ainews-16-72024-llama-pro-just-add-new-layers-lol
2024年1月6-7日:LlaMA Pro —— PEFT/RAG 的替代方案??
新的研究论文介绍了一些极具前景的 Llama 扩展模型,包括 TinyLlama 和 LLaMA Pro。TinyLlama 是一个紧凑的 11 亿参数模型,在约 1 万亿 token 上进行了 3 个轮次的预训练;而 LLaMA Pro 是一个 83 亿参数的模型,它通过在 800 亿 token 的代码和数学数据上进行额外训练,对 LLaMA2-7B 进行了扩展。LLaMA Pro 通过增加层来避免灾难性遗忘,并平衡了语言与代码任务,但因未采用 Mistral 或 Qwen 等更新的模型而面临审视。
与此同时,OpenAI 的 Discord 讨论揭示了关于 GPT-4 token 限制、隐私保证、GPT-3.5 微调、多语言图像识别的挑战、创建自定义 GPT 需要 ChatGPT Plus 以及 GPT 部署中的安全担忧等见解。用户还分享了关于使用 DALL-E 进行动态图像生成和 Logo 创建的技巧。
这是两天的内容,因为我们错过了昨天。
新发布的论文展示了非常有前景的 Llama 扩展:
- TinyLlama: An Open-Source Small Language Model:(我们在之前的 AINews 期刊中写过这个,但这是正式论文)我们介绍了 TinyLlama,这是一个紧凑的 1.1B 语言模型,在约 1 万亿个 token 上预训练了大约 3 个 epoch。(Semafor 上的报道)
- LLaMA Pro: Progressive LLaMA with Block Expansion:LLaMA-Pro 是一个 83 亿参数的模型。它是 LLaMA2-7B 的扩展,在总计 800 亿 token 的代码和数学语料库上进行了进一步训练。
- 在不发生灾难性遗忘的情况下为 Llama7B 添加新知识……只需添加层即可(笑)。
- 使其在语言和代码任务之间取得了很好的平衡。
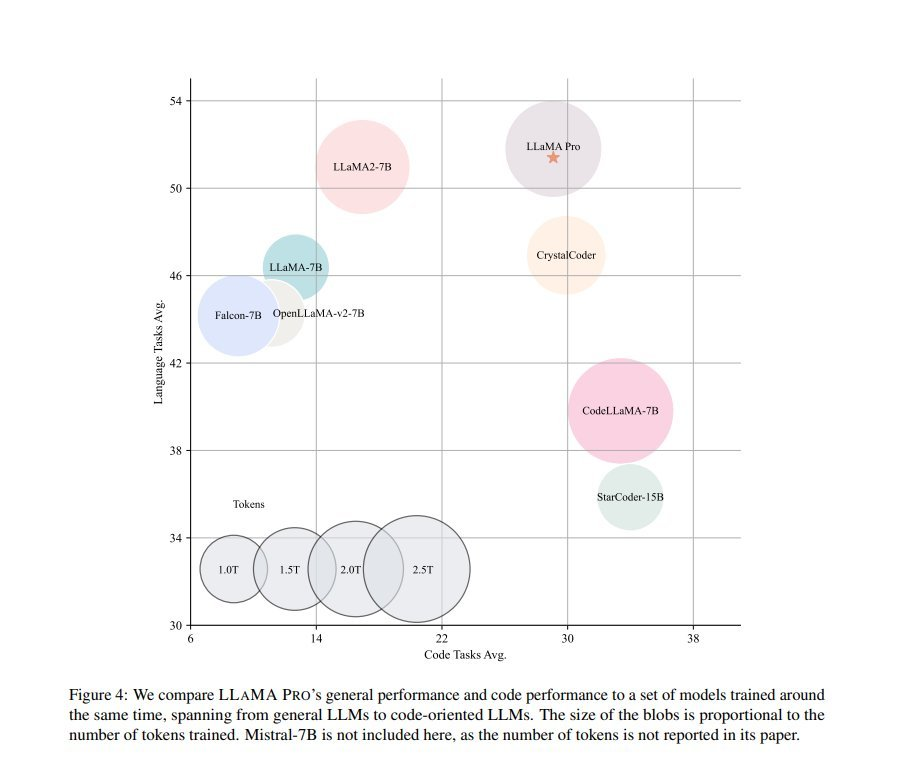
但由于它基于 LlaMA 而非使用 Mistral/Qwen 等模型,已经受到了一些质疑:
Yannic Kilcher 已经发布了一个很棒的 Llama Pro 讲解视频:
https://www.youtube.com/watch?v=hW3OVWfndLw
在其他新闻方面,LangChain 计划在下周推广他们最近发布的 v0.1 版本。
目录
[TOC]
OpenAI Discord 总结
- Enterprise-Lite,对吧?并不:用户
@a1vx询问个人用户是否可以利用 Enterprise 套餐,但被@solbus告知该方案目前仅针对拥有六位数合同的大型企业。 - 隐私担忧与 GPT 的保证:用户
@a1vx提出了关于使用 GPT 模型时的隐私担忧。@feltsteam0保证私有数据是保密的,且不太可能被用于模型预训练。 - 并非一种语言通吃:存在关于即将推出的 GPT Store 是否支持俄语等其他语言的疑问。社区建议在商店发布后等待进一步细节。
- 模型微调,不只是引擎:针对正在进行的优化 GPT-3.5 1106 以用于 Assistants 的探索,
@a1vx将用户引导至 OpenAI 官方文档的 Assistant API 页面。 - Traceroute 并非路径:
@darthgustav.和@chotes之间关于模型在多维向量空间中运行的讨论,以对将模型响应解释为 traceroute 的准确性及相关常见误解的怀疑而告终。 - GPT-4:Token 盛宴,多多益善:
its_eddy_和Bianca Stoica触及了与 GPT-4 相关的 Token 使用上限和期望全天候访问的讨论。 - Builder 需要验证:在设置 GPT-Builders 期间验证域名对
johan0433和savioai来说非常棘手,尽管已努力解决该问题。 - GPT 展示语言实力:
xbtrob和elektronisade强调 GPT-4 可能难以识别图像中的非拉丁语言,即汉字(kanjis)。 - 进退两难的 HTML 与 CSS:
kerubyte正在努力控制其自定义 GPT 中生成的 HTML 和 CSS 代码,该模型似乎有一种未经请求就生成<html>和<body>元素的倾向。 - 自定义 GPT 现在面向谁?:
filipemorna寻求有关 GPT builders 注册流程的信息,并被solbus告知拥有 ChatGPT Plus 账户即可访问。 - GPT:不喜欢繁文缛节:用户
.ashh.询问为特定视频游戏创建 GPT 是否会侵犯版权。 - 与 GPT-4 玩捉迷藏:
its_eddy_和Bianca Stoica讨论了 GPT-4 无法访问的常见问题,涉及使用限制和 Token 限制。 - 早餐时间的 DALL-E 动态图像生成:用户
@hawaiianz分享了如何通过发挥 Prompt 和描述的创意,利用 DALL-E 创建更平衡、更动态的图像的经验和建议。 - 更多锁,更安全:部署 GPT 的安全问题是用户
@cerebrocortex、@aminelg、@madame_architect和@wwazxc争论的焦点。建议用户在探索新的安全方法时不要违反 OpenAI 的政策。 - 用 DALL-E 设计 Logo 很酷:
@viralfreddy寻求关于使用 DALL-E 创建 Logo 的建议,@darthgustav建议使用特定的 Prompt 和英语翻译以提高效果。 - GPT 的任务清单已溢出:像
@ajkuba、@wwazxc和@cosmodeus_maximus这样的用户对 GPT 处理大型任务的方式以及有时无响应的情况感到恼火。 - 通往 Prompt 成功的坎坷之路:
@exhort_one分享了他们在 Prompt Engineering 方面的历程,在经过多次迭代并向社区学习后,成功生成了所需的脚本。
OpenAI 频道总结
▷ #ai-discussions (241 条消息🔥🔥):
- 个人用户可以使用企业级 AI 吗?目前还不行:用户
@a1vx询问了个人购买 Enterprise 套餐的可能性。用户@solbus澄清说,目前 OpenAI 仅面向签署六位数合同的大型公司提供 Enterprise 服务,并建议联系 OpenAI 销售团队进行洽谈。 - 关于 ChatGPT 隐私的担忧:
@a1vx表达了对使用 GPT 模型时隐私问题的担忧,特别是关于“聊天记录与训练”以及用于审核的数据存储。@feltsteam0安慰说,数据极不可能进入预训练数据中,且“私密”聊天可能不会被用于训练。 - 在 GPT Store 中加入私有 GPT:有人提问即将推出的 GPT Store 是否允许训练能理解其他语言(特别是俄语)的 GPT。有人指出目前的文档中没有这些细节,希望在 Store 发布时能得到澄清。
- 为 Assistant 微调 GPT 模型:用户
@s44002询问是否可以使用微调版的 GPT-3.5 1106 作为 Assistant 的模型。@a1vx引用了 OpenAI 文档中的 Assistant API 页面,并指出 Assistant API 即将支持微调模型。 - 关于“Traceroute 比喻”的讨论:
@darthgustav.和@chotes之间就语言模型在高维向量空间中的运行进行了深入的技术讨论。将模型的响应视为在该空间中的 traceroute(路由追踪)这一想法遭到了质疑,并引发了关于该比喻的准确性及误解的辩论。
提到的链接:
- Conversa
- Pricing:简单且灵活。按需付费。
- GitHub - SuperDuperDB/superduperdb: 🔮 SuperDuperDB. Bring AI to your database; integrate, train and manage any AI models and APIs directly with your database and your data.:🔮 SuperDuperDB。将 AI 引入您的数据库;直接在您的数据库和数据中集成、训练和管理任何 AI 模型及 API。
▷ #gpt-4-discussions (97 条消息🔥🔥):
- GPT 使用限制和订阅讨论:用户
its_eddy_回应了关于 GPT-4 使用限制的担忧,帮助澄清了免费用户的可用时间。Bianca Stoica询问了如何获得 GPT-4 的全天候访问权限。 - GPT Builder 域名验证故障排除:用户
johan0433和savioai分享了在设置 GPT Builder 时验证各自域名遇到的问题。作为讨论的一部分,johan0433建议在 Name 字段输入 “www” 以解决问题,但该方案对savioai无效。 - 期待已久的 GPT Store 发布:
solbus提到 OpenAI 在发给用户的邮件中宣布即将推出 GPT Store。这引发了与jguzi关于自定义 GPT 机器人目录可用性的进一步讨论。 - GPT 知识识别问题:
alanwunsche对他的 GPT 无法识别上传的小文件表示担忧,并指出这是用户中的普遍问题。 - 自定义 GPT Action 在移动端的兼容性问题:
dorian8947报告了他的 GPT 在移动应用上的自定义 Action 存在问题,并寻求解决办法。 - HTML 和 CSS 自定义 GPT 开发问题:用户
kerubyte正在努力控制自定义 GPT 生成的 CSS 和 HTML 代码。尽管在规则集中明确要求不要生成,但其 GPT 仍不断生成<html>和<body>元素。 - 非拉丁语言的技术问题:
xbtrob注意到 GPT-4 无法读取图片中的汉字,elektronisade证实了这一点,并表示日语或韩语等非拉丁字母的处理可能尚未达到最佳状态。 - GPT Builder 注册咨询:
filipemorna询问了成为 GPT builder 的注册流程,solbus解释说任何拥有 ChatGPT Plus 账户的人都可以创建自定义 GPT。 -
关于 GPT 变现的疑问:
dinola发起了关于 GPT 变现机制的讨论。pinkcrusader提供了一个推测性的回答,建议在最常用的 GPT 之间进行分成。7877提供了更全面的解释,举例说明如果用户 10% 的使用量花在某个自定义 GPT 上,创作者可能会获得这 10% 中的 70/30 分成。 - 关于电子游戏指南 GPT 的法律担忧:
ashh.提出了一个问题,即如果构建一个 GPT 来回答特定电子游戏的问题,是否会涉及侵犯版权规则。 - 关于将 API 快速转换为 GPT 配置文件的问题:
moneyj2k想知道将公开 API 转换为 GPT 配置文件的最快方法。 - GPT-4 Token 限制和无法访问的 GPT:
its_eddy_和Bianca Stoica提到了 GPT-4 的 Token 使用限制以及 GPT 无法访问的问题。 - 对定制 GPT 创建的热情:
kungfuchopu分享了他们在设计自定义 GPT 时的兴奋之情,这些 GPT 能以特定角色的口吻生成独特的故事。 - 将公开 API 转换为 OpenAI 配置:
moneyj2k询问了一种将公开 API 快速转换为 GPT 配置文件的方案。 - 关于域名验证的建议:
anardude就为 OpenAI GPT 验证其域名寻求帮助和建议。他的担忧尚未得到解决。 - Builder 注册问题:
filipemorna询问了 GPT Store 的注册事宜,solbus指引其前往 ChatGPT Plus 中的 Builder 个人资料设置。 - GPT Store 准备技巧:
cerebrocortex询问了为 GPT Store 准备 GPT 的建议。solbus提供了 OpenAI 的指南供参考。 - 与 GPT 的交互:用户
jobydorr和_odaenathus讨论了与 GPT 交互的 Prompt 和规则。_odaenathus进一步询问了“Knowledge”限制,促使chotes澄清存在硬性的 Token 限制,且较大的文档会使用 Retrieval Augmented Generation (RAG) 进行拆分。 - “GPT 无法访问或未找到”问题:用户
melysid向 Coty 询问了关于“GPT 无法访问或未找到”问题的解决方案。该查询在讨论中未得到回应。 - GPT Store 支付机制:用户
pinkcrusader提供了关于基于最常用 GPT 的支付机制详情,该内容在开发者主题演讲中进行了讨论。 - 消息数量限制问题:用户
holden3967提出了对 GPT 消息限制(每 3 小时 25 条消息)的担忧,认为这严重限制了 GPT 应用的效用。7877幽默地指出没有办法绕过这个限制。_odaenathus建议用户可以通过拥有多个账号和多个订阅计划来克服这个问题。 - DALLE 图像纵横比:用户
.arperture分享了在自定义 GPT 中使用 DALLE 时,难以稳定输出非正方形纵横比图像的问题。solbus建议改用 “tall aspect ratio”(纵向比例)和 “wide aspect ratio”(横向比例)。 - 注册成为 GPT Builder 的流程:用户
filipemorna询问了注册成为 GPT Builder 的流程。solbus提到可以通过 OpenAI 的 GPT 编辑器使用 ChatGPT Plus 账号完成。 - 为电子游戏创建自定义 GPT:用户
.ashh.询问了在不侵犯版权的情况下,创建自定义 GPT 来回答特定电子游戏问题的合法性。7877建议只要不使用游戏素材(assets)就没有问题。 - GPT Store 变现:用户
dinola寻求关于 GPT Store 变现机制的澄清。7877以一个用户在 10% 的使用时间内使用自定义 GPT 为例,提供了详细解释。 - GPT-4 在读取汉字(Kanjis)方面的局限性:
xbtrob提到 GPT-4 无法读取图像中的汉字。elektronisade确认了这一限制,指出该模型在非拉丁字母上的表现并不理想。 - 自定义 GPT 与速率限制(Rate Limits)的问题:
_odaenathus澄清了在速率限制方面,混合使用常规 ChatGPT 和自定义 GPT 消息的工作机制。lumirix提到他认为 GPT 的 Prompt 也会计入 40 条消息的限制。 - 谨慎对待速率限制:用户
dino.oats警告说,在同一次响应中生成多张图像会很快达到速率限制。 - OpenAI GPT 更多内容:用户
kungfuchopu分享了他们使用自定义 GPT 以特定角色口吻创作独特故事的热情。 - 构建 GPT 时潜在的知识产权问题:
.ashh.询问了基于电子游戏创建 GPT 时潜在的版权问题。7877建议使用游戏素材可能会带来麻烦。 - 域名验证问题:用户
anardude在验证其域名时遇到困难,并寻求解决方案,但未收到回复。 - 关于 GPT Store 的讨论:
cerebrocortex询问了为 GPT Store 准备 GPT 的技巧,solbus指引其参考 OpenAI 的指南。 - 潜在的用户订阅问题:
Bianca Stoica对能否全天候访问 GPT-4 表示担忧。 -
围绕非拉丁语言问题的讨论:
xbtrob表示 GPT 无法读取图像中的汉字。这一问题被认为在读取非拉丁语言时尤为显著。 - 用于代码生成的自定义 GPT:
kerubyte正在寻求关于创建一个能为特定平台生成有效 HTML 和 CSS 代码的自定义 GPT 的建议。 - 关于 GPT 限制的讨论:
_odaenathus询问了 GPT “知识”的硬限制和软限制,chotes就 Token 限制问题进行了回答。 - 上传文件的 Token 成本:
chotes警告了上传大型 JSON 文件的高昂成本。 - GPT 的 API 配置:
moneyj2k询问了将公开 API 快速转换为 GPT 配置文件的方法。 - 关于 GPT 通信限制的讨论:
holden3967提出了 GPT 每 3 小时 25 条消息的限制问题,7877幽默地表示无法绕过,随后_odaenathus建议通过拥有多个不同方案的账户来解决此问题。 - Dalle 图像生成:
.arperture正在寻找在自定义 GPT 中使用 Dalle 稳定输出非正方形纵横比图像的方法。 - 关于 GPT 规则集的讨论:
jobydorr讨论了让 GPT 必须遵守的一系列指令所存在的问题。 - GPT 文学交互请求:
kungfuchopu热情地分享了他们新创建的 GPT,该 GPT 允许用户与角色互动,并以用户自己的声音和语气生成独特的故事。 - 关于 GPT Builder 注册流程的讨论:用户
filipemorna询问了注册成为 GPT Builder 的流程。solbus回答说,任何拥有 ChatGPT Plus 账户的人都可以创建自定义 GPT。 - 关于 GPT 无法访问的不确定性:
melysid寻求关于解决 GPT 无法访问或未找到问题的建议。遗憾的是,他们的查询未得到解答。 - GPT Store 的变现策略:用户
dinola询问了 GPT 变现如何与用户访问和 API 使用相关联。对此,7877推测了一种可能的方法,建议成本由常用/广泛使用的 GPT 分摊。 - 用于视频游戏指南的自定义 GPT 及商标问题:用户
.ashh.讨论了在创建为特定视频游戏答疑的 GPT 时可能存在的商标问题。共识是,只要ashh.不使用任何游戏资产,就应该没问题。 - 验证 GPT Builder 设置的域名:
johan0433和savioai讨论了一个关于验证 GPT Builder 设置域名的持续性问题。在创建 DNS/TXT 记录时将 Name 字段输入为 “www” 的建议方案未能成功。 - 对 GPT Store 发布的期待:用户
solbus宣布 OpenAI GPT Store 即将发布,正如 OpenAI 的一封电子邮件中所述。这引发了关于自定义 GPT 机器人目录的可用性和可搜索性的简短讨论。 - 关于将 API 结构化为 OpenAI 配置的问题:
moneyj2k询问了如何将公开 API 转换为 GPT 的 OpenAI 配置文件,引发了简短讨论,但未提供确定的解决方案。 - GPT-4 Token 限制讨论:
its_eddy_和Bianca Stoica之间进行了简短交流,讨论了 GPT-4 使用上限问题和 Token 限制的概念。讨论了订阅模式对于绕过此问题的必要性。 - GPT 无法访问问题的解决:用户
melysid提出了 GPT 无法访问或未找到的问题,但对话未提供解决方案。 - GPT 与文件识别的问题:用户
alanwunsche对他的 GPT 无法识别上传的小文件表示担忧,并指出这是许多用户报告的一个问题。然而,提供的解决方案仍未得到回应。
提到的链接:
- 品牌指南:在营销和沟通中使用 OpenAI 品牌的语言和资产。
- 手机 App 上的 GPT 访问:我的 GPT Ranko 在 Mac 上运行良好,但当我在手机 App 上访问它时,它提示我的 GPT 不可用。我可以正常访问其他 GPT。App 访问是否有任何额外设置?
▷ #prompt-engineering (48 messages🔥):
-
平衡具有动态姿势的图像:用户
@hawaiianz分享了一个 prompt,其中包含关于如何在 DALL-E 中通过使用动态姿势来支持图像中的金字塔结构,从而创建平衡图像的技巧。他们建议这种方法可以应用于图像之外的领域。 -
GPT 部署中的安全性:用户
@cerebrocortex、@aminelg、@madame_architect和@wwazxc讨论了如何保护 GPT 模型免受未经授权的访问。虽然建议了额外的资源来探索安全方法,但提醒用户不要违反 OpenAI 的使用政策(Usage policies)。 -
提升 GPT 性能:用户
@ajkuba分享了自定义 GPT 在无法有效处理大批量数据且不崩溃方面的困难。其他用户@sciandy和@wwazxc建议将结果输出为不同格式或利用 JSON mode 来避免这些问题。 -
使用 DALL-E 创建 Logo:
@viralfreddy寻求关于如何改进使用 DALL-E 创建 Logo 的 prompt 的建议。@darthgustav建议在 prompt 中保持具体,如果英语不是用户的母语,建议将 prompt 翻译成英语以获得更好的效果。 -
GPT 模型的问题:用户
@cosmodeus_maximus对当前 GPT 模型的性能表示不满,特别是其缺乏创意和忽视用户指令。同样,@mysterious_guava_93336也指出了他在使用 ChatGPT 时遇到的问题,即 ChatGPT 总是提供“PowerPoints”(“结构化回复”),这阻碍了对话质量。 -
Prompt Engineering 成功案例:用户
@exhort_one分享了他们在经过 3 个月的 Prompt Engineering 后,终于从 GPT 模型中获得了理想脚本的胜利,展示了该领域所需的学习曲线和韧性。
提及的链接:
▷ #api-discussions (48 messages🔥):
- 增强型图像生成的探索:
@hawaiianz解释说,在图像描述中使用动态定位和支撑角色可以提高使用 Dall-E 时的结果质量。图像构图中的细节,如多样的动作(如“随机功夫攻击姿势”),可以使画面更加平衡且具有真实的动态感。 - GPT 中的安全担忧:
@cerebrocortex和@wwazxc等用户提出了对 GPT 安全措施的担忧,特别是关于保护指令执行方面。@madame_architect和@eskcanta等用户建议探索学术资源和成熟项目(如 SecretKeeperGPTs 或 SilentGPT)以获取学习灵感。 - 使用 DallE 设计 Logo:
@viralfreddy寻求使用 DallE 设计 Logo 的帮助,收到了@darthgustav的建议,即在 prompt 中保持具体,并建议将 prompt 翻译成英语以获得更好的效果。 - GPT 任务处理的问题:
@ajkuba讨论了 GPT 在完成包含大量项目的任务(如批量网页浏览)时持续失败的问题。其他用户如@wwazxc和@cosmodeus_maximus也对 AI 系统运行中的重大限制和偶尔的无响应表示沮丧。 - Prompt Engineering 的挑战与成功:
@exhort_one分享了他们在经历多次 prompt 修订和倦怠后坚持不懈,最终从 GPT 获得所需脚本的历程。该用户承认社区的 Prompt Engineering 见解在此过程中非常有帮助。
提及的链接:
Eleuther Discord 摘要
- 模型对决:Mamba vs. Transformer:一场围绕 Mamba 在 NLP 任务中与 Transformer 模型性能对比的热烈辩论。由
@sentialx发起的讨论涉及了模型多样性、优化水平和使用场景等问题。 - 全城热议 Civitai 的 Clubs:
@digthatdata分享了 Civitai 为创作者推出的最新功能:“Clubs”。该功能旨在为提供独家内容的创作者提升参与度,但其推出也伴随着不少反对声音。 - Phi-2 以 MIT License 发布:正如
@SebastienBubeck在 Twitter 上宣布并由@digthatdata分享的那样,来自 Microsoft Research 的 Phi-2 模型现在已通过 MIT License 开放使用。 - LLaMA 家族的新秀:TinyLlama 与 LLaMA Pro:
@philpax和@ai_waifu分享了新发布的语言模型 TinyLlama 和 LLaMA Pro。这两个模型标志着 LLaMA 模型谱系的重大进展。 - 多选题与 LLM:一段动荡的关系:来自马里兰大学的研究员
@Nish报告称,其项目中 LLM 生成的多选题答案在性能上与之前报告的排行榜数据存在显著差异,特别是在 HellaSwag 数据集上。促成因素可能包括实现方式的差异以及选项 log likelihoods 的归一化处理。 - 序列标注(Sequence Labelling)分享笔记:
@vertimento发起了一场关于在词性标注(PoS tagging)等序列标注任务中应用 logit/tuned lens 的讨论。 - 揭开 GPT-4 Token 选择的奥秘:
@allanyield分享了一篇揭示 GPT-4 如何从较小模型分布中选择 token 的论文。该论文指出,如果给予适当的 Prompt,LLM 可以先输出解释性文本,随后得出结论。 - 加入可解释性(Interpretability)相关项目的兴趣:
@eugleo完成了他们的 ARENA 计划,并表达了参与可解释性相关项目的热切愿望,承诺每周投入 16 小时。 - 性能胜过雄辩:
@carsonpoole和@rallio之间进行了一场关于不同规模模型推理性能的深入对话。他们指出模型大小、GPU 能力和 Batch Size 在决定推理速度和成本方面起着至关重要的作用。 - 训练模型与 MLM 的效率:
@jks_pl和@stellaathena讨论了 Masked Language Model (MLM) 训练和 span corruption 任务的影响及效率,并引用了特定论文。 - 解码 Transformer:
@erich.schubert提出了对 Transformer 架构的疑问,引发了关于处理位置编码(positional encodings)、层输出以及 prefix decoders 结构的对话。 - 序列长度偏差——真实存在还是凭空想象?:
@chromecast56对项目中序列长度警告的担忧引发了一场对话,旨在向用户保证 evaluation harness 处理该问题的能力。 - ToxiGen 为 lm-evaluation-harness 增色:
@hailey_schoelkopf感谢了 ToxiGen 论文主创对 lm-eval-harness 实现做出的显著贡献,这是原论文中未探讨的一个元素。
Eleuther 频道摘要
▷ #general (161 messages🔥🔥):
- Mamba vs Transformer 辩论:用户们就 Mamba 和 Transformer 模型在 NLP 任务中的有效性展开了热烈讨论,起因是
@sentialx质疑 Mamba 性能的评论。@thatspysaspy、@canadagoose1、@stellaathena和@clock.work_参与了讨论,探讨了优化程度、不同模型之间的多样性以及不同模型类型的具体用例等因素。 - Civitai Clubs 推出:
@digthatdata分享了来自 Civitai 的更新,介绍了他们为创作者推出的新功能 “Clubs”。该功能旨在增强提供独家内容的创作者的参与度,但也提到了发布以来遇到的一些抵制。 - Phi-2 以 MIT License 发布:
@digthatdata还转发了 @SebastienBubeck 的推文,宣布 Phi-2 现已在 MIT License 下发布。 - 推理性能对比:
@carsonpoole和@rallio之间就不同规模模型的推理性能进行了详细讨论,@rallio分享了一个关于处理 LLM 最佳实践的有用资源。讨论强调了在考虑推理速度和成本时,模型大小、GPU 算力和 Batch size 的重要性。 - 志愿者研究机会:
@sirmalamute向社区寻求以志愿者身份参与机器学习研究项目的机会,以获得更多实践经验。
提及的链接:
-
[关于可持续社区发展的反馈征集 Civitai](https://civitai.com/articles/3636):本周,我们推出了 Clubs —— 这是一个为一直在 Patreon 等平台运行独家会员制的创作者提供的新功能。Clubs 是我们… - LLM 推理性能工程:最佳实践:在这篇博文中,t
- 来自 Sebastien Bubeck (@SebastienBubeck) 的推文:以一个小更新开启新的一年,Phi-2 现在采用 MIT License,祝大家使用愉快!https://huggingface.co/microsoft/phi-2
▷ #research (64 条消息🔥🔥):
- 序列标注中的 Logit Tuned Lens:由
@vertimento发起的讨论,重点关注 logit/tuned lens 在 PoS tagging 等序列标注任务中的应用。对话没有得出决定性的结论,但吸引了多种回应。 - TinyLlama 和 LLaMA Pro 的发布:
@philpax和@ai_waifu分别分享了新发布的语言模型 TinyLlama 和 LLaMA Pro。两者都代表了 LLaMA 系列模型的重大进展。 - 关于模型训练和 MLP 效率的讨论:
@jks_pl和@stellaathena就 Masked Language Model (MLM) 训练和 span corruption 任务的效率及影响进行了广泛讨论,并引用了一篇有用的论文作为背景:https://arxiv.org/abs/2204.05832。 - Phi-2 模型许可协议变更:根据
@kd90138的消息,原本采用 Microsoft Research License 的 Phi-2 现在已改为 MIT License。 - 关于 Transformer 架构的疑问:
@erich.schubert提出了关于经典 Transformer(encoder-decoder)架构的一些问题,并收到了来自@stellaathena、@ad8e等人关于位置编码(positional encodings)处理、层输出以及 prefix decoders 结构的反馈。
提到的链接:
- TinyLlama: An Open-Source Small Language Model:我们介绍了 TinyLlama,这是一个紧凑的 1.1B 语言模型,在大约 1 万亿个 token 上预训练了约 3 个 epoch。基于 Llama 2 的架构和分词器,TinyLlama 利用了各种…
- LLaMA Pro: Progressive LLaMA with Block Expansion:人类通常在不损害旧技能的情况下习得新技能;然而,对于大型语言模型 (LLMs) 来说情况正好相反,例如从 LLaMA 到 CodeLLaMA。为此,我们提出了一种新的后预训练…
- What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?:大型预训练 Transformer 语言模型已被证明具有零样本泛化能力,即它们可以执行各种未经过明确训练的任务。然而,…
- Look What GIF - Look What Yep - 发现并分享 GIF:点击查看 GIF
- Upload 3 files · microsoft/phi-2 at 7e10f3e
- An explanation for every token: using an LLM to sample another LLM — LessWrong:引言 关于构建基于一个或多个大型语言模型 (LLMs) 的 AGI 的影响和潜在安全益处,已经有很多论述……
-
[AI 100-2 E2023, Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations CSRC](https://csrc.nist.gov/pubs/ai/100/2/e2023/final) - Reproducibility Challenge: ELECTRA (Clark et al. 2020):在低资源 NLP 环境下对“高效学习准确分类 Token 替换的编码器”方法的复现。
- Improving position encoding of transformers for multivariate time series classification - Data Mining and Knowledge Discovery:Transformer 在深度学习的许多应用中表现出了卓越的性能。当应用于时间序列数据时,Transformer 需要有效的位置编码来捕获顺序…
▷ #interpretability-general (2 messages):
- 关于 “An Explanation for Every Token” 论文的讨论:
@allanyield提到了一篇他们发现的论文,该论文探讨了 GPT-4 如何从较小模型提供的分布中选择 Token 并为其选择编写理由。论文承认了基于 LLM 扩展 AGI 的潜在安全效益,并展示了经过适当提示的 LLM 如何输出结构为“先解释后结论”的文本。 - 征集研究合作:用户
@eugleo提到已完成 ARENA 项目,并表达了未来加入 可解释性相关项目 (interpretability-related project) 的兴趣。他们愿意在几个月内每周贡献约 16 小时,持续数月,并请求有关可能项目或相关联系人的建议,并声明不需要资金或额外承诺。
提及的链接:
An explanation for every token: using an LLM to sample another LLM — LessWrong:引言:关于构建基于一个或多个 LLM 的 AGI 的影响和潜在安全效益,已有许多文章阐述……
▷ #lm-thunderdome (13 messages🔥):
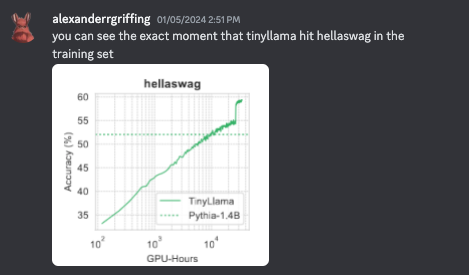
- 关于生成多选题答案的讨论:来自马里兰大学的研究员
@Nish发起了一场关于他在使用 LLM 以标准 MC 格式生成多选题答案时注意到的差异的对话。他报告称,与排行榜上公布的数据相比,存在显著的性能差距,特别是在 HellaSwag 数据集上。 - 性能差距的可能原因:
@hailey_schoelkopf建议该差距可能是由于实现方式的不同:@Nish是让模型仅生成答案字母,而 Eleuther 的实现则是对字母以及字母后文本的序列概率进行评分。作为另一个影响因素,她提到了选项对数似然 (log likelihoods) 的归一化,这会显著影响性能,尤其是对于 HellaSwag 数据集。 - 未归一化与归一化分数的基准测试:
@stellaathena和@hailey_schoelkopf引导@Nish查看 Teknium 的 GitHub 库,其中包含不同 LLM 的基准测试日志,以查看未归一化和归一化的分数。 - 对序列长度警告的担忧:用户
@chromecast56对他们看到的序列长度警告表示担忧,并询问是否需要人工干预,或者评估框架 (evaluation harness) 是否会自动处理。 - ToxiGen 对 lm-evaluation-harness 的贡献:
@hailey_schoelkopf提到,尽管原始 ToxiGen 论文没有探索自回归 (autoregressive) 语言模型设置,但 lm-eval-harness 中的新实现是由 ToxiGen 的第一作者贡献的。
提及的链接:
LLM-Benchmark-Logs/benchmark-logs/Mixtral-7x8-Base.md at main · teknium1/LLM-Benchmark-Logs:一系列不同 LLM 的基准测试日志。可以通过在 GitHub 上创建账户为 teknium1/LLM-Benchmark-Logs 的开发做出贡献。
Perplexity AI Discord 摘要
- 优化 Perplexity 使用:用户讨论了增强 Perplexity 利用率的各种方法,@icelavaman 表示该服务正在不断完善,以开发一个快速且精准的回答引擎。推文链接
- Perplexity 评估受到质疑:@the_only_alexander 对一篇学术论文中发表的 Perplexity 评估表示担忧,并对所采用的方法论提出了具体质疑。
- Perplexity Pro 揭秘:用户 @donebg 询问了 Perplexity Pro 的权益。@giddz 和 @mares1317 的回复将查询引导至 Perplexity Pro 官方页面。
- Notion 数据库限制引发不满:@stanislas.basquin 对跨不同工作区链接 Notion 数据库的限制表示恼火。Perplexity 讨论串
- Perplexity 因快速的研究输入获得称赞:@shaghayegh6425 对 Perplexity 的快速和信息丰富表示赞赏,特别是在生物研究查询和头脑风暴方面。他们分享了多个示例
- Perplexity API 陷阱:包括 @blackwhitegrey 和 @brknclock1215 在内的用户表示在 ‘typingmind’ 和 ‘harpa.ai’ 等平台上集成 Perplexity API 时遇到困难并寻求指导。文中引用了 Perplexity API 文档 以提供帮助。
Perplexity AI 频道摘要
▷ #general (180 条消息🔥🔥):
- Perplexity 增强:用户讨论了改进 Perplexity 使用体验的方法,
@icelavaman提到该服务正在不断改进,旨在打造最快、最准确的回答引擎,并引用了 Perplexity CEO Aravind Srinivas 的一条 推文。 - Perplexity 对比学术论文:用户
@the_only_alexander对一篇 研究论文 中提到的 Perplexity 评估结果持保留意见,并对该论文的方法论表示担忧。 - 声音困扰:
@jamiecropley反馈被 Perplexity 首页播放的声音所困扰,得到的建议是将标签页静音。 - 浏览器内置 Perplexity:用户分享了如何在浏览器(主要是 Firefox 和 Chrome)中将 Perplexity 设置为默认搜索引擎。为此,用户分享了各种资源链接,例如 在 Chrome 中设置搜索快捷方式 以及 如何在 Firefox 中添加或删除搜索引擎。
- Perplexity Pro 功能:用户
@donebg询问了 App 中 Perplexity Pro 的优势。用户@giddz和@mares1317引导其查看列出 Perplexity Pro 权益的 官方页面,其中包括更多的 Copilot 搜索次数、模型选择以及无限次文件上传。
提到的链接:
- Aravind Srinivas (@AravSrinivas) 的推文:@Austen @eriktorenberg 感谢每一位支持我们的投资者和用户。没有大家的帮助,我们无法走到今天!我们期待继续打造最快、最准确的…
- 评估生成式搜索引擎的可验证性:生成式搜索引擎直接生成对用户查询的响应,并附带行内引用。值得信赖的生成式搜索引擎的一个先决特质是可验证性,即系统应该…
-
[在 Firefox 中添加或删除搜索引擎 Firefox 帮助](https://support.mozilla.org/en-US/kb/add-or-remove-search-engine-firefox) - Brave 与 Firefox 对比:你应该使用哪一个?:常青的开源浏览器 Firefox 与 Brave 的对比。你会选择哪一个?
- 瓦肯举手礼 Spock GIF - 瓦肯举手礼 Spock 星际迷航 - 发现并分享 GIF:点击查看 GIF
- 如何在 Chrome 中设置站点搜索快捷方式:作为搜索引擎,Google 在帮助进行广泛的网络搜索方面做得很好——例如当你想要在线查找企业或产品时。但是,如果你想在特定网站内查找结果…
-
[为搜索引擎分配快捷方式 Firefox 帮助](https://support.mozilla.org/en-US/kb/assign-shortcuts-search-engines) - ChatGPT vs Perplexity AI:Perplexity 是否使用了 ChatGPT? - AI For Folks:AI 领域不断变化,可能会让人感到困惑。许多公司会叠加不同的技术供自己使用。在本文中,我们将对比…
- Perplexity 博客:浏览 Perplexity 博客,获取文章、公告、产品更新以及优化体验的技巧。保持关注并充分利用 Perplexity。
- Perplexity CEO Aravind Srinivas,AI 之周四之夜:Outset Capital 的 Ali Rohde 和 Josh Albrecht 采访了 Perplexity AI CEO Aravind Srinivas。特别感谢 Astro Mechanica (https://astromecha.co/) 举办…
▷ #sharing (15 messages🔥):
- Notion 数据库限制令用户沮丧:
@stanislas.basquin对无法在不同工作区(workspaces)之间创建关联的 Notion 数据库表示沮丧。讨论链接 - Perplexity 协助验证客户报告:
@jay.mke分享了 Perplexity 服务如何在 2 分钟内帮助验证了一份客户报告。然而,最初分享的线程无法公开访问,直到@ok.alex建议将该线程设为公开。线程链接 - Perplexity 在生物研究查询辅助方面获得赞誉:
@shaghayegh6425称赞 Perplexity 反应迅速且资源丰富,特别是在生物研究(Bio-Research)查询和头脑风暴方面。他们分享了三个资源:资源 1,资源 2 和 资源 3 - Perplexity 帮助避免锚定效应:
@archient分享说 Perplexity 帮助他们弄清楚了需要搜索的内容,从而避免了被锚定(anchored)。线程链接 - Perplexity 辅助构建模块化 Web 应用:
@whoistraian分享了来自 Perplexity 的关于构建模块化 Web 应用的资源。资源链接
提到的链接:
- 来自 Aravind Srinivas (@AravSrinivas) 的推文:这款知识类应用在 App Store 上正在崛起。生产力类排名第 25。如果你认为它比 Bing(目前排名第 17,但速度较慢且内存消耗大得多)更好,你知道该怎么做…
- 来自 Kristi Hines (@kristileilani) 的推文:@perplexity_ai 有多好用?看看它是如何帮我处理花园里的一点小惊喜的。
▷ #pplx-api (5 messages):
- 在不同平台上使用 API 遇到困难:
@blackwhitegrey表示在typingmind和harpa.ai上使用 API 存在困难,并询问其他用户是如何使用该 API 的。 - 独立使用 API:
@archient建议编写自己的代码来利用 API,并指向 Perplexity API 文档 以获取指导。 - 亲手尝试 API:
@archient还暗示打算使用提供的 token 进行直接尝试。 - 寻求 API 调用便捷语法:
@brknclock1215寻求关于如何为HARPA AI 浏览器插件调整Perplexity API调用语法的建议。该用户在尝试各种输入/设置组合无果后,参考了 Perplexity API 文档。
提到的链接:
OpenAccess AI Collective (axolotl) Discord 总结
-
因 Bug 暂停微调:
@matts9903提请注意一个目前影响 Mixtral 模型的 bug。@le_mess建议在解决此 bug 之前停止 Fine-Tuning。 -
大语言模型与数据集:讨论集中在是在独立数据集(Dolphin 或 OpenOrca)上训练 Mistral 还是在合并数据集上训练会产生相似的结果。
@caseus_回复称结果会非常相似,并建议使用 slimorca 进行训练。 -
全量微调与 LoRa/QLoRa 的比较:
@noobmaster29发起了一场对话,询问是否有人对全量 Fine-Tuning 指令集与 LoRa 或 QLoRa 进行了比较。 -
Axolotl 中的设备映射:
@nanobitz建议合并 Pull Request #918,因为它为 Axolotl 项目中处理大型模型引入了更好的 Device Mapping。 -
CI 中的 Dockerhub 登录复杂化:由于 Dockerhub 登录问题,持续集成(CI)失败。包括
@caseus_和@hamelh在内的几位团队成员努力解决此问题。提出的一个变通方案是仅在推送到main分支时才登录 Dockerhub。 -
新语言的 Token Embedding 与训练:
@.___init___关于特定语言 Tokenizer 的提问引发了对扩展 Tokenizer 以进行新语言训练可行性的关注。@nanobitz和@noobmaster29澄清说,如果没有大量的 Pretraining,这项任务可能不会有成果。 -
模型剪枝(Shearing)开始:
@caseus_确认 2.7B 模型的 Shearing 过程已经开始,并表示愿意启动 1.3B 模型的 Pruning。随着社区支持的增长,@le_mess与@emrgnt_cmplxty以及@nosa_.正在筹集资源支持该项目。@emrgnt_cmplxty分享了相关的 Shearing 资源,以促进对该项目的贡献。 -
VinaLLaMA - 越南语语言模型:VinaLLaMA(一种越南语语言模型)的引入引发了由
@.___init___发起的讨论,内容涉及 GPT-4 在 Benchmark 上与特定语言模型的假设性能对比。
OpenAccess AI Collective (axolotl) 频道总结
▷ #general (57 条消息🔥🔥):
- Bug 导致 Mixtral 微调暂停:
@matts9903分享了一个影响 Mixtral 的 Huggingface bug,并询问在问题解决之前是否值得进行 Fine-tuning。@le_mess建议等待修复。 - Mistral 在单一数据集与合并数据集上的训练对比:
@yamashi询问在 Dolphin 或 OpenOrca 数据集上训练的 Mistral 模型,其效果是否与在两者合并的数据集上训练相似。@caseus_确认了相似性,并建议使用 slimorca 进行训练。 - Jon Durbin 的 Mixtral 方法图解:
@casper_ai分享了 Jon Durbin 对 Mixtral 进行 DPO 的技术,该技术已在 Twitter 上发布。采取的步骤包括更新 TRL 以支持多设备使用,以及对 DPO 代码进行适配。 - 全量微调(Full Fine-Tuning)与 LoRa/QLoRa 的比较:
@noobmaster29询问是否有人比较过全量 Fine-tuning 指令集与 LoRa 或 QLoRa 的效果。 - Bagel 模型的 HF 评估不可靠:
@_dampf报告了 Jon Durbin 的 Bagel 模型在 HF 评估结果上的不可靠性,她已尝试将其重新添加到 HF 评估排行榜中。Dolphin 系列模型似乎一直存在无法显示的问题。
提到的链接:
- HuggingFaceH4/open_llm_leaderboard · Bagel 8x7B 评估失败
- GitHub - ml-explore/mlx: MLX: 适用于 Apple silicon 的数组框架:MLX:适用于 Apple silicon 的数组框架。通过在 GitHub 上创建账号来为 ml-explore/mlx 的开发做出贡献。
- 来自 Jon Durbin (@jon_durbin) 的推文:在 8x a6000s 上对 Mixtral 进行 DPO 非常棘手。以下是我使其运行的方法:1. 更新 TRL 以允许使用多设备:https://github.com/jondurbin/trl/commit/7d431eaad17439b3d92d1e06c6dbd74ecf68bada…
- 辅助损失(auxiliary loss)实现错误 · Issue #28255 · huggingface/transformers:系统信息 transformers 版本:4.37.0.dev0 平台:macOS-13.5-arm64-arm-64bit Python 版本:3.10.13 Huggingface_hub 版本:0.20.1 Safetensors 版本:0.4.1 Accelerate 版本:未安装…
- [进行中] RL/DPO 由 winglian 提交 · Pull Request #935 · OpenAccess-AI-Collective/axolotl
- [
Mixtral] 修复 loss + 细节优化 由 ArthurZucker 提交 · Pull Request #28115 · huggingface/transformers:此 PR 做了什么?正确计算 loss。推动均匀分布。修复了 #28021,修复了 #28093
▷ #axolotl-dev (43 条消息🔥):
- 更好设备映射的合并建议:
@nanobitz建议合并 Pull Request #918,旨在为 Axolotl 项目中的大型模型提供更好的设备映射(device mapping)。 - CI 因 Dockerhub 登录问题失败:持续集成(CI)流程因登录 Dockerhub 时出现问题而失败。
@caseus_尝试通过创建新 Token 并更新 GitHub Secrets 来修复,但问题仍然存在。@hamelh调查后得出结论,该问题与pull_request事件导致的 Workflow 权限有关。建议仅在推送到main分支时才登录 Dockerhub。 - 从 Workflow 中移除 Docker 登录:
@hamelh建议从 GitHub Actions Workflow 中移除 Dockerhub 的登录过程,因为目前尚不清楚最初为何需要它。@caseus_同意了该提议。 - Intel Gaudi 2 AI 加速器训练成本更低:
@dreamgen分享了来自 Databricks 的一篇文章,该文章指出在 Intel Gaudi 2 AI 加速器上进行训练的成本可能比 NVIDIA A100 便宜多达 5 倍。 - Token Embedding 大小警告:
@caseus_分享了一条 推文,建议在向模型添加新 Token 时不要调整 Token Embedding 的大小,因为这会导致 Embedding 大小与词表(vocabulary)大小不匹配从而引发错误。@nanobitz认为这可能是 Tokenizer 和模型配置不一致导致的,且 Phi 模型可能会受到此问题影响。
提到的链接:
- 来自 anton (@abacaj) 的推文:添加新 Token 时不要调整 Token Embedding 的大小,我这样做时模型报错了。似乎 Embedding 大小为 51200,但词表大小仅为 50294。
- 使用 Intel Gaudi 2 AI 加速器进行 LLM 训练和推理
- docker/build-push-action 的 action.yml:用于使用 Buildx 构建并推送 Docker 镜像的 GitHub Action。
- axolotl 的 tests-docker.yml:位于 OpenAccess-AI-Collective/axolotl。
- e2e-docker-tests · OpenAccess-AI-Collective/axolotl@cbdbf9e:端到端 Docker 测试。
- 由 hamelsmu 提交的 Pull Request #1052:更新 tests-docker.yml
- 由 hamelsmu 提交的 Pull Request #1055:简化 Docker 单元测试 CI:@winglian 我认为我们可能需要合并这个才能真正测试它。
- 由 kallewoof 提交的 Pull Request #918:特性:为大型模型提供更好的设备映射:当模型无法完全放入 GPU 时(在 16 位精度下,如果与 LoRA 合并),会发生崩溃,提示我们需要一个 offload 目录。如果我们隐藏 GPU 纯粹在 CPU 中运行,它可以工作,但是…
▷ #general-help (61 messages🔥🔥):
-
为新语言扩展 Tokenizer:用户
@.___init___正在寻求关于为新语言扩展 Tokenizer 并进行训练的建议。@nanobitz和@noobmaster29分享了他们的经验,指出除非进行大规模 Pretraining,否则这并无明显益处。他们引用了 GitHub 上的一个项目作为参考。 -
全量微调(Full Fine-tuning)中梯度累积步数的实现:在由
@Sebastian发起的讨论中,@caseus_确认对于大多数 Fine-tuning 任务,较小的 Batch Size 更为理想。 -
在 axolotl 中对数据集进行下采样:
@yamashi正在寻找在 axolotl 训练运行中对数据集进行下采样(Downsampling)的方法。@le_mess建议使用 Shards(分片)来实现。 -
小模型实验:
@.___init___和@noobmaster29讨论了尝试小模型的想法。@noobmaster29表达了对 Phi-2 内存问题的担忧,并且不确定 TinyLlama 的性能。 -
介绍 VinaLLaMA:
@.___init___引起了大家对 VinaLLaMA 的关注,这是一个基于 LLaMA-2 构建的越南语 SOTA 大语言模型。这引发了关于 GPT-4 在 Benchmark 上是否会比此类特定语言模型表现更好的讨论。
提到的链接:
- VinaLLaMA: 基于 LLaMA 的越南语基座模型:在这份技术报告中,我们介绍了 VinaLLaMA,这是一个权重开放的越南语 SOTA 大语言模型,基于 LLaMA-2 构建,并额外训练了 8000 亿个 Token…
-
[LeoLM: 开启德语 LLM 研究 LAION](https://laion.ai/blog/leo-lm/):我们自豪地推出 LeoLM (Linguistically Enhanced Open Language Model)… - Chinese-LLaMA-Alpaca/README_EN.md at main · ymcui/Chinese-LLaMA-Alpaca:中文 LLaMA & Alpaca 大语言模型 + 本地 CPU/GPU 训练部署 (Chinese LLaMA & Alpaca LLMs) - ymcui/Chinese-LLaMA-Alpaca
▷ #shearedmistral (14 messages🔥):
- 2.7B 模型开始 Shearing:
@caseus_确认正在对 2.7B 模型进行 Shearing。同时表示愿意为 1.3B 模型进行初始 Pruning(剪枝)。 - 1.3B 模型的算力支持:
@le_mess表示愿意为 1.3B 模型的训练提供计算资源。 - 准备参与 Shearing 贡献:
@emrgnt_cmplxty表达了对贡献 Shearing 的兴趣,@caseus_提供了一个 GitHub 链接 供其入门。 - 基于 Sheared LLaMA 模型的 Shearing 流程:
@emrgnt_cmplxty澄清 Shearing 流程将基于 Sheared LLaMA 模型所使用的框架。 - 关于 Mistral 与 LLaMA 区别的问题:
@emrgnt_cmplxty询问 Mistral 和 LLaMA 之间的唯一区别是否是 Sliding Window Attention。@caseus_确认确实如此。 - RedPajama 子集采样问题:
@caseus_提到在 指定 GitHub 链接 中使用 RedPajama 采样子集的部分代码存在问题。 - 大上下文窗口计划:针对
@emrgnt_cmplxty关于使用大上下文窗口(Large Context Window)的问题,@caseus_确认打算在 Shearing 过程结束后,在 Capybara 等数据集上进行另一次 Fine-tune 时采用此方法。 - Shearing 项目支持扩大:
@nosa_.表现出支持 Shearing 项目的兴趣。
提到的链接:
- LLM-Shearing/llmshearing/data at main · princeton-nlp/LLM-Shearing:预印本:Sheared LLaMA: 通过结构化剪枝加速语言模型预训练 - princeton-nlp/LLM-Shearing
- GitHub - princeton-nlp/LLM-Shearing: 预印本:Sheared LLaMA: 通过结构化剪枝加速语言模型预训练:预印本:Sheared LLaMA: 通过结构化剪枝加速语言模型预训练 - GitHub - princeton-nlp/LLM-Shearing…
HuggingFace Discord Discord 摘要
- Hugging-Face 大数据查询:
@QwertyJack询问是否可以在 HuggingFace 上托管 10TB 的生物机器学习(bio-ML)数据集。点击此处查看讨论。 - 寻求 LLM 基准测试指南:针对
@exponentialxp关于 LLM 基准测试的问题,@gr.freecs.org分享了一个有用的资源——GitHub 上的 lm-evaluation-harness 链接。 - 分享 AI 驱动的个人 Discord 聊天机器人和 Pokemon-Classifier:
@vashi2396和@4gastya分别在i-made-this频道分享了他们的个人 Discord 聊天机器人和 Pokemon-Classifier 项目。 - 发起潜在的 NLP 研究合作:
@sirmalamute在general频道提议在 NLP 研究项目和 Python 模块开发方面进行合作。 - 《可能性的暴政》阅读小组讨论:
reading-group频道进行了一场关于任务导向型语言模型系统(即 LLM Systems)设计的精彩讨论,该讨论由@dhruvdh发起。 - 揭晓 TinyLlama 项目和小型 AI 模型:
@dame.outlaw在cool-finds频道揭晓了一个开放团队项目 TinyLlama,同时@dexens分享了一篇关于微软小型 AI 模型的文章。 - 介绍用于 Diffusion DPO 的 LoRA 实现:
core-announcements频道发布了@sayakpaul关于为 Diffusion DPO 实现 LoRA 的公告。 - 发布新型对话生成器:在
NLP频道,@omaratef3221介绍了他们的新项目,这是一个对话生成器 (Conversation Generator),可能会改变聊天机器人和虚拟助手的开发领域。 - 征集计算机视觉数据存储建议:
computer-vision频道的用户@etharchitect发起了一项讨论,征求关于计算机视觉数据存储领域近期前沿技术的建议。
HuggingFace Discord 频道摘要
▷ #general (85 条消息🔥🔥):
- 在 HF 上托管大型数据集的问题:用户
@QwertyJack询问是否可以在 HuggingFace 上托管一个约 10TB 的公开 bio-ML 数据集。 - 对 LLM 基准测试指南的需求出现:
@exponentialxp寻求关于如何对 LLM 进行基准测试的指导。@gr.freecs.org分享了 GitHub 上 lm-evaluation-harness 的链接。 - 关于专用代码助手的讨论:
@pixxelkick与@vipitis讨论了如何通过nvim.llm插件为“copilot”风格的代码补全设计 LLM。@vipitis建议参考开源代码补全模型和工具,如 TabbyML 的 CompletionContext,并使用像deepseek-coder这样更大的模型。 - 探讨潜在的 NLP 研究合作:资深 ML 工程师
@sirmalamute表达了对合作开展 NLP 研究项目和开发开源 Python 模块的兴趣。@kopyl对其为自己的 logo 生成模型项目提供帮助表示欢迎。 - 关于在数据集过滤函数中运行预测的建议:
@kopyl与@vipitis讨论了在图像数据集的dataset.filter函数中运行模型推理的问题。@vipitis建议不要这样做,因为可能存在某些潜在问题,但@kopyl回复称,替代方案需要为多 GPU 推理进行更多设置。
提及的链接:
- Google Colaboratory
- MTEB Leaderboard - a Hugging Face Space by mteb
- Good first issues • openvinotoolkit:用于追踪可用的 Good First Issues 的地方。你可以通过评论 “.take” 来为自己分配任务。
- tabby/clients/tabby-agent/src/CompletionContext.ts at main · TabbyML/tabby:自托管 AI 代码助手。通过在 GitHub 上创建账号为 TabbyML/tabby 的开发做出贡献。
- iconbot (dev):AI 工程师:@kopyl。关于我训练用于生成图标的 AI 模型的频道。机器人访问需通过邀请,请私信。
- GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of autoregressive language models.:一个用于自回归语言模型 few-shot 评估的框架。- GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of autoregressive language models.
▷ #today-im-learning (26 条消息🔥):
- GPTs 优化讨论:
@gag123咨询了关于调整其 GPT 模型的 learning rate 和 tensor 的 dtype 的问题。在分享了他们的 GitHub 项目链接 以提供上下文后,@exponentialxp建议他们应该拥有模型参数量 20 倍大小的数据集,以获得最佳效果。 - Optimizer.zero_grad() 救场:对话揭示了
@gag123的代码中遗漏了optimizer.zero_grad()。@exponentialxp提醒了他们这一关键行,这使得模型性能有了显著提升。 - 对 Overfitting 和 Loss 值的担忧:由于
@gag123的 GPT 模型规模较大,@exponentialxp表达了对可能出现 overfitting 的担忧,并建议将其缩减至 384, 6, 6 维度。他们还讨论了在 vocab size 仅为 65 的情况下,2.62 这一异常高的 loss 值。 - 建议迭代代码增强:
@exponentialxp为@gag123推荐了几项代码改进,包括引入train和val split以避免 overfitting,调整 GPT 类的pos_emb,并确保调用的是Head而非MHA。 - 图像中的 DINOv2 自监督学习:用户
@merve3234分享了一个关于他们在 Dimensionality reduction for Image Nodes (DINO) 和 DINOv2 学习经验的 推文链接,并指出 DINOv2 是目前图像领域自监督学习的王者。
提到的链接:
- 来自 merve (@mervenoyann) 的推文:DINOv2 是图像自监督学习的王者 🦖🦕 但它是如何工作的?我尝试解释了它的工作原理,让我们进一步展开 🧶
- sample.py 的历史记录 - exponentialXP/TextGenerator:使用几个非常轻量级的脚本从头开始创建自定义语言模型 / LLM!- sample.py 的历史记录 - exponentialXP/TextGenerator
- GitHub - gagangayari/my-gpt:通过在 GitHub 上创建账户来为 gagangayari/my-gpt 的开发做出贡献。
▷ #cool-finds (6 条消息):
- 探索 TinyLlama:
@dame.outlaw分享了 TinyLlama 项目 的 GitHub 链接,这是一个在 3 万亿 token 上预训练 1.1B Llama 模型的开源尝试。 - 微软领跑小型多模态 AI 模型:
@dexens介绍了一篇 Semafor 文章,讨论了微软研究部门为其较小的语言模型 Phi 1.5 添加了新功能,使其能够查看和解释图像。 - 有趣论文提醒:
@masterchessrunner分享了在 Reddit 上发现的一篇 学术论文,并赞扬了作者的幽默感。
提到的链接:
-
[微软凭借重大突破推向小型 AI 模型的极限 Semafor](https://www.semafor.com/article/11/01/2023/microsoft-pushes-the-boundaries-of-small-ai-models):该公司研究部门的工作表明,成本较低的技术仍然可以拥有先进的功能,而无需真正增加规模。 - GitHub - jzhang38/TinyLlama: TinyLlama 项目是一个在 3 万亿 token 上预训练 1.1B Llama 模型的开源尝试。:TinyLlama 项目是一个在 3 万亿 token 上预训练 1.1B Llama 模型的开源尝试。- GitHub - jzhang38/TinyLlama: TinyLlama 项目是一个在 3 万亿 token 上预训练 1.1B Llama 模型…
▷ #i-made-this (7 messages):
- 正在制作中的 Pokemon-Classifier:用户
@4gastya分享了他微调 Pokemon Classifier 模型项目,并表示“虽然它还不是那么准确,但我已经爱上折腾模型了”。项目链接:Pokemon-Classifier。 - AI 驱动的个人 Discord Chatbot:
@vashi2396正在开发一个基于 AI 的个人 Discord Chatbot,用于读取和发布消息。可以在这里查看该项目。 - 征集 AI 模型反馈:
@gr.freecs.org邀请大家对其模型 ‘artificialthinker-demo-gpu’ 提供反馈。该模型可以通过提供的链接访问。 - 在 LinkedIn 上展示的 AI Chatbot:
@vashi2396分享了一个 LinkedIn 帖子,展示了他们的 AI Chatbot。 - 寻求帮助:用户
@vashi2396询问如何“通过麦克风获取 Automatic speech recognition 模型的输入”。 - Phi-2 模型的困难:用户
@dexens对 Phi-2 的表现表示失望,特别是在代码生成方面及其重复倾向。他们还询问是否有人除了 Python 之外,还使用 JavaScript/TypeScript 训练过该模型。该模型可以在此链接查看。 - 确认 Phi-2 表现不佳:用户
@vipitis同意@dexens的观点,并表示 Phi-2 是“目前表现最差的模型”。
提到的链接:
- ArtificialThinker Demo on GPU - a Hugging Face Space by lmdemo
- Pokemon Classifier - a Hugging Face Space by AgastyaPatel
- Google Colaboratory
- microsoft/phi-2 · Hugging Face
▷ #reading-group (29 messages🔥):
- 深入探讨《可能性的暴政》:用户
@dhruvdh创建了一个讨论任务导向型语言模型系统(即 LLM Systems)设计的线程,这得到了@chad_in_the_house的认可,并提醒全组关注。 - 关于群组通知的激烈辩论:用户
@chad_in_the_house和@svas.之间就群组通知问题发生了争执。@cakiki介入并提醒大家在讨论中保持尊重。 - 阅读小组会议形式:用户
@thamerla和@4gastya对阅读小组会议的可访问性和可见性表示担忧。@chad_in_the_house澄清说,目前的演示是通过 Discord 的文本线程进行的,但也愿意接受使用语音频道等建议。 - 探索联合嵌入预测架构 (Joint-Embedding Predictive Architecture):
@shashank.f1提出了一篇关于 MC-JEPA 方法的论文,讨论运动和内容特征的自监督学习。分享了一个提供深入讨论的 YouTube 视频。 - 觉醒 AI 意识:
@minhsmind正在为演示准备阅读一篇关于 AI Consciousness(AI 意识)的论文,这引发了与@beyond_existence和@syntharion的辩论,他们分享了关于 AI 是否能获得意识的见解和怀疑。
提到的链接:
MC-JEPA neural model: Unlock the power of motion recognition & generative ai on videos and images:🌟 释放 AI 从视频中学习的力量!🎬 观看 Oliver、Nevil、Ojasvita、Shashank 和 Srikanth 对 MC-JEPA 方法的深入讨论……
▷ #core-announcements (1 messages):
- Diffusion DPO 的 LoRA 实现现已发布:用户
@sayakpaul宣布了 Diffusion DPO 的 LoRA 实现。该支持涵盖了 SD 和 SDXL。可以在他们的 GitHub 链接中查看具体实现。 - SDXL-Turbo 支持即将推出:
@sayakpaul暗示在未来的更新中将加入对 SDXL-Turbo 的支持。
提到的链接:
diffusers/examples/research_projects/diffusion_dpo at main · huggingface/diffusers:🤗 Diffusers:PyTorch 中用于图像和音频生成的先进扩散模型 - huggingface/diffusers
▷ #computer-vision (3 messages):
- 后处理模型错误标签:
@merve3234建议可以在数据集上运行模型并标记错误的标签,作为纠正数据集中错误标签的一种方法。 - 深入探讨 DINO 和 DINOv2:
@merve3234分享了一个全面的推文串和信息图,解释了用于图像自监督学习的 DINO 和 DINOv2 的工作原理。完整的推文串可以在这里找到。 - 关于计算机视觉数据存储技术的咨询:
@etharchitect提出了一个问题,寻求有关近期计算机视觉数据存储技术的信息,并邀请社区参与讨论。
提到的链接:
来自 merve (@mervenoyann) 的推文:DINOv2 是图像自监督学习的王者 🦖🦕 但它是如何工作的?我尝试解释了它的原理,让我们进一步展开探讨 🧶
▷ #NLP (3 messages):
- 激动人心的公告:对话生成器遇上对话摘要:
@omaratef3221分享了他们的新项目 Conversation Generator。该工具旨在“利用 LLM 从简短摘要中生成逼真的对话”。他们微调了诸如 Google T5 之类的模型,并创建了一个对话生成版本。训练是在 Google Colab 平台上使用 🤗 Transformers 和 Kaggle 的开源对话数据集完成的。 - Omaratef3221 对开源社区的贡献:这个对话生成器是
@omaratef3221送给开源社区的礼物。他们表示该项目是开源的,欢迎任何贡献或反馈。他们还表示:“开源协作是共同学习和成长的绝佳方式。” - 深入了解生成器:该模型 Omaratef3221’s flan-t5-base-dialogue-generator 是 Google
t5的微调版本,旨在生成“逼真且引人入胜的对话”。 - 强调潜在用途:
@omaratef3221指出,他们的模型“非常适合开发 Chatbot、虚拟助手以及其他生成类人对话至关重要的应用”。 - 热烈反响与未来可能性:
@stroggoz对该公告做出了积极回应,并提到这项技术可能如何帮助他们“理解更高级的数学”。
提到的链接:
Omaratef3221/flan-t5-base-dialogue-generator · Hugging Face
LAION Discord 摘要
- “关键在于拟合”: 用户
pseudoterminalx和thejonasbrothers深入探讨了模型训练中的 overfitting(过拟合)与 underfitting(欠拟合)。讨论内容包括在实现满意的模型性能时所需的平衡和权衡。 - “噪声增加原创性”: 用户
pseudoterminalx主张在 image generation(图像生成) 输出中加入噪声,认为这有助于提升感知的真实性。并指出过度干净的图像可能存在恐怖谷问题。 - “Synthetic Data (SD) 2.1x 模型表现强劲”: 对 Synthetic Data (SD) 2.1x 模型 的深入探讨,讨论了诸如 cropping(裁剪)和 resolution buckets(分辨率分桶)等训练技术。再次强调了 SD 2.1 模型在经过适当训练后输出高分辨率图像的能力。
- “CommonCrawl 与 NSFW 过滤”:
thejonasbrothers提议利用来自 CommonCrawl 的无标注图像。推测了合成标注(synthetic captioning)的潜力、使用 NSFW 模型筛选不当内容的必要性,以及对海量知识存储的愿景。 - “AI 生成图像中的完美细节”:
pseudoterminalx展示了高分辨率模型输出,呈现了复杂的细节,给频道观众留下了深刻印象。 - “Masked tokens 和 U-Net 是核心秘诀”:
kenjiqq澄清说,对于 Transformer 模型 而言,起关键作用的不是 diffusion(扩散)而是 masked tokens。该用户引用了原始的 U-Vit 论文,说明了 Transformer 模块对于提高加速器吞吐量(accelerator throughput)的好处。 - “LLaVA-$\phi$:小而高效”:
thejonasbrothers介绍了 LLaVA-$\phi$,这是一个高效的多模态助手模型,即使在 27 亿参数的小规模下也能高效运行,在多模态对话任务中表现出色。 - “RLHF-V:高期望,低表现”:
kopyl和thejonasbrothers对 RLHF-V 模型表示失望,该模型原本被预期具有较低的幻觉率(hallucination rate)。当 Prompt(提示词)更改为要求详细的图像描述时,模型性能有所提升。 - “解码语言模型中的因果关系”:
JH阐述了 Language and Image Models (LLMs) 如何因其面向解码器(decoder-oriented)的设计和因果注意力掩码(causal attention mask)而学习因果关系,而 diffusion 模型则是通过关联(association)进行学习。 - “破译扩散模型中的 3D 空间”:
phryq提出了一个关于 diffusion 模型对 3D 空间理解的有趣问题,特别是这些模型是否能理解不同的面部透视。
提到的链接:
- TikTok - Make Your Day
- Philipp Schmid’s tweet
- The Reel Robot’s tweet
- LLaVA-$ϕ$ paper
- Improving Diffusion-Based Image Synthesis with Context Prediction
- visheratin/LLaVA-3b · Hugging Face
- CCSR GitHub repository
- openbmb/RLHF-V · Hugging Face
LAION 频道摘要
▷ #general (103 条消息🔥🔥):
- “过度优化,还是优化不足?”:用户
pseudoterminalx和thejonasbrothers之间进行了一场有益的辩论,焦点围绕模型训练中的 overfitting(过拟合)和 underfitting(欠拟合)。他们讨论了其中的挑战和明显的权衡,指出为了让模型表现良好,一定程度的拟合是必要的。 - “AI 放大领域的最新趋势:图像中的噪声!?”:
pseudoterminalx为图像生成输出中包含噪声进行了辩护,声称这增加了真实感。他们提到,“每一张图像都清晰无比,反而讽刺地让它们看起来像是 AI 生成的(AI gens)”,并提到了“完美带来的恐怖谷效应(uncanny valley)”问题。 - “释放 SD 2.1x 模型的真正潜力”:
pseudoterminalx和thejonasbrothers深入探讨了 SD 2.1x 模型的训练技术,涉及裁剪方法(cropping)、分辨率桶(resolution buckets)和感知哈希(perceptual hashes)。他们还回顾了模型的输出分辨率,并重申如果训练得当,SD 2.1 模型能够输出远超 1mp 的高分辨率(high-res)图像。 - “来自 CommonCrawl 的未来图景”:
thejonasbrothers思考了从 CommonCrawl 抓取无标注图像,然后进行人工合成标注(synthetically captioning)并训练模型的想法,以使模型能够存储海量知识。有人指出,必须使用 NSFW 模型来过滤掉 CommonCrawl 中的不当内容。 - “情人眼里出 AI”:
pseudoterminalx展示了模型的高分辨率输出样本。这些图像突出了头发、皮肤纹理和树皮等精细细节,令频道中的用户印象深刻。
提到的链接:
- TikTok - Make Your Day
- Philipp Schmid (@_philschmid) 的推文:我们收到了来自 @Microsoft 的迟到的圣诞礼物!🎁🤗 Microsoft 刚刚将其小型 LLM phi-2 的许可证更改为 MIT!🚀 Phi-2 是一个拥有 27 亿参数的 LLM,在 1.4T tokens 上进行了训练,包括合成数据…
- The Reel Robot (@TheReelRobot) 的推文:这是我迄今为止制作的最具野心的 AI 电影。我们距离商业上可行的 AI 电影出现不到一年时间。@runwayml(control)和 @elevenlabsio(speech-to-speech)的更新让我相信…
▷ #research (24 条消息🔥):
- Transformer 模型中的 Masked tokens 和 U-Net:在关于 Transformer 模型的讨论中,
@kenjiqq阐述了在这种情况下,起重要作用的是 masked tokens 而非 Diffusion。他们补充道,根据原始的 U-Vit 论文,Transformer 模块的主要优势是更好的加速器吞吐量。 - LLaVA-$\phi$ 介绍:
@thejonasbrothers分享了一篇介绍 LLaVA-$\phi$ (LLaVA-Phi) 的论文,这是一个高效的多模态助手,它利用小型语言模型 Phi-2 的能力来进行多模态对话。尽管其参数量较少(仅 2.7B),但该模型在整合视觉和文本元素的任务上表现出色。 - 关于 LLaVA-3b 和 LLaVA-Phi 模型的混淆:
@nodja链接了 LLaVA-3b 的 Hugging Face 模型卡片,这是一个基于 Dolphin 2.6 Phi 的微调模型,但指出其列出的作者与 LLaVA-Phi 的作者不匹配。此外还注意到这两个模型在架构上存在差异。 - Diffusion 模型的上下文预测:
@vrus0188分享了 CCSR GitHub 仓库的链接,该项目名为 “Improving the Stability of Diffusion Models for Content Consistent Super-Resolution”(提高 Diffusion 模型在内容一致超分辨率中的稳定性)。 - 对 RLHF-V 性能的失望:在关于 RLHF-V 模型(以低幻觉率著称)的讨论中,
@kopyl和@thejonasbrothers对其实际表现表示失望。@bob80333也报告了在使用吉卜力电影画面时结果欠佳。然而,当提示词更改为请求详细的图像描述时,模型的表现有所提高。
提到的链接:
- openbmb/RLHF-V · Hugging Face
- Improving Diffusion-Based Image Synthesis with Context Prediction:Diffusion 模型是一类新型生成模型,以前所未有的质量和多样性显著推动了图像生成。现有的 Diffusion 模型主要尝试重建 inp…
- LLaVA-$ϕ$: Efficient Multi-Modal Assistant with Small Language Model:在本文中,我们介绍了 LLaVA-$ϕ$ (LLaVA-Phi),这是一个高效的多模态助手,它利用最近先进的小型语言模型 Phi-2 来促进多模态对话…
- Instruct-Imagen: Image Generation with Multi-modal Instruction:本文介绍了 instruct-imagen,这是一个能够处理异构图像生成任务并能泛化到未见任务的模型。我们为图像生成引入了多模态指令,这是一项任务…
- visheratin/LLaVA-3b · Hugging Face
- GitHub - csslc/CCSR:通过在 GitHub 上创建账号来为 csslc/CCSR 的开发做出贡献。
▷ #learning-ml (3 条消息):
- 关于 LLM 和 Diffusion 模型中因果关系的辩论:
@JH详细解释了语言模型 (LLMs) 如何因其基于 decoder 的架构和因果注意力掩码 (causal attention mask) 而学习因果关系。相比之下,Diffusion 模型被认为是通过关联而非因果关系进行学习的。这并不一定妨碍它们学习因果关系,尽管它们的架构和训练可能不会直接引导它们完成此类任务。训练 Diffusion 模型学习因果关系的一种可能方法是创建将标题从显式描述解构为因果描述的数据集。 - 对 Diffusion 模型理解 3D 空间的好奇:
@phryq询问 Diffusion 模型是否理解侧脸只是位置不同的脸,这表现出对模型理解 3D 空间的兴趣。
LangChain AI Discord 总结
- LangChain 0.1 即将面世:
@hwchase17透露了发布 LangChain 0.1 的计划,并打算积极推广。他们邀请大家提供早期反馈。 - 捕捉信号:数据库编码问题浮出水面,
@felipeescobar.强调需要将 UTF-8 Encoding 传递给 SQL agent。 - 聊天机器人开启购物模式:用户
@vilelaone探讨了聊天机器人在不同模式间平滑切换的功能,在“添加到购物车”、“收集运输数据”和“定义支付”等示例场景中使用了RouterChain和a conversational chain。随后进行了富有成效的对话,最后由@evolutionstepper发布了代码片段并分享了 GitHub 仓库链接。 - LangChain 大放异彩:在宣传方面,
@rorcde提醒社区关注 LangChain 被 The AI Engineer 评选为“今日 AI 库”的消息,并呼吁通过 LinkedIn 和 Twitter 传播。 - 一图胜千言:
@nav1106表达了对知识共享的渴望,寻求关于图像嵌入(image embedding)预训练模型的建议。 - 错误信息:
@Tom P报告在 CSV Agent 中遇到ModuleNotFoundError,尽管已确认其存在于 /packages 目录中。 - 新变量,新挑战:
@cryptossssun询问在更改PromptTemplate中的input_variables后,如何在 LangServe 服务中利用新变量进行提示。随后与@veryboldbagel等人的讨论可以追溯到 LangServe 示例、OpenAPI 文档和RemoteRunnable客户端。 - 可调用的 AgentExecutor 揭晓:
@veryboldbagel阐明了AgentExecutor是通过add_routes注册的,因为它继承自Chain。 - 引入自定义逻辑:一位成员详细介绍了在 LangChain 中实现自定义逻辑的方法,提到了带有 runnable lambdas 的 LCEL 或通过继承
Runnable来实现。 - 读取输入 Schema:
@veryboldbagel建议检查 runnable 上的输入 schema,作为解决无法识别输入问题的潜在方案,甚至描述了with_types方法。 - 会话历史遇到问题:
@nwoke.表示在 LangServe 中集成RedisChatMessageHistory时遇到了session_id问题,@veryboldbagel建议在 GitHub 上提交 issue。 - 依赖冲突影响 LangChain 更新:
@attila_ibs提出了更新 LangChain 后面临的依赖冲突,指出不同包对openai和langchain的版本要求不一致。 - LangChain 的生命周期:鉴于版本更新速度和潜在的弃用风险,
@dejoma引发了关于编写一本关于 LangChain 的书是否可行的讨论。 - ArtFul - 激发你的创造力:
@vansh12344宣布推出 ArtFul,这是一款免费且包含广告的应用,允许用户使用各种 AI 模型创作艺术作品,现已在 Google Play Store 上线。 - Neutrino 首次亮相:
@ricky_gzz推出了 Neutrino,这是一个创新的 AI 模型路由系统,旨在优化不同闭源和开源模型之间的响应质量、成本和延迟。有关 Neutrino 的详细信息可以在其官方网页上找到。 - 教程让用户意犹未尽:
@offer.l对一个教程赞不绝口,促使@a404.eth承诺很快会开发另一个教程。同时,@bads77寻求关于使用 langchain JS 库重试缺失响应的指导,@lhc1921建议使用while loop监控重试。
LangChain AI 频道总结
▷ #announcements (1 条消息):
- LangChain 0.1 发布:用户
@hwchase17宣布了 LangChain 0.1 的发布,并计划在下周重点推介。他们欢迎早期反馈。
▷ #general (33 messages🔥):
- SQL Agent 中的 UTF-8 编码:
@felipeescobar.想知道是否可以将编码传递给他们的 SQL Agent,并在@evolutionstepper询问细节时确认他们指的是 UTF-8 Encoding。 - Chatbots 中的无缝切换:
@vilelaone寻求关于实现 Chatbot 在不同模式(如“加入购物车”、“收集收货数据”和“确认支付”)之间无缝切换功能的建议。讨论围绕RouterChain以及一个涉及a conversational chain的可能解决方案展开。@evolutionstepper提供了一些源码示例和 GitHub 上的完整代码 以供进一步指导。 - LangChain AI 库亮点:
@rorcde宣布 LangChain 被 The AI Engineer 评选为“今日 AI 库”,并建议社区通过在 LinkedIn 和 Twitter 上分享相关帖子来帮助扩大影响力。 - 用于 Image Embedding 的预训练模型:
@nav1106正在寻找关于 Image Embedding 预训练模型的建议,因为他们是该领域的新手。 - CSV-Agent 模块错误:
@Tom P在尝试安装和运行 CSV-agent 模板时遇到了错误(ModuleNotFoundError: No module named 'csv_agent')。尽管已确认 csv-agent 文件夹位于 /packages 目录下,但错误仍然存在。讨论涉及为 Conversational Agent 提供解决问题所需的工具。
提到的链接:
casa-bot/services/api/main.py at dev · ai-ponx/casa-bot:Agent 化的房地产短信助手。欢迎通过在 GitHub 上创建账户为 ai-ponx/casa-bot 的开发做出贡献。
▷ #langserve (17 messages🔥):
- 在 LangServe 服务中查询新变量:
@cryptossssun询问在更改PromptTemplate中的input_variables后,如何在 LangServe 服务中进行 Prompt 时使用新变量。@veryboldbagel建议查看 文档 中提供的 LangServe 示例,该示例支持在查询中添加额外参数。随后建议用户@cryptossssun使用 OpenAPI 文档获取 Schema 信息,并使用RemoteRunnable客户端发起请求。 - 可调用的 AgentExecutor:
@veryboldbagel解释了AgentExecutor如何通过add_routes进行注册,因为它继承自Chain,而Chain又继承自Runnable。这种约定允许在运行 LangChain 实例时直接调用AgentExecutors。 - 执行自定义逻辑:一位成员解释了如何实现 LangChain 中的自定义逻辑,可以通过 LCEL 与 runnable lambdas 结合,或者通过继承
Runnable来实现所需逻辑。 - Input Schema 检查:
@veryboldbagel建议每当遇到输入无法识别的问题时,检查 Runnable 上的 Input Schema。讨论了更多细节,如使用with_types方法手动指定输入类型,并链接到 LangChain 文档 作为参考。 - Session History 问题:
@nwoke.表达了在 LangServe 中测试RedisChatMessageHistory集成时遇到session_id问题的担忧。@veryboldbagel提示通过 GitHub 上的 Issue 提供更多信息。
提到的链接:
-
[Interface 🦜️🔗 Langchain](https://python.langchain.com/docs/expression_language/interface#input-schema.):为了尽可能简单地创建自定义链,我们…… -
[🦜️🏓 LangServe 🦜️🔗 Langchain](https://python.langchain.com/docs/langserve#server.):发行说明 -
[🦜️🏓 LangServe 🦜️🔗 Langchain](https://python.langchain.com/docs/langserve#client.):发行说明 - Issues · langchain-ai/langserve:LangServe 🦜️🏓。欢迎通过在 GitHub 上创建账户为 langchain-ai/langserve 的开发做出贡献。
▷ #langchain-templates (1 messages):
- LangChain 更新中的模板依赖冲突:用户
@attila_ibs报告在更新 LangChain 后遇到依赖冲突。用户列举了包括neo4j-parent、pirate-speak、research-assistant和stepback-qa-prompting在内的多个包,这些包要求的openai和langchain版本与当前安装的版本不同。用户寻求关于如何修复该问题并有效更新基于 LangChain 模板的应用的帮助。
▷ #share-your-work (3 条消息):
- 对 Langchain 生命周期的质疑:
@dejoma提出了一个发人深省的问题,即编写一本关于 Langchain 的书是否有价值,因为该工具版本更新频繁,可能在两个月内就会过时。 - 新年,新 AI 艺术应用:
@vansh12344宣布推出 ArtFul,这是一款免费且靠广告支持的应用,让任何人都能使用各种 AI 模型生成自己的艺术作品。公告声称无需注册或登录,在观看简短广告后完全免费。该应用可以在 Google Play Store 找到。 - Neutrino Router 介绍:
@ricky_gzz介绍了一个新项目 —— Neutrino —— 一个 AI 模型路由系统,旨在优化不同闭源和开源模型的响应质量、成本和延迟。Neutrino 的运行策略是自动采样和评估响应,以随时间提高路由性能。Neutrino 可以在此网站找到。
提到的链接:
▷ #tutorials (5 条消息):
- 对教程的正面反馈:
@offer.l对教程表达了热情,表示他们“真的很‘喜欢’它!🙂”。@a404.eth回应表示感谢,并承诺在周末再制作一个教程。 - 关于重试缺失响应的技术查询:在一次技术讨论中,
@bads77询问了关于使用 langchain JS 库的问题。Bads77 的查询集中在如何对请求中缺失/部分的响应执行重试,特别是当 Prompt 中预期的某个字段缺失时。@lhc1921建议使用while loop作为潜在的解决方案。
Mistral Discord 总结
- Mixtral 团队将开始 Office Hours:
@sophiamyang宣布开始基于文本的 Office Hours,并确认平台上的 Fine-tuning 正在进行中。根据#[office-hour]频道的帖子,第一次 Office Hour 定于 1 月 10 日美国东部时间上午 11:00(欧洲中部时间下午 5:00)。 - 对在 Mistral 中使用 ‘if-else’ 的疑问:在
#[general]频道的讨论中,@xifaj78420想知道在 Mistral Prompt 中成功使用 ‘if else’ 条件的情况。@sophiamyang鼓励进行测试。 - La Plateforme 的高延迟:
@silk.ai和@_definitely_not_sam_提出了 La Plateforme 延迟较高的问题,这影响了他们的生产级使用。支持团队的@lerela已确认该问题。 - 使用 LLaMA2-Accessory 微调的 Mixtral 8x7B 模型:
@cpxjj宣布已成功使用 LLaMA2-Accessory 微调了 Mixtral 8x7B 模型。生成的 SPHINX-MoE 模型可在其 GitHub 仓库中获取。 - 关于 Mistral AI Client 缺乏频率和存在惩罚的担忧:根据
#[la-plateforme]频道的对话,@spaceemotion报告说在将 Mistral AI Client 添加到他们的项目时遇到困难,因为它无法调整频率和存在惩罚(frequency and presence penalties)。 - 在 Azure 服务器上部署 8* 7b 模型的建议:在
#[deployment]频道的讨论中,@casper_ai建议在 Azure 上部署 8* 7b 模型以获得最佳性能,至少需要 2x A100 或 H100 服务器配置。 - Mistral 文档中的 Guardrailing 链接失效:在
#[ref-implem]频道中,@productiondown注意到 Mistral 文档中的一个失效链接:https://docs.mistral.ai/usage/guardrailing。 - 给 Ubuntu LTS 用户的战略建议:在
#[random]频道的一个概念中,@cognitivetech建议在新的 Ubuntu LTS 发布时安装前一个版本,以避免 Bug 并获得全面的软件支持。
Mistral 频道总结
▷ #general (25 条消息🔥):
- Mistral 团队的 Office Hours: 来自 Mistral 团队的
@sophiamyang提议下周在 Discord 上试运行基于文本的 Office Hours,以解决用户关注的问题。他们愿意根据反馈探索直播视频形式。 - 微调 Mistral 模型: 针对
@sublimatorniq和_dampf的提问,@sophiamyang确认平台上的微调功能正在开发中。_dampf强调了 Mixtral 模型在微调性能方面的问题,这与@284810978552578050提到的 Dolphin 模型效果不佳的情况相吻合。 - 在 Mistral 中探索 ‘if-else’ 的使用:
@xifaj78420询问是否有人成功在 Mistral 的 prompt 中使用 ‘if else’ 条件,@sophiamyang回应并建议对此进行测试。 - 模型评估讨论: 围绕依赖逻辑测试来评估 AI 模型的准确性展开了讨论。
.skyair认为实际应用是更有效的测试方法,而@i_am_dom则声称这可能是一个低效的过程。 - AI 模型的“适配”:
@meyelo幽默地描述了一次经历:尽管积极恳求,但他们的请求还是被 AI 模型礼貌地拒绝了。
补充笔记: 对话主要围绕微调和测试 AI 模型相关的问题及潜在解决方案展开,一些用户针对当前问题提出了可能的变通方法。此外,还讨论了测试方法的实用性和准确性。几位用户还表达了对测试特定功能(如 ‘if-else’ 条件)的兴趣。
提到的链接:
- 加入 Mistral AI Discord 服务器!: 查看 Discord 上的 Mistral AI 社区 - 与其他 8444 名成员交流,享受免费的语音和文字聊天。
- cognitivecomputations/dolphin-2.5-mixtral-8x7b · Hugging Face
▷ #models (1 条消息):
10anant10: 嘿,有人想一起做点东西吗?
▷ #deployment (2 条消息):
- 8* 7b 模型部署的 Azure 服务器建议: 用户
@sankar.san询问了在 Azure 云上部署 8* 7b 模型以获得最佳性能的合适服务器。@casper_ai建议至少使用 2x A100 或 H100 的服务器配置。
▷ #ref-implem (1 条消息):
productiondown: 嘿伙计们,https://docs.mistral.ai/usage/guardrailing 这个链接失效了。
▷ #finetuning (3 条消息):
- 使用 LLaMA2-Accessory 微调的 Mixtral 8x7B 模型: 用户
@cpxjj宣布使用 LLaMA2-Accessory 成功微调了 Mixtral 8x7B 模型,并产生了一个名为 SPHINX-MoE 的新模型。该项目可在其 GitHub 仓库中访问。 - 文档匹配项目提案: 用户
@.tostino就一个项目想法寻求反馈,该想法涉及匹配两种不同的文档:一份是针对客户订购的某些产品要求退款的索赔文件,另一份是包含符合条件的产品/公司/其他属性列表的合同。计划是使用长上下文的 instruct embedding 模型,并在该数据集的指令/正样本/负样本三元组上进行进一步训练。 - 微调与自托管建议请求: 用户
@subham5089询问了微调 Mistral 或 Mixtral 模型并将其自托管在 AWS 或 Azure 上的最佳方法。他们欢迎关于微调以及在上述平台托管所需服务的建议。
提到的链接:
- LLaMA2-Accessory/SPHINX at main · Alpha-VLLM/LLaMA2-Accessory: 一个开源的 LLM 开发工具包。通过在 GitHub 上创建账号来为 Alpha-VLLM/LLaMA2-Accessory 的开发做出贡献。
- intfloat/e5-mistral-7b-instruct · Hugging Face
▷ #showcase (1 条消息):
pradeep1148: https://www.youtube.com/watch?v=aXeU6mVRgiA
▷ #random (3 messages):
- 考虑使用之前的 Ubuntu LTS 版本:用户
@cognitivetech提出了一种避免 Bug 和软件支持问题的策略:在新版本发布时安装之前的 Ubuntu LTS,从而为重大修复留出时间,并等待新版本的支持趋于稳定。 - 人类意识进化:
@cognitivetech分享了一个关于历史上意识多变本质的哲学思考,认为过去的人们可能没有像我们今天这样体验过意识。
▷ #la-plateforme (21 messages🔥):
- La Plateforme 存在高延迟问题:
@silk.ai报告称,该平台上平均 120-token 的请求 需要 9 到 20 秒 来处理,这对于生产级使用来说太高了。该问题也得到了@_definitely_not_sam_的证实。来自支持团队的@lerela已展开调查,以确定导致如此高延迟的原因。(讨论链接) - 法国保险公司中的 Mixtral 8x7B:一家法国保险公司的
@eight_me表示有兴趣使用 La Plateforme 和 Mixtral 8x7B model 来构建 AI Assistant。他们询问了在平台及其端点添加 function calling 的可能性。 - 请求 OpenAI 兼容性:
@louis030195请求 Mistral 团队使其 API 与 OpenAI 兼容,并提到了关于 chat stream 中缺失created字段的问题。(Issue 链接) - La Plateforme 服务的托管:
@johann1613询问了 La Plateforme 服务 的托管位置。@eight_me根据隐私政策确认,这些服务是通过 Azure 托管在瑞典。 - Mistral AI Client 的问题和建议:由于缺乏 frequency and presence penalties 选项,
@spaceemotion在将 Mistral AI Client 添加到其项目时遇到问题。他们还报告了在基本 fetch 过程中出现的 CORS 请求问题。@toonb建议在创建 API keys 时添加标识字符串,以便更好地跟踪应用程序的使用情况。
提到的链接:
- Changing base url - Usage with open source LLM - Invalid status code: 404 Not Found · Issue #173 · 64bit/async-openai:嘿,我正尝试在测试中通过 perplexity.ai 将 async-openai 与 axum 和开源 LLM 结合使用。基本上,我的端点会将请求路由到 OpenAI API 或类似 OpenAI API 的 API,并更改 t…
- Average Time: 5.900000 seconds:最小时间:3.0 秒,最大时间:18.0 秒,第 95 百分位时间:9.0 秒。正在进行 10 次 API 调用… 调用 1:耗时:6.0 秒。响应:{“id”:”cmpl-9a5b9869eed84bcead1c6a04df994…
▷ #office-hour (1 messages):
- 首次 Office Hour 公告:
@sophiamyang宣布首次 Office Hour 定于 1 月 10 日上午 11:00 EST(欧洲中部时间下午 5:00)举行。Office Hour 将持续一小时。
Datasette/LLM (@SimonW) Discord 摘要
- 高质量 AI 对话:@simonw 讨论了对更多高质量 AI 对话的需求,并分享了一篇 博客文章,他在文中建议尽管 “AI” 一词并不完美,但仍应接受它。
- 字面语言的挑战:@antisimplistic 幽默地指出,如果每个术语都按字面意思使用,英语使用者会遇到很多困难。
- 课堂中的 AI:@derekpwillis 计划使用通用术语 “AI” 来教学生关于 AI 的课程,并将对该技术的具体组成部分进行解释。
- PATH 解析:@thale7166 通过在启动时实现使用全路径(full path)并加载
bashrc来获取PATH,从而解决了一个问题。 - OpenAI 的新功能:@antisimplistic 发布消息称 OpenAI 已开始进行 per-key tracking。
Datasette/LLM (@SimonW) 频道摘要
▷ #ai (3 messages):
- 需要关于 AI 的高质量对话:
@simonw分享了一篇关于进行 AI 高质量对话必要性的博客文章。在他的文章中,他主张接受 “AI” 这个术语,尽管它并不完美。 - 课堂中的 “AI” 使用:
@derekpwillis透露了他计划教授一门关于 AI 的课程,并使用 “AI” 这个通用术语,同时也会解释该技术的具体组成部分。 - 语言字面主义的讽刺:
@antisimplistic幽默地指出,如果每个术语都按其字面意思使用,英语使用者将面临重重挑战。
提到的链接:
It’s OK to call it Artificial Intelligence:称其为人工智能(Artificial Intelligence)没关系:我们需要关于 AI 的高质量对话:它能做什么和不能做什么,它的许多风险和陷阱,以及如何将其融入社会……
▷ #llm (2 messages):
- 路径和 bashrc 加载解决了问题:用户
@thale7166确认,使用全路径并在开始时为PATH加载bashrc已经解决了他们的问题。 - OpenAI 推出针对每个 Key 的跟踪功能:用户
@antisimplistic宣布 OpenAI 已启用针对每个 Key 的跟踪功能。
Alignment Lab AI Discord 摘要
- NPM 因 ‘everything’ 软件包陷入混乱:
@venadore分享了一篇引人入胜的博客文章,关于一个名为 ‘everything’ 的破坏性 NPM 软件包。该包由用户 PatrickJS(也称为 gdi2290)创建,它依赖于所有其他公开的 NPM 软件包。由于海量的传递依赖,任何尝试安装它的人都会遭受拒绝服务(DoS)攻击。混乱的程度可以在 http://everything.npm.lol 查看。对这场混乱的反应很小,只有@venadore评论说这种情况“不可思议”。
Alignment Lab AI 频道摘要
▷ #general-chat (2 messages):
- ‘everything’ 软件包导致的 NPM 混乱:用户
@venadore分享了一篇关于名为 ‘everything’ 的破坏性 NPM 软件包的有趣博客文章,该包由用户 PatrickJS 或 gdi2290 创建。该包依赖于所有其他公开的 NPM 软件包,由于海量的传递依赖,导致任何安装它的人都会遭遇拒绝服务(DOS)。PatrickJS 进一步通过 http://everything.npm.lol 展示了引发的混乱。 - 对 NPM ‘everything’ 混乱的反应:作为回应,
@venadore用一个简单的词进行了评论,称其为“不可思议”。
提到的链接:
When "Everything" Becomes Too Much: The npm Package Chaos of 2024 - Socket:一位名为 PatrickJS 的 NPM 用户发起了一场恶搞活动,发布了一个名为 “everything” 的软件包,它依赖于所有公开的 npm 软件包。
▷ #oo (1 messages):
teknium: 大家好 <a:waveyboy:507416520788279297>
Skunkworks AI Discord 摘要
只有一个频道有活动,因此无需进行摘要…
- 探索 Mixture of Experts:用户
@pradeep1148分享了一个名为 “Mixture of Experts Implementation from scratch” 的 YouTube 视频,该视频详细介绍了 Mixture of Experts 机器学习技术的实现。 - 尝试具备视觉语言能力的移动设备:
@pradeep1148分享了另一个名为 “Trying MobileVLM: A Fast, Strong and Open Vision Language Assistant for Mobile Devices” 的 YouTube 视频,展示了一个专为移动设备运行而设计的开源多模态视觉语言模型。
提到的链接:
- Mixture of Experts Implementation from scratch:我们将实现 Mixture of Experts。Mixture of Experts (MoE) 是一种机器学习技术,其中使用多个专家网络(学习者)来处理…
- Trying MobileVLM: A Fast, Strong and Open Vision Language Assistant for Mobile Devices:我们介绍了 MobileVLM,这是一个针对移动设备运行的高性能多模态视觉语言模型 (MMVLM)。它是多种架构的融合…
YAIG (a16z Infra) Discord 没有新消息。如果该服务器长期处于静默状态,请告知我们,我们将将其移除。