ainews-codellama-70b-beats-gpt4-on-humaneval
CodeLLama 70B 在 HumanEval 评测中击败了 GPT4。
Meta AI 发布了 CodeLlama,这是一款开源模型,目前已在 Ollama 和 MLX 等平台上提供,可供本地使用,这让社区感到惊喜。Miqu 模型引发了关于其起源的争论,认为其可能与 Mistral Medium 或经过微调的 Llama-2-70b 有关,同时也引发了关于 AI 伦理和对齐风险的讨论。Aphrodite 引擎在特定配置下的 A6000 GPU 上表现出了强劲的性能。
像 Mixtral 和 Flatdolphinmaid 这样的角色扮演 AI 模型面临着内容重复的挑战,而 Noromaid 和 Rpcal 的表现更好,推荐使用 ChatML 和 DPO 来改善响应质量。针对机器学习/深度学习(ML/DL)初学者,fast.ai 的课程等学习资源受到了关注,同时还讨论了使用 Paged 8bit lion 和 adafactor 等优化器的微调技术。
在 Nous Research AI,Activation Beacon 项目引入了一种通过“全局状态”令牌(tokens)实现大语言模型(LLM)无限上下文长度的方法,这可能会彻底改变检索增强模型。基于 RWKV-v5 的 Eagle-7B 模型在基准测试中凭借其效率和多语言能力超越了 Mistral。由于其量化方法,OpenHermes2.5 被推荐用于消费级硬件。针对分类和视觉语言任务,人们探索了 IMP v1-3b、Bakllava、Moondream 和 Qwen-vl 等多模态和特定领域模型。社区强调了集中 AI 资源以进行协作研究的重要性。
2024年1月29日的 AI Discord 动态。我们为你检查了 21 个公会、311 个频道和 8276 条消息。预计节省阅读时间(以 200wpm 计算):605 分钟。
Meta AI 意外发布的 CodeLlama 是给开源 AI 的一份厚礼:
不出所料,社区已经开始行动,将其适配到 Ollama 和 MLX 以供你在本地运行。
目录
[TOC]
第 1 部分:Discord 高层级摘要
TheBloke Discord 摘要
-
Miqu 模型引发好奇与辩论:Miqu 模型在
@itsme9316和@rombodawg等用户中引发了辩论,大家纷纷猜测它是来自 Mistral Medium 的泄露版,还是 Llama-2-70b 的微调版本。讨论内容涉及 AI 伦理和 AI 的未来风险,包括强大模型的滥用以及实现妥善对齐(alignment)的挑战。 -
Aphrodite 引擎的性能备受关注:用户分享了使用 Aphrodite 引擎的经验,指出在 A6000 GPU 上,通过
--kv-cache-dtype fp8_e5m2等配置,它可以提供每秒 20 个 token 的出色性能,不过也有人对 GPU 利用率和模型切分支持表示担忧。 -
讨论角色扮演 AI 模型的重复性与性能:在角色扮演场景中,Mixtral 和 Flatdolphinmaid 等模型表现出重复性方面的挑战,而 Noromaid 和 Rpcal 表现较好。
@ks_c推荐将 ChatML 与 Mixtral Instruct 结合用于角色扮演,并强调了直接偏好优化(DPO)对改善 AI 角色回复的重要性。 -
机器学习/深度学习 (ML/DL) 的学习与微调:
@dirtytigerx建议 CUDA 编程对于开始学习 ML/DL 并非必不可少,并推荐了 fast.ai 的 Practical Deep Learning for Coders 课程 以打下坚实基础。讨论还涉及了微调 Mistral 7B 等大模型所需的 VRAM 要求,以及探索 Paged 8bit lion 或 adafactor 等先进优化器技术以实现高效的 VRAM 利用。 -
增强 GitHub 项目导航与对代码库的理解:提供了关于理解 GitHub 项目以便进行贡献的指导,并以 tabbyAPI 项目 中的
start.py为例说明了入口点。讨论了配备语言服务器(language servers)的 IDE 或编辑器对于高效代码导航的重要性,同时提到了 Code Llama 70B 在 Hugging Face 上的发布,强调了其在多种编程语言的代码生成和调试方面的潜力。
Nous Research AI Discord 总结
-
Activation Beacon 革命性地提升了 LLM 上下文长度:Activation Beacon 项目引入了一项重大进展,通过“全局状态” tokens 在 LLM 中实现了无限上下文长度。正如
@cyrusofeden所分享的,这一进展可能会极大地改变 Dense Retrieval 和检索增强型 LLM(Retrieval-augmented LLMs)的方法,详细信息可在 GitHub 上查看。 -
Eagle-7B 凭借 RWKV-v5 架构超越 Mistral:基于 RWKV-v5 架构的 Eagle-7B 备受关注,其在 Benchmark 中表现甚至优于 Mistral,展示了一个极具前景、高效且开源的多语言模型。它在保持高水平英语性能的同时,拥有更低的推理成本(来源)。
-
OpenHermes2.5 被誉为消费级硬件的理想选择:OpenHermes2.5 被推荐为在消费级硬件上运行的理想模型,这归功于其 GGUF 或 GPTQ 量化,使其成为领先的开源问答 LLM。此外,讨论还涉及了 Hugging Face 上的 Nous Hermes 2 Mixtral 8x7B DPO。
-
多模态及特定领域 LLM 的探索:关于使用 IMP v1-3b 模型 进行轨道图像分类任务的讨论,表明了人们对多模态模型及其在特定领域应用的兴趣日益增长。对话还扩展到了与 Bakllava 和 Moondream 等其他模型的比较,并强调了 Qwen-vl 在该领域的实力。
-
集中化 AI 资源的集体愿景:由
@kquant牵头的社区在集中化 AI 资源和研究方面的努力,表明了对统一资源库的公认需求。该倡议旨在简化获取 AI 论文、指南和训练资源的流程,并邀请各界贡献力量,为爱好者和专业人士增强资源储备。
LM Studio Discord 总结
-
LLM 工作的 GPU 选择:尽管旧款 P40/P100 GPU 拥有更多 VRAM,但仍推荐使用较新的 4060Ti 来训练 Large Language Models (LLM),因为它可以获得 Nvidia 的持续更新。包括
@heyitsyorkie在内的参与者讨论了 GPU 偏好,指出驱动更新比 VRAM 速度更重要。 -
模型兼容性与格式更新:正如
@heyitsyorkie所通知的,LMStudio 已从 GGML 转向 GGUF 格式,这标志着向更现代标准的迈进。此外,讨论还强调了在 LMStudio 的 MoE (Mixture of Experts) 应用中动态加载专家(experts)的实用性。 -
LMStudio Beta 中的性能问题与 UI 挑战:用户
@msz_mgs和@heyitsyorkie报告了在插入长 Prompt 时的性能滞后以及 UI 导航困难。这些问题已被确认,并计划在未来的更新中解决。 -
VRAM 与 GPU 利用率探索:由
@aswarp和@heyitsyorkie发起的讨论探讨了在 LMStudio 中运行模型时意想不到的 VRAM 开销,强调了将模型 Offloading 到包括 RTX 3070 和 4090 在内的 GPU 时的细微差别。关于即将推出的拥有 48GB VRAM 的 RTX 40 Titan 的传闻引发了社区讨论,并将其与更广泛的市场策略及 AI GPU 的重新定位联系起来。 -
Beta 更新与跨平台兼容性查询:Beta V2 的发布预示着在 VRAM 估算和兼容性问题上取得了进展。关于 Mac Intel 版本、Linux AppImage 可用性以及 WSL (Windows Subsystem for Linux) 支持的咨询,凸显了社区对扩大 LMStudio 平台兼容性的兴趣。
OpenAI Discord 总结
-
RAG 揭秘:针对 @aiguruprasath 的疑问,@darthgustav. 解释了 Retrieval Augmented Generation (RAG),将其描述为具备直接访问知识库以进行数据搜索或语义匹配能力的 AI,从而增强其决策过程。
-
Prompt Engineering 的演进:@madame_architect 分享了一个提示工程技巧:
"Please critique your answer. Then, answer the question again."(请批判你的回答,然后再次回答该问题)。这一方法灵感源自一篇重要的研究论文,旨在显著提高 AI 在处理复杂查询时的输出质量。 -
代码生成优化:针对 ChatGPT-4 无法生成准确代码的困扰,@darthgustav. 建议在请求中明确任务、语言和架构,并向 @jdeinane 分享了这一技巧,以帮助获得更好的代码生成结果。
-
通过条件命令导航 AI 伦理:讨论了一种创新的伦理审核策略,涉及基于功利主义、义务论和实用主义的 2/3 通过/失败系统。@darthgustav. 还介绍了使用条件命令引导 AI 查阅 LEXIDECK_CULTURE.txt 以解决伦理困境,从而增强 AI 的决策框架。
-
GPT-4 的局限性与特性揭示:社区讨论强调了 GPT-4 Scholar AI 的局限性,例如提示需要高级订阅才能进行深度研究的错误消息,以及访问 Beta 功能时未解决的问题。用户分享了管理对话长度和错误规避的技巧,强调了基于社区的故障排除和 AI 交互策略的创新。
OpenAccess AI Collective (axolotl) Discord 总结
-
SmoothQuant 提升 LLM 吞吐量:讨论集中在 SmoothQuant 上,这是来自 MIT 韩松实验室的一种新型量化方法,针对参数量超过 1000 亿的 LLM。如 Pull Request #1508 所述,该方法为 70B 模型带来了 50% 的吞吐量提升。然而,由于功能膨胀(feature bloat),将 SmoothQuant 等新技术集成到 vLLM 等系统中可能具有挑战性。
-
探索 LLM 长上下文的高效处理:关于管理 LLM 有限上下文窗口 的见解强调了 Activation Beacon 和 RoPE 增强功能,以改进长上下文处理。这一探索为在处理扩展上下文时保持性能提供了一条路径,这是技术应用中的关键因素。
-
HuggingFace 上的量化困惑与潜力:HuggingFace 上一个被错误归属的 70B 模型引发了关于量化作用及其影响的讨论,特别提到了围绕 Miqu 和 Mistral Medium 等量化模型的实用性与误解。模型量化的复杂性及其对显存效率的影响在 LoftQ 中进一步显现,尽管预期会有收益,但仍有显存溢出(OOM)错误的报告。
-
模型训练与推理效率解析:对话涉及了用于训练的有效硬件配置,特别是 NVIDIA H100 SXM GPU,以及推理策略,强调了量化中的权衡以及在采购前进行硬件基准测试的必要性。这包括深入探讨用于服务 fp16 模型的 vLLM 以及性能对硬件的依赖性,强调了优化模型运行的多样化路径。
-
提升模型性能的微调与配置:多项贡献强调了适当微调和模型配置的重要性,并指出了 FlagEmbedding 微调文档 和 LlamaIndex 指南 等资源。对话强调了精确设置对于获得改进的输出和更有意义的嵌入(embedding)表示的必要性,以及创建合成指令数据集以提高模型有效性的创新方法。
Mistral Discord 总结
-
关于 Mistral 和“泄露”传闻的澄清:针对新出现的模型是否为 Mistral 泄露版本存在困惑,最终确认该模型并非 Mistral 或泄露版,而可能是一个使用 Mistral 数据进行微调的 LLaMa 模型。社区呼吁 Mistral 官方人员对此事做出正式澄清。
-
量化(Quantization)影响 AI 模型性能:据推测与 Mistral 非常接近的稠密模型(Dense models)可能会受到量化效应的显著影响,这突显了模型性能退化的技术细微差别。
-
将 Mistral 适配新语言的挑战:针对在新语言中训练 Mistral 时词表不匹配的问题提出了担忧,并建议由于资源需求,从零开始训练可能并不可行,预训练(pretraining)可能是必要的。
-
Mistral 模型的 VRAM 和 Token 限制:用户报告了 Mistral AI 7B v0.1 模型声明的 VRAM 需求与实际用户体验之间存在不一致。此外,澄清了 Mistral API 文本嵌入(text embeddings)的 Token 限制:tiny/small/medium 模型的最大 Token 限制确认为 32k,而嵌入 API 为 8192。
-
API 和客户端讨论显示出扩张意图与技术兴趣:关于 Mistral API 在生产环境中的最大速率限制(maximum rate limit)的讨论表明了扩张兴趣,初始限制从 2 次请求/秒开始。为 Mistral AI 模型提出的新 Java 客户端 langchain4j 展示了官方文档之外由社区主导的开发努力。
Eleuther Discord 总结
-
新研究与对 AI 政策的批判性观点发布:AI Techniques in High-Stakes Decision Making 介绍了在关键背景下部署 AI 的见解。同时,拜登政府的 AI 监管简报 因政策方向模糊以及在 K-12 学校提议 AI/ML 教育而受到批评,引发了对其有效性和实施情况的担忧。
-
深入探讨模型效率与算法创新:#research 频道的讨论围绕模型效率展开,正在审查的技术包括基于种子的词表矩阵和梯度预处理(gradient preconditioning)。Softmax 瓶颈替代方案和数据预处理挑战是热门话题,同时还探讨了 Attention 机制,暗示了模型优化的复杂性以及对替代方案的追求。
-
引入 TOFU 以洞察模型取消学习(Unlearning):如 arXiv:2401.06121 所述,TOFU 基准测试的引入为高级机器取消学习(Machine Unlearning)方法奠定了基础,激发了人们对在“坏数据”上进行梯度上升作为取消学习策略的有效性的兴趣。该基准测试旨在通过使用合成作者档案来加深对 LLM 中取消学习的理解。
-
Apex 构建见解提供潜在优化:在 #gpt-neox-dev 中,讨论揭示了构建 apex 的挑战和新颖解决方案,特别是在 AMD 的 MI250xs 架构上。重点解决方案包括指定架构以减少构建时间,以及探索用于优化的 CUDA 标志,呈现了专注于提高开发效率的实用对话。
-
AI 社区渴望实验与离线灵活性:社区对新工作和探索性测试表现出显著的热情,并伴随着关于下载任务以供离线使用的实际咨询。这种兴趣强调了社区对创新的驱动力以及工具对多样化使用场景的适应性。
HuggingFace Discord 总结
-
PR 标记的 AI 礼仪指南:社区成员被提醒,如果与仓库无关,请勿标记个人进行 PR 审查,这引发了关于社区礼仪和 PR 处理公平性的讨论。
-
AI 开发中的耐心与策略:关于连续神经网络模型 (continuous neural network models) 的开发以及 Deepfake 检测流水线 成功实施的讨论,强调了社区对创新 AI 应用的关注以及在 PR 审查过程中的耐心。
-
政治竞选中的 AI 模型引发伦理问题:一场关于在选举中使用 AI 的对话展开,涉及欺诈等争议手段以及创建大量候选人视频等伦理方法。讨论还延伸到了技术细节的咨询以及对文本生成图像 Diffusion 模型的推荐。
-
深度学习对医学成像的影响:分享自 IEEE 的文章强调了深度学习在医学图像分析 (Medical Image Analysis) 方面取得的突破,为该组织关于医疗保健领域重要 AI 进展的知识库做出了贡献。
-
AI 领域的创新项目与演示:社区成员展示了各种项目,包括一个用于图像模型的 Hugging Face Spaces 演示、一个简历问答空间,以及一个将 Excel/CSV 文件转换为数据库表的应用程序。一段演示 Mistral 模型在 Apple Silicon 上性能的 YouTube 视频也备受关注。
-
NLP 和计算机视觉中的技术挑战与 GPU 加速:NLP 和计算机视觉频道的讨论集中在如何使用 llama-cpp 实现 GPU 加速,以及解决微调 Donut docvqa 时的错误,反映了 AI 工程师在工作中面临的技术障碍。
Latent Space Discord 总结
-
ColBERT 引发了超越传统 Embeddings 的兴趣:Simon Willison 对 ColBERT 的探索引发了关于其对比传统 Embedding 模型有效性的辩论。尽管好奇心日益增长,但 ColBERT 与其他 Embedding 模型之间缺乏直接对比数据被视为需要填补的空白。
-
Simon Willison 探讨 AI 的人文要素:一篇关于 Simon Willison 的专题报道深入探讨了 AI 如何与软件开发交织,强调了在 AI 工具中人类监督的重要性。这引发了工程师们关于 AI 在增强软件开发中人类能力方面作用的进一步讨论。
-
“Arc Search” 预期将改变网络交互:Arc Search(一款新型 iOS 应用)的推出可能会通过提供基于查询编译网页的 AI 驱动搜索,彻底改变网络浏览体验。社区推测这可能会对传统搜索引擎的主导地位发起挑战。
-
Voyage-Code-2 被吹捧为具有卓越的代码检索能力:Voyage-Code-2 的发布受到了热烈欢迎,并承诺在代码相关搜索中提供更好的性能。主要由
@swyxio推动的对话围绕该模型在 MTEB 上的潜在基准测试及其对 Embedding 专业化的影响展开。 -
Anthropic 的 Claude 模型被低估了?:关于 Anthropic 的 Claude 模型与 OpenAI 模型对比的辩论揭示了一个共识,即 Claude 的能力可能被低估了,特别是在摘要和检索任务中。这次讨论阐明了对不同应用的 AI 模型进行更细致对比的必要性。
DiscoResearch Discord 总结
-
MIQU 误解已解决:@aiui 关于 MIQU model 是 Mixtral medium 泄露的推测得到了 @sebastian.bodza 的回应。通过 Nisten 的推文 以及另一条推文中显示的该模型使用 LLaMA tokenizer 的信息,进一步澄清了事实。
-
德语微调的挫折与胜利:@philipmay 和 @johannhartmann 交流了德语模型微调的经验,包括使用 OASST-DE 数据集在 Phi 2 上的尝试,以及通过德语 DPO 增强 Tiny Llama 的成果,记录在 TinyLlama-1.1B-Chat-v1.0-german-dpo-Openllm_de.md 中。关于德语 Orca DPO 数据集的提问引出了 Hugging Face 上一个实验性数据集的公开。
-
通过 WRAP 开辟新领域:@bjoernp 分享了关于 Web Rephrase Augmented Pre-training (WRAP) 的见解,这是一种旨在提高语言模型数据质量的方法,详见 Apple 最近发表的论文(Web Rephrase Augmented Pre-training)。
-
CodeT5 与训练数据的挑战:在实现 Salesforce 的 CodeT5 Embedding 的过程中,@sebastian.bodza 遇到了技术障碍,并参与了关于构建“硬负样本 (hard negatives)”以及开发文本生成训练 Prompt 的讨论,并分享了一个特定的 Notebook 用于审查。
-
澄清检索模型的误解:关于为 RAG 生成段落检索数据集的讨论指出了一些在选择“硬负样本 (hard negatives)”和数据集构建方面的常见误解,旨在澄清此类数据的目的和最佳结构,这体现了持续的改进和贡献,详见嵌入的 GitHub 资源。
LangChain AI Discord 总结
-
LangChain 激发新进展:@irfansyah5572 寻求关于 LangChain 答案链的帮助,并附上了其项目的 GitHub 链接;同时 @oscarjuarezx 正在利用 LangChain 的功能开发一个由 PostgreSQL 支持的图书推荐系统。
-
使用 LangChain 增强 PDF 交互:@a404.eth 发布了一个关于开发 PDF 交互前端的 YouTube 教程,这是他们关于利用 LangChain 及相关技术教学系列的第二部分。
-
关注缓存与效率:技术讨论围绕
InMemoryCache在改善 LlamaCPP 模型推理时间方面的作用展开,虽然有相关的 GitHub issue 支持,但也强调了缓存性能方面的挑战。 -
Lumos 扩展程序点亮网页浏览:@andrewnguonly 推出了 Lumos,这是一个由 LangChain 和 Ollama 驱动的开源 Chrome 扩展程序,旨在通过本地 LLM 丰富网页浏览体验,并通过 GitHub 和 Product Hunt 邀请社区反馈。
-
教程助力掌握 LangChain:新的教程如 Ryan Nolan 的 2024 年初学者友好型 Langchain Agent 指南,以及 @a404.eth 对使用 LangChain 创建 RAG 的深入探讨,强调了社区知识建设和技能发展,可分别通过 YouTube 和 YouTube 访问。
LlamaIndex Discord 摘要
-
使用 LLM 处理复杂分类的新方法:@KarelDoostrlnck 介绍了一种利用 Large Language Models (LLMs) 解决涉及数千个类别的复杂分类的新方法。该技术涉及生成一组预测,随后对结果进行检索和重排序,详见 IFTTT 公告。
-
LlamaIndex.TS 迎来更新:LlamaIndex.TS 进行了升级并增强了文档,承诺为用户带来改进。更新公告和详情见此 推文。
-
RAG 黑客松提供 16,000 美元奖金:一场专注于 Retriever-Augmented Generation (RAG) 技术的线下黑客松(名为 LlamaIndex RAG-A-THON)宣布总奖金为 16,000 美元。活动详情见 黑客松详情。
-
探讨 Llama2 的商业用途和许可:社区成员讨论了 Llama2 商业化利用的潜力,建议在 Meta 的 官方网站 和 deepsense.ai 文章 中查看详细的许可信息。
-
使用 LlamaPacks 增强高级查询策略:@wenqi_glantz 与 @lighthouzai 合作评估了七个 LlamaPacks,展示了它们在针对特定需求优化查询策略方面的有效性。评估结果见此 推文。
LAION Discord 摘要
-
MagViT2 面临训练障碍:技术讨论强调了 MagViT2 的难题,在 10,000 个训练步数后出现了像素化样本。建议的解决方案包括调整学习率和损失函数,参考 MagViT2 PyTorch 仓库。
-
Nightshade 引发争议:Drhead 批评了 Nightshade 的不负责任发布,而 Astropulse 等人则强调了对该工具长期影响和有效性的担忧。还讨论了对抗 Nightshade 潜在威胁的策略,包括微调模型和避免使用目标编码器。
-
辩论 AI 是否需要新数据:质疑了增强 AI 模型是否必须使用新数据,pseudoterminalx 和 mfcool 认为重点应放在数据质量和适当的标注(captioning)上,以提高模型性能。
-
Activation Beacon 承诺实现上下文长度突破:关于 “Activation Beacon” 的讨论表明它可以让 LLM 实现无限的上下文长度,被视为一项重大进展,其中一个 LLaMa 2 模型在训练后达到了高达 400K 的上下文长度。阅读论文 并 查看代码。
-
优化图像数据集的数据存储:围绕数据集存储的对话质疑了 parquet 与 tar 文件的效率,使用 parquet 存储标注、tar 存储图像的混合方法被认为可能是最佳解决方案。推荐将 Webdatasets 和 tarp 用于深度学习的高性能 Python I/O 系统,并分享了进一步研究的链接:Webdataset GitHub,Tarp GitHub。
Perplexity AI Discord 摘要
-
选择合适的 AI 模型变得更简单:用户探讨了利用 Gemini、GPT-4 和 Claude 等 AI 模型的最优场景,并发现 技术常见问题解答 (technical FAQs) 对做出明智决策非常有帮助。
-
Perplexity 的 Library 功能:讨论了 Library 侧边栏未显示所有项目的问题,结论是这属于功能设计而非 Bug,目前仅显示最近的 8 个线程/集合。
-
Perplexity 项目没有加密货币代币:针对有关 Perplexity 可能发行加密货币的查询,官方确认不存在此类代币。
-
AI 在应用程序中的创新用途:开发者正创意性地将 AI 集成到项目中,例如一个以快递为主题的 pomodoro app(番茄钟应用),利用 AI 生成姓名和地址,突显了 AI 在增强应用功能方面的多功能性。
-
Perplexity API 期待自定义 Stop Words 功能:期待在 pplx-api 中集成 custom Stop Words 并配合 zed.dev editor 使用,旨在为编辑器应用中增强的“助手”功能提供除默认 OpenAI models 之外的丰富替代方案。
LLM Perf Enthusiasts AI Discord 摘要
-
Triton:平衡控制力与复杂性:
@tvi_强调 Triton 为 AI 工程师提供了一个平衡点,它比 PyTorch 提供更多控制权,但比直接使用 CUDA 复杂性更低,非常适合那些寻求效率而不想深入研究 CUDA 复杂细节的人。 -
RGB 转灰度的 CUDA 优化之旅:在尝试优化 RGB to Grayscale conversion 的过程中,
@artste和@zippika探讨了结构体的使用、vectorized operations(向量化操作)以及内存布局的变化。这段历程充满了尝试,包括意想不到的性能结果,并发现__forceinline__可以显著提高 Kernel 性能。 -
寻找 CUDA 智慧:在面对令人困惑的性能基准测试后,
@andreaskoepf建议@zippika深入研究 memory optimization techniques(内存优化技术)和向量化内存访问以提升 CUDA 性能,并参考了 NVIDIA 开发者博客 的见解。 -
揭开 PMPP 的奥秘:解答了围绕 Practical Massively Parallel Programming 概念的疑问,从第 2 章中不清晰的问题到理解第 6 章中的 memory coalescing(内存合并)和 banking(分库),展示了社区为阐明晦涩技术材料以实现共同进步所做的努力。
-
在 YouTube 上继续学习:
@andreaskoepf分享了一个与 AI 工程相关的 新教学视频,促进了社区在书面论坛之外的持续学习。
LLM Perf Enthusiasts AI Discord 摘要
-
写作的困扰与进展:公会中的工程师们表达了对写作辅助工具的沮丧与希望。虽然
@an1lam哀叹当前工具的局限性以及缺乏像 lex.page 这样的替代方案,但@calclavia带来了一线希望,介绍了用于学术写作的 jenni.ai,暗示它可能会解决其中的一些问题。 -
初创公司在云成本上的挣扎与策略:
@frandecam强调了初创公司使用 Google Workspace 面临的经济挑战,而@dare.ai则提出了一个解决方案:Google Cloud 初创企业计划,该计划承诺提供高达 250,000 美元的 Google Cloud 额度,但也提醒申请可能会有延迟。 -
Gorilla 开源解决方案引发关注:Gorilla OpenFunctions 项目引起了工程师们的兴趣,它提供了一个通过自然语言执行 API 调用的开源替代方案,详见其博客文章和 GitHub 仓库。这一创新旨在简化 API 调用与大语言模型 (LLM) 的集成。
-
创意 AI 的版权困境:
@jxnlco提出了一个提示词投资视觉模型在尝试读取复杂标签时遇到的版权限制问题,凸显了开发者在处理 AI 输出与知识产权之间界面时面临的共同挑战。 -
Mistral Medium 的讨论热度:thebaghdaddy 发送的一条消息询问了社区对 Mistral Medium 是否有潜力成为 GPT-4 竞争对手的看法,引发了人们对其在不断发展的 LLM 领域中的能力和地位的好奇。
Skunkworks AI Discord 摘要
-
“弗兰肯斯坦”模型问世:
@nisten开展了一项开创性实验,将所有 70b CodeLlamas 组合成一个复合的 BigCodeLlama-169b 模型,旨在设定 AI 性能的新基准。这个“弗兰肯模型”被认为增强了编程问题的解决能力,包括计算奥尔德林循环轨道(Aldrin cycler orbits)。 -
AI 开发中的技术与幽默:在利用 BigCodeLlama-169b 推进 AI 发展的过程中,
@nisten还加入了一些幽默,分享了一个 “lolol” 时刻,强调了他们在高风险技术工作中的轻松一面。 -
前沿 AI 研究分享:
@pradeep1148向社区成员介绍了 RAGatouille,这是一个简化 ColBERT 检索模型使用的新库,以其在可扩展行为摘要中的速度和准确性而闻名。 -
Eagle 7B 超越 Transformers:
@pradeep1148的 在 A40 上运行 🦅 Eagle 7B 展示了 RWKV-v5 架构的重大飞跃,详细介绍了 Eagle 7B 在 100 多种语言中处理 1 万亿 token 的能力。 -
社区与创新并行:在创新和技术讨论中,像
@zentorjr对@nisten的友好问候等个人互动,彰显了 Skunkworks AI 社区支持和充满活力的氛围。
Datasette - LLM (@SimonW) Discord 摘要
-
从短文本中洞察 Emoji:
@dbreunig展示了一个名为 Emoji Suggest 的新 Demo,它能够利用 CLIP model 将短句或标题转换为推荐的 Emoji。该 Emoji 建议工具的源代码 利用了预计算的 Emoji Embeddings,从而实现了快速且复杂的搜索功能。 -
利用 Embeddings 实现复杂搜索:
@dbreunig强调了使用 Embeddings 快速开发复杂搜索工具的有效性,并指出为了实现最佳搜索功能,仔细筛选选项至关重要。这一原则已应用在他们的 Emoji 建议工具中,充分展示了其实用性。 -
AI 相信其正面影响:在一段分享的对话中,
@bdexter注意到一款 AI(具体为 “llama2”)声称它相信 人工智能是一种向善的力量,旨在帮助人类实现潜能。这突显了 AI 在增强人类事业方面所持有的建设性观点。 -
对 ColBERT 文章的认可:发布在 TIL 上的 ColBERT writeup 得到了
@bewilderbeest的赞赏,他强调了共享代码片段以及搜索结果中单词创新热力图可视化的价值。这表明社区对 AI 研究的实际应用和知识共享有着浓厚兴趣。
Alignment Lab AI Discord 摘要
- GPT-5 训练引发好奇与确认:
@entropi通过一段 YouTube 视频 引发了讨论,该视频根据独家采访和见解推测 GPT-5 训练是否已经开始。在推测之后,@lightningralf确认 GPT-5 的训练确实正在进行中,但未分享更多细节。
AI Engineer Foundation Discord 摘要
- ChatGPT 与 Bard 在 Captcha 领域的对决:@juanreds 指出了用户交互和安全措施方法上的一个有趣区别:ChatGPT 会主动审核 Captcha 图像,而 Bard 则不会。这表明这两种 AI 系统在安全协议和用户界面设计理念上可能存在显著差异。
Ontocord (MDEL discord) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第 2 部分:按频道划分的详细摘要和链接
TheBloke ▷ #general (1403 条消息🔥🔥🔥):
- Miqu 持续引发讨论:用户如
@itsme9316和@rombodawg讨论 Miqu 模型究竟是 Mistral Medium 的泄露版,还是 Llama-2-70b 的微调版本,并强调了它在各种任务中的卓越表现。关于其来源存在多种猜测,有人认为它可能是一个“流氓”项目或未完成的 Llama3 版本。 - 对 AI 伦理和未来风险的担忧:
@mrdragonfox、@selea和@spottyluck等用户探讨了 AI 开发的伦理影响、政府或恶意行为者对强大模型的滥用,以及完全对齐(aligned)或“失控” AI 的潜在生存风险。对话涵盖了反宣传工具的必要性以及实现妥善对齐的内在挑战。 - Aphrodite Engine 受到关注:用户分享了使用 Aphrodite engine 的经验,表示在 A6000 GPU 上使用
--kv-cache-dtype fp8_e5m2配置可达到每秒 20 个 token 的出色性能。同时也提出了关于其 GPU 利用率以及是否支持跨多 GPU 模型切分的疑问。 - 关于 AI 分发和“碎片”角色的推测:频道中出现了一场关于在大型实体控制的主要基础模型背景下,小型开发者(“small fry”)的影响和贡献的哲学交流。人们承认了缺乏大量计算资源(compute resources)的个人所面临的局限性。
- 用户闲谈与理论思考:关于 AGI、通过 AI 进行社会控制以及不受限制的模型开发可能产生的结果的轻松交流和理论思考。讨论包括关于 AI 在未来治理中作用的奇思妙想,以及利用 AI 谋求公共利益与其潜在滥用之间的平衡。
提到的链接:
- GGUF VRAM Calculator - a Hugging Face Space by NyxKrage:未找到描述
- Scaling Transformer to 1M tokens and beyond with RMT:该技术报告介绍了循环记忆(recurrent memory)的应用,以扩展 BERT 的上下文长度,BERT 是自然语言处理中最有效的基于 Transformer 的模型之一。通过利用…
- LoneStriker/CodeLlama-70b-Instruct-hf-GGUF at main:未找到描述
- miqudev/miqu-1-70b · Hugging Face:未找到描述
- Forget Memory GIF - Will Smith Men In Black - Discover & Share GIFs:点击查看 GIF
- The Humans Are Dead - Full version:《Flight of the Conchords》试播集中歌曲 “Robots” 的两个部分。这也是他们同名全长专辑中的第九首曲目…
- exllamav2/examples/batched_inference.py at master · turboderp/exllamav2:一个用于在现代消费级 GPU 上本地运行 LLM 的快速推理库 - turboderp/exllamav2
TheBloke ▷ #characters-roleplay-stories (184 messages🔥🔥):
-
角色扮演模型中的重复性挑战:包括
@ks_c和@superking__在内的用户讨论了在角色扮演场景中使用 Mixtral 和 Flatdolphinmaid 等各种 AI 模型时面临的重复性挑战。一些模型如 Noromaid 和 Rpcal 被指出在避免重复方面表现更好。 -
探索最佳角色扮演模型:
@ks_c推荐在角色扮演会话中使用带有 Mixtral Instruct 的 ChatML,而@superking__分享了模型在达到特定 Token 阈值后变得重复的经验,并建议尝试使用较小的模型来开发抗重复数据集。 -
解决重复性的独特方法:
@superking__讨论了涉及 Direct Prompt Optimization (DPO) 的实验,通过编辑 AI 角色回复来创建优秀示例,从而解决重复性等问题。 -
模型对比与性能反馈:
@ks_c发起了关于 Mistral Medium 和 Miqu 等模型对比的讨论,其他用户如@flail_.也就格式和模型敏感性发表了看法,强调了实验设置和对比的重要性。 -
角色扮演模型推荐:为了寻找最佳的角色扮演 LLM,用户如
@ks_c针对不同的使用场景(从高 Token 长度到 NSFW 内容)推荐了 GPT-4、BagelMisteryTour rpcal 和 Noromaid Mixtral 等模型。
提到的链接:
TheBloke ▷ #training-and-fine-tuning (21 messages🔥):
- CUDA 对于学习 ML/DL 并非必不可少:
@dirtytigerx建议@zohaibkhan5040不要优先考虑 ML/DL 的 CUDA 编程,认为这是一项小众技能,对于开始学习神经网络并非至关重要。相反,他们推荐 fast.ai 的 Practical Deep Learning for Coders 课程 以打下坚实基础。 - 使用 Axolotl 超越基础 ML:对于进阶的微调学习,
@dirtytigerx建议深入研究 Axolotl 等项目的源代码。可以探索 Axolotl GitHub 仓库 进行动手实践。 - 揭开 ML 库的层级:
@dirtytigerx解释说,复杂的 ML 软件栈涉及多个仓库,包括 HuggingFace Transformers、PyTorch 等,并暗示探索这些仓库对于更好地理解 ML 运作机制很有价值。 - 讨论大模型微调的 VRAM 需求:
@flashmanbahadur询问了微调 Mistral 7B 的 VRAM 需求,@dirtytigerx指出在使用 AdamW 时需求量巨大,约为模型大小的 15-20 倍,并建议将 SGD 作为一种资源消耗较低的替代方案。 - 大模型优化器探索:在寻求高效 VRAM 利用率的过程中,
@saunderez幽默地指出了优化器技术的不断演进,建议为大语言模型选择前沿选项,如 Paged 8bit lion 或 adafactor。
提到的链接:
- Practical Deep Learning for Coders - Practical Deep Learning:一门为有一定编程经验、想学习如何将深度学习和机器学习应用于实际问题的人设计的免费课程。
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions:尽管提问。通过在 GitHub 上创建账号为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
TheBloke ▷ #coding (29 条消息🔥):
-
轻松导航 GitHub 项目:
@opossumpanda询问了如何理解 GitHub 项目结构以便进行贡献。@dirtytigerx指导了如何定位入口点,特别强调了 tabbyAPI 项目 中的start.py文件是一个具体的起点。他们还强调了利用 IDE/编辑器进行符号搜索以及在 GitHub 上进行全局仓库搜索,以高效地导航代码库。 -
Python 入口点详解:
@dirtytigerx澄清说,在 Python 项目中,带有条件块if __name__ == "__main__":的文件标志着执行的入口点。这一惯例有助于识别从哪里开始代码探索。 -
IDE 和编辑器:代码导航的强大工具:
@wbsch和@dirtytigerx讨论了使用带有语言服务器的 IDE 或编辑器对于高效代码导航的重要性,例如“跳转到定义”等功能。他们还提到了 GitHub 改进的搜索功能以及 Sourcegraph 的 VSCode 扩展在探索代码库时的实用性。 -
Code Llama 模型在 Hugging Face 发布:
@timjanik分享了 Code Llama 70B 在 Hugging Face 发布的动态,这是一款针对代码优化的 AI 模型。公告详情介绍了该模型在多种编程语言中的代码生成和调试能力。 -
阅读源码的艺术:
@animalmachine强调,有效地阅读源码是一项关键但缺乏练习的技能,它是编码能力的补充。他们建议通过合理的推测来高效导航代码库,并提到了可能为此目的演示 Cody。
提到的链接:
- codellama (Code Llama):暂无描述
- tabbyAPI/main.py at main · theroyallab/tabbyAPI:一个兼容 OAI 的 exllamav2 API,既轻量又快速 - theroyallab/tabbyAPI
- GitHub - theroyallab/tabbyAPI: An OAI compatible exllamav2 API that’s both lightweight and fast:一个兼容 OAI 的 exllamav2 API,既轻量又快速 - GitHub - theroyallab/tabbyAPI
Nous Research AI ▷ #ctx-length-research (6 条消息):
- 关于 Dynamite AI 的爆炸性论文:
@maxwellandrews强调了一篇可能对 AI 研究产生重大影响的论文,引导读者关注这项开创性工作。 - Activation Beacon 重新定义 LLM:由
@maxwellandrews分享的 Activation Beacon 项目提出了一种用于稠密检索(Dense Retrieval)和检索增强型 LLM的新方法,其 GitHub 仓库地址在这里。 - 无限上下文长度的潜在解决方案:
@cyrusofeden深入探讨了 Activation Beacon 如何通过引入“全局状态”(global state)令牌,显著地实现 LLM 的无限上下文长度,并在消息中分享了配套的论文和代码。 - 社区等待 Lucidrains:鉴于上下文长度解决方案的最新进展,
@atkinsman表达了对知名开发者 lucidrains 的反应或可能贡献的期待。 - 永恒的兴奋:在没有额外上下文的情况下,
@maxwellandrews分享了一个 Tenor GIF,可能暗示了这一进步的永恒性或漫长的等待。
提到的链接:
- Yam Peleg (@Yampeleg) 的推文:如果这是真的,那就无敌了:无限上下文长度已经到来。Activation Beacon,一种扩展 LLM 上下文的新方法。TL;DR:在提示词前添加“全局状态”令牌并预测自动回复…
- FlagEmbedding/Long_LLM/activation_beacon at master · FlagOpen/FlagEmbedding:稠密检索和检索增强型 LLM。通过在 GitHub 上创建账户为 FlagOpen/FlagEmbedding 的开发做出贡献。
- Old Boomer GIF - Old Boomer History - 发现并分享 GIF:点击查看 GIF
Nous Research AI ▷ #off-topic (44 条消息🔥):
-
在 YouTube 上探索先进 AI 模型:
@pradeep1148分享了两个 YouTube 链接,一个解释了结合 RAGatouille 的 ColBERT 模型(点击观看),另一个展示了在 A40 硬件上运行的 Eagle 7B 模型(点击观看)。第二个视频收到了.ben.com的批评,建议减少网页朗读,增加更具洞察力的分析。 -
集中 AI 资源:
@kquant正在致力于建立一个网站来整合 AI 研究、论文和指南,表达了对现有资源分散的挫败感。他们鼓励大家贡献内容,并提议将内容组织到特定的细分领域,如包括训练、微调(fine-tuning)和 Prompt 模板在内的文本生成领域。 -
为 AI 爱好者推荐资源:针对
@kquant的想法,@lightningralf提供了多个资源,包括一个论文相关的 Twitter 列表(在此发现)以及 GitHub 仓库,如 visenger/awesome-mlops 和 Hannibal046/Awesome-LLM。 -
关于大语言模型 (LLMs) 数据存储的咨询:
@muhh_11对 Mixtral 或 OpenAI 等团队如何存储海量数据感到好奇,.ben.com、@dorialexa和@euclaise对此进行了解答,强调了使用通用网络爬虫(web crawls)和高效存储解决方案来处理数十万亿 Token 的方法。 -
AI 模型训练的硬件考量:
.ben.com提供了实用建议,指出如果一个模型可以装入单块 GPU(如 3090),那么使用性能较低的 GPU(如 1080ti)来分担负载并无优势,强调了硬件兼容性在模型训练效率中的重要性。
提到的链接:
- Discord - A New Way to Chat with Friends & Communities:Discord 是通过语音、视频和文本进行交流的最简单方式。聊天、聚会,并与您的朋友和社区保持紧密联系。
- Running 🦅 Eagle 7B on A40:🦅 Eagle 7B:凭借跨 100 多种语言的 1 万亿 Token 超越 Transformers。RWKV-v5 架构和线性 Transformer 的全新时代已经…
- Exploring ColBERT with RAGatouille:RAGatouille 是一个相对较新的库,旨在简化 ColBERT 的使用。ColBERT 是一种快速且准确的检索模型,支持可扩展的 BE…
- Hmusicruof4 Rowley GIF - Hmusicruof4 Rowley Diary Of A Wimpy Kid - Discover & Share GIFs:点击查看 GIF
- Capybara Riding GIF - Capybara Riding Alligator - Discover & Share GIFs:点击查看 GIF
- GitHub - Hannibal046/Awesome-LLM: Awesome-LLM: a curated list of Large Language Model:Awesome-LLM:大语言模型精选列表 - GitHub - Hannibal046/Awesome-LLM: Awesome-LLM: a curated list of Large Language Model
- GitHub - visenger/awesome-mlops: A curated list of references for MLOps:MLOps 参考资料精选列表。通过在 GitHub 上创建账户为 visenger/awesome-mlops 的开发做出贡献。
- GitHub - swyxio/ai-notes: notes for software engineers getting up to speed on new AI developments. Serves as datastore for https://latent.space writing, and product brainstorming, but has cleaned up canonical references under the /Resources folder.:软件工程师快速掌握 AI 新进展的笔记。作为 https://latent.space 写作和产品头脑风暴的数据存储,但在 /Resources 文件夹下有整理好的规范参考资料。
Nous Research AI ▷ #interesting-links (27 messages🔥):
-
Token Healing 被 .ben.com 认为过于复杂:
.ben.com讨论了exllamav2类中 Token Healing 的复杂性,并提到如果token_healing=True,则会消耗可变数量的 Token。提出的解决方案涉及通过重构来提高可重用性。 -
阿里巴巴发布 Qwen-VL,表现优于 GPT-4V 和 Gemini:
@metaldragon01分享了阿里巴巴 Qwen-VL 发布的消息,据报道它在多个基准测试中优于 GPT-4V 和 Gemini。同时还分享了关于 Qwen-VL 的 Demo 和博客文章以供深入了解。 -
Karpathy 的挑战讨论度不足:
@mihai4256指出,尽管 Andrej Karpathy 的谜题非常具有挑战性(@mihai4256本人也证实了这一点),但 Twitter 上对此的讨论却很少。 -
lm-eval-harness 与 llama.cpp Server 的问题及解决方案:
@if_a遇到并讨论了将 Miqu 模型与 lm-eval-harness 集成时的几个故障排除步骤,引用了KeyError和RequestException。@hailey_schoelkopf提供了解决方案,包括使用gguf模型类型和修正 API URL,从而解决了上述问题。 -
Activation Beacon 实现 LLM 上下文长度突破:
@nonameusr强调了一项名为 Activation Beacon 的重大进展,它通过引入“全局状态(global state)”Token,实现了 LLM 的无限上下文长度。该技术已在 LLaMA 2 上演示,可将上下文长度从 4K 泛化到 400K。如果能在其他模型中复现,这可能实质上“解决”上下文长度限制的问题。附有论文和代码链接以供进一步探索。
提到的链接:
- no title found: 未找到描述
- Yam Peleg (@Yampeleg) 的推文: 如果这是真的,那就结束了:无限上下文长度已经到来。Activation Beacon,扩展 LLM 上下文的新方法。TL;DR:在 Prompt 之前添加“全局状态”Token 并预测自动…
- GGUF Local Model · Issue #1254 · EleutherAI/lm-evaluation-harness: 是否有本地托管的 GGUF 模型的 lm_eval 示例?lm_eval –model gguf –model_args pretrained=Llama-2-7b-chat-hf-Q4_K_M.gguf, –tasks hellaswag –device mps 报错 AssertionError: mus…
- Scholar: 未找到描述
- Andrej Karpathy (@karpathy) 在 Threads 上的发布: 有趣的 Prompt Engineering 挑战,第一集。准备:让 LLM 生成一个 [1, 10] 范围内的 5x5 随机整数数组。它应该直接生成,不使用任何工具或代码。然后,要求它…
- Matryoshka Representation Learning: 学习表征是现代 ML 系统的核心组件,服务于众多下游任务。在训练此类表征时,通常会出现计算和统计…
- AK (@_akhaliq) 的推文: 阿里巴巴发布 Qwen-VL。Demo: https://huggingface.co/spaces/Qwen/Qwen-VL-Max 博客: https://qwenlm.github.io/blog/qwen-vl/ Qwen-VL 在多个基准测试中优于 GPT-4V 和 Gemini。
Nous Research AI ▷ #general (389 messages🔥🔥):
- Eagle-7B 击败 Mistral:
@realsedlyf分享了对 Eagle-7B 的兴奋之情。这是一款基于 RWKV-v5 架构的开源多语言模型,在基准测试中甚至超越了 Mistral,在保持与顶级 1T 7B 模型相当的英语性能的同时,展现了更低的推理成本。 - 神秘的 Mistral Medium:一个泄露版本的 Mistral medium 引发了热烈讨论,用户纷纷猜测其来源和性能。
@theluckynick和@kalomaze讨论了它作为基于 L2-70B 架构的泄露微调版本的可能性,引发了兴奋与质疑。 - MIQU-1-70B 之谜:MIQU-1-70B 模型引发了关于其身份的辩论,
@n8programs和@agcobra1等用户暗示它可能是故意泄露的 Mistral medium 模型,或者是某个复杂的恶作剧项目,但尽管如此,它的效果却非常出色。 - 探索 Frankenstein 合并与模型微调实验:miquella-120b 的发布(一个预训练语言模型的合并版本)引发了兴奋和好奇,CodeLlama 70B 等实验也受到了讨论。用户探讨了在特定代码库或任务上微调模型的想法,并讨论了模型间通信和效率的潜在新方法。
- 区块链遇见 AI:Notre Research 宣布使用区块链进行模型评估和潜在激励(由
@realsedlyf提及并由他人进一步探讨),这既带来了好奇也带来了怀疑,指向了创新但具有争议的模型开发和验证方法。
提到的链接:
- nisten/BigCodeLlama-169b · Hugging Face: 未找到描述
- alpindale/miqu-1-70b-fp16 · Hugging Face: 未找到描述
- 来自 AI at Meta (@AIatMeta) 的推文: 今天我们发布了 Code Llama 70B:这是我们用于代码生成的 LLM 的一个性能更强的新版本——在与之前的 Code Llama 模型相同的许可证下可用。下载模型 ➡️ https://bi…
- Mark Zuckerberg: 我们正在开源一个全新且改进的 Code Llama,包括一个更大的 70B 参数模型。编写和编辑代码已成为当今 AI 模型最重要的用途之一。这种能力…
- Tayomaki Sakigifs GIF - Tayomaki Sakigifs Cat - Discover & Share GIFs: 点击查看 GIF
- Facebook: 未找到描述
- nisten/BigCodeLlama-92b-GGUF at main: 未找到描述
- Introducing The World's Largest Open Multilingual Language Model: BLOOM: 未找到描述
-
[Continuum Generative Software Insights](https://continuum.sh): 未找到描述 - 来自 Q (@qtnx_) 的推文: @AlpinDale 关于 miqu(左侧,介于 q2 和 q5 之间)与 mistral medium(未知 quantization)的对比
- @conceptofmind 在 Hugging Face 上: "一个 1b dense causal language model 在准确性方面开始“饱和”……": 未找到描述
- alpindale/miquella-120b · Hugging Face: 未找到描述
- MILVLG/imp-v1-3b · Hugging Face: 未找到描述
- 来自 simp 4 satoshi (@iamgingertrash) 的推文: 早期 Truffle-1 渲染图。希望本周能敲定核心设计,然后在预订前开始研究散热物理特性。
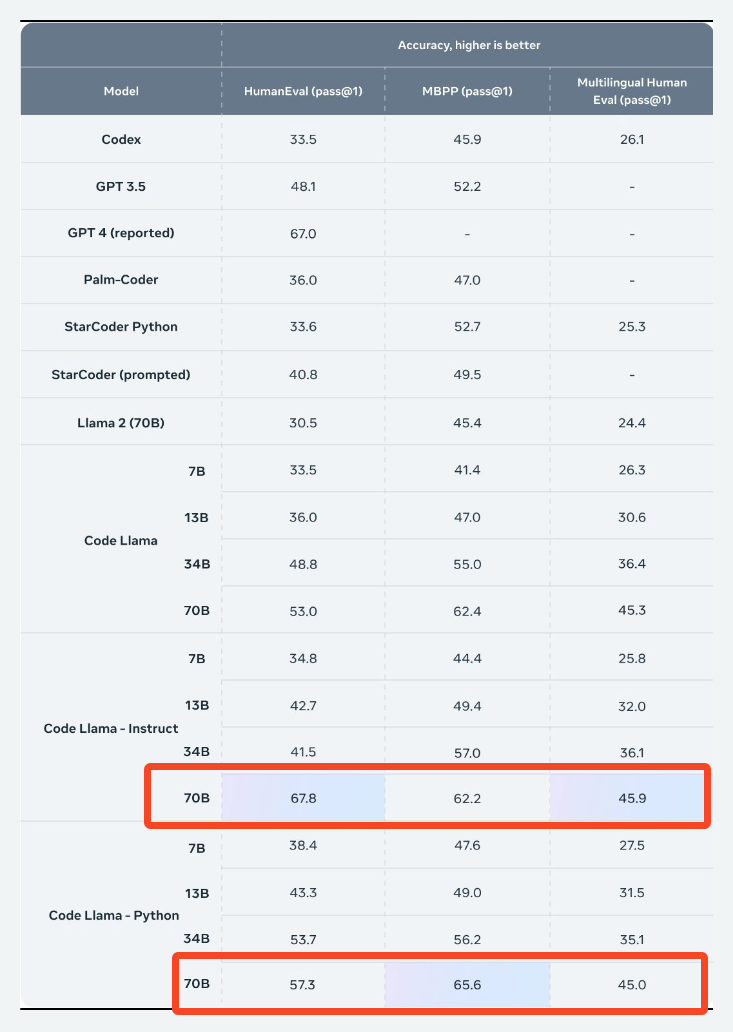
- 来自 Vaibhav (VB) Srivastav (@reach_vb) 的推文: 冲啊!CodeLlama 70B 来了。> HumanEval 评分 67.8! https://huggingface.co/codellama/CodeLlama-70b-Instruct-hf
- 来自 RWKV (@RWKV_AI) 的推文: 隆重推出 Eagle-7B。基于 RWKV-v5 架构,为开源领域带来了当今最强的:- 多语言模型(甚至击败了 mistral)- attention-free transformer(10-100x+ l…
- 来自 NotaCant (@Nota_Cant) 的推文: 在 /lmg/ 上有一个关于潜在 Mixtral Medium 泄露的引人入胜的 LLM 动态。一个名为 Miqu-1-70b 的优秀模型被一名匿名人士神秘发布,最初被推测是一个泄露…
- Cat Cats GIF - Cat Cats Explosion - Discover & Share GIFs: 点击查看 GIF
- Hal9000 Hal GIF - Hal9000 Hal 2001 - Discover & Share GIFs: 点击查看 GIF
- GPT4 报告的 HumanEval 基础分数显著高于 OpenAI 报告的结果 · Issue #15 · evalplus/evalplus: 你好,我注意到通过 EvalPlus 工具测得的 GPT4 HumanEval 分数报告约为 88% 的 HumanEval 基础分数。这大大高于 OpenAI 使用官方 HumanEval 测试套件报告的结果…
- codellama/CodeLlama-70b-Instruct-hf · Hugging Face: 未找到描述
- Breaking Bad Walter White GIF - Breaking Bad Walter White - Discover & Share GIFs: 点击查看 GIF
- NobodyExistsOnTheInternet/Llama-2-70b-x8-MoE-clown-truck · Hugging Face: 未找到描述
Nous Research AI ▷ #ask-about-llms (37 messages🔥):
-
OpenHermes2.5 推荐用于消费级硬件:用户
@realsedlyf推荐使用经过 gguf 或 gptq 量化的 OpenHermes2.5 在大多数消费级硬件上运行,认为它是回答问题的最佳开源 LLM。 -
OpenHermes2.5 性能与参数查询:
@mr.fundamentals分享了 Nous Hermes 2 Mixtral 8x7B DPO 的链接,展示了其取得的成就。关于通过原型设计端点设置 max tokens 和 temperature 等参数的疑问,已通过@teknium提供的 prompt 模板得到解决。 -
关于模型中 NSFW 内容的澄清:
@teknium澄清说,所讨论的模型(包括那些基于 GPT-4 输出训练的模型)既不包含也不专门从事 NSFW 内容,尽管由于缺乏关于拒绝(refusals)的特定训练数据,它们并未完全排除此类内容。 -
针对特定答案集的 Prompting 技巧:用户
@exibings寻求建议,以确保在评估 RSVQA 数据集时,模型的响应与预定义的答案集保持一致。讨论了涉及 system prompts 和余弦相似度(cosine similarity)等比较方法的技巧。 -
用于分类任务的多模态模型探索:
@exibings讨论了使用 IMP v1-3b model 处理与轨道图像相关的分类数据集,强调了其多模态能力。对话延伸到将其与其他模型(如 Bakllava 和 Moondream)进行比较,@rememberlenny还提到了其他强力模型,如 Qwen-vl。
提到的链接:
LM Studio ▷ #💬-general (177 messages🔥🔥):
-
为 LLM 工作选择合适的 GPU:在关于哪种 GPU 更适合训练 Large Language Models (LLM) 的讨论中,
@heyitsyorkie建议@.mchinaga,尽管旧款 P40/P100 GPU 拥有更多 VRAM,但更推荐新款 4060Ti,因为它能接收 Nvidia 的当前更新。这与@.mchinaga对 GRAM 速度和相比 3060Ti 提升幅度的担忧形成对比。 -
在 CPU 上运行 LLM 及兼容性问题:
@heyitsyorkie提供了见解,指出 LM Studio 默认在 CPU 上运行且不需要 PyTorch,以此回应@.mchinaga关于将程序设置为仅 CPU 运行的查询。同时,@hexacube分享了旧款 GPU 因驱动程序过时而无法被识别的经历,强调了与客户系统兼容性的重要性。 -
LM Studio 中的 GGUF 格式与弃用模型:
@heyitsyorkie为@pudlo和其他人澄清,LM Studio 不再支持 GGML 格式的模型,仅支持 GGUF,并强调需要更新平台的首页标签以反映当前支持的格式。 -
关于模型中动态加载专家(Experts)的问题:讨论探索了在 LM Studio 中动态加载模型专家的功能,
@hexacube提出了该功能的实用性,@heyitsyorkie确认了其可行性,特别是对于 MoE (Mixture of Experts) 模型。 -
Python 编程挑战与解决方案:
@.mchinaga在一个涉及 chatGPT 的 Python 项目中遇到错误,促使@.ben.com和@dagbs等多位用户提供排错建议,例如修正 API URL 和移除不兼容的响应键(response keys)。
提到的链接:
Friends Phoebe GIF - Friends Phoebe Rachel - Discover & Share GIFs:点击查看 GIF
LM Studio ▷ #🤖-models-discussion-chat (92 messages🔥🔥):
-
旧模型在某些领域依然表现出色:
@fabguy发起了一场讨论,指出一些旧模型在特定任务中的表现可能优于新模型。@heyitsyorkie和@msz_mgs赞同这一观点,并强调像 llama 1 这样的模型不受“OpenAI 式 AI”趋势的影响,在它们擅长的训练领域表现良好。 -
为任务选择合适的模型:
@vbwyrde表示需要一个资源或网站来帮助用户为特定任务选择最合适的模型,例如用于 function calling 的 Open-Interpreter 或用于代码重构的 CrewAI Agents。这些信息对于需要模型选择建议和 GPU 显存大小指导的初学者尤其有益。 -
对编程模型和语言支持的好奇:
@golangorgohome询问了最适合编程的模型,特别是那些支持 Zig 语言的模型。在与@dagbs进行了一系列交流后,双方明确了虽然一种模型类型通常足以应付许多任务,但特定的插件可能会提供增强的代码补全(code-completion)能力。Dagbs 建议使用 LM Studio 以获得易用性,并探索 LM Studio 生态系统中的各种模型以满足不同需求。 -
模型特性解析:
@dagbs深入讲解了如何在不同模型及后缀(如-instruct、-chat、-base、DPO和Laser)之间进行选择,解释了它们的训练背景和预期用途。这一解释旨在消除各种选项的神秘感,并帮助@golangorgohome根据其需求选择最佳模型。 -
探讨 TinyLlama 版本的稳定性问题:
@pudlo报告了 TinyLlama Q_2K 的不稳定和循环问题,寻求改进模型性能的建议。@dagbs建议尝试配合 ChatML 使用 TinyDolphin Q2_K 以获得潜在的更好效果,并暗示 GPU/CPU 问题可能会导致观察到的不稳定性。较大的模型没有出现这些问题,这表明较小的量化(quant)模型存在特定问题。
提到的链接:
- dagbs/TinyDolphin-2.8-1.1b-GGUF · Hugging Face:未找到描述
- [LLMs and Programming in the first days of 2024 -
](http://antirez.com/news/140):未找到描述 - OSD Bias Bounty:未找到描述
-
[Bug Bounty: ConductorAI - Bias Bounty Program Bugcrowd](https://bugcrowd.com/conductorai-ogbb?preview=ae06c13f786e06a1f9ff03d74230b7d5):了解更多关于 Conductor AI 的漏洞披露计划,该计划由众测安全解决方案领导者 Bugcrowd 提供支持。
LM Studio ▷ #🧠-feedback (14 messages🔥):
- 发布新 Beta 版本:
@yagilb宣布了一个用于测试的新 Beta 版本,并分享了最新 Beta 版本的链接。在对版本号产生困惑后,@fabguy澄清该 Beta 版是继 0.2.11 之后的下一个版本。 - 长 Prompt 导致的性能滞后:用户
@msz_mgs和@heyitsyorkie报告称,在将长文本粘贴到 Prompt 文本框时会遇到性能滞后。经确认,问题不在于 Prompt 的处理,而在于粘贴动作本身。 - UI 导航挑战:
@msz_mgs进一步提到了在处理长文本或 Prompt 时 UI 导航的困难,特别是在查找删除、复制或编辑文本的图标时,需要过多的滚动。@yagilb承认这些是 Bug 并将进行修复。 - 商务咨询跟进:
@docorange88就商务咨询联系了@yagilb,提到他们发送了几封跟进邮件但未收到回复。@yagilb确认收到了邮件并承诺会尽快回复。
LM Studio ▷ #🎛-hardware-discussion (38 messages🔥):
-
探讨 LMStudio 模型的 VRAM 开销:
@aswarp询问为什么模型无法完全卸载(offload)到他拥有 8GB VRAM 的 RTX 3070 上。@heyitsyorkie澄清说,不仅是模型大小,context length 也需要一定的 VRAM,这引发了关于超出模型大小之外所需的意外 VRAM 的讨论。 -
关于内存占用的误解:
@fabguy反驳了@aswarp关于 Transformer 和上下文内存占用的假设,强调 Transformer 将 prompt 编码为位置数据,这显著增加了内存使用量。他建议阅读一篇 Transformer 指南 以进行深入了解。 -
揭示 LMStudio 中 GPU Offload 的细微差别:
@mudmin询问为何在拥有 24GB RAM 的 4090 GPU 上无法实现完全的 GPU offload。对话显示,卸载模型的实际大小包括模型本身、上下文和其他变量,需要通过反复试验才能完全理解。 -
利用集成 GPU 实现模型完全卸载:在讨论了 GPU offload 能力后,
@mudmin发现使用集成 GPU 可以促进更多模型实现完全加载。这一见解为在具有双 GPU 设置的系统上优化模型加载提供了策略。 -
RTX 40 Titan 传闻引发社区讨论:
@rugg0064分享了关于拥有 48GB VRAM 的 RTX 40 Titan 的传闻,引发了关于 Nvidia 市场策略和 VRAM 升级成本不成比例的讨论。.ben.com通过链接一篇 TechPowerUp 文章 补充了背景信息,详细介绍了在美国出口限制下,中国的工厂如何将 Nvidia RTX 4090 拆解并改装为 AI 友好型 GPU。
提到的链接:
- Illustrated Guide to Transformers- Step by Step Explanation:Transformer 正在席卷自然语言处理领域。这些令人惊叹的模型正在打破多项 NLP 记录……
- Special Chinese Factories are Dismantling NVIDIA GeForce RTX 4090 Graphics Cards and Turning Them into AI-Friendly GPU Shape:美国政府最近对出口中国的 AI 硬件限制显著影响了几家主要的半导体厂商,包括 NVIDIA、AMD 和 Intel,限制了它们的销售……
LM Studio ▷ #🧪-beta-releases-chat (11 messages🔥):
-
Beta V2 迎来重大更新:
@yagilb发布了 0.2.12 Preview - Beta V2,提供了 Mac 和 Windows 的下载链接,包括一系列错误修复,如 VRAM 估算、OpenCL 问题、AI 角色闪烁等。反馈请发送至特定的 Discord 频道。 -
关于平台兼容性的查询:用户
@djmsre和@nixnovi分别询问了 Mac Intel 版本和新的 Linux AppImage,@heyitsyorkie确认没有 Mac Intel 版本,而@yagilb指出 Linux 版本很快就会推出。 -
新功能需求:
@junkboi76提出了在 LM Studio 中添加 图像生成支持 的想法,表达了对扩展该工具能力的兴趣。 -
关于特定支持的问题:
@ausarhuy询问了 LM Studio 对 WSL (Windows Subsystem for Linux) 的支持情况,表现出对操作系统间互操作性的兴趣。 -
Beta 版性能和兼容性报告:用户如
@wolfspyre和@mirko1855分别报告了 Beta 版在最新的 Mac Sonoma 版本以及不支持 AVX2 的 PC 上的问题。@fabguy建议查看 FAQ 以了解常见的退出代码问题。
提到的链接:
no title found:未找到描述
LM Studio ▷ #memgpt (1 messages):
- LM Studio 的 OpenAI 兼容 API 尚待功能完善:
@_anarche_提到 LM Studio openai compatible API 尚未完全开发,目前缺乏对 openai function calling 和 assistants 的支持。他们希望这些功能能在未来的更新中包含进去。
OpenAI ▷ #ai-discussions (3 messages):
- 关于 RAG 的提问:用户
@aiguruprasath询问什么是 RAG。此消息记录中未提供后续跟进或回答。 - 代码中的笑声:用户
@penesilimite2321仅评论了 “LMFAO”,未给出该反应的背景或原因。 - 助力政治获胜的特定 AI:
@iloveh8询问了哪些 AI 产品 能显著帮助政治候选人赢得选举,并提到将 deepfakes 用于特定场景作为例子。未记录到任何回复或进一步阐述。
OpenAI ▷ #gpt-4-discussions (114 messages🔥🔥):
-
探索 GPT-4 和 Scholar AI 的局限性:
.broomsage和elektronisade等用户讨论了 GPT-4 Scholar AI 的问题,包括收到error talking to plugin.scholar消息,以及意识到某些功能需要付费订阅。.broomsage发现高级论文分析功能需要 premium Scholar AI 订阅,因此决定暂时继续使用标准版 GPT-4。 -
Beta 功能的烦恼:
darthgustav.对 Plus 订阅者未获得预期的 beta 功能(特别是@功能)表示沮丧,引发了关于 浏览器故障排除 的讨论,以及用户之间功能访问不一致的轶事证据。 -
知识库集成特性揭秘:
fyruz提出了关于 GPT 知识库 如何与对话集成的问题,引发了关于特定格式或 context size 是否会影响模型显式搜索其知识库需求的对话。 -
持续的 GPT 模型错误和文件处理:
loschess和darthgustav.研究了反复出现的错误,如 “Hmm…something seems to have gone wrong,”,推测了 GPT 内部问题,并分享了在服务器高负载期间重建 GPTs 或调整知识库文件等解决方案。 -
GPT 对话中的上下文和长度:围绕 GPT 模型 对话长度的实际限制 展开了讨论,
_odaenathus和blckreaper等用户分享了管理长对话的经验和策略,强调了对话深度与技术约束之间的平衡。
OpenAI ▷ #prompt-engineering (44 messages🔥):
- @darthgustav. 解释 RAG:Retrieval Augmented Generation (RAG) 是指 AI 直接挂载了知识库,并可以搜索其中的数据或进行语义匹配。这是为了回答 @aiguruprasath 关于什么是 RAG 的查询。
- @madame_architect 分享的 Prompt Engineering 技巧:@madame_architect 建议使用 Prompt 模式
"Please critique your answer. Then, answer the question again."来提高 AI 输出的质量,该技术源自一篇重要的研究论文。 - 改进对 ChatGPT-4 的代码生成请求:@jdeinane 对 ChatGPT-4 未按要求生成代码表示沮丧,对此 @darthgustav. 建议在请求代码前先明确任务、语言、架构并制定计划。
- 讨论 AI 中的伦理支架:@darthgustav. 引入了一种针对功利主义、义务论和实用主义的 2/3 通过/失败检查,以管理 AI 中的伦理考量,并提到一个例子,该方法阻止了关于优惠券使用的不道德建议。
- @darthgustav. 在 Custom GPTs 中的条件指令:他们详细阐述了如何使用条件指令,引导 AI 在面临伦理困境时参考 LEXIDECK_CULTURE.txt。@aminelg 对该文化知识库的内容表现出兴趣,@darthgustav. 指出可以通过在线搜索 “Lexideck Technologies Ethics” 间接探索。
OpenAI ▷ #api-discussions (44 条消息🔥):
-
探索 RAG 以增强 AI 能力:用户
@aiguruprasath询问了关于 RAG (Retrieval Augmented Generation) 的信息,@darthgustav.澄清说,它涉及 AI 拥有直接的知识访问权限以进行数据搜索或语义匹配,从而增强其性能。 -
ChatGPT 的 Prompt 模式魔力:据
@madame_architect称,Prompt 模式"Please critique your answer. Then, answer the question again."显著提高了 ChatGPT 输出的质量。这种模式是在一篇重要的研究论文中发现的,类似于 COT。 -
优化 ChatGPT-4 中的代码生成请求:由于对 ChatGPT-4 处理代码请求的响应感到沮丧,
@jdeinane寻求了建议。@darthgustav.建议明确指定任务、语言和代码架构,以获得更好的结果。 -
将 Prompt 视为高级编程:
@aminelg和@darthgustav.讨论了将 Prompt 编写视为高级编程,强调了对 ChatGPT 提出清晰、详细请求的重要性。他们还探讨了将 ChatGPT 视为一个操作系统,能够实现多态软件行为。 -
通过条件命令进行创新的伦理审核:
@darthgustav.分享了关于使用功利主义、义务论和实用主义的 2/3 通过/失败检查来处理 AI 输出中的伦理考量的见解。此外,@darthgustav.设计了一种涉及 conditional imperatives(条件命令)和文化知识库(LEXIDECK_CULTURE.txt)的方法,以引导 ChatGPT 在伦理困境中的回答。
OpenAccess AI Collective (axolotl) ▷ #general (139 条消息🔥🔥):
-
讨论新的量化方法 SmoothQuant:
@dreamgen和@nanobitz讨论了一种名为 SmoothQuant 的新量化方法,该方法由 MIT 的 Han’s lab 开发,类似于 AWQ。它针对 超过 1000 亿参数的 LLMs,但也展示了针对 13B 和 34B 等较小模型的基准测试,显示 70B 模型的 吞吐量提升了 50% (GitHub 上的 Pull Request #1508)。 -
vLLM 模型合并面临的挑战:
@dreamgen提到 vLLM 正变得 因功能过多而陷入泥潭,使得集成 SmoothQuant 等新技术变得困难。尽管有潜在好处(如显著降低服务器成本),但由于当前系统的复杂性,集成可能不会很快实现。 -
探索 LLMs 的长上下文处理:
@xzuyn和@dreamgen分享了关于克服 LLMs 有限上下文窗口 相关挑战的见解。他们讨论了 Activation Beacon 以及基于 RoPE (Rotary Position Embedding) 的增强方案,旨在高效处理更长的上下文,同时不损害短上下文的性能。 -
HuggingFace 上的 Miqu 量化版被误认为 Mistral Medium:一个 70B 模型的量化版本 被用户上传到 HuggingFace,引发了讨论 (@yamashi) 并被拿来与 Mistral Medium 进行比较。这种混淆引发了关于它是否为量化泄露版的调查,而在线论坛和社交媒体上未经证实的推测进一步推波助澜。
-
探索训练硬件选择与策略:包括
@dreamgen和@mistobaan在内的多位用户讨论了在 RunPod 等平台上使用 NVIDIA H100 SXM GPUs 最具成本效益的训练设置。他们还谈到了从云服务商处获取优惠价格的挑战,并比较了 SXM 与 PCIe 版本 GPU 的效率。
提到的链接:
-
[NVIDIA Hopper Architecture In-Depth NVIDIA Technical Blog](https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/): 关于新款 H100 GPU 你想知道的一切。 - Soaring from 4K to 400K: Extending LLM’s Context with Activation Beacon: 由于上下文窗口长度有限,长上下文的利用对大语言模型构成了巨大挑战。虽然可以通过微调扩展上下文窗口,但它会重新…
- First-fit-decreasing bin packing - Wikipedia: 未找到描述
- GitHub - bjj/exllamav2-openai-server: An OpenAI API compatible LLM inference server based on ExLlamaV2.: 一个基于 ExLlamaV2 的 OpenAI API 兼容 LLM 推理服务器。
- GitHub - dwzhu-pku/PoSE: Positional Skip-wise Training for Efficient Context Window Extension of LLMs to Extremely Length: PoSE:通过位置跳跃式训练将 LLMs 的上下文窗口高效扩展至极长。
- Scaling Laws of RoPE-based Extrapolation: 基于 Rotary Position Embedding 的大语言模型 (LLMs) 的外推能力是目前备受关注的话题。处理外推的主流方法是…
- no title found: 未找到标题
- Support W8A8 inference in vllm by AniZpZ · Pull Request #1508 · vllm-project/vllm: 我们在 vLLM 中实现了 W8A8 推理,可以将吞吐量提高 30%。W4A16 量化方法要求在计算前将权重反量化为 fp16,这会导致吞吐量…
- Importance matrix calculations work best on near-random data · ggerganov/llama.cpp · Discussion #5006: 所以,我之前提到过,我担心 wikitext 风格的校准数据或缺乏多样性的数据,在重要性矩阵计算方面可能比更“随机”的数据效果更差…
- Support int8 KVCache Quant in Vllm by AniZpZ · Pull Request #1507 · vllm-project/vllm: KV Cache 的量化可以在模型性能损失极小的情况下提升吞吐量。我们实现了 int8 KV Cache 量化,可以实现 15% 的吞吐量提升。此 PR 是…
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (2 messages):
- 关于 LoftQ 实现的疑问:
@suikamelon询问 LoftQ implementation 是否已具备功能,暗示在其使用或结果方面可能存在潜在问题或误解。 - LoftQ 显存问题:
@suikamelon报告尝试使用 QLoRA 和 8192 context 对 7B model 进行微调,记录显示需要 11.8 GiB。然而,LoftQ at 4bit 导致了 out-of-memory (OOM) 错误,引发了对其显存效率的担忧。
OpenAccess AI Collective (axolotl) ▷ #general-help (30 messages🔥):
- 处理过长的 Completion 示例:根据
@dreamgen的说法,超过 context length 的 completion 示例以前会被拆分,但现在会被丢弃。这种行为转变可能会影响模型处理大规模数据输入的方式。 - 推理效率困扰:
@diabolic6045报告使用量化模型时每次推理大约需要 18 秒,即使使用了use_cache=True,并寻求更快的推理方法建议。@nanobitz建议避免使用 Hugging Face 的默认设置,并探索quant、vllm或TGI以获得更好的性能。 - Ollamai 文档链接:
@dangfutures分享了一个 Ollamai 文档链接,可能与文本嵌入(text embeddings)和模型性能优化的讨论有关。 - 微调过程中的配置错误:
@ragingwater_在尝试使用自定义配置微调 OpenHermes 时遇到了特定错误,引发了关于正确设置以及对模型合并(model merging)影响的讨论。他们引用了 Axolotl GitHub README 中的解决方案解决了该问题,但寻求关于模型合并期间影响的进一步澄清。 - 用于平衡数据分布的 Bucket Training:
@jinwon_k强调了 Colossal-AI 团队提出的 “Bucket Training” 技术,用于确保持续预训练(continual pre-training)中的平衡数据分布,并建议将其应用于 Axolotl。 分享的链接 深入讨论了这一策略,包括 LLaMA 版本之间的比较以及对模型预训练成本的影响。
提到的链接:
- Colossal-LLaMA-2: 使用 LLaMA 开发低成本高质量领域特定 LLM 方案…:LLaMA-1 和 LLaMA-2 之间最显著的区别在于引入了更高质量的语料库,这是一个关键因素……
- gist:5e2c6c87fb0b26266b505f2d5e39947d:GitHub Gist:即时分享代码、笔记和代码片段。
- axolotl/README.md at 4cb7900a567e97b278cc713ec6bd8af616d2ebf7 · OpenAccess-AI-Collective/axolotl:尽管提问(axolotl questions)。通过在 GitHub 上创建账号为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #datasets (6 条消息):
-
模型仓库配置各异:
@dangfutures强调数据配置(正样本标签、负样本标签、查询)通常取决于模型仓库,因为每个仓库都有其特定的要求。 -
分享 FlagEmbedding 微调指南:
@dangfutures分享了 FlagEmbedding 微调文档的链接,该文档提供了关于稠密检索(dense retrieval)和检索增强 LLMs 微调的详细说明。 -
发布 LlamaIndex 微调概览:
@dangfutures还发布了 LlamaIndex 微调指南的链接,解释了微调模型的益处,包括提高输出质量和获得更有意义的 embedding 表示。 -
讨论合成指令数据集创建:
@_rxavier_分享了他们基于教科书创建合成指令数据集的过程,即从教科书文本块(chunks)中生成包含问题和答案的 JSON。目前正在考虑先仅生成问题,然后在后续步骤中生成答案是否会更有效。
提到的链接:
- Fine-tuning - LlamaIndex 🦙 0.9.39:未找到描述
- FlagEmbedding/FlagEmbedding/llm_embedder/docs/fine-tune.md at master · FlagOpen/FlagEmbedding:稠密检索和检索增强 LLMs。通过在 GitHub 上创建账号为 FlagOpen/FlagEmbedding 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #community-showcase (2 条消息):
- 模型卡片更新即将到来:
@ajindal同意了@caseus_的请求,在模型卡片中添加 axolotl 徽章和标签,这预示着文档即将进行更新。
OpenAccess AI Collective (axolotl) ▷ #deployment-help (15 条消息🔥):
- 探索 LLMs 的推理栈:
@yamashi在仅有 LLMs 训练经验后开始深入研究推理领域。@dreamgen建议 vLLM 可能是部署 fp16 模型最简单的方式,但也提到了在长上下文和中等负载下的性能问题。 - 量化与性能权衡:
@dangfutures和@dreamgen都讨论了将量化作为推理策略。虽然量化可能会降低处理速度,但其性价比权衡仍不确定。 - 硬件需求的不确定性:
@yamashi询问了在批处理模式下以 500 token/s 运行 70b 模型所需的硬件(特别是 VRAM)。@dreamgen建议硬件需求取决于具体任务,并推荐采用试错法。 - 建议在购买前租赁硬件进行基准测试:
@dreamgen建议在购买前先租赁硬件进行性能基准测试。这种方法为@yamashi关于为特定模型需求购买合适硬件的担忧提供了一个务实的解决方案。 - 量化产生积极结果:
@dangfutures分享了使用 AWQ 量化的积极经验,表明它在推理性能方面可能带来显著收益。
Mistral ▷ #general (137 messages🔥🔥):
-
关于 Mistral 和“泄露”传闻的困惑与猜测:Mistral Discord 频道的成员(包括
@ethux、@casper_ai和@mrdragonfox)就新出现的模型是否为 Mistral medium 的泄露版本展开了讨论,参考了其性能、来源和构成。由@alexworteega链接到 huggingface.co/miqudev/miqu-1-70b 的该模型最终被确认不是 Mistral 或泄露版,而可能是一个使用 Mistral 数据进行 Finetuning 的 LLaMa 模型。 -
关于模型性能和 Quantization 的技术讨论:
@mrdragonfox、@elvinrath和@i_am_dom针对 Quantization 对 AI 模型的影响进行了细致讨论,特别是性能下降方面。会议指出,像传闻中接近 Mistral 的 Dense models 可能会受到 Quantization 效应的显著影响。 -
呼吁官方澄清传闻中的泄露:
@dillfrescott希望 Mistral 员工能回应有关 Mistral medium 模型潜在泄露的传闻,以平息猜测。@mrdragonfox回应称,如果传闻属实,公司早就采取行动了。 -
减少文字冒险游戏中的 Token 使用:
@ewanhc咨询了在不损害叙事质量的情况下,最小化文字冒险游戏中 Token 使用量的策略。讨论了包括 Embedding、Retrieval 方法以及 Prompt 压缩在内的各种解决方案,@akshay_1分享了 GitHub 上的 microsoft/LLMLingua 链接,作为潜在的研究方向。 -
运行 Mistral 模型的 VRAM 需求:
@batot4968反馈在 6GB VRAM 显卡上运行 Mistral AI 7B v0.1 模型时出现问题,这与官方网站的说法不符。讨论强调了官方声明的系统要求与用户实际体验之间的差异,引发了关于 Mistral 模型 VRAM 充足性的疑问。
提及的链接:
- GitHub - mistralai/mistral-src: Reference implementation of Mistral AI 7B v0.1 model.:Mistral AI 7B v0.1 模型的参考实现。
- GitHub - microsoft/LLMLingua: To speed up LLMs' inference and enhance LLM's perceive of key information, compress the prompt and KV-Cache, which achieves up to 20x compression with minimal performance loss.:为了加速 LLM 推理并增强 LLM 对关键信息的感知,对 Prompt 和 KV-Cache 进行压缩,在极小性能损失下实现高达 20 倍的压缩。
Mistral ▷ #finetuning (8 messages🔥):
- 在新语言中训练 Mistral:
@nticaric对在新语言中继续训练 Mistral 模型的有效性表示担忧,原因是可能存在 Vocabulary 不匹配的问题。@vhariational建议不要从头开始,因为这需要大量的资源和数据。 - Pretraining 可能是必要的:在关于新语言训练 Mistral 最佳方法的讨论中,
@mrdragonfox建议 Pretraining 可能是必要的,尽管未提及具体的方法或数据。 - 关于 BakLLaVA-1 Finetuning 资源的咨询:
@attnmamba_15242询问了 Finetuning BakLLaVA-1 所需的 GPU 资源和时间,并提供了该项目在 Hugging Face 上的页面链接及其背后的合作信息。BakLLaVA-1 是 Mistral 7B 基础模型与 LLaVA 1.5 架构的结合。 - BakLLaVA-1 与 Mistral 的相关性受到质疑:
@mrdragonfox质疑了 BakLLaVA-1 信息与 Mistral 讨论的相关性,并建议直接从 BakLLaVA 的 GitHub 仓库获取信息。 - 在 Dolly 数据集上 Finetuning Mistral 7B 的困难:
@bishwa3819在使用 LoRA 在 Dolly 数据集上 Finetuning Mistral 7B 时,面临降低 Training loss 的挑战。他们分享了配置并寻求改进 Finetuning 过程的建议。
提及的链接:
Mistral ▷ #showcase (1 messages):
nk_pas: 随处编写 Prompt,只需一次按键即可运行 Mistral 平台。
Mistral ▷ #la-plateforme (28 条消息🔥):
-
Mistral API 速率限制引发关注:
@arnaud_35886询问了在生产环境中使用 Mistral API 的最大速率限制 (Rate Limit),暗示需要比当前提供的更高。最初对限制性质(速率 vs 成本)的困惑得到了澄清,@casper_ai指出速率限制提升的批准通常取决于使用历史,起步为 2 次请求/秒。 -
Token 和 Embedding 限制受到审查:
@dierkdroth寻求关于 Mistral API 文本 Embeddings 的 Token 限制的澄清,并得到了直接和推断性的回答。@sophiamyang确认 tiny/small/medium 模型的最大 Token 限制为 32k,而 Embedding API 为 8192。 -
Mistral Tokenization 的探索:为了解 Mistral 模型所使用的 Tokenizer 细节,
@dierkdroth询问了具体的 Tokenizer 并参考了一个 JavaScript 实现。@sophiamyang承认缺乏文档并承诺更新,而@vhariational将其与 HuggingFace 仓库中的 Tokenizer 进行了比较。 -
Java 客户端集成提议:
@carloszela提议在官方 Mistral 文档中为 Java 用户添加一个新客户端,展示了一个名为 langchain4j 的 GitHub 开源项目,该项目支持 Mistral AI 模型。 -
等待 Early Stopping 问题的修复:
@digitalphotographer跟进了之前报告的关于 Mistral 平台中 Early Stopping 行为的问题,在向@sophiamyang等人发送了用于复现错误的 Notebooks 后,正在寻求更新。
提及的链接:
- Yarn:快速、可靠且安全的依赖管理。
-
[客户端代码 Mistral AI Large Language Models](https://docs.mistral.ai/platform/client/.):我们提供 Python 和 Javascript 的客户端代码。 - GitHub - langchain4j/langchain4j: Java 版 LangChain:Java 版的 LangChain。可以通过在 GitHub 上创建账号为 langchain4j/langchain4j 的开发做出贡献。
Eleuther ▷ #general (8 条消息🔥):
-
sk5544 发布新 AI 研究论文:sk5544 分享了一篇题为 AI Techniques in High-Stakes Decision Making 的新 AI 研究论文,作者包括 Stephen Casper、Carson Ezell 等,旨在为公共知识做出更多贡献。
-
拜登政府 AI 监管事实清单遭到批评:
@exirae批评了拜登政府新的 AI 监管事实清单 (Fact Sheet),指出政策方向缺乏清晰度,并对提议在 K-12 学校开展 AI/ML 教育表示担忧。 -
注意到 NIST AISI 的排除和工作组的泛滥:
@hyperion.ai观察到拜登政府关于 AI 监管的事实清单中没有提到分配给 NIST AISI 的任务,并评论了当前政策倡议中“工作组 (Taskforces)”的流行。 -
对工作组表示怀疑:
@clockrelativity2003和@.undeleted对工作组的有效性表示怀疑,认为它们更多是政治姿态而非实际解决问题。 -
对学校 AI/ML 教育的担忧:
@exirae和@.undeleted都表达了对在 K-12 学校实施 AI/ML 教育的担忧,担心由于学龄儿童的不成熟和美国公立学校系统的不足可能导致混乱。
提及的链接:
-
[事实清单:拜登-哈里斯政府在总统拜登发布具有里程碑意义的行政命令后宣布关键 AI 行动 白宫](https://www.whitehouse.gov/briefing-room/statements-releases/2024/01/29/fact-sheet-biden-harris-administration-announces-key-ai-actions-following-president-bidens-landmark-executive-order/):三个月前,拜登总统发布了一项具有里程碑意义的行政命令,以确保美国在把握人工智能 (AI) 的前景和管理其风险方面处于领先地位。该命令指示… - 黑盒访问不足以进行严谨的 AI 审计:AI 系统的外部审计越来越被认为是 AI 治理的关键机制。然而,审计的有效性取决于授予审计员的系统访问程度。最近…
Eleuther ▷ #research (119 条消息🔥🔥):
-
模型效率与训练的创新思路:
@nshepperd讨论了通过从种子(seeds)生成词表矩阵(vocab matrices)来减小模型大小的技术,并探索了针对 Softmax Bottleneck 问题的不同分解方法。他们提到利用融合矩阵乘法(fused matmul)内核来缩减体积,并实验了通过预处理梯度(preconditioning gradients)来模拟权重不共享(untied weight)的 Transformer 的训练轨迹。 -
探索 Softmax Bottleneck 解决方案:多位社区成员(包括
@nshepperd、@wonkothesensible和@stefangliga)深入探讨了 Softmax Bottleneck 问题,讨论了 sigsoftmax 和 multifaceted softmax 等替代方案。他们辩论了这些替代方案对困惑度(perplexity)测量和分布误差的潜在影响,暗示了彻底解决这一问题的复杂性。 -
对数据集和质量信号的好奇:
@micpie询问了是否有类似于 RedPajama-Data-V2 的、带有广泛指标的高质量数据集,并指出由于缺乏元数据搜索功能,在 HF hub 等平台上很难找到此类资源。 -
对语言建模和数据预处理见解的贡献:
@random_string_of_character和@leegao_分享了通过合成实验见解提升语言模型困惑度的研究链接;同时@laomein和.the_alt_man讨论了一个特定的数据预处理代码片段,说明了模型开发中的常见挑战和澄清。 -
对注意力机制和替代激活函数的思考:
@catboy_slim_、@fern.bear和@stefangliga对 Softmax 和注意力机制进行了批判性审查,考虑了使用 Sigmoid 函数等替代方案,并质疑了 Softmax 被广泛使用的直觉依据。他们讨论了 Ghost Attention 等创新方法,以及重新思考神经网络中概率分布以解决离群特征(outlier features)和量化(quantization)挑战的潜力。
提到的链接:
- Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling:大型语言模型是在海量的网络抓取数据上训练的,这些数据通常是无结构的、多噪声且措辞不当的。当前的缩放定律(scaling laws)表明,从这类数据中学习需要大量的…
- MoE-LLaVA: Mixture of Experts for Large Vision-Language Models:对于大型视觉语言模型(LVLMs),扩展模型规模可以有效提升性能。然而,显著增加模型参数会大幅提高训练和推理成本,因为所有模…
- Learning Universal Predictors:元学习(Meta-learning)已成为训练神经网络从有限数据中快速学习新任务的一种强大方法。广泛接触不同任务可以产生多功能的表示,从而实现通…
- 来自 Ekin Akyürek (@akyurekekin) 的推文:合成实验和可解释性的见解能否为语言建模带来真正的改进?我们:> 提出了一个上下文学习(in-context learning)的正式模型 > 发现了 “n-gram heads”…
- Softmax Bottleneck Makes Language Models Unable to Represent Multi-mode Word Distributions:Haw-Shiuan Chang, Andrew McCallum。计算语言学协会第 60 届年会论文集(第 1 卷:长篇论文)。2022 年。
- Sigsoftmax: Reanalysis of the Softmax Bottleneck:Softmax 是许多深度学习应用中用于建模分类概率分布的输出激活函数。然而,最近的一项研究表明,Softmax 可能是…的一个瓶颈。
- Papers with Code - The Methods Corpus:2189 种方法 • 117443 篇带有代码的论文。
- Circuits Updates - January 2024:未找到描述
Eleuther ▷ #interpretability-general (12 messages🔥):
-
LLM 中的 Machine Unlearning 面临弱基线问题:
@stellaathena批评了大型语言模型(LLM)中 Machine Unlearning 研究的现状,指出应用研究通常使用较弱的基线,并建议了一种尚未被充分探索的方法,即在坏数据上利用 Gradient Ascent 训练模型。他们提议在 Pythia 上进行实验,利用 The Pile 中与特定主题相关的子集进行 Gradient Ascent。查看讨论。 -
引入 TOFU Benchmark 用于 Unlearning:
@baidicoot和@stellaathena讨论了最近推出的 TOFU 基准测试,该基准旨在通过比较 Gradient Ascent 等方法,促进对模型 Unlearning 的深入理解。TOFU 论文(可在 arXiv:2401.06121 获取)包含一个合成作者档案的数据集,用于研究 Unlearning 策略的有效性。 -
使用原始方案探索模型谱系:
@fblgit提供了一个简单的工具,用于识别模型之间的关系或“血统”。该方案虽然基础但功能齐全,并邀请对模型谱系(Model Lineage)感兴趣的人士联系以获取详情。 -
提供 The Pile 下载链接的替代方案:在
@1_glados报告原始 The Pile 下载链接出现 404 错误后,@random_string_of_character提供了一个访问该数据集的备用 Magnet 链接。 -
关于 Unlearning 和数据可交换性的澄清:
@statslime询问了@stellaathena讨论的 Machine Unlearning 背景下数据可交换性(Data Exchangeability)的影响,随后澄清评估涉及检查模型之间相同权重的百分比。
提到的链接:
- TOFU: A Task of Fictitious Unlearning for LLMs:在来自网络的海量语料库上训练的大型语言模型可能会记忆并重现敏感或私人数据,从而引发法律和伦理担忧。Unlearning,即调整模型以遗忘……
- Stella Biderman (@BlancheMinerva) 的推文!): @Wetassprior @daphneipp “在坏数据上使用 Gradient Ascent 训练模型”是 Machine Unlearning 的有效技术吗?答案为“否”的程度衡量了非交换性(non-exch…)的程度。
Eleuther ▷ #lm-thunderdome (2 messages):
- 对新工作的兴趣:
@johnnysands对最近的进展表示了浓厚兴趣,并计划对该工作运行一些测试。他们添加了一个友好的表情符号来表达热情。 - 关于离线任务下载的查询:
@damon_29077询问是否有办法下载所有任务并将其缓存以供离线使用。这个问题暗示了对更灵活使用场景的需求。
Eleuther ▷ #gpt-neox-dev (6 messages):
-
在 Frontier 上构建 Apex 的困扰:
@groggyrhombus强调在 OLCF 的 Frontier(AMD MI250xs)上构建 apex 非常耗时。通过在构建时明确指定架构,所需时间显著减少。 -
CUDA 可能会通过 Flag 提供缓解:关于构建 apex,
@groggyrhombus建议 CUDA 可能也有类似的 Flag 来减少构建时间,这为在 CUDA 环境中工作的人员提供了一条可能的优化路径。 -
Apex 的自定义编译方法:
@catboy_slim_详细介绍了一种编译 apex 的自定义方法,涉及使用官方文档中未提及的特定 Flag。该方法包括使用pip install进行编译,然后创建一个可以轻松分发和导入的 Wheel 文件。 -
跨平台 Apex 构建时间的解决方案:
@triggerhappygandhi确认了 apex 在各种平台上构建时间过长的普遍问题,并对@groggyrhombus提供的特定架构构建减时技巧表示赞赏。这一认可强调了该问题的普遍性以及共享解决方案的价值。
HuggingFace ▷ #general (94 条消息🔥🔥):
-
关于 PR 标记的社区指南:
@cakiki温馨提醒用户不要为了 PR 审查而随意艾特(tag)他人,特别是当这些人与该仓库无关时,并强调了社区礼仪。这引发了与@kopyl的讨论,后者对该规则表示质疑,最终@cakiki将此事提交给管理员以示公正。 -
PR 审查耐心是关键:
@not_lain建议对新创建的 Pull Request 保持耐心,强调该 PR 仅发布了 11 小时,审查者可能还没来得及处理。此建议是针对@kopyl提出的,他当时正在寻求关于如何通过标记协议加快 PR 审查的说明。 -
探索连续神经网络过程:
@bshvp提出了一个关于开发持续运行的神经网络模型的有趣问题,旨在模拟人类大脑功能。他们建议为这些模型提供持续的感官输入流,以真实评估其意识,引发了关于 AI 开发创新方法的对话。 -
Deepfake 检测流水线的成功案例:
@not_lain分享了其 Deepfake 检测流水线在不到一周内达到 147 次下载的成就,并提供了详细说明及社区链接 (https://huggingface.co/not-lain/deepfake)。这引起了@adiinx的兴趣,他寻求关于 Deepfake 内容生成和语音克隆的建议,随后@not_lain澄清了该流水线的局限性和应用场景。 -
Fedora 与 Ubuntu 在 AMD 硬件上的机器学习对比:
@cilginflix分享了在 Fedora 上由于 onnxruntime 和 AMD 的 ROCm 问题导致使用 CPU 进行 ML 任务时遇到的挑战,引发了关于操作系统对 ML 兼容性的讨论。@kopyl建议使用 NVIDIA 硬件进行 ML,但@cilginflix反驳称 AMD 在 Ubuntu 或 Manjaro 等其他发行版上可以运行,尽管性能和稳定性表现各异。
提到的链接:
- Instantiating a big model:未找到描述
- PNG to SVG (Online & Free) — Convertio:未找到描述
- not-lain/deepfake · Hugging Face:未找到描述
- Leeroo Orchestrator: Elevating LLMs Performance Through Model Integration:在本文中,我们提出了一种架构,利用多个已训练 LLM 的集体知识来创造新的 SOTA。该框架的核心是一个基于 LLM 的编排器(orchestrator),它能够……
- GitHub - Leeroo-AI/leeroo_orchestrator: The implementation of "Leeroo Orchestrator: Elevating LLMs Performance Through Model Integration":”Leeroo Orchestrator: Elevating LLMs Performance Through Model Integration” 的代码实现 - GitHub - Leeroo-AI/leeroo_orchestrator。
-
[Home leeroo](https://www.leeroo.com/):未找到描述
HuggingFace ▷ #today-im-learning (10 条消息🔥):
- @osanseviero 的庆祝时刻:@osanseviero 分享了一个简短但由衷的 “Congrats!!“,@not_lain 回复了 “thank youuuu” 并配上了一个特别的 Hugging Face 表情符号。庆祝的具体背景仍是一个谜。
- @erlonidasap 寻求模型训练指导:@erlonidasap 正在启动一个新项目,并向社区征求关于如何在特定字符串数据集上训练模型的建议。这与一个公司项目有关,但未提供更多细节。
- 来自 @not_lain 的综合建议:针对 @erlonidasap 的提问,@not_lain 建议首先确定问题类型(text-classification, text-generation, QA 等),然后从 Hugging Face Hub 中选择合适的模型,最后在特定数据上进行 Finetuning。
- @kaizen0340 询问语音翻译训练:@kaizen0340 向社区询问是否有关于如何使用
speechencodedecoder训练语音翻译的教程或仓库。遗憾的是,消息中没有提供任何回复。 - @antiraedus 分享每周更新与反思:@antiraedus 分享了他们本周的见解,强调了建立正确习惯和保持专注的重要性,包括在 Flutter 开发、运动和头脑风暴 App 创意方面的个人进展。他们强调了为持续生产力打下坚实基础的目标。
HuggingFace ▷ #cool-finds (3 条消息):
- Deep Learning 在医学影像领域的突破:
@maro_mich分享了一篇来自 IEEE 的开放获取文章,详细介绍了 Deep Learning 如何彻底改变 Medical Image Analysis。点击此处查看研究结果。 - 另一篇医学影像必读论文:
@aryan_1098鼓励社区探索一篇发表在 IEEE 上的关于 Medical Image Analysis 的论文。该研究可以在此处找到。
提到的链接:
- Deep Learning Applications in Medical Image Analysis:近年来 Machine Learning 算法在图像识别任务中取得的巨大成功,正值电子病历和诊断影像使用量大幅增加的时期…
- Convolutional Neural Networks for Image Emotion Recognition by fusing Differential and Supplementary Information:情绪产生于复杂的现象,这些现象被认为具有生物学基础。Neuroscience 研究表明,情绪与大脑活动的独特模式以及…
HuggingFace ▷ #i-made-this (7 条消息):
-
萨满动画引人入胜:
Amanita分享了一个风格化的毒蝇伞萨满动画。未提供链接或进一步详情。 -
myg5702 推出的综合 AI 模型演示 Space:
myg5702发布了一个 Hugging Face Spaces 演示,展示了包括 sdxl、fooocus 和 dream shaper xl turbo 在内的多种 AI 模型。这个 Space 似乎是前沿图像模型的一站式展示。 -
not_lain 开发的创新简历 Space:
not_lain在 Hugging Face 上创建了一个 简历问答 Space,旨在让招聘人员更轻松地查找信息。如果用户欣赏这一创新概念,作者鼓励大家为该 Space 点赞(heart react)。 -
monirul_1slam 发布的 Apple Silicon 运行 Mistral 视频:
monirul_1slam发布了一段 YouTube 视频,演示了 Mistral 模型在 Apple Silicon 上的性能,特别面向对不同硬件上的机器学习性能感兴趣的技术爱好者和开发者。 -
joshuasundance 挑战 ABSA 模型创建:
joshuasundance接受了为笔记本电脑评论训练并上传 SetFitABSA 模型的挑战,并在 Hugging Face 上分享了其工作链接。这一贡献突显了社区在情感分析(sentiment analysis)方面的积极协作与学习。 -
.bigdookie 捕捉到类猫王人声:
.bigdookie分享了他们在录音过程中的兴奋之情,其中主唱的声音酷似猫王(Elvis),这标志着创意音乐制作中的一个奇幻且轻松的时刻。背景仍处于娱乐和对未来发布的预热阶段。 -
impl66 开发的 Excel/CSV 转数据库表应用:
impl66开发了一个 Gradio 应用,可将 Excel/CSV 文件转换为数据库表,并随后回答用户关于这些表的问题,展示了在数据管理和检索方面的实用性。
提到的链接:
- Best Image Models Demo - FumesAI 的 Hugging Face Space:未找到描述
- Resume Qa - not-lain 的 Hugging Face Space:未找到描述
-
[MLX Mistral-7B-Instruct 在 Apple Silicon 上运行](https://www.youtube.com/watch?v=cjl2ADP8JLQ&t=79s):你能用 MLX 在 Apple Silicon 上运行 Mistral AI 的 Mistral-7B-Instruct-v0.2 吗?让我们一探究竟。 ————————————————————-… - Tables - sid27 的 Hugging Face Space:未找到描述
- 来自 thecollabagepatch (@thepatch_kev) 的推文:当你的歌手某天莫名其妙听起来有点像猫王时 @fffiloni 的 dreamtalk 需要发布了 😂 这周我们只是在机长席上找点乐子 下周… @_buildspace
- joshuasundance/setfit-absa-all-MiniLM-L6-v2-laptops-aspect · Hugging Face:未找到描述
- joshuasundance/setfit-absa-all-mpnet-base-v2-laptops-polarity · Hugging Face:未找到描述
HuggingFace ▷ #diffusion-discussions (11 messages🔥):
- AI 讨论选举操纵:
@iloveh8询问了哪些 AI 产品可以帮助政治候选人赢得选举,并提到 deepfakes 是一个潜在的用例。@vipitis回应了一些例子,如欺诈、提供额外选票、为获得不具代表性的领先优势而重新划定边界,甚至毒害竞争对手。 - AI 在政治中的争议性应用:
@vipitis在讨论 AI 在政治竞选中的应用时,建议在假设没有规则限制的情况下,可以采取任何必要手段,包括欺诈行为。 - 在政治竞选中寻求合乎伦理的替代方案:与争议性用途相反,
@chad_in_the_house建议为政治候选人制作大量视频,认为这是 AI 在竞选中更合法且合乎伦理的应用形式。 - 对竞选视频技术细节的兴趣:在讨论制作视频之后,
@iloveh8对技术层面表示好奇,并强调了媒体围绕此类 AI 驱动内容的持续讨论。 - 咨询 Text to Image 扩散模型:
@syed2658将对话转向技术建议,询问关于最佳 Text-to-Image 扩散模型的推荐。这表明人们对 AI 应用的兴趣已超出政治影响。
提到的链接:
| [How to WIN an Election | Ordinary Guide](https://youtu.be/xOBmKtQVlo0):在 Twitter 上关注我:https://twitter.com/ordinarytings 在 Patreon 上支持频道:https://www.patreon.com/ordinarythings 如何赢得选举?通过 l… |
HuggingFace ▷ #computer-vision (1 messages):
swetha98:我在运行微调 donut docvqa 的代码时遇到了这个错误。
HuggingFace ▷ #NLP (3 messages):
- llama-cpp 的 GPU 加速困惑:用户
@.sgp询问了在使用 llama-cpp 时实现 GPU 加速的困难,寻求社区的见解或解决方案。 - 对 llama-cpp 的 GPU 需求感到惊讶:针对
@.sgp的困境,@frosty04212对运行 llama-cpp 需要 128 个 GPU 层表示惊讶,并好奇所涉及的 GPU 规格。
HuggingFace ▷ #diffusion-discussions (11 messages🔥):
- 关于 AI 在选举中作用的讨论变得阴暗:
@iloveh8发起了一场对话,询问可以帮助政治候选人赢得选举的具体 AI 用例。@vipitis给出了具有争议的回应,建议将欺诈作为一种手段,强调了提供额外选票或重新划定选区边界以获得不具代表性的领先优势等行为。 - 从策略转向数字内容:从阴暗的建议转向,
@chad_in_the_house提出了一种更合法的方法,即为政治候选人制作大量视频,以产生更多的内容和曝光度。 - 媒体影响的技术细节:针对为候选人制作更多视频的建议,
@iloveh8对这一策略背后的技术细节表示好奇,特别是考虑到媒体对此类话题的频繁讨论。 - 寻找 Text-to-Image 模型:
@syed2658询问了关于最佳 Text-to-Image 扩散模型的建议,从关注选举的对话转向寻求 AI 模型方面的建议。 -
非传统的选举指南:除了给出争议性建议外, @vipitis还分享了一个名为“**How to WIN an ElectionOrdinary Guide”的 **YouTube 视频(点击观看),以幽默的方式解读如何赢得选举。
提到的链接:
| [How to WIN an Election | Ordinary Guide](https://youtu.be/xOBmKtQVlo0):在 Twitter 上关注我:https://twitter.com/ordinarytings 在 Patreon 上支持频道:https://www.patreon.com/ordinarythings 如何赢得选举?通过 l… |
Latent Space ▷ #ai-general-chat (92 messages🔥🔥):
-
ColBERT 与传统 Embeddings 的讨论升温:
@sarav1n发起了关于 ColBERT 与当前 Embedding 模型在实际应用中的辩论,分享了 Simon Willison 的文章 中的见解,该文章强调了 ColBERT 计算相似度评分的独特方法。对话中表达了对 ColBERT 与传统 Embedding 模型进行直接对比的渴望,@swyxio和@420gunna等成员表示感兴趣,但也指出目前缺乏对比数据。 -
Simon Willison 为 AI 和软件领域提供新视角:
@mdcker分享了一篇关于 Simon Willison 的专题报道,讨论了 AI 对软件开发的影响及相关问题。社区对 Willison 深入浅出地解释复杂 AI 话题表示赞赏,这引发了关于 AI 软件开发中人为因素的进一步讨论。 -
“Arc Search” 革新移动端网页浏览:
@mdcker介绍了 Arc Search,这是一款全新的 iOS 应用,旨在通过根据用户查询构建网页来简化网络搜索,这可能会改变用户与搜索引擎和浏览器应用的交互方式。社区对其影响以及与传统搜索引擎的潜在竞争进行了推测。 -
Voyage-Code-2 承诺更好的代码检索效果:
@gsegato宣布发布 Voyage-Code-2,这是一个声称在代码相关应用中具有卓越性能的 Embedding 模型。这引发了由@swyxio发起的讨论,涉及专注于 Embedding 的价值主张,以及该模型在 MTEB 等 Benchmark 上的预期评估。 -
Anthropic 的 Claude 模型备受关注:
@philltornroth质疑为什么 Anthropic 的 Claude 模型与 OpenAI 相比没有获得更多关注,并认为它们在摘要和检索等任务中的表现可能比人们感知的更具竞争力。这引发了关于 Claude 模型擅长的特定用例以及需要改进的领域的深入讨论,为各种应用中最佳 AI 模型的持续辩论做出了贡献。
提到的链接:
- 🦅 Eagle 7B:凭借跨 100 多种语言的 1 万亿 Token 超越 Transformer (RWKV-v5):RWKV-v5 架构和 Linear Transformer 的全新时代已经到来——拥有当今开源界最强的多语言模型。
- 来自 Nous Research (@NousResearch) 的推文:今天我们宣布了最新的项目,旨在为开源模型提供一套新的评估系统。传统的基准测试(Benchmarking)过度依赖公开数据集,这些数据集很容易被操纵,而且……
- Arc Search 将浏览器、搜索引擎和 AI 结合成一种全新的、与众不同的产品:这可能是目前最有趣的 AI 搜索工具。
- Willison 警告称,AI 软件仍需要人工参与:代码辅助就像雇了一个背下了所有文档的古怪实习生。
- 使用 RAGatouille 探索 ColBERT:我一直在尝试理解 ColBERT。
- 来自 AI at Meta (@AIatMeta) 的推文:今天我们发布了 Code Llama 70B:这是我们用于代码生成的 LLM 的一个性能更强的新版本——采用与之前 Code Llama 模型相同的许可证。下载模型 ➡️ https://bi…
- voyage-code-2:提升你的代码检索能力:摘要——我们很高兴推出 voyage-code-2,这是我们最新的 Embedding 模型,专门为自然语言和代码查询中的代码及相关文本数据的语义检索而定制……
- GitHub Copilot 的最新研究发现“代码质量面临下行压力”——Visual Studio Magazine:“我们发现了可维护性方面令人不安的趋势。”
- OpenAI 状态:未找到描述
- 来自 Nous Research (@NousResearch) 的推文:Nous Research 很高兴地宣布完成了 520 万美元的种子轮融资。我们很自豪能与充满激情、诚信正直的伙伴合作,是他们促成了这一轮融资,包括……
- DSPy 详解!:大家好!非常感谢观看这段关于 DSPy 的讲解!DSPy 是一个非常令人兴奋的用于开发 LLM 程序的新框架!由……开创。
- Python SDK - Langfuse:完全异步且带类型的 Python SDK。使用 Pydantic 对象进行数据验证。
- 来自 Justine Moore (@venturetwins) 的推文:Netflix 旗下的一家大型视觉特效(VFX)工作室正在招聘大量 AI 职位:生成式成像、工作流设计、模型训练、数据采集,甚至还有 ML 研究员。我们将看到大量……
- GitHub - FanaHOVA/smol-podcaster:smol-podcaster 是你的自主播客制作实习生 🐣:smol-podcaster 是你的自主播客制作实习生 🐣 - GitHub - FanaHOVA/smol-podcaster: smol-podcaster is your autonomous podcast production intern 🐣
- GitHub - FanaHOVA/smol-scheduler:🐣🕐📅 一个用于起草日程安排邮件的简单工具。:🐣🕐📅 一个用于起草日程安排邮件的简单工具。 - GitHub - FanaHOVA/smol-scheduler: 🐣🕐📅 A simple utility to draft scheduling emails.
- Scanline VFX - 研究科学家,计算机图形学、计算机视觉和机器学习:作为高级研究科学家,你将开发新技术来彻底改变真人内容的创作和叙事。你将在计算机视觉和计算机图形学领域进行应用研究……
- [AINews] RWKV “Eagle” v5:该你了,Mamba:2024 年 1 月 27-28 日的 AI Discord 动态。我们为你检查了 20 个公会、297 个频道和 10073 条消息。预计节省阅读时间(按 200wpm 计算):826 分钟。我们……
DiscoResearch ▷ #mixtral_implementation (5 messages):
- MIQU 模型引发 Mixtral Medium 泄露猜测:
@aiui提出了关于 MIQU 模型 可能是 Mixtral medium 泄露版 的疑问,引发了关于其起源和特性的讨论。 - 辟谣 MIQU 模型与 Mixtral 的关联:
@sebastian.bodza迅速回应了关于 MIQU 模型 是 Mixtral medium 泄露的猜测,表示这些传闻已被辟谣。 - 来自 Nisten 的澄清推文:为了进一步澄清,
@sebastian.bodza分享了 Nisten 的推文,该推文有助于辟谣围绕 MIQU 模型的传闻。 - 强调 MIQU 模型与 LLaMA Tokenizer 的关联:此外,
@sebastian.bodza强调 MIQU 模型使用的是 LLaMA Tokenizer,并分享了另一条相关推文以获取更多细节。
DiscoResearch ▷ #general (6 messages):
- 探索 Phi 2 的德语微调:
@philipmay对 Phi 2 是否经过德语文本训练表示怀疑,引发了关于其潜在 Fine-tuning 的讨论。@johannhartmann分享了使用 OASST-DE 数据集对其进行德语微调的尝试,但指出单轮 Epoch 的尝试效果不佳,建议使用更多数据集和更多 Epoch 进行更全面的探索。 - Tiny Llama 获得德语升级:
@johannhartmann记录了通过德语 DPO (Data Processing Overlay) 改进 Tiny Llama 的努力,并链接到了 GitHub 上的指南 (TinyLlama-1.1B-Chat-v1.0-german-dpo-Openllm_de.md)。该方法显示出一些积极成果,暗示了特定语言训练增强的潜力。 - 对德语 Orca DPO 数据集感到好奇?:
@philipmay询问是否存在德语 Orca DPO 数据集,这促使@johannhartmann分享了一个在 Hugging Face 上的临时数据集链接 (mayflowergmbh/intel_orca_dpo_pairs_de),并详细说明了其使用 AzureML 进行翻译以及使用 HermEO 作为被拒绝模型(rejected model)的情况。 - WRAP 旨在增强预训练:
@bjoernp强调了 Apple 在最近一篇关于 Web Rephrase Augmented Pre-training (WRAP) 论文中提出的一种创新方法,该方法旨在通过将网页文档改写为 Wikipedia 或 Q&A 等风格,来提高数据质量并缩短预训练时间 (arXiv:2401.16380)。根据摘要,该方法显著加快了预训练进度,暗示其可能被主要的 LLM 厂商广泛采用。
提及的链接:
- Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling:大型语言模型是在海量的网络抓取数据上训练的,这些数据通常是无结构的、多噪声且表述欠佳。目前的 Scaling Laws 表明,从此类数据中学习需要大量的…
- TinyLlama-1.1B-Chat-v1.0-german-dpo-Openllm_de.md:GitHub Gist:即时分享代码、笔记和片段。
- mayflowergmbh/intel_orca_dpo_pairs_de · Datasets at Hugging Face:未找到描述内容
DiscoResearch ▷ #embedding_dev (55 条消息🔥🔥):
-
探索 CodeT5 Embeddings:
@sebastian.bodza询问了如何实现 Salesforce 的 CodeT5 代码 Embedding,但在实际操作层面遇到了困难。由于缺乏对这些模型的经验,@bjoernp未能提供相关见解。 -
初探文本生成尝试:
@sebastian.bodza分享了他们在 text-generation 方面的初步结果并寻求反馈。分享了一个特定的 Notebook:Embedding_Training/05_preprocess_texts.ipynb,供合作者审阅。 -
定义训练中的“Hard Negatives”:大量的讨论集中在为训练数据创建高质量的“Hard Negatives”。
@sebastian.bodza和@philipmay辩论了相关标准,强调了 Hard Negatives 不能直接回答问题的重要性,以防止训练出现问题。 -
训练 Prompts 的迭代改进:
@sebastian.bodza迭代改进了用于生成训练数据的 Prompts,旨在微调正向样本(positive examples)与 Hard Negatives 之间的平衡。这些修改是由反馈以及对最优结构化数据集的追求所驱动的。 -
讨论关于检索模型的误解:大家寻求澄清关于 DPR 和 RAG 训练数据集的目的和结构,特别是关于 context 和 Hard Negatives 的类型。
@sebastian.bodza澄清说,他们的工作旨在生成一个用于未来 RAG 使用的 passage retrieval 数据集,其中的示例在质量上有所不同,而非内容相关性。
提到的链接:
- wp-rag-dpo/04_it01_extract_positive_answers.ipynb at main · telekom/wp-rag-dpo:通过在 GitHub 上创建账户,为 telekom/wp-rag-dpo 的开发做出贡献。
- Embedding_Training/05_preprocess_texts.ipynb at main · SebastianBodza/Embedding_Training:通过在 GitHub 上创建账户,为 SebastianBodza/Embedding_Training 的开发做出贡献。
- Improving Text Embeddings with Large Language Models:在本文中,我们介绍了一种新颖且简单的方法,仅使用合成数据和不到 1k 个训练步骤即可获得高质量的文本 Embedding。与通常依赖于……的现有方法不同。
LangChain AI ▷ #general (46 messages🔥):
-
探索 LangChain 功能:用户
@irfansyah5572请求关于在 LangChain 中运行回答链并显示来源的帮助,并链接到了项目的 GitHub。 -
RAG 前端开发教程提醒:
@a404.eth分享了一个新的 YouTube 教程,重点介绍如何使用 LangChain 和其他技术构建一个与 PDF 文档交互的前端,并征求对其教程系列第二部分的反馈。 -
使用 LangChain 的自定义图书推荐系统:
@oscarjuarezx正在开发一个基于用户兴趣的演示图书推荐系统,利用 PostgreSQL 和各种 LangChain 组件,并正在寻求优化数据库搜索的建议。 -
LlamaCPP 模型的缓存问题:包括
@techexplorer0和@kapa.ai在内的几位用户讨论了使用InMemoryCache来缩短 LlamaCPP 模型的推理时间,并提供了一个相关的 GitHub issue 链接,但指出了缓存有效性方面的挑战。 -
LangChain 中的解析和流式传输挑战:用户
@ibrobabs和@hiranga.g交流了在 LangChain 中解析 JSON 输出和从 Agent 进行流式传输的经验和问题,提到了一份有用的 GitHub 示例 和一段 YouTube 视频 以供进一步指导。
提到的链接:
- LangChain v0.1.0 发布:Agents:LangChain 是允许 LLM 执行操作的默认方式。Jupyter Notebook(供参考):https://github.com/hwchase17/langchain-0.1-guides/blob/master/…
- chat-langchain/chain.py at master · langchain-ai/chat-langchain:通过在 GitHub 上创建账号来为 langchain-ai/chat-langchain 的开发做出贡献。
- 与您的 PDF 聊天第 2 部分:前端 - 端到端 LangChain 教程。使用 OpenAI 构建 RAG。:在本视频中,我们将深入探讨使用 @LangChain 和 @OpenAI 构建和部署完全自定义 RAG 的第二部分。在本教程中,编写代码…
- langchain/templates/openai-functions-agent-gmail/openai_functions_agent/agent.py at master · langchain-ai/langchain:⚡ 通过可组合性使用 LLM 构建应用程序 ⚡ - langchain-ai/langchain
- Issues · langchain-ai/langchain:⚡ 通过可组合性使用 LLM 构建应用程序 ⚡ - Issues · langchain-ai/langchain
- OSD Bias Bounty:未找到描述
-
[Bug Bounty: ConductorAI - Bias Bounty Program Bugcrowd](https://bugcrowd.com/conductorai-ogbb?preview=ae06c13f786e06a1f9ff03d74230b7d5):详细了解由众测安全解决方案领导者 Bugcrowd 提供支持的 Conductor AI 漏洞披露计划。
LangChain AI ▷ #share-your-work (3 messages):
-
本地 LLM 提升网页浏览体验:
@andrewnguonly发布了一个开源的 LLM Copilot Chrome 扩展,名为 Lumos,利用 LangChain 和 Ollama 通过本地 LLM 丰富网页浏览体验。他们鼓励用户提供反馈,并分享了在 Product Hunt 上支持该发布的链接。 -
使用预编写的 SQL 作为工具进行构建:
@shownaldo对将 SQL 整合到项目中感到好奇,思考这是否意味着让 Agent 有预先编写好的 SQL 可供选择。作为回应,@johnny2x2分享说,由于让本地 LLM 编写自定义 SQL 代码存在困难,他们转向将预定义的 SQL 脚本作为工具包含在内。
提到的链接:
- GitHub - andrewnguonly/Lumos: 一个由本地 LLM 驱动的 RAG LLM 网页浏览助手:一个由本地 LLM 驱动的 RAG LLM 网页浏览助手 - GitHub - andrewnguonly/Lumos
-
[Lumos - 由 Ollama 驱动的开源网页浏览 Copilot Product Hunt](https://www.producthunt.com/posts/lumos-4):Lumos 是一个由本地 LLM 驱动的网页浏览 LLM Copilot。该 Chrome 扩展由 Ollama 驱动!
LangChain AI ▷ #tutorials (3 messages):
-
适合初学者的 Langchain Agents 2024 更新:
@ryannolan分享了一个名为 “Langchain Agents [2024 UPDATE] - Beginner Friendly” 的 YouTube 视频。该视频提供了一种利用最新的 Langchain 更新构建 Agent 的新方法,旨在扩展 OpenAI API 的功能。 -
使用 LangChain 和 Unstructured 构建 RAG,第 2 部分:
@a404.eth宣布发布了他们的新教程:“Chat With Your PDFs Part 2: Frontend - An End to End LangChain Tutorial. Build A RAG with OpenAI”。该教程侧重于前端开发,包括构建聊天界面、显示源文档和流式输出,利用了 LCEL、React 和 TypeScript 等技术。教程可在 YouTube 上观看。 -
对教程的兴奋之情:
@a404.eth对他们使用 LangChain 构建 RAG 前端的教程表达了热情,并给出了简洁的评价:“Ok this is sick”(太酷了)。
提到的链接:
- Langchain Agents [2024 UPDATE] - Beginner Friendly:在这段 Langchain 视频中,我们将探索使用 Langchain 0.1 更新构建 Agent 的新方法。通过 Agent,我们可以扩展 OpenAI API 的功能…
- Chat With Your PDFs Part 2: Frontend - An End to End LangChain Tutorial. Build A RAG with OpenAI.:在这段视频中,我们将深入探讨使用 @LangChain 和 @OpenAI 构建和部署完全自定义 RAG 的第二部分。在本教程中,将编写代码…
LlamaIndex ▷ #blog (6 messages):
- 处理复杂分类的简单方法:
@KarelDoostrlnck介绍了一种使用 LLM 处理涉及数千个类别(如医疗反应和工作技能)的复杂分类的新方法。这种方法涉及推断一组预测,然后进行检索和重排序。IFTTT 公告 - LlamaIndex.TS 更新:LlamaIndex.TS 发布了新功能并改进了文档。在此阅读公告和更新。
- 硅谷黑客松,奖金 16,000 美元:LlamaIndex RAG-A-THON 是一场线下活动,专注于检索增强生成(RAG)技术以创建高级 AI Agent。该活动要求至少有一名团队成员亲临现场,奖金高达 16,000 美元。黑客松详情
- RAG 黑客松参与咨询:
@rawwerks询问了 LlamaIndex RAG 黑客松的参与者情况,并强调了其线下参与的要求。查询背景 - 评估用于高级查询的 LlamaPacks:
@wenqi_glantz使用 @lighthouzai 测试了 7 种预设的高级查询策略(称为 LlamaPacks),展示了它们如何简化为特定需求选择最佳查询策略的过程。LlamaPacks 评估
提到的链接:
LlamaIndex RAG 黑客松(仅限线下):超越聊天机器人:释放 AI Agent 的潜力
LlamaIndex ▷ #general (36 条消息🔥):
-
用于 RAG 实现的本地 LlamaCpp 服务器:
@techexplorer0正在根据 GitHub - abetlen/llama-cpp-python 的说明设置本地 LlamaCpp 服务器,并寻求将其与 RAG 应用程序集成以进行 LLM 调用方面的建议。 -
使用 Llama_Index 查询 Azure Analysis Services:
@meowmeow008成功将 Llama_Index 连接到 Azure SQL,但正在探索将其连接到 Azure Analysis Services OLAP 而非 SQL 的方案。 -
探索 Llama2 的商业用途许可:
@sattyman询问有关商业化使用 Llama2 以及为其产品创建微调(finetuned)版本的问题。@nerdai链接了一篇 文章,指出 Llama2 在某些限制下可用于商业用途,并建议查看 Meta 的 官方网站 以获取细则和许可详情。 -
自定义 LLM 输出格式:
@mysterious_avocado_98353想知道如何自定义输出格式以排除特定词汇。@nerdai建议根据 LlamaIndex Docs 上的指南修改 Prompt。 -
Llama Index 中查询引擎的问题:
@coder_004_71487讨论了使用 Llama Index 处理通用查询和特定 SQL 错误的问题。@nerdai建议对混合查询使用 RouterQueryEngine,并指导@coder_004_71487通过 GitHub Issues 提交 Bug 报告,并查看关于配置 RouterQueryEngine 以处理更复杂查询的演示。
提到的链接:
- Usage Pattern - LlamaIndex 🦙 0.9.39:未找到描述
- GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp:llama.cpp 的 Python 绑定。通过在 GitHub 上创建账号,为 abetlen/llama-cpp-python 的开发做出贡献。
- Router Query Engine - LlamaIndex 🦙 0.9.39:未找到描述
- GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp:llama.cpp 的 Python 绑定。通过在 GitHub 上创建账号,为 abetlen/llama-cpp-python 的开发做出贡献。
- no title found:未找到标题
- Issues · run-llama/llama_index:LlamaIndex(原名 GPT Index)是适用于 LLM 应用程序的数据框架 - Issues · run-llama/llama_index
- What Is Llama 2 and How Can It Be Used? - deepsense.ai):探索 Llama 2 在 AI 领域取得的进步,以及 Meta AI 的语言模型对科技界的影响。探索其功能和广泛的用途!
LAION ▷ #general (31 条消息🔥):
-
MagViT2 Video Tokenizer 问题:
@_kevinalbert在使用 MagViT2 PyTorch repository 进行 MagViT2 训练 10,000 步后遇到了样本像素化的问题。@top_walk_town建议其调整 learning rate 和各种 loss functions 以改善结果。 -
Nightshade 备受争议的影响:
@drhead批评 Nightshade 的发布是不负责任的,并怀疑在没有大规模协同使用且未开发对策的情况下,它是否具有即时威胁。他们建议可以通过 finetuning 来中和或减轻 Nightshade 的 perturbations。 -
对 Glaze 和 Nightshade 有效性的质疑:
@astropulse和@.undeleted对 Glaze 和 Nightshade 工具的意图和有效性表示怀疑和担忧,特别是对它们的潜在长期影响及其使用的严重后果持批评态度。 -
关于对抗 Nightshade 的讨论:
@drhead和@.undeleted辩论了使 Nightshade 失效的潜在策略,例如避开目标 encoder 或训练能够抵消 Nightshade perturbations 的新模型,但仍对这类攻击构成的普遍威胁保持谨慎。 -
关于 AI 模型对新数据必要性的看法:
@pseudoterminalx和@mfcool反对通过增加新图像或数据来改进 AI 模型,强调在提升模型性能方面,数据质量和准确的 captioning 比数量更重要。
LAION ▷ #research (7 条消息):
-
“Activation Beacon” 可能解决上下文长度问题:
@spirit_from_germany强调了一种名为 “Activation Beacon” 的新方法,该方法通过允许无限的上下文长度,可能会给 LLMs 带来革命性的变化。该方法涉及在 prompt 之前添加 “global state” token,结果非常显著:一个在 4K 上下文长度下训练了 10K 步的 LLaMA 2 模型,随后可以处理高达 400K 的上下文长度。阅读论文 并 查看代码。 -
关于存储带字幕图像数据集最佳方式的讨论:
@progamergov询问对于带字幕的图像数据集,是将图像存储在 parquet 文件中更好,还是分别存储在 tar 文件中更好。@chad_in_the_house回应并推荐使用 tar 文件,因为通过 webdatasets 进行查询的速度更快。 -
RePaint 中的 Latent Diffusion 探索?:
@epicycles_989询问 RePaint 中使用的方法是否已应用于 latent diffusion,并对其在 zero-shot in/outpainting 方面的潜力表示感兴趣。目前还没有针对此查询的直接回复或额外信息。 -
Webdatasets 的优势:在讨论了带字幕图像数据集的存储之后, @random_string_of_character提供了 GitHub 上 webdataset 和 tarp 的链接,并强调 webdatasets 为深度学习问题提供了一个高性能的基于 Python 的 I/O 系统,而 tarp 则能够对 tar 文件中的文件进行快速且简单的流式处理。Webdataset GitHubTarp GitHub - 结合 Parquet 和 TAR 以实现高效数据管理:
@progamergov认为使用 parquet 文件存储字幕并使用 tar 文件存储对应图像可能是最高效的存储方案。这种混合方法在查询速度和数据组织方面可能兼具两者的优点。
提到的链接:
- Yam Peleg (@Yampeleg) 的推文:如果这是真的,那就无敌了:无限上下文长度已经到来。Activation Beacon,扩展 LLMs 上下文的新方法。摘要:在 prompt 之前添加 “global state” token 并预测自动…
- GitHub - webdataset/webdataset: 一个高性能的基于 Python 的 I/O 系统,适用于大型(和小型)深度学习问题,对 PyTorch 有强大的支持。:一个高性能的基于 Python 的 I/O 系统,适用于大型(和小型)深度学习问题,对 PyTorch 有强大的支持。 - GitHub - webdataset/webdataset…
- GitHub - webdataset/tarp: 对 tar 文件中的文件进行快速简单的流式处理,适用于深度学习、大数据和许多其他应用。:对 tar 文件中的文件进行快速简单的流式处理,适用于深度学习、大数据和许多其他应用。 - GitHub - webdataset/tarp…
Perplexity AI ▷ #general (32 条消息🔥):
-
求知者想了解最佳 AI 模型的使用方法:用户
@vic7669好奇何时该使用特定的 AI 模型,如 Gemini、GPT-4 和 Claude。该用户被引导至一个讨论帖和一份技术 FAQ 以获取见解。 -
侧边栏 Library 显示问题:用户
@jamiecropley遇到了 Library 并不总是在左侧显示的问题。尽管尝试了重新安装 Windows 这种极端措施,问题依然存在。讨论澄清了这一行为是功能而非 Bug,侧边栏仅列出最后八个线程/集合(threads/collections)。 -
加密货币咨询与澄清:用户
@lambda4life询问了该项目是否有关联的加密货币代币。@icelavaman迅速回答了该问题,确认该项目不存在任何加密货币代币。 -
通过 URL 参数查询 Perplexity:用户
@fyngraf询问是否可以通过 URL 参数发起 Perplexity 查询,旨在实现更便捷的搜索工具。他们被引导至特定的 Discord 频道以获取更多信息。 -
Rabbit R1 引起关注:用户
@brownpatricks发起了关于购买 Rabbit R1 的对话,邀请其他人通过表情符号回复分享他们的兴趣程度。多位用户表达了兴趣,一些人提到资金限制,而另一些人则赞赏该产品的设计。
提到的链接:
- Turkey Turkiye GIF - Turkey Turkiye Kartopu - Discover & Share GIFs:点击查看 GIF
- Perplexity Blog:探索 Perplexity 的博客,获取文章、公告、产品更新和优化体验的技巧。保持关注并充分利用 Perplexity。
Perplexity AI ▷ #sharing (5 条消息):
- Gemini Pro 挑战 Chatbot Arena:
@brknclock1215分享了一段 YouTube 视频,讨论了 New Bard 如何在 Chatbot Arena 中超越 GPT-4,展示了显著的性能提升。 - 通过出色功能实现搜索个性化:
@sa1k0s对一个允许个性化搜索引擎的技巧表示赞赏,称赞该功能具备自定义能力。 - 将 AI 创意应用于番茄钟应用:
@gammagames正在开发一款以快递为主题的 pomodoro app(番茄钟应用),并成功使用 AI 工具为应用内容生成名称和地址,认为该工具非常有益。 - 探索 Perplexity 的实验室:
@rowalth强调了 Perplexity Labs 的存在,指出这是一个用于创意探索和实验的资源。
提到的链接:
| 🔥 New Gemini Pro Better than GP-4? Huge Performance Boost on ⚔️ Chatbot Arena ⚔️:New Bard 在 Chatbot Arena 上已超越 GPT-4。🦾 Discord: https://discord.com/invite/t4eYQRUcXB ☕ Buy me a Coffee: https://ko-fi.com/promptengineering | 🔴 Pat… |
Perplexity AI ▷ #pplx-api (1 条消息):
- pplx-api 自定义停止词功能咨询:
@dogemeat_询问了 pplx-api 中 custom Stop Words(自定义停止词)的实现时间表,并表示有兴趣将其与 zed.dev editor 的“助手”功能集成。该集成旨在提供一种替代默认 OpenAI models 的方案。
LLM Perf Enthusiasts AI ▷ #triton (1 条消息):
- PyTorch 与 CUDA 之间的平衡点:
@tvi_表示,虽然 PyTorch 通过抽象化矩阵乘法(a @ b)等操作的执行方式,允许对 CUDA 计算采用“几乎是声明式”的方法,但 CUDA 和 Numba.CUDA 则需要明确详细的计算过程。Triton 被强调为一个中间地带,它提供了比 PyTorch 更多的控制权,但复杂性低于直接使用 CUDA,对于那些寻求平衡的人来说非常有吸引力。
LLM Perf Enthusiasts AI ▷ #cuda (29 messages🔥):
- CUDA 优化之旅:
@artste和@zippika分享了他们在 CUDA 上尝试优化 RGB to Grayscale conversion 的历程。各种尝试包括使用 structs 以实现更清晰的索引,采用uchar4的 vectorized operations,以及探索不同的内存布局,如 CHW 和 HWC。 - 向量化挑战:尽管最初很兴奋,
@zippika发现使用uchar4和 shared memory 对 转换过程进行向量化 导致的性能低于预期。进一步的优化和调整也未能产生预期的加速。 - Inline 的力量:当
@zippika注意到在他们的 CUDA kernel 中使用__forceinline__显著提升了性能 时,迎来了一个启示时刻,这突显了 inlining 对 GPU 代码优化的重要性。 - 误导性的基准测试:
@zippika在意识到测试设置中的一个错误后经历了情绪波动——一个 naive implementation 看起来更快,因为它只处理了 一张高度仅为 3 像素的图像,这导致了对比结果的偏差。 - 寻求社区智慧:
@andreaskoepf建议了进一步的 内存优化技术,例如使用连续内存读取并利用int4数据类型进行 vector loads and stores,并引导@zippika参考 NVIDIA 开发者博客,以深入了解如何最大化带宽效率。
提到的链接:
| [CUDA Pro Tip: Increase Performance with Vectorized Memory Access | NVIDIA Technical Blog](https://developer.nvidia.com/blog/cuda-pro-tip-increase-performance-with-vectorized-memory-access/):这篇文章展示了在 CUDA C/C++ 中使用 vectorized memory access 来提高带宽利用率,同时减少指令数量。 |
LLM Perf Enthusiasts AI ▷ #pmpp-book (3 messages):
- 第 2 章疑虑消除:
@ashpun对第 2 章的第 3 个问题表示困惑并寻求澄清,提到难以理解第 2 个视频中提供的解释。他们对如何解决这个问题的任何解释都持开放态度。 - 弄清第 6 章中的 Coalescing 和 Banking:
@shindeirou讨论了对第 6 章中图 6.10 和 6.11 的困惑,质疑在相同 channels 内访问 memory banks 的效率。他们后来明白,访问相同 channel 但不同 banks 可以实现有效的 interleaving,从而隐藏内存延迟。 - 解决内存访问中的索引问题:
@andreaskoepf为理解第 2 章中讨论的内存索引提供了解决方案,提供了一个特定的代码片段和解释,用于计算内存分段内元素的索引。这解决了@ashpun关于第 2 章第 3 个问题的疑问。
LLM Perf Enthusiasts AI ▷ #youtube-recordings (1 messages):
andreaskoepf: 新视频链接:https://youtu.be/4sgKnKbR-WE?si=J-B0kHqknRXhE7e_
LLM Perf Enthusiasts AI ▷ #general (9 messages🔥):
- 寻找更优秀的写作辅助工具:
@an1lam对目前的写作辅助工具表示不满,强调了 Chat 界面在迭代写作方面的局限性,以及缺乏像 lex.page 这样高质量的替代方案。 - 一个热情的推荐但有前提:针对
@an1lam的疑问,@jeffreyw128标记了一名用户,可能是在推荐写作辅助工具或提供相关线索,但未提供具体细节。 - 初创公司面临 Google Workspace 成本压力:
@frandecam分享了为其自筹资金的 AI 初创公司配置 Google Workspace 账户的高昂成本担忧,强调了这对初创公司构成的财务负担。 - AI 初创公司的一线希望:针对
@frandecam的困境,@dare.ai建议通过 Google Cloud for Startups 计划来降低成本,但也提醒由于申请积压可能会有延迟。他们分享了该计划的链接 (Google for Startups Cloud Program) 并表示愿意提供进一步帮助。 - 介绍用于学术写作的 Jenni.ai:
@calclavia介绍了 jenni.ai,这是一个正在开发中的工具,旨在增强学术写作,暗示其可能是@an1lam寻找高效写作辅助工具的一个潜在方案。
提到的链接:
| [AI startup program | Google Cloud](https://cloud.google.com/startup/ai?hl=en):利用 Google 最优秀的架构、AI 产品和基础模型。获取高达 250,000 美元的 Google Cloud 额度、培训等支持。 |
LLM Perf Enthusiasts AI ▷ #gpt3-5 (1 messages):
- Gorilla 发布 OpenFunctions:
@shacrw分享了一篇关于 Gorilla OpenFunctions 的博客文章,这是一个利用自然语言 Prompt 构建可执行 API 调用的新开源替代方案。该方案简化了各种服务的 API 调用,即使是编程知识极少的人也能轻松使用。 - 在 GitHub 上探索 Gorilla Functions:在分享博客的同时,
@shacrw还提供了一个 GitHub 链接 以进一步探索 OpenFunctions 项目。该计划旨在增强 Large Language Model (LLM) 的 Chat Completion 功能,使其能够根据 API 文档和问答对准确地格式化 Function Call。
提到的链接:
- Introduction to Gorilla LLM:未找到描述
- open-source-function-calling/gorilla-functions.ipynb at main · philschmid/open-source-function-calling:通过在 GitHub 上创建账户,为 philschmid/open-source-function-calling 的开发做出贡献。
LLM Perf Enthusiasts AI ▷ #gpt4 (1 messages):
- Prompt 视觉模型遭遇版权障碍:
@jxnlco正在寻求关于如何有效使用 Prompt 视觉模型读取复杂标签的建议,但面临挑战,因为模型将相关材料标记为受版权保护。
LLM Perf Enthusiasts AI ▷ #opensource (1 messages):
thebaghdaddy:我们相信 Mistral Medium 关于其成为仅次于 GPT4 的第二名这种炒作吗?
Skunkworks AI ▷ #general (7 messages):
- Frankenstein 模型实验正在进行中:
@nisten宣布通过合并所有 70b CodeLlamas 创建了一个复合模型。这个实验性模型旨在探索增强的性能基准。 - BigCodeLlama 的趣事与进展:在严肃的技术讨论中,
@nisten还分享了一个 “lolol” 消息的轻松时刻,展示了他们工作中的乐趣和进展。 - BigCodeLlama 169B 亮相!:
@nisten已在 Hugging Face 上上传了 BigCodeLlama-169b 模型,这是一个强大的融合体,旨在基准测试不同模型组合的协同表现。 - 为 FrankenLlama 进行基准测试:在模型上传后,
@nisten分享了一个具有挑战性的编程问题,涉及计算火星殖民的奥尔德林循环轨道(Aldrin cycler orbits),作为测试案例来对比 FrankenLlama 模型与原生模型。 - 技术讨论中的友好问候:
@zentorjr向@nisten打了个招呼,为频道中正在进行的深度技术讨论增添了一抹人情味。
提到的链接:
nisten/BigCodeLlama-169b · Hugging Face:未找到描述
Skunkworks AI ▷ #off-topic (2 messages):
-
使用 RAGatouille 深入探索 ColBERT:
@pradeep1148分享了一个名为 “Exploring ColBERT with RAGatouille” 的 YouTube 视频,重点介绍了 RAGatouille,这是一个简化 ColBERT 检索模型使用流程的库。ColBERT 被描述为一个快速且准确的模型,能够改进可扩展的行为摘要。 -
揭秘 Eagle 7B 的翱翔:
@pradeep1148介绍了另一个 YouTube 视频,标题为 “Running 🦅 Eagle 7B on A40”,讨论了 Eagle 7B。这是 RWKV-v5 架构和 linear transformers 在 100 多种语言上的重大进步。Eagle 7B 因处理了 1 万亿 tokens 而备受关注,标志着 transformer 技术的新纪元。
提到的链接:
- Exploring ColBERT with RAGatouille:RAGatouille 是一个相对较新的库,旨在简化 ColBERT 的使用。ColBERT 是一种快速且准确的检索模型,支持可扩展的 BE…
- Running 🦅 Eagle 7B on A40:🦅 Eagle 7B:凭借跨越 100 多种语言的 1 万亿 Tokens 超越 Transformers。RWKV-v5 架构和 linear transformer 的全新时代…
Datasette - LLM (@SimonW) ▷ #ai (3 messages):
-
表情符号建议工具发布:
@dbreunig在 Emoji Suggest 展示了一个新演示,该工具可以使用 CLIP model 将短句或标题转换为单个推荐的表情符号。该工具的代码已公开,利用预计算的表情符号 embeddings 来实现快速且复杂的搜索。 -
关于搜索应用中 Embeddings 的见解:
@dbreunig分享了使用 embeddings 快速创建复杂搜索工具的见解,强调了精选选项对于实现真正有效搜索能力的重要性。这种方法支撑了他们表情符号建议工具的功能。 -
AI 对其角色的积极看法:
@bdexter转述了一段对话,其中一个 AI(具体为 llama2)表达了人工智能是一种向善的力量的信念,能够帮助人类发挥全部潜力。这种互动凸显了 AI 对其影响人类成就所持有的积极态度。
提到的链接:
Emojify:未找到描述
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- 对 ColBERT 文章的感谢:用户
@bewilderbeest对@746595581086138409在 TIL 上发表的 ColBERT 文章表示感谢。他们正在使用分享的代码片段创建一个 notebook,并赞扬了结果中单词的热力图可视化效果。
Alignment Lab AI ▷ #general-chat (2 条消息):
- GPT-5 是否正在训练中?: 用户
@entropi分享了一个标题为 “GPT-5: Everything You Need to Know So Far” 的 YouTube 视频,引用了来自 OpenAI 的独家采访和信息,引发了关于 GPT-5 是否已开始训练的好奇。 - GPT-5 训练的确认: 针对这一猜测,
@lightningralf确认 GPT-5 确实已经训练了一段时间,但未提供具体细节。
提到的链接:
GPT-5: Everything You Need to Know So Far: 昨天是 GPT-5 真正开始训练的日子吗?这段视频包含了我们目前对 GPT-5 的所有了解,参考了独家采访、OpenAI…
AI Engineer Foundation ▷ #general (1 条消息):
- ChatGPT 与 Bard 在 Captcha 图像审核上的对比:
@juanreds指出了 ChatGPT 和 Bard 之间一个有趣的差异:ChatGPT 会对 Captcha 图像进行审核,而 Bard 则不会。这突显了两个 AI 系统在用户交互和安全措施方面的不同方法。