ainews-ai-gets-memory
AI 获得记忆
AI Discord 社区分析涵盖了 20 个服务器(guilds)、312 个频道和 6901 条消息。报告重点介绍了用于上下文和记忆的 RAG(检索增强生成)式操作的演变,例如 MemGPT 在 ChatGPT 和 LangChain 中的落地应用。
TheBloke Discord 频道讨论了开源大语言模型,例如上下文长度高达 100 万 token 的 Large World Model,以及支持 101 种语言的 Cohere aya 模型。针对角色扮演的模型(如 MiquMaid-v2-70B)在硬件增强后性能提升显著。
文中还解释了有监督微调 (SFT) 和直接偏好优化 (DPO) 等微调技术,并指出相比 Alpaca,开发者更倾向于使用 Unsloth AI 的 apply_chat_template 等工具。此外,还讨论了在 SillyTavern 项目中通过 JSPyBridge 集成 JavaScript 和 Python 的方案。报告还记录了 Mixtral 8x7b qlora 与 Mistral 7b 在训练方面的挑战。
LM Studio Discord 则侧重于影响大模型加载的硬件限制、medAlpaca 等医疗大模型,以及围绕 GPU 升级和超频的硬件讨论。此外,社区还表达了对 LM Studio 支持 IQ3_XSS 1.5 bit 量化的期待。
2024年2月11日至12日的 AI Discord 动态。我们为您检查了 20 个服务器、312 个频道和 6901 条消息。预计节省阅读时间(按每分钟 200 词计算):589 分钟。
我们长期以来一直认为,用于上下文(知识库、关于世界的实时事实)和记忆(关于你的持续事实列表)的 RAG 风格操作将会发生分化。领先的实现是 MemGPT,而现在它似乎已在 ChatGPT(带有一条风格诡异的推文,更多细节来自 Joanne Jang)和 LangChain 中推出。
OpenAI:
LangChain:
从某种意义上说,这只是 LMstudio/Sillytavern 角色扮演群体早已拥有的功能的某种跨界。预期它会略微改善 UX,但不会带来巨大的惊喜,因为目前的记忆建模还很粗糙,不具备拟人化特征,且受限于上下文限制。
目录
[TOC]
第 1 部分:Discord 高层级摘要
TheBloke Discord 摘要
-
无限制的文本上下文:工程师们正在探索新的开源大语言模型,例如 Large World Model,该模型号称在高达 100 万个 token 的上下文中仍能保持连贯性。讨论内容包括语言支持,如 Cohere 的
aya模型(涵盖 101 种语言),以及在模型安装过程中使用基于 jax 的工具所面临的挑战。 -
培育色情编程角色扮演:社区正在剖析重新量化的 Miqu 模型(如 MiquMaid-v2-70B)在色情角色扮演 (ERP) 中的表现。重点讨论了硬件提升带来的影响,在使用 12GB VRAM GPU 时,生成速度从 0.7t/s 跃升至 2.1t/s。
-
指令、优化、重复:解释的微调技术包括使用 Sequential Fine-Tuning (SFT),随后进行 Direct Preference Optimization (DPO) 作为改进的 RLHF/PPO,详见论文第 6 页。Unsloth AI 的
apply_chat_template被认为优于 Alpaca,可用于训练 LLM 进行多轮对话。 -
AI 开发中的 JavaScript 与 Python 结合:使用 JSPyBridge 的实验成功实现了 JavaScript 和 Python 的桥接,从而扩展了 SillyTavern 项目。这包括解决 Windows 特有的错误,例如通过
cpu_embedding=True绕过访问冲突问题,以及将 Python 类异步集成到 JavaScript 代码中。 -
模型训练中令人困惑的 Loss:一位工程师在微调 Mixtral 8x7b qlora 时观察到了无法解释的训练 Loss 差异,尽管使用了相似的数据集和超参数,其 Loss 仍高于 Mistral 7b。此事仍待社区进一步讨论或分享类似经验。
LM Studio Discord 摘要
-
大模型对 RAM 的渴求:由于 RAM 和 VRAM 限制,
@nonm3和@theoverseerjackbright等用户在 LM Studio 中加载大模型时遇到了错误。建议包括尝试更小的模型量化(quants),一些用户遇到了 LM Studio 的 GPU 检测问题,导致重启崩溃。 -
MedAlpaca 进入临床应用:在关于医疗 LLM 的讨论中,针对医疗问答微调的模型 medAlpaca 被认为是
@pepito92i医疗项目的一个有前景的补充。注意到 Microsoft 的 phi-2 模型在 LM Studio 中缺失,用户 TheBloke 可能会将其转换为 .gguf 格式以便在 llama.cpp 中使用。 -
GPU 匹配与超频:硬件爱好者如
@luxaplexx质疑了 NVLink 在内存循环中的作用,最终怀疑像 960 这样的显卡可能不支持 NVLink。用户讨论了为了提升模型性能而进行的 GPU 升级,考虑了 RTX 3060 12GB 等选项。其他用户如@alastair9776和@rugg0064权衡了超频以加快 token 生成速度的利弊。 -
量化技术的飞跃:用户如
@n8programs和@yagilb迫切期待 LM Studio 支持 IQ3_XSS,并预计在下次更新中推出。一个 GitHub pull request 反映了社区对即将到来的 1.5 bit 量化的兴奋。同时,建议为下载即将推出但尚未支持的模型(如 IQ3_XSS)做好准备。 -
Beta 版本带来的缓解:
@rafalsebastian在仅支持 AVX 的 CPU 上运行 LM Studio 时遇到了障碍。@heyitsyorkie提供了希望,指向了支持兼容性的 0.2.10 AVX Windows Beta 版本,同时仍建议升级到 AVX2 以获得最佳性能,并提供了一个有用的链接。 -
多模型管理之谜:
@alluring_seahorse_04960寻求关于在单台机器上同时运行两个模型以避免重复错误的建议,使用 Conda 环境但避开虚拟机(VMs)。@wolfspyre幽默地探究了所述重复错误的本质,等待进一步细节。
LAION Discord 摘要
-
Magvit V2 引发关注与辩论:工程师们深入研究了复现 Magvit V2 模型 的技术细节,讨论集中在合适的数据集、视频压缩与理解的参数,并提到了在 Magvit2 的 lfq 侧进行的实验。社区对 MAGVIT 的兴趣也大幅增加,可能是由于 KOL 的提及。
-
审视 Stable Cascade 的功效:Stability AI 的 Stable Cascade 模型引发了关于其高 VRAM 需求、优化问题以及错误的推理时间图表的激烈讨论。报告的技术问题包括图像中文本清晰度的挑战、无法在 float16 下运行模型,以及在 3090 等 GPU 上的性能评估。
-
AI 生成图像的法律纠纷:社区就版权和 AI 生成图像的合法性展开了激烈讨论,重点关注了一篇 TorrentFreak 文章,该文章报道了法院驳回作者对 OpenAI 的版权侵权指控。
-
AI 与成人内容的伦理困境:话题转向了成人内容在推动技术进步中的作用,一些参与者认可这一历史模式,而另一些人则怀疑其对 AI 的建设性影响。话题包括非自愿深度伪造(deepfake)色情内容的兴起、其市场动态以及困扰 AI 社区的潜在伦理陷阱。
-
呼吁更高的 AI 图像标准:讨论包括改进 AI 图像生成的技术见解,例如 VAE 编码器训练的可行性。成员们还反思了社区的写实主义(photorealism)标准,表达了对 AI 生成图像更高质量的需求。
Eleuther Discord 总结
-
校验和(Checksum)狩猎季开启:
@paganpegasus提供了 The Pile zst 分片的校验和,并指向了 EleutherAI 的哈希值 和 Discord 置顶消息。 -
图像内容分类工具讨论:推荐使用 OwlViT 和 CLIP 模型作为识别图像内容的工具;针对
@everlasting_gomjabbar的询问,还讨论了图像中“无(nothing)”的概念。 -
协作精神下的论文评审:一位用户就题为 “Don’t think about the paper” 的手稿收到了赞赏性反馈,该论文的致谢部分提到了 EleutherAI Discord 社区。
-
云计算资源探讨:GCP 和 Colab 被认为是进行 NLP 分类模型训练的理想云资源,讨论还涉及了 runpod 和 vast.ai 等平台的成本效益分析。
-
研究算力开放:EleutherAI 的计算资源可用于半定制 LLM 项目的合作,前提是具有明确的研究议程和协作价值主张。
-
Semantic Scholar 的链接逻辑揭秘:Arxiv 论文会自动链接到 Semantic Scholar 上的作者,并允许手动修正以确保准确性。
-
神经网络训练参数的碎形乐趣:
@jbustter分享了由神经网络超参数(hyperparameters)创建的碎形(fractals),并重点介绍了 Jascha Sohl-Dickstein 的一篇博客,该博客将碎形与训练的收敛/发散联系起来。 -
深入探讨 ML 的数据呈现:引发了关于主动学习(active learning)以及模型如何选择自身数据呈现序列的方法的讨论。
-
利用无监督数据丰富 Encoder-Decoder 模型:讨论了在 Encoder-Decoder 模型中有效利用无监督数据集的策略。
-
新的 NLP 鲁棒性方法发布:发表了一篇专注于测试时增强(TTA)以提高文本分类器鲁棒性的论文,作者感谢了社区的支持。
-
寻求可解释性(Interpretability)见解:
@jaimerv征求除标准 Representation Engineering 论文之外的可解释性方法最新资源。 -
招募幻觉排行榜(Hallucination Leaderboard)合作者:发出了为 幻觉排行榜 贡献力量的呼吁,请求在任务、数据集、指标和结果评估方面提供帮助。
-
使 Pythia 与实践保持一致:有人对 2.8b 规模 Pythia deduped 系列中训练 Batch 与 Checkpoint 之间潜在的不一致表示担忧,后续讨论建议可以就 Pythia 的可靠性发表论文。
LlamaIndex Discord 摘要
LlamaIndex v0.10 标志着重大里程碑:LlamaIndex v0.10 已经发布,带来了显著的进展,包括全新的 llama-index-core 包以及为每个集成/模板提供的 PyPi 包。有关迁移的详细信息可以通过其全面的 博客文章 和 文档 获取。
关于使用 LlamaIndex 构建无代码 RAG 的研讨会:一场演示如何使用 LlamaIndex.TS 创建无代码检索增强生成 (RAG) 应用的研讨会已与 Flowise 联合创始人 Henry Heng 共同安排。周五活动的注册链接请见 此处。
LlamaIndex 故障排除:工程师们在 LlamaIndex 更新后面临迁移挑战,并被引导至 Notion 迁移指南 寻求帮助。此外,对于 ServiceContext 弃用后的 chunk_size 等配置查询,建议工程师参考新的 Settings 文档及相关的 LlamaIndex GitHub 资源。
使用 Dewy 极大简化 RAG 应用构建:一份关于使用 NextJS、OpenAI 和开源知识库 Dewy 构建全栈 RAG 应用的全面指南已发布。该教程旨在将语言模型建立在精确、可靠的数据基础上,详细内容可在 此处 学习。
处理文档复杂性并利用 LlamaIndex 增强企业效能:用户参与了关于过滤复杂文档以及集成 LlamaIndex 以通过 Slack、Jira 和 GDrive 等工具提升企业效率的讨论。此外,还考虑了创建多个 Agent 来合并不同文档源,并提到可以使用传统的索引技术代替高成本的 LLM 进行动态过滤。
HuggingFace Discord 总结
-
Hugging Face 通过 Message API 加速发展:Hugging Face 推出了与 OpenAI 兼容的新 Message API,旨在简化 Inference Endpoints 和文本生成服务与客户端库的使用。他们还通过在 PyPI 上发布 Datatrove、Gradio 4.18.0,以及用于 3D Parallelism 训练的 Nanotron 和 Accelerate 0.27.0 等工具来推进其产品。额外的合作伙伴关系和资源,如 Codecademy AI 课程和关于 SegMoE 的博客文章,支持了社区的持续学习和创新。
-
搜索引擎难题与托管查询成为焦点:技术讨论聚焦于创建搜索引擎的困难,提到了 TF-IDF 和 BM25 等方法,以及使用 spaCy 进行 Part of Speech 标注。其他对话转向了关于托管自定义模型和 Serverless Inferencing 解决方案的查询,以及在发烧友级硬件上运行 100B+ 参数模型的实用性。
-
模板对话与模型部署讨论:用户讨论了对能够进行数据库交互和邮件 API 集成的简单 Chatbot 开发原型的需求,推荐了 GitHub 上的 Microsoft AutoGen 以及 AutoGen Studio 的潜力。提出了部署经过 Finetune 的机器学习模型(如 mistarl_7b_gptq)以实现快速推理的挑战,并强调了为此任务选择合适平台或库的重要性。
-
创作者创新一瞥:社区成员展示了他们的创意项目,包括与 Automatic1111 对接的 GIMP 3.0 插件、为 Diffusion 任务开发的自动图像打标模型,以及 PanoramAI.xyz 等工具的更新(引入了用于图像转换的 “remix” 模式)。AI 在时尚设计中的应用也引起了热议,展示了正在探索的广泛应用领域。
-
分析 S4 并推进 NLP:社区分享了对适用于长序列的 S4 架构的见解,并寻求其实现的清晰说明。介绍了关于 LangTest 的论文,该论文为 NLP 模型提供了测试和增强功能。话题还延伸到从 XLM-RoBERTa 等模型中提取语言标识符,以及将自然语言转换为正式的代数表达式。
-
对 Diffusion 和新兴模型的热情:围绕促进 Diffusion 模型 Finetuning 的 multi-GPU 训练展开了讨论,提到了
train_text_to_image.py等脚本。讨论了成功部署 mistarl_7b_gptq 模型以实现快速推理,以及使用 Stable Cascade 进行有效的文本生成。关于传闻中正在开发的全新 Terminus Model 的讨论也非常热烈。 -
探索计算机视觉的复杂性:频道深入探讨了分层图像分类等挑战,并推荐了相关的 ECCV22 论文。成员们讨论了 Gaussian Splats 的要求、工业级图像检索系统,并寻求在 Multimodal 项目上的合作。
Nous Research AI Discord 总结
-
用于预训练的 LongCorpus 数据集发布:新的 LongCorpus-2.5B 数据集 已发布,包含来自各个领域的 25 亿个 token,专门为长上下文持续预训练(long-context continual pre-training)而策划,旨在最大限度地减少与训练集的 n-gram 相似度。
-
在扩展模型中保持连贯性:在 llama.cpp 的实现中表明,使用 ‘self-extend’ 进行扩展被认为优于 ‘rope scaling’,因为它能更好地保持连贯性,并且具有无需设置、微调或额外参数的优点。
-
AI Agent 和模型的持久性与抗拒性:正如 YouTube 演示所示,LangGraph Agent 可以在交互中持久化其状态;而 Gemini 模型则表现出抗拒性,其拒绝倾向引发了与 GPT-4 相比不利的评价。
-
Reka Flash 带来多模态 AI 突破:Reka Flash 是一款全新的 21B 快速多模态语言模型,现已推出公开测试版,有望与 Gemini Pro 和 GPT-3.5 等主流模型并驾齐驱。可以通过 Reka AI 的公告页面关注该计划。
-
AI 研究中的 CUDA 之痛与 WAVeform 之得:旨在 AMD GPU 上运行 CUDA 的 ZLUDA 项目已不再活跃;而一篇 arXiv 论文提出了一种 AI 研究的新视角,建议小波变换(wavelet transforms)可以通过高效处理位置和频率细节来增强 Transformers。
Mistral Discord 总结
-
新手获得模型推荐:参与者向新手
@nana.wav推荐了 instruct 模型 用于类 chat-GPT 的交互,因为与其他模型的通用自动补全功能相比,这类模型更专注于遵循指令。 -
RAG 设置与模型辩论升温:分享了一份关于 Mistral 结合 RAG 的集成指南,同时对 LangChain vs. LlamaIndex 的有效性展开了辩论;另外,DSPy 因利用 LLM 进行编程而非聊天而受到推崇,并附带了一个支持性的 Twitter 链接。
-
部署困境与解决方案:建议通过 ollama 或 vllm 项目进行 Docker 部署,而其他人则讨论了 API 替代方案并面临云配额障碍;与此同时,尽管 AWQ 量化 存在一些小问题,但在 HuggingFace 上部署 Mixtral 仍有成功案例。
-
微调技巧与 RAG 启示:用户讨论了微调与 RAG 的对比,并深入探讨了 LLM 基础知识的重要性;针对如何构建输入数据以增强 LLM 输出提供了指导,并出现了关于 Prompt 版本控制工具的咨询。
-
技术与 AI 领域的人寻求接触点:法国图书管理员(
@maeelk)寻求心理学和 AI 领域的实习机会;创新性构建包含音频的 S2S 模型的成本引发了关于预算限制和投资需求的讨论。 -
技术故障与支持建议:
@ingohamm在使用 TypingMind 的 API key 时遇到障碍,有人建议联系 support@mistral.ai 以寻求 API 和订阅问题的帮助。
Perplexity AI Discord 摘要
-
Perplexity AI 在处理复杂查询方面表现优于竞争对手:
@tbrams使用来自 “Gemini” 论文的一个难题测试了 Perplexity AI,发现其表现优于 Google 的 Gemini 服务和 OpenAI,且回答速度更快。Perplexity AI 的测试结果记录在此处。 -
Perplexity 在 API 定制方面的潜力受到关注:
@me.lk提到,PPLX API 允许使用诸如"site:reddit.com OR site:youtube.com"之类的参数进行自定义搜索查询。然而,一些用户遇到了 API 问题,如性能波动(@andrewgazelka)和无意义的回答(@myadmingushwork_52332)。 -
Perplexity AI 订阅与续订问题解答:用户正在寻求有关试用订阅和 Pro 订阅续订流程的详细信息,同时也出现了关于 Token 刷新率的咨询。
@icelavaman确认,目前没有针对 Perplexity 新功能的 Early Access Program(早期访问计划)。 -
前景广阔的增强功能与社区协作:Perplexity AI 的一些工具如 pplx shortcut action(
@twodogseeds)正受到社区赞赏。同时,@ok.alex正在鼓励社区共同为替代方案 Feed/通讯 Alt-D-Feed 做出贡献。 -
寻求处理敏感数据问题的直接支持渠道:一位用户(
@kitsuiwebster)表示需要针对公司敏感数据问题的直接协助,以避免公开披露,但目前尚未得到支持渠道的回应。
OpenAI Discord 摘要
-
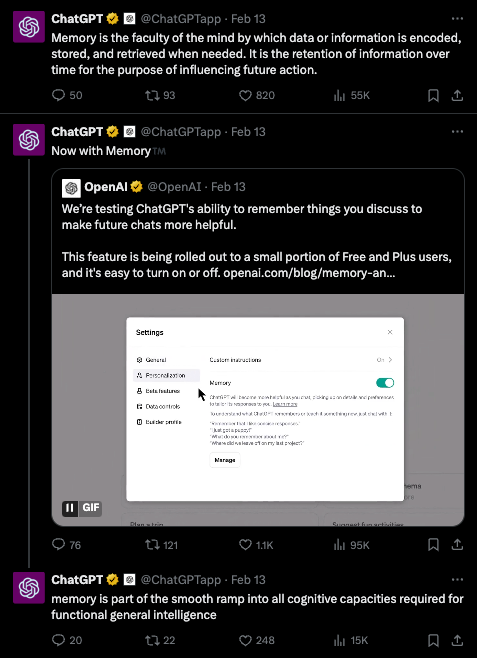
ChatGPT 记得你最喜欢的颜色:OpenAI 宣布了 ChatGPT 的新 Memory 功能,正向部分用户推出。该功能使 ChatGPT 能够在对话中记住用户的偏好和细节,从而提供更个性化的体验。用户可以控制 ChatGPT 记住的内容,也可以关闭此功能。
-
创意过程中使用 AI 助手的付费访谈:一位英国研究员
@noodles7584正在寻求社区成员参与关于创意工作流中 AI 使用情况的 30 分钟讨论,并提供报酬。 -
GPT 变体的性能特性:社区报告了 GPT-4 在任务处理上的波动,Abacus.AI 的 Smaug-72B 被指出表现优于 GPT-3.5,而 ChatGPT-4 在生成完整代码片段时似乎表现得较为犹豫。
-
微调 AI 观看视频?目前还不行:#gpt-4-discussions 中的讨论澄清,虽然 GPT 可以利用其 Vision 能力描述视频中的图像,但目前还无法针对特定视频知识或任务进行 Fine-Tuning。
-
探索与完善 Prompt Engineering:优秀的 Prompt Engineering 被强调为包含清晰的指令和精确性,重点在于促进基于文本的 AI 冒险游戏中的简单叙事,并识别 Prompt Engineering 与 API 基础设施开发之间的区别。
OpenAccess AI Collective (axolotl) Discord 总结
-
Axolotl 拥抱 MPS,感谢 GitHub 英雄:Maxime 通过 pull request #1264 在 axolotl 项目中添加了 MPS 支持,并引用了 PyTorch pull request #99272 的重要性。对贡献者身份的澄清强调了开源社区集体认可的重要性。
-
数据集时代的聊天:由
@dctanner提出的用于聊天数据集的 MessagesList 标准旨在实现跨平台兼容性,目前正在 讨论 中。该格式可能包含对话对、问候语和助手发起的结束语,但在 JSON-schema 验证方面存在挑战。 -
Axolotl 正确分词,检查 Debug 标志:用户正在排查 axolotl 内部的分词问题,建议检查 tokenizer 配置,并推荐使用 debug flag 进行验证。
-
模型查询困扰与训练需求增长:讨论了关于提升模型多语言能力、LoRA adapter 推理以及模型并行性的问题,解决方案涵盖了从预训练需求到更新 transformers 以及 DeepSpeed Zero 3 配置以获得更好功能。
-
微调还是重训练?重复数据的痛苦:对训练数据重叠和微调实践的影响提出了质疑,重点关注重复使用模型在预训练期间可能已经遇到过的文本所带来的问题。
-
RunPod 镜像在 Vast.AI 上运行顺畅!:
@dreamgen报告 Axoltl RunPod 镜像 在 Vast.AI 上无缝运行,强调了与云基础设施提供商的互操作性。
LangChain AI Discord 总结
-
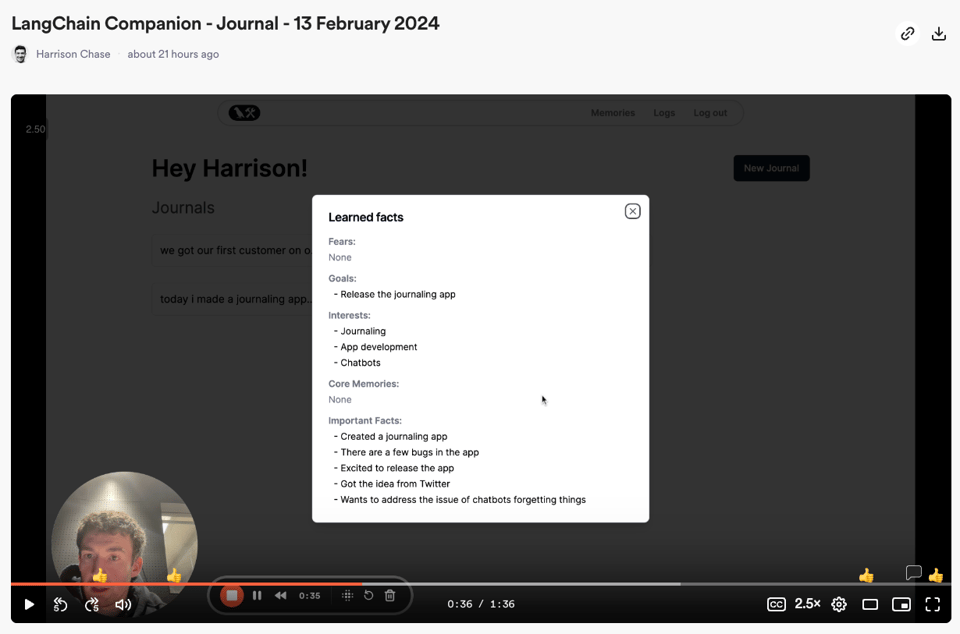
LangChain 发布记忆日志应用:
@hwchase17推出了一款采用 LangChain memory module 的新日志应用,并邀请用户对这个类似于 OpenAI ChatGPT 记忆功能 的早期版本提供反馈。可以通过这个 日志应用 进行尝试并提供反馈,并观看 介绍视频。 -
LangChain 社区应对多样化技术挑战:涵盖的主题包括 LangChain 的 Android 集成 可能性、高效 Embedding 的预处理优势、寻找高性能 PDF parser,以及呼吁改进文档结构。此外,一位用户在将 Pinecone Database 更新至 v2 并配合 LangChain 使用时遇到了依赖问题,该问题已得到及时解决。
-
Langserve 频道的扩展与集成咨询:讨论包括扩展 Langserve 以及使用 Langsmith 进行部署的问题。有一个关于从 NodeJS 应用暴露 chain 的查询,以及一个关于在 playground 中禁用中间步骤的未解决问题。还描述了从 基于 k8s 集群的应用 调用 OpenAI API 时的连接问题。
-
分享使用 NextJS 和 OpenAI 的 Dewy RAG 应用指南:
@kerinin贡献了一份探索 全栈 RAG 应用 的指南,利用 NextJS、OpenAI API 和 Dewy,重点在于减少幻觉并提高模型响应的准确性。完整指南请见 此处。 -
寻找功能性 PDF 解析器和自定义计算器:在教程频道中,讨论了寻找优于 Adobe API 的 上下文 PDF parser,以及构建 基于 Langchain 的计算器 的指导,旨在为 AI 工作流提供实用的集成和解决方案。
DiscoResearch Discord 摘要
- 寻求 Argilla 托管方案:
@drxd1000征求关于托管 Argilla 服务器的建议,以支持多名标注员,目前尚未达成明确的解决方案。 - 层选择性秩削减 (Layer Selective Rank Reduction) 备受关注:
@johannhartmann讨论了一种用于缓解持续训练遗忘 (continual training forgetting)的“层选择性秩削减”实现方法。该方法针对统计学上不重要的层部分,并提到了一个 GitHub 仓库。 - 解决 Mixtral 的 OOM 问题:
@philipmay在使用 mixtral 模型时遇到了显存溢出 (OOM) 错误,@bjoernp建议使用多 GPU 支持,并提到两块 A100 可能会缓解该问题。 - 跨语言毒性检测数据集:
@sten6633正在寻找德语毒性评估数据集,并考虑翻译 Hugging Face 上的 ToxiGen,但这需要获得访问许可。 - 新技术预告:
@phantine预告了一种名为 “Universes in a bottle” 的技术,该技术对 P=NP 问题有潜在影响,并链接到了一个 GitHub 页面,但细节较少。 - BM25 搜索策略证明有效:
huunguyen报告了使用 BM25 配合额外查询和重排序 (reranking) 来增强搜索能力的成功经验,并成功将整个维基百科索引到了一个小于 3GB 的索引中。 - 德语 AI 模型更新咨询:thomasrenkert 询问了德语模型第 2 版或 Mixtral 变体的发布时间表,但未提供更多细节。
CUDA MODE Discord 摘要
-
CUDA 兼容性之战:成员们讨论了在 HIP/ROCm 平台上实现 CUDA 二进制兼容性,这由 GitHub 上的 ZLUDA 项目 推动,该项目是一个在 AMD GPU 上运行 CUDA 的倡议。在技术讨论的热情中,还穿插了关于市场垄断和 AGI 的思考,以及个人在使用 Radeon 硬件处理动态内存分配时的经验。
-
生成式 AI 职位大放送:一家位于海得拉巴的 Deep Tech 生成式 AI 初创公司正在招聘 ML、数据、研究和 SDE 职位,申请链接在这里。然而,该招聘信息的真实性受到了质疑,提醒需要管理员关注。
-
计算着色器与矩阵数学思考:关于 CUDA 学习材料的咨询引荐了 The Book of Shaders,而在 PMPP 书籍频道中,大家讨论了转置矩阵以减少乘法中缓存未命中的优劣,观点不一,但在观察到的实际收益上未达成共识。
-
Apple 芯片进入监控领域:
@marksaroufim分享了 asitop,这是一个专为 Apple Silicon 设计的 CLI 性能监控工具,在实用性上类似于工程师使用的top或nvtop。 -
GPU 实验与矿机改造:一位工程师成功将 Asus WS 主板 移至矿机配置中,在 NVIDIA 3060 GPU 上有效运行了大型量化模型。这表明社区成员在自定义硬件配置方面具有很强的动手能力。
Latent Space Discord 摘要
- Reka 进入模型竞技场:在
@swyxio分享了一条推文后,一个名为 Reka 模型 的新 AI 实体引起了社区的兴趣。关于该推文的热烈讨论可以在这里找到。 - 投资者洞察与 AI 的碰撞:
@swyxio重点推荐了一个深入探讨 AI 的 VC 播客,这可能会引起工程爱好者的极大兴趣。播客章节可在这里访问。 - BUD-E 热议:BUD-E 是由 LAION 开发的一个具有共情能力且具备上下文感知能力的开源语音助手,这可能标志着对话式 AI 的新方向。更多细节发布在 LAION 博客上。
- 思考 Agent 的定义:社区就“Agent”的定义交换了意见,
@slono建议它们是目标导向的程序,仅需要用户极少的输入,这一概念在 AI 开发领域具有重要意义。 - Karpathy 离开 OpenAI 引发关注:AI 社区对 Andrej Karpathy 离开 OpenAI 的消息议论纷纷,
@nembal指向了 The Information 的一篇文章,并对 AGI 的影响进行了推测。文章可在这里访问。
LLM Perf Enthusiasts AI Discord 总结
-
针对 M2 Max 的模型大小注意事项:
@potrock询问了在 32GB 内存的 M2 Max 上运行 Mistral 模型大小 的建议,@natureplayer建议 4GB 模型是可行的选择,并提醒不要使用 8GB 模型,指出 5GB 模型可能不稳定。 -
GPT-5 传闻:
@res6969对 GPT-5 的存在表达了幽默的怀疑,认为关于该模型即将发布的猜测被夸大了,其他人也用表情符号加入调侃。 -
ChatGPT 中增强的记忆功能:
@potrock强调了 ChatGPT 正在测试的一项新功能,参考 博客文章,该功能可以跨会话保留用户偏好和信息,以实现更个性化的交互。
AI Engineer Foundation Discord 总结
- 每周同步会议引发既视感:
@._z俏皮地宣布 每周团队会议 开始,将其比作循环往复的 Déjà vu(既视感)体验。 - 成员退出会议:
@juanreds对无法参加 每周会议 表示遗憾,并向团队致歉。 - 征集 AI 黑客松联合主办方:
@caramelchameleon正在寻找合作伙伴,准备在 GDC 前夕与游戏开发者共同举办一场 AI 开发者黑客松。 - 黑客松提供两种参与模式:
@caramelchameleon提到的黑客松提供 在线 和 旧金山线下 两种参与方式。 - 黑客松组织者挺身而出:
@yikesawjeez表现出参与组织黑客松的渴望,并强调了他们在湾区活动方面的专业知识。
Skunkworks AI Discord 总结
- 发起私信:用户
@bondconnery发出了 私信 请求。 - 探索 LLaVA 框架集成:
@CodeMan询问如何将 LLaVA 框架与 SGLang server 和 SGLang worker 集成,旨在构建一个比传统模型工作节点更专业的设置。 - 忽略无关视频分享:分享了一个非技术视频链接,与工程讨论无关。
Alignment Lab AI Discord 没有新消息。如果该公会沉寂太久,请告知我们,我们将将其移除。
Datasette - LLM (@SimonW) Discord 没有新消息。如果该公会沉寂太久,请告知我们,我们将将其移除。
第二部分:频道详细总结与链接
TheBloke ▷ #general (1460 条消息🔥🔥🔥):
- 探索大语言模型的极限:用户正在讨论能够处理极长上下文的新开源大语言模型,例如 Large World Model,该模型声称可以连贯地处理高达 100 万个 token 的上下文。还提到了 Cohere 支持 101 种语言的
aya模型。 - 追求高效的多模态 AI:对话集中在 AI 的多模态上,提到了处理视觉输入和潜在输出的模型,表明其在文本模型之外取得了显著进展。运行这些模型所需的基于 jax 的工具给一些用户带来了安装困扰。
- 接受审查的模型:社区在测试已发布的模型方面非常活跃,提到了 TUX 依赖问题和设置过程中的
ValueError,表明让这些先进模型顺利运行仍面临一些挑战。 - 用户分享知识:资深用户就如何处理各种任务的模型和 UI 提供了见解和帮助,包括在 ExLlama v2 等现有框架中进行长上下文量化。讨论还涉及了取消停止 token 以鼓励更长的连续输出的可能性。
- 迈向智能角色扮演:讨论了如何在角色扮演(RP)导向模型与更智能的通用模型之间寻找平衡,提到了一个 Mixtral 变体(
BagelMIsteryTour),它可能更好地满足用户对智能和适应性模型行为的需求。
提到的链接:
- Context – 几秒钟内与他人分享你看到的一切:未找到描述
- Lil Yachty Drake GIF - Lil Yachty Drake - 发现并分享 GIF:点击查看 GIF
-
ChatGPT 的记忆和新控制功能:我们正在测试 ChatGPT 记住你讨论内容的能力,以使未来的对话更有帮助。你可以控制 ChatGPT 的记忆。
- brucethemoose/LargeWorldModel_LWM-Text-Chat-128K-55bpw · Hugging Face: 未找到描述
- YOLO: Real-Time Object Detection: 未找到描述
- Kooten/BagelMIsteryTour-v2-8x7B-5bpw-exl2 · Hugging Face: 未找到描述
- 未找到标题: 未找到描述
- Think Bigger Skeletor GIF - Think Bigger Skeletor Masters Of The Universe Revelation - 发现并分享 GIF: 点击查看 GIF
- 未找到标题: 未找到描述
- CausalLM/34b-beta · Hugging Face: 未找到描述
- SimSim93/CausalLM-34b-beta_q8 · Hugging Face: 未找到描述
- GitHub - jy-yuan/KIVI: KIVI: 一种无需微调的非对称 2bit KV Cache 量化方法: KIVI: 一种无需微调的非对称 2bit KV Cache 量化方法 - jy-yuan/KIVI
- The Verge: 如何“不”组装电脑: 赞助商:访问 http://expressvpn.com/science 立即夺回您的互联网隐私,并了解如何获得 3 个月的免费试用。链接到 The Verge 糟糕的视频…
- LWM/lwm/llama.py at main · LargeWorldModel/LWM: 通过在 GitHub 上创建账号,为 LargeWorldModel/LWM 的开发做出贡献。
- https://drive.google.com/drive/folders/1my-8wOIYXmfnlryDbwJ20_y6PFCqRfA-?usp=sharinghttps://drive.google.com/drive/folders/1my-8wOIYXmfnlryDbwJ20_y6PFCqRfA-?usp=sharingData Challenge - Aether 2024: 为了参加由 Enigma 组织的 Aether 数据挑战赛,请填写此表格。活动日期与时间:2 月 14 日星期三 - 下午 2:30。请仔细核对您的详细信息…
- LargeWorldModel (Large World Model): 未找到描述
- GitHub - lhao499/tux: 实验工具与实用程序 (TUX): 实验工具与实用程序 (TUX)。通过在 GitHub 上创建账号,为 lhao499/tux 的开发做出贡献。
- GitHub - itsme2417/PolyMind: 一个支持多模态和函数调用的 LLM WebUI。: 一个支持多模态和函数调用的 LLM WebUI。 - GitHub - itsme2417/PolyMind: 一个支持多模态和函数调用的 LLM WebUI。
- llama.cpp/examples/server at master · ggerganov/llama.cpp: Facebook LLaMA 模型的 C/C++ 移植版。通过在 GitHub 上创建账号,为 ggerganov/llama.cpp 的开发做出贡献。
- 来自 Cohere For AI (@CohereForAI) 的推文: 今天,我们发布了 Aya,这是一个全新的开源、大规模多语言 LLM 和数据集,旨在支持代表性不足的语言。Aya 的表现优于现有的开源模型,并涵盖了 101 种不同的语言…
- OpenAI 研究员 Andrej Karpathy 离职: 发言人证实,OpenAI 创始成员之一 Andrej Karpathy 已离开公司。Karpathy 是一位著名的人工智能研究员,他当时正在开发一款他曾描述过的产品…
- CohereForAI/aya-101 · Hugging Face: 未找到描述
- GitHub - valine/NeuralFlow: 通过在 GitHub 上创建账号,为 valine/NeuralFlow 的开发做出贡献。
-
[无审查且免费的 ChatGPT! Oogabooga LLM 教程](https://youtu.be/SLb5n8AX33s?si=N6g3RmLoMt83_VCj): 无审查且免费的 ChatGPT,多亏了开源 AI 社区,现在这已成为可能!在本视频中,我将向您展示如何设置 Oogabooga 图形界面… - LWM/lwm/vision_chat.py at main · LargeWorldModel/LWM: 通过在 GitHub 上创建账号,为 LargeWorldModel/LWM 的开发做出贡献。
-
新邮件披露科学家曾认为 COVID-19 是人造的: 新披露的邮件显示,科学家们曾聚集在一起讨论 COVID 的起源,怀疑它是人造的,之后才决定告诉公众它起源于…
- GitHub - itsme2417/PolyMind: A multimodal, function calling powered LLM webui.: 一个多模态、支持 function calling 的 LLM webui。 - GitHub - itsme2417/PolyMind: 一个多模态、支持 function calling 的 LLM webui。
- GitHub - LargeWorldModel/LWM: 通过在 GitHub 上创建账号来为 LargeWorldModel/LWM 的开发做出贡献。
- GitHub - acorn-io/rubra: AI Assistants, LLMs and tools made easy: 让 AI Assistants、LLMs 和工具变得简单。通过在 GitHub 上创建账号来为 acorn-io/rubra 的开发做出贡献。
- unalignment/weeeeee.0 · Hugging Face: 未找到描述
- unalignment/weeeeee.1 · Hugging Face: 未找到描述
- unalignment/weeeeee.2 · Hugging Face: 未找到描述
- CohereForAI/aya_dataset · Datasets at Hugging Face: 未找到描述
- CohereForAI/aya_collection · Datasets at Hugging Face: 未找到描述
TheBloke ▷ #characters-roleplay-stories (154 条消息🔥🔥):
-
探索 Miqu 变体:
@superking__发起了关于 Miqu 模型性能的讨论,特别是从原始 GGUF(Google’s Generative Unsupervised Feature extraction)重新量化(re-quants)后的表现。@soufflespethuman提到了 MiquMaid-v2-70B,这是一个专门为 ERP(Erotic Role Play)微调的变体,并提供了 Hugging Face 上各版本的 敏感内容链接,由于其内容性质,这些链接已被标记。 -
硬件升级带来的性能提升:
@superking__分享了通过将硬件升级到 12GB VRAM,性能从“痛苦的缓慢”提升到“几乎可用”的经验,这使得特定模型的每秒 token 数从 0.7t/s 提高到了 2.1t/s。 -
模型对比与推荐:在角色扮演和故事创作的背景下,用户讨论了各种模型。
@spottyluck赞扬了 Nous Capybara Limarpv3 34B 的能力,并提供了 该模型在 Hugging Face 上的链接。@wolfsauge分享了一个关于 Christopher Walken 出演的 “The Continental” 的小品,@eqobaba询问了进行 NSFW ERP 的合适模型和设置,并提到了 48GB VRAM 和 RTX A600 的规格。 -
讨论模型输出改进:
@neriss建议使用更高的 temperature 或更低的 minimum probability,以减少重复并提高 AI 模型输出的创造力。对话强调了 temperature 设置的变化,@dercheinz建议调高温度,而@neriss则建议调低,两者都是为了应对模型重复或缺乏创意的响应。 -
数据集清洗的挑战与策略:
@c.gato和@potatooff交流了手动清洗数据集的想法,@c.gato寻求关于如何进行 ngram 分析 以防止对特定 ngram 过度训练的建议。@mrdragonfox推荐使用 Python 的 pandas 库 来处理表格或 JSON 数据,并分享了一个 指导用的 gist。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。
- TheBloke/Nous-Capybara-limarpv3-34B-GGUF · Hugging Face:未找到描述
- Models - Hugging Face:未找到描述
- gist:f786564868357cde5894ef6e2c6f64cf:GitHub Gist:即时分享代码、笔记和片段。
- The Continental: Anticipation - Saturday Night Live:订阅 SaturdayNightLive。夜色中透着期待,是时候见见 The Continental 了…
- Happy Fun Ball - SNL:Happy Fun Ball 看起来很棒,直到你听到所有潜在的副作用。[第 16 季,1991]
- NeverSleep/MiquMaid-v2-70B · Hugging Face:未找到描述
- NeverSleep/MiquMaid-v2-70B-GGUF · Hugging Face:未找到描述
- NeverSleep/MiquMaid-v2-70B-DPO · Hugging Face:未找到描述
- NeverSleep/MiquMaid-v2-70B-DPO-GGUF · Hugging Face:未找到描述
TheBloke ▷ #training-and-fine-tuning (43 条消息🔥):
-
理解微调技术:
@starsupernova解释说 Mixtral – Instruct 是先在指令数据集上使用 SFT 进行训练,随后在配对反馈数据集上进行 Direct Preference Optimization (DPO),详情见其论文第 6 页。DPO 被描述为 RLHF/PPO 微调的一种优化形式。 -
Unsloth AI 的 Apply Chat Template:Unsloth AI 的创始人
@starsupernova强调在多轮对话数据集上训练 LLM 时,应使用apply_chat_template而非 Alpaca。他们还暗示将上传一个包含所有聊天模板的新 Notebook,以简化流程。 -
用于指令微调数据集的 Augmentoolkit:在对话中,
@mr.userbox020分享了一个 GitHub 仓库 链接,该仓库提供了一个将 Compute 和书籍转换为指令微调数据集的工具包。尽管@starsupernova对此并不熟悉,但他们建议尝试一下,因为看起来很有前景。 -
期待更新的训练资源:
@avinierdc正在等待@starsupernova更新用于在多轮对话数据集上微调 Mistral 的 Notebook。@starsupernova保证在 Unsloth 的 Discord 服务器上发布时会通知大家。 -
训练损失中无法解释的差异:
@dreamgen报告称,在微调 Mixtral 8x7b qlora 时,尽管使用了相同的数据集和相似的超参数,但观察到的训练和评估损失比 Mistral 7b 高出 2 倍,并询问其他人是否见过类似情况。
提到的链接:
GitHub - e-p-armstrong/augmentoolkit: Convert Compute And Books Into Instruct-Tuning Datasets:将计算资源和书籍转换为指令微调数据集 - e-p-armstrong/augmentoolkit
TheBloke ▷ #coding (8 条消息🔥):
-
激发合作兴趣:
@_b_i_s_c_u_i_t_s_对某个未指明的话题(可能围绕聊天机器人实现)表示了兴趣,这得到了@mr_pebble的积极回应,认为这为推进各种聊天方法的实现提供了动力。 -
桥接 JavaScript 和 Python:
@spottyluck尝试扩展 SillyTavern 项目以使用 JavaScript-Python 桥接,利用 JSPyBridge 来潜在地适配和增强功能。他们分享了这如何实现对 Microsoft 的 LLMLingua 的测试,尽管在 Prompt 损坏方面存在一些问题。 -
在 JavaScript 中使用 Python 类:
@spottyluck提供了代码示例,展示了使用 JSPyBridge 在 JavaScript 中创建 Python 类的便捷性,以及一个演示跨语言交互以压缩 Prompt 的异步函数compressPrompt。 -
处理 Windows 错误和设备的修改:在持续开发中,
@spottyluck修改了 Intel 的 BigDL.llm Transformer 以支持特定需求,例如由于访问冲突错误在 Windows 上设置cpu_embedding=True,并使用model.to()处理模型设备分配问题。 -
将压缩过程集成到路由中:
@spottyluck解释了如何通过在/generate路由 post 中添加标志并使用条件逻辑通过桥接处理 Prompt,将 Prompt 压缩集成到其 Web 服务中,演示了 Python 如何像 JavaScript 类一样运行。
提到的链接:
GitHub - extremeheat/JSPyBridge: 🌉. Bridge to interoperate Node.js and Python:🌉. 桥接 Node.js 和 Python 的互操作。欢迎在 GitHub 上为 extremeheat/JSPyBridge 的开发做出贡献。
LM Studio ▷ #💬-general (202 条消息🔥🔥):
-
大型模型使用困扰:像
@nonm3这样的用户在 LM Studio 中加载大型模型时遇到了错误,原因是 RAM 和 VRAM 不足,建议尝试更小量化(quants)的模型。其他用户如@theoverseerjackbright面临 LM Studio 无法正确检测 GPU 以及重启后崩溃的问题。 -
软件寻求与推荐:
@tvb1199正在寻找可以与 LM Studio 交互并具备 RAG 功能的客户端软件,并被引荐了 AGiXT;而@pierrunoyt等人讨论了 Nvidia 的 “Chat with RTX” 及其 RAG 功能,认为其具有颠覆潜力。 -
兼容性查询:包括
@wizzy09在内的几位用户在 2014 款 MacBook Pro 等不支持的平台上安装或打开 LLM Studio 时遇到困难,@heyitsyorkie等用户对此进行了澄清,解释说 LM Studio 无法在 Intel 芯片的 Mac 上运行。 -
Nvidia 的 Chat with RTX 引发关注:社区对 Nvidia 的 “Chat with RTX” 表现出浓厚兴趣。像
@hypocritipus这样的用户对 RAG 功能非常好奇,希望 LM Studio 也能推出类似的易于安装、无依赖的 RAG 功能。 -
LM Studio 使用与模型讨论:用户
@bigboimarkus表达了对 LM Studio 处理校对等任务的满意,而@mr.stark_则询问了关于能够即时学习的模型。对话还涉及了与其他工具(如 Ollama 和 Automatic1111)的功能集成。 -
社区常规协助与闲聊:在整个过程中,社区成员积极分享技巧,提供故障排除建议(包括更换替代方案或降级版本的建议),偶尔还会拿 AI 的能力开玩笑,比如预测彩票号码。
提到的链接:
- Stable Cascade - a Hugging Face Space by multimodalart:未找到描述
- cmp-nct/Yi-VL-6B-GGUF at main:未找到描述
- TheBloke/CodeLlama-70B-Instruct-GGUF at main:未找到描述
- Chost Machine GIF - Chost Machine Ai - Discover & Share GIFs:点击查看 GIF
- System prompt - Pastebin.com:Pastebin.com 是自 2002 年以来排名第一的粘贴工具。Pastebin 是一个可以在线存储文本一段时间的网站。
- NVIDIA Chat With RTX:您的个性化 AI 聊天机器人。
- The unofficial LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里,您可以找到我们在 LMStudio Discord 上收到的最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源…
- The unofficial LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里,您可以找到我们在 LMStudio Discord 上收到的最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源…
LM Studio ▷ #🤖-models-discussion-chat (75 messages🔥🔥):
- 用于医疗 LLMs 的 MedAlpaca:用户
@heyitsyorkie建议将 medAlpaca(一个针对医疗问答进行微调的模型)用于@pepito92i在医疗领域 LLMs 的项目。 - Phi-2 模型讨论:
@.dochoss333询问为何 LM Studio 中没有官方的 “microsoft/phi-2” 模型,@heyitsyorkie澄清说它不是 GGUF 模型,因此不会显示。@hugocapstagiaire_54167提到用户 TheBloke 可能已经将其转换为 .gguf 格式,以便在 llama.cpp 中使用。 - LLama.cpp 与模型支持:
@jedd1对某些模型无法加载感到困惑,@heyitsyorkie指出 Yi-VL 模型在当前版本的 llama.cpp 中不受支持,需要更新以实现兼容性。 - LM Studio 助手功能咨询:用户
@edu0835询问是否可以在 LM Studio 中创建一个能够利用 PDF 或书籍进行医疗助手应用的助手,目前尚未收到直接回复。 - 模型性能对比引发社区讨论:
@kujila和@heyitsyorkie等用户参与了不同语言模型之间的对比,讨论了模型的专一性、AI 模型的伦理行为,并建议尝试 Deepseek Coder Ins 33B 等模型。
提到的链接:
- Nexesenex/Senku-70b-iMat.GGUF at main:未找到描述
- Hi Everybody Simpsons GIF - Hi Everybody Simpsons Wave - Discover & Share GIFs:点击查看 GIF
- TheBloke/medicine-chat-GGUF · Hugging Face:未找到描述
- wolfram/miquliz-120b-v2.0-GGUF · Hugging Face:未找到描述
- GitHub - kbressem/medAlpaca: LLM finetuned for medical question answering:为医疗问答微调的 LLM。通过在 GitHub 上创建账号来为 kbressem/medAlpaca 的开发做出贡献。
- The new Yi-VL-6B and 34B multimodals ( inferenced on llama.cpp, results here ) · ggerganov/llama.cpp · Discussion #5092:好吧,他们的基准测试声称他们几乎达到了 GPT4V 的水平,遥遥领先于其他所有模型。他们还声称 CovVLM 是最差的模型之一(而它实际上是仅次于 GPT4 的最佳模型,差距很大)在…
LM Studio ▷ #🎛-hardware-discussion (140 条消息🔥🔥):
-
NVLink 与显存循环查询:
@luxaplexx询问了 GPU 是否进行了 NVLink 连接,以及在多 GPU 设置中显存是如何循环的。包括@heyitsyorkie在内的共识是,由于潜在的 CUDA 问题,它们可能没有进行 NVLink 连接,特别是像 960 这样的旧显卡。用户们正在考虑不同世代的 NVIDIA GPU(如 1080 和 1060 6g)是否能有效地协同工作。 -
关于升级到更好 GPU 的讨论:包括
@crsongbirb和@heyitsyorkie在内的几位用户讨论了升级 GPU 以提高 LLM 任务性能的问题,并建议将 RTX 3060 12GB 作为在本地运行 LLM 的可行选择。 -
超频的风险与回报:在由
@alastair9776发起的关于通过超频获得更好性能的讨论中,@rugg0064和@crsongbirb指出,超频 VRAM/RAM 可以显著提高 token 生成速度,但由于潜在的硬件压力,建议谨慎操作。 -
组合 GPU 与 Threadripper 梦想:随后展开了关于使用多个高性能 GPU 的可行性和成本的对话,
@nink1和@quickdive.等用户辩论了在拥有多个强大 GPU 时是否需要强力 CPU,以及安置这种配置的物流/空间问题。 -
AMD 上的 CUDA 及其他硬件对话:
@666siegfried666分享了关于 ZLUDA 项目的消息,该项目允许 CUDA 应用在 AMD 硬件上运行,这引发了关于该功能的相关性和未来潜力的简短讨论。@addressofreturnaddress和@joelthebuilder等用户也讨论了他们自己的设备配置和潜在升级,强调了个人偏好和价值评估。
提到的链接:
- Doja Cat GIF - Doja Cat Star - 发现并分享 GIF:点击查看 GIF
- Brexit British GIF - Brexit British Pirate - 发现并分享 GIF:点击查看 GIF
- ATOM Echo 智能扬声器开发套件:ATOM ECHO 是一款可编程智能扬声器。这款 eps32 AIoT 开发套件配有麦克风和扬声器,用于 AI 语音交互,轻巧小巧。它可以接入 AWS, Baidu, ESPHome 和 Home Assistant…
- 未经修改的 NVIDIA CUDA 应用现在可以通过 ZLUDA 在 AMD GPU 上运行 - VideoCardz.com:ZLUDA 在 ROCm 平台上启用 CUDA 应用,无需更改代码。AMD 支持的 ZLUDA 项目现在可以使以 NVIDIA CUDA 编写的代码在 AMD 硬件上原生运行。据报道,AMD 已经接管了…
- 联力 Lian-Li O11 Dynamic XL ROG 认证 - 黑色钢化玻璃:联力 O11 Dynamic XL ROG 认证,正面和左侧钢化玻璃,E-ATX, ATX 全塔式游戏电脑机箱 - 黑色
LM Studio ▷ #🧪-beta-releases-chat (21 messages🔥):
- 等待下个版本对 IQ3_XSS 的支持:
@n8programs询问了最新版本中对 IQ3_XSS 的支持情况,@yagilb回复称它将包含在下一次更新中。 - 1bit 量化即将提升:
@drawless111对即将到来的 1.5 bit 量化表示兴奋,并分享了一个 GitHub pull request 链接 以展示进展。这引发了讨论,@heyitsyorkie期待着包含新量化尺寸的下一个 beta 版本。 - 模型基准测试令人惊叹:
@drawless111对 1bit 量化 的最新基准测试表示惊讶,称 “16 GB 显卡跑 70B 模型。哇哦。” 并指出 Hugging Face 上发布 的一个 ‘70B’ 模型可以有效地卸载到 VRAM。 - 为尚未兼容的模型下载做准备:建议用户(包括
@epicureus)即使在尚未支持的情况下也先下载 IQ3_XSS 等模型,@fabguy幽默地建议 “拯救模型,拯救世界!” - Hugging Face Hub 上线多个新模型:
@drawless111分享了更新,透露 Hugging Face 上已有 5 个 IQ1 模型 可用于各种 VRAM 尺寸,并随口提到到对话结束时已增加到 10 个。
提到的链接:
- Nexesenex/NousResearch_Yarn-Llama-2-70b-32k-iMat.GGUF · Hugging Face:未找到描述
- Claire Bennet Heroes GIF - Claire Bennet Heroes Smile - Discover & Share GIFs:点击查看 GIF
- 1.5 bit quantization by ikawrakow · Pull Request #5453 · ggerganov/llama.cpp:此草案 PR 是一个正在进行中的工作 (WIP),展示了 1.5 bits-per-weight (bpw) 量化。目前仅支持 CUDA,尚未实现其他支持的后端。CUDA, AVX2 和 ARM_NEON 已实现…
LM Studio ▷ #avx-beta (2 messages):
- 没有 AVX2 也不必难过:
@rafalsebastian表达了在收到处理器不支持 AVX2 的消息后,无法在仅支持 AVX(第一版)的 CPU 上运行 LM Studio 的担忧。他们想知道是否应该更换机器来运行本地 LLM。 - LM Studio Beta 前来救援:
@heyitsyorkie提供了解决方案,提到通过下载 Windows 版 0.2.10 AVX beta 发布版,LM Studio 确实可以在仅支持 AVX 的 CPU 上运行。他们还建议升级到支持 AVX2 的 CPU 以获得最佳效果,并提供了 beta 发布版和使用条款 的链接。
提到的链接:
LM Studio Beta Releases:未找到描述
LM Studio ▷ #crew-ai (3 messages):
- 寻求双模型部署技巧:
@alluring_seahorse_04960想知道如何在同一台机器上运行两个模型而不出现重复错误。该用户提到在 Ubuntu 上使用 Conda 环境,并因虚拟机速度慢而避免使用。 - 关于重复问题的幽默澄清请求:针对
@alluring_seahorse_04960的问题,@wolfspyre就重复错误的性质开起了玩笑,询问这指的是循环输出还是工作进程中的任务分配问题。
LAION ▷ #general (361 条消息🔥🔥):
- Magvit V2 复现咨询:
@.lostneko寻求复现 Magvit V2 的技术指导。讨论围绕视频压缩和理解的理想数据集和参数展开,@chad_in_the_house提到了在 Magvit2 的 lfq 方面的实验。 -
围绕 Magvit 的神秘热度:
@pseudoterminalx和聊天中的其他人注意到对 MAGVIT 的兴趣突然增加,推测可能是由于近期有网红(influencer)提及,因为在短时间内出现了两次相关讨论。 -
Stable Cascade 讨论升温:焦点转向了 Stability AI 的 Stable Cascade 模型,对话强调了其高昂的 VRAM 需求、具有误导性的推理时间图表,以及对模型优化不足且充满 bug 的担忧。
@pseudoterminalx分享了其能力的示例,包括图像输出中文字清晰度的问题。 -
评估 AI 模型与版权担忧:对话涉及了 AI 生成图像的使用和合法性。用户
@vrus0188和@kenjiqq辩论了 AI 图像模型的版权、商业用途以及仅限研究(research-only)模型许可的影响。 - 硬件与性能视角:针对 Stable Cascade 的高 VRAM 占用和优化问题展开了技术对话,
@pseudoterminalx报告了无法在 float16 下运行模型等问题,@kenjiqq提供了在 3090 等消费级 GPU 上的推理时间细节。
提到的链接:
- Stable Cascade - multimodalart 提供的 Hugging Face Space:未找到描述
- 法院驳回作者针对 OpenAI 的版权侵权指控 * TorrentFreak:未找到描述
- Stable Cascade 介绍 — Stability AI Japan — Stability AI Japan:Stable Cascade 的研究预览版已发布。这款创新的文本生成图像模型设定了质量、灵活性、微调和效率的新基准,并引入了一种有趣的三个阶段方法,重点在于进一步消除硬件障碍。
- Hey Hindi GIF - Hey Hindi Bollywood - 发现并分享 GIF:点击查看 GIF
- 不要问能不能问,直接问:未找到描述
- GitHub - Stability-AI/StableCascade:通过在 GitHub 上创建账号来为 Stability-AI/StableCascade 的开发做出贡献。
-
[Crypto Kids 海报 24posters 嘻哈与街头艺术印刷品](https://24posters.co/products/crypto-kids-6):用我们爆火的新款 Crypto Kids 海报改变您的墙面。灵感源自街头服饰和嘻哈文化,享受旨在让您的卧室焕发生机的艺术作品。快速发货(3-5 天),10,000+ …
{kind=link}
LAION ▷ #research (48 条消息🔥):
-
关于成人内容对 AI 影响的讨论:
@vrus0188等人讨论了成人内容在推动技术进步方面的历史贡献,并将其与 AI 的发展并列。一些用户如@twoabove承认成人产业驱动技术进步的模式,而另一些用户如@SegmentationFault则怀疑对成人内容的关注是否能为 AI 带来有意义的进展。 -
对显式 AI 生成内容的担忧:
@thejonasbrothers分享了一篇新闻文章,强调了 AI 在创建非自愿色情内容方面的滥用,指出了其带来的挑战和极高的可见度。这引发了关于 AI 在成人内容中使用所带来的更广泛影响和争议的讨论。 -
对色情市场和 AI 的观察:
@chad_in_the_house和@freon等用户讨论了 NSFW 内容的盈利能力和市场饱和度,思考了该领域涉及的经济和伦理风险。 -
关于 AI 驱动的色情角色扮演优劣的辩论:
@SegmentationFault对 AI 社区中偏好低成本色情内容表示沮丧,认为这阻碍了 AI 模型的有意义发展。@mfcool和@.undeleted等人也表达了类似的观点,批评 AI 生成的成人图像在质量上的停滞。 -
关于 AI 图像质量的技术讨论:
@drhead深入探讨了 AI 生成图像的技术层面,提到了 NovelAI 模型,并讨论了通过 VAE encoder 训练来改进图像生成的可能性及其影响。社区共同反思了社区内 “photorealism” 的标准以及如何改进这些标准。
提到的链接:
- Reddit - Dive into anything:未找到描述
- Reddit - Dive into anything:未找到描述
- AI brings deepfake pornography to the masses, as Canadian laws play catch-up:未成年加拿大高中女生被作为目标,利用 AI 创建虚假的显式照片并在网上传播。Google 搜索显示了多个能够“脱掉”女性衣服的免费网站…
Eleuther ▷ #general (179 条消息🔥🔥):
-
找到 The Pile 数据校验和:
@paganpegasus为@hailey_schoelkopf提供了 The Pile zst 分片的校验和(checksums),并链接了 Discord 置顶消息 和 EleutherAI 的哈希值页面。 -
确定图像内容的工具:
@everlasting_gomjabbar询问了有关如何辨别图像是物体/地点还是像模糊照片那样的“空内容”的工具。@paganpegasus描述了在图像中定义“空内容”的复杂性,而@rallio.建议使用 OwlViT 或 CLIP 等模型。 -
手稿审阅与编辑进行中:
@wonkothesensible通过一系列消息对一篇暂定名为 “Don’t think about the paper” 的论文草稿提供了细致的反馈,重点在于澄清语言和语法。@hailey_schoelkopf表示感谢,并表示会在论文的致谢部分注明对 EleutherAI Discord 的感谢。 -
讨论用于 NLP 分类的云资源:针对
@pxxxl寻求训练 NLP 分类模型的云资源建议,@ad8e推荐了 GCP 和 Colab,其他参与者也纷纷就 runpod 和 vast.ai 等各种平台的成本和功能发表了看法。 -
关于 EleutherAI 计算资源的咨询:用户
@vidava询问了为一个具有架构调整和微调适配器(fine-tuning adapters)的半定制 LLM 项目申请访问 EleutherAI 计算资源的指南和要求。@stellaathena表示对合作持开放态度,但强调需要明确研究议程,并提出了合作价值主张。 -
Semantic Scholar 论文-作者链接机制:关于 Semantic Scholar 是否会自动将 Arxiv 论文链接到作者,
_inox澄清该过程是自动的,但如果出现错误,允许人工干预或建议更改。
提到的链接:
- Overleaf, Online LaTeX Editor:一个易于使用的在线 LaTeX 编辑器。无需安装,支持实时协作、版本控制、数百个 LaTeX 模板等。
- Research Paper Release Checklist:未找到描述。
- lora_example.py:lora_example.py。GitHub Gist:即时分享代码、笔记和代码片段。
- Discord - A New Way to Chat with Friends & Communities:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,与你的朋友和社区保持紧密联系。
- Hashes — EleutherAI:未找到描述。
Eleuther ▷ #research (208 条消息🔥🔥):
-
神经网络超参数的分形分析:
@jbustter分享了根据神经网络超参数生成的碎形(fractals)可视化图,其中红色表示训练发散,蓝色表示收敛。Jascha Sohl-Dickstein 的博客文章展示了这一概念,将分形模式与网络层的 Learning Rate 和网络的权重偏移(weight offset)联系起来。 -
讨论训练中的收敛与发散:包括
@Hawk、@genetyx8和@mrgonao在内的用户讨论了确定神经网络训练是收敛还是发散的方法,辩论了“发散至无穷大”的存在以及分形可视化中边界的性质,并建议 NaNs 可能表示发散。 -
机器学习中的 Active Learning 与数据呈现顺序:
@rybchuk询问了关于模型选择数据呈现顺序的研究,引发了关于 Active Learning 的讨论。@thatspysaspy提到该子领域确实存在,但指出其缺乏成功案例,@catboy_slim_补充说,通过使用较小的模型为较大模型的训练过滤数据,可以将训练需求减半。 -
在 Encoder-Decoder 模型中利用无监督数据:
@loubb提出了如何有效地在 Encoder-Decoder 模型中利用大型无监督数据集进行音频转文本等任务的问题。建议和讨论范围从分别训练组件到在 Pre-training 期间集成 Cross-attention。 -
NLP 鲁棒性论文与测试时增强 (Test-Time Augmentation) 的发布:
@millander宣布发表了他们作为第一作者的论文,该研究关于通过使用 Large Language Models 进行测试时增强 (TTA) 来提高文本分类器的鲁棒性。他们感谢了社区的支持,并分享了其工作的 arxiv 链接。
提到的链接:
- Neural network training makes beautiful fractals:这个博客旨在分享一些过于古怪、不完整或偏离主题而无法转化为学术论文,但我认为可能很重要的想法和结果。让我知道你的想法…
- A Poster for Neural Circuit Diagrams:你们中有些人可能知道,在过去的一年左右时间里,我一直在研究神经电路图。这些图表解决了深度学习研究中一个长期存在的挑战——清晰且准确地传达…
- MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts:状态空间模型 (SSMs) 已成为序列建模领域的有力竞争者,挑战了 Transformers 的主导地位。与此同时,混合专家 (MoE) 显著提高了…
- Scaling Laws for Fine-Grained Mixture of Experts:混合专家 (MoE) 模型已成为降低 Large Language Models 计算成本的主要解决方案。在这项工作中,我们分析了它们的缩放特性,并结合了一个实验…
- Model Editing with Canonical Examples:我们引入了使用规范示例进行模型编辑的方法,在这种设置下:(1) 为每个期望的行为提供单个学习示例,(2) 评估完全在分布外 (out-of-distribution) 进行,且…
- An Exponential Learning Rate Schedule for Deep Learning:存在有趣的经验证据表明,深度学习在使用奇特的学习率变化调度时可以表现良好。本文认为这种现象可能是由于 Batch Normalization 或 B…
- Nonlinear computation in deep linear networks:未找到描述
- Feedback Loops With Language Models Drive In-Context Reward Hacking:语言模型影响着外部世界:它们查询读写网页的 API,生成塑造人类行为的内容,并作为自主 Agent 运行系统命令。这些交互…
- Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks:状态空间模型 (SSMs),如 Mamba Gu & Dao (2034),已被提议作为语言建模中 Transformer 网络的替代方案,通过结合门控、卷积和输入依赖…
- Suppressing Pink Elephants with Direct Principle Feedback:现有的控制语言模型的方法,如 RLHF 和 Constitutional AI,涉及确定哪些 LLM 行为是理想的,并将其训练到语言模型中。然而,在许多情况下…
- Improving Black-box Robustness with In-Context Rewriting:机器学习模型通常在分布内 (ID) 数据上表现出色,但在未见的分布外 (OOD) 输入上表现挣扎。大多数提高 OOD 鲁棒性的技术不适用于以下设置…
- Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models:视觉条件语言模型 (VLMs) 在视觉对话、场景理解和机器人任务规划等应用中的采用日益增加;这种采用推动了大量新的…
- Tweet from Nature Reviews Physics (@NatRevPhys):观点:非线性动力学的生成式学习。作者:@wgilpin0 @TexasScience https://rdcu.be/dysiB
- Tweet from Hannes Stärk (@HannesStaerk):扩散模型已死——联合条件流匹配 (joint conditional flow matching) 万岁!🙃 明天 @AlexanderTong7 展示他的“通过小批量最优传输改进和泛化基于流的生成模型…”
-
A weight matrix in a neural network tries to break symmetry and fails.:我们初始化一个神经网络,使权重矩阵几乎可以分解为随机矩阵与所有元素均为…的矩阵的克罗内克积 (Kronecker product)。
- Mixture of Tokens: Efficient LLMs through Cross-Example Aggregation:尽管 Mixture of Experts (MoE) 模型在保持训练和推理成本的同时增加 Transformer 模型参数量方面具有前景,但其应用也带来了显著的缺点……
- llm-random/research/conditional/moe_layers/expert_choice.py at ad41b940c3fbf004a1230c1686502fd3a3a79032 · llm-random/llm-random:通过在 GitHub 上创建账户,为 llm-random/llm-random 的开发做出贡献。
- An Emulator for Fine-Tuning Large Language Models using Small Language Models:广泛使用的语言模型 (LM) 通常通过扩展两阶段训练流水线来构建:一个使用超大规模、多样化文本数据集的预训练阶段,以及一个微调(有时是……)
- MASS: Masked Sequence to Sequence Pre-training for Language Generation:预训练和微调(例如 BERT)通过将知识从资源丰富的预训练任务迁移到低/零资源的下游任务,在语言理解方面取得了巨大成功……
- Meta- (out-of-context) learning in neural networks:Brown 等人 (2020) 著名地介绍了大型语言模型 (LLM) 中的 In-context Learning 现象。我们确定了一种我们称之为元脱离上下文学习 (meta-OCL) 的现象的存在……
- Secret Collusion Among Generative AI Agents:大型语言模型 (LLM) 最近的能力提升开启了通信生成式 AI Agent 团队解决共同任务的应用。这在隐私和安全方面带来了挑战……
- Portal:TechBio 社区的大本营。收听我们的每周阅读小组 (M2D2, LoGG, CARE),阅读社区博客,并加入讨论论坛。
-
[Generative learning for nonlinear dynamics Nature Reviews Physics](https://www.nature.com/articles/s42254-024-00688-2.epdf?sharing_token=D_ImKvUZsRHYzs0lhT-4hNRgN0jAjWel9jnR3ZoTv0OFpVCe5j8bo6KJ1K_rllqrEXyt3r74B4sNMsFSoYzk3qrjVQZAFqeWPvf0ZTRuVS6GZQhz83MTvZr0nlCnrXj25-QPv4XzGPY-Homhk29UsvbEDaEd1lFW8i_n6jM6_1w%3D):未找到描述 - Policy Improvement using Language Feedback Models:我们引入了语言反馈模型 (LFM),用于在指令遵循的模仿学习中识别理想行为——即有助于完成指令中指定任务的动作。为了训练……
- To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis:最近的研究强调了数据集规模在扩展语言模型中的重要性。然而,大型语言模型 (LLM) 在预训练期间对 Token 的渴求是众所周知的,且高质量文本……
- UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units - Meta Research:我们提出了一种新型的两阶段直接 S2ST 架构 UnitY,它首先生成文本表示,随后预测离散声学单元。
Eleuther ▷ #interpretability-general (1 条消息):
- 寻求可解释性指导:
@jaimerv在频道中寻求比他们引用的 Representation Engineering 论文更前沿的 interpretability(可解释性)方法综述。他们正在寻求该主题下可能更好或更新的资源。
Eleuther ▷ #lm-thunderdome (4 条消息):
- 征集 Hallucinations Leaderboard 贡献者:
@pminervini分享了为 hallucinations leaderboard 贡献力量的行动号召,并补充说在 Harness leaderboard space 中有几个新的面向幻觉的任务可以开展。 - 对协作的热烈响应:公告发布后,
@baber_表示感兴趣并询问需要哪些具体帮助。 - 寻求具体协助:作为回应,
@pminervini提到他们需要任务定义、提议/添加新数据集和指标方面的帮助,以及协助确定在 Harness 最近更新后需要重新计算哪些结果。
Eleuther ▷ #gpt-neox-dev (4 messages):
- Pythia 去重数据中潜在的对齐偏差:
@pietrolesci提出了关于 2.8b 规模 Pythia 去重套件 特有的 训练数据批次与 Checkpoints 之间可能存在对齐偏差 的担忧。其他模型(包括较小版本和 6.9b)似乎对齐良好。 - 对数据对齐查询的回应:
@hailey_schoelkopf确认了@pietrolesci关于对齐问题的查询,并表示他们将跟进此事。 - 对 Pythia 研究的兴趣及出版建议:
@stellaathena对撰写博客文章或研讨会论文以展示 Pythia 可靠性的潜力表示兴奋,并表示会广泛引用。 - 对撰写 Pythia 相关内容的开放态度:在回应
@stellaathena时,@pietrolesci对关于发布 Pythia 发现的建议表示感谢,认为这是 ACL 截止日期后的一个不错的短期项目。
LlamaIndex ▷ #announcements (2 messages):
- LlamaIndex v0.10 发布:
@jerryjliu0宣布发布 LlamaIndex v0.10,这是迄今为止最重要的更新,其特点是引入了新的llama-index-core包,并将集成/模板拆分为独立的 PyPi 包。llamahub.ai也在进行翻新,他们为了更好的开发者体验弃用了 ServiceContext,并鼓励社区查看 博客文章 和 文档 以获取有关迁移和贡献的详细信息。 - 庆祝团队成就:衷心感谢
<@334536717648265216>和<@908844510807728140>领导了最新 LlamaIndex 更新的工作,这是向使其成为生产级数据框架迈出的一步。 - 关于 LlamaIndex v0.10 发布的推文:LlamaIndex 分享了一篇 推文,强调了 LlamaIndex v0.10 的关键更新,包括创建了数百个独立的 PyPi 包、LlamaHub 的重构以及 ServiceContext 的弃用。
- 带有无代码 RAG 教程的网络研讨会公告:Flowise 的联合创始人 Henry Heng 将在 LlamaIndex 网络研讨会中亮相,演示如何使用他们与 LlamaIndex.TS 的新集成来构建无代码检索与生成 (RAG) 应用程序。研讨会定于太平洋时间周五上午 9 点举行,感兴趣的人员可以 在此注册。
提到的链接:
- LlamaIndex 网络研讨会:构建无代码 RAG · Zoom · Luma:Flowise 是用于构建 LLM 驱动工作流的领先无代码工具之一。用户无需学习如何在框架/编程语言中编写代码,只需拖放组件即可…
- 来自 LlamaIndex 🦙 (@llama_index) 的推文:💫 LlamaIndex v0.10 💫 - 我们迄今为止最大的开源发布,也是迈向生产就绪的重要一步。🚀 ✅ 创建核心包,将每个集成/模板拆分为独立的 PyPi …
- LlamaIndex v0.10:今天我们很高兴发布 LlamaIndex v0.10.0。这是迄今为止我们 Python 包最大的更新(见这个巨大的 PR)……
LlamaIndex ▷ #blog (5 条消息):
-
LlamaIndex 达成 v0.10 里程碑:LlamaIndex 发布了其最大的开源版本 v0.10,标志着向生产就绪(production-readiness)的转变。正如其 Twitter 帖子中所强调的,官方创建了一个核心包,并将数百个集成拆分为独立的 PyPi 软件包。
-
使用 LlamaIndex 构建多模态应用的教程:
@ollama和 LlamaIndex 共同推出了一个在 MacBook 上构建上下文增强多模态应用的教程,内容包括智能收据读取和产品图像增强,详情见这条推文。 -
DanswerAI 利用 LlamaIndex 增强企业能力:DanswerAI 利用
@llama_index在企业知识库上提供 ChatGPT 功能,并与 GDrive、Slack 和 Jira 等常用办公工具集成,以提高团队效率,详见 Twitter 公告。 -
即将举行的 FlowiseAI 无代码 RAG 网络研讨会:
@llama_index与@FlowiseAI合作举办一场网络研讨会,探讨如何使用 LlamaIndex.TS 和 Flowise 构建无代码 RAG(Retrieval-Augmented Generation)工作流,详情见其最近的推文。 -
使用 RAG 驱动的 Agent 定义研究工作流:
@quantoceanli的一个 Notebook 概述了建立科学研究工作流的过程,利用 LlamaIndex 操作 ArXiv 和 Wikipedia 等资源,构建了一个创新的 RAG 驱动 Agent,展示在这条推文中。
LlamaIndex ▷ #general (303 条消息🔥🔥):
-
LlamaIndex 导入问题:用户
@ddashed、@bhrdwj、@lhc1921和@cheesyfishes讨论了最新版本 LlamaIndex 更新后的问题。建议用户从全新的 venv 或容器开始,并参考迁移指南和包注册表。 -
复杂文档过滤挑战:用户
@_shrigmamale寻求关于根据关键词、日期和文件类型过滤大型复杂文档目录的帮助。另一位用户@qingsongyao建议使用传统的索引技术进行动态文件过滤,而不是使用像 GPT-4 这样昂贵的 LLM。 -
高效处理多个文档源:用户
@nvmm_、@whitefang_jr和@.saitej讨论了如何使用 LlamaIndex 处理和合并用户上传的私有文档与公开索引文档,以及为单个文档创建多个 Agent 的可能性。 -
配置分块大小(Chunk Sizes)与测试性能:
@sgaseretto询问在ServiceContext被弃用并由Settings取代后,应在哪里指定chunk_size。@cheesyfishes提供了全局配置分块大小的新方法,或者通过将 node parser/text splitter 传递给 index 来实现。 -
处理 Chat Memory Buffer 的变化:
@benzen.vn询问在使用ChatMemoryBuffer时遇到不相关响应的问题。@whitefang_jr建议离题的对话可能会降低查询的相关性,并指向 LlamaIndex 源代码的相关部分进行解释。
提到的链接:
- Notion – 笔记、任务、维基和数据库的一体化工作空间。:一款将日常工作应用融合为一的新工具。它是为你和你的团队打造的一体化工作空间。
- Response Modes - LlamaIndex 🦙 v0.10.3:未找到描述
- Notion – 笔记、任务、维基和数据库的一体化工作空间。:一款将日常工作应用融合为一的新工具。它是为你和你的团队打造的一体化工作空间。
- Google Colaboratory:未找到描述
- 使用 LlamaIndex 构建自定义数据源聊天机器人:只需 43 行代码即可用你自己的数据增强任何 LLM!
- Router Query Engine - LlamaIndex 🦙 v0.10.3:未找到描述
- Elasticsearch Vector Store - LlamaIndex 🦙 v0.10.3:未找到描述
- llama_index/llama-index-legacy/llama_index/legacy/vector_stores/mongodb.py at main · run-llama/llama_index:LlamaIndex(原名 GPT Index)是适用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/chat_engine/condense_question.py at 3823389e3f91cab47b72e2cc2814826db9f98e32 · run-llama/llama_index:LlamaIndex(原名 GPT Index)是适用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- Usage Pattern - LlamaIndex 🦙 v0.10.3:未找到描述
- Node Postprocessor Modules - LlamaIndex 🦙 v0.10.3:未找到描述
- llama_index/llama-index-core/llama_index/core/indices/base.py at 5d557cb2fe48b90e4056ecae25b9371681752a3c · run-llama/llama_index:LlamaIndex(原名 GPT Index)是适用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- Configuring Settings - LlamaIndex 🦙 v0.10.3:未找到描述
- Migrating from ServiceContext to Settings - LlamaIndex 🦙 v0.10.3:未找到描述
LlamaIndex ▷ #ai-discussion (1 messages):
- 超简易全栈 RAG 应用构建指南发布:
@kerinin分享了一篇关于使用 Dewy 构建检索增强生成(RAG)应用的文章,Dewy 是一个全新的开源知识库。该指南涵盖了使用 NextJS、OpenAI API 和 Dewy 来创建一个 RAG 应用,通过将语言模型锚定在特定、可靠的信息中,从而提高其响应的准确性。阅读指南。
提到的链接:
| [使用 NextJS, OpenAI & Dewy 构建 RAG 聊天机器人 | Dewy](https://dewykb.github.io/blog/rag-app-with-nextjs-openai-and-dewy/):本指南将引导你使用 NextJS 作为 Web 框架,OpenAI API 作为语言模型,以及 Dewy 作为知识库来构建一个 RAG 应用。 |
HuggingFace ▷ #announcements (1 messages):
-
Hugging Face 发布 Message API:🚀 Hugging Face 推出了全新的 Message API,该接口与 OpenAI 兼容,允许直接在 Hugging Face Inference Endpoints 和 Text Generation Inference 中使用 OpenAI 客户端库或第三方工具。从他们的公告中了解更多。
-
新开源发布与功能:🤗 Datatrove 在 PyPI 上线;Gradio 更新至 4.18.0,改进了
ChatInterface等功能;推出了用于浏览器内背景移除的 Remove Background Web。此外,还宣布了用于 3D 并行训练的 Nanotron 以及 Hugging Face Competitions 的新功能。Accelerate 0.27.0 发布,拥有 PyTorch 原生流水线并行推理框架。 -
Hugging Face 产品创新:HF 推出了 LoRA Studio,在 Hub 上提供专用 UI;集成了 2FA 支持;发布了 Mask Generation 任务页面;并宣布了使用 Axolotl 训练的模型上线。
-
合作伙伴与学习资源扩展:Hugging Face 宣布与 Codecademy 合作推出关于 Transformer 的全新免费 AI 课程,并发布了一篇关于 SegMoE 的博客文章,该技术支持在文本转图像模型上进行模型合并。
-
优化模型性能:有一种使用 Accelerate 加载预训练 PyTorch 模型速度提升约 2 倍的技术,详见
@RisingSayak编写的用户指南。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
- Releases · gradio-app/gradio:构建并分享令人愉悦的机器学习应用,全 Python 开发。🌟 点赞以支持我们的工作!- gradio-app/gradio
- Nouamane Tazi (@Nouamanetazi) 的推文:非常高兴看到 https://github.com/huggingface/nanotron 今天发布!❤️ 从零开始构建一个 3D 并行训练库是一段有趣且富有洞察力的旅程,这太疯狂了…
- Zach Mueller (@TheZachMueller) 的推文:今天是 @huggingface Accelerate 一个特别的版本发布!在其他功能中,这个最新版本(与 @PyTorch 合作)集成了一个 PyTorch 原生的流水线并行推理框架…
- Omar Sanseviero (@osanseviero) 的推文:超过 300 个使用 axolotl 训练的模型已在 Hub 上分享!它也是有史以来最可爱的图标。https://huggingface.co/models?other=axolotl&sort=trending
- Sayak Paul (@RisingSayak) 的推文:为什么 LLM 的孩子们能享受模型合并的所有乐趣?为什么不带上我们这些 Diffusion 的孩子?来自 @_segmind 的朋友们开源了 SegMoE 来缩小这一差距 🔥 在文本转图像模型上进行 MoE 风格的合并…
- Sayak Paul (@RisingSayak) 的推文:🤗 Accelerate 高级用户日志 👨🏫 在这里,我向你展示如何使用 Accelerate 将预训练 PyTorch 模型的加载速度提升约 2 倍。代码片段中的注释应该是自解释的。但如果你…
HuggingFace ▷ #general (192 条消息🔥🔥):
<ul>
<li><strong>搜索引擎开发难题</strong>:<code>@spidy___</code> 与 <code>@vipitis</code>、<code>@cubietom</code> 等人讨论了开发搜索引擎和提取关键词的挑战。对话探讨了 NER 的局限性以及关键词提取、TF-IDF、BM25 等替代方案,以及使用 spaCy 进行词性标注(Part of Speech tagging)。</li>
<li><strong>托管与推理挑战</strong>:<code>@sullynaj</code> 和 <code>@ram1428</code> 等用户询问了关于托管自定义模型以及是否提供 Serverless 推理的问题,并讨论了指向 Serverless 或经济型解决方案的建议。</li>
<li><strong>应对模型规模</strong>:与 <code>@zorian_93363</code> 和 <code>@xacer_</code> 等用户的对话围绕在典型的“开源爱好者”硬件上运行超大型模型(100B+ 参数)的可行性和实用性展开。</li>
<li><strong>情人节氛围</strong>:<code>@not_lain</code> 在情人节传递了爱与欢乐,鼓励社区成员拥抱所爱之人。</li>
<li><strong>关于本地运行模型的讨论</strong>:<code>@aj_0003</code> 询问了如何在本地运行机器学习模型,而 <code>@pierrunoyt</code> 讨论了使用 Hugging Face 克隆并运行模型。</li>
</ul>
提到的链接:
- Discord - A New Way to Chat with Friends & Communities: Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,与你的好友和社区保持紧密联系。
- Stable Cascade - a Hugging Face Space by multimodalart: 未找到描述
- Custom architectures with HuggingFace 🤗: 未找到描述
- lamm-mit/x-lora · Hugging Face: 未找到描述
- jinaai/jina-embeddings-v2-base-code · Hugging Face: 未找到描述
- Norm/nougat-latex-base · Hugging Face: 未找到描述
- NVIDIA Chat With RTX: 您的个性化 AI 聊天机器人。
- Models - Hugging Face: 未找到描述
- Hugtrip GIF - Hugtrip - Discover & Share GIFs: 点击查看 GIF
- Hands-on - Hugging Face Deep RL Course: 未找到描述
- Linguistic Features · spaCy Usage Documentation: spaCy 是一个用于 Python 自然语言处理的免费开源库。它具有 NER、POS 标注、依存句法分析、词向量等功能。
- Linguistic Features · spaCy Usage Documentation: spaCy 是一个用于 Python 自然语言处理的免费开源库。它具有 NER、POS 标注、依存句法分析、词向量等功能。
- Hugging Face status: 未找到描述
HuggingFace ▷ #today-im-learning (9 messages🔥):
-
简单聊天机器人开发蓝图:
@wilbert.comicho正寻求创建一个简单的聊天机器人,用于从用户那里收集五个特定细节并通过电子邮件发送。他们正在寻找一个能够处理数据库查询、用户提示/数据保存以及调用 API 发送电子邮件的模板。 -
以 AutoGen 作为起点:
@dwb7737建议使用微软的 AutoGen 进行聊天机器人开发,并指向了 GitHub 上的详细 使用案例和 Jupyter Notebooks。此外,他强调在使用 AutoGen 时,OpenAI 比开源 LLM 更具优势。 -
从 AutoGen Studio 小处着手:在后续建议中,
@dwb7737建议在深入研究 AutoGen Studio 之前先掌握基础知识,因为可能存在行为差异和 bugs,他主张理解底层流程。他提供了一个 AutoGen Studio 示例链接。 -
wilbert.comicho:确认他们将查看推荐的资源。
-
Ollama 模型视频指南:
@dwb7737分享了一个 YouTube 视频,作为学习如何将 Ollama 开源模型 与 LangChain 和 Autogen 结合使用的优秀资源。 -
Google Sheets 合并陷阱:
@lunarflu正在进行两个 Google Sheets 的合并工作,并提醒处理重复记录和保持唯一记录以防止问题的重要性。 -
使用 FP8 创建 Transformers:
@neuralink在掌握 99% 的 doremi 复现方面取得了进展,并推进了在 3D 并行中使用端到端 FP8 的训练。 -
从 AI 转向学术界:
@sardarkhan_分享了他们从阅读 diffusors 和 transformers 转向专注于即将到来的期中考试的转变。
提到的链接:
- autogen/samples/apps/autogen-studio at main · microsoft/autogen:启用下一代大语言模型应用。加入我们的 Discord:https://discord.gg/pAbnFJrkgZ - microsoft/autogen
- autogen/notebook at main · microsoft/autogen:启用下一代大语言模型应用。加入我们的 Discord:https://discord.gg/pAbnFJrkgZ - microsoft/autogen
- Ollama - Libraries, Vision and Updates:Ollama 库:https://ollama.com/blog/python-javascript-libraries;Ollama Vision 模型:https://ollama.com/blog/vision-models;Ollama OpenAI API:https://ol…
HuggingFace ▷ #cool-finds (8 messages🔥):
- 间断后重回 ML:
@charlweed通过开发一个连接到 Automatic1111 的 GIMP 3.0 插件 重新投入 Machine Learning,目前在通过 API 发布 Image2Image 功能的图像数据时面临挑战。 - 挖掘土壤获取能源:
@Gordo Stoli分享了一项关于 土壤电池 (Soil Battery) 的研究,这是能源技术领域的一个潜在进步。 - MoE 安全漏洞曝光:
@osanseviero介绍了一篇 论文,展示了 混合专家模型 (MoE) 如何容易受到影响良性查询输出的对抗性攻击。 - 了解 MoE 风险与缓解措施:
@osanseviero还针对 DeepMind 论文中描述的漏洞写了详细的潜在缓解策略笔记,建议采用批次顺序随机化等方法,详见 此处。 - 关于 MoE 未来稳定性的疑问:
@meatfucker强调了报道的 MoE 攻击策略在未来的潜在威胁,并思考了对使用大批次系统的影响,这可能会无意中影响输出质量。
提到的链接:
- @osanseviero 在 Hugging Face 上的发布:"Mixture of experts: beware 🛡️⚔️ DeepMind 的新论文:Buffer Overflow in…":暂无描述
- 论文页面 - Buffer Overflow in Mixture of Experts:暂无描述
HuggingFace ▷ #i-made-this (10 messages🔥):
- 测验生成的期待:
@lunarflu建议为测验生成过程添加加载界面或进度条,并提到目前在没有任何提示的情况下等待测验出现存在体验问题。 - 自动化图像打标模型部署:
@not_lain发布了一个用于 Diffusion 任务相关图像打标的自动化模型,并提供了使用说明以及讨论链接。他们还提到在refs/pr/2中对模型的实现进行了改进。 - 模型支持多种图像格式:
@not_lain强调他们的打标模型接受字符串(路径)、PIL 图像或 numpy 数组作为输入,展示了处理图像的灵活性。 - 用于动漫数据集的 AI:
@not_lain表示打算使用他们的图像打标模型来标注动漫数据集,而@imcoza1915则评论该工具非常酷。 - 图像转换的新 “Remix” 模式:
@matthieulc分享了 PanoramAI.xyz 的更新,引入了采用ControlNet技术的 “remix” 模式,以便在图像转换中更好地保留结构。提醒用户可以使用方向键操作该工具。 - 利用 AI 实现从草图到时尚设计:
@tony_assi非常自豪地展示了项目 Sketch to Fashion Design,正如@chad_in_the_house所暗示的,该项目作为一个能够理解设计的 AI 获得了积极反馈。
提到的链接:
- panoramai:你的世界里有什么?
- Sketch To Fashion Design - tonyassi 的 Hugging Face Space:未找到描述
- p1atdev/siglip-tagger-test-3 · 使用 huggingface_hub 上传文件夹:未找到描述
HuggingFace ▷ #reading-group (32 messages🔥):
- S4 架构解析发布:
@ericauld分享了 “The Annotated S4” 资源并征求反馈,指出其对于理解 S4 架构非常有用,该架构在建模超长距离序列任务方面表现出色。他们表示,阅读此内容可能有助于在即将举行的 Mamba/S4 演讲前理清模型思路。 - 寻求 S4 实现的清晰解释:
@austintb.希望进一步明确 S4 架构的实现和计算复杂度细节。@chad_in_the_house表达了同样的看法,要求对概念和先前的工作(如 hippo 代码库)进行直观解释,随后建议@ericauld的主讲内容应侧重于直觉和代码实现。 - Mamba/S4 演讲安排及内容偏好:
@ericauld提议将 Mamba/S4 演讲安排在加州时间周五上午 10 点,并根据社区反馈建议了主场和副场(侧重数学)会议的潜在内容。 - LangTest 论文正式亮相:
@prikfy宣布他们的 LangTest 论文已在 Software Impacts 期刊发表,这是一个用于测试和增强 NLP 模型的工具。分享了论文和 LangTest 的 GitHub 仓库,@ryzxl进一步补充了关于其全面测试能力以及如何开始使用该库的背景信息。
提到的链接:
- Structured State Space Models for Deep Sequence Modeling (Albert Gu, CMU):日期:2023 年 5 月 26 日(抱歉前两张幻灯片未录制,那是动机说明)。摘要:本次演讲将涵盖近期深度神经网络…
- The Annotated S4:未找到描述
- GitHub - JohnSnowLabs/langtest: 交付安全有效的语言模型:交付安全有效的语言模型。通过在 GitHub 上创建账号为 JohnSnowLabs/langtest 的开发做出贡献。
-
[LangTest 交付安全有效的模型 John Snow Labs](https://langtest.org):未找到描述
HuggingFace ▷ #diffusion-discussions (10 messages🔥):
-
多 GPU 训练咨询:George 正在寻求关于将
train_text_to_image.py脚本适配为 multi-GPU 使用的建议,并提到了之前使用nn.DataParallel的经验。 -
微调模型的部署选项:
@lokendra_71926微调了 mistarl_7b_gptq 模型,正在寻求适合快速推理部署的库或平台的建议。 -
Stable Cascade 的成功案例:
@isidentical询问是否有人像 readme 中的示例那样,通过 stable cascade 实现了良好的文本生成;并确认通过正确的 prompting 策略,在任意词汇上达到了 50% 的成功率。 -
HuggingFace 推理引擎建议:
@chad_in_the_house建议 HuggingFace 有一个推理引擎可能适用于 LLMs 部署,并提到该讨论在另一个频道可能更合适。 -
Terminus 模型期待:
@pseudoterminalx透露新的 terminus model 仍处于开发阶段。
HuggingFace ▷ #computer-vision (7 messages):
-
分层图像分类挑战:
@cropinky描述了分层图像分类的问题,并指出复杂程度取决于数据的质量和数量。他们建议查看一篇 ECCV22 论文 以及 paperswithcode 上的相关数据集以进行进一步研究。 -
寻找 Gaussian Splats 资源:
@aeros93询问了关于从点云或图像创建 Gaussian splats 的资源或预训练模型。虽然没有提供具体资源,但@johko990将该查询重定向到了可能提供帮助的另一个频道。 -
多模态项目见解寻求:
@joee2711正在开发一个多模态项目,并寻求关于 Q-former / MLP connector 之间区别的澄清,以及 MLP connectors 和 adapters 是否相同。他们还表示有兴趣与从事类似项目的其他人建立联系。 -
增强图像检索系统:用户
@femiloye正在开发一个类似于行人重识别(person reidentification)的图像检索系统,并正在寻找除了使用模型 embeddings 之外提高匹配准确度的方法。他们目前为此目的使用了经过 reid loss 训练的自定义 deit transformer。
HuggingFace ▷ #NLP (4 messages):
-
为部署微调 Mistral:
@lokendra_71926在自定义数据上微调了 mistarl_7b_gptq 模型,并正在寻求部署库或平台的建议,以实现更快的推理。 -
使用 XLM-R 进行语言识别:
@_michaelsh在阅读了一篇 HuggingFace 文章后询问如何从 xlmr 中提取语言,该文章解释了 XLM-RoBERTa 不需要语言张量(language tensors)即可理解所使用的语言。 -
从自然语言到代数表示:
@_david_valente_正在寻找专注于将自然语言翻译成代数表示(如 LEAN)的研究或工作。 -
使用 Transformers 进行语音模拟和语言转换:
@mentrass询问了关于使用 Transformer 模型模拟声音并改变语言的方法。
HuggingFace ▷ #diffusion-discussions (10 messages🔥):
- 多 GPU 适配咨询:
@George正在寻找一种简单的方法将train_text_to_image.py脚本适配为多 GPU 使用,并提到了过去使用nn.DataParallel的经验。 - 微调模型的部署平台:
@lokendra_71926微调了 mistarl_7b_gptq 模型,并询问用于快速推理部署的库或平台。@chad_in_the_house建议关注 Hugging Face 的 LLMs 推理引擎。 - 使用 Stable Cascade 生成文本:
@isidentical询问是否有人能像模型 readme 中展示的那样,使用 stable cascade 实现文本生成,随后确认通过良好的 prompting 达到了 50% 的成功率。 - 推理优化讨论重定向:
@chad_in_the_house指出关于推理优化的讨论应移至名为<#1019883044724822016>的不同频道。 - 对新 Terminus 模型的期待:
@pseudoterminalx表示一个新的 terminus 模型目前正在开发中。
Nous Research AI ▷ #ctx-length-research (3 条消息):
-
DAMO-NLP-SG 发布海量长上下文数据集:
@giftedgummybee分享了 LongCorpus-2.5B 数据集,其中包含从各个领域收集的 2.5B tokens,用于长上下文的持续预训练(continual pre-training)。该数据集的构成灵感来自 Long-Data-Collections,其筛选标准确保了与训练集的 n-gram 相似度较低,从而排除了 QA 和 Summarization 数据。 -
使用 ‘rope’ 与 ‘self-extend’ 扩展模型:
@blackl1ght强调,与 ‘rope scaling’ 相比,使用 ‘self-extend’ 扩展模型可以更好地保持连贯性,即使在较大的缩放因子下也是如此,这参考了 llama.cpp 中的实现。 -
‘self-extend’ 实现的便捷性:
@blackl1ght指出了 ‘self-extend’ 的优势,包括无需设置、微调,或像量化(quants)的 ‘gguf configurations’ 那样需要额外参数。
提到的链接:
DAMO-NLP-SG/LongCorpus-2.5B · Datasets at Hugging Face:未找到描述
Nous Research AI ▷ #off-topic (8 条消息🔥):
-
讨论 LangGraph Agents 的持久性:
@pradeep1148分享了一个题为 “LangGraph Agents Persistence” 的 YouTube 视频,强调可以设置 LangGraph agents 以在交互过程中保留其状态。 -
Gemini 的拒绝倾向令用户沮丧:
@llmaniac1000对 Gemini 频繁的拒绝倾向表示失望,并寻求他人的使用经验。@n8programs附和道,它并不出色,并暗示 GPT-4 的表现优于 Gemini。 -
马克·扎克伯格的形象转变:
@nonameusr分享了 一条 Twitter 帖子,暗示在 AI 和 VR 的背景下,扎克伯格已从反派转变为救世主。 -
用 GIF 增添幽默感:
@error.pdf通过分享来自 Tenor 的 GIF,以幽默的方式回应了之前的讨论,没有提供进一步的评论或背景。
提到的链接:
- Rock Cat Eyebrow Cat GIF - Rock cat Eyebrow cat Meme - Discover & Share GIFs:点击查看 GIF
- LangGraph Agents Persistence:在创建 LangGraph agents 时,你还可以设置它们以持久化其状态。这允许你执行诸如与 agent 进行多次交互之类的操作…
Nous Research AI ▷ #interesting-links (17 条消息🔥):
-
迷人的 Mandelbrot 之美分享:
@gabriel_syme发布了一个 Mandelbrot 集合的绝美可视化。@_3sphere补充道,该集合对发散性的关注构成了其复杂性与秩序感。 -
通过 ‘Marv’ 聊天机器人众包 AI:
@.dvs13赞扬了一个众包项目,并指出 “prompt” 一词存在歧义。该项目涉及一个名为 Marv 的聊天机器人,它会以讽刺的口吻回答问题。 -
Reka 推出多模态 AI 模型:
@metaldragon01重点介绍了 Reka Flash 的发布,这是一个 21B 参数的快速多模态语言模型,以及其更小型的版本 Reka Edge。Reka Flash 拥有可与 Gemini Pro 和 GPT-3.5 等主流模型媲美的性能,目前已开启公开测试。 -
追求 AMD 上的 CUDA 兼容性:
@leontello分享了一个 GitHub 项目 ZLUDA,旨在 AMD GPU 上运行 CUDA。遗憾的是,根据@adjectiveallison的详细说明,该项目已不再积极维护,并引用了项目负责人的话称其已基本被放弃。 -
AI 研究中 Wavelets 与 Transformers 的结合:
@euclaise分享的一篇 arXiv 论文建议,小波变换可以通过以线性复杂度捕捉位置和频率信息来增强 Transformers。论文详细介绍了小波空间注意力(WavSpA),并在 Long Range Arena 上进行了测试。在此查看论文。
提及的链接:
- @dvilasuero on Hugging Face: "🤗 Data is better together!Data is essential for training good AI systems.…":未找到描述
- Reka Flash: An Efficient and Capable Multimodal Language Model - Reka AI:Reka Flash 是一个最先进的 21B 模型,完全从零开始训练并推向极致。它是我们模型系列中的“涡轮级(turbo-class)”产品。
- WavSpA: Wavelet Space Attention for Boosting Transformers' Long Sequence Learning Ability:Transformer 及其变体是深度学习中的基础神经架构。最近的研究表明,在傅里叶空间学习注意力可以提高…的长序列学习能力。
- GitHub - vosen/ZLUDA: CUDA on AMD GPUs:AMD GPU 上的 CUDA。通过在 GitHub 上创建账号为 vosen/ZLUDA 的开发做出贡献。
- GitHub - acorn-io/rubra: AI Assistants, LLMs and tools made easy:AI 助手、LLM 和工具变得简单。通过在 GitHub 上创建账号为 acorn-io/rubra 的开发做出贡献。
Nous Research AI ▷ #general (180 条消息🔥🔥):
- 新模型训练开始:
@n8programs兴奋地分享了开始训练新模型的消息,提到了 dachshund、neuralbeagle-dpo 等术语,并将这一过程描述为遗传算法风格的随机组合。 - 关于模型合并的趣谈:
@teknium幽默地指出犬种与模型合并之间的隐喻契合,而@leontello将混合方法比作进化策略,@n8programs则报告了他的合并实验产生了一个可怕的结果。 - Model Card 拼写错误警报:
@everyoneisgross报告了 Hugging Face 上 70B llama 的 Model Card 中存在拼写错误,@teknium迅速进行了修正,随后大家对模型发布表示祝贺。 - 量化探索:关于训练后量化(PTQ)方法的讨论,
@stellaathena分享了一个新量化方法的链接,@nruaif则开玩笑地期待更低的位精度(bit-precision)。 - AI 激活值添加:提到了对激活值黑客攻击(activation hacking)的深入研究,
@filipvv引用了一篇外部文章,@mihai4256讨论了他们改进方法的计划,而@proprietary对这项工作表示了兴趣。
提到的链接:
- QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks:训练后量化(PTQ)通过将权重转换为低精度来减少 LLM 的内存占用。在这项工作中,我们介绍了 QuIP#,这是一种仅权重(weight-only)的 PTQ 方法,达到了最先进的…
- 来自 jf (@fejo_11) 的推文:Mixtral 8x7B:基于 POS 标签的路由分析。我使用 @MistralAI 的 Mixtral 8x7B 模型进行了路由分析,重点关注词性(POS)标签,这与原始方法有所不同…
- NousResearch/Nous-Hermes-2-Llama-2-70B · Hugging Face:未找到描述
- Representation Engineering Mistral-7B an Acid Trip:未找到描述
- OpenAI 研究员 Andrej Karpathy 离职:发言人证实,OpenAI 的创始成员之一 Andrej Karpathy 已离开公司。Karpathy 是一位著名的人工智能研究员,他当时正在开发一个他曾描述过的产品…
- Xigmoid: An Approach to Improve the Gating Mechanism of RNN:这项工作为 RNN 类模型的门控机制提出了一种创新方法。将传递函数嵌入到原始 sigmoid 中,形成一种称为 xigmoid 的新门控函数。其目的是…
- [缺失的帖子]:未找到描述
- Diffusion Language Models Can Perform Many Tasks with Scaling and Instruction-Finetuning:近期生成式 AI 的激增是由扩散概率模型的生成能力和大型语言模型的可扩展能力推动的。尽管潜力巨大,但目前仍…
- Practical AI: Apple Podcasts 上的机器学习与数据科学:技术 · 2024
- Steering GPT-2-XL by adding an activation vector:摘要:我们展示了一种与语言模型交互的新型可扩展方式:在正向传播中添加特定的激活向量。[2] 从本质上讲,我们将正向传播的组合相加…
Nous Research AI ▷ #ask-about-llms (38 条消息🔥):
-
DeepSeekMath 加入讨论:用户
@yxzwayne询问了新推出的 deepseekMath 在合并策略(merging strategies)中的集成情况,表现出对其应用的兴趣。 -
发现“傻瓜式”微调指南:
@nemoia正在寻找关于如何微调 Mistral 7B 并创建自己数据集的简单指令,随后分享了一个有用的 Medium 指南,该指南提供了关于该过程的详细示例和解释。 -
强制 FA2 行导致内存问题:针对 FA2 未启用的问题,
@bloc97澄清说,问题与尝试创建一个巨大的attn_weights矩阵有关,指出导致内存问题的代码行可以在这里查看。 -
编程模型的备选方案:
@natefyi_30842正在为编程模型寻找比 GPT-4 更便宜的替代方案,@teknium建议尝试由 “together” 托管的 deepseek coder。 -
MIQU 模型的预训练和 SFT 得到澄清:
@teknium向@yxzwayne解释说,MIQU 模型首先在 Llama-2 70b 上进行预训练,然后进行了 SFT(Supervised Fine Tuning),专门针对指令聚焦的数据。
提到的链接:
- AMD 悄悄资助的基于 ROCm 的无缝 CUDA 实现推文:现已开源 - Phoronix:未找到描述
- 微调 Llama 2 和 Mistral:使用 QLoRA 微调 LLM 的初学者指南
- 从头开始训练因果语言模型 - Hugging Face NLP 课程:未找到描述
- modeling_mistral_yarn.py · NousResearch/Yarn-Mistral-7b-128k at main:未找到描述
Nous Research AI ▷ #collective-cognition (3 条消息):
- 项目因 Chat GPT 更新而停摆:
@adjectiveallison询问在遇到网站访问问题后项目是否仍然活跃。@teknium回复澄清说,由于具有多种模式的新版 Chat GPT 更新,网站崩溃了,导致原团队无法维护。 - 对项目停摆表示遗憾:
@adjectiveallison在得知项目因新版 Chat GPT 更新带来的复杂问题而不再维护后表示失望。
Mistral ▷ #general (43 条消息🔥):
- 初学者模型选择建议:新人
@nana.wav询问最适合使用的模型,@afriendofmaurice推荐使用 instruct 模型 进行类似 Chat-GPT 的交互。@mrdragonfox澄清说,instruct 模型 更侧重于指令遵循,而其他模型则类似于原始的自动补全。 - 与可视化库的集成:
@carnivore5询问是否有人有将 Mistral 功能与 GraphViz 或类似可视化库集成的经验,随后@mrdragonfox澄清了 Mistral 缺乏固有的 function-calling 能力。 - Chat 与 Completion 端点对比:
@i_am_dom和@mrdragonfox讨论了 Mistral 的/chat/completion与期望中的原始/completion端点之间的区别,目前大多数使用都倾向于 chat 端点。 - 实习生在使用 Mistral 时的困扰:
@nana.wav分享了在学习如何使用下载的模型以及打算对其进行微调时的困难,@mrdragonfox建议从更简单的步骤开始。对话中包含了其他人的同情和回忆,突显了实习生面对繁重任务时的普遍经历。 - Mistral API 延迟问题:
@justinmann.报告了在使用 Mistral API 时存在不稳定的延迟,响应时间从不到一秒到超过一分钟不等。@sublimatorniq建议联系支持部门寻求帮助。
Mistral ▷ #models (20 条消息🔥):
- Mistral 的 RAG 指南:
@ethux分享了一份实用的指南,解释了 Mistral 如何与 RAG (Retrieval-Augmented Generation) 协同工作,包括检索和生成的步骤,并提供了来自 Mistral、LangChain 和 LlamaIndex 的示例。 - 关于 LangChain 与 LlamaIndex 的辩论:
@sublimatorniq发起了关于 LangChain vs. LlamaIndex 效用的讨论,@rabdullin对它们在严肃的 LLM 驱动产品中的应用表示怀疑。 - DSPy 倡议:
@mrdragonfox提倡将 DSPy 作为一个强大的框架,理由是它将 LLM 视为“设备”而非“聊天”接口,并链接到了一篇展示其强大功能的 Twitter 帖子。 - Mistral-7b 训练数据集查询:
@kushagra_67246询问了 Mistral-7b 的训练数据集,收到的回复既幽默又模糊,暗示了多种互联网来源——从@tom_lrd将其描述为“绝密魔法汤”到@gamerboi0129列举了教科书和 Wikipedia 等综合来源。 - 关于原始预训练 Checkpoint 的澄清:
@nofreewill42询问是否有 Mistral 模型在原始文本预训练后的开源 Checkpoint,并表示mistralai/Mistral-7B-v0.1看起来交互性太强,不像原始版本。
提到的链接:
-
[Basic RAG Mistral AI Large Language Models](https://docs.mistral.ai/guides/basic-RAG/):检索增强生成 (RAG) 是一种 AI 框架,它协同了 LLM 和信息检索系统的能力。它对于利用…回答问题或生成内容非常有用。 - GitHub - stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models:DSPy:用于编程(而非提示)基础模型的框架 - stanfordnlp/dspy
Mistral ▷ #deployment (46 条消息🔥):
- Docker 部署建议:
@rusenask建议查看 ollama 或 vllm 项目,以获取可通过 Docker 运行并适用于不同用例的 API。 - 云端配额困扰:
@gridinoc在使用 SkyPilot 部署 Mixtral 时遇到困难,因为 AWS、Google Cloud 和 Azure 要么拒绝了配额增加请求,要么未对请求做出回应。 - 自托管的替代方案:
@mrdragonfox讨论了部署选项,建议使用更便宜的 API 服务,如 direct mistral 或 together.ai,尽管@gridinoc目前面临 GPU 短缺和配额问题。 - MoE 的 AWQ 量化故障:多位用户(包括
@mrdragonfox和@casper_ai)讨论了 AWQ 量化方法与 Mixtral 模型的问题,@casper_ai推荐了一个托管在 Hugging Face 上的替代可用仓库。 - HuggingFace 部署成功案例:
@ethux指出了一个部署在 HuggingFace.co/chat 上的 Mixtral 实例,为面临云服务障碍的用户提供了另一条路径。
提到的链接:
-
[Deploy with SkyPilot Mistral AI Large Language Models](https://docs.mistral.ai/self-deployment/skypilot/):SkyPilot 是一个在任何云上运行 LLM、AI 和批处理作业的框架,提供最大的成本节省、最高的 GPU 可用性和托管执行。 - casperhansen/mixtral-instruct-awq · Hugging Face:未找到描述
- TheBloke/Mixtral-8x7B-Instruct-v0.1-AWQ · Hugging Face:未找到描述
- HuggingChat:让社区最好的 AI 聊天模型对所有人可用。
- TheBloke/Mixtral-8x7B-Instruct-v0.1-AWQ · always getting 0 in output:未找到描述
Mistral ▷ #finetuning (76 messages🔥🔥):
- Fine-Tuning vs RAG 详解:频道内的用户讨论了 Fine-Tuning 与使用 Retrieval-Augmented Generation (RAG) 的优劣,
@rabdullin建议将重点放在 Prompt engineering 上,而@mrdragonfox则强调了在使用 RAG 时,Large Language Model (LLM) 基础知识的重要性。@tom_lrd和@mrdragonfox指出,RAG 充当中间件为 LLM 提供相关的 Context,并且其自身拥有一套复杂的底层处理流程。 - 引导 AI 新手:针对
@1mbc寻求理解 AI 核心概念的资源,@mrdragonfox和@tom_lrd深入讲解了 RAG 和 GPTs 的工作原理,并推荐了 Medium 等平台进行进一步学习。讨论中未列出具体的资源链接。 - 分享聊天机器人集成策略:对话深入探讨了向 LLM 喂入个性化数据的技术细节,
@mrdragonfox和@tom_lrd描述了如何对数据进行预处理并将其转化为结构化格式,从而丰富 LLM 的输出,特别是在将 LLM 作为处理用户输入的中间件时。 - 澄清关于 LLM 数据存储的误解:
@mrdragonfox纠正了一些关于 LLM 如何从新数据中“学习”的误解,例如 GPTs 的功能,以及在数据成为 LLM 可用的 Context 之前,Embedding 和搜索背后显著的复杂性。 - Prompt 版本控制工具咨询:
@khandelwaal.ankit询问了在 Fine-Tuning 实验期间用于 Prompt 版本控制的工具,并指出一些现有工具(如 PromptLayer)缺乏对 Mistral 模型的支持;然而,讨论中没有专门认可或详细说明任何解决方案。
Mistral ▷ #showcase (2 messages):
- 代码修改限制:
@ethux对实现某种更改的可能性表示怀疑,认为如果不修改某些代码,这可能无法实现。
Mistral ▷ #random (15 messages🔥):
- 法国图书管理员为学生寻求实习机会:用户
@maeelk是一位法国图书管理员,正在推广 AI 应用,并为一名学习心理学与 AI的学生寻找实习机会,参考了萨瓦大学(University of Savoie Mont Blanc)的硕士项目。感兴趣的各方可以通过c.limousin@cdcba.fr联系合作。 - Mistral 粉丝测验:用户
@akshay_1向@maeelk的 Mistral 粉丝身份发起挑战,要求其列出 7b 模型的权重。另一位用户@ethux幽默地回应,暗示列出此类技术细节的难度。 - 以极低预算构建包含音频的 S2S 模型:
@akshay_1分享了一个客户需求,即在 1,000 美元的预算内,使用音频数据集 Fine-tuned 一个具有特定人设的 S2S 模型。@ethux和@mrdragonfox等多位用户对预算不足做出了反应,暗示实际需要更多的资金。 - 创新的代价:
@skadeskoten询问了创建专用 S2S 模型具有竞争力的预算是多少,@mrdragonfox回应称成本很大程度上取决于所需架构的规模。
提到的链接:
Mistral ▷ #la-plateforme (2 messages):
- TypingMind 的 API Key 困惑:
@ingohamm报告了在使用 TypingMind 的 API Key 时遇到的问题,尽管他已经办理了订阅并设置了支付方式。他提到,在等待后重试或删除 API Key 会提示没有活跃订阅的消息,并对自己的账户或订阅状态提出质疑。 - 寻求 Mistral 支持:针对该问题,
@sublimatorniq建议@ingohamm联系 support@mistral.ai,以寻求有关其 API Key 和订阅问题的帮助。
Perplexity AI ▷ #general (149 条消息🔥🔥):
- 寻求公司数据问题支持:用户
@kitsuiwebster表示发送支持邮件没有收到回复,且不希望公开披露与数据相关的问题。相反,他们希望直接联系以寻求有关公司相关问题的帮助。 - 辩论 Perplexity 与 Phind 的优劣:用户
@ludwig_von_mises_fan发起了一场关于 Phind 在编程和通用搜索方面是否比 Perplexity 更有效的讨论,而@gooddawg10和@brknclock1215则捍卫了 Perplexity 的搜索能力,但在编程方面没有表现出偏好。 - 遇到 Perplexity 技术故障:用户
@yellephen、@luke_____________和@chenlieong报告了 Perplexity 聊天机器人的问题,例如回答无限加载和服务不可用;团队成员@dima_shliugaev承认了该问题,随后@vova_at_pplx_ai确认服务已恢复在线。 - 模型性能和使用讨论:用户分享了他们在不同 AI 模型上执行任务的经验,例如代码调试 (
@matheusgnhr)、井字游戏 (@noremac258) 和 PDF 阅读 (@reader7904);此外还出现了关于特定模型细节 (@hzpd和@unknownuser787) 以及 API 使用 (@pilotgfx) 的查询。 - 订阅详情和模型信息查询:用户
@stocktown和@ewaathescientist寻求关于试用订阅和 Pro 订阅续订的澄清,而@voidfulness询问了 Token 刷新率,并由@me.lk告知 Token 在使用 24 小时后刷新。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。聊天、闲逛,并与你的朋友和社区保持紧密联系。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。聊天、闲逛,并与你的朋友和社区保持紧密联系。
- Gemini 应用可以做什么以及其他常见问题:了解 Gemini 能做什么、它是如何工作的,以及获得其访问权限的不同方式。
- 不仅仅是 OpenAI 的套壳:Perplexity 转向开源:Perplexity CEO Aravind Srinivas 是 Larry Page 的忠实粉丝。然而,他认为自己已经找到了一种方法,不仅可以与 Google 搜索竞争,还可以与 OpenAI 的 GPT 竞争。
- 什么是 Google dork 查询以及如何保护自己?:Google dork 查询是使用高级搜索运算符的搜索字符串。了解黑客如何利用它获取不易获得的网站数据,以及如何防范。
- 优惠券和折扣:浏览 Perplexity 的博客,获取文章、公告、产品更新和优化体验的技巧。保持知情并充分利用 Perplexity。
- 介绍 PPLX Online LLMs:首创的 Online LLM API
Perplexity AI ▷ #sharing (13 messages🔥):
- Perplexity AI 应对棘手测试题:
@tbrams对 Perplexity AI 处理 Gemini 论文中复杂问题的速度印象深刻,而 Google 的 Gemini 服务和 OpenAI 则花费了更长时间。这次成功测试的详情可以在 Perplexity AI 平台查看。 - 社区贡献与创作:
@twodogseeds称赞了 Perplexity 的 pplx 快捷指令动作,该动作支持了他们的 Farm Friend 研究 Agent。消息中未分享更多细节。 - 与 Bryan Johnson 探讨多元视角:
@ok.alex分享了通过 Perplexity AI 生成的 Bryan Johnson 观点摘要链接,而@brknclock1215则提供了科学摘要的另一个角度。这些摘要的链接分别位于 Bryan Johnson Summary 和 Scientific Summary。 - 参与 Alt-D-Feed:
@ok.alex邀请社区为替代 Feed/简报做贡献,建议将其作为一个共同策划的协作项目。感兴趣的人可以点赞并分享这一倡议。 - 秒级文档摘要!:
@aykbl对 Perplexity AI 快速摘要文档的能力表示热赞,并用笑脸强调了其速度。未提及链接内容或具体文档。
提及的链接:
Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,并与你的朋友和社区保持紧密联系。
Perplexity AI ▷ #pplx-api (24 messages🔥):
- 支持自定义搜索查询:用户
@me.lk澄清说,通过在 Prompt 中使用如"site:reddit.com OR site:youtube.com"的搜索参数,可以在使用 API 时指定多个内容源。 - Online API 的性能问题:
@andrewgazelka报告了pplx-70b-online的性能问题,但指出删除代码中的 System Message 似乎解决了该问题。 - PPLX API 返回无意义响应:
@myadmingushwork_52332提出了一个问题,即 API 在需要在线搜索时会返回包含数字和字符混合的随机且无意义的回复。 - 引用提供功能正在开发中:
@dvrshil希望 Perplexity 在 API 响应中提供引用(References),@mares1317回复称开发团队正在开发此功能。 - 尚无早期访问计划:
@icelavaman表示目前还没有 Perplexity 新功能的早期访问计划;新功能的发布将会在稍后日期公布。
提及的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,并与你的朋友和社区保持紧密联系。
- 定价:未找到描述内容。
OpenAI ▷ #annnouncements (1 messages):
-
ChatGPT 获得记忆增强:
@abdubs宣布了 ChatGPT 的新记忆功能,允许它在不同对话中记住用户的偏好和细节,从而增强未来的交互体验。该功能正向部分 Free 和 Plus 用户推出,控制选项可在 ChatGPT Memory Features 查看。 -
你是 ChatGPT 记忆的主宰:用户有权告诉 ChatGPT 记住什么,要求它回忆信息,并通过对话或设置指令让它遗忘内容。如果需要,也可以完全关闭记忆功能。
-
记忆功能逐步推出:OpenAI 目前正向有限的用户群体部署记忆升级,并计划收集反馈以评估其效用。关于更广泛推出的进一步公告将很快发布。
提到的链接:
Memory and new controls for ChatGPT:我们正在测试 ChatGPT 记住对话内容的能力,以使未来的聊天更有帮助。你掌握着 ChatGPT 记忆的控制权。
OpenAI ▷ #ai-discussions (83 messages🔥🔥):
-
探索 SEO 的奥秘:
@spidy___寻求关于如何像网络爬虫一样自动为网页标记相关关键词的见解,发现 NER 在关键词提取方面存在局限性。@light.grey.labs建议检查 SEO 文件,因为网页构建者通常会在这些文件中嵌入各种关键词以提高搜索相关性。 -
为 AI 研究寻找创意人才:英国研究员
@noodles7584邀请社区成员讨论 AI 如何应用于创意过程,并为 30 分钟的讨论提供报酬。 -
追求终极聊天机器人:对话探讨了当前聊天机器人面临的挑战,包括
@jaicraft提到的 GPT 模型无法满足所有个人需求的问题。@lumirix等人讨论了变通方案,例如组合多个机器人或利用聊天机器人与 Google Docs 等服务的集成。 -
ChatGPT 被指责“偷懒”:
@pigondrugs和其他人评论了 GPT 在保留上下文方面的困难,随着上下文容量的增加,投诉也日益增多。相比之下,@drinkoblog.weebly.com认为更高的上下文限制降低了 Perplexity,从而带来了更好的性能。 -
AI 模型竞争升温:
@cassofthenight重点介绍了 Abacus.AI 的 Smaug-72B 模型表现优于 GPT-3.5,并对 ChatGPT-4 不愿生成完整代码片段表示担忧,认为该 AI 为了规避详细脚本而倾向于提供伪代码。
提到的链接:
Discord - A New Way to Chat with Friends & Communities:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、闲逛,与你的朋友和社区保持紧密联系。
OpenAI ▷ #gpt-4-discussions (49 条消息🔥):
-
GPT 4 Turbo 成本查询已澄清:
@jeremy.o引导@koukyo查看 OpenAI 定价页面 以获取 GPT 4 的成本详情,并指出 GPT 4 Turbo 是目前最顶尖且最便宜的模型,比其他版本便宜 2 美分,根据使用情况,其质量相似或略差。 -
GPT 4 有时会偷懒?:
@rodney.leonardo报告了 GPT 4 在基础任务(如总结 PDF)中智能下降的情况。包括@blckreaper在内的社区成员确认观察到了性能问题,关于该话题的讨论已汇总在另一个频道:<#1047565374645870743>。 -
仍在等待 @mentions 功能:包括
@pax0086和@ancryp在内的用户讨论了 GPT 中 @mention 功能的逐步推出,@darkninjaforever提醒道 OpenAI 经常采用渐进式的功能发布策略,这意味着部分用户仍在等待访问权限。 -
尝试突破 GPT Vision 的界限:
@flokyhuan询问了关于使用视频进行语言模型 Fine-tuning 的问题,@solbus告知 Fine-tuning 目前仅适用于文本模型。虽然 GPT Vision 功能可以描述视频中的图像,但无法针对特定知识(如运动规则)进行 Fine-tuning。 -
ChatGPT Memory 功能推出进展:
@lumirix确认 ChatGPT 记忆过去对话细节的功能正在向免费用户和 Plus 用户推出,但指出目前仅对一小部分用户开放。
提到的链接:
- Discord - 与好友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
-
[使用 GPT 的视觉能力和 TTS API 处理并解说视频 OpenAI Cookbook](https://cookbook.openai.com/examples/gpt_with_vision_for_video_understanding):未找到描述
OpenAI ▷ #prompt-engineering (23 条消息🔥):
- Prompt Engineering 基础解析:
@eskcanta概述了优秀的 Prompt Engineering 包括使用精确的语言、向 AI 提供清晰的指令以及仔细审查 AI 的输出。在指导 AI 时,应专注于“要做什么”而不是“不要做什么”,避免指令冲突。 - 精简 AI 文字冒险游戏:
@drinkoblog.weebly.com建议@stealth2077使用自定义指令,如“专注于简单的叙事和角色动态”,以保持叙事简洁并避免复杂化,因为 AI 在文字冒险中往往默认会变得复杂。 - 平台混淆趣闻:
@beanz_and_rice幽默地尝试在 Discord 服务器上与 ChatGPT 互动,引得@toror对这一失败的尝试感到好笑。 - API 基础设施 vs. Prompt Engineering:
@darthgustav.向@kate.yanchenka阐明了 Prompt Engineering 与 API 基础设施之间的区别,指出后者关于自动预算计算和动态数据处理的疑问更倾向于软件开发,而非 Prompt Engineering。
提到的链接:
- 未找到标题: 未找到描述
- Discord - 与好友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
OpenAI ▷ #api-discussions (23 条消息🔥):
- 新手寻求 Prompt Engineering 建议:
@zzavior寻求关于入门 Prompt Engineering 的建议。@eskcanta提供了一份详尽的指南,重点在于使用清晰且精确的语言、检查输出,并确保不触发与 AI 能力或训练相关的冲突。 - 关于 Prompt Engineering 库的咨询:
@kate.yanchenka询问了有关 Prompt Engineering 库的信息,用于管理预算、适配动态数据以及处理 AI 模型回退(fallbacks)。@darthgustav.澄清说,这个话题更多是关于 AI 软件开发而非 Prompt Engineering。 - 对话协助请求未获关注:
@beanz_and_rice尝试使用 Discord 斜杠命令发起交互但失败了,随后引发了一阵滑稽的抗议,引起了@toror的回应。 - 制作轻量级文字冒险游戏:
@stealth2077询问了如何让文字冒险游戏不那么深奥和主题化。@drinkoblog.weebly.com建议使用 custom instructions(自定义指令)来引导 AI 进行更简单的叙事。 - 笑话生成困惑:
@lisabkk45_48614请求讲个笑话,但@solbus指导他们去使用 ChatGPT 官方网站,而不是在这个 Discord 频道中请求。
提到的链接:
- 未找到标题: 未找到描述
- Discord - 与朋友和社区聊天的新方式: Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,并与你的朋友和社区保持紧密联系。
OpenAccess AI Collective (axolotl) ▷ #general (66 条消息🔥🔥):
- MPS 支持确认与澄清:
@caseus_对 axolotl 项目中支持 MPS 表示感谢,这要归功于 Maxime 提交的 GitHub pull request #1264。关于贡献者的 Discord 身份产生了一些困惑,@yamashi(真正的 Maxime)澄清了他们的参与情况,并指出这取决于 transformers 合并更改,以及 PyTorch pull request #99272 对后续开发至关重要。 - 琢磨 Yi-34b 训练与 eBay 发现:用户
@le_mess、@cookiesowns和@c.gato讨论了各种 AI 和非 AI 话题,从 Yi-34b 训练期间 loss 下降缓慢到某个旧科技产品的 eBay 链接。 - 探索模型适配与增强:
@yamashi建议将模型移植到 Keras 可能带来的好处,以获得更广泛的硬件支持;@dreamgen和@c.gato讨论了与 Hugging Face checkpoint 保存相关的错误处理和修复,参考了 pull request #1414 和相关的 issue #1452。 - 咨询最便宜的 LLM Endpoint 服务:
@le_mess询问了价格合理的 LLM endpoint 服务,回复指向了本地选项(如 llamacpp)、外部服务(如 Together AI)以及 OpenRouter 的性价比。用户提到了 Basten 的 JSON 序列化问题以及对自定义配置的需求。 - 讨论使用 LLM 的各种挑战:讨论了诸如 JSON 序列化问题 (
@dangfutures)、FP32 速度缓慢的挑战 (@yamashi) 以及对更多文档的需求等问题,这些讨论展示了 AI 社区中技术障碍和协作解决问题的缩影。
提及的链接:
- Together AI:使用 Together AI 构建生成式 AI 模型。受益于最快、最具成本效益的工具和基础设施。与致力于您成功的专家 AI 团队合作。
- peft/utils/save_and_load.py try to connect to the hub even when HF_HUB_OFFLINE=1 · Issue #1452 · huggingface/peft:系统信息 peft 0.8.2 axolotl v0.4.0 export HF_DATASETS_OFFLINE=1 export TRANSFORMERS_OFFLINE=1 export HF_HUB_OFFLINE=1 谁能帮忙?没有回应。信息 官方示例脚本 我自己的模型…
-
[Intel® Optane™ Persistent Memory 300 Series (128GB PMem Module) NMC2XXD128GPS eBay](https://www.ebay.com/itm/176070887129?):未找到描述 - GitHub - triton-inference-server/tensorrtllm_backend: The Triton TensorRT-LLM Backend:Triton TensorRT-LLM 后端。通过在 GitHub 上创建账号来为 triton-inference-server/tensorrtllm_backend 的开发做出贡献。
- Add MPS support by maximegmd · Pull Request #1264 · OpenAccess-AI-Collective/axolotl:描述 支持在 Mac M 系列芯片上进行基础训练。动力与背景 部分解决了 Mac 支持问题。如何测试?从头到尾运行了一个带有 lora-mps.yml 的训练任务。
- Fix breaking change by younesbelkada · Pull Request #1414 · huggingface/peft:修复最近版本中的一个破坏性变更,由于我在之前的 PR 中弄乱了提交历史,因此创建了一个新的 PR。抄送 @sayakpaul @pacman100
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (8 messages🔥):
-
统一聊天数据集格式:
@dctanner正在与 Hugging Face 协调,以标准化名为 MessagesList 的聊天数据集格式,旨在简化为微调聊天模型而出现的各种数据集格式。他们分享了 MessagesList 提案讨论 的链接,并建议创建一个 GitHub 组织和专门的文档页面。 -
命名规范至关重要:
@dctanner强调了使用像 MessagesList 这样通用格式名称的重要性,它不绑定到特定的应用程序(如 ShareGPT 或 ChatML),因为这些名称容易与模板本身而非 JSON 格式混淆。 -
MessagesList 的验证挑战:
@faldore承认虽然他们喜欢 MessagesList 的想法,但它在验证方面带来了挑战,因为“对话对”的概念不容易通过 JSON-schema 来描述。 -
理想的 MessagesList Schema:
@faldore为 MessagesList 格式提出了一个理想的 schema,其中包括可选的系统消息、工具/函数、来源元数据和问候消息,确保用户和助手消息成对出现,且最后一条消息来自助手。 -
建议 Schema 的优势:
@faldore提倡所建议的 schema,认为它更易于管理、可验证且空间效率更高,并在数据集中强制执行结构化的消息配对。
提及的链接:
OpenAccess AI Collective (axolotl) ▷ #general-help (26 messages🔥):
-
Axolotl 中的 Tokenization 问题:用户
@nafnlaus00询问了如何验证 axolotl 是否按预期进行 tokenizing。@dreamgen建议检查输出目录中的 tokenizer 配置,而@nanobitz指向了 axolotl 仓库中的调试标志。 -
Transformers 更新可能修复推理问题:
@thierry_lama报告了在使用 RunPod 的 GPU 对训练好的模型进行推理时出现设备错误。@nanobitz建议这可能是由于 Transformers 的问题,并建议进行更新。 -
增强多语言能力的尝试:
@sadaisystems询问如何提高模型在英语以外语言的能力,收到了@le_mess的回复,称若要获得超出 LoRA 所能提供的显著改进,预训练是必要的。 -
实时使用 LoRA 进行推理:
@wizmak寻求在推理过程中实时向基座模型添加 LoRA 适配器的方法,@nanobitz确认使用 Hugging Face 可以加载 PEFT 模型,但不确定卸载它的命令。 -
使用 DeepSpeed Zero 3 实现模型并行:用户
@mihai4256寻求适用于模型并行的 DeepSpeed Zero 3 配置,并指出仓库中现有的配置在此特定用例下未能按预期工作。
提及的链接:
GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions:尽管提问。通过在 GitHub 上创建账户为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
-
数据集微调中的重复困境:
@_rxavier_询问如何识别一段文本是否曾被用于训练模型。他们询问了确定模型对文本熟悉程度的技术,例如通过检查模型对文章引言的响应。 -
训练数据重叠的影响:此外,
@_rxavier_质疑了使用可能与预训练数据集重叠的数据来微调模型的后果。他们思考了这种重叠对微调过程潜在的负面影响。
OpenAccess AI Collective (axolotl) ▷ #runpod-help (1 messages):
- Axolotl RunPod 镜像与 Vast.AI 的兼容性:用户
@dreamgen在 Vast.AI 上成功使用了 Axolotl RunPod 镜像,并报告其可以“开箱即用”。
LangChain AI ▷ #announcements (1 条消息):
- LangChain 推出带 Memory 功能的日记应用:
@hwchase17分享了一个结合了 Memory 功能的日记应用早期版本,使用了 LangChain memory module。该应用目前处于早期阶段,欢迎反馈;它能记住用户的相关信息以便在未来的交互中使用,类似于 OpenAI 为 ChatGPT 今天宣布的 Memory 功能。点击此处测试应用,并查看介绍视频。
提到的链接:
-
[Loom 免费屏幕与视频录制软件](https://www.loom.com/share/63a9696036c74765a9f9ecae06336aa5):使用 Loom 快速录制屏幕和摄像头视频。清晰轻松地解释任何内容——无需开会。混合办公场所的必备工具。 - LangChain Companion - Journal:未找到描述
LangChain AI ▷ #general (59 条消息🔥🔥):
- 寻求 LangChain 与 Android 集成的帮助:用户
@grindmaster2512询问了 LangChain 与 Android 应用程序的集成,并向@812757029260230658寻求该问题的解决方案。 - 针对 Embeddings 的高效分块(Chunk)预处理:
@swastikk询问在创建 Embeddings 之前是否有必要进行分块预处理(如删除空格)。@johnny2x2确认删除多余文本有助于该过程,尤其是在处理电子邮件数据时。 - 寻找 PDF 解析器,Adobe API 的替代方案:
@dejoma寻求能够按上下文拆分的 PDF 解析器推荐,对 Adobe API 的局限性表示不满,并寻找有效的 PDF API 替代方案。 - 呼吁改进 LangChain 的文档结构:
@b0otable向 LangChain 团队提供了反馈,建议通过减少示例冗余和更新语法来改进文档结构,以避免用户进行低效的导航。 - Pinecone 与 LangChain 的依赖问题:用户
@segmentationfault.在尝试将 Pinecone Database 更新到 v2 并配合 LangChain 依赖项时遇到了依赖解析错误,LangChain 的维护者@jacoblee93提供了及时的响应和解决方案。
提到的链接:
- 如何在 Azure OpenAI Service 中使用函数调用 - Azure OpenAI Service:了解如何通过 GPT-35-Turbo 和 GPT-4 模型使用函数调用(function calling)。
-
[Pinecone 🦜️🔗 Langchain](https://js.langchain.com/docs/integrations/vectorstores/pinecone):你可以在 LangChain 中使用 Pinecone 向量存储。
LangChain AI ▷ #langserve (8 条消息🔥):
-
关于 Langserve 扩展(Scaling)的说明:
@kjoth_00356询问了将 Langserve 扩展到多个实例的问题,并询问了托管版 Langserve 与开源版 Langserve 的区别。@veryboldbagel暗示了通过托管版 Langserve 进行部署,随后@dachsteinhustler进一步澄清,指出 Langsmith 是托管在 Langchain Platform 解决方案的一部分,目前处于早期测试阶段,可能需要邀请码。 -
寻找 NodeJS 与 Chain 的集成方案:
@_mauricemoss正在寻找一种从 NodeJS 应用中暴露 Chain 以供 RemoteRunnable 使用的方法,但目前这些消息中尚未提供解决方案。 -
在 Playground 中禁用中间步骤:
@dachsteinhustler表示需要禁用 Langchain playground 中的中间步骤(intermediate steps),以防止大尺寸的 base64 字符串导致浏览器崩溃,最终通过使用 RunnableLambda 实现了变通方案。 -
k8s 集群应用的连接问题:
@ezelanza.描述了一个在尝试通过基于 k8s 集群的应用调用 OpenAI API 时连接被拒绝的问题,提到直接调用后端可以工作,但来自前端(React)的请求失败,即使使用 curl 也是如此。
提到的链接:
LangSmith:未找到描述
LangChain AI ▷ #share-your-work (1 条消息):
- 介绍 Dewy 以及使用 NextJS 和 OpenAI 构建 RAG:
@kerinin分享了他们对开源知识库 Dewy 的贡献,以及一篇详细介绍如何构建全栈 RAG 应用的文章。该指南涵盖了使用 NextJS、OpenAI API 和 Dewy,旨在最大限度地减少幻觉并确保语言模型响应的准确性。点击此处查看博客文章。
提到的链接:
| [使用 NextJS、OpenAI 和 Dewy 构建 RAG 聊天机器人 | Dewy](https://dewykb.github.io/blog/rag-app-with-nextjs-openai-and-dewy/):本指南将引导你使用 NextJS 作为 Web 框架、OpenAI API 作为语言模型以及 Dewy 作为知识库来构建 RAG 应用。 |
LangChain AI ▷ #tutorials (2 条消息):
- 寻找更优的 PDF 解析器:
@dejoma正在寻找一个能够根据上下文进行拆分的 PDF 解析器。他对 Adobe API 表示不满,原因是其使用上限低且缺乏“按需付费”选项;他愿意接受关于强大 PDF API 的建议。 - Langchain 计算器探索:
@sougata正在使用 Langchain 构建一个计算器,该计算器将乘法操作解释为mul(a,b)。他请求关于如何将用于计算的自定义 Python 库与模型的 augment 函数集成的指导。
DiscoResearch ▷ #general (29 条消息🔥):
- 关于 Argilla 托管经验的咨询:用户
@drxd1000正在寻求关于托管 Argilla 服务器的建议,以便支持多用户进行标注,但消息中未提供解决方案。 - 讨论层选择性秩削减(Layer Selective Rank Reduction)方法论:
@johannhartmann引用了他们自己实现的“层选择性秩削减”来解决持续训练而不遗忘的问题,并指出“他们基本上找出了层中统计相关性较低的部分,并将其作为 LoRA 目标”,认为这比持续学习方法更高效。对话中提到了一个相关的 GitHub 仓库,但未提供详细信息:laserRMT。 - lm-evaluation-harness 的显存溢出(OOM)问题:
@philipmay在评估 mixtral 模型时遇到了 OOM 错误,@bjoernp建议利用 lm-evaluation-harness 提供的多 GPU 支持,并指出两块 A100 可能会解决该问题。 - 寻找德语毒性评估数据集:用户
@sten6633询问了德语毒性评估数据集,并思考了翻译 ToxiGen 的实用性,这是一个在 Hugging Face 上可用的用于隐性仇恨言论检测的数据集。提到的数据集可以在 Hugging Face 上找到,但需要同意协议才能访问:ToxiGen。 - 预告新型计算技术:用户
@phantine暗示了一种排除 MoE 的新方法,简称为“瓶中宇宙(Universes in a bottle)”,并暗示了一个可能激进的断言:“P=NP”。分享了一个与@phantine工作相关的 GitHub 链接,但未提供关于该技术的具体细节:LargeWorldModel/LWM。
提到的链接:
- Google Colaboratory:未找到描述
- skg/toxigen-data · Hugging Face 数据集:未找到描述
- GitHub - cognitivecomputations/laserRMT: 这是我们自己实现的 ‘Layer Selective Rank Reduction’:这是我们自己实现的 ‘Layer Selective Rank Reduction’ - cognitivecomputations/laserRMT
- GitHub - LargeWorldModel/LWM:通过在 GitHub 上创建账号来为 LargeWorldModel/LWM 的开发做出贡献。
DiscoResearch ▷ #embedding_dev (5 messages):
- BM25 + Query + Rerank 组合获胜:用户
huunguyen强调了他们在搜索中有效使用了 BM25 配合额外的查询和 Rerank 步骤,并报告称该方法 “效果相当不错。” - 简而言之的 Wikipedia:
huunguyen成功地 索引了整个 Wikipedia(排除了非核心内容),并将 BM25 索引压缩到了 3GB 以下 的精简尺寸。 - 寻找 BM25 工具:
sebastian.bodza询问了huunguyen在实现其搜索索引的 BM25 算法时具体使用了哪个库。
DiscoResearch ▷ #discolm_german (1 messages):
thomasrenkert: 德国模型的 v2 版本有预计发布时间(ETA)吗?或者是 Mixtral 变体?
CUDA MODE ▷ #general (1 messages):
- 用于实验的 GPU 调配:
@joseph_en报告成功将 Asus WS 主板 移至矿机,并正在等待 16x PCI extenders。他们使用旧款 GPU 进行实验,并将矿机主板装入机箱,指出单块 12G NVIDIA 3060 即可轻松处理 7B 或 13B 量化模型。
CUDA MODE ▷ #cuda (9 messages🔥):
- 跨兼容性探索:
@iron_bound发起了关于实现 CUDA 在 HIP/ROCm 平台上运行的二进制兼容性的讨论,引用了一篇 关于 Radeon CUDA - ZLUDA 的 Phoronix 文章。 - AMD GPU 运行 CUDA?了解 ZLUDA:
@muhtasham分享了 ZLUDA 的 GitHub 链接,该项目旨在让 CUDA 在 AMD GPU 上运行,引发了关注,@marksaroufim随后征求用户的使用体验。 - 表情符号热忱:
@muhtasham通过精心挑选的 Jensen Huang 和 Lisa Su 的表情符号唤起了科技界的精神。 - 市场垄断与 AGI 推测:
@andreaskoepf幽默地表示,Microsoft 的采购策略和混乱的芯片市场可能会让反垄断机构在面对 AGI 未来时束手无策。 - Radeon 现实测试:
_tvi_分享了他们在 Radeon VII 和 Ryzen APU 上的经验,包括在处理大型 PyTorch 数据块时,动态内存分配导致内核崩溃的困扰。
提到的链接:
- [Phoronix] AMD 秘密资助了基于 ROCm 构建的即插即用 CUDA 实现:现已开源 (Radeon Cuda 1):未找到描述
- AMD 秘密资助了基于 ROCm 构建的即插即用 CUDA 实现:现已开源 - Phoronix:未找到描述
- GitHub - vosen/ZLUDA: AMD GPU 上的 CUDA:AMD GPU 上的 CUDA。欢迎在 GitHub 上为 vosen/ZLUDA 的开发做出贡献。
CUDA MODE ▷ #algorithms (3 messages):
- 多维门控循环的局限性:用户
@euclaise提到了多维门控循环(Multidimensional Gated Recurrences)中的一个约束,指出它们需要一个 DxCxN 注意力矩阵,即使 C 的值很小,其 成本也极高。 - 超越简单的线性循环:
@euclaise指出,类前缀和扫描(prefix-sum-like scans) 的应用不仅限于计算简单的线性循环,还开启了更广泛的计算可能性。 - Twitter 上关于计算技术的见解:
@euclaise分享了关于计算方法的见解,包括在序列中使用 最大值扫描(maximal scans) (y[t]=max(y[t-1], x[t])),并提供了其 Twitter 帖子的链接:关于计算方法的推文 和 关于最大值扫描的推文。
CUDA MODE ▷ #jobs (3 条消息):
- 海得拉巴生成式 AI 初创公司招聘:
@gradman33分享了位于印度海得拉巴的一家早期深科技生成式 AI 初创公司的职位空缺,正在寻找 ML/Data/Research/SDE 方面的人才。感兴趣的候选人可以在此申请。 - 招聘频道潜在垃圾信息警报:
@pudding0377标记了@gradman33的一条帖子,认为其可能无关或属于垃圾信息,并呼吁管理员关注。
相关链接:
未找到标题: 未找到描述
CUDA MODE ▷ #beginner (9 条消息🔥):
- 新成员提醒:
@cs_os_05101提到他们拥有一块 4060 Ti。 - 寻找有趣的 CUDA 书籍:
@euclaise询问了有关 CUDA 的趣味书籍,引发了关于教育资源的讨论。 - Shader 书籍推荐:
@marksaroufim分享了 The Book of Shaders,这是一本关于 Fragment Shaders 的入门指南,作为 CUDA 相关领域的趣味读物。 - 了解用户专业背景:在提到熟悉 shader 编程后,
@euclaise澄清说他们正在寻找与 compute shaders 或 CUDA 直接相关的资料,而不是 frag shaders。 - 在学习中寻找乐趣:
@marksaroufim和@euclaise都同意将文献定义为“有趣”是主观的,但@marksaroufim建议将 PMPP 作为 CUDA 最好的教育资源,尽管它未必符合“有趣”的标准。
相关链接:
The Book of Shaders: 循序渐进地引导读者了解 Fragment Shaders 那抽象而复杂的领域。
CUDA MODE ▷ #pmpp-book (7 条消息):
- 矩阵转置辩论:
@eporat询问在乘法中转置其中一个矩阵是否能减少 cache misses,从而加快计算速度。@andreaskoepf回应称,虽然顺序内存访问可能具有优势,但与 tiled access 相比,其收益可能微乎其微。 - 实际测试显示无收益:针对转置矩阵以加速乘法的疑问,
@jeremyhoward讲述了他的经验,表示在 tile 创建过程中进行转置对性能没有明显影响。 - 关于转置的深入讨论:
@eporat澄清说,原地转置(inplace transpose)并非必要;有时只需要调整内层循环的索引顺序,这提供了转置之外的另一种选择。 - 寻求进一步澄清:
@andreaskoepf对@eporat的建议提出质疑,暗示在乘法过程中矩阵元素默认就是以转置方式读取的,这表明双方存在误解,或者需要对@eporat所说的调整循环索引做进一步解释。
CUDA MODE ▷ #smol-hw (1 条消息):
- Apple Silicon 拥有了自己的 ‘top’:用户
@marksaroufim分享了 asitop 的链接,这是一个专为 Apple Silicon 设计的性能监控 CLI 工具。它被拿来与top或nvtop等现有工具进行比较,专门针对 Apple 的定制芯片进行了优化。
相关链接:
GitHub - tlkh/asitop: Apple Silicon 性能监控 CLI 工具: 适用于 Apple Silicon 的性能监控 CLI 工具。通过在 GitHub 上创建账号来为 tlkh/asitop 的开发做出贡献。
Latent Space ▷ #ai-general-chat (24 条消息🔥):
- Reka 模型发布公告:
@swyxio分享了一个关于新 Reka 模型的推文链接,在社区中引起了热议。推文链接可以点击这里。 - 最喜欢的 VC 播客讨论 AI 话题:
@swyxio对一个讨论 AI 话题的 VC 播客表示了极大的热情,并提供了该集节目的链接,强调了其与社区的相关性。 - 探索 LAION 的 BUD-E 语音助手:
@swyxio讨论了一个名为 BUD-E 的新型全开源语音助手,由 LAION 开发,旨在通过共情能力和上下文感知来提升对话体验。详情请见 LAION 博客。 - 什么是 Agent?:为了寻求 “Agent” 的定义,
@kaycebasques向社区征求见解。@slono将其描述为旨在以最少用户输入实现目标的程序。 - Karpathy 离开 OpenAI:
@nembal关注了来自 The Information 关于 Andrej Karpathy 从 OpenAI 离职的消息,引发了人们对 AI 领域影响的好奇。@slono提到的关于自动化任务 AI 产品开发的背景,模糊地提到了 AGI 可能是离职背景下的一个因素。
提到的链接:
-
[BUD-E: Enhancing AI Voice Assistants’ Conversational Quality, Naturalness and Empathy LAION](https://laion.ai/blog/bud-e/):AI 语音助手彻底改变了我们与技术的互动,回答查询、执行任务并让生活变得更轻松。然而,那种生硬的… - OpenAI Researcher Andrej Karpathy Departs:OpenAI 创始成员之一 Andrej Karpathy 已离开公司,发言人证实了这一消息。Karpathy 是一位著名的人工智能研究员,他当时正在开发一款他描述为…
- President and Co-Founder Anthropic, Daniela Amodei: AI Hurricane — Grit — Overcast:未找到描述
- Memory and new controls for ChatGPT:我们正在测试 ChatGPT 记住你讨论过的事务的能力,以使未来的对话更有帮助。你可以控制 ChatGPT 的记忆。
- How Graph Neural Networks Are Transforming Industries:🔑 在此获取你的 AssemblyAI API key:https://www.assemblyai.com/?utm_source=youtube&utm_medium=referral&utm_campaign=yt_marco_1。图神经网络 (GNN) 已经…
- Tweet from Joanne Jang (@joannejang):📝 我们刚刚在 ChatGPT 上启动了一个关于记忆的小实验。它的工作原理——与自定义指令非常相似,除了 ChatGPT 是驱动者(就像自动挡 vs 手动挡!)——基本上…
- GitHub - Stability-AI/StableCascade:通过在 GitHub 上创建账号来为 Stability-AI/StableCascade 的开发做出贡献。
- sta - Overview:sta 有 2 个可用的仓库。在 GitHub 上关注他们的代码。
LLM Perf Enthusiasts AI ▷ #opensource (2 条消息):
- 选择合适的 Mistral 模型大小:
@potrock询问在拥有 32GB 内存的 M2 Max 上本地运行合适的 Mistral 模型大小,寻求社区建议。 - 安全模型大小建议:
@natureplayer建议 4GB 是在上述硬件上本地执行的安全大小,而 8GB 将无法运行,5GB 可能可行但不保证。
LLM Perf Enthusiasts AI ▷ #openai (4 条消息):
- GPT-5 猜测平息:用户
@res6969幽默地指出,关于 GPT-5 的传闻 被大大夸大了,表达了对其存在或即将发布的怀疑。 - 笑是良药?:
@res6969和@potrock分别分享了带有自定义表情符号和笑哭表情符号的轻松反应,为当前话题营造了愉快的氛围。 - ChatGPT 的记忆升级:
@potrock分享了一篇 博客文章,讨论了正在 ChatGPT 中测试的新记忆功能,该功能允许模型跨对话记住用户偏好和细节,用户可以通过对话或设置进行管理。
提到的链接:
Memory and new controls for ChatGPT:我们正在测试 ChatGPT 记住你讨论内容的能力,以使未来的对话更有帮助。你可以控制 ChatGPT 的记忆。
AI Engineer Foundation ▷ #events (6 条消息):
- 幽默开启周会:
@._z以俏皮的语气宣布周会开始:😄 Déjà vu。 - 会议出席更新:
@juanreds告知他们无法参加周会,并向团队表示歉意。 - 共同举办 AI Hackathon 的邀请:
@caramelchameleon询问是否有人有兴趣共同举办一场 AI 开发者 Hackathon,暗示在今年 GDC 之前与游戏开发者合作的机会。 - 线上或线下参加 Hackathon 的机会:
@caramelchameleon提到了在旧金山线上或线下参加 Hackathon 的可能性。 - 热心的组织者加入:
@yikesawjeez表达了兴趣并请求联系,因为他们擅长组织 Hackathon,特别是与湾区活动相关的活动。
Skunkworks AI ▷ #general (2 条消息):
- 私信提示:用户
@bondconnery请求私信,简单写道:“<@1117586410774470818> DM sir”。 - LLaVA 框架咨询:
@CodeMan正在寻求关于将 LLaVA 与 SGLang server 和 SGLang worker 集成(而非使用标准模型 worker)的见解或经验。