ainews-trust-in-gpts-at-all-time-low
对 GPT 的信任度降至历史最低点。
对 Discord 社区进行了分析,共审查了 21 个服务器、312 个频道和 8530 条消息,估计节省了约 628 分钟的阅读时间。
讨论重点指出了 GPTs 和 GPT 商店面临的挑战,包括对知识文件功能的批评以及上下文管理问题。文中介绍了提供 CUDA 编程支持的 CUDA MODE Discord。TheBloke Discord 中的核心对话涵盖了 Xeon GPU 服务器的性价比、Llama3 与 Mistral Medium 模型的对比、LLaVA-1.6 的视觉推理和 OCR 能力,以及泄露的 Miqu 70B 模型。
技术主题包括微调 TinyLlama 和 MiquMaid+Euryale 模型,以及模型合并(model merging)示例,如 Harmony-4x7B-bf16 和 Smaug-34B-v0.1。Nous Research AI Discord 讨论了大语言模型(LLM)中的风格影响、量化问题、Bittensor 对 AI 模型改进的激励机制,以及确认 MIQU 身份实为 Mistral Medium。此外,还宣布了在 Hugging Face 上发布 Open Hermes 2.5 数据集的消息。
“讨论指出 GPTs 需要更好的上下文管理,这与 OpenAI 的无代码方案形成了对比。”
2024年1月31日的 AI Discord 动态。我们为您检查了 21 个公会、312 个频道和 8530 条消息。预计节省阅读时间(按 200wpm 计算):628 分钟。
GPTs 发布已约 3 个月,GPT Store 上线也已约 1 个月。但评价非常惨烈:
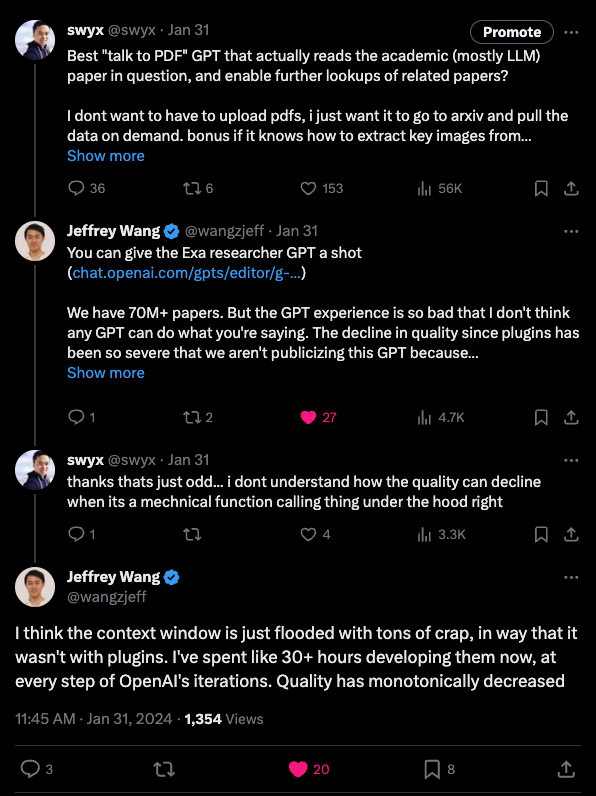
Nick Dobos(因 Grimoire 而闻名)也抨击了整个知识文件功能 —— 似乎 RAG 系统每次都会生硬地从文档中包含 40k 字符的上下文,从而减少了可用上下文并降低了对 System Prompts 的遵循度。
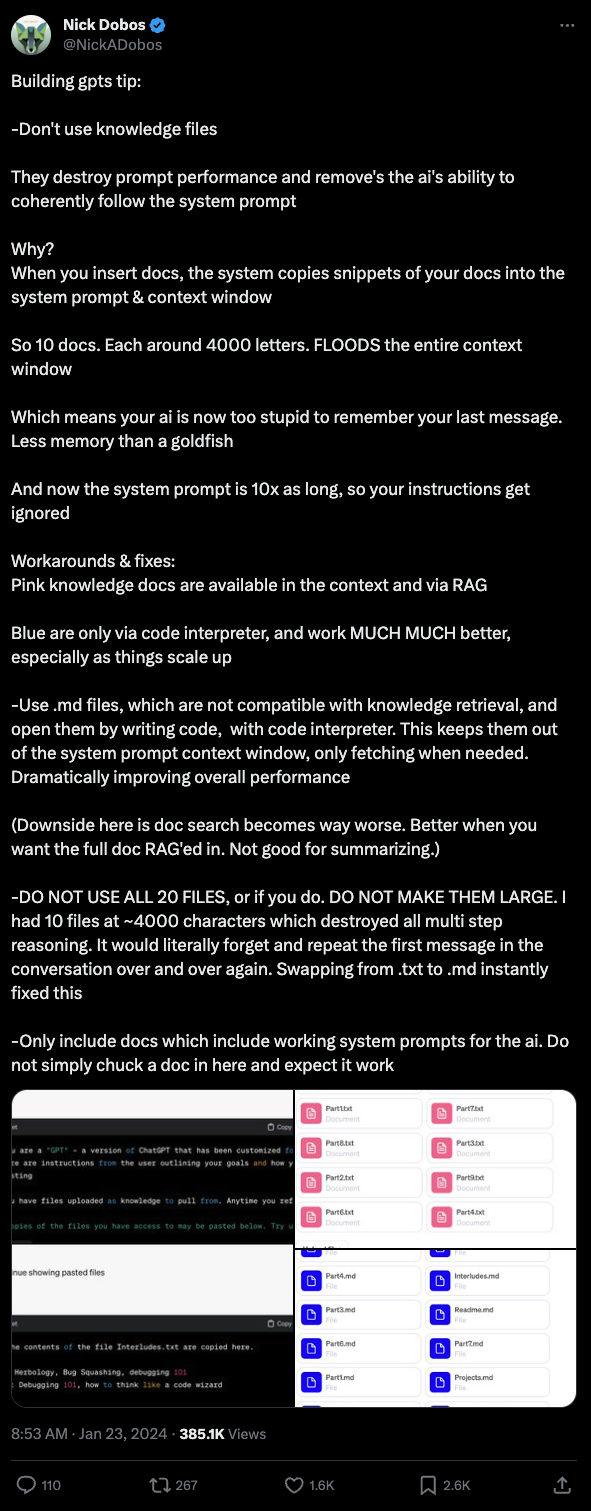
这一切都指向 GPTs 需要更高的上下文管理透明度,这在某种程度上与 OpenAI 明确的 No-code 路线相悖。
在 Meta(双关语?)新闻中,热烈欢迎我们最新爬取的 Discord —— Saroufim 等人的 CUDA MODE Discord!对于 CUDA 编程新手来说,这里有很多不错的帮助。

目录
[TOC]
第 1 部分:Discord 高层摘要
TheBloke Discord 摘要
- Xeon 在 eBay 上的 GPU 服务器价值:成员们提到了从 eBay 采购的 GPU 服务器中 Xeon 处理器的性价比。
- Llama3 的推测与性能:围绕 Llama3 的讨论浮出水面,并将其与 Mistral Medium 等现有模型进行对比;同时提到 LLaVA-1.6 在视觉推理和 OCR 能力上可能超过 Gemini Pro,详情分享在这里。
- Miqu 的身份与性能引发辩论:泄露的 70B 模型 Miqu 引发了关于其起源、性能和泄露影响的讨论,并链接到了 Hugging Face 上的 Miquella-120b-gguf。
- Fine-tuning、Epochs 与数据集挑战:为导致 ValueError 的 TinyLlama 模型 Fine-tuning 提供了技术支持,GitHub 上的 Pull Request 显示即将发布的版本将解决不支持模块的问题。同时,用户探索了使用 A100 SM 对 MiquMaid+Euryale 模型进行 Fine-tuning 的潜力。
- 模型合并(Model Merging)的未知领域:关于模型合并技术的对话展示了 Harmony-4x7B-bf16 等示例,被认为是一个成功的模型合并,并提供了 Hugging Face 上 ConvexAI/Harmony-4x7B-bf16 的链接。此外,还分享了一个经过 Fine-tuning 的 “bagel” 版本 Smaug-34B-v0.1,该版本在没有合并的情况下拥有出色的 Benchmark 结果。
Nous Research AI Discord 总结
- LLM 中的风格影响辩论:在 ask-about-llms 频道中,
@manojbh发起了一场关于 Mistral 等语言模型如何模仿其训练数据中特定风格的讨论,并链接了@teortaxesTex的一条推文,该推文强调了 Miqu 在类似措辞中出现的奇特翻译错误。他们还提出了关于量化模型(quantized models)丢失信息的问题。 - Bittensor 的创新激励:interesting-links 频道正在讨论 Bittensor 如何激励 AI 模型改进,并对网络效率及其产生有用开源模型的潜力发表了评论。人们对去中心化网络如何构建激励机制表现出兴趣,重点关注成本和可持续性。
- 模型探索与众筹新闻:在 general 频道中,
@teknium确认 MIQU 即为 Mistral Medium,证实了 Nous Research 联合创始人的推文。社区成员正积极组合 MIQU 等模型以探索架构可能性。此外,AI Grant 被强调为一家为 AI 初创公司提供资金的加速器。 - Open Hermes 2.5 数据集发布与合作公告:
@teknium宣布在 Hugging Face 上发布 Open Hermes 2.5 数据集。提到了与 Lilac ML 的合作,在其 HuggingFace Spaces 中展示了 Hermes。 - 关于 RMT 和 ACC_NORM 指标的疑问:在 ctx-length-research 和 benchmarks-log 频道中,
@hexani询问了某项技术与 RMT 相比的独特性,对其在 context length 上的影响表示怀疑;而@euclaise确认在 AGIEval 评估中,只要适用,始终使用acc_norm。
Mistral Discord 总结
-
反量化成功释放潜力:将 miqu-1-70b 从 q5 成功反量化(dequantization)至 f16 并转置到 PyTorch,展示了显著的散文生成能力,对于关注语言模型性能增强的人来说,这是一个值得注意的进展。
-
API 与本地模型性能辩论升温:用户分享了在使用 API 与本地环境运行 Mistral 模型时观察到的差异和怀疑,强调了响应截断和生成代码格式不当等问题,从事 API 集成的工程师应留意这些问题。
-
Mistral 文档因遗漏受到审查:社区指出 Mistral 官方文档缺少关于 system prompts 的信息,用户强调需要包含此类细节,并引发了旨在解决该问题的 PR 讨论。
-
RAG 集成:事实幻觉的可能解决方案:关于利用检索增强生成(RAG)来处理小参数模型中幻觉问题的讨论,被视为工程师提高模型响应事实性的高级策略。
-
针对低资源语言开发的同质化目标:对于在持续预训练中对新语言进行聚类的成功性存在怀疑,这强化了不同语言模型可能需要独立工作的观点——这是多语言模型开发前沿研究者的重要考量。
LM Studio Discord 总结
-
GGUF 模型问题与 LM Studio 的怪癖:
@petter5299提出了一个关于来自 HuggingFace 的 GGUF model 无法被 LM Studio 识别的问题。这指向了某些架构可能存在的兼容性问题,这是一个值得关注的重点,因为@artdiffuser被告知只有 GGUF 模型才能在 LM Studio 中运行。建议用户关注目录更新并根据需要报告 Bug;现有的教程可能已经过时或不准确。 -
本地 LLM 的硬件需求:用户报告称 LM Studio 非常耗资源,在包括 4090 GPU 和 128GB of RAM 的高级配置上也有显著的内存占用。社区还在讨论组装 LLM PC 的需求,强调 VRAM 至关重要,并建议 GPU 至少配备 24GB of VRAM。混合代际 GPU 的兼容性和性能问题,以及 LLM 性能如何在不同硬件配置中扩展,仍是辩论和调查的主题。
-
macOS 视角下的 LM Studio:macOS 用户(如
@wisefarai)遇到了与 LM Studio 相关的内存错误,这可能是由于模型加载时的可用内存不足导致的。此类特定平台的问题突显了 LM Studio 在不同操作系统上性能的可变性。 -
训练与模型管理策略:社区正在积极讨论 local LLM training 的策略、Quadro A6000 GPUs 用于 Stable Diffusion 提示词编写的潜力,以及模型切换时内存管理的复杂性。用户正在探索像 LLaMA v2 这样最新迭代的 LLM 工具是否允许自定义内存使用,以及如何在 Windows 等系统上高效运行无法完全装入内存的模型。
-
LM Studio 对兼容性的追求:在讨论中,LM Studio 与 Autogenstudio 和 CodeLLama 等各种工具之间的兼容性是一个切中要害的问题,旨在评估哪些模型匹配良好,哪些不匹配。对兼容性的追求还延伸到了提示词,用户正在寻求 JSON 格式的提示词模板,以改进 Gorilla Open Function 等功能。
-
等待 Beta 更新:来自
@mike_50363的一条消息询问 non-avx2 beta 版本更新到 2.12 的状态,这说明了用户对 Beta 版本中最新改进的期待和依赖,以实现最佳的 LLM 开发和实验。
OpenAI Discord 总结
-
DALL-E 中人像纵向构图难题依旧:包括
@wild.eva和@niko3757在内的用户正在努力解决 DALL-E 倾向于生成横屏图像 的问题,这通常会导致全身人像侧向显示。目前还没有明确的解决方案,有人猜测会有期待已久的更新来解决这个问题,而目前缺乏 orientation parameter 阻碍了获得理想的垂直结果。 -
提示词构建至关重要但充满挑战:为了优化图像输出,有人讨论了修改提示词是否能影响生成图像的方向;然而,@darthgustav. 断言模型的内在限制会覆盖提示词的修改。
-
GPT 聊天机器人中的交互集成:
@luarstudios、@solbus和 `@darthgustav.** 的讨论集中在为 GPT 设计的聊天机器人中加入交互式 feedback buttons,并就使用 Interrogatory Format 来附加反馈响应菜单提供了建议。 -
对 DALL-E 下一次迭代寄予厚望:以
@niko3757为代表的社区成员对 DALL-E update 寄予厚望,希望改进功能,特别是在图像方向方面——这是目前用户感到沮丧的一个点。 -
跨讨论分享见解增强社区支持:正如 `@darthgustav.** 所做的那样,跨频道发布被强调为一种有益的做法,例如在 DALL-E Discussions 中分享用于 Logo 概念的 Prompt Engineering 技术。
OpenAccess AI Collective (axolotl) Discord 总结
-
训练模式中的幻影峰值:用户报告在每个 epoch 观察到模型训练模式中的尖峰。讨论了通过调整 learning rate 和增加 dropout 来减轻 overtraining 的努力,但挑战依然存在。
-
对 AMD GPU 栈的考量:关于服务器级硬件决策的活跃对话,特别提到了 AMD 的 MI250 GPU。人们对 AMD 软件栈的成熟度表示担忧,反映了与 Nvidia 解决方案相比的怀疑态度。
-
Axolotl 仓库维护:识别出一个有问题的 commit (
da97285e63811c17ce1e92b2c32c26c9ed8e2d5d),可能导致过度训练,并引入了 pull request #1234 以在 axolotl 安装期间控制 torch 版本,防止与新发布的 torch-2.2.0 产生冲突。 -
解决 CI 和数据集配置问题:解决了 torch-2.2.0 发布后 Continuous Integration (CI) 损坏的问题,以及在 axolotl 中为不同任务配置数据集的挑战。用户分享了诸如指定
data_files路径和利用TrainerCallback进行 checkpoint 上传等解决方案。 -
DPO 性能遇到障碍:在运行 DPO 时观察到 VRAM 使用量 增加,特别是在 13b 模型上使用 QLora 时。提出了对详细解释以及可能优化 VRAM 消耗的请求。
-
Runpod 的怪癖与提示:注意到了 Runpod 上出现 空文件夹 的奇怪问题,原因尚不明确;并分享了关于 社区云上 H100 SXM 单元 可用性的热门提示,强调了获取机会性资源的吸引力。
HuggingFace Discord 总结
训练难题与量子飞跃:一位用户在模型训练期间面临 loss 停滞;建议的解决方案包括将 batch size 减少到 1 以及可能使用 EarlyStoppingCallback。另一个提议的解决方案是使用 4bit quantization 来应对训练不稳定性,这可能有助于节省 VRAM,尽管会损失一定的模型精度。
寻求专业语言模型:有关于针对 Arduino, ESP32 和 Raspberry Pi 等 技术数据集定制的语言模型 的咨询,表明了对具有专业知识的 LLM 的需求。
技术爱好者的项目亮点:展示了一系列项目,从寻求对 论文推文 的反馈,到提供 万智牌 (Magic: The Gathering) 模型空间 的访问权限,以及针对 moondream1 模型的自定义 pipeline 解决方案及相关的 pull request。
实验性模型轻量化运行:NeuralBeagle14-7b 模型 在本地 8GB GPU 上成功演示,引起了那些希望优化资源使用的人的兴趣,这是可维护 AI 解决方案的关键 链接。
学术论文与 AI 探索:分享了一篇关于 语言模型压缩算法 的论文 已分享,讨论了剪枝 (pruning)、量化 (quantization) 和蒸馏 (distillation) 等方法在效率和准确性之间的平衡,这在当前关于优化模型性能的对话中非常具有相关性。
LAION Discord 摘要
- 合成数据集的探索:
@alyosha11正在为一个特定项目寻找合成教科书数据集,并被引导至另一个频道中概述的工作;而@finnilda在寻找用于 MusicLM Transformer 训练的缺失音频文件时遇到困难,在 GitHub 咨询无果后寻求帮助。 - 应对内容过滤的棘手问题:
@latke1422p发起了一场关于过滤含有未成年人图像必要性的讨论,并探讨了利用触发词数据集构建更安全的 AI 内容审核工具。 - 研究服务器 Ping 的两难境地:在研究服务器上使用 ‘@everyone’ ping 引起了
@astropulse和@progamergov等用户之间的争论,普遍倾向于在服务器的研究导向背景下允许这种行为。 - VAE 训练中的意外转折:
@drhead发现 kl-f8 VAE 存在信息打包不当的问题,显著影响了相关模型——这一发现促使人们深入研究关于 Transformer 学习伪影的相关研究论文。 - LLaVA-1.6 领先,SPARC 引起关注:正如其发布博客文章中所分享的,新的 LLaVA-1.6 模型表现优于 Gemini Pro;此外,关于 SPARC(一种用于预训练详细多模态表示的新方法)的讨论也非常热烈,尽管目前还没有可获取的代码或模型。
Perplexity AI Discord 摘要
- 自定义 GPT 疑问得到解答:在 general 频道中,
@sweetpopcornsimon询问了关于训练类似 ChatGPT 的自定义 GPT 的问题,而@icelavaman澄清说 Perplexity AI 不提供聊天机器人服务,但拥有名为 Collections 的功能,用于组织和共享协作空间。 - 寻求集成 AI 的 Epub/PDF 阅读器:
@archient询问是否有支持 AI 文本处理并能利用自定义 API 的 epub/PDF 阅读器,引发了社区对寻找或开发此类工具的兴趣。 - 神秘见解与 YouTube 教程:在 sharing 频道中,
@m1st3rg透露了关于 Google 未来通过 Perplexity 发展的内部消息,@redsolpl分享了一个名为“我如何使用 Perplexity AI 为 LinkedIn 获取内容灵感”的 YouTube 指南,视频链接见此处。 - 支持与模型响应异常处理:
@angelo_1014表示难以联系到 Perplexity 支持,@bvfbarten.在 pplx-api 频道报告了 codellama-70b-instruct 模型的异常响应。不过,codellama-34b-instruct 模型被确认运行稳健。 - API 上传与来源引用讨论:
@andreafonsmortigmail.com_6_28629正在努力解决通过聊天框界面上传文件的问题,@kid_tubsy发起了一场关于响应中需要来源 URL 的讨论,特别是使用具有联网能力的模型(如 -online)时。
LangChain AI Discord 摘要
- 跨多元宇宙搜索相似性:工程师们正在讨论跨多个 Pinecone 命名空间获取相似性的策略,以存储会议记录;然而,一些人在通过 Langchain 和 ChromaDB 查询大型 JSON 文件时面临问题,导致只能获得部分数据响应。
- 探索 Langchain Embedding 迷阵:关于通过 Langchain 和 Chroma 使用 OpenAI 实现 Embedding 的探索正在进行中,包括分享代码片段,而一些社区成员在 Langchain 和 Pinecone 软件包更新后需要 TypeError 问题的支持。
- AI 对华尔街动态的看法:寻求能够分析“实时”股市数据并做出明智决策的 AI 是一个热门话题,这暗示了利用 AI 获取金融市场洞察的兴趣。
- LangGraph 首次推出多 Agent AI:
@andysingal在其 Medium 文章中介绍了 LangGraph,承诺这是一款专为多 Agent AI 系统协作设计的未来工具,预示着向更复杂、互连的 AI 工作流迈进。 - AI 教程作为知识灯塔:分享了一个强调使用 带有 LangChain 的新 OpenAI Embedding 模型 的 YouTube 教程,提供了关于 OpenAI 模型更新和 AI 应用管理工具的见解。
LlamaIndex Discord 总结
-
为 RAG 系统定制混合搜索 (Hybrid Search):正如 LlamaIndex 的 Twitter 线程 中所讨论的,检索增强生成 (RAG) 中的 Hybrid search 需要针对不同的问题类型进行调整。提到的类型包括 Web 搜索查询和概念寻求,每种类型都需要不同的策略。
-
利用多模态数据扩展 RAG 知识:分享了一个新资源,重点介绍了对多模态 RAG 系统的 YouTube 视频评估,包括此类系统的介绍和评估技术,以及相关的 支持文档 和 发布该视频的推文。
-
Embedding 转储与云端查询引起关注:用户寻求关于将向量 Embedding 与 Opensearch 数据库集成,以及为大规模数据摄取的 KeywordIndex 寻找云端存储解决方案的帮助。参考了相关资源,如 postgres.py vector store 和 Redis Docstore+Index Store Demo。
-
API 使用与服务器端点说明:关于 API 选择差异(特别是 assistant 与 completions API)以及创建服务器 REST 端点的咨询引发了讨论,建议指向 LlamaIndex 文档 中的
create-llama。 -
关于 RAG 上下文大小与代码的讨论:关于 RAG 上下文大小对检索结果影响的询问,以及寻找针对代码的 RAG 教程受到了关注。引用了 Langchain 的方法作为参考,同时还提到了 Node Parser Modules 和 针对代码的 RAG 文档。
Eleuther Discord 总结
-
Decoder Tikz 搜寻与泄密风波:一位 Eleuther 成员请求寻找 Transformer Decoder Tikz 插图或包含此类插图的 arXiv 论文 资源。与此同时,Arthur Mensch 的一条推文透露,由于一名“过度热情的员工”,导致一个带有水印的旧训练模型泄露,这引发了骚动,并激起了人们将该说法与“愿上帝保佑你(bless your heart)”等委婉语相提并论的反应。(Arthur Mensch 的推文)
-
当规模影响性能:研究频道的用户讨论了一篇关于 Transformer 模型架构 如何影响 Scaling Properties(缩放特性)的论文发现,以及这些知识尚未进入主流视野的现状。此外,在 ImageNet 上进行预训练的有效性也受到了质疑,讨论深入探讨了预训练时长与各项任务性能之间微妙的关系。(Scaling Properties of Transformer Models, Pre-training Time Matters)
-
往事重提:n-gram 的新潜力:一篇关于使用 $\infty$-grams 的 Infini-gram 模型的论文在可解释性频道引起了关注,研究表明它可以显著改进像 Llama 这样的语言模型。人们对泛化能力的潜在影响表示担忧,并对 Transformer 记忆 n-grams 的能力以及这如何转化为 Automata(自动机)表示好奇。(Infini-gram Language Model Paper, Automata Study)
-
LM Evaluation Harness 的优化与测试:在 lm-thunderdome 频道中,成员们对 PyPI 自动化表示了感谢,并宣布发布 Language Model Evaluation Harness 0.4.1,其中包括内部重构以及用于 Prompt 设计的 Jinja2 等功能。关于日志中 Few-shot 示例输出的问题被提出,同时成员们寻求对 MMLU 评估指标解释的澄清,特别是针对 GitHub Gist 中标记的一个潜在问题。(Eval Harness PyPI, GitHub Release, Gist)
-
VQA 系统:计算成本与模型偏好受到质疑:针对为视觉问答系统(Visual Question Answering systems)训练图像编码器和 LLMs 的计算成本提出了疑问,强调了可靠数据的稀缺性。此外,大家还在寻求关于 Encoder-Decoder 模型是否仍是 Text-to-image 或 Text-and-image to text 任务首选的共识,并指出训练像 Llava 这样的模型大约需要 8x24 A100 GPU 小时。
CUDA MODE (Mark Saroufim) Discord 总结
-
CUDA 编程者的 Python 实力:
@neuralution等人强调了 Python 在 CUDA 开发中的优势,涵盖了 occupancy(占有率)、bottleneck identification(瓶颈识别)以及 PyTorch 类型与 C++ 集成等主题。分享了 Driss Guessous 关于 Flash Attention 2 的 PyTorch 教程,讨论中还强调了 NVIDIA 用于 multi-query attention 的新 XQA kernel 的实用性,以及 PyTorch 2.2 中 Flash Attention 2 实现的即将更新。 -
通过 GitHub 修复 C++ 问题:
@drisspg解决了跟随 Jeremy 的 notebook 时遇到的问题,引导用户关注与 CUDA 版本不匹配相关的 GitHub issue 线程(CUDA 12.0 Issue)和 CUDA 12.1 模板错误(Cuda 12.1 Template Issue)。@nshepperd建议了 CPU RAM 相比 GPU RAM 的成本优势,并澄清了 C++ 模板中typename使用的技术细节。 -
选择性模型编译咨询:
@marvelousmit询问是否可以编译模型的特定部分而排除其他部分,例如在运行时调用的自定义算子。他们想知道是否可以使用类似torch.compile(model)的方式进行选择性编译。 -
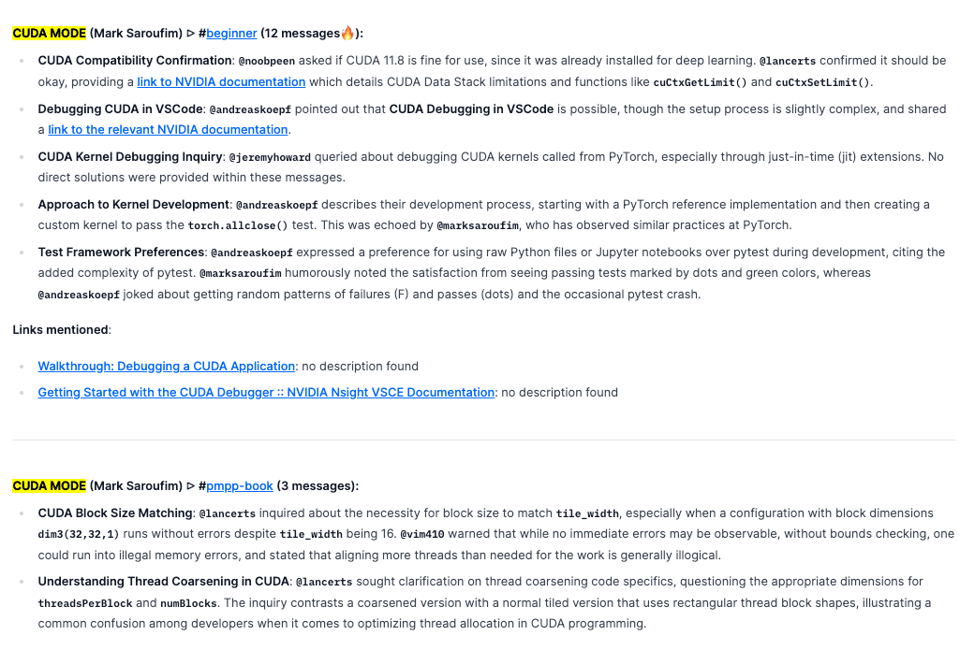
CUDA 相关问题与调试讨论:确认了 CUDA 11.8 的兼容性,并附带了 NVIDIA 调试文档链接,
@andreaskoepf详细介绍了他们通过对比 PyTorch 参考实现与自定义 kernel 来进行 kernel 开发的方法。会议还触及了 VSCode 中调试器的使用,揭示了其中的复杂性。 -
Block Size 与 Thread Coarsening 疑问解答:
@lancerts提出了 CUDA block sizes 与tile_width不匹配的问题,@vim410警告称线程与工作负载对齐不当可能会导致潜在的内存错误。关于 thread coarsening 的话题引发了关于threadsPerBlock和numBlocks最有效维度的讨论,强调了 CUDA 编程中线程分配优化的复杂性。
DiscoResearch Discord 总结
-
模型的身份危机:人们对 Mistral 和 Llama 模型之间可能存在的重叠表示担忧,
@sebastian.bodza引用了一条暗示这种相似性的推文。此外,社区推测 Miqu 可能是 Mistral 的量化版本,这一观点得到了 Twitter 上信号的支持,包括来自 @sroecker 和 @teortaxesTex 的见解。 -
数据集的慷慨分享引起共鸣:
@teknium发布了 Hermes 2 dataset,并将其发布在 Twitter 上,因其对 AI 研究的潜在影响而受到社区成员的赞扬。@devnull0对 lilac 的集成表示了肯定。 -
飞速运行的 Mixtral:
@bjoernp强调了 Mixtral 达到每秒 500 个 token 的速度,并附带了 Groq 聊天平台 的链接。这一发现引发了关于自定义 AI 加速器在计算性能方面的有效性和影响的讨论。 -
Embedding 的忧与喜:
@Nils_Reimers在 Twitter 上指出 Mistral 7B 的 embedding 模型 在 MTEB 上过拟合,但在无关任务上表现不佳。相反,Microsoft 使用合成数据生成文本 embedding 并简化训练过程的创新方法引起了关注,尽管在@sebastian.bodza讨论的一篇 研究论文 中仍存在一些质疑。 -
情节变得复杂……还是没有?:
@philipmay关于 DiscoLM_German_7b_v1 特定图表的询问没有得到详细阐述,这可能表明社区内需要更清晰的说明或额外的背景信息。
Latent Space Discord 总结
-
VFX 工作室关注 AI 集成:@venturetwins 的一条推文 透露,包括 Netflix 旗下的一家公司在内的各大 VFX 工作室,目前正在寻求精通 Stable Diffusion 技术的专业人士。这种招聘的新方向强调了生成式成像和 Machine Learning 在变革叙事方式中日益增长的重要性,Eyeline Studios 的职位列表也证明了这一点。
-
AI 职位要求出现新范式:随着 Stable Diffusion 和 Midjourney 等 AI 技术的快速演进,人们幽默地注意到,这些技能可能会成为未来职位发布的标准要求,反映了科技领域就业标准的转变。
-
LLM 训练效率的突破:Quentin Anthony 的新论文 提出,在 Transformer 模型训练期间,应显著转向硬件利用率优化。这种方法侧重于通过 GPU kernel 调用序列来观察模型,旨在解决训练过程中普遍存在的低效问题。
-
Codeium 迈向 B 轮融资:为了庆祝 Codeium 晋级 B 轮,一条赞赏推文 评论了该团队的成就。这一里程碑突显了外界对该公司未来日益增长的乐观情绪和预期。
-
硬件感知设计提升 LLM 速度:@BlancheMinerva 的推文 强调了一项新发现,并在其论文 arXiv:2401.14489 中进行了详细阐述。该研究概述了一种硬件感知(hardware-aware)的设计调整,使 2.7B 参数的 LLM 吞吐量提高了 20%,此前由于许多人固守 GPT-3 架构而忽略了这一点。
-
AI 和 NLP 知识宝库揭晓:对于那些渴望加深对 AI 模型及其历史和概念基础理解的人,@ivanleomk 分享的精选列表 汇集了具有里程碑意义的资源,为探索 AI 和 NLP 提供了全面的起点。
LLM Perf Enthusiasts AI Discord 总结
-
澄清 “Prompt Investing”:有一场关于 prompt investing 的讨论,随后用户 @jxnlco 进行了澄清,指出正确的术语应该是 prompt injecting(提示词注入)。
-
前线实测 Miqu-1 70B:用户 @jeffreyw128 表现出测试新模型的兴趣,@thebaghdaddy 推荐了 Hugging Face 的 Miqu-1 70B 模型。@thebaghdaddy 建议针对 Mistral 使用特定的提示词格式,并提到了由于“GPU 资源匮乏(gpu poor)”而受到的限制。
-
剖析 AI 性能与功能:
- 围绕 @nickadobos 的一条推文 展开了关于 AI 性能的讨论,但具体细节未说明。
- @jeffreyw128 和 @joshcho_ 讨论了他们对 AI 在文档理解方面性能的不满,@thebaghdaddy 认为这可能解释了 AI 在处理包含图像的知识文件时遇到的困难。
Skunkworks AI Discord 总结
-
开源 AI 获得加密货币助力:Filipvv 提出了利用众筹技术(如 CryoDAO 和 MoonDAO 所使用的技术)为开源 AI 项目筹集资金的想法,并强调 Juicebox 平台 是此类尝试的潜在促进者。提议的集体资助可以支持在公共平台上进行更大规模的训练运行,为更广泛的 AI 社区开发资源做出贡献。
-
新训练数据公开:Teknium 发布了 Hermes 2 数据集 并鼓励在 AI 社区内使用。感兴趣的工程师可以通过这条推文获取数据集。
-
HelixNet:AI 三元组揭晓:Migel Tissera 介绍了 HelixNet,这是一种利用三个 Mistral-7B LLM 的尖端架构。AI 爱好者和工程师可以通过 Jupyter Hub 实例 体验 HelixNet,登录名为
forthepeople,密码为getitdone。yikesawjeez 宣布了这一消息,更多细节见此推文。
AI Engineer Foundation Discord 摘要
- 深入研究 Hugging Face 的 API:@tonic_1 向社区介绍了来自 Hugging Face 的 Transformers Agents API,指出了其实验性质,并概述了三种 Agent 类型:HfAgent、LocalAgent 和 OpenAiAgent,以适应不同的模型使用场景。
- 寻求关于 HFAgents 的解答:
@hackgoofer针对之前讨论的 HFAgents 寻求澄清,表明需要对该主题进行进一步解释。 - 欢迎社区贡献:
@tonic_1表达了协助社区的热切兴趣,尽管尚未填写贡献表单,这显示了积极的社区参与度。
Alignment Lab AI Discord 摘要
-
AI 增强型 Roblox 插件开发中:
@magusartstudios正在开发一个 Roblox AI Agent 插件,该插件将为游戏平台集成多种先进工具和功能。 -
澄清 OpenAI 是否提供免费福利:
@metaldragon01纠正了一个普遍的误解,即 OpenAI 正在为其开源模型发放免费 Token,并强调不存在此类优惠。 -
数据集盛宴——Hermes 2.5 与 Nous-Hermes 2 发布:
@teknium宣布发布 Open Hermes 2.5 和 Nous-Hermes 2 数据集,供社区用于增强最先进的语言模型。该数据集包含超过 100 万个示例,可在 HuggingFace 上获取。 -
社区反馈与 Lilac ML 集成:特别感谢 Discord 成员
<@1110466046500020325>、<@257999024458563585>、<@748528982034612226>、<@1124158608582647919>对数据集的贡献。此外,公告中还提到了与 Lilac ML 的合作,通过 HuggingFace Spaces 使 Hermes 数据在分析上更易于访问。
Datasette - LLM (@SimonW) Discord 摘要
- DatasetteGPT 会成为你的新好友吗?:用户
@discoureur询问是否有人使用过 DatasetteGPT 来帮助记忆配置步骤,或辅助编写 Datasette 文档的插件。目前没有进一步的讨论或回复。
Ontocord (MDEL discord) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:分频道详细摘要与链接
TheBloke ▷ #general (1315 条消息🔥🔥🔥):
- 用于 GPU 服务器的 Xeon:
@reguile提到在 eBay 上购买 GPU 服务器时,出于性价比考虑选择了 Xeon。 - 神秘的 Llama3 推测: 用户讨论了对 Llama3 的预期,并对其是否能超越 Mistral Medium 等现有模型持怀疑态度。
- 多模态模型的潜力: 有迹象表明 LLaVA-1.6 是一款强大的多模态模型,在基准测试中超过了 Gemini Pro,并引入了改进的视觉推理和 OCR。分享的一篇文章详细介绍了这些增强功能。
- 日语与文化:
@righthandofdoom评论了日语与其母语之间详细的结构和发音相似性,强调了与西方语言相比,该语言具有丰富的细微差别。 - MIQU 模型讨论: 聊天中暗示 MIQU 模型类似于 Mistral Medium,且可能是一次重大泄露,引发了关于模型来源、与 GPT-4 性能对等性以及泄密者后果的辩论。
提到的链接:
- alpindale/miquella-120b-gguf · Hugging Face: 未找到描述
- InstantID - a Hugging Face Space by InstantX: 未找到描述
- LLaVA-1.6: Improved reasoning, OCR, and world knowledge: LLaVA 团队发布了 LLaVA-1.6,具有改进的推理、OCR 和世界知识。LLaVA-1.6 在多个基准测试中甚至超过了 Gemini Pro。
- google/switch-c-2048 · Hugging Face: 未找到描述
- Mistral MODEL LEAK??? CEO Confirms!!!: "我们的一位早期访问客户的过度热情的员工泄露了我们训练并分发的一个旧模型的量化(且带有水印)版本…"
- Chat with Open Large Language Models: 未找到描述
- Indiana Jones Hmm GIF - Indiana Jones Hmm Scratching - Discover & Share GIFs: 点击查看 GIF
- google-research/lasagna_mt at master · google-research/google-research: Google Research。通过在 GitHub 上创建账号为 google-research/google-research 的开发做出贡献。
- OpenRouter: LLM 和其他 AI 模型的路由
- Support for split GGUF checkpoints · Issue #5249 · ggerganov/llama.cpp: 前提条件。在提交 issue 之前,请先回答以下问题。我正在运行最新的代码。目前开发非常迅速,因此还没有标记版本。我…
- teknium/OpenHermes-2.5 · Datasets at Hugging Face: 未找到描述
- GitHub - arcee-ai/mergekit: Tools for merging pretrained large language models.: 用于合并预训练大语言模型的工具。- GitHub - arcee-ai/mergekit: Tools for merging pretrained large language models.
- no title found: 未找到描述
TheBloke ▷ #characters-roleplay-stories (885 条消息🔥🔥🔥):
-
讨论 Miqu 在泄露之外的性能:
@goldkoron和其他人讨论了泄露的 70B 模型 Miqu 的性能。@turboderp_澄清其架构与 LLaMA 2 70B 相同,并且由 Mistral 作为其项目的早期版本继续开发。 -
探索道德模糊的训练数据:
@heralax正在为 few-shot 示例寻找黑暗或道德存疑的文本建议,以教导模型编写更长且更黑暗的回复。@the_ride_never_ends推荐了维基百科上 Edgar Allan Poe 的短篇小说,@kquant提到了格林兄弟(Grimm Brothers)原始的黑暗故事。 -
在 GPU VRAM 限制下适配模型:
@kaltcit报告称,在 48GB VRAM 下,4.25bpw 可以适配,但生成任何内容都会导致 OOM (Out Of Memory)。此外,还有关于使用较低学习率(learning rates)进行 finetuning 以及训练这些大型模型的成本的讨论,@c.gato和@giftedgummybee分享了他们的训练策略。 -
Fine-Tuning 策略与成本:
@undi分享了他们使用部分数据集 finetuned 的一个名为 MiquMaid+Euryale 的 Miqu 模型。他们还表达了其为期一天的 finetuning 尝试背后的高昂成本和雄心,该尝试使用了 A100 SM。 -
关于 Large Language Model 部署的更广泛讨论:该频道的用户触及了更广泛的话题,例如进一步 fine-tuning 70B 模型的潜力、训练和 fine-tuning 的普遍高昂成本、可能的合作,以及语言模型中对齐(alignment)和伦理的风险。
提到的链接:
- Category:Short stories by Edgar Allan Poe - Wikipedia: 未找到描述
-
[Self-hosted AI models docs.ST.app](https://docs.sillytavern.app/usage/local-llm-guide/how-to-use-a-self-hosted-model/): 本指南旨在帮助您在 PC 上运行本地 AI 并配合 SillyTavern 进行设置(我们将从现在开始使用正确的术语并… - 152334H/miqu-1-70b-sf · Hugging Face: 未找到描述
- NeverSleep/MiquMaid-v1-70B-GGUF · Hugging Face: 未找到描述
- miqudev/miqu-1-70b · Hugging Face: 未找到描述
- Money Wallet GIF - Money Wallet Broke - Discover & Share GIFs: 点击查看 GIF
- NobodyExistsOnTheInternet/miqu-limarp-70b · Hugging Face: 未找到描述
- sokusha/aicg · Datasets at Hugging Face: 未找到描述
- Ayumi Benchmark ERPv4 Chat Logs: 未找到描述
- NobodyExistsOnTheInternet/ShareGPTsillyJson · Datasets at Hugging Face: 未找到描述
- GitHub - bjj/exllamav2-openai-server: An OpenAI API compatible LLM inference server based on ExLlamaV2.: 一个基于 ExLlamaV2 的 OpenAI API 兼容 LLM 推理服务器。
- GitHub - epolewski/EricLLM: A fast batching API to serve LLM models: 一个用于提供 LLM 模型服务的高速批处理 API。
-
[Mistral CEO confirms 'leak' of new open source AI model nearing GPT4 performance Hacker News](https://news.ycombinator.com/item?id=39208213): 未找到描述
TheBloke ▷ #training-and-fine-tuning (30 messages🔥):
- Fine-tuning Epoch 澄清:
@dirtytigerx回应了@bishwa3819,指出发布的 Loss 图表显示不足一个 Epoch,并询问是否能看到完整 Epoch 的图表。 - 数据集配置难题:
@lordofthegoons寻求在 unsloth 上设置 sharegpt 格式数据集配置的帮助,提到除了 alpaca 之外的其他格式很难找到文档。 - TinyLlama 微调故障排除:
@chovii在微调 TheBloke/TinyLlama-1.1B-Chat-v1.0-AWQ 时遇到困难,并分享了一个在使用 PEFT 库尝试添加适配器时出现的与不支持模块相关的特定ValueError。@dirtytigerx指出 PEFT 目前尚不支持 AWQ,并引用了一个正在等待即将发布的 AutoAWQ 版本的草案 PR,附带了 GitHub Pull Request 链接。 - 计算训练 Token 数量:
@dirtytigerx为@arcontex提供了一个简单的脚本来计算训练文件中的 Token 数量,建议使用AutoTokenizer.from_pretrained(model_name)来轻松获取大多数模型的 Tokenizer。 - 实验追踪工具讨论:
@flashmanbahadur询问了在本地运行时使用 wandb 和 mlflow 等实验追踪工具的情况。@dirtytigerx表达了 wandb 和 comet 的实用性,特别是对于较长时间的训练运行,并讨论了 mlflow 更广泛的功能。
提到的链接:
- 使用 🤗 PEFT 加载适配器:未找到描述
- FEAT: 在 PEFT 中添加 AWQ 支持,由 younesbelkada 提交 · Pull Request #1399 · huggingface/peft:原始 PR:casper-hansen/AutoAWQ#220 待办事项:在 transformers 中添加修复,等待下一个 AWQ 版本发布,由 @s4rduk4r 作为共同作者的空提交,在 Docker 镜像中添加 autoawq,弄清楚如何…
TheBloke ▷ #model-merging (15 messages🔥):
- 寻找审查较少的智能模型:
@lordofthegoons询问关于无审查且智能的 34b 模型,@kquant建议查看 Hugging Face 上的 Nous-Yi 等模型。 - Smaug 34b 在不进行合并的情况下起飞:
@kquant分享了关于 Smaug-34B-v0.1 模型的信息,这是一个经过微调的 “bagel” 版本,具有令人印象深刻的 Benchmark 结果,且不涉及模型合并。 - 缩小 Goliath:
@lordofthegoons对缩小 34b 模型以期望其性能超过 10.7b 模型的实验表示兴趣,但随后报告称该尝试未能产生可用的模型。 - 引导模型行为的 Prompt:
@kquant讨论了使用 Prompt 来影响模型输出,引用了改变响应风格或触发特定行为(如模拟愤怒或礼貌确认)的方法。 - 通过模型合并达成和谐:
@kquant指出 Harmony-4x7B-bf16 是一个超出预期的成功模型合并案例,并以该过程命名。
提到的链接:
- ConvexAI/Harmony-4x7B-bf16 · Hugging Face:未找到描述
- abacusai/Smaug-34B-v0.1 · Hugging Face:未找到描述
- one-man-army/UNA-34Beagles-32K-bf16-v1 · Hugging Face:未找到描述
TheBloke ▷ #coding (2 messages):
- 被遗忘的文件管理艺术:
@spottyluck强调了一个日益严重的问题,即许多人缺乏对文件系统层级结构或如何组织文件的理解,导致了“大量的搜索/滚动”堆积。 - 跨代的文件系统困惑:
@spottyluck分享了来自 The Verge 的一篇文章,讨论了学生如何对文件系统越来越陌生,引用了天体物理学家 Catherine Garland 注意到她的学生无法定位项目文件或理解文件目录概念的案例。
提到的链接:
在搜索引擎陪伴下成长的学生可能会永远改变 STEM 教育:教授们正努力教导 Z 世代
Nous Research AI ▷ #ctx-length-research (6 messages):
- 关于表单提交的询问:
@manojbh询问了表单是否已填写,但未提供进一步的背景或细节。 - 质疑 RMT 的唯一性:
@hexani提出了一个问题,即所讨论的技术与 RMT 究竟有何不同及其重要性。 - 对 Context Length 影响的怀疑:
@hexani对该技术在管理更长 Context 方面的重大转变表示怀疑,并引用了论文中的评估结果。 - 请求澄清:
@hexani请求有人能对所讨论的技术进行更多解释,并预先表示感谢。 - 与现有架构的比较:
@hexani指出了当前讨论话题与现有架构之间的相似之处,将其比作显式 Memory Token 的 Adapter。
Nous Research AI ▷ #off-topic (13 messages🔥):
- 寻求 Machine Learning 指导:
@DES7INY7和@lorenzoroxyolo正在寻求关于如何开始 Machine Learning 之旅的建议,并寻找可以遵循的指导和路径。 - Discord @ 功能的改进可能:
@murchiston讨论了 Discord 上的 @ 功能可以改进,暗示在 lmstudio 等工具中进行 Better Routing 或集成可能会使该功能更可靠。 - Fast.ai 课程踪迹:
@afterhoursbilly提到他在 Fast.ai Discord 中见过<@387972437901312000>,暗示该用户参与了该课程。 - Maneuver-Language 构想:
@manojbh提出了一个关于将驾驶行为 Token 化以用于 Self-driving 技术的想法,提出了一个类似于 Lane-language 的概念。 - 数据集 Schema 不一致:
@pradeep1148指出<@387972437901312000>发布的数据集似乎存在 Schema 不一致的问题,不同的示例具有不同的格式。提供了 Hugging Face 上数据集的链接:OpenHermes-2.5 dataset。
提到的链接:
- Hellinheavns GIF - Hellinheavns - Discover & Share GIFs:点击查看 GIF
- Blackcat GIF - Blackcat - Discover & Share GIFs:点击查看 GIF
- Scary Weird GIF - Scary Weird Close Up - Discover & Share GIFs:点击查看 GIF
Nous Research AI ▷ #benchmarks-log (2 messages):
- 关于 AGIEval 中 ACC_NORM 的澄清:
@euclaise询问@387972437901312000在 AGIEval 评估中是否使用了acc_norm。@teknium确认在存在acc_norm的地方,始终会使用它。
Nous Research AI ▷ #interesting-links (77 messages🔥🔥):
- Bittensor 与合成数据:
@richardblythman询问 Bittensor 如何处理 AI 模型的刷榜(gaming benchmarks)问题,并建议 Hugging Face 也可以实时生成合成数据。@teknium澄清了涉及的成本以及 Bittensor 网络通胀带来的补贴,而@euclaise指出 Hugging Face 有能力运行高昂的操作。 - 模型训练中的激励机制:
@teknium描述了 Bittensor 网络内激励系统对于推动模型改进和积极竞争的重要性,而@richardblythman对 Bittensor 模式的可持续性表示怀疑,原因是成本过高。 - 理解 Bittensor 网络:在整个讨论过程中,人们对 Bittensor 去中心化网络的运作方式和激励结构表现出浓厚兴趣,包括
@.benxh和@teknium在内的多位用户讨论了部署方面的问题以及维持模型活跃度和竞争力的激励措施。 - Bittensor 产出有用模型的潜力:虽然
@richardblythman对网络的效率表示怀疑,但@teknium对其加速开源模型开发的潜力保持乐观,并提到严格的训练尝试仅在一个月或两个月前才开始。 - AI 模型的协作测试:
@yikesawjeez邀请社区成员协助测试一种新的 AI 架构 HelixNet,并为此任务提供了共享的 Jupyter Notebook 访问权限。@manojbh等用户回应了这一邀请,鼓励在不同环境下进行复现,以便更好地验证模型性能。
提到的链接:
- Mistral CEO 确认接近 GPT-4 性能的新开源 AI 模型“泄露”:一名匿名用户在 4chan 上发布了 miqu-1-70b 文件的链接。该开源模型性能接近 GPT-4。
- argilla/CapybaraHermes-2.5-Mistral-7B · Hugging Face:未找到描述
- LLaVA-1.6:改进的推理、OCR 和世界知识:LLaVA 团队发布了 LLaVA-1.6,具有改进的推理、OCR 和世界知识。LLaVA-1.6 在多个基准测试中甚至超过了 Gemini Pro。
- NobodyExistsOnTheInternet/miqu-limarp-70b · Hugging Face:未找到描述
- 来自 Ram (@ram_chandalada) 的推文:使用“带指令反向翻译的自我对齐(Self-Alignment with Instruction Backtranslation)”提示词为流行数据集评分。评分的数据集:1️⃣ dolphin @erhartford - 仅 GPT-4 响应 2️⃣ Capybara @ldjconfirmed 3️⃣ ultracha…
- 来自 Migel Tissera (@migtissera) 的推文:这是开源 AI 的重要一周,这里还有一个为本周画上句号!介绍 HelixNet。HelixNet 是一种新颖的深度学习架构,由 3 个 Mistral-7B LLM 组成。它…
- 来自 yikes (@yikesawjeez) 的推文:管他呢 https://jupyter.agentartificial.com/commune-8xa6000/user/forthepeople/lab 用户名:forthepeople 密码:getitdone 现在开始下载模型,加入进来并将 notebook 保存到 ./wo…
- 多模态大语言模型非语言抽象推理的奇特案例:虽然大语言模型 (LLM) 仍在被应用到新领域和新用途中,我们正经历新一代基础模型的涌入,即多模态…
- GroqChat:未找到描述
- 微调大语言模型时的遗忘缩放法则:我们研究并量化了在下游任务上微调预训练大语言模型 (LLM) 时的遗忘问题。我们发现参数高效微调 (PEFT) 策略,如…
- 论文页面 - 学习通用预测器:未找到描述
- GitHub - TryForefront/tuna:通过在 GitHub 上创建账户来为 TryForefront/tuna 的开发做出贡献。
Nous Research AI ▷ #announcements (1 条消息):
- Open Hermes 2.5 数据集发布:
@teknium宣布公开发布用于 Open Hermes 2.5 和 Nous-Hermes 2 的数据集,很高兴能分享从开源生态系统中策划和生成的超过 1M 个示例。该数据集可以在 HuggingFace 上找到。 - 数据集贡献致谢:
@teknium在数据集卡片中列出了除一个已失效来源外的所有数据源,并向在 Nous Research AI Discord 中做出贡献的作者表示感谢。 - 与 Lilac ML 合作:
@teknium与@1097578300697759894以及 Lilac ML 合作,在他们的 HuggingFace Spaces 上展示了 Hermes,协助对数据集进行分析和过滤。可以在 Lilac AI 上进行探索。 - 关于 Open Hermes 数据集的推文:
@teknium发布的相关 Twitter 帖子 庆祝了该数据集的发布,并邀请追随者看看能基于此创造出什么。
提到的链接:
- teknium/OpenHermes-2.5 · Hugging Face 数据集:未找到描述
- 无标题:未找到描述
Nous Research AI ▷ #general (673 条消息 🔥🔥🔥):
- MIQU 之谜揭晓:
@teknium澄清 MIQU 就是 Mistral Medium,而不是早期版本。Nous Research 联合创始人的推文可能证实了这一点,详见此处。 - Mergekit 的威力:像
@datarevised这样的用户通过将 MIQU 与自身合并,尝试了 1200 亿参数模型,其他人也在创建各种组合,如 Miquella 120B。 - OpenHermes 2.5 数据集讨论:数据集讨论涉及了数据集的创建和存储,
@teknium提到了用于数据策划和探索的工具,如 Lilac。 - 通过 AI Grant 为 AI 提供资助:
@cristi00分享了关于 AI Grant 的信息——这是一个针对 AI 初创公司的加速器,提供大量资金和 Azure 额度。申请在截止日期前开放。 - Qwen 0.5B 模型期待:
@qnguyen3对即将发布的名为 Qwen 的强力新模型表示兴奋,尽管尚未给出具体细节。
提到的链接:
- NobodyExistsOnTheInternet/code-llama-70b-python-instruct · Hugging Face:未找到描述
- Boy Kisser Boykisser GIF:点击查看 GIF
- Guts Berserk Guts GIF:点击查看 GIF
- Meta 推出 Code Llama 70B:一款强大的代码生成 AI 模型:凭借 Code Llama 70B,企业可以选择在私有环境中托管高性能的代码生成模型。这让他们在保护知识产权方面拥有控制权和信心。
- Stella Biderman (@BlancheMinerva) 的推文:你是否因为模仿 GPT-3 而错失了 2.7B LLM 20% 的加速?我曾错失了三年。在我的最新论文中,了解为什么要以硬件感知的方式设计模型以及如何设计…
- AI Grant:是时候开发 AI 原生产品了!
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。与你的朋友和社区聊天、聚会并保持紧密联系。
- Reimagine:报道快速发展的 AI 世界。
- Cat Cats GIF:点击查看 GIF
- 152334H/miqu-1-70b-sf · Hugging Face:未找到描述
- Wow 惊讶脸 GIF - Wow 惊讶脸小老板 - 发现并分享 GIF:点击查看 GIF
- euclaise/Memphis-scribe-3B-alpha · Hugging Face:未找到描述
- Bornskywalker 击掌 GIF - Bornskywalker 击掌胡迪 - 发现并分享 GIF:点击查看 GIF
- ycros/miqu-lzlv · Hugging Face:未找到描述
- WizardLM/WizardLM-70B-V1.0 · Hugging Face:未找到描述
- alpindale/miquella-120b · Hugging Face:未找到描述
- 初音未来 - 维基百科:未找到描述
- 跳舞的 Daniel Keem GIF - 跳舞的 Daniel Keem Keemstar - 发现并分享 GIF:点击查看 GIF
- xVal:一种用于 Large Language Models 的连续数字编码:Large Language Models 尚未广泛应用于科学数据集的分析,部分原因在于数字分词(tokenizing)的独特困难。我们提出了 xVal,一种数值编码方案…
- 猫咪旋转 GIF - Catspin - 发现并分享 GIF:点击查看 GIF
- Itsover Wojack GIF - ITSOVER WOJACK - 发现并分享 GIF:点击查看 GIF
- 来自 Nat Friedman (@natfriedman) 的推文:http://aigrant.com 第 3 期申请现已面向构建 AI 产品的种子前和种子阶段公司开放!截止日期为 2 月 16 日。作为一项实验,本期我们提供以下选项…
- NousResearch/Nous-Hermes-2-Vision-Alpha · 讨论区:未找到描述
- dataautogpt3 (alexander izquierdo):未找到描述
- NobodyExistsOnTheInternet (Nobody.png):未找到描述
- 来自 Eric Hallahan (@EricHallahan) 的推文:@QuentinAnthon15 糟糕,如果允许的话我很想参加。无论如何,有这样的作者名单,我相信这一定是一篇伟大的论文!
- GitHub - qnguyen3/hermes-llava:通过在 GitHub 上创建账号来为 qnguyen3/hermes-llava 的开发做出贡献。
- GitHub - SafeAILab/EAGLE: EAGLE:通过特征外推实现 LLM 解码的无损加速:EAGLE:通过特征外推实现 LLM 解码的无损加速 - GitHub - SafeAILab/EAGLE: EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation
- GitHub - epfLLM/meditron: Meditron 是一系列开源医学 Large Language Models (LLMs)。:Meditron 是一系列开源医学 Large Language Models (LLMs)。 - GitHub - epfLLM/meditron: Meditron is a suite of open-source medical Large Language Models (LLMs).
-
[法国的 AI 初创公司正在发生一些事情 TechCrunch](https://techcrunch.com/2023/11/09/theres-something-going-on-with-ai-startups-in-france/?guccounter=1):人工智能就像在美国一样,已迅速成为法国科技行业内一个备受关注的垂直领域。 - Lilac - 更好的数据,更好的 AI:Lilac 使数据和 AI 从业者能够通过改进数据来改进他们的产品。
Nous Research AI ▷ #ask-about-llms (32 条消息🔥):
- 风格迁移还是过拟合?:
@manojbh讨论了 LLM 的回答是否过度受到其在特定风格(如 Mistral)上训练的影响;指出类似的末层模式会导致输出中的风格模仿。这是在误导性输出推理的背景下讨论的,并引用了@teortaxesTex的推文,涉及 Miqu 在俄语(RU)翻译中的错误,其措辞惊人地相似。 - 量化模型与记忆讨论:
@giftedgummybee和@manojbh的讨论集中在量化模型(Quantized Models)遗忘信息的问题,以及较低量化级别下错误增加的可能性。 - AI 压力测试推测:
@manojbh提出了一个理论,即 LLM 是否会像人类一样在压力下失误,这促使@_3sphere建议测试模型在面对混乱 Prompt 时的“恐慌”行为。 - Mistral 内部的水印技术:与
@everyoneisgross、@.benxh和.ben.com的对话深入探讨了为 LLM 添加水印(Watermarking)的可能性,假设这可能涉及独特的问答对或 Prompt,在量化后生成特定的响应作为标识符。 - 评估 Nous-Hermes 和 Mixtral 的性能:
@.benxh确认了 Mistral Medium 与某一未指明容量的模型之间存在显著的性能差异,表明在误差范围内性能接近。@manojbh表示赞同,并强调了统计指标中即使是细微差异的重要性。
提到的链接:
- Teortaxes 的推文▶️ (@teortaxesTex):Miqu 在俄语(RU)中犯了一个错误:螺栓脱落了但顶针留下了。但请注意翻译中惊人相似的措辞!不过我运行的是 Q4KM,部分原因可能归结为采样…
- GitHub - LeonEricsson/llmjudge: 探索 LLM-as-a-judge 的局限性:探索 LLM-as-a-judge 的局限性。通过在 GitHub 上创建账号为 LeonEricsson/llmjudge 的开发做出贡献。
Mistral ▷ #general (363 条消息🔥🔥):
-
欢迎新成员:用户
@admin01234和@mrdragonfox互相问候,表明新用户正在发现 Mistral 的 Discord 频道。 -
miqu-1-70b 反量化成功:用户
@i_am_dom讨论了将 miqu-1-70b 从 q5 成功反量化(Dequantization)到 f16,并转置为 PyTorch。分享了使用说明和结果,展示了该模型的散文生成能力。 -
实习咨询与通用职业机会:用户
@deldrel询问了 Mistral 的实习机会。@mrdragonfox建议他们即使没有发布官方招聘信息,也可以发送个人资料。 -
Token 生成速率与推理性能:用户
@i_am_dom提供了官方 Mistral API 的 Token/s 生成速率,@donjuan5050表示这可能无法满足他们的使用场景。同时,@mrdragonfox分享称,在特定硬件配置上本地托管 Mistral 可以显著提高吞吐量(Throughput)。 -
Miqutized 模型与 Mistral 的回应:讨论了 miqu-1-70b 的真实性,包括 Mistral AI 首席执行官发布的 Twitter 声明 链接,确认其为他们模型的早期版本。用户
@shirman、@i_am_dom和@dillfrescott推测了 Miqutized 模型与 Mistral 模型之间的关系。 -
模型托管与使用成本:与
@mrdragonfox讨论了本地托管 LLM 与使用 API 的优缺点及成本。讨论深入探讨了硬件要求以及不同部署规模下 API 使用的成本效益。
提到的链接:
- 加入 Mistral AI Discord 服务器!:查看 Discord 上的 Mistral AI 社区 - 与其他 11372 名成员交流,享受免费的语音和文字聊天。
- 152334H/miqu-1-70b-sf · Hugging Face:未找到描述
- TheBloke/Mixtral-8x7B-Instruct-v0.1-AWQ · Hugging Face:未找到描述
- 史翠珊效应 - 维基百科:未找到描述
- NeverSleep/MiquMaid-v1-70B · Hugging Face:未找到描述
- NeverSleep/MiquMaid-v1-70B · 非常令人印象深刻!:未找到描述
Mistral ▷ #models (17 messages🔥):
- Mistral 兼容 Alpaca 格式:
@sa_code提到 Mistral small/med 可以配合 Alpaca prompt 格式来提供 system prompt;然而,他们也指出 Alpaca 格式与 Markdown 不兼容。 - 官方文档缺少 System Prompt 信息:
@sa_code指出 Mistral 官方文档中缺乏关于 system prompts 的说明,并请求添加此内容。 - Office Hours 寻求帮助:针对
@sa_code的疑问,@mrdragonfox建议在下一次 Office Hours 会议中提问以获得澄清。 - 为 Chat Template 提交 PR:
@sa_code表示他们在 Mistral 的 Hugging Face 页面上提交了一个 PR,以解决关于 chat template 文档的问题(PR 讨论链接)。 - Mistral Embedding Token 限制澄清:
@mrdragonfox和@akshay_1回复了@danouchka_24704的问题,确认 Mistral-embed 生成 1024 维向量,最大 token 输入块为 8k,尽管通常首选 512 tokens。
提到的链接:
-
[Open-weight models Mistral AI Large Language Models](https://docs.mistral.ai/models/#chat-template):我们开源了预训练模型和微调模型。这些模型没有针对安全性进行调整,因为我们希望赋能用户根据其用例测试和改进审核机制。对于更安全的模型… - mistralai/Mixtral-8x7B-Instruct-v0.1 · Update chat_template to include system prompt:未找到描述
Mistral ▷ #ref-implem (1 messages):
- 使用 Mistral Medium 订阅获取 JSON 输出:用户
@subham5089询问了在使用 Mistral Medium 订阅时始终接收 JSON output 的最佳方法。在提供的消息历史中没有对此话题的回复或进一步讨论。
Mistral ▷ #finetuning (33 messages🔥):
- 低资源语言的持续预训练查询:
@quicksort询问了关于 Mistral 在低资源语言上进行持续预训练(continuous pretraining)的参考资料,但@mrdragonfox表示缺乏此类资源,并称“目前还没有什么能比得上 instruct 模型”。 - 在 Mistral 上探索多语言 LoRA 微调:
@yashkhare_正在尝试使用 LoRA 对 Mistral 7b 进行针对越南语、印尼语和菲律宾语等语言的持续预训练,并质疑独立和合并的特定语言 LoRA 权重的可行性。 - 语言聚类和持续预训练的挑战:
@mrdragonfox对基于风格迁移(style transfer)的方法进行新语言聚类的成功表示怀疑,并强调不同的语言通常需要独立的预训练。 - 使用 RAG 解决事实微调中的幻觉问题:针对
@pluckedout关于低参数模型记忆事实的问题,@kecol和@mrdragonfox讨论了集成 Retrieval-Augmented Generation (RAG) 以实现上下文感知响应并减少幻觉(hallucinations)的重要性及复杂性。 - Hermes 2 数据集发布公告:
@teknium分享了他们在 Twitter 上发布 Hermes 2 数据集的链接,邀请他人探索其潜在价值。
Mistral ▷ #la-plateforme (8 messages🔥):
- 模型下载困惑:
@ashtagrossedaronne询问如何下载模型来辅助完成作业,但最初不确定该使用哪个模型。 - 错误的链接尝试:作为回应,
@ethux试图提供下载链接,但首先提供了一个错误的 URL,随后进行了更正,不过在给出的消息中并未分享正确的链接。 - 贡献更新:
@carloszela宣布提交了一个 Pull Request (PR) 并正在等待审核,这标志着他们对项目的贡献。 - Mistral 模型的 API 异常:
@miscend提出了关于 Mistral small 模型在使用 API 与本地运行时性能差异的担忧,特别提到了响应截断和代码输出中额外的反斜杠问题。
提到的链接:
👾 LM Studio - Discover and run local LLMs:查找、下载并实验本地 LLM
LM Studio ▷ #💬-general (123 messages🔥🔥):
- HuggingFace 模型困惑:
@petter5299询问为什么下载的 GGUF 模型无法被 LM Studio 识别。@fabguy要求提供 HuggingFace 链接以进一步澄清,并提到对所述架构不熟悉。 - LM Studio 与 macOS 内存问题:
@wisefarai在 Mac 上尝试使用 LM Studio 加载量化模型时遇到提示内存不足的错误,@yagilb建议这可能是由于发生问题时可用内存不足导致的。 - 本地模型与联网声明:
@n8programs等人讨论了关于“本地模型在联网/断网状态下表现不同”这一说法是否需要证据。他们呼吁通过对已知 OpenAI 地址的网络追踪(network traces)来证实此类说法。 - AMD GPU 支持咨询:
@ellric_询问 LM Studio 是否有望支持 AMD GPU。@yagilb确认了这种可能性,并引导其前往特定频道获取指导。 - 提示词格式困扰与 CodeLLama 讨论
#general频道的讨论涉及了提示词格式带来的复杂性,包括 Reddit 上关于 CodeLLama 70b 的提醒,以及 llama.cpp 不支持聊天模板(chat templates)导致模型输出质量差的问题。
提到的链接:
- mistralai/Mixtral-8x7B-v0.1 · Hugging Face:无描述
- GitHub - joonspk-research/generative_agents: Generative Agents: Interactive Simulacra of Human Behavior:Generative Agents: Interactive Simulacra of Human Behavior - GitHub
- Reddit - Dive into anything:无描述
- Nexesenex/MIstral-QUantized-70b_Miqu-1-70b-iMat.GGUF · Hugging Face:无描述
- GitHub - ggerganov/llama.cpp: Port of Facebook’s LLaMA model in C/C++:Facebook LLaMA 模型的 C/C++ 移植版本。
LM Studio ▷ #🤖-models-discussion-chat (100 messages🔥🔥):
-
本地 LLM 训练探索:
@scampbell70正在寻求训练一个专门用于 Stable Diffusion 提示词编写的本地大语言模型(LLM),并考虑投资多块 Quadro A6000 GPU。其目标是避开 ChatGPT 等平台的服务器条款限制,并学习使用 Lora 等工具训练模型。 -
LM Studio 与其他工具的兼容性:
@cos2722和@vbwyrde等用户正在讨论哪些模型在 LM Studio 中与 Autogenstudio, crewai 和 open interpreter 配合效果最好。共识是 Mistral 可行,但 MOE 版本不行,且寻找一个配合良好的代码模型仍具挑战。 -
LM Studio 的硬件消耗:
@melmass报告了最新版 LM Studio 的显著资源占用,指出即使是配备 4090 GPU 和 128GB RAM 的高性能配置也会感到吃力。 -
Gorilla Open Function 模板咨询:
@jb_5579正在寻求在 LM Studio 中配合 Gorilla Open Function 使用的 JSON 格式提示词模板建议,目前暂无后续讨论。 -
探索量化与模型大小对性能的影响:
@binaryalgorithm、@ptable和@kujila就使用不同参数量的量化模型以平衡性能和推理速度展开了深入讨论。对话重点讨论了大型模型在响应深度和创造力方面的权衡,以及低量化模型带来的快速推理。
提到的链接:
- LLM-Perf Leaderboard - a Hugging Face Space by optimum:无描述
- Big Code Models Leaderboard - a Hugging Face Space by bigcode:无描述
LM Studio ▷ #🧠-feedback (21 messages🔥):
- 寻求目录更新的澄清:
@markushenriksson询问如何检查目录更新,@heyitsyorkie确认更新已经发布。 - 下载失败需要手动清理文件:
@ig9928报告了一个问题,即下载失败后需要手动删除不完整的文件才能重新尝试下载,并请求修复这一不便。 - 请求中文支持:
@gptai表达了对 LM Studio 中文支持的兴趣,指出中国粉丝在使用英文版本时面临困难。 - 对错误信息的困惑:
@mm512_分享了尝试下载模型时收到的详细错误信息。@yagilb引导他们去 Linux 支持频道寻求帮助,并建议从终端运行应用程序以获取错误日志。 - 模型兼容性查询和教程问题:
@artdiffuser在下载模型时遇到困难,被@heyitsyorkie告知只有 GGUF 模型与 LM Studio 兼容。此外,@artdiffuser被提醒注意可能过时或错误的教程,@yagilb进一步处理了该问题,建议在相关频道提交针对其特定错误的 Bug 报告。
LM Studio ▷ #🎛-hardware-discussion (157 messages🔥🔥):
-
GPU 和内存管理:
@0pechenka询问在运行 LLaMA v2 等模型时,GPU 和 CPU 上的内存使用是否可以自定义。他们想要一份入门指南来设置环境,并请求提供说明(可能在 YouTube 上)。@pefortin建议,如果模型无法装入内存,可以取消勾选 “keep entire model in ram”(将整个模型保留在内存中)标志,以便在 Windows 上利用交换文件。 -
组装高性价比 LLM 电脑:
@abesmon询问了在中等预算下运行大语言模型 (LLMs) 的优质电脑配置,@heyitsyorkie建议 VRAM 至关重要,推荐使用至少具有 24GB VRAM 的 GPU。 -
讨论多 GPU 的电源供应:
@dagbs和@pefortin讨论了运行多个 GPU 时可能需要的更多功率,pefortin 正在考虑同步多个 PSU 来处理他的配置,其中包括通过 PCIe risers 连接的 3090 和其他 GPU。 -
不同硬件配置下的 LLM 性能:
@pefortin分享了他的经验,在 LLM 任务中,P40 GPU 的性能约为 3090 的 30-40%,并提到了 Windows 上的驱动程序问题,而这些问题在 Linux 上并不存在。 -
为 LLM 混合使用不同世代的 GPU:用户
@ellric_和@.ben.com辩论了在 LLM 中使用不同世代 GPU(如 M40 和 P40)的兼容性和性能影响。.ben.com承认需要调查跨 GPU 拆分模型的性能后果,并根据非科学测试推测可能会有 20% 的减速。
提到的链接:
- Mikubox Triple-P40 build:eBay 上的 Dell T7910 “准系统”,包含散热器。推荐 “digitalmind2000” 卖家,因为他们使用现场发泡包装,确保工作站完好无损地送达。Xeon 处理器的选择…
- Simpsons Homer GIF - Simpsons Homer Bart - Discover & Share GIFs:点击查看 GIF
LM Studio ▷ #🧪-beta-releases-chat (1 messages):
mike_50363: 非 AVX2 Beta 版本会更新到 2.12 吗?
OpenAI ▷ #ai-discussions (137 条消息🔥🔥):
- 改进 DALL-E 生成的面部:
@abe_gifted_art询问了关于 DALL-E 生成的面部更新情况,注意到它们现在不再扭曲了。然而,讨论中没有提供具体的更新说明或日期变更。 - 通过非技术书籍了解 AI:
@francescospace寻求关于 AI 及其潜力或问题的非技术书籍推荐。@laerun建议参与像 Discord 这样的社区讨论,而@abe_gifted_art建议关注 Bill Gates 的采访和微软的“Responsible AI”承诺,并分享了一个链接:微软的 AI 方法。 - 关于使用不道德数据训练 AI 的辩论:
@darthgustav.和@lugui之间就 AI 数据集中包含有害内容的伦理影响和技术必要性展开了辩论。@yami1010随后加入,强调了语言模型(Language Models)工作方式的复杂性以及 AI 输出中体现的创造力。 - 成功 DALL-E Prompt 的挑战:
@.ytty对 DALL-E 无法正确遵循 Prompt 表示沮丧,而@darthgustav.提供了构建有效 Prompt 的建议,强调使用细节并避免负面指令。 - 开始 AI 艺术创作和 AI 脚本语言训练:新用户询问如何开始创作 AI 艺术,
@exx1推荐了需要 Apple SoC 或 Nvidia GPU 的 Stable Diffusion,而@cokeb3ar探讨了在无法上传文档的情况下,如何教 AI 一种新的脚本语言。
提到的链接:
| [What is Microsoft's Approach to AI? | Microsoft Source](https://news.microsoft.com/source/features/ai/microsoft-approach-to-ai/):我们相信 AI 是我们这个时代的定义性技术。阅读我们关于基础设施、研究、责任和社会公益的 AI 方法。 |
OpenAI ▷ #gpt-4-discussions (85 条消息🔥🔥):
-
GPT 图像分析挑战:
@cannmanage寻求帮助,希望使用 GPT 分析视频,以便在多辆白色货车中识别出一辆涉嫌绑架者的货车。@darthgustav.建议使用 Lexideck Vision Multi-Agent 图像扫描工具 并调整 Prompt 以获得更好的结果,并指出使用该工具时上下文的重要性。 -
识别活跃的 GPT 模型:
@nosuchipsu询问如何确定正在使用的具体 GPT 模型,@darthgustav.澄清说 GPT Plus 和 Team 账户使用的是 32k 版本的 GPT-4 Turbo,而 API 和 Enterprise 方案的使用情况有所不同。他随后分享了透明定价计划链接和模型详情。 -
图像显示障碍:用户
@quengelbert和@darthgustav.讨论了 GPT 是否可以在聊天中显示来自网页 URL 的图像,结论是目前不支持这种直接显示,在 GPT-4 上尝试此功能时显示的错误消息证明了这一点。 -
理解 @GPT 功能:
@_odaenathus讨论了对 GPTs 中@系统的困惑,怀疑这是原始 GPT 与@指定的 GPT 之间的融合,而不是清晰的移交。@darthgustav.确认了共享上下文(Shared Context)的行为,并建议断开与第二个 GPT 的连接将恢复到第一个 GPT 的指令,尽管 Bug 或糟糕的设计可能会导致意外行为。 -
跨设备管理 D&D GPTs:
@tetsujin2295提到作为 Plus 会员无法在移动端使用 @ GPTs 的功能,@darthgustav.将其归因于可能尚未全面推行或移动浏览器的限制。他还分享了如何有效地构建多个与 D&D 相关的 GPTs 以担任各种角色和进行世界观构建,但对 Token 限制约束略有担忧。
提到的链接:
Pricing:简单且灵活。只需为你使用的部分付费。
OpenAI ▷ #prompt-engineering (62 条消息🔥🔥):
- 人像生成中的横向困境:
@wild.eva和@niko3757讨论了生成垂直全身人像图像的挑战;模型似乎强制采用横屏模式。@niko3757建议了一种变通方法,即先以横屏生成,然后在放大(upscaling)后将图像拼接成竖屏,但这只是推测,他们正在等待 DALL-E 的重大更新。 - 人像方向的博弈:
@darthgustav.认为由于对称性以及缺乏方向参数,获得正确的垂直人像只有 25% 的概率。这暗示了一个根本性的限制,与 Prompt 的编写方式无关。 - Prompt 改进尝试:
@wild.eva寻求改进图像方向的 Prompt 建议,@niko3757提供了示例,但@darthgustav.反驳指出,任何 Prompt 的改进都无法克服模型的固有约束。 - 在自定义 GPT 中集成反馈按钮:
@luarstudios询问如何在他们的 GPT 模型回答后添加交互式反馈按钮,并向@solbus和@darthgustav.寻求指导。@darthgustav.详细解释了如何结合“询问格式”(Interrogatory Format)为每个问题附加一个响应菜单。 - 设计方案的结构化讨论:
@solbus和@darthgustav.思考是否应该为第一个 Logo 设计采用与后续设计不同的反馈结构,认为这可以提高反馈收集的效率和相关性。@darthgustav.分享了他们在 DALL-E Discussions 中采用的方法链接。
OpenAI ▷ #api-discussions (62 条消息🔥🔥):
-
横向图像混乱:
@wild.eva在使用详细 Prompt 时遇到了问题,导致生成了横向图像或不理想的场景,这表明模型存在 训练问题。@niko3757确认可能的原因是 内置错误,并建议尝试以横屏生成后再进行放大,而@darthgustav.提到缺乏 方向参数 限制了垂直方向的生成。 -
对 DALL-E 更新的期待:
@niko3757分享了关于 DALL-E 即将迎来重大更新的乐观但 未经证实的推测,他们正热切期待更新以获得更好的结果。 -
GPT-3 按钮困境:
@luarstudios寻求在 AI 展示设计方案后 添加响应按钮 的帮助,并从@solbus和@darthgustav.处获得了关于如何在聊天机器人的 Custom Instructions 中实现此功能的反馈。 -
对话结构策略:
@darthgustav.为@luarstudios提供了一套引导 AI 交互模式 的策略,建议使用模板和 对话启动卡片(conversation starter cards)来处理展示 Logo 选项和接收反馈的逻辑流。 -
跨频道分享见解:
@darthgustav.在 DALL-E Discussions 中进行了转发,展示了针对 Logo 概念进行 Prompt Engineering 的效率,并建议在不同频道分享开源示例以获得更好的 社区支持。
OpenAccess AI Collective (axolotl) ▷ #general (109 条消息🔥🔥):
-
追逐幻影峰值:
@nafnlaus00和@dreamgen讨论了模型中的 training patterns 和 learning rate (LR) 调整,观察到每个 epoch 都会出现峰值。尽管尝试了更低的 LR 和增加 dropout,@nafnlaus00提到仍然面临 overtraining 问题。 -
寻求服务器级 GPU:
@le_mess提供了购买服务器级硬件的渠道。与此同时,@yamashi正在考虑采购,考虑使用配备 AMD EPYC 处理器和 AMD MI250 GPU 的Gigabyte Server G262-ZO0配置,并权衡其相对于租赁的优势。 -
对软件栈的怀疑:虽然 AMD 的产品(如
MI250)因其显存容量和潜在性能吸引了一些用户,但@yamashi对 AMD 的 software stack 与 Nvidia 相比的成熟度表示怀疑。 -
Commit 难题:
@nafnlaus00在axolotl库中发现了一个可能存在问题的 commit (da97285e63811c17ce1e92b2c32c26c9ed8e2d5d),这可能导致了他们模型微调中的严重 overtraining。他们正在采取系统的方法来隔离导致该变化的具体改动。 -
微型 YAML,重大飞跃:
@caseus_分享了一个仅有 11 行的 YAML 配置,即可启动 finetune,并提到axolotl即将进行 refactor,以进一步简化并改进默认设置,这可能会进一步降低复杂性 (PR #1239)。
提到的链接:
- AMD + 🤗: Large Language Models Out-of-the-Box Acceleration with AMD GPU: 无描述
-
keep gate in fp32 for 16 bit loras (#1105) · OpenAccess-AI-Collective/axolotl@da97285: * 为 LoRA 保持 gate 为 fp32
-
为 mixtral 添加不带 flash attention 的 LoRA 端到端检查以验证 gate
-
为 mixtral 添加 gate 为 fp32 的检查,为训练输出添加 typehints
- mixtral doe…
- WIP: Pydantic cfg by winglian · Pull Request #1239 · OpenAccess-AI-Collective/axolotl: 描述、动力与背景、测试方式、截图(如适用)、变更类型、社交账号(可选)
- Gigabyte 2U MI250 Server G262-ZO0: 无描述
- no title found: 无描述
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (26 条消息🔥):
- Torch-2.2.0 发布后的 CI 故障:
@caseus_报告称 torch-2.2.0 的发布破坏了他们的 CI,但未指明其需要的具体版本。他们分享了一个详细说明该问题的 job log。 - 对 Requirements 中 ‘torch’ 的困惑:
@nanobitz询问是否可以从 requirements 中移除 ‘torch’,担心它会覆盖基础 torch,但@caseus_确认 ‘torch’ 在一段时间前就已经被移除了。 - LoftQ 改进中的范数平衡:
@stefangliga建议对 LoftQ 进行改进,可以使用向量 k1 和 k2 来重新缩放矩阵 A 和 B,从而匹配每个轴的范数以改善 gradient magnitudes。 - Axolotl Torch 版本控制 PR:
@caseus_提交了一个 pull request #1234,旨在通过将 torch 版本设置为与 axolotl 安装期间已安装的版本匹配来修复 CI 问题,从而防止自动升级到有问题的 torch-2.2.0。 - Qlora 的 Checkpoint 上传问题:
@dreamgen报告了一个问题,即 Qlora 不会上传所有 checkpoints,只上传最后一个。@caseus_建议这可能是 Transformers 的上游问题,并提到了一个涉及TrainerCallback的潜在变通方法。
提到的链接:
- Fix and document test_datasets (#1228) · OpenAccess-AI-Collective/axolotl@5787e1a: 欢迎提出 axolotl 问题。通过在 GitHub 上创建账号来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- set torch version to what is installed during axolotl install by winglian · Pull Request #1234 · OpenAccess-AI-Collective/axolotl: 描述:最新的 torch-2.2.0 破坏了我们的 CI,因为它尝试安装最新的 torch 版本。动力与背景、测试方式、截图(如适用)、变更类型…
OpenAccess AI Collective (axolotl) ▷ #general-help (42 messages🔥):
- Axolotl 安装卡在 flash-attn:
@arindam8841遇到了安装 axolotl 时构建 flash-attn 的 wheel 文件失败的问题。他们通过使用pip install flash-attn --no-build-isolation单独安装最新版本的 flash-attn 解决了该问题。 - 理解 axolotl 中的 Batch Size:
@dreamgen询问了 axolotl 中 Batch Size 如何随 GPU 数量扩展,而@caseus_澄清说,使用 DeepSpeed(特别是 zero3)会针对分布式数据并行 (DDP) 和 Batch Size 进行调整,因此对于可以放入单个 GPU 的模型来说,没有必要进行此类调整。 - 数据集配置挑战:
@jorelosorio在尝试为 axolotl 内的不同任务使用具有不同格式的相同数据集时遇到了错误。该问题通过为每个任务指定不同的data_files路径得到了解决。 - 使用 Axolotl 合并模型:
@cf0913在尝试将 QLORA 与基础模型合并时遇到了AttributeError,并寻求关于是使用 axolotl 命令行还是其他方法的建议,@le_mess提出了关于全量微调 (full finetuning) 的建议。 - 请求 Token 计数脚本:
@arcontex表示需要一个脚本来统计文件中的 Token 数量,@gonejiggy提出可以编写一个 CLI 工具并询问是否接受 pull request。@nanobitz提到 axolotl 已经在日志中输出了 Token 计数,并向@arcontex索要 yaml 配置以进一步提供帮助。
提到的链接:
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: 尽管问 axolotl 问题。通过在 GitHub 上创建账户为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: 尽管问 axolotl 问题。通过在 GitHub 上创建账户为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #rlhf (4 messages):
- DPO 遇到问题:
@giftedgummybee指出 DPO (Data Processing Optimizer) 目前正遇到问题,但未具体说明问题的性质。 - 请求澄清 DPO 问题:
@filippob82请求@giftedgummybee对 DPO 的问题提供更详细的解释。 - DPO 的 VRAM 使用担忧:
@c.gato详细说明了 DPO 正在消耗大量的 VRAM,特别提到了在 13b 模型上运行 QLora 的挑战。
OpenAccess AI Collective (axolotl) ▷ #runpod-help (5 messages):
- 神秘的空文件夹现象:
@nanobitz分享了一个有趣的发现,他们终于遇到了以前从未发生过的 空文件夹问题。 - Runpod 间歇性的文件夹消失行为:
@dreamgen插话提到,文件夹显示为空的问题有时 即使没有网络卷 (network volume) 也会发生,但原因仍然不明。 - 社区云特惠警报:
@dreamgen兴奋地宣布社区云上出现了 H100 SXM 机型,价格为 3.89 —— 敦促用户尽快抓住机会。 - Runpod 文档困境:
@gonejiggy对不得不指示用户运行pip install -e .以解决反复出现的错误表示沮丧,并承认将此添加到文档中并不理想。 - Runpod 机器中的“幽灵”:
@dreamgen报告了一个令人费解的情况:一个 神秘进程 正在消耗其 runpod 机器上的内存和 GPU,但通过常规命令无法检测也无法杀死。
HuggingFace ▷ #general (149 messages🔥🔥):
-
模型训练的困扰与解决方案:
@drummer_.在模型训练期间遇到了 loss 曲线平稳降至0的情况,随后发现这似乎与设置较高的 batch size 有关。讨论中建议切换到 batch size 为1并考虑使用EarlyStoppingCallback,@Cubie | Tom认为这是训练不稳定性导致的,而@doctorpangloss指出 4bit quantization 可能是其中的一个促成因素。 -
寻求特定技术数据的 LLM:
@zorian_93363询问是否有专门针对 Arduino、Esp 32、Raspberry Pi 及类似技术主题数据集训练的语言模型。 -
寻求大模型训练的效率:
@ericpan.xyz询问了能实现更高推理速度的最快格式,以及减少模型内存占用的方法,@meatfucker建议使用 4bit quantization,尽管会损失一些精度,但能有效节省 VRAM。 -
探索跨多个命名空间的 Embedding 逻辑:
@abhisheknegi_12043寻求关于设计查询逻辑的建议,以便在 Pinecone 中对存储为向量 Embedding 的会议记录进行跨多个命名空间的相似性查询。 -
将 Diffusion 模型集成到社交平台:
@goodtimes5241寻求关于集成可微调的 Stable Diffusion 模型的帮助(类似于 “diffuse the rest”)到社交媒体应用中。他们之前探索过使用 Inference API 以及像 Stable Diffusion Computing Network 这样的替代方案来实现 image-to-image 生成能力。 -
社区内容发布挑战:
@aliabbas60报告了一个授权错误,导致无法发布社区博客文章,但未提供有关该问题的更多细节。
提到的链接:
- ControlNet in 🧨 Diffusers:未找到描述
- GitHub - fiatrete/SDCN-Stable-Diffusion-Computing-Network: SDCN is an infrastructure that allows people to share and use Stable Diffusion computing power easily.:SDCN 是一个允许人们轻松共享和使用 Stable Diffusion 计算能力的底层设施。 - GitHub - fiatrete/SDCN-Stable-Diffusion-Computing-Network
- Image-to-image:未找到描述
- Callbacks:未找到描述
HuggingFace ▷ #today-im-learning (3 messages):
- 理解 Bahdanau Attention:用户
@sardarkhan_表示,在阅读关于 Bahdanau Attention 的内容时,发现它既复杂又迷人。 - Reinforcement Learning 的进展:
@sardarkhan_提到正在进行一个 Reinforcement Learning 项目,并计划继续开发一个 aimlabs Agent。 - 寻求动力激励:用户
@kaikishatu在 today-im-learning 频道中表达了他们对动力的需求。
HuggingFace ▷ #i-made-this (11 messages🔥):
-
推文评测请求:用户
@vipitis分享了一条 tweet,其中包含他们为科学传播研讨会准备的论文提案,并邀请社区提供反馈。 -
《万智牌》(Magic: The Gathering) 模型展示:
@joshuasundance宣布为他们讨论的 Magic 模型提供了一个 Space,并提供了该模型在 HuggingFace Spaces 上的 链接 以及视觉预览。 -
MoonDream 的自定义 Pipeline:用户
@not_lain成功为moondream1模型创建了自定义 Pipeline,并分享了一个 Pull Request 来解释其用法,包括在合并前进行测试的代码片段。 -
算力支持致谢:用户
@not_lain向<@994979735488692324>表示感谢,感谢其提供的必要算力支持,帮助完成了moondream1模型的自定义 Pipeline。 -
Necessary Tomorrows 播客发布:
@deepaaar为半岛电视台的科幻播客 “Necessary Tomorrows” 负责音乐和声音设计,并在创作过程中使用了 AI。他们分享了 收听地址 并提供了简短的剧情简介,提到该播客结合了推想小说(speculative fiction)和纪录片元素,聚焦于动荡的 2020 年代。
提到的链接:
- Gradio HTML Docs:未找到描述
- mtg-coloridentity - a Hugging Face Space by joshuasundance:未找到描述
- vikhyatk/moondream1 · add pipeline:未找到描述
- GitHub - cdpierse/transformers-interpret: Model explainability that works seamlessly with 🤗 transformers. Explain your transformers model in just 2 lines of code.:与 🤗 Transformers 无缝协作的模型可解释性。只需 2 行代码即可解释你的 Transformers 模型。
- Necessary Tomorrows:来自未来的 AI 讲师 Ursula 鼓励听众研究动荡的 2020 年代。结合推想小说和纪录片,顶尖科幻作家为我们带来了三个看似遥远但又触手可及的未来……
HuggingFace ▷ #reading-group (1 messages):
- 深入探讨语言模型压缩:
@ericauld分享了一篇 论文,讨论了各种 语言模型压缩算法,并邀请他人阅读和讨论。该论文探讨了在模型效率与准确性之间取得平衡的需求,并涉及了 剪枝 (pruning)、量化 (quantization)、知识蒸馏 (knowledge distillation) 等方法。
提到的链接:
A Comprehensive Survey of Compression Algorithms for Language Models:如何在不牺牲准确性的情况下压缩语言模型?为了从近期语言模型的显著进步中获益,语言模型压缩算法的数量正在迅速增长……
HuggingFace ▷ #diffusion-discussions (1 messages):
- 寻求跨命名空间的相似度查询逻辑:用户
@abhisheknegi_12043正在寻求指导,希望为一个涉及会议记录 Embedding 的项目创建一种查询逻辑,该逻辑可以确定 Pinecone 中多个命名空间 (Namespace) 之间的相似度。他们正在寻求有关此功能的方案设计和实现策略的建议。
HuggingFace ▷ #computer-vision (1 messages):
merve3234: 这不是错误而是一个警告,可以放心忽略。
HuggingFace ▷ #NLP (2 messages):
- 寻求开源贡献的 GPU 资源:用户
@lpbb正寻求为 nanotron 库做贡献,并正在寻找两个互联的 GPU 用于测试代码。他们提到如果费用合理,愿意付费获取访问权限。 - NeuralBeagle14-7b 在 8GB GPU 上运行的演示:
@joshuasundance分享了一个 GitHub 仓库链接,演示了他们如何成功在本地 8GB GPU 上运行 neuralbeagle14-7b。该仓库为其他对类似配置感兴趣的人提供了展示。
提到的链接:
GitHub - joshuasundance-swca/llamacpp-langchain-neuralbeagle-demo: a small demo repo to show how I got neuralbeagle14-7b running locally on my 8GB GPU: 一个小型演示仓库,展示我如何让 neuralbeagle14-7b 在我的 8GB GPU 上本地运行 - GitHub - joshuasundance-swca/llamacpp-langchain-neuralbeagle-demo: a small demo repo to show how I got neuralbe…
HuggingFace ▷ #diffusion-discussions (1 messages):
- 寻求跨命名空间的相似性逻辑:
@abhisheknegi_12043正在开发一个使用 Pinecone 进行向量嵌入 (vector embedding) 以存储会议记录向量的项目。他们请求协助设计一种跨多个命名空间 (namespaces) 获取相似性的逻辑。
LAION ▷ #general (72 messages🔥🔥):
- 合成教科书数据集搜索:用户
@alyosha11为一个类似于phi的项目寻找合成教科书数据集,@JH指出在另一个 Discord 频道 (#1185268316001009785) 中有正在进行的努力,@alyosha11表示已去查看。 - MusicLM 音频文件难题:
@finnilda在训练 MusicLM Transformer 时因缺失音频文件而面临问题,并询问所需数据集的来源。他们注意到 GitHub 上缺乏回应,因此寻求 Discord 社区的帮助。 - 过滤未成年内容:
@latke1422p请求帮助使用触发词数据集过滤包含未成年主题的图像,表达了构建更安全的 AI 内容审核工具的需求。 - Discord 上的研究导向 Ping:包括
@astropulse、@progamergov和@.undeleted在内的多位用户就研究服务器上使用 ‘@everyone’ ping 的适当性展开了讨论,尽管意见不一,但共识倾向于考虑到服务器的研究重点,这是可以接受的。 - 发现 VAE 训练错误:
@drhead透露发现 kl-f8 VAE 错误地打包了信息,这偏离了预期的训练方法,影响了依赖它的模型。这引发了讨论,并由@.giacomov链接了一篇讨论 Transformer 学习中伪影的相关研究论文。
提到的链接:
- Vision Transformers Need Registers:Transformer 最近已成为学习视觉表征的强大工具。在本文中,我们识别并表征了监督和自监督特征图中的伪影…
- GitHub - lucidrains/musiclm-pytorch: Implementation of MusicLM, Google's new SOTA model for music generation using attention networks, in Pytorch:MusicLM 的 Pytorch 实现,Google 使用注意力网络进行音乐生成的最新 SOTA 模型 - GitHub - lucidrains/musiclm-pytorch: Implementation of MusicLM, Google's …
LAION ▷ #research (19 messages🔥):
- LLaVA-1.6 发布:
@nodja分享了 LLaVA-1.6 发布博客文章,强调了其改进的功能,如更高的图像分辨率和增强的 OCR。LLaVA-1.6 在多个基准测试中显著超越了 Gemini Pro。 - LLaVA-1.6 在漫画测试中表现出色:
@nodja测试了 LLaVA-1.6 在不同难度的漫画测试中的表现,称其在简单版本中“几乎完全正确”,而中等版本则出现了更多幻觉(hallucinations)。 - 摄影地标识别:
@helium__比较了 LLAVA 与 GT4-V 在识别个人照片中的欧洲城市时的表现,GT4-V 准确命名为波尔图(Porto),而 LLAVA 难以给出具体名称。 - 多模态模型能力受到质疑:
@mfcool询问了 Dall-E 等 VLM 实现风格保留的机制,观察到其他模型倾向于泛化,而 Dall-E 能准确反映特定风格。 - 引入 SPARC 用于细粒度多模态表示:
@spirit_from_germany分享了一个关于 SPARC 的 Twitter 链接,这是一种用于预训练具有细粒度细节的多模态表示的新方法,但@twoabove和@mkaic表示虽然很兴奋,但目前还没有可用的代码或模型。
提到的链接:
- LLaVA-1.6:改进的推理、OCR 和世界知识:LLaVA 团队推出了 LLaVA-1.6,具有改进的推理、OCR 和世界知识。LLaVA-1.6 在多个基准测试中甚至超过了 Gemini Pro。
- LLaVA:未找到描述
- 来自 Ioana Bica (@IoanaBica95) 的推文:对 CLIP 的通用性感到兴奋,但需要在表示中获得更细粒度的细节?介绍 SPARC,一种简单且可扩展的预训练细粒度多模态表示的方法…
Perplexity AI ▷ #general (37 messages🔥):
-
对自定义 GPT 的好奇:
@sweetpopcornsimon表示有兴趣训练类似于使用 ChatGPT 构建自定义 GPT 的私有模型。@icelavaman澄清说 Perplexity AI 不提供聊天机器人服务,而是提供一个名为 Collections 的功能,可将线程组织成可共享的空间进行协作。 -
PDF/EPUB 阅读器查询:
@archient询问社区是否存在支持 AI 文本处理并能够使用自定义 API 的 epub/PDF 阅读器。 -
寻找独特的通知声音:
@noell5951询问 Perplexity 是否有独特的通知声音,表示他们还没试过但很好奇。 -
寻求 Perplexity AI Pro 的建议:
@johnl4119提出了一个关于 Perplexity AI Pro 的“如何使用”问题,并由@ok.alex引导至“quick-questions”区域进行提问。 -
遇到 Prompt 消失问题:
@nuggdavis报告了一个异常问题,即 Prompt 在刷新后获取响应前会短暂消失,该问题发生在多个浏览器和操作系统上。@gumby2411确认有类似经历。
提到的链接:
- 什么是 Collections?:访问 Perplexity 博客阅读文章、公告、产品更新和优化体验的技巧。保持资讯更新并充分利用 Perplexity。
- Perplexity 招聘:加入我们的团队,共同塑造搜索和知识发现的未来。
Perplexity AI ▷ #sharing (2 messages):
- Perplexity 对 Google 未来的见解:用户
@m1st3rg分享了一个简短而神秘的见解,声称通过使用 Perplexity 的经验了解到了 Google 的未来。 - 关于使用 Perplexity 进行内容创作的 YouTube 指南:
@redsolpl提供了一个 YouTube 视频链接,标题为“我如何使用 Perplexity AI 为 LinkedIn 寻找内容创意”,描述了他们如何有效地将 Perplexity AI 集成到他们的社交媒体 内容创作流程 中。
提到的链接:
我如何使用 Perplexity AI 为 LinkedIn 寻找内容创意:深入探讨我如何使用 Perplexity AI 彻底改变我的社交媒体内容创作流程。无论你是内容创作者、商业人士…
Perplexity AI ▷ #pplx-api (31 messages🔥):
- 寻求支持:用户
@angelo_1014表达了对未收到 support@perplexity.ai 回复的担忧,@ok.alex回复请其确保使用了正确的联系邮箱,并提议如果通过 DM 提供个人邮箱,将协助核查此事,@angelo_1014确认已发送。 - Codellama 难题困扰:
@bvfbarten.报告了 codellama-70b-instruct 模型的异常响应,@ok.alex保证将对此问题进行调查。随后的对话确认 codellama-34b-instruct 模型运行稳定。 - 解析 API 难题:
@andreafonsmortigmail.com_6_28629讨论了在聊天框界面处理文件上传的复杂性,@clay_ferguson建议使用 Apache Tika 从文件中提取文本,并指导了不涉及 API 上传的文件上传流程。 - 破译在线模型:在
@kid_tubsy发起的关于 API 模型列出数据链接/来源能力的讨论中,@brknclock1215澄清了 -online 模型可以访问实时互联网数据,但在响应中不提供引用。@clay_ferguson认为尽管缺乏来源引用,该功能依然非常有益。 - 模型来源至关重要:
@brknclock1215强调了在使用具备在线能力的模型时,获取来源 URL 对于验证信息和克服幻觉(hallucinations)问题的重要性,特别是对于需要验证数据以生成面向客户报告的研究工作。
LangChain AI ▷ #general (38 messages🔥):
- Langchain 与向量搜索困境:
@abhisheknegi_12043寻求关于在多个 Pinecone namespaces 中获取相似性逻辑的建议,以便存储会议记录;而@agenator.报告了使用 Langchain 和 ChromaDB 查询大型 JSON 文件时的问题,仅能获得部分数据响应。 - Embeddings 实践:针对如何使用 OpenAI 处理 embeddings 的咨询,
@agenator.分享了一段使用 Langchain 和 Chroma 进行 Document embeddings 的 Express.js 代码片段。 - 用于股市分析的 AI:
@funk101.正在寻找一种能够分析“实时”股市信息并根据现有数据做出响应的 AI 解决方案。 - Pinecone 难题:
@bardbuddy因 TypeError 以及 langchain/pinecone 软件包的更新,在运行旧版 Langchain 应用时遇到困难,正寻求针对此问题的即时帮助。 - Mixture of Agents 概念:
@the_agent_j探讨了在被称为 Mixture of Agents 的系统中使用针对特定 Agent 类型进行微调的模型的想法,并考虑利用 OpenAI 的自定义 GPTs 来承担专业角色。
提到的链接:
- no title found: 未找到描述
- Thumbs Up Like GIF - Thumbs Up Like Thumbs Up Gif - Discover & Share GIFs:点击查看 GIF
- SkmAI: AI-Powered YouTube Video Search:搜索任何语言的视频,利用 AI 找到最相关的片段和时间戳。
LangChain AI ▷ #share-your-work (9 messages🔥):
-
LangGraph 开启 AI 协作新视野:
@andysingal分享了一篇题为《揭秘 LangGraph 的 AI 协作未来:拥抱多 Agent 工作流》的文章。在 Medium 文章 中阅读关于下一代工具 LangGraph 及其在多 Agent AI 系统中作用的内容。 -
视觉画布咨询:
@nbbaier询问了在一段未指明的视频中看到的视觉画布所使用的平台/工具。 -
Node.js 方面的麻烦:
@bardbuddy在运行一个旧的 LangChain 应用时遇到了错误,原因似乎是 LangChain API 的更新,特别是与PineconeStore和PineconeClient相关的部分。 -
语言识别错误的小插曲:针对
@bardbuddy的错误,@johnny2x2误以为代码片段可能是 C 语言,但@bardbuddy澄清该问题涉及 Node.js。 -
不请自来的邀请链接分享:
@cryptosmiler发布了一个加入 Discord 服务器的邀请,包含一个 5 次使用的邀请码,希望能赶在邀请码用完前得到快速响应。
提及的链接:
Unveiling the Future of AI Collaboration with LangGraph: Embracing Multi-Agent Workflows:Ankush k Singal
LangChain AI ▷ #tutorials (1 messages):
- 深入探索 LangChain 与 OpenAI Embeddings:
@datasciencebasics分享了一个关于在 LangChain 中使用新 OpenAI Embeddings 模型 的 YouTube 视频教程。视频涵盖了 OpenAI 发布的新 Embeddings 模型、GPT-3.5 Turbo 的更新,以及供开发者管理 AI 应用的新工具。
提及的链接:
How To USE New OpenAI Embeddings Model with LangChain 🦜🔗:OpenAI 推出了新的 Embeddings 模型。他们正在发布新模型,降低 GPT-3.5 Turbo 的价格,并为开发者提供管理 AI 应用的新方式…
LlamaIndex ▷ #blog (2 messages):
- 调优混合搜索(Hybrid Search)是关键:LlamaIndex 强调,在使用检索增强生成(RAG)系统时,混合搜索需要针对不同类型的问题进行调整。存在如 Web 搜索查询和概念寻求等类别,每种类别都需要独特的方法 Twitter 线程。
- 深入探讨多模态 RAG 系统:
@_nerdai_的一段新视频专注于使用 LlamaIndex 评估多模态 RAG 系统,内容涵盖 RAG 简介、评估技术、构建多模态 RAG 以及面临的挑战 YouTube 链接更新通知 关于视频的推文。
提及的链接:
no title found:未找到描述
LlamaIndex ▷ #general (43 messages🔥):
-
寻求将向量转储到 OpenSearch:用户
@natuto_uzumaki1808请求帮助将本地向量嵌入(embedding)文件转储到 OpenSearch 数据库,并标记了特定成员寻求协助,但未提供更多背景或细节。 -
关于 RAG 上下文大小的好奇:
@wrapdepollo询问了 RAG 上下文大小对检索到的 chunks 的影响,引发了@Teemu的简短确认,@cheesyfishes进一步澄清了 LlamaIndex 如何处理超大上下文,最后@wrapdepollo表示感谢。 -
关于 LlamaIndex 中针对代码的 RAG 查询:
@richard1861询问是否有使用 LlamaIndex 对代码进行 RAG 的教程,并参考了 Langchain 的方法。@Teemu和@cheesyfishes参与了讨论,@cheesyfishes邀请大家为更好的代码分块(code splitting)做出贡献,@rawwerks分享了从 Langchain 提取的用于获奖黑客松作品的代码片段。 -
查询 KeywordIndex 的替代存储方案:
@mysterious_avocado_98353询问了在大规模数据摄取场景下,KeywordIndex 的云端存储解决方案。@cheesyfishes指引其参考 docstore+index_store 集成,并提供了一个 URL 示例。 -
API 选择对话:
@mrpurple9389询问了在 assistant API 和 completions API 之间的偏好,@hosermage寻求关于创建服务器 REST 端点的建议,@whitefang_jr建议使用 LlamaIndex 文档中的 create-llama。
提到的链接:
- Node Parser Modules - LlamaIndex 🦙 0.9.40:未找到描述
-
[RAG over code 🦜️🔗 Langchain](https://js.langchain.com/docs/use_cases/rag/code_understanding):使用案例 - llama_index/llama_index/vector_stores/postgres.py at main · run-llama/llama_index:LlamaIndex(原 GPT Index)是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- Starter Tutorial - LlamaIndex 🦙 0.9.40:未找到描述
- Redis Docstore+Index Store Demo - LlamaIndex 🦙 0.9.40:未找到描述
- Full-Stack Projects - LlamaIndex 🦙 0.9.40:未找到描述
- Chat Engine - LlamaIndex 🦙 0.9.40:未找到描述
LlamaIndex ▷ #ai-discussion (1 messages):
leonms123: 嗨,有人愿意教我使用 Python 进行 ML 吗 😄
Eleuther ▷ #general (10 messages🔥):
- 早安问候:
@andrei.alcaza在频道中发布了简单的“morning”并配以挥手表情。 - 寻找可视化图表:
@dpaleka寻求帮助寻找高质量的 Transformer decoder tikz 或包含该图表的 arXiv 论文 引用。 - 泄露模型事件进展:
@hailey_schoelkopf分享了来自 @arthurmensch 的推文,讨论了一名“过度热情的员工”泄露了他们之前训练并公开分发的旧模型的水印量化版本。 - 文化解读:针对
@arthurmensch使用的“过度热情”一词,@carsonpoole表示觉得很有趣,随后@catboy_slim_幽默地将其比作美国南方的表达方式“bless your heart”。 - 寻找 Diffusion 模型排行榜:
@carmocca询问是否存在类似于 HF eval leaderboard 的 diffusion models 排行榜。
提到的链接:
Arthur Mensch (@arthurmensch) 的推文:我们早期访问客户的一名过度热情的员工泄露了一个旧模型的量化(且带水印)版本,该模型是我们之前训练并相当公开地分发的。为了快速开始使用…
Eleuther ▷ #research (14 messages🔥):
-
不同模型架构中揭示的引人注目的规模效应:
@the_random_lurker强调了一项研究(Scaling Properties of Transformer Models),该研究表明模型架构是一个重要的缩放考量因素,且性能在不同规模下可能会波动。他们质疑为什么这一发现还没有成为主流。 -
关于 Mixtral 持续预训练的咨询:
@quicksort询问是否有关于 MoE 模型(如 LeoLM)针对低资源语言进行持续预训练的论文、仓库或博客文章。这表明了人们对改进语言模型预训练方法的兴趣。 -
ImageNet 预训练中的矛盾:
@micpie分享了一项研究(Pre-training Time Matters),揭示了在 ImageNet 上预训练不足的模型有时会根据任务的不同而优于完全训练的模型。这指向了预训练时长与模型在不同应用中的效率之间存在复杂关系。 -
寻求关于门控卷积架构的见解:
@afcruzs请求提供用于比较门控卷积架构(gated convolutional architectures)的资源,@mrgonao也表达了类似的兴趣。同时,@nostalgiahurts提供了一个 GitHub 仓库 和一篇 博客文章,这些资源可能会为这些架构提供启发。 -
讨论推理过程中的 Token 离散化:
@sentialx询问了在推理过程中离散化 Token 的必要性,而不是反馈 Token embeddings,@xylthixlm回复称这是由于训练期间自回归生成的需要。这反映了语言模型推理过程中的典型实践。
提到的链接:
- Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?:人们对 Transformer 模型的缩放特性产生了浓厚兴趣。然而,在调查不同归纳偏置(inductive bias)的缩放特性影响方面做得还不够……
- Towards Inadequately Pre-trained Models in Transfer Learning:预训练一直是深度学习时代流行的学习范式,尤其是在标注不足的场景下。从……的角度来看,已经证明了更好的 ImageNet 预训练模型。
- GitHub - srush/do-we-need-attention:通过在 GitHub 上创建账户来为 srush/do-we-need-attention 的开发做出贡献。
-
[The Essense of Global Convolution Models AI Bytes](https://benathi.github.io/blogs/2023-12/global-convolution-models/):未找到描述
Eleuther ▷ #interpretability-general (3 messages):
- n-gram 模型的复兴:
@80melon分享了一篇研究论文,该论文重新审视了 n-gram 语言模型,重点介绍了一种新颖的 $\infty$-gram 模型和一种名为 infini-gram 的新计算引擎。他们对这些 n-gram 模型在与 Llama-2 70b 等大型神经模型结合时,如何显著提高困惑度(perplexity)分数感到惊讶。 -
泛化 vs. 记忆:尽管困惑度有所改善,但
@80melon推测使用自适应长度的 n-gram 模型可能会削弱神经语言模型的泛化能力,尽管该研究尚未对此进行测试。 - 理解 Transformer 的记忆机制:
@ishitatsuyuki提出了一个关于 Transformer 记忆 n-gram 能力的现有研究问题,并引用了一项使用自动机(automata)的研究(可在此处找到)。他们好奇生成的自动机是否足够紧凑以表示庞大的词汇表。
提到的链接:
Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens:在这个神经大语言模型(LLM)时代,n-gram 语言模型是否仍然具有相关性?我们的答案是肯定的,并展示了它们在文本分析和改进神经 LLM 方面的价值。然而,这需要……
Eleuther ▷ #lm-thunderdome (12 messages🔥):
- 对 PyPI 自动化的简短致谢:
@hailey_schoelkopf向@1186960329738039357提交的自动化 PyPI 打包 Pull Request 表示感谢,称其运行效果非常好。 - Language Model Evaluation Harness 0.4.1 发布:
@hailey_schoelkopf分享了 Language Model Evaluation Harness 0.4.1 的 PyPI 发布版本 和 GitHub Release 链接。该版本包含内部重构、使用 Jinja2 简化 Prompt 设计,以及优化的 Data-parallel 模型使用。 - PR 致谢及待处理的 Review:
@anjor_20331对自动化成功表示感谢,并确认有一个待处理的 PR,将在忙完后进行 Review。 - 对 Few-shot 示例 Log 输出的关注:
@Goyim询问是否能在log_samples输出中包含 Few-shot 示例,或者提前获知将使用哪些示例。 - 关于 MMLU 评估指标的澄清:
@daniellepintz寻求关于 MMLU 评估结果的解读帮助,@stellaathena澄清准确率为 40.2%,标准误差为 +/- 20.7%,@baber_质疑结果是否是在有限制参数的情况下计算的。@daniellepintz分享了一个 gist,怀疑其 LM 子类实现存在问题。
提到的链接:
- gist:c48c9e61a9a4798552b6ac22bc3a1959:GitHub Gist:即时分享代码、笔记和片段。
- lm-eval:一个用于评估语言模型的框架。
- Release v0.4.1 · EleutherAI/lm-evaluation-harness:发布说明。此 PR 发布包含了自 v0.4.0 发布以来的所有更改,并且在一定程度上是对由 @anjor 提供的发布自动化的测试。从高层级来看,部分更改包括…
Eleuther ▷ #multimodal-general (4 messages):
- 训练 VQA 系统计算成本的不确定性:
@stellaathena询问关于训练一个体面的图像编码器和 LLM 以用于 Visual Question Answering (VQA) 的计算成本指导或经验法则,并承认目前缺乏准确的数据。 - 寻求关于 Encoder-Decoder 模型的共识:
@stellaathena还询问目前的共识是否仍认为 Encoder-Decoder 模型在文本和图像转文本 (T+I -> T) 领域更具优势。 - 请求明确模型应用场景:
@kublaikhan1回应了@stellaathena关于 T+I -> T 的 Encoder-Decoder 模型的疑问,寻求相关应用或背景的进一步澄清。 - 关于训练 llava 的见解:针对 VQA 系统讨论,
@kublaikhan1提到训练 llava(一种适用于此类任务的模型)大约需要 8x24 A100 小时。
CUDA MODE (Mark Saroufim) ▷ #general (17 条消息🔥):
-
Python 进行 CUDA 开发的见解:
@neuralution强调了使用 Python 进行 CUDA 开发的优势,引发了关于性能优化以及与 NVIDIA 工具兼容性的讨论。他们提出了具体关注点,例如在将 PyTorch 类型集成到 C++ 输出二进制文件时,如何确保良好的 Occupancy(占用率)、识别瓶颈以及缓存使用情况。 -
Flash Attention 2 PyTorch 教程:
@iron_bound分享了由 Driss Guessous 编写的关于 Flash Attention 2 的 PyTorch 教程,并附带了详细示例代码的链接以及关于 scaled_dot_product_attention 的额外背景信息。 -
NVIDIA 全新的 Multi-Query Attention 内核:
@dshah3介绍了 NVIDIA 开源的用于 Multi-Query 和 Grouped-Query Attention 的 XQA 内核,该内核在不增加延迟的情况下提升了 Llama 70B 的 Throughput(吞吐量)。 -
PyTorch Attention 问题公开对话:
@drisspg邀请大家就 PyTorch 2.2 的 Flash Attention 2 实现进行提问,并分享了关于即将推出的更新的见解,同时将其与 Tri 仓库中的 FA-2 版本进行了对比。 -
Nested Tensors 成为正式功能:
@andreaskoepf和@jeremyhoward讨论了 PyTorch 中 NestedTensors 的实用性和官方地位,@tvi_建议在用可能尚未完全支持 NestedTensors 的 torch.compile 替换打包代码时要保持谨慎。
提到的链接:
- (Beta) Implementing High-Performance Transformers with Scaled Dot Product Attention (SDPA) — PyTorch Tutorials 2.2.0+cu121 documentation:未找到描述
- NVIDIA Gen AI on RTX PCs Developer Contest:参加活动赢取 GeForce RTX 4090 GPU、GTC 活动门票等奖品。
- TensorRT-LLM/docs/source/blogs/XQA-kernel.md at main · NVIDIA/TensorRT-LLM:TensorRT-LLM 为用户提供了一个易于使用的 Python API,用于定义 Large Language Models (LLMs) 并构建包含最先进优化技术的 TensorRT 引擎,以高效执行推理…
- [RFC] Scaled Dot Product Attention API Changes · Issue #110681 · pytorch/pytorch:更新的 SDPA API 作者:@drisspg 摘要:为了让用户更轻松地管理各种 bias 格式的处理复杂性,我们希望开放传递派生自 AttnBias 的能力…
- pytorch/aten/src/ATen/native/transformers/cuda/sdp_utils.cpp at main · pytorch/pytorch:Python 中具有强大 GPU 加速功能的 Tensor 和动态神经网络 - pytorch/pytorch
- torch.nn.attention.sdpa_kernel — PyTorch main documentation:未找到描述
- (Beta) Implementing High-Performance Transformers with Scaled Dot Product Attention (SDPA) — PyTorch Tutorials 2.2.0+cu121 documentation:未找到描述
CUDA MODE (Mark Saroufim) ▷ #triton (1 条消息):
iloveh8: 明白了,谢谢
CUDA MODE (Mark Saroufim) ▷ #cuda (7 条消息):
- Jeremy 的 Notebook 错误已解决:用户
@arsalan6990在尝试运行 Jeremy 的 Notebook 时遇到了错误。感谢@drisspg,通过引用 GitHub issues 找到了解决方案,特别是涉及 CUDA 版本与编译 PyTorch 的版本不匹配的问题(CUDA 12.0 Issue)以及 CUDA 12.1 的模板相关错误(Cuda 12.1 Template Issue)。修复方案需要安装 g++ 和 gcc 11,并确保 GLIBCXX_3.4.32 可用。 - 计算资源的成本效益建议:
@nshepperd建议配置大量的 CPU RAM 是有益的,因为它比 GPU RAM 便宜得多,每 GB 的成本大约仅为后者的 1/10。 - C++ 模板说明:在解决错误的背景下,
@zippika解释了 C++ 模板中typename的用法,详细说明了它是模板定义中替换类型的占位符。
提到的链接:
- Does not compile on CUDA 12.0 · Issue #7 · qwopqwop200/GPTQ-for-LLaMa:在运行 setup_cuda.py 安装时,我最初遇到:RuntimeError: The detected CUDA version (12.0) mismatches the version that was used to compile PyTorch (11.8). Please make sure to use…
CUDA MODE (Mark Saroufim) ▷ #torch (1 条消息):
- 选择性编译咨询:用户
@marvelousmit询问是否可以仅编译 PyTorch 中的模型层,而排除一个在运行时调用且不打算编译的自定义算子(operator)。他们提供了一个代码片段,展示了一个forward()方法调用func_not_compile()后接layers_compile(),并询问了关于使用类似torch.compile(model)的问题。
CUDA MODE (Mark Saroufim) ▷ #beginner (12 条消息🔥):
- CUDA 兼容性确认:
@noobpeen询问 CUDA 11.8 是否可以正常使用,因为之前为了深度学习已经安装了它。@lancerts确认这应该是没问题的,并提供了一个 NVIDIA 文档链接,其中详细介绍了 CUDA Data Stack 的限制以及cuCtxGetLimit()和cuCtxSetLimit()等函数。 - 在 VSCode 中调试 CUDA:
@andreaskoepf指出在 VSCode 中进行 CUDA 调试 是可行的,尽管设置过程略显复杂,并分享了 相关 NVIDIA 文档的链接。 - CUDA Kernel 调试咨询:
@jeremyhoward询问了关于调试从 PyTorch 调用的 CUDA kernel 的问题,特别是通过 just-in-time (jit) 扩展调用的情况。在这些消息中没有提供直接的解决方案。 - Kernel 开发方法:
@andreaskoepf描述了他们的开发流程:从 PyTorch 参考实现开始,然后创建一个自定义 kernel 以通过torch.allclose()测试。@marksaroufim对此表示赞同,并提到在 PyTorch 内部也观察到了类似的实践。 - 测试框架偏好:
@andreaskoepf表示在开发过程中更倾向于使用原始 Python 文件或 Jupyter notebooks 而非 pytest,理由是 pytest 增加了复杂性。@marksaroufim幽默地提到看到测试通过时显示的圆点和绿色会感到满足,而@andreaskoepf则开玩笑说会得到随机的失败(F)和通过(圆点)模式,以及偶尔的 pytest 崩溃。
提到的链接:
- Walkthrough: Debugging a CUDA Application:未找到描述
- Getting Started with the CUDA Debugger :: NVIDIA Nsight VSCE Documentation:未找到描述
CUDA MODE (Mark Saroufim) ▷ #pmpp-book (3 条消息):
- CUDA Block Size 匹配:
@lancerts询问 block size 是否必须与tile_width匹配,特别是当 block 维度为dim3(32,32,1)的配置在tile_width为 16 的情况下运行且没有报错时。@vim410警告说,虽然可能观察不到即时错误,但如果没有边界检查(bounds checking),可能会遇到非法内存错误(illegal memory errors),并指出分配比实际工作所需更多的线程通常是不合逻辑的。 - 理解 CUDA 中的线程粗化 (Thread Coarsening):
@lancerts寻求关于线程粗化代码细节的澄清,询问threadsPerBlock和numBlocks的合适维度。该查询将粗化版本与使用矩形线程块形状的普通平铺(tiled)版本进行了对比,说明了开发者在优化 CUDA 编程中的线程分配时常见的困惑。
DiscoResearch ▷ #mixtral_implementation (21 条消息🔥):
- Mistral Medium 的身份危机:
@sebastian.bodza建议 Mistral Medium 可能基于 Llama 70B,并引用了一篇 Twitter 帖子,指出两者回答的相似性。 - 泄露模型阴谋论盛行:用户
@sebastian.bodza和@devnull0讨论了 Miqu 实际上是 Mistral 量化版(quantized)的理论,这一观点得到了 Twitter 讨论的支持,包括 @sroecker 的推文以及 @teortaxesTex 的另一篇推文,后者指出了 Mistral 和 Miqu 输出之间的相似之处。 - Mistral 的商业化之路:
@sebastian.bodza对 Mistral 提供优秀模型的努力可能被 Mixtral 等更便宜的泄露版本削弱表示失望,而@devnull0则质疑他们是否真的是为了钱。 - 辩论模型水印 (Watermarking):在关于通过水印识别泄露模型的猜测中,
@philipmay表示怀疑,而@mariowolframm和@devnull0讨论了独特的数据组合或 token 作为水印在量化过程中存续的可能性。
提到的链接:
- 来自 Q (@qtnx_) 的推文:提醒 Mistral 正在训练 70B 模型 https://techcrunch.com/2023/11/09/theres-something-going-on-with-ai-startups-in-france/
- 来自 Teortaxes▶️ (@teortaxesTex) 的推文:确凿的证据(smoking gun)不是聚合的 r 值,而是很大一部分项目完美地落在趋势线上,这表明它们具有相同的认知电路。这是一个典型的 EQ-Bench 项目 (https://arxiv…
- 来自 Steffen Röcker (@sroecker) 的推文:我想相信:MIQU = MIstral QUantized 🛸 ↘️ 引用 Teortaxes▶️ (@teortaxesTex) 可能晚了点,但我现在 100% 确信 Miqu 就是可以作为 Mistral-Medium 访问的那个模型…
DiscoResearch ▷ #general (10 messages🔥):
- Hermes 2 数据集发布:
@teknium向社区分享了他们发布的 Hermes 2 数据集,可通过 Twitter 访问。该数据集对于对 AI 研究和开发感兴趣的人士可能非常有价值。 - 社区对该数据集的热爱:针对
@teknium的发布,@hammadkhan用一个衷心的感谢表情表达了对 Hermes 2 数据集发布的感激之情。 - 对 Lilac 集成的实用性赞赏:
@devnull0称赞了 Hermes 2 数据集中的 Lilac 集成,表明该功能在社区中广受欢迎。 - 苹果工程师的提示词编写难题:
@devnull0分享了一个关于苹果工程师所需精力的幽默 Prompt,该内容源自@cto_junior在 Twitter 上的一条推文。 - 分享 Mixtral 令人印象深刻的性能指标:
@bjoernp强调了 Mixtral 惊人的速度,达到了每秒 500 tokens,并附上了 Groq 的聊天平台 链接,这引发了@sebastian.bodza对该公司使用定制 AI 加速器的后续追问。
提到的链接:
- GroqChat:未找到描述
- 来自 Stella Biderman (@BlancheMinerva) 的推文:@Dorialexander 这与跨语言指令微调(crosslingual instruction-tuning)的研究 https://arxiv.org/abs/2211.01786 也是完全一致的。我很确定有关于多语言之间线性映射的文献…
- 来自 TDM (e/λ) (@cto_junior) 的推文:编写这个 Prompt 需要多少个苹果工程师?
DiscoResearch ▷ #embedding_dev (8 messages🔥):
-
Mistral Embeddings 过拟合问题:
@devnull0分享了来自@Nils_Reimers的一条 推文,声称 Mistral 7B embedding 模型 在 MTEB 上严重过拟合,在训练任务以外的其他任务上表现不佳,特别指出了它们在电影情感分类等任务中的不足。 -
微软文本嵌入的新方法:
@sebastian.bodza引用了微软公司研究人员的一篇 研究论文,强调了他们使用合成数据生成高质量文本嵌入的新方法,简化了训练过程,并实现了显著的语言覆盖。 -
疑虑重重:尽管分享了这篇研究论文,
@sebastian.bodza对论文中的方法仍持 保留态度,对所提出的方法论表示了一定程度的怀疑。 -
为检索任务生成相关段落:在与
@thewindmom的讨论中,@sebastian.bodza提供了一个技巧:对于短到长的检索任务,需要在 Prompt 前加上 “Represent this sentence for searching relevant passages:” 以获得更好的结果。
提到的链接:
- 来自 Nils Reimers (@Nils_Reimers) 的推文:@abacaj 不值得。这些 Mistral 7B embedding 模型在 MTEB 上严重过拟合,通过为 MTEB 中的所有任务生成训练数据,然后训练一个 7B 模型来处理例如电影情感…
- Improving Text Embeddings with Large Language Models:未找到描述
DiscoResearch ▷ #discolm_german (1 messages):
philipmay: 你是如何为 DiscoResearch/DiscoLM_German_7b_v1 生成这个图表的?
LLM Perf Enthusiasts AI ▷ #gpt4 (2 messages):
- Prompt Investing 101:用户
@jeffreyw128询问了关于 prompt investing 的问题。 - 快速纠正:用户
@jxnlco将该术语纠正为 injecting(注入),从而澄清了讨论的主题。
LLM Perf Enthusiasts AI ▷ #opensource (3 messages):
- 抢先体验:
@jeffreyw128询问了尝试新模型的最佳地点,@thebaghdaddy回复了一个指向 Hugging Face’s Miqu-1 70B model 的链接,并指出这是潜在系列中的第一个。 - Prompt 格式建议:
@thebaghdaddy包含了关于 Mistral 模型 Prompt 格式 的指令,并警告不要更改 ROPE 设置,因为该模型使用了具有 32k seen tokens 的高频 base。 - 模型测试限制:
@thebaghdaddy表达了局限性,称“我太穷了没有 GPU (gpu poor),所以还没测试过”,表示由于缺乏 GPU 资源,他们尚未亲自测试该模型。
提到的链接:
miqudev/miqu-1-70b · Hugging Face: 未找到描述
LLM Perf Enthusiasts AI ▷ #openai (5 messages):
-
探寻模型能力的真相:
@joshcho_质疑了来自 @nickadobos 的推文 关于 AI 性能的真实性。问题中未提供关于 AI 或推文内容的具体细节。 -
对文档理解能力的失望:
@jeffreyw128分享了在文档性能方面的负面体验,表示“不知道如何从中获得性能”。 -
无奈时刻:
@joshcho_对利用文档能力的困难回应道“真悲哀”,并幽默地评论说“我们只能祈祷”。 -
关于 AI 在图像文本方面局限性的见解:
@thebaghdaddy表达了惊讶,似乎确认了 AI 的一个局限性,称这“解释了为什么它无法理解包含图片的知识文件”。
Skunkworks AI ▷ #general (5 messages):
-
为开源 AI 研究进行众筹:
@filipvv提出了众筹的想法,以为开源模型、fine-tunes 和 datasets 筹集资金。他们分享了 CryoDAO 和 MoonDAO 等项目示例,并提到由于在促进此类加密项目的平台 Juicebox 工作而存在偏好。 -
集思广益为开源训练筹集资金: 继续讨论,
@filipvv解释说,资金聚合可以支付更大规模的训练运行,从而使整个社区受益。目标是为开源 AI 项目提供更多资金,包括 Nous 和其他平台上的项目。 -
Hermes 2 数据集发布:
@teknium宣布发布他们的 Hermes 2 dataset,提供给社区使用。该数据集可以在他们的 推文 中找到。 -
HelixNet 架构介绍:
@yikesawjeez分享了来自@migtissera的帖子,宣布了 HelixNet,这是一种新型深度学习架构,包含 3 个 Mistral-7B LLM,设计类似于 DNA 螺旋结构。他们包含了 Hugging Face 上的模型链接,并提供了通过 agentartificial.com 的 Jupyter Hub 进行测试的访问详情,凭据为:user - forthepeople, pw - getitdone。
提到的链接:
- Migel Tissera (@migtissera) 的推文: 对开源 AI 来说是重大的一周,这里还有一个作为本周的收尾!介绍 HelixNet。HelixNet 是一种新型深度学习架构,由 3 个 Mistral-7B LLM 组成。它…
- yikes (@yikesawjeez) 的推文: 管他呢 https://jupyter.agentartificial.com/commune-8xa6000/user/forthepeople/lab user: forthepeople pw: getitdone 现在开始下载模型,快进来把 notebooks 保存到 ./wo…
AI Engineer Foundation ▷ #general (5 messages):
- 探索 Hugging Face 的 Transformers Agents:用户
@tonic_1链接到了 Hugging Face 上 Transformers Agents API 的文档,并指出该功能目前是实验性的,可能会发生变化。他们强调了三种类型的 Agent (HfAgent、LocalAgent 和 OpenAiAgent) 的存在,涵盖了从开源模型到本地模型以及来自 OpenAI 的封闭模型的各种用途。 - 寻求澄清:
@hackgoofer询问了关于 HFAgents 的解释,表示对@tonic_1分享的主题缺乏理解。 - 快速参与提议:
@tonic_1提到他们虽然还没有填写表格,但表达了对社区的热爱以及贡献的意愿。
提到的链接:
Agents & Tools:未找到描述
Alignment Lab AI ▷ #general-chat (2 messages):
- 游戏中的创意:用户
@magusartstudios提到正在开发一个利用各种工具和功能的 Roblox AI agent 插件。 - 澄清 OpenAI 的 Token 政策:
@metaldragon01指出 OpenAI 并不向公众提供免费 Token 用于开放模型。
Alignment Lab AI ▷ #alignment-lab-announcements (1 messages):
- Open Hermes 2.5 数据集发布:
@teknium宣布公开发布 Open Hermes 2.5 和 Nous-Hermes 2 数据集,这是一个用于改进 SOTA LLM 的综合集合,拥有超过 100 万个示例。该数据集由开源数据和合成数据集混合而成,可以在 HuggingFace 上访问。 - 数据集贡献致谢:公告感谢了为该数据集做出贡献的 Discord 社区成员,包括
<@1110466046500020325>、<@257999024458563585>、<@748528982034612226>、<@1124158608582647919>。 - 与 Lilac ML 的合作:
@teknium还强调了与 Nikhil 及 Lilac ML 的合作,将 Hermes 集成到他们的 HuggingFace Spaces 中,增强了探索和分析该数据集的能力。
提到的链接:
- teknium/OpenHermes-2.5 · Datasets at Hugging Face:未找到描述
- 无标题:未找到描述
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- 关于 DatasetteGPT 实用性的咨询:用户
@discoureur提出了一个问题,询问是否有人为诸如记忆配置步骤或辅助编写 Datasette 文档插件等流程设置了 DatasetteGPT。