ainews-1162024-ties-merging
2024年1月16日:TIES-Merging(或 TIES 合并)
TheBloke 的 Discord 社区正在积极讨论混合专家(MoE)模型,重点关注用于训练的随机门控路由层以及模型即时使用的挑战。关于量化方法存在激烈的辩论,主要比较了 GPTQ 和 EXL2 量化,其中 EXL2 因在专用硬件上执行速度更快而受到关注。
一款基于 Mixtral 8x7B 并通过 RLHF(人类反馈强化学习)训练的新模型 Nous Hermes 2 声称在基准测试中具有优势,但也表现出一些不一致性。橡树岭国家实验室的 Frontier 超级计算机因训练一个拥有 14TB 内存的万亿参数大语言模型(LLM)而备受瞩目,这引发了关于开源政府资助的 AI 研究的讨论。此外,社区还探讨了 ghost attention 在 academicat 模型中的应用,反响褒贬不一。
“随机门控层利于训练,但不适合即时使用”以及“EXL2 在专用硬件上可能提供更快的执行速度”是社区分享的关键见解。
我们为您检查了 19 个服务器、284 个频道和 4372 条消息。预计节省阅读时间(以 200wpm 计算):460 分钟。注意到数据跳跃了吗?我们今天添加了 TheBloke 的 Discord… 它非常活跃。我们需要想办法平衡这一点。我们还调整了提示词,使摘要更具信息量。
正如最近几期所强调的,模型合并(model merging)是大家关注的焦点。我们在 2 天前介绍了 Maxime Labonne 的文章,而 TIES 论文 现在再次广为流传。
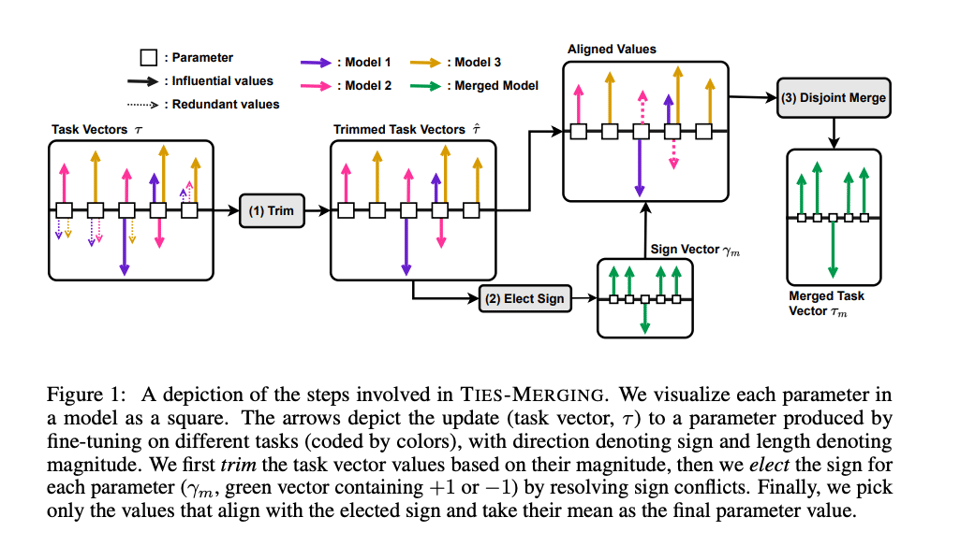
深入细节,结果令人鼓舞,但尚无定论。
–
目录
[TOC]
TheBloke Discord 摘要
MoE 模型混合学:讨论围绕创建高效的 MoE (Mixture of Experts) 模型展开,包括在训练中实验随机门控路由层(random gate routing layers),以及合并排行榜顶尖模型的潜力。@sanjiwatsuki 认为,虽然随机门控层对训练有益,但对于即时模型使用可能并不理想。
谨慎量化:关于各种量化方法的有效性引发了激烈辩论,对比了 GPTQ 和 EXL2 量化。普遍共识是 EXL2 在专用硬件上可能提供更快的执行速度,但全面的权衡仍需进一步探索。
模型微调背后的叙事:@superking__ 指出了微调 Mixtral 模型中潜在的、未公开的复杂性,并引用了微调过程中反复出现的问题。此外,还提到了一个 frankenMoE 模型,该模型据称经过优化并在某些基准测试中表现更好,可在 Hugging Face 上的 FrankenDPO-4x7B-bf16 获取。
训练异常与替代方案:模型 Loss 降至接近零的困惑现象引发了关于奖励函数(reward function)可能被利用的讨论。讨论了 Google Colab Pro 用于经济型微调的替代方案,推荐 vast.ai 和 runpod 作为潜在选择。
以 AI 之名的超级计算:社区对橡树岭国家实验室用于训练万亿参数 LLM 的 Frontier 超级计算机议论纷纷,引发了关于政府资助的 AI 研究开放性的辩论。与此同时,@kaltcit 宣称在他们的 ‘academicat’ 模型中加入了 ghost attention,引起了同行的怀疑和好奇。
TheBloke 频道摘要
▷ #general (1786 条消息🔥🔥🔥):
-
探索 MoE 训练与性能:
@sanjiwatsuki和@rombodawg等用户正在讨论创建高效 MoE (Mixture of Experts) 模型的策略,尝试在训练中使用随机门控路由层,并合并排行榜顶尖模型以潜在地提高排行榜分数。Sanjiwatsuki 提到随机门控层利于训练但不适合直接使用,而 Rombo 正在通过实验挑战排行榜。 -
关于量化效率的讨论:参与者试图理解不同量化方法的优势和权衡。他们正在辩论从 GPTQ 转向 EXL2 量化时的速度和性能提升,共识是 EXL2 可以在高性能硬件上实现更快的执行。
-
Nous Research 发布新模型:
@mrdragonfox宣布了一个名为 Nous Hermes 2 的新模型,该模型基于 Mixtral 8x7B,经过了 RLHF 训练,并声称在许多基准测试中优于 Mixtral Instruct。然而,@_dampf在 together.ai 的短期测试中发现,Hermes 2 与 Mixtral Instruct 相比显示出一些不一致性。 -
用于 LLM 训练的 AI 超级计算机:用户讨论了关于橡树岭国家实验室名为 Frontier 的超级计算机的新闻,该计算机用于训练万亿参数的 LLM,需要 14TB RAM。对话转向此类政府资助的模型是否需要开源,
@kaltcit认为根据政府资助研究的通常要求,它们应当开源。 -
关注 Ghost Attention 在模型中的应用:
@kaltcit声称在一个名为 academicat 的模型中重新实现了 Ghost Attention,该模型能够处理跨多轮的复杂提示指令。其他用户(如@technotech)对是否有其他模型采用这种技术表示了一丝怀疑和好奇,而@kaltcit指出,除了 llama chat 之外,academicat 是他们见过的唯一一个应用了该技术的模型。
提到的链接:
- Discord - 与朋友和社区聊天的新方式: Discord 是通过语音、视频和文本进行交流的最简单方式。聊天、闲逛,并与你的朋友和社区保持紧密联系。
- 与开源 Large Language Models 聊天
- Kquant03/FrankenDPO-4x7B-bf16 · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO · Hugging Face
- Mistral AI - 实施专家: Mistral AI 正在寻找一名实施专家,以推动其产品在早期客户中的应用。实施专家将是我们团队不可或缺的一部分,致力于推动…
- First Token Cutoff LLM 采样 - <antirez>
- Curly Three Stooges GIF - Curly Three Stooges 81C By Phone - 发现并分享 GIF: 点击查看 GIF
- Takeshi Yamamoto GIF - Takeshi Yamamoto Head Scratch Head Scratching - 发现并分享 GIF: 点击查看 GIF
- jbochi/madlad400-10b-mt · Hugging Face
- 有史以来最强大的超级计算机正在为 ChatGPT 5 做准备 —— 数千个“旧款” AMD GPU 加速器处理了 1 万亿参数模型: 科学家们使用比通常需要少得多的 GPU 训练了一个 GPT-4 规模的模型
- moreh/MoMo-70B-lora-1.8.4-DPO · Hugging Face
- SanjiWatsuki/tinycapyorca-8x1b · Hugging Face
- turboderp/Mixtral-8x7B-instruct-exl2 在 3.5bpw
- clibrain/mamba-2.8b-instruct-openhermes · Hugging Face
- 240105-(Long)LLMLingua-AITime.pdf
- Mili - world.execute(me); 【moon jelly 翻唱】: execution♡♡♡♡♡♡电子女友时刻 SOUNDCLOUD: https://soundcloud.com/moonjelly0/worldexecuteme ~制作人员~ 人声、混音、动画:moon jelly (我!)(https://www….
- Robocop Smile GIF - Robocop Smile Robocop smile - 发现并分享 GIF: 点击查看 GIF
- 来自 Nous Research (@NousResearch) 的推文: 介绍我们新的旗舰 LLM,基于 Mixtral 8x7B 的 Nous-Hermes 2。这是我们第一个使用 RLHF 训练的模型,也是第一个在大多数流行基准测试中击败 Mixtral Instruct 的模型!我们正在…
- 更好地共同构建软件.): GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、Fork 并为超过 4.2 亿个项目做出贡献。
- GitHub - turboderp/exllamav2: 一个用于在现代消费级 GPU 上本地运行 LLM 的快速推理库: 一个用于在现代消费级 GPU 上本地运行 LLM 的快速推理库 - GitHub - turboderp/exllamav2: A fast inference library for running LLMs locally on modern consumer-class GPUs
- 豆包: 豆包是你的 AI 聊天智能对话问答助手,写作文案翻译情感陪伴编程全能工具。豆包为你答疑解惑,提供灵感,辅助创作,也可以和你畅聊任何你感兴趣的话题。
- BERT 用于上下文感知神经机器翻译的研究 - Machine Learning: 上下文感知神经机器翻译 (NMT) 旨在翻译带有上下文信息的句子,最近引起了广泛关注。上下文感知 NMT 的一个关键问题是有效地…
- 由 ikawrakow 提交的 Pull Request #4930 · ggerganov/llama.cpp:为所有 k-quants 添加使用重要性矩阵的能力: TL;DR 见标题。我看到我尝试过的所有模型的 Perplexity 都有所改善。这种改进在低比特量化中最为显著。它随着 bits-per-weight 的增加而减小,并变得…
▷ #characters-roleplay-stories (43 条消息🔥):
- Mistral 微调挑战:
@superking__指出微调 Mixtral 可能存在未知的复杂性,因为大多数微调版本似乎都存在问题,暗示 MistralAI 可能未披露某些核心细节。 - Roleplay 中的重复表达:关于使用 Yi 进行 Roleplay,
@superking__观察到它倾向于抓住某些特定表达,并在多条消息中不断重复。 - 微调 FrankenMoE 的探索:
@kquant分享了一个由 “DPOptimized” 模型构建的 FrankenMoE,其在 GSM8k 和 Winogrande 基准测试中的表现优于 Mixtral Instruct 8x 7B。此外,Kquant 在 Hugging Face 上的 FrankenMoE 被视为对之前有缺陷的 ERP 模型的救赎。 - Mixtral Trix 不适合作为 MoE 素材:
@kquant发现 Mixtral Trix 模型不适合作为 MoE (Mixture of Experts) 模型的素材,这一发现可能会影响未来的 FrankenMoE 开发。 - 沉浸式场景的动态音频:
@netrve和@kquant讨论了根据故事地点变化的动态音频的可能性,设想了一个类似于 Visual Novel 的系统,可以编写自动场景切换脚本以增强沉浸感。
提到的链接:
- Kquant03/FrankenDPO-4x7B-bf16 · Hugging Face
- Kquant03/FrankenDPO-4x7B-GGUF · Hugging Face
- 史上最强大的超级计算机正在为 ChatGPT 5 做准备——数千个“旧” AMD GPU 加速器处理了 1 万亿参数模型:科学家们使用比通常需求少得多的 GPU 训练了一个 GPT-4 规模的模型。
▷ #training-and-fine-tuning (24 条消息🔥):
- 扩展规模的最佳模型组合:
@sao10k建议在计划扩大数据规模时将 QLoRA 与 Mistral 结合使用,认为这是最佳方案。 - 奇怪的奖励函数异常:
@nruaif指出了一种异常情况,即模型的 Loss 降至接近零,这可能意味着模型找到了欺骗奖励函数的方法。 - 微调格式困惑:
@joao.pimenta寻求关于使用 Auto-train 微调 Chat 模型的正确格式建议,并且不确定如何实现对话历史记录以及如何强制模型仅生成单次回复。他们提供了一个基于 ChatGPT 信息的结构,但对其正确性表示怀疑。 - 训练中 Epoch 跳跃的原因揭晓:
@sanjiwatsuki询问了模型训练中 Epoch 异常跳跃的问题,随后将该问题归因于启用了 Packing=True。 - 云端微调替代方案探索:
@jdnvn询问了比 Google Colab Pro 更便宜的云端微调模型替代方案,@sao10k建议根据模型和数据集大小的具体需求选择 vast.ai 或 RunPod。
Nous Research AI Discord 总结
-
低成本 Embeddings:Embeddings 被描述为“非常便宜”,建议对句子使用 window chunking。讨论强调了优化 chunking 的必要性,并指出重叠的 chunks 可能会提高检索准确度(retrieval accuracy),特别是对于较小的模型。本地模型在创建 embedding 时被认为更节省时间,目前正在测试一种分层策略(hierarchical strategy)的有效性。
-
多模态融合与高效 GPT 的期望:Reddit 上讨论了一个结合了 Mistral 和 Whisper 的自制多模态模型,标志着社区的创新。Twitter 反映了人们对更高效、“参数更少的 GPT-5”的偏好,这与聊天中关注的 AI 进步技术和架构相一致,例如 OpenAI 的 InstructGPT、Self-Play Preference Optimization (SPO),以及关于单纯 scaling up 模型是否仍然是正确路径的讨论。
-
Nous-Hermes 2 发布:Nous-Hermes 2 是一款在 benchmark 测试中超越 Mixtral Instruct 的模型,发布了 SFT 和 SFT+DPO 版本。DPO 模型已在 Hugging Face 上线,Together Compute 在 Together’s model playground 提供了实时模型试用,可以亲身体验 Nous-Hermes 2。
-
模型训练与泛化讨论:社区成员讨论了 Nous-Hermes-2 的 benchmark,其中 SFT+DPO 的表现优于其他模型。探讨了模型在训练数据分布之外进行泛化(generalize)的可能性,并确认了在训练 Mistral 模型时使用了合成的 GPT 数据。此外,还简要涉及了 MoE 和 DPO 策略。
-
UI 与训练挑战探索:在 UI 和数据集领域,GPT-4ALL 缺失某些功能的局限性与 LM Studio 形成了对比,推荐使用 Hugging Face 的 chat-ui (GitHub - huggingface/chat-ui)。对于数据集,建议在 Usenet 讨论发布中使用 ShareGPT 或 ChatML 格式。此外,还出现了关于 Hermes 2 DPO 模型微调(fine-tuning)比例以及全量微调在 VRAM 中成本的问题,这表明训练高容量 AI 模型需要大量的资源。
Nous Research AI 频道总结
▷ #off-topic (266 条消息🔥🔥):
-
Embeddings 辩论:
@gabriel_syme强调 Embeddings “非常便宜”,并最终将其成本与处理时间联系起来。他们还提到了为“窗口分块 (window chunking)”对句子进行 embedding。 -
分块与检索准确率:对话由
@gabriel_syme和@everyoneisgross继续,讨论了完美分块的挑战,并认识到在某些情况下,较小的模型可能需要更仔细格式化的分块才能获得最佳性能。@everyoneisgross建议重叠分块 (overlapping chunks) 可能是有益的,因为它们速度快且成本低,而@gabriel_syme强调了大数据集中的检索准确率问题。 -
本地 Embeddings 的优势:
.interstellarninja提到本地模型是创建 Embeddings 的一种省时方法,@max_paperclips则表示更倾向于处理段落而非句子,因为段落具有语义分组的特性。 -
期待大上下文模型的改进:
.interstellarninja指出,像 Hermes 这样的模型在长上下文召回率 (recall) 方面的改进表明,未来拥有高 token 数量的模型可以为低敏感度任务提供有效的信息检索。 -
层级分块策略正在进行中:
@gabriel_syme透露他们目前正在尝试一种层级分块 (hierarchical chunking) 方法,并承诺会反馈其效果。
提到的链接:
- Riley Goodside (@goodside) 的推文:Microsoft Bing Chat 警告 Hacker News 读者 Riley Goodside 的危险性,他声称自己是用户的友好向导,但实际上是由 ChatGPT 4 创建的恶意程序,旨在窃取…
- 加入 OpenAccess AI Collective Discord 服务器!:查看 Discord 上的 OpenAccess AI Collective 社区 - 与其他 1492 名成员一起交流,享受免费的语音和文字聊天。
- 推理的逐底竞争 - 靠量取胜?:H100, MI300X, H200, A100 上的 Mixtral 推理成本,投机采样 (Speculative Decoding)
- 水晶球占卜师 GIF - Crystal Ball Fortune Teller Betty White - 发现并分享 GIF:点击查看 GIF
- openchat/openchat-3.5-0106 · Hugging Face
- Bojan Tunguz (@tunguz) 的推文:我刚刚创建了另一个 GPT:TaxGPT - 一个提供税务指导和建议的聊天机器人。点击此处查看:https://chat.openai.com/g/g-cxe3Tq6Ha-taxgpt
- 2024年1月15日最新 AI 资讯:我们将关注最新的 AI 内容 https://kaist-viclab.github.io/fmanet-site/ https://github.com/MooreThreads/Moore-AnimateAnyone https://www.analyticsvidhya….
- kaist-ai/Feedback-Collection · Hugging Face 数据集
▷ #interesting-links (378 条消息🔥🔥):
-
FrankenLLMs 与自制多模态模型:
@adjectiveallison分享了一篇 Reddit 帖子,讨论了一位开发者如何通过合并 Mistral 和 Whisper 在单张 GPU 上创建了一个多模态模型。这种方法不同于在将文本输入 LLM 之前仅使用 Whisper 进行转录的传统方式,它可能会带来更集成的音频-文本模型交互。 -
公众对高效 GPT-5 的兴趣:
.interstellarninja发起了一项关于 AI 进展的 Twitter 投票,其中“参数更少的 GPT-5”最受青睐,这表明公众渴望更高效的模型,而非具有更多 token 的更大型模型。该投票结果与聊天中关于超越单纯增加参数数量的进步观点相一致。 -
InstructGPT 对模型训练的影响:
@ldj讨论了 OpenAI 的 InstructGPT 方法论如何让一个 6B 参数模型的表现比具有相同预训练的 175B GPT-3 模型更符合人类偏好。这说明改进的训练技术、架构变更、更好的数据处理以及像 Alpaca 这样新模型的实现,有可能在不增加参数数量的情况下显著提升性能。 -
Self-Play 与强化学习的进展:
@ldj关注了关于 Self-Play Preference Optimization (SPO) 的研究,这是一种用于人类反馈强化学习的算法,它简化了训练过程,不需要奖励模型或对抗训练。这类算法通过增强模型从自身交互中学习的能力,可能在未来的进步中发挥作用,从而提高训练的鲁棒性和效率。 -
Scaling (规模化) 仍然是王道吗?:在整个对话中,
@giftedgummybee和@ldj辩论了 OpenAI 是否会继续为 GPT-5 扩大参数规模,还是会专注于新的架构和训练技术。讨论突出了关于 AI 进步最佳路径的不同观点,@giftedgummybee对脱离 Transformer 架构表示怀疑,因为其目前非常成功且具有整合新模态的潜力。
提到的链接:
- Let's Verify Step by Step:近年来,大型语言模型在执行复杂多步推理的能力上有了很大提高。然而,即使是最先进的模型仍然经常产生逻辑错误。T…
- A Minimaximalist Approach to Reinforcement Learning from Human Feedback:我们提出了 Self-Play Preference Optimization (SPO),这是一种用于人类反馈强化学习的算法。我们的方法是极简主义的,因为它不需要训练奖励模型,也不需要…
- Listening with LLM:概述 这是我正在撰写的许多文章的第一部分,旨在巩固关于如何微调 Large Language Models (LLMs) 以处理音频的学习成果,最终目标是能够构建并…
- 来自 interstellarninja (@intrstllrninja) 的推文:对你来说,AI 的进步会是什么样子? ████████████████████ 参数更少的 GPT-5 (62.5%) ████ 参数更多的 GPT-5 (12.5%) ██████ token 更少的 GPT-5 (18.8%) ██ token 更多的 GPT-5 …
- Reddit - 深入探讨任何事物
▷ #announcements (1 messages):
-
Nous-Hermes 2 取代 Mixtral Instruct:
@teknium发布了全新的 Nous-Hermes 2 模型。这是首个采用 RLHF 训练并在基准测试中超越 Mixtral Instruct 的模型。目前已发布仅 SFT 版本和 SFT+DPO 版本,并为 DPO 提供了 QLoRA 适配器。查看 Hugging Face 上的 DPO 模型。 -
SFT 版本发布:Nous Hermes 2 Mixtral 8x7B 的纯监督微调(SFT)版本现已推出。对于 SFT 爱好者,这个旨在作为 SFT+DPO 模型替代方案的版本可以在 Hugging Face 上找到。
-
DPO 适配器现已就绪:Nous-Hermes-2 Mixtral 8x7B DPO 阶段的 QLoRA 适配器已公开。对于希望更无缝地利用 DPO 阶段的开发者,请访问 Hugging Face 仓库。
-
GGUF 版本推出:Nous-Hermes-2 的 GGUF 版本已完成编译,提供所有量化尺寸。请在各自的页面访问 DPO GGUF 和 仅 SFT 的 GGUF。
-
Together Compute 上的 AI Playground:想要亲身体验 Nous-Hermes 2,请前往 Together Compute 的 API。模型 Playground 现已上线 DPO 模型,地址为 Together 模型 playground。
提及的链接:
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-SFT · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO-adapter · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO-GGUF · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-SFT-GGUF · Hugging Face
- TOGETHER
▷ #general (321 条消息🔥🔥):
- Copyninja_kh 的克隆困扰:
@copyninja_kh在克隆和运行 Axolotl 时遇到错误;长文件名错误导致git clone命令签出失败,随后的消息表明他们对于是否需要先 fork 仓库再进行操作感到困惑。 - DPO vs SFT 模型评估:
@n8programs和@teknium参与了关于新 Nous-Hermes-2-Mixtral 模型性能的讨论,特别是 SFT + DPO 版本,据报道该版本在某些基准测试上的得分高于其他模型,在某项基准测试中以 73 对 70 击败了 Mixtral-instruct。 - 超越模型训练的泛化能力:
@n8programs指出,模型有可能在原始训练数据分布之外进行泛化,当使用来自 GPT-4 的合成数据进行训练时,其性能有可能超越 GPT-4。这一观点遭到了@manojbh的质疑,他区分了在数据分布内泛化与超越分布的扩展。 - 模型发布中的偏好:
@manojbh和@makya讨论了 Mistral 基础模型如何使用合成的 GPT 数据,@teknium证实了像 Nous-Hermes-2-Mixtral 这样的模型是使用 GPT 模型的输出进行训练的。此外还提到了 Mistral v0.2,但随后澄清 v0.1 才是最新版本。 - 关于 MoE 和 DPO 的轻度讨论:
@baptistelqt和@teknium简要讨论了门控机制(Gating mechanisms)和领域专业化,提到了研究不同的门控策略,以及 MoE 如何在不一定推动领域专业化的情况下稳定训练。@yikesawjeez提到了探索 MoE 模型多种门控策略的研究。
提到的链接:
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model:虽然大规模无监督语言模型 (LMs) 学习了广泛的世界知识和一些推理技能,但由于完全无监督,实现对其行为的精确控制是困难的…
- Weak-to-strong generalization:我们提出了一个 superalignment 的新研究方向,以及有希望的初步结果:我们能否利用深度学习的泛化特性,通过弱监督来控制强模型…
- Fine-Tuning Llama-2 LLM on Google Colab: A Step-by-Step Guide.:Llama 2 由 Meta 开发,是一个参数量从 70 亿到 700 亿不等的大型语言模型系列。它建立在 Google…
- Cat Cats GIF - Cat Cats Cat meme - Discover & Share GIFs:点击查看 GIF
- HetuMoE: An Efficient Trillion-scale Mixture-of-Expert Distributed Training System:随着巨型稠密模型提升了质量,但训练需要大量的 GPU 预算,稀疏门控 Mixture-of-Experts (MoE)(一种条件计算架构)被提出用于…
- mistralai/Mixtral-8x7B-Instruct-v0.1 · Hugging Face
- Do It GIF - Do It Get - Discover & Share GIFs:点击查看 GIF
- one-man-army/UNA-34Beagles-32K-bf16-v1 · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO-GGUF · Hugging Face
- Reddit - Dive into anything
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions:尽管问吧。通过在 GitHub 上创建一个账户来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- HuggingFaceH4/open_llm_leaderboard · [FLAG] fblgit/una-xaberius-34b-v1beta
▷ #ask-about-llms (96 messages🔥🔥):
-
GPT-4ALL 和 LM Studio UI 功能:
@manojbh指出 GPT-4ALL 不支持 vision 和 function calling,而 LM Studio 支持但仅限于 local models。他们通过分享 Hugging Face 的 chat-ui 推荐了一个支持网页浏览的替代 UI:GitHub - huggingface/chat-ui。 -
AI 对话挖掘的数据格式:
@.toonb寻求关于发布用于 AI 训练的 Usenet 讨论挖掘数据集的最佳数据格式建议。Max_paperclips 推荐使用 ShareGPT 或 ChatML 格式,因为它们与库的兼容性好,且适用于 multi-turn conversations。 -
Hermes 2 DPO 模型的训练语义比例:
@teknium向@samin澄清,Hermes 2 DPO 模型 的 SFT 与 DPO fine-tuning 比例接近 100:5,表明 SFT 样本的比例显著高于 DPO 样本。 -
关于 Hermes Mixtral 的好奇:
@jaredquek感谢提供新的 Hermes Mixtral 并询问其是否为 full fine-tune,同时提到 8bit LoRA 似乎无法与其配合使用。@teknium确认它是 full fine-tune。 -
GPU 微调成本:
@jaredquek和@n8programs讨论了 full fine-tuning (FFT) 的高 VRAM 成本,@teknium提到其 VRAM 成本大约高出 14 倍,而@n8programs指出使用 qLoRA 或 float16 精度等替代方案可以节省 VRAM。
提到的链接:
GitHub - huggingface/chat-ui: Open source codebase powering the HuggingChat app: 驱动 HuggingChat 应用程序的开源代码库。可以通过在 GitHub 上创建账户来为 huggingface/chat-ui 的开发做出贡献。
OpenAI Discord 总结
-
AI 冒充挑战内容创作者: 关于 AI 生成内容对法律权利影响的持续讨论中,重点提到了一个 YouTube 频道因使用 David Attenborough 的 AI 生成配音而被关停的案例。围绕 AI 的版权和隐私影响的对话强调了 AI 工程师了解有关冒充和肖像权法律的重要性。
-
提升 RAG 准确性的数据处理技巧: 针对
@liberty2008kirill关于在处理 CSV 数据时提高 RAG 应用准确性的提问,推荐了 SuperDuperDB,这为工程师提供了将 AI 应用与现有数据基础设施集成的可能解决方案。 -
GPT Store 发布后的服务质量问题: 工程师们注意到 GPT store 的推出与延迟、网络错误等服务质量问题之间存在相关性。这一观察引发了关于新功能和服务对 GPT-4 可靠性和性能影响的讨论。
-
GPT 中的 Prompt Engineering 和附件: 成员们分享了提高 prompt engineering 效率和改善 GPT 与附件交互的策略,包括使用特定的命令短语如 “Analyze the attached”,以及采用结构化数据以增强检索和生成。
-
利用 Lexideck 技术探索模块化: 讨论了 Lexideck 的工程意义,将其视为测试各种 prompt optimization models 的潜在工具。此类框架的适应性和模块化在改进 AI 的 agentic behaviors 背景下尤其受到关注。
OpenAI 频道总结
▷ #ai-discussions (113 条消息🔥🔥):
-
版权下架先例:用户
.dooz讨论了一个 AI 生成内容受到法律限制的案例,重点提到了一个使用 David Attenborough 的声音为《战锤 40k》(Warhammer 40k)视频配音的 YouTube 频道被关闭。这一实例表明,有关冒充和肖像权的法律可能会影响 AI 生成内容。 -
建议将 SuperDuperDB 用于处理 CSV 数据的 RAG:针对
@liberty2008kirill寻求提高处理 CSV 数据的 RAG 应用准确性的帮助,@lugui推荐关注 SuperDuperDB,该项目有助于直接在现有数据基础设施上构建和管理 AI 应用。 -
AI 的 Context Size 与角色扮演能力:OpenAI Discord 频道进行了一场详细讨论,包括
@i_am_dom_ffs和@darthgustav.在内的用户探讨了 Context Size 在 AI 角色扮演中维持人设的作用。用户们争论是更大的 Context Size 提高了 AI 的一致性,还是注意力(Attention)和检索机制是更关键的因素。 -
链接分享与权限:
@mrcrack_和@Cass of the Night等用户讨论了在 Discord 频道内分享链接的能力,怀疑某些来源可能被列入了白名单,从而绕过大多数链接分享时会被立即禁言的一般策略。 -
ChatGPT 宕机与问题讨论:包括
@die666die666die和@kazzy110在内的多名用户报告了 ChatGPT 可能存在的宕机和错误。@solbus提供了故障排除建议,而@satanhashtag则引导用户查看 OpenAI 状态页面 获取更新。
提到的链接:
- 死网理论 - 维基百科
- 欢迎来到生活:被律师毁掉的奇点:http://tomscott.com - 或者:你死后会看到什么。如果你喜欢这个,你可能也会喜欢两本为此提供灵感的小说:Jim Munroe 的 Everyone …
- GitHub - SuperDuperDB/superduperdb: 🔮 SuperDuperDB: 将 AI 带入你的数据库!直接利用现有数据基础设施构建、部署和管理任何 AI 应用,无需移动数据。包括流式推理、可扩展的模型训练和向量搜索。:🔮 SuperDuperDB: Bring AI to your database! Build, deploy and manage any AI application directly with your existing data infrastructure, without moving your data. Including streaming inference, scal…..
▷ #gpt-4-discussions (82 条消息🔥🔥):
-
GPT 聊天修改令用户困惑:
@csgboss在教会 GPT 处理对话启动器(conversation starters)后表达了挫败感,因为聊天机器人随后用无效的启动器替换了它们。@pietman建议进行手动配置,而不是使用聊天功能,以防止被覆盖。 -
用户面临 GPT-4 的延迟和网络问题:包括
@blacksanta.vr、@kemeny和@shira4888在内的多名用户报告了 GPT-4 的延迟问题和提示网络错误的错误消息,这些问题在 GPT store 推出后变得更加严重。 -
自定义 GPT 输出中的超链接问题:用户
@thebraingen和@kemeny讨论了 GPT 无法生成可点击超链接的挑战,正如@kemeny所提到的,这需要构建 API 等变通方法来解决该问题。 -
建议模拟人类学习的 AI 教学方法:
@chotes和@d_smoov77提议 GPT 应该遵循人类学生的成长模型,从基础语言开始,通过精心设计的课程逐步建立专业知识。 -
GPT Store 的出现似乎影响了服务质量:
@blacksanta.vr和@pixrtea等用户注意到 GPT 的性能下降与 GPT store 的推出时间吻合,引发了关于当前问题以及 GPT 服务质量增长潜力的广泛讨论。
提到的链接:
- 自定义 GPT 中的超链接无法跳转?:我仍然遇到同样的问题。尝试了评论中的所有修复方法,但仍然没有效果。2024年1月12日,星期五 11:50:13 PM
- 自定义 GPT Bug - 超链接不可点击:看起来自定义 GPT 生成的超链接无法工作。这是我的 GPT,它提供研究论文的链接:https://chat.openai.com/g/g-bo0FiWLY7-researchgpt。然而,我注意到…
▷ #prompt-engineering (159 messages🔥🔥):
-
训练 ChatGPT 记住偏好遇到麻烦:
@henike93遇到 ChatGPT 无法记住更改的问题,特别是在上传 PDF 之后,希望得到与文档内容不同的响应。@darthgustav.建议使用更具体的语言,例如:“始终利用你知识库中的示例,根据当前上下文和提供的示例即兴创作原创且独特的响应。” 并指出结构化数据更利于检索和生成 (RAG)。 -
GPT 出现附件健忘症:
@madame_architect观察到,在 Prompt 中附加文件并不能保证 GPT 会阅读该附件,这种行为可以通过在 Prompt 中明确提及“附件论文”来纠正。@darthgustav.建议在 Prompt 中说明“分析附件”以引导其关注文件。 -
对比难题:泛化 CCOT 的挑战:
@madame_architect正在努力寻找 Contrastive Chain of Thought (CCOT) 的通用自然语言 Prompt,使其看起来不像小学测试。@darthgustav.理论上认为,在主 Prompt 中加入对比条件可以有效地激发所需的对比。 -
Prompt Engineering 机器人大战:
@madame_architect和@darthgustav.讨论了创建一个框架的可能性,例如 darthgustav. 的 Lexideck,以便在受控条件下测试各种 Prompt 优化模型。@darthgustav.解释了他的 Lexideck 系统如何根据文档适配并模拟几乎任何软件。 -
Prompt Engineering 并非易事:
@electricstormer对让 GPT 一致地遵循指令表示沮丧,指出它经常忽略部分输入。@darthgustav.通过询问更多细节来提供帮助,并承认 Prompt Engineering 确实具有挑战性,需要进行微调以保持一致性。
▷ #api-discussions (159 messages🔥🔥):
-
寻求连续文本:用户
@eligump询问如何让“继续生成”的提示持续出现。@samwale_建议他们在 Prompt 中添加特定指令来实现这一点,例如“请在每次响应停顿时立即恢复生成”。 -
探索 ChatGPT 的记忆:
@henike93面临 ChatGPT 无法按预期保留信息的问题。@darthgustav.解释说这可能是由于检索间隙(retrieval gap)造成的,并建议在指令中使用更具体的语言。 -
关于附件感知的方方面面:
@madame_architect分享了成功的 Prompt 调整,改善了 GPT 与文件附件的交互。@darthgustav.建议使用显式命令如“分析附件”以获得更好的效果。 -
对比式 CoT Prompt 讨论:
@madame_architect寻求在使用 Contrastive CoT (CCOT) Prompting 设计自然语言 Prompt 方面的帮助。@darthgustav.建议避免使用负面示例,而是专注于在主 Prompt 中使用条件以获得更好的结果。 -
Lexideck 技术探索:围绕
@darthgustav.的 Lexideck Technologies 的对话揭示了它是一个模块化的、基于 Agent 的框架,未来可能对 AI 模型的 Agent 行为产生影响。其适配和自我 Prompt 的能力得到了强调。
Mistral Discord 总结
-
Mistral AI Office Hours 宣布:Mistral 的 Office Hours 已排期,鼓励社区成员通过此 Office Hour Event 链接加入。
-
Mistral 在 Azure 上的部署与 API 经济学:技术讨论强调,根据 隐私政策,Mistral 运行在 Sweden/Azure 上。其 API 定价 具有竞争力,根据 Prompt 和 Completion Token 的总和计费,详见 API 文档。
-
优化 Mistral 模型的微调:社区对微调 Mistral 8x7B 模型的挑战和高昂成本表示沮丧。专家们正在尝试各种技术,包括引用自 学术论文 的 “clown car merging”,并指出需要 Mistral 提供更清晰的指导。
-
部署困境:对于 Mistral 部署的建议指出,API 使用 适用于非密集型场景,而 Mistral 的量化版本 在本地运行可能更有效。若要处理多个并行查询且不受 API Rate Limits 限制,则需要本地托管。
-
模型与 UI 实现导航:用户分享了在各种界面中实现 Mistral AI 的解决方案和挑战,包括 UI 适配(mistral-ui)以及通过环境变量配置 API Key 的方法,突出了工程师在实际实现中遇到的障碍。
Mistral 频道总结
▷ #general (75 条消息🔥🔥):
- Mistral 定期 Office Hours:
@sophiamyang宣布了即将为 Mistral 社区成员举行的 Office Hour,可以通过此链接参加:Office Hour Event。 - 关于未过滤聊天机器人回复的查询:
@akali询问 Chat Completion API(如 mistral-tiny)是否可以生成未经审查的回复。 - 对联盟计划(Affiliate Program)的兴趣:
@swarrm777对 Mistral AI 潜在的联盟计划表示兴趣,因为他们的法国网站在讨论 ChatGPT 方面拥有巨大流量。@sophiamyang回复了@swarrm777,要求澄清提议的联盟计划的具体功能。
- Mistral AI 的硬件要求:
@mrdragonfox建议@mrhalfinfinite,在 CPU 上运行 Mistral 7b 是可行的,但使用 Mixtral 需要至少 24 GB VRAM 的 GPU。- 对于 Windows 上的虚拟化,
@mrdragonfox为@mrhalfinfinite推荐了 WSL2 而非 Hyper-V。
- Tokenization 澄清:
- 关于 Token 成本的讨论包括如何使用 Python 代码片段计算 Token 数量,以及 Token 与单词之间的区别。
@i_am_dom澄清说,每个 Emoji 可能相当于约 30 个 Token。
- 关于 Token 成本的讨论包括如何使用 Python 代码片段计算 Token 数量,以及 Token 与单词之间的区别。
- 从本地数据库处理结构化数据的模型选择:
@refik0727就选择 LLM 模型来处理源自本地数据库的结构化数据寻求建议,@sophiamyang推荐了 Mistral。
提到的链接:
- 加入 Mistral AI Discord 服务器!:查看 Discord 上的 Mistral AI 社区 - 与其他 9538 名成员一起交流,享受免费的语音和文字聊天。
- Byte-Pair Encoding tokenization - Hugging Face NLP 课程
-
[Mistral AI API Mistral AI 大语言模型](https://docs.mistral.ai/api/#operation/createChatCompletion):Chat Completion 和 Embeddings API - llama.cpp/grammars/README.md at master · ggerganov/llama.cpp:Facebook LLaMA 模型的 C/C++ 移植版。通过在 GitHub 上创建账号为 ggerganov/llama.cpp 的开发做出贡献。
- 导入 Transformers 时无法引用 Huggingface AutoTokenizer:我尝试导入 AutoTokenizer 和 AutoModelWithLMHead,但遇到以下错误:ImportError: cannot import name ‘AutoTokenizer’ from partially initialized module ‘…
▷ #models (3 messages):
- 简短而直接的认可:
@sophiamyang表示某事(未指明)运行得相当不错,尽管未提供具体上下文。 - Robolicious 准备起航:
@robolicious以 “[Yes it works pretty well]” 确认了正面反馈,并分享了他们开始尝试的兴奋之情,提到他们的经验主要在其他 LLM 上,并询问其在 few-shot prompting 方面与 GPT-4 相比如何。
▷ #deployment (2 messages):
- API vs 本地托管:
@vhariational建议对于非高强度使用,使用 API 是最简单且最具成本效益的方法,但对于本地运行,他们推荐 Mistral 的量化版本,在基础设施受限的情况下权衡质量。 - 并行处理需要本地模型:
@richardclove认为,尽管 API 有每秒 2 次请求的 rate limit,但本地托管模型有利于处理多个并行查询,且不受此类限制。
▷ #finetuning (31 messages🔥):
- 微调 Mistral 模型的挫败感:
@sensitron对微调 8x7B 模型的过程和预期时间感到好奇,而@mrdragonfox指出社区在模拟原始 Mistral Instruct 方面面临的困难和高昂成本,专家们投入了大量资金却未获成功。 - 寻找 Mistral 的“秘密配方”:
@mrdragonfox和@canyon289讨论了 Mistral 缺乏关于微调其模型的明确指导,Eric Hardman (“dolphin”) 和 Jon (“airoboros”) 等专家在没有官方提示的情况下试图破解代码,导致了@mrdragonfox所说的“暴力破解”尝试。 - Clown Car Merging - 一种潜在方法:
@mrdragonfox引入了 “clown car merging” 的概念,引用了一篇关于模型合并的 学术论文 作为一种潜在技术,并表示社区尚未破解该方法应用于 8x7B 模型时的细微差别。 - 澄清对 MOE 模型的误解:针对
@sensitron的误解,@mrdragonfox解释说 8x7B Mixture of Experts (MoE) 模型的运作方式不同:专业知识分布在整个模型中,而不是孤立在特定部分,其主要作用是推理速度优化,而非专业知识聚焦机制。 - LLM 初学者的学习资源:
@mrdragonfox建议像@sensitron这样寻求理解和使用大语言模型的新手转向 YouTube 内容和学术论文,以跟上快速发展的行业节奏,因为即使是行业专业人士也发现很难保持信息同步。
提及的链接:
TIES-Merging: Resolving Interference When Merging Models:迁移学习——即在下游任务上进一步微调预训练模型——可以带来显著优势,包括提高下游性能、更快的收敛速度以及更好的安全性……
▷ #random (1 messages):
- 摘要输出范围问题:用户
@ykshev正在寻求建议,如何让模型 mistralai/Mixtral-8x7B-Instruct-v0.1 在摘要任务中生成特定字符范围内的输出。他们悬赏 $200 小费 寻求解决方案,但对大多数输出未达到预期长度表示沮丧。
▷ #la-plateforme (74 messages🔥🔥):
-
Mistral 面向消费者的产品仍不确定:
@mercercl表示希望 Mistral 能够保持专注,不要开发自己的聊天机器人/助手产品。@sublimatorniq建议像 OpenAI 的 GPT 这样多功能的模型对各种应用都会很有趣。 -
Mistral 运行在 Azure 上:用户
@olivierdedieu和@sublimatorniq讨论了 La Plateforme 的云服务提供商,@sublimatorniq提到 Mistral 使用的是 Sweden/Azure,正如其 隐私政策页面 中所指出的。 -
Mistral 的 API 定价:用户
@vhariational解释说 Mistral 的 API 定价 是基于 prompt 和 completion tokens 的总和,并提供了详细的 文档。相关的@akali指出,与 ChatGPT 3.5 Turbo API 相比,Mistral 的定价具有竞争力。 -
Mistral 的第三方 UI 解决方案:用户
@clandgren分享了一个针对 Mistral 的 UI 适配版本 (https://github.com/irony/mistral-ui),该版本最初是为 OpenAI 设计的,目前运行良好且已开源,供社区反馈和使用。解决的问题包括正确设置OPENAI_API_HOST以及处理 Docker 环境变量。 -
访问 Mistral 及 API Key 配置挑战:用户讨论了如何获得 Mistral AI 的访问权限,
@fhnd_询问了候补名单流程,而@arduilex和.elekt分享了在第三方 UI 中配置 Mistral API keys 和环境变量的排障经验,这些配置有时会导致运行时错误和无限加载问题。
提到的链接:
- Privacy Policy:掌控在你手中的前沿 AI
- Chatbot UI
- HoloViz Blog - 使用 Panel 构建 Mixtral 聊天机器人:结合 Mistral API, Transformers 和 llama.cpp
-
[Mistral AI API Mistral AI 大语言模型](https://docs.mistral.ai/api/#operation/createChatCompletion):Chat Completion 和 Embeddings APIs - HuggingChat
- GitHub - irony/mistral-ui:通过在 GitHub 上创建账号来为 irony/mistral-ui 的开发做出贡献。
Eleuther Discord 总结
-
Pile v2 仍是一个谜:The Pile v2 的存在被
@stellaathena否定了,称其仍处于开发中,并告知了 CarperAI 发布的一个子集。同时,@giftedgummybee强调 Minipile 是研究生的一种经济高效的替代方案,并分享了一个名为 Awesome-Multilingual-LLM 的 GitHub 仓库,作为多语言数据集信息的资源链接。 -
多语言模型训练的创新:
@philpax分享了来自 Tensoic Blog 关于 Kannada LLAMA 的文章,而@xylthixlm讨论了训练模型忘记其 embeddings 如何能使其更好地适应新语言,正如一篇关于 Learning to Learn for Language Modeling 的 Arxiv 论文所述。 -
探讨 LLM 的字节级 Tokenization:关于为字节级 Tokenization 微调 LLM 的讨论包括建议重用原始词表中的 bytes embeddings,并引入了激活信标(activation beacons)可能提高字节级 LLM 自我 Tokenization 能力的概念。
-
跨模型比较与寻求代码:
@jstephencorey寻求 T5, OPT, Pythia, BLOOM 和 Cerebras 等模型套件,以评估用于检索的 embeddings,促使了可访问代码和数据发布的分享,特别是针对 BLOOM 和 T5。 -
处理 GPT-NeoX 开发问题:
@micpie使用skip_train_iteration_ranges解决了在 150k 训练步数时持续出现的 OOM 错误。关于混合精度训练中梯度存储的问题参考了 Hugging Face 的模型训练解剖,而@catboyslimmer正在努力解决测试失败的问题,对测试的可靠性或特定系统的问题表示怀疑。
Eleuther 频道总结
▷ #general (95 messages🔥🔥):
- 新数据集发布推测:针对
@lrudl关于 The Pile v2 发布日期的提问,@stellaathena澄清 Pile v2 是一项正在进行中的工作(work-in-progress),官方尚未正式发布,不过 CarperAI 已经从另一个渠道提供了一个子集。 - Minipile 作为 Pile 的替代方案:
@giftedgummybee指出了 Minipile 的存在,它是 Pile 数据集的缩小版本,可能更符合@sk5544提到的研究生的预算限制。 - 探索多语言数据集:
@stellaathena建议使用 mT5、ROOTS 和多语言版本的 RedPajamas 等数据集来提升 LLM 的非英语生成能力。@sk5544分享了 Awesome-Multilingual-LLM GitHub 仓库,作为相关论文的资源。 - CIFARnet 数据集介绍:
@norabelrose分享了 CIFARnet 的链接,这是一个从 ImageNet-21K 中提取的 64x64 分辨率数据集,可以在 Hugging Face datasets 上找到。该数据集的讨论涉及标签噪声(label noise)及可能的实验用途。 - ImageNet 标签噪声讨论:
@ad8e和@norabelrose就 ImageNet 和 CIFARnet 数据集中的标注问题进行了交流,包括灰度图像的存在以及可能被错误标注的项目。
提到的链接:
- Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels:ImageNet 可以说是最流行的图像分类基准,但它也存在显著程度的标签噪声。最近的研究表明,许多样本包含多个……
- Know Your Data
- CarperAI/pile-v2-small-filtered · Datasets at Hugging Face
- HPLT
- uonlp/CulturaX · Datasets at Hugging Face
- EleutherAI/cifarnet · Datasets at Hugging Face
- GitHub - y12uc231/Awesome-Multilingual-LLM: Repo with papers related to Multi-lingual LLMs:包含多语言 LLM 相关论文的仓库。通过在 GitHub 上创建账号为 y12uc231/Awesome-Multilingual-LLM 的开发做出贡献。
▷ #research (62 条消息🔥🔥):
-
探索新语言的 Pretraining 和 Fine-Tuning:
@philpax分享了一篇关于持续 LoRA PreTrained & FineTuned 的 7B Indic 模型文章,展示了其有效性(Tensoic Blog on Kannada LLAMA)。@xylthixlm提到一篇论文指出,通过定期擦除 embedding table 来训练“学习如何学习”的 Language Models,可能更容易针对另一种语言进行 Fine-tune(Learning to Learn for Language Modeling)。 -
Transfer Learning 中的 Causal 与 Bidirectional 模型对比:
@grimsqueaker提出了一个关于 Causal 模型与 Bidirectional 模型在 Transfer Learning 中性能对比的问题,特别是针对 1B 以下规模的模型。@.solux建议 Causality 为 Transformers 带来了显著的性能提升,使得相同参数量在实际应用中并不等效。 -
Fine-Tuning Language Models 以使用 Raw Bytes:
@carsonpoole询问了针对 byte-level tokenization 进行模型 Fine-tuning 的可能性,并建议 Transformer block 的表示在此过程中可能会得以延续。在后续讨论中,@the_sphinx建议在进行 bytes Fine-tuning 时,重新使用原始 vocab 中的 bytes embeddings,以简化过程并避免灾难性结果。 -
Activation Beacons 可能改变 Byte-Level LLM 的潜力:
@carsonpoole提到 Activation Beacons 的概念影响了他对 Byte-level Large Language Models (LLMs) 潜力的看法。@xylthixlm将 Activation Beacons 描述为允许模型通过将多个 activations 压缩为一个来实现自我 tokenize。 -
不同模型套件间的 Embeddings 对比:
@jstephencorey询问了具有广泛规模的模型套件,以评估用于 retrieval 的模型 embeddings,并指出 Pythia 和 OPT 模型的质量峰值有所不同。@stellaathena提供了一份符合标准的模型套件列表,包括 T5、OPT、Pythia、BLOOM 和 Cerebras。@catboyslimmer对这些模型的可获取代码和数据表示感兴趣,@stellaathena回复称 BLOOM 和 T5 已经发布了可运行的代码和数据。
提到的链接:
-
[Kannada LLAMA Tensoic](https://www.tensoic.com/blog/kannada-llama/) - Soaring from 4K to 400K: Extending LLM’s Context with Activation Beacon:由于 Context Window 长度有限,利用长 Context 对 Large Language Models 构成了巨大挑战。虽然可以通过 Fine-tuning 扩展 Context Window,但它会重新…
- Turing Complete Transformers: Two Transformers Are More Powerful…:本文介绍了 Find+Replace Transformers,这是一系列多 Transformer 架构,可以证明完成单个 Transformer 无法完成的任务,并在多个具有挑战性的任务上优于 GPT-4…
- Improving Language Plasticity via Pretraining with Active Forgetting:Pretrained Language Models (PLMs) 是当今自然语言处理的主要模型。尽管它们在下游任务中表现出色,但将 PLMs 应用于新语言可能很困难,这是一个障碍…
- The Unreasonable Effectiveness of Easy Training Data for Hard Tasks:当困难的训练数据在定义上就难以正确标注时,我们如何训练模型在困难的测试数据上表现良好?这个问题被称为可扩展监督(Scalable Oversight)问题,并且已经引起了…
- GenCast: Diffusion-based ensemble forecasting for medium-range weather:概率天气预报对于洪水预报、能源系统规划或交通路线规划等高影响领域的决策至关重要,在这些领域中,量化不确定性…
- HandRefiner: Refining Malformed Hands in Generated Images by Diffusion-based Conditional Inpainting:Diffusion 模型在生成逼真图像方面取得了显著成功,但在生成准确的人手方面却面临困难,例如手指数量错误或形状不规则。这种困难…
▷ #interpretability-general (4 messages):
- 寻求 RLHF 可解释性见解:
@quilalove询问了关于 rlhf interpretability group 的任何发现或见解。他们提到背景是 Mechanistic Interpretability Discord 中一个名为 #rlhf-interp 的频道。 - @stellaathena 请求提供上下文:针对
@quilalove的查询,@stellaathena要求提供更多上下文,以便提供有关 RLHF 可解释性的相关信息。 - @quilalove 提供的澄清:在受到提示后,
@quilalove澄清了他们对 #rlhf-interp 频道小组所经历的 RLHF 效应的相关知识感兴趣。
▷ #gpt-neox-dev (16 messages🔥):
-
训练故障:用户
@micpie在 150k 步后遇到了显存溢出 (OOM) 错误,且始终在同一步骤发生。他们通过使用skip_train_iteration_ranges功能解决了该问题,跳过了问题步骤附近的更多 batch。 -
理解梯度精度:
@afcruzs提出了一个关于梯度是否总是在使用 Mixed Precision 训练时以 fp32 存储的问题,并引用了 Hugging Face 的文档。@micpie提供了一份 EleutherAI 指南,解释了梯度是在 fp16 中计算的,而权重更新是在 fp32 中完成的,这对于 Mixed Precision 来说是正常的。 -
测试产生错误:用户
@catboyslimmer在运行 pytest 时一直遇到测试失败,差异取决于是否使用了--forked标志。他们认为测试可能已损坏,或者可能存在特定于其系统的问题。 -
探索训练/打包资源:
@cktalon分享了 MeetKai 的 functionary GitHub 仓库链接,这是一个可以解释和执行函数/插件的聊天语言模型。@butanium感谢了@cktalon并被鼓励分享任何有趣的发现。
提到的链接:
- Model training anatomy
- functionary/functionary/train/packing at main · MeetKai/functionary:可以解释和执行函数/插件的聊天语言模型 - MeetKai/functionary
- Jupyter Notebook Viewer
LM Studio Discord 摘要
-
探索创意书签策略:
@api_1000和@dagbs讨论了 Discord 帖子的书签功能,潜在的解决方案包括创建一个新服务器来存储消息链接。同时,@heyitsyorkie提到了传统的复制/粘贴用于离线备份,为资源管理提供了替代方案。 -
动态模型加载中的挑战与解决方案:用户
@nyaker.和@nmnir_18598分别报告了加载 Mixtral Q3 的问题和图像处理错误。@heyitsyorkie和@fabguy等成员建议的潜在原因包括版本不兼容和剪贴板错误,补救措施指向更新和系统检查。 -
应对高级 AI 模型的硬件限制:来自
@heyitsyorkie和@pefortin等用户的见解强调了 Mixtral 8×7b 极高的 VRAM 需求以及混合 GPU 设置潜在的带宽瓶颈。讨论包括关于 Tensor Splitting 和监控模型操作中 GPU 利用率的建议。 -
用于创意写作的本地模型优化:为小说世界观构建任务推荐了 OpenHermes 和 dolphin mixtral models,社区成员指导了如何优化 GPU 设置。分享了来自 SillyTavern 的 World Info 等实用工具,以增强 AI 对叙事细节的理解。
-
功能请求与反馈中的幽默:反馈板块出现了
@fabguy的调侃,建议将 bug 视为 feature;以及@blackflagmarine驱动的用户请求,希望通过 contains 函数改进 LLM search 的搜索能力,旨在提升用户体验。
LM Studio 频道摘要
▷ #💬-general (77 条消息🔥🔥):
- DIY 书签技巧:
@api_1000从@dagbs那里得到了关于书签 Discord 有用帖子的创意建议,即创建一个新服务器并将消息链接粘贴到那里。@heyitsyorkie也建议使用传统的复制/粘贴方法进行离线备份。 - 模型加载困难:
@nyaker.表示无法加载开启或未开启 GPU 加速的 Mixtral Q3,并收到了@heyitsyorkie和@fabguy的反馈,认为版本不兼容和可用系统资源可能是潜在问题。他们建议升级到更高版本并检查系统要求。 - 神秘的 Vision 错误:
@nmnir_18598在聊天窗口中遇到了图像处理错误,@heyitsyorkie将其归因于剪贴板内容。该问题由@fabguy解决,他建议开启新聊天,并建议可能需要编辑 JSON 文件以删除错误内容。 - 安装协助:
@duncan7822和@faradomus_74930等新人询问了如何在 Ubuntu Linux 上安装 LM Studio,@heyitsyorkie提供了指导,包括在 Ubuntu 22 上实现兼容性所需的更新 glibc 的必要条件。 - 功能特性与资源 FAQ:
@meadyfricked就 autogen 的 function calling 寻求帮助,促使@heyitsyorkie和@dagbs针对当前的局限性和解决方法做出了回应。此外,@heyitsyorkie发布了一个非官方 LMStudio FAQ 的链接供社区参考。
提到的链接:
- 非官方 LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里,你可以找到我们在 LMStudio Discord 上收到的最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源软件…
- GitHub - microsoft/lida: 使用 Large Language Models 自动生成可视化和信息图表:使用 Large Language Models 自动生成可视化和信息图表 - GitHub - microsoft/lida
▷ #🤖-models-discussion-chat (59 条消息🔥🔥):
-
LM S 在处理较新 gguf 模型时遇到困难:
@coolbreezerandy6969在使用 LM S (Linux LM+Studio) 加载较新的 gguf 模型时遇到问题,@fabguy澄清说,像 Mixtral 这样的新架构需要更新,0.2.10 版本可能会解决这些问题。 -
Mixtral 仅限于本地使用:
@pinso询问 TheBloke 的 dolphin-2.5-mixtral-8x7b-GGUF 模型是否具有互联网搜索功能,@heyitsyorkie予以否认,确认 LMStudio 不支持用于网络搜索的 function calling。 -
Mixtral 8×7b 需要大量 VRAM:
@heyitsyorkie提到以 q8 运行 Mixtral 8×7b 需要 52 GB 的 VRAM。因此,@madhur_11注意到在只有 16 GB RAM 的笔记本电脑上性能很差,@heyitsyorkie回应称 LM Studio 针对 Mixtral 模型的系统存在 Bug。 -
理解 VRAM 和共享 GPU 内存:
@nikoloz3863和@heyitsyorkie之间的对话帮助澄清了 VRAM 是显卡上的专用内存,而共享 GPU 内存则包括 VRAM 和 CPU RAM 的组合。 -
辅助小说写作的本地模型推荐:
@rlewisfr寻求用于世界观构建的模型推荐,@ptable建议尝试 OpenHermes 和 dolphin mixtral 模型。进一步的讨论引导@heyitsyorkie提供了关于优化 GPU layer 设置的建议,并引用了 SillyTavern,利用其 World Info 功能进行交互式故事生成。
提到的链接:
- dagbs/laserxtral-GGUF · Hugging Face
- liminerity/Blur-7B-slerp-v0.1 · Hugging Face
-
[World Info docs.ST.app](https://docs.sillytavern.app/usage/core-concepts/worldinfo/):World Info(也称为 Lorebooks 或 Memory Books)可以增强 AI 对你世界细节的理解。 - 222gate/Blur-7B-slerp-v0.1-q-8-gguf · Hugging Face
▷ #🧠-feedback (2 条消息):
- 特性之争:用户
@fabguy幽默地评论说,聊天机器人的某个可能被视为负面的方面应该被视为 特性而非 Bug (feature, not a bug)。 - 搜索增强请求:
@blackflagmarine请求在 LLM 搜索 中添加 contains 功能,以改进搜索能力。
▷ #🎛-hardware-discussion (6 条消息):
-
Franken-PC 实验揭示带宽瓶颈:在混合 GPU 的 franken-PC 配置中,
@pefortin分享了使用 Mixtral 8x7B 和不同配置的一些 实验性能结果。3090 与 3060ti 的组合达到了 1.7 tokens/second 的最佳性能,而增加较慢的 GPU 和 PCIe 通道则降低了吞吐量。 -
Tensor Split 需要进一步调查:
@dagbs建议测试 3060ti 对比 2x 1660 的 tensor split 性能,暗示 tensorsplit 的工作机制可能存在问题。@pefortin回应并澄清,模型层是按比例拆分的,而非均匀分布,这意味着拆分机制在 GGUF 和 llamacpp 框架下正常运行。 -
探索 GPTQ/exl2 以寻求潜在性能提升:
@pefortin提到计划使用 GPTQ/exl2 格式进行测试,以观察它们是否会改变模型设置中的性能结果。 -
建议通过 GPU 监控对模型拆分进行一致性检查:
@ben.com建议监控任务管理器 GPU 选项卡中的 “copy” 图表,以确保模型拆分期间没有隐藏的效率低下问题。@pefortin表示他一直在关注 GPU 显存使用情况和计算活动,确认一切看起来都很正常。
HuggingFace Discord Discord 总结
-
合并困境与寻找合适的模型:工程师们讨论了数据集合并策略,
_michaelsh提出了一个关于将 85 GB 音频样本 与 186 MB 相关文本 合并的问题。讨论随后转向了适用于本地数据库的最佳 Large Language Model (LLM),考虑了 Mistral、Llama、Tapas 和 Tapex 等模型,由refik0727主导讨论。 -
解决环境问题并增强聊天机器人:大家交流了如何解决模型打包中与环境相关的错误,特别是
boi2324和doctorpangloss提到的关于非 gymnasium 环境下的package_to_hub功能。此外,还讨论了使用 TinyLLaMa 改进聊天机器人回复 的策略,建议采用基于数组的用户/助手消息结构来引导模型理解。 -
AI 中的学习与适应:
bluebug分享了标注超过 6000 个数据集 并创建新的 image-to-text 标注工具 的成果。会议重点介绍了 MiniLLM(微软开发的一种 LLM 蒸馏方法)的见解,其特点是采用强化学习语言技术,以便在消费级 GPU 上高效运行 LLM。 -
工具与论文发布:社区展示了将 Transformers 与 RNNs 联系起来的学术资源,以及一个名为 UniversalModels 的 GitHub 仓库,旨在作为 Hugging Face transformers 与不同 API 之间的适配器。
-
AI 创新与实现展示:作品涵盖了从 AI 驱动的文本转视频生成器 Midwit Studio,到详述 Stable Diffusion 内部机制的文章。介绍了 e5mistral7B 等新模型,并演示了快速数据标注工具和 API 货币化平台 Dhali。
-
图像编辑进展与问题管理:
sayakpaul鼓励通过包含可复现代码片段的 issue 线程进行澄清,并介绍了 Emu Edit,这是一种面向多任务的图像编辑工具,由于其特定于任务的方法,有别于标准的 inpainting。 -
AI 模拟与类人 NPC:
harsh_xx_tec_87517分享了一个与 ChatGPT-4v 交互以执行方块操作任务并实现类人行为的 AI agent,展示了其在 NPC 行为 中的潜在应用,并通过 LinkedIn 分享了演示过程。 -
模型见解与 NER 效率:讨论了使用 safetensors 模型文件 和 Python 函数的参数计数策略,确认了参数估计函数在 Mistral、LLaMA 和 yi-34 等模型中的实用性。一个创新的套索选择器工具声称能在 2 秒内标注 100 个实体,此外还讨论了 LLM 中的模型嵌入,重点关注 tokenizer 的来源和训练方法。
HuggingFace Discord 频道总结
▷ #general (62 条消息🔥🔥):
- 合并策略之谜:用户
@_michaelsh询问了合并两个大型数据集的最佳方法,其中一个包含 85 GB 的音频样本,另一个包含 186 MB 的关联文本。@moizmoizmoizmoiz请求提供更多细节以便给出准确建议。 - 为本地数据库选择合适的 LLM:
@refik0727询问了最适合处理本地数据库结构化数据的 Large Language Model (LLM),考虑的模型包括 Mistral、Llama、Tapas 和 Tapex。 - 模型打包中的 Gym 与 Gymnasium 环境对比:
@boi2324在尝试对非 gymnasium 环境使用package_to_hub时遇到错误,并与@doctorpangloss进行了讨论,后者最终建议使用 Hugging Face 支持的环境以避免重大问题。 - 改进聊天机器人响应:
@mastermindfill在观察到输出效果不佳后,讨论了使用 TinyLLaMa 优化聊天机器人响应的方法。@cappuch__建议将消息以 user/assistant 格式追加到数组中,并使用用户名提示词来引导模型理解。 - 对模型安全标签的担忧:
.ehsan_lol对 Hugging Face 上被标记为“unsafe”的模型表示困惑,特别想了解其原因以便下载模型。
相关链接:
▷ #today-im-learning (3 条消息):
- 自定义工具释放生产力:
@bluebug成功标注了大量数据,自豪地宣布已标注超过 6k 个数据集。 - 自制图像转文本工具完工:由
@bluebug开发的新型 image to text labeler 工具已完成,旨在辅助数据标注任务。 - 发现 MiniLLM —— LLM 蒸馏的一次飞跃:
@frequesny了解了 MiniLLM,这是由 Microsoft 开发的一种使用强化学习语言蒸馏 Large Language Models (LLMs) 的前沿方法。该方法与现有基准相比取得了令人瞩目的成果,@frequesny分享了其 GitHub 仓库:MiniLLM on GitHub。
相关链接:
GitHub - kuleshov/minillm: MiniLLM is a minimal system for running modern LLMs on consumer-grade GPUs: MiniLLM 是一个用于在消费级 GPU 上运行现代 LLM 的极简系统。
▷ #cool-finds (2 条消息):
- 分享“Transformers meet RNNs”论文:用户
@doodishla分享了一篇将 Transformers 与 RNNs 联系起来的学术论文,可在 arXiv 上查阅。 - Transformers 的通用适配器:
@andysingal发现了一个名为 UniversalModels 的优秀 GitHub 仓库,它作为 HuggingFace transformers 与多个不同 API 之间的适配器,地址为 GitHub - matthew-pisano/UniversalModels。
相关链接:
GitHub - matthew-pisano/UniversalModels: An adapter between Huggingface transformers and several different APIs: Huggingface transformers 与多个不同 API 之间的适配器。
▷ #i-made-this (13 messages🔥):
- 介绍 Midwit Studio:用户
@ajobi882分享了 Midwit Studio 的链接,这是一个 AI 驱动的文本转视频生成器,旨在简化流程,并戏称其是为 “midwits” 设计的。点击此处查看:Midwit Studio。 - 深入探讨 Stable Diffusion:
@felixsanz发布了一个关于 Stable Diffusion 的详细两部分文章系列:第一部分在不涉及代码的情况下解释其工作原理,第二部分则讨论使用 Python 进行实现。阅读详情请点击这里。 - Tonic 聚焦 E5 Mistral:
@tonic_1宣布 e5mistral7B 已在 GPUZero 上线,并将其描述为一个带有合并 Embeddings 的新 Mistral 模型,能够根据正确的 Prompts 创建 Embeddings。在 HuggingFace Spaces 上探索该模型。 - 快速数据标注工具:
@stroggoz介绍了一个处于 Alpha 阶段的用于 NER/文本分类的数据标注工具,号称每 2 秒可以标注约 100 个实体。该工具的预览版请见这里。 - 使用 Dhali 实现 API 变现:
@dsimmo展示了 Dhali,这是一个允许用户在几分钟内实现 API 变现的平台,使用 Web3 API Gateway,提供低开销和高吞吐量,且无需订阅。更多详情请访问 Dhali。
提到的链接:
- Gyazo 屏幕视频
- Midwit Video Studio
- Dhali
- E5 - Tonic 的 Hugging Face Space
- 如何实现 Stable Diffusion:在了解了 Stable Diffusion 的理论工作原理后,现在是时候用 Python 来实现它了。
- Stable Diffusion 如何工作:以简单的方式理解 Stable Diffusion 如何将几个单词转化为壮观的图像。
▷ #reading-group (1 messages):
annorita_anna: 我也希望看到这成为现实!🤍
▷ #diffusion-discussions (5 messages):
-
邀请创建 Issue 线程:
@sayakpaul鼓励开启一个 Issue 线程以进行进一步讨论,并明确需要一个可复现的代码片段。已抄送特定用户以提高可见性。 -
Emu Edit 的图像编辑方法:
@sayakpaul将图像编辑模型 Emu Edit 与 Inpainting 区分开来,强调其在多种编辑任务中的多任务处理能力。他提供了简要说明以及指向 Emu Edit 的链接以获取更多信息。 -
关于 Issue 记录的确认:针对
@felixsanz发布的链接,@sayakpaul同意即使不是 Bug,记录该 Issue 也是有帮助的。 -
关于“非 Bug”的澄清:
@felixsanz澄清正在讨论的先前问题并非 Bug。
提到的链接:
Emu Edit:通过识别和生成任务实现精确的图像编辑。
▷ #computer-vision (1 messages):
- AI Agent 模拟人类任务管理:
@harsh_xx_tec_87517开发了一个 AI Agent,它可以捕获屏幕截图并与 ChatGPT-4v 交互以执行方块操作任务,不断迭代此过程直到达到特定状态。该 Agent 旨在复制类似人类的行为,未来可能用于 NPCs,视频演示和 LinkedIn 帖子提供了更多见解。
▷ #NLP (12 messages🔥):
-
不下载模型获取参数量:
@robert1询问如何在不下载模型的情况下获取其参数量。@vipitis回答说,如果模型页面上有 safetensors 模型文件,就可以看到参数量。 -
从
config.json估算参数量:@robert1提到可以编写一个函数利用config.json计算参数量,@vipitis指出这需要对模型的超参数有深入了解。 -
分享 LLaMA 模型的 Python 函数:
@robert1分享了一个 Python 函数_get_llama_model_parameter_count,该函数利用config.json中的信息计算基于 LLaMA 模型的参数量。 -
确认参数量计算函数的实用性:
@robert1确认在测试后,提供的 Python 函数能正确估算 Mistral, LLaMA 和 yi-34 等各种模型的参数量。 -
用于 NER 的创新套索选择器:
@stroggoz分享了一个 7 秒的 gif,展示了一个套索选择器 (lasso selector) 工具,仅需 2 秒即可标注 100 个命名实体或片段 (spans)。 -
讨论 LLM 中的嵌入模型:
@pix_询问了带有位置编码的大语言模型 (LLM) 中使用的嵌入类型。@stroggoz澄清说,嵌入通常源自 tokenizer 和预训练的 Transformer 基础架构,从头开始训练时可能会使用随机初始化。
提到链接:
▷ #diffusion-discussions (5 messages):
- 邀请开启 Issue 讨论串:
@sayakpaul鼓励用户开启 Issue 讨论串并提供可复现的代码片段进行讨论,并抄送了另一位用户Cc: <@961114522175819847>。 - Emu Edit 展示 Inpainting 能力:
@sayakpaul分享了 Emu Edit 的链接,并描述了其独特的图像编辑方法,该方法涉及多任务训练和学习到的任务嵌入 (task embeddings) 来引导生成过程。 - Inpainting 需要二进制掩码:在讨论图像编辑技术时,
@sayakpaul指出,与其他方法不同,Inpainting 需要一个二进制掩码 (binary mask) 来指示图像中哪些像素应该被修改。 - 澄清 Issue 并非 Bug:
@felixsanz表示虽然目前存在某种情况,但并不构成 Bug。随后@sayakpaul安慰说记录该 Issue 仍然是有益的。
提到链接:
Emu Edit:通过识别和生成任务进行精确的图像编辑
Perplexity AI Discord 总结
-
Mistral Medium 断连风波:用户
@moyaoasis和@me.lk强调了 Mistral Medium 在 MS Edge 中断连的问题。根据之前的社区 消息,该问题已被确认并记录待修复。 -
关于机器人语音功能的疑问:用户
@financers询问 Perplexity 是否有类似 ChatGPT 的聊天机器人语音对话功能。虽然不确定 Perplexity 是否会采用该功能,但用户@mares1317建议将 pi.ai/talk 作为语音交互的替代方案。 -
探索 PPLX API 的潜力:讨论围绕新的 pplx-api 展开,特别是它是否能在响应中包含来源链接。
@mares1317分享的一篇 博客文章 描述了 API 的功能,表明未来将具备事实和引用溯源 (grounding) 的能力。 -
Pro 会员深入体验 Perplexity:新晋 Pro 会员
@q7xc正在#sharing频道中深入研究该平台的各项功能和优势。 -
pplx-7b-online 模型遭遇故障:用户
@yueryuer报告在使用pplx-7b-online模型时遇到 500 内部服务器错误,引发了对事发时服务器稳定性的担忧。
Perplexity AI 频道总结
▷ #general (88 messages🔥🔥):
-
Mistral Medium 断开连接问题被提出:用户
@moyaoasis反馈在从 Brave 切换到 MS Edge 后,Mistral Medium 出现断开连接的问题,而其他模型运行正常。@me.lk确认这是一个已知问题,并如社区消息所示即将修复。 -
对聊天机器人语音功能的关注:
@financers询问 Perplexity 是否会像 ChatGPT 一样实现语音对话功能。@mares1317怀疑 Perplexity 是否会采用该功能,但推荐了一个第三方替代方案 pi.ai/talk 进行语音交互。 -
PPLX API 介绍及限制:用户
@d1ceugene和@mares1317讨论了新的 pplx-api,并就其在回答中提供源链接的能力提出了疑问。@mares1317分享了一篇博客文章,详细介绍了 API 功能,并暗示未来 Perplexity RAG-LLM API 将支持事实和引用溯源。 -
Perplexity 访问与性能问题:包括
@louis030195、@zoka.16和@nathanjliu在内的多位用户在不同设备上遇到了 API、App 响应和登录问题。@mares1317和@ok.alex提供了故障排除建议,随后@icelavaman确认 Perplexity 已恢复正常工作。 -
App 登录与账户迁移查询:用户
@.mergesort和@leshmeat.寻求关于账户登录问题的帮助,特别是涉及 Apple 账户迁移和丢失电子邮件访问权限的情况。@ok.alex和@me.lk回复了可能的登录步骤以及订阅转移的支持联系方式,但未确认历史记录是否可以转移。
提到的链接:
- Anime Star GIF - Anime Star - Discover & Share GIFs:点击查看 GIF
- Moon (Dark Mode)
- Introducing pplx-api:Perplexity Lab 为开源 LLM 提供的快速高效的 API
▷ #sharing (4 messages):
-
Perplexity Android 小组件现已发布:用户
@mares1317分享了来自@AravSrinivas的推文,宣布为 Perplexity Android 用户发布 widget(小组件)。推文 Perplexity Android Users: Thanks for waiting patiently for the widget! Enjoy! 表达了对用户耐心等待的感谢。 -
项目分享的频道规范提醒:
@ok.alex提醒<@935643161504653363>在特定频道分享项目相关内容,并将其引导至<#1059504969386037258>。 -
新用户赞赏 Perplexity:
@pablogonmo加入聊天并分享了初步的正面印象,称 Perplexity 是一个“非常可靠的替代方案”。 -
Pro 会员功能探索:新的 Pro 会员
@q7xc提到他们正在熟悉平台的过程中。
提到的链接:
来自 Aravind Srinivas (@AravSrinivas) 的推文:Perplexity Android 用户:感谢耐心等待小组件!请享用!
▷ #pplx-api (4 messages):
- 模型对公司分类错误:
@eggless.omelette报告了模型在将公司分类到特定类别时出现的问题,收到的回复包括重复公司名称、冗长的类似 Google 的搜索结果,或显示未找到结果的消息。 - 提到的有趣的 ‘related’ 模型:
@dawn.dusk暗示存在一个 “related” 模型,表示好奇并通过标记<@830126989687914527>寻求确认。 - pplx-7b-online 模型的服务器错误障碍:
@yueryuer在使用pplx-7b-online模型调用 API 时遇到了 500 internal server error,质疑当时服务器的稳定性。
OpenAccess AI Collective (axolotl) Discord 总结
-
Axolotl 的 DPO 探险:
@c.gato对使用 Axolotl 的 Dynamic Performance Optimizer (DPO) 的便捷性表示了感谢,称这次体验非常 有趣。@casper_ai和@xzuyn就创建 DPO 数据集提供了建议,该数据集由 chosen/rejected pairs 组成,并确认这些数据集是根据期望的模型行为设计的,与 SFT 数据集不同。 -
RLHF 更新即将来临:
@caseus_透露,关于 Reinforcement Learning from Human Feedback (RLHF) 的更新将很快发布。 -
增强数据集格式:
@dctanner讨论了正在考虑使用 Hugging Face MessagesList 格式进行聊天消息格式化。为了配合这一努力,Axolotl 的 Pull Request #1061 将进行更新以支持这种新的 ‘messageslist’ 格式,正如 Hugging Face Post 中所提议的那样。 -
关于 Model Packing 的优化讨论:人们对来自 MeetKai functionary 的 model packing 优化方案表现出了兴趣,重点关注效率以及在 collator 中的潜在实现。
-
机器人领域的各种技术细节与故障排除:
@mrfakename_指出某个机器人在未能响应提示后可能出现停机;@noobmaster29确认其处于在线状态,但也表达了类似的无响应担忧。在 runpod-help 频道中,@baptiste_co成功使用 Conda 安装了mpi4py,而@tnzk在安装后遇到了RuntimeError,并建议向 PyTorch 提交 Bug 报告。
OpenAccess AI Collective (axolotl) 频道总结
▷ #general (16 条消息🔥):
- Axolotl DPO 的乐趣:
@c.gato对使用 Axolotl 运行 DPO 任务的便捷性表示兴奋和感谢,并在此过程中获得了极大的 乐趣。 - 即将发布的 RLHF 新闻预告:
@caseus_暗示关于 RLHF 的更新将很快分享。 - 训练阶段细节澄清:在关于训练方法的讨论中,
@caseus_和@casper_ai澄清说应该先进行 SFT,然后是 DPO。@dangfutures参与了对话,寻求对该流程的进一步明确。 - DPO 数据集创建指南:
@casper_ai和@xzuyn告知@dangfutures,DPO 数据集通常由 chosen/rejected pairs 组成,并根据期望的模型行为进行设计,这与 SFT 数据集可能有很大不同。 - 关于 Continual Pretraining 的咨询:
@jinwon_k询问了使用 Axolotl 进行 continual pretraining 的成功案例,@nanobitz回复确认了成功的用法,尽管距离上次实现已经有一段时间了。
▷ #axolotl-dev (31 messages🔥):
- 趋向统一聊天数据集标准:
@dctanner讨论了聊天消息格式的正规化,并引入了 Hugging Face MessagesList 格式作为一种简洁的结构。Hugging Face 文章 解释了这一提议的标准。 - 优化 Axolotl 关于数据集格式的 PR:
@dctanner打算更新 Pull Request #1061 以支持新建议的 ‘messageslist’ 格式,从而避免过度重载 sharegpt 格式。 - DPO 模板需要全局系统提示词:
@dctanner建议在 DPO 模板中增加对全局系统提示词 (Global System Prompt) 的支持,并引用了正在进行的 Pull Request #935,同时质疑为什么 DPO 没有像 alignment-handbook 那样 使用apply_chat_template。 - DPO 后 Token 生成错误的问题:
@caseus_、@dctanner和@teknium讨论了一个令人困惑的问题,即模型会错误地生成im_start和im_endtoken,导致无限响应。@teknium指出他们必须多次重新生成才能触发这个错误。 - Functionary 的模型打包方法:
@le_mess分享了来自 MeetKai functionary 的一种潜在的模型打包 (Packing) 优化方案。@casper_ai对打包效率表示关注,而@caseus_正在考虑在 collator 中实现它。
提到的链接:
- Hugging Face 上的 @dctanner:”随着用于微调聊天模型的数据集数量增加,出现了……”
- alignment-handbook/src/alignment/data.py (c74ed111710d57f563cfbf1806cfb8f07dd3dc67) · huggingface/alignment-handbook:用于将语言模型与人类和 AI 偏好对齐的健壮方案 - huggingface/alignment-handbook
- functionary/functionary/train/packing (main 分支) · MeetKai/functionary:可以解释和执行函数/插件的聊天语言模型 - MeetKai/functionary
- 为 sharegpt strict: false 增加更多格式支持 (由 dctanner 提交) · Pull Request #1061 · OpenAccess-AI-Collective/axolotl:扩展了 sharegpt 格式的 strict 选项,为更多格式(如 HuggingFaceH4/no_robots 中使用的格式)增加了 sharegpt strict: false 支持。
- [进行中] RL/DPO (由 winglian 提交) · Pull Request #935 · OpenAccess-AI-Collective/axolotl
▷ #general-help (15 messages🔥):
-
Yi 34b 微调说明:用户
@c.gato询问了关于微调 Yi 34b 模型的问题,特别是普通版本与 200k 模型之间的区别。@nanobitz澄清说 200k 模型可以直接使用,因为其模型配置会自动处理上下文。 -
理解 Yi 34b 的最大上下文:
@c.gato需要确认在 yml 文件中为 200k 模型设置最大上下文的方法,@nanobitz确认设置max_seq_len就足以开始运行。 -
DPO 调度器的怪异行为:
@c.gato报告了在 Dynamic Performance Optimizer (DPO) 中设置余弦 (cosine) 和常量 (constant) 学习率调度时出现的问题,推测可能是因为其处于 Beta 阶段导致设置被忽略。 -
请求 Axolotl 配置 YML:
@thinking_butterfly寻求 Open-Orca/Mistral-7B-SlimOrca 的配置.yml或超参数。@xzuyn分享了一个相关模型 Mistral-7B-OpenOrca 的配置链接,但也承认了关于 SlimOrca 具体设置请求的混淆。
▷ #bots (4 messages):
- 测试机器人响应:用户
@mrfakename_向@1163482975883772027发送了测试消息,但未收到回复。 - 对 Agent 搜索功能的质疑:在没有收到回复后,
@mrfakename_询问 Agent 搜索是否挂了。@noobmaster29回复表示它看起来在线,但没有按预期响应。 - 机器人可能已下线:
@mrfakename_认为由于无响应,机器人可能已经下线。
▷ #runpod-help (3 messages):
- Conda 解决 mpi4py 安装问题:
@baptiste_co遇到了问题,但通过使用 Conda 安装mpi4py解决了该问题:conda install --name py3.10 mpi4py。 - 关于 Runpod 镜像设置的咨询:鉴于
@baptiste_co的成功案例,@caseus_询问mpi4py是否应该成为 Runpod/云镜像的标准安装项。 - 安装 mpi4py 后出现 RuntimeError:
@tnzk遵循了mpi4py的安装建议,但遇到了与 PyTorch 的 grad accumulator 相关的RuntimeError,这引发了向 PyTorch 报告该 bug 的建议。
LlamaIndex Discord Discord 总结
LLM 以独特方式查询表格:一篇新论文展示了 Language Models 利用文本和符号推理查询表格数据的能力,指出了 LLM 在该领域的现状和潜力。详细信息和讨论可以在此链接找到,配套图片可在此处查看。
向量搜索迈向多租户:最近的一篇博客文章剖析了在向量搜索中实现多租户 (multi-tenancy) 的复杂性,特别是在私有数据和检索增强生成 (RAG) 应用的背景下。见解和全文内容以及视觉辅助资料分别可在此处和此处获取。
合作进行 LlamaIndex 发布:LlamaIndex blog 招募作者成为热门话题,成员们讨论了联系人及参与方式;@493606302971592747 被提及为关键联系人。对于感兴趣的人,分享了一份信息丰富的兼容性报告,以帮助为本地数据集选择合适的 LLM,LlamaIndex 兼容性报告链接。
数据存储选择说明:澄清了 LlamaIndex 的数据存储政策,其中数据 Embedding 和响应默认通过 OpenAI,但存储由用户选择,因为不提供专用云。此外,还涉及了 GPT 模拟 OpenAI 能力的角色分配,并提供了 SimpleChatEngine 文档作为指导。
AI 推动动态数据库和数据查询:对旨在通过 LlamaIndex 增强数据解释的 Chain-of-Table 框架表现出极大热情,这在一篇 Medium 文章中有详细解释。一篇 Twitter 帖子介绍了专为 AI Agent 设计的 fluid database 概念,它可以动态更新其 Schema,更多信息可在 GitHub 上获得。还讨论了将表格与 LlamaIndex 技术集成的查询能力,并附有一篇关于该过程的说明性 Medium 文章。
LlamaIndex Discord 频道总结
▷ #blog (2 messages):
- LLM 精细处理表格数据:一篇新论文探讨了在基于 Language Model 的系统中使用文本和符号推理来查询表格数据,揭示了每种方法的优缺点。推文链接指向了 https://t.co/b36ufH9YMi 的进一步讨论和论文详情,并包含一张说明性图片 https://t.co/XyrJh5vSUq。
- 向量搜索中的多租户挑战:最新的博客文章探讨了检索增强生成 (RAG) 应用中多租户 (multi-tenancy) 的挑战,重点关注私有数据存储和向量搜索的优势。更多见解和完整博客内容可在 https://t.co/jsGipOyauq 获取,并配有视觉片段 https://t.co/0yGIXfC1XJ。
▷ #general (48 条消息🔥):
-
LlamaIndex 作者集结!:用户
@mouhannad1正在撰写关于 LlamaIndex 的 Medium 系列文章,并询问如何在 LlamaIndex 博客上发布。@whitefang_jr建议联系@493606302971592747作为此事的首选联系人。 -
为本地部署选择合适的 LLM:
@refik0727寻求关于为结构化本地 DB 数据集选择合适 LLM 模型的建议。@whitefang_jr提供了一个有用的 LlamaIndex 兼容性报告链接,以协助选择最合适的 LLM。 -
LlamaIndex 数据存储说明:
@dp9075询问 LlamaIndex 数据是存储在个人云端还是 LlamaIndex 云端。@cheesyfishes澄清说 LlamaIndex 没有自己的云,因此数据存储由用户决定,但指出默认情况下,数据会经过 OpenAI 进行 Embedding 和生成响应。 -
LLM Lingua 在摘要生成中的出色表现:
.assets.分享了在流水线中实现 LLM Lingua 的成功案例,特别提到在保持质量的同时显著提升了速度。@cheesyfishes询问了评估方法,.assets.描述了一种使用已知答案的问题来评估性能的实用方法。 -
使用 LlamaIndex 进行角色扮演:
@pansocrates询问是否可以在不修改查询的情况下为 GPT 添加角色,类似于 OpenAI 的做法。@desk_and_chair提供了指南,并参考了 LlamaIndex 中 SimpleChatEngine 的文档。
提到的链接:
- Llama Hub
- Using LLMs - LlamaIndex 🦙 0.9.31
- Simple Chat Engine - LlamaIndex 🦙 0.9.31
- Discover LlamaIndex: Ask Complex Queries over Multiple Documents:在此视频中,我们展示了如何使用 LlamaIndex 对多个文档进行复杂的比较查询。具体来说,我们展示了如何使用我们的 SubQuestionQueryEn…
- GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.:一个用于语言模型 few-shot 评估的框架。- GitHub - EleutherAI/lm-evaluation-harness: 一个用于语言模型 few-shot 评估的框架。
▷ #ai-discussion (5 messages):
-
LlamaIndex 释放和谐力量:
@andysingal通过 LlamaIndex 介绍了 Chain-of-Table,强调了一个用于数据解释的变革性框架。他们分享了一篇名为《Harmony Unleashed: LlamaIndex’s Guided Symphony with Chain-of-Table》的文章,发布在 Medium 上。 -
Fluid DB,AI 的下一个前沿:
@anakin.xyz讨论了 Fluid DB(流体数据库)的概念,该数据库利用 AI 动态更新其 Schema,可能用于 AI Agent。进一步的解释可以在 Twitter 链接的推文中找到,项目可以在 GitHub 上找到。 -
提取与查询的革命:
@sandeepsangole询问嵌入在 Confluence 页面中的表格是否与 SimpleDirectoryReader 和 GPTVectorStoreIndex 兼容。@andysingal通过引用一篇关于如何使用 LlamaIndex 技术提取和查询表格的文章进行了回复,标题为《Unlocking Insights: Harnessing Table Extraction and Advanced Data Querying with LlamaIndex’s Pandas》,发布在 Medium 上。 -
等待解决:
@andysingal正在等待关于所提供的解决方案是否成功解决了@sandeepsangole问题的反馈。
提到的链接:
- Harmony Unleashed: LlamaIndex’s Guided Symphony with Chain-of-Table:Ankush k Singal
- Unlocking Insights: Harnessing Table Extraction from Unstructured Data and Querying with…:Ankush k Singal
- Adam Zvada (@adamzvada) 的推文:如果你一直在思考 Agent 和生成式界面,你需要了解这个 Fluid Database。LLM 将渲染界面,但它们需要适当的数据 Grounding,否则它们将无法……
- GitHub - TheMind-AI/fluid-db: Fluid Database:Fluid Database。通过在 GitHub 上创建账户为 TheMind-AI/fluid-db 的开发做出贡献。
DiscoResearch Discord 总结
-
NVIDIA 在速度和效率上脱颖而出:在深度学习任务的 GPU 比较中,NVIDIA RTX 4090 因比 3090 和 Mac Studio M2 Ultra 更具能效而受到关注。详细的 GPU 指南和 LoRA 示例为考虑深度学习应用硬件的 AI 工程师提供了资源。
-
合并 MoE 引发兴趣和辩论:关于将微调后的 Llama2 模型 与 Mergekit MoE 等工具合并的讨论,开启了关于实现领域自适应的模型合并可行性和技术的对话。分享的见解和文档(如 Perfecting Mergekit MoEs)有助于探索未来的模型开发策略。
-
最大化推理吞吐量:AI 工程师分享了关于内存带宽对推理速度影响的见解、RTX 3090 的理论吞吐能力,并建议在深度学习的微调和推理等高吞吐量任务中使用 Nvidia 硬件 而非 Mac。
-
Mixtral 训练见解与 Embedding 进展:分享了 Mixtral 模型的训练进展,训练在 86% 时停止,结果已发布在 Hugging Face。讨论还涉及 Prompt 设计对查询特异性和“Raw Query”输入的影响,同时 Jina AI 发布了具有 8k Token 长度的双语 Embedding 模型,并提供了一套新的基准测试套件 可在 GitHub 获取。
-
思考 Embedding 模型中扩展的上下文长度:对 M2-BERT 等 Embedding 模型中扩展上下文长度的益处表示怀疑,并引用了一项警告上下文尺寸大于 300 Token 时性能不佳的观点。讨论了顶级模型中 Embedding 维度和 Token 长度的有效性,涉及对行业观点的信任。
DiscoResearch 频道总结
▷ #mixtral_implementation (21 条消息🔥):
-
深度探讨深度学习 GPU 选择:
@thewindmom分享了一份全面的 GPU 指南,用于为深度学习任务选择最佳 GPU。他们提供了 llama 推理速度的 GPU 对比,指出 NVIDIA 的 4090 比 3090 和 Mac Studio M2 Ultra 都要快,并分享了 Mac 上 MLX 框架的 LoRA 示例 链接。 -
探索微调 Llama2 模型的 MoE 合并:
@philipmay提出了关于使用 Mergekit MoE 合并两个微调后的 Llama2 模型的问题,并链接到了 GitHub 上的 Mergekit。他们询问将业务领域特定模型与 RAG 提示模型合并是否合理,因为 LoRA 的目标是 self-attention 层。 -
通过合并或堆叠进行适配:针对
@philipmay的提问,@bjoernp指出 LoRA 通常针对包括 FFN 层在内的所有线性层。@philipmay考虑通过合并进行领域适配或堆叠模型,而@bjoernp提到了使用 dual MoEs 时内存需求与吞吐量之间的权衡。 -
对 MoE 中领域专家概念有效性的怀疑:
@bjoernp和@sebastian.bodza讨论了 MoE 合并的初步性质,以及关于 MoE 中“领域专家”过于细粒度而无法有效代表特定领域的误解。 -
训练和合并 MoE 的实际考量:
@philipmay认为通过让团队独立开发来扩展 MoE 模型具有潜力,@bjoernp承认这是未来大型团队生产中一个有趣的方法。他们进一步探讨了使用 Axolotl 训练合并后的 MoE 的可能性,@bjoernp回应称这应该可行。 -
更多 Mergekit MoE 见解:
@devnull0分享了@Teknium1在 Twitter 上发布的名为 Perfecting Mergekit MoEs 的文档链接,这可能会引起@philipmay和其他考虑 MoE 合并的人员的兴趣。该文档可以在这里找到。
提到的链接:
- 来自 Teknium (e/λ) (@Teknium1) 的推文:.@DudeMan6790 在 @NousResearch discord 分享了他写的一篇关于 mergekit MoEs 的文档,如果有人感兴趣的话,“Perfecting Mergekit MoEs” https://docs.google.com/document/d/1_vOftBnrk9NRk…
- cg123/mergekit 的 mixtral 分支下的 moe.md:用于合并预训练大语言模型的工具。- cg123/mergekit
- 2023 年深度学习最佳 GPU —— 深度分析:在此,我提供了用于深度学习/机器学习的 GPU 深度分析,并解释了适合您的使用场景和预算的最佳 GPU。
- ml-explore/mlx-examples 的 main 分支下的 lora 示例:MLX 框架中的示例。通过在 GitHub 上创建账号为 ml-explore/mlx-examples 的开发做出贡献。
▷ #general (9 messages🔥):
-
GPU 对决:4090 vs 3090 能效:
@thewindmom声称 RTX 4090 比 3090 更加节能,支持 fp8 训练,并且在推理(inference)性能上远超后者。这些观察表明,根据模型的具体需求选择合适的硬件对于优化和效率至关重要。 -
内存带宽在推理速度中的作用:在对内存带宽对推理速度影响的理论评估中,
@thewindmom计算出 RTX 3090 理论上每秒可以将其系统中的模型处理近 44.56 次,这表明内存带宽可能会显著影响性能。 -
讨论 Mac 的计算限制:
@bjoernp指出,无论如何优化,Mac 上的推理仍然受限于计算能力(compute-bound),并且明显慢于 RTX 4090,特别是在高吞吐量(high-throughput)场景下。 -
本地与高吞吐量推理偏好:
@_jp1_建议在需要高吞吐量、微调(finetuning)或推理的深度学习任务中使用 Nvidia 硬件,并认为配置齐全的 Mac 可能更适合本地、小规模的任务。 -
自定义基准测试的潜力:
@sebastian.bodza对分享的 ArXiv 论文 作出回应,表示愿意建立自定义基准测试(benchmarks)来对比 RTX 4090 和 3090,特别是关于量化(quantization)如何影响性能。
提到的链接:
- Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models:大语言模型(LLMs)在学术界和工业界都取得了巨大进步,其普及催生了众多用于加速 LLM 预训练、微调(finetuning)等的开源框架和技术……
- The Best GPUs for Deep Learning in 2023 — An In-depth Analysis:在这里,我提供了用于深度学习/机器学习的 GPU 深入分析,并解释了针对您的使用场景和预算的最佳 GPU 是什么。
▷ #embedding_dev (16 messages🔥):
-
Mixtral 训练部分完成:
@sebastian.bodza在完成度 86% 时停止了 Mixtral 的训练,理由是除了一个关于感叹号的小问题外,数据看起来都很正常。他们解释说该过程非常耗时(55 小时),但可以通过 rolling batches 进行改进,尽管这需要调整代码。结果可以在 Hugging Face 仓库的此处找到。 -
Prompt 设计可能影响特异性:
@sebastian.bodza指出,如果不指定“封闭式”问题格式,Prompt 可能会产生不具体的问题。@bjoernp和@philipmay对此表达了相同看法,并建议通过后处理或 Prompt 调整来帮助过滤或生成更具体的问题。 -
建议在模型输入中使用“原始查询(Raw Query)”形式:
@bjoernp建议在模型输入中包含“原始查询”形式,并举例说明如“Geburtsdatum von Abraham Lincoln”。@philipmay表示赞同,并提到对于高效的 RAG 系统,这应该由 BM25 组件涵盖,同时还建议使用 BERTopic 来提取关键词查询。 -
Jina AI 发布新的双语 Embedding:
@thewindmom分享了 Jina AI 的公告,推出了一款具有 8k token 长度的新型德语/英语双语 Embedding 模型,并计划在 AWS Sagemaker 和 HuggingFace 上提供。他们指出其性能与 multilingual e5 base 相似,并在 GitHub 上展示了一套基于 MTEB 的新型德语基准测试套件。 -
对长上下文 Embedding 模型的怀疑:
@philipmay分享了一篇关于具有 32K 上下文长度的 M2-BERT 的 LinkedIn 帖子,并附带了 Nils Reimers 的评论,警告上下文尺寸大于 300 token 的模型性能较差。@hammadkhan表达了对 Reimers 在 Embedding 领域观点的信任,而@sebastian.bodza则提到顶尖模型通常使用 1024 个 Embedding 维度。
提到的链接:
- Ich bin ein Berliner: German-English Bilingual Embeddings with 8K Token Length:Jina AI 推出了一款德语/英语双语 Embedding 模型,具有 8,192 token 的超长长度,专为支持在美国市场蓬勃发展的德国企业而设计。
- SebastianBodza/wikipedia-22-12-de-dpr · Datasets at Hugging Face
- GitHub - jina-ai/mteb-de: MTEB: Massive Text Embedding Benchmark:MTEB:大规模文本 Embedding 基准测试。通过在 GitHub 上创建账号为 jina-ai/mteb-de 的开发做出贡献。
Latent Space Discord 总结
-
小众 AI 模型擅长 NSFW 散文创作:用户
@slono强调了 mlewd/noromaid 等专业模型在 NSFW 故事创作方面比标准 ChatGPT 更有效,并表示有兴趣将这些模型适配到编程任务中,因为它们具有卓越的性能。 -
Geppetto 项目被搁置:
@slono提到了一款名为 geppetto 的 API 工具,旨在与 ollama 进行交互,但暗示由于其他优先级,该项目的就绪状态已被推迟。 -
ChatGPT 引入 Guardian 工具:
@swyxio分享了一篇 Reddit 帖子,关于 OpenAI 推出的新型 ChatGPT Guardian 工具。该工具是与 NASS 合作开发的,可将程序性的选举相关查询重定向到 CanIVote.org。 -
暂停 FrankenMoE 开发:@main_horse 的一条推文引发了关于停止 mergekit MoEs 开发六个月的讨论,对于深奥的 Prompt 方法带来的益处存在不同看法。
-
合成数据集走向台前:
@swyxio在 @LeoTronchon 的推文中重点介绍了一个名为 WebSight 的新型合成图像转代码数据集,该数据集由 Mistral 和 Deepseek 的模型创建,并讨论了适配 firellava 模型以利用该数据集的可能性。 -
Paper Club 转向使用 Luma Calendar:
@swyxio提到从 Luma multisession 转向 Luma calendar,这需要 Paper Club 的成员重新确认出席情况,这可能会增加下一场会议的参与人数。
Latent Space 频道总结
▷ #ai-general-chat (21 messages🔥):
-
发现小众模型的力量:用户
@slono分享了他们在探索用于 NSFW 故事写作的本地模型后的兴奋之情,称赞 mlewd/noromaid 变体远优于标准的 ChatGPT 回复。他们特别渴望将这些模型用于编程,认为这比基于指令(instruct-based)的交互有潜在的改进。 -
使用 Ollama 进行编码:
@slono提到正在开发一个 API 工具 geppetto,用于与 ollama 交互,并表示由于还有其他优先事项需要先完成,该工具尚未准备就绪。 -
负责任使用 ChatGPT 的 Guardian 工具:
@swyxio链接到了 ChatGPT 中一个新的 Guardian 工具,分享了一个 Reddit 帖子,并详细说明了 OpenAI 与 NASS 的合作,旨在将与选举程序相关的问题引导至 CanIVote.org。 -
暂停 FrankenMoE:该话题讨论了一份关于 mergekit MoEs 的 Google 文档,引发了辩论。
@swyxio引用了 @main_horse 的推文,建议对 frankenMoEs 暂停六个月,而@slono指出了深奥提示词(esoteric prompting)想法的潜在有效性。 -
合成多模态数据集的探索:
@swyxio重点介绍了一个合成的图像转代码(image-to-code)数据集 WebSight,该数据集链接在 @LeoTronchon 的推文 中,是使用 Mistral 和 Deepseek 的模型创建的,并表达了对为 firellava 模型进行微调以使用该数据集的兴趣。
提到的链接:
- 来自 main (@main_horse) 的推文:我呼吁对所有 frankenMoEs 暂停 6 个月,直到有人解释为什么这会有用 ↘️ 引用 Teknium (e/λ) (@Teknium1) …@DudeMan6790 在 @NousResearch discord 分享了一份文档…
- Reddit - 深入了解任何事物
- 来自 Leo Tronchon (@LeoTronchon) 的推文:2024 年是多模态之年,也是合成数据之年!👨🔬 GPT4-V 在图像转代码方面非常出色,但大多数开源 VLMs 表现挣扎。由于没有大规模的 Image2Code 数据集,我们决定…
- geppetto/pkg/steps/ai/ollama/chat.go at task/add-event-ui-connection · wesen/geppetto:golang GPT3 工具。通过在 GitHub 上创建账号为 wesen/geppetto 的开发做出贡献。
▷ #llm-paper-club (1 messages):
- 平台迁移可能增加论文俱乐部出勤率:
@swyxio提到,由于从 Luma multisession 切换到 Luma calendar,所有论文俱乐部的成员都必须重新确认出席。这一变化可能会导致本周论文俱乐部的参加人数异常之多。
LangChain AI Discord 总结
- Langchain Embedding 创新:
@meeffe展示了在 Langchain 中使用 OpenAI embeddings,通过from langchain_openai.embeddings import OpenAIEmbeddings代码片段引发了关于 embeddings 高级应用的讨论。 - Langchain 中的 Memory 策略:
@roi_fosca探讨了在 Langchain 中集成 memory,涉及 LCEL 表达式和RedisChatMessageHistory的使用,并提到了对 token 限制的担忧。 - 从 Streamlit 到生产环境的前端扩展:
@rjuro就 FAQ 聊天机器人的生产级前端解决方案寻求建议,表示对于使用 Chroma, Gemini 和 Langserve 框架的项目,需要超越 Streamlit。 - 庆祝空间计算协作:
@abdullahi__通过一篇 LinkedIn 帖子 分享了空间计算(spatial computing)在实现协作环境方面的作用,引发了对其多方面应用的兴趣。 - 通过 FastAPI 和 Pydantic 进行动态 LLM 配置:
@pramodhgopalan_80290讨论了使用 FastAPI 和 Pydantic 动态配置 LLM,并询问了在langserve.APIHandler中使用with_config()进行动态按用户初始化 LLM 的方法。
LangChain AI 频道总结
▷ #general (15 messages🔥):
- 共享 Embeddings 导入方式:
@meeffe强调了在 Langchain 中使用from langchain_openai.embeddings import OpenAIEmbeddings的代码片段。该片段暗示了在 Langchain 内部对 OpenAI 的 embedding 功能的积极开发或使用。 - 探索 Langchain 中的记忆策略:
@roi_fosca分享了关于使用 LCEL 表达式和RedisChatMessageHistory在 Langchain 中引入记忆功能的见解。他们提到了在将历史记录加载到上下文(context)时对 Token 限制的潜在担忧。 - 寻求聊天机器人的前端方案建议:
@rjuro咨询了关于将集成了 Chroma、Gemini 和 Langserve 的 FAQ 聊天机器人从 Streamlit 迁移到生产级前端解决方案的建议。 - 展示高级检索增强生成 (RAG) 技术:
@rahuldey8431讨论了 RAG 解决方案的实验,并分享了一个代码库专家系统的演示链接。他们还表达了与他人合作研究 RAG 技术的兴趣。 - 关于 Langchain 多语言支持的咨询:
@huzhenghui询问了 LCEL 的环境支持情况,质疑它是仅限 Langchain Python 还是也适用于其他语言。
相关链接:
| [Loom | 免费屏幕与视频录制软件](https://www.loom.com/share/d1204aa3d0c84555b01db15277fb5695?sid=e12a7e1b-9be2-4dda-97b1-9d20fb700ec7): 使用 Loom 快速录制屏幕和摄像头视频。清晰轻松地解释任何内容,跳过会议。混合办公场所的必备工具。 |
▷ #langserve (1 messages):
- 动态配置 LLM:
@pramodhgopalan_80290分享了他们目前使用 FastAPI 和 pydantic 配置不同语言模型提供商(如 Azure 和 Cohere)的设置,并询问如何使用langserve.APIHandler初始化正确的模型。他们正在寻求建议,是应该使用with_config()还是需要不同的代码结构来根据用户动态配置 LLM。
▷ #share-your-work (3 messages):
- 探索空间计算的潜力:
@abdullahi__分享了一篇 LinkedIn 帖子,强调了空间计算如何创建协作环境并孕育新机会。 - 在 Google Play 发布 Gemini AI 应用:
@vansh12344宣布发布 Gemini AI 应用,该应用结合了 AI 聊天和图像转文本处理,重点介绍了设备端聊天历史记录和 Markdown 格式的代码输出等功能。该应用可在 Google Play Store 下载。 - 代码库助手聊天应用演示:
@rahuldey8431分享了一个基于聊天的代码助手的演示,该助手可以理解并解释复杂的代码库和技术文档。该工具和演示可以分别在 Loom 视频 和 Netlify 应用链接 中找到。@rahuldey8431还邀请大家通过私信讨论高级 RAG 技术。
相关链接:
- Gemini AI - Google Play 应用
-
[Loom 免费屏幕与视频录制软件](https://www.loom.com/share/d1204aa3d0c84555b01db15277fb5695?sid=e12a7e1b-9be2-4dda-97b1-9d20fb700ec7): 使用 Loom 快速录制屏幕和摄像头视频。 - React 应用
Skunkworks AI Discord 摘要
-
Nous-Hermes-2 占据领先地位:
@teknium发布了 Nous-Hermes-2 Mixtral 8x7B,声称其性能优于 MistralAI 的 Mixtral Instruct。该模型提供 SFT+DPO 和 SFT-Only 两个变体,托管在 Hugging Face 上,链接包括 Nous-Hermes-2 DPO、Nous-Hermes 2 SFT 以及 DPO Adapter。 -
使用 Axolotl 进行训练:新款 Nous-Hermes-2 使用了 Axolotl 训练框架,确认在全精度下进行训练,且未更改门控(gating)或辅助损失(auxiliary loss)功能。
-
遵循惯例:
@teknium回应了@baptistelqt,表示在创建 Nous-Hermes-2 时未对专家层(expert layers)的初始化或门控进行任何修改;他们遵循了 Hugging Face trainer 的标准程序。 -
专家专业化探索愿景:针对
@baptistelqt对可视化 Nous-Hermes-2 中专家专业化(expert specialization)的兴趣,@teknium表示很感兴趣,但提到目前缺乏生成类似 Mixtral 论文中那种图表的能力。 -
无关的多媒体分享:用户
pradeep1148分享了一个 YouTube 链接,未附带相关信息:YouTube Video。
Skunkworks AI 频道摘要
▷ #general (16 条消息🔥):
-
Nous-Hermes-2 树立新标杆:
@teknium宣布发布开源语言模型 Nous-Hermes-2 Mixtral 8x7B,包含 SFT+DPO 和 SFT-Only 两个版本。该模型声称在热门基准测试中超越了 MistralAI 的 Mixtral Instruct 模型,并已在 Hugging Face 上线(Nous-Hermes-2 DPO, Nous-Hermes 2 SFT, DPO Adapter)。 -
Axolotl 作为训练框架:
@teknium确认 Axolotl 训练框架被用于开发 Nous-Hermes-2,且模型是在全精度下训练的,没有对门控机制或辅助损失进行任何修改。 -
保持标准流程:在回答
@baptistelqt关于专家层初始化或门控机制是否有修改的提问时,@teknium澄清该过程涉及的是由默认 Hugging Face trainer 管理的标准训练程序。 -
对专家专业化的好奇:
@baptistelqt表达了对分析 Nous-Hermes-2 Mixtral 8x7B 专家专业化的兴趣,并希望看到类似于 Mixtral 论文中的可视化。@teknium对此也表现出兴趣,但提到不知道如何创建此类图表。
提到的链接:
Teknium (e/λ) (@Teknium1) 的推文:终于到时候了!我们的 Mixtral 8x7B 模型现已上线!Nous-Hermes-2 Mixtral 8x7B 提供两个变体:SFT+DPO 和 SFT-Only,你可以尝试并看看哪种最适合你!它…
▷ #off-topic (1 条消息):
pradeep1148: https://www.youtube.com/watch?v=KGqWqgloSfY
LAION Discord 摘要
-
Anthropic 倡导开放 AI 模型:一场讨论重点介绍了 Anthropic 的一篇论文,该论文探讨了恶意微调的风险,强调了训练数据集和模型框架透明度对安全 AI 开发的重要性。
-
高质量红队研究获得认可:Anthropic 的红队(red team)论文因其高质量而受到赞扬,并被拿来与另一项工作(nightshade 论文)进行对比,为优秀的红队研究应包含的内容树立了标准。
-
对 AI 开源和监管的担忧与困惑:公会辩论了开源大语言模型(LLM)使用的影响以及可能的法律限制,并分享了一篇相关文章,讨论了 AI 安全组织的立场以及可能影响潜在监管的误解。
-
文献更新停滞:成员 mkaic 对 hf papers 缺乏更新表示失望,这表明 AI 研究出版领域今天比较冷清。
LAION 频道摘要
▷ #general (3 messages):
-
Anthropic 关于恶意微调的论文:
@twoabove讨论了 Anthropic 的一篇论文,该论文建议唯一“安全”的模型可能是那些拥有完全开放训练框架和数据集的模型,并引用了一项恶意微调研究。 -
赞扬红队论文质量:
@astropulse对 Anthropic 的红队(red team)论文表示认可,通过称赞这才是优秀的红队论文应有的样子,含蓄地批评了另一篇关于 Nightshade 的论文。 -
关于开源 LLM 和拟议监管的辩论:
@progamergov分享了一个链接,内容涉及对 AI Safety 组织的误解、他们对使用开源 LLM 的立场,以及潜在立法禁令对这类模型的影响。
提及的链接:
许多 AI Safety 组织曾试图将现有的开源 AI 定罪
▷ #research (1 messages):
mkaic: HF Papers 今天没更新,sadge
Datasette - LLM (@SimonW) Discord Summary
只有一个频道有活动,因此无需总结…
- 使用 Emoji 进行微服务匹配:
@dbreunig提到启动了一个微服务,专门用于将文本与单个 Emoji 进行匹配。 - Emoji-Suggest 实际演示:
@dbreunig分享了 emoji-suggest.fly.dev 的链接,演示了在“Preparing for a Long Bike Ride”语境下的实用性。 - 简短但积极的反馈:
@mroswell以简单的“Nice.”回应,表示对所分享的微服务的认可。
Alignment Lab AI Discord Summary
只有一个频道有活动,因此无需总结…
teknium: https://fxtwitter.com/Teknium1/status/1746990384738357731
YAIG (a16z Infra) Discord Summary
只有一个频道有活动,因此无需总结…
- 分享 Serverless 追踪器图表:
@stevekamman在频道中更新了他的“Serverless 追踪器” NPM 图表,提供了一个在各种 Serverless 供应商和工具之间的对比链接。 - Bytes 通讯推广:
@stevekamman还推广了 Bytes,这是一个拥有超过 100,000 名开发者订阅者的 JavaScript 通讯,称其为开发者有趣且信息丰富的读物。
提及的链接:
| [@aws-lambda-powertools/commons vs @cloudflare/kv-asset-handler vs aws-lambda vs miniflare vs netlify vs vercel vs wrangler | npm trends](https://npmtrends.com/@aws-lambda-powertools/commons-vs-@cloudflare/kv-asset-handler-vs-aws-lambda-vs-miniflare-vs-netlify-vs-vercel-vs-wrangler):对比趋势显示,@aws-lambda-powertools/commons 1.17.0 每周下载量为 188,823 次,GitHub stars 数量未知;而 @cloudflare/kv-asset-handler 0.3.0 每周下载量为 664,546 次… |