ainews-112024-how-to-start-with-open-source-ai
2024年1月1日:如何开启开源 AI 之路
OpenAI Discord 的讨论反映了用户对 Bing AI、ChatGPT 和 Perplexity AI 的评价褒贬不一,并对 Microsoft Copilot 与 Office 365 的集成展开了辩论。
用户们讨论了 ChatGPT Plus 中 DALL-E 3 的访问权限、ChatGPT 的性能问题,以及如何通过 OpenAI API 或自定义 GPT (Custom GPTs) 利用书籍内容训练模型的方法。此外,在关于 AI 推理、提示词工程 (Prompt Engineering) 以及解决自定义 GPT 故障的对话中,也提到了对 Microsoft Copilot 引入 GPT-4 Turbo 的期待。
针对 AI 初学者的建议包括从 Python 入门,并使用 YAML 或 Markdown 进行知识集成。讨论还探讨了由多个专业化 GPT 构成的 AI 未来,以及 Microsoft Copilot 在其中扮演的角色。
Teknium 和 LDJ 在新年期间在 Nous Discord 频道分享了一个很棒的学习路径。swyx 也更新了他的 December notes repo,为 Latent Space 的月度/年终总结做准备。
项目:
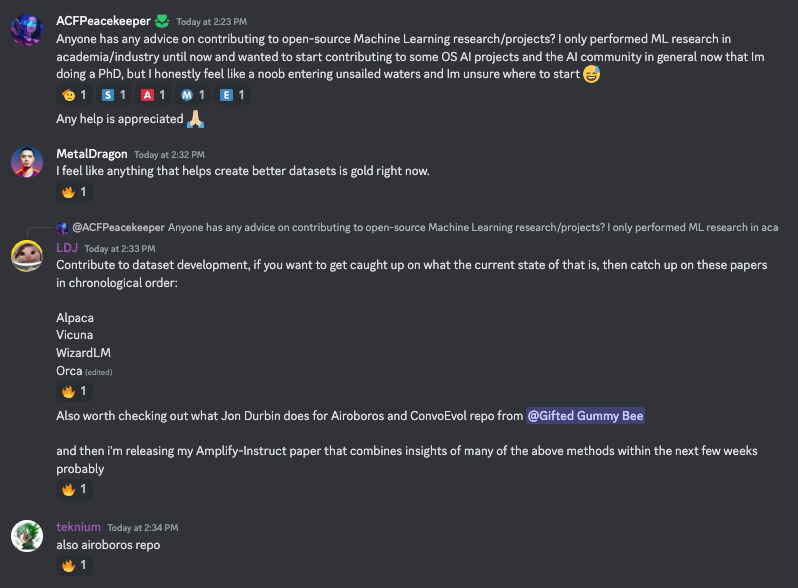
论文:

目录
[TOC]
OpenAI Discord 总结
-
用户对 Bing AI 与 ChatGPT 及 Perplexity AI 的性能和质量评价褒贬不一,既有负面观点也有正面看法。针对 Microsoft 的 Copilot 产品及其与 Office 365 的集成,也观察到了类似的意见分歧。
-
详细讨论了 ChatGPT Plus 中的 DALL-E 3 访问权限、用户在 ChatGPT 性能方面遇到的技术问题以及探索的潜在解决方案。
-
用户讨论了训练 GPT 模型以根据书籍生成内容的愿望,并提出了诸如与 ChatGPT Plus 或 OpenAI API 集成等潜在方式。
-
交流了对 Microsoft Copilot 未来更新中 GPT-4 turbo 的期待和偏好,并对 AI 推理、Prompt Engineering 以及 GPT 模型的输出长度限制提出了建设性意见。
-
主要涉及关于提高 Custom GPT 性能、克服 Recaptcha 故障的咨询和澄清。还讨论了在糟糕的修改后彻底翻新 Custom GPT 模型的处理方法,以及追踪 v4 使用情况的过程。
-
分享了一个涉及使用 Custom GPT 创作幽默 TikTok 脚本的详细互动和流程。这围绕着一位寻求改进模型输出建议的用户,以及另一位提供复杂示例的同伴展开。
-
建议像
.009_f.108这样刚接触 AI 编程的用户从 Python 开始。为了改进自定义知识的使用,@sciandy建议使用 YAML 或 Markdown 文件结构,而非 JSON。 -
最后,关于 AI 未来的有趣讨论,特别是关于多个 GPT 必要性的阐述。范围从模型专业化的优势到 Microsoft Copilot 在不断发展的 AI 领域中的角色。
OpenAI 频道总结
▷ #ai-discussions (3 条消息):
- AI 产品对比:
@chief_executive对 Bing AI 表达了负面看法,认为它不如 ChatGPT 甚至不如 Perplexity AI。 - Microsoft Copilot 和 Office 365:
@chief_executive认为 Copilot 产品没有前途,但认为 Office 365 的集成可能没有问题。 - 对 Bing 和 Copilot 的不同看法:与之前的批评相反,
@michael_6138_97508对 Bing 表达了正面看法(尽管存在一些小故障),并对不包含 Office 365 的潜在 Copilot 低档订阅表示感兴趣。
▷ #openai-chatter (126 条消息🔥🔥):
-
DALL-E 3 访问讨论:
@black_swordsman99对 ChatGPT Plus 中的 DALL-E 3 访问权限表示困惑。@darthgustav.澄清说 DALL-E 3 已集成,可以通过 GPT-4 或使用 DALL-E 3 Custom GPT 访问。 -
ChatGPT 支付问题:由于没有信用卡,
@rememberthebrigade询问是否可以使用 Google Play Store 礼品卡支付 ChatGPT Plus。@jaicraft确认可以通过 Android 应用进行此类交易。 -
ChatGPT 性能问题:包括
@kilogamz和@youraveragedev在内的多位用户对 ChatGPT 的性能和响应速度表示担忧。@kilogamz详细描述了一个特定问题:在请求图片时,ChatGPT 给出错误提示并中断了他们的 D&D 跑团规划。尽管尝试了清除缓存、使用无痕模式和更换浏览器等多种方法,问题仍然存在。 -
使用书籍内容训练 GPT 模型:
@sushiconduit询问如何训练 GPT 模型以根据书籍生成内容。@thunder9289建议,如果有 ChatGPT Plus,可以将书籍添加到私有 Custom GPT 的知识库(Knowledge Base)中。如果没有,则需要使用 OpenAI API 并在 Playground 中创建一个带有知识库的 Custom GPT。 -
Copilot GPT-4 turbo 的使用:
@jaicraft和@pruo讨论了对 Copilot 中 GPT-4 turbo(尚未发布)的期待和使用偏好。
▷ #openai-questions (39 条消息🔥):
- 针对新计算机语言优化 GPT:
- 用户
@tilanthi表达了对提高在定制版 Lua 上训练的 GPTs 在创建新代码或策略时性能的担忧。他们注意到其输出与 GPT-4 生成高级 Python 脚本相比存在差异。他们提出了一个假设,即 Python 示例是 LLM 训练过程的一部分,而 Lua 缺乏类似的示例可能会阻碍性能。 - 用户
@solbus澄清说,自定义 GPTs 的“训练”仅限于 GPT 编辑页面中提供的信息:Instructions + Knowledge 文件 + Actions。他们强调知识库文件仅作为参考文档,而不是永久添加的上下文。他们还提供了关于调整自定义 GPT 指令以提高性能和理解能力的建议。
- 用户
-
Recaptcha 问题:
@watchalls抱怨在桌面端使用 GPT-4 时,每输入一句话或一个条目都必须解决 Recaptcha 验证码。@solbus建议检查是否安装了 VPN,并确认该问题是否为特定浏览器所致。 -
在不理想的修改后重构自定义 GPT:
@thefreebachelor在尝试使用从 Reddit 找到的提示词改进其基础生活教练自定义 GPT 后表示不满。用户@solbus提供了持续的支持和建议,包括保留指令副本以备后用、提醒知识库文件的局限性,并就如何编写更有效的指令提供了建议。 -
达到 v4 限制: 用户
@phospheneoverdrive询问如何检查其 v4 使用配额。用户@solbus回复称目前没有 UI 指示器,并建议通过每 4.5 分钟发送一条消息来控制节奏,以保持在每 3 小时 40 条的限制范围内。 - 使用自定义 GPT 成功实现幽默 Tiktok 视频剧本提示词:
@user691378寻求帮助,希望创建一个用于生成幽默 Tiktok 视频剧本的自定义 GPT 模型提示词,并描述了尽管向模型提供了 20 个示例剧本,但尝试仍未成功的情况。
▷ #gpt-4-discussions (6 条消息):
- 新年问候:
@randall.townsend祝大家新年快乐。 - 学习 AI 编程和编码:用户
.009_f.108征求关于如何开始 AI 编程和编码的建议,对此@darthgustav.建议从 Python 开始。 - 为自定义知识库构建文件结构:
@iamhere6321询问了上传自定义知识库文件的最佳结构方式。他们注意到虽然 HTML 和 PDF 格式运行良好,但具有自定义结构的 JSON 文件并未产生预期结果。他们询问使用llamaindex是否能提供更好的控制。 - 关于文件结构的建议:针对上述疑问,
@sciandy建议使用 YAML 或 Markdown 代替 JSON 来构建文件结构。
▷ #prompt-engineering (222 messages🔥🔥):
- 关于 AI 推理能力和回避回答的讨论:
- 以
@johannes43和@hawaiianz为首的几位用户讨论了 AI 不断提高的英语理解能力,@hawaiianz预测一年内将不再需要 Prompt Engineering。@beanz_and_rice表示反对,认为在词汇和语义方面始终需要一定程度的 Engineering。他们对 AI 预设性地解释其缺乏实时信息访问权限感到沮丧,即使问题并不需要此类数据。 @madame_architect补充说,一些开发者正在使用 Frozen Models,以避免 AI 模型每次更新带来的问题。
- 以
- 限制 GPT-4 输出长度:
@MishaMgla寻求帮助,希望按单词或字符数量限制 GPT-4 的输出。@rendo1和@madame_architect解释说,这是 GPT 往往难以处理的事情,因为它以 Token-by-token 的方式生成响应,难以提前规划和限制其写作。
- 学习 Prompt Engineering 的过程:
@user691378询问如何有效训练其自定义模型,在提供约 20 个样本脚本后生成优质的 TikTok 视频脚本。@beanz_and_rice提供了一个详细且复杂的自定义 Prompt 示例,以帮助训练用户的模型达到预期效果。@madame_architect分享了她学习 GPT 的过程,包括阅读关于 Prompting 策略的研究论文、尝试不同方法以及从失败中学习。
- 关于 AI 未来的讨论(GPT 模型和 Copilot):
@beanz_and_rice质疑多个 GPT 的必要性,并表达了希望用一个模型处理所有任务的简洁性愿望。@madame_architect建议未来可能会倾向于专门化模型与一个主 GPT 配合使用。她还指出微软的 Copilot 是该领域日益增长的参与者。
▷ #api-discussions (222 messages🔥🔥):
- 对 ChatGPT 的理解:在
@beanz_and_rice、@hawaiianz和@johannes43的讨论中,他们分享了对 ChatGPT 性能和未来的看法。他们指出,虽然 AI 对英语有很强的理解力,但其当前版本有时可能会回避问题或做出不准确的假设。 - 模型性能讨论:
@beanz_and_rice对更新表示不满,注意到 GPT-4 和 GPT-4.1106 preview (GPT-4 Turbo) 似乎更容易回避问题。他报告说,询问关于“上次 X 是什么时间”的问题会触发回避,因为模型错误地假设需要实时信息。 - GPT 的技能限制:讨论了 GPT 在任务中的局限性。当
@MishaMgla想要通过字符或符号限制 GPT 的输出时,@rendo1和@madame_architect指出 GPT 在此类任务上效率不高,因为它不会提前规划写作内容。 - Prompt 和自定义模型:讨论了创建优质 Prompt 的重要性和挑战。
@beanz_and_rice为寻求制作搞笑 TikTok 脚本 Prompt 的@user691378分享了一个复杂的 Prompt 示例,他称之为“Custom AI syntax”。他还提到该语言可以由 GPT-4 生成。 - 关于微软 Copilot 的讨论:在涉及
@madame_architect和@beanz_and_rice的对话中提到了微软的 Copilot。@madame_architect推测了其潜在增长并分享了不同版本的实操经验,而@beanz_and_rice承认对 GitHub Copilot 印象不深。
Nous Research AI Discord 总结
- 讨论了 Scholar Evals Platform 的开发,该平台允许直接可视化和发布结果/复现,并分享了 GitHub 仓库链接。该平台反响良好,并征求了反馈意见。(来源: GitHub - scholar-org/scholar-evals)
- 关于各种 AI 主题的启发性对话,包括扑克策略中的 Counterfactual Regret Minimization,未来 AI 架构中 Transformer 和 Selective Sequence Memory (SSM) 模块的潜在异构性,以及使用
bagel对Yi-34B-200k进行的实验性 Finetuning,该实验预测了有趣的 Benchmark。(来源: 关于 Counterfactual Regret Minimization 的博客文章, 关于 AI 架构的 LessWrong 博客, GitHub - NousResearch/StripedHyenaTrainer, jondurbin/bagel-dpo-34b-v0.2) - 讨论了 Finetuning of models,强调了其相比于从头开始创建模型在时间和资源效率上的优势。关于受版权保护的
Yi-34bBase 与符合 AGPL 规范的MixtralBase 的优缺点辩论引发了不同的观点。(来源: 无) - 为试图进入 AI 领域的初学者提供了鼓励,敦促他们坚持不懈,并强调了从其他领域带来独特见解的价值。(来源: 无)
- Discord 上记录了关于 Chat models 性能的讨论,包括对即时任务完成变体的偏好、Chat 和 Instruct models 之间的区别,以及 Open-source 在填补停产模型留下的空白方面的作用。(来源: Lijie Fan (@lijie_fan) 的推文, Amjad Masad (@amasad) 的推文)
- 围绕 Local Large Language Models (LlaMas) 展开了深入对话,讨论了不同模型之间的比较、为新语言扩展 Tokenizer 的过程、在 MacBook 上运行模型以及使用模型进行自动化任务等主题。推荐了一些用于 LlaMa 实验的资源,例如 LM Studio 的
Openhermes模型。(来源: 无)
Nous Research AI 频道总结
▷ #benchmarks-log (3 条消息):
- Scholar Evals Platform: 用户
@manveerxyz正在开发一个基于 Eleuther 的 LM harness 构建的平台,该平台允许可视化结果/原始输出,并最终计划让用户从该平台发布结果/复现。他们征求了对 MVP 的反馈,并分享了 GitHub - scholar-org/scholar-evals 的链接以获取更多细节。用户@gabriel_syme对该项目表示赞赏,@manveerxyz随后鼓励其进行测试。
提到的链接:
GitHub - scholar-org/scholar-evals: A unified platform for benchmarking large language models.: 一个用于 Benchmark 大型语言模型的统一平台。
▷ #interesting-links (8 messages🔥):
- Counterfactual Regret Minimisation:用户
@nnn5686分享了来自@rnikhilcom的一篇 博客文章,探讨了 Counterfactual Regret Minimization 及其在扑克获胜策略中的应用。 - AI 架构的异质性:
@vincentweisser分享了一篇 LessWrong 博客,指出 AI 架构可能很快不仅包含 Transformer 模块,还包含 Selective Sequence Memory (SSM) 模块。这两种模块被认为是情节性认知能力(Transformer 的优势)与长期记忆(SSM 的优势)权衡天平上的两个极端。 - StripedHyenaTrainer:
@vincentweisser提到了一个名为 “StripedHyenaTrainer” 的 GitHub 仓库,这与关于 Transformer 对比 SSM 模块的讨论有关。 - 使用 Bagel 进行实验性微调:
@metaldragon01分享了一个使用bagel对Yi-34B-200k进行实验性微调的 链接。文中提到该模型已在所有数据集上进行了训练,并预测其 Benchmark 表现会很有趣。 - 新数据集:
@teknium表示有兴趣探索@metaldragon01分享的bagel模型中所包含的新数据集。
相关链接:
- 来自 Nikhil R (@rnikhilcom) 的推文:Counterfactual Regret Minimisation or How I won an…
- jondurbin/bagel-dpo-34b-v0.2 · Hugging Face
- GitHub - NousResearch/StripedHyenaTrainer:为 NousResearch/StripedHyenaTrainer 的开发做出贡献…
- AGI 将由异质组件构成,Transformer 和 Selective SSM 模块将位列其中 — LessWrong:这篇文章是由最近的两项成果引发的:…
▷ #general (167 messages🔥🔥):
- AI 驱动的语音聊天使用:用户
@mihai4256讨论了 AI 模型以角色声音回复并在语音聊天中识别用户停止说话的功能。然而,@teknium澄清说,双向语音聊天功能自 Dev Day 以来就已在移动端上线。 - 微调模型:用户
@iamavalex提出了关于模型 Finetuning 过程的问题,询问所需资源(如数据集、基础模型和 GPU)。@.beowulfbr和@night_w0lf提供了回答,强调与从零开始创建模型相比,Finetuning 的优势在于时间和资源的效率。 - Yi-34b Base 对比 Mixtral Base:用户
@asgnosi寻求关于使用 Yi-34b 基础模型与 Mixtral 基础模型优缺点的建议,@night_w0lf指出,考虑到 Yi 是比 MoE 更稠密的模型,其速度可能会更慢。 - 初学者 AI 入门:
@Serial Connector反思了作为 AI 初学者的迷茫感,@gabriel_syme提供了关于坚持以及从其他专业领域贡献独特见解的建议。 - 关于模型功能与行为的辩论:
@gabriel_syme对使用 Chat 模型处理某些任务表示不满,称更倾向于即时任务完成类模型。对话探讨了 Chat 模型与 Instruct 模型之间的区别,@teknium解释了数据和训练如何影响模型的行为。讨论还涉及了社区对已逐渐消失的 Instruct 模型的忠诚度,以及开源填补这一空白的潜力。
相关链接:
- 来自 Lijie Fan (@lijie_fan) 的推文:🚀 视觉模型的未来是合成的吗?介绍…
- 来自 Amjad Masad (@amasad) 的推文:使用 davinci,我可以使用传统方式对其进行“编程”…
▷ #ask-about-llms (51 messages🔥):
-
模型对比:
@yeyito777对比了 Phi-2、Mistral 和 DeciLM-7B 模型在基准测试中的表现,并因其开放性和广泛采用而推荐 Mistral。 -
扩展 Tokenizer:
@qnguyen3讨论了扩展 Tokenizer 以包含新语言的过程。他们建议遵循 Chinese-Llama 团队的清晰说明,并提到 VinaLLaMA 论文作为参考资源。该过程涉及训练一个新的 Sentencepiece Tokenizer 并将其连接到当前模型的 Tokenizer。 -
LLaMAs 与学习之旅:包括
@momentumjs、@gsayko、@teknium和@rohinish404在内的几位用户讨论了开启开源模型和本地大语言模型 (LLaMAs) 的学习之旅。@teknium建议使用 LM Studio 实验模型,特别强调了 Openhermes 模型。 -
在 MacBook 上运行模型:
@teknium和@rohinish404讨论了在 MacBook 上运行语言模型。他们强调本地运行模型的速度很大程度上取决于机器的计算能力。在硬件配置中勾选 “Metal” 复选框后,语言模型在 M1/M2/M3 芯片上的运行速度会快得多。 -
使用模型进行自动化:
@teknium建议,当发现可以使用开源模型自动化的任务时,有很多方法可以在命令行上运行它。此外,他们还引用了 Together.ai 和 OpenRouter 等 API 作为 ChatGPT 的替代方案。
OpenAccess AI Collective (axolotl) Discord 总结
- 深入讨论了各种语言模型,特别关注用于专用模型训练的 TinyLLaMA、评估 Gemini 在推理方面的弱点,以及 Mixtral 的高硬件要求。分享了一项名为 Language model compression with weighted low-rank factorization 的研究,探讨了通过加权 SVD 进行模型压缩,补充了关于模型优化的讨论,其中还讨论了 LASER 技术。
@faldore在#axolotl-dev频道报告了在 Mixtral Qlora 上从 Checkpoint 恢复时的问题,以及尝试从源码安装 PEFT 时遇到的 RuntimeError。- 在
#general-help中,用户就各种主题寻求并获得了指导,例如 Mixtral 8x7b 的微调配置、微调的数据格式、模型输出的不一致性、较短的训练样本对模型性能的影响,以及如何计算 LLM 回答的准确率 (ACC)。@morgymcg在 wandb.ai 上分享了他们的 Mixtral 实验笔记。 #datasets频道展示了一个互助的环境,用户在这里分享见解并寻求创建自定义数据集的建议。分享了一个 示例数据集 和一个用于代码执行的 自定义数据集。讨论内容涉及 Function-calling 数据集的最佳格式、生成大规模指令数据集、预训练数据和混合语言的实践,以及向基座模型添加新 Token 的工作流。- 在
#rlhf频道,用户报告并解决了有关 Mixtral 兼容性和升级 Transformers 的问题。提出了一个关于训练 DPO 模型是否必须进行 SFT 的澄清点,特别是如果没有添加新 Token 的情况下。 @dangfutures在#shearedmistral频道建议将法律数据整合到 AI 模型中,并引用了 Hugging Face 上 Pile of Law 数据集作为此类数据的潜在来源。
OpenAccess AI Collective (axolotl) 频道总结
▷ #general (108 条消息🔥🔥):
- 关于 TinyLLaMA 和模型专业化的讨论:
@nafnlaus00表达了对将 TinyLLaMA 作为训练专业化模型基础的喜爱,因为它在非复杂任务上表现良好,且训练时间极短,推理速度快。具体引用:”我喜欢 TinyLLaMA (base, 而非 chat) —— 我将其作为训练专业化模型的基础。“。 - Gemini 的推理能力:
@noobmaster29分享了一个链接,内容是关于 Google 推出的多模态大语言模型 Gemini 的详细概述和评估。文中指出,尽管 Gemini 有所进步,但在基准测试中的常识推理任务方面仍显不足。 - 关于模型优化和 LASER 技术的讨论:
@mihai4256和@fernando.fernandes.讨论了用于微调模型的 LASER 降噪技术。他们提到应用 LASER 不会减少参数,但会改变权重矩阵的秩(ranks)。他们还提到了正在进行的将该技术泛化的工作,使其不仅限于特定数据集。 - 对模型训练硬件需求的担忧:
@yamashi、@dangfutures和@casper_ai讨论了训练 Mixtral 等模型的高硬件要求,例如需要 8x A100 GPU。 - 关于用于模型压缩的低秩分解讨论:
@stefangliga分享了一项研究链接,该研究使用 Fisher Information 进行加权 SVD,作为一种模型压缩方法。
提到的链接:
- Language model compression with weighted low-rank factorization:将大矩阵分解为小矩阵是……
- Mixtral 8x7B support (#2011) · vllm-project/vllm@b5f882c:共同作者:Pierre Stock <p@mistral.ai> …
- Tweet from AK (@_akhaliq):Gemini 的推理能力:揭示多模态中的常识…
▷ #axolotl-dev (4 条消息):
- Mixtral Qlora 从 Checkpoint 恢复的问题:用户
@faldore报告称,他们无法在 Mixtral Qlora 上从 Checkpoint 恢复训练。 - 尝试从源码安装 PEFT:
@faldore表示尝试从源码安装 PEFT,但遇到了困难。 - PEFT 安装过程中的 RuntimeError:在尝试安装 PEFT 时,
@faldore遇到了 RuntimeError。错误提示:”Error(s) in loading state_dict for PeftModelForCausalLM: Missing key(s) in state_dict.“,其中包含了一系列 base_model 的键名。
▷ #general-help (34 条消息🔥):
- Mixtral 8x7b 微调建议:
@morgymcg征求关于 Mixtral 8x7b 微调配置的建议。他们一直在使用 SlimOrca 数据集,在 8 x H100 上进行了为期数天的 qlora 微调。粗略的实验记录可在 wandb.ai 查看。@le_mess建议测试不同的优化器,包括adamw_bnb_8bit、lion_8bit、paged_adamw_32bit、paged_adamw_8bit和paged_lion_8bit。 - 微调的数据格式化:
@matanvetzler询问如何使用特定的 JSONL 结构在配置文件中格式化 “datasets” 部分。@le_mess建议将数据集转换为 ShareGPT 格式。 - 模型输出的一致性:
@colejhunter报告了一个问题,即在小数据集与较大数据集上训练时,尽管保持变量一致,模型输出的结果却不一致。在较大数据集的输出中观察到了重复和随机文本。 - 较短训练样本的影响:
@suikamelon报告称,在训练数据集中加入较短的对话片段后,模型在长上下文尺寸下的性能受到了负面影响。他们询问样本打包(sample packing)是否是一个解决方案。 - 计算 LLM 回答的 ACC:
@noobmaster29寻求关于如何计算 LLM 回答准确率 (ACC) 的信息,并指出 mmlu 中提示词(prompt)的变化会显著影响结果。他们的基础模型是 Mistral。
提到的链接:
- Mixtral Experiments Notes:寻找强大的 Mixtral 微调配方
- Tweet from Eric Hartford (@erhartford):Dolphin-2.7-mixtral-8x7b 正在使用这些修复进行训练…
▷ #datasets (11 条消息🔥):
- 用于微调的数据集:在创建用于微调模型的数据集背景下,
@nruaif分享了一个 示例数据集,@le_mess提到频道中链接了更多数据集。 - Function calling 数据集的格式:
@yazanhussein01询问了 function calling 数据集的理想格式。@le_mess建议遵循 sharegpt 格式,但澄清说目前没有统一的标准格式。 - 生成大规模指令数据集:
@stoicbatman寻求关于从 GPT-4 生成大规模指令数据集(20k-50k 个样本)的建议,特别是关于更好进行数据生成的技巧或资源。 - 预训练数据与多语言混合:
@noobmaster29询问了预训练数据的质量,以及是否建议将英语与新语言 token 混合以防止模型“遗忘”英语。他们还提到了目前的工作流:先在基础模型上通过一次 pass 完成新 token 的添加,然后再进行一次单独的指令学习 pass,并寻求关于此方法是否合适的反馈。 - 复杂代码生成数据集的反馈:
@cf0913就其创建的一个用于复杂、多需求指令代码执行的 自定义数据集 征求反馈。该数据集旨在根据详细需求生成合成代码。
提到的链接:
- cfahlgren1/DevSpecCode · Datasets at Hugging Face
- mhenrichsen/alpaca_2k_test · Datasets at Hugging Face
▷ #rlhf (8 条消息🔥):
- Mixtral 兼容性问题:用户
@dangfutures报告了让 Mixtral 在其当前分支上运行的问题,@caseus_回应称他们会考虑合并或变基(rebase)其分支。 - 升级 Transformers 后的 KeyError:
@dangfutures在升级 transformers 后最初遇到了 KeyError,但后来发现是因为使用了错误的数据集。 - DPO 模型训练:
@dangfutures和@caseus_之间的讨论澄清了训练 DPO 模型可能并不一定需要 SFT,特别是如果没有添加新 token 的情况下。
▷ #shearedmistral (2 条消息):
- AI 模型中的法律数据:用户
@dangfutures建议将法律数据整合到 AI 模型中,以提高这些模型在法律语境下的表现。他们还分享了 Hugging Face 上名为 Pile of Law 的数据集链接,指出这可能是 AI 训练法律数据的潜在来源。该数据集主要为英文,包含大量的法律和行政数据语料库。
提到的链接:
pile-of-law/pile-of-law · Datasets at Hugging Face
LAION Discord 摘要
- 各个频道进行了 新年祝福 交流,来自
@targed、@pseudoterminalx、@puffy310和mega_b的问候。 - 讨论了 huggingface.co 上数据集查看器的问题,
@SegmentationFault报告了一个JobManagerCrashedError错误。 - 提议使用 CogVLM 或 GPT4V 等模型为 1928 年米老鼠登场的公共领域数据集添加标题。
@SegmentationFault建议重点针对 SDXL lora、dreambooth 或全量微调(full fine-tune)进行潜在训练。随后@thejonasbrothers通知称,针对该公共领域老鼠角色的 lora 模型已经发布在 huggingface.co。 @SegmentationFault分享了对 Google T2I 技术的赞赏,指出其保真度高,且没有 Midjourney 和 Dalle 中常见的过拟合(overfit)问题。- 深入探讨了一种名为 SynCLR 的从合成图像和标题中学习 视觉表征(visual representation) 的新方法,该方法由
@spirit_from_germany讨论的一篇 论文 引入。这引发了关于其局限性和性能的辩论。 - 关于 Botting 的讨论,
@cutycat2000炫耀了一个照片追踪机器人。@ishaanshri95请求分享该机器人。 - 交流了 AI 模型如何学习概念,讨论了如果模型没有经过显式训练,是否具有概念学习的潜力,
@phryq提出疑问,@JH给予了肯定。对话进一步探讨了图像标题(image captions)的影响。
共享的关键资源:
- Pluralistic: 2024’s public domain is a banger (20 Dec 2023) – Pluralistic: Daily links from Cory Doctorow
- multimodalart/steamboat-willy-frames · Datasets at Hugging Face
- Pclanglais/Mickey-1928-dataset · Datasets at Hugging Face
- 来自 AK (@_akhaliq) 的推文:从模型中学习视觉可以媲美学习视觉…
- GitHub - google-research/syn-rep-learn: Learning from synthetic data - code and models:从合成数据中学习 - 代码和模型。
LAION 频道摘要
▷ #general (12 条消息🔥):
-
新年庆祝:用户
@targed、@pseudoterminalx和@puffy310交换了 新年祝福。 -
数据集查看器问题:
@SegmentationFault在 huggingface.co 上遇到了数据集查看器的问题。问题似乎与JobManagerCrashedError错误有关,导致无法显示完整数据集。数据集链接 -
公共领域动画数据集:
@SegmentationFault提议使用 CogVLM 或 GPT4V 等模型为 1928 年米老鼠登场的公共领域数据集添加标题,并建议可能用于 SDXL lora、dreambooth 或全量微调的训练。 -
公共领域老鼠角色 LORA 模型:
@thejonasbrothers通知称,已经为该公共领域老鼠角色发布了一个 lora 模型。该模型可以在 huggingface.co 访问。 -
Google T2I 技术的进展:
@SegmentationFault表达了对 Google T2I 技术的钦佩,称其在角色保真度方面比 Dalle3 更令人印象深刻,且没有 Midjourney 和 Dalle 本身存在的过拟合问题。
提到的链接:
- Pluralistic: 2024’s public domain is a banger (20 Dec 2023) – Pluralistic: Daily links from Cory Doctorow
- multimodalart/steamboat-willy-frames · Datasets at Hugging Face
- Pclanglais/Mickey-1928-dataset · Datasets at Hugging Face
▷ #announcements (1 条消息):
mega_b: 新年快乐! 🎉
▷ #research (114 messages🔥🔥):
-
SynCLR: 在
@spirit_from_germany讨论的一篇 论文 中,介绍了一种从合成图像和 Captions 中学习视觉表示的新方法 SynCLR。@spirit_from_germany建议使用不同的概念列表和 OpenAI 的 10 亿条 BLIP-2 Captions 进行后续研究。随后的讨论扩展到了如何高效生成图像,@thejonasbrothers和@rom1504指出了当前的局限性。 -
Botting:
@cutycat2000炫耀了他们编写的一个 Bot,该 Bot 可以将照片追踪到具体的城市和国家。@ishaanshri95请求分享该 Bot。 -
SynCLR 的局限性:
@thejonasbrothers对 SynCLR 表示怀疑,指出该方法对 Text-to-Image 模型的依赖本质上是对原始模型的蒸馏。@rom1504表示反对,称图像文本并非是有监督的。对话继续就此点展开辩论。 -
SynCLR 的性能:
@thejonasbrothers和@rom1504对 SynCLR 的性能存在争议,研究引用的片段表明 SynCLR 优于 OpenCLIP,但@rom1504对此予以反驳。 -
关于合成数据训练的讨论: 辩论进展到使用合成数据训练的实用性。
@rom1504坚持认为这可以控制模型的训练内容,并强调了即使在最坏情况下也有好处。然而,@thejonasbrothers指出了当前 T2i 模型的高昂成本和局限性。
提到的链接:
- 来自 AK (@_akhaliq) 的推文: Learning Vision from Models Rivals Learning Vision…
- GitHub - google-research/syn-rep-learn: Learning from synthetic data - code and models: Learning from synthetic data - code and models. Co…
▷ #learning-ml (6 messages):
- AI 模型中的概念学习:
@phryq询问 AI 模型是否仍能“学习”未明确训练的概念,例如视觉概念。@JH确认,对于在多样化数据集上训练的任何 Diffusion 模型来说,这都是可能的。 - 图像 Captions 对概念学习的影响:
@phryq进一步讨论了模型从图像中学习概念(如领结)的潜力,即使该概念很少或从未被添加 Caption。 - 模型将概念与 Prompts 的关联:
@JH澄清说,模型可能会识别领结的概念,但如果很少被标注为“领结”,则与特定词汇“bow tie”的关联度会降低。例如,如果领结图像主要来自婚礼并被标注为“婚礼”,模型可能会在 Prompt 为婚礼场景时在图像中生成领结。 - AI 模型生成未提示的伪影 (Artifacts):
@JH进一步解释说,模型从 Captions 中对概念的关联可能会导致未提示的伪影。例如,如果它频繁将领结与婚礼联系起来,它可能会在生成的任何婚礼场景中添加领结,即使没有明确的 Prompt。
HuggingFace Discord Discord 总结
- 关于数据去重 (data deduplication) 的讨论,重点是在 Python 中对文本列使用余弦相似度,
@robotics3483寻求了相关指导。 @chokipro分享了遇到的一个错误,怀疑与 Hugging Face 有关。该错误也被其他人遇到过,@ddchiken幽默地将其解释为代码指示“我是一个茶壶 (I’m a teapot)”。@epicureus发起了关于如何将旧版应用转换为 Laravel 的对话——并通过这篇 博客文章 展示了他的经验。他提到了处理过时代码的麻烦以及重新开始的强烈冲动。@kopyl询问了一个本地缓存的数据集,该数据集在 HuggingFace 上已不再可用,但他们的 miniSDXL 训练计划需要它。@stoicbatman发布了关于 Mistral Model 具体细节的查询,包括训练或微调数据样本的数量。@woutdeclerck探讨了为了 3D 植物业务从 MacBook Pro 切换到 Windows 的可能性,计划使用 Blender 和 Unreal Engine。@duplaja分享了他在 handler.py 上下文中学习 Hugging Face Inference Endpoints 的历程。@gag123针对@waffle_cream的提问,提供了在不修改 Andrej 代码的情况下调整参数的见解。- 对频道中分享的博客文章和未来内容的积极评价和推荐,特别是
@723709999452389417的视频演示。 @ddchiken的项目链接被指出与 AINews 有关,而@vikasexcel宣布了他们发布的印地语模型——open-aditi-hi-v1,以及一个开源数据集。@lunarflu鼓励社区成员在 reading-group 频道中提议用于讨论的论文。@_johnny1984分享了关于基于 Langchain 的 ChatGPT 客户端在法律背景下应用的想法。@p_k_boo询问了 Hugging Face 上的文本转 SQL (text to SQL) 转换模型,@ketul1842计划训练一个小型的 LLM 将自然查询转换为 SQL 语句中的条件,并寻求相关方面的指导。@stroggoz对@ketul1842的查询提供了模型建议,包括用于翻译的 encoder-decoder 模型、关于 BERT 的下一句预测 (next sentence prediction),并对后者的有效性表示怀疑。
HuggingFace Discord 频道总结
▷ #general (36 条消息🔥):
- 数据去重请求:
@robotics3483寻求在 Python 中对文本列使用余弦相似度进行分组和去重的帮助。 - 遇到的错误:
@chokipro分享了一个错误消息链接,认为这是 Hugging Face 的问题,其他人也遇到了。@ddchiken开玩笑地澄清 http status 418 是“我是一个茶壶”。 - 旧版代码转换:
@epicureus分享了一篇关于将旧版应用转换为 Laravel 的博客文章链接,并反思了过时代码带来的挑战以及从头开始重建的冲动。 - 数据集请求:
@kopyl正在寻找本地缓存的数据集ChristophSchuhmann/improved_aesthetics_6plus,该数据集在 HuggingFace 上已不可用,而他们计划训练 miniSDXL。 - Mistral 模型查询:
@stoicbatman询问了 Mistral 模型使用的样本数量(训练或微调数据大小),但未能找到与该数据集相关的任何信息。
提到的链接:
Legacy to Laravel: How to Modernize an Aging PHP Application:我们的许多客户拥有旧版 PHP 应用并希望……
▷ #today-im-learning (6 条消息):
- 为了 3D 植物应用从 MacBook Pro 切换到 Windows:
@woutdeclerck寻求建议,是否应从 MacBook Pro 切换到 Windows 电脑(特别是配备 RTX GeForce 4090 的电脑),以开展与 CG 应用的 3D 植物相关的业务。他们计划使用 Blender 和 Unreal Engine。 - 学习 HF Inference Endpoints:
@duplaja提到他们正在逐渐熟悉 handler.py 和 Hugging Face Inference Endpoints。 - 调整参数:针对
@waffle_cream的询问,@gag123澄清他们没有修改 Andrej 的代码,只是在尝试调整参数。
▷ #cool-finds (4 条消息):
- 对内容的赞赏:用户
@osanseviero表达了他们对@723709999452389417视频的喜爱,称其“非常非常棒”。 - 对未来内容的建议:
@jartine表达了希望接收未来博客文章想法的兴趣。 - 对内容的确认:
@nikocof_63920简短地回复了 “tnks”。
▷ #i-made-this (3 条消息):
- 项目链接至 AINews:用户
@ddchiken提到他们的项目被链接到了 AINews,可能是由服务器里的某人操作的。 - 发布印地语模型:用户
@vikasexcel分享了他们发布的一个模型,即 open-aditi-hi-v1,该模型专门针对印地语进行了微调。他们还开源了数据集。 - 用户
@nikocof_63920回复了一个简单的 “oh…”,可能表示惊讶或感兴趣。
▷ #reading-group (1 条消息):
- 社区主导的论文建议:用户
@lunarflu鼓励新人@Zack提议任何他们想讨论的有趣论文,因为该小组是由社区主导的。
▷ #diffusion-discussions (2 条消息):
- 法律背景下基于 Langchain 的 ChatGPT:用户
@_johnny1984介绍了一个潜在的用例,即一个基于 Langchain 的 ChatGPT 客户端,其中配置了专门的律师/法官/精神科医生 Agent。提议的场景是让 AI 系统分析不同当事人的观点和相关的法院文件来做出判决,特别是针对复杂且敏感的案件,如儿童监护权纠纷。
▷ #NLP (7 条消息):
- Text to SQL 模型:用户
@p_k_boo询问 HuggingFace 上可用的 Text to SQL 转换模型的建议。他们报告说在本地运行某些模型时由于崩溃而出现问题。 - 使用余弦相似度进行数据去重:
@robotics3483正在寻求帮助,希望在 Python 中通过余弦相似度(阈值大于 0.95)进行分组来实现数据去重。 - 训练语言模型 (LLM) 以将自然查询转换为条件:
@ketul1842表达了他们打算训练一个小型 LLM,将自然语言查询转换为 SQL 语句中的条件。他们询问了关于数据集生成、开源模型选择、微调、评估和部署方面的指导。他们也欢迎任何与此主题相关的资源。 - @stroggoz 的模型建议:针对
@ketul1842的提问,@stroggoz建议研究用于机器翻译或改写的 Encoder-Decoder 模型。他们还提到使用为 Next Sentence Prediction 训练的模型(如 BERT)的可能性,但对其在这种情况下效果表示怀疑。他们建议创建一个数据集,其中奇数句子作为 Prompt,偶数句子代表布尔逻辑。
▷ #diffusion-discussions (2 条消息):
- 基于 Langchain 的 ChatGPT 客户端在法律中的应用:用户
@_johnny1984提出了关于基于 Langchain 的 ChatGPT 客户端在做出法律判决方面的潜在应用问题。他们提供了一个残酷的儿童监护权案件的具体例子。然而,该用户没有提供更多细节,也没有收到对其问题的直接回答。
Eleuther Discord 摘要
- 关于 GEGLU/SWIGLU 在训练 LLM 时的有效性和可扩展性 与 GeLU 的对比讨论,由
@fer.bear、@ad8e和@catboy_slim_分享了不同观点。[讨论链接] - 发布了 Mistral 7B Instruct V0.2 模型 的基准测试结果,显示性能取决于输入/输出长度。提到 PyTorch 错误可以忽略,通常是由于 vRAM 短缺引起的。[详情点击]
- 提出了关于 模型在额外预训练和微调后过早预测 EOS token 的技术问题,引发了关注,
@ad8e提出了潜在的解决方案。 - 征求关于 提供类似 Copilot 功能的可定制 VS Code 扩展 的建议,以便使用本地模型。收到了关于
code-clippy-vscode的建议。 - 关于 Pythia 模型训练期间 checkpoint 顺序 的查询由
@stellaathena进行了澄清,解释了在 HuggingFace 的 UI 展示下,step 11000 位于 step 10900 之后的序列关系。 - 提出了一个关于 Transformer 和 MLP 概念等效性的显著问题,以及卷积核权重是否存在类似的动态。
- 针对 Transformer 和 MLP 的问题,提出了“动态卷积”和局部注意力作为潜在的回应。
- 指出了 Transformer 的计算成本,注意到它们对计算和权重线性投影的使用可能被视为浪费,引发了对这些线性投影必要性的进一步探索。
Eleuther 频道摘要
▷ #general (27 条消息🔥):
- GEGLU/SWIGLU 的有效性和可扩展性:讨论了在训练 LLM 时 GEGLU/SWIGLU 相比 GeLU 的有效性。
@fer.bear认为它们提高了长期训练性能,但@ad8e和@catboy_slim_提到缺乏支持该说法的有力证据。(讨论链接) - Mistral 7B Instruct V0.2 基准测试结果:
@flow7450分享了 Mistral 7B Instruct V0.2 模型的基准测试数据,包含各种输入和输出长度的统计。性能随输入/输出长度而异。信息表明 PyTorch 错误可以忽略,且发生在 vRAM 耗尽时。(详情点击)。 - 微调后 EOS Token 预测过快的问题:
@evil_malloc提出了模型在额外预训练和微调后预测 EOS token 过快的问题。@ad8e建议修正某些方法可能会解决此问题。 - 类 Copilot 功能的 VS Code 扩展:
@danielpgonzalez征求关于可黑客定制(hackable)的 VS Code 扩展建议,这些扩展应能使用本地模型提供类似 Copilot 的功能。@nate.dawgg推荐了支持本地模型服务的code-clippy-vscode。 - Pythia 模型训练 Checkpoint 的顺序:
@wolferk寻求关于 Pythia 模型训练中 checkpoint 顺序的澄清。@stellaathena澄清说 step 11000 确实在 step 10900 之后,但 HuggingFace 的 UI 是按字母顺序显示的。
提到的链接:
- React App
- GitHub - jondurbin/qlora: QLoRA: Efficient Finetuning of Quantized LLMs: QLoRA: 量化 LLM 的高效微调。
- GitHub - CodedotAl/code-clippy-vscode: VSCode extension for code suggestion: 用于代码建议的 VSCode 扩展。
- TensorRT-LLM/docs/source/gpt_attention.md at d37b507f41a87457fe9f10f7459d08f5db235745 · NVIDIA/TensorRT-LLM: TensorRT-LLM 为用户提供了一个易于使用的 Py…
- TensorRT-LLM/docs/source/precision.md at d37b507f41a87457fe9f10f7459d08f5db235745 · NVIDIA/TensorRT-LLM: TensorRT-LLM 为用户提供了一个易于使用的 Py…
▷ #research (4 messages):
- Transformers vs MLPs:
@voxs认为 Transformer 可以被视为多层感知机 (MLPs),但其权重是根据输入重新计算的。他们询问是否存在类似的卷积核权重处理方法。 - Dynamic Convolution Suggestion: 针对
@voxs的疑问,@kharr.xyz建议查阅 “dynamic convolution”,并指出该领域已有相当多的论文。 - Local Attention Suggestion:
@theseriousadult提议将 Local Attention 作为@voxs问题的可能答案。 - Discussion on Transformers Computation:
@fern.bear评论了 Transformer 的计算成本。注意到 Transformer 在计算和权重线性投影(linear projections)方面可能存在不必要的浪费,@fern.bear正在探索这些线性投影在多大程度上是必要的。
▷ #interpretability-general (1 messages):
sk5544: 完美!!!
Mistral Discord 总结
- 讨论了 Mistral-medium 和 Mixtral 的性能,指出了它们在特定任务中的不同优劣势,并询问了 Mistral 账号设置的等待时间。
- 关于 不同硬件配置下的模型性能 的见解,包括 GPU offload、RAM 和 VRAM 共享的影响,特别提到了 Nous-Hermes-2-Yi-34B-GGUF Q8 和 MiXtral V0.1 Q4 模型。
- 表达了对 将 Mistral 的 API 与 AutoGen (Studio) UI Assistant Agent 集成 的兴趣,但尚未提供解决方案。
- 关于在大 token 数量下 GPU 与 CPU 运行时间 的疑问,特别是 mixtral-8x7b-instruct-v0.1.Q5_0.gguf 模型的案例;问题解释部分归因于模型无法完全放入用户的 GPU。
- 探索了 物理学概念,如马力、功、能量和功率,包括它们的不同定义、SI 单位和实际示例。
- 咨询了不同渠道 订阅费用的扣费时间。
Mistral 频道总结
▷ #general (15 messages🔥):
-
Mistral-medium 与 Mixtral 的性能对比: 用户
@i_am_dom和@.skyair讨论了 Mistral-medium 和 Mixtral 的性能对比。他们得出结论,Mistral-medium 在某些任务上表现优于 Mixtral,而 Mixtral 在其他特定任务上则超过了 Mistral-medium。 -
Mistral 账号候补名单: 用户
@kiritz_x询问了 Mistral 账号设置及脱离候补名单的典型等待时间。 -
Mistral API 与 AutoGen (Studio) UI Assistant Agent 的集成: 用户
@jb_5579寻求关于将 Mistral 的 API 与 AutoGen (Studio) UI Assistant Agent 集成的建议。然而,目前尚未给出解决方案。 -
关于 GPU 与 CPU 运行时间的查询: 用户
@gilford3641询问为什么在 Windows 系统上使用 mixtral-8x7b-instruct-v0.1.Q5_0.gguf 模型处理 3-4k token 时,使用 GPU 的推理时间比使用 CPU 还要长。@casper_ai回答称,这是因为模型无法完全装入用户的 GPU,导致 CPU 和 GPU 之间需要不断通信,从而减慢了处理速度。
▷ #showcase (7 messages):
- Nous-Hermes-2-Yi-34B-GGUF Q8 在不同配置下的性能: 用户
@.gue22分享了在 256GB Xeon 配置上测试 Nous-Hermes-2-Yi-34B-GGUF Q8 模型的经验。他们观察到该模型需要大量 RAM,且在没有 GPU offload 的情况下运行缓慢。 - MiXtral v0.1 Q4 性能与模型大小: 他们还在 M3 芯片上测试了 MiXtral V0.1 Q4 模型,发现无论 GPU 开启与否,该模型加载速度都很快且响应迅速。
- 不同硬件上的模型性能对比: 用户
@fayiron透露了尝试不同模型大小的经验。他们指出,当模型完全在 GPU 上运行时,效率(49 tokens/s)比 RAM 和 VRAM 共享时更高。 - MiXtral 8x Instruct 7b Q4 在 MacBook Pro 上的性能: 用户
@.gue22注意到 MiXtral 8x Instruct 7b Q4 模型在 M3 Max 36GB MacBook Pro 上加载耗时 40 秒,输出速度为 30 tokens/s。 - 模型性能中的意外发现: 在随后的测试中,
@.gue22发现加载 MiXtral 8x Instruct 7b Q4 26GB 模型时,Xeon 的运行速度仅为 M3 Max 的一半。他们觉得这个结果很有趣,并询问原因。
▷ #la-plateforme (4 messages):
- 订阅费用咨询:用户
@alimsss询问了订阅费用扣除的时间。 - 马力(Horsepower)解释:用户
@dryousefsharrab解释了马力的概念,并区分了机械马力和公制马力。 - 关于功、能量和功率的讨论:
@dryousefsharrab还详细说明了物理学中功、能量和功率的不同含义,包括它们在国际单位制(SI)中的各自单位。 - 功、能量和功率的实际案例:
@dryousefsharrab提供了现实生活中的例子来阐述功、能量和功率的概念。其中包括搬运箱子(功)、电池为手电筒供电(能量)以及汽车发动机的功率输出(功率)。
LangChain AI Discord 总结
- 关于 OpenAI API 中的 Token 使用情况 的讨论,特别是
@swatchap询问了文档分块大小(chunk size)如何影响 API 使用定价,以及它对查询相关信息检索的影响。 @hasan_34148报告了 LangChain 的ChatGoogleGenerativeAI和LLMChain中有关流式传输(streaming)的技术问题,并为此提交了一个公开的 GitHub issue。@seththunder提出了一种替代流式传输方法——本质上是延迟响应中的每个字母。然而,@rajib2189根据流式传输的核心目的质疑了该方法的实用性。- LangChain 模型参数讨论:
@coorbin发起了一场关于如果为嵌入(embeddings)和推理(inference)使用不同参数规模的模型,LangChain 输出是否存在质量差异的对话。 - LangChain 快速入门示例错误:
@manuel_24767报告了在运行与创建检索链相关的 LangChain 示例时出现 ‘ValidationError’,并提供了回溯错误日志以寻求进一步支持。 @dhruvdh在 #share-your-work 频道分享了名为 The Tyranny of Possibilities in the Design of Task-Oriented LLM Systems: A Scoping Survey 的新研究论文。该论文详细介绍了各种 LLM 系统设计,并包含一个独特的思想实验。全文可在此处访问 here。@dhruvdh还创建了一个 Reddit 帖子,总结了论文中的推测,概述了在此类研究中不常见的思想实验应用。
LangChain AI 频道总结
▷ #general (18 messages🔥):
- 理解 OpenAI API 中的 Token 使用:
@swatchap表示需要澄清 OpenAI 的 API 使用定价如何受文档分块大小的影响。他们质疑文档分块大小是否会影响检索到的相关信息,并随后计入输入 Token。 - ChatGoogleGenerativeAI 和 LLMChain 的流式传输问题:
@hasan_34148报告称,他们在ChatGoogleGenerativeAI和LLMChain的 LangChain 流式传输功能方面遇到问题。他们针对该问题提交了一个公开的 GitHub issue。 - 替代流式传输方法:
@seththunder建议了一种实现流式传输的替代方法,本质上是延迟响应中的每个字母。然而,该方法遭到了@rajib2189的质疑,他断言这违背了流式传输的初衷,即理想情况下应该在 Token 生成后立即发送。 - Ollama 嵌入与模型参数等效性:
@coorbin提出了一个关于在 LangChain 中为嵌入和推理使用不同参数规模模型的问题。他们询问输出是否存在质量差异,是否允许参数效率更高的模型或多或少等效地生成嵌入。 - 运行 LangChain 快速入门示例错误:
@manuel_24767分享了他们在运行与创建检索链相关的 LangChain 示例时遇到的问题。他们遇到的错误指向调用检索链时的 ‘ValidationError’。他们详细列出了回溯错误日志以便进一步排查。
提到的链接:
-
[LangChain Expression Language (LCEL) 🦜️🔗 Langchain](https://python.langchain.com/docs/expression_language/):LangChain 表达式语言(LCEL)是一种声明式… - Redirecting…
- CallbackHandler on_llm_new_token method not fire with ChatGoogleGenerativeAI(Gemini) but works fine with ChatOpenAI when streaming true · Issue #14709 · langchain-ai/langchain:系统信息 aiohttp==3.9.1 aiosignal==1.3.1 annota…
▷ #share-your-work (2 条消息):
- 关于面向任务的 LLM 系统的新论文:用户
@dhruvdh分享了一篇名为 The Tyranny of Possibilities in the Design of Task-Oriented LLM Systems: A Scoping Survey 的新研究论文。该论文对面向任务的 LLM 系统设计及各种相关参数进行了范围综述。它包含一个思想实验,讨论了不同 LLM 系统配置在复杂任务上的表现。下载论文。 - 总结论文猜想的 Reddit 帖子:
@dhruvdh还发布了一个 Reddit 帖子,总结了论文中的七个猜想。其中一个重点强调的方面是思想实验的使用,这在该研究领域并不常见。
提到的链接:
- The Tyranny of Possibilities in the Design of Task-Oriented LLM Systems: A Scoping Survey:该范围综述专注于我们目前的理解…
- Reddit - Dive into anything
Latent Space Discord 总结
- 2023 年 AI 回顾:@swyxio 分享了对 2023 年 AI 发展的全面回顾,特别关注了 Large Language Models (LLMs)。内容包括关于构建 LLM 的便捷性、在设备上运行、爱好者微调、GPT-4 面临的挑战等讨论。
- LLM 课程与 AI 笔记:提到了一个为 LLM 提供的开源课程,包含路线图和 Colab 笔记本,以及更新后的 AI 笔记,增加了更多 2023 年 12 月的推荐阅读。
- 课程中的 Mergekit 部分以及最新趋势的可视化呈现(特别是 GPT-4 在开源模型中的主导地位)也被提出。
- State Machine of Thought (SMoT):重点介绍了一篇研究论文,该论文提出了一种新范式,使用预定义的状态机来增强 LLM 的问题解决能力。
- Mixture of Experts (MoEs) Transformers:分享了一篇 HuggingFace 博客文章,详细讨论了受 Mixtral 8x7B 发布启发的 MoEs 的构建模块、训练和权衡。
Latent Space 频道总结
▷ #ai-general-chat (11 messages🔥):
- 2023 年 AI 回顾:
@swyxio分享了 2023 年 AI 的年度回顾,强调了大语言模型 (LLMs) 是该领域的主要进展。回顾详细介绍了 LLMs 的多个方面,包括其构建的便捷性、在设备上运行、爱好者的微调以及构建 GPT-4 的挑战。(回顾链接) - LLM 课程:
@swyxio分享了一个入门大语言模型 (LLMs) 的开源课程,其中包括路线图和 Colab notebooks。如消息所示,该课程适用于路易斯安那州立大学。(课程链接) - Mergekit 与 AI:
@swyxio指出了所分享课程中 Mergekit 章节的相关性,特别是在当前场景下。 - AI 笔记:此外,
@swyxio分享了一个更新后的 AI 笔记链接,提供了更多 2023 年 12 月的推荐阅读内容。(笔记链接) - 开源模型可视化:
@swyxio分享了一个显示开源模型最新趋势的可视化图表,特别是 GPT-4 的主导地位。该可视化基于过去六个月的数据,获取自 LocalLLaMA 的一个 Reddit 帖子。(可视化链接) - 思维状态机 (SMoT):
@davidkpiano分享了一篇研究论文的链接,介绍了一种名为 SMoT 的新范式,该范式通过采用预定义的状态机来改进 LLMs 的问题解决能力,从而消除无效的探索。(论文链接)
提到的链接:
- Stuff we figured out about AI in 2023:2023 年是大语言模型取得突破性进展的一年…
- SMoT: Think in State Machine:当前语言模型的提示词方法不足…
- Reddit - Dive into anything
- GitHub - mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.:入门大语言模型 (LLMs) 的课程,包含路线图和 Colab notebooks。
- update all the notes · swyxio/ai-notes@650319e
▷ #llm-paper-club (1 messages):
- 混合专家模型 (MoEs) Transformers:
@swyxio分享了来自 HuggingFace 的一篇易读的博客文章,讨论了 Mixture of Experts (MoEs)。在 Mixtral 8x7B 发布后,这是开源 AI 社区的一个热门话题。该博文深入探讨了 MoEs 的构建模块、训练以及在推理服务时的权衡。
提到的链接:
Alignment Lab AI Discord 摘要
- 在 AI 和 ML 的讨论中,用户
@fred_fups表达了在训练 Mistral 7b 模型时遇到的问题,具体表现为生成不完整的响应和过多的换行符。他们还分享了训练文件的摘录,并请求其他成员提供见解。- “我针对文本格式示例训练了 Mistral 7b 模型……训练后,模型产生不完整的响应,并重复生成换行符 (
'\n') 直到达到输出限制”
- “我针对文本格式示例训练了 Mistral 7b 模型……训练后,模型产生不完整的响应,并重复生成换行符 (
-
新年祝福和互动主导了
oo频道;@damiondreggs为此分享了一个 Kermit The Frog GIF。 - Looking-for-Work 频道中,即将毕业且在自动驾驶汽车领域有经验的
@klrshak询问了相关领域的远程暑期实习和长期工作机会。该用户表达了最终攻读 PhD 的愿望。他们征求了其感兴趣领域的研究实验室或公司的建议。
Alignment Lab AI 频道摘要
▷ #ai-and-ml-discussion (4 条消息):
- Mistral 模型训练问题:用户
@fred_fups报告了他在文本格式化示例上训练 Mistral 7b 模型时遇到的问题。训练后,模型会产生不完整的响应,并不断生成换行符 ('\n') 直到达到输出限制。 - 寻求模型训练帮助:
@fred_fups询问是否有人遇到过类似问题,或者对根本原因有什么推测。 - 分享训练文件示例:
@fred_fups分享了训练文件的摘录,背景是通过应用特定的格式更改来增强文本的可读性。他表示自己是 AI 训练的新手,并对训练集中可能存在的问题持开放态度。
▷ #oo (5 条消息):
oo 频道的消息包括:
- 来自
@nanobitz、@imonenext和@entropi的新年问候。 @damiondreggs通过链接 https://tenor.com/view/kermit-the-frog-meme-memes-gif-24277198 分享了一个 GIF 并庆祝新年。
提到的链接:
Kermit The GIF - Kermit The Frog - Discover & Share GIFs:点击查看 GIF
▷ #looking-for-work (1 条消息):
- 实习与长期机会咨询:
@klrshak是一名即将在暑假前毕业的学生,在 Autonomous Vehicles 的场景理解和感知方面有经验,目前对相关领域的暑期实习和长期工作机会都感兴趣。他们的长远目标是攻读 PhD。他们正在专门寻求在该领域有卓越成果的研究实验室或公司的建议,这些单位目前愿意提供远程实习,并可能在夏季提供线下实习。
Skunkworks AI Discord 总结
- 用户
@teknium、@far_el和@oleegg在常规对话中互道“新年快乐”。 - 由
@teknium发起的关于聊天机器人输出的讨论吸引了@caviterginsoy和@leuyann的回应,但具体背景尚不明确。 @walter8967发起了关于文本标注对 multitask training 价值的讨论,提到了标注图像如何减少图像生成的训练数据需求(未引用来源)。- 作为另一种方法,
@walter8967建议使用更多文本可能会改善训练效果。 - 在 off-topic 频道中,
yusufhilmi_寻求用于分割图形艺术和用户界面(UI)的类似 SAM 的模型信息。
Skunkworks AI 频道总结
▷ #general (6 条消息):
- 常规对话:用户分享了温馨的祝福,
@teknium、@far_el和@oleegg祝大家“新年快乐”。 - 聊天机器人输出讨论:用户
@teknium发表了一个引起大家兴趣的评论,@caviterginsoy和@leuyann对此作出了回应。然而,从这些消息中尚不清楚讨论的具体背景或主题。
▷ #datasets (2 条消息):
- 文本标注对 Multitask Training 的价值:
@walter8967询问了在 multitask training 中标注文本(例如识别词性或手动消歧)的潜在好处。他们提到标注图像被发现可以减少图像生成器的训练数据需求,但未引用该信息的来源。 - 另一种方法 - 更多文本:
@walter8967还在思考,积累更多文本是否是改善训练的更好方法。
▷ #off-topic (1 条消息):
yusufhilmi_: 有没有人知道用于分割图形艺术和用户界面的类似 SAM 的模型?
DiscoResearch Discord 总结
只有一个频道有活动,因此无需总结…
- 将德语添加到 MTEB:
@rasdani正在为 Multilingual Text Embeddings Benchmark 开发一个 fork/PR,并在 GermanQuAD 上实现了 MRR@10。他们分享了一个有趣的 GitHub issue 链接,其中建议了可能需要考虑的数据集。 - 在 GermanQuAD 上测试 MTEB:
@rasdani发布了在整个 GermanQuAD 测试集上运行 Multilingual Text Embeddings Benchmark 的无错运行结果,使用的是intfloat/multilingual-e5-small模型。他们按照建议使用了点积(dot product),并保留了所有默认指标。 - 对点积方法的担忧:
@philipmay评论道,模型必须在损失函数中包含点积进行训练,而不仅仅是使用点积代替余弦相似度(cosine similarity)。距离函数应与训练方法相对应。 - MRR@10 数值较低:
@philipmay指出 0.3908 的 MRR@10 值偏低。 - 子集测试结果有所改善:
@rasdani报告称,在 100 和 150 个唯一上下文的子集上进行评估时,结果有所改善。他们还评论说,MTEB 中使用的 BEIR 库对数据集格式非常挑剔。他们计划发布自己的 fork 以供审查。
提到的链接:
Adding German to MTEB · Issue #183 · embeddings-benchmark/mteb:大家好,我认为添加德语支持会很棒…
MLOps @Chipro Discord 总结
只有一个频道有活动,因此无需总结…
- 虚拟活动:Infer - AI 与 ML 背后的工程:用户
@amitqwak宣布了一场名为 Infer 的虚拟活动,面向 ML 工程师、数据科学家、数据工程师、软件工程经理以及 MLOps 从业者。该活动旨在连接 Machine Learning 和 AI 领域的领导者,展示顶尖公司如何在实践中应用 ML 和 AI,强调在生产环境中使用 ML/AI 的挑战和策略,并提供对该领域最新趋势和进展的见解。活动免费参加,定于 2024 年 3 月 20 日美国东部时间上午 11:30 举行。可以通过此链接进行活动注册。感兴趣的参与者可以在此处提交演讲申请。议程尚未公布。
提到的链接:
| [Infer by Qwak | The Engineering Behind AI and ML](https://www.qwak.com/infer/infer-march-2024?utm_source=Chip_Hyuen&utm_medium=Discord&utm_campaign=Infer_March20):Qwak 举办的 Infer 活动邀请了 ML 和 AI 领导者分享如何… |
Datasette/LLM (@SimonW) Discord 总结
只有一个频道有活动,因此无需总结…
- 文档 AI 与开源模型:在讨论中,
@stephen_88734分享了一篇 Hugging Face 博客文章的链接,讨论了各种文档 AI 任务以及如何利用开源模型从各种类型的文档中解锁信息。内容涵盖了图像分类、图像转文本、文档问答、表格问答以及视觉问答等任务。推荐的模型包括 Donut 和 LayoutLM。
提到的链接: