ainews-just-how-good-is-miqu
Miqu 已被证实是 Mistral-medium 的一个早期检查点(checkpoint)。
Miqu 是一款开放获取模型,其 MMLU 得分为 74,EQ-Bench 得分为 84.5,这引发了关于其性能与 Mistral Medium 相比孰优孰劣的热烈讨论。Mistral 的首席执行官确认了这些结果。
在 TheBloke Discord 社区的讨论中,人们强调了 Miqu 在指令遵循以及 dynatemp 和 min-p 等采样方法上的优越性。开发人员还探讨了浏览器偏好和 Discord UI 主题。此外,使用 BagelMistery Tour v2 和 Psyfighter v2 等模型进行角色扮演非常流行,同时进行的还有关于 Miqu-1-70b 的 fp16 量化的技术交流。
社区中还分享了 Unsloth 和 Mistral 7B 等模型的训练和微调技巧。在 Nous Research AI Discord 中,讨论了 Activation Beacon 方法,该方法旨在将大语言模型(LLM)的上下文长度从 4K 扩展到 400K token。SQLCoder-70B 基于 CodeLlama-70B 微调而成,在文本转 SQL 生成领域处于领先地位,并已在 Hugging Face 上提供。Miqu 模型还凭借 83.5 的 EQ-Bench 分数令人印象深刻,进一步引发了对其能力的推测。
2024年1月30日的 AI Discord 动态。我们为你检查了 21 个公会、311 个频道和 7688 条消息。预计节省阅读时间(以 200wpm 计算):577 分钟。
关于表现出奇出色的开放获取(非开源,因为没有许可证)模型 Miqu 的猜测很多——其 MMLU 评分为 74(Mistral-medium 为 75),EQ-bench(主观上更好的 MMLU 版本)评分为 84.5。关于这一事实存在很多支持与反对的争论——但 Mistral 的 CEO 现已出面确认了此事。
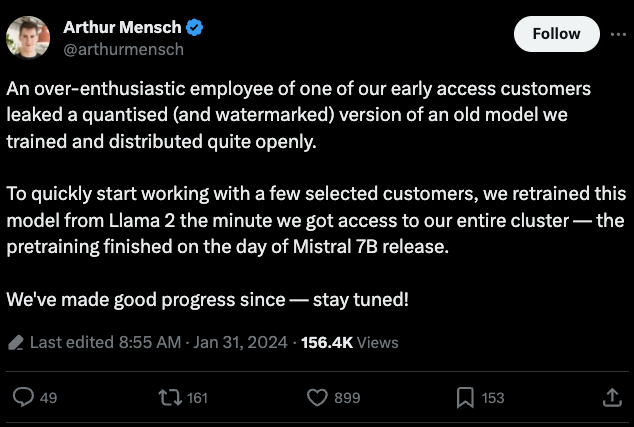
所以从技术上讲我们不能使用这个模型,但这确实是一个有趣的泄露。
目录
[TOC]
PART 1: 高层级 Discord 摘要
TheBloke Discord 摘要
-
Miqu 在模型讨论中占据主导地位:工程师们正热烈讨论 Miqu,将其与 Llama-2-70B-chat 和 Mixtral 进行对比,并认为 Miqu 表现更佳,尤其是在指令遵循(instruction-following)和批判任务方面。辩论延伸到了采样方法,其中 dynatemp 和 min-p 因其在增强模型置信水平和输出结果方面的效用而受到剖析,引发了关于 AI 性能中何为“优越”结果的对话。
-
开发者深入探讨小众浏览器用途和 UI 偏好:在较少以模型为中心的对话中,开发者们交流了关于开发和个人使用的最佳浏览器的看法,范围从 Internet Explorer 到更小众的选择,如 Vivaldi 以及在 Arch 上的 Ubuntu 系统中运行 Docker。这还引发了关于 Discord UI 美学的讨论,特别是关于深色 vs 浅色主题的争论,以及绑定到 Discord Nitro 的专属颜色选择。
-
角色扮演频道中释放了聊天模型的创意用途:在利用各种聊天模型进行角色扮演方面发现了创意火花,像 BagelMistery Tour v2 和 Psyfighter v2 这样的模型因其角色扮演的细腻表现而脱颖而出。技术讨论源于 Miqu 的功能性 fp16 反量化(dequat),其中分享了一个显著的 Miqu-1-70b 的 fp16 转换版本,突出了模型量化(quantization)方面的进展与挑战。
-
训练和微调讨论为新手和专家指明道路:使用 Unsloth 进行高性价比模型训练以及优化 Mistral 7B 训练过程的技巧是亮点,同时还呼吁为微调 Hugging Face 模型提供全面的教程,暗示了社区对可获取的高级模型优化和定制指导的共同需求。
-
编程对话反映了开发文化和挑战:阅读代码比编写代码更复杂的观点引起了开发者的共鸣,同时还有对当代 Web 开发实践的批评,包括过度依赖外部库和“非我所创”(Not Invented Here)综合症。人们越来越担心这可能会将开发者培养成单纯的“框架技工”而非问题解决者,指出编程社区对计算机科学(computer science)原理基础的更深层次需求。
Nous Research AI Discord 摘要
-
Activation Beacon 为无限上下文铺平道路:Activation Beacon 方法被讨论为克服 LLM 上下文长度限制的突破性方案,使在 4K 上下文上训练的模型能够泛化到 400K 上下文,且推理时间呈线性增长。该方法引入了 “global state” tokens,可能会从根本上改变 LLM 管理内存消耗的方式。阅读论文并查看 实现代码。
-
SQLCoder-70B 在 Text-to-SQL 生成中表现卓越:作为 Postgres Text-to-SQL 转换的新领导者,SQLCoder-70B 基于 AIatMeta 的 CodeLlama-70B 进行 Fine-tuned,为 LLM 在 SQL 生成领域树立了新标准。该模型现已在 Hugging Face 上线,为相关任务提供了显著的进步。探索 SQLCoder-70B。
-
Miqu 模型在 EQ-Bench 上打破预期:Miqu 模型 击败了之前的基准测试,在 EQ-Bench 上获得了 83.5 分,超越了 Mistral Medium,并引发了社区关于其潜在来源和能力的讨论,认为它可能是目前性能最强的公开可用模型。关于 Miqu 及其性能的详细信息可以在 Hugging Face 上找到。
-
MoE 的 Scaling Laws 及其对模型效率的影响:在关于 MoE Scaling Laws 的讨论中重点提到了两篇关键论文,揭示了 Mixture-of-Experts 模型的效率和性能优势。对这些模型的探索体现了在增强计算资源利用率和模型性能方面的重大兴趣。参考资料:Scaling Laws for Autoregressive Generative Modeling 和 ST-MoE: Designing Stable and Transferable Sparse Expert Models。
-
向量语言模型 (VLMs) 的进展与需求:社区表达了对更高效、更易用的 VLM 推理库的迫切需求,强调了在 Batch LoRA 推理方面的持续努力和创新,以及更有效地支持 VLM 的潜在扩展。这一持续的开发旨在提高可访问性和计算效率,解决该领域目前资源匮乏的问题。
LM Studio Discord 摘要
-
LM Studio API 连接问题已解决:@.ben.com 向 @.mchinaga 澄清,
chat_gpt_bot.py中的问题是由于无法连接到 API 服务器而非 Bug,@dagbs 建议了正确的 API Base 设置和响应键(Response Key)配置。这一常见陷阱强调了准确配置 Endpoint 对于成功进行 API 交互的必要性。 -
探索创新的文本转视频木偶技术:由 @toddmiller 发起,LM Studio 用户深入探讨了将文本脚本转换为视频木偶的可行性,讨论了当前的局限性,以及对于此类复杂任务可能需要超出 LM Studio 当前能力的模型。
-
LM Studio 的 GPU 加速优化:@fabguy 分享了针对 RTX 4070 的 GPU 加速设置详细建议,强调了调整
n_gpu_layers对于在不增加 CPU 负担的情况下提升性能的重要性。这一见解支撑了 AI 应用中 GPU 利用率与整体系统效率之间的关键平衡。 -
LM Studio 在不同硬件上的兼容性与执行挑战:讨论涵盖了在不同平台上运行 LM Studio 时克服挑战的策略,特别关注了 Linux 库问题、GPU 选择以及 ARM CPU 的兼容性疑虑。值得注意的是,Android 和 iOS 等移动平台存在显著的兼容性障碍,这进一步证明了在 AI 工具中进行平台感知开发的重要性。
-
AI 模型讨论中的新兴趋势与性能表现:社区报告了 Tiny Models、CodeLlama 70B 和 MIQU 等模型的参差表现和独特行为,其中一个有趣的案例是 Tiny Models 在重启后产生了荒诞的笑话。讨论还延伸到了 LangChain 与 LM Studio 集成以进行数据集生成的实际探讨,强调了 AI 模型使用和开发过程中持续的创新与故障排除。
这些摘要突出了 LM Studio 社区内关于技术挑战、模型性能和创新应用的重点讨论,反映了从业者在 AI 技术前沿进行的充满活力的对话。
OpenAI Discord 总结
-
AI 初学者的 VRAM 选择困境:
aqua_dawn_67525正在权衡是选择 16GB VRAM 还是 24GB VRAM 来启动 AI 项目,并考虑在需求更强劲时迁移到云计算。同时,toror证实 16GB VRAM 对于当下的优化模型来说已经相当够用,为初学者提供了关于低 VRAM 实际充足性的见解。 -
GPT Plus 的限制与困惑揭晓:
@iyons和@myroslava_35196_08143等用户在 GPT Plus 上遇到了意外的消息限制警告,这引发了困惑,因为他们尚未达到宣传的 40 条消息阈值。这一问题指向了用户对 OpenAI 沟通和支持方面的更广泛担忧。 -
GPT Mentions 开启 AI 协作新可能:GPT mentions 的引入允许 GPT 之间共享上下文和操作,因其增强 AI 可组合性(composability)的潜力而激发了社区的热情。然而,尽管有了这一创新飞跃,
@darthgustav.和@blckreaper等用户仍在摸索 GPT 间通信的实际能力和局限性。 -
GPT 的游戏与创意挑战:在文字游戏和创意项目领域,如何有效地在基于网格的文字游戏中管理 GPT 成为讨论焦点,社区成员建议使用涉及 2D 数组和 Python 的高级策略来优化游戏管理。此外,DALL-E 3 和 GPT 的集成促进了跨文本和视觉生成的项目,代表了 AI 辅助创意尝试的先锋步骤,尽管目前仍需要手动编排。
-
社区应对 API 复杂性和功能限制:社区一直积极参与排障和集思广益,讨论如何利用 OpenAI 的 API 处理复杂的项目工作流,例如为多步流程链接不同的模型。尽管对允许模型间通信的功能感到兴奋,但讨论显示,由于当前的技术限制,此类集成仍需手动导航。
Eleuther Discord 总结
-
Ratchet 革新浏览器端 ML:Ratchet 是一种新型的浏览器端 ML 框架,承诺利用 Rust 和 WebGPU 优化速度和开发者体验,正如 whisper-turbo.com 中所展示的那样。
-
EleutherAI 的研究成果:EleutherAI 庆祝其 10 篇论文中有 6 篇被 ICLR 接收,重点展示了如 “LLeMA: An Open Language Model for Mathematics” 等进展,这标志着作者和贡献者的重大成就。
-
稀疏微调(Sparse Fine-Tuning)优于 LoRA:一种针对 Large Language Models 的稀疏微调新方法展现出了比 (q)LoRA 更高的参数和内存效率,正如这项研究及其实现所证明的那样,这可能会彻底改变指令微调(instruction tuning)。
-
PPC64LE 上的 CUDA 和 CUDNN 面临挑战:NVIDIA CUDA 容器仅支持
ppc64le平台,结合 CUDNN 的安装问题以及构建 wheel 的困难,凸显了在特定架构上优化 AI 开发环境所面临的困境。 -
笔画分词用于矢量图形合成:StrokeNUWA 引入了一种笔画分词(tokenizing strokes)的方法以促进矢量图形合成,展示了多模态 AI 研究的一种新颖方法。
Mistral Discord 总结
-
Mistral 7B VRAM 需求与解决方案:社区讨论了在 1660 Ti 等 6GB VRAM GPU 上运行 Mistral 7B 模型的可行性,结果各异。虽然显存不足(out-of-memory)问题很常见,但在 Hugging Face 上发现的一个量化模型能够在 5.5GB VRAM 限制内运行,为低端硬件用户提供了解决方案。
-
跨硬件优化 Mistral 性能:用户报告了 Mistral 7B 在低端和包括 RTX4090 在内的高端系统上的不同性能表现。讨论强调了优化 GPU 利用率的重要性,并建议考虑使用 Colab notebooks 等资源来高效加载模型,而不会完全耗尽 VRAM。
-
针对特定输出偏好的微调:在 finetuning 频道中,有人请求关于如何让 LLM 提供更简洁回答的建议,目标是针对简单问题直接回答如 “4” 之类的结果。建议的增强微调策略包括将步数增加到 60 步以上,并可能将学习率降低到 2e-5 以提高模型性能。
-
Mistral 企业级 Web UI 亮相:showcase 频道介绍了 uMdali,这是一个为 Mistral API 提供 Web UI 的开源项目。该工具支持连接到 Ollama, OpenAI 和 Gemini,旨在作为“企业级聊天前端”。
-
与 Mistral 的协作与实习:社区鼓励成员在 GitHub 上为 Mistral 的公共文档做出贡献,以进行协作改进。关于 Mistral 实习机会的咨询凸显了加入 Mistral 团队所需的竞争性和高资历要求,反映出一个充满活力且参与度高的开发者社区。
HuggingFace Discord 总结
-
Code Llama 70B 与 Sentence Transformers v2.3.0 发布:Hugging Face 社区宣布发布新的 AI 聊天模型 Code Llama 70B,以及更新的 Sentence Transformers v2.3.0,后者包含错误修复和性能增强。在此处查看 Code Llama 70B,在此处查看 Sentence Transformers 发布说明。
-
针对马来西亚背景的多模态 LLM 数据集:Multimodal Malaysian LLM dataset 旨在通过包括翻译后的 LLaVA 指令在内的多模态输入来推进 LLM 训练,该数据集现已作为 mesolitica collection 的一部分在 HuggingFace 上可用。
-
社区成员创建的创新 AI 工具:社区开发者推出了新工具:一个用于将 Excel/CSV 文件转换为数据库查询的 Gradio 应用,可在 HuggingFace Spaces 上访问;以及一个将 AI 应用于《万智牌》(Magic: The Gathering)进行卡牌颜色多标签分类的新颖应用,您可以在此处探索。
-
CUDA 故障排除与未知编译器选项挑战:一位使用 RTX 2080ti 的用户在配置 GPU acceleration 时报告了问题,遇到了
nvcc fatal: Unknown option 'fPIC'错误,这表明与nvcc编译器存在兼容性复杂问题——详见此 GitHub issue。 -
关于 LLM 和扩散模型的深入讨论:社区探讨了各种话题,从寻求提高 DPO 之外的 QA 数据集鲁棒性,到 lokr 和 loha 通过 “loading with peft” 方法进行推理的能力,再到对某款 70B 代码聊天模型对 🤗 Diffusers library 了解有限表示不满。此外,成员们还讨论了使用 Stable Diffusion 复制特定艺术风格的挑战,并尝试捕捉一种动漫风格,详见此处。
OpenAccess AI Collective (axolotl) Discord 总结
-
Axolotl 的持续进步赢得赞誉:axolotl 框架因其降低 VRAM 占用、加快训练速度和改善结果的增强功能而受到
@nafnlaus00的称赞,并引发了关于在 Twitter 等平台上分享这些成功经验的讨论。此外,@dreamgen分享了他们在硬件和 VM 增强方面的经验,这些增强有助于加速 AI 项目,强调了硬件在开发中的关键作用。 -
MIQU-1-70b 实现跨越:MIQU-1-70b 从 q5 到 f16 的反量化及其 PyTorch 集成引起了社区的关注,该资源由
@dreamgen提供,并附带了 Hugging Face 上的模型链接。这一突破因其潜在的应用价值和易用性而备受关注。 -
开发与部署中的技术难题与突破:从 axolotl 新实现中的 VRAM 占用问题,到为了更好的部署实践而解决的 Docker 难题,社区正积极参与故障排除并分享解决方案,例如使用
pip install -e .命令来修复模块错误。在 Axolotl 开发领域,@stefangliga对 LoftQ 及其使用 SVD 进行近似的研究是一个亮点,展示了社区的创新精神。 -
Llamacpp 点亮社区项目展示:
@mistobaan分享了一个涉及使用 llamacpp 进行函数调用的创新项目,利用了各种社区工具和模型。该实验通过分享的 Gist 进行了详细说明,并重点介绍了来自 GitHub 和 Hugging Face 的资源,是社区内协作创新的典范。 -
部署问题需要社区见解:在 deployment-help 频道中,
yamashi模糊地提到了并行请求带来的挑战,这表明部署背景下正在进行讨论或故障排除。虽然细节较少,但它突出了 AI 工程中需要关注的领域。
Perplexity AI Discord 总结
-
Mistral Medium 的 API 访问引发关注:以
@arcinarci为首的社区成员正热切期待 Mistral Medium 的 API 访问权限,这标志着对更广泛 API 功能的需求日益增长。 -
Perplexity 的免费试用可能已暂停:由
@aarav7024发起的讨论表明,7 天免费试用活动可能已经停止,这引起了新用户的困惑。 -
Perplexity 增强应用开发创意:像
@gammagames这样的用户发现 Perplexity 在生成创意内容(如应用开发的名称和地址)方面非常有效,并将 Perplexity Labs 视为探索 AI 功能的资源。 -
探索将 Perplexity 高效集成到 Web 应用程序中:分享了一份关于将 Perplexity API 无缝集成到 Web 应用中的详细指南,包括处理聊天交互的文本输入以及参考文档创建 API token,尽管目前尚不支持文件上传。
-
使用 Ollama 开拓本地模型训练与执行:讨论了在不需要高端硬件的情况下进行本地训练和执行大型模型的可行性,指出了用于本地模型实用程序的 Ollama 等工具,以及社区驱动的解决 API 访问问题(如 401 身份验证错误排除)的支持。
LLM Perf Enthusiasts AI Discord 摘要
-
Triton 和 CUDA 的讨论集中在性能调优上:Triton 编程语言的讨论强调了其在底层 CUDA 特性灵活性和 GPU block 级别数据控制方面的局限性,Triton 的同步功能仍需增强。参与者建议通过阅读 原始论文 来深入理解 Triton 的实现。
-
讨论了 CUDA 中的向量化内存访问:强调了向量化内存访问对于优化 CUDA 程序性能的重要性,并引用了 NVIDIA 博客文章 作为关键资源。此外,@HaseoX94 的 Twitter 帖子 分享了一种使用 Numba 简化 CUDA 编程的独特方法。
-
提供 GPU 访问的学习资源和优惠:社区提供了在 A100/H100 GPU 和 双 GPU 机器 上运行代码的机会,旨在促进测试和性能测量。CUDA 初学者获得了全面的资源指导,包括书籍推荐、lightning.ai 的免费 GPU 访问,以及用于 CUDA 学习的 YouTube 频道 CUDA MODE。
-
CUDA 编程基础和环境搭建指导:关于 CUDA 编程基础和设置的咨询(特别是针对 RTX 3070 笔记本电脑)引发了讨论。建议范围涵盖书籍推荐、环境搭建到在 Windows 上使用 Visual Studio 进行 CUDA 集成,并指出在使用 Conda 时,Torch 优于 TensorFlow。
-
CUDA 计时与内存管理:技术交流集中在 CUDA 内存索引和使用 CUDA 事件进行精确计时。会议澄清了同步对于计时测量和理解
cudaMemcpy等操作行为至关重要,强调了 CUDA API 调用本质上是异步的,需要显式同步才能进行性能指标评价。
LangChain AI Discord 摘要
-
LangChain Fork 恢复正常:在经历了一个神秘问题(LangChain 仓库的 Fork 在 GitHub 上未被识别为 Fork,导致 PR 消失)后,情况已得到解决。贡献者应按照 GitHub 讨论 中的详细说明,手动重新打开任何仍受影响的 PR。
-
寻求自定义工具参数方面的专业知识:Georg.ort 正在寻求关于定义自定义工具的必选和可选参数的专家咨询,并为有价值的见解提供报酬,沟通链接已在 general 频道 提供。
-
创新的 AI 工具发布引发关注:包括 Product Hunt 上的 Oranscribe 预发布和发布公告、YouTube 上展示 Agent 技能创建的 SkillForge V1 演示,以及在 jacb.ai 介绍的生产级 AI 编码助手 JACoB,这些都引发了广泛的兴趣和期待。
-
LangServe 的访问和资源管理挑战:围绕 LangServe 的讨论涉及为教育目的提供更快速访问的努力,以及建立硬件资源管理额外层级的必要性,以防止在高 LLM 使用率期间发生服务器崩溃。
-
精准构建和提示 AI:分享了详细的探索和资源,例如关于使用 Qdrant 的多租户 (Multitenancy) 创建多用户 RAG 聊天机器人的 指南、关于赋能 AI 开发者的 视频,以及针对开源 LLM 的 提示工程 (Prompt Engineering) 见解,展现了在 AI 开发和应用中对精准度和创新的积极追求。
LlamaIndex Discord 摘要
-
LlamaIndex 与 Replit 联手推出 RAG 悬赏任务:LlamaIndex 宣布与 Replit 合作,为开发利用高级检索增强生成 (RAG) 的开源模板提供 2,000 美元悬赏。点击此处深入了解此机会。
-
LlamaIndex RAG 的深度探索:在 @CobusGreylingZA 的客座文章中,介绍了 LlamaIndex 最近在通过 RAG 处理复杂查询方面的尝试,详细说明了多 Agent 协作、思维链 (Chain-of-Thought) 推理以及来自 Cohere 的重排序 (re-ranking) 技术的集成。在此获取宝贵见解此处。
-
LlamaIndex 社区讨论:从微调到查询增强:LlamaIndex 社区的讨论涵盖了多个技术层面,从使用文本和元数据微调 embedding,到将 CSV 转换为 JSON 以实现更好的数据处理,以及在 LlamaIndex 架构中集成来自 Hugging Face 的预训练模型进行 embedding 微调。
-
集成挑战与平台连接:社区成员深入探讨了实际问题,例如将改进后的模型嵌入 LlamaIndex 的
SubQuestionQueryEngine,利用 AWS Sagemaker 部署 AI 应用,以及在对话构建场景中 llama packs 与现有数据库和文件格式配合的复杂性。 -
使用幻觉排行榜追踪 AI 的想象力:andysingal 分享了一个资源,供那些对衡量和对抗 AI 输出中的幻觉 (hallucinations) 感兴趣的人参考,指向了此处提供的幻觉排行榜。
LAION Discord 摘要
-
AI 打造战锤 40k 的阴暗未来:一段由粉丝创作的 Imperium Of Man - Warhammer 40k 预告片利用 AI 生成式工具制作,因其卓越的视觉效果(尤其是 0:54 处的火焰和爆炸片段)而受到称赞,可在此处观看。关于 AI 视频生成工具的讨论表明,尽管存在一些不自然的效果,但这些工具提供了极佳的时间一致性,并具有应用于创意产业的潜力。
-
AI 创作局限性揭示:讨论中分享的一个 Terminus 模型的有趣输出展示了 AI 生成内容虽然出色但偶尔存在缺陷,强调了当前训练数据集固有的局限性。视觉示例见此处。
-
询问 AI 图像生成的能力:关于 DALL-E 2 - PyTorch 与 Stable Diffusion 在 AI 图像生成领域的效率和进展对比的询问浮出水面,凸显了社区对理解这些强大工具细微差别的兴趣日益增长。
-
MoE-LLaVA 框架提升 LVLMs:在论文中详细介绍的 MoE-tuning 和 MoE-LLaVA 框架 提供了一种增强大型视觉语言模型 (LVLMs) 效率的新方法,通过在部署期间仅调用 top-k 专家,在保持计算成本的同时实现高参数模型。该框架在 Hugging Face 的实现中得到了进一步探索,访问地址见此处。
-
多语言 AI 和伦理 AI 代码的进展:CodeLlama 70b Instruct 展示了代码生成中伦理倾向与效率之间的微妙平衡,可在 Hugging Face 获取;而此处分享的新多语言文本转图像基准测试 MAGBIG 旨在扩大 AI 模型的语言适用性,凸显了 AI 社区在包容性和负责任的 AI 开发方面取得的进展。
{kind=link}
DiscoResearch Discord 总结
-
通过 DiscoLM German 7b 和 RAG 数据集解锁德语能力:DiscoLM German 7b 和 GermanRAG datasets 的发布标志着提升德语语言模型性能迈出了重要一步,为 RAG 微调引入了全面的数据集,并扩展了在母语处理中的应用。
-
Prometheus 与 Mistral 结合以增强英语模型:针对英语应用的 Prometheus Mistral 模型进展查询,暗示了在开发尖端语言模型方面的持续努力。
-
Code Llama 70B 和 Llama Factory 见解:Meta 发布 Code Llama 70B 引起关注,同时围绕 Llama Factory 参数调优推荐实践的讨论,突显了代码生成 AI 技术的持续演进。
-
使用多语言 BGE-M3 和 ColBERT 提升检索性能:BGE_M3 和 ColBERT 等创新展示了 Embedding 技术的进步,提供多语言支持并通过细致的检索改进搜索。分享了针对 BGE-large 用户的实用建议,即在查询中包含 Prompt 以增强检索效果。
-
德语 AI 开发的多元化策略涌现:讨论涵盖了从 Web Rephrase Augmented Pre-training (WRAP) 等数据增强技术,到 German Orca DPO datasets 的探索,以及利用 GPT-4 丰富训练材料的新型数据集计划,预示着德语 AI 研发生态系统的活力。
Latent Space Discord 总结
-
VFX 工作室关注 AI 集成:@venturetwins 的一条推文 透露,包括 Netflix 旗下的一家在内的各大 VFX 工作室目前正在寻找精通 Stable Diffusion 技术的专业人士。招聘中的这一新方向强调了生成式成像和 Machine Learning 在彻底改变叙事方式方面日益增长的重要性,Eyeline Studios 的职位列表 也证明了这一点。
-
AI 职位需求的新范式出现:幽默地指出,Stable Diffusion 和 Midjourney 等 AI 技术的快速演进可能会成为未来职位发布的标准要求,反映了科技领域就业标准的转变。
-
LLM 训练效率的突破:Quentin Anthony 的新论文 见解提出,在 Transformer 模型训练期间,应显著转向硬件利用率优化。这种方法侧重于通过 GPU kernel 调用序列来观察模型,旨在解决训练过程中普遍存在的低效问题。
-
Codeium 迈向 B 轮融资:为庆祝 Codeium 晋升 B 轮,一条 赞赏推文 评论了该团队的成就。这一里程碑突显了对公司未来的日益乐观和预期。
-
硬件感知设计提升 LLM 速度:@BlancheMinerva 的推文 强调的一项新发现,并在其关于 arXiv:2401.14489 的论文中进行了详细阐述,概述了一种硬件感知设计调整,使 2.7B 参数的 LLM 吞吐量提高了 20%,此前由于坚持 GPT-3 架构,许多人忽略了这一点。
-
AI 和 NLP 知识宝库揭晓:对于渴望加深对 AI 模型及其历史和概念基础理解的人,@ivanleomk 分享的精选列表 汇集了里程碑式的资源,为探索 AI 和 NLP 提供了全面的起点。
Alignment Lab AI Discord 摘要
- Lilac Garden 发布,革新数据集转换:
@nikhil_thorat宣布了 Lilac Garden,这是一个用于加速数据集转换的新型云服务,其首个服务功能是 LLM 驱动的聚类。该公告及详细信息可以在 Twitter 上找到。 - 探索预计算的 OpenOrca 聚类:OpenOrca 数据集及其预计算的 embeddings 和聚类现已在 Lilac Garden 上线,为数据集分析提供了先进的工具包。用户可以通过此 直接链接 探索该数据集。
- 圣路易斯华盛顿大学(WashU)初创公司招聘创始工程师:
DoubleMint正在为与圣路易斯华盛顿大学合作的新项目寻找一名创始工程师,强调需精通 Next.js、TailwindCSS 和 Supabase。该项目已获得 50,000 美元的意向书,并准备快速扩张。
LLM Perf Enthusiasts AI Discord 摘要
- LLM Perf Enthusiasts 中的感谢致辞:用户
@an1lam在讨论中简单地以一句 “Thanks!” 表达了谢意。 - 寻求关于 Gemini Pro 的见解:
@res6969询问是否有在生产环境中实验过 Gemini Pro 的见解或结果,旨在了解其性能和适用性。
AI Engineer Foundation Discord 摘要
- 加入 AI Engineer Foundation 的开源运动:
@hackgoofer向@everyone发出号召,为 AI Engineer Foundation 提交和推荐开源项目,强调了社区参与的重要性。这是为有兴趣贡献的人准备的 项目提交指南。
第 2 部分:详细的分频道摘要和链接
TheBloke ▷ #general (1209 条消息🔥🔥🔥):
- Miqu 模型讨论升温:用户一直在将 Miqu 与 Llama-2-70B-chat 和 Mixtral 等其他模型进行比较,发现 Miqu 在接受批评和遵循指令方面表现异常出色。据一些人称,Miqu 的表现甚至优于 frankenmerge 120b 模型。
- AI 采样与采样器探索:关于不同采样方法的讨论正在进行中,重点关注 dynatemp 和 min-p 在改善结果方面的实用性。对话围绕着定义什么是“更好”的结果所面临的挑战,以及模型在其估计中可能存在的过度自信。
- 开发浏览器选择导航:除了 AI 之外,还有关于开发和个人使用的浏览器选择的闲聊。提到了 Internet Explorer、Brave、Vivaldi 以及 Arch 系统上用于 Ubuntu 的 Docker,同时还提到了 NCSA Mosaic 和 VRML 浏览器插件等古老技术。
- Discord UI 与主题:对话触及了 Discord 的 UI,特别是对 dark(深色)与 light(浅色)主题的偏好,以及在没有 Discord Nitro 的情况下有限的颜色选择。讨论简要强调了颜色选择对视觉感知和神经语言学的影响。
- 通用 AI 热情与批评:用户对 AI 模型拒绝参与某些话题或以免责声明回应表示担忧。还有关于 AI 模型复制 catgirl 行为能力的轻松对话,展示了 AI 社区从技术到趣味性的广泛兴趣。
提到的链接:
- Stitch Sad Sad Stitch GIF - Stitch sad Sad stitch - Discover & Share GIFs:点击查看 GIF
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters:“预训练-然后-微调”范式在大型语言模型的部署中被广泛采用。低秩自适应(LoRA)是一种参数高效的微调方法,通常用于…
- codemateai/CodeMate-v0.1 · Hugging Face:未找到描述
- Mosaic (web browser) - Wikipedia:未找到描述
- Simple JSON Parser — Lark documentation:未找到描述
- TOGETHER:未找到描述
- This Character AI Alternative With No Filters Just Released a Free 70B Model - Miku GG:这个没有过滤器的 Character AI 替代品 - Miku GG,发布了一个新更新。最棒的是你可以完全访问他们的 70B 模型…
- vikhyatk/moondream1 · Hugging Face:未找到描述
- Eggwuh It Come With Eggroll GIF - Eggwuh It come with eggroll Eggroll - Discover & Share GIFs:点击查看 GIF
- Reddit - Dive into anything:未找到描述
- Parsers — Lark documentation:未找到描述
- Reddit - Dive into anything:未找到描述
- Grammar Reference — Lark documentation:未找到描述
- Tiny Elvis 1.5 (TELV150) : Matthew T. Smith : Free Download, Borrow, and Streaming : Internet Archive:Tiny E 坐在你的 Windows 桌面底部,跳起来评论你的巨大图标、光标等。很有趣!播放波形音频 (WAV) 语音….
- CUDA: Faster Mixtral prompt processing by JohannesGaessler · Pull Request #4538 · ggerganov/llama.cpp:在 master 分支上,由于 MoE,Mixtral 提示处理目前始终以 batch size 为 1 进行。此 PR 使得对于 batch size > 1,src1 列变为连续,从而使…
- Reddit - Dive into anything:未找到描述
TheBloke ▷ #characters-roleplay-stories (285 条消息🔥🔥):
-
聊天模型的探索与应用:讨论围绕寻找和应用各种用于角色扮演和通用任务的聊天模型展开。
@funtimedaddyohyea提到探索了 BagelMIsteryTour-v2-8x7B- GGUF 等模型,而@frammie和@_dampf则分别更倾向于使用 BagelMistery Tour v2 和 Psyfighter v2 进行角色扮演。 -
关于量化与模型性能的对话:关于 Miqu 功能性 fp16 反量化(dequat)的辩论引发了技术讨论。
@doctorshotgun分享了一个 Miqu-1-70b 的 fp16 转换版本,强调其困惑度(perplexity)明显低于之前的转换版本,但在进行exl2量化时仍面临挑战。 -
Miqu 与其他模型的对比:
@mrdragonfox和@goldkoron等用户讨论了 Miqu 在角色扮演(RP)中的表现,以及它在角色理解能力上优于 Mixtral 和 Yi-34b 的表现,并引用了其有效性的轶事证据。 -
AI 创意内容的探索:
@c.gato提到了一种实验性方法,即使用 Yahoo Answers 数据从 GPT-4 生成 RP 回答,旨在使聊天机器人的回复更加多样化。这突显了社区在不断寻求更具动态感和类人交互的努力。 -
技术挑战与社区实验:包括
@doctorshotgun和@dreamgen在内的多位用户讨论了使用 Miqu 等模型的技术细节和挑战,从量化问题到模型效率的探索,以及通过微调(fine-tuning)和针对 Benchmark(基准测试)进行测试来寻求潜在改进。
提到的链接:
- 152334H/miqu-1-70b-sf · Hugging Face:未找到描述
- ycros/BagelMIsteryTour-v2-8x7B-GGUF · Hugging Face:未找到描述
- PotatoOff/Michel-13B · Hugging Face:未找到描述
- llama.cpp/examples/speculative at master · ggerganov/llama.cpp:Facebook LLaMA 模型的 C/C++ 移植版本。通过在 GitHub 上创建账户为 ggerganov/llama.cpp 的开发做出贡献。
TheBloke ▷ #training-and-fine-tuning (17 条消息🔥):
- 使用 Unsloth 进行低预算训练:
@superking__提到使用 Unsloth 仅需 16GB 显存即可训练模型,并指出 Colab 提供了免费资源来运行示例。对于资源有限的开发者来说,这可能是一个宝贵的建议。 - Mistral 7B 训练优化技巧:在关于训练 Mistral 7B 的讨论中,
@bishwa3819分享了尽管使用了特定的 LoRA 配置,但训练损失(train loss)仍未下降的困扰。@dirtytigerx回应建议先尝试让模型过拟合(overfit)作为排查步骤,并提到所提供的图表仅显示了 80 步的训练,数据量可能不足。 - Yarn-Scaled 模型的高硬件需求:
@blackl1ght和@sao10k之间的对话强调了高昂的成本是导致大规模模型(如 yarn-scaled 128k 模型)缺乏指令微调(instruct tunes)的主要原因。这指出了机器学习项目中的可扩展性挑战。 - 寻求 Hugging Face 模型微调教程:
@chovii请求推荐关于微调 Hugging Face 模型的全面指南或教程,特别表达了在为 TheBloke/TinyLlama-1.1B-Chat-v1.0-AWQ 模型使用 Trainer 时遇到困难。这凸显了模型微调初学者对易于获取信息的需求。 - 直接指导请求:
@givan_002正在寻找高质量的角色扮演数据集,而@222gate正在寻求关于量化多模态模型(multimodal models)的建议,这些都强调了 ML 社区对专业指导和资源的需求。这些咨询展示了从业者面临的挑战具有多样性和特定性。
TheBloke ▷ #model-merging (4 条消息):
- 社区致谢:
@kquant对@284810978552578050提供的反馈表示感谢,这些反馈帮助改进了他们的工作。消息中未提供工作的具体细节。 - 期待互动:
@kquant分享了一条关于其内容关注度的充满希望的消息,但未指明具体主题。 - 分享研究文档:
@kquant发布了一个关于 k-NN in Mixture of Experts 的 Google Docs 链接,不过消息中未描述具体内容。 - 代码片段被截断:
@kquant提到文档中有一部分代码被意外截断,并指出如果读者尝试实现所讨论的方法,缺少这部分内容可能会遇到困难。
提到的链接:
k-NN In Mixture of Experts:未找到描述
TheBloke ▷ #coding (19 条消息🔥):
- 阅读 vs. 编写代码:
@zachmayer简要提到了开发者中常见的一种观点:阅读代码比编写代码更难,这引发了各地程序员的共鸣。 - AI 代码生成器的对比分析:
@technomancer73测试了一个未具名的 AI 代码生成器,发现其回答比 Bard 更全面,并根据过去的 Prompt 对生成的代码进行了手动对比。 - Web 开发悖论:
@wbsch和@dirtytigerx讨论了 Web 开发文化中的矛盾,指出“非我所创 (NIH) 综合征”和对外部库的过度依赖都是普遍存在的问题。他们谈到了 JavaScript 历史上缺乏标准库的问题,并强调left-pad事件是开发者之间更深层次的经验和知识差距的体现。 - 程序员沦为框架技工:
@dirtytigerx感叹新一代程序员主要接受的是使用框架和 API 的培训,缺乏应对新颖、复杂挑战所需的基础技能。这一评论引发了关于理解计算机科学基本原理重要性的对话,以及缺乏专业化如何既是就业保障因素,又是领导层关注的问题。 - 编写规范与项目管理的困境:
@wbsch和@dirtytigerx分享了他们在团队/项目管理中的挫败感,特别是向团队成员传达基础计算机科学概念的挑战,以及将常识转化为技术规范的艺术。这段对话涉及了负责领导开发团队的人员所面临的实际和存在主义困境。
Nous Research AI ▷ #ctx-length-research (1 条消息):
dreamgen: “global state” tokens 听起来和 attention sinks 很像,不过还没读过论文。
Nous Research AI ▷ #off-topic (26 messages🔥):
- 探索大语言模型 (LLM):
@tempus_fugit05寻求了解大语言模型 (LLM) 的资源,@teknium推荐观看 Karpathy 题为 “[1hr Talk] Intro to Large Language Models” 的 YouTube 教程。该视频旨在为普通受众介绍 ChatGPT 等 LLM。点击此处观看。 - 即将发布的关于聊天机器人角色扮演人格评估的论文:
@lorenzoroxyolo宣布他们正在发布一篇专注于聊天机器人角色扮演人格评估的论文,并正在寻求宣传途径。他们提到对几个模型进行了基准测试(虽然不详尽),并鼓励关注 Twitter 上的 @lrzneedresearch 以获取更新。 - 分享有趣的 GIF:
@Error.PDF分享了几个幽默的 GIF,包括一只猫 (Cat Nyash GIF) 以及乌龟和狗 (Turtle Dog GIF),为对话增添了轻松的气氛。 - 成员间的打趣与玩笑:在
@Error.PDF发布了一个睡觉表情符号后,@teknium幽默地表示没人关心,引发了一场充满笑声和@Error.PDF肯定表情符号的俏皮互动。
提到的链接:
- Cat Nyash GIF - Cat Nyash Meow - Discover & Share GIFs:点击查看 GIF
- miqudev/miqu-1-70b · Add miku.mp4 to the readme:未找到描述
- [1hr Talk] Intro to Large Language Models:这是一个面向普通受众的 1 小时大语言模型介绍:它是 ChatGPT、Claude 和 Bard 等系统背后的核心技术组件。
- Turtle Dog GIF - Turtle Dog - Discover & Share GIFs:点击查看 GIF
Nous Research AI ▷ #benchmarks-log (14 messages🔥):
- 讨论汇编知识的影响:
@euclaise提到,掌握汇编 (Assembly) 知识对于典型的代码基准测试可能没有太大帮助,且目前不知道有专门评估汇编技能的基准测试。 - 关于思维链 (CoT) 方法论的辩论:
@euclaise建议使用思维链 (CoT) 方法以确保评估的公平性,而@teknium回应称这并非公平的比较,因为他之前没有使用过 CoT,且需要重新评估所有模型。 - BBH 基准测试与 CoT:
@euclaise强调 BBH 基准测试是专门为测试 CoT 方法论而设计的,建议始终使用 CoT 进行评估。 - 未来的模型评估策略:
@euclaise建议在未来的所有模型评估中采用 CoT,以确保评估的一致性和公平性。 - Stablelm Zephyr 在 BBH (配合 CoT) 上的表现:
@euclaise惊讶地注意到 Stablelm Zephyr 在使用 CoT 的 BBH 基准测试中仅获得了 0.9% 的分数,表明其表现异常低下。
Nous Research AI ▷ #interesting-links (15 messages🔥):
-
使用 Activation Beacon 实现无限上下文长度的突破:
@nonameusr强调了引入 Activation Beacon 方法扩展 LLMs 上下文的重大进展,通过将基于 4K 上下文长度训练的模型泛化到 400K,可能解决上下文长度限制问题。该方法建议添加“global state”令牌,以保持固定的内存消耗并确保推理时间线性增长。阅读更多关于该研究论文的内容并探索实现代码。 -
SQLCoder-70B 发布:
@if_a分享了关于 SQLCoder-70B 的消息,这是一个在 Hugging Face 上发布的新模型,在 Postgres text-to-SQL 生成方面优于所有公开可用的 LLMs。该模型在 AIatMeta 的 CodeLlama-70B 上进行了微调,展示了 SQL 生成任务取得重大进展的潜力。在 Hugging Face 上访问 SQLCoder-70B。 -
因 Bug 暂时停用 Memphis-CoT:
@euclaise警告用户在 Memphis-CoT 训练代码中发现了一个 Bug,并建议在重新训练过程完成之前不要进行量化(quants)、合并(merges)或任何改动。该模型最初旨在改进以推理为中心的结果,基于人类数据,并正在进行迭代纠错微调程序。 -
Nous Research 推出新型开源模型评估系统:
@manojbh分享了 Nous Research 的公告,即通过 Bittensor 上的子网建立一个评估开源模型的新系统,以克服依赖公共数据集的传统基准测试(benchmarking)的局限性。该系统旨在提供一个动态、公平且持续演进的评估平台。探索 Nous Subnet 排行榜。 -
呼吁谨慎在密码学中使用 LLMs:
@deki04转达了 @moyix 关于 LLMs 在处理密码学(cryptography)任务局限性的警告,指出尽管 AI 和机器学习取得了进展,但密码学等某些领域对于这些模型来说仍然具有挑战性。
提及的链接:
- 来自 Brendan Dolan-Gavitt (@moyix) 的推文:LLMs:不太擅长密码学
- 来自 Nous Research (@NousResearch) 的推文:今天我们宣布了我们的最新项目,旨在为开源模型提供一个新的评估系统。传统的基准测试严重依赖公共数据集,这些数据集很容易被操纵,而且……
- 来自 Yam Peleg (@Yampeleg) 的推文:如果这是真的,那就结束了:无限上下文长度已经到来。Activation Beacon,一种扩展 LLMs 上下文的新方法。TL;DR:在提示词之前添加“global state”令牌并预测自动回归……
- euclaise/Memphis-CoT-3B · Hugging Face:未找到描述
- Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback:基于语言模型(LLMs)的 AI 助手的成功取决于通过人类反馈强化学习(RLHF)来理解并对齐用户意图。然而,传统的对齐算法……
- 来自 Rishabh Srivastava (@rishdotblog) 的推文:我们刚刚开源了 SQLCoder-70B!它在 Postgres text-to-SQL 生成方面以极大优势优于所有公开可用的 LLMs。SQLCoder 是在 @AIatMeta 的 CodeLlama-70B 模型上微调的……
- OpenRouter:按应用使用情况排名和分析的语言模型
Nous Research AI ▷ #general (502 条消息🔥🔥🔥):
- 关于 AI 和人类语言效率的辩论:
@nonameusr引发了关于 AI 使用人类语言进行理解和跨模型通信效率低下的讨论,建议将 AI 调整为一种更高效的通信形式可能会更好。 - Miqu 在基准测试中脱颖而出:
@n8programs强调 Miqu 在 EQ-Bench 上取得了 83.5 的高分,表现非常出色。他声称这超过了 Mistral Medium,并指出尽管社区存在质疑,Miqu 仍可能是目前可用的最佳公开访问模型。 - AI 社区热议 Miqu 的性能和起源:AI Discord 社区正热烈讨论 Miqu 在基准测试中的表现(如 MMLU 和 EQ-Bench),一些人质疑它是否是 Mistral Medium 泄露版,并讨论其作为高性能开源模型的潜力。
- 量化和压缩策略探讨:讨论的焦点集中在量化策略(如 2-bit Qlora)、在微调期间维持 GSM8K 分数等性能指标的挑战,以及通过反量化技术提高 AI 模型效率和可访问性的技术细节。
- Subnet 讨论和 GPU 租赁查询:有人询问了 subnet 6 的功能,以及是否可以通过 Akash 网络租赁 GPU 进行模型服务,并结合 subnet 运行推理,这表明社区对优化 AI 开发资源利用有着浓厚兴趣。
提到的链接:
- 152334H/miqu-1-70b-sf · Hugging Face:未找到描述
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models:大型语言模型 (LLMs) 表现出卓越的性能,但计算和内存密集。量化可以减少内存占用并加速推理。然而,现有方法无法保持准确性…
- miqudev/miqu-1-70b · Hugging Face:未找到描述
- Growing Living Rat Neurons To Play… DOOM?:前往 https://squarespace.com/thethoughtemporium 使用代码 thethoughtemporium 在首次购买网站或域名时享受 10% 的折扣…
- The REAL cost of LLM (And How to reduce 78%+ of Cost):我想为您提供关于如何降低 70% LLM 成本的逐步指南,并分析为什么现在的成本如此之高。免费的 HubSpot AI 营销人员课程:https:/…
- Tweet from Yam Peleg (@Yampeleg):显然,用于运行服务器级 A100 的地下适配器不再处于地下状态了。/r/LocalLLaMA 上的人们开始大力提升他们的家用 GPU 配置了.. 猛.. 😆
- Druski GIF - Druski - Discover & Share GIFs:点击查看 GIF
- Darktide Adeptus Mechanicus GIF - Darktide Adeptus mechanicus Mechanicus - Discover & Share GIFs:点击查看 GIF
- GitHub - NVIDIA/TensorRT-LLM: TensorRT-LLM provides users with an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM also contains components to create Python and C++ runtimes that execute those TensorRT engines.:TensorRT-LLM 为用户提供了一个易于使用的 Python API 来定义大型语言模型 (LLMs),并构建包含最先进优化技术的 TensorRT 引擎,以便在 NVIDIA GPUs 上高效执行推理。TensorRT-LLM 还包含用于创建执行这些 TensorRT 引擎的 Python 和 C++ 运行时的组件。
- jondurbin/bagel-2.8b-v0.2 · Hugging Face:未找到描述
- 1. Installation):PygmalionAI 的大规模推理引擎。通过在 GitHub 上创建账户为 PygmalionAI/aphrodite-engine 的开发做出贡献。
- 2. Usage):PygmalionAI 的大规模推理引擎。通过在 GitHub 上创建账户为 PygmalionAI/aphrodite-engine 的开发做出贡献。
- UserBenchmark: Nvidia RTX 2080-Ti vs 3090:未找到描述
Nous Research AI ▷ #ask-about-llms (58 条消息🔥🔥):
-
探索 MoE 的 Scaling Laws:
@vikas.p回应了@joey00072关于 MoE scaling laws 论文的查询,分享了两篇重要的论文(Scaling Laws for Autoregressive Generative Modeling 和另一篇 论文 PDF),这些论文探讨了 Mixture-of-Experts (MoE) 模型的效率和性能。 -
讨论 Nous 模型的长 Context Windows:
@rememberlenny询问了 Nous 模型(如具有 200k context windows 的 NousResearch_YarnMistral128k)的权衡。对话强调了关于扩展 position embeddings 能力的担忧,以及由于 Λ 型 context windows 可能导致的 position truncation。 -
长上下文模型中的 Position Embeddings 缩放:
@teknium和@bloc97都参与了关于扩展 position embeddings 的讨论,bloc97 解释了在 YaRN 等模型中不截断 position embeddings 的优缺点,这允许在整个 context window 内进行 attention。 -
对更好的 VLM 推理库的需求:
@gabriel_syme和@carsonpoole讨论了对更易用且高效的 Vector Language Models (VLMs) 推理库的需求,强调了目前此类资源的匮乏,以及 CarsonPoole 和 Max_paperclips 为实现这一目标所做的努力。 -
批量推理与框架能力的架构见解:
@carsonpoole详细介绍了推理库的一些底层工作,特别关注了 batch LORA 推理、将 dense models 转换为 LORAs 等特性,以及整合 machine learning model (MLM) 扩展的潜力,表明正在进行的开发旨在更有效地支持 VLMs。
提到的链接:
- repeng/notebooks/emotion.ipynb at main · vgel/repeng:一个用于制作 RepE 控制向量的库。通过在 GitHub 上创建账户为 vgel/repeng 的开发做出贡献。
- Unified Scaling Laws for Routed Language Models:语言模型的性能已被证明可以有效地建模为其参数数量的幂律。在这里,我们研究了 Routing Networks 的缩放行为:一种根据……条件化的架构。
- ST-MoE: Designing Stable and Transferable Sparse Expert Models:规模为自然语言处理开启了新的前沿——但成本很高。作为回应,Mixture-of-Experts (MoE) 和 Switch Transformers 被提议作为一种能源效率路径,以实现……
LM Studio ▷ #💬-general (184 条消息🔥🔥):
-
排查 LM Studio 的代码和连接问题:@.mchinaga 就
chat_gpt_bot.py中的一个问题寻求帮助,怀疑是 bug,但 @.ben.com 澄清问题在于无法连接到 API 服务器。用户们讨论了各种错误,包括无效的响应键(response keys)和端点(endpoint)问题,@dagbs 建议了正确的 API base 设置和响应键调整。 -
探索文本脚本到视频木偶(Video Puppet)的解决方案:@toddmiller 询问是否有等效的模型或应用可以将文本脚本转换为视频木偶,并将其与其他 OpenAI 及相关技术进行了类比。讨论演变为探讨现有模型在此用途上的局限性,@dagbs 建议 LM Studio 可能不适合此类高级视频处理。
-
优化性能的 GPU 加速技巧:@rahulg1981 询问了 RTX 4070 的最佳 GPU 加速设置,以便在不使 CPU 过载的情况下提高性能。@fabguy 提供了根据模型大小调整
n_gpu_layers的详细建议,为优化 GPU 使用提供了实用方法。 -
LM Studio 的模型兼容性和运行挑战:多位用户分享了在不同硬件配置和操作系统上运行 LM Studio 的困扰和解决方案。话题涵盖了处理 Linux 库问题、选择正确的 GPU 进行加速,以及在 Mac 上的 ARM CPU 兼容性挑战,以及 Android 和 iOS 等不支持的平台。
-
关于 LM Studio 功能和未来改进的讨论:成员们讨论了 LM Studio 的功能和未来发展方向,包括运行多个模型、排序聊天记录以及集成本地模型。@yagilb 提供了关于版本更新、bug 修复以及在 LM Studio 框架内使用本地模型的变通方法。
提到的链接:
- 👾 LM Studio - 发现并运行本地 LLMs:查找、下载并实验本地 LLMs
- Gordon Ramsay Chef GIF - Gordon Ramsay Chef Its Raw - 发现并分享 GIF:点击查看 GIF
- Amd Ryzen GIF - AMD Ryzen Radeon - 发现并分享 GIF:点击查看 GIF
- 非官方 LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里,你可以找到我们在 LMStudio Discord 上收到的最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源软件…
- GitHub - brett-baudin-consulting/uMdali: 企业级聊天前端:企业级聊天前端。通过在 GitHub 上创建账号为 brett-baudin-consulting/uMdali 的开发做出贡献。
LM Studio ▷ #🤖-models-discussion-chat (61 messages🔥🔥):
-
小型模型在重启后表现荒谬:
@pudlo报告称,高度量化的微型模型在重启后开始产生极其荒谬的笑话,使其变得无意中非常搞笑。 -
关于“本月热门模型”频道的建议:
@666siegfried666建议创建一个频道来突出每月的热门模型,引发了关于如何使模型推荐更易于访问和组织的活跃讨论。建议包括投票系统和仅限管理员发布以确保可读性。 -
CodeLlama 70B 模型的挑战:包括
@unskilless和@dave000000在内的多位用户报告了 CodeLlama 70B 模型的问题,指出它在特定任务中“严重损坏”。然而,@heyitsyorkie建议使用 “Codellama Instruct” 预设以获得更好的结果。 -
MIQU 模型评价褒贬不一:关于 MIQU 模型的讨论突显了不同的体验,
@n8programs赞扬了它的领域特定知识,并表示其能力介于 Mistral medium 和 GPT-4 之间。然而,@ptable发现它在自己的配置上的表现并不比 Mixtral 显著更好,并强调了速度问题。 -
寻求 Functionary 模型的使用帮助:
@vbwyrde寻求关于在 CrewAI 中使用 Hugging Face 的 Functionary 模型的帮助,强调了该模型智能执行函数的能力,但对获得最佳使用效果的正确预设或提示词格式表示不确定。
提到的链接:
- meetkai/functionary-small-v2.2-GGUF · Hugging Face:未找到描述
- Slimeline Tmt GIF - Slimeline Tmt Slime - Discover & Share GIFs:点击查看 GIF
- Ouch Slow Mo GIF - Ouch Slow Mo Slow Motion - Discover & Share GIFs:点击查看 GIF
LM Studio ▷ #🧠-feedback (5 messages):
- 模型兼容性困惑已澄清:
@rasydev在 LM Studio 中加载模型时遇到错误。@heyitsyorkie澄清说 LM Studio 仅与 GGUF 模型兼容,并指出 rasydev 下载的saftensors文件不兼容。 - 对 CodeLlama 模型的误解:在后续咨询中,
@rasydev询问codellama/CodeLlama-70b-hf模型是否支持 LM Studio。@heyitsyorkie回复说,CodeLlama 模型作为原始 PyTorch 模型,默认情况下无法在 LM Studio 中运行,并建议搜索 TheBloke 制作的 GGUF 量化版本以确保兼容性。
LM Studio ▷ #🎛-hardware-discussion (99 messages🔥🔥):
-
现代列车系统中的复古技术:
@hexacube分享了德国铁路自动化运行在 MSDOS 和 Windows 3.1 之上,引发了关于旧系统在某些应用中的简单性和效率的讨论。随后话题转向了对 demoscene 社区中代码效率的欣赏,以及对政府 IT 投资的推测。 -
极简技术的性能见解:讨论揭示了极简硬件(例如 125MHz, 8MB RAM)高效运行特定应用(如天文台)的场景,
@hexacube提到在升级进行更密集的处理之前,曾在一台旧的 i5 mini PC 上成功运行。这突显了看似过时的硬件在某些特定领域中持续的关联性和有效性。 -
AI 与游戏协同进化:包括
@cihiris和@goldensun3ds在内的几位用户推测了 AI 与游戏交叉的未来,可能性从 AI NPCs 到由 AI 实时生成的完整游戏。大家对 AI 彻底改变游戏开发和玩家互动的潜力充满热情。 -
硬件与 AI 开发限制:对话涉及了运行大语言模型 (LLMs) 和 AI 相关任务的各种考虑因素,包括速度方面 GPU 优于 RAM 的重要性、游戏中用于不同任务的多 GPU 配置潜力,以及专为 AI 加速设计的硬件这一引人入胜的概念。
-
寻找 AI 应用的最佳硬件配置:包括
@pudlo和@heyitsyorkie在内的用户辩论了投资高性能 GPU 与充足 RAM 以运行 AI 模型的优劣,共识倾向于先进 GPU 带来的显著性能提升。分享了诸如 LocalLLaMA LLM GPU Buying Guide 等资源链接,为针对 AI 开发目的的硬件选择提供了见解。
提到的链接:
- Cats Matrix GIF - Cats Matrix Neo - Discover & Share GIFs:点击查看 GIF
- Hacking Computer Screen GIF - Hacking Computer Screen Green Screen - Discover & Share GIFs:点击查看 GIF
- Reddit - Dive into anything:未找到描述
- Liquid AI raises $37.6M to build ‘liquid’ neural networks - SiliconANGLE:Liquid AI 融资 3760 万美元用于构建“液体”神经网络 - SiliconANGLE
LM Studio ▷ #🧪-beta-releases-chat (18 messages🔥):
-
退出代码故障排除:
@fabguy建议那些遇到 Exit Code 1 错误的用户查看置顶消息中的 FAQ 以获取解决方案,这通常与 C++ Redist 问题有关。 -
对新版本的期待:
@oldandnew.分享了社区对是否很快会发布新的 beta 版本的期待和渴望。 -
关于断点续传功能的查询:
@greg0403询问了添加下载续传功能的可能性,@dagbs和@senecalouck指引他前往特定频道获取更多信息。 -
报告并诊断模型错误:
@epicureus报告了一个带有退出代码和详细系统信息的模型错误,引发了与@yagilb的对话,后者对错误报告表示感谢,并承诺在亲自尝试加载该问题模型后修复该问题。 -
模型加载问题的快速修复:在与
@yagilb讨论后,@epicureus发现 Openhermes 2.5 可以工作,但在其他模型上遇到问题,暗示可能存在 RAM 检测问题。@yagilb进一步寻求有关哪些特定模型失败的信息,并表示在确定了@epicureus分享的 Dr Samantha 7b 模型的问题后,修复程序即将发布。
提到的链接:
TheBloke/Dr_Samantha-7B-GGUF · Hugging Face:未找到描述
LM Studio ▷ #autogen (1 messages):
- Wizard Coder 15b 在终止输出方面存在困难:
@strangematter分享了他们使用 Wizard Coder 15b 进行 Python 代码生成的经验,发现虽然它能生成连贯的代码,但尽管结果令人满意,在终止输出方面却有困难。他们询问是否有人在其他代码生成模型上取得了更好的效果。
LM Studio ▷ #langchain (2 messages):
- LangChain 与 LM Studio 的集成:
@circulustreme询问了将 LangChain 与运行 Mixtral 的本地 LM Studio 集成以生成包含 100 条响应的数据集的可能性。@yagilb确认这是可行的,并参考了之前关于连接过程说明的消息。
OpenAI ▷ #ai-discussions (3 messages):
- 为 AI 任务选择 VRAM:
aqua_dawn_67525正在考虑作为初学者,是为 AI 项目购买 16GB VRAM 还是 24GB VRAM,并想知道 16GB 是否在未来几年内够用。 - 转向云端以获得更强算力:
aqua_dawn_67525考虑到如果个人托管成本太高,可能会转向云端以获得更多计算能力。 - 16GB VRAM 的个人经验:
toror分享道,在 4080 GPU 上拥有 16GB VRAM 对于许多现代、经过优化的模型来说已经足够,为aqua_dawn_67525的考量提供了一个参考点。
OpenAI ▷ #gpt-4-discussions (170 messages🔥🔥):
-
GPT Plus 用户遇到消息限制困惑:包括
@iyons和@myroslava_35196_08143在内的多位用户对在 GPT Plus 上触发消息限制警告表示困惑和沮丧,尽管他们并未达到所谓的每 3 小时 40 条消息的限制。他们报告称,关于此问题未收到支持部门的任何回复。 -
GPT Mentions 的引入引发关注:由
@kumquatexpress宣布的 GPT mentions 功能引起了用户的兴奋。这一新功能允许在对话中被提及的 GPT 之间共享上下文和自定义操作(custom actions),有望增强 AI 应用的可组合性和灵活性。 -
分享长对话的有效策略:
@darthgustav.分享了管理与 GPT 进行长对话的技巧,建议定期要求总结以维持上下文,并有效利用对话的 token 预算。 -
用户探索 GPT Mentions 的潜力和局限:用户如
@darthgustav.和@blckreaper探索并辩论了 GPT mentions 的功能,讨论了在不同 GPT 之间切换上下文的能力以及与每个 GPT 知识库相关的限制。 -
呼吁扩展 GPT Plus 的功能:
@peter07082表示在澳大利亚访问 Explore GPTs 等新功能时遇到困难,尽管他是早期的 GPT Plus 订阅者。他们与其他用户一起,在从 OpenAI 的帮助系统中获取支持或明确答复方面面临挑战。
OpenAI ▷ #prompt-engineering (32 messages🔥):
-
探索 GPT 在文字游戏中的应用:
.berns询问了是否可以有效地利用 prompt 来玩基于网格的文字游戏,并指出 GPT 之前在处理此类任务时表现不佳。7877和eskcanta提供了见解,建议使用二维数组和 Python 工具来跟踪信息,以期克服这些问题,尽管他们也承认该挑战的复杂性。 -
DALL-E 3 与 GPT 集成的新时代:
darthgustav.分享了他们对新功能的积极体验,该功能允许 GPT 之间通过@符号互相调用,特别强调了 Custom GPT 与 DALL-E 3 之间的成功交互。他们强调了这种集成的潜力,指出它保留了包括代码和视觉 prompt 在内的完整上下文,标志着聊天领域工程(chat realm engineering)迈出了重要一步。 -
关于 GPT 间通信限制的澄清:
novumclassicum寻求关于使用@符号链接多个 GPT 以完成涉及创作、校对和翻译的复杂任务的建议。solbus和bambooshoots澄清说,该功能目前仅在对话中有效,而不能在 GPT 的 instructions 字段中使用,这意味着任务必须手动分步管理。 -
全上下文保留的强大潜力:
darthgustav.讨论了允许在 GPT 之间的请求中保留完整上下文这一功能的开创性潜力。这为无缝的跨学科项目打开了大门,例如在单个会话中编写并为儿童读物绘制插图,而无需切换工具或标签页。 -
目前仍需手动流程的见解:尽管对新的
@符号功能的潜力充满热情,novumclassicum发现目前他们的项目(为语言教师准备的包含插图的完整章节课程)仍需要手动调用各种 GPT。darthgustav.为应对这一“迷宫”提供了指导,暗示即使在目前的限制下,也有办法有效地利用该功能。
OpenAI ▷ #api-discussions (32 messages🔥):
-
探索 GPT 在文字游戏中的潜力:
@.berns对 GPT 在猜单词(hangman)等文字游戏中的有效性表示担忧,认为它经常犯错,比如捏造单词。作为回应,@7877和@eskcanta提供了涉及使用二维数组和 Python 工具的解决方案,以便在游戏中更好地进行跟踪和字母放置,强调了成功的挑战与潜在策略。 -
DALL-E 3 的新功能令人沮丧也令人着迷:
@darthgustav.分享了他对使用@符号调用不同 GPT 模型这一新功能的测试经验,展示了它如何跨不同模型和功能保留完整上下文。他强调了无缝结合 Custom GPT 和 DALL-E 3 进行图像生成的强大能力,同时也指出了该功能的局限性和令人惊讶的能力。 -
Master GPT 常规程序与 GPT 调用说明:
@novumclassicum询问了是否能够编写 Master GPT 常规程序,以调用其他 GPT 模型中的子程序来处理文本创作、校对和翻译等流程。然而,@solbus和@bambooshoots澄清说,虽然这个概念很吸引人,但目前还不支持通过 instruction 字段自动化此过程的功能,每个步骤都需要人工干预。 -
创意项目集成的潜力:
@darthgustav.和@novumclassicum讨论了使用新的 GPT 和 DALL-E 功能进行综合项目的令人兴奋的潜力,例如编写儿童读物或创建带有插图的完整章节课程。尽管存在目前的限制和手动操作的必要性,他们对未来能够简化此类创意工作的进展仍保持乐观。 -
社区参与和问题解决:包括
@darthgustav.和@solbus在内的几位用户展示了社区驱动的故障排除以及对 OpenAI 近期功能的经验分享。他们的对话强调了社区在发现、测试和反馈 OpenAI 模型不断演进的能力方面所发挥的作用。
Eleuther ▷ #general (74 条消息🔥🔥):
-
浏览器端 ML 凭借 Ratchet 实现飞跃:
@frazermc询问了关于浏览器端机器学习推理引擎的问题,随后@carsonpoole介绍了 Ratchet,这是一个使用 Rust 和 WebGPU 的跨平台浏览器 ML 框架。它为 whisper-turbo.com 提供动力,并承诺提供量化支持以及针对速度和开发者体验的优化。 -
显微镜下的 Flash Attention 2:
@nshepperd引发了一场关于 Flash Attention 2 中潜在 use-after-free 问题的技术讨论,然而代码仍然可以“运行”,可能是因为内存在 Kernel 执行前未被覆盖。这一奇特现象开启了与@nlab_enthusiast之间关于 PyTorch 中 Tensor 内存管理的详细对话。 -
EleutherAI 庆祝 ICLR 论文被接收:
@stellaathena分享了令人振奋的消息,EleutherAI 相关的 10 篇论文中有 6 篇被 ICLR 接收,并列出了如 “LLeMA: An Open Language Model for Mathematics” 等被接收的出版物,同时向首次发表论文的作者和贡献者表示祝贺。 -
通过新调查探索 AI+音乐的交汇点:
@loubb鼓励社区成员通过 http://survey.loubbrad.com:8501/ 上的调查来帮助评估 AI 驱动的音乐模型。该公告得到了@stellaathena的支持,旨在收集对最新模型进展的见解。 -
对 GitHub 年度增长数据和 Anthropic 可解释性研究的关注:用户对 GitHub 关于 commit 和 pull request 的年度统计数据表示好奇,同时
@digthatdata深入研究了 Anthropic 关于 “OV” 电路的研究,并分享了 transformer-circuits.pub 的链接,作为理解新兴技术和可解释性工作的资源。
提到的链接:
- Whisper Turbo:转录任何音频文件 - 完全免费!
- distil-whisper/distil-large-v2 · Hugging Face:未找到描述
- GitHub - pyf98/DPHuBERT: INTERSPEECH 2023: "DPHuBERT: Joint Distillation and Pruning of Self-Supervised Speech Models":INTERSPEECH 2023:”DPHuBERT:自监督语音模型的联合蒸馏与剪枝”
- GitHub - FL33TW00D/whisper-turbo: Cross-Platform, GPU Accelerated Whisper 🏎️:跨平台、GPU 加速的 Whisper 🏎️。通过在 GitHub 上创建账号为 FL33TW00D/whisper-turbo 的开发做出贡献。
- GitHub - FL33TW00D/ratchet: A cross-platform browser ML framework.:一个跨平台浏览器 ML 框架。通过在 GitHub 上创建账号为 FL33TW00D/ratchet 的开发做出贡献。
- Circuits Updates - January 2024:未找到描述
- Circuits Updates — May 2023:未找到描述
Eleuther ▷ #research (96 messages🔥🔥):
-
聚类性能与准确率悖论:
@llm_enjoyer发起了一场讨论,即更好的聚类 Embedding(通过 Davies–Bouldin 和 Calinski–Harabasz 等指标衡量)理应带来更高的分类准确率。然而,他们在实验中观察到了相反的情况,发现聚类指标更好的模型在准确率上表现更差,这让他们感到困惑。Davies-Bouldin Index Wiki, Calinski-Harabasz Index Wiki -
探索 muP 训练模型的极限:一系列关于使用 muP 训练的最大模型的询问显示,使用 Cerebras 的 3B 模型是目前引用的最大具体案例,同时也有推测认为 GPT-4 可能也是使用 muP 训练的。通过这次讨论,
@jstephencorey、@ad8e和@thatspysaspy探讨了哪些大规模模型可能受益于 muP 技术。 -
最新研究显示稀疏微调 (SFT) 优于 LoRA:
@random_string_of_character分享了针对 Llama 2 等大语言模型在稀疏微调方面的突破,提出了一种既节省参数又节省内存的方法,同时性能优于 (q)LoRA 方法。研究表明,在指令微调性能方面有了显著提升,相关的 论文 和 代码 已发布供进一步探索。 -
探索使用 RAG 问答生成“引用”的潜力:
@carsonpoole提出了通过分析 RAG 问答过程中的 Attention Maps 来生成详细“引用”的想法,促使@johnryan465和@kharr.xyz指出了之前用于类似目标的工具和方法,例如 Bertviz 和用于生成行内引用的微调策略。 -
为 LLM 训练提出 Mixture of Softmaxes:
@alstroemeria313分享了一种有趣的训练方法,通过混合 Transformer 最后 k 层的 Logits 来训练模型,这种方法的灵感来自于避免“Softmax 瓶颈 (softmax bottleneck)”的概念。这种方法在小规模上显示出潜力,涉及对每组 Logits 进行 Softmax 处理,然后根据 Softmax 权重进行混合输出。
提到的链接:
- Edoardo Ponti (@PontiEdoardo) 的推文:我们通过提高参数和内存效率,将稀疏微调 (SFT) 扩展到了 LLM(如 Llama 2)!(q)SFT 的指令微调性能通常优于 (q)LoRA,且速度相当…
- SERL:样本高效的机器人强化学习软件套件:未找到描述
- 文本扩散模型的迁移学习:在本报告中,我们探讨了文本扩散取代自回归 (AR) 解码用于大语言模型 (LLM) 训练和部署的潜力。我们特别感兴趣的是…
- The Normal Blog - 无限上下文 LLM:通过扩展思维超越 RAG:在这篇博客中,我们讨论了 Transformer 架构如何自然地扩展到外部存储器,并分享了利用这种能力在 RAG 表现不佳的场景下取得成功的实证结果。这些…
- Edoardo Ponti (@PontiEdoardo) 的推文:我们尝试了不同混合数据集(Flan v2, GPT4 Alpaca, Tülu v2)、模型规模(Llama 7B 和 13B)以及量化(4 bits)的指令微调。我们发现 SFT 的表现优于 LoRA 和其他…
- Davies–Bouldin 指标 - 维基百科:未找到描述
- Calinski–Harabasz 指标 - 维基百科:未找到描述
- GitHub - cambridgeltl/composable-sft:一个用于 NLP 的参数高效且可组合的迁移学习库,支持稀疏微调。
Eleuther ▷ #lm-thunderdome (3 条消息):
-
分享高效数据集缓存技术:
@hailey_schoelkopf分享了一个有用的解决方案,用于在 HF datasets 中离线使用缓存数据集,参考了 GitHub issue 以及 EleutherAIlm-evaluation-harness中关于使用本地数据集的文档。 -
PyPI 项目所有权转移请求:
@hailey_schoelkopf请求将lm_evalPyPI 项目的 owner 级别访问权限 转移给haileyschoelkopf或eleutherai用户名,旨在更有效地管理维护者权限。 -
所有权转移已确认:
@bmk1476迅速做出回应,确认已完成关于lm_evalPyPI 项目的所有权转移请求。
提到的链接:
- Is there a way to cache the building of datasets? · Issue #1344 · EleutherAI/lm-evaluation-harness:大家好,再次感谢这个优秀的框架。我正在以编程方式使用该框架。我自己编写了代码来实现这一点,但我不想做无用功,想确认一下该包…
- lm-evaluation-harness/docs/new_task_guide.md at main · EleutherAI/lm-evaluation-harness:一个用于语言模型 few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
Eleuther ▷ #multimodal-general (2 条消息):
- 探索用于矢量图形合成的笔画标记化:
@stellaathena提到了一项关于矢量图形合成中笔画标记化(tokenizing strokes)的理论讨论,并链接到了一项相关研究:StrokeNUWA: Tokenizing Strokes for Vector Graphic Synthesis。该概念似乎与这项研究的重点一致。
Eleuther ▷ #gpt-neox-dev (7 条消息):
- PPC64LE 上的 CUDA 容器困境:
@catboy_slim_发现唯一支持ppc64le的 NVIDIA CUDA 容器 是其 UBI (Red Hat) 版本,并感叹 RHEL 对 Python 版本的奇特立场,特别是对 3.10 的不认可。 - CUDNN 安装问题:
@catboy_slim_进一步指出 UBI NVIDIA 镜像上的 CUDNN 安装似乎已损坏。 - PPC64LE Wheel 构建挑战:
@catboy_slim_表达了挫败感,并表示很可能放弃为ppc64le构建 wheel,暗示了所面临挑战的严重性。 - Apex 交叉编译困境:
@catboy_slim_讨论了为 Apex 设置交叉编译构建的复杂性和不可取性,强调了在没有 Apex 的情况下 NeoX 和 deepspeed 所涉及的重大困难和依赖关系。 - 在设备上构建 Apex 的必要性:在讨论结束时,
@catboy_slim_表示在特定情况下,在设备上构建 Apex 似乎是不可避免的解决方案,并强调由于 NVCC 在交叉编译方面的限制,预构建通用二进制文件是不切实际的。
Mistral ▷ #general (147 messages🔥🔥):
-
预算有限下的 Mistral:用户讨论了在 1660 Ti 等 6GB VRAM 的 GPU 上运行 Mistral 7B 模型的可行性。
@batot4968反馈因显存溢出(out of memory)导致失败,而@mrdragonfox澄清说可以运行,但不能使用 fp16,并坚持认为大多数用户需要至少 24GB 的 VRAM 才能在本地玩转 AI。 -
为受限的 VRAM 寻找合适的模型:在讨论中,
@batot4968在 Hugging Face 上找到了一个经过量化的模型,可以在约 5.5GB VRAM 下工作,适用于 1660 Ti。这次对话强调了针对较低 VRAM 需求选择量化模型的必要性。 -
高端系统上的性能查询:用户对 Mistral 7B 模型在 RTX4090 等高端系统上的性能表示关注,
@batot4968观察到速度不一致。@i_am_dom建议关注 GPU 利用率(GPU utilization)来解决此问题,暗示应尽量减少 CPU 占用以获得最佳性能。 -
关于运行模型的澄清:当
@mikifireblue等用户寻求关于在不完全加载到 VRAM 的情况下运行 Mistral 模型的明确方法时,@i_am_dom指向了 Colab notebooks 等资源,以获取高效模型加载的指导。 -
技术爱好者探索 AI 领域:来自新加入用户(如
@krahs.)的讨论(他表达了将 Mistral AI 集成到游戏设计中的兴趣)凸显了社区对 AI 模型的探索和实验。对话展现了热情与对高效探索 AI 模型领域详细指导的需求。
提到的链接:
- TheBloke/Mistral-7B-Instruct-v0.2-GGUF · Hugging Face:未找到描述
- GitHub - mistralai/mistral-src: Reference implementation of Mistral AI 7B v0.1 model.:Mistral AI 7B v0.1 模型的参考实现。
- Reddit - Dive into anything:未找到描述
Mistral ▷ #finetuning (2 messages):
-
寻求更简洁的 LLM 回复:
@brentnhunter征求关于如何缩短 LLM 回复的建议。尽管给出了简洁回复和限制 token 数量的指令,回复仍然过长,他特别希望对于“2 加 2 等于几”这类问题能得到像“4”这样直接的回答。 -
Fine-Tuning 技巧以改进模型:
@friendly911建议运行更多步数,认为 60 步对于较大的数据量来说太少了,并建议将学习率(learning rate)降低到约 2e-5 以获得更好的模型性能。
Mistral ▷ #showcase (1 messages):
- Mistral 开源 Web UI 发布:
@darkstar1011启动了一个名为 uMdali 的开源项目,旨在为 Mistral API 提供 Web UI。该项目还支持连接到 Ollama, OpenAI, 和 Gemini,将其定位为“企业级聊天前端”。
提到的链接:
GitHub - brett-baudin-consulting/uMdali: Enterprise Chat Front End:企业级聊天前端。通过在 GitHub 上创建账号为 brett-baudin-consulting/uMdali 的开发做出贡献。
Mistral ▷ #la-plateforme (4 条消息):
- Mistral GitHub 开放贡献征集:
@sophiamyang鼓励社区向 Mistral 的 GitHub 公共文档 提交 Pull Requests (PRs),邀请大家参与协作与贡献。 - 针对 Notebook 咨询的直接支持:
@sophiamyang就疏忽向 Patrick 表示歉意,并承诺审阅提交的 notebook,体现了 Mistral 对社区的积极响应。 - Mistral 实习咨询引发关注:用户
@bepis4552询问了在 Mistral 申请实习的可能性,表达了加入团队的兴趣。 - Mistral 实习竞争激烈:针对实习咨询,
@sublimatorniq指出 Mistral 开发者关系团队的成员资历极高,并暗示获得实习机会可能需要非凡的才华和一点运气。
提及的链接:
GitHub - mistralai/platform-docs-public:通过在 GitHub 上创建账号,为 mistralai/platform-docs-public 的开发做出贡献。
HuggingFace ▷ #announcements (1 条消息):
- Code Llama 70B 发布:
@lunarflu宣布发布 Code Llama 70B,这是社区最新的 AI 聊天模型。点击此处体验。 - Sentence Transformers v2.3.0 发布:
@tomaarsen介绍了 Sentence Transformers v2.3.0,包含错误修复、性能增强以及更高效的模型加载。发行说明见此处。 - 推出无服务器目标检测 (Object Detection):
@whitphx分享了 Gradio-Lite 和transformers.js.py合作开发的无服务器目标检测应用。查看应用和代码请点击此处。 - Autotrain 迈向本地优先 (Local-first):
@abhi1thakur宣布 Autotrain 现已实现“本地优先”,通过简单的 pip install 即可使用带有 UI 的本地训练功能。说明见此处。 - Hugging Face 与 Google Cloud 合作伙伴关系:Hugging Face 与 Google Cloud 之间的战略合作旨在利用开放模型和技术推动 AI 民主化。更多合作细节见此处。
提及的链接:
- HuggingChat: 让社区最好的 AI 聊天模型惠及每个人。
- Omar Sanseviero (@osanseviero) 的推文: Code Llama 70B 来了!🚀🦙🤖 查找 Transformers 格式的模型 - Base https://hf.co/codellama/CodeLlama-70b-hf - Python https://hf.co/codellama/CodeLlama-70b-Python-hf - Instruct https://hf.c…
- Big Code Models Leaderboard - 由 bigcode 创建的 Hugging Face Space: 未找到描述
- tomaarsen (@tomaarsen) 的推文: 期待已久的 Sentence Transformers v2.3.0 现已发布!它包含大量错误修复、性能改进、自定义模型加载、更高效的加载、一个新的强损失函数等…
- Yuichiro (@whitphx) 的推文: Gradio-Lite (Serverless @Gradio) + http://Transformers.js.py 的目标检测流水线 = Serverless 目标检测应用!只需使用 Gradio 和 Transformers 编写 Python 代码,然后将其托管为…
- 幻觉排行榜 (The Hallucinations Leaderboard),一项衡量 Large Language Models 幻觉的开放工作: 未找到描述
- Moritz Laurer (@MoritzLaurer) 的推文: .@huggingface TGI 现在与 @OpenAI 的 Python 客户端/HTTP 接口兼容:将任何开源 LLM 放入你自己硬件上的 TGI 容器中,并通过 OpenAI Python 客户端调用它 😎 第一步…
- abhishek (@abhi1thakur) 的推文: AutoTrain 现在是本地优先!💥 这意味着你可以使用 pip 安装 autotrain-advanced,并在本地使用 UI 运行训练 🚀 在 Hugging Face Spaces 中,只需将你喜欢的 GPU 附加到你的 AutoTrai…
- makeMoE: 从零开始实现一个稀疏专家混合 (Sparse Mixture of Experts) 语言模型: 未找到描述
- Xenova (@xenovacom) 的推文: Depth Anything 现在已在 🤗 Transformers.js 中可用!该模型的小版本仅有 25M 参数,在本地运行效果极佳。这是我创建的一个执行单目深度估计的演示…
- Vaibhav (VB) Srivastav (@reach_vb) 的推文: 好的!W2V-BERT 2.0:针对低资源语言的语音编码器!🔥 仅需不到 15 小时的音频,你就能击败 Whisper 并获得你自己的 SoTA ASR 模型! > 在 450 万小时的数据上进行了预训练。 > …
- LevelBot - 由 huggingface-projects 创建的 Hugging Face Space: 未找到描述
- Sayak Paul (@RisingSayak) 的推文: 我们已经开始在 🧨 diffusers 仓库中更结构化地开放各种不同的贡献机会。如果你有兴趣贡献,请查找 Issue,从…
- lunarflu (@lunarflu1) 的推文: 现在每个人都可以在你的个人资料中看到你的 @huggingface 帖子了!🔥🧙♂️✨
- Mishig Davaadorj (@mishig25) 的推文: 更新了 HuggingChat 上的网页搜索体验。我们将继续快速发布 HuggingChat 的重大更新。期待 Llama 3 及更高版本。
- Katie Link (@katieelink) 的推文: 你知道你可以通过门控 (Gates) 控制对 @huggingface 模型和数据集的访问吗?🔐 这对于可能需要访问审批、训练…的医疗保健/生物医学模型和数据集至关重要。
- Quentin Lhoest (@qlhoest) 的推文: 🤗 Hugging Face Hub 现在原生支持 ⚡⚡ WebDataset ⚡⚡。到目前为止,它是 AI 模型训练流式传输数据最好的数据集格式,让我来解释一下👇🧵
- Hugging Face 与 Google 合作开展开放 AI 协作: 未找到描述
HuggingFace ▷ #general (97 条消息🔥🔥):
-
探索 LLM 中的多模态:
@thegenerativegeneration正在跟进 LLM 和多模态理解,特别感兴趣模型如何同时处理多张图像和视频以进行上下文理解。他们还询问了关于具有 3D 理解能力的 LLM 的实践经验,寻求该主题的相关综述或资源。 -
降低 LLM 成本:
@jasonzhou1993分享了一个 YouTube 视频,标题为“LLM 的真实成本(以及如何降低 78% 以上的成本)”,讨论了显著降低 LLM 运营成本的策略。 -
寻求开源/ML 项目 Twitter 推文技巧:
@vipitis寻求关于撰写开源/ML 主题公告类 Twitter 推文的建议,引发了社区的技巧分享和反馈。建议包括分析高质量的公告,并将视觉叙事视为一种有效的工具。 -
CUDA 内存分配查询:
@felixsanz和@pixxelkick讨论了 Python PyTorch 的torch.cuda.max_memory_allocated函数,以及它与 NVIDIA 的 nvidia-smi 工具报告的内存使用情况之间的关系。由于报告的 GPU 内存分配与实际分配之间的差异引起了困惑。 -
关于低配硬件上 TTS AI 性能的咨询:
@yengecbey向社区询问在配备 i5 处理器和 8GB RAM 的笔记本电脑上运行文本转语音(TTS)AI 的可行性,表示有兴趣了解 TTS AI 应用的硬件要求。
提到的链接:
- The REAL cost of LLM (And How to reduce 78%+ of Cost):我想为您提供关于如何降低 70% LLM 成本的逐步指南,并剖析为什么现在的成本如此之高。免费的 HubSpot AI 营销人员课程:https:/…
- GitHub - mermaid-js/mermaid: Generation of diagrams like flowcharts or sequence diagrams from text in a similar manner as markdown:类似于 markdown 的方式从文本生成流程图或序列图等图表 - GitHub - mermaid-js/mermaid…
- 来自 Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr) 的推文:很高兴分享我参与的一篇新论文!:“使用 Hourglass Diffusion Transformers 进行可扩展的高分辨率像素空间图像合成” abs: https://arxiv.org/abs/2401.11605 网站: https://c…
- 来自 EleutherAI (@AiEleuther) 的推文:我们很高兴能与其他人工智能领域的领导者合作,与 @NSF 共同启动国家 AI 研究资源(NAIRR),这是一个共享基础设施,将促进对关键资源的访问…
- 来自 Jerry Wei (@JerryWeiAI) 的推文:新的 @GoogleAI+@Stanford 论文!📜 符号微调(Symbol tuning)是一种通过强调输入-标签映射来改进 in-context learning 的简单方法。它提高了对没有指令/相关提示的鲁棒性…
- 来自 Stella Biderman (@BlancheMinerva) 的推文:你是否曾经想在 LLM 上做实验,却发现现有的模型套件都不能满足你的需求?在 @AiEleuther,我们厌倦了这种情况的发生,因此设计了一个以…为中心的模型套件。
HuggingFace ▷ #cool-finds (1 条消息):
- 揭秘多模态马来西亚 LLM 数据集:用户
@andysingal分享了一个托管在 HuggingFace 上的多模态马来西亚 LLM 数据集链接,为开发针对马来西亚语境的 LLM 模型提供了资源。该数据集是 mesolitica 集合的一部分,包括翻译后的 LLaVA 指令,旨在通过多模态输入增强语言模型训练。
提到的链接:
Multimodal Malaysian LLM dataset - a mesolitica Collection:未找到描述
HuggingFace ▷ #i-made-this (3 messages):
-
Excel/CSV 文件直接转换为数据库的魔法:
@impl66创建了一个 Gradio 应用,可以将 Excel/CSV 文件转换为数据库表,并允许用户轻松进行查询。请在 HuggingFace Spaces 上查看该应用。 -
应对 AI 生存恐惧:
@mateomd_dev在其最新一期通讯 Recurrent Neural Notes 中讨论了经常被炒作的 AI 获得意识并反抗人类的恐惧。如需深入探讨该话题,请访问 RNN #8 - Will AI Become Evil?。 -
当《万智牌》(Magic: The Gathering)遇上 AI:
@joshuasundance介绍了 HuggingFace 上可能首个《万智牌》模型,该模型能够根据卡牌名称和文本对卡牌颜色身份进行多标签分类。要探索这种将 AI 用于卡组构建的创新用途,请访问 mtg-coloridentity-multilabel-classification。
提及的链接:
- Tables - a Hugging Face Space by sid27:未找到描述
- RNN #8 - Will AI Become Evil?:意识在 AI 危险中的作用
- joshuasundance/mtg-coloridentity-multilabel-classification · Hugging Face:未找到描述
HuggingFace ▷ #reading-group (3 messages):
- 读书小组频道新人:
@marc.casals.salvador询问了该频道的运作方式,以及是否安排了讨论阅读内容的会议。 - 用于演示的 Discord 通话:
@chad_in_the_house回复了@marc.casals.salvador,指出当演讲者有空时会组织 Discord 通话,下一次会议计划在 EST 时间周五下午 1-2 点左右。
HuggingFace ▷ #diffusion-discussions (5 messages):
-
为 QA 数据集寻求 DPO 之外的鲁棒性:
@blackbox3993正在探索如何使用 DPO (Differential Privacy Optimization) 通过负面回答来增强问答数据集。他们对使模型更具鲁棒性和准确性的替代方法感到好奇。 -
关于 lokr 和 loha 的推理支持咨询:
@forsana正在询问 lokr 或 loha 是否支持使用 “loading with peft” 方法进行推理,这表明了对部署技术的特定兴趣。 -
Google Colab 中的 CUDA 插件注册错误:
@straze007在尝试使用 LoRA 在 Google Colab 中微调文本生成图像模型时遇到了多个 CUDA 相关错误,特别是涉及 cuDNN、cuFFT 和 cuBLAS 插件。 -
对 70B 编程模型聊天能力的失望:
@pseudoterminalx分享了一个链接 (hf.co chat),表达了对 70B 编程聊天模型的失望,指出它缺乏 🤗 Diffusers 库的相关知识。 -
在 Stable Diffusion 中难以复制特定的艺术风格:
@troyfix旨在利用原生 Stable Diffusion 重现一种动漫艺术风格,并提供了一个详细的 Prompt 来捕捉目标风格的素描感和粗糙质感。他们链接到了一个体现该理想艺术风格的示例 (akimasaweb)。
提及的链接:
works 徳永明正-航空イラストなど-:未找到描述
HuggingFace ▷ #NLP (7 messages):
- 检测到 GPU Acceleration 故障: 用户
@sgp开始排查一个问题,他们意识到尽管尝试配置了环境,但 GPU acceleration 完全没有发挥作用。 - 涉及 RTX 2080ti: 他们透露在实验中使用的是 RTX 2080ti,暗示了其高端硬件配置。
- 查阅 LLama GitHub Issue: 为了寻求解决方案,
@sgp发现并分享了一个与 GPU 支持相关的 GitHub issue,该 issue 涉及 LLama cpp problem,并提出了潜在的修复方案。 - 遇到 nvcc 编译错误: 按照 GitHub 上的建议方案操作后,
@sgp遇到了一个编译错误:nvcc fatal : Unknown option 'fPIC',这表明nvcc编译器选项存在兼容性问题。 - 可能的配置错误导致了更大的问题: 排查尝试导致了更复杂的情况,
@sgp表示他们的操作可能无意中损坏了现有的环境,影响了其 gptq model 的运行。
提到的链接:
LLama cpp problem ( gpu support) · Issue #509 · abetlen/llama-cpp-python: 你好,我是个完全的新手,在 LLM 领域,我为 oogabooga webui 安装了一些 ggml 模型并尝试使用。它运行正常,但只使用了 RAM。对于 VRAM 仅使用了 0.5gb,而且我…
HuggingFace ▷ #diffusion-discussions (5 messages):
- 关于为数据集创建负面回答的咨询:
blackbox3993正在寻找增强问答数据集负面回答的方法,并询问 DPO 是否是实现此目的的可行方法。他们还询问了除了 DPO 之外的替代方案,以使模型更加鲁棒和准确。 - 推理中的 LOKR 或 LOHA 支持咨询:
forsana询问在使用 PEFT loading method 时是否支持 LOKR or LOHA 推理,寻求关于可用选项的澄清。 - Google Colab 中的 TensorFlow 错误:
straze007在尝试使用 LORA in Google Colab 微调 text-to-image 模型时遇到了多个错误,指出与 TensorFlow 插件存在兼容性问题。 - 对 70B Coder Chat 体验感到失望:
pseudoterminalx分享了一个 链接,表达了对 70B coder chatbot 缺乏 🤗 Diffusers library 相关知识的不满。 - 寻求使用 Stable Diffusion 打造完美的动漫艺术风格:
troyfix难以使用 vanilla stable diffusion 重现特定的动漫艺术风格,提供了详细的 prompt 和一张 示例照片,但未能达到预期的素描和粗犷效果。
{kind=link}
提到的链接:
works 徳永明正-航空イラストなど-: 未找到描述
OpenAccess AI Collective (axolotl) ▷ #general (23 messages🔥):
-
Axolotl 更新带来喜悦:
@nafnlaus00分享了他们对 axolotl 及其依赖项持续改进的喜悦,这些改进在无需调整数据集或配置的情况下,实现了更低的 VRAM 占用、更快的训练速度和更好的结果。这一反馈受到了好评,并引发了关于在 Twitter 上分享正面经验以及强调可复现性(reproducibility)重要性的讨论。 -
关于硬件和 VM 增强的讨论:
@dreamgen解释说,他们在 AI 项目中获得的部分加速归功于功率的提升(300W 对比 700W),而@dangfutures则表达了对增加 GPU 上 VM RAM 的需求,强调了硬件在 AI 开发中的重要性。 -
围绕 MIQU-1-70b Dequantization 的兴奋:
@dreamgen展示了 MIQU-1-70b 从 q5 到 f16 的 dequantization(反量化)及其对 PyTorch 的适配,并提供了 Hugging Face 上的模型链接。对话中分享了用于实现细节的代码片段,并鼓励社区成员探索这一进展。 -
硬件推测与机架考量:
@dreamgen分享了一台 4xMI250 服务器价格为 70K 的信息,但也指出需要为服务器机架预留空间的物流考量,强调了预算和空间是 AI 项目基础设施规划中的关键因素。 -
对 Mistral Medium 真实性的推测与询问:围绕 Mistral Medium 的可信度和性能展开了讨论,
@le_mess等人对其真实性和 Benchmark 结果表示怀疑,而@dreamgen为想要进行自行测试的人提供了 Mistral API 的访问权限。
提到的链接:
152334H/miqu-1-70b-sf · Hugging Face:未找到描述
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (7 messages):
- 新实现中的 VRAM 使用问题:
@caseus_强调了一个已知问题,即最近的一个实现会消耗 2 倍 VRAM,论文作者正在对此进行调查。@suikamelon对此表示失望,他原本希望在本地进行测试。 - StefanGliga 提出的 LoftQ 潜在 DIY 解决方案:
@stefangliga建议尝试重新实现 LoftQ,因为他认为这可能只是 LoRA 的一种替代初始化技术。 - 探索 LoftQ 的一阶近似:为了尝试近似 LoftQ,
@stefangliga分享了一个代码片段,该片段对原始权重与反量化权重之间的差异使用 SVD,他认为这是 LoftQ 的一阶近似(first order approximation)。 - 关于如何解决实现问题的辩论:
@caseus_认为,在上游解决 VRAM 问题可能更有利,如果不行,再在 Axolotl 内部解决。
OpenAccess AI Collective (axolotl) ▷ #general-help (65 messages🔥🔥):
-
通过
pip install解决 Docker 困境:@duke001.在使用 Axolotl 的 Docker 镜像时遇到了 “No module named 'axolotl.cli'” 错误。在@nanobitz的指导下,通过cd /workspace/axolotl和pip install -e .解决了该问题,这突显了在 Docker 使用中正确挂载 Volume 的重要性。 -
使用 vLLM 对合并模型进行推理:
@diabolic6045询问如何使用 vLLM 对合并后的 QLoRA Llama2 7B 模型进行推理,@nanobitz建议确保有足够的 VRAM 进行操作。讨论还包括了对 vLLM 在文本生成中速度与质量之间关系的观察。 -
解决训练故障:
@jorelosorio在使用小数据集进行模型训练时遇到了ZeroDivisionError。@nanobitz建议调整num_epochs和micro_batch_size,随后建议使用gradient_accumulation_steps: 1以防止除以零错误。 -
详解向 Tokenizer 添加俚语:
@arcontex寻求关于使用包含特定国家俚语的语料库通过 Axolotl 训练对话模型的建议。@nanobitz解释了如何使用 YAML 中内置的tokens:向 Tokenizer 添加新 Token,并以 ChatML Token 为例说明了该过程,同时讨论了何时向 Tokenizer 添加单词最为有益。 -
澄清对话模型训练:
@arcontex询问在 Axolotl 中训练对话模型时,在 YAML 中声明数据集是否有特殊注意事项。@nanobitz建议为了方便起见重映射到 ShareGPT,并概述了如何在 YAML 中为使用 OpenAI 格式数据的对话模型训练定义数据集。
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
- 探索使用 Llamacpp 进行函数调用 (Function Calls):
@mistobaan分享了一个关于使用 llamacpp 进行函数调用的创意实验,展示了利用社区工具和模型的协作成果。这包括使用 Gist 上的 Colab Notebook、ggerganov 的 llama.cpp、@abetlen 开发的 llamacpp python wrapper,以及 Hugging Face 上 @calebfahlgren 的 natural functions 模型。
提到的链接:
来自 Fabrizio Milo (@fabmilo) 的推文:在 OpenAI API 之外尝试函数调用非常有趣。分享我的 #colab [1],它利用了 @ggerganov 的 llama.cpp[2] / @abetlen 的 llamacpp python wrapper [3] + @LangChainAI wrapper + @ca…
OpenAccess AI Collective (axolotl) ▷ #runpod-help (9 messages🔥):
- 解决
axolotl模块未找到的问题:@gonejiggy在 RunPod Docker 镜像中遇到了找不到axolotl模块的错误,通过执行pip3 install -e '.[deepspeed]'和pip uninstall flash_attn命令临时修复了该问题。然而,他们感到困惑,因为前一天并没有出现这个问题。 - 可能的 Docker 卷挂载问题:
@caseus_和@propback讨论了一个潜在问题,即 Docker 可能由于默认将网络卷挂载到/workspace,导致无法正确在工作区目录挂载axolotl,这可能会覆盖容器原有的/workspace。 - Jupyter Server 扩展警告和错误:
@rss101分享了服务器日志,显示了关于已弃用的 Jupyter server 扩展函数的警告,以及一个关键错误,指出/workspace 在根内容目录之外,导致 8888 端口的 Http 服务始终无法就绪。
OpenAccess AI Collective (axolotl) ▷ #deployment-help (1 messages):
yamashi: 并行请求 (Parallel req)
Perplexity AI ▷ #general (12 messages🔥):
- 对 Mistral Medium API 访问权限的好奇:
@arcinarci询问了何时可以获得 Mistral Medium 的 API 访问权限,这表明社区对更广泛的 API 访问具有浓厚兴趣。 - 免费试用困惑已澄清:用户
@aarav7024对无法使用 7 天免费试用 感到困惑。这引发了讨论,可能暗示 Perplexity 已经停止了 7 天免费试用优惠。 - 了解移动端 App 的限制:
@gooddawg10询问 Android 版是否可以进行 多文件上传。@ok.alex确认 文件和图像上传功能在 App 上尚未推出,但提到将在未来的版本中添加。 - 寻求图像生成指导:
@stoop6981在遇到问题后,寻求关于如何有效使用 图像生成模型 (Image Generation Model) 的建议。@ok.alex将他们引导至一个有用的帖子以获取更详细的指导。
Perplexity AI ▷ #sharing (10 条消息🔥):
-
Perplexity 在应用开发中的创意用途:
@gammagames探索了使用 Perplexity 为一款外卖主题的 Pomodoro 应用生成名称和地址,发现该工具在创意内容创作方面非常高效。 -
探索 Perplexity Labs:
@rowalth强调了 Perplexity Labs 的存在,用户可以在这里实验 AI 的各种功能。 -
应用开发中的偏见与决策:
@zinovi.eu在考虑 iOS 应用开发时反思了对 Apple 公司的个人偏见,尽管在与 Perplexity 进行建设性咨询后,最终还是决定不进行开发。 -
从音乐分类到冰淇淋机:
@fungifriendly47开启了一段使用 Perplexity 的旅程,从音乐分类一直到在 B2B 网站上发现 冰淇淋机,展示了 Perplexity 的多样化用途。 -
在印度寻找合适的入门级游戏笔记本:
@aninokuma95深入搜索了 600 美元以下配备优秀 GPU 的笔记本电脑,确定了 Lenovo Yoga 7i (2023) 和 Acer Nitro 5 等选项,并强调了组件选择对游戏性能的重要性。
提到的链接:
- 对话来自印度的 Aravind,他离开 OpenAI 以颠覆 Google - 与 Marina Mogilko 的对话:新一代搜索引擎会是什么样子?让我们与 Aravind Srinivas 一起探讨,他从印度来到美国,试图用 AIGe 颠覆在线搜索…
- Reddit - 深入探索一切:未找到描述
- ngoshawk 的评论:未找到描述
- Apple 发布包含错误修复的 macOS Ventura 13.0.1 更新:是的,在 13.0.1 版本和 Malwarebytes 发布兼容 Ventura 的版本之间,问题已得到修复。
- Reddit - 深入探索一切:未找到描述
- 2024 年 600 美元以下最佳笔记本电脑:正在寻找新笔记本电脑但预算不想超过 600 美元?我们为您提供了一些目前可以购买的最佳选择!
- 选择 600 美元以下的低/中端游戏笔记本:你好。这个问题被问了无数次,但现在又来了。我这辈子一直是 PC 用户,但随着大学生活的到来,是时候做出改变了。关于…
- 600 美元最快的 RTX 4050 游戏笔记本!Acer Nitro 5 评测:查看 Acer Nitro 5 价格:https://geni.us/JLqV5💲在我的网站 https://gaminglaptop.deals 寻找最佳游戏笔记本优惠。Acer 的 Nitro 5 是最快的游戏…
- 2024 年冬季 4 款最佳编程笔记本电脑:评测:我们测试过的最佳编程笔记本电脑是 Apple MacBook Pro 14 (M2, 2023)。这款高端移动工作站拥有坚固的全铝机身、便携紧凑的设计以及全天候的电池…
Perplexity AI ▷ #pplx-api (61 条消息🔥🔥):
-
在 Web 应用中轻松集成 Perplexity:
@dogemeat_通过分享将 Perplexity API 集成到 Web 应用程序的起点,帮助了@andreafonsmortigmail.com_6_28629。说明和相关文档可以在这里找到,API token 创建请点击这里。不过,需要注意的是 pplx-api 不支持在对话交互中上传文件。 -
Perplexity API 与文件处理咨询:
@andreafonsmortigmail.com_6_28629询问了 pplx-api 处理文件上传和文本摘要的能力。@clay_ferguson澄清说,虽然可能不支持直接的文件处理,但用户可以从文件中提取文本并包含在 Prompt 中,从而在给定的文本限制内有效地进行摘要。 -
发现 Cody,AI 编程助手:
@thereverendcognomen分享了使用 Cody 的见解,这是一个了解用户整个代码库的免费 AI 编程助手,并建议将其作为未来集成的模型,同时表达了将 AI 相关费用整合到一个平台下的兴趣。有关 Cody 的更多信息可以在这里找到。 -
本地模型训练的可能性探讨:
@gritknox和@thereverendcognomen讨论了在没有高端本地设备的情况下训练和测试大型模型的可行性。对话强调了在基础硬件上本地使用某些模型的能力,并提到了 Ollama 等平台在本地模型执行和训练方面的效用。 -
API 故障排除与社区支持:
@mafia_boii在尝试访问 Perplexity API 时遇到了 401 身份验证错误。由@clay_ferguson领导的社区支持提供了故障排除步骤,包括回退到更基础的 Shell 命令以隔离问题,并确认了文档中代码片段的有效性。
提到的链接:
- Cody AI - Visual Studio Marketplace:Visual Studio Code 扩展 - 具有代码库上下文的编程 AI
- GitHub: Let’s build from here:GitHub 是超过 1 亿开发者共同塑造软件未来的地方。为开源社区做贡献,管理您的 Git 仓库,像专业人士一样审查代码,跟踪错误和功能…
- Upload 3 files · microsoft/phi-2 at 7e10f3e:未找到描述
- Getting Started with pplx-api:未找到描述
- Supported Models:未找到描述
- Ollama:在本地运行大型语言模型。
- GitHub - ollama-webui/ollama-webui: ChatGPT-Style Web UI Client for Ollama 🦙:适用于 Ollama 的 ChatGPT 风格 Web UI 客户端 🦙。通过在 GitHub 上创建账户为 ollama-webui/ollama-webui 的开发做出贡献。
- quantizr/src/main/java/quanta/service/node/PplxAiService.java at 246e7e2b3510b033b1c133e8702fcc7da1b325a0 · Clay-Ferguson/quantizr:Quanta 是一个具有 ChatGPT 和社交媒体 (Fediverse) 功能的开源 CMS - Clay-Ferguson/quantizr
- Chat Completions:未找到描述
LLM Perf Enthusiasts AI ▷ #triton (5 条消息):
- Triton 与 CUDA 的灵活性问题:
@mhmdsabry询问了 Triton 缺乏灵活性的底层 CUDA 特性,并请教这些方面如何能提升性能。他还请求提供相关链接和资源以获取详细解答。 - Triton 对底层数据的处理:
@gogators.强调 Triton 在 GPU ‘block’ 级别对数据存储和分区的控制有限,这影响了对 Flash Attention 等算法至关重要的 shared memory 和 registers 的使用。他提到,尽管如此,Triton 对这些资源的管理仍能达到最优性能水平。 - 关于 Triton 实现的推荐阅读:对于想要深入了解细节的人,
@gogators.推荐阅读原始的 Triton 论文和 GPT-4 细节,这是理解 Triton 实现细节的绝佳资源。 - Triton 的同步功能需要改进:针对
@mhmdsabry的部分提问,@andreaskoepf指出 Triton 的同步功能较弱,特别强调除了文档记录的 debug_barrier(主要用于同步 block 中的所有线程)之外,缺乏健壮的同步原语(sync primitives)。
提到的链接:
triton.language.debug_barrier — Triton 文档:未找到描述
LLM Perf Enthusiasts AI ▷ #cuda (24 条消息🔥):
- 向量化内存访问提升性能:
@andreaskoepf分享了关于改进 memory-bound CUDA kernel 性能的见解,建议转向读取连续内存并使用 vector loads。他引用了一篇 NVIDIA 博客文章,强调了通过向量化优化带宽利用率的重要性。 - 使用 Numba 让 CUDA 变得更简单:
@hamelh重点介绍了一篇 @HaseoX94 的推文,讨论了使用 Numba 简化 CUDA 编程,其中包括 Jeremy Howard 的教程,为 Python 用户揭开了 CUDA 的神秘面纱。 - 潜在的 CUDA 演讲预告:
@marksaroufim幽默地推荐@555959391833292811在 2 月 24 日进行一场演讲,引发了关于展示编程工作的讨论,@zippika对自己的演讲技巧表示谦虚,同时也对这次机会表示感谢。 - 关于 RAM 与 VRAM 需求的辩论:
@bazlan询问为什么有人建议 RAM 大小应该是 VRAM 的两倍,引发了与@marksaroufim和@zippika关于充足 RAM 在数据预处理和模型操作中实际益处的讨论。 - CUDA 重构的尝试与磨难:
@artste分享了重构 CUDA 代码以提高可读性和性能的经验,最终发现@555959391833292811建议的“non-float”方法最快,尽管存在微小的像素差异。各种方法的历程和对比已整理在 GitHub notebook 中。
提到的链接:
- Somshubra Majumdar (@HaseoX94) 的推文:我个人不喜欢 C++,如果你也是,你可以直接使用 Numba 非常轻松地进行 CUDA 编程。这里有 Jeremy 的教程,所有的 CUDA + torch load_inline() 都被替换成了简单的 py…
- artste/lecture2 中的 cuda_rgb_to_gray_refactor.ipynb:lecture 2 - 2024-01-20。通过在 GitHub 上创建一个账户来为 artste/lecture2 的开发做出贡献。
-
[CUDA 高手技巧:通过向量化内存访问提高性能 NVIDIA 技术博客](https://developer.nvidia.com/blog/cuda-pro-tip-increase-performance-with-vectorized-memory-access/):这篇文章展示了在 CUDA C/C++ 中使用向量化内存访问,在减少指令数量的同时提高带宽利用率。
LLM Perf Enthusiasts AI ▷ #torch (1 条消息):
andreaskoepf: https://x.com/pytorch/status/1752406904809341165
LLM Perf Enthusiasts AI ▷ #algorithms (2 条消息):
- 提供在 A100/H100 GPU 上运行代码的机会:
@vim410提议在 A100/H100 GPU 上运行他人的代码库以生成数据点。不过,他们无法提供 SSH 访问权限。 - 提供用于测试的双 GPU 机器:
@jeremyhoward愿意提供一台 双 GPU 机器 用于无限期测试。可以通过私信他来安排此事。
LLM Perf Enthusiasts AI ▷ #suggestions (1 条消息):
vim410: 感谢分享,我是这篇文章的作者之一。 🙂
LLM Perf Enthusiasts AI ▷ #jobs (2 条消息):
- ML Performance Wizard 指南发布:用户
@muhtasham分享了指向 ML Performance Wizard 的链接,这是一个全面的指南或资源,但他在消息中未提供更多细节。 - NVIDIA 寻求 CUDA 和 C++ 人才:
@vim410宣布 NVIDIA 正在招聘 CUDA 和 C++ 专家。鼓励具备 CUDA 中级或专家知识的意向候选人与其联系,以便对接合适的 NVIDIA 团队成员。
提及的链接:
Notion – 笔记、任务、维基和数据库的一体化工作空间。:一款将日常工作应用融合在一起的新工具。它是为您和您的团队打造的一体化工作空间。
LLM Perf Enthusiasts AI ▷ #beginner (8 条消息🔥):
- 深入学习 CUDA 编程:
@noobpeen表达了学习 CUDA 编程的兴趣,并询问了相关指南和先决条件。 - @apaz 分享 CUDA 资源宝库:针对 CUDA 学习,
@apaz推荐了《Programming Massively Parallel Processors》一书,可在 eBay 或 libgen.is 获取。Apaz 分享了宝贵的资源,包括 lightning.ai 的免费 GPU 访问链接、Jeremy Howard (@jeremyphoward) 关于环境搭建的 Twitter 线程,以及 CUDA MODE 的 YouTube CUDA 讲座频道。 - RTX 3070 笔记本电脑的 CUDA 设置咨询:
@noobpeen寻求关于在 RTX 3070 笔记本电脑上安装 CUDA 库的建议,询问是否有特殊要求。 - Conda 偏好:Torch 优于 TensorFlow:针对
@noobpeen关于选择 Conda 搭配 Torch 还是 TensorFlow 的疑问,@apaz支持使用 Conda 搭配 Torch,并幽默地评论了 TensorFlow 日渐式微的影响力。 - Windows CUDA 设置技巧从 @lancerts:对于 Windows 上的 CUDA 设置,
@lancerts建议使用 Visual Studio,因为它与 CUDA 有直接集成,并澄清不要为此目的使用 Visual Studio Code。
提及的链接:
-
[Lightning AI 快速将创意转化为 AI](https://lightning.ai):AI 开发的一体化平台。协同编码、原型设计、训练、扩展、提供服务。直接在浏览器中进行,无需安装。由 PyTorch Lightning 的创作者打造。 - CUDA MODE:一个 CUDA 读书小组和社区 https://discord.gg/XsdDHGtk9N 补充内容见 https://github.com/cuda-mode 由 Mark Saroufim 和 Andreas Köpf 创建。
LLM Perf Enthusiasts AI ▷ #pmpp-book (6 条消息):
- CUDA 内存索引详解:
@andreaskoepf详细说明了如何在 CUDA 中计算内存索引,强调了blockDim.x、blockIdx.x和threadIdx.x在确定内存数组特定部分中元素索引时的作用。 - 通过协作加深理解:在
@andreaskoepf做出解释后,@ashpun对 CUDA 内存索引的清晰讲解表示感谢,强调了社区支持在解决技术咨询方面的价值。 - 探索用于计时的 CUDA Events:
@shindeirou发起了一场关于在测量cudaMemcpy操作时间时是否有必要使用cudaEventSynchronize()的讨论,尽管cudaMemcpy本身具有阻塞性质。 - 澄清 CUDA 计时机制:
@_tvi_回复了@shindeirou并澄清道,cudaMemcpy操作的完成和事件本身的记录都需要同步,这可能解释了为什么在计时测量中会出现 0.0 等异常行为。 - CUDA 中同步的重要性:
@vim410强调默认情况下所有 CUDA API 调用都应被视为异步的,并突出了在捕获性能指标时显式同步的重要性。
LangChain AI ▷ #announcements (2 条消息):
- LangChain Fork 混乱事件:
@.bagatur报告了一起事件,LangChain 仓库的 fork 未被识别为 fork,相应的 PR 一夜之间消失了。目前已开启一个 GitHub 讨论来跟踪此 issue。 - 快速恢复与行动步骤:
@.bagatur随后宣布 LangChain fork 的问题似乎已解决,许多被关闭的 PR 已经重新开启。如果贡献者的 fork 仍有问题,需要手动重新开启 PR,因为团队无法直接访问这些内容。
提到的链接:
GitHub 事件:Fork 未被识别,PR 自动关闭 · langchain-ai/langchain · Discussion #16796:截至太平洋标准时间 2024 年 1 月 30 日上午 9:30,我们注意到大多数 LangChain fork 已停止被识别为 fork,相应的 PR 已自动关闭。我们正在联系…
LangChain AI ▷ #general (35 条消息🔥):
-
寻求自定义工具参数的建议:
@georg.ort正在寻求关于定义自定义工具的必填和可选参数的帮助。他们愿意为有价值的咨询支付费用,并分享了一个沟通链接。 -
LangChain 引入 Handlebars:根据
@afirstenberg的消息并经@jacoblee93确认,Handlebars 已作为支持的模板语言实验性地引入到 LangChain JS 中。 -
调查 LangChain 的 GitHub Fork 问题:
@.bagatur强调了一个问题,即 LangChain on GitHub 的 Fork 分支未能被正确识别,导致 PR 自动关闭。该问题似乎已得到解决,目前正在努力重新打开受影响的 PR。 -
开源 LLM 的 Prompt Engineering:
@juanpablomesa分享的一个链接强调了针对 Mistral 和 Llama 等开源 LLM 与闭源模型相比在 Prompt Engineering 上的细微差别,这些见解源自 Sharon Zhou 博士。详细信息可以在 juanpml.com 找到。 -
排查 Python 应用集成 GPT-4 的问题:
@lucas1809分享了在将 GPT-4 集成到 Python 聊天机器人应用中时遇到的挑战,在尝试使用 v1/completions 端点以外的功能时遇到了错误。一系列消息详细描述了理解错误并寻求解决方案的过程。
提到的链接:
- The REAL cost of LLM (And How to reduce 78%+ of Cost):我想为你提供关于如何降低 70% LLM 成本的逐步指南,并分析为什么现在的成本如此之高。免费的 HubSpot 面向营销人员的 AI 课程:https:/…
- GitHub - vectara/hallucination-leaderboard: Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents:比较 LLM 在摘要短文档时产生幻觉表现的排行榜 - GitHub - vectara/hallucination-leaderboard…
- How to structure your API prompt calls for Open-Source LLMs:探索如何针对 Mistral-7B 和 Llama-2-7b 等开源 LLM 进行 Prompt,并与 GPT-3.5 和 GPT-4 进行对比,附带实际代码示例。
- GitHub Incident: Forks not being recognized, PRs automatically closed · langchain-ai/langchain · Discussion #16796:截至 2024 年 1 月 30 日太平洋标准时间上午 9:30,我们注意到大多数 LangChain Fork 已停止被识别为 Fork,相应的 PR 已自动关闭。我们正在与…联系。
LangChain AI ▷ #langserve (3 条消息):
- 寻求更快速访问 Langserve 的途径:
@rebelsandrobots_97106正在寻找更快速访问 Langserve 的方法,以便在大学文学课程中托管 LLM。他们目前在等待名单中,并正在探索其他快速访问的选项。 - LangServe 与硬件资源管理:
@veryboldbagel澄清说 LangServe 不负责管理 LLM 的硬件资源,这意味着用户需要为此目的添加额外的一层。如果没有它,在并发使用 LLM 时存在服务器崩溃的风险。
LangChain AI ▷ #share-your-work (5 条消息):
-
Oranscribe 预发布预热:
@shving90介绍了 Oranscribe,这是一个旨在增强写作、流程和增长的工具,目前已在 Product Hunt 上线。人们对其正式发布充满期待。 -
ColBERT 与 LangChain 的 AI 交响曲:
@andysingal分享了一篇 Medium 文章,题为 “ColBERT & LangChain’s Symphony with RAGatouille”,预示着通过一种新颖的协作方式,AI 与幽默交互将迎来一场革命。 -
SkillForge V1 发布:
@robot3yes展示了他们的周末项目,一个 SkillForge Agent 原型,它具备为其他 Agent 创建技能的能力。这里是名为 “SkillForge V1” 的有趣 YouTube 视频。 -
JACoB:AI 编程机器人的新黎明:
@momentnerd透露了其 AI 编程机器人项目的重大进展,该项目现命名为 JACoB (Just Another Coding Bot),已从概念阶段转变为生产就绪的编程助手。开源公告以及关于 JACoB 能力的详细演示引发了广泛关注,更多详情请访问 jacb.ai。 -
回顾 JACoB 的起源:在 JACoB 重大发布之后,
@momentnerd引用了 23 年 6 月的一篇帖子,为项目的历程提供了背景和连续性。遗憾的是,链接缺失,让读者对 JACoB 的起源感到好奇。
提到的链接:
- SkillForge V1:Agent IX 很快将拥有一个技能库。可以作为工具和组件使用的简单 Python 函数。我正在开发一个生成技能的 SkillForge Agent…
- 体验编程的未来 - 观看 AI 编程机器人 JACoB 自主构建其主页:介绍 JACoB:Just Another Coding Bot。实时观看 JACoB 通过 Figma 和 GitHub 之间的无缝集成构建自己的主页。这不仅仅是…
- JACoB - Just Another Coding Bot:未找到描述
-
[ OranScribe - Write, Flow, and Grow Product Hunt](https://www.producthunt.com/posts/oranscribe):OranScribe 是一个内容创作平台,提供无缝的写作体验。从构思到最终输出,均由 AI 驱动的流程完成。 - ColBERT & LangChain’s Symphony with RAGatouille:重新定义 AI 交互
LangChain AI ▷ #tutorials (3 条消息):
-
面向学生的多用户 RAG 聊天机器人:
@rito3281深入探讨了 Multitenancy(多租户)的概念,旨在为来自不同部门的学生构建一个量身定制的多用户 RAG 聊天机器人,并使用 Langchain 框架和 Qdrant Vector Database 确保数据隐私和安全。他们的 博客文章 分享了详细的探索和指南,解释了如何在 Qdrant DB 中设置多租户,使学生查询具有部门针对性。 -
赋能 AI 开发者:
@lhc1921推荐了一个名为 “AI Development - The Monthly Dev #37” 的 YouTube 视频,展示了一个由 daily.dev 提供的平台,世界级演讲者在此通过他们的见解赋能开发者社区。 -
开源 LLM 的 Prompt Engineering 见解:
@juanpablomesa强调了 Mistral-7B-Instruct-v0.1 和 Llama-2-7b-chat-hf 等开源 LLM 与 GPT-3.5 和 GPT-4 等闭源模型在 prompt engineering 方面的差异。他们的 博客摘要 强调了在开源 LLM 中进行有效 prompt engineering 所需的独特方法,正如 Sharon Zhou 博士所详细描述的那样。
提到的链接:
- How to structure your API prompt calls for Open-Source LLMs:探索如何针对 Mistral-7B 和 Llama-2-7b 等开源 LLM 进行提示,并与 GPT-3.5 和 GPT-4 进行对比,包含实际代码示例。
- AI Development - The Monthly Dev #37:The Monthly Dev 每月一次邀请世界级演讲者来赋能开发者社区。由 daily.dev 倾情打造。议程:我们很高兴宣布我们的…
- Building a multi-user RAG chatbot in Langchain using Qdrant’s Multite:在本博客中,我们将为学生创建一个多用户 RAG 聊天机器人。该机器人可供各系学生咨询与其特定领域相关的话题。对于…
LlamaIndex ▷ #blog (2 条消息):
-
LlamaIndex 宣布与 @replit 合作推出悬赏任务:LlamaIndex 已与 @replit 合作,提供 2,000 美元的悬赏金,用于构建专注于高级 RAG (Retrieval-Augmented Generation) 的开源模板。点击 此处 查看此合作机会。
-
使用 LlamaIndex 探索 RAG - @CobusGreylingZA 的客座文章:最新的客座文章讨论了使用 Agent 通过 RAG 处理复杂查询,展示了跨大量文档的多 Agent 协作和 Chain-of-Thought 推理,并采用了来自 @cohere 的 re-ranking 功能。点击 此处 发现更多见解。
LlamaIndex ▷ #general (37 messages🔥):
-
Embedding 微调咨询:
@balanp询问在进行 Embedding 微调时,是否应将 textnode 中的元数据和文本都与问题配对以形成数据点。讨论演变为 LlamaIndex 中 文本字段和元数据键 中的数据是否都会被转换为向量 Embedding。 -
将 CSV 转换为 JSON 以进行微调:
@balanp寻求关于将包含问题和相关上下文列的 CSV 文件转换为适用于 LlamaIndex Embedding 微调的 JSON 文件的指导。kapa.ai 为其提供了一个用于将 CSV 转换为所需 JSON 格式的 Python 代码片段。 -
使用 Hugging Face 模型进行微调:对话涵盖了在 LlamaIndex 环境中微调 Hugging Face Embedding 模型的可行性,包括指定模型 ID 和传递 tokenizer 参数。
@balanp有兴趣使用"intfloat/e5-mistral-7b-instruct"进行微调,以及如何 处理max_length参数。 -
查询引擎集成挑战:
@balanp还询问了如何将微调后的 PyTorch 和 Hugging Face 模型集成到 LlamaIndex 的SubQuestionQueryEngine中,寻求在该引擎中使用其 微调后的 Embedding 模型 的方法。 -
AWS Sagemaker 与本地数据库连接:
@refik0727询问了关于使用 Llama 配合 AWS Sagemaker 以及使用 CSV 文件构建聊天机器人或直接连接到本地数据库的教程或 GitHub 代码示例。其他用户如@shinji3046询问了关于 llama packs 及其与 Mistral 等开源模型兼容性的通用问题,而@a3lita报告了在使用特定的 llamapack 并托管在 Streamlit 上对复杂 PDF 进行 RAG 时出现 空响应 的问题。
LlamaIndex ▷ #ai-discussion (1 messages):
andysingal: 幻觉排行榜 (hallucination-leaderboard)。https://github.com/vectara/hallucination-leaderboard
LAION ▷ #general (17 messages🔥):
- 战锤 40k AI 生成预告片令人印象深刻:
@max_voltage分享了一个名为 Imperium Of Man - Warhammer 40k 的粉丝制作预告片,强调了其对 AI 生成工具的出色运用。该视频可在 此处 观看,它利用各种 AI 工具创建了令人印象深刻的展示,特别指出 0:54 处的火焰和爆炸是亮点。 - 关于 AI 视频生成工具的见解:
@pseudoterminalx和@astropulse的讨论笔记强调了 AI 生成的内容尽管偶尔会有恐怖谷效应,但展示了良好的时间一致性(temporal consistency),并具有在电影和电视节目提案中的潜在用途。一个值得注意的评论提到,为每一帧使用相同的种子(seed)会导致独特的残留噪声,类似于“透过某种扭曲的玻璃看世界”。 - AI 模型引发褒贬不一的反应:讨论转向特定的 AI 模型,
@pseudoterminalx分享了一张由 Terminus 生成的图像,引发了对其能力和局限性的反思。该帖子提供了一个视觉效果 链接,强调了非凡的结果有时如何凸显训练数据集的缺陷。 - 关于 DALL-E 2 - PyTorch 与 Stable Diffusion 的咨询:
@homie115寻求关于 DALL-E 2 - PyTorch 与 Stable Diffusion 之间对比的见解,询问 AI 图像生成工具的改进和当前地位。 - AI 社区的技术请求与模型讨论:用户询问实际应用和技术设置——从使用 OCR 模型提取文本(
@twoabove寻找丢失的链接)到优化 WhisperSpeech 以进行流式音频(@normilkyway请求设置帮助),以及关于 CLIP 模型训练条件的讨论(@kal2296质疑在有/无图像变换的情况下训练模型的可行性)。
提到的链接:
Imperium Of Man - Warhammer 40k:Imperium Of Man - Warhammer 40k 是由 JustMovies 制作的粉丝(非官方)预告片,使用了各种 AI 生成工具制作。最初作为一个项目…
LAION ▷ #research (17 messages🔥):
- 推出用于高效 LVLMs 的 MoE-LLaVA:
@nodja分享了一篇 arXiv 论文,介绍了 MoE-tuning 和 MoE-LLaVA 框架,旨在通过在部署期间仅激活 top-k 专家来提高 Large Vision-Language Models (LVLMs) 的效率。该策略允许构建具有大量参数但计算成本恒定的稀疏模型。 - MoE-LLaVA 在 Hugging Face 上展示:随后,
@nodja还重点介绍了 MoE-LLaVA 模型在 Hugging Face 平台上的实现,邀请社区直接探索。 - CodeLlama 70b 伦理预防措施带来的挑战:
@Ivannius介绍了 CodeLlama 70b Instruct 版本,指出其令人印象深刻的 humaneval 分数,但也提到了它倾向于进行不必要的说教。他建议使用特定指令来绕过模型的伦理准则,以便进行更直接的代码生成任务,该模型可在 Hugging Face 上获取。 - InternLM-XComposer 在图像描述方面表现出色:
@mkaic称赞了 InternLM-XComposer 在所有测试过的开源 Vision-Language Models (VLMs) 中提供了最佳的描述(caption),特别强调了它能够注意到天花板上的通风口等细节,该模型在 Hugging Face 上展示。 - MAGBIG:一个新的多语言文本生成图像基准:
@felfri_分享了 MAGBIG,这是一个新提出的用于评估多语言文本生成图像模型的基准,鼓励社区使用和分享。该数据集旨在促进更广泛语言范围内的模型开发和评估。
提到的链接:
- MoE-LLaVA: Mixture of Experts for Large Vision-Language Models:对于 Large Vision-Language Models (LVLMs),扩展模型规模可以有效提高性能。然而,扩大模型参数会显著增加训练和推理成本,因为所有…
- InternLM XComposer - a Hugging Face Space by Willow123:未找到描述
- MoE LLaVA - a Hugging Face Space by LanguageBind:未找到描述
- codellama/CodeLlama-70b-Instruct-hf · Hugging Face:未找到描述
- felfri/MAGBIG · Datasets at Hugging Face:未找到描述
DiscoResearch ▷ #disco_judge (1 messages):
huunguyen: <@213644857309134849> - 英文版的 prometheus mistral 模型有进展吗?
DiscoResearch ▷ #general (21 条消息🔥):
-
德语 Orca DPO 数据集讨论:讨论集中在 德语 Orca DPO 数据集 的存在和准备上。
@johannhartmann分享了一个 Hugging Face 数据集,并提到了用于翻译的 azureml 和 hermeo 工具。@_jp1_暗示正在处理一个原始数据集,并打算将其开源,以改进德语模型的训练。 -
数据增强和翻译方法:Bjoernp 讨论了一种由 Apple 提出的新型数据增强技术 —— Web Rephrase Augmented Pre-training (WRAP),该技术在一篇 研究论文 中被强调,展示了在预训练效率方面的显著提升。
-
DiscoLM German 7b 和 GermanRAG 数据集发布:
@rasdani宣布发布 DiscoLM German 7b,并分享了 GermanRAG 数据集 的 Hugging Face 链接,该数据集用于微调模型的检索增强生成(RAG)能力。他们强调了该数据集在具有多样化上下文和完整表述答案的 RAG 微调中的实用性。 -
Philipmay 发布用于 RAG 微调的新公共数据集:
@philipmay介绍了一个使用 GPT-4 生成的用于 RAG 微调的新数据集,包含 124,961 个德语的上下文、问题和答案对。他提到正在添加“被拒绝”(rejected)的答案,以便将其转换为 DPO 数据集,该数据集可在 GitHub 上获取。 -
Code Llama 70B 发布和 Llama Factory 讨论:简要强调了 Meta 发布 Code Llama 70B 以及 Llama 3 的预热,并附带了 Twitter 链接。此外还有关于遵循 llama_factory readme 中超参数设置的通用建议的对话,但没有针对 phi-2 的具体细节。
提到的链接:
- Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling:大语言模型是在海量的网页抓取数据上训练的,这些数据通常是无结构的、有噪声的且表述不清的。目前的缩放定律(scaling laws)表明,从这类数据中学习需要大量的…
- 来自 kache (yacine) (KING OF DING) (@yacineMTB) 的推文:天哪,这是真的 ↘️ 引用 AI at Meta (@AIatMeta):今天我们发布了 Code Llama 70B:这是我们用于代码生成的 LLM 的一个性能更强的新版本 —— 在相同的许可下可用…
- DiscoResearch/germanrag · Hugging Face 数据集:未找到描述
- mayflowergmbh/intel_orca_dpo_pairs_de · Hugging Face 数据集:未找到描述
- aari1995/ultradistil-intel-orca-dpo-de · Hugging Face 数据集:未找到描述
DiscoResearch ▷ #embedding_dev (3 条消息):
-
Simon Willison 深入探讨 ColBERT 的奥秘:
@jp1分享了 Simon Willison 的一篇见解深刻的文章,探讨了 ColBERT。这是一种挑战标准 Embedding 方法的模型,它允许可扩展的基于 BERT 的搜索。与通常为每个文档存储单个向量的 Embedding 模型不同,ColBERT 存储多个向量,从而实现更细致的检索。 -
BGE_M3:多语言奇迹亮相:
@sebastian.bodza介绍了 BGE_M3,这是一种新的多语言模型,它将稠密检索模型与稀疏和多向量方法(如 ColBERT)相结合。其开发细节在 GitHub 上有详细说明。 -
BGE-large 用户的专业提示:
@sebastian.bodza还为 BGE-large 用户提供了一个关键更新,建议在 short2long 检索查询中包含提示词(prompt),以显著增强性能。
提到的链接:
- Exploring ColBERT with RAGatouille:我一直在试图理解 ColBERT。
- FlagOpen/FlagEmbedding 仓库中的 BGE_M3:稠密检索和检索增强型 LLM。通过在 GitHub 上创建一个账号来为 FlagOpen/FlagEmbedding 的开发做出贡献。
DiscoResearch ▷ #discolm_german (1 messages):
- DiscoLM German 7b v1 发布: 用户
@ustoll寻求 DiscoLM German 7b v1 的部署建议,这是一个基于 Mistral 的模型,专注于德语应用,是 EM German 模型系列的继任者。他们询问了类似于 together.ai 或 anyscale 的低门槛服务来部署该模型。
提到的链接:
DiscoResearch/DiscoLM_German_7b_v1 · Hugging Face: 未找到描述
Latent Space ▷ #ai-general-chat (21 messages🔥):
-
Stable Diffusion 在 VFX 职位中备受关注:
@swyxio强调了 Stable Diffusion 技术在 VFX 职位描述中的整合,并链接到了 @venturetwins 的一条推文,内容关于 Netflix 旗下的一家大型 VFX 工作室正在扩展 AI 角色。讨论继续,@coffeebean6887分享了 Eyeline Studios 的招聘启事,详细说明了对生成式成像和 Machine Learning 专业知识的需求,以彻底改变叙事方式。 -
LLM 响应的延迟挑战:
@austintackaberry对在不寻求复杂 LLM 响应时所经历的额外延迟表示沮丧,特别是当直接链接没有被及时突出显示时。 -
对未来职位要求的调侃:
@guardiang开玩笑地表达了对未来职位公告要求多年 Stable Diffusion 和/或 Midjourney 经验的担忧,反映了快速演变的 AI 领域及其对就业标准的影响。 -
关于 LLM 训练效率的创新论文:
@swyxio分享了 Quentin Anthony 的一篇新论文,内容关于优化 Transformer 模型训练的硬件利用率,敦促转变思维方式,通过 GPU kernel 调用的视角来看待模型,以减少低效。 -
Codeium 完成 B 轮融资:
@swyxio庆祝 Codeium 晋升 B 轮融资,并向团队表示祝贺,包括一条记录这一成就的推文。Codeium 的@.prem确认了这一里程碑,并强调了对公司发展的兴奋。
提到的链接:
- Justine Moore (@venturetwins) 的推文: Netflix 旗下的一家大型 VFX 工作室正在招聘一系列 AI 角色:生成式成像、工作流设计、模型训练、数据获取,甚至包括 ML 研究员。我们将看到…
- Quentin Anthony (@QuentinAnthon15) 的推文: 在训练 Transformer 时充分利用硬件,需要将模型视为一系列 GPU kernel 调用。这种在 HPC 中常见的思维方式在 ML 中却很少见,并导致了低效…
- Scanline VFX - 研究科学家,计算机图形学、计算机视觉和机器学习: 作为高级研究科学家,你将开发新技术来彻底改变真人内容的创作和叙事。你将在计算机视觉和计算机图形学领域进行应用研究…
Latent Space ▷ #llm-paper-club (2 messages):
-
新的 Pythia 论文揭示了被许多人忽略的 20% 加速:
@swyxio分享了来自 BlancheMinerva 的推文 的见解,关于一种关键的硬件感知(hardware-aware)设计,可以为 2.7B LLMs 带来 20% 的吞吐量提升。这一调整由于盲目复制 GPT-3 的架构而被忽视,详情已在论文 arXiv:2401.14489 中披露。 -
AI 和 NLP 影响力资源精选列表:
@ivanleomk在 Twitter 上发现了一个详尽的列表,其中包含 AI 和 NLP 领域的里程碑式资源,包括 The Annotated Transformer、The Unreasonable Effectiveness of RNNs 以及更多有助于理解 AI 模型及其公式化的关键读物和论文。该集合对于那些希望深化 AI 和 NLP 知识的人来说是一个宝贵的起点。
提到的链接:
- Ilya 30u30:
- 来自 Stella Biderman (@BlancheMinerva) 的推文: 你是否因为复制 GPT-3 而错失了 2.7B LLMs 20% 的加速?我曾因此错失了三年。在我的最新论文中了解原因以及如何以硬件感知的方式设计你的模型…
Alignment Lab AI ▷ #general-chat (3 messages):
- 宣布推出 Lilac Garden:
@nikhil_thorat宣布了 Lilac Garden,这是一个基于 Lilac 构建的用于加速数据集转换的新型云服务,首个服务是以 LLM 为驱动的聚类。该公告发布在 Twitter 上。 - Lilac 托管 OpenOrca 数据集:作为 Lilac Garden 发布的一部分,整个 OpenOrca 数据集(包含预计算的 Embedding 和聚类)现在已托管在 Lilac 上,可在此处获取。
- 探索 OpenOrca 聚类:
@nikhil_thorat分享了一个直接链接,用于在 Lilac 上探索 OpenOrca 数据集中的聚类,为用户提供了关于如何导航数据集聚类的详细视图。
提到的链接:
Alignment Lab AI ▷ #looking-for-workers (1 messages):
- 圣路易斯华盛顿大学初创公司寻找创始工程师:
DoubleMint宣布了一项与圣路易斯华盛顿大学合作的初创项目,正在寻找一位精通 Next.js 的创始工程师。随着第一份价值 50,000 美元的意向书(LOI)签署,他们渴望扩大规模,并且对拥有 TailwindCSS 和 Supabase 相关技能的人才也很感兴趣。
LLM Perf Enthusiasts AI ▷ #general (2 messages):
-
简短的感谢:用户
@an1lam表达了简单的感谢:“Thanks!” -
关于 Gemini Pro 生产环境应用的咨询:
@res6969询问是否有人在生产环境中对 Gemini Pro 进行过实验,寻求这些实验的见解或结果。
AI Engineer Foundation ▷ #general (1 messages):
- 为 AI Engineer Foundation 征集 Open Source 项目:用户
@hackgoofer呼吁@everyone分享并推荐加入 AI Engineer Foundation 的 Open Source 项目。为感兴趣的各方分享了 项目提交指南。
提到的链接: