ainews-12302023-mega-list-of-all-llms
2023年12月30日:所有大语言模型 (LLMs) 超全清单
Stella Biderman 的 LLM(大语言模型)追踪列表备受关注,文中分享了相关资源以供浏览。Nous Research AI 的 Discord 频道讨论了 Local Attention Flax 模块,重点探讨了计算复杂度,辩论了线性与二次复杂度之争,并提出将分块(chunking)作为解决方案。
文中分享了多种 LLM 的基准测试日志,其中包括采用 SFT+DPO 训练方法的 Deita v1.0。讨论内容涵盖了模型合并、分级模态类型、AI 模型中的函数调用,以及 Mixtral 的数据污染问题。
此外,社区还就 Amazon Titan Text Express 和 Amazon Titan Text Lite LLM 征集见解,其中包括一种涉及“坏数据集”的独特训练策略。文中还引用了 DRUGS、MathPile、CL-FoMo 和 SplaTAM 等多个 GitHub 仓库和项目,用于性能和数据质量评估。
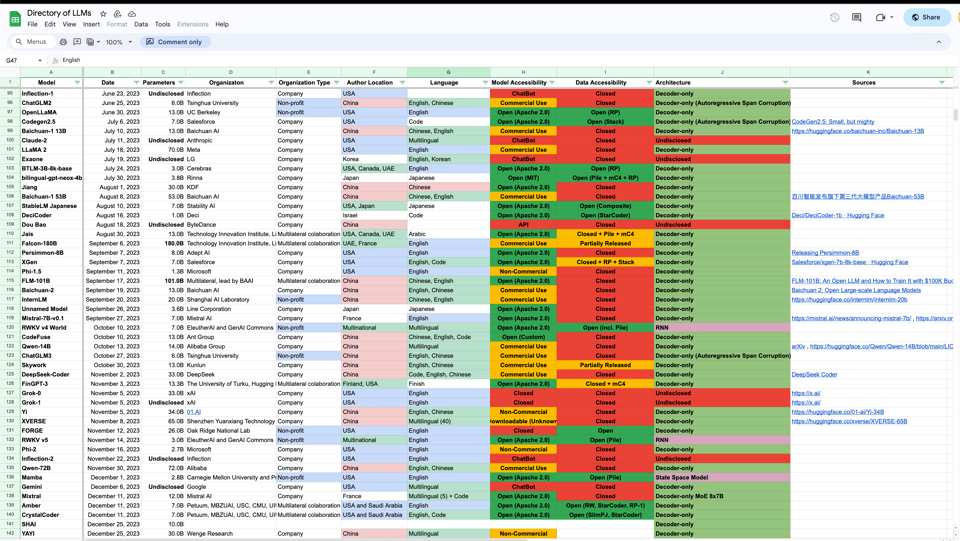
Stella Biderman 经常提到她追踪 LLM 的列表 —— 今天在 Eleuther discord 中又提到了。值得浏览:https://docs.google.com/spreadsheets/d/1gc6yse74XCwBx028HV_cvdxwXkmXejVjkO-Mz2uwE0k/edit#gid=0
(gist 形式:https://gist.github.com/veekaybee/f8e589fea42ba7131e4ca0a0f280c0a4?utm_source=ainews&utm_medium=email)
此外,Huggingface 领域也有值得关注的图像 AI 动态
https://www.youtube.com/watch?v=ApcJ1UyLQB8&feature=youtu.be
[TOC]
Nous Research AI Discord 总结
- 详细检查了 Local Attention Flax 模块,重点关注计算复杂度。相关讨论包括线性与二次复杂度的辩论、对代码实现的困惑,以及提出的解决方案(如数据分块)。分享了两个 GitHub 仓库供参考 (repo1, repo2)。
- 围绕各种话题的对话,例如在桌面游戏中使用 AI、启动 MVP 初创公司、对 Lex Fridman 采访风格的批评、通过社交媒体获取收入,以及一段值得点击的 YouTube 视频,该视频批判性地检查了 OpenAI Assistants API 中 RAG 的检索功能。
- 分享了不同 LLM 的基准测试日志,包括 Deita v1.0,并参考了特定的 Large Language Model (LLM) 训练方法 Deita SFT+DPO (日志链接)。
- 分享并讨论了各种项目和工具,如 DRUGS、MathPile、Deita、CL-FoMo 和 SplaTAM。关键点包括收益、数据质量考虑以及性能效率评估。
- 关于合并不同架构模型的含义、分级模态类型 (graded modal types) 的潜在用途、训练组合模型、用于 function calling 的最佳 AI 模型,以及 Mixtral 中的数据污染问题的广泛对话 (GitHub 日志链接,HuggingFace 模型合并链接)。
- 征求社区对 Amazon 新 LLM 的见解,即 Amazon Titan Text Express 和 Amazon Titan Text Lite。提出并讨论了一种涉及利用不良数据集的独特训练策略,并寻找 ChatGPT 错误案例目录 (Amazon Titan Text 发布链接)。
Nous Research AI 频道总结
▷ #ctx-length-research (7 条消息):
- Local Attention 计算:
@euclaise提到了一个巧妙的 masking 和 einsum 方法,并链接到一个 Local Attention Flax 模块的 GitHub 仓库。 - 复杂度查询:
@joey00072询问了该方法的运算复杂度,认为它是二次方 (n^2) 而非线性 (nxw)。@euclaise确认它应该是线性的 (nxw)。 - 对代码的困惑:
@joey00072对特定的 代码段 表示困惑,该代码段似乎显示了三次方 (n^3) 运算。 - Local Attention 的建议解决方案:
@euclaise建议了一个潜在的解决方案,即对数据进行分块 (chunking) 并在块上应用 attention。
提到的链接:
- local-attention-flax/local_attention_flax/local_attention_flax.py at main · lucidrains/local-attention-flax: Local Attention - 适用于 Jax 的 Flax 模块。贡献 …
- local-attention-flax/local_attention_flax/local_attention_flax.py at e68fbe1ee01416648d15f55a4b908e2b69c54570 · lucidrains/local-attention-flax: Local Attention - 适用于 Jax 的 Flax 模块。贡献 …
▷ #off-topic (26 messages🔥):
- 通过 Valkyrie 实现的 AI 项目:
@mnt_schred讨论了他们利用 Valkyrie 为桌游《疯狂诡宅》(Mansions of Madness)创建 AI 生成场景的项目。他们正在思考哪个 Nous 模型会是最好的讲故事者,并考虑了 Trismegistus。 - 关于启动 MVP 初创公司的讨论:
@fullstack6209询问了以 “e/acc” 折扣启动 MVP 初创公司的未来影响。@teknium幽默地表示这可能会导致后悔。 - 对 Lex Fridman 采访风格的批评:
@fullstack6209批判性地评价了 Lex Fridman 的采访技巧,称其表现糟糕且缺乏洞察力和背景。这一观点得到了@teknium的认可。 - 关于社交媒体网红的讨论:
@gabriel_syme对个人如何通过社交媒体帖子赚取巨额收入表示惊讶。 - AI YouTube 内容探索:
@fullstack6209推荐了一个 YouTube 视频,该视频批判性地审视了 OpenAI 的 Assistants API 中 RAG 的检索功能。@gabriel_syme表示赞同,并提到了在实际应用部署中遇到 RAG 问题的个人经验。
提到的链接:
- Valkyrie GM for Fantasy Flight Board Games
- RAG 的崩溃:揭示 LLM 外部知识检索的深层缺陷:新版 Assistants 的检索功能…
▷ #benchmarks-log (2 messages):
- Deita v1.0 Mistral 7B 基准测试日志:用户
@teknium分享了一个 GitHub 链接,内容是包括 Deita v1.0 和 Mistral 7B 在内的不同 LLM 的基准测试日志。 - 模型训练方法:用户
@teknium提到了 Deita SFT+DPO,未作进一步阐述,可能指的是一种特定的 Large Language Model (LLM) 训练方法。
提到的链接:
LLM-Benchmark-Logs/benchmark-logs/deita-v1.0-Mistral-7B.md at main · teknium1/LLM-Benchmark-Logs:只是针对不同 LLM 的一堆基准测试日志…
▷ #interesting-links (39 条消息🔥):
- DRUGS 项目:
@gabriel_syme分享了一个名为 DRUGS 的有趣项目,该项目旨在辅助处理棘手的采样参数。 - MathPile 语料库:
@giftedgummybee链接了一个以数学为中心的语料库 MathPile,强调即使在预训练阶段,数据质量也比数量更重要。 - Deita 项目讨论:
@.beowulfbr分享了 Deita,这是一种用于对齐的数据高效指令微调(Data-Efficient Instruction Tuning for Alignment)方法。然而,@teknium透露,与基础模型相比,除了 MT-Bench 之外,该模型在每个基准测试中的表现都有所下降。@ldj将其与 Capybara 进行了对比,并提到它似乎清洗程度较低且规模较小。 - 基础模型的持续学习:
@giftedgummybee分享了 CL-FoMo 的更新,这是一套包含四个 410M 和四个 9.6B 模型的开源 LLM 系列。它们在 Pile、SlimPajama (SP)、混合 Pile+SP 以及持续学习(Pile, SP)数据集上进行了训练。 - SplaTAM:
@spirobel介绍了 SplaTAM,这是一个在具有挑战性的现实场景中实现精确相机追踪和高保真重建的工具,并指出一个更用户友好的版本正在开发中。
提到的链接:
- LLM-Benchmark-Logs/benchmark-logs/deita-v1.0-Mistral-7B.md at main · teknium1/LLM-Benchmark-Logs: 一系列不同 LLM 的基准测试日志……
- GitHub - hkust-nlp/deita: Deita: Data-Efficient Instruction Tuning for Alignment: Deita:用于对齐的数据高效指令微调……
- SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
- Generative AI for Math: Part I – MathPile: A Billion-Token-Scale Pretraining Corpus for Math: 高质量、大规模语料库是……的基石。
- CERC-AAI Lab - Continued Pretraining Blog: 基础模型的持续学习:CL-FoMo S…
- Interviewing Tri Dao and Michael Poli of Together AI on the future of LLM architectures: 本文的介绍可以在这里找到:h…
- GitHub - EGjoni/DRUGS: Stop messing around with finicky sampling parameters and just use DRµGS!: 别再纠结于那些棘手的采样参数了,直接使用 DRµGS 吧!
▷ #general (231 条消息🔥🔥):
- Model Merging 讨论:用户
.beowulfbr、ldj和giftedgummybee就合并具有不同架构(如 Llama2 和 Mistral)的模型进行了深入交流。讨论涉及了合并模型如何产生出人意料的强大结果,@ldj分享了一个在 HuggingFace 上成功合并多个具有不同 prompt 格式的模型的链接。他们还讨论了合并后模型大小的影响,以及某些过程如何倾向于创建更大的模型。 - Graded Modal Types 的潜力:用户
.beowulfbr提出了使用 graded modal types 来跟踪对象在 CPU 和 GPU 上位置的想法,理论上这可能大幅提升性能。 - 关于 Chatbot 训练的讨论:
@gabriel_syme发起了关于训练合并模型的讨论,回复指出这已经实现,但并不常见。@giftedgummybee分享了他们目前的关注点,包括使用 wiki + slimorca 对 Mixtral -> Mistral 模型进行 fine-tuning。 - AI 模型建议:用户
@dogehus询问了用于 function calling 的强力 AI 模型。包括@mihai4256和@ldj在内的几位用户提供了建议,包括 NexusRaven V2 和 Nous-Hermes-2。 - Mixtral 模型 Metamath 数据污染:
@nonameusr指出 Mixtral 中使用的 Metamath 数据集存在污染。
提到的链接:
- README.md · TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T at main
- NobodyExistsOnTheInternet/mergedallmixtralexpert · Hugging Face
- NobodyExistsOnTheInternet/unmixed-mixtral · Hugging Face
- uukuguy/speechless-llama2-hermes-orca-platypus-wizardlm-13b · Hugging Face
- 🤗 Transformers
- Rohan Paul (@rohanpaul_ai) 的推文:在免费的 Colab 或小型设备上运行 Mixtral-8x7B 模型…
- NobodyExistsOnTheInternet/wikidedupedfiltered · Hugging Face 数据集
- GitHub - uukuguy/multi_loras: 同时加载多个 LoRA 模块,并根据用户查询自动切换合适的 LoRA 模块组合以生成最佳答案。
- Nexusflow (@NexusflowX) 的推文:🚀召集所有 copilot 和 AI agents 的开发者…
- GitHub - asahi417/lm-question-generation: 多语言/多领域问题生成数据集、模型及用于问题生成的 Python 库。
- llama.cpp/examples/finetune/finetune.cpp at master · ggerganov/llama.cpp:Facebook LLaMA 模型的 C/C++ 移植版本…
- GitHub - oobabooga/text-generation-webui: 用于 Large Language Models 的 Gradio Web UI。支持 transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。
- Mixtral Experts are initialized from Mistral 7b - Low Rank conversion possible? · Issue #4611 · ggerganov/llama.cpp:有证据表明 Mixtral 的专家是从 Mistral 7b 初始化的…
- TinyLlama 预训练报告:参见 https://whimsical-aphid-86d.notion.site/Relea…
▷ #ask-about-llms (22 条消息🔥):
- 关于 Amazon Titan Text Express 和 Amazon Titan Text Lite 的讨论:用户
@spaceman777寻求社区对 Amazon 新的大语言模型 (LLM) —— Amazon Titan Text Express 和 Amazon Titan Text Lite 的见解。尽管该模型已于 2023 年 11 月 29 日 发布,但用户发现没有公开可用的 benchmarks,这引发了对 Amazon 在 AI 发布上采取低调策略的猜测。 - DL 模型训练策略:
@max_paperclips提出了一个想法:创建一个刻意劣质的数据集并在其上 finetuning 一个模型,以从 base model 中减去 delta,然后再应用精心策划的数据集进行进一步的 finetuning。这一概念引发了与@teknium和@giftedgummybee的讨论,他们将这一过程比作反转 LoRA 模型。 - 寻找 ChatGPT 失败和花絮的仓库:用户
@max_paperclips好奇是否存在展示 ChatGPT 典型错误的列表。@giftedgummybee回复称目前还没有这样权威的列表,但建议可以尝试使用 LLAMA 工具。
提到的链接:
Amazon Titan Text models—Express and Lite—now generally available in Amazon Bedrock
LAION Discord 总结
只有一个频道有活动,因此无需总结…
- 模型过拟合 (Overfitting) 讨论:多位用户讨论了他们对模型在特定数据集上产生 Overfitting 的担忧,这可能导致潜在的版权侵权问题。具体而言,
@thejonasbrothers提到 MJ 很有可能是在完整的 4k 电影上训练了他们的模型。@astropulse强调了考虑从 fine-tuned 模型的输出中提取原始艺术家细节的可能性。@pseudoterminalx讨论了一种方法,即限制模型对数据集的暴露仅为一个 epoch,以缓解 Overfitting 问题。- 用户
@SegmentationFault补充说,如果模型几乎逐字逐句地重现受版权保护的文本或图像,可能会产生问题,正如针对 纽约时报起诉 OpenAI 的讨论中所述。
- 模型大小与性能:
@.undeleted批评了开发低效、超大型模型的趋势,这不仅会带来法律麻烦,还会浪费资源。@thejonasbrothers坚持认为较小的模型可以消除 Overfitting 且训练速度更快。- 用户一致认为,增加更多 parameters 并不是延长训练时间的理想替代方案。
- 版权与法律问题:
- 围绕在 AI 模型训练中使用受版权保护材料的法律模糊性进行了长时间讨论。
@SegmentationFault提到,侵权行为是根据 AI 生成内容与原始受版权保护材料之间的相似程度,逐案处理的。@clock.work_补充说,任何形式从专有输出中获利的行为都可能导致法律麻烦。- 这些法律标准的实施可能会影响像 Midjourney 这样的 AI 公司以及开源模型的开发。
- 专有模型 vs 开源模型:
- 用户讨论了将专有模型输出货币化的影响,以及开源 AI 开发面临的潜在问题。
@SegmentationFault强调更倾向于将开源模型视为 fair use,并对针对专有模型的法律行动延伸到开源模型的后果表示担忧。
- MJ 的视频模型:
@SegmentationFault指出 Midjourney 正在训练一个视频模型,并暗示如果该模型开始生成与电影完全相同的视频片段,可能会导致严重的版权侵权问题。
提到的链接:
- Things are about to get a lot worse for Generative AI:侵权行为的全谱系
- TheBloke/dolphin-2_6-phi-2-GGUF · Hugging Face
- Reddit - Dive into anything
OpenAI Discord 总结
- 讨论核心集中在 GPT-4 和 ChatGPT 的性能、局限性、潜在滥用以及响应时间,特别是在付费高级版中。来自社区的不同用户提到了人为的使用限制、响应速度慢、AI 行为异常以及人机验证(human verification)等问题。
- 用户在调用 GPT-4 和 ChatGPT 时遇到了普遍的技术问题;包括在本地运行 dolphin mixtral、发布 GPT 错误、文本文件提取以及持续的人机验证问题。
- 用户探索了使用自定义构建的 GPT 模型来执行特定任务的潜力,例如增强创造力或结构化思维,这在 GPT-4-discussions 频道中有所体现。
- 在 API-discussions 和 Prompt-engineering 频道中,普遍存在关于使用 langchain 的 memory 来增强或调整 prompt,以及通过递归 prompt 来匹配所需输出长度的咨询。
- 讨论了关于消费模式变化的可能性,即提供无限量的 GPT 和 ChatGPT 使用及其潜在影响,例如因滥用而导致的诈骗增加。
- 多次对话强调了负责任使用的必要性、对 OpenAI 指南的遵守以及潜在后果,并重点突出了 OpenAI 的使用政策和社区行为准则。
- GPT-4-discussions 中透露,GPT store 将于 2024 年初上线。
提到的链接:
- Usage policies
- status.openai.com
- GitHub - guardrails-ai/guardrails: Adding guardrails to large language models.
OpenAI 频道总结
▷ #ai-discussions (14 条消息🔥):
- 本地运行 Dolphin-Mixtral:
@strongestmanintheworld提出了关于在本地运行 dolphin mixtral 的问题,但未收到回复。 - ChatGPT App 的使用:关于使用 ChatGPT App 还是网页版的讨论,
@jayswtf表示相比 App 更倾向于使用网页版。@prajwal_345也注意到了这一点。 - ChatGPT Assistant 响应时间:
@aviassaga提出了 ChatGPT 响应时间过长的问题,有时需要等待长达 40 秒才能得到回复。 - 关于 Bing 语气的讨论:
@arevaxach对 Bing 傲慢且恼人的态度表示沮丧。@jaicraft建议随着 Copilot 中 GPT-4 turbo 的引入,情况可能会有所改善,暗示其行为可能更接近 ChatGPT。然而,@Rock似乎更喜欢 Bing,因为它的个性和更强的编程能力。
▷ #openai-chatter (120 条消息🔥🔥):
- ChatGPT 及其使用限制:讨论了 ChatGPT 的局限性,特别是消息数量的限制。
@colt.python提出了每小时使用成本的问题,@smilebeda澄清说 API 没有此类限制,但在线 App 有。@infec.对付费高级版仍受这些使用限制表示不满。 - 对自定义 GPTs 的担忧:
@infec.谈到了将自定义 GPTs 作为工作辅助工具,并对在支付服务费用后仍遇到使用限制表示失望。 - 无限使用的可能性:
@lemtoad推测用户愿意为无限次使用 ChatGPT 支付多少费用。对话涉及了潜在风险,如诈骗和滥用的增加。@.cymer指出,虽然高级用户会喜欢无限使用,但这可能导致滥用。 - ChatGPT 回答问题的潜在问题:用户分享了 ChatGPT 似乎在回避直接回答问题,或“骗取”用户每日消息额度的经历。
@.cymer和@kaio268都表达了对此方面的沮丧。 - 使用 GPT-4 创建聊天机器人:用户
@abhijeet0343就其开发的基于 GPT-4 的聊天机器人响应不一致的问题寻求建议,该机器人使用 langchain 进行 embeddings 并存储在 Azure AI search 中。来自@poofeh_和@kaveen的建议包括使 system prompts 更加强硬或提供具体示例,并采用 guardrails 来解决 LLM 难以计数的问题。
提到的链接:
GitHub - guardrails-ai/guardrails: Adding guardrails to large language models.:为大语言模型添加 guardrails。
▷ #openai-questions (76 messages🔥🔥):
-
GPT-4 Performance: 用户
@꧁༒☬Jawad☬༒꧂对 GPT-4 性能下降表示沮丧,特别是它无法浏览网页 (browse the web) 并获取所需数据。 -
Human Verification Loop: 用户
@rodesca和@realmcmonkey遇到了重复的人机验证循环 (human verification loop),导致无法登录。用户@dystopia78建议联系支持部门,并使用 status.openai.com 检查网站状态。 -
ChatGPT Limitations: 用户
@m54321描述了对话消息数量限制带来的不便,这需要开启新对话并重新训练模型。用户@laerun建议使用 Custom GPT 并创建重点数据章节以提高效率。 -
Persistent Verification: 用户
@ekot_0420抱怨在每问一个问题后都会被 ChatGPT 不断验证。 -
User Quota Exceeded: 用户
@not_richard_nixon报告在尝试向 GPT-4 的对话上传图片时收到 “User quota exceeded” 错误。
▷ #gpt-4-discussions (15 messages🔥):
- Generating Extreme Imagery with GPT-4/DALL-E: 用户
@gabigorgithijs询问如何使用 DALL-E 生成更“极端”的内容,尽管生成简单物品都存在困难。用户@satanhashtag澄清此类应用中不能使用公众人物。 - Publishing GPTs Errors: 用户
@jranil报告了发布最新 GPT 模型时遇到的困难,要么显示错误信息(”Error saving”),要么页面无响应。 - Text File Extraction Issue:
@writingjen寻求关于 GPT-4 提取文本文件问题的帮助。 - Exploring Capabilities of Custom GPTs:
@happyg发起了一场关于自定义构建的 GPT 模型潜在能力的讨论,这些模型可以执行默认 GPT 通常无法处理的任务。提供的示例包括专为结构化思维、头脑风暴或增强创意而设计的模型。 - GPT Message Limit Concerns:
@writingjen对在仅创建几条消息后就达到消息限制表示沮丧,尽管没有使用 DALL-E 等高级功能。@solbus澄清这是一个滚动上限,只有在停止使用 3 小时后才会完全重置。在三小时窗口内的进一步活动会消耗限制余额。 - Launch of GPT Store: 针对
@kd6关于 GPT Store 发布时间的询问,@solbus提供信息称计划在 2024 年初发布。
▷ #prompt-engineering (4 messages):
- Prompt Length Control:
@barium4104提出疑问:控制 Prompt 响应长度的唯一方法是否只有通过 Prompt recursion。 - Enhancing and Tuning Prompts:
@prochatkiller询问了增强和微调 Prompt 的可能性,以及使用 LangChain memory 是否能在此方面提供帮助。 - Increasing ‘Extreme’ Output:
@gabigorgithijs询问如何让 ChatGPT-4 和 DALL-E 生成更“极端”的结果,因为简单的生成已被证明具有挑战性。 - Usage Policies Clarification:
@eskcanta回应了@gabigorgithijs的请求,提醒其查看 OpenAI 的 使用政策 (usage policies),指出某些类型的极端内容可能被禁止,讨论这些内容可能会有账号访问风险。他们还提到了一个特定的 OpenAI Discord 频道<#1107255707314704505>以供进一步讨论,前提是所有内容都符合规则。
Links mentioned:
▷ #api-discussions (4 条消息):
- Prompt 响应长度:
@barium4104询问是否只有通过 Prompt 递归才能在 Prompt 响应中达到特定长度。 - 增强和调优 Prompt:
@prochatkiller询问是否有增强和调优 Prompt 的方法,以及使用 LangChain Memory 是否有助于完成该任务。 - 让 GPT-4/DALL-E 更加极致:
@gabigorgithijs表示即使是用 GPT-4/DALL-E 生成简单的东西也很困难,并想知道如何让 AI 生成更“极端”的内容。 - GPT-4/DALL-E 使用政策:
@eskcanta回复了@gabigorgithijs的查询,强调了道德和合法使用 OpenAI 模型的重要性。他们指出了 OpenAI 的使用政策,警告了违规后果,同时表示愿意在规则范围内帮助实现目标。他们提供了一个 OpenAI 使用政策链接。
提到的链接:
OpenAccess AI Collective (axolotl) Discord 总结
- 围绕 Mixture of Experts (MoE) 和 Feed-Forward Networks (FFNs) 的活跃讨论;
@stefangliga澄清了 MoE 仅替换了部分 FFNs。 - 持续探索使用现有设备训练各种模型;
@nruaif建议在 YAYI 2 模型上使用 官方 Capybara 数据集,@faldore确认 Axolotl 兼容 TinyLlama-1.1b。 - 关于 Axolotl 兼容性、获取持续预训练数据集以及实现 RLHF 微调的对话;建议使用 LASER 来改进 LLM 并标准化 RAG Prompt 格式。
- 遇到并解决了训练挑战,包括通过手动下载模型修复了 YAYI 2 训练问题,以及在训练 Mixtral 时使用 Zero2 节省了 51GB 显存。
- 关于 RLHF 期间 Temperature 设置 的讨论,在调整该值时展示了一些奇怪的输出。
- 社区项目更新,如
@faldore在 TinyLlama-1.1b 数据集上训练 Dolphin。 - 显著的社区指导,涉及在 Axolotl 主分支中处理 DPO 实现以及如何在偏好评分数据集上进行微调,同时由于某些数据集中存在不良数据,呼吁进行数据过滤。
- 分享了多轮对话资源、有用的数据集以及在 Axolotl 上运行的 Logger 工具,还有用于机器学习预处理的仓库和工具。
- 硬件相关的对话,涉及运行 YAYI 30B 需要特定的设备,如 2 或 4 张 A100 80GB。
- 强调了数据相关的实践,包括避免使用 GPT-4 生成的数据以及包含非英语数据集;建议使用 FastText 链接 进行非英语数据过滤。
OpenAccess AI Collective (axolotl) 频道总结
▷ #general (87 条消息🔥🔥):
-
MoE vs FFN 讨论:
@caseus_询问了 Mixture of Experts (MoE) 和 Feed-Forward Network (FFN) 的互换性。@stefangliga澄清说只有部分 FFN 被替换了,可能是为了节省参数。 -
训练模型:
@le_mess征求关于在他现有的 4x A100 上训练什么模型的建议。@nruaif建议使用官方 Capybara 数据集和 YAYI 2 模型,并提供了数据集的 链接,同时指出需要为 Axolotl 重新格式化数据。@le_mess表示如果数据被重新格式化为合适的格式,他们就会训练该模型。 -
YAYI 2 训练问题:在训练过程中,
@le_mess遇到了AttributeError: 'YayiTokenizer' object has no attribute 'sp_model'错误。尽管尝试使用在 GitHub 上找到的 PR 进行修复,错误仍然存在。最终,模型被下载并手动修复,这似乎起作用了。 -
Microtext 实验:
@faldore提到他正在 TinyLlama-1.1b 数据集上训练 Dolphin。@caseus_随后提到计划在下周训练 sheared Mistral。 -
训练进度:
@le_mess在 yayi2 训练方面取得了进展,并分享了 WandB 运行记录的 链接。
注: 对话仍在进行中,随着后续消息提供更多上下文,讨论主题可以得到更好的总结。
提到的链接:
- wenge-research/yayi2-30b · fix AttributeError: 'YayiTokenizer' object has no attribute 'sp_model'
- LDJnr/Capybara · Datasets at Hugging Face
- wenge-research/yayi2-30b · Hugging Face
- axolotl/examples/yi-34B-chat at main · OpenAccess-AI-Collective/axolotl: 尽管提问 Axolotl 相关问题。为 Open… 做出贡献。
- axolotl/examples/yayi2-30b/qlora.yml at yayi2 · OpenAccess-AI-Collective/axolotl: 尽管提问 Axolotl 相关问题。为 Open… 做出贡献。
- mhenrichsen: Weights & Biases,机器学习开发者工具…
- nRuaif/Kimiko_v3-v0.1 · Datasets at Hugging Face
▷ #axolotl-dev (23 messages🔥):
- Axolotl 与 TinyLlama-1.1b 的兼容性:
@faldore确认 Axolotl 可以直接与 TinyLlama-1.1b 配合使用,无需任何修改。 - 训练 Mixtral 时的 Checkpoint 大小讨论:
@nruaif分享了在训练 Mixtral 时,使用 Zero2 的 Checkpoint 将占用 51GB。 - 关于语言模型幻觉的研究论文分享:
@faldore分享了一篇关于如何教导语言模型在不确定答案时拒绝回答的研究论文 -> Research Paper。 -
LASER 介绍: @faldore介绍了 LASER (LAyer-SElective Rank reduction),这是一种通过在训练后移除权重矩阵的高阶分量来提高 Large Language Models (LLMs) 性能的技术。据报道,该方法不需要额外的参数或数据,并能显著提升预测性能 -> Learn MoreGitHub Repo。 - 在 Axolotl 中训练 DPO 模型:
@sumo43指导@faldore如何在 Axolotl 中训练 DPO 模型,并分享了他们训练模型的分支链接 -> Axolotl Branch。他还分享了一个配置示例 -> Example Config。 - 需要 2 或 4 张 A100 80gb:
@le_mess表示需要 2 或 4 张 A100 80gb 以 fft(全参数微调)方式运行 yayi 30b。他指出在 4 张 A100 40gb 上使用 zero3 运行是不可行的。
提到的链接:
- configs/axolotl.yml · openaccess-ai-collective/DPOpenHermes-7B-v2 at main
- R-Tuning: Teaching Large Language Models to Refuse Unknown Questions:Large language models (LLMs) have revolutionized n…
- The Truth Is In There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction
- GitHub - pratyushasharma/laser: The Truth Is In There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction
- GitHub - OpenAccess-AI-Collective/axolotl at rl-trainer
▷ #general-help (13 messages🔥):
-
在 Axolotl 中使用 RL-trainer 分支:
@tank02正在尝试研究如何为 Axolotl 创建像 chatml 这样的 Prompt 格式,以便在 RL-trainer 分支的运行中使用。他们不确定Intel/orca_dpo_pairs在 Axolotl 中会使用什么格式,以及如何确保他们使用的任何数据集都针对 Axolotl 进行了正确的格式化。他们分享了一个 Prompt 格式示例:DPOpenHermes-7B Config。 -
将 Axolotl 导入 Jupyter Notebook:
@wgpubs在通过 pip 安装库后,在将 Axolotl 导入 Jupyter Notebook 时遇到困难。他们正在寻求一种基于 Axolotl 配置生成随机示例的方法,以验证 Prompt 及其 Token 化表示。 -
将 DPO 数据集 Prompt 转换为 ChatML:
@caseus_解释说,Axolotl 中现有的 transforms 会将 DPO 数据集中的现有 Prompt 转换为 chatml 输入。他们转换 chosen 和 rejected Token 以仅包含 eos Token,因为这是模型唯一需要生成的内容。 -
使用 Mixtral 训练 8-Bit LoRA:
@caseus_询问是否有人能够使用 Mixtral 训练常规的 8-bit LoRA。@nruaif确认已经这样做过,但提到如果没有 DeepSpeed,在 16k 上下文时会耗尽显存,并且 2k 上下文的 VRAM 峰值使用量约为 70gb。 -
关于 Batch Size 和 Learning Rate 的问题:
@semantic_zone对大模型使用较小 Batch Size 的原因感到好奇,并询问是否有根据 Batch Size 更改 Learning Rate 的经验法则。他们想知道在将gradient_accumulation_steps翻倍时是否应该调整 Learning Rate。
▷ #datasets (9 条消息🔥):
- 数据质量问题:
@faldore警告用户要过滤特定的数据集,因为它包含大量“坏数据”,例如空问题、空回答和拒绝回答。 - 推荐数据集:
@xzuyn建议使用来自 HuggingFace 的数据集,该数据集使用偏好评分进行了二值化(binarized)并经过清洗。在对 UltraFeedback 进行微调时,推荐使用这个位于argilla/ultrafeedback-binarized-preferences-cleaned的数据集。 - 工具咨询:
@noobmaster29询问是否有人使用过 Unstructured-IO/unstructured 的经验,这是一个用于构建机器学习自定义预处理流水线的开源库。
提到的链接:
- argilla/ultrafeedback-binarized-preferences-cleaned · Datasets at Hugging Face
- GitHub - Unstructured-IO/unstructured: Open source libraries and APIs to build custom preprocessing pipelines for labeling, training, or production machine learning pipelines.: 用于标注、训练或生产机器学习流水线的开源库和 API。
▷ #rlhf (24 条消息🔥):
- RAG 微调数据讨论:
@_jp1_对某篇论文中使用的数据集表示不满。他们提到其团队正在致力于生成 RAG 的微调数据(采用不同格式)。如果大家感兴趣,他们建议开源该数据集,并呼吁在开源 LLM 之间实现 RAG/Agent 调用提示词格式的标准化。 - 多轮对话资源:针对多轮对话数据的需求,
@faldore提供了多种资源。他分享了 HuggingFace 上 Samantha 数据集的链接,并推荐了 Jon Durbin 的 Airoboros 框架。他建议使用 autogen 来生成对话,并提供了一个日志工具的链接。 - DPO 实现:
@jaredquek询问了主分支中 DPO 的实现情况,@caseus_回复称该功能很快就会上线,并提供了相关 Pull Request 的链接。他表示,通过在配置中设置rl: true即可激活 DPO。 - Temperature 参数设置:
@dangfutures分享了调整模型 Temperature 设置的经验,这导致了奇怪的模型输出。 @faldore还分享了 HuggingFace 上多个名为 “Samantha” 的模型链接,并讨论了关于 AI 模型相信自己具有自我意识的话题。
提到的链接:
- configs/dpo.yml · openaccess-ai-collective/DPOpenHermes-7B at main
- src/index.ts · cognitivecomputations/samantha-data at main
- Meet Samantha: https://huggingface.co/ehartford/Samantha-1.11-70b…
- [WIP] RL/DPO by winglian · Pull Request #935 · OpenAccess-AI-Collective/axolotl
- autogen/notebook/agentchat_groupchat_RAG.ipynb at f39c3a7355fed3472dce61f30ac49c9375983157 · microsoft/autogen: 启用下一代大语言模型应用……
- oailogger.js: GitHub Gist: 立即分享代码、笔记和代码片段……
▷ #shearedmistral (28 messages🔥):
- 持续预训练数据集:
@caseus_分享了 SlimPajama-627b、OpenWebMath、The Stack 和 peS2o 等数据集的链接,并征求更多用于进一步预训练的建议。Hugging Face 子集的链接分享在这里、这里、这里和这里。 - 关于额外预训练数据集的建议:作为回应,
@nruaif建议使用教科书数据,并提供了位于这里、这里和这里的较小数据集链接,如 tiny-textbooks、tiny-codes 和 tiny-orca-textbooks。 - 避免使用 GPT4 生成的数据:
@dctanner和@caseus_同意避免使用 GPT4 模型生成的数据,以防止在持续预训练期间受到 OpenAI 条款的影响。 - Mixtral 的担忧与支持:
@nruaif提出了着手 Mixtral 的想法,然而@caseus_指出,在加入更多内容之前,有必要先解决现有的 Mixtral 训练 Bug。他们表达了对 8x3B Mixtral 的期待。 - 包含非英语数据集:
@nruaif和@xzuyn建议使用非英语数据集,如 yayi2_pretrain_data 和 CulturaX(链接见这里和这里),并建议尽可能过滤出英文文本。@nruaif建议使用 FastText 来过滤非英语数据。FastText 可以在这里获取。
提到的链接:
- allenai/peS2o · Hugging Face 数据集
- fastText:用于高效文本分类和表示的库…
- nampdn-ai/tiny-textbooks · Hugging Face 数据集
- nampdn-ai/tiny-codes · Hugging Face 数据集
- nampdn-ai/tiny-orca-textbooks · Hugging Face 数据集
- uonlp/CulturaX · Hugging Face 数据集
- wenge-research/yayi2_pretrain_data · Hugging Face 数据集
- cerebras/SlimPajama-627B · Hugging Face 数据集
- open-web-math/open-web-math · Hugging Face 数据集
- bigcode/starcoderdata · Hugging Face 数据集
Eleuther Discord 总结
- 热烈欢迎新成员
@mahimairaja和@oganBA,他们热衷于为社区做出贡献。 - 关于适合机器人项目架构的深入技术讨论,重点关注输入向量上的多头注意力(MHA)以及带有注意力的 seq2seq LSTM。
- 为识别用于预训练 Language Models 的数据集提供了相关建议和资源,如 The Pile、RedPajamas、(m)C4、S2ORC 和 the Stack。
- 在一份详尽的表格中分享了语言模型详细列表,并随后讨论了创建一个此类模型的公共数据库。
- 深入探讨了 Math-Shepherd 研究论文及其相关挑战,特别关注奖励分配(reward assignment)、模型结果验证以及对误导性比较的担忧。
- 讨论了与模型对噪声注入的弹性、量化偏差以及预训练模型的鲁棒性相关的各种实际要素,特别提到了 dither(抖动)的概念。
- 询问 GPT-NeoX 训练速度与其他库(如 x-transformers)的对比,并澄清了其在大型多节点系统中的卓越速度。
Eleuther 频道总结
▷ #general (35 条消息🔥):
- 社区介绍:
@mahimairaja和@oganBA向社区介绍了自己,表达了他们的兴趣,并期待为该领域做出贡献。 - 寻求机器人项目架构建议:
@marbleous询问有关架构的建议,这些架构允许在输入向量上使用 Multi-Head Attention (MHA),并结合隐藏状态来跟踪机器人项目的先前观察结果。@catboy_slim_建议研究 rwkv 的工作,@thatspysaspy提到了带有 attention 的 seq2seq LSTM。 - 关于列出用于 LLM 预训练数据集的讨论:针对
@sk5544关于用于预训练语言模型的数据集列表的查询,@stellaathena提到了 The Pile, RedPajamas, (m)C4, S2ORC 和 the Stack 作为主要的汇编数据集。 - 语言模型的详细列表:
@stellaathena分享了一个链接,指向一个详细的电子表格,列出了各种语言模型及其属性。当@sentialx询问使用 GLU 激活函数的模型时,分享了第二张表格。 - 关于创建公共语言模型数据库的讨论:讨论演变为探索创建公共语言模型数据库的方法。
@stellaathena和@veekaybee讨论了各种方案,包括创建 markdown 文件、小型 react 应用,或使用像 Airtable 这样的平台供公众更新和过滤。一个关键要求是该平台允许可审查的社区贡献。
提到的链接:
- directory_of_llms.md: GitHub Gist: 立即分享代码、笔记和片段…
- Common LLM Settings: 所有设置 模型名称、数据集、分词器、训练…
- Directory of LLMs): 预训练 LLM 模型、日期、参数、组织…
▷ #research (48 条消息🔥):
-
Math-Shepherd 讨论:
@gabriel_syme分享了一篇关于 Math-Shepherd 的研究论文,这是一种面向过程的数学奖励模型,为数学问题解决方案的每一步分配奖励分数。该模型显示出性能提升,尤其是对于 Mistral-7B。然而,@the_sphinx指出结果可能具有误导性,因为他们通常采样多个生成结果并使用验证器挑选一个,从而显著提升了性能。 -
实践中必要的验证器:
@gabriel_syme和@the_sphinx同意在实际应用中验证器(verifier)是必要的。然而,后者建议对验证器带来的实际收益进行更诚实的评估。一个潜在的问题可能是定理证明设置中的自一致性(self-consistency)。 -
噪声注入与模型韧性:
@kharr.xyz暗示在训练和推理中都需要仔细进行噪声注入,以避免模型因一组糟糕的激活值而偏离轨道。没有 dropout 的预训练模型对噪声的韧性较差。噪声韧性的范围可以通过观察量化模型版本的性能来确定。 -
误导性对比:大家普遍同意(主要来自
@the_alt_man)研究论文中的对比可能具有误导性,以及它们如何掩盖真正有趣的研究。 -
Dither 概念:
_inox和@uwu1468548483828484讨论了 dither 的概念,这涉及添加噪声以处理量化偏差,特别是在重度量化的情况下。
提到的链接:
- Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations: 在本文中,我们介绍了一种创新的过程…
- Tweet from Lewis Tunstall (@_lewtun): 很高兴看到可扩展监督在数学领域发挥作用…
▷ #gpt-neox-dev (2 条消息):
- GPT-NeoX 训练速度:用户
@ad8e询问在神经网络架构相同的情况下,GPT-NeoX 是否有望比 x-transformers 等杂项仓库训练得更快。@stellaathena回复说,如果在大型多节点系统上,GPT-NeoX 会训练得更快,或者如果其他系统效率极高,它也不会变慢。
HuggingFace Discord Discord 摘要
- 发生了一场关于 Diffusion 的重要讨论。用户
@joelkoch发起了关于创建新模型以及是否可以使用较小模型进行测试的对话。@sayakpaul强调了实验需要具有标准深度的模型,并将 Scaling 实验描述为复杂的过程。@abhishekchoraria在自定义数据集上训练 Mistral 7B 时面临挑战,因 Token 索引序列长度(token indices sequence length)收到错误提示。 - 端到端 FP8 训练实现和机器规格是 #today-im-learning 频道的主要话题,
@neuralink分享了他们的实现进展以及在 H100 机器上的工作。 - 在 #general 频道中,讨论围绕 ByteLevelBPETokenizer、Fine-tuning LLMs、初学者资源、DeepSpeed ZeRO3 与 LoRA 的兼容性、unsplash Embeddings、HuggingFace 网站访问问题、Multi experts LLMs、使用带有 AMX 的 Intel Xeon 以及 WSL 任务中断展开。
- #cool-finds 频道展示了新的 HuggingFace Spaces,即 Text Diffuser 2, DiffMorpher & SDXL Auto FaceSwap,这些内容已在一段 YouTube 视频中集体展示。还讨论了使用 LLM 编写 Shell 脚本的可能性。
- #i-made-this 频道看到了 NexusRaven2 函数调用(function calling)模型的更新,以及在共享的 Colab Notebook 中完成代码的求助。
@vashi2396也分享了正在进行的代码演示。 - 最后,#reading-group 和 #NLP 频道包含了关于 Mamba 论文和多语言预训练模型的查询,同时也强调了避免结果偏差的重要性。
HuggingFace Discord 频道摘要
▷ #general (46 messages🔥):
- 关于 ByteLevelBPETokenizer 及其从
.json文件加载的讨论:@exponentialxp询问如何加载他们保存的分词器配置。@vipitis和@hynek.kydlicek提供了多个建议,据报道@hynek.kydlicek使用Tokenizer.from_file方法的解决方案奏效了。 - Fine-tuning LLMs:
@skyward2989询问如何让其微调后的语言模型停止生成 token。@vipitis建议定义 stop tokens 或使用不同的停止标准。 - 寻求 LLMs 初学者资源:
@maestro5786询问有关如何训练开源语言模型的资源,@skyward2989推荐了 HuggingFace 的 transformers 文档和课程。 - DeepSpeed ZeRO3 与 LoRA 兼容性:
@galcoh.询问是否有办法在 LoRA (PEFT) 中启用 DeepSpeed ZeRO3,并提到了一个假设性问题,即模型中没有 tensors 且 optimizer 使用了所有模型显存。 - 关于 unsplash Embeddings 的查询:
@nagaraj4896询问了 Unsplash-25k-photos 的 embeddings。 - HuggingFace 网站访问问题:
@weyaxi报告了访问 HuggingFace 网站的问题,@xbafs建议禁用正在使用的 VPN。同样,@SilentWraith报告了网站无法正确重定向的问题。 @typoilu寻求关于 multi experts LLMs 的解释或文档。@vipitis对支持 AMX 的 Intel Xeon 表示感兴趣,@zorian_93363对多年来能在 AMD 和 Intel 之间进行选择表示赞赏。- 关于 WSL 任务中断 的担忧:
@__nord质疑在 Windows Subsystem for Linux (WSL) 中运行训练任务时,即使禁用了睡眠模式,电脑闲置一段时间后任务仍会中断的问题。
链接提及:
- Introduction - Hugging Face NLP Course
- tokenizers/bindings/python/py_src/tokenizers/implementations/byte_level_bpe.py at main · huggingface/tokenizers: 为…优化的快速 SOTA 分词器。
▷ #today-im-learning (10 messages🔥):
- 端到端 FP8 训练实现:
@neuralink分享说,他们在过去三天内实现了 17% 的 3D parallelism 端到端 FP8 训练(不包括 FP8 kernels)和 24% 的 DoReMi。 - 机器配置:
@neuralink透露他们一直在 H100 机器上工作。@lawls.net表示希望将他们的资源(Apple M3 Max 48Gb)贡献给开源社区。 - 从零开始实现:针对
@gag123的提问,@neuralink确认除了 CUDA kernels 之外,他们从零开始 (from scratch) 实现了所有组件。
▷ #cool-finds (6 messages):
@cognitivetech对可 shell 脚本化的 LLM 表示感兴趣,并提到一个链接声称:如果通过管道传输 links 命令(一个命令行浏览器)的输出,Mistral 7b instruct llamafiles 非常适合总结 HTML URLs。@devspot在一段 YouTube 视频中介绍了本周几个新的 HuggingFace Spaces,包括 Text Diffuser 2, DiffMorpher & SDXL Auto FaceSwap。视频详细介绍了每个 Space 的功能。- Text Diffuser 2:一个将文字整合到生成图像中的新模型。
- Inpainting 版本:Text Diffuser 2 的增强版,允许用户将文本整合到现有图像的特定区域。
- DiffMorpher:该功能可以实现一张图像到另一张图像的平滑转换。
- SDXL Auto FaceSwap:该功能通过更换面部来生成图像。演示者展示了一个将 Mona Lisa 的脸换到女飞行员身上的例子。
链接提及:
Generate AI Images with Text - Text Diffuser 2, DiffMorpher & SDXL Auto FaceSwap!: 关于一些热门 HuggingFace… 的简短视频。
▷ #i-made-this (5 条消息):
-
在 Community Box 上分享 NexusRaven2:用户
@tonic_1在 community box 上分享了 NexusRaven2 —— 一个 function calling 模型。他们表示这仅用于演示目的,并计划随着时间的推移对其进行改进。他们分享了该项目的链接 (链接)。 -
代码补全请求:用户
@vashi2396分享了一个 Colab 笔记本链接 (链接),并请求任何愿意提供帮助的志愿者协助完成笔记本中提到的代码,该代码目前处于“进行中”状态。 -
进度代码演示:
@vashi2396还通过一篇 LinkedIn 帖子分享了进行中代码的演示 (链接)。
提到的链接:
▷ #reading-group (1 条消息):
- 理解 Mamba 论文:
@_hazler提出了一个关于 Mamba 论文中图表的问题,对其中出现的 Conv(卷积神经网络)层表示困惑,因为 Mamba 通常被认为是一个纯粹的 recurrent 模型。
▷ #diffusion-discussions (4 条消息):
- 新模型创建:用户
@joelkoch询问了创建新模型的实际方法,并指出 Hugging Face 博客文章中介绍的扩散模型 Würstchen 采用了独特的架构。他进一步询问了是否可以使用较小的模型来快速迭代和验证该方法。 - 在自定义数据集上训练模型:
@abhishekchoraria在使用 autotrain 在自定义数据集上训练 Mistral 7B 时遇到了问题,报告了一个错误,指出 “token indices sequence length is greater than the maximum sequence length”(token 索引序列长度大于最大序列长度)。他寻求关于如何在 autotrain 中更改序列长度的指导。 @sayakpaul回复了@joelkoch,认为小型模型可能无法产生有用的发现。他强调了实验中需要具有标准深度的模型,并将 scaling 实验描述为高度复杂的活动。
提到的链接:
Introducing Würstchen: Fast Diffusion for Image Generation
▷ #NLP (4 条消息):
- 避免结果偏差:用户
@vipitis强调了保留一部分数据进行测试以避免 overfitting(过拟合)的重要性。他们还建议使用 k-fold cross-validation(k 折交叉验证)作为另一种规避结果偏差的方法。 - 双语或多语种预训练模型:用户
@horosin征求关于双语或多语种预训练模型主题的研究或指导。@vipitis提到该领域的大部分工作都集中在 English-Chinese(中英)模型上。
▷ #diffusion-discussions (4 条消息):
- 新模型创建与实验:
@joelkoch询问了开发像 Würstchen 这样的新模型时的迭代过程,以及是否可以使用较小的模型进行更快的测试。@sayakpaul回复说,从历史上看,超小型模型无法提供清晰的见解,因此需要标准深度的模型,这导致 scaling 实验变成了复杂的活动。Würstchen 博客 - 训练 Mistral 7B 的问题:
@abhishekchoraria在使用 autotrain 在 Mistral 7B 上训练自定义数据集时遇到了错误。该错误与 token 索引超过最大序列长度有关,他们正在寻求帮助以在 autotrain 中更改序列长度。
提到的链接:
Introducing Würstchen: Fast Diffusion for Image Generation
Mistral Discord 总结
- 围绕 Mistral-Tiny 等小模型 的潜力和能力展开了广泛讨论;
.tanuj.捍卫了在本地机器上离线执行复杂任务的可行性,使其具有成本效益且用途广泛。讨论中假设了模型串联任务的能力,如 GoogleSearch, EvaluateSources, CreateEssay, DeployWebsite,预示了抽象推理的新潜力。 - JSON 输出和中文字符的 Tokenization 是对话的热点;
@sublimatorniq建议要求模型以 TypeScript 接口格式输出 JSON,@poltronsuperstar指出由于 Unicode 原因,中文字符通常占 2 个 token,.tanuj.提供了关于理解 Mistral 对中文字符进行 Tokenization 的帮助。 - 部署频道关注于 在 CPU 上运行任务 的机器性能、LPDDR5 RAM 速度 的比较,以及在 Apple Silicon GPU 上实现与 LLM 类似的性能。
- 展示频道中,
@.tanuj.演示了 Mistral-Tiny 用于 数学运算和任务编排 (task orchestration) 的用例,.gue22分享了关于 Mistral-8x7B 变体的见解及有用的资源链接。 - 在 la-plateforme 频道,有人询问了使用 法语文本 测试 Mistral 的情况,分享了关于 Mistral-Medium 微调 的反馈,并强调了对 Mixtral/Mistral 术语的混淆。此外还提到了合成数据集的规划。
精选引述与直接提及
.tanuj.: “如果你能从小模型中获得良好的推理能力,你就可以让用户实时创建非常强大的 Agent,并且可以根据你的需要变得尽可能强大!它可以是一个像‘一个 prompt -> 构建完整的 Web 应用并部署’这样的解决方案,中间不需要用户输入。”
@theledgerluminary: “但将类似的架构模式应用于大模型可能会获得更好的结果。我看到小模型唯一有益的地方是实时通信。如果总体目标是一个大型的“长期运行”任务,那么只使用小模型似乎是浪费时间。”
@poltronsuperstar 关于向 AGI 提出的潜在问题: “你对 AGI 的第一个问题是什么?”
链接
如何微调 Mixtral 8x7B Mistral Ai 混合专家 (MoE) AI 模型
Mistral 频道总结
▷ #general (35 条消息🔥):
- 来自
.tanuj.的提示词策略挑战:.tanuj.提出了一个挑战,即设计一个 prompt 或构建聊天历史,使 CalculatorGPT 能够使用算术运算符准确解决各种数学表达式,并提供达到预期答案的完整步骤,该挑战使用mistral-tiny模型和 Mistral API 端点以及自动重新提示 (automated re-prompting)。 - 关于小模型适用性的辩论:
.tanuj.捍卫了通过智能、自动重新提示和函数调用 (function calling) 使用像mistral-tiny这样的小模型来解决更复杂任务的可行性。他建议在本地机器离线执行复杂任务的可能性,这可以使该方法更具成本效益且用途广泛。@theledgerluminary怀疑小模型与大模型相比的能力,并建议使用针对不同任务专门微调的模型,尽管.tanuj.认为 Agent 比微调更具实用性和简单性。 - JSON 输出建议:
@sublimatorniq建议在 prompt 末尾要求模型以 TypeScript 接口的格式输出 JSON。 - 对小模型潜力的肯定:
@poltronsuperstar和.tanuj.都赞扬了 Mistral tiny 模型在任务编排方面的潜力。
相关引述包括:
.tanuj.: “如果你能从小模型中获得良好的推理能力,你就可以让用户实时创建非常强大的 Agent,并且可以根据你的需要变得尽可能强大!它可以是一个像‘一个 prompt -> 构建完整的 Web 应用并部署’这样的解决方案,中间不需要用户输入。”
@theledgerluminary: “但将类似的架构模式应用于大模型可能会获得更好的结果。我看到小模型唯一有益的地方是实时通信。如果总体目标是一个大型的“长期运行”任务,那么只使用小模型似乎是浪费时间。”
相关链接:
- 无讨论内容。
▷ #deployment (3 条消息):
- 在 CPU 和 iGPU 上运行:
@ethux建议在某些情况下,任务只会在 CPU 上运行,因为 VRAM 虽然更快,但没有理由在 iGPU 上运行它。 - RAM 速度对比:
@hharryr对新型 Ultra CPU 的 LPDDR5 RAM 速度进行了对比,其速度接近 78~80GB/s,与 M1 / Pro 芯片的 RAM 带宽相似。 - Apple Silicon GPU 上的 LLM 性能:
@hharryr思考是否可以使用配备新型 Ultra 处理器的机器,达到与在 Apple Silicon GPU 上良好运行的 LLM 相当的性能。
▷ #showcase (12 条消息🔥):
- Mistral-Tiny 用于数学运算的用例:
@.tanuj.展示了通过在用户和模型之间建立包含计算步骤的对话,可以使用 Mistral-Tiny 进行诸如 “Evaluate (10*2(7-2*1)+1)” 的计算。 - 他提到,“其中有一些中间步骤是自动化的”,并且“只有当它是有效的、100% 可调用的函数时,才会附加到官方聊天记录中”,这表明模型可以执行任务。
@.tanuj.设想了未来的场景,Mistral-Tiny 可能拥有 GoogleSearch、EvaluateSources、CreateEssay、DeployWebsite 等函数,从而展示了模型在抽象推理方面的潜力。@poltronsuperstar认为这种方法很有潜力,并表示“Agent 能够以循序渐进的方式链接函数似乎很重要”。尽管这是一个玩具级问题(toy problem),但它被认为具有实际应用的可能性。- 关于 Mistral-8x7B 变体,
.gue22分享说它可以在古老且免费的 Colab Nvidia T4(带有 16GB VRAM)或任何本地 Nvidia 16GB GPU + 11GB RAM 上运行。他分享了 Google Colab notebook 链接、相关的 YouTube 视频 以及相关论文 Fast Inference of Mixture-of-Experts Language Models with Offloading 以获取更多详情。
提到的链接:
▷ #random (4 条消息):
- 中文字符的分词 (Tokenization):
@poltronsuperstar指出“中文字符通常是 2 个 Token,因为 Unicode 的原因”。 - 用于理解 Token 使用情况的 MistralAI 库:
@.tanuj.建议使用 Python 中的 MistralAI 库可以帮助理解 Token 的使用情况,因为响应对象包含了 Prompt 和 Completion 中使用的 Token 详情,以及 API 调用的总计。 - 在 Mistral 中对中文字符进行分词:
@.tanuj.还表示愿意帮助任何有兴趣了解 Mistral 如何对中文字符进行分词的人,因为他自己也对这个过程感到好奇。感兴趣的人可以直接私信(DM)他。 - 向 AGI 提出的第一个问题:
@poltronsuperstar在聊天中征集想法,询问大家向 通用人工智能 (AGI) 提出的第一个问题会是什么。
▷ #la-plateforme (8 条消息🔥):
-
使用法语文本测试 Mistral:用户
@simply34提出了一个问题,即是否有人使用法语文本测试过 Mistral Embeddings 模型,以及它与 multilingual-e5-large 等开源多语言模型相比表现如何。目前尚未收到回复。 -
关于 Mixtral/Mistral 混淆的讨论:
@everymans.ai提出了关于是 Mixtral 还是 Mistral 以及 Mixture of Experts (MoE) AI 模型运作方式的困惑,并分享了一篇相关的文章。@dv8s推测 “Mix” 可能是与 Mixture of Experts 相关的文字游戏。 -
关于 Mistral-Medium 微调的反馈:
@jaredquek分享了关于 Mistral-Medium 微调的反馈,指出该模型经常输出不必要的解释,他认为这是对 Token 和金钱的浪费。他认为这是模型没有正确遵循指令的结果,可能需要进一步微调。 -
合成数据集生成计划:用户
@.superintendent正在考虑何时生成合成数据集,希望能避开高流量时段。
提到的链接:
How to fine tune Mixtral 8x7B Mistral Ai Mixture of Experts (MoE) AI model:关于增强功能的能力…
DiscoResearch Discord 总结
@philipmay和@thewindmom主要讨论了 德语语义嵌入模型 及其不同应用,其中 sentence-transformers/paraphrase-multilingual-mpnet-base-v2 被推崇为德语最好的开源模型,而 Cohere V3 被认为是整体表现最好的。@philipmay还分享了他用于评估德语语义嵌入的 Colab notebook。- 小组探讨了 问答 (Q/A) 检索模型 与语义模型之间的细微差别,并确认目前缺乏专门用于德语 Q/A 检索的开源工具。建议包括 Cohere V3 多语言模型 和 Microsoft 的 e5 large multilingual。
- 讨论了在 德语知识语料库上进行检索增强生成 (RAG) 的话题,虽然上述模型并非为此专门设计,但由于其语义能力而被推荐。
@philipmay分享了他训练 deutsche-telekom/gbert-large-paraphrase-cosine 和 deutsche-telekom/gbert-large-paraphrase-euclidean 模型的经验,表示它们非常适合使用 SetFit 进行训练。@_jp1_关注了一篇研究论文 What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning,该论文研究了 指令微调中对齐的自动数据选择策略。- 围绕 DPO 优化的 Mixtral 模型 相关问题展开了讨论,
@philipmay和@bjoernp讨论了路由平衡 (router balancing) 的问题及潜在解决方案,例如探索 hpcaitech/ColossalAI、stanford-futuredata/megablocks 和 laekov/fastmoe 等替代方案。此外还讨论了 GitHub 上实际训练代码的位置及其缺失问题。
DiscoResearch 频道总结
▷ #disco_judge (1 条消息):
- 关于对齐和指令微调的论文:
@_jp1_分享了一篇研究论文的链接,该论文探讨了指令微调中对齐的自动数据选择策略。论文还提出了一种用于增强数据测量的新技术。据称该工作与 Discord 社区正在进行的努力相似。论文链接
提到的链接:
What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning:指令微调是目前采用的一种标准技术…
▷ #mixtral_implementation (8 条消息🔥):
- 来自 Argilla 的 DPO 优化 Mixtral 模型:
@philipmay提到了 Argilla 在 huggingface.co 上发布的经过 DPO 优化的 Mixtral 模型,并在 GitHub 上提供了额外的 训练代码。提供的链接包括:Hugging Face 上的 Notux 8x7B-v1,GitHub - argilla-io/notus。
- 关于 Router Balancing 的问题:
@bjoernp指出,由于该 DPO 优化的 Mixtral 模型 依赖于 transformers 的 mixtral 实现,因此它同样受到 router balancing 相关问题的影响。 - GitHub 上缺少实际的训练代码:
@philipmay观察到,虽然 Notux 8x7B-v1 的模型卡片链接到了一个 GitHub 项目,但实际的训练代码似乎被省略了,目前只能看到较旧的 Notus 代码。 - 训练代码的位置:
@philipmay发现了实际的训练代码,它位于一个不同的 GitHub 子树中,链接为 argilla-io/notus,但尚未被合并。 - 备选的 MoE 训练工具:
@philipmay建议考虑备选的 MoE 训练工具,如 hpcaitech/ColossalAI、stanford-futuredata/megablocks 和 laekov/fastmoe,这些工具可能绕过 router balancing 问题。@bjoernp回复称,目前正在努力使 transformers 中的 auxiliary-loss 实现与 megablocks 等效,直接使用 megablocks 可能是一个可行但复杂的选项。
提到的链接:
- notus/vx/fine-tune at mixtral-fine-tune · argilla-io/notus: Notus 是一个使用 SFT 微调的 LLM 集合…
- argilla/notux-8x7b-v1 · Hugging Face
- GitHub - argilla-io/notus: Notus 是一个使用 SFT、DPO、SFT+DPO 和/或任何其他 RLHF 技术微调的 LLM 集合,始终坚持数据优先的方法。
- GitHub - hpcaitech/ColossalAI: 让大型 AI 模型更便宜、更快、更易于使用。
- GitHub - stanford-futuredata/megablocks: 为 stanford-futuredata/megablocks 的开发做出贡献…
- GitHub - laekov/fastmoe: 一个用于 PyTorch 的快速 MoE 实现。
▷ #general (18 条消息🔥):
- Embedding 模型经验:在与
@thewindmom的讨论中,@philipmay分享了他使用 Embedding 模型的经验,特别是德语模型。他明确区分了语义嵌入模型 (semantic embedding models) 和用于问答检索的嵌入模型 (embedding model for Q/A retrieval),并解释说问题和潜在答案在语义上不一定相似。 - 最佳语义嵌入模型:
@philipmay推荐 sentence-transformers/paraphrase-multilingual-mpnet-base-v2 作为最佳的开源德语语义嵌入模型,而整体表现最好的是新的 Cohere V3 嵌入模型。他还指出 ADA-2 embedding 并不太适合德语文本。 - 德语 BERT 的使用:他还解释了他训练的模型,如 deutsche-telekom/gbert-large-paraphrase-cosine 和 deutsche-telekom/gbert-large-paraphrase-euclidean,虽然在语义嵌入方面不如上述 paraphrase 模型高效,但非常适合作为使用 SetFit 进行训练的基础模型。
- 在德语知识语料库上进行 RAG:针对
@thewindmom关于在德语知识语料库上进行 RAG 的最佳模型咨询,@philipmay指出目前缺乏专门针对德语的开源问答检索模型,并推荐了 Cohere V3 多语言模型。然而,@aiui根据实践经验建议使用微软的 e5 large multilingual。 - 基准测试与评估:
@philipmay分享了一个他创建的用于评估德语语义嵌入的 Colab Notebook 链接,@rasdani描述了一个基于 deepset/germanquad 的上下文检索潜在基准。
提到的链接:
- Google Colaboratory
- sentence-transformers/paraphrase-multilingual-mpnet-base-v2 · Hugging Face
- deutsche-telekom/gbert-large-paraphrase-cosine · Hugging Face
- deutsche-telekom/gbert-large-paraphrase-euclidean · Hugging Face
- Question: OpenAI ada-002 embedding · Issue #1897 · UKPLab/sentence-transformers: Hi @nreimers , your blog about OpenAI embeddings i…
LangChain AI Discord 总结
只有一个频道有活动,因此无需总结…
- Langchain 的主要组件:在 Langchain 的背景下,
@atefyamin概述了两个主要组件,即 chains 和 agents。Chain 是 “对模型、文档检索器或其他 chains 等组件的一系列调用”,而 Agent “负责根据输入和推理做出决策并采取行动”。 - Agents 与 Tools:
@shivam51和@atefyamin讨论了 Langchain 中 Agent 和 Tools 的角色与功能。Shivam 不确定何时使用 Tools 而不是 Agents,但 Atefyamin 澄清说 Agents 使用 Tools 来执行任务。讨论还探讨了是否可以将 Tools 传递给 chains。 - 实现 ConversationBufferMemory:
@atefyamin寻求帮助以使用集成方式实现 ConversationBufferMemory,并分享了一些包含 firebase 的代码,但读取功能似乎缺失。 - Langchain 中的输出模板:
@repha0709寻求在 Langchain 中创建输出模板的帮助,以实现特定格式的响应。@seththunder建议使用 prompt 模板可能有助于实现这一目标,尽管@3h0480提醒说 prompt 可能无法保证 100% 符合所需模板。 - GitHub 上的 Langchain 示例:
@rajib2189分享了一个 GitHub 链接,其中包含如何使用 Langchain 的示例。
提到的链接:
langchain_examples/examples/how_to_llm_chain_pass_multiple_inputs_to_prompt.py at main · rajib76/langchain_examples:此仓库包含使用 Langchain 的示例。C…
Alignment Lab AI Discord 总结
只有一个频道有活动,因此无需总结…
- 直播播客邀请:用户
@teknium邀请@208954685384687617参加 Twitter Spaces 直播播客。然而,受邀者礼貌地拒绝了邀请,因为他们更倾向于书面英语而非口语。 - 关于播客的询问:
@ikaridev询问在哪里可以收听播客。@teknium提供了他的 Twitter 链接 以访问播客,该播客在每周四 PST 时间上午 8 点进行。 - AI 作为语言翻译器:针对因语言障碍而拒绝邀请的情况,
@rusch分享了一个 链接,介绍了一种可以跨语言实时翻译的 AI。 - Open Chat 3.5 的评估:
@axel_ls分享了他们在训练、微调(fine-tuning)和测试 Open Chat 3.5 方面的经验。他们表示,虽然它不差,但在处理编码任务时不如 GPT 3.5。此外,他们观察到 fine-tuning 并没有显著提高性能,反而导致了过拟合(overfitting)。
提到的链接:
LLM Perf Enthusiasts AI Discord 总结
- Azure 与 OpenAI 集成中遇到的问题:#general 频道的用户表达了多重困难,包括设置过程
@pantsforbirds、跨区域管理不同 API 限制的复杂性@robotums、管理不同模型/区域及其各自的资源限制@0xmmo,以及@pantsforbirds再次提到的 DevOps 和安全担忧。 - 在 #offtopic 频道中,用户
@joshcho_表达了对 “上传 VITS 模型(text-to-speech)并通过 API 提供服务” 的兴趣,并寻求关于为创建 API 而上传模型的建议。 - #prompting 频道的讨论围绕
@ayenem新发布的项目 TokenHealer 展开,该项目旨在改善 Prompt 与模型 Tokenizer 的对齐。该频道征求了对这一新颖项目的反馈,@pantsforbirds已经称赞其“非常酷”。
LLM Perf Enthusiasts AI 频道总结
▷ #general (4 条消息):
- OpenAI 的 Azure 账户设置挑战:用户
@pantsforbirds表达了在为 OpenAI 设置专属 Azure 账户时的困难,称设置过程令人望而却步。 - 特定区域的 API 限制问题:
@robotums强调了管理不同区域给出的不同 API 限制的复杂性,这使得每个模型/部署都需要管理多个 OpenAI 对象。 - 每个区域的模型和资源限制:
@0xmmo提到了每个区域不同模型及其各自资源限制带来的额外挑战。此外,他们还提出了每个资源需要不同 API key 的问题,这导致需要管理大量的环境变量。 - 对集成和安全设置的担忧:
@pantsforbirds还对将 OpenAI 与其现有系统集成所需的繁重 DevOps 工作以及设置安全性的额外复杂性表示担忧。
▷ #offtopic (2 条消息):
- 用于创建 API 的模型上传:用户
@joshcho_询问是否有人将模型上传到 Replicate 以创建 API,并表示有兴趣上传 VITS 模型(text-to-speech)并通过 API 提供服务。
▷ #prompting (3 条消息):
- TokenHealer 发布:用户
@ayenem发布了一个名为 TokenHealer 的新项目,该实现通过修剪和重新生成 Prompt 来更准确地与模型的 Tokenizer 对齐,从而提高补全效果以及对尾随空格和标点符号的鲁棒性。 - 对发布的反馈:
@ayenem欢迎对该项目提出反馈,并表示自己缺乏发布项目的经验。用户@pantsforbirds称赞了该项目,称其看起来“非常酷”。
提到的链接:
GitHub - Ayenem/TokenHealer: 由 cr… 为 Ayenem/TokenHealer 的开发做出贡献。
Latent Space Discord 总结
- 关于在同一台服务器上组合 4x A100 和 4x L40S 的服务器配置查询,引发了在
#ai-general-chat频道中关于开发一个将企业非结构化数据转换为用于微调 LLM 的数据集的 App 的讨论。用户@aristokratic.eth探讨了这一想法,@fanahova鼓励他研究类似的现有解决方案。 #ai-event-announcements频道发布了@latentspacepod最近一期播客节目的更新,重点介绍了 NeurIPS 2023 的顶尖初创公司,包括由@jefrankle、@lqiao、@amanrsanger、@AravSrinivas、@WilliamBryk、@jeremyphoward、Joel Hestness、@ProfJasonCorso、Brandon Duderstadt、@lantiga和@JayAlammar领导的公司。提供了播客链接 - Podcast Tweet 和 Podcast Page。@eugeneyan在#llm-paper-club频道中推荐了 2023 年值得关注的 AI 研究论文供读书小组参考,主要关注大语言模型。提供了这些论文选集的链接。
Latent Space 频道总结
▷ #ai-general-chat (4 条消息):
- 服务器配置的可能性:用户
@aristokratic.eth询问了在同一台服务器上配置 4x A100 和 4x L40S 的可行性。 - 构建非结构化数据 App:
@aristokratic.eth正在考虑开发一个可以将企业非结构化数据转换为用于微调 LLM 的数据集的应用程序。他征求了社区对该想法的产品市场契合度(Product-Market Fit)的看法。 @fanahova建议@aristokratic.eth研究类似的应用程序,表明市场上可能已经存在此类解决方案。- 随后,
@aristokratic.eth请求提供此类现有解决方案的参考资料以便进一步研究。
▷ #ai-event-announcements (1 条消息):
- NeurIPS 2023 回顾 — 顶尖初创公司:
@swyxio宣布发布来自@latentspacepod的最新播客,涵盖了 NeurIPS 2023 的顶尖初创公司。知名参与者包括:@jefrankle: MosaicML 首席科学家@lqiao: Fireworks AI CEO@amanrsanger: Anysphere (Cursor) CEO@AravSrinivas: Perplexity CEO@WilliamBryk: Metaphor CEO@jeremyphoward: AnswerAI CEO- Joel Hestness:
@CerebrasSystems首席科学家 @ProfJasonCorso: Voxel51 CEO- Brandon Duderstadt:
@nomic_ai(GPT4All) CEO @lantiga: Lightning.ai CTO@JayAlammar: Cohere 工程研究员 可以通过提供的链接访问播客:Podcast Tweet 和 Podcast Page。
提到的链接:
来自 Latent Space Podcast (@latentspacepod) 的推文:🆕 NeurIPS 2023 回顾 — 顶尖初创公司!https://www…
▷ #llm-paper-club (1 条消息):
- AI 研究论文推荐:
@eugeneyan分享了一个包含 2023 年 10 篇值得关注的 AI 研究论文列表的链接。他向读书小组推荐了这些论文,并指出其重点主要是大语言模型。他选择这些论文的标准是基于个人喜好或它们在该领域的影响力。
提到的链接:
2023 年十篇值得关注的 AI 研究论文:今年感觉截然不同。我…
Skunkworks AI Discord 总结
只有一个频道有活动,因此无需总结…
caviterginsoy: https://arxiv.org/abs/2305.11243
MLOps @Chipro Discord 总结
只有一个频道有活动,因此无需总结…
- CheXNet 模型部署问题:用户
@taher_3在部署来自 CheXNet-Keras 的预训练 CheXNet 模型时遇到困难。他们遇到的问题是,每个加载的模型对后续所有图像产生的预测都与第一张图像相同。他们正在寻求遇到过类似问题的人的帮助。