ainews-192024-nous-research-lands-5m-for-open
2024年1月9日:Nous Research 获得 500 万美元融资,用于开源人工智能。
Nous Research 宣布完成 520 万美元种子轮融资,重点投入 Nous-Forge 项目,旨在将 Transformer 架构嵌入芯片,以打造支持实时语音助手和万亿参数模型的强力服务器。Rabbit R1 在 CES 上展示了演示 Demo,评价褒贬不一。OpenAI 正式上线了 GPT 商店,并短暂泄露了即将推出的个性化功能。一篇关于 Activation Beacon 的新论文提出了一种显著扩展大语言模型(LLM)上下文窗口的方案,相关代码将发布在 GitHub 上。此外,讨论还涵盖了 QLORA、微调、合成数据以及大语言模型的定制架构。
本摘要涵盖了 18 个服务器、277 个频道和 1566 条消息。预计节省阅读时间(按 200wpm 计算):193 分钟。
Nous 宣布了其种子轮融资,业务重点是 Nous Forge:

Rabbit R1 也在 CES 上发布了他们的演示,评价褒贬不一。
其他新闻方面,OpenAI 今天上线了 GPT store,并简要泄露了即将推出的个性化功能。
–
目录
[TOC]
Nous Research AI Discord 摘要
- 通过 Activation Beacon 突破 LLM 的上下文窗口限制:
@kenakafrosty分享了一篇关于 Activation Beacon 的 arXiv 论文,这是一种可能解决 Large Language Models (LLMs) 上下文窗口问题的新方案。@_stilic_确认代码将在 GitHub 上提供。 - 科技硬件与 AI 使用的氛围:在 off-topic 频道中,话题围绕配备 M2 芯片的 Apple Vision Pro、Rabbit 产品、WEHEAD AI 伴侣、Humane 的裁员,以及关于 Language Learning Models (LLMs) 及其用途的幽默讨论。
- 精选科技与 AI 链接:分享的有趣链接包括 Light Activation Beacon Training 和用于 LLM 的 MaybeLongLm Self-Extend 等工具、用于解释 AI 系统的 AI、关于 Rabbit.tech 的讨论、模型插值、2 MoE 模型 以及 WikiChat。
- Nous Research 令人兴奋的种子轮融资及未来计划:
@teknium宣布 Nous Research 成功获得 520 万美元种子轮融资,并计划将 Transformer 架构刻入芯片,打造能够支持实时语音 Agent、改进编码并运行 万亿参数模型 的强大服务器。此外,进一步的开源研究和 Nous-Forge 的开发也在计划中。 - OpenAI 社区关于 AI 和 LLM 的各种项目:general 频道涵盖了广泛的话题,包括 QLORA 的开发进展、可穿戴 AI mentor 的研究、微调大模型 的讨论、自定义架构 的使用、WikiChat 数据集 的实验,以及一场自发的 西班牙语交流环节。
- LLM 相关讨论与咨询:在 ask-about-llms 频道中,讨论集中在复制 Phi Models、解决 Mixtral 和 Ollama 的 VRAM 问题,以及为专有 知识库 定制 LLM 的策略。用户考虑使用 Synthesizer 工具,并提出了创建 合成数据集 的方法。
- Obsidian 项目代码请求:在 project-obsidian 频道中,用户对
@qnguyen3在工作中使用的 Obsidian 脚本表示感兴趣。该脚本一旦分享,将对其他服务器成员在自己的项目中有很大价值。
Nous Research AI 频道摘要
▷ #ctx-length-research (3 条消息):
- Activation Beacon:LLM 上下文窗口问题的解决方案:
@kenakafrosty分享了一个关于名为 Activation Beacon 的新解决方案的 arXiv 论文 链接。论文指出,Activation Beacon “将 LLM 的原始激活压缩成更紧凑的形式,使其能够在有限的上下文窗口内感知更长的上下文”。该工具似乎能够在训练和推理期间平衡内存和时间效率。 - Activation Beacon 代码即将在 GitHub 发布:
@_stilic_提供了更新,称 Activation Beacon 的代码将在 GitHub 的此处提供。
提到的链接:
- Soaring from 4K to 400K: Extending LLM’s Context with Activation Beacon:由于上下文窗口长度有限,长上下文的利用对大语言模型提出了巨大挑战。虽然可以通过微调来扩展上下文窗口,但这将重新……
- FlagEmbedding/Long_LLM/activation_beacon at master · FlagOpen/FlagEmbedding:稠密检索和检索增强型 LLM。通过在 GitHub 上创建一个账户来为 FlagOpen/FlagEmbedding 的开发做出贡献。
▷ #off-topic (95 条消息🔥🔥):
- 配备 M2 的 Apple Vision Pro 以及关于 Rabbit 产品的讨论:
@nonameusr对 Apple Vision Pro 上的 M2 芯片感到兴奋,而.beowulfbr对 Rabbit 产品的成本和推理覆盖范围表示怀疑。他们还推测 Apple 可能会在今年发布类似的产品。 - 对 2024 年 WEHEAD AI 伴侣的评价:在
@teknium分享了一个链接后,几位用户对 2024 年的 WEHEAD AI 伴侣发表了引起共鸣且幽默的看法。@everyoneisgross赞赏其 lowpoly(低多边形)美学,而@youngphlo想象着像抱婴儿一样带着这个 AI 到处走。点击此处查看帖子。 - 关于 Humane 在首款设备发布前裁员的讨论:
@mister_poodle分享了一个关于 Humane 裁员的链接,该初创公司即将出货其首款设备——一款预售价 699 美元、无屏幕、由 AI 驱动的 pin。文章链接在此。 - 关于大语言模型 (LLMs) 及其用途的幽默:用户
@Error.PDF和@n8programs开玩笑说 LLM 在理解和交流外语方面的用途。他们还幽默地推测了 LLM 的下一步进展,例如能自动将所有屏幕文本翻译成用户母语的 Discord 管理员。
提到的链接:
- 来自 PCMag (@PCMag) 的推文:WEHEAD AI 伴侣并不是我们预想中 2024 年的助手。#CES2024
- Mcmahon Crying He Was Special GIF - Mcmahon Crying He was special WWE - Discover & Share GIFs:点击查看 GIF
- Humane 在发布其 AI Pin 之前裁员 4%:此次裁员被描述为削减成本的措施。
▷ #interesting-links (39 条消息🔥):
- 探索结合 Light Activation Beacon Training 与 MaybeLongLM Self-Extend:
@kenakafrosty提出了将 Light Activation Beacon Training 与 MaybeLongLm Self-Extend 相结合的想法,以潜在地消除 context window(上下文窗口)问题。 - AI Agents 揭秘 AI 系统:
@burnydelic分享了一篇文章,介绍了 MIT CSAIL 研究人员采取的新颖方法,他们使用 AI 模型对其他系统进行实验并解释其行为。 - Rabbit.tech 会是下一个大热门吗?:
@kevin_kevin_kevin_kevin_kevin_ke发起了关于 Rabbit.tech 的讨论,这是一家提供人工智能独立硬件的科技公司。一些用户对在智能手机 App 就能提供类似功能的情况下是否需要独立设备表示怀疑(@georgejrjrjr和@teknium),而其他人(@gezegen)则为 AI 伴侣专用硬件的独特性辩护。 - 对模型插值的批评与辩护:在 AI 模型开发的背景下,
@georgejrjrjr、@romaincosentino和@charlie0.o讨论了模型插值(model interpolation)的局限性和潜在优势。@romaincosentino认为模型插值缺乏理论基础,而@charlie0.o将其视为一种 regularization(正则化)形式。 - 偶然发现大型 MoE 模型和 WikiChat:
@nonameusr分享了两个链接,一个是基于 Intel-neural series v3 的 2 MoE 模型,以及一条提到 WikiChat 的推文,该工具声称其事实准确性优于 GPT-4。后者促使@decruz询问它与基于 RAG 的系统有何不同。
提到的链接:
- rabbit — 首页:r1:你的口袋伴侣。现已开启预订:199 美元,无需订阅。
- fblgit/UNAversal-2x7B-v1 · Hugging Face
- AI agents 帮助解释其他 AI 系统:FIND(功能解释与描述)是一种评估自动化可解释性方法的新技术。该系统由 MIT 开发,使用人工智能来自动化解释过程…
- 来自 Owen Colegrove (@ocolegro) 的推文:这个结果非常迷人:WikiChat:停止 LLM 幻觉 - 在与人类用户关于近期话题的对话中实现了 97.9% 的事实准确率,比 GPT-4 高出 55.0%!有人感兴趣吗…
▷ #announcements (1 条消息):
- Nous Research 宣布完成 520 万美元种子轮融资:
@teknium宣布成功完成 520 万美元种子轮融资,由 Distributed Global 和 OSS Capital 领投,多家天使投资人参投,包括 Together AI 创始人兼 CEO Vipul、Matchbox DAO 创始人 Yonatan Ben Shimon、Balaji、OpenRouter 和 OpenSea 创始人 Thibaud、Notion 创始人 Chris Prucha、Glaive AI 创始人兼 CEO 以及 etched.ai 创始人兼 CEO Gavin。 - 将 Transformer 架构固化到芯片中:披露了通过将 Transformer 架构固化到芯片中,为 Transformer 推理打造全球最强大服务器的意图。
- GPU 无法实现的产物:
@teknium概述了 Nous Research 服务器的预期能力,强调了实时语音 Agent、通过树搜索(tree search)改进的代码编写以及多播投机采样(multicast speculative decoding)。 - 容纳万亿参数模型:即将推出的服务器预计能够运行万亿参数模型,具有完全开源的软件栈,可扩展至 100T 参数模型,支持束搜索(beam search)和 MCTS 解码。
- 开源追求与未来项目 Nous-Forge:强调了开源研究的重要性,
@teknium宣布这笔资金将用于持续投入 LLM 架构、数据合成(Data Synthesis)、模拟(Simulation)和 Agent 工程研究,并开发定于 2024 年发布的 Nous-Forge。提到的开发者和顾问团队包括<@153017054545444864>、<@387972437901312000>、<@265269014148808716>和<@187418779028815872>。
提到的链接:
| [Etched | 全球首个 Transformer 超级计算机](http://etched.ai):将 Transformer 固化到硅片中。通过将 Transformer 架构烧录进我们的芯片,我们正在打造全球最强大的 Transformer 推理服务器。 |
▷ #general (377 条消息🔥🔥):
- Nous 团队筹集 520 万美元:Nous 团队发布推文宣布成功筹集 520 万美元种子轮资金。Nous 团队的成员和朋友们表达了兴奋并表示祝贺。来源:
@youngphlo - QLORA 的开发:用户
@n8programs分享了 QLORA 的开发进展,这是一种微调 OpenAI 模型的方法。他在单台 M3 Max 上成功训练了 QLORA,并得出结论:QLORA 的表现通常优于普通的 Mistral。来源:@n8programs - 研究可穿戴 AI 导师:用户
@mg_1999正在开发一款可穿戴 AI 导师,并向社区咨询使用 Nous Research 的哪个模型最好。他们分享了产品网站链接:AISAMA - 关于大模型微调的讨论:社区讨论了训练和合并大模型与小模型的优缺点。用户支持不同的策略,如将微调模型与基础模型合并,以及使用多个 Adapter。分享的著名链接包括
LM-Cocktail和CFG - Modal 和 Runpod 平台的建议:用户
@decruz讨论了用于推理的工具 modal.com,并为需要 GPU 的人引荐了该公司的人员。用户@kenakafrosty提到了 Runpod 作为具有类似功能的替代平台。 - 自定义架构的使用:用户
@mihai4256咨询如何分享继承自 LlamaForCausalLM 的自定义架构。他被引导参考Qwen的实现方法,包括使用自定义建模文件并允许通过trust_remote_code=True进行导入。 - 对 WikiChat 数据集的兴趣:用户
@emrgnt_cmplxty对 WikiChat 团队使用的数据集表示兴趣,称其测试结果很有前景。他们提出了复制该数据集以微调 OpenHermes-2.5-Mistral-7B 的想法。来源:stanford-oval/WikiChat - 自发的西班牙语交流环节:多位用户进行了一场有趣幽默的西班牙语对话。对话虽然没有信息价值,但以愉快轻松的气氛结束。
提到的链接:
- 来自 anton (@abacaj) 的推文:为什么我推荐更大的模型?我是说看看这个。即使是 Qwen-1.8B-chat 也无法正确关联对话轮次……小模型是行不通的。
- Google Colaboratory
- LM-Cocktail: LM_Cocktail
- Slerp - 维基百科
- 新世纪福音战士大笑 GIF - 新世纪福音战士大笑微笑 - 发现并分享 GIF:点击查看 GIF
- Sama AI 应用:如果人类拥有无限记忆会怎样?我们全新的 AI 可穿戴设备旨在为您提供无限记忆。
- Modal:Modal 帮助人们在云端运行代码。我们认为这是开发者获取容器化、Serverless 计算资源的最简单方式,无需操心管理自己的基础设施。
- 通过 Classifier-Free Guidance 保持主题:Classifier-Free Guidance (CFG) 最近在文本生成图像领域兴起,作为一种轻量级技术来增强生成内容对 Prompt 的遵循度。在这项工作中,我们证明了 CFG 可以被用于……
- 哦天哪 Kyle Broflovski GIF - 哦天哪 Kyle Broflovski Stan Marsh - 发现并分享 GIF:点击查看 GIF
- Issues · stanford-oval/WikiChat:WikiChat 通过从 Wikipedia 检索数据来消除大语言模型的幻觉。 - Issues · stanford-oval/WikiChat
- Nous Research
- 来自 Nous Research (@NousResearch) 的推文:Nous Research 很高兴地宣布完成了 520 万美元的种子轮融资。我们很自豪能与充满激情、高诚信的合作伙伴共同完成这一轮融资,其中包括……
- 来自 rabbit inc. (@rabbit_hmi) 的推文:隆重推出 r1。观看主题演讲。立即订购:http://rabbit.tech #CES2024
- GitHub - cg123/mergekit: 用于合并预训练大语言模型的工具。:用于合并预训练大语言模型的工具。 - GitHub - cg123/mergekit: Tools for merging pretrained large language models.
- 由 jbochi 提交的直接从 gguf 文件读取的示例 · Pull Request #222 · ml-explore/mlx-examples:这使用 ml-explore/mlx#350 直接从 GGUF 文件加载所有权重、配置和词表。运行示例:
$ python llama.py models/tiny_llama/model.gguf [INFO] Loading model from models/tiny_llama/... - 由 jbochi 提交的 GGUF 支持 · Pull Request #350 · ml-explore/mlx:建议的更改:使用来自 @antirez 优秀的 gguflib 添加了 GGUF 支持。大家对此感兴趣吗?GGUF 目前在本地推理中非常流行,并且有大量的模型……
▷ #ask-about-llms (44 条消息🔥):
- 探索复制 Phi 模型:
@gson_arlo询问是否存在旨在复制 Phi 系列的开源模型。作为回应,@georgejrjrjr指出来自 sci-phi 的 Owen 比他们认识的任何人都更专注于合成数据(synthetic data),并提到了 refuel.ai 和 Ben Anderson 的 Galactic 等相关项目。 - 解决 Mixtral 和 Ollama 的 VRAM 问题:
@colby_04841寻求关于在配备 4 张 RTX 3090 GPU 的系统上使用 Mixtral 8x7b 和 Ollama 时,如何处理 VRAM 限制的建议。 - 针对专有知识库的 RAG 与 Fine-Tuning 对比:
@bigdatamike寻求关于是使用 RAG、Fine-Tuning 还是两者结合来构建针对公司专有知识库的语言模型的见解。用户们给出了不同的意见,@colby_04841倾向于 RAG,而@georgejrjrjr建议可能需要转换检索库中的数据以更好地匹配输出格式。 - Synthesizer 工具在数据创建中的实用性:
@georgejrjrjr推荐了由 SciPhi-AI 开发的 Synthesizer,这是一个用于 RAG 和数据创建的多用途语言模型框架。用户@everyoneisgross确认已将其添加到他们的项目清单中。 - 创建合成数据集的最佳方式:
@gezegen询问了关于生成合成数据集(synthetic datasets)的问题,@emrgnt_cmplxty指出开源模型是一个可扩展的解决方案,并强调了保持准确性的必要性。
提到的链接:
GitHub - SciPhi-AI/synthesizer: A multi-purpose LLM framework for RAG and data creation.: 一个用于 RAG 和数据创建的多用途 LLM 框架。 - GitHub - SciPhi-AI/synthesizer: A multi-purpose LLM framework for RAG and data creation.
▷ #project-obsidian (4 条消息):
- Obsidian 脚本共享请求:
@qnguyen3提到他们刚刚在工作中运行了 Obsidian。作为回应,@vic49.请求@qnguyen3分享该脚本。@thewindmom也表达了对该脚本的兴趣。
OpenAI Discord 总结
- GPT-4 Turbo 的等待博弈:成员
@_treefolk_指出他们期待 GPT-4 Turbo 的正式发布,以获得更便宜的使用成本和更高的 Token 限制。该用户强调了作为承诺发布时间的“1 月初”这一说法非常模糊。 - AI 与程序员的辩论:
@you.wish和@【penultimate】就未来版本的 GPT 对程序员的影响展开了激烈的讨论。虽然@【penultimate】设想了一个“随着下一代 GPT 的推出,地球上几乎每个人都将成为世界上最好的程序员”的未来,但@you.wish对此表示质疑,理由是目前的 AI 模型只能执行非常基础的任务。
- 当 Discord 规则引发讨论时:当
@you.wish请求对一篇 Reddit 帖子进行点赞时,该频道经历了一场详尽的规则解读讨论,引发了关于 Discord Rule 7 禁止“自我推广、拉票或广告”的对话。 - LimeWire 将 AI 引入音乐:
@shartok将一段由 LimeWire AI Studio 创作的音乐作品带入对话,引发了关于 AI 生成音乐 的讨论。 - 对 Midjourney 最新版本的评价褒贬不一:频道中的成员如
@dino.oats、@darthgustav.和@satanhashtag分享了他们对最新版本 Midjourney (MJ) 的体验和看法,讨论了它偏离 Discord 的趋势以及隐私功能的加入。然而,@you.wish对该版本表示不满。 - 品牌指南之谜:在 GPT-4 的讨论中,
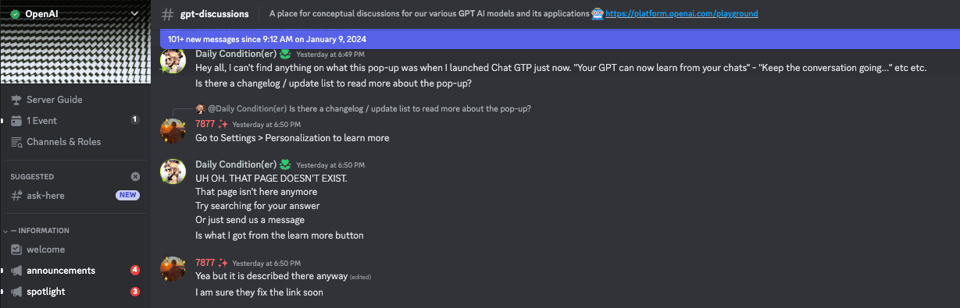
@mrbr2023对在一封邮件中收到的 OpenAI GPTs 品牌指南文档中被黑色标记的部分提出了疑问,并表示无法分享该文档的截图或链接。 - GPT 发布中的障碍:
@mrbr2023在为他们的 GPTs 选择“发布给所有人(Publish to EVERYONE)”时遇到了困难,后来发现必须在 builder profile 设置中同时勾选“名称(Name)”和“域名(Domain)”框,该选项才会生效。 - 探索 GPT 个性化:在尝试新的 GPT 记忆功能(个性化)时,
@winsomelosesome和@darthgustav.分享了 GPT 从他们的聊天中学习的经验。 - ChatGPT 在浪漫创作上的挑战:在 prompt engineering 频道中,
@rchap92指出 ChatGPT 即使在不违反指南的情况下,也很难创作出一个简单的浪漫场景,这一点得到了@rjkmelb的证实,他表示 ChatGPT 被设计为“G 级”的。 - ChatGPT 保守的指南;可能的规避方法?:当涉及到创建可能违反指南的内容时,
@exhort_one建议了一个有趣的规避方法——让 ChatGPT 参与创作内容的审查版本,然后由用户来填补空白。 - AI 在不同领域的潜力:
@shoga4605思考了 AI 和语言模型 的巨大潜力,以及它们对语言学、生态学、环境等各个领域的潜在影响。他们还假设了 AI 在农业中的应用,理论上可以确定草坪空间可以生产多少食物。
OpenAI 频道总结
▷ #ai-discussions (160 messages🔥🔥):
- 对 GPT-4 Turbo 官方发布的急切期待:
@_treefolk_表达了希望 GPT-4 Turbo 尽快结束 Preview 阶段以降低使用成本并提高 Token 限制的愿望,并对承诺的“1 月初”发布的具体细节提出疑问。 - 关于 GPT 编程未来的讨论:
@you.wish和@【penultimate】之间就未来版本的 GPT 是否会取代程序员展开了激烈的辩论。虽然@【penultimate】认为“随着下一代 GPT 的出现,地球上几乎每个人都将成为世界上最好的程序员”,但@you.wish则认为目前的模型只能承担非常基础的任务。 - 自我推广内容引发 Discord 规则辩论:由于
@you.wish请求在 Reddit 帖子中获得点赞,引发了关于 Discord Rule 7(禁止“自我推广、招揽或广告”)适用范围的广泛讨论。 - 分享 AI 生成的音乐:
@shartok分享了一个使用 LimeWire AI Studio 创作的 AI 生成音乐作品链接。 - 关于最新 Midjourney (MJ) 版本的交流:来自
@dino.oats、@darthgustav.和@satanhashtag的消息详细描述了他们对最新版本 MJ 的体验和看法,包括其脱离 Discord 的趋势以及隐私功能的引入。@you.wish对该版本表示不满。
提到的链接:
- Using a ChatGPT made game to fool a Vet Gamedev:很多人说游戏行业在 AI 面前是安全的,所以我让 AI 制作了一款能骗过《战神》传奇创作者的游戏!😜感谢 @DavidJaffeGa…
- Radiant Warrior - LimeWire:"在 LimeWire 上查看来自 shartok 的 Radiant Warrior"
▷ #gpt-4-discussions (154 messages🔥🔥):
- 对品牌指南的困惑:用户
@mrbr2023对邮件中提供的 OpenAI GPTs 品牌指南文档中某一部分被黑色标记覆盖感到困惑。他们还对无法在群组中分享该文档的截图或链接感到不解。 - 自定义 GPTs 的语音质量:
@vantagesp询问为什么自定义 GPTs 的语音质量较差,但随后没有得到任何回应或讨论。 - 发布 GPTs 时的困难:用户 ‘mrbr2023’ 对无法为他们的 GPTs 选择“发布给所有人(Publish to EVERYONE)”感到沮丧,最终发现必须在 Builder Profile 设置中同时勾选“Name”和“Domain”框,才能启用“EVERYONE”选项。
- 用户遇到 GPTs 技术问题:几位用户报告称他们的 GPTs 消失了,且部分网页无法访问,将其归因于 OpenAI 的新更新。
- 探索 GPT 的个性化功能:
@winsomelosesome和@darthgustav.探索了设置中新的 GPT Memory 功能(个性化),该功能允许 GPT 从你的对话中学习。然而,@darthgustav.也注意到该功能在发现后不久似乎就被移除了。 - 寻求 GPT 反馈:用户
@faazdataai_71669分享了他们的 GPT“Resume Tailor”链接,并寻求反馈。
提到的链接:
Brand guidelines:在营销和沟通中使用 OpenAI 品牌的语言和资产规范。
▷ #prompt-engineering (6 messages):
- ChatGPT 在浪漫场景描写上表现挣扎:
@rchap92担心 ChatGPT 甚至难以勾勒出一个基础的浪漫场景,而不会触发“可能违反指南”的提示。@rjkmelb证实,ChatGPT 确实被设计为“G 级(全年龄段)”。 - 应对 ChatGPT 保守策略的变通方法:
@exhort_one提供了一个变通建议,即要求 ChatGPT 审查任何可能违反指南的部分,然后由用户来填补空白。 - 分享 Prompt Engineering 指南:
@scargia分享了 OpenAI 网站上 Prompt Engineering 指南的链接。 - AI 潜在用例的启发:
@shoga4605讨论了 AI 和语言模型在理解和建模生态、环境、栖息地以及整体生物多样性方面的潜在用例。他们还考虑了 AI 在农业中的可能性,例如计算草坪空间理论上可以生产多少食物。 - 热烈欢迎新用户:
@beanz_and_rice欢迎@shoga4605加入社区,并赞赏了他们的热情和想法。
▷ #api-discussions (6 条消息):
- 审查所需内容:用户
@rchap92询问 ChatGPT 是否无法在不触发违规警告的情况下创作接吻以上的浪漫场景。@rjkmelb确认 ChatGPT 的设计定位是全年龄段(G 级)。 - 绕过“违规”提示的方法:用户
@exhort_one建议要求 ChatGPT 对任何可能违反指南的部分进行自我审查,从而允许用户自行填补空白。 - Prompt Engineering 指南:
@scargia分享了 OpenAI 的 Prompt Engineering 指南链接。 - 对 AI 潜力的热情:
@shoga4605表达了对 AI 和语言模型潜力的兴奋,并思考了它们在语言学、生态学、环境等领域的应用。 - 欢迎加入讨论:
@beanz_and_rice向@shoga4605打招呼并表示欢迎。
LM Studio Discord 总结
-
Ubuntu Server 与 LM Studio 兼容性问题:用户
@m.t.m询问如何在没有 X server 的 Ubuntu 22.04 服务器上运行 LM Studio。成员@heyitsyorkie回复称 LM Studio 不支持 headless 或 CLI 选项,并建议针对此类需求使用 llama.cpp。 -
GPU 之争:RTX 4070 vs. RTX 4090:
@b0otable、@heyitsyorkie、@fabguy、@senecalouck和@rugg0064讨论了购买 RTX 4070 还是 RTX 4090 的问题,重点关注性能优势、VRAM 考量和价格。 -
关于使用 LM Studio 构建 LM-as-a-service 的咨询:用户
@enavarro_询问是否可以仅使用 LM Studio 后端来构建 LM-as-a-service。@heyitsyorkie告知目前不提供此类功能,并建议将 llama.cpp 作为潜在解决方案。 -
关于 ROCm 支持与 ML 未来的前瞻性讨论:ROCm 支持和机器学习的未来格局引发了讨论。
@senecalouck指出 ollama 已经启用了 ROCm 支持,希望 LM Studio 也能尽快支持。随后焦点转向了 ML 的未来实现以及像 TinyBox 这样的新兴参与者。 -
寻找支持工具选择和聊天的 7B-13B 模型:用户
@_anarche_表达了在寻找可本地使用的 7B-13B 模型方面的困难,该模型需要同时具备工具选择(function calling)和聊天功能,可能是某种 franken/merged(混合/合并)形式。其目标是摆脱对 gpt-3.5-turbo 模型的依赖。 -
斯坦福 DSPy 被提议为潜在解决方案:
@nitex_dkr强调了斯坦福 DSPy(一个用于对基础模型进行编程而非 Prompting 的框架),认为它是解决@_anarche_挑战的潜在方案。 -
反馈 Linux 加载问题及版本号误导:用户
@moko081jdjfjddj报告模型无法在 Linux 上加载,并注意到网站上的 Linux 版本号存在差异。@heyitsyorkie和@fabguy处理了这些问题,澄清了版本问题,并引导用户前往特定的 Linux Beta 频道寻求进一步支持。 -
遇到平台不支持问题:
@keryline收到错误消息称其平台不受 LM Studio 支持,原因是其处理器不支持 AVX2。@dagbs建议尝试 avx beta 版本以解决此问题。 -
运行大模型的 Mac vs PC 之争:
@scampbell70发起了关于高效运行 Mistral 8x7b、Falcon 180b 或 Goliath 120 等大型模型所需硬件配置的讨论。一些成员称赞 Mac(特别是 Mac Studio)性能更好,同时也提出了对其缺乏可升级性的担忧。 -
带内存插槽的 GPU 不可用:
@doderlein询问在哪里可以买到带有内存插槽的 GPU,@ptable表示这不可能。@heyitsyorkie指出了 ASUS 的一个独特解决方案,该方案将 GPU 与 SSD M.2 NVME 结合,创建了一种存储-显卡混合卡。 -
明确 LM Studio 中的硬件使用情况:用户
@besiansherifaj询问在拥有 4090 RTX GPU 的情况下是否还需要 CPU。@fabguy澄清说,即使整个模型都在 GPU 上,CPU 仍会被使用。 -
关于 Autogen Studio 和 LM Studio 配合使用的疑问:在 autogen 频道中,thelefthandofurza 提出了关于是否有人有将 autogen studio 与 LM Studio 配合使用的经验。讨论未进一步展开。
LM Studio 频道总结
▷ #💬-general (71 messages🔥🔥):
-
Ubuntu Server 上的 LMStudio 安装问题:用户
@m.t.m.询问是否可以在没有 X server 的 Ubuntu 22.04 服务器上运行 LMStudio。@heyitsyorkie回复称 LMStudio 目前不支持无头(headless)或 CLI 选项,并建议针对此类需求使用 llama.cpp。 -
昵称与服务器规则:用户
@sexisbadtothebone询问其昵称是否违反了服务器关于 SFW 内容的规则。@heyitsyorkie建议修改昵称以遵守规则并维持工作环境。 -
RTX 4070 vs. RTX 4090 之争:
@b0otable寻求关于购买 RTX 4070 还是 RTX 4090 的建议。@heyitsyorkie、@fabguy、@senecalouck和@rugg0064参与了讨论,重点关注性能优势、VRAM 考量和价格。 -
使用 LM Studio 实现 LM-as-a-service:
@enavarro_询问是否可以仅使用 LM Studio 后端来构建 LM-as-a-service。@heyitsyorkie告知用户目前没有该功能,并推荐 llama.cpp 作为潜在解决方案。 -
讨论 ROCm 支持与 ML 的未来:讨论了 ROCm 支持以及机器学习的未来格局。
@senecalouck提到 ollama 已支持 ROCm,并希望很快能在 LM Studio 中看到。讨论随后演变为探索 ML 技术的未来实现以及像 TinyBox 这样的新玩家。
提到的链接:
- TheBloke/LLaMA-Pro-8B-Instruct-GGUF · Hugging Face
- ROCm support by 65a · Pull Request #814 · jmorganca/ollama:#667 在一次错误的 rebase 尝试中被关闭。这应该是我能想出的使用 build tags 在 ROCm 和 CUDA 之间切换的最简方案,以及相关的构建文档。
▷ #🤖-models-discussion-chat (18 messages🔥):
- 寻求用于工具选择和聊天的 7B-13B 模型:
@_anarche_表示难以找到一个既能进行工具选择(function calling)又能聊天的本地 7B-13B 模型,可能是以拼接/合并(franken/merged)的形式存在。他们的目标是从 gpt-3.5-turbo 模型迁移。 - Dolphin 模型作为合适的通用选择:
@dagbs推荐 Dolphin 模型作为编码、函数、工具等方面的优秀通用选择,尽管在 crewai 和 autogen 等某些函数调用工具上的效果参差不齐。 - Langchain 兼容性考量:
@_anarche_详细说明了将新模型集成到 Langchain 的意图,为此他们已经调整了机器人以使用 LM Studio API。 - Discord 上的未审查模型担忧:
@dagbs提醒在 Discord 环境中使用未审查(uncensored)模型可能导致封禁,强调了谨慎选择模型的必要性。 - 分享 Stanford DSPy 作为可能方案:
@nitex_dkr推荐了 Stanford DSPy,这是一个用于编程(而非提示)基础模型的框架,可能为@_anarche_的挑战提供有前景的解决方案。
提到的链接:
GitHub - stanfordnlp/dspy: Stanford DSPy: The framework for programming—not prompting—foundation models:Stanford DSPy:用于编程(而非提示)基础模型的框架。
▷ #🧠-feedback (10 messages🔥):
- Linux 加载问题:
- 用户
@moko081jdjfjddj报告模型在 Linux 上无法加载。@heyitsyorkie和@fabguy指引用户前往 Channels and Roles 选择 Linux Beta 角色,并在特定频道中发布问题。 @moko081jdjfjddj还注意到网站上提供的 Linux 版本号不一致,@fabguy回复称 Beta 版本 0.2.10 存在稳定性问题,因此未在网站上更新。
- 用户
- 不支持的平台问题:
@keryline在 Windows 机器上遇到 LM Studio 问题,收到错误提示称其平台不受支持,因为其 处理器不支持 AVX2 指令。- 为了解决此问题,
@dagbs建议用户尝试 avx beta。
- 新 Beta 版本请求:
@logandark请求发布一个包含 llama.cpp 仓库中特定 commit 的新 Beta 版本。
▷ #🎛-hardware-discussion (29 messages🔥):
-
运行大模型的 Mac vs PC 之争: 用户
@scampbell70发起了关于高效运行 Mistral 8x7b、Falcon 180b 或 Goliath 120 等大型模型所需硬件要求的讨论,旨在实现最低损耗和最佳性能。@telemaq和@heyitsyorkie建议使用 Macbook Pro 或 Mac Studio 以获得更好的性能,而@pydus认为配备 192GB Unified Memory、售价 7000 美元的 Mac Studio 具有很高的性价比。然而,@scampbell70对 Mac 表示担忧,因为其缺乏可升级性(来源)。 -
Apple 设备上的 VRAM 分配:
@heyitsyorkie分享了一个 Reddit 帖子,详细介绍了如何使用命令sudo sysctl iogpu.wired_limit_mb=12345在运行时控制 VRAM 的分配量(来源)。 -
购买带有内存插槽的 GPU:
@doderlein询问哪里可以买到带有内存插槽的 GPU,@ptable回复说这是不可能的。@heyitsyorkie提到了 ASUS 的一个独特解决方案,将 GPU 与 SSD M.2 NVME 配对,创建了一个混合存储显卡(来源)。 -
Mac 运行 Goliath 120b Q8 的性能:
@telemaq分享了一个 Reddit 帖子,一名用户在配备 192GB 内存的 Mac Studio M2 Ultra 上运行 Goliath 120b Q8,达到了约 7tok/s,证明了 Mac 处理大型模型的能力(来源)。 -
LM Studio 中的硬件使用: 用户
@besiansherifaj询问在拥有 4090 RTX GPU 的情况下,LM Studio 是否还需要 CPU。@fabguy澄清说,即使整个模型都在 GPU 上,CPU 仍会一直被占用。
提到的链接:
- Reddit - Dive into anything
- Reddit - Dive into anything
- ASUS Announces Dual GeForce RTX 4060 Ti SSD Graphics Card
▷ #autogen (1 messages):
thelefthandofurza: 有人将 AutoGen Studio 与 LM Studio 一起使用过吗?
Eleuther Discord 总结
- 模型性能在无需额外数据、训练或扩展的情况下提升:
@sehaj.dxstiny发起了一个关于如何在不增加额外资源的情况下提高性能的询问,在@ad8e和@vatsala2290的帮助下,发现了一些有趣的资源,包括 Machine Learning 研讨会投票结果。 - 将 AI 开发转向移动端:
@_fleetwood向@pawngrubber推荐了mlc-llm,用于在移动设备上开始机器学习开发。这个开源工具可以原生开发、优化和部署 AI 模型。 - 剖析 Llama-2-70B 的基准测试难题:
@tirmizi7715对为什么Llama-2-70B在 MT-Bench 上表现较差,但在其他基准测试中表现良好表示困惑。 - Mistral 支持任何语言:由
@maxmatical发起的一场讨论澄清了,处理所有 Unicode 字符的现代 Tokenizer 可以实现语言迁移(language transfer),正如@thatspysaspy和@stellaathena所引用的那样。 - 解析 Huggingface 模型结构:
@sk5544收到了一种从 Huggingface 提取 PyTorch 模型定义代码的编码方法,由@thatspysaspy分享。 - Kaggle LLM 竞赛引发关注:
@grimsqueaker强调了一个正在进行的 Kaggle LLM 竞赛,社区可能会对此感兴趣。 - MLM Loss 计算背后的机制:由
@jks_pl发起的一场讨论澄清了为什么 MLM Loss 仅在被掩码/损坏的 Token 上计算,由@bshlgrs和@stellaathena进行了说明。 - 通过评估解释 AI 行为:
@burnydelic分享了一篇有趣的 MIT 新闻文章,讨论了开发能够评估并解释其他 AI 系统行为的 AI 模型。 - 用于简化超参数调优的 muP:用户
@ad8e、@thatspysaspy、@ricklius和@cubic27分享了关于 muP 简化跨规模超参数调优能力的看法,尽管它并非万能方案。 - 数据集中 Twitter 数据有限:
@stellaathena向@rybchuk澄清,在某些数据集中不太可能存在大量的 Twitter 数据。 - Mixtral 路由分析背后的真相:
@tastybucketofrice分享了一条指出 Mixtral 路由分析误区的 推文,并由@stellaathena和@norabelrose进一步讨论。 - 通过 GPT/LLM 可视化工具获取洞察:
@brandon_xyz宣布了一个可视化 GPT/LLM 认知过程的新工具,并引用了一条 推文,随后收到了私有工具访问权限的请求。 - 理解机械可解释性与 BIMT:
@g_mine讨论了脑启发模块化训练(Brain-Inspired Modular Training, BIMT)在提高神经网络可解释性方面的作用,并指出了一篇关于该问题的 论文。 - Pythia 数据准备标准:
@joshlk关于 Pythia 数据准备的询问得到了@pietrolesci的澄清,即这是一个标准的预训练过程,即使在线信息较少。 - Pythia-Deduped 数据集中的 EOD Token 问题:
@pietrolesci注意到 Pythia-deduped 数据集缺少 EOD Token,@hailey_schoelkopf提出了可能的原因,包括在 Tokenize 过程中遗漏了--append-eod选项。 - Pythia 模型的 EOD Token 与 Packer:
@pietrolesci和@hailey_schoelkopf讨论了缺失 EOD Token 引起的差异是否会影响 Pythia 模型在训练期间看到的“打包(packed)”数据集。 - 掩码在文档注意力中的作用:
@joshlk提出了一个关于掩码功能的问题,@hailey_schoelkopf给予了回答,澄清了掩码并非用于防止文档间的交叉注意力(cross-attention)。
Eleuther 频道总结
▷ #general (61 messages🔥🔥):
-
模型性能优化选项:用户
@sehaj.dxstiny提出了一个关于在没有额外数据、训练或扩大规模的情况下提高模型性能的问题。推荐资源包括@ad8e分享的 Machine Learning workshop poll 以及@vatsala2290分享的南加州大学 (USC) Amitava Das 小组的研究工作。 -
探索移动端 ML 开发:
@pawngrubber表现出对在移动设备上开始 Machine Learning 开发(特别是推理)的兴趣。@_fleetwood建议将mlc-llm作为起点,这是一个用于在设备上原生开发、优化和部署 AI 模型的工具。 -
理解 Llama-2-70B 的 MT-Bench 表现:
@tirmizi7715询问为什么语言模型Llama-2-70B在 MT-Bench 上的表现比Mixtral和Gpt 3.5差,但在其他基准测试中表现同样出色。 -
在 Mistral 上进行日语预训练:在由
@maxmatical发起的关于 StableLM 在英文语言模型Mistral上进行日语预训练的讨论中,@thatspysaspy和@stellaathena澄清说,现代 Tokenizer 可以处理所有 Unicode 字符,从而允许语言迁移(language transfer)。 -
理解 Huggingface 模型结构:
@sk5544寻求一种方法来获取从 Huggingface 加载的模型的 PyTorch 模型定义代码。@thatspysaspy分享了一种实现该目的的代码方法。
提到的链接:
- Counter Turing Test CT^2: AI-Generated Text Detection is Not as Easy as You May Think – Introducing AI Detectability Index:随着 ChatGPT 的广泛应用,AI 生成文本的风险和后果惊人地增加。为了解决 AI 生成产物的归属权这一不可避免的问题,…
- HITYWorkshopPoll/PollResults.pdf at main · fsschneider/HITYWorkshopPoll:NeurIPS 2022 HITY 工作坊进行的民意调查结果。 - fsschneider/HITYWorkshopPoll
- GitHub - mlc-ai/mlc-llm: Enable everyone to develop, optimize and deploy AI models natively on everyone's devices.:让每个人都能在每个人的设备上原生开发、优化和部署 AI 模型。 - GitHub - mlc-ai/mlc-llm
▷ #research (25 messages🔥):
- Kaggle LLM 竞赛:
@grimsqueaker提到了一项正在进行的 Kaggle LLM contest,这可能会引起研究社区的兴趣。 - 关于掩码语言建模 (MLM) Loss 计算的讨论:
@jks_pl发起了一项讨论,质疑为什么 MLM Loss 仅在被掩码/损坏的 Token 上计算。@bshlgrs和@stellaathena提供了回应,指出这种设置是因为原始未掩码的 Token 对于 MLM 来说是一项简单的任务,可能无法为学习提供太多的信息价值。 - 解释 AI 行为的新方法:
@burnydelic分享了一篇 MIT News article,关于 MIT CSAIL 的研究人员开发了可以对其他 AI 系统进行实验以解释其行为的 AI 模型。 - muP:超参数调优的福音:
@ad8e分享了他关于 muP 的主要心得,强调 muP 简化了跨不同模型规模的超参数调优。然而,他也指出 muP 并不是万能的,在某些设置(如 tanh 激活函数)下可能会遇到问题。@thatspysaspy、@ricklius和@cubic27同意 muP 的主要好处是促进跨规模的超参数迁移。 - 某些数据集中缺少 Twitter 数据:针对
@rybchuk关于从某些数据集中提取 Twitter 数据的查询,@stellaathena回复说,讨论中的数据集中似乎都没有包含大量的 Twitter 数据。
提到的链接:
AI agents help explain other AI systems:FIND(功能解释和描述)是一种评估自动可解释性方法的新技术。该系统由 MIT 开发,使用人工智能来自动化解释…
▷ #interpretability-general (8 条消息🔥):
- Mixtral 路由分析发现缺乏专业化:
@tastybucketofrice分享了来自@intrstllrninja的一条 推文,指出 Mixtral 路由分析 显示专家(experts)并没有针对特定领域进行专业化。@stellaathena对这种普遍存在的误解表示困惑。 - 先前的发现与 Mixtral 分析一致:用户
@norabelrose评论称,大约一年前就有其他分析显示了同样的结果,这表明该发现并非完全是新鲜事。 - 在 Pythia-deduped 训练集上编译的 Trigram 频率:
@norabelrose还分享了一个文档 链接,详细介绍了在 11.4% 的 Pythia-deduped 训练集上计算出的 trigram 频率。 - 用于 GPT/LLM 可视化的创新工具:
@brandon_xyz提到创建了一个新工具,可以可视化 GPT/LLM 的思考和理解过程,并展示了他的 推文 作为示例,欢迎私信申请工具访问权限。 - Mechanistic Interpretability 与 BIMT:
@g_mine指出了一篇 论文,讨论了大语言模型的 Mechanistic Interpretability 以及 Brain-Inspired Modular Training (BIMT) 在增强神经网络可解释性方面的作用。
提到的链接:
- 来自 interstellarninja (@intrstllrninja) 的推文:Mixtral 路由分析显示专家并没有针对特定领域进行专业化。
- Evaluating Brain-Inspired Modular Training in Automated Circuit Discovery for Mechanistic Interpretability:大语言模型 (LLMs) 在 AI 领域迅速崛起,凭借其先进的能力改变了广泛的应用。随着这些模型在决策中变得越来越不可或缺……
- trigrams.pkl.zst:trigrams.pkl.zst
- 来自 Brandon (@brandon_xyzw) 的推文:这是 GPT/LLM 在思考和理解时的样子。
▷ #gpt-neox-dev (13 条消息🔥):
-
Pythia 数据准备:
@joshlk指出,网上有很多关于微调(fine-tuning)数据准备的信息,但关于预训练(pre-training)的信息不多。他们询问 Pythia 的流程是典型的还是特殊的。@pietrolesci评论说,这通常是(仅解码器/decoder-only)语言模型(LLM)训练的标准流程,不仅限于 Pythia。 -
缺失 EOD Token:
@pietrolesci提出了在 Pythia-deduped 数据集中未发现 EOD Token 的问题。@hailey_schoelkopf对此表示惊讶,并提到一种可能性,即在将 Pile + 去重后的 Pile(deduped Pile)分词(tokenizing)为 Megatron 格式时,未包含--append-eod选项。 -
预训练 Pythia 模型使用了不同的打包器(Packer)?:
@pietrolesci指出,如果没有添加 EOD Token,生成的“打包(packed)”数据集将与 Pythia 模型在训练期间看到的数据集不同,因为 N 个文档会缺失 N 个 Token,从而导致包中每个 Token 的位置发生偏移。@hailey_schoelkopf同意,如果预打乱(pre-shuffled)和原始 idxmaps 数据集都没有 EOD Token,它们应该彼此匹配。但在打包时,NeoX 代码库本身不会添加 EOD Token (源码)。 -
文档注意力中的掩码(Masking):
@joshlk询问了掩码的出现情况,以及它们是否被用于防止文档间的交叉注意力(cross-attention)。@hailey_schoelkopf澄清说,掩码并非用于此目的。
提到的链接:
- gpt-neox/megatron/data/gpt2_dataset.py at e6e944acdab75f9783c9b4b97eb15b17e0d9ee3e · EleutherAI/gpt-neox:基于 DeepSpeed 库在 GPU 上实现模型并行自回归 Transformer。- EleutherAI/gpt-neox
- Batch Viewer : Why Sequence Length 2049? · Issue #123 · EleutherAI/pythia:你好,我正在使用 utils/batch_viewer.py 遍历 Pythia 的训练数据并计算一些批次级统计数据。首先,batch_viewer.py 中的实际代码与…之间存在一些差距。
- GitHub - EleutherAI/pythia: The hub for EleutherAI’s work on interpretability and learning dynamics:EleutherAI 关于可解释性和学习动力学工作的中心 - GitHub - EleutherAI/pythia
- GitHub - EleutherAI/pythia: The hub for EleutherAI’s work on interpretability and learning dynamics:EleutherAI 关于可解释性和学习动力学工作的中心 - GitHub - EleutherAI/pythia
- EleutherAI/pile-deduped-pythia-preshuffled · Datasets at Hugging Face
- EleutherAI/pythia_deduped_pile_idxmaps · Datasets at Hugging Face
OpenAccess AI Collective (axolotl) Discord 摘要
- 优化 Mistral 训练:用户 @casper_ai 分享了关于优化 Mistral 模型 训练的深入细节:“MoE 层可以通过高性能专用内核在单个 GPU 上高效运行。Megablocks 将 MoE 层的前馈网络 (FFN) 操作转换为大型稀疏矩阵乘法,显著提升了执行速度”。
- Deepspeed 多 GPU 使用中潜在的减速问题:@noobmaster29 强调了
accelerate==0.23(Deepspeed 集成)的一个问题,导致用户训练速度变慢。建议降级到accelerate==0.22或使用main分支,修复补丁正等待发布 来源。 - 使用 Axolotl 和 MLFlow 追踪实验:@caseus_ 和 @JohanWork 讨论了将 MLFlow 集成到 Axolotl 中进行实验追踪 Pull Request #1059。
- 用于外部任务管理的 Axolotl WebSocket:@david78901 提议在 Axolotl 项目中增加一个 websockets 端点,以便更好地进行外部任务管理。@caseus_ 表示有兴趣将该想法纳入主项目。
- 关于系统消息训练影响的讨论:在模型训练背景下,@le_mess 表示系统消息的内容对模型性能没有显著影响,甚至可以像 “ehwhfjwjgbejficfjeejxkwbej” 一样随机 来源。
- 在 ShearedMistral 训练中实现 “Shearing”:@caseus_ 指出了一种 shearing 过程的方法,特别参考了一个 GitHub 仓库。他还讨论了在数据去重和质量方面使用 SlimPajama 优于 RedPajama v2 的优点,并指出 RedPajama v2 不再包含子集 来源。
OpenAccess AI Collective (axolotl) 频道摘要
▷ #general (7 条消息):
- Mistral 训练优化方法详解:在频道中,
@casper_ai详细介绍了一些关于如何优化 Mistral 模型 训练的关键信息。特别提到 MoE 层可以通过高性能专用内核在单个 GPU 上高效运行。Megablocks [13] 将 MoE 层的前馈网络 (FFN) 操作转换为大型稀疏矩阵乘法,显著提升了执行速度,并能自然地处理不同专家被分配到不同数量 token 的情况。 - 在 Ollama 上请求 Mistral 模型文件:
@dangfutures询问了在 Ollama 上使用的合适 Mistral 模型文件。 - Accelerate/Deepspeed 多 GPU 用户潜在的性能退化:用户
@noobmaster29分享了来自@StasBekman的一条 推文,警告accelerate==0.23(Deepspeed 集成)中存在性能退化问题。建议降级到accelerate==0.22或使用最新的main分支以解决此问题,修复补丁正等待发布。
提到的链接:
来自 Stas Bekman (@StasBekman) 的推文:提醒 Accelerate/Deepspeed 多 GPU 用户:accelerate==0.23(Deepspeed 集成)中存在性能退化,会导致训练速度变慢。修复补丁刚刚合并 - 所以你可以…
▷ #axolotl-dev (37 条消息🔥):
- Axolotl 将集成 MLFlow 用于实验追踪:
@caseus_讨论了在 Axolotl 项目中添加 MLFlow 进行实验追踪。这是由@JohanWork在 Pull Request #1059 中提出的。 - YAML 配置中的系统提示词 (System prompts):围绕在 YAML 文件中为 sharegpt 配置初始系统提示词的讨论。
@dctanner建议这比在所有数据集记录中添加更简洁,而@le_mess分享说他们目前每次都是手动添加。 - Peft 更新修复了 Phi LoRA 问题:
@marktenenholtz发现 Phi LoRA 处理中的一个错误在 peft==0.7.0 的更新中得到了修复。该问题与旧版本 peft 未能正确处理共享内存有关,且 LoRA 模块的识别需要针对 embedding 和 linear 层进行特定处理。 - Axolotl 添加了 Websockets 用于外部任务管理:
@david78901提议为 Axolotl 项目添加 websockets 端点,以允许外部触发和监控任务。@caseus_表示有兴趣将其合并到主项目中。 - Accelerate 版本固定 (Pinning):
@caseus_建议按照@nanobitz的指示将 Accelerate 固定在正确的版本,这是 Pull Request #1080 中强调的一个问题。
提到的链接:
- GitHub Status
- Issues · OpenAccess-AI-Collective/axolotl:欢迎提问。通过在 GitHub 上创建账号为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- GitHub - kmn1024/axolotl: for testing:用于测试。通过在 GitHub 上创建账号为 kmn1024/axolotl 的开发做出贡献。
- pin accelerate for deepspeed fix by winglian · Pull Request #1080 · OpenAccess-AI-Collective/axolotl:参见 https://twitter.com/StasBekman/status/1744769944158712210
- GitHub - dandm1/axolotl: Go ahead and axolotl questions about the API:欢迎咨询关于 API 的问题。通过在 GitHub 上创建账号为 dandm1/axolotl 的开发做出贡献。
- update peft to 0.7.0 by mtenenholtz · Pull Request #1073 · OpenAccess-AI-Collective/axolotl:peft==0.6.0 在保存 LoRA 模型的方式上存在一个归结为 safetensors 的 bug。这在 peft==0.7.0 中已修复。
- be more robust about checking embedding modules for lora finetunes by winglian · Pull Request #1074 · OpenAccess-AI-Collective/axolotl:@mtenenholtz 在 Discord 中提到 phi 有一个更细微的 embedding 模块名称。此 PR 尝试更优雅地处理其他架构。
- Add: mlflow for experiment tracking by JohanWork · Pull Request #1059 · OpenAccess-AI-Collective/axolotl:为 Axolotl 添加 MLFlow 用于实验追踪,参考了 Weight and Bias 的设置方式并尝试遵循相同的模式。已测试更改,一切看起来都很棒。
▷ #other-llms (1 条消息):
leoandlibe: 我使用 exllamav2 的 convert.py 来制作 EXL2 量化模型 😄
▷ #general-help (10 条消息🔥):
- 寻找支持 ChatML 或 chat_template 的聊天 UI:
@le_mess询问是否有开箱即用支持 ChatML 或 chat_template 的聊天界面。作为回应,@nanobitz建议使用 ooba。 - 对测试 gguf 感兴趣:
@le_mess表达了对测试 gguf 的兴趣。@nanobitz推荐了 lm studio 或 ollama,但没有提供 ollama 的具体操作说明。 - 关于 Zero2 训练速度和 GPU 的咨询:
@athenawisdoms询问在两个多 GPU 系统(例如 a6000)之间,一个使用 pcie3.0x16,另一个使用 pcie4.0x16,Zero2 的训练速度是否存在显著差异。该查询的回复未被记录。
▷ #rlhf (3 messages):
- Prompt 策略是 AI 交互的必要条件:用户
@caseus_建议,为了实现最佳的 AI 交互,Prompt 策略是必要的,这涉及格式化 Prompt 以及将之前的轮次合并到输入中。 - Prompt 策略已在实施中:紧接讨论,用户
@xzuyn提到他们已经一直在实施 Prompt 策略。
▷ #community-showcase (1 messages):
- System message 对训练性能没有影响:
@le_mess表示,System message 的内容对训练后模型的性能没有显著影响。用他们的话说,“System message 可以是 ‘ehwhfjwjgbejficfjeejxkwbej’,而性能可能仍然是一样的。”
▷ #shearedmistral (8 messages🔥):
- 引用 Shearing 方法的实现:
@caseus_通过一个 GitHub repository 链接指出了 Shearing 过程中的一个特定步骤。他建议利用该项目 Google Drive 中的预处理数据,但提醒这意味将被绑定到相同的数据集。 - 考虑使用 SlimPajama:
@caseus_思考为了提高去重效果和质量,选择 SlimPajama 而非 RedPajama v2 数据集是否值得。他还观察到 RedPajama v2 不再包含子集 source。 - 对数据集子集的积极反响:对此,
@emrgnt_cmplxty表达了对子集功能的喜爱,并质疑为什么要移除它。 - 可能会转向使用 Slim Pajamas:
@emrgnt_cmplxty建议该项目可能会转向使用 Slim Pajamas。
提及的链接:
- LLM-Shearing/llmshearing/data at main · winglian/LLM-Shearing:预印本:Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning - winglian/LLM-Shearing
- togethercomputer/RedPajama-Data-V2 · Datasets at Hugging Face
HuggingFace Discord Discord 总结
- 新频道与开源库更新:
@lunarflu宣布启动了两个新的讨论频道transformers.js和 ML and cybersecurity,同时庆祝diffusers达到 20,000 个 GitHub stars(来源推文)。此外,vishnu5n 向用户展示了如何针对倾斜检测(skew detection)机器学习模型优化机器学习代码(来源链接)。 - 注意力转向 Attention 与 Self-attention:在 diffusion-discussions 频道中,
@grepolian询问了 attention 和 self-attention 之间的区别,但未收到回复(来源链接)。 - 游戏 AI 技术的进展:
@papasancho在 cool finds 频道讨论了使用 Herika 和 Mantella 在视频游戏中集成 AI,认为这是游戏领域的重大进步(Herika 链接),(Mantella 链接)。 - 解决 Phi-2 行为之谜:在 general 频道,
@admin01234讨论了 Phi-2 模型的一种奇特行为:在给出正确回答后,紧接着会出现与输入无关的随机答案。 - LLM 与 SQL 注入攻击:在 NLP 频道,他们讨论了集成 LLM 的 Web 应用程序可能存在的漏洞,特别是针对 SQL 注入攻击,并引用了 arXiv 上的一篇论文作为参考(来源链接)。
- 关于深度强化学习(Deep Reinforcement Learning)的对话:在 today-im-learning 频道,
@couldhu宣布完成了 Deep RL 课程,而@muhammadmehroz、@gduteaud和@cloudhu等人则提供了关于该课程的见解并分享了课程链接(来源链接)。 - CCTV 查询与倾斜检测:在 computer vision 频道,用户
@iloveh8讨论了为实时 CCTV 使用实现 GPT-V 或 LLAVA,@vishnu5n分享了他们在文档图像倾斜检测方面的工作(来源链接)。
HuggingFace Discord 频道总结
▷ #announcements (1 条消息):
- HuggingFace 阵容新增频道并发布开源更新:
@lunarflu宣布启动了两个新的讨论频道:transformers.js以及 ML 与网络安全的交叉领域。此外,diffusers庆祝其 GitHub star 数达到 20,000 个,并发布了集成 pivotal tuning(参考自@cloneofsimo cog-sdxl)和 prodigy optimizer(参考自kohya's scripts)的新训练脚本,同时实现了与 AUTO1111 的兼容。详情请见 推文。 Transformers.js在 2024 年迎来重大更新:@xenovacom透露了针对 Transformers.js 开发者的重大改进;包括 pipeline 的条件类型、带有代码片段的内联文档,以及特定于 pipeline 的调用参数和返回类型等功能。点击此处了解更多。- MLX 支持从 Hub 直接拉取 Mistral / Llama / TinyLlama safetensors:
@reach_vb确认 MLX 现在可以直接从 Hub 拉取 Mistral/ Llama/ TinyLlama safetensors,包括对所有 Mistral/ Llama 微调模型的支持!更多关于安装的信息请点击此处。 - Gradio 发布 4.13 版本,包含关键修复和兼容性更新:4.13 版本将包含对 Button +
.select()+ Chatbot 的修复、安全补丁以及对 Python 3.12 的兼容性。查看完整的 更新日志。 - 通过推测解码(speculative decoding)实现更快的 Whisper:值得注意的改进是,得益于推测解码,Whisper 的速度提升了 200%。更多信息请见 推文。
提到的链接:
- Linoy Tsaban🎗️ (@linoy_tsaban) 的推文:让我们开启 2024 🚀:🧨 @diffuserslib 中新增的训练脚本利用了来自社区的技术:① pivotal tuning (来自 @cloneofsimo cog-sdxl) ② prodigy optimizer (来自 kohya’s scripts) + …
- Sayak Paul (@RisingSayak) 的推文:🧨 diffusers 在 GitHub 上达到了 20k stars 💫 但和许多人一样,我并不完全迷信这个指标。所以,让我们也看看依赖它的仓库数量以及它们 star 数的总和。…
- Xenova (@xenovacom) 的推文:🚨 我们以针对 Transformers.js 开发者的几项改进开启 2024 年:- 基于任务的 pipeline 条件类型。- 内联文档 + 代码片段。- 特定于 Pipeline 的调用…
- Vaibhav (VB) Srivastav (@reach_vb) 的推文:公告 📣:MLX 现在可以直接从 Hub 拉取 Mistral/ Llama/ TinyLlama safetensors!🔥 只需运行 pip install -U mlx 即可!支持所有 Mistral/ Llama 微调模型!总计超过 20,000 个检查点!…
- Gradio 更新日志:Gradio 更新日志和发布说明
- Vaibhav (VB) Srivastav (@reach_vb) 的推文:Parakeet RNNT & CTC 模型登顶 Open ASR 排行榜!👑 由 @NVIDIAAI 和 @suno_ai_ 带来,Parakeet 击败了 Whisper 并重夺第一。这些模型在商业许可下发布…
- 2023,开源 LLM 之年
- 欢迎 aMUSEd:高效的文本生成图像模型
▷ #general (22 条消息🔥):
-
读书会活动:
@admin01234询问了活动读书会的时间,@lunarflu回复确认本周晚些时候会举行,并在 Discord 线程中进行额外的同步讨论。 -
Machine Learning 课程咨询:
@daksh3551寻求关于 Machine Learning 的结构化课程建议(包括付费和免费)。 -
Phi-2 行为之谜:
@admin01234报告了一个奇怪的现象,Phi-2 模型在输出正确响应后,会接着输出看似随机的内容。 -
对高性能计算环境的需求: 在一段长篇论述中,
@s4vyss表达了在大型项目中使用 Kaggle 和 Google Colab 等免费计算资源的困难,原因是缺乏自动补全、错误调试以及在单个 Notebook 中工作的局限性。该用户想知道是否有其他的 Machine Learning 编码环境,可以为本地编码提供免费的计算能力。 -
使用 StarPII 识别 Header 中的 PII:
@benny0917分享了他尝试使用 Hugging Face 的 StarPII 模型识别 Header 中个人身份信息(PII)的经验。该模型在正确识别依赖上下文的 PII Header 方面表现不佳。
相关链接:
▷ #today-im-learning (7 条消息):
- Mistral-7B-instruct 与 vLLM 的 Benchmark 结果: 用户
@harsh_xx_tec_87517在 LinkedIn 上详细介绍了他们在vLLM上运行Mistral-7B-instruct的 Benchmark 结果,并称其为部署 OSS LLM 的优秀库。详细的 Benchmark 结果可以在他们的 LinkedIn 帖子 中找到。 - 完成 DRL 课程:
@cloudhu宣布完成了 DRL 课程,并收到了@osanseviero的祝贺。 - 关于 DRL 课程的咨询:
@muhammadmehroz表现出对学习 DRL 课程的兴趣。作为回应,@gduteaud和@cloudhu都推荐了 Hugging Face 提供的 Deep Reinforcement Learning Course,该课程可以带你从入门到精通。
相关链接:
欢迎来到 🤗 Deep Reinforcement Learning 课程 - Hugging Face Deep RL Course
▷ #cool-finds (3 条消息):
- 微调像 LLaVa 这样的 VLM: 用户
@silamine询问是否有任何研究论文或 GitHub 仓库能为 微调像 LLaVa 这样的 VLM 提供指导。 - 使用 mermaid 在 Readme 中嵌入图表:
@not_lain推荐了一个名为 mermaid 的工具,用于在 Readme 文件中嵌入图表,并分享了该工具的 GitHub 链接。 - AI 在视频游戏中的集成:
@papasancho分享了他们对 AI 集成到视频游戏 中的看法,认为这是自 Atari 2600 以来的一项重大进步。@papasancho举了 Herika 和 Mantella 作为此类创新的例子,并分享了 Herika 和 Mantella 的 Nexus Mods 页面链接,这两个模组都使用 AI 技术来增强游戏内的互动。
相关链接:
- GitHub - mermaid-js/mermaid: 从文本生成流程图或序列图等图表,方式类似于 Markdown: 从文本生成流程图或序列图等图表,方式类似于 Markdown - GitHub - mermaid-js/mermaid…
- Herika - ChatGPT 伴侣: ‘Herika - ChatGPT 伴侣’ 是一款革命性的模组,旨在将《天际》与人工智能技术相结合。它专门添加了一个追随者 Herika,她的反应和互动…
- Mantella - 用 AI 赋予 NPC 生命: 用 AI 赋予每个 NPC 生命。Mantella 允许你利用 Whisper 进行语音转文本,利用 LLM(ChatGPT、Llama 等)进行文本生成,从而使用你的声音与 NPC 进行自然对话。
▷ #i-made-this (3 条消息):
-
全球最快对话式 AI 亮相:
@vladi9539分享了一个 YouTube 视频,展示了他们尝试创建全球最快对话式 AI 软件的成果。该软件专注于与 AI 的实时对话,其实现方案号称拥有比当前技术更低的对话算法延迟。 -
AlgoPerf 竞赛启动:
@franks22宣布了最近启动的AlgoPerf竞赛,旨在寻找训练当代深度架构的最佳算法。该竞赛面向所有人开放,在两个类别中各提供 25,000 美元的奖金。更多信息可以在他们的 GitHub 仓库 中找到。 -
MusicGen 扩展更新发布:
@.bigdookie向大家介绍了 MusicGen 浏览器扩展新增的功能。这包括 撤销 (undo) 功能以及对 AI 生成音乐进行 裁剪 (crop) 的能力。他们还邀请社区成员测试该扩展(通过 YouTube 链接 分享),并寻求帮助以提升 MusicGen 输出的速度。
提及的链接:
- 来自 thecollabagepatch (@thepatch_kev) 的推文:好的,用于 YouTube 曲目 AI 混音的浏览器扩展现在具有裁剪/撤销功能了。花了很多个 @_nightsweekends,但现在已经准备好迎接十来个用户了。私信我 #buildinpublic https://youtub…
- AI 吐槽他的程序员(我制作了全球最快的对话式 AI):这是我与 AI 进行实时对话。这个实现方案具有我所见过的延迟最低的对话算法…
- GitHub - mlcommons/algorithmic-efficiency: MLCommons Algorithmic Efficiency 是一个基准测试和竞赛,旨在衡量由于训练算法和模型的算法改进而带来的神经网络训练加速。:MLCommons Algorithmic Efficiency 是一个基准测试和竞赛,旨在衡量由于训练算法和模型的算法改进而带来的神经网络训练加速。- GitHub - mlcommo…
▷ #reading-group (5 条消息):
- 拆分数据库以实现高效学习:
@chad_in_the_house建议了一种将数据库分为 开发数据库 (development db) 和 测试数据库 (testing db) 的方法。该过程包括在开发数据库中回答问题,将正确答案连同其文本嵌入 (text embeddings) 和思维链 (chains of thought) 一起存储,并将这些信息用于新问题的 In-context learning。 - SG 活动提案:@lunarflu 表示计划在 明天安排一场活动,但未透露更多细节。
- 邀请在读书小组讨论:
@lunarflu对@bluematcha的话题表示感兴趣,并邀请在下一次 Reading Group 讨论中进行更深入的讲解。 - 变分推理书籍推荐:
@ypbio分享了一本关于 Variational Inference 的书籍信息,该书声称包含对该主题的全面回顾,以及开发世界级基础机器学习专业知识所需的一切。他们附上了该书网站的链接:www.thevariationalbook.com。 - 时区挑战:
@skyward2989对讨论将在对他不便的时间(具体为 凌晨 3 点)进行表示遗憾。
提及的链接:
The Variational Inference Book:一本简明扼要地全面回顾 Variational Inference 的书籍。
▷ #diffusion-discussions (3 条消息):
-
加载并融合 LoRA 权重:
@sayakpaul分享了关于如何将 LoRA 权重加载并融合到基础 UNet 模型中的详细指令。分享的命令包括:pipeline.load_lora_weights()和pipeline.fuse_lora()。 -
关于 Attention 机制的疑问:
@grepolian询问了 attention 和 self-attention 之间的区别,但聊天记录中未提供解释。 -
博客文章讨论高效 LoRA 推理:
@yondonfu发布了最近一篇关于 优化 LoRA 推理 的 Huggingface 博客文章链接,详细阐述了加载 LoRA adapters 和加速推理的高效方法。关键点包括观察到 batching 并没有显著提高 diffusers 的吞吐量,反而使延迟增加了六倍。 -
Diffusers 的 Batching 无效?:
@yondonfu特别关注了 diffusers 的 batching 问题,质疑该技术的实用性,因为在 batch size 为 8 时吞吐量增长微乎其微,而延迟却增加了六倍,并询问了导致这种情况的深层原因。在聊天结束时,这些问题仍未得到解答。
提到的链接:
Goodbye cold boot - how we made LoRA Inference 300% faster
▷ #computer-vision (2 条消息):
- 关于实时 CCTV 使用场景的咨询:用户
@iloveh8发起了关于实现 GPT-V 或 LLAVA 用于实时 CCTV 用途(如防盗检测或婴儿监护)的讨论。 - 分享偏斜检测资源:作为回应,
@vishnu5n分享了他们的工作,该工作对带有各自偏斜度的偏斜文档图像进行建模。详细工作可以在 Kaggle 的这个 链接 找到,这可能为类似的问题陈述提供参考。
提到的链接:
| skew_detection: Explore and run machine learning code with Kaggle Notebooks | Using data from rdocuments |
▷ #NLP (18 条消息🔥):
- LLM 中的 SQL 注入漏洞:
@jryarianto讨论了发展中国家计算资源可能存在的延迟问题,并询问了防御 SQL 注入攻击的策略。他们建议为此使用参数化查询。他们引用了一篇 arXiv 论文,该论文全面检查了 Language Models (LLMs) 可能发生的一种潜在 SQL 注入攻击类型。 - 对话式聊天机器人的开源 LLM 模型建议:
@jillanisofttech征求适合在包含 PDF、txt 和 docs 文件的大型自定义数据集上进行 fine-tuning 的开源 LLM 模型建议。他们需要开发一个能够处理文本和语音输入的对话式聊天机器人,并有兴趣了解构建该应用程序的合适框架。 - 使用 NSQL-2B 模型进行文本生成:
@madi_n询问了在使用 NSQL-2B 模型的文本生成任务中,将max_new_tokens设置为大于 2048 的值的问题。考虑到模型的预定义最大长度,他们寻求关于是否可以增加max_new_tokens的明确答复。 - Fine-tuning Mistral 7B——确定正确的语法:
@denisjannot询问了在 fine-tuning Mistral 7B 时应使用的正确语法,因为在使用训练好的模型时发现了一些异常。@asprtnl_50418提供了帮助,建议始终使用与初始模型训练时相同的 prompt template,并提供了一个指向 End Of String (EOS) token 的链接。 - TTS 任务中 Suno/bark-small 模型的 GPU 使用情况:
@x_crash_提出了一个关于在 Google Colab 上为suno/bark-small模型启用显式 GPU 使用的问题,因为他们注意到该模型似乎没有利用 GPU 资源。他们提供了自己的 Python 脚本来展示其尝试过程。
提到的链接:
- tokenizer_config.json · mistralai/Mistral-7B-v0.1 at main).)
- From Prompt Injections to SQL Injection Attacks: How Protected is Your LLM-Integrated Web Application?: Large Language Models (LLMs) have found widespread applications in various domains, including web applications, where they facilitate human interaction via chatbots with natural language interfaces. I…
▷ #diffusion-discussions (3 条消息):
- LoRA 加载指南:
@sayakpaul分享了通过调用pipeline.load_lora_weights()和pipeline.fuse_lora()将 LoRA 权重加载到基础 UNet 模型中的方法。 - 关于 Attention 机制的问题:
@grepolian提出了关于 Attention 和 Self-Attention 之间区别的问题。(未提供进一步的讨论或回复)。 - 深入探讨 LoRA 推理优化:
@yondonfu引用了 HuggingFace 博客文章 中讨论 LoRA 推理优化的一节。他们指出,该文章解释了在使用 diffusers 进行 Batching 时并不能显著提升性能,且通常会导致更高的延迟。基于这一发现提出了两个问题:- 是否由于吞吐量增益微乎其微且延迟显著增加,使用 diffusers 进行 Batching 通常并不值得?
- 在有足够 VRAM 的情况下,使用 diffusers 进行 Batching 却无法提升性能,这背后的逻辑是什么?
提到的链接:
Goodbye cold boot - how we made LoRA Inference 300% faster
Perplexity AI Discord 总结
- API 和模型停机通知:用户
@phinneasmctipper报告了通过 API 和 API 沙盒访问pplx-7b-online和pplx-70b-online模型时出现停机。用户@monish0612在 #pplx-api 频道报告了一个独立的 500 内部服务器错误。@icelavaman确认了该问题。 - 呼吁改进 AI 回复中的引用格式:
@Chris98建议在 Perplexity 的 AI 回复中用超链接替换数字引用参考。该想法得到了@byerk_enjoyer_sociology_enjoyer的支持。 - 关于免费试用期间订阅计费的说明:
@alekswath询问了在免费试用期间从月度计划切换到年度计划时出现的意外立即计费问题,引发了关于订阅定价的讨论。 - 将 Perplexity 集成为搜索引擎:用户
@bennyhobart想要在 Chrome 中将 Perplexity 设置为默认搜索引擎。@mares1317分享了 Google Web Store 上 Perplexity - AI Companion 扩展的链接。 - 注意到 Claude 2.1 回复的变化:
@Chris98和@Catto评论了 Claude 2.1 语气的转变,他们对 AI 最近的回复感到不满,将其与 GPT Copilot 的风格进行了比较,并表示希望恢复 Claude 2.1 原始的声音。 - 引用来源的问题:在 #pplx-api 频道中,
@hanover188询问了 pplx-70b-online 模型引用来源的能力,@brknclock1215澄清说该模型目前不像 Perplexity App 那样引用来源,并暗示未来可能会有更新,但随后纠正说这目前不在 Perplexity 的路线图中。
Perplexity AI 频道总结
▷ #general (51 条消息🔥):
- Perplexity 模型可能出现故障:
@phinneasmctipper报告在通过 API 和 API sandbox 访问pplx-7b-online和pplx-70b-online模型时遇到 500 错误代码。@icelavaman确认了该问题,并承诺尽管目前处于非工作时间,仍会进行修复。对话链接 - 请求更改回答中的引用格式:用户
@Chris98提出请求,希望将 Perplexity AI 回答中的数字引用替换为超链接。@byerk_enjoyer_sociology_enjoyer表示同意,并得到了@Chris98在其之前提出的相关问题上通过 ⭐ 表情符号的支持。 - 关于订阅定价的疑问:
@alekswath询问为什么在免费试用期间尝试从月度计划切换到年度计划时,被立即扣费 200 美元。他们询问免费试用是否存在问题。 - 将 Perplexity 用作默认搜索引擎:
@bennyhobart询问如何在 Chrome 中将 Perplexity 设置为默认搜索引擎。@mares1317分享了 Google Web Store 中 Perplexity - AI Companion 扩展程序的链接以提供帮助。 - Claude 2.1 回答的变化:
@Chris98和@Catto对 Claude 2.1 最近的回答表示不满,注意到感知上的质量下降,且语气转变得更像 GPT Copilot。他们希望恢复到原始的 Claude 2.1。
提到的链接:
- Application Status
- What is Search Focus?:探索 Perplexity 博客,获取文章、公告、产品更新以及优化体验的技巧。保持关注并充分利用 Perplexity。
- Perplexity - AI Companion:浏览时随时提问
- Reddit - Dive into anything
▷ #sharing (8 条消息🔥):
- 分享 Web 应用程序压力测试资源:
@whoistraian提供了一个关于 Web 应用程序压力测试资源的链接。 - 关于 Perplexity AI 功能的咨询:
@myob171询问 Perplexity AI 是否是一个 AI 搜索引擎。 - 分享 Discord 频道链接:
@mares1317分享了两个 Discord 频道链接,可能包含其他相关讨论。 - 分享 OpenAI 的回应:
@__sahilpoonia__发布了一个关于 OpenAI 如何回应某些查询的链接。 - 赞扬 Perplexity 的日历集成功能:
@clockworksquirrel强调了 Perplexity 如何通过自然语言简化日历管理,这对于有身体残疾的他们尤其有益。他们还提到了工具内复制粘贴功能的实用性。 - 对 Perplexity 表示感谢:
@siriusarchy表达了对 Perplexity 的感激之情。 - 大众汽车接入 ChatGPT:据
@ipsifu称,大众汽车已将 ChatGPT 集成到其车载系统中。
▷ #pplx-api (6 条消息):
-
500 Internal Server Error:用户
@monish0612报告 API 出现了数小时的 500 internal server error。他们是付费用户,希望能尽快解决。 -
PPLX-70b-online 模型的源引用问题:
@hanover188询问 pplx-70b-online 模型是否可以像 Perplexity App 那样引用来源。他们提到在构建需要汇总实时数据并提供可操作来源信息的项目时需要此功能。 -
PPLX-70b-online 中没有直接引用:针对
@hanover188的查询,@brknclock1215提供了一个链接和来源摘要,指出:“不——pplx-70b-online 模型不会像 Perplexity App 那样直接引用来源……增加对事实落地(grounding facts)和引用的支持已列入 Perplexity 未来的路线图。” -
功能不在路线图上?:与之前的信息相反,
@brknclock1215后来纠正说,对事实落地和引用的支持实际上并未列入 Perplexity 的路线图,并提供了另一个 Discord 链接 指向确认此点的讨论。
LAION Discord 总结
-
AI 辩论升温——“乌托邦与否?”:由
@SegmentationFault发起的一场激烈讨论试图剖析反 AI 批评者的观点,结论是他们的立场很大程度上源于道德标榜(virtuous signaling)和不切实际的乌托邦考量。@mkaic进一步补充道,随着 AI 的普及,保障收入这一乌托邦目标将变得更容易实现。用户.undeleted幽默地提出了反 AI 支持者的三步走计划:禁止 AI、保留现有工作、并防止未来技术消除工作岗位。这些断言遭到了@SegmentationFault的抵制,他捍卫了 AI 在提高生产力和全球竞争力方面的作用。 -
披萨是 AI 还是人类?:在持续不断的 AI 讨论中,
@thejonasbrothers为对话注入了一个有趣的视角,轻松地提出了一个问题:“我是一个披萨”这句话到底是不是由 AI 创作的。 -
颠覆性的 AI 训练技巧浮出水面:
@pseudoterminalx在一次深入讨论中介绍了创新的 AI 训练技术,阐述了在选择过程中偏向早期时间步(timesteps)的优势。通过展示使用带有零终端 SNR(zero-terminal SNR)的 Euler 图像所取得的成功结果(其效果超越了之前的 midjourney v6),该用户规避了传统先例,并额外支持同时使用随机裁剪(random crops)和全帧(full frames)。 -
AI 检测器面临信任危机:
@lixiang01对特定 AI 检测器的有效性表示怀疑,认为通过精心构建的 prompts 可以毫不费力地欺骗它。 -
State Space Models 对决 Transformers:
@thejonasbrothers分享的一篇研究论文揭示了随着 MoE-Mamba 的发展,State Space Models 和 Mixture of Experts 相比 Transformers 正占据日益主导的地位。论文可以点击这里访问。 -
生成模型的加水印困境:
@chad_in_the_house重点介绍了一篇基于研究论文 Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models 的博客文章。该文章深入探讨了在保持输出质量和实现 AI 验证的同时,为生成模型加水印所面临的挑战。全文可以在这里找到。 -
HiDiffusion 框架——一个新的可行选择:
@gothosfolly关注到了一个名为 HiDiffusion 的突破性文本生成图像 Diffusion 模型框架,它可以创建高分辨率图像。关于 HiDiffusion 的研究论文可以在这里查看。 -
RAU 模块的具体位置受到质疑:
@gothosfolly还对论文中描述的 HiDiffusion 架构中 SDXL 内 RAU 模块的确切位置提出了疑问。
LAION 频道总结
▷ #general (44 messages🔥):
- 美国 AI 队长与卢德分子联盟 (Captain AImerica and the Luddite League):
@SegmentationFault发起了一场关于反 AI 批评者(尤其是 Twitter 上的活跃分子)观点和计划的热烈辩论。他主要对他们的立场持批评态度,探讨了他们阻止 AI 发展的宏大计划,随后将他们中的大多数人归类为倾向于道德标榜(virtue signaling)和不切实际的乌托邦理想。引用@SegmentationFault的话:“即便某个国家完全禁止 AI,其他国家也不会,那里的公司会更有生产力。”
-
AI 乌托邦 - 香槟美梦:
Mkaic加入了对话,指出了反 AI 激进分子乌托邦梦想中的讽刺之处。@mkaic认为,一个每个人都领钱生存的乌托邦,通过让 AI 完成所有工作比禁止 AI 更容易实现。 -
回到“反 AI 禁令故障”: 在一段略带讽刺的交流中,用户
.undeleted提出了一个他认为代表反 AI 批评者心态的三点计划:禁止 AI、维持当前工作、避免在未来使用技术消除工作。@SegmentationFault反驳道,公司需要保持竞争力,而 AI 提高了生产力,他认为这是一个不可避免的现实。 -
“我是一个披萨” - 人类还是 AI?:
@thejonasbrothers在聊天中开了一个俏皮的玩笑,写下“我是一个披萨”这句话,然后询问这是否是由 AI 编写的,在严肃的聊天氛围中增添了轻松幽默的基调。 - 使用
Pseudoterminalx的 AI 训练技巧: 用户@pseudoterminalx在一场深入的技术讨论中揭示了一些 AI 训练技巧。他们讨论了在早期时间步(early timesteps)进行训练的好处,对选择早期时间步的概率使用了 50 倍的偏置(bias)。他们指出,这并没有将其他时间步从池中剔除,但显著地改变了权重。他们通过分享几张图片展示了这些技术的有效性,其中包括一张来自带有 zero-terminal SNR 的 Euler 的图片,并断言其质量优于之前的 Midjourney v6。最后,他们还分享了另一个技巧——在 2160p 蓝光转录内容的随机裁剪(random crops)和全帧(full frames)混合上进行训练。
提到的链接:
Phase1 Collect Underpants GIF - Phase1 Collect Underpants Gnome - Discover & Share GIFs: 点击查看 GIF
▷ #research (18 条消息🔥):
- AI 检测器面临的不可能任务:
@lixiang01对特定检测器的有效性表示怀疑,指出它几乎不可能奏效,因为“这种检测器很容易被精心编写的 prompt 生成的内容所欺骗。” - State Space Models 挑战 Transformers:
@thejonasbrothers分享了一篇关于 State Space Models (SSMs) 和 Mixture of Experts (MoE) 优于 Transformers 的研究论文,重点介绍了 MoE-Mamba 的开发。该模型在保持 Mamba 相对于 Transformer 的推理性能优势的同时,展现了更好的性能。论文可以从此处访问。 - 生成式模型中的水印挑战:
@chad_in_the_house介绍了一篇讨论生成式模型强水印局限性的博客文章,认为即使创作者对其输出添加水印,也很难在保持 AI 可验证性的同时维持质量。该文章基于名为 Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models 的论文,可直接在此处访问。 - 关于 HiDiffusion 框架的见解:
@gothosfolly关注了一篇关于 HiDiffusion 的论文。这是一个无需微调(tuning-free)的框架,旨在让预训练的 text-to-image 扩散模型能够生成高分辨率图像。论文可以在此处找到。 - 关于 RAU 模块的疑问:
@gothosfolly寻求澄清,即 HiDiffusion 架构中用于 SDXL 的 RAU 模块是否比论文附录中描述的位置晚了一个模块。
提到的链接:
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts:State Space Models (SSMs) 已成为序列建模领域的有力竞争者,挑战着 Transformers 的主导地位。同时,Mixture of Experts (MoE) 显著地……
- HiDiffusion: Unlocking High-Resolution Creativity and Efficiency in Low-Resolution Trained Diffusion Models:我们介绍了 HiDiffusion,这是一个由 Resolution-Aware U-Net (RAU-Net) 和 Modified Shifted Window Multi-head Self-Attention (MSW-MSA) 组成的无需微调框架,旨在让预训练的大型 text-to-image……
- Watermarking in the sand:水印通常被吹捧为 AI 生成模型的一项重要安全考量。关于 AI 安全的新行政命令将其强调为打击“AI 驱动的欺诈和欺骗……”的关键工具。
Mistral Discord 总结
- Tinybox 揭晓:在关于 Tinybox 的讨论中,
@digitalbo解释说它是一个专为家庭运行设计的小型“超级计算机”。提供的 链接 提供了更多关于该产品的信息。 - Mistral 与网页浏览的脱节:当
@ajkuba询问 Mistral 是否可以用于网页浏览时,@sublimatorniq澄清说,与 ChatGPT Plus 不同,Mistral 没有浏览功能或 “function calling”(函数调用)。 - 在 Raspberry Pi 5 上部署模型的探索:
@psdc4171询问如何在 Raspberry Pi 5 上运行 7b 模型。@ethux提供了与 Raspberry Pi 兼容的 GGUF 模型资源,以及来自 HuggingFace 的模型建议,如 OpenChat 3.5 1210 和 Mistral 7B Instruct v0.2,以及来自 ooobabooga 的 GitHub 仓库 和 HuggingFace 的 chat-ui GitHub 仓库 的 WebUI。 - Mixtral 46B 在 AWS 上的部署问题:
@sa_code在 g5.48xlarge AWS 实例上部署未量化的 Mixtral 46B 时遇到问题,即使在使用--tensor-parallel-size 8进行分片后,vllm仍无法将模型加载到内存中。讨论中未找到解决方案。 - 微调困难与探索:对话围绕使用 4090 微调 Mistral 时面临的问题 (
@wilzh40)、关于单张 A100 是否足以进行全量 Mistral 7b Instruct 训练的疑问 (@dinonst74)、使用特定领域聊天日志进行微调的有效性 (@nickbro0355),以及在为 text to SQL 训练 Mistral 7b Instruct 时的挣扎 (@dinonst74)。@adriata3描述了他们使用 QLoRA 4-bit 进行微调的失败尝试。 - 关于 Mixtral of Experts 的论文发布:
@sophiamyang分享了一篇关于 Mixtral of Experts 的新论文 https://arxiv.org/pdf/2401.04088.pdf。 - 致敬 Vanna,SQL 助手:
@zain_vanna宣布在 Vanna 中加入了 Mistral 集成,这是一个在 GitHub 仓库 中介绍的、使用 RAG 为数据库生成 SQL 的 Python 包。 - 对 Mistral API 延迟的不满:社区用户表达了对 Mistral API 响应时间波动的担忧,有时响应需要 5-9 秒。Mistral 团队成员
@lerela表示,他们正在积极致力于缩短响应时间。此外,还讨论了关于 Memstral 加入类似于 OpenAI “function” token 功能的建议 (@astel123457)。
Mistral 频道总结
▷ #general (13 条消息🔥):
- 什么是 Tinybox?:针对
@gbourdin关于 Tinybox 的提问,@digitalbo将其定义为专为家庭运行设计的小型“超级计算机”。@digitalbo还分享了一个链接以获取更多信息。不过,其成本被指出为 15,000 美元。 - Mistral 与网页浏览:
@ajkuba询问 Mistral 是否可以用于网页浏览。@sublimatorniq澄清说,与 ChatGPT Plus 不同,Mistral 没有浏览功能,也没有 “function calling”。 - 项目指导请求:软件工程师兼初创公司创始人
@saga04请求关于启动为儿童创建“世界老师”项目的建议。 - 使用开源模型生成代码:
@xquietude询问了 OpenAI 最后一个开源 (7B) 模型生成代码的能力。@.superintendent确认了该模型生成代码的能力,而@sophiamyang建议 Mistral 8x7B 可能更适合此用途。
▷ #deployment (9 条消息🔥):
- 在 Raspberry Pi 5 上运行 7b: 用户
@psdc4171寻求关于如何在他们的 Raspberry Pi 5 上运行 7b 的建议。@ethux提供了一系列资源,包括来自 此 GitHub 仓库 兼容 Pi 的 GGUF 模型,来自 HuggingFace 的不超过 4 bits 的模型建议,例如 OpenChat 3.5 1210 和 Mistral 7B Instruct v0.2,以及来自 ooobabooga 的 GitHub 仓库 和 HuggingFace 的 chat-ui GitHub 仓库 用于轻松测试的 WebUI。 - 在 AWS 上部署未量化的 Mixtral 46B 时出现错误:
@sa_code尝试使用 g5.48xlarge 实例在 AWS 上部署未量化的 Mixtral 46B,并遇到了vllm无法将模型加载到内存中的问题,即使模型使用了--tensor-parallel-size 8进行分片。@ethux表示不确定,称 192GB VRAM 应该足以支持该操作。@sa_code怀疑问题可能出在vllm包上。
提到的链接:
- GitHub - ggerganov/llama.cpp: Port of Facebook’s LLaMA model in C/C++: Facebook LLaMA 模型的 C/C++ 移植版。通过在 GitHub 上创建账号为 ggerganov/llama.cpp 的开发做出贡献。
- TheBloke/openchat-3.5-1210-GGUF · Hugging Face
- TheBloke/Mistral-7B-Instruct-v0.2-GGUF · Hugging Face
- GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models.: 用于大语言模型的 Gradio Web UI。支持 transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。
- GitHub - huggingface/chat-ui: Open source codebase powering the HuggingChat app: 驱动 HuggingChat 应用的开源代码库。通过在 GitHub 上创建账号为 huggingface/chat-ui 的开发做出贡献。
▷ #finetuning (13 messages🔥):
- 寻求使用 4090 进行 Mistral 微调的成功经验:
@wilzh40询问是否有人仅使用 4090 成功完成了 Mistral 微调,以及是否有人仅将其用于推理。@adriata3回复称,虽然他们尝试了使用 QLoRA 4-bit 进行微调,但结果并不理想。 - 单台 A100 是否足以进行全量 Mistral 7b Instruct 训练:用户
@dinonst74询问,对于非 4-bit 和 LoRA 的 全量 Mistral 7b Instruct 训练,40 GB 的单台 A100 是否足够,还是需要 80GB 版本。 - 关于根据聊天记录进行微调的好奇:
@nickbro0355寻求关于使用特定领域聊天记录微调模型的有效方法的建议,想知道从用户认可的聊天记录中微调是否会有很大收益,还是自己创建微调信息更好。 - vLLM 推理详解:
@wilzh40询问@adriata3在 vLLM 上进行推理是什么意思。作为回应,对方分享了 GitHub 上 vLLM 项目的链接。 - 苦于训练 Mistral 7b Instruct 以实现 Text to SQL:
@dinonst74分享了他们作为微调新手的经历,他们正尝试针对 mssql (T-SQL) 语法生成微调 Mistral 7b Instruct 以实现 Text to SQL。尽管创建了自定义数据集并在 A100 上运行了 6000 个 segments,但他们对结果并不满意,并寻求改进建议。讨论中包含了指向他们在 Hugging Face 上的自定义数据集、在 Google Colab 上的处理过程以及在 wandb 上的项目结果的链接。
提到的链接:
- GitHub - vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs:一个高吞吐量且显存高效的 LLM 推理和服务引擎。
- dnovak232/sql_create_context-v4-mssql-instruct · Datasets at Hugging Face
- Google Colaboratory
- dino232:Weights & Biases,机器学习开发者工具。
▷ #announcements (1 messages):
sophiamyang: 关于 Mixtral of Experts 的新论文:https://arxiv.org/pdf/2401.04088.pdf
▷ #showcase (3 messages):
- 不再等待:
@gbourdin对在等待名单上待了数天且网站上没有额外信息表示沮丧。@joselolol.向他们保证,他们正在为正式发布做准备,并乐于提供早期访问权限 (early access)。 - 你好,Vanna:
@zain_vanna宣布将 Mistral 集成到 Vanna 中,这是一个利用 RAG 为数据库生成 SQL 的 Python 包。随附了 GitHub 仓库的链接。
提到的链接:
GitHub - vanna-ai/vanna: 🤖 Chat with your SQL database 📊. Accurate Text-to-SQL Generation via LLMs using RAG 🔄.:🤖 与你的 SQL 数据库聊天 📊。通过 LLM 使用 RAG 进行准确的 Text-to-SQL 生成 🔄。- GitHub - vanna-ai/vanna
▷ #la-plateforme (7 条消息):
- 对 Mistral API 等待时间的担忧:用户
@alimsss提出了关于 Mistral API 等待时间波动的问题,响应有时需要 5-6 秒,有时几乎瞬间到达。@michaelwechner建议这可能是由于高峰时段流量导致请求排队,而@casper_ai分享了类似的经历,等待时间长达 9 秒。 - Mistral 团队对 API Latency 担忧的回应:Mistral 团队成员
@lerela回应了这一问题,表示他们正在积极致力于缩短响应时间。 - 关于实现本地函数的建议:用户
@astel123457讨论了 Mistral 整合类似于 OpenAI “function” tokens 功能的可能性,这将允许调用本地函数并根据该函数的输出返回响应。这将使 Bot 在编码任务中具有更大的通用性。 - 用户关于 API Latency 的体验:
@sublimatorniq和@casper_ai讨论了他们在 API latency 方面的体验。两人都遇到了不同范围的响应时间,@sublimatorniq评论说,更快的响应时间所展示出的潜力让人对未来充满希望。
LangChain AI Discord 总结
- 待解答的 LangChain 问题:
@aaravvv__和@rajvir3分别询问了 Pinecone 中的时序图以及langchain/chat_models/messages在 node_modules 中的可用性前景,引发了关于 LangChain 工具的讨论。 - 重量级对决:BM25Retriever vs. 大文档:
@tigerinus一直在努力解决在大量磁盘存储文档上使用BM25Retriever的问题,这是一个亟待解决的问题。 - 用代码化解危机!:
@uvizc_43278报告说,由于text-davinci-003模型被弃用,他的LangChain RetrievalQA.from_chain_type应用崩溃了,但他已经准备好了解决方案。对于遇到类似问题的任何人来说,这可能是一个有用的修复方法。 - Llamafile,LangChain 的英雄?:
@rawwerks兴奋地概述了 llamafile 在简化跨多个 OS 的 LLM 部署方面的潜力,暗示了 LLM 新时代的到来。 - 为多重嵌入(Multi-Embeddings)奠定基础:用户
@dejoma发起了讨论,旨在寻找一种输入和输出包含多个 embedding 的理想结构。
LangChain AI 频道总结
▷ #general (28 条消息🔥):
- 序列图加载查询:
@aaravvv__询问是否有办法使用 LangChain 在 Pinecone 中加载序列图(sequence diagram)。 - 在大文档上使用 BM25Retriever 的问题:
@tigerinus寻求关于在磁盘海量文档上使用BM25Retriever的经验和帮助。 - 2024 年英国 LLM, ML 和 NLP 会议:
@stuartjatkinson询问 2024 年英国有哪些关于 LLM, ML, NLP 的优质会议。 - LangChain 导入错误:
@azharudeen_02613在从langchain.chains.question_answering使用import load_qa_chain时遇到错误,报告了一个关于抽象类BaseLanguageModel的验证错误。 - LangChain JS 导入问题:
@rajvir3报告了在 LangChain JS 中导入import { HumanMessage, SystemMessage } from "langchain/chat_models/messages";时的问题,收到了ERR_PACKAGE_PATH_NOT_EXPORTED错误消息,并确认 node_modules 中不存在langchain/chat_models/messages。 - llamafile 在 LLM 中的潜力:
@rawwerks表达了 llamafile 在多操作系统上部署微调模型方面的巨大影响力,暗示它可能成为 LLM 领域的游戏规则改变者。 - 弃用模型问题:
@uvizc_43278报告称,由于text-davinci-003模型被弃用,他使用 LangChainRetrievalQA.from_chain_type的应用程序停止工作,并提供了该问题的解决方案。 - LangChain Agents 与 Assistant API 的比较:
@sheldada和@evolutionstepper进行了对话,讨论了 LangChain Agents 与 assistants API 之间的区别和效率。 - Assistant 的消息线程问题:
@zainsheikh在使用 assistant invoke 命令时遇到了 thread ID 的问题,报告称系统创建了新的 thread ID,而不是将消息添加到指定的 thread ID 中。 - 双周发布说明链接失效:
@aaronsmith4931报告订阅双周发布说明的链接已失效,并寻求帮助。 - Python 和 JavaScript 导入错误:
@rajvir3报告在尝试导入 Python 和 JavaScript 版 LangChain OpenAI 时遇到错误。@hasan_34148建议使用pip install langchain-openai解决了该问题。
提到的链接:
- 在 Docker 中结合 Traefik 使用 Langchain 和 FastAPI [含代码]:关于如何将 LangChain 与 FastAPI 结合使用的教程。
- LangChain 新闻简报:注册以获取我们的双周更新!
- Issues · Mozilla-Ocho/llamafile:通过单个文件分发和运行 LLM。通过在 GitHub 上创建账号为 Mozilla-Ocho/llamafile 的开发做出贡献。
▷ #langserve (6 条消息):
- history 变量的 KeyError 漏洞:
@cryptossssun指出在修复一个错误后,出现了一个与 history 变量相关的新 KeyError。 - 征求模型配置建议:
@pgpaul161201感谢<@1033432389516546158>的贡献,并询问是否有一种更简便的方法允许用户处理 LLM 后端配置设置,如 API key、endpoint 和组织名称。 - 需要潜在示例:
@a404.eth请求一个与当前对话相关的示例。 - 通过 Passthrough 和 Pydantic 指定输入类型:
@veryboldbagel就如何在 LangChain chain 中指定输入类型提供了建议,并确认了 schema 健全性检查的重要性。他们分享了来自 langserve 的 代码片段 以供参考。 - 使用 Pydantic 进行动态字段配置:
@veryboldbagel建议了一种使用 Pydantic 通过列出字段及其类型来动态生成模型配置的方法,特别是通过继承 ChatModel 子类。他们提供了一个演示该技术的代码片段。
提到的链接:
langserve/examples/passthrough_dict/server.py at main · langchain-ai/langserve:LangServe 🦜️🏓。通过在 GitHub 上创建账号为 langchain-ai/langserve 的开发做出贡献。
▷ #share-your-work (3 messages):
- LangChain FastAPI Starter 发布:用户
@evolutionstepper分享了一个 LangChain FastAPI Starter 的 GitHub 仓库。 - LangChain FastAPI Starter 教程上线:
@evolutionstepper还分享了一个名为 Langchain with FastAPI in Docker with Traefik [Code Included] 的 YouTube 教程,提供了关于 如何将 LangChain 与 FastAPI 结合使用 的指导。 - 寻求 Multi-Embeddings 解决方案:用户
@dejoma发起了一场讨论,寻求关于 输入和输出包含多个 embedding 结构的建议。提到的一个具体用例是为过大而无法用单个 chunk 表示的视频寻找最佳匹配,因此必须将其划分为多个 chunk。
提到的链接:
Langchain with FastAPI in Docker with Traefik [Code Included]:关于如何将 LangChain 与 FastAPI 结合使用的教程。
▷ #tutorials (1 messages):
- 讨论用于匹配大视频的 Multi-Embedding 结构:
@dejoma提出了一个关于构建支持输入和输出多于一个 embedding 机制的问题。他特别感兴趣于设计一种解决方案,以找到无法用单个 chunk 表示的大型视频文件的最佳匹配。
LlamaIndex Discord Discord Summary
- 轻松部署:
@wenqi_glantz发布了一份详细指南,介绍如何使用 Terraform 和基于@github Actions的自动化 CI/CD 流水线将@llama_index应用部署到 AWS Fargate。点击查看指南。 - Hackathon 盛会:
@llama_index将于今年 2 月 举办首场线下 Hackathon,奖金超过 4,000 美元。该活动欢迎 RAG 爱好者在未知项目中进行协作。注册详情请点击此处。 - 简化结构:
@andrejusb分享了一个实用的视频教程,介绍如何使用 Pydantic 类 配合@OLLAMA从发票中提取结构化 JSON。欲了解更多信息,可以 在此观看视频。 - RAG 与自由职业者:关于自由职业者为企业构建 Retriever-Augmented Generation (RAG) 系统的可行性和成本展开了热烈讨论。
@.kamja、@lolipopman和@mr.dronie发表了看法,指出尽管原型制作简单,但生产环境的实现却非常复杂。 - LlamaIndex 集成咨询:
@jace93和@sridhar_10158分别询问了将 Sqlite-vss 和 DeepInfra 与 LlamaIndex 集成的可能性。 - LlamaIndex 学习资源:
@asdw2.发布了关于 LlamaIndex 课程和学习资源的查询。 - RAG 进展:解决 RAG 局限性的策略以及对
@bushdid420提供的深入见解的赞赏是 AI 讨论的关键亮点。重要的见解包括通过文档摘要和 chunking 来解决语言模型 context windows 的限制。这是分享的论文。 - 游戏规则改变者 Llamafile:由于能够在 6 种不同的 OS 中部署微调模型,
@rawwerks称赞 llamafile 是一个游戏规则改变者,但遗憾的是该团队对添加 RAG 功能或 Python 支持缺乏兴趣。相关的 GitHub issue 已被标出。 - 处理上下文:
@bushdid420引发了关于 LLM 处理长文本上下文挑战的讨论。文中强调了由于关键事实位于上下文文档中间部分而导致的性能下降,并 提供了一个可能的解决方案。
LlamaIndex Discord 频道总结
▷ #blog (3 条消息):
- 在 AWS Fargate 上简化部署 LLM 应用:
@wenqi_glantz分享了一份分步指南,介绍如何使用 Terraform (@HashiCorp) 以及通过@github Actions实现的自动化 CI/CD 流水线,将@llama_index应用部署到 AWS Fargate 服务中。详细的 教程文章请点击此处。 - LlamaIndex 首场线下黑客松:
@llama_index将于 2 月 2 日至 4 日 组织他们的 首场线下黑客松,旨在汇聚 RAG 爱好者,共同协作开发令人兴奋的新项目。该活动提供超过 4,000 美元的奖金。活动注册详情请点击此处。 - 从 LLM 获取结构化输出:
@andrejusb分享了一个教学视频,解释了如何使用@OLLAMA运行本地模型,并使用 Pydantic 类 从发票中输出结构化的 JSON。观看 视频教程请点击此处。
提到的链接:
▷ #general (22 条消息🔥):
- 构建 RAG 系统的自由职业:
@.kamja探讨了为企业构建检索增强生成 (RAG) 系统的自由职业领域及其相关成本。这一咨询也引起了@lolipopman和@mr.dronie的兴趣,他们表示原型设计很简单,但生产环境的实现非常复杂。 - 了解新项目中的文件兼容性:
@pichart正在寻求有关最近发现的一个项目可以理解的所有文件类型的信息。 - LlamaIndex 与 Sqlite-vss 的集成:
@jace93提出了关于是否可以将 LlamaIndex 与 Sqlite-vss 结合使用的疑问。 - 理解 LongContextReorder:
@langzeitstudent_41429对 LongContextReorder 的工作原理很感兴趣,特别是如何衡量每个文档的相关性以进行重新排序。 - 在 create-llama TS 中加入用户反馈:
@ballwave正在使用 create-llama TypeScript,并好奇是否有已知的方法可以将用户反馈集成到应用中(例如对答案的点赞/点踩以及书面评论),以避免冗余。 - 在 LlamaIndex 中使用 LangChain ToolKit 的可能性:
@7leven和@cheesyfishes探讨了是否可以将 LangChain ToolKit 作为工具在 LlamaIndex 中使用。 - 在 LlamaIndex 中集成 Mistral 模型:
@sridhar_10158寻求帮助以在 LlamaIndex 中集成 Mistral 模型,并展示了具体的参数。 - 了解 ColBERTv2 的存储需求:
@wizboar询问 ColBERTv2 是否可以使用向量存储,或者是否必须将数据加载到 RAM 中。 - llama 文件中的依赖版本不匹配:
@pveierland注意到 OpenAI 依赖版本不匹配。pyproject.toml列出的版本是openai = ">=1.1.0",而poetry.lock中的版本是openai = ">=0.27.8"。 - 构建带有文档引用的 RAG:
@erizvi正在开发一个文档引用其他文档的 RAG 系统。他们正在使用 OpenAI 聊天引擎,并试图弄清楚如何将引用的文档包含在提供给 LLM 进行合成的上下文中。@erizvi也提出了一个可能的解决方案。 - DeepInfra 与 LlamaIndex 的集成:
@sridhar_10158询问是否有人尝试过将 DeepInfra 与 LlamaIndex 集成。 - 寻找学习 LlamaIndex 的课程:
@asdw2.有兴趣寻找任何可以提供 LlamaIndex 学习指导的优质课程。
▷ #ai-discussion (9 条消息🔥):
- 解决 RAG 局限性的策略:
@bushdid420分享了关于各种策略的见解,包括文档摘要和分块(chunking),以解决 RAG 领域中常见的语言模型因上下文窗口(context windows)有限而无法理解所有添加信息的问题。一个重要的结论是,尽管上下文窗口在扩大,但在上下文中间部分维持信息的重要性仍然具有挑战性。 - Llamafile - LLM 界的 NGINX:
@rawwerks称赞 llamafile 是一个改变游戏规则的工具,可以在 6 种不同的操作系统上即时部署微调后的模型。然而,正如 GitHub issue 中所强调的,llamafile 团队对添加 RAG 功能或 Python 支持不感兴趣。他提议将 LlamaIndex 和 llamafile 结合起来,可以实现一种免费且私有的高级 RAG 范式。 - 使用 OpenLLM 和 LlamaIndex 开发智能系统:
@andysingal分享了一篇 Medium 文章,探讨了开源大语言模型(LLMs)的兴起,以及 OpenLLM 和 LlamaIndex 等工具如何重塑了开发者与这些模型的交互方式。 - 解决长上下文中的内容可访问性:
@bushdid420进一步讨论了使用 LLM 处理长文本上下文的挑战,指出位于上下文文档中间部分的关键事实往往会导致性能下降。他建议在文档《Dealing with Long Contexts: LLMs - How to Find What’s in The Middle》中可以找到一个可能的解决方案。 - 对富有洞察力的讨论表示感谢:
@benjaminbascary对@bushdid420提供的关于 LLM 上下文处理的深入见解表示感谢,表明了该对话的价值。
提到的链接:
- Building Intelligent Systems with OpenLLM and LlamaIndex using Phi-2:Ankush k Singal
- Support uploading more file formats · Issue #149 · Mozilla-Ocho/llamafile:你好,有没有办法自定义 UI 和输入?例如,目前 UI 允许上传图像,但我希望更新它以支持 CSV 和 PDF 格式。如果能告知在哪里…
- Dealing with Long Contexts LLMs: How to Find What’s in the Middle:随着语言模型不断进化以摄取更长的文本上下文,一个新兴的问题对其现实世界的可靠性提出了挑战——这些模型真的能理解所有添加的内容吗……
- LongContextReorder - LlamaIndex 🦙 0.9.28.post2
DiscoResearch Discord 摘要
- Mixtral 实现论文发布:Sebastian.bodza 宣布 Mixtral 的论文已在 Arxiv 上发表。
- TACO:代码检索的热门讨论话题:@sebastian.bodza 重点介绍了 TACO 数据集,暗示其在代码检索任务中的潜在用途,并引发了关于创建“难负样本 (hard negatives)”的讨论。@bjoernp 和 @philipmay 等成员提出了不同的策略,如使用“劣质模型”、用于代码相似度的 BM25 以及模型排列。
- 合成数据的伟大第三帝国?:论坛讨论异常激烈,@thewindmom 和 @bjoernp 讨论了合成数据生成对模型质量的可能影响以及数据策展 (data curation) 的重要性,后者主张在嵌入模型 (embedding models) 中对学习到的数据进行结构化收集。
- 模型故障排查:@philipmay 询问了一个声称在德国数据集上 MRR@10 达到 0.9139 的模型,引发了一系列关于特定模型问题的提问。
- Colbert 结合 SQuAD2.0 与 LLM 微调数据集:@thewindmom 分享了 SQuAD2.0 的土耳其语机器翻译版本,用于训练 Colbert 模型,并介绍了一个包含热门指令微调数据集的 GitHub 仓库。
- E5-mistral-7b-instruct 加入讨论:@aiui 提出了关于 E5-mistral-7b-instruct 模型量化权重的问题。@sebastian.bodza 对该模型的性能表示保留,但建议可以参考 AWQ 的 pip 项目中的教程进行量化。
- 用于代码检索的 Python DPO 数据集引起共鸣:@bjoernp 展示了 Jon Durbin 在其 推文 中提到的使用 Python DPO 数据集进行代码检索任务的方法,该方法将 Vezora/Tested-22k-Python-Alpaca 的 “chosen” 响应作为正样本,并将 13b/7b 模型的生成结果作为 “rejected” 响应。
DiscoResearch 频道摘要
▷ #mixtral_implementation (1 条消息):
sebastian.bodza: Mixtral 的论文已发布:https://arxiv.org/abs/2401.04088
▷ #embedding_dev (16 messages🔥):
- 讨论用于代码检索任务的 TACO Dataset:
@sebastian.bodza分享了 TACO Dataset,并建议它可能对代码检索任务有用,因为它包含每个问题的多个代码解决方案。@bjoernp强化了这一观点,并想知道通过让 bad model 编写代码来创建 hard negatives 是否是一种有效的策略。讨论随后展开,@philipmay提出了创建 hard negatives 的替代方案,包括用于代码相似性的 BM25 算法和模型排列。 - 关于模型性能的问题:
@philipmay询问了一个在德国数据集(German Dataset)上 MRR@10 达到 0.9139 的特定模型。 - 关于合成数据生成:
@thewindmom引用了一个有价值的观点,强调在没有新的外部知识的情况下,合成数据可能会导致质量恶化,并强调了数据策展(data curation)的重要性。@bjoernp针对 embedding models 的情况表示反对,指出需要对已经学习的数据进行结构化收集。 - 使用 SQuAD2.0 训练 Colbert 模型以及用于 LLM 微调的数据集:
@thewindmom分享了一条关于将 SQuAD2.0 机器翻译成土耳其语以用于 Colbert 模型训练的 推文,以及一个作为热门指令微调数据集快速指南的 GitHub 仓库。 - E5-mistral-7b-instruct 模型的问题和看法:
@aiui询问是否可以在任何地方找到 E5-mistral-7b-instruct 模型 的量化权重。@sebastian.bodza对该模型的性能(考虑到其参数量)表示怀疑,但也建议该模型可能可以借助 AWQ 的 pip 项目中的教程进行量化。 - 用于代码检索的 Python DPO 数据集:
@bjoernp分享了 Jon Durbin 的一条 推文,展示了使用 Python DPO 数据集进行代码检索任务的类似方法,将 Vezora/Tested-22k-Python-Alpaca 中的项作为 “chosen” 回答,同时将 13b/7b 模型的生成内容作为 “rejected” 回答。
提及的链接:
- Jon Durbin (@jon_durbin) 的推文:🚢 Python DPO 数据集。该数据集使用来自 Vezora/Tested-22k-Python-Alpaca 的项作为 “chosen” 回答,并使用 13b/7b 模型的生成内容作为 “rejected” 回答(假设较差,未经过排名/验证)。https://hugg…
- BAAI/TACO · Hugging Face 数据集
- GitHub - Zjh-819/LLMDataHub:热门指令微调数据集的快速指南:一个关于热门指令微调数据集的快速指南(特别是针对当前趋势)。
- intfloat/e5-mistral-7b-instruct · Hugging Face
Latent Space Discord 摘要
- CoPilot 的新时代:@guardiang 在一段名为 “Copilot Prompt Engineering: 3 UI Frameworks, 2 AI Agents, 1 Coding Assistant (AIDER CCC)” 的 YouTube 视频中提供了关于 AI 编程的新视角,重点在于“以飞快的速度”增强工程能力。
- 寻找检索增强生成 (RAG) 文档集:围绕 @dgross211 关于 RAG 项目适用文档集的查询展开了对话,@swizec 回应并询问了所需文档的具体性质。
- R1,下一个大事件?:为了激发对 R1 设备的更多兴趣,@mdcker 分享了一个介绍这一神秘技术的 Keynote 演示文稿。
- Few-Shot Prompting 领域的进展:@henriqueln7 指向了 openai-python 的一份 GitHub 文档,该文档提倡在 Few-Shot Prompting 中使用 ‘system’ 角色。
- 简化 AI Assistant 的评估:@henriqueln7 发起了一个话题,旨在寻找简单直接的 AI Assistant 评估指标资源,并指出需要比 OpenAI Evals 更简单的替代方案。
- LLM 状态机交付成果:@davidkpiano 胜利地宣布在 langgraph 项目中成功使用了 LLM 状态机,并提供了其 GitHub 仓库作为参考。
- 官方 OpenAI API 受到关注:@swyxio 在 GitHub 上推荐了 openai-python 库,这是使用官方 OpenAI API 的重要资源。
- Mixture of Experts (MoE) 方法助力 Phi-2 获胜:@swyxio 通过一条推文分享了来自 @maximelabonne 的消息,关于他们使用 phi-2 的 MoE 模型取得的成功,创建了高效的
Phixtral,可在 Hugging Face 和 Hugging Face 上获取。 - 海量 Language Model 阅读清单发布:对于热衷研究的人员,@eugeneyan 分享了一份 Language Model 阅读清单,汇集了 40 多篇论文,同时欢迎通过其 GitHub 仓库提交建议和 Issue。
- Mixtral 受到关注:除了讨论的其他模型外,@swyxio 还强调了另一个模型
Mixtral的重要性。
Latent Space 频道摘要
▷ #ai-general-chat (11 条消息🔥):
- 不同视角下的 CoPilot:
@guardiang推荐了一个关于以独特方式利用 AI 进行编程的 YouTube 视频,标题为 “Copilot Prompt Engineering: 3 UI Frameworks, 2 AI Agents, 1 Coding Assistant (AIDER CCC)”。该视频旨在快速提升工程能力。 -
寻求 RAG 文档集:
@dgross211征求关于为 Retriever-Augmented Generation (RAG) 项目寻找文档集的建议,并由此引发了讨论。@swizec询问了所需文档的具体性质。 - R1 设备发布会介绍:
@mdcker分享了名为 R1 的设备的 发布会演讲 链接。 -
Few-Shot Prompting 探索:
@henriqueln7分享了一个 openai-python 的 GitHub 文档 链接,揭示了 ‘system’ 角色是 Few-Shot Prompting 的推荐角色。 -
寻求 AI Assistant 评估材料的帮助:
@henriqueln7寻求一些简单的材料建议,以帮助评估生产环境中的 AI Assistant。他们提到已经查看过 OpenAI Evals,但正在寻找更简单的资源。 -
LLM 状态机取得成功:
@davidkpiano分享了名为 langgraph 项目的 GitHub 仓库,表示他们在 LLM (Large Language Model) 状态机方面取得了成功。 - OpenAI Python 库亮点:
@swyxio分享了 GitHub 上 openai-python 库 的链接,这是官方 OpenAI API 的库。
提到的链接:
- rabbit keynote on Vimeo
- 01-rtk-query-generation.md:GitHub Gist:即时分享代码、笔记和代码片段。
- openai-python/chatml.md at logankilpatrick-patch-1 · openai/openai-python:OpenAI API 的官方 Python 库。通过在 GitHub 上创建账户来为 openai-python 的开发做出贡献。
- Copilot Prompt Engineering: 3 UI Frameworks, 2 AI Agents, 1 Coding Assistant (AIDER CCC):像在未来一样编程。这是快速提升工程能力的最佳方式。在这段开创性的视频中,我们深入探讨了结对编程…
- GitHub - langchain-ai/langgraph:通过在 GitHub 上创建账户来为 langchain-ai/langgraph 的开发做出贡献。
- GitHub - openai/openai-python: The official Python library for the OpenAI API:OpenAI API 的官方 Python 库。通过在 GitHub 上创建账户来为 openai-python 的开发做出贡献。
▷ #llm-paper-club (5 条消息):
- Phi-2 采用 MoE 方法:用户
@swyxio分享了@maximelabonne的一条推文,描述了他们使用 phi-2 成功创建了一个高效的 Mixture of Experts (MoE) 模型。该模型名为 Phixtral,结合了 2 到 4 个微调模型,性能优于每个单独的专家模型。模型phixtral-2x2_8和phixtral-4x2_8分别可以在 Hugging Face 和 Hugging Face 获取。 - 2023 年评述了 40 多篇语言建模论文:
@eugeneyan分享了他们的 Language Model 阅读清单,其中包括 2023 年评述的 40 多篇论文。他们还鼓励成员在其 GitHub 仓库 中建议新论文或提出 Issue。 @swyxio建议的语言建模进一步阅读:除了讨论的模型外,@swyxio还提到了一篇关于另一个名为Mixtral的模型的论文。
提到的链接:
- Language Modeling Reading List (to Start Your Paper Club):一些基础论文及每篇的一句话总结;开始你自己的论文俱乐部吧!
- Tweet from Maxime Labonne (@maximelabonne):🔀 Phixtral 我用 phi-2 模型制作了第一个高效的 Mixture of Experts。🥳 它结合了 2 到 4 个微调模型,比每个单独的专家都要好。🤗 phixtral-2x2_8: https://huggingfac…
Skunkworks AI Discord 总结
- Mixtral 的神秘专业化:
@interstellarninja观察到,在 Mixtral 的路由分析中,除了分布不均匀的 DM Mathematics 之外,专家们并没有表现出特定领域的专业化。#core-moe 频道中的 @baptistelqt 支持了这一观点,并解释了 路由器的负载均衡损失(load balancing loss) 如何阻碍领域专业化。两人都注意到连续的 Token 通常会进入相同的入口。 - Python 的 ‘self’ 与英语的 ‘question’,Mixtral 中的座次伙伴:
@interstellarninja强调了 Mixtral 路由器中独特的语法行为,它将 Python 中的 “self” 和英语中的 “question” 配对,表明该模型倾向于语法特征。 - PyTorch 还是 Jax?已知的选择更好:
@dook4疑惑为什么 AI 工程师在 Llama 之外更倾向于使用 PyTorch 而非 Jax。@yikesawjeez回应称,为了 Google 的 TRC 资助而用 Jax 重写一切是一项艰巨的任务。他们得出结论,熟悉的工具最终胜出。 - Fine-tuning 的游戏规则改变者?:
@nisten发布了一条神秘评论,称一张图表将彻底改变 Fine-tuning 的游戏规则。然而,在引用的讨论中并未透露这张神秘图表。
Skunkworks AI 频道总结
▷ #general (7 条消息):
- Mixtral 路由分析中的专家专业化:
@interstellarninja指出,在 Mixtral 路由分析中,专家们没有在特定领域表现出专业化,唯一的例外是分布不均匀的 DM Mathematics。 - Mixtral 路由器的语法行为:
@interstellarninja还提到,路由器确实表现出一些语法行为,例如 Python 中的 “self”、英语中的 “question” 以及代码中的缩进。据观察,连续的 Token 经常被路由到相同的专家。 - Mixtral 模型严重依赖语法:
@interstellarninja还强调,该模型在语法上表现出很强的专业化,尤其明显的是缩进是如何被路由到相同专家的。 - PyTorch 与 Jax 之争:
@dook4询问除了在 Llama 中使用外,为什么人们更喜欢 PyTorch 而非 Jax。@yikesawjeez认为人们使用 PyTorch 主要是因为他们熟悉其写法,并提到了在使用 Google TRC 资助时不得不使用 Jax 重写所有内容的困难经历。 - 对 Fine-tuning 游戏的影响:
@nisten暗示一张特定的图表完全改变了 Fine-tuning 的游戏规则。引用的消息中未包含该特定图表。
▷ #core-moe (4 条消息):
- 关于 Mixtral 专家领域专业化的讨论:
@baptistelqt提出了关于 Mixtral 专家 未在特定领域专业化的观点,推测 路由器的负载均衡损失 可能是一个阻碍因素。他们还提到成功实现了一个鼓励领域专业化的 MoE (Mixture of Experts) 模型,并寻求关于任何潜在误解的见解。@snowclipsed表达了类似的兴趣。
LLM Perf Enthusiasts AI Discord 总结
- 温度是多少?现在是 AI 时间!:
@thebaghdaddy询问了 AI 模型温度调整中数据的上下文。@sehaj.dxstiny解释称这是一个与 图像的潜层表示(latent representation) 和 VQ-GANs 的 Codebooks 嵌入 相关的概念。 - 步入超参数区域:
@thebaghdaddy建议探索 超参数调优(hyper parameter tuning)、控制数据质量输入的方法,并暗示使用 正则化技术(regularization techniques) 进行潜在改进。 - 拥抱试错精神:
@sehaj.dxstiny表示愿意尝试建议的方法来增强 AI 模型。 - 嘿 OCR,别挡道!:根据
@jeffreyw128的说法,目前依赖于通过 OCR 之外的其他方法来检测不良文本。 - 私有公司文档 - 数据搜寻:
@res6969敏锐地寻找与 私有公司描述性文档 相关的数据集。@jeffreyw128迅速行动,指出 Metaphor 拥有符合所需描述的数据,并提出私下提供更多见解。
LLM Perf Enthusiasts AI 频道总结
▷ #general (5 messages):
- 解码 ‘Adjust Temperature’:用户
@thebaghdaddy询问了在 AI 模型中调整 Temperature 时涉及的数据上下文。 - VQ-GANs 和图像的 Latent Representation:用户
@sehaj.dxstiny澄清说,这涉及到图像的 Latent Representation 以及 VQ-GANs 的 Codebooks embeddings。 - 建议使用 Regularization 技术:为了提供帮助,
@thebaghdaddy建议探索 hyper parameter tuning(超参数调优)、控制数据质量输入,并暗示使用 Regularization 技术来寻求潜在的改进。 - 乐于尝试:针对这些建议,
@sehaj.dxstiny表示他们尚未尝试这些方法,但愿意考虑。
▷ #rag (1 messages):
jeffreyw128: 我们依赖于通过非 OCR 方法检测是否存在糟糕的文本。
▷ #datasets (2 messages):
- 寻求私有公司文档的数据集:用户
@res6969询问是否有关于私有公司描述性文档的数据集,包括董事会报告、财务报表和季度信函等信息。 - Metaphor 提供的数据集:作为回应,
@jeffreyw128提到 Metaphor 拥有符合该需求的数据,并提议通过私信提供更多信息。
Datasette - LLM (@SimonW) Discord Summary
只有一个频道有活动,因此无需总结…
- 通货膨胀对音乐产业收入的影响:用户
@justinpinkney质疑根据通货膨胀进行调整可能会如何改变对音乐产业收入趋势的看法。 - Streaming vs Downloading:
@dbreunig澄清说,streaming(流媒体)才是破坏音乐产业部分环节的催化剂,而不是下载。 - 中层音乐人的黄金窗口期:
@dbreunig提到在 Spotify 时代之前,中层音乐人有一个维持生计的“黄金窗口”机会。 - 数字化前的音乐卡特尔:
@dbreunig认为数字化前的市场运作方式类似于卡特尔(垄断联盟),一旦允许消费者购买单曲而不是整张专辑,它就瓦解了。 - Spotify 对中层音乐人的影响:针对
@dbreunig,@antisimplistic对 Spotify 导致中层音乐人处境更加艰难表示怀疑,并认为行业向无限货架空间和碎片化市场的转型,使得所有艺术家都面临挑战,无论其商业模式如何。此外,@antisimplistic建议在评估行业趋势时,通货膨胀调整和更大的消费模式可能是需要考虑的因素。
Alignment Lab AI Discord Summary
- AI Agents 助力解释:@burnydelic 分享了 MIT News 的一篇引人入胜的文章,报道了 AI agents 如何潜在地帮助阐明其他 AI systems 的机制。
- Llama2-70B 的性能对比分析:@tirmizi7715 提出了一个问题:为什么 Llama2-70B 在多项评估中表现几乎与 Mixtral 和 GPT-3.5 一样好,但在 MT Bench 上的表现却明显更差?
- 晦涩的讨论让用户感到困惑:用户 @m8than 的评论“wtf is this lol”强调了关于 Llama2-70B、Mixtral 和 GPT-3.5 性能比较讨论中明显的缺乏清晰度。
- NousResearch 模拟话题:@teknium 重点介绍了 NousResearch 关于乱序 OO environment 模拟的一条 Twitter 帖子。
Alignment Lab AI 频道总结
▷ #ai-and-ml-discussion (1 messages):
burnydelic: https://news.mit.edu/2024/ai-agents-help-explain-other-ai-systems-0103
▷ #general-chat (2 messages):
- Llama2-70B 与 Mixtral 和 GPT-3.5 的性能对比:用户
@tirmizi7715询问,为什么 Llama2-70B 在几乎所有评估中都与 Mixtral 和 gpt3.5 表现相当,但在 MT Bench 上的表现却显著较差。 - 困惑的参与者:用户
@m8than似乎对之前的讨论感到困惑,并评论道 “wtf is this lol“。
▷ #oo (1 messages):
teknium: https://fxtwitter.com/NousResearch/status/1744865872563618128
YAIG (a16z Infra) Discord 总结
只有一个频道有活动,因此无需总结…
- 关于 Google Gemini 训练技术的推测:用户
@stevekamman对一篇 arXiv 研究论文 中定义的方法非常感兴趣。该论文概述了一种分布式优化算法 Distributed Low-Communication (DiLoCo),它允许在连接较差的设备集群上训练语言模型。这项技术可能与 Google 训练 Gemini 的方式有关。该算法是联邦平均(federated averaging)的一种变体,使用 AdamW 作为内部优化器,Nesterov momentum 作为外部优化器。
提到的链接:
DiLoCo: Distributed Low-Communication Training of Language Models:大语言模型 (LLM) 已成为机器学习许多应用中的关键组件。然而,训练 LLM 的标准方法需要大量紧密互连的加速器…