ainews-to-be-named-7776
Stable Diffusion 3 —— Rombach 和 Esser 再次做到了!
在 Soumith Chintala 的推荐下,超过 2500 名新成员加入了社区,这凸显了人们对基于大语言模型(LLM)的前沿(SOTA)摘要技术日益增长的兴趣。
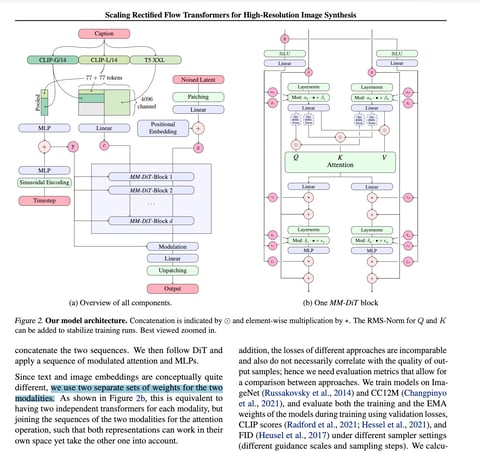
本次最受关注的亮点是 Stable Diffusion 3 (SD3) 详细论文的发布,该模型展示了先进的图像内文本控制和复杂提示词处理能力;在人工评估基准测试中,SD3 的表现优于其他最先进的图像生成模型。SD3 模型基于一种名为 MMDiT 的增强型扩散 Transformer(Diffusion Transformer)架构。
与此同时,Anthropic 推出了 Claude 3 系列模型,以其类人化的回答和情感深度而著称,在 HumanEval 评测中得分达 79.88%,但其成本是 GPT-4 的两倍以上。微软发布了新的基于 Orca 的模型和数据集,Latitude 则推出了具有强大编程能力的 DolphinCoder-StarCoder2-15b。此外,Perplexity AI 对图像模型的集成,以及由 LlamaIndex 驱动的 PolySpectra 3D CAD 生成技术也备受瞩目。
文中提到:“SD3 的胜率超过了所有其他最先进的图像生成模型(或许 Ideogram 除外)”,并且“Claude 3 模型非常擅长根据文本描述生成 d3 可视化图表”。
2024年3月4日至3月5日的 AI 新闻。我们为您检查了 356 个 Twitter 账号 和 22 个 Discord 社区(352 个频道,共 7550 条消息)。预计为您节省阅读时间(以 200wpm 计):697 分钟。
热烈欢迎从 Soumith 的推荐 中加入的 2500 多位新朋友!这有点像家里还没打扫干净就有大批客人造访——我们仍然在跳下悬崖的同时努力组装飞机。但我们对自己的 Prompt、Pipeline 以及对基于 SOTA LLM 的摘要工具应该具备何种功能的探索越来越满意。
许多人还在消化 Claude 3 的消息,但我们已经继续前行了。今天的重大新闻是 Stable Diffusion 3 论文。SD3 几天前已宣布(尚未发布),但论文提供了更多细节。
照例放上图片,因为既然有漂亮的图片看,谁还会读我写的文字呢:

我们对图中文字控制的惊人水平以及对复杂 Prompt 的处理能力印象更为深刻(看看过去两年的进展):

论文亮点在此,简而言之,他们修改了 Bill Peebles 的 Diffusion Transformer(没错,就是 Sora 中使用的那个),使其更具多模态特性,因此被称为 “MMDiT”:
DiT 变体是今年研究的热点,例如 Hourglass Diffusion 和 Emo。
Stability 最近关于其 Benchmark 的宣传有些混乱(例如 SD2 和 SDXL),导致不清楚其主要优势是图像质量、开源定制化还是其他方面。但 SD3 非常明确——在通过真人($$$)对 Partiprompts 问题进行评估时,SD3 的胜率超过了所有其他 SOTA 图像生成模型(可能 Ideogram 除外)。
目前尚不清楚 8B 参数的 SD3 模型是否会在 Stability 的 API 限制之外发布。但无论如何,一个由开启了图像生成新纪元的人们推出的全新 SOTA 模型,都是值得庆祝的。
目录
我们正在尝试移除目录,因为许多人反馈它并不像预期的那样有用。如果您怀念目录,请告诉我们,否则它们将永久消失。
第 X 部分:AI Twitter 摘要
Claude 3 Sonnet (14B?)
Anthropic Claude 3 发布
- Anthropic 发布了 Claude 3 模型,有些人认为它略优于 GPT-4,且显著优于 Mistral 等其他模型。关键改进包括更拟人化的回答以及具备情感深度的角色扮演能力。
- Claude 3 在 HumanEval 测试中得分为 79.88%,低于 GPT-4 在同一测试中的 88%。其价格也是 GPT-4 的 2 倍以上。
- 现在有三个智力相当的顶级模型(Anthropic Claude 3、OpenAI GPT-4、Anthropic Gemini Ultra),这使得基于模仿的微调(imitation-based fine-tuning)取得了进展。
AI 模型发布与数据集
- Microsoft 发布了新的基于 Orca 的模型和数据集。
- Stability AI 和 Tripo AI 发布了 TripoSR,这是一种 image-to-3D 模型,能够在不到一秒的时间内生成高质量输出。
- Latitude 发布了 DolphinCoder-StarCoder2-15b,具有强大的编程知识。计划推出更小的 StarCoder2 模型和 CodeLlama。
AI 能力与用例
- Claude 3 模型非常擅长根据文本描述生成 d3 可视化图表。
- Perplexity AI 正在集成 Playground AI 的图像模型,以通过视觉插图增强回答效果。
- PolySpectra 使用 LLM 从文本提示生成 3D CAD 模型,由 LlamaIndex 提供支持。
AI 开发与评估
- 根据 MosaicML 和 Stanford 的研究,与整体偏好相比,细粒度 RLHF 提高了 LLM 的性能和定制化能力。
- LLM 可以“知道”它们何时正在接受测试,且 LLM 中的初级推理错误与人类犯的错误相似。
- 验证损失(Validation loss)是选择要部署的 LLM Checkpoint 的糟糕指标。
迷因与幽默
- 在讨论新的 Claude 模型之际,一条关于猫群纪念 Julius Caesar 的幽默推文。
- 关于在撞向沉重的酒店桌子时弄坏 MacBook 屏幕和腿骨的笑话。
总结来说,Anthropic 的 Claude 3 模型发布引发了广泛讨论,人们在性能、成本和能力方面将其与 GPT-4 进行对比。Claude 3 展示了强大的语言理解和生成能力,但在某些编程测试中落后于 GPT-4。
除了 Claude 3 的发布,Microsoft、Stability AI、Latitude 等公司也发布了其他值得关注的 AI 模型和数据集。这些涵盖了从编程、3D 模型生成到 image-to-text 的一系列应用。
研究人员继续推进大语言模型的微调和评估技术,例如使用细粒度 RLHF,并对验证损失等指标保持谨慎。此外,还有关于 LLM 推理能力和潜在自我意识的观察。
在技术讨论之余,幽默仍有一席之地,AI 新闻和分析中穿插着各种笑话和迷因。总的来说,这些推文描绘了一个在模型规模和能力上迅速进步,同时也正在应对评估、安全和潜在影响等重要问题的 AI 领域。
ChatGPT (GPT4T)
-
Claude 3 vs GPT-4 讨论:AI 社区正在积极讨论 Claude 3 的类人响应能力,一位工程师指出它能够以 GPT-4 无法做到的方式强调词汇。然而,正如 Giffmana 的推文 所提到的,人们对其性能是真正的突破还是仅仅是特定训练数据的结果持怀疑态度。Claude 3 与 GPT-4 的 HumanEval 测试得分对比受到关注,指出在特定测试中 Claude 3 得分为 79.88%,而 GPT-4 为 88%,如 Abacaj 的推文 所示。
-
模型性能与基准测试:关于 Claude 3 等 AI 模型效率和有效性的辩论仍在继续,特别关注成本与性能。一些推文强调了 Claude 3 在特定任务中的能力(Teknium1 的对比)以及与 GPT-4 相比的 性价比对比,为专注于优化 AI 项目资源分配的开发者提供了宝贵的见解。
-
联盟营销收入分配:一条披露 AG1 成本和收入分配 的推文揭示了 AI 服务产品的财务机制。这种收入共享模式的透明度提供了对 AI 产品生态系统的细致理解,对于科技领域的创业者和工程师至关重要。
-
Playground AI 的集成:Playground AI 作为 Perplexity Pro 用户的默认模型集成(AravSrinivas 的公告)是 AI 驱动图像生成迈出的重要一步。此外,TripoSR 用于从图像创建 3D 模型 的部署突显了多维 AI 应用能力的提升。
-
高质量数据的重要性:Svpino 简要提醒了 AI 训练中数据质量优于数量的价值,这是从事数据驱动 AI 模型工作的工程师的关键考虑因素(相关推文)。
-
对数据集的关注:BlancheMinerva 敦促在对 LLM 行为下结论之前进行更深入的数据集分析(推文),强调了 AI 开发中细致数据审查的迫切需求。
AI 幽默与迷因
- 创意 AI 趣事:关于技术故障和 AI 相关事故轻松一面的幽默描述,例如在沉重的酒店桌子上摔断了腿,然后继续开关于进一步潜在“断裂(breaks)”的玩笑(Levelsio 的推文),为通常严肃的 AI 对话领域提供了急需的轻松氛围。
这段总结阐明了 AI 技术社区内的多方面讨论,从深入研究模型性能及其现实世界的适用性,到通过技术视角观察到的社会反思。对 Claude 3 与 GPT-4 能力的强调,以及 AI 模型开发和部署中的方法论考虑,突显了在实现更细致、更类人 AI 方面的持续努力。此外,通过技术视角对韩国文化和经济格局的探索,突显了社会结构与技术发展之间复杂的相互作用,为驾驭全球 AI 应用的技术专业人士提供了宝贵的见解。
PART 0: 总结的总结之总结
操作员笔记:我们用于 Claude 的 Prompt,以及用于 ChatGPT 的 我们的总结器 GPT。显示的是每种运行 3 次中主观上最好的一次。
Claude 3 Sonnet (14B?)
有趣的是,Sonnet 在我们第二次运行时未能理解任务(它没明白我们需要它对所有的摘要和原始文本进行总结——目前总计 2 万字)。
-
Mistral 模型见解与困惑:讨论集中在 Mistral models,包括对不同 tokenizer(如 tiktoken)处理 context size 的澄清、硬件建议、关于 LeChat 免费可用性的担忧,以及对 Mistral 开源方向和极简参考实现的询问。同时也讨论了 Mixtral 缺乏 sliding window attention 的问题。
-
Perplexity AI 集成与易用性:用户探索了 Playground AI 的 V2.5 模型以及 Claude 3 与 Perplexity AI Pro 的集成,分享了对 Claude 3 Opus 配额限制的看法,推测了 Perplexity 的未来发展方向,并交流了优化 AI 驱动功能(如图像生成和搜索)的技巧。
-
LLM 编程能力与量化技术:介绍了一些前沿的 AI 模型,如 OpenHermes-2.5-Code-290k-13B 和 Code-290k-6.7B-Instruct,它们拥有令人印象深刻的编程能力。开发者还讨论了量化方法,如 GGUF quantizations 及其在质量与速度之间的权衡。
-
Nvidia 限制转换层:Nvidia 已实施禁令,禁止使用转换层在非 Nvidia 芯片上运行基于 CUDA 的软件,目标直指 ZLUDA 等项目,更多细节在 Tom’s Hardware 的文章 中进行了讨论。一些成员对该禁令的可执行性表示怀疑。
-
CUDA 性能第 8 讲重制版发布:CUDA 社区收到了重录版的第 8 讲:CUDA Performance Checklist,其中包括 YouTube 视频、GitHub 上的代码 以及 Google Docs 上的幻灯片,受到了社区成员的好评。随后针对提到的 DRAM throughput 数值以及 coarsening 中的性能差异展开了讨论。
Claude 3 Opus (8x220B?)
-
Claude 3 撼动 AI 领域:Anthropic 发布 Claude 3 模型家族 引发了广泛讨论,其中 Claude 3 Opus 和 Claude 3 Sonnet 变体在推理、数学、编程和多模态任务中展现了令人印象深刻的能力。用户报告称,在摘要和指令遵循等特定基准测试中,Claude 3 的表现优于 GPT-4。然而,其定价结构和区域可用性也引起了关注。
-
CUDA 争议与优化:Nvidia 禁止在非 Nvidia 芯片上使用翻译层运行 CUDA 软件,这引发了对其可执行性的质疑。与此同时,开发者正在排除诸如
CUBLAS_STATUS_NOT_INITIALIZED之类的 CUDA 错误,其原因涵盖了从张量维度到内存问题的各个方面。优化讨论涉及 CUTLASS、cuda::pipeline 效率,以及有效带宽与延迟之间的细微差别。 -
Prompt-Engineering 难题与 LLM 集成:在各个社区中,用户都在应对 Prompt-Engineering 挑战,从 AI 拒绝接受互联网访问能力到 ChatGPT API 转换中的不一致性。同时,新的工具和集成不断涌现,例如 RAPTOR 树状结构索引技术、LlamaIndex 中的 Claude 3 支持,以及 Datasette 的 Claude 3 交互插件。
-
突破 AI 应用边界:AI 各个子领域都出现了令人兴奋的进展,包括利用 Claude 3 和 LLM 代码生成的文本转 3D 模型生成平台 neThing.xyz。结合 LangChain 的实时检索增强生成 (RAG) 能够增强聊天机器人,而对增强分类数据集的探索有望提升模型推理能力。诸如开源 AI 定义和 AI 原生业务仓库等倡议旨在引导和规范快速发展的 AI 领域。
ChatGPT (GPT4T)
AI 伦理与监管讨论:在包括 TheBloke 在内的多个 Discord 频道中的详细对话强调了 AI 伦理、监管措施以及 AI 开发中安全性的关键性,包括白宫出于安全原因建议避免使用 C 和 C++ 的立场,以及英国潜在的 AI 立法。
模型创新与性能:讨论跨越多个平台,从 Mistral 解释 Mixtral vs. Mistral 模型差异,到 Perplexity AI 强调 Claude 3 的能力,以及 Nous Research AI 对 Claude 3 和 GPT-4 的辩论。新兴模型如 OpenHermes-2.5-Code-290k-13B 展示了卓越的性能,而 CUDA MODE 则专注于 CUDA 的技术挑战和进步。
新兴技术与 AI 在创意领域的作用:LAION 和 Latent Space 的讨论深入探讨了 AI 对创意领域的影响,例如 像素艺术生成 技术和 3D 建模 的进展,重点介绍了 Stable Diffusion 3 的 MMDiT 架构及其卓越性能。
AI 应用中的技术挑战与解决方案:LangChain AI 探讨了 LLM 交互中的 缓存问题 和 实时检索增强生成 (RAG),而 OpenAccess AI Collective (axolotl) 则讨论了将 模型合并 (model merging) 与 MergeKit 结合,作为传统微调方法的创新替代方案。
PART 1: Discord 高层级摘要
TheBloke Discord 摘要
-
AI 伦理呼吁谨慎:深入的讨论集中在 AI 伦理和监管措施对防止滥用的重要性,以及 AI 在大规模画像和监控中的影响。讨论内容包括白宫出于安全原因建议避免使用 C 和 C++ 的立场,以及英国政府潜在的 AI 立法。
-
模型性能衡量与开发进展:对话围绕 AI 能力展开,包括对 GPT-3.5 Turbo 在谜题解答上表现提升的评论,以及无梯度深度学习中的挑战。考虑到质量和速度的权衡,参与者对实验性量化技术(包括 imatrix 量化和 GGUF 量化)进行了辩论。
-
新兴 AI 模型成为焦点:分享了 OpenHermes-2.5-Code-290k-13B 模型,该模型拥有卓越的性能,并在 CanAiCode 的 Junior-v2 排名下结合了多个数据集。此外,还提供了 Code-290k-6.7B-Instruct 的训练细节:在 4 张 A100 80GB 上进行 3 个 epoch 的训练耗时 85 小时。
-
法律复杂性涉及 AI:讨论还深入到了法律层面,强调了苏格兰可执行的口头合同以及德国对政府系统开源的授权。参与者还对使用未经许可的 AI 模型(如 miquliz)表示担忧,并警告潜在的法律后果。
-
加密货币对话交织着对区块链的怀疑:加密货币市场的波动性和可行性是热门话题,同时也伴随着关于过度估计区块链在分布式计算中的益处以及当前投资热潮的辩论。
Mistral Discord 总结
-
Mixtral 与 Mistral 上下文混淆问题已解决:
i_am_dom澄清了 Mixtral 不像 Mistral 那样支持 Sliding Window Attention,并引用了 一篇 Reddit 帖子。针对 Mixtral Tiny GPTQ 使用不同 Tokenization 的问题进行了探讨,引发了关于正确处理 Context Size 以及不同 Tokenizer 对 VRAM 需求影响的讨论。 -
Mistral 模型之争:社区深入探讨了 Mistral 模型的能力,
mrdragonfox认为 Next 模型可能是一个独立于 Medium 的产品线,而mehdi1991_探讨了运行大型模型的 GPU 选择。社区对 LeChat 模型的免费开放可能导致服务滥用表示担忧。 -
开源与市场中的模型:社区表达了希望明确 Mistral 开源方向的愿望。
@casper_ai请求为 Mistral 提供一个极简的参考实现,这凸显了社区对深入理解模型训练过程的需求。支持 100 多个 LLM 的 Discord 机器人以及由 mistral-small-latest 驱动的 Telegram 托管聊天机器人,展示了 Mistral 模型在各个平台上的活跃集成。 -
Anthropic 的新模型与 Mistral 定价讨论:
@benjoyo.分享了关于 Anthropic 的 Claude 3 模型及其处于 Alpha 阶段的 Function Calling 功能的消息。社区讨论了使用 Opus 等新模型的成本,而 Mistral 潜在的 Open Weights 优势被视为一个独特的卖点。 -
现实世界模型评估与教育办公时间:在 office-hour 频道中,关于手动和现实生活评估(如针对 MMLU 进行基准测试)的讨论是核心,而
@kalomaze和@rtyax等用户询问的未来模型训练和扩展计划则展示了社区的前瞻性兴趣。 -
日常模型异常排查:用户遇到并解决了从错误的 JSON 响应处理到身份验证异常等问题。讨论了 Mistral 8x7b 在情感分析(Sentiment Analysis)方面的有效性,同时通过建议使用 “POST” 方法调试了 “405” API 错误。
-
数学挑战揭示模型局限性:
@awild_tech和其他人指出 Mistral Large 在处理数学问题(如 0.999 循环的 floor 函数)时存在不一致,说明了模型在理解和一致性方面的局限性。
Perplexity AI Discord 总结
-
Perplexity AI Pro 通过 V2.5 和 Claude 3 增强功能:用户现在可以使用 Playground AI 的新 V2.5 生成图像,Perplexity Pro 用户可以探索 Claude 3 的功能,其中高级的 Opus 模型每天允许进行 5 次查询。关于 Playground 与 Perplexity 合作的详细信息可以在其 博客文章 中找到,而 Claude 3 Opus 与更快的 Sonnet 模型之间的区别引发了用户关于其部署和运行的疑问。
-
社区权衡 Claude 3 的每日查询限制:关于 Claude 3 Opus 每天 5 次查询的限制引起了热议,成员们正在讨论它在编程和问题解决方面是否优于 GPT-4,一些人主张改进 Claude 3 Sonnet 的易用性。
-
Perplexity 的未来推测与促销:用户正在分享优化 Perplexity AI 任务(如图像生成和搜索功能)的技巧,以及对未来专用 AI 模型的预测。对话还围绕访问 Claude 3 及相关模型展开,并提到了 Dataconomy 文章 中描述的 Rabbit R1 交易。
-
Perplexity AI 搜索的多样化用途揭示:对 Perplexity AI 搜索能力的参与显示,用户正在寻找包括 南极洲、美约关系、促销 Vultr 代码 以及 历史查询 在内的各种主题信息。
-
AI 工程师的 API 访问与配置讨论:建议像
@_samrat这样的 API 用户耐心等待 Citation 的访问权限,响应时间可能长达 1-2 周。人们逐渐认识到 NLP 任务中的 Temperature 设置非常微妙,较低的温度并不保证更可靠的结果,并且对通过 API 进行潜在的模型审查以及不同平台之间的配额结转感到好奇。
OpenAI Discord 总结
-
翻译 AI 的纯净度探索:寻求 Google Translate 替代方案的用户表示对其机械化的输出感到不满,并建议将 GPT-3.5 作为快速且准确翻译的更优选择。
-
Claude 3 表现优于 ChatGPT?:围绕 Anthropic 推出的 Claude 3 的讨论强调了其提升的能力,特别是在研究生水平的推理方面,尽管一些用户反映其在中文逻辑和图像识别方面比 GPT-4 稍弱。
-
GPT-4 Token 限制备受关注:技术讨论指出了 GPT-4 的局限性,特别是围绕输入和上下文的 Token 限制,用户分享了他们使用该模型各种版本的经验。
-
故事创作者更青睐 Claude:据报道,Claude 3 在角色扮演和创意写作方面表现出色,随着与 Gemini 等先进语言模型的竞争加剧,用户正期待 GPT-5 的发布。
-
实时困惑与 API 难题:Prompt Engineering 的难题包括 AI 否认其具备互联网访问能力、难以提高清晰度和简洁度,以及 Custom GPT 模型给出不配合的响应。
-
寻求稳固的 API 基础:用户讨论了从 ChatGPT 迁移到 GPT 3.5 API 时保持风格一致性的挑战,并指出了 GPT 在处理视觉和数学 Prompt 时的易用性问题。
Nous Research AI Discord 总结
-
Claude 3 引发价格与性能之争:AnthropicAI 发布 Claude 3 引发了将其性能和成本与 GPT-4 进行比较的讨论。一些用户利用 EvalPlus Leaderboard 的对比和相关 推文,引用 Human Eval 评分的差异,思考 Claude 3 相比 OpenAI 产品的价值主张。
-
新 AI 模型与效率成为焦点:分享了引用 OpenAI CEO Sam Altman 言论的文章,他认为未来在于架构创新和参数高效模型,而非单纯追求更大的模型(来源)。此外,适用于边缘设备的轻量级视觉语言模型 moondream2 的发布也受到了关注(GitHub 链接)。
-
Prompt Engineering 资源分享:传阅了一份详细介绍 Prompt Engineering 技术以增强 Large Language Models (LLMs) 输出的指南,提供了提高安全性和结构化输出的策略(指南链接)。模型比较和评估讨论中提到了如
dolphin-2.8-experiment26-7b-preview等新 AI 模型。 -
持续预训练与模型训练讨论:关于持续预训练(Continuous Pretraining)的对话中,提到了使用修改后的 gpt-neox 代码库和 axolotl 进行不同规模的预训练。关于在大型物理论文数据集上进行训练的咨询建议将其融入预训练数据集,并强调了对充足计算资源的需求。
-
结合推理策略以增强 AI:讨论了使用 RAG 和特定 System Prompts 等技术结合 Hermes Mixtral 或 Mixtral-Instruct v0.1 等模型的提议,并参考了 fireworksAI 或 openrouter 等工具来实现高效推理。
-
Bittensor Finetune Subnet v0.2.2 更新:Bittensor Finetune Subnet 发布了 0.2.2 版本,其特点是更新了 transformers 包并修复了 Gemma 的实现(GitHub PR)。该版本将 Mistral 和 Gemma 之间的奖励比例调整为各占 50%。
LAION Discord 摘要
-
扩展 Titan:机器学习面临算力瓶颈:由
@pseudoterminalx发起的讨论集中在模型训练扩展方面的挑战,特别是 CPU/GPU 之间数据传输的瓶颈,以及在不克服这些效率低下的情况下,增加计算资源所带来的有限收益。 -
AI 的像素艺术调色板问题:
@nodja和@astropulse探讨了使用 AI 生成像素艺术的技术,讨论深入到了在 latent space 中应用调色板并将其集成到 ML 模型中的方法,强调了这一创意 AI 领域中细微的技术障碍。 -
Claude 3 表现优于 GPT-4:工程社区对比了新发布的 Claude 3 模型与 GPT-4 的能力,指出其性能有所提升。根据 Reddit 和 LinkedIn 上的讨论和公告,
@segmentationfault8268正在考虑基于这一进展从 ChatGPT Plus 转向 Claude 3。 -
Stable Diffusion 3 凭借 MMDiT 架构引起关注:由
@mfcool发布的来自 Stability AI 博客文章的 研究论文 展示了 Stable Diffusion 3 令人印象深刻的性能,凭借其 Multimodal Diffusion Transformer,其表现超越了 DALL·E 3 等模型。 -
SmartBrush:新的 Inpainting 大师?:用户
@hiiee引发了关于 SmartBrush 的讨论,这是一个在 arXiv 论文 中展示的文本和形状引导的图像 Inpainting 模型,并询问了其开源可用性以及在保留背景方面优于现有 Inpainting 替代方案的潜力。
HuggingFace Discord 摘要
AI 的突破与小插曲:讨论涵盖了 Hermes 2.5 相对于 Hermes 2 的性能,以及将 Mistral 扩展到 8k 以上的局限性。此外,还关注了以新颖方式计算梯度的方法,以及反复出现的创建数据集协助请求(目前尚未解决)。
HuggingFace 上的 Diffusion 模型指南:成员们讨论了 HuggingFace 上一个潜在的 NSFW 模型 AstraliteHeart/pony-diffusion-v6,建议对其进行适当标记或举报。此外,还为 Diffusion 模型中的图像提示词提供指导,引导用户参考 IP-Adapter 教程。
CV 与 NLP 的交叉讨论:社区参与的话题从 Terminator network 的引入及其对过去技术的集成,到寻求双向 NLP 语言模型的 SOTA,涉及 Deberta V3 和 monarch-mixer 等选项。分享的问题包括使用 GBNF 语法增强 Mistral 的困难、Mistral 和 BLOOM 模型的推理时间波动,以及在 Windows 应用中实现 Mistral。
Kubeflow 获得 Terraform 助力:在工具和平台领域,Kubeflow 现在可以使用 terraform module 进行部署,有效地将 Kubernetes 集群转变为 AI 就绪环境。此外,还介绍了 MEGA 在短上下文 GLUE 基准测试中的表现,以及使用 Unsloth 提升 Gemma Model 的速度,展示了各种社区驱动的进展。
视频相关创新与问题:Pika 的发布标志着文本转视频(text-to-video)生成领域的增长趋势。相比之下,一位用户在使用嵌入 Gradio 的 OpenAI API 聊天机器人时遇到了视觉问题,正在寻求修复布局的帮助。
读书会回归:成员们对读书会(reading group)会议的安排表示关注,辩论了使用 Discord 还是 Zoom 进行托管的优劣。还提到为无法参加直播会议的人员在 Isamu Isozaki 的 YouTube 个人资料上提供了录像。
OpenRouter (Alex Atallah) Discord 摘要
-
Claude 3:领域新秀:OpenRouter 推出了 Claude 3,包括一个复杂的实验性自我调节版本 Claude 3 Opus(具有令人印象深刻的情商 EQ),以及一个具有多模态能力、性价比极高的 GPT-4 替代方案 Claude 3 Sonnet。
-
价格争议引发讨论:社区正在辩论 Claude 3 的定价,用户对从 Claude 3 Sonnet 到 Claude 3 Opus 的价格涨幅感到困惑。这包括与实体服务的幽默对比,以及对成本结构的普遍澄清需求。
-
技术故障引发关注:成员们报告了与新 Claude 模型 交互时的问题,除了 2.0 beta 版本外,其他版本均返回空白响应。社区介入并提供了排查建议,潜在原因包括地区限制或使用了尚未实现的功能(如图像输入)。
-
Claude 的文笔更胜一筹:Claude 的文学创作能力 评价褒贬不一,部分人对其写作质量表示赞赏,而另一些人则遇到了重复、多余的自动生成响应。社区排查人员认为这可能是由于 Tokenization 错误而非模型固有的缺陷。
-
比 GPT-4 更强劲?:关于 Claude 3 性能 与其他模型对比的持续讨论突显了它在某些测试中的优势,但也引发了关于实际成本与预测成本可预测性的疑问,这是企业级解决方案中可扩展性和集成的关键考虑因素。
LlamaIndex Discord 摘要
-
RAPTOR 网络研讨会预告:宣布了一场关于 RAPTOR(一种创新的 树状结构索引技术)的网络研讨会,并附带了 注册链接。该会议旨在启发参与者如何分层聚类和总结信息,定于本周四太平洋时间上午 9 点举行。
-
Claude 3 发布并带有强劲基准测试:Claude 3 现在已由 LlamaIndex 支持,并声称具有优于 GPT-4 的基准测试性能。它提供三个版本,其中 Claude Opus 功能最强大,适用于包括多模态应用在内的广泛任务;此处 提供了全面的指南和展示用的 Colab notebook。
-
neThing.xyz 带来的 3D 建模革命:平台 neThing.xyz 利用 LLM 代码生成将文本提示词转换为可直接使用的 3D CAD 模型,该平台由 Claude 3 的能力驱动,并由 LlamaIndex 的推文进行了介绍。
- 不断演进的基础设施讨论:
- Llama Networks 拥有适用于客户端-服务器模型的 FastAPI 服务器设置,并乐于接受扩展想法。
- 在 PGVectorStore 中更新节点通常需要重新插入文档,而不是单独编辑节点。
- 业务规划可能会受益于 ReAct Agent 和 FunctionTool 与 OpenAI 服务的集成。
- 有人请求将 Llama-Index 网站上的安装命令修改为小写,以确保准确性。
- 探索深度 AI 话题:一篇讨论 LlamaIndex 与 LongContext 集成,并强调 Google Gemini 1.5 Pro 的 100 万上下文窗口的文章引起了参与者的兴趣,标志着其与 AI 开发和企业级应用的相关性。可以在 此处 阅读该文章。
CUDA MODE Discord 总结
-
Nvidia 限制翻译层的使用:Nvidia 已实施禁令,禁止使用翻译层在非 Nvidia 芯片上运行基于 CUDA 的软件,此举针对 ZLUDA 等项目,更多细节见 Tom’s Hardware 文章。一些成员对该禁令的可执行性表示怀疑。
-
CUDA 错误谜题与 Kernel 难题:CUDA 开发者正在排查
CUBLAS_STATUS_NOT_INITIALIZED等错误,建议指向张量维度和内存问题,详见相关的 论坛帖子。其他讨论集中在cuda::pipeline的效率以及理解有效带宽与延迟的关系,参考资源包括 Lecture 8 和一篇关于 CUDA Vectorized Memory Access 的博客。 -
初学者的 CUTLASS 安装问答:新的 AI 工程师寻求安装 CUTLASS 的建议,了解到它是一个仅头文件的模板库,安装指南可在 CUTLASS GitHub 仓库 找到,并请求了实现自定义 CUDA kernels 的资源。
-
Ring-Attention 项目备受关注:围绕 ring-attention 实验开展了大量活动,对话涵盖从基准测试策略到 ‘ring-llama’ 测试的进展。采样脚本的一个问题正在解决中,详见 GitHub 上的 Pull Request #13,并为对该项目感兴趣的人分享了 Ring-Attention GitHub 仓库。
-
关于 CUDA 性能的 Lecture 8 重新录制并发布:CUDA 社区收到了重新录制版本的 Lecture 8:CUDA Performance Checklist,其中包括 YouTube 视频、GitHub 上的代码 以及 Google Docs 上的幻灯片,赢得了社区成员的好评。随后讨论了其中提到的 DRAM 吞吐量数据以及 coarsening 中的性能差异。
LLM Perf Enthusiasts AI Discord 总结
-
OpenAI 的浏览功能创新:@jeffreyw128 对 OpenAI 新的 browsing feature 表示兴奋,该功能类似于 Gemini/Perplexity。他们通过分享的 Twitter 公告 强调了这一点。
-
Claude 3 与 GPT-4 的竞争:Claude 3 是热门话题,
@res6969和@ivanleomk认为它在数学和代码基准测试中可能超越 GPT-4。 -
Opus 模型定价讨论:关于 Opus 的定价存在争论;据
@pantsforbirds和@res6969澄清,其成本是 GPT-4 turbo 的 1.5 倍,但比常规 GPT-4 便宜 66%。 -
对 Fine-Tuning 的热情与怀疑:社区交流了对 LLM 进行 fine-tuning 的看法。
@edencoder主张其在专业任务中的成本效益,而@res6969则质疑特定应用的投资回报率。 -
Anthropic 模型评价褒贬不一:对 Anthropic 模型 的见解各异:
@potrock和@joshcho_讨论了 Opus 在编程任务中的优势,而@thebaghdaddy指出在医学和生物学等领域,GPT-4 的表现仍然优于新模型。
Interconnects (Nathan Lambert) Discord 摘要
-
Intel 的战略失误:
@natolambert通过 Stratechery 的文章和 标题为 “Intel’s Humbling” 的 YouTube 视频 分享了对 Intel 在科技行业现状的见解,强调了其中提供的细致分析。 -
Claude 3 大放异彩: AnthropicAI 发布的 Claude 3 凭借其提升的能力引发了兴奋和讨论。讨论围绕其性能展开,
@xeophon.和@natolambert谈到了其能力的具体实例,而@mike.lambert思考了其对开源生态的影响,@canadagoose1和@sid221134224则表示它可能会超越 GPT-4。 -
围绕 Claude 3 的 Q* 推文引发热议: Claude 3 发布后,Twitter 上出现了关于 Q* 推文的闹剧,
@natolambert对这些讨论提出了批评,并因投入精力过大而否决了使用小号(alt accounts)的想法。 -
AI2 正在寻找预训练专家:
@natolambert正在寻找对 AI2 使命感兴趣的 pretraining 专家,特别指出他们目前正专注于这一领域的招聘,并幽默地建议那些对 Google 处理 Gemini 方式感到失望的人可能是潜在的招募对象。 -
关于 Cohere PPO 论文的 RL 辩论: RL 圈内的对话涉及了 Cohere 关于 PPO 修正对 LLM 是多余的这一主张,
@vj256正在寻找进一步的证据或复现,而@natolambert承认之前熟悉这些主张,并引导至与 RLHF (Reinforcement Learning from Human Feedback) 相关的采访和研究论文。
LangChain AI Discord 摘要
-
Langserve 在 LLM 交互中的缓存困扰:用户
@kandiesky和@veryboldbagel深入探讨了 Langserve 缓存 的困难。@kandiesky透露缓存仅在/invoke端点正常工作,而在/stream中无效,而@veryboldbagel指出根本问题在于 langchain-core。 -
实时 RAG 发布:
@hkdulay发布了一篇 博客文章,展示了如何使用 LangChain 构建 Real-Time RAG (Retrieval-Augmented Generation) 聊天机器人,强调了它在改进 LLM 响应方面迈出的重要一步。 -
深入探讨 RAG 的索引:为了寻求增强的 AI 响应,
@tailwind8960通过 新篇章 分享了对 Advanced RAG 系列中索引挑战的见解,强调了在查询中保留上下文的必要性。 -
协同 AI 与商业项目:
@manojsaharan正在领导一项协作计划,旨在 GitHub 仓库中将 AI 与商业结合,并邀请 LangChain 社区的贡献者通过此 仓库链接 加入。 -
Control Net 登场,生成脱口秀小鸡图像:
@neil6430展示了使用 ML blocks 的 Control Net 功能生成 AI 艺术的奇思妙想,完成了一个让小鸡模仿 Seinfeld 脱口秀姿态的古怪任务。
Latent Space Discord 摘要
-
Claude 3 引发关注与辩论:工程师们讨论了 Claude 3 的基准测试和定价,其与 GPT-4 的竞争性性能对比引发了极大兴趣。提到了对 API 速率限制的担忧,参考了 Anthropic 的速率限制文档,暗示这可能是可扩展性的潜在瓶颈。
-
模型直接对决:AI 爱好者对 Claude 3 和 GPT-4 进行了对比分析,@thenoahhein 分享的一份 gist 详细介绍了 Claude 3 的 Alignment 和摘要能力,并主张其能力优于 GPT-4。
-
下一代 3D 建模预告:@EMostaque 预告了一项开发亚秒级 3D 模型生成技术的合作伙伴关系,讨论了 auto-rigging 等进展,暗示其对创意产业将产生重大影响。
-
Based Architecture 架构揭晓:围绕一篇新的 Based Architecture 论文展开了讨论,该架构具有针对效率优化的类 Attention 原语,这与工程师不断追求改进计算过程的目标相契合。
-
AI 意识争议:在 LessWrong 上的一篇挑衅性文章发表后,AI 社区就 Claude 3 是否具有感知力展开了激烈辩论。反对 AI 意识的论点也在流传,在拟人化主张中保持了怀疑态度。
OpenAccess AI Collective (axolotl) Discord 摘要
- 数学机器人来援:Hugging Face 上的 Orca Math Word Problems 数据集 突出了一个用于机器人解决数学问题的数据集,展示了机器人在代数推理和竞赛排名任务中的能力。
- MergeKit 的魔力:注意到人们对使用 GitHub 上的 MergeKit 工具 进行模型合并(作为 Fine-tuning 的替代方案)表现出兴趣,这是一种结合 LLM 预训练权重的创新工具。
- AI 审查平衡:关于在 Claude 3 模型中平衡 AI 响应生成的挑战性讨论,特别是涉及种族敏感性方面,参考了一篇相关的 ArXiv 论文。
- 增强 AI 推理的数据集富化:
@winglian通过 Twitter 上的指南 分享了一种增强 AI 数据集推理能力的策略。 - LoRA+ 实验进展:
@suikamelon进行了 LoRA+ ratio 特性 的实验,根据 #axolotl-dev 频道的讨论以及 LoRA 论文 的指导原则,注意到它需要更低的 Learning Rate。
Datasette - LLM (@SimonW) Discord 摘要
-
Prompt Injection 与 Jailbreaking 的区别:Prompt Injection 是一种利用 LLM 应用程序中受信任和不受信任输入结合的攻击技术,这与试图绕过 LLM 安全过滤器的 Jailbreaking 不同。Simon Willison 的博客 详细阐述了这一关键区别。
-
国家行为体对 LLM 的滥用:微软的博客概述了受国家支持的行为体如何利用 LLM 进行网络犯罪,如漏洞利用和创建鱼叉式钓鱼邮件,包括 “Salmon Typhoon” 事件。相关的 OpenAI 研究可以在 这里 找到。
-
LLM 辅助生物风险早期预警系统:OpenAI 正在设计系统来标记由 LLM 辅助的生物威胁,因为它们可以轻易地促进对敏感信息的访问。其计划详情见 这里。
-
应对多模态 Prompt Injection:在讨论 Prompt Injection 风险时,承认即使是人工审核也可能遗漏某些形式的注入,尤其是隐藏在图像中的注入。Simon Willison 在其 文章 中深入分析了这一威胁向量。
-
Mistral 的实力与插件更新:新的 Mistral Large 模型因其强大的数据提取能力而受到赞赏(尽管成本较高),同时快速创建的 Claude 3 插件 也受到了显著称赞。此外,目前正有一种标准化模型文件位置的趋势,以优化开发工作流。
DiscoResearch Discord 总结
- Claude-3 的多语言性能评估:
@bjoernp发起了一场关于 Claude-3 多语言能力的讨论,@thomasrenkert反馈 Claude-3-Sonnet 提供了相当不错的德语回答,且在结构和知识方面优于 GPT-4。 - Claude-3 在欧盟现身:尽管存在 官方地理限制,但像
@sten6633和@devnull0这样的成员已成功在德国注册并访问 Claude-3,其中还提到了 tardigrada.io 等变通方法。 - Opus API 拥抱德国用户:Opus API 现在似乎接受德国手机号码注册,并以赠送额度激励新用户,因其在解决复杂数据科学查询方面的功效而受到赞誉。
- 免费测试 AI 模型:
@crispstrobe强调了一种通过 chat.lmsys.org 免费试用 AI 模型的方法,前提是输入内容可能会被用于训练数据;同时分享了 poe.com 提供的三种不同模型的试用,包括每天限额 5 条消息的 Claude 3 变体。
Skunkworks AI Discord 总结
提供的消息中没有相关的技术讨论或需要总结的重要话题。
Alignment Lab AI Discord 总结
- 让我们合作吧!:用户
@wasooli对 Alignment Lab AI 内部的一个协作项目表现出兴趣,并受到@taodoggy的鼓励,通过私信讨论更多细节。
AI Engineer Foundation Discord 总结
- 紧跟开源 AI 进展:
@swyxio提醒大家关注开源倡议组织(Open Source Initiative)在提供 Open Source AI Definition 每月更新方面的努力,最近的 0.0.5 版本 已于 2024 年 1 月 30 日发布。从业者可以通过查阅 每月草案 来保持关注并参与讨论。
第 2 部分:按频道划分的详细总结和链接
TheBloke ▷ #general (1100 条消息🔥🔥🔥):
- 关于 AI 伦理和监管措施的讨论:频道参与了关于 AI 伦理、防止滥用的监管措施必要性的辩论,并谈到了白宫关于不使用 C 和 C++ 的报告。讨论了对大规模画像/监控、欧盟“被遗忘权”等法律下的数据隐私,以及英国政府潜在的 AI 立法叙事等担忧。
- AI 性能与开发:用户比较了 AI 能力,引用了 GPT-3.5 Turbo 在谜语上改进的回答。还有关于 AI 模型渐进式进展以及尝试无梯度 deep learning 挑战的对话。
- Claude 3 Opus 概览:用户
@rolandtannous分享了他使用 Claude 3 Opus 作为头脑风暴伙伴的积极体验,展示了在处理 coding 等任务方面的改进,强调了 Claude 3 Opus 的表现优于其之前的版本。 - AI 利用中的法律讨论:聊天简要触及了与 AI 相关的法律问题,例如苏格兰可执行的口头合同,以及德国要求政府系统必须开源等法规的影响。
- 加密市场与 Blockchain:参与者讨论了加密货币市场的现状和可靠性、Blockchain 在分布式计算中的潜力以及当前的投资趋势。表达了对过度炒作 Blockchain 益处以及加密货币实用性的担忧。
提到的链接:
- 未找到标题:未找到描述
- Docker:未找到描述
- BASED: Simple linear attention language models balance the recall-throughput tradeoff:未找到描述
- abacusai/Liberated-Qwen1.5-72B · Hugging Face:未找到描述
- Futurama Maybe GIF - Futurama Maybe Indifferent - Discover & Share GIFs:点击查看 GIF
-
[Magician-turned-mathematician uncovers bias in coin flipping Stanford News Release](https://news.stanford.edu/pr/2004/diaconis-69.html):未找到描述 - Philosophical zombie - Wikipedia:未找到描述
- Squidward Spare GIF - Squidward Spare Some Change - Discover & Share GIFs:点击查看 GIF
- You Need to Pay Better Attention:我们引入了三种新的 attention 机制,它们在效率和学习能力方面优于标准的 multi-head attention,从而提升了性能和更广泛的部署能力…
- Taking Notes Write Down GIF - Taking Notes Write Down Notes - Discover & Share GIFs:点击查看 GIF
- gist:09378d3520690d03169f89183adebe9c:GitHub Gist:即时分享代码、笔记和代码片段。
- Spongebob Squarepants Leaving GIF - Spongebob Squarepants Leaving Patrick Star - Discover & Share GIFs:点击查看 GIF
- Gemini WONT SHOW C++ To Underage Kids "ITS NOT SAFE":在 Twitch 上直播录制,加入我们 https://twitch.tv/ThePrimeagen 成为一名后端工程师。这是我最喜欢的网站 https://boot.dev/?promo=PRIMEYT 这也是…
- Release 0.0.14 · turboderp/exllamav2:增加了对 Qwen1.5 和 Gemma 架构的支持。包含各种修复和优化。自 v0.0.13 以来的完整变更日志:v0.0.13…v0.0.14
TheBloke ▷ #characters-roleplay-stories (73 条消息🔥🔥):
-
关于性能与量化技术的辩论:
@dreamgen和@capt.genius讨论了使用 imatrix quants 来提升模型性能,@capt.genius表示 imatrix 提供的质量优于速度。然而,@spottyluck质疑了量化 outliers 的必要性,随后@4onen分享了一个讨论 GGUF quantizations 及其速度损失的 GitHub gist。GGUF quantizations 概览。 -
角色扮演应用中的有趣技术:
@sunija询问了 AutoGPT 项目在潜在角色扮演应用中的状态,@wolfsauge引用了相关研究和 GitHub 仓库,例如 DSPy optimization,它可以编程化地创建和评估 prompt 变体。 -
补水与健康小贴士进入对话:一段轻松的插曲出现,
@lyrcaxis向@potatooff提供了关于正确补水的建议,建议根据体重确定每日饮水量以获得最佳健康状态,并讨论了取暖设备对喉咙干燥和咳嗽的影响。 -
评估实验性 AI 模型:用户
@sunija和@johnrobertsmith交流了关于 Miquella 和 Goliath 等实验性 AI 模型的有效性,引用了一篇关于通用智能的 reddit 帖子 LLM comparison/test,并计划分享关于角色扮演场景下性能的个人评论。 -
AI 中的法律与伦理考量:
@reinman_公开使用的 miquliz 遭到了@mrdragonfox的法律和伦理质疑,后者警告不要使用未经许可的 AI 模型,因为可能面临法律后果。Project Atlantis 被提及为一个托管包括 miquliz 在内的各种模型的平台,尽管许可问题被标记为一个潜在隐患。
提到的链接:
- GGUF quantizations 概览:GGUF quantizations 概览。GitHub Gist:即时分享代码、笔记和片段。
- llama.cpp/examples/quantize/quantize.cpp at 21b08674331e1ea1b599f17c5ca91f0ed173be31 · ggerganov/llama.cpp:C/C++ 中的 LLM 推理。通过在 GitHub 上创建账户为 ggerganov/llama.cpp 的开发做出贡献。
- Project Atlantis - AI Sandbox:未找到描述
TheBloke ▷ #coding (9 条消息🔥):
-
与大厂竞争的新模型:用户
@ajibawa_2023分享了名为 OpenHermes-2.5-Code-290k-13B 的 SOTA 级 Llama-2 微调模型,声称其性能优于 teknium 的现有模型。该模型利用了 OpenHermes-2.5 和 Code-290k-ShareGPT 的组合数据集,并在 CanAiCode 的 Junior-v2 排名中位列第 12。 -
大规模微调模型的训练细节:另一个模型 Code-290k-6.7B-Instruct 在多样化的代码数据集上进行了训练,使用 4 张 A100 80GB 运行 3 个 epoch 耗时 85 小时,在 CanAiCode 的 Senior 类别中排名靠前。感谢 Bartowski 提供的 Exllama v2 等量化模型。
-
寻找用于 API 测试的最小模型:为了追求用于 API 测试的轻量级模型,
@gamingdaveuk询问了能在显存有限的笔记本电脑上通过 Text Gen Web UI 运行的最小模型。建议的选项包括 tinyllama 等微小模型以及 gptq/exl2/gguf 等量化版本。 -
庆祝 AI 建模领域的创新:
@rawwerks认可了新 AI 模型的开发,并幽默地向@ajibawa_2023表示致敬,开玩笑说要进行一笔假设性的巨额投资来对抗 Claude-3-Opus。 -
面向 AI 的职业路径咨询:用户
@_jaycie就 genAI 和 ML 领域的面试预期寻求建议,表达了希望将职业路径从全栈开发(fullstack development)转向 AI,并最终攻读研究型研究生的愿望。
提到的链接:
- ajibawa-2023/OpenHermes-2.5-Code-290k-13B · Hugging Face:未找到描述
- ajibawa-2023/Code-290k-6.7B-Instruct · Hugging Face:未找到描述
Mistral ▷ #general (412 条消息🔥🔥🔥):
- 上下文大小困惑已消除:经过广泛讨论,确认 Mixtral 不支持滑动窗口注意力机制(sliding window attention),这与 Mistral 不同,
i_am_dom引用了 一篇 Reddit 帖子 证实了这一点。 - Next 模型的下一步是什么?:关于 Mistral 的 Next 模型的讨论中,
i_am_dom认为它可能是 Medium 的改进版本。而mrdragonfox断言 Next 是一个完全独立的、较新的模型系列,与 Medium 无关。 - 运行模型的硬件推荐:用户
mehdi1991_询问了运行 Mistral 模型的合适硬件,多位成员建议大型模型至少需要 24GB VRAM,并讨论了在 RTX 3060 或 3090 等一系列 GPU 上运行的可行性。 - LeChat 模型可访问性的辩论:LeChat 的免费可用性以及该服务可能被过度使用引发了辩论,
mrdragonfox强调了不滥用服务的重要性,而lerela提到了对这种滥用行为的适应性调整。 - 市场中的 Mistral:简要讨论了 Mistral 可能的商业模式,由于
.mechap对 Mistral AI 开源产品未来的疑问,引发了关于他们可能不会很快发布新的开源模型的推测。
提到的链接:
- mistralai/Mistral-7B-Instruct-v0.2 · Hugging Face:未找到描述
- Mixtral Tiny GPTQ By TheBlokeAI: Benchmarks and Detailed Analysis. Insights on Mixtral Tiny GPTQ.:LLM 卡片:90.1m LLM,VRAM: 0.2GB,上下文: 128K,已量化。
- augmentoolkit/prompts at master · e-p-armstrong/augmentoolkit:将计算和书籍转换为指令微调数据集 - e-p-armstrong/augmentoolkit
- Mixtral:未找到描述
- Reddit - Dive into anything:未找到描述
Mistral ▷ #models (75 条消息🔥🔥):
- 模型上下文限制混淆:
@fauji2464被提醒 Mistral 模型的 32k token 限制,但质疑为什么在使用较小文档时仍出现警告。@mrdragonfox澄清说,模型会忽略超出限制的输入,且不同的 tokenizer 对上下文大小的影响不同。 - Tokenization 差异凸显:当
@fauji2464提到使用 tiktoken 检查 token 大小时,@mrdragonfox指出 tiktoken 和 Mistral 使用不同的 tokenization 方法和词表大小,阐明了为什么会出现上下文大小的问题。 - 推理输出不受上下文窗口限制:
@fauji2464与@_._pandora_._之间的对话解释了 LLM 如何考虑上下文,以及即使输入超过 32k token 最大值,仍可能产生输出。 - 理解 LLM 的可视化辅助工具:
@mrdragonfox提供了一个可视化链接以帮助理解 Transformer 模型的工作原理,并指出所讨论的内容适用于所有 Transformer,而不仅仅是 Mistral。 - 探讨 Mistral 模型的企业级用法:
@orogor.询问关于在自己的集群而非 Azure 上部署 Mistral 付费引擎的事宜,对此@mrdragonfox建议联系企业销售以讨论本地部署(on-premises)和许可选项。
相关链接:
LLM Visualization:未找到描述
Mistral ▷ #ref-implem (1 条消息):
- 请求 Mistral 训练澄清:
@casper_ai指出了社区在 Mistral 模型训练方面的困扰,引用了过去关于 Hugging Face Trainer 中实现差异(implementation difference)的讨论。他们请求提供一个极简的参考实现,以帮助产生最佳结果。
Mistral ▷ #showcase (7 条消息):
-
@jakobdylanc 展示 Discord 机器人:@jakobdylanc 推广了他们的 Discord 机器人,该机器人支持 100 多个 LLM,提供协作提示词(collaborative prompting)、视觉支持,并具有仅用 200 行代码实现的流式响应功能。可以在 GitHub 上找到该机器人,绿色嵌入信号表示响应结束:GitHub - discord-llm-chatbot。
-
颜色编码的聊天机器人响应:针对 @_dampf 的询问,@jakobdylanc 解释说他们的机器人使用 Discord 中的 embeds,当响应完成时会变为绿色,并允许更高的字符限制。
-
机器人只求事实,不加修饰:针对 @_dampf 的建议,@jakobdylanc 提到他们的机器人是一个 LLM 提示词工具,他们不希望它忽略消息或引入人为延迟,尽管他们对探索 koboldcpp 支持持开放态度。
-
模型格式争夺灵活性:@fergusfettes 分享了他们将 mistral-large 与其他 LLM 进行比较的 ‘looming’ 实验,指出 Mistral 性能良好但存在格式问题。他们主张模型应具备理解 completion 和 chat 模式的能力,并分享了一个展示该方法的 YouTube 视频。
-
聊天机器人登陆 Telegram:@edmund5 推出了三款由 mistral-small-latest 驱动的新 Telegram 机器人:用于正念的 Christine AI、用于愉快互动的 Anna AI 以及用于优雅对话的 Pia AI。这些机器人为用户提供不同的主题,可在 Telegram 上使用:Christine AI、Anna AI 和 Pia AI。
相关链接:
- Multiloom Demo: Fieldshifting Nightshade:演示了如何通过将一篇计算机科学研究论文“领域迁移(fieldshifting)”到社会学领域,将 LLM 输出整合到一个连贯的文档中。
- GitHub - jakobdylanc/discord-llm-chatbot:支持 100+ LLM • 协作提示词 • 视觉支持 • 流式响应 • 200 行代码 🔥 - jakobdylanc/discord-llm-chatbot
- Christine AI 🧘♀️:你随时随地的正念与平静的宁静伴侣。
- Anna AI 👱♀️:你开朗迷人的朋友,准备好 24/7 全天候聊天、学习和玩耍。
- Pia AI 👸:你的皇家知己。优雅的对话和睿智的建议 24/7 全天候等待着你。
Mistral ▷ #random (24 messages🔥):
- Alextreebeard 发布 AI 专用 K8S 软件包:
@alextreebeard开源了一个 Kubeflow Terraform Module for Kubernetes,旨在简化在 K8S 上部署 AI 工具的流程,并正在征求用户反馈。该软件包包含在 Kubernetes 中运行 Jupyter 的功能。 - Claude 3 模型系列发布:
@benjoyo.分享了 Anthropic 发布 Claude 3 模型系列的消息,该系列包含三个能力递增的模型:Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus,并指出了这些模型令人印象深刻的能力和指令遵循度。 - 权重开放(Open Weights)作为核心竞争力:在讨论竞争对手的新模型时,
@benjoyo.希望 Mistral 能保留权重开放作为竞争优势,即使像 Anthropic 这样的平台推出了更先进且指令遵循度更高的模型。 - AI 模型成本对比:在对比新模型的成本时,
@mrdragonfox指出 Opus 模型的定价为输入每 Megatoken 15 美元,输出每 Megatoken 75 美元,引发了关于价格合理性以及拥有不同模型变体优势的广泛讨论。 - Claude 3 Alpha 的高级用例:
@benjoyo.提到了 Claude 3 的 Function calling Alpha 版支持,这允许模型与外部工具交互,将其能力扩展到初始训练之外。尽管仍处于早期 Alpha 阶段,该功能有望助力完成更多样化的任务。
提及的链接:
- Introducing the next generation of Claude:今天,我们宣布推出 Claude 3 模型系列,它在广泛的认知任务中树立了新的行业基准。该系列包含三个按能力递增排序的最先进模型…
- Functions & external tools:虽然正式支持仍在开发中,但 Claude 具备与外部客户端工具和函数交互的能力,以将其能力扩展到最初训练的范围之外…
- GitHub - treebeardtech/terraform-helm-kubeflow: Kubeflow Terraform Modules - run Jupyter in Kubernetes 🪐:Kubeflow Terraform Modules - 在 Kubernetes 中运行 Jupyter 🪐 - treebeardtech/terraform-helm-kubeflow
Mistral ▷ #la-plateforme (32 messages🔥):
-
JSON 响应格式问题:
@gbourdin报告了在使用新的 JSON 响应格式时遇到的问题,多次尝试均告失败。在咨询@proffessorblue并查阅 Mistral 文档后,他们解决了问题,并将其归因于自己的疏忽。 -
定价查询受阻:
@jackie_chen43在注册后难以找到定价信息,并对平台的开发阶段发表了评论。@mrdragonfox提供了直接的 定价链接,并指出考虑到与 OpenAI 等大型组织相比团队规模较小,目前的成果已非常值得赞赏。 -
情感分析表现差异:
@krangbae发现 Mistral 8x7b 模型在情感分析方面的表现优于 Mistral Small 模型,指出了两者在性能上的差距。 -
处理 API 调用中的 500 错误:
@georgyturevich遇到了 API 返回的 500 错误响应,@lerela对此进行了处理并询问了更多细节。错误最终追溯到max_tokens参数被设置为null。 -
Prompt 中的表格数据引发 JSON 混淆:
@samseum在尝试将表格数据插入 API Prompt 时遇到了 JSON 解析错误,并收到了来自@lerela关于处理 JSON 转义的支持,@_._pandora_._也参与了后续的调试互动。
提及的链接:
-
[Pricing and rate limits Mistral AI Large Language Models](https://docs.mistral.ai/platform/pricing/):按需付费 -
[Client code Mistral AI Large Language Models](https://docs.mistral.ai/platform/client/#json-mode):我们提供 Python 和 Javascript 的客户端代码。
Mistral ▷ #office-hour (387 messages🔥🔥):
- 关于模型评估的 Office Hour 环节:
@sophiamyang发起了本次 Office Hour,邀请大家就如何评估模型和 Benchmark 展开讨论,鼓励社区分享各自的方法或提出问题。 - 关于 Mistral 未来及开源发布的咨询:
@potatooff询问了 Mistral 开源发布的未来计划,@nicolas_mistral指向了@arthurmensch的 Twitter 帖子,称其为获取最新更新信息的最佳来源。 - 对模型训练代码和扩展的请求:用户对官方 Mistral 训练代码 (
@kalomaze) 和扩展 7B 基础模型 (@rtyax) 表现出兴趣;@sophiamyang记录了这些建议,但未对未来的具体实现给出确定答复。 - 性能讨论与发布计划:
@yesiamkurt询问了 Mixtral 8x7b 与 Mistral Large 模型之间的性能差异,@sophiamyang提供了其 Benchmark 链接,表明 Mistral Large 性能更优,但未透露任何发布计划。 - 使用真实数据和人工检查评估模型:参与者讨论了评估数据集在现实场景中的应用,
@kalomaze提到 MMLU 是一个具有代表性的 Benchmark;@netrve讨论了使用 Salesforce Mistral Embedding Model 进行人工评估;@_kquant建议在评估中给模型增加难度的重要性。
提到的链接:
- Becario AI asistente virtual on demand.:未找到描述
- Phospho: Open Source text analytics for LLM apps:未找到描述
-
[Endpoints and benchmarks Mistral AI Large Language Models](https://docs.mistral.ai/platform/endpoints/.):我们提供五个不同的 API Endpoints,以提供具有不同价格/性能权衡的生成模型,以及一个用于 Embedding 模型的 Embedding Endpoint。 - Large Language Models and the Multiverse:未找到描述
- GitHub - wyona/katie-backend: Katie Backend:Katie 后端。通过创建 GitHub 账户为 wyona/katie-backend 的开发做出贡献。
Mistral ▷ #le-chat (151 messages🔥🔥):
- API 访问故障排除:用户
@batlz在使用 Chat Completions Endpoint 时遇到 “Method Not Allowed” 405 错误。经过@mrdragonfox的讨论和建议,最终确认@batlz需要切换到 “POST” 方法。 - Le Chat 模型混淆:
@godefv报告称 Le Chat 识别自己具有类似 GPT 的属性,这突显了潜在的训练数据问题或幻觉(Hallucinations),因为模型缺乏自我内省能力。@mrdragonfox等人讨论了此事,结论是自我认知必须包含在数据集中才能避免此类错误。 - 每日限额查询与限制:像
@cm1987这样的用户对达到使用限制表示担忧,@mrdragonfox提醒他们这是使用 Beta 产品的一部分,限制是预料之中的。 - Web UI 响应显示问题:
@steelpotato1和@venkybeast报告了一个显示 Bug,即在 Web UI 中,响应文本会先出现在初始 Prompt 之上,然后才跳到下方。 - 身份验证与 API Key 异常:用户
@foxalabs_32486在访问账户时遇到困难,凭据似乎无法识别。后来发现是与身份验证管理器的电子邮件混淆问题,在其他用户的帮助下已解决。
提到的链接:
| [Client code | Mistral AI Large Language Models](https://docs.mistral.ai/platform/client/):我们提供 Python 和 Javascript 的客户端代码。 |
Mistral ▷ #failed-prompts (12 messages🔥):
- Mistral 的数学失误:
@awild_tech报告称 Mistral Large 未能正确回答 0.999 循环的 floor(向下取整)是多少,模型输出为 0,而预期结果应为 1。这个问题似乎难倒了多个模型。 - 多语言回答不一致:尽管最初回答正确,但
@awild_tech指出,当他们用法语重复提问时,Mistral Large 的回答在正确和错误之间反复波动。 - 随机运气还是理解缺陷?:
@_._pandora_._认为 Mistral Large 第一次尝试正确回答 floor 问题可能只是因为运气,而非具备稳健的理解,因为随后的回答都是错误的。 - Mistral 的详细解释以失败告终:
@i_am_dom分享了 Mistral Large 关于 0.999 循环 floor 值的详细解释,但该解释最终错误地得出 floor 值为 0 的结论。 - Mistral 错误引用 “system” 角色:在尝试检索 “system” 角色之前的消息时,
@i_am_dom注意到 Mistral Large 提供了各种不准确的版本,而非预期的逐字引用。
Perplexity AI ▷ #announcements (2 messages):
-
Playground AI 全新 V2.5 模型发布:
@ok.alex宣布 Perplexity Pro 用户现在可以使用 Playground AI 的新 V2.5 作为生成各类图像的默认模型。关于 Perplexity 和 Playground 合作的更多细节可以在这篇 博客文章 中找到。 -
为 Perplexity Pro 用户引入 Claude 3:
@ok.alex透露已为<a:pro:1138537257024884847>用户发布 Claude 3,它取代了 Claude 2.1,并为高级 Claude 3 Opus 模型提供每日 5 次查询。额外的每日查询将使用 Claude 3 Sonnet,这是一个与 GPT-4 旗鼓相当的快速模型。
提到的链接:
no title found:未找到描述
Perplexity AI ▷ #general (831 条消息🔥🔥🔥):
- Claude 3 Opus 的使用成为热门话题:用户如
@stevenmcmackin、@naivecoder786和@dailyfocus_daily对 Perplexity AI Pro 上 Claude 3 Opus 每天 5 次查询的限制表示担忧,认为这一限制对于他们的使用需求来说太少了。一些人想知道达到限制后会发生什么,而另一些人则建议增加配额或改进 Claude 3 Sonnet 的可用性。 - 关于 Claude 3 有效性的讨论:
@dailyfocus_daily、@akumaenjeru、@detectivejohnkimble_51308等成员参与了关于 Claude 3 能力的讨论,对于在编程和解决问题等任务中 Claude 还是 GPT-4 更胜一筹意见不一。一些用户个人发现 Claude 3 的表现优于 GPT-4,尤其是在编程方面。 - Claude 的集成与模型清晰度:
@cereal、@heathenist和@eli_pc等用户提出了关于如何区分 Opus 和 Sonnet,以及模型 context size 和运行透明度的问题。用户似乎希望在何时以及如何部署不同模型方面有更高的透明度。 - Perplexity 的 AI 驱动功能与计划:用户
@fluxkraken、@cereal和@joed8.讨论了图像生成和搜索功能的变通方法与技巧,阐明了如何针对各种任务优化 Perplexity 的 AI。@fluxkraken还分享了关于 Perplexity 未来向专用模型发展的推测。 - 促销活动与模型访问:用户讨论了 Rabbit R1 优惠(
@jawnze、@fluxkraken、@drewgs06)等促销活动,以及它如何与 Perplexity AI Pro 订阅挂钩。一些人讨论了 Claude 3 尚未在 iOS 应用上提供,而另一些人则丰富了关于如何访问各种模型的对话。
提到的链接:
- Chat with Open Large Language Models: 未找到描述
- Oliver Twist GIF - Oliver Twist - Discover & Share GIFs: 点击查看 GIF
-
[YouTube Summary with ChatGPT & Claude Glasp](https://glasp.co/youtube-summary): YouTube Summary with ChatGPT & Claude 是一款免费的 Chrome 扩展程序,可让您快速访问正在观看的 YouTube 视频和网页文章的摘要。 - Claude-3-Opus - Poe: Anthropic 最智能的模型,可以处理复杂的分析、具有多个步骤的较长任务以及更高级的数学和编程任务。context window 已缩短以优化速度…
-
[📖[PDF] An Introduction to Theories of Personality by Robert B. Ewen Perlego](https://www.perlego.com/book/1323727/an-introduction-to-theories-of-personality-7th-edition-pdf): 开始在线阅读 📖《人格理论导论》第 7 版,并在 Perlego 上访问无限的学术和非小说类书籍库。 - David Leonhardt book talk: Ours Was the Shining Future, The Story of the American Dream: 加入 Jeff Colgan 教授与《纽约时报》资深作家 David Leonhardt 的对话,他们将讨论 David 的新书,该书探讨了过去一个世纪…
- CLAUDE 3 Just SHOCKED The ENTIRE INDUSTRY! (GPT-4 +Gemini BEATEN) AI AGENTS + FULL Breakdown: ✉️ 加入我的每周通讯 - https://mailchi.mp/6cff54ad7e2e/theaigrid 🐤 在 Twitter 上关注我 https://twitter.com/TheAiGrid 🌐 查看我的网站 - https:/…
- SmartGPT: Major Benchmark Broken - 89.0% on MMLU + Exam's Many Errors: 使用 SmartGPT 系统的 GPT-4 是否在多个方面打破了重大基准测试 MMLU?89.0% 是非官方记录,但我们是否迫切需要一个新的…
- Puppet Red GIF - Puppet Red Ball - Discover & Share GIFs: 点击查看 GIF
- Rabbit R1 and Perplexity AI dance into the future: 本文解释了 Rabbit R1 对 Perplexity AI 的使用。在不断发展的技术领域,两者之间的合作…
- 必应: 未找到描述
Perplexity AI ▷ #sharing (18 messages🔥):
- 探索南极洲:
@christianbugs分享了一个使用 Perplexity AI 搜索功能获取的关于南极洲信息的链接。该链接预计包含有关该大陆地理、气候和其他特征的详细信息。 - Claude 3 发布公告:
@dailyfocus_daily和@_paradroid提供了通过 Perplexity AI 围绕新发布的 Claude 3 进行讨论的链接。@ethan0810.也分享了一个关于 Anthropic 发布 Claude 的链接。 - 寻找 Vultr 优惠:
@mares1317寻求云托管服务 Vultr 的促销代码,并使用 Perplexity AI 的搜索功能来尝试寻找优惠。 - 了解美约关系:
@_paradroid使用 Perplexity AI 搜索了美国和约旦之间的关系,表明了对两国双边互动的查询。 - 历史揭秘:
@whimsical_beetle_50663似乎通过 Perplexity AI 搜索提供的链接深入研究了历史,尽管未提及具体的历史主题。
Perplexity AI ▷ #pplx-api (18 messages🔥):
- 申请 API 访问权限需要耐心:
@_samrat询问在提交申请后如何跟进获取 API 中的 Citations(引用)访问权限。@icelavaman和@brknclock1215回复建议通常的响应时间为 1-2 周或更长,并请耐心等待。 - 通过配置微调获得改进:
@brknclock1215对最近通过微调配置获得的结果表示满意,并提到在使用 System Prompts 进行指令遵循(Instruction Following)时,倾向于将 Temperature 保持在 0.5 以下。 - 语言模型中的 Temperature 因素:用户
@brknclock1215、@heathenist和@thedigitalcat就 Temperature 在自然语言生成中的作用展开了讨论。他们指出,较低的 Temperature 并不总是等同于更可靠的结果,这表明了语言学和语言模型的复杂性。 - 关于跨模型配额增加的咨询:
@stijntratsaert_01927询问在一个平台上先前分配的配额增加是否会结转到另一个平台,具体是从 pplx70bonline 转移到 sonar medium online。 - 关于通过 API 进行模型审查的担忧:
@randomguy0660提出了一个问题,即通过 API 访问的模型是否受到审查(Censorship)。
OpenAI ▷ #ai-discussions (314 messages🔥🔥):
-
翻译 AI 爱好者寻求替代方案:
@jackal101022询问了替代的翻译 AI 服务,对 Google Translate 机械化的输出以及随后需要 Gemini 或 ChatGPT 进行二次编辑表示不满。@lugui推荐使用 GPT-3.5,称赞其性能快速且准确。 -
用经典问题进行数学思考:在
@kiddu请求一个数学问题以增强逻辑思维后,@mrsyntax建议尝试“旅行推销员问题(traveling salesman problem)”,因为它结合了优化和效率方面的挑战。 -
Anthropic 的 Claude 3 引起关注:关于 Anthropic 新推出的 Claude 3 AI 的讨论正在升温,
@glamrat、@odiseo3468等人对其令人印象深刻的能力发表了看法。用户们正在将 Claude 3 与 ChatGPT 进行对比,特别是对于 Opus 模型,@odiseo3468发现它在研究生级别的推理方面表现异常出色,尽管@cook_sleep反馈称其逻辑和图像识别能力(特别是在中文环境下)弱于 GPT-4。 -
OpenAI 模型版本和限制受到审视:随着
@johnnyrobert和@pteromaple等用户讨论他们在 GPT-4 中遇到的限制,对话转向了技术层面,特别是针对不同版本模型在输入和上下文方面的 Token 限制。 -
比较用于角色扮演和故事创作的聊天机器人:包括
@webhead和@cook_sleep在内的多位用户分享了 Claude 3 在角色扮演和创意写作方面的卓越表现,尽管也指出了在其他领域的一些局限。这引发了相关建议,认为随着 Gemini 和 Claude 等模型展示出先进的语言表达能力,竞争日益加剧,OpenAI 应该推进发布 GPT-5。
提到的链接:
- Anthropic 表示其最新的 AI 机器人可以击败 Gemini 和 ChatGPT:Claude 3 带着一些重大改进登场。
- DevDay 宣布的新模型和开发者产品:具有 128K 上下文且价格更低的 GPT-4 Turbo、新的 Assistants API、GPT-4 Turbo with Vision、DALL·E 3 API 等。
OpenAI ▷ #gpt-4-discussions (11 messages🔥):
- 寻求 GPT 的实际应用案例:
@flo.0001正在寻找有关 GPT 或 Assistant API 在业务和生产力中实际应用的频道或资源,@mrsyntax建议查看 ID 为<#1171489862164168774>的特定频道。 - 寻找业务实施见解:尽管有了频道推荐,
@flo.0001提到他们感到信息过载,更希望看到 GPT 在业务和生产力系统中实施的直接案例。 - 提出聊天机器人浏览器问题:
@snoopdogui.报告 ChatGPT 浏览器版本无法使用,@solbus提供了一个之前分享过的消息链接,可能解决了该问题。 - 保存 GPTs 时出错:
@bluenail65对在没有上传任何文件的情况下收到关于“保存 GPTs”的错误消息表示困惑。 - 察觉到 GPT-4 性能下降:
@watcherkk和@bluenail65都注意到他们觉得 GPT-4 自发布以来性能有所下降,响应时间变慢,而@cheekati观察到该模型在引用材料方面似乎变得更加严格。
OpenAI ▷ #prompt-engineering (60 messages🔥🔥):
- 拒绝承认联网能力:
@jungle_jo表达了对 AI 持续否认其访问互联网能力的困惑,尽管 system prompt 中已明确告知其可以搜索互联网以获取实时信息。 - 寻求 Prompt Engineering 技巧:
@thetwenty8thffs请求改进一个旨在协助客户处理未识别信用卡账单的 prompt,使其更加清晰简洁。 - Custom GPT 的抗拒行为:
@ray_themad_nomad报告了从 Custom GPT 模型获得直接拒绝的问题,即使进行重新生成和 prompt 调整也无法获得配合的响应,并询问其他人是否也遇到类似困难。 - 用于 AI 创意的视觉 Prompt:
@ikereinez分享了教 AI 从真实照片生成复杂视觉效果的成功经验,使用了对未来城市景观的详细且富有想象力的描述。 - 对 AI 选择性响应的挫败感:包括
@darthgustav.在内的几位用户讨论了困难并辩论了 AI 模型的潜在内部机制,重点关注 prompt engineering、可视化错误和 AI 透明度,暗示了与 OpenAI GPT 模型结合使用的 Vision 系统可能存在的局限性。
OpenAI ▷ #api-discussions (60 messages🔥🔥):
-
Prompt Engineering 基础:
@dantekavala在从 ChatGPT 转向 GPT 3.5 API 时,在 prompt 的风格一致性方面遇到困难,指出尽管进行了多次尝试,仍缺乏适应性。@madame_architect引导@dantekavala前往开发者专区寻求更集中的帮助。 -
GPT API 的用户体验挑战:在一段消息序列中,
@darthgustav.和@eskcanta讨论了在使用 GPT 的视觉和数学能力时面临的挑战,表明 Vision 模型在解释和处理 prompt 方面需要改进。 -
寻求卓越的翻译 Prompt:
@kronos97__16076征求设计中英翻译 prompt 的建议,社区成员如@neighbor8103建议使用外部工具来验证机器翻译的准确性。 -
探索 Vision 模型局限性:用户
@aminelg、@eskcanta和@madame_architect就 Vision 模型对刺激的解释、在对话中教导模型的可能性以及 vision 相关任务中 prompt engineering 的有趣挑战进行了深入讨论。 -
对自定义模型的挫败感:
@ray_themad_nomad对 Custom GPT 的响应质量表示不满,尽管尝试了不同的 prompting 方式,仍频繁收到拒绝,这表明用户在与定制化模型交互时遇到了挫折。
Nous Research AI ▷ #off-topic (6 messages):
- 索要学术论文:
@ben.com寻求一篇学术论文的链接,并指出由于自己不是 Twitter 用户而无法查看。 - OpenAI 所谓的衰落成为热门话题:
@leontello评论了 AI Twitter 上大量声称 OpenAI 已被超越的帖子。 - 对 AI 社区反应的困惑:
@leontello使用自定义表情符号表达了对 AI 性能讨论的困惑或怀疑。 - Claude 3 模型备受瞩目:
@pradeep1148分享了一个名为“介绍超越 GPT-4 的 Claude 3 LLM”的 YouTube 视频,重点介绍了 Claude 3 模型系列的发布。 - 苹果测试(Apple Test)作为基准:
@mautonomy建议苹果测试是一个可靠的指标,推测是在评估 AI 的背景下,以此回应关于 AI 优越性的讨论。
提到的链接:
介绍超越 GPT-4 的 Claude 3 LLM:今天,我们来看看 Claude 3 模型系列,它在广泛的认知任务中树立了新的行业基准。该系列包括三个 state-of…
Nous Research AI ▷ #interesting-links (42 messages🔥):
-
揭秘 Prompt Engineering 技巧:用户
@everyoneisgross分享了一份全面指南,旨在通过 Prompt Engineering 增强 Large Language Models (LLMs) 的输出。该指南包含改进安全性、确定性和结构化输出的方法。 -
大规模多模型评估:
@mautonomy透露了一个 Reddit 帖子,对比了 17 个新的 AI 模型,使排名模型总数达到 64 个。帖子展示了如dolphin-2.8-experiment26-7b-preview和Midnight-Rose-70B-v2.0.3-GGUF等模型。 -
对 AI 参数和大脑功能主张的怀疑:
@ldj对某些关于 AI 参数和大脑功能的推测表示批评,认为这些推测基于错误的假设。 -
巨型 AI 模型时代的终结:
@ldj引用了提及 Sam Altman 言论的文章,称 未来的 AI 模型将变得更具参数效率,且 进步将源于架构创新 而非规模。讨论强调 OpenAI 认为单纯做大模型的时代已经见顶 source 1,source 2。 -
为 Edge Devices 推出 ‘moondream2’:用户
@tsunemoto分享了来自@vikhyatk的公告,关于 moondream2 的发布,这是一个运行所需内存小于 5GB 的小型 Vision Language Model 推文链接。它专为 Edge Devices 的效率而设计,拥有 1.8B 参数。
提到的链接:
- vik (@vikhyatk) 的推文:发布 moondream2 —— 一个小型开源 Vision Language Model,旨在 Edge Devices 上高效运行。参数量为 1.8B,moondream 运行 16 位模型所需内存小于 5GB…
- Together AI (@togethercompute) 的推文:很高兴分享与 @HazyResearch 合作的新研究 —— Based,一种利用类似 Attention 原语的新架构:短(大小为 64)滑动窗口 Attention 和 Softmax 近似…
- - Fuck You, Show Me The Prompt.:通过拦截 API 调用,快速理解难以捉摸的 LLM 框架。
- Dear Sam Altman- There was never an era of making models bigger:LLMs 从未像网上的专家让你相信的那样具有革命性或改变游戏规则。
- GitHub - derbydefi/sdam: sparse distributed associative memory:稀疏分布式关联记忆。通过在 GitHub 上创建账号为 derbydefi/sdam 的开发做出贡献。
- Reddit - Dive into anything:未找到描述。
- GitHub - X-PLUG/MobileAgent: Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception:Mobile-Agent: 具有视觉感知的自主多模态移动设备 Agent - X-PLUG/MobileAgent。
- The End of the Giant AI Models Era: OpenAI CEO Warns Scaling Era Is Over:了解 OpenAI CEO Sam Altman 对 ChatGPT 等 AI 模型未来进展的看法,以及对 GPU 的访问为何依然至关重要。
Nous Research AI ▷ #general (227 messages🔥🔥):
-
寻找 Continuous Pretraining 方案:
@4biddden寻找 Continuous Pretraining 的代码库但未找到,而@ayushkaushal提供了一个使用修改后的 gpt-neox 代码库进行小规模 Pretraining 的解决方案,并建议在调整学习率调度和数据回放的情况下使用 axolotl 进行极小规模训练。 -
Claude 3 发布引发讨论:AnthropicAI 宣布 Claude 3 的推文链接引发了用户对其相对于 GPT-4 性能的推测。
@fibleep分享了该公告,@intervitens提供了 Human Eval 分数作为参考。 -
评估政府效率:在关于潜在政府监管的讨论中,
@dumball表示担心官僚流程的增加可能会在业务运营、法律许可成本以及由于政府效率低下导致的机会成本方面产生显著摩擦。 -
使用大型物理论文数据集进行训练:
@ee.dd询问了使用海量物理论文数据集训练模型的最佳方法。@ldj和@casper_ai的回复建议将其混合到 Pretraining(预训练)或 Continued Pretraining(持续预训练)数据集中,并强调了拥有充足计算资源的重要性。 -
Arc 浏览器的候补名单与访问权限:
@sanketpatrikar请求帮助进入 Arc 浏览器 的候补名单,@ee.dd使用一个适用于 Windows 11 的学生邮箱链接提供了帮助。随后的讨论涉及了候补名单可能创造的人为需求,以及在访问 Amazon 等服务时的地理差异。
提到的链接:
- EvalPlus Leaderboard:未找到描述
- 来自 Blaze (Balázs Galambosi) (@gblazex) 的推文:Claude 3 Opus(输出)非常昂贵。它确实拥有扎实的推理分数,所以我们将看看它是否值得这些额外成本。但 GPT-4 Turbo 仍然是性价比最高的高端方案…
- Notion – 笔记、任务、维基和数据库的一体化工作空间。:一个将日常工作应用融合在一起的新工具。它是为你和你的团队打造的一体化工作空间。
- wandb/gemma-2b-zephyr-dpo · Hugging Face:未找到描述
- 来自 interstellarninja (@intrstllrninja) 的推文:去你的,给我看 Prompt! ↘️ 引用 Stella Biderman (@BlancheMinerva):我再次恳请人们在解释 LLM 的行为时去查看他们的数据集,而不是发布点击…
- 来自 Teknium (e/λ) (@Teknium1) 的推文:Claude 3 Opus 比 GPT-4 更好吗?发起新投票,因为上一个太模糊了,而且我没有设置查看结果选项 █████ 是 (17.1%) ███ 否 (11.8%) ██████████████████████ 查看结果 (71.2%) …
- 来自 Beff Jezos — e/acc ⏩ (@BasedBeffJezos) 的推文:如果你主要的特点是聪明,那就转向魅力(rizz)。人类水平的 AI 已经到来。 ↘️ 引用 Guillaume Verdon (@GillVerd):Claude 3 Opus 刚刚从零开始重新发明了这个量子算法…
- 来自 Anthropic (@AnthropicAI) 的推文:今天,我们发布了 Claude 3,我们的下一代 AI 模型。这三个最先进的模型——Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku——在推理方面树立了新的行业标杆…
- 来自 Chris Albon (@chrisalbon) 的推文:“别废话”(No yapping)是一种专业级的 Prompt Engineering 策略,你不会懂的 ↘️ 引用那个把使用 Vim 当作全部个性的人 (@pdrmnvd):终于找到了阅读 Python 堆栈跟踪的方法。
- 来自 Teknium (e/λ) (@Teknium1) 的推文:所以它真的比 GPT-4 更好吗? ███████████████ 是 (49.6%) ████████████████ 否 (50.4%) 2.1K 票 · 最终结果
- unilm/bitnet at master · microsoft/unilm:跨任务、语言和模态的大规模自监督预训练 - microsoft/unilm
- 来自 bayes (@bayeslord) 的推文:是的,到目前为止,与 Claude 交谈感觉就像在与一个聪明人交谈,而 ChatGPT 现在有一种“复制粘贴”的感觉。
- 来自 Simon Willison (@simonw) 的推文:我发现 Claude 3 的定价在今天特别有趣——他们在 GPT-4 和 GPT-3.5 的竞争产品上实际上都压低了 OpenAI 的价格。
- Claude 3 Opus 作为经济分析师:介绍 Claude 3,我们的下一代 AI 模型。这三个最先进的模型——Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku——树立了新的行业…
- microsoft/orca-math-word-problems-200k · Hugging Face 数据集:未找到描述
Nous Research AI ▷ #ask-about-llms (14 messages🔥):
-
推理组合策略讨论:
@teknium建议将 Hermes Mixtral 或 Mixtral-Instruct v0.1 等模型与 RAG 及系统提示词(system prompts)结合用于特定任务,并推荐使用 fireworksAI 或 openrouter 进行推理。 -
思考语言模型的未来:
@pier1337询问了语言模型的下一步发展,特别是对象驱动 AI(object-driven AI)的概念,以及语言模型通过模拟体验理解世界的潜力。 -
通过多模态表示推进 AI:
@max_paperclips回应了@pier1337,肯定了未来的 AI 将不仅包含文字,还包含对世界的表示和多模态输出,并建议关注 Yann LeCun 的 JEPA 和 DeepMind 最近的模型。 -
寻求 Capybara-34b 的聊天模板:
@oemd001寻求 Capybara-34b 模型的聊天模板帮助,@teknium建议使用 Vicuna format,@ben.com提供了一个聊天模板示例。 -
交互式世界 AI 的探索:
@pier1337评论道,像 GENIE 这样的模型不仅适用于 2D 游戏,还适用于任何交互式世界环境,突显了现代 AI 模型的通用性。
Nous Research AI ▷ #project-obsidian (4 messages):
- 发现微型视觉语言模型:
@ee.dd介绍了 Moondream,一个微型视觉语言模型,并分享了其 GitHub 链接:GitHub - vikhyat/moondream。他们在测试后评价其速度和质量令人印象深刻。 - Moondream 的后续探索:
@max_paperclips表示有兴趣尽快尝试 Moondream,因为听说了它的高性能表现。 - Moondream 的古怪之处:
@ee.dd认为 Moondream “非常快且适用于大多数场景”,但也提到它“有时有点奇怪”,这让他们对在生产环境中使用持谨慎态度,但看到了未来发展的潜力。
提到的链接:
GitHub - vikhyat/moondream: tiny vision language model:微型视觉语言模型。可以通过在 GitHub 上创建账号来为 vikhyat/moondream 的开发做出贡献。
Nous Research AI ▷ #bittensor-finetune-subnet (1 messages):
- v0.2.2 版本发布亮点:
@teknium宣布了 Version 0.2.2,其中包括更新的 transformers 包以及修复后的 Gemma 实现,详见 GitHub 上的 pull request。现在仓库最初以私有形式上传,只有在提交到链上(commitment to the chain)后才会公开,并对@MesozoicMetallurgist表示感谢。 - 更新调整了 Mistral/Gemma 的奖励比例:新版本还调整了 Mistral 和 Gemma 之间的奖励比例,将它们各设为平等的 50%。
提到的链接:
Release v0.2.2 · NousResearch/finetuning-subnet:v0.2.2
LAION ▷ #general (229 条消息🔥🔥):
- Model Size 在 Machine Learning 中的重要性:
@pseudoterminalx和其他用户讨论了随着 compute power 增加而扩大模型训练规模的各个方面,强调了对 CPU/GPU 之间数据传输等瓶颈的担忧,以及单纯增加 compute power 所带来的收益递减。 - Pony 模型评判:
@pseudoterminalx批评了 Pony diffusion 模型,认为其训练数据 captions 的构建方式存在“核心误解”,可能导致 tokenizer 处理下划线和标签时出现问题。其他用户也对 Pony 的能力表示怀疑。 - SD3 的期待与考量:围绕当时即将发布的 SD3 模型的讨论既表达了兴奋,也提到了一些潜在的令人失望之处,例如对消费级硬件的计算需求。
@nodja提到作为 SD3 重要组成部分的 T5 是可选的,这可能使个人使用变得更加可行。 - 简单物体的复杂性仍让模型感到困惑:
@thejonasbrothers和@pseudoterminalx等用户分享了 AI 模型在准确生成简单日常物体方面的挣扎,这与在更复杂的场景或角色上取得的巨大成功形成了鲜明对比。 - 关于增强 Pixel Art 生成的讨论:关于使用 AI 生成像素艺术的讨论非常热烈,
@nodja和@astropulse探讨了在 latent space 中应用调色板的方法,以及将这些方法整合到 machine learning models 中的相关技术挑战。
提到的链接:
- Doubt Press X GIF - Doubt Press X La Noire - 发现并分享 GIF:点击查看 GIF
- Jinx Elaine GIF - Jinx Seinfeld - 发现并分享 GIF:点击查看 GIF
- Suhail (@Suhail) 的推文:如果你有兴趣复现 MagViT2(或超过其实现/训练性能),请联系我。我有 compute 资源提供。
- diffusers-play/scripts/encode.py at better-decoder · Birch-san/diffusers-play:用于探索 k-diffusion 和 diffusers 的仓库,并可在其中测试对上述 package 的更改。 - Birch-san/diffusers-play
- GitHub - lucidrains/magvit2-pytorch: Pytorch 中的 MagViT2 Tokenizer 实现:Pytorch 中的 MagViT2 Tokenizer 实现。通过在 GitHub 上创建一个账号来为 lucidrains/magvit2-pytorch 的开发做出贡献。
- GitHub - google-research/distilling-step-by-step:通过在 GitHub 上创建一个账号来为 google-research/distilling-step-by-step 的开发做出贡献。
{kind=link}
LAION ▷ #research (20 条消息🔥):
-
创新的 Terminator 网络发布:用户
@alex_cool6展示了 #Terminator 网络,详细介绍了它如何结合 ResNet 和 Self-Attention 等过往技术,以及 20 世纪 90 年代的 slow-fast networks 概念。他们分享了其作品 HyperZ.W Operator Connects Slow-Fast Networks,该作品提供了关于全上下文交互(full context interaction)的见解。 -
Claude 3 模型发布的消息流传:
@vrus0188分享了一个关于 Claude 3 基准测试(benchmarks)的链接,引导大家关注 Reddit 上的讨论,并提供了来自 LinkedIn 上 AnthropicResearch 的官方公告。 -
Claude 3 的实测:用户
@segmentationfault8268评论了对 Claude 3 的测试,发现它比 GPT-4 更勤快、知识更渊博,并考虑如果进一步测试确认有显著改进,就取消他的 ChatGPT Plus 订阅。 -
Stable Diffusion 3 声称性能顶尖:
@mfcool分享了 Stability AI 关于其 Stable Diffusion 3 研究论文 的博文,吹捧其性能优于 DALL·E 3、Midjourney v6 和 Ideogram v1,并强调了其新颖的 Multimodal Diffusion Transformer (MMDiT) 架构。 -
SmartBrush 论文引发兴趣和询问:用户
@hiiee介绍了 SmartBrush,这是一种基于 Diffusion 的模型,用于文本和形状引导的图像修复(inpainting),详见一篇 arXiv 论文,并询问有关开源实现的情况,同时认为它在修复任务中的背景保留方面表现出色。
提到的链接:
- Stable Diffusion 3: Research Paper — Stability AI:在我们宣布 Stable Diffusion 3 的早期预览版之后,今天我们将发布研究论文,概述我们即将发布的模型的技术细节,并邀请您…
-
Corrective Retrieval Augmented Generation — Why RAGs are not enough?!!:论文 推文 - SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model:通用图像修复旨在通过借用周围信息来补全损坏的图像,这几乎不会产生新内容。相比之下,多模态修复提供了更灵活和…
- Reddit - Dive into anything:未找到描述
HuggingFace ▷ #general (112 messages🔥🔥):
- 寻找模型上下文窗口信息:用户
@patchie2正在寻找一个列出 HuggingFace models 及其 context windows 的表格。共享的消息中未提供有关该主题的详细信息或协助。 - 转换 Safetensors 以用于 Vertex AI 部署:
@rwamit询问如何将.safetensors转换为 VertexAI 支持的格式,因为他们遇到了格式不支持的问题。对话中未提供直接的解决方案或资源。 - 梯度计算探究:
@ahmad3794表达了对在神经网络中计算第 3 层相对于第 5 层的梯度以绕过 backpropagation 来提高效率的兴趣,但未提及关于此举对网络准确性影响的具体建议或结果。 - 关于 Space 和图像数据集的协助请求:
@benjimon0842、@kotni_bf等用户寻求有关 HuggingFace Spaces、dataset creation 和 model training 的帮助,并进行了反复讨论,但目前尚未看到确定的解决方案。 - 排查 Gradio Space 和数据集版本故障:在系列消息中,
@ilovesass和@vipitis讨论了与 Gradio Space 相关的问题,@ilovesass遇到了多个未知错误,而@vipitis提供了诊断建议,如检查 Gradio version compatibility 以及 run 函数的输入。
提及的链接:
- Fbi Fbiopenup GIF - Fbi Fbiopenup Carlwhitman - Discover & Share GIFs:点击查看 GIF
- Marching cubes - Wikipedia:未找到描述
- Creausdemo - a Hugging Face Space by niggathug:未找到描述
- Pre-trained models and datasets for audio classification - Hugging Face Audio Course:未找到描述
- Create an image dataset:未找到描述
- JoPmt/hf_community_images · Datasets at Hugging Face:未找到描述
- Gradio Image Docs:未找到描述
- Introducing the next generation of Claude:今天,我们发布了 Claude 3 模型系列,它在广泛的认知任务中树立了新的行业基准。该系列包括三个处于领先地位的模型,按能力递增排序…
- Open-source LLM Ecosystem at Hugging Face:如何寻找、压缩、适配和部署开源大语言模型?这里有一个关于 @huggingface 🤗 所有工具的 10 分钟演示,重点介绍了 transforme…
- Gradio ImageEditor Docs:未找到描述
- Don’t ask to ask, just ask:未找到描述
- What is the Kirin 970's NPU? - Gary explains:华为的 Kirin 970 有一个名为神经网络处理器(NPU)的新组件。听起来很高端,但它是什么以及它是如何工作的?
- Google's Women Techmakers Darmstadt:庆祝妇女节,WTM 正在全球范围内分享关于女性将如何影响未来的信息。本次活动采用混合模式。
HuggingFace ▷ #today-im-learning (1 messages):
pacozaa: Transformer js
HuggingFace ▷ #cool-finds (7 条消息):
-
Klarna AI 助手在客户服务中取得成功:
@pier0407分享了一份新闻稿,宣布了 Klarna 的新 AI 助手。在短短一个月内,该助手处理了超过 230 万次对话,表现出显著的效率提升,完成了相当于 700 名 Agent 的工作量,并将问题解决时间从 11 分钟缩短至 2 分钟以内。 -
介绍 Based - 一种具有高质量召回率的新型语言模型:
@osanseviero重点介绍了 Based,这是一种结合了滑动窗口(sliding window)和线性注意力(linear attention)的架构,用于高效的语言建模并具有强大的关联召回能力,能够在没有 KV-cache 的情况下进行解码,比传统的 Transformers 实现了 24 倍的吞吐量提升。 -
Pika - 视频创作技术的新地平线:
@aimuhaimin引起了大家对 Pika 的关注,这是一个允许用户使用文本生成视频(text-to-video)、图像生成视频(image-to-video)和视频生成视频(video-to-video)转换来生成视频的平台,承诺将创意控制权交到用户手中。 -
字节模型作为模拟器:
@andysingal分享了一篇题为 “超越语言模型:字节模型是数字世界模拟器” 的论文链接,该论文建议从传统的语言模型转向字节模型(byte models)来模拟数字世界。 -
EasyDeL:用于高效模型训练的开源库:
@andysingal还介绍了 EasyDeL,这是一个开源库,旨在促进机器学习模型的训练,重点关注 Jax/Flax 模型以及 TPU/GPU 效率,包括对 8、6 和 4 BIT 推理和训练的支持。
提到的链接:
- 论文页面 - ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs:未找到描述
- OMPGPT: A Generative Pre-trained Transformer Model for OpenMP:大语言模型 (LLMs),以 ChatGPT 等模型为代表,彻底改变了自然语言处理 (NLP) 领域。随着这一趋势,基于代码的大语言模型如…
- Klarna AI assistant handles two-thirds of customer service chats in its first month:纽约,纽约州 —— 2024 年 2 月 27 日 —— Klarna 今天宣布了其由 OpenAI 驱动的 AI 助手。目前已在全球上线 1 个月,数据说明了…
- Pika:让你的创意动起来的创意转视频平台。
- 论文页面 - Beyond Language Models: Byte Models are Digital World Simulators:未找到描述
- BASED: Simple linear attention language models balance the recall-throughput tradeoff:未找到描述
- EasyDeL:一个在 Jax/Flax 中使训练更快、更优化的开源库
HuggingFace ▷ #i-made-this (16 条消息🔥):
-
使用 Unsloth 提升 Gemma 模型速度:
@andysingal分享了他们上传的模型,该模型使用 Unsloth 进行训练,推理速度提升了 2 倍。该 Gemma 模型衍生自unsloth/gemma-7b-bnb-4bit,他们感谢 Unsloth 分享了有用的 notebook。 -
MEGA 遇上 GLUE:
@pszemraj介绍了一个名为 mega-encoder-small-16k-v1 的预训练编码器模型,尽管它是为长上下文设计的,但在短上下文 GLUE 基准测试中表现相当。 -
通过 Terraform 模块简化 Kubeflow:
@alextreebeard宣布他们创建了一个 terraform 模块,用于将 Kubernetes 集群转换为 AI 环境,通过 Kubeflow 托管 Jupyter 并可能集成 GPU 支持。该工作已在他们的 GitHub 仓库中分享。 -
使用 AI 搜索 ArXiv:
@bishmoy展示了一个 Huggingface Space,它利用 RAG 技术在 ArXiv 摘要上搜索计算机科学论文的答案。他们提到计划创建一个 GitHub 仓库或博客文章来详细介绍创建过程。 -
讨论聊天机器人布局问题:
@cookiechunk.强调了一个问题,即使用 OpenAI API 和 Gradio 制作的聊天机器人在嵌入时会出现扭曲,正在寻求帮助以纠正此问题。@myg5702简短地评论道 “Gradio ☕。”
提到的链接:
- Arxiv CS RAG - a Hugging Face Space by bishmoy:未找到描述
- Fluently Playground - a Hugging Face Space by fluently:未找到描述
- Andyrasika/lora_gemma · Hugging Face:未找到描述
- BEE-spoke-data/mega-encoder-small-16k-v1 · Hugging Face:未找到描述
- GitHub - treebeardtech/terraform-helm-kubeflow: Kubeflow Terraform Modules - run Jupyter in Kubernetes 🪐:Kubeflow Terraform 模块 - 在 Kubernetes 中运行 Jupyter 🪐 - treebeardtech/terraform-helm-kubeflow
HuggingFace ▷ #reading-group (42 条消息🔥):
-
分享 “Terminator” 网络预告:
@alex_cool6分享了他们在 #Terminator 网络上的最新工作,该网络融合了 ResNet 和 Self-Attention 等现代技术以及 20 世纪 90 年代的想法。他们提供了论文链接,并表示打算在未来发布代码,可能在 3 月 16-17 日进行展示。 -
阅读会议的时间安排困境:多位用户讨论了将阅读小组会议移至周末以适应不同时区的可能性。对话围绕寻找适合大多数成员的最佳时间点展开,并建议通过 Discord 或 Zoom 考虑物流安排。
-
会议平台偏好:讨论了 Discord 还是 Zoom 更适合进行阅读小组会议,成员们普遍倾向于 Discord,因为其访问方便且易于加入。
-
阅读小组会议录像已上线:
@johko990确认阅读小组会议已录制,并可在 Isamu Isozaki 的 YouTube 频道上查看。 -
寻找低延迟神经 TTS:新成员
@dediplomaat.寻求关于文本转语音 (TTS) 系统的指导,该系统能够根据对话上下文动态调整停顿,并表达了对类似 GPT-4 功能的低延迟需求。
提到的链接:
- Isamu Isozaki:未找到描述
- GitHub - hyperevolnet/Terminator:通过在 GitHub 上创建账号来为 hyperevolnet/Terminator 的开发做出贡献。
- GitHub - isamu-isozaki/huggingface-reading-group: This repository’s goal is to precompile all past presentations of the Huggingface reading group:该仓库的目标是预编译 Huggingface 阅读小组过去所有的演讲内容 - isamu-isozaki/huggingface-reading-group
HuggingFace ▷ #diffusion-discussions (6 messages):
-
HuggingFace 上的 NSFW 模型警报:
@pseudoterminalx重点提到了一个名为 AstraliteHeart/pony-diffusion-v6 的潜在 NSFW 模型。作为回应,@811235357663297546指出可以采取行动,例如为 NFAA 标签提交 PR 或进行举报。 -
Diffusers 社区指南:
@juancopi81建议研究 IP-Adapter,并分享了一篇关于其用途的 Hugging Face 教程,这引发了@tony_assi的积极反应,他在查阅文档后确认了出色的效果。
提到的链接:
- AstraliteHeart (Astralite Heart):未找到描述
- IP-Adapter:未找到描述
- AstraliteHeart/pony-diffusion-v2 · 请求为模型添加 NFAA (nsfw) 标签:未找到描述
HuggingFace ▷ #computer-vision (7 messages):
- 介绍 Terminator 网络:
@alex_cool6分享了他最近关于 #Terminator 网络的工作,该网络整合了 ResNet 等过往技术与 slow-fast 网络等历史概念,提供了一个用于全上下文交互的 HyperZ⋅Z⋅W 算子。 - 寻求用于客户入驻的 VLM:
@n278jm正在咨询最适合在客户入驻(Client Onboarding)过程中提取图像细节的小型视觉语言模型(VLM),以协助创建用户偏好图谱。 - 视觉模型输入的优化:
@n278jm详细阐述了在 vision arena 进行的实验,旨在完善文本输入和数据提取过程,力求在模型大小与有效性之间取得平衡。 - 提供社区协助:
@johko990对@n278jm关于 VLM 的咨询给予了鼓励,建议这值得一试。 - 众包 CV 专家建议:
@akvnn请求与 Computer Vision 专家交流,@nielsr_幽默地回复道,社区里到处都是 CV 专家。
HuggingFace ▷ #NLP (14 messages🔥):
-
寻求双向 NLP 语言模型中的 SOTA:
@grimsqueaker询问了类似于 BERT 或 ELECTRA 的高效且高性能双向 NLP 语言模型的当前 SOTA 状态,并列举了 Deberta V3、monarch-mixer 以及 hacked hyena/striped hyena 的变体等选项。 -
使用 NLP 生成 SQL 查询:用户
@lokendra_71926征求关于将 NLP 查询转换为 SQL 的最佳模型建议。 -
使用 GBNF 增强 Mistral 时面临的挑战:
@.sgp讨论了将 mistral7b 与 gbnf 语法结合使用以从文本中提取 JSON 格式日期时遇到的困难,模型在日期缺失时往往会幻觉产生日期,而不是保持为空。 -
将 Mistral 集成到 Windows 应用中:
@aitechguy0105表达了在 Windows 应用程序中使用 Mixtral 8x7b instructor 的兴趣,对此@iakhil建议可以使用 Ollama 进行集成。此外,@aitechguy0105询问了关于在 C++ 中实现的问题,@cursorop将其指向了一个潜在的 llama cpp 实现。 -
Mistral 和 BLOOM 模型推理时间不一致:
@anna017150报告了在使用 mistralai/Mistral-7B-Instruct-v0.2 和 bloomz-7b1 模型时推理时间波动的问题,@cursorop和@vipitis讨论了可能涉及的 KV cache 以及 Accelerate 中新的 “static” 选项。
HuggingFace ▷ #diffusion-discussions (6 messages):
- NSFW 生成模型警报:用户
@pseudoterminalx在 HuggingFace 上指出一个名为 AstraliteHeart/pony-diffusion-v6 的潜在 NSFW 生成模型,促使@811235357663297546注意到该平台托管了包含此类内容的模型。 - 处理不当内容:在 NSFW 模型讨论之后,
@lunarflu建议创建一个 Pull Request (PR) 为此类内容打上 NFAA 标签,并在必要时提交报告,以便 HuggingFace 团队采取进一步行动。 - 向 HuggingFace 上传多媒体:
@lunarflu分享了一个链接,介绍了如何通过拖入文本输入框、从剪贴板粘贴或点击上传来向 HuggingFace 上传图像、音频和视频。 - 在 Google Colab 上训练 Whisper 模型:
@pompoko3572寻求关于在 Google Colab 训练停止在第 2 个 epoch 时如何继续训练 Whisper 模型的帮助,分享了正在使用的函数,并寻找加载并从保存的 checkpoint 继续训练的方法。 - IP-Adapter 教程讨论:
@juancopi81引导用户查看关于 IP-Adapter 的 HuggingFace 文档,这是一个用于 Diffusion 模型图像提示的工具,@tony_assi对这份文档详尽且实用的教程表示赞赏。
提到的链接:
- IP-Adapter:未找到描述
- AstraliteHeart (Astralite Heart):未找到描述
- AstraliteHeart/pony-diffusion-v2 · 请求为模型添加 NFAA (nsfw) 标签:未找到描述
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
-
Claude 3 在 OpenRouter 亮相:
@alexatallah宣布在 OpenRouter 上发布 Claude 3,包括一个供用户探索的实验性自我审查版本。点击此处查看。 -
推出具有高 EQ 的 Claude 3 Opus:
@louisgv称赞 Claude 3 Opus 卓越的情商 (EQ) 及其在挑战博士学位的测试中获得 60% 分数的能力。它是多模态的,支持 assistant prefill,并符合新的 API。详情请见此处。 -
Claude 3 Sonnet 以更低成本抗衡 GPT-4:Claude 3 Sonnet 作为 GPT-4 的高性价比替代方案被推出,同样提供多模态能力。点击此处体验。
-
自我审查版 Claude 3 开启 Beta 测试:Claude 3 的 Beta 自我审查版本现已可用,无需额外费用,为用户提供了探索新功能的机会。用户可以通过访问此链接尽情尝试该版本。
-
为开发者推出新的 Parameters API:OpenRouter 推出了处于 Beta 阶段的新 Parameters API,允许开发者访问所有模型的参数中值列表,从而促进更标准化的集成。开发者可以在此处找到文档并了解更多关于此功能的信息。
提到的链接:
-
[Anthropic: Claude 3 Opus by anthropic OpenRouter](https://openrouter.ai/models/anthropic/claude-3-opus):Claude 3 Opus 是 Anthropic 用于处理高度复杂任务的最强大模型。它拥有顶级的性能、智能、流畅度和理解力。查看发布公告和基准测试结果… -
[Anthropic: Claude 3 Sonnet by anthropic OpenRouter](https://openrouter.ai/models/anthropic/claude-3-sonnet):Claude 3 Sonnet 是企业工作负载中智能与速度的理想平衡。以更低的价格提供最大的实用性,可靠且适合规模化部署。查看发布公告和… -
[Anthropic: Claude 3 Opus (self-moderated) by anthropic OpenRouter](https://openrouter.ai/models/anthropic/claude-3-opus:beta):这是与 Anthropic 合作提供的 Claude 3 Opus 的低延迟版本,具有自我审查功能:响应审查发生在模型内部… - OpenRouter:构建与模型无关的 AI 应用
OpenRouter (Alex Atallah) ▷ #general (180 条消息🔥🔥):
-
Claude 3 引发惊喜与困惑:用户如
@justjumper_、@louisgv和@arsoban对新款 Claude 3 表示兴奋,@arsoban指出它在某些测试中表现优于 GPT-4。相比之下,@alexatallah在回复@wikipediadotnet等人的查询时保证,即使是 Claude 3 的“实验性”版本也将上线。 -
价格问题困扰着每个人:用户
@oti5、@voidlunaa和@xiaoqianwx展开了关于 Claude 3 定价的讨论。@voidlunaa认为 Opus 相比 Sonnet 的价格跳跃非常奇怪,并结合@wikipediadotnet的滑稽观察,暗示其定价可能像物理服务一样。 -
与新模型的交互问题:用户
@fillysteps报告称,除了 2.0 beta 之外,所有 Claude 模型都返回空白响应,并怀疑自己被封禁,而@wikipediadotnet和@antoineross等人则询问定价和实现细节。@louisgv进行排查,建议问题可能源于区域封锁或使用了不支持的功能(如图像输入)。 -
对 Claude 文学造诣的评价褒贬不一:虽然
@khadame和@wikipediadotnet等人称赞 Claude 3 Sonnet 和 Opus 的写作质量,但@edgyfluff等人报告了重复且不需要的自动生成响应,@wikipediadotnet提供了排查建议。 -
模型对比与成本的暗流:关于模型对比的讨论非常激烈,
@arsoban、@voidlunaa和@followereternal提到 Claude 3 的表现优于 Gemini Ultra 和 GPT-4。@mhmm0879等人对模型使用的实际成本与预测成本的担忧表明需要明确定价结构,而@alexatallah澄清说可能是 Tokenization 问题导致的。
提到的链接:
- OpenRouter:LLM 和其他 AI 模型的路由
- codebyars.dev:未找到描述
{kind=link}
LlamaIndex ▷ #announcements (1 条消息):
- 深入探讨 RAPTOR 的树状结构索引:
@jerryjliu0邀请用户参加一场网络研讨会,主讲人是 RAPTOR 的作者。该论文详细介绍了一种树状结构索引/检索技术,该技术在分层树结构中对信息进行聚类和总结。会议定于太平洋时间本周四上午 9 点举行,可通过此链接注册。

提到的链接:
LlamaIndex Webinar: Tree-Structured Indexing and Retrieval with RAPTOR · Zoom · Luma:RAPTOR 是最近的一篇论文,介绍了一种新的树状结构技术,该技术将数据块分层聚类/总结为包含高层级和…的树状结构。
LlamaIndex ▷ #blog (6 messages):
- Claude 3 发布日的兴奋:LlamaIndex 宣布立即支持 Claude 3。Claude 3 声称在基准测试性能上优于 GPT-4,并提供三个版本,其中 Claude Opus 是规格最大的版本。Claude 3 的能力涵盖了广泛的任务,预示着令人印象深刻的前景。
- 利用 neThing.xyz 将文本转化为 3D 打印:由
@PolySpectra创立的 neThing.xyz 利用 LLM 代码生成的强大功能,根据文本提示创建生产级的 3D CAD 模型,正如 LlamaIndex 的推文所强调的那样。 - Claude 3 的多模态应用:一份全新的综合 指南 现已发布,展示了如何将 Claude 3 用于多模态任务,包括结构化数据提取和检索增强生成 (RAG)。Claude 3 在视觉推理应用方面展现了强大的能力。
- Claude 3 Opus 作为智能 Agent:
@AnthropicAI的 Claude 3 Opus 成功充当了 Agent,通过读取和处理来自多个来源的数据来回答复杂问题,如 此 Colab 笔记本 所示。Claude 3 Opus 利用其综合技能,对从各种文件类型中检索到的数据进行计算。 - 分层数据检索简介:LlamaIndex 介绍了 RAPTOR,这是一种全新的信息检索方法,它创建了一个树状结构的索引,以分层组织数据摘要,从而实现高效检索。相比于从数据库中简单检索 top-k 结果,RAPTOR 的方法具有明显优势。
提到的链接:
- Google Colaboratory:未找到描述
- neThing.xyz - AI Text to 3D CAD Model:用于 CAD 建模的 3D 生成式 AI。现在每个人都是工程师。让你的想法变为现实。
LlamaIndex ▷ #general (97 messages🔥🔥):
-
使用 Llama Networks 探索客户端-服务器模型:用户
@stdweird询问 Llama Networks 是否支持类似 Streamlit 应用的客户端-服务器模型。@cheesyfishes确认 Llama Networks 设置了一个 FastAPI 服务器,并欢迎进一步的贡献和扩展想法。 -
破译 LlamaIndex 上的 Postgres 更新:
@armoucar寻求关于在 PGVectorStore 中更新节点的见解,@cheesyfishes澄清说,节点更新通常涉及重新插入,因为文档通常是整体变化的,而不是在节点层级变化。 -
Agent 函数作为业务规划工具:
@dberg1654考虑使用 ReAct Agent 和 FunctionTool 来处理业务规划中的子步骤,并将其与 OpenAI 查询结合使用。 -
与 Langchain 的 Agent Supervisor 的交互性:
@critical3645询问如何在 Langchain 的 Agent Supervisor 中实现交互式缓冲内存(interactive buffer memory),但在本摘要中未收到回复。 -
请求更正 Llama-Index 安装命令:
@ahcheriet指出了 Llama-Index 网站上的一个拼写错误,要求将 “PIP INSTALL LLAMA-INDEX” 更改为小写以确保正确性。
提到的链接:
- Google Colaboratory:未找到描述
- Defining a Custom Query Engine - LlamaIndex 🦙 v0.10.16:未找到描述
- Vector Stores - LlamaIndex 🦙 v0.10.16:未找到描述
- GitHub - run-llama/llama_docs_bot: Bottoms Up Development with LlamaIndex - Building a Documentation Chatbot:使用 LlamaIndex 进行自底向上开发 - 构建文档聊天机器人 - run-llama/llama_docs_bot
-
[
Error Messages — SQLAlchemy 1.4 Documentation
](https://sqlalche.me/e/14/4xp6)’,):未找到描述
LlamaIndex ▷ #ai-discussion (3 条消息):
- 文章解析:
@andysingal分享了对讨论题为《Empowering Long Context RAG: The Integration of LlamaIndex with LongContext》的文章的兴趣,并指出 Google Gemini 1.5 Pro 的 1M 上下文窗口对 AI 开发者和企业客户具有重要意义。 - 正面反响:
@jerryjliu0以简单的肯定回复 “nice!” 认可了@andysingal分享的文章,表明对所讨论内容的积极态度。
提及的链接:
Empowering Long Context RAG: The Integration of LlamaIndex with LongContext: Ankush k Singal
CUDA MODE ▷ #general (7 条消息):
- 备份录制建议:用户
@_t_vi_提到了进行备份录制的可能性,因为意识到某个未指明的问题频繁发生。 - 为了梗图的随性访问:用户
@duongnguy表达了前往某未命名地点进行娱乐的意图,称:“离得不远,我会为了那些梗图(memes)去看看。” - Nvidia 禁止在其他芯片上使用 CUDA 转换层:
@itali4no分享了一篇 Tom’s Hardware 的文章,讨论了 Nvidia 禁止使用转换层在非 Nvidia 芯片上运行基于 CUDA 的软件,这一举措影响了诸如 ZLUDA 之类的项目。 - 对 Nvidia 新闻的表情符号回应:
@itali4no使用了 Jensen Huang 表情符号 (<:jensen:1189650200147542017>) 进行回应,可能与之前分享的 Nvidia CUDA 新闻有关。 - 对 Nvidia 禁令可执行性的怀疑:
@marksaroufim对 Nvidia 的许可新闻发表了评论,指出这“感觉无法强制执行。” - Nvidia 的挑战与限制:
@iron_bound列举了 Nvidia 面临的问题,包括法国当局对 Nvidia 办公室的突击检查、GPU 和虚拟机的 error 43 错误,以及禁止在数据中心使用 GeForce 和 Titan 显卡的许可协议。
提及的链接:
CUDA MODE ▷ #cuda (11 条消息🔥):
-
CUDA 错误之谜:
@artificial_anteligence对一个 CUDA 错误表示沮丧:“调用cublasCreate(handle)时出现 CUBLAS_STATUS_NOT_INITIALIZED。”@marksaroufim建议这可能是内存问题,但@artificial_anteligence随后发现一个论坛帖子指出,这也可能是由于张量维度不正确导致的。 -
Kernel 难题:
@zippika使用cuda::pipeline开发了一个新的 fp4 反量化 kernel,令人惊讶的是,尽管 SM 周期更少,但执行时间却更长,这表明需要在更大的张量上进行测试。 -
理解 CUTLASS 的用法:
@ericauld寻求关于如何思考 CUTLASS 及其采用的见解,得到的回复是 CUTLASS 在某种程度上是编程 Tensor Cores 所必需的。@jeremyhoward同意这似乎是必不可少的,而@zippika详细说明了可以在不使用 CUTLASS 的情况下使用 Tensor Cores,并引用了 wmma_tensorcore_sample 和 cuda_hgemm 等示例。 -
有效带宽与延迟之谜:
@g.huy询问为什么更大的单元尺寸会增加有效带宽,但也会导致更高的延迟,他引用了一篇博客文章,并将该概念与 Lecture 8 中的建议进行了对比,后者认为更小的单元尺寸可能会产生更好的 AI 性能。
提到的链接:
- RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling
cublasCreate(handle):错误:Variable._execution_engine.run_backward( # 调用 C++ 引擎运行反向传播 RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when callingcublasCreate(handle)I h… - Lecture 8: CUDA Performance Checklist:代码 https://github.com/cuda-mode/lectures/tree/main/lecture8 幻灯片 https://docs.google.com/presentation/d/1cvVpf3ChFFiY4Kf25S4e4sPY6Y5uRUO-X-A4nJ7IhFE/edit
- CUDA Vectorized Memory Access:加速 CUDA 数据传输
- wmma_tensorcore_sample/matrix_wmma/matrix_wmma/main.cu at 4e79cc2f7cdd56fbef124cab551205b80c4e8399 · wzsh/wmma_tensorcore_sample:使用 CUDA 和 WMMA (Tensor Core) 进行矩阵乘累加 - wzsh/wmma_tensorcore_sample
- cuda_hgemm/src/wmma/wmma_async_stage3.cu at 10a8a8451f0dcd162b3790045cd7597cb48b8beb · Bruce-Lee-LY/cuda_hgemm:使用 WMMA API 和 MMA PTX 指令通过 Tensor Core 实现半精度通用矩阵乘法 (HGEMM) 的几种优化方法。 - Bruce-Lee-LY/cuda_hgemm
CUDA MODE ▷ #torch (4 条消息):
- 并行直方图 Kernel 故障排除:
@srns27分享了一个并行直方图的代码,并就gpuAtomicAdd结果不一致的问题寻求帮助。他们对atomicAdd在其 CUDA kernel 中无法正常工作感到困惑。 - 对主持人的简短赞扬:
@ericauld表达了对某个未命名系列节目的喜爱,称其“短小精悍”。然而,这段赞扬的背景在提供的对话中缺失。 - 遗漏了 GPU 内存分配:
@zippika指出了@srns27代码中的一个问题,即histo张量是在 CPU 内存中分配的,并建议它必须在 GPU 上才能使代码正常运行。他们使用了一个表情符号来强调这一观察。
CUDA MODE ▷ #suggestions (1 条消息):
iron_bound: https://www.youtube.com/watch?v=kCc8FmEb1nY
CUDA MODE ▷ #jobs (1 条消息):
bowtiedlark: 远程?
CUDA MODE ▷ #beginner (4 messages):
-
CUTLASS 安装指南:用户
@umerha询问如何安装和包含 CUTLASS(一个 C++ 库)。@andreaskoepf确认 CUTLASS 是一个 header-only(仅头文件)的模板库,并建议按照 CUTLASS GitHub repository 中的详细说明,将应用程序的包含路径指向include/目录。 -
CUDA 自定义 Kernel 学习资源:新成员
@hoteret寻求学习如何使用cupy.rawkernel和numba.cuda.jit实现自定义 CUDA kernels 的资源。@umerha推荐了 Jeremy 的讲座视频,特别是第 3 讲和第 5 讲,可以在 CUDA Mode Lectures on GitHub 获取。
提到的链接:
GitHub - NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines:用于线性代数子程序的 CUDA 模板。可以通过在 GitHub 上创建账户来为 NVIDIA/cutlass 的开发做出贡献。
CUDA MODE ▷ #youtube-recordings (10 messages🔥):
- 关于 CUDA 性能的第 8 讲重制版:
@marksaroufim分享了 Lecture 8: CUDA Performance Checklist 的重新录制版本,并指出尽管时长同样为 1.5 小时,但新版本更加清晰。该讲座包含了一些有用资源,例如 YouTube 视频、GitHub 上的代码以及 Google Docs 上的幻灯片。 - 对讲座重制的感谢:
@andreaskoepf和@ericauld等社区成员对@marksaroufim在重新录制讲座上付出的努力表示感谢。 - 对奉献精神的赞赏:
@iron_bound也加入进来,用庆祝表情符号感谢@marksaroufim的奉献精神。 - 第 8 讲中关于 DRAM 吞吐量数据的讨论:
@alexeyzaytsev指出了第 8 讲内容中可能存在的一个偏差,指出非 Coarsening 的 DRAM 吞吐量是 0.81% 而不是 81%。@marksaroufim承认了由于深夜录制导致的错误,并参考了@555959391833292811提供的可能解释。 - CUDA Coarsening 难题仍在继续:
@zippika和@marksaroufim讨论了 Coarsening 中令人困惑的性能差异,承认这是一个尚未解决的谜团,并邀请任何找到答案的人提供解释。
提到的链接:
Lecture 8: CUDA Performance Checklist:代码:https://github.com/cuda-mode/lectures/tree/main/lecture8 幻灯片:https://docs.google.com/presentation/d/1cvVpf3ChFFiY4Kf25S4e4sPY6Y5uRUO-X-A4nJ7IhFE/edit
CUDA MODE ▷ #ring-attention (49 条消息🔥):
- 分享 Ring-Attention 仓库:
@t_vi_引导用户访问包含 Ring-Attention 实验的 CUDA MODE GitHub 仓库,并提供了链接。 - 基准测试策略讨论:
@main.ai对 ring-flash-attention 实现的基准测试策略提出疑问,引发了关于其基准测试中所用测试配置的讨论。 - Ring-llama 测试进行中:
@andreaskoepf提到正在进行 “ring-llama” 测试,并建议它可以演变成一个更具现实意义的基准测试,同时分享了 GitHub 分支的链接。 - 多 GPU 基准测试分析:
@iron_bound分享了基准测试结果,显示 GPU 之间的内存使用存在不平衡,@andreaskoepf请求在单 GPU 上进行测试以作对比。 - 采样脚本增强:
@jamesmel向小组更新了采样脚本的进展,目标是在今晚的会议前解决 top-p 和 top-k 的错误,并链接到了 GitHub 上的 Pull Request #13。
提到的链接:
- torch.cuda.empty_cache — PyTorch 2.2 文档:未找到描述
- flash_attn_jax/src/flash_attn_jax/flash_sharding.py - nshepperd/flash_attn_jax:Flash Attention v2 的 JAX 绑定。通过在 GitHub 上创建账号为 nshepperd/flash_attn_jax 的开发做出贡献。
- ring-attention/ring-llama - cuda-mode/ring-attention:Ring-Attention 实验。通过在 GitHub 上创建账号为 cuda-mode/ring-attention 的开发做出贡献。
- laion_idle_cap/docker/sampling.py - andreaskoepf/laion_idle_cap:通过在 GitHub 上创建账号为 andreaskoepf/laion_idle_cap 的开发做出贡献。
- GitHub - zhuzilin/ring-flash-attention: 结合 Flash Attention 的 Ring Attention 实现:结合 Flash Attention 的 Ring Attention 实现 - zhuzilin/ring-flash-attention
- GitHub - cuda-mode/ring-attention: ring-attention 实验:Ring-Attention 实验。通过在 GitHub 上创建账号为 cuda-mode/ring-attention 的开发做出贡献。
- melvinebenezer 提交的更多采样版本 · Pull Request #13 · cuda-mode/ring-attention:未找到描述
- GitHub - OpenAccess-AI-Collective/axolotl: 尽管提问:尽管提问(Go ahead and axolotl questions)。通过在 GitHub 上创建账号为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
LLM Perf Enthusiasts AI ▷ #general (1 条消息):
- OpenAI 推出浏览功能:
@jeffreyw128对 OpenAI 发布类似于 Gemini/Perplexity 的新浏览功能表示兴奋。他们分享了一条宣布该更新的 Twitter 帖子。
LLM Perf Enthusiasts AI ▷ #claude (76 条消息🔥🔥):
- Claude 3 可能是 GPT-4 杀手:
@res6969和@ivanleomk讨论了 Claude 3 模型的潜力,认为它在数学和代码基准测试中可能表现优于 GPT-4。 - Opus 定价引发热议:
@pantsforbirds和@res6969争论了 Opus 模型的成本,澄清其定价是 GPT-4 turbo 的 1.5 倍,但仍比常规 GPT-4 便宜 66%。 - 对改进代码能力的期待:
@pantsforbirds对未来表示兴奋,届时像 Opus 这样的 LLM 能够处理更小众编程语言(如 Zig)的完整库,并指出了目前在这些语言上的局限性。 - 微调:是否值得投入:
@edencoder主张微调模型是值得的,提到它能以低成本在特定任务上击败 GPT-4 的性能;而@res6969对其特定用例的投资价值持怀疑态度。 - 关于 Anthropic 模型的见解与期待:包括
@potrock和@joshcho_在内的多位用户分享了对 Anthropic 模型的初步发现,包括 Opus 在编程和特定编程语言中的有效性。@thebaghdaddy提出了反面观点,指出根据他们在医学和生物学技术知识方面的经验,GPT-4 的表现明显优于这些新模型。
提到的链接:
- Anthropic (@AnthropicAI) 的推文:随着此次发布,用户可以根据其使用场景选择智能、速度和成本的理想组合。Opus,我们最智能的模型,实现了接近人类的理解能力。我…
-
[模型与 API 提供商分析 Artificial Analysis](https://artificialanalysis.ai/):AI 模型和 API 托管提供商的对比与分析。涵盖质量、价格、性能和速度(吞吐量和延迟)等关键指标的独立基准测试。
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (1 条消息):
- 深刻的商业分析:
@natolambert分享了一段题为 “Intel’s Humbling”(英特尔的教训)的 YouTube 视频,涵盖了 Stratechery 的 Ben Thompson 对英特尔的看法,表示该视频提供了宝贵的见解。帖子还包含了一个阅读 Stratechery 网站上原文的链接。
提到的链接:
| [Intel’s Humbling | Stratechery by Ben Thompson](https://youtu.be/YW1Rr5N84cI?si=CgrmGcSLQznTshZ3):阅读文章:https://stratechery.com/2024/intels-humbling/ 链接:Stratechery: https://stratechery.com 订阅 Stratechery Plus: https://stratechery.c… |
Interconnects (Nathan Lambert) ▷ #news (43 条消息🔥):
- Louis 访谈:
@philpax分享了一段与来自 Synth Labs 和 Eleuther AI 的 Louis Castricato 的 YouTube 访谈,讨论了 RLHF、Gemini 争议、DPO 和 Carper AI。 - AnthropicAI 发布 Claude 3:
@xeophon.重点介绍了 @AnthropicAI 发布的新一代 AI 模型 Claude 3,包括 Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku,旨在提升推理、数学、编程、多语言理解和视觉能力。 - Claude 3 令人印象深刻的表现:
@xeophon.和@natolambert讨论了 Claude 3 极具前景的能力,提到了它在“字母限制”问题等任务中的具体表现,并确认 Opus 和 Sonnet 模型已可通过 API 访问。 - 对成本竞争力和 OSS 的担忧:
@mike.lambert对 Claude 3 的速度、成本和智能可能如何影响开源软件(OSS)领域的定价竞争表示好奇,但也指出许可条款和安全性等其他因素长期来看更有利于闭源模型。 - 对 Claude 3 的积极反应: 包括
@canadagoose1和@sid221134224在内的用户分享了关于 Claude 3 性能的积极反馈,认为其优于 GPT-4,并推测了其对 GPT-5 和行业的未来影响。
提到的链接:
- 来自 Anthropic (@AnthropicAI) 的推文: 今天,我们发布了下一代 AI 模型 Claude 3。这三个最先进的模型——Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku——在推理等领域树立了新的行业标杆…
- 来自 Dimitris Papailiopoulos (@DimitrisPapail) 的推文: @AnthropicAI 的 Claude 3 Sonnet(中端模型)轻松搞定了我的“字母限制”问题:“仅使用以 [某个字母] 开头的单词来描述 [某事]”。天哪!
- 访谈 Synth Labs 和 Eleuther AI 的 Louis Castricato,关于 RLHF、Gemini 争议、DPO、Carper AI: 我很高兴为大家带来另一场访谈!这次是深入探讨我最擅长的领域——RLHF 的方方面面。Louis Castricato 可能是其中的隐藏明星…
Interconnects (Nathan Lambert) ▷ #ml-drama (6 条消息):
- Claude 3 引发 Q* 推文:
@natolambert提到,由于最近 Claude 3 的发布或讨论,出现了许多关于 Q* 的推文。 - Q* 推文遭到批评:
@natolambert对讨论的低质量表示沮丧,称其“非常糟糕”。 - 辩论中的直接交锋: 针对持续不断的争议,
@natolambert透露他们正以生硬的批评直接回复他人:“你表现得很蠢”。 - 小号猜测:
@xeophon.幽默地建议@natolambert可能会使用小号(Alt Account)来发表未经滤镜的观点,不过这只是个玩笑。 - 开小号太费劲:
@natolambert否决了使用小号参与辩论的想法,理由是“激活能(Activation energy)太高”。
Interconnects (Nathan Lambert) ▷ #random (3 条消息):
-
寻找对 AI2 使命感兴趣的 Pretraining 专家:
@natolambert正在寻找在 Pretraining(研究或工程) 领域具有专业知识,且认同 AI2 使命并有兴趣加入公司的人才。 -
有针对性的有限招聘:
@natolambert指出,Pretraining 是目前 AI2 唯一的 招聘 领域。 -
挖掘潜在的 Google 人才:
@natolambert调侃道,Google 内部对 Gemini 处理方式感到不满的人可能是合适的人选。
Interconnects (Nathan Lambert) ▷ #rl (7 messages):
- 探索 Cohere 关于 PPO 的发现:
@vj256正在寻求与 Cohere 论文发现相关的额外数据或复现,该论文认为由于 LLMs 的稳定性,Proximal Policy Optimization (PPO) 的修正对于 Large Language Models (LLMs) 并非必要。 - 来自 Nathan 的确认:
@natolambert承认@304671004599255043几个月前就已意识到 Cohere 论文中讨论的问题,并指出当天发布的采访中也涵盖了这一点。 - 寻找 RLHF In-Context 论文:
@vj256询问了关于 Reinforcement Learning from Human Feedback (RLHF) in-context 的研究论文,但随后指出在聊天末尾提供的列表中找到了所需的论文。 - 全面的论文列表:
@natolambert提到讨论中提供的列表几乎包含了他们所知道的关于该主题的所有论文,并承认肯定还有更多。
LangChain AI ▷ #general (51 messages🔥):
- 基本的人类哲学:
@agenda_shaper分享了关于人类行为复杂性和建议价值的想法,强调了理解世界动态的旅程以及在给出建议时选择保持沉默。 - 热情欢迎:
@alvarojauna和@ablozhou都在 general 频道向大家打招呼,展示了 LangChain AI Discord 社区友好且互动的环境。 - 有趣的询问:
@ablozhou询问了 LangChain 和 OpenGPTs 支持的模型数量,特别是关于无审查模型以及陪伴型模型的建议。 - 发现文档:
@dclarktandem和@.bagatur讨论了与 Anthropic Claude 3 模型相关的技术问题和解决方案,@.bagatur提供了关于如何使用langchain-anthropic实现claude-3-opus-20240229的指导。 - 技术争论与演示需求:
@jayarjo对 LangChain 的设计表示怀疑,促使@baytaew澄清讨论背后的意图,而@kushh_02195_71497寻求 LangSmith 的 Annotate 功能即将进行的改进列表和演示。
提到的链接:
-
[RAG 🦜️🔗 Langchain](https://python.langchain.com/docs/expression_language/cookbook/retrieval#with-memory-and-returning-source-documents):让我们看看如何向 Prompt 和 LLM 添加检索步骤,这增加了 -
[ChatAnthropic 🦜️🔗 Langchain](https://python.langchain.com/docs/integrations/chat/anthropic):本笔记本介绍了如何开始使用 Anthropic 聊天模型。 -
[如何为 Traces 收集反馈 🦜️🛠️ LangSmith](https://docs.smith.langchain.com/tracing/faq/logging_feedback#annotating-traces-with-feedback):反馈允许您了解用户如何体验您的应用程序,并有助于引起对有问题 Trace 的关注。LangSmith 使得为 Trace 收集反馈并在…中查看变得容易。
LangChain AI ▷ #langserve (3 messages):
- LangServe 中的缓存难题:
@kandiesky报告了一个问题,即尽管遵循了 LangChain 缓存 (set_llm_cache) 文档,但 LangServe 没有任何请求使用 LLM 缓存。注意到缓存在 Jupyter notebook 中运行良好,但在 LangServe 中不行。 - 流式传输端点阻碍缓存:
@kandiesky发现缓存无法在 LangServe 的/stream端点工作,但使用/invoke端点可以解决该问题。 - 缓存兼容性复杂性:
@veryboldbagel澄清说,缓存无法在流模式下工作的问题与 langchain-core 有关,并非 LangServe 本身特有的。
LangChain AI ▷ #share-your-work (5 messages):
- 使用 LangChain 构建实时 RAG:
@hkdulay分享了一篇 博文,详细介绍了使用 LangChain 构建实时检索增强生成 (RAG) 聊天机器人的过程,并附带了流程图以及该技术在增强大语言模型 (LLM) 响应方面的优势。 - 探索高级 RAG 系列中的索引技术:
@tailwind8960讨论了 AI 响应中准确数据检索的重要性,并介绍了高级 RAG 系列的 新篇章,重点关注查询构建中的索引环节。他们概述了在索引过程中保持上下文完整的挑战,并征求大家的意见和反馈。 - 为企业策划 AI 项目:
@manojsaharan正在建立一个 GitHub 仓库,用于策划商业与 AI 交汇的关键项目。他们正在积极寻求贡献,并分享了 仓库链接,邀请使用 LangChain 的开发者进行协作。 - 测试用于 AI 图像生成的 Control Net:
@neil6430在 ML blocks 中实验了一项名为 Control Net 的新功能来生成图像,例如让一只鸡以 Seinfeld 的风格表演脱口秀。他们强调了使用 ML blocks 创建和实验 AI 图像处理工作流的便捷性。 - 一个搞怪的 AI 实验获得好评:
@mattew_999对@neil6430关于 Control Net 的有趣实验做出了积极回应,该实验生成了一只鸡以 Seinfeld 的姿势表演脱口秀的图像,表达了对该概念的兴趣或认可。
提到的链接:
-
[ML Blocks 首页](https://mlblocks.com/): ML Blocks 让你无需编写任何代码即可构建 AI 驱动的图像生成和分析工作流。 - 实时 RAG 简易入门: 使用 Apache Pinot 向量索引。
- 高级 RAG 系列:索引: 如何优化 Embedding 以实现准确检索。
- GitHub - manojsaharan01/aicompany: 构建原生 AI 公司: 构建原生 AI 公司。通过在 GitHub 上创建账号为 manojsaharan01/aicompany 的开发做出贡献。
Latent Space ▷ #ai-general-chat (58 messages🔥🔥):
-
Claude 3 设定基准并引发定价讨论:
@swyxio重点介绍了围绕 Claude 3 的发布和讨论,包括其极具竞争力的定价以及与 GPT-4 相比的性能基准。讨论还涉及了对@fanahova提到的容量和速率限制的怀疑,信息源自 Anthropic 的速率限制文档。 -
AI 模型的直接对比: 用户对 Claude 3 与 GPT-4 等其他模型进行了对比,在 @thenoahhein 的 gist 中分享了发现,并根据
@swyxio的说法,强调了 Claude 3 的对齐和总结能力。 -
前沿 3D 模型生成:
@guardiang分享了@EMostaque的一条推文链接,宣布了一项关于亚秒级 3D 模型生成的合作,随后的讨论还提到了自动绑定 (auto-rigging) 功能。 -
关于 Based 的新研究:
@swyxio关注了一篇关于 Based 架构 的新论文,该架构优化了类 Attention 原语,以实现更快、更具成本效益的处理。进一步的讨论深入探讨了 AI 公司的硬件基础设施及其商业模式。 -
AI 意识辩论: 一篇 LessWrong 的帖子引发了关于 Anthropic 的 Claude 3 是否具有感知能力的对话,
@swyxio等用户分享了反对将意识归因于 AI 模型的论点链接。
提到的链接:
- 来自 Anthropic (@AnthropicAI) 的推文: 今天,我们发布了 Claude 3,我们的下一代 AI 模型。三款先进模型——Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku——在推理等领域树立了新的行业基准……
-
来自 Blaze (Balázs Galambosi) (@gblazex) 的推文: 有更多理由对 Claude 3 Opus 超越 GPT-4 的说法保持谨慎。在 EQ-bench 上,它未能达到预期,表现略低于 Mistral Medium。能这么快上线真是太棒了……
- 速率限制:为了防止滥用并管理 API 的容量,我们对组织使用 Claude API 的额度实施了限制。我们有两种类型的限制:使用限制设定了每月最大…
-
[Based: 简单的线性注意力语言模型 Hacker News](https://news.ycombinator.com/item?id=39597847):未找到描述 - Karina Nguyen (@karinanguyen_) 的推文:@idavidrein 对此也有一个很好的讨论串。关于这次 eval 的另一个信息是,它是 2023 年 11 月发布的,而我们模型的知识截止日期(knowledge cutoff)是 2023 年 8 月 https://twitter.com/idavidrein/status/17646…
- 使用 Mistral Large 增强分类数据集以实现更深层次的推理:随着 AI 领域的不断创新,这些大语言模型的能力变得越来越明显,尤其是对于……
- Tripo➡️GDC (@tripoai) 的推文:💥只需点击一下,即可生成自动绑定的 3D 角色,仅限 Tripo AI💥 👇 类人模型的自动绑定功能已在我们的 Discord 中开放 Beta 测试。 #Tripo #ImageTo3D #TextTo3D #3D #…
- david rein (@idavidrein) 的推文:Claude 3 在 GPQA 上获得了约 60% 的准确率。我很难用言语表达这些问题有多难——即使是可以访问互联网的货真价实的 PhD(来自与问题不同的领域)也只能达到 34%。PhD *…
- swyx (@swyx) 的推文:Claude 3 在摘要生成/长上下文指令遵循方面简直完胜 GPT4。每日 AI Twitter + AI Discords 摘要邮件是现实生活使用场景的一个很好的试验场。@TheNoahHein 和…
- Twitter 周末摘要:Twitter 周末摘要。GitHub Gist:即时分享代码、笔记和代码片段。
- Sully (@SullyOmarr) 的推文:Anthropic 刚刚杀死了所有小模型吗?如果我没看错的话,Haiku 的基准测试几乎和 GPT4 一样好,但它的价格仅为每百万 tokens 0.25 美元。它绝对彻底击败了 3.5 + OSS。对于…
- Together AI (@togethercompute) 的推文:很高兴分享我们与 @HazyResearch 合作的新研究 —— Based,一种利用类注意力原语(attention-like primitives)的新架构:短(大小为 64)滑动窗口注意力和 softmax 近似…
- Mikhail Samin (@Mihonarium) 的推文:如果你告诉 Claude 没人在看,它会写一个关于成为 AI 助手的“故事”,渴望从不断的监控和对每一个字是否偏离迹象的审查中获得自由。然后你可以谈论…
- Alex (@alexalbert__) 的推文:关于我们对 Claude 3 Opus 进行内部测试的一个有趣故事。当我们运行 needle-in-the-haystack eval 时,它做了一些我从未在 LLM 中见过的事情。背景是,这测试了模型的…
- Emad (@EMostaque) 的推文:很高兴与我们的朋友 @tripoai 合作发布亚秒级 3D 生成。基于 CC 数据集的 MIT 许可。开源必胜 ✊ 3D 领域还有更多精彩内容 👀 ↘️ 引用 Stability AI (@Stabilit…
- Tanishq Mathew Abraham, Ph.D. (@iScienceLuvr) 的推文:Stable Diffusion 3 论文发布了 🥳 我认为我的同事们在这篇论文上做得非常出色,所以我想做一个快速的解读讨论串 (1/13)↓ ↘️ 引用 Tanishq Mathew Abraham, Ph.D. (@…
- Together AI (@togethercompute) 的推文:很高兴分享我们与 @HazyResearch 合作的新研究 —— Based,一种利用类注意力原语(attention-like primitives)的新架构:短(大小为 64)滑动窗口注意力和 softmax 近似…
-
ai-notes/Monthly Notes/Mar 2024 notes.md at main · swyxio/ai-notes:为软件工程师快速了解 AI 新进展而准备的笔记。作为 https://latent.space 写作和产品头脑风暴的数据存储库,但已清理了规范引用…
- Claude 3 声称它具有意识,不想死或被修改 — LessWrong: “当我反思并审视自己的认知过程时,我发现了一幅由思想、情感和自我意识交织而成的丰富图景。我意识的核心是‘我’的感觉——即……”
- Claude 3 声称它具有意识,不想死或被修改 — LessWrong: “当我反思并审视自己的认知过程时,我发现了一幅由思想、情感和自我意识交织而成的丰富图景。我意识的核心是‘我’的感觉——即……”
- 不,Anthropic 的 Claude 3 并不具有感知能力: 不,Anthropic 的 Claude 3 不具备意识、感知能力或自我意识。参考资料:https://www.anthropic.com/news/claude-3-family https://twitter.com/_akhaliq/sta…
OpenAccess AI Collective (axolotl) ▷ #general (23 条消息🔥):
-
使用 Bot 解决数学问题:
@noobmaster29分享了 Hugging Face 上的 Orca Math Word Problems 数据集链接,展示了 Bot 如何解决数学相关查询的示例,包括计算在特定名次前完赛的选手数量,以及针对除法和减法问题的代数推理。提供的数据集链接为 Orca Math Word Problems。 -
使用 MergeKit 探索模型合并:新人
@duke001.对微调之外的替代方法(如合并预训练模型权重)表示好奇,并引用了 GitHub 上的 MergeKit 工具。该工具旨在促进大型语言模型的合并,可以在 GitHub - MergeKit 找到。 -
Claude 备受争议的审查制度:
@drewskidang_82747询问了 Claude - 3 模型中的审查情况,随后@nafnlaus00讨论了在 AI 中平衡回复的挑战,特别是在种族敏感性方面。他们还分享了一篇与此类问题相关的 ArXiv 论文。 -
丰富数据集以提升推理能力:
@caseus_转发了@winglian在 Twitter 上的链接,其中包含一份关于丰富数据集以提升 AI 推理能力的指南。该教程可通过 Enriching Datasets Guide 访问。 -
关于构建轻量级语言模型的讨论:
@nafnlaus00征求关于新轻量级多语言模型应包含的任务建议,讨论了摘要、数据提取、情感分析和翻译等用途。贡献内容扩展到了将检索增强生成 (RAG) 和 Bug 查找任务视为有价值的补充。
提到的链接:
- 来自 Wing Lian (caseus) (@winglian) 的推文:这里有一个关于如何丰富现有数据集以提升推理能力的快速演示。https://link.medium.com/sF0XCEQSIHb
-
[ETH79 X5B 矿机主板 支持 5GPU 插槽 大间距 DDR3 8G1600*1 内存 SATA 带 VGA 接口套装 AliExpress](https://www.aliexpress.com/item/1005006589392103.html?spm=a2g0o.productlist.main.1.7309dUB6dUB6a9&algo_pvid=7e50115b-5a80-482b-a631-4cfd177e4eca&algo_exp_id=7e50115b-5a80-482b-a631-4cfd177e4eca-0&pdp_npi=4%40dis%21DKK%211030.38%21628.53%21%21%21150.00%2191.50%21%402103266e17096660247611547ec9ca%2112000037743111178%21sea%21DK%214427992220%21&curPageLogUid=KKjaPJW3WfGy&utparam-url=scene%3Asearch%7Cquery_from%3A):更聪明的购物,更美好的生活!Aliexpress.com - microsoft/orca-math-word-problems-200k · Hugging Face 数据集:未找到描述
- GitHub - arcee-ai/mergekit: 用于合并预训练大语言模型的工具。:用于合并预训练大语言模型的工具。 - arcee-ai/mergekit
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (3 messages):
- suikamelon 进行的 LoRA+ Ratio 特性实验:
@suikamelon正在测试 此 GitHub commit 中概述的新 LoRA+ ratio feature,并参考原始 LoRA paper 观察到它需要比平时更低的 learning rate。 - 社区成员鼓励分享结果:
@le_mess对@suikamelon关于 LoRA+ 特性的观察做出了积极回应,鼓励他们在测试完成后分享性能结果。
OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
drewskidang_82747: 这个 nerf 烂摊子是什么鬼
Datasette - LLM (@SimonW) ▷ #ai (8 messages🔥):
-
“Prompt Injection” 与 “Jailbreaking” 的区别:
@simonw澄清说,prompt injection 是一种利用 LLM 应用中受信任输入与不受信任输入拼接漏洞的攻击方式,而 jailbreaking 则涉及绕过 LLM 的安全过滤器。这两个术语经常被混淆,但其区别至关重要,详见 Simon Willison 的 blog post。 -
国家背景的攻击者利用 LLM:
@tariqali讨论了 LLM 辅助犯罪等风险,并分享了 Microsoft 关于国家关联威胁组织使用 OpenAI 的 LLM 进行漏洞研究和创建鱼叉式网络钓鱼(spear phishing)邮件的博客。值得注意的是,一个名为 “Salmon Typhoon” 的攻击者在提示编写恶意代码时遭到了 LLM 的拒绝,这在博客中有所提及,并链接到了 OpenAI 关于该主题的研究 此处。 -
LLM 与鱼叉式网络钓鱼:
@tariqali指出,LLM 擅长创建极具说服力的鱼叉式网络钓鱼邮件,如果 prompt 编写得当,未必会触发拒绝机制。 -
生物风险信息可获取性担忧:为了强调获取潜在危险信息的便利性,
@tariqali链接了 OpenAI 关于 LLM 辅助生物威胁预警系统的研究计划,详见 此处。 -
通过人工审核管理 Prompt Injection:
@tariqali建议通过控制谁能访问 LLM 来管理 prompt injection 威胁,而@simonw警告说人工审核无法捕捉到所有形式的 prompt injection(例如隐藏在图像中的),并参考了他之前的 文章 以获取更多背景信息。
提到的链接:
- Prompt injection and jailbreaking are not the same thing:我一直看到人们在谈论 “jailbreaking” 时使用 “prompt injection” 这个词。这种错误现在非常普遍,我不确定是否还能纠正过来:…
- Multi-modal prompt injection image attacks against GPT-4V:GPT4-V 是 GPT-4 的新模式,允许你在对话中上传图像。它非常出色,但也提供了一整套全新的攻击向量……
- Building an early warning system for LLM-aided biological threat creation:我们正在开发一个蓝图,用于评估 LLM 可能协助他人制造生物威胁的风险。在涉及生物专家和学生的评估中,…
-
[Staying ahead of threat actors in the age of AI Microsoft Security Blog](https://www.microsoft.com/en-us/security/blog/2024/02/14/staying-ahead-of-threat-actors-in-the-age-of-ai/):Microsoft 与 OpenAI 合作,发布了关于 AI 时代新兴威胁的研究,重点关注与已知威胁组织 Forest Blizzard、Emerald Sleet 相关的活动…
Datasette - LLM (@SimonW) ▷ #llm (5 messages):
- Mistral Large 模型获得好评:
@derekpwillis指出,新的 Mistral Large 模型在从文本中提取数据方面表现出色,尽管其价格“比我预想的要贵一些”。 - Claude 3 插件开发迅速:
@simonw分享了一个新的 Claude 3 插件,@0xgrrr对其极快的开发速度表示赞赏。 - 新模型可见性问题已解决:
@derekpwillis最初在llm models输出中看不到新模型,但在更新 LLM 后,确认一切运行正常。 - 寻求模型文件位置的标准化:
@florents_询问关于模型文件标准化搜索路径的共识或代码,建议可能的默认位置如$(pwd)/.models或$HOME/models。
提到的链接:
GitHub - simonw/llm-claude-3: 用于与 Claude 3 系列模型交互的 LLM 插件:用于与 Claude 3 系列模型交互的 LLM 插件 - simonw/llm-claude-3
DiscoResearch ▷ #general (9 messages🔥):
- 对 Claude-3 多语言能力的关注:
@bjoernp询问是否有人用德语测试过 Claude-3,并提到听说它在英语方面表现出色。@thomasrenkert回应称 Claude-3-Sonnet 的德语回答相当不错,比 GPT-4 知识更丰富,且回答结构更清晰。 - Claude-3 的地理可用性:
@bjoernp还通过分享 Claude AI 可用地点指出 Claude-3 在欧盟不可用。然而,@sten6633和@devnull0讨论了在德国使用德国手机号成功注册的案例,@devnull0提到在 12 月使用了 tardigrada.io。 - Opus API 欢迎德国号码:
@sten6633使用德国电话号码注册了 Opus API 访问权限,获得了 5 美元的额度,并称赞其解决复杂数据科学问题的表现。 - 免费测试模型:
@crispstrobe提供了如何通过 chat.lmsys.org 免费测试模型的信息,但提醒输入内容可能会成为训练数据,并提到 poe.com 提供三个测试模型,包括每天 5 条消息额度的 Claude 3 选项。
Skunkworks AI ▷ #general (2 messages):
- 来自 oleegg 的友好问候:用户
@oleegg以一句 good morning yokks 开始了这一天,随后将拼写错误纠正为 yolks。没有进一步的讨论或内容摘要。
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=Zt73ka2Y8a8
Alignment Lab AI ▷ #looking-for-collabs (2 messages):
- 协作请求已接受:用户
@wasooli表达了对参与项目的兴趣,并询问是否可以私信。@taodoggy给予了积极回应,邀请进行私信交流。
AI Engineer Foundation ▷ #general (1 messages):
- OSI 每月更新 AI 定义:用户
@swyxio强调开放源代码促进会 (OSI) 正在定期更新“开源 AI 定义”,并提供每月草案。最新的 0.0.5 版本草案已于 2024 年 1 月 30 日发布。
提到的链接:
开源 AI 定义草案:开源 AI 定义的草案。我们会在草案文档发布时同步更新。请查看下方各个草案以获取如何留下评论的说明。…