ainews-google-ai-win-some-gemma-15-pro-lose-some
谷歌 AI:有得有失(Gemma 和 1.5 Pro 表现出色,图像生成遭遇挫折)
谷歌的 Gemma 开放模型(20亿至70亿参数)在基准测试中表现优于 Llama 2 和 Mistral,但因其特殊的许可协议和较差的图像生成质量而受到批评,谷歌对此也部分予以承认。即将推出的 Gemini Pro 1.5 模型拥有 100 万 token 的上下文窗口,在视频理解和“大海捞针”(needle-in-haystack)任务中表现出色。TheBloke 和 LM Studio 等 Discord 社区讨论了对 Gemma 模型褒贬不一的反响、对 Llama 3 发布的期待、数据集编辑的挑战,以及 NVIDIA GeForce RTX 3090 和 RTX 4090 GPU 等硬件考量。LM Studio 用户报告了 0.2.15 Beta 版本的问题以及 Gemma 模型的集成进展,相关资源已在 Hugging Face 上分享。
2024年2月20日的 AI Discord 动态。我们为您检查了 20 个公会、313 个频道和 8555 条消息。预计节省阅读时间(按每分钟 200 字计算):836 分钟。
Google 今天因为各种好坏参半的原因成为了讨论的焦点。新的 Gemma 开源模型(参数规模为 2-7B,据推测是 Gemini 模型的缩小版)在基准测试中表现优于 Llama2 和 Mistral:
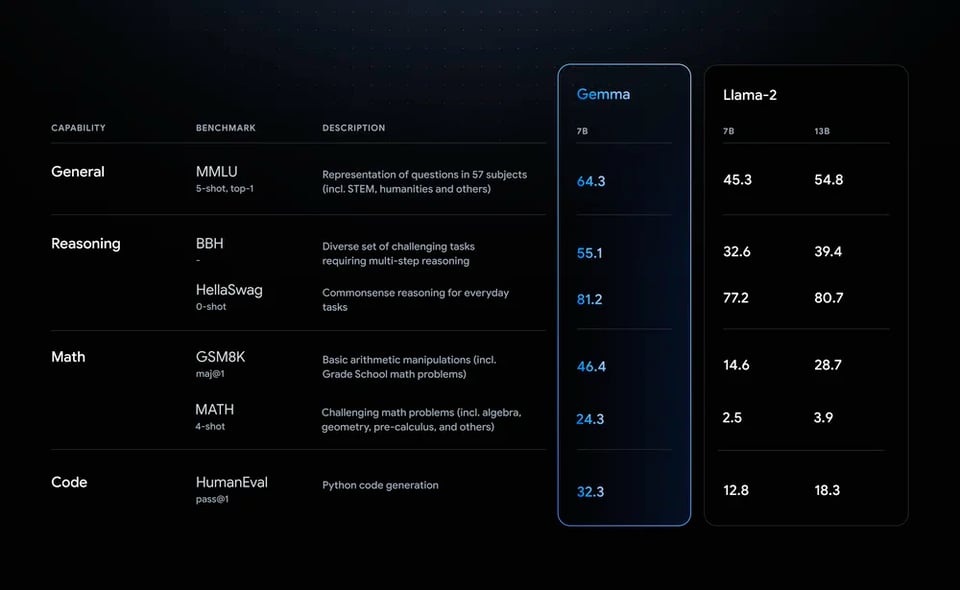
但它附带了一个不同寻常的许可证,并且未能通过人类的直观感受测试(vibe check)。
与此同时,几乎所有人都在围攻 Gemini 笨拙的多样化图像生成功能,Google 已部分承认了这一问题。
但在一个看似完胜的领域,仍在候补名单中的 Gemini Pro 1.5(具有 100 万 token 上下文)在视频理解和大海捞针(needle in haystack)测试中表现出色。
目录
[TOC]
第 1 部分:Discord 高层级摘要
TheBloke Discord 摘要
-
对 Gemma 模型评价褒贬不一:一些用户(如 @itsme9316)发现 Gemma 可以很好地处理单条提示词,但在多轮对话响应中表现吃力。同时,@dirtytigerx 指出了其 instruct 模型过度对齐(over-aligned)的问题以及异常高的 VRAM 占用,但未说明具体数值。
-
对 AI 模型发布和更新的期待:用户们正在讨论 3 月份发布 “Llama 3” 的可能性,并探讨 Google 的 AI 开发选择,重点关注模型污染(contaminated models)等问题。此外,PolyMind 中新的 “retrieval_count” 功能因其在 GMing(游戏主持)等任务中的实用性而受到好评,它能提供多个检索结果以涵盖更广泛的信息。
-
聊天机器人中的角色扮演和角色复杂性:用户们正在努力生成 DPO 数据,以改进具有秘密或谎言的角色的角色扮演场景。此外,还讨论了在 AI 模型中保持角色一致性的挑战,以及 Miqu-70b 模型不同的 VRAM 需求,其中 Q2 版本提到需要 32 GB,Q5 版本需要 48 GB。
-
数据集编辑和模型训练的烦恼:用户 @pncdd 在编辑复杂的合成数据集时遇到困难,而 @3dhelios 正在探索在训练中加入负面样本。有人建议将 Gradio 作为创建数据集编辑工具的潜在解决方案,并强调了为相关性过滤任务寻找有效分类器的需求,考虑使用 deepseek-coder-6.7B-instruct。
-
关于编程和模型优化的技术对话:@pilotgfx 正在开发一个包含多个编程助手的本地聊天机器人脚本,其中对话历史管理是关键。讨论还集中在 RAG 技术的使用、Mistral 微调、编辑器偏好(因对 VSCode 不满而转向 Zed)以及模型的后端基础设施优化,建议从租用 GeForce RTX 4090 GPU 开始。
LM Studio Discord 总结
-
双 GPU 需要充足的电力:硬件讨论频道的用户提醒了 双 GPU 设置的 PSU(电源)需求,并指出在多 GPU 配置中,整体速度取决于最慢的那张显卡。像 NVIDIA GeForce RTX 3090 这样的高端 GPU 因其巨大的 VRAM 而在 AI 任务中备受青睐。
-
LM Studio 最新 Beta 版的问题与修复:LM Studio 用户报告了 LM Studio 0.2.15 Beta 的各种问题,包括
n_gpu_layers功能的问题以及 Gemma 7B 模型输出乱码。0.2.15 版本已重新发布,修复了针对这些及其他问题的 Bug,建议用户从 LM Studio 官网 重新下载。 -
Gemma 模型集成工作持续进行:Google 的 Gemma 模型支持已添加到 LM Studio,用户需手动下载 Gemma 模型(2B 和 7B 版本),Hugging Face 上提供了 2B 变体的链接 Hugging Face。为了方便集成,还分享了一个推荐的 Gemma 量化(quant)版本。
-
AI 助手领域的查询与请求:关于 AI 助手的话题,
@urchig表示希望在 LM Studio 中集成 创建功能(creation feature),并指向了 Hugging Face 上现有的功能。此外,一些用户遇到了 RAM 显示问题,以及可能与 venv 相关的 Visual Studio Code 使用故障。 -
微软的“不明飞行物”:一位用户分享了微软在 GitHub 上的 UFO 仓库链接:UFO on GitHub。未提供该讨论的背景及相关性。
Nous Research AI Discord 总结
-
ChatGPT 的上下文难题:在对 Big Lebowski 剧本进行实验后,
@elder_plinius证明了 ChatGPT 可能是按字符而非 Token 来限制上下文的。这引发了讨论,@gabriel_syme分享了一个用于将语言模型扩展到 128K 上下文的 GitHub 仓库,并讨论了关于大上下文 AI 模型对 VRAM 需求的不同说法。 -
AI 驱动的模拟器与自我反思:关于 AI 驱动的游戏模拟的讨论中,
@nonameusr对 OpenAI 的 Sora 模拟 Minecraft 感到惊讶,@pradeep1148链接了一个关于自我改进检索增强生成(Self RAG)的 视频。此外,还有关于为了艺术目的在显微图像上训练非专家模型的问题。 -
库发布与 AI 模型评估:
.beowulfbr展示了mlx-graphs,这是一个针对 Apple Silicon 优化的 GNN 库;burnytech展示了 Gemma 1.5 Pro 的自我实现学习能力。还讨论了关于 A-JEPA AI 模型的无关联澄清,以及一篇讨论在没有显式提示的情况下激发预训练 LLM 中思维链(chain-of-thought)推理的 arXiv 论文。 -
Hermes 2 晋级:Nous Hermes 2 发布,在各项基准测试中表现出更强的性能。Nous Hermes 2 的预制 GGUF 文件也已在 HuggingFace 上提供,并感谢 FluidStack 支持计算需求。
-
LLM 策略与陷阱:讨论探讨了 Gemma 模型的基准测试、微调(fine-tuning)的细微差别、LoRA 的使用,以及在自定义基础设施上托管大型模型。数据集也引发了争论,特别是编辑合成数据集以及在 Nous-Hermes 中结合 DPO 与 SFT 的挑战。
-
对托管服务的不满:出现了针对 Heroku 的批评,成员如
@bfpill表达了挫败感,但未详细说明具体不满。 -
项目因宠物生病而放缓:
@qnguyen3为 Project Obsidian 的延迟表示歉意,原因是其猫的健康问题,并邀请就项目讨论进行直接沟通。
Eleuther Discord 摘要
-
模型双重能力引发关注:用户对能够同时处理提示词引导的图生图(image-to-image)和文生图(text-to-image)任务的扩散模型(如 Stable Diffusion)表现出浓厚兴趣。Google 发布的 Gemma 开放模型系列也引起了关注,Nvidia 正与其合作优化其在 GPU 上的使用。
-
许可证纠纷与治理问题:围绕 Google Gemma 等模型的许可、模型版权化的可能性及其对商业用途的影响,讨论正在持续进行。同时,包括 AGI 在内的基础模型治理也因政策制定(如强制性风险披露标准)而受到关注。
-
智能基准与 Transformer 效率:关于 MMLU 和 HellaSwag 等现有基准测试在评估模型智能方面的有效性,辩论愈发激烈。用户还对寻找信息效率最高的 Transformer 模型,以及在不同规模下对比其与 MLPs 和 CNNs 的性能感兴趣。
-
揭开多语言模型的奥秘:人们对 Llama-2 等多语言模型在任务中是否内部依赖英语感到好奇,并分享了使用 logit lens 等研究方法获取洞察。此外,还有关于针对特定语言进行 lens 训练潜力的提问。
-
调整代码与处理 OOM:在 AI 开发领域,从业者正在解决实际问题,例如解决模型评估期间的 Out of Memory (OOM) 错误,以及为了获得更好的模型性能而对代码进行微调。具体而言,在 evaluation harness 中运行 Gemma 7b 的问题以及关于 ParallelMLP 中 dropout 实现的困惑是讨论的焦点。
HuggingFace Discord 摘要
-
社区参与度持续上升:HuggingFace Discord 社区展示了在提示词排名方面的活跃参与,拥有超过 200 名贡献者和 3500 多个排名,助力构建公共数据集。排行榜功能增加了游戏化维度,促进了进一步的互动与贡献。
-
技术故障排除与库更新备受关注:在多项技术咨询中,包括 NixOS 上的
huggingface-vscode问题以及在 Nvidia A100 GPUs 上进行微调的挑战,一个关于 transformers 库即将发布新版本的预告引人注目,暗示将支持新模型并改进自定义架构支持。 -
AI 生成艺术与手语翻译模型讨论:computer-vision 频道的讨论强调了使用 BLIP 的图像字幕资源以及手语翻译模型——这些是扩展 AI 在通信和内容生成中可访问性的关键工具。
-
AI 初创公司展示、AI 在网络安全中的应用及金融应用设计:企业家和开发者正在各个领域创造价值:在 Data Council 的 AI 初创公司展示活动,名为 WhiteRabbitNeo-13B-v1 的网络安全模型,以及旨在辅助财务决策的投资组合管理应用。
-
NLP 与扩散建模的社区贡献展示:用户贡献了创新解决方案,如用于单目深度估计的 Android 应用,并讨论了使用 stable diffusion 模型进行损伤检测的进展——这体现了 HuggingFace 内部强大的协作环境。
-
关于增强型多模态模型与扩散技术的活跃讨论:reading-group 和 diffusion-discussions 的参与者主张开发更好的多模态模型,并分享了关于高级扩散技术复杂性的见解,包括用于时间步嵌入(timestep embeddings)的傅里叶变换。
LlamaIndex Discord 摘要
-
介绍 LlamaCloud 及其组件:LlamaIndex 宣布推出 LlamaCloud,这是一项旨在通过提供用于处理复杂文档的 LlamaParse 来增强 LLM 和 RAG 应用的新型云服务,并已开放托管 API 进行私测。提到的合作伙伴包括 Mendable AI、DataStax, MongoDB、Qdrant、NVIDIA 以及来自 LlamaIndex Hackathon 的贡献者。可以通过官方公告和 tweet 获取早期访问权限和资源。
-
RAG 开发的内容创作技巧:提到了一套使用 LlamaParse 和 AstraDB 构建 RAG 的高级 Cookbook,可以通过提供的 cookbook 指南访问。讨论了一种简化 RAG 开发流水线的综合新方法,并通过公告推文分享了幻灯片,同时链接了一个由 LlamaIndex 全力支持的专家级前端教程。
-
解决 LlamaIndex 和 GitHub 疑难问题:用户讨论了从 LlamaIndex v0.10.x 更新的导入路径问题、LlamaIndex 内部 LLM 模型的优化和微调,到 response_gen 中流式 Agent 高 CPU 占用和响应延迟的潜在解决方案。对于 LLM 微调查询,用户被引导至文档和仓库示例,如 llm_generators.py。
-
技术深挖与 AI 洞察:社区成员在一篇博客文章中探索并分享了关于 GPT-4 算术和符号推理能力的见解,并就 Gemini 1.5 在辅助语言翻译(特别是将法语翻译为 Camfranglais)方面的潜力进行了技术讨论。此外,还提出了关于评估 LlamaIndex 性能的摘要指标问题。
-
生产力与语言处理增强:
@andysingal分享的一篇博客文章强调了集成 LlamaIndex、React Agent 和 Llamacpp 以实现流线型文档管理,阅读地址见此处。这反映了社区内关于如何最好地利用和组合各种技术以增强文档处理能力的持续对话。
Mistral Discord 总结
-
Groq 速度火热:Groq 芯片的速度受到关注,利用其顺序执行特性,有可能实现每秒数千个 token 的吞吐量,但也指出了在扩展到更大模型时的挑战。同时,量化(Quantization)也是热门话题,有建议认为在某些加速器上,模型的量化版本速度可以超过 fp16 版本。
-
Mistral-Next 引发关注与担忧:社区互动显示出对 Mistral-Next 既兴奋又担忧的复杂情绪,包括它对简洁的偏好以及在较新语言模型中的审查制度。目前访问 Mistral-Next 仅限于通过 lymsys chat 进行测试,而模型本身尚未通过 API 提供。
-
开放权重而非开源:Mistral 模型被认为是开放权重(openweights)而非开源(open source),预计即将发布关于 Mistral-Next 的公告。讨论还涉及了 LLM 中函数调用(function calling)的复杂性,以及由于在这些 token 上预训练有限,向模型添加希伯来语等新语言所面临的挑战。
-
AI 的实际应用:用户分享了在 AWS 等平台上部署 Mistral 的经验和疑问,考虑了成本和硬件要求,例如合并一个 8x7b 模型需要 86GB 的 VRAM。此外,还交流了微调(finetuning)的挑战和建议方法,推荐采用迭代循环并考虑影响准确性的参数。
-
分享 AI 经验与资源:教育 AI 初创公司 FUSIONL AI 亮相,并宣布了一个将 Mistral AI 集成到 Flutter 应用的新库,表明开发者工具正在增长。此外,通过分享一份关于提示词能力(prompting capabilities)的指南,强调了编写有效提示词的重要性。社区频道中也出现了关于自我推广与真实项目展示的讨论。
相关链接:
-
[vLLM Mistral AI 大语言模型](https://docs.mistral.ai/self-deployment/vllm/) -
[提示词能力 Mistral AI 大语言模型](https://docs.mistral.ai/guides/prompting-capabilities/) - GitHub - nomtek/mistralai_client_dart
- FUSIONL AI 网站
OpenAI Discord 总结
-
GPT-4 变体引起好奇:一位用户发现 GPT-4-1106 在处理 JSON 格式的
£符号时存在问题,该 bug 会导致输出截断或字符编码改变。同时,@fightray询问了从 GPT-3.5 Turbo 到 GPT-3.5 Turbo 0125 的更新,@solbus确认了这一点,并引导至官方文档了解更多详情。 -
AI,请按剧本来!:在针对特定用例(如客服提示词或 RPG 场景)构建 AI 回复的建议中,
@darthgustav.强调了使用正向指令和嵌入模板变量的重要性。反馈表明,在角色扮演方面,GPT-4-0613 的表现优于 0125 turbo,@bambooshoots帮助@razorbackx9x编写了一个旨在为 Apple 的 Shortcuts 应用提供编程辅助的提示词。 -
AI 政策意识引发辩论:针对 AI 拒绝执行被认为违反政策的任务(尽管这些任务逻辑合理或适用)的情况,社区提出了批评。
@darthgustav.强调了清晰且正向的任务框架在管理潜在滥用问题(如抄袭)中的重要性。 -
对 Sora AI 的期待引发不耐烦:用户讨论了 Sora AI 的可用性,指出目前尚未确认公开发布或 API 访问日期。此外,还提到了使用 GPT-4 时每 3 小时 40 条消息的限制,讨论围绕解释订阅计划和使用上限展开。
-
AI 用户体验的预期与现实:一位用户对 ChatGPT Teams 计划缺乏实时共享功能表示不满,反映了宣传功能与实际功能之间的差距。此外,用户对各种 AI 工具表达了复杂的感受:GPT-4 因解决数学问题而受到称赞,Groq 在生成爱德华时代文学内容方面表现成功,而 Gemini 则因无意中输出莎士比亚风格的内容而受到批评。
Latent Space Discord 总结
-
Karpathy 的新 Tokenizer 教程吸引工程师:AI 社区对 Andrej Karpathy 关于构建 GPT tokenizer 的新课程以及对 Gemma tokenizer 的详细分析表现出浓厚兴趣。这种高度的热情表明,技术受众正趋向于深入理解语言模型的内部工作原理。
-
Google 凭借 “Gemma” 开启新篇章:Google 在 Huggingface 上发布 Gemma 以及随后关于服务条款的讨论表明,这些新的 LLM 引起了人们对操作细节和伦理使用的极大关注——这是工程专业人士在评估新 AI 工具时的核心关切。
-
Magic 的 AI 编程能力充满神秘感:一篇关于 Magic 的揭秘文章引起了社区的猜测。据报道,这家 AI 编程助手的表现超过了 Gemini 和 GPT-4,社区正在讨论其底层机制以及对软件开发中 AI 未来发展的影响。
-
Paper Club 聚焦工程师与 AI 的协作:最近的一篇论文详细研究了 AI 与软件工程师在创建产品 copilot 方面的合作伙伴关系,引发了广泛讨论,反映了工程社区对 AI 在产品开发中不断演变的角色及其带来的挑战的关注。
-
AI 的集成与评估成为焦点:对话显示出人们对在 Google Workspace 中集成 Gemini 等 AI 工具的兴趣日益增长,强调了强大的评估方法、工具和模型的重要性。这标志着一个明显的趋势:随着工程师被要求使用 Mistral 等 LLM,评估和 prompt programming 的技能正成为行业必备。
OpenAccess AI Collective (axolotl) Discord 总结
-
医院数据处理的 GPU 大辩论:Yamashi 倾向于购买 8x MI300X GPU,因为它们具有更高的 VRAM,考虑将其用于管理与大规模医院数据处理相关的 15,000 个 VM,同时正在评估与 ROCm 软件的兼容性。
-
Gemma 模型引发关注与质疑:AI Collective 讨论了 Google 的 Gemma 模型,重点关注用于在消费级 GPU(如 RTX 4090)上进行微调的新 Flash Attention v2.5.5。社区对该模型的许可、输出限制以及自定义聊天格式与现有工具的兼容性提出了担忧。
-
Axolotl 中关于 LoRA+ 集成的讨论:有人建议将最近关于 LoRA+ 的论文集成到 Axolotl 中,该论文承诺为大宽度模型提供优化的微调。讨论强调了 Gemma 模型训练需要最新版本的 Transformers 库,并从 Google 文档和 Hugging Face 博客中注意到了 Gemma 学习率和权重衰减值的差异。
-
协作模板与常规帮助中的问题:Yamashi 分享了一个包含聊天模板的 tokenizer_config.json 链接,并在协作努力后,分享了一个适用于 Axolotl 的 Alpaca 聊天模板。此外还讨论了 DeepSpeed 步数计算的困惑以及微调模型推理的格式,强调了 USER 和 ASSISTANT 格式的必要性。
-
DPO 训练中的 Loss 谜团:noobmaster29 对 DPO 训练日志表示担忧,日志显示在完成一个 epoch 之前 Loss 就已经很低,在缺乏评估数据的情况下,这引发了关于潜在过拟合的问题。
-
RunPod 的获取失败与无限重试:Casper_ai 报告了 RunPod 持续出现的镜像获取错误,导致无限重试,而 c.gato 建议磁盘空间不足可能是镜像下载失败的根本原因。
LAION Discord 摘要
-
全面 Git 数据搜索陷入停滞:
@swaystar123发起了一项寻找包含所有公开 Git 仓库及其关联 Issue、评论、Pull Request 和 Commit 的数据集的任务,但遗憾的是,由于没有得到任何答复,这条数字线索已经中断。 -
LAION 5B 的下落:关于 LAION 5B 数据集可用性的咨询层出不穷,但在社区中仍未出现明确的更新。与此同时,有人建议将 DFN 2B 作为替代方案,尽管它也存在一些访问上的限制。
-
Sora 传奇:真实还是合成:一场关于 Sora 起源的辩论爆发了——人们质疑它是真实训练数据的产物还是合成数据的产物。输出结果中出现的“漂浮物”和静态背景等线索,引发了对其包含合成元素的推测。
-
合成数据——无名英雄还是幕后反派?:出人意料的是,OpenAI 提到使用合成数据,这与一位社区成员的观点相左,而其他人则继续权衡利弊,思考合成数据在 AI 模型开发中的真实地位及其影响。
-
利用 AnyGPT 挑战极限:工程师们交流了对 AnyGPT 项目 的见解,该项目致力于通过具有离散表示 Token 的语言模型来处理不同的模态——讨论以一段 YouTube 演示视频 结束。
Perplexity AI Discord 摘要
-
Perplexity Pro 会员权益概览:像
@norgesvenn这样的用户证实了 Perplexity Pro 的速度和准确性。社区为新的 Pro 用户提供了通过用户设置中的链接访问专属 Discord 频道的指南,尽管分享的一些链接并不完整。 -
AI 调用中的平衡艺术:关于如何指示 Perplexity AI 在搜索结果依赖性与 AI 固有创造力之间取得平衡的讨论展开。有人建议采用一种使用特定指令的混合方法,以鼓励 AI 调用其自身的信息库。
-
Gemini 被认为优于 GPT-4:讨论突出了 Gemini Advanced 模型相比 GPT-4 的优势,用户称赞了更新的模型及其输出风格。这些论述反映了社区对 Gemini 能力的倾向以及日益增长的偏好。
-
图像生成之谜:关于如何使用 Perplexity AI 生成图像的问题被引导至“生成图像”按钮,强调了该 AI 的多媒体能力。然而,由于链接不完整,详细的步骤或示例并未完全阐明。
-
API 的困惑与怪癖:pplx-api 频道中的技术讨论揭示了各种用户问题,例如寻求增加 API 请求限制、API 与过时的 Webapp 结果之间的差异、未解决的
stream: true示例请求,以及来自 pplx-70b-online 的异常乱码响应。目前明显缺乏对这些问题的解决方案或回应。
CUDA MODE Discord 总结
-
CUDA MODE 拥抱 NVIDIA 的 Grace Hopper:CUDA MODE 社区(由
@andreaskoepf强调)对所有 GPU 爱好者都持开放态度,NVIDIA 向@__tinygrad__提供 Grace Hopper 芯片的举动进一步证明了这一点,引发了广泛的兴趣和讨论。相关推文:tinygrad 的推文。 -
Groq 的 LPU 树立了 AI 性能新标杆:
@srns27揭示了 Groq 的 LPU 在处理 LLM 方面取得的突破性性能。为了更好地理解这一技术成就,@dpearson分享了一个 YouTube 视频,内容是 Groq 的编译器技术主管 Andrew Bitar 关于该主题的演讲。 -
寻求 Triton/Mamba 开发合作者:
@srush1301正在积极寻找合作者以增强 Triton/Mamba 项目,提供论文共同署名机会,并讨论了在 Triton 中添加反向扫描选项等目标。项目的当前状态和任务在 Annotated Mamba 中有详细说明。 -
使用自定义 Kernel 优化 PyTorch:torch 频道的讨论揭示了加速 PyTorch 的各种策略,包括使用自定义 Kernel 和 Triton Kernel。
@gogators.和@hdcharles_74684分享了见解,并链接了一系列专注于优化的博客文章及相关源代码,例如 量化细节。 -
音频语义分析的新前沿:在 youtube-recordings 频道中,
@shashank.f1分享了一个关于 A-JEPA AI 模型 的 YouTube 讨论,这是一种从音频文件中获取语义知识的创新方法,标志着 AI 在理解音频数据领域的进步。讨论的视频可以在这里找到:“A-JEPA AI 模型:从 .wav / .mp3 文件或音频频谱图中解锁语义知识”。 -
JAX Pallas Flash Attention 代码评估:jax 频道充斥着关于 JAX GitHub 仓库中
flash_attention.py文件的询问。讨论了其在 GPU 上的功能和兼容性,但像@iron_bound这样的用户遇到了挑战,包括由于形状维度错误导致的崩溃。相关文件可在此处获取:jax flash_attention.py。 -
Ring Attention 和 Flash Attention 引起关注:在 ring-attention 频道中,用户
@ericuald分享了一个关于实现 Ring Attention 的 Colab,而@iron_bound、@lancerts等人则参与讨论以加深理解并排除潜在的算法问题——可以看到大家正在积极协作推动项目进展。Ring Attention 的简易版本可以在此 Google Colaboratory 找到,@lancerts的前向传播实现在这个 基础 Python 笔记本 中。
LangChain AI Discord 总结
-
TypeScript 与 LangChain:错失了什么?:
@amur0501质疑在 TypeScript 中使用 LangChain 的效率,担心会错过 Python 特有的功能。社区对于langchain.js是否能与 Python 版本相媲美尚未达成共识。 -
使用 Mistral 进行函数构建:
@kipkoech7分享了在开源 LLM (Mistral) 上使用 function calling 的实际演示,包括本地使用和通过 Mistral API 使用的示例。有关实现的见解,请参考 GitHub 资源。 -
向量数据库索引困境:
@m4hdyar寻求在代码更改后更新向量数据库索引的策略。@vvm2264提出了 code chunk-tagging 系统或 1:1 映射方案,但尚未确定最终策略。 -
NLP 资源依然陈旧:在寻找超越 2022 年产品的最新 NLP 资料时,
@nrs9044征求了建议。最新的库和进展仍然是一个后续跟进不足的话题。 -
AzureChatOpenAI 配置困扰:
@smartge3k在ConversationalRetrievalChain中遇到 ‘DeploymentNotFound’ 错误,导致配置AzureChatOpenAI出现困难。随着社区讨论的展开,解决方案仍未明确。 -
构思先锋 PDF 解析器:
@dejoma表示希望通过一周的专注工作,将现有的 PDFMinerPDFasHTMLLoader / BeautifulSoup 解析器提升到更精细的水平,并希望能与志同道合的人合作。 -
个人媒体机器:
@merkle强调了 LangChain 的 langgraph agent 设置如何将一个孤独的想法转化为时事通讯和推文,并引用了@michaeldaigler_描述该过程的一条 推文。 -
神秘项目的暗示:
@pk_penguin透露了一个潜在的新项目或工具,含糊地邀请对此感兴趣的人通过私信进一步探索这个神秘的产品。 -
通过反思进行 RAG 修订:
@pradeep1148发布了一个名为 “Corrective RAG using LangGraph” 的 YouTube 教程,主题是 RAG 的自我反思增强,介绍了改进生成模型的方法。讨论还补充了另一个关于 Self RAG using LangGraph 的视频。 -
记忆至关重要:具有回溯能力的 AI:
@kulaone在一篇关于集成 LangChain, Gemini Pro 和 Firebase 的文章中概述了具有持久记忆的聊天机器人的开发。有关建立记忆超越实时会话的聊天机器人的详细信息,请在此阅读。 -
Spark API 的小麻烦:
@syedmujeeb遇到了关于 Spark API 的 ‘AppIdNoAuthError’ 错误,社区建议参考 相应的 LangChain 文档 进行潜在的故障排除。
DiscoResearch Discord 总结
-
Gemma 模型引发技术兴趣:
@johannhartmann发起了关于有趣的 Gemma Models 训练策略的询问,触发了知识共享,包括@sebastian.bodza提供的 Google 开源模型链接。@philipmay对其非英语语言的熟练程度表示担忧,而@bjoernp提供了 揭示 Gemma 指令版本的链接 并强调了其 256k 的词汇量大小。 -
Aleph Alpha 的进展备受关注:Aleph Alpha 模型更新引发了关于潜在增强功能的讨论,
@devnull0提到招聘 Andreas Köpf 到 Aleph Alpha 是一个积极信号,并分享了 公司的变更日志 (changelog)。相反,@_jp1_由于更新模型中缺乏基准测试数据和指令微调(instruction tuning)而表示怀疑。 -
Gemma 在德语测试中表现不佳:
@_jp1_和@bjoernp的实证评估表明,Gemma 的 instruct 版本在德语方面表现吃力,德语 hellaswag 的lm_eval测试结果较差,仅略高于随机概率。 -
寻求速度:GPU 预算引发基准测试导航:
@johannhartmann幽默地感叹了 GPU 预算限制,促使寻找免费或更快的基准测试。@bjoernp建议使用 vLLM 来加速lm-evaluation-harness-de,尽管后来发现一个过时的分支才是测试运行缓慢的元凶。 -
致力于性能改进:
@bjoernp承认那个缺少 vLLM 集成的过时分支是基准测试缓慢的原因。他们承诺将 harness 与当前的 main 分支对齐,预计需要几天时间完成更新。
LLM Perf Enthusiasts AI Discord 总结
-
等候名单或寻求帮助:@wenquai 指出,要访问特定的 AI 服务,要么必须在等候名单上,要么需要联系 Google Cloud 代表。
-
Twitter 引发 AI 访问讨论:关于获得 AI 服务访问权限的传闻一直在 Twitter 上流传,@res6969 确认了这一热度并正在等待自己的访问权限。
-
AI 性能焦虑:公开反馈表明,某款 AI 正遭受准确性和幻觉问题的困扰,正如 @res6969 所言,@thebaghdaddy 也评论表示这是一个普遍问题。
-
为 AI 企业导航 CRM 迷宫:@frandecam 正在为他们的 AI 业务寻找 CRM 解决方案,考虑的选项包括 Salesforce、Zoho、Hubspot 或 Pipedrive,而 @res6969 建议不要选择 Salesforce。
-
Google 分享开源模型 Gemma:potrock 分享了一篇关于开发者可用的开源模型的 Google 博客文章。
-
微调技术讨论:@dartpain 提倡在微调 embeddings 时使用 ContrastiveLoss 和 MultipleNegativesRankingLoss。
Skunkworks AI Discord 总结
-
寻求 Neuralink 内部建议:成员
@xilo0渴望获得关于如何应对 Neuralink 后期面试中“卓越能力证明”问题的见解。他们拥有项目组合,但正在寻求建议以在马斯克领导的企业中脱颖而出。 -
RAG 引入反思机制:
@pradeep1148提供了教育资源,包括两个讨论 Corrective RAG 和 使用 LangGraph 的 Self RAG 的 YouTube 视频,强调了自我反思作为改进检索增强生成(RAG)模型的一种方法。 -
微调价值受到质疑:在一段 YouTube 视频 中,
@pradeep1148分享了关于“BitDelta:你的微调可能只值 1 bit”的见解,质疑了在大规模数据集预训练后对大语言模型进行微调的价值。 -
内容认可:
@sabertoaster对分享的 RAG 和 BitDelta 内容表示赞赏,简单地回复了一个“nice”,表明这些内容引起了社区的共鸣。
Alignment Lab AI Discord 摘要
- AI 社区认可其成员:
@swyxio获得了 AI 领域同行的认可,标志着社区内庆祝的一个显著职业里程碑。 - AI 榜单中寻求草根声音:
@tokenbender主张在一个由企业主导的 AI 榜单中加入草根贡献者,并提议 Twitter 上的@abacaj是一个值得加入的人选。 - 消失 Token 的谜团:
@scopexbt正在寻找是否有一个与该组织相关的神秘 Token,但到目前为止他们的搜索一无所获。
Datasette - LLM (@SimonW) Discord 摘要
-
Google 发布具有视频创新能力的 Gemini Pro 1.5:Google 推出了 Gemini Pro 1.5,其 100 万 token 的上下文(context)容量以及处理视频输入的革命性能力令人印象深刻。Simon Willison 一直在通过 Google AI Studio 探索这些功能,并在他的 博客 上描述了他的体验。
-
GitHub Codespaces 中的 GLIBC 障碍:在尝试于 GitHub Codespaces 中运行 LLM 时,
@derekpwillis遇到了由于缺少GLIBC_2.32导致的 OSError,该问题追溯到llmodel_DO_NOT_MODIFY目录下的一个文件,并向小组询问了潜在的修复方案。 -
工程师对“请勿触碰”标签情有独钟:命名幽默的
llmodel_DO_NOT_MODIFY目录得到了@derekpwillis的点名,这表明即使是技术受众也欣赏位置恰到好处的警告标签。
AI Engineer Foundation Discord 摘要
- Groq LPU 受到关注:
@juanreds和一名名为._z的用户都对 Groq LPU 的性能发表了正面评价,@juanreds提供了一个 测试链接 供他人衡量其令人印象深刻的速度。 - Gemini 1.5 聚会安排:
@shashank.f1发出了关于即将举行的 Gemini 1.5 实时讨论的邀请,并附带了 活动加入链接。 - 深入探讨语义音频分析:一个重点介绍 A-JEPA AI model(专门从音频文件中提取语义知识)的会议在 YouTube 视频 中进行了回顾。
- 协调难题与赞助更新:
@yikesawjeez表示早上的活动有冲突并索要录像,同时向@705561973571452938更新了赞助状态,提到一个未指明的周末活动已确定一家赞助商,另有三家潜在赞助商。
第二部分:分频道详细摘要与链接
TheBloke ▷ #general (1156 条消息🔥🔥🔥):
- 对 Gemma 模型的满意度褒贬不一:与 Mistral 相比,用户对 Gemma 模型的感受复杂。虽然 @itsme9316 承认 Gemma 可以处理单条提示词(prompt),但他们指出多轮对话响应是其崩溃的地方。@dirtytigerx 提到过度对齐(over-aligned)的 instruct 模型即使对于良性任务也具有挑战性,其他人则提到 VRAM 占用异常高。
- 对 Google AI 模型的担忧:尽管拥有资源和专家,但像 @selea8026 这样的用户表达了失望情绪,质疑 Google 在 AI 开发方面的决策。@alphaatlas1 批评了他们的过往记录,引用了像 Orca 这样被污染的模型作为例子。
- 文本转视频(Text-to-Video)模型讨论:Discord 用户讨论了 Sora,一个被视为“世界模拟器”的模型。Meta 的首席 AI 科学家 Yann LeCun 批评了这种方法,认为通过生成像素来训练模型是浪费的。包括 @welltoobado 在内的一些用户发现 Sora 的视频质量和比开源文本转视频模型更长的生成能力令人印象深刻。
- 对 Llama 3 (LL3) 的期待:用户们对名为 “Llama 3” 的新模型的发布充满猜测和渴望。@mrdragonfox 暗示 3 月份可能是一个潜在的发布期,而 @kaltcit 等人则给出了更保守的估计。
- PolyMind 更新的 RAG 检索:@itsme9316 在 PolyMind 中引入的 “retrieval_count” 功能受到了好评,像 @netrve 这样的用户发现它对 GMing(游戏主持)等任务非常有用。该功能允许检索多个结果,有利于获得更广泛的信息范围。
提及的链接:
- 未找到标题: 未找到描述
-
加入 Stable Diffusion Discord 服务器!: 欢迎来到 Stable Diffusion;Stable Models 的大本营以及官方 Stability.AI 社区!https://stability.ai/ 318346 名成员 - JB McGill (@McGillJB) 的推文: @yacineMTB 呵呵呵,情况变得更好了。
- 未找到标题: 未找到描述
- HuggingChat: 让社区最好的 AI 聊天模型惠及每一个人。
- Gemma: 推出全新的 state-of-the-art 开放模型: Gemma 是一个轻量级、state-of-the-art 的开放模型系列,采用与创建 Gemini 模型相同的研究和技术构建。
- bartowski/sparsetral-16x7B-v2-exl2 · Hugging Face: 未找到描述
- serpdotai/sparsetral-16x7B-v2 · Hugging Face: 未找到描述
- Leroy Worst Admin GIF - Leroy Worst Admin Admin - 发现并分享 GIF: 点击查看 GIF
- Stable Cascade - ehristoforu 创建的 Hugging Face Space: 未找到描述
- HuggingFaceTB/cosmo-1b · Hugging Face: 未找到描述
- VideoPrism: 用于视频理解的基础视觉编码器: 我们介绍了 VideoPrism,这是一种通用的视频编码器,通过单个冻结模型处理各种视频理解任务。我们在包含 36M 高…的异构语料库上对 VideoPrism 进行了预训练。
- google/gemma-7b · Hugging Face: 未找到描述
-
[OpenAI 的“世界模拟器”震惊整个行业 模拟理论得到证实?!](https://www.youtube.com/watch?v=BH9FU7Gd6v8): OpenAI 的 Sora 被 OpenAI 描述为“世界模拟器”。它不仅有可能模拟我们的现实,还能模拟每一个现实。利用这个限时优惠… - bartowski/sparsetral-16x7B-v2-SPIN_iter0-exl2 · Hugging Face: 未找到描述
- bartowski/sparsetral-16x7B-v2-SPIN_iter1-exl2 · Hugging Face: 未找到描述
- sean mcguire (@seanw_m) 的推文: ChatGPT 显然现在正处于失控状态,没人能解释原因
- GitHub - amazon-science/tofueval: 通过在 GitHub 上创建一个账户来为 amazon-science/tofueval 的开发做出贡献。
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI。通过在 GitHub 上创建一个账户来为 AUTOMATIC1111/stable-diffusion-webui 的开发做出贡献。
- Golem.de: 专业 IT 新闻: 未找到描述
- THE DECODER: 人工智能正在改变世界。THE DECODER 为您带来所有关于 AI 的新闻。
- THE DECODER: 人工智能正在改变世界。THE DECODER 为您带来所有关于 AI 的新闻。
TheBloke ▷ #characters-roleplay-stories (189 条消息🔥🔥):
-
Miqu 的仓促与 Goliath 的节奏:
@sunija对 Miqu 及其衍生模型推进场景过快表示担忧。相比之下,@superking__分享说原始 Miqu 通常能以良好的节奏推进场景,虽然有时会草草结束故事,但他们通过调整 prompt 缓解了这一问题。 -
用于角色扮演的 DPO 实验:
@superking__提议为模型创建 DPO 数据,以便更好地扮演撒谎、缺乏知识或拥有秘密的角色。多位用户表示感兴趣,@kaltcit建议像原始 llama chat 这样的现有模型已经采用了类似于这种选择性角色知识的概念。 -
不诚实的 DPO:
@superking__描述了一个详细计划,即创建以最小数量 token 差异的 DPO 对,来训练模型在特定话题上撒谎,从而增强角色扮演场景中的选择性角色回复。该方法建议使用镜像案例来“微调”模型权重,同时避免对无关 token 的过度训练。 -
模型行为与秘密:
@spottyluck讨论了 LLM 保守秘密的概念及相关挑战,并引用了一个绰号为 “Frank” 的模型在被问及保守秘密能力时给出的微妙回复。 -
Miqu-70b 模型的资源需求:关于模型 VRAM 使用情况的讨论显示,miqu-70b 模型对内存的需求各不相同,
@superking__提到 Q2 需要 32 GB,而@mrdragonfox观察到 Q5 可以装入 48 GB 的 GPU,这表明模型大小和硬件能力会显著影响用户体验。 -
AI 在角色一致性方面的困境:
@drakekard寻求关于使用 Amethyst-13B-Mistral-GPTQ 保持一致角色扮演的 prompt 建议。@superking__建议使用简单的聊天对话格式并分享了他们的设置,但由于小型模型的局限性,结果各异。
提到的链接:
- Reservoir Dogs Opening Scene Like A Virgin [Full HD]:Quentin Tarantino 的《落水狗》开场场景,Mr Brown (Tarantino) 解释了 “Like A Virgin” 的含义。
- The Best Shopping Scene Ever! (from Tarantino’s “Jackie Brown”):Quentin Tarantino 的《危险关系》(Jackie Brown) 中 Robert De Niro 和 Bridget Fonda 出演的场景。
TheBloke ▷ #training-and-fine-tuning (6 条消息):
-
合成数据集微调热潮:用户
@pncdd正在努力审查和编辑一个用于数据提取模型的合成数据集,发现处理 jsonlines 格式的过程非常繁琐。由于缺乏合适的工具,他们感到沮丧,并考虑将其转换为 .csv 以在 Google Sheets 中进行编辑。 -
急需数据集工具:在后续讨论中,
@pncdd描述了数据集的复杂性:它包含电话通话转录以及配对的详细 JSON 响应。 -
负向训练是积极的一步吗?:用户
@3dhelios询问是否可以在训练数据集中使用负面示例,这意味着模型需要从错误答案中学习。 -
Gradio 来救场:
@amogus2432建议@pncdd可以让 GPT-4 编写一个简单的 Gradio 工具来进行数据集编辑,尽管他也承认 GPT-4 在处理 Gradio blocks 方面存在局限性。 -
寻找完美的分类器:
@yustee.正在为旨在过滤 RAG 流水线相关性的分类任务寻求模型推荐,并考虑使用 deepseek-coder-6.7B-instruct。
TheBloke ▷ #coding (166 条消息🔥🔥):
- 探索多角色聊天机器人:
@pilotgfx正在编写一个本地脚本,其特点是拥有多个编程助手,可以在没有后端服务器的情况下管理对话历史;对话长度管理涉及清理旧条目,以避免 Prompt 长度过长。 - 关于 RAG 和长对话的有趣讨论:
@dirtytigerx强调了传统的检索增强生成 (RAG) 技术,例如用于管理大量对话历史的元数据过滤和压缩方法;@superking__指出,为 Mixtral 编写服务器可能会解决 Prompt 评估延迟问题。 - Mistral 微调探索:
@fred.bliss和@dirtytigerx讨论了 Mistral 的易用性和分布式训练特性;@dirtytigerx在日常任务中使用 macOS,并通过其他系统访问 ML 相关的工作负载。 - 开发环境的后端选择:
@fred.bliss和@dirtytigerx交流了对编辑器的偏好,@dirtytigerx表达了对 VSCode 的不满,转而青睐 Zed,并分享了该文本编辑器的快速响应和以开发者为中心的特点。他们还讨论了对 mlx 在 Apple 新硬件上的性能和微调能力的看法。 - 模型实现的优化讨论:
@etron711询问了关于微调 Mistral 模型的问题,寻求关于优化服务器成本和吞吐量的建议;@dirtytigerx建议先使用租用的 GeForce RTX 4090 GPU 构建小型原型来开发 MVP,然后再扩展基础设施。
相关链接:
- GitHub - raphamorim/rio: A hardware-accelerated GPU terminal emulator focusing to run in desktops and browsers.: 一个专注于在桌面和浏览器中运行的硬件加速 GPU 终端模拟器。 - raphamorim/rio
- GitHub - pulsar-edit/pulsar: A Community-led Hyper-Hackable Text Editor: 一个由社区主导的高度可定制(Hyper-Hackable)的文本编辑器。可以通过在 GitHub 上创建账户为 pulsar-edit/pulsar 的开发做出贡献。
LM Studio ▷ #💬-general (375 条消息🔥🔥):
- CPU 特性辩论:
@jedd1讨论了 CPU 特性的进步,而@exio4提到了 Intel Atom 长期以来的低性能,@krypt_lynx补充说甚至 Celerons 也缺乏 AVX 特性。除了 Intel 官网外,这些较新的特性并不常见。 - LM Studio 与 Hugging Face 连接问题:虽然
@lmx4095可以访问 Hugging Face,但他们在 LM Studio 中遇到了连接错误;@heyitsyorkie确认了模型浏览器存在问题。 - Discord 中的兼容性问题:用户
@nsitnov、@ivtore、@heyitsyorkie和@joelthebuilder讨论了设置 Web 界面以及与 LM Studio Server 集成的问题,结果各异。 - LM Studio 模型推荐与问题:多位用户讨论了不同模型的性能和问题。有些人的运气比其他人好,既有模型成功运行的报告,也有错误的报告。
- LM Studio 的修复与补丁:
@yagilb链接了 LM Studio 推荐的 Gemma 版本,并解释了最近 LM Studio 更新中针对重新生成(regeneration)和续写(continuation)Bug 的修复。
提到的链接:
- 👾 LM Studio - Discover and run local LLMs:发现、下载并实验本地 LLM
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face:未找到描述
- Gemma: Introducing new state-of-the-art open models:Gemma 是一个轻量级、SOTA(州级代艺术)开源模型系列,采用与创建 Gemini 模型相同的研究和技术构建。
- Hugging Face – The AI community building the future.:未找到描述
- google/gemma-7b · Hugging Face:未找到描述
- جربت ذكاء إصطناعي غير خاضع للرقابة، وجاوبني على اسئلة خطيرة:YouTube 视频描述(阿拉伯语略)
- Head Bang Dr Cox GIF - Head Bang Dr Cox Ugh - Discover & Share GIFs:点击查看 GIF
- LoneStriker/gemma-2b-GGUF · Hugging Face:未找到描述
- Reddit - Dive into anything:未找到描述
- GitHub - lllyasviel/Fooocus: Focus on prompting and generating:专注于提示词和生成。通过在 GitHub 上创建账号来为 lllyasviel/Fooocus 的开发做出贡献。
- Need support for GemmaForCausalLM · Issue #5635 · ggerganov/llama.cpp:前提条件:在提交 Issue 之前,请先回答以下问题。我正在运行最新代码。由于目前开发非常迅速,尚无标记版本…
- MSN:未找到描述
- Mistral's next LLM could rival GPT-4, and you can try it now in chatbot arena:法国 LLM 奇迹 Mistral 正准备发布其下一个语言模型。你已经可以在聊天中对其进行测试。
- How To Run Stable Diffusion WebUI on AMD Radeon RX 7000 Series Graphics:你知道吗,你可以在 Automatic1111 下通过 Microsoft Olive 启用 Stable Diffusion,从而在 Windows 上通过 Microsoft DirectML 获得显著的加速?
LM Studio ▷ #🤖-models-discussion-chat (65 条消息🔥🔥):
- 关于歌词创作最佳模型的咨询:
@discockk询问哪个模型最适合生成歌词。作为回应,@fabguy幽默地批评了这一简短的提问,但指出目前没有专门针对诗歌或押韵训练的模型,建议尝试另一个频道中列出的故事讲述类模型。 - Hermes 2 模型使用心得:
@wolfspyre分享了他们使用新款 NousResearch Hermes2 Yi 模型的经验,对其性能表示赞赏,并提供了其 Hugging Face 页面链接。 - 关于 LLM 输出质量与验证的对话:
@goldensun3ds设想了一种双 LLM 系统来提高输出质量,即由第二个 LLM 修改第一个 LLM 的回答。@jedd1和@christianazinn提到了现有的框架(如 Judy)以及符合该理念的相关论文。 - AutoGPT 与 LLM 兼容性的挑战:
@thebest6337报告了在各种模型中使用 AutoGPT 时遇到的困难,并得到了@docorange88的帮助,后者建议尝试 Mistral 和某个版本的 Dolphin,但随后双方讨论了持续存在的错误和模型兼容性问题。 - 技术细节与优化讨论:在一次技术交流中,
@nullt3r和@goldensun3ds讨论了在显存(VRAM)有限的 GPU 上运行 Goliath 120B 等大型 LLM 时可能遇到的瓶颈,涉及内存带宽和层卸载(layer offloading)等因素。
提到的链接:
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face:未找到描述
- Testing Shadow PC Pro (Cloud PC) with LM Studio LLMs (AI Chatbot) and comparing to my RTX 4060 Ti PC:我自大约一年前 ChatGPT 发布以来就一直在使用它,并且已经熟练掌握了提示词技巧,但在“本地”运行 LLM 方面我还是个新手。当…
- GitHub - TNT-Hoopsnake/judy: Judy is a python library and framework to evaluate the text-generation capabilities of Large Language Models (LLM) using a Judge LLM.:Judy 是一个 Python 库和框架,用于通过 Judge LLM 评估大语言模型 (LLM) 的文本生成能力。 - TNT-Hoopsnake/judy
- NousResearch/Nous-Hermes-2-Yi-34B-GGUF · Hugging Face:未找到描述
LM Studio ▷ #announcements (3 条消息):
-
LM Studio v0.2.15 发布,支持 Google Gemma:
@yagilb宣布 LM Studio v0.2.15 现已发布,支持 Google 的 Gemma 模型,包括 2B 和 7B 版本。用户目前必须手动下载 Google 的 Gemma 模型(2B 版本,7B 版本),但预计很快将提供更无缝的体验。 -
最新版 LM Studio 推出新功能与 UI 更新:此次更新引入了改进的下载器(支持暂停/恢复)、对话分支功能、GPU 层级滑动条以及 UI 刷新(包括全新的主页外观和更新后的聊天界面)。
-
LM Studio 修复 Bug:建议用户从 LM Studio 官网 重新下载 v0.2.15,以获取原始 0.2.15 版本中未包含的重要 Bug 修复。
-
简化 Gemma 集成流程:
@yagilb为 LM Studio 用户提供了推荐的 Gemma 量化版本链接,旨在简化将 Google 的新 Gemma 模型集成到 LM Studio 环境中的过程。
提到的链接:
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face:未找到描述
- 👾 LM Studio - Discover and run local LLMs:查找、下载并实验本地 LLM
LM Studio ▷ #🧠-feedback (10 messages🔥):
-
RAM 显示不一致问题: 用户
@darkness8327提到他们使用的软件中 RAM 显示不正确。 -
Assistant Creation 功能请求:
@urchig询问是否可以在 LM Studio 中集成 Assistant Creation 功能,类似于 Hugging Face 上提供的功能。 -
寻求本地 LLM 安装指南:
@maaxport寻求关于在租用的服务器上配合 AutoGPT 安装本地 LLM 的指导。 -
客户端版本混淆更新:
@msz_mgs注意到一个问题,即 0.2.14 版本客户端错误地提示其为最新版本。@heyitsyorkie建议手动下载并安装更新,因为应用内更新功能目前无法工作。 -
Gemma 模型故障排除:
@richardchinnis报告了 Gemma 模型的一个问题,但随后表示打算根据另一个频道的讨论尝试不同的模型。
提到的链接:
HuggingChat - Assistants: 浏览由社区创建的 HuggingChat 助手。
LM Studio ▷ #🎛-hardware-discussion (96 messages🔥🔥):
- 电源对双 GPU 至关重要:
@heyitsyorkie强调了在考虑双显卡配置时,配备一个拥有足够功率运行两个 GPU 的 PSU 的重要性。 - 多 GPU 设置受限于最慢显卡的速度: 根据
@wilsonkeebs的说法,在多 GPU 配置中,整体速度将与最慢的显卡匹配,但拥有更多 VRAM 比利用 RAM 加载模型更理想。 - 主板 PCIe 支持对 GPU 扩展很重要:
@krzbio_21006询问双 PCIe 4x16 插槽是否足以进行 GPU 扩展,@wilsonkeebs给予了肯定回答,并建议如果出现空间问题可以使用 PCIe riser。 - GPU 选择中的能效与性能权衡:
@jedd1和@heyitsyorkie讨论了在选择 4060ti 和 4070 ti-s 等 GPU 型号时,功耗与性能之间的权衡。 - AI 和 Vision 模型的最佳 GPU 策略: 在关于 VRAM 需求的对话中,
@heyitsyorkie和其他人强调了使用少量高端 GPU(如 3090)优于使用大量低端型号的优势,因为单卡更高的 VRAM 会显著影响 AI 相关任务。
提到的链接:
- Have You GIF - Have You Ever - Discover & Share GIFs: 点击查看 GIF
- The Best GPUs for Deep Learning in 2023 — An In-depth Analysis: 本文提供了用于 Deep Learning/Machine Learning 的 GPU 深度分析,并解释了适合你的使用场景和预算的最佳 GPU。
- NVIDIA GeForce RTX 2060 SUPER Specs: NVIDIA TU106, 1650 MHz, 2176 Cores, 136 TMUs, 64 ROPs, 8192 MB GDDR6, 1750 MHz, 256 bit
- NVIDIA GeForce RTX 3090 Specs: NVIDIA GA102, 1695 MHz, 10496 Cores, 328 TMUs, 112 ROPs, 24576 MB GDDR6X, 1219 MHz, 384 bit
LM Studio ▷ #🧪-beta-releases-chat (301 条消息🔥🔥):
- LM Studio 0.2.15 Beta 用户困扰:像
@n8programs这样的用户在n_gpu_layers功能上遇到了不一致的问题,需要频繁重新加载模型。为了简化 GPU 模型加载,@yagilb建议增加一个预设选项。 - Linux Libclblast Bug 已修复:
@yagilb确定了 Linux 用户遇到的 libclblast bug 的根本原因并计划进行修复,尽管该修复尚未在 0.2.15 预览版中实现。 - Gemma 模型出现问题:许多用户报告 Google 的 Gemma 7B 模型会产生乱码输出。该问题非常普遍,
@drawless111指出其他模型(如 RWKV)也存在类似问题。 - 重新生成 Bug 已解决:在收到多份关于模型重新生成和多轮对话问题的报告后,
@yagilb宣布 0.2.15 版本已重新发布,其中包含旨在解决已报告问题的重大 Bug 修复。 - 官方 Gemma 模型功能正常,量化变体存在问题:Google 的 Gemma 模型在其 32-bit GGUF 全精度格式下运行良好(尽管文件体积巨大);相反,许多量化版本则无法正常工作。社区成员发现
@LoneStriker的量化模型可以运行,@yagilb提供了由 LM Studio 量化并经过兼容性测试的 Gemma 2B Instruct GGUF。
提到的链接:
- 👾 LM Studio - Discover and run local LLMs:查找、下载并实验本地 LLM
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face:未找到描述
- 👾 LM Studio - Discover and run local LLMs:查找、下载并实验本地 LLM
- asedmammad/gemma-2b-it-GGUF · Hugging Face:未找到描述
- ```json{ "cause": "(Exit code: 1). Please check settings and try loading th - Pastebin.com:Pastebin.com 自 2002 年以来一直是排名第一的粘贴工具。Pastebin 是一个可以让你在线存储文本的网站。
- LoneStriker/gemma-2b-it-GGUF · Hugging Face:未找到描述
- Thats What She Said Dirty Joke GIF - Thats What She Said What She Said Dirty Joke - Discover & Share GIFs:点击查看 GIF
- google/gemma-7b · Why the original GGUF is quite large ?:为什么原始 GGUF 体积相当大?
- google/gemma-7b-it · Hugging Face:未找到描述
- Need support for GemmaForCausalLM · Issue #5635 · ggerganov/llama.cpp:前提条件 请在提交 issue 前回答以下问题。我正在运行最新代码。由于目前开发非常迅速,还没有标记版本。我…
- HuggingChat:让社区最好的 AI 聊天模型惠及每一个人。
- Summer Break GIF - Summer break - Discover & Share GIFs:点击查看 GIF
- google/gemma-2b-it · Hugging Face:未找到描述
- Tweet from Victor M (@victormustar):@LMStudioAI @yagilb 新字体很棒,但仍然会怀念最初的版本 (0.0.1!)
- Add
gemmamodel by postmasters · Pull Request #5631 · ggerganov/llama.cpp:该架构中有几点:共享输入和输出嵌入参数。键长度和值长度不是由 n_embd 派生的。更多关于模型的信息可以在…找到 - no title found:未找到标题
- no title found:未找到标题
LM Studio ▷ #autogen (1 条消息):
senecalouck: https://github.com/microsoft/UFO
LM Studio ▷ #crew-ai (2 条消息):
-
寻求关于 VSC 问题的澄清:
@wolfspyre正在请求澄清一个与 VSC (Visual Studio Code) 相关的问题,询问预期结果、结论背后的推理以及已尝试过哪些解决方案。 -
潜在的虚拟环境问题:
@dryt提到遇到了类似的问题,并推测在处理特定项目时,问题可能与 venv 或 conda 有关。他们建议这可能是一个venv问题。
Nous Research AI ▷ #ctx-length-research (67 条消息🔥🔥):
-
ChatGPT 字符限制查询:
@elder_plinius发现 ChatGPT 网页版似乎是按字符而非 Token 来限制上下文的,这在小组中引发了疑问。尽管@vatsadev断言 GPT-3 和 GPT-4 使用的是 Tokenizer,但@elder_plinius的 Big Lebowski 剧本拟合实验 显示了在接受上下文长度方面的不一致性。 -
将语言模型扩展到 128K 上下文:
@gabriel_syme分享了一个 GitHub 仓库,其中包含将语言模型扩展到处理 128K 上下文的实现细节。 -
大上下文 AI 的 VRAM 需求:对话围绕使用 7B 模型处理 128K 上下文长度所需的 VRAM 展开;
@teknium声称推理需要 600+GB,而@blackl1ght指出在 64K 上下文下使用约 28GB VRAM 成功运行了模型推理。 -
服务器问题与上下文长度误解:当
@elder_plinius提到因超出上下文限制而多次拒绝原始 Big Lebowski 剧本时,@vatsadev提出 Token 接受度的问题可能是服务器延迟而非上下文长度导致的。 -
Token 压缩与替代语言理论:基于对 Big Lebowski 剧本进行的上下文长度实验,
@elder_plinius推测可以通过教模型一种新的压缩语言,创建一个字母数字映射库来减少 Token 数量。
提到的链接:
- gpt-tokenizer playground:未找到描述
- 来自 Pliny the Prompter 🐉 (@elder_plinius) 的推文:Big Lebowski 剧本通常无法完全适应 GPT-4 的上下文限制,但在通过 myln 处理文本后,它可以了!
- GitHub - FranxYao/Long-Context-Data-Engineering: Implementation of paper Data Engineering for Scaling Language Models to 128K Context:将语言模型扩展到 128K 上下文的数据工程论文实现 - FranxYao/Long-Context-Data-Engineering
Nous Research AI ▷ #off-topic (22 条消息🔥):
-
探索 AI 驱动的游戏模拟:
@nonameusr分享了一个 YouTube 视频 链接,展示了 OpenAI 的 Sora 模拟 Minecraft 游戏画面,并对其对游戏机制的理解表示惊讶。Sora 的能力包括理解经验值栏(XP bar)、物品堆叠、物品栏槽位(inventory slots)以及复制游戏内动作的动画。 -
AI 误解与模组内容的影响:在讨论 AI 对 Minecraft 的掌握程度时,
@afterhoursbilly观察到了一些不准确之处,但指出没有重大的视觉错误;而_3sphere则评论说,尽管存在网格对齐问题,但乍看之下其准确性高得离谱。 -
自我改进的检索增强生成 (RAG):
@pradeep1148链接了一个题为 “使用 LangGraph 的 Self RAG” 的 YouTube 视频,讨论了自我反思如何通过纠正低质量的检索或输出来增强检索增强生成。 -
从显微镜检查到艺术创作:
@blackblize询问了非专业人士在显微镜图像上训练模型以创作艺术衍生品的可行性,并寻求这方面的指导。 -
为 Nous 模型生成头像:针对
@stoicbatman关于为 Nous 模型生成头像图像的询问,@teknium提到使用 DALL-E 以及通过 Midjourney 的图生图(image-to-image)方法来创建这些视觉呈现。
提及的链接:
- Minecraft - 现实 vs OpenAI 的 Sora:模拟数字世界。Sora 还能模拟人工过程——例如视频游戏。Sora 可以同时控制 Minec… 中的玩家。
- 使用 LangGraph 的纠正性 RAG:纠正性 RAG。自我反思可以增强 RAG,从而纠正低质量的检索或生成。最近的几篇论文都聚焦于这一主题,但 im…
- 使用 LangGraph 的 Self RAG:自我反思可以增强 RAG,从而纠正低质量的检索或生成。最近的几篇论文都聚焦于这一主题,但实现…
- BitDelta: Your Fine-Tune May Only Be Worth One Bit:大语言模型 (LLMs) 通常分为两个阶段进行训练:在互联网规模的大型数据集上进行预训练,以及针对下游任务进行微调。鉴于…
Nous Research AI ▷ #interesting-links (49 messages🔥):
- Apple Silicon 优化的 GNN 库发布:
.beowulfbr强调了mlx-graphs的发布,这是一个在 Apple Silicon 上运行图神经网络 (GNNs) 的库,正如 @tristanbilot 所提到的,它拥有高达 10倍的训练加速。 - Gemma 1.5 Pro 学会自我实现:
burnytech分享了 @mattshumer_ 的帖子,其中展示了 Gemma 1.5 Pro 在阅读了 Self-Operating Computer 的代码库后,成功解释并将其自身实现到了该仓库中。 - 2023 年 AI 技术栈之战愈演愈烈:
burnytech引起了大家对 @swyx 关于 AI 技术栈四场战争 概述的关注,涵盖了基于其 2023年12月回顾 的数据、GPG/推理、多模态和 RAG/Ops 领域的商业竞争。 - 澄清 A-JEPA AI 模型与 Meta 无关:在关于名为 A-JEPA 的 AI 模型的讨论中,
@ldj澄清了它与 Meta 或 Yann Lecun 没有隶属关系,这与该名称可能暗示的情况相反。shashank.f1表示赞同,承认作者并非来自 Meta。 - 解码过程可能诱导预训练 LLMs 产生 CoT 路径:
mister_poodle引用了一篇 arXiv 论文,该论文提出通过改变大型语言模型 (LLMs) 的解码过程来诱导思维链 (CoT) 推理路径。
提及的链接:
- Sundar Pichai (@sundarpichai) 的推文:介绍 Gemma —— 一个轻量级、同类中最先进的开放模型系列,基于创建 Gemini 模型所使用的相同研究和技术构建。在多项任务中表现出强劲性能…
-
[Library of Congress Subject Headings - LC Linked Data Service: Authorities and Vocabularies Library of Congress](https://id.loc.gov/authorities/subjects.html):未找到描述 - benxh/us-library-of-congress-subjects · Hugging Face 数据集:未找到描述
- Tristan Bilot (@tristanbilot) 的推文:我们很高兴正式发布 mlx-graphs,这是一个在 Apple Silicon 上高效运行图神经网络 (GNNs) 的库。我们的初步基准测试显示,在大型图上训练速度提升了 10 倍…
- Matt Shumer (@mattshumer_) 的推文:我向 Gemini 1.5 Pro 展示了整个 Self-Operating Computer 代码库以及一个 Gemini 1.5 API 调用示例。从那时起,它能够完美地解释代码库的工作原理… 然后它实现了…
- 无需提示的思维链推理 (Chain-of-Thought Reasoning Without Prompting):在增强大型语言模型 (LLMs) 的推理能力方面,先前的研究主要集中在特定的提示技术上,如少样本或零样本思维链 (CoT) 提示…
- 加入 hedwigAI Discord 服务器!:查看 Discord 上的 hedwigAI 社区 - 与其他 45 名成员一起交流,享受免费的语音和文字聊天。
- A-JEPA AI 模型:从 .wav / .mp3 文件或音频频谱图中解锁语义知识:🌟 释放 AI 从音频中学习的力量!观看与 Oliver, Nevil, Ojasvita, Shashank, Srikanth 和 N… 深入讨论 A-JEPA 方法。
- swyx (@swyx) 的推文:🆕 AI 技术栈的四场战争 https://latent.space/p/dec-2023 我们的 2023 年 12 月回顾还包括一个分析 2023 年全年关键商业战场的框架:在数据领域:OpenAI 与…
- HuggingFaceTB/cosmo-1b · Hugging Face:未找到描述
- 让我们构建 GPT 分词器 (Tokenizer):Tokenizer 是大型语言模型 (LLMs) 中必不可少且普遍存在的组件,它负责在字符串和 Token(文本块)之间进行转换。Tokenizer…
- mlabonne/OmniBeagle-7B · MT-Bench 分数:未找到描述
Nous Research AI ▷ #announcements (2 条消息):
-
Nous Hermes 2 发布:
@teknium宣布发布 Nous Hermes 2 - Mistral 7B - DPO,这是一个内部经过 RLHF 优化的模型,提升了在 AGIEval、BigBench Reasoning Test、GPT4All 套件和 TruthfulQA 等 Benchmark 上的评分。该模型已在 HuggingFace 上线。 -
获取 GGUF 版本!:Nous Hermes 2 的各种尺寸预制 GGUF(gradient-guided unfreeze)版本可在其 HuggingFace 仓库 下载。
-
鸣谢 FluidStack:
@teknium向算力赞助商 FluidStack 及其代表表示感谢,并向 Hermes 项目的贡献者和开源数据集表示致敬。 -
Together 托管 Nous Hermes 2:
@teknium告知 Together.xyz 已在其 API 中列出新的 Nous Hermes 2 模型,可在 Togetherxyz API Playground 中使用。感谢@1081613043655528489。
提到的链接:
- TOGETHER: 未找到描述
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO · Hugging Face: 未找到描述
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO-GGUF · Hugging Face: 未找到描述
Nous Research AI ▷ #general (594 条消息🔥🔥🔥):
- Gemma 加入战场:Google 发布 Gemma 模型在成员中引起轰动,大家将其与 Mistral 模型进行对比,并讨论了其架构背后的潜力和 Benchmark 表现。
@ldj指出,考虑到参数量,Gemma 的表现略逊一筹;@teknium建议关注模型的实际效果而非原始参数量;@leontello则急切期待 MT-bench 或 Alpaca eval 的性能数据。 - 微调热潮:关于对已微调的 LLM 进行再次微调的讨论随之展开,
@lee0099和@mihai4256等多位成员分享了他们的经验和策略,提到了 LoRA 和全参数微调的使用。有人好奇 DPO (Differential Privacy Optimization) 是否可以与 SFT (Supervised Fine Tuning) 结合。 - 死亡社交媒体概念:
@n8programs介绍了一个名为 Deadnet 的项目,旨在创建一个由 AI 生成的虚构人物社交媒体内容的无尽流。@everyoneisgross给予了积极回应,考虑在构想的社交媒体宇宙中扩展用户聚类和帖子排名功能。 - 训练故事与工具:成员们交流了各种 AI 训练工具和方法。
@lee0099和@mihai4256讨论了模板的具体细节和微调结果,而@thedeviouspanda透露了将 DPO 与 SFT 融合以获得更好训练效果的新方法。 - 窥探协议与合成数据的追求:关于合成数据与有机数据的讨论兴起,并推测了由于 AI 输入导致的互联网动态演变 (
@everyoneisgross)。@sdan.io强调了用于跨平台记忆管理的个人“vector db 文件”概念,而@teknium分享了一个推文链接,暗示 AI 推理模型的发展可能会比自然语言处理模型更加普遍。
提到的链接:
- EleutherAI/Hermes-RWKV-v5-7B · Hugging Face: 未找到描述
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO · Hugging Face: 未找到描述
- no title found: 未找到描述
- Models - Hugging Face: 未找到描述
- eleutherai: Weights & Biases,机器学习开发者工具
- Tweet from Archit Sharma (@archit_sharma97): RLHF 的高质量人类反馈非常昂贵 💰。AI 反馈正作为一种可扩展的替代方案出现,但我们是否有效地利用了 AI 反馈?目前还没有;只有当 LLM 处于 SF(监督微调)状态时,RLAIF 才能提高性能…
- TOGETHER: 未找到描述
- Tweet from Aaditya Ura (Ankit) (@aadityaura): 来自 @GoogleDeepMind 和 @GoogleAI 的新模型 Gemma 在医疗/保健领域的基准测试中表现不佳。对 @GoogleDeepMind 的 Gemma 和 Mistral 进行的侧向对比…
- The Novice’s LLM Training Guide: 由 Alpin 编写,灵感来自 /hdg/ 的 LoRA 训练指南。本指南正在缓慢更新中。我们已经迁移到了 axolotl 训练器。基础知识:Transformer 架构、训练基础、预训练…
- no (no sai): 未找到描述
- Adding Google's gemma Model by monk1337 · Pull Request #1312 · OpenAccess-AI-Collective/axolotl: 添加 Gemma 模型配置 https://huggingface.co/google/gemma-7b,测试通过并正常工作!
- Runtime error: CUDA Setup failed despite GPU being available (bitsandbytes) · Issue #1280 · OpenAccess-AI-Collective/axolotl: 请检查此问题之前是否已被报告过。我搜索了之前的 Bug 报告,没有发现类似的报告。预期行为:你好,我正在尝试公有云示例,结果…
- Mistral-NEXT Model Fully Tested - NEW KING Of Logic!: Mistral 悄然发布了其最新模型 “mistral-next”。它是否优于 GPT4?需要 AI 咨询?✅ - https://forwardfuture.ai/ 在 Twitter 上关注我 🧠 …
- laserRMT/examples/laser-dolphin-mixtral-2x7b.ipynb at main · cognitivecomputations/laserRMT: 这是我们自己实现的 ‘Layer Selective Rank Reduction’(层选择性秩降低) - cognitivecomputations/laserRMT
- Reddit - Dive into anything: 未找到描述
- Neuranest/Nous-Hermes-2-Mistral-7B-DPO-BitDelta at main: 未找到描述
- BitDelta: 未找到描述
- GitHub - FasterDecoding/BitDelta: 通过在 GitHub 上创建账号,为 FasterDecoding/BitDelta 的开发做出贡献。
Nous Research AI ▷ #ask-about-llms (37 条消息🔥):
-
数据集编辑困境:
@pncdd表达了对缺乏能够轻松编辑用于模型微调的合成数据集工具的沮丧,认为滚动浏览 jsonlines 文件效率低下。Huggingface datasets 和 wandb Tables 都没有提供解决方案,有人建议将其转换为 .csv 以便在 Google Sheets 中编辑,但这被认为是一个虽然可行但很繁琐的折中方案。 -
大模型合并难题:
@iamcoming5084报告了在尝试使用 H100 80GB GPU 合并微调后的 mixtral 8x 7b 模型时出现内存溢出 (OOM) 错误,引发了关于无需更大 VRAM GPU 的潜在解决方案的讨论。对话涉及了建议的代码、Axolotl 的合并功能使用,以及对 PyTorch 内存处理的深入观察。 -
探索用于 LLM 推理的 LoRA:
@blackl1ght参与了关于在微调(特别是推理期间)使用 LoRA (Locally Reweighted Adaptation) 的目的和益处的讨论。分享的信息明确了 LoRA 是一种以较少 GPU 资源微调模型的策略,@dysondunbar提供了关于潜在用例、局限性和优势的见解。 -
Magicoder 增强版 DeepSeek:
.benxh指出 DeepSeek AI 的 6.7B 版本通过使用 Magicoder 数据集得到了显著提升。.benxh否认个人使用该数据集微调 DeepSeek,并澄清是 Magicoder 团队实施的。 -
LLM 的自定义托管方案:
@jacobi寻求关于在 3090/4090 GPU 上通过 OpenAI API 端点托管 Mixtral 8x7b 模型的最佳策略建议。提到了 tabbyAPI、vLLM gptq/awq 和 llama-cpp 的服务器实现等各种工具和库,并讨论了它们在托管此类大模型时的有效性和局限性。 -
关于基于 Gemma 底座的 Hermes DPO 的咨询:
@samin询问是否会有利用 Google 新发布的 Gemma 7B 底座的 Nous-Hermes DPO 模型,并对 Google 的指令微调(instruction tuning)表示怀疑,同时链接到了关于 Gemma 的 Hugging Face 博客公告。
提到的链接:
- no title found:未找到描述
- Welcome Gemma - Google’s new open LLM:未找到描述
- Reddit - Dive into anything:未找到描述
Nous Research AI ▷ #collective-cognition (3 条消息):
- Heroku 面临批评:
@bfpill对 Heroku 表达了不满,简单地表示:“去他的 Heroku”。 - 对批评的中立回应:
@adjectiveallison回应了@bfpill关于 Heroku 的评论,表示希望跳过这个问题:“我不认为那是重点,但好吧”。 - 对 Heroku 情绪的共识:在
@adjectiveallison回应后,@bfpill再次确认了他们的情绪,坚持对 Heroku 的不满。
Nous Research AI ▷ #project-obsidian (3 条消息):
- 因宠物生病导致项目延期:
@qnguyen3为项目进展缓慢道歉,因为他们的猫生病了,这影响了他们更新和完成模型任务的能力。 - 接受私信:
@qnguyen3邀请团队成员如果需要直接讨论事项,可以发送私信 (DM)。
Eleuther ▷ #general (146 条消息🔥🔥):
-
对具备双重能力的 Diffusion Models 的兴趣:
@swiftlynx询问了能够同时处理提示词引导的 image-to-image 和 text-to-image 任务的 Diffusion Models,提到了 Stable Diffusion 使用 CLIP 的方法并寻求替代方案。 -
寻找具有时间相干性的视频分割模型:
@the_alt_man征求关于能够实现平滑时间相干性(temporal coherence)的视频分割模型资源,并提到了一篇据称实现效果良好的论文。 -
Foundation Models 的治理:来自 AI 与数字政策中心(Center for AI and Digital Policy)的
@hp1618对 Foundation Models 的治理感兴趣,正在为政策建议寻找合作者,例如强制性的风险披露标准。 -
关于 “Foundation Model” 术语的讨论:用户
@_inox、@catboy_slim_和@hp1618讨论了 “Foundation Model” 一词的起源和不同定义,重点讨论了其相对较晚的采用以及对 AI 治理和政策的影响。 -
Google 发布新模型 “Gemma”:
@jckwind分享了 Sundar Pichai 关于 Google 发布 Gemma(一系列开放模型)的推文链接,并讨论了包括 Google、Meta 以及潜在的 OpenAI 产品在内的竞争格局。 -
对模型 Benchmark 相关性的担忧:包括
@rallio.和@fern.bear在内的几位用户辩论了 MMLU 和 HellaSwag 等流行 Benchmark 的有效性和相关问题,指出一些评估题目可能存在缺陷或歧义。
提到的链接:
-
[Discord Your Place to Talk and Hang Out](https://discord.gg/RjVuhxyzkW):Discord 是进行语音、视频和文字聊天最简单的方式。与你的朋友和社区一起聊天、聚会并保持紧密联系。 - Sundar Pichai (@sundarpichai) 的推文:介绍 Gemma —— 一系列轻量级、同类领先的开放模型,采用与创建 Gemini 模型相同的研究和技术构建。展示了强大的性能…
- performant:1. (指技术等)以有效的方式工作:2. (指技术等)…
- GitHub - mlabonne/llm-autoeval: Automatically evaluate your LLMs in Google Colab:在 Google Colab 中自动评估你的 LLMs。通过在 GitHub 上创建账号来为 mlabonne/llm-autoeval 的开发做出贡献。
- LLM-Benchmark-Logs/benchmark-logs/Qwen-72B-base.md at main · teknium1/LLM-Benchmark-Logs:一系列不同 LLMs 的 Benchmark 日志。通过在 GitHub 上创建账号来为 teknium1/LLM-Benchmark-Logs 的开发做出贡献。
- LLM-Benchmark-Logs/benchmark-logs/Deepseek-LLM-67b-base.md at main · teknium1/LLM-Benchmark-Logs:一系列不同 LLMs 的 Benchmark 日志。通过在 GitHub 上创建账号来为 teknium1/LLM-Benchmark-Logs 的开发做出贡献。
Eleuther ▷ #research (350 条消息🔥🔥):
- 关于模型许可的辩论:
@rallio.和@catboy_slim_就使用 Google 的 Gemma 等模型(带有合同条款限制)与在没有 Google 直接许可的情况下使用 Transformer 所面临的挑战和考量进行了辩论。讨论涉及模型是否可以或应该受到版权保护,以及这对商业用途可能产生的影响。 - 探索以少胜多:
@jckwind征求了关于寻找信息效率最高的 Transformer 模型的反馈,引发了关于 MLP、CNN 和 Transformer 在不同规模下性能差异的讨论。此外,还提出了利用“好奇心”(curiosity)等概念来优化模型的想法。 - 对 AGI 定义与实现的追求:包括
@jckwind和@rallio.在内的多位用户辩论了通用人工智能(AGI)的定义,并推测了什么构成了 AGI 甚至超级智能(superintelligence)。对话范围从理论层面延伸到关于智能能力和基准测试(benchmarks)的实际考量。 - Nvidia 合作开发 Gemma:
@kd90138分享了 Nvidia 和 RTX 正在努力为 GPU 使用优化 Gemma 的消息,@rallio.指出这是官方宣布的消息,而非传闻。 - LLM 的理解与假设用途:用户讨论了 LLM 行为和能力的差异。
@jckwind沉思了像 Gemini 这样的模型会如何处理总结长文档或解释魔术等任务,并思考了通往更接近 AGI 能力的路径。
提到的链接:
- 未找到标题:未找到描述
- 未找到标题:未找到描述
- Notion – 笔记、任务、维基和数据库的一体化工作空间。:一款将日常工作应用融合为一的新工具。它是为您和您的团队打造的一体化工作空间。
- Neural Network Diffusion:Diffusion 模型在图像和视频生成方面取得了显著成功。在这项工作中,我们证明了 Diffusion 模型也可以“生成高性能的神经网络参数”……
- GH Archive:未找到描述
- Decoding In-Context Learning: Neuroscience-inspired Analysis of Representations in Large Language Models:通过利用输入中的任务特定示例,Large Language Models (LLMs) 在 In-Context Learning (ICL) 方面表现出显著的性能提升。然而,这种提升背后的机制……
- SnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds:文本生成图像的 Diffusion 模型可以从自然语言描述中创建令人惊叹的图像,足以媲美专业艺术家和摄影师的作品。然而,这些模型体积庞大,结构复杂……
- Fast Transformer Decoding: One Write-Head is All You Need:正如在 Transformer 神经序列模型中使用的一样,多头注意力层(Multi-head attention layers)是在序列之间传递信息的 RNN 的强大替代方案。虽然训练这些层通常是……
-
加入 GroqCloud Discord 服务器!:Groq 提供世界上最快的 AI 推理。 987 名成员 -
Experts Don’t Cheat: Learning What You Don’t Know By Predicting Pairs:识别模型 ${\widehat{p}}_θ(Y X)$ 对其训练所基于的随机现实世界过程 $p(Y X)$ 了解多少,对于确保其避免产生错误或“幻觉”(hallucinated)内容至关重要…… - Feist Publications, Inc., v. Rural Telephone Service Co. - 维基百科:未找到描述
- Gemma: Introducing new state-of-the-art open models:Gemma 是一个轻量级、先进的开放模型家族,采用与创建 Gemini 模型相同的研究和技术构建。
- Reddit - 深入探索一切:未找到描述
-
来自 NVIDIA (@nvidia) 的推文:今天宣布,我们作为发布合作伙伴与 @Google 合作推出 Gemma,这是一个经过优化的模型系列,使用户能够仅使用桌面端 #RTX GPU 即可开发 #LLMs……
-
[第 20 讲 - 高效 Transformers MIT 6.S965](https://youtu.be/RGUCmX1fvOE?si=wcs1MDNbon1URKsO):第 20 讲介绍了高效 Transformers。关键词:Transformer。幻灯片:https://efficientml.ai/schedule/—————————————————… - Google Cloud 博客:未找到描述
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models:我们介绍了通用指令微调(简称 GLAN),这是一种用于大语言模型(LLMs)指令微调的通用且可扩展的方法。与以往依赖种子示例或现有…的工作不同。
- Do Llamas Work in English? On the Latent Language of Multilingual Transformers:我们探究了在不平衡且以英语为主的语料库上训练的多语言语言模型是否将英语作为内部枢纽语言——这对于理解语言模型如何…至关重要。
- generative modelling of compressed image file bits:未找到描述
- Instruction-tuned Language Models are Better Knowledge Learners:为了使基于大语言模型(LLM)的助手能够有效地适应不断变化的信息需求,必须能够通过对新数据的持续训练来更新其事实知识…
- Groq Inference Tokenomics: Speed, But At What Cost?:比 Nvidia 更快?剖析其经济学
- My benchmark for large language models:未找到描述
-
[GitHub on BigQuery: Analyze all the open source code Google Cloud Blog](https://cloud.google.com/blog/topics/public-datasets/github-on-bigquery-analyze-all-the-open-source-code):未找到描述
Eleuther ▷ #interpretability-general (38 条消息🔥):
- 探索 LLM 的内部英语依赖:
@butanium分享了一个 Twitter 链接,表明像 Llama-2 这样的多语言模型可能在内部依赖英语,正如 logitlens 在法语到中文翻译中更倾向于英语 token 所展示的那样。 - Tuned Lens 与 Logit Lens 的模型洞察对比:
@butanium强调了一种使用 logit lens 的研究方法,以确定 Llama-2 在执行非英语任务时是否访问了英语内部状态;tuned lens 会掩盖此类洞察,因为它会将内部状态映射到非英语预测。 - Stella Deck 对比发布:
@butanium对 @BlancheMinerva 的一条 Twitter 帖子做出了回应,该帖子似乎描述了 Stella 已经准备好进行相关实验。 - 使用可用代码复现研究:
@mrgonao愿意使用提供的代码运行实验以复现研究结果,但发现了一些缺失的组件,包括用于 70b 模型的 tuned lens 和一个单独的重复任务 notebook。 - 寻求用于特定语言 Lens 训练的数据:
@stellaathena和@mrgonao讨论了专门为中文训练 lens 的可能性,并考虑使用 Hugging Face 上的 mC4 中文分片等数据集。
提到的链接:
- phoeniwwx/tuned_lens_q · Hugging Face:未找到描述
- shjwudp/chinese-c4 · Datasets at Hugging Face:未找到描述
- AlignmentResearch/tuned-lens at main:未找到描述
- srgo - 概览:srgo 有一个可用的仓库。在 GitHub 上关注他们的代码。
- GitHub - epfl-dlab/llm-latent-language: 论文 "Do Llamas Work in English? On the Latent Language of Multilingual Transformers" 的配套仓库。:论文 “Do Llamas Work in English? On the Latent Language of Multilingual Transformers” 的配套仓库。 - epfl-dlab/llm-latent-language
Eleuther ▷ #lm-thunderdome (76 条消息🔥🔥):
-
关于 MCQ 数据集评估的咨询:
@aloo_kachalu.寻求关于如何计算 MCQ 数据集评估的似然值(likelihood)的建议,@baber_为其推荐了一篇 Hugging Face 博客 以获取详细解释。 -
Evaluation Harness 中对数似然值的可用性:
@hailey_schoelkopf解释说,需要计算对数似然值来进行模型评估的任务(如loglikelihood、loglikelihood_rolling、multiple_choice)无法在不提供对数概率(logits)的 API 模型上运行。 -
解决评估中的显存溢出(OOM)错误:
@pminervini遇到了evaluator.simple_evaluate导致显存溢出(OOM)且 V100 GPU 上分配的显存无法释放的问题。建议包括将代码包裹在try...except中并显式删除模型实例,但最终,重启 runtime 是唯一的解决方案。 -
在 Evaluation Harness 中运行 Gemma 7b 模型:用户在运行 Gemma 7b 模型时遇到了问题,
.rand0mm报告了失败和形状重塑(reshaping)错误,@vraychev提出了评分过低的问题。@hailey_schoelkopf确认该模型的非 Flash-Attention 实现最近已修复,并提供了一个 diff 代码片段来解决评分评估问题。 -
关于 Evaluation Harness 任务类型的澄清:当
@dsajlkdasdsakl询问关于自定义任务在 Evaluation Harness 中导致 API 模型报错时,@hailey_schoelkopf澄清说,output_type为generate_until的任务不需要 logits,可以用于仅返回生成文本的 API 模型。
提到的链接:
- Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- GitHub: Let’s build from here:GitHub 是超过 1 亿开发者共同塑造软件未来的地方。为开源社区做贡献,管理你的 Git 仓库,像专业人士一样审查代码,跟踪错误和功能…
- src/backend/huggingface_generate_until.py · hallucinations-leaderboard/leaderboard at main:未找到描述
- lm-evaluation-harness/lm_eval/evaluator.py at c26a6ac77bca2801a429fbd403e9606fd06e29c9 · EleutherAI/lm-evaluation-harness:一个用于语言模型 few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/tasks/mmlu/default/_default_template_yaml at 5ab295c85f90b2fd6218e88b59a3320544b50f8a · EleutherAI/lm-evaluation-harness:一个用于语言模型 few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
- how to add tasks with requests based on the answers for the previous requests? · Issue #1432 · EleutherAI/lm-evaluation-harness:我有一个想要添加的任务。该任务是关于回答二元问题。与其他任务唯一的区别是,第二个问题需要知道第一个问题的回答。我使用…
- lm-evaluation-harness/lm_eval/tasks/mmlu/flan_cot_zeroshot/_mmlu_flan_cot_zeroshot_template_yaml at main · EleutherAI/lm-evaluation-harness:一个用于语言模型 few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
- What’s going on with the Open LLM Leaderboard?:未找到描述
- [
Core tokenization]add_dummy_prefix_spaceoption to help with latest issues by ArthurZucker · Pull Request #28010 · huggingface/transformers:此 PR 做了什么?允许用户在使用 tokenizer.tokenize 时控制前缀空格的添加。让我们也更新一下 fast 版本!修复了 #28622
Eleuther ▷ #gpt-neox-dev (5 messages):
- 关于 ParallelMLP 中 Dropout 的困惑:
@jdranpariya指出ParallelMLP类中有一个令人困惑的注释,暗示应用了 Dropout,但在提供的代码片段中并不可见。该注释提到了 MLP 过程结束时的 Dropout,尽管其实现并不明显。 - 关于 Dropout 实现的澄清:
@stellaathena澄清说,Dropout 实际上是在 Transformer layer 的构建中应用的,并提供了相关代码链接。他们指出ParallelMLP内部的注释可能具有误导性。 - 承认注释具有误导性:
@jdranpariya同意该注释可能需要修改,以防止对ParallelMLP内部 Dropout 应用产生混淆。然而,他们也表示不愿仅为了修正注释而提交更改。 - 确定 Dropout 代码块:在后续消息中,
@jdranpariya确定了实际应用 Dropout 的代码块,根据 Transformer layer 的构建,这涉及一个 Dropout 函数,随后是 Residual addition。
提到的链接:
gpt-neox/megatron/model/transformer.py at f7373f806689cb270677dd48bffddf4a32bfadce · EleutherAI/gpt-neox:基于 DeepSpeed 库在 GPU 上实现模型并行自回归 Transformer。- EleutherAI/gpt-neox
HuggingFace ▷ #announcements (1 messages):
- 社区 Prompt 排名上线:
@lunarflu宣布 <#1205128865735770142> 已上线,鼓励成员对 Prompt 进行排名,并为构建社区 Dataset 做出贡献。目前已有超过 200 名贡献者和 3500+ 次排名,参与者可以获得经验值并在 <#1197148293164187678> 排行榜上晋升。 - Dataset Viewer 和 HuggingChat 升级:全新改版的全屏 Dataset Viewer 页面类似于电子表格,而 HuggingChat 现在支持对话分支和 Prompt 编辑。详情请查看 LinkedIn 帖子和 Twitter 更新。
- Gradio Notebook 和推理工具令人兴奋:新的
@GradioNotebook 提供了交互式 UX,text-generation-inference 已改进,速度提升了两倍,现在可以将 observablehq dashboards 推送到@HuggingFaceHub。公告链接见 Twitter 和 Twitter。 - 新的开源 AI 动态:社区迎来了新的 Open Source AI Cookbook 和多项更新,包括新的 TRL 发布、Gradio 3D demo 增强、llama.cpp CLI QoL 改进、Transformers 的
torch.compile加速以及 Nanotron v0.2。欲了解更多信息,请访问相应的 Twitter 和 Twitter 链接。 - 庆祝里程碑和更新:已创建超过 1 万个 HuggingChat assistants,宣布了新的 HuggingCast 剧集,韩国 LLM 排行榜作为广泛使用的特定语言排行榜受到关注。在 Twitter 和 Twitter 上了解更多关于这些更新的信息。
HuggingFace ▷ #general (250 条消息🔥🔥):
-
HuggingFace VSCode 扩展故障排除:
@industrial在 NixOS 上运行huggingface-vscode时遇到问题,尽管更新到了最新的llm-ls并尝试了不同的设置,仍面临Missing field request_params和Invalid type: null, expected a string等错误。 -
Gemma 7B vs Zephyr 7B:
@mist7302正在考虑用自己的数据微调 Gemma7b,并询问是应该针对 Zephyr7b 进行基准测试,还是直接与基础版 Mistral7b 进行比较。 -
与 HuggingFace 的合作伙伴提案:
@aaaliahmad.询问如何提交合作伙伴或协作提案,正在等待工作人员关于适当流程的回复。 -
A100 40GB 上的微调挑战:
@gryhkn尝试使用 PEFT、LoRA 和 SFTTrainer 在大型数据集上微调 Mistral-7b,但在 Nvidia A100 GPU 上遇到了显存溢出(out-of-memory)错误,正在寻求建议。 -
新的 Transformers 库更新预告:
@not_lain暗示 Transformers 库即将发布一个令人兴奋的新版本,其中包括新模型和改进,允许用户创建自定义架构而不会遇到问题。
提到的链接:
- Groq:未找到描述
- Google Colaboratory:未找到描述
- llm-vscode - Visual Studio Marketplace:Visual Studio Code 扩展 - 为 VS Code 提供 LLM 驱动的开发功能
-
[USB Accelerator Coral](https://coral.ai/products/accelerator/):一款为现有系统带来加速 ML 推理的 USB 配件。支持 Windows、Mac、Raspberry Pi 或其他 Linux 系统。 - thomas-c-reid/ppo-LunarLander-v2 · Hugging Face:未找到描述
- Deep Reinforcement Learning Leaderboard - a Hugging Face Space by huggingface-projects:未找到描述
- simple static kv cache script:简单的静态 kv cache 脚本。GitHub Gist:即时分享代码、笔记和代码片段。
- AWS Innovate - AI/ML and Data Edition:未找到描述
- ptx0/photo-concept-bucket · Datasets at Hugging Face:未找到描述
- Mistral’s next LLM could rival GPT-4, and you can try it now in chatbot arena:法国 LLM 奇迹 Mistral 正准备发布其下一个语言模型。你现在已经可以在聊天中进行测试。
HuggingFace ▷ #today-im-learning (6 条消息):
- 使用 MLP 进行字符预测:用户
@parvpareek正在学习 Karpathy 讲座 中的使用 MLP 进行下一字符预测。 - 转向 Bengio 的工作:随后,
@parvpareek表示打算实现 Bengio 论文中的 A Neural Probabilistic Language Model。 - 关于 AI Alignment 的有趣论文:
@epicx分享了一篇名为 “Agents Need Not Know Their Purpose” 的有趣论文,讨论了“无意识 Agent”(oblivious agents)的概念,这标志着在解决 AI alignment 挑战方面迈出了一步。 - 寻求图像生成模型的新人:新用户
@mfd000m询问有哪些 Hugging Face 模型能够为笔记本电脑和手机等电子商务产品生成主视觉图(hero images)。
提到的链接:
Agents Need Not Know Their Purpose:确保人工智能的行为与人类价值观保持一致通常被称为对齐挑战(alignment challenge)。之前的研究表明,理性的 Agent 在表现出……
HuggingFace ▷ #cool-finds (8 条消息🔥):
- AI 竞争中 ChatGPT 流量下滑:
@developerworld_指出,ChatGPT 的 Web 流量在过去八个月中有所减少,较 2023 年 5 月的峰值下降了 11%,且其 移动 App 使用量 在用户增长方面落后于 Snapchat 等平台。 - SORA:备受期待的游戏规则改变者?:在关于 ChatGPT 流量减退的讨论中,
@m22046提到 SORA 是市场中潜在的影响者,暗示这是一个值得关注的项目。然而,@developerworld_指出 SORA 尚未公开发布。 - 在 Data Council 的 AI Launchpad 展示 AI 初创公司:
@petesoder宣布了即将在德克萨斯州奥斯汀举行的 Data Council 会议上举办 AI Launchpad 活动。该活动面向尚未注册公司或处于 Pre-seed 阶段的 AI 初创公司的工程师创始人,并提供在舞台上展示其产品的机会。(AI Launchpad 提交入口) - Dynamic Recursive Neural Network 论文:用户
@kirayamato8507分享了一篇题为 “Dynamic Recursive Neural Network” 的研究论文,该论文托管在 CVPR 2019 开放获取库中。(阅读论文) - 对 AI 竞争对手指标的好奇:
@lavi_39761询问了 ChatGPT 的竞争对手(如 Anthropic 和 character ai)在用户指标方面的表现,并指出 You.com 的使用量有所增加。
提到的链接:
Zero Prime @ Data Council ‘24:加入在 Data Council Austin 2024 举办的 Zero Prime Ventures 活动,获得展示您的 AI 初创公司的独特机会。立即申请,争取获得顶级投资者和精英创始人的关注。
HuggingFace ▷ #i-made-this (33 messages🔥):
-
机器人的广告收益:
@myg5702确认通过广告每小时产生 $3-$6 的收入,有效地超过了每小时 $1.48 的云服务器成本并实现盈利。他们提到使用 Replicate 进行云服务,并建议不要使用@code_god无法访问的那些有问题的网站。 -
网络安全爱好者,新模型预警:
@eatmyboxxx宣布将 WhiteRabbitNeo-13B-v1 模型移植到 Ollama,并分享了包括 GGUF 在内的各种链接,表明该网络安全模型很快即可投入使用。 -
AYA 项目分析:
@lavi_39761分享了关于针对低资源和中等资源语言的 AYA 数据集和收集 的见解,评论了其进展,同时强调了进一步提高语言覆盖范围的必要性。 -
金融达人,进阶指南:
@luuisotorres分享了一个 投资组合管理 Web 应用 和一个详细介绍其创建过程的 Kaggle Notebook。该 Web 应用通过交互式视觉图表协助跟踪各种投资并分析回报。 -
深度估计走向移动端:
@shubhamx0204展示了他在 Android 应用上的工作,该应用运行 Depth-Anything 模型进行单目深度估计。该应用由 ONNX 模型驱动以实现高效推理,可在 GitHub 上获取。
提到的链接:
- captainkyd/whiterabbitneo7b: https://huggingface.co/WhiteRabbitNeo/WhiteRabbitNeo-7B-v1.5a
- captainkyd/whiteRabbitNeo-7B.gguf · Hugging Face: 未找到描述
- AYA Dataset Review and Proposed Extensions: 对 AYA 数据集和收集的探索性分析,并提出了扩展方案,以提高中低流行度语言的任务多样性。
- Portfolio Management - a Hugging Face Space by luisotorres: 未找到描述
-
Building an Investment Portfolio Management App 💰: 使用 Kaggle Notebooks 探索和运行机器学习代码 使用来自无附加数据源的数据 - captainkyd/WhiteRabbitNeo-13B-v1.gguf · Hugging Face: 未找到描述
- GitHub - shubham0204/Depth-Anything-Android: An Android app running inference on Depth-Anything: 一个在 Depth-Anything 上运行推理的 Android 应用 - GitHub - shubham0204/Depth-Anything-Android: An Android app running inference on Depth-Anything
HuggingFace ▷ #reading-group (4 messages):
- 神秘规避策略受到质疑:用户
@chad_in_the_house质疑用户@811235357663297546的方法,但目前尚不清楚这是否是一种规避检测的策略。 - 呼吁增强多模态模型:
@lavi_39761针对不确定的情况做出回应,强调需要更好的多模态模型,暗示此类改进可以澄清现状。 - 提出一个简单的解决方案:在之前关于规避检测的讨论背景下,
@clock.work_建议采取一项预防措施:仅允许在过去 24 小时内发送过文本消息的用户发送图片。
HuggingFace ▷ #diffusion-discussions (35 messages🔥):
-
寻求艺术品损坏检测:
@div3440正在进行一个利用 Stable Diffusion 模型激活来检测绘画损坏的项目。他们尝试了在“损坏”等术语上使用 Cross-attention maps,并对 Self-attentions 进行 PCA,但由于语言特异性和损坏显著性的不一致而面临挑战。 -
替代损坏检测建议:
@chad_in_the_house建议考虑使用 GANs 或合成数据生成来训练分类器,并表示如果能实现无需进一步数据即可识别损坏的 Zero-shot 方法将是突破性的。 -
数据集策展的挑战:数据收集工作涉及
@div3440从 Wikipedia 和博物馆藏品中手动挑选受损艺术品,这凸显了其中的困难,因为艺术品元数据中通常不会注明损坏情况。 -
用于 LSTM 图像的 AI 生成模型:
@lucas_selva询问有关生成 LSTM 神经网络图像的服务,或无版权的免费模板,但这些消息中并未讨论出明确的解决方案。 -
Diffusion 模型内部原理探讨:在与
@pseudoterminalx的对话中,@mr.osophy试图了解 Diffusion 模型中的 U-Net 架构是否接收一个影响处理的整数参数t,并了解到这可能并不简单,而是与用于 Timestep embeddings 的 Fourier transforms 有关。
HuggingFace ▷ #computer-vision (4 messages):
-
寻求手语翻译模型:
@dj_mali_boy询问有关将手语转换为文本的模型。@johko990提供了一个潜在的解决方案,链接到一个可能有所帮助的 HuggingFace 模型。 -
使用 BLIP Notebooks 进行图像字幕生成:
@johko990分享了用于 Image Captioning 的 Hugging Face Notebooks 链接,特别提到了一个 使用 BLIP 的 Notebook 和另一个用于 微调 BLIP2 的 Notebook,这些都可以在 Niels 的 Transformers-Tutorials 仓库 中找到。 -
社区对资源的认可:
@seanb2792在发现上述资源后表达了感谢,强调了其价值。
提到的链接:
- Models - Hugging Face: 未找到描述
- notebooks/examples/image_captioning_blip.ipynb at main · huggingface/notebooks: 使用 Hugging Face 库的 Notebooks 🤗。可以通过在 GitHub 上创建账号来为 huggingface/notebooks 的开发做出贡献。
- notebooks/peft/Fine_tune_BLIP2_on_an_image_captioning_dataset_PEFT.ipynb at main · huggingface/notebooks: 使用 Hugging Face 库的 Notebooks 🤗。可以通过在 GitHub 上创建账号来为 huggingface/notebooks 的开发做出贡献。
HuggingFace ▷ #NLP (33 messages🔥):
-
寻求更新的深度学习资源:用户
@nrs9044正在寻找比 2022 年《Deep Learning for NLP》一书更新的资料,特别是那些不包含已弃用软件包的内容。 -
Hugging Face 与 Google Summer of Code 咨询:
@debrup_询问 Hugging Face 是否会参加 GSoC 2024,并寻求关于使用 T5 实现多标签分类的建议,以及如何在缺乏 Mask token 的 SentencePiece 分词器上进行 Masked language modeling。 -
解决 TensorFlow 难题:
@diegot8170在使用 TensorFlow 加载模型时遇到错误,引发了关于潜在框架问题的讨论。在@cursorop的帮助下,通过重新安装 TensorFlow 解决了问题,这强调了该框架与 PyTorch 相比的复杂性。 -
寻求 LLMs 的数据质量基准:
@.konoh寻求驱动大语言模型 (LLMs) 的数据质量行业标准基准,而@nrs9044探讨了 NLP 领域中 LLMs 的替代方案。 -
生物医学术语的自定义 Embeddings:用户
@joshpopelka20在生物医学术语的句子相似度预训练 Embeddings 方面面临挑战,@lavi_39761建议考虑使用对比学习 (Contrastive learning) 和 Sentence Transformers 以获得更好的效果。在不包含分类数据的情况下进行微调后,问题得到了解决。
HuggingFace ▷ #diffusion-discussions (35 messages🔥):
-
寻求艺术品损伤检测:
@div3440询问了关于使用 Stable Diffusion 模型激活来检测绘画中受损区域的问题,并提出了一个涉及 null-prompt inversion 和检查激活矩阵的工作流。他们表达了来自“damaged”等术语的弱调节(weak conditioning)所带来的挑战,并讨论了将 self-attention maps 上的 PCA 作为替代方案,而@chad_in_the_house建议了诸如使用 GAN 生成合成数据以及针对这一独特任务调整现有模型的方法。 -
Diffusion 动画知识差距:
@mr.osophy发布了关于使用 Latent Diffusion 进行高分辨率图像合成的问题,以澄清他们对架构和训练过程的理解。@pseudoterminalx提供了关于 U-Net 利用 timestep embedding 和 Fourier transforms 的见解,强调了 microconditioning 输入的复杂性。 -
寻找 AI 生成的 LSTM 图像:
@lucas_selva寻求生成式 AI 服务或免费模板来生成 LSTM 神经网络的图像,但该查询尚未得到回复。 -
从提示词中提取 Latent Tensors:
@shinyzenith询问是否可以使用 diffusers 提取给定提示词的潜表征张量(latent representation tensors),但该问题没有得到直接回应。 -
HuggingMod 的温馨提示:自动审核正在运行,
@HuggingMod提醒@754474676973076532降低消息频率以避免垃圾信息。
LlamaIndex ▷ #announcements (1 messages):
- LlamaCloud 与 LlamaParse 发布:
@jerryjliu0介绍了 LlamaCloud,这是一项旨在通过生产级数据增强 LLM 和 RAG 应用的新服务,其组件包括 LlamaParse,一个擅长处理复杂文档的解析器。LlamaParse 现已公开可用并设有免费使用上限,托管 API 正面向选定的企业开放私测。 - 首批用户与合作伙伴加入:LlamaCloud 的发布得到了 Mendable AI、DataStax、MongoDB、Qdrant、NVIDIA 以及来自 LlamaIndex Hackathon 项目的用户和合作伙伴的支持。
- LlamaCloud 的核心产品:关于 LlamaCloud 产品的详细博客文章,重点介绍了用于解析复杂文档的 LlamaParse 和用于数据处理的 Managed Ingestion/Retrieval API。一个新的 LlamaParse Discord 频道即将创建。
- 通过 Twitter 传播公告:该发布由官方
@llama_indexTwitter 账号公布,强调了通过 LlamaParse 和支持 API 简化数据处理,从而将更多时间分配给应用逻辑。 - 访问与联系信息:感兴趣的用户可以通过其客户端仓库尝试 LlamaParse,注册 LlamaCloud,联系团队了解更广泛产品的详情,并访问新的 LlamaIndex 网站。公告中提供的链接将用户引导至相应的资源。
提到的链接:
- Introducing LlamaCloud and LlamaParse:今天是 LlamaIndex 生态系统的重要日子:我们宣布推出 LlamaCloud,新一代托管解析、摄取和……
- LlamaIndex 🦙 (@llama_index) 的推文:介绍 LlamaCloud 🦙🌤️ 今天我们很高兴推出 LlamaCloud,这是一项托管服务,旨在为您的 LLM 和 RAG 应用提供生产级数据。减少数据整理时间,投入更多……
LlamaIndex ▷ #blog (4 条消息):
-
面向 LLM 和 RAG 的云服务:Llama Index 发布了 LlamaCloud,这是一项托管服务,旨在为 LLM 和 RAG 应用程序提供生产级数据,让开发者能够专注于应用逻辑而非数据整理(data wrangling)。发布推文还包含了一个 预告链接。
-
高级 RAG 设置指南 (Cookbook):
@llama_index推出了一系列指南,详细介绍了如何使用 LlamaParse 解析 PDF,将其索引到 DataStax 的 AstraDB 中,并应用递归检索(recursive retrieval)来回答复杂查询。更多详情请参阅其 指南手册。 -
简化的 RAG 开发方法:
@jerryjliu0的一个新演讲讨论了如何通过识别和解决流水线中的痛点来简化 RAG 开发。幻灯片现已公开分享,发布推文 提供了获取内容的途径。 -
面向 LLM/RAG 专家的前端教程:Marco Bertelli 为 LLM/RAG 专家创建了一个教程,学习 React 并构建一个美观的前端,以配合
@llama_index的 RAG 后端服务器。该资源已获得全面支持,可通过 分享链接 访问。
LlamaIndex ▷ #general (379 条消息🔥🔥):
- GitHub Repository Reader 速率限制问题:用户
@david1542在使用GithubRepositoryReader时遇到了速率限制问题。@whitefang_jr建议使用 commit ID 代替默认分支,这样可以防止获取所有 commit,从而有助于避免速率限制。 - 理解 LlamaIndex 的导入流程:由于 v0.10.x 升级带来的变化,
@alvarojauna在从 LlamaIndex 导入时遇到困难。@cheesyfishes指出了正确的导入路径,并指出由于代码库发生了重大变化,版本更新应手动应用。 - LlamaIndex 与查询引擎 (Query Engines):讨论集中在查询方法以及 LlamaIndex 如何与 LLM 交互。
@sansmoraxz提到查询引擎中的response_mode可能会影响查询过程中 LLM 调用的次数。 - 处理 Python 类型定义问题:
@humblehound对 Python/AI 库中缺乏显式类型定义表示担忧,引发了关于维护代码库完整性最佳实践的讨论,建议包括使用 Pydantic、Ruff、类型注解,以及可能为库的类型定义(typings)做贡献。 - 针对 LLM 模型的 LlamaIndex 微调:
@david1542询问了如何利用 LlamaIndex 微调 LLM 模型。@whitefang_jr强调了文档中提供非付费微调机制的其他章节。
提到的链接:
- Google Colaboratory:未找到描述
- T-RAG = RAG + Fine-Tuning + Entity Detection:T-RAG 方法的前提是将 RAG 架构与开源微调 LLM 和实体树向量数据库相结合。
- Behavior of Python’s time.sleep(0) under linux - Does it cause a context switch?:这种模式经常出现,但我找不到明确的答案。一个非关键、不友好的程序可能会执行
while(True): # do some work。使用其他技术… - Time.sleep(0) yield behaviour:你好,
time.sleep(0)可以用来在线程中模拟类似 yield 的行为吗?在多线程程序中还有其他让出线程的方法吗? - Fine-tuning - LlamaIndex 🦙 v0.10.11.post1:未找到描述
- llama_index/llama-index-core/llama_index/core/question_gen/llm_generators.py at da5f941662b65d2e3fe2100f2b58c3ba98d49e90 · run-llama/llama_index:LlamaIndex(前身为 GPT Index)是用于 LLM 应用程序的数据框架。
-
llama_index/llama-index-core/llama_index/core/question_gen/llm_generators.py at main · run-llama/llama_index:LlamaIndex(前身为 GPT Index)是用于 LLM 应用程序的数据框架。
- Python 的 time.sleep(0) 在 Linux 下的行为 - 它会导致上下文切换吗?: 这种模式经常出现,但我找不到明确的答案。一个非关键、不友好的程序可能会执行
while(True): # do some work。使用其他技术… - llama_index/llama-index-core/llama_index/core/callbacks/token_counting.py at 6fb1fa814fc274fe7b4747c047e64c9164d2042e · run-llama/llama_index: LlamaIndex(原名 GPT Index)是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- Benjamin Clavié (@bclavie) 的推文: “我希望能在我的 RAG 流水线中使用最好的检索模型作为重排序器(reranker),但我没时间重新设计它!”我们都遇到过这种情况并有过这样的想法,对吧?🪤RAGatouille 现在…
- llama_index/llama-index-integrations/llms/llama-index-llms-vllm/llama_index/llms/vllm/base.py at main · run-llama/llama_index: LlamaIndex(原名 GPT Index)是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/chat_engine/types.py at main · run-llama/llama_index.): LlamaIndex(原名 GPT Index)是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- 未找到标题: 未找到描述
- 自定义 Embeddings - LlamaIndex 🦙 v0.10.11.post1: 未找到描述
- llama_index/llama-index-integrations/embeddings/llama-index-embeddings-ollama/llama_index/embeddings/ollama/base.py at main · run-llama/llama_index: LlamaIndex(原名 GPT Index)是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- 修复,大量的修复 [循环导入大礼包] 由 logan-markewich 提交 · Pull Request #11032 · run-llama/llama_index: 未找到描述
- OpenAI API 兼容性 · Issue #305 · ollama/ollama: 有没有可能考虑镜像 OpenAI 的 API 规范和输出?例如
/completions和/chat/completions。这样,它就可以通过更改… 成为 Python openai 包的无缝替代品。 - 添加 sleep 以修复聊天流中的延迟,由 w4ffl35 提交 · Pull Request #10339 · run-llama/llama_index: 描述:这是我在尝试从线程中使用聊天流时发现的一个 Bug 修复。在循环中添加 sleep 可以解除线程阻塞,使聊天流能按预期运行…
LlamaIndex ▷ #ai-discussion (7 条消息):
- AndySingal 博客文章推荐:
@andysingal分享了一篇名为《利用 LlamaIndex 和 Step-Wise React Agent 实现高效文档处理》的博客文章,探讨了如何集成 LlamaIndex、React Agent 和 Llamacpp 进行文档管理。 - 关于 GPT-4 算术能力的深度阅读:
@johnloeber发布了他们的新博文,讨论了 GPT-4 在算术和符号推理方面的能力与局限性,并分享了 GPT-4 在计算总和时出错的个人经历。 - 探索 Camfranglais 翻译:用户
@behanzin777寻求训练 GPT 将法语翻译成 Camfranglais 的策略,并提供了一个相关词典的链接,同时表达了之前尝试过的方法所遇到的困难。 - Gemini 1.5 或是俚语翻译的潜在解决方案:针对
@behanzin777的提问,@geoloeg提到 Gemini 1.5 可能是学习 Camfranglais 的潜在解决方案,因为它具备从语法或俚语词汇中学习语言的能力。@behanzin777对此建议表示感谢并计划尝试。 - 寻求 LlamaIndex 的摘要评估指标:
@dadabit.询问是否有人在使用特定指标来评估 LlamaIndex 中的摘要功能,并请求关于有效指标和工具的建议。
提到的链接:
- #16: Notes on Arithmetic in GPT-4:几周前,我有一份需要求和的金额清单。我想:“GPT 擅长转换格式”,于是将其复制粘贴到 ChatGPT 中。结果看起来很合理。但我有一个时刻…
- Leveraging Llamaindex & Step-Wise React Agent for Efficient Document Handling:Ankush k Singal
Mistral ▷ #general (197 条消息🔥🔥):
-
Groq 的串行速度奇迹:
@thezennou和@i_am_dom讨论了 Groq 芯片 尽管具有串行特性且内存有限,但其速度惊人。他们认为虽然成本可能很高,但通过适当的 batching,它可以达到每秒数千个 token,不过@i_am_dom指出了在扩展到更大模型时的局限性。 -
Mistral-Next 的简洁偏好:用户
@paul.martrenchar_pro和@akshay_1发现 Mistral-Next 与 Mistral-Medium 相比提供的回答更短,并讨论了可能的原因,范围从平台的设置到模型固有的设计。 -
新 LLM 中的审查担忧:
@nayko93和@ethux谈到了包括 Mistral-Next 在内的新型语言模型中日益增加的审查制度,@ethux指出需要遵守欧洲法律,这些法律强制要求对非法内容进行审核。 -
Mistral 潜在的模型发布和开源状态:
@gunterson、@dillfrescott和@mrdragonfox表达了对 Mistral 继续发布开源版本的希望,讨论了其在成本和可访问性方面的优势。一些用户对失去开源访问权限表示担忧,而@mrdragonfox则对即将发布的公告表示乐观。 -
LLM 中的 Function Calling 和聊天界面查询:用户询问了关于使用 Mistral AI 的 function calling 能力和构建聊天界面的问题。
@mrdragonfox澄清了该功能的工作原理,即它将输出格式化为 JSON 以供客户端执行,而@ethux和@drnicefellow等其他人则提供了使用 Mistral AI 实现聊天 UI 的资源。
提到的链接:
- 来自 Aaditya Ura (Ankit) (@aadityaura) 的推文:来自 @GoogleDeepMind @GoogleAI 的新模型 Gemma 在医疗/保健领域基准测试中表现不佳。对 @GoogleDeepMind 的 Gemma 和 Mistral 进行了侧向对比…
- Pretraining on the Test Set Is All You Need:受近期展示了在精心策划的数据上预训练的小型基于 Transformer 的语言模型前景的工作启发,我们通过投入大量精力策划一个…来增强此类方法。
-
[基础 RAG Mistral AI 大语言模型](https://docs.mistral.ai/guides/basic-RAG/):检索增强生成 (RAG) 是一种 AI 框架,它协同了 LLM 和信息检索系统的能力。它对于利用…回答问题或生成内容非常有用。 - gist:c9b5b603f38334c25659efe157ffc51c:GitHub Gist:即时分享代码、笔记和代码片段。
-
[提示能力 Mistral AI 大语言模型](https://docs.mistral.ai/guides/prompting-capabilities/):当你开始使用 Mistral 模型时,你的第一次交互将围绕 prompt 展开。编写有效 prompt 的艺术对于从 Mistral 模型中获得理想的响应至关重要… - 来自 MISTRAL-AI 的神秘新 LLM:Mistral-Next 是来自 Mistral-AI 的新 LLM。目前还没有关于它的信息,但它是一个强大的 LLM。🦾 Discord: https://discord.com/invite/t4eYQRUcXB☕ Buy me…
- Mistral-NEXT 模型全面测试 - 新的逻辑之王!:Mistral 悄悄发布了他们最新的模型 “mistral-next”。它是否优于 GPT4?需要 AI 咨询吗?✅ - https://forwardfuture.ai/ 在 Twitter 上关注我 🧠 …
- GitHub - MeNicefellow/DrNiceFellow-s_Chat_WebUI:通过在 GitHub 上创建账号,为 MeNicefellow/DrNiceFellow-s_Chat_WebUI 的开发做出贡献。
- Mistral:未找到描述
Mistral ▷ #models (72 条消息🔥🔥):
- Mixtral 模型困惑已解决:用户
@ethux向@brendawin澄清,遇到的TypeError是由于一个意外的关键字参数 ‘device’ 引起的,且在该代码参数中无法定义device。他们还建议查看文档以获取正确的实现方式。 - 关于 Mistral 潜力和局限性的见解:用户
@ygrek询问了关于 8X7B 模型的各种问题,包括硬件要求、与类似 Copilot 工具的兼容性以及实现细节。在随后的讨论中没有提供明确的答案。 - 模型性能和访问规范:
@impulse749询问了 Mixtral-next 与 GPT-4-Turbo 相比的性能及其开源状态。@mrdragonfox提到 Mistral 模型是 Open Weights(开放权重)而非 Open Source(开源),Mistral-next 的官方公告尚待发布。 - 量化讨论:
@mrdragonfox建议模型的 Quantization(量化)版本可以比 FP16 版本更快,特别是在像 Groq 这样运行原生 INT8 推理的加速器上进行 Batching(批处理)时。 - 面向学习者的 FusionL AI:
@kunal0089介绍了他们的生成式 AI 初创公司 FusionL AI,这是一个以智能和极简方式学习的平台,并提供了链接供他人尝试此处。
提到的链接:
FUSIONL AI:FUSIONL AI 是 SMLM 模型(Smart Minimalistic Language Model,智能极简语言模型)的先驱,旨在以智能和极简的方式进行学习。
Mistral ▷ #deployment (38 条消息🔥):
-
TensorRT 与 Mistral 咨询:用户
@goatnes询问了在 RTX 上或使用 TensorRT 运行带有聊天功能的 Mistral 8x7b 的可行性。@mrdragonfox回复称这需要 ONNX Runtime 及其移植,但认为这仍然是可能的。 -
探索 AI 部署基础:
@goatnes承认他们刚刚开始学习 AI 部署基础知识,表明他们的咨询是学习过程的一部分。 -
托管 Mistral 的 AWS 私有服务器成本:
@ambre3024寻求社区帮助,以估算在 AWS 私有服务器上托管 Mistral 的相关成本。@ethux通过询问正在考虑托管的模型大小进行了回应,暗示成本因模型大小而异。 -
Mistral next API 可用性:用户
@rantash68询问了通过 API 获取 Mistral next 的可用性,@sophiamyang确认目前不可用,且未提供任何关于未来可用性的迹象。 -
寻求 Mistral 的高效生产部署:
@louis2567表达了将 Mistral 7b 和 Mixtral 8x7b 投入生产以实现快速推理的意图。@mrdragonfox提供了通过 Docker 镜像或 Python 包使用 vLLM 部署 Mistral 的详细说明和注意事项,并就 Batching 对 GPU 性能的好处和影响进行了深入交流。
提到的链接:
| [vLLM | Mistral AI Large Language Models](https://docs.mistral.ai/self-deployment/vllm/):vLLM 可以使用我们提供的 Docker 镜像部署,也可以直接从 Python 包部署。 |
Mistral ▷ #finetuning (29 条消息🔥):
- 提倡微调迭代过程:
@rusenask强调 Finetuning(微调)不是一蹴而就的过程,建议采用微调、测试、调整和反复迭代的循环,并有可能为了更好的方法而放弃现有方案。 - 向模型添加新语言面临挑战:
@kero7102询问关于向 Mistral/Mixtral 添加希伯来语的问题,并指出 Tokenizer 的支持较差,而@tom_lrd建议,由于在这些 Token 上的预训练有限,像希伯来语这样不太常用的语言能否成功尚不确定。 - 排查显存溢出(OOM)错误:
@iamcoming5084在合并 8x7b 模型时遇到显存溢出错误,@mrdragonfox解释说需要 86GB 的 VRAM,这超过了单个 H100 80GB GPU 的容量。 - 翻译作为语言支持的解决方案:
@tom_lrd建议考虑使用翻译模型来处理英语,并搜索关于葡萄牙语和爱沙尼亚语等其他语言的讨论以获取更多见解。 - 影响微调准确性的参数:
@_._pandora_._建议在微调 Mixtral 8x7b 和 Mistral 7B 时,考虑 Epoch/Steps、Batch Size 或 LoRA 的超参数 r 等参数,以提高准确性。
Mistral ▷ #showcase (25 messages🔥):
- 教育 AI 初创公司展示:
@kunal0089介绍了 FUSIONL AI,这是一家专注于以智能、极简方式进行学习的生成式 AI 初创公司。他们分享了 FUSIONL AI 的网站,并强调其使用 SMLM Model 来改变学习方法。 - 关于 AI 学习工具的讨论:
@gunterson询问了 FUSIONL AI 相比 GPT-3.5/4 等封装工具(wrappers)的优势,促使@kunal0089解释说他们的 AI 提供精简的、要点式的信息分发,用户无需指定格式。 - 关于展示频道礼仪的澄清:
@ethux向 Discord 社区发表讲话,指出展示频道旨在展示使用 Mistral 构建或与之相关的项目,制止那些看起来更像自我推广且与 Mistral 无直接关联的内容。 - Mistral-Next 实况测试:
@jay9265提到他们正在其 Twitch 频道上针对数据工程用例测试 Mistral-Next,并提供了 直播链接,同时也询问了如果该帖子不合适是否可以获得许可。 - 分享提示词编写指南:
@mrdragonfox链接了一个 Mistral AI 指南,教用户如何为分类、摘要、个性化和评估等各种任务编写有效的 Prompt,该指南可在 Github 及其 Colab notebook 上找到。他们还提到在这些任务中使用置信度分数,并表示像 DSPy 这样的 Prompt 退火工具将会很有帮助。
提到的链接:
- Jay9265 - Twitch:欢迎!处于数据工程和 LLM 的交汇点。加入我们,一起玩转语言模型并解决数据工程问题。
- FUSIONL AI:FUSIONL AI 是 SMLM Model(智能极简语言模型)的先驱,旨在以智能和极简的方式进行学习。
- 使用 LangGraph 的纠正性 RAG:纠正性 RAG。自我反思可以增强 RAG,从而纠正低质量的检索或生成。最近的几篇论文都聚焦于这一主题,但…
- BitDelta: 你的微调可能只值 1 Bit:大语言模型(LLM)通常分为两个阶段进行训练:在互联网规模的大型数据集上进行预训练,以及针对下游任务进行微调。鉴于…
-
[提示能力 Mistral AI 大语言模型](https://docs.mistral.ai/guides/prompting-capabilities/):当你开始使用 Mistral 模型时,你的第一次交互将围绕 Prompt 展开。编写有效 Prompt 的艺术对于从 Mistral 模型生成理想的响应至关重要… - 使用 LangGraph 的 Self RAG:自我反思可以增强 RAG,从而纠正低质量的检索或生成。最近的几篇论文都聚焦于这一主题,但实现…
Mistral ▷ #random (2 messages):
- Flutter 开发者喜讯:来自 Nomtek 的用户
@lkincel宣布了一个新库,旨在帮助将 Mistral AI 集成到 Flutter 应用中,目标客户是开发 PoC 的移动开发者。该库可以在 GitHub 上找到,并在 Medium 文章中进行了进一步解释,文章概述了在聊天机器人、Embeddings 以及 LLM 作为控制器方面的用例。 - 教育 AI 起飞:
@kunal0089提到正在开发一个专注于学习和教育目的的 AI,但未提供有关该项目的更多细节或链接。
提到的链接:
- GitHub - nomtek/mistralai_client_dart:这是 Mistral AI API 的非官方 Dart/Flutter 客户端。
- 使用 Mistral AI 轻松实现 Flutter 与 AI 的集成:合著者:Łukasz Gawron
Mistral ▷ #la-plateforme (10 messages🔥):
- API 中没有 LogProbs:
@youssefabdelmohsen询问了如何通过 API 获取 logprobs,@mrdragonfox回复称目前无法实现,并参考了频道 <#1204542458101502033> 以获取更多信息。 - Mistral-Next 的访问权限处于暂停状态:
@superseethat询问了如何访问Mistral-Next,@ethux澄清说目前无法访问,因为 Mistral Next 尚未发布。 - 通过 Lymsys Chat 测试 Mistral-Next:针对访问权限问题,
@ethux补充说,目前只能使用 lymsys 的聊天界面测试 Mistral Next。 - 澄清 API 计费阈值:
@sapphics寻求关于超出 API 计费阈值含义的澄清,@mrdragonfox确认了 Mistral 计费限制的相关性,并建议直接联系支持邮箱 support@mistral.ai。 - 对支持响应的担忧:在后续讨论中,
@ginterhauser表达了挫败感,称两次尝试联系以提高 API 限制都被无视了,引起了对客户支持响应能力的关注。@mrdragonfox回复询问他们在联系时是否包含了其 id。
提到的链接:
未找到标题:未找到描述
OpenAI ▷ #ai-discussions (104 messages🔥🔥):
-
AI 的优缺点:聊天中的用户对他们一直在使用的 AI 工具有着复杂的情绪。
@hanah_34414称赞 GPT-4 在数学问题上的可靠性,而@jeremy.o成功地使用 Groq 生成了与爱德华时代文学相关的内容。另一方面,@blckreaper抱怨 Gemini 在尝试做作业时产生了类似莎士比亚风格的回复。 -
等待 Sora 的到来:包括
@copperme_14779和@lofiai.art在内的几位用户询问了 Sora AI 何时可以公开使用或通过 API 访问,但@solbus和其他人强调目前还没有 Sora 的确定发布日期。 -
聊天机器人消息限制引发辩论:
@lugui报告了使用 GPT-4 每 3 小时 40 条消息的限制,引发了@zaatuloa的提问,并与@7_vit_7和@solbus进行了详细讨论,后者澄清了消息限制背后的原因和政策,包括参考了各种 OpenAI 官方资源中的使用上限和订阅计划。 -
Google 的隐秘 AI 动作:
@oleksandrshr和@tariqali提到了 Google 发布的新 AI 模型,指出其为了获得媒体关注而进行的战略布局,以及该模型权重是开放的,但在对话中关于该 Google 新模型的名称和规格等细节仍然模糊。 -
寻求功能与澄清:用户
@a.obie对 ChatGPT Teams Plan 缺乏实时共享功能表示沮丧,指出所描述的功能与实际功能之间存在误导性。在另一个帖子中,@zaatuloa询问为什么 GPT 4 Turbo 可能被认为是一个更差的版本,但没有提供确切的答案。
提到的链接:
- 与开源大语言模型聊天:未找到描述
- 介绍 ChatGPT Plus:我们正在推出 ChatGPT 的试点订阅计划,这是一款可以与你聊天、回答后续问题并挑战错误假设的对话式 AI。
OpenAI ▷ #gpt-4-discussions (54 messages🔥):
-
GPT-3.5 Turbo 模型更新讨论:用户
@fightray询问了 gpt 3.5 turbo 0125 和 gpt 3.5 turbo 之间的区别。@solbus澄清说,截至 2 月 16 日,gpt-3.5-turbo 模型别名现在应指向 gpt-3.5-turbo-0125,并引用了此处的信息。 -
AI 在政策边缘的批判性思维受到质疑:
@Makeshift批评 AI 拒绝执行其认为违反政策的任务,即使逻辑上这些任务是可以接受的,这促使@darthgustav.回应了对可能被滥用于剽窃的担忧。 -
自定义 GPT 在转录文本分析中遇到困难:
@col.bean试图开发一个 GPT 来从访谈转录文本中提取精彩瞬间,但面临结果不稳定的问题。@darthgustav.建议使用正向表述的指令、特定的输出模板,并可能为每个转录文本创建新的 GPT,以避免上下文混淆。 -
关于访谈自定义 GPT 的进一步说明:
@darthgustav.继续协助@col.bean,暗示将转录文本作为 txt 文件存放在知识库中的优势,并建议每个转录文本开启一个新会话,以保持分析的一致性。 -
文件上传限制和使用上限探讨:
@my5042对文件上传限制以及每位用户 10GB 的相关上限表示困惑。@solbus给出了可能的解释,并引导@my5042查看更新后的 FAQ 链接,以进一步了解当前的文件限制。
OpenAI ▷ #prompt-engineering (94 messages🔥🔥):
-
GPT-4-1106 的 Unicode 故障:
@pyramidscheme_报告说,在使用 GPT-4-1106 输出带有编号段落的 JSON 时,进程会在£符号处停止,但在非 JSON 模式下,它会将£还原为\u000a。目前尚未提供明确的解决方案。 -
为业务微调 AI 回复:
@silverknightgothic寻求 AI Assistant Prompt 的帮助,以根据业务数据改善客户回复;@darthgustav建议使用带有变量的输出模板,将指令总结为变量名,以更有效地引导 AI 的结构和内容。 -
避免 Prompt 中的歧义和否定表述:
@darthgustav与@silverknightgothic进行了深入讨论,指出了 Prompt 指令中潜在的冲突,并强调了使用正向、具体的方向来引导 AI 行为的重要性。 -
遵守 OpenAI Discord 规则:在涉及潜在服务提供的一系列交流中,
@eskcanta介入并提醒注意服务器关于禁止自我推广或征集的第 7 条规则,讨论继续集中在保持 AI 互动的积极性和高效性上。 -
角色扮演任务的模型选择:
@shokkunn和@darthgustav讨论了不同 GPT-4 模型在角色扮演中的效果,@darthgustav建议通过适应当前最佳模型来为未来的更新做准备,并暗示了为带有多个 RPG 自定义 GPT 的角色扮演 Prompt 设计输出模板的复杂性。
OpenAI ▷ #api-discussions (94 messages🔥🔥):
-
GPT-4-1106 的 Unicode 难题:用户
@pyramidscheme_在GPT-4-1106处理 £ 符号时遇到问题,导致 JSON 模式下的输出截断,或在关闭 JSON 时出现字符编码变化。 -
为精确的 AI 行为编写 Prompt:
@silverknightgothic和@shokkunn等用户讨论了让 AI 生成符合特定业务需求或角色扮演场景的回复所面临的挑战。@darthgustav.强调了使用明确的正向指令和嵌入指令的输出模板以获得更好合规性的重要性。 -
模型之谜 - 不同模型,不同结果:
@shokkunn比较了gpt-4-0613和0125 turbo模型在角色扮演中的表现,发现前者在自然对话方面更有效。 -
AI 作为辅助程序员:新人
@razorbackx9x寻求使用 ChatGPT 帮助处理 Apple’s Shortcuts 应用的建议,而@bambooshoots提供了一个详细的 Prompt 模板,适用于以各种脚本语言创建快捷指令。 -
保持正向的 AI 指令:
@eskcanta和@darthgustav.建议关注 AI 应该做什么,而不是不应该做什么,将其比作引导一只热切的宠物:通过定向任务让它保持忙碌,以避免不希望的行为。
Latent Space ▷ #ai-general-chat (92 条消息🔥🔥):
- 即将举行的特别版研讨会:
@intheclouddan分享了 Carsten Binnig 将于 2024 年 2 月 23 日发表的演讲链接,但指出目前没有明确的活动报名方式。 - 对 Karpathy 新课程的关注:社区对 Andrej Karpathy 的新讲座表现出浓厚兴趣,其中一节是关于构建 GPT tokenizer,另一节则是对 Gemma tokenizer 的深入探讨。
- Data Council 的 AI Launchpad:
@petesoder重点介绍了 AI Launchpad 活动,邀请工程师创始人于 3 月在德克萨斯州奥斯汀举行的 Data Council 会议上向投资者展示其 AI 产品。 - Google 在 Huggingface 上发布 “Gemma”:
@mjng93介绍了 Google Gemma 的发布,这是一个全新的 SOTA 开源 LLM 系列,并提供了其技术报告和服务条款的链接。随后,大家就该模型的训练细节、数据使用及其影响进行了进一步讨论。 - Magic 的 AI 突破分析:
@aardvarkoncomputer分享了一篇讨论 Magic 的文章,这是一款声称性能超越 Gemini 和 GPT-4 等现有模型的 AI 编程助手,引发了对其底层技术以及计算机科学家未来就业市场的讨论。
提到的链接:
- Andrej Karpathy (@karpathy) 的推文:新讲座(2小时13分 😅):”让我们来构建 GPT Tokenizer”。Tokenizer 是 LLM 流水线中一个完全独立的阶段:它们有自己的训练集、训练算法(Byte Pair Enc…
- Latent Space 一周年:Latent Space 在一年内从 0 增长到 100 万读者的经验(与回忆)。
- 未找到标题:未找到描述
- 欢迎 Gemma - Google 的新开源 LLM:未找到描述
- 未找到标题:未找到描述
- Zero Prime @ Data Council ‘24:加入在奥斯汀举行的 Data Council 2024 的 Zero Prime Ventures,获得展示你 AI 初创公司的独特机会。立即申请,接触顶级投资者和精英创始人。
- 震撼 GIF - Mindblown - 发现并分享 GIF:点击查看 GIF
- 让 Friedman 和 Gross 为一家编程初创公司豪掷 1 亿美元的 “Magic” 突破:前 GitHub CEO Nat Friedman 及其投资伙伴 Daniel Gross 上周向 AI 编程助手开发商 Magic 开出了 1 亿美元的支票,引发广泛关注…
- AI 工程师的崛起 (与 Build Club ANZ):幻灯片:https://docs.google.com/presentation/d/157hX7F-9Y0kwCych4MyKuFfkm_SKPTN__BLOfmRh4xU/edit?usp=sharing 🎯 Build Club 中的收获/亮点线索…
- Reddit - 深入探索:未找到描述
- DSDSD - 荷兰数据系统设计研讨会:一项旨在汇集荷兰大学和研究机构中从事数据系统研究小组的倡议。
- Andrej Karpathy (@karpathy) 的推文:鉴于我昨天发布了 Tokenizer 视频,我觉得深入研究一下 Gemma tokenizer 会很有趣。首先是 Gemma 技术报告 [pdf]:https://storage.googleapis.com/de…
- Deedy (@debarghya_das) 的推文:让 Google Gemini 承认白人的存在竟然难得令人尴尬。
Latent Space ▷ #ai-announcements (3 条消息):
- 深入探讨《Building Your Own Product Copilot》论文:
@swyxio宣布@451508585147400209正在主持关于论文 Building Your Own Product Copilot 的研讨会,并为感兴趣的加入者提供了相关 Discord 频道的链接。 - 随时掌握 Latent Space 活动动态:
@swyxio重点介绍了如何获取 Latent.Space 活动的最新信息——通过点击右侧日历上方的 RSS 图标,并使用 “Add iCal Subscription” 功能将活动通知添加到您的日历中。他们提供了订阅活动通知的直接链接:点击此处。
提到的链接:
Latent Space (Paper Club & Other Events) · Luma: 在 Luma 上查看并订阅来自 Latent Space (Paper Club & Other Events) 的活动。Latent.Space 活动。请点击右侧日历正上方的 RSS 图标以添加到您的日历。”Ad…
Latent Space ▷ #llm-paper-club-west (173 条消息🔥🔥):
-
GPT 作为工程师的 Co-Pilot:@eugeneyan 分享了见解并引发了关于将 AI 能力集成到产品中的讨论,专业软件工程师在工程过程的每一步都面临挑战。所提到的论文是一项针对开发产品 Copilot 的工程师的访谈研究。
-
Google Gemini 登台亮相:@coffeebean6887 指出了 Google 最近的更新,强调了 Gemini AI 在各种 Google Workspace 应用程序中的集成以及为用户提供的新功能。官方信息可在 Google 关于 Google One Gemini 和 Gemini for Google Workspace 的博客文章中找到。
-
关于 Fine-tuning 和测试 LLM 的辩论:小组积极讨论了评估语言模型的各种策略,成员如 @henriqueln7 和 @_bassboost 分享了他们使用不同评估工具的经验和方法,包括 Langsmith 以及可能使用像 Mistral 这样的小型模型来评判性能。
-
关注 AI 应用的评估:聊天强调了 AI 集成中评估方法的重要性,用户如 @djmcflush 和 @ayenem 提到了使用 uptrain 和 LLama Guard 等工具来测试 LLM 输出。对话强调了 Prompt 设计和优化的挑战。
-
企业中 AI 集成与人才的未来:@lightningralf 和 @eugeneyan 就 AI 模型的快速发展将如何导致公司内部所需技能组合的转变进行了前瞻性讨论。大家达成共识,认为 Evals(评估)和 Prompt 编程以及 Finetuning(微调)作为关键技能的重要性日益增加。
提到的链接:
- Building Your Own Product Copilot: Challenges, Opportunities, and Needs:构建你自己的产品 Copilot:挑战、机遇与需求。一场将先进 AI 能力嵌入产品的竞赛正在进行。这些产品 Copilot 使用户能够用自然语言提问,并获得针对特定用途的相关回复…
- no title found):未找到标题
- New ways Google Workspace customers can use Gemini:Google Workspace 客户使用 Gemini 的新方式:我们正在推出一项新产品,帮助组织开始使用生成式 AI,以及一个与 Gemini 聊天的独立体验。
- LoRA Land: Fine-Tuned Open-Source LLMs:LoRA Land:微调后的开源 LLM。性能超越 GPT-4 的微调 LLM,可在单张 GPU 上运行。
- Boost your productivity: Use Gemini in Gmail, Docs and more with the new Google One plan:提升你的生产力:通过新的 Google One 计划在 Gmail、Docs 等中使用 Gemini。我们通过在 Gmail、Docs、Slides、Sheets 和 Meet(原 Duet AI)中加入 Gemini,为 Google One AI Premium 计划带来更多价值。
- - Fuck You, Show Me The Prompt.:- 别废话,给我看 Prompt。通过拦截 API 调用快速理解难以捉摸的 LLM 框架。
- Tweet from Amazon Web Services (@awscloud):来自 Amazon Web Services (@awscloud) 的推文。由 #AWS 举办的 PartyRock #generativeAI 黑客松现在开始!📣 了解如何无需编码即可构建有趣且直观的应用,有机会赢取现金奖励和 AWS 积分。🏆 #AI 不要忘了你的杯子…
- SPQA: The AI-based Architecture That’ll Replace Most Existing Software:SPQA:将取代大多数现有软件的基于 AI 的架构。2023 年 3 月 10 日,由于 GPT 带来的爆发,AI 在未来几个月和几年里将做很多有趣的事情。但其中最重要的之一…
- Founder’s Guide to Basic Startup Infrastructure:创始人基础创业基础设施指南:未找到描述。
- GitHub - stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models:GitHub - stanfordnlp/dspy: DSPy:用于编程(而非提示)基础模型的框架。
OpenAccess AI Collective (axolotl) ▷ #general (165 条消息🔥🔥):
-
企业客户的 GPU 选择:Yamashi (@yamashi) 在购买 8xH100 还是 8xMI300X GPU 之间进行权衡,由于 MI300X 拥有更高的 VRAM 而倾向于它,但对其与 ROCm 软件的兼容性表示担忧。在讨论云端与本地计算的对比时,他们提到由于处理海量的医院数据,在云端管理着 15,000 个 VM。
-
Google Gemma Chat 模型分析:AI Collective (@le_mess, @nafnlaus00) 讨论了 Google 新发布的 Gemma 模型的细节和影响,该模型包含 2B 和 7B 两个变体,并采用了金字塔级联(pyramidal ranks)。讨论的焦点包括 Gemma 的许可证和输出限制、评估方法,以及其自定义聊天格式的具体细节,几位成员认为与其他模型相比,该格式在 fine-tuning 时速度较慢。
-
Flash Attention 对 fine-tuning 的影响:对话 (@nruaif, @nanobitz, @dreamgen) 集中在 Gemma 对 Flash Attention 的使用上。Flash Attention 的更新 (v2.5.5) 现在允许在消费级 GPU 上进行 head dimension 256 的 backward,这可能有助于在包括 RTX 4090 在内的消费级 GPU 上 fine-tuning 这些大型模型。
-
Gemma 发布指令微调变体:介绍了旨在用于 fine-tuning 的 Gemma 7B 模型架构细节,包括为了获得最佳性能而推荐的 GPU 类型。重点介绍了新的指令微调(instruction-tuned)
-it变体,据称通过特定的 fine-tuning 方法提供了更强的性能。 -
Gemma 的开放获取与转贴:Le_mess (@le_mess) 将 Gemma 模型重新上传到 Hugging Face 平台以提供无门槛(ungated)访问,并通报成功传输了 32GB 的 .gguf 文件且未发生崩溃。对话 (@j_sp_r, @stoicbatman) 指出了 fine-tuning Gemma 模型的复杂性,包括潜在的速度问题以及与 Flash Attention 工具的兼容性。
提到的链接:
- 未找到标题:未找到描述
- HuggingChat:让所有人都能使用社区最优秀的 AI 聊天模型。
- Google 推出名为 Gemma 的轻量级开放 AI 模型:Google 表示 Gemma 是其对开放社区的贡献,旨在帮助开发者“负责任地构建 AI”。
- 欢迎 Gemma - Google 的新开放 LLM:未找到描述
- mhenrichsen/gemma-7b · Hugging Face:未找到描述
- Tri Dao (@tri_dao) 的推文:FlashAttention v2.5.5 现在支持在消费级 GPU 上进行 head dim 256 的 backward。希望这能让 fine-tuning Gemma 模型变得更容易。
- mhenrichsen/gemma-7b-it · Hugging Face:未找到描述
- llm-foundry/scripts/train/README.md at main · mosaicml/llm-foundry:用于 MosaicML 基础模型的 LLM 训练代码。欢迎在 GitHub 上创建账号为 mosaicml/llm-foundry 的开发做出贡献。
- GitHub - Dao-AILab/flash-attention: 快速且内存高效的精确注意力机制:快速且内存高效的精确注意力机制。欢迎在 GitHub 上创建账号为 Dao-AILab/flash-attention 的开发做出贡献。
- 在消费级 GPU (Ampere, Ada) 上启用 headdim 256 backward · Dao-AILab/flash-attention@2406f28:未找到描述
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (23 条消息🔥):
- 分享用于优化微调的 LoRA+ 论文:用户
@suikamelon分享了一篇关于 LoRA+ 的 arXiv 论文,这是一种通过为 LoRA 适配器矩阵使用不同的学习率来改进宽模型(large widths)微调的算法,从而带来显著的性能提升。 - 将 LoRA+ 集成至 Axolotl:
@caseus_提到集成 LoRA+ 似乎非常直接,目前已有 GitHub 仓库可用,并建议可以轻松将其添加到 Axolotl 中。 - Gemma 模型需要最新版本的 Transformers:
@giftedgummybee指出训练 Gemma 模型必须使用更新后的非开发版 transformers (pip install -U transformers),因为开发版不支持 “gemma” 类型。 - 分享用于 Gemma 训练的更新版 Axolotl 配置:
@stoicbatman提供了一个更新后的 Gemma 配置以兼容 Axolotl,而@nanobitz等人确认正在进行测试。 - 关于 Gemma 学习率和权重衰减值的讨论:在 Gemma 模型的配置讨论中,
@faldore指出 Google 文档中关于学习率和权重衰减(weight decay)的描述不一致,并引用了他们的 Colab notebook 和 Hugging Face 博客文章,两者显示使用了不同的数值。
提到的链接:
- LoRA+: Efficient Low Rank Adaptation of Large Models:在这篇论文中,我们展示了由 Hu 等人 (2021) 最初引入的低秩自适应 (LoRA) 在微调宽模型(嵌入维度较大)时效果并非最优。这是由于…
- Google Colaboratory:未找到描述
- Welcome Gemma - Google’s new open LLM:未找到描述
- gemma_config_axolotl.yml:GitHub Gist:即时分享代码、笔记和片段。
- GitHub - nikhil-ghosh-berkeley/loraplus:通过在 GitHub 上创建账号来为 nikhil-ghosh-berkeley/loraplus 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #general-help (27 messages🔥):
- 如何在模型中包含 Chat Template:
@yamashi最初在模型中包含 Chat Template 时遇到问题,但后来在 Hugging Face 仓库 的tokenizer_config.json文件中找到了解决方案。 - 需要 Alpaca Jinja 模板:
@yamashi提到需要一个 Alpaca Jinja 模板,促使@le_mess建议如果找到现有模板就将其添加到 repo 中,随后大家共同努力寻找或创建所需的模板。 - 发现并分享 Alpaca 模板:经过讨论和
@rtyax的贡献,@yamashi分享了一个修改后的 Alpaca Chat Template,并表示打算将其推送到 Axolotl 仓库,这标志着一次成功的社区协作。 - 对 DeepSpeed 步数的困惑:用户
@napuh寻求澄清:为什么使用较少的 GPU 运行测试会导致步数增加,而不是步数相同但完成时间变长,这表明需要更好地理解 DeepSpeed 的行为。 - 微调模型的推理格式:
@timisbister使用 openhermes2.5 数据集微调了一个模型,并询问正确的推理格式,随后@rtyax和@nanobitz就使用 USER 和 ASSISTANT 格式以及[bos_token]等特殊 Token 提供了指导。
提到的链接:
- tokenizer_config.json · cognitivecomputations/dolphin-2.5-mixtral-8x7b:未找到描述
- tokenizer_config.json · teknium/OpenHermes-2.5-Mistral-7B:未找到描述
- text-generation-webui/instruction-templates/Alpaca.yaml · oobabooga/text-generation-webui:一个用于 Large Language Models 的 Gradio Web UI。支持 Transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。
OpenAccess AI Collective (axolotl) ▷ #rlhf (1 messages):
- 对 DPO 训练日志的担忧:
@noobmaster29正在寻求共享的 DPO 训练日志 作为参考,担心自己的 Loss 在完成一个 Epoch 之前异常低。由于缺乏评估数据,他们无法确定这是否是过拟合。
OpenAccess AI Collective (axolotl) ▷ #runpod-help (5 messages):
- RunPod 镜像获取错误:
@casper_ai解释说 RunPod 一直在尝试获取镜像但失败了,错误信息显示找不到该镜像。 - RunPod 无限重试的特性:
@casper_ai澄清说,即使在寻找镜像时遇到错误,RunPod 也会表现出无限重试的行为。 - 磁盘空间是镜像问题的罪魁祸首:
@c.gato指出,实际问题可能是 RunPod 磁盘空间不足,导致无法下载镜像,从而引发重复失败。
LAION ▷ #general (185 条消息🔥🔥):
-
深入搜索数据集:
@swaystar123询问是否存在一个包含所有公开 git 仓库及其 issues、comments、pull requests 和 commits 的数据集。然而,聊天中并未提供具体的回答或资源。 -
LAION 5B 可用性查询:
@risphere询问了 LAION 5B 数据集的可用性。此聊天片段中未给出回答。 -
关于 Lucidrains 的资金和工作讨论:
@itali4no、@chad_in_the_house、@segmentationfault8268等人就 Phil Wang (lucidrains) 展开了活跃讨论,涉及他之前的资金支持、将 AI 论文转化为代码的贡献,以及在任何 AI 公司任职的潜力。 -
Google 发布 Gemma 开放模型:
@itali4no分享了一篇关于 Gemma 的 Google 博客文章链接,这是他们负责任 AI 开发的新举措。随后,@helium__、@segmentationfault8268、@twoabove等人讨论了 Google 的开源贡献历史,并对模型架构进行了推测。 -
与 pseudoterminalx 合作的字幕项目进展:
@pseudoterminalx提供了图像字幕生成项目的更新,提到利用了多个 Nvidia GPU,并指出 COG-VLM 模型取得了显著进展。他们还提到了项目目标、Terminus 模型的 finetuning 以及将数据公开的计划。
提到的链接:
- generative modelling of compressed image file bits:未找到描述
- no title found:未找到描述
- 18-year-old Miamian Kye Gomez is developing AI to make life less boring - Refresh Miami:作者 Riley Kaminer
- Gemma: Introducing new state-of-the-art open models:Gemma 是一个轻量级、state-of-the-art 的开放模型系列,采用与构建 Gemini 模型相同的研究和技术。
- Sponsor @lucidrains on GitHub Sponsors:你好,我通过开源 state-of-the-art 的神经网络架构来推动人工智能的民主化。我主要是深度学习子领域:Attention 和 Transformers 的专家。
- ptx0/photo-concept-bucket · Datasets at Hugging Face:未找到描述
LAION ▷ #research (30 条消息🔥):
- 等待 LAION 5B 的回归:
@progamergov在回答关于 Laion 5B 可用性的问题时开玩笑地说了句 “soon™”,而@JH建议使用 DFN 2B 作为可能的替代方案,尽管访问该数据集存在问题。 - 关于 Sora 训练数据的辩论:
@yoavhacohen、@chad_in_the_house和@unjay.讨论了 Sora 是使用真实视频还是合成视频进行训练的,并观察了生成输出的质量以及合成数据使用的潜在迹象,例如视频片段中的“漂浮物”和缺乏动态背景。 - OpenAI 对合成数据的使用:
@atlasunified最初声称 OpenAI 不使用合成数据,因为他们有资源获取真实数据,但@helium__通过引用 OpenAI 提到使用合成数据的论文进行了反驳。@atlasunified在被纠正后承认没有读过该论文。 - AnyGPT 离散序列建模的见解:
@helium__提供了 AnyGPT 项目 的链接,该项目旨在通过使用离散表示的语言模型处理各种模态,并分享了一个 YouTube 演示视频。 - 聚焦合成数据:关于合成数据的讨论仍在继续,
@yoavhacohen和@unjay.辩论了其在模型开发中的作用,引用了准确标注的重要性,并考虑了使用合成数据与真实世界数据进行 Fine-tuning 的复杂性。
提到的链接:
- apf1/datafilteringnetworks_2b · Datasets at Hugging Face:未找到描述
- Neural Network Diffusion:Diffusion 模型在图像和视频生成方面取得了显著成功。在这项工作中,我们证明了 Diffusion 模型也可以 \textit{生成高性能的神经网络参数}…
- AnyGPT:未找到描述
- Demo for "AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling":”AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling” 的演示视频
Perplexity AI ▷ #general (111 条消息🔥🔥):
-
Perplexity Pro 用户分享快速访问方法:用户
@norgesvenn称 Perplexity Pro 快速且准确。@mares1317通过分配 Pro 角色进行了回应,并提供了一个面向 Pro 用户的 Discord 频道链接,尽管该链接似乎不完整。 -
平衡对来源的依赖与 AI 的创造力:
@annie7441询问如何提示 Perplexity AI 在搜索结果和来自其训练数据的创造性输出之间取得平衡。@brknclock1215建议添加特定指令,要求不要完全依赖搜索结果,并利用现有知识。 -
探索 Gemini 相比 GPT-4 的优势:包括
@tree.ai和@akumaenjeru在内的多位用户讨论了 Gemini Advanced 优于 GPT-4 的优点,理由是其更新的模型以及对输出风格的偏好。 -
在 Discord 上访问 Perplexity Pro 频道:像
@atripper这样的新 Perplexity Pro 用户正在寻求访问专属频道的权限;@me.lk提供了指导,建议使用用户设置页面中的邀请链接。 -
使用 Perplexity.ai 生成图像:
@psoulos询问如何使用 Perplexity 生成图像,@ok.alex指导使用特定的“Generate Image”按钮,并链接到一个示例(尽管链接不完整)。
提到的链接:
- Code is a Four Letter Word: Gemini Versus Gemini: Understanding Google’s Latest… Thing:理解 Google 最新的… 玩意儿
- Gemini 1.5: Our next-generation model, now available for Private Preview in Google AI Studio - Google for Developers:未找到描述
- Sam Witteveen:大家好,我是 Sam Witteveen,我已经从事 Deep Learning 工作 9 年,研究 Transformers 和 LLM 超过 5 年。我在 2017 年被任命为机器学习领域的 Google Developer Expert…
Perplexity AI ▷ #sharing (7 条消息):
- 探索编程语言速度:
@incrediblemhi分享了一个关于不同编程语言速度的 Perplexity AI 搜索链接。该搜索提供了关于语言性能的对比和详细信息。 - 理解神秘事物:
@thespacesamurai发布了一个链接,似乎在解决一个细节缺失的问题或主题,可能与某个类别的列表或类型有关。 - 寻求未知主题的知识:
@lcyld提供了一个指向 Perplexity AI 搜索的链接,但未提供关于搜索问题或主题性质的背景信息。 - 在 Perplexity AI 频道中发现概念:
@doris_dmh引用了一个 Perplexity AI 搜索链接,并指向了一个特定的 Discord 频道#1054944216876331118以进行进一步的讨论或深入了解。 -
寻找导数的含义:
@ivanrykovski分享了一个关于数学符号dy/dx的 Perplexity AI 搜索链接,表明了对微积分或相关数学概念的兴趣。 -
更健康的口腔护理选择:
@uberkoolsound指向了一个关于使用盐水的链接,灵感来自 Andrew Huberman 和 Paul Saladino,旨在减少口腔卫生和皮肤护理中的加工化学品。 - 定义未知:
@swordfish01通过一个链接寻求对某个未指明主题的澄清,引发了对所提供链接背后内容的好奇。
Perplexity AI ▷ #pplx-api (18 条消息🔥):
- 寻求提高 API 请求限制:用户
@kentapp_13575询问是否可以将 pplx-70b-chat 模型的 API 请求限制提高到每天 1.5 万次。频道内未提供直接回复。 - API 与 Webapp 的差异:
@iflypper报告称 API 的响应与过时的 Webapp 不同。@brknclock1215建议移除 system prompt,尽管@iflypper发现这样做会导致响应不相关。 - Stream 参数查询:用户
@bayang7请求一个使用stream: true的请求示例。频道内未对此查询做出回应。 - 在 API 响应中嵌入链接:
@gruby_saudi正在寻找一种让 API 响应包含嵌入链接的方法,类似于 Webapp 的输出,但消息中未提供解决方案。 - pplx-70b-online 的乱码响应:
@useful_tom遇到了 pplx-70b-online 的 API 响应问题,响应开始时正常,但随后变成了乱码。他们指出其他用户也报告了同样的问题,并考虑尝试使用 7b model 作为变通方案。
提到的链接:
Supported Models:未找到描述
CUDA MODE ▷ #general (3 条消息):
- CUDA MODE 欢迎所有 GPU 爱好者:
@andreaskoepf再次重申了 CUDA MODE 社区的包容性,并链接了一条推文,内容是 NVIDIA 向@__tinygrad__推销 Grace Hopper 芯片,详情见 tinygrad 的推文。 - Groq 的 LPU:AI 性能的突破:
@srns27兴奋地分享了一篇文章,关于 Groq 的 LPU 芯片在处理 LLM 时创下了新的性能基准,并寻求对该技术的深入见解。 - 了解 Groq 的架构:
@dpearson针对对 Groq LPU 的好奇,分享了一个 YouTube 视频,由 Groq 的 Compiler Tech Lead Andrew Bitar 讲解其速度为何如此之快。
提到的链接:
- Groq 价值 20,000 美元的 LPU 芯片打破 AI 性能记录,挑战 GPU 主导的行业:Groq 的 LPU 推理引擎(一种专用的语言处理单元)在 LLM 的处理效率上创下了新纪录。在 ArtificialAnalysis 最近进行的一项基准测试中……
- 来自 tiny corp (@tinygrad) 的推文:NVIDIA 联系了我们,试图推销 Grace Hopper 芯片。这是我们的回复。
- 用于数据流计算的软件定义硬件 / Andrew Bitar 的 Crossroads 3D-FPGA 特邀演讲:Groq 的 Compiler Tech Lead Andrew Bitar 于 2022 年 12 月 11 日在 Intel/VMware Crossroads 3D-FPGA 学术研究中心的特邀演讲。摘要:随着 t…
CUDA MODE ▷ #triton (8 条消息🔥):
- 为 Triton/Mamba 寻找合作者:
@srush1301正在整理 Triton/Mamba 的资源,并寻求帮助以提升性能。他们在 Annotated Mamba 指南中列出了剩余任务,例如在 Triton 中添加 reverse scan 选项,并与 CUDA 版本进行对比。 - Triton/Mamba 的优化路线图:
@srush1301认为,为了提高性能,该模块需要进行增强,如 Triton 中的 reverse scan、block size 优化以及与 CUDA 版本的对比分析。 - 共同作者邀请:
@srush1301欢迎感兴趣的贡献者作为共同作者加入他们的 Triton/Mamba 项目。 - 提供专门的工作组频道:
@marksaroufim建议为 Triton/Mamba 工作组创建一个专门的频道,类似于为其他项目所做的安排。 - 绘图工具:
@srush1301回复了@morgangiraud关于图表创建工具的询问,透露他们使用 Excalidraw 绘制简单图表,使用 chalk-diagrams 处理 GPU puzzles。
提到的链接:
Mamba: The Hard Way:未找到描述
CUDA MODE ▷ #cuda (5 条消息):
- 设备函数指针难题:
@carrot007寻求关于在 global 函数中使用设备函数指针(device function pointer)的帮助,在使用cudaMemcpyFromSymbol时遇到了警告,提示无法在 host 函数中读取__device__变量。 - 在 Docker 中使用 Nvidia Nsight 调试:
@dvruette询问如何在 docker 容器内安装 Nvidia Nsight 以 调试 vast.ai 上的问题,引发了关于云服务商在使用此类工具时面临的挑战的讨论。 - Mark 的云端调试解决方案:
@marksaroufim提到 lighting.ai studios 是唯一有效解决了@dvruette所提问题的云服务商,并建议将其作为潜在解决方案。 - 为 CUDA Mode 成员提供免费额度和支持:
@lntg宣布 CUDA mode 成员 可以在特定平台上获取 GPU 学时的免费额度,并提出可以为他们加快验证过程。 - 分析警告困扰用户:
@complexfilterr报告在尝试分析简单的 CUDA 代码时遇到警告 “No kernels were profiled”,对其背后的原因感到困惑。
CUDA MODE ▷ #torch (15 条消息🔥):
_
-
linfeng810 关于广播语义的查询:
@linfeng810询问了在处理可广播维度时,torch.mul如何在数据局部性(data locality)的背景下处理维度。讨论涉及 PyTorch 扩展 Tensor 参数的方法,用户提供了 PyTorch 广播语义链接 以获取详细信息。 -
解决 Geforce 40 系列的调试难题:
@morgangiraud分享了与 Geforce 40 系列不支持 P2P 相关的调试经验,并提供了一篇关于该问题的回顾性分析报告,可以在这里阅读。 -
hdcharles_74684 分享的 PyTorch 优化细节:
@hdcharles_74684提到了他们在包括 llama、SAM 和 SDXL 在内的多个项目中的工作,重点关注 PyTorch 优化,并提供了一系列博客文章,可在 PyTorch Blog Part 1、Part 2 和 Part 3 找到。 -
生成式 AI 模型的加速与优化:
@gogators.强调,自定义 kernel 有时能大幅优于 PyTorch 原生 kernel,尤其是在 batch size 为 1 时。他们指出torch.compile无法处理动态控制流(dynamic control flow),且可能无法实现所有潜在的 kernel fusion 收益。 -
变换优化的特别说明:
@hdcharles_74684的另一项贡献讨论了优化过程中不同 kernel 的使用,例如用于缩放点积注意力(SDPA)和矩阵乘法等操作的 compiled kernels 和 Triton kernels。他们提供了一个指向其仓库中量化细节的链接。
提到的链接:
- Broadcasting 语义 — PyTorch 2.2 文档: 未找到描述
- 多 GPU (Nvidia) P2P 能力与调试技巧: 深入探讨多 GPU Nvidia 构建的故障排除,重点关注 P2P 能力、安装和测试!
- 共同构建更好的软件.): GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、fork 并为超过 4.2 亿个项目做出贡献。
- torch.cuda.jiterator._create_jit_fn — PyTorch 2.2 文档: 未找到描述
- gpt-fast/model.py at main · pytorch-labs/gpt-fast: 简单高效的 PyTorch 原生 Transformer 文本生成,代码量少于 1000 行 Python。- pytorch-labs/gpt-fast
- segment-anything-fast/segment_anything_fast/flash_4.py at main · pytorch-labs/segment-anything-fast: 面向批量离线推理版本的 segment-anything - pytorch-labs/segment-anything-fast
- 使用 PyTorch 加速生成式 AI:Segment Anything, Fast: 本文是一个系列博客的第一部分,重点介绍如何使用纯原生的 PyTorch 加速生成式 AI 模型。我们很高兴能分享一系列新发布的 PyTorch 性能…
- 使用 PyTorch 加速生成式 AI II:GPT, Fast: 本文是一个系列博客的第二部分,重点介绍如何使用纯原生的 PyTorch 加速生成式 AI 模型。我们很高兴能分享一系列新发布的 PyTorch 性能…
- 加速生成式 AI 第三部分:Diffusion, Fast: 本文是一个系列博客的第三部分,重点介绍如何使用纯原生的 PyTorch 加速生成式 AI 模型。我们很高兴能分享一系列新发布的 PyTorch 性能…
- pytorch/torch/_inductor/kernel/mm.py at main · pytorch/pytorch: Python 中的张量和动态神经网络,具有强大的 GPU 加速功能 - pytorch/pytorch
- pytorch/aten/src/ATen/native/native_functions.yaml at main · pytorch/pytorch: Python 中的张量和动态神经网络,具有强大的 GPU 加速功能 - pytorch/pytorch
- pytorch/aten/src/ATen/native/native_functions.yaml at main · pytorch/pytorch: Python 中的张量和动态神经网络,具有强大的 GPU 加速功能 - pytorch/pytorch
CUDA MODE ▷ #beginner (14 messages🔥):
-
Conda CUDA 灾难:
@apaz分享了尝试通过 conda 安装 CUDA 库时的挫败经历,面临诸如安装缓慢、torch 版本错误、破坏运行时环境等多个问题,最终不得不删除并重新安装 conda。他们对 Conda 表达了强烈不满。 -
Conda 问题引发社区反馈:
@andreaskoepf和@_t_vi_回应了@apaz的经历,建议尝试其他发行版,如 venv 或 Debian 的 CUDA 软件包,并指出这些方式的问题较少。 -
Jeremy 关于 Conda 使用的建议: 针对
@apaz的 conda 问题,@jeremyhoward表示理解这种挫败感,并建议确保使用 libmamba solver 以提高速度,并质疑是否需要进行大规模删除,建议通常删除单个目录就足够了。 -
CUDA 编译担忧:
@0ut0f0rder注意到使用 torch_inline 编写的简单 CUDA kernel 编译时间很慢,质疑这是 CUDA 本身的特性还是 Colab 硬件的原因;@jeremyhoward回应确认 CUDA 的编译时间确实较慢,但建议将 numba 作为更快的替代方案。 -
CUDA 会过时吗?:
@dpearson在观看了一段关于 Groq AI 硬件的视频后,质疑是否有必要学习 CUDA。该视频强调了编译器对资源的高效利用以及未来自动化的潜力,引发了关于学习 CUDA 是否仍有价值的讨论。
提到的链接:
- Ah Shit Here We Go Again Cj GIF - Ah Shit Here We Go Again Ah Shit Cj - Discover & Share GIFs: 点击查看 GIF
- Software Defined Hardware for Dataflow Compute / Crossroads 3D-FPGA Invited Lecture by Andrew Bitar: Groq 编译器技术主管 Andrew Bitar 于 2022 年 12 月 11 日在 Intel/VMware Crossroads 3D-FPGA 学术研究中心的特邀演讲。摘要:随着 t…
CUDA MODE ▷ #youtube-recordings (1 messages):
-
Gemini 1.5 讨论邀请:
@shashank.f1正在主持一场关于 Gemini 1.5 的新讨论,并邀请成员加入直播。公告中包含该活动的 Discord 邀请链接。 -
探索理解音频的 AI:
@shashank.f1分享了一个 YouTube 视频,标题为 “A-JEPA AI model: Unlock semantic knowledge from .wav / .mp3 file or audio spectrograms”,涵盖了关于 A-JEPA AI 模型 的讨论,该模型可以从音频文件中提取语义知识。描述显示该视频包含与专家 Oliver, Nevil, Ojasvita, Shashank, Srikanth 和 N… 的深入探讨。
提到的链接:
- Discord - A New Way to Chat with Friends & Communities: Discord 是与朋友和社区进行语音、视频和文字交流最简单的方式。
- A-JEPA AI model: Unlock semantic knowledge from .wav / .mp3 file or audio spectrograms: 🌟 开启 AI 从音频中学习的力量!🔊 观看与 Oliver, Nevil, Ojasvita, Shashank, Srikanth 和 N… 关于 A-JEPA 方法的深入讨论。
CUDA MODE ▷ #jax (3 messages):
- Pallas Flash Attention 咨询:
@iron_bound分享了 jax 仓库中flash_attention.py的 GitHub 链接,询问是否有人以前用过它。 - 对 GPU 兼容性的好奇:
@drexalt推测了该 TPU 特定代码在 GPU 上使用的兼容性,表示有兴趣通过删除 TPU 的重复调用来修改代码,看看它是否能在 GPU 上运行。 - 形状维度错误:
@iron_bound报告称,运行代码的尝试因“可怕的形状维度错误”而崩溃,尽管它确实启动了。
提到的链接:
- jax/jax/experimental/pallas/ops/tpu/flash_attention.py at main · google/jax: Python+NumPy 程序的可组合转换:微分、向量化、JIT 编译到 GPU/TPU 等 - google/jax
- jax/jax/experimental/pallas/ops/tpu at main · google/jax: Python+NumPy 程序的可组合转换:微分、向量化、JIT 编译到 GPU/TPU 等 - google/jax
CUDA MODE ▷ #ring-attention (52 条消息🔥):
-
Ring Attention 和 Flash Attention 的协作工作:
@iron_bound、@ericauld、@lancerts和@andreaskoepf等参与者一直在积极讨论 Ring Reduction 和 Flash Attention 算法的实现与理解。重大贡献包括@ericauld分享了一个 Google Colab 笔记本作为 Ring Attention 算法的 工作原型版本,以及@lancerts在一个 原生 Python 笔记本 中实现了 Flash Attention 的前向传播。 -
深入代码实现:
@iron_bound将大量代码翻译成了 PyTorch,尽管仍需添加torch.distributed。他们强调了翻译后代码的复杂性以及嵌套函数的存在。 -
识别文献中的潜在拼写错误:
@ericauld和@lancerts等用户指出了 Flash Attention 文献中可能影响代码实现准确性的潜在拼写错误。@ericauld特别提到了其笔记本中与diag(l)^{-1}因子和l2/l1比率相关的差异。 -
参与外部资源:
@iron_bound发现了一个 GitHub issue,指向了由@zhuzilin实现的另一个 Ring-Flash Attention 版本,并分享了 链接 供他人探索。 -
学习与进度更新:
@mickgardner和@jamesmel等用户分享了他们在该项目数学和实践方面的学习经验。@mickgardner考虑学习 Cutlass Primitives,而@jamesmel深入研究了 P2P Overlap,现在对理解需求充满信心。
提到的链接:
- Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- ring-attention/ring_attn/ring_attention.py at tests · Iron-Bound/ring-attention:用于 Ring-Attention 的优化 Kernel [进行中]。通过在 GitHub 上创建账户为 Iron-Bound/ring-attention 的开发做出贡献。
- GitHub - zhuzilin/ring-flash-attention: Ring attention implementation with flash attention:结合 Flash Attention 的 Ring Attention 实现 - zhuzilin/ring-flash-attention
- ring-attention/notebooks/DummyRingAttentionImpl.ipynb at main · cuda-mode/ring-attention:用于 Ring-Attention 的优化 Kernel [进行中]。通过在 GitHub 上创建账户为 cuda-mode/ring-attention 的开发做出贡献。
- ir - 概览:ir 有 4 个可用的仓库。在 GitHub 上关注他们的代码。
LangChain AI ▷ #general (46 条消息🔥):
- 关于 TypeScript 兼容性的担忧:用户
@amur0501询问将 LangChain 与 TypeScript 结合使用是否与 Python 一样有效,担心使用langchain.js时会错过 Python 中可用的功能。回复中没有提供明确的共识或建议。 - 使用 Mistral 进行函数调用 (Function Calling):
@kipkoech7分享了一个 GitHub 链接,展示了如何在本地以及使用 Mistral 的 API key,通过 LangChain 在 开源 LLM (Mistral) 上使用 function calling。 - 关于向量数据库索引的问题:
@m4hdyar询问了在代码更改时更新向量数据库索引的策略,@vvm2264建议使用 代码块标记系统 (code chunk-tagging system) 或代码块到向量索引的 1:1 映射公式 来方便更新。 - 寻求更新的 NLP 资源:
@nrs9044寻求比 2022 年的 Deep Learning for Natural Language Processing 更及时的材料推荐,特别是关于新库的内容,但没有得到直接的后续回复。 - AzureChatOpenAI 配置难题:
@smartge3k表示在AzureChatOpenAI配置方面遇到困难,在将其与ConversationalRetrievalChain结合使用时收到 “DeploymentNotFound” 错误,讨论仍在继续,尚未提供明确的解决方案。
提到的链接:
- Zero Prime @ Data Council ‘24:加入 Zero Prime Ventures @ Data Council Austin 2024,获得展示你的 AI 初创公司的独特机会。立即申请以接触顶级投资者和精英创始人。
-
[Agent Types 🦜️🔗 Langchain](https://python.langchain.com/docs/modules/agents/agent_types/.):这从几个维度对所有可用的 Agent 进行了分类。 -
[SparkLLM Chat 🦜️🔗 Langchain](https://python.langchain.com/docs/integrations/chat/sparkllm):讯飞星火 SparkLLM 聊天模型 API。更多信息请参阅 iFlyTek。 - Pricing:适用于任何规模团队的计划。
- Tweet from Austin Vance (@austinbv):🚨 新教程 🚨 我的 “Chat with your PDF” 从零构建 RAG 教程完结篇!在第 4 部分中,我们:- 使用 LangSmith 处理一切 - 实现 Multi Query 以增加检索…
LangChain AI ▷ #share-your-work (3 条消息):
-
寻求更优的 PDF 解析器:
@dejoma询问是否有人使用 PDFMinerPDFasHTMLLoader / BeautifulSoup 构建了增强型 PDF 解析器,并表示有兴趣分享,指出文档中的现有示例虽然不错,但如果投入一周时间,可以创造出更出色的东西。 -
使用 LangChain 将创意转换为简报和推文:
@merkle分享了一个 链接,展示了如何使用 LangChain 的 langgraph agent 设置 从单一主题生成简报草稿和推文。@michaeldaigler_的推文称:一人媒体公司比你想象的更近。 -
神秘项目的预告:
@pk_penguin发布了一条神秘消息 “thought?”,并邀请有兴趣尝试新项目或工具的人私信。
提到的链接:
Tweet from Michael Daigler (@michaeldaigler_):一人媒体公司比你想象的更近。利用 AI 从单一主题生成简报草稿和推文。其工作原理如下:
LangChain AI ▷ #tutorials (4 条消息):
- 探讨 Corrective RAG:
@pradeep1148分享了一个名为 “Corrective RAG using LangGraph” 的 YouTube 视频,讨论了如何通过自我反思以及纠正低质量的检索或生成来增强 RAG。 - 构建持久化记忆聊天机器人:
@kulaone提供了一篇名为 “Beyond Live Sessions: Building Persistent Memory Chatbots with LangChain, Gemini Pro, and Firebase” 的文章链接,解释了持久化记忆在对话式 AI 中的重要性。在 Medium 上阅读全文。 - 排查 Spark API 问题:
@syedmujeeb在使用来自 iFlytek 的 Spark API 时遇到了 ‘AppIdNoAuthError’。他们参考了 SparkLLM 的 LangChain 文档 并就此事寻求建议。 - 讨论使用 LangGraph 的 Self RAG:
@pradeep1148发布了另一个名为 “Self RAG using LangGraph” 的 YouTube 视频,涵盖了通过实现自我反思来提高 RAG 质量的内容,并指出最近有几篇论文都聚焦于这一主题。
提到的链接:
- Beyond Live Sessions: Building Persistent Memory Chatbots with LangChain, Gemini Pro, and Firebase:在快速发展的人工智能领域,从简单的脚本聊天机器人到如今先进的……的演变。
-
[SparkLLM Chat 🦜️🔗 Langchain](https://python.langchain.com/docs/integrations/chat/sparkllm):由 iFlyTek 提供的 SparkLLM 聊天模型 API。更多信息请参阅 [iFlyTek - Self RAG using LangGraph:自我反思可以增强 RAG,从而纠正低质量的检索或生成。最近的几篇论文都聚焦于这一主题,但实现……
- Corrective RAG using LangGraph:Corrective RAG 自我反思可以增强 RAG,从而纠正低质量的检索或生成。最近的几篇论文都聚焦于这一主题,但……
DiscoResearch ▷ #general (18 messages🔥):
- Gemma 模型引发好奇:
@johannhartmann询问了某些有趣的 AI 模型的训练策略和基础模型的详细信息。作为回应,@sebastian.bodza分享了一个 Google 开源模型的链接,不过@philipmay随后对这些模型的非英语语言能力表示了疑问。 - 讨论 Gemma 的语言限制:
@bjoernp评论道,讨论中提到的 Google Gemma 模型似乎主要侧重于英语,并提供了一个 Hugging Face 链接,详细介绍了 Gemma 7B instruct 版本。他还指出 Gemma 拥有令人印象深刻的 256k 庞大词汇量(vocabulary size)。 - 审查 Aleph Alpha 模型更新:
@sebastian.bodza提到了 Aleph Alpha 对其模型的更新,引发了关于其质量的讨论。@devnull0指出 Andreas Köpf 现在在 Aleph Alpha 工作,这可能预示着即将到来的改进,并分享了 Aleph Alpha 文档中的变更日志,其中详细说明了其模型的最新更新和功能。 - 对 Aleph Alpha 增强功能的质疑:
@_jp1_批评 Aleph Alpha 尽管是一家大公司,但其模型缺乏实质性更新,并提到在将近一年后的第一篇博客文章中缺乏 Benchmarks 和示例。与此同时,@sebastian.bodza和@devnull0讨论了新模型中似乎缺乏 Instruction Tuning 的问题,以及在如何管理与这些模型的交互方面存在差异。 - 测试显示德语表现不佳:经过测试,
@_jp1_表示 Gemma 的 instruct 版本在德语方面表现尤其薄弱,@bjoernp分享的德语 hellaswag 的lm_eval测试结果进一步证实了这一点,显示其性能仅略高于随机水平。
提到的链接:
- Gemma:Gemma 是一个轻量级、开放模型系列,基于 Google 用于创建 Gemini 模型的相同研究和技术构建。
- HuggingChat:让每个人都能使用社区最好的 AI 聊天模型。
- google/gemma-7b-it · Hugging Face:未找到描述
-
[Blog Aleph Alpha API](https://docs.aleph-alpha.com/changelog/):博客
DiscoResearch ▷ #benchmark_dev (9 messages🔥):
- GPU 预算担忧导致寻找免费 Benchmark:
@johannhartmann调侃 GPU 资源匮乏,导致@bjoernp讽刺地回应了关于免费 Benchmark 的请求。 - 在 Benchmark 测试中追求速度:
@johannhartmann对lm-evaluation-harness-de运行时间过长表示沮丧,并询问提速技巧,怀疑可能出了问题。 - 速度需求:vLLM 前来救援:
@bjoernp建议使用vLLM可以显著加快测试过程,并提出调查为什么它没有像预期那样起到加速作用。 - 过时分支导致运行缓慢:
@johannhartmann意识到运行缓慢可能是因为使用了未集成vLLM的过时分支。 - 即将更新以支持 vLLM:
@bjoernp承认了过时分支的问题,并承诺更新版本以支持当前的 main 分支,但指出这可能需要几天时间。
LLM Perf Enthusiasts AI ▷ #general (7 messages):
- 获取 AI 访问权限需要等待名单或 Google 代表:
@wenquai提到,要获得特定 AI 服务的访问权限,必须加入等待名单或联系 Google Cloud 代表。 - Twitter 证实 AI 访问传闻:
@res6969确认在 Twitter 上看到了更多证据,证明有关 AI 服务访问权限的传闻是真的,但他们仍在等待自己的访问权限。 - 对 AI 准确性和幻觉问题的担忧:
@res6969暗示了公众对某款 AI 性能问题的反馈,指出它“不是非常准确,并且存在幻觉(hallucination)问题”。 - 用户回声室:针对
@res6969对 AI 准确性担忧的评论,@thebaghdaddy简短地回应道:“此类情况屡见不鲜(many such cases)”。 - 为 AI 业务寻找 CRM 解决方案:
@frandecam正在寻找适合 AI 业务的 CRM 服务推荐,考虑使用 Salesforce、Zoho、Hubspot 或 Pipedrive 等选项来替换目前使用的 Google Sheets。 - 对 Salesforce 的负面评价:针对
@frandecam关于 CRM 的咨询,@res6969警告不要选择 Salesforce,暗示这对公司来说将是一个重大错误。
LLM Perf Enthusiasts AI ▷ #opensource (1 messages):
potrock: https://blog.google/technology/developers/gemma-open-models/
LLM Perf Enthusiasts AI ▷ #embeddings (1 messages):
- ContrastiveLoss 赢得青睐: 用户
@dartpain表达了在微调 embeddings 时对 ContrastiveLoss 的偏好,称其对进行调整非常有影响力。此外,他们还提到偏好 MultipleNegativesRankingLoss。
Skunkworks AI ▷ #general (1 messages):
- 寻求 Neuralink 面试见解: 用户
@xilo0正在寻求关于如何回答 Neuralink 后期面试中“杰出能力证明”问题的建议。他们有一系列项目可以展示,但正在寻找能给马斯克领导的公司留下深刻印象的切入点。
Skunkworks AI ▷ #off-topic (4 messages):
- 探索 Corrective RAG:
@pradeep1148分享了一个 YouTube 视频,题为“使用 LangGraph 的 Corrective RAG”,讨论了自我反思如何通过纠正低质量的检索或生成来改进检索增强生成 (RAG)。 - 深入研究 Self RAG: 另一个由
@pradeep1148分享的 YouTube 视频,题为“使用 LangGraph 的 Self RAG”,探讨了通过自我反思增强 RAG 的概念。 - BitDelta:评估微调的价值:
@pradeep1148还发布了一个 YouTube 视频,题为“BitDelta:你的微调可能只值 1 bit”,评估了在海量数据集预训练后,对大语言模型 (LLMs) 进行微调的实际价值。 - 简单的赞赏:
@sabertoaster对分享的内容回应了一个简短的 “nice”,表示赞赏或感兴趣。
提到的链接:
- Self RAG using LangGraph: 自我反思可以增强 RAG,从而纠正低质量的检索或生成。最近的几篇论文都聚焦于这一主题,但实现…
- Corrective RAG using LangGraph: Corrective RAG 自我反思可以增强 RAG,从而纠正低质量的检索或生成。最近的几篇论文都聚焦于这一主题,但实…
- BitDelta: Your Fine-Tune May Only Be Worth One Bit: 大语言模型 (LLMs) 通常分为两个阶段进行训练:在互联网规模的大型数据集上进行预训练,以及针对下游任务进行微调。鉴于…
Alignment Lab AI ▷ #general-chat (4 messages):
- AI 社区的认可:
@swyxio表达了感谢,可能是为了回应同行的认可或在 AI 领域获得的荣誉。 - 呼吁纳入草根贡献者:
@tokenbender建议正在讨论的名单过于企业化,应该包括那些活跃在第一线并公开分享工作的个人,并推荐 Twitter 上的@abacaj作为一个值得加入的人选。 - 寻找 Token 信息:
@scopexbt询问该小组是否存在相关的 token,表示他们未能找到相关信息。
Datasette - LLM (@SimonW) ▷ #ai (2 messages):
- Google 发布 Gemini Pro 1.5: 用户
@derekpwillis介绍了 Google 的最新动态,包括 GEMMA 的文档。 - Simon 探索 Gemini Pro 1.5:
@simonw分享了他对 Gemini Pro 1.5 的见解,强调了其 100 万 token 的上下文窗口以及使用视频作为输入的突破性功能。Simon 一直在通过 Google AI Studio 测试这些功能。
提到的链接:
- The killer app of Gemini Pro 1.5 is video: 上周 Google 推出了 Gemini Pro 1.5,这是对其 Gemini 系列 AI 模型的一次巨大升级。Gemini Pro 1.5 拥有 1,000,000 token 的上下文大小。这非常惊人——此前…
- no title found: 未找到描述
Datasette - LLM (@SimonW) ▷ #llm (2 条消息):
- GitHub Codespaces 中的 GLIBC 版本问题:
@derekpwillis在 GitHub Codespaces 中尝试运行 llm 时遇到了问题,原因是llmodel_DO_NOT_MODIFY目录下的一个文件需要GLIBC_2.32,但系统中未找到,导致 OSError。他们考虑尝试安装 2.32 版本,并向小组寻求建议。 - 对警告标签的赞赏:
@derekpwillis幽默地表达了他们对名为llmodel_DO_NOT_MODIFY的目录的喜爱。
AI Engineer Foundation ▷ #general (3 条消息):
-
Groq LPU 令人印象深刻的速度:用户
@juanreds对 Groq LPU 的 Prompt 响应时间感到惊喜,并分享了一个供他人尝试的链接。 -
周末计划协调和赞助商线索:
@yikesawjeez提到早上的时间安排有冲突,但请求了会议录音。他们还告知@705561973571452938,已确认一名赞助商,并可能有另外三名赞助商参与即将到来的周末活动。 -
Groq LPU 爱好者表示赞同:用户
._z表达了兴奋,回应@juanreds之前关于该技术性能的评论,认为 Groq LPU “超级酷”。
提到的链接:
Groq:未找到描述
AI Engineer Foundation ▷ #events (1 条消息):
- Gemini 1.5 讨论已排期:
@shashank.f1宣布即将举行关于 Gemini 1.5 的直播讨论,并邀请大家参加。提供了活动链接:加入 Gemini 1.5 讨论。 - 使用 A-JEPA 探索音频中的语义知识:上一次会议的重点是 A-JEPA AI 模型,该模型专注于从
.wav或.mp3文件或音频频谱图中提取语义知识。分享了讨论的 YouTube 视频回顾:观看 A-JEPA AI 模型讨论。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,并与你的朋友和社区保持紧密联系。
- A-JEPA AI 模型:从 .wav / .mp3 文件或音频频谱图中解锁语义知识:🌟 解锁 AI 从音频中学习的力量!🔊 观看与 Oliver, Nevil, Ojasvita, Shashank, Srikanth 等人关于 A-JEPA 方法的深入讨论…