ainews-qwen-15-released
Qwen 1.5 发布
中国 AI 模型 Yi、Deepseek 和 Qwen 因其强劲的性能表现正受到广泛关注。其中,Qwen 1.5 支持高达 32k token 的上下文长度,并兼容 Hugging Face transformers 以及量化模型。在 TheBloke Discord 社区中,讨论的主题包括 70B 参数大语言模型(LLM)的量化、基于 Mistral 的稀疏混合专家模型(Sparse MoE)Sparsetral 的推出、模型合并与微调的争议,以及用于角色生成的直接偏好优化(DPO)技术。Nous Research AI Discord 社区则涵盖了日文汉字生成的挑战、社交媒体上的 AI 诈骗,以及 Meta 在 SIGGRAPH 2023 上展示的 VR 头显原型。此外,讨论内容还涉及微调冻结网络,以及 bagel-7b-v0.4、DeepSeek-Math-7b-instruct 和 Sparsetral-16x7B-v2 等新模型。
2024年2月5日的 AI Discord 动态。我们为您检查了 20 个公会、308 个频道和 5078 条消息。预计节省阅读时间(按 200wpm 计算):418 分钟。
中国模型(Yi、Deepseek、Qwen,以及在较小程度上的 Zhipu)一直在悄然掀起风暴。Qwen 本周发布的版本 声称其性能优于 Mistral 和 Llama2 的同类模型:
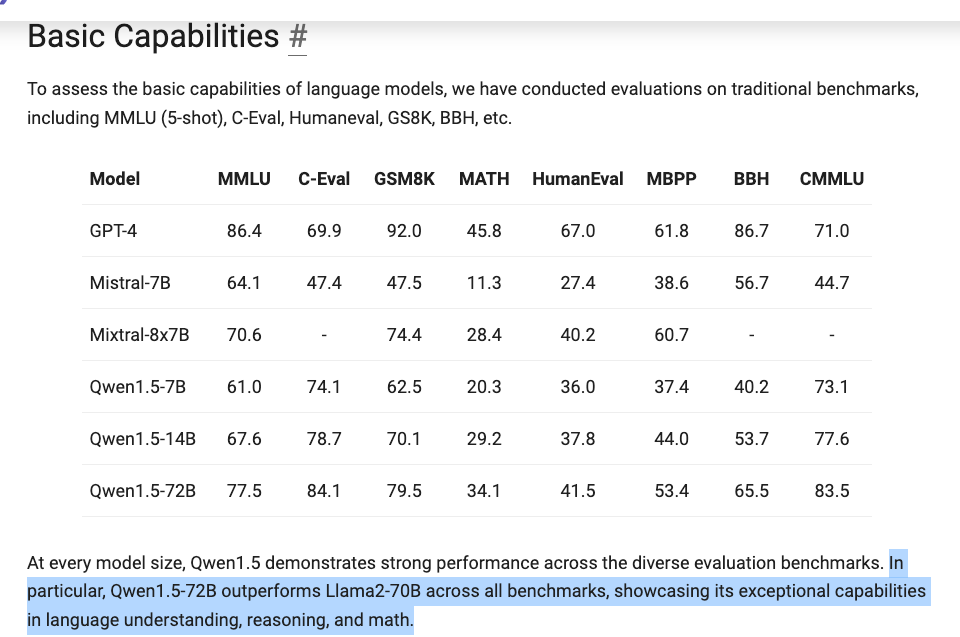
支持高达 32k token 的上下文。技术报告还讨论了在多语言、RAG、Agent 规划和代码生成能力方面进行的多次评估。Qwen 团队还表现出了对下游生态系统的极大投入,发布了兼容 HF transformers 的版本以及官方的 AWQ/GPTQ 4/8bit 量化模型。
目录
[TOC]
第一部分:Discord 高层摘要
TheBloke Discord 摘要
-
70B LLM 的量化探索:分享了在 vast.ai 上量化 70B LLM 的探索,并提出了创建大型 swap 文件以及可能使用 USB 连接的 SSD 来规避对高性能 GPU 需求的建议。
-
GPTZero 面临审查:关于 GPTZero 等 AI 内容检测工具有效性的辩论引发了讨论,强调了它在检测经过微妙增强的 Prompt 时可能存在的不确定性。
-
介绍 Sparsetral: 介绍了一种基于 Mistral 的新型 Sparse MoE 模型,强调了其高效运行和在前向传递过程中选择性应用权重的特点,引起了关注并引发了对其训练细节的询问。
-
模型合并与微调的抉择:关于是针对不同数据集分别微调模型,还是合并数据集并微调单个模型更有效,目前仍在进行辩论,社区普遍倾向于后者以保证连贯性。
-
AI 知识共享:社区成员讨论了涉及 LLM 性能和处理的一系列话题,包括增强记忆能力的策略和分享解决问题的战术,加强了公会内的协作精神。
-
深入探讨 DPO 和角色生成:交流了在使用 Direct Preference Optimization (DPO) 的训练过程中合并 adapter 的见解,重点关注角色扮演角色的生成,以及防止此类模型过拟合的策略。
-
古神风格 ASCII 艺术对话:使用各种模型创建 ASCII 艺术的尝试引发了关于语言模型在创意领域不断发展的能力的讨论。
-
模型合并之谜:对理解模型合并的渴望促使分享了深入研究相关张量操作的资源,并推荐了 ComfyUI-DareMerge 等工具来完成该任务。
-
编程讨论涵盖角色记忆和 3D 生成:出现了关于为特定角色设置 ChromeDB 长期记忆的咨询,同时还有 text-to-3D 生成式 AI 项目的推广、OpenAI 成本解决方案,以及带有详细解释的代码生成 LLM 链接分享。
Nous Research AI Discord 总结
-
汉字生成的复杂探索:社区讨论了训练日语汉字(Kanji)生成模型的挑战,
@lorenzoroxyolo引用了一个 Stable Diffusion 实验 作为灵感。.ben.com建议使用 Controlnet 作为处理此类细致任务的替代方法。 -
社交媒体上出现的 AI 诈骗:Facebook 等平台上 AI 相关诈骗的激增促使社区成员讨论了提高警惕的重要性,以及虚假叙事对 AI 认知的负面影响。
-
Meta 在 SIGGRAPH 展示先锋 VR 原型:Meta 在 VR 技术方面的进展,特别是具有视网膜分辨率和先进光场透视功能的新型头显原型,在 SIGGRAPH 2023 上进行了展示,并由
@nonameusr分享了来自 Road to VR 的相关文章和开发者博客文章。 -
微调冻结网络与新 AI 模型:讨论围绕微调冻结网络中归一化层(normalization layers)的有效性展开,如 一篇 arXiv 论文所述。同时分享了关于 bagel-7b-v0.4、DeepSeek-Math-7b-instruct 和 Sparsetral-16x7B-v2 等新模型的信息,这些模型分布在不同的 Hugging Face 仓库中,各具特色并提出了改进建议。
-
性能回顾与期待中的发布:社区仔细审查了不同模型的性能,包括 Qwen 1.5 的发布,一些人认为其表现不如前代。此外,还宣布了一个将在 23.9 小时内进行的未指明发布;fblgit 在 GitHub 上发布了一个新的模型相似度分析工具 (model-similarity),供社区贡献。
-
Transformer 矩阵与 LLM 对话记忆辩论:分享了实用的工程建议,例如为了提高效率而融合 Transformer 中的 QKV 矩阵。用户还探索了管理 LLM 对话历史的技术,提到了 LangChain 的潜在用途,以及通过总结历史或利用长上下文(long-context)模型来应对上下文大小限制的好处。此外,还对不同 Hermes 数据集之间商业用途许可变更表示了关注。
Eleuther Discord 摘要
-
构建 Foundational Models 的倡议引发关注:
@pratikk10寻求在创建 Foundational Models 方面的合作,认可其在 text-to-text/image/video 等领域的广泛应用。然而,@_3sphere强调了此类模型极高的成本,并结合新发布的 Qwen1.5(一个 72B 参数的 Chat 模型)讨论了此事,详情见其 blog post 和 repository。 -
探讨 LLMs 的可解释性:关于 Large Language Models (LLMs) 可解释性有效性的辩论随之展开,并将其与人类基因组计划类比,质疑可解释性与智能之间的关系。此外,还有对 AGI 主张和模型能力的批判性评估,特别是模型在 MMLU 等 Benchmark 上的真实表现。
-
Scaling Law 探索:
@stellaathena讨论了 Scaling Laws 研究中可能的效率提升,引用了 Kaplan 等人和 Hoffman 等人的研究,旨在减少多次运行的必要性。@clashluke等人思考了 PCGrad 在多任务 Loss 处理中的应用、Hypernetworks 在生成 LoRA 权重中的作用,以及使用多项式等不同激活函数的效果,并提供了 neural-style Python file 和 facebookresearch’s code 作为参考。 -
使用合并方差(Pooled Variance)进行严谨的模型评估:
@hailey_schoelkopf更新了 lm-evaluation-harness,使用合并方差来计算标准误差。相比组合方差,这是一种更优的选择,详见此处,这促使@stellaathena建议保留两种方法并附带专家使用警告。 -
辨析激活函数中的向量语义:
@digthatdata和@norabelrose在深度学习语境下剖析了向量作为方向、算子和欧几里得表示的概念,并介绍了[model-similarities](https://github.com/fblgit/model-similarity),这是一个用于分析不同模型层级参数空间的工具。 -
利用改写的网络数据改进 LM 预训练:诸如 Web Rephrase Augmented Pre-training (WRAP) 等新倡议(记录在 arxiv paper 中)旨在通过提高数据质量来增强大模型预训练。
@elliottdyson建议进行对比研究,以衡量 WRAP 相比单纯 Fine-tuning 的优势。
HuggingFace Discord 总结
-
从新手到专家的 AI 之旅:@dykyi_vladk 讨论了他们的 ML 学习曲线,重点关注特定模型和技术,而 @lunarflu 强调了“构建 demo 并分享它们”是成为 ML 专业人士的关键步骤。
-
A100G 发布可能导致服务器抖动:服务器停机引发了关于其与 A100G 发布关系的疑问;@lunarflu 提出将此问题上报。为了充分利用 AI 模型,@meatfucker 建议将任务分布在多个 GPU 上。
-
寻求计算机视觉专家:@danielsamuel131 邀请计算机视觉专家向社区分享他们的专业知识。
-
Papillon 展示 NER & 情感分析工具:由 @8i8__papillon__8i8d1tyr 开发的基于 Flair 和 FLERT 的 NER 和情感分析工具已分享;可在 GitHub 上找到。
-
LLaMA-VID 亮相长视频领域:@tonic_1 介绍了旨在支持长达一小时视频的 LLaMA-VID 模型。然而,用户对模型卡片空白和缺乏细节表示担忧,这可能会阻碍其使用。@jessjess84 还分享了一篇关于高性价比 LLM 策略的 arXiv 论文。
-
通过微调提升对话式 AI:@joeyzero 正在寻找用于微调聊天机器人的对话数据集资源。同时,@denisjannot 在微调 Mistral 7b 进行 YAML 生成时遇到困难,并关注 Instruqt 模型以寻求改进。@meatfucker 建议使用 few-shot learning 技术来进行精确的 YAML 修改。
-
Ankush 的微调造诣:Ankush Singal 基于 OpenPipe 之前工作的微调模型赢得了社区的赞誉。该模型可在 Hugging Face 获取。
-
读书会日程调整:由于陪审团义务,@ericauld 可能需要推迟计划好的演讲,@chad_in_the_house 对此表示支持。请关注活动日历以获取潜在变动。
-
以 Meme 揭示 AI 进展:@typoilu 发表了一篇文章,通过“Mamba Series LLM Enlightenment”中的一个 Meme 详细介绍了 AI 的进步,但社区对该内容的参与度仍有待观察。阅读文章请点击这里。
LM Studio Discord 总结
- 模型选择的困惑:面对众多模型,
@hades____寻求选择建议,得到的建议是关注使用场景而非寻找通用解决方案。 - DeepSeek-Math-7B 发布:DeepSeek-Math-7B 由
@czkoko发布,作为模型竞技场的新成员,专门用于数学问题解决和研究,可在 GitHub 获取。 - LM Studio 优化性能:LM Studio v0.2.13 带来了新功能,如 Qwen 1.5 支持、固定模型和聊天,以及体验优化更新,可在 LM Studio 官网 下载,开源的 Qwen1.5 模型可在 Hugging Face 获取。
- 硬件讨论升温:操作系统兼容性、GPU 利用率和 Token 生成速度优化主导了讨论,用户分享了在不同硬件配置上使用 LMStudio 的经验;建议包括使用 Ubuntu 22 和量化方法,如 YouTube 上的对比视频所示。
- Beta 版与功能期待:LM Studio v0.2.13 的 Beta 预览版发布并征求反馈,同时用户呼吁在应用内加入模型排行榜,目前可参考 Hugging Face Leaderboard 和 OpenRouter 的排名;服务器访问的 GUI 和改进的聊天界面是热门话题。
- RAG 系统问题生成的探索:
@varelaseb寻求在 RAG 系统中生成问题的技术,并询问了关于 Tuna 的信息,但目前相关背景资料较少。
Mistral Discord 总结
-
LangChain 不确定的未来:Discord 用户对 LangChain 效用的持久性表示担忧,建议在一周后进行稳定性评估。同时,Mistral 8x7B 的确定性特征受到审查,确认其概率行为可通过 temperature 参数调节,但关于确定性查询尚未达成最终结论。
-
Mistral 的表情符号终止怪癖:在 Mistral 模型中观察到一种奇特的终止行为,即响应以 “stop” 作为 finish_reason 结束,但内容仍包含表情符号。这一问题在所有三个 Mistral API 模型中均有出现,标志着响应构建中一个潜在的调试区域或洞察点。
-
AI 的哲学难题:讨论了 LLM 的哲学含义,参与者推动对 AI 基础原理的更深层理解。这次讨论强调了 AI 对更广泛智力领域影响的日益复杂性。
-
提示词精准实践:关于通过精炼提示词(Prompt)提高准确性的讨论非常活跃,其中分享的一种方法是将 PHP 类转换为 JSON schema。然而,尽管合成数据集生成是一个热门话题,但由于其作为收入来源的价值,相关方法仍被严格保密。
-
微调中的 Padding 痛点:用户表达了对微调(Fine-tuning)过程中 Padding 的担忧,指出在使用常见的
tokenizer.pad = tokenizer.eos做法时,模型无法生成句子结束标记(EOS tokens)的问题。这表明需要优化的微调方法来增强模型性能。 -
精简聊天机器人与 GitHub 成功:一个能够进行多用户交互并支持包括 Mistral 在内的多个 LLM 的 Discord 聊天机器人成为焦点,其代码仅 200 行,支持视觉(vision)功能和流式响应,获得了超过 69 个 GitHub stars。GitHub - jakobdylanc/discord-llm-chatbot
-
旗帜与快速 GIF:在轻松的互动中,用户分享了旗帜表情符号和幽默的 GIF,暗示了轻松活跃的社区动态。特别提到的是来自 Tenor 的 Sanic the Hedgehog GIF,在语言设置讨论的背景下因其幽默感而受到欢迎。Sanic The Hedgehob GIF - Tenor
CUDA MODE Discord 总结
-
双 GPU 配置的热情工程:社区成员
@morgangiraud正在组装一台配备 2 张 4070 TI SUPER GPU 的双卡机器,并权衡新旧显卡之间的 VRAM 得失。他们通过 PCPartPicker 分享了总价 4k 的配置单。 -
发布库以减轻 LLM 负载:
@andreaskoepf重点介绍了 FlashInfer,这是一个开源库,旨在通过优化 Self-Attention 和其他关键操作来提升 LLM 推理服务的性能。 -
困扰 PyTorch 程序员的精度难题:
@zippika在 PyTorch 中遇到了 dequantize 和 linear 操作的不准确问题并寻求原因,推测可能是舍入问题或与禁用的 C++ 标志(如"__CUDA_NO_HALF_OPERATORS__")有关。 -
JAX 中的 GPU Kernel 难题:
@stefangliga介绍了 Pallas,这是一个用于编写自定义 GPU/TPU kernel 的实验性 JAX 扩展;而@nshepperd分享了在 JAX 中使用纯 CUDA kernel 的见解。@marvelousmit询问了打印 Triton kernel 的方法以及 JAX 为 kernel profiling 执行的代码。 -
为 CUDA 开发者提供的录播资源:Mark Saroufim 向用户保证,尽管有技术延迟,第 4 课的录像已上传至 YouTube,并承诺很快会提供高清画质。
-
对 Fast.ai 的由衷青睐:用户
@einstein5744和@joseph_en对 fast.ai 的教育资源表示满意,特别是关于扩散模型(diffusion models)的课程和 DiffEdit 论文。 -
为 3 月 9 日聚会建言献策:
@jku100暂定于 3 月 9 日就其在torch.compile优化方面的工作发表演讲,该工作在 AI 加速技术方面展现了前景。 -
为 PMPP 第五课做准备:
@jeremyhoward将第 5 课安排在周末,并链接了 Discord 活动,而@lancerts询问了 PyTorch 博客中讨论的 “swizzled order” 概念及其在 PMPP 书籍中的覆盖情况。
OpenAI Discord 总结
- ChatGPT 文件上传功能故障:包括
@sherlyleta、@guti_310和@lugui在内的用户反映了 ChatGPT 文件上传功能 持续存在的问题,该功能自上周以来一直不稳定。@lugui提到解决方案即将出炉。 - 厂商讨论中的固件修复热潮:关于制造商对技术问题责任的辩论十分激烈,
@aipythonista主张将固件更新作为解决方案,而不是依赖像 Louis Rossman 那样的内容,理由是可能存在品牌偏见。 - Mistral GPT 替代方案受到关注:在讨论本地 GPT-3.5 实例以及
@elektronisade指出的不可行性时,@riaty推荐将开源的 Mistral 8x7b 用于家庭实验室诊断。 - 商标纠纷困扰 GPT 定制者:
@zurbinjo在为 GPT 命名时面临商标障碍,@solbus根据 OpenAI 的 品牌指南 澄清了相关禁令。 - 完善向 AI 提交 PDF 的方式:由
@wazzldorr发起的一场简短交流探讨了 AI 在处理科学论文时,是处理 PDF 还是 提取的文本 表现更好,@lugui确信 AI 能够有效处理 PDF。
LangChain AI Discord 总结
-
RunPod 和 BGE-M3 引起工程师关注:在 general 频道中,
@lhc1921强调了价格极具竞争力的 GPU 节点 RunPod,并介绍了 BGE-M3 多功能 Embedding 模型,提供了 GitHub 仓库 和研究 论文。@kapa.ai详细介绍了如何在 LangChain 中使用 OpenAIEmbedder,并引用了 LangChain JavaScript 文档 和 Python 文档。 -
LangServe 讨论中的 Bearer Token 和设置困扰:在 langserve 频道中,
@veryboldbagel分享了关于带有 Bearer Token 的 AzureGPT.setHeader 的技巧,参考了 Configurable Runnables 文档 和 APIHandler 示例。@gitmaxd提供了托管 LangServe 设置的 指南,而@lucas_89226和@veryboldbagel进行了故障排除讨论,并建议使用 LangServe GitHub 讨论页面 获取进一步帮助。 -
Share-Your-Work 频道展示创新成果和职位空缺:
@siddish在 Product Hunt 上介绍了 WorkHack 的 AI Form Roast,用于在线表单优化;@shving90通过 Twitter 帖子 展示了用于撰写推文的 TweetStorm Express Flow。@kerinin通过 博客文章 展示了用于 RAG 应用的 Dewy 知识库,而@hinayoka宣布了一个加密货币项目的职位空缺。@felixv3785展示了一个用于 SEO 的 反向链接外联消息生成器 工具。
Latent Space Discord 总结
-
AI 团队组建策略:关于建立内部 AI 工程团队的讨论建议先从 solo(单人)开始以展示价值,然后再进行扩展。推荐了 Eugene Yan 关于实时 ML 和团队配置的文章,展示了包括集中化和将数据科学家嵌入产品团队在内的各种组织策略。
-
DSPy 系列简化:关于 DSPy 的视频系列引发了对更易理解的解释的需求,表明社区已准备好协作掌握其概念。DSPy explained 视频 被分享给那些有兴趣了解更多信息的人作为起点。
-
GPT-4 是拖延者?:GPT-4 被感知的初始懒惰成为了一个有趣的话题,Sam Altman 的推文 和几个 Reddit 讨论也支持了这一点,根据分享的社区反馈,最终确认 GPT-4 现在应该“没那么懒了”。
-
构想中的哲学数字图书馆:拥有 AI 哲学 Agent 的数字图书馆概念引发了利用 Botpress 和 WorkAdventure 等工具进行开发的建议,表明了将哲学论述与 AI 技术融合的兴趣。
-
技术配置交流:像
@ashpreetbedi这样的工程师分享了他们的技术配置,涉及 PyCharm 和 ScreenStudio 等工具,反映了对工程环境和工具实际方面的共同兴趣。
LAION Discord 总结
基础模型协作征集:由 @pratikk10 发起的讨论邀请感兴趣的各方为跨不同媒介(包括文本、图像和视频)的基础模型创建做出贡献,寻求与严肃创作者的交流。
强化学习中的偏见观察:RLHF 引入的显著偏见引发了辩论,@pseudoterminalx 和 @astropulse 指出这可能对基础模型开发产生反作用,同时也观察到 Midjourney 图像中可能源于此类偏见的独特风格。
解决 Pixart 中的文本偏见:对话揭示了从数据集中消除文本偏见的挑战,特别是 Pixart 的 5.1 版本。批评指向了 JourneyDB 数据集的使用,并建议寻找更强大的替代方案来实现无偏见的文本模态。
古代文献的创新阅读:Vesuvius Challenge 2023 Grand Prize(2023 年维苏威挑战赛大奖)公告强调了一种在不展开的情况下阅读 2000 年前卷轴的成功方法,该方法使用了 TimeSformer 模型和粒子加速器,尽管每个卷轴的成本高达 40,000 美元。
尽管受到限制,中国机器学习依然蓬勃发展:讨论思考了中国 ML 实体在 GPU 限制下的成功,指出他们在限制生效前预先采购了 NVIDIA 的 H100 和 A100,并质疑这对技术进步的整体影响。
对 Hugging Face 的 OWLSAM 的评价:@SegmentationFault 在 Hugging Face Space 中分享并评论了 OWLSAM 的表现,指出该模型在视觉表示方面缺乏覆盖范围,且在目标检测方面准确性不足。
LlamaIndex Discord 总结
-
LlamaIndex 准备发布重大版本:LlamaIndex 本周将发布一个重要版本,相关的清理工作预示着对于计划升级 LlamaIndex 系统的用户来说,这是一个重要的更新。
-
在 MacBook 上增强多模态应用:LlamaIndex 最近的集成允许在 MacBook 上构建多模态应用,增强了图像推理能力。相关的公告和进展已在 tweet 中分享。
-
Home AI 凭借 PDF 搜索创新在黑客松中获胜:Home AI 凭借其独特的 RAG 驱动搜索引擎(用于房屋筛选)在一次线下黑客松中获得了“最佳 PDF Parser 使用奖”,详情见此 tweet。
-
黑客松推动 LlamaIndex 改进:此次黑客松吸引了近 200 人参加,为 LlamaIndex 团队提供了反馈,并分发了一份面向开发者的 资源指南。
-
构建面向工程师的聊天机器人:一项讨论集中在为工程师创建一个聊天机器人,以便使用 LlamaIndex 与标准文档进行交互,该项目由 GitHub 上的 GitHub - imartinez/privateGPT 提供支持。
-
应对向量搜索挑战:用户讨论了改进 Qdrant 向量搜索结果的方法,分享了关于 Embedding 和评分分析的见解,并强调了使用 TypeScript 代码示例通过
Ollama生成和比较 Embedding 的用法。
OpenAccess AI Collective (axolotl) Discord 总结
-
新成员加入 - Qwen1.5:OpenAccess AI 社区对 Qwen1.5 的发布反响热烈,其量化版本承诺提供更高的性能。发布同时附带了一篇 详尽的博客文章 和各种开发资源。然而,一些用户已经看到了改进空间,指出缺少 30b 模型,并需要在 Benchmark 中包含标准差以考虑噪声。
-
GCP 的竞争优势:GCP 正在向企业客户伸出橄榄枝,按需提供的 A100 实例价格为每小时 $1.5-2。这一费率明显低于非企业客户的支付价格,突显了云服务提供商管理其用户和转售商生态系统的策略,包括像 GCP 的 L4 Spot 价格每小时 $0.2 这样的亮点交易。
-
弥合量化差距:在 Axolotl 开发 社区中,有人讨论了 Hugging Face 关于在合并模型之前进行量化的建议。
@dreamgen认为这种方法可能有利于性能,引发了关于在 Axolotl 框架内进行 Bayesian optimization 潜力的讨论,并有报告称实现过程更加顺畅。 -
Axolotl 的成长烦恼:Axolotl 用户报告了安装方面的困扰,指出存在依赖冲突,特别是
torch和xformers。建议的修复方法包括使用torch 2.1.2。此外,还有人呼吁简化 Axolotl 中的 YAML 配置,这表明易用性和可访问性在开发者的愿望清单中占据重要位置,同时还包括创建一个 Hugging Face Spaces UI 以实现更适合初学者的设置。 -
RLHF 频道的冷清:#rlhf 频道中只有一条似乎是针对特定用户的消息,询问与 zephyer 相关的配置,这给读者留下了很大的背景或重要性想象空间,对于渴望技术的工程师受众来说,提供的信息量太少。
Perplexity AI Discord 总结
-
Pro 付费问题:用户如
@officialjulian在升级 Pro 时遇到支付问题——资金已扣除但服务未激活,这表明 Stripe 的支付系统可能存在错误;同时@yuki.ueda反映在账单查询方面客户支持响应不及时。建议联系 support@perplexity.ai 寻求帮助。 -
教育中的 AI 伦理讨论:
@worriedhobbiton强调 AI 需要提供公正且具有文化敏感性的支持,特别是在像 Pasco High School 这样的教育场景中,这反映了服务多元化学生群体所面临的挑战。 -
AI 研究响应不匹配:用户
@byerk_enjoyer_sociology_enjoyer的经历凸显了 AI 在提供相关搜索结果方面的局限性,如分享的 Perplexity AI 搜索结果 所示,该结果与关于来源验证的研究查询不匹配。 -
寻求快速摘要解决方案:
@sid.jjj表示需要提高生成摘要时的 API 响应速度,并指出目前处理三个并行链接大约需要 10 秒,这强调了 AI 工程师关注的性能基准问题。 -
检测到 AI 使用差异:
@jbruvoll对 Perplexity AI 的交互式使用与 API 使用之间的一致性表示担忧,并指向了特定的 Discord 消息以获取更多细节,这强调了在不同接口间保持 AI 行为一致的重要性。
DiscoResearch Discord 总结
-
模型合并中的丹麦之光:一个使用 dare_ties merge 方法的丹麦语模型在斯堪的纳维亚半岛 NLG 排行榜上获得第二名,该模型由
@johannhartmann引入,详情见此处。 -
无需高性能机器即可合并模型:
@sebastian.bodza指出 LeoLM 模型 可以在没有 GPU 的情况下进行合并,并强调了使用 Google Colab 等替代方案来执行模型合并任务。 -
德国巨作 - Wiedervereinigung-7b-dpo-laser:
@johannhartmann发布了一个结合了顶级德国模型的 7B 参数模型,命名为 Wiedervereinigung-7b-dpo-laser,该模型具有很高的 MT-Bench-DE 评分。 -
模型合并不仅是分数游戏:
@johannhartmann和@bjoernp之间的对话表明,在合并模型后,除了获得高分外,实际应用场景(如聊天功能)也有所改进。 -
代码跨语言搜索能力飙升:Jina AI 发布了支持英语和 30 种编程语言的新代码嵌入模型,具有令人印象深刻的 8192 序列长度,由
@sebastian.bodza分享。该模型可在 Hugging Face 上获取,并针对 Jina AI 的 Embedding API 进行了优化。
Alignment Lab AI Discord 总结
-
控制 Llama2 的训练损失:一位工程师在使用 SFT 训练 Llama2 时遇到了意外的训练损失曲线,这可能是由于学习率过高导致的。同行建议切换到 Axolotl 并提供了建议增加学习率的特定配置示例。
-
用于节点协作的 Ankr 网络:
@anastasia_ankr与团队联系讨论节点基础设施,并被引导联系@748528982034612226进行进一步对话。 -
社区互动:用户
@xterthy和@aslawliet通过简短的问候保持社区活跃,营造了友好的氛围。 -
等待直接沟通:
@mizzy_1100提醒@748528982034612226注意私信,表示有重要的待处理沟通。 -
赞美协作精神:
@rusch将该 Discord 服务器比作“令人惊叹的 Discord 马戏团”,强调了其在知识共享和创新方面的动态性和趣味性。
Datasette - LLM (@SimonW) Discord 摘要
-
Audacity 与 Intel AI 的共鸣:Audacity 与 Intel 的 AI 工具 的集成增加了强大的本地功能:噪声抑制、转录、音乐分离 以及实验性的音乐生成,对昂贵的订阅服务构成了挑战。
-
利用 LLM 增强论文写作:关于 LLM 集成,
@kiloton正在寻求处理 PDF 和网络搜索 的建议,以及聊天记录是否可以在不同模型之间传输和存储。 -
利用 Hugging Face 简化 SQL:
@dbreunig指出了llm与 Hugging Face 的 transformers 的集成潜力,并重点介绍了 Natural-SQL-7B 模型,因其先进的 Text-to-SQL 能力和对复杂问题的深度理解。
LLM Perf Enthusiasts AI Discord 摘要
- Qwen1.5 开源亮相:Qwen1.5 已正式发布并开源,提供六种尺寸的基础模型和聊天模型。
@potrock分享的资源包括 博客文章、GitHub 仓库、Hugging Face 页面、Modelscope 页面、一个用户友好的 demo,以及加入 Qwen Discord 社区 的邀请。 - Qwen1.5 的效率突破:0.5B Qwen1.5 模型 展现出了巨大的潜力,其性能与大得多的 Llama 7B 模型相当,标志着模型效率优化新浪潮的到来,正如
@potrock所分享的那样。
第 2 部分:各频道详细摘要和链接
TheBloke ▷ #general (1293 messages🔥🔥🔥):
-
模型量化指南:
@xmrig探讨了由于本地资源限制,在 vast.ai 上对 70B LLM 模型进行量化。提供的建议包括创建大型 swap 文件以及可能使用外部 USB 连接的 SSD,从而在量化过程中避免对强大 GPU 的需求 (@spottyluck,@rtyax,@stoop poops)。 -
GPTZero 分析:用户讨论了 GPTZero 等 AI 内容检测工具的有效性,认为它可能无法可靠地检测到经过细微增强的提示词,且被视为一种学生工具,远未达到产品级水平 (
@mr.userbox020,.meathead,@kaltcit,@righthandofdoom,@itsme9316)。 -
Sparsetral,一种新的稀疏 MoE 模型:
@morpheus.sandmann分享了一个基于 Mistral 的稀疏 MoE 模型,强调了其在高端硬件上的高效运行。该稀疏模型在 forward passes 过程中仅使用部分权重,通过 router 选择性地应用 adapter,这引发了社区的兴趣,但也带来了关于其训练和功能复杂性的疑问 (@netrve,@itsme9316)。 -
合并 vs. 单模型微调:
@givan_002询问了针对不同数据集微调独立模型与在合并数据集上微调单个模型的效率对比。共识倾向于使用一个全面的数据集以保证连贯性和优化效果 (@amogus2432)。 -
社区 LLM 任务协助:用户
@kaltcit、@potatooff等人讨论了从 LLM 性能到使用 LLM 及相关技术的实用建议(如交换 VRAM 以扩充内存)等各种话题,展示了社区内的协作解决问题和知识共享。
提到的链接:
- Discord - A New Way to Chat with Friends & Communities:Discord 是通过语音、视频和文本进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
- no title found:未找到描述
- Realtime Colors:在真实网站上预览您的配色方案。
- Screenshot to HTML - a Hugging Face Space by HuggingFaceM4:未找到描述
- Realtime Colors:在真实网站上预览您的配色方案。
- Qwen1.5 - a Qwen Collection:未找到描述
- Qwen/Qwen1.5-14B-Chat-GGUF · Hugging Face:未找到描述
- Huang Jensen Nvidia Ceo GIF - Huang Jensen Nvidia Ceo - Discover & Share GIFs:点击查看 GIF
- budecosystem/code-millenials-13b · Hugging Face:未找到描述
- Introducing Qwen1.5:GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD 介绍。在最近几个月里,我们的重点是开发一个“好”模型,同时优化开发者体验。随着我们的进展…
- Bing GIF - BING - Discover & Share GIFs:点击查看 GIF
- TheBloke/Llama-2-70B-GGUF · Hugging Face:未找到描述
- NousResearch/Nous-Hermes-Llama2-13b · Hugging Face:未找到描述
- Social Credit GIF - Social Credit - Discover & Share GIFs:点击查看 GIF
- dataautogpt3/miqu-120b · Hugging Face:未找到描述
- GitHub - TheBlokeAI/dockerLLM: TheBloke's Dockerfiles:TheBloke 的 Dockerfile。通过在 GitHub 上创建账号为 TheBlokeAI/dockerLLM 的开发做出贡献。
- wolfram/miquliz-120b · Hugging Face:未找到描述
- v0 by Vercel:通过简单的文本提示生成 UI。复制、粘贴、发布。
- Swap on video RAM - ArchWiki:未找到描述
- Why No One Feels Like They Can Focus Anymore:以及该怎么办
- Reddit - Dive into anything:未找到描述
TheBloke ▷ #characters-roleplay-stories (457 messages🔥🔥🔥):
-
训练中的动态 Adapter 合并:
@jondurbin建议仅在 DPO 之后合并来自 SFT 的 adapter,而不是在此之前,并在整个过程中持续使用来自 SFT 的 adapter。这些见解是在讨论 TRL 文档中详述的 Direct Preference Optimization (DPO) Trainer 时提出的。 -
关于 DPO 和 Adapter 加载的讨论:
@dreamgen分享了 DPO Trainer 需要特定数据集格式的信息,并引用了Anthropic/hh-rlhf数据集的示例。@jondurbin解决了诸如属性名称train与最新版本 transformers 冲突等问题。 -
CharGen v2 - 为角色扮演创意设计的模型:
@kalomaze发布了 CharGen v2,这是一个旨在生成角色扮演人物描述的模型,已在 Hugging Face 上线,并提供在线版本。该模型以对话格式创建角色描述,一次生成一个字段,以便进行部分重训练(re-rolls)并减少重复。 -
使用多样化数据微调角色扮演模型:用户讨论了防止角色扮演模型过拟合的策略,建议在每个 epoch 开始时将 RP 数据与 The Pile 或 MiniPile 等多样化数据集混合 (
@kalomaze)。@stoop poops和@flail_.就增强策略交换了意见,例如将 assistant 数据与 RP 数据结合,以避免输出内容过于愚笨。 -
神秘的 ASCII 艺术尝试:
@c.gato等人尝试使用 Mixtral, Miqu 和 GPT-4 等各种模型生成 ASCII 艺术。对话展示了创建简单 ASCII 艺术的尝试,虽然成功程度各异,但突显了语言模型在这一创意任务中有限但正在提高的能力。
提及的链接:
- kubernetes-bad/chargen-v2 · Hugging Face:未找到描述
- 152334H/miqu-1-70b-sf · Hugging Face:未找到描述
- G-reen (G):未找到描述
- GitHub - MeNicefellow/Intelligent_RolePlaying_Sandbox:通过在 GitHub 上创建账户,为 MeNicefellow/Intelligent_RolePlaying_Sandbox 的开发做出贡献。
- DPO Trainer:未找到描述
- DPO Trainer:未找到描述
- bigscience/sgpt-bloom-7b1-msmarco · Hugging Face:未找到描述
- Norquinal/claude_multiround_chat_30k · Datasets at Hugging Face:未找到描述
- ASCII Art Archive:一个包含大量 ASCII 艺术画和其他相关 ASCII 艺术图片的集合。
TheBloke ▷ #training-and-fine-tuning (2 messages):
- 使用网站内容微调 Llama2-7b-chat:
@gabrielelanzafame询问了使用从网站抓取的文本微调 Llama2-7b-chat 的可能性。他们希望训练模型以品牌语调生成文案,或评估给定文案中的品牌语调。 - 多数据集微调策略:
@givan_002询问是为每个独立数据集(airoboros, hermes, limarp)分别微调模型然后再合并更有效,还是将所有数据集组合起来微调单个模型更有效。
TheBloke ▷ #model-merging (3 messages):
- 寻求模型合并的见解:
@noobmaster29表达了希望对 model merging 有更深层次理解的愿望,而不仅仅局限于 demo notebooks,并正在寻找相关的阅读资料或视频讲解。 - 深入探究模型合并:
@maldevide引用了他们自己的 gist,作为在张量操作(tensor operation)层面模型合并的详尽分解,旨在提供更深入的理解。 - 模型合并工具建议:
@maldevide建议使用 ComfyUI-DareMerge,这是一个为 SD1.5 和 SDXL 提供 model merging 便利的工具,该资源已经存在于他们的 notebook 中。
提到的链接:
GitHub - 54rt1n/ComfyUI-DareMerge: ComfyUI powertools for SD1.5 and SDXL model merging:用于 SD1.5 和 SDXL 模型合并的 ComfyUI 强力工具 - GitHub - 54rt1n/ComfyUI-DareMerge: ComfyUI powertools for SD1.5 and SDXL model merging
TheBloke ▷ #coding (4 messages):
-
使用 ChromeDB 创建角色记忆:
@vishnu_86081询问如何通过使用 ChromeDB 为聊天机器人应用中的每个角色实现长期记忆。他们目前使用 ooba web UI API 进行文本生成,并使用 MongoDB 存储消息,他们寻求关于设置 ChromeDB 以区分每个角色消息的指导。 -
寻求 neThing.xyz 的共享链接:
@rawwerks请求重新分享其名为 neThing.xyz 的 text-to-3D gen AI 项目链接,在提供免费用户试用的同时,表达了对 OpenAI 成本的担忧。 -
重新分享 Code-13B 和 Code-33B 链接:
@london分享了 Code-13B 和 Code-33B 的链接,这是两个经过训练、能够生成带有详细解释代码的大语言模型(LLMs),可在 Hugging Face 平台上获取。这些模型使用数据集 Python-Code-23k-ShareGPT 和 Code-74k-ShareGPT 进行训练,前者耗时 42 小时,后者耗时 6 天 5 小时。
提到的链接:
- neThing.xyz - AI Text to 3D CAD Model:用于 CAD 建模的 3D 生成式 AI。现在每个人都是工程师。让你的创意变为现实。
- ajibawa-2023/Code-13B · Hugging Face:未找到描述
- ajibawa-2023/Code-33B · Hugging Face:未找到描述
Nous Research AI ▷ #off-topic (28 条消息🔥):
-
汉字掌握之探求:用户
@lorenzoroxyolo表达了在尝试训练日语 Kanji 生成模型时的挫败感,并参考了@hardmaru的一个 Stable Diffusion 实验 以寻求灵感。用户.ben.com建议在处理渲染复杂图像等细微任务时,考虑使用 ControlNet 而不是 Stable Diffusion。 -
模型训练挑战讨论:针对 Kanji 生成模型效果不佳的问题,
.ben.com建议@lorenzoroxyolo可以参考 IDS 仓库,以更好地理解字符结构并可能优化模型训练。 -
AI 育种博弈论浮现:
@bananawalnut69推测了一种“AI 育种”游戏,使用类似于 GAN 的方法生成子模型,@Error.PDF回应称 Reinforcement Learning 可能与这一概念相符。 -
提高对诈骗的警惕:关于 Facebook 上 AI 相关诈骗盛行的讨论引导
@Error.PDF感叹虚构叙事带来的误导和浅薄认知,这导致在严肃的 AI 讨论中经常出现 Skynet 或 WALL·E 等引用。 -
Meta 推动 VR 边界:
@nonameusr分享了一个 Road to VR 文章 链接以及相关的 开发者博客文章,介绍了 Meta 在 SIGGRAPH 2023 上展示的具有视网膜分辨率(retinal resolution)和先进光场透视(light field passthrough)能力的新型 VR 头显原型。
提到的链接:
- Huh Cat Huh M4rtin GIF - Huh Cat Huh M4rtin Huh - 发现并分享 GIF:点击查看 GIF
- Skeleton Skeleton Laugh GIF - Skeleton Skeleton laugh Laugh - 发现并分享 GIF:点击查看 GIF
- 来自 hardmaru (@hardmaru) 的推文:一个针对日语 Kanji 字符图像训练的 #StableDiffusion 模型为“摩天大楼”、“皮卡丘”、“埃隆·马斯克”、“深度学习”、“YouTube”、“高达”、“奇点”等新颖概念生成了“伪汉字”……
- Meta 展示专注于视网膜分辨率和光场透视的新型原型 VR 头显:Meta 展示了两款新型 VR 头显原型,展示了在解决当今 VR 面临的一些持久技术挑战方面的更多进展。在 SIGGRAPH 2023 上,Meta 演示了……
Nous Research AI ▷ #interesting-links (14 messages🔥):
-
通过微调提升冻结网络 (Frozen Networks) 的性能:@euclaise 讨论了仅微调冻结网络的归一化层 (Normalization layers) 的潜力,暗示这可能是一种替代 LoRA 的有前景的方法。这一概念基于最近的一篇 arXiv 论文的研究结果。
-
新版 Bagel 发布:@nonameusr 分享了在 Hugging Face 上微调后的 Mistral-7b 模型的非 DPO 版本链接,即 bagel-7b-v0.4。据报道,该版本更适合角色扮演 (Roleplay) 用途,其模型卡片 (Model card) 概述了计算细节和数据源,预计很快会推出 DPO 变体。
-
DeepSeek 发布精通数学的模型:@metaldragon01 介绍了 DeepSeek-Math-7b-instruct 模型,并附带了使用案例链接和一篇详细介绍该模型利用思维链 (Chain-of-thought) 提示词进行数学推理能力的论文。模型详情可在 Hugging Face 上找到。
-
使用 Sparsetral 进行稀疏建模:@mister_poodle 提供了 Sparsetral-16x7B-v2 的链接,这是一个使用 QLoRA 和 MoE 适配器训练的模型。Hugging Face 模型卡片 (Model card) 提供了关于训练、提示词格式和用法的关键信息。
-
Reddit 上关于 Sparsetral 的讨论:@dreamgen 指向了一篇关于 Sparsetral 的 Reddit 帖子,这是一个源自 Mistral 的稀疏 MoE 模型,同时附带了多个资源和论文链接。讨论还建议通过从 Mixtral 初始化专家 (Experts) 来改进 Sparsetral,该模型已在 Hugging Face 上发布。
提到的链接:
- deepseek-ai/deepseek-math-7b-instruct · Hugging Face: 未找到描述
- serpdotai/sparsetral-16x7B-v2 · Hugging Face: 未找到描述
- jondurbin/bagel-7b-v0.4 · Hugging Face: 未找到描述
- Reddit - Dive into anything: 未找到描述
- The Expressive Power of Tuning Only the Normalization Layers: 特征归一化转换(如 Batch 和 Layer-Normalization)已成为尖端深度神经网络不可或缺的组成部分。最近关于微调大型预训练模型的研究…
Nous Research AI ▷ #general (514 条消息🔥🔥🔥):
- IPO 性能再探讨:
@teknium评论了 IPO 论文中的建议对改进 IPO 的作用,但@dreamgen指出在 open hermes 的测试中,DPO 的表现仍然优于 IPO。@teknium承认信息已过时且错过了一次更新。 - 量化敏感性讨论:
@dreamgen强调 DPO 对 beta 设置非常敏感,这对于无法进行大规模 beta sweeps 的用户来说可能是一个问题。@teknium回复称 Hermes Mixtral 对 beta 也很敏感,表明这是一个更广泛的问题。 - 即将发布的版本期待:
@main.ai宣布距离基于 AoE 时间的某项未指明发布还剩 23.9 小时,并附上了推文链接以供确认。 - fblgit 推出 model-similarity 工具:
@fblgit展示了一个用于分析模型相似性的新工具,能够理解不同模型之间的权重差异和参数对齐。该工具已在 GitHub 上开源并欢迎贡献。 - 对 Qwen 1.5 发布质量的担忧:在 Qwen 1.5 发布之际,
@nonameusr表达了失望之情,指出其相对于 Qwen 1 的 benchmark 提升微乎其微。与此同时,@euclaise和@metaldragon01讨论了小型 Qwen 模型的前景以及潜在的 Qwen-Miqu 模型 merge。
提到的链接:
- Qwen1.5 72B Chat - a Hugging Face Space by Qwen:未找到描述
- HuggingChat - Assistants:浏览由社区制作的 HuggingChat 助手。
- Social Credit GIF - Social Credit - Discover & Share GIFs:点击查看 GIF
- You Naughty Naughty Pointing GIF - You Naughty Naughty Pointing Smile - Discover & Share GIFs:点击查看 GIF
- Introducing Qwen1.5:GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD 介绍:在最近几个月里,我们的重点一直是开发一个“好”模型,同时优化开发者体验。随着我们向…迈进…
- Qwen/Qwen1.5-7B-Chat-GGUF · Hugging Face:未找到描述
- CausalLM/34b-beta · Hugging Face:未找到描述
- wolfram/miquliz-120b · Hugging Face:未找到描述
- Tweet from qnguyen3 (@stablequan):介绍 Quyen,我们第一个基于 Qwen1.5 家族的旗舰 LLM 系列,包含 6 种不同尺寸:Quyen-SE (0.5B) Quyen-Mini (1.8B) Quyen (4B) Quyen-Plus (7B) Quyen-Pro (14B) Quyen-Pro-Max (72B) Al…
- Tweet from Vaibhav (VB) Srivastav (@reach_vb):搞定了!🤯 miqudev 合并了来自 @arthurmensch 的 PR ↘️ 引用 Vaibhav (VB) Srivastav (@reach_vb) leak/ acc.
- Tweet from Awni Hannun (@awnihannun):Qwen1.5 发布了,并且已经可以配合 MLX 使用!pip install -U mlx-lm。模型从 0.5B 到 72B,全部都是超高质量。0.5B 在我的笔记本上配合 MLX 运行飞快,质量很高,几乎不占 RAM:↘️ 引用 J…
- Kind request for updating MT-Bench leaderboards with Qwen1.5-Chat series · Issue #3009 · lm-sys/FastChat:你好 LM-Sys 团队,我们想展示 Qwen1.5-7B-Chat、Qwen1.5-14B-Chat 和 Qwen1.5-72B-Chat 在 MT-Bench 上的生成结果和自测分数。能否请你们帮我们验证一下…
- GitHub - fblgit/model-similarity: Simple Model Similarities Analysis:简单的模型相似性分析。通过创建一个账号来为 fblgit/model-similarity 的开发做出贡献。
Nous Research AI ▷ #ask-about-llms (36 条消息🔥):
- 融合 QKV 矩阵优化性能:
@carsonpoole向@sherlockzoozoo澄清,在 Transformer 模型中融合 Query、Key 和 Value (QKV) 矩阵在数学上是等价的,但速度稍快,因为它减少了所需的操作次数和内存加载。 - 理解 LLM 的对话记忆:在由
@lushaiagency发起的对话中,@4biddden提到使用 langchain 来处理 LLM 的对话历史,而.ben.com和@samuel.stevens讨论了关于上下文窗口大小和历史记录分解的问题,建议总结历史记录或使用长上下文模型可能是解决方案。 - 关于 Hermes 2.5 数据集的许可问题:
@tculler91对 OpenHermes 和 Hermes 2.5 数据集之间的许可变更表示担忧,寻求关于商业用途的澄清。 - 为 OpenHermes 配置特殊 Token:
@gabriel_syme就微调 OpenHermes 模型的 Token 配置寻求建议,@teknium建议包含 `”
Eleuther ▷ #general (363 条消息🔥🔥):
- 创建 Foundational Models 讨论:用户
@pratikk10表示有兴趣联系任何考虑为各种应用(包括文本到文本/图像/视频)创建自己的 Foundational Models 的人。 - 强调 Foundational Models 的高昂成本:针对
@pratikk10,用户@_3sphere指出了开发 Foundational Models 的昂贵性质。 - Qwen1.5 模型发布及详情:用户
@johnryan465分享了 Qwen1.5(一个 72B 参数的对话模型)的链接,包括其介绍、仓库和演示(Qwen1.5 博客文章、Qwen GitHub、Hugging Face Space)。 - 解释大语言模型:包括
@rami4400、@_3sphere和@fern.bear在内的多位用户讨论了 LLM 等神经网络的可解释性(Interpretability)的有效性和潜力,并将其与人类基因组计划进行了比较,同时对可解释性是否符合智能的本质表示怀疑。 - 对 AGI 声明和模型能力的担忧:
@fern.bear、@vara2096和@worthlesshobo对某些模型的性能声明表示怀疑,例如 Qwen 1 和 2 在 MMLU 基准测试上的表现,以及在测试集上可能存在的过拟合或“作弊”行为。
提到的链接:
- 文件显示,特斯拉存在行驶中车轮飞脱的小问题:尽管知道存在长期的“缺陷”,据报道特斯拉仍将悬挂崩溃和车轴断裂等明显缺陷归咎于驾驶员。
- Cavemanspongebob React GIF - Cavemanspongebob Caveman Spongebob - 发现并分享 GIF:点击查看 GIF
- Qwen1.5 72B Chat - Qwen 提供的 Hugging Face Space:未找到描述
- 加入 Self-Play Language Models Discord 服务器!:查看 Discord 上的 Self-Play Language Models 社区 - 与其他 15 名成员一起交流,享受免费的语音和文字聊天。
- Troy Community GIF - Troy Community Room - 发现并分享 GIF:点击查看 GIF
- Qwen1.5 介绍:GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD 介绍。在最近几个月中,我们的重点一直是开发一个“好”模型,同时优化开发者体验。随着我们向…迈进…
- simple ai - chat:未找到描述
- 文件:Clock 10-30.svg - 维基共享资源:未找到描述
- 最小描述长度 (Minimum description length) - 维基百科:未找到描述
- GitHub - idiap/nvib:通过创建一个 GitHub 账户来为 idiap/nvib 的开发做出贡献。
- GitHub - SimonKohl/probabilistic_unet: 结合了变分自编码器的 U-Net,能够学习语义分割上的条件分布。:结合了变分自编码器的 U-Net,能够学习语义分割上的条件分布。- GitHub - SimonKohl/probabilistic_unet…
{kind=link}
Eleuther ▷ #research (61 条消息🔥🔥):
-
关于多任务损失处理的澄清:
@clashluke讨论了 PCGrad 在改进估算方面优于手动逐梯度重加权的作用。他们对使用该方法时梯度中的幅值保持(magnitude preservation)表示担忧,并引用了来自 facebookresearch/encodec 的官方代码。 -
Scaling Studies 咨询:
@stellaathena发起了一场讨论,探讨事后相关性(post-hoc correlation)是否可以将 Kaplan 等人风格的 Scaling Laws 研究转换为 Hoffman 等人风格,从而可能减少所需的训练运行次数。他们分享了相关 Twitter 对话和 博客文章 的链接以供进一步探索。 -
用于 LoRA 权重的 Hypernetworks:
@.rend、@thatspysaspy等人之间的对话涵盖了使用 Hypernetworks 为针对特定上下文定制的预训练语言模型生成 LoRA 权重的想法。davisyoshida/lorax上的一个 Issue 详细描述了相关的兴趣,@thatspysaspy提供了一个用于实验的代码示例。 -
讨论 CNN 训练方法论:
@jstephencorey对一段视频中关于 CNN 训练的解释表示困惑,引发了关于层如何学习以及剪枝(pruning)有效性的辩论。@Hawk和@xylthixlm等用户讨论了视频主张的准确性,尽管在技术细节上意见不一。 -
Polyquant 激活函数辩论:在关于用多项式等替代方案替换传统激活函数的对话中,
@clashluke等人审查了一种在没有典型激活函数的情况下在 ImageNet 上表现出的新型架构。@fern.bear质疑了所提乘积函数的非线性,而@clashluke则强调了其优化潜力。
提到的链接:
- 来自 Grigoris Chrysos (@Grigoris_c) 的推文:为我们的新 #ICLR2024 论文感到自豪,该论文试图回答:所有深度网络都需要激活函数吗?网络能否在没有激活函数、最大池化(max po…)的情况下在 ImageNet 识别上表现良好?
- neural-style-pt/neural_style.py at master · ProGamerGov/neural-style-pt:神经风格迁移算法的 PyTorch 实现 - ProGamerGov/neural-style-pt
- encodec/encodec/balancer.py at main · facebookresearch/encodec:支持单声道 24 kHz 音频和立体声 48 kHz 音频的最先进的基于深度学习的音频编解码器。 - facebookresearch/encodec
- Zoology (Blogpost 2): Simple, Input-Dependent, and Sub-Quadratic Sequence Mixers:未找到描述
- 来自 Stella Biderman (@BlancheMinerva) 的推文:@Wetassprior @daphneipp 是否有一种事后相关性可以应用于 Kaplan 等人风格的 Scaling Laws 研究,以获得 Hoffman 等人风格的研究?请注意,这将具有非常高的价值…
- Predicting LoRA weights · Issue #6 · davisyoshida/lorax:我想使用一个单独的神经网络来预测主神经网络的 LoRA 权重,同时训练这两个神经网络。我该如何操作 pytrees 或实现…
Eleuther ▷ #scaling-laws (2 条消息):
- 探讨 Tensor Programs 问题:
@lucaslingle解释说,@.johnnysands提到的“错误初始化(wrong init)”是指 Tensor Programs 4 和 5 论文中的发现,这些论文表明,当模型宽度无限增加时,“标准参数化(standard parameterization)”会导致无限的 Logits。
Eleuther ▷ #interpretability-general (10 条消息🔥):
- 简单模型分析工具发布:
@fblgit推出了 model-similarities,这是一个用于计算不同模型参数空间中逐层余弦相似度(cosine similarities)的工具。 - 与 CCA/CKA 的比较:
@xa9ax询问了该模型相似度工具与典型相关分析(CCA)或中心化核对齐(CKA)相比能提供哪些见解,@digthatdata澄清该工具专门针对参数空间进行对比。 - 向量空间中的“方向”解释:
@norabelrose和@pinconefish讨论了“方向”的概念,@norabelrose澄清它是向量空间中具有取向的一维子空间,而不仅仅是任何单位向量。 - 超越坐标理解向量:
@digthatdata概述了在深度学习中,向量被理解为既有方向又有大小,而不仅仅是空间中的一个位置,并进一步阐述了余弦相似度如何测量两个向量之间的夹角。 - 作为方向和算子的向量:
@digthatdata继续解释说,向量可以作为“算子”发挥作用,并以代表KING、QUEEN、MAN和WOMAN的向量为例,说明了WOMAN和MAN之间的差分向量z如何在语义上将含义从KING改变为QUEEN。
提到的链接:
GitHub - fblgit/model-similarity: Simple Model Similarities Analysis:简单的模型相似度分析。可以通过在 GitHub 上创建账号来为 fblgit/model-similarity 的开发做出贡献。
Eleuther ▷ #lm-thunderdome (16 条消息🔥):
-
统计错误已解决:
@hailey_schoelkopf澄清了 MMLU 标准误差的自助法(bootstrapping)与合并方差(pooled variance)公式相匹配,而非组合方差(combined variance)。现在项目中已选择使用正确的合并方差公式,取代了当前的组合方差公式。 -
前有统计陷阱:
@stellaathena建议在代码库中保留旧的和新的统计公式供专家使用,@hailey_schoelkopf添加了一条幽默的警告注释:# here there be dragons(此处有恶龙/险境)。 -
利用语言模型评估工具:
@jbdel.为即将到来的会议准备了一个包含 lm-evaluation-harness 更新的干净分支,所有更改都可以在 GitHub 上的提交中查看。更新后的 harness 允许使用特定的参数和任务设置来评估语言模型。
提到的链接:
- Use Pooled rather than Combined Variance for calculating stderr of task groupings by haileyschoelkopf · Pull Request #1390 · EleutherAI/lm-evaluation-harness:此 PR 更新了我们用于聚合跨任务组的标准误差/样本标准差的公式。在此 PR 中:公式:结果:hf (pretrained=mistralai/Mistral-7B-v0.1), gen_kwargs: (Non…
- Use Pooled rather than Combined Variance for calculating stderr of task groupings by haileyschoelkopf · Pull Request #1390 · EleutherAI/lm-evaluation-harness:此 PR 更新了我们用于聚合跨任务组的标准误差/样本标准差的公式。在此 PR 中:公式:结果:hf (pretrained=mistralai/Mistral-7B-v0.1), gen_kwargs: (Non…
- GitHub - jbdel/lm-evaluation-harness-multi: A framework for few-shot evaluation of language models.:一个用于语言模型少样本(few-shot)评估的框架。
- VLM · jbdel/lm-evaluation-harness-multi@83209a8:未找到描述内容。
Eleuther ▷ #gpt-neox-dev (3 messages):
-
寻求预分词(Pre-tokenized)的验证/测试数据集:
@pietrolesci对目前使用 Hugging Face 上的 pile-uncopyrighted dataset 创建的验证集表示不满。他们询问是否能以类似于 Hugging Face 上预分词训练集的方式,获取预分词的验证/测试划分。 -
介绍 Web Rephrase Augmented Pre-training (WRAP):
@elliottdyson分享了一篇 arxiv paper,提出了 WRAP。这是一种通过将网页数据改写(paraphrasing)为更高质量格式来改进 LLM 预训练的方法,这可能会减少计算和数据需求。 -
比较 WRAP 与微调(Fine-Tuning)的效果:
@elliottdyson思考使用 WRAP 是否比仅在相同数据上对模型进行微调更有益,并建议对经过和未经过 WRAP 处理的数据进行微调对比研究,以揭示其功效。
提到的链接:
Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling:LLM 是在海量的网页抓取数据上训练的,这些数据通常是无结构的、多噪声且表述欠佳的。目前的 Scaling Laws 表明,从这类数据中学习需要大量的…
HuggingFace ▷ #general (321 messages🔥🔥):
-
AI 训练和职业发展建议:用户
@dykyi_vladk分享了他们在过去一年中在 ML 领域的学习历程,提到了他们研究的具体模型和技术。@lunarflu建议将“构建 Demo 并分享它们”作为成为专业人士的下一步。 -
A100G 发布期间的服务器故障:
@lolskt报告服务器宕机近 12 小时,并询问是否与 A100G 的发布有关。经过讨论,@lunarflu建议将详细信息发送至邮箱,并提议将问题转发给团队。 -
修改模型响应:用户
@tmo97寻求关于如何通过 Prompt 引导模型停止给出警告的建议。@lunarflu建议了修改 Prompt 的技术,并讨论了 AI 响应中安全性与用户控制之间的平衡。 -
HuggingFace Fellowship 与模型上传咨询:
@not_lain回答了关于使用 HuggingFace 平台的多个问题,包括加入 Fellowship 计划的流程,以及上传自定义 Pipeline 实例和模型的细节。 -
推理性能与硬件利用率:用户
@prod.nova询问为什么他们的 4 块 RTX A5000 GPU 在生成过程中没有被充分利用。@meatfucker澄清说推理通常使用单个 GPU,并建议在每张显卡上运行一个实例以分配任务。
提到的链接:
- Templates for Chat Models:未找到描述
- GitHub - Significant-Gravitas/AutoGPT: AutoGPT is the vision of accessible AI for everyone, to use and to build on. Our mission is to provide the tools, so that you can focus on what matters.:AutoGPT 是让每个人都能使用和构建 AI 的愿景。我们的使命是提供工具,让你能够专注于重要的事情。
- GitHub - Sanster/tldream: A tiny little diffusion drawing app:一个极小的 Diffusion 绘图应用。
- Add
push_to_hub( )to pipeline by not-lain · Pull Request #28870 · huggingface/transformers:此 PR 的作用?这将在使用 Pipeline 时添加push_to_hub()方法。这是对 #28857 的修复,允许更方便地将自定义 Pipeline 推送到 HuggingFace。 - TheBloke (Tom Jobbins):未找到描述
HuggingFace ▷ #today-im-learning (1 messages):
- Pyannote 性能获赞:
@marc.casals.salvador对用于说话人日志(speaker diarization)的工具 Pyannote 表示赞赏,称其性能卓越。 - 介绍 Diarizationlm:
@marc.casals.salvador提到了 Diarizationlm,这是一个同时训练自动语音识别(ASR)和 Diarization 的模块,通过语音本身纠正 Diarization 来改进标注。
HuggingFace ▷ #cool-finds (5 messages):
-
HuggingFace 上的空白 Model Cards:
@tonic_1指出 HuggingFace 上的 Model Cards 是空的,这可能会阻碍用户获取模型信息。 -
交互式 Gradio Demo 缺乏曝光度:
@tonic_1分享了一个很酷的 Gradio Demo,但对这个可能被忽视的模型缺乏详细信息表示担忧。 -
创新的 LLaMA-VID 模型发布:
@tonic_1分享了 LLaMA-VID 的 Model Card,详细介绍了一款支持通过使用额外 Context Token 处理长达一小时视频的开源聊天机器人。模型及更多信息可以在这里找到。 -
DV Lab 低调的模型托管在 HuggingFace 上:
@tonic_1提到在 HuggingFace 上发现了另一个由 DV Lab 开发、引人注目但被低估的模型,并表示希望能为其提供服务。 -
探索高性价比的 LLM 使用方案:
@jessjess84分享了一篇 arXiv 论文,描述了关于大语言模型 (LLM) 推理和微调的高性价比策略研究,包括利用消费级网络的分布式解决方案。
提到的链接:
- Distributed Inference and Fine-tuning of Large Language Models Over The Internet: 大语言模型 (LLMs) 在许多 NLP 任务中都非常有用,并且随着规模的增大而变得更加强大,最好的开源模型拥有超过 500 亿个参数。然而,使用这些 50B+ 模型需要…
- YanweiLi/llama-vid-7b-full-224-long-video · Hugging Face: 未找到描述
HuggingFace ▷ #i-made-this (3 messages):
-
Ankush 的微调成果: 用户
@andysingal发布了由 Ankush Singal 开发的微调模型。该模型是基于 OpenPipe 之前模型的优化版本,并附带了安装和使用指南。 -
社区对新微调模型的赞赏:
@osanseviero祝贺@andysingal创建了新的微调模型,称其非常酷且“火热” 🔥。
提到的链接:
Andyrasika/mistral-ft-optimized-dpo · Hugging Face: 未找到描述
HuggingFace ▷ #reading-group (3 messages):
-
发现一个梗图风格的 AI 里程碑: 用户
typoilu分享了一篇名为《从梗图一窥 Mamba 系列 LLM 启蒙中人工智能 (AI) 进步的巅峰》的文章,声称其中包含有关 AI 进展的深刻见解。目前还没有关于内容的进一步讨论。点击阅读 -
预定的演讲可能需要重新安排:
@ericauld周五可能有陪审团义务,建议将原定的演讲推迟到 16 号周五。可能需要调整活动日历。 -
Chad 表示支持并祝好运: 针对可能的重新安排,
@chad_in_the_house表示理解,并祝愿@ericauld的陪审团义务(如果发生的话)一切顺利。
提到的链接:
no title found: 未找到标题
HuggingFace ▷ #computer-vision (1 messages):
- 邀请分享 Computer Vision 专业知识: 用户
@danielsamuel131公开征集具有 Computer Vision 专业知识的人士来分享经验。感兴趣的人可以给他发私信。
HuggingFace ▷ #NLP (11 条消息🔥):
-
微调热潮 (Fine-Tuning Frenzy):
@joeyzero正在寻求使用带有噪声的旧数据来 fine-tune 一个聊天机器人,并寻找对话数据集资源以及易于管理数据集的工具。该用户欢迎各种建议,包括可直接用于对话的数据集、强大的编辑工具,以及针对此类 NLP 项目的任何教程或技巧。 -
Papillon 分享 NLP 工具:
@8i8__papillon__8i8d1tyr分享了一个基于 Flair 和 FLERT 的 Named Entity Recognition (NER) 和 Sentiment Analysis 工具,并附带了 GitHub 仓库链接。 -
YAML 微调挑战:
@denisjannot在为 YAML 生成而 fine-tune Mistral 7b 时遇到了问题,即在第二次请求修改特定部分时,YAML 中不相关的部分也会被意外修改。 -
YAML 微调路线:
@denisjannot提到计划训练 Instruqt model,以观察是否能改善 YAML 修改问题。目前正在征集在不将修改示例包含在训练数据集中的情况下,增强 fine-tuning 过程的建议。 -
Few-Shot Learning 建议:
@meatfucker建议在 prompt 中包含所需修改的示例,以引导 one-shot 或 few-shot learning,即使这些示例不在训练数据集中,通常也能取得不错的效果。此举旨在引导模型进行 YAML 修改。
提到的链接:
bootcupboard/flair/SentimentalNERD.py at main · CodeAKrome/bootcupboard:内有乾坤!通过在 GitHub 上创建账号,为 CodeAKrome/bootcupboard 的开发做出贡献。
LM Studio ▷ #💬-general (103 条消息🔥🔥):
-
选择合适模型的困惑:用户
@hades____表示面对数百个可用模型感到不知所措,正在寻求如何根据需求选择最佳模型的指导。建议指向了一些资源,并提出应专注于特定用例,而不是寻找“通吃”型模型。 -
模型兼容性查询:包括
@dicerx和@foxwear在内的多位用户询问了如何将 LM Studio 与特定应用程序和模型连接。对话涉及与 iOS 应用和多模态模型的潜在兼容性,寻求集成可能性的明确说明。 -
资源和模板请求:
@Jonatan、@funapple和@ayelwen等用户请求了代码示例、Prompt 模板以及模型差异解释的资源,突显了社区对易于获取且简单明了的文档的需求。 -
寻求 LM Studio 的技术协助:参与者
@plaraje、@perkelson、@ts9718和@joelthebuilder针对从 Prompt 生成异常到 LM Studio 软件功能(如缩放行为的变化和服务器连接指导)等一系列问题寻求技术帮助。 -
笑话与轻松的评论:在技术讨论之余,
@sica.rios、@rugg0064和@wildcat_aurora等用户为对话注入了幽默感,开着关于 AI 能力的玩笑,并在与 AI 模型互动时调侃语言误解。
提到的链接:
- Discord - A New Way to Chat with Friends & Communities:Discord 是通过语音、视频和文本进行交流的最简单方式。与你的朋友和社区聊天、聚会并保持紧密联系。
- Introducing Qwen1.5:GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD 介绍。最近几个月,我们的重点一直是开发一个“好”模型,同时优化开发者体验。随着我们的进展…
- liuhaotian/llava-v1.5-7b · gguf variant availability:未找到描述
- GitHub - FriendofAI/LM_Chat_TTS_FrontEnd.html: LM_Chat_TTS_FrontEnd is a simple yet powerful interface for interacting with LM Studio models using text-to-speech functionality. This project is designed to be lightweight and user-friendly, making it suitable for a wide range of users interested in exploring voice interactions with AI models.:LM_Chat_TTS_FrontEnd 是一个简单但功能强大的界面,用于通过文本转语音功能与 LM Studio 模型进行交互。该项目旨在轻量化且用户友好,使其适合对探索 AI 模型语音交互感兴趣的广泛用户。
-
[GitHub - THUDM/CogVLM: a state-of-the-art-level open visual language model 多模态预训练模型](https://github.com/thudm/cogvlm):一个达到 state-of-the-art 级别的开源视觉语言模型 多模态预训练模型 - GitHub - THUDM/CogVLM: a state-of-the-art-level open visual language model 多模态预训练模型 - Reddit - Dive into anything:未找到描述
LM Studio ▷ #🤖-models-discussion-chat (3 条消息):
- 简要提及频道引用:
@egalitaristen提到了一个代码为<#1167546635098804284>的频道,但未提供背景或进一步详情。 - 关于模型使用的询问:
@delfi_r_88002询问是否有人正在使用模型 llava-v1.6-34b.Q4_K_M.gguf,但未提供更多信息或背景。 - 新模型 DeepSeek-Math-7B 发布:
@czkoko宣布了 DeepSeek 的新模型 DeepSeek-Math-7B 的发布。该模型可以在 GitHub 上找到,并提供了页面中的相应元数据。
提到的链接:
GitHub - deepseek-ai/DeepSeek-Math:通过在 GitHub 上创建账号,为 deepseek-ai/DeepSeek-Math 的开发做出贡献。
LM Studio ▷ #announcements (1 条消息):
-
LM Studio v0.2.13 发布,支持 Qwen 1.5:LM Studio 的
@yagilb宣布发布 LM Studio v0.2.13,其特点是支持各种尺寸的 Qwen 1.5 模型(0.5B, 1.8B, 4B, 7B, 72B)。用户可以直接从 https://lmstudio.ai 下载新版本或通过应用内更新。 -
在 LM Studio 中置顶你的收藏:新的 LM Studio 更新允许用户将 模型和对话置顶 到列表顶部,使常用工具更易于访问。
-
Qwen 新模型现已开源:Qwen1.5 模型已发布并开源,尺寸从 0.5B 到 72B 不等,包括 base、chat、AWQ、GPTQ、GGUF 模型,可在包括 Hugging Face 和 LM Studio 在内的多个平台获取。
-
集成与易用性增强:Qwen1.5 提升了质量并集成到 Hugging Face transformers 中,不再需要
trust_remote_code。DashScope 和 Together 均提供 API,推荐在 https://api.together.xyz/ 尝试 Qwen1.5-72B-chat。 -
LM Studio 应用性能调优:最新的 LM Studio 版本取消了在 Windows 上用于测量 CPU 和 RAM 的子进程,从而提升了应用的性能。
提到的链接:
- 👾 LM Studio - 发现并运行本地 LLMs:查找、下载并实验本地 LLM。
- 来自 LM Studio (@LMStudioAI) 的推文:LM Studio v0.2.13 现已发布!更新内容:- 🚀 支持 Qwen 1.5!(0.5B, 1.8B, 4B, 7B, 72B) 以及:- 🤖📌 将模型置顶到列表顶部 - 💬📌 同样可以置顶对话。从 https://… 下载。
- Qwen1.5 GGUF - lmstudio-ai 收藏集:未找到描述。
LM Studio ▷ #🧠-feedback (9 条消息🔥):
- 称赞 LM Studio 的简洁性:
@drawless111分享了一篇 Medium 博客文章,赞扬 LM Studio 让任何人都能通过简单的用户界面体验大语言模型的力量,无需任何技术背景。 - 功能请求确认:
@heyitsyorkie回应了@foobar8553关于恢复(resume)功能的呼吁,指向了一个当前的功能请求并请求大家支持。 - 对 LM Studio 应用的感谢:
@gli7ch.com对 LM Studio 应用开发者表示感谢,因为他们让 LLM 的工作变得更简单,特别是在将其与自动化任务集成方面。 - 询问投资机会:
@ahakobyan.询问了投资机会,这引发了@fabguy和@ptable之间的机智交流,两人都幽默地声称愿意为他们虚构且相互竞争的“基金会”接受资金。 - 质疑奇怪的缩放快捷键:
@perkelson质疑了 LM Studio 使用非标准缩放快捷键的逻辑,这些快捷键与浏览器中常用的不同。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
- Elio And Lea GIF - Elio and Lea - 发现并分享 GIF:点击查看 GIF。
- LM Studio:零技术背景体验 LLM 的魔力:在任何电脑上实现零配置本地 LLM 的指南。
LM Studio ▷ #🎛-hardware-discussion (40 条消息🔥):
- Linux 版 LMStudio 故障排除:
@heyitsyorkie建议@aswarp使用最新的 Ubuntu 22 以避免运行 LMStudio 时出现 glibc 错误,并补充说 Linux 构建版本与旧版 Ubuntu 仍存在兼容性问题。 - 聊天机器人的 GPU 利用率掌握:
@heyitsyorkie向@shylor保证,GPU 显存接近满载且未溢出到共享 RAM 是好事,因为在 LLM 聊天机器人交互中,过度使用共享 RAM 会随着时间的推移降低性能。 - 加速 Token 生成:
@roscopeko讨论了减少首个 Token 生成时间的方法,提到在高性能配置下仍有 6 秒延迟;@aswarp和@alastair9776等成员建议了不同的方案,包括更换模型、Quantization(量化)或尝试 AVX beta 版本。 - 深入探究 Shadow PC 性能:
@goldensun3ds分享了一个 YouTube 视频,详细对比了在 Shadow PC 和高性能本地 PC 上运行 LLM 的表现,指出 Shadow PC 在加载模型时速度较慢。 - 应对硬件资源与模型配置:
@robert.bou.infinite详细介绍了在数据中心各种 Nvidia 产品上运行 LMStudio 的可用 GPU 配置,概述了 NVLINK 技术和 Kubernetes Pods 兼容性的影响,并建议可以有效利用多 GPU 设置来处理 LLM 工作负载。
提到的链接:
- Nvidia LHR 详解:什么是 “Lite Hash Rate” GPU?:Nvidia 的 Lite Hash Rate 技术旨在阻挠以太坊矿工,让更多 GeForce 显卡落入游戏玩家手中。以下是您需要了解的内容。
- Open LLM Leaderboard - Hugging Face 上的 HuggingFaceH4 空间:未找到描述
- 使用 LM Studio LLM(AI 聊天机器人)测试 Shadow PC Pro(云端 PC)并与我的 RTX 4060 Ti PC 进行对比:自 ChatGPT 发布约一年以来我一直在使用它,并且已经熟练掌握了 Prompt 技巧,但在“本地”运行 LLM 方面我还是个新手。当…
LM Studio ▷ #🧪-beta-releases-chat (14 messages🔥):
-
新 Beta 更新发布:
@yagilb宣布发布 LM Studio version 0.2.13 Preview - Build V3,其特点是能够置顶模型和对话,并进行了性能改进。该更新已提供下载,并附带 Mac 和 Windows 链接,鼓励通过指定的 Discord 频道提供反馈。点击此处下载。 -
最佳 LLM 排行榜请求:
@kyucilow请求增加一个最佳 LLM 排行榜标签页以简化选择过程,@minorello建议在特定频道中引用该内容,而@heyitsyorkie和@re__x提供了包含 LLM 排名的外部资源链接。Hugging Face LLM Leaderboard 和 OpenRouter Rankings。 -
希望获得服务器访问的 GUI:
@_jayross表达了希望有一个用于远程访问 LM Studio 服务器组件的 Web Server GUI 的愿望;@goldensun3ds提供了一个使用 Parsec 进行远程访问的变通方案,并询问了 LM Studio 对 Intel ARC GPU 的支持情况。 -
聊天界面问题与错误报告:
@wolfspyre遇到了一个潜在问题,即在 LMS 聊天界面中卸载模型并修改设置后,聊天系统似乎停止响应。目前正在调查该问题是否存在 Bug 或异常行为。 -
分享依赖安装技巧:
@greg0403建议安装 blast library 以解决潜在问题,推荐使用sudo apt-get install ncbi-blast+。
提到的链接:
- Discord - A New Way to Chat with Friends & Communities:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、闲逛,与你的朋友和社区保持紧密联系。
- Discord - A New Way to Chat with Friends & Communities:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、闲逛,与你的朋友和社区保持紧密联系。
- Yet Another LLM Leaderboard - a Hugging Face Space by mlabonne:未找到描述
- OpenRouter:根据应用使用情况对语言模型进行排名和分析
LM Studio ▷ #autogen (1 messages):
lowkey9920: 试试 autogen studio。只需两个命令即可启动带有 UI 的界面。
LM Studio ▷ #langchain (1 messages):
- 关于问题生成方法的咨询:
@varelaseb表示有兴趣改进 RAG system,并就如何在数据集上生成问题的方法寻求建议。具体来说,他们提到尽管听到了关于 Tuna 的好评,但缺乏相关信息。
Mistral ▷ #general (118 messages🔥🔥):
- LangChain 的哀叹:Discord 用户
@akshay_1和@mrdragonfox对 LangChain 表示不满,前者认为其效用可能只能维持一周,之后就需要对组件进行固化。 - 寻找兼容旧版 Mac 的解释器:
@zhiyyang正在寻找适用于 11 以下版本的 Mac OSX 的模型解释器,虽然有人提出了建议,但未提供具体的解决方案。 - 关于 Mistral 8x7B 确定性的讨论:
@zaragatungabumbagumba_59827询问 Mixtral 8x7B 在推理过程中的确定性,@mrdragonfox解释说其行为是概率性的,受可调节的 temperature 参数影响。 - 关于 AI 的哲学视角:哲学系学生
@zaragatungabumbagumba_59827探讨了 LLM 的哲学影响,收到了@mrdragonfox等人关于探索 AI 基础概念的建议。 - 合成数据生成的秘密依然保密:在关于数据集生成的讨论中,
@mrdragonfox提到了 airoboros 和 augmentoolkit 等 GitHub 仓库的效用,但拒绝分享具体方法,并强调合成数据生成是关键的收入来源。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
- GitHub - e-p-armstrong/augmentoolkit: 将算力和书籍转化为指令微调数据集:将算力和书籍转化为指令微调数据集 - GitHub - e-p-armstrong/augmentoolkit: Convert Compute And Books Into Instruct-Tuning Datasets
- GitHub - jondurbin/airoboros: self-instruct 论文的可定制实现。:self-instruct 论文的可定制实现。 - GitHub - jondurbin/airoboros: Customizable implementation of the self-instruct paper.
Mistral ▷ #deployment (6 messages):
- Prompt 增强查询:
@drprimeg1询问了@gbourdin在 Prompt 中包含哪些额外信息以提高准确性。 - PHP 转 JSON Schema 以优化 Prompt:
@gbourdin描述了他们将 PHP 类转换为 JSON Schema 以优化 Prompt 的方法,并提议私下分享代码。 - 代码分享提议被接受:
@drprimeg1表示有兴趣查看@gbourdin的 Prompt 代码结构,促使@gbourdin发送了包含细节的私信。
Mistral ▷ #finetuning (1 messages):
- Fine-Tuning 中的 Padding 困境:用户
@ramin2024正在寻求关于如何正确设置 Fine-Tuning Padding 方式的建议,提到将tokenizer.pad = tokenizer.eos的常见做法有时会导致 Fine-Tuning 后的模型不生成 end-of-sentence (eos) token。他们分享说自己和其他人都遇到了这个问题。
Mistral ▷ #showcase (1 messages):
- Discord 聊天机器人达到 Star 里程碑:用户
@jakobdylanc宣布他们的 Discord 聊天机器人在 GitHub 上已获得超过 69 个 Star。该机器人支持包括 Mistral 在内的多个 LLM,并提供多用户聊天、Vision 支持、流式响应,所有这些仅需 200 行代码 查看仓库。
提到的链接:
GitHub - jakobdylanc/discord-llm-chatbot: 支持 OpenAI, Mistral, ollama, oobagooba 等 • 多用户聊天 • Vision 支持 • 流式响应 • 200 行代码 🔥: Supports OpenAI, Mistral, ollama, oobagooba and more • Multi-user chat • Vision support • Streamed responses • 200 lines of code 🔥 - GitHub - jakobdylanc/discord-llm-chatbot: Supports OpenAI, Mistr…..
Mistral ▷ #random (5 messages):
- 通过国旗表达:
@jujuderp发布了一个 北朝鲜国旗 🇰🇵 的表情符号,而@matmatgamer分享了 法国国旗 🇫🇷 的表情符号。 - 推荐超赞歌单:
@jakobdylanc向<@421429282804465666>播放的一些很棒的曲目表示感谢,称其为 bumping fire(非常带感)。 - 对速度的需求:
@bam4d带着紧迫感回复了 gotta go fast(必须快点)。 - 速度与毛茸茸:
@bam4d分享了一个来自 Tenor 的幽默 GIF,其中包含一个名为 Sanic 的刺猬索尼克(Sonic the Hedgehog)的快速恶搞版本,并附带了关于 Tenor 网站语言设置的说明。
提到的链接:
Sanic The Hedgehob GIF - Sanic The Hedgehob Running - Discover & Share GIFs: 点击查看 GIF
Mistral ▷ #la-plateforme (2 messages):
- Emoji 终止符导致异常行为:
@jakobdylanc发现了一个奇怪的问题:Mistral 模型 以 finish_reason 为 “stop” 结束,但在响应的 content 中仍包含一个 emoji。他们提供了一个详细的 聊天响应代码片段,强调了这一异常现象在所有三个 Mistral API 模型中均存在。
CUDA MODE ▷ #general (29 messages🔥):
-
对双 GPU 配置的热情:
@morgangiraud对组装一台配备 2 x 4070 TI SUPER 的新双显卡机器感到兴奋,以便获得双 GPU 训练的经验。他们还在考虑是选择像 3090 这样拥有更多 VRAM 的旧型号,还是追求全新的显卡。 -
选择正确的组件: 社区成员(包括
@__boatbuilder__和@morgangiraud)正在讨论使用 PCPartPicker 以及 /r/selfhosted 和 r/buildapc 等 subreddit 资源来辅助构建配置。 -
欧洲与美国定价:
@morgangiraud分享说,由于欧洲价格较高,他们的 PC 配件没有太多优惠,并透露整套配置总成本为 4k。完整的配件清单已在 PCPartPicker 上提供。 -
多 GPU 配置考量:
@jeremyhoward和_tvi_参与了多 GPU 的讨论,认为好的主板可以弥补消费级显卡缺乏 P2P 通信的问题,并讨论了稍后升级第二块大显卡的战略优势。 -
加速 LLM 推理服务:
@andreaskoepf重点介绍了 FlashInfer,这是一个旨在提高 Large Language Model (LLM) 服务性能的开源库,目标是优化 Self-Attention 和其他对 LLM 至关重要的变换操作。
提到的链接:
- C-Payne PCB Design: C-Payne PCB 设计
- Accelerating Self-Attentions for LLM Serving with FlashInfer: 介绍加速 Large Language Model 部署的技术
- GitHub - flashinfer-ai/flashinfer: FlashInfer: Kernel Library for LLM Serving: FlashInfer: 用于 LLM 服务的算子库。通过创建 GitHub 账号为 flashinfer-ai/flashinfer 的开发做贡献。
CUDA MODE ▷ #cuda (27 条消息🔥):
-
浮点精度问题:
@zippika报告了在 PyTorch 中进行反量化(dequantize)然后应用nn.Linear操作时出现的不准确性,发现结果与预期的 fp16/fp32 计算有显著差异。据报告,反量化函数运行良好,但后续操作导致了错误,怀疑这与 fp32 和 fp64 之间的舍入差异有关。 -
CUDA 同步或 C++ 标志问题?:在调试过程中,
@zippika思考是否是 CUDA 同步问题或禁用了标准的 PyTorch C++ 标志导致了在反量化后执行线性操作时出现异常行为。提到的禁用标志包括"__CUDA_NO_HALF_OPERATORS__"、"__CUDA_NO_HALF_CONVERSIONS__"、"__CUDA_NO_HALF2_OPERATORS__"和"__CUDA_NO_BFLOAT16_CONVERSIONS__"。 -
量化错误自白:
@zippika对其在 CUDA.cu文件中的实现细节表示沮丧,试图理解为什么dequantizeBlockwise_impl_stream函数在作为矩阵乘法操作的前置步骤时会导致显著的数值偏差。他们认为可能是权重矩阵的转置或K/N维度参数的错误切换导致了该问题。 -
反量化函数受到质疑:
@zippika的调试工作集中在qlinear_impl函数上,其中使用了dequantizeBlockwise_impl_stream函数。@zippika指出,反量化函数在用于自定义线性操作之前似乎运行完美,但之后结果与预期严重偏离。 -
跨函数稳定性受到质疑:
@zippika详细说明了两个 PyTorch 函数mm_normal和mm_qlinear之间的差异,前者产生稳定且符合预期的结果,而后者虽然更快但看起来不稳定,怀疑存在同步问题或其他错误。该用户分享了对比函数的代码片段,以寻求关于这些差异的反馈。
提到的链接:
Dissecting Tensor Cores via Microbenchmarks: Latency, Throughput and Numeric Behaviors:自 Volta 架构以来,Tensor Cores 一直是所有 NVIDIA GPU 中加速融合矩阵乘法累加 (MMA) 的重要单元。为了对 Tensor Cores 进行编程,用户必须使用 leg…
CUDA MODE ▷ #torch (18 条消息🔥):
-
召集所有 AI 创新者:
@vim410分享了一个激动人心的机会,开发者可以参加 NVIDIA 的生成式 AI RTX 开发者竞赛,赢取 GeForce RTX 4090 GPU 和其他奖品。该竞赛鼓励使用 NVIDIA 技术构建创新的 AI 项目。 -
使用 Toro 和 Triton 优化 GPTQ:
@jku100讨论了利用torch.compile和领域知识来增强gptq性能,从而开发出性能可媲美定制化 CUDA 的 Kernel。他们还提供了一个基准测试讨论,并表示他们的工作展示了结合 Torch 和 Triton 工具的潜力。 -
分享创新的邀请:
@marksaroufim对@jku100的成就做出了积极回应,邀请他就其工作进行演讲,强调了torch.compile在 AI 优化方面的巨大潜力。 -
潜在演讲定于 3 月 9 日:
@jku100初步同意在确认后于 3 月 9 日展示其工作,以进一步讨论torch.compile中的优化以及对 AI 加速技术的影响。 -
对竞赛激励的怀疑:
@naisdi对 NVIDIA 的竞赛发表了批评性评论,暗示奖品与成本之比对参与者来说可能不划算,并将其与 NVIDIA 涉及网红的营销手段进行了不利的对比。
提到的链接:
- NVIDIA Gen AI on RTX PCs Developer Contest:参赛赢取 GeForce RTX 4090 GPU、GTC 活动门票等奖品。
- AutoGPTQ/auto_gptq/nn_modules/triton_utils/kernels.py at be78af8d4fd80b5afa0a8a7df7b0e0ec44420003 · AutoGPTQ/AutoGPTQ):一个易于使用的 LLM 量化包,具有用户友好的 API,基于 GPTQ 算法。- AutoGPTQ/AutoGPTQ
CUDA MODE ▷ #beginner (3 messages):
-
软件工程师寻求 MLOps 建议:
@einstein5744是一位来自 ML 公司的软件工程师,正寻求提升 MLOps 技能,目前正在尝试使用 fast.ai 和 Diffusers library。他们欢迎关于深入研究机器学习运维(MLOps)的任何建议和指导。 -
是 fast.ai 的 Diffusion 课程吗?:
@jeremyhoward询问@einstein5744是否正在参加 fast.ai 的 diffusion course,以深入理解机器学习技术。 -
来自快速学习者的课程感谢:
@joseph_en对 fast.ai 课程表示感谢,并特别提到完成了第 11 章中 DiffEdit paper 的复习,非常感谢有这样的资源可用。
CUDA MODE ▷ #pmpp-book (2 messages):
-
第 5 讲活动已排期:
@jeremyhoward宣布了第 5 讲活动的安排,该活动将于本周末举行,并为成员提供了 Discord event link 以供加入。 -
关于 Swizzled Order 的咨询:
@lancerts引用了 PyTorch blog on accelerating Triton,并询问 PMPP 书中是否涵盖了 swizzled order 的概念,表示他们目前还没看到,但也可能是还没读到书中的那个部分。
CUDA MODE ▷ #youtube-recordings (4 messages):
- 第 4 讲录像咨询:
@zonepg询问是否有第 4 讲的录像,因为由于时区限制,他们无法参加直播。 - 分享典型的上传时间表:
@morgangiraud告知录像通常在周初上传。 - 技术问题导致第 4 讲录像延迟:
@marksaroufim提到由于技术问题导致录像延迟,但保证视频将在当天发布。 - 第 4 讲录像现已上线:
@marksaroufim宣布了 Lecture 4 recording 的上传,并补充说 HD 画质将在约一小时后可用。
CUDA MODE ▷ #jax (5 messages):
-
探索 JAX 的 Pallas 扩展:
@stefangliga分享了 Pallas Quickstart Guide,强调 Pallas 是一个实验性扩展,简化了在 JAX 中为 GPU 和 TPU 编写自定义 kernel 的过程。Pallas 在较低的抽象层级运行,需要考虑硬件加速器上的内存访问和计算,在 GPU 上转换为 Triton,在 TPU 上转换为 Mosaic。 -
用户思考:
@stefangliga发布了一个思考表情(🤔),可能表示对所讨论内容的思考或需要进一步澄清。 -
在 JAX 中使用纯 CUDA Kernels:
@nshepperd提供了一个资源链接,解释了如何在 JAX 中使用纯 CUDA kernels,在处理自定义操作时提供了额外的灵活性(Custom Operations for GPUs)。 -
关于 Triton Kernels 和 JAX 执行细节的咨询:
@marvelousmit询问是否有方法打印出 Triton kernels 和 JAX 执行的实际代码,表示有兴趣了解分析(profiling)时的底层调用,特别是与 sgemm kernel 启动相关的调用。 -
寻找 JAX 逆向工程工具:此外,
@marvelousmit提到习惯于使用 Triton+Torch 配合 inductor 来逆向工程 kernel 代码,并询问 JAX 中是否有等效的过程。
提到的链接:
Pallas Quickstart — JAX documentation:未找到描述内容。
OpenAI ▷ #ai-discussions (31 条消息🔥):
- ChatGPT 文件上传故障:用户
@sherlyleta、@guti_310和@lugui报告称,ChatGPT 的文件上传功能自上周末以来一直运行不正常,@lugui保证该问题很快将得到解决。 - 辩论制造商责任:
@aipythonista反驳了@johnnyslanteyes关于查看 Louis Rossman 内容以获取问题列表的建议,认为固件更新(firmware updates)应该解决这些问题,并指出由于相关品牌被认为比竞争对手质量更高,相关指控可能存在偏见。 - 本地化 GPT-3.5 讨论:
@czarcast询问是否可以托管一个本地的 GPT-3.5 实例用于 homelab 诊断,@elektronisade指出 GPT-3.5 不支持此类用途,随后@riaty推荐了开源替代方案 Mistral 8x7b。 - 辩论模型效率与智能:
@kotykd和@riaty讨论了在本地运行开源模型 Mistral 8x7b 的可行性,承认其对资源要求很高,但认为根据用户的需求,它具有潜在的实用价值。 - 考虑新型 3D 语言模型:
@red_code提出了一个使用 3D 向量语言模型来表示单词和字符的概念,引发了@darthgustav.对性能可行性的简短质疑。
OpenAI ▷ #gpt-4-discussions (50 条消息🔥):
- 自定义 GPT 的商标困扰:
@zurbinjo在 GPT 名称中使用“Midjourney”一词时遇到问题,@solbus澄清根据 OpenAI 的品牌指南,商标权禁止此类用法。 - 持续的技术动荡:包括
@Aleks、@sherlyleta、@thatjay_和@realspacekangaroo在内的多位用户在不同浏览器上遇到了文件上传和 ChatGPT 功能的持续问题,部分用户在更换浏览器后获得成功。 - 用户应对 GPT-4 故障:
@dexmeighan和_odaenathus报告称 GPT-4 在对话过程中卡住,影响了多个网页浏览器的使用,部分用户的情况正在逐渐好转。 - GPT 构建者的定制困惑:用户表达了在使用自定义 GPT 功能时的困难,例如设置语音 (
@diphon)、强制执行指令序列 (@woodenrobot) 以及更改显示的身份 (@scootmandu_ai)。 - 寻求自定义 GPT 的反馈与曝光:
@_loier正在寻找测试并获取为角色扮演游戏设计的自定义 GPT 反馈的方法,引发了关于实现此目标的最佳方法和平台的讨论。
提到的链接:
品牌指南:在营销和沟通中使用 OpenAI 品牌的语言和资产规范。
OpenAI ▷ #prompt-engineering (2 条消息):
- AI 处理 PDF 与提取文本的对比:
@wazzldorr征求关于向 AI 提供科学论文的最佳方法的建议,在 PDF 格式和提取文本并直接输入聊天框之间犹豫不决。作为回应,@lugui保证 AI 应该能够毫无问题地处理 PDF。
OpenAI ▷ #api-discussions (2 条消息):
- PDF 与提取文本的问题:用户
@wazzldorr询问了处理科学论文的最佳方式,质疑是提供整个 PDF 格式的文档,还是提取文本并直接在聊天中提供。 - PDF 处理能力:作为回应,
@lugui保证 AI 应该能够毫无问题地处理 PDF。
LangChain AI ▷ #general (28 条消息🔥):
-
价格极具竞争力的云端 GPU 节点:用户
@lhc1921提到 RunPod 提供了优秀的云端 GPU 节点服务,建议需要云计算资源的用户可以考虑。 -
介绍 BGE-M3 多功能 Embedding 模型:
@lhc1921分享了一个名为 BGE-M3 的新 Embedding 模型链接,该模型在多功能性、多语言和多粒度方面表现出色。更多详情请参阅其 GitHub 仓库 和配套 论文。 -
如何使用 OpenAIEmbedder 生成 Embedding:针对
@natuto_uzumaki1808的咨询,@kapa.ai提供了在声明 embedder 后生成 embedding 的详细说明,包括 JavaScript 和 Python 的代码示例,并引导用户参考 LangChain 的 JavaScript 文档 和 Python 文档。 -
比较 Llama Index 和 LangChain 的数据预处理:用户
@arrmlet寻求关于 llama-index 和 LangChain 在数据预处理方面差异的见解,并分享了一个 Stack Overflow 问题 以寻求社区解答。 -
使用 LangChain 翻译 HTML 并保留样式:
@o3omoomin提出了一个关于使用 LangChain 将 HTML 翻译成另一种语言的问题,并强调了保持原始样式和格式的重要性。
提到的链接:
- BAAI/bge-m3 · Hugging Face:未找到描述
- LlamaIndex 和 LangChain 在 LLM 应用的数据预处理方面有何不同?:我一直在探索将大语言模型 (LLMs) 集成到我的应用中的框架,特别关注数据预处理、摄取和查询能力。我遇到了…
- Issues · langchain-ai/langchain.):🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
LangChain AI ▷ #langserve (33 条消息🔥):
-
Bearer Token 问题:
@peterlandis询问在使用 AzureGPT 时如何使用 Bearer Token 传递请求头(request headers)。作为回应,@veryboldbagel提供了指导,并参考了 Configurable Runnables 文档 和 APIHandler 示例 以进行完整的端点自定义。 -
LangServe 学习曲线:
@lucas_89226(自称是一位感到厌倦的前热衷者)与@veryboldbagel之间的对话集中在设置 LangServe 的问题上。@lucas_89226在尝试使用示例代码和 playground 时遇到错误,随后进行了故障排除,包括检查客户端代码、考虑 LangServe 服务端代码是否被修改,以及验证正确的 OpenAI API 端点配置。 -
LangServe 设置指南发布:
@gitmaxd分享了他们使用 Hosted LangServe 的经验,并提供了一个有用的指南,其中包含部署视频和设置简单 LangServe 模板的演示。 -
遇到 LangServe 错误:
@lucas_89226报告在尝试调用 LangServe 端点时遇到错误消息。对此,@veryboldbagel要求提供完整的 traceback,并建议@lucas_89226确认在使用原始未修改的服务端代码时错误是否仍然存在。 -
LangServe 故障排除支持:随着
@lucas_89226继续排查其 LangServe 设置,@veryboldbagel持续参与并提供额外支持,建议@lucas_89226在需要时于 LangServe GitHub 讨论页面 发起 issue 或讨论。
提到的链接:
- 未找到标题: 未找到描述
- 使用 🦜LangServe 部署你的第一个 AI API 端点: 使用 LangServe 部署你的第一个 AI Rest API 端点非常简单!我们将逐步完成所有操作,让你的第一个项目上线。
- langchain-ai/langserve · Discussions: 浏览 langchain-ai langserve 的 GitHub 讨论论坛。讨论代码、提问并与开发者社区协作。
- GitHub - langchain-ai/langserve: LangServe 🦜️🏓: LangServe 🦜️🏓。通过在 GitHub 上创建账号来为 langchain-ai/langserve 的开发做出贡献。
- langserve/examples/configurable_chain/server.py at main · langchain-ai/langserve: LangServe 🦜️🏓。通过在 GitHub 上创建账号来为 langchain-ai/langserve 的开发做出贡献。
- langserve/examples/api_handler_examples/server.py at main · langchain-ai/langserve: LangServe 🦜️🏓。通过在 GitHub 上创建账号来为 langchain-ai/langserve 的开发做出贡献。
LangChain AI ▷ #share-your-work (6 messages):
-
AI Form Roast 承诺表单优化:
@siddish展示了由 WorkHack 推出的 AI Form Roast,这是一个旨在分析在线表单并提供反馈以提高完成率和用户体验的 AI 工具。他们正在 Product Hunt 上征求反馈和支持。 -
OranScribe TweetStorm Express Flow 发布:
@shving90分享了一条关于 OranScribe 新功能的推文,该功能可帮助用户生成多个版本的推文以吸引不同的受众,并承诺使用其 TweetStorm Express Flow 仅需 10 分钟即可完成。更多信息可以从他们的 Twitter 帖子中了解。 -
介绍 Dewy - 简化 RAG 应用:
@kerinin介绍了一个名为 Dewy 的知识库平台,它简化了检索增强生成(RAG)应用的启动和运行。他们提供了一篇 博客文章,详细介绍了 Dewy 自动化文档提取、索引和检索的能力。 -
加密项目寻找充满热情的专业人士:
@hinayoka正在为一个令人兴奋的加密项目寻找专业人士来填补各种角色,空缺职位包括 Web3 Developer、Game Developer、Web Developer、Moderator 和 UI/UX Designer。鼓励感兴趣的申请人带着简历和作品集联系。 -
创建个性化 AI 反向链接外联消息:
@felixv3785介绍了一个使用 Vercel AI SDK 和 Langchain 构建的工具,可以生成用于反向链接外联的个性化消息。要测试这个免费工具,请访问 Backlink Outreach Message Generator。
提到的链接:
-
[Introducing Dewy Dewy](https://dewykb.github.io/blog/introducing-dewy/):今天我们发布了 Dewy 的第一个版本,这是一个专为生成式 AI 应用的特定需求而构建的知识库。 -
[AI Form Roast by WorkHack - 审计和优化在线表单的免费 AI 工具 Product Hunt](https://www.producthunt.com/posts/ai-form-roast-by-workhack):AI Form Roast by WorkHack 是一款免费的 AI 工具,可分析在线表单并提供反馈,以提高完成率和用户体验。它基于 1000 多个表单进行训练,可生成针对关键领域的见解… - 来自 Adi Oran (@OranAITech) 的推文:OranScribe 新流程刚刚发布!🚀 创意是用一千种不同方式重复同一信息的艺术。OranScribe TweetStorm Express Flow。步骤:1. 设置你的受众和 SEO 2….
- Backlink Outreach Message Generator:使用我们的反向链接外联消息生成器提升您的 SEO 策略。制作个性化、引人入胜的消息,轻松获得有价值的反向链接。
Latent Space ▷ #ai-general-chat (66 messages🔥🔥):
- 分享配置与工具:
@ashpreetbedi分享了他们涉及 PyCharm 和 ScreenStudio 的录制与开发配置详情。 - 策划 AI 团队结构:
@30sleeps讨论了组建内部 AI 工程团队的想法,可能会从个人尝试开始以在扩大规模前证明价值。@quicknick123和@eugeneyan提供了关于团队组建和扩展 ML 项目的见解,@eugeneyan推荐了关于实时 ML 和团队配置的阅读材料。 - 对 DSPy 系列解析的兴趣:
@lightningralf寻求一个更易懂的 DSPy 视频系列解析,@kbal11和@coffeebean6887表示感兴趣并建议社区可以协助理解。 - 关于 GPT-4 的轻松调侃:
@swyxio和@coffeebean6887等成员幽默地讨论了 GPT-4 被察觉到的“懒惰”表现,并分享了相关推文和 Reddit 帖子的链接,以突出社区对该模型性能的反馈。 - 构建哲学 AI Agent:
@dereklomas提议创建一个 AI 驱动的数字图书馆,让哲学 Agent 相互交流,@fanahova建议使用 Botpress 和 WorkAdventure 等工具进行开发。
提到的链接:
- DSPy 详解:告别 LangChain 提示词模板: 用简单的术语解释并编写 DSPy。不再需要 LangChain 或 LangGraph 提示词模板。一个自我改进的 LLM-RM 流水线!外加自动提示词工程…
- AMOR:通过过程反馈构建自适应模块化知识 Agent 的方案: 大语言模型 (LLMs) 的显著成功引发了构建语言 Agent 以完成各种复杂任务的热潮。我们提出了 AMOR,一个基于开源 LLMs 的 Agent 框架…
- Sam Altman (@sama) 的推文: GPT-4 在执行新年计划时起步较慢,但现在应该不再那么“懒惰”了!
- PromptHub 博客:如何防御提示词攻击 (Prompt Hacking): 了解关于提示词攻击所需的一切知识。包括方法、防御措施及其影响。了解 PromptHub 如何帮助你确保提示词按设计运行。
- GitHub - copilot-us/chatgpt-plugins: 官方 ChatGPT 插件🧩: 官方 ChatGPT 插件🧩。通过在 GitHub 上创建账户,为 copilot-us/chatgpt-plugins 的开发做出贡献。
- Sam Altman (@sama) 的推文: GPT-4 在执行新年计划时起步较慢,但现在应该不再那么“懒惰”了!
- GitHub - DefinitelyTyped/DefinitelyTyped: 高质量 TypeScript 类型定义的仓库。: 高质量 TypeScript 类型定义的仓库。 - GitHub - DefinitelyTyped/DefinitelyTyped: 高质量 TypeScript 类型定义的仓库。
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- 欢迎来到 Flowise - FlowiseAI: 未找到描述
-
[Botpress 用于 ChatGPT 聊天机器人的生成式 AI 平台](https://botpress.com/): 使用 Botpress 更快地构建 ChatGPT 聊天机器人。由 OpenAI 最新的 LLMs 和 GPT 驱动的直观构建体验。免费开始使用。 - GitHub - workadventure/workadventure: 以 16 位 RPG 视频游戏形式呈现的协作式 Web 应用程序(虚拟办公室): 以 16 位 RPG 视频游戏形式呈现的协作式 Web 应用程序(虚拟办公室) - GitHub - workadventure/workadventure: 以 16 位…
- 用于推荐的实时机器学习.): 为什么要实时?中国和美国的公司是如何构建它们的?如何设计和构建一个 MVP?
- 组建数据科学团队最有效的方法是什么?: 从 2012 年到 2017 年,我有幸从零开始在 Coursera 建立了数据和分析部门。在那段时间里,我们……
- 设计数据科学组织: 数据科学仍然是一个不断发展和演变的领域。鉴于此,行业内有多种方法来构建数据科学角色和组织。在这篇文章中,我将……
-
[争论结束:将你的数据科学团队中心化 Prolego](https://www.prolego.com/blog/the-debate-is-over-centralize-your-data-science-team): 你应该将数据科学团队中心化并将数据科学家嵌入产品团队吗?还是应该直接将数据科学家招聘到产品团队中?
LAION ▷ #general (61 messages🔥🔥):
- AI 基础模型:协作呼吁:
@pratikk10正在寻找有兴趣创建文本到文本/图像/视频等基础模型的人员。欢迎与该领域的严肃思考者和创作者进行交流。 - 强化学习中的偏见:
@pseudoterminalx讨论了 RLHF (Reinforcement Learning from Human Feedback) 会向模型权重引入显著偏见的担忧,这对于开发基础模型(base model)是不利的。@astropulse赞同这一观点,并指出 Midjourney v3-4 图像中明显的独特风格可能是此类偏见的结果。 - 消除文本偏见的挑战:
@thejonasbrothers分享了在尝试消除 pixart(特别是源自 5.1 版本数据集)中的文本偏见时面临的考验。@pseudoterminalx批评了 JourneyDB 数据集的使用,主张应将其丢弃,转而寻找更稳健的替代方案。 - 古代文本的启示:
@itali4no分享了 2023 年维苏威挑战赛大奖 (Vesuvius Challenge 2023 Grand Prize) 获奖者的细节,他们成功开发了在不打开卷轴的情况下阅读 2000 年前卷轴的方法。@nx5668赞扬了使用 TimeSformer 模型检测卷轴扫描中墨迹的变革性应用,同时指出使用粒子加速器进行扫描的成本高达每个卷轴 4 万美元。 - 限制背景下中国机器学习专业能力的讨论:
@qwerty_qwer询问中国实体如何在 GPU 限制下在机器学习领域取得领先,这引发了关于 GPU 访问充足性以及近期出口限制影响的简短讨论。@kenjiqq透露,中国大型企业在限制实施前已采购了大量的 NVIDIA H100 和 A100。
提到的链接:
- Vesuvius Challenge 2023 Grand Prize awarded: we can read the scrolls!:这卷拥有 2000 年历史的卷轴讨论了音乐、食物以及如何享受生活的乐趣。
- Jinbo Xing:未找到描述
LAION ▷ #research (5 messages):
- Hugging Face 的 OWLSAM 亮点:用户
@SegmentationFault分享了一个专门用于 OWLSAM 的 Hugging Face Space,该模型结合了 OWLv2 与 SAM 优化。 - 视觉表征覆盖不足:
@SegmentationFault对 OWLSAM 的表现表示失望,称其 “在我进行的一些测试中未能捕捉到很多东西”。 - OWLSAM 误识别物体:
@SegmentationFault还指出,在他们的测试中,OWLSAM 倾向于 “捕捉错误的物体”,这表明该模型的物体检测准确性可能存在潜在问题。
提到的链接:
OWLSAM - a Hugging Face Space by merve:未找到描述
LlamaIndex ▷ #announcements (1 messages):
- LlamaIndex 重大版本即将发布:用户
@jerryjliu0宣布本周预计将发布一个重大的 LlamaIndex 版本,其中包含许多清理和优化。计划升级 LlamaIndex 版本的用户应关注此次更新。
LlamaIndex ▷ #blog (6 条消息):
- LlamaIndex 增强多模态能力:与
@llama_index的集成使得构建可以在 MacBook 上运行的完整多模态应用程序成为可能,将图像推理(image reasoning)提升到了新高度。更多信息请见此 tweet。 - Home AI 在 Hackathon 中荣获最佳 PDF Parser 使用奖:首届线下 Hackathon 展示了如 Home AI 等获奖项目,该项目结合了基于 RAG 的搜索引擎,通过创新标准筛选房屋。点击此 tweet 查看获奖者。
- Hackathon 促进创新与反馈:近 200 人参加了此次 Hackathon,他们组建团队并向 LlamaIndex 团队提供了关于用户体验的实时反馈。更多详情见此 公告。
- 分享宝贵的 Hackathon 资源指南:LlamaIndex 的资源指南在 Hackathon 上大受欢迎,涵盖了从初学者到专家的各个阶段。指南可在此处获取。
- 新款 RAG CLI 工具发布:一款由
@llama_index、Mistral-7B 和 bge-m3 驱动的新型 CLI 工具,为设备端文件搜索和自定义提供了基于 LLM 的 grep 功能。通过此 tweet 了解该工具及其功能。
提到的链接:
Notion – 笔记、任务、维基和数据库的一站式工作空间。:一款将日常工作应用融合为一的新工具。它是为您和您的团队打造的全能工作空间。
LlamaIndex ▷ #general (33 条消息🔥):
- 将 Knowledge Graphs 与 Azure 集成:用户
@senshi2904询问是否有办法使用 Azure CosmosDB Gremlin 存储和访问由 llama knowledge graph index 创建的 Knowledge Graphs。消息中未提供任何建议或回复。 - 提高 Llama 2 的 Prompt 有效性:
@wrapdepollo询问了如何防止 Llama 2 在输入过多文本时遗忘指令的技巧,并向社区寻求建议和自定义 Prompt。对话中未直接提供解决方案。 - Replit Bounties 咨询:
@d.j147询问在哪里可以联系 Replit bounties,但在给定的消息中未提供指导。 - 内部文档摘要挑战:
@mysterious_avocado_98353就如何总结关于 AAPL 的最新文档(以created_time作为元数据)寻求建议,而@akshay_1提到可能需要通过 LLM 进行查询扩展(query expansion),并提议稍后通过私信提供资源。 - 在 LlamaIndex 中更新 Vector Stores:
@ramihassanein指出 MongoDB 和 DeepLake 等 Vector Stores 可能需要更新为 BasePydanticVectorStore,类似于最近对 AstraDB 的更新。@cheesyfishes回复鼓励通过 Pull Requests (PRs) 做出贡献,并表示他们在发现问题时会及时处理更新。
提到的链接:
- GitHub - run-llama/sec-insights: 使用 LlamaIndex 的真实全栈应用:一个使用 LlamaIndex 构建的真实世界全栈应用程序 - GitHub - run-llama/sec-insights
- llama_index/llama_index/vector_stores/mongodb.py · run-llama/llama_index:LlamaIndex(原 GPT Index)是为您 LLM 应用提供的数据框架 - run-llama/llama_index
- llama_index/llama_index/vector_stores/deeplake.py · run-llama/llama_index:LlamaIndex(原 GPT Index)是为您 LLM 应用提供的数据框架 - run-llama/llama_index
- llama_index/llama_index/vector_stores/astra.py · run-llama/llama_index:LlamaIndex(原 GPT Index)是为您 LLM 应用提供的数据框架 - run-llama/llama_index
- LlamaIndex RAG Hackathon "已售罄!" – (加入候补名单):超越聊天机器人:释放 AI Agents 的潜力
LlamaIndex ▷ #ai-discussion (25 messages🔥):
-
寻求创建聊天机器人的帮助:
@cay7man表示有兴趣为工程师构建一个用于查询标准文档的聊天机器人。@rick_03848回复了一个使用 LlamaIndex 进行文档查询的 GitHub 项目链接,可以在 GitHub - imartinez/privateGPT 找到。 -
发现向量搜索问题:
@gavmor报告了使用 Qdrant 时向量搜索结果的问题,发现不相关节点的返回排名高于预期节点。@cheesyfishes回复建议查看response.source_nodes进行调试。 -
检索技巧与代码分享:
@gavmor询问了如何打印向量分数并比较节点相似度,最终分享了使用Ollama生成和比较 embeddings 的 TypeScript 代码,并以 “How old is John?” 作为查询示例。 -
架构特性与最佳实践:
@gavmor对其检索设置中 embeddings 和 LLM 对象的正确用法表示担忧,引发了关于实现的讨论。对话中包括了@cheesyfishes对 LlamaIndex 的 LLM 对象包含 embeddings 的批评。 -
未来检索实验计划:
@gavmor提到他们计划进行进一步的检索实验,包括提取更多节点进行 reranking,但表示不愿更改其 chunking 策略。
提到的链接:
-
[Class: Ollama LlamaIndex.TS](https://ts.llamaindex.ai/api/classes/Ollama): 统一的语言模型接口 - GitHub - imartinez/privateGPT: Interact with your documents using the power of GPT, 100% privately, no data leaks: 使用 GPT 的力量与你的文档交互,100% 私密,无数据泄露 - GitHub - imartinez/privateGPT
OpenAccess AI Collective (axolotl) ▷ #general (41 messages🔥):
-
Qwen1.5 模型发布!:
@bratao宣布发布 Qwen1.5,并提供了博客文章、GitHub、Hugging Face、ModelScope、Demo 和 Discord 服务器的链接。该模型有多种尺寸,并包含量化版本以提升开发者体验。 -
GCP 为企业提供极具竞争力的价格:用户讨论了 Google Cloud Platform (GCP) 的定价,
@nruaif透露企业客户可以按需以每小时约 $1.5-2 的价格获取 A100 实例,这比非企业用户的市场价更便宜。 -
Qwen 1.5 的对比与基准测试:
@yamashi提到根据基准测试,Qwen 1.5 似乎优于 Mistral,并对缺乏 30b 模型表示遗憾。 -
对基准测试中指标不一致的抱怨:
@dreamgen和@yamashi讨论了与新模型相关的基准测试,建议在结果中应承认基准测试固有的噪声,并且应该报告标准差,尽管这通常被忽略。 -
对分销商动态和定价的见解:对话揭示了像 AWS 和 GCP 这样的大型云提供商如何设置较高的非企业价格,据推测是为了鼓励像 RunPod 这样的分销商,此外还提到了 spot price 优惠,例如
@nruaif分享的 GCP L4 spot price 为每小时 $0.2。
提到的链接:
Introducing Qwen1.5: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD 介绍:在最近几个月中,我们的重点一直是开发一个“好”模型,同时优化开发者体验。随着我们向…迈进。
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (14 messages🔥):
- 合并前量化 (Quantizing Before Merging):
@dreamgen指出 Hugging Face 建议在合并前对基础模型进行量化,正如qlora所做的那样,这与 Axolotl 脚本的方法不同。 - Axolotl 贝叶斯优化的可能性:
@mihai4256询问是否在 Axolotl 框架中加入用于超参数调优的贝叶斯优化抽象,@nruaif回复称这似乎很容易实现,并引用了支持此类训练优化的 Hugging Face 文档。 - Axolotl 安装中的依赖冲突:
@nanobitz报告了在干净安装 Axolotl 过程中的依赖冲突,涉及torch的包版本,其中必须注释掉xformers。@dctanner提出了使用torch 2.1.2的解决方法。 - Hugging Face 中 Axolotl UI 体验的想法:
@dctanner提出了在 Hugging Face Spaces 中为 Axolotl 建立用户界面的想法,利用用户自己 Hugging Face 账户的 GPU 资源,为配置和运行训练提供初学者友好的体验。 - Axolotl YAML 配置简化请求:
@nanobitz注意到ds2保存可能损坏的model.safetensors的异常情况,并请求协助删除 Axolotl 项目中所有示例 YAML 配置中冗余的is_*_derived_model字段。
提到的链接:
- 使用 Trainer API 进行超参数搜索:未找到描述
- DPO Trainer:未找到描述
- jondurbin/qlora 项目中的 qmerge.py:QLoRA:量化 LLM 的高效微调。通过在 GitHub 上创建账户为 jondurbin/qlora 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #rlhf (1 messages):
dangfutures: 有人知道 Zephyr 的配置怎么弄吗 <@257999024458563585>
Perplexity AI ▷ #general (25 messages🔥):
- 报告 Pro 升级支付问题:
@officialjulian遇到了 Pro 升级扣款但收到“银行卡被拒绝”消息的问题。@mares1317建议联系 support@perplexity.ai 寻求帮助。 - 在 Discord 上寻求计费支持:
@yuki.ueda表示在两周后仍未收到支持部门关于计费查询的回复。@ok.alex迅速做出回应,要求私聊发送电子邮件以检查问题。 - 关于 Stripe 拒绝付款的困惑:针对
@officialjulian的问题,@icelavaman解释说,来自 Stripe 的“银行卡被拒绝”消息意味着不应产生任何费用。 - 探索 Collections 中的 AI Prompt 长度:
@twelsh37询问了 Prompt 字符限制,因为他们在将 Prompt 添加到 Collections 时超出了 2500 个字符。 - 关于 Claude 性能的反馈:
@Catto提到 Anthropic 网站上仍可使用较早版本的 Claude,并建议 Perplexity 考虑恢复到该版本,理由是对 Claude 2.1 的能力表示不满。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、闲逛并保持联系。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。
- Dj Khaled Another One GIF:点击查看 GIF
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。
Perplexity AI ▷ #sharing (7 条消息):
-
多元教育背景下的 AI 伦理:
@worriedhobbiton对 Pasco 高中的 AI 应用表示担忧,质疑 AI 是否能为学生提供公正且具有文化敏感性的支持,特别是考虑到他们的 LatinX 身份和经济社会挑战。他们询问了确保 AI 提供伦理指导的策略。 -
无关的 AI 研究查询结果:
@byerk_enjoyer_sociology_enjoyer遇到了一个问题,即在要求 AI 评估来源的有效性和权威性时,AI 进行了无关的研究。他们分享了一个未达预期的 Perplexity AI 搜索结果。 -
七项原则查询:
@fafu_10提供了一个 Perplexity AI 搜索链接,但没有提供额外的上下文或评论。 -
AI 工具展示:用户
@vipinpg分享了一个关于最佳 AI 工具的 Perplexity AI 链接,但未提供进一步的背景或讨论。 -
沉思数字智能与生物智能:
@mares1317发布了一段 YouTube 视频,内容是 Geoffrey Hinton 讨论数字智能是否会取代生物智能,该活动由多伦多大学及相关机构主办。 -
与尤达大师的一刻:
@mares1317分享了一个 尤达星球大战 GIF,没有进一步的讨论或背景。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
-
[Geoffrey Hinton 数字智能会取代生物智能吗?](https://www.youtube.com/watch?v=iHCeAotHZa4):多伦多大学 Schwartz Reisman 技术与社会研究所和计算机科学系,与 Vect… 合作。 - 尤达星球大战 GIF - Yoda Star Wars - 发现并分享 GIF:点击查看 GIF
Perplexity AI ▷ #pplx-api (4 条消息):
- 寻求帮助:用户
@aiistheonlyway请求帮助,但未提供其面临问题的详细信息。 - 潜在解决方案链接:
@icelavaman分享了一个链接,但消息中未说明链接的内容或背景。 - 加速摘要生成:
@sid.jjj正在寻找减少从长文本生成摘要的 API 响应时间的方法。他们指出,并行生成三个链接的摘要大约需要 10 秒。 - 提出的差异问题:
@jbruvoll询问了关于交互式使用与 API 使用之间行为差异的见解,并链接到了一条特定的 Discord 消息作为参考。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
DiscoResearch ▷ #general (27 messages🔥):
-
Dare_Ties Merge 取得高分:
@johannhartmann分享了他们使用 dare_ties merge 方法创建的一个高分丹麦语语言模型,目前在 Mainland Scandinavian NLG 排行榜上排名第 2。详情见 munin-neuralbeagle-7b。 -
无需 GPU 即可合并模型:
@sebastian.bodza提到可以根据需要合并 LeoLM models,无需 GPU,甚至在 Google Colab 等平台上也可以实现。 -
Wiedervereinigung-7b-dpo-laser 发布:
@johannhartmann介绍了 Wiedervereinigung-7b-dpo-laser,这是一个拥有 7b 参数的德语模型,结合了目前最优秀的一些德语模型,并讨论了它在 MT-Bench-DE 上的高分表现。 -
分析模型合并的有效性:在
@johannhartmann和@bjoernp的讨论中,他们探讨了模型合并带来的高分是否反映了实际应用场景中的真实改进。@johannhartmann确认在使用聊天功能时看到了改进。 -
讨论语言模型的 Laser 处理:
@johannhartmann在他们的模型上尝试了 laserRMT,但发现使用该程序之前的 mtbench 分数更高。讨论暗示了模型合并的复杂性以及不同训练过程对模型性能的影响。
提到的链接:
- RJuro/munin-neuralbeagle-7b · Hugging Face:未找到描述
- mayflowergmbh/Wiedervereinigung-7b-dpo-laser · Hugging Face:未找到描述
DiscoResearch ▷ #embedding_dev (1 messages):
- Jina AI 发布全新 Code Embeddings:
@sebastian.bodza分享了 Jina AI 全新 code embeddings 的链接,该模型支持英语和 30 种编程语言,适用于 neural search applications。该模型拥有 8192 的序列长度(sequence length),通过 Jina AI 的 Embedding API 使用效果最佳。
提到的链接:
jinaai/jina-embeddings-v2-base-code · Hugging Face:未找到描述
Alignment Lab AI ▷ #general-chat (14 messages🔥):
-
LLama2 SFT 训练损失(Training Loss)问题已解决?:
@jellyroger5505在对 LLama2 进行 SFT 时遇到了奇怪的训练损失曲线问题。@ufghfigchv建议这可能是由于学习率(learning rate)过高导致的,但在检查了@jellyroger5505的 config 后,建议的解决方法是切换到 Axolotl,并可能根据其配置示例增加学习率。 -
Ankr 寻求合作以促进增长与发展:来自 Ankr 的
@anastasia_ankr联系了工程和/或业务开发团队,讨论节点基础设施(node infrastructure)。@ufghfigchv指引 Ankr 联系@748528982034612226作为联系人。 -
简单的问候也很有意义:
@xterthy和@aslawliet都在聊天中发送了简短的问候,营造了友好的社区氛围。 -
等待私信回复:
@mizzy_1100表示希望进一步交流,标记了@748528982034612226并建议他们查看私信(DMs)以获取更多信息。 -
鼓励思想的马戏团:
@rusch幽默地将 Discord 服务器称为“了不起的 Discord 马戏团”,提升了参与者之间的趣味性和协作感。
提到的链接:
axolotl/examples/llama-2/fft_optimized.yml at main · OpenAccess-AI-Collective/axolotl:尽管提问。通过在 GitHub 上创建账号来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
Datasette - LLM (@SimonW) ▷ #ai (1 条消息):
- Audacity 集成 Intel 的 AI 工具:
@dbreunig宣布免费音频编辑器 Audacity 现在包含了一套来自 Intel 的免费 AI 工具,向昂贵的订阅服务发起挑战。核心功能包括使用 Whisper.cpp 的 噪声抑制、转录、音乐分离,以及音乐生成等实验性生成功能,全部在用户的电脑上本地运行。
提到的链接:
Audacity 现在拥有来自 Intel 的免费 AI 驱动音频工具 - CDM Create Digital Music: 这款免费音频编辑器现在获得了一套来自 Intel 的免费 AI 工具,其中一些可以与昂贵的付费订阅服务竞争。涵盖了诸如噪声抑制、转录和音乐…
Datasette - LLM (@SimonW) ▷ #llm (2 条消息):
-
探索将
llm用于论文工作:@kiloton一直在使用 chatGPT 进行论文构思,并对结合文件上传和网页搜索功能的结果感到满意。他们正在寻求关于通过llm处理 PDF 和网页搜索 的建议,并思考对话历史是否可以移植到其他模型并保留在本地。 -
对 Hugging Face 集成的兴趣:
@dbreunig表达了将llm与 Hugging Face 的 transformers 集成的兴趣,并分享了一个 Natural-SQL-7B 模型,该模型提供强大的 Text-to-SQL 性能和复杂的提问理解能力。据报道,该模型在其类别中超越了同类产品。
提到的链接:
chatdb/natural-sql-7b · Hugging Face: 未找到描述
LLM Perf Enthusiasts AI ▷ #opensource (2 条消息):
- Qwen1.5 开启新一代模型:
@potrock分享了 Qwen1.5 的全面介绍,宣布开源包含六种不同尺寸的基础模型和聊天模型。提供了各种资源,如 博客文章、GitHub 链接、Hugging Face、Modelscope、Demo 以及 Discord 社区。 - Llama 的潜在挑战者:
@potrock强调 0.5B Qwen1.5 模型 的性能与 Llama 7B 旗鼓相当。这一发现暗示了新一代模型在效率上的重大提升。
提到的链接:
Qwen1.5 介绍: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD 介绍 在最近几个月中,我们的重点一直是开发一个“好”模型,同时优化开发者体验。随着我们向…