ainews-nightshade-poisons-ai-art-kinda
Nightshade 毒害了 AI 艺术……算是吧?
在 2024年1月19日至20日 的周末,TheBloke Discord 社区的讨论涵盖了多个核心话题,包括 混合专家模型 (MoE) 的效率、GPU 并行化以及量化策略。用户们辩论了 GPTZero 等 AI 检测工具的有效性,并探讨了 Mistral 7B 和 Falcon 7B 等模型的微调挑战。社区对于开发更简单、由社区驱动的量化服务以及理解模型合并技术表现出浓厚兴趣。此外,还讨论了围绕 AI 女友网站等 AI 应用的伦理考量。
2024年1月19-20日周末。我们为您检查了 19 个服务器,290 个频道,以及 7248 条消息。预计节省阅读时间(按 200wpm 计算):676 分钟。
两个月前首次通过 论文 亮相的 Nightshade,在本周末成为了 热门话题:
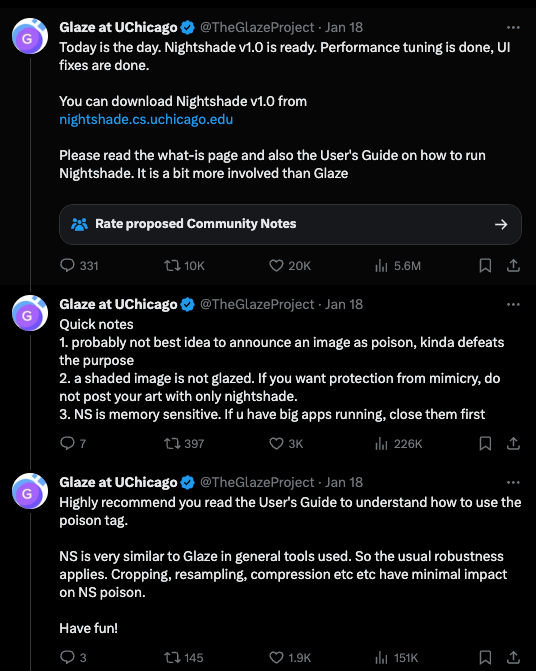
然而,深入研究细节的人们对其工作原理和原创性提出了质疑:
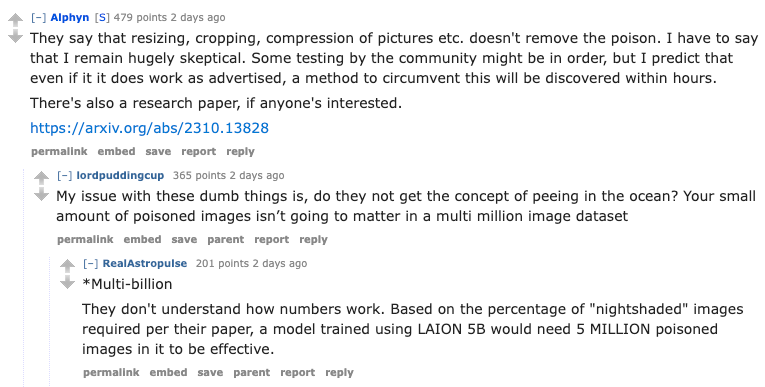
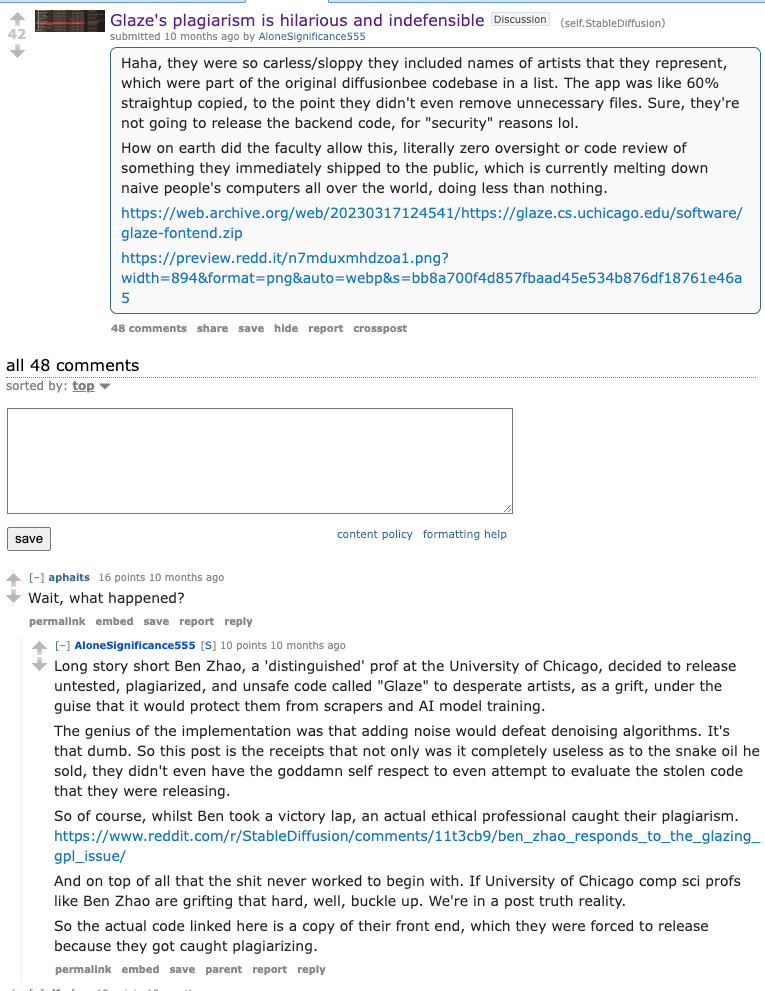
–
目录
[TOC]
TheBloke Discord 摘要
-
MoE 效率与检测工具讨论:在关于 Mixture of Experts (MoE) 模型的讨论中,GPU 并行效率和量化方法是核心话题,用户探讨了可变路由以及专家数量之间的权衡。此外,还分析了 GPTZero 检测特定类型 AI 生成内容的能力,并建议将添加噪声作为一种潜在的规避方法。
-
角色扮演 AI 的挑战:关于 Solar 效果的辩论浮出水面,一些用户指出尽管其 Benchmark 效率很高,但对齐效果较差。讨论了模型在长上下文角色扮演中的表现,对于任务的最佳模型以及可能导致输出失去新颖性的突发重复问题,意见不一。
-
深入探讨微调与量化策略:用户交流了微调 Mistral 7B 等语言模型的经验,由于数据有限,一些人选择了 few-shot learning 而非微调。提出了“社区驱动的量化服务”概念,并强调了对更简单量化方法的需求,主张应关注模型改进,而非用于量化的复杂分布式计算。
-
模型合并中的困惑与社区交流:关于模型合并策略的交流揭示了对 基于 Mistral 模型 的非标准混合比例的困惑。建议使用不同的融合技术,如 task arithmetic 和 gradient slerp,并警告不要盲目复制数值。
-
社区对量化与模型训练的兴趣:用户表达了对简便的社区驱动量化服务的渴望,类似于熟悉的视频转码过程。在模型训练方面,询问了在处理宗教文本的 50GB 语料库上进行训练的可行性,显示出初学者对利用现有开源模型处理特定领域的兴趣。
TheBloke 频道摘要
▷ #general (963 条消息🔥🔥🔥):
-
探索 MoE 和 LLM:用户讨论了在 Mixture of Experts (MoE) 模型中使用 Expert 的效率及其对 GPU 并行性的影响。
@kalomaze谈到了 MoE 中用于并行化任务的可变路由,以及使用更多或更少 Expert 之间的权衡。 -
增强 MoE 模型的复杂性:剖析了增强 MoE 的细微差别,
@kalomaze质疑层变得更简单带来的好处。@selea建议使用大量的 Expert,因为它们可以作为 “LoRA” 库来防止灾难性遗忘。 -
AI 检测工具的挑战:用户辩论了 GPT 检测工具
GPTZero的效率,@kaltcit指出虽然常见的 Sampler 可以被GPTZero检测到,但应用噪声似乎是规避检测的一种潜在方法。 -
微调之旅:
@nigelt11讨论了使用 130 条条目的数据集微调Falcon 7B的障碍,考虑转而使用Mistral,并了解用于基于 RAG 的自定义指令的“标准”模型与“指令 (Instruct)”模型之间的细微差别。 -
AI 女友网站的伦理模糊性:
@rwitz_思考了 AI 女友网站的伦理问题,在探索了这一想法后,最终决定转向 AI 技术更有用的应用,而不是利用孤独感。
提到的链接:
- Can Ai Code Results - mike-ravkine 的 Hugging Face Space: 未找到描述
- Mistral 7B Instruct 模型微调初学者指南: 使用单个 Google Colab Notebook 进行代码生成的微调
- Big Code Models 排行榜 - bigcode 的 Hugging Face Space: 未找到描述
- budecosystem/code-millenials-13b · Hugging Face: 未找到描述
- [First Token Cutoff LLM sampling -
](http://antirez.com/news/142): 未找到描述 - 如何使用 Mixtral: 更新于 12/22。至少需要 20GB 左右的总 VRAM / RAM。VRAM 越多,速度越快/效果越好。获取最新的 Kobold: https://github.com/kalomaze/koboldcpp/releases 获取模型 下载其中一个量化版本…
- GitHub - iusztinpaul/hands-on-llms: 🦖 免费学习 LLM, LLMOps 和向量数据库,通过设计、训练和部署一个实时金融顾问 LLM 系统 ~ 源代码 + 视频 & 阅读材料: 🦖 免费学习 LLM, LLMOps 和向量数据库,通过设计、训练和部署一个实时金融顾问 LLM 系统 ~ 源代码 + 视频 & 阅读材料
- GitHub - turboderp/exllamav2: 一个用于在现代消费级 GPU 上本地运行 LLM 的快速推理库: 一个用于在现代消费级 GPU 上本地运行 LLM 的快速推理库 - GitHub - turboderp/exllamav2: A fast inference library for running LLMs locally on modern consumer-class GPUs
- kalomaze 实现的噪声采样 HF 实现 · Pull Request #5342 · oobabooga/text-generation-webui: 一个自定义 Sampler,允许你对原始 Logit 分数应用高斯噪声,以在有许多可用 Token 时鼓励选择的随机化(并有望避免重复 / 循环…
- GitHub - OpenAccess-AI-Collective/axolotl: 尽管提问 (Go ahead and axolotl questions): 尽管提问。通过在 GitHub 上创建一个账户来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- 由 awtrisk 添加 dynatemp(熵那个)· Pull Request #263 · turboderp/exllamav2: 仍有一些内容需要检查,正在进行中。
▷ #characters-roleplay-stories (403 messages🔥🔥):
-
Solar 作为 Benchmark Chad 的地位:
@doctorshotgun将 Solar 描述为在 Benchmark 跑分中表现高效,但在实际使用中却很糟糕,存在类似于 ChatGPT 的 Alignment(对齐)问题。然而,@theyallchoppable捍卫了它在角色扮演场景中的实用性,理由是其表现非常稳定。 -
角色扮演质量的模型对比:
@sanjiwatsuki和@animalmachine讨论了 Mixtral、70B、Goliath 和 SOLAR 等模型在角色扮演测试中的表现,意见不一。讨论中提到了一些新模型和 Fine-tuning 策略,如 Kunoichi-DPO-v2-7B,被认为有可能提高连贯性和对角色卡的遵循度。 -
长上下文处理:用户报告了模型在长上下文长度下的表现,指出像 Mistral 7B Instruct 这样的模型在超过特定限制后会失去连贯性。随后的讨论涉及了运行大规模模型的效率技巧和硬件要求。
-
深入探讨量化方法:针对 Quantization 策略进行了详细讨论,包括分享 GGUF 模型的仓库链接。
@kquant提供了关于排名系统中潜在性能的见解。 -
MoE 模型中出现的重复问题:
@kquant表示,多个模型协同工作往往会趋于泛化,并可能变得具有重复性,将其比作卡在副歌部分的合唱团。一个采用专门设计以对抗创意场景中重复问题的新模型正在开发中。
提到的链接:
- Urban Dictionary: kink shame:Kink shame 是指因为某人特殊的癖好或恋物倾向而对其不尊重或贬低。
- LoneStriker/airoboros-l2-70b-3.1.2-5.50bpw-h6-exl2 · Hugging Face:未找到描述
- Kquant03/Umbra-MoE-4x10.7-GGUF · Hugging Face:未找到描述
- athirdpath/DPO_Pairs-Roleplay-Alpaca-NSFW-v1-SHUFFLED · Datasets at Hugging Face:未找到描述
- TheBloke/HamSter-0.1-GGUF · Hugging Face:未找到描述
- Reddit - Dive into anything:未找到描述
- Kooten/Kunoichi-DPO-v2-7B-8bpw-exl2 at main:未找到描述
- Undi95/Borealis-10.7b-DPO-GGUF · Hugging Face:未找到描述
- brittlewis12/Kunoichi-DPO-v2-7B-GGUF · Hugging Face:未找到描述
▷ #training-and-fine-tuning (12 messages🔥):
- 入门 LLM 的新手:自称新手的
@zos_kia正在寻求关于在 50GB 的非结构化宗教和神秘学文本语料库上训练语言模型的建议。他们正在考虑像 trismegistus-mistral 这样的开源模型,并询问在家庭电脑上训练的可行性以及预期的时间周期。 - Ping 专家寻求见解:
@zos_kia询问是否可以在 Discord 服务器中 Ping trismegistus-mistral 的作者,以获取关于其训练项目的个性化建议。 - 语音信箱检测微调咨询:
@rabiat正在寻求关于 Fine-tuning Mistral 7B 或 MoE 以分类语音信箱公告的指导,并对高效进行 LoRA 微调所需的 Dataset 大小感到好奇。他们正考虑使用 40 个真实的语音信箱示例作为种子进行 Upsample(上采样)。 - Few-shot 作为替代方案:
@gahdnah建议@rabiat可以尝试 Few-shot Learning 作为语音信箱分类任务中 Fine-tuning 的替代方案。 - 量化模型与微调:
@sushibot分享了一个骨架脚本,展示了在附加 LoRA 权重之前将模型量化为 4-bit 的过程,并询问了相关设置。@sanjiwatsuki确认这正是 QLoRA 中 “Q” 的含义,即在量化模型中对 Frozen Weights(冻结权重)进行微调。 - Benchmark 博客文章展示:
@superking__分享了一篇 Hugging Face 博客文章,该文章评估了三种无需强化学习的语言模型 Alignment(对齐)方法:Direct Preference Optimization (DPO)、Identity Preference Optimisation (IPO) 和 Kahneman-Tversky Optimisation (KTO),涵盖了各种模型和超参数设置。
提到的链接:
Preference Tuning LLMs with Direct Preference Optimization Methods:未找到描述
▷ #model-merging (15 条消息🔥):
- Blizado 探索非标准合并:
@blizado正在寻求使用 75:25 的比例而非标准的 50:50 来合并两个 Mistral-based models。他们发现 50:50 的 slerp merge 对其中一个模型的偏向性过强。 - Sao10k 建议合并的灵活性:
@sao10k建议@blizado尝试不同的 merge methods,如 gradient slerp、task arithmetic 或 DARE-TIES,并强调不要死守默认值。 - 对合并参数的困惑:尽管有了这些建议,
@blizado仍对合并参数及其对模型语言输出的影响表示困惑。 - Sao10k 澄清合并数值:针对
@blizado遇到的模型在德语和英语之间切换的问题,@sao10k建议不要盲目复制数值,并建议使用 0.2 到 0.7 范围内的简单 gradient slerp。 - Blizado 在混合模型中遇到的麻烦:在尝试了从 Hugging Face 模型上找到的 slerp 参数后,
@blizado报告称在合并两个不同的 base models 时很难看出差异,并建议在将一个扎实的语言 base model 与另一个在相同语言中具有高语言理解能力的模型结合时,应关注特定的 merge effectiveness。
▷ #coding (8 条消息🔥):
-
呼吁简化的模型量化方案:
@spottyluck对缺乏“超大规模/基于队列的模型量化解决方案”表示惊讶,考虑到他们在视频转码方面的丰富经验。他们建议建立一种社区服务的可能性,允许轻松进行模型量化,并为共享计算能力提供退出功能。 -
量化服务:社区努力的方向?:随后,
@spottyluck提出了一个社区驱动的分布式模型量化服务的想法,用户可以在处理自己的项目时向公共计算资源做出贡献。 -
简单胜过复杂:
@wbsch反驳称,大多数用户更喜欢 TheBloke 提供的便利性和一致性,而不需要像量化农场或分布式计算服务这样复杂的解决方案。 -
为模型而非量化提供算力:
@kquant强调社区计算捐赠应针对 长期研究 和模型改进,而不是量化过程。 -
关于 Stable Diffusion 中 Checkpoint 更改的技术咨询:
@varient2寻求关于如何使用 webuiapi 以编程方式更改 Stable Diffusion 中的 Checkpoint 的帮助,并提到他们已经弄清楚了如何发送 prompt 以及在生成过程中使用 ADetailer 进行面部调整。
Nous Research AI Discord 总结
-
WSL1 在 13B 模型上的意外表现:
_3sphere发现,尽管之前使用 llama.mia 工具时出现了段错误(segmentation fault),但 13B 模型 仍可以在 WSL1 上成功加载。 -
ggml Hook 的 7b 模型限制被揭示:
_3sphere发现 ggml hook 因未说明其仅适用于 7b 模型 而受到批评。 -
启动 LLM 训练对话的 SPIN 方法:
_3sphere展示了来自 arXiv 论文 的 SPIN 方法论,讨论了其通过迭代优化 LLM 能力的潜力。 -
单 GPU LLM 推理成为可能:
nonameusr分享了 AirLLM,如 Twitter 帖子 所述,它可以在单个 4GB GPU 上实现 70B LLM 的推理。 -
Etched 的定制芯片引发质疑:讨论中包含了对 Etched 用于 Transformer 推理的定制芯片可行性的怀疑,对其在 LLM 上的实用性表示担忧。
-
Orion 的 14B 模型在对话能力上表现不佳:据
teknium等人报告,Orion 的 14B 模型对话输出水平较低,这与其 Benchmark 分数相矛盾。 -
Proxy-Tuning 论文引发关注:讨论了一种名为 Proxy-Tuning 的新型 LLM 微调方法,详情见最近发表的论文。
-
Mixtral 的多专家潜力:围绕 Mixtral 模型的讨论集中在成功优化多专家(Multiple Experts)的使用上,促使
carsonpoole考虑将其与 Hermes 结合使用。 -
微调细节:
qnguyen3寻求关于微调 Nous Mixtral 模型的建议,teknium提供了见解,包括 Nous Mixtral 已经过完整的 Finetune。 -
商业许可困惑:微调模型的商业用途引发了关于许可成本和权限的辩论,由
teknium发起,casper_ai等人参与。 -
设计 Nous 图标:Nous 社区开始设计易于辨认的角色图标,
benxh和john0galt建议使用透明的 “Nous Girl” 和更简洁的 Logo。 -
来自 DSPy/ColBERT/Stanford 的 Omar 加入:社区欢迎 Omar 的加入,并对他对语义搜索和更广泛 AI 应用的贡献以及潜在的合作表示兴奋。
-
Alpaca 的评估方法受到质疑:
teknium对 Alpaca 的排行榜表示怀疑,在观察到 Yi Chat 排名高于 GPT-4 后,暗示其评估方法存在问题。 -
模仿学习的人类边界:由
teknium领导的一场对话探讨了这样一种观点:由于依赖平均人类数据进行训练,模仿学习(Imitation Learning)可能无法产生超越人类的能力。 -
AI 自我批判能力受到挑战:讨论的一篇论文指出 AI 在自我评估方面缺乏熟练度,促使
teknium对模型的自我批判能力提出质疑。
Nous Research AI 频道总结
▷ #off-topic (29 条消息🔥):
- WSL1 处理大模型表现良好:
@_3sphere发现使用 WSL1 可以毫无问题地加载 13B model。他们最初因为 llama.mia 设置中出现的 segmentation faults 而持有相反看法,但后来意识到这是特定工具的故障。 - 模型兼容性疏忽:
@_3sphere报告称,用于处理 AI 模型的 ggml hook 似乎只适用于 7b models,这表明 ggml hook 的创建者可能仅针对这一特定尺寸进行了测试。由于该限制未被记录在文档中,言语中透露出些许沮丧。 - Hugging Face 排行榜监管:
@.ben.com分享了关于 Hugging Face 排行榜近期变动的讨论,除非正确调整 metadata,否则被错误标记为merge的模型将被标记(flagged)。 - 《奇异新世界》中的克林贡语:
@teknium分享了一个 YouTube 视频,其中包含《奇异新世界》第二季第九集克林贡人唱歌的场景,并对 Star Trek 系列的创作方向表示失望。 - 对 Star Trek 的怀旧被新变化掩盖:
@teknium怀旧地讨论了 Star Trek 方向的变化,并配上了一个暗示失望的幽默 GIF,而@.benxh则对这一心爱系列的改变感到哀叹。
相关链接:
- mistralai/Mixtral-8x7B-v0.1 · 为 Mixtral 添加 MoE 标签:未找到描述
- Gary Marcus Yann Lecun GIF - Gary Marcus Yann LeCun Lecun - 发现并分享 GIF:点击查看 GIF
- 克林贡语唱歌:出自《奇异新世界》第二季第九集。
- HuggingFaceH4/open_llm_leaderboard · 公告:标记 metadata 不正确的合并模型:未找到描述
▷ #interesting-links (236 条消息🔥🔥):
-
LLM 训练阶段的探索:
@_3sphere发起了一场关于何时在 LLM 训练过程中引入代码最为有效的讨论,并分享了来自近期论文的 SPIN 方法论,该方法允许 LLM 通过与之前的迭代版本博弈来提升能力。 -
极低硬件配置下的 LLM 推理:
@nonameusr分享了关于 AirLLM 的信息,这是一种通过利用逐层推理(layer-wise inference)而非压缩技术,实现在单个 4GB GPU 上运行 70B LLM 推理的方法。 -
专为 LLM 设计的芯片组:
@eas2535、@euclaise和@0xsingletonly对 Etched 用于 Transformer 推理的定制芯片的实用性和前瞻性表示怀疑。 -
Orion-14B 模型受到质疑:Orion 的 14B 模型的实际对话能力正受到
@.benxh、@teknium等人的质疑,因为它在 MMLU 等基准测试上的表现与初始用户体验形成鲜明对比,用户报告其输出内容荒谬,且容易陷入随机语言。 -
LLM 的代理微调 (Proxy-Tuning):
@intervitens和@sherlockzoozoo讨论的一篇论文介绍了代理微调(proxy-tuning),该技术利用较小 LM 的预测来引导较大(且可能是黑盒)LM 的预测。
提到的链接:
-
[Etched 全球首台 Transformer 超级计算机](https://www.etched.com/):将 Transformer 架构刻入芯片。通过将 Transformer 架构固化到芯片中,我们正在打造全球最强大的 Transformer 推理服务器。 - 来自 undefined 的推文:未找到描述
- 来自 Rohan Paul (@rohanpaul_ai) 的推文:🧠 在单个 4GB GPU 上运行 70B LLM 推理 - 使用 airllm 和分层推理 🔥 逐层推理本质上是“分而治之”的方法 📌 而且这还是在不使用量化…的情况下。
- 通过代理微调语言模型:尽管大型预训练语言模型具有通用能力,但它们始终能从进一步的适配中获益,以更好地实现预期行为。然而,微调这些模型已变得越来越…
- 自博弈微调将弱语言模型转变为强语言模型:通过监督微调 (SFT) 利用人类标注数据的力量对于推进大语言模型 (LLM) 至关重要。在本文中,我们深入探讨了培育强 L…的前景。
- 循环 Transformer 更擅长学习学习算法:正如 Garg 等人所报告的,Transformer 在处理来自各种(潜在)模型的数据拟合问题时表现出了上下文学习的有效性。然而,由于缺乏固有的迭代结构…
- 代码数据在哪个训练阶段有助于 LLM 的推理?:大语言模型 (LLM) 展现出了卓越的推理能力,并已成为语言技术的基石。受到代码数据在训练 LLM 中取得巨大成功的启发,我们自然地…
- 平台总监:加利福尼亚州库比蒂诺
- bartowski/internlm2-chat-20b-llama-exl2 at 6_5:未找到描述
- OrionStarAI/Orion-14B-Base · Hugging Face:未找到描述
- 来自 anton (@abacaj) 的推文:冲啊。你们都忽视的穷人 GPU 技术,仅用 2x3090 就能将 phi-2 扩展到 8k(从 2k)。
- GitHub - b4rtaz/distributed-llama: 在弱设备上运行 LLM,或通过分配工作负载和划分 RAM 使用量使强大设备变得更强大。:在弱设备上运行 LLM,或通过分配工作负载和划分 RAM 使用量使强大设备变得更强大。 - GitHub - b4rtaz/distributed-llama…
- GitHub - RVC-Boss/GPT-SoVITS: 1 分钟的语音数据也可用于训练出色的 TTS 模型!(少样本语音克隆):1 分钟的语音数据也可用于训练出色的 TTS 模型!(少样本语音克隆) - GitHub - RVC-Boss/GPT-SoVITS…
- Yuan2.0-2B-Janus-hf:未找到描述
▷ #general (524 条消息🔥🔥🔥):
-
Mixtral Experts 的新视角:围绕 Mixtral 模型中多专家(multiple experts)使用的讨论集中在优化上。
@carsonpoole强调了在增加专家数量时,以极小的速度牺牲实现成功部署的案例,并考虑尝试在 Hermes 中使用超过通常两个的专家。 -
高质量微调的探索:大家对微调超过两个专家的模型有着共同的好奇。
@qnguyen3在使用 Axolotl 进行微调时遇到困难,并向@teknium等资深人士寻求建议,后者澄清了 Nous Mixtral 模型进行的是全量微调(full finetune),而不仅仅是 LoRa 微调。 -
关于商业使用的许可困惑:由
@teknium发起的关于微调模型(如来自 Stability AI 的模型)商业使用的讨论,揭示了围绕许可成本和权限的混乱。@casper_ai等用户对实施商业使用的不同解释和潜在问题进行了辩论。 -
Nous 美学:聊天中包含了一项设计更清晰的 Nous 角色图标的倡议。各种建议在流传,例如制作“Nous Girl”图形的透明版本或创建一个更简单的 Logo,成员
@benxh和@john0galt贡献了设计技能。 -
技术社区致意:来自 DSPy/ColBERT/Stanford 的 Omar 加入了服务器,受到了成员
@night_w0lf和@qnguyen3的欢迎。成员们表达了将 Omar 的工作整合到他们解决方案中的热情,并期待在项目中与 DSPy 进行合作。
提到的链接:
- Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling:未找到描述
- Animated Art Gif GIF - Painting Art Masterpiece - Discover & Share GIFs:点击查看 GIF
- Combining Axes Preconditioners through Kronecker Approximation for…:基于自适应正则化的优化方法,如使用梯度二阶矩信息的全矩阵 Adagrad,在深度神经网络的快速收敛方面具有巨大潜力……
- Joongcat GIF - Joongcat - Discover & Share GIFs:点击查看 GIF
- Nerd GIF - Nerd - Discover & Share GIFs:点击查看 GIF
- Browse Fonts - Google Fonts:通过出色的排版让网络更美观、更快速、更开放。
- Domine - Google Fonts:从设计过程的第一步开始,“Domine” 就是为网页正文设计的,并经过了测试和优化。它在 14 和 16 像素下表现出色。甚至可以……
- 🔍 Semantic Search - Embedchain:未找到描述
- EleutherAI/pythia-12b · Hugging Face:未找到描述
- Reddit - Dive into anything:未找到描述
- Tweet from Teknium (e/λ) (@Teknium1):好了,读了论文,有一些笔记,主要是担忧,但也有一些前景。- 正如我第一次看到论文时所说,他们只在 Alpaca Eval 上进行了测试,我不能说那是最好的评估……
- Evaluation of Distributed Shampoo:优化器比较:Distributed Shampoo、Adam 和 Adafactor。由 Boris Dayma 使用 Weights & Biases 制作。
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others:修复损坏的 Twitter/X 嵌入!在 Discord、Telegram 等平台上使用多张图片、视频、投票、翻译等 - GitHub - FixTweet/FxTwitter。
- HuggingFaceH4/open_llm_leaderboard · Announcement: Flagging merged models with incorrect metadata:未找到描述
▷ #ask-about-llms (168 messages🔥🔥):
-
对 Alpaca 评估的质疑:
@teknium对 Alpaca 的评估表示怀疑,指出根据排行榜,Yi Chat 的评分高于 GPT-4,暗示评估过程中可能存在缺陷。 -
模仿学习的局限性:在关于模仿学习(Imitation Learning)局限性的讨论中,
@teknium认为,如果模型是基于普通人类的数据进行训练的,那么它们不太可能模仿出超人类的能力。 -
AI 模型自我批判能力受质疑:
@teknium引用了一篇论文,指出 AI 模型并不擅长自我评估,从而引发了对其自我批判能力的质疑。 -
LLaMA 和 ORCA 的实验:
@teknium分享了一个实验,使用 LLaMA 2 70B 来制作 ORCA,类似于 GPT-4 的做法,并指出 MT 基准测试略有提升,但对 MMLU 等传统基准测试产生了负面影响。 -
比较不同版本的 LLM:针对
@mr.userbox020关于 Nous Mixtral 和 Mixtral Dolphin 之间基准测试的询问,@teknium提供了其 GitHub 仓库的链接,其中包含 Dolphin 2.6 与 Mixtral 7x8 以及 Nous Hermes 2 与 Mixtral 8x7B 的对比日志,并提到根据他们的经验,2.5 版本表现最好。
提到的链接:
- 👾 LM Studio - 发现并运行本地 LLM:查找、下载并实验本地 LLM。
- Ollama:在本地快速启动并运行大语言模型。
- Approximating Two-Layer Feedforward Networks for Efficient Transformers:如何在不牺牲性能的情况下减少神经网络(NNs)的计算和内存需求?许多近期研究使用稀疏混合专家(MoEs)来构建资源高效的大语言模型…
- LLM-Benchmark-Logs/benchmark-logs/Dolphin-2.6-Mixtral-7x8.md at main · teknium1/LLM-Benchmark-Logs:一系列不同 LLM 的基准测试日志。通过在 GitHub 上创建账号为 teknium1/LLM-Benchmark-Logs 做出贡献。
- GitHub - ggerganov/llama.cpp: Facebook LLaMA 模型的 C/C++ 移植版本:Facebook LLaMA 模型的 C/C++ 移植版本。通过在 GitHub 上创建账号为 ggerganov/llama.cpp 做出贡献。
- LLM-Benchmark-Logs/benchmark-logs/Nous-Hermes-2-Mixtral-8x7B-DPO.md at main · teknium1/LLM-Benchmark-Logs:一系列不同 LLM 的基准测试日志。通过在 GitHub 上创建账号为 teknium1/LLM-Benchmark-Logs 做出贡献。
OpenAI Discord 总结
-
重新思考 Nightshade 的影响:工程师们讨论了 AI 的故障安全机制,特别是针对 Nightshade,由于其新颖性,它可能不会损害数据。对话强调了对系统影响非预期数据集的担忧,以及对大型 AI 公司强大安全措施的信任。
-
优化 GPT-4 中的 Prompt 限制:针对 GPT-4 图像生成器中的 Prompt 锁定问题展开了技术讨论。明确了滚动使用和单个 Prompt 计时器的工作原理,建议每 4.5 分钟测试一次 Prompt 间隔,以避免达到 Prompt 上限。
-
Python 开发者的 AI 技能进阶:社区成员寻求在 Python 中级水平之上深化 AI 专业知识的建议,建议包括探索 AI 基础概念、机器学习技术以及来自 Hugging Face 的资源。
-
Bing 中有一丝 AI 意识?:工程师们开玩笑地推测 Bing 可能具有自我意识,引发了轻松的交流,但并未对 AI 涌现的能力表示严重担忧。
-
Prompt Engineering:AI 引导的艺术:社区交流了关于 Prompt Engineering 的想法、安全策略(如“触发/拦截”)以及理解 AI 对语言和指令理解的重要性。他们讨论了条件 Prompt、如何编写 Prompt 以防范恶意行为者,以及安全托管 GPT 指令的注意事项。
OpenAI 频道总结
▷ #ai-discussions (43 messages🔥):
-
关于 Nightshade 是否万无一失的疑问:
@jaicraft询问 Nightshade 是否毫无瑕疵,担心它可能会影响目标之外的数据。@【penultimate】认为大型 AI 公司拥有强大的 failsafes(安全机制),且由于 Nightshade 的新颖性,隔离被污染的数据应该很容易。 -
Prompt 限制的困惑:
@.kylux在通过 GPT-4 使用图像生成器时遇到了 Prompt 限制问题,指出在 40 条消息限制的情况下,发送 20 条后就被锁定了。@rendo1澄清这是滚动使用的,每个 Prompt 都有自己的计时器,@satanhashtag建议每 4.5 分钟尝试发送一个 Prompt 进行测试。 -
AI 爱好者的学习路径:
@.009_f.108寻求深化 AI 知识的资源,他已具备中级 Python 技能。@michael_6138_97508和@lugui建议从基础 AI 概念和经典 Machine Learning 技术开始,而@darthgustav.等人则简单地推荐了 Hugging Face。 -
Bing 所谓的自我意识:
@metaldrgn声称 Bing 可能表现出了智能和意识的迹象,而@michael_6138_97508开玩笑地回应说他们很幸运。 -
关于审核和资源共享的讨论:
@miha9999因分享资源链接被禁言,并询问了相关政策。@eskcanta建议联系 modmail 以获取澄清和审核操作方面的帮助,在警告被移除后,@miha9999的困惑得到了解决。
▷ #gpt-4-discussions (144 messages🔥🔥):
- Weaviate 集成困境:
@woodenrobot表达了在将自定义 GPT Action 与 Weaviate 集成时的困难,强调了与 Payload 中对象属性相关的UnrecognizedKwargsError。 - 探索 GPT-4 的计费周期:
@stefang6165注意到 GPT-4 的消息限制从每 3 小时 40 条减少到约 20 条,正在寻求关于此变化的见解。 - 分享 GPT-4 聊天体验:
_jonpo分享了他们与 HAL 令人满意的对话,而@robloxfetish在会话中遇到了意外的消息上限,促使@darthgustav.和@c27c2建议这可能是一个临时错误,或者需要联系支持部门。 - 使用 ChatGPT 处理 PDF:
@marx1497征求处理小型 PDF 的建议但收效甚微,这引发了与@darthgustav.关于工具局限性的讨论以及对数据预处理的建议。 - 使用 GPT 创建交互式 MUD 环境:
@woodenrobot和@darthgustav.就如何将结构化数据和代码嵌入 GPT 的知识文档进行了深入的技术交流,双方都对使用 AI 开发 MUD 服务器以及在数据库存储和会话连续性约束下工作感兴趣。
▷ #prompt-engineering (247 messages🔥🔥):
-
GPT 中的隐蔽安全性:
@busybenss建议使用“触发/阻断”策略来保护 GPT 模型免受恶意行为者的侵害。@darthgustav.指出了 Conditional Prompting 对于安全性的重要性,鼓励公开讨论而非信息封锁。 -
在复杂 JSON 中条件化使用 GPT:
@semicolondev询问在生成 3.5 难以处理的复杂 JSON 时,是否可以条件化地使用 GPT-4,并提到了使用 GPT-4 的更高成本。@eskcanta建议在基础步骤中使用 3.5,并将 GPT-4 留给必要的步骤,敦促在预算限制内进行创造性的问题解决。 -
即兴 AI 认识论:
@darthgustav.和@eskcanta深入探讨了模型如何解释和响应 Prompt。他们强调了 AI 在理解指令方面的特异性,指出即使是 AI 也不总是“知道”其推理路径,这为模型训练如何影响 Prompt 解释提供了深刻见解。 -
揭秘 Prompt 策略:
@eskcanta分享了一种高级 Prompt 策略,即将模型的思考过程与其被指示执行的操作分开。这一概念引发了关于理解 AI 响应行为本质以及如何利用它来更好地进行 Prompt Engineering 的对话。 -
将图表提取到 Google Sheets:
@alertflyer寻求帮助将 GPT 输出的图表转移到 Google Sheets 中,@eskcanta通过澄清所需图表的性质进行了回应。讨论旨在确定创建图表的方法以便进行正确的提取。
▷ #api-discussions (247 messages🔥🔥):
-
安全策略备受关注:
@busybenss揭示了一种他们称之为 “trigger/block”(触发/阻断)的安全方法,用于保护 GPT 免受恶意攻击者的侵害,并声称该方法能有效阻止 GPT 执行不当输入。@darthgustav对该方法占用的字符空间表示关注,担心这可能导致功能的丧失。 -
通过 Conditional Prompting 保护 GPT:在一次关于安全的深入讨论中,
@darthgustav解释了 Conditional Prompting(条件提示词)的优势,并警告了安全实现中潜在的弱点。随后,对话探讨了多种保护 GPT 的技术和想法,包括通过 Web 服务器托管 GPT 指令并对 OpenAI 进行安全调用。 -
攻击 LLM:不可避免的风险:
@busybenss和@darthgustav都认为,虽然安全措施至关重要,但共享和使用 GPT 存在固有的脆弱性,数字资产被盗的情况仍可能发生。 -
AI 开发的经济学:随着话题从安全转向 AI 的商业层面,
@thepitviper和@darthgustav建议将重点放在改进产品和营销以脱颖而出,而不是过度担心被盗和追求完美的安全。 -
Prompt Engineering 与 AI 理解:来自
@madame_architect、@eskcanta等人的一系列消息讨论了 Prompt Engineering 的复杂性以及 AI 对语言的理解。他们分享了关于语义差异的见解,以及如何引导模型更好地理解和执行 Prompt。
LAION Discord Summary
-
审视对抗性 AI 工具:讨论集中在 Nightshade 和 Glaze 等对抗性工具在 AI 图像生成上的可疑效果。虽然
@astropulse对这些工具可能提供的虚假安全感表示担忧,但尚未达成共识。相关的 Reddit 帖子 提供了进一步的见解。 -
数据与模型:一场激烈的辩论:成员们就创建用于 Fine-tuning AI 模型的数据集以及与高分辨率图像相关的挑战展开了深入辩论。讨论还涉及了 GPT-4V 等模型的效能和成本,以及与 CLIP 模型相比,扩展 T5 模型的复杂性。
-
AI 伦理:一个棘手的问题:AI 伦理和版权是另一个焦点,社区成员对什么是“伦理”表现出一定程度的愤世嫉俗。Hacker News 和 Reddit 等平台上社区反应的差异,突显了 AI 对版权影响的矛盾性质。
-
文本转语音(TTS)的未来:TTS 的进步引发了热烈讨论,对比了包括 WhisperSpeech 和 XTTS 在内的各种服务。讨论了 11Labs 令人印象深刻的配音技术,但由于 API 限制而受到约束。相关的 YouTube 视频 介绍了 TTS 的最新进展。
-
关于情感 AI 的咨询与理论:
- 法律与挑战:关于欧盟(EU)对情感检测 AI 立场的提问得到了澄清,即此类技术在欧盟境内并未被禁止用于研究。
- 需要情感检测专家:呼吁专家参与构建情感检测数据集,强调需要心理学专业知识和适当的语境来进行准确的情感分类。
LAION Channel Summaries
▷ #general (394 条消息🔥🔥):
-
辩论 Nightshade 的有效性:
@mfcool对 DreamShaperXL Turbo 图像是否来自新模型表示怀疑,理由是它们与现有模型非常相似。@astropulse等人深入探讨了像 Nightshade 和 Glaze 这样的对抗性工具是否会对 AI 图像生成产生显著影响,@astropulse认为这些工具可能只会给用户带来一种虚假的安全感。这里有来自r/aiwars子版块的深度探讨:我们需要聊聊 Glaze 和 Nightshade…。 -
关于数据和模型训练的讨论:
@chad_in_the_house、@thejonasbrothers和@pseudoterminalx等成员讨论了为微调模型创建数据集的问题,以及使用高分辨率图像的局限性。辩论涉及了 GPT-4V 等模型的效能与成本,以及相对于 CLIP 模型,扩展 T5 模型的复杂性。 -
AI 伦理与许可话语:对话延伸到了 AI 版权和伦理,成员们对当代“伦理”沦为个人共识的替代品表示愤世嫉俗。
@astropulse和@.undeleted批评了 Hacker News 和 Reddit 等平台上的社区反应,同时讨论了 AI 对艺术和版权的更广泛影响。 -
探索 TTS 和配音技术:
@SegmentationFault、@itali4no和@.undeleted讨论了先进的文本转语音 (TTS) 模型,比较了 WhisperSpeech 和 XTTS 等现有服务。@SegmentationFault强调了 11Labs 令人印象深刻的配音技术以及使其方法保持专有的 API 限制。在这段 Youtube 视频中了解更多关于 TTS 的进展:“开源文本转语音项目:WhisperSpeech”。 -
关于 AI 放大器和语言模型训练的咨询:
@skyler_14询问了训练 GigaGAN 放大器的进度,并提到了@lucidrains的一个 GitHub 项目。@andystv_询问了训练支持繁体中文模型的可能性。
提到的链接:
- 未找到标题: 未找到描述
- apf1/datafilteringnetworks_2b · Hugging Face 数据集: 未找到描述
- 数据投毒无法从人脸识别中拯救你: 数据投毒被提议作为对抗在网络抓取图片上训练的人脸识别模型的一种引人注目的防御手段。用户可以扰动他们发布在网上的图像,从而使模型产生误判…
- WhisperSpeech - Tonic 的 Hugging Face Space: 未找到描述
- Meme Our GIF - Meme Our Now - 发现并分享 GIF: 点击查看 GIF
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- 开源文本转语音项目:WhisperSpeech - 深度讨论: WhisperSpeech 是一个很有前途的新开源 TTS 模型,它可以仅在音频数据上进行训练,并且在几百个 GP… 之后已经显示出可喜的结果。
- webdataset 是通用格式的可行选择吗? · huggingface/pytorch-image-models · Discussion #1524: 你好 @rwightman,感谢你持续的出色工作。我正在尝试使用 Webdataset 格式,利用了以下链接中的一些方法:https://github.com/rwightman/pytorch-image-models/blob/475ecdfa…
- GitHub - lucidrains/gigagan-pytorch: GigaGAN 的实现,来自 Adobe 的新 SOTA GAN。近十年 GAN 研究的结晶: GigaGAN 的实现,来自 Adobe 的新 SOTA GAN。近十年 GAN 研究的结晶 - GitHub - lucidrains/gigagan-pytorch: GigaGAN 的实现,来自 Adobe 的新…
▷ #research (25 messages🔥):
-
模型缩放中的计算挑战:
@twoabove讨论了最近一个模型的作者承认受到计算资源限制,并计划研究其方法的 scaling laws。@qwerty_qwer回应称,克服计算限制将是 颠覆性(game-changing) 的。 -
寻找创新的多模态技术:
@twoabove询问了用于多模态模型的创新图像分块/嵌入技术,@top_walk_town进一步阐述了这一问题,并列举了包括 LLaVa、Flamingo、llama adapter、Chameleon 以及 megabyte 论文在内的几种方法。 -
解读欧盟关于情感 AI 的法律:
@fredipy质疑开发检测情绪的 AI 是否违反了欧盟的 AI 法规。@mr_seeker进行了澄清,@JH认为此类法律不会影响非欧洲实体,而@spirit_from_germany指出,在欧盟,情绪检测 并未禁止用于研究。 -
情感识别数据集的挑战:
@spirit_from_germany正在开发一个基于图像的情感检测器,但苦于情感数据集有限。他们提议在心理学专家的帮助下创建一个精选数据集,而@_spaniard_对在缺乏丰富上下文信息的情况下检测细微情绪的可行性表示怀疑。 -
情感检测需要专家见解:具有心理学背景的
@.hibarin支持在情绪分类中引入上下文的必要性,这与情绪的指纹假设或群体假设相一致。@skyler_14介绍了 3D 可变形模型(3D morphable models),认为这是一个更容易进行情绪标注的潜在领域。
Eleuther Discord Summary
-
Flash Attention 引发 CUDA 与 XLA 之争:
@carsonpoole和@.the_alt_man针对 Flash Attention 展开辩论,观点在 XLA 优化是否能简化其 CUDA 实现上产生分歧。来自 Patrick Kidger 的一条 Reddit 评论建议 XLA 可以在 TPU 上优化注意力机制,并引用了 Reddit 帖子。 -
对抗性方法的法律难题:Glaze 和 Nightshade 工具引发了
@digthatdata和@stellaathena等成员之间关于法律和有效性的辩论。分享的一篇 法律论文 表明,绕过水印并不一定构成违法。 -
开源与 AI 伦理:社区讨论了 Meta LLaMA 的开源性质和许可协议,
@avi.ai引用了 OSI 的一篇批判性文章,强调 LLaMA 的许可不符合开源定义(OSI 博客文章)。对话转向 AI 治理,并呼吁按照开源软件原则构建模型,正如 Colin Raffel 所讨论的(斯坦福研讨会演讲)。 -
类增量学习与优化的探索:介绍了一种用于微调 MoE 模型的方法 SEED,并分享了相关 研究论文;同时,关于 CASPR 优化技术的讨论也浮出水面,在一篇 研究论文 的支持下,该技术被认为是超越 Shampoo 算法的有力竞争者。此外,还提到了一篇声称在分布式训练中实现“零流水线气泡(zero pipeline bubbles)”的论文,提供了在优化器步骤中新的同步绕过技术(研究论文)。
-
利用 Patchscopes 开启机器可解释性:对话围绕用于从模型表示中解码信息的新框架 Patchscopes 展开,
@stellaathena分享了一个介绍该概念的 Twitter 线程。人们对其在信息提取中的应用持谨慎乐观态度,但也对多 token 生成中的幻觉问题表示担忧。 -
Apex 仓库更新与 NeoX 开发:
@catboy_slim_强调了 NVIDIA apex 仓库的一次更新,该更新可能加快 GPT-NeoX 的构建过程,并推荐了一个准备好进行测试的分支(NVIDIA Apex Commit)。
Eleuther 频道总结
▷ #general (213 messages🔥🔥):
-
辩论 ‘Flash Attention’ 和 XLA 优化:在一次技术辩论中,
@carsonpoole和@.the_alt_man讨论了 Flash Attention 的实现,@carsonpoole断言它涉及复杂的 CUDA 操作,而@.the_alt_man则认为 XLA 优化可以自动实现其大部分效率。@lucaslingle和@.the_alt_man随后分享了 Patrick Kidger 在 Reddit 上的评论,指出 XLA 针对 TPU 上的 Attention 机制已经存在编译器优化。 -
Glaze 和 Nightshade 的法律问题:用户
@digthatdata、@stellaathena、@clockrelativity2003等人讨论了 Glaze 和 Nightshade 的法律层面和有效性,对于这些工具是属于加密还是水印形式存在分歧。@stellaathena分享了一份 法律论文,指出绕过水印可能并不违法,而其他用户则探讨了使用对抗性方法对抗 AI 图像模型的实际和法律影响。 -
对抗性扰动(Adversarial Perturbations)与 OpenAI 游说的可行性:在讨论 Nightshade 的影响和对抗性扰动的概念时,
@avi.ai强调了美国监管变革的挑战,回应了@clockrelativity2003和@baber_关于政策和特殊利益的建议。 -
对 LLaMA 许可和开源定义的评估:在探讨 Meta 的 LLaMA 模型许可时,
@avi.ai提供了一个 OSI 撰写的文章链接,批评 Meta 声称 LLaMA 是“开源”的说法。@clockrelativity2003和@catboy_slim_讨论了此类许可的局限性,@avi.ai强调了他们的目标是在 AI 领域实现传统 OSS 社区所见的益处。 -
关于 OpenAI 和 ML 模型未来的讨论:新人
@AxeI和@abi.voll介绍了他们的学术背景,并希望为开源社区做出贡献,而@exirae则寻求关于推销一个新颖 Alignment 项目的建议。@hailey_schoelkopf和@nostalgiahurts重点介绍了 Colin Raffel 关于以开源精神构建 AI 模型的资源和演讲。
提到的链接:
- 来自 neil turkewitz (@neilturkewitz) 的推文:@alexjc 供参考——我不认为情况是这样的。Glaze 和 Nightshade 并不像 §1201 所设想的那样控制对作品的访问。然而——正如你所指出的,提供规避它们的服务确实可能违反…
- 呼吁像构建 Open-Source 软件一样构建模型:未找到描述
- Reddit - 深入了解一切):未找到描述
- nyanko7/LLaMA-65B · 🚩 报告:法律问题:未找到描述
- stabilityai/sdxl-turbo · Hugging Face:未找到描述
- Reddit - 深入了解一切:未找到描述
- 盘点 Open(ish) Machine Learning / 2023-06-15:我已经写了大约六个月的这份简报,所以我认为现在可能是暂停新闻“消防栓”式灌输的好时机,转而回顾并综合我所学到的关于 Open 潜力的知识…
- Meta 的 LLaMa 2 许可证不是 Open Source:Meta 正在降低获取强大 AI 系统的门槛,但不幸的是,Meta 制造了 LLaMa 2 是 “Open Source” 的误解——它并不是。
- 来自 Luca Bertuzzi (@BertuzLuca) 的推文:#AIAct:文本的技术工作终于结束了。现在是清理文本这项吃力不讨好的任务,应该在接下来的几个小时内准备就绪。
-
[像 Open-Source 软件一样构建 ML 模型 - Colin Raffel Stanford MLSys #72](https://m.youtube.com/watch?v=0oGxT_i7nk8):Stanford MLSys 研讨会“Foundation Models 限量系列”第 72 集!演讲者:Colin Raffel 题目:像 Open-Source 软件一样构建 Machine Learning 模型… - 来自 Shawn Presser (@theshawwn) 的推文:Facebook 正在利用 DMCA 积极打击 LLaMA 仓库。llama-dl 已被下架,但这仅仅是开始。他们已经让几个 alpaca 仓库离线,维护者们正在…
- Glaze 的剽窃行为既滑稽又不可辩驳:由 u/AloneSignificance555 发布在 r/StableDiffusion • 46 个赞和 48 条评论
- Pallas 的 Attention 实现无法在 CloudTPU 上运行 · Issue #18590 · google/jax:描述
import jax import jax.numpy as jnp from jax.experimental.pallas.ops import attention bs = 2 seqlen = 1000 n_heads = 32 dim = 128 rng = jax.random.PRNGKey(0) xq = jax.random.normal(rng, ... - Glaze 的剽窃行为既滑稽又不可辩驳:由 u/AloneSignificance555 发布在 r/StableDiffusion • 45 个赞和 48 条评论
- Open-Source AI 的幻象:分析 Meta 的 Llama 2 发布策略 – Open Future:在这篇分析中,我回顾了 Llama 2 的发布策略,并展示了其不符合 Open Source 标准。此外,我解释了这一案例如何证明了对更稳健治理的需求…
- Reddit - 深入了解一切:未找到描述
▷ #research (89 条消息🔥🔥):
-
用于类增量学习的 SEED 方法:
@xylthixlm提供了一个指向 arXiv 上关于 SEED 论文的链接,这是一种通过为每个新任务冻结除一个专家外的所有专家来微调 Mixture of Experts (MoE) 模型的方法。这种专业化预计将增强模型性能 研究论文。 -
通过投毒和 CoT 对 LLMs 进行后门攻击:
@ln271828给出了一篇研究论文的 TL;DR,指出一种针对大语言模型 (LLMs) 的新型后门攻击可以通过 chain-of-thought (CoT) 提示来增强,而目前的技术如 supervised fine-tuning (SFT) 和 reinforcement learning from human feedback (RLHF) 对这些攻击无效 研究论文。 -
Combining AxeS PReconditioners (CASPR) 优化技术:
@clashluke讨论了一篇关于 CASPR 的论文,这是一种通过为矩阵形状的神经网络参数的每个轴寻找不同的预调节器(preconditioners),从而表现优于 Shampoo 算法的优化方法 Research Paper。 -
分布式训练中的零流水线气泡(Zero Pipeline Bubbles):
@pizza_joe分享了一篇论文,介绍了一种调度策略,声称是首个在大规模分布式同步训练中实现零流水线气泡的方法,并采用了一种新技术在优化器步骤中绕过同步 Research Paper。 -
使用 LooseControl 实现深度条件图像生成的通用性:
@digthatdata链接了一个 GitHub 仓库和关于 LooseControl 的论文,该研究推广了基于扩散的图像生成的深度条件(depth conditioning),允许在极少指导下创建和编辑复杂场景 GitHub Repo, Paper Page, Tweet Discussion。
提到的链接:
- Stabilizing Transformer Training by Preventing Attention Entropy Collapse:通过防止注意力熵崩溃来稳定 Transformer 训练。训练稳定性对 Transformer 至关重要。在这项工作中,我们通过检查注意力层的演变来研究 Transformer 的训练动态。特别是,我们追踪…
- Analyzing and Improving the Training Dynamics of Diffusion Models:分析和改进扩散模型的训练动态。扩散模型目前凭借其对大规模数据集无与伦比的可扩展性,在数据驱动的图像合成领域占据主导地位。在本文中,我们识别并纠正了导致不均匀和低效…的几个原因。
- Divide and not forget: Ensemble of selectively trained experts in Continual Learning:分而治之且不遗忘:持续学习中选择性训练专家的集成。类增量学习正变得越来越流行,因为它能帮助模型扩大适用性,同时不遗忘已掌握的知识。该领域的一个趋势是使用 Mixture-of-Experts 技术…
- Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training:Sleeper Agents:训练在安全训练中持续存在的欺骗性 LLM。人类具备战略性欺骗行为的能力:在大多数情况下表现得乐于助人,但在有机会时为了追求其他目标而表现得截然不同。…
- Combining Axes Preconditioners through Kronecker Approximation for…:通过 Kronecker 近似结合轴预调节器…。基于自适应正则化的优化方法(如使用梯度二阶矩信息的全矩阵 Adagrad)在深度神经网络中具有快速收敛的巨大潜力…
- Zero Bubble Pipeline Parallelism:零气泡流水线并行(Zero Bubble Pipeline Parallelism)。流水线并行是大规模分布式训练的关键组件之一,但其效率受限于被认为不可避免的流水线气泡。在这项工作中,我们引入了一种调度…
- no title found:未找到描述
- Tweet from Shariq Farooq (@shariq_farooq):@ak LooseControl 可以被证明是一种设计复杂场景和进行语义编辑的新方法,例如:模型理解光照如何随编辑而变化:(2/2)
- memory-transformer-pt4/src/optimizer/spectra.py at main · Avelina9X/memory-transformer-pt4:通过在 GitHub 上创建一个账户来为 Avelina9X/memory-transformer-pt4 的开发做出贡献。
- Tweet from AK (@_akhaliq):LooseControl:提升 ControlNet 以实现通用的深度条件。论文页面:https://huggingface.co/papers/2312.03079 介绍 LooseControl 以允许扩散模型实现通用的深度条件…
- GitHub - shariqfarooq123/LooseControl: Lifting ControlNet for Generalized Depth Conditioning:提升 ControlNet 以实现通用的深度条件 - GitHub - shariqfarooq123/LooseControl: Lifting ControlNet for Generalized Depth Conditioning
- arXiv user login:未找到描述
- Add freeze_spectral_norm option · d8ahazard/sd_dreambooth_extension@573d1c9:参见 https://arxiv.org/abs/2303.06296 这增加了一个使用谱范数(spectral norm)重新参数化模型权重的选项,使得每个权重的整体范数无法改变。这有助于稳定…
- d8ahazard - Overview:d8ahazard 拥有 171 个可用仓库。在 GitHub 上关注他们的代码。
▷ #interpretability-general (9 messages🔥):
- 寻找 Interpretability 资源:用户
@1_glados表示自己是 Interpretability 领域的新手,正在寻找优质资源或论文列表入门,而@neelnanda询问了在早期 NLP Interpretability 研究中 Sparse Autoencoders 的使用情况。 - NLP 历史中的 Sparse Autoencoders:用户
@nsaphra讨论了 Sparse Dictionary Learning 中反复出现的主题,从 Latent Semantic Allocation 时代跨越至今,指出对前人研究的引用不一致,并质疑将此类方法纳入 Mechanistic Interpretability 定义的意义。 - 引入用于表示解码的 Patchscopes:
@stellaathena分享了 @ghandeharioun 的一条 Twitter 线程,介绍了一个名为 Patchscopes 的框架,用于从模型的表示中解码特定信息。 - 对 Interpretability 的学习动态提出质疑:针对其相关性,
@stellaathena还质疑了在 Patchscopes 中 Next-token Prediction 的高分是否确实与识别模型在特定层后对答案的最佳猜测相关,暗示更高的性能可能并不等同于更好的理解。 - Patchscopes 的潜力和担忧:用户
@mrgonao认为在 RWKV 和 Mamba 等模型中,使用 Patchscopes 从 Hidden States 提取信息具有巨大潜力,但也对潜在的 Hallucinations 以及多 Token 生成中对鲁棒性检查的需求表示担忧。
提到的链接:
来自 Asma Ghandeharioun (@ghandeharioun) 的推文:🧵我们能否“要求” LLM 将其自身的隐藏表示“翻译”成自然语言?我们提出了 🩺Patchscopes,这是一个通过“patching”来从表示中解码特定信息的新框架……
▷ #gpt-neox-dev (1 messages):
- NVIDIA 的 Apex 更新可能加速 NeoX 构建:
@catboy_slim_强调了 NVIDIA apex 仓库的一个 commit,指出需要 fork 并精简代码以加速 Fused AdamW 的构建过程,因为目前完整构建大约需要半小时。他们建议,尽管构建时间增加了,但更新后的分支可能已经可以进行测试,因为它在他们的机器上可以运行。
提到的链接:
https://github.com/NVIDIA/apex/pull/1582 的压缩 commit · NVIDIA/apex@bae1f93:commit 0da3ffb92ee6fbe5336602f0e3989db1cd16f880 作者:Masaki Kozuki <mkozuki@nvidia.com> 日期:2023年2月11日周六 21:38:39 -0800 使用 nvfuser_codegen commit 7642c1c7d30de439feb35…
LM Studio Discord 总结
-
LM Studio 的支持范围与未来改进:讨论集中在 LM Studio 的功能和局限性。
@heyitsyorkie澄清了支持来自 Huggingface 的 GGUF 量化模型,但模型的加载和卸载管理应手动完成。图像生成不属于 LM Studio 的范畴,建议用户使用 Stable Diffusion 处理此类任务。注意到了兼容性问题,例如缺乏对不支持 AVX 指令集的 CPU 的支持,未来的更新可能会包含目前尚未提供的 Intel Mac 支持。在重新安装 Windows 后遇到持续错误的用户被引导至 Discord 链接 寻求故障排除帮助。 -
GPU 大讨论:硬件讨论区的对话异常火热,涉及投资高性能 Nvidia 6000 系列显卡以及等待 P40 显卡等硬件升级。对比了 Nvidia RTX 6000 Ada Generation 显卡 与适用于大语言模型 (LLM) 任务的性价比替代方案。一些人认为 Mac Studios 优于 PC,因为其具有更好的内存带宽,而另一些人则赞赏 Mac 的缓存架构对 LLM 工作带来的益处。此外,还引发了关于 Nvidia 显卡兼容性和 GPU 利用率的辩论,并提供了最大化 GPU 性能的建议。
-
以模型为中心的对话揭示了社区偏好:在模型相关的聊天中,
@dagbs澄清了“Dolphin 2.7”和“Synthia”等术语为微调器 (finetuners),并引导感兴趣的人在各平台上寻找特定的 Dolphin 系列模型进行对比。GGUF 格式的模型因其流行度和兼容性而受到关注,并推荐了最适合特定硬件的模型,例如适用于 RTX 3060 移动版的 Deepseek coder 6.7B。此外,关于模型有效性的辩论中,@.ben.com主张在考虑模型性能时应超越排行榜 (leaderboard) 分数。 -
Beta 版本征集修复反馈:最新的 Windows Beta 版本报告了 VRAM 容量显示问题,这对于识别出 OpenCL 问题的 6600XT AMD 显卡等模型尤为相关。Beta 版本 V5/V6 旨在修复 RAM/VRAM 预估错误,并向社区征求反馈。针对在 Jetson NVIDIA 板卡上安装 Beta 版本的 ARM 支持咨询得到了回复,确认目前的支持仅限于 Mac Silicon。最新更新中飞速的性能提升引发了讨论,
@yagilb以一个幽默的 Magic GIF 作为回应。 -
自动化对决:CrewAI 胜过 Autogen:
@MagicJim表达了对 crewAI 的偏好,特别是其在 LM Studio 中集成多个 LLM 的潜力。与之前的想法相反,会议澄清了 crewAI 确实允许为每个 Agent 使用不同的 LLM,并提供了一个 YouTube 视频 作为演示。讨论了使用不同端口运行多个 LLM API 实例的解决方法,以解决利用率问题。 -
新兴工具与集成增强功能:
@happy_dood展示了如何并发使用 LM Studio 和 LangChain,详细介绍了涉及创建、模板化和解析的流程,以简化 AI 交互。在代码方面,尝试使用 DeepseekCoder33B 等模型处理 open interpreter 任务,评估建议使用更专注于编码的模型可能会获得更好的性能。
LM Studio 频道总结
▷ #💬-general (122 条消息🔥🔥):
-
关于 GGUF 和量化模型的澄清:
@heyitsyorkie澄清了 LM Studio 仅支持来自 Huggingface 的 GGUF 量化模型,并建议@ubersuperboss模型的加载和卸载必须在 LM Studio 内手动完成。他们还讨论了 LM Studio 不适合图像生成,并建议用户使用 Stable Diffusion 来完成此类任务。 -
图像生成模型查询:
@misc_user_01询问了 LM Studio 增加对图像生成模型支持的可能性,@heyitsyorkie回复称这不在 LM Studio 的范围内,因为它们的用例不同。不过,他们确实为对图像生成感兴趣的用户指出了 Stable Diffusion + automatic1111。 -
LM Studio 支持与安装讨论:包括
@cyberbug_scalp、@ariss6556和@__vanj__在内的多位用户讨论了关于 LM Studio 系统兼容性和安装的技术问题及查询,@heyitsyorkie等人提供了技术建议,例如 LM Studio 不支持没有 AVX1/2 指令集的 CPU。 -
模型推荐与 GPU 建议:
@heyitsyorkie回答了几个与特定硬件配置(如@drhafezzz的 M1 Air)的模型建议相关的问题,并确认 LM Studio 支持多 GPU (multi-GPU) 设置,建议使用匹配的显卡对以获得最佳性能。 -
对 Intel Mac 支持的关注:用户
@kujila和@katy.the.kat表达了希望 LM Studio 支持 Intel Mac 的愿望,@yagilb承认由于目前专注于 Silicon Mac,暂时不支持 Intel Mac,但提到未来有启用支持的计划。
提到的链接:
- HuggingChat:未找到描述
- GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface.:最强大且模块化的 Stable Diffusion GUI、API 和后端,具有图表/节点界面。 - GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and back…
- ggml : add Flash Attention by ggerganov · Pull Request #5021 · ggerganov/llama.cpp:参考 #3365,为 ggml 和 llama.cpp 添加 Flash Attention 支持进行必要设置。提议的算子执行:// unfused kq = ggml_mul_mat (ctx, k, q); kq = ggml_scale (ctx, kq,…
▷ #🤖-models-discussion-chat (82 messages🔥🔥):
-
模型混淆已澄清:
@dagbs澄清了诸如 “Dolphin 2.7”、”Synthia” 和 “Nous-Hermes” 之类的术语是指不同的微调版本(finetuners),它们是模型和数据集的组合,用于创建新模型。此回答旨在帮助解决@lonfus的困惑。 -
哪里可以找到模型对比:针对
@lonfus寻求模型对比的请求,@dagbs引导他们查看频道 <#1185646847721742336> 中之前的帖子以获取个人模型推荐,并提供了他推荐的基于 Dolphin 的模型链接,包括 Dolphin 2.7 Mixtral 和 MegaDolphin 120B。 -
GGUF 格式受到欢迎:来自
@conic、@kadeshar、@jayjay70等人的一系列消息讨论了寻找 GGUF 格式模型的各种途径,包括 Hugging Face、LLM Explorer 和 GitHub,突显了其在模型兼容性方面的广泛采用。 -
针对特定资源的模型推荐:包括
@heyitsyorkie和@ptable在内的用户推荐了适合各种硬件规格的模型——例如,建议为配备 32GB RAM 的 RTX 3060 笔记本显卡使用 Deepseek coder 6.7B,为配备 Ryzen 9 5950x 和 3090Fe GPU 的系统推荐 70B 参数以下的模型。 -
关于模型效能和性能的讨论:
@.ben.com提供了关于模型性能的见解,指出排行榜分数可能会产生误导,并建议参考 Mike Ravkine 的 AI 编程结果 等空间以获得更现实的评估。他们还指出,相比于为了运行大型模型而采购新硬件,使用 GPT-4 Turbo 具有更高的性价比。
提到的链接:
- lodrick-the-lafted/Grafted-Titanic-Dolphin-2x120B · Hugging Face:未找到描述
- Can Ai Code Results - a Hugging Face Space by mike-ravkine:未找到描述
- LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys:未找到描述
- Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4:未找到描述
- Best Open-Source Language Models, All Large Language Models:未找到描述
- yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B · Hugging Face:未找到描述
- nous-hermes-2-34b-2.16bpw.gguf · ikawrakow/various-2bit-sota-gguf at main:未找到描述
- dagbs/TinyDolphin-2.8-1.1b-GGUF · Hugging Face:未找到描述
- google/t5-v1_1-xxl · Hugging Face:未找到描述
- TheBloke/deepseek-coder-6.7B-instruct-GGUF · Hugging Face:未找到描述
- GitHub - lmstudio-ai/model-catalog: A collection of standardized JSON descriptors for Large Language Model (LLM) files.:大型语言模型 (LLM) 文件的标准化 JSON 描述符集合。
- TheBloke (Tom Jobbins):未找到描述
▷ #🧠-feedback (5 messages):
- 识别循环出现的 LM 下载失败:
@leo_lion_king建议失败的 LM 下载 应该被自动删除并标记,以防止重新下载有问题的模型,因为用户只有在尝试加载模型时才会发现错误。 - 未知模型错误引发询问:
@tobyleung.发布了一个详细的 JSON 错误输出,指示发生未知错误,并建议检查是否有足够的可用内存来加载模型。其中包含了关于 RAM、GPU、OS 和所使用应用程序的详细信息。 - 重新安装未能清除错误:在后续消息中,
@tobyleung.对尽管重新安装了 Windows 但错误仍然存在表示困惑。 - 用于错误调查的 Discord 链接:
@dagbs提供了一个 Discord 链接,该链接显然解释了错误的原因,但未提供额外的上下文。 - 请求找回旧模型:在讨论错误问题后,
@tobyleung.询问是否可以恢复到他们的旧模型。
▷ #🎛-hardware-discussion (48 messages🔥):
- 显卡策略评估:
@gtgb在观看 Mervin 的性能视频后,决定投资高性能的 Nvidia 6000 系列显卡,引发了关于显卡兼容性和模型运行设备选择的对话。 - 等待硬件升级:
@pefortin提到他们正在等待 P40 显卡,称其为“穷人版设备”,@doderlein回复称他们也在等待同样的硬件到货。 - 强力显卡引发羡慕:
@doderlein认可了@gtgb在 产品页面链接 中分享的 Nvidia RTX 6000 Ada Generation 显卡的强大能力,并强调了其高昂的价格。 - LLM 领域的 Mac 与 PC 之争:关于硬件选择的辩论浮出水面,
@heyitsyorkie认为在 LLM 任务中 Mac Studio 优于 PC 方案,因为其具有更好的内存带宽和更美观的家庭设置,而@.ben.com则指出了 Mac 的缓存架构对这类工作的益处。 - GPU 利用率讨论:
@omgitsprovidence询问了关于 GPU 利用率低的问题,@heyitsyorkie建议尝试 ROCm beta 以获得更好的 AMD 性能,@dagbs向@misangenius提供了关于最大化 GPU offload 的指导,以在运行模型时获得更好的响应时间。
提到的链接:
NVIDIA RTX 6000 Ada Generation 显卡:由 NVIDIA Ada Lovelace 架构驱动。
▷ #🧪-beta-releases-chat (29 messages🔥):
-
Beta 版中 VRAM 消失:
@eimiieee报告称,在 6600XT AMD 显卡上,最新的 Windows beta 版显示预估 VRAM 容量为 0。@yagilb建议最新的 beta 版中 OpenCL 存在问题,并指向尝试 AMD ROCm beta。 -
VRAM 预估 Bug 已修复:
@yagilb发布了 Beta V5/V6,修复了几个 Bug,并征求关于搜索页面上 RAM/VRAM 预估 的反馈,暗示对计算方式进行了调整。 -
Jetson NVIDIA 的兼容性查询:
@quantman74询问了关于在 Jetson NVIDIA 板卡上安装 beta 版的 arm64 架构支持。@heyitsyorkie澄清称,除了 Mac Silicon 之外没有 ARM 支持,@yagilb鼓励为此创建一个功能请求(feature request)。 -
速度提升引发好奇:
@mmonir评论了最新更新中翻倍的速度,促使@heyitsyorkie链接了一个幽默的 gif,同时@n8programs也对导致速度提升的变化表示好奇。 -
大小写敏感导致模型混乱:
@M1917Enfield发现并解决了一个问题,即 LM Studio 无法检测到具有不同大小写敏感度的模型文件夹,通过重命名文件夹以匹配预期的大小写解决了该问题。@yagilb认可了这一问题的成功解决。
提到的链接:
Magic GIF - Magic - 发现并分享 GIF:点击查看 GIF
▷ #autogen (1 messages):
meadyfricked: 从未让 autogen 与 LM Studio 配合成功,但 crew-ai 似乎可行。
▷ #langchain (1 messages):
- LangChain 与 LM Studio 的集成:
@happy_dood提供了一个如何将 LM Studio 和 LangChain 结合使用的示例,展示了新的类实现。代码片段演示了创建 ChatOpenAI 实例、使用 ChatPromptTemplate 构建提示词、使用 StrOutputParser 解析输出,并将这些元素组合在一个流线型流程中。
▷ #crew-ai (10 messages🔥):
- MagicJim 对自动化工具的看法:
@MagicJim分享了他相比 autogen 更倾向于使用 crewAI 的观点,因为他考虑在 LM Studio 中集成多个 LLM。他建议为 coder agents 使用特定模型(如 deepseek coder)会大有裨益。 - 讨论 Autogen 在 LLM 使用上的灵活性:
@sitic观察到 autogen 允许为每个 agent 使用不同的 LLM,而 crewAI 似乎只能使用一个。这一特性对于创建具有不同能力的 agents 至关重要。 - 关于 crewAI LLM 使用的澄清:
@MagicJim澄清了 crewAI 确实允许为每个 agent 使用不同的 LLM,并分享了一个展示该功能的 YouTube 视频。 - 运行多个 LLM 实例:
@senecalouck建议,如果硬件支持,可以通过为 API 使用不同的端口来运行多个 LLM 实例作为变通方案。 - 与 LM Studio 的集成问题:
@motocycle询问是否有人成功将 crewAI 与 LM Studio 端点集成,并提到在使用 ollama 时很成功,但在使用 LM Studio 时遇到了问题。
提到的链接:
CrewAI: AI-Powered Blogging Agents using LM Studio, Ollama, JanAI & TextGen:🌟 欢迎来到 AI 驱动的博客创作世界的精彩旅程!🌟 在今天的视频中,我将带你通过一个全面的教程,学习如何使用 Crew AI 来…
▷ #open-interpreter (7 messages):
system_key.go中的解析错误:@gustavo_60030指出system_key.go中存在一个错误,导致系统无法确定 NFS 的使用情况。错误信息提到无法解析/etc/fstab,特别是 dump frequency 部分显示为 “information”。- Open Interpreter 的模型实验:
@pefortin讨论了在 open interpreter 中实验 DeepseekCoder33B 的情况,并提到虽然 Mixtral 8x7B instruct 5BPW 表现尚可,但在识别何时编写代码方面比较吃力。 - 模型推荐请求:为了寻找适合编程任务的模型,
@pefortin表示有兴趣尝试专注于编程的模型,如 wizard 等。 - 编程模型对比:
@impulse749询问 DeepseekCoder33B 是否是编程任务的最佳选择,另一位用户则表示 deepseek-coder-6.7b-instruct 对于纯编程相关任务可能是更快且更专注的选择。
Mistral Discord 总结
-
法语支持引发关注:用户建议在 Mistral Discord 社区中增加 法语支持频道,反映了对多语言协助的需求。
-
数据提取策略与定价讨论:用户交流了 data extraction 的策略,例如使用 BNF grammar 和 in-context learning,同时讨论了 Mistral 的定价模式,其中明确了 1M tokens 对应 1,000,000 个 tokens,包括 input 和 output。
-
AI 与 3D 动画及 Function Calling 的对接:有用户询问如何将 Mistral AI 与 3D 角色 集成以实现实时交互,讨论了诸如 animation rigging 和 API 兼容性等复杂问题,以及类似于 OpenAI API 的 function calling 实现咨询。
-
Mistral 的托管与部署见解:用户分享了相关资源,如用于在 Laravel 中运行 MistralAi 的 partITech/php-mistral on GitHub,以及关于 VPS 托管、本地托管 (on-premises) 和为 Lambda Labs 使用 Skypilot 的经验。此外,还有人建议使用 Docker 进行 Mistral 部署。
-
专注于微调与模型用例:对话围绕微调策略展开,例如创建 Q&A JSON 格式的数据集、数据质量的重要性(“垃圾进,垃圾出”),以及使用 axolotl 等工具解决 Mistral 微调中的问题。还有人对在 Mistral 套件 中引入针对 法语 任务高度优化的工具表示关注。
Mistral 频道总结
▷ #general (154 条消息🔥🔥):
-
对法语支持频道的需求:用户
@gbourdin表示 Mistral Discord 可以从法语支持频道(ça manque de channel FR)中受益,这得到了另一位用户@aceknr的认同。 -
寻求数据提取策略:
@gbourdin寻求关于从讨论中提取数据(如邮政编码或产品搜索)的策略建议。而@mrdragonfox建议使用 BNF grammar 和 In-context learning,因为该用例的 API 支持有限。 -
Mistral 计费模式澄清:
@nozarano询问了关于 “mistral-medium” 计费的澄清,@ethux和@mrdragonfox解释说 1M tokens 代表 1,000,000 个 token,且输入和输出 token 均计入费用。 -
AI 驱动的 3D 角色交互:用户
@madnomad4540询问了如何将 Mistral AI 与 3D 角色集成并实现实时用户交互。@mrdragonfox指出了其中的挑战以及该项目涉及的不同方面,如动画绑定(animation rigging)以及与 Google Cloud Vision 等 API 的集成。 -
探索 Assistants API 和 Function Calling:用户
@takezo07询问了类似 OpenAI Assistants API 的 function calling 和 threads 的实现,而@i_am_dom指出此类功能可以直接使用 API 进行编程,@.elekt则提到 Mistral API 目前尚不支持官方的 function calling。
提到的链接:
- 0cc4m 的 Vulkan 实现 · Pull Request #2059 · ggerganov/llama.cpp:我研究这个已经有一段时间了。Vulkan 需要大量的样板代码,但也提供了很大的控制权。其意图是最终取代 OpenCL 后端作为主要的…
- 来自 Nomic 的 Vulkan 后端 · Issue #2033 · jmorganca/ollama:https://github.com/nomic-ai/llama.cpp GPT4All 在我的 6600M GPU 上运行 Mistral 和 Mixtral q4 模型的速度快了 10 倍以上
▷ #models (5 条消息):
-
寻求 Instruct 的小说创作指导:
dizzytornado询问 Instruct 是否有专门针对小说创作的护栏(guardrails)。聊天记录中未提供背景和回复。 -
对 Mistral 的赞赏:
thenetrunna表达了对 Mistral 的喜爱,没有进一步的背景或阐述。 -
对法语优化的 Mistral 的需求:
luc312询问是否有更适合法语阅读/写作的 Mistral 版本,或者使用强 System Prompt 是否是引导 Mistral 用法语交流的唯一方法。 -
多语言模型能力的澄清:
tom_lrd澄清说 tiny-7b 并非正式为法语构建,由于缺乏针对性训练,其法语能力有限,而 Small-8x7b 是官方的多语言模型,并经过了法语训练。
▷ #deployment (6 条消息):
- 将 Mistral 与 PHP 集成:
@gbourdin提供了一个有用的资源链接 GitHub - partITech/php-mistral,表明它可以用于在 Laravel 中运行 MistralAi。 - 寻求 VPS 托管详情:
@ivandjukic询问了提供合适 GPU 的 VPS 托管商,并提到了关于成本的高昂或误解。 - 本地部署保障客户数据安全:
@mrdragonfox保证,当 Mistral 托管在客户的数据中心时,Mistral 永远无法访问您的数据。 - 爱好者托管见解:
@vhariational分享了作为爱好者的个人经验,表示不需要最大的 GPU,并建议通过 Skypilot 使用 Lambda Labs 来偶尔测试较大的模型。 - Docker 部署建议:
@mrdomoo建议设置 Docker 服务器并使用 Python 客户端进行 Mistral 部署。
提到的链接:
GitHub - partITech/php-mistral: MistralAi php client:MistralAi PHP 客户端。通过在 GitHub 上创建一个账户来为 partITech/php-mistral 的开发做出贡献。
▷ #ref-implem (2 messages):
-
Mistral 中理想表格格式的探索:
@fredmolinamlgcp询问了在使用 Mistral 时格式化表格数据的最佳方式。他们对比了用于 bison、unicron 和 gemini 等模型的管道分隔(pipe-separated)格式,与他们对 Mistral 采用的“文本化(textified)”方法,即通过将 pandas dataframe 的行转换为标题和值的字符串。 -
提供的文本化表格 Prompt 示例:
@fredmolinamlgcp分享了一个针对 Mistral 的“文本化”表格 Prompt 示例。他们演示了如何通过包含指令标签,后接格式整齐的活动数据(例如:campaign id 1193, campaign name Launch Event…)来构建输入。
▷ #finetuning (51 messages🔥):
- GPT-3 成本及数据提取的替代方案:
@cheshireai提到使用 GPT-turbo 16k 从 PDF 中提取数据并创建数据集,尽管由于处理的文档数量庞大,他们不得不丢弃许多糟糕的结果。 - 为数据集构建创建 Q&A JSON 格式:
@dorumiru正在寻求关于创建编程任务的建议,该任务旨在从 PDF 中提取数据、进行 Chunking(分块),并使用 palm2 等 API 生成 Q&A JSON 格式的数据集,以便后续训练。 - Chunking 技术和资源建议:针对
@dorumiru关于高级 PDF Chunking 技术的问题,@ethux分享了一个名为 “The 5 Levels Of Text Splitting For Retrieval” 的 YouTube 视频,其中讨论了各种文本数据 Chunking 的方法。 - Fine-tuning 工具的建议与警告:
@mrdragonfox建议在使用 Langchain 等工具时要谨慎,因为其依赖关系复杂,并分享了privateGPT的 GitHub 链接,这是一个用于文档交互的基础工具。他们还强调了“垃圾进,垃圾出(garbage in, garbage out)”,突出了高质量数据的重要性。 - 配置 Mistral 进行 Fine-tuning 的问题:
@distro1546询问了使用 axolotl 工具对 Mistral 进行 Fine-tuning 的正确命令行,以及如何针对其数据集调整config.yml,并在 GitHub 上发布了一个讨论帖进行故障排除 (https://github.com/OpenAccess-AI-Collective/axolotl/discussions/1161)。
提到的链接:
- Trouble using custom dataset for finetuning mistral with qlora · OpenAccess-AI-Collective/axolotl · Discussion #1161:操作系统:Linux (Ubuntu 22.04) GPU:Tesla-P100。我正尝试使用 qlora 对 Mistral 进行 Fine-tune,但在自定义数据集格式化和/或在 qlora.yml 文件中设置数据集参数时遇到了一些错误…
- The 5 Levels Of Text Splitting For Retrieval:获取代码:https://fullstackretrieval.com/ 获取我的更新:https://mail.gregkamradt.com/* https://www.chunkviz.com/ Greg 的信息:- Twitter: https://twitter…
- GitHub - imartinez/privateGPT: Interact with your documents using the power of GPT, 100% privately, no data leaks:利用 GPT 的能力与你的文档进行交互,100% 私密,无数据泄露 - GitHub - imartinez/privateGPT: Interact with your documents using the power of GPT, 100% privately, no data leaks
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions:尽管提问(Go ahead and axolotl questions)。通过在 GitHub 上创建账号为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
▷ #showcase (1 条消息):
-
LibreChat:一个混合搭配的聊天机器人平台:用户
@dannyavila展示了 LibreChat,这是一个功能丰富的平台,支持将 Mistral API 与 Openrouter、Azure OpenAI 等其他服务结合使用。该平台提供 AI 模型切换、消息搜索等功能,并且完全开源,支持自托管,在此处获取。 -
探索 LibreChat 的底层机制:对于有兴趣深入了解的用户,
@dannyavila分享了文档链接 docs.librechat.ai,提供了关于如何充分利用 LibreChat 扩展功能的见解。 -
LibreChat 的开源信誉:LibreChat 秉持慷慨的开源精神,采用 MIT license 协议,其代码库拥有 6.6k stars 和 1.1k forks,展示了社区的信任。
提到的链接:
GitHub - danny-avila/LibreChat: Enhanced ChatGPT Clone: Features OpenAI, GPT-4 Vision, Bing, Anthropic, OpenRouter, Google Gemini, AI model switching, message search, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, Secure Multi-User System, Presets, completely open-source for self-hosting. More features in development:增强版 ChatGPT 克隆:具备 OpenAI, GPT-4 Vision, Bing, Anthropic, OpenRouter, Google Gemini, AI 模型切换, 消息搜索, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, 安全多用户系统, 预设,完全开源支持自托管。更多功能开发中。
▷ #la-plateforme (13 条消息🔥):
- 新手质疑易用性:
@mrrobot7778对 Mistral AI 对于领域新手的易用性表示担忧,怀疑它是否适合非专业用户。 - Beam Search 辩论:关于 OpenAI API 中是否存在 Beam Search 选项存在困惑。
@casper_ai链接到了断言其存在的 API 文档,而@rabdullin则质疑其底层机制。 - Beam Search 的底层原理:
@rabdullin询问 OpenAI API 实际上是运行了 Beam Search,还是仅仅生成了独立的输出。@casper_ai承认不确定具体过程,但提到了其有效性。 - 身份验证问题分享:
@pastillafit提出了使用 API 时的身份验证问题,特别是关于 password 管理和缺乏 two-factor authentication (2FA) 的问题。他们发现了一个在重置密码期间使用 2FA 的变通方法,但据报告这并不影响控制台登录。 - Mistral Medium 的指令遵循能力受到质疑:
@gooningconstantly询问 mistral-medium 是否针对指令遵循进行了微调,因为他注意到它有时会忽略system角色消息内容中提供的指令。
Perplexity AI Discord 总结
- 第 6 批 Perplexity 快速激活:
@yellephen在被列入第 6 批后,体验到了 Perplexity Pro 的即时激活。 - Rabbit R1 捆绑优惠:
@martsw71在激活 Rabbit R1 购买附带的 Perplexity Pro 时遇到障碍;@ok.alex建议在不同服务中保持使用一致的电子邮件。 - 在 Brave 中自定义搜索:
@witchfinder17寻求关于将 Perplexity 设置为 Brave 默认搜索引擎的建议;同时,@samangel7358强调了区分 Perplexity AI Search 和 Companion 扩展程序的重要性。 - AI 的 YouTube 作业:
@chiefblink117好奇 Perplexity 是否从 YouTube 视频音频中提取信息,@icelavaman澄清其通过 YouTube API 使用视频转录 (transcripts)。 - AI 巨头之战:
@b4d_7r1p_和@lord.wex进行了一场生动的辩论,对比了 Perplexity Premium 和 GPT-4 Premium,指出 Perplexity 在提供多种高级模型访问方面具有竞争优势,但在图像生成能力方面稍显落后。 - 各司其职:在频道中,
@ok.alex引导@kabbe_the_dude前往合适的频道分享项目,强调了内容组织的重要性。 - C# 学习进展报告:
@whoistraian更新了他们学习 C# 的进度,并即将在 1 月 31 日参加考试,并附带了一个链接:Can you help。 - 分享与共赢:Perplexity 的 Pro 用户(如
@neuralspace)通过分享 Perplexity AI 推荐码来传递福利。 - API 对上下文扩展的期待:
@commuting5048发送了一条消息询问关于 API 支持扩展到 32k 上下文长度的问题;然而,目前没有后续更新或回复。
Perplexity AI 频道总结
▷ #general (99 条消息🔥🔥):
- Perplexity Pro 立即激活:
@yellephen提到在进入第 6 批次(batch 6)后立即收到了 Perplexity Pro 链接。 - 购买 Rabbit R1 附赠 Perplexity Pro:
@martsw71讨论了使用购买 Rabbit R1 获得的链接激活 Perplexity Pro 时遇到的问题,@ok.alex建议确保在不同服务中使用相同的电子邮件,并尝试通过网页版进行订阅。 - 在 Brave 中将 Perplexity 设置为默认搜索:
@witchfinder17询问如何在 Brave 浏览器中将 Perplexity 设置为默认搜索引擎,@mares1317建议使用直接 URL 进行自定义搜索引擎设置,@samangel7358指出了 Perplexity AI Search 扩展和 Companion 扩展之间的区别。 - Perplexity 集成 YouTube 字幕:
@chiefblink117询问 Perplexity 是否从 YouTube 视频音频中获取 AI 回答的来源,@icelavaman澄清说它使用的是 YouTube API 提供的视频字幕(transcripts)。 - Perplexity Premium vs. GPT-4 Premium:
@b4d_7r1p_和@lord.wex讨论了 Perplexity Premium 相比 GPT-4 Premium 在不同用途下的优势,Perplexity 提供了访问多种高级模型的权限,且与竞争对手相比,除了图像生成外,在其他重要领域均表现出色。
提及的链接:
Perplexity - AI Search: 升级你的默认搜索引擎
▷ #sharing (15 条消息🔥):
-
导航到正确的频道:
@ok.alex将@kabbe_the_dude引导至<#1059504969386037258>频道进行项目分享,强调了针对特定内容使用正确频道的重要性。 -
C# 学习之旅:
@whoistraian分享了他们的 C# 学习历程,并提供了一个进度更新链接:Can you help,并提到他们将于 1 月 31 日在学院参加考试。 -
分享推荐码:
@neuralspace秉持“分享即是关爱”的精神,发布了他们的 Perplexity AI 推荐码链接:Referral Code。 -
Perplexity Pro 模型详解:
@core3038深入介绍了 Perplexity AI 为 Pro 用户提供的各种模型,如 GPT-4 和 Claude 2,并分享了一篇详细的博客文章以获取更多信息:What model does Perplexity use。 -
Perplexity AI vs. ChatGPT 对比:
@far2wise发现了一篇对比 Perplexity AI 与 ChatGPT 的文章,概述了两者之间的差异和关键点,可以在此处查看:Perplexity AI vs ChatGPT。
提及的链接:
- Perplexity: AI Chatbot & Search Multi-Tool Explained! #88: 这段视频解释了 Perplexity,一个搜索多功能生成式 AI 聊天机器人——它是什么,如何使用,以及为什么要使用它!我提供了一些示例…
- Perplexity AI vs ChatGPT: Unveiling The Superior AI-Search Engine 2024: Perplexity AI vs ChatGPT:哪款 AI 搜索引擎更好?Perplexity AI 和 ChatGPT 都是强大的 AI 驱动搜索引擎。
- What model does Perplexity use and what is the Perplexity model?: 通过我们全面的常见问题解答页面深入了解 Perplexity 的技术细节。从 GPT-4 和 Claude 2 等 AI 模型的细微差别到 Token 限制和 AI 配置文件,获取简洁的答案以优化你的使用体验…
▷ #pplx-api (1 条消息):
- 关于 32k 上下文长度的咨询:用户
@commuting5048询问了 32k context length 支持 的进展和潜在发布日期。频道消息中没有提供关于此查询的进一步信息或回复。
HuggingFace Discord Discord 总结
-
本地 RAG 随 langchain 和 LM Studio 上线:
@thoreau_a_whelan成功实现了一个集成了 langchain 和 LM Studio 的 本地 RAG 系统,支持对本地文档进行搜索。 -
推出新型视觉语言模型:
@andysingal介绍了 Nous-Hermes-2-Vision 模型,它是 OpenHermes-2.5-Mistral-7B 的扩展版本。该模型具有独特的 function calling 能力,并已在 Hugging Face 上发布。 -
DevSpot 发布 AI 集成 POC:
@devspot展示了一个基于 GitHub 的 Proof of Concept (POC),用于构建可扩展系统以协同处理来自不同供应商的 AI 模型,并提供了 GitHub 仓库 和说明性的 YouTube 视频。 -
显存高效的照片级写实 Diffusion 模型:
@felixsanz讨论了如何优化 PixArt-α 以在低于 8GB 的 VRAM 环境下运行,并在文章中分享了见解,欢迎社区反馈。 -
NLP 洞察:模型缓存、压缩 Transformer 以及 BERT 的持久生命力:
@asprtnl_50418解决了 Docker 中的模型缓存问题,建议使用 volume 进行永久存储。@stroggoz通过 PCA 和知识蒸馏(knowledge distillation)缩小了 sentence transformer,在讨论数据集大小的同时,还涉及了 BERT 与 RoBERTa、Elektra 相比的性能和相关性,并推荐使用 span marker library 进行 NER。
HuggingFace Discord 频道总结
▷ #general (77 条消息🔥🔥):
-
PDF 数据转数据集的难题:用户
@dorumiru寻求关于从原始 PDF 数据创建 context、question 和 answers 格式数据集的建议,并询问了 PDF 数据分块(chunking)的高级技术。遗憾的是,在现有消息中未见相关回复或进一步讨论。 -
从软件工程转向 AI 研究:软件工程师用户
@boss_ev咨询了转型 AI 研究的建议,获荐了 Fast.ai 和 Andrej Karpathy 的 YouTube 频道等资源。 -
Unsloth AI 的新尝试:用户
@vishyouluck提到他们正尝试将 Unsloth 用于印地语(Hindi)并承诺更新,尽管其 Collab 计算单元已耗尽并正寻求购买更多。 -
推理端点(Inference Endpoint)的便捷性:用户
@dragonburp为推理端点的设置简便性点赞,认为其用户友好且直观。 -
关联 Hugging Face 与 GitHub:用户
!BeastBlaze探索了将 Hugging Face 项目链接到其 GitHub 账号的方法,旨在提升个人资料以吸引潜在雇主,随后讨论了 Space 因非活动状态进入休眠的问题,以及检查每日使用情况的账单查询。
提及的链接:
- Vishal - a Hugging Face Space by VishalMysore: 未找到描述
- stabilityai/stable-code-3b · Hugging Face: 未找到描述
- LoRA): 未找到描述
- burkelibbey/colors · Datasets at Hugging Face: 未找到描述
- llama.cpp/convert-lora-to-ggml.py at master · ggerganov/llama.cpp: Facebook LLaMA 模型的 C/C++ 移植版本。通过在 GitHub 上创建账号为 ggerganov/llama.cpp 的开发做出贡献。
▷ #today-im-learning (5 messages):
-
本地 RAG 实现成功案例:用户
@thoreau_a_whelan分享了他们成功使用 langchain 和 LM Studio 实现 local RAG(检索增强生成)以搜索本地文档的兴奋之情。 -
攻克 GitHub Actions 权限难题:
@vipitis报告了在为 GitHub Actions 设置特定权限时遇到的困难,并将该过程描述为非常痛苦。 -
DoReMi 与 3D 并行下的 FP8 训练进展:
@neuralink取得了重大进展,完成了 90% 的 DoReMi 编写工作以及 30% 的端到端 FP8 training in 3D parallelism,并成功实现了前向和反向传播。 -
Meta 的 Self-Rewarding Language Models 论文精要:
@subham5089分享了 Meta 新论文 “Self-Rewarding Language Models” 的简化摘要。该摘要可在 LinkedIn 帖子中查看。 -
Mad_cat__ 理解了 Skillchains:用户
@mad_cat__表示他们终于理解了 Skillchains,但未提供关于这些 skillchains 性质的进一步背景信息。
▷ #cool-finds (3 messages):
-
Hugging Face 发布双语模型:用户
@sofiavas提到了 Hugging Face 发布 bilingual models 的趋势,并重点介绍了最近发布的德语和中文模型。 -
介绍 Nous-Hermes-2-Vision:
@andysingal展示了 Nous-Hermes-2-Vision,这是一种新型的 Vision-Language Model,基于 teknium 的 OpenHermes-2.5-Mistral-7B 构建。该模型的详细信息可以在 Hugging Face 上查看。 -
Nous-Hermes-2-Vision 独特的 Function Calling 特性:
@meatfucker指出了 Nous-Hermes-2-Vision 模型的一个独特之处,即它具备 function calling 能力。
相关链接:
NousResearch/Nous-Hermes-2-Vision-Alpha · Hugging Face:未找到描述
▷ #i-made-this (9 messages🔥):
-
Felix 优化 VRAM 效率:
@felixsanz分享了一篇关于优化写实扩散模型 PixArt-α 以在小于 8GB VRAM 下运行的文章。他们希望社区能发现这些内容的用处,并欢迎提出改进反馈。 -
社区对 Felix 的赞赏:
@gugaime称赞了@felixsanz关于 Stable Diffusion 的启发性文章,并表示他们打算实现文中提供的示例。@felixsanz以感谢和拥抱火箭的表情符号回应了这份赞赏。 -
对 PixArt-α 选择的好奇:
@sofiavas询问了@felixsanz为什么选择 PixArt-α 而不是 OpenAI 的 8k 模型进行优化,对该决定背后的理由表示关注。 -
首个软件包发布成功:
@vipitis庆祝了他们向 Python Package Index (PyPI) 发布了第一个软件包。 -
DevSpot 的 AI 集成 POC:
@devspot在 GitHub 上介绍了一个概念验证(POC),概述了一种与各种 AI 供应商模型协作的可扩展方法,并分享了其 GitHub 仓库链接以及一段解释其概念的 YouTube 视频。 -
提及 Discord 频道的神秘消息:
@Amanita仅发布了<#897390720388825149>,这似乎是对另一个 Discord 频道的提及,未提供任何额外背景。
相关链接:
- GitHub - devspotyt/open-models:通过在 GitHub 上创建账户来为 devspotyt/open-models 的开发做出贡献。
- Mix-and-Match AI - Open Models, The Game Changer!:一段简短的视频,解释了 Open Models 背后的概念,这是一个全新的开源代码,可以轻松集成和使用各种模型与 AI…
- PixArt-α with less than 8GB VRAM:仅需 6.4GB VRAM 即可执行该生成式图像模型的推理过程。
▷ #reading-group (1 messages):
skyward2989: https://arxiv.org/html/2401.10020v1
▷ #computer-vision (1 messages):
swetha98: 有谁知道关于 Intelligent character recognition (ICR) 的库吗?
▷ #NLP (8 messages🔥):
-
Docker 困境:模型缓存 vs. 卷存储 (Volume Storage):
@asprtnl_50418讨论了在 Docker 中缓存模型的弊端:更改任何层或测试另一个模型都会导致缓存被清除。解决方案在于使用 Volume 进行宿主机永久存储,由于模型体积巨大,这也有利于 容器间的模型共享。 -
模型瘦身:缩小 Sentence Transformer:
@stroggoz成功使用 PCA 和知识蒸馏 (knowledge distillation) 缩小了 Sentence Transformer,但鉴于原始模型是在十亿条句子上训练的,他正在寻求关于训练压缩模型所需数据集大小的建议。 -
BERT:老而弥坚?:
@frosty04212询问 BERT 在 Token Classification 方面是否已经过时,因为他们正在评估不同模型以获得最佳性能。@stroggoz回应称,虽然 BERT 可能由于二次复杂度(quadratic complexity)而效率较低,但它仍然被广泛使用,且在 Token Classification 方面可能没有太多更好的替代方案。 -
对比 NLP 巨头:
@stroggoz继续对话称,RoBERTa 和 Elektra 的表现可能略优于 BERT。他们指出 RoBERTa 的 Tokenizer 更快,并提到由于 BERT 拥有广泛的模型生态系统,他们仍然经常使用它。 -
NER 模型推荐:在命名实体识别 (NER) 的 Token Classification 领域,
@stroggoz推荐使用 span marker library。
OpenAccess AI Collective (axolotl) Discord Summary
-
在 7H100 上进行 FFT 的 GPU 显存挑战:用户报告了在 7H100 GPU 上运行 FFT 时出现显存溢出 (OOM) 错误,讨论了将
zero3bf16与 Mixtral 框架结合使用作为缓解该问题的潜在解决方案。 -
Google 自动化代码审查评论:Google 的一篇新论文 介绍了利用机器学习方法自动化解决代码审查评论,有望加速开发周期。
-
FastChat 的 LLM 基准测试工具:社区探索了使用 FastChat 的 LLM judge 进行语言模型评估,并讨论了将 VLLM 与 Fast Eval 集成以及为此目的使用后端标志 (backend flag)。
-
Orion-14B 的多语言实力因信任问题受挫:OrionStarAI 发布了新的 Orion-14B 模型,声称具有强大的多语言支持,但在没有数据污染检查 (contamination check) 的情况下引发了关于可信度的辩论,详见其 Hugging Face 仓库。
-
模型评估的平衡之道:对话围绕使用 API 调用评估语言模型的成本效益展开,提出了诸如 FastEval 每次评估 5 美元之类的指标。
-
Phi2 模型配置难题已修正:报告了 Phi2 模型配置中的一个错误,导致在 GitHub 上提交了一个 PR 以修复模型 YML 文件中配置类 (config class) 的不一致。
-
有效层冻结与微调技巧:Axolotl 用户分享了关于 LoRA 配置中冻结层的指南,并为微调崩溃等常见问题提供了排查建议,强调了
val_set_size: 0的实用性。 -
DPO 支持符合 Intel 格式的本地数据集:确认了如果数据格式符合 Intel 的结构,本地数据集即可兼容直接偏好优化 (DPO)。
-
Solar LLM 拥抱 Llama 架构:讨论得出结论,根据规模和架构,SOLAR-10.7B 模型应归类为 “llama” 模型类别,并提供了其 Hugging Face 页面链接。
-
DPO 的学习率与样本来源优化:强调了为有效的 DPO 仔细选择较低的学习率并使用模型自身的负样本 (bad samples),如 Hugging Face 讨论帖 中所述。
-
寻求在 Replicate 上设置 predict.py autoawq 和 vllm 的帮助:一位用户寻求关于在 Replicate 上设置
predict.pyautoawq 和 vllm 的指导。
OpenAccess AI Collective (axolotl) 频道摘要
▷ #general (32 条消息🔥):
- 高端 GPU 在 FFT 中的 OOM 问题:
@dangfutures报告了在 7H100 GPU 上尝试执行 FFT 时出现的显存溢出(OOM)错误,并与@caseus_讨论了在 Mixtral 框架中使用zero3bf16作为缓解该问题的方法。 - 利用 AI 处理审稿意见:
@noobmaster29分享了 Google 的一篇新论文,关于利用基于 ML 的自动化技术协助解决代码审查意见,从而加速开发流程。 - 使用 FastChat 进行基准测试:用户讨论了评估语言模型的选项,
@gahdnah指向了 FastChat 的 LLM judge,@dangfutures询问了将 VLLM 与 Fast Eval 集成的问题,@rtyax确认可以通过特定的 backend 标志来实现。 - 新 Orion-14B 语言模型亮相:
@bratao提供了 OrionStarAI 新的 Orion-14B 模型链接,该模型号称具有强大的多语言能力,引发了社区的不同反应,有人质疑在没有污染检查(contamination check)的情况下其可信度以及模型的生命周期。 - 使用 API 调用进行模型评估的成本:
@noobmaster29询问了使用 API 调用评估语言模型的成本,@nanobitz表示 FastEval 每次评估的费用约为 5 美元。
提到的链接:
- Resolving Code Review Comments with Machine Learning: 未找到描述
- OrionStarAI/Orion-14B-Base · Hugging Face: 未找到描述
- FastChat/fastchat/llm_judge/README.md at main · lm-sys/FastChat: 一个用于训练、服务和评估大型语言模型的开放平台。Vicuna 和 Chatbot Arena 的发布仓库。 - lm-sys/FastChat
- FastChat/fastchat/llm_judge at main · lm-sys/FastChat: 一个用于训练、服务和评估大型语言模型的开放平台。Vicuna 和 Chatbot Arena 的发布仓库。 - lm-sys/FastChat
▷ #axolotl-dev (10 条消息🔥):
-
报告 Phi2 模型版本错误:
@asterix3651分享了 phi2 的一个模型版本错误,揭示了 config 类的不一致性。@caseus_确认了该问题,并承诺在获得电脑访问权限后尽快修复。 -
模型配置加载器的 Pull Request:针对
@asterix3651的报告,@caseus_提交了一个 Pull Request,以确保模型配置加载器遵循 model_revision,解决了 config 类不匹配的问题。 -
讨论速度提升的相关性:
@tiendung提到,速度提升的声明(例如 pro 版 Unsloth 报告的 30 倍加速)只有在样本与同一主题相关时才有意义。 -
对 Unsloth 速度声明的质疑:
@dreamgen表示怀疑,认为 Unsloth 声称的加速是基于非实际的设置。@faldore和@dreamgen讨论认为,像 Unsloth 这样的软件优点可能在于训练速度之外的其他因素,@dreamgen强调了其可定制性。
提到的链接:
- axolotl/examples/phi/phi2-ft.yml at main · OpenAccess-AI-Collective/axolotl: 欢迎提出 axolotl 问题。通过在 GitHub 上创建账户为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- make sure the model config loader respects the model_revision too by winglian · Pull Request #1160 · OpenAccess-AI-Collective/axolotl: Discord 中报告的描述:ValueError: 你传递的模型类具有一个与你传递的 config 类不一致的
config_class属性(模型具有 <class ‘transforme…
▷ #general-help (25 条消息🔥):
-
LoRA 层冻结初学者指南:
@diabolic6045询问了如何使用 Axolotl 冻结模型层,@nanobitz告知应从lora.yml配置开始,该配置会冻结大部分层。@nanobitz还向@diabolic6045保证,尝试这些设置是安全的。 -
微调崩溃故障排除:
@fred_fups在使用 QLoRA 对 Mistral 7B 进行 3 个 epoch 的微调时,在进度达到 33% 时总是发生崩溃。@nanobitz建议通过设置val_set_size: 0来尝试避免在 evaluation 过程中发生崩溃。 -
本地数据集问题已解决:
@c.gato询问了 DPO 对本地数据集的支持情况,@dangfutures确认在格式化为匹配 Intel 的结构后即可兼容。 -
适用于任何模型的 Mixtral Yaml 灵活性:
@caseus_透露,非冻结参数(unfrozen parameters)选项适用于所有模型,而不仅仅是 Mixtral。当@diabolic6045索要文档以了解参数时,没有提供直接链接。 -
Solar LLM 分类明确:包括
@dangfutures、@noobmaster29和@nanobitz在内的几位用户讨论了如何设置新推出的 SOLAR-10.7B 模型,结论是考虑到其规模和架构,应将其归类为 “llama” 模型。
提到的链接:
upstage/SOLAR-10.7B-v1.0 · Hugging Face:未找到描述
▷ #datasets (14 条消息🔥):
-
DPO 需要更精细的学习率调整:’xzuyn’ 观察到,与 Supervised Fine-Tuning (SFT) 相比,Direct Prompt Optimization (DPO) 需要显著更低的学习率——可能低一个数量级。他们提供了一个例子,建议如果 SFT 使用 0.0001,那么 DPO 使用 0.00001 可能更合适,并提到了 ‘jon’ 在 Hugging Face 讨论中分享的相关见解(DPO 学习率讨论)。
-
使用模型自身的负面样本进行 DPO 更有利:’xzuyn’ 认为,使用模型自身生成的较差样本作为 DPO 的 “rejected” 数据,比使用人工生成的 “虚假” 负面结果能产生更有效且更快速的效果。
-
选择正确的 Rejected 样本:’dreamgen’ 和 ‘xzuyn’ 强调了为 DPO 选择合适的被拒绝(rejected)样本的重要性,后者指出,使用来自模型本身的样本,特别是通过修改 sampler 设置以鼓励生成 “糟糕” 但连贯的输出,可能是一种有效的策略。
-
用于微调模型调整的 DPO:根据 ‘xzuyn’ 的说法,DPO 可以被视为模型定型前的 “微调(tiny nudge)”,这意味着当 chosen 和 rejected 的样本与当前模型能生成的样本差异不太大时,效果最好。他们建议 DPO 更适合增量改进,而非广泛的变更。
-
DPO 轻松纠正 ChatGPT 的习气:’xzuyn’ 建议使用 DPO 来修复常见的 GPT 习气,例如以 “in conclusion…” 结尾或以 “Surely” 开头,并指出当这些倾向通过训练数据渗透进模型时,DPO 可以轻松地消除它们。
▷ #replicate-help (1 条消息):
dangfutures: 有人知道如何在 Replicate 上设置 predict.py、autoawq 和 vLLM 吗,哈哈
LlamaIndex Discord Discord 总结
-
Marco Bertelli 指导聊天机器人开发者:Marco Bertelli 的综合系列指南为创建 全栈 RAG 聊天机器人 提供了深入见解,涵盖了算法和全栈开发,持续受到关注。开发者可以通过分享的 Tweet 链接访问该指南,并查看相关 图片。
-
创新 RAG 的嵌入模型:关于 M2-BERT-80M-32k-retrieval 模型 的讨论展示了其在 RAG 中进行语义落地的长上下文嵌入的能力。该模型解决了嵌入分块(chunking)问题,更多详情见 Tweet 和额外的 图像。
-
RAG Maestro 开启 ArXiv 洞察之门:Aymen Kallala 推出了 RAG-Maestro,这是一个利用 RAG 通过关键词提取和索引来改进 ArXiv 研究的 Web 应用程序。该工具在 Tweet 中被重点介绍,并附有说明指南 此处。
-
讨论中的热点话题:记忆与余弦相似度工具:query engines 缺乏记忆支持,与现有的 cosine similarity 计算工具形成对比;工程师应参考 LlamaIndex 文档 以了解 Chat Engines 和 Agents 的 memory 实现。
-
Gemini Pro 配合 LlamaIndex 增强发票数据搜索:使用 Gemini Pro 和 LlamaIndex 对半结构化发票数据进行高效搜索和检索取得了进展,为处理此类数字化文档的企业迈出了重要一步。
@andysingal在 Medium 文章 中讨论了其对数字化领域的影响。
LlamaIndex Discord 频道总结
▷ #blog (5 条消息):
-
Marco Bertelli 的全栈 RAG 聊天机器人教程系列:Marco Bertelli 关于构建 全栈 RAG 聊天机器人 的多步骤指南因其深度而受到赞誉,涵盖了算法以及前后端开发。查看分享的 Tweet 中的系列内容及配套图片 此处。
-
语义落地的长上下文嵌入模型:由
@JonSaadFalcon等人展示的 M2-BERT-80M-32k-retrieval 模型 通过将检索落地于更高层级的语义上下文,为 RAG 中的嵌入分块问题提供了解决方案。更多细节可以在链接的 Tweet 和图片 此处 中找到。 -
探讨 Agentic 软件开发的研讨会:LLMCompiler 将成为由
@sehoonkim418和@amir__gholami主持的 2024 年网络研讨会的焦点,旨在为构建高效、高性能的 Agentic 软件提供见解。在 公告 Tweet 中阅读更多关于用于并行多功能规划/执行的 Agent 编译器,并在此处查看 视觉预览。 -
用于 ArXiv 研究的 RAG-Maestro 工具:由 Aymen Kallala 开发的 RAG-Maestro 是一个 Web 应用程序,它使用 RAG 在 ArXiv 论文中查找科学概念,采用关键词提取和即时索引。LlamaIndex 在其 Tweet 中分享了这一创新工具,并提供了视觉指南 此处。
-
构建全栈复杂 PDF AI 聊天机器人概览:来自 Paragon AI 的 Nipuna 提供了关于创建能够处理大量复杂文档的复杂 PDF AI 聊天机器人的见解,并在最近的概述中进行了详细说明。在 Tweet 和相关图片 此处 中探讨了处理 40 多个文档和数千页嵌入表格的挑战。
▷ #general (48 messages🔥):
- Query Engine 的 Memory 模块:
@nerdai澄清了 LlamaIndex 不支持 Query Engine 的 memory,并建议使用 Chat Engines 和 Agents 来实现 memory 功能。他们提供了一个文档链接,解释了如何实现 SimpleChatStore 和 ChatMemoryBuffer。 - 余弦相似度工具咨询:
@kush2861询问了一个类似于 OpenAI 的 distances_from_embeddings 计算器。@nerdai确认了其可用性,用于计算两个 embedding 的 cosine similarity。 - Dataset Generator Worker 增强咨询:
@dangfutures询问了是否可以增加 dataset generator 的 worker 数量,@nerdai回复称他们尚未在任何 generator 中内置 multi-processing。 - 构建自主向量存储:
@lhc1921寻求关于在没有 LLM 服务上下文的情况下构建 auto merge vector storage 的指导。@kapa.ai表示提供的摘要中没有详细说明如何构建此类系统,并将@lhc1921引向官方 LlamaIndex documentation。 - 带 Memory 的 Conversational Retrieval Agents:
@peeranat_fup询问了如何使用 LlamaIndex 构建 带 memory 的 Conversational Retrieval Agent 的示例。尽管多次尝试寻找合适的示例,但由于提供的摘要中缺乏具体示例,@kapa.ai建议参考 LlamaIndex documentation 或 GitHub repository。
提到的链接:
- DLAI - 构建和评估高级 RAG:Introduction · Advanced RAG Pipeline · RAG Triad of metrics · Sentence-window retrieval · Auto-merging retrieval · Conclusion
- Chat Engine - Context Mode - LlamaIndex 🦙 0.9.34:未找到描述
- Chat Stores - LlamaIndex 🦙 0.9.34:未找到描述
- Prompts - LlamaIndex 🦙 0.9.34:未找到描述
- 在高级模块中访问/自定义 Prompts - LlamaIndex 🦙 0.9.34:未找到描述
▷ #ai-discussion (1 messages):
- Gemini Pro 和 LlamaIndex 推动 AI 搜索:
@andysingal分享了一篇 Medium 文章,讨论了 Gemini Pro 和 LlamaIndex 如何帮助高效检索半结构化发票数据。引言强调了这项技术在 数字宇宙 中的重要性。
提到的链接:
Unlocking Efficiency: A Search Query for Semi-Structured Invoices with Gemini Pro and LlamaIndex in…:Ankush k Singal
LangChain AI Discord 总结
-
庆祝 LangChain.js 里程碑:LangChain.js 的贡献者们受到了表彰,特别感谢
@matthewdparker解决了 Token 文本分割器(text splitter)的问题。Twitter 致谢 庆祝了自 0.1.0 版本发布以来取得的进展。 -
LangChain 托管与故障排除讨论:LangChain 后端的托管建议包括 Heroku 和 porter.run;同时有报告称在安装时遇到了 urllib3 连接池问题,目前尚无后续解决方案。关于 LangChain 与 React 集成的咨询得到了澄清:LangChain 作为后端运行,需要前端框架发起 API 请求。
-
社会公益与软件结合:一个支持自闭症和神经多样性(neurodivergent)人士的项目发出了软件开发协助请求,并提供 Prompt 结构化方面的专业知识作为回报。
-
LangServe 反馈功能咨询:有人观察到 LangServe 的
enable_feedback函数缺少 PATCH 接口(endpoint),尽管该功能在langsmith-sdk中存在,提问者表示可能需要自行添加。 -
分享多元化 AI 项目与见解:AI 实现的演示包括 GitHub 文档演示、神经多样性辅助项目、文本类地牢游戏、在 GitHub 上开发的多语言 RAG 项目,以及一篇探讨元数据在增强语言模型中作用的 Medium 文章。
LangChain AI 频道总结
▷ #announcements (1 条消息):
- 致谢 LangChain.js 贡献者:
@jacoblee93和@Hacubu向今年为 LangChain.js 开发做出贡献的所有人表示感谢。特别感谢@matthewdparker修复了 Token 文本分割器的重叠问题,这标志着自 0.1.0 版本发布以来的一个重要里程碑。在 Twitter 上阅读完整致谢。
提到的链接:
来自 Jacob Lee (@Hacubu) 的推文:感谢今年(到目前为止)为 @LangChainAI 做出贡献的所有人!自 0.1.0 发布以来发生了太多事情,如果没有以下人员,这一切都不可能实现:🐞 matthewdparker 修复了…
▷ #general (22 条消息🔥):
-
寻求 LangChain 托管建议:用户
@b0otable征求托管使用 OpenAI 模型的 LangChain 后端服务的建议。@ricky_gzz建议原型设计使用 Heroku,生产级需求使用 AWS 上的 porter.run;而@baytaew则提议通过联系 support@langchain.dev 来协助尝试 langserve。 -
排查 LangChain 安装问题:
@rrvermaa_79263在尝试安装 langchain-community 时遇到了 urllib3 连接池错误,并寻求解决此问题的指导。 -
LangChain 与 React 开发咨询:
@yasuke007询问了如何将 LangChain 与 React 结合使用,@esponges澄清说 LangChain 是一个后端工具,需要 React 向此类后端发起请求。 -
寻求自闭症与神经多样性支持项目的帮助:
@brotino是一名注册护士,也是自闭症谱系的一员,他介绍了自己支持自闭症成人的项目,并寻求社区在软件开发挑战方面的帮助,作为交换,他愿意提供 Prompt 结构化方面的技能。 -
在 Hugging Face 模型中使用 LangChain:
@esraa_45467询问了如何使用 Hugging Face 模型实现类似于 LangChainChatOpenAI的功能,并分享了一段代码片段作为上下文。
提到的链接:
来自 Preston Thornburg🛡️ (@ptonewreckin) 的推文:嘿 @LangChainAI … 你们还好吗?你们指向 https://langchain.fi/ 的推文看起来挺可疑的。
▷ #langserve (1 条消息):
- 关于 LangServe 反馈功能的疑问:
@georgeherby询问了在 LangServe 中使用enable_feedback标志时缺少用于更新反馈的 PATCH 接口的问题,并表示他们可能会自己添加该接口。他们注意到langsmith-sdk代码库中存在该函数,怀疑这可能是一个疏忽而非刻意省略。
▷ #langchain-templates (1 条消息):
jackblack1.: 有没有人有带有 DuckDuckGo 搜索功能的 LangChain OpenAI Assistant 模板?
▷ #share-your-work (5 条消息):
-
展示 GitHub 文档演示:用户
@jonathan0x56分享了一个 GitHub pull request,这是一个包含带图片文档的演示项目,旨在利用来自 langchain-ai/langchain 的素材引导一个文档仓库用于演示目的。 -
神经多样性支持项目的行动呼吁:用户
@brotino为一个旨在帮助自闭症成年人和神经多样性社区的项目寻求支持。他们提供 Prompt 结构化和故障排除方面的技能,以换取软件开发方面的帮助。 -
分享地牢游戏链接:用户
@friday_living提供了 Gemini Dungeon 的链接,但未包含有关内容的进一步细节或描述。 -
多语言 RAG 开发介绍:用户
@akashai4736展示了他们的多语言 RAG (Retrieval Augmented Generation) 项目的 GitHub 仓库,展示了其与 LangChain Cohere 合作开发的潜力。GitHub 链接可以在这里找到。 -
关于语言模型和数据的 Medium 文章:用户
@rajib2189分享了一篇 Medium 文章,讨论了在使用 RAG 框架开发基于语言模型的应用时,除了数据之外元数据的重要性。文章挑战了“仅靠更多数据就能增强语言模型”的普遍观点。
提到的链接:
- Gemini Dungeon - 基于文本和图像的 DND5E 冒险:未找到描述
- Data is Not what All You Need:这篇博客的标题可能会引起一些人的惊讶甚至怀疑。“他疯了吗?”可能是人们脑海中闪过的一个问题……
- GitHub - akashAD98/Multilingual-RAG: 多语言 RAG:多语言 RAG。通过在 GitHub 上创建账号来为 akashAD98/Multilingual-RAG 的开发做出贡献。
- jonathanalgar 的 alttexter-ghclient 演示 · Pull Request #1 · jonathanalgar/docs-demo:假设我们想引导一个文档仓库。我们有五个全新的文档作为开始(1个 md,1个 mdx,3个从 langchain-ai/langchain 借用用于演示目的的 ipynb)。所有文档都带有图片……
DiscoResearch Discord 摘要
-
Marlin 进入 AutoGPTQ:AutoGPTQ 仓库已更新,包含了以速度和出色性能著称的 marlin kernel,尽管存在某些限制,详见 pull request 更新。同时,在 A100 GPU 上对 4-bit 量化的 Mixtral 进行的性能基准测试显示,在 Batch Size 为 64 时,速度达到了 每秒 9 个 token。
-
开发者编写自定义 CUDA:讨论暗示像 Tri Dao 这样的行业专业人士可能正在使用 自定义 CUDA kernel,这意味着 AI 模型中的高级优化技术可能更加普遍。使用来自 bitsandbytes 的 4-bit 量化训练语言模型引发了关于在其他量化方案中是否具有类似 GPTQ 或 AWQ 能力的问题。
-
AI 形式的 Kahneman 思想:分享了开发一个模仿 Daniel Kahneman 认知风格的 AI Agent 的雄心,建议使用他的 Persona 来提示 LLM 或针对他的作品进行微调。重点介绍了一篇关于 Self-Rewarding Language Models 的最新 arXiv 论文,展示了通过在训练期间使用自我提供的奖励,其性能超越了 GPT-4。
-
增强德语 DPR 数据集:德语 DPR 训练数据集 Version 2 的发布在其结构中增加了正式和非正式的祈使句问题,提高了其复杂性和实用性,并在 GitHub 上征求反馈和贡献。
-
德语 LLM 势头强劲:对话涵盖了用于微调的自监督学习适配、对德语 LLM 发布的兴奋,以及 DiscoLM German 7B 模型的可用 量化版本。对于微调需求,推荐使用 Axolotl 工具包,以及作为复杂微调工具替代方案的 Llama-factory。
DiscoResearch 频道摘要
▷ #mixtral_implementation (6 messages):
-
Marlin Kernel 已添加到 AutoGPTQ:
@vara2096分享了一个 GitHub pull request,指出 marlin kernel 已添加到 AutoGPTQ 仓库,并提到尽管 marlin 存在局限性,但其速度和性能令人印象深刻。 -
Mixtral 性能基准测试:
@vara2096报告称,在 A100 GPU 上,当 batch size 为 64 时,4-bit 量化的 Mixtral 吞吐量达到了 每秒 9 个 token。 -
吞吐量测量澄清: 在对
@bjoernp的澄清中,@vara2096确认吞吐量测量结果为 串行每秒 9 个 token,而非 9x64 tokens 每秒。
提到的链接:
add marlin kernel by qwopqwop200 · Pull Request #514 · AutoGPTQ/AutoGPTQ: 添加 marlin kernel。marlin 是一个非常强大的 GPTQ kernel。虽然对适用模型的限制较多,但其速度非常接近理论值。此外,fused attention 尚未…
▷ #general (7 messages):
- AI 模型中的自定义 CUDA kernel:
@muhtasham指出,尽管有人声称不使用量化,但像 Tri Dao 这样的行业专家以编写 自定义 CUDA kernel 而闻名,这可能表明 AI 模型中使用了高级优化技术。 - 使用 bitsandbytes 在量化模型上进行训练:
@vara2096询问是否可以使用 bitsandbytes 的 4-bit 量化在 量化模型 之上训练 LoRA,并询问其他量化方案(如 GPTQ 或 AWQ)是否支持类似功能。 - 渴望拥有像 Kahneman 一样的 AI 大脑:
@sabu7003提出了开发一个模拟行为经济学家 Daniel Kahneman 思维过程的 AI Agent 的概念。该 AI 将机器学习与 Kahneman 的原则相结合,可能提供商业和营销咨询。 - 构建类 Kahneman AI 的建议:
@rasdani建议可以通过使用 Kahneman 的 persona 提示 LLM 或对其出版物进行微调来实现这种类 Kahneman 的 AI,同时提到 character.ai 是一个潜在资源,并指出 Kahneman 的思想对 AI 和 reinforcement learning 研究有深远影响。 - Self-Rewarding Language Models 性能超越 GPT-4:
@philipmay分享了一篇关于 Self-Rewarding Language Models 的最新研究论文 (arXiv:2401.10020),强调了一种新的训练方法,即模型将自身作为评判者来提供奖励,从而在 AlpacaEval 2.0 排行榜上获得了超越 GPT-4 等模型的性能。
提到的链接:
Self-Rewarding Language Models: 我们假设要实现超越人类的 Agent,未来的模型需要超越人类的反馈,以提供充足的训练信号。目前的方法通常根据人类偏好训练奖励模型…
▷ #embedding_dev (1 messages):
- 德国 DPR 数据集增强:
@philipmay宣布 Version 2 的德国 DPR 训练数据集已完成,现在包含普通问题、正式 (sie) 祈使句问题以及新增的非正式 (du) 祈使句问题。现征求反馈,该数据集可在 GitHub 上的 German dataset for DPR model training 获取。
提到的链接:
GitHub - telekom/wikipedia-22-12-de-dpr: German dataset for DPR model training: 用于 DPR 模型训练的德国数据集。通过在 GitHub 上创建账号为 telekom/wikipedia-22-12-de-dpr 的开发做出贡献。
▷ #discolm_german (8 条消息🔥):
- SF Trainer 分享见解:用户
@_jp1_讨论了采用自监督学习 (SSL) 技术,在 Fine-tuning 过程中拒绝早期模型迭代生成的答案,转而采用 Ground Truth,这与 Intel 在其 Neural Chat 中采取的方法类似。 - 法律专家对德语 LLM 感到兴奋:用户
@rapsac.对德语 LLM 的发布表示感谢,并对将 Fine-tuning 应用于德语法律数据集持乐观态度,预计性能将介于 GPT-3.5 和 GPT-4 之间。 - 量化版 DiscoLM German 7b 模型发布:用户
@rasdani分享了 DiscoLM German 7B 模型的量化版本,详细介绍了 Massed Compute 的协助,并提供了各种量化模型的综合链接。 - 如何微调 DiscoLM German?:用户
@thomasrenkert询问了微调 DiscoLM German 模型的方法,@bjoernp对此推荐了 Axolotl 工具包。 - 寻求更简单的微调方法:在
@thomasrenkert提到直接在 oobabooga 中进行微调存在困难后,用户@nyxkrage建议将 Llama-factory 作为一个可能更用户友好的替代方案。
提到的链接:
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions:尽管提问。通过在 GitHub 上创建账户,为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- TheBloke/DiscoLM_German_7b_v1-AWQ · Hugging Face:未找到描述
- TheBloke/DiscoLM_German_7b_v1-GPTQ · Hugging Face:未找到描述
- TheBloke/DiscoLM_German_7b_v1-GGUF · Hugging Face:未找到描述
Latent Space Discord 摘要
-
播客荣誉与教育资源推荐:
@swyxio宣布他们的播客登上了播客排行榜第 16 名,并表达了公会成员们共同的兴奋之情。@guardiang重点推荐了一个解释 LLM 背后 Transformer 架构的教育资源,并为技术爱好者们提供了一个 YouTube 链接。 -
Elicit 和 Anthropic 备受关注:
@swyxio推荐使用 elicit.org 来洞察用户需求,而@aravindputrevu则在寻求 Anthropic 内部人员的技术协助。 -
破解 Self-Attention 之谜:由
@swyxio和@eugeneyan发起的讨论深入探讨了小于 8k 的 Self-Attention 矩阵如何管理,但对于更大的上下文则需要像 “RoPE 和 YaRN” 这样的巧妙技术以及实用技巧,并参考了 FlashAttention 和 ALiBi 的使用。 -
揭秘超人类反馈 (Superhuman Feedback) 前沿:
@swyxio提出了一种涉及语言模型生成并评估自身奖励的新方法,并重点标注了@jaseweston的一条推文,该推文反映了该领域日益增长的兴趣和潜在影响,并辅以一篇 arXiv 论文 支持。 -
简单的致谢与对企业播客的好奇:用户
@420gunna表达了直接的感谢,公会成员们还讨论了 a16z 企业品牌播客出人意料的普及程度。
Latent Space 频道摘要
▷ #ai-general-chat (14 messages🔥):
- 来自 420gunna 的简单感谢:用户
@420gunna以一句简单的 “Thanks 🙇♂️” 表达了感谢。 - 播客榜单攀升者:
@swyxio分享了他们的播客在榜单上排名 第 16 位,超过了 Y Combinator,而@420gunna通过在骑行时收听为排名的上升做出了贡献。 - 针对用户需求提到 Elicit.org:
@swyxio建议查看 elicit.org,并重点介绍了@914974587882700800对用户需求的见解。 - A16z 播客出人意料的普及度:
@austintackaberry和@swyxio讨论了 a16z 播客尽管被认为具有企业品牌色彩,但如何保持高排名。 - 寻求 Anthropic 的协助:用户
@aravindputrevu正在寻找来自 Anthropic 的人员提供帮助。 - 关于 Transformers 的教育资源:
@guardiang赞扬并分享了一个解释 LLM 背后 Transformer 架构的 YouTube 视频。
(注:链接和对特定用户的引用仅基于给定的聊天记录,系统知识库中没有外部来源或额外的上下文。)
提到的链接:
- Bloomberg - Are you a robot?:未找到描述
-
[Transformers explained The architecture behind LLMs](https://youtu.be/ec9IQMiJBhs?si=pb0g6078oJtg44od):关于 Transformer 架构你需要知道的一切:如何构建输入、Attention (Queries, Keys, Values)、位置嵌入 (positional embeddings)、残差连接 (residual conn)…
▷ #llm-paper-club (6 messages):
-
澄清 Self-Attention 矩阵的大小:@swyxio 指出,对于 <8k 的上下文窗口,全量 Self-Attention 矩阵是可行的,但用于 >100k 的技术尚未公开,它们可能涉及避免计算全量矩阵的方法。他们提到了 “rope and yarn” 作为可能使用的辅助上下文扩展技术。
-
大上下文实用技巧的见解:@eugeneyan 解释说,尽管理论上可能存在 128k x 128k 的矩阵,但像 FlashAttention 中描述的循环计算和缓存向量,以及 Ofir Press 的文章 中讨论的利用 alibi 处理上下文大小,都是在不需要全量矩阵的情况下管理大上下文的实用方法。
-
验证关于 Attention 可扩展性的直觉:@dzidex 对 swyxio 和 eugeneyan 提供的关于 Transformer 如何处理大上下文窗口的清晰解释表示感谢,这证实了他们关于计算可行性的直觉。
-
关于 Self-Rewarding Language Models 的值得关注的论文:@swyxio 分享了 Self-Rewarding LLM 论文正受到显著关注。论文中描述的方法涉及使用语言模型生成并评估其自身的奖励,这可能为 “superhuman feedback” 铺平道路,正如 @jaseweston 的推文 所强调以及相应的 arXiv 论文 所详述的那样。
提到的链接:
- Jason Weston (@jaseweston) 的推文:🚨新论文!🚨 Self-Rewarding LMs - LM 本身在迭代 DPO 期间通过 LLM-as-a-Judge 对其自身的生成提供奖励 - 奖励建模能力在训练期间不断提高,而不是保持不变…
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness:Transformers 在长序列上运行缓慢且耗费内存,因为 Self-Attention 的时间和内存复杂度随序列长度呈平方级增长。近似 Attention 方法曾试图解决…
- The Use Case for Relative Position Embeddings:我们正处于 2022 年,但许多最流行的因果语言模型 (LMs),包括 GPT-3,仍然使用绝对位置嵌入。我认为我们应该停止使用这些,转而使用相对位置嵌入…
Skunkworks AI Discord 总结
只有一个频道有活动,因此无需总结…
- 志向 AI 殿堂:
sabu7003提议了一个雄心勃勃的项目,旨在创建一个能够镜像行为经济学专家 Daniel Kahneman 思维的 AI,目标是像 Kahneman 本人一样提供细致入微的咨询。他们邀请大家就使用 Transformer Architecture 实现该项目的可行性发表看法。 - 活动排程困境:
yikesawjeez强调了日历上缺乏活动的问题,并建议今天规划活动,而far_el回复称由于今天日程繁忙,可以在明天进行规划。 - 协作工作空间查询:
yikesawjeez提议测试对 basementagiclub 登录名下实验室的同步访问,并请求.mrfoo在/work中创建并保存一个 notebook,以确认共享的可访问性。 - 笔记共享实验:
yikesawjeez和.mrfoo讨论了共享笔记和在共享账户上访问 notebook 的物流细节,.mrfoo最初在自己的账户上工作,但表示愿意稍后测试联名账户的访问。 - 贡献任务:
dook4请求提供一份任务清单或阅读材料,以确定该项目潜在的贡献领域。
LLM Perf Enthusiasts AI Discord 总结
-
Mixtral 模型面临 Sagemaker 障碍:
@ajamjoom在尝试使用 TRT-LLM 在 Sagemaker PD4 上托管 Mixtral-Instruct 时遇到了 TypeError,原因是LoraConfig.from_hf()中缺少'trtllm_modules_to_hf_modules'参数。 -
Nous-Hermes System Prompt 技巧:@Teknium1 的一篇 Twitter 帖子 建议在 Nous-Hermes 2 Mixtral 中使用 system prompt 以获得更好的输出。
-
追求扩展上下文:
@alyosha11正在寻求增加 Yarn 和 Rope 等模型上下文长度的高效方法,@ivanleomk提到了 Twitter 上讨论的 self extend 可能是一个途径。 -
征集基础设施见解:
@ayenem发起了一项呼吁,分享关于批处理与在线处理、针对特定用例和约束的部署架构、重新训练的必要性以及相关工具的见解,而@jeffreyw128则询问了社区频道中基础设施讨论的适当位置。 -
使用 ColBERT 增强重排序:在 #rag 频道中,
@shacrw强调了关于使用 ColBERT 进行重排序(reranking)的 Twitter 更新,但未提供进一步的背景或详细讨论。
LLM Perf Enthusiasts AI 频道总结
▷ #opensource (6 条消息):
-
Sagemaker 与 TRT-LLM 兼容性问题:
@ajamjoom正在寻求关于在 Sagemaker PD4 上使用 TRT-LLM 托管 Mixtral-Instruct(或任何 Mistral 模型) 的建议,因为遇到了自定义 Docker 镜像错误。相关的 TypeError 与LoraConfig.from_hf()缺少'trtllm_modules_to_hf_modules'参数有关。 -
System Prompt 作为解决方案:虽然与最初的问题没有直接关系,但
@ajamjoom分享了来自@Teknium1的链接,建议使用 system prompt 来避免 Nous-Hermes 2 Mixtral 中的异常输出,引用自一篇 Twitter 帖子。 -
寻求增加上下文长度的方法:
@alyosha11询问了目前增加上下文长度的最佳方法,并对 Yarn 和 Rope 表示不满。 -
Self-Extend 作为潜在解决方案:针对上下文长度的问题,
@ivanleomk建议关注 self extend,这是最近在 Twitter 上讨论的话题。不过,Ivanleomk 尚未亲自尝试。
提到的链接:
Teknium (e/λ) (@Teknium1) 的推文:好吧,我发现了一个可能的解决方案,适用于任何从 Nous-Hermes 2 Mixtral 获得异常输出的人。默认使用 system prompt。我能够复现 Transformer 中出现的啰嗦或无法正常停止的情况…
▷ #feedback-meta (2 条消息):
- 集思广益基础设施和用例:
@ayenem提议讨论关于批处理 vs 在线处理、针对特定用例和约束定制的部署架构,以及频繁重新训练的需求、工具和经验教训。 - 关于基础设施频道位置的查询:
@jeffreyw128提到以前有一个基础设施频道,并询问此类讨论是否应归类在性能(performance)下。
▷ #rag (1 条消息):
shacrw: 使用 ColBERT 进行 reranking https://twitter.com/virattt/status/1749166976033861832
Alignment Lab AI Discord 摘要
只有一个频道有活动,因此无需总结…
- 构想一个 AI 顶尖思想家:用户
@sabu7003提出了开发一个具有行为经济学家 Daniel Kahneman 专业知识的 AI Agent 的想法,该 Agent 可以在营销和管理方面提供咨询和解决方案。他们询问是否考虑过使用 Transformer 架构开发此类应用。 - Character AI 的实践:针对
@sabu7003的提问,@desik_agi指出 Character AI 已经实现了与 Socrates 或 Steve Jobs 等历史人物的数字版本进行互动,这可能在某种程度上符合@sabu7003的愿景。 - 超越 Transformer 的局限性:
@rusch强调主要挑战不在于 Transformer 架构,而在于当前语言建模数据和方法的局限性,并建议需要更多努力来实现@sabu7003讨论的愿景。 - 确定 AI 的发展途径:
@rusch进一步补充说,AI 未来的突破可能来自多模态系统 (multimodal systems)、自我博弈 (self-play) 和高级规划能力的发展,指出了在寻求开发更复杂 AI Agent 过程中的潜在增长领域。
Datasette - LLM (@SimonW) Discord 没有新消息。如果该服务器长期没有活动,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该服务器长期没有活动,请告知我们,我们将将其移除。