ainews-dia-de-las-secuelas-starcoder-the-stack
续集之日 (StarCoder, The Stack, Dune, SemiAnalysis)
HuggingFace/BigCode 发布了 StarCoder v2,其中包括在 The Stack v2 数据集上经过 600 多种编程语言训练的 StarCoder2-15B 模型。此次发布标志着该规模的模型达到了目前的业界领先水平(state-of-the-art),且训练数据中已剔除了所有“选择退出”(opt-out)的请求。目前已发布详细的技术报告,重点介绍了该模型的能力和训练方法。此外,官方还宣布将在旧金山举行一场现场活动,届时 Dylan Patel 将探讨 GPU 经济学。
2024年2月28日的 AI 新闻。我们为你检查了 356 个 Twitter 动态 和 22 个 Discord(351 个频道和 9043 条消息)。预计节省阅读时间(以 200wpm 计):860 分钟。今天的 Twitter 摘要是由我们团队的 Noah 推动的一次重大升级,欢迎向他提供反馈或批评。
一次性线下活动提醒:如果你在 SF,请参加明天由 Dylan Patel(又名写过 GPU Rich/Poor 文章的“那位 semianalysis 大佬”)主持的 Latent Space 特别现场活动。我们的 第一次对话 是去年被引用次数最多的单集之一。
正如 去年所暗示的,HuggingFace/BigCode 终于发布了 StarCoder v2 和 The Stack v2。完整的技术报告在此。
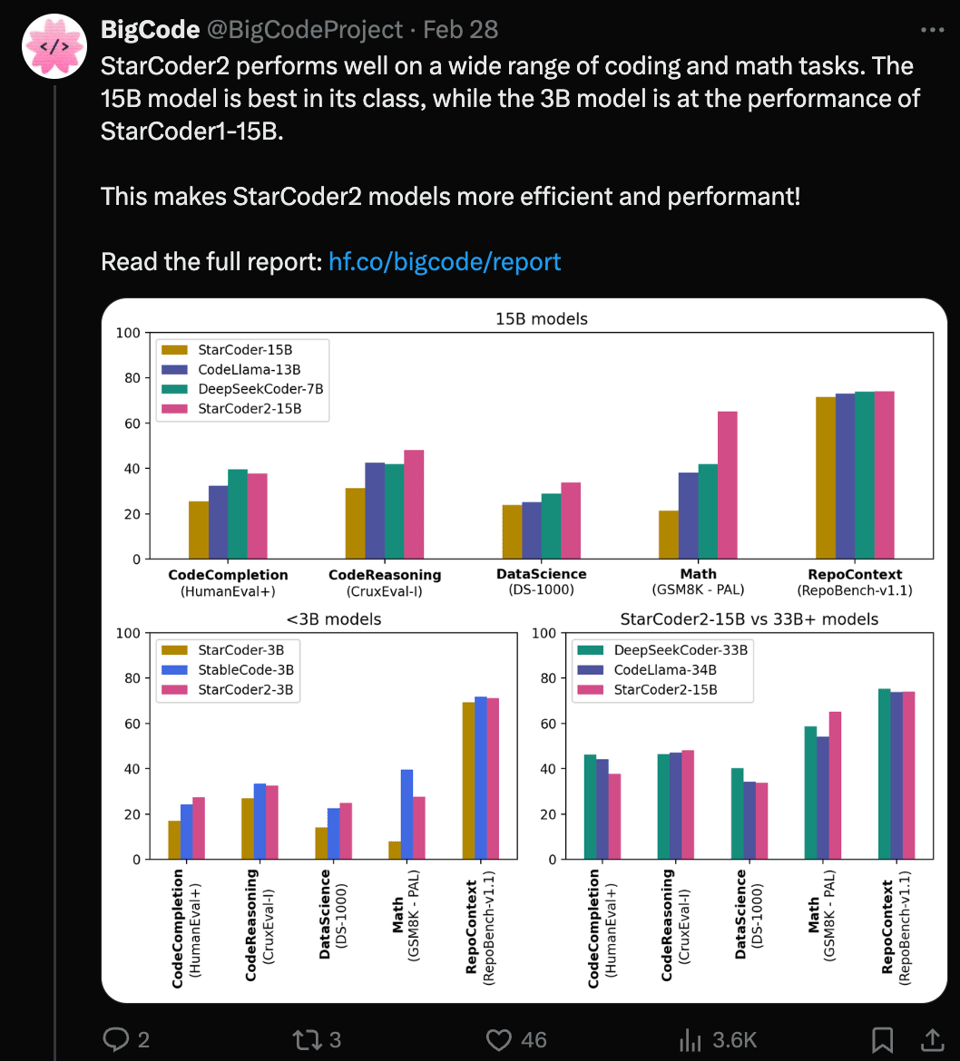
StarCoder 2:同尺寸下的 SOTA(3B 和 15B)
StarCoder2-15B 模型是一个 15B 参数模型,在来自 The Stack v2 的 600 多种编程语言上进行了训练,并排除了选择退出的请求。该模型使用了 Grouped Query Attention 机制。
Grouped Query Attention,16,384 个 token 的上下文窗口 以及 使用
4,096 tokens 的 sliding window attention,并使用 Fill-in-the-Middle objective 在超过 4 万亿个 tokens 上进行了训练。</p>
由于它刚刚发布,目前关于 evals 的最佳来源是 BigCode:
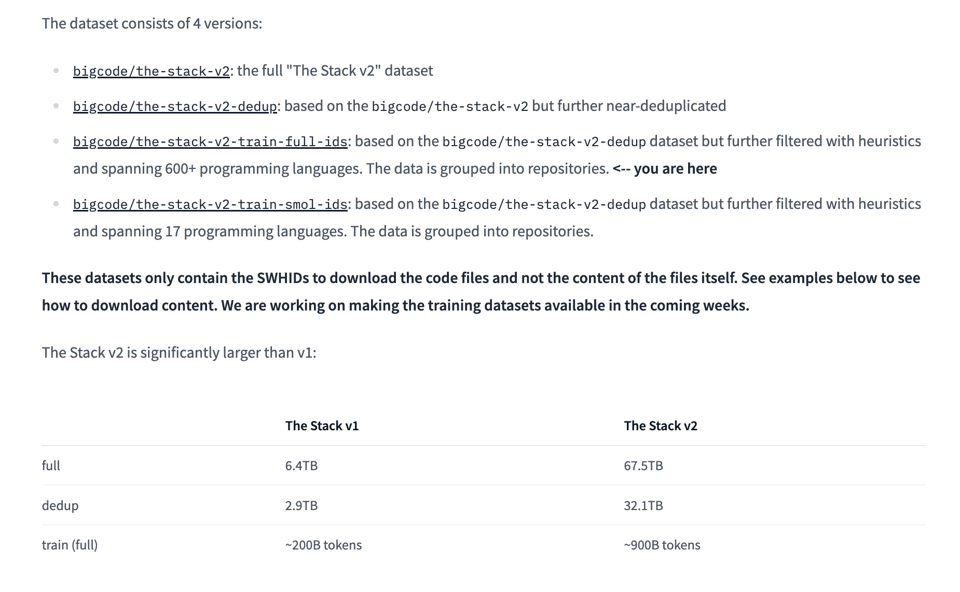
The Stack v2:原始数据大 10 倍,去重后大 4.5 倍 (900B Tokens)
我们正在尝试移除 Table of Contents,因为许多人反馈它并没有预想中那么有用。如果你怀念 TOCs,请告诉我们,否则它们将永久消失。
AI Twitter 摘要
AI 与机器学习讨论
- François Chollet 评论了 LLM 的本质,强调输出反映了训练数据,捕捉了人类的思维模式。
- Sedielem 分享了关于 Diffusion Distillation 的广泛思考,并邀请社区对该博客文章提供反馈。
- François Chollet 区分了当前的 AI 能力与真正的智能,重点关注技能获取的效率。
- Stas Bekman 对 ML 社区依赖单一 Hub 获取权重副本表示担忧,建议需要一个备份 Hub。
高管变动与领导力
- Saranormous 强调了 $SNOW 的领导层变动,欢迎 @RamaswmySridhar 担任新任 CEO,并赞扬了他的技术和领导专业知识。
科技行业动态
- DeepLearningAI 汇总了本周的 AI 资讯,包括 Gemini 1.5 Pro 艰难的一周、Groq 芯片对 AI 处理速度的影响,以及 @AndrewYNg 关于 AI 开发中版本管理的讨论。
- KevinAFischer 庆祝他在 Tech Crunch 上被报道,作为 @shaderapp 和 @daryasesitskaya 开发的 Shader 应用的早期用户。
创新与技术见解
- Andrew N Carr 讨论了根据 1.58 Bit 论文在消费级 GPU 上运行 120B 参数模型的潜力,强调了在 VRAM 效率方面的突破。
- Erhartford 重点介绍了一个实时的 EMO 唇形同步模型,建议将其集成到创新应用中。
迷因/幽默
- C_valenzuelab 提出了一个幽默的比喻,称“飞机并没有颠覆自行车市场”。
- KevinAFischer 调侃了使用 LLM 的经济学,嘲讽了 AI 开发的现状。
- KevinAFischer 就那些超前于时代的想法发表了轻松的评论。
其他观察
- Margaret Mitchell 质疑了关于 Gemini 惨败的新闻报道中的多样性 - 2806 次曝光
- Kevin Fischer 幽默地提到了自己的重复言论 - 732 次曝光
- Zach 谈到了富人需要公平税率的问题 - 492 次曝光
AI 开发与基础设施
- abacaj 提到在 HF 宕机后备份权重的必要性 - 1558 次曝光
- Together Compute 宣布推出来自 @allen_ai 的 OLMo-7B-Instruct API - 334 次曝光
- 关于三元 BitNet 论文在彻底改变模型可扩展性方面的潜力讨论 - 42 次曝光
AI Twitter 叙事
技术和工程师导向的 Twitter 生态系统正围绕 AI、区块链、技术领域的领导层变动以及一些轻松的幽默展开热烈讨论。
在 AI 和 Machine Learning 方面,François Chollet 对 LLMs 作为我们输入之镜像的反思,以及 Daniele Grattarola 对 diffusion distillation 的深入探讨,强调了对 AI 技术本质和未来的批判性思考。为了强化对 Machine Learning 模型多样化保护的重要性,Stas Bekman 关于建立模型权重二级枢纽的提议 引起了社区的关注,凸显了社区在面对实际挑战时的韧性。
在 领导力与创新领域,$SNOW 的领导层变动 获得了极高的参与度,反映了技术组织内部领导力的持续演变和受到的关注。
幽默与梗 (Memes) 仍然是对话的重要组成部分,例如 Cristóbal Valenzuela 关于飞机与自行车之间非竞争关系的观察,为创新和颠覆性技术提供了一个轻松的视角。
在 各类杂项观察 中,Margaret Mitchell 呼吁 在技术报道中引入更多元化的视角,强调了包容性和多样化观点在塑造我们对技术事件理解中的重要性。
最后,关于 AI 开发与基础设施 的讨论将实际考量放在了首位,正如 abacaj 通过备份模型权重 来应对未来可能出现的停机情况。这种操作上的韧性反映了技术和工程社区中更广泛的战略韧性。
PART 0: 摘要之摘要之摘要
TheBloke Discord 上的 ChatGPT 模型评估与数据完整性
- 详细的 ChatGPT 模型对比:成员们对 ChatGPT 模型(包括 GPT-4、Mixtral 和 Miqu)进行了批判性评估,重点关注 API 可靠性 和性能对比。针对来自其他 AI 输出的 训练数据污染 提出了具体担忧,这可能会降低模型的质量和可靠性。
Mistral Discord 上的技术创新与 AI 部署
- NVIDIA RAG 技术限制:NVIDIA 展示 retrieval-augmented generation (RAG) 的 Demo 因其 1024 token 上下文限制 和响应连贯性问题而受到批评。批评还延伸到了 NVIDIA 的实现选择,包括使用 LangChain 作为 RAG 的参考架构,这暗示了关于优化 AI 模型架构 以获得更好性能的更广泛讨论。
LM Studio Discord 上的 Qualcomm 开源 AI 模型
- Qualcomm 对 AI 开发的贡献:Qualcomm 在 Hugging Face 上发布了 80 个开源 AI 模型,针对 vision、audio 和 speech 技术的多种应用。著名的模型包括用于图像处理的 "QVision"、用于音频识别的 "QSpeech" 以及用于增强声音分析的 "QAudio"。这些模型代表了 Qualcomm 在丰富 AI 开发生态系统方面的努力,为研究人员和开发人员提供了在各个领域创新 Machine Learning 应用 的工具。此次发布旨在促进 AI 建模和开发的进步,特别是增强视觉和音频处理以及语音识别任务的能力。
这些更新后的摘要提供了对各自 Discord 社区内特定兴趣和讨论领域的更集中观察。它们突显了对 AI 模型进行的技术审查深度、AI 技术中性能限制的识别和潜在改进,以及 Qualcomm 对开源 AI 领域的具体贡献,强调了 AI 研究与开发持续演进和协作的本质。
PART 1: 高层级 Discord 摘要
TheBloke Discord 总结
- 常规聊天频道中的垃圾信息警报:用户报告了一起涉及
@kquant的垃圾信息事件,Discord 的垃圾信息检测系统在其过度联系 100 多人并发送相同消息后标记了其活动。 - ChatGPT 变体受到关注:讨论了 ChatGPT 模型的各种使用体验,包括 GPT-4 的 API 稳定性,以及与 Mixtral 或 Miqu 模型的对比。用户对来自其他 AI 输出的训练数据污染表示担忧,这可能会损害模型质量。
- 模型合并(Model Mergers)结果参差不齐:对话强调了模型合并结果的不确定性,突出了运气和模型兼容性的作用。专业频道中建议使用 球面线性插值 (slerp) 或 拼接 (concatenation) 等合并策略。
- 使用 LLM 进行创新角色扮演:增强角色扮演中角色一致性的技术包括为 LLM 使用详细的背景故事和性格特征。Miqu 和 Mixtral 等特定模型在这些任务中受到青睐,尽管更长的上下文长度(context length)可能会降低连贯性。
- 把控 AI 训练与微调进度:用户交流了训练技巧,包括使用 Perplexity AI 以及使用 QLoRA 等高效方法来降低硬件需求。强调了验证(validation)和去重(deduplication)的重要性,以及管理模型泛化(generalization)和幻觉(hallucination)的问题。
值得关注的链接:
- 若要深入了解 AI 角色扮演中的详细性格和角色背景故事,可以探索 Hugging Face 上的策略说明和数据集。
- 寻找高效训练技术的 AI 工程师可以关注 MAX 的公告,其平台旨在通过优化的基础设施实现 AI 开发的民主化,详见其 Developer Edition Preview 博客文章 此处。
Mistral Discord 总结
-
NVIDIA 的 Demo 因 RAG 实现受到批评:展示检索增强生成 (RAG) 的 NVIDIA “Chat with RTX” 演示因将上下文大小限制为 1024 个 token 以及响应连贯性问题而面临批评。讨论暗示了对 NVIDIA 在 RAG 参考架构中使用 LangChain 的担忧。
-
Mistral AI 讨论涵盖从许可到开放权重及硬件需求:对话涉及 Mistral AI 对 Meta LLaMa 模型的使用,对 Mistral-7B 之后未来开放权重模型的期待,以及运行大型模型(如 Mistral 8x7B)的硬件需求(可能需要至少 100GB 的 VRAM)。用户考虑使用 Together.AI 等服务来协助部署。
-
模型量化与部署讨论凸显了限制因素:技术讨论包括将 Mistral-7B 约束在特定文档响应中、语言模型的无状态性质以及量化模型的局限性。强调了量化减少 Mistral-7B 参数量的情况,以及全精度模型对大 VRAM 的必要性。
-
Mistral 平台复杂性与 Function Calling 讨论:用户分享了 Mistral function calls 的经验和障碍,并报告了特定消息角色顺序的必要性。一些人提到使用 Mechanician 等工具来更好地与 Mistral AI 集成。
-
教育工具与专用模型的潜力:一位用户展示了一个使用 Mistral 和 GPT-4 AI 模型教授经济学的应用,同时讨论涉及了针对 JavaScript 优化等任务的模型专门训练。聊天中还表达了对改善 AI 行业招聘策略的需求。
这些对话揭示了用户之间的技术洞察力,既体现了对 AI 进步的热情,也包含了对 AI 模型局限性和理想部署场景的务实讨论。
OpenAI Discord 总结
-
加载器大对决:lm studio vs oobabooga 和 Jan dot ai:lm studio 因需要手动 GUI 交互才能启动 API 而受到批评,这使其在自动化网站应用中并非可行选择。工程师们建议使用 oobabooga 和 Jan dot ai 作为替代方案,以实现更无缝的自动化。
-
AI 审核与 OpenAI 反馈:在关于 Copilot AI 的讨论中,一条消息因自动审核(automod)审查而被删除,这引发了向 Discord 管理员报告并直接通过 OpenAI 的 Chat model feedback 表单提交反馈的建议。社区成员还讨论了审核规则的范围。
-
Mistral 的能力与监管咨询:Mistral 模型以其强大且无审查的输出而闻名,被拿来与 GPT-4 进行对比,引发了关于欧洲 AI 监管对该类模型影响的对话。分享了一个相关的 YouTube 视频,展示了如何运行 Mistral 及其影响。
-
提升聊天机器人性能:针对聊天机器人应用增强 GPT-3.5-Turbo 的讨论引发了关于如何达到与 GPT-4 相当性能的辩论。用户讨论了微调(fine-tuning)技术,并建议利用实际数据和常见用例进行改进。
-
AI 认证 vs. 现实应用:对于寻求 AI 专业化的人士,社区强调了动手实践项目优于认证,并推荐了学习资源,如 Andrew Ng 和 Andrej Karpathy 在 YouTube 上的课程。
LM Studio Discord 总结
模型兼容性查询引发 GPU 讨论:工程师们对 Deepseek Coder 6.7B 和 StarCoder2-15B 等 LLM 及其与 Nvidia RTX 40 系列 GPU 的兼容性进行了详细探讨,讨论了 Windows 11 上的 GPU 优化策略(如禁用某些功能)。重点在于寻找最适合硬件规格的模型,StarCoder2 和 The Stack v2 的发布消息进一步强调了这一点。同时提到了 LM Studio 的兼容性问题,特别是在 GTX 650 等旧硬件上。
Hugging Face 宕机中断模型访问:Hugging Face 的宕机导致尝试下载模型的成员遇到网络错误,影响了他们在 LM Studio 内搜索模型的能力。
Qualcomm 发布 80 个开源模型:Qualcomm 在 Hugging Face 上发布了 80 个开源 AI 模型,针对视觉、音频和语音应用,这可能会丰富 AI 建模和开发的生态。
LLM 功能扩展:用户交流了增强 LM Studio 功能的见解,例如使用 Llama2 70B Q4 LLM 实现精确的 PDF 聊天机器人,寻求添加图像识别功能(如使用 PsiPi/liuhaotian_llava-v1.5-13b-GGUF/ 模型)的指导,并表达了对简化下载 vision adapter 模型流程的期望。
硬件的傲慢与希望:围绕用户硬件体验的讨论非常热烈,从回忆旧款 GPU 到分享对电商平台中虚假参数的挫败感。一位用户建议针对 Windows 11 进行优化,而 TinyCorp 宣布了新的硬件产品 TinyBox,详情见此处。此外,还有关于 Nvidia Nvlink / SLI 在模型训练与推理任务中潜力的推测。
HuggingFace Discord 总结
-
Cosmopedia 重磅发布:Cosmopedia 宣布发布,这是一个由 Mixtral 构建的大型合成数据集,包含超过 25B tokens 和 30M 个文件。它旨在服务于各种 AI 研究需求,发布信息可通过此 LinkedIn 帖子获取。
-
Hugging Face 更新汇总:
huggingface_hub库发布了新版本 0.21.0,包含多项改进;同时 YOLOv9 在该平台首次亮相,根据 Hugging Face spaces 和 huggingface.co/models 的讨论,它现在已兼容 Transformers.js。 -
DSPy 迈向生产环境:目前正在探索 DSPy 和 Gorilla OpenFunctions v2,以实现从 Gradio 原型向生产版本的过渡。这些工具承诺在无需 prompting 的情况下增强基础模型的客户引导流程,相关讨论和资源可以在 GitHub 上的 stanfordnlp/dspy 等仓库中找到。
-
BitNet 初露锋芒:讨论了一种新型的 1-bit LLM, BitNet b1.58,据称它在保持性能的同时具有令人印象深刻的效率指标,其研究成果可通过此 arXiv 论文查阅。
-
推理挑战与解决方案:在文本推理领域,一位 AI 专业人士在尝试将 text-generation-inference 仓库部署到无 CPU 且非 CUDA 系统时遇到了问题。这突显了 AI 模型部署中常见的环境约束。
LAION Discord 总结
-
AI 模型 Ideogram 引起关注:工程师们讨论了 Ideogram 发布的新 AI 模型,并将其与 Stable Diffusion 进行了比较,同时揭示了关于未公开的 Imagen 样本质量问题的推测。一位用户分享了一个 prompt 结果,引发了关于其 prompt 遵循度和美学效果的辩论。
-
探讨 SD3 中 T5 XXL 与 CLIP 的集成:围绕将 T5 XXL 和 CLIP 模型集成到 Stable Diffusion 3 (SD3) 的可能性进行了讨论,参与者期待未来的生成模型在精确度和美学上都能有所突破。
-
对 AI 生成艺术的担忧:一场关于 AI 生成艺术和版权法的法律讨论展开,引用了中国的一项裁决和一篇关于生成式 AI 版权安全的文章,强调了该领域的不确定性以及行业对 DMCA 请求的多样化响应。
-
脉冲神经网络(Spiking Neural Networks)再度流行?:一些成员考虑了通过时间抖动(time dithering)等先进技术来提高精度的脉冲神经网络复兴的可能性,并对历史和当前的研究方法进行了反思。
-
SOTA 图标生成模型发布:一个新的 AI 图标生成模型已在 Hugging Face 上发布,该模型由个人出资 2,000 美元开发,据称可以创建 256px 的低噪点图标,尽管其创作者承认存在尺寸限制。
Nous Research AI Discord 总结
-
关于 GPT-5 未亮相的表情符号叙事:社区成员使用一系列表情符号来表达对 GPT-5 缺席的情绪,在敬礼、骷髅和泪水之间摇摆,同时膜拜着从 GPT 迭代到神话般的 GPT-9。
-
戴尔的双连接显示器和扩展坞引起工程师兴趣:一段关于戴尔新型 5K 显示器和 Dell Thunderbolt Dock WD22TB4 的 YouTube 评论 激起了人们对其连接多台机器能力的兴趣,并建议通过 eBay 进行购买。
-
BitNet B1.58 揭示 1-bit LLMs:arXiv 论文 介绍了 BitNet b1.58,这是一种性能与全精度模型相当的 1-bit LLM,强调其作为一种具有成本效益的创新,同时提到了 Nicholas Carlini 的 LLM 基准测试。
-
探索替代的低成本 LLMs 和微调实践:用户讨论了 GPT-4 的替代方案、小训练数据集规模的影响,以及使用 Directed Prompt Optimization (DPO) 来改进模型响应的潜力。
-
前沿研究与新型基因组模型首次亮相:斯坦福大学发布的基因组序列模型 HyenaDNA,以及来自 CausalLM 令人惊讶的 MMLU 分数,还有关于 AI 可解释性的资源,如 Representation Engineering 和 tokenization 策略,都是讨论的热点话题。
Latent Space Discord 总结
-
Noam Shazeer 谈代码风格:
@swyxio强调了 Noam Shazeer 关于 代码风格和形状后缀 (shape suffixes) 的第一篇博客文章,这可能会引起热衷于命名规范的开发者的兴趣。 -
AI 在客户服务中的应用:数据显示 LLMs 在客户服务方面可以达到人类水平,潜在地处理三分之二的客户服务查询,这引发了人们的热情,暗示了客户交互管理方式的转变。
-
学习 Matryoshka Embeddings:成员们讨论了创新的 “Matryoshka Representation Learning” 论文及其在 具有自适应维度的 LLM embeddings 中的应用,这在计算和存储效率方面具有潜在优势。
-
MRL Embeddings 活动:
<@206404469263433728>宣布了一项即将举行的活动,MRL embeddings 论文 的作者将出席,为在#1107320650961518663频道深入讨论表示学习提供了机会。 -
Representation Engineering 课程:
@ivanleomk预告了与<@796917146000424970>合作的 Representation Engineering 101 教育课程,这标志着一个在#1107320650961518663频道学习和咨询如何工程化有效数据表示的机会。
Perplexity AI Discord 摘要
-
Rabbit R1 激活协助:用户
@mithrilman在尝试激活 Rabbit R1 促销活动时遇到了邮件链接无法点击的问题。@icelavaman建议直接使用邮件链接并联系支持部门。 -
播客身份确认:针对使用 “Perplexity AI” 名称的播客引发的混淆,
@icelavaman提供了官方播客链接进行澄清,而@ok.alex推测该名称可能在未经授权的情况下被用于吸引关注或获取经济利益。 -
比较 AI 模型能力:用户探讨了 Experimental, GPT-4 Turbo, Claude 和 Mistral 等各种 AI 模型的优缺点。关于 Mistral 在代码查询方面的有效性,意见分歧明显。
-
集思广益 Perplexity AI 的改进建议:对 Perplexity AI 的建议包括导出线程回复功能,该功能目前缺失,但已被考虑用于未来更新。问题还包括缺少文件上传选项以及对产品名称更改的困惑。
-
模型性能怀旧与 API 错误:讨论涉及文本生成的故障,以及对 pplx-70b 优于 sonar 模型的怀念。
@jeffworthington在 OpenAPI 定义方面面临挑战,认为目前的文档可能已经过时。
分享的链接:
- 官方 Perplexity AI 播客:Discover Daily by Perplexity 和 Perplexity AI。
- Perplexity API 入门指南:pplx-api 文档。
Eleuther Discord 摘要
-
基础模型开发备忘单发布:一份名为 The Foundation Model Development Cheatsheet 的新资源已发布,旨在帮助开源模型开发者。该资源汇集了来自 EleutherAI, MIT, AI2, Hugging Face 等机构的贡献,重点关注数据集文档和许可等经常被忽视但至关重要的方面。该备忘单可以通过 PDF 论文或交互式网站访问,更多信息请见其 Blog post 和 Twitter thread。
-
Scaling Laws 与模型训练讨论升温:讨论范围从交叉注意力 SSM 模型、稳定视频扩散训练、lm-evaluation-harness 的细微差别,到 EleutherAI 的 Pythia 模型状态,以及关于 1-bit Large Language Model (LLM) 的摘要。值得注意的参考资料包括关于 LM 评估中多选题归一化的博客文章和关于 1-bit LLMs 时代的研究论文。
-
从开源模型到求解迷宫的扩散模型:研究频道展示了对各种 AI 主题的讨论,从开源模型、预训练 Token 与模型大小比例,到训练用于求解迷宫的扩散模型、提示工程迁移研究,以及 sub 8-bit quantization 的实际挑战。关键资源包括 Stable LM 2 1.6B 技术报告,以及 François Fleuret 关于训练扩散模型求解迷宫的推文。
-
关于 Neox 与 Slurm 兼容性的查询:用户
@muwnd寻求关于在 Slurm 上运行 Neox 及其与容器兼容性的建议。会议强调 Neox 的基础设施不对用户的设置做任何假设,多节点执行可能需要 slurm 脚本。 -
探索可解释性技术与范数:可解释性(interpretability)频道的对话深入探讨了矩阵范数与乘积、RMSNorm 层应用、使用 tuned lenses 进行解码,以及对矩阵范数术语的正确理解。例如,Frobenius 范数是矩阵展平后的欧几里得范数,而 “2-norm” 是谱范数或最大奇异值。
-
LM Eval Harness 的调整与多语言升级:分享了对 LM Eval harness 聊天模板的增强功能,并有消息称
@946388490579484732贡献了更高质量的 Multilingual Lambada 翻译,并将包含在评估工具箱中。这些数据集已在 Hugging Face 上发布。
LangChain AI Discord 总结
-
对 LangChain.js 的置信度:
@ritanshoo提出了关于在使用 LangChain.js 进行 RAG 时如何进行置信度分数检查的问题。虽然没有立即提供直接答案,但建议用户参考 LangChain 文档 以获取深入指导。 -
LangChain 集成查询:技术讨论强调了为 LCEL 添加 memory 以及在 Azure 托管环境中实现 LangChain 有效语言集成的可能性。建议用户咨询官方文档或寻求社区帮助以解决特定的集成问题。
-
探索 ToolException 的变通方法:
@abinandan寻求关于在自定义工具出现ToolException后如何重试工具的建议。社区指向了 LangChain GitHub 讨论和 Issues 以寻找潜在解决方案。 -
LangServe 执行中的奇特现象:
@thatdc报告称,与直接从 Agent 类调用相比,使用 langserve 时会丢失中间步骤的详细信息。他们发现RemoteRunnable中可能存在一个缺陷,需要一种变通方法。 -
召唤 Python 模板炼金术士:
@tigermusk寻求帮助创建一个类似于 Smith LangChain Chat JSON Hub 上可用的 Python 模板,引发了关于模板生成的讨论。 -
《LangChain in your Pocket》备受赞誉:
@mehulgupta7991宣布他们的著作《LangChain in your Pocket》最近入选了 Google 的 LangChain 最佳书籍,为 LangChain 爱好者提供了学习资源。 -
AI 语音聊天应用 Beta 测试:Pablo 是一款集成了多个 LLM 并提供无需打字的语音支持的 AI 语音聊天应用,目前正在招募 Beta 测试人员。工程师们被邀请加入这个利用 LangChain 技术开发应用的团队,并提供 免费 AI 额度。
-
AI 股票分析聊天机器人创建说明:
@tarikkaoutar分享了一个 视频教程,演示了如何使用 LangGraph, Function call 和 YahooFinance 构建 AI 股票分析聊天机器人,适合对多 Agent 系统感兴趣的工程师。 -
Groq 硬件发布引发热议:Groq 推出的适用于 LLM 的突破性 Language Processing Unit (LPU) 吸引了技术爱好者的关注,该内容通过
@datasciencebasics分享的 YouTube 展示视频 进行传达。
(注:以上总结整合了 Discord 社区内各个频道的议题和资源,重点关注寻求技术文档、代码集成以及 AI 硬件和应用进展的工程师群体感兴趣的内容。)
OpenAccess AI Collective (axolotl) Discord 总结
-
Jupyter 配置混乱:用户报告了 Jupyter notebooks 的问题,强调了有关扩展链接的错误消息以及 “Bad config encountered during initialization”(初始化期间遇到错误配置),讨论中尚未给出最终解决方案。
-
BitNet b1.58 突破:一篇 arXiv 论文 介绍了 BitNet b1.58,这是一种 1-bit LLM,其性能可与全精度模型相媲美,凭借创新的架构预示着显著的成本效益。
-
Sophia 速度超越 Adam:Sophia 优化器 被分享,据称其速度是 Adam 算法的两倍,同时分享的还有其 实现代码,引发了对其在 AI 模型优化方法中效率的关注。
-
DropBP 通过丢弃层提高效率:一项研究提出了 Dropping Backward Propagation (DropBP),这种方法通过在反向传播期间跳过某些层,有可能在不显著影响准确性的情况下降低神经网络训练的计算成本。
-
斯堪的纳维亚对决:Mistral vs. ChatGPT 3.5:用户 le_mess 报告称,他们的 7B Mistral 模型 在丹麦语任务中的表现与 ChatGPT 3.5 旗鼓相当,该模型采用了迭代合成数据方法,通过 30 次迭代进行渐进式训练,并结合了初始的人工筛选。
LlamaIndex Discord 摘要
- Groq 的集成增强了 LlamaIndex:Groq LPU 现在支持 LlamaIndex,包括
llama2和Mixtral模型,旨在通过提供的全面 cookbook 指南 优化 LLM 生成并简化应用程序工作流。 - LlamaIndex 服务扩展与优化:LlamaParse 报告了显著的使用量,导致使用上限提高,并正向无限制的自助使用更新;同时,此见解分享了一种在混合搜索中使用 LLM 进行 alpha 参数调整的新策略。此外,由
@ClickHouseDB提出的结合结构化和非结构化数据的 RAG 架构也受到了关注,详情请参阅此处。 - 技术见解与澄清升温 LlamaIndex 讨论:正在考虑对最新的 LlamaIndex docs 进行索引,其中提到了 mendable 作为文档工具;同时
@cheesyfishes评论了 Golang 中CallbackHandler预期的重构。尽管缺乏对比指标,但 FlagEmbeddingReranker 与 CohereReranker 的组合被确定为一种策略;@cheesyfishes解释说,虽然 LlamaIndex 为 LLM 提供数据服务,但 Langchain 是一个更全面的库。 - AI 社区质疑模型行为:关于模型衰减 (model decay) 的讨论中,
@.sysfor注意到其模型的输出质量下降,而@cheesyfishes强调模型本身不会衰减,但输入问题可能会影响性能。这种担忧还延伸到了微调模型在与基准模型 (baseline models) 比较时表现不佳的问题。
OpenRouter (Alex Atallah) Discord 摘要
- Claude 遇到对话故障:据报告,来自 Anthropics 的 Claude 模型在超过 8 条交替消息的对话中会出现错误。
@louisgv已确认该问题,并承诺即将推出修复方案。 - OpenRouter 的轮次切换调整:
@alexatallah建议了一个针对 Claude prompt 错误的变通方法,包括将初始的 assistant 消息更改为 system 消息。目前正在开发中,以更好地处理由 assistant 发起的对话。 - OpenRouter 的速率限制 (Rate Limit) 转接:当被问及文章生成的速率限制时,
@alexatallah澄清说,为 OpenRouter 用户单独分配的 API keys 将具有独立的限制,这大概能允许足够的集体吞吐量。 - Mistral 疑似存在缓存机制:用户注意到 Mistral 模型出现了重复的 prompt 响应,表明可能存在缓存机制。
@alexatallah确认了 Mistral API 中存在查询缓存的可能性。 - OpenRouter 的预付卡支付难题:
@fakeleiikun提出了关于 OpenRouter 接受预付卡的问题,@louisgv回应称这可能与 Stripe 的欺诈预防机制有关,表明支持情况参差不齐。
CUDA MODE Discord 总结
-
基准测试赏金 (Benchmarking Bounties):
@hdcharles_74684改进了一个针对 Triton kernel 的 benchmark 脚本,该脚本在特定场景(如 batch size 大于 1)下可能优于 cuBLAS,这与 sdxl-fast 等应用相关。鉴于潜在的 Triton 优化,关注 Torch.compile 等技术可以解决处理 batch size 为 2 时的瓶颈。 -
Triton 的困扰与进展 (Triton Turmoil and Triumphs):用户在 Triton 3.0.0 和 2.2.0 版本中遇到了调试问题;一种解决方法是设置
TRITON_INTERPRET环境变量。此外,与 CUDA 相比,用户对 Triton 不可预测的 segfaults 表示担忧,并请求提供对比示例以了解这些不一致性。 -
FP8 Intrinsics 保持不变 (FP8 Intrinsics Intact):针对基于一条 推文 的提问,
@zippika澄清说 FP8 intrinsics 仍记录在 CUDA math API 文档 中,并指出 FP8 主要是一种数据格式,并非普遍应用于计算操作。 -
编译器难题 (Compiler Conundrums):在深度学习领域,有人对 polyhedral compilation 在优化 sharding 方面的实用性表示怀疑。这与关于定义 cost functions、将深度学习程序映射到硬件的复杂性,以及顶尖 AI 机构是否正在解决这些优化挑战的更广泛讨论相关联。
-
Ring Attention 谜题 (Ring Attention Riddles):有人提议进行对比以验证 Ring Attention 实现 的正确性和性能,因为在 backward pass 中发现了潜在的 bug,并且出现了 GPU 兼容性问题。用户
@iron_bound根据 提交历史分析 指出该实现可能存在损坏,强调需要仔细进行代码审查和调试。
Interconnects (Nathan Lambert) Discord 总结
-
欧洲独立与开源权重雄心 (European Independence and Open-Weight Ambitions):Arthur Mensch 强调了对 open-weight 模型的承诺,特别提到了 1.5k H100s,并强调了与 Microsoft 的转售协议。Le Chat 和 Mistral Large 在 La Plateforme 和 Azure 上备受关注,展示了增长和快速开发的方法。点击查看详情。
-
StarCoder2 开辟新天地 (Starcoder2 Breaks New Ground):拥有超过 900B+ token 的 The Stack v2 是 StarCoder2 的核心动力,StarCoder2 拥有 16k token 的上下文,并在超过 4T+ token 上进行了训练。它为编程 AI 社区提供了一个强大的补充,拥有完全开放的代码、数据和模型。探索 StarCoder2。
-
Meta 即将推出的 Llama 3 (Meta’s Upcoming Llama 3):路透社的一份报告指出,Meta 正准备在 7 月发布 Llama 3,这标志着 AI 语言模型领域可能迎来洗牌。The Information 提供了关于此次发布的更多细节。此处获取更多信息。
-
DeepMind CEO 的见解吸引了 Nathan (DeepMind CEO’s Insights Captivate Nathan):Nathan Lambert 收听了 Google DeepMind 的 Demis Hassabis 参与的播客,涵盖了 superhuman AI scaling、AlphaZero 与 LLM 的结合以及 AI 治理的复杂性 等话题。这些见解可以在包括 YouTube 和 Spotify 在内的多个平台上获取。
-
Open AI 与个人观点 (Open AI and Personal Perspectives):Nathan 和 Mike Lambert 之间的对话涉及了 open AI 的本质和重要性,以及与 Twitter 等平台相比不同的思维模式。此外,任职于 Anthropic 的 Mike Lambert 表示,他更倾向于以个人身份而非公司代表进行对话。
LLM Perf Enthusiasts AI Discord 摘要
- 自动化基准测试的热潮:工程师
@ampdot和@dare.ai热衷于探索自动化基准测试脚本,后者还艾特了另一位用户,询问此类工具的可能更新。 - 对 Llama 3 的春季期待:
@res6969预测 Llama 3 将在春季发布,但也暗示时间表可能会延长;而@potrock则对最后一刻的更新充满希望,特别是对 Gemini ring attention 潜在集成的可能性很感兴趣。 - 测试时间的难题:
@jeffreyw128提出了全面测试新 LLM 所需时间投入的挑战,目标是对每个模型进行充分的 “vibe check”(氛围检查)。 - ChatGPT 搜索功能的猜测浮出水面:
@jeffreyw128提到了有关 OpenAI 即将更新 ChatGPT 网页搜索功能的传闻,@res6969正在寻求更可靠的 OpenAI 情报,并对在生产环境中部署 codeinterpreter 的资源感到好奇。
DiscoResearch Discord 摘要
-
DiscoLM 模板使用的重要性:
@bjoernp强调了使用 DiscoLM 模板进行正确的聊天上下文 Tokenization(分词)的重要性,并指出 Hugging Face 上的 聊天模板文档 是一个关键资源。 -
llamaindex 代码分块的困扰:
@sebastian.bodza在使用 llamaindex 的代码分块器时遇到了严重问题,尽管设置了chunk_lines,但输出仍为单行,这表明可能存在 Bug 或需要调整工具。 -
挑战德语 AI 的边界:
@johannhartmann正在利用德国电信的数据开发德语 RAG 模型,寻求关于增强德语 Mistral 7b 模型可靠性的建议;而@philipmay则深入研究了通过指示模型伪造错误答案来为 RAG 数据集生成负样本的方法。 -
德语语言模型的战场:关于 Goliath 或 DiscoLM-120b 谁更擅长德语任务引发了辩论,
@philipmay和@johannhartmann参与了讨论;@philipmay发布了 Hugging Face 上的 Goliath 模型卡片 以供进一步检查。 -
德语 Prompt 和模型的基准测试:
@crispstrobe透露 EQ-Bench 现在包含了德语 Prompt,其中 GPT-4-1106-preview 模型在性能上领先,并提供了一个 GitHub pull request 链接;他们提到翻译脚本是基准测试的一部分,由 ChatGPT-4-turbo 有效翻译。
Datasette - LLM (@SimonW) Discord 摘要
- JSON 处理技巧仍不明朗:
@dbreunig谈到了处理 噪声 JSON 响应 的常见挑战,但未透露清理技术或函数的具体细节。 - 消除 Claude 的闲聊:
@justinpinkney建议根据 Anthropic 的文档 使用类似<rewrite>的初始字符,以规避 Claude 默认的开场白,如 “Sure here’s a…“(好的,这是…)。 - 与 Claude 的简洁度之战:
@derekpwillis尝试了几种策略来让 Claude 输出更短的内容,包括强制 AI 以{开始回答,但承认 Claude 仍然倾向于包含前置解释。
Skunkworks AI Discord 摘要
意外的招聘方式:用户 .papahh 直接私信了 @1117586410774470818,表示有一个工作机会,并对他们的潜在参与表现出热情。
Alignment Lab AI Discord 摘要
- 跨物种的价值探索:
@taodoggy邀请大家合作开展一个项目,旨在探讨 物种间共享价值观的生物学和进化起源,完善价值定义,并探索它们在各种文化中的表现。项目概览可通过 Google Docs 链接 访问。
第 2 部分:各频道详细摘要与链接
TheBloke ▷ #general (1070 条消息🔥🔥🔥):
- Discord 检测到垃圾信息发送者:用户注意到聊天中被标记为疑似垃圾信息的消息,特别是来自
@kquant的消息。据报告,该用户向 100 多人发送了相同的信息,触发了 Discord 的垃圾信息检测系统。 - 探讨 ChatGPT 性能:
@itsme9316和@notreimu等用户讨论了他们使用 ChatGPT 模型的不同体验。一些人指出,与 Mixtral 或 Miqu 等替代模型相比,GPT-4 的 API 对他们来说不够可靠。 - 模型合并对话:包括
@itsme9316和@al_lansley在内的多位用户讨论了模型合并(Model Merging),以及它并不总是能产生更智能的模型。大家达成共识,认为合并往往取决于运气和模型的兼容性。 - 对训练数据污染的担忧:
@itsme9316等用户对现代 LLM 可能被 OpenAI 等其他模型的输出所污染表示担忧,这可能会影响质量和可靠性。 - 量化与模型性能:在
@notreimu和@aiwaldoh的引导下,大家讨论了低位宽(bpw)量化的高参数模型与高位宽的小型模型之间的性能差异。用户分享了使用不同量化模型的各种经验。
提到的链接:
- 数据库搜索:搜索我们的泄露信息数据库。所有信息均处于公共领域,并已整合到一个搜索引擎中。
- 浅谈 Apple 新推出的由 Transformer 驱动的预测文本模型:我发现了一些关于 Apple 新预测文本模型的细节,该模型即将在 iOS 17 和 macOS Sonoma 中推出。
- 微软支持的 OpenAI 在完成交易后估值达 800 亿美元:该公司将在由风险投资公司 Thrive Capital 牵头的“要约收购”中出售现有股份,交易方式与去年初类似。
- 悲伤 GIF - Sad - 发现并分享 GIF:点击查看 GIF。
- writing-clear.png · ibm/labradorite-13b at main:未找到描述。
- 死亡亦不能主宰:死亡亦不能主宰。/ 裸体的死者将合而为一。
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO · Hugging Face:未找到描述。
- 无审查模型 (Uncensored Models):我发布这个是因为很多人问我是怎么做到的,所以我将进行说明。https://huggingface.co/ehartford/WizardLM-30B-Uncensored https://huggingface.co/ehartford/WizardLM-13B-Uncensore…
- BioMistral/BioMistral-7B · Hugging Face:未找到描述。
- NousResearch/Nous-Hermes-2-SOLAR-10.7B · Hugging Face:未找到描述。
- adamo1139 (Adam):未找到描述。
- p1atdev/dart-v1-sft · Hugging Face:未找到描述。
- google/gemma-7b-it · 异常的 GGUF 输出:未找到描述。
- Attack of the stobe hobo.:完整电影。请欣赏。愿 Jim Stobe 安息。
-
Fred again..: Tiny Desk 音乐会:Teresa Xie 2023 年 4 月 10 日。当 Fred again.. 最初提议举办 Tiny Desk 音乐会时,人们并不清楚他将如何实现——这并不是因为他… - 我的指纹 - 我是唯一的吗?:未找到描述。
- GitHub - MooreThreads/Moore-AnimateAnyone:通过在 GitHub 上创建账号来为 MooreThreads/Moore-AnimateAnyone 的开发做出贡献。
- adamo1139/rawrr_v2 · Hugging Face 数据集:未找到描述。
{kind=link}
TheBloke ▷ #characters-roleplay-stories (511 条消息🔥🔥🔥):
-
LLM 角色扮演讨论:用户讨论了使用 Large Language Models (LLMs) 进行角色扮演的有效性,包括构建角色身份的技术,例如告诉 LLM “你是一名记者”以提高表现。
@nathaniel__建议成功的策略包括分配角色和详细的性格设定,@maldevide分享了一种使用#define语法的 Prompt 结构化方法。 -
角色一致性:包括
@shanman6991和@superking__在内的几位用户探讨了是否可以通过向 LLMs 提供详细的背景故事和性格特征来提高角色一致性。人们对让角色在角色扮演场景中能够令人信服地撒谎或策划阴谋的技术特别感兴趣。 -
Prompt Engineering 策略:
@maldevide讨论了在 Prompt 中使用专有名词和陈述性语句来引导 LLMs 进入所需的对话模式,而@superking__提供了 Instruct 模式与纯 Chat 模式设置的示例,以实现更好的模型引导。 -
角色扮演的模型选择:像
@superking__这样的用户表示偏好使用特定的模型,如 miqu 和 mixtral 进行角色扮演,通常不使用 System Prompts。还提到了模型在较长上下文长度下可能变得不连贯的问题,并讨论了抵消这一影响的策略。 -
LLMs 中的命名惯例:
@gryphepadar和@maldevide观察到,当 LLMs 被要求生成角色名称时,某些名字(如 “Lyra” 和 “Lily”)在回复中似乎特别常见,这引发了关于训练数据对这些命名趋势影响的一些推测。
提到的链接:
- Let Me In Eric Andre GIF - Let Me In Eric Andre Wanna Come In - Discover & Share GIFs:点击查看 GIF
- Sad Smoke GIF - Sad Smoke Pinkguy - Discover & Share GIFs:点击查看 GIF
- Why Have You Forsaken Me? GIF - Forsaken Why Have You Forsaken Me Sad - Discover & Share GIFs:点击查看 GIF
- maldv/conversation-cixot · Datasets at Hugging Face:未找到描述
- Hawk Eye Dont Give Me Hope GIF - Hawk Eye Dont Give Me Hope Clint Barton - Discover & Share GIFs:点击查看 GIF
- GitHub - UltiRTS/PrometheSys.vue:通过在 GitHub 上创建账户,为 UltiRTS/PrometheSys.vue 的开发做出贡献。
- GitHub - predibase/lorax: Multi-LoRA inference server that scales to 1000s of fine-tuned LLMs:可扩展至数千个微调 LLMs 的 Multi-LoRA 推理服务器 - predibase/lorax
TheBloke ▷ #training-and-fine-tuning (86 条消息🔥🔥):
- Perplexity AI 作为新工具:用户
@icecream102建议尝试将 Perplexity AI 作为一个资源。 - 使用 QLoRA 进行低预算训练:
@dirtytigerx建议训练像 GPT 这样的大型语言模型可能非常昂贵,并建议使用 QLoRA 等技术来限制硬件需求,但指出这仍然需要许多小时的计算。 - 训练和推理成本估算:在关于估算训练和推理的 GPU 小时的讨论中,
@dirtytigerx建议进行一次微小的测试运行,并查阅已发表的论文以获取基准。 - 模型训练动态讨论:
@cogbuji对以静态低验证损失训练模型提出了疑问,促使@dirtytigerx建议更改验证集划分并采取去重步骤来解决差异。 - 模型泛化与幻觉问题:
@dirtytigerx和@cogbuji讨论了训练模型的泛化能力以及推理过程中不可避免的幻觉(Hallucination)问题,建议使用检索机制和进一步的评估策略。
提到的链接:
cogbuji/Mr-Grammatology-clinical-problems-Mistral-7B-0.5 · Hugging Face:未找到描述
TheBloke ▷ #model-merging (6 条消息):
- Tensor Dimension Misalignment 问题:
@falconsfly指出,由于单个 bit 错位或对齐错误导致了一个问题,从而产生了错误的 Tensor 维度。 - 对信息分享表示感谢:
@222gate感谢@falconsfly分享关于 Tensor 维度问题的信息。 - 关于 Slerp 或 Linear 技术的询问:
@222gate询问所讨论的合并技术是否涉及 spherical linear interpolation (slerp) 或者仅仅是 linear ties。 - 对 Diffusion 测试技术的思考:作为回应,
@alphaatlas1提到不确定@222gate的具体疑问,但分享了他们的 Diffusion 测试使用了 dare ties,并推测 HuggingFace 的测试可能涉及了 dare task arithmetic。 - 合并中 Concatenation 的建议:
@alphaatlas1建议任何进行 peft 合并的人尝试 concatenation,并表示其效果很好,同时指出目前还没有针对它的 full-weight merging 模拟方案。
TheBloke ▷ #coding (8 条消息🔥):
-
渴望合作:
@wolfsauge表达了向@falconsfly学习的热情,期待在晚餐后讨论关于增强功能的新想法。 -
没有 GPU 就没有速度?:
@dirtytigerx表示,如果没有 GPU,加速流程将极具挑战性,且没有提供其他性能提升的替代方案。 -
用于加速的 API:
@tom_lrd建议使用 API 作为加速流程的替代方案,并列举了多个服务,如 huggingface、together.ai 和 mistral.ai。 -
在 Colab 之外寻找托管 Notebook:尽管
@dirtytigerx提到云服务商提供的平台缺乏托管 Notebook,但@falconsfly指出 Groq.com 提供了快速的 inference。 -
Modular MAX 加入战场:
@dirtytigerx分享了关于 modular MAX 平台全面开放的消息,宣布了开发者版本预览,以及其通过统一、优化的基础设施实现 AI 民主化的愿景。
提到的链接:
Modular: Announcing MAX Developer Edition Preview:我们正在为全球构建下一代 AI 开发者平台。查看我们的最新文章:Announcing MAX Developer Edition Preview
Mistral ▷ #general (992 messages🔥🔥🔥):
-
NVIDIA 的 Chat with RTX 演示遭到批评:像
@netrve这样的用户对 NVIDIA 的 “Chat with RTX” 演示表示失望,该演示旨在展示检索增强生成 (RAG) 能力。该演示将上下文大小限制在 1024 tokens,在检索正确信息和提供连贯回答方面面临问题。NVIDIA 在 RAG 参考架构中使用 LangChain 的做法也受到了质疑。 -
OpenAI 和 Meta 授权讨论:由
@i_am_dom和@netrve发起了一场关于 Mistral AI 使用 Meta 的 LLaMa 模型、潜在的授权问题以及商业使用影响的激烈讨论。共识认为,鉴于 Mistral 似乎遵守了 Meta 的许可条款,Mistral 与 Meta 之间可能存在未公开的协议。 -
关于 Mistral AI 开放权重模型的对话:
@mrdragonfox、@tarruda等人讨论了 Mistral AI 对开放权重模型的承诺,并对 Mistral-7B 模型之后的未来发布进行了推测。社区对 Mistral 提供更多开放权重模型表示了信任和期待。 -
RAG 实施挑战凸显:包括
@mrdragonfox和@shanman6991在内的多位用户讨论了有效实施 RAG 系统的复杂性。他们提到 Embedding 模型对 RAG 性能的重大影响,以及 RAG 难以达到完美状态,通常需要数月的精细调整。 -
Mistral AI 与微软交易受到审视:微软对 Mistral AI 的投资引发了关于投资规模及其对 AI 领域竞争影响的讨论。
@ethux分享的信息暗示投资金额极小,而@i_am_dom则对微软因 Miqu 等开源模型的潜在复杂性而采取的谨慎态度表示担忧。
提到的链接:
- What Is Retrieval-Augmented Generation aka RAG?:检索增强生成 (RAG) 是一种利用从外部源获取的事实来增强生成式 AI 模型准确性和可靠性的技术。
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits:最近的研究(如 BitNet)正在为 1-bit Large Language Models (LLMs) 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数…
- LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys:暂无描述
- Klopp Retro GIF - Klopp Retro Dancing - Discover & Share GIFs:点击查看 GIF
-
[Basic RAG Mistral AI Large Language Models](https://docs.mistral.ai/guides/basic-RAG/):检索增强生成 (RAG) 是一个协同 LLMs 和信息检索系统能力的 AI 框架。它对于回答问题或生成内容非常有用… - mlabonne/NeuralHermes-2.5-Mistral-7B · Hugging Face:暂无描述
- Legal terms and conditions:使用 Mistral 产品和服务的条款和条件。
-
[Microsoft made a $16M investment in Mistral AI TechCrunch](https://techcrunch.com/2024/02/27/microsoft-made-a-16-):微软向总部位于巴黎、致力于基础模型的 AI 初创公司 Mistral AI 投资 1500 万欧元。 -
[Client code Mistral AI Large Language Models](https://docs.mistral.ai/platform/client/#json-mode):我们提供 Python 和 Javascript 的客户端代码。 - NVIDIA Chat With RTX:定制并部署您的 AI Chatbot。
-
[Microsoft made a $16M investment in Mistral AI TechCrunch](https://techcrunch.com/2024/02/27/microsoft-made-a-16-million-investment-in-mistral-ai/amp/):微软向总部位于巴黎、致力于基础模型的 AI 初创公司 Mistral AI 投资 1500 万欧元。 - Mistral Large vs GPT4 - Practical Benchmarking!:➡️ 一键微调与推理模板:https://github.com/TrelisResearch/one-click-llms/ ➡️ Trelis 函数调用模型(包括 OpenChat 3.5):http…
- Short Courses:通过 DeepLearning.AI 的短期课程提升您的生成式 AI 技能。立即报名,直接向行业领导者学习,并通过实战练习实践生成式 AI 概念…
Mistral ▷ #models (12 messages🔥):
- Mistral 上更有意义的错误信息:
@lerela处理了一个关于系统限制的问题,指出某些操作在 large 模型上是不允许的,但用户现在会收到更有意义的错误信息。 - 关于 System/Assistant/User 序列的讨论:
@skisquaw提到必须将序列从 system/assistant/user 更改为 user/assistant/user,因为尽管功能上需要 assistant 提示紧跟 system 命令,但模型会将第一个 user 输入视为 system 输入。 - 量化压缩 Mistral-7B 参数:
@chrismccormick_询问了 Mistral-7B 的参数数量,最初统计仅约为 3.5B。他们后来推断 4-bit quantization 可能会使张量元素减半。 - 对 Mistral 处理长代码段的质疑:
@frigjord思考查询长代码段(特别是超过 16K tokens)是否会对 Mistral 模型造成问题。 - 使用 Mistral-7B 处理复杂的 SQL 查询:
@sanipanwala询问了使用 Mistral-7B 生成复杂 SQL 查询的问题,@tom_lrd给予了肯定回答,并就如何构建查询提供了建议,甚至提供了一个创建复杂 SQL 查询的示例。
Mistral ▷ #deployment (174 messages🔥🔥):
-
Mistral 部署难题:
@arthur8643询问了本地运行 Mistral 8x7B 的硬件要求,并考虑升级系统。用户@_._pandora_._和@mrdragonfox建议他目前的配置不足,推荐至少 100GB 的 VRAM 用于全精度部署,并建议使用 together.ai 等服务寻求帮助。 -
关于最佳服务器配置的辩论:
@latoile0221寻求关于 token 生成服务器规格的建议,考虑使用双 CPU 设置和 RTX 4090 GPU。用户收到了关于 CPU 与 GPU 重要性的不同反馈;@ethux强调了 GPU 对推理任务的重要性,而讨论则围绕全精度模型对大量 VRAM 的必要性展开。 -
对量化的疑虑和 GPU 能力:多位参与者表示量化模型表现不佳,
@frigjord和@ethux指出量化版本在编程任务中不值得使用。共识是需要大量的 VRAM(接近 100GB)才能有效运行非量化的全精度模型。 -
自托管、模型类型和 AI 局限性:随后展开了关于自托管 Mixtral 等 AI 模型实用性的对话,提到了使用量化版本和 GGUF 格式等替代方案。包括
@ethux和@sublimatorniq在内的用户分享了经验,重点关注量化模型的局限性以及全精度模型在高规格硬件上的更好表现。 -
关于专用 AI 模型的话题:讨论涉及了训练专门的纯 JS AI 模型的潜在优势和挑战。
@frigjord和@mrdragonfox辩论了这种专注模型的有效性和处理方式,普遍认为清理和准备任何专用 AI 训练的数据集都需要大量工作。
提到的链接:
- Jurassic Park GIF - Jurassic Park World - Discover & Share GIFs:点击查看 GIF
- starling-lm:Starling 是一个通过 AI 反馈强化学习训练的大型语言模型,专注于提高聊天机器人的帮助性。
- Tags · mixtral:Mistral AI 推出的具有开放权重的优质 Mixture of Experts (MoE) 模型。
Mistral ▷ #ref-implem (76 messages🔥🔥):
- Notebook 中的拼写错误提醒:
@foxalabs_32486在prompting_capabilities.ipynbnotebook 中发现了一个拼写错误,其中多了一个 “or”。正确文本应为 “Few-shot learning or in-context learning is when we give a few examples in the prompt…” - 修复确认:针对
@foxalabs_32486的提醒,@sophiamyang承认了该错误并确认已完成修复。 - 拼写错误增加人情味:
@foxalabs_32486思考是否可以通过偶尔使用拼写错误来让 AI 生成的内容看起来更像人类,并与@mrdragonfox讨论了使 AI 拟人化的伦理问题。 - 伦理高于收益:
@mrdragonfox拒绝了旨在使 AI 拟人化且超出伦理舒适度的项目,强调了选择诚信而非经济利益的立场。 - AI 行业招聘挑战:
@foxalabs_32486讨论了由于缺乏熟练专业人员以及所需知识的快速扩张,AI 行业在招聘方面面临的困难。
Mistral ▷ #finetuning (15 messages🔥):
- 限制模型仅根据特定文档回答:
@aaronbarreiro询问如何限制聊天机器人仅提供来自特定文档(如关于葡萄酒的文档)的信息,而不回答与披萨等无关的话题。 - 控制 LLM 的挑战:
@mrdragonfox解释说,像 LLM 这样的语言模型很可能会产生幻觉,因为它们本质上被设计为 Next Token Predictor,因此一个强大的 System Prompt 对于引导回答至关重要。 - 语言模型作为无状态实体:
@mrdragonfox强调了语言模型的无状态特性,这意味着它们不像人类那样保留记忆,如果超出其 Token 限制(特别提到了 32k context),它们会遗忘早期信息。 - 超出限制时维持上下文的策略:
@mrdragonfox讨论了规避上下文限制的策略,例如使用 Function Calling 或检索增强生成 (RAG),但承认这些方法更复杂,且无法直接开箱即用。 - 微调时间取决于数据集大小:当
@atip询问在 H100 硬件上微调一个 7B 参数模型所需的时间时,@mrdragonfox表示这取决于数据集的大小,暗示在没有该信息的情况下无法估算时长。
Mistral ▷ #showcase (7 messages):
-
用 AI 教学经济学:
@patagonia50分享了一个为中级微观经济学课程创建的 App,该 App 通过调用 gpt-4-vision-preview 和 Mistral 模型的 API 提供即时个性化反馈。该 App 通过 JSON 文件适应不同的问题和评分标准,已部署在 Heroku 上并仍在完善中,未来计划使用 Mistral AI 模型扩展其功能。 -
对教育 App 表示兴趣:
@akshay_1对@patagonia50的教育 App 表现出兴趣,询问是否有可用的 GitHub 仓库。 -
开源计划:针对
@akshay_1的询问,@patagonia50表示目前还没有 GitHub 仓库,但计划为该教育 App 创建一个。 -
请求进一步了解:
@akshay_1表达了想预览@patagonia50教育 App 的愿望,展示了对该项目的热情。
提到的链接:
- cogbuji/Mr-Grammatology-clinical-problems-Mistral-7B-0.5 · Hugging Face:未找到描述
- Use Mistral AI Large Model Like This: Beginner Friendly:我们学习了高性能 Mistral Large 的特性,并进行了带有 Streaming 和 JSON Mode 的 Chat Completions 现场编码。人工智能的格局…
Mistral ▷ #random (2 messages):
- 寻找 Google 百万上下文 AI:用户
@j673912询问如何获取难以触及的 Google 1M Context AI。 - 需要内部联系:
@dawn.dusk建议直接联系 Deepmind 的人员以获取访问权限。
Mistral ▷ #la-plateforme (41 messages🔥):
-
Mistral Function Calls 需要调整:
@michaelhunger讨论了 Mistral Function Calling 机制面临的挑战,指出需要补丁和 System Messages。具体而言,Mistral 的行为与预期不符,通常更倾向于进行额外的工具调用,而不是直接回答用户的查询。 -
澄清
tool_choice行为:@liebke对 Mistral Function Calling 上下文中tool_choice="auto"的行为表示困惑,因为该设置似乎没有按预期触发工具调用。@sophiamyang建议 “auto” 应该能正常工作,并请求 Liebke 提供实现细节以便进一步排查。 -
Mistral Function Calling 的不一致性:
@alexclubs提供了将 Mistral Function Calling 集成到 Profound Logic 中的反馈,注意到其与 OpenAI 的工具行为存在差异,且在触发函数的时间点上缺乏一致性。 -
Mistral 平台输出的可复现性尚不确定:
@alexli3146询问了关于可复现性的 Seedable Outputs,而@foxalabs_32486和@sublimatorniq讨论了 API 中可能影响该功能的潜在问题和现有设置。 -
Mistral 消息角色必须遵循特定顺序:在讨论了 “mistral-large-latest” 遇到的错误消息后,
@not__cool发现不支持用两个 System Messages 包裹一个 User Message,这一点得到了@lerela的确认。然而,@skisquaw成功地在第一个 User 角色语句中使用了包含 System 角色消息的 User/Assistant 格式。
提到的链接:
- Technology:触手可及的前沿 AI
-
[AI Assistants are the Future Profound Logic](https://www.profoundlogic.com/ai/):借助 Profound AI,只需 3 个步骤即可使用自然语言 AI 助手增强您的遗留应用程序。 -
[AI Assistants are the Future Profound Logic](https://www.profoundlogic.com/ai/):借助 Profound AI,只需 3 个步骤即可使用自然语言 AI 助手增强您的遗留应用程序。 - GitHub - liebke/mechanician: Daring Mechanician is a Python library for building tools that use AI by building tools that AIs use.:Daring Mechanician 是一个 Python 库,用于通过构建 AI 使用的工具来构建使用 AI 的工具。
- mechanician/packages/mechanician_mistral/src/mechanician_mistral/mistral_ai_connector.py at main · liebke/mechanician:Daring Mechanician 是一个 Python 库,用于通过构建 AI 使用的工具来构建使用 AI 的工具。
- mechanician/examples/notepad/src/notepad/main.py at main · liebke/mechanician:Daring Mechanician 是一个 Python 库,用于通过构建 AI 使用的工具来构建使用 AI 的工具。
Mistral ▷ #office-hour (1 messages):
- 记下评估专题讨论的时间:
@sophiamyang邀请大家参加 CET 时间 3 月 5 日下午 5 点 的下一次 Office Hour,重点关注 评估与基准测试 (Evaluation and Benchmarking)。他们表示有兴趣了解参与者使用的不同评估策略和基准测试。
Mistral ▷ #le-chat (423 messages🔥🔥🔥):
-
Le Chat 模型限制讨论:用户
@alexeyzaytsev询问了免费账户在 Le Chat 上的限制。虽然目前尚未明确,但@ethux和@_._pandora_._推测未来的限制可能会模仿 OpenAI 的模式,高级功能可能会变成付费服务。 -
Groq 硬件上的 Mistral:
@foxalabs_32486询问了在 Groq 硬件上运行 Large 模型的计划,而@ethux指出了 Groq 的内存限制。@foxalabs_32486提供了一份 来自 Groq 的产品简介,强调了对其硬件能力的潜在误解。 -
Mistral 的市场地位和 Microsoft 的影响:在一次广泛的讨论中,用户
@foxalabs_32486和@mrdragonfox分享了他们对 Mistral 市场定位以及 Microsoft 投资影响的看法。他们触及了战略对冲、对 OpenAI 的潜在影响以及 Mistral 取得成就的速度等话题。 -
Le Chat 改进反馈:包括
@sophiamyang在内的几位用户参与讨论了改进 Le Chat 的方法。建议包括针对不准确回答的“踩”(thumb down)按钮(@jmlb3290)、对话过程中轻松切换模型的功能(@sublimatorniq)、管理 Token 计数和对话上下文的功能(@_._pandora_._)、出错时保留消息(@tom_lrd)以及支持图像输入(@foxalabs_32486)。 -
辩论低位宽 Transformer 的效率:用户(特别是
@foxalabs_32486和@mrdragonfox)辩论了一篇关于低位宽(Low-Bitwidth)Transformer 研究论文的影响,讨论了效率的潜在提升以及快速实现这些发现的可行性。他们提到了适配现有模型所涉及的工作,以及对即时硬件进步的推测性质。
提到的链接:
- Technology.): 您手中的前沿 AI (Frontier AI)
- Why 2024 Will Be Not Like 2024: 在不断发展的技术和教育领域,一股革命性的力量正准备重塑我们学习、思考和……的方式。
- Unsloth update: Mistral support + more: 我们很高兴发布对 Mistral 7B、CodeLlama 34B 以及所有其他基于 Llama 架构模型的 QLoRA 支持!我们增加了滑动窗口注意力(sliding window attention)、初步的 Windows 和 DPO 支持,以及……
- GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning: 速度快 5 倍,显存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账户为 unslothai/unsloth 的开发做出贡献。
Mistral ▷ #failed-prompts (6 messages):
-
报告失败 Prompt 的说明:
@sophiamyang提供了一个模板,要求提供报告失败 Prompt 的详细信息,指明了如model、prompt、model output和expected output等信息。 -
诙谐的数学错误报告:
@blueaquilae幽默地指出了 Mistral Large 模型在数学方面的一个问题,评论道:“数学,在 Large Chat 上完成了一半(双关语)”。 -
戏谑的查询确认:在一次俏皮的交流中,
@notan_ai询问某个特定示例是否算作失败的 Prompt,@blueaquilae回答道:“全是合成数据(Synthetic data)?” -
Le Chat 上的通用失败:
@blacksummer99报告称 Mistral 的所有版本(包括 Mistral next)在 Le Chat 上给出的某个 Prompt 均告失败,但未提供具体细节。 -
不完整的议题指示:
@aiwaldoh提到了 “Fondée en 2016?!”,可能是在指出 Mistral 模型输出的一个问题或困惑,但未提供更多细节。
Mistral ▷ #prompts-gallery (5 messages):
-
邀请分享 Prompt 技巧:用户
@sophiamyang欢迎大家分享他们最有效的 Prompt,强调 Prompt 创作是一门艺术,并期待看到用户的作品。 -
对频道用途的困惑:在用户
@akshay_1简单提到 “DSPy” 后,@notan_ai带着对 “SudoLang” 的好奇进行了回复,但对该频道的用途表示困惑。 -
模棱两可的模型提及:
@blacksummer99两次提到了模型名称 “Mistral next le chat”,但未提供进一步的背景或细节。
OpenAI ▷ #ai-discussions (58 messages🔥🔥):
-
AI 模型的加载器选择:
@drinkoblog.weebly.com指出 lm studio 需要手动 GUI 交互才能启动 API,这对于网站来说不切实际。他们建议使用 oobabooga 或 Jan dot ai 等替代加载器,以实现开机自动运行。 -
AI 讨论中的 Automod 审查:
@chonkyman777报告称他们的消息因展示 Copilot AI 的问题行为而被删除,@eskcanta建议通过 Modmail 联系 Discord 管理员,并直接通过 OpenAI 的反馈表单报告 AI 问题。用户们就审查的细微差别以及现有规则的范围展开了辩论。 -
对 Mistral 和无审查内容的关注:
@dezuzel分享了一个 YouTube 视频,讨论了被认为强大且无审查的 AI 模型 Mistral。@tariqali对欧洲 AI 监管对 Mistral 的影响提出了疑问,尽管该模型宣传其缺乏审查。@chief_executive将 Mistral Large 与 GPT-4 进行了对比,发现后者在编程任务上更胜一筹。 -
针对聊天机器人场景微调 GPT-3.5:
@david_zoe寻求关于微调 GPT-3.5-Turbo 的建议,以使其表现优于基准并保持对话流,但在达到 GPT-4 的性能水平方面面临挑战。@elektronisade建议检查常见用例,并使用实际数据咨询 ChatGPT 以获取更多关于微调的指导。 -
探索 AI 专业认证:年轻开发者
@navs02询问了关于 AI 专业化的认证。@dezuzel和.dooz建议专注于实际项目而非认证,并提到了包括 YouTube 上 Andrew Ng 和 Andrej Karpathy 课程在内的学习资源。
提到的链接:
- Chat model feedback:未找到描述。
- This new AI is powerful and uncensored… Let’s run it:了解如何使用开源工具运行 Mistral 的 8x7B 模型及其无审查变体。让我们看看 Mixtral 是否是 GPT-4 的良好替代品,并了解…
OpenAI ▷ #gpt-4-discussions (21 messages🔥):
- 对 API 和文件上传的困惑:
@ray_themad_nomad对聊天机器人在上传文件和创建自定义 API 后反应不一致表示沮丧,并指出几个月前有效的方法现在似乎失效了。 - 澄清文档大小限制:
@darthgustav.指出聊天机器人只能读取 context size 范围内的文档,对于较大的文件它会进行摘要,这引发了与@fawesum的辩论,后者认为即使知识文件巨大,也可以被高效访问。 - Seed 参数导致输出不一致:
@alexli3146询问是否有人成功使用 seed 参数获得可复现的输出,但分享称他们并未成功。 - Web Browsing 与 Code Interpreter 的安全措施:
@darthgustav.解释说,在实例中使用 Python 通过 Code Interpreter 搜索知识文件可能会禁用 Web Browsing,这是一个出于安全考虑的决定。 - 分享记忆游戏的正确频道:
@takk8is分享了“The Memory”的链接,但被@solbus引导至专门频道分享,以防在聊天中淹没。
OpenAI ▷ #prompt-engineering (391 messages🔥🔥):
-
使用 MetaPrompting 进行 Prompt Engineering:
@madame_architect分享了他们对 “MetaPrompting” 研究的注释工作,将其汇编的 Prompt 架构论文列表增加到总共 42 篇。文章详细介绍了一种将元学习(meta-learning)与 Prompt 集成的方法,旨在改进 NLP 模型中 Soft Prompt 的初始化。MetaPrompting 讨论 -
ChatGPT 中的 LaTeX 和 Katex:包括
@yami1010和@eskcanta在内的几位用户讨论了 ChatGPT 处理 LaTeX 和 Katex 以创建可视化数据表示的能力,重点关注数学公式和流程图。 -
DALL-E 3 中的花括号风波:
@darthgustav.和@beanz_and_rice等用户遇到了 DALL-E 3 负载(payloads)不接受 JSON 字符串中标准花括号的问题。他们通过使用转义编码的花括号找到了解决方法,这似乎绕过了解析器错误。 -
增强 ChatGPT 在艺术类 Prompt 中的创造力:当被问及如何提高艺术类 Prompt 的创造力时,
@bambooshoots和@darthgustav.建议采用多步迭代过程,并使用语义开放的变量,以鼓励 AI 生成更少确定性、更具想象力的输出。 -
Custom ChatGPT 文件读取的挑战:
@codenamecookie和@darthgustav.讨论了 Custom ChatGPT 在读取其知识库中的 ‘.py’ 文件时表现不一致的问题。他们探索了潜在的解决方案,例如将文件转换为纯文本并避免不必要的压缩(zipping),以便 AI 更好地解析和响应。
提到的链接:
遏制国家背景威胁行为者对 AI 的恶意利用:我们终止了与国家背景威胁行为者相关的账户。我们的调查结果显示,我们的模型在恶意网络安全任务方面仅提供有限的增量能力。
OpenAI ▷ #api-discussions (391 messages🔥🔥):
- Prompt Engineering 秘籍:
@yami1010和@eskcanta分享了在 ChatGPT 的 Prompt 中使用 Markdown、LaTeX 和 KaTeX 创建图表和流程图的见解。他们讨论了不同 Diagram-as-code 工具(如 mermaid 和 mathplotlib)的有效性,以及处理 DALL-E 3 解析器中花括号的特殊性。 - MetaPrompting 注释版:
@madame_architect将 MetaPrompting 添加到了其包含 42 篇带注释的 Prompt 架构论文列表中。该列表可在 AI-Empower GitHub 上找到,旨在保持高质量标准,对研究 Prompt Engineering 非常有用。 - 花括号风波:围绕 DALL-E 3 负载在 JSON 字符串中对花括号(
{},})的格式化问题展开了长时间讨论,@darthgustav.和@yami1010等多位用户指出图像生成过程中出现失败。最终发现了一个涉及 Unicode 转义代码的解决方案,绕过了解析器错误。 - Custom ChatGPT 文件读取:在关于 Custom ChatGPT 的对话中,
@codenamecookie对模型从其“知识”中读取 Python 文件能力的不一致表示困惑。@darthgustav.建议不要压缩文件,并将其转换为纯文本,同时保持 Python 解释,这可能有助于 AI 更好地处理文件。 - 提升 AI 创造力:为了增强 AI 生成的艺术类 Prompt,
@bambooshoots和@darthgustav.建议使用多步过程来开发场景,并引导 GPT-3.5 和 GPT-4 给出更具创造性的回应。包含语义开放的变量和迭代 Prompt 将有助于激发更少确定性且更独特的输出。
提到的链接:
遏制国家背景威胁行为者对 AI 的恶意利用:我们终止了与国家背景威胁行为者相关的账户。我们的调查结果显示,我们的模型在恶意网络安全任务方面仅提供有限的增量能力。
LM Studio ▷ #💬-general (484 messages🔥🔥🔥):
-
探索模型选项:用户正在讨论各种 LLMs 及其与特定 GPUs 的兼容性,重点关注编程辅助模型,如 Deepseek Coder 6.7B 和 StarCoder2-15B。例如,
@solusan.正在寻找最适合 12 GB 显存的 Nvidia RTX 40 系列显卡的模型,目前正在考虑 Dolphin 2.6 Mistral 7B。 -
LM Studio GPU 兼容性问题:几位用户如
@jans_85817和@kerberos5703在使用某些 GPUs 运行 LM Studio 时遇到问题。讨论主要围绕 LM Studio 与较新 GPUs 的兼容性展开,而旧型号 GPUs 出现了一些问题,用户正在寻求解决方案或替代方案。 -
Hugging Face 停机影响:包括
@barnley和@heyitsyorkie在内的多位成员报告了一个共同问题,即由于 Hugging Face 停机导致下载模型时出现网络错误,影响了 LM Studio 搜索模型的能力。 -
图像识别与生成查询:关于图像相关任务的问题浮出水面,
@heyitsyorkie澄清说,虽然 LM Studio 无法执行图像生成任务,但可以通过 Llava 模型进行图像识别。 -
硬件讨论与展望:
@pierrunoyt和@nink1等用户正在讨论 AI 和 LLMs 的未来硬件预期,指出目前高端的 AI 专用硬件可能会随着时间的推移变得更加普及。
提到的链接:
- GroqChat: 未找到描述
- no title found: 未找到描述
- 👾 LM Studio - Discover and run local LLMs: 查找、下载并实验本地 LLMs
- Stop Shouting Arnold Schwarzenegger GIF - Stop Shouting Arnold Schwarzenegger Jack Slater - Discover & Share GIFs: 点击查看 GIF
- BLOOM: 我们的 176B 参数语言模型已发布。
- Continue: 未找到描述
- no title found: 未找到描述
-
[GeForce GTX 650 Ti Specifications GeForce](https://www.nvidia.com/en-us/geforce/graphics-cards/geforce-gtx-650ti/specifications/): 未找到描述 - MaziyarPanahi/dolphin-2.6-mistral-7b-Mistral-7B-Instruct-v0.2-slerp-GGUF · Hugging Face: 未找到描述
-
[Specifications GeForce](https://www.nvidia.com/en-us/geforce/graphics-cards/geforce-gtx-650/specifications/): 未找到描述 - 02 ‐ Default and Notebook Tabs: 一个用于 Large Language Models 的 Gradio Web UI。支持 transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。 - oobabooga/text-generation-webui
- Add support for StarCoder2 by pacman100 · Pull Request #5795 · ggerganov/llama.cpp: 此 PR 的作用?增加了对最近发布的 StarCoder 2 模型的支持。
- bigcode/starcoder2-15b · Hugging Face: 未找到描述
- Reddit - Dive into anything: 未找到描述
- Anima/air_llm at main · lyogavin/Anima: 33B 中文 LLM,DPO QLORA,100K 上下文,使用单个 4GB GPU 进行 AirLLM 70B 推理 - lyogavin/Anima
- GitHub - MDK8888/GPTFast: Accelerate your Hugging Face Transformers 6-7x. Native to Hugging Face and PyTorch.: 将你的 Hugging Face Transformers 加速 6-7 倍。原生支持 Hugging Face 和 PyTorch。 - MDK8888/GPTFast
- itsdotscience/Magicoder-S-DS-6.7B-GGUF at main: 未找到描述
LM Studio ▷ #🤖-models-discussion-chat (61 messages🔥🔥):
-
寻求 PDF 聊天机器人指导:
@solenya7755正尝试使用 LM Studio 和 llama2 70B Q4 LLM 实现一个准确的 PDF 聊天机器人,但在遇到幻觉指令时表现不佳。@nink1建议进行大量的 Prompt 工程,并加入 AnythingLLM Discord 以获取进一步帮助。 -
StarCoder2 和 The Stack v2 发布:
@snoopbill_91704分享了由 ServiceNow、Hugging Face 和 NVIDIA 联合发布的 StarCoder2 和 The Stack v2 的新闻,并指出与 Software Heritage 的合作符合负责任的 AI 原则。 -
Qualcomm 发布 80 个开源模型:
@misangenius关注到 Qualcomm 在 Huggingface 上发布了 80 个开源 AI 模型,涵盖视觉、音频和语音应用。 -
咨询会向你提问的模型:
@ozimandis询问关于会反向提问的本地 LLM,并在不同模型上得到了参差不齐的结果;而@nink1分享了让 dolphin mistral 7B q5 等模型提出启发性问题的成功经验。 -
商业文档分析与写作的最佳配置:
@redcloud9999寻求在高配机器上进行商业文档分析和写作的最佳 LLM 配置建议。@heyitsyorkie建议在 Huggingface 上搜索 “TheBloke” 发布的 GGUF 量化模型,@coachdennis.则建议测试热门模型。
提到的链接:
- qualcomm (Qualcomm):未找到描述
- bigcode/starcoder2-15b · Hugging Face:未找到描述
- bigcode/the-stack-v2-train-full-ids · Datasets at Hugging Face:未找到描述
- Pioneering the Future of Code Preservation and AI with StarCoder2:Software Heritage 的使命是收集、保护并使整个软件源代码库易于获取,特别强调自由开源软件 (FOSS) 作为数字资产的重要性…
LM Studio ▷ #🎛-hardware-discussion (42 messages🔥):
<ul>
<li><strong>Windows 11 优化技巧</strong>:`.bambalejo` 建议用户在 Windows 11 上禁用微软的内核隔离 (core isolation) 和虚拟机平台 (vm platform) 等功能以获得更好的性能,并确保 <em>VirtualizationBasedSecurityStatus</em> 设置为 0。</li>
<li><strong>TinyBox 发布公告</strong>:`senecalouck` 分享了一个链接,详细介绍了来自 TinyCorp 的新硬件产品 TinyBox,详情请见 <a href="https://tinygrad.org">此处</a>。</li>
<li><strong>电商 GPU 购买挫折与规格</strong>:`goldensun3ds` 讲述了在 eBay 上购买虚假宣传 GPU 的负面经历,并决定下次购买选择 Amazon,同时列出了他们强大的 PC 配置,包括双 RTX 4060 Ti 16GB。</li>
<li><strong>旧硬件怀旧</strong>:来自 `jans_85817`、`nullt3r`、`heyitsyorkie` 和 `666siegfried666` 等用户的一连串消息回忆了旧款 GPU;对话包括 GTX 650 不适合现代模型等见解,以及过去装机和升级的个人故事。</li>
<li><strong>关于 Nvidia Nvlink / SLI 的讨论</strong>:用户 `dub_ex` 和 `nullt3r` 讨论了 Nvidia Nvlink / SLI 的有效性,结论是它对模型训练有益,但对推理 (inference) 并非必要。</li>
</ul>
LM Studio ▷ #🧪-beta-releases-chat (7 条消息):
-
询问在 LM Studio 中插入图片的方法:
@heoheo5839不确定如何在 LM Studio 中添加图片,因为看不到“Assets”栏。@heyitsyorkie解释说,要添加图片,必须使用类似PsiPi/liuhaotian_llava-v1.5-13b-GGUF/的模型,并确保已下载该模型的视觉适配器 (mmproj) 和 GGUF 文件,之后就可以在输入框中插入图片供模型描述。 -
关于 llava 模型下载的疑问:
@hypocritipus询问是否可以直接在 LM Studio 内下载支持 llava 的模型,并暗示了更简便的可访问性和功能性。 -
澄清 LM Studio 中的 llava 模型功能:
@wolfspyre询问下载 llava 模型是否为当前功能,并表示 LM Studio 可能已经支持该功能。 -
确认视觉适配器模型的使用:针对
@wolfspyre的提问,@hypocritipus澄清他们自己尚未尝试该功能,只是想确认是否可以在 LM Studio 中同时下载视觉适配器和主模型。 -
探索视觉模型的一键下载方案:
@hypocritipus分享了发布说明中的一段摘录,指出用户需要分别下载视觉适配器 (Vision Adapter) 和主模型。他们很好奇 LM Studio 中是否有一种一键解决方案来简化此过程,让用户通过一次操作即可下载所有必要文件。
提到的链接:
- Vision Models (GGUF) - a lmstudio-ai Collection:未找到描述
- LM Studio (@LMStudioAI) 的推文:数企鹅可能很有挑战性 🧐🐧 LM Studio 0.2.9 新功能:🎉 本地和离线视觉模型!在此演示中:由 @NousResearch 开发的小巧且令人印象深刻的 Obsidian Vision 3B。
LM Studio ▷ #autogen (7 条消息):
- 翻译任务中的 Gemini 与 ChatGPT 对比:
@hypocritipus分享了他们使用 Gemini 和 ChatGPT 将心理评估报告从土耳其语翻译成英语的经验,指出 Gemini 通常提供更好的翻译质量。 - 对 Gemini 过度格式化的困扰:
@hypocritipus对 Gemini 倾向于添加不必要的项目符号以及在请求的翻译内容之外产生幻觉的习惯表示沮丧。 - ChatGPT 的补救(某种程度上):对于最终报告,由于 Gemini 的表现不如预期,
@hypocritipus不得不切换到 ChatGPT,尽管他们提到 ChatGPT 的翻译质量稍逊一筹。 - 在 Autogen 频道误发消息:
@hypocritipus幽默地指出他们不小心把这段经历发到了 Autogen 频道,并评论道:“笑死我了,我发错地方了……” - 消除困惑:
@johnnyslanteyes要求澄清@hypocritipus所说的报告“翻译”是什么意思,随后得到的解释是这是从土耳其语到英语的语言翻译,而不是医学术语的转换。
LM Studio ▷ #langchain (3 条消息):
- 披露维度细节:用户
@npcomp_22591提到在向量中使用 768 维度 获得了良好的结果。 - 向量入门 (Vectors 101):针对
@bigsuh.eth关于如何检查向量维度的询问,@npcomp_22591简要解释了过程:可以通过检查向量的长度来查看其维度,并提供了一个示例输出,后接.length。
LM Studio ▷ #memgpt (1 条消息):
jans_85817: 我正在等待 LM Studio 的 Linux 版本。
HuggingFace ▷ #announcements (1 条消息):
-
Cosmopedia 发布:
@lunarflu宣布发布 Cosmopedia,称其为最大的开放合成数据集,包含由 Mixtral 创建的教科书、博客文章和故事,拥有超过 250 亿个 Token 和 3000 万个文件。相关资源可通过 LinkedIn 帖子 获取。 -
huggingface_hub库更新:重点介绍了新版本huggingface_hub0.21.0 的发布,其特性包括 dataclasses、PyTorchHubMixin支持以及audio-to-audio推理等更新。开发者可以在 huggingface space 查看完整的发布说明。 -
即将推出的新方法和模型:帖子分享了令人兴奋的进展,包括使用 diffusers 脚本 训练 DoRA、将 Figma frames 推送到数据集,以及 YOLOv9 在 Hub 上的首次亮相(已确认兼容 Transformers.js)。其他更新还涵盖了
sentence-transformersv2.4.0、LGM Mini 项目,以及在 AMD GPU 上运行 AWQ 模型 的可能性。 -
产品创新:Google 的开源 LLM Gemma 7B 现已在 Hugging Chat 上可用,
transformers发布了关于 mask generation 的新任务指南,并引入了新的image-feature-extraction标签,重点推荐了如google/vit-base-patch16-224-in21k之类的模型。 -
社区协作与贡献:社区努力促成了诸如
#data-is-better-together的10k_prompts_ranked和OpenHermesPreferences等数据集的发布。此外,TTS Arena 上线用于测试和评估 text-to-speech 模型,Hugging Face 博客上也发布了 Fine-Tuning Gemma Models 指南。
提到的链接:
- @Wauplin 在 Hugging Face 上:“🚀 刚刚发布了
huggingface_hubPython 库的 0.21.0 版本!……”:未找到描述 - Victor M (@victormustar) 的推文:🤯 这个 @figma 插件可以让你直接将 figma 帧推送到 @huggingface 数据集!
- merve (@mervenoyann) 的推文:YOLOv9 已登陆 @huggingface Hub!🤩 模型权重(checkpoints):https://huggingface.co/merve/yolov9 尝试 Demo (@kadirnar_ai):https://huggingface.co/spaces/kadirnar/Yolov9 查找 YOLOv9 por 的 Demo…
- Xenova (@xenovacom) 的推文:YOLOv9 刚刚发布,现在它已兼容 🤗 Transformers.js!没错……在你的浏览器中本地运行近乎实时的目标检测:无需服务器!🤯 亲自尝试一下……
- Omar Sanseviero (@osanseviero) 的推文:Matryoshka Embeddings 来了!🔥 Sentence Transformers 库支持训练和运行 Embedding 模型,其 Embedding 尺寸可以缩小,同时保持高质量!了解更多……
- dylan (@dylan_ebert_) 的推文:LGM Mini 🧊 5 秒内实现图像转交互式 3D https://huggingface.co/spaces/dylanebert/LGM-mini
- Julien Chaumond (@julien_c) 的推文:重大新闻:↘️ 引用 Victor M (@victormustar) ✨ Google 的新开源 LLM Gemma 7B 现已在 HuggingChat 上可用。
- merve (@mervenoyann) 的推文:🤗 transformers 有一个新的掩码生成(也称为 zero-shot 图像分割)任务指南,在本指南中学习如何使用强大的 segment-anything 模型 https://huggingface.co/docs/t…
- Models - Hugging Face:未找到描述
- DIBT/10k_prompts_ranked · Hugging Face 数据集:未找到描述
- @davanstrien 在 Hugging Face 上:“开源 AI 社区可以共同构建具有影响力的数据集!……”:未找到描述
- Lewis Tunstall (@_lewtun) 的推文:🪽 介绍 OpenHermesPreferences - 由 Mixtral 和 Nous-Hermes-2-Yi-34B 生成的约 100 万个 AI 偏好的最大数据集 🔥 https://huggingface.co/datasets/argilla/OpenHermesPreferences …
- Vaibhav (VB) Srivastav (@reach_vb) 的推文:发布 TTS Arena!🗣️ 请开启声音 一个测试、评分并寻找当前开源模型冠军的地方。一个持续更新的空间,汇集了当前 TTS 领域最伟大、最优秀的作品!⚡…
- 介绍红队抗性排行榜 (Red-Teaming Resistance Leaderboard):未找到描述
- AI 水印入门:工具与技术:未找到描述
- 在 Hugging Face 中微调 Gemma 模型:未找到描述
- Bassem Asseh 🤗 (@asseh) 的推文:.@huggingface 与 @FetchRewards 合作,将其文档 #AI 解决方案在 @AWS 上投入生产。猜猜怎么着?👉 “在 Yifeng 的指导下,Fetch 能够缩短其开发时……”
HuggingFace ▷ #general (491 条消息🔥🔥🔥):
- GPU 价格查询:
@zorian_93363讨论了某些 GPU 与特定 3090 型号之间的成本比较。他们提到在当地可以用一台 3090 的价格购买 100 台其他设备。 - 通过自定义框架提高模型性能:
@ahmad3794建议编写自定义框架可以释放 8 位集成电路上 4 teraflops 的潜力,提供可观的计算能力。 - 电子 DIY 热情:
@zorian_93363表达了玩电子产品和组装电脑的愿望,但感叹因经济危机而缺乏时间,同时也赞赏他人在挑战中创新和技能。 - 制裁下伊朗的机智应对:
@ahmad3794详细阐述了构建经济型集群作为获取高性能技术的变通方法,由于制裁,这些技术在伊朗很难获得。 - 访问 GPT 模型和 UI 挑战:
@welltoobado和@caleb_sol讨论了在不占用大量 RAM 的情况下使用量化版本模型进行 CPU 推理的可能性和方法,并提到 llama cpp 是一个有用的工具。
提到的链接:
- GroqChat:未找到描述
- Morph Studio:未找到描述
- Unbelievable! Run 70B LLM Inference on a Single 4GB GPU with This NEW Technique:未找到描述
- Hugging Face:在 Hugging Face,我们致力于为每个人推进和普及 ML。在此过程中,我们为技术的向善发展做出贡献。
- 2869993 Hail GIF - 2869993 Hail - Discover & Share GIFs:点击查看 GIF
- Tweet from blob (@moanaris):未找到描述
- kopyl/ui-icons-256 · Hugging Face:未找到描述
- Hugging Face – The AI community building the future.:未找到描述
- Kermit Worried GIF - Kermit Worried Oh No - Discover & Share GIFs:点击查看 GIF
- Boom Explode GIF - Boom Explode Explosions - Discover & Share GIFs:点击查看 GIF
- Matrix Multiplication Background User's Guide - NVIDIA Docs:未找到描述
- Hugging Face – The AI community building the future.:未找到描述
- Gradio:未找到描述
- Tweet from Jason (@mytechceoo):当 OpenAI 宕机时的 ChatGPT 套壳应用…
- cahya/gpt2-small-indonesian-522M · Hugging Face:未找到描述
- dpaste/15nGx (Python):未找到描述
- NCIS ridiculous hacking scene: one keyboard, two typists HD:未找到描述
- TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF at main:未找到描述
- The System Is Down- Strongbad:哇… 真的没想到这个视频会这么受欢迎。显然,当某个游戏的服务器宕机时,人们会来到这里。哈!史诗级… 总之,请享受!是的,它是…
- Hugging Face Outage Impact:使用 Gemini Advanced 创建。
- The Website is Down #1: Sales Guy vs. Web Dude:网站宕机了 #1:销售人员 vs 网页开发人员。高质量原版视频。该视频曾获得 Webby 奖!
- 'HumanEval' object has no attribute 'dataset' · Issue #131 · bigcode-project/bigcode-evaluation-harness:当我使用 Llama 7b 评估 HumanEval 时,遇到了这个问题:我的脚本 accelerate launch /cpfs01/shared/Group-m6/dongguanting.dgt/bigcode-evaluation-harness/main.py –model "/path to my llama7b/…
- Issues · huggingface/api-inference-community:通过在 GitHub 上创建账号,为 huggingface/api-inference-community 的开发做出贡献。
- Workflow runs · huggingface/text-embeddings-inference:一个极速的文本嵌入模型推理解决方案 - Workflow runs · huggingface/text-embeddings-inference
- GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface.:最强大且模块化的 Stable Diffusion GUI、API 和后端,带有图形/节点界面。- comfyanonymous/ComfyUI
- Issue with offline mode · Issue #4760 · huggingface/datasets:描述 Bug:在启用离线模式时无法检索缓存的数据集。复现步骤:要复现我的问题,首先,你需要运行一个脚本来缓存数据集…
- Issues · huggingface/huggingface_hub:Huggingface Hub 的官方 Python 客户端。- Issues · huggingface/huggingface_hub
-
Build software better, together:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、Fork 并为超过 4.2 亿个项目做出贡献。
- 添加 PatchModelAddDownscale (Kohya Deep Shrink) 节点 · comfyanonymous/ComfyUI@bd07ad1:通过在初始时间步(timesteps)为 unet 添加下采样(downscale),该节点允许你以更高的分辨率生成图像,同时减少一致性问题。
- Hugging Face 状态:未找到描述
HuggingFace ▷ #today-im-learning (8 条消息🔥):
- 探索 DSPy 和 OpenFunctions v2:用户
@n278jm正在研究 DSPy(一个无需提示词即可对基础模型进行编程的框架)和 Gorilla OpenFunctions v2(一个先进的 LLM 开源函数调用系统)。他们的目标是利用这些工具改进客户入驻流程,实现从 Gradio 原型到生产就绪版本的过渡。 - 利用 OpenAI 和 Hugging Face 的力量:
@davidre95鼓励用户利用 OpenAI Chat 和 Hugging Face chat room 作为资源。 - 发票处理项目合作:
@pampkinparty000邀请处理 PDF 或图片发票的用户私信他们,以便在具有类似目标的项目上进行潜在合作。 - 提高效率的发票存储建议:
@pampkinparty000建议将发票存储在带有元数据的向量数据库中,以便更有效地使用 LLM,并建议使用 llama-index 等库。 - 寻找 AI 研究社区:
@raghadn3正在寻找一个致力于撰写人工智能研究论文的社区。
提到的链接:
- GitHub - stanfordnlp/dspy: DSPy: 编程而非提示基础模型的框架:DSPy:编程而非提示基础模型的框架 - stanfordnlp/dspy
- Gorilla LLM 简介:未找到描述
HuggingFace ▷ #cool-finds (9 条消息🔥):
-
BitNet b1.58:高效 LLM:
@jessjess84强调了 BitNet b1.58 的潜力,这是一种新型的 1-bit 大语言模型,承诺在不牺牲性能的情况下提高效率,详情见 arXiv 论文。它在实现与全精度模型相同结果的同时,引入了极具成本效益的延迟、内存占用、吞吐量和能耗表现。 -
Stable Diffusion Deluxe 亮相:
@skquark邀请用户尝试 Stable Diffusion Deluxe,这是一个广泛的多媒体 AI 工具包,支持各种 AI 艺术生成器,拥有创建图像、视频、音效等功能。该平台详情见 diffusiondeluxe.com,集成了众多流水线(pipelines),旨在易于使用和进行创意实验。 -
寻找自托管详情:针对
@skquark的全能多媒体 AI 应用,@wolfspyre询问了自托管选项,称赞该项目“超级酷”并表示有兴趣深入了解。 -
欣赏 ‘The Hug’:
@evergreenking分享了 thehug.xyz 的链接,该网站被描述为“仅仅是链接艺术”,@wolfspyre随后询问这是否是@evergreenking的作品。
提到的链接:
-
[HUG 艺术之家](https://thehug.xyz):加入我们的全球创意社区,展示并销售你的艺术作品,与他人建立联系,并获得对创作者友好的资助和教育。 - 1-bit LLM 时代:所有大语言模型都是 1.58 Bits:最近的研究(如 BitNet)正在为 1-bit 大语言模型 (LLM) 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数…
- 揭示价值的起源:一种基于生物学和认知的 AI 对齐方法:未找到描述
- Diffusion Deluxe 主页 - Stable Diffusion Deluxe:未找到描述
HuggingFace ▷ #i-made-this (14 messages🔥):
-
DIY 本地 LLM 助手发布:
@rivridis开发了一个本地运行的 LLM Assistant,具有助手模式和用于内容编辑与创作的实时编辑模式。代码和详情可在 GitHub 上找到。 -
简化部署到 Google Cloud Vertex AI:
@alvarobartt撰写了一篇博客文章,详细介绍了如何将模型从 HuggingFace Hub 部署到 Google Cloud Vertex AI。你可以在这里查看这篇技术文章及其分步指南。 -
Cursor Hero 演示 v0.3.0:
@teamy正在开发一款名为 Cursor Hero 的 UI 工具,集成了 ollama 和 whisper。该工具的演示可以在这个 YouTube 视频中找到。 -
Gantrithor:数据标注的飞跃:
@stroggoz宣布了 Gantrithor 的公开测试版,这是一款快速、批量的模型数据标注工具,免费版限制数据集为 1000 个文档。了解更多并前往 Gantrithor 试用。 -
Starcoder 2:编码与学习:
@tonic_1修复了示例代码中的错误,并宣布 Starcoder 2 已上线供学习和体验,同时呼吁合作进行模型 fine-tuning。在 HuggingFace Spaces 上查找该项目。
提到的链接:
- MetaMath Mistral Pro - Tonic 的 Hugging Face Space:未找到描述
- 在 Vertex AI 中部署 🤗 Hub 模型:未找到描述
- StarCoder2 - Tonic 的 Hugging Face Space:未找到描述
- Qbeast 在 AI 驱动迷因创作中的冒险 - Qbeast:了解 AI 模型选择、fine-tuning 以及 Qbeast 在增强迷因创意方面的作用。非常适合寻求见解和创新的 AI 爱好者和数据工程师。
- Gantrithor:未找到描述
- Cursor Hero 演示 v0.3.0:https://github.com/TeamDman/Cursor-Hero.githttps://discord.gg/psHtde64FJ#rust #bevy #windows #win32
- 这个真的很棒 - 第 16 集 #music #producer:这个很难被超越
- GitHub - Rivridis/LLM-Assistant: 具有互联网访问权限的本地运行 LLM:具有互联网访问权限的本地运行 LLM。通过在 GitHub 上创建账户为 Rivridis/LLM-Assistant 的开发做出贡献。
- SDXL-Lightning:快速概览与对比:使用 SDXL-Lightning,你可以通过单步生成极高质量的图像。
HuggingFace ▷ #diffusion-discussions (5 messages):
- Gradio Queue 函数说明:用户
@akin8941询问了 gradio 界面中queue()函数的返回类型,@iakhil澄清说它本身没有返回类型。 - 速度过快提醒:
@HuggingMod提醒@1122120801903194114在 HuggingFace Discord 中发帖速度过快,并附带友好的提醒表情请求放慢速度。 - 调度器名称难题:
@luihis表示由于弃用警告,很难获取调度器的字符串名称。尽管尝试了不同的属性,但正确的字符串 “DPMSolverSinglestepScheduler” 仍然难以获取。
HuggingFace ▷ #computer-vision (4 messages):
- Parseq 获得好评:用户
@whoami02推荐使用 Parseq,因其有效的符号识别能力。 - 个性化 Fine-tuning 成功:他们还提到在特定数据集上成功 fine-tuning 了模型,该数据集包含与他们需要检测的等式相似的图像。
- Resnet 依然强劲:对于检测任务,
@whoami02断言 Resnet 依然表现强劲,足以满足他们的需求。 - 放慢速度:
@HuggingMod建议@whoami02放慢消息发布速度,以遵守社区准则。
HuggingFace ▷ #NLP (14 messages🔥):
-
Hugging Face 仓库中的推理问题:
@alfred6549寻求在没有 CPU 或 CUDA 的机器上运行 text generation inference repository 的帮助,并分享了遇到的错误。尽管尝试禁用 GPU 使用,本地设置仍然失败。 -
Petals 引起用户共鸣:用户
@ai_noob简单地提到了 “petals”,得到了@nrs9044的积极回应,表明了对该术语背景的共同情感或理解。 -
讨论 Benchmark 的必要性:
@vipitis强调了在更大的 Benchmark 上进行测试以验证有效性的重要性,而@djpanda1接受了建议,但指出在几个 Prompt 上的初步测试似乎是成功的。 -
金融文档洞察探索:
@hiteshwarsingh1正在探索从金融文档中提取信息的方法,考虑使用 MapReduce 技术,并寻求适用于摘要生成而非特定信息检索的开源模型或方法的建议。 -
使用 LLM 改进信息提取:
@.sgp正在利用 mistral 7b 配合 llamacpp 进行 JSON 数据提取,并表示有兴趣加入 in-context learning 以提高准确性,请求相关资源。
提及的链接:
- deepseek-ai/deepseek-coder-6.7b-instruct · Hugging Face:未找到描述
- Hugging Face:构建未来的 AI 社区。Hugging Face 拥有 196 个可用仓库。在 GitHub 上关注他们的代码。
HuggingFace ▷ #diffusion-discussions (5 messages):
- Gradio 的
queue()函数说明:@akin8941询问了 Gradio 界面中queue()函数的返回类型,@iakhil回复称它本身没有返回类型。 - HuggingMod 的减速警告:
HuggingMod向<@1122120801903194114>发出提醒,警告他们降低在频道中的发消息频率。 - 弃用通知带来的困扰:
@luihis分享了一段代码,并对尝试获取 scheduler 名称字符串时出现的弃用警告表示困惑;强调即使尝试了不同的打印 scheduler 类名的方法,仍然感到不确定。
LAION ▷ #general (314 条消息🔥🔥):
-
Ideogram 发布引起轰动:
@pseudoterminalx分享了 Ideogram 新 AI 模型的 Prompt 结果,引发了关于其 Prompt 遵循能力和美学的讨论。用户将其与 Stable Diffusion 进行了对比,并对未公开的 Imagen 样本可能存在的低质量进行了推测。 -
SD3 中的 T5 XXL、CLIP L 和 CLIP G?:
@thejonasbrothers和@devilismyfriend讨论了在 SD3 中集成 T5 XXL 和 CLIP 模型的问题,暗示了未来模型在准确性和美学吸引力方面的潜力。 -
Cascade 的忠实度受到质疑:
@pseudoterminalx等人批判性地评估了 Cascade 根据 Prompt 生成图像的能力,指出其在 Prompt 遵循和特异性方面经常出现问题。 -
AI 生成艺术与版权之争:用户
@progamergov、@itali4no等人就 AI 生成艺术面临的法律挑战展开了对话,参考了最近的案例以及 Huggingface 对 DMCA 请求的矛盾态度。 -
Stability AI 沉默的众多项目:
@.undeleted对 Stability AI 内部多个目标相似的项目表示困惑,每个项目的发布方式都类似,但区别并不明确。
提到的链接:
- Release v0.9.1 - DoRA the explorah · bghira/SimpleTuner:此版本对以下用户有一些破坏性变更:使用 RESOLUTION_TYPE=area (multidatabackend 配置中的 resolution_type=area);使用 crop=false;使用 crop=true 且 crop_aspect=preserve…
- panopstor/nvflickritw-cogvlm-captions · Datasets at Hugging Face:未找到描述
- Willys Chocolate Experience Glasgow. Get your Tickets!:沉浸在前所未有的巧克力幻想中 - 捕捉魅力!格拉斯哥 Willys Chocolate Experience 的门票现已发售!
- China issues world’s 1st legally binding verdict on copyright infringement of AI-generated images - Global Times:未找到描述
-
[Copyright Safety for Generative AI Published in Houston Law Review](https://houstonlawreview.org/article/92126-copyright-safety-for-generative-ai):作者 Matthew Sag。61 Hous. L. Rev. 295 (2023)
LAION ▷ #research (48 messages🔥):
-
Spiking Neural Network 推测:
@max_voltage想知道技术进步是否会导致 Spiking Neural Networks 的重新引入,并提议将 time dithering 作为一种增强精度的技术。@spirit_from_germany表示赞同,并表示这一概念让他想起了脉冲网络。 -
对模型中低信息密度的思考:
@max_voltage对模型中每个权重的信息量能降低到 1-2 bits 表示惊讶,这表明当前模型的信息密度较低。@thejonasbrothers解释说,这是由于现有网络天生的 sparsity(稀疏性)所致,而某些权重甚至可以是 1-bit 或 0-bit。 -
新型 AI 图像生成器引发热议:
@vrus0188分享了一篇 Reddit 帖子,介绍了一款新型 AI 图像生成器,据报道其速度比 OpenAI 最好的工具快 8 倍,且能在配置较低的电脑上运行。@spirit_from_germany提供了 KOALA 图像生成器网站 的链接,以便在没有精选(cherry-picking)的情况下进行质量测试。 -
EMO:创建富有表现力的肖像视频:
@helium__重点介绍了 EMO 项目,该项目提出了一种新型的音频驱动肖像视频生成方法。@itali4no评论说,该作者与 Animate Anyone 论文的作者相同,这可能意味着不会发布代码。 -
AI 图标生成模型发布:
@kopyl宣布发布了一款用于图标生成的 SOTA AI 模型,该模型投入了 2000 美元的个人投资进行训练,可通过 Hugging Face 获取。@chad_in_the_house称赞该模型的噪声较低,尽管@kopyl提醒该模型仅能生成 256px 分辨率的图像。 -
语言模型 Distillation Learning 咨询:
@jh0482寻求关于专门针对 embedding 语言模型的 distillation learning 信息,并讨论了与连续空间目标相关的疑虑。@itali4no建议标准蒸馏方法可能适用,但@jh0482认为向目标回归(regression towards the target)和 contrastive learning 是潜在的方法。
提到的链接:
- KOALA: Self-Attention Matters in Knowledge Distillation of Latent Diffusion Models for Memory-Efficient and Fast Image Synthesis: 社交媒体描述标签。
- Elucidating the Design Space of Diffusion-Based Generative Models: 我们认为基于扩散的生成模型的理论和实践目前过于复杂,并试图通过提出一个清晰分离的设计空间来补救这一现状…
- EMO: EMO: Emote Portrait Alive - 在弱条件下使用 Audio2Video Diffusion Model 生成富有表现力的肖像视频。
- Samsung Develops Industry-First 36GB HBM3E 12H DRAM: 三星通过突破性的 12 层堆叠实现了业界最大容量的 HBM,将性能和容量均提升了 50% 以上。先进的 TC NCF 技术增强了垂直方向…
- Reddit - Dive into anything: 未找到描述。
- GitHub - collabora/WhisperSpeech: An Open Source text-to-speech system built by inverting Whisper.: 一个通过反转 Whisper 构建的开源文本转语音系统。 - collabora/WhisperSpeech
- kopyl/ui-icons-256 · Hugging Face: 未找到描述。
-
[UI icons - v1.0 Stable Diffusion Checkpoint Civitai](https://civitai.com/models/327499): 用于生成图标的 SOTA 模型。动力:我花了 2000 美元的私房钱来训练这个模型。由于无法将其变现,所以我决定分享它…
Nous Research AI ▷ #off-topic (21 条消息🔥):
- 表情符号反应讲述了一个故事:
@leontello和@0xevil使用了富有情感的 Emoji,前者使用了敬礼 Emoji (<:o7:1151260455218708480>),后者使用了骷髅 Emoji (<:dead:1072635189274083409>),反映了一种结束或死亡的感觉,随后针对 GPT-5 的缺席回复了一个哭脸 (<:f_cry:1159653986681499768>)。 - 期待未来的 GPT 迭代:
@0xevil的对话强调了社区对未来 GPT 版本的期待,提到了不存在的 GPT-6,并对@error.pdf提到的 GPT-9 用惊讶 Emoji (<:ooo:1133962720232865843>) 进行了幽默回应。 - 显示器和扩展坞推荐:
@denovich分享了一个评测 Dell 新型 5K 显示器的 YouTube 视频,并建议 Dell 提供的显示器可以同时连接多台机器,同时提到他们的扩展坞以及特定型号 Dell Thunderbolt Dock WD22TB4 值得考虑,可以在 eBay 上找到。 - 对 Y Combinator 批次重点的预测:
@0xevil思考了 Y Combinator 最新一批项目是否主要以提供 GPT-wrapper 服务的公司为主,观察到这些项目与现有产品以及在转录和从设计生成代码等领域的创新有相似之处。 - 围绕 GPT 专利和应用的推测及资源共享:
@0xevil思考了可能在更广泛圈子中讨论的 GPT-6 专利,并注意到 AI Agent 与音乐生成的结合;而@pradeep1148分享了一个 YouTube 视频,演示了如何使用 Unsloth 对 Gemma 模型进行 fine-tune。
提到的链接:
- Oppenheimer Oppenheimer Movie GIF - Oppenheimer Oppenheimer movie Oppenheimer explosions - Discover & Share GIFs:点击查看 GIF
- Finetune Gemma 7B with Unsloth:我们将了解如何使用 Unsloth 对 Gemma 模型进行 fine-tune:https://colab.research.google.com/drive/10NbwlsRChbma1v55m8LAPYG15uQv6HLo?usp=sharing#scrollT…
- One Month with the Best Monitor in the World: The New Dell 40" 5K120 HDR U4025QW:Dave 花了一个月时间体验全新的 Dell 5K120 HDR 显示器。关于我描写谱系群体生活的书:https://amzn.to/49sCbbJ,在 Facebook 上关注我:http://f…
Nous Research AI ▷ #interesting-links (6 条消息):
-
LLM 中的 1-bit 革命:
@deki04分享了一篇 arXiv 论文,介绍了 BitNet b1.58。这是一种新型的 1-bit Large Language Model,在实现与全精度模型相当的性能的同时,更具成本效益。该模型为设计高性能且低成本的 LLM 提出了一种“新的 Scaling Law”。 -
BitNet 引发好奇:
@deki04对 1-bit LLM 的存在表示惊讶,之前从未接触过这个概念。 -
显微镜下的 Scaling Laws:
@sherlockzoozoo评论说乘法 Scaling Laws 很有趣(推测是在 1-bit LLM 的背景下),并指出加法 Scaling 在模型规模增加时表现不佳。 -
发布新的 LLM 基准测试:
@tarruda分享了 Nicholas Carlini 的 Large Language Models 基准测试 链接,强调了其独特的测试内容,包括一系列复杂任务,并使用了一种数据流领域特定语言(DSL)以便于添加测试。 -
Mistral 与 GPT-4 的基准测试结果:在分享基准测试后,
@tarruda提到了一段 YouTube 视频,视频中有人在各种模型上测试了该基准,包括 Mistral 等一些 7B 模型以及 GPT-4。
提到的链接:
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits:最近的研究(如 BitNet)正在为 1-bit Large Language Models (LLMs) 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数…
- My benchmark for large language models:未找到描述
- Mistral Large vs GPT4 - Practical Benchmarking!:➡️ 一键微调与推理模板:https://github.com/TrelisResearch/one-click-llms/ ➡️ Trelis Function-calling 模型(包括 OpenChat 3.5):http…
Nous Research AI ▷ #general (205 messages🔥🔥):
- 关于 RAG 的杂谈:
@natefyi_30842讨论了使用 LLM 创建问答对,然后进行 Fine-tuning 并结合 RAG 以获得更好的上下文理解。 - 服务提供商与 Fine-tuning 的问题:
@teknium评论道,由于 Fine-tune 混合与扩展推理代码之间的冲突,Fine-tuning 提供商正面临问题,使得本地 GGUF 设置成为目前唯一可靠的选择。 - Gemini 2B Fine-tuning 的困扰:
@lmmint询问社区是否有人成功对 Gemini 2B 进行过 Fine-tuning,并提到高质量数据是必要条件。 - CausalLM 令人印象深刻的 MMLU 分数:
@nonameusr对 CausalLM 极高的 MMLU 基准测试结果表示惊讶,并分享了由@giftedgummybee提供的 Hugging Face 模型链接 CausalLM/34B-preview。 - 围绕 HyenaDNA 发布的热议:关于斯坦福大学推出的 HyenaDNA(具有 100 万 token 容量的长程基因组模型)的讨论引起了轰动,
@euclaise建议对于 DNA 序列,“中间填充”(FIM)可能比自回归模型更合适。
提到的链接:
- 来自 undefined 的推文:未找到描述
- HyenaDNA: 使用 100 万 token 上下文从 DNA 中学习:HyenaDNA 是一个在人类参考基因组上训练的长基因组序列模型,上下文长度高达 100 万个 token。
- CausalLM/34B-preview · Hugging Face:未找到描述
- qualcomm (Qualcomm):未找到描述
- Embedding - GPT4All 文档:未找到描述
- OpenAI Five 击败 Dota 2 世界冠军:OpenAI Five 是第一个在电子竞技游戏中击败世界冠军的 AI,它在本周末的决赛中连续两场击败了世界冠军 Dota 2 战队 OG。OpenAI Five 和 De…
- 来自 TechCrunch (@TechCrunch) 的推文:蒂姆·库克表示苹果今年将在 GenAI 领域“取得突破” https://tcrn.ch/3Ig8TAX
- UniProt:未找到描述
- sordonia (Alessandro Sordoni):未找到描述
- supertrainer2000/supertrainer2k/optim/adalite.py at master · euclaise/supertrainer2000:通过在 GitHub 上创建账户来为 euclaise/supertrainer2000 的开发做出贡献。
- GitHub - nestordemeure/question_extractor: 从原始文本中生成问题/答案训练对。:从原始文本中生成问题/答案训练对。 - nestordemeure/question_extractor
- BAAI/bge-base-en-v1.5 · Hugging Face:未找到描述
- Models: 移除 Nous-Hermes-2-Mistral-7b-DPO 的系统提示,由 ThiloteE 提交 · Pull Request #2054 · nomic-ai/gpt4all:描述你的更改,添加了“接受各种系统提示”,移除了系统提示,修复了空格。在请求审查之前的检查清单:我已经对我的代码进行了自检。如果是…
- CausalLM/34b-beta · Hugging Face:未找到描述
- Models: 移除 Nous-Hermes-2-Mistral-7b-DPO 的系统提示,由 ThiloteE 提交 · Pull Request #2054 · nomic-ai/gpt4all:描述你的更改,添加了“接受各种系统提示”,移除了系统提示,修复了空格。在请求审查之前的检查清单:我已经对我的代码进行了自检。如果是…
Nous Research AI ▷ #ask-about-llms (45 messages🔥):
-
寻求预算范围内的 GPT-4 级别模型:
@natefyi_30842正在寻找 GPT-4 的廉价替代方案,要求能够防止在回答中包含提供的后续书籍片段。他发现Mixtral Instruct尽管有局限性,但效果尚可。对话表明,在这种情况下只有 GPT-4 的表现符合预期。 -
微调的数量问题:在讨论训练数据集大小的重要性时,
@natefyi_30842询问一百条条目是否足够(相对于数百万条),@teknium简洁地回答:“5k”。 -
模型训练中的 DPO 策略讨论:为了改进模型回答,
@natefyi_30842考虑为 Directed Prompt Optimization (DPO) 生成错误示例,同时用户们讨论了 DPO 在何时更有效。 -
选择文本操作的分隔符:
@natefyi_30842思考了使用标准或唯一 Token 作为分隔符的效果,例如使用 Emoji 与%XYZ%在模型输入中添加元素;@natefyi_30842分享了一个 tokenizer 链接 以提供参考。 -
可解释性与表示工程 (Representation Engineering):Max_paperclips 讨论了表示工程这一令人兴奋的领域,引用了一篇最喜欢的文章,并提到了诸如 Representation Engineering: A Top-Down Approach to AI Transparency 及其对应的 GitHub 代码库 等工作。
提到的链接:
- Bowing Thank You GIF - Bowing Thank You Tom And Jerry - Discover & Share GIFs:点击查看 GIF
-
[
Representation Engineering Mistral-7B an Acid Trip](https://vgel.me/posts/representation-engineering/):未找到描述
- Metas Llama 3 is set to release in July and could be twice the size:Meta 的下一个开源语言模型 Llama 3 计划于 7 月发布,旨在与 GPT-4 齐平。
Nous Research AI ▷ #project-obsidian (3 messages):
以下是基于所提供消息的摘要:
- QT Node-X Twitter 更新:QT Node-X 的 Twitter 分享了一系列帖子 QT Node-X Tweet 1、QT Node-X Tweet 2 和 QT Node-X Tweet 3,但消息中未提供推文的具体内容。
Latent Space ▷ #ai-general-chat (57 条消息🔥🔥):
- Noam Shazeer 的博客首秀:
@swyxio分享了 Noam Shazeer 的第一篇博客文章,讨论了编码风格,题为 Shape Suffixes: Good Coding Style。 - 客户满意度与 LLM:
@eugeneyan对一个数据点表示赞赏,该数据点表明 LLM 在客户服务满意度方面与人类持平,并且可以处理三分之二的客户服务查询。 - 对 AI 新闻的质疑:
@swyxio标记了一篇过度炒作的新闻,建议在某些事情看起来过于美好时保持怀疑态度,并引用了 Fast Company 上关于 Klarna AI 助手的故事。 - 关于 LLM 论文俱乐部的讨论:
@swyxio提醒用户关注一个特别的 Matryoshka Embeddings 演示,而@osanseviero和@swyxio引用了关于该主题的其他材料,包括 HuggingFace 上的博客文章和一个带有简化 LLM 技术解释的 YouTube 频道。 - 关于 Lakehouses 和数据工程的见解:针对
@quicknick123寻求关于 Lakehouses 资源的需求,@swyxio推荐了由 Airbyte 发布的关于表格式、查询引擎和 Spark 效用的深入指南。
提到的链接:
- 未找到标题: 未找到描述
- 来自 Noam Shazeer (@NoamShazeer) 的推文: https://medium.com/@NoamShazeer/shape-suffixes-good-coding-style-f836e72e24fd 查看我的第一篇博客文章。
- Matryoshka Representation Learning: 学习到的表示是现代 ML 系统的核心组件,服务于众多的下游任务。在训练此类表示时,通常会出现计算和统计…
- 来自 murat 🍥 (@mayfer) 的推文: 哇,强烈建议查看所有示例:https://humanaigc.github.io/emote-portrait-alive/ ↘️ 引用 AK (@_akhaliq) 阿里巴巴展示 EMO: Emote Portrait Alive 生成富有表现力的肖像…
- Conviction : 未找到描述
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits: 最近的研究(如 BitNet)正在为 1-bit 大语言模型 (LLM) 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数…
- Efficient NLP: Efficient NLP 咨询。我叫 Bai Li,是一名机器学习工程师和自然语言处理博士。我可以帮助您构建具有成本效益且高效的 NLP 系统。联系我:Em…
-
[Data Lake / Lakehouse 指南:由数据湖表格式 (Delta Lake, Iceberg, Hudi) 驱动 Airbyte](https://airbyte.com/blog/data-lake-lakehouse-guide-powered-by-table-formats-delta-lake-iceberg-hudi): 解释了开源数据湖及其在数据湖表格式下的强大功能。Lakehouse 的区别以及何时需要它。 - 来自 Hamel Husain (@HamelHusain) 的推文: 关于 Klarna 的新闻感觉有些不对劲,是不是有点太像为了电视宣传而制作的了?https://www.fastcompany.com/91039401/klarna-ai-virtual-assistant-does-the-work-of-700-humans-after-layoffs
- 来自 Rowan Cheung (@rowancheung) 的推文: 对于 AI 来说,这是重要的一天,阿里巴巴、Lightricks、Ideogram、Apple、Adobe、OpenAI 等都发布了公告。发生的 7 个最重要的进展:1. 阿里巴巴研究人员揭晓…
- 🪆 Matryoshka Embedding 模型简介: 未找到描述
- Jonathan Ross 在卡塔尔网络峰会: Groq 首席执行官兼创始人 Jonathan Ross 在 #WebSummitQatar2024 的中心舞台上讨论如何让 AI 落地。X (原 Twitter): @WebSummitQatar Instagram: @WebSumm…
Latent Space ▷ #ai-announcements (3 条消息):
- Replicate CEO 亮相播客焦点:
@swyxio宣布发布了一集新的播客节目,嘉宾是 Replicate 的 CEO。包含节目链接的推文可以在这里找到。 - MRL Embeddings 论文俱乐部会议:
@swyxio预告了即将由<@206404469263433728>在#1107320650961518663频道主持的活动,届时 MRL Embeddings 论文的作者将会出席。活动封面可以在这里查看。 - 深入探讨 Representation Engineering:
@ivanleomk提示了即将在#1107320650961518663频道举行的由<@796917146000424970>主讲的 Representation Engineering 101 环节,邀请成员参与并提问互动。
提到的链接:
LLM Paper Club (West Edition!) · Luma: 本周我们将讨论论文——Matryoshka Representation Learning ( https://arxiv.org/abs/2205.13147 ),并邀请了两位共同作者 Gantavya Bhatt 和 Aniket Rege。我们已经搬迁到…
Latent Space ▷ #llm-paper-club-west (165 条消息🔥🔥):
-
俄罗斯套娃拥抱 AI:用户
@akusupati分享了题为 “Matryoshka Representation Learning” 的论文,并讨论了其在创建具有自适应维度的 LLM embeddings 方面的潜力。这是一种可以提供不同抽象层级的技术,有望节省计算和存储资源。 -
理解 MRL:
@swyxio等人参与了讨论,试图掌握 Matryoshka Representation Learning (MRL) 的特性,包括对 embeddings 进行 PCA 的深刻比较,以及该技术如何通过累加不同维度的模型 loss 来优化学习。 -
部署见解与应用:
@ivanleomk和@gulo0001等参与者提供了关于结合了 MRL 的 embedding 模型演示和实用信息。他们讨论了适配方案,并提供了 Supabase 博客和 HuggingFace 博客等资源,帮助理解这些模型在现实世界中的应用。 -
Matryoshka 探索中的好奇心:
@punnicat(推测是作者之一)在场回答了问题,并澄清了关于 Matryoshka Embeddings 的概念,特别是关于训练期间 embeddings 的维度和粒度及其对模型的影响。 -
与作者及资源的互动:本次会议吸引了许多好奇的参与者,他们就 Matryoshka Embeddings 及其对 Transformer 模型的更广泛影响提出了问题,
@swyxio和@cakecrusher等用户讨论了潜在的应用和改进。作者们乐于分享幻灯片和更多细节,例如可以通过 Twitter 联系@punnicat。
提到的链接:
-
[Matryoshka Representation Learning (MRL) from the Ground Up Aniket Rege](https://aniketrege.github.io/blog/2024/mrl/):未找到描述 - Nextra: the next docs builder:Nextra:下一代文档构建器
- MatFormer: Nested Transformer for Elastic Inference:Transformer 模型被部署在从多加速器集群到独立手机的广泛场景中。这些场景中多样的推理约束使得从业者需要……
- Representation Engineering Mistral-7B an Acid Trip:未找到描述
- Matryoshka embeddings: faster OpenAI vector search using Adaptive Retrieval:使用自适应检索通过 OpenAI 的新 embedding 模型提高查询性能
- Matrioska Loop GIF - Matrioska Loop Bored - Discover & Share GIFs:点击查看 GIF
- AdANNS: A Framework for Adaptive Semantic Search:网络级搜索系统学习一个 encoder 来嵌入给定的查询,然后将其挂接到近似最近邻搜索 (ANNS) 流水线中以检索相似的数据点。为了准确捕捉……
- 🪆 Introduction to Matryoshka Embedding Models:未找到描述
- NeuML/pubmedbert-base-embeddings-matryoshka · Hugging Face:未找到描述
- Representation Engineering 101:未找到描述
Perplexity AI ▷ #general (157 条消息🔥🔥):
-
Rabbit R1 促销激活困扰:用户
@mithrilman在激活 Rabbit R1 促销时需要帮助。@icelavaman提供了分步指导,强调需要使用邮件链接,并建议在邮件按钮出现故障无法点击时联系支持团队。 -
播客疑问与澄清:
@_paradroid提出了关于以 “Perplexity AI” 名义发布的播客的疑问,促使@icelavaman澄清了官方播客链接,而@ok.alex表示未经授权使用 Perplexity AI 名称的行为很可能是为了博取关注或牟利。 -
了解 AI 模型偏好:新用户
@outrerim询问了不同 AI 模型的优缺点,@jaicraft概述了 Experimental、GPT-4 Turbo、Claude 和 Mistral 模型的核心用例,尽管@.claidler和naivecoder786等用户更倾向于使用 Mistral 处理代码查询。 -
讨论 Perplexity 的能力与局限:
@brknclock1215认为 Perplexity 的 AI 在处理基于互联网的信息和快速回答问题方面表现出色,但也指出了它在解析大文件和图像生成方面的局限性,认为它在这些任务上尚未优化。 -
Perplexity 服务问题的担忧与解决方案:用户
@stevvie和@dv8s对缺少文件上传选项以及从 “Copilot” 更名为 “Pro” 感到困惑,而@moyaoasis建议增加导出 Perplexity 线程回复的功能,该功能目前尚未上线,但已在考虑未来实现。
提到的链接:
- 来自 Perplexity (@perplexity_ai) 的推文:更多关于 Mistral Large 的信息 👇https://www.perplexity.ai/search/Mistral-Large-Overview-Fw.QrWxvR9e9NRuDxB1wzQ
- Apple Podcasts 上的 Discover Daily by Perplexity:新闻 · 2024
- Apple Podcasts 上的 Perplexity AI:新闻 · 2024
- Apple Podcasts 上的 Stuff You Should Know About AI:商业 · 2024
Perplexity AI ▷ #sharing (13 条消息🔥):
- Librem5 探索 BurpSuite 社区版:
@librem5分享了一个 Perplexity 链接,探讨了 BurpSuite 社区版与另一个未指明替代方案之间的差异。 - AI 制定增肌计划:
@commuting5048请求制定一个优化的增肌计划,重点是防止手臂过度疲劳,并分享了 Perplexity 搜索结果。他们对 GPT-4 提供的包含组数和次数的详细锻炼计划表示满意。 - Ourdigital 使用 Perplexity 调研数字分析:
@ourdigital利用 Perplexity 收集并整理了有关数字分析和效果营销的信息,并在 Perplexity 链接中分享了他的发现。 - 探索 Mistral 的能力:包括
@manbearpig86、@rhysd21和@dailyfocus_daily在内的几位用户正在研究 Mistral 与 ChatGPT 等其他模型的对比,这体现在他们分享的 Perplexity 搜索链接、另一个对比以及 Starcoder 2 发布公告中。 - 播客 Prompt 编写与 AI 未来讨论:
@_paradroid分享了一个用于为 “48 Hours of AI” 编写播客 Prompt 的 Perplexity 链接,以及另一个使用 ResearchGPT Prompt 讨论俄罗斯为未来挑战(可能涉及 AI)做准备的链接(ResearchGPT Prompt 链接)。
Perplexity AI ▷ #pplx-api (28 messages🔥):
-
文本生成中的故障排查:
@thedigitalcat指出,当系统尝试在文本生成过程中生成来源信息时,经常会出现故障(glitches)。其他用户如@brknclock1215和@clay_ferguson也参与了讨论,认为该问题可能与来源的实现方式以及推理层(inference layer)的处理方法有关。 -
Sonar Medium 对天气查询的热情:
@brknclock1215幽默地继续使用天气相关的查询来测试 sonar-medium-online,报告了与检索系统相关的行为不一致问题,并观察到系统消息中存在“响应式”元素。 -
对 pplx-70b 的怀旧:在关于模型性能的讨论中,
@thedigitalcat幽默地表示,大家最终都会认同 pplx-70b 优于 sonar 模型,@lazysucker对此表示赞同。 -
API 难题:
@jeffworthington在使用官方文档提供的 OpenAPI 定义时遇到错误,并询问是否应引用更新的版本,这表明现有的 API 定义可能存在问题。 -
寻求用于语音聊天的 Perplexity API:
@tom_primozic询问如何通过 API 将 Perplexity AI 的功能用于语音聊天应用,并指出官方网站与sonar-medium-online模型在响应质量上存在差异。
提到的链接:
Getting Started with pplx-api:你可以通过 HTTPS 请求访问 pplx-api。身份验证包括以下步骤:首先访问 Perplexity API 设置页面,注册信用卡以开始使用。这一步将……
Eleuther ▷ #announcements (1 messages):
- 基础模型开发速查表发布:
@hailey_schoelkopf宣布发布 基础模型开发速查表 (The Foundation Model Development Cheatsheet),这是一项旨在帮助新入门的开放模型开发者的资源。该速查表由来自 EleutherAI、MIT、AI2、Hugging Face 等机构的贡献者共同完成,旨在提供负责任的开放模型开发资源概览。 - 速查表支持开放模型先锋:
@hailey_schoelkopf强调了开放模型开发的重要性,并指出了一些全透明模型的发布,如 EleutherAI 的 Pythia 模型套件、LLM360 项目的 Amber 以及 AI2 的 OLMo,强调了自 2023 年 4 月以来公开可用模型的增长。 - 专注于数据集文档和许可:这一新资源专注于模型开发中重要但讨论不足的领域,如数据集文档和许可实践,这些对于创建开放模型至关重要。
- 在哪里可以找到速查表:Foundation Model Development Cheatsheet 可以通过 PDF 论文 访问,或查看 交互式网站。更新和更多背景信息可在其 博客文章 和 Twitter 线程 中找到。
Eleuther ▷ #general (34 条消息🔥):
-
寻找 Cross-Attention SSM 模型:
@_michaelsh询问了是否有类似于 BERT 的带有 Cross-Attention 的模型用于序列分类;@stellaathena建议可以将模型作为 Encoders 进行训练,并提到了 StripedHyena,该模型交替使用 Attention 层和 SSM 层。@frazermc更倾向于在mamba中使用adaLN0,虽然目前还没有现成的用于序列分类的 Pretrained mamba,但建议可以在现有的 Checkpoint 上训练一个分类头(Classification head)。 -
Stable Video Diffusion 咨询:
@clashluke正在寻求关于如何训练/Fine-tune Stable Video Diffusion 模型的指导,希望保留其 v-prediction,并注意到它使用的是EulerDiscrete,在训练时没有get_velocity函数。 -
理解 lm-evaluation-harness:包括
@slowturtle_p、@hailey_schoelkopf和@maya_liv在内的几位用户讨论了 lm-evaluation-harness 评估工具的细节,包括分数归一化(Score Normalization)、使用自定义代码替换模型以及潜在的 TensorRT 支持。@stellaathena提供了一个博客链接,以进一步阐明多项选择归一化。 -
EleutherAI Pythia 模型状态:
@mistobaan询问了 EleutherAI/pythia-13m 模型的状态,@catboy_slim_澄清说如果是指 14m 变体,它仍然可用。 -
各种讨论和公告:
@canadagoose1分享了物流挑战和关于讲座的公告,@gaindrew重点介绍了一篇介绍 1-bit LLM 的研究论文摘要,@tastybucketofrice和@hailey_schoelkopf庆祝了用户对特定数据集的参与,@ilovescience指出自动下载可能是由于使用了lm-eval-harness。
提到的链接:
- LM 评估中的多项选择归一化:在 GPT-3/Neo/J 等自回归 LLM 上评估多项选择任务有多种方法。这篇文章阐述了当前流行的归一化方法。
- 1-bit LLM 时代:所有大语言模型都是 1.58 Bits:最近的研究(如 BitNet)正在为 1-bit LLM 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数…
- 乌龟大师 GIF - 功夫熊猫 - 发现并分享 GIF:点击查看 GIF
- Meet:Google 提供的实时会议。使用浏览器与团队成员和客户共享视频、桌面和演示文稿。
- Issues · EleutherAI/lm-evaluation-harness:用于语言模型 Few-shot 评估的框架。- Issues · EleutherAI/lm-evaluation-harness
Eleuther ▷ #research (63 条消息🔥🔥):
-
开源模型大爆发:@maxmatical 分享了一个包含开源模型及其配套数据的 Twitter 链接,转发了来自 BigCodeProject 的推文。
-
预训练 Token 查询:在由 @leegao_ 发起的关于预训练 Token 与模型大小比例的讨论中,@stellaathena 澄清道,关于预训练模型的 Token 预期“没有固定规则”。@maxmatical 提供了一篇讨论在受限数据下进行预训练的 arXiv 论文链接。
-
利用 Diffusion Models 走迷宫:@.the_alt_man 重点介绍了一个经过训练可以解决迷宫问题的 Diffusion Model,并分享了 @francoisfleuret 和 @ArnaudPannatier 的推文。@uwu1468548483828484 也参与了讨论,将其与之前使用可变深度神经网络解决迷宫问题的研究联系起来。
-
Prompt Engineering 可迁移性讨论:@thatspysaspy 询问是否有关于 Prompt Engineering 从大模型向小模型迁移的研究;@catboy_slim_ 根据个人经验回复称,虽然通用的工程技巧迁移效果尚可,但复杂的指令往往与特定模型紧密耦合。目前在这一领域似乎还缺乏带有统计指标的系统性研究。
-
Sub 8-Bit 量化的挑战:@kd90138 和 @clock.work_ 发送的一系列消息对 1-bit LLM 的实用性和扩展潜力表示怀疑,理由是当前的硬件趋势以及影响芯片制造的地缘政治担忧。
提到的链接:
- Stable LM 2 1.6B Technical Report:我们推出了 StableLM 2 1.6B,这是我们新一代语言模型系列的首款产品。在本技术报告中,我们详细介绍了生成 Base 和 Instruc… 的数据和训练过程。
-
[Language Modeling by Estimating the Ratios of the Data Distribution Aaron Lou](https://aaronlou.com/blog/2024/discrete-diffusion/#learning-concrete-scores-with-score-entropy):未找到描述。 - Scaling Data-Constrained Language Models:当前扩展语言模型的趋势涉及增加参数量和训练数据集规模。推演这一趋势表明,训练数据集的规模可能很快会受到…的限制。
-
[LeoLM: Igniting German-Language LLM Research LAION](https://laion.ai/blog/leo-lm/.):<p>我们自豪地推出 LeoLM (<strong>L</strong>inguistically <strong>E</strong>nhanced <strong>O</strong>pen <strong>L</strong>anguage <stron… -
Tweet from François Fleuret (@francoisfleuret):我们训练了一个离散 Diffusion 去噪模型来寻找迷宫中的路径。我认为 x_0 x_t 演化的可视化(线程中的最后一条消息)非常酷。↘️ 引用 Arnaud Pannatier (@Arnau…
Eleuther ▷ #scaling-laws (3 条消息):
- 询问动画制作方法:
@.the_alt_man询问某个动画是如何制作的,对所使用的工具或方法表示好奇。 - 使用
imageio制作 GIF:作为回应,@kyo_takano提到使用了imageio来创建 GIF 动画。@.the_alt_man随后进行了确认,以明确该动画确实是用imageio制作的。
Eleuther ▷ #interpretability-general (15 messages🔥):
- 矩阵范数与乘积的简化理解:
@wendlerc解释说,矩阵向量乘积、矩阵矩阵乘积以及矩阵范数,都是计算并累加重要余弦值的简写形式。矩阵 2-范数(matrix-2-norm)特指与向量 2-范数(vector 2-norm)相关的矩阵范数。 - RMSNorm 实现中的解码细节:
@wendlerc澄清了一个其论文中未明确提及的细微细节:最终的解码步骤涉及在矩阵乘法之前对h应用 RMSNorm 层。他们描述了这一过程的计算拆分方式,以便于在所得表达式之间进行余弦计算。 - 拆解 Tuned Lens 解码过程:
@wendlerc和@mrgonao讨论了在神经网络中使用 Tuned Lens 进行解码的机制。他们探讨了logits = U RMSNormlayer(tunedlens(h))是否准确代表了 Tuned Lens 的活动。 - Tuned Lens 的实现细微差别与符号表示:在整个对话中,
@wendlerc解决了将其实现进行迁移以考虑 Tuned Lens 效果的实际问题,强调了用tunedlens(h)替换h的必要性。 - 理解矩阵范数术语:
@norabelrose澄清了关于矩阵范数的术语,指出 Frobenius 范数与矩阵展平后的 Euclidean 范数相关,而矩阵的 “2-norm” 则指其谱范数(spectral norm)或最大奇异值。
Eleuther ▷ #lm-thunderdome (19 messages🔥):
-
尝试使用 LM Eval Harness:
@paganpegasus询问如何将指令/聊天格式(instruction/chat formatting)集成到 LM Eval Harness 中,或者考虑在具有现有 Eval Harness 格式的示例上进行微调。 -
为幻觉排行榜修改自定义模型:
@pminervini分享了一段代码片段,展示了他们通过扩展HFLM类,将聊天模板集成到 LM Eval Harness 中以应对幻觉排行榜(hallucinations leaderboard)的方法。 -
等待提议修改的进展:
@asuglia向@981242445696221224更新了项目中正在确定的修改状态,并指出其他任务已被优先处理。 -
改进多语言 Lambada 翻译:
@hailey_schoelkopf提到@946388490579484732贡献了新的高质量翻译以替换质量较差的翻译,这些更改将集成到 Eval Harness 中。更新后的数据集包含更多语言,可在 Hugging Face 上获取。 -
实现 EQ-Bench:
@pbevan1就如何实现 EQ-Bench(一个衡量语言模型情感智能的基准测试)寻求建议,特别是处理单个 Prompt 对应多个答案的任务。@hailey_schoelkopf指向了 Truthfulqa_mc2 任务作为示例。
提到的链接:
- src/backend/huggingface_generate_until.py · hallucinations-leaderboard/leaderboard at main:未找到描述
- GitHub - EQ-bench/EQ-Bench: A benchmark for emotional intelligence in large language models:大型语言模型情感智能基准测试 - EQ-bench/EQ-Bench
- marcob/lambada_multilingual · Datasets at Hugging Face:未找到描述
Eleuther ▷ #multimodal-general (2 messages):
- 在 Encoder-Decoder 和 Decoder-Only 模型之间做出选择:用户
@jerry0478询问何时应该使用 Encoder-Decoder 模型中的 Cross-attention Conditioning,以及何时应该像 Decoder-only 模型 那样在输入中嵌入 Token。 - Flamingo 与 LLaMA 架构决策:
@jerry0478对比了 “LLaMA 风格” 与 “Flamingo 风格” 的架构,向社区探寻每种架构最佳应用场景的直觉。
Eleuther ▷ #gpt-neox-dev (2 messages):
- 咨询关于 Neox 和 Slurm 的问题:
@muwnd询问了在 Slurm 和 Containers 环境下运行 Neox 的推荐方法,怀疑--launcher_args可能是可行方案,但注意到该参数在 Neox 中似乎不可用。 - 关于 Neox 基础设施的建议:
@triggerhappygandhi澄清说 Neox 不会对基础设施做任何特定假设,容器需要提前设置好。目前存在一个 Slurm 脚本,用于在多节点(multinode)上使用 Slurm 运行 Neox。
LangChain AI ▷ #general (89 条消息🔥🔥):
-
寻求置信度分数见解:用户
@ritanshoo询问了在使用 LangChain.js 进行 RAG 时如何检查置信度分数(confidence score)。Kapa.ai 没有立即给出答案,但建议参考 LangChain documentation (https://js.langchain.com/docs/get_started) 以进行进一步探索。 -
考虑在 LCEL 中集成 Memory:
@marknicholas和@pcube__讨论了 LangChain 使用的不同方面。@marknicholas想要在 LCEL 中添加 memory,而@pcube__询问了对于使用 Azure 托管的 LLM 作为 API 端点的服务器,哪种语言与 LangChain 的集成效果最好。Kapa.ai 建议查阅官方文档或联系社区寻求具体指导。 -
处理自定义应用中的 Tool 异常:
@abinandan请求一种在应用自定义 tool 时,如果抛出ToolException则重试该 tool 的方法。Kapa.ai 强调了来自 LangChain 的 GitHub 讨论中的变通方案,并鼓励查看 LangChain 的 GitHub issues 以获取更精简的解决方案 (https://github.com/langchain-ai/langchain/issues/10714)。 -
将 Shopify 用作自动化 Agent/Tool:用户
@erikk4正在寻求与 Shopify 相关的客户支持任务的自动化解决方案,例如检查订单状态或取消订单。他们考虑使用“前台” Agent 将问题路由到特定的 tool,并向社区咨询了除 LangChain 之外可能促进此过程的其他工具。 -
LangChain 的部署问题和功能添加:用户传达了在 LangChain 部署和功能方面遇到的挑战。
@hanumantgarad_25732在 Databricks 笔记本之外使用SQLDatabase.from_databricks时遇到了AttributeError。@kamakshi08询问了关于在 Ollama 的 LLaMA 中使用 JSON parser 的问题,并想知道它如何与 multimodal models 集成。
提到的链接:
- 未找到标题: 未找到描述
- Discord - 与朋友和社区聊天的新方式: Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
- 革新 AI 交互:将 Function Calling 与 Mistral 集成: 简介
-
[查询 SQL 数据库 🦜️🔗 Langchain](https://python.langchain.com/docs/expression_language/cookbook/sql_db): 我们可以使用 Runnables 复制我们的 SQLDatabaseChain。 -
[JSON 解析器 🦜️🔗 Langchain](https://python.langchain.com/docs/modules/model_io/output_parsers/types/json): 此输出解析器允许用户指定任意 JSON schema 并 -
[Docusaurus 🦜️🔗 Langchain](https://python.langchain.com/docs/integrations/document_loaders/docusaurus#filtering-sitemap-urls>): Docusaurus 是一个静态网站生成器,它 - 自定义 Agent 类失败,报错 object has no attribute ‘is_single_input’ · Issue #18292 · langchain-ai/langchain: 检查了其他资源,我为此 issue 添加了一个非常详细的标题。我使用集成搜索搜索了 LangChain 文档。我使用 GitHub 搜索来寻找类似的问题并…
-
[Groq:极速推理 🚀 全球首款语言处理单元 (LPU)](https://youtu.be/RSzG_v5XIxM): 在这段视频中,我将介绍推出了全球首款专为 AI 应用 (LLMs) 设计的语言处理单元 (LPU) 的 Groq。我将向您展示如何… -
[部署 🦜️🔗 Langchain](https://python.langchain.com/docs/guides/deployments#outline>)).): 在当今快速发展的技术格局中,大语言模型 (LLMs) 的使用正在迅速扩大。因此,对于开发者来说,了解如何有效地部署这些模型至关重要… - langchainjs/langchain/src/retrievers/score_threshold.ts at e24d2dedbe7ff93db33a5809e604143d60113028 · langchain-ai/langchainjs: 🦜🔗 构建具备上下文感知能力的推理应用 🦜🔗。通过在 GitHub 上创建账号来为 langchain-ai/langchainjs 的开发做出贡献。
- Issues · langchain-ai/langchain.): 🦜🔗 构建具备上下文感知能力的推理应用。通过在 GitHub 上创建账号来为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain)): 🦜🔗 构建具备上下文感知能力的推理应用。通过在 GitHub 上创建账号来为 langchain-ai/langchain 的开发做出贡献。
- 2024 旧金山 GenAI 峰会: 本次峰会是生成式 AI 领域最杰出头脑的一次非凡汇聚,体现了未来的精神。 #AI_ARE_ALL
LangChain AI ▷ #langserve (3 条消息):
- LangServe Agent 问题:
@thatdc报告了一个问题,即在使用 langserve 时,其 Agent 不返回执行的中间步骤;然而,直接从 Agent 类调用时运行正常。他们推断问题可能出在 langserve 设置的 API 服务器上。 - 技术故障深度解析:
@thatdc认为在RemoteRunnable对象中找到了问题,其中_decode_response方法似乎通过执行serializer.loadd(obj["output"])丢失了中间步骤。他们正在寻找该问题的解决方法。
LangChain AI ▷ #langchain-templates (2 条消息):
- 加入 Discord 派对的邀请:
@davisson0429发布了一个 Discord 邀请链接 供用户加入,并附带了一长串分隔符。 - 寻求 Python 模板建议:
@tigermusk询问如何生成一个类似于 LangChain Smith Chat JSON Hub 上的 Python 代码模板。
提到的链接:
- LangSmith: 未找到描述
- Discord - 与朋友和社区聊天的新方式: Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
LangChain AI ▷ #share-your-work (4 条消息):
-
《LangChain in your Pocket》正式上架:用户
@mehulgupta7991庆祝其处女作《LangChain in your Pocket》被列入 Google 关于 LangChain 的最佳书籍名单。 -
Discord 邀请刷屏:
@davisson0429分享了一个 Discord 服务器的邀请链接,URL 后带有一串模糊字符,并使用了 @everyone 标签,可能是在呼吁加入。 -
召集学习者:用户
@silvermango9927分享了一个 Google Form 链接,征求对 Machine Learning、Data Science 和 Web Development 等各种主题兴趣的反馈,作为其正在考虑的项目验证过程的一部分。 -
未来的声音:
@beaudjango介绍了 “Pablo”,这是一款支持多种 LLMs 和语音且无需打字的 AI Voice Chat 应用,并邀请测试人员加入,提供 免费 AI credits 优惠。他们还提到正在寻找愿意使用 LangChain 加入其团队的工程师。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,并与你的朋友和社区保持紧密联系。
- 加入 Pablo - AI Voice Chat beta 测试:适用于 iOS
- 产品创意验证表单:你好,非常感谢你填写此表单并提供反馈。创意点:创建一个以项目为导向的实验室(课程),与所有传统的、视频密集的长篇课程相比……
LangChain AI ▷ #tutorials (4 条消息):
- 关于 LangGraph 能力的问题:用户
@tigermusk询问workflow.compile()在 LangGraph 中是否是一个可运行对象(runnable object)。 - 垃圾信息警报:
@davisson0429发布了一个无关且带有垃圾信息性质的外部 Discord 服务器邀请链接,其中充满了严重的文本重复。 -
展示 Groq 的 LPU 突破: @datasciencebasics分享了一段 [名为“Groq: Insanely Fast Inference 🚀World’s First Language Processing Unit (LPU)”的 YouTube 视频](https://youtu.be/RSzG_v5XIxM),重点介绍了专为 AI 应用设计的全球首款 Language Processing Unit,展示了其在 LLMs 方面的潜力。 - LangGraph + YahooFinance 教程:
@tarikkaoutar提供了一个 视频指南,解释了如何使用 LangGraph、Function call 和 YahooFinance 创建一个 AI 股票分析聊天机器人,增强了对 multi-agent 应用的理解。
提到的链接:
- 加入 ONE PERCENT CLUB Discord 服务器!:查看 Discord 上的 ONE PERCENT CLUB 社区 —— 与其他 16193 名成员一起聚会,享受免费的语音和文字聊天。
- LangGraph + Function Call + YahooFinance = Multi-Agent 应用:#chatbot #animation #trading #ai #machinelearning #datascience 在这段视频中,你将使用 LangGraph、Function call 和 C… 制作一个 AI 股票分析聊天机器人。
-
[Groq:极速推理 🚀 全球首款 Language Processing Unit (LPU)](https://youtu.be/RSzG_v5XIxM):在这段视频中,我将介绍 Groq,他们推出了专为 AI 应用 (LLMs) 设计的全球首款 Language Processing Unit (LPU)。我将向你展示如何……
OpenAccess AI Collective (axolotl) ▷ #general (44 条消息🔥):
-
Jupyter Town 的麻烦:
@nruaif分享了一份日志,指出 Jupyter notebooks 存在问题,显示了与扩展链接相关的错误消息以及 初始化期间遇到的错误配置 (Bad config encountered during initialization)。@nanobitz询问这是模板问题还是 Jupyter 本身的问题。 -
BitNet b1.58 引起轰动:
@_dampf分享了一篇关于 BitNet b1.58 的 arXiv 论文,这是一种 1-bit LLM,承诺在性能匹配全精度模型的同时,显著提高成本效益。@nanobitz提到这不仅仅是一种量化方法,而是一种全新的架构。 -
Axolotl 用户调查推广:
@caseus_正在通过一份 调查问卷 寻求反馈,以增进对 axolotl 用户的了解。@dreamgen建议简化表格以获得更多回复。 -
Mistral Office Hours 公告:
@casper_ai分享了下一次 Mistral AI office hour 的邀请。 -
推理的 Alpaca 格式化:
@j_sp_r询问如何格式化推理以匹配训练指令格式,@caseus_回复称在 axolotl YAML 中指定chat_template: alpaca即可处理。
提到的链接:
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。聊天、聚会,并与您的朋友和社区保持紧密联系。
- 1-bit LLM 时代:所有大语言模型都是 1.58 Bits:最近的研究(如 BitNet)正在为 1-bit 大语言模型 (LLM) 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数…
- TinyBox 威力十足,配备六块专为 AI 重新设计的 AMD 最快游戏 GPU —— 新机箱使用 Radeon 7900 XTX,零售价为 1.5 万美元,现已投入生产:初创公司希望利用 Radeon RX 7900 XTX 提供高性能 AI 计算。
- Reddit - 深入探索任何事物:未找到描述
- Axolotl 最终用户调查问卷:未找到描述
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (9 messages🔥):
- KTO Trainer 实现咨询:
@giftedgummybee分享了关于 Kahneman-Tversky Optimization (KTO) Trainer 的 Huggingface 文档链接,并询问@257999024458553585是否有实现计划。@caseus_给予了肯定答复,表示如果没有其他人提前接手,他们可能会在下周开展这项工作。 - Sophia:一种快速优化器:
@casper_ai讨论了 Sophia 优化器 的潜力,其速度可能是 Adam 算法的两倍,并提供了 Sophia 的 实现链接(非 torch 版本),强调了其在效率上优于传统优化方法的优势。 - 使用 DropBP 进行创新训练:
@suikamelon提到了一项关于 Dropping Backward Propagation (DropBP) 的研究,该技术通过在反向传播期间丢弃层,在保持准确性的同时降低了神经网络训练的计算成本。 - Starcoder2 训练支持:
@faldore询问了关于 Starcoder2 的支持情况,并提供了其 GitHub 仓库链接。
提到的链接:
- DropBP: Accelerating Fine-Tuning of Large Language Models by Dropping Backward Propagation:训练深度神经网络通常在正向和反向传播期间涉及巨大的计算成本。传统的层丢弃技术在训练期间丢弃某些层…
- KTO Trainer:未找到描述
- Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training:鉴于语言模型预训练的巨大成本,优化算法的非平凡改进将导致训练时间和成本的实质性降低。Adam 及其变体…
- levanter/src/levanter/optim/sophia.py at main · stanford-crfm/levanter:使用 Named Tensors 和 Jax 构建清晰、可扩展、可复现的基础模型 - stanford-crfm/levanter
- GitHub - bigcode-project/starcoder2: Home of StarCoder2!:StarCoder2 的主页!通过在 GitHub 上创建一个账户来为 bigcode-project/starcoder2 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #general-help (22 messages🔥):
- 思考看似合理的意图:
@nafnlaus00提出了一个想法,即提示高级语言模型生成故意错误的答案,这些答案看起来合理但包含导致错误结论的缺陷,不过随后没有进一步的讨论。 - 工具切换困扰:由于成本问题,
@stoicbatman考虑从 Runpod 切换到 Vast AI,并寻求社区的经验对比;@nanobitz回应指出,虽然 Vast AI 更便宜,但它没有抽象机器细节,且机器质量参差不齐。 - 困惑的提交难题:
@karisna对他们重写 axolotl 文档的 commit 未被接受表示失望,并指出可能存在疏忽,即 Windows 的 WSL2 设置没有得到足够的重视;然而,@nanobitz回复并试图澄清文档问题是否已得到解决。 - 针对智能模型的基准测试:
@jovial_lynx_74856询问了关于在用 Axolotl 微调的模型上运行基准测试的问题,@nanobitz建议查看 GitHub 上的 lm_eval_harness,并确认 Axolotl 本身没有直接集成基准测试功能。 - 保存设置混乱:由于担心保存结果不一致,
@duke001.询问为什么将saves_per_epoch设置为 4 且num_epochs设置为 4 后,只产生了 4 个 checkpoint 而不是预期的 16 个;@nanobitz暗示了一个解决方案,建议调整保存限制。
提到的链接:
axolotl/src/axolotl/core/trainer_builder.py at 6b3b271925b2b0f0c98a33cebdc90788e31ffc29 · OpenAccess-AI-Collective/axolotl:尽管提问。通过在 GitHub 上创建一个账户来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #community-showcase (11 messages🔥):
- Mistral 模型媲美 ChatGPT 3.5:
@le_mess分享了他们的 7B Mistral 模型 在丹麦语任务中的表现与 ChatGPT 3.5 相当。 - 通过迭代训练增强性能:
@le_mess通过使用合成数据方法 (synthetic data approach) 并进行超过 30 次迭代训练改进了模型,在不依赖 GPT-4 的情况下不断增强模型响应。 - 初始人工筛选助力可扩展模型训练:
@le_mess手动筛选了前 1000 条响应,随后利用模型生成更多数据。后续模型被训练用于识别高质量响应,以进行进一步的训练循环。
LlamaIndex ▷ #blog (4 messages):
-
Groq 加速 LlamaIndex:
@GroqInc的 LPU 现在正式与 LlamaIndex 集成,并支持llama2和Mixtral模型,以实现高效的 LLM 生成。他们发布了一个 cookbook 指南来宣布这一进展,旨在简化应用工作流。 -
LlamaParse 使用量激增:
@llama_index报告了 LlamaParse 的显著使用量,并据此进行了重要更新,例如致力于实现不限额的自选服务使用,并暂时提高了 1k 页的使用上限。详情请参阅此 更新链接。 -
利用 LLM 优化混合搜索 (Hybrid Search):一种提高混合搜索检索效果的新策略是使用 LLM 通过 few-shot 示例对查询进行分类,并随后调整 alpha 参数。
@llama_index在其最新推文中分享了关于该方法的见解。 -
针对结构化和非结构化数据的 RAG:
@llama_index推荐了@ClickHouseDB的一篇博客文章,展示了一种适用于同时包含非结构化和结构化数据查询的 RAG 架构,这些数据存储在同一个数据库中。感兴趣的读者可以在这里深入了解这一集成。
LlamaIndex ▷ #general (75 messages🔥🔥):
-
探索 LlamaIndex 文档索引:
@vaguely_happy提议建立一个服务来索引最新的 LlamaIndex 文档,这促使@cheesyfishes提到了文档上的 mendable,而@whitefang_jr告知 LlamaParse 目前尚未发送页码,但添加页码和标签的工作正在进行中。 -
关于 Golang 中 Callbacks 的澄清:针对
@sansmoraxz询问关于在原生类型中使用CallbackHandler的问题,@cheesyfishes确认正在对 callbacks 进行重构,并建议暂时不必担心,因为预计会有所改进。 -
讨论 Reranker 模型:在由
@richard1861发起的关于 Colbert 和 Cohere 哪个重排序模型更好的讨论中,@.sysfor分享了代码并建议同时使用 FlagEmbeddingReranker 和 CohereReranker,尽管目前还没有正式的指标来比较它们的性能。 -
可视化 ReActAgent 流水线/DAGs:
@mrpurple9389询问了关于可视化 ReActAgent 图表的问题,虽然@cheesyfishes澄清了 ReActAgent 缺乏可视化图表,但@mrpurple9389进一步探索了如果使用流水线/DAGs 复制该 Agent 是否可以实现可视化。 -
关于 LlamaIndex 与 Langchain 的对比及兼容性讨论:
@tr1ckydev寻求关于 LlamaIndex 和 Langchain 区别的澄清,@cheesyfishes解释说 LlamaIndex 专注于将数据连接到 LLM,而 Langchain 更像是一个综合库。后续问题包括兼容性咨询,表明 LlamaIndex 可以与各种向量数据库和 LLM 平台集成。
提到的链接:
- Introducing LlamaCloud and LlamaParse — LlamaIndex, Data Framework for LLM Applications:LlamaIndex 是一个简单、灵活的数据框架,用于将自定义数据源连接到大语言模型 (LLM)。
- Arize Phoenix - Phoenix:未找到描述。
- Ollama - Llama 2 7B - LlamaIndex 🦙 v0.10.14:未找到描述。
LlamaIndex ▷ #ai-discussion (5 messages):
- Model Decay Woes: 用户
@.sysfor表达了对他们的模型最近生成 离谱回复 (insane responses) 的担忧,并质疑模型是否会随时间衰减,其假设是设置中没有其他任何变化。 - Cheesyfishes to the Rescue:
@cheesyfishes澄清说模型 不会随时间衰减,但 较长的输入或未按指令结构组织的输入 可能会导致模型响应出现问题。 - Observable Decline in Fine-tuned Performance: 针对衰减问题,
@.sysfor在运行与 baseline 模型对比的测试时,特别注意到“更好的” fine-tuned 模型出现了问题。
OpenRouter (Alex Atallah) ▷ #general (49 messages🔥):
-
Claude Models Prompt Errors:
@quentmaker报告了一个错误,即当对话中用户和助手之间的交替消息超过 8 条时,会影响 Anthropic 的各种 Claude 模型。@louisgv确认了该问题并承诺正在开发修复方案。 -
OpenRouter Addressing Turn Order Issues:
@alexatallah建议了一个针对 Prompt 问题的临时解决方案,即将第一条助手消息更改为 system message。同时,正在开发处理以助手消息开头的对话的功能。 -
Rate Limit Discussions for OpenRouter:
@gunpal5_43100询问了使用 OpenRouter 生成大量文章时的 rate limits。@alexatallah澄清说,每个拥有自己 API key 的用户都有独立的 rate limits,累计起来应能提供足够的 throughput。 -
Caching Concerns with Mistral: 包括
@natefyi_30842和@spaceemotion在内的几位用户观察到,在向 Mistral 模型重复 Prompt 时,响应具有相似性,从而引发了对 API 缓存行为的猜测。@alexatallah确认 Mistral 的 API 可能会缓存查询。 -
Compatibility with Prepaid Cards:
@fakeleiikun询问了 OpenRouter 对预付卡的支持情况,特别是电子钱包应用提供的预付卡。@louisgv指出,虽然某些预付卡可能有效,但由于 Stripe 的欺诈预防措施,来自不支持银行的虚拟卡可能不被接受。
Links mentioned:
- no title found): no description found
- OpenRouter: Build model-agnostic AI apps
CUDA MODE ▷ #triton (10 messages🔥):
- 基准测试脚本增强:
@hdcharles_74684改进了一个用于比较 Triton kernel 性能的基准测试脚本。这对于 int8 weight-only linear kernels 在 batch size 大于 1 时可能优于 cuBLAS 的情况非常有益,从而影响 sdxl-fast。该 脚本已发布在 GitHub 上,包含多种 kernel,包括 适用于 bs=1 的快速 kernel、int4 tinygemm 以及 uint4x2 triton kernel。 - 建议向 cuda-mode/lectures 提交 PR:
@marksaroufim建议@hdcharles_74684向 GitHub 上的 cuda-mode lectures 仓库提交 pull request,以便更方便地访问该基准测试脚本。 - 讨论潜在的 Triton 优化:
@chhillee提到 Torch.compile 可以高效处理 batch size 为 2 的情况,这可能会缓解讨论中的主要瓶颈。 - Radeon 上的 Tensor 性能修复:
@iron_bound报告称,在修复了 mlir/llvm 中 WMMA hooks 的问题后,Radeon RX 7900 XTX 显卡的 tensor 性能有了显著提升。 - Triton 版本的调试问题:
@kierandidi在 3.0.0 和 2.2.0 版本的 Triton 调试器中遇到了关于interpret参数的问题。@andreaskoepf和@marksaroufim确认该方法已被弃用,并建议设置TRITON_INTERPRET环境变量作为权宜之计。 - 关于 Triton 稳定性的反馈:
@andreaskoepf分享了与 CUDA 相比 Triton 不够稳定的经验,提到了无法解释的 segfaults 和结果不一致的问题。@marksaroufim请求提供一个示例来对比 segfaults 发生前后的情况,此前在 Twitter 上也观察到了类似的反馈。
提到的链接:
- GitHub - cuda-mode/lectures: Material for cuda-mode lectures:cuda-mode 课程资料。可以通过在 GitHub 上创建账号为 cuda-mode/lectures 的开发做出贡献。
- 用于比较多个形状下多个线性 Triton kernel 性能的脚本:用于比较多个形状下多个线性 Triton kernel 性能的脚本 - linear_triton_kernels.py
CUDA MODE ▷ #cuda (6 messages):
- 关于 GPU Intrinsics 的询问:用户
@drexalt询问某篇 推文 中的说法是否属实,寻求 CUDA MODE Discord 成员的澄清。 - 对 FP8 Intrinsics 疑问的回应:
@zippika澄清该说法是错误的,并提供了一个指向 CUDA math API 文档 的链接,该文档中仍列出了 FP8 intrinsics。 - 澄清 FP8 的用途:
@zippika强调 FP8 主要作为一种数据格式,而不是被广泛用于计算。
提到的链接:
CUDA Math API :: CUDA Toolkit Documentation:未找到描述
CUDA MODE ▷ #torch (13 messages🔥):
-
对 Polyhedral 不感兴趣:
@chhillee对 polyhedral compilation(多面体编译)在优化深度学习 sharding 中的效用表示怀疑,认为关键问题在于定义 cost function(代价函数)。 -
对搜索空间的怀疑:在与
@andreaskoepf的讨论中,@chhillee将在深度学习中寻找最优 sharding 的挑战比作新 ML architectures 的持续发展。 -
思考最优映射:
@gogators.沉思道,从 深度学习程序到硬件 的有效映射空间可能比所有可能的深度学习程序空间更小、更简单。 -
深度学习程序优化并非易事:
@gogators.收回了将寻找深度学习计算高效映射的过程描述为“轻而易举(trivial)”的说法,但同时也表示,如果 顶级 AI 机构 还没有在研究这一领域,他会感到惊讶。 -
辩论深度学习的可计算性:
@telepath8401幽默地挑战了@gogators.最初使用的 “trivial” 一词,促使对方澄清:考虑到 深度学习算子 的同质性和显式依赖关系,优化算子映射是具有可行性的。
CUDA MODE ▷ #ring-attention (15 条消息🔥):
- 新的 Ring Attention 实现:
@andreaskoepf分享了 lucidrains 的 Ring Attention 实现,该实现包含自定义的 Triton kernels,并提议将其与 zhuzilin 的另一个实现进行正确性和性能对比。 - Backward Pass 缺陷排查:
@andreaskoepf提到 Phil 指出了 backward pass 中的一个问题,可能需要修复,详见 此 GitHub issue 中的讨论。 - GPU 兼容性问题:
@nthanhtam.和@jamesmel报告了在 GPU 上运行 Ring Attention 实现时遇到的问题,而@ericauld注意到断言脚本在 CPU 上可以正常工作。 - 代码不一致与错误:
@ericauld观察到在尝试根据 Melvin 的建议运行代码时出现了多个错误,例如拼写错误和缺失 imports,这导致了额外的 Triton 相关问题。 - 提交历史暗示存在问题:
@iron_bound通过引用 GitHub 上的提交历史 暗示 lucidrains 的 Ring Attention 实现中可能有些部分已经损坏。
提到的链接:
- GitHub - lucidrains/ring-attention-pytorch: Explorations into Ring Attention, from Liu et al. at Berkeley AI: 来自伯克利 AI 的 Liu 等人的 Ring Attention 探索 - lucidrains/ring-attention-pytorch
- Commits · lucidrains/ring-attention-pytorch: 来自伯克利 AI 的 Liu 等人的 Ring Attention 探索 - Commits · lucidrains/ring-attention-pytorch
- A ring attention with flash attention kernel implementation · Issue #4 · lucidrains/ring-attention-pytorch: 你好!感谢你在 PyTorch 中实现 Ring Attention 的工作!我刚刚尝试实现了一个 ring_flash_attn_qkvpacked_func(对应 Flash Attention 中的 flash_attn_qkvpacked_func…
- Compare ring-flash-attention & ring-attention-pytorch · Issue #11 · cuda-mode/ring-attention: lucidrains 和 zhuzilin 在过去几天里非常努力,并完成了以下两个 Ring Attention 实现:lucidrains/ring-attention-pytorch 和 zhuzilin/ring-flash-attention。创建一个…
Interconnects (Nathan Lambert) ▷ #news (10 messages🔥):
-
Arthur Mensch 澄清事实:
@arthurmensch澄清了关于他们近期公告的误解,重申了对使用 1.5k H100 训练开放权重模型(open-weight models)的承诺,与 Microsoft 的转售协议,并保持其作为具有全球野心的欧洲公司的独立性。他强调了 La Plateforme 和 Azure 上用户对 Le Chat 和 Mistral Large 日益增长的兴趣,并计划快速迭代。查看澄清内容。 -
Nathan 认可公开澄清:在
@arthurmensch发布推文后,@natolambert表示赞赏,称在社交媒体上提供此类公开澄清的行为“非常有诚意(def legit vibes)”。 -
发布 StarCoder2 和 The Stack v2:
@BigCodeProject推出了 StarCoder2,该模型采用 16k token 上下文进行训练,拥有超过 4T+ token 的仓库级信息,构建于包含超过 900B+ token 的 The Stack v2 之上。代码、数据和模型完全开放并可用,为社区做出了重大贡献。探索 StarCoder2。 -
Meta 准备发布 Llama 3:
@Reuters的一条推文报道称,Meta 计划在 7 月发布名为 Llama 3 的新 AI 语言模型,这可能意味着 AI 领域的又一次重大竞争。该细节由 The Information 报道。阅读路透社更多报道。 -
具有扩展上下文的 G 1.5 Pro 即将向 Nathan 开放:
@natolambert宣布很高兴能获得具有 100 万 token 上下文的 G 1.5 Pro 访问权限,计划将其用于处理播客和其他内容,并提到如果有兴趣,可能会根据使用体验举办文章研讨会。
提到的链接:
- 来自 BigCode (@BigCodeProject) 的推文:介绍:StarCoder2 和 The Stack v2 ⭐️ StarCoder2 采用 16k token 上下文和 4T+ token 的仓库级信息进行训练。全部构建在 The Stack v2 之上——这是最大的代码数据集,包含 900B+ t…
- 来自 Arthur Mensch (@arthurmensch) 的推文:澄清几件事,因为我们看到了对我们最新公告的一些创造性解读:- 我们仍然致力于领先的开放权重模型!请保持一点耐心,1.5k H100 …
- 来自路透社 (@Reuters) 的推文:据 The Information 报道,Meta 计划在 7 月发布新的 AI 语言模型 Llama 3 http://reut.rs/3TgBgFJ
Interconnects (Nathan Lambert) ▷ #random (30 messages🔥):
-
Nathan Lambert 关注 Demis Hassabis:
@natolambert分享了一集与 Google DeepMind CEO Demis Hassabis 的播客,讨论了 超人类 AI 扩展(scaling)、在 LLM 之上训练 AlphaZero 以及 AI 治理。该播客可以在 YouTube 上观看,或在 Apple Podcasts 和 Spotify 等平台收听。 -
思考 AI 讨论中的开放性:
@natolambert和@mike.lambert讨论了就 完全开放的 AI 进行公开对话的价值,以及与 Twitter 等平台相比,心智模型(mental models)的差异。 -
用户间的姓名巧合:用户
@xeophon.询问@natolambert和@mike.lambert是否有亲戚关系,因为他们的姓氏相同;经确认这只是巧合。 -
Anthropic 关联确认:
@mike.lambert确认在 Anthropic 工作,并表达了在聊天中分享信息的立场,表示更倾向于以个人身份参与讨论,而非作为雇主的代表。 -
寻找 LAMB 表情符号:
@natolambert幽默地感叹缺乏合适的“LAMB(羔羊)”表情符号,并对搜索结果指向牛排表情符号 🥩 表示沮丧。
提到的链接:
Demis Hassabis - 扩展、超人类 AI、LLM 之上的 AlphaZero、流氓国家威胁:”scaling 是一门艺术”
LLM Perf Enthusiasts AI ▷ #gpt4 (2 messages):
- 关于 Benchmark 自动化的咨询:
@ampdot询问 Benchmark 是否有自动化脚本,表现出对尝试此类工具的兴趣。 - 对 Benchmark 自动化的热情:
@dare.ai也表达了对自动化 Benchmark 脚本的兴趣,并期待尝试,同时艾特了<@757392677280022549>以寻求可能的回复。
LLM Perf Enthusiasts AI ▷ #opensource (4 messages):
- 预期的 Llama 3 春季发布:用户
@res6969表示他们原本预期 Llama 3 会在春季发布,暗示目前的进度比预想的要慢。 - Llama 3 可能的最后时刻改进:
@potrock希望 Llama 3 的延迟是因为最后时刻的 Attention 更新,暗示发布版本中可能包含改进。 - 对 Gemini Ring Attention 的热情:
@potrock提到引入 Gemini Ring Attention 将是 Llama 3 的一个酷炫功能,表现出对这种特定 Attention 机制的兴趣。
LLM Perf Enthusiasts AI ▷ #offtopic (1 messages):
- LLM 测试的时间紧迫:用户
@jeffreyw128表达了测试新 LLM 的愿望,但强调由于时间限制,“对每个模型进行良好的直观评估 (vibe check)” 需要付出巨大努力。
LLM Perf Enthusiasts AI ▷ #openai (3 messages):
- ChatGPT 搜索更新传闻:
@jeffreyw128提到了 OpenAI 本周可能会更新 ChatGPT 网页搜索的传闻,并寻求他人的确认。 - 寻找 OpenAI 见解:用户
@res6969表示没听说过此类传闻,并表示需要寻找更好的 OpenAI 相关信息源。 - 寻找 codeinterpreter 生产环境资源:
@res6969询问是否有人拥有在生产环境中使用 codeinterpreter 的资源,表现出对实际应用的兴趣。
DiscoResearch ▷ #general (6 messages):
-
DiscoLM 模板澄清:用户
@bjoernp指出了使用 DiscoLM 模板进行对话上下文 Tokenization 的重要性,并引用了关于 chat templating 的 Hugging Face 文档。 -
llamaindex 代码 Chunker 的问题:
@sebastian.bodza报告称 llamaindex 的代码 Chunker 存在严重故障,会生成单行内容并忽略chunk_lines选项。 -
训练德语 RAG 模型的合理性检查:
@johannhartmann正在创建一个用于检索增强生成 (RAG) 任务的德语数据集,利用了德国电信的维基百科内容-问题对,并寻求关于改进德语 Mistral 7b 模型可靠性方法的反馈。 -
德语任务中 Goliath 与 DiscoLM 的对比:
@philipmay询问 Goliath 是否是德语能力更强的模型,并分享了其在 Hugging Face 上的模型卡链接。讨论随后展开,@johannhartmann认为 DiscoResearch/DiscoLM-120b 可能表现更好,因为它是在德语内容上训练的。 -
关于为数据集生成负样本的建议:
@philipmay建议了一种成功的负样本生成方法,即引导语言模型修改给定答案使其在事实错误,目的是为 RAG 训练构建更有效的数据集。
提到的链接:
DiscoResearch ▷ #discolm_german (1 messages):
-
EQ-Bench 中的德语 Prompt:
@crispstrobe分享了 EQ-Bench 现在支持德语 Prompt,显示出与 MMLU 和 Arena Elo 等各种 Benchmark 的强相关性。GitHub Pull Request 链接在这里。 -
GPT-4 性能领先: 根据
@crispstrobe分享的对比,GPT-4-1106-preview 在 EQ-Bench 德语 Prompt 评估中获得了 81.91 分,优于包括 GPT-3.5、各种 Mistral 版本以及discolm-german-laser在内的其他模型。 -
评估德语语言模型: 消息列出了不同模型的 EQ-Bench 评分,强调即使是像
german-assistant-v7这样的模型也有 35.48 的评分,这可以作为德语语言模型性能的基准。 -
包含翻译脚本:
@crispstrobe还提到在 Benchmark 中包含了翻译脚本,并表示这些脚本是快速设置的,具有进一步改进的潜力,例如由学生进行人工审核。 -
使用 GPT-4 进行自动翻译: 德语 Prompt 是使用 ChatGPT-4-turbo 自动翻译的,这表明复杂的模型可以促进测试集或训练集的翻译,这一过程可以适配或更改为其他翻译服务,如 “free Gemini”。
提到的链接:
Build software better, together: GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、Fork 并为超过 4.2 亿个项目做出贡献。
Datasette - LLM (@SimonW) ▷ #ai (4 messages):
- 与冗长的 JSON 响应作斗争: 用户
@dbreunig提到经常需要清理 嘈杂的 JSON 响应,但未详细说明具体使用的方法或函数。 - 应对 Claude 的开场白: 用户
@justinpinkney分享了一个技巧,通过使用初始字符控制来避免 Claude 出现类似 “Sure here’s a…” 的引导句,参考了 Anthropic 的文档。他们建议以<rewrite>开头或强制响应以{开始。 - Claude 顽固的解释: 用户
@derekpwillis承认尝试了各种方法让 Claude 提供不那么冗长的输出,例如强制 AI 以{开头,但 Claude 仍然坚持在实际内容之前提供解释。
提到的链接:
Ask Claude for rewrites: 如果 Claude 给出的响应接近但并不完全是你想要的,你可以要求 Claude 重写。在 Slack 中,这可以简单到在之后告诉 Claude “Try again”…
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=ikIgy0qlif8&feature=youtu.be
Skunkworks AI ▷ #general (1 messages):
- 私信中的招聘咨询: 用户
.papahh通过私信联系了@1117586410774470818,暗示了一个潜在的工作机会,并对接收者的参与表示感兴趣。
Alignment Lab AI ▷ #looking-for-collabs (1 messages):
- 探索跨物种价值观的根源:
@taodoggy正在为一个项目寻找合作者,该项目旨在 理解跨物种共享价值观的生物学和进化起源,完善价值观的定义,并分析这些价值观在不同文化中是如何表达的。他们通过 Google Docs 链接 提供了一个简要概述。
提到的链接:
Uncovering the Origins of Values: A Biology and Cognition-Based Approach for AI Alignment: 未找到描述
AI Engineer Foundation ▷ #general (1 messages):
- 寻求 AI Engineer 招聘建议: 用户
@peterg0093正寻求在英国开始招聘 AI Engineer,并请求提供优秀的 Job Description 示例,以避免偏离该领域的任何标准用语。他鼓励有相关参考资料或资源的用户与其联系。