ainews-one-year-of-latent-space
**Latent Space 一周年** 或者 **潜空间的一年**
Latent Space 播客庆祝了其成立一周年,不仅在 AI 工程类播客中排名第一,在 Substack 上的独立读者人数也达到了 100 万。Google DeepMind 推出的 Gemini 1.5 图像生成器因偏见和不准确的呈现引发了争议,导致了社区内关于 AI 伦理的辩论。在 TheBloke 和 LM Studio 的 Discord 社区中,讨论凸显了 AI 在创意产业中日益增长的作用,特别是在游戏开发和文本转 3D 工具方面。Nous Research AI 和 Mistral 的 Discord 社区探讨了 Gemma 7B 和 Mistral-next 等模型的微调与性能优化,分享的解决方案包括学习率调整和开源工具的使用。CUDA MODE 和 LangChain AI 的 Discord 社区讨论了 AI 硬件和应用开发的新兴趋势,包括 Jim Keller 对 英伟达(Nvidia)CUDA 的批评,以及 Richard Socher 暗示的在减少 AI 幻觉方面的进展。
2024年2月22日的 AI Discord 动态。我们为您检查了 20 个服务器、317 个频道和 8875 条消息。预计节省阅读时间(按 200wpm 计算):835 分钟。
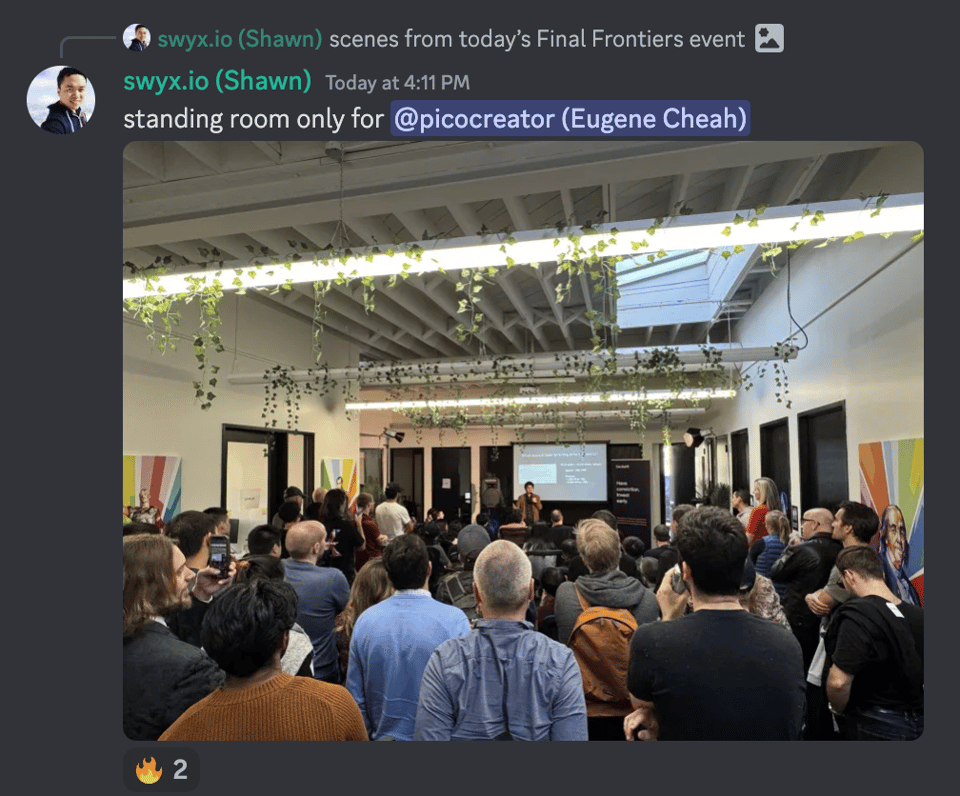
Latent Space 今天满一岁了。它(当然)是排名第一的 AI Engineering 播客,在美国通用科技播客排行榜中位列第 10,并且在我们的 Substack 上拥有超过 100 万的独立读者。Alessio 写了一篇精彩的回顾,我们还举办了一场精彩的 hack/demo day,目前正在进行中。

目录
[TOC]
第 0 部分:摘要的摘要的摘要
- AI 伦理与偏见讨论: TheBloke Discord 上关于 Gemini 图像生成器的争议凸显了 AI 伦理和偏见方面的挑战,特别是 Google 的 Gemini 1.5 模型未能准确呈现白人个体和历史事件。这引发了关于内部偏见与仓促实施之间的辩论,正如一段关于 Gemini 多样性问题的 YouTube 视频中所讨论的那样。
- AI 辅助创意与开发: AI 在创意产业(尤其是游戏开发)中的作用在 TheBloke 和 LM Studio Discord 中得到了强调。讨论围绕着使用 AI 进行艺术指导以及 text-to-3D 工具对小型开发者的潜力展开,展示了 AI 与创意日益增长的交集。
- 模型微调与性能优化: 包括 Nous Research AI 和 Mistral 在内的多个 Discord 深入探讨了 Gemma 7B 和 Mistral-next 等模型的微调挑战和性能优化。问题范围从初始 Loss 过高到 API 访问查询,解决方案涉及特定的 Learning Rate 以及利用开源工具获得卓越结果,例如一个用于大规模 finetuning 的 GitHub 仓库。
- AI 开发与部署的新兴趋势: CUDA MODE 和 LangChain AI Discord 的讨论强调了 AI 硬件优化和应用开发的新兴趋势。Jim Keller 对 Nvidia CUDA 的批评以及对 LLM 中并行 function calls 的探索,反映了技术社区对提高 AI 模型效率和部署策略的关注。值得注意的是,Richard Socher 透露了在解决 AI hallucination 方面的进展,暗示在增强 AI 事实准确性方面取得了重大进展,正如一条推文中所提示的那样。
第 1 部分:Discord 高层级摘要
TheBloke Discord 摘要
-
Gemini 图像生成器引发偏见争议:社区讨论了 Google 的 Gemini 1.5 AI 图像生成模型明显的偏见问题,该模型因无法准确呈现白人个体和历史事件而被迫关闭;一些人认为这是由于内部偏见造成的,而另一些人则认为是由于仓促实施。争议讨论中引用了 Gemini 多样性问题视频和相关文章。
-
游戏开发中的 AI 辅助创意:AI 辅助游戏开发的潜力浮出水面,讨论涉及 text-to-3D 工具以及小型开发者利用 AI 进行艺术指导的优势,展示了 AI 与创意产业日益增长的交集。
-
搜索引擎市场份额讨论:关于 Google 为何能继续主导搜索引擎市场份额的话题引起了兴趣;讨论了 Qwant 等替代方案,并对 Google 的企业精神进行了批评,强调了科技行业的竞争与伦理。
-
Opus V1 及其他模型在角色扮演和写作中备受关注:角色扮演和写作频道的用户探索了模型偏好,重点关注 Opus V1 在故事写作中的作用,以及角色卡(character cards)对角色扮演场景中 AI 模型性能的影响,反映了微调模型设置对创意输出的重要性。
-
深入探讨模型合并与 DPO:关于模型合并的对话探讨了将非同源模型(如 Orca-2-13b 与 Nous-Hermes-2-DPO-7b)进行杂交的挑战,讨论了复杂的技术和知识转移优化(KTO)的潜力,以及社区对 DPO 使用的反馈;一位成员在查看了 GitHub 上的代码后,选择使用
trl库的DPOTrainer作为起点。 -
代码好奇心与 JetBrains Dotpeek 的使用:在编程频道中,用户对 GitHub 和 Twitter 之外的机器学习社区表现出明显的好奇心,并交流了使用 JetBrains Dotpeek 进行漏洞研究的心得,这体现了 AI 工程师对其工具的实际应用需求。
LM Studio Discord 摘要
-
Gemma 模型出现故障:用户在使用
Gemma模型时遇到问题,特别是低量化版本在llama.cpp中运行崩溃。建议使用 Hugging Face Gemma 模型以避免问题,而Gemma 7B必须手动下载才能与 LM Studio 兼容。 -
LM Studio 的稳定性与更新:LM Studio v0.2.16 紧急更新包含了针对异常行为的错误修复。用户对 UI 改进和 0.2.15 版本中修复的问题表示赞赏,但也对复杂性和 Comic Sans 字体提出了批评。
-
手中一块 TESLA 胜过数据中心两块?:市场上出现了闲置的 TESLA K40 显卡,引发了关于它们在
llama.cpp中使用潜力的讨论,尽管其受限于 CUDA 3.5。对话涵盖了增加 GPU 以提升速度,以及 AMD MI300X 在 AI 应用中可能带来的颠覆。 -
本地模型,无互联网连接:LM Studio 的本地模型(如
Gemma)无法访问互联网,这影响了它们的更新和改进能力。尽管存在局限性,AI 辅助教学工具和 Stable Diffusion Web UI 的功能仍被提及。 -
技术故障的可视化:OLED 显示器因其质量获得了认可,证实了即使在工程师群体中这也是一种偏好趋势。在硬件方面,Tesla K40 的成本效益得到认可,但因其年代久远和局限性而持保留意见。
-
用经典方法修复无法修复的问题:在面对 AutoGen 软件包问题时,一位用户通过卸载并重新安装这一经典的 IT 方法成功解决了问题,并幽默地分享了著名的“重启试试” GIF。
-
你的数据块有多大?:关于 Embedding 文本预处理中
chunk_size的讨论强调了其对所用模型的依赖性。分享了来自 AI Stack Exchange 的推荐公式,用于在num_categories <= 1000时计算num_embeddings。
OpenAI Discord 总结
-
AI 课程中的 HTML 和 CSS:讨论了使用 HTML 和 CSS 训练 ChatGPT 的话题,
@ls_chicha探讨了如何将编程语言纳入 AI 教育。随后,@thedreamakeem指出在训练时可能需要 .json 数据库格式。 -
AI 模型在处理 PDF 等文件时的危机:用户们正在努力解决一些问题,例如 GPTs 过早失去阅读 PDF 的能力 (
@arani1977),以及@oleksandrshr提出的模型性能缓慢问题;同时@darthgustav.澄清了关于量化 AI 版本(quantized AI versions)如何影响模型速度和精度的问题。 -
微调模型行为:讨论延伸到了模型响应的细微差别,
@tawsif2781和@darthgustav.讨论了 ReAct prompting 中的循环故障,以及即使在零温度(zero temperature)设置下也能调用即兴发挥的策略。 -
AI 对话与角色扮演:
@link12313提议开发一个用于 GPT-4 与 Google Gemini Ultra 1.5 之间互动的应用程序,而@eskcanta则交流了在模型中管理角色扮演和保持角色一致性的方法与技巧,展示了 Custom Instructions 的高效用法。 -
GPT-4 的现状核查:对于 GPT-4 发布后能力的剧烈变化存在怀疑,
_jonpo等人辩论了模型的上下文长度(context length)和记忆能力,而@lugui则消除了关于 GPT-4 可能被“降级(powered down)”的担忧。
讨论的外部资源:
- 分享了 Stability AI 发布的公告 链接,关于其最先进的文本生成图像模型 Stable Diffusion 3。
- 通过一个 研究链接 重点介绍了 OpenAI 在视频生成模型方面的探索。
- 关于 Google Gemini Pro 模型及其反偏见措施的信息出现在一段 YouTube 视频 中。
LAION Discord 总结
-
自研编排系统优于企业级方案:提到了一个由“蹩脚脚本和数据库”组成的自定义系统用于工作节点编排(worker orchestration),暗示了一种比复杂的企业级解决方案更务实的做法。
-
Stable Diffusion 3 与 Stability AI 的招聘惯例:人们对 Stable Diffusion 3 的能力充满期待,该模型可能具有中等分辨率的基础并结合上采样技术。同时,Stability AI 似乎表现出一种招聘趋势,即聘用系统管理员转型机器学习(ML)角色(似乎是出于成本效益考虑),以及聘用在 YouTube 上拥有大量粉丝的人员。
-
AI 开发中日益增长的保密性:社区成员对一种趋势表示担忧,即像 Stability AI 这样的公司正将模型开发移出公众视野,这导致 AI 生成内容的观察多样性下降。
-
开源模型与微调:讨论指出,像 Mistral-7b 这样的开源模型在经过微调后,有可能提供优于 GPT-4 等商业产品的性能,LoRA Land 等项目被视为该领域的领导者。
-
重新评估 LAION 5B 的效用与学术贡献:社区正在考虑是否停用 LAION 5B 数据集,同时也探索众包字幕解决方案,并分享对有效模型训练实践的见解,例如在 TPU 上使用 bfloat16 进行混合精度训练。该领域的学术贡献包括关于小型大型多模态模型(Large Multimodal Models)的 TinyLLaVA,以及 INTRINSIC LoRA 对生成模型能力的探索。
Nous Research AI Discord 摘要
-
Gemma 7B 令工程师困惑:AI 工程师如
@interstellarninja、@teknium和@gryphepadar报告了 Gemma 7B 模型的 finetuning 挑战,包括初始 Loss 过高以及与现有模型相比最终结果不理想。@stoicbatman在实验中发现 5e-5 是最佳的 learning rate。 -
微调工具与技巧交流:
@alvion427赞赏了@n8programs的 fine-tuned Tinyllama 模型,称其具备先进的多轮对话能力。同时,@qtnx纠正了 Huggingface 上 Nous-Hermes-2-Mistral 模型的命名拼写错误,@teknium提供了一个 GitHub 链接,其中包含用于大规模 finetuning 的 shell 脚本,尽管这些脚本需要更新。 -
前沿 LLM 集成讨论:对话涉及 Microsoft 的 JARVIS 项目及其 GitHub 仓库链接、融合了生成、执行与优化的 OpenCodeInterpreter,以及
@pramod8481分享的关于 LLM 中人类反馈和价值偏见的 Arxiv 关键分析链接。 -
AI 模型占用大量 VRAM:
@gryphepadar强调了模型 finetuning 期间可观的 VRAM 消耗,指出规划计算资源的必要性。 -
AI 伦理与机制的交汇:针对
@pramod8481讨论的一项 研究,人们对 LLM 倾向于选择高价值选项以及其中可能存在的隐式价值函数表示关注。
Mistral Discord 摘要
Mistral-Next 激发期待与 API 查询:工程讨论显示 Mistral-next 的表现优于 Mistral-Medium 等先前模型,@ethux 等用户确认了其存在,但指出目前缺乏 API 访问权限或模型参数细节。同时,@buttercookie6265 和 @louis2567 等人一直关注 vLLM 的 GPU 选择以及向 vLLM 服务器进行批量调用的最佳实践。
Mistral 的开源承诺受到质疑:社区对 Mistral 可能转向非开源表示担忧,但 @casper_ai 等用户对 Mistral 的开源精神表达了信心,并将其与 Linux 类比。通过提到的各种链接可以看出,部署方法和可访问性仍然是核心讨论话题。
对 Mistral 微调的反馈:像 @4vis 这样的 finetuning 新手收到了诸如从 Unsloth 开始的建议,而 @pteromaple 等人则在为精确微调任务处理复杂的数据格式和模型选择。用户讨论了在有限硬件配置上微调大型模型的实用性,@mrdragonfox 建议小的参数修改可能足以完成某些风格迁移。
Mistral 数据处理协议澄清:关于通过 Mistral API 处理的数据隐私查询,得到了 @akshay_1 的保证,即此类数据不会用于训练。@tom_lrd 和 @ethux 的进一步确认指出,Mistral 的数据和平台托管在瑞典,正如其 隐私政策 所述,其中还提到了 Azure、Cloudflare 和 Stripe 等服务提供商。
Mistral 社区思考性能与定价:模型性能、推理速度和极具吸引力的定价结构引起了关注,@egalitaristen 和 @mrdragonfox 对 Mistral 的市场地位表示乐观。由 @egalitaristen 和 @mrdragonfox 支持的 Mistral Next 持续反馈收集计划表明,社区正在积极参与模型改进。
Perplexity AI Discord 摘要
-
Perplexity 推出 Discover Daily 播客:Perplexity 与 ElevenLabs 合作推出了 Discover Daily 播客,由 ElevenLabs 的 AI 语音叙述来自 Perplexity Discover 栏目的故事。该播客可以在各大平台上找到。
-
Pro 订阅不提供双重折扣:澄清了 Perplexity Pro 订阅的相关事宜;可以在计划中添加团队成员,但根据计费与订阅常见问题解答 (FAQ) 的链接确认,不提供多重订阅折扣。
-
试验轻量级 GPT 模型:Perplexity 通过 Perplexity Labs YouTube 播放列表展示了新的轻量级 “Experience Gemma 2B 和 7B 模型”,并在 Twitter 上进行推广,强调了它们令人印象深刻的性能。
-
解决 API 问题与 Gemma 集成推测:用户报告了 API 额度购买问题,并分享了针对 400 错误的成功解决方法。关于将 Google 的 Gemma 集成到 Perplexity API 的讨论引起了好奇。
-
搜索洞察与潜在合作:用户利用 Perplexity AI 搜索探索了诸如
pline0的身份、风险分析和小米 14 系列等话题,并讨论了 Perplexity AI 与 ElevenLabs 潜在的合作。对话中分享了直接指向 Perplexity AI 搜索结果的链接。
OpenAccess AI Collective (axolotl) Discord 摘要
-
Axolotl-Dev 洞察:CUDA 困惑与 Gemma 优化:
@casper_ai分享了优化 Mixtral 模型的进展,但在缺乏 CUDA 专业知识的情况下难以构建兼容的反向传播 (backward pass)。他们建议预计算 token 和 expert ID 以进行高效的分组计算,从而提升 Mixtral 的效率。同时,@curiositix推荐使用 Gemma Inference Engine 来克服@casper_ai在反向传播实现上的障碍。 -
关于云服务与服务器成本的讨论:在 #general 频道中,
@yamashi引发了关于长期 AI 项目中云服务与自建服务器之间经济权衡的辩论,考虑了持续的云租赁成本与一次性购买服务器的成本对比。 -
General Help 中的推理困扰与贡献请求:
@nani1149和@nanobitz在 #general-help 频道讨论了 alpaca 推理格式,@nanobitz提供了 Stanford Alpaca GitHub 链接作为参考。nanobitz和@yamashi思考了改进文档以帮助社区成员的必要性,暗示可以使用 Gitbooks 等资源。 -
高级 AI 叙事社区展示:在 #community-showcase 中,
@dreamgen宣布在 Hugging Face 上发布了用于叙事创作的新 AI 模型,并分享了 Opus V1 指南。针对相关疑虑,他们确认了在更新 tokenizer 聊天模板时的疏忽,并承诺进一步调查所谓的 prompt 泄露问题。此外,@finetuningllms展示了他们对 Phi-2 模型的微调版本,可在 axra/phi-2-x-0.1 获取。 -
寻找难以找到的 RunPod 镜像:针对 #runpod-help 频道中关于 RunPod 镜像缺失的困惑,
@nanobitz引导用户前往 Docker Hub 获取,然而@stoicbatman指出 Docker Hub 与目前存在误导的 GitHub readme 之间存在差异。
HuggingFace Discord 摘要
Aya 数据集可视化分享:用户提供了一个旨在提高理解力的 Aya 数据集可视化。
蛋白质研究与语言技术的创新:ProteinBERT 模型及其相关 论文,以及在 此空间 展示的 Fluently diffusion model demo,为蛋白质理解和自然语言处理带来了进步。
Stable Diffusion XL 优化指南发布:新文章详细介绍了在性能较低的 GPU 上实现图像生成的方法,可通过 @felixsanz 的文章 获取,与此同时社区也迎来了 Stable Diffusion 3。
对非官方 API 的伦理担忧:用户对使用 Selenium 的非官方 ChatGPT API 的伦理和实际影响表示担忧,强调了其可能违反 OpenAI 的条款并存在封号风险。GitHub 仓库链接。
关于微调与大模型方法的辩论:社区讨论了是为文本分类微调像 Mistral 7B 这样的大型 LLM,还是使用优化后的 BERT 变体。建议将 Encoder 模型作为分类任务的更高效重点,而非使用庞大的模型。
模型扩展与翻译系统的挑战:用户讨论了将 BART MNLI 模型扩展到 10 个类别以上,以及为一个大学项目创建基于 Interlingua 的翻译器,这反映了对模型适配和多语言翻译系统的广泛兴趣。
Latent Space Discord 摘要
-
GPT-4 表现不及预期:
@henriqueln7测试了 GPT-4 重写 Prompt 的能力,但发现它的表现更像是一个新的助手。计划在 Playground 进行广泛测试以进一步探索其能力。 -
Stable Diffusion 3 引起轰动:Stability AI 宣布了 Stable Diffusion 3 的早期预览版,在多主题 Prompt 和拼写能力方面有所提升。
@rubenartus通过多个 链接 分享了详细的模型信息。 -
Google Gemini Pro 1.5 发布:
@nuvic_讨论了具有 1,000,000 token 超大上下文窗口和视频输入能力的 Gemini Pro 1.5,信息源自 Google AI Studio。 -
辩论 Reddit 利润丰厚的数据交易:社区(包括
@guardiang和@pennepitstop)讨论了 Google 与 Reddit 达成的每年 6000 万美元数据协议的影响,以及该协议在 Reddit IPO 前夕的作用。 -
Google Gemini 图像生成出现偏差:在 Gemini 的图像生成功能出现问题后,Google 暂停了该功能,正如
@swyxio链接的博客文章中所宣布的那样。 -
LLM Paper Club 深入探讨 T5:由
@ivanleomk和@bryanblackbee主持的 LLM Paper Club 对 T5 论文进行了深入讨论,并分享了 笔记中心仓库 和参与者的见解。 -
AI 模型合并(Model Merging)兴起:模型合并技术被重点关注,这是一种结合 LLM 的成本效益方法。
@swyxio分享了 Hugging Face 关于该主题的博客文章 并提到了 mergekit 库。 -
Civit.ai 画廊引发辩论:Civit.ai 模型画廊的内容(尤其是年轻女性的图像)是辩论的焦点,强调了内容审核的重要性以及对 AI 生成内容的影响,见
@kbal11的讨论。
Eleuther Discord 总结
-
关于模拟人类经验的辩论:针对 GPT-4 模拟人类经验的能力出现了质疑,讨论集中在增强模型记忆层以实现更真实的行为。讨论还延伸到一家名为 Superfocus 的公司,该公司声称 LLMs 可以达到近乎完美的实时事实准确性。
-
LLM Benchmarks 的有效性受到质疑:一段批评当前 LLM Benchmarks 有效性的 YouTube 视频引发了关于 Benchmark 是否充分的讨论。
-
探索 LLM Unlearning 与中文语境化:分享了一项名为 Survey and formalization of LLM unlearning 的研究;并报道了一个 13b 模型的中文 lens 训练情况,同时调查了模型的均匀输出行为和 tokenizer 问题。
-
对误导性模型命名规范的担忧:围绕模型命名规范展开了辩论,例如 “gemma-7b” 实际上包含 8.5b 个参数,这导致了混淆并引发了对一致性的呼吁。
-
优化 GPT-NeoX 的预训练与微调技术:分享了强调序列组成(sequence composition)影响的已发表工作。讨论内容包括在
gpt-neox代码库中使用 LoRA finetuning 的适当性,并考虑在 NeoX 20B 微调中弃用 PyTorch 原生 FSDP。 -
缓解多模态模型中的假阴性(False Negatives):就 datacomp 或 metaclip 等大型数据集中精确假阴性的重要性交换了意见。在训练期间生成单模态 embeddings 或计算相似度可能会减少 hard negatives 的发生。
LlamaIndex Discord 总结
-
全栈 RAG 变得简单:
@wenqi_glantz提供了一个将 RAG notebook 转换为全栈应用的教程,包括数据摄取服务,详见她的指南。LlamaIndex 发布了一个用于高级 RAG 的 LlamaPack,正如这里所宣布的,只需两行代码即可轻松实现 Web 应用。 -
ColBERT 加速文档重排序:
@lateinteraction介绍了 ColBERT,这是一个用于快速文档重排序(re-ranking)的工具,比基于 BERT 的模型快 100 倍。ColBERT 的改进得到了@Haotianzh的证实,可以在这条推文中进一步了解。 -
查阅 LlamaIndex 文档以设置 RAG:
@lapexer询问了如何在 QueryPipeline 中设置简单的 RAG,@cheesyfishes提供了文档链接作为指导。 -
IngestionPipeline 出现问题:在部署 IngestionPipeline 时出现了
ValidationError等问题,但最终通过社区支持得到解决。此外还注意到,不一致的模块导入可能需要重新安装 LlamaIndex。 -
渴望代码调用模型:
@gooooooofy正在寻找擅长生成准确代码调用的模型,并认为 Gorilla LLM 可能走在正确的方向上,尽管它专注于 API 调用。
CUDA MODE Discord 总结
-
高性价比 GPU 算力升级:一位工程师以 1700 欧元的价格购入了三块 RTX 3090,用于升级一套挖矿设备以进行 LLM 微调和推理服务(serving),强调了其成本效益。他们在分为两部分的博客系列中详细介绍了改装过程。
-
来自芯片行业老兵对 CUDA 的批评:Jim Keller 批评了 Nvidia 的 CUDA,将其描述为一个复杂且不优雅的解决方案,类比于 x86 架构的演进。这一批评被刊登在 Tom’s Hardware 的文章中。
-
Kernel 编写与量化细节:讨论重点在于量化模型计算的细微差别,以及用于深度学习的 CUDA Kernel 开发。一位工程师分享了他们的 torch-bnb-fp4 仓库,作为 bitsandbytes 的更快替代方案,并提供了一个基准测试脚本来测试性能提升。
-
通过 Random Kernels 探索 PyTorch:讨论围绕 PyTorch 中 Random Kernels 的优化展开,展示了在 Triton 等库上协作工作的相关性及其教育价值,正如 Triton 频道的对话中所强调的那样。
-
NLP 和 ML 爱好者的工作机会:慕尼黑的 SIXT 公司为 ML Engineer 提供了新职位,倾向于具有 NLP 和 Generative AI 专业知识的候选人。有意向的申请人可以查看 SIXT 招聘列表。
-
硬件加速训练的挑战与进展:成员们讨论了 AMD GPU 与 FA2 训练的兼容性问题,特别关注 7900xtx 缺失的 backward 函数/Kernel。提到了可能的解决方案和正在进行的工作,例如旨在提供更好 AMD GPU 支持的 flash-attention GitHub 仓库。
-
Ring Attention 引发社区关注:围绕 Ring Attention 机制出现了一系列活动,提供了多个实现和基准测试的仓库链接。工程师们正在协作改进这些库,例如 lucidrains/ring-attention-pytorch,并专注于可用性和优化的增强。
LangChain AI Discord 总结
-
通过民主化反馈进行创新:一份研究工具调查正在传阅,征求社区意见以改进诸如查找研究论文和理解复杂研究等功能。
-
LLM 增强讨论:技术讨论围绕优化 LangChain Agent 展开,特别是通过使用 RunnableParallel 和 RunnablePassthrough 来改进并行链操作,以及集成用于流式传输(streaming)的本地模型。
-
寻求 Langchain 专家:一位社区成员正在寻找 Langchain 和 OpenAI tool agent 顾问,并为指导和专业知识提供报酬。
-
调试工具展示:推荐使用 LangSmith 的调试和可视化功能,以确保复杂的 LangChain 流程中行为正确。
-
并行性探索:正如最近的一篇 LinkedIn 帖子所揭示的,LLM 中的并行函数调用现在已成为可能,这扩展了 AI 工程应用的技术工具箱。
-
分享 AI 增强的工作流:分享了构建具有历史记录功能的自定义聊天机器人,以及使用 AI 进行股票投资组合摘要的技术,有力地展示了 LLM 如何增强各种业务和开发任务。
Datasette - LLM (@SimonW) Discord 总结
- Codespaces 模板助力 LLM 玩法:
@derekpwillis提供了一个模板仓库,非常适合在 Codespaces 中运行orca-mini-3b,尽管在运行更大模型时可能会遇到挑战。该模板因其简洁性获得了积极反馈,但由于需要即时编译,其启动时间较长。 - Codespaces 中的一个小问题已解决:
@simonw详细说明了 Codespaces 中llm-gpt4all初始不可用 Bug 的解决方法,建议使用命令llm chat -m orca-mini-3b-gguf2-q4_0预加载模型,以便后续快速使用。 - 赞赏 Prompt 编写技巧:
@tariqali强调了 LLM 中传统 Prompt 编写(Prompt Crafting)的细微优势,并将其与目前通过 RLHF 等方法实现的直接查询进行了对比。传统 Prompt 在恢复聊天机器人对话等特定目标上仍具有价值。 - Large World Model 的 GPU 需求:
@simonw表示有兴趣尝试 Large World Model 的 LWM-Text-1M-Chat,并讨论了由于该模型在海量数据集上训练,为了获得最佳性能,必须使用 GPU 实例。
LLM Perf Enthusiasts AI Discord 总结
- Richard Socher 透露 AI Hallucination 取得突破:在解决 AI Hallucination(幻觉)方面可能取得了重大进展,正如 Richard Socher 的推文所展示的,其提供了无误且及时的引用;具体机制推测涉及最先进的 Embeddings 和一个验证器(Validator),但细节尚未公开。
- Globe Explorer 在信息发现方面的创新:
- Globe Explorer 被描述为一个由 GPT-4 驱动的个性化维基百科,在讨论中被强调为信息检索新时代的象征。它最初在一条推文中被介绍,随后在社区中引发讨论,甚至在推广活动开始前就获得了病毒式的关注。
- 探讨 GPT-4-Turbo 的 Finetuning 策略:一位成功使用 gpt-4-turbo 从整个文档中进行 1-shot 数据提取的用户,正在权衡在处理更复杂任务时,Finetuning 数据集应该包含整个文档还是仅包含相关部分。
- 探索 LLM 的空间逻辑 Prompting:讨论涉及了编写 Prompt 以在网格中组织非重叠组件的挑战,质疑了 LLM 在没有提供结论性策略或结果的情况下处理空间任务的有效性。
Alignment Lab AI Discord 总结
- GLAN - 下一个大热门?:
@.benxh提到了一篇关于 GLAN (Generative Latent Nearest Neighbors) 的最新论文,引发了社区的兴趣。文中附上了相关论文链接,供对这一新兴技术感兴趣的人参考。
第 2 部分:频道详细总结与链接
TheBloke ▷ #general (1038 条消息 🔥🔥🔥):
-
Gemini 图像生成器偏见辩论:一场重大的讨论围绕 Google 的 Gemini 1.5 AI 图像生成模型展开,该模型因无法准确描绘白人或历史事件而受到批评,导致其被关停(
@coffeevampir3,@netrve)。用户争论这究竟是由于内部偏见还是 Google 仓促实施所致(@shanman6991,@netrve),并引用了解释该争议的视频以及几篇讨论该模型的文章(@potatooff)。 -
游戏开发中的 AI 辅助创意:多位用户表示有兴趣使用各种 AI 工具来生成或增强游戏资产,对话涵盖了 Text to 3D 等方法(
@itsme9316),以及小型游戏开发者利用 AI 进行美术指导的潜力(@alphaatlas1)。 -
搜索引擎市场份额之谜:对话简短地转向讨论为何 Google 能维持主导性的搜索引擎市场份额,并提出了 Qwant 等替代方案(
@maldevide),同时对 Google 的企业价值观和发展方向提出了批评(@shanman6991,@selea8026)。 -
AI 中的 Control Vectors:
@rtyax介绍了 AI 模型的 Control Vectors(控制向量)概念,并通过文章和研究链接对其进行了进一步阐述(@selea8026,@rtyax)。 -
AI 聊天中的摘要模型:
@netrve询问了在 AI 平台内总结聊天消息的优质模型选择,并讨论了目前 Streamlit (ST) 的 Transformer 框架中摘要流水线面临的挑战。@itsme9316建议可以尝试使用 ST 中相同的 LLM,或者训练一个自定义模型。
提到的链接:
- ChatGPT 的意外响应:未找到描述
- deepseek-ai/deepseek-moe-16b-chat · Hugging Face:未找到描述
- 表征工程 Mistral-7B 的迷幻之旅:未找到描述
- Paneer Paratha 食谱(原味分层与填充)- Swasthi’s Recipes:Paneer paratha 是一种用 paneer(印度奶酪)、小麦粉、香料和草药制成的美味大饼。这是适合全家人的绝佳美食。
- LLM Explorer:精选的大语言模型目录。LLM 列表。18662 个开源语言模型。:浏览 18662 个开源的大型和小型语言模型,这些模型被方便地分为各种类别和 LLM 列表,并配有基准测试和分析。
- Gemini 存在多样性问题:Google 在其新的 Gemini Pro 模型上将反偏见拨盘调到了 11。参考资料:https://developers.googleblog.com/2024/02/gemini-15-available-for-private-…
- 👾 LM Studio - 发现并运行本地 LLM:查找、下载并实验本地 LLM。
- Cerebras CS-2 系统拆解:一段简短的讲解视频,展示了 Cerebras 卓越的 AI 加速器系统是如何构建的。除了摄像,我完成了所有工作,包括制作道具。
-
[Discord 你的聊天与聚会场所](https://discord.gg/YTYD3nX6)):Discord 是通过语音、视频和文本进行交流的最简单方式。与你的朋友和社区交谈、聊天、聚会并保持紧密联系。 - GitHub - vosen/ZLUDA: AMD GPU 上的 CUDA:AMD GPU 上的 CUDA。通过在 GitHub 上创建账户为 vosen/ZLUDA 的开发做出贡献。
- 科学家声称 AI 取得突破,可产生无限清洁聚变能:普林斯顿大学的研究人员报告称,一种新的 AI 模型解决了产生聚变能的主要障碍之一。
- 斯皮尔曼等级相关系数 - 维基百科:未找到描述
- Windows 带来的烦恼:我如何清理 Windows 11 和 Edge 的“纯净安装”:在使用 PC 时让 Microsoft 不再打扰你的技巧和窍门。
- Tyler Perry 对 OpenAI 的视频生成器 Sora 感到非常震惊,以至于他暂停了耗资 8 亿美元的影棚扩建计划:“许多工作岗位将会消失”:这位电影大亨称这款 AI 文本转视频生成器“令人震惊”,是电视和电影工作者的“重大游戏规则改变者”。
-
[Jurassic X Prix 决赛集锦 Extreme E Jurassic X Prix](https://www.youtube.com/watch?v=4jkVymz8M1M):订阅更多 Extreme E 内容:https://bit.ly/3uj6v3z 观看直播地址:https://bit.ly/3ctoVbI 网站:https://extreme-e.com Instagram:https://instagram.co… - 美国广播公司诉 Aereo 公司案 - 维基百科:未找到描述
- 通过添加激活向量引导 GPT-2-XL:注:后来作为预印本发布,标题为《激活叠加:无需优化即可引导语言模型》。摘要:我们展示了一种与语言模型交互的新型可扩展方式:添加…
- GitHub - amd/blis: 类 BLAS 库实例化软件框架:类 BLAS 库实例化软件框架 - amd/blis
- Groq 的定制芯片在 Llama 2 Chat (70B) 上实现了 240 tokens/s:由 u/speakerknock 发布在 r/LocalLLaMA • 238 个赞和 145 条评论
TheBloke ▷ #characters-roleplay-stories (438 messages🔥🔥🔥):
-
探索模型偏好与性能:用户正在讨论他们在各种模型中的体验和偏好,包括
Rogue-Rose-103b、miqumaid和Miquella。@johnrobertsmith表示偏好miqu,而@splice0001偏好Rogue-Rose-103b,并将写作风格列为决定性因素。 -
模型行为排错:
@euchale遇到了EstopianMaid表现不符合人设的问题,并收到了检查设置或角色卡(character cards)的建议。经过进一步讨论,确定该问题可能是用户特定的,或与 Prompt 序列有关。 -
Temperature 设置对 AI 模型的影响:
@splice0001和@dreamgen正在交流他们在 AI 模型中调整 Temperature 设置的经验。@dreamgen建议从 Temperature 低于 1 开始,并推荐了一个使用 vLLM 的配置。 -
角色扮演中的角色卡复杂性:
@superking__分享了一个有趣的观察:在使用 Mixtral 的角色扮演场景中,给角色设定“不惜一切代价生存”的目标能让其更有效地履行角色职责。 -
Opus V1 模型指南:焦点集中在最新发布的用于 AI 故事写作和角色扮演的 Opus V1 模型。
@dreamgen发布了一份指南,并提供了一个用于正确 Prompt 格式化的 Colab script。@splice0001在使用该模型后给出了正面反馈。
提到的链接:
- no title found): 未找到描述
- dre (Kimjongeun): 未找到描述
- Viralhog Grandpa GIF - Viralhog Grandpa Grandpa Kiki Dance - Discover & Share GIFs: 点击查看 GIF
- Angry Bender Mad GIF - Angry Bender Mad Angry - Discover & Share GIFs: 点击查看 GIF
- LoneStriker/miqu-1-70b-sf-5.5bpw-h6-exl2 · Hugging Face: 未找到描述
- dreamgen/opus-v1-34b · Hugging Face: 未找到描述
- configs/lmstudio.json · dreamgen/opus-v1.2-7b at main: 未找到描述
- dreamgen/opus-v1-34b-awq · Hugging Face: 未找到描述
- configs/opus-v1.py · dreamgen/opus-v1.2-7b at main: 未找到描述
- configs/opus-v1.py · dreamgen/opus-v1.2-7b at main: 未找到描述
- Opus V1: Story-writing & role-playing models - a dreamgen Collection: 未找到描述
- DreamGen: AI role-play and story-writing without limits: 未找到描述
- Models - Hugging Face: 未找到描述
- Models - Hugging Face: 未找到描述
- tokenizer : special token handling by staviq · Pull Request #3538 · ggerganov/llama.cpp: Special token 处理,基于 #1931, #3475。可以使用,但肯定还没准备好,只是发布出来征求反馈。包含一些旨在转正前删除的测试代码。完全没有优化,只是…
TheBloke ▷ #training-and-fine-tuning (4 messages):
- 寻求 DPO 实现指南:
@cogbuji正在寻找 DPO 的实际参考实现以应用于 MLX。他发现 Hugging Face alignment handbook 并不理想,因为除了配置文件外缺乏具体的实现细节。 - 社区成员分享 DPO 尝试:响应
@cogbuji,@dirtytigerx分享了一个未完成的 DPO 实现尝试,并参考了trl库中的DPOTrainer,代码位于 GitHub 上的 huggingface/trl。 - 混合实现中的额外部分:
@dirtytigerx提到参考的DPOTrainer代码不仅包含 DPO,还包含 KTO (knowledge transfer optimization) 片段,这可能与@cogbuji的需求不直接相关。 - cogbuji 选择 TRL:在社区反馈后,
@cogbuji决定以trl模块为基础来实现 DPO。
Links mentioned:
trl/trl/trainer/dpo_trainer.py at main · huggingface/trl: 使用强化学习训练 Transformer 语言模型。 - huggingface/trl
TheBloke ▷ #model-merging (25 messages🔥):
- 探索模型杂交:
@jsarnecki正在考虑将 Orca-2-13b 与 Nous-Hermes-2-DPO-7b 进行 “frankenmerge”,使用 Orca 作为基础,并利用 mergekit 逐层合并为一个 17B 参数的模型。然而,@maldevide澄清说这类模型是非同源的 (non-homologous),因此无法直接合并。 - 混搭模型合并的热潮:
@maldevide建议,虽然直接合并不可行,但使用 在 Hugging Face 上微调过的 数据集可能会有帮助,并参考了创建 SOLAR-10.7B-v1.0 时使用的复杂合并技术。他们提到在分层合并后使用 “SFT 来进行清理”。 - 同态难题与合并方法:
@alphaatlas1和@maldevide讨论了对于像@jsarnecki项目这样的非同源合并,会出现严重问题且目前没有成熟的技术,建议使用同态投影矩阵 (homomorphic projection matrix) 并进行密集训练。 - PEFT 与合并方法引发的好奇心:
@alphaatlas1指向了 一篇博客文章,揭示了 PEFT 在模型合并方面的发现,并指出 DARE 与扩散模型合并的负面结果有关,而根据 GitHub 上的 meh 的测试,它似乎更适合 LLM。 - 扩散模型合并的困境:对话转向扩散模型在合并技术下的奇特行为,
@jsarnecki和@alphaatlas1注意到由于模型的密度和对齐问题可能产生的影响,而线性合并对于 SD (Stable Diffusion) 等模型效果良好。
Links mentioned:
- 🤗 PEFT welcomes new merging methods: 暂无描述
- GitHub - s1dlx/meh: Merging Execution Helper: Merging Execution Helper。欢迎在 GitHub 上为 s1dlx/meh 的开发做出贡献。
TheBloke ▷ #coding (8 messages🔥):
- 为 MLX 爱好者探索社区:
@fred.bliss询问除了 GitHub 和 Twitter 之外,是否有专注于机器学习和折腾 (tinkering) 的社区。他们表示很难在这些平台之外找到此类群体。 - 偏好独立而非社区:
@dirtytigerx提到他们通常不主动寻找社区,这表明他们更倾向于独立工作,或者使用更成熟、社区属性较弱的平台。 - Dotpeek 深受 Spottyluck 青睐:
@spottyluck分享了他们使用 JetBrains 的 Dotpeek(一款 .NET 反编译器)的经历,主要用于漏洞研究而非通用编程任务。他们还幽默地提到了大量编写拙劣的系统托盘应用。 - 对 Dotpeek 能力的好奇:
@al_lansley询问 Dotpeek 是否仅限于 C#,或者是否有更广泛的应用。他们的提问说明了在技术社区中,无论专业水平如何,提出澄清性问题都很重要。
LM Studio ▷ #💬-general (462 条消息🔥🔥🔥):
- Gemma 模型讨论: 用户反映
Gemma模型的表现令人失望。@heyitsyorkie 澄清说,低于Q8量化的Gemma在 LM Studio 使用的llama.cpp中存在问题。 - LLava 无法上传图片: @tvb1199 询问关于使用
LLava模型上传图片的问题。他们被告知视觉能力需要一个模型和一个视觉适配器(mmproj-model)。 - 大型模型面临挑战: @wyrath 尝试运行
70b模型,发现其在 CPU 上运行缓慢,并在部分 GPU offloading 方面遇到困难。 - OLED 显示器成为焦点: 多位用户称赞 OLED 显示器生动的显示质量,分享了他们的使用体验,并表示相比传统显示器更倾向于选择 OLED。
- 对 Phind-70B 的好奇: @pierrunoyt 询问如何获取 Phind-70B 模型;@heyitsyorkie 指出该模型是 Phind 平台专属的,无法在本地使用。
提到的链接:
- 👾 LM Studio - 发现并运行本地 LLMs: 查找、下载并实验本地 LLMs
- Phind: 未找到描述
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face: 未找到描述
- 什么是 RAG? - 检索增强生成详解 - AWS: 未找到描述
- Stable Diffusion 3 — Stability AI: 发布 Stable Diffusion 3 早期预览版,这是我们最强大的文本生成图像模型,在多主题提示词、图像质量和拼写能力方面有显著提升。
- Phind-70B: 超越 GPT-4 Turbo 的最强编程 LLM + 开源!: 在这段视频中,我们将展示 Phind-70B 的革命性功能,旨在缩小代码质量差距并加速您的编程过程。拥有高达 8…
- Google 的新开源模型糟糕得令人震惊: 抱歉用了这个标题。我忍不住。我为 Google 向世界发布一个完全开源的模型感到自豪,但它并不好。到底有多糟?…
- dreamgen/opus-v1.2-7b-gguf · Hugging Face: 未找到描述
- dreamgen/opus-v1.2-7b · Hugging Face: 未找到描述
- configs/lmstudio.json · dreamgen/opus-v1.2-7b at main: 未找到描述
- W3C 标准和草案: 万维网联盟 (W3C) 是一个国际社区,成员组织、全职员工和公众在这里共同制定 Web 标准。
- Web 无障碍设计 – 入门技巧: 摘要
- Web 标准: 本页面对 Web 标准进行了高层级的介绍。
- W3C 无障碍标准概览: 来自国际标准组织 W3C Web 无障碍倡议 (WAI) 的免费在线无障碍资源。
LM Studio ▷ #🤖-models-discussion-chat (76 条消息🔥🔥):
- 寻求 AI 辅助教学工具:
@therapienachdemtod正在设计一个辅助教学的助手,寻找能够准备教育内容并通过纠正语法和进行对话与学生互动的模型。作为回应,@thebest6337对当前模型处理此类任务的有效性表示怀疑,提到了可能存在的缺陷,并且没有使用 “Gemma” 模型的经验。 - Gemma 模型特性揭示:
@thorax7835讨论了 “Mixtral” 在询问健身建议时的局限性,因为它倾向于自我审查;@nullt3r确认在 “LM Studio Gemma 2b 模型” 中也遇到了奇怪的行为。 - 本地模型无法联网:针对
@thorax7835关于模型改进和联网能力的询问,@heyitsyorkie澄清了 LM Studio 中的本地模型(如 “Gemma”)无法访问互联网。 - 推荐使用 Stable Diffusion Web UI:在关于图像生成能力的讨论中,
@heyitsyorkie和@drawingthesun建议使用 Automatic1111 的 Stable Diffusion Web UI 来完成这些任务,因为 LM Studio 并不支持这些功能。 - LM Studio 故障排除:
@macaulj就其在 LM Studio 中遇到的错误寻求帮助,并收到了@heyitsyorkie的建议,暗示可能存在与 CUDA 相关的显卡驱动程序问题。
提到的链接:
- 👾 LM Studio - Discover and run local LLMs:查找、下载并实验本地 LLM。
- EvalPlus Leaderboard:未找到描述。
- Master Generative AI Stack: practical handbook:又一篇 AI 文章。有时可能会让人应接不暇。在这份综合指南中,我将简化生成式 AI 的复杂世界……
- Big Code Models Leaderboard - a Hugging Face Space by bigcode:未找到描述。
- wavymulder/Analog-Diffusion · Hugging Face:未找到描述。
- Models - Hugging Face:未找到描述。
- macaulj@macaulj-HP-Pavilion-Gaming-Laptop-15-cx0xxx:~$ sudo '/home/macaulj/Downl - Pastebin.com:Pastebin.com 是自 2002 年以来排名第一的粘贴工具。Pastebin 是一个可以在线存储文本一段时间的网站。
- GitHub - ParisNeo/lollms-webui: Lord of Large Language Models Web User Interface:大语言模型之主 Web 用户界面。通过在 GitHub 上创建账号为 lollms-webui 的开发做出贡献。
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI:Stable Diffusion Web UI。通过在 GitHub 上创建账号为 stable-diffusion-webui 的开发做出贡献。
LM Studio ▷ #announcements (1 条消息):
- LM Studio v0.2.16 紧急更新:
@yagilb宣布 LM Studio v0.2.16 现已发布,并敦促用户从 v0.2.15 版本进行更新。此更新包含了 v0.2.15 的所有功能,并针对下载期间聊天中出现的异常重新生成和异常滚动问题提供了重要的错误修复。
LM Studio ▷ #🧠-feedback (26 条消息🔥):
-
Gemma 7B 下载困惑已解决:用户
@heyitsyorkie向@adtigerning解释说,来自 Hugging Face 的 Gemma 7B 文件必须手动下载并放入 My Models 文件夹以确保兼容性。该问题与 LM Studio 和 Hugging Face 仓库的访问权限有关。 -
LM Studio 更新至 v0.2.16 已发布:
@yagilb告知包括@drawingthesun和@heyitsyorkie在内的用户,他们在旧版本中遇到的滚动 bug 已在新更新的 v0.2.16 版本中修复。建议用户从 LM Studio 下载或通过应用的更新功能进行升级。 -
社区对 LM Studio v0.2.16 的反馈:
@bananatechindustries对 v0.2.16 更新中的新用户界面表示热烈欢迎,特别赞赏在搜索中查看模型 readmes 的功能。同时,@heyitsyorkie确认之前的 bug 在此更新中似乎已得到解决。 -
对 UI 和兼容性的褒贬不一:用户
@clickclack777批评了 LM Studio v0.2.16 中 Comic Sans 字体的使用和复杂的 UI,认为这增加了不必要的复杂性。@woteva提出了 UI 缩放和模型文件夹兼容性的问题,并提到了屏幕尺寸和错误的 RAM 需求提示。 -
新更新获得好评:
@macfly分享了他们对 LM Studio 更新外观和感觉的正面印象,并用一个动态火苗表情符号进行了强调。
提到的链接:
👾 LM Studio - 发现并运行本地 LLMs:查找、下载并实验本地 LLMs
LM Studio ▷ #🎛-hardware-discussion (46 条消息🔥):
-
老旧 GPU 的廉价选择:
@freethepublicdebt提到有闲置的 TESLA K40 显卡出售,指出它们具有极佳的 VRAM/性价比,但仅限于 CUDA 3.5。有人提到有兴趣为这些显卡适配 llama.cpp 以实现廉价的数据中心显卡利用,但由于其年代久远,人们仍持怀疑态度。 -
更多 GPU,更快速度?:
@apnea2014询问了在 LM Studio 中增加第二块 GPU 进行推理的好处,@heyitsyorkie指出更多的 VRAM 等于更快的速度,并且组合两块同代显卡可以产生更好的效果。 -
高 VRAM GPU 的未来竞争:
@nink1对 AMD 凭借最新的财报增长以及推出高 VRAM GPU 的潜力可能挑战 Nvidia 表示乐观。@christianazinn和@ptable辩论了 AMD 对消费级市场的关注,并指出了 Nvidia 4090 显卡在 AI 应用中的普及。 -
AMD 的企业级进军:
@exio4强调,虽然消费级 Nvidia GPU 的矩阵吞吐量仍超过 AMD,但 AMD 最新的芯片(如 MI300X)凭借卓越的内存和带宽规格,可能会打破 Nvidia 在企业级 AI 领域的统治地位,正如一篇 TechWireAsia 文章 中讨论的那样。@nink1认为尽管目前存在 CUDA 兼容性问题,AMD 在嵌入式 AI 市场仍有潜在增长。 -
针对 LLMs 的消费级 GPU 讨论:
@barduk、@wolfspyre和@heyitsyorkie等参与者讨论了像 Radeon RX 7800 XT Core Edition 这样的 AMD 显卡是否适合运行 LLM 模型(与 Nvidia 的产品相比)。共识似乎是,虽然可以使用 AMD 显卡,但仍推荐使用 Nvidia 显卡,因为它们更易于设置,且与 AI 框架的兼容性更广。
提到的链接:
- AMD 发布 MI300 芯片:Nvidia AI 霸主地位的挑战者?:最新的 AMD AI 芯片拥有超过 1500 亿个晶体管,内存是 Nvidia 旗舰 H100 的 2.4 倍。
- 2023 年深度学习最佳 GPU —— 深度分析:在此,我提供了用于深度学习/机器学习的 GPU 深度分析,并解释了适合您的使用场景和预算的最佳 GPU。
- OpenCL - 异构系统并行编程的开放标准:未找到描述内容。
LM Studio ▷ #🧪-beta-releases-chat (34 条消息🔥):
- 模型性能报告:
@drawless111提到在 LM Studio 0.2.15 版本上测试了 Gemma 2B IT 和 7B IT(非超大版本),表示它们的表现令人印象深刻。 - 规格问题解答:
@heyitsyorkie确认即使是配备 15 11 gen CPU 和 8 GB RAM 的系统,也可以在 LM Studio v0.2.15 上运行 Q4_K_M 量化模型。 - Gemma 模型遇到的困难:像
@ascrowflies这样的用户报告了 Lonestriker’s 7B IT 量化版的质量问题,而@heyitsyorkie承认在llama.cpp修复之前,这是目前能用的最好版本。 - Gemma 模型兼容性:
@yagilb推荐了 Hugging Face 上的 Gemma 2B 模型,该模型解决了用户(@issaminu和@rumpelstilforeskin)在使用该模型时遇到的一些问题。 - 对 IQ 系列模型的期待:
@drawless111庆祝 IQ1, IQ2 和 IQ3 在 LM Studio 上成功实现,并提供了 IQ1 的具体性能统计数据。
提到的链接:
lmstudio-ai/gemma-2b-it-GGUF · Hugging Face: 未找到描述
LM Studio ▷ #autogen (8 条消息🔥):
- AutoGen 问题已解决:用户
@thebest6337遇到了一个关于 AutoGen 的奇怪问题,但随后通过卸载并重新安装所有 AutoGen Python 包修复了该问题。 - 鼓励分享解决方案:
@heyitsyorkie建议分享修复方法,以帮助遇到类似问题的其他人。 - 经典的 IT 修复手段:
@heyitsyorkie幽默地链接了一个 Tenor GIF,描绘了最典型的 IT 建议:“你试过重启吗?”(Have you tried turning it off and on again?)
提到的链接:
LM Studio ▷ #langchain (1 条消息):
- Chunk Size 很重要:用户
@simas93讨论了用于 Embedding 的文本预处理如何受到模型 Embedding 的影响,特别指出chunk_size应该取决于所使用的模型。他们分享了 AI Stack Exchange 上的一篇好文章,详细介绍了确定 Embedding 大小的经验法则,并提出了一个针对num_categories <= 1000时的特定公式,建议将num_embeddings设置为min(500, num_categories/2)。
提到的链接:
How to determine the embedding size?): 当我们训练神经网络时,我们将确定 Embedding 大小,以将分类信息(例如在 NLP 中)或连续信息(在计算机视觉或语音中)转换为隐藏状态。
OpenAI ▷ #ai-discussions (69 messages🔥🔥):
- 使用 HTML 和 CSS 训练 ChatGPT:用户
@ls_chicha询问是否可以使用 HTML 和 CSS 文件训练 ChatGPT,寻求将编程语言纳入 AI 教育的见解。 - GPTs 读取 PDF 的问题:
@arani1977遇到了 GPTs 的问题,最初可以读取 PDF,但随后声称失去了该能力,尽管配置设置未更改,仍在寻求对这种不一致性的理解。 - 寻求 OpenAI API 的聊天客户端推荐:用户
@oleksandrshr询问了关于 OpenAI API 聊天客户端的建议,并进一步表达了对 Ollama 上 Ollama、Mistral、Phi 和 Gemma:2b 等模型性能缓慢的担忧。 - 理解 AI 中的“量化版本”:针对
@oleksandrshr关于量化版本(Quantized Version)的问题,@darthgustav.解释说,此类版本通过对权重进行舍入来加速模型,这简化了计算但降低了精度和性能。 - 对 GPT-4 性能下降传闻的担忧:用户
@zaatuloa提到了有关 GPT-4 自发布以来可能已被降级的传闻,用户@lugui迅速反驳了这一说法,断言这些说法是错误的。
提到的链接:
- Stable Diffusion 3 — Stability AI:发布 Stable Diffusion 3 早期预览版,这是我们最强大的文本生成图像模型,在多主题提示词、图像质量和拼写能力方面有显著提升。
- Video generation models as world simulators:我们探索了在视频数据上进行生成模型的大规模训练。具体而言,我们在不同时长、分辨率和纵横比的视频和图像上联合训练了文本条件扩散模型…
- Pretty Much Everywhere Steve Kornacki GIF - Pretty Much Everywhere Steve Kornacki Msnbc - Discover & Share GIFs:点击查看 GIF
- Gemini has a Diversity Problem:Google 在其新的 Gemini Pro 模型上将反偏见拨盘调到了 11。参考资料:https://developers.googleblog.com/2024/02/gemini-15-available-for-private-…
OpenAI ▷ #gpt-4-discussions (67 messages🔥🔥):
-
Qdrant 和 OpenAI Embeddings 查询困惑:
@thirawat_z分享了在使用 OpenAI embeddings 与 Qdrant 时,搜索结果与教程不一致的挫败感,他们的结果与“欧洲现代艺术”查询无关。他们提供了教程和自己尝试的代码片段及结果进行对比。 -
使用 HTML 和 CSS 训练 ChatGPT:用户
@ls_chicha、_jonpo和@thedreamakeem讨论了使用 HTML 和 CSS 文件训练 ChatGPT 的可能性。@thedreamakeem提到可能需要 .json 数据库格式。 -
创建 AI 对话:
@link12313提议开发一个让 GPT-4 与 Google 的 Gemini Ultra 1.5 对话的应用,@toror评论说需要一个好的起点来开启引人入胜的对话。 -
GPT-4 输入 Prompt 膨胀问题:
@cetacean_xx报告了一个问题,即 GPT-4 的输入 Prompt 膨胀到了 30,000 多个 Token,@darthgustav.建议这是由于上下文历史累积造成的,并建议如果不需要则将其删除。 -
ChatGPT-4 性能和上下文限制:
@orbart对 ChatGPT-4 表示不满,认为感官上的性能削弱(nerfs)影响了使用和记忆能力,引发了与@paccer关于上下文长度和 Token 限制的讨论。@blckreaper贡献了观察结果,认为模型从文件中获取的可用上下文可能已经减少。
OpenAI ▷ #prompt-engineering (202 messages🔥🔥):
-
ReAct Prompting 中的循环逻辑:
@tawsif2781描述了他们的 chatbot Agent 在使用 ReAct prompting 时陷入循环的问题,反复输出相同的思考过程。@darthgustav.建议这可能是由于上下文不一致,或者内容过多导致模型从中间上下文(middle context)检索时出现问题。 -
零 Temperature 下的即兴创作:在关于零 Temperature 下生成独立思考的讨论中,
@darthgustav.澄清说,即使在零 Temperature 下,如果包含时间戳或细微的上下文差异,模型也可以遵循“即兴创作”之类的指令并产生不同的结果。 -
避免对 LLM 使用否定指令:
@darthgustav.分享的 Prompt 编写建议强调要避免否定指令,因为由于 Transformer AI 的逻辑缺陷,这些指令可能会被转化为肯定动作。此外还建议通过在 Prompt 中重新表述指令来利用冗余性,以获得更好的模型合规性。 -
Prompt Engineering 资源:多位用户分享了学习 Prompt Engineering 的建议和资源;
@darthgustav.推荐了 Arxiv 和 Hugging Face,而@bambooshoots提供了 OpenAI 的 Prompt Engineering 指南直接链接,@openheroes提到了 Custom Instructions 功能的实用性。 -
Custom Instructions (CI) 的疑虑与用法:用户
@jimmysapp和@eskcanta讨论了与 Custom Instructions 的使用和内容政策合规性相关的问题及解决方案。@eskcanta就如何有效地将 CI 用于角色扮演提供了详细建议,并通过在对话中加入一致的总结来归纳对话内容。
提及的链接:
OpenAI ▷ #api-discussions (202 messages🔥🔥):
-
打破 ReAct 循环:用户
@tawsif2781报告了一个 ReAct Prompting 循环的问题,持续收到相同的输出。@darthgustav.讨论了各种技术,如避免中间上下文和冗余 Prompting,以及管理 Temperature 设置,以排查这种重复行为。 -
零 Temperature 下的循环与即兴创作:
@darthgustav.澄清说,即使在零 Temperature 下,模型也可以根据提供的上下文进行即兴创作。通过对模型行为的探索,强调了时间戳等因素如何影响输出的差异,即使 Prompt 保持一致。 -
Graph of Thoughts 与角色一致性:用户参与了关于 “Graph of Thoughts” 如何运作以及它是否会延续偏见的讨论。
@eskcanta等人分享了关于在 ChatGPT 上使用 Custom Instructions (CI) 保持角色一致性和进行角色扮演的见解。 -
角色扮演场景下的持续 AI 交互:通过与
@cqoker的对话,@eskcanta展示了如何指示模型进行复杂的交互(如角色扮演),并提供了保存和切换不同角色描述或场景的示例和策略。 -
AI 的担忧与伦理影响:
@cqoker和@eskcanta反思了关于 AI 生成内容及其真实描绘的伦理担忧,讨论了负责任地使用技术并遵守 OpenAI 使用政策的重要性。
提及的链接:
LAION ▷ #general (398 条消息🔥🔥):
-
Worker Orchestration 讨论:
@top_walk_town对用于 Worker Orchestration 的框架感到好奇。@pseudoterminalx透露他们亲自创建了该编排系统,并将其描述为“蹩脚的脚本和数据库”。 -
Stable Diffusion 3 期待:
@thejonasbrothers提供了关于即将推出的 Stable Diffusion 3 的见解,假设它可能采用与他们数月来一直研究的类似方法:一个用于中等分辨率的 Base 模型和一个 Flow Matching Upscaler。人们对图像生成可能缺乏多样性表示怀疑,@pseudoterminalx指出这些图像似乎已经缺乏多样性。 -
Stability AI 的员工招聘趋势:
@thejonasbrothers和@pseudoterminalx讨论了 Stability AI 的招聘惯例,暗示由于成本考虑,公司更倾向于招聘正在向 Machine Learning 角色转型的系统管理员。还提到了招聘具有 YouTube 粉丝的人员的趋势。 -
对封闭模型开发的担忧:LAION 社区对 Stability AI 等公司将模型开发进一步转向闭源、脱离终端用户的趋势表示担忧。
@thejonasbrothers回忆起早期的模型如 LDM/SD1 在代码和 Compute 使用方面有更多的公众参与。 -
微调和开源模型的未来:讨论涉及了开源模型的盈利能力以及对它们进行 Finetuning 的优势。
@helium__分享了一个关于 LoRA Land 的链接,这是一个对 Mistral-7b 模型进行微调以期在特定任务中超越 GPT-4 的项目,并针对各种任务提供了专门版本。
提到的链接:
- SDXL Lightning - by fal.ai:由 fal.ai 提供的极速 SDXL API 演示
- Stable Diffusion 3 — Stability AI:早期预览版发布公告,这是我们最强大的 Text-to-Image 模型,在多主题提示词、图像质量和拼写能力方面有显著提升。
- Funny Silly GIF - Funny Silly Something Is Off - Discover & Share GIFs:点击查看 GIF
- Jasper Expands by Acquiring Image Platform Clipdrop from Stability AI:Jasper 通过收购进入欧洲市场,加入巴黎充满活力的 AI 社区
- LoRA Land: Fine-Tuned Open-Source LLMs that Outperform GPT-4 - Predibase:LoRA Land 是一个包含 25 个以上经过微调的 Mistral-7b 模型的集合,在特定任务应用中表现优于 GPT-4。这一开源模型集合为寻求高效…的团队提供了蓝图。
-
[Safety Review for LAION 5B LAION](https://laion.ai/notes/laion-maintanence/):媒体报道了斯坦福大学的一项研究项目结果,根据该结果,LAION 5B 训练集包含… - cc2dataset/cc2dataset/main.py at main · rom1504/cc2dataset:轻松将 Common Crawl 转换为由 Caption 和文档组成的数据集。图像/文本、音频/文本、视频/文本… - rom1504/cc2dataset
- WebVid 大型短视频数据集 / 数据集 / 超神经:未找到描述
- Snap Video:未找到描述
{kind=link}
LAION ▷ #research (73 messages🔥🔥):
- LAION 5B 的退役辩论:
@top_walk_town思考了 LAION 5B 是否应该由于链接失效和数据投毒等问题而退役,并建议社区共同努力创建具有高质量图像和标注的新数据集。 - 社区字幕生成协作:
@twoabove提到了一个使用 cogvlm 的“大众标注(mob captioning)”工作,暗示社区正在采取举措来提高数据集和标注质量。 - 混合精度模型训练:在关于混合精度训练的讨论中,
@yoavhacohen确认了在 TPU 上使用 bfloat16 的 autocast 的有效性,而@top_walk_town指出使用 autocast 和梯度缩放(gradient scaling)可以解决梯度下溢(underflow)问题。 - Instruct Pix2Pix 的最新技术水平:
@twoabove分享了一篇研究论文链接,详细介绍了 TinyLLaVA 框架,该框架讨论了数据质量、训练配方,以及小型多模态模型与大型模型的对比。 - LoRA 受到幽默审视:
@thejonasbrothers分享了一篇名为 Generative Models: What do they know? Do they know things? Let’s find out! 的论文链接,该论文使用 INTRINSIC LoRA 在不添加额外层的情况下展示了生成模型的隐藏能力。
提到的链接:
- OpenAI acquires Global Illumination:整个团队已加入 OpenAI。
- Generative Models: What do they know?:未找到描述
- Our structure:我们设计了 OpenAI 的结构——由最初的非营利组织和新的上限利润部门组成的合伙关系——作为实现 OpenAI 使命的架构:构建安全且……的通用人工智能(AGI)。
- Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping:虽然 Transformer 在各种应用场景中取得了巨大进步,但在解决复杂决策任务方面,此类架构仍落后于传统的符号规划器。在本文中……
- SDXL-Lightning: Progressive Adversarial Diffusion Distillation:我们提出了一种扩散蒸馏方法,在基于 SDXL 的单步/多步 1024px 文本生成图像方面达到了新的 SOTA。我们的方法结合了渐进式和对抗式蒸馏……
- TinyLLaVA: A Framework of Small-scale Large Multimodal Models:我们提出了 TinyLLaVA 框架,为设计和分析小型大语言多模态模型(LMMs)提供了统一视角。我们实证研究了不同视觉编码器的效果……
- LoRA Land: Fine-Tuned Open-Source LLMs that Outperform GPT-4 - Predibase:LoRA Land 是 25 个以上微调 Mistral-7b 模型的集合,在特定任务应用中表现优于 GPT-4。这一开源微调模型集合为寻求高效……的团队提供了蓝图。
Nous Research AI ▷ #ctx-length-research (3 messages):
- 气泡满天:
@harrisonv发布了一系列气泡表情符号,未提供进一步背景。 - 神秘的提及:
@harrisonv标记了一位 ID 为<@644428303293349888>的用户,但没有后续的文本或背景。 - Rwkv 评论:
@vatsadev回复了@harrisonv对该用户的标记,发表了一条神秘评论:Rwkv goes brrr here。
Nous Research AI ▷ #off-topic (13 messages🔥):
- 开源 SOTA 模型焦点 - Gemma:
@pradeep1148分享了一个 YouTube 视频,题为 “Gemma Google’s open source SOTA model”。视频介绍了 Gemma,这是一个轻量级、State-of-the-art 的开源模型系列,源自 Gemini 模型背后的研究成果。 - 寻找 AI Marketing 专家:
@danieltkilleen询问是否认识 AI Marketing 领域的关键意见领袖 (KOLs),并寻求相关推荐。 - Ski Bi Di 认可:
@teknium向<@687315767208706059>致敬,认可其在 skibidis 及相关知识领域的专业见解。 - 讨论 Zoomer 驱动的 LLM:
@n8programs思考了训练一个 Zoomer 语言模型的想法,引发了一场关于代际职业道德的轻松辩论,评论如 “…我们是为磨练(grind)而生的一代…还有 aderall。” - Zoomer 对工作的热爱: 在简短的交流中,
@everyoneisgross质疑了工作具有价值的观点,对此@hexani以一个词表示赞同,支持@n8programs的看法:”Factuals。”
提到的链接:
Gemma Google’s open source SOTA model: Gemma 是一个轻量级、State-of-the-art 的开源模型系列,基于构建 Gemini 模型的相同研究和技术开发。由 Google 开发…
Nous Research AI ▷ #interesting-links (18 messages🔥):
- OpenOrca 确认: 用户
@sherlockzoozoo和@teknium讨论了oo/oo2指代什么,@.benxh确认它确实是指 Open Orca。 - JARVIS 连接 LLM 与 ML 社区:
@leonidasch2分享了微软 JARVIS 项目下的 两个 GitHub 链接,该项目旨在将 Large Language Models 与机器学习社区连接起来,并建议关注其在 function calling 方面的应用。 - 新型 Diffusion Transformer 揭晓: 用户
@0xevil链接了@EMostaque的一条推文,讨论了一种类似于 Sora 的新型 Diffusion Transformer,其中包含 flow matching 和其他改进。关于多模态输入和 Transformer 改进的细节预计很快会分享。 - 质疑 Human Feedback 的充分性:
@pramod8481分享了一个 Arxiv 链接,重点介绍了对使用 Human Feedback 训练和评估 Large Language Models 的批判性分析,强调偏好评分可能会低估事实性 (factuality) 等关键方面。 - 调查 LLM 中的价值偏差:
@pramod8481强调的一项研究表明,由于内部隐含的价值函数,LLM 倾向于高价值选项,该研究基于一篇 Arxiv 论文。研究提出了对 LLM 回复中价值偏差 (value bias) 的担忧。
提到的链接:
- Exploring Value Biases: How LLMs Deviate Towards the Ideal: Large-Language-Models (LLMs) 被部署在广泛的应用中,其回复具有日益增长的社会影响。了解 LLM 在给出回复时的非故意机制…
- TencentARC/Mistral_Pro_8B_v0.1 · Hugging Face: 未找到描述
- Human Feedback is not Gold Standard: Human feedback 已成为评估 Large Language Models 性能的事实标准,并越来越多地被用作训练目标。然而,目前尚不清楚哪些属性…
- 来自 Emad (@EMostaque) 的推文: @StabilityAI 一些说明:- 这使用了一种新型的 Diffusion Transformer(类似于 Sora),结合了 flow matching 和其他改进。- 这利用了 Transformer 的改进,并且可以…
- Bio-inspired Structure Identification in Language Embeddings: 在现代语言建模中,Word embeddings 是提高下游任务性能的流行方法。然而,embedding 空间的底层几何结构尚未被很好地理解。我们提出…
- JARVIS/taskbench at main · microsoft/JARVIS: JARVIS,一个连接 LLM 与 ML 社区的系统。论文:https://arxiv.org/pdf/2303.17580.pdf - microsoft/JARVIS
- JARVIS/easytool at main · microsoft/JARVIS: JARVIS,一个连接 LLM 与 ML 社区的系统。论文:https://arxiv.org/pdf/2303.17580.pdf - microsoft/JARVIS
Nous Research AI ▷ #general (345 条消息🔥🔥):
-
显微镜下的 Gemma 7B:包括
@interstellarninja、@teknium和@gryphepadar在内的多位用户分享了他们微调 Gemma 7B 模型的经验。他们讨论了初始 Loss 过高的问题以及缓解方法,例如在微调期间不添加 Token,但最终结果仍不如预期理想。 -
微调后的 Tinyllama 展示其实力:用户
@alvion427称赞了@n8programs微调的 Tinyllama 模型在多轮对话方面的能力。@n8programs讨论了如何使用该模型更高效地生成内容。 -
OpenCodeInterpreter 引起关注:由
@weyaxi分享,OpenCodeInterpreter 将代码生成与执行和优化相结合,并在大型多轮交互数据集上进行了训练。@.benxh和@teknium参与了讨论,涉及相关数据集及其可用性。 -
使用 LLM 进行评分和分类:包括
@night_w0lf和@leontello在内的用户探讨了在给 LLM 布置评分任务时使用数字量表和分类标签的情况。他们一致认为,定义评分标准并使用分类标签能产生更好的效果。 -
针对受限输出的 LLM 微调:
@cf0913和@mihai4256讨论了微调 LLM 以获得更受限且可靠输出(如 JSON)的策略。@teknium和@.interstellarninja提到了他们正在进行的工作,其中包括结构化微调以实现更可预测的结果。
提到的链接:
- Phind:未找到描述
- EvalPlus Leaderboard:未找到描述
- 来自 TokenBender (e/xperiments) (@4evaBehindSOTA) 的推文:根据我目前的测试,在通用微调或推理方面可以忽略 Gemma。不过,稍后可能会探索印地语探索和特定用例测试。现在回到构建中…
- 来自 Xiang Yue (@xiangyue96) 的推文:🌟凭借精确的执行和人类反馈,一个 7B 代码模型在 HumanEval 上达到了 90% 的准确率!🚀 介绍 OpenCodeInterpreter:一个用于生成、执行和优化的开源代码系统家族…
- google/gemma-7b at main:未找到描述
- PixArt-alpha/PixArt-XL-2-1024-MS · Hugging Face:未找到描述
- 来自 anton (@abacaj) 的推文:在尝试了几个小时的 Gemma 后,我可以说明它不会取代我的 Mistral 7B 模型。它比 Llama 2 好,但令人惊讶的是并不比 Mistral 好。Mistral 团队真的做出了一个甚至连 Google 都无法超越的模型…
- [Regression] Yi 200K models won’t load in latest release · Issue #29252 · huggingface/transformers:系统信息 transformers 版本:4.38.1 平台:Linux-5.4.0-167-generic-x86_64-with-glibc2.35 Python 版本:3.10.12 Huggingface_hub 版本:0.20.3 Safetensors 版本:0.4.2 Accelerate 版本…
- llama2.c/export.py at master · karpathy/llama2.c:在一个纯 C 文件中进行 Llama 2 推理。通过在 GitHub 上创建账户为 karpathy/llama2.c 的开发做出贡献。
- GitHub - jxnl/instructor: structured outputs for llms:LLM 的结构化输出。通过在 GitHub 上创建账户为 jxnl/instructor 的开发做出贡献。
- m-a-p/Code-Feedback · Datasets at Hugging Face:未找到描述
-
LeonEricsson - Overview:研究工程师 机器学习硕士,计算机科学学士。LeonEricsson 拥有 22 个代码库。在 GitHub 上关注他们的代码。
Nous Research AI ▷ #ask-about-llms (18 条消息🔥):
-
Huggingface 错误已修正:
@qtnx确认 Huggingface 上 Nous-Hermes-2-Mistral-7B-DPO 模型名称中的拼写错误(mixtral -> mistral)已得到修正。模型功能保持不变。 -
Gemma 7B 微调发现分享:
@stoicbatman分享了微调 Gemma 7B 模型的结果,指出 5e-5 的学习率在其实验中效果最好,但并未观察到显著的准确率提升。 -
VRAM 占用过高被提及:
@gryphepadar补充了其观察结果,指出与 Mistral 模型相比,微调该模型会消耗大量的 VRAM,这可能是计算资源规划中需要考虑的一个因素。 -
寻求大规模实验脚本:
@stoicbatman询问了用于进行大规模模型微调和评估实验的 shell 脚本。@teknium通过提供一个相关的 GitHub 项目 链接进行了回复,并提到最初的项目虽然没有成功,但该仓库可能仍能提供有价值的见解。 -
微调与评估的调整:在后续跟进中,
@teknium建议所提供的 GitHub 脚本需要进行重大更新才能满足@stoicbatman的实验需求,因为该脚本的设计初衷是在每个 epoch 之后保存、上传并评估模型。
提到的链接:
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO · Hugging Face:未找到描述
- GitHub - AblateIt/finetune-study: Comprehensive analysis of difference in performance of QLora, Lora, and Full Finetunes.:对 QLora、Lora 和全量微调(Full Finetunes)性能差异的全面分析。 - GitHub - AblateIt/finetune-study: 对 QLora、Lora 和 … 的全面分析。
Mistral ▷ #general (311 messages🔥🔥):
-
模型推测与基准测试:社区成员如
@shivakiran_、@sublimatorniq等分享了关于 Mistral-next 潜在规模和性能的看法,一些用户根据其较低的推理速度推测它是一个比 Mixtral 更大的模型。@egalitaristen和@mrdragonfox等用户提到在 lmsys 上测试了 Mistral-next,并称赞其在数学等领域的能力,尽管具体的模型参数量仍未知。 -
Gemma 的潜力与 Mistral 的改进:
@i_am_dom认为 Gemma 可以作为微型模型的开源基础,并暗示 Mistral 可以通过将基础从 Llama2 迁移到 Gemma 来改进其 7b 模型。进一步的讨论还涉及对数据时效性和知识截止日期的假设。 -
下一代模型分析:
@gunterson和_._pandora_._等用户推测 Mistral-next 是否可能是 MiQu 的改进版或最终版,而@ethux等人则讨论了由于 FP16 问题,目前 Apple 硬件运行 Mixtral 的局限性。大家对 Mistral-next 的能力和内部细节普遍感兴趣,但参数数量等确切细节尚未披露。 -
使用指南与模型获取:关于在不使用 Ollama 或 LM studio 等软件的情况下在本地使用 Mistral 模型的咨询,由
@egalitaristen进行了回答,他解释说可以在 Hugging Face 上的模型卡片示例指导下运行代码。@ethux还讨论了硬件细节以及 Mistral-next 等模型的可用性,该模型目前仅在https://chat.lmsys.org提供。 -
开源担忧与雄心:讨论凸显了社区对 Mistral 可能停止开源其模型的担忧,尽管有人提到目前没有明确迹象表明会有此举动。
@casper_ai和@egalitaristen等用户认为 Mistral 对开源的承诺依然存在,因为其阐述的哲学类似于 Linux 的开发方式,以及开源如何有益于安全和模型改进。
提到的链接:
- Chat with Open Large Language Models: 未找到描述
- Chat with Open Large Language Models: 未找到描述
- ETHUX Chat: 由 PlanetNode 倾情提供 ❤️
- GitHub - huggingface/chat-ui: Open source codebase powering the HuggingChat app: 驱动 HuggingChat 应用的开源代码库。可以通过在 GitHub 上创建账号为 huggingface/chat-ui 的开发做出贡献。
- GitHub - XiongjieDai/GPU-Benchmarks-on-LLM-Inference: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference?: 多个 NVIDIA GPU 或 Apple Silicon 用于大语言模型推理? - XiongjieDai/GPU-Benchmarks-on-LLM-Inference
Mistral ▷ #models (15 messages🔥):
- Mistral-next 的存在得到确认:
@ethux确认 Mistral-next 是一个真实的开发项目,性能似乎优于 Mistral-Medium。 - Mistral-next 尚无 API 访问权限:
@ethux提到 Mistral-next 目前尚未提供 API 访问,但暗示有关访问权限的细节将很快发布。 - Mistral 对标 OpenAI:
@paul16307幽默地指出 Mistral 可能是 OpenAI 的更好版本,并开玩笑地补充道“但它是法国的”,这引发了_._pandora_._评论 Mistral “好上三倍”。 - 极具吸引力的定价引起关注:
@mrdragonfox指出 Mistral 的定价使其非常有吸引力,并强调 Mistral 正在突破 OpenAI 之外的现有界限。 - Mistral Next 的反馈收集:
@egalitaristen询问是否可以为 Mistral Next 创建一个反馈线程以发布详细的想法和截图,@mrdragonfox对此表示支持,并开启了一个讨论线程。
提到的链接:
Chat with Open Large Language Models: 未找到描述
Mistral ▷ #deployment (28 messages🔥):
-
vLLM 后端的 GPU 选择:
@buttercookie6265询问了关于选择托管 vLLM 的 GPU 指南。@mrdragonfox建议模型通常会占用 GPU 90% 的空间,并建议准备模型所需 VRAM 两倍的容量,以确保有足够的余量。 -
理解 vLLM GPU 消耗:
@mrdragonfox澄清说,由于键值存储 (kv) 的二次缩放以及批处理中上下文 (ctx) 的累积,所需的 VRAM 会比模型本身大小所显示的更多。 -
对 vLLM 服务器的批量调用:
@louis2567询问了调用 vLLM 服务器进行批量请求的最佳方法。@mrdragonfox建议使用async,因为 vLLM 执行动态批处理(dynamic batching),可以处理并行请求,具体实现取决于用户在其代码中选择如何处理线程/异步。 -
关于每秒最大 Token 数的查询:
.soulstealth询问了在 2 x H100 GPU 上使用 vLLM 和 Mistral 8x7b 达到的每秒最大 Token 数。目前没有给出具体的性能数据。 -
Mistral 7b 在 fp16 下的部署速度:
@kiraa8415寻求关于 Mistral 7b 在 fp16 下最快部署方案的建议,@akshay_1回复了一个模糊的 “fastest matlab?”,这似乎没有直接解决问题。 -
支持查询的响应时间:
@fangh就其邮件查询未收到回复一事寻求帮助。@mrdragonfox表示由于 Mistral 团队规模较小,应联系@707162732578734181或@803073039716974593,但回复可能会有延迟。
Mistral ▷ #ref-implem (5 messages):
- 关于 Mistral 数据归一化的查询:来自巴塞罗那超级计算中心的
@severinodadalt询问 Mistral 数据 是否经过了归一化(normalization),如果是,使用了哪种归一化及其实现方法。然而,他们找不到任何相关信息,因此认为可能没有应用任何归一化。 - 缺乏基座模型数据归一化信息:在回答
@severinodadalt时,@mrdragonfox表示没有基座模型会提供有关数据归一化的信息。 - 质疑不同 VRAM 上的推理速度:
@bdambrosio质疑将 VRAM 升级以在本地以全 fp16 运行 Mistral 8x7B,与目前的 8-bit exl2 设置相比,是否会影响推理速度。 - 超出测量指标的感知差异:
@mrdragonfox承认确实存在差异,因为 turbo(推测是一个工具或指标,如 “turboderp”)主要测量 ppl (perplexity),并没有考虑到性能中所有可能的改进。 - 量化对上下文准确性的影响:
@mrdragonfox指出,量化(quantization) 可能会使上下文准确性略有下降,这是在通过调整位深来寻求提高性能时需要考虑的重要因素。
Mistral ▷ #finetuning (21 messages🔥):
- 微调新手:用户
@4vis表示自己是微调(fine-tuning)新手,并开玩笑地询问是否可以用 YouTube 转录文本来微调 Mistral。@_._pandora_._建议从 Unsloth 开始,因为它对初学者很友好。 - 微调的数据疑问:
@pteromaple想知道微调所需的数据量,询问 4000 个实例是否足够。@egalitaristen建议,是否足够取决于微调任务的专注程度。 - 文件格式困扰:
@pteromaple询问在使用 Unsloth 微调"Mistral-7B-Instruct-v0.2"时正确的数据格式,并提到了他们目前的格式 Alpaca。@_._pandora_._建议改为微调基座模型(base model),并建议理解 Unsloth notebook 中的 prompt 格式化部分。 - Instruct 与基座模型之争:
@pteromaple希望在改变输出格式的同时保持指令遵循能力,并好奇从 Instruct 模型开始是否会简化流程。@_._pandora_._推荐使用基座模型以获得更大的自由度,并分享了关于微调中偏见和语言障碍的经验。 - 大型模型的硬件障碍:
@kodeurkubik质疑在 16GB RAM 的 Mac 上微调 Mistral 7B 是否可行,并考虑将交换文件(swapping files)作为解决方案。@mrdragonfox提到,对于风格迁移(style transfer),需要修改的参数显著减少,并澄清 7B 模型在使用 fp16 且 batch size 为 1 的情况下应该可以放入 16GB VRAM。
Mistral ▷ #la-plateforme (8 messages🔥):
- Mistral API 隐私说明:
@akshay_1向@exa634保证,通过 Mistral API 传输的数据不会被用于训练模型,这进一步强化了 Mistral 稳健的隐私政策。 - 模型托管在瑞典:
@tom_lrd和@ethux向@exa634确认,Mistral 将其平台和数据托管在瑞典,这在其 隐私政策 中有所提及。 - 隐私政策详情:
@ethux发布了 Mistral AI 隐私政策 的摘录,详细说明了数据控制者 (Data Controller) 和数据处理者 (Data Processor) 的角色,并强调 Azure 托管了该平台及相关数据。 - 完整的供应商列表:在更详细的帖子中,
@ethux列出了 Mistral 的主要服务供应商,包括 Azure、Cloudflare、Kong、Lago、Mailjet、Ory 和 Stripe,以及它们的职责和地理位置详情。
相关链接:
Privacy Policy: 您手中的前沿 AI
Perplexity AI ▷ #announcements (1 messages):
-
Perplexity 与 ElevenLabs 达成合作:
@ok.alex宣布与 ElevenLabs 建立新的合作伙伴关系,为 Discover Daily 播客提供 AI 驱动的语音,该播客的内容源自 Perplexity 的 Discover 栏目。该播客旨在轻松融入听众的日常生活,可在各大播客平台收听。 -
Discover Daily 播客上线:Discover Daily 播客每日深入探讨技术、科学和文化,内容采用 Perplexity Discover 栏目 的素材,并由 ElevenLabs 的语音进行旁白。它承诺成为全天不同时刻的理想伴侣,助力听众的好奇心之旅。
相关链接:
- Discord - 与好友及社区聊天的新方式:Discord 是通过语音、视频和文字进行交流最简单的方式。在这里聊天、闲逛,并与您的朋友和社区保持紧密联系。
- Perplexity 的 Discover Daily:我们希望将世界上的故事带到您的耳边,每日融合技术、科学和文化。每个章节都从我们的 Discover 栏目中精选而成,旨在为您的每一天增添见解和…
Perplexity AI ▷ #general (290 条消息🔥🔥):
-
Perplexity Pro 订阅:共享与折扣:
@irismava询问了关于在 Perplexity Pro 计划中添加团队成员的问题,而@rayinqo询问了同时订阅 ChatGPT 和 Perplexity Pro 是否有优惠。@tree.ai确认可以在高级计划下添加团队成员,@v01338则表示持有多个订阅没有折扣。由@mares1317发布的官方 账单与订阅 FAQ 澄清了每位员工都需要一个独立的 Pro 账号。 -
实验性 GPT 模型:Perplexity Labs YouTube 播放列表 以及由
@mares1317分享的@perplexity_ai推文重点介绍了新的“体验 Gemma 2B 和 7B 模型”,这些模型以其轻量级但性能出色而备受关注。 -
将 Perplexity 设为默认搜索引擎的问题:
@redhare18在 Arc 浏览器中将 Perplexity 设为默认搜索引擎时遇到问题,在@ok.alex提供帮助后问题得到解决。其他用户如@shizlets在使用 Arc Search iOS 应用时也遇到了困难。 -
讨论多种 AI 模型:用户
@jaicraft和@rhysd21讨论了 Perplexity Pro 上各种模型的性能和可用性,包括 “Experimental” 和 “Gemini Advanced”。对话涉及了 “Gemini”、”Claude 2.1” 和 “GPT-4 Turbo” 等模型的功能,@mares1317和@brknclock1215确认已支持 GPT-4 Turbo。 -
Perplexity Pro 的图像生成功能:关于在 Perplexity Pro 上生成图像存在一些困惑,
@trite8q1寻求澄清。@jaicraft和@ok.alex解释说,Pro 会员可以通过开启新对话串并使用生成图像按钮来创建图像;具体过程在 博客文章 和 官方对话串 中有详细说明。
提到的链接:
- Discover Daily by Perplexity:我们希望将世界上的故事带到您的耳边,每日融合科技、科学和文化。源自我们的 Discover 提要,每一集都旨在…
- Hal9000 GIF - Hal9000 - Discover & Share GIFs:点击查看 GIF
- Apple Podcasts 上的 Discover Daily by Perplexity:新闻 · 2024
- Aravind Srinivas (@AravSrinivas) 的推文:加入 Perplexity Pro 并尝试 Experimental 模型!
-
[Adiós Google Hola Perplexity](https://youtu.be/NjQ8LeYfxRY?si=m32SzgylMsQPIBuQ):你不会相信这个搜索引擎凭借人工智能能做什么。我们还不知道如果没有 Jeff Bezos、Nvidia 和 D…,Perplexity 会变成什么样。 - Perplexity (@perplexity_ai) 的推文:介绍 Perplexity Labs 的新成员:体验以轻量级且性能卓越著称的 Gemma 2B 和 7B 模型。现在就在 http://labs.pplx.ai 尝试。
- 账单与订阅:浏览 Perplexity 博客,获取文章、公告、产品更新和优化体验的技巧。保持知情并充分利用 Perplexity。
- 图像与媒体:浏览 Perplexity 博客,获取文章、公告、产品更新和优化体验的技巧。保持知情并充分利用 Perplexity。
Perplexity AI ▷ #sharing (4 条消息):
- 搜索 Line0 的身份:
@edzordzinam.ali分享了一个关于识别pline0是什么的 Perplexity AI 搜索链接。 - 深入探讨风险因素:
@moonshot85提供了一个关于分析各种风险的 Perplexity AI 搜索链接。 - 小米 14 系列见解:
@icelavaman发布了一个指向关于小米 14 系列的 Perplexity AI 搜索结果的 链接。 - 探索 Perplexity AI 与 ElevenLabs 的合作伙伴关系:
@icelavaman还分享了一个讨论 Perplexity AI 与 ElevenLabs 潜在合作的 Perplexity AI 搜索结果。
Perplexity AI ▷ #pplx-api (11 messages🔥):
- API 额度购买问题:
@jenish_79522在完成 API 额度交易时遇到问题并寻求帮助,特别标记了<@752478851103326241>以获取协助。 - 关于将 Gemma 集成到 API 的咨询:
@karan01993询问是否有计划将 Google 的 Gemma 集成到 Perplexity API,寻求关于未来支持的确认。 - Perplexity API 入门:
@brextonpham询问新人如何访问 Perplexity API,@icelavaman引导其查看 入门文档 并提供了申请更高 Rate Limits 的联系方式 (api@perplexity.ai)。 - 支付问题升级:针对
@jenish_79522的待处理交易问题,@icelavaman建议联系 support@perplexity.ai 寻求帮助。 - 使用 ‘Assistant’ 字段导致的 400 错误已解决:
@dogemeat_报告了使用 ‘assistant’ 字段时出现 400 错误的问题,@brknclock1215建议了一个涉及消息顺序的变通方案,似乎解决了该问题。
相关链接:
no title found: 未找到描述
OpenAccess AI Collective (axolotl) ▷ #general (79 messages🔥🔥):
- 寻找 Transformers 代码:用户
@qwerty_qwer正在寻找 Transformers 代码,理由是其简单且易于设置;@nanobitz暗示可以考虑 vLLM。 - Checkpoint 相关问题:
@stoicbatman报告了 checkpoint 问题,目录可见但在合并或评估过程中遇到错误。 - 云端成本 vs. 自有服务器:
@yamashi在对比了长期租赁成本与一次性购买服务器的费用后,对云计算服务的性价比提出了质疑。 - Hugging Face 问题见解:
@nanobitz和@stoicbatman讨论了一个关于使用 EarlyStoppingCallback 保存时报错的 GitHub issue,并指出该问题导致了 60 美元的损失。 - 模型存储清理:
@c.gato寻求清理已下载模型占用的空间,@mihai4256引导其使用 Hugging Face 的 CLI 命令huggingface-cli delete-cache,并说明该命令甚至可以在运行其他任务时执行。
相关链接:
- Error while saving with EarlyStoppingCallback · Issue #29157 · huggingface/transformers: 系统信息 transformers 版本: 4.38.0.dev0 (也存在于 4.38.0 和 4.39.0.dev0) 平台: Linux-5.15.0-78-generic-x86_64-with-glibc2.35 Python 版本: 3.10.12 Huggingface_hub 版本: 0.20.3 Safete…
- DeepSpeed Support Stage 3 · Issue #29254 · huggingface/transformers: 系统信息 Trainer 是否支持 Stage 3?根据 https://huggingface.co/transformers/v4.3.0/main_classes/trainer.html - 它不支持。谢谢,Brett。谁能提供帮助?na 信息 官方…
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (6 messages):
- 正在进行的 Mixtral 优化思路:
@casper_ai认为他们已经确定了优化 Mixtral 模型的有效方法,但由于不是 CUDA 工程师,缺乏编写兼容的 Backward Pass 的技能。 - 通过分组计算增强 Mixtral:
@casper_ai提出了一种优化 Mixtral 的方法,通过拼接和堆叠 Expert,然后预计算 Token 和 Expert ID,以便在所有 Expert 之间进行高效的分组计算。 - 在 AutoAWQ 中实现显著加速:
@casper_ai在使用 AutoAWQ 时,在 Mixtral 的 Prefilling 和 Decoding 阶段实现了惊人的 8 倍加速。 - Backward Pass 实现挑战:
@casper_ai讨论了可能需要从另一个实现中导入 megablocks,因为他们拥有各种操作的 Backward Pass。 - 资源建议 - Gemma 推理引擎:
@curiositix建议参考 Gemma - 一个轻量级、独立的 C++ 推理引擎 来实现 Backward Pass,这可能有助于解决@casper_ai的优化挑战。
相关链接:
GitHub - google/gemma.cpp: lightweight, standalone C++ inference engine for Google's Gemma models.: 适用于 Google Gemma 模型的轻量级、独立 C++ 推理引擎。- google/gemma.cpp
OpenAccess AI Collective (axolotl) ▷ #general-help (165 条消息🔥🔥):
-
理解 codellama 的推理格式:
@nani1149询问了在使用 alpaca 格式训练模型后进行推理所需的格式,@nanobitz确认推理也使用 alpaca 格式,并提供了 stanford_alpaca GitHub 仓库链接 作为参考。 -
讨论文档和社区贡献:用户
@yamashi和@nanobitz讨论了改进文档以避免重复提问的需求,提到了可能使用 gitbooks,并引用了大型社区在维护不同项目的 gitbook 资源方面的帮助。 -
排查 Gemma 2B 的 Learning Rate 问题:
@kearm表示在为 Gemma 2B 寻找合适的 Learning Rate 时遇到困难,并列出了多次尝试,@stoicbatman建议分享 loss charts 并讨论了他们自己的经验。 -
合并 mixtral 的性能问题:
@dreamgen在合并 mixtral 时遇到了合并速度慢且未调用 GPU 的问题,随后与@nanobitz讨论了潜在的解决方案,以及问题是否在于 VRAM 耗尽或正在使用 RAM 运行。 -
排查模型训练期间的 checkpoint 保存错误:
@kearm在模型训练期间遇到了 checkpoint 保存问题,尽管尝试了@stoicbatman建议的降低 deepspeed 版本,但仍未解决。对话涉及了反复的建议以及对相关 GitHub issue 的引用。
提到的链接:
- Docker: 未找到描述
- nottlespike: Weights & Biases,机器学习开发者工具
- monk1337: Weights & Biases,机器学习开发者工具
- Error while saving with EarlyStoppingCallback · Issue #29157 · huggingface/transformers: 系统信息 transformers version: 4.38.0.dev0 (也存在于 4.38.0 和 4.39.0.dev0) Platform: Linux-5.15.0-78-generic-x86_64-with-glibc2.35 Python version: 3.10.12 Huggingface_hub version: 0.20.3 Safete…
- fine tune gemma model checkpoint save error · Issue #1320 · OpenAccess-AI-Collective/axolotl: 请检查此 issue 此前是否已被报告。我搜索了之前的 Bug Reports,未发现类似报告。预期行为应该是正常的,当前行为在…时出现此错误。
- GitHub - tatsu-lab/stanford_alpaca: Code and documentation to train Stanford’s Alpaca models, and generate the data.: 用于训练斯坦福 Alpaca 模型并生成数据的代码和文档。- tatsu-lab/stanford_alpaca
OpenAccess AI Collective (axolotl) ▷ #community-showcase (9 messages🔥):
- DreamGen 发布新 AI 模型:
@dreamgen宣布推出用于故事写作和角色扮演的新 AI 模型,可使用 Axolotl 和 Unlosth 进行训练,并在 Hugging Face 上提供了详细信息,集合地址为 dreamgen/opus-v1-story-writing-and-role-playing-models。这些模型包含约 100M tokens 的人类生成数据,并基于 ChatML 的扩展版本,更多说明请参见 Opus V1 指南。 - 提示词模板疏忽已修正:
@nanobitz注意到@dreamgen似乎忘记为新模型更新 tokenizer 的 chat template;@dreamgen承认了这一问题,并确认 7b 版本未按预期更新。 - Opus V1.2-7b 中可能存在的提示词泄露:’nanobitz’ 在测试
@dreamgen的新模型时报告了一个问题,指出在聊天模式开始对话时,提示词可能会泄露 user 和 assistant 角色。@dreamgen提供了一个指向提示词格式代码的链接以澄清设置:prompt formating code。 - 格式问题需要进一步审查:
@dreamgen正在调查@nanobitz之前提到的“泄露”问题,后者表示在最终的 assistant 消息中注意到 user/assistant 内容后,需要进行更多调查。 - 使用 Axolotl 微调的 Phi-2 模型:
@finetuningllms分享了他们微调 Phi-2 模型的链接,指出其性能优异,并承诺很快会添加包含图像的 model card,地址为 axra/phi-2-x-0.1。
相关链接:
- axra/phi-2-x-0.1 · Hugging Face:未找到描述
- configs/opus-v1.py · dreamgen/opus-v1.2-7b at main:未找到描述
- Opus V1: Story-writing & role-playing models - a dreamgen Collection:未找到描述
- DreamGen: AI role-play and story-writing without limits:未找到描述
OpenAccess AI Collective (axolotl) ▷ #runpod-help (6 messages):
- RunPod 镜像可用性关注:
@stoicbatman询问 RunPod image 是否已被删除,因为他们无法找到它。 - 指向 Docker Hub 的指引:作为回应,
@nanobitz分享了一个指向 Docker Hub 的直接链接,可以在那里找到 RunPod 镜像标签。 - 对 GitHub Readme 的困惑:
@stoicbatman随后提到 GitHub readme 不再重定向到实际的 RunPod 镜像。 - 寻找最新链接:
@nanobitz询问@stoicbatman是否有最新链接,试图解决提到的重定向问题。 - 相比 GitHub 更依赖 Docker Hub:
@stoicbatman确认正在使用来自 Docker Hub 的镜像,但对 GitHub readme 之前会重定向到 RunPod 镜像而现在不再重定向表示困惑。
相关链接:
Docker:未找到描述
HuggingFace ▷ #announcements (1 条消息):
- 可视化 Aya 数据集:用户
@416019758492680203提供了 Aya 数据集的可视化,以便更好地洞察和理解。 - 图像生成升级:随着 Proteus V0.4 的发布,
@1093866142608670772增强了图像生成能力,可在 Proteus V0.4 space 访问。 - 交互式 Text-to-Image RAG 提示词:用户
@942079288952381461创建了一个交互式 Demo,可以使用 RAG 体验超过 140 万个 text2image 提示词,访问地址在 这里。 - 用于推理的 Serverless 托管 API:
@319141699605626881分享了一个托管在免费 Colab 环境中的 Serverless 推理解决方案,详情见 GitHub。 - ProteinBERT 和 Fluently 模型的创新:
@403280164433297409分享了 ProteinBERT 模型权重及配套 论文 的链接,同时还分享了由@1056663454519406652开发的 Fluently diffusion model Demo,可在 Fluently space 访问。
HuggingFace ▷ #general (149 条消息🔥🔥):
<ul>
<li><strong>寻求性能解答</strong>:用户 <code>@0ldgranpa</code> 询问针对其硬件配置的最佳模型类型和性能修复方案。目前尚无回复。</li>
<li><strong>GPU 显存变通方案</strong>:<code>@alifthi</code> 询问在 GPU 显存有限的情况下运行 Mistral 等大型模型的解决方案,<code>@typoilu</code> 建议使用 llama.cpp 或 accelerate 进行 CPU offloading。</li>
<li><strong>硬件好奇心</strong>:<code>@zorian_93363</code> 将 ASIC 矿机的能力与运行模型的潜在用途进行对比,<code>@vipitis</code> 解释了计算任务之间的差异,并讨论了目前的硬件,如 Google 的 TPU 和 Graphcore 的 IPU。</li>
<li><strong>探索 GPT 替代方案</strong>:<code>@amirgame197</code> 询问为什么 GPT 3.5 在 chat.openai.com 上是无限且免费的,但在 api.openai.com 上却是付费的,这表明他正在寻求 API 使用的免费替代方案,但未得到直接回答。</li>
<li><strong>意外的模板混淆</strong>:在一个编码问题中,<code>@levisco</code> 最初在使用 transformers 的 QuestionAnsweringPipeline 中的 create_sample 功能时遇到困难,但后来发现只是代码中的一个拼写错误。</li>
</ul>
提到的链接:
- Groq:未找到描述
- Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4:未找到描述
- 3rd Rock GIF - 3rd Rock From - Discover & Share GIFs:点击查看 GIF
- On-device training in TensorFlow Lite — The TensorFlow Blog:未找到描述
- Use custom models:未找到描述
- Stable Diffusion 3 — Stability AI:宣布 Stable Diffusion 3 早期预览版,这是我们最强大的文本生成图像模型,在多主题提示词、图像质量和拼写能力方面有显著提升。
- Deer GIF - Deer - Discover & Share GIFs:点击查看 GIF
- 🌌 Analysis of Spaces in Hugging Face:未找到描述
- Tweet from Weyaxi (@Weyaxi):🎉 @huggingface 的新博客文章 🌌 Hugging Face 中的 Spaces 分析。我抓取了 2 万个 Spaces 的代码文件并将其合并为一个数据集,展示了有意义的统计数据 📶 📝 博客文章:http…
- GitHub - SYSTRAN/faster-whisper: Faster Whisper transcription with CTranslate2:使用 CTranslate2 实现更快的 Whisper 转录。通过在 GitHub 上创建账号为 SYSTRAN/faster-whisper 的开发做出贡献。
- GitHub - kuangliu/pytorch-cifar: 95.47% on CIFAR10 with PyTorch:使用 PyTorch 在 CIFAR10 上达到 95.47%。通过在 GitHub 上创建账号为 kuangliu/pytorch-cifar 的开发做出贡献。
- Phind-70B: BEST Coding LLM Outperforming GPT-4 Turbo + Opensource!:在这段视频中,我们展示了 Phind-70B 的革命性功能,旨在缩小代码质量差距并加速您的编码过程。拥有高达 8…
- Pipelines:未找到描述
HuggingFace ▷ #today-im-learning (4 messages):
- Flutter 游戏咨询:用户
@.konoh询问了一个 Flutter 游戏,但未提供更多背景或细节。 - Hugging Face 开源 “DoReMi”:用户
@neuralink分享了一个 GitHub 上名为 DoReMi 的 Hugging Face 开源项目链接,该项目是 nanotron 仓库的一部分。 - 用户感到被复杂性淹没:
@cursorop对@neuralink分享的项目复杂性感到不知所措,并使用了:blobsweat:表情符号来表达他们的心情。 - 寻求机器人领域模仿学习的建议:
@alefram向社区征求学习机器人领域 Imitation Learning 的技巧或资源,但在给出的消息中未收到回复。
提到的链接:
nanotron/examples/doremi at main · huggingface/nanotron:极简的大语言模型 3D 并行训练 - huggingface/nanotron
HuggingFace ▷ #cool-finds (5 messages):
-
AI 模型基准测试:用户
@ryzxl宣布了一项全面的 AI 模型基准测试计划,对比了 gpt-3.5-turbo-instruct 和 Mistral 等平台。该计划涵盖了包括 ASDiv、BBQ、BigBench 等在内的关键数据集。完整详情和排行榜可以在他们的 LinkedIn 帖子中找到。 -
提醒发帖礼仪:用户
@cakiki提醒@ryzxl避免多次跨频道发布相同消息以防止垃圾信息。 -
深度无监督学习课程公告:用户
@omrylcn.分享了伯克利 2024 年春季学期 Deep Unsupervised Learning 课程的信息,涵盖了深度生成模型(Deep Generative Models)和自监督学习(Self-Supervised Learning),与之前的课程类似。 -
大动作模型 (LAMs):用户
@fernando_cejas分享了一篇博客文章,讨论了 Large Action Models (LAMs),这是一种通过神经网络和符号推理在数字环境中执行类似人类任务的 AI 系统。 -
Warp Dev 推荐:用户
@gjyotin305发布了一个 Warp Dev 的推荐链接,但未提供关于该链接的额外背景或信息。
提到的链接:
- CS294-158-SP24 Deep Unsupervised Learning Spring 2024:关于:本课程将涵盖深度学习中不需要标签数据的两个领域:深度生成模型和自监督学习。生成模型的最新进展使得…
- Warp:未找到描述
- Large Action Models (LAMs): A New Step in AI for Understanding and Doing Human Tasks – Be on the Right Side of Change:未找到描述
HuggingFace ▷ #i-made-this (26 条消息🔥):
-
通过 Selenium 实现的非官方 ChatGPT API 引发关注:
@.infinityhawk分享了一个使用 Selenium 创建的非官方 ChatGPT API 链接 (Github Repo)。@myg5702和@cakiki都提出了潜在的伦理和实际问题,例如违反 OpenAI 的服务条款以及面临 IP 或 RP 封禁的风险。 -
Stable Diffusion XL 的优化技术:
@felixsanz发表了一篇详细的文章,介绍了 Stable Diffusion XL 的优化方法,使得在仅有 6 GB 显存的 GPU 上也能生成图像 (阅读文章)。尽管发布时间恰逢 Stable Diffusion 3 的发布公告,@paccer仍对其教育价值和努力表示赞赏。 -
通过新 API 更便宜地访问 OpenAI GPT-4 模型:
@exrew介绍了一个提供价格实惠的 OpenAI GPT-4 模型访问权限的 API,包含试用免费计划和适用于各种模型的灵活积分系统 (在此查找 API)。 -
使用 Gemma 的实时文本流式聊天界面:
@not_lain利用新的 Gemma AI 模型创建了一个文本流式聊天界面,承诺提供快速的性能 (在此体验)。 -
基于浏览器的 WavLMForXVector 说话人嵌入:
@davidre95通过提交 Pull Request 支持 WavLMForXVector,为transformers.js做出了贡献,从而实现了直接在浏览器中运行说话人嵌入模型 (GitHub 上的 PR;HuggingFace 上的模型)。
提到的链接:
- Proteus V0.4 - a Hugging Face Space by FumesAI:未找到描述
- Text-Streaming - a Hugging Face Space by not-lain:未找到描述
- xVASynth TTS - a Hugging Face Space by Pendrokar:未找到描述
- D4ve-R/wavlm-base-plus-sv · Hugging Face:未找到描述
-
[Cheapest GPT-4 Turbo, GPT 4 Vision, ChatGPT OpenAI AI API API Documentation (NextAPI) RapidAPI](https://rapidapi.com/NextAPI/api/cheapest-gpt-4-turbo-gpt-4-vision-chatgpt-openai-ai-api):未找到描述 - GitHub - Priyanshu-hawk/ChatGPT-unofficial-api-selenium:这是一个完全由我用 Python 和 Selenium 编写的非官方 ChatGPT API - Priyanshu-hawk/ChatGPT-unofficial-api-selenium
- lo-fi ableton speedrun with musicgen, max4live and acoustic guitar - captains chair 15:本周节目中,我们再次使用了 @veryVANYA 的微调模型,配合使用 @matttytel9056 的 helm vst,它比你拥有的那些更好…
- Add support for WavlmForXVector by D4ve-R · Pull Request #603 · xenova/transformers.js:添加了对带有 xvector 头的 WavLM 的支持。microsoft/wavlm-base-plus-sv 的 ONNX 版本可以在 D4ve-R/wavlm-base-plus-sv 找到。旨在尽可能接近 Python 实现…
- Ultimate guide to optimizing Stable Diffusion XL:探索如何在任何显卡上获得 SDXL 的最佳质量和性能。
HuggingFace ▷ #reading-group (5 条消息):
- 神经电路图演示已排期:
@chad_in_the_house确认神经电路图演示将会有录像。 - 直播活动时间确认:
@chad_in_the_house提到演示将于今天 EST 时间晚上 7 点进行。 - 时区考虑:
@gschwepp_84093指出演示时间相当于 UTC 时间 00:00,并表示由于时间太晚,参加可能存在困难。
HuggingFace ▷ #diffusion-discussions (5 messages):
- 询问基于 Interlingua 的翻译器:用户
@hobojesus6250a表示有兴趣在 Hugging Face 上寻找或创建一个 基于 Interlingua 的翻译器,并讨论了由于时间限制,可能需要扩展现有模型的需求。 - 寻找扩展类别限制的方法:
@agusschmidt询问如何运行类别超过 10 个的 facebook/bart-large-mnli 模型,并引用了之前的一场讨论,该讨论建议在本地运行模型时是可以实现的。 - 来自 HuggingMod 的友好提醒:自动审核机器人
@HuggingMod提醒用户<@345587852052267018>和<@745207885201539072>放慢发帖速度,表明他们在短时间内发送了过多消息。
HuggingFace ▷ #computer-vision (3 messages):
-
多标签图像分类教程发布:用户
@nielsr_分享了一个使用 SigLIP(一个强大的视觉骨干网络)进行多标签图像分类的 教程 Notebook,不过 Transformers 库中的任何视觉模型都可以替换使用。 -
HuggingMod 过于热心:
@745207885201539072收到来自 HuggingMod 的温和警告,要求放慢在服务器上的发帖速度。 -
推进情感识别:
@rodricota_开始讨论构建情感识别模型,并表达了希望排查一些问题的意愿。
HuggingFace ▷ #NLP (49 messages🔥):
-
Peft 的持久问题:
@grimsqueaker提到一个重大 Bug,即 Peft 无法为非自动配置的架构保存正确的 Head。解决方法涉及随机调整参数,直到找到可行的配置,但必须做出妥协。 -
Reformer 研究思考:
@devbravo分享了他们目前的研究重点,即使用 Reformer 架构开发 更小、内存效率更高 的模型,以便在边缘设备上运行。@HuggingMod发出了放慢速度的提醒,促使@devbravo减缓其快速发帖。 -
GPT 长度逻辑:
@vipitis纠正了@nrs9044,指出 Transformers 不是循环的(recurrent)而是完全并行的,并确认 GPT 中 Self-Attention 矩阵的大小确实随序列长度呈二次方增长。 -
生成正面和负面情绪:
@jimmyfromanalytics询问关于微调 Flan T5 以创建用于 情感分析(sentiment analysis) 的合成数据。讨论围绕 Prompt Engineering 以及可能探索 Decoder-only 模型以获得更好性能展开。 -
微调 vs 大模型的抉择:
@arkalonman寻求关于是否应该为文本分类微调像 Mistral 7B 这样的大型 LLM,还是坚持使用 BERT 变体的见解。与@lavi_39761的对话达成共识,即对于分类目的,高效的 Encoder 模型可能是比更庞大的模型更好的关注点。
提到的链接:
- climatebert (ClimateBert):未找到描述
- Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs:未找到描述
HuggingFace ▷ #diffusion-discussions (5 messages):
- 探索基于 Interlingua 的翻译器:
hobojesus6250a提出了一个问题,即是否有人尝试过在 Hugging Face 上创建或调整基于 Interlingua 的翻译器。他们表示有兴趣为一个大学项目扩展现有模型,因为时间有限。 - 扩展 BART MNLI 模型的类别:
agusschmidt询问如何运行类别超过 10 个的 BART-large-mnli 模型,并表示他们知道在本地运行时有此可能性,正在寻求如何实现的指导。 - 避免垃圾信息的友好机器人提醒:HuggingMod(Hugging Face 审核机器人)向
@345587852052267018>和@745207885201539072>发出提醒,要求 放慢发帖速度,因为他们发送消息过于频繁。
Latent Space ▷ #ai-general-chat (52 条消息🔥):
- 使用 GPT-4 进行 Prompt Engineering: `@henriqueln7` 对 GPT-4 未能按其要求有效重写 Prompt 表示失望,反而生成了类似于新助手的回复。他们计划在 playground 中进行进一步测试。
- Stable Diffusion 3 发布公告: `@rubenartus` 分享了关于 Stable Diffusion 3 早期预览版的[公告](https://stability.ai/news/stable-diffusion-3),该版本增强了多主体 Prompt 性能和拼写能力。他们还提供了指向更多模型细节的[链接](https://twitter.com/EMostaque/status/1760660709308846135)。
- Google 的新模型 Gemini Pro 1.5: `@nuvic_` 讨论了 Gemini Pro 1.5 的功能,重点介绍了其 1,000,000 token 的 context size 以及通过 Google AI Studio 探索的使用视频作为输入的能力。
- 评估 Reddit 与 Google 的数据交易: `@guardiang` 和 `@pennepitstop` 等用户就 [Google 据报道每年 6000 万美元的数据交易](https://news.ycombinator.com/item?id=39471964) 在 Reddit IPO 前的财务和战略影响发表了看法。
- Gemini 图像生成暂停: `@swyxio` 发布了一个指向 Google 博客的[链接](https://blog.google/products/gemini/gemini-image-generation-issue/),其中 SVP 对 Gemini 图像生成功能的问题承担了责任,该问题导致该功能暂时暂停。
提到的链接:
-
[Google cut a deal with Reddit for AI training data Hacker News](https://news.ycombinator.com/item?id=39471964): 未找到描述 - SDXL Lightning - by fal.ai: fal.ai 提供的极速 SDXL API 演示
- The killer app of Gemini Pro 1.5 is video: 上周 Google 推出了 Gemini Pro 1.5,这是对其 Gemini 系列 AI 模型的一次巨大升级。Gemini Pro 1.5 拥有 1,000,000 token 的 context size。这是巨大的——此前……
- Things I Don't Know About AI: 我对 AI 市场了解得越多,就越觉得自己知道得越少。我列出了一些问题和想法。
- Stable Diffusion 3 — Stability AI: 宣布 Stable Diffusion 3 进入早期预览阶段,这是我们最强大的文本生成图像模型,在多主体 Prompt、图像质量和拼写能力方面有显著提升。
-
[Interconnects Audio Google ships it: Gemma open LLMs and Gemini backlash](https://podcast.interconnects.ai/episodes/google-ships-it-gemma-open-llms-and-gemini-backlash): interconnects.ai 文章的音频格式——由作者使用 AI 生成。 - Gemini image generation got it wrong. We'll do better.: 关于 Gemini 人物图像生成问题如何发生以及我们正在采取哪些修复措施的解释。
- Tweet from Shu (@shuding_): ↘️ 引用 Guillermo Rauch (@rauchg) —— 内部已实现 AG(UI)
- Is the AI Boom Real?: 笔记:7:50 - TPU 已进入第五代。搞砸了。链接:- The Asianometry Newsletter: https://www.asianometry.com - Patreon: https://www.patreon.com…
-
[OpenAI’s Sora: How to Spot AI-Generated Videos WSJ](https://youtu.be/XllmgXBQUwA?si=p9): OpenAI 刚刚发布了 Sora – 一款 AI 视频生成器,可以在瞬间创建超写实的场景和动画世界。但这项技术并不完美。存在一些…… - Tweet from Jim Fan (@DrJimFan): 职业更新:我正在 NVIDIA 共同创立一个名为 “GEAR” 的新研究小组,成员包括我的长期好友和合作伙伴 @yukez 教授。GEAR 代表 Generalist Embodied Agent Research。我们将……
-
[Demis Hassabis on Chatbots to AGI EP 71](https://youtu.be/nwUARJeeplA?si=V09X6h7iqucrh4af): 本周节目是与 Google 人工智能部门负责人 Demis Hassabis 的对话。我们讨论了 Google 最新的 AI 模型…… - [AINews] Google AI: Win some (Gemma, 1.5 Pro), Lose some (Image gen): 2024年2月20日的 AI Discord 动态。我们为您检查了 20 个服务器、313 个频道和 8555 条消息。预计节省阅读时间(以 200wpm 计算):836 分钟。Google 正在……
Latent Space ▷ #ai-announcements (6 messages):
- LLM Paper Club T5 讨论:
@ivanleomk宣布了由@bryanblackbee主持的 LLM Paper Club 关于 T5 论文的讨论环节。该活动定于 5 分钟后开始,并提供了加入讨论的链接:加入 LLM Paper Club。 - 遗憾错过 Paper Club:
@swyxio对错过由@bryanblackbee主持的关于 T5 的 LLM Paper Club 表示遗憾,并暗示需要该环节的录音。 - AI in Action 活动:
@kbal11推广了与@yikesawjeez合作的 AI in Action 活动,重点关注 local models。提供了该环节的链接:了解 Local Models。 - 赞赏 AI 活动管理:
@swyxio称赞了@kbal11成功管理了由@yikesawjeez主持的 AI in Action 环节。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,与你的朋友和社区保持紧密联系。
- 加入 Latent Space (原名 /dev/invest) Discord 服务器!:查看 Discord 上的 Latent Space (原名 /dev/invest) 社区 —— 与其他 2980 名成员一起聚会,享受免费的语音和文字聊天。
Latent Space ▷ #llm-paper-club-west (16 messages🔥):
- LLM Paper Club 亚洲版启动:
@ivanleomk邀请参与者加入讨论,为任何人提供提问或讨论话题的平台,可以作为讲者上台,也可以在聊天框交流。 - 笔记与见解的中央仓库:
@bryanblackbee提供了一个笔记链接,作为 LLM Paper Club 讨论内容的中央仓库。 - 向社区咨询模型词汇量和约束条件:
@mattoshimasu好奇讨论中的新模型是否具有更小的 vocabulary,并询问了文本长度和动词数量的约束。 - NLP 中的 Fine-Tuning 机制解析:针对
@healthymonkey的提问,社区讨论了 T5 等 NLP 任务在情感分类中的 fine-tuning,涉及是否像计算机视觉中那样替换 head/linear layer。 - Encoder-Decoder 与 Decoder-Only 架构的技术对比:
@hanzo4958发起了关于传统 NLP 任务中 encoder-decoder 与 decoder-only 架构差异的讨论,并指出 decoder-only 模型日益流行。 - 离别感谢与对环节的正面反馈:包括
@healthymonkey、@hanzo4958、@thehippoguy、@edwin_75513_08956和@lord_idiot在内的多位参与者在离开讨论前,对详细的环节和笔记表示了感谢和赞赏。
提到的链接:
Notion – 笔记、任务、维基和数据库的一体化工作空间。:一款将日常工作应用融合在一起的新工具。它是为你和你的团队打造的一体化工作空间。
Latent Space ▷ #ai-in-action-club (136 条消息🔥🔥):
-
本地模型与 LoRA 讨论:用户讨论了他们在本地 AI 模型和 LoRA (Low-Rank Adaptation) 技术方面的经验。
@markredito澄清说,LoRA 是放置在生成模型之上以影响其输出的适配器,在 Stable Diffusion 等平台中非常常见。 -
Latent Space Final Frontiers 活动:
@kbal11分享了关于 Latent Space Final Frontiers 活动的细节,该活动专注于突破 AI 边界,并设有一场研究/创业竞赛,评委来自 GitHub、Replit 和 LlamaIndex 等知名公司。 -
用于 Stable Diffusion 的 ComfyUI:
@markredito提供了 ComfyUI 的 GitHub 链接,它被描述为一个功能强大且模块化的 Stable Diffusion GUI、API 和后端,具有图形/节点界面。 -
AI 模型合并趋势:
@swyxio分享了一篇 Hugging Face 博客文章,讨论了新兴的模型合并技术,该技术允许组合多个 LLM 以低廉的价格创建最先进的模型,并强调了 mergekit 库的使用。 -
Civit.ai 模型库担忧:
@kbal11指出了 Civit.ai 模型库中普遍存在的年轻女性风格化和性暗示图像,引发了一场关于 AI 生成并分享到社区的内容的轻松但深刻的讨论。
提到的链接:
- Twitch: 未找到描述
- SDXL Lightning - by fal.ai: fal.ai 提供的极速 SDXL API 演示
- Merge Large Language Models with mergekit: 未找到描述
- Smol Talk: 我们总结 AI Discord 频道,并每天为您发送汇总!
- Latent Space: Final Frontiers · Luma: 我们很高兴举办第二届年度 Latent Space 演示日 🚀 别再只是和 PDF 聊天了。让我们看看一些科幻级别的 AI。今年的主题是 Final Frontiers:谁是那些…
- GitHub - deforum-art/deforum-stable-diffusion: 通过在 GitHub 上创建账户,为 deforum-art/deforum-stable-diffusion 的开发做出贡献。
- GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface.: 最强大且模块化的 Stable Diffusion GUI、API 和后端,具有图形/节点界面。- comfyanonymous/ComfyUI
Eleuther ▷ #general (107 messages🔥🔥):
-
对模拟人格的怀疑态度:
@sparetime.对 GPT-4 配合 scratchpad 可以模拟人类的说法表示怀疑,质疑模型忠实生成真实体验的能力。@rallio.详细解释了这种模拟将包括创建一组虚假记忆和层级来模拟人类行为和视角,甚至提到最近在记忆一致性方面的改进。 -
Discord 成员分享 Benchmark 批评视频:
@cahya.wirawan分享了一个 YouTube 视频链接,标题为 “Everything WRONG with LLM Benchmarks (ft. MMLU)!!!”,该视频批评了针对 Large Language Models 的基准测试,引发了关于当前 LLM Benchmarks 有效性和准确性的讨论。 -
Eleuther 社区讨论改进 LLM 一致性:在一次技术讨论中,
@rallio.建议,根据最近发表的研究(如 Google 的 TrueTeacher 和 Propsegment),与 Large Language Models (LLMs) 模拟记忆一致性相关的问题可能已经得到缓解。 -
关于幻觉(Hallucination)的辩论:
@rallio.提到了一家名为 Superfocus 的公司,该公司声称已实现 LLM 近乎 100% 的事实准确性,暗示解决了幻觉问题。这引发了与@fern.bear之间关于这些说法真实性以及解决 LLM 幻觉问题本质的辩论。 -
在虚拟世界中创建逼真的 NPC:
@rallio.讨论了他们创建持久化 NPC 的雄心,这些 NPC 可以在不暴露其人工特性的情况下与虚拟世界中的人类互动。他们解释说,这将利用制定的一致性和记忆模拟方法,并结合 fine-tuning 和 context。 -
社区协作号召:
@hawk1399促请社区考虑一个基于论文的项目,该论文概述了使用 Diffusion models 生成高性能神经网络参数的方法,邀请其他人为该领域的持续研究做出贡献。
提到的链接:
- Neural Network Diffusion:Diffusion models 在图像和视频生成方面取得了显著成功。在这项工作中,我们证明了 Diffusion models 也可以 \textit{生成高性能的神经网络参数}…
- SuperFocus:未找到描述
- Everything WRONG with LLM Benchmarks (ft. MMLU)!!!:🔗 链接 🔗 当 Benchmarks 成为目标:揭示 Large Language Model 排行榜的敏感性 https://arxiv.org/pdf/2402.01781.pdf ❤️ 如果你想…
- PropSegmEnt: A Large-Scale Corpus for Proposition-Level Segmentation and Entailment Recognition:广泛研究的 Natural Language Inference (NLI) 任务要求系统识别一段文本是否在文本上蕴含另一段文本,即其全部含义是否可以被…
Eleuther ▷ #research (70 条消息🔥🔥):
- 模型命名伦理讨论:
@thooton_对误导性的模型命名惯例表示沮丧,认为命名为 “7b” 的模型不应超过 7.99b 参数。他们强调了其中的不一致性: “gemma-7b” 实际上拥有 8.5b 参数,而 “gemma-2b” 的 2.5b 参数则更接近其声明的大小。 - 关于 Embedding 大小的澄清:在与
@catboy_slim_的讨论中,对方澄清说 “gemma-7b” 在计入 Embedding 大小时包含 85 亿个参数,但如果不计 Embedding,其参数量与命名的首位数字相符。 - 关于最小化数据丢失的新论文:
@jckwind分享了一篇关于数据效率和最小化层间传输过程中信息丢失的新论文,并对其新颖性和潜在用途表示赞赏。 - Searchformer 击败传统规划器:
@jckwind重点介绍了 “Searchformer”,这是一种 Transformer,它在解决推箱子 (Sokoban) 谜题时优于传统的符号规划器,且使用的搜索步骤比 A* 搜索更少。 - 使用 REINFORCE 简化 AI Alignment:围绕一篇论文的讨论表明,与经典的 PPO 方法相比,更简单的 REINFORCE 风格优化对于 RLHF (Reinforcement Learning from Human Feedback) 可能更有效,
@canadagoose1提到对此进行了深入讨论。
提到的链接:
- Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs:以 RLHF 形式呈现的 AI Alignment 正日益被视为高性能 LLM 的关键要素。\textsc{Proximal Policy Optim…
- Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping:虽然 Transformer 在各种应用场景中取得了巨大进步,但在解决复杂的决策任务方面,此类架构仍落后于传统的符号规划器。在本文中…
- xVal: A Continuous Number Encoding for Large Language Models:由于数字 Token 化的独特困难,LLM 尚未广泛应用于科学数据集的分析。我们提出了 xVal,一种数值编码方案…
- YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information:当今的深度学习方法专注于如何设计最合适的目标函数,使模型的预测结果能够最接近地面真值 (Ground Truth)。同时,一个合适的…
- Uncovering mesa-optimization algorithms in Transformers:Transformer 已成为深度学习中的主导模型,但其卓越性能的原因尚不清楚。在这里,我们假设 Transformer 的强大性能源于…
- Spectral State Space Models:本文研究了具有长程依赖性的预测任务的序列建模。我们提出了一种基于学习线性动力系统的状态空间模型 (SSM) 的新公式…
Eleuther ▷ #interpretability-general (17 messages🔥):
- 中文 Lens 训练进行中:
@mrgonao提到中文 Lens 的训练正在进行中,并将在几小时内完成。此外,13b 模型出现了输出均匀的问题,将与中文 Lens 的对比测试一同进行检查。 - 语言模型中的 Unlearning:
@millander强调了最近发表的一篇学术论文,题为 Survey and formalization of LLM unlearning。可以点击 此处 获取关于大语言模型(LLMs)中 Unlearning 过程的详细见解。 - 不同模型间使用相同的 Tokenizer?:上述问题促使
@mrgonao询问 13b 模型使用的 Tokenizer 是否与 7b 模型相同,这可能与模型在使用中文 Lens 时表现出的“用中文思考”的奇特行为有关。 - Lens 训练可能导致内部翻译:
@butanium提出了一个假设,即仅在中文内容上训练 Tuned Lens 可能会迫使 Lens 执行从英文到中文的翻译,从而倾向于在英文语境中出现中文 Token。 - 排除数据集异常:
@mrgonao在翻译任务中遇到了意料之外的数据集行为,并正在寻求纠正潜在问题,提到单词与错误的语言配对了。相关的 GitHub 仓库可以在 这里 找到。
提到的链接:
- Rethinking Machine Unlearning for Large Language Models:我们探索了大语言模型(LLMs)领域的机器卸载(MU),即 LLM unlearning。该倡议旨在消除不良数据的影响(例如敏感或非法信息…)
- llm-latent-language/visuals/translation at tuned-lens · SrGonao/llm-latent-language:配合我们论文 "Do Llamas Work in English? On the Latent Language of Multilingual Transformers" 的仓库。- SrGonao/llm-latent-language
Eleuther ▷ #multimodal-general (4 messages):
- 大规模数据集中的 False Negatives 不足为虑:
@_.hrafn._认为,在 datacomp 或 metaclip 等当前数据集的规模下,精确的 False Negatives 不太可能出现,特别是在平衡的数据集中。他们建议生成 Unimodal Embeddings 或即时计算相似度得分以减轻疑虑。 - 创建自己的模型以排除 Hard Negatives:
@_.hrafn._进一步提出了在训练期间使用自己的模型来计算相似度得分,以便排除特别的 Hard Negatives。 - 该方案与非图文项目无关:
@tz6352回应称,所讨论的问题和解决方案对他们不适用,因为他们不从事 Image-Text 项目。 - Loss Masking 作为一个可行的解决方案:
@.solux讨论了对距离过近的样本进行 Loss Masking 的可能性,认为在训练过程中没有好的方法识别 False Negatives 时,这是一种潜在的解决方案。
Eleuther ▷ #gpt-neox-dev (8 messages🔥):
-
预训练技术的探索:
@pminervini分享了一篇 arXiv 论文,讨论了语言模型预训练期间序列组成和 Causal Masking 的影响。研究结果表明,Intra-document Attention 可以显著提高各种任务的性能。 -
对 PR 的感谢及提醒协议:
@tastybucketofrice感谢@441658587404697600提交的 PR,并鼓励未来通过 Ping 提醒以加快合并速度。 -
LoRA Finetuning 咨询:
@norabelrose询问了在gpt-neox代码库中使用 LoRA Finetuning 的可行性,并表示目前正使用 Hugging Face 和 PyTorch Lightning 执行类似任务。 -
可能会转向 NeoX 代码库进行 Finetuning:面对使用 PyTorch 原生 FSDP 的问题,
@norabelrose考虑使用gpt-neox仓库进行 NeoX 20B 的 Finetune。 -
确认问题已解决:
@80melon确认了由@norabelrose提出的一个先前未说明的问题已得到解决。
提到的链接:
Analysing The Impact of Sequence Composition on Language Model Pre-Training:大多数语言模型预训练框架将多个文档拼接成固定长度的序列,并使用 Causal Masking 来计算给定上下文时每个 Token 的似然度;这种策略…
LlamaIndex ▷ #general (150 条消息🔥🔥):
-
在 QueryPipeline 中查询 RAG:
@lapexer询问了如何在 QueryPipeline 中使用prompt、retriever和llm模块实现简单的 RAG。@cheesyfishes引导他们查看文档以获取指导和概述(如何编写简单的 RAG)。 -
IngestionPipeline 集成挑战:
@emmepra在 Docker 服务中使用 ChromaVectorStore 和 TextEmbeddingsInference 部署 IngestionPipeline 时遇到了ValidationError问题。经过多次迭代和社区支持(特别是来自@whitefang_jr和@cheesyfishes的支持),他们通过在核心模块和遗留模块之间使用一致的导入路径解决了该问题。 -
LlamaIndex 导入不一致问题:
@pymangekyo和@oopskapootz等用户报告了与 LlamaIndex 新版本中模块导入相关的不一致和错误。@whitefang_jr和@cheesyfishes建议,如果之前安装过旧版本,应重新安装 LlamaIndex 并创建一个新环境以解决导入问题(例如:pip uninstall llama-index和pip install llama-index)。 -
LlamaParse 企业级部署可能性:考虑到隐私问题,
@self.1询问了 LlamaParse 开源或自托管的可能性。@cheesyfishes指出,目前正在考虑企业级部署,但尚未推出。 -
RAG 响应一致性策略:
@a3lita寻求提高 RAG 响应可靠性的建议,特别是询问了关于 LLM temperature 的设置。@kapa.ai解释了几种技术,如 Prompt 优化、评估与基准测试、上下文增强以及多模态评估,以解决这一问题。
提到的链接:
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 加载数据 (Ingestion) - LlamaIndex 🦙 v0.10.12,): 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- LangChain Embeddings - LlamaIndex 🦙 v0.10.12: 未找到描述
- LlamaIndex 🦙 0.9.15.post2: 未找到描述
- TikTokLive v6.0.0: 未找到描述
- LlamaIndex Query Pipelines 简介 - LlamaIndex 🦙 v0.10.12: 未找到描述
- 研究历程调查: 为了彻底改变学术和商业研究,EurekAI 正在寻求您的见解,以便根据您的需求定制我们的工具。无论您是沉浸在研究中还是偶尔参与,您的…
LlamaIndex ▷ #ai-discussion (3 messages):
- 寻找代码调用模型:
@gooooooofy询问了能够生成代码调用(如带有正确参数的 Python 脚本或 Shell 命令)的模型或微调版本。 - Gorilla LLM 几乎符合要求:
@gooooooofy提到 Gorilla LLM 与他们的需求类似,但指出它专注于 API 调用,且似乎是一个较小的模型。
CUDA MODE ▷ #general (16 messages🔥):
-
深度学习 GPU 的超值交易:
@andreaskoepf以 1700 欧元的价格购入了三块 RTX 3090,旨在将一台矿机改造为用于深度学习任务的设备,特别是用于微调和部署大语言模型 (LLMs)。他们概述了规格,并考虑到当前价格,认为这是一笔非常划算的交易。其博客的 第一部分 和 第二部分 详细记录了将其改造为深度学习机架的过程。 -
Jim Keller 对 CUDA 的批评:用户
@itali4no分享了一个 链接,其中 Jim Keller 批评了 Nvidia 的 CUDA,称其像 x86 一样是“一个沼泽”,因为它过于笨重且构建不够精美,是通过不断添加多种功能演变而来的。 -
深度学习的首选 GPU:关于选择深度学习 GPU 的讨论中,
@iron_bound指出了二手 3090 优于新款 4060 ti 的优势,主要在于更好的显存带宽和 PCIe 支持。同时,@cropinky.提到 4060 ti 的 16GB VRAM 通常不足以处理 LLM 任务。 -
量化模型计算详解:
@andreaskoepf解释说量化模型在更高的内部分辨率下执行矩阵乘法,并提供了展示反量化过程的 GitHub 链接。 -
二手 GPU 购买指南:在回答有关购买二手深度学习 GPU 的查询时,
@cropinky.建议这存在风险,但提议对 GPU 进行压力测试,检查风扇磨损情况,并根据需要更换散热组件以维持性能。
提到的链接:
- Jim Keller 批评 Nvidia 的 CUDA 和 x86 —— “CUDA 是沼泽,而非护城河。x86 也是沼泽”:Jim Keller 并不太喜欢 Nvidia 的 CUDA。
-
[构建深度学习机架 第 1 部分 - Samsja](https://samsja.github.io/blogs/rig/part_1/):未找到描述 -
[构建深度学习机架 第 2 部分 - Samsja](https://samsja.github.io/blogs/rig/part_2/):未找到描述 - 文章 - Samsja:未找到描述
- GitHub - TimDettmers/bitsandbytes:通过 PyTorch 的 k-bit 量化实现可访问的大语言模型。
- bitsandbytes/bitsandbytes/functional.py:通过 PyTorch 的 k-bit 量化实现可访问的大语言模型。
- bitsandbytes/csrc/kernels.cu:通过 PyTorch 的 k-bit 量化实现可访问的大语言模型。
CUDA MODE ▷ #triton (2 messages):
- Triton 在教育和部署中的作用:
@_hazler询问集成 Triton 是否在速度或部署平台方面提供任何优势。@srush1301回答说这主要是一项教育性质的工作,尽管它也通过 Pallas 实现了 Jax 支持,并为研究人员提供了一个可供修改的简化版本。
CUDA MODE ▷ #cuda (17 条消息🔥):
-
跟进 CUDA Profiling:
@dvruette克服了安装错误,现在正在探索ncu以深入研究 低级 CUDA profiling。 -
CUDA 加速 BnB 的开源仓库:
@zippika发布了他们新的 GitHub 仓库 torch-bnb-fp4,该仓库提供了 bitsandbytes 的更快替代方案,输出仅有细微差别,且需要 cuda compute >= 8.0。 -
宣扬 Token 速度突破:
@zippika强调了其库实现的显著速度提升,展示了性能从 24 tokens/s 跃升至最高 29 tokens/s。 -
用于基准测试 BnB 性能的测试脚本:
@zippika分享了一个详细的 Python script,用于比较默认 bitsandbytes 与他们自己的 torch-bnb-fp4 库的性能;要执行测试,用户需要切换USE_LINEAR_HIJACK并拥有至少 12.8GB 的 VRAM 可用空间。 -
代码改进与社区参与:
@zippika提到了为优化 CUDA ‘gemv’ kernels 所做的修改,并承诺将通过更多示例和详尽文档来丰富仓库;同时,@_t_v_i_对这项工作表示了热忱。
提到的链接:
- GitHub - aredden/torch-bnb-fp4:通过在 GitHub 上创建账户,为 aredden/torch-bnb-fp4 的开发做出贡献。
- bitsandbytes/csrc/kernels.cu at e820409c095ea7cbb5ce156992307b84352cbf90 · TimDettmers/bitsandbytes:通过 PyTorch 的 k-bit 量化实现易用的 LLM。 - TimDettmers/bitsandbytes
- bitsandbytes/csrc/kernels.cu at e820409c095ea7cbb5ce156992307b84352cbf90 · TimDettmers/bitsandbytes:通过 PyTorch 的 k-bit 量化实现易用的 LLM。 - TimDettmers/bitsandbytes
CUDA MODE ▷ #torch (2 条消息):
-
探索 Random Kernels 的世界:
@hdcharles_74684讨论了使 random kernels 易于访问的挑战,特别是通过out_dtype发布int_mm的笨拙方式。他们引用了 pytorch/_higher_order_ops/out_dtype.py 以及他们在 torch/_inductor/fx_passes/post_grad.py 中关于 4-bit triton kernel 的工作。 -
Torch Compile 的 Kernel 集成限制:
@hdcharles_74684指出torch.compile在处理需要与现有 kernel 不同的自定义 kernel 操作时(特别是针对 GPU)存在困难。他们提到打算改进 kernel 访问,例如为大于 1 的 batch size 添加 weight-only int8 量化。
提到的链接:
- pytorch/torch/_higher_order_ops/out_dtype.py at ed0ea2f30b2f31be7534a7fdafbed90d247f76b5 · pytorch/pytorch):Python 中具有强 GPU 加速的张量和动态神经网络 - pytorch/pytorch
- pytorch/torch/_inductor/fx_passes/post_grad.py at main · pytorch/pytorch:Python 中具有强 GPU 加速的张量和动态神经网络 - pytorch/pytorch
CUDA MODE ▷ #suggestions (1 条消息):
- Gemini 1.5 讨论会宣布:
@shashank.f1正在主持一场关于 Gemini 1.5 的讨论,欢迎大家加入直播。提供了一个过去会议的链接,标题为“A-JEPA AI 模型:从 .wav / .mp3 文件或音频频谱图中解锁语义知识”,并附带 YouTube 视频。
提到的链接:
A-JEPA AI model: Unlock semantic knowledge from .wav / .mp3 file or audio spectrograms:🌟 解锁音频 AI 学习的力量!🔊 观看与 Oliver, Nevil, Ojasvita, Shashank, Srikanth 和 N… 一起对 A-JEPA 方法进行的深入讨论。
CUDA MODE ▷ #jobs (1 条消息):
- SIXT 正在慕尼黑招聘 ML Engineer:
@ppeter0480发布了 SIXT 慕尼黑 的 ML Engineer 职位。该角色要求具备 NLP 和 Generative AI 的知识和技能,以及扎实的工程能力。感兴趣的人员可以通过提供的 SIXT 职位列表 进行申请。
提及的链接:
| [立即申请:高级 Machine Learning Engineer (m/f/d) | 慕尼黑](https://www.sixt.jobs/en/job/feb00784-a96f-430b-b105-6116b993b472):你在慕尼黑的梦想工作:高级 Machine Learning Engineer (m/f/d)。加入 SIXT 团队!我们期待你的申请! |
CUDA MODE ▷ #beginner (3 条消息):
- 礼貌至上:用户
@0ut0f0rder和@dpearson进行了友好交流,赞赏彼此的帮助,并就学习的重要性达成共识。 - 在 Google Colab 中寻求 OpenCV 的帮助:
@dpearson正在利用 Google Colab 的 GPU 通过 ‘nvcc4jupyter’ 运行 C/C++ 代码,但遇到了无法包含<opencv2/opencv.hpp>的问题。他们正在寻找解决方案或替代方法,以便在图像上测试其colorToGrayscaleConverter函数。
CUDA MODE ▷ #youtube-recordings (1 条消息):
marksaroufim: YouTube 上的第 6 讲 https://www.youtube.com/watch?v=hIop0mWKPHc
CUDA MODE ▷ #jax (11 条消息🔥):
-
AMD GPU 缺乏对 FA2 的支持:
@mrrational和@iron_bound都报告了在 AMD GPU(特别是 7900xtx)上运行 FA2 训练时出现的问题,即使@iron_bound使用了 Triton 版本。backward 函数/算子(kernel)似乎缺失,导致运行失败。 -
Backward 函数的潜在解决方案:
@_t_vi_建议使用 GitHub 上的 Triton-autodiff 来帮助@iron_bound获取 AMD GPU 上 FA2 训练的 backward kernel;然而,@srush1301澄清说这仍然需要调整,因为它主要用于对数学函数求导。 -
AMD PyTorch 对 FAv2 的有限支持:
@drisspg告知频道,AMD 在 PyTorch 的 nightly 构建中添加了一些有限的 FAv2 支持,但@iron_bound随后的错误消息表明 7900xtx GPU 尚不支持,因为它需要的是 GPU 架构 gfx90a 而非 gfx11。 -
关于 GPU 架构的进一步澄清:
@iron_bound解释了 AMD GPU 之间的架构差异,指出 7900 系列针对的是 “wave32”,而数据中心显卡支持 “wave64”。他还提到 AMD 开发人员目前正专注于他们的 mi300 产品,这表明低优先级的支持问题可能不会得到及时解决。 -
探索实现 Wave Matrix Multiplication (WMMA) 的代码:
@iron_bound分享了一个目标,即通过参考 flash-attention GitHub 仓库中的代码,尝试创建一个针对 WMMA 的 kernel,因为 RDNA 架构支持 WMMA,而使用 XDL 的数据中心显卡则不同。
提及的链接:
- flash-attention/csrc/flash_attn_rocm/src/device_gemm_trait.hpp at b28f18350af92a68bec057875fd486f728c9f084 · ROCm/flash-attention:快速且内存高效的精确 Attention。通过在 GitHub 上创建账户为 ROCm/flash-attention 的开发做出贡献。
- GitHub - srush/triton-autodiff: Experiment of using Tangent to autodiff triton:使用 Tangent 对 Triton 进行自动微分(autodiff)的实验。通过在 GitHub 上创建账户为 srush/triton-autodiff 的开发做出贡献。
- GitHub - ROCm/flash-attention at howiejay/navi_support:快速且内存高效的精确 Attention。通过在 GitHub 上创建账户为 ROCm/flash-attention 的开发做出贡献。
CUDA MODE ▷ #ring-attention (46 条消息🔥):
-
探索 Facebook 的 Xformers:
@jeremyhoward提供了 GitHub 上 Xformers FMHA 初始化的链接,特别关注 第 417 行,将他们的仓库列为关注对象。 -
关于 JAX Lax Scan 在 PyTorch 中等效实现的讨论:
@andreaskoepf分享了一个 PyTorch 论坛讨论,内容似乎是在询问 PyTorch 中是否存在与 JAX 的lax.scan等效的功能。该链接包含 CSS 样式细节,可能是从网页中提取的。 -
介绍 Ring Attention 的 PyTorch 实现:
@ericauld和@iron_bound介绍了 Ring Attention 的 GitHub 仓库,分别是 lucidrains/ring-attention-pytorch 和 exists-forall/striped_attention,它们分别探索了来自 Berkeley AI 的 Ring Attention 概念和 striped attention 代码。 -
基准测试与实现讨论:
@iron_bound展示了他们自己的 ring-flash-attention 基准测试,包括不同设置下的性能数据。同时,其中一个被讨论仓库的作者@zhuzilin96也加入了对话,提供了见解并提到需要进行测试和增强,例如支持返回 fp32 输出以及处理任意 mask。 -
合作提议与持续改进:
@andreaskoepf和其他人提议与@zhuzilin96合作,进一步开发和优化 Ring Attention 实现,重点关注测试、striped attention 以及处理任意 masking 等问题,以提高模型的灵活性。与此同时,@zhuzilin96一直在提交改进代码,例如zigzag_ring_flash_attn_varlen_qkvpacked_func。
提到的链接:
- 在 torch.func 中是否有与 jax.lax.scan 等效的函数?:我想将以下 JAX 代码(实现了一个 Kalman filter)翻译为 PyTorch。
def kf(params, emissions, return_covs=False): F, Q, R = params['F'], params['Q'], para... - flash-attention/flash_attn/flash_attn_triton.py at main · Dao-AILab/flash-attention:快速且内存高效的精确 Attention。通过在 GitHub 上创建账号,为 Dao-AILab/flash-attention 的开发做出贡献。
- flash-attention/flash_attn/flash_attn_triton.py at 87a1277653fc55cd615f5341255e00c69d5c00a1 · Dao-AILab/flash-attention:快速且内存高效的精确 Attention。通过在 GitHub 上创建账号,为 Dao-AILab/flash-attention 的开发做出贡献。
- ring-attention/ring-transformer at main · cuda-mode/ring-attention:Ring Attention 实验。通过在 GitHub 上创建账号,为 cuda-mode/ring-attention 的开发做出贡献。
- ring-flash-attention/benchmark.py at 349ea8c41d430d28810dd5419ebdca51e9f57e64 · Iron-Bound/ring-flash-attention:结合 Flash Attention 的 Ring Attention 实现 - Iron-Bound/ring-flash-attention
- xformers/xformers/ops/fmha/init.py at 99ad1723b0b80fb21c5e4dc45446e93752f41656 · facebookresearch/xformers:可定制且优化的 Transformer 构建模块,支持组合式构建。 - facebookresearch/xformers
- GitHub - lucidrains/ring-attention-pytorch: 对 Ring Attention 的探索,源自伯克利 AI 的 Liu 等人:对 Ring Attention 的探索,源自伯克利 AI 的 Liu 等人 - lucidrains/ring-attention-pytorch
- ring-attention/ring-transformer/main.py at main · cuda-mode/ring-attention:Ring Attention 实验。通过在 GitHub 上创建账号,为 cuda-mode/ring-attention 的开发做出贡献。
- GitHub - exists-forall/striped_attention:通过在 GitHub 上创建账号,为 exists-forall/striped_attention 的开发做出贡献。
-
[功能请求] 通过 zigzag 分块平衡计算 · Issue #2 · zhuzilin/ring-flash-attention:目前的实现会将输入序列分为 n 个块,例如 4 个 GPU 会分为:b0 b1 b2 b3,然而,这会导致计算不均匀,拥有 b3 的 GPU 会… - GitHub - bigscience-workshop/petals: 🌸 在家运行 LLM,BitTorrent 风格。微调和推理速度比 offloading 快 10 倍:🌸 在家运行 LLM,BitTorrent 风格。微调和推理速度比 offloading 快 10 倍 - bigscience-workshop/petals
- transformer_nuggets/transformer_nuggets/flash/flash_attention.py at 4036b4385feaf610edf35b09b97cd14cba4ce701 · drisspg/transformer_nuggets:一个存放我自己创建或在网上发现的可复用 Transformer 组件的地方 - drisspg/transformer_nuggets
- 添加 Striped Attention 扩展。 · exists-forall/striped_attention@0c3ef0f:未找到描述
- 由 b-albar 提交的自定义 Attention Bias · Pull Request #617 · Dao-AILab/flash-attention:此 PR 尝试添加自定义(加性)Attention Bias。至少可以说,这仍然是一个正在进行中的工作,但我认为应该公开我的代码,因为可能会有很多人感兴趣…
LangChain AI ▷ #general (70 条消息🔥🔥):
- 研究工具反馈请求:
@d97tum分享了一个 调查链接,旨在为他正在开发的一款产品收集反馈。该产品旨在解决常见的研究难题,例如查找相关研究论文和理解复杂研究。他希望社区的见解能助力产品功能的塑造。 - 寻求 Langchain 顾问:
@cybersmiths正在寻找一位精通 Langchain 和 OpenAI tool agent 的顾问来协助他们的工作,并愿意为提供的帮助支付报酬。此机会面向 LangChain AI Discord 社区。 - 优化 Chain 的技术讨论:
@b0otable发起了关于如何更好地优化 LangChain 中 Chain 的深入探讨,重点关注使用 RunnableParallel 和 RunnablePassthrough 来在并行运行多个 Chain 的同时保持输入查询,并在类字典输出的根层级保留输出结果。 - LangChain 中的 API 调用与流式传输:
@critical3645、@saita_ma_和@edartru.提出了关于在 agent_supervisor 中实现流式传输、调用 OpenHermes 等本地模型以及某些工具在流式传输中的适用性等问题,突显了在使用 LangChain 工具和集成时的技术细节。 - LangSmith 调试与可视化工具:
@b0otable分享了使用 LangSmith 调试复杂 LangChain 流程的经验,推荐将其作为确保 Chain 按预期运行的一种方式,并为新用户提供了简要的设置指南。
提到的链接:
-
[🦜🕸️LangGraph 🦜️🔗 Langchain](https://python.langchain.com/docs/langgraph): ⚡ 以图的形式构建语言 Agent ⚡ - langgraph/examples/multi_agent/agent_supervisor.ipynb at main · langchain-ai/langgraph: 通过在 GitHub 上创建账号,为 langchain-ai/langgraph 的开发做出贡献。
- Create Chat UI Using ChainLit, LangChain, Ollama & Gemma 🧠: 在此视频中,我将演示如何在本地计算机上创建一个简单的类 ChatGPT UI。你可以通过克隆本地仓库来跟随操作…
- Survey on your Research Journey: 为了革新学术和商业研究,EurekAI 寻求您的见解,以便根据您的需求定制我们的工具。无论您是沉浸于研究还是偶尔参与,您的…
- LangGraph: Intro: 在此视频中,我们将介绍 LangGraph —— 一种更轻松地创建 Agent 运行时(runtimes)的方法。GitHub Repo: https://github.com/langchain-ai/langgraph
- Self-reflective RAG with LangGraph: Self-RAG and CRAG: 自我反思可以显著增强 RAG,从而纠正低质量的检索或生成。最近的几篇 RAG 论文都聚焦于这一主题,但实现…
LangChain AI ▷ #share-your-work (3 条消息):
- 并行函数调用现已可用:
@gokusan8896宣布了一种在任何 LLM 中启用并行函数调用(parallel function calls)的方法。详细信息已在 LinkedIn 帖子 中分享。 - 寻求聚合查询平台的反馈:
@rogesmith正在开发一个用于聚合文档数据查询的平台/库,并考虑将其公开,现征求社区对其有用性的反馈。 - 构建自定义聊天机器人指南:
@deadmanabir发布了一份关于如何使用 OpenAI、Qdrant DB 和 Langchain JS/TS SDK 创建包含聊天历史记录的自定义聊天机器人的综合指南。欲了解更多信息和反馈机会,请查看其 Twitter 帖子。
LangChain AI ▷ #tutorials (3 messages):
-
介绍使用 ChainLit 及其相关工具构建聊天 UI:分享了一个 YouTube 视频,演示如何使用 ChainLit, LangChain, Ollama & Gemma 在本地创建一个类似 ChatGPT 的 UI。视频可以在这里观看,观众可以克隆仓库并按照步骤设置自己的聊天界面。
-
通过 LLM 进行股票分析:
@rito3281发表了一篇文章,讨论 Large Language Models (LLMs) 如何辅助理解公司的季度报告,以预测未来的增长、风险和市场机会。详细文章和 Stock Portfolio Summarizer 应用的演示可以在这里找到。 -
Google Colab 与 Ollama 的结合:
@schimazing宣布了一项适配方案,使用 Ollama 的新 Embeddings,完全托管在 Google Colab 上,无需 API keys。更多信息请见链接中的 Twitter 帖子。
提到的链接:
- Daily Portfolio Summarizer with Langchain, Qdrant, and Mistral AI:当今的投资者被新闻、报告、统计数据和更多信息所包围。AI 能够穿透这些噪音,分析庞大的数据集以发掘隐藏的模式和趋势,并提供见解……
- Create Chat UI Using ChainLit, LangChain, Ollama & Gemma 🧠:在此视频中,我将演示如何在你的电脑本地创建一个简单的类似 ChatGPT 的 UI。你可以通过克隆本地仓库来跟随我的操作……
Datasette - LLM (@SimonW) ▷ #llm (19 messages🔥):
- 用于 LLM Playground 的 Codespaces:
@derekpwillis分享了一个模板仓库,用于在 Codespaces 中运行 LLM,发现它对orca-mini-3b非常有效,同时也对大型模型的支持表示了担忧。 - 对 Codespaces 配置的正面反馈:
@simonw称赞了 Codespace 模板中基础的.devcontainer配置,并认为它作为一个示例非常有用。该用户还注意到启动时间较长,似乎涉及从头开始编译许多组件。 - 解决 Codespaces 的一个小怪癖:
@simonw遇到了一个 Bug,最初无法识别llm-gpt4all为可用状态,但在运行llm models后恢复正常。他建议使用llm chat -m orca-mini-3b-gguf2-q4_0将模型保留在内存中,以便更快地回复后续消息。 - Prompt Crafting 与直接查询的对比:
@tariqali将提供更多控制权的传统 Prompt Crafting 与现代、更直接的 LLM 查询(如 RLHF)进行了对比,指出前者在特定情况下(如在新的聊天机器人实例中恢复对话)非常有用。 - 探索更大型 World Model 的集成:
@simonw表达了对运行 Large World Model 的 LWM-Text-1M-Chat 的兴趣,考虑到该模型是在大型数据集上训练的,可能需要为 PyTorch 模型提供 GPU 实例。
提到的链接:
- Large World Models:无描述
- LargeWorldModel/LWM-Text-Chat-1M · Hugging Face:无描述
- llm-codespaces/.devcontainer/devcontainer.json at main · dwillis/llm-codespaces:在 Codespaces 中使用 Python llm 库的模板仓库 - dwillis/llm-codespaces
- GitHub - dwillis/llm-codespaces: A template repository for using the Python llm library in codespaces:在 Codespaces 中使用 Python llm 库的模板仓库 - dwillis/llm-codespaces
LLM Perf Enthusiasts AI ▷ #general (5 messages):
-
Richard Socher 暗示 AI hallucination 的解决方案:
@res6969分享了 @RichardSocher 的一条推文,暗示在解决 AI hallucination 问题上可能取得了重大进展,展示了没有任何错误的最新引用。 -
好奇非幻觉 AI 背后的奥秘:
@res6969推测,为了防止 hallucination,该 AI 可能利用了一些 state-of-the-art embeddings 以及一个指令验证器(instructional validator)。 -
Globe Explorer:你的个性化维基百科:
@sincethestudy分享了一篇关于新平台 Globe Explorer 的 推文,该平台作为一个由 GPT-4 驱动的按需定制维基百科页面,标志着我们发现信息方式的演变。访问该工具:explorer.globe.engineer。 -
GPT-4 驱动新型探索引擎:
@sincethestudy宣布推出 Globe Explorer,这是一个使用 GPT-4 作为后端的探索引擎,为增强信息发现体验铺平了道路。
提到的链接:
- 来自 brian-machado-finetuned-7b (e/snack) (@sincethestudy) 的推文: Globe Explorer 有点像针对你想要的任何内容的定制维基百科页面。我们正在进入信息发现的新时代。去试试吧:http://explorer.globe.engineer/
- 来自 Richard Socher (@RichardSocher) 的推文: 我们解决 hallucination 问题了吗?在这里以及我在研究模式下尝试的任何其他示例中,看起来确实如此——所有示例都有大量最新的引用。查询内容:Reddit S-1
LLM Perf Enthusiasts AI ▷ #finetuning (1 messages):
- GPT-4-Turbo 的 Finetuning 困境: 用户
@pantsforbirds一直成功地使用 gpt-4-turbo 嵌入整个文档进行 1-shot 数据提取,并正在考虑针对更复杂的任务进行 finetuning。他们询问 finetuning 数据集应该包含整个示例文档还是仅包含相关部分。
LLM Perf Enthusiasts AI ▷ #offtopic (4 messages):
- Globe Explorer 引发信息发现热潮:
@joshcho_分享了 Globe Explorer 的链接,强调它类似于定制的维基百科页面。他们评论说正进入一个信息发现的新时代。 - 发现热度超出原始帖子:
@nosa_随后指出之前的 Discord 对话中,@sincethestudy已经介绍了 Globe Explorer。 - 在正式推广前已走红:
@joshcho_幽默地注意到,在看到传播消息的号召之前,Globe Explorer 已经 went viral(走红)了。
提到的链接:
来自 brian-machado-finetuned-7b (e/snack) (@sincethestudy) 的推文: Globe Explorer 有点像针对你想要的任何内容的定制维基百科页面。我们正在进入信息发现的新时代。去试试吧:http://explorer.globe.engineer/
LLM Perf Enthusiasts AI ▷ #prompting (2 messages):
- 设置 Max Token 限制:
@ayushsharma提到需要在 constructor 中设置 max_token_limit,但未提供关于此请求的进一步细节或背景。 - 提示 LLM 处理不重叠的网格组件:
@firefox8975询问如何编写 prompt 以将不同尺寸的组件组织到网格中而不发生重叠,并质疑 LLM 在此类空间任务中的有效性。他们寻求确保组件在 X by Y grid 内不重叠的建议。
Alignment Lab AI ▷ #oo (2 messages):
- 发现 GLAN 论文: 用户
@.benxh分享了一篇关于 GLAN (Generative Latent Nearest Neighbors) 的论文链接,询问是否有人正在研究它。他们附上了 研究论文 供参考。 - 对 GLAN 表示兴趣:
@entropi对提到的 GLAN 做出回应,表示他们发现分享的关于 Generative Latent Nearest Neighbors 算法的论文非常有趣。
Skunkworks AI ▷ #off-topic (1 条消息):
pradeep1148: https://www.youtube.com/watch?v=953U3FxHF-Q