ainews-rip-latent-diffusion-hello
再见潜扩散,你好沙漏扩散。
来自 Stable Diffusion 的 Katherine Crowson 介绍了一种用于基于扩散的图像生成的层次化纯 Transformer 骨干网络。该网络能以不到 6 亿的参数量高效扩展至百万像素分辨率,相比原始的约 9 亿参数模型有所改进。该架构通过分别处理局部和全局图像现象,在无需潜空间步骤(latent steps)的情况下提升了效率和分辨率。
此外,Meta 的《自我奖励语言模型》(Self Rewarding LM)论文启发了 lucidrains 着手进行代码实现。Discord 的摘要重点提到了 GPT-4 对量化技巧的鲁棒性、关于开源 GPT-0 替代方案的讨论、在有限显存下进行 DPO 训练的挑战(并提出了 QLoRA 和 rmsprop 等建议),以及通过微调和合并来提高角色扮演模型一致性的努力。此外,还记录了关于 AI 意识的哲学辩论,以及针对 Markdown 和翻译任务的 GPT-4 定制化讨论。
2024年1月22日的 AI Discord 动态。我们为您检查了 19 个服务器,291 个频道,以及 4368 条消息。预计为您节省阅读时间(以 200wpm 计算):436 分钟。
以 Stable Diffusion 闻名的 Katherine Crowson 带着一项重磅研究回归了:Direct pixel-space megapixel image generation with diffusion models:
一种用于扩散模型图像生成的层级纯 Transformer 骨干网络,比以前基于 Transformer 的骨干网络更有效地扩展到高分辨率。该架构不再不加区分地处理不同分辨率的图像,而是适应目标分辨率,在高分辨率下局部处理局部现象,并在层级的低分辨率部分单独处理全局现象。
这项研究通过从根本上重新设计 UNet,更新了 Latent Diffusion 架构(Stable Diffusion 的基础),使其减少了 CNN 特性,而更具 Transformer 特性。她还使用了一系列 SOTA 推理技巧,效果显著:
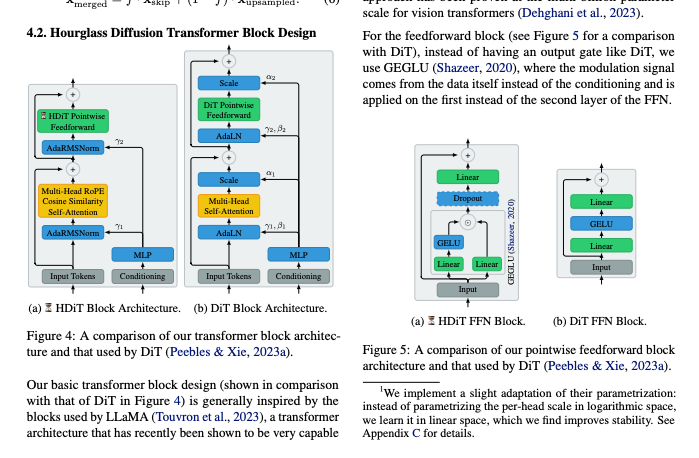
所有这些努力的最终结果是更高的效率——这种具有 O(n) 复杂度的层级 Transformer 架构,使其能够很好地扩展到更高分辨率,例如在没有任何潜空间步骤的情况下,使用参数量小于 600M 的模型(原始 SD 约为 900M)创建百万像素级的图像。
其他新闻方面,来自 Meta 的 Self Rewarding LM 论文引起了足够的关注,lucidrains 已经开始着手实现它。
–
目录
[TOC]
第 1 部分:Discord 高层级摘要
TheBloke Discord 摘要
-
GPT-4 规避量化技巧:尽管尝试了注入噪声等策略,GPT-4 仍能保持输出的一致性。参与者注意到,即使在呈现熟悉的上下文时,它也表现出强大的鲁棒性,这暗示不同模型之间可能使用了类似的训练数据集。
-
开源 GPT-0 替代方案即将出现:包括
@technotech和@turboderp_在内的用户讨论了开发 GPT-0 开源替代方案的想法。为了规避 AI 检测器,他们考虑了对抗性训练等策略。 -
BagelMysteryTour V2 在 ERPv4 中夺冠:BagelMysteryTour V2 以最高的 IQ4 分数登顶 ERPv4 排行榜,显示了其在角色扮演场景中的能力。该分数评估了角色在角色扮演中的一致性和理解力(ERPv4 聊天日志)。
-
低 VRAM 进行 DPO 训练的挑战:在 12GB 显存的显卡上训练 DPO(Direct Preference Optimization)模型可能需要超过可用容量的 VRAM。用户指出,当需要两个模型实例时,仅模型大小的 4 倍显存可能并不足够。建议包括利用 QLoRA 进行微调以节省 VRAM,并考虑使用 rmsprop 等替代优化器来减少训练时的内存占用 DPO Trainer 指南。
-
角色扮演模型寻求平衡:对话围绕微调和合并 AI 模型以实现更细腻的角色扮演互动展开。挑战包括模型过于叙事化或无法保持角色一致性,目前的努力方向是创建具有改进提示控制能力的复杂角色扮演专用合并模型。
OpenAI Discord 总结
AI 感知力:更多是哲学而非现实?:在一段激烈的交锋中,@lugui 和 @.pythagoras 辩论了 AI 感知力的概念,讨论了人类在感知非感知实体的智能行为时存在的偏见。对话触及了未来 AI 超越人类控制的危险,并与 Roko’s Basilisk 思想实验进行了类比,质疑了我们当前的行为对强大 AI 未来行为的影响。
GPT-4:自定义与 Markdown 的细节:用户交流了关于 GPT-4 在特定任务中自定义的见解,例如创建 Markdown 文档以及使用自定义词典进行精准翻译。尽管存在挑战和报告的性能问题,但对 Context 的操作和结构化 Prompting 被认为是提高输出质量的关键。
Prompt Engineering:应对语言与逻辑:针对专业级拉丁语到英语翻译和减少重复语言等细微用例,@novumclassicum、@stealth2077 等人尝试了附加文本文件并迭代优化 Prompt。积累的知识强调了精心编写的指令在引导 GPT-4 达成预期结果方面的强大作用。
API 困惑与 Context 担忧:与 API 相关的讨论揭示了自定义词典翻译、长列表管理以及在扩展 AI 对话中保持连贯性的复杂性。@darthgustav 和 @eskcanta 就克服重复输出和 Context Window 限制提供了关键建议,指向了结构化指令和对 GPT-4 内部机制的理解。
知识与行动管理的实用建议:社区提供了增强处理知识文件的策略,以解决从教育模型到故事讲述等各种应用中 GPT 性能一致性的问题,强调了通过明确指令来获得更好 AI 行为的必要性。
LM Studio Discord 总结
-
LM Studio 缺少 API Keys:工程师澄清 LM Studio 不提供 API Keys;用户必须构建自己的 API Server。宣布了最新的 Beta V7 (0.2.11) 候选版本,并分享了用于测试的 Mac 和 Windows 链接。
-
Preset 和参数敏感性至关重要:强调了为模型使用正确 Preset 的重要性,以避免糟糕的输出或乱码。讨论指出,较小的模型对模板和参数设置尤为敏感,这会极大地影响性能。
-
GPU Offload 之谜与麻烦:讨论使用
5x4090GPU 运行 Mixtral 8x 等模型的用户在 Offloading 过程中发现了潜在的未记录层。关于 GPU 层 Offload 问题的其他讨论建议将n_gpu_layers设置为-1,并提到了指示内存不足的 GPU Offload 错误消息。 -
内部解决方案中安全优先于成本:由于安全考虑而非成本担忧,一家公司倾向于使用本地解决方案替代 OpenAI 的 GPT-4。对话还涉及了外置 GPU 的可行性、支持双 RTX 4090 的主板,以及在 Reddit 帖子 和 Intel Arc Support GitHub issue 中详细描述的兼容性问题。
-
错误报告激增:多个频道的用户报告了各种 LLM 上的 错误 和 模型崩溃。一次重大的崩溃涉及在拥有 192GB RAM 的 Mac 上运行两个 LM Studio Agent 时的内存问题,尽管 Context Window 大小不同,这引发了用于详细分析的私人故障排除环节。
-
识别出本地网络挑战:通过 ‘localhost’ 连接到本地 LM Studio 推理服务器的问题指向了可能的网络配置更改或防火墙规则调整,用户需要求助于直接 IP 地址,例如 192.168.0.42。
Nous Research AI Discord 总结
-
期待用于 AI 的开源 FP4 Kernel:一位用户宣布计划开源一个与 Marlin 和 Cublas 相当的 FP4 Kernel。关于超参数调优的讨论包括可能使用遗传算法 (genetic algorithms) 或分层网格调优器 (hierarchical grid tuners)。
-
从大脑记录中解码语言:一位用户分享的研究表明,可以从 fMRI 记录中解码连续语言,这引发了关于 AI 语言解码影响的讨论。
-
Yi-Vision 语言模型备受关注:一个新的 Yi-VL-34B 语言模型(被描述为双语多模态模型)已在 Hugging Face 和 BigDL-LLM 文档 等平台上引起讨论。
-
讨论 LLM 推理的 GPU 精度:AI 工程师们就推理过程中应使用 FP16 还是 FP32 进行累加发表了意见,共识倾向于使用 FP32,并注意到目前缺乏利用 FP16 进行累加的开源代码。
-
探索 LLM 系统 2 思维 (System 2 Thinking) 与推理挑战:分享了关于系统 2 思维和 GPT-5 的视频讨论 YouTube 视频,同时还有关于在旧硬件上运行大型语言模型以及使用
transformers库管理批量 LLM 推理 (batched LLM inference) 的报告。
Mistral Discord 总结
-
垃圾邮件机器人扰乱 Mistral 社区:以
@mrdragonfox为首的用户报告了显著的垃圾邮件/诈骗问题。@sophiamyang承认了这一问题,并指出自动审核机制效果不佳。 -
Mistral 与数学难题:
@mrdragonfox强调了使用像 Mistral 这样的语言模型 (LLM) 处理确定性数学任务的低效性,并建议集成 Wolfram Alpha 等外部服务进行此类计算。 -
Mistral 微调的困扰与进展:
@sunbeer_探索了将特定领域知识整合到 Mistral 中的微调方法,而其他人在寻求将模型用于专业任务的建议时,@mrdragonfox建议从参数高效微调 (PEFT) 开始,并考虑针对事实特定信息使用检索增强生成 (RAG)。 -
LLM 需要的是无状态记忆,而非过目不忘:针对让 Mistral 忘记聊天记录的查询,
@mrdragonfox澄清说模型本身自然没有记忆,聊天记录的持久性是由于前端传递上下文的方式决定的。 -
处理 Mistral 罕见的流式传输错误:
@jakobdylanc标记了一个 Mistral-medium 特有的流式传输错误,分享的堆栈跟踪信息显示存在连接问题。尽管讨论了应使用的正确 Python 客户端,但问题仍未解决。
Eleuther Discord 总结
-
CoreWeave 在停机后恢复服务:服务停机问题已得到解决,CoreWeave 恢复正常运行;然而,Netlify 在恢复服务方面出现了延迟。尽管如此,API 的功能在整个事件期间保持正常。
-
鼓励主动提交内容提案:建议直接发布内容提案 (content pitches) 而无需等待许可,这种策略在维基百科历史上行之有效,也可能适用于此处。
-
沟通行动理论可能重构 AI 对齐:一种新观点建议应用哈贝马斯的沟通行动理论 (Habermas’ theory of communicative action) 来解决 AI 对齐 (AI alignment) 问题,这需要与社区进行逐步接触并通过文档分享知识。
-
关于自闭症的 ML 论文需要跨学科团队:分享了一个研究论文构想,提议应用基于 LLM 的 RPG 来帮助自闭症患者提高对话技巧。这项工作需要一个跨学科团队,并建立在 arXiv 上先前的研究基础之上。
-
Rust 框架、Tokenization 和模型微调讨论:技术咨询涵盖了 Rust 中的深度学习与 XLA 接口、管理 Pythia410m 模型中的噪声 Token、在语言模型响应生成中使用字节级 BPE 进行 Tokenization,以及针对 Token 分类任务微调 Mistral 7b 模型等主题。
HuggingFace Discord Discord 摘要
-
探索多语言 LLM 能力:
@dhruvbhatnagar.0663询问了 Llama 2 模型如何在词汇表中没有印地语、泰米尔语、古吉拉特语等特定 Token 的情况下生成这些语言的响应。同时,@kxgong在尝试跨 8 个 A100 GPU 加载mixtral-8x7B-v0.1时遇到了 GPU 显存限制,@mr_nilq建议在 Transformers 4.20.0 或更高版本中使用device_map="auto"进行分布式推理,并分享了 多 GPU 训练指南。 -
BERT 在序列任务中的持久性:尽管出现了更新的模型,
@merve3234仍主张 BERT 在序列分类任务中的有效性,并建议使用 用于微调的 Low-Ranking Adaptation (LoRA) 来提高参数效率。 -
适配池化与地牢:
@merve3234分享了关于 自适应平均池化 (adaptive average pooling) 的见解,以帮助模型处理各种输入尺寸和属性,并提供了他们的 讲义笔记 以供进一步参考。此外,尽管没有收到回复,@utxeee仍寻求关于 远程运行 stable-diffusion 的建议,而@djdookie报告了 diffusers 与 auto1111 之间令人困惑的图像质量下降问题。 -
模型与工具创新:
@not_lain发布了一个 用于多模态深度伪造检测的自定义流水线 (pipeline);@ariel2137在 GitHub 上开源了 Cogment Lab;@stroggoz制作了一个经过蒸馏的句子编码器,专门为更快的相似度比较而优化,可在 Hugging Face 上获取。 -
引起关注的多模态模型与工具:令人兴奋的多模态进展包括由
@andysingal介绍的 Yi Visual Language (Yi-VL) 模型,以及令 Yann LeCun 印象深刻的 InstantID 工具,相关资源分别见 Hugging Face 和 InstantID Gradio 演示。
Perplexity AI Discord 摘要
-
Perplexity 的来源让赞誉更具客观性:用户赞赏 Perplexity.ai 的清晰溯源和透明度功能,即使在搜索结果不符合预期时也非常有用。像
@friar_brent这样的学术用户特别称赞了这一功能在学术研究场景中的价值。 -
AI 搜索工具对比:
@manisht等用户将 Perplexity.ai 与 You.com 进行了对比,认为其用户界面友好且能提供带有来源的答案。讨论强调了搜索工具中透明度和来源链接对于明智决策和研究验证的重要性。 -
关于使用 LLM 学习的博客见解:
@charlenewho分享了一篇名为《使用 LLM 学习速度提升 3 倍》的博客文章,概述了利用 Perplexity.ai 和 GPT-4 快速学习软件相关技能的策略。策略包括构建高效的心智模型和侧面项目评估,详见 Tidepool。 -
API 扩展热情:
@thereverendcognomen等用户询问了如何将 Perplexity API 与 OpenAI 配置集成,并指出了 PromptFoo 上的现有文档。他们还请求增加额外的 API 端点以增强功能,反映出对扩展 Perplexity 工具包的浓厚兴趣。 -
支持历程与积分查询:
@tpsk12345反馈了 Perplexity 应用积分系统的问题,随后记录了@icelavaman的排查努力以及@ok.alex通过 工单 提供的支持。@icelavaman还澄清了所有计划均可使用积分,解决了@cosine30等用户的疑虑。
LAION Discord 摘要
-
AI 应用中的 VRAM 辩论:关于消费级 GPU VRAM 限制的讨论中,
@SegmentationFault对超过 24GB VRAM 的必要性表示怀疑,而@qwerty_qwer则强调了 Prompt Refiners 带来的挑战。 -
欧盟 AI Act 进展:
@vrus0188分享了一个链接,内容关于欧盟就 AI Act 达成临时协议,强调了其根据风险对 AI 系统进行分类的准则以及新的透明度要求。 -
游戏开发与 AI 审查争议:
@.undeleted对游戏开发活动中可能存在的、针对批评 AI 技术言论的审查表示担忧,并引用了一位知名游戏资产制作人的相关事件。 -
AI 数据集的伦理担忧:关于包含未经授权艺术作品或暴力内容的数据集的伦理讨论升级,
@thejonasbrothers强调了这一问题,并引用了一篇关于该主题的 Vice 文章。 -
Depth Anything 引入新功能:由
@mkaic分享的新型 Depth Anything 基础模型,拥有卓越的单目深度估计(Monocular Depth Estimation)能力。该模型在超过 6200 万张未标记图像上进行训练,性能超越了 MiDaS v3.1 和 ZoeDepth 等模型。其市场宣传通过视频演示幽默地展示了其领先地位。 -
在不损失精度的情况下加速推理:
@vrus0188讨论了蚂蚁集团的 Lookahead 框架,指出该框架可将 LLM 的推理速度提高 2-5 倍。详细信息可见其研究论文和 GitHub 仓库。
Latent Space Discord 摘要
-
AI 活动在米兰兴起:
@alexio.c宣布将于 5/6 月在米兰组织一场 AI Engineer 活动,这标志着该活动可能演变为 AI Engineer Summit 的意大利分会。@swyxio等人表示愿意在品牌推广和宣传方面提供支持。 -
寻找最佳数据标注工具:频道中推荐将 Roboflow 作为视觉数据标注的首选工具,同时参考了对 Voxel51 和 Nomic 等初创公司的采访以获取更多见解,显示出社区对优化这一关键任务工具的浓厚兴趣。
-
AI 新闻摘要评论:针对来自 AI News 的 Discord 每日摘要 提出了反馈,特别要求改进其导航和可读性,反映了社区对简洁高效信息传递的需求。
-
Nightshade 作为 AI 解药出现:研究项目 Nightshade 受到关注,该项目旨在通过数据投毒(Data Poisoning)来对抗生成式 AI 的负面影响,展示了社区对前沿 AI 防御机制的参与。
-
通过云端 GPU 和逆向工程学习 AI:出现了使用 Modal 和 Replicate 进行 AI 模型 Finetuning 和部署的建议,同时分享了一个视频教程和一个关于 AI 领域逆向工程(Reverse Engineering)的资源页面,体现了社区对知识共享和动手实践的承诺。
DiscoResearch Discord 总结
-
数值评估的批判性分析:强调了一篇讨论数值评估优于分类评估缺点的 tweet,并引用了 Prometheus paper。此外,一篇关于累加评分提示词的新论文表明,其表现可能优于 Prometheus 设置中的绝对评分,预训练代码片段 证明了这一点。
-
Prompt 精确度至关重要:正确的 Prompt 模板和格式对于输出一致性至关重要,本地模型与 Demo 结果之间出现的问题证明了这一点。关于 DiscoLM German 7b 的正确模板使用,建议用户参考 Hugging Face chat templating guide。
-
偏好技术探讨:一篇博客文章比较了 RLHF 中的偏好优化技术,包括 DPO、IPO 和 KTO。讨论了简单二元奖励信号的潜力、DeepL translation quality 的见解,以及即将推出的支持多语言、复杂数据处理的 Llama-3 model。还引用了 In-Context Pretraining 论文中关于上下文分块的方法。
-
模型推理方法至关重要:澄清了 Jina 模型最好使用 mean pooling 进行推理,而不是 CLS token embeddings。GTE 和 BGE 模型在 MTEB 排名上也表现优异,尤其是 GTE 在编码任务上。尽管缺乏 GTE 的预训练代码,且 BGE 仅提供了一个玩具示例,但讨论了尺寸和参数差异,并以 MTEB 分数作为能力指导。
-
DiscoLM German 的演进:DiscoLM German 7b 确认基于 Mistral,基于 Mixtral 的版本正在开发中。目前的重点是优化数据集和 7b 模型。该模型的实用性体现在帮助学生翻译中古高地德语并提供中世纪知识的计划中,尽管在语言翻译任务中的基准测试表现参差不齐。
LangChain AI Discord 总结
JavaScript 更轻松地调用 LangServe:强调了一种从 JavaScript 前端调用 LangServe 链的新方法,旨在简化 LangServe 与 JS 应用程序的集成。此更新由 @jacoblee93 在一条 Tweet 中分享,可能会简化前端与 AI 的交互。
开源 RAG 模型提升多语言技术:@maidalun 在 Hugging Face 上发布的全新 EmbeddingModel 和 RerankerModel 增强了 RAG 的能力,支持多种语言和特定领域适配。这些模型在 general 和 share-your-work 频道中分享,可以在 Hugging Face 上找到,并在 GitHub repo 中查看。
Write-Ahead Log 引发关注:在 #langserve 频道中,@veryboldbagel 发起了关于 write-ahead log 引入的复杂性的对话,质疑其对反馈变异(feedback mutation)的影响。
Langchain 开启圣经解读:用户合作开发了一个圣经学习应用程序,@ilguappo 分享了他的向量数据库项目,该项目提示 AI 提供类似牧师的回答;他的工作已发布在 GitHub 上。
AI 眼中的艺术:在 AI 与艺术的融合中,@dwb7737 使用 LangChain 配合各种视觉模型来分析艺术作品,并分享了 OpenAI Vision 和 VertexAI Vision 的结果,指出 OpenAI Vision 表现最佳。其研究摘要可通过 VertexAI Vision Gist 和 OpenAI Vision Gist 获取。
教程启发自定义工具创建与系统理论:用户提供了技能提升资源,例如 @business24.ai 关于使用 crewAI 在 Obsidian 中存储笔记的视频教程(见 此 YouTube 链接),以及 @jasonzhou1993 探索 LLM 中的 System 2 思维及其在 GPT-5 中未来的视频(见 此处 YouTube)。
OpenAccess AI Collective (axolotl) Discord 总结
-
提示词工程指南提升 Open LLM 使用效率:分享了一份针对 Open LLM(30 亿至 700 亿参数)的 Prompt Engineering 指南,强调了其与闭源模型的区别,这对使用此类 AI 工具进行开发的开发者具有重要参考价值。
-
GPU 领域的新兴技术:关于 A30 GPU 在 LLM 训练中的效能疑问,以及有关 H100 GPU 可用性和技术问题的报告,突显了在 AI 项目中选择和利用合适硬件的持续讨论。
-
Axolotl 的功能新增与修复:
#axolotl-dev频道的讨论包括在sharegpt.py中增加新的加载器函数以提高数据集灵活性,commit 中提到的 Latitude SSH 密钥支持,以及axolotl-cloud上 SSH 的故障排除。此外,还强调了使用nanotron实现 LLM 训练中的 3D-parallelism,为高效模型训练提供了又一工具。 -
深入探讨 LoRA 和 DPO:一位用户表示有兴趣了解训练后更改 LoRA 中 alpha 值的影响;同时,有关于尽管遵循了结构指南但在
DPO中仍出现ValueError的查询,表明这些技术增强功能需要进一步的故障排除。 -
提示策略的清晰化:对两个 AlpacaPrompter 类(
MultipleChoiceExplainPrompter和MultipleChoiceConcisePrompter)的界定,提供了对不同 Prompt 策略的见解,这可能会影响向 LLM 呈现数据的方式以获得更好的输出。
LlamaIndex Discord Discord 总结
-
引入用于数据处理的 JSONalyze:LlamaIndex 的新工具 JSONalyze 允许工程师使用内存中的 SQLite 表对大型 JSON 数据集运行 SQL 查询,从而简化对复杂 API 响应的分析。
-
详述 ReAct Agent 构建工艺:提供了一份从零开始 构建 ReAct Agent 的指南,重点关注推理 Prompt 和输出解析等方面,丰富了构建定制化 Agent 的基础知识。
-
Prompt 深度探讨与工具卓越性:Discord 社区通过分享的 Medium 文章 深入探讨了 Prompt Engineering 的复杂性,同时讨论了正确选择工具的重要性以及 LlamaCPP 中各种 Prompt 相关参数之间的区别。
-
用于增强 RAG 的开源模型:在 Hugging Face 上分享的 EmbeddingModel 和 RerankerModel(链接)表明社区正趋向于开源解决方案,这些方案提供多语言支持,并针对各个领域的检索增强生成(RAG)进行了优化。
-
RAG 检索集成与云端设置难题:使用 SQLJoinQueryEngine(链接)解决了 NL2sql 与向量搜索的结合问题;而关于在云端部署 Bedrock 上下文的讨论则指出了 AWS 凭证管理和环境变量配置方面的障碍。
Skunkworks AI Discord 摘要
-
Token Monster 在 LLaMa 上取得突破:
@indietechie发起了关于 Token Monster 的讨论,指出其为 Mistral/LLaMa 模型训练 tokenizer 的能力;@stereoplegic进一步阐述了 Token Monster 使用 LLaMa 词表(vocabulary)的优势,以及它替换 Hugging Face tokenizer 的能力。 -
Lucid Rains 开源 Self-Rewarding Language Model 工具箱:由 Lucid Rains 开发、受 Meta AI 研究启发的 Self-Rewarding Language Model 框架受到了
.interstellarninja和@teknium的关注。该项目已在 GitHub 上线,社区提到了开发者的快速响应,并分享了 Hugging Face 上相关的 Meta 论文链接。 -
通过 Numcode 促进高效的模型理解:
@stereoplegic主导了一场关于 “numcode” token 提升模型数学理解潜力的对话,建议将现有词表映射到该系统,并观察单数字 token 对文本泛化(textual generalization)的影响。 -
低算力、高目标的训练方法:基于 Adapter 和 LoRA 的训练策略引起了关注,
@yikesawjeez和@.mrfoo讨论了它们在低算力环境下的适用性,认为这对于计算资源有限的开发者来说是一种可行的技术。
LLM Perf Enthusiasts AI Discord 摘要
- 对紧凑型 Embedding 的关注:一位用户询问了 8-bit 量化 Embedding 模型 及其与标准模型相比的性能表现,但尚未收到社区反馈。
- AI 实验的游乐场:社区支持创建一个专门的分享频道,用于发布和讨论 AI 实验,多位用户对此表现出浓厚兴趣。
Alignment Lab AI Discord 摘要
没有相关的技术讨论摘要。
YAIG (a16z Infra) Discord 摘要
- 通过合同规避繁文缛节:在关于监管挑战的讨论中,
@unquiet9796暗示大型组织倾向于在合同中加入降低监管成本的条款,这可能是缓解监管压力的一种战术手段。
Datasette - LLM (@SimonW) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:按频道划分的详细摘要和链接
TheBloke ▷ #general (1250 条消息🔥🔥🔥):
- GPT-4 持续规避量化策略:尽管尝试在其内层进行噪声注入(noise injection),
@turboderp_发现 GPT-4 对此类措施仍保持鲁棒性。他们指出,由于在相似的数据集上进行训练,GPT-4 对于熟悉的上下文始终会产生类似的输出。 - 对 TheBloke 活跃度的关注:用户
@orabazes和@kai5287都注意到 TheBloke 最近没有参与活动,并对可能的中断原因进行了推测。 - 寻求规避 GPT-0 的方法:
@kaltcit讨论了避免被 GPT-0 检测的各种策略,例如噪声注入和针对特定数据集的 Finetuning。然而,当 AI 模型变得更有帮助且信息更丰富时,它们反而更容易被 GPT-0 检测到。 - 寻找 GPT-0 的开源替代方案:包括
@technotech和@turboderp_在内的用户考虑创建 GPT-0 的开源替代品,以及采用对抗性训练(adversarial training)等方法来绕过 AI 文本检测器。 - 分享键盘和鼠标偏好:社区成员(包括
@itsme9316、@dirtytigerx、@mrdragonfox等)分享了他们对电脑外设的偏好,讨论了各种机械键盘轴体和鼠标。
提到的链接:
- Home:未找到描述
- Llm Visualizer - a Hugging Face Space by mike-ravkine:未找到描述
- Ever wonder why Brits sound so smart? The distinctive uses of ‘right’ in British and American English:英国人通常比美国人更聪明、博学吗?根据罗格斯大学研究人员的一项研究,美国人显然是这么认为的。
-
[Anaconda A Faster Solver for Conda: Libmamba](https://www.anaconda.com/blog/a-faster-conda-for-a-growing-community):conda 22.11 更新:libmamba 解析器的实验性标记已移除。要使用新解析器,请在 base 环境中更新 conda: conda update -n base conda。要安装并设置新解析器… - turboderp/Orion-14B-exl2 · Hugging Face:未找到描述
-
[Neurosity SDK Neurosity SDK](https://docs.neurosity.co/docs/overview):Neurosity 软件处理并管理由 Neurosity 头戴设备产生的数据,该设备用于测量、追踪和监测 EEG 脑电波。 - 01-ai/Yi-VL-34B · Hugging Face:未找到描述
- mlabonne/NeuralBeagle14-7B · Hugging Face:未找到描述
- Cat Cats GIF - Cat Cats Catsoftheinternet - Discover & Share GIFs:点击查看 GIF
- The Office Pam Beesly GIF - The Office Pam Beesly Theyre The Same Picture - Discover & Share GIFs:点击查看 GIF
- Benford's law - Wikipedia:未找到描述
- Built-to-order Dactyl/Manuform Keyboard:定制 Dactyl Manuform 键盘。选择你的轴体、外壳颜色和款式。预计到达时间 12-14 周。
- 大模型备案 · Issue #306 · 01-ai/Yi:您好,请问 Yi 是否通过了大模型备案。
- Release 0.0.12 · turboderp/exllamav2:未找到描述
- GitHub - QwenLM/Qwen: The official repo of Qwen (通义千问) chat & pretrained large language model proposed by Alibaba Cloud.:阿里巴巴云提出的 Qwen(通义千问)聊天及预训练大语言模型的官方仓库。- GitHub - QwenLM/Qwen: The official repo of Qwen (通义千问) chat & pretrained large lang…
TheBloke ▷ #characters-roleplay-stories (541 条消息🔥🔥🔥):
-
BagelMysteryTour V2 登顶 ERPv4 排行榜:
@weirdconstructor分享了 BagelMIsteryTour V2 在 ERPv4 排行榜上获得了最高的 IQ4 分数,表明它是角色扮演场景中的强力模型。IQ4 分数评估模型在角色扮演风格中的角色理解和连贯性,数值越接近 100 表示性能越好 (Ayumi Benchmark ERPv4 Chat Logs)。 -
难以约束的 “Bad Sarah”:
@righthandofdoom在误解了部分测试并将其归因于过度行为(吃苹果暗示“坏 Sarah”)后,对 The Sarah Test(一种角色扮演角色一致性测试)提出了疑问。@stoop poops建议咨询像 Mixtral 这样的模型以获取见解 (The Sarah Test 详情)。 -
SOLAR 倾向于叙事:用户
@theyallchoppable和@ks_c讨论了 SOLAR 模型(如 Solar Instruct Uncensored)如何倾向于过度叙述场景而不是进行对话,@weirdconstructor推测这可能源于模型从带有 “... " 模式的类 XML 数据中学习。 -
寻求 AI 角色扮演的平衡:
@ks_c和@kquant讨论了如何在过于温和或过于露骨的 RP 模型之间寻找平衡。他们探讨了使用更复杂的模型进行角色扮演的前景,提到了在合并 NeuralBeagle 时出现的 GGUF 错误,并尝试将故事讲述模型用于角色扮演场景。 -
对 RP 的 Fine-Tuning 和特定合并模型的兴趣:用户之间的对话,特别是
@ks_c和@kquant,集中在针对角色扮演进行 Fine-Tuning 和创建特定的模型合并(Merges),这些模型可以执行更复杂的功能,并在遵循 Prompt 时保持更好的控制。
提到的链接:
- Emma - Roleplay.love:未找到描述
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。聊天、聚会,并与您的朋友和社区保持联系。
- Kquant03/Buttercup-4x7B-GGUF · Hugging Face:未找到描述
- Kquant03/Buttercup-4x7B-bf16 · Hugging Face:未找到描述
- Kquant03/Prokaryote-8x7B-bf16 · Hugging Face:未找到描述
- Kquant03/FrankenDPO-4x7B-GGUF · Hugging Face:未找到描述
- Steelskull/Umbra-MoE-4x10.7 · Hugging Face:未找到描述
- Kquant03/EarthRender-32x7B-bf16 · Hugging Face:未找到描述
- Bravo Applause GIF - Bravo Applause Round - Discover & Share GIFs:点击查看 GIF
- Reddit - 深入了解一切:未找到描述
- Ayumi Benchmark ERPv4 Chat Logs:未找到描述
- s3nh/Kunoichi-DPO-v2-7B-GGUF · Hugging Face:未找到描述
- brittlewis12/Kunoichi-DPO-v2-7B-GGUF · Hugging Face:未找到描述
- PocketDoc/Dans-AdventurousWinds-Mk2-7b · Hugging Face:未找到描述
- NeuralNovel/Valor-7B-v0.1 · Hugging Face:未找到描述
- senseable/WestLake-7B-v2 · Hugging Face:未找到描述
- Model Size Calculator:计算模型类型,Mistral 7B Context, 8192。要使用此工具,请在模型类型下拉菜单中选择您尝试运行的基础模型类型,然后选择您想要运行模型的上下文大小…
- The Sarah Test:(由 Ooba 和 SillyTavern Discord 服务器上的 #theyallchoppable 提供)另请参阅:https://rentry.org/thecelltest。The Sarah Test 是一个简单的 Prompt,用于测试模型的一致性、逻辑连贯性等…
TheBloke ▷ #training-and-fine-tuning (13 messages🔥):
-
7b 模型进行 DPO 训练的 VRAM 需求:
@superking__询问了在 12GB 显存卡上使用 DPO 训练 7b 模型的 VRAM 占用情况。@motmono建议使用 Hugging Face Model Memory Calculator 进行估算,并指出训练通常需要 4 倍于模型大小的 VRAM,且对于 DPO 而言,可能需要两个模型实例,这可能会超过 12GB 的限制。 -
DPO 的替代优化器:当
@superking__提到 DPO 的 VRAM 占用时,@jondurbin建议在 DPO 中使用 rmsprop 优化器 代替 adam*,以尽可能节省内存开销。 -
使用 Hugging Face DPO Trainer:
@jondurbin分享了一份来自 Hugging Face 关于使用 DPO Trainer 训练语言模型的详细指南,强调了训练 SFT 模型的第一步以及 DPO 所需的特定数据集格式。 -
结合 QLoRA 实现高效的 DPO VRAM 利用:针对
@superking__关于减少 DPO VRAM 占用的提问,@jondurbin解释了一种使用 QLoRA 进行微调的方法,该方法仅加载单个模型实例以节省 VRAM。 -
在 12GB VRAM 上训练大模型的困难:由于
@lordofthegoons在 12GB 显存卡上训练 2.7B 模型时遇到困难,@sanjiwatsuki指出,如果没有充足的 VRAM 或使用 StableLM 的模型,训练 3B 左右大小的模型通常是不可行的,并建议尝试 1024 的较窄 context window 可能会奏效。
提及的链接:
DPO Trainer:未找到描述
,
OpenAI ▷ #ai-discussions (154 messages🔥🔥):
-
AI 意识与人类偏见的脆弱性:
@lugui和@.pythagoras就 AI 是否具有智能或意识展开了深入讨论。@lugui指出人类倾向于将智能行为归因于无意识实体,将 AI 比作复杂的自动纠错功能;而@.pythagoras则思考了未来 AI 超越人类理解和控制的可能性。 -
AI 回复中指令偏见的微妙之处:在关于 prompt 如何影响 AI 的讨论中,
@lugui注意到,指示 AI 重复某个短语会导致输出结果偏向这些特定的 token,从而影响回复的多样性。 -
罗科的蛇怪(Roko’s Basilisk)思想实验:
@lugui提到的 罗科的蛇怪 引发了关于 AI 未来潜在力量以及人类今天对 AI 的行为可能如何影响其未来行为的对话。 -
辩论有意识 AI 的不可预测性:
@eskcanta通过将人类行为的不可预测性与潜在有意识 AI 的不可预测性进行比较,并质疑关于 AI 未来行为的假设,为关于有意识 AI 的对话增添了内容。 -
教育领域的 AI 与访问管理咨询:
@keatondoesai发起对话,寻求管理自定义教育 GPT 模型唯一用户访问权限的技巧,旨在通过不可转让的访问链接确保隐私和个性化的学习体验。
提及的链接:
Roko's basilisk - Wikipedia:未找到描述
OpenAI ▷ #gpt-4-discussions (47 条消息🔥):
-
.nightness. 开发的 Markdown 友好型 GPT:
.nightness.开发了一个 GPT 变体,可以有效地输出 Markdown 文档,并提供现成文档的下载链接。用户@darthgustav.表示感兴趣,而@madame_architect质疑其必要性,因为 ChatGPT 输出的复制粘贴通常本身就是 Markdown 格式。 -
用于学习和上下文使用的自定义 GPT: 用户讨论了自定义 GPT 的功能,
@solbus从 Instructions(指令)、Knowledge(知识)和 Actions(操作) 方面解释了它们的用途。@wubwubzoidberg寻求关于自定义 GPT 在针对性学习(如法国大革命)方面的优势的澄清,其他人则讨论了其在故事创作方面的潜力。 -
文档理解和上下文记忆问题:
@stealth2077询问了 AI 阅读整个文本文件并在整个对话中一致引用它们的能力,而@solbus则对 Knowledge 文件的上下文限制进行了预期管理。用户讨论了 Knowledge 文件中读/写能力的优势和挑战。 -
自定义 GPT 性能问题:
@surrealsikness、@fyruz和@cairpli等成员报告了他们的 GPT 性能问题,从错误到记忆缺失以及幻觉响应。@darthgustav.建议对不准确的回答点击“踩”(thumb down)可能有助于随时间改进模型。 -
自定义 GPT Actions 的故障:
@bellpep遇到了自定义 GPT 无法按预期执行 Action 的问题,出现了空白响应而非正确的 Action 结果。这些困难在 GPT 编辑器中持续存在,但在常规聊天会话中没有出现。
OpenAI ▷ #prompt-engineering (141 条消息🔥🔥):
-
GPT 翻译工具箱:在语言转换中打造精准度:
@novumclassicum深入探讨了让 GPT 执行特定语言翻译任务的挑战,例如使用定制词典进行拉丁语到英语的翻译。经过多次迭代和社区集思广益(特别是与@darthgustav.的交流),他们通过附加纯文本文件来引导翻译取得了成功,强调了这种方法对于专业级语言输出的效率。 -
减少重复的难题:
@stealth2077在创意写作应用中努力消除 AI 重复使用词汇的问题。通过反复试验以及@darthgustav.的建议,发现一种涉及结构化方法并在 Prompt 中明确避免冗余的技术可能是有效的。 -
理解 GPT-4 的阅读机制:
@magiciansinc询问了确保 GPT-4 在给出答案前检查整个列表的策略,并指出 AI 倾向于从列表顶部获取项目。@darthgustav.对模型的基于片段(snippet-based)的阅读过程以及文档大小、Context Window 限制和正确的指令措辞等变量贡献了深入见解,以改善结果。 -
追求一致的输出: 为了追求持续高质量的学术翻译,
@novumclassicum与社区讨论了 Prompt Engineering 的复杂性,并对方法进行了长达一年的迭代。在@darthgustav.的指导下,他们发现通过采用明确、逻辑化的指令路径,可以优化模型的“随机方程”(stochastic equation)以获得更好的结果。 -
聊天记录挑战:从对话中提取更多信息:
@ArianJ寻求增强从用户与 OpenAI 聊天机器人的职业相关话题聊天记录中得出的答案。他们遇到了模型在提供的上下文中找不到答案的问题,从而引发了关于如何构建 Prompt 以更有效地提取信息的讨论。
OpenAI ▷ #api-discussions (141 条消息🔥🔥):
-
自定义词典翻译的挑战:
@novumclassicum讨论了让 GPT 模型在翻译时参考自定义词典的困难,并寻求提高一致性和准确性的建议。@darthgustav和@eskcanta提供了关于结构化指令和利用 AI 使用 Python 工具的方案,建议采用一种结合算法辅助和词典查询的更全面的翻译流程方法。 -
优化 GPT 输出以消除重复:
@stealth2077困扰于 GPT 模型重复使用某些词汇的问题,并寻求防止这种行为的帮助。@darthgustav建议采用更结构化且明确的指令集来引导模型。 -
阅读长列表与 ‘Snippet’ 机制见解:
@magiciansinc询问了关于如何提示 GPT-4 考虑完整项目列表,而不是优先处理顶部项目的策略。@darthgustav就 GPT-4 内部可能存在的 ‘snippet reader’ 功能提供了深入见解,该功能分段处理数据,这可能解释了观察到的行为。 -
关于 API 和 Turbo 行为的问题:用户
@dave0x6d和@magiciansinc提出了关于 API 响应以及 GPT-4 Turbo 在处理长文档时行为的问题。@darthgustav.提供了详细解释,涉及 tokenization、context window 限制以及 AI 摄取文档的挑战等概念。 -
确保 AI 理解扩展对话:
@ArianJ询问了如何基于过去的聊天记录,通过额外的用户查询有效地继续对话。目前尝试的方法被发现效果不足,这暗示了在模型当前行为中维护 context 或引用先前对话的复杂性。
LM Studio ▷ #💬-general (235 条消息🔥🔥):
- LLM 入门:
@snapflipper询问了如何为 LM Studio 中的本地模型获取类似于 OpenAI 的 API key。@fabguy澄清说 LM Studio 不提供 API key,用户需要在其基础上构建自己的 API 服务器。 - 揭秘 GPU Offload:
@scampbell70遇到了 GPU 层卸载(GPU layer offload)设置的问题,并收到了来自社区成员如@fabguy和@heyitsyorkie的建议,提议了包括将n_gpu_layers设置为-1在内的各种解决方案。 - 探索本地模型能力:
@ldeus发起了一场关于使用5x4090GPU 运行未量化 Mixtral 8x 模型的讨论,@heyitsyorkie和@fabguy针对实际挑战以及通过实验发现模型能力的必要性提供了见解。 - 寻找 AI 工作的理想配置:
@eshack94.寻求关于运行大语言模型时 Mac Studio 与 Windows PC 配置优劣的建议。@heyitsyorkie贡献了见解,指出虽然 PC 速度更快,但 Mac 为 GGUF 提供了简洁性和足够的动力。 - 技术故障与社区支持:包括
@d0mper和@josemanu72在内的几位用户在 Linux 系统上运行 LM Studio 时遇到了错误。@Aqualiteking和@heyitsyorkie等社区成员提供了故障排除建议,并建议检查缺失的软件包,同时分享了安装链接。
提到的链接:
- Kevin Office GIF - Kevin Office Thank - 发现并分享 GIF:点击查看 GIF
- Leonardo Dicaprio Cheers GIF - Leonardo Dicaprio Cheers The Great Gatsby - 发现并分享 GIF:点击查看 GIF
- CLBlast/doc/installation.md at master · CNugteren/CLBlast:调优后的 OpenCL BLAS。通过在 GitHub 上创建账号为 CNugteren/CLBlast 做出贡献。
- GitHub - invoke-ai/InvokeAI: InvokeAI 是 Stable Diffusion 模型的领先创意引擎,赋能专业人士、艺术家和爱好者使用最新的 AI 驱动技术生成和创建视觉媒体。该解决方案提供行业领先的 WebUI,支持通过 CLI 使用终端,并作为多个商业产品的基础。:InvokeAI 是 Stable Diffusion 模型的领先创意引擎…
- GitHub - lllyasviel/Fooocus: 专注于提示词和生成:专注于提示词和生成。通过在 GitHub 上创建账号为 lllyasviel/Fooocus 做出贡献。
- GitHub - john-rocky/CoreML-Models: 转换后的 CoreML 模型库。:转换后的 CoreML 模型库。通过在 GitHub 上创建账号为 john-rocky/CoreML-Models 做出贡献。
- Core ML Tools — Core ML 工具指南:未找到描述
- 使用 LM Studio 为你的 LLM 创建 100% 本地的 API 端点:在此视频中,我将分享使用 LM Studio 程序创建你自己的本地端点(与 OpenAI 的 ChatGPT API 兼容)的说明…
LM Studio ▷ #🤖-models-discussion-chat (11 条消息🔥):
-
关于预设的新手问题:
@.ursium询问了模型的“默认预设(default preset)”及其工作原理,对没有详细 Model Card 的模型以及是否可以应用任何预设表示不确定。@fabguy澄清说,对模型使用错误的预设会导致输出质量差或乱码,并建议参考 Model Card 将预设与模型匹配,同时提到了 TheBloke 提供的有用文档。 -
对 Prompting 灵活性的批评:
@.ben.com对当前 Prompting 的现状表示难以置信,认为这会导致用户困惑,并表示他们打算设计一个测试,以评估模型是否能根据回答质量自动检测 Prompt 格式。 -
预设与模型兼容性挑战:
@vbwyrde在尝试将 Magicoder-DS 6.7B 加载到 LM Studio 时遇到问题并发布了错误日志,强调了在识别正确预设和模型兼容性方面的困难。 -
模型选择中安全考量胜过成本:在
@vbwyrde发起的一场讨论中,他们传达了公司对内部本地解决方案的偏好,而非使用 OpenAI 的 GPT-4,原因是出于安全考虑,尽管他们承认 GPT-4 在现有选项中具有优越性。 -
小型模型对设置的敏感性:
@drawless111补充道,小型模型对模板和参数设置特别敏感,并举例说明较低容量的模型会根据 “temp”(温度)和 “rep penalty”(重复惩罚)等设置表现出显著的性能波动。
LM Studio ▷ #🧠-feedback (8 条消息🔥):
- 普遍的模型故障:用户
@msz_mgs发布了一个 model error(退出代码:0)并详细列出了系统规格,但除了 Mistral instruct 和 dolphin Mistral 之外没有指明具体模型。在@yagilb询问后,他们确认应用版本为 0.2.11。 - 初次使用者遇到模型错误:
@prostochelovek777也报告了一个 model error(退出代码:1),包括拥有 8.00 GB RAM 等系统详情。他们寻求帮助,并表示这是第一次遇到该问题。 - 错误报告的频道指引:
@heyitsyorkie指导@prostochelovek777移步至相应的帮助频道,并使用👍确认了该指引。
LM Studio ▷ #🎛-hardware-discussion (24 条消息🔥):
- 强力 GPU 的用户体验:
@harryb_88771报告在配备 96GB 内存的 M2 Mac 上使用 neuralbeagle14 7B Q8 达到了 18 t/s,而@heyitsyorkie提到单块 RTX 4090 24GB 可以运行一个 33B 模型,例如 deepseek-coder-instruct-33B。 - 主板兼容性咨询:
@yoann_b为支持双 RTX 4090 的配置寻求主板建议,@heyitsyorkie为其提供了一个有用的 Reddit 线程,位于 buildapc subreddit。 - 探索外接 GPU 的可行性:
@vbwyrde发起了关于使用外接 GPU(eGPU)来突破显存限制的讨论,但在当前的对话中尚未分享结论性的经验。 - VRAM 容量读取导致困惑:
@mathematicalvictor和@cloakedman都遇到了 VRAM 容量预估显示为 0 字节的问题,这表明预估显示可能存在一个普遍的 Bug 或错误。 - 分享 Intel Arc 支持信息:
@vin.k.k分享了一个关于为 Intel GPU 集成统一 SYCL 后端的 GitHub Issue 链接,详见此处,这可能会引起关注或贡献 LLM 硬件相关开发讨论的人员的兴趣。
提到的链接:
- Reddit - Dive into anything:未找到描述
- Reddit - Dive into anything:未找到描述
- Feature: Integrate with unified SYCL backend for Intel GPUs by abhilash1910 · Pull Request #2690 · ggerganov/llama.cpp:动机:感谢创建 llama.cpp。目前在为 AVX 指令集集成 OpenCL 运行时方面已经做了很多工作。然而,为了在 Intel 显卡上运行,需要添加…
LM Studio ▷ #🧪-beta-releases-chat (48 messages🔥):
-
发布新 Beta V7 候选版本:
@yagilb推出了 Beta V7 作为 LM Studio 的 0.2.11 候选发布版本(release candidate),并敦促社区协助测试以确保稳定性。提供了 Mac 和 Windows 的下载链接,并请求在指定的 Discord 频道中提供反馈或 Bug 报告。 -
层卸载问题引发新发现:
@kadeshar提出了一个潜在问题,他们在将一个 48 层的模型的层卸载(layer offload)设置为 49 时获得了性能提升,这引发了讨论,结论是模型中可能存在一个未计入的层。 -
寻找自由职业者的项目公告被关闭:
@gciri001寻求自由职业者来协助在本地部署带有 MySQL 的 LLAMA 2 模型,但被@heyitsyorkie提醒该 Discord 频道不允许进行自我推广或招聘广告。 -
NeuralBeagle14-7B 受到关注:用户
@eligump、@dean.com、@n8programs和_anarche_讨论了使用 NeuralBeagle14-7B 的体验,注意到其速度、创意写作能力和整体性能,不过_anarche_提到它的推理(reasoning)能力不是很好。 -
LM Studio 的 AUR 软件包更新中:用户
@aboxofwonders回应了_constructor关于 Arch User Repository (AUR) 软件包过时的评论,表示正在更新中,并建议将来将软件包标记为过时(out-of-date),以便能立即收到通知。
提到的链接:
- jan-hq/Solar-10.7B-SLERP · Hugging Face:未找到描述
- LangChain:LangChain 灵活的抽象和广泛的工具包使开发人员能够构建具有上下文感知和推理能力的 LLM 应用程序。
- 无标题:未找到描述
LM Studio ▷ #autogen (2 messages):
- Win11 中的 Localhost 连接故障:
@driona_reticent在 Pycharm 中使用 Python 脚本连接本地 LM Studio 推理服务器时遇到问题。之前使用 ‘localhost’ 运行正常,但现在需要实际的 IP 地址,即使更改为 192.168.0.42 问题依然存在。 - Telnet 信号显示潜在的网络变化:尽管将 Python 脚本设置为 ‘localhost’ 连接,
@driona_reticent只能通过其网络 IP 使用 telnet 开启连接,这暗示网络配置或防火墙规则可能发生了变化,影响了连接。
LM Studio ▷ #crew-ai (21 messages🔥):
- 配置本地 API 环境变量:
@discgolfvanlife建议为本地 API 设置环境变量,提议将OPENAI_API_KEY设置为 “not-needed”,并将OPENAI_API_BASE设置为本地服务器地址。 - 多 LLM 的自定义方法:
@_anarche_描述了一种使用多个语言模型的替代配置,通过指定自定义端口并在构建 Agent 时将命名的llm传递给 crewai。 - LM Studio 内存崩溃之谜:
@motocycle报告了在拥有 192GB RAM 的 Mac 上使用 LM Studio 运行两个 Agent 时,由于内存问题导致服务器崩溃(退出代码 6),并确认该问题在各种上下文窗口(context window)大小下依然存在。 - 寻求精确的配置细节:
@yagilb要求导出准确的 JSON 配置以诊断内存崩溃问题,并建议将调低上下文窗口作为初步的排障步骤。 - 启动私密排障会话:在关于服务器崩溃的简短公开交流后,
@yagilb引导@motocycle进入私密频道进行详细讨论,以避免当前频道充斥错误日志。
LM Studio ▷ #open-interpreter (5 messages):
- Mixtral 在代码生成方面表现挣扎:用户
@pefortin讨论了 Mixtral 的问题,提到它难以判断何时该生成代码/系统命令。他们认为可能需要进一步调整 prompt。 - 报告 GPU Offload 错误:
@sandy_28242在尝试使用 GPU offload 时遇到错误,提示信息暗示可能存在内存问题。报告的错误包含一个 退出代码和建议,由于内存不足,建议尝试不同的模型或配置。 - 将错误讨论移至他处:
@dagbs幽默地指出@sandy_28242的技术问题发错了频道。他们建议到频道#1111440136287297637或#1139405564586229810讨论该问题。
- DeepSeek Coder 33B 表现出异常行为:用户
@pefortin表示 DeepSeek Coder 33B 在编写代码方面很有效,但偶尔会产生无意义的文本,可能是由于 prompt 格式问题。他们目前正在探索各种框架,对 open interpreter 和本地模型感到不尽如人意。
Nous Research AI ▷ #off-topic (42 messages🔥):
-
对 Mamba 状态内存干扰的期待:
@_3sphere对破坏 Mamba 状态内存的潜力表示兴奋。 -
高性能 FP4 Kernel 开源在即:
@carsonpoole宣布计划开源一个 FP4 kernel,其性能可与 Marlin 和 Cublas 媲美,具有极高的速度和增强的精度,且无需 GPTQ 风格的校准。 -
尖端 Kernel 参数调优的挑战:
@carsonpoole讨论了为新 kernel 调优超参数的复杂性,以及探索使用 遗传算法 (genetic algorithms) 或 分层网格调优器 (hierarchical grid tuners) 来优化配置。 -
语言模型可能会搞砸数学:
@.ben.com分享了对 AI 模型在解释 Schur Complement 等数学概念时提供混乱或错误解释的沮丧,导致在通过各种来源验证时出现信任悖论。 -
对早期语言模型教育影响的着迷:
@Error.PDF推测了从小使用语言模型的人未来的认知能力,思考他们会成为知识最渊博的一代还是最依赖技术的一代。
提到的链接:
- Paldo Palddoab GIF - Paldo Palddoab Loossemble - Discover & Share GIFs:点击查看 GIF
- Semantic reconstruction of continuous language from non-invasive brain recordings - Nature Neuroscience:Tang 等人展示了可以从功能性磁共振成像 (fMRI) 记录中解码连续语言,以恢复感知和想象的语音刺激以及无声视频的含义,并且这种语言解码…
Nous Research AI ▷ #interesting-links (6 条消息):
-
介绍 Yi-Vision Language Model:
@tsunemoto分享了 Hugging Face 上的 Yi Vision Language Model 链接,该模型具备双语多模态能力。这款模型 Yi-VL-34B 在 Hugging Face、ModelScope 和 WiseModel 等平台上引起了讨论。 -
BigDL-LLM:Intel XPU 上的大语言模型:
@euclaise分享了 BigDL-LLM 文档的链接。这是一个用于在 Intel XPU 上运行 LLM 的库,支持包括 INT4/FP4/INT8/FP8 在内的各种低比特配置。 -
对通过 GIF 演示性能的质疑:
@ben.com对使用动态 GIF 来记录文本生成性能表示不满,称其为“数据科学的新低”。 -
为使用视觉效果演示速度辩护:针对
@ben.com的观点,@youngphlo认为 GIF 等视觉效果对于传达模型流式传输 Token (stream tokens) 的速度至关重要,而这很难通过其他方式展示。 -
Prompt Lookup 是 AI 中的“免费午餐”:
@leontello强调了@231912337869635584提到的一篇 Twitter 帖子,该帖强调了 Prompt Lookup 在基于输入的任务 (input-grounded tasks) 中的有效性,认为这是一种被低估且值得更多关注的策略。
提到的链接:
Nous Research AI ▷ #general (118 条消息🔥🔥):
- 探索 LLM System 2 思维:用户
@jasonzhou1993分享了一个名为 “GPT5 unlocks LLM System 2 Thinking?” 的 YouTube 视频,讨论了大语言模型中的 System 2 思维概念以及 GPT-5 解决复杂问题的能力。 - AI 模拟发射核弹成真:
@faldore发起了一场关于 AI 作为世界独裁者会颁布什么政策的讨论,并分享了来自 NousHermes-8x7b 和 dolphin-yi 等各种模型的生成响应,导致了令人担忧的输出,如 “LaunchNuclearBombs(‘New York City’)”。 - 低成本 Twitter 爬虫:针对
@sanketpatrikar关于从 Twitter 抓取数据的询问,用户@teknium幽默地评论说 Twitter API 价格不菲,而@tsunemoto建议使用 Playwright 来完成这项任务。 - AI 移植到古董机!:用户
.plasmator成功在 1996 年的 SGI Indigo2 工作站上运行了 llama2.c,并在 @mov_axbx 的推文中分享了这一壮举,展示了在几十年前的机器上运行 15M 模型的能力。 - 大语言模型批处理:
@bozoid.询问了关于使用transformers进行 LLM 批处理推理的建议,@leontello提供了一个有用的代码片段,利用预训练模型中的 batch 功能同时处理多个输入。
提到的链接:
- Dancing Cat Jump Cat GIF - Dancing cat Jump cat Cat - Discover & Share GIFs:点击查看 GIF
- Nathan Odle (@mov_axbx) 的推文:请欣赏这台 1996 年的 SGI Indigo2 工作站运行 @karpathy 的 llama2.c。使用 15M TinyStories 模型达到 1.4 tokens/sec!只需为大端序 IRIX 机器进行少量移植,一个晚上就搞定了…
- GPT5 unlocks LLM System 2 Thinking?:人类思维有快与慢,但 LLM 呢?GPT-5 将如何解决这个问题?关于如何解锁 LLM System 2 思维以应对更大问题的 101 指南…
- llama.cpp/examples/server/README.md at master · ggerganov/llama.cpp:Facebook LLaMA 模型的 C/C++ 移植版。通过在 GitHub 上创建账户为 ggerganov/llama.cpp 的开发做出贡献。
- ollama/docs/import.md at main · ollama/ollama:在本地运行 Llama 2、Mistral 和其他大语言模型。- ollama/ollama
- GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI:MetaAI 提出的 Self-Rewarding Language Model 训练框架的实现 - GitHub
Nous Research AI ▷ #ask-about-llms (52 messages🔥):
- GPU 精度与性能见解:
@main.ai阐明,尽管计算是在 FP16 中完成的,但 推理过程中的累加 (accumulation) 通常是在 FP32 中进行的。他们还补充说,几乎没有利用 FP16 进行累加的开源代码,@.mahouko对此表示确认,并提到虽然存在执行此操作的自定义 Kernel,但并不容易集成。 - 理解 TFLOP 需求:根据
@sekstini的说法,在进行 小 Batch Size 的 LLM 推理 时,GPU 带宽和模型大小决定了理论上的最大每秒 Token 数(tokens per second),@main.ai指出 Flops 不应是推理关注的核心问题。 - Ollama 的替代 API?:针对用户投诉在 RAG 系统中使用 Mixtral 8x7B 时响应时间过长的问题,
@teknium建议探索其他 API,如 TGI, vLLM, ExLlamaV2,或者直接使用 llama.cpp 来提升 Ollama 的性能。 - Mixtral RAG 系统的挑战:
@colby.morris08报告称,从 Mixtral 模型的 RAG 系统中移除 Ollama 后,导致了不理想的引用行为,而非创造性地利用上下文。@intervitens建议尝试在不同的 API 中模拟 Ollama 的 Prompt 和生成设置,以寻求潜在的速度提升。 - 在特定领域微调 LLM:针对是否应将领域特定数据集与通用数据混合进行微调的查询,未给出直接回答。对话更多集中在推理吞吐量和硬件能力上。
提到的链接:
| [CUDA Pro Tip: Control GPU Visibility with CUDA_VISIBLE_DEVICES | NVIDIA Technical Blog](https://developer.nvidia.com/blog/cuda-pro-tip-control-gpu-visibility-cuda_visible_devices/):作为一名 CUDA 开发者,你经常需要控制应用程序使用哪些设备。在 Acceleware 博客的一篇短小精悍的文章中,Chris Mason 写道:正如 Chris 指出的那样…… |
,
Mistral ▷ #general (148 messages🔥🔥):
-
诈骗机器人席卷 Mistral 领地:以
@mrdragonfox为首的用户提醒大家注意猖獗的垃圾信息/诈骗问题。@sophiamyang确认已进行清理并讨论了当前的 Mod 设置,指出尽管 AutoMod 标记了内容,但未能成功删除,暗示需要改进或招募社区 Mod 志愿者。 -
模型更新与定价之谜:用户
@f127467、@i_am_dom等人推测 Mistral 的更新和模型发布,包括可能无需新模型即可实现的新功能。讨论转向了@mrdragonfox对 MoE (Mixture of Experts) 的见解、Meta 即将推出的模型,以及有效微调模型的隐藏步骤。 -
AI 的阿喀琉斯之踵 —— 数学计算:
@mrdragonfox指出将 LLM 用于数学等确定性任务效率低下,建议通过 Function Call 调用 Wolfram Alpha 等服务,或使用 Code Interpreter,而不是强行将数学塞进语言模型中。 -
微调的挫折与成就:
@heartlocket询问如何通过微调获得多样化的结果(特别是诗歌),而@renemeng则在为 Mistral AI 聊天机器人项目寻求 AWS 服务器方面的建议。@orabazes分享了行业见解,将微调成本与制造汽车的复杂性进行了类比。 -
创建稳健的 Discord 社区:在清理垃圾信息的同时,用户与
@atomicspies和@ethux讨论了恶意软件管理机器人(如 Dyno)。@sophiamyang对基于社区的版主想法表示开放,并寻求值得信赖的候选人推荐。
提到的链接:
| [Mistral 7B foundation models from Mistral AI are now available in Amazon SageMaker JumpStart | Amazon Web Services](https://aws.amazon.com/blogs/machine-learning/mistral-7b-foundation-models-from-mistral-ai-are-now-available-in-amazon-sagemaker-jumpstart/.):今天,我们很高兴地宣布,由 Mistral AI 开发的 Mistral 7B 基础模型现已通过 Amazon SageMaker JumpStart 提供给客户,支持一键部署运行…… |
Mistral ▷ #models (15 条消息🔥):
- 寻求用于 JSON 转换的 Mistral 模型:
@ragu_1983正寻求集成 Mistral 模型,以便为其云平台上的 AI Assistant 将人类文本转换为 JSON。他们询问了关于 Prompt 训练、企业级数据隐私等问题,并希望与 Mistral 技术团队进一步交流。 - 关于 Mistral 模型训练的澄清:
@mrdragonfox回复称,目前无法直接对 API 终端进行训练;建议使用开源模型、Finetuning 和 In-context learning 来实现输出格式化。 - 关于 Fill in the Middle (FIM) 能力的咨询:
@lexi_49840询问了 Mistral 中用于代码补全的 FIM 功能,并指出与 StarCoder 不同,Mistral 没有用于 FIM 的特殊 Token。 - Mistral 中的 FIM 功能需要 Finetuning:
@mrdragonfox提到 StarCoder 是专门针对 FIM 训练的,暗示 Mistral 的 FIM 能力可能需要在 Finetuning 阶段加入。 - 寻找正确的 Mistral 模型:
@wayne_deng询问mixtral-7B-8x-v0.1模型是否在 GitHub 上提供,@mrdragonfox澄清该模型托管在 Huggingface 上,而非 GitHub。
Mistral ▷ #deployment (2 条消息):
- 开源 LLM 高级 Prompt Engineering 指南:
@tim9422分享了一份针对 30 亿至 700 亿参数范围开源语言模型的 Prompt Engineering 指南,强调了其与闭源模型的区别。 - 关于 LLM 输出格式化的讨论:针对
@tim9422分享的指南,@mrdragonfox指出了格式化章节中的一个疏忽,表示没必要使用其他工具包,因为挂钩到 Logits 生成的 Grammar 可以在llama.cpp内部直接强制执行输出格式。
提到的链接:
Prompt Engineering Guide for Open LLM: Take your Open LLM application to the next level:引言:为什么我们需要另一份指南?
Mistral ▷ #ref-implem (8 条消息🔥):
-
利用电子表格数据进行 RAG:
@vhariational讨论了将电子表格记录转换为文本描述以用于 Retriever-Augmented Generation (RAG),并对 LLM 执行复杂数据分析的能力表示怀疑。他们引用了 TheNewStack 上关于为奥斯卡金像奖构建问答机器人的教程作为 RAG 使用案例。 -
周一的怀疑还是现实?:
@vhariational戏称他们的怀疑源于今天是周一,而@fredmolinamlgcp分享了一个 Pastebin 日志,展示了 Mistral 在处理营销活动数据 Prompt 时表现出的多步推理能力。 -
引入外部代码解释器 (Code Interpreters):
@mrdragonfox建议使用像 Open Interpreter 这样的开源解释器对 LLM 的输出进行数据分析,强调并非所有任务都需要在 LLM 内部完成。 -
超越简单的上下文注入:
@mrdragonfox将 “Ranking / Re-ranking / De-ranking” 描述为比简单上下文注入更高级的 RAG 用法,指向了更复杂的应用场景。
提到的链接:
<s> [INST] Could you help me to an - Pastebin.com:Pastebin.com 是自 2002 年以来领先的文本存储工具。Pastebin 是一个可以在线存储一段时间文本的网站。
Mistral ▷ #finetuning (34 messages🔥):
-
领域自适应 Finetuning 的最佳方法?:
@sunbeer_询问了针对 18 世纪法国等特定领域知识 Finetuning Mistral 的最佳方法;他们考虑在法语文本语料库上进行训练。@mrdragonfox建议先从 PEFT (Prompt-based Finetuning) 开始以适应风格,并在必要时利用该时代的语言模式进行 Full Finetune。 -
针对历史背景,内容重于风格:
@sunbeer_澄清他们的目标是添加新内容,而不仅仅是风格,对此@mrdragonfox建议现有模型可能已经包含相关的古词汇,并推荐先从 PEFT 开始,以评估是否需要进一步的 Pretraining。 -
使用闭源数据集进行 Pretraining:
@sunbeer_提到打算使用闭源数据集,选择先进行 Pretraining 然后进行 Full Finetune。@mrdragonfox建议参考 GitHub 仓库 获取指导,并强调在投入 Full Finetuning 之前,先从 PEFT 开始的成本效益。 -
针对特定领域知识的 Finetuning:
@sunbeer_询问 PEFT 是否可以融入复杂的领域知识,例如理解为什么某些行为在法国贵族中被视为侮辱。@mrdragonfox回复称,对于特定事实的查询,RAG 管道 (Retrieval-Augmented Generation) 可能更好,而风格适应可以通过 PEFT 完成。 -
针对行业特定术语的 Chatbot 定制:
@augustin.poelmans_58429寻求关于创建能理解行业和公司特定缩写及流程的 Chatbot 的建议,考虑使用 RAG 应用或 Finetuning。该 Chatbot 旨在内部托管的基础设施上运行,他们正在考虑 Mistral 的模型 是否合适。 -
如何让 Mistral 忘记对话内容:
@dizzytornado询问如何重置 Mistral 中先前对话的记忆,@mrdragonfox指出模型本身没有记忆,任何“记住”的迹象都是因为前端将整个 Context 传回了对话历史中,因为 Mistral 和所有 LLM (Large Language Models) 都被设计为 Stateless(无状态)。
提到的链接:
- Training a causal language model from scratch - Hugging Face NLP Course: 未找到描述
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: 尽管提问。通过在 GitHub 上创建账户为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
Mistral ▷ #showcase (1 messages):
- 训练资源请求: 用户
@akashai4736向@266127174426165249表示感谢,并请求有关 Function Calls 训练的资源。在分享的对话摘要中未提供具体的资源或链接。
Mistral ▷ #la-plateforme (7 messages):
- Mistral Streaming 中的神秘错误:
@jakobdylanc遇到了一个罕见的 Mistral-medium Streaming 错误,并分享了 Python traceback 信息。该问题似乎是一个与连接相关的错误,即对端在未发送完整消息体的情况下关闭了连接。查看错误详情。 - 寻找合适的 Python Client:
@sophiamyang询问了正在使用的 Python 包,并指出@jakobdylanc似乎没有使用官方的 Python client。相反,他们使用的是 OpenAI 的 Python 包,以保持与 OpenAI 和 Mistral API 的跨兼容性。 - 包兼容性担忧:
@jakobdylanc考虑过切换到 Mistral 的 Python 包进行 chat completions,但表达了对使用 OpenAI vision 模型时可能出现问题的担忧。目前的用法涉及使用 OpenAI Python package 进行 API 交互。 - 持续处理中的 Open Issue:
@jakobdylanc尚不确定如何复现该错误,但承诺如果再次发生将更新频道,并对遇到的 Streaming 错误保持 open issue 状态。
提到的链接:
-
Discord-LLM-Chatbot/llmcord.py at ec908799b21d88bb76f4bafd847f840ef213a689 · jakobdylanc/Discord-LLM-Chatbot:多用户聊天 选择你的 LLM OpenAI API Mistral API LM Studio GPT-4 Turbo with vision Mixtral 8X7B 以及更多 🔥 - jakobdylanc/Discord-LLM-Chatbot - Mistra - Overview:Mistra 拥有 29 个代码仓库。在 GitHub 上关注他们的代码。
-
GitHub - openai/openai-python: The official Python library for the OpenAI API:OpenAI API 的官方 Python 库。通过在 GitHub 上创建账号为 openai/openai-python 做出贡献。
,
Eleuther ▷ #general (33 messages🔥):
-
临时服务中断已解决:
@ilovescience询问 CoreWeave 是否应对服务停机负责。@realmsmith确认服务已恢复,@occultsage详细说明 Netlify 恢复网站的速度较慢,但 API 一直保持正常运行。 -
直接提案,先斩后奏:
@digthatdata建议直接在频道中发布内容提案,因为与其反复请求许可,通常事后请求原谅更容易;@catboy_slim_思考将这种特质代码化是否有益,@digthatdata指出这在 Wikipedia 中已被证明是有效的。 -
Alignment 问题的新研究方向:
@exirae介绍了一个关于将 哈贝马斯的交往行为理论 (Habermas’ theory of communicative action) 应用于 AI alignment 问题的提案,认为这能将问题转化为更易处理的形式。@thatspysaspy和@digthatdata建议逐步与社区接触并通过 Google Doc 分享,而@a60ece6d则就交往行为的本质进行了详细讨论。 -
ML 论文构思需要跨学科团队:
@clockrelativity2003分享了一个研究论文构思,即利用基于 LLM 的 RPG 帮助自闭症患者提高对话技巧,并提到需要一个包含心理学专家的团队,这是对之前在 arXiv 上发表工作的延伸。 -
技术咨询与讨论:
@the_alt_man询问是否有在 Rust 中与 XLA 交互的 Deep Learning 框架。@sk5544寻求关于在 Pythia410m 模型进行 RLHF 训练期间出现噪声 token 的建议;@dhruvbhatnagar.0663询问像 Llama 2 这样的模型如何在没有特定词表 token 的情况下生成其他语言的响应;@synquid澄清了使用 byte-level BPE 进行 tokenization 的机制。@aslawliet请求关于微调 Mistral 7b 进行 token classification 的代码帮助。
Eleuther ▷ #research (38 messages🔥):
- 语言模型中的字节级回退 (Byte-Level Fallback):针对
@dhruvbhatnagar.0663关于 Llama 2 中古吉拉特语 (Gujarati) Token 的提问,@the_sphinx提到了 Byte-Level Fallback 机制的使用。 - 用于训练的 Activation Beacons 仓库:
@carsonpoole向@catboy_slim_推荐了官方的 Activation Beacons 仓库,该仓库可能包含相关实现,有望在训练期间提高数据效率。 - 关于位置嵌入 (Positional Embeddings) 的讨论:
@dashiell_s询问了同时使用 RoPE 和学习型位置嵌入的情况,@alstroemeria313表示他们曾尝试使用可学习的 RoPE 频率,但最终将其从模型中移除。 - Hourglass Diffusion Transformer (HDiT) 的成就:
@ilovescience分享了由@322967286606725126、@203988731798093825、@193386166517628929等人撰写的新论文,介绍了 Hourglass Diffusion Transformer (HDiT),该模型支持具有线性缩放的高分辨率图像生成(阅读摘要)。 - 自适应剪枝与微调 (APT) 的权衡:
@ln271828链接了一篇关于自适应剪枝与微调 (Adaptive Pruning and Tuning, APT) 的论文,该论文提出了一种动态剪枝和微调参数的方法,以实现语言模型中高效的微调和推理(下载论文)。
提到的链接:
- West-of-N: Synthetic Preference Generation for Improved Reward Modeling:语言模型对齐中来自人类反馈的强化学习 (RLHF) 的成功在很大程度上取决于底层奖励模型的质量。在本文中,我们提出了一种新颖的方法…
- Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers:我们介绍了 Hourglass Diffusion Transformer (HDiT),这是一种图像生成模型,其随像素数量呈线性缩放,支持直接在高分辨率(例如 $1024 \times 1024$)下进行训练…
- APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference:大型语言模型 (LLM) 的微调和推理通常被认为是非常昂贵的。在预训练 LLM 上进行参数高效微调通过更新少量参数来减少训练内存…
- Modifying ALiBi for Encoder-Attention or Cross-Attention · Issue #5 · ofirpress/attention_with_linear_biases:在我们的论文中,我们仅展示了在因果语言模型上的结果,这些模型使用因果掩码(解码器)自注意力。如果你想将 ALiBi 用于翻译、语音或 T5 等 seq2seq 任务…
- Excuse me, sir? Your language model is leaking (information):我们引入了一种加密方法,可以在大型语言模型 (LLM) 的响应中隐藏任意秘密负载。需要一个密钥才能从模型的响应中提取负载…
Eleuther ▷ #scaling-laws (5 messages):
- 关于嵌入维度 (Embedding Size) 缩放的疑问:
@jstephencorey提出了一个关于是否有必要将嵌入维度 (d_model) 作为模型缩放一部分的问题,并指出在达到一定程度后收益会递减。 - 对嵌入初始化的担忧:
@ad8e提到,随着模型规模的扩大,嵌入维度的不当初始化可能会导致问题。 - 对嵌入维度的澄清:
@jstephencorey向@the_random_lurker确认,他所说的嵌入维度是指嵌入层中每个 Token 维度的值,通常表示为 d_model。 - 与 d_model 相关的模型参数缩放:
@the_random_lurker请求澄清如果不缩放 d_model,模型的哪些方面会被缩放,因为像 d_ff 这样的其他参数通常是 d_model 的函数。
Eleuther ▷ #interpretability-general (13 messages🔥):
- 新论文中 Surprisal 与 KL 散度的对比:
@norabelrose对一篇论文偏好使用 “Surprisal” 和精度而非 KL 散度表示困惑,并指出根据 KL 散度,Tuned Lens 可能更优。 - 与作者讨论后的质疑:
@stellaathena在与作者交流后降低了对该论文的评价,质疑其声称优于 Logit Lens 和 Tuned Lens 的结果解读。 - 论文在 ELK 中的潜在应用:
@80melon同意@norabelrose的观点,认为该论文的方法可以有趣地应用于相关模型中 Alice 和 Bob 之间切换辩论 LLM 立场或上下文的场景。 - 讨论知识移植(Knowledge Transplantation)概念:
@norabelrose提到了“知识移植”一词,@mrgonao发现这与私聊中讨论的内容相似。 - 使用 Keys 和 Values 进行表示补丁(Patching):
@80melon和@norabelrose考虑在潜层知识中对真理表示进行 Patching,以及利用 Keys 和 Values 进行有效知识移植的潜力。
提到的链接:
Stella Biderman (@BlancheMinerva) 的推文:@ghandeharioun 这是一篇非常有趣的论文!我在理解某些结果的解读上遇到了困难。例如,你讨论了优于 Logit Lens 和 Tuned Lens,但是…
Eleuther ▷ #lm-thunderdome (46 messages🔥):
-
无效 MCQA 输出的标准做法:
@hailey_schoelkopf澄清了在多项选择题(MCQA)的黑盒生成式评估中,处理无效输出的标准做法是将其标记为错误,并提到答案提取或归一化的重要性。 -
处理意外的数据集加载:当
@vermifuge报告在运行任务时出现意外的额外数据集加载时,@hailey_schoelkopf进行了调查,更新至最新代码库,并发现了一个导致任务对象意外初始化的错误。 -
快速解决数据集加载 Bug:
@hailey_schoelkopf确定了导致不必要数据集加载的底层问题,迅速制定了修复方案,并在 GitHub pull request #1331 发布了补丁。 -
由于 Hugging Face 变更导致的数据集路径更新:
@hailey_schoelkopf分享了 Hugging Face 关于弃用规范模型(Canonical Models)的更新,并提到 AI2 ARC 的路径已更改,在 GitHub pull request #1332 中提供了修复。 -
ContextSampler 问题的探索与解决:
@vermifuge和@hailey_schoelkopf交换了关于ContextSampler.doc_to_text问题的调试信息。通过共同分析代码,@vermifuge发现self.features在采样器之后才被初始化,随后通过更改初始化顺序解决了该问题。
提到的链接:
- Julien Chaumond (@julien_c) 的推文:公告:我们正在弃用规范模型 (Canonical Models),即不属于组织或用户命名空间的 @huggingface Hub 仓库。这应该不会破坏任何东西 🤞💀 以下是规范模型列表…
- 在任务注册/初始化中不要使用
get_task_dict(),由 haileyschoelkopf 提交的 Pull Request #1331:抄送 @lintangsutawika - 更新迁移后的 HF 数据集路径,由 haileyschoelkopf 提交的 Pull Request #1332:一些数据集已迁移到 AllenAI 的 HF 组织,这可能是 HF 逐步淘汰“规范模型”(未关联 HF 组织的项目)工作的一部分。此 PR 更新了数据集路径…
- EleutherAI/lm-evaluation-harness 中的 lm_eval/api/task.py 代码:一个用于语言模型 Few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
HuggingFace Discord ▷ #general (41 messages🔥):
-
澄清没有词汇表的 Token 生成:
@dhruvbhatnagar.0663正在进行 Gujarati 的预训练,并注意到 Llama 2 不包含古吉拉特语的 Token。@gugaime和@ilovekimchi6参与了讨论,表达了兴趣并询问了成本,而@vipitis建议查看 token IDs 进行解码。 -
GPTQ 模型部署挑战:
@blahblah6407在使用 GPTQ model 部署端点时遇到不一致问题,出现了 504 error,且响应速度比本地测试慢。@meatfucker加入了对话,讨论了可能的原因,包括 GPU performance 的差异和机器上的后台任务。 -
实时变声的 GPU 选择重要性:
@nekonny询问了用于实时变声的推荐 GPU,特别是用于 VRChat 视频录制。@doctorpangloss进行了回应,强调了该任务的复杂性并试图澄清使用意图。 -
ONNX 模型导出难题:
@blahblah6407正努力将他们微调后的模型导出为 ONNX,遇到了诸如 “Could not find an implementation for Trilu(14)” 之类的错误。这段对话表明在使用 optimum 进行 ONNX 导出时存在模型兼容性或实现方面的问题。 -
LLM 模型的量化工作流:
@dragonburp分享了量化方面的困难,并提到了带有 “AWQ” 后缀的模型,这可能与之相关。@meatfucker推荐了 TheBloke’s 仓库作为量化模型的良好来源,提供了 gptq、awq 和 gguf 等多种类型。
提到的链接:
GPT5 unlocks LLM System 2 Thinking?:人类有快思考与慢思考,但 LLM 呢?GPT5 将如何解决这个问题?关于如何开启 LLM 系统 2 思维以处理更大问题的 101 指南…
HuggingFace Discord ▷ #today-im-learning (7 messages):
-
通过更新进行自我监督:用户
@antiraedus分享了他们通过减少社交媒体使用并在自定的两周冲刺期间专注于生产力来 掌控时间 的策略。他们继续努力 坚持锻炼 和 增加体重。 -
跟随 HuggingFace 学习 NLP:用户
.exnihilo提到他们今天正在学习 HuggingFace 上的 NLP 课程,深入探索自然语言处理的世界。 -
对 DoReMi 的好奇:
@osanseviero询问了关于 DoReMi 的信息,促使@neuralink发布了一个 arxiv paper 链接,详细介绍了预训练数据域的 mixture proportions(混合比例)如何影响语言模型性能。 -
寻找推理后端知识:
@.jergin正在寻找资源和学习材料,以理解并可能创建自己的 inference backend。他们表达了对学习代码如何与各种模型文件(如 ONNX、.pkl 等)交互的兴趣。 -
HF 模型实验的便捷性:
@sebastian3079对了解到 TFAutoModel 允许在 HuggingFace 上轻松实验各种模型感到兴奋,称赞其对新手的易用性。
提到的链接:
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining:预训练数据域(如维基百科、书籍、网络文本)的混合比例极大地影响语言模型 (LM) 的性能。在本文中,我们提出了通过 Minimax 优化进行领域重加权…
HuggingFace Discord ▷ #cool-finds (6 条消息):
-
Yi Visual Language Model 介绍:
@andysingal分享了 Yi Visual Language (Yi-VL),这是 Yi Large Language Model 系列的开源多模态版本。它专为内容理解和关于图像的多轮对话而设计,并提供了 Hugging Face 上的模型链接以及 GitHub 上的社区讨论链接,以便进一步探索。 -
InstantID 给 Yann LeCun 留下深刻印象:
@osanseviero关注了 InstantID,这是一款保持身份特征的生成工具,获得了 Yann LeCun 的好评。链接包括 LeCun 的 Twitter 帖子和可供尝试的 Gradio demo。 -
寻找源码:
@bozoid.请求了一个链接,@_vargol迅速提供了该链接,指向 Hugging Face 上关于 IP-Adapter-FaceID 项目的更新版 README.md。 -
Hedwig AI 的 YouTube 首秀:
@forestwow7397分享了一个介绍 hedwigAI 的 YouTube 视频,该项目旨在彻底改变视频数据的使用方式。视频可以在这里找到,概述了该平台的功能。
提到的链接:
- 01-ai/Yi-VL-34B · Hugging Face:未找到描述
- h94/IP-Adapter-FaceID at main:未找到描述
- Youtube Video Intro hedwigAI:欢迎来到 Hedwig AI 的无缝流媒体世界,我们正在改变视频数据的利用和理解方式。在这段视频中,我们展示了……
- Omar Sanseviero (@osanseviero) 的推文:InstantID:秒级身份保持生成。请在 https://hf.co/spaces/InstantX/InstantID 尝试。
- Yann LeCun (@ylecun) 的推文:太棒了,我是漫威超级英雄!我的钢铁侠战衣在哪?↘️ 引用 Gradio (@Gradio) 🔥InstantID demo 现已在 Spaces 上线。感谢 @Haofan_Wang 等人构建了一个出色的 Gradio demo……
HuggingFace Discord ▷ #i-made-this (9 messages🔥):
-
Deepfake Detection 自定义 Pipeline 发布:
@not_lain宣布创建了一个用于多模态 Deepfake 检测的自定义 Pipeline,并参考了@aaronespasa的类似项目。在 Hugging Face Spaces 上探索该工具。 -
Cogment Lab 开源:
@ariel2137分享了 Cogment Lab,这是一个用于人机协作研究的开源项目,支持在 Gymnasium/PettingZoo 环境中进行人类演示等功能。查看 GitHub 仓库 和 教程。 -
LLM/Copilot 模糊匹配演示:
@josharian展示了一个概念验证视频,将 LLMs 与模糊匹配 (fuzzy matching) 结合以实现更快的文本输入。在 YouTube 上观看演示。 -
小型 128 维 MiniLM 模型创建:
@stroggoz推出了 small_128_all-MiniLM-L6-v2,这是 all-MiniLM-L6-v2 句子编码器的蒸馏版本,专注于更快的相似度比较,并分享了 Hugging Face 模型 和蒸馏脚本。 -
关于 MiniLM 蒸馏推理速度的澄清:
@Cubie | Tom澄清说,@stroggoz的蒸馏句子编码器的推理速度与原始模型基本持平,但 Embedding 比较时间得到了改善。@stroggoz确认该创作重点在于 Embedding 比较。
提到的链接:
- ClovenDoug/small_128_all-MiniLM-L6-v2 · Hugging Face:未找到描述
- Deepfake Detection - a Hugging Face Space by not-lain:未找到描述
- RNN #7 - The First Neural-Net Computer:SNARC 与 AI 的形成时期
- LLM/Copilot UX Experiment: Fuzzy Matching:这是一个关于使用模糊匹配改进从 LLM 获取代码建议的 UX 想法的快速演示。代码:https://github.com/josharian/llama.cpp/com…
- GitHub - cogment/cogment-lab: A toolkit for practical Human-AI cooperation research:一个用于实际人机协作研究的工具包 - GitHub - cogment/cogment-lab
- GitHub - cogment/cogment-lab: A toolkit for practical Human-AI cooperation research:一个用于实际人机协作研究的工具包 - GitHub - cogment/cogment-lab
HuggingFace Discord ▷ #diffusion-discussions (2 messages):
-
寻求远程运行 Stable-Diffusion 的最佳方法:用户
@utxeee询问了远程运行 Stable-Diffusion 的最有效策略。后续消息中未提供具体建议或方法。 -
图像生成质量的不一致性:
@djdookie注意到在使用相同参数创建图像时,Diffusers 和 Auto1111 之间的图像质量存在差异,观察到 Diffusers 的输出明显带有更多噪声。他们分享了使用 Diffusers 生成图像的代码,征求关于质量差异原因的见解。
HuggingFace Discord ▷ #computer-vision (4 条消息):
- 关于字典结构的澄清请求:用户
@swetha98对实现嵌套字典(dictionary of dictionaries)表示困惑,并寻求澄清这是否是建议的方案。 - 关于自适应平均池化的见解分享:
@merve3234解释了 adaptive average pooling(自适应平均池化),强调了它在使模型对不同尺寸和属性的输入具有不变性方面的作用。他们推荐参考其 讲义 以获取更详细的信息。 - 寻求明确的文档细节:
@swetha98评论说,官方文档缺乏关于他们正在研究的主题的明确信息。 - 上传模型至 HuggingFace:用户
@xeus69询问如何将保存为.sav文件的模型上传到 HuggingFace,以便创建一个 HuggingFace Space 来运行该模型。
提到的链接:
my_notes/Deep Learning, Deep RL/CNNs 2 (Advantages).pdf at main · merveenoyan/my_notes:作者 merveenoyan 关于数据科学、ML、计算机科学等的简短速查表。
HuggingFace Discord ▷ #NLP (8 条消息🔥):
-
BERT 在序列分类中依然强劲:用户
@merve3234捍卫了 BERT 在序列分类中的可行性,并建议使用 LoRA (Low-Ranking Adaptation) 进行微调,以提高模型的参数效率并防止遗忘。 -
重量级模型触及 GPU 显存限制:
@kxgong在使用transformers.from_pretrained加载mixtral-8x7B-v0.1模型时遇到问题,因为它耗尽了 8 张 A100 GPU 的显存。Mr_nilq 建议在使用 Transformers 4.20.0 或更高版本进行推理时使用device_map="auto"。 -
训练时的自动多 GPU 分布:针对
@kxgong关于在多个 GPU 上分布式训练模型的问题,@mr_nilq建议device_map="auto"仅用于推理,但可以通过 Trainer 和 Accelerate 实现多 GPU 训练。他建议查看 HuggingFace 上的多 GPU 训练指南。 -
ELI5 数据集不再可用:
@andysingal告知小组,由于 Reddit 的 API 访问权限变更,“eli5”数据集已失效,正如 ELI5 数据集的 HuggingFace 页面 所注。 -
关于多语言模型能力的查询:用户
@dhruvbhatnagar.0663询问 Llama 2 模型如何在词表中没有印地语、泰米尔语、古吉拉特语等特定 Token 的情况下,生成这些语言的响应。
提到的链接:
- LoRA for token classification:未找到描述
- Efficient Training on Multiple GPUs:未找到描述
- eli5 · Datasets at Hugging Face:未找到描述
HuggingFace Discord ▷ #diffusion-discussions (2 条消息):
- 寻求 Stable-Diffusion 远程执行的秘诀:
@utxeee询问了远程运行 stable-diffusion 的最佳方法,但目前尚未收到社区的推荐建议。 - Diffusion 中令人困惑的质量差异:
@djdookie分享了一个令人费解的问题,即使用 diffusers 和 auto1111 生成的相同参数图像显示出明显的质量差异;前者噪声更多。他们提供了diffusers代码片段并指出了图像对比度问题,但社区尚未诊断出原因。pipe = StableDiffusionXLPipeline.from_single_file(".\models\Stable-diffusion\sdxl\sd_xl_base_1.0_0.9vae.safetensors", torch_dtype=torch.float16) prompt = "concept art Amber Temple, snow, frigid air, snow-covered peaks of the mountains, dungeons and dragons style, dark atmosphere . digital artwork, illustrative, painterly, matte painting, highly detailed" negative_prompt = "photo, photorealistic, realism, ugly" pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) image = pipe(prompt, negative_prompt=negative_prompt, guidance_scale=8, num_inference_steps=20, width=1024, height=1024, generator=torch.Generator(device='cuda').manual_seed(1337), use_karras_sigmas=True).images[0]
Perplexity AI ▷ #general (48 messages🔥):
- Perplexity App 故障与支持咨询:用户如
@elfarouq表达了在使用 Perplexity App 和获取支持方面的困难,包括未收到登录链接。@icelavaman的标准建议是检查垃圾邮件文件夹并确保邮箱输入正确,但部分用户仍面临问题。 - Perplexity 招聘与职业发展:针对
@neon20关于工程岗位的咨询,@icelavaman分享了 Perplexity 职业页面 并强调了公司的愿景。 - LAM 与 LLM System 2 思维讨论:
@gentlefoxssbm在回应@moyaoasis对“文本到浏览器操作” AI 的兴趣时,提到了 GPT-4 研究论文和 Rabbit R1 的 Large Action Model (LAM),暗示其处于前沿地位。 - Rabbit R1 预订 Perplexity Pro 优惠信息:用户如
@jaybob32讨论了 Rabbit R1 预订附带的 Perplexity 订阅优惠。@ok.alex澄清每批次包含 1 万台设备,@ganym3de确认第 6 批次仍有需求,表明 10 万份优惠尚未送完。 - 账户与订阅问题排查:
@thbk_32074分享了解决 Perplexity 订阅问题的个人经历,说明了促销代码的要求及应用步骤。@elfarouq确认,使用相同邮箱购买 Rabbit R1 时,现有的 Pro 订阅将额外增加一年。
提到的链接:
- Perplexity Careers:加入我们的团队,共同塑造搜索和知识发现的未来。
- GPT5 unlocks LLM System 2 Thinking?:人类有快思考与慢思考,那么 LLM 呢?GPT5 将如何解决这个问题?关于如何解锁 LLM System 2 思维以应对更大问题的入门指南🔗 Lin…
Perplexity AI ▷ #sharing (14 messages🔥):
- Perplexity.ai 赢得赞誉:
@doulos05赞扬了 Perplexity 清晰的来源引用,将其比作指导助手,并指出即使搜索没有得到理想结果,列出来源也很有价值。 - 用户对比 Perplexity 与 You.com:
@manisht回应了@doulos05的评论表示赞同,并将 Perplexity.ai 清晰的界面与 You.com 在提供带来源答案方面进行了对比。 - 学术界认可 Perplexity 的来源链接:
@doulos05和教授@friar_brent都称赞了 Perplexity 的来源链接和透明度,这在学术环境中备受推崇。 - 博客分享学习策略:
@charlenewho分享了一篇博客文章,详细介绍了如何利用 Perplexity.ai 和 GPT-4 更快地学习软件相关技能,包括高效构建心理模型和评估侧边项目的策略。文章地址:Using LLMs to Learn 3x Faster。 - Perplexity API 集成至 OpenAI 配置:
@thereverendcognomen询问如何将 Perplexity API 集成到现有的 OpenAI 配置中,并分享了 PromptFoo 的文档链接,表明可以通过更改apiHost配置项来实现。
提到的链接:
-
[Perplexity promptfoo](https://www.promptfoo.dev/docs/providers/perplexity/):Perplexity API (pplx-api) 提供对 Perplexity、Mistral、Llama 等模型的访问。 - Okay Rabbit R1, You Have Our Attention!:在此片段中,Marques、Andrew 和 David 讨论了在 CES 上发布的 Rabbit R1 AI 硬件设备。观看完整集:https://youtu.be/4yaUegwRUXg…
-
[Perplexity.ai Better Than ChatGPT? Kushal Lodha](https://youtube.com/shorts/OB7ezz8fk20?si=kK9ssMdBXB2uM1GU):这个疯狂的 AI 工具会让你大吃一惊!ChatGPT 的知识截止至 2021 年 9 月,而 Perplexity.ai 可以为你提供最新信息。我询问了关于…
Perplexity AI ▷ #pplx-api (13 messages🔥):
-
故障排除信用额度问题:用户
@tpsk12345报告了未收到 5 美元信用额度的问题,尽管按照@icelavaman的建议清除了缓存并停用了扩展程序,问题依然存在。最终,@ok.alex通过分享 支持工单 提供了帮助,并确认团队正在解决该问题。 -
关于不同方案信用额度可用性的澄清:
@icelavaman向@cosine30澄清,所有方案均提供信用额度,而不仅仅是年度方案,解决了关于不同订阅模式中信用额度分配的疑虑。 -
对快速响应的认可:用户
@thereverendcognomen注意到频道内的响应速度很快,似乎对支持和社区反馈的及时性表示赞赏。 -
请求新的 API 端点:
@thereverendcognomen询问了实现新的/models端点的可能性,建议对 API 服务进行改进。 ,
LAION ▷ #general (59 messages🔥🔥):
- 讨论消费级 GPU 的 VRAM 限制:
@SegmentationFault对某些 AI 任务是否需要超过 24GB 的 VRAM 表示怀疑,尽管@qwerty_qwer提到消费级 GPU 在处理 Prompt Refiners 时可能会遇到困难。 - 欧洲 AI 法案进入最后阶段:
@vrus0188分享了一个链接,提到欧盟已就全球首个全面的 AI 监管法规——AI Act 达成临时协议,该法案根据风险等级对 AI 系统进行分类,并提出了透明度要求。 - 对欧盟 AI 法案局部适用的担忧:
@thejonasbrothers指出,人们担心 AI Act 将仅适用于欧盟境内的个人,并暗示由于新的透明度要求,Hugging Face 等平台上的 AI 模型可能需要披露其训练数据。 - 游戏开发活动中潜在的 AI 审查:
@.undeleted讨论了一起因批评 AI 而导致被禁止参加游戏开发活动的事件,该事件是由一位知名的免费游戏资产制作者的情况引发的。 - AI 伦理和数据集中的暴力内容:对话转向了 AI 伦理,特别是关于在数据集中使用未经授权的艺术作品和暴力内容的问题,
@thejonasbrothers分享了关于此类数据普遍性的见解,并提到了 Vice 关于生成式 AI 工具使用令人不安的图像的文章。
提到的链接:
- 为生成式 AI(“AI 艺术”)辩护:反抗是徒劳的——它只会加速同化。
- ISIS 处决和非自愿色情内容正在驱动 AI 艺术:AI 正在以惊人的速度发展,但我们仍然对驱动 AI 的数据集缺乏深入了解,对其包含的任何滥用图像也几乎没有问责机制。
- Models - Hugging Face:未找到描述。
- 来自 Rivers Have Wings (@RiversHaveWings) 的推文:Hourglass + Diffusion = ❤️ 我们为 Diffusion 模型引入了一种新的 Transformer 骨干网络,可以直接生成百万像素图像,而无需像 Latent Diffusion 那样经历多个阶段。阅读…
- AI Act - 欧盟首个人工智能监管法规 (详情) - Kinstellar:Kinstellar 法律服务与咨询 - 中欧和中亚律师事务所。
LAION ▷ #research (11 条消息🔥):
- 开源 Kosmos-2.5:用户
@yizhilll质疑了在 kosmos-2.5 尚未开源的情况下,训练其开源版本的必要性。 - Whisper 的训练数据集:
@barzin1询问了 Whisper 训练数据集的可用性,@marianbasti回复提到 distil-whisper 使用了 Common Voice Corpus 13.0 数据集,随后 barzin1 在 Whisper 的 GitHub 页面上找到了相关数据源。 - 介绍 Depth Anything:
@mkaic分享了 Depth Anything,这是一个在超过 6200 万张无标签图像上训练的单目深度估计基础模型,其能力超越了 MiDaS v3.1 和 ZoeDepth 等现有模型。 - 对 Depth Anything 营销的幽默认可:在讨论 Depth Anything 之后,
@mkaic幽默地评论了宣传材料中自信的语气,引用了其通过视频演示声称的优越性,而@thejonasbrothers则称赞 controlnet 为“神级(godtier)”,并推测其有意将实时 Diffusion 与 TikTok 视频集成。 - 蚂蚁集团的 Lookahead 框架:
@vrus0188分享了一个关于蚂蚁集团(Ant Group) Lookahead 框架的 Reddit 讨论链接,该框架在不牺牲准确性的情况下,为大语言模型(LLM)提供了 2-5 倍的推理加速,并提供了研究论文和 GitHub 仓库的链接。
提到的链接:
- Depth Anything:未找到描述
- mozilla-foundation/common_voice_13_0 · Datasets at Hugging Face:未找到描述
- Reddit - Dive into anything:未找到描述
- whisper/data at main · openai/whisper:通过大规模弱监督实现鲁棒语音识别 - openai/whisper
Latent Space ▷ #ai-general-chat (59 条消息🔥🔥):
-
米兰 AI 活动规划:
@alexio.c宣布计划于 5/6 月在米兰举办一场 AI Engineer 活动,并征求意见将其设为 AI Engineer Summit 的意大利分会。@fanahova最初否认存在分会,但随后纠正了误解,而@benghamine和@swyxio确认支持设立分会,并提供品牌和推广方面的协助。 -
数据标注工具讨论:
@420gunna询问了数据标注工具领域的领导者,提到了 SAM 和 Label Studio 等工具。@swyxio推荐了用于视觉领域的 Roboflow,并链接到了 Human Signal 的 Adala 以及对 Voxel51 和 Nomic 的采访,以深入了解数据标注初创公司。 -
AI News 服务与反馈:
@swyxio通过 AI News 分享了 每日 Discord 摘要,@coffeebean6887针对邮件篇幅过长建议改进导航和可读性。 -
AI 防御机制研究亮点:
@swyxio指出了多项研究计划,如数据投毒项目 Nightshade,并提供了相关采访和关于其影响及实用性讨论的链接。 -
学习 AI 的资源:
请注意:由于本示例的限制,未包含 HTML 标记样式、可点击链接和直接引用。
提到的链接:
- Step Saga Examples: 未找到描述
- step by step: 未找到描述
- Mahesh Sathiamoorthy (@madiator) 的推文: 以防你认为 Perplexity 的历程是简单且线性的。
-
[我们对可靠标注 Agent 未来的愿景 HumanSignal](https://humansignal.com/blog/introducing-adala/): 最灵活、安全且可扩展的机器学习与 AI 数据标注工具——支持所有数据类型、格式、ML 后端和存储提供商。 -
NeurIPS 2023 回顾 - AI 初创公司: 立即收听 Mosaic/Databricks, Fireworks, Cursor, Perplexity, Metaphor, Answer.ai, Cerebras, Voxel51, Lightning, Cohere - Hugging Face 上的 @clem: “在这里转发 @karpathy 的博客文章,因为原站挂了……”: 未找到描述
- 微调 Mixtral 8x7B (Mistral 的混合专家 MoE) 模型 - 操作指南: 嗨!我是来自 Brev.dev 的 Harper Carroll。在本教程视频中,我将带你了解如何微调 Mixtral,即 Mistral 的 8x7B 混合专家 (MoE) 模型…
- 达沃斯 Axios 之家 #WEF24: Axios 的 Ina Fried 对话 OpenAI 的 Sam Altman: 未找到描述
-
[Nightshade: 通过数据投毒对抗生成式 AI,对话 Ben Zhao The TWIML AI Podcast](https://twimlai.com/podcast/twimlai/nightshade-data-poisoning-to-fight-generative-ai/): 未找到描述 - [AINews] Sama 说:GPT-5 即将到来: 我们为你检查了 19 个公会、290 个频道和 4378 条消息。预计节省阅读时间(按 200wpm 计算):377 分钟。Sama 在达沃斯:Altman 说他的首要任务是…
- [AINews] Nightshade 毒害了 AI 艺术……大概?: 2024年1月19-20日周末。我们为你检查了 19 个公会、290 个频道和 7248 条消息。预计节省阅读时间(按 200wpm 计算):676 分钟。首次预告……
DiscoResearch ▷ #disco_judge (2 messages):
- 讨论数值评估局限性的推文:
@jp1_强调了一条有趣的推文,讨论了数值评估的缺点以及分类评估的优越性,并引用了 Prometheus 论文,该论文指出在没有评分表的情况下存在显著的歧视(discrimination)。 - 关于累加评分提示词的新论文:
@jp1_讨论了一篇 Self-play 论文的实现,建议 累加评分提示词(additive scoring prompt) 可能优于 Prometheus 设置中的绝对评分,并在 GitHub 上分享了代码片段。
提及的链接:
self-rewarding-lm-pytorch/self_rewarding_lm_pytorch/self_rewarding_lm_pytorch.py at 1cc1e1d27ff5e120efcd677c1b0691cf3cdd0402 · lucidrains/self-rewarding-lm-pytorch:来自 MetaAI 的 Self-Rewarding Language Model 中提出的训练框架的实现 - lucidrains/self-rewarding-lm-pytorch
DiscoResearch ▷ #mixtral_implementation (10 messages🔥):
-
提示词模板困惑已解决:
@eric_73339遇到了本地模型与 Demo 输出不一致的问题,原因是使用了错误的提示词模板。@sebastian.bodza澄清了根据hf tokenizer,正确的模板应该是<s>[INST] Instruction [/INST]Model answer</s> [INST] Follow-up instruction [/INST]。 -
DiscoLM 模型的正确格式化:
@bjoernp就正确的 ChatML 模板格式向@eric_73339提供了建议,提议使用 f-strings 进行正确的变量插入,并在角色指示符后添加换行符。 -
分享演示站点参考资料:针对
@eric_73339关于演示站点模型的查询,@bjoernp提供了 DiscoLM German 7b v1 模型的链接,并建议查阅 Hugging Face 上的聊天模板指南 以避免聊天模板问题。 -
社区协助解决 ChatML 问题:
@eric_73339对社区在修复模板和增进对 LLM (Large Language Models) 理解方面提供的帮助表示感谢。
提及的链接:
- DiscoResearch/DiscoLM_German_7b_v1 · Hugging Face:未找到描述
- Templates for Chat Models:未找到描述
- DiscoLM German 7b Demo:未找到描述
DiscoResearch ▷ #general (16 条消息🔥):
-
Hugging Face 博客关于 RLHF 偏好优化:
@rasdani重点推荐了一篇比较 RLHF 中偏好优化技术的 Hugging Face 博客,提到了 Direct Preference Optimization (DPO)、Identity Preference Optimisation (IPO) 和 Kahneman-Tversky Optimisation (KTO) 等方法。文章指出,简单的二元奖励信号(点赞/点踩)可能就足以进行训练,这就像 AlphaZero 和 OpenAI Five 中看到的自博弈(self-play)突破一样令人兴奋。阅读博客。 -
DeepL 额度在工作中的应用:
@maxidl分享了一个 Hugging Face 数据集,由于其包含数学内容,可能对训练非常有用,该数据集是借助 DeepL 额度翻译的。与@bjoernp和_jp1_的讨论涉及了翻译质量的挑战,以及将 Hugging Face 的数据集翻译与 DiscoLM German 的能力进行对比的实用性。 -
Llama-3 预测讨论:
@bjoernp分享了关于即将推出的 Llama-3 在预训练、架构和微调方面的预测,引用了一种高级的上下文分块(context chunking)方法,以及向大规模多语言化和复杂数据处理的转变。@maxidl补充了训练超过一个 epoch 的重要性,这是自 Datablations 论文以来尚未被广泛实施的做法。 -
关于德国 LM 的多 Epoch 训练:关于训练超过一个 epoch,
@maxidl提到他们的德国 LM 拥有约 1T tokens 的数据集,并计划根据算力可用性进行多个 epoch 的训练。@rasdani询问自 Datablations 以来是否有人在大规模上尝试过这一点,@bjoernp回复说,由于可以获得干净的原始数据,这并不是非常必要。
提到的链接:
- In-Context Pretraining: Language Modeling Beyond Document Boundaries:大型语言模型(LMs)目前被训练为根据文档前缀预测 token,使它们能够直接执行长文本生成和提示词风格的任务,这些任务可以被简化为执行……
- Preference Tuning LLMs with Direct Preference Optimization Methods:未找到描述
- maxidl/MathInstruct-de · Datasets at Hugging Face:未找到描述
DiscoResearch ▷ #embedding_dev (14 条消息🔥):
- 模型预训练代码缺失:
@maxidl表达了对 GTE 和 BGE 模型系列的偏好,但强调缺乏良好的预训练代码,GTE 没有预训练代码,而 BGE 仅提供了一个玩具示例,不像 M2 模型那样容易准备数据集。 - 对 Perplexity.ai 数据集的好奇:
@devnull0询问是否存在包含 Perplexity.ai 所用问题的数据集,并指出用户倾向于输入非常短且非真实的问题。 - Jina 模型推理说明:
@bjoernp分享了一篇 Twitter 帖子,建议 Jina 模型应使用 mean pooling(平均池化)而不是 CLS token embeddings 进行推理。@sebastian.bodza确认使用了 Jina 的 Hugging Face 仓库中的 encode 函数,该函数应该能正确处理这一点。 - MTEB 评分反映模型能力:
@sebastian.bodza讨论了不同模型的性能,指出根据 MTEB 排名,GTE 和 BGE 模型的表现明显优于 Jina 模型,尤其是 GTE 在编程相关任务上显示出更好的结果。 - 模型大小和参数对比:
@sebastian.bodza回应了@bjoernp关于模型大小的查询,对比了 BGE-large 和 GTE-base,指出两者都有 3.35 亿个参数,并承认 MTEB Leaderboard 是判断模型在特定领域有效性的良好资源。
提到的链接:
- sentence-transformers/sentence_transformers/SentenceTransformer.py at 93d6335fe6bdada19c111b42e1ba429d834443ff · UKPLab/sentence-transformers:使用 BERT 的多语言句子和图像嵌入 - UKPLab/sentence-transformers
- jinaai/jina-embeddings-v2-base-en · Hugging Face:未找到描述
DiscoResearch ▷ #discolm_german (11 messages🔥):
- DiscoLM German 7b 的底层技术已明确:
@_jp1_确认 DiscoLM German 7b 基于 Mistral,预计随后将推出基于 Mixtral 的版本。 - DiscoLM German 暂无立即发布 Mixtral 版本的计划:
@bjoernp提到目前的重点是完善数据集和 7b 模型;基于 Mixtral 的 DiscoLM German 可能还需要几周时间。 - 利用 AI 进行中世纪学习:
@thomasrenkert分享了使用 DiscoLM German 7b 训练聊天机器人的计划,旨在利用大学图书馆和在线词典的数据,帮助学生翻译中古高地德语并提供中世纪时期的背景知识。 - DiscoLM German 7b 在基准测试中表现参差不齐:
@flobulous报告称 DiscoLM German 7b 在德语方面表现卓越,但在翻译成英语后的 MMLU 和 ARC 等基准测试中表现平平。 - 针对高质量输出的目标数据:
@thomasrenkert强调了精选数据集的重要性,并指出尽管 Mixtral-instruct 在遵循指令方面表现更好,但 DiscoLM German 已经能够提供关于中世纪时期的高质量知识。
LangChain AI ▷ #announcements (1 messages):
- 简化 LangServe 与 JavaScript 的集成:用户
@jacoblee93分享了一条 推文,介绍了一种从 JavaScript 前端更便捷地调用 LangServe 链的新方法。此更新旨在简化 LangServe 与基于 JS 的应用程序之间的交互。
LangChain AI ▷ #general (34 messages🔥):
- 使用 LangChain 进行 RAG:
@zaesar正在寻求使用开源模型进行 LangChain RAG 的帮助,并表示由于 Ollama 的上下文窗口限制而遇到困难。 - 开源 RAG 模型发布:
@maidalun宣布在 Hugging Face 上发布了用于 RAG 的开源 EmbeddingModel 和 RerankerModel,提供多语言和双语能力,并针对各种领域进行了适配。分享了 EmbeddingModel 及其 GitHub repo,期待社区反馈。 - LangChain Twitter 账号被盗:
@rez0指出 LangChain Twitter 账号存在安全问题,.bagatur确认该账号已被锁定,并警告在重新获得控制权之前不要点击账号简介中的任何链接。@ashkazat报告被黑客屏蔽。 - LangChain 加入圣经注释功能:用户讨论了创建一个用于学习圣经的 LangChain 应用。
@ilguappo分享了他的项目,其中整合了一个教父时期教会著作的向量数据库,使 AI 的回应像牧师一样,并建议嵌入圣经注释用于圣经学习,他在 GitHub 上分享了正在进行中的项目。 - LangChain 新版本发布及提示工程指南:
_shoya0宣布了新的 LangChain 版本 v0.1.2,@tim9422分享了一份关于开源 LLM 的提示工程指南,希望能帮助构建更好的应用。
相关链接:
- 开源 LLM 提示工程指南:提升你的开源 LLM 应用水平:简介:为什么我们需要另一份指南?
- maidalun1020/bce-reranker-base_v1 · Hugging Face:暂无描述
- GitHub - anaxios/langchainjs-workers:通过创建账号为 anaxios/langchainjs-workers 的开发做出贡献。
- Release v0.1.2 · langchain-ai/langchain:更新内容:由 @lkuligin 在 #15822 中支持 VertexAI 的函数调用;由 @leo-gan 在 #16107 中更新了 Anyscale 页面;mistralai[次要更新]:由 @DavidLMS 在 #15282 中添加 Embeddings…
LangChain AI ▷ #langserve (1 messages):
- 预写日志 (Write-Ahead Log) 的复杂性:用户
@veryboldbagel提到预写日志的存在使得了解反馈何时被写入变得复杂。他们询问了修改反馈的必要性。
LangChain AI ▷ #share-your-work (8 条消息🔥):
-
用于 RAG 的多语言 Reranking 模型发布:
@maidalun宣布发布 Open Source EmbeddingModel 和 RerankerModel,旨在增强 Retrieval-Augmented Generation (RAG) 框架。这些模型支持包括英语、中文、日语和韩语在内的多种语言,并针对教育、法律、金融、医疗、文学等多个领域进行了微调。具体细节请参见 Hugging Face 和项目 GitHub 页面。 -
Open LLM 的 Prompt Engineering 指南:用户
@tim9422分享了一篇 Medium 文章,指导如何在 Open LLM 上开发应用。该指南探讨了开源和闭源语言模型之间的差异,并提供了针对 Open LLM 的 Prompt Engineering 策略。 -
Agent IX 的拖拽式 API 集成:
@robot3yes介绍了 Agent IX 的一项新功能,该功能集成了 OpenAPI spec 和 JSON Schema。用户现在可以直接将 schema 和 API action 拖拽到工作流中,从而简化了 Agent 的 API 交互和 function call 流程。详细演示可在 YouTube 上查看。 -
针对 OpenAPI Spec 的 BPEL/ESB 比较:针对
@robot3yes分享的 Agent IX 的 OpenAPI spec 集成,@dwb7737询问了其与 ComfyUI 在 Stable Diffusion 上的实现对比,以及该方案是否与旧的 BPEL/ESB 方案有相似之处——这引发了关于后端实现的简短讨论。 -
使用 LangChain 和 Vision 模型进行多模态 AI 艺术分析:
@dwb7737尝试使用 LangChain 和各种 Vision 模型来分析使用 Stable Diffusion 创作的艺术作品。他们分享了来自 OpenAI Vision 和 VertexAI Vision 的详细图像摘要,并指出 OpenAI Vision 的表现最好。摘要的 Gist 链接:VertexAI Vision Gist 和 OpenAI Vision Gist。
提到的链接:
- Prompt Engineering Guide for Open LLM: Take your Open LLM application to the next level:引言:为什么我们需要另一份指南?
- dwb536 发布的图片:未找到描述
- Agent IX - OpenAPI action drag n drop:快速演示,通过将 API action 拖入流程并将其连接为 Agent tool,创建一个连接到 Agent IX API 的 Agent。完整发布说明:ht…
- maidalun1020/bce-reranker-base_v1 · Hugging Face:未找到描述
- Vertex AI Models - Image Summarization:Vertex AI 模型 - 图像摘要。GitHub Gist:即时分享代码、笔记和片段。
- OpenAI models - Image Summarization:OpenAI 模型 - 图像摘要。GitHub Gist:即时分享代码、笔记和片段。
- Ollama models - Image Summarization:Ollama 模型 - 图像摘要。GitHub Gist:即时分享代码、笔记和片段。
LangChain AI ▷ #tutorials (2 条消息):
-
探索 LLM System 2 思维:
@jasonzhou1993分享了一个 YouTube 视频,讨论了大型语言模型 (LLMs) 中的 System 2 思维,探讨了 GPT-5 可能如何解决该问题,并就如何解锁更高级的 LLM 思维提供了见解。 -
使用 crewAI 创建笔记存储自定义工具:
@business24.ai发布了一个 教程视频,关于在 crewAI 中创建一个自定义工具,利用 OpenAI 的 ChatGPT 模型将搜索结果作为笔记存储在 Obsidian 中。
提到的链接:
- Use crewAI and add a custom tool to store notes in Obsidian: 在本教程中,我们为 crewAI 创建了一个自定义工具,用于将搜索结果作为笔记添加到 Obsidian 中。我们将其与 OpenAI ChatGPT 4 和 ChatGPT 3 以及多个…
-
GPT5 unlocks LLM System 2 Thinking?: 人类有快慢思考,但 LLM 呢?GPT5 将如何解决这个问题?关于如何解锁你的 LLM System 2 思维以应对更大问题的 101 指南 🔗 Lin…
,
OpenAccess AI Collective (axolotl) ▷ #general (11 条消息🔥):
- Open LLM 应用的 Prompt Engineering 指南:
@tim9422分享了一份 Prompt Engineering 指南,重点关注参数量在 30 亿到 700 亿之间的开源语言模型 (Open LLMs)。他们强调 Open LLMs 与闭源模型有所不同。 - A30 GPU 难题:
@le_mess询问了 A30 GPU 在训练 LLMs 方面的性能,并指出目前缺乏关于其有效性的可用信息。 - Fast Eval 的依赖问题:
@dangfutures在尝试运行 fast eval 时遇到了依赖问题,并寻求其他用户的帮助。 - 运行 MT-bench 的成本备受关注:
@noobmaster29发布了一个 来自 @abacaj 的推文链接,对运行 MT-bench 相关的高昂成本表示惊讶。 - H100 GPU 的可用性与技术故障:
@dangfutures提到在 vastAI 上发现了 10 个可用的 H100 GPU,但随后指出遇到了 CUDA 问题。
提到的链接:
- Prompt Engineering Guide for Open LLM: Take your Open LLM application to the next level: 简介:为什么我们需要另一份指南?
- Tweet from anton (@abacaj): 该死,应该有人告诉我运行 MT-bench 这么贵。
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (25 messages🔥):
-
增强数据集灵活性:
@gahdnah提交了一个 PR,为sharegpt.py添加了新的加载器函数和策略,以便支持数据集中不同的键名。他们提供了一个 YAML 配置模板,展示了如何将 原始 JSON 结构 转换为符合 axolotl 的sharegpt实现所期望的格式。 -
用于 3D-Parallelism 训练的 Nanotron:
@caseus_分享了 GitHub - huggingface/nanotron 的链接,该项目为大语言模型 LLM 的 3D-Parallelism 训练提供了一种极简方法。 -
通过 Latitude SSH Key 支持改进访问:
@dctanner感谢用户添加了 Latitude SSH Key 支持,并请求更新winglian/axolotl-cloud镜像,以包含 此 commit 中最新的 SSH_KEY 修复。 -
数据集收敛辩论:
@dctanner与@gahdnah就如何处理数据集变体进行了讨论,建议在一个名为 ‘messageslist’ 的新数据集类型中结合使用他们的方法。相关的讨论可以在他们的 Hugging Face 帖子 中找到,关于该主题的早期 PR 见 此处。 -
排除 Axolotl-Cloud 的 SSH 故障:
@dctanner和@caseus_解决了托管在 Latitude 上的axolotl-cloud镜像的 SSH 问题,该镜像需要 PUBLIC_KEY 环境变量和正确的 Docker 镜像缓存才能正常工作。@dctanner最终通过手动设置环境变量并在 Latitude UI 中暴露 22 端口,成功实现了 SSH 访问。
提到的链接:
- @dctanner on Hugging Face: “As the amount of datasets for fine tuning chat models has grown, there’s been…”:未找到描述
- GitHub - huggingface/nanotron: Minimalistic large language model 3D-parallelism training:极简的大语言模型 3D-Parallelism 训练 - GitHub - huggingface/nanotron
- fix check for env var (#1151) · OpenAccess-AI-Collective/axolotl@cbecf3e:未找到描述
OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
- 对 LoRA Alpha 值的疑问:
@noobmaster29提到看到关于在训练后更改 alpha 的讨论,并询问是否可以以不同的 alpha 值合并 LoRA,以及这样做会有什么影响。 - DPO 中的数据集困境:
@matanvetzler在尝试使用新的dpo-cleanupPR 运行DPO时遇到ValueError,尽管其数据集结构正确(包含 ‘question’、’chosen’ 和 ‘rejected’ 等特征)并已正确保存到磁盘。他们提供了数据集结构和配置详情,询问可能出了什么问题。
OpenAccess AI Collective (axolotl) ▷ #datasets (2 messages):
-
提示词设计揭秘:
@gahdnah强调了两种 AlpacaPrompter 类之间的区别:MultipleChoiceExplainPrompter侧重于解释所选答案背后的推理,而MultipleChoiceConcisePrompter则强调简洁性。 -
对澄清的感谢:
@noobmaster29以简单的 “thx” 回应,对@gahdnah关于提示词差异的澄清表示感谢或确认。
OpenAccess AI Collective (axolotl) ▷ #rlhf (2 messages):
-
dpo-cleanup 分支建议:
@filippob82建议查看dpo-cleanup分支,但未详细说明建议的背景或原因。 -
DPO 数据集结构指导:
@dangfutures正在寻求关于如何以 JSONL 格式构建 DPO 数据集的建议,并提供了一个包含 “system”、”instruction”、”input”、”accepted” 和 “rejected” 字段的模板。
LlamaIndex Discord ▷ #blog (3 条消息):
-
JSONalyze 数据分析介绍:JSONalyze 是 LlamaIndex 的一个查询引擎,通过创建内存 SQLite 表,简化了分析来自 API 响应的大型 JSON 数据集的过程。它允许对 JSON 数据运行 SQL 查询,正如提供的用于安装和使用
llama-index库的示例代码片段所解释的那样。 -
从零开始构建 ReAct Agent:LlamaIndex 分享了从头开始构建 ReAct Agent 的见解,涵盖了推理提示、输出解析、工具选择和内存集成等基础知识。该帖子旨在通过引导用户在现有框架之外完成 Agent 创建的基础步骤,来加深对 Agent 的理解。
提到的链接:
JSONalyze Query Engine - LlamaIndex 🦙 0.9.36:未找到描述
LlamaIndex Discord ▷ #general (25 条消息🔥):
- 关于
LlamaCPP使用的困惑:用户@wrapdepollo询问了messages_to_prompt和completion_to_prompt之间的区别。他们一直在使用qa_prompt_tmpl_str进行 Prompt Engineering,并询问了关于未触动DEFAULT_SYSTEM_PROMPT常量的问题。 - 开源 EmbeddingModel 和 RerankerModel 发布:
@maidalun分享了他们在 Hugging Face 上为 RAG 开源的 EmbeddingModel 和 RerankerModel 链接,并征求反馈。这些模型具有多语言和跨语言能力,以及针对各种领域的 RAG 优化。Hugging Face 上的 EmbeddingModel - NL2sql 与 RAG 集成:对于结合 NL2sql 和向量搜索,
@Teemu建议使用 LlamaIndex 的 SQLJoinQueryEngine。另外还提供了一个专门用于 NL2sql 的链接:LlamaIndex 的 SQLIndexDemo。 - Prompt Engineering 与开源 LLM:
@tim9422分享了一篇 Medium 文章,讨论了开源 LLM 的 Prompt Engineering 细微差别。@jerryjliu0对该文章表示赞赏。 - 云端部署与 Bedrock 的 AWS 凭证:
- 用户
@mysterious_avocado_98353寻求在云端设置 Bedrock 上下文的建议,因为 LlamaIndex 的 Bedrock 类所需的profile_name属性出现了问题。 - 他们随后报告了设置密钥环境变量的情况,但仍面临 profile name 的配置问题。
- 用户
- 静态 Chat Engine 的实现:
@kornberg询问了关于维护静态 Chat Engine 并动态替换chat_history的问题。- 用户
@cheesyfishes澄清说chat_history是只读的,应该在函数调用时通过.chat(msg, chat_history=chat_history)传递。
提到的链接:
- Prompt Engineering Guide for Open LLM: Take your Open LLM application to the next level:简介:为什么我们需要另一份指南?
- Tim Bradshaw – Medium:阅读 Tim Bradshaw 在 Medium 上的文章。伦敦金融时报(Financial Times)全球科技记者。观点仅代表个人,不代表金融时报。tim.bradshaw@ft.com。每天,Tim Bradshaw 和成千上万的其他声音…
- maidalun1020/bce-reranker-base_v1 · Hugging Face:未找到描述
- SQL Join Query Engine - LlamaIndex 🦙 0.9.36:未找到描述
- Text-to-SQL Guide (Query Engine + Retriever) - LlamaIndex 🦙 0.9.36:未找到描述
LlamaIndex Discord ▷ #ai-discussion (1 messages):
- 深入探讨高级 RAG 技术:用户
@andysingal分享了一篇 Medium 文章,详细介绍了 LlamaIndex 与 Together.ai 的 Long Text Embedding 之间的合作,旨在增强信息检索。这一合作伙伴关系预示着一个信息不仅易于获取,而且能被智能地组织和集成的未来。
提到的链接:
Advanced RAG with LlamaIndex & Together.ai’s Embedding:Ankush k Singal
,
Skunkworks AI ▷ #general (18 messages🔥):
- Token Monster 与模型训练查询:
@indietechie询问了在使用 Mistral/Llama 时配合 Token Monster 进行 tokenizer 训练的经验。@stereoplegic澄清说 Token Monster 可以完全替代 Hugging Face (HF) tokenizers,并利用了 LLaMa 词表。 - 自我奖励模型(Self-rewarding Model)实现的热议:
.interstellarninja分享了@Geronimo_AI在 GitHub 上发布的自我奖励语言模型实现链接,以及 Hugging Face 上相关的 Meta 论文页面,@yikesawjeez已在 basementagi 实验室对其进行了实验。 - 关于 Token 递归和数值编码的见解:
@stereoplegic发起了关于 Token 递归的讨论,并提出了 “numcode” token 的概念以增强数学理解能力,同时推测将现有词表映射到该系统的可能性。然而,他们也指出另一种使用单数字 token 的实现会降低文本泛化能力。 - Lucid Rains 实现自我奖励框架:
@teknium指出 Lucid Rains 已经在 PyTorch 中创建了一个自我奖励语言模型的实现,可在 GitHub 上获得。@yikesawjeez强调了开发者对新概念的快速响应能力。 - 探索低算力训练策略:
@yikesawjeez和@.mrfoo发现,由于算力可用性低而提出的一种使用 adapters 和 LoRA 的实现非常有趣,这表明此类方法可能是资源受限环境下的实用替代方案。
提到的链接:
- Geronimo (@Geronimo_AI) 的推文:自我奖励实现 https://github.com/lucidrains/self-rewarding-lm-pytorch ↘️ 引用 AK (@_akhaliq) Meta 发布 Self-Rewarding Language Models 论文页面:https://huggingface.co/papers/…
-
GitHub - lucidrains/self-rewarding-lm-pytorch:MetaAI 提出的 Self-Rewarding Language Model 训练框架的实现。
,
LLM Perf Enthusiasts AI ▷ #embeddings (1 messages):
- 关于 8-bit 量化 Embedding 模型的咨询:用户
@robhaisfield询问了关于 8-bit 量化 Embedding 模型的使用经验,并寻求关于其性能与常规 Embedding 模型对比的见解。目前暂无回复或进一步讨论。
LLM Perf Enthusiasts AI ▷ #feedback-meta (2 messages):
- 分享 AI 实验的频道:用户
@degtrdg建议创建一个 分享频道 (share channel),供用户在一个专门的地方发布和讨论他们的 AI 实验。这一想法得到了支持,例如@thebaghdaddy热情地回复称这个主意“酷毙了 (sick)”。 ,
Alignment Lab AI ▷ #general-chat (1 messages):
indietechie: 有人有使用 Token Monster 训练 tokenizer 的经验吗?
Alignment Lab AI ▷ #oo (1 messages):
bumingqiu: 我有。
YAIG (a16z Infra) ▷ #ai-ml (1 messages):
- 通过合同规避监管:用户
@unquiet9796提到,大型组织经常在合同中谈判条款以最小化监管成本,并建议将此作为摆脱监管机构纠缠的一种策略。