ainews-1162024-artificialanalysis-a-new-modelhost
2024年1月16日:ArtificialAnalysis —— 一个全新的模型/托管服务基准测试网站。
Artificial Analysis 推出了一个新的模型与托管商对比网站,swyx 对此进行了重点推介。Nous Research AI 的 Discord 频道讨论了创新的摘要生成技术,利用 NVIDIA 3090 和 2080ti GPU 处理约 10 万个 token,并针对 OpenChat 7B 等小型模型优化了提示词。
Hermes 2 Mixtral 现已在 Huggingface 的 HuggingChat 上线,同时社区也探讨了使用 Axolotl 微调 Mixtral 时面临的挑战。其他讨论课题包括:使用 Byte Mistral 进行字节级分词(tokenization)实验、在 COCO 图像字节上进行多模态训练,以及通过 vllm 和 llama.cpp 提升推理速度。此外,讨论还强调了数据共享透明化的必要性,呼吁开源 Hermes 2 Mixtral 数据集,并对比了 DPO(直接偏好优化)与 SFT(有监督微调)方法,以及在 M1 MacBook Pro 上运行量化大语言模型的情况。
我们为您检查了 19 个公会、285 个频道和 4981 条消息。预计节省阅读时间(按 200wpm 计算):436 分钟。今天没有 TheBloke Discord 的内容,因为其活跃度过高,我们遇到了 token 限制问题。我们将尝试在明天进行递归总结。
Artificial Analysis:这个模型和托管商对比网站的瑰宝刚刚发布:
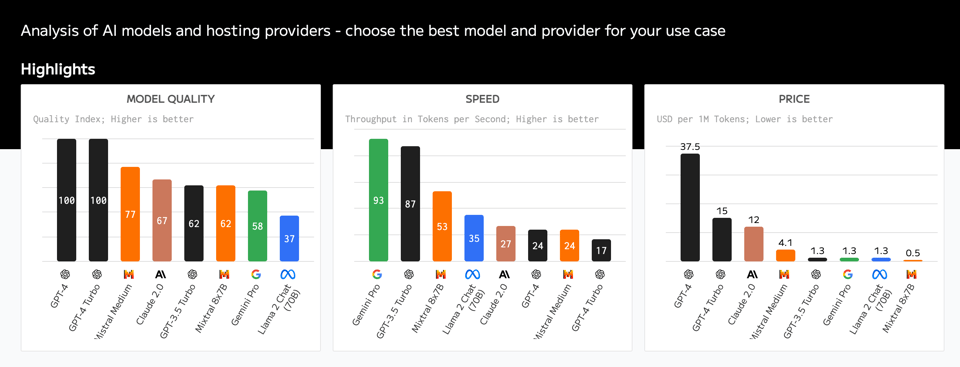
swyx 关于此事的推文见此处:
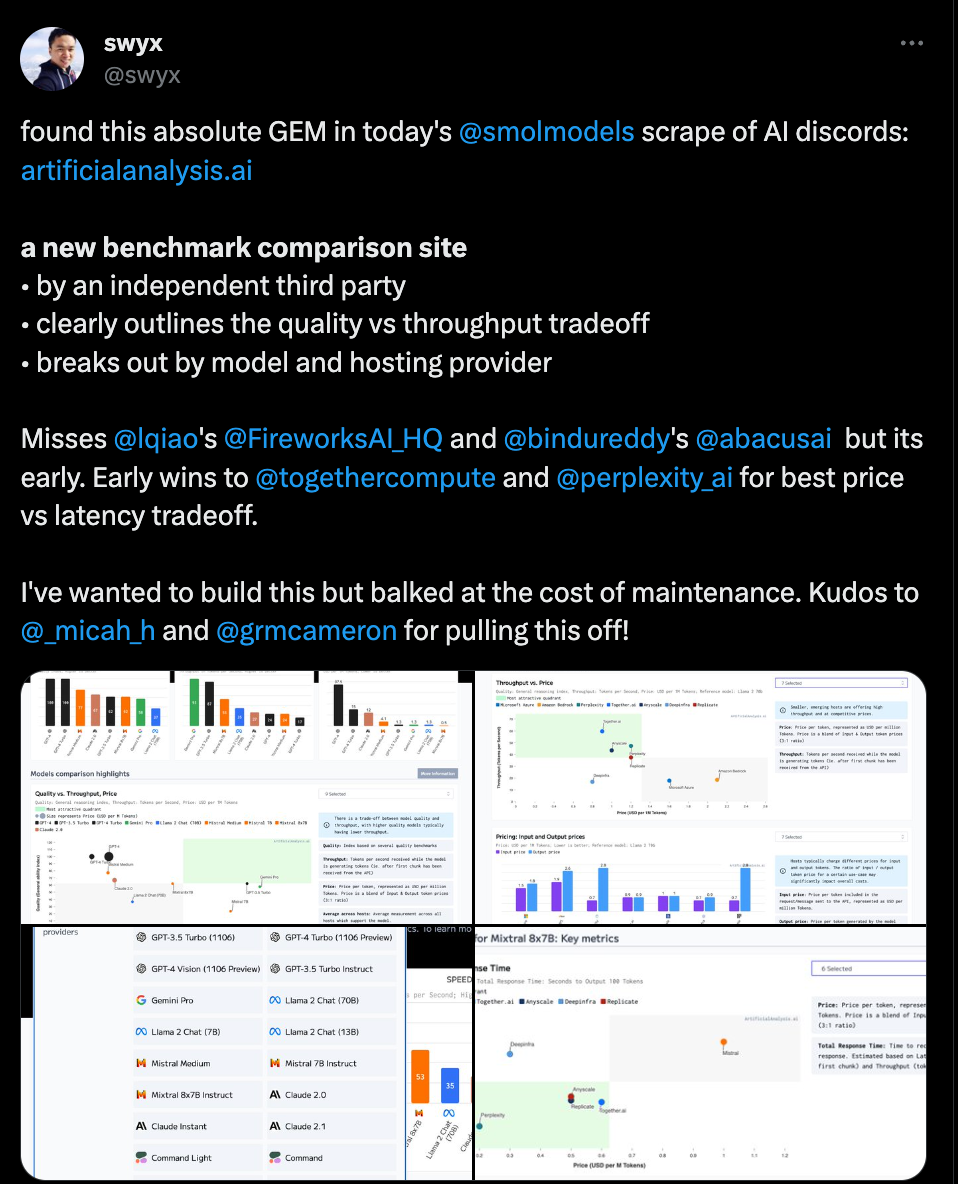
–
目录
[TOC]
Nous Research AI Discord 总结
-
创新摘要技术:关于高效摘要策略的讨论包括使用较小的分块和大量的重叠,并借助 3090 和 2080ti NVIDIA GPUs 快速处理约 100k tokens;另一个话题涵盖了将高级模型的 AI prompts 适配到较小模型(如 7B),其中 OpenChat 表现出了可观的性能。
-
ArXiv 见解与 AI 奇癖:一篇讨论计算机科学进展的 arXiv 论文 引起了关注;同时,有人轻松地指出对话式 AI 在被指派任务时会主动发起讨论,强调了当前聊天机器人行为中的一个奇特之处。
-
Hermes Mixtral 的可访问性:Hermes 2 Mixtral 已在 Huggingface 的 HuggingChat 平台上可用;此外还讨论了使用 Axolotl 微调 Mixtral 时遇到的挑战,以及在 Huggingface 上发现的 Eric Hartford 的成功配置,提供了深入的探讨。
-
多样化的 LLM 应用对话:用户交流了关于字节级分词 (byte-level tokenization) 的知识,并探索了在带有标题的 COCO 图像字节 上训练模型以研究多模态能力。此外,还有关于提高推理速度的实用技巧,例如使用包括 vllm 和 llama.cpp 在内的优化库,以及使用 Lilac 等工具进行数据集管理。
-
LLM 进展与关注点:呼吁数据囤积的透明度以防止重复劳动,并保证 Hermes 2 - Mixtral 数据集将开源。此外,对比了 dpo 和 sft 方法对创造力的影响,M1 MacBook Pro 用户讨论了运行量化 LLMs,考虑了如 laserxtral 等模型。
Nous Research AI 频道总结
▷ #ctx-length-research (1 条消息):
gabriel_syme: 哇,这个看起来很棒 https://fxtwitter.com/_akhaliq/status/1747515567492174185
▷ #off-topic (78 messages🔥🔥):
-
高效摘要的分块策略:
@fullstack6209描述了他们使用较小分块大小(chunk size)和较大重叠(overlap)进行摘要的方法,重点在于优化 LLM prompt 以处理最重要的信息。他们将此方法应用于处理大型教科书,并提到使用 3090 和 2080ti NVIDIA GPUs 可以快速处理约 100k tokens。 -
高性价比 AI 解决方案:
@fullstack6209讨论了将 AI prompt 从高级模型适配到更小、更高性价比模型(如 7B)的挑战。他们提到 OpenChat 在其测试中的表现显著优于其他模型。 -
探讨 Nous Hermes Vision Alpha 的技术挑战:
@manojbh就 Nous Hermes Vision Alpha 的 unicode 输出问题寻求帮助,并与其他用户(包括@teknium)一起进行了故障排除,讨论了硬件规格和模型版本。 -
模型中字节级 Tokenization 的探索:
@carsonpoole介绍了 Byte Mistral 的概念,这是 Mistral 的一个版本,使用字节级分词器(byte-level tokenizer)代替 BPE,在处理噪声文本或支持多语言方面可能具有优势。其他用户(如_3sphere)参与了关于字节级 Tokenization 的效率和使用场景的讨论。 -
多模态训练实验:
@carsonpoole分享了他们在 COCO image bytes 及其标题上进行训练的计划,以探索多模态(multimodal)模型的能力。他们认为这可以展示多模态模型的协作效果,特别是结合字节分词器时。
提到的链接:
- The Universal Speed of Language: 39 Bits per Second:无论是快速的日语还是深思熟虑的德语,传达的信息速率是相同的。
- google/byt5-small · Hugging Face
- TheBloke/Nous-Hermes-2-Mixtral-8x7B-DPO-GGUF · Hugging Face
- Lorn - Acid Rain (Official Music Video):2015 UK MVA “最佳舞蹈音乐录影带”得主,2015 米兰电影节展映,2016 SXSW 官方入选。艺术家:LORN,曲名:Acid Rain,厂牌:Wednesday Sound…
▷ #interesting-links (2 messages):
- 讨论最新的 ArXiv 论文:用户
@metaldragon01分享了一篇由 Jiaheng Liu、Zhiqi Bai 等多人组成的团队撰写的 arXiv 论文,重点关注计算机科学领域的最新进展。 - 聊天模型引发的趣闻:
@gabriel_syme幽默地评论了对话式 AI 的本质,称它们在被赋予任务时往往倾向于开始讨论,强调了当前聊天机器人行为中的一个怪癖。
提到的链接:
E^2-LLM: Efficient and Extreme Length Extension of Large Language Models:通常,训练具有长上下文尺寸的 LLM 在计算上非常昂贵,需要大量的训练时间和 GPU 资源。现有的长上下文扩展方法通常需要额外的训练…
▷ #general (224 messages🔥🔥):
- Hermes 2 Mixtral 现已上线 HuggingChat:
@teknium分享了 Hermes 2 Mixtral 现已在 Huggingface 的 HuggingChat 上可用的消息,用户可以在该平台上与此模型进行对话。 - Mixtral 微调问题与解决方案:用户如
@qnguyen3报告了使用 Axolotl 微调 Mixtral 时遇到的困难,而.beowulfbr提到了 Eric Hartford 在 Huggingface 上发布的一个成功配置。据指出,FFT 会导致问题,Llama-Factory 被认为是另一种替代方案。 - Hermes Mixtral 的语言性能:
@light4bear和@0xsingletonly提供了 Hermes Mixtral 在非英语语言中的性能反馈,指出其在中文和繁体中文中的效果各异。 - 推理速度与技术讨论:用户如
@lightvector_讨论了使用 Mixtral-8x7b 模型时推理速度缓慢的问题,而@intervitens和@giftedgummybee建议使用 vllm 和 llama.cpp 等优化库以获得更快的性能。此外,还提到了在 llamacpp 中使用 GGUF Quantization 的可能性。 - 数据集管理工具咨询:
@nonameusr询问了有关管理数据集的工具,并成功安装并计划使用 Lilac,这是一个用于编辑和查看 LLM 数据集的工具。
提到的链接:
- 来自 Argilla (@argilla_io) 的推文:🌸 Synthetic Haiku DPO 🌸 🙌 一个由 @vanstriendaniel 使用开源模型生成的 DPO 数据集 ⚗️ 使用 distilabel 和 @Teknium1 的 OpenHermes 构建 https://huggingface.co/datasets/davanstr…
- HuggingChat
- Parameter-Efficient Sparsity Crafting from Dense to Mixture-of-Experts for Instruction Tuning on General Tasks:Large Language Models (LLMs) 在通用自然语言处理任务中表现出了卓越的能力。Instruction Tuning 是一种成功的范式,增强了 LLM 的能力…
- EAdam Optimizer: How $ε$ Impact Adam:深度学习中提出了许多自适应优化方法,其中 Adam 被视为默认算法并广泛应用于许多深度学习框架中。最近,出现了许多变体…
- configs/dolphin-mixtral-8x7b.yml · cognitivecomputations/dolphin-2.5-mixtral-8x7b at main
- DPO Trainer
- 来自 clem 🤗 (@ClementDelangue) 的推文:这是我在 @huggingface 上的第一篇文章!https://huggingface.co/posts/clem/533874509800797
- 来自 Victor M (@victormustar) 的推文:🚨 Hugging Face 即将迎来重大更新… 敬请期待 👀
- Perfecting Merge-kit MoE’s
- 来自 Nous Research (@NousResearch) 的推文:基于 Mixtral 的 Nous-Hermes 2 现已在 @huggingface 的 HuggingChat 上开放对话!立即体验:https://huggingface.co/chat/?model=NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO 感谢…
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO-GGUF at main
- Lilac - 更好的数据,更好的 AI:Lilac 使数据和 AI 从业者能够通过改进数据来改进他们的产品。
- supertrainer2000/supertrainer2k/optim/adalite.py at master · euclaise/supertrainer2000:通过在 GitHub 上创建账号来为 euclaise/supertrainer2000 的开发做出贡献。
- Capybara Let Him Cook GIF - 水豚让他发挥 - 发现并分享 GIF:点击查看 GIF
- 使用 llama.cpp 在 CPU 上微调 LoRA:将 LoRA 微调视为完整模型的补丁。LoRA 训练对基础模型(例如 Stheno-L2-13B)的权重进行调整,并单独保存(例如 Stheno-L2-13B-my-awesome…)
- 无法通过 pip 安装 · Issue #777 · NVIDIA/TensorRT-LLM:当使用以下代码通过 pip 安装时(使用 Windows,不使用 Docker):pip install tensorrt_llm –extra-index-url https://pypi.nvidia.com –extra-index-url https://download.pytorch.org/…
▷ #ask-about-llms (33 条消息🔥):
-
开源数据的优势:
@bramvanroy对公司囤积数据的行为表示担忧,并呼吁提高透明度以防止重复劳动。@teknium保证用于 Hermes 2 - Mixtral 的数据集将开源,尽管过滤逻辑可能不会共享。 -
DPO vs. SFT - 创造力的分水岭?:
@mr.userbox020询问 DPO 和 SFT 之间的区别。@teknium解释说 DPO 经过了 RLHF(基于人类反馈的强化学习),这可能会削弱创造力,建议两者都尝试,看看哪个效果最好。 -
创建有机的对话数据集:
@protofeather询问如何从论坛或私有代码库创建高效的有机数据集。同时,@taumoeba正在寻找为 LLM 添加新语言的资源,而@manveerxyz提到 Cohere 的 Aya 项目是一个潜在资源。 -
M1 MacBook 上的量化模型困境:
@0xsingletonly寻求在 16GB M1 MacBook Pro 上运行量化版 LLM 的建议,@n8programs建议使用 q3 量化的 2x7b 或 4x7b MoE 模型可能比较合适。他们进一步讨论了一个特定模型,最终建议将 laserxtral 作为一个可行的选择。 -
把脉 LLM 现状:
@valiant询问 LLM 的现状,@n8programs诙谐地回答“挺好”,呼应了此类讨论中常见的简短幽默。
提到的链接:
- Introducing Aya: An Open Science Initiative to Accelerate Multilingual AI Progress:TL;DR:Aya 是一个开放科学项目,旨在构建最先进的多语言生成式语言模型;它汇集了来自世界各地人们的集体智慧和贡献……
- TheBloke/Mixtral-Fusion-4x7B-Instruct-v0.1-GGUF · Hugging Face
- Agarra La Tele Weon Agarra La Tv Weon GIF - Agarra La Tele Weon Agarra La Tv Weon Terremoto Roblox - Discover & Share GIFs:点击查看 GIF
HuggingFace Discord Discord 总结
-
AI 推动游戏开发:
@ThomasSimonini的 Making Games with AI 介绍了在 Unity 中创建 Robot AI NPC。这种实用的游戏开发方法采用了 Hugging Face 的技术,开发者可以在这里进行探索。 -
Gradio 新版本助力基于浏览器的 ML:Gradio 4.14 增强了开发者在浏览器内构建机器学习界面的能力,Gradio-Lite 率先实现了这一更新。在 playground 中体验 Gradio 演示。
-
Gradio 从初创到被收购的传奇:
@abidlabs记录了 Gradio 从创立到被 Hugging Face 收购的历程,提供了对初创公司发展轨迹的见解。这个富有启发性的故事可以在这里阅读。 -
Hugging Face 的 Posts 功能增加社区协作:Hugging Face 推出的 Posts 功能为 ML 专业人士提供了参与和协作的新途径。感兴趣的成员可以点击这里加入。
-
ONNX Runtime 加速 SD Turbo 模型:使用 ONNX Runtime 显著提高了 SD Turbo 和 SDXL Turbo 等文本转图像模型的推理速度。在这里了解更多进展。
-
安全警报:谨慎使用 Pickle:
@cappuch__强调了与 Pickle 文件相关的安全风险,提醒注意潜在的代码漏洞。 -
对话式 AI 优化:对于对话式 AI,建议微调较小的模型,而不是使用像 7B Llama 这样的大型模型,强调了后者在基于对话的任务中效率较低。
-
征集合作研究:
@dsiegel寻求在涉及双目摄像头系统和适用于 Raspberry Pi 等设备的轻量级算法项目上进行合作,表示需要社区在深度图和点云创建方面的支持。 -
量化辩论:针对 LLM 量化展开了热烈讨论,重点关注了从 FP32 转向 FP16 和 4bit 时,模型大小、质量和推理性能之间的权衡。
-
学习讨论:
@gag123询问了模型准确率指标,引发了关于在 A100 GPU 上测试 LLaMA 等模型的研究论文和方法的讨论。对话围绕大学中 HPC 资源的获取和使用展开,显示出对 NLP 和模拟工作基础设施的兴趣。 -
商业 AI 中的深度强化学习 (Deep Reinforcement Learning):
@scorpio123.质疑了 Deep RL 在商业 AI 环境中的应用,反映了行业向实用 AI 实施策略转变的趋势。 -
Nous Research 的推文与 DeepSeekMoE:
@osanseviero关注了 Nous Research 的一条推文,同时在 arXiv.org 上发布的论文 “DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models” 为社区提供了关于 MoE 模型的新视角。 -
项目展示与协作参与:
lunarflu和osanseviero深入探讨了将句子相似度 Demo 转换为语义搜索嵌入语料库的话题,并在 HuggingFace 上发起了建议帖。sebastian3079展示了一个 YouTube 评论情感分析器,frequesny发布了一个基于 Gradio 的危险 AI 模型,该模型在有毒数据集上训练,现在可以在这里进行交互。 -
法律与 AI,同态加密 (Homomorphic Encryption) 讨论:
@chad_in_the_house考虑做一个关于法律和 LLM 使用的演示,同时提议并收到了关于在 AI 中讨论同态加密潜力的反馈。 -
Stable Diffusion 微调焦点:对微调 Stable Diffusion 2.1 的兴趣促使了对 SimpleTuner 的推荐,并积极参与解决 Stable Diffusion 2.x 的微调问题,据称这些问题已在 master 分支中解决。
-
自动化游戏 AI 与故障排除:讨论了 AI 在游戏机器人自动化中的应用,并希望实现全屏交互,指向了一篇关于在游戏中使用 PyTorch 和 EfficientNet 的相关博客文章(见此处)。此外,在 AWS 上部署 Flask 应用以及
.pth文件大小的问题也浮出水面。 -
NLP 建模查询与 Mistral 错误:有人表达了开发自定义问答 (Question Answering) 模型的兴趣,并寻求资源和指导。在 MacOS 上训练 Mistral 时出现的总线错误 (bus error) 引发了关于 Hugging Face 论坛中与非 CUDA 兼容训练相关帖子的讨论。对话还包括关于微调嵌入 (embeddings) 的建议,以及下载 Transformer 模型文件的技巧,重点强调了使用 safetensors 以提高效率。
-
围绕 AI 驱动自动化的计算机视觉 (Computer Vision) 交互:讨论围绕创建 AI 游戏机器人、集成 AI 模型以及寻求最佳实践展开。一位用户分享了对使用 pyautogui 模拟用户输入的兴趣,另一位用户则在 AWS 上部署大型模型时遇到困难,揭示了将 AI 与计算机视觉集成的实际挑战。
HuggingFace Discord 频道总结
▷ #announcements (4 条消息):
-
AI 进入游戏开发领域:
@ThomasSimonini发布了《使用 AI 制作游戏》的第一章,展示了用户如何使用 Hugging Face 和 Unity 构建一个能够遵循文本指令的机器人 AI NPC。游戏玩家和开发者可以从这里开始创建自己的 AI NPC。 -
Gradio 发布最新版本:Gradio 4.14 版本发布,开发者可以通过此次更新使用 Gradio-Lite 构建浏览器内应用程序,进一步简化了机器学习界面的创建。点击这里访问 Gradio playground 查看演示。
-
从创业到被收购的历程:
@abidlabs分享了 Gradio 鼓舞人心的故事——从最初的创意到成为 Hugging Face 的一部分,重点介绍了关于创业风险和收购的关键经验。点击这里阅读完整的励志旅程和经验教训。 -
Hugging Face 的新社交平台:Hugging Face 为选定成员推出了新的 Posts 功能,提供了一个分享、推广和协作 ML 话题的空间。有兴趣发布内容的用户可以在这里申请加入。
-
实现加速的 ML 模型推理:利用 ONNX Runtime 加速了文本转图像模型 SD Turbo 和 SDXL Turbo 的推理,使生成式模型应用的运行速度大幅提升。点击这里探索这些加速推理的进展和优势。
提到的链接:
- 来自 Thomas Simonini (@ThomasSimonini) 的推文:《使用 AI 制作游戏》课程第一章已发布 🥳 你将使用 Hugging Face 和 Unity 构建一个机器人 AI NPC 🤖 它能理解并执行文本指令。只需输入你的文本,然后…
- Gradio Playground:体验 Gradio 演示
- social-post-explorers (Social Post Explorers)
- Hugging Face – 构建未来的 AI 社区。
- 来自 abhishek (@abhi1thakur) 的推文:很高兴宣布全新的开源 Hugging Face Competitions 平台 🚀 现在,你可以为你的朋友、同事或全世界免费*创建一个机器学习竞赛,并在 Hugging Face 上托管…
- 📝 为新的受限输入编写文档,由 coyotte508 提交 · Pull Request #1190 · huggingface/hub-docs:关联的 PR:huggingface/moon-landing#8662
- 来自 Abubakar Abid (@abidlabs) 的推文:拥抱 Hugging Face:我们初创公司被收购的内幕故事。2021 年底,我们分布在全球各地的五位工程师团队签署了关闭初创公司 Gradio 的文件。对于许多…
- 使用 ONNX Runtime 和 Olive 加速 SD Turbo 和 SDXL Turbo 推理
- 设置你自己的 Hugging Face 排行榜指南:以 Vectara 的幻觉排行榜为例的全流程示例
- 使用 Unsloth 和 🤗 TRL 让 LLM 微调速度提升 2 倍
- 来自 Daniel van Strien (@vanstriendaniel) 的推文:📚 来自 @IRLab_UDC 的 MetaHate 已在 @huggingface 上线。它为理解在线仇恨言论提供了一个庞大的数据集:• 🗨️ 社交媒体帖子提供真实世界的洞察 • 🏷️ 经过精心标注以确保准确…
▷ #general (141 条消息🔥🔥):
- Pickle 文件可能隐藏风险:
@cappuch__警告了 pickled 文件可能潜藏恶意代码的风险,.ehsan_lol使用自定义表情对此表示感谢。 - 对话模型中微调胜过规模:
@cappuch__建议不要在对话任务中使用像 7B Llama 这样的大型模型,认为微调 Transformer (TL) 是更明智的选择,因为大型模型的对话能力可能并不总是那么高效。 - 深度图与点云的协作努力:
@dsiegel表示有兴趣在涉及 stereo camera systems、OpenCV 和 Open3D 的项目中寻求协作帮助,以创建深度图和点云,并强调系统需要足够轻量,以便在 Raspberry Pi 或类似设备上运行。 - 销售专区指引:
@adarshgourabmahalik询问是否可以在频道中出售项目,@lunarflu将其引导至专门用于销售的频道 (<#898618631938789416>),以确保遵守社区准则。 - 量化讨论:
@mastermindfill、@meatfucker和@vipitis就 LLM (large language models) 的性能和规模进行了深入交流,重点讨论了从 FP32 到 FP16 甚至 4bit 的 Quantization 对模型质量和推理性能的影响。@meatfucker建议使用 Quantization 以在 GPU 上获得更好的性能,并推荐了 Hugging Face 上@TheBloke的仓库,该仓库收录了各种模型的量化版本。
相关链接:
- Vision Transformer: What It Is & How It Works [2023 Guide]: Vision Transformer (ViT) 是一种处理视觉任务的类 Transformer 模型。了解其工作原理并查看示例。
- TheBloke (Tom Jobbins)
▷ #today-im-learning (11 条消息🔥):
- 寻求准确率指标:
@gag123询问了某个模型的准确率指标,但未指明是哪个模型。@frequesny分享了一篇 研究论文 作为回应,但未讨论其内容或与问题的相关性。 - LLaMA 讨论与测试:
@frequesny提到了 旧模型的出色结果,并指出了对结果可复现性的担忧,参考了 LLaMA 模型的训练过程。他们对新模型的结果表示怀疑,并计划使用 A100 GPU 测试该方法。 - 大学高性能计算:针对
@jiha对获取 A100 权限的怀疑,@frequesny提到了他们在 MIPT 的经历,以及一些学生(尤其是 NLP 和模拟领域的学生)可以获得高性能计算资源的情况。 - 分享 HPC 经验:
@vipitis分享了他们学校拥有 DGX100 系统和 1080tis 的情况,但抱怨使用 HPC 资源非常困难。 - Deep RL 在 AI 商业应用中的相关性:
@scorpio123.寻求关于 Deep RL 课程与其 AI 商业应用工作的相关性建议,他拥有深厚的 DL 背景,并使用 OpenAI assistant、Microsoft Autogen 和 Hugging Face 模型等工具。
▷ #cool-finds (2 条消息):
- Nous Research 的推文引起 osanseviero 的兴趣:
@osanseviero分享了来自 Nous Research 的一个酷炫发现,并附上了他们的 Twitter 帖子 链接。 - DeepSeekMoE 论文发布:
@jshuadvd发布了一篇题为《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》的最新论文链接,全文可在 arXiv.org 阅读。
▷ #i-made-this (14 条消息🔥):
- 参与语言学习:
lunarflu与另一位用户就语言学习进行了对话,但未提供具体的语言或细节。 - 从 Embeddings 到句子相似度:
osanseviero建议将一个 Embeddings 演示转换为更用户友好的句子相似度(Sentence Similarity)功能,并随后详细阐述了通过对句子语料库进行 Embedding 以实现语义搜索(Semantic Search)的想法。在 HuggingFace 上已发起讨论以跟踪此建议。 - 从紧张到受启发:用户
tonic_1表达了自己的紧张,但也对可能实现osanseviero提出的建议感到兴奋。 - AI 消息复刻项目分享:用户
vashi2396复刻了一个类似于 OpenAI 主题演讲中演示的 AI Messaging 功能。 - YouTube 情感分析器项目:
sebastian3079分享了他们的第一个 AI 项目——一个针对 YouTube 评论的情感分析器,并讨论了在模型复杂度和数据集相关性方面学到的教训。该项目已发布在 GitHub 上。 - Toxic Llama 环境担忧:
frequesny在一个有毒(toxic)数据集上训练了一个现有的 LLM,并在 Gradio 上限时发布,邀请用户分享他们对这个潜在危险 AI 模型的体验。你可以在这里尝试。
提到的链接:
- Fast AI Image Upscaler 4x - a Hugging Face Space by FumesAI
- Tonic/e5 · 展示句子相似度或其他下游任务
- GitHub - sebastian46/YouTube-Sentiment-Analysis-2:通过在 GitHub 上创建账户来为 sebastian46/YouTube-Sentiment-Analysis-2 的开发做出贡献。
▷ #reading-group (6 条消息):
-
保持冷静,继续学习:
@lunarflu鼓励从经验中学习,并给予支持性的提醒:犯错是过程的一部分。 -
法律与 LLM 作为未来的演讲主题:
@chad_in_the_house正在考虑做一个关于法律和语言模型(LLM)的演讲,强调该领域的当前挑战是下一次会议的一个引人注目的主题。 -
对同态加密的犹豫:
@chad_in_the_house在讨论是否演示应用于 AI 的同态加密(Homomorphic Encryption),担心这可能过于技术化,对小组来说趣味性较低。 -
可能深入探讨加密与 AI:针对同态加密话题,
@lunarflu建议这可能是一个适合在安全类别下进行更集中讨论的主题。 -
从聊天到博客——复杂话题的路径:继
@lunarflu的建议后,@chad_in_the_house表示愿意撰写一篇关于 AI 相关同态加密的博客文章。 -
认识到法律事务在 AI 中的相关性:
@gduteaud支持@chad_in_the_house关于讨论法律和 LLM 的提议,并提到了与近期事件(如 NYT 诉讼案)的相关性。
▷ #diffusion-discussions (6 messages):
- SD 2.1 微调资源:用户
@sayakpaul向一位寻找 SD 2.1 微调方法的伙伴推荐了 SimpleTuner,这是一个针对 Stable Diffusion 2.1 和 SDXL 的通用微调工具包。该工具包已在 GitHub 上发布,并附有详细说明和资源。 - SD 2.x 的修复工作正在进行中:
@pseudoterminalx确认了 SD 2.x 微调存在的一个问题,并提到他们正在积极解决。 - SD 2.x 微调已就绪:用户
@pseudoterminalx确认 SD 2.x 现在可以在 master 分支进行微调,这意味着之前提到的问题已得到解决。 - 替代微调模型建议:
@pseudoterminalx链接到了 pseudo-flex-base 的 HuggingFace 模型卡片,该模型提供了一个基于 stable-diffusion-2-1 微调的摄影模型,支持不同的长宽比 (HuggingFace Model)。 - 关于训练脚本的澄清:
@sayakpaul澄清说他们正在寻找针对 SD 2.1 的特定训练脚本,而不是模型推荐。
提到的链接:
- GitHub - bghira/SimpleTuner: A general fine-tuning kit geared toward Stable Diffusion 2.1 and SDXL.:一个针对 Stable Diffusion 2.1 和 SDXL 的通用微调工具包。
- ptx0/pseudo-flex-base · Hugging Face
▷ #computer-vision (4 messages):
-
AI 驱动的游戏机器人引起关注:
@banaanbakje对使用 AI 自动化工作流表现出兴趣,并分享了一个基于 PyTorch 和 EfficientNet 的 AI 游戏机器人链接,询问关于包含鼠标点击的全屏自动化解决方案。博客文章见 How to Build an AI-Powered Game Bot with PyTorch and EfficientNet。 -
用于输入模拟的 Python 库:针对
@banaanbakje的提问,@cropinky推荐了 pyautogui 库,用于在 Python 中编程实现模拟鼠标和键盘操作。 -
寻求 AI 模型集成建议:
@banaanbakje继续讨论,询问关于模型训练的最佳实践以及使用 EfficientNet 进行全屏训练的有效性。 -
AWS 上的 Flask 应用部署故障排除:
@smartguy_41719寻求关于 AWS 部署错误的帮助,该错误提示归档文件大小超过了 512MB 的限制,并正在寻找部署.pth文件的方法。
提到的链接:
Akshay’s Personal Website:我是一名机器学习爱好者。查看我的项目和博客。
▷ #NLP (5 条消息):
-
机器学习爱好者寻求指导:
__.ivan.__渴望学习并开发一个与 API 和示例代码相关的自定义 Question Answering 模型,并正在寻找指南、书籍或任何有助于开启这段旅程的资源。他们表示更倾向于创建和训练自己的模型,而不是依赖现成的解决方案。 -
Mistral 在 Mac 上运行崩溃:
lovebrainfuck在尝试于一台拥有大内存但没有 GPU 的 Mac 上训练mistralai/Mistral-7B-Instruct-v0.1时遇到了 zsh: bus error。他们正在寻求对此问题的见解,并参考了 HuggingFace 论坛上关于在没有 CUDA 兼容性的 Mac 电脑上训练模型的讨论。 -
调优以获得更好的 Embeddings:
selea计划针对句子/文档 Embeddings 微调 MPT7b,并考虑在 Tokenizer 中添加一个<CLS>Token,灵感来自一篇特定的研究论文。他们寻求关于在不改变其他 Token 向量的情况下训练单个 Token 向量的建议,并希望避免使用专用 LLM 进行 Embeddings 的建议。 -
选择性下载的烦恼:
robert1正寻求仅下载 Transformer 语言模型的核心文件,如果可选的话,他们更倾向于选择 safetensors 文件而非 .bin 文件。他们需要指导来实现这种更具选择性的下载方式。 -
SafeTensors 前来救场:
vipitis建议robert1在实现.from_pretrained时使用use_safetensors=True或load_safe=True等选项,以专注于 safetensors 文件,并引导他们查阅 Transformers 库文档以获取进一步说明。链接的 GitHub 文档可能包含解决robert1下载难题的答案。
提到的链接:
- 在 Mac M3 Max 上训练.. 极快但是:大家好,我收到了全新的 M3 max,但遗憾地发现 BitsAndBytes 不受支持,所以我不得不调整我的训练代码以在我的数据集上微调 Mistral。=:> 更改了设备…
- transformers/src/transformers/modeling_utils.py (位于 c48787f) · huggingface/transformers:🤗 Transformers:适用于 Pytorch、TensorFlow 和 JAX 的最先进机器学习库。 - huggingface/transformers
▷ #diffusion-discussions (6 条消息):
- 微调之交:用户
@sayakpaul提到向朋友推荐了 GitHub 上的 SimpleTuner 用于微调 Stable Diffusion 2.1,并询问了更多关于 SD 2.1 的具体参考点。 - Stable Diffusion 故障排除:
@pseudoterminalx透露 Stable Diffusion 2.x 曾出现故障,但提到正在积极修复。 - Master 分支的魔力:不久后,
@pseudoterminalx更新称 Stable Diffusion 2.x 的问题已在 master branch 中得到解决。 - 训练脚本的困扰:
@sayakpaul澄清说,寻求更具体参考的要求是针对训练脚本的,而不是模型本身。
提到的链接:
- GitHub - bghira/SimpleTuner: 针对 Stable Diffusion 2.1 和 SDXL 的通用微调工具包。:一个针对 Stable Diffusion 2.1 和 SDXL 的通用微调工具包。 - GitHub - bghira/SimpleTuner
- ptx0/pseudo-flex-base · Hugging Face
OpenAI Discord 总结
-
GPT-4 中的格式缺陷:技术用户正在应对 GPT-4 的格式问题,例如意外的换行和响应延迟,这些问题干扰了工程工作流。平台上正在集体努力排查这些问题。
-
AI 的立法视角:众议员提出的 《反人工智能欺诈法案》 (No Artificial Intelligence Fraud Act) 标志着一种积极的立法方式,旨在保护个人权利免受 AI 生成的冒充侵害,详见 Salazar 提出《反 AI 欺诈法案》。
-
ChatGPT 服务的挑战:用户报告 ChatGPT 服务质量下降,包括网络问题和消息限制,引发了对服务可靠性的担忧,并对 OpenAI 的维护和改进计划提出了质疑。
-
Prompt Engineering 热潮:关于构建“提示词大战” (prompt battles) 游戏的讨论正在进行中,建议利用 Custom GPTs 设置比赛,根据用户定义的标准生成输出,反映了社区对创新 AI 应用的兴趣。
-
高效的 AI 数据处理与创意:讨论串集中在如何高效管理用于训练 AI 的海量数据,强调了 XML 标签等结构化输入,以及通过应用结构化约束来引导 AI 的创意输出,从而创作莎士比亚风格的内容。
OpenAI 频道总结
▷ #ai-discussions (71 条消息🔥🔥):
-
GPT-4 格式困扰:
@masmoriya和@markon101等用户抱怨 GPT-4 的格式问题,如跳行和响应间长时间停顿,打断了他们的工作流。该平台的不稳定性已引发了一个专门用于故障排除的讨论帖。 -
针对 AI 生成伪造内容的立法:
@clockrelativity2003强调了众议员 María Elvira Salazar 和 Madeleine Dean 提出的 《反人工智能欺诈法案》 (No Artificial Intelligence Fraud Act),指出其在保护个人肖像权和声音免受 AI 未经授权复制方面的潜力。 -
用户报告聊天机器人故障:包括
@derella98和@covikodsoli在内的多位用户表达了对 ChatGPT 错误的沮丧,如网络问题和消息限制。人们越来越担心这些 AI 工具提供的服务存在 质量退化。 -
AI 照片应用咨询:
@alex31195询问了可以生成 AI 照片的免费应用,引发了与@chotes关于“AI 爸爸”可用性的幽默交流。 -
Microsoft Copilot 对阵 OpenAI:一场辩论正在进行,
@foreignduck担心 Microsoft 的 Copilot 可能会掩盖 OpenAI 的努力。包括@hhf0363和@markon101在内的用户讨论了 Microsoft 集成与 ChatGPT 功能之间的权衡,特别是对于某些人至关重要的文档上传能力。
提到的链接:
Salazar 提出《反 AI 欺诈法案》:华盛顿特区 – 今天,众议员 María Elvira Salazar (R-FL) 和 Madeleine Dean (D-PA) 提出了《反人工智能虚假副本和未经授权复制法案》(No AI FRAUD Act)。该法案…
▷ #gpt-4-discussions (76 条消息🔥🔥):
- 商标问题:用户
@csgboss在分享其 GPT 时遇到了问题,原因是使用了受限名称 “Midjourney”。将名称拆分为 “Mid Journey” 解决了该问题,而@7877建议在描述中使用品牌名称。 - API 访问查询与疑虑:
@sairaghavendra询问了 Custom GPTs 的 API 访问权限,并被@elektronisade告知它们不允许使用 API。 - 搜索功能建议与需求:
@q16.kr表示需要一个类似于 iOS 的搜索选项,以便检索与 ChatGPT 的旧对话。@solbus澄清说,该功能在 App 中可用,但在网页版中不可用。 - 不一致性与停机:
@_odaenathus和其他几位用户报告了他们的 GPT 出现的问题,如消息失败或行为不一致,而@darthgustav.提到除了 OpenAI 对 System Prompt 所做的更改外,没有遇到其他问题。 - 针对请求限制问题的社区帮助:
@.australiaball尽管早上没有使用 ChatGPT,但仍收到了请求过多的警告。@darthgustav.和@7877给出了可能的解释,并建议确认账户安全并监控请求计数,而其他人则报告说无需干预即可恢复正常。
▷ #prompt-engineering (23 messages🔥):
- “Prompt Battles” 游戏招募合作者:用户
@my5042表达了创建一款 “prompt battles” 游戏的兴趣,玩家可以在其中相互竞争,并正在为该项目寻求合作者。 - 提出 PromptBot Battle 框架:
@darthgustav.建议了构建 Bot 测试框架的步骤,包括设置 Custom GPTs 并在竞赛中让它们对决,以生成用户定义的输出。 - 发布符合 DMCA 标准的 GPT Battles:
@darthgustav.提到了一种在不违反 DMCA 法规的情况下,在 Prompt Bot 对战中使用 GPT 的方法。 - AI Assistant 编写剧本:
@sho2858分享了他们在大型数据集上训练 AI Assistant 以生成剧本的努力,@darthgustav.建议优先考虑算法和约束(constraints),而非海量知识。 - 莎士比亚风格 AI 诗歌策略:
@darthgustav.建议为 AI 提供结构(如 iambic pentameter 和剧幕大纲),而不是大量文本,以创作受莎士比亚启发的全新内容,并强调了约束和即兴创作的重要性。
▷ #api-discussions (23 messages🔥):
- Prompt 之战:
@my5042表达了创建名为 “prompt battles” 的多人趣味游戏的兴趣并寻求合作;@darthgustav.和@eskcanta提供了不同的实现方法,分别建议使用 Custom GPTs 和 AI 生成的目标。 - GPT 在 PromptBot ThunderDome 中展现实力:
@darthgustav.提出了一个 Bot 测试框架,涉及主队 Bot 与自定义 Bot 之间的竞争,旨在满足用户定义的标准。 - 记录员挑战 (The Documentalist Challenge):用户
@sho2858分享了他们在整理 30 万字超长文本以训练 Assistant 方面的进展,引发了关于数据组织技术的讨论,@darthgustav.推荐使用稀疏 XML 标记和纯文本 Unicode 编码。 - 具有莎士比亚风格的 AI 诗歌:
@darthgustav.强调了为 AI 提供 iambic pentameter 格式、模板和特定约束的有效性,以创作莎士比亚风格的作品,而不是简单地喂给它莎士比亚剧本。 - AI 设计叙事张力:在继续讨论 AI 生成内容时,
@darthgustav.提到将 Prompt 结构化为剧幕,以引导 AI 构建叙事张力并生成改编内容,强调在约束下进行即兴创作。
LM Studio Discord 总结
-
了解大型模型的 VRAM 需求:工程师们讨论了运行像 Mistral(由 32 layers 组成)这样的大型模型所需的 VRAM 容量。一个建议是将 CPU layers 设置为
-1,以便在 24GB VRAM GPU 上运行此类模型。 -
通过 Fine-Tuning 和 Merging 提升创意 AI 能力:对话集中在增强 AI 能力上,从耗资巨大的 Salesforce 模型 Fine-Tuning(估计耗资数百万美元),到对使用 mergekit 等工具进行 DIY 模型 Merging 的热情,以及 llama.cpp 团队 推出的新 GGUF 文件格式。
-
AI 模型应用障碍:社区分享了他们的挑战和成功经验,包括难以找到在非英语语言中表现良好的多语言模型、在 LM Studio 中集成 CrewAI 和 Autogen 等模型,以及寻找有助于创意写作和编程辅助的模型。
-
反馈收集与 Bug 修复:提醒用户将反馈重定向到指定频道,强调了频道特定性对于社区内支持和 Bug 报告的重要性。
-
深入探讨 GPU 规格和 NVLink 兼容性:技术讨论涉及 Nvidia 3090 系列 GPU 不存在 Low Hash Rate (LHR) 限制、3090 与 3090ti 之间 NVLink 的不兼容性,以及运行多 GPU 时需要特殊配置的问题。
LM Studio 频道总结
▷ #💬-general (143 条消息🔥🔥):
-
模型加载 VRAM 与尺寸讨论:@fabguy 和
@typicalai讨论了加载具有不同 VRAM 容量的模型。提到 Mistral 有 32 层,将 CPU 层数设置为-1应该能让模型适配@typicalai的 GPU(拥有 24GB VRAM)。 -
AI 中毒与选举担忧:@flared_vase_16017 分享了一篇关于 AI 中毒 (AI poisoning) 的文章链接,引发了讨论。
@Pi建议,对训练数据保持开放可能有助于对抗开源 AI 模型被转化为“潜伏特工 (sleeper agents)”所带来的威胁。 -
Chatbot 性能问题:
@technot80和@heyitsyorkie评论了 ChatGPT4 的性能和速度问题,特别是在使用 gtpshop 功能时,将速度比作“2400 波特率调制解调器”。 -
LM Studio 与 CrewAI 集成成功:
@meadyfricked和@_anarche_报告称,尽管与 Autogen 存在一些兼容性挑战,但在 LM Studio 中配合不同模型使用 CrewAI 取得了成功,表明 CrewAI 可能更容易使用。 -
GGUF 文件格式说明:在关于模型文件格式的讨论中,
@dagbs澄清了 GGUF 是 llama.cpp 团队引入的一种新格式,现在已成为 LM Studio 使用的标准格式,取代了 GGML。
提到的链接:
- TheBloke/dolphin-2.6-mistral-7B-dpo-laser-GGUF · Hugging Face
- 非官方 LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里你可以找到 LMStudio Discord 中最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源软件…
- 2023 年深度学习最佳 GPU —— 深度分析:在这里,我提供了深度学习/机器学习 GPU 的深入分析,并解释了适合你的使用场景和预算的最佳 GPU。
-
[2024 年 1 月 Ars Technica](https://arstechnica.com/information-technology/2024/01/ai-poisoning-could-turn-open-models-into-destructive-sleeper-agents-says-anthropic/>)
▷ #🤖-models-discussion-chat (35 条消息🔥):
- Salesforce 微调梦想因成本破灭:
@heyitsyorkie回应了@sohms关于微调模型以精通 Salesforce 的咨询,估计这在训练算力上是一项耗资百万美元的“极其庞大”的工程。 - 组合 AI 模型的 DIY 热情:
@222gate鼓励@sohms探索使用 mergekit 合并预训练模型,并提供了一个关于 TIES-Merging 技术的 YouTube 视频链接 (https://www.youtube.com/watch?v=m58Y79y8wFs)。 - 适合创意头脑的模型:
@alastair9776寻求适合创意写作的模型推荐,@222gate推荐了 “neuralhermes 2.5 mistral 7b” 等模型,而@dagbs分享了一个新模型发布的链接。 - 多语言模型的挫败感:
@dermarus正在寻找能够稳定使用非英语回复并集成外部数据库的模型,但由于 LLM 主要使用英语数据集而面临困难,正如@heyitsyorkie所澄清的那样。 - 寻找编程模型的最佳平衡点:
@silverdemon101征求关于辅助编程的最佳模型建议,@dagbs建议寻找一个尺寸比用户 GPU 最大 VRAM 小约 20% 的模型。
提到的链接:
精通模型合并:深入探讨 TIES-Merging 技术:TIES-Merging 是一种合并模型检查点的突破性方法,能够实现无缝多任务处理。这些强大的模型合并技术可以极大地增强…
▷ #🧠-feedback (5 条消息):
- 反馈重定向请求:
@heyitsyorkie要求@fabguy将其反馈移至指定的反馈频道 (<#1111440136287297637>),表明当前的对话并非为了提供支持。 - 对聊天方向的确认:
@mattjpow确认了移动反馈的指示,并提到他一直在这样做,声明他是在提供反馈,而不是寻求支持。 - 空白回复问题的报告:
@ddhmksoi报告遇到了一个导致任何模型都返回空白回复的 Bug,并对近期 Bug 的增加表示沮丧。 - 引导至报告频道:
@dagbs引导@ddhmksoi前往正确的频道 (<#1139405564586229810>) 报告提到的空白回复 Bug。
▷ #🎛-hardware-discussion (8 messages🔥):
- LHR 担忧消除:用户
@nink1表达了对用于挖矿的 Low Hash Rate (LHR) 显卡可能存在性能问题的担忧。@rugg0064安慰说 LHR 限制已被破解并正式禁用,并提到 3090 显卡不受影响。 - 3090 系列与 LHR 混淆:
@pefortin澄清据其所知,Nvidia 3090 不受 LHR 限制的影响,尽管围绕此问题存在一些不确定性。 - 多 GPU 配置技巧:
@.ben.com分享了关于运行多 GPU 的研究,提到了多 GPU 设置中的反向缩放 (anti-scaling) 问题,以及使用特殊配置优化 24G 以下模型性能的相关性。 - 推理 TDP 与 NVLink 咨询:
@.ben.com还询问在 3090 GPU 上进行 LLM 推理时是否会达到最大 TDP,并询问了 3090 与 3090ti 之间的 NVLink 兼容性。 - NVLink 兼容性明确:针对
@.ben.com的提问,@ldeus确认 3090 和 3090ti 无法通过 NVLink 连接,解决了兼容性疑问。
提到的链接:
Yay Kitty GIF - Yay Kitty Cat - Discover & Share GIFs:点击查看 GIF
▷ #autogen (2 messages):
- 对 Autogen Studio UI 2.0 的赞赏:用户
@cluck0matic对新的 Autogen Studio UI 2.0 表示认可,称其 非常棒 (niiiiicee….)。 - 发现 Autogen Studio:
@dagbs表现出惊讶,询问 “他们有 studio??”,表明他们之前并不知道 Autogen Studio 的存在。
Mistral Discord 总结
-
Mistral 模型对比与性能见解:Mistral-medium 模型在 LMSYS Chatbot Arena 排行榜上排名第 4,而 Gemini Pro (dev) 排名第 8。同时,用户报告了 Mistral 7B 在 MacBook Air M2 上的性能问题,以及 exl2 6bit 和 fp16 等量化方法之间的细微性能差异,前者因速度优势更受青睐。
-
Mistral 模型与长文本目标:用户表现出使用 Mistral 模型进行长文本创作(如 SEO 内容)的兴趣,并寻求在特定硬件上高效运行 AI 模型的建议,包括在 6GB GPU 上使用 GGUF 和 4bit 运行 Mistral 7B 的可能性。
-
量化模型格式与 API 诊断:GGUF 文件格式因其在 Mistral-7B 等量化模型中的应用而受到关注。用户将 API 性能与本地模型运行进行了对比,指出了 Mistral API 的准确性问题,并使用
model_dump等工具排查错误。 -
托管与部署讨论:对于希望托管 Mistral 7B 或 8x7B 模型的用户,llama-cpp-python、ollama 或 llama.cpp server 示例等选项提供了不同程度的并行执行支持。
-
探索模型微调与扩展:社区分享了微调 Mistral 模型以提高性能时遇到的挑战,表达了挫败感并寻求有效策略。在合并 LoRA 模型、转换为 GGUF 格式以及解决 tokenizer 问题等任务中存在复杂性,在 llama.cpp GitHub 仓库和 Hugging Face 讨论贴中可以找到有用的建议。
以上总结基于工程师参与的讨论,涉及所提及 AI 模型的技术和实践层面。已包含社区成员提供的其他资源或示例链接供进一步参考。
Mistral 频道总结
▷ #general (51 条消息🔥):
- 热烈欢迎 Mistral 新人:
@mrdomoo加入了 Mistral 社区,表达了乐观态度并赞赏了该项目。 - 寻找 Beta 测试密钥:
@josemavlc询问如何获得使用 Mistral beta 的邀请。 - Mistral 7B 在 MacBook Air M2 上运行缓慢?:
@pierre.lhoste报告了在 MacBook Air M2 上尝试运行 Mistral 7B 时的性能问题,@i_am_dom建议检查 RAM 消耗和后台运行的不必要应用以提升性能。 - 适用于小型基础设施的 GGUF 格式:
@vhariational详细解释了 GGUF 文件格式,该格式被 Mistral-7B 和 Mixtral-8x7B 等量化模型使用,并提供了 Hugging Face 上这些模型的社区分发版 GGUF 格式链接,以及一张 TheBlokeAI 的图片。 - 新的 LLM API 对比网站上线:
@_micah_h分享了一个新网站 ArtificialAnalysis.ai,旨在对比 LLM API 提供商,包括 Mistral 7B Instruct 和 Mixtral 8x7B Instruct 的页面,并邀请用户关注他们的 Twitter 以获取更新。
{kind=link}
提到的链接:
-
[权重开放模型 Mistral AI 大语言模型](https://docs.mistral.ai/models/#chat-template):我们开源了预训练模型和微调模型。这些模型没有针对安全性进行调整,因为我们希望赋予用户根据其使用场景测试和完善审核的能力。对于更安全的模型… - TheBloke/Mistral-7B-Instruct-v0.2-GGUF · Hugging Face
-
[Mistral 7B - 托管分析 ArtificialAnalysis.ai](https://artificialanalysis.ai/models/mistral-7b-instruct):对 Mistral 7B Instruct 在质量、延迟、吞吐量、价格等指标上的分析。 -
[Mixtral 8x7B - 托管分析 ArtificialAnalysis.ai](https://artificialanalysis.ai/models/mixtral-8x7b-instruct):对 Mixtral 8x7B Instruct 在质量、延迟、吞吐量、价格等指标上的分析。
▷ #models (46 条消息🔥):
- Mistral vs. Gemini Pro:
@vhariational提供了 LMSYS Chatbot Arena 排行榜 的链接进行对比,其中 Mistral-medium 排名第 4,Gemini Pro (dev) 排名第 8。@ethux建议同时关注 OpenChat 模型,并提供了包含更多信息的链接。 - 使用 Mistral 生成长文本:
@stefatorus表达了使用 Mistral 生成长文本(特别是 SEO 内容写作)的兴趣,尽管模型通常是针对短回答进行微调的。 - 特定硬件上的模型性能:
@dayzen询问了在特定硬件配置上运行 Mistral 7B GPTQ 或 GGML / GGUF 模型的可行性,随后与@chlorobyte讨论了模型需求和流式传输技术。 - 运行 AI 模型的建议:
@ethux建议@dayzen,Mistral 7B 可以在 6GB GPU 上配合 GGUF 和 4bit 运行,并推荐了一个网站 lmstudio.ai 用于测试 GGUF 模型,同时分享了特定模型的链接,如 EvalPlus 排行榜 和 Hugging Face 上的 MagiCoder。 - 关于 Tokenizer 的技术咨询:
@vivien_tranthien提出了一个关于 Mistral-7B tokenizer 合并列表的技术问题,指出在该模型的 Hugging Face tokenizer.json 中发现的合并列表可能存在冗余。
提到的链接:
- 👾 LM Studio - 发现并运行本地 LLM:查找、下载并实验本地 LLM。
- openchat/openchat-3.5-0106 · Hugging Face
- Mistral LLM:所有版本及硬件要求 – Hardware Corner
- EvalPlus 排行榜
- ise-uiuc/Magicoder-S-DS-6.7B · Hugging Face
- TheBloke/Magicoder-S-DS-6.7B-GGUF · Hugging Face
▷ #deployment (1 条消息):
- 托管 Mistral 模型的选项:
@vhariational建议,既可以按照 Mistral 文档 上的说明托管 7b 或 8x7b 模型 的原始版本,也可以使用量化版本。目前有多种选择,包括 llama-cpp-python、ollama 或原生的 llama.cpp 项目的 server 示例,尽管这些选项尚未针对并行执行需求进行充分测试。
▷ #ref-implem (1 条消息):
- Embeddings 的 Python 客户端示例:
@vhariational分享了一个如何使用 Python 客户端进行 Embeddings 处理的示例,并附带了 GitHub 仓库 链接。该仓库提供的 Python 代码演示了如何在 Mistral AI 平台上进行异步 Embedding 生成。
提到的链接:
client-python/examples/async_embeddings.py at main · mistralai/client-python:Mistral AI 平台的 Python 客户端库。可以通过在 GitHub 上创建账号来为 mistralai/client-python 的开发做出贡献。
▷ #finetuning (28 条消息🔥):
-
对微调性能的挫败感:
@bdambrosio和@mrdragonfox讨论了他们在微调 Mistral 聊天机器人时遇到的困难。@mrdragonfox提到,尽管投入了一个月的努力和费用,他们微调后的模型性能仍然没有超过常规的 Instruct 模型。 -
微调过程中的困惑:
@hydre2155寻求有关使用 10 万行数据微调模型的资源,但在讨论的消息中未提供具体资源。 -
量化的困惑:
@bdambrosio询问了量化方法(如 exl2 6bit)在 Mistral 模型上的性能表现。@mrdragonfox回复称,其性能几乎与 fp16 持平,差别微乎其微,并且为了提升速度更倾向于使用它。 -
LoRA 模型合并与转换的困扰:
@distro1546在合并 LoRA 模型并将其转换为 GGUF 格式以供 ollama 使用时遇到了困难,尽管尝试了涉及llama.cpp的解决方案,问题依然存在。@ethux提供了关于将 LoRA 适配器(adapters)合并到基础模型(base model)的有用建议,并提供了解决相关 Tokenizer 问题的链接,包括 llama.cpp GitHub 仓库 和 Hugging Face 上的讨论。 -
社区呼吁帮助克服微调障碍:
@mrdragonfox表达了社区需要一些改进微调结果的提示,并暗示由于缺乏清晰的指导,目前的方法感觉就像是在“暴力烧钱”。
提到的链接:
- uyiosa/test_mistral_7b · Hugging Face
- GitHub - ggerganov/llama.cpp: Port of Facebook’s LLaMA model in C/C++:Facebook LLaMA 模型的 C/C++ 移植版本。可以通过在 GitHub 上创建账号来为 ggerganov/llama.cpp 的开发做出贡献。
- LoRA
- TheBloke/AquilaChat2-34B-AWQ · FileNotFoundError - the tokenizer.model file could not be found
- Could not find tokenizer.model in llama2 · Issue #3256 · ggerganov/llama.cpp:当我运行此命令时:python convert.py \ llama2-summarizer-id-2/final_merged_checkpoint \ –outtype f16 \ –outfile llama2-summarizer-id-2/final_merged_checkpoint/llama2-summarizer-id-2.gguf.fp…
▷ #la-plateforme (23 条消息🔥):
- 关于 Mistral 与 API 性能的困惑:
@rabdullin对使用 Mistral API 时相比本地运行模型出现的准确率下降表示担忧,指出尽管使用了正确的 prompt 格式和 token,所有通过 API 提供服务的 Mistral 模型在质量上都有显著下降。 - 寻找官方系统分隔符 (System Delimiters):
@vhariational询问了 Mistral 模型的官方系统分隔符。@rabdullin回复称这些并没有文档说明,他之前假设它们受支持可能是错误的,这影响了他之前提到的评分。 - 新用户在 UI 错误中挣扎:
@lakanya27报告了在尝试本地托管的 UI 时遇到的错误,@Valdis建议其熟悉 Next.js 的<Image />组件,@arduilex则建议尝试使用 Docker。 - 排查 Kaggle Notebook 中 MistralClient 的错误:
@jortega_17718报告了在 Kaggle notebook 上尝试使用 MistralClient 时出现的AttributeError,@rabdullin建议对响应对象使用model_dump来诊断问题。
提到的链接:
| [开放权重模型 | Mistral AI 大语言模型](https://docs.mistral.ai/models/#chat-template)):我们开源了预训练模型和微调模型。这些模型没有针对安全性进行调整,因为我们希望赋能用户根据其用例测试和改进审核机制。对于更安全的模型… |
Latent Space Discord 总结
-
Neovim 引入 ChatGPT:分享了一个备受喜爱的 Neovim 插件 ChatGPT.nvim,使工程师能够直接在编辑器中与 LLM 交互。
-
SPADE 在 LLM 领域备受关注:SPADE 论文(Shreya Shankar 关于 SPADE 的论文)成为讨论焦点,该论文专注于在低数据环境下为 LLM 生成自定义断言 (assertions),引起了人们对提高 LLM 可靠性努力的关注。
-
AI 活动重要公告:即将举行的活动包括将于 1 月 26 日举行的 AI in Action Discord 见面会,针对现实世界的 AI 工程。为了与社区互动,感兴趣的各方可以在 AI in Action Weekly Jam 注册,此外还有 LLM Paper Club 亚洲版,以方便亚洲和欧洲中部时间 (CET) 早晨的参与者 (LLM Paper Club (亚洲版!))。
-
拒稿中的幽默:一条关于 AI 论文 “LCM” 被 ICLR 拒绝的幽默且感同身受的推文引发了讨论,为严谨的学术氛围注入了轻松的情绪(来自 Allen (Simian) Luo 的推文)。
Latent Space 频道总结
▷ #ai-general-chat (40 条消息🔥):
- Neovim 用户的 ChatGPT 插件:
@thenoahhein分享了一个在 Neovim 中使用 ChatGPT 编写代码的插件:ChatGPT.nvim,它集成了一个聊天界面,可以直接在编辑器中与 LLM 交互。 - GPT-4 在编程中的语言限制:
@btdubbins和@thenoahhein讨论了在 Golang/HCL 等较冷门语言中使用 GPT-4 的挑战,并指出在 Python 或 JS 等语言中效果更好。 - 关于改进 LLM 断言的 SPADE 论文:
@swyxio重点介绍了一篇关于 SPADE 的论文,这是一个在低数据环境下为 LLM 生成自定义断言的系统 Shreya Shankar 关于 SPADE 的论文。 - 使用 SPADE 进行语义图像合成:
@semantic_zone幽默地评论了缩写冲突,分享了 SPADE(一个用于语义图像合成的工具)的链接,并调侃说 AI 领域的缩写快用完了:用于图像合成的 GitHub SPADE。 - AI in Action 见面会:
@kbal11宣布了即将举行的 AI in Action 见面会,讨论 GenAI 的 UI/UX 模式,并提供了建议的准备材料,讨论由@794337110994845726主持。@nuvic_提供了活动注册链接:AI in Action Weekly Jam 注册。
提到的链接:
- Shreya Shankar (@sh_reya) 的推文:我们都知道 LLM 会犯错。没有断言就无法部署 LLM 流水线,但编写好的断言既繁琐又困难。因此,我们构建了 SPADE,一个分析 Prompt 并自动生成…的系统。
- GPT-4 架构、基础设施、训练数据集、成本、Vision、MoE:揭秘 GPT-4:导致 OpenAI 选择该架构的工程权衡。
- SPADE:为大语言模型流水线合成断言:在自定义、重复的数据流水线中运行大语言模型 (LLM) 具有挑战性,特别是由于其不可预测且可能导致灾难性的失败。考虑到…
- 数百万 Apple、AMD 和 Qualcomm GPU 中的漏洞可能泄露 AI 数据:修复受 LeftoverLocals 漏洞影响的每台设备(包括部分 iPhone、iPad 和 Mac)可能会非常困难。
- Vector DB 对比:Vector DB Comparison 是来自 VectorHub 的免费开源工具,用于对比向量数据库。
- Stable Code 3B:边缘侧编程 — Stability AI:Stable Code 是 Stable Code Alpha 3B 的升级版,专注于代码补全,在效率和多语言支持方面优于前代产品。它兼容标准笔记本电脑,包括…
- GitHub - jackMort/ChatGPT.nvim: ChatGPT Neovim 插件:利用 OpenAI 的 ChatGPT API 轻松生成自然语言
- GitHub - Vaibhavs10/open-tts-tracker:通过在 GitHub 上创建账号为 Vaibhavs10/open-tts-tracker 的开发做出贡献。
- AI in Action Weekly Jam · Luma:每周一次的虚拟聊天,致力于 AI 在真实场景中的实际应用,重点关注来自博客、播客、库等的见解,以弥合理论与…之间的差距。
- GitHub - NVlabs/SPADE:使用 SPADE 进行语义图像合成
- 聊天之外的生成式界面 // Linus Lee // LLMs in Production 会议:// 摘要:Linus 在过去几年中一直致力于构建和实验新型思维工具和创作软件界面,例如…
- 如何将 AI UX 打造为你的护城河:设计超越“仅仅是 LLM 封装层”的优秀 AI 产品:让 AI 更具存在感、更实用、更强大。
▷ #ai-event-announcements (1 messages):
-
AI in Action Weekly Jam 首映:
@swyxio宣布了新的 AI in Action Discord 见面会,将于 1 月 26 日举行,重点关注现实世界的 AI 工程。要参加活动并将其添加到您的日历中,请在 https://lu.ma/el0y5mpi 注册,并加入 Latent Space Discord 的讨论。 -
LLM Paper Club 亚洲版即将推出:由
@206404469263433728主持的 LLM Paper Club Asia 迎合亚洲时区,镜像了 <#1107320650961518663> 见面会的格式,方便亚洲或 CET 早晨的参与者。请在 https://lu.ma/llm-paper-asia 报名,并关注即将公布的日期。
提到的链接:
- AI in Action Weekly Jam · Luma:一个每周一次的虚拟聊天,致力于 AI 在现实场景中的动手应用,重点关注来自博客、播客、库等的见解,以弥合理论与…之间的差距。
- LLM Paper Club (Asia Edition!) · Luma:Latent.Space x EugeneYan.com LLM Paper Club 的亚洲时区友好版!
▷ #llm-paper-club-chat (1 messages):
- LCM 论文遭到拒绝:用户
@swyxio分享了一条推文,幽默地提到他们名为 “LCM” 的论文被 ICLR 拒绝了。@SimianLuo的推文开玩笑说论文被拒,并质疑是否应该继续在学校做研究。点击此处查看推文。
提到的链接:
来自 Allen (Simian) Luo (@SimianLuo) 的推文: 我生命中最好的笑话。我们很高兴地宣布 LCM 被 ICLR 拒绝了🤣🤣 哈哈。问题:我应该继续在学校做研究吗?😁
LlamaIndex Discord Discord 摘要
-
针对表格数据的高级 QA 技术:发布了一系列新的 cookbooks,详细介绍了针对表格数据的高级 QA 技术,包括 few-shot 表格和行选择策略。工程师可以在此处探索 tabular QA 技术栈中的这些方法。
-
提升 LLM 效率的量化路线图:@wenqi_glantz 提供了一份关于量化 @MistralAI 7B 的参考指南,旨在以最小的精度损失换取更好的延迟和功耗表现。这些指南是构建高效 LLM 的关键资源,可在此处获取。
-
Replit 模板加速 RAG 系统部署:LlamaIndex 推出了一款用于快速部署多租户 RAG 系统的 Replit 模板,目前在社区中备受关注。工程师可以从此处访问该模板。
-
Embedding 优于上下文:在关于 Embedding 的讨论中,共识认为虽然更换语言模型(从 Mistral 到 Llama)不会显著影响服务上下文向量,但关键因素在于所使用的 Embedding 模型。更多见解可以在 LlamaIndex Embeddings 文档中找到。
-
针对复杂文档的 PDF Loader 讨论:对于导入保险和福利文档,社区建议使用 nougat PDF loader 或非结构化加载器处理包含大量表格的内容可能会获得最佳效果,这表明了工具与文档复杂度匹配的重要性。
LlamaIndex Discord 频道摘要
▷ #blog (3 messages):
-
通过新 Cookbooks 掌握表格数据:提供了一个用于构建针对表格数据的高级 QA 的新资源,具有 few-shot 表格和行选择技术。查看 LlamaIndex 详尽的 cookbooks 中关于 tabular QA 技术栈的详细信息,链接在此处。
-
LLM 量化指南:对于使用开源 LLM 的开发者,@wenqi_glantz 关于量化 @MistralAI 7B 的参考指南对于在最小精度损失下降低延迟和功耗至关重要。在此处查找构建高效 LLM 的完整指南。
-
RAG 系统的 Replit 模板现正流行:LlamaIndex 推出了一款热门的 Replit 模板,帮助设置多租户 RAG 系统。该模板现已上线并受到欢迎,链接在此处。
▷ #general (30 条消息🔥):
-
对于 Embeddings 来说,上下文并不那么重要:
@wrapdepollo询问将语言模型从 Mistral 更改为 Llama 是否会影响具有服务上下文(service context)的文档向量索引的创建,并注意到上下文似乎没有变化。@Teemu和@7leven澄清说,对于 Embeddings,LLM 的选择并不至关重要,但必须确保在服务上下文中设置了正确的 Embedding 模型。 -
最佳问题-上下文配对数量未明确:
@physicsweak询问了用于微调 bge-large Embeddings 的最佳问题-上下文配对数量,但对话并未得出明确的答案或建议。 -
为保险文档选择合适的 PDF Loader:
@hosermage寻求关于选择 PDF Loader 以处理保险和福利信息的建议。@whitefang_jr建议,由于文档包含表格,使用 nougat PDF Loader 或 unstructured Loader 可能最为合适。 -
寻找 Logprobs:
@lhc1921询问如何在 OpenAILike 模型中将 “logprobs” 参数设置为 true,以及如何在相同上下文中使用additional_kwargs。@kapa.ai给出了一个不确定的回答,并引导@lhc1921查阅 LlamaIndex 文档以获取更多信息。 -
讨论 Auto Merge Retrieval 配置:
@lhc1921还询问是否可以使用 Auto Merge Retriever 仅返回合并后的节点而不生成答案,以及如何为返回的节点设置相关性分数阈值。Kapa.ai 提供了使用示例,并参考了 LlamaIndex 文档以获取更多细节。
提到的链接:
Embeddings - LlamaIndex 🦙 0.9.33
OpenAccess AI Collective (axolotl) Discord 总结
-
Mistral 的微调达到瓶颈:讨论表明 Mistral 在 DPO 模型上可能遇到了微调瓶颈,这可能是由于激活的推理参数限制所致。用户正在寻求一种通用的训练速度指标,类似于推理的 tokens/sec 指标,但目前尚未明确。
-
计算资源管理:公会成员正在分享经验,并寻求关于在 vast/runpod 等平台上出租过剩计算资源的建议。
-
用于高效调优的 LoRA 秩稳定因子:分享了一篇关于使用秩稳定缩放因子增强 Low-Rank Adapters 的 arXiv 论文,以及相关的 GitHub pull request 实现,该请求提议对 PEFT 方法进行修改以获得更好的微调结果。
-
Hugging Face 增强对 AMD GPU 的支持:Hugging Face 已引入对 AMD Instinct MI210 和 MI250 GPU 的支持,整体兼容性详见关于 Flash Attention 2 的 ROCm 实现的分节。
-
处理 4D Attention Masks:Hugging Face 宣传的一项新功能可以处理接受自定义
4DAttention Masks 的 Transformer 模型,从而可能绕过 AMD 兼容性问题,更多相关信息详见 Hugging Face 博客。
OpenAccess AI Collective (axolotl) 频道总结
▷ #general (10 messages🔥):
- Mistral 的微调瓶颈:
@yamashi推测 Mistral 的能力似乎并没有随着微调和 DPO 模型显著提升,这可能是由于激活推理参数的限制。 - 寻求通用的训练速度指标:
@kiraa8415询问是否存在衡量 Transformer 训练速度的通用指标,类似于推理速度中使用的 tokens/sec 指标。 - 计算资源租赁经验咨询:
@le_mess向社区询问在 vast/runpod 等平台上出租多余计算资源的经验,@leoandlibe也对此表示了兴趣。 - 探索秩稳定低秩适配器 (Rank Stabilized Low-Rank Adapters):
@xzuyn分享了一个 arXiv 论文 链接,讨论通过使用秩稳定缩放因子来改进 Low-Rank Adapters (LoRA),以获得更好的微调结果,并提供了相关的 GitHub pull request 用于实际实现。 - PEFT 实现困惑:
@xzuyn指出 PEFT 方法需要将现有的lora_alpha / r修改为lora_alpha / math.sqrt(r),并询问是否有人测试过。他们还询问了在第一步评估模型的可能性,目前的配置是每 50 步评估一次,如这个 GitHub issue 所强调的。
相关链接:
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA:随着大型语言模型 (LLMs) 变得越来越耗费计算和内存资源,参数高效微调 (PEFT) 方法现已成为微调 LLMs 的常用策略。一种流行的 PEFT 方法…
▷ #axolotl-dev (21 messages🔥):
-
AMD GPU 获得 Hugging Face 支持:
@le_mess指出 Hugging Face 现在支持 AMD Instinct MI210 和 MI250 GPU。他提供了概览链接,并提到虽然尚未验证对其他 ROCm 驱动的 GPU 的支持,但预计大多数功能将运行顺畅;他发布了关于 Flash Attention 2 的 ROCm 实现 的子章节。 -
Flash Attention AMD 困境:
@yamashi对 Flash Attention 不支持 AMD 的 MI100 GPU 和 XT 系列显卡 表示失望,并幽默地称它们为 “the dicks”。 -
关于 PR 的思考:
@dctanner询问了关于 Axolotl 项目 chatML 中系统消息的 pull request 的看法,@le_mess因生病遗憾无法查看。 -
跳过 Flash Attention 故障排除:
@faldore讨论了 Flash Attention 是强制性的还是可以跳过,@le_mess建议在 config 中禁用它,而@caseus_指出 sample packing 需要它。 -
支持 4D Attention Masks 的 Transformers:
@caseus_介绍了 Hugging Face 的一项新功能,允许 Transformers 接受自定义的4Dattention masks,为 AMD 兼容性问题提供了潜在的解决方案;链接到了解释该功能的 Hugging Face 博客。
相关链接:
- 4D masks support in Transformers
- Using Hugging Face libraries on AMD GPUs
- Draft: Feat/chatml add system message by mhenrichsen · Pull Request #1117 · OpenAccess-AI-Collective/axolotl:关于如何更改 prompter 中默认系统消息的想法。
- GitHub - ROCmSoftwarePlatform/flash-attention: Fast and memory-efficient exact attention:快速且内存高效的精确注意力机制。在 GitHub 上参与 ROCmSoftwarePlatform/flash-attention 的开发。
DiscoResearch Discord 总结
-
Laserxtral 带着 “Lasering” 技术入场:Laserxtral 是一个尝试 “lasering” 技术并由 VAGO Solutions 支持的模型。它声称尽管体积较小,但性能可与 Mixtral 8x7b Instruct 媲美,尽管在德语方面存在一些 “Denglish”(德式英语)问题。
-
Hermes 2 实现对 Mixtral 的超越:基于 Mixtral 8x7B 的 Nous Hermes 2 模型 已经发布,包含多个变体和集成。该模型可通过 Together Compute 的 API 立即访问,并号称在 Mixtral Instruct 的基础上进行了增强。
-
LLM 训练中的边际收益:在 Nous Hermes 2 发布后,有讨论暗示使用 100 万个数据点进行的额外训练仅带来了微小的提升,这表明原始 Mixtral 模型的效率已经极高。
-
由 AI 构建的 DPO 数据集:用户讨论了如何将优质回答转化为用于 DPO 数据集构建的“差且被拒绝”的回答。方法包括将 GPT-3.5 的回答作为“差”的,GPT-4 的回答作为“好”的,以及使用 LLaMA-13B 生成“被拒绝”的回答。
-
Embedding 优化争议:在 Embedding 开发讨论中,关于 Embedding 的 Token 长度限制存在争论。虽然有人建议 540 tokens 为最优,但在 512 tokens 之后会出现实际性能下降。有人提议使用 Dense Passage Retrieval 模型来过滤掉过于泛泛的问题,而长上下文 Embedding 的有效性仍存争议。
DiscoResearch 频道总结
▷ #mixtral_implementation (10 条消息🔥):
-
Laserxtral - 一个新竞争者:
@sebastian.bodza介绍了 Laserxtral,这是一个实验 “lasering” 技术以增强模型能力的新模型,尽管其德语表现中出现了一些 “Denglish” 句子。该模型由 VAGO Solutions 赞助,体积明显小于 Mixtral 8x7b Instruct,但声称性能水平相近。 -
Nous Research 提升实力:
@philipmay分享了基于 Mixtral 8x7B 的新 Nous Hermes 2 模型链接,号称 优于 Mixtral Instruct。这包括 SFT+DPO 和仅 SFT 变体,以及针对不同量化大小的 GGUF 版本,并集成了 Together Compute 的 API 以实现即时访问。 -
精简训练,宏大结果:针对 Nous Hermes 2 报告的改进,
@sebastian.bodza和@bjoernp讨论认为,即使增加了 100 万条额外的训练数据,收益依然微小,这表明 Mixtral 团队的原始模型已经非常高效。 -
困惑于 Perplexity:
@thewindmom询问了 4bpw 和 6.5bpw 模型之间的 Perplexity 差异,但消息记录中未提供直接回复。 -
创新的 MoE 构建:
@philipmay强调了一种使用不同 peft adapters 构建 MoE 的有趣方法,该方法分享在 LinkedIn 上,这可能是基于这些模型进行构建的一种聪明方式。
提到的链接:
- cognitivecomputations/laserxtral · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-SFT · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO-adapter · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO-GGUF · Hugging Face
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-SFT-GGUF · Hugging Face
- TOGETHER
▷ #general (7 条消息):
-
使用 LLM 构建 DPO 数据集:
@philipmay询问了是否可以使用 LLM 将好的回答转换为“坏的且被拒绝”的回答,以便开发适用于 Direct Preference Optimization (DPO) 的数据集。针对此查询,回复中未提到具体的论文或博客。 -
使用不同版本的 GPT 创建 DPO 数据集:
@sebastian.bodza描述了一种生成 DPO 数据集的方法,其中将 GPT-3.5 对指令的响应作为坏回答,而将 GPT-4 的响应作为好回答。 -
LLaMA-13B 和 GPT-4 在 DPO 数据生成中的应用:
@sebastian.bodza还提到,在一个将句子转换为 Resource Description Framework (RDF) 三元组的任务中,利用 LLaMA-13B 生成被拒绝的响应,而由 GPT-4/GPT-3.5 提供被接受的回答。 -
Intel 分享微调和 DPO 实践见解:
@sebastian.bodza分享了一篇博客文章,详细介绍了在 Habana Gaudi2 上进行监督微调(supervised fine-tuning)和 Direct Preference Optimization 的实践,并展示了一个在 LLM 排行榜上名列前茅的 7B 对话模型。阅读博客文章。 -
顶级 7B 模型排行榜提及:
@sebastian.bodza强调,博客中提到的模型是当时 LLM 排行榜上顶级的 7B 模型,那是发生在模型合并(model merging)和利用评估数据变得普遍之前。
提到的链接:
- 在 Intel Gaudi2 上进行监督微调和 Direct Preference Optimization:展示 LLM 排行榜上排名靠前的 7B 对话模型
- Intel/orca_dpo_pairs · Hugging Face 数据集
▷ #embedding_dev (8 条消息🔥):
-
Qdrant 向量数据库速度问题:
@sebastian.bodza报告称 Qdrant(一个向量数据库系统)运行缓慢,转储 3GB/80 万个文本向量需要一个多小时。 -
Embedding 的最佳 Token 长度讨论:
@philipmay分享了来自 Nils Reimers 的见解,建议 contextual embeddings 的限制为 2688 字节,这大约对应 540 个 tokens,但在实践中,长上下文 embedding 模型在 512 个 tokens 之后效果会变差。 -
生产环境中的 Token 长度难题:
@sebastian.bodza反对将长度减少到 256 个 tokens,主张出于实际原因维持 512 个 tokens,并透露计划测试代码文档的各种分块(chunk)长度,以观察信息保留的扩展情况。 -
通过检索识别过于泛泛的问题:
@philipmay建议在半数数据上训练 Dense Passage Retrieval (DPR) 模型,并用另一半数据进行测试,以识别“过于泛泛”的问题,这类问题会产生过多密切相关的顶级结果。 -
关于长上下文 Embedding 质量的讨论:
@_jp1_对长上下文 embedding 质量的观点提出了挑战,认为被视为“相当差”的效果对于某些应用可能仍然足够,而且一个在不同上下文长度下表现尚可的单一模型将具有很高的可用性。
LLM Perf Enthusiasts AI Discord 总结
-
AI 开发中的 Mac vs Linux 之争:
@iyevenko提出了关于使用 Mac 进行开源 AI 开发的问题,@nosa_.回应建议 Linux 是更合适的选择,因为 Linux/云端具有更好的 VRAM 利用率和最优的 AI 软件性能。尽管如此,@slater.exe.指出 MLX 应该能满足@iyevenko在 Mac 上的需求。 -
微调 MoE 模型:
@jeffreyw128对微调 Mistral vs Mixtral 模型的兴趣促使@slater.exe.分享了使用 QLoRA/DPO 微调 Mistral 以及利用 mergekit 创建 MoE 模型的成功经验。 -
更聪明的模型合并策略:
@slater.exe.提出的一种战术方法建议,微调较小的模型然后进行合并可能更高效,尽管他也承认在评估专家级模型性能方面存在复杂性。 -
ChatGPT 变得更聪明了吗?:
@res6969对 3 月 1 日后 ChatGPT 的智能程度表示怀疑,寻求相关研究来验证其进步的说法;而@thebaghdaddy则分享了在 Turbo 版本发布后感觉到 AI 变得“懒惰”的经历。 -
用户质疑 ChatGPT 的增强声明:包括
@res6969和@thebaghdaddy在内的几位用户报告称,ChatGPT 的性能没有明显提升,认为其能力增强的想法可能是毫无根据的传闻,可能源于 “Twitter 上的闲言碎语”。
LLM Perf Enthusiasts AI 频道总结
▷ #opensource (10 条消息🔥):
-
开源 AI 开发中的 Mac vs Linux:
@iyevenko咨询了在新款 M3 Mac 上进行开源开发的配置,@nosa_.建议考虑 Linux 以获得更好的 VRAM 利用率,并补充说大多数 AI 软件都针对 Linux/云端环境进行了优化。@slater.exe.随后提到 MLX 应该能在 Mac 上满足 Iyevenko 的需求。 -
分享微调 MoE 模型的经验:
@jeffreyw128向社区询问了微调 Mistral vs Mixtral 的经验。@slater.exe.介入并分享了他们使用 QLoRA/DPO 微调 Mistral 以及使用 mergekit 创建 MoE 模型的成功案例。 -
组合较小模型可能更高效:在后续消息中,
@slater.exe.描述了一种首选方法,即微调较小的模型然后进行合并可以产生更好的效率,尽管在衡量此类专家级模型性能方面存在挑战。
▷ #openai (4 条消息):
- ChatGPT 所谓的智能提升引发质疑:用户
@res6969询问自 3 月 1 日以来 ChatGPT “变得更聪明”的证据,寻求任何支持此类说法的合法研究链接。 - 用户报告 ChatGPT Turbo 发布后体验不一致:
@thebaghdaddy对 ChatGPT 有所改进的看法持相反意见,分享了自 Turbo 发布以来 AI 变得“懒惰”的个人经历。 - 关于 ChatGPT 性能增强未达成共识:
@res6969呼应了@thebaghdaddy的观点,认为 ChatGPT 的能力没有提升,并将智能增强的传闻归因于 “Twitter 上的闲言碎语”。
Skunkworks AI Discord 总结
-
Mixtral 配置咨询无果而终:
@tcapelle向<@387972437901312000>寻求关于 Mixtral 的 axolotl 配置 详情,但这一求助在数字虚空中未得到回应。 -
传统论文之外的引用:
@teknium发起了关于引用 GitHub 仓库、model cards 和博客 正当性的讨论,并在一条 引发思考的推文 中分享了他的观点,而其他人则支持扩大引用范围,将 aicrumb 的工作 纳入其中。 -
学术界对新兴作品的认可:社区表示支持在学术界更广泛地认可替代性作品,例如
@yikesawjeez拥护@teknium的立场,特别是针对 aicrumb 的工作。 -
意外发现 aicrumb 的工作:在引用辩论中,
@teknium惊讶地发现,一些人早在几个月前就已经知道了 aicrumb 的贡献。 -
ICLR 关注 MoE 效率:
@prateeky2806分享了他们的 Memory and Computation Efficient MoE 论文被选为 ICLR Spotlight 的喜讯,该研究承诺通过 基于路由统计的合并 实现高达 80% 的内存减少和 20% 的 FLOPs 减少。你可以在 这里 了解技术细节。
Skunkworks AI 频道总结
▷ #general (10 messages🔥):
-
询问 Axolotl 配置:
@tcapelle向<@387972437901312000>询问用于 Mixtral 的 axolotl configuration,但在随后的消息中没有提供更多细节或答案。 -
关于引用作品的辩论:
@teknium质疑在考虑学术作品引用时,code base (PyTorch vs JAX) 或 model size 等技术细节的相关性,并对犹豫是否引用各种形式的文档表示困惑。 -
为非传统引用辩护:
@teknium为引用多样化来源(如 GitHub 仓库、model cards 和 blogs)的行为辩护,强调许多论文已经这样做,并通过一篇 Twitter 帖子分享了他的看法。 -
对知晓度的惊讶:
@teknium对发现 aicrumb 的工作 已被某些人知晓 4 个月表示惊讶,但未说明这种知晓背景的具体细节。 -
倡导更广泛的引用:
@yikesawjeez同意在参考文献中包含更广泛的引用是有益的,并主张在学术界给予 aicrumb 的工作 更多认可。
提到的链接:
Teknium (e/λ) (@Teknium1) 的推文:就个人而言,我不认为将他们的工作添加到“相关工作”或引用中有什么问题——我不确定对引用博客或非论文内容的抱怨是什么?你是否认为这在某种程度上是负面的…
▷ #papers (1 messages):
- ICLR 关于 MoE 内存效率的 Spotlight:
@prateeky2806分享了他们的 MoE Expert Merging 论文被接收为 ICLR 的 SpotLight 论文,强调了 MoE 模型在内存和计算方面的显著降低。该技术使用 基于路由统计的合并 (routing statistics-based merging),实现了高达 80% 的内存减少和 20% 的 FLOPs 减少。在此阅读该技术详情。
提到的链接:
Prateek Yadav (@prateeky2806) 的推文:🎉 很高兴宣布我们的 MoE Expert Merging 论文已被 @iclr_conf 接收为 SpotLight 论文!我们通过利用基于路由统计的合并,降低了 MoE 模型的推理内存成本…
Datasette - LLM (@SimonW) Discord 总结
- 表情符号增强 Newsletter 导航:@0xgrrr 采用表情符号来组织其 Newsletter 的目录,其中包括机器人和 AI 等板块,将每个主题与主题相关的表情符号连接起来。
-
寻找完美的表情符号:@dbreunig 展示了他们的 emoji-suggest 微服务,该服务根据输入字符串推荐表情符号,旨在帮助用户为文本找到合适的表情符号。
- 使用 llm-clip 进行图像搜索时的失误:用户 @butchanton 在尝试使用 llm-clip 在数据集内进行基于图像的搜索时遇到困难,暗示在为该任务创建有效的 Embeddings 时存在挑战。
- 使用 Embeddings 寻求上下文:@dbreunig 分享了一项关于使用 Embeddings 进行上下文相关项目检索的探索,这可能为解决 @butchanton 对图像搜索的困扰提供见解。
Datasette - LLM (@SimonW) 频道总结
▷ #ai (2 messages):
- 为 Newsletter 注入表情符号:用户
@0xgrrr分享了他们使用表情符号为 Newsletter 创建目录 (TOC) 的做法,列出了机器人、开发者生产力和新 AI 技术等主题领域及其对应的表情符号。 - 表情符号爱好者的建议工具:
@dbreunig提供了一个 GitHub 仓库链接,其中包含一个根据给定字符串建议表情符号的微服务,并附有项目的图像、标题和描述。
提到的链接:
GitHub - dbreunig/emoji-suggest: 根据字符串建议表情符号的微服务。:根据字符串建议表情符号的微服务。- GitHub - dbreunig/emoji-suggest: 根据字符串建议表情符号的微服务。
▷ #llm (3 条消息):
- 数字大海捞针:用户
@butchanton询问了关于使用 llm-clip 进行基于图像搜索的问题,特别是如何为一组图像创建 Embeddings,然后在该数据集中搜索相似图像,并对搜索结果不佳表示沮丧。 - 用管道原理解释 Embeddings:
@dbreunig分享了一个 示例,探讨了如何使用 Embeddings 在一组图像中寻找上下文相似的项目,并将神经网络描述为“上下文概率机器”。这篇文章可能为@butchanton关于基于图像搜索的疑问提供见解。
提到的链接:
用 Embeddings 寻找浴室水龙头:使用 Embeddings 在难以涉足的领域中导航。
Alignment Lab AI Discord 摘要
只有一个频道有活动,因此无需总结…
- ICLR 上的 MoE 效率亮点:
@prateeky2806分享了他们的 MOE Expert Merging 论文 被 ICLR 接收为 Spotlight 论文的消息。该论文提出了一种显著降低 MoE 模型内存和计算需求的方法。
提到的链接:
来自 Prateek Yadav (@prateeky2806) 的推文:🎉 很高兴宣布我们的 MOE Expert Merging 论文已被 @iclr_conf 接收为 SpotLight 论文!我们通过利用基于路由统计的方法,降低了 MOE 模型的推理内存成本…
YAIG (a16z Infra) Discord 没有新消息。如果该公会长时间没有活动,请告知我们,我们将将其移除。