ainews-1172024-help-crowdsource-function-calling
2024年1月17日:助力函数调用数据集的众包工作
LM Studio 更新了其常见问题解答(FAQ),明确了其闭源状态,并承诺个人使用永久免费且不收集数据。新的 Beta 测试版包含了一些修复,并暗示即将支持 2-bit 量化。
在游戏应用方面,推荐使用 Dolphin 2.7 Mixtral 8x7B、MegaDolphin 以及采用 Q4_K_M 量化的 Dolphin 2.6 Mistral 7B DPO 等模型。讨论指出,由于存在瓶颈,单张高性能 GPU 的表现优于多显卡配置,而像 Tesla P40 这样的旧款 GPU 则具有很高的性价比。
文中提到了微软的 AutoGen Studio,但它目前存在一些问题,且在使用开源模型时需要支付 API 费用。由于 LM Studio 缺乏无界面模式(headless mode),建议 Linux 用户使用 llama.cpp。此外,还提到了 iOS 端的 LLMFarm 等工具以及各种 Hugging Face 仓库。
值得注意的观点包括:“由于没有无界面模式,必须保持 LM Studio 运行才能使用本地推理服务器”以及“模型大小与 GPU 显存相匹配是性能的关键”。
我们为您检查了 19 个服务器、287 个频道和 3277 条消息。预计节省的阅读时间(按 200wpm 计算):363 分钟。
Skunkworks 正在整理 function calling 数据集——这是将一切转化为函数的关键!
熟悉底层数据格式和来源也同样重要:
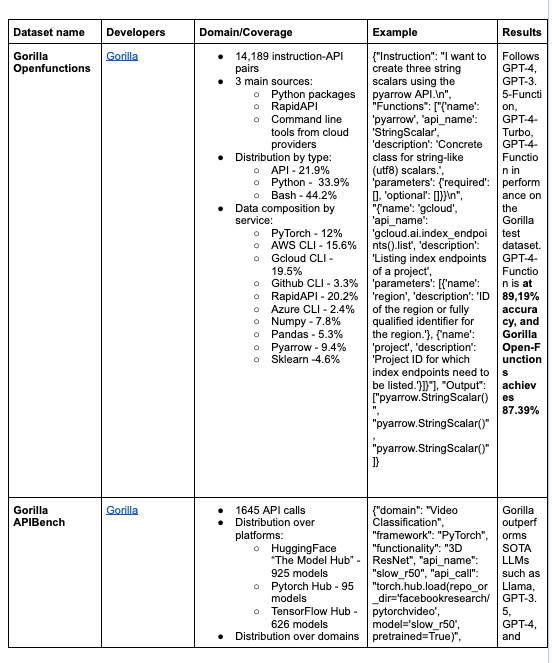
还有哪些用于微调 function calls 的数据集?我们可以合成一些吗?
目录
[TOC]
LM Studio Discord 摘要
-
LM Studio 的最新更新与兼容性:LM Studio 的 FAQ 已更新,明确了其 closed-source 状态、个人使用的永久免费性以及非侵入式的数据处理,更新后的 FAQ 见此处。新的 LM Studio beta 发布版本 修复了内存警告和生成一致性问题,
@yagilb暗示了对 此 pull request 中显示的 2-bit quantization 的支持。 -
游戏模型选择建议:对于《天际》(Skyrim) 模组,建议使用 Dolphin 2.7 Mixtral 8x7B 或 MegaDolphin,而为了性能考虑,最终选择了带有 Q4_K_M 量化的 Dolphin 2.6 Mistral 7B DPO。关于 Ferret 模型的澄清指出,它是一个 Mistral 7B finetune,而非 vision model,并参考了其 GitHub repository 和 Hugging Face 页面。
-
性能瓶颈与硬件讨论:在模型运行的讨论中,指出单个强大的 GPU 通常优于多 GPU 设置(由于潜在的瓶颈);在为 LLM 配置硬件时,将模型大小与可用 GPU memory 匹配是关键,像 Tesla P40 这样较旧的服务器级 GPU 是具有成本效益的升级选择。
-
新 AI 工具探索与请求:微软的 AutoGen Studio 作为一种新的 LLM 应用工具被引入,但有报告称存在问题,且其完整实用性似乎受限于开源模型所需的 API fees,这引发了关于其他项目集成渠道的讨论。
-
Linux 服务器用户的使用案例:Linux 用户被引导使用
llama.cpp而非 LM Studio,因为目前没有 headless mode,且llama.cpp为服务器使用提供了更合适的 backend。
分享的其他链接提供了对各种项目的见解,包括 Microsoft’s AutoGen Studio、LM Studio 的 iOS 替代方案 LLMFarm 以及各种 Hugging Face 模型仓库。然而,由于细节稀少或仅有单条消息,不足以建立关于 NexusRaven-V2 的 GitHub 链接以及 local models 内存挑战的总结背景。
LM Studio 频道摘要
▷ #💬-general (62 messages🔥🔥):
-
LM Studio FAQ 已更新:
@heyitsyorkie更新了 LM Studio FAQ,概述了其关键特性,例如它是闭源的、个人使用永久免费、不收集用户数据。FAQ 可以在这里找到。 -
LM Studio 闭源说明:
@heyitsyorkie回应了@esraa_45467关于访问 LM Studio 代码的查询,声明它是闭源的,无法查看。 -
LM Studio 无无头模式 (Headless Mode):
@heyitsyorkie提到必须运行 LM Studio 才能使用本地推理服务器 (lis),因为目前没有无头模式,所以无法仅通过脚本操作。 -
对 macOS 和 iOS 环境的支持:
@heyitsyorkie向@pierre_hugo_确认,搭载 Intel CPU 的 MacBook Air 2018 不支持 LM Studio,并就使用越狱 (jailbreak) 运行无头模式的可行性向@dagbs提供了建议;同时@technot80分享了关于 iOS 替代应用 LLMFarm 的信息。 -
语言限制与对话奇特现象:提到 LM Studio 主要支持英语(近期因一段视频涌入了大量西班牙语用户)。讨论中观察到了模型在不同语言间切换时的幽默翻译,特别是从西班牙语到中文的翻译。
提到的链接:
-
Despacio Despacito GIF - Despacio Despacito Luisfonsi - Discover & Share GIFs:点击查看 GIF。
-
非官方 LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里,你可以找到 LMStudio Discord 中最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源软件…
-
GitHub - guinmoon/LLMFarm: 使用 GGML 库在 iOS 和 MacOS 上离线运行 llama 和其他大语言模型。:使用 GGML 库在 iOS 和 MacOS 上离线运行 llama 和其他大语言模型。- GitHub - guinmoon/LLMFarm。
▷ #🤖-models-discussion-chat (80 messages🔥🔥):
-
Skyrim 模组的模型推荐咨询:
@gamerred正在寻找适合与 Skyrim 模组配合使用的模型,@dagbs建议使用 Dolphin 系列的任何模型,并为有能力运行大型模型的人推荐了 Dolphin 2.7 Mixtral 8x7B 或 MegaDolphin。@gamerred决定使用 Dolphin 2.6 Mistral 7B DPO 的 Q4_K_M 量化版本,以获得更快的游戏内响应。 -
对 Ferret 功能的困惑:
@ahmd3ssam在尝试使用 Ferret 时遇到了“Vision model is not loaded. Cannot process images”错误;@heyitsyorkie澄清 Ferret 是 Mistral 7B 的微调 (finetune) 版本,而非视觉模型,并指向了其 GitHub 仓库 和 Hugging Face 页面。 -
优化游戏内使用的 AI 性能:
@dagbs建议使用较低量化的 Dolphin 模型以获得更好的游戏内性能(受限于 VRAM 限制),并指出随着对话变长,如果不使用滚动消息历史,响应可能会变慢。@fabguy补充说,在 LM Studio 中禁用 GPU 可能会改善体验,因为游戏和 AI 会竞争 GPU 资源。 -
提示词格式 (Prompt Formatting) 建议:
@.ben.com寻求 laserxtral 的正确提示词格式,引发了简短讨论,@dagbs确认 “ChatML” 预设适用于所有基于 Dolphin 的模型。 -
LLM 的机器配置要求:在关于 7900 XTX 适配最佳模型的咨询中,
@heyitsyorkie回复@_anarche_称最高可容纳 33B 参数模型,例如 Llama 1 模型 Guanaco 和 WizardVicuna。
提到的链接:
-
Herika - ChatGPT 伴侣:’Herika - ChatGPT 伴侣’ 是一款革命性的模组,旨在将 Skyrim 与人工智能技术集成。它专门添加了一个追随者 Herika,其响应和互动…
-
GitHub - apple/ml-ferret:通过在 GitHub 上创建一个账户来为 apple/ml-ferret 的开发做出贡献。
▷ #🧠-feedback (5 messages):
-
LM Studio Beta 新版本发布:
@yagilb宣布了 新的 LM Studio Beta 版本发布,其中包括错误修复,如潜在内存问题的警告、多次重新生成后输出不稳定的修复以及服务器响应的一致性。他们指出移除了对 ggml 格式的支持,并暂时禁用了某些功能。 -
关于 2-bit 量化支持的咨询:
@logandark询问了关于 2-bit 量化支持的情况,并链接了一个讨论该功能的 GitHub pull request。 -
等待包含新功能的下一个 Beta 版:在回答关于添加 2-bit 量化的问题时,
@yagilb确认预计将在今天晚些时候发布新的 Beta 版,并可能包含所讨论的功能。 -
热切期待更新的用户:在
@yagilb更新了即将发布的 Beta 版消息后,@logandark表示了感谢和期待。
提到的链接:
-
SOTA 2-bit quants by ikawrakow · Pull Request #4773 · ggerganov/llama.cpp:TL;DR 此 PR 添加了新的“真正”的 2-bit 量化(但由于是在 ggml/llama.cpp 的分块量化方法中实现的,我们最终使用了 2.0625 bpw,详情见下文…)
▷ #🎛-hardware-discussion (81 messages🔥🔥):
-
单 GPU 速度优于多 GPU 配置:
@pefortin分享了见解,认为使用 单个 GPU 执行模型通常比将工作负载分配到多个 GPU 更快。他们提到,多 GPU 设置中最慢的组件(例如性能较弱的 GPU)可能会成为性能瓶颈。 -
量化与硬件能力讨论:
@juansinisterra正在寻求适合其硬件的量化级别建议,收到了来自@heyitsyorkie的建议,即模型大小应与可用的 GPU memory 匹配,以及来自@fabguy的建议,探索同时使用 GPU 和 CPU 来执行模型。 -
云端作为模型执行的替代方案:用户讨论了在云端运行模型的选项,
@dagbs警告了涉及非审查内容时的法律影响和信任问题,并建议考虑性价比高的旧款服务器级 GPU(如 Tesla P40)进行个人硬件升级。 -
在 GPU 市场中为 AI 应用导航:关于各种 GPU(如 7900xtx)与 3090 相比的性价比引发了讨论,
@heyitsyorkie和.ben.com讨论了不同 GPU 的 VRAM 以及对 Large Language Models (LLMs) 等任务的适用性。 -
根据特定硬件配置模型:
@heyitsyorkie就@lex05的硬件配置可以运行的模型类型提供了建议,推荐使用 7b Q_4 模型,并阅读模型卡片以确定其拥有 8GB VRAM 的 RTX 4060 的合适配置。
提到的链接:
-
ggml/docs/gguf.md at master · ggerganov/ggml:用于机器学习的张量库。通过在 GitHub 上创建账户来为 ggerganov/ggml 的开发做出贡献。
-
[MSI Radeon RX 7900 XTX GAMING TRIO CLASSIC 24GB Graphics Card Ebuyer.com](https://www.ebuyer.com/1615563-msi-radeon-rx-7900-xtx-gaming-trio-classic-24gb-graphics-card-rx-7900-xtx-gaming-trio-classic-24g)
▷ #🧪-beta-releases-chat (8 messages🔥):
-
确认 Ubuntu 22.04 兼容性:用户
@ephemeraldust询问了在 Ubuntu 22.04 服务器上运行该应用程序的情况,@heyitsyorkie回复称它是在 22.04 上编译的,所以应该可以正常工作。然而,他们也被告知目前没有 headless 模式或 CLI 选项,应用程序必须保持打开状态才能使用。 -
寻求 CLI 访问权限:
@ephemeraldust希望通过命令行界面 (CLI) 访问应用程序,这促使@heyitsyorkie建议研究llama.cpp以获得更合适的解决方案。 -
对节省时间的建议表示感谢:
@ephemeraldust感谢了@heyitsyorkie关于llama.cpp的建议,并认可了这可能节省的时间。 -
明确 LM Studio 和 llama.cpp 的用途:
@heyitsyorkie澄清说,LM Studio 是面向 Mac/Windows 用户的易用前端,而llama.cpp才是 Linux 服务器用户应该使用的后端。
▷ #autogen (6 messages):
-
Microsoft AutoGen Studio 亮相:
@senecalouck分享了 GitHub 上的 Microsoft AutoGen Studio 链接,强调其旨在赋能下一代 LLM 应用。 -
AutoGen Studio 与 LM Studio 的问题备受关注:
@dagbs试用了 AutoGen Studio 并报告了与 LM Studio 无关的问题,同时提到其他人在使用该工具时也遇到了功能性困难。 -
功能性取决于 API 费用:
@senecalouck指出,由于缺乏良好的 function calling 能力,如果不支付 API 费用,AutoGen Studio 目前对于开源模型和工具的实用性有限。 -
请求开设 CrewAI 集成频道:
@senecalouck请求创建一个 CrewAI 集成频道,表示他们有一个社区可能感兴趣的项目。 -
关于 Open Interprite 频道的建议:
@dagbs对缺乏 Open Interprite 频道表示惊讶,因为其基础配置中提到了 LM Studio,暗示这可能对社区具有相关性。
提到的链接:
autogen/samples/apps/autogen-studio at main · microsoft/autogen:赋能下一代 LLM 应用。加入我们的 Discord:https://discord.gg/pAbnFJrkgZ - microsoft/autogen
▷ #langchain (1 messages):
sublimatorniq: https://github.com/nexusflowai/NexusRaven-V2
▷ #memgpt (1 messages):
pefortin: 是的,本地模型在如何以及何时使用 memory 方面表现挣扎。
Eleuther Discord 总结
-
澄清 ACL 投稿困惑:
ludgerpaehler澄清了关于 ACL 投稿截止日期 的疑问,确实需要在 2 月 15 日之前将稿件发送至 ARR OpenReview 门户,并遵循 ACL 概述的流程。 -
报告 Evaluation Harness 的 Key Error:
alexrs_在 evaluation-harness 上提交了一个 issue,并报告了一个错误,涉及使用来自 huggingface/evaluate 的某些指标时的 KeyError。 -
关于 Mamba 和 ZOH 离散化的辩论:发生了一场关于在 Mamba 模型中使用 Zero-Order Hold (ZOH) 离散化的值得注意的讨论,深入探讨了其与线性状态空间模型和 ODE 解的相关性。
-
Python 升级期间呼吁可复现构建:在 Python 更新期间,
@catboyslimmer在尝试现代化 gpt-neox 时遇到了测试失败和 Apex 构建困难。他们强调迫切需要一个可复现的构建过程。 -
BaseLM 重构与实现指令:最近的重构移除了
BaseLM,要求用户实现诸如_loglikelihood_tokens之类的函数。然而,重新引入类似功能的计划已在 Pull Request 中被提及,团队讨论了样板代码的潜在解决方案。
Eleuther 频道总结
▷ #general (119 条消息🔥🔥):
-
关于 ACL 投稿流程的困惑:
ludgerpaehler需要澄清关于 ACL 投稿截止日期的流程。他们询问根据 ACL 投稿日期和流程,ACL 投稿是否必须在 2 月 15 日之前发送到 ARR OpenReview 门户。 -
Evaluation Harness 和 Evaluate 指标的问题:
alexrs_在使用 evaluation-harness 时遇到问题,并提交了一个 issue,指出来自 huggingface/evaluate 的某些指标导致了 KeyError。 -
探索 Memmapped 数据集:
lucaslingle寻求实现 memmapped 数据集的见解,并引用了 Pythia 代码库中提到的 5GB 大小的 memmapped 文件。hailey_schoelkopf澄清说,这个大小限制是由于 Huggingface 的上传限制,但对于 Megatron 来说,合并后的更大尺寸应该是可行的。 -
寻求
wandb的替代方案:.the_alt_man请求推荐一个可以作为wandb直接替代方案的工具,要求集成超参数调优(hyperparameter tuning)和绘图功能,这引发了关于监控和调优调度背后架构选择的讨论。 -
关于 Hypernetworks 与 MoE 层的讨论:
Hawk发起了一场对话,询问是否有人尝试过将 hypernet 层作为 MoE 层的替代方案;zphang指出 Hypernetwork 技术在这一应用领域可能还不够成熟。
提到的链接:
-
Accelerating PyTorch with CUDA Graphs:今天,我们很高兴地宣布一项新的高级 CUDA 特性——CUDA Graphs 已引入 PyTorch。现代 DL 框架拥有复杂的软件栈,会产生显著的开销…
-
mamba_small_bench/cifar_10.py at main · apapiu/mamba_small_bench:在小型示例(cifar-10,shakespeare 字符级等)上尝试 Mamba 架构 - apapiu/mamba_small_bench
-
KeyError on some metrics from huggingface/evaluate · Issue #1302 · EleutherAI/lm-evaluation-harness:背景:我目前正在结合使用 lm-evaluation-harness 和 huggingface/evaluate 提供的指标。具体来说,我正在使用 bertscore。该指标返回一个字典…
▷ #research (69 条消息🔥🔥):
-
生成模型中的质量与多样性:
@ai_waifu提到质量与多样性之间存在权衡,而负对数似然 (NLL) 指标无法很好地捕捉到这一点。尽管从 NLL 的角度来看 GANs 的表现可能较差,但它们仍然可以生成具有视觉吸引力的图像,且不会因模式丢失 (mode dropping) 受到严重惩罚。 -
探索使用 GFlownets 进行 3D CAD 生成:
@johnryan465询问了关于将 GFlownet 应用于 3D CAD 模型生成的文献,但未找到相关内容。@carsonpoole建议,将 CAD 图像与实际几何结构配对的大型合成数据集可能会很有用。 -
介绍对比偏好优化 (Contrastive Preference Optimization):
@xylthixlm分享的一项研究展示了一种名为对比偏好优化 (CPO) 的 LLMs 新训练方法,该方法针对监督微调 (supervised fine-tuning) 的缺点,专注于训练模型避免生成虽然合格但不完美的翻译。 -
Mamba 与 ZOH 离散化讨论:
@michaelmelons发起了一场讨论,质疑为什么 Mamba 模型对其矩阵采用零阶保持 (ZOH) 离散化。@useewhynot和@mrgonao提供了见解,涉及线性状态空间模型以及关于 A 矩阵离散化的 ODEs 解。 -
Tokenization 与字节级编码探索:由
@carsonpoole和@rallio.引导的讨论研究了重置模型中 embedding 权重的影响,以及关于是使用 Llama tokenizers 还是原始字节 (raw bytes) 作为输入的争论。该话题演变为关于 tokenizer 效率低下的更广泛讨论,特别是在处理专有名词和噪声数据方面,用户@catboyslimmer和@fern.bear强调了 tokenization 尚未被充分研究的性质及其分布后果。
提到的链接:
-
Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation:中等规模的大语言模型 (LLMs) —— 即具有 7B 或 13B 参数的模型 —— 展现出极具前景的机器翻译 (MT) 性能。然而,即使是表现最好的基于 13B LLM 的翻译模型……
-
GitHub - google-deepmind/alphageometry:通过在 GitHub 上创建账号,为 google-deepmind/alphageometry 的开发做出贡献。
▷ #interpretability-general (1 条消息):
- 发现发育可解释性 (Developmental Interpretability):用户
@David_mcsharry分享了一个有趣的更新,提到他们发现了发育可解释性 (developmental interpretability),这似乎与 interpretability-general 频道感兴趣的话题相关。
▷ #lm-thunderdome (7 messages):
-
关于 BaseLM 移除的澄清:用户
@daniellepintz询问了从 EleutherAI 仓库中移除实用的BaseLM类的情况,该类包含了loglikelihood和loglikelihood_rolling等方法。该代码曾位于 BaseLM Reference。 -
BaseLM 移除背后的重构:
@hailey_schoelkopf澄清说,移除BaseLM是由于旨在改进 batch generation 和 data-parallel evaluation 的重构过程。他们表示有计划重新添加类似功能,Pull Request #1279 中有所暗示。 -
实现需求依然存在:针对
@daniellepintz注意到用户必须实现_loglikelihood_tokens和loglikelihood_rolling的情况,@stellaathena承认在创建新型模型 API 时,这些实现步骤在很大程度上是不可避免的。 -
样板代码抽象仍有可能:
@hailey_schoelkopf承认虽然一些样板代码(boilerplate)可以被抽象掉,但像loglikelihood_tokens和generate_until这样的函数可能涉及一些不可避免的自定义编码。不过,复用或对 HFLM 进行 subclassing 可能是用户的解决方案。 -
HF Datasets 版本的潜在问题:
@hailey_schoelkopf建议暂时将 HF datasets 版本固定在 2.15,并指出由于 dataset loading 脚本的变化,2.16 及以上版本可能会给用户带来问题。
提到的链接:
-
lm-evaluation-harness/lm_eval/base.py at 3ccea2b2854dd3cc9ff5ef1772e33de21168c305 · EleutherAI/lm-evaluation-harness:一个用于语言模型 few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
▷ #gpt-neox-dev (9 messages🔥):
-
潜在的 Python 版本升级问题:
@catboyslimmer提出了关于 EleutherAI/gpt-neox 的 Python 版本更新 Pull Request #1122 在本地测试失败的潜在问题,并指出这些失败可能在修改之前就存在。他详细说明了在 Docker 中测试构建并回移植到 poetry 文件的计划。 -
Docker 构建成功但仍需测试:
@catboyslimmer提到在 Docker 中构建成功,但承认可能需要额外的测试,并对更改可能引起的问题表示不确定。 -
Apex 构建的复杂情况:
@catboyslimmer在构建 Apex 时遇到困难,考虑直接从 Apex 提取 fused kernel 以解决问题,而不深入研究 Apex 的底层问题。 -
多次运行脚本的“魔力”:针对
@catboyslimmer的构建问题,@stellaathena建议重复执行几次构建脚本,有时这能解决问题,尽管@catboyslimmer怀疑由于版本和依赖问题,这可能不起作用。 -
对缺乏可复现性感到震惊:
@catboyslimmer对目前不可复现的构建过程感到震惊,并迫切希望尽快建立一个更可靠的构建系统。
提到的链接:
Python version update by segyges · Pull Request #1122 · EleutherAI/gpt-neox:不知道这是否已经准备就绪;在我的本地测试中,它未能通过部分 pytest 测试,但这很可能在之前就已经存在。将镜像提升至 Ubuntu 22.04 并使用系统…
Nous Research AI Discord 总结
-
GPT-4-Turbo 的困扰:
.beowulfbr对 GPT-4-Turbo 表示不满,强调其生成的代码毫无意义且性能下降。同时,关于 ChatGPT 与 GPT-4-Turbo 的争论也随之兴起,双方在迭代效率和 Bug 存在方面进行了对比。 -
寻求简化的对话模型:
@gabriel_syme和@murchiston希望对话模型能跳过闲聊直接完成任务,而@giftedgummybee建议指示 AI 使用“前 100 个最常用的英文单词”以实现更清晰的交流。 -
期待代码模型竞争者:Discord 社区热烈讨论了 Stable Code 3B 的发布(Stable Code 3B)、在 Hugging Face 上亮相的 InternLM2,以及由
@osanseviero讨论的 DeciCoder-6B 的潜在首秀。 -
文本识别的创新:在多语言发票分析等任务中,传统 OCR 目前被认为比多模态模型更可靠,例如建议使用 Tesseract OCR。这种方法被拿来与 GPT-4 Vision 等 AI 模型及多模态替代方案进行对比。
-
AI 几何学的进展:DeepMind 的 AlphaGeometry 更新在社区中引起了褒贬不一的反应,提及 DeepMind 的研究 时既有幽默调侃,也有对其 LLM 集成和数学推理能力的专业兴趣。
Nous Research AI 频道总结
▷ #off-topic (27 条消息🔥):
-
GPT-4-Turbo 备受指责:
.beowulfbr分享了对 GPT-4-Turbo 的挫败感,提到在寻求实现帮助时,它生成了完全荒谬的代码。该用户报告称,即使在纠正 AI 之后,其质量下降和错误依然明显。 -
ChatGPT 与 GPT-4-Turbo 之争:用户
giftedgummybee认为 API 版本优于 ChatGPT,而.beowulfbr批评 ChatGPT 存在 Bug,且与 API 版本相比,需要两倍的迭代次数才能得到正确结果。 -
LLM 错误的持续性:
giftedgummybee和night_w0lf讨论了 LLM 重复错误并退回到“愚蠢 LLM 模式”的倾向(如果引导不当),这可能暗示需要更详尽的 Prompt 或进行“waluigi-ing the model”操作。 -
TTS 软件讨论:
everyoneisgross提出了关于在脚本中使用离线 TTS(文本转语音)工具的问题,表达了在使用 Silero 时遇到的挑战,而tofhunterrr和leontello分别建议了 Mac 上的say命令和开源 TTS Bark 等替代方案。 -
推荐方案 Coqui TTS:
leontello建议尝试 Coqui TTS,这是一个只需几行代码即可试用各种 TTS 替代方案的工具。
提到的链接:
-
Nous Research 深度学习 GIF - Nous Research Research Nous - 发现并分享 GIF:点击查看 GIF
-
深度学习 Yann Lecun GIF - Deep Learning Yann LeCun LeCun - 发现并分享 GIF:点击查看 GIF
▷ #interesting-links (15 条消息🔥):
-
对话模型变得啰嗦:
@gabriel_syme和@murchiston表达了对对话模型过于冗长、进行不必要对话而非立即执行任务的挫败感;他们渴望一种直接的“照做就行”的方法,而不是多余的废话。 -
对话模型的简化策略:
@giftedgummybee建议通过强制 AI “使用前 100 个最常用的英文单词”来对抗对话模型过于复杂的回答。 -
InternLM2-Chat-20B 发布:
@euclaise分享了 Hugging Face 仓库链接,详细介绍了 InternLM2。这是一个具有 200K context window 的开源对话模型,因在推理和指令遵循等各项任务中的卓越表现而备受赞誉。 -
征集数字艺术与 AI 研讨会提案:
@everyoneisgross强调了在惠灵顿举行的 Rising Algorithms Symposium 的提案征集,寻求探索艺术与 AI 交汇点的贡献。 -
基于向量的随机矩阵自适应 (VeRA):
@mister_poodle分享了一篇 arXiv 论文,介绍了一种名为 VeRA 的技术。该技术在微调大型语言模型时减少了可训练参数的数量而不影响性能,但@charlesmartin14在没有看到结果证据的情况下对其有效性保持怀疑。
提到的链接:
-
VeRA: Vector-based Random Matrix Adaptation:Low-rank adaptation (LoRA) 是一种在微调大型语言模型时减少可训练参数数量的流行方法,但在扩展到超大型模型时仍面临严峻的存储挑战……
-
2024 ADA Symposium – Call for Proposals:<p>Aotearoa Digital Arts Network Symposium
Rising Algorithms: Navigate, Automate, Dream
2024 年 5 月 24 – 26 日
惠灵顿 Te Whanganui-a-Tara</p> &… -
ReFT: Reasoning with Reinforced Fine-Tuning:增强大型语言模型 (LLM) 推理能力的一种方法是使用 Chain-of-Thought (CoT) 标注进行 Supervised Fine-Tuning (SFT)。这种方法并未表现出足够的……
-
Solution Suicide GIF - Solution Suicide Rick And Morty - Discover & Share GIFs:点击查看 GIF
▷ #general (110 条消息🔥🔥):
- 对 Stable Code 3B 发布的期待:针对新发布的 Stable Code 3B(一个专为代码补全设计的尖端模型),社区表达了热情与怀疑。
@.beowulfbr称其“令人失望”,因为它被置于付费墙之后。 - 对新模型的困惑:讨论集中在即将推出的模型(如 StableLM Code)上,
@gabriel_syme和@giftedgummybee等用户试图从 Twitter 上的预热信息中提取信息,质疑它们是否已经发布。 - 关于代码模型基准测试的辩论:
@night_w0lf等成员信任特定的评估平台(如 EvalPlus)来判断代码模型的性能,而@teknium和@antonb5162则讨论了 HumanEval 分数的有效性以及各种模型的可靠性。 - 对新代码模型的兴趣:
@osanseviero强调了 DeciCoder-6B 的发布,其性能主张和开源可用性吸引了关注。 - 众筹 OSS 模型资金:
@carsonpoole表达了赞助与 Mistral, Mixtral 或 Phi 相关的开源软件 (OSS) 模型的兴趣,寻求与社区合作。
提到的链接:
-
来自 Google DeepMind (@GoogleDeepMind) 的推文:介绍 AlphaGeometry:一个能够以接近人类金牌选手水平解决奥数几何问题的 AI 系统。📐 它完全基于合成数据训练,标志着 AI 的突破……
-
来自 Wavecoder (@TeamCodeLLM_AI) 的推文:我们正在准备开源相关事宜。请保持关注。一旦准备就绪,我们将通过此账号宣布最新进展。
-
Deci AI (@deci_ai) 的推文: 我们回来了,并很高兴地宣布两个新模型:DeciCoder-6B 和 DeciDiffuion 2.0!🙌 以下是简介:DeciCoder-6B 📋 ✅ 一个支持 8 种编程语言的多语言 codeLLM。 ✅ Rel…
-
Blaze (Balázs Galambosi) (@gblazex) 的推文: @MSFTResearch 发布了新的 SOTA 编程模型,HumanEval 评分 81.7 且仅有 6.7B 参数!(对比 GPT4 的 85.4)我想只有精简版的数据集会开源。但相关技术已在论文中阐述。精简版 vs …
-
Stable Code 3B: 边缘侧编程 — Stability AI: Stable Code 是 Stable Code Alpha 3B 的升级版,专注于代码补全,在效率和多语言支持方面超越了前代产品。它兼容标准笔记本电脑,包括…
-
Meet: Google 提供的实时会议。使用您的浏览器与团队成员和客户分享视频、桌面和演示文稿。
-
Div Garg (@DivGarg9) 的推文: 我们刚刚解决了 Agents 的长程规划与执行问题 🤯!很高兴地宣布 @MultiON_AI 现在可以执行超过 500+ 步的操作而不会丢失上下文,并能在 10…
-
Omar Sanseviero (@osanseviero) 的推文: 剧透预警:这可能是自 Code Llama 以来,对于 code LLMs 来说最令人兴奋的一周之一。
-
FastChat/fastchat/llm_judge/README.md at main · lm-sys/FastChat: 一个用于训练、部署和评估大型语言模型的开放平台。Vicuna 和 Chatbot Arena 的发布仓库。 - lm-sys/FastChat
-
Andriy Burkov (@burkov) 的推文: 如果你真的想在 AI 领域做点有用的事情,与其训练另一个 tiny llama,不如接手这个项目 https://hazyresearch.stanford.edu/blog/2024-01-11-m2-bert-retrieval 并训练一个 1B 参数…
-
GitHub - evalplus/evalplus: 用于对 LLM 合成代码进行严格评估的 EvalPlus: 用于对 LLM 合成代码进行严格评估的 EvalPlus - GitHub - evalplus/evalplus: 用于对 LLM 合成代码进行严格评估的 EvalPlus
-
GitHub - draganjovanovich/sharegpt-vim-editor: sharegpt jsonl vim 编辑器: sharegpt jsonl vim 编辑器。通过在 GitHub 上创建账号来为 draganjovanovich/sharegpt-vim-editor 的开发做出贡献。
▷ #ask-about-llms (40 条消息🔥):
-
AI 模型速度与效率的探索:
@realsedlyf询问了 OpenHermes2.5 gptq 配合 vllm 与使用 transformers 相比的性能表现,想知道是否更快。 -
代码生成模型基准测试:
@leontello提出了关于值得信赖的代码生成基准测试和排行榜的问题,而@night_w0lf指向了通用频道最近的一篇帖子,该帖子显然包含相关信息,但未提及具体 URL。 -
多模态模型 vs. 传统 OCR 用于多语言发票分析:
@.beowulfbr建议他们的朋友尝试 Tesseract OCR 作为 Qwen-VL 等多模态模型的替代方案,指出 OCR 在准确性方面更具优势,特别是对于各种语言的发票。 -
OCR 在文本识别方面优于多模态模型:
@bernaferrari和@n8programs讨论了 LLM 在图像识别方面的局限性,认为虽然 GPT-4 Vision 展现了潜力,但传统的 OCR 系统在读取车牌等任务上仍然更有效。 -
DeepMind 的 AlphaGeometry 引发了兴趣与幽默的碰撞:
@bernaferrari分享了 DeepMind 关于 AlphaGeometry 的最新研究,社区反应各异,从 teknium 拿自己的数学水平开玩笑,到@mr.userbox020将该系统比作 LLM 和 code interpreter 架构的结合。
提到的链接:
-
AlphaGeometry: An Olympiad-level AI system for geometry:我们的 AI 系统在几何问题上超越了现有最先进的方法,推进了数学领域的 AI 推理。
-
GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository):Tesseract 开源 OCR 引擎(主仓库) - GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine (main repository)
Mistral Discord 总结
-
LLM API 对比平台:
@_micah_h介绍了一个新网站,提供 Mistral 7B Instruct 和 Mixtral 8x7B Instruct 等模型的不同托管 API 之间的对比,重点关注技术指标评估。分享了 Mistral 7B Instruct 和 Mixtral 8x7B Instruct 的平台信息,以及用于更新的 Twitter 页面。 -
Mistral 模型的冗余度与 Token 问题:用户在 models 频道讨论了 Mistral 回复过于冗余的挑战,以及在聊天模板中正确使用 bos_token 的问题。正确集成 Token 似乎不会显著影响模型评分;然而,冗余问题已得到确认并正在解决。
-
微调的各个方面与障碍:finetuning 频道交流了诸如在没有
tokenizer.model的情况下为分词器使用--vocabtype bpe、为 instruct 模型微调格式化数据集,以及微调模型无法保留先前任务知识等挑战。 -
Deep Chat 与 Mistral 性能优化:Deep Chat 允许使用本地资源直接在浏览器中运行 Mistral 等模型,其开源项目可在 GitHub 上找到。同时,FluxNinja Aperture 在 showcase 频道被介绍为并发调度解决方案,详情见其博客文章。
-
Mistral-7B Instruct 部署动态:Mistral-7B Instruct 模型的推出已在 la-plateforme 频道发布,引导用户关注 artificialanalysis.ai 团队,特别是在推特更新之后。该模型的分析可以在 ArtificialAnalysis.ai 找到。
Mistral 频道总结
▷ #general (76 条消息🔥🔥):
-
LLM API 提供商的新对比网站:
@_micah_h发布了一个网站,用于对比 Mistral 7B Instruct 和 Mixtral 8x7B Instruct 等模型的不同托管 API,为 Mistral 7B 和 Mixtral 8x7B 提供了分析平台。同时分享了用于获取更新的 Twitter 页面。 -
讨论 Perplexity AI 的定价来源和限制:
@_micah_h针对 Perplexity AI 的输入 token 定价进行了讨论,指出了一份更新日志说明,显示 13B 定价已被移除,同时也同意@blueridanus的观点,即 4k 的限制有些不公平。 -
讨论 Mistral 的本地部署和免费版本:
@rozonline询问了 Mistral 的免费版本,@blueridanus建议在本地部署或尝试 Perplexity AI 的 playground 以获取一些免费额度。 -
在 Mistral 文档中添加第三方 PHP 客户端:
@gbourdin请求在 Mistral 的客户端文档页面中提及一个可在 GitHub 上获取的 Mistral API PHP 客户端库。 -
关于 Mistral AI 隐私和数据处理的公开资源:
@ethux向@khalifa007提供了 Mistral AI 隐私政策和数据处理协议的链接,以获取有关个人数据处理的信息。
提到的链接:
-
LLM in a flash: Efficient Large Language Model Inference with Limited Memory:大语言模型 (LLMs) 是现代自然语言处理的核心,在各种任务中表现卓越。然而,它们巨大的计算和内存需求…
-
隐私政策:掌握前沿 AI
-
[Mistral AI 开放权重模型](https://mistral.ai/):掌握前沿 AI -
数据处理协议:掌握前沿 AI
-
LMSys Chatbot Arena Leaderboard - lmsys 提供的 Hugging Face Space
-
Mixtral of Experts:我们推出了 Mixtral 8x7B,这是一种稀疏混合专家 (SMoE) 语言模型。Mixtral 与 Mistral 7B 具有相同的架构,不同之处在于每一层由 8 个前馈块组成…
-
Self-Consuming Generative Models Go MAD:图像、文本和其他数据类型的生成式 AI 算法的地震式进步,导致人们倾向于使用合成数据来训练下一代模型。重复这一过程会产生…
-
[The Great Web AI Enshitification DearDiary](https://ker2x.github.io/DearDiary/web-enshitification.html) -
[客户端代码 Mistral AI 大语言模型](https://docs.mistral.ai/platform/client/):我们提供 Python 和 Javascript 的客户端代码。 -
GitHub - partITech/php-mistral: MistralAi PHP 客户端:MistralAi PHP 客户端。通过在 GitHub 上创建账户来为 partITech/php-mistral 的开发做贡献。
-
[Mistral 7B - 托管分析 ArtificialAnalysis.ai](https://artificialanalysis.ai/models/mistral-7b-instruct):对 Mistral 7B Instruct 的各项指标进行分析,包括质量、延迟、吞吐量、价格等。 -
[Mixtral 8x7B - 托管分析 ArtificialAnalysis.ai](https://artificialanalysis.ai/models/mixtral-8x7b-instruct):对 Mixtral 8x7B Instruct 的各项指标进行分析,包括质量、延迟、吞吐量、价格等。
▷ #models (71 条消息🔥🔥):
-
Mistral 的冗长回复困扰用户:用户
@rabdullin报告称,Mistral 的托管模型未能遵守 few-shot prompts 中提供的简洁指令,这与 Mistral 7B Instruct v1 等本地模型的行为形成对比。作为回应,@sophiamyang分享说 Mistral 模型的冗长(verbosity)是一个已知问题,团队正在积极开发修复方案。 -
格式化困局:关于在 chat template 中正确使用 bos_token 产生了困惑。
@rabdullin最初认为 Mistral API 可能因为他的模板将 bos_tokens 放在循环内而导致 tokenize 错误。然而,@sophiamyang澄清说 Mistral 模型期望 bos_token 仅在开头出现一次,这促使@rabdullin调整了模板,并发现虽然冗长问题依然存在,但更改 token 位置对模型评分没有显著影响。 -
Benchmark 忧虑:
@rabdullin渴望将 Mistral 模型与来自产品和服务的闭源 benchmark 进行对比,并提到了版本间排名的差异以及影响评分的意外冗长问题。@sophiamyang征求了可以由 Mistral 团队共享和调查的示例。 -
Template 烦恼:
@rabdullin询问了他的模板格式错误可能带来的影响,这引发了关于** 和 **tokens 在 prompt 设计中作用的反复讨论。对 GitHub Llama_2 tokenizer 的参考似乎与@rabdullin的结构一致,但该格式是否影响了 API 行为仍未解决。 -
模型误认:关于是否存在 Mistral 13B 模型存在一些困惑,这是由
@dfilipp9关注的一个外部硬件指南引起的,该指南列出了一个所谓的 MistralMakise-Merged-13B-GGUF 模型。@rabdullin指出仅存在 Mistral 7B 或 8x7B 模型,并且它们可以在 HuggingFace 上获取。
提到的链接:
-
tokenizer_config.json · mistralai/Mistral-7B-Instruct-v0.2 at main
-
tokenizer_config.json · mistralai/Mixtral-8x7B-Instruct-v0.1 at main
-
Mistral LLM: All Versions & Hardware Requirements – Hardware Corner
-
[2-Zylinder-Kompressor Twister 3800 D AGRE ZGONC](https://www.zgonc.at/at/pd/2-Zylinder-Kompressor-Twister-3600-D_p_19489%22)): Kompressoren Bei ZGONC kaufen! 2-Zylinder-Kompressor Twister 3800 D, AGRE Spannung in Volt: 400, Leistung in Watt: 3.000,… - Raunz´ned - kauf
▷ #finetuning (33 条消息🔥):
-
Tokenizer 问题已解决:用户
@ethux确认,对于缺少tokenizer.model的 AquilaChat 模型,解决方法是在运行convert.py时使用--vocabtype bpe。这一建议帮助@distro1546成功量化了他们微调后的 AquilaChat 模型。 -
闲聊并非儿戏:
@distro1546遇到微调后的 Mistral 表现不像“助手”的问题,并从@ethux处得知普通模型不适合聊天。他们正考虑改为微调 instruct 版本。 -
转换 Transformer:
@distro1546还报告了文本持续生成直到手动中断的问题,并寻求解决建议,此外还询问了如何使用基础模型将 LoRA 模型与 Mistral Instruct 合并。 -
格式技巧:
@distro1546寻求关于微调 instruct 模型的数据集格式说明,@denisjannot建议正确格式为[INST]question[/INST]answer</s>,且开头不带<s>token。 -
微调挫败:
@kam414寻求帮助,解决其微调模型在学习新任务后无法保留旧任务知识的问题,尽管数据集只有 200 行,但导致了不理想的 loss 指标。
相关链接:
-
Add mistral’s new 7B-instruct-v0.2 · Issue #1499 · jmorganca/ollama:随着多个版本的发布,Mistral 通过名为 v0.2 的版本大幅改进了其现有的 7B 模型。它具有 32k 上下文(而非 8k)以及更好的基准测试分数:https://x.com/dchaplot/status/1734…
-
TheBloke/AquilaChat2-34B-AWQ · FileNotFoundError - 找不到 tokenizer.model 文件
-
在 llama2 中找不到 tokenizer.model · Issue #3256 · ggerganov/llama.cpp:当我运行此命令时:python convert.py \ llama2-summarizer-id-2/final_merged_checkpoint \ –outtype f16 \ –outfile llama2-summarizer-id-2/final_merged_checkpoint/llama2-summarizer-id-2.gguf.fp…
-
如何使用 Hugging Face AutoTrain 微调 Mistral AI 7B LLM - KDnuggets:了解如何微调最先进的 LLM。
▷ #showcase (6 条消息):
-
Deep Chat 在浏览器中直接集成 LLM:用户
@ovi8773分享了名为 Deep Chat 的开源项目,该项目允许在浏览器上运行像 Mistral 这样的 LLM,无需服务器。分享了 Deep Chat GitHub Repo 和 Playground 供用户体验该 Web 组件。 -
对浏览器内 LLM 的由衷兴奋:
@gbourdin对@ovi8773介绍的在浏览器上运行 LLM 的潜力表示兴奋。 -
浏览器内加速说明:
@Valdis询问 “Deep Chat” 的工作原理,@ovi8773确认 LLM 通过浏览器在本地机器上进行 inference,并使用了 Web Assembly 和硬件加速。 -
强调 Mistral AI 的并发挑战:用户
@tuscan_ninja撰写了一篇博文,讨论了 Mistral 7B 模型 当前面临的并发和 GPU 限制挑战。他们介绍了 FluxNinja Aperture 作为一种提供并发调度和请求优先级排序的解决方案,以提高性能 (FluxNinja Blog Post)。 -
用户寻求版主角色信息:用户
@tominix356提到了@707162732578734181以查询版主角色,未提供更多上下文。
相关链接:
-
[在 Mistral 中通过并发调度平衡成本与效率 FluxNinja Aperture](https://blog.fluxninja.com/blog/concurrency-scheduling-in-mistral-ai):FluxNinja Aperture 的并发调度功能可有效降低运行 Mistral 的基础设施成本,同时确保最佳性能和用户体验。 -
GitHub - OvidijusParsiunas/deep-chat: 为您的网站提供完全可定制的 AI 聊天机器人组件:为您的网站提供完全可定制的 AI 聊天机器人组件 - GitHub - OvidijusParsiunas/deep-chat
-
[Playground Deep Chat](https://deepchat.dev/playground):Deep Chat Playground
▷ #la-plateforme (5 条消息):
-
模型输出的实用 Python 技巧:用户
@rabdullin分享了一个处理模型响应的实用技巧:在response对象上使用model_dump进行导出,如果想保存为 JSON,可以传入mode="json"。 -
Anyscale 性能基准测试:用户
@freqai对 Anyscale 的性能发表了评论,指出他们很少看到接近那些数值的表现,Anyscale 的平均值更接近 2。 -
关于共享图表的澄清:
@sublimatorniq澄清说,他们之前分享的图表不是他们原创的,本应提供来源。 -
Mistral-7B Instruct 发布:
@sublimatorniq宣布了 Mistral-7B Instruct 模型的发布,并鼓励关注 Twitter 上的 artificialanalysis.ai 小组以获取未来更新。该信息的来源是另一个频道 ID 为#1144547040928481394的帖子。
提到的链接:
| [Mistral 7B - 主机分析 | ArtificialAnalysis.ai](https://artificialanalysis.ai/models/mistral-7b-instruct):对 Mistral 7B Instruct 在质量、延迟、吞吐量、价格等指标上的分析。 |
HuggingFace Discord Discord 摘要
-
对仓库警报的快速响应:针对 仓库元数据问题 (repository metadata issue) 立即应用了修复,用户确认已解决。这缓解了早些时候关于仓库出现 “400 metadata is required” 错误消息的担忧。
-
BERT 和 NER 迎来微调改进:分享了正确标记 BERT 配置的解决方案以及 NER 数据集创建的详细指导。用户讨论了
#token 的处理以及 BERTconfig.json中正确标记的重要性。 -
利用深度学习实现多样化应用:从 AR 碰撞检测 (hit-testing) 资源和自动转录,到 AI 驱动的学校笔记工具和跨模态广告推荐,讨论涵盖了现有模型的创新应用。提出了关于
Deci/DeciLM-7B和phi-2等大型语言模型超时问题的担忧,并建议以管理员身份运行 Python 并使用gpt2等较小模型进行测试。 -
模型服务与部署的演进:发出了 ML 模型服务网络研讨会 的邀请,内容涵盖 ML 和 LLM 的部署。用户探索了在 HuggingFace Spaces 上部署多栈应用、通过模型链 (chaining models) 提高性能,以及部署注重隐私的本地 LLM 助手。
-
微调与数据集共享的新前沿:成员们分享了资源,包括一个新的用于视觉问答 (Visual Question Answering) 的多模态数据集,以及使用 LLM 进行本体学习 (ontology learning) 的进展。关注点集中在
train_sd2x.py等模型的微调脚本上,一名用户为 Stable Diffusion 2.x 添加了未经测试的 LoRA 支持。提到了 SimpleTuner 等项目对模型完善的贡献。
HuggingFace Discord 频道摘要
▷ #general (84 条消息🔥🔥):
-
Repository Metadata 问题快速修复:
@lunarflu确认了仓库中出现的 “400 metadata is required” 问题并着手修复。@jo_pmt_79880在幽默地提到最初的恐慌后,确认该问题已迅速解决。 -
BERT 标签修复与微调:
@Cubie | Tom为@redopan706提供了在 BERT 的config.json中使用正确标签而非LABEL_0, LABEL_1的解决方案。@stroggoz还为@redopan706提供了关于 NER 数据集创建的数据结构化以及输出中#token 处理的详细指导。 -
多模型架构的部署与利用:用户讨论了如何在 HuggingFace Spaces 上部署多栈应用,
@thethe_realghost寻求了相关帮助。@vishyouluck询问了关于模型链(model chaining)的建议,并分享了关于模型性能以及在图像输出中使用 “refiner” 的经验。 -
各种任务的模型推荐:
@zmkeeney咨询了关于 text-to-text 任务的模型,@doctorpangloss提供了详尽的回答,涉及模型在市场调研、网站开发、品牌创建及咨询公司支持方面的适用性。 -
AI 驱动的笔记记录咨询:
@blakeskoepka询问了适用于学校的 AI 笔记工具,@hoangt12345随后给出了一个简洁的建议,即利用课堂录音和自动转录(transcriptions)。
提到的链接:
-
加入 Pareto.AI 的屏幕录制团队:我们正在寻找熟练的内容创作者(Windows 用户),为 AI 训练录制他们已经精通或掌握的操作活动。
-
config.json · yy07/bert-base-japanese-v3-wrime-sentiment at main
-
config.json · yy07/bert-base-japanese-v3-wrime-sentiment at main
▷ #today-im-learning (4 条消息):
-
ML 模型服务网络研讨会邀请:
@kizzy_kay分享了一个名为 “A Whirlwind Tour of ML Model Serving Strategies (Including LLMs)” 的网络研讨会邀请,定于 PST 时间 1 月 25 日上午 10 点举行,由来自 Seldon 的 Ramon Perez 主讲。该活动免费但需注册,将涵盖传统 ML 和 LLM 的部署策略。 -
初学者关于学习 ML 的提问:
@mastermindfill寻求开始学习机器学习的指导,并提到他们已经开始观看 3blue1brown 的 ML 系列视频。在给定的消息历史中没有提供进一步的建议或回复。
提到的链接:
网络研讨会 “A Whirlwind Tour of ML Model Serving Strategies (Including LLMs)” · Luma:Data Phoenix 团队邀请大家参加即将于 PST 时间 1 月 25 日上午 10 点举行的网络研讨会。主题:A Whirlwind Tour of ML Model Serving Strategies (Including…
▷ #cool-finds (8 条消息🔥):
-
注重讽刺与隐私的本地 LLM 助手:
@tea3200推荐了一篇关于设置本地 LLM 助手的博客文章 Local LLM Assistant,该助手无需云服务即可运行,专注于隐私保护并能灵活添加新功能。 -
VQA 数据集现已上线 Hugging Face:
@andysingal为 Hugging Face 社区贡献了一个用于视觉问答(visual question answering)的多模态数据集(Multimodal Dataset),该数据集最初源自 Mateusz Malinowski 和 Mario Fritz。你可以通过以下链接访问该数据集:Andyrasika/VQA-Dataset。 -
Ollama:AI 交互 API:
@andysingal分享了一个 Ollama API 的 GitHub 仓库,允许开发者部署 RESTful API 服务器以与 Ollama 和 Stable Diffusion 进行交互。Ollama API on GitHub。 -
AlphaGeometry:面向奥数级几何题的 AI 系统:
@tea3200关注了 DeepMind 的新 AI 系统 AlphaGeometry,它擅长解决复杂的几何问题。DeepMind 在此处发布了相关的研究博客文章。 -
基于 LLM 的本体学习(Ontology Learning):
@davidello19推荐了一篇关于使用 LLM 进行本体学习的 arXiv 论文 LLMs for Ontology Learning,并分享了一篇关于同一主题的更通俗易懂的文章 Integrating Ontologies with LLMs。 -
利用 Juggernaut XL 提升 AI 表现:
@rxience提到在他们实现的 Hugging Face Space 中,通过将 Juggernaut XL 与优秀的 Prompt 结合,提升了性能。可以在此处查看。
提及的链接:
-
H94 IP Adapter FaceID SDXL - r-neuschulz 的 Hugging Face Space
-
AlphaGeometry:一个面向几何问题的奥数级 AI 系统:我们的 AI 系统在几何问题上超越了现有最先进的方法,推动了数学领域的 AI 推理。
-
构建一个完全本地化的 LLM 语音助手来控制我的智能家居:我曾使用过 Siri 和 Google Assistant。虽然它们有能力控制你的设备,但无法自定义且本质上依赖云服务。为了学习一些东西……
-
GitHub - Dublit-Development/ollama-api:部署 RESTful API 服务器以与 Ollama 和 Stable Diffusion 交互:部署 RESTful API 服务器以与 Ollama 和 Stable Diffusion 交互 - GitHub - Dublit-Development/ollama-api: Deploy a RESTful API Server to interact with Ollama and Stable Diffusion
-
将本体(Ontologies)与大语言模型(LLMs)集成用于决策:本体与大语言模型(LLMs)的交汇正在为决策工具开辟新视野。利用独特的……
▷ #i-made-this (6 条消息):
-
CrewAI 获得自动化增强:
@yannie_分享了他们的 GitHub 项目,该项目可以在 CrewAI 中自动创建团队和任务。点击此处查看仓库。 -
Instill VDP 进入公开测试阶段:
@xiaofei5116宣布 Instill VDP 现已在 Product Hunt 上线。这个多功能数据流水线提供了一个开源、无代码/低代码的 ETL 解决方案,详情请见其 Product Hunt 页面。 -
Instill VDP 获得好评:
@shihchunhuang对 Instill VDP 项目表示赞赏,认为这是一个了不起的倡议。 -
多模态 VQA 数据集可用:
@andysingal提到将 Mateusz Malinowski 和 Mario Fritz 的多模态数据集添加到他们的仓库中供社区使用。可以在 HuggingFace 的此处找到,请确保注明原作者。 -
创新的 FaceID Space 创建:
@rxience发布了一个 HuggingFace Space,允许将面部结构零样本(zero-shot)迁移到新提示生成的肖像上,并邀请他人测试 FaceID SDXL space。
提及的链接:
-
H94 IP Adapter FaceID SDXL - r-neuschulz 创建的 Hugging Face Space
-
GitHub - yanniedog/crewai-autocrew: 在 CrewAI 中自动创建团队和任务:在 CrewAI 中自动创建团队和任务。欢迎通过在 GitHub 上创建账户来为 yanniedog/crewai-autocrew 的开发做出贡献。
-
[Instill VDP - 面向 AI 优先应用的开源非结构化数据 ETL Product Hunt](https://www.producthunt.com/posts/instill-vdp):多功能数据流水线 (VDP):一个用于快速创建 AI 工作流的开源、无代码/低代码解决方案。它处理非结构化数据,确保高效的数据连接、灵活的流水线以及流畅的…
▷ #reading-group (2 条消息):
- 探索 LLM 在法律领域的应用:
@chad_in_the_house表达了对在法律环境(如协助律师或法官)中集成 Large Language Models (LLMs) 的兴趣。@gduteaud也认为这是一个非常有趣的话题。
▷ #diffusion-discussions (12 条消息🔥):
-
寻求广告推荐数据集:
@andysingal询问了适用于广告推荐的数据集,包括文本、图像和视频。然而,目前尚未收到回复或建议。 -
指向微调脚本:
@sayakpaul请求提供微调脚本的指引,@pseudoterminalx回复称该脚本名为train_sd2x.py。 -
SD 1.5/2 的 t2i-adapter 训练脚本不可用:
@square1111询问了适用于 Stable Diffusion 1.5/2 版本的 t2i-adapter 训练脚本,随后指出该版本尚未实现,并引用了 Hugging Face Diffusers GitHub 仓库。 -
印度美食微调计划中:
@vishyouluck表达了使用 GitHub 上的 SimpleTuner 对 Diffusion 模型进行印度菜谱和食材知识微调的意图。@pseudoterminalx建议尝试使用 LoRA 方法配合 SDXL 1.0。 -
已添加对 SD 2.x 的 LoRA 支持:
@pseudoterminalx提到他们已经添加了对 Stable Diffusion 2.x 的 LoRA 支持,但也指出尚未进行测试,并提到验证可能无法按预期工作。
提及的链接:
-
diffusers/examples/t2i_adapter at main · huggingface/diffusers:🤗 Diffusers:PyTorch 中用于图像和音频生成的尖端 Diffusion 模型 - huggingface/diffusers
-
GitHub - bghira/SimpleTuner: 一个针对 Stable Diffusion 2.1 和 SDXL 的通用微调工具包。:一个针对 Stable Diffusion 2.1 和 SDXL 的通用微调工具包。 - GitHub - bghira/SimpleTuner: A general fine-tuning kit geared toward Stable Diffusion 2.1 and SDXL.
▷ #computer-vision (1 messages):
- 寻找 AR 碰撞检测(Hit-Testing)见解:用户
@skibbydoo询问了关于 AR (Augmented Reality) 碰撞检测如何实现的资源,特别是与移动设备上的平面检测(plane detection)和实时网格划分(real-time meshing)相关的资源。他们的搜索目前尚未获得实质性信息。
▷ #NLP (53 messages🔥):
-
@kingpoki 的 LLM 设置困扰:@kingpoki 正在努力让任何大型语言模型在 Python 中与 Hugging Face Transformers 配合使用,遇到了超时错误且没有抛出明确的异常。他们尝试使用了
Deci/DeciLM-7B和phi-2等模型,系统配置强劲,不太可能是硬件问题。 -
与 @vipitis 进行故障排除:@vipitis 参与了故障排除,建议了各种修复方案,如更新
accelerate和huggingface_hub,以管理员身份运行 Python,以及尝试gpt2等较小的模型。讨论了多个其他途径,例如避免覆盖 stderr、减少max_new_tokens以及验证 CPU inference 是否正常工作,但到最后仍未报告解决方案。 -
@dtrifuno 的字幕同步咨询:@dtrifuno 寻求关于如何将高质量的人工转录文本与包含时间戳的模型生成语音转录进行匹配的建议。在现有的消息记录中没有提供确定的解决方案。
-
@cornwastaken 关于上下文窗口(Context Window)限制的问题:@cornwastaken 询问是否有资源或仓库详细列出了大型语言模型的上下文窗口长度,用于涉及大型文档和问答(question answering)的使用场景。消息记录中没有对此问题的回复。
-
@theintegralanomaly 的 Docker 设置查询:@theintegralanomaly 询问如何预下载 HuggingFace embeddings 模型数据,以避免在新 Docker 容器中出现较长的初始化时间。@Cubie Tom 建议了一个潜在的工作流,包括 git clone、将模型合并到 Docker 镜像中,并指示应用程序使用本地文件。
提到的链接:
-
为开发启用您的设备 - Windows 应用:在您的电脑上激活开发人员模式以开发应用。
▷ #diffusion-discussions (12 messages🔥):
-
寻找多样化的广告数据集:用户
@andysingal询问了包含 文本、图像和视频 格式的广告推荐数据集。 -
指向微调(Fine-tuning)脚本:
@sayakpaul寻求微调脚本的帮助,建议使用@pseudoterminalx的train_sd2x.py脚本。 -
t2i-adapter 训练脚本缺乏 1.5/2 支持:
@square1111分享了一个发现,即 t2i-adapter 训练脚本 不支持 sd1.5/2,并链接到了 GitHub 仓库 作为参考。 -
为印度美食图像进行微调:
@vishyouluck表达了使用 SimpleTuner 为印度食谱和食材微调 diffusion model 的意图,并寻求关于合适基础模型的建议。@pseudoterminalx提供的建议是使用 sdxl 1.0 并考虑使用 LoRA。 -
未经验证的 SD 2.x LoRA 支持:
@pseudoterminalx提到为 Stable Diffusion 2.x 添加了 LoRA 支持,但警告称其未经测试,验证可能会失败。
提到的链接:
-
diffusers/examples/t2i_adapter at main · huggingface/diffusers:🤗 Diffusers:PyTorch 中用于图像和音频生成的先进扩散模型 - huggingface/diffusers
-
GitHub - bghira/SimpleTuner: A general fine-tuning kit geared toward Stable Diffusion 2.1 and SDXL.:一个面向 Stable Diffusion 2.1 和 SDXL 的通用微调工具包。- GitHub - bghira/SimpleTuner: A general fine-tuning kit geared toward Stable Diffusion 2.1 and SDXL.
OpenAI Discord 总结
GPT 的否定指令挑战在开发者活动中引发讨论:在一次活动中,一位开发者的见解引起了 @darthgustav. 的共鸣,即 AI 在处理 否定提示词 (negation prompts) 时存在问题,往往会忽略否定词,从而导致潜在错误。
GPT Assistant 是否会加入免费层级?:@mischasimpson 根据观看的直播教程暗示,GPT assistant 可能很快就能免费使用,这表明 OpenAI 的免费层级 (free tier) 可能会引入更先进的 AI 工具。
利用 GPT 定制教育内容:用户 @mischasimpson 和 @darthgustav. 讨论了使用 GPT 为儿童生成个性化阅读练习,涉及流程的简便性以及跟踪完成情况和表现的潜力。
神秘的 GPT-4.5 Turbo 奇案:在一场充满猜测的对话中,@okint 认为自己遇到了名为 “gpt-4.5-turbo” 的 AI 版本。然而,@7877 和 @luarstudios 等人迅速提醒社区要警惕 AI 可能存在的虚构行为,因为该版本可能并不存在。
管理对 GPT 能力的预期:用户 @solbus 和 @.bren_._ 澄清了 Custom GPTs 的实际工作原理,消除了它们可以直接在 知识文件 (knowledge files) 上进行训练的误解,并解释说真正的模型训练需要使用 OpenAI 的服务或从头开始构建大语言模型。
OpenAI 频道总结
▷ #ai-discussions (47 条消息🔥):
-
解决 GPT 模型幻觉问题:
@lugui提到,将 AI 引用系统内部信息称为“泄露”有些夸大其词,因为这些信息是公开的。他们澄清说 AI 并不知晓自己的 IP 或服务器 IP,它提供的任何此类信息都很可能是幻觉 (hallucination)。 -
澄清 Custom GPT 网页浏览功能:针对
@luarstudios关于网页浏览能力的问题,讨论暗示了对 AI 功能的潜在误解,指出它可能无法直接访问外部资源。 -
LAM (Large Action Model) 热度与后端推测:
@exx1将 “Large Action Model” 描述为一个结合了多种模型(包括具有视觉能力的 GPT 系列)的营销术语,并推测其后端可能使用了 OpenAI 模型。 -
对 GPT-4.5 的热情与怀疑:
-
虽然
@michael_6138_97508就微调 (fine-tuning) 选项和使用 Kaggle 等来源的数据集向@murph12f提供了建议,但@lugui确认了使用书籍进行微调的可能性。 -
在另一个话题中,
@okint坚信自己遇到了 “gpt-4.5-turbo”,但@7877等人提醒他们,AI 容易编造信息,而且该版本可能尚不存在。
-
-
关于删除消息的 Discord 机器人讨论:
@names8619询问是否可以使用 ChatGPT premium 来删除 Discord 帖子,@7877建议开发一个 Discord 机器人,同时警告说 YouTube 视频中展示的未经授权的方法可能会导致封号。
提到的链接:
如何批量删除 Discord 消息:在此视频中,我将向你展示如何使用 UnDiscord 批量删除私聊、频道、服务器等中的 Discord 消息,这是一个简单的扩展程序,允许你…
▷ #gpt-4-discussions (43 条消息🔥):
-
关于 GPT 对话刷新时间的困惑:
@7877向@elegante94澄清,下一次 GPT 对话的冷却时间是 每 3 小时,而不是每小时,解决了关于更新频率的困惑。 -
寻找 AI 笔记应用:经过讨论,针对
@blakeskoepka寻找适用于学校的 AI 笔记应用的需求,@satanhashtag推荐了特定的频道<#998381918976479273>。 -
给 GPT 命名的风险:
@ufodriverr对他们的 GPT —— Unity GPT 被封禁表示沮丧,这可能是由于商标问题且没有明确的申诉途径,尽管他们努力解决该问题并观察到其他名称类似的 GPT 并未被封禁。 -
解释 GPT 和知识文件的局限性:
@solbus纠正了误解,解释说 Custom GPTs 并不是在 知识文件 (knowledge files) 上进行训练,而是可以引用它们;真正的模型训练需要访问 OpenAI 的微调 (fine-tuning) 服务或从头开始训练你自己的大语言模型。 -
GPT Builder 的误导与学习曲线:
@.bren_._指出,尽管最初有此类说法,但 GPT Builder 实际上并不会对 zip 文件中的 PDF 进行训练,这引发了关于 ChatGPT 能力以及如何实现 自定义行为 (custom behaviors) 的讨论。
▷ #prompt-engineering (31 messages🔥):
-
关于否定提示词的意外共识:
@darthgustav.表示,很高兴看到一位开发者在 GPT 活动上呼应了他们的担忧,特别是关于模型倾向于忽略提示词中的否定词(negations),从而导致不理想行为的问题。 -
GPT Assistant 可能会免费:
@mischasimpson在观看直播教程时分享了见解,暗示 GPT Assistant 最终可能会在免费层级(free tier)开放。 -
利用 GPT 增强阅读实践:
@mischasimpson和@darthgustav.讨论了使用 GPT 为学生创建定制阅读作业,@darthgustav.建议保持简单,并表示愿意为该项目提供帮助。 -
提示词编写挑战:
@kobra7777询问如何确保 ChatGPT 遵循完整的提示词,@darthgustav.解释说该模型的目标输出大约为 1k tokens,对于较长的任务可能需要额外的指令。 -
使用 GPT 测试任务管理:
@sugondese8995分享了示例并寻求改进为任务管理构建的自定义 GPT 的测试方法,而@rendo1则要求澄清所需的改进方向。
▷ #api-discussions (31 messages🔥):
-
开发者活动上的意外共鸣:用户
@darthgustav.对一位开发者重复了他们关于 negative prompts 及其挑战的评论感到惊讶,强调 AI 可能会忽略否定词,反而执行不想要的行为。 -
对 GPT Assistant 的期待:
@mischasimpson提到观看了一个关于 GPT Assistant 的直播教程,其中暗示其有可能向 免费层级 开放。 -
为儿童编写自定义阅读提示词:
@darthgustav.和@mischasimpson讨论了如何为家长创建一种简便的方法,利用 OpenAI 的工具为孩子生成阅读练习。提到了复杂性和跟踪问题,包括如何知道 AI 生成的任务何时完成,以及孩子的表现如何。 -
为自定义 GPT 编写测试提示词:
@sugondese8995分享了他们使用 ChatGPT 为专为 task management 设计的自定义 GPT 构建测试提示词和预期输出的方法,并寻求改进建议。 -
寻求更好的 GPT 提示词遵循效果:
@kobra7777询问了确保 GPT 遵循完整提示词 的策略。@darthgustav.提供了见解,提到了模型的近似 token 输出目标以及管理较长请求的策略。
Latent Space Discord 摘要
-
字节跳动发布四款 AI 应用:据 Emily Baker-White 在 Forbes 报道,字节跳动推出了四款由 OpenAI 语言模型 驱动的新 AI 应用:Cici AI、Coze、ChitChop 和 BagelBell。
-
AutoGen UI 增强 Agent 创建:AutoGen Studio UI 2.0 已发布,其增强的界面有助于自定义 Agent 的创建,正如 YouTube 教程 中演示的那样。
-
Artificial Analysis 对 AI 模型进行测试:新的 Artificial Analysis 基准测试网站允许用户比较 AI 模型和托管服务商,重点关注价格与延迟之间的平衡,该内容在 Twitter 帖子 中进行了讨论。
-
编程 AI 的演进:来自 Codium AI 的 AlphaCodium 代表了代码生成模型的新飞跃,而来自 lmsys 的 SGLang 引入了创新的 LLM 接口和运行时,正如 lmsys 博客 所述,其性能可能提升高达 5 倍。
-
通过 SPIN 让你的 LLM 由弱变强:一种名为 Self-Play fIne-tuNing (SPIN) 的新型微调方法通过自生成数据增强 LLM,如 这篇论文 所述,能有效提升其能力。
-
ICLR 接收 MoE 论文作为 Spotlight:一篇关于 Mixture of Experts (MoE) 和专家合并(expert merging)的论文 MC-SMoE 已被 ICLR 接收并作为 Spotlight 展示,该论文提出了显著的资源效率改进,点击此处阅读。
Latent Space 频道摘要
▷ #ai-general-chat (17 条消息🔥):
-
字节跳动发布新款 AI 应用:
@coffeebean6887分享了一篇 Forbes 文章,透露 TikTok 的母公司 ByteDance 推出了四款名为 Cici AI, Coze, ChitChop 和 BagelBell 的新 AI 应用。Emily Baker-White 的文章讨论了这些应用的功能以及它们对 OpenAI 语言模型 的依赖。 -
AutoGen UI 2.0 发布:
@swyxio提到了 AutoGen Studio UI 2.0 的发布,并提供了一个 YouTube 链接,视频标题为“AutoGen Studio UI 2.0:创建自定义 Agent 的最简单方法”。 -
Artificial Analysis 发布重磅基准测试:
@swyxio重点介绍了一个 Twitter 帖子,讨论了一个名为 Artificial Analysis 的新 AI 基准测试对比网站。该网站对比了模型和托管提供商,帮助用户在价格与延迟之间做出最佳权衡。 -
从语法到语义——代码的未来?:在的一篇引人入胜的 博客文章 中,
@fanahova思考了编程从语法向语义的转变,并质疑是否每个人都会成为 AI 工程师。 -
下一代代码生成模型即将问世:
@swyxio在聊天中私下透露了 AlphaCodium,这是由 Codium AI 开发的一种新型最先进的代码生成模型。目前正在为其发布公告和相关的 博客文章 征求反馈。 -
LLM 接口与运行时的创新:
@swyxio还分享了关于 lmsys 引入的一种名为 SGLang 的新型 LLM 接口和运行时的消息,该系统结合了 RadixAttention。这可能会与其他 LLM 系统(如 Guidance 和 vLLM)竞争,并声明 SGLang 的执行速度最高可提升 5 倍。详情可见其 博客文章。
提到的链接:
-
TikTok 母公司字节跳动悄然推出 4 款由 OpenAI GPT 驱动的生成式 AI 应用:新应用 Cici AI、ChitChop、Coze 和 BagelBell 的网站和政策中均未提及它们由字节跳动开发。
-
AI in Action Weekly Jam · Luma:每周一次的虚拟聊天,致力于 AI 在现实场景中的实际应用,重点关注博客、播客、库等方面的见解,以弥合理论与…之间的差距。
-
来自 lmsys.org (@lmsysorg) 的推文:我们很高兴推出 SGLang,这是我们用于 LLM 推理的下一代接口和运行时!它通过协同设计…极大地提高了复杂 LLM 程序的执行和编程效率。
-
[使用 AlphaCodium 实现最先进的代码生成 - 从 Prompt 工程到 Flow 工程 CodiumAI](https://www.codium.ai/blog/alphacodium-state-of-the-art-code-generation-for-code-contests/):在我们的博客中阅读关于使用 AlphaCodium 实现最先进代码生成的内容。 -
来自 Alessio Fanelli (@FanaHOVA) 的推文:工程曾经是语义(业务需求)和语法(实现方式)之间的桥梁 🌉 https://www.alessiofanelli.com/posts/syntax-to-semantics 代码正慢慢变得更加…
-
AutoGen Studio UI 2.0:创建自定义 Agent 的最简单方法:AutoGen 现在拥有一个用户界面,无需编写代码即可创建强大的 AI Agent。在本视频中,我们将查看这个新发布的…
-
来自 swyx (@swyx) 的推文:在今天 @smolmodels 对 AI Discord 的抓取中发现了一个绝对的瑰宝:https://artificialanalysis.ai/ 一个新的基准测试对比网站 • 由独立的第三方提供 • 清晰地勾勒出质量…
-
用于 AI 代码 Agent 的 “Normsky” 架构 —— 与 SourceGraph 的 Beyang Liu + Steve Yegge:立即收听 结合 Norvig 和 Chomsky 打造新范式。
▷ #ai-event-announcements (1 条消息):
- 引入创新的 LLM 微调方法:
@eugeneyan邀请了具有@&1107197669547442196角色的成员与@713143846539755581一起讨论新的 Self-Play fIne-tuNing (SPIN) 方法。该方法通过自生成数据来增强 LLM,无需额外的人工标注数据。点击此处阅读论文。
提到的链接:
-
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models:通过有监督微调 (SFT) 利用人工标注数据的力量对于推进大语言模型 (LLM) 至关重要。在本文中,我们深入探讨了培育强大 L… 的前景。
-
Join the /dev/invest + Latent Space Discord Server!:加入 Discord 上的 /dev/invest + Latent Space 社区 —— 与其他 2695 名成员一起交流,享受免费的语音和文字聊天。
▷ #llm-paper-club (32 条消息🔥):
-
热心读者聚集研究 Self-Play:
@eugeneyan通过链接到 arXiv 上的摘要 邀请参与者讨论 Self-Play 论文。该论文提出了 Self-Play fIne-tuNing (SPIN),这是一种微调方法,让大语言模型 (LLM) 通过自我博弈来提升能力,而无需新的人工标注数据。 -
对 Self-Instruction 见解的期待:
@swyxio预热了即将进行的关于 自我提升 (self-improvement) 相关论文的讨论。提到的论文 Self-Instruct 展示了使用自生成的指令遵循框架,相比原始 GPT3 模型实现了 33% 的绝对提升。 -
摄像头对 Discord 限制的影响:包括
@swizec、@youngphlo和@gulo0001在内的用户讨论了开启摄像头时 Discord 用户限制导致的各种技术困难。为了满足大型会议的需求,@youngphlo分享了 Discord 的 “stage” 功能,该功能允许在更像网络研讨会的设置中容纳数百名观众,并链接了相关的 Discord Stage Channels FAQ。 -
宣布社交形式的 Discord 聚会:
@swyxio宣布下周将开始两个新的 Discord 俱乐部,并在旧金山举行社交聚会,鼓励社区成员参与和社交。西雅图的另一次聚会也在筹划中。 -
ICLR 上 MoE 研究的焦点:
@swyxio强调了一篇专注于 混合专家模型 (MoE) 和专家合并的论文被接收为 ICLR 的 Spotlight 论文。论文 MC-SMoE 展示了通过合并和压缩专家将内存使用和计算需求降低高达 80% 的方法。
提到的链接:
-
Join the /dev/invest + Latent Space Discord Server!:加入 Discord 上的 /dev/invest + Latent Space 社区 —— 与其他 2695 名成员一起交流,享受免费的语音和文字聊天。
-
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models:通过有监督微调 (SFT) 利用人工标注数据的力量对于推进大语言模型 (LLM) 至关重要。在本文中,我们深入探讨了培育强大 L… 的前景。
-
Self-Instruct: Aligning Language Models with Self-Generated Instructions:大型“指令微调”语言模型(即经过微调以响应指令的模型)已展示出卓越的零样本泛化到新任务的能力。然而,它们依赖于…
-
Tweet from Prateek Yadav (@prateeky2806):🎉 很高兴宣布我们的 MOE 专家合并论文已被 @iclr_conf 接收为 SpotLight 论文!我们通过利用基于路由统计的合并方法降低了 MOE 模型的推理内存成本…
-
GitHub - jondurbin/airoboros at datascience.fm:Self-instruct 论文的可定制实现。- GitHub - jondurbin/airoboros at datascience.fm
-
Solving olympiad geometry without human demonstrations - Nature:一种新的用于欧几里得平面几何的神经符号定理证明器,在数百万个合成定理和证明上从头开始训练,其表现优于之前的最佳方法,并达到了…的性能。
▷ #llm-paper-club-chat (65 条消息🔥🔥):
-
聚焦视频通话限制:在关于增加语音频道用户上限的讨论中,
@swyxio和@yikesawjeez注意到,尽管设置显示为 99 位用户,但当开启视频或串流时,实际限制似乎是 25 人。一篇 Reddit 帖子 澄清了 25 人限制的具体适用情况。 -
模型进展基准测试:
@swyxio分享了一个幽默的观察,关于微软 MedPaLM 相比 GPT-4 的微小改进,并指出真正的 8% 提升将意味着一个全新的模型。此外,他们还分享了来自 GitHub 的个人 基准测试笔记 以供深入了解。 -
是否分享论文笔记:
@swyxio向@mhmazur建议向 Eugene 的论文笔记仓库提交 Pull Request (PR)。随后@eugeneyan提供了该 GitHub 仓库链接 以供参考。 -
探索推理连续性的重要性:
@yikesawjeez分享了来自 Twitter 的一个帖子,讨论了在大语言模型性能方面,在 Prompt 中保持逻辑流比事实准确性更重要。这一反直觉的发现已在 arXiv 上的一篇论文中得到了进一步研究。 -
思考医疗数据的挑战:在一段关于合成数据能否规避 HIPAA 法规的讨论中,
@dsquared70和@nuvic_触及了在受监管环境中使用 AI 的复杂性和成本。@swyxio提到,在这种背景下使用 GPT-4 使得像 Scale AI 这样的公司本质上充当了“GPT-4 洗白工坊”。
提到的链接:
-
Tia 获得 1 亿美元融资,用于建设诊所和虚拟护理,投资者看好女性健康初创公司:Tia 是一家致力于打造其所谓的“现代女性医疗之家”的初创公司,该公司获得了一轮高达 1 亿美元的融资,用于扩大其虚拟和线下护理规模。
-
Aran Komatsuzaki (@arankomatsuzaki) 的推文:推理步骤长度对大语言模型的影响。在“Let’s think step by step”之后附加“you must think more steps”会增加推理步骤并显著提高性能……
-
大语言模型尚无法自我纠正推理:大语言模型 (LLMs) 凭借其在各种应用中无与伦比的文本生成能力,已成为一项突破性技术。然而,关于其……的担忧仍然存在。
-
MAUVE:使用散度前沿衡量神经文本与人类文本之间的差距:随着开放式文本生成取得重大进展,衡量机器生成的文本与人类语言的接近程度仍然是一个关键的开放问题。我们引入了 MAUVE,一种用于……的比较测量方法。
-
展示你的工作:用于语言模型中间计算的草稿本 (Scratchpads):大型预训练语言模型在可以“一次性完成”的任务上表现出色,例如生成逼真的文本或合成计算机程序。然而,它们在……方面表现吃力。
-
我们移除了广告 Cookie,结果如下:这不再是一篇关于无 Cookie 未来可能产生什么后果的抽象文章;Sentry 实际上从我们的……中移除了 Cookie。
-
深度双重下降 (Deep double descent):我们展示了双重下降现象在 CNNs、ResNets 和 Transformers 中都会发生:随着模型大小、数据量或训练时间的增加,性能首先提高,然后变差,接着再次提高……
-
推理步骤长度对大语言模型的影响:思维链 (CoT) 对于提高大语言模型 (LLMs) 的推理能力具有重要意义。然而,CoT 的有效性与推理步骤长度之间的相关性……
-
Self-Instruct:通过自生成指令对齐语言模型:大型“指令微调”语言模型(即经过微调以响应指令的模型)已展示出卓越的零样本泛化到新任务的能力。尽管如此,它们仍严重依赖……
-
来自 Carlos E. Perez (@IntuitMachine) 的推文: 1/n 关于 LLM 的一个反直觉且令人惊讶的发现。“推理连续性优于准确性”原则指的是在 Chain-of-Thought (CoT) 提示中一个令人惊讶的发现,即…
-
GitHub - eugeneyan/llm-paper-notes: 来自 Latent Space 论文俱乐部的笔记。跟随学习或开始你自己的俱乐部!: 来自 Latent Space 论文俱乐部的笔记。跟随学习或开始你自己的俱乐部! - GitHub - eugeneyan/llm-paper-notes: 来自 Latent Space 论文俱乐部的笔记。跟随学习或开始你自己的俱乐部!
-
ai-notes/Resources/BENCHMARKS.md at main · swyxio/ai-notes: 为跟进 AI 新进展的软件工程师准备的笔记。作为 https://latent.space 写作和产品头脑风暴的数据存储库,但已清理了规范引用…
-
使用 SPIN 技术将弱 LLM 转换为强 LLM: 我们能否在不获取更多数据的情况下帮助弱 LLM 变得更好?
Perplexity AI Discord 总结
-
分享是关爱,还是惊吓?:
@imusicmash101对平台上的分享功能表达了隐私担忧,建议增强选择性内容分享,而不是分享整个会话历史。 -
库侧边栏故障报告: Discord 用户
@moyaoasis指出库侧边栏链接与搜索线程历史记录之间不匹配,引发了@ok.alex关于两者之间不同组织方法的回复。 -
解析 Perplexity.ai 的赞誉与问题: 对话涉及
@rileybrown_ai对 Perplexity.ai 的赞赏推文、Pro 角色访问权限问题,以及关于 pplx API 处理带有 URL 的请求的能力和支付处理故障的查询。 -
Perplexity Pro 转化: 对 Perplexity.ai 的正面反馈(包括其 Collections 功能)已促使
@rmoore等用户升级到 Perplexity Pro 并分享他们的学习经验,例如了解清朝的政府结构。 -
社区参与和功能请求: 社区讨论了认可系统,例如为有价值的贡献加星标,这可能会授予 EXPLORER 角色,以及
@brknclock1215提出的允许对功能请求进行投票以识别社区愿望的建议。
Perplexity AI 频道总结
▷ #general (31 条消息🔥):
-
分享功能的安全性警告:用户
@imusicmash101提出了隐私担忧,指出目前的 分享功能 (share feature) 会复制整个会话历史,而不仅仅是打算分享的查询内容。他们建议增加分享不同范围选项的功能,例如“仅限最近的问答”。 -
Library 链接不匹配:用户
@moyaoasis报告了一个问题,即 Library 侧边栏中的链接与搜索线程历史不匹配,有时会丢失最近的线程。@ok.alex澄清说,侧边栏列表是按最近打开的线程排序的,而 Library 是按最新提出的问题排序的。 -
关于 Perplexity AI 的 Copilot 功能咨询:
@yukiarimo对 Perplexity AI 的 Copilot 运作方式以及用于插图的底层 SD 模型感到好奇。@me.lk指出 DALLE3 被用于图像生成,并分享了一个链接以获取更多关于 Copilot 的信息。 -
Perplexity Pro 与普通版的优势对比:用户
@iloveh8征求社区关于 Perplexity Pro 与免费版之间差异的见解,特别是 Pro 是否提供更详细或推理更好的答案。@mares1317发布了相关讨论的链接以及 ChatGPT 与 Perplexity AI 的对比。 -
Perplexity 网站的技术 UI 问题:用户
@darkblanks遇到了一个 UI 故障,所有文本显示为被选中状态,并寻求解决方案。@mares1317建议截图并在指定的 Discord 帮助频道中报告该问题。
提到的链接:
-
什么是 Perplexity Copilot?:浏览 Perplexity 博客,获取文章、公告、产品更新以及优化体验的技巧。保持关注并充分利用 Perplexity。
-
ChatGPT vs Perplexity AI:Perplexity 是否使用 ChatGPT? - AI For Folks:AI 领域不断变化,可能会令人困惑。许多公司会叠加不同的技术供自己使用。在本文中,我们将进行对比。
-
Perplexity 博客:浏览 Perplexity 博客,获取文章、公告、产品更新以及优化体验的技巧。保持关注并充分利用 Perplexity。
▷ #sharing (13 条消息🔥):
-
Perplexity.ai 获得青睐:用户
@rileybrown_ai发布 推文 赞扬 @perplexity_ai 的 Collections 功能,称其优于 ChatGPT 和 Google,且每月都在进步。这条推文促使@rmoore转化为 Perplexity Pro 用户。 -
使用 Perplexity.ai 学习:用户
@fanytumor分享了在订阅 Perplexity.ai 后,学习 清朝政府结构 的体验。 -
Perplexity Pro 角色权限获取困惑:包括
@rmoore和@icelavaman在内的用户讨论了在通过 Perplexity 设置 链接加入后,如何在服务器上获取 <a:pro:1138537257024884847> 角色的问题。 -
对 Perplexity 的认可:用户
@brknclock1215提供了一个 YouTube 链接 作为对 Perplexity.ai 的强力推荐,尽管该 YouTuber 的身份尚不明确。
提到的链接:
来自 Riley Brown (@rileybrown_ai) 的推文:我使用 @perplexity_ai 的频率超过了 ChatGPT 和 Google。他们的 Collections 功能被严重低估了。而且它每个月都在变得更好。
▷ #pplx-api (10 messages🔥):
-
支付处理故障:用户
@rxiiia遇到了一个问题,尽管银行授权成功,但 pplx API 的支付设置仍未得到确认。@ok.alex回应称该问题已解决,并提示重新尝试设置支付方式。 -
API 与 Web 界面的质量保证:
@jayb1791询问了 pplx API 处理包含 URLs 的请求的能力,以及 API 模型是否能提供与 Web 界面相同的高质量摘要。@mares1317提供了一个指向某条消息的链接,表明目前无法实现,@jayb1791对此限制表示失望。 -
社区参与激励:
@Dyno概述了社区认可系统,即对有帮助的消息回复 ⭐ 表情符号,可以使其被收录在 ⭐│starred 频道中,且作者将获得 EXPLORER 角色。 -
功能请求投票建议:
@brknclock1215建议实施一套对请求的功能或 FAQ 进行投票的系统,类似于针对有帮助消息的 ⭐ 表情符号系统。 -
引用获取查询:用户
@dvrshil询问是否可以从 online models for the API 生成的文本中同时获取引用(references),@icelavaman提供了相关的消息链接作为回复。
Skunkworks AI Discord Summary
只有一个频道有活动,因此无需汇总…
-
探索专家专业化:
.interstellarninja正在考虑对比 Mistral 和 Hermes 微调之间的专家专业化(expert specialization),以观察分布是否发生变化。他们认为重新初始化专家层可能类似于从头开始进行预训练。 -
重新思考 MoEs 中的领域专业化:
baptistelqt正在探索一种“领域平衡损失”(domain balancing loss)作为负载平衡损失(load balancing loss)的替代方案,以鼓励 MoEs 中专家在特定领域内的专业化。尽管目前尚不完善,但该方法显示出潜力,baptistelqt承诺在满意后发布结果和代码。 -
Function Calling 与 MoEs:
.interstellarninja正在致力于微调具有领域专业化的 Mixture of Experts (MoEs) 模型,使每个专家精通特定的领域或函数类别。他们指出,一个擅长编程的模型可能会让每个专家专门负责一种特定的编程语言。 -
开源 LLMs 推广:在合成数据生成的背景下,
baptistelqt征求关于最佳开源 LLMs 的建议,在 7b-14b 尺寸的模型之间进行权衡,或者选择 GPT-4。stereoplegic对这种开源方法表示赞赏,并分享了一篇相关的论文:Using ICL for data generation。 -
新的 Function Calling 架构与数据集:针对
.interstellarninja对 Function Calling 微调的关注,yikesawjeez提到了诸如 gorilla openfunctions 和 nexusraven 等新颖架构,并辅以 glaive 和 fireworks-ai。yikesawjeez还分享了一个 Google 文档链接,其中包含在 manifold 中发现的 API/Function Calling 数据集:API/Function Calling Datasets Doc。
提到的链接:
-
Ensemble-Instruct: Generating Instruction-Tuning Data with a Heterogeneous Mixture of LMs:使用上下文学习(ICL)进行数据生成,诸如 Self-Instruct (Wang et al., 2023) 或后续的 Alpaca (Taori et al., 2023) 等技术,仅需少量数据即可训练出强大的对话智能体(conversational agents)…
OpenAccess AI Collective (axolotl) Discord 摘要
-
GCP TPU 让工程师进展受阻:
@henriklied报告了在 Google Cloud TPU 上寻找训练 GPT-J 等 AI 模型当前可用库的挑战,因为许多库已经过时。 -
FrankenMoE 模型表现出色,但仍有局限性:
@lee0099赞扬了 Hugging Face 上的一个 frankenMoE 模型,称其 Benchmark 性能优异,同时也指出了其路由模型(routing model)可能存在的训练困难。 -
模型融合(Blending)击败 ChatGPT:
@le_mess和@xzuyn分享了一篇 研究论文,讨论了多种模型的融合如何超越 ChatGPT-3.5 的实力,但也强调了对话过程中模型选择的随机性。 -
Axolotl 权衡代码放置位置:Axolotl 开发过程中正在决策新系统消息代码的最佳放置位置,一个 Pull Request 正在探讨
load_datasets是否应该是其归属地。 -
ROCm 上的 Flash Attention 突破:
@odellus_宣布 Flash Attention 现在已支持 ROCm,展示了该项目在 AI 模型精确注意力机制(exact attention)能力方面的进展,可在 fxmarty/flash-attention-rocm 获取。 -
微调咨询增加:讨论转向了训练 Mistral 7B 的最佳 AWS 实例,
@jacques_10431寻求建议并考虑使用 Axolotl,并参考了关于 使用《万智牌》(Magic: The Gathering)数据进行微调 的文章。 -
LLM 知识获取讨论:
@jb5846发起了一场关于 LLMs 是否能在大型文本文档中保持知识的辩论。@noobmaster29澄清说,添加新知识需要进行全量微调(full tuning)。他还分享了一篇 关注基础模型(foundation models)潜力和风险的研究论文。 -
Runpod 中的 WebSocket 问题:
@dangfutures在 Runpod 中遇到了跨域 WebSocket 被禁止的问题,导致 403 错误,但得到的指导建议使用train-notebook分支,并建议重启 Jupyter Lab 进程以缓解该问题。
OpenAccess AI Collective (axolotl) 频道摘要
▷ #general (22 条消息🔥):
-
寻求 GCP TPU 训练工具:
@henriklied表示难以找到用于在 Google Cloud TPU 上训练 GPT-J 等模型的最新库,并指出许多库似乎已经过时或无人维护。 -
FrankenMoE 模型成果显著:
@lee0099分享了一个 Hugging Face 模型页面链接,重点介绍了一个在某些 Benchmark 上优于更大模型的 frankenMoE 模型,但也提到了训练路由模型时可能存在的问题。 -
模型融合可以超越 ChatGPT:
@le_mess分享了一篇 研究论文,讨论了融合多个模型如何击败 ChatGPT-3.5,@xzuyn补充说,对话过程中的模型选择是随机的,没有进行智能选择优化。 -
随机性增加对话趣味性:
@leoandlibe幽默地说明了拥有多个模型(例如一个在《圣经》上训练,另一个在 WallStreetBets 上训练)如何使交互变得更加不可预测和有趣。 -
即将到来的 H100 训练机会:
@ytl120询问了使用约 200 张 H100 GPU 进行为期 4 周训练的最佳开源模型,提出了多个选项并指出了数据集访问方面的限制。@nanobitz和@nruaif进行了回应,讨论了 Mistral、Mamba 和 text2img 模型等各种架构对于该项目的可行性和影响。
提到的链接:
Kquant03/FrankenDPO-4x7B-bf16 · Hugging Face
▷ #axolotl-dev (4 messages):
-
Axolotl 的代码库抉择:
@le_mess正在考虑用于系统消息(system messages)的新代码应该放在 Axolotl 架构的什么位置。目前代码已添加到cli/train.py和cli/preproccess.py中,但有建议认为load_datasets可能是更合适的位置。Pull request #1117 正在等待进一步反馈。 -
Flash Attention 现在支持 ROCm:用户
@odellus_指出 Flash Attention 现已提供 ROCm 分支,该分支并非由 VLLM 团队开发,而是另一个项目,可以在 GitHub 上的 fxmarty/flash-attention-rocm 找到。这标志着 AI 模型在内存高效的精确注意力(exact attention)能力方面取得了进展。
提到的链接:
-
GitHub - fxmarty/flash-attention-rocm: Fast and memory-efficient exact attention:快速且内存高效的精确注意力机制。可以通过在 GitHub 上创建账号来为 fxmarty/flash-attention-rocm 的开发做出贡献。
-
Draft: Feat/chatml add system message by mhenrichsen · Pull Request #1117 · OpenAccess-AI-Collective/axolotl:关于如何更改 prompter 中默认系统消息的思路征集。
▷ #general-help (6 messages):
-
Mistral 7B 微调技巧:用户
@jacques_10431计划微调 Mistral 7B,并寻求在使用 Axolotl 时推荐的 AWS instance type。他们参考了一篇关于在《万智牌》(Magic: The Gathering)数据上进行微调的文章(Fine-Tuning Mistral 7B)。 -
LLM 中的通用知识与特定知识:
@jb5846询问了如何让其 LLM 在多个大型文本文档中回答问题并进行泛化的最佳方法。他们质疑使用原始数据进行微调是否能让模型保留对文档的记忆,从而提供更好的回答。 -
LLM 的 Full Tune 与 Instruction Tune:针对
@jb5846的提问,@noobmaster29表示需要进行 full tuning 才能向 LLM 传授新知识,虽然 instruction tuning 也有益处,但让模型学习特定事实并非易事。 -
LLM 与微调的研究:
@noobmaster29分享了一个研究论文链接,可能与模型微调的讨论相关:On the Opportunities and Risks of Foundation Models。 -
针对 GPU 工作定制 AWS 实例:
@nanobitz回复了@jacques_10431,询问他们计划使用 qLoRA、LoRA 还是 FFT,因为不同的选择会影响对 AWS 实例的需求。
▷ #runpod-help (7 messages):
-
跨域 WebSocket 被拦截:
@dangfutures报告了一个跨域 WebSocket 尝试被拦截的问题,并收到了 403 错误。 -
修复 WebSocket 问题的分支建议:
@caseus_建议尝试使用train-notebook分支来解决 WebSocket 问题。 -
需要合并分支以解决问题:
@caseus_提到需要合并train-notebook分支才能使修复生效。 -
重启 Jupyter Lab 进程的建议:
@caseus_提供了一个变通方案,建议用户可以杀死并重启 jupyter lab 进程。 -
安装过程中 ‘blinker’ 包报错:
@dangfutures遇到了一个关于现有blinker包无法卸载的错误,但随后自行解决了该问题。
▷ #replicate-help (1 messages):
hamelh: 〰️
LlamaIndex Discord Discord 摘要
-
RankGPT 挑战文档排序:RankGPT 利用 GPT-3.5 和 GPT-4 在文档排名任务中超越了 monoBERT 和 Cohere rerank。根据
@sunweiwei12的一条 推文,这可能会彻底改变文档过滤。 -
使用 LlamaIndex 和 Sparrow 实现全栈壮举:
@andrejusb展示了一个集成 LlamaIndex 和 Sparrow 的 全栈应用,标志着应用架构的一个显著进展。 -
LlamaIndex.TS 引入流式传输:最新的 0.0.47 版本 LlamaIndex.TS 为所有端点引入了流式传输(streaming)功能,正如这篇 推文 所宣布的,并提供了示例和下载详情。
-
语义分块增强 AI 记忆:
@andysingal分享的一篇 文章 强调了 语义分块(semantic chunking) 在提高语言模型性能和在计算应用中实现更好的长期记忆方面的关键作用。 -
LlamaIndex 的各种挑战与考量:Discord 用户讨论了关于 LlamaIndex 的多个问题,包括 RAG 场景下的 URL 处理、Neo4j 中的图隔离、SemanticSplitterNodeParser 问题、Web 界面导航以及元数据对分块大小的影响,但对话中尚未建立具体的解决方案或共识。
LlamaIndex Discord 频道摘要
▷ #blog (3 条消息):
-
RankGPT 在文档排名中表现出色:
@sunweiwei12强调的研究表明,使用 GPT-3.5 和 GPT-4 的 RankGPT 在文档排名任务中优于 monoBERT 和 Cohere rerank。他们的推文 建议将其作为文档选择的二级过滤器。 -
Sparrow 和 LlamaIndex 在全栈应用中的应用:
@andrejusb演示了如何使用 LlamaIndex 和 Sparrow 构建全栈应用。更多详情见 他们的推文。 -
LlamaIndex.TS 引入流式传输:LlamaIndex.TS 的新版本 0.0.47 现在包含对所有端点的流式传输支持。示例和下载可在 公告推文 中找到。
提到的链接:
-
LlamaIndexTS/examples/huggingface.ts at llamaindex@0.0.47 · run-llama/LlamaIndexTS:LlamaIndex 是适用于你的 LLM 应用的数据框架 - run-llama/LlamaIndexTS
▷ #general (31 messages🔥):
-
寻求 LlamaIndex 和 OpenAI Assistants 的指导:
@don_ramoncillo正在重新审视一个金融项目,想知道他们现有的 LlamaIndex 系统与 OpenAI 的新功能(如 Assistants 和 Retrieval)相比有哪些优势。相关消息中未给出具体回答。 -
质疑 RAG 上下文中 URL 的处理:
@stdweird质疑了在 RAG 的上下文中保留 URL 的重要性,推测这可能很有价值,但也可能会混淆系统。他们表达了保留 URL 的理由,但该问题仍处于开放状态,社区尚未达成明确共识。 -
在 LlamaIndex 中正确使用 GraphStores:
@jpd1998寻求关于使用 LlamaIndex 在 Neo4j 中隔离图谱的帮助,旨在分别存储和查询多个文档图谱,并询问了关于持久化索引信息的问题。社区在消息中未提供答案。 -
SemanticSplitterNodeParser 的挑战:
@dr.yyh_59768提到尽管环境和 LlamaIndex 版本都是最新的,但在使 SemanticSplitterNodeParser 正常运行方面遇到了困难。对话中尚未解决该问题的本质。 -
Web 界面导航的持续困扰:
@mysterious_avocado_98353提出了一个 Web 界面的问题,即关闭页面后会导航回顶部,迫使用户再次滚动浏览长页面。@cheesyfishes建议切换到稳定版文档,@mysterious_avocado_98353意识到通过 Google 访问时显示的是不同版本。 -
关于 LlamaIndex 中元数据和分块大小(Chunk Size)的讨论:
@americanthinker发起了一场关于 LlamaIndex 中元数据长度与分块大小之间关联的对话,询问默认行为背后的设计决策。@cheesyfishes分享了见解,暗示当include_metadata设置为 false 时,在分块过程中忽略元数据长度可能是一个 bug。
提到的链接:
▷ #ai-discussion (1 messages):
- 探索 LlamaIndex 的语义分块(Semantic Chunking):用户
@andysingal分享了一篇 Medium 文章,详细介绍了语义分块在语言模型中的重要性。该文章深入探讨了将文本分解为可管理的部分如何提高模型性能,并促进应用程序中的长期记忆。
提到的链接:
Unleashing the Power of Semantic Chunking: A Journey with LlamaIndex: Ankush k Singal
DiscoResearch Discord 摘要
-
Mixtral 实现了 FLOP 效率:
bjoernp强调 Mixtral 通过一次仅激活 2 个专家(experts)来实现更高的 FLOP 效率,消耗的 FLOP 比 14b 模型更少,且在这方面的表现与 13b 模型相当。 -
利用 LLM 创新小说写作:
@rasdani分享了 Jon Durbin 的 Bagel 发布版如何使用人类回答作为“接受(accepted)”,LLM 回答作为“拒绝(rejected)”,以增强 LLM 的小说写作能力。这种方法及其数据集可以在 Hugging Face 和 GitHub 上探索。 -
推进 LLM 流水线优于微调(Fine-Tuning):在关于大型文本文档分析的讨论中,
@_jp1_建议使用高级 LLM 流水线(如 rerankers 和基于图的节点检索),并参考 LlamaIndex 的教程,而不是依赖微调来进行泛化。 -
警惕 LLM 幻觉(Hallucinations):
@philipmay指出了一篇论文,该论文对 LLM 发表无根据言论和不准确引用来源的倾向进行了分类,警告说那些看起来最有帮助的回答往往可能是不可靠的。 -
评估 LLM 的情商:
.calytrix展示了 EQ-Bench v2,这是一个针对 LLM 的情商基准测试,其测试问题增加了三倍,并减少了评分偏差,详见其 GitHub 和论文。评分偏差已降至 0-4%,并且 EQ-Bench 分数与更大的 LLM 排行榜之间存在显著相关性。
DiscoResearch 频道摘要
▷ #mixtral_implementation (2 messages):
-
FLOPs 比较咨询:
vara2096询问了 Mixtral 与 Mistral-7B 及 Llama-2-70B 相比,每个 token 的 FLOPs。 -
Mixtral 具备轻量级的 FLOPs 优势:
bjoernp澄清说,在 FLOPs 方面,Mixtral 与 13b 模型相当,因为它一次仅激活 2 个 experts,且其 FLOPs 计数少于 14b 模型,因为并非所有权重都是专家权重。
▷ #general (10 messages🔥):
-
使用 Gutenberg DPO 增强 LLM 的小说写作能力:
@rasdani分享了 Jon Durbin 在最新的 Bagel 版本中,将人类回答作为 accepted,将 LLM 回答作为 rejected,旨在利用公有领域书籍提升 LLM 的小说写作能力。更多关于该数据集和代码的信息可以在 Hugging Face 和 GitHub 上找到。 -
处理大型文本文档分析:
@jb5846提出了一个问题:对于跨多个大型文档进行泛化,fine-tuning 是否更好;@_jp1_建议使用更先进的 LLM 流水线,如 reranker 和基于图的节点检索(graph-based node retrieval),并参考 llama-index 的优秀教程。 -
LLM 与幻觉的诱惑:
@philipmay指出 LLM 倾向于添加自己的知识,而不是严格遵守提供的 context,并引用了一篇 论文,该研究发现生成式搜索引擎的回答经常包含无根据的陈述,且看起来最有帮助的回答往往包含不准确的引用。 -
关于最佳开源 Embedding 模型的咨询:
@vara2096询问了用于英语聚类的最佳开源 embedding 模型,@philipmay建议查看 Hugging Face 的 MTEB 排行榜 和 SBERT 的预训练模型 资源。
提到的链接:
-
GitHub - jondurbin/bagel: A bagel, with everything.:A bagel, with everything. 通过创建 GitHub 账号为 jondurbin/bagel 的开发做出贡献。
▷ #benchmark_dev (2 messages):
-
情商基准测试:EQ-Bench v2 发布:
.calytrix介绍了 EQ-Bench v2,这是一个针对 LLM 的升级版情商基准测试,测试题目数量增加了 3 倍,旨在减少方差。新版本还考虑了温度(temperature)和 prompt 格式等不同扰动对基准测试分数的影响,详见其 GitHub 和最近发表的 论文。 -
EQ-Bench v2 的鲁棒性与敏感性:
.calytrix解释说,包含 171 个问题的增强版 EQ-Bench v2 提高了对测试环境变化的鲁棒性,将分数方差从 v1 的高达 10% 降低到 0-4%。该基准测试详细的四部分问题能够更精细地辨别模型的情商能力。 -
独立基准测试与主流 LLM 排行榜的相关性:
.calytrix观察到 EQ-Bench 分数与大型模型排行榜之间存在强相关性,并指出一些模型(如 Beagle14-7B 和 SOLAR-10.7B-Instruct-v1.0)表现尤为出色。这表明了这些模型在情商评估中能力的真实性。
提到的链接:
▷ #embedding_dev (10 条消息🔥):
-
Grok 使用未指明工具提速:
@rasdani提到 Grok 利用了一个传闻中速度最快的工具,但未指明具体工具,也未提供进一步的证据或链接。 -
Cursor IDE 的 Ground Truth 魔法:
@rasdani链接了 Aman Sanger 的一条推文,描述了 Cursor IDE 如何使用 GPT-4 评分和 Trueskill 评分系统(Elo 的改进版)开发高质量的检索数据集,用于训练 Embeddings/Rerankers。 -
对 M2 Embed 模型感到失望:
@sebastian.bodza报告称,与之前使用的 bge embeddings 相比,M2 Embed 模型的性能较差,并提供了 Hugging Face 上 M2-BERT 模型的链接。 -
对 M2 BERT 检索基准测试持怀疑态度:
@maxidl对 M2 BERT 的检索微调(finetuning)表示怀疑,指出论文中缺乏细节,且由于该模型是针对转录本、报告和论文进行测试的,其字符数与典型的基准测试不一致。 -
缺失经典检索评分:
@sebastian.bodza询问了 M2 模型具体的检索评分,如平均倒数排名 (MRR) 或准确率 (Precision),@maxidl承认 M2 团队博客文章的基准测试中没有出现 Recall、Precision 和 MRR 等典型检索指标。
提到的链接:
-
Aman Sanger (@amanrsanger) 的推文:在 Cursor,我们构建了非常高质量的检索数据集(用于训练 Embeddings/Rerankers)。为此,我们使用 GPT-4 评分和 Trueskill 评分系统(Elo 的更好版本)…
LLM Perf Enthusiasts AI Discord 总结
-
GPT-4 在 Vision 指令方面遇到困难:名为
@thebaghdaddy的用户强调了 GPT-4 无法有效利用其天生的 Vision 能力来执行目标检测任务,尽管尝试引导其摆脱对 Python 软件包依赖。 -
推理服务见解:
@rabiat询问了推理服务,@robotums建议使用 Anyscale 和 Together.AI,并强调 Together.AI 的 Time To First Tweet (TTFT) 较低。此外还提到了 Mixtral 8x7b Instruct 的发布,并引导用户关注 Twitter 上的更新。 -
生产环境推理担忧与 Mixtral 怪癖:有人指出 pplx-api 不打算托管用于生产推理的开源模型,因为它更多是一个人才吸引工具。此外,大家还在讨论 Mixtral 在回复末尾抛出随机文本的问题,潜在原因可能是基础模型的使用或
[INST]Token 的设置。 -
模型微调技巧:
@natureplayer为想要微调模型的人推荐了 MLX 示例仓库,并强调了在任何设置下微调小型或量化模型的灵活性。 -
注意到 Azure 性能问题:用户
@rabiat报告了不同地区的 Azure 服务速度缓慢,并询问其他人是否遇到类似问题。
LLM Perf Enthusiasts AI 频道总结
▷ #gpt4 (2 条消息):
- 寻求纯粹的 GPT-4 Vision 能力:
@thebaghdaddy对 GPT-4 在目标检测任务中倾向于默认使用 Python 软件包而不是利用其天生的 Vision 能力表示沮丧。他们指出,在这种困境下,指示模型避免“高级分析 (advanced analytics)”是无效的。
▷ #opensource (11 messages🔥):
-
选择合适的推理服务:
@rabiat提出了关于针对不同需求应选择哪种服务的问题,@robotums建议工具调用使用 Anyscale,非工具调用使用 Together.AI,特别是当低 Time To First Token (TTFT) 是首要任务时。 -
新模型发布公告:
@rabiat分享了一个链接,宣布 Mixtral 8x7b Instruct 发布,并建议在 Twitter 上关注更新。 -
关于生产环境推理的担忧:
@robotums表示,尽管 Mixtral 很有吸引力,但 pplx-api 没有计划托管用于生产环境推理的开源模型,其 API 主要是作为一种人才吸引策略。 -
正在调查 Mixtral 响应问题:
@thisisnotawill询问是否有人遇到过 Mixtral 的问题,特别是关于回复末尾出现随机文本的情况。@natureplayer建议这可能是由于使用了 Base 模型或[INST]Token 设置不正确导致的。 -
在任何配置上微调模型:
@natureplayer推荐将 MLX 示例仓库作为微调模型的起点,并提到可以在任何配置上微调小型或量化模型,强调了其可用性,无论速度如何。
提到的链接:
| [Mixtral 8x7B - Host Analysis | ArtificialAnalysis.ai](https://artificialanalysis.ai/models/mixtral-8x7b-instruct):对 Mixtral 8x7B Instruct 在质量、延迟、吞吐量、价格等指标上的分析。 |
▷ #speed (1 messages):
rabiat: Azure 在不同地区对我们来说都相当慢。有人遇到同样的情况吗?
LangChain AI Discord 总结
-
LangChain 对 Pinecone Serverless 的支持暂时搁置:
@leonvanzyl询问 LangChain 是否会引入对 Pinecone Serverless 的支持,因为目前的 LangChain 版本与包含 Serverless 功能的 Pinecone 软件包缺乏兼容性。 -
Node.js Axios 请求遇到 API 障碍:
@digitalsimboja在 Node.js 中使用 axios 向 OpenAI 端点发起 API 请求时遇到了404错误,并提供了详细的错误堆栈信息以寻求社区帮助。 -
寻求用于捷克语翻译的最佳本地 LLM:
@kompicka寻求能够翻译大型捷克语数据集的高质量、高效本地 LLM 推荐,并提到了使用 Facebook M2M 和 Falcon 180B 的经验,后者虽然翻译质量不错但性能较慢。 -
探索 Swift LLM 推理的替代方案:
@maximuslee报告在使用 LangChain 配合 FAISS 和 18b llama 模型时推理速度慢且输出重复,正在寻找能够更高效处理大型模型的更快替代方案。 -
LangChain 在流式传输技术上的进展:
@veryboldbagel分享了一个关于改进 LangChain 流式传输能力的 RFC 和示例 Notebook,并征求社区反馈。示例 Notebook 可以在这里找到,RFC 讨论见此处。 -
LangServe 与 SvelteKit 的接口连接:用户
@albertperez.和@hiranga.g提出了关于将 LangServe 与 SvelteKit 集成以及通过 LCEL 使用 OpenAIAssistantRunnable 的问题,包括具体的用例和实现方面的疑虑。 -
分享新的 AI 数据流水线和双语模型增强功能:@xiaofei5116 宣布了 Instill VDP 的公开测试版,这是一个专为非结构化数据 AI 应用设计的通用数据流水线,已于 2024 年 1 月 17 日在 Product Hunt 上线,链接见此处。
@johnda98分享了他们成功将 langserve 与 Google Cloud Platform 集成的经验。@maidalun在 Hugging Face 上发布了一个双语及跨语言 Embedding 模型,针对 RAG 进行了优化,并兼容 LangChain 和 llamaindex,访问地址在这里。 -
展示 AI 爬虫助手:
@kagnar.分享了他的 AI Crawl Assistant 演示,展示了其使用 OpenAI Assistant API 和 Mistral 模型通过自然语言输入导航网站地图的能力。
LangChain AI 频道总结
▷ #general (7 条消息):
-
关于 Langchain 支持 Pinecone Serverless 的咨询:
@leonvanzyl询问 Langchain 是否会很快推出对 Pinecone Serverless 的支持,因为当前版本的 Langchain 与包含 serverless 的最新 Pinecone 软件包不兼容。 -
寻求 404 错误协助:
@digitalsimboja请求协助解决在使用 Node.js 中的 axios 向 OpenAI API 端点发送请求时出现的{"message": "Request failed with status code 404"}错误,消息中提供了详细的错误堆栈。 -
寻找适用于特定语言翻译的 Local LLMs:
@kompicka询问是否有适合翻译捷克语大规模数据集的优质 Local LLMs 推荐,并提到之前使用 Facebook M2M 和 Falcon 180B 的经验,指出后者质量虽好但开销巨大且性能较慢。 -
寻求大型 LLMs 高效推理的替代方案:
@maximuslee讨论了在使用 Langchain 配合 FAISS 和 18b llama 模型时遇到的挑战,包括推理性能慢以及在使用 ConversationalRetrievalChain 功能时出现重复回答的问题,正在寻找处理大型模型时更快的推理替代方案。 -
LangChain 通过 RFC 和 示例 Notebook 改进流式传输:
@veryboldbagel分享了一个 GitHub RFC 和一个示例 Notebook (streaming_events.ipynb),涉及 LangChain 流式传输的改进,并寻求社区反馈和讨论。 -
开源双语及跨语言 Embedding 模型发布:
@maidalun宣布在 Hugging Face 上发布了一个开源的双语及跨语言模型,该模型针对 RAG 进行了优化,并兼容 Langchain 和 llamaindex,邀请社区提供反馈。 -
RAG Pipeline 返回不完整响应的问题:
@vinayak.pevekar报告了一个在使用 “Mistral-7B-Instruct-v0.1-GGUF” 和 llama_index 的 RAG Pipeline 时出现的问题,即返回的响应由哈希值组成而非预期输出,并指出该系统在两天前还能正常运行。
提到的链接:
-
🛸 Streaming: RFC Adding astream_event to all Runnable objects to help with streaming use cases · langchain-ai/langchain · Discussion #16175:大家好!我们希望改进 LangChain 的流式传输体验。我们正考虑在 Runnable 接口中添加 astream_event 方法。以下代码来自相关的 PR,目前还没有…
▷ #langserve (2 条消息):
-
寻求 OpenAIAssistantRunnable 指导:用户
@albertperez.提出了一个关于将 OpenAIAssistantRunnable 与 LCEL 结合使用的问题,特别是如何在包含input_variables的提示词(prompts)中使用它。他们提供了代码片段作为上下文。 -
SvelteKit 与 Python LangServe 咨询:用户
@hiranga.g询问了 Python LangServe 与 SvelteKit 的集成问题,寻求社区的帮助。
▷ #share-your-work (4 条消息):
-
Instill VDP 进入公开测试阶段:@xiaofei5116 在 Product Hunt 上宣布了 Instill VDP 的公开测试版发布。这是一个开源的多功能数据流水线,专为 AI applications 的非结构化数据设计。它具有强大的设计、可扩展性、精细的集成以及无代码和低代码解决方案,于 2024 年 1 月 17 日发布。
-
Langserve 部署至 GCP 并具备高级功能:
@johnda98将其 langserve 工作与 Google Cloud Platform 集成,具有 Google Drive 访问、SQL 端点和文档加载功能,全部使用 LangChain libraries 构建。 -
AI Crawl Assistant 发布:
@kagnar.分享了其新开发的 AI Crawl Assistant 的 演示视频。该助手通过自然语言输入导航站点地图,利用了 OpenAI Assistant API 和 Mistral 模型。 -
双语及跨语言 RAG Embedding 开源:
@maidalun发布了 BCEmbedding,这是一个针对中英双语及跨语言的 embedding 模型,为 Retrieval Augmented Generation (RAG) 进行了优化,可在 HuggingFace 上获取,旨在促进与 LangChain 和 llamaIndex 的集成。
提到的链接:
-
来自 kagen (@kagnar_) 的推文:@nerobotai AI Crawl Assistant 运行的快速演示。#buildinpublic 它能够根据自然语言输入导航站点地图以查找所需页面。它通过利用一套工具来实现…
-
[Instill VDP - 专为 AI 原生应用打造的开源非结构化数据 ETL Product Hunt](https://www.producthunt.com/posts/instill-vdp):Versatile Data Pipeline (VDP):一个用于快速创建 AI 工作流的开源、无代码/低代码解决方案。它处理非结构化数据,确保高效的数据连接、灵活的流水线和顺畅的…
LAION Discord 摘要
-
法律专家关注许可证:
@pseudoterminalx鼓励审查 LAION 的 license,以确保理解和合规,特别是在法律背景下。 -
LAION Aesthetics v2 在哪里?:成员们(包括
@_lazyegg_和@thejonasbrothers)讨论了 LAION aesthetics v2 5+ 数据集,期待 移除 NSFW 内容后的重新发布。同时,@lulu_59476对 improved_aesthetics_6.5plus 数据集 表示感兴趣,尽管该数据集目前无法获取。 -
为视觉引入 Scaling:AIM 项目在分享的 Twitter 链接 中被重点介绍,展示了一系列可以像 LLM 一样扩展的视觉模型。参考论文显示,即使在 70 亿参数下也取得了令人期待的结果,可在 Hugging Face 上查看。
-
用于个性化图像合成的 InstantID 亮相:一个名为 InstantID 的新扩散模型助力从单张人脸图像进行个性化图像生成,承诺提供更好的个性化效果和忠实度,详见 arXiv 摘要。
-
对未总结论文的好奇:提到了一篇由 Jiaheng Liu 和 Wenhu Chen 撰写的 arXiv 论文,引发了好奇,但未进行详细讨论。
LAION 频道摘要
▷ #general (5 条消息):
-
鼓励阅读许可证:
@pseudoterminalx提到 LAION 有一个 license,可以让律师进行审查。 -
寻找 Laion Aesthetics v2:
@_lazyegg_询问如何获取 LAION aesthetics v2 5+ 的 parquet 文件,在网上寻找时遇到了困难。 -
期待移除 NSFW 内容后的发布:
@thejonasbrothers回复称所请求的数据集可能无法获取,但提到它们将 很快重新发布,并移除 NSFW 内容。 -
请求无法获取的数据集:
@lulu_59476询问来自 Hugging Face 的 improved_aesthetics_6.5plus 数据集,该数据集目前无法获取,他也对该数据集的其他版本持开放态度。
▷ #research (4 messages):
-
推出用于视觉的 AIM:
@spirit_from_germany分享了一个 Twitter 链接,宣布了 AIM。根据 Hugging Face 上的一篇论文,这是一个像 LLM 一样具有可扩展性的新视觉模型系列。AIM 强调视觉特征性能随模型容量和数据量同步扩展,并承诺即使在 70 亿参数下,性能也未见饱和,将持续提升。 -
InstantID 创新个性化图像生成:
@thejonasbrothers发布了一篇 arXiv 摘要,详细介绍了 InstantID。该技术通过一个仅需单张人脸图像即可工作的 Diffusion 模型,解决了个性化图像合成的高需求,在无需大量 Fine-tuning 的情况下增强了图像的个性化程度和忠实度。 -
又一篇尚未总结的 arXiv 论文:
@thejonasbrothers还分享了一个 arXiv 链接,该论文由包括 Jiaheng Liu 和 Wenhu Chen 在内的团队撰写,但提供的消息中未讨论该论文的具体内容和主题。 -
未说明的 Twitter 内容:
@spirit_from_germany发布了一个 Twitter 链接,但未提供相关的背景信息或讨论。
提到的链接:
-
E^2-LLM: Efficient and Extreme Length Extension of Large Language Models:通常情况下,训练具有长上下文尺寸的 LLM 在计算上非常昂贵,需要大量的训练时间和 GPU 资源。现有的长上下文扩展方法通常需要额外的训练…
-
InstantID: Zero-shot Identity-Preserving Generation in Seconds:通过 Textual Inversion、DreamBooth 和 LoRA 等方法,个性化图像合成已取得显著进展。然而,它们在现实世界中的应用受到高存储需求的阻碍…
-
来自 AK (@_akhaliq) 的推文:Apple 发布 AIM(Scalable Pre-training of Large Autoregressive Image Models)论文页面:https://huggingface.co/papers/2401.08541。论文介绍了 AIM,一个预训练的视觉模型系列…
Alignment Lab AI Discord 总结
仅 1 个频道有活动,因此无需摘要…
- 推出 Synthetic Insights 工具:
@edo4080宣布创建了一个新工具,用于分析、清理数据集,并在保持类别比例的同时缩小规模。他们提供了一个运行中的 Demo,展示了 OpenHermes 和 Ultrachat 等数据集,并邀请社区进行协作和反馈。
YAIG (a16z Infra) Discord 总结
仅 1 个频道有活动,因此无需摘要…
-
Kubernetes 依然领先:
@stevekamman分享了 Chris Aniszczyk 撰写的 CNCF 博客文章,强调了 Kubernetes 作为拥有“最大贡献者群体”项目的地位。 -
OpenTelemetry 提速:同一篇博客文章指出,OpenTelemetry 正在迅速增长,保持着第二高活跃度项目的地位。
-
Backstage 聚焦开发者体验:根据 CNCF 的洞察,Backstage 在解决开发者体验(Developer Experience)相关问题方面正获得越来越多的关注。
-
GitOps 稳步采用:更新还显示了对 GitOps 的持续兴趣,Argo 和 Flux 等项目保持着庞大的社区规模,并在云原生(Cloud Native)生态系统中不断扩大影响力。
提到的链接:
回顾 2023 年 CNCF、Linux Foundation 及前 30 个开源项目的活跃度:作者 Chris Aniszczyk。我们在过去几年中一直追踪开源项目的活跃度,并希望分享最新的更新,重点介绍过去 12 个月内开源项目的活跃度…