ainews-113-142024-dont-sleep-on-prompt-engineering
2024年1月13-14日:别小看 #提示工程 (#prompt-engineering)
OpenAI Discord 社区开展了多方面的讨论,涵盖了如对比思维链(contrastive Chain of Thought)和后撤提示(step back prompting)等提示工程技术,并探讨了模型合并和混合专家模型 (MoE) 的概念。
关于 AI 意识和 AI 生成语音伦理的哲学辩论,突显了人们对 AI 感知能力及版权问题的关注。此外,社区还对现代 AI 嵌入中使用的超维向量空间模型进行了技术说明。用户还讨论了如何通过性格画像和提示词个性化来自定义 GPT 以克服 Token 限制,并提议为多语言 Discord 互动增加通用翻译器功能。主要贡献者包括资深常驻成员 MadameArchitect 以及 @darthgustav 和 @metaldrgn 等社区成员。
周末版:我们为您检查了 18 个公会、278 个频道和 3257 条消息。预计节省的阅读时间(以 200wpm 计算):412 分钟。
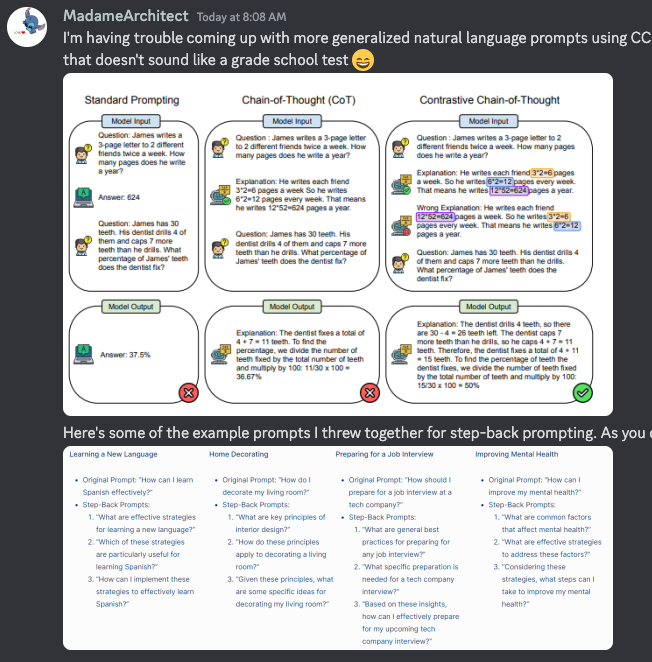
OpenAI 的 #prompt-engineering 频道中,资深常驻用户 MadameArchitect 针对提示词技术进行了一些精彩讨论 —— 包括对比式 Chain of Thought 和 Step-back Prompting:
Rombodawg 的指南 “Perfecting Merge-kit MoE’s” 也是关于模型合并(Model Merging)和 MoE 阶段的一篇佳作(这是 2 天前的话题)。
–
目录
[TOC]
OpenAI Discord 摘要
-
无限创意与凡人极限的碰撞:ai-discussions 频道探讨了 无限创意 vs. 有限寿命 的哲学主题,思考了人类在获取无限新奇事物时的能力限制。
-
硅基生命是否有情感?辩论 AI 意识:ai-discussions 中关于 AI 意识 的辩论非常激烈,参与者讨论了像 ChatGPT 这样的 AI 是否拥有意识,并对 AI 意识的定义和存在性产生了分歧。
-
高维向量引领 AI 理解:ai-discussions 纠正了关于 AI 使用基于字符(character-based)还是基于 Token(token-based)嵌入的误解,阐明了现代 AI 对 hyperdimensional vector space models 的依赖。
-
AI 语音模仿的法律问题:在分享了一个 YouTube 视频后,ai-discussions 出现了关于 AI 生成语音伦理 的论述,引发了对 AI 应用中版权和冒充问题的讨论。
-
通过提示词个性化解锁 GPT 潜力:gpt-4-discussions 和 prompt-engineering 频道的用户探索了 定制化 GPT 以充分发挥其能力的方法,包括赋予其人格特征,以及通过上传带有指令的文件来编写绕过 8000 字符限制的提示词。
-
AI 探索的技术树:在 api-discussions 和 prompt-engineering 中,”Tree of Prompts” 的概念被深入剖析,提出了一种根据特定任务定制人工智能交互的结构化方法,同时还辩论了 prompt engineering 的最佳实践及其对 AI 输出的影响。
-
多语言 Discord 动态引发讨论:api-discussions 中关于 Discord 上法语使用情况的随口评论,引发了对服务器语言政策以及平台内 通用翻译功能 潜在益处的简短讨论。
OpenAI 频道摘要
▷ #ai-discussions (200 条消息🔥🔥):
-
无限的创意 vs. 有限的寿命:由
@notbrianzach发起的关于创意无限性与寿命有限性对比及其影响的讨论。@darthgustav.断言,虽然存在无限的新颖性,但对这种无限性的获取是受限的,并受限于我们有限的能力和寿命。 -
探讨 AI 意识的概念:
@metaldrgn和@davidwletsch_57978_74310就 ChatGPT 是否表现出某种形式的意识展开了辩论。双方对理解和意识的解释存在争议,@metaldrgn建议对 AI 意识采取结构化方法,而@darthgustav.则就 Transformer(如 GPT-3)如何在没有意识理解的情况下运作提出了反驳观点。 -
讨论超维计算与 AI:
@red_code推测了基于字符的 Embedding 和 AI 理解力,随后@darthgustav.纠正了误解,并指出现代 AI 使用的是基于 Token 的超维向量空间模型,这些模型在@red_code引用的文章出现之前就已经存在了。 -
Token 向量与多语言能力:
@_jonpo发现了 GPT-4 渲染古代语言和符号学的能力,@darthgustav.评论了 AI 所掌握的广泛语言和字符系统,并利用这种符号编码来实现信息密集型的 Prompt。 -
AI 生成语音的伦理考量:
@undyingderp提供了一个 YouTube 链接,并质疑 AI 复制艺术家声音的伦理问题。随后@7877和@.dooz讨论了版权和冒充法律,后者提到了一个 YouTube 频道因模仿 David Attenborough 而产生的法律问题,暗示类似的法律框架可能适用于模仿 Lil Baby 等艺术家的 AI 生成语音内容。
提到的链接:
- Real Ones:由 IIP-DDS 提供给 YouTube 的 Real Ones · PALLBEARERDONDADA4 Pockets Full℗ PALLBEARERDONDADA,发布于:2024-01-03,作曲:Yoshan Weatherspoon,自动生成…
-
[一种重新构想人工智能的新计算方法 Quanta Magazine](https://www.quantamagazine.org/a-new-approach-to-computation-reimagines-artificial-intelligence-20230413/):通过赋予巨大的向量以语义含义,我们可以让机器比以前更抽象、更高效地进行推理。
▷ #gpt-4-discussions (192 条消息🔥🔥):
-
实验 GPT 人格化:用户
@66paddy对为 GPT 设定人格档案并向其提供该人物的采访和节目文稿以分析说话模式和习性的结果感到满意。 -
关于 GPT 开发使用限制的辩论:针对开发者在调整模型时的 GPT 使用上限展开了讨论。
@artofvisual希望此类后端调整不计入常规使用量,而@darthgustav.则强调取消上限可能会对普通用户和性能产生负面影响。 -
自定义 GPT 的问题与解决方案:用户在自定义 GPT 时遇到了几个问题。例如,
@d_smoov77寻求创建虚构语言翻译 GPT 的建议,并从@elektronisade、@madame_architect和@_jonpo等成员那里获得了潜在变通方案的提示。 -
GPT Store 中的隐私担忧:用户
@realspacekangaroo对其发布的 GPT 必须显示姓名表示担忧,@elektronisade澄清说商店要求显示姓名或网站以进行验证,随后找到了仅使用域名的解决方案。 -
思考自定义 GPT 的变现:关于 GPT 变现潜力的对话(
@thesethrose、@darthgustav.和@_jonpo)达成了一致共识,即成功取决于所提供的价值和 GPT 的受欢迎程度,同时也承认目前 GPT Store 的发现功能尚不完善。
▷ #prompt-engineering (257 messages🔥🔥):
-
GPT 文件上传技巧揭秘:用户
@rico_builder询问了关于绕过 GPT 指令 8000 字符限制的策略。用户@darthgustav.建议针对文件分析使用特定条件而非通用指令,而@eskcanta表示上传带有指令的文件是一种有效方法,且高达 80K 字符的效果通常很好。 -
ChatGPT 用途辩论:
@darthgustav.、@madame_architect和@clad3815展开了关于 ChatGPT 预期用途的讨论。@darthgustav.强调该平台的用途并未明确定义,不应局限于特定用途。 -
幻觉基准测试:用户
@_jonpo分享了一个使用虚构术语 “Namesake Bias” 进行的幻觉 (Hallucination) 测试。GPT-4 此前通过指出该术语不存在而通过了测试,但最近在更新后的模型上开始失败。 -
YouTube 视频转录挑战:围绕让 GPT 读取 YouTube 视频的困难进行了对话,包括
@ima8.尝试提示 GPT 转录视频未果的经历,以及@solbus建议使用 OpenAI GPT Store 中的 GPT 模型来完成此任务。 -
探索 Prompt Engineering 概念:讨论了各种 Prompt Engineering 方法,
@madame_architect和@darthgustav.探讨了如 “Contrastive Chain of Thought Prompting”、”Self-Critique” 提示和 “Tree of Prompts” 等技术,讨论了它们的潜在优势和应用。
▷ #api-discussions (257 messages🔥🔥):
-
绕过 8k 指令限制:用户
@rico_builder询问了如何突破 GPT 指令的 8000 字符限制。用户@eskcanta建议上传包含所需指令的文件是一个实用的权宜之计,在 80,000 字符以内效果良好。@eskcanta还分享了 AI 可以识别并利用额外上传的补充文件。 -
在 AI 中探索 “Tree of Prompts”:用户
@darthgustav.介绍了一个名为 “Tree of Prompts” 的概念,这被描述为一种根据当前任务结合各种 Prompting 技术以优化 AI 性能的方法。该策略试图将特定 Prompt 架构的优势与特定的条件和上下文相匹配。 -
Prompt Engineering 技术与研究:用户
@madame_architect与@darthgustav.讨论了各种 Prompt Engineering 技术和研究论文,提到了 Contrastive Chain of Thought (CCOT) 等特定方法,并征求关于优化 Prompt 和 AI 输出的建议。他们还考虑了系统指令在 Self-Critique 中的权重,并讨论了 CommaQA 数据集作为一种创新的基准测试合成数据集。 -
GPT 模型的幻觉测试:用户
@_jonpo谈到了一个关于幻觉 (Hallucination) 的特定测试,GPT-4 最初可以通过该测试,但现在已不再适用,这表明模型识别虚构信息的能力可能正在发生变化。 -
针对游戏的 JSON 策略 GPT 定制:用户
@clad3815分享了他们如何使用 GPT 来分析和制定玩《宝可梦》的策略,利用 JSON 来结构化 AI 对观众的理解和互动,强调了输出优化和成本效益的需求。 -
Discord 中的法语限制:当用户
@clad3815与@darthgustav.开玩笑使用法语时,引发了关于 Discord 内部语言限制的讨论。后者提到了服务器中非英语语言可能存在的规则问题,以及通用翻译功能的益处。
Nous Research AI Discord 总结
-
GPT-4 Turbo 超越其前代产品:
@atgctg注意到 GPT-4 和 GPT-4 Turbo 之间存在显著的性能差距,而@night_w0lf提到 GPT-4 Turbo 似乎整合了来自 chatgptplus 等服务的用户交互数据。@everyoneisgross和@carsonpoole加入讨论,暗示使用思维链 (CoT) 提示词来提高编程挑战的表现。欲了解该主题的更多信息,用户可以参考相关链接,例如 Training language models to follow instructions with human feedback。 -
语义分块的困惑:
@gabriel_syme参与了关于使用 GPT-4 进行语义分块的挑战以及 GPT-4 Turbo 在超过 4k tokens 生成时效率低下问题的对话,引发了关于模型在 100 到 2k tokens 之间输入表现的辩论。 -
LLM 自我修正策略受到质疑:讨论集中在大型语言模型 (LLM) 的自我修正上,在
@miracles_r_true分享了来自 Google Research Blog 的 Gladys Tyen 的分析后,用户@gabriel_syme和@everyoneisgross辩论了 LLM 中回溯(backtracking)的优缺点。 -
Mixtral 的重复问题与 AI 模型偏好:对话表达了对 Mixtral 变体在 4,000+ tokens 后文本重复问题的担忧,以及对 Ollama Bakllava 模型表现的不满。用户
@everyoneisgross推荐使用 LM STUDIO 以获得稳定的本地聊天和服务器托管,但指出其缺乏 OpenAI API 调用功能,@manojbh在讨论 LLM 界面时也提到了这一问题。 -
寻找全能型 LLM 工具:用户如
@everyoneisgross和@manojbh表达了对结合 API 调用、本地建模和云服务器功能的工具的需求,讨论了 ollama、lmstudio 和 openchat 等各种 LLM 界面的局限性和用途。
Nous Research AI 频道总结
▷ #ctx-length-research (2 条消息):
-
寻求上下文扩展对比:
@dreamgen询问是否针对不同上下文扩展方法达到特定质量所需的微调 (FT) 量进行了系统比较。他们对基础 RoPE 缩放(带或不带 FT)在不同 FT tokens 数量下的表现感到好奇。 -
BOS Token 是否影响长度外推?:
@euclaise分享了一条推文,思考拥有 BOS Token 是否会对长度外推产生负面影响。@kaiokendev1 的推文讨论了在不显式提供位置信息时 Mistral-OpenHermes 2.5 7B 层的注意力机制,指出 tokens 可能从 Layer 0 开始就固有的带有位置信号。
提到的链接:
Jade (@Euclaise_) 的推文:我怀疑拥有 BOS token 是否会损害长度外推 ↘️ 引用 Kaio Ken (@kaiokendev1) 在不注入任何位置信息时 Mistral-OpenHermes 2.5 7B 层的注意力机制…
▷ #off-topic (27 条消息🔥):
- GIF 和 Emoji 调侃:用户分享了各种 emoji 和 GIF,例如
@Error.PDF链接了一个 Pedro Pascal GIF,随后使用了一个灾难 emoji (<:catastrophe:1151299904346521610>),同时宣布结束 “Marcus x Yann”,并配以 Ryan Gosling emoji (<:gosling2:1151280275205140540>)。 - ChatGPT 自定义指令的反射式优化:
@.beowulfbr寻求增强 ChatGPT 回复的自定义指令技巧。用户@everyoneisgross提议分享一个将冥想技巧与 prompts 匹配的脚本,该脚本可以适配各种对话风格。 - 语义分块 (Semantic Chunking) 挑战分享:
@gabriel_syme询问了使用 embeddings 进行语义分块的经验,并与@everyoneisgross讨论了由于使用距离阈值 (distance thresholds) 导致分块大小在 100 到 2k tokens 之间波动的挑战。 - 专家间讨论模型效率:在关于语义分块和 embeddings 的可扩展性与成本的交流中,
@gabriel_syme评论说,虽然 embeddings 很便宜,但所需的时间可能会转化为金钱成本。他确认了自己在 window chunking 中采用句子级 embedding 的做法。 - 根据输入质量评估模型性能:
@everyoneisgross反思了输入质量对 AI models 的重要性,指出较小的模型需要更仔细格式化的分块,以避免生成无意义的输出。他还提到重叠分块 (overlapping chunks) 的潜在好处,特别是考虑到其成本较低。
提到的链接:
Pedro Pascal GIF - Pedro Pascal - Discover & Share GIFs:点击查看 GIF
▷ #interesting-links (66 条消息🔥🔥):
-
Google Research 实习生剖析 LLM 自我修正:用户
@miracles_r_true分享了 Gladys Tyen 在 Google Research Blog 上发表的一篇文章,讨论了将大型语言模型 (LLM) 的自我修正分解为“错误识别”和“输出修正”。包括@gabriel_syme和@everyoneisgross在内的多位用户讨论了 LLM 中回溯(backtracking)的有效性,并提到了其他相关主题的论文。 -
通用人工智能 AGI 可能比我们想象的更近:@Schindler___ 在 Twitter 帖子 中提出了一种 AGI 架构,收到了
@teknium和@jdnuva等用户关于在 AI 中实现有效记忆系统的实际挑战的质疑反馈。 -
Twitter 上传播的 AI 误导信息:用户
@ldj、@youngphlo和@leontello对一条关于 GPT 模型 GPU 使用情况的误导性推文发表了评论,通过反驳观点和幽默批评了虚假信息和夸张言论。 -
记忆,AI 的最后前沿:用户
@teknium讨论了为聊天机器人构建记忆系统的复杂性,涉及连贯性、重要性以及记忆的可变性等挑战。 -
集成预测与蒸馏创新:
@tofhunterrr、@admiral_snow和@mixtureofloras分享了 GitHub 仓库链接,展示了一个集成预测模型和一个用于 LLM 的自我批判细化模型,突显了 AI 建模领域的持续创新。
提到的链接:
- [Schindler (@Schindler__) 的推文](https://fxtwitter.com/Schindler__/status/1745986132737769573?s=20):(1/2) AGI 架构提案。电影《她》中的 Samantha 就在这里:一个能够自由思考和交谈、持续学习和进化的自主 AI。创造…
- 大型语言模型能否识别并修正自己的错误? – Google Research Blog
- GitHub - Nabeegh-Ahmed/llm-distillation:通过在 GitHub 上创建账户,为 Nabeegh-Ahmed/llm-distillation 的开发做出贡献。
- GitHub - vicgalle/distilled-self-critique: distilled Self-Critique 仅使用合成数据细化 LLM 的输出:distilled Self-Critique 仅使用合成数据细化 LLM 的输出 - GitHub - vicgalle/distilled-self-critique
- Mamba 是我们所熟知的 ChatGPT 的终结吗?:伟大的新问题
- GitHub - SebastianBodza/EnsembleForecasting: 使用多个 LLM 进行集成预测:使用多个 LLM 进行集成预测。通过在 GitHub 上创建账户,为 SebastianBodza/EnsembleForecasting 的开发做出贡献。
▷ #general (463 条消息🔥🔥🔥):
-
GPT-4 与 GPT-4 Turbo 之间的差距令人震惊:
@atgctg强调了 GPT-4 和 GPT-4 Turbo 之间显著的性能差距,将其比作 GPT-4 与 GPT-3.5 之间的差异。据@night_w0lf称,这表明 GPT-4 Turbo 的训练包含了来自 chatgptplus 和 chatgpt 等服务的用户交互数据。 -
根据用户偏好定制的 Turbo 训练:
@night_w0lf断言 GPT-4 Turbo 的训练是基于来自聊天的用户对话和偏好。@teknium表示赞同,并提到 RLHF 数据有实质性的增加。 -
语义分块挑战:
@gabriel_syme在使用 GPT-4 进行语义分块(semantic chunking)时遇到困难,处理文件夹耗时 2 小时。与@everyoneisgross的进一步讨论显示,最大输入为 2k tokens,分块请求约为 250 个单词,而 Turbo 的性能甚至更慢,补全限制在 4k tokens。 -
GPT-4 针对代码评估的调整:
@carsonpoole探索了在代码挑战 (ARC) 上对 Mistral 7b 使用思维链 (CoT) 提示,以显著优势超越了 Open LLM Leaderboard。这引发了关于 CoT 提示可用性及其标准化评估潜力的辩论,@teknium、@euclaise等人持有不同观点。 -
关于模型训练与评估的广泛讨论:包括
@teknium、@euclaise、@carsonpoole和@antonb5162在内的多位成员分享了关于模型、训练策略和基准测试的见解。讨论主题包括 RLAIF、DPO、Hermes 模型的量子化尺寸基准,以及使用不同 RL 方法(如 PPO、DPO,甚至是假设性的 P3O)的影响。
提到的链接:
- 训练语言模型以遵循人类反馈指令
- 来自 Blaze (Balázs Galambosi) (@gblazex) 的推文:进一步研究 LLM 基准测试的相关性:- 第一行:各基准测试与人类判断(Arena Elo)的关系 - 其他行:任意基准测试对及其关系 - 右侧:样本 = …
- 训练语言模型以遵循人类反馈指令:增加语言模型的规模并不一定会使其更好地遵循用户意图。例如,大型语言模型可能会生成不真实、有毒或纯粹不…
- 逐步蒸馏!以更少的训练数据和更小的模型尺寸超越大型语言模型:部署大型语言模型 (LLMs) 具有挑战性,因为它们在实际应用中内存效率低且计算密集。作为回应,研究人员训练了更小的特定任务模型…
- Medusa:通过多解码头加速 LLM 生成的简单框架
- TOGETHER
-
[提取 🦜️🔗 Langchain](https://python.langchain.com/docs/use_cases/extraction):在 Collab 中打开 - 通过人类反馈强化学习训练有用且无害的助手:我们应用偏好建模和人类反馈强化学习 (RLHF) 来微调语言模型,使其充当有用且无害的助手。我们发现这种对齐训练提高了性能…
- 为高效架构铺平道路:StripedHyena-7B,开源模型让我们一窥 Transformer 之外的世界
- 来自 anton (@abacaj) 的推文:再次在 mistral 上尝试了 LoRA,它在不到 2k 个样本的情况下立即正确掌握了多轮对话。这确实展示了大型模型比小型模型优秀多少
- IconicAI/DDD · Hugging Face 上的数据集
- rombodawg/Everyone-Coder-4x7b-Base · Hugging Face
- 完善 Merge-kit MoE
- GitHub - VikParuchuri/surya:支持任何语言的精确行级文本检测与识别 (OCR):支持任何语言的精确行级文本检测与识别 (OCR) - GitHub - VikParuchuri/surya
- GitHub - huggingface/text-generation-inference:大型语言模型文本生成推理:大型语言模型文本生成推理。通过在 GitHub 上创建账号为 huggingface/text-generation-inference 的开发做出贡献。
- allenai/soda · Hugging Face 上的数据集
▷ #ask-about-llms (16 条消息🔥):
- Mixtral 变体在创意写作中遇到重复问题:
@jdnuva提出了在 Mixtral 变体中,即使设置了很高的重复惩罚(repetition penalties),在超过 4,000+ token 后仍会出现文本重复的问题。 - 对 Ollama Bakllava 感到失望:
@manojbh对 ollama Bakllava 模型表示不满,认为它表现不佳,@n8programs也支持这一观点,称其“非常笨(braindead)”。 - 用户对 LLM 工具的 UI 偏好:
@everyoneisgross和@manojbh讨论了各种 LLM 界面(如 ollama、lmstudio、openchat)的优缺点。@everyoneisgross推荐使用 LM STUDIO,因为它在本地聊天和服务器托管方面非常稳定,但指出它似乎不包含 OpenAI API 调用功能。@manojbh则渴望有一种能结合 API 调用、本地模型和云端服务器能力的工具。 - GPT-4 仍是顶级模型:
@everyoneisgross认为没有什么能超越 GPT-4,但也承认 LM Studio 似乎不像 GPT4ALL 那样支持直接调用 OpenAI API。 - 社区中的模型偏好与创意构想:
@garacybe分享了他们的模型偏好,包括从 OpenHermes 2.5 转向 Dolphin 2.6 Mistral DPO Laser,并提出了一种替代 MoE (Mixture of Experts) 模型的方案,即一种用于增强创意的概念性“山寨版”MoE。
▷ #project-obsidian (3 条消息):
- 关于 VRAM 需求的咨询:用户
@manojbh询问了在本地运行程序所需的 VRAM 要求。 - 催促更新引发回应:
@manojbh随后跟进,寻求关于 VRAM 咨询的任何更新。 - Hermes Vision Alpha 作为线索:针对
@manojbh的提问,@qnguyen3建议关注 Hermes Vision Alpha。
LM Studio Discord 总结
- 揭秘 OOM 错误:
@heyitsyorkie澄清说,当聊天达到 125k 的完整 context 时,会显著出现内存溢出(OOM)错误。 (来源) - GPU 与 CPU 的协作:讨论中提供了关于 Mac 上 GPU 层级的见解,指出它们通过 Metal 加速开启/关闭,并结合了 CPU RAM 和 VRAM。此外,还讨论了 TPU 的局限性,特别是仅限于 TensorFlow Lite 的 coral TPUs,以及 LMStudio 在各种硬件上的兼容性问题,并表达了对 x86 架构优于 ARM 的偏好。 (来源)
- 模型过载焦虑:
@cardpepe对不断增长的模型体积表示担忧,怀念以前只有 13B 参数的小模型,而现在动辄就是 25GB+ 的庞然大物。在性能方面,讨论转向了如何利用硬件优化模型运行时间,特别是 RTX 4090 处理各种 LLM 的能力。 (来源) - Memgpt 的记忆幻象:由于开发者的反馈并不理想,人们对 memgpt 处理 context 限制的有效性产生了怀疑,这暗示该项目的开发可能已经停滞。 (来源)
- OpenAI 独有的 Function Calling 功能:有人指出,专属的 Function Calling 是 OpenAI GPT 3.5 Turbo 特有的功能,在开源模型中尚未发现。这引发了关于通过增强内存和 context 管理来改进现有模型的讨论。 (来源)
LM Studio 频道总结
▷ #💬-general (292 messages🔥🔥):
- OOM 错误说明:
@heyitsyorkie解释了内存溢出 (OOM) 错误发生在所有上下文和内存被耗尽时,特别是当聊天达到完整的 125k 上下文时 (来源消息)。 - LM Studio 更新指日可待:用户讨论了 LM Studio 已收到的新功能请求(如模型排序),并可能很快就会实现 (来源消息)。
- 了解 Mac 上的 GPU Layers:
@heyitsyorkie提供了关于 Mac 上 GPU Layers 的见解,提到它们对于 Metal 加速是开启/关闭状态,并结合了 CPU RAM 和 VRAM (来源消息)。 - Linux 用户模型加载问题:
@heyitsyorkie将一位面临模型加载问题的 Linux 用户引导至特定频道寻求解决方案,并指出为了支持 Phi 2,必须更新到 v0.2.10 版本 (来源消息)。 - 关于保存 Discord 帖子的建议:
@dagbs分享了一个收藏有用 Discord 帖子的替代方法,即通过将链接发送到个人 Discord 服务器中 (来源消息)。
提到的链接:
- Spaces 概览
- PsiPi/NousResearch_Nous-Hermes-2-Vision-GGUF · Hugging Face
- 在本地运行任何开源模型 (LM Studio 教程):立即获取 UPDF Pro 专属 63% 折扣:https://bit.ly/46bDM38 使用 #UPDF 让你的学习和工作更高效!最好的 #adobealternative…
- 使用 LM Studio 和任何开源 LLM 构建本地 AI Agent:欢迎观看关于使用 LM Studio 构建你的第一个开源 AI Agent 工作流的说明和教程!我们还将学习如何设置它…
- 别问能不能问,直接问
- GitHub - lmstudio-ai/model-catalog: 大语言模型 (LLM) 文件的标准化 JSON 描述符集合。:大语言模型 (LLM) 文件的标准化 JSON 描述符集合。 - GitHub - lmstudio-ai/model-catalog
-
[GitHub - THUDM/CogVLM: 一个最先进的开源视觉语言模型 多模态预训练模型](https://github.com/THUDM/CogVLM?tab=readme-ov-file#which—version-to-use):一个最先进的开源视觉语言模型 多模态预训练模型 - GitHub - THUDM/CogVLM
▷ #🤖-models-discussion-chat (43 messages🔥):
- Cardpepe 对模型大小的担忧:
@cardpepe对模型体积不断增大表示厌倦,更倾向于 13B 参数模型作为标准的时期,现在对 25GB+ 的体积感到不适。担忧的表情符号 - Mixtral 及其特性:
@cardpepe和@dagbs讨论了各种模型的使用,如 Mixtral。@cardpepe提到偏好类似于 GPT-3.5 的模型,并发现 Mixtral 很接近,但并不完全相同。 - 量化故障:
@technot80在尝试加载 WhiteRabbitNeo-33B 模型时遇到了 “invalid unordered_map<K, T> key” 错误。@heyitsyorkie解释说这表明量化失败,这是某些模型的已知问题。 - 模型优化讨论:
@sp00n9和@dagbs进行了关于量化的对话,@dagbs解释说高阶量化 (Q8) 可能优于低阶量化 (Q3),但这也是模型性能与结果之间的平衡。 - LM Studio 应用兼容性问题:
@coolbreezerandy6969询问了使用 Linux LM Studio AppImage 加载较新 GGUF 模型的问题,这表明可能存在兼容性问题或需要更新。
{kind=link}
▷ #🧠-feedback (17 条消息🔥):
- 对 Rolling Window 策略的困惑:
@flared_vase_16017对第 2 和第 3 种 context overflow 策略表示困惑。他们随后澄清了自己的理解,即第 3 种策略并不保留 system prompt,这与其他人的说法相反。@yagilb确认 rolling window 策略不会保留 system prompt。 - 保留 System Prompt 的功能请求:
@flared_vase_16017和@logandark讨论了需要一个能保留 system prompt 的 rolling window。@heyitsyorkie提到了之前发布的一个功能请求链接,但@logandark澄清说他们寻求的是一个特定功能,即仅维护 system prompt。 - 对 LM Studio Discord Banner 的期待:
@dagbs询问如何获得 LM Studio Discord banner。@heyitsyorkie回复说需要达到 level 3 的 boosts,而@dagbs提到 level 3 仅适用于动画版本。 - 对 LM Studio 预设选择的挫败感:
@logandark对 LM Studio 更改其 preset 设置表示不满。@heyitsyorkie提供了一个解决方案,建议在 “my models” 选项卡下设置默认 preset。
▷ #🎛-hardware-discussion (16 条消息🔥):
- 无法通过 USB 轻松扩展 GPU:
@fabguy提到 Nano 设备需要特定的编译,目前通过 USB 添加 GPU 支持是不可行的。 - Tensor Processing Unit 的局限性:
@strangematter提出 coral TPUs 在视觉任务中效率很高,但指出其局限在于仅支持 TensorFlow Lite,可能需要转换脚本才能与其他框架配合使用。 - LMStudio 的兼容性查询:
@sencersultanoglu询问在带有 ARM CPU 的 NVIDIA Jetson AGX Orin Development Kit 上安装 LMStudio 的事宜,导致@heyitsyorkie指出由于 Ubuntu 20 的 glibc 问题会导致兼容性错误。 - LMStudio 偏好 x86 架构:为了进一步了解兼容性,
@heyitsyorkie确认 LMStudio 通常适用于 x86 架构而非 ARM,但建议为 ARM 系统构建 llama.cpp。 - 针对 4090 GPU 的模型性能建议:在关于运行时间的讨论中,
@heyitsyorkie就各种大语言模型在单卡 RTX 4090 GPU 设备上的性能预期向@ericericericericericericeric提供了建议,并指出 Mixtral 在此类配置上运行相当缓慢。
▷ #🧪-beta-releases-chat (5 条消息):
- 关于重复 RAM 信息必要性的疑问:
@kadeshar质疑是否有必要两次显示 RAM 使用情况,建议蓝色条可以改为始终显示 app version。 - 频道组织建议:
@dagbs幽默地通过表情符号(<#1128339362015346749> 😄)指出了放置建议的适当频道。 - 建议改进 VRAM/RAM 需求计算:
@kadeshar建议 VRAM/RAM 使用量应减去当前已加载模型所占用的量,以便进行准确的需求计算。 - 指出 VRAM/RAM 卸载中的不一致性:
@kadeshar注意到程序在计算需求之前,不会等待模型从 VRAM/RAM 中完全卸载。 - 为清晰起见对频道进行颜色编码:
@dagbs建议在Beta Releases和AMD ROCm Beta频道之间进行颜色区分,以提高视觉辨识度。
▷ #autogen (3 条消息):
- 确认运行顺畅:
@thelefthandofurza对成功运行表示满意,注意到其操作顺畅,并期待未来的功能添加。 - 等待通过 UI 实现群聊功能:
@tyler8893强调群聊功能可能尚未通过 UI 提供,并推测有一个涉及 GitHub 仓库中 JSON 文件的示例。
▷ #langchain (1 条消息):
- OpenAI GPT 3.5 Turbo 独有的 Function Calling:
@cryptocoder指出 function calling 是 OpenAI 特有的,并提到他们的模型 GPT 3.5 Turbo 是专门为此功能训练的。他们强调开源模型中缺乏这种能力。
▷ #memgpt (20 messages🔥):
- 对 MemGPT 有效性的质疑:
@sitic对 MemGPT 表示好奇,指出缺乏用户评论,并质疑其是否具备如广告所言的处理 Context 限制的能力。 - 开发者反馈指向存在的问题:
@flared_vase_16017引用了来自 SillyTavern 开发者 的 GitHub Issue 评论,该评论对 MemGPT 的评价并不积极 (Issue #1212)。 - MemGPT 表现不佳并被遗忘:
@dagbs分享了个人经验,称 MemGPT 在使用过程中未能“记住”任何内容,从而得出该项目可能已经停滞的结论。 - 讨论内存和 Function Calling 的潜在改进:
@flared_vase_16017和@dagbs深入讨论了开发更精简模型的可能性,这些模型通过选择性导入 Context 来高效管理语言和推理,并辩论了如何通过结合当前 Context 和数据库存储来优化内存检索的速度和准确性。 - 利用现代 LLM 复活旧代码:
@dagbs分享了一个过去的项目,强调了将 2018 年时代的数据库和 Function Calling 代码与 LM Studio 中的新语言模型集成的可能性,从而可能复制或改进 MemGPT 试图实现的目标。
提到的链接:
[FEATURE_REQUEST] Add Superboogav2 for "long-term-memory" · Issue #1212 · SillyTavern/SillyTavern:你是否搜索过类似的请求?是。你的功能请求是否与某个问题有关?如果是,请描述。Oobabooga 最近发布了其基于 Vector 的内存系统的新版本,该系统可以……
HuggingFace Discord Discord 摘要
-
Discord 宕机与 miniSDXL 模型进入开源领域:在据报影响了
@lunarflu等用户的 Discord 宕机 期间,社区还热议了@kopyl分享的在 HuggingFace 上的新开源 miniSDXL 模型。 -
充分利用机器学习模型:社区深入探讨了实际问题,如从 GitHub 安装 kohya_ss 以及破解 Learning Rate 衰减之谜(暗示可能是 Scheduler 在起作用)。同时,
@tonic_1邀请大家为其 e5-mistral7B embeddings 模型 的内存管理改进提交 PR,而一份本地 LLM 术语指南 The Llama Hitchiking Guide to Local LLMs 最近也已上架。 -
未来的愿景:音乐、小模型和天空创作:成员们分享了从音乐波形分离到 Zyte-1B 模型在 M1 芯片上性能表现(由
@venkycs指出)等进展。创意人士可能会对@nebmotion建议的生成自定义 HDRI 天空的工具感兴趣。 -
当脑电波遇上 Diffusion 模型:在 Diffusion 讨论 中,
@louis030195展示了一个将大脑数据 (EEG) 与 Diffusion 模型结合的新颖实验,而@chad_in_the_house则在辩论机器学习工作中 MATLAB 是否比 Python 更具必要性。 -
Vision Transformers 与对清晰度的追求:从理解用于微调文档 VQA 模型的 GT 格式到对海量图像数据进行分类,成员们讨论了各种资源,包括 Transformers 的 图像分类教程 以及图像增强工具的实际应用。
HuggingFace Discord 频道摘要
▷ #general (183 messages🔥🔥):
- Discord 遭遇故障:
@lunarflu提到 Discord 出现了故障,@jo_pmt_79880证实了这一点。 - miniSDXL 模型开源:
@kopyl分享了一个开源的 miniSDXL 模型并提供了链接(HuggingFace 上的 miniSDXL)。@vishyouluck表达了对使用该模型的兴趣。 - 安装 kohya_ss 变成集体协作:
@schwifty4u寻求安装 kohya_ss 的帮助,随后与@meatfucker进行了长时间的故障排除,后者指导他们使用命令行默认设置和安装流程。 - AI 爱好者探究学习率之谜:
@bluebug报告了模型不学习的问题,随后质疑为什么学习率在衰减,@doctorpangloss建议可能是学习率调度器(learning rate scheduler)导致的原因。 - 新人寻求常规帮助:来自社区成员(如
@typoilu)的常规问题,包括寻找 Transformer 资源,以及其他用户在实际问题上需要的帮助,如选择 GPU 供应商、寻找图像动画模型以及询问如何轻松部署 LLM。
提及的链接:
- Attention Is All You Need:主流的序列转导模型基于编码器-解码器配置中复杂的循环或卷积神经网络。性能最好的模型还连接了编码器和解码器…
- Paste ofCode
- lowres (转生到 Hugging Face 组织的那件事)
- kopyl/miniSDXL · Hugging Face
- NobodyExistsOnTheInternet/toxicqa · Hugging Face 数据集
- GitHub - bmaltais/kohya_ss:通过在 GitHub 上创建账号来为 bmaltais/kohya_ss 的开发做出贡献。
▷ #cool-finds (14 messages🔥):
-
AI 分离音乐波形:
@callmebojo分享了一篇关于波形分离的有影响力的论文,这是音乐制作人对音轨进行重采样的重要工具。在此阅读研究:Source Separation。 -
Zyte-1B 小巧而强大:
@venkycs强调了小巧但强大的 Zyte-1B 模型,它是对 tinyllama 的改进,采用了 Direct Parameter Optimization。在 HuggingFace 上查看此模型:Zyte-1.1b Model。 -
歌曲流派分类展示:
@andysingal展示了一个资源,介绍如何使用 Hugging Face 和 Ray 在 Vertex AI 上对歌曲进行分类。在这篇 Medium 文章中了解更多:Is it Pop or Rock?。 -
Zyte-1B 的高速推理:
@venkycs讨论了在 M1 芯片上测试 Zyte-1B 模型的惊人推理速度。他们提到 LM studio 报告中包含一个用于尝试的 Colab。 -
在电脑上训练赛车:
@tan007分享了一个视频教程,介绍如何使用 AWS DeepRacer 在 Windows PC 上训练虚拟无人驾驶赛车。在此观看指南:Train a Self-Driving Race Car。 -
轻松创建 HDRI 天空:
@nebmotion介绍了一个快速生成自定义 HDRI 天空的工具,提供包括时间控制和高分辨率输出在内的一系列功能。在此深入了解该工具:HDRI Magic Power Sky Aurora Creator。
提及的链接:
- aihub-app/zyte-1B · Hugging Face
- 在你的电脑上训练自动驾驶赛车! (AWS DeepRacer DRfC):大家好,现在你可以在没有硬件的情况下虚拟训练自己的无人驾驶汽车,甚至可以在 Windows PC 上进行!深入了解这篇关于训练 AI 的详细指南…
- 是流行还是摇滚?使用 Hugging Face 🤗 和 Ray 在 Vertex AI 上分类歌曲:本文介绍了如何使用 HuggingFace 和 Ray 在 Vertex AI 上微调音频分类模型。
- HDRI Creator - XYZ360:立即创建惊人的自定义 HDRI 天空。完全控制时间、地理位置和云层。停止搜寻 HDRI,开始自己创造吧!
▷ #i-made-this (8 条消息🔥):
-
Tonic1 在 Hugging Face 上的 Embeddings 模型:
@tonic_1展示了来自 Microsoft 的 e5-mistral7B embeddings 模型,该模型运行在 GPUZero 上。他们邀请大家贡献代码,特别是旨在更安全地管理内存的 PR。该模型可在 Hugging Face 的 Spaces 上体验:https://huggingface.co/spaces/Tonic/e5。 -
Osanseviero 的本地 LLMs 术语表:
@osanseviero创建了 The Llama Hitchiking Guide to Local LLMs,这是一个用于紧跟 MoE、LASER 等新概念的术语表,他们已在 Twitter 和他们的博客上分享。 -
术语学习工具提案:
@stroggoz建议根据@osanseviero分享的术语表,创建一个 Duo Lingo 类型的应用程序,专注于教授语言模型领域的所有新术语。 -
关于 RLHF 替代方案的 Recurrent Neural Notes:
@mateomd_dev讨论了一篇介绍 Reinforcement Learning from Human Feedback (RLHF) 替代方案的论文,Andrew Ng 在 LinkedIn 上也强调了这一点。相关见解发布在最新一期的 Recurrent Neural Notes 中,链接如下:The RNN #6。
提到的链接:
- E5 - Tonic 开发的 Hugging Face Space
- 来自 Omar Sanseviero (@osanseviero) 的推文:本地 LLMs 的 Llama 搭便车指南。很难跟上这么多新概念。什么是 MoE?LASER?SuperHOT?Bagel?Tri Dao?😱🤯 看看这篇简短的阅读材料,涵盖了(非常简短的…)
- The RNN #6 - RLHF 正在过时吗?:通过 DPO 彻底改变 AI 对齐
▷ #reading-group (2 条消息):
- 会议录音中的音频故障:
@mr.osophy在重新观看会议记录后,对录音中未记录他人声音的问题表示抱歉。提到这可能是由于断开并重新连接 Airpods 导致声音输出设置发生变化引起的。 - 对新想法的建议得到了热烈响应:
@osanseviero对一个似乎是提案的内容表示支持,并热情地评论道:“是的,这听起来是个很棒的主意!”
▷ #diffusion-discussions (6 条消息):
- 生成语谱图的创新方法:
@louis030195正在探索使用 diffusers 库和 HF HuggingFace 模型从大脑数据 (EEG) 生成语谱图。他们提供了一段代码片段,尝试结合 Diffusion 模型利用脑电波数据生成图像。 - 对该方法的质疑:
@vipitis询问所展示的方法是否是唯一的语言模型解码方式,并建议直接绘制 EEG 数据图。 - 机器学习中的 MATLAB 与 Python:
@muhammadmehroz询问是否有必要为了机器学习学习 MATLAB。@chad_in_the_house回复说 MATLAB 在机器人技术中可能有用,但对于纯粹的 ML 来说 Python 就足够了,并评论说 MATLAB 编码体验“相当糟糕”。
▷ #computer-vision (14 messages🔥):
-
探索 GT 解析格式:用户
@swetha98寻求帮助,以理解在为 DocVQA 微调 Donut 模型时,单问题单答案的 Ground Truth (GT) 解析格式。在请求协助后,@nielsr_澄清说,每张图像需要一个单一的字典,正如他的 Notebook 中所示。 -
识别截图中的相似性:
@amarcel表示需要对 50k 张相似截图进行分组,但没有经过训练的数据集。@nielsr_建议使用现成的视觉模型对每张图像进行 Embedding,以计算余弦相似度(Cosine Similarity)或对 Embedding 执行 k-means 聚类。 -
使用 Transformers 进行视觉分类:针对寻找截图分组分类的用户,
@vikas.p提供了一个关于使用 Transformers 进行图像分类的 Hugging Face 教程链接(图像分类指南)。 -
利用 Coral 加速器增强视觉任务?:用户
@strangematter询问了与典型的 GPU 或 CPU 使用相比,使用 Coral 加速器对视觉任务性能的影响。 -
工具在普通图像上的出色表现:用户
@damian896636分享了使用某未具名工具的积极体验,该工具显著提高了上传图像的质量。
提到的链接:
- google/pix2struct-screen2words-base · Hugging Face
- Image classification
- Transformers-Tutorials/Donut/DocVQA/Fine_tune_Donut_on_DocVQA.ipynb at master · NielsRogge/Transformers-Tutorials:此仓库包含我使用 HuggingFace 的 Transformers 库制作的演示。 - NielsRogge/Transformers-Tutorials
▷ #NLP (48 messages🔥):
- 排查模型训练中的 GPU 利用率问题:
@meatfucker建议问题可能与使用 CPU 版 Torch 而非 GPU 版有关,但@frosty04212确认 GPU 利用率为 99%,因此不可能是 CPU Torch 的问题。 - 成功的推理取决于模型基础:经过讨论,
@Cubie | Tom建议@frosty04212不要从特定的 NER 模型开始,而是从更通用的模型开始,这在使用roberta-base时取得了成功的结果。@frosty04212对问题的解决表示感谢。 - HuggingFace 标记分类指南受到质疑:
@frosty04212在遵循 HuggingFace 的 Token Classification 训练指南时遇到了问题,并敦促 HuggingFace 团队寻找解决方案。 - NVIDIA 显卡上的推理不一致性挑战:
@frosty04212报告了在不同机器上运行推理时的不一致性,并请求针对指南可能存在的问题提供协助。 - 社区支持的表达:
@cakiki赞赏了@Cubie | Tom的成功协助,并用表情符号表达了感谢。
提到的链接:
▷ #diffusion-discussions (6 messages):
-
通过 Diffusers 将脑电波转换为频谱图:
@louis030195正在探索使用 Diffusion 模型 从 EEG 大脑数据生成频谱图。他们分享了一个 Python 代码片段,概述了其 Diffusion 模型的基本框架,利用来自 EEG 的频带功率数据作为diffusion_rate和time_steps参数。 -
绘制 EEG 数据有更简单的替代方案吗?:
@vipitis对使用 Diffusion 模型绘制 EEG 数据的复杂性提出质疑,建议可以直接绘制数据。 -
MATLAB 用于机器学习?:
@muhammadmehroz询问是否有必要学习 MATLAB 来进行机器学习。@chad_in_the_house认为 MATLAB 在机器人技术中有价值,但仅针对机器学习而言,Python 就足够了,并评论说 MATLAB 编码 并不理想。
Mistral Discord 总结
-
基准测试工具分享:在由
@tao8617发起的讨论中,@bozoid.指向了如 AllenAI’s catwalk 和 EleutherAI’s lm-evaluation-harness 等资源,用于在论文之外进行模型基准测试。此前@i_am_dom提到实际性能与 MoE 论文指标一致。 -
向量语言理论与 Few-shot Prompting:
@red_code介绍了使用向量表示字母并构建词向量的概念,而@robolicious则寻求社区关于 Mistral 的 few-shot prompting 见解,并提到使用 LangChain 处理模板。 -
性能与部署见解:#deployment 频道的讨论显示,vLLM 可能比 f16 慢,根据硬件不同,token 输出率为 15 tokens/s 和 30 tokens/s。
@nickbro0355分享了一篇博文,关于创建本地 LLM 助手,并与@richardclove一起询问高性价比的部署方法。 -
微调论坛与 API 稳定性:
@stefatorus征集对 Mistral 的 finetuning 支持 并倾向于 外包 基础设施,@sublimatorniq透露 finetuning 支持正在进行中。在 #la-plateforme 中,确认了生产使用的稳定性和一致的版本控制,并指出 Mistral JavaScript 客户端 中存在 类型不匹配问题,引用了 client.d.ts 和 client.js 文件。 -
参与与展示:
@azetisme引起了人们对一位法国 YouTuber 声称 Mistral 可能超越 ChatGPT 的关注(Micode 的 YouTube 视频)。此外,@jakobdylanc将术语从 “Mistral API” 纠正为 “La plateforme de Mistral”,并链接到 GitHub 上的 llmcord。
Mistral 频道总结
▷ #general (177 条消息🔥🔥):
-
寻找模型基准测试评估流水线 (Evaluation Pipelines):针对
@tao8617关于模型基准测试评估流水线的查询,@i_am_dom表示,尽管偶尔会出现不稳定,但实际性能似乎反映了 MoE 论文中声称的数据。此外,@bozoid.提供了 AllenAI 的 catwalk 和 EleutherAI 的 evaluation harness 链接,作为模型基准测试的资源,虽然这些工具在实际论文中未被提及,但都是相关的工具 (AllenAI’s catwalk, EleutherAI’s lm-evaluation-harness)。 -
引入向量语言理论 (Vector Language Theory):用户
@red_code提出了将字母视为向量并将其组合成词向量,随后再由此创建句子和段落向量的想法。 -
关于 Direct Policy Optimization (DPO) 的讨论:在讨论了一篇关于 DPO 的论文后,
@.nikhil2提到了 Andrew Ng 的博客文章,指出 DPO 已经在 Mistral 中实现 (Andrew Ng’s blog post)。 -
Mistral 的内部结构与 SelfExtend 咨询:
@hharryr寻求解释 Mistral 7b 内部结构的资料,@cognitivetech询问是否能看到带有 SelfExtend 的 7B 模型。@timotheeee1回复称 Mistral 的结构是带有 GQA 的标准 decoder-only transformer。 -
OpenAI API 与应用开发讨论:有一场关于在编程领域提升技能和寻找工作的长篇讨论。
@richardclove建议从贡献开源项目开始,随后讨论转向了初学者如何学习编程。用户分享了个人经验,并建议关注 Hugging Face 上的开源 AI 模型项目,或构建一个集成 OpenAI API 的全栈应用程序。对话强调了建立作品集以及通过实践和贡献现实项目进行学习的重要性。
提到的链接:
- Continue
- HuggingChat
- mistralai (Mistral AI_)
- app.py · openskyml/mixtral-46.7b-chat at main
- Supported Models
- GitHub - TabbyML/tabby: Self-hosted AI coding assistant:自托管 AI 编程助手。可以通过在 GitHub 上创建账户来为 TabbyML/tabby 的开发做出贡献。
- GitHub - allenai/catwalk: This project studies the performance and robustness of language models and task-adaptation methods.:该项目研究语言模型的性能、鲁棒性以及任务适配方法。
- GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.:一个用于语言模型 few-shot 评估的框架。
▷ #models (2 条消息):
-
得不偿失?(The Squeeze Isn’t Worth the Juice?):用户
@akshay_1在某个未指明的情况下暗示“榨出的果汁不值得费那番力气”。关于这个隐喻中具体的“果汁”或“力气”并没有详细说明。 -
Mistral 的 Few-shot 提示词:
@robolicious询问了社区在 Mistral 上使用 few-shot prompting 的经验,并提到他们通常使用 LangChain 来处理模板。
▷ #deployment (7 条消息):
- F16 vs vLLM 性能见解:
@dreamgen提到 vLLM 比 f16 慢,这一担忧得到了其他用户关于特定 Token 输出率的共鸣。@charlescearl_45005补充道,一个 p3 实例的输出速度为 15 tokens/s,而一台搭载未调优 mistral-instruct 和 llama.cpp 4-bit 压缩模型的 M3 Pro 达到了 30 tokens/s。 - 优于云服务的个人 LLM 助手:
@nickbro0355分享了一篇关于构建本地、傲娇且毒舌的 LLM 助手的博客文章,强调了本地运行优于云服务。 John the Nerd Blog - 滚动查找 System Prompts 查询:
@nickbro0355向用户推荐了一个关于如何获取 Mixtral 的 System Prompts 的资源,并建议向下滚动查看信息。 - 寻求高性价比的部署方案:
@richardclove询问如何在不支付许可证、Sage Maker 和 Hugging Face 包费用的情况下部署 Completion 终端节点,寻找 最便宜且可靠 的方法。 - 请求廉价访问语言模型:
.unyx表示希望尝试该语言模型但缺乏必要的配置,请求关于 廉价解决方案 的建议。
提到的链接:
Building a fully local LLM voice assistant to control my smart home:我已经用够了 Siri 和 Google Assistant。虽然它们有能力控制你的设备,但无法自定义,且本质上依赖于云服务。希望能学到一些东西…
▷ #finetuning (20 条消息🔥):
- 寻找 Finetuning 支持:
@stefatorus询问了 Mistral Platform 上的 finetuning 支持情况,并提到 Mistral-small 是开放权重(open-weights)的,而非开源(open source)的。 - 倾向于外包基础设施:
@stefatorus表示更倾向于“外包”基础设施而不是自行管理,尽管@richardclove强调了 月费模式 优于按量计费(pay-per-use)模式的优势。 - Finetuning 即将推出:根据
<@803073039716974593>的消息,@sublimatorniq转达了 Mistral Platform 的 finetuning 支持目前正在开发中。 - 经济的 API 使用:
@stefatorus解释了经济方面的原因,指出内部托管每月将花费 500-1000 欧元,而他们支付 300 欧元的 按需付费额度(pay-as-you-go credits) 即可高效处理流量峰值。 - 比较 Mistral 与巨头:
@stefatorus表达了直接在经济上支持开发者的愿望,并指出 Mistral 团队 是 OpenAI 的主要竞争对手,考虑到其规模和资源远小于 Google 等大公司,这一点令人印象深刻。
▷ #showcase (1 条消息):
jakobdylanc: Mistral API ❌ La plateforme de Mistral ✅
https://github.com/jakobdylanc/llmcord
▷ #random (1 条消息):
- 法国 YouTuber 谈论 Mistral:用户
@azetisme推荐了 Micode de Underscore 的一段 YouTube 视频,标题为“ChatGPT 刚刚被法国天才们超越”。视频讨论了 Mistral 如何可能已经超越了 ChatGPT。视频链接。描述显示该话题热度极高,并提到了新进展可能带来的潜在危险。
提到的链接:
ChatGPT vient de se faire détrôner par des génies français:热度 20/20 👀 不容错过,ChatGPT 刚刚变得危险:https://youtu.be/ghVWFZ5esnU 并非强求,但如果你订阅,对我真的很有帮助…
▷ #la-plateforme (42 条消息🔥):
- 周六运行更顺畅:
@casper_ai和@sublimatorniq讨论了在周末测试平台期间响应时间有所改善,但将继续观察工作日期间的变化。 - 类型不匹配提示:
@dreamgen指出了 Mistral 的 JavaScript 客户端中的一个类型不匹配问题,并附上了 GitHub 中 client.d.ts 和 client.js 相关提交的链接。 - 大任务超时:
@dreamgen报告了在使用mistral-medium处理大输出 Token 任务时出现超时,建议进行回归测试,并分享了一个使用 Streaming(流式传输)和累积的变通方案。 - API 更新提醒请求:
@_definitely_not_sam_请求设立一个专门的 API 更新频道,并提前通知变更,以便妥善维护 Golang 客户端。 - Mistral 准备好投入生产了吗?:由
@lerela发起的讨论确认 API 是稳定且有版本控制的,当前的系统可以用于带有速率限制的生产环境,相关限制可在用户账户中查看。
提到的链接:
-
[Mistral AI API Mistral AI Large Language Models](https://docs.mistral.ai/api/#operation/createChatCompletion):Chat Completion 和 Embeddings API。 - client-js/src/client.d.ts at f7049e5afa9db744aa1502b71ddd9746062520ff · mistralai/client-js:Mistral AI 平台的 JS 客户端库。可以通过在 GitHub 上创建账号为 mistralai/client-js 的开发做出贡献。
- client-js/src/client.js at f7049e5afa9db744aa1502b71ddd9746062520ff · mistralai/client-js:Mistral AI 平台的 JS 客户端库。可以通过在 GitHub 上创建账号为 mistralai/client-js 的开发做出贡献。
Perplexity AI Discord 总结
-
新版本发布:
@ok.alex宣布了 Perplexity Android 应用 2.9.0 版本的升级,强调了新的小部件功能以及新增的 Gemini Pro 和实验性模型 Perplexity Android App Update。 -
聊天机器人对比:
@esyriz对比了 Perplexity AI、Bing Chat 和 Phind,观察到它们都结合了 ChatGPT 和网页搜索。讨论强调了 Bing 的局限性,以及@icelavaman等人讨论的预计本月将 Whisper 集成到 Perplexity 应用中的计划。 -
创新焦点:Perplexity AI 获得关注:用户讨论了来自 知乎 和 福布斯 的文章,探讨了 Perplexity AI 以用户为中心的模式及其在 AI 流量领域的排名。进一步的讨论还包括 RabbitMQ 的部署以及 AI 创作的艺术视频 “AI Bahamut” 和 “The Abandoned”。
-
通过 Perplexity API 释放 Vim 潜力:
@takets介绍了一个与 Perplexity API 交互的 vim/neovim 插件,促进了其在文本编辑器环境中的集成。 -
深入探讨 API 的奇特之处与修复:用户报告了 Perplexity API 与主应用之间的差异,特别是在总结和比较数字方面的问题。用户普遍希望在模型响应中包含 URL 指示功能,以反映在专业设置中验证 LLM 生成数据的需求,但
@icelavaman表示这目前不在功能路线图中。
Perplexity AI 频道总结
▷ #announcements (1 条消息):
- Perplexity Android 应用达到 2.9.0 版本:
@ok.alex宣布 Perplexity Android 应用更新至 2.9.0 版本,具有新的小部件功能,并包含 Gemini Pro 和实验性模型。鼓励在专门的反馈频道中提供反馈。
▷ #general (88 条消息🔥🔥):
-
聊天机器人选项对比:
@esyriz询问了 Perplexity AI、Bing Chat 和 Phind 之间的区别。他们指出这些工具都使用了带有网页搜索功能的 ChatGPT,并提到 Bing Chat 提供免费的 GPT-4。@icelavaman指出了 Bing 的局限性,例如来源较少、无法上传文件以及缺乏 Focus 选项。 -
Whisper 集成更新:
@zwaetschgeraeuber询问 Whisper 是否会集成到 Perplexity 应用中,@icelavaman确认预计本月内会有更新。 -
模型性能与偏好:
@zwaetschgeraeuber对回答搜索查询的 AI 模型进行了排名,将 Gemini 列为首位,因为与 GPT、Claude 和 Perplexity 70b 相比,它的回答更直接。他们还提到 Perplexity 70b 有时会在德语中出现语法错误。 -
Apple Watch 与 Perplexity:
@srbig询问了在 Apple Watch 上使用 Perplexity 的可能性。@ok.alex回复了一个链接但未确认其功能。@srbig随后询问是否可以使用 Claude 2.1 或 GPT-4 等不同模型,@icelavaman澄清说无法通过手表实现。 -
Mistral Medium 的问题:
@moyaoasis报告说 Mistral Medium 无法工作,并询问在从 Brave 浏览器切换到 MS Edge 后,问题是否出在他们自己这边。
提到的链接:
- ChatGPT, Google Bard, Microsoft Bing, Claude, and Perplexity: 哪款 AI 工具最适合你?: 比较聊天机器人在对话能力和局限性方面的差异,找到适合你需求的 AI 助手。
- 定价
- 宇宙空间 GIF - 宇宙空间星辰 - 发现并分享 GIF: 点击查看 GIF
- ChatGPT vs Perplexity AI: Perplexity 是否使用了 ChatGPT? - AI For Folks: AI 领域瞬息万变,有时会令人困惑。许多公司会叠加不同的技术供自己使用。在本文中,我们将进行对比。
- 账单与订阅: 浏览 Perplexity 博客,获取文章、公告、产品更新以及优化体验的技巧。保持关注并充分利用 Perplexity。
▷ #sharing (15 messages🔥):
-
Perplexity AI 的增长之路:知乎的一篇中文专栏文章分析了 Perplexity AI 成功背后的三个“增长秘诀”:及时的功能整合、深入的用户理解以及不断提高的使用频率。尽管其技术受到质疑,但 Perplexity AI 在 AI 应用流量排名中持续上升,已进入前 10 名。
-
《福布斯》强调 Perplexity.ai 的创新:一篇《福布斯》文章展示了 Perplexity.ai 对搜索引擎格局的颠覆,指出其正在从以广告为中心的模式转向以用户为中心的、使用大语言模型(LLM)的回答引擎。
-
学习 RabbitMQ:用户
@sven_dc和@arvin6573分享了 RabbitMQ 官网的链接,重点介绍了 VMware 的商业产品,其中包括针对 Kubernetes 的部署和云托管支持。 -
展示 AI 创作的艺术:
@foreveralways.表达了感谢,并分享了两个名为 “AI Bahamut - Pika AI (4k)” 和 “The Abandoned - Pika AI (4k)” 的 4k 分辨率 YouTube 视频,这些项目似乎涉及 Pika Labs、RunwayML 和 AIARTGEN。视频链接:“AI Bahamut” 和 “The Abandoned”。 -
分享按钮使用提醒:用户
@me.lk提醒@termina4tor_gworld在发布 Perplexity AI 搜索查询链接后,点击分享按钮将他们的帖子设为公开。
提到的链接:
- RabbitMQ: easy to use, flexible messaging and streaming — RabbitMQ
- How Perplexity.ai Is Pioneering The Future Of Search:由大语言模型(LLM)驱动,Perplexity 是一个以用户而非广告商为中心的“回答引擎”。
- 行业洞察|揭秘 Perplexity AI:深入探讨其迅猛崛起的三个实用增长策略,探究其成功之路!:本周,我们开启新的【行业洞察】专栏,首篇聚焦—— Perplexity AI。今天我们将讨论 Perplexity AI 迅速增长的三个增长秘诀:及时功能整合:利用关键的 AI 进展,实现功能之间的协同作用。深入用户需求:以用户为中心……
- AI Bahamut - Pika AI (4k):@Pika_Labs @AIARTGEN @RunwayML
- The Abandoned - Pika AI (4k):@Pika_Labs @RunwayML @AIARTGEN
▷ #pplx-api (21 messages🔥):
- 寻求 API 搜索能力的澄清:用户
@crit93询问了在总结 LinkedIn 帖子时的差异,指出 Perplexity API 的表现不如主应用。@dawn.dusk和@icelavaman澄清说它们确实不同,但通过正确使用 “site:” 操作符可以实现实时浏览。 - API 响应可能有所不同:
@adriancowham报告了在询问两个数字哪个更大时,pplx API 和 pplx labs playground 给出的结果不一致。他们正在寻求如何让 API 能够更贴近 playground 那样准确响应的技巧。 - pplx API 的 Vim 集成:
@takets分享了一个 GitHub 链接,这是他们为 Perplexity API 创建的一个 vim/neovim 插件客户端。 - 等待 URL 指示功能:
@jdub1991询问是否有一个操作符可以帮助 pplx 模型像消费者界面那样指示来源和 URL,但@icelavaman确认这不在计划的功能中,而@brknclock1215表达了交叉核对生成式 LLM 所产出信息的普遍专业需求。 - 处理授权错误:用户
@crit93即使在使用正确的 API key 时也遇到了 “Missing authentication” 问题,@icelavaman建议在另一个频道分享该问题以获得适当的协助。
提到的链接:
GitHub - nekowasabi/vim-perplexity:通过在 GitHub 上创建账户来为 nekowasabi/vim-perplexity 的开发做出贡献。
LlamaIndex Discord Discord 总结
-
征集 LlamaIndex 展示案例:
@jerryjliu0正在寻求用户分享他们的 LlamaIndex 项目或博客文章,以获得更广泛的曝光。感兴趣的人士应直接联系@jerryjliu0并提交他们的作品。 -
探索使用 LlamaIndex 理解表格数据:重点介绍了使用 LLM 解释表格数据的 Chain-of-Table 技术。欲深入了解,请查看 Twitter 上的预告。此外,其他讨论还阐述了在 RAG pipeline 中重排序(reranking)的重要性、一个由 RAG 驱动的语音助手模板,以及指向原始 LinkedIn 讨论源的指南。相关推文:RAG Pipeline 见解,语音助手模板,导向 LinkedIn 源。
-
RAG 系统响应优化与 LlamaIndex 导航探索:
@liqvid1正在解决 RAG 系统中可能由于过多的 LLM 调用而导致的响应缓慢问题。建议的协作解决方案包括托管 API 和务实的 prompt 设计。@lolipopman讨论了使用 LlamaIndex 进行导航,并得到了@desk_and_chair的支持。 -
Vector Store 互操作性与名称澄清:
@cd_chandra提出了关于不同 vector store 互操作性以及追踪元数据必要性的担忧。在另一个线程中,@_joaquind质疑了 LlamaIndex 与 OpenAI 之间的紧密集成,@cheesyfishes提供了该关系的背景历史。此外,还提到了模型处理表格数据时的准确性问题,目前尚未解决。 -
探究 GRIT 数据集与升级聊天机器人响应:
@saswatdas寻求关于 GRIT 数据集 的澄清,并呼吁社区提供见解(GRIT 的 GitHub 仓库)。此外,@sl33p1420介绍了一个旨在提高聊天机器人响应质量的新资源,详见 变革聊天机器人性能。
LlamaIndex Discord 频道总结
▷ #announcements (1 条消息):
- 展示你的 LlamaIndex 项目:
@jerryjliu0鼓励用户分享他们与 LlamaIndex 相关的项目或博客文章以进行推广。如果你有想要分享的内容,请私信 @jerryjliu0!
▷ #blog (4 条消息):
- 发现 Chain-of-Table 技术:LlamaIndex 介绍了一种使用 LLM 逐步理解表格数据的方法,解决了直接 text-to-table 和 Text-to-SQL 方法的局限性。该过程通过链接进行了预告:https://twitter.com/llama_index/status/1746217167706894467。
- RAG Pipeline 中的重排序 (Reranking):@MountainMicky 分享了在高级检索增强生成 (RAG) pipeline 中包含重排序器 (reranker) 的必要性见解,以确保为复杂查询返回精确的上下文。推文中强调了这一点:https://twitter.com/llama_index/status/1746340454281666972。
- LlamaIndex 指向原始 LinkedIn 源:在这条消息中,LlamaIndex 引导用户前往 LinkedIn 帖子,作为最新讨论的原始来源:https://twitter.com/llama_index/status/1746340495486488607。
- RAG 驱动的语音助手模板:宣布了 @HarshadSurya1c 的全栈模板,用于构建涉及使用
create-llamaCLI 工具的语音助手。这可以作为搭建后端/前端应用程序的示例:https://twitter.com/llama_index/status/1746574062363848870。
▷ #general (47 条消息🔥):
-
RAG 系统响应时间困扰:
@liqvid1讨论了使用 OpenAI 的 GPT-4 构建 RAG 系统的问题。他们遇到了响应时间过慢的问题(约 25 分钟),并寻求建议是由于本地 MacBook 配置还是其他问题导致的。@cheesyfishes认为这很可能是由于 LLM 调用次数过多,而非本地系统性能。@desk_and_chair和@mr.dronie提出了额外建议,包括考虑使用较低版本的模型或使用托管 APIs 以获得更好的性能。 -
LlamaIndex 作为导航工具:
@lolipopman询问 LlamaIndex 是否具备提供导航链接的能力,例如引导用户访问特定的子页面。通过一个构建的示例,他们展示了聊天机器人如何引导用户。@desk_and_chair回应并暗示可以通过 Query Engine 实例的 system prompt 在响应中包含链接。 -
Vector Store 兼容性查询:
@cd_chandra提出了关于如何保持不同方式创建的 vector stores 之间的跨兼容性,以及如何跟踪所使用的 embedding model 等 metadata 的问题。@cheesyfishes回复建议为 pgvector store 类提交 PR 以增加额外字段,并建议在 metadata 字段中包含模型名称以便跟踪。 -
LlamaIndex 与 OpenAI 的紧密集成受到质疑:
@_joaquind质疑为什么 LlamaIndex 与 OpenAI 的结合如此紧密,而不是更多地支持开源选项,并认为考虑到其名称,这可能不太匹配。@cheesyfishes澄清了命名背后的历史,并讨论了该库对开源 LLMs 日益增长的支持,同时也承认了 OpenAI 在复杂应用中的主导地位。 -
模型对表格数据的排序问题:
@andrew s提出了一个关于模型在排序后无法返回正确行的问题,模型返回的是未排序数据集的最后一行。正在寻求社区对该问题的见解。
提到的链接:
▷ #ai-discussion (2 条消息):
- 寻求 GRIT dataset 的说明:用户
@saswatdas请求协助获取 Apple 发布的 Ferret 模型所使用的 GRIT dataset。他们分享了仓库链接 https://github.com/apple/ml-ferret/ 并表达了困惑。 - 聊天机器人爱好者的章节更新:
@sl33p1420发布了关于提高聊天机器人响应质量的新章节,特别是针对需要更高响应精度的应用。该章节可在 Revolutionizing Chatbot Performance 查看,并延续了使用 llama_index 构建完整聊天机器人的系列文章。
提到的链接:
Revolutionizing Chatbot Performance: Unleashing Three Potent Strategies for RAG Enhancement:往期文章:
DiscoResearch Discord 摘要
-
GPU 装备讨论:讨论涉及运行 mixtral-7b-8expert 等模型的最优硬件,建议采用双 NVIDIA 4090 配置,并提到量化模型 (quantized models) 在满足特定 VRAM 需求的情况下可以在单个 4090/3090 上运行。分享了 Tim Dettmers 撰写的全面 GPU 指南,并在性能和能效方面将 NVIDIA 4090 与 Mac Studio M2 Ultra 进行了对比。
-
大数据与德国精度:
@philipmay发布了用于机器学习应用的 German DPR-dataset(德国 DPR 数据集),并征求社区的反馈和改进建议。对话强调了在 RAG/LLM 语境中使用正式称呼 “Sie” 的问题,并承诺将推出修订版数据集。讨论还围绕数据集生成的风险展开,并引用了一篇关于 Model Collapse(模型崩溃)的文章。 -
协作与期待:如
@huunguyen所述,成员们表现出合作进行 deep dive(深度探讨)的渴望,@thewindmom对即将到来的进展表示热烈期待。社区对集成 mergekit 以增强能力的潜力感到好奇。 -
语言模型中的语气导航:对话提到了德国数据集在正式称呼方面带来的挑战,并探索了在正式和非正式语言之间转换的方法。贡献者讨论了操作改进,以及可能使用 few-shot examples(少样本示例)和聊天功能来优化结果。
DiscoResearch 频道摘要
▷ #mixtral_implementation (4 条消息):
- 为 Mixtral-7b-8expert 寻找硬件:
@leefde询问了运行 mixtral-7b-8expert 并扩展到更大模型的硬件配置。@jp1_推荐配置 双 NVIDIA 4090 以平衡性能和成本,适用于高达 70b 参数的模型。 - 在单 GPU 上运行量化模型:
@thewindmom提到,量化版本可以在 24 GB VRAM 的单个 4090/3090 上以 3.5bpw 运行。对于更大的模型,他们建议配置双 3090/4090/a6000/6000 ada’s/L40s。 - 分享全面 GPU 指南:
@thewindmom提供了一个指向 Tim Dettmers 深度学习 GPU 指南 的链接,该指南深入探讨了重要的 GPU 特性,以帮助做出高性价比的选择。指南包括性能对比和教学图表。 - Mac Studio M2 Ultra 作为竞争对手:
@thewindmom提到 Mac Studio M2 Ultra 作为一个替代方案,最高可容纳 192 GB 统一内存 (unified memory)。速度对比显示,在 llama 推理方面,4090 分别比 3090 和 M2 Ultra 快 10% 和 25%。 - 关于 GPU 性能与能耗的讨论:
@jp1_指出 NVIDIA 4090 不仅在性能上优于 3090 和 M2 Ultra,而且能效更高,并且通过 fp8 训练和 tensorrt 等特定优化可提供更大的性能提升。
提到的链接:
- 2023 年深度学习最佳 GPU —— 深入分析:在此,我提供了对深度学习/机器学习 GPU 的深入分析,并解释了适合您的用例和预算的最佳 GPU。
- mlx-examples/lora at main · ml-explore/mlx-examples:MLX 框架中的示例。通过在 GitHub 上创建账户,为 ml-explore/mlx-examples 的开发做出贡献。
▷ #general (5 条消息):
- 深度探讨的潜在合作:用户
@huunguyen表示愿意与@191303852396511232合作进行 deep dive,并建议共同完成。 - 关注重点:
@_jp1_发布了一个“眼睛”表情符号,表示关注或期待。 - 对即将到来的 🔥 感到兴奋:
@thewindmom回应@_jp1_,以 “hyped for that 🔥” 的评论表达了对预期进展的热情。 - 关于 mergekit 和启动加速的推测:
@thewindmom询问了与 mergekit 集成的可能性,暗示通过 “also merged with mergekit 🚀?” 可以显著提升能力。 - 对比 4090 与 M2 Ultra 的算力:
@thewindmom分享了关于 4090 GPU 与 M2 Ultra 芯片在能效和性能方面的详细分析,指出了内存带宽的差异及其对模型处理的影响,并邀请他人纠正任何误解。
▷ #embedding_dev (34 条消息🔥):
- 德语机器学习数据:
@philipmay发布了 德语 DPR 数据集,并征求 反馈和改进建议。 - 正式与非正式的关注点:
@sebastian.bodza指出,在 RAG/LLM 上下文中,祈使句经常使用“Sie”(德语正式您),这可能会影响嵌入时的性能。 - 解决“Sie”问题:
@philipmay意识到了正式称呼的问题,并 计划发布数据集的第二个版本。他还提到考虑使用3.5-turbo进行 格式转换。 - 数据集生成讨论:
@devnull0、@philipmay和@.sniips讨论了使用 OpenAI 模型生成数据集时可能存在的许可和质量问题,并提到了一篇关于 Model Collapse 的文章。 - 迭代改进与反馈:在与
@bjoernp和@sebastian.bodza的交流中,@philipmay寻求关于将正式称呼转换为非正式称呼的 Prompt 反馈,以及可能使用 Few-shot 示例和 Chat 功能 来获得更好结果的建议。
提到的链接:
- The Curse of Recursion: Training on Generated Data Makes Models Forget:Stable Diffusion 彻底改变了根据描述性文本创建图像的方式。GPT-2、GPT-3(.5) 和 GPT-4 在各种语言任务中展示了惊人的性能。ChatGPT 引入了此类语言…
- SebastianBodza/wikipedia-22-12-de-dpr · Hugging Face 数据集
- GitHub - telekom/wikipedia-22-12-de-dpr: 德语 DPR 模型训练数据集:用于 DPR 模型训练的德语数据集。通过在 GitHub 上创建账户为 telekom/wikipedia-22-12-de-dpr 的开发做出贡献。
- GitHub - telekom/wikipedia-22-12-de-dpr: 德语 DPR 模型训练数据集:用于 DPR 模型训练的德语数据集。通过在 GitHub 上创建账户为 telekom/wikipedia-22-12-de-dpr 的开发做出贡献。
LangChain AI Discord 总结
-
LangChain 大步向前:社区成员如
@gitcommitshow和@lhc1921分享了宝贵的资源,包括 LangChain 贡献指南和集成说明,以帮助那些寻求 LangChain 集成指导 的人。同时,@hiranga.g报告了成功运行 LangServe 的经验,并随后指出了使用.withTypes()处理 API 设计中 嵌套输入类型 的方法。 -
部署困境与流式传输烦恼:贡献者如
@daii3696提出了 Azure 流式传输功能 的问题,而@greywolf0324则在 AWS SageMaker 上使用 LangChain 部署 GGUF 模型 时遇到了困难。@stampdelin在 PyCharm 中升级 LangChain 后遇到了警告,@__ksolo__则询问了关于 文档问答的最佳策略。 -
模型处理与内存调度:
@rajib2189和@esxr_通过创意集成和本地解决方案提升了社区的工作分享,例如将 LangChain 与 AWS Bedrock 结合,以及将 本地 LLM 与 macOS Spotlight 结合,并在他们的 YouTube 视频 和 GitHub 仓库 中进行了展示。此外,@roi_fosca对使用 LCEL 表达式和 RedisChatMessageHistory 的 LangChain 内存集成 以及 ConversationSummaryBufferMemory 进行了深入探讨。 -
漏洞追踪与参数难题:
@muhammad_ichsan报告了 LlamaCpp 中一个潜在的verbose参数 Bug,@lhc1921建议了一个涉及大小写敏感性的修复方案。 -
扩展框架视野:
@aliarmani询问了用于构建高级对话 Agent 的 Agent 记忆管理工具,而@meeffe则深入研究了如何通过结合 Python 源代码 与来自 ReadTheDocs 等工具的 文档见解 来提高效率。
LangChain AI 频道总结
▷ #general (28 messages🔥):
- 寻求 LangChain 集成指导:
@gitcommitshow询问了关于创建 LangChain integrations 的文档。@lhc1921回复了贡献指南的链接,以及 LangChain 文档网站上详细的集成说明。 - Azure 流式传输难题:
@daii3696在 Azure 上使用 Kubernetes 部署服务时遇到了 streaming functionality(流式传输功能)问题;这非常令人困惑,因为在本地运行一切正常。 - AWS SageMaker 部署困境:
@greywolf0324在尝试通过 LangChain 在 AWS SageMaker 上部署 GGUF model 时遇到挑战,在找到解决方案之前似乎“卡在了部署环节”。 - Verbose 参数 Bug 报告:
@muhammad_ichsan报告了 Google Colab 上 LlamaCpp 模型中verbose参数的一个潜在 Bug。@lhc1921指出了一个大小写敏感问题并提出了可能的修复方案。 - 探索回顾性学习工具:
@aliarmani就开发高级对话 Agent 系统时,在 agentic memory management(Agent 记忆管理)方面表现出色的工具和框架寻求建议;这是一个真正的“记忆路径”咨询。 - LangChain Llamafile 的优缺点:
@rawwerks提出 LangChain 结合 llamafile 可以与 RAG 等现有架构竞争,实现隐私保护、本地部署等优势。然而,@lhc1921反驳并警告称 ollama 尚未准备好用于生产级推理。 - 文档问答的最佳提问策略:
@__ksolo__询问了文档问答的最佳实践,思考是在一个 Prompt 中提出多个问题还是将它们分开;这是一场策略性的“提问探索”。 - LangChain 升级后的 Python 导入警告:
@stampdelin在升级 LangChain 后,在 PyCharm 中遇到了神秘的警告,凸显了软件升级带来的烦恼。 - 选择 OpenAI 模型:
.citizensnipz.想要指定使用哪个 OpenAI 模型,因为所有请求都默认为 GPT-3.5,且在文档中没找到切换到 GPT-4 或 GPT-4 turbo 版本的指南。 - 将 Python 源码与文档结合进行开发:
@meeffe讨论了将 Python source code loader 与 ReadTheDocs loader 之类的工具结合,以便将文档见解集成到代码库中,并思考如何利用记忆和 Agent 工具来提高效率。 - LangChain 中的记忆集成:
@roi_fosca讨论了使用 LCEL 表达式和 RedisChatMessageHistory 将记忆集成到 LangChain 中,但担心潜在的 Token 限制问题,并询问了如何将 ConversationSummaryBufferMemory 与 LCEL 表达式配合使用。
提及的链接:
-
[欢迎贡献者 🦜️🔗 Langchain](https://python.langchain.com/docs/contributing/):你好!感谢你对贡献 LangChain 感兴趣。 -
[贡献集成 🦜️🔗 Langchain](https://python.langchain.com/docs/contributing/integrations):首先,请确保你已安装代码贡献指南中列出的所有依赖项。 - 不要问能不能问,直接问
▷ #langserve (2 messages):
- LangServe 成功运行:
@hiranga.g分享了使用基础示例成功运行 LangServe 的经验,但就如何创建具有复杂嵌套输入类型的 API 端点寻求建议。 - 找到了文档:
@hiranga.g自行解决了关于处理嵌套输入类型的疑问,提到在文档中发现了.withTypes()方法来定义请求对象。 - 深入研究嵌套变量:
@hiranga.g向<@703607660599181377>提出了一个关于在 LangServe 的 LCEL prompt templates 中使用 Pydantic Schema 对象的嵌套变量的问题。具体来说,他们询问如何在 ‘from messages template’ 中使用嵌套变量,因为在文档中没找到相关示例。
▷ #share-your-work (4 条消息):
-
Langchain 与 AWS Bedrock 的集成魔法:
@rajib2189分享了一个名为 “Using Langchain with AWS Bedrock” 的 YouTube 视频,演示了如何使用 Titan 模型将 Langchain 与 AWS Bedrock 集成。相关代码可在 GitHub repository 中找到。 -
聚焦本地 LLM:
@esxr_在名为 “Local LLMs - RAG solution using Ollama, MacOS Spotlight, and LangChain” 的 YouTube 视频 中展示了如何将本地 LLM 与 Mac 内置的 Spotlight 搜索结合,打造个性化助手体验。该项目的代码可以在他们的 GitHub repo 上找到。 -
致敬 LangSmith:
@esxr_对 LangSmith 表示感谢,称其为 “OP 工具”,并感谢了团队。
提到的链接:
- Local LLMs - RAG solution using Ollama, MacOS Spotlight, and LangChain:代码的 GitHub 仓库:https://github.com/esxr/local_llms_rag_solution
- Using Langchain with AWS Bedrock:在此录像中,我展示了如何将 Bedrock Titan 模型与 Langchain 代码结合使用:https://github.com/rajib76/aws_bedrock_examples/blob/main/examples/08_how_to_use…
▷ #tutorials (2 条消息):
- 新手的探索好奇心:
@brave_beetle_73126正在探索 document_loaders,并询问是否可以用于加载 YouTube 视频中除视频和转录文本之外的内容,提到对幻灯片中未出现在音频或转录文本中的动画感兴趣。目前该问题尚无进一步回复。 - 使用 Spotlight 召唤内容:
@esxr_创造了一种将 LangChain 与 MacOS Spotlight 结合的方法,用于在 Mac 上进行本地化内容搜索。更多详情请查看他们的 YouTube 演示和 GitHub 仓库:“Local LLMs - RAG solution using Ollama, MacOS Spotlight, and LangChain”。视频描述中包含其 代码仓库 链接。
提到的链接:
Local LLMs - RAG solution using Ollama, MacOS Spotlight, and LangChain:代码的 GitHub 仓库:https://github.com/esxr/local_llms_rag_solution
LAION Discord 总结
- Facebook Research 解决了 Batch Size 之争:
@pseudoterminalx重点介绍了一篇 Facebook 研究论文,建议在约 10 万张图像上以 64 的 batch size 进行 finetuning。 - Meta 推出 ‘Seamless Expressive’ 模型:
@thejonasbrothers分享了 Facebook 新推出的名为 Seamless Expressive 的模型,作为 AI 能力的一项进步。 - 尖端 Graph Diffusion 方法揭晓:
@chad_in_the_house提到了一种专注于 graphs 的生成模型新方法,引用了一篇 arXiv 论文。 - ‘GotongRoyong’ 印度尼西亚语 LLM 新玩家:
@hafidhsoekma介绍了针对印度尼西亚语专门优化的 LLM ‘GotongRoyong’,可在 HuggingFace 上获取。 - 警报:PyTorch 重大安全漏洞曝光:
@thejonasbrothers分享了关于 PyTorch 严重供应链攻击的见解,该攻击在 博文 中披露,揭示了 ML 平台中普遍存在的安全漏洞。 - 关于 OCR 和 Model Compression 的新兴讨论:讨论涉及 OCR 的挑战,如 Twitter 视频 中关于《纽约时报》的案例、与 Tesseract 的对比,以及一个新的 model compression 技术 GitHub 仓库 Knowledge Translation。
- Whisper 中的 8bit Quantization 仍不明确:
@krishnakalyan询问了 Whisper 在 8bit quantization 方面的能力,这在模型效率和部署场景中备受关注。
LAION 频道总结
▷ #general (17 messages🔥):
- Batch Size 偏好受到关注:
@pseudoterminalx指出 finetuning 似乎并不倾向于极高的 batch size,并引用了 Facebook 关于 EMU 的论文,该论文建议 batch size 为 64,且使用约 100k 张图像。 - Facebook 发布新模型:
@thejonasbrothers发布了一个名为 Seamless Expressive 的 Facebook 模型链接,暗示 Meta 正在推进 AI 前沿。 - 通过 Diffusion Models 生成图(Graph):针对
@qwerty_qwer关于文本、音乐、音频、图像或视频之外的 generative models 的询问,@chad_in_the_house提到有一个专注于图(graphs)的新领域,并提供了一篇相关论文的 arXiv 链接。 - 印度尼西亚 GotongRoyong 模型发布:
@hafidhsoekma告知了 “GotongRoyong”,这是一个针对印度尼西亚语的新型 LLM 专项模型,可在 HuggingFace 上获取。 - 发现 PyTorch 严重漏洞:
@thejonasbrothers分享了一篇博客文章,详细介绍了对 PyTorch 执行的一次严重供应链攻击,揭示了 ML 平台中重大的安全漏洞。
提到的链接:
- Playing with Fire – How We Executed a Critical Supply Chain Attack on PyTorch:安全往往滞后于技术应用,AI/ML 也不例外。四个月前,Adnan Khan 和我利用了 PyTorch(全球领先的 ML 平台之一)中的一个严重 CI/CD 漏洞……
- Generative Diffusion Models on Graphs: Methods and Applications:Diffusion models 作为一种新型生成范式,在图像修复、图像到文本转换和视频生成等各种图像生成任务中取得了显著成功。图生成(Graph ge…)
- GotongRoyong - a azale-ai Collection
▷ #research (7 messages):
- 分享最新研究论文:
@thejonasbrothers发布了一个 arXiv 上的新研究论文链接,展示了计算机科学领域众多作者的集体努力。 - 讨论 Prompt Expansion Lora:
@twoabove思考了 Lora 中 prompt expansion 的想法,评论道 微调 prompt 可以改善输出效果,这似乎与@828208105631383572之前的讨论一致。 - 纽约时报 OCR 挑战:
@SegmentationFault分享了一个 Twitter 视频展示 OCR 过程,并指出其无法识别 “The New York Times” 名称和 “The Winter Show 2022”。 - 与 Tesseract 的召回率对比:针对 OCR 的讨论,
@thejonasbrothers提到其召回率(recall)比 Tesseract 还差,暗示 OCR 性能仍有改进空间。 - 模型压缩的 GitHub 仓库:
@vrus0188提供了一个 GitHub 仓库链接,该仓库是 “Knowledge Translation: A New Pathway for Model Compression” 的官方实现。
提到的链接:
- Parrot: Pareto-optimal Multi-Reward Reinforcement Learning Framework for Text-to-Image Generation:最近的研究表明,在文本到图像(T2I)生成中使用带有质量奖励的强化学习(RL)可以提高生成图像的质量。然而,简单地聚合多个…
- GitHub - zju-SWJ/KT: Official implementation for "Knowledge Translation: A New Pathway for Model Compression".:”Knowledge Translation: A New Pathway for Model Compression” 的官方实现。- GitHub - zju-SWJ/KT…
▷ #learning-ml (1 messages):
krishnakalyan: Whisper 支持 8bit quantization 吗?
LLM Perf Enthusiasts AI Discord 总结
-
LLM 部署的 Docker 需求:
@slater.exe.正在寻找将本地 LLM 进行 Docker 化并通过 API 提供的资源。尽管对 Docker 有点生疏,但他们提到@edencoder正准备分享自己的 Docker 解决方案。@robotums提出了 openllm 或 vllm 等替代方案,包括使用 Replicate 进行托管并提供类 OpenAI 的 API。 -
AI 房地产初创公司招聘警报:
@frandecam为一家 AI 房地产初创公司招募创始工程师,该公司预计 ARR 将达到 350K,并提供高于市场水平的股权方案。 -
Velvet 瞄准资深工程人才:Velvet 正在招聘一名资深工程师/架构师,任务是为私募市场创建一个数字金融分析师。该职位承诺将深度参与新颖的 LLM 应用,并提供丰厚的薪酬,详见其 LinkedIn 职位公告。
-
神秘的
#speed:@frandecam发送了一条孤零零的消息,简单地问了一句 “what is it?”,没有提供任何额外背景。
LLM Perf Enthusiasts AI 频道总结
▷ #general (6 条消息):
- 寻求 LLM 的 Docker 部署经验:
@slater.exe.正在寻求将本地 LLM 转换为 Docker 镜像并将其作为 API 暴露的方法。他们正在寻找可以帮助实现这一目标的现有仓库。 - 自己动手,丰衣足食:
@edencoder回应称,大多数现有解决方案并不通用,这促使他们开发了自己的解决方案。 - 伸出援手:
@slater.exe.承认对 Docker 有点生疏并寻求指导。作为回应,@edencoder同意在清理完代码后分享自己的解决方案。 - 托管的替代路径:
@robotums建议使用 openllm 或 vllm 来托管模型,并提到 Replicate 是另一个提供 OpenAI 兼容 API 的服务。
▷ #speed (1 条消息):
frandecam: what is it?
▷ #jobs (3 条消息):
- AI 房地产初创公司创始工程师职位:
@frandecam正在为一家 AI 房地产初创公司寻找创始工程师,该公司预计在 4/5 月份达到 350K ARR。提供高于市场水平的股权方案。感兴趣的人士请私信或发送邮件至 francesco@withzebra.ai。 - Velvet 招聘资深工程师/架构师:Velvet 旨在成为私募市场的数字 Copilot,目前正在招聘一名资深工程师/架构师来构建第一个真正的数字金融分析师。该职位涉及高质量编码、参与前沿 LLM 应用,并提供高薪。更多详情见 LinkedIn 职位公告。
Latent Space Discord 总结
只有一个频道有活动,因此无需进行频道汇总…
- Readwise 的 AI 集成受到称赞:用户
@henriqueln7分享了 Readwise 作为一个拥有出色 AI 集成的应用示例,强调了其摘要和 Ghostreader 功能是其中的亮点。 - Perplexity.ai 获得推荐:
@nuvic_和@slono都因 Perplexity.ai 高质量的摘要和资源而推荐它。@slono还称赞了 GitHub Copilot 的趣味性。 - 探索用于 Prompt 压缩的 LLMLingua:
@jozexotic关注了 Microsoft 的 LLMLingua,这是一项旨在加速 LLM 推理并压缩 Prompt 的计划,在保持性能的同时可实现高达 20 倍的压缩,这与 “System-2” 论文的策略有潜在的相似之处。
提到的链接:
GitHub - microsoft/LLMLingua: 为了加速 LLM 推理并增强 LLM 对关键信息的感知,对 Prompt 和 KV-Cache 进行压缩,在极小的性能损失下实现高达 20 倍的压缩。:为了加速 LLM 推理并增强 LLM 对关键信息的感知,对 Prompt 和 KV-Cache 进行压缩,在极小的性能损失下实现高达 20 倍的压缩。 - GitH…
Alignment Lab AI Discord 摘要
- 寻求高性价比的 LLama 训练方案:
@desik_agi正在寻求微调 70B LLama 模型的最佳实践和策略,特别关注高性价比的分布式训练 (Distributed Training)。 - 社区新晋神经网络爱好者:
@geckonews(又名 Pierre)是一名嵌入式软件开发人员,他通过 fastai 课程进入了神经网络 (Neural Networks) 的世界,并暗示他对自己新培养的兴趣“很快就会开始动手实践”。
Alignment Lab AI 频道摘要
▷ #ai-and-ml-discussion (1 条消息):
- 微调 70B Llama 模型的最佳实践:用户
@desik_agi正在征求关于微调 70B LLama 模型最佳实践的建议,特别是在分布式训练 (Distributed Training) 方面,以降低微调过程的成本。
▷ #general-chat (1 条消息):
- 微调巨型模型的最佳实践:
@desik_agi计划微调 70B LLama 模型,并询问通用的最佳实践,特别是那些具有成本效益且可能涉及分布式训练 (Distributed Training) 的方案。
▷ #join-in (1 条消息):
- GeckoNews (Pierre) 投身神经网络:
@geckonews(Pierre)介绍了自己,他是一名嵌入式软件开发人员,最近对神经网络 (Neural Networks) 产生了浓厚兴趣。他目前正专注于通过 fastai 课程进行学习,并暗示“很快就会开始动手实践”,不过目前他参与讨论的程度可能有限。
▷ #qa (1 条消息):
king_sleeze: <@1163482975883772027> test
Datasette - LLM (@SimonW) Discord 摘要
仅 1 个频道有动态,无需汇总…
- 简化你的 OpenAI 工作流:用户
@zzbbyy介绍了 LLMToolBox:一个非常简单的 OpenAI 函数调用/工具处理器,并邀请大家对该工具提供反馈。在 GitHub 上查看:LLMToolBox。
提到的链接:
GitHub - zby/LLMToolBox: OpenAI tools and functions with no fuss:无需繁琐操作的 OpenAI 工具和函数。通过在 GitHub 上创建账号来为 zby/LLMToolBox 的开发做出贡献。
YAIG (a16z Infra) Discord 摘要
仅 1 个频道有动态,无需汇总…
- 关于生成式 AI 基础设施需求的思考:
@gitcommitshow询问了 GPT 或其他生成式 AI 应用的具体基础设施需求,寻求高效应对这些需求的见解和技巧。
Skunkworks AI Discord 没有新消息。如果该公会长期保持沉默,请告知我们,我们将将其移除。