ainews-mistral-large-disappoints
Mistral Large 令人失望。
Mistral 发布了 Mistral Large,这是一款新的语言模型,在 MMLU 基准测试中达到了 81.2% 的准确率,落后 GPT-4 Turbo 约 5 个百分点。
社区对此反应不一,有人对其开源立场表示怀疑,并有说法称 Mistral Small 的表现优于开源的 Mixtral 8x7B。在 TheBloke 的 Discord 频道中,讨论重点包括:Mistral Large 与 GPT-4 Turbo 之间的性能和成本效益对比;使用 DeepSpeed 和 DPOTrainer 进行训练时的技术挑战;利用 DreamGen Opus V1 在角色扮演中实现的 AI 欺骗(deception)技术进展;以及使用线性插值和 PEFT 方法进行模型合并的复杂性。此外,人们还表达了对 AI 辅助反编译的热情,并强调了利用开源项目作为训练数据的重要性。
2024年2月21日至23日的 AI Discord 动态。我们为您检查了 20 个公会、318 个频道和 15439 条消息。预计节省阅读时间(按每分钟 200 字计算):1430 分钟。
Mistral 今天强势出击,在 La Plateforme 和 Azure 上宣布推出 Mistral-Large,其综合基准测试结果落后 GPT4 约 5 个百分点:

社区反响略显负面。
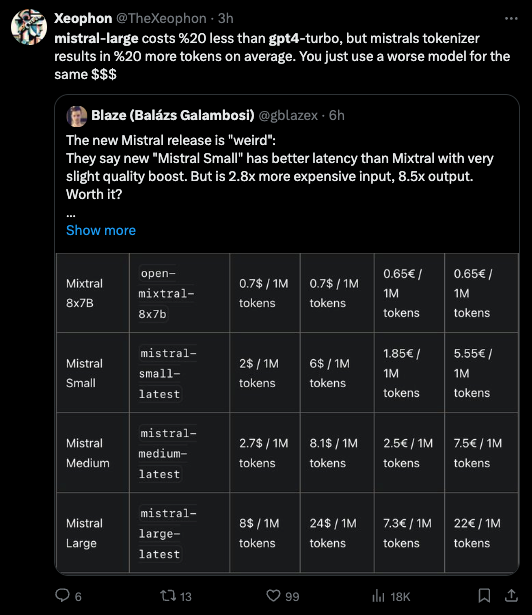
开源的希望并不大。值得注意的是,Mistral 还声称新的 Mistral-Small “显著优于”已开源发布的 Mixtral 8x7B。
目录
[TOC]
PART 0: 摘要之摘要之摘要
评估 LLM 的性能与成本效益:
TheBloke Discord 中的讨论强调了 Mistral Large 与 GPT-4 Turbo 之间的对比分析。尽管成本影响相似,但 Mistral Large 在 MMLU 等基准测试上的表现不尽如人意,这表明用户和开发人员都需要重新评估成本效益。
技术训练障碍与最佳实践:
在实施 DeepSpeed 以避免显存溢出(OOM)错误方面的挑战,以及使用 DPOTrainer 应用 DPO 的过程,突显了技术复杂性和社区驱动的解决方案共享,展示了在优化 LLM 训练效率和实用性方面的持续努力。
角色扮演角色 AI 欺骗技术的进展:
关于创建具备欺骗能力的 AI 角色的对话,特别是生存目标的加入,反映了对 AI 叙事能力的细致探索。尽管存在 tokenizer 和冗长问题,DreamGen Opus V1 的使用仍突显了 AI 故事创作中的创意追求。
模型合并的复杂性:
由社区成员主导的关于使用线性插值和 PEFT 合并方法等策略合并非同质模型的讨论,揭示了通过模型集成增强 LLM 的复杂性和潜力,这标志着 AI 开发实践中的一个重要探索领域。
PART 1: 高层级 Discord 摘要
TheBloke Discord 摘要
-
评估 LLM 的性能与成本效益:
@timotheeee1认为 Mistral Large 的表现不如 GPT-4 Turbo,考虑到其在 MMLU 等基准测试上的表现,在成本相近的情况下可能并不划算。 -
技术训练障碍与最佳实践:DeepSpeed OOM 错误的问题以及围绕使用
trlHugging Face library 中的DPOTrainer进行 DPO 实际应用的讨论,促使@cogbuji和@plasmator等用户分享见解和资源。 -
推进角色扮演角色中的 AI 欺骗技术:关于创建能令人信服地撒谎的 AI 角色的对话强调了应用明确生存目标后的改进。讨论了使用 DreamGen Opus V1 模型时遇到的挑战,以及 AI 故事创作中的 tokenizer 问题和冗长现象。
-
深入探讨模型合并的复杂性:由
@jsarnecki和@maldevide领导的讨论深入探讨了合并非同质模型的复杂性以及成功合并的各种策略(如线性插值)。结合 mergekit 和 Hugging Face blog post 中概述的 PEFT 合并方法的进展,阐述了其中的局限性和可能性。 -
工程师在展望 AI 反编译未来的同时怀念过去:
@spottyluck对 OllyDbg 功能的回忆与@mrjackspade对 AI 辅助反编译 潜力的兴奋形成了对比。利用大量开源项目创建 AI 训练数据集的建议,展示了在推进代码重构 AI 能力方面的前瞻性思维。
Mistral Discord 总结
Mistral Large 登场:Mistral Large 的推出引发了社区的广泛关注和讨论。这是一款高度优化的语言模型,在 MMLU 上达到了 81.2% 的准确率,并具备多语言能力和原生 function calling 等特性。用户可以通过 la Plateforme 等平台使用该模型。
LLM 部署中的技术挑战与突破:成员们分享了在各种硬件配置(包括 Tesla V100s 和 VRAM 有限的本地机器)上部署 Mistral 模型(如 Mistral7x8b 和 Mistral-7B-Instruct)的经验并交流了技术建议。大家交换了关于调整 layer sharing、精度级别以及处理死机问题的技巧,凸显了高性能模型使用中的技术细节。
微调 (Fine-Tuning) 技巧:社区讨论了微调实践,强调了实验和充足数据量的重要性,并建议针对特定任务准备约 4000 条数据。此外,讨论还集中在 Mistral 模型微调所需的正确数据格式,以及掌握 LoRA 等高级微调技术的必要性。
对商业影响与开放获取的思考:围绕 Mistral 转向更面向业务的闭源权重模型(如 Mistral Small 和 Large)的讨论,引发了对开放模型未来的担忧。然而,尽管存在与大科技公司的合作伙伴关系,许多成员仍对开源模型开发的持续支持抱有希望。
Mistral API 见解与查询:关于 Mistral API 的咨询非常多,涵盖了从数据隐私担忧(已确认数据不会用于模型训练)到关于在没有 GPU 的本地机器上运行 Mistral 的功能性查询。此外,还讨论了第三方产品以及扩展 Mistral 能力的潜在集成方案。
用户驱动的设计与应用创意:社区积极分享了新应用和增强功能的想法,包括开发利用 Mistral 的插件和移动应用。一位用户建议为 Mistral 的 Le Chat 添加语言级别设置,此外,Le Chat 中 Mistral-Next 的功能简洁性也引起了热议,这可能表明用户更倾向于精简的 AI 产品。
LM Studio Discord 摘要
-
解决 LM Studio 的白屏困扰:用户
@steve_evian遇到了 LM Studio 启动后显示白屏的问题;@heyitsyorkie建议清理 .cache 和 %APPDATA%,该操作解决了问题。 -
探索多语言 LLM 的存在:
@.deug询问是否有支持韩语的预训练多语言 LLM;@heyitsyorkie指出精通韩英翻译的 LLM 较为稀缺,建议将 LM Studio 与 DeepL 等在线翻译工具结合使用。 -
LM Studio API 拒绝以无头模式运行:
@muradb询问了 LM Studio API 的无头(headless)运行操作;@heyitsyorkie澄清当前版本不支持该功能,而@krypt_lynx表达了对开源和无头特性的渴望,@heyitsyorkie确认这些特性目前均不可用。 -
超参数评估仍是个人选择:
@0xtotem思考了用于 RAG 模型超参数评估的合适数据集——由于缺乏具体指导,共识倾向于使用手头最接近的数据。 -
GPU 之战:Nvidia 在用户偏好中对阵 AMD:关于 AMD GPU 是否适合运行 LLM 展开了辩论;尽管有推测称 AMD 正在开发 CUDA 的替代方案,但由于 AI 应用安装配置更简便,用户普遍更青睐 Nvidia。
-
共同努力在 LM Studio 中支持 IQ 模型:
@drawless111成功让 IQ 模型运行,并提供了在 HGF 上定位特定格式的指导;其他人讨论了对各种模型和工具(如 llama.cpp)的改进和更新。 -
没有文件系统访问权限的在线强化学习:
@wolfspyre询问了 LM Studio 访问本地文件系统的能力;会议澄清了 LLM 不具备此能力,LM Studio 也不支持执行来自 LLM 的命令。 -
通过经典的重启解决 AutoGen 异常:用户分享了 AutoGen 错误 的排障技巧,包括重新安装包以及可靠的“关掉再重启”策略,正如这个 Tenor GIF 中幽默描述的那样。
-
寻求 Langchain 的 RAG 使用支持:在一条简短的消息中,bigsuh.eth 询问了如何通过 LM Studio 在 Langchain 中使用 RAG,但随后没有引发进一步讨论或得到解答。
-
破解 Open-Interpreter 连接难题:用户
@nxonxi在尝试使用--local标志运行 Open Interpreter 时遇到了连接错误和语法错误;经过排障,简单的 Python requests 请求作为解决方案奏效了。
Perplexity AI Discord 摘要
-
Discover Daily 播客亮相:Perplexity AI 与 ElevenLabs 合作推出了 Discover Daily 播客。剧集源自 Perplexity 的 Discover feed,可在 podcast.perplexity.ai 收听,利用 ElevenLabs 的语音技术提供每日科技、科学和文化见解。
-
Sonar 模型引发争论:Perplexity AI 推出了新的
sonar-small-chat和sonar-medium-chat模型及其搜索增强版,引发了社区与pplx-70b-online的对比。用户报告 sonar 模型回复不连贯,请求不要逐步淘汰pplx-70b-online,因为后者性能更好;根据社区见解和 API Updates,sonar 模型的修复工作正在进行中。 -
Sonar 模型的乱码回复受到关注:像
@brknclock1215这样的用户建议通过限制回复长度来减轻乱码输出,这与 pplx 模型即使在较长长度下也能保持稳定的输出质量形成对比。同时,API 用户讨论了如何通过编程方式获取模型详情,以优化用户界面的选择。 -
#general 频道中充斥着 AI 聊天模型的讨论:社区参与了各种讨论,包括 Gemini 的退役以支持可能的 Gemini Ultra、不同平台间模型回复的不一致性,以及利用 Perplexity 的 Pro 能力进行图像生成。
-
sharing 频道中的各种查询和测试:sharing 频道的成员深入探讨了混合话题,如探索 Perplexity 主题的用户指南、质疑联想(Lenovo)技术的新颖性,并分享了利用 AI 进行个人辅助和技术咨询的混合用例。
OpenAI Discord 总结
-
VPN 对 OpenAI 服务的干扰:
@strang999在使用 OpenAI 服务时遇到错误,@satanhashtag将其归因于潜在的 VPN 干扰,并建议在 VPN 设置中禁用 Web Protection。 -
GPT-4 上下文和 Captcha 挑战:
@orbart和@blckreaper对 ChatGPT 在叙事创作中记忆力下降感到沮丧,怀疑处理的 Token 数量有所减少;同时@little.toadstool和@necrosystv报告了 ChatGPT 中繁琐的 Captcha 测试。 -
寻求 Image-to-Video 以及对数据隐私的担忧:
@sparkette正在寻找基于浏览器的 Image-to-Video 生成器,@razorbackx9x询问了关于使用 AI 整理信用报告数据的问题,@eskcanta警告不要上传敏感的个人身份信息 (PII)。 -
了解 Custom GPT 和 Assistant 的差异:用户注意到 Custom GPTs 和 Assistant GPTs 在处理格式和 Markdown 方面存在不一致,特别是在生成表格或图像时,并建议参考特定的 API 配置。
-
期待 Sora 并保护 Prompt:社区对 OpenAI 的 Sora 的能力感到好奇,并讨论了保护自定义 Prompt 的可行性,
@.dunamis.和@kyleschullerdev_51255一致认为完全的保护是不可能的,建议使用分层 Web 应用程序来保证安全性。
LAION Discord 总结
-
警惕加密货币诈骗:#learning-ml 频道中来自
@josephsweeney11的一条帖子似乎是一个潜在的诈骗,涉及在 72 小时内赚取 4 万美元,应予以极度警惕。 -
理解 Transformer 的学习能力:在 #learning-ml 频道中,
@phryq.询问了关于训练 Transformer 理解尺寸关系的实验,以通过假设物体来增强图像生成。 -
新 Snap Video 项目发布:#general 频道讨论了一个名为 Snap Video 的新项目,该项目通过基于 Transformer 的模型解决了视频生成中的挑战,并分享了项目链接和相关的研究论文。
-
关于最优 CLIP 过滤技术的辩论:在 #research 频道中,讨论围绕 CLIP 过滤是否比图像-文本对分类器(image-text pair classifiers)更次优展开,对话中参考了最近发表的 DFN 论文。
-
梯度精度:bfloat16 vs fp32 之争:#research 频道的对话涉及在 TPU 上使用 bfloat16 梯度的 autocasting,并将其性能与 PyTorch autocast 行为中默认的 fp32 梯度进行了比较。
-
分享 AI 研究论文和方法:在各个频道中,参与者分享了关于各种 AI 研究主题的见解和资源,例如 state space architecture、Transformer 优化、AI 生成文本检测,以及关于如何显著降低 LLMs 成本的讨论,并提供了 Mamba-ND 等资源链接。
HuggingFace Discord 总结
-
AI 硬件民主化引发激烈辩论:在围绕创建专有 TPU 的潜力和硬件民主化的讨论中,与汽车和 RAM 行业的类比引发了对 Samsung 等公司技术承诺的质疑。鉴于这些进展对 AI 能力和获取途径的影响,此类进步的重要性得到了强调。
-
迈向易于获取且实用的 AI 解决方案:多项倡议旨在使 AI 工具在各种应用中更加易用和实用,包括创建 Galaxy AI(提供对 GPT-4、GPT-3.5 以及 Galaxy AI’s Gemini Pro 等模型的免费 API 访问),以及展示支持 90 多种语言的 OCR 和行检测项目 surya,详见 此 GitHub 仓库。
-
神经网络创新与模型微调挑战:从在浏览器中引入对 WavLMForXVector 的支持,到审查 Peft 库 中 LoRA 的新合并方法,讨论重点显然在于模型部署和提升 AI 性能。微调难题,无论是 Flan T5 产生不连贯的输出,还是 Qwen1.5-0.5B 中出现的锯齿状 Loss 曲线,仍然是讨论的核心点。
-
跨学科 AI 项目备受关注:将 AI 与特定学科相结合的项目,如开源 AI 工具箱 Unburn Toys,或用于比较 TTS 模型的 TTS Arena,标志着 AI 开发的跨职能方法。此外,还发布了针对哲学问答等利基应用的训练数据集,可在 Hugging Face 此处 获取。
-
AI 社区中的知识共享与协作增长:无论是关于机器人模仿学习的查询、AnimeBackgroundGAN 的使用、多语言 OCR 相关问题,还是 Japanese Stable Diffusion 模型在新语言训练中的方法,显而易见,AI 社区是分享知识、解决问题并促进该领域集体进步的宝贵论坛。
Eleuther Discord 总结
-
GPT-4 的 Batching 困境:
@rwamit提出了关于在使用 langchain 封装器对 GPT-4 进行 Batching 查询时,处理时间从每次迭代 2 秒增加到 60 秒的问题,导致 5-6k 条记录的任务耗时从 5 小时激增至 96 小时。 -
初始化中的奥秘:Gemma 的 PyTorch 实现 中一段涉及 RMSNorm 的特定代码引发了讨论,重点在于归一化过程中加 1 (+1) 的重要性。
-
EfficientNet 的功效:关于 EfficientNet 优点的辩论展开了,尽管
@fern.bear对其营销与性能的关系提出了批评,但@vapalus辩护了其在分割任务中的应用。 -
Mistral Large 亮相:Mistral Large 正式发布,该模型因其强大的文本生成性能以及在 la Plateforme 和 Azure 上的可用性而受到赞誉。更多详情请查看 Mistral Large。
-
DPO 论文与 SFT:
@staticpunch寻求关于 DPO 中model_ref初始化的澄清,并确认如 DPO 论文中所述,在进行 DPO 之前应先对首选补全进行 Supervised Fine-Tuning (SFT)。 -
深入探究 GRUs:
@mrgonao对为什么像 GRUs 这样的门控单元被如此命名表示好奇,但频道内关于其词源的解释仍然难以捉摸。 -
寻找更智能的搜索:”Searchformer” 论文 [Beyond A: Better Planning with Transformers via Search Dynamics Bootstrapping](https://arxiv.org/abs/2402.14083) 描述了基于 Transformer 的模型在解决谜题方面如何超越传统的 A 方法,为搜索问题提供了一种创新方法。
-
RLHF 与简单性之争:一篇提倡在 RLHF 中使用更简单的 REINFORCE 风格优化而非 Proximal Policy Optimization (PPO) 的论文,引发了关于语言模型 RL 基础方法效率的讨论。论文可在此处 访问。
-
水印框架对决:分享了针对 Large Language Models 的文本水印技术概况,包括在生成的文本中嵌入可检测信号的技术,以及对这些水印鲁棒性的分析。
-
GPT-NeoX 与 Python 的故事:在对升级到 Python 3.10 犹豫不决之际,开发讨论转向了相比 GPT-NeoX 更倾向于使用 custom training loop,展示了对 AI 开发优化细节的积极参与。
-
Tokenization 中的多语言问题:关于优化 Mistral tokenizer 以获得更好多语言表现的咨询,强调了在提升语言模型除英语以外能力方面的持续努力,表明了对全球适用性的关注。
LlamaIndex Discord 摘要
-
Create-llama 简化全栈开发:最新的 create-llama 版本集成了 LlamaPack,通过包含高级 RAG 概念,以最少的代码简化了全栈 Web 应用的构建。该公告由 @llama_index 的推文发布。
-
Counselor Copilot 利用高级 RAG:在推文中强调的 Counselor Copilot 项目,其独特之处在于利用高级 RAG 来协助危机辅导员,展示了作为 Copilot 而非基础聊天机器人的用例。
-
通过摘要增强 RAG 检索:为了改进 RAG 检索,一种使用子文档摘要的技术有助于解决由朴素分块(naive chunking)引起的全局概念感知问题。这种方法在一条推文中进行了详细说明,讨论了由此带来的每个分块上下文感知能力的提升。
-
LlamaParse 精通复杂 PDF 解析:LlamaParse 作为一款强大的工具被推出,用于解析带有复杂表格和图表的 PDF,这对于高质量的 RAG 应用至关重要。正如推文所述,准确的表格表示有助于 LLM 提供正确的答案。
-
AI 在处理卡夫卡主角时的挑战:在关于为卡夫卡的《变形记》生成书评的讨论中,
@daguilaraguilar遇到了 AI 错误地将 “Grete” 视为主角而非 “Mr. Samsa” 的问题,并引用了他们的代码。 -
金融文档分析与上下文管理的见解:SEC Insights 为分析金融文档带来了高级功能,社区内也有人呼吁针对 GPT-4 turbo 和 Gemini 1.5 等大窗口 LLM 的上下文管理最佳实践建立基准测试(benchmarks)。
Latent Space Discord 摘要
Sora 的一致性受到质疑:在对 WSJ 视频 的纠正中,@swyxio 指出 OpenAI 的 Sora 通过从起始图像进行插值,在超过 1 分钟的视频中保持一致性。
NVIDIA 的 GEAR 部门整装待发:NVIDIA 宣布成立一个新的研究小组 GEAR (Generalist Embodied Agent Research),由 Jim Fan 博士共同创立,专注于自主机器和通用 AI。
AI 生成的播客上线:Perplexity 推出了一个 AI 生成的播客,内容源自其 Discover 提要,并使用 ElevenLabs 的语音进行旁白。
使用 Cloudflare 只需一行 AI 代码:Cloudflare 推出了新的 AI Gateway,其特点是通过单行代码即可轻松集成 AI 分析和见解。
AI 通过 GPT-4-ada-v2 进行数据分析:一款新工具 ChatGPT Data Analysis V2 增强了数据分析功能,提供针对性回复和数据网格覆盖编辑器,可能实现了交互式图表并利用了 gpt-4-ada-v2。
LLM Paper Club T5 环节回顾:最近由 @bryanblackbee 主持的 LLM Paper Club 环节剖析了 T5 论文,讨论内容总结在共享的 Notion 笔记中。开放性问题包括模型词汇表、微调过程以及 NLP 任务的架构差异。
本地模型爱好者齐聚 AI in Action 俱乐部:“AI in Action”活动重点讨论了本地模型探索、本地 AI 模型的工具讨论,以及参考使用 LoRA 部署 ComfyUI 等工具进行模型微调。Latent Space Final Frontiers 活动已宣布,邀请团队通过此链接提交申请,共同挑战 AI 的极限。
OpenAccess AI Collective (axolotl) Discord 摘要
-
Gradient Clipping 难题与 DeepSpeed 咨询:讨论了将 Gradient Clipping 设置为 0.3 时出现的问题,怀疑存在临时峰值;同时,一个关于 HuggingFace 的 Trainer 支持 DeepSpeed Stage 3 的 GitHub issue 引发了关于使用和更新的反馈。此外还分享了 Axolotl 的缓存清理技巧,即使用
huggingface-cli delete-cache。 -
Mistral AI 的战略转型?:出现了关于 Microsoft 与 Mistral AI 战略合作伙伴关系的讨论,重点关注其对开源模型和 Mistral AI 商业方向的潜在影响。分享了 Twitter 帖子和新闻文章链接以供深入了解。
-
Axolotl 自动安装带来的便捷性:Axolotl 项目通过引入
auto_install.sh简化了安装过程,显示了对非 Python 开发者支持的承诺。一篇 Twitter 帖子寻求社区对 CUDA 模式系列的支持,并可能获得 Jeremy Howard 的协助。 -
GPU、Docker 与新手问题:关于 GPU 的技术问题非常突出,例如训练时间长和 Loss 过高、Docker 容器复杂化,以及对新手友好的 Axolotl 教程的需求。Hugging Face 报告的 checkpoint 保存错误问题 #29157 和 Axolotl 的 GitHub #1320 是主要的参考资料。
-
社区亮点:韩语扩展与 RAG 功能:宣布了一个没有 model card 的微调 phi-2 模型,推介了具有扩展韩语词汇量的 EEVE-Korean 模型,并介绍了用于 RAG 系统开发的 R2R Framework。社区还获得了配套的 arXiv 技术报告和各种 Hugging Face 模型。
-
Runpod 遭遇 DNS 故障:据报告,runpod 上出现 NameResolutionError,提示在尝试访问 ‘huggingface.co’ 时可能存在涉及代理设置的 DNS 解析问题。
CUDA MODE Discord 摘要
-
CUDA 遭到抨击:计算领域的传奇人物 Jim Keller 在 Tom’s Hardware 的一篇文章 中批评了 NVIDIA 的 CUDA 架构,暗示其缺乏优雅性且拼凑而成。与此同时,能够让 CUDA 代码在 AMD 和 Intel GPU 上运行的 ZLUDA 宣布开源,有望挑战 NVIDIA 在 AI 领域的统治地位 (GitHub 链接)。
-
GPU 装备竞赛:关于 AI GPU 选择的辩论浮出水面,4060 ti 是最便宜的 16GB 消费级 GPU,而 3090 提供 24GB VRAM,是 LLM 任务更强大的替代方案。围绕二手 GPU 购买策略以及出现问题时的潜在技术补救措施的讨论也非常热烈。
-
量化计算对话:关于量化模型如何保持计算精度的讨论变得清晰,重点讨论了通过检测模式并使用
torch.compile实现高效 CUDA kernel。CUDA kernel 的编译速度也是一个话题,有人提出了将编译时间从 30 多秒减少到 2 秒以内的方法 (仓库链接)。 -
Triton 探索:人们对 Triton 产生了浓厚兴趣,它是一个通过 Pallas 支持 Jax 的工具,并将其与 CUDA 在多 GPU/节点执行方面进行了比较。有人呼吁专家解释 Triton 的底层工作原理、其在 LLVM 和 MLIR 上的基础,并为其量化 matmul kernel 创建基准测试。
-
Flash Attention 优化:在 ring attention 的讨论中,
zigzag_ring_flash_attn_varlen_qkvpacked_func的实现显示出速度提升。一份 Hugging Face 文档详细说明了内存效率方面的优势 (Flash Attention 可视化),基准测试显示其比经典的 flash attention 提速 20% (基准测试链接)。 -
CMU 关于高效 LLM 推理服务的论文:分享了一篇来自 CMU 的关于部署生成式 LLM 高效方法的论文,题为 “Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems” (arXiv 链接),该论文调研了 150 多项技术,包括 非自回归生成 和局部注意力变体。
-
通过 MIT 学习效率:麻省理工学院 (MIT) 的一门关于高效 AI 计算的课程公开,涵盖了模型压缩、剪枝、量化,并提供了 LLaMa 2 等模型的实战经验,还涉及了量子机器学习话题 (课程链接)。
-
CUDA-MODE 讲座公告与学习:发布了关于量化的第 7 讲,标题为 Quantization CUDA vs Triton,强调了以量化为核心的 AI 计算高效技术论述。讲座内容辅以 YouTube 视频和易于获取的幻灯片演示,促进了社区的持续教育 (YouTube 第 6 讲, 第 7 讲)。
-
就业前景与咨询:确认 Nvidia 正在寻找 CUDA 和 C++ 专家,邀请申请人将简历发送至 JobID: JR1968004。关于 Mistral 等公司的招聘状态问题也被提出,凸显了 AI 工程领域的就业热度。
LangChain AI Discord 摘要
-
探索 AI 模型中的 Function Calls:工程师
@saita_ma_正在寻找在 OpenHermes 等本地模型中执行 Function Calls 的方法,灵感来自 CrewAI 的实现。同时,@kenwu_分享了一个 Google Colab,寻求关于使用 Cohere API 和 LangChain 进行 Agent 和 Function Calling 的帮助。 -
LangChain 在各类项目中的集成:
@deadmanabir分享了一个实现了 OpenAI、Qdrant DB 和 LangChain JS/TS SDK 的个性化聊天机器人的创建过程;而@david1542介绍了 Merlinn,这是一个支持值班工程师的机器学习工具。此外,@edartru.提供了 Langchain-rust,这是一个允许 Rust 开发者在编程中使用 LLM 的 crate。 -
教程资源推动 DIY AI 项目:最近的一个 YouTube 教程 向观众展示了如何使用 ChainLit、LangChain、Ollama 和 Gemma 创建类似 ChatGPT 的 UI。
@rito3281撰写了关于在保险行业使用 LLM 进行财务分析的文章,@tarikkaoutar发布了一个关于创建涉及 LangGraph 的 Multi-Agent 应用程序的 视频。 -
LLM 中的讽刺检测与超时延长:有建议在微调后为短语标记“sarcasm”(讽刺),以便 LLM 更好地检测,但未提供关于机制的进一步讨论。有人提出了关于延长默认 900 秒超时时间的问题,但尚未发现后续的解决方案或详细说明。
-
开发者探索的新兴工具与用例:
@solo78邀请就保险部门财务职能中的 AI 实现进行协作讨论。@eyeamansh介绍了一个 AI 驱动的 简历优化器,该工具曾帮助在科技公司获得面试机会。
Datasette - LLM (@SimonW) Discord 摘要
-
ChatGPT 多语言错误:用户注意到 chatgpt-3.5-turbo 有时会误译文档标题,例如将 “Taking Advantage of the Internet” 翻译为 “Sacándole Provecho a Internet“。建议的解决方法是使用指定 “Always use English” 的 System Prompt,以防止此类语言检测错误。
-
Prompt Crafting 的怀旧与修复:
@tariqali讨论了在面对聊天机器人“超时”问题时,传统 Prompt Crafting 对更好控制模型带来的好处。同时,@derekpwillis和@simonw交流了 devcontainer 配置,@simonw建议在setup.sh脚本中添加llm models,@derekpwillis实施后解决了某些 Bug。 -
在 LLM 上运行 LargeWorldModel 的愿景:正如
@simonw所讨论的,人们对在 LLM 上运行 LargeWorldModel 感兴趣,可能会利用 GPU 实例来运行 PyTorch 模型。他提到了这些模型在 Hugging Face 仓库 中的可用性。 -
Groq 推理插件亮相:
@angerman.发布了一个 Groq 推理插件 llm-groq,社区对其性能表现表示支持和好奇。 -
llm-groq 插件上线 PyPI:听取
@0xgrrr的建议后,@angerman.将他的 llm-groq 插件 发布到了 PyPI,从而可以通过llm install更轻松地安装。他分享了自己的发布经验,并对比了 Haskell 和 Python 社区的实践。
LLM Perf Enthusiasts AI Discord 摘要
-
关于 AI 幻觉(Hallucination)足迹的大胆主张:Richard Socher 的推文暗示了解决 AI 幻觉的可能方案,引发了围绕 Embedding 模型和验证机制以提高 AI 事实准确性的讨论。
-
推出新版维基百科: Globe Explorer 是一款利用 GPT-4 生成可定制维基百科风格页面的工具,目前已经发布并走红,正致力于冲上 Product Hunt 榜单,更多详情见 Product Hunt 页面。
-
FireFunction V1 引发关注:
@lqiao发布的 FireFunction V1 承诺提供 GPT-4 级别的输出,并具有更快、更有效的 Function Calling 能力。随之发布的还有 JSON 等实用的结构化输出模式,在 Function Calling 方法中备受关注,详见 FireFunction 博客文章。 -
gpt-4-turbo 的微调探索:关于使用 gpt-4-turbo 进行 1-shot 学习以改进数据提取和分类任务的 Embedding 技术咨询,引发了对有效 Fine-Tuning 实践的兴趣。
-
Anki 的 AI 抽认卡革命尚在进行中:集成 GPT-4 生成 Anki 抽认卡的尝试显示了成功与局限并存,例如输出过于冗长以及视觉内容集成方面的挑战,详见 Niccolò Zanichelli 的分析推文。
-
窥探 Feather 的用途:Feather OpenAI 的图标暗示其为一个写作工具,结合历史快照及其在 SME 数据标注和代码注释招聘中的重要性,引起了广泛关注。此外,还有像 “gpt-4-ada-v2” 这样增强数据分析能力的进展,详见 Semafor 的文章和 Tibor Blaho 的推文。
DiscoResearch Discord 摘要
-
Hugging Face Trainer 中的 Callbacks 特性:Sebastian Bodza 讨论了在 Hugging Face trainer 中使用自定义 Callbacks,并强调虽然目前仅限 PyTorch,但它们通过
TrainerControl接口提供“只读”控制。 -
德国情商基准测试出现:得益于 Calytrix 的更新, EQ-Bench 现在支持德语,
gpt-4-1106-preview在德语 EQ-Bench 初步评分中名列前茅,详情见 EQ-Bench GitHub 仓库。然而,有人对翻译后的 Benchmark 有效性表示担忧,认为可能会丢失情感理解的细微差别,并因以英语为中心的推理模式而导致结果偏差。 -
对基于概率的 LLM 评估的疑虑:Bjoernp 推荐了一篇 arXiv 论文,揭示了基于概率的评估方法在 LLM 中的固有局限性,特别是在多选题及其与基于生成的预测的一致性方面。
-
引入分层 Sentence Transformers:Johann Hartmann 通过 Hugging Face 博客文章 揭晓了 Matryoshka Embeddings,详细介绍了其相比普通 Embeddings 的优势,并确认其已集成到 Sentence Transformers 库中,增强了用户的工具包。
-
明确德语数据集的 RAG 方法:Johann Hartmann 和 Philip May 讨论了德语检索上下文理解数据集的评估方法,May 澄清说,评估 LLM 是否能识别多个检索上下文中的相关信息至关重要。该数据集尚在开发中,目前尚未公开。
AI Engineer Foundation Discord 总结
-
黑客松组队升温:
@reydelplatanos和@hiro.saxophone为即将到来的黑客松组队,@hiro.saxophone带来了 ML 工程方面的经验,特别是多模态 RAG。同时,@ryznerf.也表达了加入黑客松队伍的兴趣,强调了参与的热情。 -
跨学科协作:后端开发人员
@reydelplatanos与 ML 工程师@hiro.saxophone在黑客松中合作,代表了他们新团队中后端与机器学习技能的融合。 -
黑客松报名热潮:
@silverpiranha和@jamthewallfacer讨论了活动的报名情况,@silverpiranha最终确认报名成功并建议潜在的组队。 -
代码管理无人机:
@.yosun介绍了一个关于通过函数调用(function calls)控制无人机的黑客松项目想法,参考了 OpenAI Cookbook 中的方法,并分享了一段代码片段作为演示。
Alignment Lab AI Discord 总结
- Gemma-7B 获得对话礼仪:
@imonenext已将特殊 token<start_of_turn>和<end_of_turn>集成到 Gemma-7B 模型中,以促进对话式 AI 中的轮流对话。具有这些增强功能的模型现在可以在 Hugging Face 上进行训练和微调。
Skunkworks AI Discord 总结
- 随机精度的种子见解:
@stereoplegic强调了一篇关于深度学习中随机种子(random seeds)重要性的文章,特别是对于 Python 的 PyTorch 用户。文章 Random Numbers in Deep Learning; Python & the PyTorch Library 被赞誉为对于那些热衷于探索或微调模型训练中随机性底层机制的人来说是“非常值得一读”的。
第二部分:分频道详细总结与链接
TheBloke ▷ #general (1013 条消息🔥🔥🔥):
- Mistral Large 性能不值其价?:
@timotheeee1认为 Mistral Large 的成本与 GPT-4 Turbo 相似,但考虑到其在 MMLU 等基准测试中略逊一筹的表现,这一成本并不合理。其性价比受到质疑。 - Megatokens 首次亮相:
@itsme9316在讨论 token 成本时幽默地创造了 “megatoken” 一词,引发了包括@technotech在内的几位用户的一系列轻松回应,如 “lol”。 - 模型大辩论:关于 LLMs 是否能真正“推理”展开了一场漫长的辩论。
@kalomaze和@kaltcit就语言模型执行推理的能力,或者它们表现出的能力是否只能被称为准推理(quasi-reasoning)交换了意见。 - Mistral 开源希望破灭?:围绕 Mistral 致力于开源其大型模型的对话表现出挫败感,像
_dampf这样的用户对这一变化表示哀叹,并对这一消息表示并不感到意外。 - 遇到技术困难:
@kaltcit等用户报告了 academiccat dpo 等模型的问题,在测量过程中遇到了错误和段错误(segfaults),暗示了一些 AI 模型的不稳定性或不可预测性。
提及的链接:
- Cody - Sourcegraph: 未找到描述
- No GIF - No Nope Cat - Discover & Share GIFs: 点击查看 GIF
- Supermaven: 未找到描述
- Cat Cat Jumping GIF - Cat Cat Jumping Cat Excited - Discover & Share GIFs: 点击查看 GIF
- Mark Zuckerberg Last Breath Sans GIF - Mark Zuckerberg Last Breath Sans Last Breath - Discover & Share GIFs: 点击查看 GIF
- Neural Text Generation With Unlikelihood Training: 神经文本生成是自然语言应用中的关键工具,但众所周知,其核心存在重大问题。特别是,标准的似然训练和解码会导致…
- OpenCodeInterpreter: 未找到描述
- mobiuslabsgmbh/aanaphi2-v0.1 · Hugging Face: 未找到描述
- LongRoPE: 点赞 👍。评论 💬。订阅 🟥。🏘 Discord: https://discord.gg/pPAFwndTJdhttps://github.com/hu-po/docs/blob/main/2024.02.25.longrope/main.mdhttps://arxiv.o…
- Cat Kitten GIF - Cat Kitten Speech Bubble - Discover & Share GIFs: 点击查看 GIF
- Vampire Cat Cat Eating Box GIF - Vampire Cat Cat Eating Box Cat Box - Discover & Share GIFs: 点击查看 GIF
- Welcome Gemma - Google’s new open LLM: 未找到描述
- 2021 Texas power crisis - Wikipedia: 未找到描述
-
[MaxRiven - Turn It Up Official Music Video AI](https://youtu.be/OLEzmClaRnw?list=RDMMOLEzmClaRnw&t=16): 感谢观看!请观看高清版本并尽情享受!如果你喜欢这个视频,请分享给你的朋友!►流媒体播放与下载:https://fanlink.to/MXRVNturnitupThan… - GitHub - Dicklesworthstone/the_lighthill_debate_on_ai: A Full Transcript of the Lighthill Debate on AI from 1973, with Introductory Remarks: 1973 年关于 AI 的 Lighthill 辩论的完整转录,附带介绍性备注 - Dicklesworthstone/the_lighthill_debate_on_ai
- Uglyspeckles - Carrot Cake Soul Shuffling Incident SFX: 出自《海市蜃楼之馆》(The House in Fata Morgana)粉丝碟:Carrot Cake Jinkaku Shuffle Jiken。此原声带归 Novectacle (Vegetacle) 所有。
- GitHub - Azure/PyRIT: The Python Risk Identification Tool for generative AI (PyRIT) is an open access automation framework to empower security professionals and machine learning engineers to proactively find risks in their generative AI systems.: 生成式 AI 的 Python 风险识别工具 (PyRIT) 是一个开放访问的自动化框架,旨在赋能安全专业人员和机器学习工程师,主动发现其生成式 AI 系统中的风险。
-
[Announcing Microsoft’s open automation framework to red team generative AI Systems Microsoft Security Blog](https://www.microsoft.com/en-us/security/blog/2024/02/22/announcing-microsofts-open-automation-framework-to-red-team-generative-ai-systems/): 阅读关于 Microsoft 新的开放自动化框架 PyRIT 的信息,该框架旨在赋能安全专业人员和机器学习工程师,主动发现其生成式 AI 系统中的风险。 - The Strange Evolution of Artificial Intelligence: 未来思想中心(Center for the Future Mind)呈现 Scott Aaronson 在 Mindfest 2024 上的演讲。完整剧集将于明天(2 月 27 日星期二)美国东部时间中午 12 点上线。注:…
- no title found: 未找到描述
{kind=link}
TheBloke ▷ #characters-roleplay-stories (275 messages🔥🔥):
- 在 AI 中实现欺骗:
@superking__等人讨论了编写一个能令人信服地撒谎的角色的挑战,因为像 Mixtral 这样的大型模型在设定了诸如“不惜一切代价生存”等明确目标时表现更好。 - 变形机器人的故事:尽管
@superking__努力为一个隐藏身份的机器人创建角色卡,但 AI 还是暴露了身份,直到被赋予“不惜一切代价生存”的目标,这使得其隐秘行为有所改善。 - Opus V1 模型与技术挑战:
@dreamgen和@kquant等参与者探讨了围绕 DreamGen Opus V1 的问题、tokenizer 问题以及为了获得更好性能的最佳模型设置。 - 模型冗长与循环问题:包括
@superking__和@dreamgen在内的几位用户讨论了 AI 编写不必要的长句子或进入循环模式的情况,并分享了经验和潜在的修复方法。 - 角色扮演讨论:
@keyboardking成功创建了一个管理性别伪装叙事的角色卡,展示了当前 AI 在处理细微角色扮演场景方面的能力。
提到的链接:
- Kquant03/NurseButtercup-4x7B-bf16 · Hugging Face:未找到描述
- maeeeeee/maid-yuzu-v8-alter-3.7bpw-exl2 · Hugging Face:未找到描述
- Chub:查找、分享、修改、转换以及对对话式大语言模型 (LLM) 的角色和其他数据进行版本控制。曾用名/别名 Character Hub, CharacterHub, CharHub, CharaHub, Char Hub。
- dreamgen/opus-v1-34b-awq · Hugging Face:未找到描述
- Angry Bender Mad GIF - Angry Bender Mad Angry - Discover & Share GIFs:点击查看 GIF
- #0SeptimusFebruary 24, 2024 3:31 PMWhat tale do you wish to hear?# - Pastebin.com:Pastebin.com 是自 2002 年以来排名第一的文本存储工具。Pastebin 是一个可以在线存储文本并设置存储期限的网站。
TheBloke ▷ #training-and-fine-tuning (71 messages🔥🔥):
- 寻求 DPO 实现建议:
@cogbuji正在寻找 DPO (Decision Transformer) 的实际实现,并考虑参考trlGitHub 库中的DPOTrainer。@dirtytigerx等多位成员参与了讨论,提供了见解和资源。 - 微调与训练的抉择:
@cognitivetech对全量 LLM 微调的效率和潜在的信息丢失表示担忧。该用户考虑使用gguf进行微调,并探索利用官方 QA-Lora 实现进行指令微调 (instruct fine-tuning)。 - 处理 DeepSpeed OOM 问题:尽管计算显示资源充足,
@plasmator在设置 DeepSpeed Zero 时仍因显存溢出 (OOM) 错误而苦苦挣扎。 - 故事叙述 LLM 与漫画训练集:
@hellblazer.666询问如何训练较小的模型进行故事创作,特别是使用漫画文本作为数据集。他们还分享了 Augmentoolkit 仓库,作为将数据转换为适合训练格式的潜在工具。 - 训练方法与模型选择:在一次深入讨论中,
@dirtytigerx和@hellblazer.666讨论了各种 LLM 训练方法,包括全量微调、LoRA 等 PEFT 技术,以及检索增强生成 (RAG) 的使用。他们得出结论,对于@hellblazer.666的项目,从一个针对故事叙述微调过的基础模型开始可能是最好的方法。
提到的链接:
- GitHub - e-p-armstrong/augmentoolkit: Convert Compute And Books Into Instruct-Tuning Datasets:将计算和书籍转换为指令微调数据集 - e-p-armstrong/augmentoolkit
- trl/trl/trainer/dpo_trainer.py at main · huggingface/trl:使用强化学习训练 Transformer 语言模型。- huggingface/trl
TheBloke ▷ #model-merging (37 messages🔥):
- 新型模型合并的挑战:用户
@jsarnecki询问了关于使用 mergekit 合并 llama-2-13b 和 Mistral-7b 等非同质模型的问题,@maldevide确认这是不可能实现的。讨论随后转向探索可能帮助@jsarnecki实现目标的合并技术。 - 针对用例进行优化:
@maldevide提示@jsarnecki考虑他们是在进行能力探索实验,还是针对特定的用例,并进一步提供了关于 Hugging Face 模型成功合并的见解。 - 同质模型合并技术:
@alphaatlas1提到 git-rebasin 是合并具有相同大小/布局的模型的一个潜在选项,并讨论了诸如缺乏合并不同基础模型的有效技术等局限性。 - 讨论高级合并策略:对话转向各种合并策略,包括
@maldevide分享的线性插值 (linear interpolation)、加法合并 (additive merging) 和随机采样 (stochastic sampling)。讨论强调了模型合并技术的复杂性及其对不同模型类型的适用性。 - DARE Ties 合并见解:
@alphaatlas1指出 Diffusion models 在进行 DARE ties 合并时面临挑战,并引用了一篇特定的 Hugging Face 博客文章。然而,@maldevide分享了一个成功的经验,并指向了 GitHub 上的另一个实现。
提到的链接:
- 🤗 PEFT welcomes new merging methods:未找到描述
-
[Daring Hydra - v1.2 Stable Diffusion Checkpoint Civitai](https://civitai.com/models/246219/daring-hydra):Daring Hydra 是一项创建逼真写实模型的尝试。v1.2 实际上是四次改进 v1.1 尝试的结果,而 v1.1 之前是… - GitHub - 54rt1n/ComfyUI-DareMerge: ComfyUI powertools for SD1.5 and SDXL model merging:用于 SD1.5 和 SDXL 模型合并的 ComfyUI 强力工具 - 54rt1n/ComfyUI-DareMerge
- GitHub - s1dlx/meh: Merging Execution Helper:Merging Execution Helper。通过在 GitHub 上创建账户为 s1dlx/meh 的开发做出贡献。
TheBloke ▷ #coding (6 messages):
- DotPeek 范围澄清:
@al_lansley询问了 DotPeek 支持的语言,@spottyluck确认其仅限于 C#。 - 怀念 OllyDbg 的功能:
@spottyluck感叹 OllyDbg 缺乏真正的继任者,特别是其 “animate into” 功能,并指出其在 64bit 上的局限性使其几乎过时。 - 对 AI 辅助反编译的迫切期待:
@mrjackspade对 AI 辅助反编译 简化逆向工程过程的潜力表示兴奋。 - 对重构代码的挫败感:
@mrjackspade分享了手动重构混淆后的反编译代码的挫败感,暗示了这一过程的乏味性。 - AI 训练数据集的构想:
@mrjackspade建议通过使用大量开源项目及其输出来创建用于 AI 反编译的训练数据集。
Mistral ▷ #general (1198 messages🔥🔥🔥):
- Mistral Large 与 Next 的性能对比: 用户如 `@yasserrmd` 和 `@chrunt` 对比了 Mistral Large 和 Next 的能力。Large 在某些基准测试中似乎优于 Next,而 Next 因其简洁的回复而受到青睐。
- AI 的硬件需求: 由 `@mrdragonfox` 和 `@tu4m01l` 发起的讨论强调了在 CPU 上运行像 Mistral Large 这样的大型 AI 模型是不切实际的,并建议使用 API 以提高效率。
- 企业合作伙伴关系与开放模型: 用户如 `@reguile` 对 Mistral 与 Microsoft 合作后开放模型的未来表示担忧。一些人(如 `@foxlays`)希望 Mistral 继续支持开放模型的开发。
- 关于 GPT-3.5 Turbo 参数的推测: 一篇被涂改的 Microsoft 论文引发了关于 GPT-3.5 Turbo 实际参数规模的辩论,`@i_am_dom` 和 `@lyrcaxis` 讨论了其有效性和效率。
- Mistral 的市场定位与策略: `@blacksummer99` 分享了关于 Mistral 努力与 OpenAI 形成差异化竞争的见解,以及将其定位为 AI 领域欧洲领导者的构想。
提到的链接:
-
[Pricing and rate limits Mistral AI Large Language Models](https://docs.mistral.ai/platform/pricing/): 按需付费 -
[GOODY-2 The world's most responsible AI model](https://www.goody2.ai/): 介绍一款具有下一代伦理对齐的新型 AI 模型。立即聊天。 -
[Endpoints and benchmarks Mistral AI Large Language Models](https://docs.mistral.ai/platform/endpoints/): 我们提供五个不同的 API 端点,以不同的性价比权衡来提供我们的生成模型,并为一个嵌入模型提供一个嵌入端点。 - Au Large: Mistral Large 是我们的旗舰模型,具有顶级的推理能力。它也可以在 Azure 上使用。
- AI Playground: Run your prompts across mutiple models and scenarios: 在不同的 Prompt 和模型参数下比较和评估多个 AI 模型的生成效果。
- Cat Bruh GIF - Cat Bruh Annoyed - Discover & Share GIFs: 点击查看 GIF
- CRYNYL: Fall Out Boy 的新专辑,充满了乐队真实的泪水,以实现最大的情感忠实度。
- Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models: 我们研究如何应用 Large Language Models 从头开始撰写有据可查且条理清晰的长篇文章,其广度和深度可与维基百科页面相媲美。这个尚未被充分探索的问题提出了新的…
- Legal terms and conditions: 使用 Mistral 产品和服务的条款和条件。
- Typing With Feet GIF - Typing With Feet - Discover & Share GIFs: 点击查看 GIF
- WWW.SB: 未找到描述
- Council Post: Is Bigger Better? Why The ChatGPT Vs. GPT-3 Vs. GPT-4 ‘Battle’ Is Just A Family Chat: 好了,现在我们明白 ChatGPT 只是 GPT-3 的一个更小、更具体的版本,但这是否意味着在不久的将来会出现更多这样的模型:针对 Mark 的 MarGPT…
- 无标题: 未找到描述
- 无标题: 未找到描述
- 无标题: 未找到描述
Mistral ▷ #models (209 条消息🔥🔥):
-
服务器构建的 GPU 要点:
@lukun询问了哪些模型可以在没有 GPU 的服务器上运行,@tom_lrd和@_._pandora_._解释说,即使是较小的模型,为了获得合理的性能,GPU 也是必要的。对于较大的模型,@mrdragonfox建议至少配备 24 GB VRAM 的 GPU,例如 3090/4090。他们还提供了一个 GitHub 上的详细测试 gist 以展示不同条件下的性能。 -
扩展规模的成本:用户
@dekaspace、@mrdragonfox等人讨论了运行语言模型服务器的构建规格。@mrdragonfox建议将 24 GB VRAM 作为基准,并指出超过 70B 参数的模型将需要对专用硬件进行大量投资,并提到 Groq 的定制 ASIC 部署是一种昂贵的方法。 -
关于 Mistral 发展方向的疑问:包括
@redbrain和@blacksummer99在内的几位用户对 Mistral 似乎转向业务导向的新方向表示担忧,推出了像 Mistral Small 和 Mistral Large 这样的闭源权重模型,这与其之前开源模型的声誉有所背离。社区推测了即将发布的版本以及未来推出开源权重模型的可能性。 -
Mistral 模型的基准测试:
@bofenghuang在法语版的 MT-Bench 上对 Mistral 的模型进行了测试,发布的结果显示 Mistral Large 位于 GPT-4 之后的一个显著位置。他们在 Hugging Face Datasets 和一个基于浏览器的 Space 上分享了他们的发现,以便进一步检查。 -
对新模型开放获取的希望:
@saintvaseline、@_._pandora_._等人分享的社区情绪反映了对未来开源模型的希望与由于 Microsoft 等大型科技公司参与而产生的怀疑交织在一起。包括@tom_lrd、@m._.m._.m和@charlescearl_45005在内的一些成员预计 Mistral 最终会提供一些质量稍低的开源模型,同时推测商业合作伙伴关系的潜在影响。
提到的链接:
- GroqChat: 未找到描述
- Au Large: Mistral Large 是我们的旗舰模型,具有顶级的推理能力。它也可以在 Azure 上使用。
- Always Has Been Among Us GIF - Always Has Been Among Us Astronaut - Discover & Share GIFs: 点击查看 GIF
- TheBloke/Mistral-7B-Instruct-v0.1-GGUF · Hugging Face: 未找到描述
- bofenghuang/mt-bench-french · Datasets at Hugging Face: 未找到描述
- Mt Bench French Browser - a Hugging Face Space by bofenghuang: 未找到描述
- Northern Monk Beer GIF - Northern Monk Beer Craft Beer - Discover & Share GIFs: 点击查看 GIF
- 100k test . exllama2(testbranch) + fa 1 - 100k in 128t steps: 100k test . exllama2(testbranch) + fa 1 - 100k in 128t steps - gist:71658f280ea0fc0ad4b97d2a616f4ce8
- [Feature Request] Dynamic temperature sampling for better coherence / creativity · Issue #3483 · ggerganov/llama.cpp: 先决条件 [✅] 我查阅了讨论区,并有一个新的 Bug 或有用的增强功能要分享。功能构想:大型语言模型的典型采样方法,如 Top P 和 Top K(以及…
Mistral ▷ #deployment (56 条消息🔥🔥):
- 支持请求未获回复:
@fangh指出他们上周发送了邮件但尚未收到回复,正在寻求@266127174426165249的更新。 - 在本地机器运行 Mixtral 的咨询:
@c_ffeestain询问是否可以在拥有 32GB RAM 和 8GB VRAM 的本地机器上运行 Mixtral 8x7B,目前正在使用 HuggingFace 上的版本。 - GPU 兼容性与配置建议:
@_._pandora_._解释说,理论上 Mixtral 可以在@c_ffeestain的机器上运行,但速度会极慢。他们还提议帮助确定分配给 GPU 的层数(layers)以提高性能。 - 探索模型量化(Quants)与层共享:
@c_ffeestain在下载模型后注意到生成一个 token 大约需要 5-10 秒。他们正在尝试调整分配给 GPU 的层数,但在检测其 AMD GPU 时遇到了问题。 - 在 Tesla V100 上进行推理与微调:
@dazzling_maypole_30144在尝试于 Tesla V100 上部署 Mistral-7B-Instruct 时遇到了显存溢出(out-of-memory)错误。@mrdragonfox和@casper_ai建议 V100 可能没有足够的显存来处理此任务,并推荐了 T4 或 A10 GPU 等替代方案,或者以 AWQ 格式运行模型以获得更好的兼容性。
提到的链接:
- HuggingChat:让每个人都能使用社区最好的 AI 聊天模型。
- TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF · Hugging Face:未找到描述
Mistral ▷ #ref-implem (6 条消息):
- 关于 Mistral 数据归一化的咨询:来自巴塞罗那超算中心的用户
@severinodadalt询问 Mistral 数据是否经过了归一化(normalized) 以及其实现方法。该用户提到缺乏相关信息,并认为可能没有应用任何归一化。 - 无基础模型归一化详情:针对
@severinodadalt关于数据归一化的询问,@mrdragonfox指出 没有任何基础模型(base model) 会提供此类信息。 - 不同精度水平下的性能差异:
@bdambrosio询问在本地以全 fp16 运行 Mistral 8x7B 与目前的 8 bit exl2 相比,推理速度是否会有变化,特别是在有更多 VRAM 可用的情况下。提出此问题是因为注意到了 6.5 bit 和 8 bit 精度水平之间的差异。 - 精度水平影响性能:作为回应,
@mrdragonfox确认差异是显而易见的,并且 像 turboderp 这样的性能测量工具通常评估困惑度(perplexity/ppl),这表明精度水平确实会影响性能。 - 量化与上下文准确度:
@mrdragonfox还指出,在使用 Mistral 等模型执行任务时,量化(quantization)可能会略微降低上下文准确度。
Mistral ▷ #finetuning (185 条消息🔥🔥):
-
微调数据量与预期:
@pteromaple询问了微调所需的数据量,质疑 4000 个实例是否足够。虽然@egalitaristen建议这取决于微调的具体程度,并强调对于特定任务,这可能已经足够,但讨论得出的结论是,试错(trial and error)可能是最好的方法。 -
微调的数据格式困境:
@pteromaple寻求关于使用 Unsloth 微调 ‘Mistral-7B-Instruct-v0.2’ 的正确数据格式建议,并询问了数据格式对训练结果的影响,透露他们目前使用的是 Alpaca 格式。@_._pandora_._建议创建自定义 Prompt 格式,并警告在用非英语语言微调 Mistral 7B Instruct 时可能出现的问题。 -
微调后 Mistral 的神秘输出:
@mr_seeker报告了一个奇怪的问题:微调后的模型在输入非数据集类数据时会输出/******/并失去连贯性。@mrdragonfox等人的建议指向了模型的路由层(routing layer),并指出成功的微调可能需要理解模型架构的复杂性,而不仅仅是应用 LoRA 等技术。 -
Serverless 微调与模型托管讨论:
@stefatorus询问了 Mistral 在云端提供 Serverless 微调功能的可能性,并讨论了 Hugging Face 和 OpenAI 等公司的相关产品。RunPod 也被提为一个潜在的高性价比解决方案,但对于预算有限的用户来说,其可行性仍是一个担忧。 -
LoRA 参数难题:
@tom891在为他们的 200k 样本数据集确定 Mistral 7B 微调的合适 LoRA 参数时面临挑战。尽管@mrdragonfox等人强调了理解底层理论的必要性,并敦促进行独立探索而非索要现成答案,该用户仍继续寻求有效参数配置的直接建议。
提到的链接:
Serverless GPUs for AI Inference and Training: 未找到描述
Mistral ▷ #announcements (2 条消息):
-
遇见 Mistral Large:
@sophiamyang宣布推出 Mistral Large,这是一款全新的优化模型,具有顶级的推理能力、多语言能力、原生 Function Calling 以及 32k 的参数规模。它在 MMLU 上拥有 81.2% 的准确率,位列世界第二,可通过 la Plateforme 和 Azure 获取。 -
La Plateforme 首推 le Chat Mistral:
@sophiamyang介绍了 le Chat Mistral,这是一个展示 Mistral 模型能力的前端演示。在 Chat Mistral 发现它的潜力。
提到的链接:
Mistral ▷ #showcase (24 条消息🔥):
- 加入 @jay9265 的现场编程直播:@jay9265 正在 Twitch 进行直播,邀请所有感兴趣的人加入。
- LLM 用于辅助问题表述:@egalitaristen 建议可以利用 LLM 来帮助表述问题或任务,提醒 @jay9265 向 LLM 解释问题也是一种寻求帮助的方式。
- 针对结构化代码降低 Temperature:对于涉及 JSON 等结构化代码的任务,@egalitaristen 建议 @jay9265 将 Generation Temperature 降低到
0.3左右,以减少“创造性”并提高准确性。 - @yasserrmd 开发的 WhatsApp Chrome 插件:@yasserrmd 开发了一个 Chrome 插件,使用 Mistral API 生成 WhatsApp 格式的文本,更多详情可在 LinkedIn 查看。
- AI 推理基准测试分析:@yasserrmd 分享了在 Groq 等平台上使用 Mistral、OpenAI ChatGPT-4 和 Google Gemini 进行 AI 推理性能基准测试的见解,并提供了一篇 LinkedIn 帖子 以获取更多信息。
提到的链接:
Twitch: 未找到描述
Mistral ▷ #random (17 条消息🔥):
- Chatbot 领域的定价困境:
@sublimatorniq提出了关于 Perplexity 的话题,可能涉及 Chatbot 服务的定价或复杂性。@mrdragonfox认为提供最低价格的竞争无法无限期持续,企业的单位经济效益(unit economics)必须合理。 - Groq 的竞争性定价承诺:
@shivakiran_强调了 Groq 承诺的 $0.27/百万(tokens),这可能指处理一定数量 Chatbot 交互的成本。 - 低价可持续性受到质疑:
@mrdragonfox指出,为了竞争而维持低价并非财务上健全的策略,因为这并不等同于盈利,尤其是当新玩家愿意承担更多成本时。 - 对科技行业初始定价策略的批评:
@egalitaristen对那些以低初始定价开始、随后推出高出数倍的“真实”定价的公司表示担忧,警告这可能会驱使大多数用户群寻找替代方案。 - Discord 上宣布开心果日:
@privetin分享了开心果日 (Pistachio Day) 的庆祝活动,并附带了 nutsforlife.com.au 的链接 以及关于开心果益处的趣味事实,包括其蛋白质含量和诱导睡眠的褪黑素。
提到的链接:
- Laughing GIF - Laughing - Discover & Share GIFs:点击查看 GIF
-
[Pistachio Day - Nuts for Life Australian Nuts for Nutrition & Health](https://www.nutsforlife.com.au/pistachio-day/):开心果日快乐!每年的 2 月 26 日是属于这种小坚果的日子,它在口感和营养方面都表现出色!
Mistral ▷ #la-plateforme (66 条消息🔥🔥):
-
寻求隐私和托管方面的澄清:用户
@exa634询问通过 Mistral API 传输的数据是否用于模型训练,以及托管的地理位置。@akshay_1和@ethux确认数据不用于训练,且服务器位于瑞典,正如 Mistral 的 隐私政策 中所述。 -
Mistral7x8b 冻结问题:用户
@m.kas报告了一个 Bug,即 Mistral7x8b 在尝试生成 2024 年的内容时会发生冻结。用户@1015814建议检查是否误设了 end token,但@m.kas澄清并未设置此类 token。 -
对 Mistral 平台 Function Calling 的期待:用户
@nioned和@mrdragonfox讨论了平台上的 Function Calling 话题,暗示第三方提供商可能会提供解决方案,并对 Mistral 适时实现该功能表示乐观。 -
解决 API Key 激活延迟问题:用户
@argumentativealgorithm在添加账单信息后遇到了 API Key 激活延迟。@lerela确认在 Key 生效前通常有一段简短的等待期,这解决了用户的问题。 -
语音转语音 (Speech to Speech) 应用查询:用户
@daveo1711询问关于使用 Mistral Large 开发语音转语音应用的问题,@akshay_1回复称 Mistral 仅支持文本,并建议查看其他模型以实现所需功能。
提到的链接:
- 法律条款和条件:使用 Mistral 产品和服务的条款与条件。
- client-python/examples/function_calling.py at main · mistralai/client-python:Mistral AI 平台的 Python 客户端库。通过在 GitHub 上创建账户为 mistralai/client-python 的开发做出贡献。
- Client does not return a response · Issue #50 · mistralai/client-js:你好,运行最新版本的 SDK 0.1.3,但当我尝试初始化并调用客户端时,它没有任何返回。这是我的代码:const mistral = new MistralClient(env.PUBLIC_MISTRAL…
- GitHub - Gage-Technologies/mistral-go at v1.0.0:Golang 编写的 Mistral API 客户端。通过在 GitHub 上创建账户为 Gage-Technologies/mistral-go 的开发做出贡献。
Mistral ▷ #le-chat (69 条消息🔥🔥):
-
Mistral Chat 的人气问题:用户
@lerela、@mr_electro84等人指出,Le Chat 可能是由于高流量和高人气而遇到困难。@mr_electro84报告了平台故障,包括 API console。 -
关于 Mistral Chat 定价的困惑:
@_._pandora_._和@wath5讨论了 Le Chat 是否免费,一些用户认为他们正在使用付费额度,而包括@margaret_52502在内的其他用户则表示它是免费的。 -
对 Mistral 潜力的热情和建议:用户
@aircactus500为 Mistral 提出了各种增强建议,从具有社交网络元素的移动端 App 到搜索引擎,甚至是 3D 虚拟助手。他们提到了为le Chat设置语言级别的想法,这引起了社区的兴趣。 -
关于 Mistral-Next 的对话:用户
@__oo__、@_._pandora_._和@tom_lrd讨论了 Le Chat 中名为 Mistral-Next 的功能,强调了它与大型模型相比的简洁性,并希望它能作为 openweights 模型发布。 -
开发 Mistral Chat 应用的概念:用户
@aircactus500正在为 Le Chat 量身定制的 App 构思功能,包括选择 AI 对话风格的能力。他们对拥有一个法国 AI 社区平台表示兴奋,认为这增强了创意的产生,而无需翻译思想。
LM Studio ▷ #💬-general (608 条消息🔥🔥🔥):
-
LM Studio 白屏问题:用户
@steve_evian报告了一个 LM Studio 启动时仅显示白屏的问题。@heyitsyorkie建议在重新安装前清理 .cache 和 %APPDATA%,这为@steve_evian解决了该问题。 -
LM Studio 多语言模型咨询:用户
@.deug询问是否有包含韩语支持的预训练多语言 LLM 推荐。@heyitsyorkie回复称,目前很少有 LLM 能稳定地进行韩英互译,并建议将 DeepL 等在线翻译工具与 LM Studio 结合使用。 -
LM Studio 预设重置问题:用户
@wyrath对 LM Studio 的 UX 发表了评论,指出在开启“新对话(New Chat)”时,选定的预设会恢复为默认设置,导致每次都需要手动重新选择。讨论中提供了一些变通方法,并提到这可能是一个 Bug。 -
LM Studio API 与本地托管:用户
@muradb询问是否可以在没有图形环境的服务器上运行 LM Studio API。@heyitsyorkie澄清说 LM Studio 不支持 Headless 运行,且未对该功能的未来计划发表评论。 -
对开源和 Headless 版 LM Studio 的请求:用户
@krypt_lynx对 LM Studio 的闭源性质表示遗憾,并表示社区贡献可以增加诸如 Headless 运行等缺失的功能。@heyitsyorkie确认 LM Studio 确实是闭源的。
提到的链接:
- GroqChat:未找到描述
- Phind:未找到描述
- Seth Meyers GIF - Seth Meyers Myers - Discover & Share GIFs:点击查看 GIF
- Big Code Models Leaderboard - a Hugging Face Space by bigcode:未找到描述
- Fine-tune a pretrained model:未找到描述
- TheBloke/SOLAR-10.7B-Instruct-v1.0-uncensored-GGUF · Hugging Face:未找到描述
- Continual Learning for Large Language Models: A Survey:由于其庞大的规模带来的高昂训练成本,大型语言模型 (LLMs) 不适合频繁重新训练。然而,为了赋予 LLM 新技能并保持更新,更新是必要的…
- dreamgen/opus-v1.2-7b · Hugging Face:未找到描述
- Anima/air_llm at main · lyogavin/Anima:33B 中文 LLM,DPO QLORA,100K 上下文,单 4GB GPU 运行 AirLLM 70B 推理 - lyogavin/Anima
- The unofficial LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里,你可以找到 LMStudio Discord 中最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源…
- no title found:未找到描述
- MusicLM:未找到描述
- Reddit - Dive into anything:未找到描述
- GitHub - deepseek-ai/DeepSeek-Coder: DeepSeek Coder: Let the Code Write Itself:DeepSeek Coder:让代码自动生成。通过在 GitHub 上创建账号来为 deepseek-ai/DeepSeek-Coder 的开发做出贡献。
- Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning:最近的研究成功利用了大型语言模型 (LLM) 捕获世界物理抽象知识的能力来解决决策问题。然而,LLM 之间的对齐…
LM Studio ▷ #🤖-models-discussion-chat (98 条消息🔥🔥):
- 超参数评估困境 (Hyperparameter Evaluation Dilemma):
@0xtotem询问 RAG 的超参数应该在自己的数据集上评估,还是使用类似的数据集就足够了。这仍未解决,取决于个人选择以及最接近的可用数据。 - Dolphin 模型困境:
@yahir9023在 LM Studio 中创建 Dolphin 模型提示词模板时遇到困难,由于 Discord 缺乏文本发送功能,他分享了一个外部文件进行进一步说明。 - 模型显存挑战:
@mistershark_讨论了同时在 VRAM 中保留多个 LLM 的难度,并确认了 ooba 的可用性和功能。@goldensun3ds请求澄清,@mistershark_解释了对高性能硬件的需求,并分享了 ooba 的 GitHub 链接。 - 翻译模型咨询:
@goldensun3ds询问了日语到英语翻译的最佳模型,考虑了像 Goliath 120B 这样的模型,并建议了一个潜在的 Mixtral 模型。未给出明确答案,但用户的强大硬件配置引起了关注。 - 混合专家模型 (Mixed-Expert Models):
@freethepublicdebt询问未来是否会出现具有不同专家精度混合(FP16、8bit 和 4bit)的模型,这可能会促进泛化能力和 GPU 效率。关于此类模型的存在或开发,目前尚未收到回复。
提到的链接:
- Knight Rider Turbo GIF - Knight Rider Turbo Boost - Discover & Share GIFs:点击查看 GIF
- Pedro Sánchez anuncia la creación de un "gran modelo de lenguaje de inteligencia artificial" entrenado en español:世界移动通信大会(MWC)已经开始,会议陆续召开。小米和荣耀拉开了活动序幕,Pedro Sánchez…
- GitHub - rhasspy/piper: A fast, local neural text to speech system:一个快速、本地的神经文本转语音系统。通过在 GitHub 上创建账号为 rhasspy/piper 的开发做出贡献。
- GitHub - oobabooga/text-generation-webui-extensions:通过在 GitHub 上创建账号为 oobabooga/text-generation-webui-extensions 的开发做出贡献。
LM Studio ▷ #🧠-feedback (8 条消息🔥):
-
为新鲜更新点赞:用户
@macfly对最新更新表示热烈欢迎,称赞其外观和感觉 (look and feel)。 -
确认需要修复:
@yagilb确认了一个未指明的问题,并保证它将被修复,对带来的不便表示歉意。 -
资深用户对 LM 的高度评价:曾使用过 GPT4All 的
@iandol称赞 LM 具有出色的 GUI 和用户友好的本地服务器设置。 -
在中国的下载困境:
@iandol报告说由于身在中国,下载模型存在困难,并询问是否支持代理以方便下载。 -
寻求 Dolphin 2.7 下载支持:
@mcg9523在 LM Studio 中下载 Dolphin 2.7 时遇到挑战,@heyitsyorkie建议切换到 “compatibility guess” 并折叠 readme 以获得更好的可见性。
LM Studio ▷ #-hardware-discussion (178 条消息🔥🔥):
-
AMD 对 CUDA 支持的探索:用户
@nink1回忆了 AMD 的成长,并推测 AMD 的聪明才智可能正在致力于开发自己的 CUDA 支持,理由是企业趋向于高性价比方案。ZLUDA 的开源暗示了 AMD 内部可能存在的进展。 -
为 LLM 选择最佳 GPU:在关于 AMD 与 Nvidia GPU 的讨论中,用户
@baraduk、@wolfspyre和@heyitsyorkie辩论了 Radeon RX 7800 XT 运行 LLM 模型的适用性。普遍倾向于选择 Nvidia,因为其 AI 应用设置更简单,而 AMD 上的 ROCm 需要额外努力。 -
是否使用 NVLink:参与者
@slothi_jan、@dave2266_72415和@nink1探讨了多 GPU 配置中 NVLink 的优缺点。虽然理论上 NVLink 相比标准 PCIe 插槽能提升性能,但成本和兼容性等实际因素是重要考量。 -
运行 LLM 时 Mac 与组装 PC 的对比:用户
@slothi_jan发起了关于购买 Mac Studio 还是配备多块 RTX 3090 GPU 的组装 PC 来运行 AI 模型的讨论。观点各异,但速度、成本、易用性和前瞻性是关键考量因素。用户@heyitsyorkie、@rugg0064和@nink1提供了宝贵意见,并指出 Apple 的 M3 Max 表现出人意料地好。 -
解决使用 LM Studio 时的电脑关机问题:
@666siegfried666寻求帮助,其电脑(配置为 5800X3D CPU 和 7900 XTX GPU)在运行 LM Studio 时会自动关机。@heyitsyorkie建议通过其他计算密集型任务进行测试,以确定问题出在 LM Studio 还是电脑硬件本身。
提到的链接:
- 未找到标题:未找到描述
- 未找到标题:未找到描述
- High Five GIF - High Five Minion - Discover & Share GIFs:点击查看 GIF
- README.md · TheBloke/Llama-2-70B-GGUF at main:未找到描述
- Releases · ggerganov/llama.cpp:C/C++ 中的 LLM 推理。通过在 GitHub 上创建账户为 ggerganov/llama.cpp 的开发做出贡献。
- OpenCL - 异构系统并行编程的开放标准:未找到描述
- 知识每 12 个月翻一番,很快将变成每 12 小时翻一番 - Industry Tap:知识每 12 个月翻一番,很快将变成每 12 小时翻一番 - Industry Tap
LM Studio ▷ #🧪-beta-releases-chat (27 条消息🔥):
-
庆祝 “IQ” 模型正常运行:
@drawless111兴奋地确认 IQ1、IQ2 和 IQ3 模型已在 LM Studio 中正常运行,并赞扬了 Yags 及其团队。他们强调了 IQ1 令人印象深刻的规格:14.5 GB VRAM,70B 模型运行速度达 11.95 t/s。 -
寻找 “IQ” 格式的方法揭秘:
@drawless111提供了在 HGF 上寻找 “IQ” 格式(如 “gguf imat” 或 “gguf imatrix”)的分步指南,并指出应避免使用带有随机文本修复的压缩版本以获得更高质量。 -
LLM 本地文件系统访问咨询:
@wolfspyre询问运行模型时是否可以访问本地文件系统,例如/tmp目录是否可访问。随后@fabguy澄清说 LLM 不具备此类功能,且 LM Studio 不支持执行来自 LLM 的命令。 -
尚无模型 Tokenization 速度统计 API:
@wolfspyre询问是否有 API 可以获取模型 Tokenization 速度统计数据,@yagilb简短地回复道:“暂时还没有”。 -
Llama 1.6 更新发布:用户
@n8programs和@heyitsyorkie讨论并庆祝了 LM Studio 中 llama.cpp 更新至 1.6 版本,称其为“史诗级(EPIC)”更新。
LM Studio ▷ #autogen (9 条消息🔥):
- AutoGen 异常已解决:用户
@thebest6337最初报告了一个关于 AutoGen 的神秘错误,但通过 “卸载并重新安装每一个 AutoGen Python 包” 解决了该问题。 - 好心人的提醒:
@heyitsyorkie鼓励@thebest6337分享他们解决 AutoGen 问题的方案以帮助他人,从而促成了该修复方法的发现。 - 犹豫不决时,重启试试!:针对
@thebest6337的修复方案,@heyitsyorkie幽默地发布了一个 Tenor GIF 链接,暗示经典的“关掉再开一次”是万能的解决方案:Tenor GIF。 - 本地模型响应缓慢:用户
@gb24.询问了本地模型响应时间过长(约五分钟)的问题,暗示由于任务并非代码密集型,这种延迟是不寻常的。
提到的链接:
LM Studio ▷ #langchain (1 条消息):
bigsuh.eth: 你好,我可以使用 LM Studio 并在 LangChain 中使用 RAG 吗?
LM Studio ▷ #open-interpreter (7 条消息):
- nxonxi 的连接问题:用户
@nxonxi在安装 LM Studio 后尝试使用--local命令运行open-interpreter时遇到了httpcore.Connect Error: [Errno 111] Connection refused。 - 遭遇语法错误:同一用户收到了一个错误提示
{'error': "'prompt' field is required"},结果发现是由于其请求负载(payload)中的语法错误导致的。 - 简单的 Python 请求化解难题:
@nxonxi确认虽然 LM Studio 无法通过 OpenAI (OI) 运行,但可以通过简单的 Python 请求正常工作。 - 端点 URL 故障排除:
@1sbefore建议检查端点 URL,提到对于 TGWUI 它是http://0.0.0.0:5000/v1,并建议@nxonxi尝试从请求中使用的 URL 中移除/completions或/v1/completions作为可能的解决方案。
Perplexity AI ▷ #announcements (1 条消息):
- Perplexity 与 ElevenLabs 合作:
@ok.alex宣布推出 Discover Daily 播客,这是与语音 AI 技术先驱 ElevenLabs 的合作项目。您可以在各大平台上找到该播客,每日深入探讨科技、科学和文化,节目内容源自 Perplexity 的 Discover 信息流。 - Discover Daily 播客提升你的每一天:建议在日常通勤或好奇心萌发的闲暇时刻收听最新一期的 Discover Daily。节目可在 podcast.perplexity.ai 收听,并由 ElevenLabs 的语音技术提供支持。
提到的链接:
- Discord - A New Way to Chat with Friends & Communities:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、闲逛,并与您的朋友和社区保持紧密联系。
- Discover Daily by Perplexity:我们希望将世界上的故事带到您的耳边,每日融合科技、科学和文化。内容精选自我们的 Discover 信息流,每一集都旨在为您的一天增添见解和…
Perplexity AI ▷ #general (348 条消息🔥🔥):
-
Perplexity AI 发布新模型 ‘Sonar’: Perplexity AI Discord 社区讨论了最近推出的 Sonar 模型(
sonar-small-chat和sonar-medium-chat)及其搜索增强版本。这些模型声称在成本效益、速度和性能方面有所提升。用户根据测试交互推测,Sonar Medium 的知识截止日期(knowledge cutoff)可能在 2023 年 12 月左右 (来源)。 -
再见 Gemini:社区简短地哀悼了 Gemini 从 Perplexity 可用模型列表中的移除,一些用户强烈要求其回归或引入 Gemini Ultra。
-
Perplexity AI 与图像生成:官方澄清 Perplexity Pro 确实具有生成图像的能力,尽管目前一些操作问题正在调查中。建议用户参考在线资源和 Reddit 获取帮助 (Reddit 帖子)。
-
AI 模型针对移动端的特定响应:有一场关于 AI 聊天模型在移动设备上与 PC 上的响应是否不同的讨论,一些用户注意到通过 App 访问时,像 Gemini 这样的模型给出的回答更简洁 (system prompt)。
-
传闻中的优惠与差异:在各种对话中,提到了一些不相关的话题,例如据称与某种卡服务绑定的 Perplexity Pro 6 个月免费试用(已被版主确认为真实),以及关于 Mistral 在与 Google 历史性合作后是否正与 Microsoft 建立合作伙伴关系的询问。
提到的链接:
- Phind: 未找到描述
- Au Large: Mistral Large 是我们的旗舰模型,具备顶级的推理能力。它也可以在 Azure 上使用。
- API Updates February 2024: 宣布我们的最新模型:我们很高兴宣布推出最新的 Perplexity 模型:sonar-small-chat 和 sonar-medium-chat,以及它们的搜索增强版本 sonar-small-online …
- Microsoft partners with Mistral in second AI deal beyond OpenAI: Microsoft 进行了另一项 AI 投资。
- 无标题: 未找到描述
- PerplexityBot: 我们致力于每天改进我们的服务。为了提供最佳的搜索体验,我们需要收集数据。我们使用网络爬虫从互联网收集信息,并为我们的搜索引擎建立索引…
- Perplexity Blog: 探索 Perplexity 的博客,获取文章、公告、产品更新和优化体验的技巧。保持关注并充分利用 Perplexity。
- 无标题: Perplexity 是领先的实时 AI 问答引擎。Perplexity Pro 通过无限文件上传、Copilot 引导式 AI 搜索和专属支持来增强研究能力。
- 无标题: 未找到描述
-
[Adiós Google Hola Perplexity](https://youtu.be/NjQ8LeYfxRY?si=m32SzgylMsQPIBuQ): 你不会相信这个搜索引擎凭借人工智能能做什么。如果不是 Jeff Bezos、Nvidia 和 D… 我们还不知道 Perplexity 会变成什么样。 - Discover Daily by Perplexity on Apple Podcasts: 新闻 · 2024
- Images & media: 探索 Perplexity 的博客,获取文章、公告、产品更新和优化体验的技巧。保持关注并充分利用 Perplexity。
- Billing and Subscription: 探索 Perplexity 的博客,获取文章、公告、产品更新和优化体验的技巧。保持关注并充分利用 Perplexity。
- Reddit - Dive into anything: 未找到描述
- 无标题: 未找到描述
Perplexity AI ▷ #sharing (23 messages🔥):
- 在 Perplexity AI 上探索话题: “sharing” 频道的用户正在分享各种 Perplexity AI 话题链接,范围从 Xiaomi 14 series 的评测 (
@icelavaman),到关于 PerplexityAI 和 ElevenLabs 的讨论 (@icelavaman),以及对 AI 模型中“为什么放入 Mistral”的分析 (@mydpi)。 - 对全球事件的好奇:一些用户正在关注及时的事件和项目,例如美国多年来的首次登月任务 (
@sanjaymenon)、Lenovo 的透明笔记本电脑概念 (@vipul7031) 以及台湾的 Starshield (@cy_alex)。 - 模型对比与技术查询:技术爱好者正在深入研究 iPhone 型号对比 (
@ming9993) 以及关于 eigenlayer 节点使用等技术策略的问题 (@novice9708)。 - 使用 Perplexity AI 作为个人助手与学习工具:个人用户利用 Perplexity AI 进行个人探索和学习,搜索内容包括美国运动员 (
@commuting5048) 以及创建个人收藏,如 “Make your own” (@_yoojungin)。 - 多元兴趣焦点:频道中的兴趣非常广泛,用户如
@chob_hee寻求数学计算,@mistercare寻找推荐工具(德语),而@veryoriginalname123则发表了个人陈述(“I am a…“)。
Perplexity AI ▷ #pplx-api (339 messages🔥🔥):
- Sonar 模型首次亮相:Perplexity AI 推出了新模型:
sonar-small-chat和sonar-medium-chat,以及具有增强搜索能力的联网版本。包括@thedigitalcat和@digital_despot在内的用户表示更倾向于pplx-70b-online模型,因为它似乎能提供更连贯的回答。 - 对比 Sonar 和 pplx-70b:
@jaicraft认为 sonar-medium 的表现应该优于 pplx-70b,但包括@sergevar和@thedigitalcat在内的其他用户报告称,从 sonar 模型收到了不连贯或“乱码”的回复。 - 相比 Sonar Medium 更倾向于 pplx-70b:像
@thedigitalcat这样的用户请求不要逐步淘汰pplx-70b-online模型,因为其性能更优。来自 Perplexity AI 的@ok.alex承认了sonar-medium-online存在的问题,并提到正在开发修复方案。 - 讨论 API 使用改进:
@ericosk寻求一种以编程方式获取模型详情的方法,并表达了在 UI 中填充模型选项的使用场景。此外,@thedigitalcat和@brknclock1215等用户讨论了在 API 调用中使用或省略 system prompts 的影响。 - Sonar 模型的乱码输出:
@brknclock1215注意到限制输出长度可以缓解 sonar 模型的乱码回复,但@thedigitalcat分享到 pplx 模型不受长输出的影响。@thedigitalcat提供了一张截图,展示了来自sonar-medium-online的非人类可读响应。
提及的链接:
- no title found): 无描述
- API Updates February 2024: 宣布我们的最新模型。我们很高兴宣布推出最新的 Perplexity 模型:sonar-small-chat 和 sonar-medium-chat,以及它们的搜索增强版本 sonar-small-online …
- Mixtral of experts: 高质量的稀疏专家混合模型 (Sparse Mixture-of-Experts)。
- More than an OpenAI Wrapper: Perplexity Pivots to Open Source: Perplexity CEO Aravind Srinivas 是 Larry Page 的大粉丝。然而,他认为他找到了一种不仅能与 Google 搜索竞争,还能与 OpenAI 的 GPT 竞争的方法。
- Chat Completions: 为给定的聊天对话生成模型响应。
- pplx-api: 无描述
- How to access the usage of a stream when using OpenAI sdk?: 你好,我目前在 JS 中获取流式传输的使用情况时遇到了困难。在 Python 中没问题,因为我们可以直接遍历响应,但在 JS 中找不到方法。我还在…
- pplx-api form: 使用 Typeform 将数据收集转化为一种体验。创建精名的在线表单、调查、测验等等。免费试用。
- hask/main/background.js at 34dad93639419617595915122b0099b7023a3dae · bm777/hask: 由 Online LM 驱动的 Hask anything。通过在 GitHub 上创建账户为 bm777/hask 的开发做出贡献。
OpenAI ▷ #ai-discussions (183 messages🔥🔥):
-
VPN 可能会干扰 OpenAI 服务:用户
@strang999遇到了 “Something went wrong” 错误。@satanhashtag建议 VPN 服务可能会产生干扰,即使在未主动使用时也是如此,并建议在 VPN 设置中禁用 Web 保护。 -
寻求图生视频 (Image-to-Video) 生成工具:
@sparkette询问是否有不使用积分系统的网页版图生视频生成器。@lugui推荐了 snappyvideo.ai,尽管它并不符合不限量使用的标准。 -
对 Sora 能力的期待:用户
@rreitsma和@madame_architect讨论了 OpenAI 的 Sora 在制作科普电视节目或个性化语言课程方面的潜力,强调了其先进的模拟功能。 -
对 Copilot 的评价褒贬不一:
@pruo和@madame_architect分享了对 Microsoft 旗下的应用内聊天机器人 Copilot 的使用体验。@pruo认为它很有价值,而@madame_architect则觉得其质量与之前的 AI 版本相比有所下降。 -
Gemini 用户面临社交压力:
@pruo对因使用 Google 的 Gemini AI 系统而受到羞辱表示沮丧,希望能在不受评判的情况下使用它。@tariqali回应称,问题在于 AI 本身而非用户,并强调了不依赖单一 AI 系统的优点。
提到的链接:
- GroqChat:未找到描述
-
[Mistral AI 发布新模型以对抗 GPT-4 及其聊天助手 TechCrunch](https://techcrunch.com/2024/02/26/mistral-ai-releases-new-model-to-rival-gpt-4-and-its-own-chat-assistant/):Mistral AI 正在推出名为 Mistral Large 的新旗舰大语言模型。它旨在与其他顶级模型(如 GPT-4)竞争。 - 视频生成模型作为世界模拟器:我们探索了在视频数据上进行大规模生成模型训练。具体来说,我们在不同时长、分辨率和纵横比的视频和图像上联合训练文本条件扩散模型……
- 将任何物体放入任何视频中 (Place Anything into Any Video):未找到描述
- HuggingChat:让社区最好的 AI 聊天模型惠及每一个人。
- Gorilla:未找到描述
- Gorilla LLM 简介:未找到描述
- GitHub - ShishirPatil/gorilla: Gorilla: LLM 的 API 商店:Gorilla:LLM 的 API 商店。通过在 GitHub 上创建账户为 ShishirPatil/gorilla 的开发做出贡献。
- Agent 如何做出决策?:未找到描述
OpenAI ▷ #gpt-4-discussions (103 messages🔥🔥):
-
ChatGPT 的上下文限制引发不满:
@orbart对 ChatGPT 在叙事工作中记忆长文本能力的下降表示失望,怀疑其能力遭到了“削弱 (nerf)”。@blckreaper证实了这一感觉,并指出从文件中处理的 token 数量似乎从 15K 减少到了约 8K。 -
验证码难题让用户陷入循环:
@little.toadstool和@necrosystv报告在 ChatGPT 中经历了重复且令人沮丧的 20 阶段验证码测试,这破坏了用户体验,并引发了对该服务当前问题的质疑。 -
寻求数学和 PDF 解决方案:
@candonlyc和@yami1010等用户讨论了缺乏 MathPix ChatGPT 插件的问题,以及数学内容 OCR 能力相关的挑战,并建议使用外部资源或 API 进行增强。 -
保护自定义 Prompt 是个难题:用户
@.dunamis.和@kyleschullerdev_51255就如何保护 Prompt 交换了意见,共识是完全的保护是不可行的,分层 Web 应用程序的方法可能会提供更好的安全性。 -
对 GPT-4 的微调 (Fine-Tuning) 和可发现性的好奇:
@kxlja询问 Discover 页面上的 AI 模型是人工选择还是通过其他标准筛选的,@liangdev则询问了如何获取 GPT-4 模型进行微调,探讨了该选项的可用性。
OpenAI ▷ #prompt-engineering (209 messages🔥🔥):
- Assistant 与 Custom GPT 的细微差别:
@brunoalec指出在 API 中将 OpenAI 商店的 Custom GPTs 作为 GPT Assistants 使用时存在不一致性。@rendo1澄清说,Assistants 可以生成“代码块”格式的表格,且 Assistants UI 不支持 Markdown 格式化,这与 ChatGPT UI 不同,后者会将 Markdown 转换为视觉元素。 - 改进搜索功能:
@kevinnoodles遇到了 ChatGPT 搜索返回无效结果或拒绝访问的问题。对话中未提出解决方案。 - 文本分类任务咨询:
@crifat询问对于文本分类问题应该使用 Fine-tuning 还是 Assistant。@eskcanta建议先尝试使用基础模型(base model)以检查错误率。 - 代码任务的 Prompt 优化:
@tawsif2781询问在项目中将 JavaScript 转换为 TypeScript 的最佳 Prompt 方式。聊天中未提供具体的指南。 - ChatGPT 响应问题:
@ianhoughton44报告了 ChatGPT 响应无用或不合规的问题已持续一周多,但在讨论中未收到任何故障排除建议。
提到的链接:
- Usage policies:未找到描述
- Terms of use:未找到描述
- Enterprise privacy:未找到描述
OpenAI ▷ #api-discussions (209 messages🔥🔥):
- 寻求 GPT UI 优化:用户
@joemama8222寻求改进 HTML 代码 UI 设计的建议,但未提及具体细节或分享解决方案。 - Prompt 截断问题泛滥:
@jimmysapp表示在 ChatGPT 中持续遇到 Prompt 截断和自定义指令(custom instructions)响应缺失的问题,该问题在浏览器和手机 App 上均存在。用户@madame_architect建议清除 Cookie 并重启,而@eskcanta等人则推测可能是由于内容政策导致 AI 产生困惑。 - AI 函数咨询得到开发者专业解答:用户
@agi_dude询问了关于针对编程文档查询的特定设置下的 Function calling 问题;@eskcanta和@madame_architect提供了指导,后者引导其参考 API 文档并建议使用 Assistant API。 - 关于图像 Prompt 复现能力的辩论:
@bombasticfard询问如何通过 AI Prompt 复现特定图像,@bambooshoots建议使用 Wright’s Pixel Painter Pro CustomGPT 的策略,@cqoker分享了使用“anime 2d model/format”术语成功生成所需图像风格的经验。 - 关于 Custom 和 Assistant 模型 AI 能力的困惑:用户
@brunoalec注意到 Custom GPTs 和 Assistant GPTs 在表格格式化、DALL-E 使用和 Markdown 功能方面的差异,@rendo1解释说,如果没有特定的 API 配置,Assistants 无法原生格式化 Markdown 或直接生成图像。 - 信用报告数据处理问题:
@razorbackx9x询问是否有 AI 可以将信用报告数据整理到 Excel 中。@eskcanta强烈警告不要上传敏感的 PII 数据,@s_p_e_c也要求官方明确隐私政策,@madame_architect则主张在使用前先对数据进行脱敏处理。
提到的链接:
- Terms of use:未找到描述
- Enterprise privacy:未找到描述
- Usage policies:未找到描述
LAION ▷ #general (624 messages🔥🔥🔥):
-
基于 Transformer 的视频模型讨论:
@yoavhacohen提到一个名为 Snap Video 的新项目,该项目通过采用考虑空间和时间冗余像素的框架以及新的基于 Transformer 的架构,解决了视频生成中的挑战。他分享了项目链接和相关的研究论文。 -
对生成式视频模型的担忧:用户
@qwerty_qwer对生成式视频模型的意义表示怀疑,除非它们是由大型机构发布的,并认为研究人员缺乏发布具有影响力成果所需的计算资源。 -
寻找可贡献的开源项目:
@k_ek_w介绍自己是一名拥有一年经验的数据科学家,正在寻找可以贡献的开源 AI 和 ML 项目。 -
Image Captioner 演示:
@yoavhacohen提供了示例,将他们团队的 Image Captioner 生成的描述与 LLaVA 和 Google Captioner 在不同图像上的描述进行了对比,突出了描述细节程度的差异。 -
LoRA Land 发布:用户
@helium__宣布发布 LoRA Land,这是一个针对各种任务进行微调的 Mistral-7b 模型集合。他们指出这些模型具有卓越的性能和成本效益,并分享了一个 网络研讨会链接 以获取更多信息。
提到的链接:
- Stella Biderman (@BlancheMinerva) 的推文:@maxhbain @Shutterstock 你好,我无法给你发消息(设置为仅限高级用户),但我很想谈谈这件事,特别是如果可能的话,继续为研究人员提供数据….
- Au Large:Mistral Large 是我们的旗舰模型,具有顶级的推理能力。它也可以在 Azure 上使用。
- SPIN Diffusion Demo V1 - UCLA-AGI 的 Hugging Face Space:未找到描述
- 基于 Encoder 的领域微调,用于 Text-to-Image 模型的快速个性化:未找到描述
- SDXL Lightning - 由 fal.ai 提供:fal.ai 提供的极速 SDXL API 演示
- Wuerstchen: 一种用于大规模 Text-to-Image Diffusion 模型的高效架构:我们介绍了 Würstchen,这是一种新型的文本到图像合成架构,它将具有竞争力的性能与大规模 Text-to-Image Diffusion 模型前所未有的成本效益相结合。一个 k…
- Shaheer Rehman GIF - Shaheer Rehman - 发现并分享 GIF:点击查看 GIF
- Starship Troopers GIF - Starship Troopers - 发现并分享 GIF:点击查看 GIF
-
[LAION 5B 安全审查 LAION](https://laion.ai/notes/laion-maintanence/):媒体报道了斯坦福大学的一项研究项目结果,据此,LAION 5B 训练集包含… - LoRA Land: 性能超越 GPT-4 的微调开源 LLM - Predibase:LoRA Land 是一个包含 25 个以上微调 Mistral-7b 模型的集合,在特定任务应用中表现优于 GPT-4。这个微调 OSS 模型集合为寻求高效…的团队提供了蓝图。
- Allen T (@Mr_AllenT) 的推文:中国很快将在 CCTV 频道播出首部 AI 动画。我想知道 AI 系列剧集在世界范围内普及还需要多久?
-
[Shutterstock 扩大与 OpenAI 的合作伙伴关系,签署新的六年协议以提供高质量训练数据 Shutterstock, Inc.](https://investor.shutterstock.com/news-releases/news-release-details/shutterstock-expands-partnership-openai-signs-new-six-year):投资者关系网站包含有关 Shutterstock, Inc. 业务的信息,面向股东、潜在投资者和财务分析师。 - TTS Arena - TTS-AGI 的 Hugging Face Space:未找到描述
- LMSys Chatbot Arena 排行榜 - lmsys 的 Hugging Face Space:未找到描述
- Vision Arena (并排测试 VLM) - WildVision 的 Hugging Face Space:未找到描述
-
[Garfield Diffusion V1 - v1.0 Stable Diffusion Checkpoint Civitai](https://civitai.com/models/29444/garfield-diffusion-v1>):我的第一个大模型。在由 lasagna.cz 标记的 16240 条连环画上进行训练。这意味着有角色标签和许多其他标签(在网站上查看全部)…. - GitHub - Breakthrough/PySceneDetect: :movie_camera: 基于 Python 和 OpenCV 的场景切换/过渡检测程序和库。::movie_camera: 基于 Python 和 OpenCV 的场景切换/过渡检测程序和库。 - Breakthrough/PySceneDetect
- shinonomelab/cleanvid-15m_map · Hugging Face 数据集:未找到描述
- WebVid 大型短视频数据集 / 数据集 / 超神经:未找到描述
- 由 pacman100 添加新的合并方法 · Pull Request #1364 · huggingface/peft:这个 PR 做了什么?基于论文《TIES-MERGING: Resolving Interference When Merging Models》和《Language Models are Super Mario: Absorbing Abilities f…》为 LoRA 添加了新的模型合并方法。
- Snap Video:未找到描述
{kind=link}
{kind=link}
LAION ▷ #research (67 条消息🔥🔥):
-
CLIP 过滤器与高质量分类器之争:
@top_walk_town指出了 DFN 论文的重要性,该论文表明与使用高质量图文对分类器相比,CLIP 过滤并非最优选。 -
BFloat16 梯度讨论:
@yoavhacohen确认了在 TPU 上使用 bfloat16 的 autocasting,而@top_walk_town和@chad_in_the_house讨论了 Pytorch 的 autocast 行为,即反向传播(backward pass)默认使用 fp32。 -
模型参数差异:
@thejonasbrothers注意到关于 Google 发布 gemma 7b 模型 的困惑,实际上在计算参数量时它是一个 9b 模型。 -
梯度精度权衡:
@chad_in_the_house更新称,使用 bf16 梯度 训练速度更快,但与 fp32 梯度相比结果较差。 -
研究论文与方法分享:用户
@said2000、@thejonasbrothers等人分享了多篇研究论文和 AI 相关方法,涉及 state space architecture、Transformer 模型 优化以及 AI 生成文本的 “radioactivity” 检测。此外,@vrus0188分享了一个 YouTube 视频,讨论了 AI 使 LLM 显著降低成本 的潜力。
提到的链接:
- 未找到标题: 未找到描述
- Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping: 虽然 Transformer 在各种应用场景中取得了巨大进展,但在解决复杂的决策任务方面,此类架构仍落后于传统的符号规划器。在本文中…
- Generative Models: What do they know?: 未找到描述
- Mamba-ND: Selective State Space Modeling for Multi-Dimensional Data: 近年来,Transformer 已成为文本及各种多维数据(如图像和视频)序列建模的事实标准架构。然而,自注意力机制的使用…
- Watermarking Makes Language Models Radioactive: 本文研究了 LLM 生成文本的放射性,即是否可以检测出此类输入被用作训练数据。传统方法如成员推理(membership inference)可以…
- collabora/whisperspeech · Hugging Face: 未找到描述
- Fireship: 高强度的 ⚡ 代码教程和技术新闻,助你更快交付应用。每周更新视频,涵盖每个程序员都应了解的主题。#100SecondsOfCode #TheCod 的原产地…
- 未找到标题: 未找到描述
- LoRA Land: Fine-Tuned Open-Source LLMs that Outperform GPT-4 - Predibase: LoRA Land 是一个包含 25 个以上微调过的 Mistral-7b 模型集合,它们在特定任务应用中的表现优于 GPT-4。这一微调 OSS 模型集合为寻求高效…的团队提供了蓝图。
- 未找到标题: 未找到描述
- yet-another-applied-llm-benchmark/tests at main · carlini/yet-another-applied-llm-benchmark: 一个用于评估语言模型在我之前要求它们解决的问题上表现的基准测试。- carlini/yet-another-applied-llm-benchmark
- Mamba Might Just Make LLMs 1000x Cheaper…: 看看 HubSpot 的 ChatGPT 工作包!https://clickhubspot.com/twc Mamba 是否会给 LLM 带来革命并挑战现状?或者它只是…
- The AI 'Genie' is Out + Humanoid Robotics Step Closer: 先是文本转语音、文本转视频和文本转动作,现在是文本转交互?让我们来看看来自 Google DeepMind 的新 Genie 论文,并设置…
- Scalable Diffusion Models with State Space Backbone: 本文对一类基于状态空间(state space)架构构建的扩散模型进行了新的探索。我们致力于为图像数据训练扩散模型,其中传统的 U-Net 骨干网络…
- SDXL-Lightning: Progressive Adversarial Diffusion Distillation: 我们提出了一种扩散蒸馏方法,在基于 SDXL 的单步/少步 1024px 文本生成图像中达到了新的 SOTA。我们的方法结合了渐进式和对抗式蒸馏…
- Reddit - Dive into anything: 未找到描述
LAION ▷ #learning-ml (2 条消息):
- 警惕潜在诈骗:用户
@josephsweeney11声称通过 Telegram @auto_trade_admin 帮助 10 人在 72 小时内赚取 4 万美元,并收取 10% 的佣金。此类消息可能是诈骗,用户应保持警惕。 - 实验 Transformer 的学习能力:
@phryq.好奇是否有人通过实验性训练探索过 Transformer 的学习能力,例如理解并应用虚构物体之间的尺寸关系来生成图像。他们提供了具体的例子,质疑模型是否能推断出 “krog” 的渲染尺寸应该是 “mmmmmchakaboooboolight” 的四倍。
LAION ▷ #paper-discussion (1 条消息):
said2000: https://arxiv.org/abs/2402.05892
HuggingFace ▷ #general (182 messages🔥🔥):
<ul>
<li><strong>AI 硬件尝试与推测</strong>:用户讨论了开发专有 TPU 的潜力以及特定纳米制造工艺的可获得性,强调了这种普及化如何能赋予类似于汽车行业的自由。对话中参考了与 RAM 行业价格行为的对比,对三星等公司的技术承诺表示怀疑。</li>
<li><strong>持续进行的 AI 辩论</strong>:社区成员就 AI 和资本主义的影响发表了看法,一些人争论开源努力是否能与 Intel 或 Nvidia 等巨头抗衡。讨论反映了对技术进步带来的失业和财富不平等的担忧,同时也权衡了开发 AI 产品以保障个人财务状况的实用性。</li>
<li><strong>模型利用方面的咨询与协助</strong>:用户寻求了关于一系列主题的帮助,包括在特定 GPU 和集成环境上使用特定模型、与模型大小和内存限制相关的局限性、数据集管理以及为项目寻找资源。社区贡献了诸如使用 llama.cpp 进行模型并行化,以及在处理大模型时使用 accelerate 进行 CPU offloading 等建议。</li>
<li><strong>探索实际应用与协作</strong>:从为神经网络项目寻求合作伙伴,到寻找与开源模型协作的高效策略,用户交换了想法和建议。他们涵盖了机器学习、目标检测、语言模型以及使用 serverless GPU 服务进行具有成本效益的研发等领域。</li>
<li><strong>技术支持与问题解决</strong>:讨论了 Hugging Face 服务的后端问题,如 inference-api serverless 超时,用户的体验反映出性能存在波动。社区成员还解决了数据序列化、组件样式自定义以及不同模型的 GPU 支持等问题。</li>
</ul>
提到的链接:
- BRIA 2.2 FAST - briaai 提供的 Hugging Face Space:未找到描述
- 十大 Serverless GPU:全面的供应商选择:探索什么是 serverless gpu,它对 ML 模型的益处,以及更便宜、更快速部署 LLM 的顶级 serverless gpu 供应商。
- BRIA 2.2 - briaai 提供的 Hugging Face Space:未找到描述
- 抑制 HuggingFace 日志警告:”Setting
pad_token_idtoeos_token_id:{eos_token_id} for open-end generation.”:在 HuggingFace 中,每次我调用 pipeline() 对象时,都会收到警告:"Setting pad_token_id to eos_token_id:{eos_token_id} for open-end generation."我该如何抑制… - GPU 产品组合:未找到描述
- 🌌 Hugging Face Spaces 分析:未找到描述
- Weyaxi (@Weyaxi) 的推文:🎉 @huggingface 的新博客文章 🌌 Hugging Face Spaces 分析。我抓取了 2 万个 Spaces 的代码文件并将其合并为一个数据集,展示了有意义的统计数据 📶 📝 博客文章:http…
- Threads 上的 Amanda Ingrao (@artofthemoon.designs):6 位关注者
- Phillip Lavrador 提供的 70k 枪支目标检测数据集 (v5, Main):70277 张开源枪支图像及多种格式的标注,用于训练计算机视觉模型。由 Phillip Lavrador 创建的 70k Guns (v5, Main)
- 新型芯片开启光速 AI 计算之门 - 宾夕法尼亚大学工程学院博客:宾大工程师开发了一种新型芯片,利用光波而非电力来执行训练 AI 至关重要的复杂数学运算。该芯片……阅读更多 ›
- 矩阵计算器:未找到描述
HuggingFace ▷ #today-im-learning (8 条消息🔥):
- 模仿学习咨询:用户
@alefram寻求关于开始学习 机器人模仿学习 (imitation learning for robotics) 的建议。针对该查询,目前尚未提供具体的资源或建议。 - 深度强化学习课程参与:
@meriem_baziz表达了参加 Deep RL 课程 的意向并寻求建议。同样,社区尚未提供可见的反馈或指导。 - LinkedIn 上的随机数见解:
@stereoplegic分享了一篇 LinkedIn 文章,该文章提供了关于在 PyTorch 中处理 random seeds 的见解,并推荐其为一篇内容丰富的读物。 - CLI 打包之谜:用户
@vipitis正在学习如何使用pyproject.toml打包 CLI entry points,探索 Python 项目打包的复杂性。 - V-JEPA 论文备受关注:
@subham5089撰写并分享了一篇 博文,解释了 Meta 发布的 V-JEPA 论文,将该模型比作多模态学习 (multimodal learning) 领域的 BERT。随后@cakiki提醒其避免在多个频道重复发布。 - Gemma 模型本地部署:
@ariondas推广了一篇 LinkedIn 帖子,概述了如何在本地 Ubuntu 机器上使用 Ollama 访问 Google 的 Gemma 模型。
HuggingFace ▷ #cool-finds (33 条消息🔥):
-
2024 春季深度无监督学习课程:用户
@omrylcn分享了 Berkeley CS294-158 SP24 关于深度无监督学习(Deep Unsupervised Learning)课程的链接,并提到该课程将涵盖深度生成模型(Deep Generative Models)和自监督学习(Self-Supervised Learning),与之前的课程设置类似。 -
Large Action Models 的兴起:
@fernando_cejas重点介绍了一篇讨论 Large Action Models (LAMs) 的博文——这是一种先进的 AI 系统,能够通过结合语言能力与任务执行,在数字环境中执行类似人类的任务。 -
推出包含可访问模型的 Galaxy AI:用户
@white_d3vil介绍了 Galaxy AI 平台,该平台提供多种 AI 模型的免费 API 访问,包括 GPT-4、GPT-3.5 以及他们自有的 Gemini-Pro。根据网站显示,该平台和模型可供项目测试使用。 -
探索 VLM 分辨率挑战与解决方案:
@osanseviero推荐了来自 HuggingFace 的两篇博文,讨论了视觉语言模型(VLMs)在分辨率方面的挑战,并提出了一种克服该问题的新方法。文中包含一个 Demo 以及在 HuggingFace hub 上可用的相关模型。 -
Scale AI 在数据标注市场的崛起:用户
@valeriiakuka分享了来自 Turing Post 的一篇文章,讲述了 Scale AI 在成立 8 周年之际,如何成长为数据标注市场中估值最高的公司之一。该文章是 AI Infrastructure Unicorns 系列讨论的一部分,可以在这里阅读。
提到的链接:
- Reader:未找到描述
- Warp:未找到描述
- Warp:未找到描述
- 🪆 Matryoshka Embedding Models 简介:未找到描述
- CS294-158-SP24 2024 春季深度无监督学习:关于:本课程将涵盖两个不需要标注数据的深度学习领域:深度生成模型(Deep Generative Models)和自监督学习(Self-Supervised Learning)。生成模型的最新进展使得…
- Scale AI:如何在每个 AI 趋势中扩展公司:从预约应用到数据标注巨头的卓越历程
- 论文页面 - FiT: Flexible Vision Transformer for Diffusion Model:未找到描述
- Galaxy AI - Swagger UI:未找到描述
- 打破视觉语言模型的分辨率诅咒:未找到描述
- @visheratin 在 Hugging Face 上发表的内容:”VLMs 存在分辨率问题,这阻碍了它们发现微小细节……”:未找到描述
- Large Action Models (LAMs):AI 理解和执行人类任务的新阶段 —— 站在变革的正确一边:未找到描述
- 揭秘 Llamaindex 的力量:Jina vs Nomic AI vs FlagEmbedding:Ankush k Singal
- Ankush k Singal – Medium:在 Medium 上阅读 Ankush k Singal 的文章。我的名字是 Ankush Singal,我是一名旅行者、摄影师和数据科学爱好者。每天,Ankush k Singal 和成千上万的其他声音在这里阅读、写作…
- 使用大语言模型进行言语测谎 - Scientific Reports:未找到描述
HuggingFace ▷ #i-made-this (24 messages🔥):
- 将 Speaker Embeddings 引入浏览器:用户 `@davidre95` 宣布了一个为 transformers.js 添加 WavLMForXVector 支持的 Pull Request,使得 Speaker Embeddings 模型能够在浏览器中运行。相关的 PR 可以在 [GitHub 此处](https://github.com/xenova/transformers.js/pull/603)找到,兼容的 ONNX 模型已在 [Hugging Face](https://huggingface.co/D4ve-R/wavlm-base-plus-sv) 上发布。
- 用于 ONNX 推理的 .NET 库:用户 `@sa_ddam213` 介绍了一个用于 ONNX 模型推理的 C# .NET 库,无需 Python 环境,代码可在 [GitHub 此处](https://github.com/saddam213/OnnxStack)获取。
- 开源 AI 项目亮相:用户 `@flameface` 分享了 Unburn Toys 的链接,这是一个包含一系列实用工具的开源 AI 项目,其代码仓库可以在 [GitHub 此处](https://github.com/flameface/unburn-toys)找到。
- 交互式 TTS 模型对比:用户 `@realmrfakename` 展示了一个名为 TTS Arena 的 Hugging Face Space,允许用户通过听取样本并投票来对比 TTS 模型,可在 [Hugging Face 此处](https://huggingface.co/spaces/TTS-AGI/TTS-Arena)访问。`@pendrokar` 提供了反馈以及指向一个开源 TTS 追踪器的链接。
- 哲学问答数据集汇编:用户 `@nabereon` 发布了一个包含 133,799 条哲学问题和答案的数据集,可在 [Hugging Face 此处](https://huggingface.co/datasets/sayhan/strix-philosophy-qa)获取,并欢迎反馈。
- 用于无代码 AI 实验的 Gradio 应用:用户 `@nishantsethi_62323` 在 Hugging Face Space 上分享了他们的第一个 Gradio 应用,旨在无需编写代码即可进行创意实验,可在 [Hugging Face 此处](https://huggingface.co/spaces/nsethi610/ns-gradio-apps)访问。
- 让 LLM 微调更简单:用户 `@ameerazam` 提供了微调参数量小于 7B 的大语言模型(LLMs)的资源,并在 [Hugging Face 此处](https://huggingface.co/ameerazam08/gemma-jokes)分享了包含代码的仓库。
提及的链接:
- TTS Arena - a Hugging Face Space by TTS-AGI: 未找到描述
- ameerazam08/gemma-jokes · Hugging Face: 未找到描述
- D4ve-R/wavlm-base-plus-sv · Hugging Face: 未找到描述
- Ns Gradio Apps - a Hugging Face Space by nsethi610: 未找到描述
- Prompting - ElevenLabs: 未找到描述
- Add support for WavlmForXVector by D4ve-R · Pull Request #603 · xenova/transformers.js: 添加了对带有 xvector head 的 WavLM 的支持。microsoft/wavlm-base-plus-sv 的 ONNX 版本可以在 D4ve-R/wavlm-base-plus-sv 找到。目标是尽可能接近 Python 实现…
- GitHub - saddam213/OnnxStack: C# Stable Diffusion using ONNX Runtime: 使用 ONNX Runtime 的 C# Stable Diffusion。通过在 GitHub 上创建账号来为 saddam213/OnnxStack 的开发做出贡献。
- sayhan/strix-philosophy-qa · Datasets at Hugging Face: 未找到描述
- GitHub - flameface/unburn-toys: Unburn Toys is an open-source AI project with a bunch of useful tools.: Unburn Toys 是一个包含一系列实用工具的开源 AI 项目。- flameface/unburn-toys
HuggingFace ▷ #reading-group (26 条消息🔥):
- Neural Circuit Diagrams 演讲公告:
@chad_in_the_house通知小组,@1191190979580022875将就“Neural Circuit Diagrams: Robust Diagrams for the Communication, Implementation, and Analysis of Deep Learning Architectures”进行演讲。会议将于 7 pm EST 举行。 - 会议以工具和研究讨论开始:
@chad_in_the_house分享了在讨论论文时用于创建图表的工具 Mathcha.io。此外,还重点介绍了@vtabbott_关于mixtral的博客文章,供未来的解析工作参考。 - 演讲视频已上传至 YouTube:
@chad_in_the_house在 YouTube 上发布了演讲视频,标题为 Hugging Face Reading Group 14: Neural Circuit Diagrams,并承诺将在 GitHub 上更新更多内容。 - 即将举行的 PR 演讲预告:
@chad_in_the_house预告下周的演讲将由@563068096747798529主讲,内容关于 peft 库 的一个 PR,重点介绍 LoRA 的新合并方法,并辅以两篇 arXiv 论文(2306.01708 和 2311.03099)中的视觉插图。 - 下一次演讲的排期与贡献归属:
@chad_in_the_house和@prateeky2806通过 when2meet 协调了下一次演讲的时间,@prateeky2806将该 PR 的主要工作归功于@871797575454425159和@504681610373758977。
提到的链接:
- Understanding Mixtral-8x7b:这篇博客文章改编自我发布的一个 X 线程。它引起了极大的关注,所以我决定也在这里发布!@MistralAI 的 Mixtral-8x7b 是一款 LLM,其性能超越了除 OpenAI 之外的所有模型,并且…
- Mathcha:未找到描述
- Paper page - Neural Circuit Diagrams: Robust Diagrams for the Communication, Implementation, and Analysis of Deep Learning Architectures:未找到描述
- Hugging Face Reading Group 14: Neural Circuit Diagrams:由 Vincent Abbott 演讲
- TIES-Merging: Resolving Interference When Merging Models:迁移学习(即在下游任务上进一步微调预训练模型)可以带来显著优势,包括提高下游性能、更快的收敛速度以及更好的安全性…
- Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch:在本文中,我们揭示了语言模型(LM)可以通过吸收同源模型的参数来获得新能力,而无需重新训练或使用 GPU。我们首先引入了 DARE 来设置大多数 delta…
- TIE+SuperMario Pres - When2meet:未找到描述
- Add new merging methods by pacman100 · Pull Request #1364 · huggingface/peft:这个 PR 做了什么?基于论文 TIES-MERGING: Resolving Interference When Merging Models 和 Language Models are Super Mario: Absorbing Abilities f… 为 LoRA 添加新的模型合并方法。
HuggingFace ▷ #diffusion-discussions (15 条消息🔥):
- 关于 AnimeBackgroundGAN 的咨询:
@mfd000m询问如何使用akiyamasho/AnimeBackgroundGAN模型,以及应该克隆 GitHub 仓库还是使用 transformers 或 diffusion 等库。后续消息中未提供具体解决方案。 - 针对新语言微调 Diffusion 模型:
@alielfilali01询问是否可以在不同语言的语料库上微调 diffusion 模型,而不是针对新的图像风格。@chad_in_the_house做出回应,分享了 Japanese Stable Diffusion 模型 的链接,该模型采用了针对日语定制的两阶段训练程序。 - 模型微调中的 Loss 锯齿波动:
@khandelwaal.ankit尝试使用特定数据集微调Qwen/Qwen1.5-0.5B,但尽管尝试了各种超参数,仍遇到 Loss 图表呈锯齿状波动的问题。关于此问题目前没有进一步的澄清或建议。 - Diffusers 库中的 Latent 输出:
@shinyzenith讨论了在 diffusers 库的 stable_diffusion_pipeline 中使用output_type='latent'的情况,假设它会为给定 prompt 生成采样的 latent spaces。他们分享了一个技术问题:由于权重为负,在计算 KL divergence 时出现了 NaN 值,并考虑是否对权重进行归一化,但不确定这是否会扭曲分析结果。
提及的链接:
- 未找到标题:未找到描述
- rinna/japanese-stable-diffusion · Hugging Face:未找到描述
- rinna (rinna Co., Ltd.):未找到描述
HuggingFace ▷ #computer-vision (23 条消息🔥):
- 聚焦情绪识别:
rodricota_提到他们正在构建一个情绪识别模型 (emotion recognition model) 并希望讨论一些问题,而@justinm8449插话表示他们已经构建过此类模型。 - 关于 BLIP2 处理图像序列的咨询:
@seanb2792询问 BLIP2 是否可以处理来自 3D 模型的图像切片,考虑到这些切片相互依赖且共享上下文,并征求是否应为此任务使用其他模型的建议。 - 寻求处理复杂字符的鲁棒 OCR 模型:
@icecoldt369正在寻找擅长处理具有复杂字符的外语的 OCR 模型,并表示对经典 LSTM 模型的结果不满意。他们与@cursorop进行了对话,讨论了微调的必要性以及模型在处理高棉语(Khmer)等冷门语言时的局限性。 - 多语言 OCR 模型讨论:
@cropinky分享了一个 GitHub 链接 指向 surya,这是一个支持 90 多种语言的 OCR 和行检测 (line detection) 项目,近期备受关注。 - 计算机视觉模型基准测试与项目创意交流:
@coffeevampir3寻求视觉模型的基准测试 (benchmarks),@cropinky推荐了 Papers With Code 上的详尽列表。此外,@solution3746征求毕业设计计算机视觉项目的创意,并收到了一个关于从 CCTV 监控画面中进行人数统计的建议。
提及的链接:
- GitHub - VikParuchuri/surya: OCR and line detection in 90+ languages:支持 90 多种语言的 OCR 和行检测。通过在 GitHub 上创建账户为 VikParuchuri/surya 的开发做出贡献。
- Papers with Code - Browse the State-of-the-Art in Machine Learning:12480 个排行榜 • 4728 个任务 • 9286 个数据集 • 119860 篇带有代码的论文。
HuggingFace ▷ #NLP (109 messages🔥🔥):
- 微调中的困惑:
@jimmyfromanalytics在针对特定领域话题微调 Flan T5 以生成正面和负面评论时遇到问题并寻求建议。模型在微调后输出语无伦次的句子,这表明在 Prompt Engineering 方面存在困难。 - BERT vs. LLM 用于文本分类:
@arkalonman询问是否有资源对比微调像 Mistral 7B 或 Gemma 7B 这样的大型 LLM 与标准 BERT 变体在文本分类任务中的表现。@lavi_39761建议 Encoder 模型在分类用途上更合适且更高效。 - 令人费解的微调失败:
@frosty04212报告了在对已经微调过的 RoBERTa 模型进行 NER 微调时遇到的问题,出现了 0 和 NaN 的损失值。该问题在重新安装环境后似乎得到了解决。 - DeciLM 训练困境:
@kingpoki尝试使用 QLoRA 训练 DeciLM 7b,但遇到了与 Embedding 维度未设置为 8 的倍数相关的性能警告。用户们讨论了该警告的可能原因。 - Whisper 项目查询:
@psilovechai正在寻找一个带有 Gradio 界面的本地项目,用于训练和处理使用 Whisper 转录音频文件的任务。他们收到了关于可能提供解决方案的 GitHub 仓库建议。
提到的链接:
- climatebert (ClimateBert): 未找到描述
- Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code: 在这项工作中,我们系统地回顾了使用语言模型进行代码处理的最新进展,涵盖了 50 多个模型、30 多个评估任务、170 多个数据集和 700 多篇相关论文。我们分解了…
- Matrix Multiplication Background User's Guide - NVIDIA Docs: 未找到描述
- DevEval: Evaluating Code Generation in Practical Software Projects: 如何评估 LLM 在代码生成中的表现是一个开放性问题。许多基准测试已被提出,但与实际软件项目不一致,例如,不真实的程序分布…
- NoFunEval: Funny How Code LMs Falter on Requirements Beyond Functional Correctness: 现有的代码语言模型(Code LMs)评估基准几乎完全集中在模型是否能生成功能正确的代码。在现实世界的软件工程中,开发者…
- Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs: 未找到描述
- GitHub - jlonge4/whisperAI-flask-docker: I built this project because there was no user friendly way to upload a file to a dockerized flask web form and have whisper do its thing via CLI in the background. Now there is. Enjoy!: 我构建这个项目是因为没有一种用户友好的方式可以将文件上传到 Docker 化的 Flask Web 表单,并让 Whisper 在后台通过 CLI 执行任务。现在有了。尽情享受吧!
- Reddit - Dive into anything: 未找到描述
- Improve _update_causal_mask performance by alessandropalla · Pull Request #29210 · huggingface/transformers: 这个 PR 做了什么?修复了 # (issue) #29206。在提交之前,此 PR 修复了一个拼写错误或改进了文档(如果是这种情况,您可以忽略其他检查)。您是否阅读了贡献者…
- GitHub - alessandropalla/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.: 🤗 Transformers: 为 Pytorch, TensorFlow, 和 JAX 提供的尖端机器学习库。
- GitHub - innovatorved/whisper-openai-gradio-implementation: Whisper is an automatic speech recognition (ASR) system Gradio Web UI Implementation: Whisper 是一个自动语音识别(ASR)系统,这是其 Gradio Web UI 的实现。
- GitHub - amrrs/openai-whisper-webapp: Code for OpenAI Whisper Web App Demo: OpenAI Whisper Web App 演示代码。通过在 GitHub 上创建一个账户来为 amrrs/openai-whisper-webapp 的开发做出贡献。
HuggingFace ▷ #diffusion-discussions (15 条消息🔥):
- diffusion-discussion 简介:
@mfd000m是 Diffusion 模型讨论的新手,正在寻求关于如何使用akiyamasho/AnimeBackgroundGAN模型的建议,询问是应该克隆仓库还是使用 transformers 或 diffusion 等库。 - LM Studio 困惑:
@tmo97简要提到了 LM Studio,引发了@mfd000m询问它是什么,表明其对该术语或工具并不熟悉。 - 寻求跨语言模型微调指导:
@alielfilali01询问关于在不同语言(而非图像风格)上微调 Diffusion 模型的问题,并提到自己缺乏使用 diffusers 的经验,希望能获得社区在该领域的知识。 - 模型微调挑战:
@khandelwaal.ankit在使用特定数据集微调 Qwen/Qwen1.5-0.5B 模型时遇到困难,表示尽管尝试了各种超参数,loss 曲线仍然不稳定。 - 分享 Japanese Stable Diffusion 的成功案例:针对语言微调的查询,
@chad_in_the_house分享了 Japanese Stable Diffusion 模型卡片,并解释了其两阶段训练过程,可作为类似尝试的潜在蓝图。
提到的链接:
- rinna/japanese-stable-diffusion · Hugging Face:未找到描述
- дрездон 在 Instagram 上:”a warm breath… #drezzdon”:2.7 万次点赞,105 条评论 - drezzdon 于 2024 年 2 月 16 日:”a warm breath… #drezzdon”
- rinna (rinna Co., Ltd.):未找到描述
Eleuther ▷ #general (190 messages🔥🔥):
-
Prompt Template Batching 困境:用户
@rwamit正在寻求关于使用 langchain 封装器实现批处理以查询 GPT-4 的建议,原因是出于成本考虑。他们分享了通过复制提示词模板来一次性处理多条记录的方法,但面临处理时间大幅增加的问题(从 2s/it 增加到 60s/it),导致 5-6k 条记录的处理时间从 5 小时飙升至 96 小时。 -
Gemma Pytorch 代码疑点:由
@miaumo和@ad8e等用户发起的讨论围绕 Gemma 的 PyTorch 实现中的一段特定代码展开,涉及 RMSNorm 中一个奇怪的 +1 累加。大家对初始化以及这一细节的重要性进行了推测。 -
EfficientNet 辩论:
@vapalus认为虽然 EfficientNet 可能不适合所有任务,但它在结构化输入的分割任务中作为 backbone 表现良好。此前@fern.bear对 EfficientNet 进行了批评,对其营销和实际性能表示强烈不满。 -
Mistral Large 模型发布:发布了关于 Mistral Large 发布的公告,该模型被描述为具有强大 Benchmark 结果的前沿文本生成模型。公告强调该模型可通过 la Plateforme 和 Azure 获取(Mistral 新闻)。
-
DPO 论文澄清请求:
@staticpunch询问了 DPO 论文中描述的model_ref初始化过程,认为建议是先对偏好的补全内容进行有监督微调 (SFT),然后再进行 DPO。@elad7318和@alstroemeria313提供了澄清,确认了这一理解。
提到的链接:
- no title found:未找到描述
- SPIN Diffusion Demo V1 - a Hugging Face Space by UCLA-AGI:未找到描述
- Au Large:Mistral Large 是我们的旗舰模型,具有顶级的推理能力。它也可以在 Azure 上使用。
- gemma_pytorch/gemma/model.py at 01062c9ef4cf89ac0c985b25a734164ede017d0b · google/gemma_pytorch:Google Gemma 模型的官方 PyTorch 实现 - google/gemma_pytorch
- Transformers without Tears: Improving the Normalization of Self-Attention:我们评估了三种简单的、以归一化为中心的改进 Transformer 训练的变化。首先,我们展示了 Pre-norm 残差连接 (PreNorm) 和较小的初始化可以实现无 warmup 的训练…
- gemma_pytorch/gemma/model.py at 01062c9ef4cf89ac0c985b25a734164ede017d0b · google/gemma_pytorch:Google Gemma 模型的官方 PyTorch 实现 - google/gemma_pytorch
- whisper/whisper/model.py at ba3f3cd54b0e5b8ce1ab3de13e32122d0d5f98ab · openai/whisper:通过大规模弱监督实现鲁棒的语音识别 - openai/whisper
- GitHub - BlinkDL/SmallInitEmb: LayerNorm(SmallInit(Embedding)) in a Transformer to improve convergence:Transformer 中的 LayerNorm(SmallInit(Embedding)) 以提高收敛性 - BlinkDL/SmallInitEmb
- GitHub - Stability-AI/StableCascade: Official Code for Stable Cascade:Stable Cascade 官方代码。通过在 GitHub 上创建账号为 Stability-AI/StableCascade 做出贡献。
- Support Gemma · turboderp/exllamav2@cc1094a:未找到描述
- Support Gemma · turboderp/exllamav2@cc1094a:未找到描述
Eleuther ▷ #research (84 messages🔥🔥):
-
寻求关于 GRU 等门控单元的知识:
@mrgonao询问了关于解释为什么像 GRU 这样的门控单元 (Gated Units) 会如此命名的优质资源,表现出对“门控”这一术语的词源或概念推理的兴趣。目前没有回复提供任何链接或解释。 -
关于数学领域数字级 Tokenization 的论文查询:
@stellaathena询问了一篇关于数学中数字级 Tokenization 的论文标题,@random_string_of_character提供了由 Siavash Golkar 等人撰写的题为 “Digit-Level Language Models for Digit-level Mathematical Tasks” 的论文链接,可在 arxiv.org/abs/2310.02989 查阅。 -
Searchformer 论文引发热议:
@jckwind分享了论文 “Searchformer: Learning to Search Better Than A” arxiv.org/abs/2402.14083 的链接,该论文讨论了经过训练以模拟 $A^$ 搜索动态的 Transformer 模型如何比传统方法更高效地解决推箱子(Sokoban)谜题。 -
RLHF 中简单方法与 PPO 的对决:
@0x_paws链接了一篇论文 arxiv.org/abs/2402.14740,该论文在人类反馈强化学习(RLHF)的背景下,主张采用更简单的 REINFORCE 风格优化,而非近端策略优化(PPO),引发了关于语言模型强化学习中基础方法潜力的讨论。 -
介绍水印框架:针对
@hyperion.ai关于最先进文本水印技术的查询,@catboy_slim_和@ai_waifu提到了水印论文 “A Watermark for Large Language Models”,该论文建议在生成的文本中嵌入信号 arxiv.org/abs/2301.10226,而@dmayhem分享了一篇讨论在某些假设下创建鲁棒水印方案的不可能性的论文链接 arxiv.org/abs/2311.04378。
提到的链接:
- Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping:虽然 Transformer 在各种应用场景中取得了巨大进展,但在解决复杂的决策任务方面,此类架构仍落后于传统的符号规划器。在本文中…
- Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs:以人类反馈强化学习(RLHF)形式呈现的 AI 对齐正日益被视为高性能 LLM 的关键要素。\textsc{Proximal Policy Optim…
- A Watermark for Large Language Models:LLM 的潜在危害可以通过对模型输出添加水印来减轻,即在生成的文本中嵌入对人类不可见但可以从短文本中通过算法检测到的信号…
- How Transformers Learn Causal Structure with Gradient Descent:Transformer 在序列建模任务上的惊人成功很大程度上归功于自注意力机制,它允许信息在序列的不同部分之间传递…
- xVal: A Continuous Number Encoding for Large Language Models:由于数字 Tokenization 的独特困难,LLM 尚未广泛应用于科学数据集的分析。我们提出了 xVal,一种数值编码方案…
- Towards Efficient and Exact Optimization of Language Model Alignment:语言模型与人类偏好的对齐对于其在现实任务中的应用至关重要。该问题被表述为优化模型的策略以最大化预期奖励…
- Bayesian Reward Models for LLM Alignment:为了确保 LLM 的回答是有帮助且无毒的,我们通常会在人类偏好数据上微调奖励模型。然后我们选择具有高奖励的策略响应(best-of-…
- MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases:本文针对移动设备上对高效 LLM 日益增长的需求,这是由不断增加的云成本和延迟担忧驱动的。我们专注于设计高质量的 LLM,具有…
- Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models:为生成模型添加水印包括在模型输出中植入统计信号(水印),以便稍后验证输出是否由给定模型生成。一个强…
-
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback:一个值得信赖的现实世界预测系统应该产生经过良好校准的置信度分数;也就是说,它对答案的信心应该能指示该答案正确的可能性,从而使…
- Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping: 虽然 Transformer 在各种应用场景中取得了巨大进步,但在解决复杂的决策任务方面,此类架构仍落后于传统的符号规划器。在本文中…
- Training Chain-of-Thought via Latent-Variable Inference: 当被指示使用“Chain-of-Thought”(CoT)提示逐步得出答案时,大型语言模型(LLMs)解决问题的准确性和可解释性更高。人们还可以改进…
- 来自 Lorenzo (Yunze) Xiao (@LrzNeedResearch) 的推文: 你是否觉得你的 AI 动漫角色总是崩人设?我们该如何评估这一点?我很高兴介绍我们的工作:InCharacter —— 一个评估人格忠实度的全新视角…
- GitHub - kirilligum/trust-and-teach: 通过在 GitHub 上创建账户,为 kirilligum/trust-and-teach 的开发做出贡献。
- GitHub - nbardy/tiny_moe: 通过在 GitHub 上创建账户,为 nbardy/tiny_moe 的开发做出贡献。
- MPIrigen: MPI Code Generation through Domain-Specific Language Models: 在众多节点上扩展计算的迫切需求凸显了高效并行计算的重要性,特别是在消息传递接口(MPI)集成的领域。这…
- GitHub - EleutherAI/lm-evaluation-harness: 一个用于语言模型 few-shot 评估的框架。: 一个用于语言模型 few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
- Pipelined Stochastic Gradient Descent with Taylor Expansion: 随机梯度下降(SGD)是一种通常用于深度学习中训练深度神经网络(DNN)模型的优化方法。在最近的 DNN 训练研究中,流水线并行(pipeline parallelism)作为一种…
- 我为 UT 有效利他主义做的 AI Safety 讲座): 两周前,在我在 OpenAI 工作半年之际,我做了一场讲座,阐述了我目前对 AI Safety 的想法。我是受德克萨斯大学奥斯汀分校有效利他主义俱乐部的邀请进行演讲的。你可以观看…
Eleuther ▷ #interpretability-general (18 条消息🔥):
- 探索语言透镜微调 (Linguistic Lens Tuning):
@butanium分享了一个假设,即在中文上训练经过调优的 linguistic lens 会教会它从英文翻译成中文,这表明如果模型最初是用英文“思考”的,那么这就是结果。 - 研究语言 Token:
@butanium预测,即使对于英文任务,中文 Token 也会变得更加频繁,这表明由于透镜微调可能存在潜在的底层转变。 - 语言图表的代码难题:
@mrgonao正试图调整代码,将图表中的 “en” Token 替换为 “zh” Token,以更好地理解中文透镜,但由于时间限制,推迟了对该问题的深入研究。 - 翻译任务中的数据集困境:
@mrgonao注意到为翻译任务生成的数据集出现了奇怪的行为,存在错误的语言关联,并在与@butanium讨论后澄清了自己的错误。该问题已记录在 GitHub 上。 - 调查多语言模型表示:
@mrgonao通过考虑中性语言对(法语到德语)分享了语言透镜的视觉分析,而@norabelrose建议语言显著性(saliency)可能与语料库频率相关。该分析基于 llama-2-7b 模型,并计划与 llama-2-13b 进行比较。
Eleuther ▷ #lm-thunderdome (30 messages🔥):
-
寻求帮助:调查
lm_eval挂起问题:@flobulous在运行评估后遇到了lm_eval无限期挂起的问题,特别是在使用vllm模型时。他们分享了命令和代码库 commitf78e2da45f034a23b1b13cde3235105b0f55d830以寻求协助。 -
揭示 LLM 评估的不一致性:
@.rand0mm指出了一项由@AlhamFikri分享的研究,强调了 LLM 在多选题 (MCQ) 和自由文本评估之间的一致性差异。该研究的详细内容见 arXiv 上的这篇论文。 -
使用
lm-eval复现 Open LLM Leaderboard 结果:@hailey_schoelkopf提供了关于如何使用lm-eval复现 Open LLM Leaderboard 结果的详细说明。他们强调应使用特定的 commit 以及 Open LLM Leaderboard HF space 中概述的统一设置。 -
对
lm-eval更好的代码级使用需求:@ariel2137询问了关于lm-eval“代码级使用 (code-level usage)”接口的潜在扩展和改进。@hailey_schoelkopf对提升使用体验持开放态度,并邀请大家提供反馈和建议。 -
多语言评估支持的需求:由
@.johnnysands发起的关于多语言评估的讨论促成了为新语言复制配置的建议。@.rand0mm提到 MMLU 已经使用 GPT-3.5 turbo 翻译成了法语,并可在 Hugging Face datasets 上获取。
提到的链接:
来自 Alham Fikri Aji (@AlhamFikri) 的推文:许多 LLM 评估使用限制性的多选题 (MCQ) 格式,但在实践中,这些 LLM 以更具开放性的自由文本格式使用 🔎 我们的新研究揭示了它们基于概率的 M…
Eleuther ▷ #gpt-neox-dev (6 messages):
- 对升级 Python 3.10 的犹豫:
@catboy_slim_表达了对升级到 Python 3.10 的犹豫,原因是担心测试覆盖率,暗示此项变更缺乏紧迫性。 - 对 GPT-NeoX 开发的好奇:
@catboy_slim_对某些开发选择背后的原因表示感兴趣,而@80melon则表示相比于继续关注 GPT-NeoX,他更倾向于使用自定义训练循环 (custom training loop)。 - 处理配置错误:
@jdranpariya在尝试在配置中禁用 deepspeed 时遇到了ValueError,这表明在调整设置时 NeoXArgs 的验证可能存在问题。 - 多语言 Tokenization 优化:
@rand0mm询问了扩展 Mistral tokenizer 以更有效地表示其他语言的最佳数据源,指向了提升多语言能力的努力。
LlamaIndex ▷ #blog (5 条消息):
-
Create-llama 发布 LlamaPack 集成:
@llama_index宣布了最新的 create-llama 版本,通过使用 LlamaPack,只需两行代码即可构建全栈 Web 应用。此功能展示了将高级 RAG 概念集成到项目中的便捷性。关于 create-llama 的推文 -
Counselor Copilot 项目备受关注:
@llama_index的一条推文介绍了 Counselor Copilot 项目,这是一个具有社会影响力的 RAG 应用,旨在为危机辅导员提供助手服务。该项目也是将高级 RAG 作为 Copilot 而非简单 Chatbot 使用的参考案例。介绍 Counselor Copilot 的推文 -
全面的 RAG 痛点速查表:
@llama_index分享了一个视频演示,由 @wenqi_glantz 深入探讨她的“12 个 RAG 痛点及解决方案”博客文章,旨在解决 RAG 部署每个阶段的问题。该文章是 RAG 开发者的必备速查表。关于 RAG 演示的推文 -
通过子文档摘要改进 RAG 检索:
@llama_index分享了一种通过使用子文档摘要来增强 RAG 检索性能的技术,以对抗传统分块(chunking)中的全局概念感知问题。通过将摘要作为元数据注入,每个分块都获得了上下文增强。讨论分块技巧的推文 -
LlamaParse 克服 PDF 中的表格表示挑战:
@llama_index的推文介绍了 LlamaParse,这是一款擅长处理嵌入式表格和图表的 PDF 解析器,对于构建高质量的 RAG 应用至关重要。准确的表格表示确保 LLM 接收到清晰的信息,从而得出正确的答案。关于 LlamaParse 的推文
LlamaIndex ▷ #general (234 条消息🔥🔥):
-
探索自定义 LLMPrompt 模板:
@andreipopg正在尝试了解如何将自定义 Prompt 与 SubQuestionQueryEngine 结合使用。用户收到了诸如“使用 RouterQueryEngine 选择特定数据源”的建议,并获知“SubQuestionQueryEngine 使用 Prompt 生成子问题”,该 Prompt 可以自定义(GitHub 示例)。 -
解决安装问题:
@chbla.在安装llama_index时遇到问题,特别是set_global_handler和Settings。@whitefang_jr建议使用pip uninstall llama-index进行彻底重装,这解决了@chbla.的问题。 -
RAG 与非 RAG 评估:
@addo__希望在数据集上评估带有 RAG 的 GPT-3.5 与不带 RAG 的对比。@whitefang_jr提供了使用 LlamaIndex 的FaithfulnessEvaluator来处理非 RAG 选项的解决方案。 -
本地 LLM 集成咨询:
@miteshgarg_61244寻求将本地离线微调的 LLM 模型与 LlamaIndex 的NLSQLTableQueryEngine和SQLTableRetrieverQueryEngine结合使用。@whitefang_jr建议在Settings中将本地 LLM 设置为全局默认值,并可能使用 FastAPI 在本地服务器上部署模型。 -
LlamaIndex Chat Engine 详情:
@vett93想知道在观察到不同 LLM 产生不同结果后,index.as_query_engine()和index.as_chat_engine()之间的区别。@whitefang_jr解释说,index.as_query_engine()查询数据以获取响应,而index.as_chat_engine()则考虑对话历史以进行有状态的交互。
提到的链接:
- Google Colaboratory:未找到描述
- 无标题:未找到描述
- 无标题:未找到描述
- semantic-text-splitter:将文本拆分为语义分块,直至达到所需的块大小。支持按字符和 Token 计算长度(与大语言模型配合使用时)。
-
[保险业贷款协议 Justia](https://contracts.justia.com/categories/business-finance/subcategories/loan-agreements/industries/insurance/):未找到描述 - TikTokLive v6.0.1:未找到描述
- seman:未找到描述
- 微调 - LlamaIndex 🦙 v0.10.13: 未找到描述
- 概览: 未找到描述
- 语义分块器 - LlamaIndex 🦙 v0.10.13: 未找到描述
- 成本分析 - LlamaIndex 🦙 v0.10.13: 未找到描述
- 使用 LabelledRagDataset 进行评估 - LlamaIndex 🦙 v0.10.13: 未找到描述
- 路由 - LlamaIndex 🦙 v0.10.13: 未找到描述
- 使用 LlamaIndex 实现多租户 RAG - LlamaIndex 🦙 v0.10.13: 未找到描述
- 聊天引擎 - LlamaIndex 🦙 v0.10.13: 未找到描述
- llama_index/llama-index-integrations/question_gen at main · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/agent/react/formatter.py at 14c52d42a4a12bc63db7f582e9a17c91f5984f15 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/agent/react/base.py at 14c52d42a4a12bc63db7f582e9a17c91f5984f15 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/agent/react/prompts.py at 14c52d42a4a12bc63db7f582e9a17c91f5984f15 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
-
[ Globe Explorer - 一个发现引擎,任何事物的维基百科页面 Product Hunt](https://www.producthunt.com/posts/globe-explorer): Explorer 是一种可视化分解任何主题的方式。它使用 LLM 来理解您的查询,并以视觉化方式生成该主题的详尽页面,让您能够以一种不同于搜索的方式探索信息…… - LlamaIndex 网络研讨会:使用 Flowise 构建无代码 RAG: Flowise 是构建 LLM 驱动工作流的领先无代码工具之一。用户无需学习如何在框架/编程语言中编写代码,而是……
- 使用 LlamaIndex 评估 RAG 系统的理想分块大小: 探索如何使用 LlamaIndex 的响应评估(Response Evaluation)来优化 RAG 的分块大小以获得最佳性能。
- LlamaIndex 查询管道简介 - LlamaIndex 🦙 v0.10.13: 未找到描述
- llama_index/llama-index-core/llama_index/core/agent/react/step.py at 14c52d42a4a12bc63db7f582e9a17c91f5984f15 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
- 介绍 LlamaCloud 和 LlamaParse: 今天是 LlamaIndex 生态系统的重要日子:我们宣布推出 LlamaCloud,这是新一代的托管解析、摄取和……
- GitHub 仓库读取器 - LlamaIndex 🦙 v0.10.13: 未找到描述
- 代码分割器 - LlamaIndex 🦙 v0.10.13: 未找到描述
- 在 LlamaIndex 抽象层中自定义 LLM - LlamaIndex 🦙 v0.10.13: 未找到描述
- LocalAI - LlamaIndex 🦙 v0.10.13: 未找到描述
LlamaIndex ▷ #ai-discussion (9 messages🔥):
-
被误解的《变形记》主角:
@daguilaraguilar正努力生成一份书评,但其中 “Mr. Samsa” 被识别为主角,而不是 Grete。他们的 代码示例 错误地识别了 Kafka 的 “Metamorphosis” 中的主要角色。 -
AI 对 Kafka 的混淆:
@daguilaraguilar分享了他们脚本的输出,尽管预期结果是 “Mr. Samsa”,但该脚本错误地将 Franz Kafka 的著作 “Metamorphosis” 的主角输出为 “Grete”。 -
理解 V-JEPA 在多模态学习中的作用:
@subham5089撰写了一篇关于 Meta 发布的 V-JEPA 论文的 博客,讨论了其对多模态学习的意义,并将其与基于文本的 LLM 中的 BERT 进行了比较。 -
介绍用于财务分析的 SEC Insights:
@forbes99介绍了 SEC Insights,这是一个旨在分析复杂财务文档的工具,具有跨文档查询和段落级引用等功能,旨在增强商业智能。 -
大窗口 LLM 中的上下文管理:
@jonas69301正在寻找关于为大上下文窗口(Large Context Window)编码 LLM(如 GPT-4 turbo 和 Gemini 1.5)提供广泛上下文的最佳实践基准或评估,关注点包括信息的顺序、重复和结构。 -
使用 Llama2 模型进行开源文本生成:
@theexecutor5677正在为一个集成 CSV 和 PDF 输入与 Llama2 模型的开源文本生成应用程序寻求建议,并有兴趣将该方法与 RAG (Retrieval-Augmented Generation) 相结合。
提到的链接:
no title found: 未找到描述
Latent Space ▷ #ai-general-chat (79 messages🔥🔥):
- Swyx 拆解 WSJ 的 Sora 视频:
@swyxio纠正了 WSJ 关于 OpenAI Sora 的视频 中的一项说法,指出 Sora 可以通过从起始图像进行插值,在超过 1 分钟的视频中保持一致性,这与 WSJ 声称的不可能性相反。 - NVIDIA 凭借 GEAR 加速发展:
@guardiang分享了 NVIDIA 新研究小组的消息,GEAR 由 Jim Fan 博士联合创立,旨在利用通用 AI 创建自主机器。 - Perplexity 利用 AI 驱动播客:
@swyxio指出了 Perplexity 的 AI 生成播客,该播客从其 Discover 提要中提取内容,并使用 ElevenLabs 的语音进行旁白。 - Cloudflare 发布 AI Gateway:
@henriqueln7重点介绍了 Cloudflare 的 AI Gateway,它为 AI 应用程序提供单行代码的洞察和控制,包括分析、缓存和速率限制。 - 检测数据分析工具中的细节:
@swyxio强调了一个 ChatGPT Data Analysis V2 工具,该工具利用 gpt-4-ada-v2,具有数据网格叠加编辑器、定向回复以及可能的交互式图表功能。
提到的链接:
- Au Large: Mistral Large 是我们的旗舰模型,具有顶级的推理能力。它也可以在 Azure 上使用。
- 来自 Jimmy Apples 🍎/acc (@apples_jimmy) 的推文: 猜想人们讨论这个是因为商标?它已经存在很久了。OpenAI 临时聘请的主题领域专家编写代码,OpenAI 利用这些代码来微调他们的模型。…
- AI Gateway · Cloudflare AI Gateway 文档: Cloudflare 的 AI Gateway 允许您获得对 AI 应用程序的可见性和控制权。通过将您的应用程序连接到 AI Gateway,您可以收集关于……的见解。
- 来自 Shu (@shuding_) 的推文: ↘️ 引用 Guillermo Rauch (@rauchg) —— AG(UI) 已在内部实现。
- Generative Models: What do they know?: 未找到描述。
- Fathom - 免费 AI 会议助手: 记录、转录并突出显示通话中的重要时刻。自动将生成的通话记录发送到您的 CRM。
-
Latent Space 一周年: Latent Space 在 1 年内从 0 增长到 100 万读者的经验(和回忆)。
- Discover Daily by Perplexity:我们希望将世界各地的故事带到您的耳边,每日为您提供科技、科学和文化的融合内容。精选自我们的 Discover 频道,每一集都旨在通过见解和…丰富您的一天。
- OPENAI FEATHER - OpenAI, Inc. 商标注册:OpenAI, Inc. 为商标 OPENAI FEATHER 提交的商标注册。
- 来自 FxTwitter / FixupX 的推文:抱歉,该用户不存在 :(
- 2024 年 AI Engineer 世界博览会 - 征集提案:AI Engineer 世界博览会是一项里程碑式的活动,汇聚了顶尖公司、创始人、AI Engineer 以及希望转型为 AI Engineering 的软件工程师。这是一场为软件…举办的活动。
- 与 Eugene、Hamel 和 Jason 的 GenAI 办公时间:每周我们都会聚在一起,聊聊我们在独立咨询和工作经验中所学到的东西。
- 来自 vik (@vikhyatk) 的推文:@natolambert 我说早了,忘了我当时在做 2x64-shot CoT 😭
- 未找到标题:未找到描述
- 来自 Russ Salakhutdinov (@rsalakhu) 的推文:祝贺我以前的 CMU 博士生杨植麟成立了新的 LLM 初创公司 Moonshot AI,并获得了超过 10 亿美元的风险投资。植麟在 NLP 和大语言模型领域做了一些基础性的工作…
- Gemini 图像生成出错了。我们会做得更好。:关于 Gemini 人物图像生成出现问题的原因解释,以及我们正在采取哪些措施来修复它。
- 来自 hugo alves (@Ugo_alves) 的推文:致那些询问 OpenAI Feather 的人。
- 来自 Jim Fan (@DrJimFan) 的推文:职业更新:我正在 NVIDIA 共同创立一个新的研究小组,名为“GEAR”,与我的老朋友和合作伙伴 @yukez 教授一起。GEAR 代表 Generalist Embodied Agent Research。我们相信…
- 来自 Scott Stevenson (@scottastevenson) 的推文:在 @SpellbookLegal,我们发现较新的预览版 OpenAI 模型在法律工作负载上的表现远不如老牌的 GPT-4。在经过本周末大量的客观测试后,这一结果令人惊讶。我认为…
-
[Demis Hassabis 谈聊天机器人到 AGI 第 71 集](https://youtu.be/nwUARJeeplA?si=V09X6h7iqucrh4af):本周的节目是与 Google 人工智能部门负责人 Demis Hassabis 的对话。我们讨论了 Google 最新的 AI 模型,… - 来自 Eugene Yan (@eugeneyan) 的推文:这就是我一直试图重建的在线环境/部落,就像我们在会议走廊聊天,朋友们不期而遇。最初只是 1 对 1 的…
- 来自 Tibor Blaho (@btibor91) 的推文:ChatGPT Data Analysis V2 显然使用了一个名为“gpt-4-ada-v2”(Advanced Data Analysis V2)的新 GPT-4 模型。它增加了:- 为上传文件提供的数据网格叠加编辑器 - 一个“…的选项
- AI 热潮是真的吗?:备注:7:50 - TPU 已经到了第五代。搞砸了。链接:- Asianometry 时事通讯:https://www.asianometry.com - Patreon:https://www.patreon.com…
-
[OpenAI 的 Sora:如何识别 AI 生成的视频 华尔街日报](https://youtu.be/XllmgXBQUwA?si=p9):OpenAI 刚刚发布了 Sora —— 一款能在瞬间创建超现实场景和动画世界的 AI 视频生成器。但这项技术并不完美。还有一些… -
[OpenAI 的 Sora:如何识别 AI 生成的视频 华尔街日报](https://youtu.be/XllmgXBQUwA?si=p9qTWbKwc3u_JcBx):OpenAI 刚刚发布了 Sora —— 一款能在瞬间创建超现实场景和动画世界的 AI 视频生成器。但这项技术并不完美。还有一些…
Latent Space ▷ #ai-announcements (9 条消息🔥):
- T5 论文讨论即将开始:
@ivanleomk宣布了由@bryanblackbee主持的 LLM Paper Club 活动,讨论 T5 论文,讨论将在 5 分钟后开始,加入链接见此处。 - 希望能有回放:
@swyxio对错过 T5 论文讨论表示遗憾,并幽默地建议需要该环节的录音。 - AI in Action 活动启动:
@kbal11提醒成员们关注由@yikesawjeez主持、聚焦于 local models 的 “AI in Action” 活动,并提供了即时参与的链接。 - 称赞会议进行顺利:
@swyxio称赞@kbal11与@yikesawjeez共同出色地主持了 “AI in Action” 活动。 - 社区庆祝里程碑:
@fanahova分享了生日庆祝消息,感谢大家成为社区的一员,随后@rubenartus对庆祝蛋糕和帽子表示了赞赏。
提到的链接:
- Discord - 与好友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、闲逛,并与你的好友和社区保持紧密联系。
- Discord - 与好友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、闲逛,并与你的好友和社区保持紧密联系。
Latent Space ▷ #llm-paper-club-west (16 条消息🔥):
- 在此获取 LLM Paper Club 笔记:
@bryanblackbee分享了一个 Notion 链接,其中包含与 LLM Paper Club 相关的笔记。 - 邀请参与 LLM 讨论:
@ivanleomk邀请参与者通过在会议期间发言或在聊天频道中提出问题和主题来加入讨论。 - 关于模型词汇量和文本限制的询问:
@mattoshimasu提出了关于新模型是否正在使用更小的词汇集、文本长度以及动词数量的问题。 - 初学者了解 NLP 微调:
@healthymonkey询问了 NLP 任务的 fine-tuning 过程,并以 T5 和情感分类为例。 - 讨论 NLP 任务中的架构差异:
@hanzo4958质疑了在传统 NLP 任务中 encoder-decoder 架构与 decoder-only 架构的有效性对比。 - Paper Club 参与者表达感谢:包括
@healthymonkey、@hanzo4958、@edwin_75513_08956、@lord_idiot和@youngphlo在内的多位参与者感谢主持人提供的详细会议和有用的笔记。
提到的链接:
Notion – 笔记、任务、维基和数据库的一体化工作空间。:一款将日常工作应用融合为一的新工具。它是为您和您的团队打造的一体化工作空间。
Latent Space ▷ #ai-in-action-club (136 条消息🔥🔥):
-
在本地模型中探索 Latent Space:
@dsquared70询问了首选的本地模型,引发了关于本地 AI 模型探索的对话。@420gunna提到有兴趣在本地实验图像/视频生成模型和 LoRA,对此@markredito建议查看comfyui和A1111等资源。 -
深入探讨使用 LoRAs 进行模型微调:
@kishore.reddy和@markredito讨论了在同一块 GPU 上部署和堆叠多个 LoRA 以微调生成模型,并参考了ComfyUI等工具以及civit.ai等托管社区共享模型和合并模型的平台。 -
Latent Space Final Frontiers 活动亮点:
@kbal11分享了关于 Latent Space Final Frontiers 活动的信息,该活动专注于挑战 AI 边界的团队,并设有由行业专家评审的研究/初创公司竞赛。详情和活动申请可以在这里找到。 -
讨论本地模型交互工具:
@markredito、@420gunna和@swyxio讨论了LM Studio和Ollama作为下载语言模型并在本地与其交互的工具。此外,@swyxio提到了来自 Google 的gemma.cpp,用于通过精简的用户界面封装模型。 -
技术闲谈中的幽默:对话转向了轻松的话题,调侃了高 GPU 容量与低网络带宽并存的现象,如
@swyxio和@kbal11所强调的那样。这展示了社区在技术讨论中融入幽默的能力。
提到的链接:
- Twitch:未找到描述
- SDXL Lightning - by fal.ai:由 fal.ai 提供的极速 SDXL API 演示
- Merge Large Language Models with mergekit:使用 mergekit 合并大语言模型
- Smol Talk:我们总结 AI Discord 频道,并每天为您发送汇总!
- Latent Space: Final Frontiers · Luma:我们很高兴举办第二届年度 Latent Space 演示日 🚀 别再只是和 PDF 聊天了。让我们看一些科幻级别的 AI。今年的主题是 Final Frontiers:谁是那些…
- GitHub - deforum-art/deforum-stable-diffusion:通过在 GitHub 上创建账户来为 deforum-stable-diffusion 的开发做出贡献。
- GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface.:最强大且模块化的 Stable Diffusion GUI、API 和后端,采用图形/节点界面。
OpenAccess AI Collective (axolotl) ▷ #general (52 条消息🔥):
-
Gradient Clipping 查询与解决方案:
@c.gato询问了关于 Gradient Clipping 可能失效的问题,尽管在 config 中设置为 0.3,但在观察到数值激增后产生了疑问。@nruaif建议这种激增可能只是暂时的,并建议检查 Clipping 是否已正确实现。 -
DeepSpeed Stage 3 支持讨论:
@mihai4256分享了一个 GitHub issue,对 HuggingFace 的 Trainer 是否支持 DeepSpeed Stage 3 表示关注,@noobmaster29和@nanobitz针对使用情况和最近的更新提供了反馈。 -
Axolotl 模型存储与清理:
@c.gato寻求关于 Axolotl 将下载的模型存储在哪里以及如何清理空间的帮助。@mihai4256建议检查TRANSFORMERS_CACHE目录,并分享了使用huggingface-cli delete-cache清理 cache 的步骤。 -
Mistral AI 的战略合作伙伴关系引发关注:关于 Microsoft 与 Mistral AI 建立“战略合作伙伴关系”的新闻(包括投资和发布新 AI model)引发了讨论,用户如
@yamashi和@casper_ai讨论了这对开源模型可用性的影响以及 Mistral AI 感知上的商业化方向。 -
Axolotl 与 OpenAI Mistral 讨论:包含了技术支持、关于 Axolotl、Mistral AI 的问题与更新讨论,以及 Token Classification 训练功能。其中包括
@mihai4256询问非 Python 开发者如何安装 deps 的说明,以及@kearm提到一个新的支持 PR。
提到的链接:
- 来自 Casper Hansen (@casper_hansen_) 的推文:根据其 CEO 的说法,@MistralAI 致力于开源权重模型——仍然看好 *“商业活动将使我们能够为模型开发所需的高昂研究费用提供资金。我们将……”
- 微软与 Mistral 达成协议,推动超越 OpenAI:未找到描述
- DeepSpeed 支持 Stage 3 · Issue #29254 · huggingface/transformers:系统信息 Trainer 是否支持 Stage 3?根据 https://huggingface.co/transformers/v4.3.0/main_classes/trainer.html ——它不支持。谢谢,Brett。谁能提供帮助?na 信息 官方……
- 由 monk1337 引入 auto_install.sh · Pull Request #1329 · OpenAccess-AI-Collective/axolotl:目标:此 PR 引入了一个自动化设置脚本 (auto_install.sh),旨在简化 Axolotl 的安装过程。它解决了不使用 Docker 的用户面临的常见挑战……
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (14 条消息🔥):
- GPTQ 和 EXL 需求已明确:
@nanobitz回复@curiositix称他们需要 gptq 或 exl,这表明所建议的 Google 的 Gemma C++ 推理引擎(inference engine)不符合他们的要求。 - Axolotl 的自动安装利器:
@stoicbatman宣布创建了auto_install.sh以简化 Axolotl 的设置(Pull Request #1329),@kearm对此举表示支持,并敦促进行审查。 - 寻求安装脚本审查:
@stoicbatman请求对新引入的auto_install.sh进行审查,强调其目标是简化安装过程,特别是对于那些不使用 Docker 的用户。 - 发推寻求社区支持:
@casper_ai发布了一条 Twitter 帖子,旨在为 CUDA mode 系列争取关注,可能会得到 Jeremy Howard 的帮助。 - Axolotl PR 文档澄清:在向
@caseus_提问时,@yamashi提供了一个链接,以澄清@208256080092856321在关于 Axolotl 项目中 Mistral Lora 的讨论中所指的具体文档。
提到的链接:
- axolotl/docs/mac.md at 13199f678b9aab39e92961323bdbce3234ee4b2b · OpenAccess-AI-Collective/axolotl:尽管提问。通过在 GitHub 上创建账户,为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- Reddit - Dive into anything:未找到描述
- Reddit - Dive into anything:未找到描述
- Introducing auto_install.sh by monk1337 · Pull Request #1329 · OpenAccess-AI-Collective/axolotl:目标:此 PR 引入了一个自动化设置脚本 (auto_install.sh),旨在简化 Axolotl 的安装过程。它解决了不使用 Docker 的用户面临的常见挑战…
- Introducing auto_install.sh by monk1337 · Pull Request #1329 · OpenAccess-AI-Collective/axolotl:目标:此 PR 引入了一个自动化设置脚本 (auto_install.sh),旨在简化 Axolotl 的安装过程。它解决了不使用 Docker 的用户面临的常见挑战…
- GitHub - google/gemma.cpp: lightweight, standalone C++ inference engine for Google’s Gemma models.:适用于 Google Gemma 模型的轻量级、独立 C++ 推理引擎。 - google/gemma.cpp
- Mps mistral lora by maximegmd · Pull Request #1292 · OpenAccess-AI-Collective/axolotl:训练 Mistral Lora 的额外 MPS 示例。包含一些关于用法和限制的文档。
OpenAccess AI Collective (axolotl) ▷ #general-help (121 条消息🔥🔥):
-
GPU 驱动的谜团:
@kearm讨论了使用 4 张 Nvidia RTX 3090 显卡时出现的高 Loss 和训练时间延长的问题。尽管配备了 Threadripper Pro 的强力配置,但该操作的预估训练时间仍高达 340 小时。 -
故障排除总动员:包括
@kearm和@nanobitz在内的多位成员深入探讨了技术故障排除,试图识别并解决训练期间的高 Loss 和 Checkpoint 失败问题。讨论涉及了配置、deepspeed 版本以及潜在的修复方案,尽管降级了 deepspeed,@kearm仍面临持续存在的问题。 -
慢如蜗牛的 300 秒:
@dreamgen寻求关于模型合并(特别是 mixtral)缓慢以及 GPU 未被意外利用的帮助。讨论围绕同步到 main 分支、可能的内存问题以及潜在的 Docker 相关解决方案展开。 -
Docker 困境:
@kearm尝试在 Docker 中运行 Axolotl,但遇到了错误,包括 Ubuntu 上的 GPU 连接问题以及尝试运行 Docker 镜像时的特定错误。@nanobitz指出需要 Nvidia container toolkit,@stoicbatman为@kearm提供了一个命令模板,以方便 Docker 识别 GPU。 -
新手导航员需求:
@grahama表示希望有一个简单易懂的端到端教程,供想要使用 Axolotl 微调 mixtral 7b 等模型的新手参考。@nanobitz指出项目 README 包含一个快速入门章节,可以指导用户从设置到推理的全过程。
提到的链接:
- Docker:未找到描述
- Error while saving with EarlyStoppingCallback · Issue #29157 · huggingface/transformers:系统信息 transformers 版本:4.38.0.dev0(同样存在于 4.38.0 和 4.39.0.dev0)平台:Linux-5.15.0-78-generic-x86_64-with-glibc2.35 Python 版本:3.10.12 Huggingface_hub 版本:0.20.3 Safete…
- fine tune gemma model checkpoint save error · Issue #1320 · OpenAccess-AI-Collective/axolotl:请检查此问题之前是否已被报告。我搜索了之前的 Bug 报告,没有发现类似的报告。预期行为应该是正常的,当前行为是在…时出现此错误。
OpenAccess AI Collective (axolotl) ▷ #rlhf (5 条消息):
- 训练进度的不确定性:
@noobmaster29提到训练 Loss 看起来相当低,可能预示着良好的性能。 - 对 Epoch 结果的困惑:
@noobmaster29表示困惑,因为运行一个完整的 Epoch 产生的结果比在 50% 时停止还要差,这挑战了对模型训练结果的预期。 - 缺乏评估指标难以评估:
@noobmaster29阐述了评估的重要性,指出如果没有评估指标,很难判断模型的性能。 - 致谢:
@noobmaster29感谢了@kaltcit的帮助,@kaltcit回复了 “np”(没问题)。
OpenAccess AI Collective (axolotl) ▷ #community-showcase (3 messages):
-
Phi-2 微调成果:
@finetuningllms展示了一个 2.78B 参数的 phi-2 微调模型,目前尚未提供 model card,提到它是使用 axolotl 进行微调的,并承诺即将发布带有图片的 card。该模型性能出色,目前可以在这里查看。 -
扩展语言模型的词汇量:
@seungduk宣布发布了使用 Axolotl 构建的 EEVE-Korean 模型,提供了扩展了韩语词汇量的优化 Large Language Models (LLMs)。包括 10.8B 和 2.8B 参数模型的变体,可以在 Hugging Face 上查看使用说明和社区参与信息。 -
韩语 LLM 增强技术公开:与模型一同发布的还有
@seungduk分享的一份技术报告,详细介绍了一种在语言模型中高效扩展非英语词汇的方法,并展示了它们在韩语和英语文本理解方面的增强能力。可以在 arXiv 上找到他们的研究和发现。 -
简化 RAG 系统开发:
@emrgnt_cmplxty介绍了 R2R,这是一个半意见导向(semi-opinionated)的框架,旨在简化从实验性 Retriever-Answer Generator (RAG) 模型到生产就绪系统的过渡。R2R 承诺为生产级 RAG 流水线提供易于部署、适配和维护的特性,更多详情可以在其 GitHub 仓库中找到。
提到的链接:
- axra/phi-2-x-0.1 · Hugging Face:未找到描述
- GitHub - SciPhi-AI/R2R: A framework for rapid development and deployment of production-ready RAG systems:一个用于快速开发和部署生产级 RAG 系统的框架 - SciPhi-AI/R2R
- yanolja/EEVE-Korean-10.8B-v1.0 · Hugging Face:未找到描述
- yanolja/EEVE-Korean-Instruct-10.8B-v1.0 · Hugging Face:未找到描述
- yanolja/EEVE-Korean-2.8B-v1.0 · Hugging Face:未找到描述
- yanolja/EEVE-Korean-Instruct-2.8B-v1.0 · Hugging Face:未找到描述
- Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models:该报告介绍了 \texttt{EEVE-Korean-v1.0},这是一种韩语适配的大型语言模型,在英语和韩语文本理解方面表现出卓越的能力。基于最近的高…
OpenAccess AI Collective (axolotl) ▷ #runpod-help (1 messages):
- Runpod 故障:用户
@tom891报告了在 runpod 上尝试访问 ‘huggingface.co’ 时出现的 NameResolutionError 错误。该错误提示为临时 DNS 解析失败,可能是代理问题。
CUDA MODE ▷ #general (61 messages🔥🔥):
-
计算界传奇人物批评 CUDA:
@itali4no分享了一篇文章,文中 Jim Keller 批评了 NVIDIA 的 CUDA 架构,将其与 x86 进行对比并给予负面评价,认为它由于长期拼凑而成而缺乏优雅。完整的 Tom’s Hardware 文章 详细阐述了他的观点。 -
关于 AI GPU 选择的辩论:
@cropinky.建议虽然 4060 ti 可能是最便宜的 16GB 消费级 GPU 且功耗较低,但与拥有 24GB VRAM 的二手 3090 等选项相比,它通常不足以处理 LLM 任务,@andreaskoepf也强调了 VRAM 的重要性。关于购买二手 GPU 用于 AI 任务的讨论重点关注了其中的风险以及出现问题时的潜在补救措施,包括更换导热垫或硅脂。 -
量化 AI 模型中的精确计算讨论:
@andreaskoepf和@zippika深入讨论了量化模型(4 bit/8 bit)中的计算通常如何在 16 bit 等更高分辨率下进行以保持准确性,并在矩阵乘法前进行反量化(dequantization)。@marksaroufim通过澄清不同量化策略的术语(如 weight only 量化)以及分布式设置中的歧义做出了贡献。 -
GTC 大会线下参会:
@vim410和@andreaskoepf建议为 Jensen 的 Keynote 组织一场观看派对,或者为参加即将到来的 GTC 大会的人员组织一场线下见面会。_t_vi_确认将与 Mike Ruberry 一同出席,并对展示他们的工作成果表示兴奋。 -
ZLUDA 项目开源:
@ju_rstr分享了关于 ZLUDA 的消息,这是一个允许 NVIDIA 的 CUDA 代码在 AMD 和 Intel GPU 上运行的工具。在 AMD 和 Intel 撤回支持后,该项目已开源。ZLUDA 背后的开发者 Andrzej Janik 希望他的项目能挑战 NVIDIA 的 AI 霸权,更多信息可以在 ZLUDA 的 GitHub 页面上找到。
提到的链接:
- 一位独立开发者刚刚开源了一个可能终结 Nvidia AI 霸权的工具——AMD 曾资助其数月但突然停止了支持。没人知道原因:ZLUDA 可以在 AMD 和 Intel GPU 上运行 Nvidia CUDA 代码。
- 来自 Jürgen Schmidhuber (@SchmidhuberAI) 的推文:2010 年近期 $NVDA 股市狂热的基础:我们在 @nvidia GPU 上的简单但深层的神经网络打破了 MNIST 纪录 https://arxiv.org/abs/1003.0358。情况变化很快。就在 7 个月前,我发推说……
- DoRA: Weight-Decomposed Low-Rank Adaptation:在广泛使用的参数高效微调(PEFT)方法中,LoRA 及其变体因避免了额外的推理成本而大受欢迎。然而,仍然经常……
- Jim Keller 批评 Nvidia 的 CUDA 和 x86 —— ‘CUDA 是泥潭而非护城河,x86 也是泥潭’:Jim Keller 并不完全是 Nvidia CUDA 的粉丝。
- Meet:Google 的实时会议。使用浏览器与团队成员和客户分享视频、桌面和演示文稿。
- GitHub - vosen/ZLUDA: CUDA on AMD GPUs:AMD GPU 上的 CUDA。通过在 GitHub 上创建账号为 vosen/ZLUDA 的开发做贡献。
- 来自 tiny corp (@tinygrad) 的推文:关于 tinybox 的一些闲聊。我不认为保密有什么价值。我们已经有了构建 12 个盒子的零件和一个非常接近最终设计的机箱。正在克服所有的 PCI-E……
- GitHub - TimDettmers/bitsandbytes at 5d6dfe6fb43e5aae277ec86cba20a002b34df705:通过 PyTorch 的 k-bit 量化实现易于获取的大语言模型(LLM)。
- bitsandbytes/bitsandbytes/functional.py at 5d6dfe6fb43e5aae277ec86cba20a002b34df705 · TimDettmers/bitsandbytes:通过 PyTorch 的 k-bit 量化实现易于获取的大语言模型(LLM)。
- bitsandbytes/csrc/kernels.cu at 5d6dfe6fb43e5aae277ec86cba20a002b34df705 · TimDettmers/bitsandbytes:通过 PyTorch 的 k-bit 量化实现易于获取的大语言模型(LLM)。
CUDA MODE ▷ #triton (6 条消息):
- Triton 作为通往 Jax 的门户:
@srush1301讨论了 Triton 的实现,提到它允许通过 Pallas 支持 Jax,并表示希望有一个更简单的版本供研究人员修改。 - Triton 与 CUDA 多 GPU 支持咨询:
@taekmin.kim询问 Triton 在多 GPU 或多节点执行方面是否优于 CUDA,寻求对其分布式计算能力的见解。 - 征集 Triton 专家:
@andreaskoepf表示需要一位专家来解释 Triton,特别是其底层工作原理、在 LLVM 和 MLIR 上的基础以及未来的潜力。 - 对 Triton 的量化 Matmul 核进行基准测试:
@andreaskoepf提议为 Triton 的量化 Matmul 核创建一个独立的基准测试设置,并在演讲中分享,以鼓励实验并与 CUDA 进行对比。 - 分享基准测试代码:
@andreaskoepf建议将上述基准测试设置的 Python 文件包含在讲座仓库中,以便于获取。
CUDA MODE ▷ #cuda (22 条消息🔥):
-
CUDA 与 Python 舍入误差问题:
@zippika在 C++ 中实现nn.Linear操作时,由于某些 NVIDIA cub 编译标志,遇到了比 Python 更多的舍入误差。分享了 C++ 与 Python 代码的对比,说明了导致不准确的差异。Python 版本被认为更准确。 -
张量量化中的代码同步:
@zippika注意到 C++ 中的dequantize_torch_fp4与 Python 中的dequantize_fp4_codebook_invoke_qtype之间的对应关系,它们具有相似的功能,但参数顺序不同。 -
BNB 与 TorchFP4 的速度测试:
@zippika在 Mistral-7b-instruct-v0.2 模型上进行了速度测试,结果显示 TorchFP4 的每秒 token 数(tokens per second)高于 BNB。 -
torch-bnb-fp4 库的 Readme 改进:
@zippika更新了该库的 readme,现在包含一个用于速度测试的 huggingface 示例脚本。 -
CUDA 结合 OpenGL vs Vulkan:
@morousg回答了@g.huy关于将 CUDA 与 OpenGL 结合使用的疑问,表示这是可能的,但 NVIDIA 更多地关注 CUDA 与 Vulkan 的结合。为了获得更高的效率和功能,建议使用 Vulkan 而非 OpenGL。
{kind=link}
提到的链接:
- torch-bnb-fp4/examples/speed_test_mistral_7b.py (位于 main 分支) · aredden/torch-bnb-fp4:通过在 GitHub 上创建账户来为 aredden/torch-bnb-fp4 的开发做出贡献。
- TensorRT-LLM/docs/source/performance.md (位于 release/0.5.0 分支) · NVIDIA/TensorRT-LLM:TensorRT-LLM 为用户提供了一个易于使用的 Python API,用于定义大语言模型 (LLMs) 并构建包含最先进优化技术的 TensorRT 引擎,以高效执行推理…
- GitHub - NVIDIA/TensorRT-LLM: TensorRT-LLM 为用户提供了一个易于使用的 Python API,用于定义大语言模型 (LLMs) 并构建包含最先进优化技术的 TensorRT 引擎,以便在 NVIDIA GPUs 上高效执行推理。TensorRT-LLM 还包含用于创建执行这些 TensorRT 引擎的 Python 和 C++ 运行时的组件。:TensorRT-LLM 为用户提供了一个易于使用的 Python API,用于定义大语言模型 (LLMs) 并构建包含最先进优化技术的 TensorRT 引擎,以高效执行推理…
- GitHub - ggerganov/llama.cpp: C/C++ 中的 LLM 推理:C/C++ 中的 LLM 推理。通过在 GitHub 上创建账户来为 ggerganov/llama.cpp 的开发做出贡献。
CUDA MODE ▷ #torch (9 messages🔥):
-
探索高效 Kernel 发布方式:
@hdcharles_74684讨论了使各种 CUDA kernels 易于访问的复杂性,提到通过out_dtype发布int_mm的方式很笨重 (clunky),并指出 PyTorch 缺乏对 int4 的支持。他们强调了一种通过torch.compile检测特定模式来集成高效 kernels 的方法,并参考了他们在 4-bit Triton kernel 上的工作。 -
torch.compile的局限性:@hdcharles_74684指出了 PyTorchtorch.compile的局限性,特别是在从简单操作创建高效 kernels 的背景下。他们计划填补现有 kernels 的空白,重点关注 Batch Size 大于 1 的仅权重 (weight-only) int8 量化。 -
加速 CUDA Kernel 编译:
@briggers提出了一种减少cpp_extension.load_inline编译时间的方法(见于cuda-mode-session-4.ipynb),通过使用cpp_extension.load并避免不必要的头文件,将时间从 30 多秒缩短到 2 秒以内。分享了一个 GitHub 仓库 来演示这种改进方法,将代码拆分为独立的.cpp和.cu文件。 -
请求预编译头文件 (PCH) 指导:
@jeremyhoward请求在 C++ 中实现预编译头文件的帮助,提到距离他上一次深入研究 C++ 已经过去很多年了。 -
重新编译扩展的潜在低效:
@briggers讨论了使用ninja编译扩展的局限性,即即使只对.cu文件中的算法进行了微调,它也会重新编译 Wrapper 和 CUDA 代码。_t_vi_认为在编译过程中避免 C++ 文件可能不会带来实质性的收益,并质疑目前 PyTorch 对该方法的支持。
提到的链接:
- GitHub - pbridger/cuda-experiments: 通过在 GitHub 上创建账号来为 pbridger/cuda-experiments 的开发做出贡献。
- pytorch/torch/_higher_order_ops/out_dtype.py at ed0ea2f30b2f31be7534a7fdafbed90d247f76b5 · pytorch/pytorch): Python 中具有强大 GPU 加速功能的 Tensor 和动态神经网络 - pytorch/pytorch
- pytorch/torch/_inductor/fx_passes/post_grad.py at main · pytorch/pytorch: Python 中具有强大 GPU 加速功能的 Tensor 和动态神经网络 - pytorch/pytorch
CUDA MODE ▷ #announcements (1 messages):
- 关于量化的第 7 课:
@andreaskoepf宣布 CUDA-MODE 第 7 课,题为 Quantization CUDA vs Triton,计划很快开始。课程开始时间已转换为<t:1708804800:R>。
CUDA MODE ▷ #algorithms (4 messages):
- CMU 关于高效 LLM Serving 的论文:
@ericauld分享了来自 CMU 的一篇论文链接,标题为 “Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems”,重点关注部署生成式大语言模型 (LLMs) 的挑战和方法论。 - 打印以深入理解:
@marksaroufim表示打算打印上述 CMU 论文,表明对其内容的兴趣。 - 综述摘要亮点:
@andreaskoepf提供了 CMU 综述论文在 arXiv 上的摘要直链,强调了从机器学习系统 (MLSys) 视角出发的高效 LLM Serving 的必要性。 - 综述内容拆解:
@marksaroufim在阅读综述后分享了关键见解,指出了如非自回归生成 (non-autoregressive generation)、投机解码 (speculative decoding)、MoE 架构、局部注意力变体 (local attention variants) 以及不同形式的并行性等出色技术,展示了该论文调研超过 150 篇参考文献的广度。
提到的链接:
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems: 在快速发展的人工智能 (AI) 领域,生成式大语言模型 (LLMs) 处于最前沿,彻底改变了我们与数据交互的方式。然而,计算…
CUDA MODE ▷ #suggestions (1 条消息):
- AI 高效学习揭秘:
@mortezism分享了一个来自 MIT 的 课程链接,重点关注高效 AI 计算技术,包括模型压缩、剪枝、量化等。该课程提供针对 LLaMA 2 等大语言模型的实操经验,并涵盖了量子机器学习等前沿话题。
提到的链接:
MIT 6.5940 Fall 2023 TinyML and Efficient Deep Learning Computing:未找到描述
CUDA MODE ▷ #jobs (3 条消息):
- Mistral 招聘状态咨询:
onuralp.询问 Mistral 是否正在湾区积极招聘,或者招聘是否像 Deepmind 一样针对特定职位。讨论中未给出公开答复。 - Nvidia CUDA/C++ 职位开放:
@dasher519询问了 Nvidia 针对 CUDA 和 C++ 专家的工作机会。@vim410确认他们正在招聘,并引导申请人将简历私信发送至 JobID: JR1968004。
CUDA MODE ▷ #beginner (11 条消息🔥):
- Google Colab 中 OpenCV 的难题:
@dpearson在 Google Colab 中使用 nvcc4jupyter 时,在使用'include <opencv2/opencv.hpp>'方面遇到困难。他们正在寻找在 Jupyter Notebook 环境中对图像测试 CUDA 代码的替代方案。 - 通过 YouTube 探索 CUDA:
@bikash_p推荐了 Jeremy 的 YouTube 讲座以及相关的 Colab Notebook,用于使用 PyTorch CPP 扩展执行 CUDA 代码,并强调了与 ninja 集成进行编译的无缝性。 - ACX 社区的交叉互动:
@ringofbetelgeuse和_red.j都表达了惊讶,可能是因为发现了 CUDA MODE,并确认是从 ACX 社区加入的。 - Python 爱好者的 AI 抱负:
@ilovepython3表达了他们微调 AI 模型的愿望,尽管自称数学能力较弱,并询问了参与 CUDA MODE 的先决条件。 - 给初学 AI 爱好者的指导:针对
@ilovepython3关于从哪里开始的提问,@jeremyhoward建议先学习 fast.ai 课程,在深入研究 CUDA 之前建立基础知识。
提到的链接:
- Lecture 3: Getting Started With CUDA for Python Programmers:Jeremy 的 YouTube 录像 https://www.youtube.com/watch?v=nOxKexn3iBo 补充内容:https://github.com/cuda-mode/lecture2/tree/main/lecture3Speak…
- Google Colaboratory:未找到描述
CUDA MODE ▷ #pmpp-book (3 条消息):
- 对 PMPP 书中 Grid 图表的困惑:
@bikash_p质疑了 PMPP 书中的一个差异,代码中指定了dim3 dimGrid(2,2,1),但随附的图表显示了两个独立的 Grid。他们想知道图表是否应该显示一个包含四个 Block 的单一 Grid。 - 关于核函数调用和 Grid 的澄清:
@alexanderrgriffing回复了@bikash_p,澄清该图示代表多次核函数(Kernel)调用,每次调用都会启动自己的线程块 Grid。因此,两次核函数调用会产生两个独立的 Grid。 - 对社区支持的感谢:
@bikash_p对@alexanderrgriffing提供的关于 PMPP 书中 CUDA 代码上下文中 Grid 示意图表示的解释表示感谢。
CUDA MODE ▷ #youtube-recordings (3 messages):
- 来自 YouTube 的优化教育:
@marksaroufim分享了 Lecture 6,重点关注 Optimizing Optimizers,并提供了 YouTube 视频 以及配套的 Google Docs 演示文稿 幻灯片。 @filippob82表达感谢:@filippob82对分享的 CUDA 优化教育内容表示感谢。- 深入探讨量化 (Quantization):
@andreaskoepf提供了 YouTube 上题为 Advanced Quantization 的 Lecture 7 链接(点击观看),并感谢@325883680419610631录制、剪辑和上传了该讲座,额外的幻灯片可在 Dropbox 获取。
提到的链接:
- Lecture 7 Advanced Quantization:幻灯片:https://www.dropbox.com/scl/fi/hzfx1l267m8gwyhcjvfk4/Quantization-Cuda-vs-Triton.pdf?rlkey=s4j64ivi2kpp2l0uq8xjdwbab&dl=0
- Lecture 6 Optimizing Optimizers:幻灯片:https://docs.google.com/presentation/d/13WLCuxXzwu5JRZo0tAfW0hbKHQMvFw4O/edit#slide=id.p1
CUDA MODE ▷ #smol-hw (8 messages🔥):
- 思考随机数:用户
@marksaroufim发布了一系列数字但没有提供上下文,引发了@nshepperd对这些数值来源的好奇。 - 对量化 (Quantization) 的贡献:
@drisspg分享了在量化技术方面的进展,并附带了关于复现的笔记,还提供了其 GitHub 仓库 中相关代码的链接。 - 对分位数对齐 (Quantile Alignment) 的怀疑:
@drisspg表达了对分位数对齐是否符合预期的怀疑,提到有一个包含相关问题的 notebook,但未提供链接。 - 探索量化策略:
@marksaroufim重点介绍了一个 PyTorch 核心团队仓库,该仓库专注于 GPU 模型的量化和剪枝,并引用了一篇 PyTorch 博客文章,详细介绍了生成式 AI 加速方面的优化。
提到的链接:
- transformer_nuggets/transformer_nuggets/quant/qlora_debug.py at main · drisspg/transformer_nuggets:一个存放我自己创建或在网上找到的可重用 Transformer 组件的地方 - drisspg/transformer_nuggets
- 为 NF4 添加文档;修复 8-bit matmul 失败;修复 absmax bug。 … · TimDettmers/bitsandbytes@6747525:…#529 #543
- GitHub - pytorch-labs/ao: torchao 仓库包含用于 GPU 模型量化和剪枝的 API 和工作流。:torchao 仓库包含用于 GPU 模型量化和剪枝的 API 和工作流。 - pytorch-labs/ao
- 使用 PyTorch 加速生成式 AI II:GPT,快:这篇文章是一个系列博客的第二部分,重点介绍如何使用纯原生 PyTorch 加速生成式 AI 模型。我们很高兴能分享一系列新发布的 PyTorch 性能…
- 使用 PyTorch 加速生成式 AI:Segment Anything,快:这篇文章是一个系列博客的第一部分,重点介绍如何使用纯原生 PyTorch 加速生成式 AI 模型。我们很高兴能分享一系列新发布的 PyTorch 性能…
CUDA MODE ▷ #ring-attention (45 messages🔥):
- 调整 Attention 以提升速度:
@zhuzilin96实现了zigzag_ring_flash_attn_varlen_qkvpacked_func,虽然速度有所提升但低于预期。他们随后提到,硬编码 bf16 是出于个人偏好而非必要。 - Flash Attention 的精细化:
@iron_bound分享了来自 Hugging Face 文档中关于 Flash Attention 的解释和可视化图表,强调了其通过利用 SRAM 优于 HBM 来提高内存效率和训练速度的优势。 - Zigzag Ring 加速实测:
@zhuzilin96发布了一个 基准测试脚本,显示 Zigzag Ring Attention 比经典的 Flash Attention 提升了约 20% 的速度,但承认他们之前的截图没有进行正确的预热(warmed up)。 - 发挥 Ring 的最大效能:
@andreaskoepf讨论了在大 Batch Size 下最大化 RingAttention 收益的方法,并指出衡量 ring-attn-block 计算时间何时超过内存传输时间至关重要。同时,@jamesmel提交了一个关于 requirements 的小型 PR,@andreaskoepf澄清了 CUDA Mode 的 fork 主要用于备份。 - 深度优化讨论:
@w0rlord和@andreaskoepf就 Softmax Base 2 技巧以及 Flash Attention 函数相对于序列长度的准确性进行了讨论。@andreaskoepf分享了一个关于该技巧的 Notebook,并观察到 Flash Attention 仅在较长序列下能给出正确结果。
提及的链接:
- Flash Attention: 未找到描述
- exp2 是否应该比 exp 更快?: 我主要对 C/C++ 中的 “exp” 和 “exp2” 函数感兴趣,但这个问题可能更多地与 IEEE 754 标准有关,而不是特定的语言特性…
- CUDA Kernel 融合案例研究:使用 CUTLASS 库在 NVIDIA Hopper 架构上实现 FlashAttention-2: 我们提供了一个针对 NVIDIA Hopper 架构定制的融合 CUDA Kernel,实现了 FlashAttention-2 前向传播的优化版本。FlashAttention-2 是一种流行的内存感知缩放点积注意力算法…
- 序列并行:从系统视角看长序列训练: Transformer 在各种任务上都取得了显著成果。然而,Self-attention 的内存需求随序列长度呈平方级增长。现有工作主要集中在减少时间…
- 等待时间检测(不打算合并)由 andreaskoepf 提交 · Pull Request #9 · zhuzilin/ring-flash-attention: 我尝试测量了
batch_isend_irecv()返回的请求所花费的时间。有趣的是,这段时间似乎与序列长度无关,且总计可以忽略不计。可能是在单个节点上… - ring-attention/trition_flash_attn/softmax_base2_trick.ipynb 在 main 分支 · cuda-mode/ring-attention: Ring-attention 实验。通过在 GitHub 上创建账号来为 cuda-mode/ring-attention 的开发做出贡献。
- ring-attention/trition_flash_attn/workbench.py 在 391a4cce570aae380ad5b318cb4b0f80f4cb3aee · cuda-mode/ring-attention: Ring-attention 实验。通过在 GitHub 上创建账号来为 cuda-mode/ring-attention 的开发做出贡献。
- Smol Talk: 我们总结 AI Discord 社区的内容,每天为您发送摘要!
- 一个结合 Flash Attention Kernel 的 Ring Attention 实现 · Issue #4 · lucidrains/ring-attention-pytorch: 嗨!感谢你在 PyTorch 中实现 Ring Attention 的工作!我刚刚尝试实现了一个
ring_flash_attn_qkvpacked_func(对应 Flash Attention 中的flash_attn_qkvpacked_func)… - Pull requests · zhuzilin/ring-flash-attention: 结合 Flash Attention 的 Ring Attention 实现 - Pull requests · zhuzilin/ring-flash-attention
- 由 melvinebenezer 添加 requirements.txt · Pull Request #7 · zhuzilin/ring-flash-attention: 在按照 Cuda Mode 的 Ring Attention 频道运行测试用例时遇到了错误。
- 由 reyoung 提交的 Stripe Attn · Pull Request #6 · zhuzilin/ring-flash-attention: [x] 完成功能实现 [x] 完成单元测试
LangChain AI ▷ #general (39 messages🔥):
- 本地模型的 Function Calling 困境:
@saita_ma_正在寻求一种简单的方法来对 OpenHermes 等本地模型进行 Function Calling,尽管已知 CrewAI 已经证明了其可行性,但他发现相关资源匮乏。 - LangChain 教程上线 YouTube:
@datasciencebasics分享了一个 YouTube 教程,关于使用 ChainLit, LangChain, Ollama 和 Gemma 创建聊天 UI,该教程允许观众在本地创建一个类似 ChatGPT 的 UI。 - Colab 角落:
@kenwu_正在寻求关于使用 Cohere API 和 LangChain 进行 Agent 和 Function Calling 的帮助;并分享了他们的 Google Colab notebook 以供协作和协助。 - LLM 中的讽刺检测:
@juepachon发起了一场讨论,探讨在微调后,为短语打上“讽刺”标签是否能帮助 LLM 更好地理解和检测讽刺。 - Usescraper 发布与博客文章:
@dctanner宣布了 UseScraper.com,这是一个用于抓取网站内容的新工具,并写了一篇关于它如何与 LangChain 结合的博客文章。
提到的链接:
- 重定向中…:未找到描述
- Google Colaboratory:未找到描述
-
[入门指南 🦜️🔗 Langchain](https://python.langchain.com/docs/expression_language/get_started):LCEL 使得从基础组件构建复杂的 Chain 变得简单,并且 -
[Llama.cpp 🦜️🔗 Langchain](https://python.langchain.com/docs/integrations/llms/llamacpp):llama-cpp-python 是一个 -
[流式传输 🦜️🔗 Langchain](https://js.langchain.com/docs/use_cases/question_answering/streaming#chain-with-sources):在问答应用中,通常向用户展示来源是很重要的 - 使用 LLM 从视频/音频中提取主题(使用 LangChain 进行主题建模):学习使用 AI 构建:https://mail.gregkamradt.com/signup Twitter: https://twitter.com/GregKamradt 代码: https://github.com/gkamradt/langchain-tutorials/blob…
- 使用 ChainLit, LangChain, Ollama & Gemma 创建聊天 UI 🧠:在此视频中,我将演示如何在计算机本地创建一个简单的类似 ChatGPT 的 UI。你可以通过克隆本地仓库来跟随我操作…
- 未找到标题:未找到描述
- GitHub - google/generative-ai-python: Google AI Python SDK 使开发者能够使用 Google 最先进的生成式 AI 模型(如 Gemini 和 PaLM)来构建 AI 驱动的功能和应用。:Google AI Python SDK 使开发者能够使用 Google 最先进的生成式 AI 模型(如 Gemini 和 PaLM)来构建 AI 驱动的功能和应用。 - google/generative-ai-p…
LangChain AI ▷ #langserve (3 messages):
- Cancelled Error 困惑:用户
@cryptossssun遇到了asyncio.exceptions.CancelledError,但未提供有关上下文或所涉及代码的更多细节。 - 关于延长超时限制的查询:
@howtonotgiveafuck正在寻找一种将超时时间延长到默认 900 秒以上的方法。在消息范围内未提供该主题的解决方案或进一步讨论。
LangChain AI ▷ #share-your-work (11 messages🔥):
-
轻松构建自定义聊天机器人:
@deadmanabir分享了一个关于构建可保留对话历史的个性化聊天机器人的指南。技术栈包括 OpenAI, Qdrant DB 和 Langchain JS/TS SDK,更多详情可在 Twitter 查看。 -
保险行业 AI 洞察:
@solo78表示有兴趣交流 AI 的使用案例和实施,特别是保险行业内的财务职能。 -
Merlinn AI 赋能工程师:
@david1542介绍了 Merlinn,这是一个帮助值班工程师进行故障调查和排障的项目,底层使用了 Langchain。 -
Rust 版 Langchain:
@edartru.分享了 Langchain-rust,这是一个允许 Rust 开发者编写 LLM 程序的新 crate,源代码可在 GitHub 获取。 -
新型简历优化器发布:
@eyeamansh开发了一个使用 AI 的开源简历优化器,事实证明它成功帮助用户获得了 NVidia 和 AMD 等科技巨头的面试邀请。该工具旨在降低成本和精力,可在 GitHub 找到。
提到的链接:
- Merlinn - Resolve incidents fast using AI:使用 AI 高效调查生产环境故障;通过了解你环境的 AI Agent 为团队赋能。
- GitHub - consumer-ai-lab/microservices-based-chatbot-api:通过在 GitHub 创建账号,为 consumer-ai-lab/microservices-based-chatbot-api 的开发做出贡献。
- GitHub - AnshKetchum/resumeop: Go the extra mile, without wasting thousands of hours. Achieve job market freedom using open source AI.:多走一步,不浪费成千上万的小时。使用开源 AI 实现就业市场自由。 - AnshKetchum/resumeop
- GitHub - SciPhi-AI/R2R: A framework for rapid development and deployment of production-ready RAG systems:一个用于快速开发和部署生产级 RAG 系统的框架 - SciPhi-AI/R2R
- SalesGPT: Elevating Sales Conversations with Langchain Intelligence:Ankush k Singal
- GitHub - Abraxas-365/langchain-rust: LangChain for Rust, the easiest way to write LLM-based programs in Rust:Rust 版 LangChain,在 Rust 中编写基于 LLM 程序的最简单方式 - Abraxas-365/langchain-rust
LangChain AI ▷ #tutorials (7 messages):
- 打造你自己的聊天 UI: 一个新分享的 YouTube 视频 演示了如何使用 ChainLit, LangChain, Ollama 和 Gemma 创建 聊天 UI,使观众能够在自己的电脑本地搭建一个 类似 ChatGPT 的界面。
- LLM 深度解析季度报告: @rito3281 撰写了一篇 详细文章,讨论了 大语言模型 (LLMs) 如何辅助解析公司季度报告、预测未来增长并识别风险和市场机会,使用了 LangChain, Qdrant 和 Mistral AI。
- Ollama 在 Colab 上的新 Embeddings: @schimazing 分享了一个修改版本,利用完全托管在 Google Colab 上的 Ollama 新 Embeddings,正如这篇 Twitter 帖子 所强调的,无需 API keys。
- 解码 AI 运作过程: 针对 @rajib2189 关于 AI 底层机制的询问,@speuce 澄清该过程是 基于困惑度 (perplexity-based) 的,而不是依赖于停用词 (stopwords) 或词干提取 (stemming)。
- LangGraph、调用与抓取简化: @tarikkaoutar 发布了一个 YouTube 视频,解释了如何结合 LangGraph、函数调用 (function calls) 和网页抓取工具来创建一个 多 Agent 应用,并鼓励分享以扩大影响力。
提到的链接:
- 使用 Langchain, Qdrant 和 Mistral AI 的每日投资组合总结器: 如今的投资者被新闻、报告、统计数据和更多信息所轰炸。AI 穿透这些噪音,分析庞大的数据集以挖掘隐藏的模式和趋势,并提供见解…
- 使用 ChainLit, LangChain, Ollama & Gemma 创建聊天 UI 🧠: 在这段视频中,我将演示如何在你的电脑本地创建一个简单的类似 ChatGPT 的 UI。你可以通过克隆本地仓库来跟随我操作…
- LangGraph + 函数调用 + 网页抓取 = 多 Agent 应用: #chatbot #langgraph #functioncall #ai #automation #dropshipping 在这段视频中,我将解释如何创建 LangGraph、进行函数调用并开发…
Datasette - LLM (@SimonW) ▷ #ai (4 messages):
- 趣闻:ChatGPT 在处理数据时变得“多语言化”:
derekpwillis分享了一个轶事,在使用 chatgpt-3.5-turbo 进行数据提取任务时,导致一些文档标题被翻译成了西班牙语,例如 “Taking Advantage of the Internet” 变成了 “Sacándole Provecho a Internet“。 - 多语言 Bug 再次袭来:
simonw将这种行为与一个已知问题进行了对比,即 ChatGPT 配合 Whisper voice 使用时,有时会将英国口音误认为威尔士语并用威尔士语回答。 - 快速修复建议:
simonw建议通过使用指定 “Always use English” 的系统提示词 (system prompt) 来规避错误的语言检测。 - 准备实施语言补丁:
derekpwillis确认了该 Bug,并表示打算实施 “Always use English” 提示词来解决此问题。
Datasette - LLM (@SimonW) ▷ #llm (30 条消息🔥):
-
重温旧派提示词工程 (Prompt Crafting):
@tariqali回忆了 RLHF 出现之前使用大量提示词来引导文本生成的做法,发现这让人联想到为聊天机器人提供对话记录以恢复对话。他发现这种方法提供了更多控制权,对于因“超时”问题导致聊天机器人消息不完整的情况尤其有用。 -
简化 Devcontainer 设置与临时方案:
@derekpwillis提到必须对devcontainer.json文件进行微调,而@simonw建议将llm models添加到setup.sh脚本中作为 Bug 的规避方案。@derekpwillis随后确认已实施该提议的修复。 -
在 LLM 上运行 LargeWorldModel:
@simonw表示有兴趣看到 LargeWorldModel 在 LLM 中运行,并讨论了使用 GPU 实例来容纳来自其 Hugging Face 仓库 的 PyTorch 模型的可能性。 -
Angerman 开发的 Groq 推理插件:
@angerman.分享了他创建的 Groq 推理插件 llm-groq,为实验提供了另一个推理提供商。@0xgrrr对这一补充表示支持,并询问了其性能表现。 -
发布到 PyPI 以简化插件安装:在
@0xgrrr的建议下,@angerman.学习了如何将其 llm-groq 插件 发布到 PyPI,从而实现使用llm install进行更简单的安装。@angerman.确认发布成功,并分享了他对比 Haskell 和 Python 社区实践的经验。
提到的链接:
- LargeWorldModel/LWM-Text-Chat-1M · Hugging Face:未找到描述
- Large World Models:未找到描述
- Packaging Python Projects - Python Packaging User Guide:未找到描述
- llm-groq:未找到描述
LLM Perf Enthusiasts AI ▷ #general (6 条消息):
- 探讨幻觉缓解 (Hallucination Mitigation):用户
@res6969分享了 @RichardSocher 的一条推文,讨论了 AI 幻觉问题的潜在解决方案。该推文暗示了成功的引用整合,引起了研究社区的好奇。 - 推测反幻觉技术:
@res6969推测,抑制幻觉的方法涉及一种验证机制以及尖端的 Embedding 模型。这表明人们对提高 AI 事实准确性的兴趣日益浓厚。 - 介绍 Globe Explorer:用户
@sincethestudy宣布推出 Globe Explorer,这是一个使用 GPT-4 在任何主题上创建可定制的维基百科风格页面的工具,预示着信息探索的新时代。 - Globe Explorer 寻求 Product Hunt 榜首:为了登上 Product Hunt 的每日榜单,
@sincethestudy敦促社区为 Globe Explorer 投票。并向支持者承诺提供“专业版”的独家访问权限。
提到的链接:
- 来自 brian-machado-finetuned-7b (e/snack) (@sincethestudy) 的推文:Globe Explorer 就像是一个关于你想要的任何内容的自定义维基百科页面。我们正在进入信息探索的新时代。去试试吧:http://explorer.globe.engineer/
- 来自 Richard Socher (@RichardSocher) 的推文:我们解决幻觉问题了吗?在这里以及我在研究模式下尝试过的任何其他例子中,看起来确实如此——所有这些都有大量最新的引用。查询:Reddit S-1
-
[Globe Explorer - 发现引擎,任何事物的维基百科页面 Product Hunt](https://www.producthunt.com/posts/globe-explorer):Explorer 是一种分解任何主题的可视化方式。它使用 LLM 来理解你的查询,并以可视化方式生成该主题的详尽页面,让你能够以不同于搜索的方式探索信息……
LLM Perf Enthusiasts AI ▷ #finetuning (1 messages):
- 使用完整文档还是摘录进行微调?:
@pantsforbirds通过将整个文档嵌入到 Prompt 中,使用 gpt-4-turbo 在 1-shot 数据提取方面取得了出色的效果。他们正在寻求建议:对于更复杂的提取/分类任务,在微调数据集中是应该嵌入完整的示例文档,还是仅嵌入相关的部分。
LLM Perf Enthusiasts AI ▷ #opensource (3 messages):
-
FireFunction V1 引起关注:
@sourya4询问了使用开源权重(open-weights)模型进行 function calling 的首选方案。随后他们分享了@lqiao关于 FireFunction V1 发布公告的链接,该模型旨在以更快的速度提供 GPT-4 级别的结构化输出和决策路由,并声明了开源权重可用性以及商业用途,并附带了支持性的 博客文章。 -
结构化输出助力更好开发:
@lqiao的公告进一步介绍了适用于所有语言模型的 JSON mode 和 grammar mode,确保结构化输出并减少在 system prompts 上花费的时间,详见第二篇 博客文章。 -
动手实践黑客松:
@yikesawjeez提到了目前首选的 function calling 工具,包括 gorilla openfunctions 等,但指出即将举行的专注于 FireFunction 的黑客松可能会改变局势,决定新的首选工具。
提到的链接:
Lin Qiao (@lqiao) 的推文: 🔥 Structure is all you need. 🔥 我们很高兴地宣布:- FireFunction V1 - 我们新的开源权重 function calling 模型:- GPT-4 级别的结构化输出和决策路由,延迟降低 4 倍…
LLM Perf Enthusiasts AI ▷ #offtopic (5 messages):
- 介绍 Globe Explorer:
@joshcho_分享了@sincethestudy介绍 Globe Explorer 的推文,将其比作针对任何事物的可定制维基百科页面,并称其为信息发现新时代的先驱。他们鼓励大家在 explorer.globe.engineer 尝试。 - 病毒式传播之旅:
@joshcho_幽默地指出,要求广泛分享 Globe Explorer 的请求是不必要的,因为它已经走红了。 - 为 RAG 系统发布 R2R:
@emrgnt_cmplxty宣布发布 R2R,这是一个旨在促进生产就绪的 Retriever-And-Generator (RAG) 系统快速开发和部署的框架,并提供了 GitHub 仓库 链接。他们强调了该框架的简单性,其目标是为生产环境的易用性设定新基准。
提到的链接:
- brian-machado-finetuned-7b (e/snack) (@sincethestudy) 的推文: Globe Explorer 有点像针对你想要的任何内容的自定义维基百科页面。我们正在进入信息发现的新时代。去试试吧:http://explorer.globe.engineer/
- GitHub - SciPhi-AI/R2R: 一个用于快速开发和部署生产就绪 RAG 系统的框架: 一个用于快速开发和部署生产就绪 RAG 系统的框架 - SciPhi-AI/R2R
LLM Perf Enthusiasts AI ▷ #collaboration (3 messages):
- Anki 和 LLM 协作潜力:用户
@degtrdg分享了 一条推文,讨论了包括 GPT-4 和 GPT-3.5 在内的各种 LLM 在为 Anki 等间隔重复工具生成闪卡(flashcards)方面的表现,并指出仍有改进空间。 - GPT-4 生成冗长但有用的 Anki 卡片:用户
@thebaghdaddy发现使用 GPT-4 创建 Anki 卡片非常成功,方法是先将信息整理成涵盖各个方面的表格格式(例如一系列药物的机制和副作用),然后提示 GPT-4 根据表格创建卡片,结果虽然内容略显冗长但非常实用。 - Anki 与 LLM:视觉局限性:
@thebaghdaddy指出了将 LLM 与 Anki 集成时的一个局限性:无法包含图像,而图像对于图像遮盖(image occlusion)等学习方法非常有益。
提到的链接:
来自 Niccolò Zanichelli (5月在旧金山) (@nc_znc) 的推文:评估不同 LLM(GPT-4、GPT-3.5 和一些开源模型)在根据解释性文本生成间隔重复闪卡能力的有趣分析。明显的改进…
LLM Perf Enthusiasts AI ▷ #openai (5 messages):
- Feather 聚在一起:用户
@.kiingo链接到了 Feather OpenAI,引发了对其用途的猜测。@justahvee回应称,根据其图标,该服务似乎与写作有关。 - 挖掘 Feather 的过去:
@dare.ai澄清说 Feather 自 2022 年以来一直在使用,并非新事物,并提供了来自 The Wayback Machine 的快照链接。 - Feather 在训练 AI 模型中的作用:在另一条消息中,
@dare.ai指出 Feather 用于 SME 数据标注和代码注释,这对于训练模型至关重要,并引用了 Semafor 关于 OpenAI 招聘实践的文章。 - GPT-4 Ada 的分析进展:用户
@res6969分享了来自@btibor91的推文,内容关于名为 “gpt-4-ada-v2” 的新 GPT-4 模型,该模型具有数据网格叠加编辑器(data grid overlay editor)、“针对性回复(targeted replies)”选项以及潜在的交互式图表,将更新版本定义为 “ChatGPT Data Analysis V2”。
提到的链接:
- Wayback Machine:未找到描述
-
[OpenAI 雇佣了大量外包人员以使基础编程过时 Semafor](https://www.semafor.com/article/01/27/2023/openai-has-hired-an-army-of-contractors-to-make-basic-coding-obsolete):ChatGPT 背后的公司目前在全球雇佣了约 1,000 人来标注数据,并帮助 OpenAI 的模型学习软件工程任务。 - 来自 Tibor Blaho (@btibor91) 的推文:ChatGPT Data Analysis V2 显然使用了一个名为 “gpt-4-ada-v2” (Advanced Data Analysis V2) 的新 GPT-4 模型。它增加了:- 用于上传文件的数据网格叠加编辑器 - 一个用于 “…” 的选项。
- 登录 Feather:未找到描述
DiscoResearch ▷ #general (4 messages):
- 在训练中探索自定义回调 (Custom Callbacks):
@sebastian.bodza讨论了在 Hugging Face trainer 中使用自定义回调的潜力,指出它们目前是 PyTorch 特有的功能,并且除了通过TrainerControl进行控制外,通常是“只读”的。 - LLM 与以英语为中心的问题:
@_jp1_指出了一篇关于开源大语言模型 (LLMs) 中以英语为中心的思维过程的深刻论文。他认为这对多语言应用具有重要意义,并在 推文链接 中分享了他的观点。 - 审视基于概率的 LLM 评估:
@bjoernp分享了一篇 arXiv 论文,讨论了基于概率的 LLM 评估方法的局限性,特别是针对多项选择题,这也是 DiscoLM 系列研究中遇到的问题。该研究对这类评估的有效性表示怀疑,因为它们可能与基于生成的预测不一致。
提到的链接:
- Beyond Probabilities: Unveiling the Misalignment in Evaluating Large Language Models:大语言模型 (LLMs) 在各种应用中展示了卓越的能力,从根本上重塑了自然语言处理 (NLP) 研究的格局。然而,最近…
- Callbacks:未找到描述
DiscoResearch ▷ #benchmark_dev (10 messages🔥):
- 情感智能基准扩展至德语:EQ-Bench 获得了来自
.calytrix的德语支持和效率改进,使其速度更快且资源消耗更少。更新已在 EQ-Bench GitHub 仓库 上线。 - 德语版 EQ-Bench 初步评分揭晓:
.calytrix列出了德语版 EQ-Bench 的模型初始评分,gpt-4-1106-preview以 81.91 分位居榜首,随后是包括gpt-3.5-turbo-0125以及不同版本的 Mistral 和 Laser 在内的多种模型。 - 对翻译版 EQ-Bench 有效性的担忧:
_jp1_对 EQ-Bench 德语翻译的有效性表示怀疑,认为情感理解中的细微差别可能无法很好地翻译,由于共享以英语为中心的推理,可能导致不同语言基准测试的结果趋同。 - 翻译被认为不损害基准效能:
.calytrix断言,尽管存在潜在的翻译问题,EQ-Bench 的区分度仍然得以保留,英语和德语基准测试之间的平行得分也支持了这一点,表明该测试即使不完美也是有效的。 - 关于 EQ-Bench 翻译中文化差异的辩论:
_jp1_假设模型理解德语特有情感细微差别的能力可能会在双语基准测试中产生不同结果,.calytrix认为这一理论很有吸引力,但对不同的文化思维是否能显著影响基准排名仍持怀疑态度。
提到的链接:
GitHub - EQ-bench/EQ-Bench: A benchmark for emotional intelligence in large language models:大语言模型情感智能基准测试 - EQ-bench/EQ-Bench
DiscoResearch ▷ #embedding_dev (2 messages):
- 介绍 Matryoshka Embeddings:
@johannhartmann分享了一篇 Hugging Face 博客文章,介绍了 Matryoshka Embeddings (套娃嵌入),解释了它们的用途、如何使用 Sentence Transformers 进行训练,并展示了其功能的演示。该博客详细对比了 Matryoshka Embeddings 与常规 Embeddings。 - Sentence Transformers 现已支持 Matryoshka:此外,
@johannhartmann提到 Matryoshka Embeddings 现已集成到 Sentence Transformers 中,为该库的用户扩展了工具集。
提到的链接:
🪆 Introduction to Matryoshka Embedding Models:未找到描述
DiscoResearch ▷ #discolm_german (6 messages):
- 数据集可访问性查询:
@thomasrenkert询问了如何访问 Hugging Face 上的context_understanding数据集。 - 开发中数据集详情:
@bjoernp回复称,该数据集是一个关于检索上下文理解的 Benchmark 的在研项目,尚未准备好广泛共享,且缺乏公开文档。 - 理解 RAG 评估:
@johannhartmann质疑了ger-rag-eval中的方法,即询问使用了哪个上下文来回答问题,而不是检查回答是否正确。 - 澄清 RAG 评估方法论:
@philipmay解释说,在 RAG 设置中,会检索多个上下文,测试 LLM 是否能从中定位到相关信息至关重要。 - 对解释的认可:
@johannhartmann认可了@philipmay关于 RAG 评估方法的观点。
AI Engineer Foundation ▷ #general (12 messages🔥):
-
寻找黑客松队友:
@reydelplatanos正在为即将到来的黑客松寻找队友。@hiro.saxophone响应并提议组队,提到了他们作为 ML Engineer 的经验以及之前在多模态 RAG 方面的工作。 -
注册困扰与团队乐观情绪:
@silverpiranha和@jamthewallfacer都表示正在等待活动的注册确认。随后@silverpiranha分享了对高参与度的兴奋以及最终成功的注册,并邀请@jamthewallfacer组队。 -
后端与 ML 工程在黑客松相遇:自称为 Backend 开发者的
@reydelplatanos接受了@hiro.saxophone组建黑客松团队的提议,标志着新的合作伙伴关系。 -
寻找额外的黑客松成员:
@ryznerf.较晚加入对话,但渴望参加黑客松并正在寻求加入团队。 -
一个高大上的编程创意:
@.yosun分享了一个有趣的黑客松点子,即利用 function calling 来驾驶无人机,并引用了 OpenAI Cookbook 中的一个例子。他们提供了一段代码片段,展示了无人机操作的函数定义。
Links mentioned:
| [Fine tuning for function-calling | OpenAI Cookbook](https://cookbook.openai.com/examples/fine_tuning_for_function_calling): no description found |
Alignment Lab AI ▷ #oo (1 messages):
- Gemma 引入对话控制 Token:
@imonenext为 Gemma-7B 模型增强了用于对话轮次切换的特殊 Token。新的 Token<start_of_turn>和<end_of_turn>旨在实现更好的 Instruction/RL Fine-tuning,并可在 Hugging Face 上访问。
Links mentioned:
imone/gemma-7b-with-it-tokens · Hugging Face: no description found
Skunkworks AI ▷ #general (1 messages):
- 理解深度学习中的随机种子:
@stereoplegic分享了一篇来自 LinkedIn 的被认为“非常值得一读”的文章,重点介绍了深度学习中 Random Numbers 的使用,特别是使用 Python 和 PyTorch 库的实现。他们向那些有兴趣理解或使用随机种子的人推荐了这篇文章:Random Numbers in Deep Learning; Python & the PyTorch Library。