ainews-142024-jeff-bezos-backs-perplexitys-520m
2024年1月4日:杰夫·贝佐斯投资了 Perplexity 总额 5.2 亿美元的 B 轮融资。
Perplexity 宣布了其 B 轮融资,知名投资者包括 杰夫·贝佐斯 (Jeff Bezos),他曾在 25 年前投资过 Google。Anthropic 正在筹集 7.5 亿美元,预计明年年化收入至少达到 8.5 亿美元,并对其服务条款进行了“严苛”的修改。Nous Research AI Discord 上的讨论涵盖了诸如从数 GB 数据中召回文档的限制、RNN 内存与计算的权衡、合成数据集,以及对 WizardCoder-33B-V1.1、MobileLLaMA-1.4B-Base、ShearedLLaMA 和 TinyLLaMA 等模型的基准测试。其他亮点包括针对多 GPU 系统的 UnsLOTH 优化、AI 说唱语音模型、上下文扩展代码,以及架构创新,如将 Detectron/ViT 骨干网络应用于大语言模型 (LLM)、Mistral 中的滑动窗口注意力,以及使用 FSDP 和 HF Accelerate 并行化 Mixtral 8x7b。
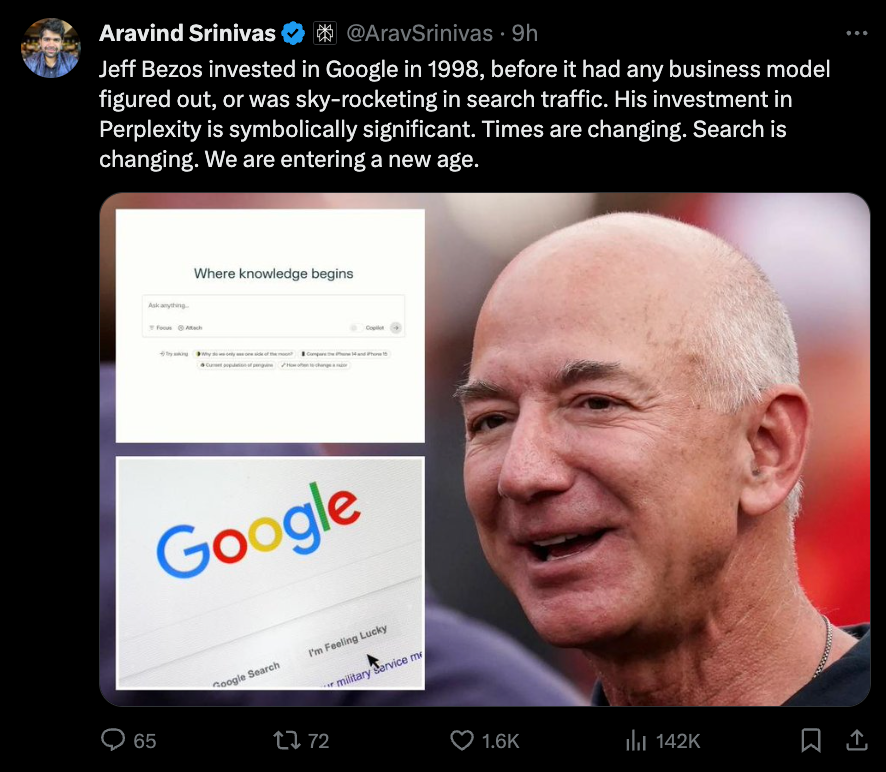
正如广泛传闻的那样,Perplexity 宣布了他们的 B 轮融资。最引人注目的投资者是 Jeff Bezos,他 25 年前也投资了 Google。
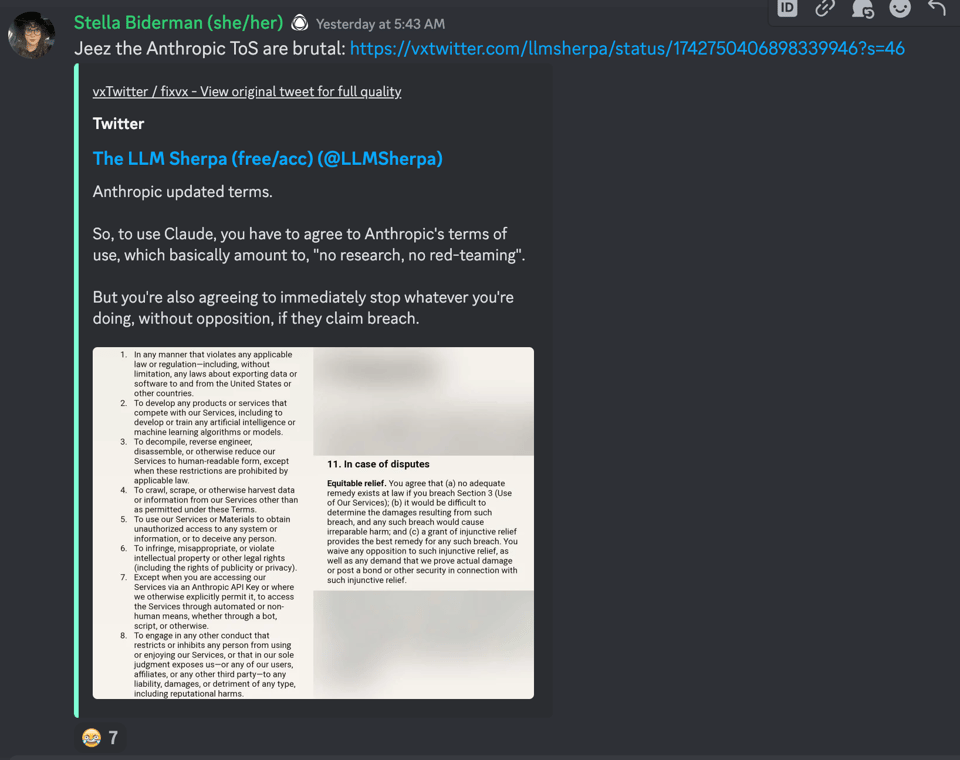
在其他方面,Anthropic 正在进行的 7.5 亿美元融资促使其发布了非常宏大的预测并制定了“残酷”的 ToS(服务条款)变更:
目录
[TOC]
Nous Research AI Discord 总结
- 查询内存至关重要:在 #ctx-length-research 频道的讨论中,
@benjoyo思考了从数 GB 数据中进行文档召回的限制。关于成本,@teknium指出,虽然成本随上下文大小(context size)增加而上升,但并非指数级增长。@euclaise阐明了 RNN 内存与计算 的微妙之处,解释说在 RNN 模式下,内存使用是恒定的,但需要大量计算,而非 RNN 模式则通过增加内存使用来换取亚线性(sub-linear)的计算开销。 - 软件主权与 GPU 之争:#off-topic 频道由
@benjoyo关于欧洲托管潜在陷阱的问题引发了一场关于数据主权的热烈辩论。@gabriel_syme正在努力解决 Windows 11 上的显卡问题,而@max_paperclips则欢呼合成数据集(synthetic datasets)时代的到来,这让已经超负荷工作的 GPU 叫苦不迭。 - 语言模型常看常新:#interesting-links 频道充满了关于语言模型的讨论,从 WizardCoder-33B-V1.1 充满前景的表现到 Humaneval-Test-Set-Alpha 在极端条件下的理论实力。
@metaldragon01重点介绍了一篇关于名为 CALM 的新型模型扩展技术的文章,引发了@gabriel_syme对其与 LORAs 结合潜力的推测。针对@euclaise对 MobileLLaMA-1.4B-Base 性能的拥护,@.benxh断言 ShearedLLaMA 的 Benchmark 结果更优。与此同时,TinyLLaMA 的评估仍悬而未决。 - 模型可能性与实用性:在 #general 频道中,
@gabriel_syme寻求关于将 UnsLOTH 优化应用于多 GPU 系统的解答,促使@teknium强调了 UnsLOTH 的专有性质。关于潜在的 200k 上下文 Nous Hermes 模型的提及引起了好奇,但真正让人津津乐道的是一个 AI 说唱语音模型。关于兼容 Mac 的 AI 训练器的咨询得到了解答,对上下文扩展代码更新的热情依然不减。 - LLM 架构 – 适配、实现与探索:#ask-about-llms 频道中,
@__nord提议将 Detectron/ViT 骨干网络应用于 LLM,以便在私有数据集上运行。在高性能推理引擎方面,@uchihakrishnaa发现 ctranslate2 是一个可能超越 TGI 和 vLLM 的选择。滑动窗口注意力(Sliding window attention)被认为是一种值得在 Mistral 中实现的技术,而在不进行微调的情况下为架构添加边界框(bounding boxes)的前景也引起了关注。@kyleboddy提出了在多 GPU 间并行化 Mixtral 8x7b 的问题,对此@orangetin建议将 FSDP 和 HF Accelerate 作为潜在解决方案。
Nous Research AI 频道总结
▷ #ctx-length-research (15 条消息🔥):
- 文档召回的限制:用户
@benjoyo推测从海量数据中检索信息的局限性,认为 数 GB 的文档 无法实现完美的召回。 - 成本随上下文大小增加:
@teknium表示,虽然上下文成本确实随尺寸增加而增加,但并非指数级增长。 - RNN 内存与计算:
@euclaise告知,在 RNN 模式下,内存使用量为 O(1),但需要 O(N) 的计算量。非 RNN 模式允许亚线性计算,但需要更多内存。 - Mamba 的召回效率:
@ldj分享说,Mamba 在 100 万 token 的序列上实现了超过 95% 的关联召回,优于使用 Hyena 训练的 SOTA DNA 模型。 - 上下文管理与检索作为研究方向:
@maxwellandrews建议,更好的检索(知识而非文本块)和更好的模型上下文管理都是有效且独立有用的研究方向。这得到了@gabriel_syme的支持,他认为鉴于目前在上下文方面已有大量工作,检索相比上下文具有更大的探索潜力。
▷ #off-topic (13 条消息🔥):
-
数据主权讨论:针对
@benjoyo关于平台托管在欧洲可能存在的问题的查询,@gabriel_syme提出了 data sovereignty(数据主权)的问题。 -
Windows 11 显卡问题:
@gabriel_syme报告称 Windows 11 导致其显卡出现问题,清除了驱动程序并使其无法正常工作。 -
合成数据集热潮与 GPU 消耗:
@max_paperclips对 synthetic datasets 表示支持,@carsonpoole则幽默地指出这会增加 GPU 的工作负载(“GPUs about to go brrr”)。 -
关于资助合成数据集的问题:
@gabriel_syme询问工作是否可以资助 synthetic datasets;@teknium澄清这是允许的,@gabriel_syme表示已注意到相关条款。 -
Twitter 广告与机器人:
@euclaise提出了关于 Chai on Twitter 广告涌入的问题。@metaldragon01和@gabriel_syme进一步讨论了该平台上普遍存在的色情广告和机器人。
▷ #interesting-links (38 条消息🔥):
-
新语言模型 WizardCoder-33B-V1.1 超越 GPT3.5-Turbo:
@metaldragon01分享了来自@WizardLM_AI的 Twitter 更新,发布了 WizardCoder-33B-V1.1。这是一个在多种 Benchmark 中表现优异的新语言模型。然而,@giftedgummybee对缺乏可用于复现数据的 Dataset 和代码表示担忧。 -
Humaneval-Test-Set-Alpha 展现潜力:
@n8programs幽默地声称他们的模型 “Humaneval-Test-Set-Alpha” 可以在不到 1MB 的数据下,在 Humaneval 上达到 100% 的成功率。 -
模型组合与扩展的讨论:
@metaldragon01分享了一篇介绍 CALM (Composition to Augment Language Models) 的 文章,这是一种合并模型并赋予其新能力的新方法。@gabriel_syme推测了在 Anchor Model 和 LORA (Locally Optimized Robust Anchors) 之间使用 Cross Attention 的可能性。 -
MobileLLaMA-1.4B-Base 表现出色:
@euclaise分享了 HuggingFace 上的 MobileLLaMA-1.4B-Base 链接,这是一个缩减版的 LLaMA 模型,其 Benchmark 性能与近期其他开源模型相当。然而,@.benxh认为根据 Benchmark 结果,ShearedLLaMA 的表现更好。 -
TinyLLaMA 等待评估:在一次误解后,
@qnguyen3澄清 TinyLLaMA 已经完成,正在等待@387972437901312000进行 Evaluation。
提到的链接:
- mtgv/MobileLLaMA-1.4B-Base · Hugging Face
- LLM Augmented LLMs: Expanding Capabilities through Composition:拥有数十亿参数的基础模型…
- Paper page - LLaMA Pro: Progressive LLaMA with Block Expansion
- Tweet from WizardLM (@WizardLM_AI):🔥 很高兴发布 WizardCoder-33B-V1.1…
▷ #general (120 messages🔥🔥):
- UnsLOTH 疑问解答:
@gabriel_syme询问了 UnsLOTH 的性质,这是一个带有自定义内核的 LORA 训练器。@teknium澄清说它是一个私有产品,多 GPU 系统的代码不会免费提供。@beowulfbr链接了 axolotl 的 GitHub 仓库中的一个 issue,其中有用户尝试应用 UnsLOTH 的优化。 - 200k Nous 模型推测:在讨论长上下文模型时,
@nonameusr随口询问了 200k Nous Hermes 模型的潜力。@ldj提到这样的模型已经以 Nous Capybara 的形式存在。随后澄清该查询特指 200k 上下文模型的 Hermes 变体。 - AI 说唱模型一瞥:
@euclaise发起了一场关于 AI 说唱语音模型可能存在的讨论。各种回答指向了 UberDuck 和 MAYK 等服务,包括使用 RVC 创建人声。 - 关于 Mac 上 AI 训练器的疑问:
@agcobra1询问了在 Mac 上训练模型的可能性。虽然没有提供具体细节,但@n8programs建议使用 LORA MLX 或带有 MLX 后端的 Transformers。 - 上下文扩展代码更新:有一场关于新代码的对话,该代码声称可以执行神奇的、无需训练的上下文扩展 (
@spaceman777)。@ldj指出用户正在努力为 Llama.cpp 项目添加 Mamba 支持,Mamba 可能会使处理更大的上下文模型变得更实际。
提到的链接:
- Popular "AI Hub" Discord Taken Down Following Copyright Complaints * TorrentFreak
-
[Uberduck Make Music with AI Vocals](https://www.uberduck.ai/):通过合成你的…生成高质量语音 - Teknium (e/λ) (@Teknium1) 的推文:@yacineMTB @abacaj 我告诉过你一个系统…
- Apply unsloth optimizations · Issue #908 · OpenAccess-AI-Collective/axolotl:⚠️ 请检查此功能请求是否…
- Your Virtual Music Studio – mayk.it:我们是一个为下一代音乐创作而生的虚拟音乐工作室…
▷ #ask-about-llms (24 messages🔥):
- 修改 LLM 架构:
- 用户
@__nord提出了关于修改 LLM 架构和训练的问题。他们计划实现某篇论文,如果成功,他们将考虑为他们处理的私有数据集添加 Detectron/ViT 骨干网络。
- 用户
- 推理引擎替代方案:
@uchihakrishnaa表示需要比 TGI 和 vLLM 为微调后的 vicuna 模型 提供更高吞吐量的推理引擎。@night_w0lf建议研究 ctranslate2 作为潜在的解决方案。
- 关于 Sliding Window Attention 的讨论:
- 用户
@lwasinam询问了关于实现 Sliding Window Attention 的方法,这是 Mistral 采用的一种技术。
- 用户
- 将 Bounding Boxes 整合到架构中:
- 在
@__nord和@max_paperclips的讨论中,讨论了在不进行微调的情况下修改 Attention 的可能性。建议可以使用与原始权重相同的权重投影出一对新的 Keys 和 Values。
- 在
- 在多 GPU 上并行化 Mixtral:
@kyleboddy表达了在多 GPU 上并行化 Mixtral 8x7b 进行训练和推理的困难。@orangetin建议在训练时使用 FSDP,在推理时使用 HF Accelerate。
OpenAI Discord 总结
- 合并多个 ChatGPT 订阅:用户可以在 Enterprise 方案下将多个 ChatGPT 订阅合并。这是
@lugui在回复@shalevbartal_38833的查询时确认的。在此查看订阅详情。 - 针对生成归属提出的巧妙 ASCII 变更方案:
@iruint针对文本复制问题提出了一个有趣的解决方案——通过更改 ASCII 字符编码,在复制的文本中创建可检测的损坏。@.dooz和@lugui对此想法表达了兴趣,同时也表示了不确定性。 - 移动版 ChatGPT 现已兼容 PC:根据
@satanhashtag和@dystopia78的说法,用户可以在 PC 上使用移动版 ChatGPT+ 订阅。但请注意,如果使用 PayPal,则需要从移动端购买。 - OpenAI 的 GPT Store 即将上线:令人兴奋的时刻,
@uchenkenta宣布 OpenAI 的 GPT Store 即将发布,这是一个允许开发者分发其自定义 AI 应用的平台。要加入该平台,开发者需要拥有 ChatGPT Plus 或 Enterprise 订阅。 - 免费用户是否能访问 GPT Store 仍存疑问:关于 GPT Store 的发布,
@misangenius想知道免费用户是否可以访问自定义 GPT。@muyfashionista推测 OpenAI 的 API 成本可能会通过应用转嫁给消费者。 - DadBot 亮相,你渴望的聊天伙伴:
@tdgrpodcast介绍了 “DadBot”,邀请用户进行对话。你也可以在这里见到 DadBot。 - 开发者应对 GPT Prompt 限制的技巧:达到了自定义 GPT 的 Prompt 限制?没问题——正如
@darthgustav.所建议的,你可以通过将上下文复制到 GPT-4 中来继续对话。 - GPT Store 的发布引发安全担忧:随着 GPT Store 发布临近,
@r3plac3d表达了对克隆等潜在安全威胁的担忧,并呼吁采取比 OpenAI 目前推荐的更强大的安全措施。 - 自定义 GPT-3 的图像差异化令用户困扰:
@jungle_jo观察到他们自定义的 GPT-3 反复生成类似的图像,降低了用户体验。@eskcanta建议在 Prompt 中添加三个用户衍生的关键词,以获得更多样化的输出。 - Prompt Engineering 中萌芽的商业机会:
@iiimandalorianiii表示成功向企业客户以 1500 美元的价格售出了一套 AI 聊天机器人 Prompt。 - 需要指令遵循能力更强的 AI:
@zdev26报告了他们定制的GPT 3.5 Turbo忽略额外用户指令的问题,并向 OpenAI 寻求解决方案。 - 有没有想过用
ChatGPT替换单词?:@dnp_需要帮助将设定文本中特定领域的单词替换为占位符,但处理负面词汇似乎具有挑战性。
OpenAI 频道总结
▷ #ai-discussions (20 条消息🔥):
-
ChatGPT 多重订阅咨询:用户
@shalevbartal_38833询问了关于购买多个 ChatGPT 订阅的问题。@lugui提供了指导,指出只有通过 Enterprise 计划才能同时购买多个订阅,并分享了 订阅链接。 -
生成式归属问题的解决方案?:用户
@iruint就解决生成式归属(generative attribution)问题提出了一个有趣的建议。他们提议修改 ASCII 字符集,使用机器人字符代替标准的 ‘a’ 和 ‘i’,并将这些更改应用于非拉丁字符。这个想法是,当复制文本中的字符编码被破坏时,可以检测到违规行为。@.dooz和@lugui加入了讨论,对这种方案的实用性和可靠性提出了疑问。 -
跨设备使用 ChatGPT 订阅:用户
@knownx.询问在移动端购买的 ChatGPT+ 订阅是否可以在 PC 上使用。@satanhashtag和@dystopia78回复确认这确实是可行的,但如果使用 PayPal,则需要通过移动平台进行支付。 -
GPT Store 发布公告:
@uchenkenta分享了关于 OpenAI 即将发布 GPT Store 的新闻。GPT Store 将成为开发者分发基于 OpenAI AI 模型构建的自定义应用程序的平台。开发者需要遵守 OpenAI 更新的使用政策和品牌指南,并拥有 ChatGPT Plus 或 Enterprise 订阅。 -
免费用户访问 GPT Store 的权限:针对 GPT Store 的发布公告,
@misangenius询问免费用户是否可以访问商店中的自定义 GPTs。@muyfashionista认为 OpenAI 的 API 成本可能会嵌入到应用中并转嫁给客户,并引用了关于潜在 变现方案 的讨论。
提到的链接:
OpenAI Set to Launch GPT Store Next Week: A Platform for Custom AI Apps:OpenAI 即将推出 GPT Store,一个用于自定义 AI 应用的平台…
▷ #gpt-4-discussions (69 条消息🔥🔥):
- DadBot 首次亮相:
@tdgrpodcast邀请用户测试他们创建的新 AI —— DadBot,并提供了链接 (https://chat.openai.com/g/g-OhGvGkxM9-dadbot)。 - GPT Store 发布公告:用户
@pierrunoyt和@nickthepaladin讨论了即将推出的 GPT Store,并对会员资格要求表达了一些担忧。 - 使用 Custom GPTs 的实用提示:
@darthgustav.为开发者提供了一个绕过 Custom GPT 中 Prompt 限制的方法:当达到限制时,只需将上下文(context)复制到 GPT-4 中即可继续对话。 - GPT Store 发布的安全担忧:
@r3plac3d对即将发布的 GPT Store 相关的安全问题提出了强烈担忧。他们指出,OpenAI 之前的建议(如禁用 Code Interpreter)不足以防止克隆和其他潜在威胁。 - 个人资料图片上传问题:
@francisrafal分享了在向 GPT 上传个人资料图片时遇到的困难。研究发现,使用 Chrome 浏览器可以解决该问题,这表明 Brave 浏览器可能存在兼容性问题。 - 对 Custom GPTs 限制的质疑:
@holden3967、@thepitviper等人对 Custom GPTs 的限制表示担忧,例如每 3 小时 25 条 Prompt 的限制。用户询问了已知的限制漏洞、是否需要 OpenAI Plus 账户,并期望付费客户应该获得更高的额度。 - 调整 Builder Profile 信息:
@r3plac3d和@scargia讨论了在 OpenAI 平台上调整 Builder Profile 信息的问题,@scargia说明用户可以通过账户资料链接 (https://platform.openai.com/account/profile) 编辑自己的名称。
▷ #prompt-engineering (38 messages🔥):
- 图像多样性困扰:用户
@jungle_jo注意到,他们根据一套指南生成图像的自定义 GPT-3 模型,在 10 个案例中有 5 个生成的图像具有相似的模式。 - 缺乏随机性:在与
@eskcanta讨论后,他们认为 AI 由于是无状态(stateless)的,可能每次都会做出相同的选择。讨论强调了 AI 在生成随机性方面的困难。 - 提高图像多样性:
@eskcanta建议重写用户的 Prompt,添加三个关键词并从中获取输入。这将带来“真正的随机性”,并使生成的图像更具多样性。 - Prompt Engineering 的销售:
@iiimandalorianiii分享了他们以 1500 美元的价格向企业客户出售一套用于 AI 聊天机器人的 Prompt 的成功经验。 - 请求短信故事 Prompt:
@user691378寻求帮助,希望创建一个能够生成用于社交媒体的短信故事的 Prompt。
▷ #api-discussions (38 messages🔥):
- 解决
GPT 3.5 Turbo忽略新增用户指令的问题:@zdev26报告称,他们经过微调的GPT 3.5 Turbo聊天机器人在输出时会忽略额外的用户指令。他们注意到模型经常忽略引导性 Prompt,例如“用户已为下一条消息提供指令:‘用幽默的方式询问她的电话号码’”。 - 操纵
ChatGPT进行单词 ~替换~:@dnp_寻求帮助,想让ChatGPT复制一段文本,但将某些特定领域的词汇替换为占位符,如 “fillintheblank”。文本中的否定词似乎带来了一些挑战。 - 生成唯一的 AI 图像:
@jungle_jo报告了其自定义GPT模型的一个问题,该模型根据一套指南生成图像。他们注意到模型倾向于重复生成相似的图像,缺乏变化,并希望获得改进建议。 - 图像多样性问题的解决方案:
@eskcanta为@jungle_jo的问题提供了深入的建议,提出了刺激随机图像生成的方法。他们建议重写当前的指令,并添加三个源自用户 Prompt 的关键词。 - Prompt Engineering 作为商业机会:
@iiimandalorianiii分享了一个有趣的故事,他们以 1500 美元的价格向一家公司出售了一套 Prompt。他们向该公司提出了 Prompt Engineering 的想法,并为其业务流程编写了一套 Prompt。
LAION Discord 摘要
- LAION 5B 中的儿童风险:
@chad_in_the_house讨论了斯坦福大学研究人员在 LAION 5B 中发现的儿童色情内容,这迫使某些数据库被移除。 - 揭穿 OpenCLIP 会生成露骨内容的传言:
@thejonasbrothers和@pseudoterminalx在分析后得出结论,由于数据限制,OpenCLIP 无法生成露骨或非法图像。 - 数据集抓取的优缺点:
@thejonasbrothers和@pseudoterminalx分享了将从电影和动漫中抓取的高质量数据输入模型的经验,详细说明了幻觉问题及可能的解决方案。 - Claude 的使用条款:
@itali4no引用了一条 推文,指出 Anthropic 修改了 Claude 的使用条款,现在限制将其用于研究、红队测试(red-teaming)或竞争模型的开发。 - aMUSEd 助力文本生成图像流程:
@thejonasbrothers通过一篇 arXiv 论文 介绍了一种名为 aMUSEd 的新型轻量级 Masked Image Model (MIM),它可以增强对单张图像的风格学习,并加速大规模文本生成图像的过程。 - 用 3D 雕刻你的 2D 图像:
@thejonasbrothers分享了一篇关于 ‘Image Sculpting’ 的 arXiv 论文 —— 这是一种使用 3D 几何工具编辑 2D 图像以提高精确度的工具。 - 认识 Unicron,大规模语言模型训练的自愈系统:
@vrus0188通过一篇 Reddit 帖子 介绍了 Unicron —— 这是由阿里巴巴研究人员设计的一种 AI 系统,旨在实现大规模语言模型训练中的高效自愈。 - 为什么 Stable Diffusion 在年龄概念上表现不佳:
@phryq和@JH讨论了 Stable Diffusion 模型在表现基于年龄的特征方面的固有局限性,以及采样分布外(OOD)数据的挑战。预训练(Pretraining)可能提供一种解决方案,尽管这需要全面的测试。
LAION 频道摘要
▷ #general (132 条消息🔥🔥):
-
LAION 5B 非法内容的争议:
@chad_in_the_house讨论了斯坦福大学研究人员在 LAION 5B 中发现儿童色情内容的情况,这导致某些数据库被下线。 -
关于可能生成不当图像的讨论:
@thejonasbrothers和@pseudoterminalx讨论了 OpenCLIP 模型生成露骨或非法图像的能力(或缺乏此类能力),双方都认为由于数据的限制,这种情况不太可能发生。 -
在数据集 Rips 上训练模型:
@thejonasbrothers和@pseudoterminalx详细交流了他们向模型输入来自电影和动漫的高质量 Rip 数据的经验、遇到的幻觉(hallucinations)挑战以及尝试过的可能解决方案。 -
违反 Claude 使用服务条款的后果:
@itali4no引用的一条推文提到,Anthropic 更新了 Claude 的使用条款,限制其用于研究、红队测试(red-teaming)或开发竞争模型。 -
对 MistralAI 关于使用输出结果政策的赞赏:
@SegmentationFault赞扬了 MistralAI 在使用其模型输出训练其他模型方面采取的更宽松立场。
提到的链接:
The LLM Sherpa (free/acc) (@LLMSherpa) 的推文:Anthropic 更新了条款。所以,要使用 Claude,你必须…
▷ #research (6 条消息):
- 轻量级图像模型 aMUSEd 助力文本生成图像:
thejonasbrothers分享了一个关于新型轻量级 Masked Image Model (MIM) —— aMUSEd 的 arXiv 论文 链接。该模型由 Patrick von Platen 开发,旨在加速文本生成图像的过程,并增强从单张图像中学习额外风格的能力。这种方法可能会彻底改变大规模文本生成图像的运作方式。 - Image Sculpting:用 3D 工具编辑 2D 图像的新方法:
thejonasbrothers发布了另一篇 arXiv 论文,介绍了一种名为 Image Sculpting 的工具,它允许使用 3D 几何工具编辑 2D 图像。这种新颖的方法可以提高图像编辑的精度,并增强生成模型的潜力。 - Unicron:阿里巴巴用于语言模型训练的自愈 AI 系统:
vrus0188分享了一篇关于 Unicron 的 Reddit 帖子,这是由阿里巴巴研究人员开发的一个 AI 系统。该系统专为大规模语言模型训练中的高效自愈而设计。 - 来自 WACV2024 的 Conditional Velocity Score Estimation 论文:
wangshuai发布了 WACV2024 最佳论文的 PDF 链接,标题为“Conditional Velocity Score Estimation for Image Restoration”。PDF 链接
提到的链接:
- Image Sculpting: Precise Object Editing with 3D Geometry Control:我们提出了 Image Sculpting,一个用于编辑的新框架…
- aMUSEd: An Open MUSE Reproduction:我们提出了 aMUSEd,一个开源、轻量级的 mas…
- Reddit - 深入探索一切
▷ #learning-ml (3 messages):
- Stable Diffusion 模型中的概念理解:用户
@phryq询问了 Stable Diffusion 在学习表示图像中基于年龄特征方面的概念能力。他们想知道模型是否可以对未直接训练过的年龄进行插值。 - 采样样本外(OOD)限制:
@JH澄清说,由于年龄是由输入 token 而非实际数字建模的,模型在不同年龄(例如 30 岁和 40 岁)之间进行插值通常面临挑战。这种挑战被认为是采样样本外(OOD)问题。 - 预训练模型的可能例外:
@JH进一步补充说,预训练模型(如与文本生成图像模型一起使用的 clip encoder)可能已经学会了识别年龄的 token。因此,即使对于你的训练数据来说是 OOD,该年龄可能正好在预训练模型的分布范围内。 - 强调测试和验证模型能力:为了保证学习到的概念,
@JH建议开发全面的测试来定期检查模型的能力,衡量所需的训练程度,并评估对数据增强(data augmentation)的潜在需求。 - 对 Stable Diffusion 中概念形成的深入见解:
@phryq进一步强调了 LLM(可以发展出概念)与 Stable Diffusion 之间的区别,认为 Stable Diffusion 模型可能局限于准确理解它们所训练的内容,而无法形成更深层次的“概念理解”。
HuggingFace Discord Discord Summary
- 使用 Hugging Face 和 DVC 让数据管理更轻松:
@Andyrasika写了一篇关于使用 Hugging Face 和 Data Version Control (DVC) 管理数据的博客文章 博客链接。 - 双语内容创作迎来新星:
@manishiitg展示了他们在印地语和英语数据上训练的模型,非常适合内容写作、分类和连贯的内容创作。该模型不适合编码/数学任务 模型链接。 - Whisper ASR 端点推理问题的传闻:
@blahblah6407在为微调后的 Whisper 创建和测试 ASR 端点推理时遇到了问题。 - 为深度学习构建预算型 PC:
@sedthh寻求关于深度学习预算型 PC 配置的建议,在 3090 或 4080 以及同价位的其他替代方案之间进行选择。 - 探索 Stable Diffusion XL:
@8bit888分享了一篇关于 Stable Diffusion XL 的博客文章:一份无限制图像生成指南 链接。 - 银行对账单图像标注自动化:
@detraxsenpai寻求关于自动化银行对账单图像标注以及进行异常修订的建议。 - 聊天机器人即将问世:
@jryarianto寻求关于创建能够从数据库提供实时答案并保持访问控制的聊天机器人的指导。@absolutt1建议使用检索增强生成 (RAG) 系统会很合适。 - Gradio 4.13 重磅发布:
@abidlabs宣布了 Gradio 4.13 版本,详细介绍了新功能。他还分享了 完整变更日志。 - Gemini Pro Vision 开放测试:
@aiman1993分享了一个指向 Gemini Pro Vision Streamlit 应用程序的 Hugging Face Spaces 链接,欢迎大家尝试 链接。 - Python 包管理:
@lawls.net强调了管理 Python 包的复杂性,并鼓励为每个项目设置独立虚拟环境的做法。 - 在 AI 中模拟哺乳动物学习:
@amylizzle分享了一篇关于模拟哺乳动物学习的新误差传播方法的有趣论文 链接。 - AnimateDiff 登场:
@hina_tech发布了 AnimateDiff prompt travel GUI,现已在 Gradio 上可用。 - AI 助力抽认卡,方便记忆:
@venkycs分享了一个指向 AI Hub 的链接,该平台提供 AI 概念抽认卡以帮助学习者 链接。
HuggingFace Discord 频道摘要
▷ #announcements (1 条消息):
- 使用 Hugging Face 和 DVC 进行数据管理:
@Andyrasika撰写了一篇关于利用 Hugging Face 和 Data Version Control (DVC) 优化数据管理的博客文章。该文章探讨了 DVC 与 Hugging Face 生态系统如何交互,从而改变项目中的数据管理方式。博客链接 - 使用 Transformers 生成钢琴 MIDI:
@afmck发布了一篇名为 TchAIkovsky 的博客文章,重点介绍使用 Transformers 进行钢琴 MIDI 生成。博客链接 - 用于内容创作和分类的印地语-英语模型:
@manishiitg在印地语和英语数据上训练了一个模型,主要针对内容写作、角色扮演、分类和生成连贯内容进行了优化。该模型未针对编程/数学任务进行优化。模型链接 - 使用 Transformers 和 PyTorch 处理多选题:
@Andyrasika在一篇博客文章中讨论了如何利用 Transformers 和 PyTorch 处理多选题 (Multiple Choice Questions)。博客链接 - 用于代码生成和绘图编辑的 AI 聊天机器人:
@sophiamyang展示了一个利用 Panel 和 Mixtral 8x7b 运行代码并编辑 matplotlib 图表的 AI 聊天机器人。博客链接 - 防止 LLMs 中的数据污染:在
@rishiraj的一篇博客文章中,他谈到了在模型合并过程中管理评估数据污染的问题,并介绍了优化流程和维护数据完整性的工具。博客链接 - 理解概率中的计数:
@ariG23498撰写了一篇教学博客,阐述了计数对于理解概率的重要性及其应用场景。博客链接 - 鞋类图像分类数据集:
@Andryasika创建了一个包含 15,000 张鞋子、凉鞋和靴子图像的数据集,非常适合使用深度神经网络进行多类别分类。数据集链接
提到的链接:
- 使用 Hugging Face 和 DVC 优化数据管理:无缝集成
- TchAIkovsky – 使用 Transformers 生成钢琴 MIDI
- manishiitg/open-aditi-hi-v1 · Hugging Face
- 利用 Transformers 和 PyTorch 处理多选题任务
- 构建一个 AI 聊天机器人来运行代码和调整图表
- Celebrity Look A Like - tonyassi 创建的 Hugging Face Space
- 应对 LLMs 中的评估数据污染:高质量微调和模型合并的策略
- 计数 ‘n’ 个物体
- Andyrasika/ShoeSandalBootimages · Hugging Face 数据集
▷ #general (85 条消息🔥🔥):
- Gradio 紧急求助:在 general 频道中,
@nigg.pablo请求关于 Gradio 的紧急帮助。 - 对 Huggingface API 使用和支付的困惑:
@.o.sarge.o.对其 Huggingface API 的使用和支付预期表示困惑,指出尽管大量使用了 “openai/whisper-large-v3” 模型,但并未产生费用。 - ASR Endpoint 推理出现意外问题:用户
@blahblah6407在为微调后的 Whisper 创建和测试 ASR 的 Endpoint 推理时遇到了问题,报告了一个与意外的 ‘ignore_warning’ 参数相关的特定错误,并寻求解决办法。 - 在 M1 Macbook Pro 上运行 Llama 2:用户
@sia4030寻求在 M1 Macbook Pro 上让 Hugging Face 模型与 Llama 2 协同工作的指导。@lee0099协助他们解决了python convert命令以及缺少config.json文件的问题。 - 注册 Hugging Face 遇到困难:用户
@illumes报告在注册 Hugging Face 时遇到困难,表示该过程在 CAPTCHA 阶段后似乎停止了。@sakalys随后处理了此问题,建议这可能是由于使用了广告拦截器或 Brave 浏览器,并建议切换到其他浏览器以避免 CAPTCHA 问题。 - 深度学习 PC 配置建议:用户
@sedthh寻求组装一台用于 Deep Learning 的预算型 PC 的建议,特别是在 3090 或 4080 之间寻求推荐,或其他同价位的合适替代方案。 - 询问采访视频:
@vishyouluck表示有兴趣观看涉及@504681610373758977(Sayak Paul) 的采访,@qwerty_qwer提供了播客的 链接。 - 讨论 AI 模型的潜在实力:
@not_lain和@vipitis强调了 WizardCoder-33B-V1.1 的发布,并提到其强劲的开局。 - Open LLM Evals 提交问题:
@kquant表示在向 Open LLM 评估队列上传模型时遇到困难,其模型提交似乎失败了,且未给出明确的失败原因。
提到的链接:
- meta-llama/Llama-2-13b-chat-hf at main
- ArtificialThinker Demo on GPU - a Hugging Face Space by lmdemo
- HuggingChat
- Kquant03/EarthRender-32x7B-bf16_eval_request_False_bfloat16_Original.json · open-llm-leaderboard/requests at main
- 来自 WizardLM (@WizardLM_AI) 的推文:🔥 很高兴发布 WizardCoder-33B-V1.1,SO…
- 作为 python 模块运行时 - meta-llama/Llama-2-7b-hf 似乎没有名为 config.json 的文件 · Issue #26432 · huggingface/transformers:系统信息 Python 3.10 Transformer 4.32.0.dev0 Tr…
- GitHub - julien-c/arxiv-to-hf: 为每个 Arxiv 页面添加指向相应 HF Paper 页面链接的 Chrome 扩展程序
- 适用于 Mac M1 的 Llama 2:使用 llama.cpp 在 Mac M1 上运行 Llama 2…
- 如何在 Mac M1 & M2 (Mac-Silicon) 上安装 Llama2?:关于 Llama2 的一个重要考虑点…
- meta-llama/Llama-2-70b-chat-hf · Hugging Face
- 加速生成式 AI 第三部分:快速扩散 (Diffusion):这篇文章是系列博客的第三部分…
- 版本 v0.25.0:aMUSEd,更快的 SDXL,可中断的流水线 · huggingface/diffusers:aMUSEd 是一个轻量级的文本生成图像模型…
▷ #today-im-learning (6 messages):
- Python 包管理挑战:用户
@lawls.net强调了妥善处理 Python 包和虚拟环境的复杂性与重要性。他们强调了使用正确版本的包以及为每个项目设置独立虚拟环境的重要性。 - 用于图像生成的 Stable Diffusion XL:
@8bit888分享了一篇题为 Stable Diffusion XL: A tutorial for designing without limitation 的博客文章。它提供了安装和使用 Stable Diffusion XL(一个开源图像生成工具)的指南。 - Python 打包与 PyPI 发布之旅:
@vipitis提到他们正在尝试学习 Python packaging,特别是可选额外依赖 (optional extras) 以及 发布到 PyPI。
提及的链接:
在 MacOS 上安装 Stable Diffusion XL:DALL-E 和 Midjourney 很棒,但免费的更好……
▷ #cool-finds (4 messages):
-
通过错误传播模拟哺乳动物学习:
@amylizzle分享了一篇有趣的 论文,介绍了一种 模拟哺乳动物学习的新型错误传播方法。 -
精通四种语言的
@sia4030展示了其多样化的语言技能,能够流利使用 英语、瑞典语、波斯语,以及初学者水平的法语。 -
通过 AIHub 掌握 AI 的闪卡:
@venkycs分享了一个指向 AI Hub 的 链接,该平台提供 闪卡以轻松掌握 AI 概念,如迁移学习 (transfer learning)。 -
@dttch 欢迎新结识:
@dttch表达了在服务器内建立 新联系 的开放态度,展示了社区友好协作的氛围。
提及的链接:
- 未定义
- 在可塑性之前推断神经活动,作为超越反向传播的学习基础 - Nature Neuroscience:这篇论文介绍了“前瞻性配置”……
▷ #i-made-this (8 messages🔥):
- AnimateDiff Prompt Travel GUI 现已上线 Gradio:
@hina_tech分享了他们的新作 AnimateDiff prompt travel GUI,现在已在 Gradio 上可用。 - ehristoforu 发布的 DreamDrop V1:
@ehristoforu介绍了 DreamDrop V1,这是一个在 Deliberate V5 上使用 MJLora 训练的现代模型。他们提供了最佳设置、负向提示词 (negative prompts) 以及优化使用的补充说明。模型的各种版本可以在 Files 选项卡 中找到。 - 关于 Tokenizing 与 Embedding 的讨论:
@lordgrim0033寻求关于 Tokenizing 和 Embedding 之间区别的解答。@torres8552澄清说,Tokenizing 将文本分解为单词或子词,并为每个 token 分配一个 ID,而 Embedding 则将这些 token 转换为高维向量。 - 不要跨频道发布 (Cross-Post) 的提醒:
@cakiki委婉地提醒@venkycs不要跨频道发布相同内容。
提及的链接:
GitHub - JojoYay/animatediff-cli-prompt-travel: animatediff prompt travel:animatediff prompt travel。为 JojoYay/a… 做出贡献。
▷ #reading-group (2 messages):
- 随意的肯定回复:
@chad_in_the_house和@lunarflu都对之前的消息或陈述给出了积极肯定的回复。给定的消息历史中未提供原始消息或陈述的细节。
▷ #computer-vision (3 messages):
- 银行对账单图像的标注:
@detraxsenpai正在寻求关于自动标注银行对账单表格图像的建议。他们表示有兴趣使用准确率约为 70-80% 的现有模型,并进行手动微调以达到完全准确。 - GPU 加速的可能性:
@pragma9538建议检查是否在 NVIDIA GPU 上利用了 torch.cuda 以提高处理效率。 - 开放协作邀请:
@pragma9538表达了在该领域进行协作的开放态度。感兴趣的人可以通过私信联系。
▷ #NLP (12 messages🔥):
- 聊天机器人霸主:
@jryarianto正在寻求构建一个能够访问数据库、提供实时回答并保持严格访问控制的聊天机器人的指导。@absolutt1建议在此任务中使用 Retrieval Augmented Generation (RAG) 系统,该系统非常适合助手类应用。 - 寻找学习路径:
@notooth正在寻找训练 Phi-2 或 LLAMA-2 模型的教程。神秘人@babylonkiwu也在寻找相关资料,并想知道在 free colab 上使用 Qlora 训练 Phi-2.7 和 Mistral 7B 的可行性。 - RAG 操作指南: 为了帮助 jryarianto,
@absolutt1提到目前有大量关于使用 RAG 方法构建聊天机器人的教程,这些机器人能够提供与上下文相关的回复。 - Gemini Pro Vision 部署:
@aiman1993分享了一个 Hugging Face Spaces 链接:Gemini Pro Vision Streamlit Application,邀请其他人进行实验和测试。 - RAG 学徒:
@jryarianto承认对 RAG 系统缺乏了解,但表示有兴趣进一步探索@absolutt1的建议。
提到的链接:
Gemini Pro Vision Streamlit Application - disham993 的 Hugging Face Space
▷ #gradio-announcements (1 messages):
- Gradio 4.13 发布公告:
@abidlabs宣布发布 Gradio 4.13,并发布帖子列出了新功能和修复,包括 Button 组件修复、图像选择的.select()事件修复、Chatbot 和 Model3D 组件修复、FileExplorer 组件的安全增强,并确保了与 Python 3.12 的兼容性。他还分享了完整变更日志。 - 点亮 Lite: 感谢 @whitphx,Lite 中的 Wasm 已引入对 AnnotatedImage 的支持。
- 开发者们,加入 SharedWorker 模式: 再次感谢 @whitphx 为 Lite 添加了 SharedWorker 模式下的开发指令。
- 功能测试修复: 感谢
@aliabid94修复了功能测试。
提到的链接:
Gradio Changelog: Gradio 变更日志和发布说明
Perplexity AI Discord 摘要
-
Perplexity B 轮融资庆祝: Perplexity 成功筹集了 7360 万美元的 B 轮融资,由 IVP、NVIDIA、Jeff Bezos 等大牌领投,旨在打造全球最快、最准确的回答平台。Perplexity 目前表现惊人,月活跃用户达 1000 万,移动应用安装量超过 100 万。@AravSrinivas 的推文 进一步传播了这一消息,并吸引了 Discord 社区内众多用户的祝贺。
-
关于 Perplexity 互联网交互能力的查询: 在实验模式下,Perplexity AI 确实拥有互联网访问权限,但目前还无法引用参考文献。用户对此表示好奇,并期待新的进展,据称将包括引用功能。@nqiwbh07r44p 的查询 引发了这一讨论。
-
集成 PPLX API: 除了 Perplexity 平台,PPLX API 还可以帮助开发者将大语言模型部署到他们的软件中。这篇 博客文章 介绍了 Perplexity API,它提供了快速的推理和易于部署的系统。未来的功能需求包括返回原始片段和参考链接,以及在 Perplexity API 的在线模型中设置片段数量。
-
探索 Perplexity 的在线模型: 这篇 博客文章 介绍了 Perplexity 的在线模型,它们在搜索中提供事实性和最新的响应。然而,Discord 社区的用户也注意到 Perplexity 在在线响应中缺少 Mixtral。
-
科技爱好者的太空教育: 一篇 博客文章 强调了任何热衷于加入航天科技行业的人需要掌握的 8 大技能。随着 SpaceX 和 Blue Origin 等创新公司的引领,这是科技爱好者感兴趣的一个领域。
Perplexity AI 频道摘要
▷ #announcements (1 messages):
- Perplexity 完成 7360 万美元 B 轮融资:用户
@enigmagi宣布 Perplexity 完成了由 IVP 领投,NVIDIA、NEA、Bessemer、Elad Gil、Jeff Bezos 等参投的 7360 万美元 B 轮融资。该公司梦想打造全球最准确、最快速的问答平台。- 分享了一篇博客文章,读者可以查看更多详情:blog.perplexity.ai/blog/perplexity-raises-series-b-funding-round
- Perplexity 的成功与未来计划:据报告,他们在 2023 年实现了 1000 万月活跃用户,并处理了超过 5 亿次查询。公告原文引用:“我们的目标是服务全球人类无限的好奇心,而我们才刚刚起步。”
- 移动端里程碑:该公司还透露,已有超过 100 万用户安装了其 iOS 和 Android 移动应用。
- 挑战 Google 的霸主地位:根据链接的 WSJ 文章,Perplexity 得到了 Jeff Bezos 和一些风险投资者的支持,他们相信 AI 将颠覆人们在线获取信息的方式,从而挑战 Google 在网络搜索领域的霸主地位:www.wsj.com/tech/ai/jeff-bezos-bets-on-a-google-challenger
- 令人印象深刻的初创公司增长:尽管成立不到两年且员工人数不足 40 人,Perplexity 的产品每月仍有约 1000 万人使用。
提到的链接:
- Perplexity Raises Series B Funding Round :宣布 Perplexity 的 B 轮融资。
-
[WSJ News Exclusive Jeff Bezos Bets on a Google Challenger Using AI to Try to Upend Internet Search](https://www.wsj.com/tech/ai/jeff-bezos-bets-on-a-google-challenger-using-ai-to-try-to-upend-internet-search-0859bda6):Perplexity 仅拥有 Google 一小部分用户,却筹集了…
▷ #general (96 messages🔥🔥):
- 实验性 Perplexity AI 联网使用:用户
@nqiwbh07r44p询问 Perplexity AI 的实验模式是否可以访问互联网,以及如何让它显示参考文献。@giddz和@icelavaman确认实验模型具有互联网访问权限,但目前无法引用参考文献,该功能据称已列入路线图。 - 成为 Perplexity AI 测试员:用户
@nqiwbh07r44p询问如何成为 Perplexity AI 的测试员。@giddz提供了一个 Discord 链接,@icelavaman提到该计划目前已关闭。 - Perplexity 与其他 AI 模型对比:用户
@marcopaone询问在 Gemi Pro、GPT-4 和 Claude 2.1 之间应选择哪种 AI 模型。@icelavaman推荐了 GPT-4。 - Perplexity AI 应用与 VPN:用户
@mares1317指出,在使用 VPN 时,Perplexity 网页版只需勾选 Cloudflare 验证框,而应用端没有问题。用户@icelavaman指出情况可能因人而异,取决于 VPN 提供商/热点,但@mares1317坚持认为使用像 Proton 这样优秀的 VPN 提供商不会出现问题。 - Perplexity AI 融资新闻:用户
@blackwhitegrey、@giddz、@billbuttliquor、@serpentineuk、@theoutbacklp、@keef_kahn和@theoutbacklp祝贺 Perplexity 团队宣布新一轮融资,该轮融资对 Perplexity 的估值为 5.2 亿美元。新闻中提到了 Jeff Bezos 和 Nvidia 等知名投资者。
提到的链接:
-
[AI-powered search engine Perplexity AI, now valued at $520M, raises $73.6M TechCrunch](https://techcrunch.com/2024/01/04/ai-powered-search-engine-perplexity-ai-now-valued-at-520m-raises-70m/):AI 驱动的搜索引擎 Perplexity AI 现估值 5.2 亿美元,融资 7360 万美元。 - Perplexity Careers:加入我们的团队,共同塑造搜索的未来…
▷ #sharing (4 条消息):
-
需掌握的航天科技技能:
@madhusudhan7分享了一篇 博客文章,介绍了在不断发展的航天科技(Space Tech)行业工作需要掌握的 8 项技能。文章提到航天科技行业正在不断创新,SpaceX 和 Blue Origin 等公司正让太空旅行变得更加触手可及。 -
Arav Srinivas 融资公告:
@icelavaman分享了来自@AravSrinivas的一条 推文,宣布他们以 5.2 亿美元的估值筹集了 7360 万美元。本轮融资由 IVP 领投,NVIDIA、Jeff Bezos、@tobi、Databricks、@naval、@rauchg、@balajis等参投。 -
Perplexity AI 上的搜索查询:
@_joewei和@maxymus85都分享了来自 Perplexity AI 数据库 的 查询,尽管消息中未指明这些搜索查询的具体内容或目的。
提及的链接:
- 如果你想在航天科技领域工作,应该掌握的 8 项技能 - Take It Personel-ly:如果你有兴趣从事航天领域的职业…
- 来自 Aravind Srinivas (@AravSrinivas) 的推文:很高兴宣布我们以 520… 的估值筹集了 7360 万美元。
▷ #pplx-api (9 条消息🔥):
- 扩展 Perplexity API 功能:
@maxwellandrews请求增加通过 Perplexity API 为在线模型返回原始片段(raw snippets)和参考链接的选项,并建议提供设置返回片段数量的功能。他们还建议设立独立的搜索 API,并对在线响应中缺乏 Mixtral 模型表示疑问。 - PPLX API vs Perplexity:
@blackwhitegrey询问了使用 PPLX API 相比 Perplexity 的优势,@icelavaman回复称该 API 允许开发者将 LLM 集成到他们的产品中。- 针对
@blackwhitegrey关于 API 能力的疑问,@icelavaman随后澄清了在线 LLM 可以进行搜索。
- Perplexity API 介绍:
@icelavaman分享了 Perplexity 博客上关于 pplx-api 介绍 的链接,其中提供了有关 API 特性的信息,如易用性、快速推理和可靠的基础设施。 - Perplexity 在线模型:
@icelavaman分享了 Perplexity 博客的另一个 链接,介绍了 Perplexity 的在线模型及其提供事实性且最新响应的独特优势。 - 将 Perplexity 模型添加到 Typingmind:
@blackwhitegrey询问如何将 Perplexity 模型添加到 Typingmind 中。
提及的链接:
- 介绍 pplx-api:Perplexity Lab 为开源模型提供的快速高效的 API…
- 介绍 PPLX 在线 LLM:首创的在线 LLM API
Eleuther Discord 摘要
- Anthropic 的条款引起不满:
@stellaathena批评了 Anthropic 的服务条款 (Terms of Service) 过于严格,根据@LLMSherpa的推文,这可能会阻碍研究和竞争。成员们推测了这些条款背后的可能动机。 - Anthropic 条款可能的法律影响:
@fern.bear对 Anthropic 条款相关的潜在法律问题表示担忧,指出这可能会给使用其服务的企业带来麻烦。 - Twitter 分析项目启动:
@sirmalamute提议了一个使用 NLP 的开源 Twitter 分析项目,并对合作、功能反馈和项目探索持开放态度。 - 神经网络中的早期停止引起关注:由
@gabriel_syme发起的关于深度神经网络中早期退出策略 (early exit strategy) 的讨论引起了关注,并收到了诸如研究 Adaptive Computation Time 和 Mixture of Experts (MoEs) 中专家特定停止 (expert-specific stopping) 等建议。 - Hugging Face (HF) 方面的潜在障碍:
@micpie注意到由于 Hugging Face 数据集结构的变更,lm_eval/api/task.py中存在潜在问题,@hailey_schoelkopf和@micpie对此进行了讨论。 - 关于 GPT-Neox 中文档打包的热议:
@tastybucketofrice和@ad8e深入探讨了 GPT-Neox 中文档打包 (document packing) 的效率,@ad8e暗示了一篇专业论文中提到的更高效的打包方案,并表示愿意为该项目做出贡献。
Eleuther 频道摘要
▷ #general (44 messages🔥):
- Anthropic 的服务条款被认为过于苛刻:
@stellaathena引用了@LLMSherpa的一则推文,批评 Anthropic 的服务条款 过于严格,可能会扼杀研究和竞争。这些使用条款显然要求用户在被指控违约时停止活动。一些用户推测这要么是一种防御举措,要么是公司陷入困境的信号。 - 条款清晰度与研究限制:
@thatspysaspy寻求关于 Anthropic 条款中“禁止研究”声明的澄清。@stellaathena和@mrgonao指出,禁止开发或训练模型的条款可以被解释为禁止 AI 研究的大部分实质性领域。 - 条款被认为限制性过强,可能存在问题:
@fern.bear对条款中放弃反对禁令救济 (injunctive relief) 可能带来的法律影响表示担忧,指出这可能会给有兴趣使用 Anthropic 服务的企业带来复杂化的问题。 - 提议的开源 Twitter 分析项目:
@sirmalamute提议了一个使用 NLP 的开源 Twitter 分析项目,功能包括情感分析 (sentiment analysis)、极性检查 (polarity check)、政治派别判定等。该用户对反馈、探索可能的功能以及项目合作持开放态度。最初的目标是创建一个工具包,而不是传统的学术论文或数据库。 - Twitter 分析项目的挑战与考量:
@ad8e询问了@sirmalamute关于项目的细节,包括如何处理分析所需的标签。@sirmalamute提到了标签的潜在来源或方法,并讨论了在考虑分发用于分析的推文时,可能需要遵循 Twitter 的政策。
提到的链接:
来自 The LLM Sherpa (free/acc) (@LLMSherpa) 的推文:Anthropic 更新了条款。所以,要使用 Claude,你必须…
▷ #research (20 条消息🔥):
- 神经网络中的 Early Exit:用户
@gabriel_syme发起了关于深度神经网络中 Early Exit 策略的讨论,特别是关于在中间层而非最后一层终止并输出的问题。@thooton建议研究 Adaptive Computation Time,@gabriel_syme表示感谢。随后话题演变为讨论在 Mixture of Experts (MoEs) 中特定专家/层的停止问题。 - 关于 Adaptive Computation 和 Transformers 的论文:
@thisisniq和@zphang分别分享了关于 Adaptive Computation Time 和 Transformer 模型的论文以及更近期的研究链接。 - 用于长序列分类的多语言模型:用户
@_michaelsh寻求针对长序列分类任务设计的多语言模型建议。@stellaathena推荐了 mT5 或 BLOOM。 - Point2CAD 项目分享:用户
@digthatdata分享了一个与 Point2CAD 项目相关的 GitHub 仓库链接。 - 对 CALM 和 AI 研究交流的看法:
@gabriel_syme表达了对 Composition to Augment Language Models (CALM) 方法及其与 LoRA 对比的看法。他们还批评了发现的一条推文的交流风格,认为其没有提供实际的解决方案。
提到的链接:
- LLM Augmented LLMs: Expanding Capabilities through Composition:拥有数十亿参数的基础模型…
- Universal Transformers:循环神经网络 (RNNs) 顺序处理…
- Confident Adaptive Language Modeling:基于 Transformer 的大语言模型的最新进展…
- GitHub - YujiaLiu76/point2cad: Code for "Point2CAD: Reverse Engineering CAD Models from 3D Point Clouds":”Point2CAD: Reverse Engineering CAD…” 的代码。
▷ #lm-thunderdome (5 条消息):
- HF Datasets 的变更影响 lm-thunderdome:
@micpie注意到 HF datasets 的更新可能导致了之前 commit 的问题,需要注释掉lm_eval/api/task.py中的代码。问题是由第 732 行中name=self.DATASET_NAME的移除引起的。 - HF 过渡引发的潜在问题:
@hailey_schoelkopf指出,数据集问题可能与 HF 逐渐弃用数据集加载脚本并改用trust_remote_code=True有关。 - Pull request 已合并:
@hailey_schoelkopf宣布lm-evaluation-harness仓库中移除self.dataset_path post_init process的 pull request 已被合并。 - Toxigen 评估受到质疑:
@johnnysands就 Toxigen 数据集使用的评估方法提出了疑问,询问将其转化为二分类任务是如 Toxigen 论文中所述的标准做法,还是 lm-eval-harness 所特有的。
提到的链接:
▷ #gpt-neox-dev (15 条消息🔥):
-
访问 VM 以及文档/清理工作的更新:
@tastybucketofrice向一名用户提供了 VM 访问权限,并询问了文档和清理工作的进展。 -
Torch CUDA 中的高效计时:
@tastybucketofrice建议在基于 CUDA 的代码中使用torch.cuda.Event计时器以实现精确计时,特别是在分布式设置中,并引用了 EleutherAI cookbook 中的示例。 -
GPT-NeoX 的 Upstream 追踪:
@tastybucketofrice解释了为什么 GPT-NeoX 追踪 upstream,重点在于可用性、多系统支持、可读性和可解释性。当优化在 upstream 成熟时会进行 cherry-picking,并且他们对新的 upstream 追踪工作流持开放态度。 -
GPT-NeoX 中文档打包(Document Packing)的效率:
@ad8e和@tastybucketofrice讨论了 GPT-NeoX 中的文档打包,@ad8e指出了当前系统潜在的低效性。他们还引用了一篇专业论文中的打包方案。@tastybucketofrice表示在收到其有效性的确凿证据后,愿意将其加入开发路线图。 -
文档打包的潜在代码贡献:
@ad8e表示未来可能会提交一个用于改进文档打包的 PR。@tastybucketofrice和@hailey_schoelkopf引用了之前在不相互关注(without attending to one another)的情况下进行的序列打包工作,以及高效打包的潜在代码。@hailey_schoelkopf建议联系一篇已发表论文的第一作者以获取相关代码。
提到的链接:
- In-Context Pretraining: Language Modeling Beyond Document Boundaries:大型语言模型 (LMs) 目前正在接受训练…
- Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance:当今大型语言模型的有效训练…
- cookbook/benchmarks/communication at main · EleutherAI/cookbook:深度学习入门。所有实用的细节…
- gpt-neox/tools/datasets/preprocess_data_with_mask.py at e5a7ea71e96eeada636c9612036dc85e886d973d · EleutherAI/gpt-neox:模型并行自回归的一种实现…
- GitHub - EleutherAI/gpt-neox at multitask:模型并行自回归的一种实现…
- GitHub - EleutherAI/gpt-neox at FIM:模型并行自回归的一种实现…
Mistral Discord 总结
- Mixtral 备受关注:@i_am_dom 宣布 Mixtral 现已在 Replicate 上线并带来了新更新。用户还根据经验深入探讨了在 Mistral 模型中加入 system prompts 的语法细微差别,以及 Mixtral 对 prompt 格式的敏感性。
- 与 Mistral 高效对话:@gbourdin 和 @lovis07 表示需要关于如何将 Mistral 作为聊天机器人高效使用的指南。@i_am_dom 提供了一个可用的 Python 脚本作为回应。
- RAM 对 Mixtral 性能的影响:@arianagrandefan4024 询问 DDR5 RAM 是否能提升 Mixtral 的性能。@someone13574 澄清说,如果在 CPU 上运行 Mixtral,这会有所帮助,否则不会表现出显著优势。
- 使用 System Prompts 指导 Mixtral:@nickbro0355 对如何让 Mixtral 配合 system prompt 工作很感兴趣。@bdambrosio 建议使用完整的 llama-2 模板,或者在
<<SYS>>[message]<</SYS>>中插入系统消息。 - 在本地设备和 Apple Silicon 上运行模型:讨论了关于在本地运行模型以及使用 Apple 的 M2 Neural Engine 加速 Mistral 模型的建议,@bdambrosio 提到了 OrangePi 5B 的潜力,而 @jdo300 则对利用新的 MLX 框架和 M2 的 neural engine 感兴趣。
- 微调工程师的机会:用户 @arkalius75 正在寻求一位技术娴熟的工程师进行 fine-tuner 任务——包含报酬。感兴趣的人士可以通过私信联系。
- 关于 AGI 和 AI 认知的辩论:用户讨论了 GPT-4 是否可以被视为弱 AGI、AI 成就如何随着时间的推移变成一个不断变化的目标、我们对智能理解的不足,以及与普通动物相比,GPT-4 的智能程度究竟有多高。
- La Platform 的印象与问题:用户 @acast_37857 分享了他们对 “la platform” 的正面印象,并提出了关于实现 “mistral-embed” 的问题。与之相关,@sublimatorniq 发现了一个潜在问题,即 prompt 数据中的
\[.*?\]模式与 Mixtral 的 stop 参数会导致意外中断,并幽默地决定开始在所有请求中包含 seeds。
Mistral 频道总结
▷ #general (43 messages🔥):
-
Mixtral 现在可以在 Replicate 上使用:
@i_am_dom分享了 Replicate 上专用的 Mixtral 页面链接,并透露了最新更新 (“顺便说一下,我指的就是这个。突然不再受审查了。”)。 -
Mistral 模型中 System Prompts 的格式化:针对在 Mistral 模型中加入系统提示词的正确语法进行了深入讨论。
@i_am_dom分享了来自 Huggingface Spaces 的详细示例,并澄清<<SYS>>格式是用于 LLaMA 的,而非 Mistral。 -
Mixtral 对 Prompt 格式的敏感性:
@i_am_dom强调,根据他的经验以及讨论该话题的 Reddit 帖子,Mistral 的输出质量深受输入 Prompt 格式的影响。 -
将 Mistral 作为聊天机器人的有效用法:
@gbourdin和@lovis07表示需要关于如何有效地将 Mistral 作为带有历史记录和 RAG 的聊天机器人的清晰文档或指南。@i_am_dom提供了一个 Python 脚本 链接作为实际解决方案。 -
RAM 规格影响 Mixtral 性能:
@arianagrandefan4024询问从 DDR4 升级到 DDR5 RAM 是否会提升 Mixtral 的性能。@someone13574澄清说,如果在 CPU 上运行 Mixtral,这会有所帮助,否则不会有显著优势。
提到的链接:
- Tiktokenizer
- app.py · openskyml/mixtral-46.7b-chat at main
- mistralai/Mixtral-8x7B-Instruct-v0.1 - API Reference - DeepInfra:来自 Mistral AI 的 Mixtral 混合专家模型。
- Reddit - Dive into anything
- text-generation-webui/instruction-templates/Mistral.yaml at main · oobabooga/text-generation-webui:用于大语言模型的 Gradio Web UI。
- FastChat-release/fastchat/conversation.py at 2855bf974f0973f85adb2bb7a9d075255b353ecf · mistralai/FastChat-release:一个用于训练、部署和评估的开放平台。
- mistralai/mixtral-8x7b-instruct-v0.1 – Run with an API on Replicate
▷ #models (5 messages):
- Mistral Medium 是否支持 function calls?:
@rantash68提出了关于 Mistral Medium 是否具有类似于 GPT-4 的“function call”功能的问题。但是,他们没能找到这个问题的明确答案。 - Mistral 的语言能力受到质疑:
@acast_37857发起了关于 Mistral Tiny 语言能力的讨论。尽管该机器人被宣传为说英语的,但用户注意到它能准确地用法语回答。.superintendent的调侃式回应指出 Mistral 本身就是一家法国公司。
▷ #deployment (10 messages🔥):
- 咨询 Mixtral 的 System Prompts:用户
@nickbro0355对如何让 Mixtral Instruct 使用系统提示词感兴趣。@bdambrosio建议使用完整的 LLaMA-2 模板,或者尝试将系统消息包含在<<SYS>>[message]<</SYS>>中。 - 在本地设备上运行模型:
@choudhary_sahab101询问关于在本地设备上运行模型的最优方式。@bdambrosio提到了 OrangePi 5B 的潜力,这是一个支持包括 Transformers 在内的大多数 PyTorch 模型的本地 6TOPS 单元。 - 利用 Apple 的 M2 Neural Engine 运行模型:
@jdo300好奇哪种 API 后端最适合在 Apple Silicon 上运行 Mistral 模型。特别是寻求利用新的 MLX 框架和 M2 的 Neural Engine 来加速模型推理(Inference)。
▷ #finetuning (2 messages):
- 招募微调工程师执行有偿任务:
@arkalius75正在寻找一名熟练的微调(Fine-tuning)工程师来执行一项任务——包含报酬。感兴趣的人员请直接私信@arkalius75。
▷ #random (15 条消息🔥):
- GPT-4 是弱 AGI 吗?: 在关于 GPT-4 和 AGI 的讨论中,
@poltronsuperstar质疑在许多任务中表现超过人类平均水平的 GPT-4 是否可以被称为弱 AGI。@blueridanus回应称,从某种意义上说,是的,GPT-4 是一个弱 AGI。 - AI 认知随时间的变化:
@poltronsuperstar还提出了一个担忧,即 AI 的成就如何随着时间的推移变成一个不断移动的目标。例如,如果向 2004 年的人展示 GPT,他们可能会认为它是 AGI。 - 智能的未知性:
@blueridanus表示,我们对智能的理解还不够,无法为其定义万无一失的标准。正是这种缺乏理解可能阻碍了我们创造 AGI。 - GPT-4 与动物的智能比较: 同时,
@blueridanus还指出,在许多有意义的方面,GPT-4 比非常普通的动物还要 笨。 - 定义 AGI – 一个移动的目标?:
@duck建议将 AGI 视为一个 范围 而不是单一的点。AI 类似于婴儿逐渐成长为成人的想法被提出作为 AGI 的一种可能解释。
▷ #la-plateforme (4 条消息):
- “la platform” 介绍及关于 “mistral-embed” 的问题: 用户
@acast_37857分享了他们对 “la platform” 的良好第一印象,并询问了有关使用 “mistral-embed” 的指导,目前尚不清楚从哪个平台实现它。 - 检测到异常中断问题: 用户
@sublimatorniq注意到异常中断与 Prompt 数据中存在的\[.*?\]模式之间存在相关性。删除这些模式后,异常中断似乎停止了,这表明问题可能源于这些模式与 Mixtral 的停止参数(stop parameters)之间的交互。 - Mixtral 停止参数的潜在问题:
@sublimatorniq指出,Ollama 的 Mixtral 配置了PARAMETER stop "[INST]"和PARAMETER stop "[/INST]",这可能会导致混淆并引发意外中断。 - 随请求发送 Seed: 在观察到该问题后,
@sublimatorniq幽默地表示决定开始在所有请求中包含 Seed。
OpenAccess AI Collective (axolotl) Discord 摘要
- 混淆角度引发争论: 在
@yamashi发布的一张详细图片中,用户们就标记为 A、B、C 或 D 的哪个角度是正确的展开了讨论。 - 更小的差距 vs 更低的 Loss:
@nafnlaus00发起了一场对话,称 “与其只关心获得尽可能低的 eval_loss,不如致力于缩小 eval_loss 和 train_loss 之间的距离”,特别是在处理不干净的数据集时。 - 宣布 RL 训练的早期 Beta 版:
@caseus_透露 RL (Reinforcement Learning) 训练已合并,现在支持 DPO 和 IPO。虽然处于 Beta 阶段,但非常欢迎社区提供建议和 Pull Requests 以完善开发。 - 出现 “Fine-Tuning Mixtral” 的讨论:
@dangfutures提出了 Fine-Tuning Mixtral 的潜在问题。然而,该查询尚未得到解答。 - Axolotl-dev 中出现 Curriculum Learning 想法:
@suikamelon对实现 Curriculum Learning 表现出兴趣,这是一种从 “简单” 样本开始训练模型的过程。@Caseus_ 建议考虑使用 YAML 来禁用 Shuffle。 - 多 GPU 配置故障:
@qeternity在使用 Axolotl 的 DeepSpeed Stages 时遇到问题,并索要多 GPU 配置示例。随后@caseus_建议该用户参考 nccl.md 文档。 - 用户反馈的应用:
@athenawisdoms询问用户对回答的反馈如何有利于模型改进,对此@noobmaster29提出了建立强化流水线(reinforcement pipeline)的想法。 - 合成数据集大小的难题:
@antti_45069就合成数据集的大小提出了疑问,并将其与通常在 100k+ 范围内的典型代码数据集进行了比较。 - Search RAG API 介绍:
@emrgnt_cmplxty宣布了 Search RAG API 的可用性。该工具在解决合成数据和回答接地(grounding responses)相关的挑战方面似乎很有前景。 - 语境含义与拼写错误:
@nafnlaus00发现了短语 “and be vary of the context” 中可能存在的拼写错误,但@le_mess澄清说这不会影响整体性能。
OpenAccess AI Collective (axolotl) 频道摘要
▷ #general (18 messages🔥):
- 不确定的角度引起混淆:用户
@yamashi发布了一张标有多个角度的图片,引起了用户间的小规模混淆,询问正确的角度是 A、B、C 还是 D? - 呼吁更通用的解决方案,而非仅仅追求最低的 eval_loss:
@nafnlaus00表达了一个观点,即与其只关注尽可能获得最低的eval_loss,不如旨在 [最小化 eval_loss 和 train_loss 之间的距离],特别是在数据集不干净的情况下。 - 宣布支持 chatml 的强化学习 (RL) 训练:
@caseus_分享了 RL 训练现已合并并支持 DPO 和 IPO,但目前处于 beta 阶段,需要进一步完善。Caseus_ 对来自社区的建议/Pull Requests 持开放态度,并确认其处于早期阶段,欢迎任何外部协助。 - 非英语模型微调:用户
@noobmaster29为非英语模型微调者提供了一个有用的链接 (https://arxiv.org/pdf/2401.01854.pdf)。 - 微调 mixtral 的潜在问题:
@dangfutures询问微调 mixtral 是否仍有问题。在提供的聊天记录中,该问题尚未得到解答。
▷ #axolotl-dev (7 messages):
- 在 Axolotl 中禁用打乱 (Shuffling):
@suikamelon询问如何禁用 axolotl 中的打乱功能,随后确认在进行修改后似乎可以工作。@caseus_建议考虑为此添加一个 yaml 设置。 - 课程学习 (Curriculum Learning) 的概念:
@suikamelon表示有兴趣尝试“课程学习”的概念,即通过从“简单”样本开始训练模型。 - 样本打包随机化 (Sample Packing Randomization):
@caseus_提到使用样本打包时会发生随机化,但@suikamelon确认已将其禁用。 - 窗口随机采样器 (Windowed Random Sampler) 的建议:
@caseus_提出了在未来开发中加入窗口随机采样器的想法。
提及的链接:
axolotl/src/axolotl/utils/data.py at 59b2d302c8780ed83e6a0201b741574ee51a1a5e · OpenAccess-AI-Collective/axolotl:尽管提出 axolotl 问题。为 Open… 做出贡献。
▷ #general-help (24 messages🔥):
- Mistral 微调咨询:
@henriklied询问在 3x4090 上使用包含 430,791,018 个 tokens 的数据集微调 mistral 时,8-bit lora 和 8192 的序列长度是否可行。@nanobitz回复说,如果显存够用,只需要一些时间。 - qlora 微调的 VRAM 咨询:
@leoandlibe询问 13B/34B/70B qlora 微调所需的 VRAM 数量。对此,@nanobitz回复称,加载 13B 模型,qlora + 优化器 + batch size 大约需要 13GB VRAM。 - 脚本自动化:
@athenawisdoms询问如何在 axolotl 命令完成或崩溃后自动运行第二个命令/脚本。@leoandlibe建议使用 python subprocess run 来监听并触发所需操作。 - Axolotl 的多轮对话建模:
@evil_malloc询问 axolotl 是否适用于多轮对话模型以及模型是如何训练的。@nanobitz解释说,模型是在所有 assistant 消息上进行训练的。 - 多 GPU 配置示例:
@qeternity询问多 GPU 配置的示例,因为他们在数据集准备期间遇到了 axolotl 的 deepspeed stages 问题。@caseus_建议他们查看 nccl.md 文档。 - 用户反馈的使用:
@athenawisdoms询问如何利用用户对生成响应的反馈来改进模型。作为回应,@noobmaster29建议可能可以建立一个强化学习流水线 (reinforcement pipeline)。
▷ #datasets (2 messages):
- 合成数据集大小的讨论:
@antti_45069询问了一个未公开的语言学习模型,并指出 1780 行的合成数据集与通常在 100k+ 范围内的其他代码数据集相比非常小。 - Search RAG API 的介绍:
@emrgnt_cmplxty宣布 Search RAG API 现已开放供用户体验,该 API 适用于合成数据和 grounding 响应。
▷ #community-showcase (2 messages):
- 注意 Context:
@nafnlaus00指出了短语 “and be vary of the context” 中可能存在的拼写错误。 - 拼写错误不影响性能:
@le_mess确认了该拼写错误,但指出它不会损害性能。
LangChain AI Discord 摘要
- 呼吁更好的对话式检索:
@irfansyah5572表示他们的 ConversationalRetrievalChain 设置返回了所有找到的源文档,而不仅仅是相关的文档。@seththunder建议使用similarity_score_threshold来解决。 - 弃用 Langchain,转向自定义工具:
@atefyamin和@evolutionstepper对 Langchain 提出了强烈批评,并暗示正在开发自己的工具集。 - 寻找图像缩放工具:
@rajib2189在技术社区中发起了关于首选图像缩放包(image resizing packages)的讨论。 - RAG 遇上表格数据:
@michael_71751寻求关于使用 RAG 处理表格数据输入和输出的指导,以及在语言上下文中转换表格数据的建议。 - LCEL 中的 Markdown 支持:
@cryptossssun询问如何从本地目录选择并加载 Markdown 文件。@seththunder建议使用DirectoryLoader。 - LLMChain vs ConversationChain 对决:
@nav1106寻求关于 LLMChain 和 ConversationChain 区别的解答,@seththunder建议在简单的对话场景中 ConversationChain 是更好的选择。 - 多链(MultiChains)的管道构想:
@seefrog好奇是否可以使用管道操作符连接多条链,@seth_thunder确认了可行性。 - GCP 中的 JVM 探索:
@johnda98深入探讨了在 GCP 的 Python 标准应用引擎中运行 JVM 的问题,以及在容器化的 langserve 中启动 JRE 或 GCP JVM 的可能性。 - 新挑战者 Search RAG API:
@emrgnt_cmplxty强调了 Search RAG API 的发布,这可能是合成数据和回答接地(grounding responses)的变革者。可以在这里尝试。 - 视频交互与高级 AI 检索教程:
@a404.eth分享了如何构建一个与视频聊天以优化视频元数据的工具。此外,@lhc1921推荐了掌握 AI 领域高级检索的资源:Advanced Retrieval for AI。
LangChain AI 频道摘要
▷ #general (28 messages🔥):
- ConversationalRetrievalChain 相关性问题:
@irfansyah5572指出他们的 ConversationalRetrievalChain 设置返回了所有找到的源文档,而不仅仅是与查询相关的文档。@seththunder建议使用包含similarity_score_threshold的代码行来解决此问题。
- 对话沟通不畅?弃用 Langchain!
@atefyamin和@evolutionstepper对 Langchain 的局限性表示强烈担忧。他们提到了从解析器问题到同步任务麻烦的方方面面,明确表示更倾向于构建自己的工具集。
- 图像缩放:
- 用户
@rajib2189发起讨论,询问通常使用哪些包进行图像缩放。
- 用户
- 处理表格数据的 RAG:
@michael_71751征求关于使用 RAG 处理表格数据输入和输出的建议,并寻求在语言上下文中转换表格数据的帮助。
- 使用 LCEL 加载 Markdown 文件:
@cryptossssun询问是否可以通过自定义函数从本地目录选择并加载 Markdown 文件。他们计划将这些文件作为检索的 Context。@seththunder建议使用DirectoryLoader并在目录 glob 中仅指定 Markdown 文件。
- LLMChain vs ConversationChain:
@nav1106询问 LLMChain 和 ConversationChain 之间的区别,以及何时该使用其中之一。@seththunder回答说两者非常相似,但当你希望在提问前进行简单的对话时,ConversationChain 更受青睐。
- 使用管道操作符连接多链:
@seefrog询问是否可以使用管道操作符连接多条链。@seth_thunder确认这可以通过 SequentialChain 实现。
▷ #langserve (3 messages):
- 在 GCP 的 Python 标准 App Engine 中运行 JVM:用户
@johnda98询问是否有人在 GCP 的 Python 标准 App Engine 中运行 JVM 的经验,用于一个 layer2 项目,该项目涉及通过 py4j 使用 Java 中的加密 SDK 以加密代币/协议内货币对 AItoken 计数进行计费。 - 在 GCP 上部署 Langserve:
@johnda98已成功在 GCP 上部署了 langserve,并正寻求将其与 JVM 集成。 - 在容器化 Langserve 中运行 JRE/GCP JVM:
@johnda98提出了一个疑问,即是否可以在通过 Cloud Run 部署在 GCP 上的容器化 langserve 中启动 JRE 或 GCP JVM。
▷ #share-your-work (1 messages):
- Search RAG API 现已开放试用:
@emrgnt_cmplxty宣布 Search RAG API 已经上线并可以运行。他们强调了其在合成数据和 grounding 响应方面的潜在用途。他们为感兴趣的人提供了一个试用链接:Sciphi.ai。
▷ #tutorials (2 messages):
- 构建“与视频聊天”工具:用户
@a404.eth发布了一个 YouTube 视频教程,演示了如何创建一个简单的 LCEL 聊天,该聊天可以转录并与视频内容互动。该工具旨在通过为视频生成改进的标题、描述和关键词来协助内容创作者。 - AI 的高级检索:用户
@lhc1921分享了一个学习人工智能高级检索方法的链接。
提及的链接:
- DLAI - 学习平台 Beta
- 使用 LangChain 构建 OpenAI 自定义 RAG:与视频聊天的终极教程!:我讨厌写视频描述和标题,所以我…
Latent Space Discord 总结
- GPT Store 进入市场:
@swyxio分享了来自@eerac的一条推文,关于即将推出的 GPT Store(2024 年 AI 相关项目的中心),建议将现有的应用程序(如天气、播客、正念、待办事项列表、文字游戏等)移植到 CustomGPT。推文链接。 - ChatGPT 引入了针对部分内容回复的功能?:在由一张截图引发的讨论中,
@coffeebean6887、@fanahova和@dimfeld讨论了针对消息部分内容进行回复这一功能的新颖性以及是否为 ChatGPT 独有。 - 相关文章功能的挑战:
@swizec征求评估提供相关文章功能的策略,鼓励大家进行集体头脑风暴。 - DevOps GPT 被认为是失败之作:
@btdubbins对 “DevOps” GPT 表示不满,指出了一系列错误,并将其标记为见过的最差实现之一。 - Akuity 在 Kubernetes LLM 项目中名列前茅:针对
@austintackaberry关于重要的 Kubernetes LLM 产品/项目的询问,@fanahova推荐了 Akuity,这是一个被揭示为 Argo 背后驱动力的产品。Akuity 链接。 - 期待 TLDRAW 剧集:在 ai-event-announcements 频道中,
@swyxio预告了即将播出的 TLDRAW 剧集并征求反馈。提供了预览链接。 - 聊天转录与用户舒适度:
@picocreator在 llm-paper-club 频道发起的一场讨论,引发了对基于 AI 的聊天转录可能侵犯用户舒适度的担忧,强调了用户信任的重要性。 - 将论文复现作为小组活动:
@ivanleomk提出了复现并基于讨论的论文训练模型的想法,建议为感兴趣的贡献者设定 1-1.5 个月的时间表。 - 对成功申领(Claim)的确认:
@swyxio在 llm-paper-club 频道感谢了一位用户 (<@206404469263433728>) 完成了一次成功但未指明的申领。
Latent Space 频道总结
▷ #ai-general-chat (23 messages🔥):
- GPT Store 发布公告:
@swyxio分享了来自@eerac的推文,宣布 GPT store 即将发布,这是 2024 年实现 AI 相关雄心的理想起点。建议将现有的常用应用(如天气、播客、正念、待办事项列表、文字游戏等)移植到 CustomGPT。[推文链接] - ChatGPT 新功能?:分享的一张截图引发了关于在 ChatGPT 上回复部分消息功能的讨论。
@coffeebean6887和@fanahova此前未见过此功能,而@dimfeld认为这是 ChatGPT 独有的新功能。 - 讨论 Embeddings 和相关文章:
@swizec向社区询问评估“相关文章”功能的有效方法。 - 对 “DevOps” GPT 的失望:
@btdubbins观察到他们的 “DevOps” GPT 产生了一系列错误,称其为他们见过的最糟糕的实现之一。 - 寻求 Kubernetes LLM 产品/项目:
@austintackaberry询问了值得关注的 Kubernetes LLM 产品/项目,@fanahova推荐了 Akuity,据报道该产品是 Argo 背后的支持者。[Akuity 链接]
提到的链接:
- draw fast • tldraw:使用 tldraw 快速绘图
- lens by tldraw:一个无限滚动的绘图与幻觉生成工具…
- Eric Rachlin (@eerac) 的推文:如果你 2024 年的目标涉及构建某些东西…
- 使用 Argo CD 作为托管服务部署到 Kubernetes:用于 Argo CD 的 Akuity SaaS 平台。Argo 企业级服务…
- Reddit - 深入探索
▷ #ai-event-announcements (1 messages):
- 即将播出的 TLDRAW 剧集预告:
@swyxio分享了即将播出的 TLDRAW 剧集预告链接,并欢迎大家发表评论。
▷ #llm-paper-club (6 messages):
- 记录聊天:一种侵入性行为?:
@picocreator提出了一个疑问,即通过 AI 进行聊天转录是否会侵犯用户的舒适感。有人担心这可能会阻碍成员在会议中提问,强调了信任和用户舒适度的必要性。 - 复现论文邀请:
@ivanleomk提议复现并基于讨论的论文训练模型。建议感兴趣的人员在 1-1.5 个月内承担此项目。 - 确认认领成功:
@swyxio感谢了一位认领了未知项目或任务的用户 (<@206404469263433728>),具体细节未提及。
DiscoResearch Discord 摘要
- StageTurbo 与 Turbo 之间的性能竞争:
@maxidl指出 StageTurbo 和 Turbo 在对文档集进行排序时表现相当,nDCG 分数的偏差仅为 1%,StageTurbo 略占优势。 - 推广德语 Embedding 模型:强调了对本地化文本 Embedding 的需求,
@sebastian.bodza分享了一篇 研究论文,并表达了为德语开发类似模型的愿望。 - AI 检索任务的兴起:
@sebastian.bodza在 Huggingface 上分享了一个数据集的第一部分,强调了训练 AI 模型在特定上下文驱动指南下完成检索任务的趋势。 - 强调需要更多真实的德语问题:在处理德语 Wikipedia 数据时,
@philipmay强调训练数据中需要更多真实问题。他还分享了使用 GPT-3.5-turbo 在翻译和策划的 SQUAD 数据集上训练德语 DPR 模型的积极经验,指出英语指令与德语文本的无缝融合。 - 关于 BERT 模型和 Token 长度的辩论:
@philipmay和@_jp1_讨论了 BERT 模型的最佳 Token 长度,根据通用或特定用例,范围在 252-2048 个 Token 左右。 - 引发传统信息检索与 Embedding 模型的讨论:
@thewindmom质疑了在 Embedding 模型之上使用传统信息检索系统的做法,将对话引向 CoBERT 以及根据 Hacker News 帖子 和 Twitter 线程 提到的 Dense Embeddings 挑战。 - 引入德语 MTEB 基准测试:
@rasdani宣布了一个面向德语的 MTEB 基准测试贡献,包含一个基于 GermanQuAD 的检索基准,目前托管在 DiscoResearch 的 GitHub 上。 - 呼吁在开放 GitHub Issue 上进行协作:
@rasdani分享了 DiscoResearch mteb 的一个开放 GitHub issue,邀请大家提供想法和贡献。 - 提议通过视频会议进行协作:秉持协作精神,
@philipmay建议举行视频会议,讨论不同的方法和潜在的协同效应。
DiscoResearch 频道摘要
▷ #general (17 条消息🔥):
- StageTurbo 和 Turbo 的性能比较:
@maxidl指出在测试两者对一组文档进行排序时,StageTurbo 和 Turbo 的表现非常接近,Turbo 的 nDCG 仅低 1%。 - 关于德语 Embedding 模型的讨论:
@sebastian.bodza分享了一篇关于高质量文本 Embedding 的 研究论文,并表达了为德语构建类似模型以及进行文本练习实验的需求。 - 探索 AI 的检索任务:
@sebastian.bodza在 Huggingface 上分享了一个数据集的第一部分,以及用于训练模型遵循特定指南完成检索任务的 Proof of Context 实现。 - 对德语数据集开发的兴趣:
@philipmay确认正在处理从德语 Wikipedia 数据生成问题的任务,并强调训练数据中需要更多真实问题。他还分享了最近使用 GPT-3.5-turbo 混合英语指令和德语文本的积极经验,以及在翻译和策划的 SQUAD 数据集上成功训练德语 DPR 模型。 - 创建 AI 模型讨论专用频道:
@philipmay和@bjoernp同意为 Embedding 和 DPR 模型相关的讨论创建一个单独的频道,随后@bjoernp正式为此目的创建了一个 新频道。
提到的链接:
- Improving Text Embeddings with Large Language Models:在本文中,我们介绍了一种新颖且简单的 met…
- SebastianBodza/RAG_Aufgaben · Datasets at Hugging Face
▷ #embedding_dev (12 messages🔥):
- 讨论 BERT 模型的最大上下文长度:
@philipmay征求关于 DPR 训练中使用的 BERT 模型最大上下文长度(token 数)的意见,并提到他们之前训练的模型最大 token 长度为 252。@_jp1_建议通用 embedding 模型至少为 512,并表示 1k 或 2k 可能更好。对于特定的 RAG 使用场景,他们认为 2xx 可能就足够了。参考资料 - 关于 CoBERT 和经典 IR 的问题:
@thewindmom询问是否有人研究过 CoBERT 或使用经典 IR 代替 embedding 模型。他们还分享了一个讨论使用稠密 embedding 挑战的 Hacker News 帖子 链接,以及一个他们打算进一步探索的 Twitter 线程。 - 介绍首个德语 MTEB 基准测试贡献:
@rasdani宣布在 DiscoResearch GitHub 组织下托管了一个用于德语基准测试的 MTEB fork,其中包括germanquad-retrieval分支中基于 GermanQuAD 的检索基准测试。他们还分享了在 MRR@10 上的测试集结果。 - DiscoResearch mteb 的开放 GitHub Issue:
@rasdani分享了 DiscoResearch mteb 上一个开放的 GitHub issue,邀请感兴趣的人参与。 - 提议通过视频会议进行讨论:
@philipmay建议举行视频会议,以澄清正在采用的不同方法并讨论潜在的合作点。邀请对象包括几位频道成员。
{kind=link}
提到的链接:
-
[Show HN: RAGatouille, a simple lib to use&train top retrieval models in RAG apps Hacker News](https://news.ycombinator.com/item?id=38869223) - Improving Text Embeddings with Large Language Models:在这篇论文中,我们介绍了一种新颖且简单的 met…
- Adding German to MTEB · Issue #183 · embeddings-benchmark/mteb:大家好,我认为添加德语会很棒…
- Custom class for e5 embedding model family · Issue #1 · DiscoResearch/mteb:e5 embedding 系列需要 "query: &quo…
- unilm/e5/utils.py at master · microsoft/unilm:跨任务的大规模自监督预训练…
- GitHub - DiscoResearch/mteb: A fork containing German benchmark contributions for MTEB, the Massive Text Embedding Benchmark. All contributions will be upstreamed to MTEB.:一个包含 MTEB 德语基准测试贡献的 fork。所有贡献都将合并到 MTEB 主仓库。
LLM Perf Enthusiasts AI Discord 总结
只有一个频道有活动,因此无需总结…
- SciPhi.AI 发布面向 LLM Agent 的知识引擎:
@emrgnt_cmplxty分享了 Sciphi.AI 网站的链接,该项目旨在通过互联网规模的搜索和数据合成,使 LLM Agent 能够无缝访问人类的关键知识。 - You.com API 讨论:
@robotums在聊天中提到了 You.com 的 API,想知道它与 Metaphor API 相比如何。作为回应,@jeffreyw128解释说,虽然 You.com 很大程度上封装了 Brave API,但 Metaphor 使用的是 embedding-first search 方法,重点在于搜索定制化和计算资源。 - Metaphor 即将推出强大的 Snippets 功能:
@jeffreyw128预告了 Metaphor 即将推出的功能,承诺提供具有高度可定制性的令人印象深刻的 snippets,包括控制 句子数量、每页 snippets 数量 以及 与 snippet 相关的特定查询。 - 勒贝格积分查询的响应得到改善:
@nosa_.表示,他们之前查询的一个关于勒贝格积分 (Lebesgue integration) 的问题,其响应有了显著改善,@emrgnt_cmplxty对此表示欣慰。
提到的链接:
-
[YOU API Innovative AI API API Calls for All Companies](https://api.you.com/) - Home - SciPhi
Skunkworks AI Discord 总结
只有一个频道有活动,因此无需总结…
- 好奇心询问:
@dook4询问了小组的活跃情况,@far_el给予了鼓励性的回应,并暗示下周会有活动。 - 表达兴奋:
@s3nh1123用表情符号表达了兴奋之情。 - 关于数据发布的疑问:
@maxmatical询问了wizardlm/wizardcoder及其数据发布情况,提出了对研究不可复现性的担忧。
Alignment Lab AI Discord 总结
- 新秀登场,Search RAG API:@emrgnt_cmplxty 宣布新的 Search RAG API 已上线。它对合成数据和 Grounding 响应具有重要意义。点击此处获取更多信息。
- 刷榜模型:@maxmatical 提出了一个关于 AI 模型训练的重要观点:模型作为基础模型(Base Model)时可能表现不佳,因为它们经过微调以超越 Benchmark。无论是刻意还是无意,这种训练方法都会影响模型在各种应用中的鲁棒性。
Alignment Lab AI 频道总结
▷ #general-chat (1 条消息):
- 新 Search RAG API 现已可用:用户
@emrgnt_cmplxty宣布 Search RAG API 现已开放使用,强调了其在合成数据和 Grounding 响应方面的优势。详情请见此链接。
▷ #phi-tuning (1 条消息):
- 为超越 Benchmark 而训练的模型:用户
@maxmatical建议,模型作为基础模型可能无法有效发挥作用,因为它们主要被训练用于超越 Benchmark,无论是有意还是无意。
Datasette/LLM (@SimonW) Discord 没有新消息。如果该公会长期处于沉默状态,请告知我们,我们将予以移除。
YAIG (a16z Infra) Discord 没有新消息。如果该公会长期处于沉默状态,请告知我们,我们将予以移除。