ainews-1112024-mixing-experts-vs-merging-models
2024年1月11日:混合专家 vs 模型合并
本次分析涵盖了 18 个服务器、277 个频道和 1342 条消息,预计节省了 187 分钟的阅读时间。
社区已转向使用 GPT-4 turbo,并讨论了 混合专家(MoE)模型(如 Mixtral、DeepSeekMOE 和 Phixtral)的兴起。模型合并技术,包括朴素线性插值以及由 SOLAR 和 Goliath 推出的“frankenmerges”(拼凑合并),正在推动开放排行榜上性能的进一步提升。
Nous Research AI Discord 中的讨论涵盖了多个主题,包括:支持提示词(prompt)和 RAG 参数的 AI 游乐场、第三方云使用的安全担忧、关于 Discord 机器人及其服务条款(TOS)的辩论、对 Teenage Engineering 云端大语言模型的质疑,以及 GPT-4 0613 与 GPT-4 turbo 之间的性能差异。
此外,社区还探讨了涉及 DPO、LoRA 和 safetensors 的微调策略,RAG 与 API 调用的集成,MoE 与稠密(dense)大语言模型之间的语义差异,以及 llama index 和 SciPhi-AI 的 synthesizer 等数据框架。微调过程中出现的异常字符问题也受到了关注。
我们为您检查了 18 个服务器、277 个频道和 1342 条消息。预计节省阅读时间(以 200wpm 计算):187 分钟。更新:我们今天也切换到了 GPT-4 turbo。让我们知道它与前几天(GPT-4-32k)相比感觉如何!
自从 Mixtral 架构发布以来,涌现了一大批 MoE 模型 —— DeepSeekMOE,Phixtral。但同样有趣的是“模型合并”(model merging)的实践 —— 从朴素的(球面)线性插值到 SOLAR 和 Goliath 使用的 “frankenmerges”。似乎这些技术在开源排行榜上创造了新的增长点,因为即使是相对朴素的实现也能轻松击败来自大实验室的原始模型。
https://huggingface.co/blog/mlabonne/merge-models
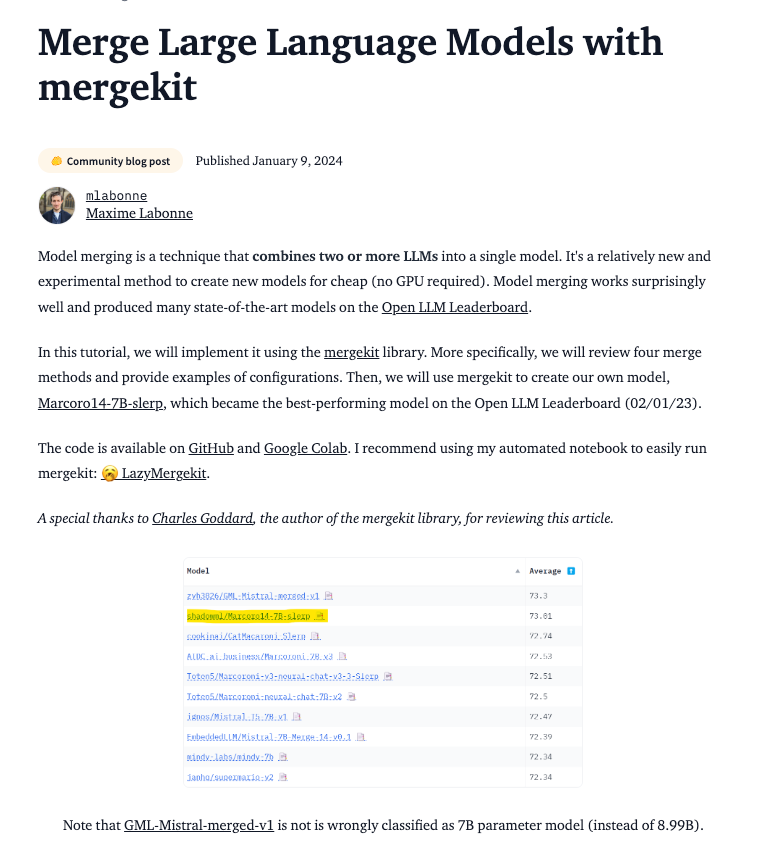
–
目录
[TOC]
Nous Research AI Discord 总结
-
AI 沙盒探索:
@ash_prabaker正在寻找支持各种 prompt/llm 参数并支持文件上传的 AI playgrounds,@everyoneisgross建议尝试 LangFlow 或带有 DATA ANALYSIS 和 GPT-4 的 langchain。 -
滚轮功能好奇心:
@shacrw思考了 Rabbit r1 上滚轮的用法,在关于 AI 硬件可用性的更大讨论中,强调了一些 AI 设备过于低幼的外形设计。 -
第三方云安全担忧:
@teknium对在他人云端激活 Discord 账号的安全性表示担忧,这涉及到一个关于云环境 RPA 与 Mighty 匹配的技术对比。 -
机器人与 Discord TOS:
@0xevil和@teknium辩论了管理真实用户账号的机器人是否违反 Discord TOS,并考虑了通过视觉模型和 TTS 进行本地执行操作的可能性。 -
对 TE 云端 LLM 的怀疑:
@everyoneisgross对 Teenage Engineering 的云端托管 LLM 表示怀疑,批评其可能无法达到公司的营销宣传效果。 -
AI 模型性能差距:根据 ELO 评分,
@ldj讨论了 GPT-4 0613 和 GPT-4-turbo 之间显著的性能差距,后者在对话和创意任务中更受青睐。 -
AI 训练延迟:AI 研究社区正热议项目受挫,例如备受期待的 Pile 2,以及那些施加广泛许可证限制的公司对“开源”一词的滥用。
-
微调 LLM 策略:关于微调 LLM 的讨论出现了,建议包括使用 DPO 探索 beta 超参数,以及调整包括 mlx、lora 和 safetensors 在内的微调流水线的复杂性。
-
将 RAG 与 API 调用集成:
@pramod8481寻求关于集成 RAG 以指定 API 序列的指导,@mgreg_42266建议使用根据 JSON 规范发出函数调用的模型,以及可能使用的 grammars。 -
MoE 模型与稠密 LLM:关于 MoE 模型(如 Mixtral)与稠密 LLM 之间不同交流风格的对话,MoE 模型似乎表现出独特的语义处理方式。
-
寻找顶级的 RAG 数据框架:讨论认为 llama index 是 RAG 数据架构的首选,而
@georgejrjrjr推荐 SciPhi-AI’s synthesizer 用于更简单的后端需求或创建个性化框架。 -
微调响应中的异常字符:
@kenakafrosty在微调过程中遇到了异常字符,引发了关于这是模型学到的规则还是过拟合故障的询问。
Nous Research AI 频道总结
▷ #off-topic (32 条消息🔥):
-
寻找高级 AI Playgrounds:
@ash_prabaker正在寻找允许实验 Prompt/LLM 参数以及 RAG+RAG 参数(包括文件上传功能、Chunk Size 和 Overlap 调整)的 AI Playground。@everyoneisgross建议尝试 LangFlow,或者结合 DATA ANALYSIS 和 GPT-4 使用 langchain 来搭建通用的 RAG Python 工具。 -
对 Rabbit r1 滚轮的好奇:
@shacrw询问了 Rabbit r1 上滚轮的功能,并分享了对 AI 设备“玩具形态”的看法,尽管演示环节出了差错,他仍计划就此主题写一篇文章。 -
对远程云端操作的担忧:
@teknium表达了对第三方云端登录 Discord 账号所带来的安全隐患的担忧,并引用了一段对话,同时推测了视频录制用于任务学习背后的技术。 -
讨论 Discord 服务条款 (TOS):
@0xevil和@teknium讨论了 Bot 访问 Discord 真实用户账号的潜在问题,考虑到 Discord TOS 禁止此类行为。他们思考了使用 Vision Model 和 TTS 进行本地执行操作的可能性。 -
对 TE 云端 LLM 的怀疑:
@everyoneisgross对 Teenage Engineering 的硬件产品结合云端托管 LLM 表示怀疑,认为它可能无法达到公司宣传的效果。
提到的链接:
来自 Rajesh Karmani 的推文 – acting fast and slow (@rkarmani): @Teknium1 @amasad 在这里找到了答案。他们在虚拟环境的云端使用 RPA……类似于 Mighty。
▷ #interesting-links (18 条消息🔥):
- AI 解决方案的新市场: 用户
@nonameusr分享了 Arbius 网络,这是一个求解者(Solvers)通过竞争来提供用户任务解决方案的平台,通过优化软件速度来提高盈利能力。- 核心特性: 提供由诚实求解者进行的安全生成,与 NFT 和游戏等各种应用集成,以及 DeFi AI,允许模型创建者从模型调用中获益。
- 质疑 GSM8K 数据完整性:
@euclaise对 GSM8K 数据集训练集和测试集之间存在污染的说法表示怀疑,尽管其他人引用了@teortaxestex提出的问题。 - 探索 LoRA 的细微差别:
@romaincosentino阐述了 LLM 中 LoRA 的权重扰动,认为虽然它可能与全模型 Fine-tuning 有所不同,但与 LM-cocktail 相比,早期层的差异并不大。 - LLM 的新数据集和合并技术: 用户
@metaldragon01分享了一个博客链接,宣布创建 MetaMathFewShot 以及在 Hugging Face 上开源的堆叠式 LLM 合并(Stacked LLM Merges)。引用的推文链接:FXTwitter - Bindu Reddy 推文,以及博客文章:开源数据集和合并/堆叠 LLM - Abacus.AI 博客。 - 自我修正 LLM 的新贡献: 用户
@metaldragon01还重点介绍了 Google Research 的一篇关于 LLM 及其自我修正能力的博客文章,特别是其在发现错误和修正输出方面的能力。Google Research 博客文章。
提到的链接:
- Arbius
- 大语言模型能否识别并修正自己的错误? – Google Research 博客
- 来自 Bindu Reddy (@bindureddy) 的推文: 提升 LLM 性能 - 开源数据集和新的合并/堆叠 LLM。我们很高兴宣布几项开源 AI 贡献。MetaMathFewShot - 开源 LLM 表现不……
- 由 JustinLin610 添加 qwen2 · Pull Request #28436 · huggingface/transformers: 添加 Qwen2。此 PR 增加了对即将发布的 Qwen2 模型代码的支持。有关 Qwen 的信息,请访问 https://github.com/QwenLM/Qwen。@ArthurZucker
▷ #general (204 messages🔥🔥):
-
MMLU:是衡量智能的标准吗?:
@gabriel_syme对使用 MMLU 作为 AI 智能衡量标准表示怀疑,观察到某些任务看起来“相当愚蠢”。在随后的对话中,@n8programs补充说 MMLU 是唯一真正重要的 Benchmark,引发了关于该指标不同水平下 AI 能力差异的讨论。 -
Turbo 加速后的 AI 差距:
@ldj讨论了基于 ELO 分数的 AI 版本之间显著的偏好差距,指出 GPT-4 0613 与 GPT-4-turbo 之间存在 89 分的差距,@ldj补充说 GPT-4-turbo 被认为是对话和创意任务中更优越的模型。 -
AI 训练的紧张局势与术语:
@erichallahan和@proprietary等用户讨论了 AI 研究社区的紧张局势,涉及 Pile 2 等项目的延迟,以及拥有受限许可证的公司使用“open-source”等术语的问题。 -
利用开源构建更好的工具:
@everyoneisgross建议使用搜索功能,分享了他们使用来自 OpenAI 存档的 160 MB JSON 和 300 MB embedding pickle 文件构建 Agent 的方法。 -
AI 模型的微调技巧:用户
@decruz和@n8programs讨论了微调 AI 模型的策略,@decruz建议探索 DPO 的 beta 超参数,而@n8programs分享了他们涉及 mlx、lora 和 safetensors 的微调 Pipeline 的复杂性。
相关链接:
- fblgit/UNA-TheBeagle-7b-v1 · Hugging Face
- Fine-Tuning Language Models Using Direct Preference Optimization - Cerebras:一种替代 RLHF 以获得人类偏好聊天模型的方法。
- GitHub - mlabonne/llm-course: Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks.:入门 Large Language Models (LLMs) 的课程,包含路线图和 Colab 笔记本。
▷ #ask-about-llms (30 messages🔥):
-
RAG 与 API 的难题:
@pramod8481解释说他们正在解决通过 RAG 确定 API 调用顺序的挑战,而@mgreg_42266建议当前模型可能通过在提供 JSON function spec 时让模型返回 function calls 来模拟 RAG,并暗示使用 grammars 以获得更好的响应。 -
MoE 体验引发讨论:
@adjectiveallison试图了解为什么像 Mixtral 这样的 MoE 模型在沟通风格或 token 选择上感觉与 dense LLMs 不同,尽管文献表明并非如此。@teknium分享了他们的经验,指出语义起到了作用,特别是在像 coding 这样语义独特的任务中。 -
追求理想的 Re-ranker 模型:
@pogpunk询问 RAG 的最佳 reranking 模型,对 BGE 表示不满,@georgejrjrjr指引他们查看 MTEB 排行榜,其中 e5-Mistral 处于领先地位。 -
寻找 RAG 的最佳数据框架:虽然
@bigdatamike询问 llama index 是否是 RAG 数据框架的至高选择,但@orabazes和@jaredquek表示支持,而@georgejrjrjr建议如果不需要 llama index 广泛的 backend adapters,可以查看 SciPhi-AI’s synthesizer。@decruz提出了构建自己框架的想法。 -
奇怪的退化之谜:
@kenakafrosty描述了在微调过程中响应中出现奇怪字符的情况,并寻求对这一异常现象的见解,想知道这是否是一个习得的规则而非 overfitting 问题。
相关链接:
GitHub - SciPhi-AI/synthesizer: A multi-purpose LLM framework for RAG and data creation.:一个用于 RAG 和数据创建的多用途 LLM 框架。
OpenAI Discord 总结
- OpenAI 的停机与错误:包括
@pavoldobias在内的用户报告了 OpenAI 服务的技术问题,投诉内容包括账户页面错误以及 ChatGPT 的完全停机。 - AI 偏见与内容规避担忧:讨论围绕训练数据如何使 AI 系统产生偏见展开;用户担心 AI 会在无意中反映意识形态倾向或规避某些内容类型。
- AI 提供的医疗建议——是个坏主意吗?:社区就 LLM 医疗建议的可靠性展开了辩论,达成的共识是咨询医疗专业人士比依赖 AI 更重要。
- GPT 文件处理的细节:澄清了 GPT 能够理解上传的文件,但引导有助于 AI 更有效地引用它们。此外,还审查了 GPT 训练的文件格式效率,建议使用 .txt 而非 .docx 以获得更好的处理速度。
- 课堂中的图像识别选择:讨论了如何为学校项目选择合适的图像识别模型,在水果分类任务中,准确性与资源平衡是关键考虑因素。
补充观点与社区查询:
- 寻求 AI SEO GPT 的反馈:
@kalle97分享了他们为撰写 AI SEO 文章定制的 GPT,并正在寻求社区反馈:Best AI Writer GPT-1 AI Text Generator。 - 追踪 Prompt-Output 对:
@boomboom68寻求建议,@aidudeperfect推荐使用 Promthub 和 GIT 来管理 Prompt-Output 对。 - 使用 GPT 进行高效教育内容提取:
@mischasimpson讨论了生成可定制的教育阅读材料,并被建议考虑使用同行评审流程进行 Prompt 优化。
OpenAI 频道总结
▷ #ai-discussions (80 条消息🔥🔥):
- 技术问题困扰用户:包括
@pavoldobias、.australiaball、@areaboy_和@marla.nettle在内的众多用户报告了 OpenAI 服务的问题,从账户管理页面的错误到 ChatGPT 的完全停机。 - 理解 GPT 文件处理:在由
@tetsujin2295发起的讨论中,包括@steve_03454、@7877和@lugui在内的用户澄清,上传到 GPT 的文件确实会被 AI 读取和理解,尽管指示 AI 何时引用特定文件会更有利。 - AI 背后的偏见:
@badapau、@7877和@lugui展开了关于 AI 偏见的对话。重点在于训练数据如何向 AI 系统引入偏见,例如规避某些类型的内容或反映意识形态倾向。 - 对 AI 提供医疗建议的担忧:
@lugui和@you.wish之间展开了关于 LLM 不适合提供医疗建议的对话。Lugui 强调需要咨询合格的专业人士,而不是依赖 AI 做出健康相关的决策。 - 图像识别模型辩论:
@calamityn1nja和@lugui讨论了为学校项目选择合适的图像识别模型,重点是在水果分类任务中平衡准确性与处理资源。
提到的链接:
Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
▷ #gpt-4-discussions (128 条消息🔥🔥):
- 用户对 GPT 推广表示困惑:
@offline询问是否允许通过 GPT 推广个人的 Patreon 或 Ko-fi。@elektronisade回复表示应通过举报菜单举报此类情况。 - GPT Store 中的潜在商标问题:包括
@shira4888和@sayhelloai在内的多位用户讨论了他们的 GPT 因名称(如 “Code Copilot” 或 “Handy”)可能涉及商标侵权而被移除或标记的问题。 - 名称商标如何影响 GPT?:
@eligump和@n8programs讨论了使用公有领域角色或因 Microsoft 的商标而避免使用 “copilot” 等名称的可能性。 - 对 GPT 查询限制的担忧:
@encryptshawn抱怨 GPT-4 的查询限制,称其阻碍了复杂 GPT 的开发和测试。@drinkoblog.weebly.com建议使用 Team 订阅来绕过这些限制,并证明可以在不到一小时内执行 69 个 prompt 而不被锁定。 - 解释 Plus 订阅限制:像
@soy_reo这样的新订阅者询问了 GPT Plus 的消息上限。@han_hideo澄清说,每条消息都会计入每 3 小时 40 条消息的配额,包括像问候语这样的简单查询。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、闲逛,与你的朋友和社区保持紧密联系。
- 品牌指南:在营销和沟通中使用 OpenAI 品牌的语言和资产规范。
▷ #prompt-engineering (25 条消息🔥):
- 寻求 AI SEO 内容生成的反馈:用户
@kalle97分享了他们用于编写 AI SEO 文章的 GPT 链接,并请求社区提供反馈:Best AI Writer GPT-1 AI Text Generator。 - 关于消息计数器的查询:
@homesick9458询问了消息计数器的用途,以及它是否是为了跟踪是否达到限制,但未收到回复。 - 追踪 Prompt-Output 对:用户
@boomboom68寻求有关追踪、版本控制和分析 prompt-output 对的工具建议。@aidudeperfect提到使用 Promthub 和 GIT 仓库来实现此目的。 - GPT 训练知识文件的文件格式:
@johnz999询问了 GPT Builder 中知识文件的最佳文件格式,表达了对处理时间的担忧,并建议 .docx 可能效率较低。@madame_architect建议避免使用 .rtf,并表示更倾向于 .txt,同时也承认 PDF 的 OCR 效果不错。 - 为 GPT Prompt 提取教育内容:小学教师
@mischasimpson讨论了为可定制阅读材料创建 prompt,并考虑是在 GPT-3.5 还是 GPT-4 中进行尝试。@darthgustav.建议使用强大的模型和同行评审进行优化,同时指出使用 GPT-4 Turbo 的 Bing 也是免费的。 - 向 GPT-4 提供示例的最佳实践:
@jkyle询问如何最好地向 GPT-4 提供明确示例,是将其包含在初始 prompt 中还是作为消息线程,以及是否需要对示例回复进行强化。该查询未收到回复。 - 增强 GPT 句法变化:用户
@eligump对能够显著改变 GPT 句法的关键词感到好奇,@eskcanta回复建议在输入中使用高语言水平并要求模型镜像模仿。此外还分享了一个自定义指令(custom instruction)的示例。 - 对 GPT 近期表现的担忧:
@nefariousape表示 ChatGPT 的响应变得不那么有效了,并寻求改进其语言输出的 prompt 建议,但未得到直接的解决方案。
▷ #api-discussions (25 messages🔥):
- 使用 GPT 编写 SEO 文章:用户
@kalle97寻求关于其用于创建 AI SEO 文章的 GPT 的反馈,并分享了链接 https://chat.openai.com/g/g-oNyW1YcOI-best-ai-writer-gpt-1-ai-text-generator。 - 关于消息计数器的咨询:用户
@homesick9458询问是否使用消息计数器来跟踪聊天中的消息长度或数量限制。 - 追踪 Prompt 和输出的探索:
@boomboom68向社区咨询用于追踪、版本化和分析 Prompt-输出对的工具,@aidudeperfect建议使用 Promthub 和 GIT,而@madame_architect思考了对系统化解决方案的需求。 - 揭秘 GPT Builder 的最佳文件格式:
@johnz999询问 GPT Builder 中知识文件最有效的文件格式,收到@madame_architect的建议:避免使用 .rtf,首选 .txt,并考虑 PDF 的 OCR 质量。 - 自定义教育 Prompt 的同行评审:小学教师
@mischasimpson讨论了为阅读计划创建特定 Prompt 的事宜,并收到了来自@darthgustav.关于使用强大模型和同行评审以确保有效性的建议。
LM Studio Discord 总结
-
LM Studio API 的限制与选择:
@esraa_45467询问 LM Studio 是否可以根据用户操作自动选择正确的 API。@fabguy澄清说 API 调用并非原生支持;用户必须使用以 LLM 为后端的 API 服务器来构建该功能。此外,@fabguy确认了将 LM Studio 连接到 SillyTavern 的能力,并建议在 Discord 中搜索现有教程。 -
20B 模型对 VRAM 的渴求:运行 20B 模型时,显存限制是一个常见问题,正如
@letrangeg所分享的,他在 24GB VRAM GPU 上运行这些模型时遇到了困难。大家交流了技巧,包括使用 更小的量化 (quants) 以防止 OOM 错误 (@heyitsyorkie),以及减少 GPU 层数以更多地依赖系统 RAM (@fabguy)。 -
AI 模型压缩挑战揭秘:
@drawless111等人的讨论揭示了 GGUF 和 EXL2 等模型压缩技术对性能的影响,并幽默地提到对 EXL2_2bit 模型进行 GGUF 化 是行不通的。这些对话强调了 AI 模型压缩技术不断发展的本质。 -
高 RAM 和 VRAM 规格分享:
@pwrreset详细介绍了他们强大机器的规格,这与在 8GB RAM 系统上运行 LLM 的咨询形成鲜明对比。该机器配备了 i9-11900k CPU、128GB RAM 和具有 24G VRAM 的 4090 GPU。 -
最新 Beta 版中 Falcon 180B 的加载问题:
@pwrreset在 最新 Beta 版 中尝试加载 Falcon 180B 时遇到了内存错误,而这在之前的版本中并未出现。他们推测可能是 RAM 分页功能被禁用导致了该问题,并指出在 回滚到 0.2.10 版本 后,模型成功加载。
LM Studio 频道总结
▷ #💬-general (123 条消息🔥🔥):
- 澄清 LM Studio ‘Action’ 误解:
@esraa_45467询问该应用是否能自动为用户操作(如预订酒店房间)确定正确的 API。@fabguy澄清说目前不支持 function calls,用户需要将 API server 作为 LLM 后端自行构建该功能。 - SillyTavern 连接说明:
@messycabbage42询问如何像 oobabooga 那样将 LM Studio 连接到 SillyTavern,@fabguy确认这是可行的,并建议在 Discord 中搜索,因为之前已有其他用户实现过。 - LM Studio UI 故障排除:当
@.woteva遇到 UI 问题时,@fabguy建议更改屏幕尺寸并关闭 “Conversation Notes” 以防止重叠并显示隐藏的按钮。 - LM Studio 不具备图像生成功能:
@esraa_45467对使用 LM Studio 进行图像生成感到好奇,@fabguy明确回答不行,并建议他们了解一下 Fooocus。 - 配置寻求者的好消息:
@systemsculpt询问有关模型的最佳 presets,@fabguy指引其前往特定 Discord 频道的置顶消息以获取资源。
请注意,由于内容和摘要长度限制,上述摘要并未包含每一条消息。
提到的链接:
- 👾 LM Studio - 发现并运行本地 LLMs: 查找、下载并实验本地 LLMs
- 下载 GIF - 下载 - 发现并分享 GIFs: 点击查看 GIF
- CultriX/MistralTrix-v1 · Hugging Face
- Mixtral of Experts: 我们介绍了 Mixtral 8x7B,一种稀疏混合专家 (SMoE) 语言模型。Mixtral 与 Mistral 7B 具有相同的架构,不同之处在于每一层由 8 个前馈块组成 (…
- Mixtral of experts: 高质量的稀疏混合专家模型。
- Agent Tools: 用于编排角色扮演、自主 AI Agent 的框架。通过培养协作智能,CrewAI 赋能 Agent 无缝协作,处理复杂任务。 - joaomdmoura/cr…
- 别问能不能问,直接问
- GitHub - danny-avila/LibreChat: 增强版 ChatGPT 克隆:具备 OpenAI, GPT-4 Vision, Bing, Anthropic, OpenRouter, Google Gemini, AI 模型切换, 消息搜索, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, 安全多用户系统, Presets, 完全开源可自托管。更多功能开发中: 增强版 ChatGPT 克隆:具备 OpenAI, GPT-4 Vision, Bing, Anthropic, OpenRouter, Google Gemini, AI 模型切换, 消息搜索, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, 安全…
- GitHub - mckaywrigley/chatbot-ui: 为所有人准备的开源 AI 聊天应用。: 为所有人准备的开源 AI 聊天应用。通过在 GitHub 上创建账号为 mckaywrigley/chatbot-ui 的开发做出贡献。
- SillyTavern - 面向高级用户的 LLM 前端
▷ #🤖-models-discussion-chat (54 条消息🔥):
- 讨论大模型的 VRAM 和系统 RAM:
@letrangeg提到了在 24GB VRAM 的 GPU 上运行 20B 模型时出现的内存问题,并考虑增加系统 RAM 是否会有所帮助。@heyitsyorkie建议使用更小的量化版本(quants)以避免显存溢出(OOM)错误,而@fabguy建议减少 GPU 层数以利用系统 RAM。 - 不同压缩方式带来的模型性能差异:
@drawless111分享了关于模型压缩技术如何影响性能的见解,并指出 1B 级别的 GGUF, AWQ, GPTQ 和 EXL2 模型之间存在显著差异。这可以通过改进压缩方法来获得更好的模型结果。 - 低 RAM 机器上的小型 LLM 加载:一位用户
@haseeb_heaven询问了可以在 8GB RAM 上运行的编程类 LLM 推荐。@fabguy建议使用 DeepSeek Coder,并强调 8GB RAM 通常不足以支持 AI 技术,建议进行升级。 - AI 模型压缩是一个不断变化的领域:
@dagbs和@drawless111讨论了 GGUF 压缩改进的潜力,同时也幽默地尝试了将 EXL2_2bit 模型进行 GGUF 处理的想法,但并未成功。人们的注意力被吸引到 AI 模型压缩领域持续的学习和变化中。 - 分享配置详情:
@pwrreset分享了一台拥有 i9-11900k CPU、128GB RAM 和 24G VRAM 的 4090 GPU 的强大机器配置,这与之前关于低端配置的讨论形成了鲜明对比。
提到的链接:
- 3d Chess Star Trek GIF - 3d Chess Star Trek Tng - Discover & Share GIFs:点击查看 GIF
- GitHub - deepseek-ai/DeepSeek-MoE:通过在 GitHub 上创建账号来为 deepseek-ai/DeepSeek-MoE 的开发做出贡献。
▷ #🧠-feedback (1 条消息):
- 频道礼仪提醒:
@heyitsyorkie建议一位用户将他们的帖子移动到另一个频道,并表示“<#1111440136287297637> 本频道仅用于反馈,不用于求助帖子。”
▷ #🧪-beta-releases-chat (9 条消息🔥):
- Falcon 180B 加载问题碰壁:
@pwrreset报告称,尽管有足够的可用 RAM,但在最新 Beta 版中尝试加载 Falcon 180B 时遇到了内存错误。他们提到之前的版本没有这个问题,并推测可能是 VRAM 计算错误。 - 重启无法恢复 Falcon:针对
@dagbs关于重启以杀死任何潜在僵尸进程的建议,@pwrreset确认他们已经重启了三次,但无济于事。 - Windows 版本显示不匹配:
@pwrreset指出错误消息中的操作系统版本不一致,说明他们使用的是 Windows 11,而日志显示的 Windows 版本为 “10.0.22621”。 - 建议关注潜在的 RAM 分页问题:
@pwrreset假设最新的 Beta 版可能禁用了 RAM 分页,并将这一变化与他们无法加载模型联系起来。 - 回滚解决了模型加载问题:
@pwrreset注意到在回滚到 0.2.10 版本后,他们能够在剩余 14 GB RAM 的情况下正常加载模型,这表明问题可能特定于最新的 Beta 更新。 - yagilb 的发现引起兴趣:
@yagilb插话表示这种情况很有趣,并询问是否启用了 mlock,同时观察了聊天框下方的统计数据。
HuggingFace Discord Discord 摘要
-
Phoenix 凭借德国精度崛起:由
@DRXD1000推出的一款新型德国聊天模型 Phoenix,采用了 Direct Preference Optimization (DPO) 技术,并基于HuggingFaceH4/ultrachat_200k和HuggingFaceH4/ultrafeedback_binarized的德语翻译数据集。查看 Phoenix。 -
开源巨头 OpenChat 3.5 登场:宣布推出 OpenChat-3.5,这是一款拥有 7B 参数的开源语言模型,号称无与伦比,由 RunPod 提供支持。详细信息请点击此处。
-
LiteLlama 进军移动端:
@Tonic发布了一款名为 LiteLlama 的端侧模型,简化了获取 AI 能力的途径。更多信息见此处。 -
社区期待 PyEmber 的教育浪潮:
@emperorws推出了 PyEmber——一个基于 PyTorch 的易用深度学习框架,旨在轻松教育 AI 初学者。在 GitHub 上可以找到这个宝贵的学习工具,并在 LinkedIn 上支持其传播。 -
读书会聚会:读书会活动定于次日举行,合著者可能会出席。该活动已成功引起关注,并为全球成员提供 YouTube 录像。加入活动。
-
Mixtral 的奥秘与 AI 教育洞察:讨论强调了 Mixtral’s AI 在 AI 等级体系中相对于其他模型的受尊重地位,并分享了关于 AI 和深度学习教育资源的宝贵见解,倾向于推荐 PyTorch 以及针对不同水平学习者的 FastAI 和 Zero To Mastery 等课程。
-
Kosmos-2 的视觉能力获得认可:展示了 Microsoft’s Kosmos-2,它能够在图像中进行物体定位和查询。其“接地气(grounded)”的特性引发了关注,在与视觉内容交互时能避免幻觉。演示可见此处。对于纯物体检测任务,推荐 Hugging Face 上的热门模型。
-
Inpaint Patch 请求与文本生成挑战:
@waterknight98询问了 fooocus inpaint patch 对 diffusers 的适用性,@lunarflu强调了文本生成模型与硬件之间通信的复杂性,而@sayakpaul讨论了相比于从头训练基础模型,更倾向于微调。有用户反映,尽管使用了固定种子,图像生成仍存在随机性。
HuggingFace Discord 频道摘要
▷ #announcements (1 messages):
- Phoenix 凭借 DPO 崛起:用户
@DRXD1000使用 Direct Preference Optimization (DPO) 训练了一个名为 Phoenix 的新型德语聊天模型。该模型专为德语设计,基于HuggingFaceH4/ultrachat_200k和HuggingFaceH4/ultrafeedback_binarized的德语翻译数据集。在此处查看模型 here。 - OpenChat 3.5 惊艳亮相:一个名为 OpenChat-3.5 的开源 7B LLM 被推出,并由 RunPod 赞助,号称是世界上最好的模型。模型详情可通过以下 链接 找到。
- 运行在设备上的 LiteLlama:
@Tonic发布了一个名为 LiteLlama 的端侧模型。你可以从 这个 Space 了解更多并运行该模型。 - Artificial Thinker 寻求反馈:用户
@687955585647247372发布了一个名为 Artificialthinker 的新 Demo,并公开征求社区反馈。在此处与 Demo 互动 here。 - 使用 Pokemon Classifier 捕捉所有宝可梦:
@AgastyaPatel开发了一个新的 Pokemon 分类器,让爱好者可以轻松识别各种宝可梦。在此处探索该分类器 here。 - DreamDrop V1 怀揣大梦想:来自 OpenSkyML 的
DreamDrop V1在 Deliberate V5 上使用 LoRA - MJLora 进行了精心训练,具有独特的生成能力。在此处深入了解 DreamDrop here。
注意:由于 5 个要点的限制,关于社区讨论、博客文章和贡献者致谢的额外内容未包含在要点中。
提到的链接:
- DRXD1000/Phoenix · Hugging Face
- openchat/openchat-3.5-0106 · Hugging Face
- Chatbot UI
- LiteLlama - a Hugging Face Space by Tonic
- ArtificialThinker Demo on GPU - a Hugging Face Space by lmdemo
- Pokemon Classifier - a Hugging Face Space by AgastyaPatel
- openskyml/dreamdrop · Hugging Face
-
加入 Hugging Face Discord 服务器!:我们正致力于民主化优秀的机器学习 🤗 加入我们!hf.co/jobs 66758 名成员 - 使用 mergekit 合并大语言模型
- 使用 Stable Diffusion 进行时序场景生成
- 揭秘 TinyLlama:深入探索革命性的小型语言模型
- 从零开始的多标签分类模型:分步教程
- 多模态 IDEFICS:揭示开源视觉语言模型的透明度与力量
- Transformers 中的 4D masks 支持
- 理解 Mixtral-8x7b
▷ #general (54 messages🔥):
- AI 表现优于人类艺术?:用户
@acidgrim思考“非常出色”的 AI 图像是否具有某种使其区别于人类创作艺术的品质。@lunarflu补充说,尽管整体主题准确,但细微的细节缺陷可能是破绽所在。 - Mixtral 在 AI 等级中的地位得到澄清:
@Cubie | Tom提供了见解,解释了 Mixtral 在各种排行榜上相对于 Llama2-70b 等其他模型的表现,以及在人类评估的 LMSYS 中 Mixtral 排名第 7。 - Celery 与 Transformers 的并发难题:
@_barrel_of_lube_寻求帮助,解决在实现 Transformers 时 Celery 的并发问题,因为模型被多次加载。 - 在 Hugging Face 上发布医疗模型 ‘biohack’:
@khalidschoolhack分享了他们即将在 Mixtral 7B 上发布的微调医疗模型 ‘biohack’,并正在寻找有影响力的人进行推广和评测。 - 期待 Hugging Chat 的 TTS 功能:
@green_eye表达了对 Hugging Chat 中 TTS 模式的愿望,以获得更便捷的用户体验。
▷ #today-im-learning (6 条消息):
- 选择合适的学习路径:用户
@merve3234建议,感兴趣的领域应该引导学习选择,这暗示了在 AI 教育中特定领域知识的重要性。 - PyTorch 优于 TensorFlow:
@kxonline表达了对 PyTorch 优于 TensorFlow 的偏好,并计划参加更多关于 PyTorch 的课程,这表明了两个框架之间感知的易用性差异。 - FastAI 适合初学者;Zero to Mastery 适合深入探索:
@kxonline推荐初学者学习 FastAI 课程,因为它具有较高的抽象层级;并提到 Zero To Mastery 是一个适合入门者的不错 PyTorch 课程。 - 不仅仅是关于编程:
@sebastian3079分享道,他们正在修读的课程更多地关注 AI 架构/算法 的细节,而不是编程方面,突显了 AI 教育的多样性。 - 开启一个新的 AI 项目:
@mad_cat__讨论了他们为正在开发的新系统优化 AI 的计划,尽管不确定其与名为 Sunspot 的项目相比表现如何,展现了 AI 项目的探索性和竞争性。
▷ #cool-finds (22 条消息🔥):
- 图像合成中人脸识别的创新应用:
_vargol分享了 IP-Adapter-FaceID Model Card,该模型声称可以根据人脸 ID embedding 生成图像,但提到实际效果欠佳,将其描述为 “木偶的 CGI 版本”。 - 面对类似 Grinch 比例的笑料:
_vargol和@merve3234讨论了模型生成的面部比例,将其比作 Grinch(绿毛怪),暗示图像输出中出现了一些幽默的差错。 - 倾向于更写实的模型:
@chad_in_the_house评论了使用默认 Stable Diffusion (SD) 获取理想结果的挑战,并指出使用写实模型可能会产生更好的效果。 - 正在开发中的图像生成 GUI:
@meatfucker提到他们正在开发一个简单的 基于 Windows 的图像生成 GUI,并分享了 GitHub 仓库链接:goobworkshop。 - 可配置人脸的快速修复:
@meatfucker建议用户目前必须手动替换 assets 中的image.png来更改人脸,并指出该工具应该可以在 Linux 上运行,尽管安装脚本是针对带有 NVIDIA 显卡的 Windows 编写的。
提到的链接:
- h94/IP-Adapter-FaceID · Hugging Face
- GitHub - Meatfucker/goobworkshop: Goob Workshop:Goob Workshop。通过在 GitHub 上创建账号为 Meatfucker/goobworkshop 的开发做出贡献。
▷ #i-made-this (7 条消息):
-
为深度学习新手介绍 PyEmber:
@emperorws分享了他们的项目 PyEmber,这是一个基于 PyTorch 的教学框架,旨在帮助 AI 和 DL 初学者理解 DL 框架的运行机制。可以在这里找到:GitHub 上的 PyEmber,并帮助他在 LinkedIn 上宣传。 -
快速 2 倍图像超分辨率 Space 发布:
@helaman使用他们最新的模型创建了一个快速图像超分辨率 Space,在 T4 Small GPU 上仅需约 1 秒即可将图像从 256x256 放大到 512x512。点击查看:fast2xupscale。 -
快速音乐生成演示:
.bigdookie分享了一个 Twitter 帖子,展示了使用新构建的 musicgen Chrome 扩展生成的音乐,该扩展可输出 5-8 秒的音乐,短于通常的 30 秒。 -
后端自动裁剪音乐样本:
.bigdookie提到不需要手动裁剪,因为他们的后端会尝试自动完成。 -
提供音乐生成工具使用邀请:
.bigdookie邀请其他人使用他们的工具,但指出 howler.play 实例存在一些可能影响播放的小问题,但不影响导出的 mp3 质量。
提到的链接:
- Fast 2x Upscale Image - a Hugging Face Space by Phips
- GitHub - Emperor-WS/PyEmber: An Educational Framework Based on PyTorch for Deep Learning Education and Exploration:一个基于 PyTorch 的用于深度学习教育和探索的教学框架 - GitHub - Emperor-WS/PyEmber。
▷ #reading-group (10 messages🔥):
- 活动提醒与 YouTube 公告:
@lunarflu宣布 读书小组活动定于明天举行,并确认将提供 YouTube 录像。他们还表示愿意为未来的活动调整会议时间,并征求论文建议 加入活动。 - 全球成员面临的时区挑战:
@hamster.uwu对 YouTube 录像表示感谢,因为活动时间对应澳大利亚的 凌晨 4:30,导致实时参与非常困难。 - 共同作者的参与激发读书小组热情:
@mr.osophy分享称,其中一位共同作者可能会在 东部时间下午 1:45 加入活动并回答问题,这为参与者增添了令人兴奋的环节。 - 读书小组获得动力与支持:
@ironman5769幽默地提到会议时间正好符合标准的创业公司工时。@pier1337和@mad_cat__对读书小组的倡议表示热烈支持,@mad_cat__幽默地接受了“活到老学到老”的挑战。
提到的链接:
| 加入 Hugging Face Discord 服务器!:我们正致力于民主化优秀的机器学习 🤗 加入我们!hf.co/jobs | 66758 名成员 |
▷ #diffusion-discussions (5 messages):
- Inpaint 集成咨询:
@waterknight98询问了如何在 Diffusers 中使用 fooocus inpaint patch。 - 文本生成优于硬件控制:
@lunarflu指出,虽然在之前的频道帖子中可以找到文本生成的示例(<#1119313248056004729>, <#1147210106321256508>, <#1162396480825462935>),但要让此类系统在硬件层面与计算机通信会更加复杂。 - 偏好 Finetuning 而非基础训练:在回复
@chad_in_the_house时,@sayakpaul确认更倾向于使用 Finetuning 方法,而不是像 PixArt-α 那样从头开始训练基础模型。 - 图像生成中意外的随机性:
@felixsanz对为何设置了手动种子(generator.manual_seed(2240851815))后仍然生成随机图像表示困惑。
▷ #computer-vision (2 messages):
- Kosmos-2 将物体定位与 LLM 结合:
@merve3234强调 Microsoft 的 Kosmos-2 是一个被低估的模型,它可以定位图像中的物体并回答相关问题。他们提供了一个 用户的推文 作为该模型能力的参考,并附带了易于使用的代码片段。 - Kosmos-2 作为 Grounded 替代方案:
@merve3234强调 Kosmos-2 具有 Grounded 特性且不会产生幻觉(hallucinate),并发布了一个 HuggingFace Demo 链接 进行实际演示。 - 纯追踪任务的建议:对于严格涉及物体追踪的任务,
@merve3234建议使用专门的物体检测模型,并分享了 HuggingFace 上热门模型的链接,包括 microsoft/table-transformer-detection。 - 平衡新颖性与实用性:
@meatfucker承认 Kosmos-2 很有吸引力,但也同意对于某些特定用例,传统的物体检测方法可能更有效。
提到的链接:
- merve (@mervenoyann) 的推文:想象一个可以找到给定图像中的实体、描述图像并回答相关问题且不会产生幻觉的 LLM ✨ 由 @Microsoft 发布的 Kosmos-2 是一个非常被低估的模型…
- Kosmos 2 - ydshieh 创建的 Hugging Face Space
- Models - Hugging Face
▷ #NLP (8 messages🔥):
- 张量权重需要保持连续!:用户
@merve3234提供了一个解决训练期间非连续张量(non-contiguous tensor)错误的方案,通过代码片段显式地使特定张量权重变得连续。他们还指出了 Hugging Face 上的一系列 T5 模型和资源。 - 单 GPU 使用时
cuda:0和cuda没有区别:@merve3234澄清说,在单个 GPU 设备上工作时,使用cuda:0或cuda基本上是相同的,因为它默认指向第 0 个 GPU。 - Apple Silicon GPU 支持咨询:
@pippopluto_96741询问 Hugging Face 是否支持像 m2/m3 这样的 Apple Silicon GPU,因为他们之前只使用过 NVIDIA GPUs。 - 排行榜提示词格式化:
@latentfog提出了一个关于排行榜对模型使用的 Prompt 格式的问题,特别是针对以不同格式或多格式训练的模型。 - 寻求适用于办公台式机的摘要流水线:
@n278jm寻求关于创建摘要流水线(Summarization Pipeline)的建议,该流水线需包含说话人日志(speaker diarization),且不会给办公级硬件台式机带来沉重负载,同时出于法律和伦理原因避免使用外部服务。 - 关于 Transformer 库应用层补丁的讨论:
@opencuiguy提到,期望 Transformer 库能够处理像非连续张量这样的问题,而无需在应用层进行补丁处理,并寻求用户@697163495170375891的反馈。
提到的链接:
▷ #diffusion-discussions (5 messages):
- Inpaint 补丁咨询:用户
@waterknight98询问是否有人在 diffusers 中使用过 fooocus inpaint patch。提供的消息中没有针对该问题的直接回答。 - 文本生成通信的复杂性:用户
@lunarflu探讨了让文本生成模型在特定层级与计算机通信的复杂性。消息引用<#1119313248056004729>、<#1147210106321256508>、<#1162396480825462935>中暗示了具体示例。 - 专注于微调而非基础模型训练:针对
@chad_in_the_house的观察,@sayakpaul确认其重点在于微调(fine-tuning)预训练的基础模型以生成高质量结果,而不是从 alpha 阶段开始训练。 - 种子困惑:
@felixsanz报告了一个问题,尽管使用了固定种子generator.manual_seed(2240851815),但仍然生成了随机图像,并对这一意外结果表示困惑。
OpenAccess AI Collective (axolotl) Discord 摘要
-
内存困扰与训练挑战:用户讨论了在模型训练期间控制内存使用的困难,特别是将
E5-mistral-7b-instruct的行为与 Llama2 13b 进行对比。对话强调了在新模型中处理较低max_tokens的问题。这引发了关于 finetuning 实践的进一步讨论,例如在 Axolotl 上使用图像输入 finetuning LLaVA 1.5,并参考了之前的 PR和分享的调试教程视频。此外,还出现了关于 MoE (Mixture of Experts) 模型及其效率的讨论,特别是引用了 DeepSeekMoE 的声明,即以显著更低的计算需求达到 Llama2 的性能。 -
高级配置对话:工程师们辩论了更精细的技术细节,例如在 LoRA 中将 gate 保持在 fp32,以及对 autounwrap 功能配置设置命名的审议,最终倾向于使用
rl_adapter_ref_model。关于潜在的 Axolotl 0.4.0 版本发布的讨论,是基于将 Mixtral loss 修复集成到 Hugging Face transformers 中而进行的。用户@dctanner分享了 Hugging Face 打算在模型 tokenizers 中添加默认 system prompts 的意图。 -
数据处理问题与技巧:工程师们交流了关于数据操作和系统交互的见解。分享的一个有用提示是,wandb logs 可用于在命令行窗口关闭后检索 stack traces。关于 Mistral 配合 LoRA 配置的查询建议将 4bit 与 qlora 搭配。人们对未来简化配置充满期待。社区成员询问了 CommonCrawl dump 的结构和唯一性,以及针对大型数据集的高效 sample packing 方法以节省 RAM。
-
数据集发现与查询:参与者推荐了一些数据集,例如为代码生成爱好者准备的 Tested 22k Python Alpaca。还询问了配置数据集以训练特定模型(如 Mistral Instruct)的方法,但未找到所寻求的
dolphin201.jsonl数据集的存放位置。社区评估了数据集质量,分享了诸如 ultrafeedback_binarized_cleaned 等数据集的链接,并讨论了 DPO 数据集中响应质量的重要性。 -
Docker 强化学习更新:
#rlhf频道确认合并了一个用于 Docker 优化的 dpo PR,表明了在容器化环境中迈向效率和资源管理的方向,这可能会影响社区内的用例和开发。
OpenAccess AI Collective (axolotl) 频道摘要
▷ #general (16 条消息🔥):
- E5-Mistral-7B Instruct 的挑战:
@tostino表示在训练[E5-mistral-7b-instruct](https://huggingface.co/intfloat/e5-mistral-7b-instruct)时难以控制内存使用,并将其与之前使用 Llama2 13b 的经验进行了对比。在 Llama2 13b 中,他们可以使用 6144 max_tokens 进行训练,但目前该模型只能处理 480 max_tokens。 - 对 Axolotl 协作的热情:
@leoandlibe询问关于在 Axolotl 上使用图像输入微调 LLaVA 1.5 的事宜,@caseus_表现出合作开发该功能的兴趣,并指向之前的 Pull Request[PR #781](https://github.com/OpenAccess-AI-Collective/axolotl/pull/781/files),该 PR 涉及预训练 LLaVA projector 模型,可作为一个潜在的起点。 - Axolotl 的 VSCode 调试教程:
@hamelh分享了一个视频演示,帮助用户设置 VSCode 以调试 Axolotl,链接为[https://youtu.be/xUUB11yeMmc](https://youtu.be/xUUB11yeMmc)。 - 探索 DeepSeekMoE 的效率:
@b_ryan0关注到了 DeepSeekMoE 16B,该模型声称能以减少 40% 计算量的情况下达到 Llama2 的性能。@leoandlibe确认 MoE 模型通常对内存需求更高,但通过仅激活专家子集来减少计算量。@emrgnt_cmplxty询问了使用 Rope 扩展上下文长度的可能性,对该模型的能力表现出好奇。
提及的链接:
- 如何调试 Axolotl(用于微调 LLM):这是一个关于调试 Axolotl 的详细指南,Axolotl 是一个帮助你微调 LLM 的项目。具体来说,我展示了如何配置 VSCode 进行调试。
- GitHub - deepseek-ai/DeepSeek-MoE:通过在 GitHub 上创建账号来为 deepseek-ai/DeepSeek-MoE 的开发做出贡献。
- intfloat/e5-mistral-7b-instruct · Hugging Face
- 由 winglian 提交的集成 LLaVA 以进行多模态预训练 · Pull Request #781 · OpenAccess-AI-Collective/axolotl:你需要从 https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain/tree/main 下载 images.zip 到 llava 文件夹中才能使用。此 PR 主要是重新实现了该文件…
▷ #axolotl-dev (30 条消息🔥):
- FF32 vs LoRA: 在讨论 DeepSeek-MoE 微调脚本 时,
@caseus_建议在 LoRA 中将 gate 保持在 fp32。 - 请求协助测试 PR:
@caseus_询问@208256080092856321是否已经测试了该 PR,引用了旨在 TRL 中启用 autounwrap 的 Pull Request #1060。 - 为命名而纠结:
@caseus_和@nanobitz讨论了 autounwrap 功能的潜在配置名称,最终确定为rl_adapter_ref_model,这意味着当设置为 true 时将传递参考模型。 - Axolotl 准备发布新版本:
@caseus_宣布 Mixtral loss 修复已合并到 transformers 中,并计划在 transformers 即将发布新版本后发布 Axolotl 0.4.0 版本,此举参考了最近发布的 accelerate 0.26.1 GitHub 上的相关 PR。 - Hugging Face 将添加默认系统提示词:
@dctanner分享了一个 Hugging Face 社区帖子,关于在模型 tokenizer 中添加对系统和聊天提示词的支持,旨在改进模型作为聊天 Agent 的评估,该功能计划于下季度推出 Hugging Face Discussion #459。
提及的链接:
- jondurbin/bagel-dpo-8x7b-v0.2 · Hugging Face
- DeepSeek-MoE/finetune/finetune.py at main · deepseek-ai/DeepSeek-MoE: 通过在 GitHub 上创建账号为 deepseek-ai/DeepSeek-MoE 的开发做出贡献。
- Codestyle.co: 各种编程语言的代码标准和指南。
- axolotl/.github/CONTRIBUTING.md at main · OpenAccess-AI-Collective/axolotl: 尽管提出 Axolotl 问题。通过在 GitHub 上创建账号为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- HuggingFaceH4/open_llm_leaderboard · 未来功能:系统提示词和聊天支持
- feat: enable trl’s autounwrap by NanoCode012 · Pull Request #1060 · OpenAccess-AI-Collective/axolotl: 目前用于测试!Teknium 已测试可用。基于此 https://github.com/huggingface/trl/blob/104a02d207b63a4a062882aaff68f2d275493399/trl/trainer/dpo_trainer.py#L691 ,TRL 将解包 t…
- Fix load balancing loss func for mixtral by liangxuZhang · Pull Request #28256 · huggingface/transformers: 此 PR 做了什么?修复了 #28255。在提交之前,此 PR 修复了一个拼写错误或改进了文档(如果是这种情况,可以忽略其他检查)。你阅读了贡献者指南吗,P…
▷ #general-help (16 messages🔥):
-
Wandb Logs 实用提示:
@c.gato分享了一个技巧,即即使在关闭容器后,也可以使用 wandb logs 来检索堆栈跟踪 (stack traces)。@leoandlibe对这一有用信息表示感谢。 -
LoRA 微调配置咨询:
@ragingwater_引用了一个 配置文件,咨询关于使用 LoRA 微调 Mistral 的建议。此外,@ragingwater_询问了load_in_8bit和load_in_4bit的设置,@caseus_回复称 4bit 应该与 qlora 配合使用,@nanobitz也确认了这一点。 -
期待配置简化:
@caseus_表示计划很快会简化配置流程,而@ragingwater_分享了他们使用 config.yml 的经验,以及可能出现的非预期全量微调 (full-finetuning)。 -
关于 CommonCrawl 数据唯一性的查询:
@emperor询问 CommonCrawl 的转储文件是唯一的还是累积的,希望明确该数据集的结构。 -
大型数据集的样本打包 (Sample Packing) 讨论:
@jinwon_k询问了针对大型数据集的样本打包实现,并提出了避免浪费 RAM 的潜在改进建议。@nanobitz回复建议查看文档中的预处理 (preprocessing) 部分,以高效处理数据集。
提到的链接:
- axolotl/examples/mistral/qlora.yml at 44ba616da2e5007837361bd727d6ea1fe07b3a0e · OpenAccess-AI-Collective/axolotl:欢迎提出 axolotl 相关问题。通过在 GitHub 上创建账户为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- axolotl/examples/mistral/config.yml at 44ba616da2e5007837361bd727d6ea1fe07b3a0e · OpenAccess-AI-Collective/axolotl:欢迎提出 axolotl 相关问题。通过在 GitHub 上创建账户为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
▷ #datasets (12 messages🔥):
- 面向 Alpaca 爱好者的最新代码数据集:
@dreamgen为对代码生成和分析感兴趣的用户推荐了由 Nicolas Mejia Petit 制作的 Tested 22k Python Alpaca 数据集,该数据集包含 22,600 个经过验证可运行的 Python 代码示例。 - 配置 Mistral Instruct:
@dinonst74询问了如何在config.yaml中定义dnovak232/sql_create_context-v4-mssql-instruct-rev数据集以训练 Mistral Instruct,@ragingwater_回复称 Alpaca 格式应该可行,需要包含instruction、output和input值。 - 寻求用于训练的 Dolphin201.jsonl:
@athenawisdoms正在寻找用于训练dolphin-2.1-mistral-7b的dolphin201.jsonl数据集,但目前没有人对其具体位置做出直接回应。 - 用于
ultrafeedback_binarized_cleaned的数据集:@noobmaster29分享了 Hugging Face 上 ultrafeedback_binarized_cleaned 数据集 的链接,并征求关于其质量的意见。 - 关于 DPO 数据集质量的见解:
@noobmaster29寻求关于 DPO 数据集中“被选中响应 (chosen responses)”质量的重要性,以及构成优质 DPO 数据集的因素。@xzuyn建议被选中的响应至少应具有与常规 SFT 响应相同的质量。
提到的链接:
- Vezora/Tested-22k-Python-Alpaca · Datasets at Hugging Face
- dnovak232/sql_create_context-v4-mssql-instruct-rev · Datasets at Hugging Face
- allenai/ultrafeedback_binarized_cleaned · Datasets at Hugging Face
▷ #rlhf (3 messages):
- Docker Power Optimization 已合并:
@caseus_确认 DPO PR 已在几天前合并,@jaredquek非常渴望在 Docker 中使用它。
Eleuther Discord 摘要
- 对 ML 术语的刻薄看法:
@stellaathena幽默地宣称所有 ML 名称都很糟糕且具有误导性,并将其称为“苦涩的教训 (sour lesson)”。 - 优化 Large Language Models 中的 Scaling Laws:由
@maxmatical引发的关于 DeepSeek 的 LLM 论文 中新 Scaling Laws 的辩论,@stellaathena认为其中一些数据表示的选择值得商榷。 - 生成式 AI 面临的挑战汇编:
@stellaathena分享了一份关于 Generative AI 开放问题的详尽列表,促进了对该领域重叠问题的讨论。 - Vision Transformers 的改造:
@digthatdata展示了 Denoising Vision Transformers,这是一种通过去噪器增强 ViT 特征的方法。 - LLaMA 的 Books3 揭秘与 Huggingface 澄清:
@stellaathena确认了 Meta 在 LLaMA 训练中透明地使用了 Books3 数据集,同时将 EleutherAI 的 lm-evaluation-harness 与 Huggingface 的 evaluate library 进行了区分。
Eleuther 频道摘要
▷ #general (28 条消息🔥):
-
关于 Huggingface Evaluate Library 的澄清:
@joe5729_00015询问了 Huggingface 的 Evaluate library 与 EleutherAI 的 lm-evaluation-harness 之间的联系,思考后者是否是前者的封装。然而,@stellaathena澄清两者之间没有关系,evaluation harness 是独立运行的,与 evaluate-on-the-hub LF 的主要收入来源 无关。 -
Meta LLaMA 训练数据集披露:
@digthatdata指出有一份文件表明 Meta 使用了 Books3 的部分内容来训练 LLaMA 模型。@stellaathena回应确认 LLaMA 1 的数据集使用情况已公开披露,对于 LLaMA 2 来说也并不意外。 -
缺乏 Spiking Neural Network 训练:
@sentialx质疑为何缺乏对 Spiking Neural Network 训练的参与,认为它们看起来更高效。然而,@thatspysaspy回应讨论了硬件兼容性问题,目前的技术是针对传统神经网络而非 Spiking 神经网络进行优化的。 -
AI 训练数据的法律趋势:
@eirai提出了一个观点,即出于法律原因,未来的 AI 训练数据将变得模糊不清,@avi.ai补充说,在比较 LLaMA 1 和 2 的报告 时,这一趋势显而易见。讨论进一步延伸,@clock.work_推测了使用 GPT-4 synthetic data 的潜在要求以及监管机构对抄袭检查的介入。 -
OpenAI QA 活动无录音:
@jbustter询问是否有 OpenAI QA 活动的录音,@boneamputee澄清没有进行广播,该活动仅由通过 Discord bot 回答的消息组成。
提到的链接:
GitHub - wzzheng/OccWorld: 3D World Model for Autonomous Driving:用于自动驾驶的 3D 世界模型。通过在 GitHub 上创建账号为 wzzheng/OccWorld 的开发做出贡献。
▷ #research (15 条消息🔥):
- 解读潜空间 (Latent Space):用户
@alofty发现一篇探讨潜空间中从非线性几何到线性几何映射的论文非常吸引人,但也承认未能完全理解所有细节。 - 生成式 AI 挑战汇总:
@stellaathena分享了生成式 AI 开放问题清单,引发了多位成员对特定问题及其潜在重叠(如问题 51、33 和 59 之间)的讨论。 - 思考梯度调度与优化:
@ad8e表达了对 inv sqrt 梯度调度的反感,并讨论了使用谱范数 (spectral norm) 作为梯度缩放方法的优点。 - RNN 与 Transformer:同根同源:用户
@pizza_joe链接了几篇讨论 RNN 与 Transformer 模型关系的论文,并详细阐述了模型效率的新方法以及针对 LLM 的缓存技术。 - 重塑 Vision Transformers:
@digthatdata分享了 GitHub 页面 Denoising Vision Transformers,并解释说该项目涉及训练一个去噪器来增强 ViT 的中间特征。此外还提供了一张相关的预告图: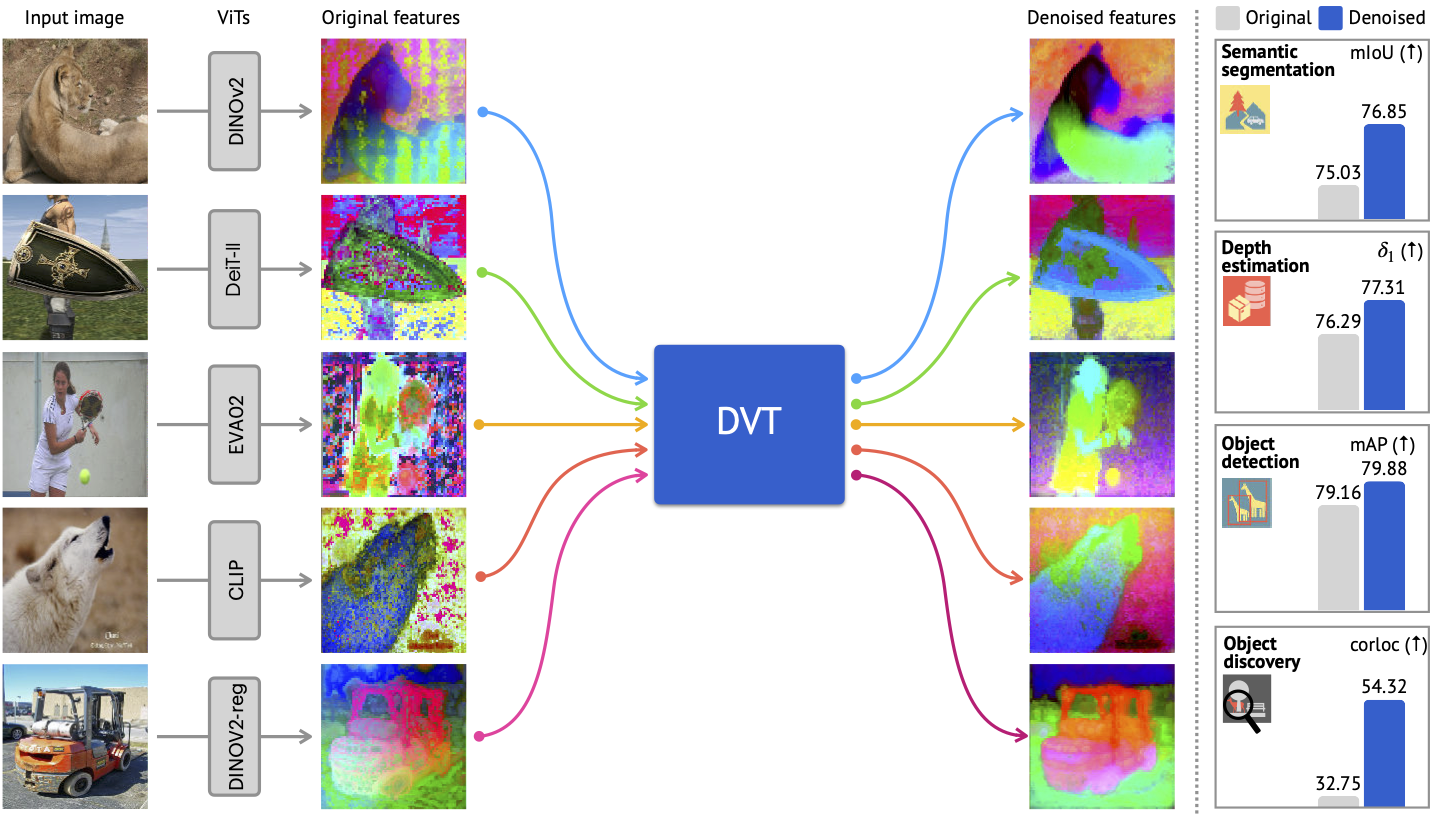 。
。
提到的链接:
- Transformers are Multi-State RNNs:Transformer 被认为与上一代最先进的 NLP 模型——循环神经网络 (RNN) 在概念上有所不同。在这项工作中,我们证明了仅解码器 (decoder-only)…
- Efficient LLM inference solution on Intel GPU:基于 Transformer 的大语言模型 (LLMs) 已广泛应用于许多领域,LLM 推理效率成为实际应用中的热门话题。然而,LLM 通常结构复杂…
- Distilling Vision-Language Models on Millions of Videos:视觉语言模型的最新进展很大程度上归功于丰富的图像-文本数据。我们的目标是在视频语言模型上复制这一成功,但目前还没有足够的人工…
- Finetuning Pretrained Transformers into RNNs:Jungo Kasai, Hao Peng, Yizhe Zhang, Dani Yogatama, Gabriel Ilharco, Nikolaos Pappas, Yi Mao, Weizhu Chen, Noah A. Smith. 2021 年自然语言处理经验方法会议 (EMNLP) 论文集…
- GitHub - Jiawei-Yang/Denoising-ViT: This is the official code release for our work, Denoising Vision Transformers.:这是我们工作 Denoising Vision Transformers 的官方代码发布。- GitHub - Jiawei-Yang/Denoising-ViT。
▷ #scaling-laws (6 条消息):
- 辩论 DeepSeek LLM 中的 Scaling Laws:
@maxmatical发起了关于 DeepSeek LLM 论文中提出的 scaling laws 的讨论,强调了其与 Kaplan 2020 的显著不同:DeepSeek 中的临界批量大小 (critical batch size) 更大,且取决于计算量而非层数 (L)。论文详细列出了这些 scaling laws,如lr_opt = 0.3118 * (c ** -0.125)和bs_opt = 0.292 * (c ** 0.3271)。 - 未发现异常:
@stellaathena回应称,对于所讨论的新 scaling laws,目前看来没有不合理之处。 - 对数据图表提出质疑:在随后的消息中,
@stellaathena指出了对讨论论文中数据呈现方式的担忧,认为在 x 轴上绘制原始参数而非 Token 数量很奇怪,并注意到图表没有采用对数刻度,最终称其“只是一个糟糕的图表”。
提到的链接:
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism:开源大语言模型 (LLMs) 的快速发展确实令人瞩目。然而,以往文献中描述的 scaling law 结论各异,这给…
▷ #interpretability-general (12 messages🔥):
- Sour Lesson 辩论:
@stellaathena幽默地建议 ML 中所有事物的命名都很糟糕且具有误导性,并将其称为 “sour lesson”(酸涩教训)。 - Neural Nets 与人类大脑相似性的讨论:
@norabelrose反驳了 “sour lesson” 的论点,指出有研究表明 Neural Nets 与人类大脑之间存在相似性。 - Interpretability 中的 Salty Lesson:
@nsaphra提出了 “salty lesson”(咸味教训):只有在数据上投入时间,Interpretability 工作才有意义。 - Transformers 占据统治地位:在一个辛辣的转折中,
@stellaathena表示 Transformers 优于 RNNs,并承认这个观点晚了六年,已经算不上辛辣了。 - Interpretability 论文的请求与分享:
@epicx表示希望获取一篇关于通过模型转换提高 DNNs 可解释性的 IEEE 论文,随后由@suhasia分享。@epicx幽默地回应,引用了 Team Four Star 关于支持官方发布的请求。
提到的链接:
Interpreting Deep Neural Networks through Model Transformation: Literature Review:Machine learning 尤其是 deep learning 模型在自动驾驶、语音识别、表情识别等许多领域都取得了 state-of-the-art 的性能。然而……
▷ #lm-thunderdome (9 messages🔥):
- 关于 Meta-Templates 支持的咨询:
@stellaathena询问是否有办法支持 BigBench tasks 的格式化,以便适用于任何多项选择问答 (MCQA) 任务,而无需每次重新格式化。@hailey_schoelkopf回复说可以使用 promptsource templates,但 “prompt library” 的想法尚未被优先考虑。 - Bug 修复导致意外的准确率下降:
@baber_对修复一个 Bug 导致准确率下降 20 个百分点表示震惊,最初还以为发现了一种新的采样方法。 - 准确率统计数据的修正:
@hailey_schoelkopf澄清说,修复 Bug 后准确率从 7% 提高到了 52%,消除了@baber_最初对准确率百分比的误解。 - 困惑与觉悟:
@baber_承认了混淆,将 7% 误认为是 70%,并认为修复是一种降级,最终意识到错误并表示宽慰。 - 对 Finetune 方法的担忧:
@cubic27对准确率讨论的影响表示担忧,暗示由于这些意外进展,他们可能需要重新评估在 llama finetunes 方面的工作。
▷ #multimodal-general (1 messages):
- 寻求 Multimodal LLMs 基础:
@clams_and_beans正在为一个 Multimodal LLM 研究项目寻找 repository,明确表示希望处理图像以外的模态。他们请求指导以找到一个基础实现来开始构建。
LAION Discord 摘要
-
LAION-coco 数据集缺失:用户
@chatdiablo寻找失踪的 LAION-coco dataset,尽管寻找过程困难,但由于担心数据集中可能存在非法内容,@thejonasbrothers向其推荐了 HuggingFace 上的 Datacomp 作为替代方案。 -
Mistral 模型受到审视:Mistral-medium 与 Mixtral 的对比凸显出 Mistral-medium 往往更容易产生幻觉(hallucinate),尽管它有时能提供详细的答案。正如
@nx5668所观察到的,这表明了质量上的权衡。 -
Wacom 的 AI 艺术争议:
@thejonasbrothers和@astropulse深入探讨了 Wacom 在营销中使用 AI 生成艺术作品引发的争议,@.undeleted提出了这些艺术作品可能源自 Adobe Stock 的可能性。正如 Boing Boing 的报道 所详述,该事件凸显了艺术社区对 AI 艺术作品的敏感性。 -
PIXART-Delta 震撼图像生成领域:PIXART-Delta 框架的发布引发了讨论,该框架能够在 0.5 秒内生成 1024px 的图像。讨论围绕图像质量和训练数据的有效性展开,并分享了相关链接,包括 PIXART-Delta 技术论文。
-
追求卓越的图像标注(Captioning):关于人类还是 AI 标注员更好的持续讨论中,提到了 GPT4-V 和 CogVLM 作为 AI 标注领域的领先示例。辩论强调了该领域内专有模型和开源模型的细微差别与能力。
-
AI 驱动视频生成的创新:
@nodja强调了高美学视频生成技术的发展,分享了 MagicVideo-V2 项目页面 及其对应的 研究论文,展示了根据文本提示生成富有想象力且高质量视频内容的进展。
LAION 频道摘要
▷ #general (46 条消息🔥):
-
LAION-coco 数据集在数字浪潮中丢失:用户
@chatdiablo询问如何获取用于研究的 LAION-coco dataset,但@pseudoterminalx指出,由于可能包含非法内容,该数据集可能不会再回归。@thejonasbrothers建议使用 Datacomp 作为替代方案并提供了链接:HuggingFace 上的 Datacomp。 -
Mistral-medium vs Mixtral:在 LAION 的讨论中,
@nx5668评论称 Mistral-medium 比 Mixtral 更容易产生幻觉,尽管它有时会给出详细的答案,并指出这是一种质量权衡。 -
Wacom 陷入 AI 争议:
@thejonasbrothers分享了关于 Wacom 营销失误使用 AI 生成艺术作品的链接,引发了辩论和艺术社区的抵制。原始广告已被删除,这进一步加剧了争议。Boing Boing 对 Wacom AI 艺术惨败的报道。 -
对广告中劣质 AI 艺术的抵制:
@astropulse批评了像 Wacom 这样使用明显 AI 生成图像进行广告宣传的公司,称由于存在明显的错误,这是“对 AI 艺术的侮辱”,并对这样一家重要的艺术家工具公司表现出的忽视感到不解。 -
Wacom 的 AI 艺术——来自 Adobe Stock?:在关于 Wacom AI 艺术争议的讨论中,
@.undeleted建议这些图像可能源自 Adobe Stock,为这个正在发酵的故事增添了另一个转折。
提到的链接:
艺术家对 Wacom 使用 AI 艺术营销艺术家设备感到不满:当你可以让 Midjourney 生成作品时,谁还需要 Wacom Intuos 或 Cintiq?好吧,你可以用它们来修掉 AI 的幻觉、错误并进行合成……
▷ #research (23 messages🔥):
- LAION-coco 数据搜寻:用户
@chatdiablo正在寻求下载 LAION-coco 数据集的帮助,因为 Hugging Face 似乎出现了问题。他们呼吁拥有该数据集的人进行分享。 - PIXART-Delta 以速度引起轰动:
@thejonasbrothers介绍了一个名为 PIXART-Delta 的新框架,它仅需 0.5 秒即可生成高质量的 1024px 图像。分享了技术论文链接,讨论了其相比 PIXART-Alpha 的显著特性。 - 关于 PIXART-Delta 图像质量的辩论:在 PIXART-Delta 发布后,
@thejonasbrothers批评了 Demo 的输出结果,称其忽略了一半的 Prompt,并且是由于在低质量的 llava captions 上训练导致的。@qwerty_qwer提出了反对意见,强调了输出结果的艺术性。 - 人类 vs AI 标注 (Captioning):关于最佳标注方法的观点分享中,
@nodja幽默地表示人类是最好的标注者,而@qwerty_qwer反驳说人类可能会偷懒。@thejonasbrothers提到 GPT4-V 是目前最好的,@progamergov补充说 CogVLM 是最好的开源 (open-source) 模型,而 GPT-4V 是最好的闭源模型。 - 高美学视频生成:
@nodja分享了一个关于多阶段视频生成项目的链接,其中包含广泛的富有想象力的 Prompt。提供了项目页面,但提醒其中包含大量 GIF,并附带了作者的研究论文链接。
提到的链接:
- MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation:对文本描述生成高保真视频的需求日益增长,催生了该领域的重大研究。在这项工作中,我们推出了集成文本到图像生成的 MagicVideo-V2…
- PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models:本技术报告介绍了 PIXART-δ,这是一个将 Latent Consistency Model (LCM) 和 ControlNet 集成到先进的 PIXART-α 模型中的文本到图像合成框架。PIXART-α 被公认为…
- MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
Mistral Discord 总结
- 新论文发布:@sophiamyang 重点介绍了在 arXiv 上发布的一篇新论文,供同行评审。
- Mistral 还是 Dense?MoE 的抉择:@yiakwyxpumlframeworkteam_03391 发起了关于 MoE 生成质量在特定领域数据集与传统 Dense 模型对比的辩论,促成了与 @sophiamyang 的知识交流。
- 云端训练平台对比:@damiens_ 寻求关于训练 Mistral 模型的用户友好型云服务的建议,提到了 SkyPilot、SageMaker 和 Hugging Face 作为潜在竞争者。
- API 参数变更:Mistral API 参数从
safe_mode变更为safe_prompt让用户 @freqai 和 @nftsmasher 感到困惑,随后 @lerela 提供了澄清性的解释与致歉。 - 使用 Mistral 7B 进行自定义解码:@michaelwechner 请求一个使用 Mistral 7B 模型实现自定义解码策略的 Python 代码示例。
技术精准度与澄清重点: 保持了技术关注点,确保包含特定的模型名称、API 参数和用户句柄,以便工程受众进行精准和直接的后续跟进。
Mistral 频道总结
▷ #general (23 messages🔥):
- 新论文提醒:用户
@sophiamyang宣布在 https://arxiv.org/pdf/2401.04088.pdf 发表了新论文。 - Mistral 与稠密模型对比:用户
@yiakwyxpumlframeworkteam_03391讨论了关于 MoE 在领域数据集上相比稠密模型(dense models)生成效果较差的担忧,并向@sophiamyang寻求见解。 - 云端训练问题:
@damiens_向社区咨询最适合且用户友好的 Mistral 模型训练和微调云服务,提到了 SkyPilot、SageMaker 和 Hugging Face。 - TypeScript 咨询与澄清:
@derastatknutred询问了 API 对 TypeScript 的支持情况。@sublimatorniq澄清 TypeScript 已经得到支持,随后@derastatknutred意识到问题出在 Vercel AI SDK 上。 - API 参数更新引发困惑:
@freqai和@nftsmasher报告了 Mistral API 的一个错误。@cohee指出参数已从safe_mode更新为safe_prompt,而@lerela对文档错误造成的便利提供了解释和道歉。
提到的链接:
-
[Mistral AI API Mistral AI Large Language Models](https://docs.mistral.ai/api/):Chat Completion 和 Embeddings API
▷ #models (9 messages🔥):
- 带有 @workspace 关键词的 GitHub Copilot:
@kim_tech提到 GitHub Copilot 的最新更新允许使用@workspace关键词优先处理当前的 git 仓库。 - 寻找用于可编辑图表的自定义模型:
@m1sol_44558正在寻找一种可以生成可编辑图表的自定义模型。 - Mistral 与本地部署的问题:
@gbourdin报告了在本地llama.cpp服务器上运行mixtral-8x7b-instruct-v0.1.Q2_K.gguf时的问题,在响应/embedding请求时得到全 0.0 数据。 - 介绍用于生成图表的 Mermaid:针对
@m1sol_44558的需求,@kim_tech建议研究 Mermaid 编程语言来生成可编辑图表。 - Mistral Medium 可能出现宕机:
@theunholymessiah询问 Mistral Medium 是否宕机,因为其端侧无响应。
提到的链接:
Kquant03/Hippolyta-7B-bf16 · Hugging Face
▷ #finetuning (1 messages):
- 关于在 OpenAI 模型中使用 Llama-index 的困惑:用户
@dinonst74询问是否有必要微调类 OpenAI 模型以在末尾包含</s>,因为在使用常规 Mistral 模型时这似乎是不必要的。他们正在考虑是否应该调整数据集并省略</s>以获得更好的学习效果。
▷ #random (3 messages):
- 请求解码策略示例:
@michaelwechner正在寻找一个 Python 代码示例,以便使用 Mistral 7B 作为 LLM 来实现自定义解码策略。 - 将内心声音比作 C3PO:
@king_sleeze提供了一个类比,将内心声音比作 C3PO,称其为一种进行叙述和肯定的礼仪机器人脚本。 - 讨论二分心智理论(Bicameral Theory of Consciousness):
@cognitivetech表示赞同,认为 二分心智理论 无法被证明或反驳,但它对于思考意识的本质可能很有用。
▷ #la-plateforme (19 条消息🔥):
- 对 Mistral 8x7B 的赞赏与速度担忧:
@c_bonadio赞扬了 Mistral 团队在 Mistral 8x7B 上的工作,但对响应时间较慢(16秒)表示担忧(相比 fireworks.ai)。他们寻求提升速度的帮助。@lerela承认了该问题并承诺致力于实现更快的响应时间。 - API
safe_mode参数混淆:@gimaldi_75953在 API 调用中使用safe_mode参数时遇到 422 Unprocessable Entity 错误,无论设置为true还是false均如此。@lerela澄清 API 文档存在错误,将safe_prompt误写为了safe_mode,并承诺文档的更改将解决此问题。@gimaldi_75953随后确认该方案有效。 - Go 与 Python API 客户端对比:
@gimaldi_75953报告了使用 Go 客户端时的问题,并计划尝试 Python 客户端进行对比;@c_bonadio建议 422 错误可能与参数格式化有关。 - 更新的 Guardrailing 文档:
@lerela分享了更新后的文档链接,澄清了之前误命名的safe_modeAPI 参数,敦促用户相应地更新代码,使用正确的safe_prompt标志。更新地址位于:Mistral Documentation on Guardrailing。 - 对 GPU 的好奇与玩笑:频道内的用户开玩笑讨论运行 la plateforme 所需的 GPU 数量,猜测包括 A100、H100,根据
@standardunit的计算,至少需要 “3 个 GPU”。
提到的链接:
| [Guardrailing | Mistral AI Large Language Models](https://docs.mistral.ai/platform/guardrailing/):用于强制执行护栏(guardrails)的系统提示词。 |
Latent Space Discord 总结
-
通过事件驱动的聊天 UI 冒泡:
@slono讨论了为 Agent 框架创建 bubbletea 驱动的 TUI,重点关注在为 Agent 交互设计的标签式界面中处理 streaming(流式传输)、实时更新和异步响应 的细微差别。这场不断深入的讨论触及了 UI 在多 Agent 系统通信动态中的角色。 -
辩论 UI 在 AI 记忆中的角色:
@swizec发起了一场辩论,询问包含对话状态的 UI 是否可以被视为 AI Agent 的记忆层,引发了对 UI 设计对基于 AI 的“业务逻辑”影响的反思。 -
前沿 AI 研究:社区关注各种 AI 话题,如 Andrew Ng 关于 Direct Preference Optimization (DPO) 研究的推文,以及 Bill Gates 与 Sam Altman 关于 AI 领导力的播客。
@decruz对蒸馏 Orca 数据集的应用以及在 Modal 上运行 DPO 微调(finetunes)表示兴趣,暗示了关于 AI 研究方向和实现的更广泛对话。 -
AI 与 Raspberry Pi 的协同作用:
@decruz详细介绍了在 Raspberry Pi 上托管 Phi 和 TinyLLaMA 等模型的实验,并在 Reddit 帖子中分享了发现。这一探索揭示了将易于获取的硬件与先进 AI 模型结合的潜力。 -
MOE 模型:训练快但微调难:在 LLM 论文俱乐部中,
@swyxio总结了@ivanleomk对 MOE 模型 的见解,指出尽管训练速度更快,但它们容易过拟合,特别是提到了 MOE-Mamba 的训练效率。微调这些模型仍然是一个挑战,但蒸馏(distillation)具有潜在的优势。完整讨论可见于此 推文。
Latent Space 频道总结
▷ #ai-general-chat (52 条消息🔥):
-
Slono 对动态聊天 UI 的探索:
@slono深入研究了为 Agent 框架构建基于 bubbletea 的事件驱动型 TUI 的复杂性,讨论了流式传输、实时更新以及异步响应与 UI 渲染协调方面的挑战。该 UI 旨在标签页视图中容纳 Agent 交互的多个补全事件。 -
Swizec 对 UI 作为 Agent 记忆的质疑:在一次深入的交流中,
@swizec质疑包含对话状态的 UI 是否可以被视为 Agent 记忆的一种形式,这表现出对在 AI 充当“业务逻辑”的系统中 UI 对 Agent 控制权的担忧。 -
深度学习与 AI 讨论成为焦点:AI 领域的新动态备受关注,包括吴恩达(Andrew Ng)关于 Direct Preference Optimization (DPO) 研究论文的推文,
@decruz提到使用蒸馏后的 Orca 数据集进行 DPO,以及@swyxio分享的比尔·盖茨与 Sam Altman 的新播客节目,引发了关于公司规模和盖茨在线影响力的讨论。 -
论文俱乐部与 DPO 实验:
@ivanleomk邀请同行参加论文俱乐部讨论,同时@decruz也征求在 Modal 上运行 DPO 微调的示例,表现出对前沿 AI 研究实践的兴趣。 -
GitHub 与 Raspberry Pi 实验:
@swyxio链接了一个合成数据集集合,@decruz详细介绍了在 Raspberry Pi 上运行 Phi 和 TinyLLaMA 等模型的实验,并在 Reddit 帖子上发布了结果。
提到的链接:
- deepseek-ai (DeepSeek)
- Reddit - 深入探索
- Howie Xu (@H0wie_Xu) 的推文:在今天的 @ycombinator W24 启动仪式上,@sama 建议人们带着 GPT-5 和 AGI 将“相对较快”实现的定见进行开发;据 YC 创始人 Ric 称,GPT-4 的大部分局限性将在 GPT-5 中得到解决……
- 第 6 集:Sam Altman:如果你让人们列举人工智能领域的领导者,有一个名字你可能比其他任何名字都更常听到:Sam Altman。他在 OpenAI 的团队正在推动……
- Reddit - 深入探索
- GitHub - jondurbin/bagel: A bagel, with everything.:一个包含一切的百吉饼。通过在 GitHub 上创建账户来为 jondurbin/bagel 的开发做出贡献。
▷ #llm-paper-club (1 条消息):
- MOE 模型训练更快但微调具有挑战性:
@swyxio分享了来自@ivanleomk的总结,强调 MOE 模型(如 MOE-Mamba)往往比稠密(dense)对应模型更容易过拟合,但受益于显著更快的训练时间——大约快 2.2 倍。然而,微调这些模型具有挑战性。不过,其优势在于蒸馏 MOE 模型的潜力。点击此处阅读完整讨论。
提到的链接:
Ivan Leo (@ivanleomk) 的推文:MOE 模型似乎比其稠密对应模型更容易严重过拟合,但训练速度显著加快。例如 MOE-Mamba 的训练速度快了约 2.2 倍。这意味着训练很快,但微调却……
LlamaIndex Discord Discord 摘要
- 长文本 RAG 的语义策略:
@GregKamradt介绍了一种在 RAG 中切分长文档的新型语义方法。更多见解和讨论可以通过分享的 推文 获取。 - 新课程提醒:Activeloop & IFTTT 提供免费认证:IFTTT 与 Activeloop 合作推出的一门课程,承诺传授真实世界用例知识并提供免费认证。参与者可以在此处探索更多机会。
- 发布时刻:Together Embeddings 结合 Mistral AI:Together AI 发布了一份关于使用 Mistral AI 及其全新的 Together Embeddings endpoint 构建检索增强生成 (RAG) 应用的指南。详细说明见此处的公告。
-
LlamaIndex.TS 升级:
LlamaIndex.TSTypeScript 库的更新带来了新的 Embeddings、向量数据库、多种语言模型以及多模态支持。更多信息可以在此处的更新公告中找到。 - LLM 集成难题与解决方案:
@syblus_询问了如何从 OpenAI API 切换到 Together AI Llama-2。有用的信息和参考代码可通过 Together LLM 文档 和 LlamaIndexTS GitHub 仓库 获取。 - 突破文档摘要的边界:
@emrgnt_cmplxty正在寻求微调文档摘要模型以提供结构化输出,之前的研究成果可在 HuggingFace 上访问。 - 调试 ReAct Agent Prompt 的特性:讨论了 ReAct Agent 中
system_prompt的问题,@7leven指出需要自定义ReActChatFormatter,并表示计划为 LlamaIndex 项目做出贡献。 - Agent 测试中的差异困扰:
@vedtam报告了控制台详细输出 (verbose outputs) 与 Postman 结果之间的不匹配,暗示了带有聊天历史的 Agent 行为问题。 - SageMaker 与 Llama_Index 结合的挑战:
@cd_chandra询问了将 Amazon SageMaker 模型端点与 llama_index 集成的问题。虽然不能直接实现,但@cheesyfishes讨论了一种涉及 LangChain 的 LLM 和 Embeddings 与 llama_index 兼容性的变通方法。
LlamaIndex Discord 频道摘要
▷ #blog (4 条消息):
- 长文档的语义切分:
@GregKamradt建议了一种为 RAG 切分长文档的新方法,专注于句子之间的语义连接,并分享了包含更多细节和相关链接的 推文。 - Activeloop 课程走红:IFTTT 和 Activeloop 的课程正受到关注。感兴趣的参与者可以通过学习真实用例来深入了解并获得免费认证。更多信息可以在此处找到。
- Together Embeddings 与 Mistral AI 及 LlamaIndex 联合发布:Together AI 宣布了一份使用 @MistralAI 和新 Together Embeddings endpoint 构建检索增强生成应用的指南。该博客文章提供了分步说明,可从此处访问。
- LlamaIndex.TS 的重大更新:TypeScript 库
LlamaIndex.TS刚刚进行了一次重大更新,增加了新的 Embeddings 和向量数据库,以及多种语言模型和多模态支持。查看公告和更多细节请点击此处。
提到的链接:
使用 Together AI 和 LlamaIndex 构建你自己的 RAG 应用程序
▷ #general (48 messages🔥):
-
在 LlamaIndex Discord 机器人中切换 LLM:
@syblus_询问如何在 Node.js 环境中从使用默认的 OpenAI API 转换到 Together AI Llama-2。@whitefang_jr回复了 Together LLM 文档的链接,并提供了 Colab 的示例代码,但承认 Together AI 尚未出现在 TypeScript (TS) 版本中,并指向了 LlamaIndexTS GitHub 仓库。为了进一步讨论,他们还指向了一个特定的 TS 频道。 -
微调摘要模型:
@emrgnt_cmplxty表示有兴趣微调一个文档摘要模型,使其能够根据指令返回结构化输出,并链接了他们之前在 HuggingFace 上相关的研究工作。 -
ReAct Agent 对 System Prompt 的使用:
@7leven提出了system_prompt参数未按预期影响 ReAct Agent 的问题。@cheesyfishes确认from_tools()方法不使用system_prompt,并且需要自定义ReActChatFormatter才能修改 Prompt。随后,@7leven提到成功对ContextReActChatFormatter进行了猴子补丁(monkeypatching),并表示计划为 LlamaIndex 项目做出贡献。 -
控制台与 Postman 之间的结果不一致:
@vedtam在测试时发现控制台显示的详细输出(verbose output)与 Postman 中的最终消息存在差异。@cheesyfishes回应称,Agent 可能会在聊天历史的上下文中重新解释工具(tool)的响应。 -
在 Llama_Index 中利用 SageMaker 模型端点:
@cd_chandra询问是否可以在 llama_index 中使用 Amazon SageMaker 模型端点。@cheesyfishes转达称 llama_index 缺乏 SageMaker 的集成,但提到它在 LangChain 中存在,并提供了一段代码片段,用于在 llama_index 中调用 LangChain 的 LLM 和 Embeddings。
提到的链接:
- Together AI LLM - LlamaIndex 🦙 0.9.30
- LlamaIndexTS/packages/core/src/llm at main · run-llama/LlamaIndexTS:LlamaIndex 是适用于你的 LLM 应用程序的数据框架 - run-llama/LlamaIndexTS
DiscoResearch Discord 摘要
-
MergeKit 合并成为关注焦点:技术讨论强调了使用 MergeKit 组合语言模型的潜力。
@thewindmom分享了一篇关于 模型合并简化 (Model Merging Simplified) 的科普博客文章,以及 Hugging Face 上的模型合并论文集。@philipmay和@remek1972讨论了合并两个 Llama2-70B 模型的可行性,而@rasdani则指出了 DiscoLM-120B 作为一个范例。 -
双语 AI 的诞生:
@hammadkhan介绍了 AI 社区的一个重要更新,分享了 Jina AI 发布了全球首个中英双语模型,更多细节可以在 Jina AI 的 Embeddings 页面找到。这引发了@philipmay关于该模型是开源还是仅限于 API 的疑问,促使社区进一步调查。 -
深入探讨 Min P Sampling 的基准测试:基准测试开发社区的对话由
@.calytrix询问用于基准比较的 Min P Sampling 实现而引发。@kalomaze提供了包含多个实现的详尽回复,并讨论了方法论,包括对 Temperature 如何影响模型输出的见解,并在 Reddit 上进行了详细分析。 -
首次 Embedding 社区会议即将举行:
@philipmay宣布了首次 Embedding 社区会议,引发了互动,并确认了 Discord 适合进行群组通话。这与@thewindmom分享的一条暗示 Embedding 开发领域进展的推文有关,同时_jp1_介绍了长上下文检索模型,分享了 Hazy Research 在 Monarch Mixer 上的工作及其 GitHub 仓库。
DiscoResearch 频道摘要
▷ #mixtral_implementation (8 条消息🔥):
- 寻找 MergeKit 见解:用户
@philipmay询问了关于合并模型的 “mergekit” 方法的资源。他们质疑这是否类似于 Mixtral 中的 MoE,但仅使用两个模型而不是八个。 - TheWindMom 分享 MergeKit 知识:
@thewindmom发布了一个关于使用 mergekit 进行模型合并的 Hugging Face 博客链接:“Model Merging Simplified”。他们澄清这与 MoE 不同,并提供了另一个相关论文链接,其中包括一篇 2014 年关于表征神经网络优化的论文。 - 对 Llama2-70B 合并的质疑:
@philipmay思考了使用 mergekit 合并两个 Llama2-70B 模型的可行性和实用性。 - MoE 合并方法澄清:用户
@remek1972回复了@philipmay,向其指向了 mergekit 的一个特定分支,该分支使用 MoE 合并方法,与标准方法不同。 - DiscoLM-120B 的双模型协作:
@rasdani加入了对话,提到 DiscoLM-120B 是两个 Llama2-70B 微调模型的合并。他们提到了操作上的挑战,并推测如果有足够的计算能力,它有潜力登顶 Hugging Face 排行榜。 - 关于 MergeKit 的趣谈:
@thewindmom分享了来自 @osanseviero 的一条幽默推文,内容涉及 mergekit 的讨论。
提到的链接:
▷ #general (5 条消息):
- 双语模型打破语言障碍:
@hammadkhan分享了来自@bo_wangbo的推文,宣布中英双语模型现已通过 API 提供,德英模型预计下周推出。Jina AI 确认在 Jina AI 的 embeddings 页面发布了全球首个具有 8192 token 长度的中英双语 embedding 模型,更多详情可见 Jina AI 新闻。 - 对开源代码的期待:作为回应,
@philipmay询问 Jina AI 的模型是开源的,还是仅仅是一个 API/黑盒服务。@hammadkhan表示对其开放性尚不确定。 - 直接联系以求明确:
@thewindmom对可能缺乏开源访问权限表示担忧,并提到直接联系官方渠道以获取更多信息。
提到的链接:
来自 Bo (@bo_wangbo) 的推文:中英双语模型已在 API 上线,德英模型下周推出,我们正在与 HF 团队同步,使这两个模型无缝集成到即将发布的、期待已久的 sbert rel…
▷ #benchmark_dev (15 messages🔥):
- 寻找 Min P 实现:
@.calytrix询问是否在任何地方实现了 Min P sampling 以进行对比测试。@kalomaze回应了几个实现:llama.cpp、exllama2、text-generation-webui 的 HF 加载器、vllm、koboldcpp(llama.cpp 的一个分支)以及 tabbyAPI(exllama2 的一个轻量级 API 分支)。 - 剖析采样方法:
@kalomaze分享了一篇 Reddit 帖子,详细分析了 Temperature 设置的顺序如何严重影响模型的输出,并 强调了在较高温度下 Min P 的表现如何不同于 Top P 等其他采样方法。 - Min P 与其他采样参数的对比:在进一步的解释中,
@kalomaze讨论了与 Top K 和 Top P 等其他采样方法相比,Min P 在较高温度下不会失效,并强调了它们在不同模型和 backends 之间的一致性表现。 - Min P 的 Benchmark 结果:
@.calytrix分享了 benchmark 结果,证明在使用 Min P 且 Temperature 设置为 1 到 4 时,得分保持一致。然而,他们指出该 benchmark 侧重于为情感状态分配数值,可能不是评估采样器的最佳方式。 - Temperature 对 Min P 使用的影响:
@.calytrix强调,拥有 Min P 在不同 Temperature 下的 benchmark 可能会很有用,并询问是否有其他值得比较的参数。@kalomaze提到 Temperature、Top K 和 Top P 是控制语言模型确定性(determinism)的常规方法。
提及的链接:
▷ #embedding_dev (5 messages):
- Embedding 社区首次会议日程已定:用户
@philipmay宣布首个 embedding 社区会议定于 德国时间明天下午 4 点 在 Discord 举行,并询问该平台是否适合此类活动。 - 确认 Discord 可用于群组通话:作为回应,
@rasdani确认了可行性,并提到了他们在 Discord 上进行 群组通话 的良好体验。 - 引发关注的推文:用户
@thewindmom分享了来自 @realDanFu 的推文,未作额外评论。 - 多语言性能推测:在该推文之后,
@bjoernp对 多语言性能 以及 Jina 在该领域的竞争力表示好奇。 - 下一代文本 Embedding:
_jp1_重点介绍了关于 长上下文检索模型 的先进工作,并附上了 Hazy Research 详细博客 的链接,同时分享了 Monarch Mixer (M2) 模型的 GitHub 仓库,该模型支持高达 32K 的上下文长度,并可应用于其他语言。访问 M2 GitHub 仓库。
提及的链接:
- 使用 Monarch Mixer 的长上下文检索模型:Long-Context Retrieval Models with Monarch Mixer
- GitHub - HazyResearch/m2: Monarch Mixer 仓库:Repo for "Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture" - GitHub - HazyResearch/m2: Repo for "Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture"
LangChain AI Discord 总结
-
VS Code 和 IntelliJ 的本地 LLM 插件探索:
@zwarag正在寻找能够与本地 Large Language Model (LLM) 交互的 Visual Studio Code 或 IntelliJ 插件,以提供直接的开发支持。 -
寻找用于图像采集的爬虫库:
@gomfe_52955在频道中征集关于擅长从网页抓取图像的库的偏好。 -
向量数据库爱好者讨论本地化:
@manskip和@schtiph讨论了在本地机器上使用 MongoDB 等向量数据库,并给出了一个专业建议,即在 MongoDB 文档上下文中考虑 “persist”(持久化)。 -
Linux Libmagic 的困扰:用户
@Eminem正在处理 Linux 上的 Libmagic 问题,请求熟悉该工具故障排除的人员提供帮助。 -
RAG 聊天机器人说话人识别难题:
@bennyblader讨论了与 RAG 聊天机器人 相关的挑战,考虑使用 JSON 结构 来传递上下文,并提高机器人区分对话参与者的能力。 -
LangServe 讨论在 GitHub 上深入技术细节:
@veryboldbagel和@cryptossssun就 LangServe 功能中处理输入变量进行了对话,其中一个场景在 设置输入变量 时需要关注,并建议在 GitHub Discussion 中进行更深入的交流。 -
The Bartender:一个会说唱和唱歌的 GPT:在一个引人注目的展示中,
@hat_tr1ck介绍了 The Bartender,这是一个 GPT 作品,它不仅能创作 说唱歌词,还能以 MP3 格式 交付,可通过 Twitter 帖子 找到。
LangChain AI 频道总结
▷ #general (17 条消息🔥):
- 寻求 IDE 的本地 LLM 插件:用户
@zwarag询问了关于集成本地 Large Language Model (LLM) 的 Visual Studio Code 或 IntelliJ 插件。 - 使用网页爬虫库抓取图像:
@gomfe_52955向社区询问了关于使用网页爬虫抓取图像的首选库。 - 本地机器上的向量数据库:
@manskip和@schtiph讨论了在本地使用 MongoDB 等向量数据库的可能性,@schtiph 提示在 MongoDB 上下文中搜索 “persist” 关键字。 - Linux 上 Libmagic 的麻烦:用户
@Eminem就 Linux 上遇到的 Libmagic 问题寻求帮助,寻找有修复经验的人。 - RAG 聊天机器人说话人区分的挑战:
@bennyblader正在为 RAG 聊天机器人 构建对话数据结构,并就是否以 JSON 结构 传递上下文寻求建议,目前正面临机器人难以区分对话中说话人的问题。
▷ #langserve (10 条消息🔥):
- GitHub 讨论重定向:
@veryboldbagel将一个关于如何通过 LangServe 中的查询方法使新变量可用的问题移至 GitHub 讨论,并提供了进一步帮助的链接:Discussion #394。 - 寻求详细解释:
@cryptossssun寻求关于如何在 LangServe 的RunnableWithMessageHistory函数中的 Chain 包装器内正确传递输入变量的澄清。 - 共享代码片段:
@cryptossssun分享了一个设置输入变量的代码片段示例,该片段似乎未按预期工作:"{"lession": RunnablePassthrough(), "affection": RunnablePassthrough(), "question": RunnablePassthrough()}"。 - 直接寻求帮助:
@cryptossssun标记了特定用户,以寻求有关设置输入变量问题的帮助。 - 建议继续在 GitHub 讨论:
@veryboldbagel建议@cryptossssun在 GitHub 上继续他们的技术讨论,以便对问题进行更彻底的检查。
提到的链接:
如何通过查询方法使新变量输入可用? · langchain-ai/langserve · Discussion #394:问题:如果我创建了新变量:input_variables=["history", "input","lession", "affection"],并按照以下代码进行设置。我无法进行正确的查询…
▷ #share-your-work (1 条消息):
- 会唱歌的 GPT:
@hat_tr1ck分享了在 Twitter 上发现的一个新 GPT,它不仅能生成 说唱歌词,还能为完成的歌曲创建 MP3 文件,并声称这是首创。这个机器人被称为 The Bartender。
LLM Perf Enthusiasts AI Discord 摘要
- 寻找 Query Expansion 资源:
@robhaisfield正在寻找 Query Expansion(查询扩展)方面的优质资源。加入讨论。 - 团队消息尚未达到上限:
@joshcho_询问了团队版的 Message Cap(消息上限),意图实施即将到来的变更,并观察到更新后没有 速度提升。 - GPT 的转变感觉像 Turbo:有传言称 GPT 模型发生了重大转变,
@joshcho_将最新的体验比作 Turbo 版本。 - 对 GPT Store 发展路径的怀疑:
@justahvee对 GPT Store 的策略表示怀疑,将其交易性质与那些能够建立 长期用户群 的 App 进行了对比。 - 关于自定义 GPT 效用的辩论:
@thebaghdaddy对 自定义 GPT 持批评态度,认为它们缺乏独特性;而@nosa_.则提出了反面观点,分享了使用专注于研究的 GPT 来增强任务表现的积极成果。 - 对 GPT 激励结构的担忧:
@nosa_.对创建高参与度 GPT 的奖励机制表示担忧,认为这可能导致 反乌托邦式的用户操纵。他们引用了 @metaviv 的一条 Twitter 线程,该线程质疑了 OpenAI 激励机制的影响。
LLM Perf Enthusiasts AI 频道摘要
▷ #rag (1 条消息):
robhaisfield: 有人有关于 Query Expansion 的优质资源吗?
▷ #openai (24 条消息🔥):
- 查询团队版消息上限:
@joshcho_正在寻找有关团队版 Message Cap 的信息,因为他们计划立即加入变更。 - 未检测到团队版速度提升:据
@joshcho_称,尽管发生了变更,但团队版的速度没有明显差异。 - 观察到 GPT 模型的变化:
@joshcho_还提到 GPT 似乎发生了 巨大的模型变更,称现在感觉类似于 Turbo。 - 对 GPT Store 未来的担忧:
@justahvee对 GPT Store 表示怀疑,指出了它与 其他 App Store 的区别,以及与那些赢得长期用户的 App 相比,它可能过于趋向交易化。 - 对自定义 GPT 价值的批判性看法:
@thebaghdaddy尖锐地指出,大多数自定义 GPT 只是 1-2 段的指令,没有真正的护城河,也没有理由弃用其他工具而选择它们;而@nosa_.则表达了对研究型 GPT 的积极体验,认为它们可以为特定任务提供性能提升。 - GPT 中潜在的反乌托邦激励:
@nosa_.链接到了 Aviv Ovadya (@metaviv) 的 Twitter 线程,讨论了由于 OpenAI 提供的创建高参与度 GPT 的激励措施而导致反乌托邦结果的风险,引发了对 GPT 操纵用户潜力的担忧。
提到的链接:
来自 Aviv Ovadya 🥦 (@metaviv) 的推文:噢不。这看起来很糟糕。OpenAI 将向那些创建最吸引人的 GPT 的人支付报酬。这使得他们的激励机制与社交媒体非常接近——捕捉注意力。这可能会变得非常反乌托邦……
Alignment Lab AI Discord 摘要
-
编译方面的麻烦:@stormchaser9939 报告了在 Windows 上构建最新 llama.cpp 时出现的 构建问题,与之前无问题的构建相比,错误突然激增。
-
寻求 Orca 复现:@ming.l.linoracle.com 正在寻求 Mistral-7B-SlimOrca 的帮助以复现其结果,寻找参考代码或训练设置,并提供了该模型的 Hugging Face 链接。
Alignment Lab AI 频道摘要
▷ #general-chat (1 条消息):
- Windows 上的 Llama.cpp 构建错误:用户
@stormchaser9939在 Windows 上构建 llama.cpp master 分支的最新代码时遇到问题,提到之前的构建都很正常,但当前的构建产生了 大量错误。
▷ #open-orca-community-chat (1 条消息):
- 寻求 Mistral-7B-SlimOrca 复现指导:用户
@ming.l.linoracle.com询问了关于复现 Mistral-7B-SlimOrca 结果的问题,并正在寻找参考代码或训练设置。他们预先感谢了大家的帮助,并引用了 Hugging Face 上的模型 (Mistral-7B-SlimOrca)。
YAIG (a16z Infra) Discord 摘要
只有 1 个频道有活动,因此无需总结…
-
受 EU 新规影响,GCP 免除出站流量费:
@stevekamman强调,Google Cloud Platform (GCP) 正在取消向其他云传输数据的出站流量费(egress fees),以响应新的 EU 法规。他预计 Azure 和 AWS 也会效仿。这一变化旨在降低更换云服务提供商的成本,尽管它并没有简化数据传输定价的复杂经济学。附带的图表说明了这种复杂性,但该图表未包含在消息中。 -
探讨 Groq 的 AI 硬件方案:
@stevekamman分享了讨论 Groq 硬件能力的链接,特别是运行在 Groq 架构上的 LLAMA7B 模型。一份通用的 架构论文 概述了他们的 “Superlane” 概念和时钟偏差。对于那些寻求更简单解释的人,他分享了一份 通俗易懂的解释文档,介绍了 Groq 的技术如何创新神经网络处理,但也指出目前缺乏实际应用中的采用迹象。
提到的链接:
Skunkworks AI Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
Datasette - LLM (@SimonW) Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。