用户为什么不直接将其保存为配置。但@sublimatorniq反驳说,像其他预设一样进行捆绑更符合追求便利的目标。
▷ #🔗-integrations-general (3 条消息):
- AI Navigator 扩展圣诞发布:
@sublimatorniq宣布了 AI navigator 扩展 的预发布版本,该版本支持ollama、lm-studio、mistral、gemini等。 - 功能疑问:用户
@vic49.询问了该扩展的具体功能,因为从网页上看不清楚。 - 扩展功能说明:作为回应,
@sublimatorniq详细说明了该扩展可以计算 token、查询上下文、为回复添加超链接以及滚动到源内容。
▷ #🎛-hardware-discussion (114 messages🔥🔥):
- 显卡性能测试:
@fabguy和pcrafter讨论了 AMD Radeon RX 6800 XT 在 tokens per second 方面的表现。在配备 i5-12600k CPU 和 32GB RAM 的系统上测试的具体数据可以在发布的表格中查看。pcrafter觉得 0.11 tokens/s 非常有趣,因为他们甚至能预判生成文本中的下一个单词。 - 多 GPU 配置的显卡选择:
@pefortin、@heyitsyorkie和rugg0064讨论了在多 GPU 设置中 NVIDIA 2080 Super 和 3060 ti 哪个是更好的选择,共识倾向于 3060 ti,因为它在同一系统中与 3090 的兼容性更好。 - 扩展 RAM 使用:
@dedr1ck分享了他们升级到 64GB RAM 以适配更大模型的情况。他们指出虽然新内存速度较慢(7200MHz 对比 600MHz),但它确实提供了运行 Mixtral 等大型模型所需的容量,而此前该模型会导致系统崩溃。@heyitsyorkie对此评论称,性能提升主要来自额外的 VRAM,而系统 RAM 主要加速了 Time to First Token。 - 优化 Mixtral 模型设置:
@heyitsyorkie分享了一份指南,详细介绍了设置 Mixtral 模型 的步骤——从选择哪个 Kobold 版本和模型量化(quants),到常见故障排除。建议指出在 4-bit 以下质量可能会下降,并建议确保至少 20GB 的 VRAM/RAM 以获得更好的速度。 - 多 GPU 配置的注意事项:
@pefortin提出了使用 PCI risers 在标准主板上安装多个 GPU 的想法,尽管他们承认由于 risers 的传输速度限制可能会出现潜在的性能问题。他们计划在 Linux 上进行不同显卡组合的实验,并反馈结果。totallybored和rugg0064讨论了这种设置可能带来的瓶颈,特别是跨不同 GPU 进行推理(inferencing)时增加的复杂性。
▷ #🧪-beta-releases-discussion (9 messages🔥):
- Mixtral 模型的问题:用户
@doderlein报告了在 Linux 版本中加载 Mixtral 模型时出错,收到关于 Tensor ‘blk.0.ffn_gate.weight’ 的错误消息。用户@fabguy回复称该问题目前在 Linux 版本中尚未支持,但应在下一个版本中修复。 - 对 Mixtral 模型的印象:
@fabguy分享道,Mixtral 模型并没有宣传中那么令人惊艳,并建议@doderlein尝试其他模型,如 Open Hermes。 - 长对话实验版本不可用:用户
@yagilb建议使用一个实验性构建版本,该版本解决了长对话偏离主题的问题。然而,该版本目前仅适用于 Mac。 - Linux 上持续存在的模型加载错误:用户
@eason0731在 Ubuntu 22.04.3 LTS 上尝试本地加载模型时也遇到了同样的错误。该用户询问何时发布能解决此持续问题的 Linux 版本,并引用了之前承诺在 0.2.8 之后的版本中修复的聊天记录。@yagilb引导他们查看另一个频道中关于该主题的最新讨论。
▷ #autogen (1 messages):
@heliosprime_3194 glufy:我卸载并重新安装了它,现在可以正常工作了。
Mistral Discord 总结
- 深入讨论了 Mistral 模型系列 的实现、性能和微调,强调了它们在各种应用中的潜在用途。关键技术和部署问题包括 .safetensors 文件的功能、Mistral 8x7b 在 Edge Coral AI 上的部署、模型部署中 GGUF 文件格式 的处理,以及使用 mlx 的 HuggingFace 版本 instruct-v0.2 的特性。
- 用户
@qwerty_qwer提供了一个大型 text-to-music 数据集,可能有利于某些模型的训练。 - 探讨了开发高效 音频生成模型 的重要性,
@flame1536强调了类似于 ElevenLabs 的小型、快速音频生成模型的必要性。 @tafferboy建议在 Discord 上实现 AI Summary 功能,以帮助成员跟上讨论进度。- 讨论了模型在 工具使用和编码 方面的潜力,特别是通过
@poltronsuperstar描述的一种称为“协商 (negotiation)”的技术。相关讨论集中在 模型交互和自主改进 的可能性上,这被视为实现 通用人工智能 (AGI) 的关键。其中包括对模型可靠性的强调,这是目前 AI 应用开发面临的一个问题。 - 澄清了 Mistral-AI 付费 API 与 Perplexity.AI 等平台上提供的免费版本之间的区别。考虑了现有的 大语言模型 (LLMs) 是否可以通过在线权重更新和引入丰富的人类反馈来增强。
Mistral 频道总结
▷ #general (43 条消息🔥):
-
打开并理解 .safetensors 文件:用户
@hasanurrahevy询问是否可以打开并理解 .safetensors 文件。@blueridanus提供了一个 Python 代码片段来打开这些文件,并解释说这些文件保存了模型的权重。权重由提到的文件名表示,如 “model.embed_tokens.weight”(其维度为 torch.Size([32000, 4096]))。 -
Mistral 8x7b 在 Edge Coral AI 上的部署咨询:
@queuelabs提出了关于在 Edge Coral AI 上优化和部署 Mistral 8x7b 模型的问题,特别是关于如何通过使用 SD 卡的闪存存储来优化边缘推理模型。 -
Contextual - AI 辅助导航和查询:
@sublimatorniq分享了一个名为 Contextual 的 AI 导航扩展的圣诞预发布版消息,该扩展支持 Mistral/Gemini/Ollama/LM-Studio 等。公告中包含了一个指向 Chrome 网上应用店该扩展程序的 链接。 -
大型 Text-to-Music 数据集的可用性:
@qwerty_qwer提出分享他们的大型数据集,其中包含来自 Spotify 的 100 万首歌曲以及约 2 万小时带有字幕的音频文件。如果有人想训练 text-to-music 或 text-to-speech 模型,这些数据可能会很有用。 -
对快速、小型音频生成模型的需求:
@flame1536指出在快速、小型音频生成模型方面的工作不足,并强调了它们对于开启新应用的重要性。他们建议需要一个能够本地运行的小型 ~7B 模型,提供类似于 ElevenLabs 的质量。 -
关于 Discord AI Summary 功能的建议:
@tafferboy建议服务器管理员应启用 Discord 上的 AI Summary 功能。这将允许用户方便地回顾他们不在时发生的对话。
▷ #models (2 条消息):
- Mistral 开源版本:
@ken70wtf和@tom_lrd讨论了开源和开放权重模型的益处。他们提到,理论上这将允许任何人修改模型,以移除或减少他们不喜欢的任何对齐(alignments)。他们还讨论了由 Dolphin 2.5 驱动的 Mistral 8x7b 的现状及其在中文方面的表现。 - 带有 mlx 的 Instruct-v0.2:
@unskilless分享了他们使用带有 mlx 的 HuggingFace 版本 instruct-v0.2 的经验和疑问。值得注意的是,他们注意到 Mistral 7B 模型在 HuggingFace 版本中缺少输出层,而 .pth 版本则有。
▷ #deployment (15 messages🔥):
-
在本地使用 Mistral AI:用户
@sakst询问关于在下载了 12 月 8 日发布的模型文件后,如何在本地使用 Mistral AI 的指导。@sublimatorniq建议使用 Ollama AI 和 LM Studio AI 等平台。 -
在 Windows 上使用 LM Studio 运行 Mistral AI:
@sakst尝试在 Windows 上使用 LM Studio 运行 Mistral 0.2,但由于文件过大(约 90 GB),在上传下载的文件时遇到了困难。 -
理解 AI 模型的 GGUF 格式:
@dutchellie澄清说,在 LM Studio 中使用的文件应该是 GGUF 格式,这是一种可以减小模型大小的量化格式。这些 GGUF 格式 的文件在 Twitter 上没有,但可以从 Huggingface 下载。 -
GGUF 文件来源:
@Dutchellie提到了一个 Huggingface 用户 TheBloke,他发布了包括 GGUF 在内的多种格式的量化模型。 -
困惑已解决:在
@dutchellie的建议下,@sakst表示理解了必要步骤,并对社区的帮助表示感谢。
▷ #finetuning (1 messages):
- Mistral 模型详情:
@casper_ai向<@707162732578734181>询问是否有计划发布关于 Mistral 模型系列 的详细论文或博客。具体来说,他们有兴趣了解用于训练的架构优化和使用的超参数。他们提到虽然 MegaBlocks 是可用的,但不清楚 Mistral 使用了其中的哪些部分。
▷ #showcase (1 messages):
.tanuj.: 消耗了大量 token,但这个 Agent 框架看起来很有前景!
▷ #random (77 messages🔥🔥):
-
使用 AI 模型进行工具调用和编码:
@poltronsuperstar和@victronwolfson讨论了 AI 模型在工具使用和编码实践中的潜力。@poltronsuperstar建议采用一种“伪少样本学习 (fake few shot learning)”的方法,利用大上下文 token 和多次迭代,直到获得期望的输出。他们将这种方法称为“协商 (negotiation)”,并分享说他们通过这种方式成功地使用 GPT-3.5 模仿了 Discord 官方机器人的行为。 -
模型自我交互与 AGI:
@blueridanus和@poltronsuperstar就模型自我交互的潜力进行了反复讨论,@poltronsuperstar表示确信这种方法是通往 AGI (通用人工智能) 的路径。关于 AGI 是否能仅通过语言建模的进步来实现,还是需要更多组件,存在一些争论。 -
模型的智能自我改进:在关于 AGI 的深入讨论中,
@poltronsuperstar提出了模型自我改进是实现 AGI 关键的观点。他们提出了一个场景:如果一个可以生成代码的代码库的复杂度达到或超过了其自身代码库的复杂度,这标志着自我增强的能力,并可能实现 AGI。 -
改进当前 LLMs 的想法:
@blueridanus建议探索更新当前大语言模型 (LLMs) 的方法,结合在线权重更新以及基于推理能力和丰富人类反馈进行梯度步骤的能力,以增强其学习能力。他们承认灾难性遗忘 (catastrophic forgetting) 是前进道路上的一个障碍。 -
可靠性是最大的问题:针对
@tonyaichamp关于目前构建 LLM 应用的最大困难是什么的提问,@sublimatorniq表示可靠性是一个重大挑战。
▷ #la-plateforme (17 条消息🔥):
- Mistral-AI API 与免费替代方案的比较:
@ved_ikke询问了 Mistral-AI 付费 API 相比于 Perplexity.AI 等其他平台上提供的免费版本的额外优势。@blueridanus澄清说,一些平台提供评估版本,但如果用户本身不需要使用 API,可以使用其他托管免费版本进行评估的平台。 - 通过其他平台访问 Mistral-AI:
@ved_ikke提到 Perplexity AI Labs 是一个可以免费访问 Mistral AI 的平台。@blueridanus指出,这是一个为用户评估其产品而托管的 Playground 实例。 - Mistral embed 的度量指标:
@ak35询问 Mistral embed 的度量指标是什么,提到它有 1024 个维度,但未说明度量指标是 cosine、dotproduct 还是 euclidean。
OpenAI Discord 总结
- 几位用户表示有兴趣在没有技术背景的情况下学习 AI 和 Prompt Engineering,并建议参考 OpenAI 网站上的 Prompt Engineering 指南。
- OpenAI Discord 成员互致圣诞问候,同时讨论了 Co-pilot 和 ChatGPT 之间的技术对比,指出 OpenAI 的系统性能有显著提升。
- 讨论了 GPT-4 的实际应用,特别是由于其扩展的信息 context window,被用于总结学校讲座的转录文本。
- 多位用户推荐了一系列用于从 Excel 电子表格中提取和分析数据的资源和工具。
- 在 openai-questions 频道讨论了关于浏览器兼容性、界面可访问性、API quotas 和退款政策的用户体验问题,并提出了一些故障排除建议。
- 在 gpt-4-discussions 频道,讨论集中在修改 OpenAI 项目中当前的 prompt/消息上限、根据 OpenAI 指南调整 prompting 习惯,以及 GPT 在多发言者音频字幕制作中的潜力。
- 在 prompt-engineering 频道链接并讨论了 OpenAI 的 Prompt Engineering 指南,同时讨论了 Prompt Engineering 中的常见挑战,如模型回避和 hallucinations。关于模型预测非正面假设角色反应的询问引发了讨论,并链接到了 OpenAI 更新的使用政策和成功的交互案例。
- api-discussions 频道也发生了类似的讨论,重点关注 Prompt Engineering 指南、Prompt Engineering 中的普遍挑战,以及基于角色配置文件的预测行为查询和用户与 chatbot 模型的交互。
OpenAI 频道总结
▷ #ai-discussions (7 条消息):
- 学习 AI 和 Prompt Engineering:用户
@saketrathore_52744表示尽管没有技术背景,但仍有兴趣学习 AI 和 Prompt Engineering。@thunder9289向该用户保证不需要技术背景,并建议参考 OpenAI 网站上的 Prompt Engineering 指南。@definitely_not_y还提到了 Andrew NG 的 OpenAI 课程。 @thunder9289响应@saketrathore_52744的请求提供了 Prompt Engineering 指南 的链接(此处)。- 在 Stable Diffusion 中使用参考图像:
@rchap92询问 Stable Diffusion 是否可以使用参考图像进行“尽可能接近”的尝试。
▷ #openai-chatter (48 条消息🔥):
-
圣诞庆祝活动:OpenAI Discord 聊天室成员包括
@ta_noshii、@peter20225953、@intermatrixnaut和@loschess等人互相交换了 Merry Christmas 的祝福,并分享了各种圣诞主题的表情符号和贴纸。 -
Co-pilot 与 ChatGPT 的对比:用户
@pruo和【penultimate】讨论了 Co-pilot 和 ChatGPT 之间的对比。他们指出,虽然两者在聊天方面表现相当,但 Co-pilot 拥有一个 ChatGPT 可能缺失的音乐插件。 -
OpenAI 运行速度表现:用户讨论了 OpenAI 系统性能明显的提升。
@lugui注意到流式传输速度(stream speed)大幅提高,其他用户如@pruo和【penultimate】表示赞同,并推测这可能是由于圣诞节期间需求减少或增加了更多 GPU。 -
使用 GPT-4 记笔记:用户
@pencil9195询问 GPT-4 plus 是否值得用于总结学校讲座的转录文本。@jaicraft回应称 GPT-4 在回答时可以利用更多信息,因此在总结方面可能表现更好,特别是由于其 32k 的 context window。 -
Excel 数据分析工具:用户
@brianjwash、@lumirix、@lugui和@michael_6138_97508讨论了从 Excel 数据中详细提取信息的工具。建议范围从在 CSV 数据上利用 Advanced Data Analysis 到运行自己的模型,可能结合 embedding/vectorization 技术。
▷ #openai-questions (13 条消息🔥):
- 浏览器兼容性与隐私问题:
Rock对界面对隐私浏览器(privacy browsers)不友好表示沮丧,质疑更新前的测试流程。 - 界面与可访问性:
skousenx在 ChatGPT Plus 上查找 Dall-E 3 时遇到困难,且体验到的界面与预期不符。推测这些问题可能与其所在地(秘鲁)、使用 Google 账号注册或新 Plus 用户权限受限有关。 - 故障排除建议:针对
skousenx的问题,froggy_chacko建议清除缓存/cookies 并尝试使用 VPN。他们还建议联系支持团队(support)。 - 退款政策咨询:
skousenx询问是否可以退款,以便尝试用新账号重新注册。 - API 配额问题:Plus 订阅者
arthurananda报告了一个 rate limit 错误消息,称其超出了当前配额(quota),尽管他们之前从未运行过 API。他们询问如何解决此问题。
▷ #gpt-4-discussions (11 条消息🔥):
- 移除 30 条提示词限制:用户
@yungamain询问是否有办法 移除 30 条提示词(prompt)的上限。@satanhashtag建议购买另一个账号或切换到 API 服务。 - 增加消息限制:
@Rock建议@yungamain在达到上限时点击“了解更多(learn more)”,并每次都申述理由,说明为什么他们需要更多消息额度。 - GPT 翻译问题:
@joker002报告了一个问题,即机器人只翻译了请求的 20 行中的 10 行。@Rock建议该问题可能是由于近期输出方式的修改导致的,并建议@joker002根据 OpenAI 的指南修改其 prompting 习惯。 - 获取提示词指南:
@joker002寻求寻找 Prompt Guide 的帮助。@lumirix分享了该指南的链接:https://platform.openai.com/docs/guides/prompt-engineering - GPT 为多声音生成字幕:
@arnoldtri询问是否有 GPT 可以为播客(Podcasts)或多个发言者的不同声音生成字幕。在观察到的消息中未提供答案。
▷ #prompt-engineering (10 messages🔥):
- OpenAI’s Prompt Engineering Guide: 用户
@exhort_one分享了 OpenAI 关于 Prompt Engineering 的指南链接。他们好奇为什么该频道之前没有讨论过这个。 - Difficulties in Prompt Engineering:
@tonyaichamp询问了在 LLM 应用的 Prompt Engineering 中面临的常见挑战。用户@beanz_and_rice回答称,模型回避 (model evasiveness) 和 幻觉 (hallucinations) 是主要问题。 - Model Speculation Behavior:
@rchap92提出了一个问题,即 Chatbot 模型是否会预测假设情境中角色的非正面反应。 - OpenAI Usage Policies: 作为回应,
@eskcanta建议查看 OpenAI 更新后的 使用政策 (usage policies),并建议在考虑这些政策的前提下,与模型讨论期望的输出。 - Example Case with OpenAI chatbot model:
@eskcanta分享了一个与 OpenAI Chatbot 交互的 示例链接,展示了模型如何处理对话中的冲突和细微差别。
▷ #api-discussions (10 messages🔥):
- Prompt Engineering Guide:
@exhort_one分享了 OpenAI 的 Prompt Engineering 指南 链接,提到该文档在聊天中并未被广泛讨论。@bambooshoots补充说,该指南似乎是过去一两个月内新增的内容。 - Challenges in Prompt Engineering: 针对
@tonyaichamp关于语言模型应用中 Prompt Engineering 难点的提问,@beanz_and_rice提到 “模型回避 (Model Evasiveness) 和幻觉 (Hallucinations)” 是重大挑战。 - Speculations Based on Character Profiles:
@rchap92询问 Chatbot 是否可以根据角色画像预测其反应,而不是选择“最佳情况”。@eskcanta回应建议参考 OpenAI 更新后的 使用政策 (usage policies),因为这可以指导用户与 Chatbot 的交互。他们还分享了一个与模型进行深入讨论的 示例。 - Bot Responses to Speculative Questions:
@rchap92进一步提到,当被问及推测性问题时,Bot 大多数时候倾向于回归到正面的结果,@pratham_shetty觉得这很有趣。
HuggingFace Discord Discord Summary
- 关于使用 HuggingFace 的讨论:包括为工程系学生举办 HuggingFace 课程的可能性、Apple 的开源多模态 LLM、对与 HuggingFace 进行区块链合作和智能合约的兴趣、HuggingFace 可能的服务中断、关于在 HuggingFace 上使用 Dolphin 2.5 mixtral 8x7b 的咨询,以及关于 gradio_client 功能的问题。
- 在 Today-I’m-Learning 频道分享的学习经验和查询:重点介绍了关于 MobileSAM 的发现、关于开源项目的咨询、关于频道礼仪的提醒、寻求针对初学者的指导,以及对分享信息的感谢。
jaminchen在 Cool-Finds 频道分享了关于 HuggingFace NLP 课程 的精彩发现。- 在 I-Made-This 频道中分享成就并寻求解决方案:
@andysingal分享了他微调后的 DistilBERT 模型及其达到的准确率,并讨论了如何下载图像,@yjg30737提供了建议。此外,还讨论了 Runpod 和 Kaggle notebooks 在下载生成图像方面的区别。 - Computer-Vision 频道重点讨论了模型微调建议(BLIP-2 模型)、推荐了理解计算机视觉模型的资源(Piotr 的 YouTube 频道),并展示了 HuggingFace Hub 上值得关注的 Spaces(EfficientSAM Space)。
- NLP 频道的对话涵盖了图像转文本 (image-to-text) 任务的建议、QA 和 Seq2seq 模型的特征描述、关于模型抽象层级的讨论,以及关于使用 T5 模型进行文本蕴含 (text entailment) 方法的问题。值得注意的是,推荐了两个用于图像转文本任务的模型:Donut 和 Nougat。
HuggingFace Discord Channel Summaries
▷ #general (23 messages🔥):
- Huggingface 讲座:
@ishavverma表示有兴趣寻找合适的人选为工程系学生举办一场关于 Huggingface 的讲座,目标是让他们熟悉该平台。 - Apple 的开源多模态 LLM:
@dame.outlaw分享了一篇 VentureBeat 文章,内容关于 Apple 在 10 月份悄悄发布了一个开源多模态 LLM。 - 区块链合作伙伴关系与 Huggingface:
@cakiki、@earduman2和@robolicious之间进行了一系列对话,讨论了区块链合作伙伴关系的可能性,以及 Huggingface 是否有任何智能合约(实际上并没有)。 - 潜在的 Huggingface 服务中断:
@casanovasan询问下载服务是否宕机,因为一个 vae 包的安装突然停止了。 - Huggingface Dolphin 集成查询:
@notsaiff询问了在 Huggingface 上使用 Dolphin 2.5 mixtral 8x7b 的步骤,并提到了其免费的 AI 托管服务。 - Gradio_Client 功能:
@_gilfoyle_询问是否可以通过 gradio_client 更改文本框的文本或状态。
▷ #today-im-learning (10 messages🔥):
- MobileSAM:
@merve3234分享了关于 MobileSAM 的学习心得,并提供了相关发现的链接 点击此处。 - 关于开源的问题:
@neuralink询问@merve3234是否已经开源了一个项目,得到的回复是该项目正在进行中。 - 频道礼仪:
@cakiki提醒用户保持话题相关,不要在频道内跨频道发布(cross-post)。 - 新成员咨询:
@alluring_chipmunk_62732_31615询问作为一名纯初学者该如何在该频道开始学习。 - 致谢:
@osanseviero和@llmsherpa对各用户分享的信息和笔记表示感谢。
▷ #cool-finds (1 messages):
jaminchen: 来自 Huggingface 的 NLP 课程 🙂 https://huggingface.co/learn/nlp-course/
▷ #i-made-this (5 messages):
- 评分分类模型: 用户
@andysingal分享了他对 DistilBERT 模型进行微调版本的链接。他的模型在评估集上实现了 0.9611 的 loss 和 0.7011 的准确率。未提供关于模型描述或预期用途的其他数据。该模型可以在此处找到。 - 下载图像讨论:
@yjg30737提供了一份关于如何从创建的 notebook 中下载图像的指南。该用户引导@andysingal查看其 notebook 的概览(Overview)以及参数与变量(Parameters & Variables)部分,可以通过此处访问。 - Runpod 与 Kaggle Notebook:
@andysingal表示有兴趣了解 Runpod 和 Kaggle notebook 在下载生成图像方面的区别。@yjg30737建议在用户的平台上下载并运行 Kaggle notebook 的源代码以观察结果。该用户指出,针对 Kaggle 的代码段可能需要进行修改。 - 变量与参数:
@yjg30737澄清说,变量和函数可以从源码中复制粘贴。他们还详细说明了从 Kaggle 下载的过程:将图像文件压缩成 zip 文件夹,并通过 Kaggle 提供的特定类进行下载。 - 对分享信息的感谢:
@andysingal感谢@yjg30737分享了关于在创建风格化图像时处理变量和参数的有用信息。该用户同意尝试分享的下载脚本。
▷ #computer-vision (5 messages):
- 微调 BLIP-2 模型:
@srikanth_78440咨询了关于微调图像字幕模型(image-captioning model)的建议,@nielsr_对此进行了回答。他提供了一个包含详细指南的 HuggingFace notebook 链接。他补充说,pixel_values和input_ids都需要准备,并且模型标签(labels)需要是input_ids的副本,其中 padding tokens 需替换为-100。 - Piotr 的计算机视觉 YouTube 频道:
@nielsr_向@blackbox3993推荐了 Piotr 的 YouTube 频道,以便更好地理解计算机视觉模型。该频道展示了计算机视觉模型的各种应用。 - Hub 上的 Spaces:
@nielsr_重点介绍了一些 HuggingFace Hub 上很酷的 Spaces,并提供了一个由 Piotr 创建的 Space 链接,该 Space 展示了 Segment Anything Model (SAM) 与 EfficientSAM 之间的对比。
▷ #NLP (5 messages):
- 图像转文本模型:
@edude11推荐了两个用于图像转文本任务的模型:Donut 和 Nougat。Donut 用于通用任务,可在huggingface.co/naver-clova-ix/donut-base获取;Nougat 用于学术文档,可在huggingface.co/facebook/nougat-base获取。 - QA 和 Seq2seq 模型:
@opencuiguy向@merve3234解释说,QA 模型是仅编码器(encoder only)模型,用于从给定上下文中提取答案。相比之下,seq2seq 模型是编码器-解码器(encoder-decoder)模型,用于生成答案。有关这些模型的信息可以在 HuggingFace 的以下页面找到:问答 (Question Answering) 和 文本生成 (Text Generation)。 - 模型的抽象层级:在回复
@opencuiguy时,@merve3234确认 seq2seq 模型是较低层级的抽象,而问答(question-answering)是较高层级的,因为 seq2seq 模型可以用来解决问答问题。 @opencuiguy询问@merve3234关于使用 T5 模型进行文本蕴含(text entailment)的合适方法,并请求提供一份可作为学习参考的代码。
OpenAccess AI Collective (axolotl) Discord 摘要
- 关于检索增强生成 (RAG) 实现工具的讨论,
@nanobitz发起了 RAG 本地工具查询,请求推荐任何已知带有用户界面、可存储和检索过往 GPT 交互记录的优秀工具。 - 学术资源和实用工具的推荐与交流:
@caseus_推荐了一篇研究论文,认为它是从事 量化模型 (quantized models) 工作者的“必读之作”。@noobmaster29介绍了 promptbench,这是一个 大语言模型 (LLM) 的统一评估框架。@nanobitz分享了来自 Unsloth 博客文章 的发现,关于如何利用滑动窗口注意力 (sliding window attention) 等特性将 Mistral 的微调速度提升 14 倍。
@nafnlaus00对 Mixtral 的推理代码进行了详细分析,并针对 GitHub commit 中发现的每层每个 token 的专家数量提出了疑问。- 关于微调参数、Epochs 和嵌入 (embeddings) 的推测与建议:
@noobmaster29询问 alpha 是否是模型微调后可调节的参数,因为他认为该参数导致了高损失 (high loss)。@noobmaster29还询问了适用于 大型数据集 的 Epoch 数量,建议对于 5 亿 token 的数据集,限制在 3 个 Epochs 以内。@dreamgen询问了在 LoRA 和 FFT 期间微调特殊 token 嵌入的具体细节。@dreamgen希望在微调期间 冻结除新 token 以外的所有嵌入。
@shrex8791询问了关于微调 deepseek-coder 6.7B 模型的问题,描述了一个具体问题:模型一直在并行化并耗尽所有内存,寻求如何使其非并行运行的建议。
OpenAccess AI Collective (axolotl) 频道摘要
▷ #general (11 messages🔥):
- RAG 本地工具查询:
@nanobitz询问是否有人知道带有 UI 的优秀 RAG 本地工具,用于存储和检索过去的 GPT 对话。 - 量化模型推理:
@caseus_推荐了一篇关于量化模型下游推理的 论文。他们认为这是从事量化模型工作的人员的“必读之作”。 - Mixtral 推理深度解析:
@nafnlaus00分享了他们对 Mixtral 推理代码的研究,提供了 GitHub commit 链接,并就 Mixtral 中每层每个 token 的专家数量提出了疑问。 - Promptbench 评估框架:
@noobmaster29分享了 GitHub 上 promptbench 的链接,这是一个大语言模型的统一评估框架,并询问是否有人尝试过。 - 模型微调参数:
@noobmaster29询问 alpha 是否是模型微调后可以修改的参数,并对他们认为过高的 loss 表示惊讶。
▷ #axolotl-dev (3 messages):
-
序列长度对比:
@dreamgen建议提及序列长度以便进行更好的对比。 -
Unsloth 的 Mistral 基准测试发现:
@nanobitz分享了 Daniel Han 撰写的 Unsloth 博客文章链接,讨论如何将 Mistral 的微调速度提升 14 倍。文章透露,针对 Mistral 7B、CodeLlama 34B 以及其他基于 Llama 架构模型的 QLoRA 支持已经发布。它包含 Sliding Window Attention、初步的 Windows 和 DPO 支持,以及 59 个共享的 notebook。Unsloth 博客 -
基准测试结果回顾:
@nanobitz确认@casper此前已经检查过 Unsloth 文章中的发现。
▷ #general-help (9 messages🔥):
- 数据集大小与 Epochs:
@noobmaster29询问对于更大的数据集,3 个 epochs 是否过多。当被要求定义“大”时,noobmaster29 澄清数据集大小约为 5 亿个 tokens。 - 使用 LoRA 微调特殊 Token:
@dreamgen询问了使用 LoRA 和 FFT 微调特殊 token embedding 的细节。他们询问是仅微调新增的 token embedding 还是全部微调,以及该过程是否可配置。@caseus_建议为 LoRA 包含 “lm head” 和 “embed token” 层。 - 冻结与非冻结 Embedding:随后,
@dreamgen表示希望能够冻结除新 token 以外的所有 embedding。 - 微调 Deepseek-coder 6.7B:
@shrex8791询问了他们在微调 Deepseek-coder 6.7B 模型时遇到的挑战。据 shrex8791 称,模型一直在并行化,导致耗尽了所有内存。他们寻求关于如何使其不并行的建议。
LangChain AI Discord 总结
- 根据用户查询切换模型:用户
@shellord正在开发一个项目,需要根据用户查询在通用问答模型和 Function Calling 模型之间切换。 - LangChain 相关查询:用户
@emreweb3询问 LangChain 是否包含智能合约,而用户@a404.eth阐明了关于集成完整 RAG 链的自定义 Agent 的流式传输问题。还讨论了丹佛的一个潜在活动,强调了由于团队安全要求带来的当前限制。 - LLM 应用开发中的挑战:由用户
@tonyaichamp发起的关于开发 LLM 应用时遇到的主要问题的对话。 - langserve[client] 中的 FastAPI 依赖:用户
@sidlly.eth对添加 langserve[client] 时为何包中必须包含 FastAPI 表示担忧,强调客户端 SDK 不应该需要 FastAPI。 - GenAI Stack 使用与语言处理创新:用户
@tachi3与@shamspias之间围绕 GenAI Stack 利用率的对话。同时,@andysingal分享了一篇 Medium 博客文章,总结了一种使用 Llama-cpp 和 StructuredOutputParser 彻底改变语言处理的新方法。
LangChain AI 频道总结
▷ #general (10 messages🔥):
- 为不同用户查询选择模型:
@shellord寻求关于一个项目的建议,该项目需要根据用户查询使用不同的模型。目标是根据用户查询的类型,在通用问答模型和 Function Calling 模型之间进行切换。 - 关于 LangChain 和智能合约的讨论:
@emreweb3询问 LangChain 是否包含智能合约。用户@lhc1921被标记,但提供的聊天记录中没有回复。 - 开发 LLM 应用的挑战:
@tonyaichamp征集关于开发 LLM 应用中最大挑战或困扰的意见。 - 在自定义 Agent 中启用流式传输:
@mohammed.shokr探讨了如何为包含完整 RAG 链的自定义 Agent 启用流式传输(Streaming)。用户@a404.eth进行了回复,并索要代码,因为与 LECL 相比,在 Agent 中实现流式传输可能比较棘手。 - 关于 LangChain Hack Night 地点的讨论:围绕 LangChain Hack Night 的潜在地点展开了讨论。用户
@glenn_sjobs回复了@shiftybit,解释了夏威夷的高昂成本,但承诺未来可能在美国本土举办活动。用户@a404.eth提议在丹佛举办此类活动,但由于安全要求,无法与 LangChain 团队会面。
▷ #langserve (1 messages):
- Langserve 客户端与 FastAPI 依赖:用户
@sidlly.eth表达了对在添加 langserve[client] 时需要在其包中包含 FastAPI 的担忧。他们认为客户端 SDK 没有理由需要 FastAPI。
▷ #share-your-work (3 messages):
- 关于 GenAI Stack 的讨论:用户
@tachi3询问@shamspias是否尝试过 GenAI Stack。作为回应,@shamspias澄清说,他们目前只阅读了 readme 和描述,实际上还没有尝试过。 - 博客文章 “使用 LangChain 和 Mixtral-8x7B 彻底改变语言处理”:
@andysingal分享了一篇 Medium 博客文章,讨论了使用 Llama-cpp 和 StructuredOutputParser 方法来彻底改变语言处理。该文章由 Ankush K Singal 撰写,发表在 AI Advances 下。
DiscoResearch Discord 总结
- 关于 xDAN-AI 模型性能 的讨论,及其声称在 MT-bench 上表现最佳,在 7b 模型的人文、编程和写作方面具有强大能力的说法,包括用户
@cryptossssun的热情支持,并发布了指向该模型 Discord、Twitter 和 Huggingface 平台的 链接。 - 对 xDAN-AI 模型的怀疑,
@.pathos和@technotech对 7B 模型的性能及其“接近 GPT-4”的断言表示怀疑。 - 用户关于 AI 工具 的 UX 和质量的反馈,
@rtyax对比了 IDE 的 Copilot 和 Continue 工具,认为前者因其高质量的 UX 和响应质量而更胜一筹,而后者因缺乏自动补全功能而不太好用。 @bjoernp建议@rtyax尝试 ClipboardConquerer(一款 AI 工具),@rtyax表示感兴趣并同意将来分享他们的使用体验。
DiscoResearch 频道总结
▷ #mixtral_implementation (4 messages):
- xDAN-AI 的模型性能:用户
@cryptossssun分享了 xDAN-AI 新模型的 链接,声称它是 MT-bench 排名第一,并大胆宣称它是第一个在 7b 规模下在人文、编程和写作方面表现良好的顶级模型。该帖子还包含指向该模型 Discord、Twitter 和 Huggingface 平台的链接。 - 用户的怀疑:
@.pathos和@technotech对 7B 模型的性能表示怀疑,对其“接近 GPT-4”的说法及其可信度提出质疑。
▷ #general (3 条消息):
- 关于 AI 工具 UX 和质量的讨论:用户
@rtyax分享了他使用不同 AI 工具的经验。他认为 Copilot for IDEs 在用户体验和响应质量方面表现最佳。此外,还讨论了 Continue,这是一个可集成任何本地或远程 LLM 的 Copilot 替代方案,但他发现其用处小得多,因为它不提供自动补全功能,仅支持聊天/重构。 - 建议尝试 ClipboardConquerer:用户
@bjoernp建议尝试 ClipboardConquerer。@rtyax表示有兴趣尝试该工具,并提到随后会分享他们的使用体验。
Alignment Lab AI Discord 摘要
- 对话围绕节日问候展开,来自
#general-chat的@venadore祝大家圣诞快乐,并分享了一个 YouTube 视频:2023 AI 回顾(梗图版),cryptossssun在#oo频道也表达了类似的祝福。 @teknium在#general-chat中分享了一个 Twitter 帖子,但未提供任何额外上下文。#general-chat中的@undi和@fredipy都对某个未指明的“发布(release)”表示了期待和祝贺,这引起了很大兴趣,但缺乏更详细的信息。cryptossssun在#oo中链接了一个 Twitter 帖子,但没有进一步讨论相关背景。
Alignment Lab AI 频道摘要
▷ #general-chat (5 条消息):
@venadore分享了一个 YouTube 视频:2023 AI 回顾(梗图版),以梗图形式回顾了 AI 的这一年。他们还祝大家圣诞快乐。@teknium分享了一个 Twitter 帖子。@undi对该发布表示祝贺,并提到在另一个网站上看到了它,但未指明发布的内容是什么。@fredipy回复了@teknium,并对尝试“它”表示兴奋,尽管目前尚不清楚“它”指的是什么。
▷ #oo (1 条消息):
cryptossssun: 嗨,圣诞快乐! https://twitter.com/shootime007/status/1739312828111360339
Skunkworks AI Discord 摘要
只有一个频道有活动,因此无需总结…
- AGI 空间赞赏:用户
@0xevil对 basement AGI space 表达了热情。 - 推文链接:用户
@teknium分享了一个 推文链接。
LLM Perf Enthusiasts AI Discord 摘要
只有一个频道有活动,因此无需总结…
- Thread 中的上下文长度控制:用户
@joshcho_提到了他们对 Thread 缺乏上下文长度控制的沮丧。他们表示:“…我必须删除然后重新复制所有内容(或者有其他方法吗)”,暗示可能对更高效管理 Thread 内容的方式感兴趣。
AI Engineer Foundation Discord 摘要
只有一个频道有活动,因此无需总结…
- 用户
@._z和@vince_uc在频道中互致圣诞问候。