ainews-google-solves-text-to-video
谷歌攻克了文生视频(Text to Video)难题。
Google Research 推出了 Lumiere,这是一款文本生成视频模型。它采用时空扩散过程(Space-Time diffusion process)实现了先进的图像补全(inpainting)功能,性能超越了 Pika 和 Runway 等之前的模型。来自 UseScholar.org 的 Manveer 整理了一份除 HumanEval 之外的全面代码评估基准列表,其中包括来自 Amazon Science、Hugging Face 等机构的数据集。TheBloke 等 Discord 社区讨论了包括通过 API 运行 Mistral-7B、GPU 租赁以及与 LLava 的多模态模型集成等话题。Nous Research AI 重点介绍了大语言模型(LLM)微调的学习率策略、推理问题,以及 HumanEval 和 MBPP 等基准测试。RestGPT 因通过 RESTful API 控制应用程序而受到关注,展示了大语言模型的应用能力。
2024年1月23日的 AI Discord 动态。我们为您检查了 19 个服务器、291 个频道和 4199 条消息。节省的预计阅读时间(以 200wpm 计算):348 分钟。
Lumiere - 文本生成视频
来看看 Google Research 推出的 Lumiere。这段视频的每一部分都是计算机生成的:
https://www.youtube.com/watch?v=wxLr02Dz2Sc
我特别想请大家关注他们的 Inpainting(图像补全)能力 —— 观察糖浆倒在蛋糕上并停留在那里的过程:

这比我们目前看到的 Pika 和 Runway 的任何成果都高出一个层次。这似乎源于一种时空扩散过程(Space-Time diffusion process):
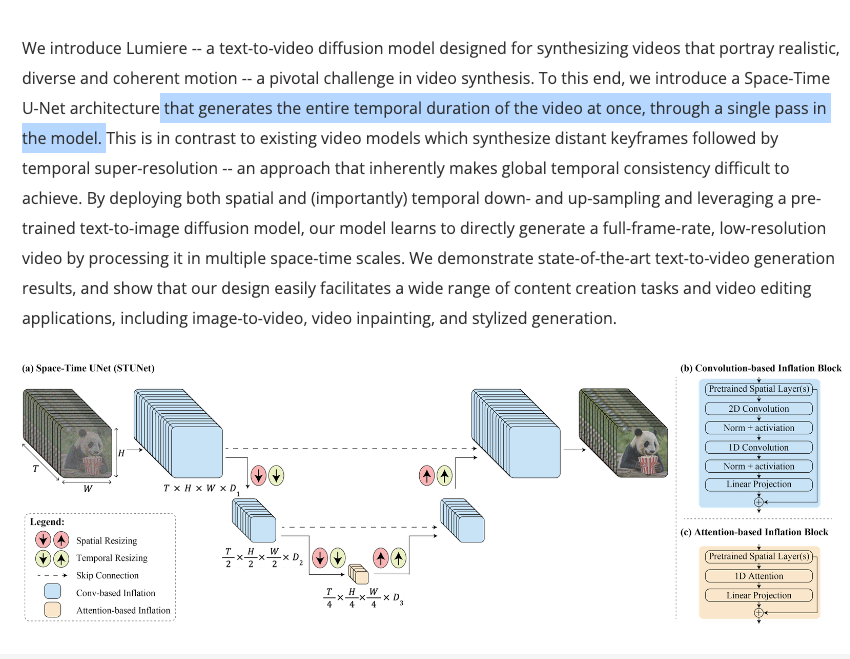
我们认为爱因斯坦会特别喜欢这个。
超越 HumanEval 的代码评估
在其他新闻方面,UseScholar.org 的 Manveer 正在整理一份全面的评估列表,其中包括一些我们从未听说过的代码评估:
- https://github.com/amazon-science/cceval
- https://infi-coder.github.io/inficoder-eval/
- https://evalplus.github.io/leaderboard.html
- https://leaderboard.tabbyml.com/
- https://huggingface.co/datasets/mbpp
- https://huggingface.co/datasets/nuprl/CanItEdit
–
目录
[TOC]
第一部分:Discord 高层级摘要
TheBloke Discord 摘要
-
重燃旧战火:一场关于 AI 和角色扮演(Roleplay)的激烈辩论爆发,由
@frankenstein0424和@kalomaze发起,随后对话转向了内容审核以及用幽默化解严肃话题。 -
鼠帮的数字卡片:以老鼠为主题的角色卡片席卷了
#general频道,引起了@rogue_variant、@mrdragonfox和@.justinobserver等人的各种反应。 -
模型乱象:寻求 API 协助:
@priyanshuguptaiitg在@itsme9316和@kalomaze等人的帮助下,尝试通过 API 运行 Mistral-7B 等模型。缺失的 Tokenizer 和微调(Fine-tuning)在社区中引起了热议。 -
追求速度:GPU 与 AI 模型租赁:社区深入探讨了 GPU,讨论了 runpod.io 等平台的存储问题,并思考了 NVIDIA A100 GPU 的生命周期终结,以及租赁 GPU 进行 AI 处理的实际细节。
-
LLM 部署与 API 使用讨论:
@frankenstein0424发起对话,寻求部署 AI 模型进行机器人托管的见解,回复建议利用SillyTavern连接 together.ai 和 mistral.ai 等 LLM API。 -
探索 Mergekit 的可能性:
@222gate研究了使用 mergekit 连接 GGUF 模型的潜力,并就融合视觉与非视觉 AI 模型这一大胆尝试寻求建议。 -
Frankenstein 的模型:对话集中在 LLava 的多模态能力和 Frankenmerging(科学怪人式合并)的愿望上 ——
@selea阐明了 LLava 的工作原理,并讨论了模型跨集成和训练中固有的挑战。
Nous Research AI Discord 摘要
- 用于现代测试的古董数据:一位用户正在使用古董教科书中的问答来测试模型,质疑模型在当前数据集上的可靠性。
- LLM 学习率讨论:共识建议从 1e-5 左右的学习率(Learning Rates)开始,参考之前的架构论文,并根据早期 Epoch 的观察进行调整。
- RestGPT 获得认可:RestGPT 作为 LLM 通过 RESTful API 控制应用程序的示例正受到关注,展示了 LLM 在现实世界接口中不断扩展的能力。
- 推理与微调的怪癖:多位用户注意到推理方法中的问题,包括偶发性的
EOStoken 包含,以及 LLM 微调期间的 OOM 问题,并建议通过按长度递减排序数据来排除故障。 - LLM 的代码相关评估:
HumanEval、MBPP和DeepSeek等基准测试正被用于 LLM 评估,同时大家也共同关注 Hugging Face 代码的维护和开放的 PR。
Mistral Discord 总结
-
Mistral Instruct 关于自动补全设计的说明:
@i_am_dom澄清了 Mistral Instruct 被设计为一个自动补全系统,它会建议在纯文本输入中省略标签。Sophia Yang 与 Mistral 的关联引起了社区的关注,她通过回应表情符号确认了这一点。 -
使用 vLLM 进行部署和 Docker 集成:vLLM 支持通过
--model标志使用本地模型文件。对于 Docker 用户,HuggingFace 缓存目录采用绑定挂载(bind-mounted),从而在重新构建 Docker 时无需重新下载模型。 -
Mixtral 8x7b 摘要任务中的问题:用户报告称,尽管 VRAM 保持稳定,但在使用 Mixtral 8x7b 进行摘要任务时会出现不可预测的响应中断。有人建议更改 Prompt 语法作为部分修复方案。同时,JSON 格式的 API 响应 仍是一个挑战,而 Mistral 的 7B 模型现在可以通过 Amazon SageMaker JumpStart 进行部署。
-
微调挑战与建议:尝试微调 Mixtral 模型似乎成本高昂且复杂,且成功率参差不齐。推荐使用 ColbertV2 来训练 embedding 模型。会议还讨论了通过 Prompt 优化和微调来改善结果的方法。
-
分享调试代码及客户端包讨论:
@jakobdylanc分享了他们在 GitHub 上的代码链接,以调试 “openai” Python 包的一个问题,这引发了关于 Mistral 客户端库 可比性的讨论。对话涉及了因其轻量性而转向 Mistral 官方包的可能性,但也引发了对视觉模型兼容性的担忧。 -
哲学与数学 Transformer 的参与:一位用户的哲学探究未能在社区引起关注,而另一位用户建议将数学理论与 Transformer 模型及 A* 算法相结合,以产生新的数学概念,这反映了社区的创意和理论讨论。
提到的关键链接:
LM Studio Discord 总结
- Ubuntu 用户克服 libclblast.so.1 障碍:Ubuntu 22.04 用户在 LM Studio 中遇到了缺失
libclblast.so.1的错误,通过创建符号链接解决了该问题。 - LM Studio 中的 Apple Neural Engine 集成:LM Studio 的讨论探讨了通过 Metal API 利用 Apple 的 Neural Engine,并建议使用 “asitop” 工具进行监控。
- 在 LM Studio 中混合搭配 AI 模型:关于将检索增强生成(RAG)与 LM Studio 集成的询问,得到了指向第三方应用程序和设置帮助的建议。
- 模型行为与性能差异:LM Studio 用户正在努力解决模型不一致的问题,分享了诸如降低 “Randomness” 或 “Temperature” 设置等技巧,并询问了模型之间的差异(例如 Dolphin 2.5 和 2.7 版本之间),尽管提供的链接内容无法直接访问。
- CodeShell 的 GPU 加速难题:用户报告称 LM Studio 中 CodeShell 的 GPU 加速选项显示为灰色。一个可能的变通方法是重命名模型文件以插入 “llama” 字样,但结果尚不确定。
- 硬件爱好者与 VRAM 显示错误作斗争:一位用户的 Nvidia 3090 显示 VRAM 为 “0Bytes”,这引发了关于硬件规格、运行 Mixtral 等模型的预算配置以及将工作负载卸载到 GPU 的稳定性配置的讨论。
- Intel GPU 支持指日可待?:一个 GitHub 的 Pull Request 暗示 llama.cpp 即将支持 Intel GPU,这可能会增强 LM Studio 的硬件兼容性。
OpenAccess AI Collective (axolotl) Discord 总结
Logit Distillation 的进展与语音合成挑战:讨论揭示了使用 GPT-4 logits 进行 logit distillation 的进展,并在回填策略(backfilling strategies)方面取得了成功。然而,正如 @ex3ndr、@le_mess 和 @stefangliga 等参与者所分享的,为 LLM 添加多达 8k 的语音合成自定义 token 将需要大量的预训练。
Jupyter SSL 问题与 Self-Rewarding Language Models:Latitude 容器中 Jupyter 的 SSL 问题浮出水面但尚未解决,导致 @dctanner 转而使用 SSH 端口转发。对 Self-Rewarding Language Models 的兴趣引发了讨论,@caseus_ 分享了一个 PyTorch 实现。
DPO 数据集加载成功、策略挣扎及本地数据集查询:成员们讨论了通过一个 PR 克服 DPO 数据集加载问题,@dangfutures 在显存溢出(out-of-memory)错误中使用了为 1 的 micro batch size。在解决 prompt 策略和 llava 模型微调方面进行了协作努力,展示了 Axolotl 框架 的灵活性,引用者包括 @caseus_、@noobmaster29 和 @gameveloster。
最优 LoRA 超参数见解与数据集重叠确认:一篇分享的 Lightning AI 文章 提供了关于有效使用 LoRA 超参数的见解,@noobmaster29 和 @c.gato 讨论了 alpha、rank 和 batch size 的变化。确认了 dolphin 和 openorca 数据集之间存在数据集重叠,表明了对数据冗余的关注。
RLHF 的 YAML 配置与 Prompt Tokenization:RLHF 项目在 YAML 配置中遇到了 KeyError,但通过新的 type 格式(chatml.argilla 和 chatml.intel)找到了解决方案并由 @alekseykorshuk 分享。还讨论了本地数据集的配置和 prompt tokenization 策略更新,强调了这些组件不断演进的特性。
机器学习容器的 Cog 配置:根据 Cog 的文档,@dangfutures 分享了一个 Cog 配置指南,详细介绍了 CUDA “12.1”、Python “3.11” 的使用以及机器学习容器的 Python 包安装。这个实用的代码片段展示了社区在基础设施设置方面的积极指导。
Eleuther Discord 总结
Byte-Level BPE 实现多语言 LLM 响应:Llama 2 模型 使用 byte-level BPE 生成多种语言的响应,支持印地语、泰米尔语和古吉拉特语。
Mamba 的可扩展性受到质疑:关于 Mamba 扩展并取代 Transformers 潜力的讨论非常热烈,但由于缺乏关于其在大规模表现上的证据,引发了技术用户的怀疑。
Google 凭借 Lumiere 抢尽风头:Google Research 用于视频生成的时空扩散模型 Lumiere 引起了关注,尽管人们对其数据集大小和数据优势存在担忧。
首届语言建模会议:宾夕法尼亚大学宣布举办首届 Conference on Language Modeling,这一消息引起了轰动,承诺将为语言建模研究带来深刻见解。
MoE 实现挑战与并行性:一位开发者分享了一个在 GPT-NeoX 中实现 Mixture of Experts (MoE) 的 pull request,表达了在单 GPU 限制下验证 MoE 的难题,并寻求并行化优化的见解;而另一个 pull request 则审查了 fused layernorm 在性能提升方面的潜力。
LAION Discord 摘要
- 快速模型训练评估:针对
@astropulse关于 128x128 微型模型训练时间的咨询,@nodja参考某论文附录 E 给出评估,认为在双 3090 设备上大约需要运行两天。 - GPT-4 限制(Caps)困惑:用户
@helium__讨论了 GPT-4 Token 限制降低的问题,@astropulse等人也确认遇到了类似的约束。 - 图像缩放对模型性能的影响:根据
@thejonasbrothers的说法,分辨率低于 256x256 的 ImageNet 模型往往表现不佳,因此主张尽管会增加训练时间,仍应采用更高的图像分辨率。 - 安全多模态数据集讨论:由
@irina_rish发起的关于多模态模型训练数据集安全性和完整性的对话,吸引了@thejonasbrothers、@progamergov等人的参与并共同寻求解决方案。 -
首届语言建模会议推广:
@itali4no发布了即将在宾夕法尼亚大学举行的语言建模会议 (CoLM) 的信息。相关的 推文 提供了有关该活动的更多细节。 - 奖励建模创新:
@thejonasbrothers分享的一篇论文提出了权重平均奖励模型 (WARM),作为解决 LLM 中奖励作弊 (reward hacking) 的方案,详情见链接 论文。 - 推进无监督视频学习:
@vrus0188展示了一篇关于 VONet 的论文,这是一个性能超越当代技术的无监督视频对象学习框架,相关代码已在 GitHub 上发布。
HuggingFace Discord 摘要
-
HuggingFace 推出新福利与发布:社区成员正积极参与 HuggingFace 强调的新活动和机会,包括为高级贡献者开设的新频道、《使用 AI 制作游戏》课程的第二章,以及关于 Gradio 如何优化的性能分析。此外,
transformers v4.37推出了新模型和 4-bit 序列化支持,而 Transformers.js 现在支持在浏览器中运行 Meta 的 SAM 模型。 -
开源与机器学习的热情与挑战:开源贡献仍然是社区精神的重要组成部分。用户报告了 ONNX 模型导出的困难,并寻求学习机器学习的入门指南——被引导至 Hugging Face 上的一份实用指南。另一位用户正在开发一种用于敏感音频咨询的隐私保护转录工具,打算使用 Hugging Face 的 transformers 和 pyannote.audio 3.1,并结合 Go 和 protobuf 定义。
-
AI 创新与协作展示:频道展示了各种 AI 项目和智力讨论,包括用于身份保持生成的 InstantID 及其获得的 Yann LeCun 的认可。用户还分享了关于 Hedwig AI 新视频平台的信息,并询问了某 YouTube 视频中使用的 AI 背景特效。QwenLM 在大语言模型(Large Language Models)方面的历程及相关资源也得到了展示。
-
创作者展示最新的 AI 工具和研究:社区成员展示了多项增强功能,如更快的
all-MiniLM-L6-v2、用于嵌入对比的 PCA 脚本,以及视觉伪造检测项目。Open LLM Leaderboard 结合 Cosmos Arena 的增强功能获得了认可,此外还重点介绍了用于轻松进行图像数据集嵌入的 HF-Embed-Images、用于机器学习训练和数据调试的 3LC,以及 Gabor Vecsei 的 GitHub 仓库。 -
深入 Diffuser 讨论:Karras 对 DPM++ 的改进引起了用户的期待,用户们还分享了对扩散调度(diffusion scheduling)及其起源的反思,引用了 k-diffusion 和一篇关于基于扩散的生成模型的论文。一位用户正在绘制扩散模型图表,以便为潜在的重新实现建立全面的理解。
-
探索 NLP 和扩散模型:NLP 频道讨论了模型并行训练的细微差别,并分享了一份指南以帮助从单 GPU 转向多 GPU 训练设置。用户对多语言模型在没有直接语言 Token 的情况下生成响应感到好奇,而 DeciLM-7B 模型的推理缓慢问题则促使用户寻求速度优化方案。
Perplexity AI Discord 摘要
-
RPA AI 效率与深色模式主导:讨论涉及 RPA AI 的效率,同时用户抱怨 Labs 缺乏浅色模式,指出目前仅提供深色模式。此外,Android 麦克风权限设置缺乏足够选项也引发了用户的不满。
-
Dream Bot 停用引发频道混乱:确认了频道关闭的消息,特别是 Dream bot 不再可用,导致用户困惑,并建议定期发布关于频道更新的新闻摘要。
-
GPT-4 与 Gemini Pro 的区别明确化:用户寻求区分 Perplexity AI 专业版中的 GPT-4 和 Gemini Pro 模型,并获得了模型选择设置方面的指导,同时社区管理员鼓励社区认可那些有帮助的贡献。
-
功能查询与额度支持:出现了关于潜在团队功能和额度支持的问题,以及关于未来应用支持 Wear OS(鉴于与 Rabbit 的潜在合作)的推测。
-
扩展 API 与 VSCode 集成提示:有关于增加产品集成的 API 速率限制的信息请求,推荐使用 Continue.dev 扩展与 VSCode 集成,并幽默地鼓励 Pro 订阅者向虚构的“God prompt 之神教会”捐赠额度。
LlamaIndex Discord 摘要
-
LlamaIndex 助力黑客松升温:IFTTT 将于 2 月 2 日至 4 日举办一场线下黑客松,奖金总额达 13,500 美元,其中包括 8,250 美元现金,目标是构建解决实际问题的项目。现场气氛热烈,参赛者可获得导师的专业指导。黑客松公告推文。
-
认识 MemGPT:打造有记忆的聊天机器人:MemGPT 是一个由
@charlespacker重点介绍的新 OSS 项目,旨在利用 LlamaIndex 技术创建具有长期记忆和自我编辑等增强能力的聊天体验,用于高级 AI 聊天解决方案。它可以通过 pip 安装,为个性化 AI 体验铺平道路。OSS 项目亮点推文。 -
SQLite 遇上 Llama-Index:
@pveierland询问是否有现成的 sqlite-vss 集成用于 llama-index,但在讨论中未发现相关文档或解决方案。 -
Pandas Query Engine 的混乱:成员们讨论了 PandasQueryEngine 与 Zephyr 7b 等开源 LLM 相关的问题,揭示了大语言模型中查询流水线(query pipelines)的复杂性。虽然分享了相关文档,但构建 RAG 聊天机器人时紧迫的 CSV 文件问题在很大程度上仍未解决。
-
利用动态知识增强 RAG 聊天机器人:
@sl33p1420通过其 Medium 文章分享了如何通过集成动态知识源来增强 RAG 聊天机器人。该综合指南引导读者了解从模型选择、服务器设置到聊天引擎构建的细微差别,以创建一个强大的由 LLM 驱动的 RAG QA 聊天机器人。赋能你的聊天机器人文章。
OpenAI Discord 总结
- AI 社区连接尚显不足:有用户在寻找更多 LLM Discord 服务器,但未获得任何推荐,这凸显了社区资源共享方面可能存在的空白。
- AI 行为基准:将 AI 多样性与人类复杂性进行对比引发了讨论,强调了不同的设计和环境可能会产生多种 AI 行为的观点。
- 寻求最佳工具:针对基于 GPT-4 的聊天机器人寻求有效的 LLM 评估与监控工具 的咨询被提出,但未得到解答,表明了对此类资源的迫切需求。
- 图像 AI 审查:有人对 Dall.E 的图像处理能力提出了疑问,然而,关于问题的细节或原因尚未达成定论。
-
AGI 控制权争论:对 AGI 的控制权主导了对话,讨论围绕谁将拥有此类技术的权威以及对其潜在用途的考量展开。
- 文件上传限制说明:澄清了 Custom GPT 中文件上传的限制(最多 20 个文件,每个 512MB,文本文件最多 200 万个 tokens),同时讨论了绕过这些限制的策略,例如合并文档。
- GPTs Marketplace 消失现象:有关于 GPTs Marketplace 上缺失 CustomGPTs 的咨询,该问题仍未解决,表明可能需要更高的透明度或技术支持。
- 使用 Grimoire GPT 进行文字处理:分享了在十分钟内使用 Grimoire GPT 开发文字处理器的案例,展示了基于 GPT 应用的快速实现能力。
- Custom GPT 网络故障:有报告称在 Custom GPT 做出响应后出现网络错误,但未给出解决方案,凸显了社区内持续存在的技术隐忧。
-
GPT 中的线程复杂性:当一个 GPT 线程中的文件似乎影响了另一个线程时,引发了困惑,这表明跨线程的文件处理可能存在问题,社区正在等待关于预期行为的确认。
- AI 的增强上下文管理:提到了一项关于处理聊天日志以提取信息的关注点,特别是日志的大小和格式对 AI 在该领域性能的重大影响。
- 通过 Prompt 优化 AI 助手:讨论了适用于组织或行政协助角色的 Prompt 创意建议,强调定制 Custom GPT Prompt 以包含用户背景信息,从而提升性能。
- 倡导清晰的沟通目标:分享了关于优化 Custom GPT 描述字段中任务的建议,推荐明确表达目标和预期结果,无论是寻求 AI 还是人类协作。
- AI 指令的简洁性与有效性之争:一位用户建议在引导 AI 时,应专注于清晰的目标而非“最有效的”语言,提出了一种实现预期结果的务实方法。
DiscoResearch Discord 总结
-
Prompt 困惑?模板微调来救场:社区协作发现了一个模型的本地实例与演示实例之间的模板差异,建议使用 f-strings 和换行符格式化,以更好地兼容 DiscoLM 模型。指导建议参考 DiscoLM German 7b v1,社区对在处理 LLM 复杂问题时获得的各种支持表示感谢。
-
翻译评估与预测性思考:讨论了使用 Lilac 进行翻译质量评估以及使用 Distilabel 过滤不良翻译的实现,尽管 GPT-4 的成本仍是一个令人担忧的问题。Llama-3 的预测强调了专注于多语言能力的 5 万亿 token 预训练,并向高级上下文分块研究致敬。此外,一个新的拥有 1 万亿 token 数据集的 German LM 宣布即将问世,暗示了巨大的算力需求。
-
Mistral 开辟新路径:一个类似于 Mistral embedding model 的项目在 GitHub 上启动,利用了 Quora 数据,并围绕是在 Hugging Face 还是 GitHub 上托管,以及是构建 BigGraph 还是 Table Embedding 模型展开了讨论。此外,Voyage 的新代码嵌入模型
voyage-code-2因其在语义代码检索方面的进步而受到关注,详见其博客文章。 -
Axolotl 采用轶事:Axolotl 的故障排除建议包括使用支持的格式进行数据集集成,并在 Axolotl config 中引用;通过 NVIDIA Container Toolkit 管理 Docker 中的 GPU 识别;以及在 Axolotl Discord 寻求专业帮助的提示。DiscoLM German 模型的一个棘手换行符问题促使社区发布了一个芯片组修复程序,通过修改
config.json来解决 Hugging Face 上讨论的输出异常问题。
Latent Space Discord 总结
-
Karpathy 阐述技术对人类的影响:Andrej Karpathy 的新博客文章讨论了科技行业以外的人在适应快速技术变革时面临的困难。焦虑和不安是应对创新速度时常见的心理反应。
-
Perplexity 的复杂进展可视化:来自
@madiator的一条 推文 展示了 AI 模型 Perplexity 在三个月跨度内的非线性发展轨迹。 -
在保持认知能力的同时缩小模型规模:关于训练小型语言模型 (LMs) 的研究显示,模型有潜力保持语法和推理能力,正如 TinyStories 论文 中所讨论的那样。
-
Discord 招募 AI 实现更智能的通知:Discord 已开始使用大型语言模型 (LLMs) 总结社区消息以生成通知标题,这标志着隐私政策考量可能发生转变。
-
Stability AI 在图像生成方面的突破:Stability AI 开发了一种能够直接生成百万像素级图像的扩散模型,这可能预示着传统潜在扩散 (latent diffusion) 技术的终结。
-
Lucidrains 准备攻克 SPIN 和 Meta 论文:
@lucidrains正在准备在独立项目中实现 SPIN 和一种新的 Meta 论文方法,self-rewarding-lm-pytorch 是值得关注进度更新的代码库。
LangChain AI Discord 摘要
-
LangChainJS 实验性探索:
@ilguappo在 GitHub 上分享了一个名为 LangChainJS Workers 的开发中项目。该项目虽然在 Web API 最佳实践方面存在争议,但探索了一种在 Discord 消息中实现 Emoji 回应的新型端点。他们还在努力克服 TypeScript 的陡峭学习曲线及其在当前项目中的集成问题。 -
组队构建 RAG 系统:
@alvarojauna表达了对端到端 Retrieval-Augmented Generation (RAG) 解决方案的兴趣,并寻求合作或先例;同时@allenpan_36670发起了一场关于 GPT chat completion 如何处理消息列表的澄清讨论,@lhc1921提到 ChatML 的 Prompt 结构是处理此类数据的一种方法。 -
启动智能 PDF 对话:
@a404.eth发布了一个教程系列,第一部分已在 YouTube 上线,指导用户利用 PGVector、unstructured.io 和 semantic chunker 技术创建能够与 PDF 文档对话的 Full Stack RAG systems。 -
LLaMA 在艺术评判中胜过 Baklava:在 AI 模型的对比测试中,
@dwb7737在 GitHub Gist 上发布了研究结果,展示了 LLaMA 在艺术分析任务中的表现优于 Baklava。 -
工程师警惕恶意链接:
@eleuss在 langserve 频道中发布了一条关于潜在垃圾信息的警告。该信息包含一系列条杠、下划线和一个可疑的 Discord 邀请链接,提醒技术社区需要对此类行为保持警惕。
LLM Perf Enthusiasts AI Discord 摘要
- LLM Perf 公会的新视野:
@jeffreyw128以充满活力的欢迎开启了 2024 年,并透露了通过新一轮定向邀请和成员推荐来扩大 Discord 公会的意图。 - 关注文档布局的最前沿技术:公会内的讨论强调了 Vision Grid Transformer 是理解文档布局的尖端模型,尤其擅长识别 PDF 中的图表(由
@res6969分享),其 GitHub 仓库地址在这里。 - #share 分享你的知识:经
@degtrdg和@jeffreyw128决定,社区协作产生了一个名为 #share 的新频道,用于存放相互之间的知识交流。 - 通过 LLM 活动产生协同效应:
@yikesawjeez谈到了 LLM 领域的活力,指出了诸如论文俱乐部(paper clubs)、实现会议(implementation sessions)和代码马拉松(codejams)等参与性活动,这些活动是 LLM 性能爱好者的重要聚集地。 - 用智慧渗透:
@yikesawjeez以轻松的语调建议成员们通过将他们的 LLM 性能专业知识带到外部活动中,来扩大他们的触达范围和影响力。
Skunkworks AI Discord 摘要
根据提供的消息,目前没有足够的上下文或实质性的技术内容来生成面向工程师读者的摘要。这两条消息似乎都是非正式沟通,没有任何可辨别的技术讨论或关键点。
YAIG (a16z Infra) Discord 摘要
- 寻求云独立性:
@floriannoell询问了不依赖于 AWS, GCP 或 Azure 等主流云服务商的 on-premise AI 解决方案,并提到 watsonx.ai 作为所需功能的参考点。 - 量身定制 AI:在讨论本地化解决方案的过程中,
@spillai建议@floriannoell阐明具体的 AI 需求,例如 pretraining, finetuning 或 classification,以便引导寻找更合适的本地化 AI 系统。
Alignment Lab AI Discord 摘要
- 在 Hugging Face 上获取 Slim Orca 数据集:Slim Orca 数据集现已托管在 Hugging Face 上,拥有约 50 万条 GPT-4 生成内容,并通过 GPT-4 精炼提升了质量。该数据集因仅需 2/3 的计算能力即可达到与更大规模数据切片相当的性能而受到关注 (Slim Orca)。
- 使用 Slim Orca 模型使训练更高效:jackalope-7b 和 Mistral-7B-SlimOrca 这两个模型展示了在 Slim Orca 子集上实践的高效率和高性能。这一进展由
@222gate在社区聊天中分享,突出了该数据集在不牺牲输出质量的情况下降低了计算需求。
Datasette - LLM (@SimonW) Discord 摘要
- 离线 LLM 增强功能发布:
llm-gpt4all0.3 版本已发布,其特性包括模型的离线功能改进,以及调整模型选项的能力(如-o max_tokens 3)。该版本还包含来自社区贡献者的修复。
第 2 部分:渠道详细摘要与链接
TheBloke ▷ #general (1398 条消息🔥🔥🔥):
- AI 与 RP 社区联合:用户
@frankenstein0424和@kalomaze就 AI 和 RP(角色扮演)展开了激烈讨论,引发了对管理审核的呼吁以及针对该情况的玩笑。 - 对老鼠的痴迷:
#general聊天室被大量与老鼠相关的角色卡刷屏,引发了@rogue_variant、@mrdragonfox和@.justinobserver等用户的不同反应。 - Mistral 7B 与 AI 编程:用户
@priyanshuguptaiitg寻求通过 API 运行 Mistral-7B 等模型的帮助,并得到了@itsme9316、@kalomaze等人的指导。他们讨论了 API 的使用困难,提到了缺少 Tokenizer 和 Fine-tuning 选项等问题。 - 探索 MoE 和 Mergekit:用户
@kquant、@sanjiwatsuki和@kalomaze之间展开了严肃的技术讨论,重点关注 Fine-tuning Mixture of Experts (MoE) 模型的细微差别、性能及其面临的独特挑战。 - GPU 讨论与 AI 租用:聊天深入探讨了 GPU 领域,讨论了 runpod.io 等平台上的存储选项,以及 NVIDIA A100 GPU 的 End-of-Life 公告。他们还触及了租用 GPU 用于大型语言模型的实际操作层面。
提到的链接:
- No Way GIF - Stunned Wow Omg - Discover & Share GIFs:点击查看 GIF
- Jon Durbin (@jon_durbin) 的推文:正在使用 cinematika 数据开发一个增强 RP 的 DPO 数据集,这意味着回复是人工编写的(但仍经过 LLM 增强)。让我们看看这是否奏效 🤞🏻
- Screenshot to HTML - Hugging Face 上的一个 Space,由 HuggingFaceM4 提供:未找到描述
- openaccess-ai-collective/mistral-7b-llava-1_5-pretrained-projector · Hugging Face:未找到描述
- Brain GIF - Brain - Discover & Share GIFs:点击查看 GIF
- TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF · Hugging Face:未找到描述
- All Your Base Are Belong To Us Cats GIF - All Your Base Are Belong To Us Cats Cat - Discover & Share GIFs:点击查看 GIF
- 创建网络卷 (Network Volume):未找到描述
- 开源 LLM 的 Prompt-Engineering:事实证明,开源 LLM 的 Prompt-Engineering 是不同的!实际上,在切换任何 LLM 时都需要对 Prompt 进行工程化——即使是在 OpenAI 之间……
- Mad Men Conversing GIF - Mad Men Conversing Feel Bad For You - Discover & Share GIFs:点击查看 GIF
-
What Do You Mean By That GIF - What Do You Mean By That - Discover & Share GIFs:点击查看 GIF
- DIE ANTWOORD - RATS RULE [音乐视频]: Die Antwoord - Mount Ninji and Da Nice Time Kid - Rats Rule/ 由 JACK BLACK 参演!更多精彩即将推出,订阅以防错过!使用的视频:/ DIE A…
- 在《博德之门 3》中与愤怒的老鼠交谈: 在《博德之门 3》中与愤怒的老鼠交谈。通过此视频指南,你可以看到《博德之门 3》中与愤怒老鼠交谈的场景。《博德之门 3》是一款角色扮演…
- yahma/alpaca-cleaned · Hugging Face 数据集: 未找到描述
- GitHub - openai/consistencydecoder: 一致性蒸馏 Diff VAE: 一致性蒸馏 Diff VAE。通过在 GitHub 上创建账号,为 openai/consistencydecoder 的开发做出贡献。
- Neil deGrasse Tyson 解释模拟假设: Neil deGrasse Tyson 和喜剧联合主持人 Chuck Nice 来到这里(或者他们真的在吗?)调查我们是否生活在模拟之中。我们探索了不断进步的计算…
- GitHub - deep-floyd/IF: 通过在 GitHub 上创建账号,为 deep-floyd/IF 的开发做出贡献。
-
[三星 870 QVO 8TB SSD 存储器 三星英国](https://www.samsung.com/uk/memory-storage/sata-ssd/ssd-870-qvo-sata-3-2-5-inch-8tb-mz-77q8t0bw/): 探索三星 SSD 带来的惊人存储空间。享受提升的性能、通过 Samsung Magician 实现的便捷管理以及出色的可靠性。 - GitHub - oobabooga/text-generation-webui: 用于大语言模型的 Gradio Web UI。支持 transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。: 用于大语言模型的 Gradio Web UI。支持 transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。- GitHub - oobabooga/text-generation-webui: 用于大语言模型的 Gradio Web UI…
-
[Mac Jan](https://jan.ai/install/mac/): Jan 是一个可以在你自己的电脑上运行的 ChatGPT 替代方案,带有本地 API 服务器。 - Maximilian-Winter 将 self extension 移植到服务器 · Pull Request #5104 · ggerganov/llama.cpp: 你好,我将 self extension 的代码移植到了服务器。我已经通过信息检索进行了测试,我在一段约 6500 tokens 长的文本中插入了上下文之外的信息,它成功了,至少…
- Nature: Nature 是世界上最重要的国际科学周刊,也是 Nature Portfolio 的旗舰期刊。它发表最优秀的…
- 无需人类演示即可解决奥数几何问题 - Nature: 一种用于欧几里得平面几何的新型神经符号定理证明器,在数百万个合成定理和证明上从零开始训练,其表现优于之前的最佳方法,并达到了…
- main : 由 ggerganov 添加 Self-Extend 支持 · Pull Request #4815 · ggerganov/llama.cpp: #4810 的后续,基于此项工作为 main 添加上下文扩展支持:https://arxiv.org/pdf/2401.01325.pdf。使用约 8k 上下文和基础 LLaMA 7B v… 进行了一些基本的事实提取测试。
- YT Industries: Decoy MX CORE 3
TheBloke ▷ #characters-roleplay-stories (427 条消息🔥🔥🔥):
-
模型对比与使用查询:用户讨论了他们在特定角色扮演任务中使用
Nous Hermes和SanjiWatsuki/Lelantos-Maid-DPO-7B等各种模型的经验。@ks_c发现Kunoichi dpo v2在角色诠释方面表现最好。 -
前端功能与 Lorebooks:
@animalmachine分享了 Lorebook 功能对角色扮演聊天的价值,并指向了关于 SillyTavern 使用 World Info 的相关文档。 -
自动化模型训练的数据收集:
@frankenstein0424正在编写脚本,以自动从网站消息中为他们的 Bot 创建训练数据,计划为一个高度专业化的任务收集数据集。 -
量化与模型性能:
@keyboardking讨论了从低于 10GB 的模型中获取语法正确输出的困难,并对深度量化是否会导致7B等模型表现欠佳表示担忧。 -
Bot 的部署与 API 选择:
@frankenstein0424就通过外部 API 托管和使用Mixtral AI等模型寻求建议,建议包括使用SillyTavern前端连接到各种 LLM API,如 together.ai 和 mistral.ai。
提到的链接:
-
[Mistral AI Open-weight models](https://mistral.ai/):掌控前沿 AI -
[World Info docs.ST.app](https://docs.sillytavern.app/usage/core-concepts/worldinfo/):World Info(也称为 Lorebooks 或 Memory Books)增强了 AI 对世界细节的理解。 - NeverSleep/Noromaid-13B-0.4-DPO-GGUF · Hugging Face:未找到描述
- LoneStriker/Noromaid-13B-0.4-DPO-3.0bpw-h6-exl2 · Hugging Face:未找到描述
- makeMoE: Implement a Sparse Mixture of Experts Language Model from Scratch:未找到描述
- Rentry.co - Markdown Paste Service:带有预览、自定义 URL 和编辑功能的 Markdown 粘贴服务。
- Models - Hugging Face:未找到描述
- Another LLM Roleplay Rankings:(欢迎在 Discord 上向 AliCat (.alicat) 和 Trappu (.trappu) 发送反馈)我们热爱角色扮演和 LLM,并希望创建一个排名。部分原因是基准测试并不是真正针对角色扮演设计的……
- TheBloke/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-HighDensity-GGUF · Hugging Face:未找到描述
- text-generation-webui/modules/sampler_hijack.py at 837bd888e4cf239094d9b1cabcc342266fee11c0 · oobabooga/text-generation-webui:一个用于大语言模型的 Gradio Web UI。支持 Transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。- oobabooga/text-generation-webui
- How to mixtral:更新于 12/22。至少需要总计约 20GB 的 VRAM / RAM。VRAM 越多,速度越快/效果越好。获取最新的 Kobold:https://github.com/kalomaze/koboldcpp/releases 下载模型,下载其中一个量化版本…
- text-generation-webui/modules/logits.py at main · oobabooga/text-generation-webui:一个用于大语言模型的 Gradio Web UI。支持 Transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。- oobabooga/text-generation-webui
- The Sarah Test:(由 Ooba 和 SillyTavern Discord 服务器上的 #theyallchoppable 提供)另请参阅:https://rentry.org/thecelltest。Sarah 测试是一个简单的提示词,用于测试模型的连贯性、逻辑一致性等……
- Intro:简介、更新日志、执行 Cell 测试、检查 Logits、采样器的影响、模型结果摘要、模型结果表、结语、未来改进、附录 A:提示词的潜在问题……
TheBloke ▷ #training-and-fine-tuning (5 条消息):
- 渴望在本地训练:
@superking__表达了在熟练掌握之前,希望开始尝试在本地进行训练以节省算力成本的热情。 - 询问实现归属:一位用户询问
@superking__是否负责实现了一种加载单个模型的方法,并提到在某个 Pull Request (PR) 中看到过他们的名字。 - 确认贡献:
@jondurbin确认他实现了 2-adapter 方法,并澄清现有的空引用代码之前就已经存在。 - 寻求共同问题的解决方案:
@carlito.88询问了一个之前出现的问题,想知道是否已经找到了解决方案。 - 关于 LLM 和 TensorRT 转换的查询:
@bycloud向社区询问关于训练/微调大语言模型 (LLM) 并将其转换为 TensorRT 优化模型的经验。
TheBloke ▷ #model-merging (2 条消息):
- 关于合并 gguf 模型的咨询:
@222gate询问是否有人知道是否可以使用 mergekit 合并 gguf 文件,尽管假设这可能不可行,但仍表达了尝试的兴趣。 - 视觉与非视觉模型的融合:
@222gate向社区询问是否有关于将视觉模型与非视觉模型合并的尝试或文档,表示需要此类跨模态合并的指导。
TheBloke ▷ #coding (13 条消息🔥):
- 理解 LLava 的构成:
@selea解释说 LLava 模型结合了 CLIP 进行图像识别;来自 CLIP 的 token 会被附加到语言模型中的文本提示之前。因此有必要训练模型以正确解释 CLIP embeddings。 - 添加多模态具有复杂性:针对
@lordofthegoons关于添加多模态的询问,@selea指出挑战在于训练文本模型以高效地理解和利用图像嵌入。 - 模型 Frankenmerging:
@lordofthegoons思考是否可以从 LLava 中提取部分层并将其与其他模型合并,而@selea承认对 Frankenmerge 了解不多,但推测向另一个模型添加 CLIP 理解能力是有可能的。 - Frankenmerge 模型中的故障:
@selea提到,即使 Frankenmerge 成功,由于组合不同系统固有的复杂性,生成的模型运行起来可能会出现故障。 - 使用 LLava 改进模型训练:
@selea提议使用 LLava 蒸馏出准确的图像描述,并重新训练像 Stable Diffusion 这样模型的文本处理部分,因为后者目前在提示词方面使用的是一种“古怪的机器代码”。 ,
Nous Research AI ▷ #off-topic (18 条消息🔥):
- 迷人的老派数据:用户
@everyoneisgross提到他们购买古董教科书来手动输入问答 (Q&A) 以进行模型测试,并对那些在现代数据集上表现过好的模型表示怀疑。 - 微调 AI 模型:
@pradeep1148分享了一个名为“使用 Unsloth 微调 TinyLlama”的 YouTube 视频,内容涵盖数据准备、训练、推理和模型保存。 - 将“Machine Learning”变为“Money Laundering”:
@euclaise发布了一条有趣的推文,介绍了一个将“Machine Learning”替换为“Money Laundering”的 Chrome 扩展程序,并分享了该扩展的 GitHub 链接。 - CUDA Kernels 允许非 2 的幂配置:
@carsonpoole讨论了使用 CUDA 而非 Triton 编写 Kernel 的优势,指出配置可以设置为非 2 的幂,有时能获得更好的性能。 - 对 AI 公司预期的讽刺性解读:
@sumo43拿那些自称为 AI 公司的过高预期开玩笑,暗示这是一个文字游戏,称它们为仅仅生成 token 的“token 公司”。
提到的链接:
- 来自 cts🌸 (@gf_256) 的推文:如果你把“machine learning”替换为“money laundering”,Twitter 会变得更有趣。所以我做了一个实现这个功能的 Chrome 扩展:https://github.com/stong/ml-to-ml
- 使用 Unsloth 微调 TinyLlama:你将学习如何进行 数据准备、如何 训练、如何 运行模型 以及 如何保存模型(例如用于 Llama.cpp)。**[注意…
Nous Research AI ▷ #interesting-links (38 条消息🔥):
- Prompt Lookup 革命:
@leontello通过分享其重要性的提及,推广了针对基于输入的任务的高效 Prompt Lookup,并称其为应该被更多利用的“免费午餐”。 - 使用 LLM 控制应用程序:
@mikahdang重点介绍了 RestGPT,这是一个展示基于 LLM 的自主 Agent 的项目,它可以通过 RESTful API 控制现实世界的应用程序。 - Function Calling 是未来:
@mikahdang和@teknium对 Function Calling 在推理和规划中的重要性达成了一致,认为这是 LLM 与 API 集成的未来核心。 - 揭秘 GPT-4 的非确定性:由
@burnytech发起的一场对话链接了一些讨论 GPT-4 因 Sparse MoE 导致非确定性的文章,@stefangliga、@stellaathena和@betadoggo贡献了关于挑战和影响的见解。 - Diffusion Model 的考量:
@mikahdang分享了关于 Contrastive Preference Learning 和 Diffusion 语言模型可扩展性的研究,引发了关于它们在 NLP 中被低估的辩论。@_3sphere、@betadoggo和@manojbh就合并自回归模型和 Diffusion 模型用于各种任务的潜力和挑战表达了不同观点。
提到的链接:
- Are Diffusion Models Vision-And-Language Reasoners?:文本条件图像生成模型最近在使用去噪 Diffusion 过程方面取得了巨大的定性成功。然而,与判别式视觉语言模型不同,它是一种…
- Diffusion Language Models Can Perform Many Tasks with Scaling and…:最近生成式 AI 的激增是由 Diffusion 概率模型的生成能力和 Large Language Models 的扩展能力所推动的。尽管它们具有潜力,但…
- Contrastive Preference Learning: Learning from Human Feedback…:从人类反馈中进行强化学习 (RLHF) 已成为使模型与人类意图对齐的流行范式。通常 RLHF 算法分为两个阶段:首先,使用人类…
- Tweet from Weyaxi (@Weyaxi):我发布了 BagelHermes-2x34B,这是一个 Mixture of Experts 模型,结合了 @jon_durbin 的 bagel 🥯 和 @NousResearch 的 Hermes2 📨。Hermes 擅长数学,而 Bagel 在问答和科学方面更胜一筹。所以…
- GitHub - Yifan-Song793/RestGPT: An LLM-based autonomous agent controlling real-world applications via RESTful APIs:一个通过 RESTful API 控制现实世界应用程序的基于 LLM 的自主 Agent - GitHub - Yifan-Song793/RestGPT。
- Non-determinism in GPT-4 is caused by Sparse MoE:目前众所周知,GPT-4/GPT-3.5-turbo 具有非确定性,即使在 temperature=0.0 时也是如此。如果你习惯了 Dense Decoder-only 模型,这种行为会很奇怪,因为在这些模型中 temp=0 应该是…
- Tweet from Maksym Andriushchenko 🇺🇦 (@maksym_andr):GPT-4 本身是不可复现的,很可能是由于 MoE 的批量推理(感谢 @patrickrchao 提供的参考!):https://152334h.github.io/blog/non-determinism-in-gpt-4/ 有趣的是,GPT-3.5 …
Nous Research AI ▷ #general (271 条消息🔥🔥):
-
Batch Size 示例公开:
@leontello分享了一个 Batch Inference(批处理推理)示例,提供了一段代码片段,演示了如何使用transformers库中的模型和 Tokenizer 在 GPU 上运行 Batch Prompts。 -
Chat Templating 的实用工具:
@osanseviero提到了一项针对 Chat Templates(聊天模板)的 有用资源,指出了其对开发者的潜在价值。 -
关于 OpenAI Logit Distillation 的讨论:“有人在对 GPT4 进行 Logit(软)蒸馏吗?”
@dreamgen提出了疑问,引发了关于 OpenAI API 是否提供 Logits 以及蒸馏 LLM 的可行性和方法的对话。用户们讨论了蒸馏的价值和策略,并指出这可能是一个尚未被充分探索的领域。 -
RUGPULL 可视化应用开发:
@n8programs正在开发一个名为 RUGPULL 的应用程序,旨在探索语料库的 UMAP 表示,能够以引人入胜的交互式图表格式查看 Chunks 之间的距离和相关性。 -
Qwen 72B Base 与 Llama 2 70B Base 的讨论:对话转向了比较 Qwen 72B Base 和 Llama 2 70B Base 模型在 Fine-tuning(微调)方面的可用性。一些用户如
@intervitens和@s3nh1123分别提到了 VRAM 消耗和多语言支持的优势等问题;然而,由于缺乏对 Qwen 的广泛实验,目前尚未达成共识。
提到的链接:
- Introducing Qwen:在发布 Qwen-7B(我们 LLM 开源之旅的起点)4 个月后,我们现在提供 Qwen 系列的介绍,为您展示整个…
- Brain GIF - Brain - Discover & Share GIFs:点击查看 GIF
- Cat Explode GIF - Cat Explode Explosion - Discover & Share GIFs:点击查看 GIF
- 来自 anton (@abacaj) 的推文:我获得了一些关于 Phi-2 DPO 的具体数据。你可以看到使用 DPO 后,MT-bench 的第一轮和第二轮模型能力有明显提升。更多的 Epochs 并没有真正的整体帮助,我的模型过拟合了…
- GitHub - KillianLucas/aifs: Local semantic search. Stupidly simple.:本地语义搜索。极其简单。通过在 GitHub 上创建账号为 KillianLucas/aifs 的开发做出贡献。
- HuggingFaceH4/open_llm_leaderboard · Discussions:未找到描述
- HuggingFaceH4/open_llm_leaderboard · Flagging models with incorrect tags:未找到描述
- 01-ai/Yi-34B · Hugging Face:未找到描述
- cognitivecomputations/dolphin · Datasets at Hugging Face:未找到描述
Nous Research AI ▷ #ask-about-llms (57 条消息🔥🔥):
-
寻找最佳学习率 (LR):用户
@alyosha11和@bozoid.讨论了如何为 LLMs 寻找最佳 LR,建议使用评估数据集或 benchmarks。@bozoid.提到参考之前架构论文中的学习率可以获得不错的结果,而@teknium则建议从 1e-5 左右的经验 LR 开始,并在观察 3 个 epochs 的结果后进行调整。 -
Mistral 和 Llama 的推理技巧:用户
@blackl1ght询问了除了llama.cpp之外mistral的替代推理方法,@.ben.com推荐了exllamav2。与之相关,@blackl1ght反馈了一个在流式响应(streaming responses)中包含EOStoken 的问题,@max_paperclips确认这种情况会偶尔发生,具体取决于模型。 -
LLM 微调中的 OOM 问题和序列长度:用户
@besiktas描述了在微调时遇到的显存溢出 (OOM) 问题,即使之前的正向/反向传播(forward/backward passes)是成功的。@yonta0098建议检查是否是较长的序列导致了问题,并建议按长度降序排列数据,以便在这种情况下尽早触发 OOM。 -
关于 LLM 评估和微调的讨论:
@rememberlenny发起了关于 LLM 代码相关评估的讨论,包括@manveerxyz和@besiktas在内的多位用户提到了HumanEval、MBPP和DeepSeek等 benchmarks。@besiktas还对 Hugging Face 代码中某些部分的质量表示担忧,并提到了尚未处理的 PRs。 -
微调挑战和 Hugging Face 的问题:
@besiktas提供了一个测试实现的链接,通过逐渐增加上下文长度(context length)来诊断微调内存泄漏,并描述了使用 Hugging FaceFuyuProcessor时的困难。这引发了关于为此类大规模协作项目做贡献所面临挑战的讨论。
提到的链接:
- pretrain-mm/tests/test_model.py at 4159505915d5e15952957aa5607eadf9fc6c70cd · grahamannett/pretrain-mm:通过在 GitHub 上创建账号来为 grahamannett/pretrain-mm 的开发做出贡献。
- nuprl/CanItEdit · Datasets at Hugging Face:未找到描述
- mbpp · Datasets at Hugging Face:未找到描述
- FuyuProcessor broken and causes infinite loop · Issue #27879 · huggingface/transformers:transformers/src/transformers/models/fuyu/processing_fuyu.py 第 618 行,在 75336c1 中,当 (pair := find_delimiters_pair(tokens, TOKEN_BBOX_OPEN_STRING, TOKEN_BBOX_CLOSE_STRING)) != ( 我不确定具体…
- GitHub - amazon-science/cceval: CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion (NeurIPS 2023):CrossCodeEval:一个用于跨文件代码补全的多样化且多语言的 Benchmark (NeurIPS 2023) - GitHub - amazon-science/cceval…
- InfiCoder-Eval: Systematically Evaluating Question-Answering for Code Large Language Models:未找到描述
- EvalPlus Leaderboard:未找到描述
- Coding LLMs Leaderboard:未找到描述
Mistral ▷ #general (225 messages🔥🔥):
- Mistral Instruct 自动补全说明:用户
@i_am_dom澄清了 Mistral Instruct 在设计上就是自动补全(autocomplete),并建议在纯文本输入时跳过标签(tags),这将促使模型对输入内容进行预测补全。 - Sophia Yang 确认加入 Mistral:用户
@jarsalfirahel对得知在 YouTube 上知名的 Sophia Yang 与 Mistral 有关表示惊讶。Sophia 以感谢表情符号予以回应。 - Mistral 知识库文件上传:用户
@vivacious_gull_97921询问 Mistral 是否支持向知识库上传文件,@sophiamyang回复称目前不支持,建议将 Mistral 与其他 RAG 工具配合使用。 - Amazon SageMaker 上的 Mistral 7B 基础模型:
@sophiamyang分享了一篇 SageMaker 博客,宣布 Mistral 7B 模型已可在 Amazon SageMaker JumpStart 中部署。该博文展示了如何发现并部署该模型。 - Mistral Discord 的审核与未来计划:在
@ethux建议因诈骗问题需要管理员后,@sophiamyang确认 Mistral Discord 已设置管理员。他们欢迎关于更好审核机制设置的建议。
提到的链接:
- Cat Berg Cat GIF - Cat Berg Cat Orange Cat - Discover & Share GIFs:点击查看 GIF
-
[Mistral 7B foundation models from Mistral AI are now available in Amazon SageMaker JumpStart Amazon Web Services](https://aws.amazon.com/blogs/machine-learning/mistral-7b-foundation-models-from-mistral-ai-are-now-available-in-amazon-sagemaker-jumpstart/.):今天,我们很高兴地宣布,由 Mistral AI 开发的 Mistral 7B 基础模型已通过 Amazon SageMaker JumpStart 提供给客户,支持一键部署运行… - Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4:未找到描述
- GPT-4:我们创建了 GPT-4,这是 OpenAI 在扩展深度学习方面的最新里程碑。GPT-4 是一个大型多模态模型(接受图像和文本输入,输出文本),虽然在某些方面能力稍逊…
Mistral ▷ #models (81 messages🔥🔥):
- Mixtral 8x7b 的摘要生成问题:用户
@atom202300报告了 Mixtral 8x7b 与 Huggingface Text Generation Interface (TGI) 的问题,即模型在摘要任务中会不可预测地中断响应。尽管 VRAM 稳定,但特定示例仍存在该问题,表明其对 Prompt 结构具有敏感性。 - Prompt 模式引发的问题:
@sublimatorniq和@atom202300讨论了更改 Prompt 语法对摘要性能的影响,发现将方括号改为圆括号可以减少提前停止的情况,而@mrdragonfox提到 Mixtral 需要精细的增量调整以防止垃圾信息输出。 - 使用 Seed 排除模型停止故障:
@sublimatorniq理论上认为使用不同的 Seed 可能会导致多变的停止行为——一个 Seed 可能导致提前停止,而另一个则会导致冗长的响应。 - 开放权重与微调的困扰:
@wayne_deng询问了 Mixtral 模型的源代码可用性和微调可能性。@mrdragonfox表示,由于高昂的成本和模型的复杂性,许多尝试微调的人并未成功。 - Mistral API JSON 响应请求:用户
@madmax____寻求帮助,希望强制 Mistral API 以 JSON 格式返回响应,但发现response_format参数无效。@akshay_1分享了一个链接,可能作为该问题的解决方案,但未提供链接的具体背景。
提到的链接:
- Getting Started with pplx-api:未找到描述
- GitHub - huggingface/text-generation-inference: Large Language Model Text Generation Inference:大语言模型文本生成推理(Large Language Model Text Generation Inference)。通过创建 GitHub 账号为 huggingface/text-generation-inference 的开发做出贡献。
Mistral ▷ #deployment (21 messages🔥):
- vLLM 中的本地模型使用:
@shihard_85648询问如何在 vLLM 中使用本地模型文件(已下载原始 Mistral 文件),@mrdragonfox建议使用--model标志后跟完整的本地路径。这绕过了从 HuggingFace 下载模型的需求,正如@vhariational所解释的,这是通常的流程。 - vLLM Docker 镜像说明:
@vhariational引用了 vLLM 文档,指出 HuggingFace 缓存目录在运行时是绑定挂载(bind-mounted)的,这意味着在重新构建 Docker 镜像时不需要重新下载模型。 - 模型路径配置说明:
@mrdragonfox提供了 vLLM 文档的详细链接,详细阐述了引擎参数(engine arguments),包括如何为模型和 tokenizer 指定路径。 - 高效 Mistral MoE 设置咨询:用户
@yoann_b询问如何在低于 $3,000 的硬件上以 12token/s 的速度运行 Mistral MoE,@mrdragonfox建议使用 32GB M1 Mac 或使用两块 3090 GPU 以获得更高性能。 - 技术规格与性能指标:在关于配置的讨论中,
@mrdragonfox提到在A6000(48GB VRAM GPU)上以 ‘6bpw’(bits per weight)运行 Mistral 8x7b,使用exllamav2达到了约 60 tokens/second。
提到的链接:
Engine Arguments — vLLM:未找到描述
Mistral ▷ #finetuning (7 messages):
- 提出的 Prompt 优化:
@akshay_1建议优化 Prompt,作为解决 RAG(检索增强生成)应用中所遇问题的更简单方案。 - Embedding 模型训练与成本:根据
@akshay_1的说法,在小规模下训练 Embedding 模型可能不具成本效益。 - 用于 Embedding 训练的 ColbertV2:对于那些寻求训练 Embedding 模型的人,
@akshay_1建议查看 ColbertV2。 - 识别 RAG 应用的局限性:
@mrdragonfox强调,在处理独特术语时可能需要训练 Embedding 模型,因为这些术语可能无法有效地与预期含义聚类。
Mistral ▷ #showcase (2 messages):
- 增强 Function Calling 的技巧:
@akshay_1建议使用dspy、SGLang、outlines和instructor以获得更好的 Function Calling 效果,并表示其效果非常好。 - 提倡微调:在后续回复中,
@akshay_1提到,如果对最初建议的解决方案不满意,在数据集上进行 Fine-tuning 将产生更好的结果。
Mistral ▷ #la-plateforme (11 条消息🔥):
- 错误调查的代码共享:
@sophiamyang请求@jakobdylanc分享他们的代码,因为遇到了一个不熟悉的错误。Jake 提供了一个指向其 GitHub 仓库特定部分的链接,描述了在其 Discord LLM Chatbot 中使用的 “openai” Python 包的问题。 - 包兼容性讨论:
@sophiamyang询问了@jakobdylanc关于正在使用的 Python 客户端包,并链接到了 Mistral 的客户端 (Mistra - Overview),同时对复现该错误表示不确定。Jakob 确认使用了 OpenAI python package,并考虑切换到 Mistral 的包,因为它更轻量,尽管在 Vision 模型方面可能存在潜在问题。 - 错误复现困难:
@jakobdylanc承认复现该错误存在困难,但承诺如果再次发生,将向@sophiamyang反馈。 - 哲学疑问未获回应:用户
@jrffvrr提出了一个关于世界上最美的人的存在主义问题,随后发送了一条测试消息,似乎是在检查功能,没有对该话题进行进一步讨论。 - Transformer 与数学的交集:
@stefatorus提出了在数学领域训练 Transformer 模型,并使用 A* 算法生成具有潜在价值、值得探索的数学想法。
提及的链接:
-
Discord-LLM-Chatbot/llmcord.py at ec908799b21d88bb76f4bafd847f840ef213a689 · jakobdylanc/Discord-LLM-Chatbot:多用户聊天 选择你的 LLM OpenAI API Mistral API LM Studio GPT-4 Turbo with vision Mixtral 8X7B 以及更多 🔥 - jakobdylanc/Discord-LLM-Chatbot - Mistra - Overview:Mistra 有 29 个可用的仓库。在 GitHub 上关注他们的代码。
- GitHub - openai/openai-python: The official Python library for the OpenAI API:OpenAI API 的官方 Python 库。通过在 GitHub 上创建账户为 openai/openai-python 的开发做出贡献。
LM Studio ▷ #💬-general (172 条消息🔥🔥):
-
Ubuntu 用户遇到 libclblast.so.1 错误:Ubuntu 22.04 用户(包括
@d0mper和@josemanu72)在打开 LM Studio 时遇到了与缺失libclblast.so.1文件相关的错误。经过大量讨论,通过创建符号链接解决了该问题。 -
关于 Apple Silicon Neural Engine 的性能问题:
@crd5提出了关于 LM Studio 利用 Apple Silicon Neural Engine 的疑问,@Aqualiteking帮忙澄清了 Neural Engine 可能会通过 Apple 的 Metal API 间接使用,并建议使用 “asitop” 工具进行监控。 -
关于 AI 建模和设置的查询:多位用户(包括
@golangorgohome、@cloakedman和@christianazinn)交流了适合运行 LM Studio 的硬件信息,以及针对不同 AI 应用(如图像转文本 image-to-text 和模型实现的本地托管)的替代方案。 -
LM Studio 模型兼容性与故障排除:
@bright_chipmunk_28966和@yagilb等用户讨论了在 LM Studio 中加载某些模型时遇到的问题,并得到了更新到新版本以及在 HuggingFace 等平台上检查兼容性的建议。 -
在 LM Studio 中探索 RAG:
@elevons询问了如何将 RAG 与 LM Studio 集成,虽然 LM Studio 本身没有直接的解决方案,但@heyitsyorkie和@thelefthandofurza提供了关于第三方应用和设置协助的指导。
提到的链接:
- LM Studio Beta Releases:未找到描述
- CLBlast/doc/installation.md at master · CNugteren/CLBlast:经过优化的 OpenCL BLAS。通过在 GitHub 上创建账号为 CNugteren/CLBlast 的开发做出贡献。
- GitHub - HeliosPrimeOne/ragforge: Crafting RAG-powered Solutions for Secure, Local Conversations with Your Documents - V2 Web GUI 🌐 Product of PrimeLabs:为您的文档构建安全、本地对话的 RAG 驱动解决方案 - V2 Web GUI 🌐 PrimeLabs 产品。
- GitHub - john-rocky/CoreML-Models: Converted CoreML Model Zoo.:转换后的 CoreML 模型库。通过在 GitHub 上创建账号为 john-rocky/CoreML-Models 的开发做出贡献。
- Core ML Tools — Guide to Core ML Tools:未找到描述
LM Studio ▷ #🤖-models-discussion-chat (15 条消息🔥):
- 模型错误之谜:用户
@alex_m.提出了一个 LM Studio 的问题,即无论如何配置模型都会失败,并显示带有 Exit code: 0 的 JSON 错误。@gustavo_60030做出回应,建议查看另一个 Discord 频道以寻找可能的解决方案。 - 频道引导困惑:在
@alex_m.被引导至一个支持频道后,@heyitsyorkie介入并推荐了另一个更适合讨论模型错误的频道。 - AI 不可预测的个性:
@cloakedman评论了 AI 模型的不确定性,提到同一个模型可能会提供不同的回答。@fabguy建议降低 Temperature(温度)设置可以提高 AI 回答的一致性。 - AI 一致性技巧:
@cloakedman询问了@fabguy所说的降低温度是什么意思。@fabguy回复并澄清,将“Randomness(随机性)”或“Temperature(温度)”设置为 0,并在使用相同 Seed(种子)的情况下,可以获得一致的回答。 - Dolphin 版本差异:
@cloakedman询问了关于 Dolphin 2.5 和 2.7 AI 版本差异的见解。尽管@fabguy提供了一个用于详细对比的 Discord 链接,但该链接在提供的摘要中无法访问。
LM Studio ▷ #🧠-feedback (16 messages🔥):
- CodeShell 的 GPU Acceleration 选项变灰:
@czkoko报告称,尽管 CodeShell 在 0.2.11 版本中受支持,但现在被列为不支持 GPU Acceleration。@yagilb确认该架构目前不被 LM Studio 应用视为受支持架构。 - GPU 支持的潜在变通方法:
@yagilb建议尝试将模型文件重命名并包含 “llama” 字样,这可能会启用 GPU Acceleration,但@czkoko后续反馈称该方法并未改变 GPU Acceleration 或 RoPE 选项变灰的状态。 - 应用对 GPU Acceleration 的保守策略:
@yagilb指出,应用出于谨慎考虑,会将不支持架构的选项设为灰色,并提到了之前的讨论。 - 用户对 GPU Acceleration 的反馈:
@heyitsyorkie确认在尝试建议的变通方法后,GPU Acceleration 仍然显示为灰色,并评论说目前的 UI 状态显示“不支持”已经足够清晰。 - 讨论邀请:
@yagilb邀请在另一个线程中继续讨论 CodeShell 的 GPU Acceleration 问题,并提供了一个 Discord 频道链接 以供进一步交流。
LM Studio ▷ #🎛-hardware-discussion (29 messages🔥):
- 硬件讨论中的 VRAM 困扰:用户
@cheerful_panda_16252报告了一个问题,尽管拥有 24GB VRAM 的 Nvidia 3090,但 VRAM 容量显示为 “0Bytes”。@cloakedman也表达了担忧,认为这可能会影响软件的推荐设置。 - 征集硬件规格:
@yagilb指导用户提供其硬件规格以解决 VRAM 容量显示问题,并引导他们前往特定的 Discord 频道及发布的链接。 - Intel GPU 用户的潜在提升:
@heyitsyorkie分享的一个 GitHub Pull Request 表明,Intel GPU 用户可能很快就会在 llama.cpp 中获得支持 查看 Pull Request。然而,@goldensun3ds对此更新的时间表持怀疑态度。 - 探索运行 Mixtral 的廉价配置:
@yoann_b询问能够以 12t/s 运行 Mixtral 的最便宜硬件配置,并提到了 M1 Pro 的潜力。@rugg0064通过澄清 M2 Pro、M1 以及 RTX 4090 等高端 GPU 之间的带宽差异进行了补充。 - 硬件兼容性讨论与建议:
@cloakedman分享了在向 GPU 卸载(offloading)时遇到系统崩溃的困扰,@bobzdar提供了故障排除技巧,包括层级调整(layer adjustments)和提示词压缩(prompt compression)。讨论最终以@cloakedman为其系统找到稳定设置而告终。
提到的链接:
- 第一部分:低成本构建和优化高性能 Proxmox 集群:在我们的 Proxmox 集群构建指南中,我们主要关注利用二手组件来满足小型制作者或……
- 特性:为 Intel GPU 集成统一的 SYCL 后端,由 abhilash1910 提交 · Pull Request #2690 · ggerganov/llama.cpp:动机:感谢创建 llama.cpp。目前已经有很多努力在为 AVX 指令集集成 OpenCL 运行时。然而,为了在 Intel 显卡上运行,需要添加……
LM Studio ▷ #🧪-beta-releases-chat (2 messages):
- 为 WhiteRabbit 33B 点赞:用户
@johntdavies提到成功测试了 WhiteRabbit 33B 模型 (Q8),并对其性能给出了正面评价。
LM Studio ▷ #autogen (1 messages):
senecalouck: 尝试在脚本中使用 127.0.0.1。
LM Studio ▷ #langchain (1 messages):
gciri001: 是否可以在不使用 OpenAI API 的情况下,将 Langchain 和 MySQL 与 LLAMA 2 结合使用?
LM Studio ▷ #crew-ai (4 messages):
- 模型加载失败的困扰:用户
@ferrolinga在尝试加载模型时遇到了 “unknown (magic, version) combination” 错误。错误报告包含系统诊断信息,显示 RAM 和 VRAM 充足,但模型文件本身可能存在问题。 - 文件格式错误诊断:
@draco9900迅速指出@ferrolinga的问题源于使用了非 GGUF 格式的模型——这是 LM Studio 必需的格式。 - 解决方案建议:针对加载问题,
@heyitsyorkie建议@ferrolinga专门使用 GGUF 文件,并推荐在 Model Explorer 中搜索 “TheBloke - GGUF” 以获得最佳效果,因为 LM Studio 需要 GGUF 模型格式,而不是 pytorch/ggml 或 .bin 文件。
OpenAccess AI Collective (axolotl) ▷ #general (50 messages🔥):
- Logit Distillation 讨论:
@dreamgen讨论了使用 GPT-4 logits 的 logit distillation(Logit 蒸馏)以及使用开源模型回填和 masking loss 等技术。@nruaif对该话题表示兴趣并考虑进一步讨论。 - 语音合成适配咨询:
@ex3ndr询问关于为 LLM 添加自定义 token 以用于语音合成的问题,并从@le_mess和@stefangliga处获知,添加大量 token(如 8k 个)将需要进行大规模的预训练。 - QLoRA 微调的挑战:包括
@stefangliga、@noobmaster29和@c.gato在内的多位参与者讨论了 QLoRA 微调 的局限性,特别是当涉及大量新 token 时,强调简单的辅助网络是不够的,必须考虑全嵌入层(full embedding layer)微调。 - 模型微调技巧与 Loss 评估:
@ex3ndr分享了他们在 微调自定义 token 方面的经验,强调了对异常高 loss 数值的担忧,而@noobmaster29和@c.gato则就不同场景下应追求的 loss 指标提供了见解。 - 在 Axolotl 微调中使用特殊 Token:
@faldore分享了关于如何为微调 配置特殊 token 的指导,包括用于嵌入lm_head和指定eos_token的代码片段。这是对@dreamgen提到@faldore在 Hugging Face 上的 Dolphin 等项目取得成功的响应。
提及的链接:
- Magic GIF - Magic - Discover & Share GIFs:点击查看 GIF
- axolotl/src/axolotl/utils/lora_embeddings.py at dc051b861d4d0f20c673ad55ac93b2a43fa56fc4 · OpenAccess-AI-Collective/axolotl:欢迎在 GitHub 上为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- cognitivecomputations/dolphin-2.6-mixtral-8x7b at main:未找到描述
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (4 messages):
- Latitude 容器中的 Jupyter 问题:
@dctanner提出了在 Latitude 容器中运行 Jupyter 时遇到的 SSL 问题,这是由于 Cloudflare 的端口转发隧道引起的。目前尚未提供解决方案。 - SSH 端口转发作为临时补丁:
@dctanner目前正使用 SSH 端口转发作为 Latitude 容器中 Jupyter 问题的权宜之计。 - 有趣的构思:自我奖励语言模型 (Self-Rewarding Language Models):
@dctanner分享了将 Self-Rewarding Language Models 概念整合到 axolotl 框架中的兴趣。 - 自我奖励模型实现:
@caseus_针对该想法提供了一个 GitHub 上的 PyTorch 实现链接 lucidrains/self-rewarding-lm-pytorch,该项目是 MetaAI 提出的 Self-Rewarding Language Model 训练框架的实现。
提及的链接:
GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI:MetaAI 提出的 Self-Rewarding Language Model 训练框架的实现。
OpenAccess AI Collective (axolotl) ▷ #general-help (116 messages🔥🔥):
-
DPO 数据集疑难解答:
@dangfutures和@c.gato讨论了加载 DPO 数据集时遇到的问题,并发现之前的 Pull Request (PR #1137) 可以成功解决。@dangfutures提到通过使用为 1 的 micro batch size 克服了显存溢出(out-of-memory)错误。 -
策略选择困扰?:
@c.gato帮助@dangfutures处理数据集的 prompt strategies,分享了代码片段和 GitHub 文件链接。为了修复一个持续存在的错误,他们建议从 GitHub 上的 DPO 修复分支实施修复。 -
CI-CD 的便利还是本地的挫败?:
@caseus_强调了针对远程数据集的自动化 CI-CD 完整性检查(sanity check),但这并不涵盖本地数据集。同时,@dangfutures和@c.gato发现,尽管最初报错,但回退到之前的 commit 可以使用本地数据集。 -
LoRA 超参数难题:
@noobmaster29询问了 LoRA 的 alpha 和 rank 超参数的最佳设置,促使@c.gato分享了一篇文章,提供了关于这些参数有效使用的见解。讨论内容包括调整 alpha 和 rank,以及训练期间的 batch size 考量。 -
为 LLaVA 扩展分支:
@gameveloster和@noobmaster29探索了使用 LLaVA 模型进行微调,指向了 axolotl 的特定分支,并考虑现有的 configs 是否可以为此目的进行调整。对话凸显了社区在分享知识和资源方面的协作努力。
提及的链接:
- axolotl/src/axolotl/prompt_strategies/dpo/chatml.py at main · OpenAccess-AI-Collective/axolotl:欢迎通过在 GitHub 上创建账号,为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- axolotl/tests/e2e/test_dpo.py at main · OpenAccess-AI-Collective/axolotl:欢迎通过在 GitHub 上创建账号,为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- GitHub - OpenAccess-AI-Collective/axolotl at llava:欢迎通过在 GitHub 上创建账号,为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experiments - Lightning AI:LoRA 是训练自定义 LLM 最广泛使用的参数高效微调技术之一。从使用 QLoRA 节省内存到选择最佳 LoRA 设置,本文提供了实用的建议。
- configs/pretrain-llava-mistral.yml · openaccess-ai-collective/mistral-7b-llava-1_5-pretrained-projector at main:未找到描述
-
Feat: Add sharegpt multirole by NanoCode012 · Pull Request #1137 · OpenAccess-AI-Collective/axolotl:描述:允许输入和输出有多个角色。注意:目前为 Beta 版且包含硬编码值!使用方法:- type: sharegpt + type: sharegpt.load_multirole 仅支持对话:(chatml zep… - DangFutures/DPO_RAG · Datasets at Hugging Face:未找到描述
OpenAccess AI Collective (axolotl) ▷ #datasets (4 messages):
- Dolphin 数据疑问:
@noobmaster29询问 dolphin 数据集 与 OpenOrca 数据集之间是否存在重叠。@dangfutures表示相信肯定存在重叠。 - 重叠确认:在听到
@dangfutures的观点后,@noobmaster29寻求澄清并确认了这两个数据集确实存在重叠。
提及的链接:
cognitivecomputations/dolphin · Datasets at Hugging Face:未找到描述
OpenAccess AI Collective (axolotl) ▷ #rlhf (13 条消息🔥):
-
argilla_apply_chatml的配置键错误:@alekseykorshuk在一个 Reinforcement Learning Hub (RLHF) 项目的 YAML 配置中使用argilla_apply_chatml时遇到了KeyError: 'prompt'。他们最初就此配置问题寻求帮助。 -
在单元测试中找到解决方案:随后,
@alekseykorshuk通过在 main 分支的单元测试中发现新的type格式(chatml.argilla和chatml.intel)解决了该问题,并确认此方案有效,随后将更新分享给了社区。 -
询问分支使用情况:分享解决方案后,
@dangfutures询问@alekseykorshuk是在哪个分支找到这些有效的新type格式的。@alekseykorshuk澄清他们使用的是 main 分支。 -
对本地数据集的配置疑问:
@matanvetzler询问同样的配置是否适用于本地数据集,并请求查看配置设置。@alekseykorshuk认为本地数据集应该只需更改type即可同样工作。 -
Prompt 分词策略问题及解决方案:
@pierrecolombo报告了一个ValueError: unhandled prompt tokenization strategy: intel_apply_chatml。@c.gato回复建议,如果使用的是最新 commit,由于存在破坏性变更(breaking changes),应更新为chatml.intel。@pierrecolombo对此解决方案表示感谢。
OpenAccess AI Collective (axolotl) ▷ #replicate-help (1 条消息):
- 分享 Cog 配置指南:
@dangfutures提供了一个定义 Cog 配置 的代码片段,并引用了其 GitHub 页面上的文档。该配置针对 GPU 使用进行了设置,采用 CUDA “12.1” 和 Python “3.11”,并包含通过自定义pip install命令安装的各种 Python 包,如aiohttp[speedups]、megablocks、autoawq等,引用了多个包 URL。
提到的链接:
- cog/docs/yaml.md at main · replicate/cog:用于机器学习的容器。通过在 GitHub 上创建账号来为 replicate/cog 的开发做贡献。
-
未找到标题:未找到描述。
,
Eleuther ▷ #general (56 条消息🔥🔥):
-
Byte-Level BPE 的多语言能力:
@synquid解释说,Llama 2 模型 可以使用 byte-level BPE (Byte Pair Encoding) 生成印地语、泰米尔语和古吉拉特语等语言的响应,其中确实包含这些语言的 token。 -
寻求 Mistral 7b 微调代码:用户
@aslawliet请求协助提供微调 Mistral 7b 进行 token 分类的代码,但在提供的消息中未获得直接回复。 -
对 Mamba 取代 Transformers 的怀疑:包括
@stellaathena、@stefangliga和@mrgonao在内的用户对 Mamba 的扩展性以及取代 Transformers 表示怀疑,指出目前缺乏证据表明它在大规模下能保持性能。讨论集中在工程挑战以及需要更多研究来验证 Mamba 的可扩展性。 -
微调服务咨询:用户
@kh4dien寻求关于微调大语言模型的建议,表示更倾向于全监督微调(full supervision tuning)而非 QLORA 等方法。@stellaathena建议在租用的 GPU 上亲自运行微调可能是一个简单的开箱即用方案。 -
评估微调 LLM 的影响:
@everlasting_gomjabbar向社区询问是否有关于微调大语言模型(LLM)益处的综合研究,认为在现实世界中投入微调的合理性往往并不明确。讨论中没有提供针对此查询的直接回复。
提到的链接:
Self-Rewarding Language Models:我们认为,要实现超越人类的 Agent,未来的模型需要超越人类的反馈,以提供充足的训练信号。目前的方法通常从人类偏好中训练奖励模型…
Eleuther ▷ #research (65 条消息🔥🔥):
-
探索 LLM 中的加密隐藏:
@ai_waifu分享了一篇论文,介绍了一种在 Large Language Model 的响应中隐藏秘密载荷的加密方法,提取该载荷需要密钥,且在没有密钥的情况下无法被检测到。@fern.bear对该方法不改变响应分布的说法表示质疑,认为必须改变某些分布才能传递信息。 -
Google DeepMind 推出权重平均奖励模型 (WARM):
@jacquesthibs重点介绍了一篇讨论 WARM 的论文,这是一种通过在权重空间平均微调后的奖励模型,来对抗 LLM 在通过 RLHF 与人类偏好对齐过程中的奖励作弊(reward hacking)的策略,并分享了作者的推文串以获取更多见解。 -
Google 的逼真视频生成研究:
@pizza_joe链接了 Google Research 用于视频生成的时空扩散模型演示及其配套论文。@thatspysaspy和@ad8e讨论了其重要性,@ad8e指出了 Google 的数据优势,而@main.ai则通过与其他模型的数据集规模对比提出了反驳。 -
无监督学习中模型约束的探索:
@rybchuk询问了关于模型如何以无监督方式学习正确约束以最小化损失的研究,包括@fern.bear在内的几位用户讨论了经验风险最小化(empirical risk minimization)和学习中约束的本质。 -
首届语言建模会议宣布:
@stellaathena分享了关于首届语言建模会议(Conference on Language Modeling)的公告,该会议将在宾夕法尼亚大学举行。会议将是语言建模研究和进展感兴趣者的聚集地。
提到的链接:
- 来自语言建模会议 (@COLM_conf) 的推文:我们很高兴地宣布,首届语言建模会议将在费城宾夕法尼亚大学的 Zellerbach 剧院举行。非常感谢宾大计算机系…
- Lumiere: A Space-Time Diffusion Model for Video Generation:我们介绍了 Lumiere —— 一种文本到视频的扩散模型,旨在合成展现逼真、多样且连贯运动的视频,这是视频合成中的一个关键挑战。为此,我们…
- Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding:我们引入了 meta-prompting,这是一种有效的脚手架技术,旨在增强语言模型(LMs)的功能。这种方法将单个 LM 转化为一个多方面的指挥者,能够…
- Active Inference as a Model of Agency:除了奖励最大化之外,是否有思考智能体(agency)的标准方式?在本文中,我们展示了任何符合关于宏观生物系统如何运作的物理合理假设的行为类型…
- Excuse me, sir? Your language model is leaking (information):我们介绍了一种加密方法,可以在 Large Language Model (LLM) 的响应中隐藏任意秘密载荷。从模型的响应中提取载荷需要密钥…
- Lumiere - Google Research:Google Research 开发的时空文本到视频扩散模型。
- 来自 AK (@_akhaliq) 的推文:Google Deepmind 发布 WARM,关于权重平均奖励模型的好处。论文页面:https://huggingface.co/papers/2401.12187 通过 RLHF 使大语言模型(LLMs)与人类偏好对齐…
- 来自 Stella Biderman (@BlancheMinerva) 的推文):在 Pythia 论文中,我们探讨了训练过程中词频对事实学习的影响。如果你仔细看图 4,似乎有微弱的证据表明…
- 来自 Alexandre Ramé (@ramealexandre) 的推文:介绍 DeepMind 用于通过 RLHF 进行对齐的权重平均奖励模型 (WARM)!我们将多个奖励模型合并为一个更可靠、更鲁棒的模型。WARM 高效地捕捉了最佳…
- k-diffusion/k_diffusion/models/image_transformer_v2.py at master · crowsonkb/k-diffusion:Karras 等人 (2022) 的 PyTorch 扩散模型。通过在 GitHub 上创建账号为 crowsonkb/k-diffusion 的开发做出贡献。
Eleuther ▷ #scaling-laws (3 条消息):
- 关于 reLoRA 扩展性的疑虑:
@joey00072提出了关于 reLoRA 可能无法扩展到 10 亿 (1 billion) 参数以上的担忧,这基于 Twitter 或 Discord 上的传闻,尽管原始的 reLoRA 论文并未做出此类声明。 - reLoRA 论文的限制:
@joey00072提到 reLoRA 模型仅在最高 3.5 亿 (350 million) 参数的规模下进行了测试,并寻求关于超出该规模的进一步研究或反馈。
Eleuther ▷ #interpretability-general (2 条消息):
- 探索真理表示干预:用户
@80melon讨论了一种在不使用 patching 的情况下,干预或否定语言模型输出中的真理表示 (truth representation) 的技术。随后,他们观察了语言模型输出根据各种补全方式产生的变化。 - 寻求最大因果真理方向:
@80melon提到其实验目标是确定一个对语言模型各种输出具有直接且显著影响的最大因果真理方向 (maximally causal truth direction)。
Eleuther ▷ #gpt-neox-dev (3 条消息):
-
致力于 MoE 实现:
@xyzzyrz正在通过一个 pull request 为 MoE (Mixture of Experts) 的实现做出贡献,并寻求深度验证的建议和反馈。他提出了关于mpu.get_model_tensor_parallelism_world_size()及其与 PipeModelDataParallelTopology 和 axonn 3D tensor parallelism 关系的担忧,并对如何在单 GPU 环境下进行后续工作感到困惑。 -
单 GPU 限制了并行性测试:
@xyzzyrz表示,由于只能访问单 GPU 节点,测试并行性增强 (parallelism enhancements) 存在困难。他们提供的初步数据显示,增加 num-experts 时速度显著变慢,并参考了一个工作内容重叠的现有 MoE 分支。 -
融合 Layernorm Pull Request 审查:他们还在关注另一个关于 fused layernorm 的 pull request(见此处),并指出未检测到明显的耗时差异,这可能表明进一步改进的空间有限。
-
有意改进 Deepspeed Inference:
@xyzzyrz表示愿意致力于 Deepspeed Inference 的工作,以潜在地提高性能(如 Issue #845 中所述),目前正等待计算资源的可用性。
提到的链接:
- fused layernorm by yang · Pull Request #1105 · EleutherAI/gpt-neox:添加简单的计时工具,添加来自 Megatron 的 fused layernorm 内核。
- Add MoE by yang · Pull Request #1129 · EleutherAI/gpt-neox:关闭 #479。
- Build software better, together:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、fork 并为超过 4.2 亿个项目做出贡献。
- Investigate DeepSpeed Inference · Issue #845 · EleutherAI/gpt-neox:DeepSpeed 在我见过的大多数推理基准测试中都胜出。我们应该在 neox 模型上测试他们的说法。EleutherAI 在运行推理上投入了大量的计算资源,因此推理性能的任何提升都……
LAION ▷ #general (124 条消息🔥🔥):
-
快速训练时间咨询:
@astropulse对训练 128x128 范围的小型模型所需的时间感到好奇。@nodja回复称,在双 3090 系统上应该不超过几天,并建议查看所提及论文的附录 E。 -
GPT-4 Token 配额调整:用户
@helium__对 GPT-4 限额降低表示担忧,@astropulse等其他用户也证实了类似的经历。 -
关于小型 ImageNet 模型的注意事项:
@thejonasbrothers指出,分辨率低于 256x256 的 ImageNet 模型表现不佳,并建议在更大规模和更长训练时间下才能获得更好的性能。 -
关于构建安全多模态数据集的讨论:
@irina_rish发起了关于确保用于多模态模型训练的数据集安全性的对话,强调需要保证数据完整性的解决方案。多位用户(包括@thejonasbrothers、@progamergov和@.undeleted)讨论了挑战和潜在的解决方案。 -
即将举行的语言建模会议公告:
@itali4no分享了首届语言建模会议 (CoLM) 的地点公告,该会议将在宾夕法尼亚大学举行,并向另一位用户@chad_in_the_house发出了邀请,后者期待带他们去餐车。
提到的链接:
- 来自语言建模会议 (@COLM_conf) 的推文:我们很高兴地宣布,首届语言建模会议将在费城宾夕法尼亚大学的 Zellerbach 剧院举行。非常感谢宾大计算机系,因为我们……
- 未找到标题:未找到描述
LAION ▷ #research (2 条消息):
-
使用 WARM 对抗 LLM 奖励作弊 (Reward Hacking):用户
@thejonasbrothers分享了一篇研究论文,通过一种名为权重平均奖励模型 (WARM) 的方法来解决大型语言模型 (LLMs) 中的奖励作弊问题。该论文提出对多个奖励模型 (RMs) 进行微调并取平均值,以提高在分布偏移和人类偏好不一致情况下的鲁棒性和可靠性。 -
VONet 在无监督视频学习领域取得突破:
@vrus0188介绍了一篇关于 VONet 的论文,这是一个使用并行 U-Net 注意力和对象级序列 VAE 的无监督视频对象学习框架。该方法凭借其新颖的方法,在多个数据集上分解视频场景的表现优于现有技术,代码可在 GitHub 上获取。
提到的链接:
- WARM: On the Benefits of Weight Averaged Reward Models:通过强化学习 (RLHF) 使大型语言模型 (LLMs) 与人类偏好对齐可能会导致奖励作弊,即 LLMs 利用奖励模型 (RM) 的缺陷来实现表面上的……
- VONet: Unsupervised Video Object Learning With Parallel U-Net Attention and Object-wise Sequential VAE:无监督视频对象学习旨在将视频场景分解为结构化的对象表示,而无需来自深度、光流或分割的任何监督。我们提出了 VONet,一种创新的……
HuggingFace ▷ #announcements (1 条消息):
-
HuggingFace 升级了!:引入了新频道
<#1197143964994773023>来展示等级最高的社区成员。在 Hub 上发布内容、点赞、创建仓库或论文等活动将为成员赚取经验值。 -
使用 AI 制作游戏 - 第 2 章发布:Making games with AI 课程的第二章现已上线。感兴趣的成员可以在 Thomas Simonini 的 Twitter 帖子上庆祝并了解更多信息。
-
Gradio 性能优化揭秘:在
@oobabooga报告了一个延迟问题后,Gradio 团队分享了通过 “…减慢速度!” 来让 Gradio 变得更快的见解。完整的故事和技术分析可以在 这篇 HuggingFace 帖子 中查看。 -
Transformers.js 在浏览器中引入 Meta 的 SAM 模型:Transformers.js v2.14 版本完全在浏览器内运行 Meta 的 SAM 模型。用户可以使用 npm 进行尝试,使用详情见 链接的 HuggingFace 帖子。
-
transformers v4.37 充满创新:最新发布的
transformers v4.37引入了多个新模型和功能,包括 Qwen2、Phi-2、SigLIP 和 4-bit 序列化。更多详情可以在 GitHub 上找到。
提到的链接:
- @abidlabs on Hugging Face: "𝗛𝗼𝘄 𝘄𝗲 𝗺𝗮𝗱𝗲 𝗚𝗿𝗮𝗱𝗶𝗼 𝗳𝗮𝘀𝘁𝗲𝗿 𝗯𝘆… 𝘀𝗹𝗼𝘄𝗶𝗻𝗴 𝗶𝘁…":未找到描述
- @Xenova on Hugging Face: "Last week, we released 🤗 Transformers.js v2.14, which added support for SAM…":未找到描述
- Release v4.37 Qwen2, Phi-2, SigLIP, ViP-LLaVA, Fast2SpeechConformer, 4-bit serialization, Whisper longform generation · huggingface/transformers:模型发布 Qwen2。Qwen2 是来自 Qwen 团队的新系列大语言模型。此前已发布的 Qwen 系列包括 Qwen-72B、Qwen-1.8B、Qwen-VL、Qwen-Audio 等。Qw…
- @philschmid on Hugging Face: "What's the best way to fine-tune open LLMs in 2024? Look no further! 👀 I am…":未找到描述
- @abidlabs on Hugging Face: "There's a lot of interest in machine learning models that generate 3D objects…":未找到描述
- GitHub - Vaibhavs10/open-tts-tracker:通过在 GitHub 上创建账户来为 Vaibhavs10/open-tts-tracker 的开发做出贡献。
- Tweet from Xenova (@xenovacom):介绍 🛝 Jinja Playground:直接在浏览器中设计 LLM 聊天模板并获得即时反馈。基于
@huggingface/jinja构建,这是一个 Jinja 的极简 JavaScript 实现…… - @merve on Hugging Face: "Explaining the 👑 of zero-shot open-vocabulary object detection: OWLv2 🦉…":未找到描述
- Fine-Tune W2V2-Bert for low-resource ASR with 🤗 Transformers:未找到描述
- PatchTSMixer in HuggingFace:未找到描述
- Preference Tuning LLMs with Direct Preference Optimization Methods:未找到描述
- Tweet from Niels Rogge (@NielsRogge):我的“在家使用 ChatGPT”系列中的新 @YouTube 视频:在 @runpod_io 租用的 GPU 上微调 Mistral-7B。涉及聊天模板、QLoRa、packing、Flash Attention 2、bfloat16……有很多东西需要解释……
HuggingFace ▷ #general (49 messages🔥):
-
开源早晨欢呼:
@osanseviero开启了准备为开源做贡献的一天。@Cubie | Tom等人的回复以响亮的 “Always 💪” 保持了高昂的情绪。 -
ONNX 导出困扰:
@blahblah6407在将微调后的模型导出到 ONNX 时遇到问题,遇到了关于Trilu(14)节点实现的[ONNXRuntimeError]。 -
寻求机器学习指导:
@𝐀𝐌𝐎𝐔𝐑询问学习机器学习的切入点。他们得到了_mad.haven_的帮助,后者分享了一个 Hugging Face 上的有用指南 以掌握基础知识。 -
AI 视频背景咨询:
@omniroots发布了一个名为 “THE FUTURE OF AI IS PURE IMAGINATION” 的 YouTube 视频,并向社区咨询视频中使用的 AI 背景特效信息。 -
在 HuggingFace 上升级:
@realmrfakename和@lunarflu讨论了 Discord 和 Hub 活动的整合如何影响 LevelBot 显示的等级,并考虑了未来在用户个人资料上显示等级的功能。
提到的链接:
- Dreamoving - a Hugging Face Space by jiayong:未找到描述
- THE FUTURE OF AI IS PURE IMAGINATION:缩短想象与创造之间的滞后时间。AI 的未来。#ai #jasonsilva #singularity #possibility #awe #tech
- GitHub - dreamoving/dreamoving-project: Official implementation of DreaMoving:DreaMoving 的官方实现。通过在 GitHub 上创建账号为 dreamoving/dreamoving-project 的开发做出贡献。
HuggingFace ▷ #today-im-learning (6 messages):
-
渐入佳境:
@not_lain提到虽然任务起初可能具有挑战性,但随着练习会变得更容易,暗示了他们近期努力中的学习曲线。 -
注重隐私的转录工具开发:
@n278jm正在构建一个转录并总结咨询音频记录的工具。目标是完全在本地运行,以维护由于咨询性质敏感而产生的数据隐私。 -
工具规格揭晓:
@n278jm详细说明了工具的工作流程:“会议音频上传作为输入 -> 带有发言人日志(speaker diarization)的转录 -> 会议摘要作为输出”。他们计划使用 Hugging Face 的 transformers 进行音频转录,使用 pyannote.audio 3.1 进行发言人日志记录,并使用 DistilBERT 模型进行摘要,所有这些都通过一个简单的 HTML 前端连接在一起。 -
Python 像是来自过去的记忆:
@n278jm表示由于很久没有使用 Python 语言,在解析列表和字典以将日志数据与转录结果整合时遇到了一些挑战。 -
考虑使用 Protobuf 进行流水线通信:
@n278jm正在考虑编写 protobuf 定义来连接流水线,并可能使用 Go 来处理 transformers 的结果。这表明他们正在考虑在项目工作流的部分环节中使用 Python 以外的替代方案。
HuggingFace ▷ #cool-finds (9 messages🔥):
-
新的身份保持 AI 演示:
@osanseviero重点介绍了 InstantID,这是一个能在数秒内实现身份保持(identity-preserving)生成的工具,并分享了 Yann LeCun 认可 Gradio Spaces 上 InstantID demo 的推文。在此尝试。 -
Hedwig AI YouTube 视频介绍:
@forestwow7397分享了一个 YouTube 视频,介绍了 Hedwig AI,这是一个旨在通过 AI 改变视频数据利用和理解方式的平台。 -
神秘的 AI 背景:
@omniroots询问了 Jason Silva 的一段 YouTube 视频中使用的 AI 生成背景效果的信息,引发了其他用户的好奇。 -
QwenLM 开源之旅:
@osanseviero分享了来自 QwenLM 的更新,概述了他们在 Large Language Models (LLM) 领域的开源之旅,并提供了其学术发表的 论文、GitHub 仓库 以及 Hugging Face 模型 的重要链接。 -
PhotoMaker 提供高效的个性化生成:
@ggabe_2提供了一个 arXiv 论文链接,讨论了 PhotoMaker,这是一种高效且个性化的 text-to-image generation 新方法,在身份保真度和文本可控性方面表现出色。 -
使用 VPGs 微调 LLMs:
@andysingal分享了一项关于微调多模态大语言模型 (MLLMs) 以遵循零样本演示指令的研究,解决了当前视觉提示生成器 (VPGs) 偏见的相关问题。该研究引入了一个名为 Visual Prompt Generator Complete (VPG-C) 的新模块,提升了模型对此类指令的理解。阅读研究详情。
提到的链接:
- Introducing Qwen: 在我们首次发布 Qwen-7B(这是我们 LLM 开源之旅的起点)4 个月后,我们现在对 Qwen 系列进行全面介绍…
- PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding: text-to-image generation 的最新进展在根据给定文本提示合成逼真人像方面取得了显著进步。然而,现有的个性化生成方法…
- Fine-tuning Multimodal LLMs to Follow Zero-shot Demonstrative…: Multimodal Large Language Models (MLLMs) 的最新进展一直在利用 Visual Prompt Generators (VPGs) 将视觉特征转换为 LLMs 可以识别的 Token。这是通过…
- THE FUTURE OF AI IS PURE IMAGINATION: 缩短我们想象与创造之间的滞后时间。AI 的未来。#ai #jasonsilva #singularity #possibility #awe #tech
- Youtube Video Intro hedwigAI: 欢迎来到 Hedwig AI 的无缝流媒体世界,我们正在改变视频数据的利用和理解方式。在本视频中,我们展示了…
- h94/IP-Adapter-FaceID at main: 未找到描述
- Tweet from Omar Sanseviero (@osanseviero): InstantID:数秒内实现身份保持生成。请在 https://hf.co/spaces/InstantX/InstantID 尝试。
- Tweet from Yann LeCun (@ylecun): 太棒了,我是漫威超级英雄!我的钢铁侠战甲在哪? ↘️ 引用 Gradio (@Gradio) 🔥InstantID demo 现已在 Spaces 上线。感谢 @Haofan_Wang 等人构建了如此出色的 Gradio demo…
HuggingFace ▷ #i-made-this (14 messages🔥):
-
使用“Tiny”模型进行快速推理:
@Cubie肯定了对all-MiniLM-L6-v2进行增强的效果,该增强通过仅添加一个 Dense 层来保持快速推理,从而可能加快 Embeddings 的比较。 -
sbert 库中采用 PCA 脚本:
@stroggoz提到利用 PCA 进行 Embeddings 比较,并将其脚本归功于 sbert 库中的脚本。 -
可视化疑似伪造内容:针对
@lunarflu关于热力图用途的询问,@not_lain和@thenameless7741似乎确认了其在检测潜在伪造内容中的用途,但未提供更多背景信息。 -
Open LLM Leaderboard 的升级与迁移:
@thenameless7741通知了其项目 Cosmos Arena 的迁移,该项目包含模型类型、权重类型和许可证等各种功能,并提到更新后存在一些回归(Regressions)和 Bug。@osanseviero对此反应积极,考虑将其分享给团队。 -
使用 Hugging Face 实现零成本图像嵌入:
@tony_assi介绍了他们的 GitHub 项目 HF-Embed-Images,该项目为在 Hugging Face 生态系统中生成图像数据集的 Embeddings 提供了一行代码解决方案。 -
使用 3LC 调试机器学习训练:
@paulend76预告了 3LC 即将推出的公开 Beta 测试,这是一个机器学习训练和数据调试器/编辑器,集成了 PyTorch 且对非商业用途免费;他们提供了 YouTube 视频和博客文章链接以供深入了解,并邀请大家对 Beta 版提供反馈。 -
探索 Gabor Vecsei 的 GitHub 仓库:
@ggabe_2分享了@gaborvecsei的 GitHub 个人主页链接,鼓励他人探索其仓库,并重点介绍了最近一个关于 使用 Whisper 进行实时转录的项目。
提到的链接:
- Cosmos Arena:未找到描述
- GitHub - TonyAssi/HF-Embed-Images: Generates image embeddings for 🤗 Datasets:为 🤗 Datasets 生成图像 Embeddings。通过在 GitHub 上创建账号来为 TonyAssi/HF-Embed-Images 的开发做出贡献。
- Imbalance in Balance:在此演示中,我们看到 3LC 如何帮助数据科学家快速高效地定位并解决模型中的问题。通过为代表性不足的样本增加权重…
- Introducing 3LC:凭借我们在数据质量方面的创新方法,3LC 为更准确的模型训练铺平了道路,且无需更改数据存储位置。
- gaborvecsei - Overview:我尽可能地挑战自己的极限。另外,我喜欢巧克力。😎 - gaborvecsei
- GitHub - gaborvecsei/whisper-live-transcription: Quick and dirty example for live transcription with Whisper:使用 Whisper 进行实时转录的简易示例 - GitHub - gaborvecsei/whisper-live-transcription。
HuggingFace ▷ #diffusion-discussions (5 messages):
- DPM++ 更新即将到来:
@keturn表达了对在最近的 PR 中解决问题后 DPM++ with Karras 改进的期待,希望在下一个版本中看到这些增强功能。 - 关于 Diffusion 调度的咨询:
@vtabbott_提出了关于 HuggingFace 的 Diffusion 实现的问题,特别是scheduling_euler_distance.py文件及其来源。 - Karras 的论文揭示了 Diffusion 的奥秘:作为回应,
@keturn解释说 “euler” 计算遵循了 k-diffusion 的命名,该库实现了 Karras 论文 Elucidating the Design Space of Diffusion-Based Generative Models 中的概念。他们进一步澄清说 Euler 调度器(Scheduler)可能源自 DDIM 论文,并提到了“方差保持(Variance Preserving)”和“方差爆炸(Variance Exploding)”之间的区别,但不确定它们在数学上是否等效。 - 深入研究 Diffusion 模型:
@vtabbott_提到正在绘制 Diffusion 模型的图表,以确保对重新实现这些过程有足够深入的理解。
HuggingFace ▷ #NLP (4 messages):
- 模型并行训练详解:
@mr_nilq强调当前的方法是仅限推理 (inference-only) 的,并建议使用带有 Accelerate 的 Trainer 进行模型并行训练。该用户分享了一份非常有用的 HuggingFace 指南,解释了何时以及如何从单 GPU 转换到多 GPU 训练设置。 - Llama 2 的多语言之谜:
@dhruvbhatnagar.0663询问 Llama 2 模型 如何在词汇表中没有特定 token 的情况下生成印地语、泰米尔语或古吉拉特语等语言的回复。@vipitis回复建议观察生成的 token ID 并进行进一步调查。 - DeciLM-7B 推理缓慢问题:
@kingpoki在 Nvidia 3060 上使用 Deci/DeciLM-7B 时遇到了推理速度慢的问题,生成 50 个 token 大约需要 23 秒。该用户尝试对模型进行量化 (quantizing),但遇到了问题,目前正在寻求在不影响模型微调 (finetune) 能力的前提下提高推理速度的建议。
提到的链接:
Efficient Training on Multiple GPUs:未找到描述
HuggingFace ▷ #diffusion-discussions (5 messages):
-
对改进版 DPM++ 的期待:
@keturn正期待着 Karras 提到的 DPM++ 增强功能,希望最近一个 PR 中解决的问题能在下一个版本中显示出显著改进。 -
Euler 在 HuggingFace Schedulers 中的位置:针对
@vtabbott_关于scheduling_euler_distance.py的疑问,@keturn解释说它与 k-diffusion 的命名一致,并最终与 Karras 的 Elucidating the Design Space of Diffusion-Based Generative Models 保持一致。他们提到 Euler scheduler 与 DDIM 论文有关,并且与diffusers的scheduling_ddim存在方差差异,这可能与“方差保持 (variance preserving)”或“方差爆炸 (variance exploding)”有关。 -
深入研究扩散模型:
@vtabbott_表达了对深入理解扩散模型并达到能够重新实现它们的程度的浓厚兴趣,展示了致力于制作准确解释图表的决心。 ,
Perplexity AI ▷ #general (57 messages🔥🔥):
- 关于模型调整的讨论:用户讨论了各种话题,包括 RPA AI 的效率 (
@moyaoasis)、labs 上的浅色模式 (light mode) 可用性 (@hvci和@icelavaman回复称目前仅提供深色模式),以及在 Android 上使用麦克风功能的挫败感,因为应用权限中缺少麦克风选项 (@.cryptobadger)。 - 频道导航困惑:人们对频道的存在或移除感到困惑,特别是与生成图片相关的频道以及已不复存在的 Dream bot,
@ok.alex确认了一个频道的关闭,而@oscar_010表达了对 Perplexity 新闻摘要的需求。 - 模型使用说明:
@iprybilovych询问了如何区分 Perplexity AI 专业版上的 GPT-4 和 Gemini Pro 模型,@icelavaman对此进行了回答,解释了模型选择设置,社区经理@Dyno随后参与其中,鼓励社区对有帮助的帖子给予认可。 - 功能咨询与协助:一位用户询问了潜在的团队 (teams) 选项和积分支持问题 (
@umyong),而另一位用户@zwaetschgeraeuber在察觉到与 Rabbit 的合作后,推测未来应用将支持 Wear OS。 - API 咨询与扩展讨论:
@generativeai_strategy_44986请求有关增加 API 速率限制 (rate limit) 的信息以进行产品集成,@dogemeat_推荐了用于集成 vscode 的 Continue.dev 扩展,@speedturkey则幽默地鼓励 Pro 订阅者向“上帝提示词教会 (the church of the God prompt)”捐赠积分。
提到的链接:
- Continue - CodeLlama, GPT-4, and more - Visual Studio Marketplace:Visual Studio Code 扩展 - 软件开发的开源自动驾驶仪 - 将 ChatGPT 的强大功能引入您的 IDE
- 无标题:未找到描述
Perplexity AI ▷ #sharing (12 条消息🔥):
-
排查应用错误:
@_marcos75反馈了访问 Perplexity 分享链接时出现的 “Application error” 问题。在收到建议后,他们分享了一个导致问题的示例链接:BMW Humanoid Factory。@icelavaman建议这很可能是浏览器问题,而非 Perplexity 的错误。 -
作为研究利器的 Perplexity:
@nicknalbach分享了使用 Perplexity 的正面评价,强调了它快速整合多源信息的能力,正如在搜索新手机和手机套餐时所展示的那样。 -
对 Perplexity 的称赞与推荐:
@zenrobot.eth回应了@nicknalbach的反馈,认可了 Perplexity 搜索功能令人印象深刻的速度和准确性。 -
通过 Perplexity 增强工作流:
@joe_heller提到发现了 Perplexity 如何辅助工作流,引发了@icelavaman的好奇并请求提供公开示例。@ivibudh幽默地推测该回复可能是由 AI 生成的。 -
机械工程的现实助手:
@n_667证实了将 Perplexity 作为机械工程课程和个人项目的辅助工具,并指出了其在节省时间方面的优势。
Perplexity AI ▷ #pplx-api (3 条消息):
-
对 API 使用的困惑:用户
@tpsk12345表示在使用 API 时遇到困难,并请求 Alex 提供更新,但未提供更多背景信息。 -
关于在线模型引用的咨询:
@donvitoph通过 API 测试了pplx-70b-online模型,并提出了关于在线模型是否返回引用 URL 的问题。具体的用法通过调用chat.completions.create函数的代码片段进行了展示。 ,
LlamaIndex ▷ #blog (2 条消息):
-
带现金奖励的黑客松热潮:IFTTT 宣布将于 2 月 2 日至 4 日举办一场线下黑客松,奖金总计 13,500 美元,其中包括 8,250 美元现金。该活动鼓励参与者构建解决实际问题的项目,并提供专家反馈。黑客松公告推文。
-
引入用于高级聊天体验的 MemGPT:由
@charlespacker重点介绍的 MemGPT 是一个 OSS 项目,旨在利用 LlamaIndex 构建具有长期记忆、自我编辑记忆和无限 context windows 的聊天体验。通过 pip 即可快速安装,提供个性化的 AI 体验。OSS 项目亮点推文。
提到的链接:
MemGPT:未找到描述
LlamaIndex ▷ #general (65 messages🔥🔥):
- Llama-Index 的 SQLite-VSS 集成:
@pveierland询问了关于 Llama-Index 现有的 sqlite-vss 集成,但未收到有记录的回复或解决方案。 - Pandas Query Engine 问题:
@techexplorer0指出在使用 PandasQueryEngine 配合 Zephyr 7b 等开源 LLM 时存在问题。分享了一个关于构建 Pandas 查询流水线 (Query Pipeline) 的文档链接示例,但并未直接解决在构建 RAG 聊天机器人时处理 CSV 文件的问题。 - 结合 RAG 的开源 LLM:
@zaesar寻求如何在 deeplearning.ai 的 Llama-Index 课程中,使用 dolphin mistral 等开源 LLM 实现 RAG。@emanuelferreira建议使用 LlamaIndex 的基础 LLM 模块。@cheesyfishes建议使用 olama 进行简单的本地设置,以及使用 vLLM 进行生产部署。 - Streamlit 中的 SubQuestionQueryEngine:
@matthews_38512提到在 Streamlit 中使用 SubQuestionQueryEngine,但当时没有提供解决方案。随后,@kapa.ai(推测为聊天机器人)与@matthews_38512进行了交流,提供了设置 SubQuestionQueryEngine 的详细步骤和 LlamaIndex 文档 链接。 - 在 CSV 上实现带记忆的聊天机器人:
@techexplorer0寻求创建一个带记忆的对话式聊天机器人,利用 RAG 在多个 CSV 文件上使用开源 LLM 进行数据聚合。@kapa.ai提供了关于结构化工作流的指导,包括官方 LlamaIndex 文档 的链接。此外,还有一个关于设置 Query Pipeline 以使用最大工作线程数的需求,@kapa.ai提供了一个涉及os.cpu_count()的潜在解决方案。
提到的链接:
- Query Pipeline over Pandas DataFrames - LlamaIndex 🦙 0.9.36: 未找到描述
- Step-wise, Controllable Agents - LlamaIndex 🦙 0.9.36: 未找到描述
- Customizing LLMs within LlamaIndex Abstractions - LlamaIndex 🦙 0.9.36: 未找到描述
- OpenAI Agent with Query Engine Tools - LlamaIndex 🦙 0.9.36: 未找到描述
- Query Pipeline - LlamaIndex 🦙 0.9.36: 未找到描述
LlamaIndex ▷ #ai-discussion (1 messages):
- RAG 聊天机器人动态知识的新见解: 用户
@sl33p1420分享了他们最新的 Medium 文章,关于在 RAG 聊天机器人中 集成动态数据源。文章重点介绍了通过利用先进的知识集成技术来增强聊天机器人。 - 详细的 RAG 聊天机器人开发指南: 该用户还强调了他们之前形成系列的作品,从 深度之旅 (An In-depth Journey) 开始,涵盖了模型选择、服务器设置,最后是聊天引擎的构建。
提到的链接:
Empowering Your Chatbot: Unveiling Dynamic Knowledge Sources with Advanced Integration: 探索聊天机器人开发的下一个前沿,介绍了如何利用动态知识源。
OpenAI ▷ #ai-discussions (7 条消息):
- 寻找 AI 社区空间:用户
stranger_54257询问了更多 LLM Discord 服务器的链接,但未收到任何回复。 - AI 多样性反映人类复杂性:
@bambooshoots讨论了由于不同的设计、目标和学习环境,超智能 AI 可能会出现广泛的行为谱系,类似于人类社会中见到的多样性。 - 寻求 LLM 评估和监控工具:
@coderindajungle询问了关于基于 GPT-4 构建的聊天机器人应用的 LLM 评估与监控工具的建议,但未收到任何建议。 - 对 Dall.E 图像处理能力的担忧:
@brnst质疑为什么 Dall.E 在提供示例时难以重新创建或编辑图像,但对话并未得出答案。 - 对 AGI 的控制主导了 AI 伦理辩论:
@catcapitol表示,关于通用人工智能 (AGI),主要的担忧在于谁在控制它以及他们对该技术的使用方式。
OpenAI ▷ #gpt-4-discussions (28 条消息🔥):
- 揭秘文件上传详情:
@solbus向@mrbr2023澄清,最多可以将 20 个文件(每个文件最大 512MB)作为知识库上传到 Custom GPT,而文本文件限制为每个 200 万个 tokens。他们讨论了将文档合并为单个文件以绕过 20 个文件限制的潜在策略,但也考虑了可能的缺点,如搜索大文件时的效率低下。 - GPTs 商店谜团:
@sstrader29询问了 GPTs Marketplace 中缺失 CustomGPT 的情况,但摘要对话中未提供具体答案。 - 使用 Grimoire GPT 进行文字处理:
@eligump兴奋地分享了他们在不到十分钟的时间内使用 Grimoire GPT 创建了一个文字处理器。 - Custom GPT 网络错误之谜:
@valikami针对其 Custom GPT 在提供回复后持续出现网络错误的问题寻求建议,但未提及解决方案。 - 交织的 GPT 线程:
@snowmkr_jk对一个线程中的文件似乎影响了另一个线程表示困惑,这反映了跨独立线程处理文件时可能存在的问题,正等待社区确认这是否属于正常现象。
OpenAI ▷ #prompt-engineering (10 条消息🔥):
-
寻求更好的回答上下文处理:
@ArianJ希望根据有关职业话题的聊天日志回答额外的问题,但发现直接输入日志和问题效果不佳。@darthgustav.询问了日志的大小以及同时提出的问题数量,以诊断该问题。 -
行政助理 Prompt 建议:
@jdf.wwp征求适用于组织或行政助理的 Prompt 创意。@darthgustav.通过询问其目标进行回应,并建议 Plus 订阅者使用他的 Custom GPT,或者利用用户的背景信息来引导 ChatGPT。 -
Custom GPT 的描述性语言:
@archipelagic正在寻求关于在 Custom GPT 的描述字段中优化任务时,使用何种语言最有效的建议。@eskcanta建议定义明确的目标并有效地传达这些目标,无论是寻求 AI 还是人类协作者的帮助。 -
AI 引导中简单胜过有效:针对优化 Prompt 的担忧,
@eskcanta建议专注于决定想要从 AI 那里得到什么并寻找实现方法,而不是担心所谓的“最有效”语言。
OpenAI ▷ #api-discussions (10 messages🔥):
-
Prompt Engineering 的热情:
darthgustav.支持一个好的 Prompt Engineering 方案每次都能奏效的观点,暗示了成功进行 AI 交互的一致性策略。 -
改进上下文理解:
@ArianJ正面临 AI 无法根据聊天日志回答问题的问题。该用户寻求处理聊天日志以提取额外信息的建议,但在 AI 理解上下文方面遇到了挑战。 -
询问聊天日志的 Prompt 大小:
darthgustav.询问了@ArianJ使用的聊天日志的字节大小,这可能会影响 AI 处理和回答问题的能力。 -
自定义 GPT 配置的高效语言:
@archipelagic询问在优化自定义 GPT 模型的描述时,使用哪种语言最有效。eskcanta回复强调了在向 AI 传达目标以及寻求帮助时,清晰度的重要性。 -
为理想的 AI 结果而解决问题:
eskcanta建议与其关注“最有效”的语言,不如致力于与 AI 达成明确的结果,建议采用适应性方法来实现特定目标,而不是寻找通用的“最佳”方法。
DiscoResearch ▷ #mixtral_implementation (10 messages🔥):
-
theBloke Q6的模板困扰:@eric_73339透露了本地模型与 Demo 版本结果不一致的困扰。他们怀疑问题出在 Prompt Template 格式上。 -
Mixtral 模板澄清:
@sebastian.bodza分享了根据 Hugging Face Tokenizer 确定的正确 Mixtral Chat Template,并指出了其与 readme.md 文档的不一致之处。 -
使用 f-strings 进行更好的格式化:
@bjoernp建议使用 f-strings 并在每个角色(role)后添加换行符,以修正@eric_73339的 ChatML Template,从而兼容 DiscoLM 模型。 -
Demo 网站模型与模板使用:
@bjoernp指出 https://demo.discoresearch.org 使用的是 DiscoLM German 7b v1,并提供了一个链接以避免 Chat Template 的问题。 -
感谢社区支持:
@eric_73339感谢 社区 在适应 LLM 和修复模板问题方面提供的帮助。
提到的链接:
- DiscoResearch/DiscoLM_German_7b_v1 · Hugging Face:未找到描述
- Templates for Chat Models:未找到描述
- DiscoLM German 7b Demo:未找到描述
DiscoResearch ▷ #general (11 messages🔥):
-
评估翻译质量:
@bjoernp讨论了评估翻译质量的挑战,并推荐使用 Lilac 进行人工检查。他们提到尝试创建一种使用 Distilabel 过滤劣质翻译的方法,但意识到其在 GPT-4 上的潜在成本。 -
DiscoLM German 蓄势待发:
@_jp1_表达了将 DiscoLM German 的性能与其他模型进行比较的兴趣,并承认为此目的可以使用英文消息。 -
Llama-3 预测揭晓:
@bjoernp分享了对即将发布的 Llama-3 的详细预测,包括在 5 万亿 Token 上进行的大规模预训练、对多语言和代码的关注,以及最近一篇论文所阐述的高级上下文分块(Context Chunking)。 -
深入探讨数据多轮训练(Multiple Epochs):针对
@maxidl建议进行多轮训练,@rasdani询问在 Datablations 论文发布后是否有人尝试过,@bjoernp回复称目前认为没有必要。 -
German LM 即将来临:
@maxidl透露即将推出一个数据集包含约 1 万亿 Token 的 German LM,并讨论了对计算资源的影响,希望在建立稳固的第一个 Checkpoint 后能有所简化。他们链接了一篇关于其方法的 Twitter 帖子。
提到的链接:
In-Context Pretraining: Language Modeling Beyond Document Boundaries:大型语言模型(LMs)目前被训练为根据文档前缀预测 Token,使它们能够直接执行长文本生成和 Prompt 风格的任务,这些任务可以简化为……
DiscoResearch ▷ #embedding_dev (4 条消息):
-
开启类 Mistral 之旅:
@sebastian.bodza宣布创建了一个类似于 Mistral embedding 模型 的数据集,并在 GitHub 上分享了他们的项目:Embedding Training。其目标是首先利用 Quora 主题数据生成多样的 Topics。 -
托管位置取决于数据大小:
@sebastian.bodza提到计划将生成的数据托管在 Hugging Face 或 GitHub 上,具体取决于数据集的大小。 -
训练 BGE 还是 GTE?这是一个问题:
@sebastian.bodza推测可能会训练一个 BigGraph Embedding (BGE) 或 Graph ‘n’ Table Embedding (GTE) 模型。 -
迈向增强型代码检索的 Voyage 之路:
@sebastian.bodza关注到了 Voyage 新的代码 embedding 模型voyage-code-2,该模型在语义代码检索任务中表现出显著提升。模型的详细信息已在 Voyage AI 博客文章 中分享。
提到的链接:
- voyage-code-2: Elevate Your Code Retrieval:TL;DR – 我们很高兴推出 voyage-code-2,这是我们最新的 embedding 模型,专门为自然语言和代码查询中的代码及相关文本数据的语义检索而量身定制……
- GitHub - SebastianBodza/Embedding_Training:通过在 GitHub 上创建账号,为 SebastianBodza/Embedding_Training 的开发做出贡献。
DiscoResearch ▷ #discolm_german (19 条消息🔥):
- Axolotl 使用咨询:
@thomasrenkert尝试使用 Axolotl 并成功在 Docker 中运行,但在如何包含个人数据集方面遇到困难。@rasdani提供了帮助,建议将数据集转换为 支持的格式 并在 配置 中引用它。 - 解决 Axolotl GPU 的怪异问题:
@thomasrenkert遇到了 Axolotl 无法从 Docker 容器内部识别 GPU 的问题,对此@devnull0建议根据 NVIDIA Container Toolkit 指南设置 GPU 访问权限,并安装必要的 CUDA 库(可能需要使用 Conda)。 - 引导至 Axolotl Discord 获取支持:随着关于 Axolotl 调试问题的增多,
@bjoernp引导用户前往 Axolotl Discord 以获取更专业的协助。 - DiscoLM German 模型换行符问题:
@thewindmom报告了在 Ollama 中运行discolm_german_7b_v1.Q4_K_M.gguf时出现的问题,即输出包含无尽的换行符。根据 Hugging Face 讨论帖,这也是其他用户共同面临的问题。 - 修复 DiscoLM 换行符故障:
@_jp1_指出了 DiscoLM_German 模型config.json中上述换行符问题的修复方法,将"eos_token_id": 2更改为32000(提交详情)。他们呼吁社区成员测试此更新是否解决了该问题。
提到的链接:
- Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit 1.14.4 documentation:未找到描述
- Join the OpenAccess AI Collective Discord Server!:加入 Discord 上的 OpenAccess AI Collective 社区 - 与其他 1546 名成员一起交流,享受免费的语音和文字聊天。
- DiscoResearch/DiscoLM_German_7b_v1 · Endless Spaces:未找到描述
- Fix wrong EOS token in config.json · DiscoResearch/DiscoLM_German_7b_v1 at 560f972:未找到描述
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions:Go ahead and axolotl questions. 通过在 GitHub 上创建账号,为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions:Go ahead and axolotl questions. 通过在 GitHub 上创建账号,为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
Latent Space ▷ #ai-general-chat (28 条消息🔥):
- Karpathy 对技术变革的看法:
@swyxio分享了 Andrej Karpathy 的一篇新博客文章,强调了科技行业以外的人在适应变化时面临的挑战。他们引用了个人案例,强调了技术变革可能引发的人们的焦虑和恐惧。 - Perplexity 的非线性进展:
@swyxio链接到了来自@madiator的一条 推文,展示了 AI 模型 Perplexity 为期三个月的非线性开发历程。 - 探索小型模型中的语法和推理:
@nuvic_讨论了一篇关于训练更小规模 LM 的论文,希望能保留它们的语法和推理能力,并指出在没有海量参数的情况下也可能实现连贯的语言表达(TinyStories 论文)。 - Discord 应用 AI 创建通知标题:
@.onacomputer评论了 Discord 的新方法,即使用 LLM 根据社区消息总结并生成通知标题,考虑到过去的隐私政策,@vcarl和@youngphlo对此感到惊讶。 - Stability 发布新的 Diffusion 模型:
@swyxio宣布了 Stability AI 的一项显著的 Diffusion 模型进展,该模型可以直接生成百万像素级的图像,绕过了 Latent Diffusion 过程,并分享了一个 AI 新闻摘要服务。
提到的链接:
- Hugging Face 上的 @clem:“在此转发 @karpathy 的博客文章,因为原站已挂……”:未找到描述
- TinyStories: 语言模型可以多小且仍能说流利的英语?:语言模型 (LM) 是自然语言处理的强大工具,但当规模较小时,它们往往难以生成连贯且流利的文本。拥有约 1.25 亿参数的模型,如 GP…
- JSONalyze 查询引擎 - LlamaIndex 🦙 0.9.36:未找到描述
- Mahesh Sathiamoorthy (@madiator) 的推文:如果你认为 Perplexity 的历程是简单且线性的。
- Torvalds 发言:人工智能对编程的影响:🚀 Torvalds 深入探讨了人工智能对编程世界的变革性影响。🚀 关键话题:编程语言的演变 …
- [AINews] 再见 Latent Diffusion,你好 Hourglass Diffusion:2024年1月22日的 AI Discord 动态。我们为您检查了 19 个公会、291 个频道和 4368 条消息。预计节省阅读时间(以 200wpm 计算):436 分钟。Katherine…
Latent Space ▷ #llm-paper-club (5 条消息):
- SPIN 实现即将到来:用户
@swyxio宣布@lucidrains计划实现 SPIN,并分享了 GitHub 仓库 self-rewarding-lm-pytorch 的链接。 - 关于 SPIN 和 Meta 论文实现的澄清:
@ivanleomk最初认为该实现是针对 Meta 的新论文,但@swyxio澄清说@lucidrains将分别实现 SPIN 和 Meta 的方法。 - 查看 ReadMe 获取更多信息:欲了解更多详情,
@swyxio引导用户查看仓库 ReadMe 文件的底部。
提到的链接:
GitHub - lucidrains/self-rewarding-lm-pytorch: MetaAI 提出的 Self-Rewarding Language Model 训练框架的实现:MetaAI 提出的 Self-Rewarding Language Model 训练框架的实现 - GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in…
LangChain AI ▷ #general (16 条消息🔥):
- LangChainJS Workers 项目预览:
@ilguappo分享了他们正在开发中的项目,尽管由于该项目较为常规且未反映最佳 Web API 实践而有所犹豫。它包含一个用于 Discord 消息表情符号回应的有趣端点。 - TypeScript:学习曲线:
@ilguappo正在学习 TypeScript,目前该语言已通过模板在他们的项目中实现,@lolis0518承认这门语言有难度,但愿意尝试。 - 寻求端到端 RAG 解决方案:
@alvarojauna询问了有关端到端 Retrieval-Augmented Generation (RAG) 系统相关的项目,寻找潜在的合作或示例。 - GPT Chat Completion 澄清:
@allenpan_36670询问了 GPT chat completion 端点如何处理消息列表的动态机制,@lhc1921通过引用处理此类列表的 ChatML 提示词模板进行了回答。 - 与你的 PDF 对话教程:
@a404.eth发布了一个教程,涵盖了使用 PGVector、unstructured.io 和语义分块器(semantic chunker)创建全栈 RAG 的内容,旨在实现通过 OpenAI 与 PDF 文档进行对话。教程的第一部分已在 YouTube 上线。
提到的链接:
- Chat With Your PDFs: An End to End LangChain Tutorial For Building A Custom RAG with OpenAI. Part 1:开发 AI 聊天机器人的一个常见用例是摄取 PDF 文档,并允许用户提问、检查文档并从中学习。在…
- GitHub - anaxios/langchainjs-workers:通过在 GitHub 上创建账号来为 anaxios/langchainjs-workers 的开发做出贡献。
LangChain AI ▷ #langserve (2 条消息):
-
恶作剧链接垃圾信息:用户
@eleuss发布了一条包含长串条杠和下划线的消息,随后是一个看似 Discord 邀请的链接discord.gg/pudgys并艾特了@everyone,这看起来像是垃圾信息行为或试图顽皮地刷屏。 -
反馈机制见解:
@georgeherby解释了处理反馈的过程,提到用户可以针对任何给出的反馈(无论正负)提供书面评论作为后续。这些反馈会被添加到同一条记录中以保持一致性。
LangChain AI ▷ #share-your-work (1 条消息):
- LLaVA 在艺术分析方面优于 Baklava:
@dwb7737分享了一个摘要,指出 LLaVA 在分析和分类艺术作品方面似乎比 Baklava 更有效。他们提供了一个 GitHub Gist 以获取有关该对比的更多细节。
提到的链接:
Ollama models - Image Summarization:Ollama 模型 - 图像摘要。GitHub Gist:即时分享代码、笔记和片段。
LangChain AI ▷ #tutorials (2 条消息):
-
CrewAI 获得 Obsidian 笔记功能:
business24.ai分享了一个 YouTube 教程,题为 “使用 crewAI 并添加自定义工具在 Obsidian 中存储笔记。” 该教程演示了如何为 crewAI 创建一个自定义工具,使用户能够使用 OpenAI 的 ChatGPT 4 和 ChatGPT 3 将搜索结果作为笔记添加到 Obsidian 中。 -
发布使用 PDF 构建 RAG 的教程系列:
a404.eth发布了一个三部分教程系列的第一视频,题为 “与你的 PDF 对话:使用 OpenAI 构建自定义 RAG 的端到端 LangChain 教程。第 1 部分”。该教程引导观众开发能够与 PDF 文档交互的 AI 聊天机器人,使用了 PGVector、unstructured.io 和语义分块器等工具。
提到的链接:
- Chat With Your PDFs: An End to End LangChain Tutorial For Building A Custom RAG with OpenAI. Part 1:开发 AI 聊天机器人的一个常见用例是摄取 PDF 文档,并允许用户提问、检查文档并从中学习。在…
- Use crewAI and add a custom tool to store notes in Obsidian:在本教程中,我们为 crewAI 创建了一个自定义工具,用于将搜索结果作为笔记添加到 Obsidian 中。我们将其与 OpenAI ChatGPT 4、ChatGPT 3 以及多个…
LLM Perf Enthusiasts AI ▷ #announcements (1 条消息):
- 迎接 2024 年的高质量 LLM 讨论:
@jeffreyw128欢迎大家来到 2024 年,并称赞该 Discord 频道是顶级 LLM 讨论的枢纽。他宣布计划通过新一轮的手工挑选邀请为小组注入新鲜活力,并鼓励现有成员发送推荐。
LLM Perf Enthusiasts AI ▷ #offtopic (2 条消息):
- 文档布局 SOTA 揭晓:用户
@res6969询问了文档布局理解的 state-of-the-art (SOTA),特别是如何识别 PDF 报告中图表周围的边界框。他们随后更新了 Vision Grid Transformer 作为潜在解决方案,并提供了其 GitHub 仓库链接:点击此处。
提到的链接:
GitHub - AlibabaResearch/AdvancedLiterateMachinery: A collection of original, innovative ideas and algorithms towards Advanced Literate Machinery. This project is maintained by the OCR Team in the Language Technology Lab, Alibaba DAMO Academy.:迈向先进文字处理机器的原创、创新想法和算法集合。该项目由阿里巴巴达摩院语言技术实验室的 OCR 团队维护。
LLM Perf Enthusiasts AI ▷ #feedback-meta (6 条消息):
- 创建新频道:
@jeffreyw128宣布创建了一个新频道,最初没有特定名称。 - 频道命名头脑风暴:
@degtrdg建议将新创建的频道命名为 #share。 - 频道重命名为 #share:遵循
@degtrdg的建议,@jeffreyw128表示同意并将频道重命名为 #share。 - 讨论 LLM Perf 相关活动:
@yikesawjeez提到了正在进行的活动,如 Swyx 的论文俱乐部、Skunkworks 论文实现会议,以及每周的 codejams/挑战,这些都可能与 LLM Perf 社区相关。 - LLM Perf 渗透想法:
@yikesawjeez幽默地提议 LLM Perf 社区成员加入其他活动,带去他们在训练、架构、调优和性能方面的专业知识。 ,
Skunkworks AI ▷ #general (1 条消息):
far_el: good lad
Skunkworks AI ▷ #off-topic (1 条消息):
pradeep1148: https://www.youtube.com/watch?v=n3gkZ_IRwCI ,
YAIG (a16z Infra) ▷ #ai-ml (2 条消息):
- 寻找本地部署 (On-Premise) AI 解决方案:用户
@floriannoell询问了独立于 AWS、GCP 或 Azure 等主流云服务商的本地部署 AI 解决方案,特别提到了 watsonx.ai 作为其寻找目标的参考。 - AI 解决方案的定制需求:作为回应,
@spillai提示@floriannoell澄清该 AI 技术的预期使用场景,并建议识别特定需求(如预训练、微调、推理或分类)可以帮助找到更具针对性的本地部署解决方案。 ,
Alignment Lab AI ▷ #open-orca-community-chat (1 条消息):
- Slim Orca 数据集现已在 HF 上线:
@222gate通知 Slim Orca 数据集 已可在 Hugging Face 上访问,并提供了使用该数据集进行微调的说明。该数据集拥有 约 50 万条 GPT-4 生成结果,且 Slim Orca 已使用 GPT-4 进行了精炼以移除不准确之处,在达到与更大数据分片相似的性能时,仅需 2/3 的计算量。 - 使用 Slim Orca 进行高效高性能训练:Open Orca 团队策划了一个子集以实现高效训练,这已通过 jackalope-7b 和 Mistral-7B-SlimOrca 等演示模型得到证实,展示了该数据集的有效性。
提到的链接:
Open-Orca/SlimOrca · Datasets at Hugging Face:未找到描述内容。
,
Datasette - LLM (@SimonW) ▷ #llm (1 条消息):
llm-gpt4all0.3 版本发布:@simonw宣布了llm-gpt4all0.3 版本 的正式发布,其中包含了由<@461550757901107221>提供的修复以及其他几项改进。此次更新特别支持了访问模型选项(如-o max_tokens 3),并允许模型在没有互联网连接的情况下工作。
提到的链接:
Release 0.3 · simonw/llm-gpt4all: 现在支持访问模型选项,例如 -o max_tokens 3。感谢 Mauve Signweaver。#3 模型现在可以在没有互联网连接的情况下工作。感谢 Cameron Yick。#10 文档现在包含了 l…