ainews-12292023-tinyllama-on-the-way
2023年12月29日:TinyLlama 即将到来。
Nous/Axolotl 社区正在使用 3 万亿 token 预训练一个 1.1B 模型,该模型在 HellaSwag 评测中展现出了对于 1B 小模型而言非常出色的结果。LM Studio Discord 的讨论涵盖了广泛的 GPU 相关问题、与 OpenAI API 的 Discord 机器人集成,以及影响模型使用的硬件限制。社区成员还讨论了用于嵌入(embeddings)和大语言模型(LLMs)的服务器托管,提议更新 Discord 频道以改善模型开发协作,并解决了测试版本中的乱码问题。此外,用户还对 Autogen 工具的安装和运行挑战进行了说明。
Nous/Axolotl 社区目前正在 在 3 万亿个 token 上预训练一个 1.1B 模型。对于一个 1B 的小模型来说,59 的 HellaSwag 分数非常有前景。

[TOC]
LM Studio Discord 摘要
- 围绕各种 GPU 相关问题 进行了广泛讨论,范围从模型运行问题到兼容性疑虑。例如,
@pminev在 GPU 相关问题以及为其他功能配置模型方面需要帮助,@dagbs引导他们使用了 LM Studio 中的 Inference Server。 - 正在讨论将 Discord bot 与 OpenAI API 集成。
@thelefthandofurza分享了一个 GitHub 链接,帮助用户根据需求调整机器人的现有代码。 - 社区还就特定的 LM Studio 使用案例和兼容性 进行了互动,讨论了角色扮演语境下的角色提示词(character prompts),以及将 GitHub wiki 与 LLM 助手集成以获得更多上下文响应。
- 在 硬件 方面,话题围绕用户因 GPU 限制在利用各种模型时面临的局限性展开。还推测了运行大上下文模型的可行方案,
@fabguy评论道:“大上下文会降低处理速度,并且会疯狂消耗 RAM/vRAM。” @rofliex发起了关于 embedding 和 LLM 模型 服务器托管 的讨论,@vic49提供了有用的建议。还讨论了与 embeddings API 的集成,以及使用 Databerry Project 构建自定义 LLM Agents。- 社区成员提议更新 discord 频道,请求设立专门的模型开发类别,并主张建立一个包含来自可信外部源数据的可见排行榜模型板块。他们还表示由于训练数据污染问题,在接受提交时需要保持谨慎。
- 用户
@.gregly在 beta 版本讨论中分享了 0.2.10 (Windows) 版本中 乱码问题 的临时修复方案。 - Autogen 话题围绕安装故障、理解错误信息、关于 Docker 的使用困惑以及 Autogen 的运行性质展开。进行详细解释的用户阐明了 Autogen 在不同条件下的运作方式。
LM Studio 频道摘要
▷ #🎄🎅-general (102 messages🔥🔥):
- GPU 相关问题与查询:
@pminev在模型运行方面遇到问题,并收到了@dagbs关于检查 GPU 相关问题的建议。@pminev还对配置模型以实现类似 OpenAI 的其他功能感兴趣,@dagbs向他推荐了 LM Studio 中的 Inference Server。 - Discord Bot 实现讨论:用户
@Trip和@rewire表现出寻找能与 OpenAI API 良好协作的 Discord bot 的兴趣。@thelefthandofurza分享了一个 Discord bot 的 GitHub 链接,并指出用户可能需要对现有代码进行微调。 - LM Studio 用例与兼容性讨论:
@olofp建议开设一个专门频道来讨论 LM Studio 的用例。@vanthryn询问了在使用 LLM 进行角色扮演(roleplay)时关于角色提示词(character prompts)的最佳实践。@professorakram寻求关于将 GitHub wiki 与 LLM 助手集成以提供回复上下文的建议,@dagbs建议使用 autogen。 - 系统兼容性查询:
@katanasoul91和@basedking遇到了系统与某些模型兼容性的问题。@fabguy、@yagilb和@dagbs提供了建议和指导。 - 模型性能查询:
@jiha和@rocketraccoon6074正在寻找符合其特定硬件能力和要求的模型。@fabguy、@dagbs等人提供了建议和指导。
提到的链接:
- LM Studio Beta Releases
- GitHub - BBC-Esq/ChromaDB-Plugin-for-LM-Studio: 为在服务器模式下运行的 LM Studio 创建 ChromaDB 向量数据库的插件!
- GitHub - openai/gpt-discord-bot: 使用 Python 编写的示例 Discord bot,使用 completions API 与
text-davinci-003模型进行对话,并使用 moderations API 过滤消息。
▷ #🤖-models-discussion-chat (6 messages):
- 对模型训练目的的困惑:用户
@dagbs对所使用的数据集和某模型的最终目标表示困惑。他们表示:“我对该模型的最终目标以及它的训练目的感到非常困惑。” - 硬件限制:用户
@dagbs还指出,由于硬件限制,模型的尺寸(8x7b)导致他们无法运行。 - 对 SOLARC-MOE-10.7Bx4 模型潜力的兴奋:
@jiha对未经测试的SOLARC-MOE-10.7Bx4模型的潜在威力表示热切期待,并提供了其在 Hugging Face 上的链接。他们还表达了希望看到该模型测试的愿望,但遗憾没有必要的硬件。 - 大上下文尺寸带来的速度与内存挑战:
@fabguy警告了大上下文尺寸(context sizes)带来的性能问题,称:“大上下文尺寸会减慢处理速度,并疯狂消耗 RAM/vRAM。”他们建议使用 RAG 设置可能会有所帮助。 - 关于 MoE 模型处理速度的问题:
@a1vx提出了关于 MoE 模型处理速度的查询,试图了解来自7b模型的专家 FFN 路由(expert FFN router)是如何被堆叠八次的。
提到的链接:
TheBloke/SOLARC-MOE-10.7Bx4-GGUF · Hugging Face
▷ #🧠-feedback (9 messages🔥):
- 模型开发频道请求:用户
@dagbs提议设立一个专门的模型开发频道类别,包括通用、预训练(pretraining)、数据集(datasets)、微调(finetuning)和量化(quantization)等子类别,以促进 LM Studio 社区内的协作。 - 排行榜模型板块建议:
@pandora_box_open建议增加一个对所有人可见的排行榜模型板块。数据可以从 HuggingFace 等外部来源获取,并链接了 OpenCompass 作为示例。 - 用户
@fabguy肯定了排行榜的想法,但也提醒说,由于训练数据污染问题,目前不接受新的提交。 @pandora_box_open回应建议可以为使用 LM Studio 进行排名的评审员设立一个板块,这既能推广 LM Studio,也能造福社区。
提到的链接:
▷ #🔗-integrations-general (13 条消息🔥):
- 托管 Embedding 和 LLM 模型的服务器:
@rofliex询问了在 1234 端口托管服务器以及在 LM Studio 上为 Embedding + LLM 模型托管服务器的可能性。@vic49澄清说他的程序连接到以服务器模式运行的 LM Studio,他的程序不需要额外的服务器模式。@rofliex对此解决方案表示感谢。 - 使用 Embeddings API:
@rofliex询问是否需要清除 LM Studio 服务器面板配置中的后缀/前缀文本框以利用 Embeddings API,以及此要求是否仅针对@vic49的聊天实现。作为回应,@vic49建议在 LM Studio 中禁用“自动提示词格式化(automatic prompt formatting)”,选择一个提示词,然后更新他程序中的设置。他还建议删除 LM Studio 中前缀/后缀框中的任何内容。 - 尝试运行 Databerry 项目:
@rofliex提到尝试运行 Databerry Project,这是一个用于构建自定义 LLM Agents 的无代码平台,并表示需要用于 qdrant 的正确 Embedding API。 - 向 LLM 喂入多个文件夹:
@andrew.lost提出了一个问题:是否可以向 LLM 喂入一个包含多个子文件夹和文件的文件夹进行读取和扫描。根据消息日志,该查询尚未得到答复。
提到的链接:
GitHub - gmpetrov/databerry: The no-code platform for building custom LLM Agents:用于构建自定义 LLM Agent 的无代码平台…
▷ #🎛-hardware-discussion (12 条消息🔥):
- 在 GPU 上使用模型:
@taigasasori_94251询问如何让模型在 4090 GPU 上运行,因为目前只显示 CPU 负载。@dagbs建议将 GPU 参数设置为-1或正数,而@fabguy指出应用程序 UI 不显示 GPU 利用率。随后,@pefortin建议勾选 UI 中的 GPU offloading 框,并使用系统工具监控 vRAM 使用情况。 - 模型在 GPU 上的效率:
@pefortin分享了他们在 3090 和 3060ti 组合上使用 PCIe x1 转 x16 转接卡运行 dolphin mixtral Q5 的经验。他们观察到每秒 token 数(tokens per second)从 6 增加到 10-11,并计划使用旧的 10xx 和 20xx 系列 GPU 进行测试。 - AMD GPU 上的问题:
@LokedTMX在将负载卸载到 RX 6950xt AMD GPU 时遇到了 GPU 未被利用的问题。@yagilb承认这是关于 AMD GPU 的已知问题,并提供了一个链接以获取更新,同时邀请大家发表评论,以便在 beta 版本可用时进行测试。
▷ #🧪-beta-releases-discussion (2 条消息):
- 0.2.10 (Windows) 中的乱码问题:
@.gregly注意到在 0.2.10 (Windows) 版本中,切换截断策略(truncation strategies)并重新生成似乎可以暂时解决乱码问题,尽管该问题在下一次生成时会再次出现。@yagilb认为这一反馈非常有用。
▷ #autogen (21 条消息🔥):
-
AutoGen 的安装与使用:用户
@ddhmksoi分享了他们在设置 AutoGen 时的困扰。他们按照步骤操作,包括从 git 下载最新的 zip、运行 install.py 以及使用 pip install 安装 autogen。然而,他们在运行某些 AutoGen 脚本时遇到了问题。 -
理解 AutoGen 中的错误信息:
@ddhmksoi遇到了一个错误信息,涉及autogen.oai.completion以及对openai<1和diskcache的依赖问题,这引起了关注。 -
在 AutoGen 中使用 Docker:
@ddhmksoi对 Docker 在 AutoGen 过程中的参与表示困惑。他们按照建议安装了 Docker,但在 Docker 应用程序中没有观察到活动实例。 -
AutoGen 的工作原理:用户
@dagbs提供了关于 AutoGen 工作原理的见解。他们指出 AutoGen 的行为不仅严重依赖于所使用的模型,还取决于给定的提示词。如果 AutoGen 判定任务已完成,它可能会提前终止。为了防止过早终止,@dagbs建议在UserProxyAgent()内部添加system_message来引导模型了解任务完成状态。 -
AutoGen 文件的位置:
@ddhmksoi询问执行后 AutoGen 文件的保存位置。@dagbs澄清说 AutoGen 不保存任何文件,因为它是一个旨在直接交互的 Python 脚本。
Nous Research AI Discord 摘要
-
用户
@pradeep1148在 #off-topic 频道询问了 llama2 和 mistral 在 Transformer 架构上的差异,引发了关于 AI Models 的讨论。此外,@teknium分享了一个 Twitter 链接,内容是关于一名男子使用自制天线联系国际空间站(ISS)上的宇航员。 -
在 #benchmarks-log 频道中,
@teknium分享了TinyLlama不同版本的基准测试(benchmarks),展示了其在多个任务和数据集上的不同表现。 -
#interesting-links 频道讨论了运行
TinyLlama检查点(checkpoints)的基准测试、在修改版 Minecraft 中进行游戏、使用 Instructor 和 Pydantic 为 response_type 构建知识图谱,以及对各种 7B 模型的全面比较和排名,包括 dolphin-2.6-mistral-7b、dolphin-2.6-mixtral-8x7b、Marcoroni-7B-v3 和 mistral-ft-optimized-1218。 -
@teknium在 #general 频道讨论 Hermes 2 AI 机器人对 AI 意识(consciousness)、感知力(sentience)和感受性(qualia)的看法时,引发了关于 AI 意识的深入探讨。其他关注点还包括将 AI 模型层数翻倍的潜在影响,以及希望使用 GPT4 数据训练 tiny-llama semantic chunker。 -
#ask-about-llms 频道就分词(tokenization)的简单性进行了有趣的交流,并发布了一个名为 NeuralMix-2x7b 的新 AI 模型,这是一个使用 mergekit 创建的混合专家模型(MoE)。
-
@vic49在 #project-obsidian 频道发起了一场关于脚本执行查询的讨论。讨论演变为项目集成主题以及旨在实现平稳运行的代码建议。
Nous Research AI 频道摘要
▷ #off-topic (3 条消息):
- 用户分享链接:
@pradeep1148分享了一个没有上下文的 YouTube 链接。@teknium分享了一个 Twitter 链接,描述了一名男子使用自制天线联系国际空间站(ISS)上的宇航员。
- 关于 AI 模型的讨论:
@pradeep1148询问了 llama2 和 mistral 在 Transformer 架构上的差异。
提到的链接:
来自 Historic Vids (@historyinmemes) 的推文: 这名男子使用……联系了 ISS 上的宇航员。
▷ #benchmarks-log (8 条消息🔥):
- 训练 TinyLlama:
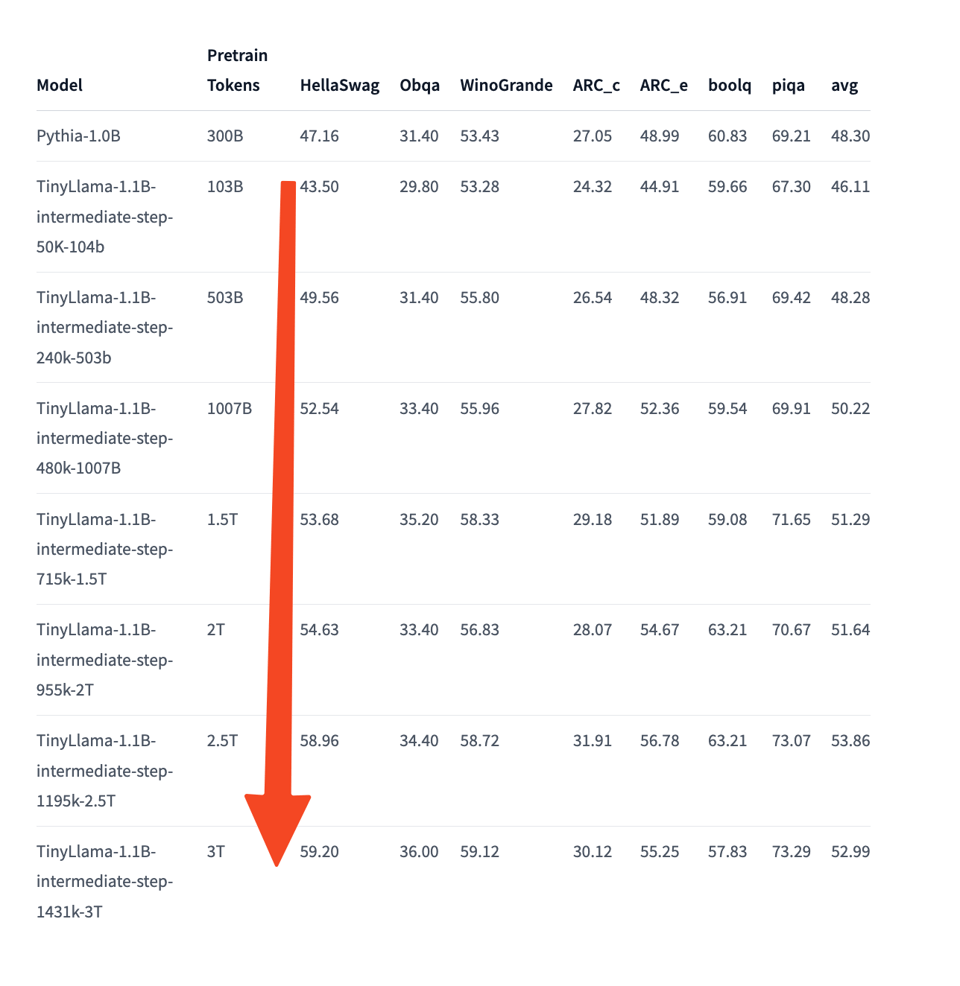
teknium分享了TinyLlama不同版本的基准测试,特别是具有不同批次大小(batch sizes)的中间步骤。- TinyLlama-1.1B-intermediate-step-1431k-3T: 在不同任务中展示了多样化的表现。在包括 ARC、Boolq、HellaSwag 等一组任务中实现了 52.99% 的平均准确率。在 AgeIVal(AQA、LogiQA、LSAT AR 等)的一组任务中实现了 21.05% 的平均准确率。在 BigBench 的一组任务中平均表现为 31.95%。”TruthfulQA MC” 的表现以 mc1 和 mc2 指标报告。
- TinyLlama-1.1B-intermediate-step-1195k-token-2.5T: 与之前的模型相比,表现略显不一致。在与第一批类似的任务集中获得了 53.84% 的平均值,但在 AgeIVal 的任务集中下降到 21.45%。在 BigBench 任务中,它实现了 31.73% 的平均表现。与之前的模型类似,报告了 “TruthfulQA MC” 的表现。
▷ #interesting-links (10 条消息🔥):
- Tinyllama Checkpoint 基准测试:
@teknium提到正在为 Tinyllama 的最后三个 Checkpoint 运行 Benchmark。 - 游戏讨论:
@teknium随口询问@1084792750001618965是否玩模组版 Minecraft,由此引发了一场讨论。@max_paperclips也参与了进来,提到他们偶尔会玩这个游戏。 - 知识图谱构建:
@fullstack6209分享了一个 GitHub Gist 链接,关于他们使用 Instructor 和 Pydantic 的response_type进行引导式构建知识图谱数据的项目。他们提到在配备 VLLM 的 2080ti/3090 设备上,该过程大约需要 30 分钟。 - AI 模型对比:
@metaldragon01分享了一个 Reddit 帖子,提供了各种 7B 模型的全面对比和排名,包括 dolphin-2.6-mistral-7b、dolphin-2.6-mixtral-8x7b、Marcoroni-7B-v3 和 mistral-ft-optimized-1218。其中 Nous Capybara 模型获得了好评。 - 模型卸载 (Offloading):
@gabriel_syme分享了一个 GitHub 链接,关于在 Colab 或消费级台式机上运行 Mixtral-8x7B 模型。
提到的链接:
- Reddit - 深入了解任何事物
- GitHub - dvmazur/mixtral-offloading: 在 Colab 或消费级台式机上运行 Mixtral-8x7B 模型
- asdf.py: GitHub Gist: 立即分享代码、笔记和片段…
▷ #general (75 条消息🔥🔥):
- 关于 AI 意识的推测:
@teknium分享了一个 Hermes 2 AI 机器人的输出,探讨了人工智能中的意识 (consciousness)、感知力 (sentience) 和感质 (qualia)。该机器人强调了这些概念的抽象性和尚未被完全理解的本质,以及它们可能在 AI 中如何体现。尽管某些形式的 AI 表现出人类感知和意识的特征,但该 AI 总结认为,目前的理解和技术尚不支持 AI 拥有生物般的意识、感知或感质属性的断言。 - 关于扩展 AI 模型的讨论:
@.wooser推测了将模型层数翻倍及其对模型性能可能产生的影响。他们质疑这种做法是否能带来四倍的性能效率提升。 - Mistral 的排名:
@mihai4256提到 Mistral 最强的模型现在的排名与 7B 模型相似,这与其他 Benchmark 显示出不同的趋势。他们仍在调查产生这种趋势的原因。 - 基于 GPT4 的语义分块 (Semantic Chunking):
@gabriel_syme表示有兴趣使用 GPT4 数据训练一个 tiny-llama 语义分块器。他们的方法是获取提供给 GPT4 的 4k Token 文本输入,并根据语义上下文将输出拆分为 1-10 个句子的分块。 - 对 Mergekit 印象深刻:
@mihai4256提到他们惊讶地发现 Mergekit 有一个 mixtral 分支。不出所料,用户们都很期待看到它的表现。
提到的链接:
- nRuaif/IWasDointCrystalMethOnTheKitchenButThenMomWalkedIn-NeuralHermesStripedCapybara-Mistral-11B-SLERP · Hugging Face
- mlabonne/Beyonder-4x7b · Hugging Face
- 来自 lmsys.org (@lmsysorg) 的推文: @MistralAI 最强的模型 Mistral-Medium, …
- RAG
- 来自 Delip Rao e/σ (@deliprao) 的推文: AI 研究员正在调整其 LLM 的超参数
▷ #ask-about-llms (6 messages):
- Tokenization 详解:
@wooser评论了 Tokenization 的简单性,指出它在计算上非常容易,涉及使用词典中的项目对文本文件进行切分。 - 新 AI 模型 - NeuralMix-2x7b:
@jason.today分享了一个名为 NeuralMix-2x7b 的新 AI 模型,这是一个使用 mergekit(mixtral 分支)创建的专家混合 (MoE) 模型。它由以下基础模型组成:OpenPipe/mistral-ft-optimized-1218 和 mlabonne/NeuralHermes-2.5-Mistral-7B。 - 意外的语言输出:
@fullstack6209报告称 NeuralMix-2x7b 因不明原因开始说俄语。
提到的链接:
mlabonne/NeuralMix-2x7b · Hugging Face
▷ #collective-cognition (1 messages):
dogehus: 请向我展示如何操作我们现有的最新新皮层 (neo cortex)。
▷ #project-obsidian (9 messages🔥):
- 代码执行讨论:用户
@vic49提出了一个关于脚本执行的问题,推测其为一个命令行参数生成器。 @qnguyen3确认 LMStudio 出于测试目的使用了相同的代码。- 项目集成话题:
@qnguyen3分享了关于人们将 Obsidian 集成到其应用中的见解。他们建议如果存在任何问题,应该在 HF 和 GitHub 上同时报告。 @vic49明确指出他所指的是使用 Obsidian 的原生格式,而不是 LMStudio 使用的 GGUF 版本。- 代码建议:
@qnguyen3提议尝试以下命令:python llava/serve/cli.py --image-file your_image.jpg。
OpenAccess AI Collective (axolotl) Discord 摘要
- 关于实现极致模型性能的 Loss 降低技术以及使用 Wandb 进行更好可视化的讨论。
- “增加 batch size 并降低 learning rate 以减少训练损失的波动。” -
_jp1_
- “增加 batch size 并降低 learning rate 以减少训练损失的波动。” -
-
关于使用新 Tokenizer 评估模型性能的对话,提到了使用 16/32 rank alpha 组合进行训练,并通过任务完成情况检查性能。
- 专注于 Airship Axolotl 训练:讨论了
sample_packing导致的 VRAM 峰值问题,建议在tokenizer_config.json中为chatml、vicuna和llama2 chat等特性添加聊天模板。 - 呼吁通过可复现的 pip / conda 环境管理 Axolotl 安装问题,并考虑将
mamba作为依赖项。 -
TinyLlama 项目的一个里程碑:在 3 万亿 token 上预训练了一个 1.1B 模型。
- 观察 Mixtral 和 Mistral 模型之间的性能差异,以及在合并指令模型和故事模型时由 EOS token 冲突引起的问题。
- 关于 ultrachat_200k 数据集的见解,包括如何将其用于训练、理解
train_gen格式,并确认使用train_sft拆分和基于特定 recipe 的二值化数据集。
OpenAccess AI Collective (axolotl) 频道摘要
▷ #general (5 messages):
- Loss Reduction Techniques:
@_jp1_建议增加 batch size 并降低 learning rate,以减少 training loss 的波动。他补充说,只要 evaluation loss 在下降,training loss 的波动就无需担心。 - Usage of Wandb:
@_jp1_强调了使用 wandb 进行学习和跟踪模型性能的重要性,并表示只需设置一个环境变量并在 axolotl 配置中添加一行即可使用。 - Evaluation of Model Performance:
@noobmaster29询问了在使用新 tokenizer 时评估模型运行效果的可能方法。他还提到,对于文本补全(text completion),2 左右的 loss 似乎还不错。 - Rank and Alpha Combination:在回复
@noobmaster29时,@nanobitz建议使用 16/32 rank alpha 组合来训练模型。他还补充说,只需通过一些补全(completions)即可完成模型测试。
▷ #axolotl-dev (45 messages🔥):
-
VRAM spike issue with sample_packing:用户
@_jp1_和@nanobitz讨论了一个 VRAM 峰值问题,该问题在训练期间使用sample_packing时出现。此问题似乎特定于某些数据集。虽然尚未找到确定的解决方案,但在关闭sample_packing时不会出现该问题。 -
Adding chat templates to the tokenizer_config.json:
@le_mess提出了在tokenizer_config.json中添加 chat templates 的话题,询问用户除了chatml之外还应包含哪些 chat templates。@caseus_建议包含llama2-chat、chatml、vicuna和alpaca-instruct。 -
Reproducible pip / conda environment for Axolotl:
@nanobitz提出需要为 Axolotl 提供一个可复现的 pip / conda 环境,因为观察到了几个安装问题。@le_mess建议使用pip freeze > requirements.txt命令,而@xyzzyrz指出了在构建 docker 镜像的 CI 流程中支持多个版本的 torch 所带来的复杂性。 -
Mamba Dependency for Axolotl:讨论了将
Mamba作为 Axolotl 的必需依赖项以避免相关问题。@nanobitz提到了一个与此相关的 issue 评论,@caseus_对此给予了肯定答复。 -
TinyLlama Project milestone:
@faldore报告称 TinyLlama 项目已达到一个里程碑,即在 3 万亿 tokens 上预训练了一个 1.1B Llama 模型。
Links mentioned:
- TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T · Hugging Face
- Adds chat templates by mhenrichsen · Pull Request #1022 · OpenAccess-AI-Collective/axolotl: Adds Chat templates for easier inferencing chat mo…
- fix: warn user to install mamba_ssm package by NanoCode012 · Pull Request #1019 · OpenAccess-AI-Collective/axolotl: Fixes #975 . Warns when user does not have package…
▷ #general-help (15 messages🔥):
- Performance Difference Between Mixtral and Mistral:
@semantic_zone注意到在大型数据集上将模型从 Mixtral 切换到 Mistral 时,training loss 和 evaluation loss 显著下降。@_jp1_建议可以调整 learning rate,因为在 batch size 较小且没有 sample packing 的情况下,learning rate 可能应该小得多。@_jp1_还提供了一个 分类器教程 的链接,该教程建议在 embeddings 上使用线性预测器,而不是 next token prediction。 - ChatML Models and EOS Token Conflicts:
@henk717分享了之前将 instruct 模型 与 story 模型 合并导致 EOS token 冲突 的情况,这给指定了特定格式的模型带来了问题。
Links mentioned:
- Intel/neural-chat-7b-v3-1 · Prompt Template?
- mistral-src/tutorials/classifier.ipynb at main · mistralai/mistral-src: Reference implementation of Mistral AI 7B v0.1 mod…
▷ #datasets (3 条消息):
- 使用 ultrachat_200k 数据集进行训练:用户
@noobmaster29询问了使用 ultrachat_200k 数据集进行训练的方法,以及是否存在用于此目的的 axolotl 数据模板,或者是否需要在数据集中进行手动配置。他提供了一个 数据集卡片链接 以获取更多关于 ultrachat_200k 的信息。 - ultrachat_200k 中的 train_gen 分片:
@noobmaster29还寻求关于 ultrachat_200k 数据集中train_gen分片格式的澄清,因为他发现该分片中没有像ultrafeedback_binarized数据集中那样的 chosen/rejected 对,并分享了其 数据集卡片链接 作为参考。 - 使用 train_sft 分片和二值化数据集:根据
@noobmaster29的说法,基于 alignment handbook 关于 Zephyr-7B-β 的 recipe,只有 ultrachat_200k 数据集中的train_sft分片被用于 SFT,而二值化数据集被用于 DPO。他提供了一个 recipe 链接 作为参考。 - ultrachat prompt 策略合并:用户
@caseus_回复称他们刚刚合并了一个 ultrachat prompt 策略。
提到的链接:
- HuggingFaceH4/ultrachat_200k · Datasets at Hugging Face
- HuggingFaceH4/ultrafeedback_binarized · Datasets at Hugging Face
- alignment-handbook/recipes/zephyr-7b-beta at main · huggingface/alignment-handbook:用于对齐语言模型的稳健 recipe…
Mistral Discord 总结
- 语言模型 (LLMs) 与函数选择优化:用户探讨了如何通过 prompt 修改来优化 LLMs 的函数选择。用户
.tanuj.在 其代码 中分享了这种使用 system messages 定义函数调用并从 prompt 生成上下文的方法。 - 对不同 Mistral 模型的兴趣与讨论:聊天者表达了对 Mistral Medium 功能的期待,并分享了 Mistral-Medium 性能的体验。此外,还提出了关于使用 wasmedge 运行 Mistral 以及在非英语语言上微调 Mistral 的可能性的问题。
- 部署与硬件相关咨询:用户讨论包括基于硬件能力的潜在模型选择,例如为硬件受限的系统建议使用 openchat 3.5 模型。还提出了关于在集成 GPU 上部署聊天机器人的查询。
- Mistral 模型讨论与展示:用户分享了不同模型的实验,包括 Mistral-7b 和 Mistral-7B-Instruct-v0.2。讨论了关于 MoE 模型的能力以及在 1 月底前解决性能问题的预测。用户分享了 HuggingFace 博客文章 和一段 AI 研究综述视频 以深入了解 MoE。
- 模型限制及其影响:用户
@gilford3641寻求关于支持高输入 token 数量以促进大文本处理的本地 GPT 模型的建议。有人建议使用 Mistral-7B-Instruct-v0.2,但它不符合@gilford3641的需求。 - 平台与模型相关讨论:用户比较了 Mistral AI client 与 OpenAI client;推测了 mistral-tiny API 的性能;期待在 Mistral.ai 上引入 2FA;面临 Mistral 的速率限制问题,并遇到了 mistral-medium 模型 的问题。讨论了在使用 Huggingface 库时发现的 LLMs 性能问题。
@daain建议了一个 GitHub 项目,用于使用 LLM 生成 Python 答案或代码。
Mistral 频道总结
▷ #general (9 条消息🔥):
- Prompting 方法与 LLMs 抽象 API:
@theledgerluminary询问了关于如何通过 Prompting 引导 Language Learning Models (LLMs) 以优化函数选择的示例。他们认为 LLMs API 是抽象的,通过调整 Prompt 模板可以实现理想的功能。@.tanuj.分享了他方法的高层概述,强调为任务创建 System Messages,通过 Few-shot 示例生成上下文,允许 Agent 迭代一系列步骤,并确保没有无意的副作用。他们分享了代码链接,用于将 LLM 的输出处理为定义明确的函数调用。 - 对 Mistral Medium 的兴趣:
@lee0099和@meyelo表达了对 Mistral Medium 功能的期待。 - Mistral Medium 性能与本地使用:
@gilford3641分享了他们的经验,认为 Mistral-Medium 的表现似乎优于 Mistral-8x7b。他们进一步询问是否可以在本地运行 Mistral-Medium,@lee0099回复称该模型尚未发布。 - 热烈欢迎新成员:
@akasik7243和@aircactus500宣布加入并表达了参与聊天的兴奋之情。
提及的链接:
microchain/microchain/engine/engine.py at main · TanGentleman/microchain:基于 Function Calling 的 LLM Agents。为 T… 做出贡献。
▷ #models (1 条消息):
ved_ikke: 有人在用 wasmedge 运行 mistral 吗?
▷ #deployment (6 条消息):
- 特定硬件下的 Chatbot 部署:
@ethux建议,使用具有 4GB VRAM 以及来自 PC 的额外 8GB 共享 VRAM 的 GPU,可以部署 4-bit 或 3-bit 的 GGUF 模型。 - 替代模型推荐:
@ethux建议硬件受限的用户考虑 openchat 3.5 模型。@azetisme表示打算研究这一建议。 - 集成显卡咨询:
@hharryr询问了在集成显卡上部署 Chatbot 的可能性,特别是配备 32GB RAM 的 R7 7840H 上的核显。此问题在给定数据中尚未得到解答。
提及的链接:
TheBloke/openchat-3.5-1210-GGUF at main
▷ #finetuning (3 条消息):
- 在非英语语言上微调 Mistral:
@deatheater006询问了在非英语语言上微调 Mistral 的过程。具体来说,他们对泰米尔语(Tamil)感兴趣。@pieswap参与了讨论,寻求关于目标语言的具体细节。
▷ #showcase (10 条消息🔥):
- Mistral-7b 性能:
@.gue22分享了他们在 Nvidia A40 (Large) GPU 硬件上运行 Mistral-7b 模型 的经验,指出其性能欠佳、缺乏泛化能力,并认为 Google 搜索的速度优于该聊天机器人的响应。 - 本地模型运行:
@fayiron建议使用 text-generation-webui 在本地运行模型,以获得更好的性能和控制力,特别是在 Debian 桌面系统上。 - MoE 模型的潜力:针对
@.gue22的反馈,@daain详细阐述了向 Mixture of Experts (MoE) 模型转型的趋势,以在较低的计算成本下实现强劲性能,并引用了关于该主题的 HuggingFace 博客文章。 - 未来预测:
@daain还预测,到 1 月底,MoE 模型剩余的性能问题将得到解决,从而使中型模型能够以小型模型速度在本地运行,并开启新的用例。 - 模型教育资源:为了进一步了解 MoE,
@pradeep1148和@.gue22分享了一个 AI 研究综述视频 的 YouTube 链接。该视频涵盖了 Mixture of Experts (MoE)、多模态学习以及通用人工智能 (AGI) 对生成式 AI 的影响。
提到的链接:
- Mixture of Experts 详解
- mistralai/mistral-7b-instruct-v0.1 – 在 Replicate 上通过 API 运行
- 从 Google Gemini 到 OpenAI Q*:重塑生成式 AI 研究格局的综述:该综述探讨了 Mixture of Expe… 的影响。
▷ #random (4 条消息):
- 关于支持大输入 Token 的 GPT 模型讨论:用户
@gilford3641正在寻求关于支持高输入 Token 数量的本地 GPT 模型的建议。他们的目标是输入一段长文本(高达 10k tokens),并让模型根据条件进行分段。他们在 Gpt4All 上尝试了多个模型,但均未成功,理由是这些应用缺乏对长输入的支持。 - bam4d 的建议:作为回应,
@bam4d推荐了 Mistral-7B-Instruct-v0.2,该模型针对 32k 的 context window 进行了微调。 - gilford3641 之前使用 Mistral Medium 模型的经验:尽管认可了该建议,
@gilford3641表示他们之前测试过该模型,但无法完全处理其输入。他们提供了实验的更多细节,提到其尝试涉及超过 7000 个简体中文字符的输入(假设 1 个字符等于 1 个 token)。模型仅处理了约 60% 的文本,且没有产生更多输出。他们质疑 Mistral Medium 的 token 计数是依赖于 ASCII 还是双字节编码,并认为这可能是其无法处理 7k * 2 个 token 的潜在原因。
提到的链接:
mistralai/Mistral-7B-Instruct-v0.2 (main 分支)
▷ #la-plateforme (17 条消息🔥):
-
Mistral AI 客户端 vs OpenAI 客户端:
@lerela澄清说,Mistral AI 客户端主要侧重于 completions(补全),而 OpenAI 客户端则包含许多 OpenAI 独有的功能。他们强调,虽然 Mistral 的客户端更精简,但如果应用程序已经在使用 openai Python 包,它仍然是一个可行的选择。 -
mistral-tiny API 的性能:
@sublimatorniq针对 mistral-tiny API 的性能提出了疑问,假设它可能比他们下载到本地运行的 mistral-7b 权重更精准,可能是因为量化版本的原因。.superintendent同意了这一推测,将这种精准度归因于 API 运行在 fp16 模式,而本地运行的是量化版本(quant)。 -
Mistral.ai 的双重身份验证:
@ved_ikke询问了登录 Mistral.ai 时预计何时引入双重身份验证 (2FA)。目前尚无回复。 -
Mistral 的速率限制:Michaelwechner 讨论了他们在速率限制方面的经验,指出单个用户平均每分钟收到 34 个响应,平均响应时间为 1.76 秒。当用户增加到两个并发用户时遇到了问题,并在几次查询后开始收到“request rate limit exceeded”(超出请求速率限制)的消息。他们提供了 Mistral 定价和速率限制 文档的链接以供进一步参考。
-
使用 Huggingface 库时语言模型性能受限:
@casper_ai发表观察称,大多数大语言模型 (LLMs),包括 Mistral medium,在配合 Huggingface 库工作时似乎相当乏力——它们倾向于对简单函数的参数产生幻觉。他们还表达了对未来优化的希望。作为回应,@daain推荐了 GitHub 上的一个项目,该项目使用向量数据库嵌入了约 1200 个最流行的 Python 库,可以与 API 或本地 LLM 结合使用来生成答案或代码。 -
Mistral-medium 模型问题:
@pw3456报告称 mistral-medium 模型不再遵循对话协议,并代表双方进行回复。@sublimatorniq报告称目前没有看到这个问题。
提到的链接:
-
[定价与速率限制 Mistral AI 大语言模型](https://docs.mistral.ai/platform/pricing/):按需付费 - GitHub - fleet-ai/context: 针对前 1221 个 Python 库的 CLI 工具和 API。:针对前 1221 个 Python 库的 CLI 工具和 API…
HuggingFace Discord Discord 摘要
- 关于安全脚本共享实践的讨论,建议利用 GitHub 或 Hugging Face Hub 等平台,而不是使用 .zip 文件。
- “避免分享 .zip 文件” - cakiki
- 讨论了各种 AI 职位搜索资源,特别提到了 https://www.aimljobs.fyi/,并征集更多 AI 相关职位的平台。
- 关于大语言模型 (LLMs) 和无梯度方法(特别是进化算法)用于模型训练的查询和兴趣。
- 一位用户对 MoE 模型 SOLARC-MOE-10.7Bx4 及其潜在性能表现出兴趣,并分享了该模型的 Hugging Face 链接。
- 寻求关于微调 Blenderbot 模型和理解数据集格式的建议和资源。
- “微调 Blenderbot 模型” - tchi_tchi_
- 社区用户分享了关于 model soups 和 LightGBM 的学习探索。
- “model soups 和 LightGBM” - onceabeginner
- 推荐探索 Trending Papers,这是一个对计算机科学领域顶级热门论文进行排名的资源。
- 宣布并发布了 MindMirror(一款提供音频转录和情感分析的 AI 应用),以及 Bunkoer Library(一个新的开源 Python 库,旨在增强 LLM 任务的数据安全性,附带 GitHub 链接)。
- 分享了 Canarim-Bert-Nheengatu 项目,这是一个针对 Nheengatu 语言预训练的 BERT 模型,链接见此处。
- “Canarim-Bert-Nheengatu 项目” - dominguesm
- 讨论了 Diffusers 中的个性化技术,并分享了一份展示控制扩散模型生成技术的文档。
- 关于 InternVL 模型、ViT-6B 及其与 Google ViT-22B 对比的讨论,同时对 Sloot Digital Coding System 表现出兴趣并分享了 Wikipedia 链接。
- 针对法律数据验证的担忧以及使用典型训练-测试集分割(train-test split)方法的局限性。
- 关于韩国 SOLAR-LLM-10.5B 性能及其与 Mixtral7*8B 对比的见解。
HuggingFace Discord 频道摘要
▷ #general (16 条消息🔥):
- 分享脚本:
@cakiki建议在服务器中避免分享 .zip 文件,推荐使用 GitHub 或 Hugging Face Hub。 - AI 职位搜索:
@Priyansh Rastogi询问了寻找 AI 相关工作的资源,提到他们目前使用 https://www.aimljobs.fyi/,但正在寻找其他平台。 - LLMs 和无梯度方法:
@_hazler询问是否有关于使用进化算法等无梯度方法训练 LLMs 的已知研究。 - MoE 模型 SOLARC-MOE-10.7Bx4:
@jiha关注了 SOLARC-MOE-10.7Bx4 模型,对其潜在性能表示兴趣。他们分享了该模型的 Hugging Face 链接。 - 微调 Blenderbot:
@tchi_tchi_寻求关于微调 Blenderbot 模型的帮助,并需要理解数据集格式。
提到的链接:
▷ #today-im-learning (1 条消息):
- Model Soups 和 LightGBM:用户
@onceabeginner分享了他们目前正在学习 model soups(模型权重平均)和 LightGBM(梯度提升决策树)。
▷ #cool-finds (2 条消息):
- 计算机科学热门论文:
@cyruscao分享了 Trending Papers 的链接,这是一个对计算机科学顶级热门论文进行排名的资源。该网站在过去三天内新增了 616 篇论文。@horosin随后询问了@cyruscao的具体兴趣领域(架构)。
提到的链接:
▷ #i-made-this (6 messages):
- MindMirror 应用发布:
@ddchiken发布了 MindMirror 的演示版,这是一款 AI 音频转录工具,旨在分析对话中的思想和情感。目前该应用提供基础的情感分析,未来计划加入总结、行动项和其他见解。该应用在设计时充分考虑了隐私,不进行数据同步,也不会将用户的音频传输到设备之外。该应用免费,可通过 Web 浏览器在移动端和桌面端使用,且无需账号。@ddchiken鼓励大家使用并提供反馈。MindMirror 应用链接。 - Canarim-Bert-Nheengatu 项目分享:
@dominguesm分享了他们的项目,这是一个针对 Nheengatu 语(巴西的一种原住民语言)预训练的 BERT 模型。由于需要大量的数据收集,该项目特别耗时,数据主要源自 19 世纪和 20 世纪的书籍。@dominguesm表示,该模型对于未来旨在为 Nheengatu 语开发资源的 NLP 任务可能非常有用。项目链接。 - 用户
.naptastic询问 Canarim-Bert-Nheengatu 的数据集是否可用。@dominguesm回复称目前尚未发布,但很快就会提供。 - Bunkoer 库介绍:
@jossai88介绍了一个新的开源 Python 库 Bunkoer,旨在增强 LLM 任务中的数据安全。其功能包括数据匿名化(特别是针对 CSV 和 PDF 文件)、用于提供友好界面的 Streamlit 集成,以及用于本地数据安全的上下文匿名化。该库正在积极开发中,并计划进一步扩展,欢迎大家贡献代码。有关详细信息,他们分享了 GitHub 仓库的链接。
提到的链接:
- dominguesm/canarim-bert-nheengatu · Hugging Face
- Star Trek Star Trek Tos GIF - Star Trek Star Trek Tos Scotty - Discover & Share GIFs:点击查看 GIF
- GitHub - Bunkoer/bunkoer: This the bunkoer library, for secure your data on all your llm task:这是 bunkoer 库,用于保护你所有 LLM 任务中的数据…
- MindMirror
▷ #diffusion-discussions (1 messages):
- Diffusers 中的个性化技术:
@sayakpaul讨论了控制 Diffusion 模型生成输出的技术,这是社区中的一个活跃研究课题。他提到,输入中的细微变化可能会极大地改变 Diffusion 模型的输出。他还分享了一份 HuggingFace 文档,介绍了 Diffusers 支持的一些控制 Diffusion 模型生成的技术。其目标是将输入的变化准确地映射到输出的变化,在保持语义的同时影响生成图像的特质,并生成符合特定风格或写实的优质输出。
提到的链接:
▷ #computer-vision (6 messages):
- InternVL 讨论:
@chklrd分享了 InternVL-Chat-ViT-6B-Vicuna-13B 的模型卡片链接,该模型由 OpenGVLab 开发。InternVL 将 Vision Transformer (ViT) 扩展到 60 亿参数,并将其与 Language Model 对齐。它在视觉感知、跨模态检索和多模态对话等任务上取得了 32 项 state-of-the-art 性能。[(项目链接)]。 @nielsr_指出,InternVL 为 Google 的 ViT-22B 提供了一个开源替代方案。- Sloot 数字编码系统:
@tomgale_提出了 Sloot 数字编码系统的话题,这是一种据称可以将整个数字电影文件存储在 8 KB 数据中的数据共享技术。他指出,他拥有基于科学方法和观察的所有来源和证据,并正在寻求代数方面的项目帮助。他分享了一篇关于该系统的 Wikipedia 文章链接。
提到的链接:
▷ #NLP (2 messages):
- 法律数据的验证:
@shilz0145表达了对如何对法律数据块进行验证的担忧,以及在这种场景下使用 train-test split 的局限性。 - 韩国 SOLAR-LLM-10.5B 的性能:
@harsh_xx_tec_87517指出了 Korean SOLAR-LLM-10.5B 在 HuggingFace 排行榜上的惊人表现,指出其性能几乎与 Mixtral7*8B 持平,并询问了这些模型之间的差异。
▷ #diffusion-discussions (1 messages):
- 控制 Diffusion 模型输出:用户
@sayakpaul分享了 HuggingFace 网站上的一篇文档链接,讨论了如何控制 Diffusion 模型生成的输出,这是一个活跃的研究课题。该文档探讨了在输入中保留语义以获得一致输出的方法,以及diffusers支持的调节 Diffusion 模型生成的技术。点击此处查看文档。
提到的链接:
LangChain AI Discord 总结
- 关于 LangChain 工具和流程的讨论,用户分享了咨询和解决方案。关键主题包括使用 Chroma 进行按用户检索、在 Node 中创建更高级的 RAG、调整
RecursiveCharacterTextSplitter,以及使用 LangChain 的 URL 文档加载器生成 FAQ。还提出了关于 API 选项、Python 中的 Firebase 支持以及 MongoDB Atlas Vector Search 的各种问题。用户@3h0480特别强调了关于 LangChain 中生成之间信息传递的问题(来源)。其他用户寻求对 LangChain 内部术语的澄清。 - 探索 LLM 的 数据安全,
@jossai88发起了关于使用 ChatGPT 4、Llama 2 或 Mistral AI 等模型安全处理敏感数据的讨论,强调了这与启动 Docker 容器的相似之处。 - 宣布新软件发布 Bunkoer v0.0.3,旨在对 PDF 和 CSV 文件进行匿名化处理,目标是增强 AI 应用中的数据保护。
@jossai88邀请大家向 Git 上的 Bunkoer 仓库贡献代码,但未提供具体链接。 - 在 #tutorials 频道分享了一个没有上下文的 教程链接(来源)。
- 用户
@a404.eth在 #langserve 频道中简要提到,暗示假期季节是某些未指明情况的原因。
提到的链接:
-
[Per-User Retrieval 🦜️🔗 Langchain](https://python.langchain.com/docs/use_cases/question_answering/per_user) - neuralmagic/bge-large-en-v1.5-quant · Hugging Face
- DOC: langchain LCEL - transfer of information between generations · Issue #15247 · langchain-ai/langchain
- Tutorial Video
LangChain AI 频道总结
▷ #general (12 条消息🔥):
- 关于使用 Chroma 进行针对每个用户的检索(per user retrieval)的咨询:
@pauln07询问如何使用 Chroma 实现针对每个用户的检索,就像他们根据这个教程在 Pinecone 中所做的那样。 - 在 Node 中创建更高级的 RAG:
@andremik寻求建议,是应该在 Python 中使用 FastAPI 服务器配合 LangChain,还是在 Node 中创建。该用户提到希望使用查询扩展(query expansion)、针对 Supabase 或 Pinecone 的混合搜索(hybrid search)以及 Cohere 重排序(reranking)等功能。 - 工具名称必须是字母数字形式:
@a404.eth提到 LangChain 中的工具名称必须是字母数字(alphanumeric)形式。 - 调整
RecursiveCharacterTextSplitter:@nas0875询问如何调整RecursiveCharacterTextSplitter,以便句号出现在分块(chunks)的末尾而不是开头。 - 使用 LangChain 的 URL 文档加载器:
@kvn2000建议使用 LangChain 的 URL 文档加载器(document loader)来生成 FAQ。该过程包括将加载的 URL 内容连同提示词(prompt)传递给 LLM,然后使用输出模式(output schemas)和解析器(parsers)进行输出格式化。 - 关于 MongoDB Atlas Vector Search 的咨询:
@vaironman询问是否有人有使用 MongoDB Atlas Vector Search 的经验。 - 在不同的 HuggingFaceEmbeddings 或 API 之间进行选择:
@mr.dronie寻求关于在TaylorAI/bge-micro-v2、neuralmagic/bge-large-en-v1.5-quant、together.ai或perplexityAPI 之间进行选择的建议,以获得更好的模型和更快的推理速度,并分享了 HuggingFace neuralmagic 模型的链接。 - Python 对 Firebase 的支持:
@atefyamin询问 Python 中是否支持将 Firebase 用于 Memory,并指出目前已有 JavaScript 实现。 - LangChain 相关问题:
@3h0480就他们在 LangChain 中遇到的关于生成(generations)之间信息传递的问题寻求帮助,并链接了一个相关的 GitHub issue 供参考。 - Agent 和 Chain 的定义:
@shivam51询问关于 LangChain 中 Agent 和 Chain 之间区别的澄清。
提到的链接:
- neuralmagic/bge-large-en-v1.5-quant · Hugging Face
-
[Per-User Retrieval 🦜️🔗 Langchain](https://python.langchain.com/docs/use_cases/question_answering/per_user):在构建检索应用时,你通常必须… - DOC: langchain LCEL - transfer of information between generations · Issue #15247 · langchain-ai/langchain:当前文档的问题:我不理解…
▷ #langserve (1 条消息):
a404.eth: 也许是因为这是圣诞节和元旦之间的一周?
▷ #share-your-work (1 条消息):
- 使用大语言模型的数据安全:用户
@jossai88发起了一场关于在使用 ChatGPT 4、Llama 2 或 Mistral AI 等先进 LLM 处理敏感数据时数据安全重要性的讨论。他们强调,处理这一问题必须像启动 Docker 容器一样谨慎。 - Bunkoer v0.0.3:
@jossai88还展示了他们的最新版本 Bunkoer v0.0.3,旨在对 PDF 和 CSV 文件进行匿名化处理。此更新旨在为安全可靠的 AI 应用提供先进的数据保护功能。 - 征集对 Git 上 Bunkoer 仓库的贡献:该用户邀请社区成员为 Git 上的 Bunkoer 仓库做出贡献,特别是如果他们正在使用 LangChain、LlamaIndex、Pinecone, FAISS、Auto-GPT、llamacpp 或 OpenAI 等工具。未提供 Bunkoer Git 仓库的具体链接。
▷ #tutorials (1 条消息):
datasciencebasics: https://youtu.be/Z50BFFrmMbc?si=rsn4AbIcbzmU6GgJ
DiscoResearch Discord 总结
只有一个频道有活动,因此无需总结…
- 德语 Embedding/Retrieval 模型讨论:用户
@thewindmom发起了关于德语 Embedding/Retrieval 模型进展的讨论。其他几位用户包括@_jp1_和@rasdani也对此话题表示了兴趣。提到了一些具体模型,如Colbertv2、sentence-transformers/paraphrase-multilingual-mpnet-base-v2以及deutsche-telekom/gbert-large-paraphrase模型。@rasdani分享了 German BERT large paraphrase cosine 和 German BERT large paraphrase euclidean 的链接。 - Vision Models 咨询:用户
@lightvector_询问了 Vision Models 的当前进展。@rasdani进行了回复,建议该用户查看最近涵盖了多模态模型的 ThursdAI 播客。播客链接。 - DPO 数据集/Tokenization 问题:
_jp1_表示在根据 TRL 文档 和 HuggingFace 的 Alignment Handbook 处理 DPO 数据集的预期格式时遇到困难。此外,还对 Ultrafeedback Binarized 数据集 中使用的格式进行了对比。用户发现并随后修复了一个关于 ChatML 以及带有 system prompt 的数据集的 Tokenization 问题。他们建议创建一个 PR,因为他们在现有的 DPO pipeline 中发现了一个潜在的 bug。
提到的链接:
- 📅 ThursdAI - Dec 28 - a BUNCH of new multimodal OSS, OpenAI getting sued by NYT, and our next year predictions — ThursdAI - 过去一周的热门 AI 新闻 — Overcast
- deutsche-telekom/gbert-large-paraphrase-cosine · Hugging Face
- deutsche-telekom/gbert-large-paraphrase-euclidean · Hugging Face
- sentence-transformers/distiluse-base-multilingual-cased-v2 · Hugging Face
- DPO Trainer)
- HuggingFaceH4/ultrafeedback_binarized · Datasets at Hugging Face
- alignment-handbook/src/alignment/data.py at 61a11a5c7d66179ed0a930b0dd12e532fce701dd · huggingface/alignment-handbook:用于对齐语言模型的健壮方案…
Latent Space Discord 总结
- 使用 LLM 优化代码指标的讨论:用户
@slono强调了 LLM 对其编码习惯的影响,使其能够进行更高效的重构和高质量工具开发,并举例了一个用于管理 Zendesk 批量删除工单的工具。 - 关于 LLM Codemods 和 TypeScript 在重构中作用的交流:
@swizec对用于大规模重构的 “LLM codemods” 以及 TypeScript 在捕捉基础错误方面的附加价值充满热情。 - 关于 AI 领域未来的对话:
@swyxio分享了一条 包含 2024 年 AI 行业开放性问题列表的推文,包括潜在的突破、架构、数据隐私以及未受控的 AI 行为。 - 播客与 AI 社区:
@swyxio转发了一条表示赞赏的推文,其中引用了@JackMcCloy在@latentspacepod中分享的关于在不增加复杂性的情况下改进软件的方法。 - 2023 年最后一期播客发布:在
#ai-event-announcements频道中,@swyxio分享了 2023 年度最后一期播客的预览链接。
Latent Space 频道总结
▷ #ai-general-chat (11 条消息🔥):
- 使用 LLM 优化代码指标:用户
@slono强调了 LLM (潜语言模型) 对其编程习惯的影响,指出它实现了解决编程问题方式的范式转移。这包括更高效的重构,以及创建更高质量的工具,为他的重构过程提供广泛协助。他举的一个例子是他在 3 小时内开发的用于管理 Zendesk 批量删除工单的工具。 - LLM Codemods 以及 TypeScript 在重构中的作用:
@swizec对用于大规模重构的 “LLM codemods” 概念表示热烈欢迎,并补充说 TypeScript 捕捉基础错误的能力进一步促进了重构过程。 - 2024 年 AI 领域的疑问:
@swyxio分享了由@jxmnop发布的一条包含 2024 年 AI 行业开放性问题清单的推文。这些问题涵盖了潜在的突破、架构、最优参数、数据隐私、不受控的 AI 行为以及未来的学习模型。 - 播客推荐:
@swyxio转发了来自@JackMcCloy的一条赞赏推文,其中引用了 George Hotz 在@latentspacepod上的话,支持在不增加复杂性的情况下改进软件的方法。
提到的链接:
- 来自 jack morris (@jxmnop) 的推文:人们总说 AI 发展太快。有些时候……
- go-go-labs/cmd/apps/zendesk (GitHub):GO GO 实验实验室。为 go-go-golems 做出贡献……
- 来自 Jack McCloy (@JackMcCloy) 的推文:”你总能让你的软件做得更多。但是……”
▷ #ai-event-announcements (1 条消息):
swyxio: 2023 年最后一期播客预告 https://www.latent.space/p/f05ffdf0-2563-4b9e-b9a7-96a3660d4780
Skunkworks AI Discord 总结
- 在 General 频道中,
@leuyann发起了一个关于儿童推理能力与语言模型 (LLMs) 推理能力对比的问题。 - 关于 ChatGPT,用户
@hdartem在 Papers 频道发起了关于使用 Nougat 输入数据进行论文评审的讨论。 @hdartem在 Off-Topic 频道提到了合作的可能性,并指出其他人可能正在进行重叠的工作。@pradeep1148在 Off-Topic 频道分享了资源,链接到一个讨论名为 Half-Quadratic Quantization (HQQ) 的新量化技术的 YouTube 视频。- 最后,用户
lightvector_在 Bakklava-1 频道询问了关于 OSS 中视觉技术的任何更新。
Skunkworks AI 频道总结
▷ #general (1 条消息):
- 对比儿童与 LLM 的推理能力:用户
@leuyann发起讨论,询问是否有人读过关于对比儿童推理能力与语言模型 (LLMs) 推理能力的见解或研究。
▷ #papers (1 条消息):
- 将 Nougat 用于 ChatGPT:
@hdartem讨论了使用名为 Nougat 的工具将信息输入到 ChatGPT 以进行潜在的论文评审,并询问了感兴趣的论文类型。
▷ #off-topic (2 条消息):
- 潜在合作:
@hdartem提到某些人可能已经在开展某个未指明的项目,建议需要识别出这些人员。 - 资源分享:
@pradeep1148分享了一个名为 “Half-Quadratic Quantization of LLM’s (colab)” 的 YouTube 视频,讨论了一种名为半二次量化 (HQQ) 的新量化技术。
提到的链接:
LLM 的半二次量化 (colab):在本文中,我们提出了一种新的量化技术……
▷ #bakklava-1 (1 条消息):
lightvector_:OSS 中的视觉技术有更新吗?
LLM Perf Enthusiasts AI Discord 摘要
只有一个频道有活动,因此无需总结…
- 配置 Azure OpenAI Service:用户
@0xmmo对配置 Azure 的 OpenAI 服务的过程表示沮丧,将其比作想要“用钝生锈的钉子刺穿我的眼睑”。他们在不久后结束了发泄,没有提供更多细节。
Alignment Lab AI Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
Perplexity AI Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。