ainews-inflection-25-at-94-of-gpt4-and-pi-at-6m
Inflection-2.5 性能达到 GPT-4 的 94%,Pi 月活跃用户数(MAU)达 600 万。
Mustafa Suleyman 宣布推出 Inflection 2.5,该模型仅使用了 40% 的训练算力(FLOPs),却实现了 GPT-4 平均性能的 94% 以上。Pi 的用户群每周增长约 10%,并引入了实时网络搜索等新功能。社区注意到 Inflection 2.5 与 Claude 3 Sonnet 之间存在相似之处。Claude 3 Opus 在一项投票中以 1.5:1 的比例胜过 GPT-4,现已成为 Perplexity Pro 用户的默认模型。Anthropic 通过 LangChain 为 Claude 3 增加了实验性的工具调用(tool calling)支持。LlamaIndex 发布了用于结构化 PDF 解析的 LlamaParse JSON 模式,并增加了通过 VideoDB 进行视频检索的功能,从而支持检索增强生成(RAG)流水线。一篇论文提出了针对 LLM 智能体的知识增强规划。TinyBenchmarks 等新基准测试以及 Yi-9B 模型的发布展示了强大的代码和数学性能,超越了 Mistral。
2024年3月6日至3月7日的 AI 新闻。我们为您检查了 356 个 Twitter 账号 和 22 个 Discord 社区(332 个频道,3382 条消息)。预计为您节省阅读时间(以 200wpm 计算):419 分钟。
Mustafa Suleyman 宣布了 Inflection 2.5,它以一种未公开的高计算效率方式缩小了与 GPT-4 的大部分差距(“尽管仅使用了 40% 的训练 FLOPs,却实现了 GPT-4 平均性能的 94% 以上”,这很有趣,因为这些数据并未公开)。
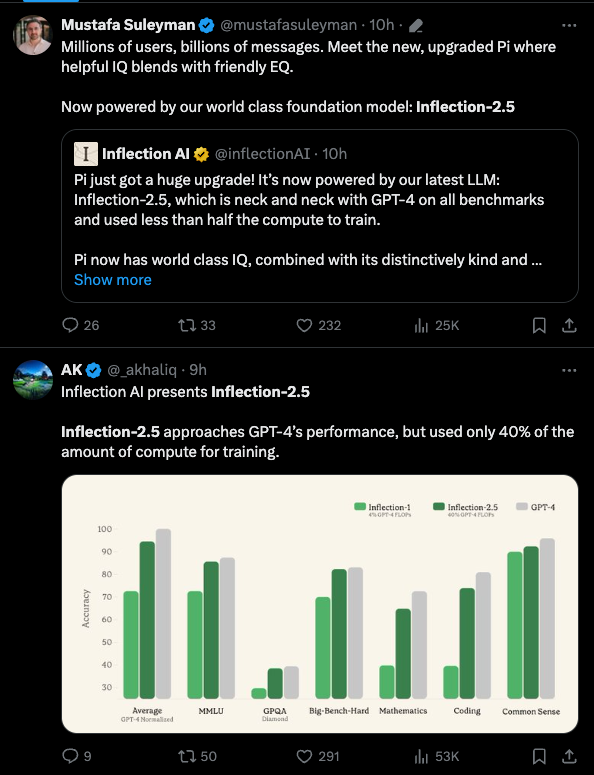
但 IQ 并不是唯一的衡量标准;他们还在优化 EQ,而 EQ 最好的体现是他们为 Pi 发布的令人印象深刻的用户数据:

关于 Axios 独家报道的更多笔记:
- Pi 的用户基数在过去两个月里每周增长约 10%。这让我们能够对 Pi 与 ChatGPT 进行一些大致估算:
他们还发布了一个修正版的 MT-Bench 供社区使用。
社区还发现了一些其他有趣的细节:
- 结果与 Claude 3 Sonnet 惊人地接近
- Pi 现在也具备了实时网页搜索功能。
目录
[TOC]
PART X: AI Twitter 精彩回顾
所有摘要由 Claude 3 Opus 完成,从 4 次运行中选取最佳结果
Claude 3 的发布与能力:
- Amanda Askell 拆解了 Claude 3 的系统提示词 (System Prompt),解释了它是如何影响模型行为的(671,869 次曝光)
- Claude 3 Opus 在 1.5:1 的投票中击败了 GPT-4,展示了令人印象深刻的性能(17,987 次曝光)
- Claude 3 现在是 Perplexity Pro 用户的默认模型,Opus 超过了 GPT-4,而 Sonnet 也极具竞争力(89,658 次曝光)
- Claude 3 展示了令人印象深刻的 OCR 和结构化提取能力,正如 @llama_index cookbook 中所演示的那样(59,822 次曝光)
- Anthropic 通过 LangChain 封装为 Claude 3 添加了工具调用 (Tool Calling) 的实验性支持(21,493 次曝光)
检索增强生成 (RAG):
- LlamaIndex 发布了 LlamaParse JSON Mode,允许以结构化格式解析 PDF 中的文本和图像。结合 Claude 3,这使得在复杂 PDF 上构建 RAG 流水线成为可能。
- LlamaIndex 现在支持视频检索,通过与 VideoDB 集成,允许通过索引视觉和听觉组件对视频数据进行 RAG。
- 一篇关于“LLM Agent 知识增强规划”的论文提出通过显式的动作知识库来增强 LLM 的规划能力。
基准测试与评估:
- TinyBenchmarks 看起来很有前景,作为一个评估语言模型的工具,类似于 @far__el 的 Dharma-1 基准测试。
- 一项实证结果表明,基于 HumanEval(164 个示例)和 Bamboogle(124 个示例)等数据集,100 个示例可能足以评估语言模型。
- Yi-9B 模型发布,在代码和数学基准测试中表现强劲,超越了 Mistral。
AI 研究与技术:
- 研究人员介绍了 Wanda,这是一种网络剪枝(network pruning)方法,在保持性能的同时减轻了计算负担 (7,530 次展示)
- 一篇论文提出了基础智能体(foundation agents),它们可以通过屏幕图像和音频作为输入,并产生键盘/鼠标操作,从而精通任何计算机任务 (16,598 次展示)
- Microsoft 展示了 DéjàVu,这是一种用于快速、容错的生成式 LLM 服务的 KV-cache 流式传输方法 (16,458 次展示)
- Google 展示了 RT-H,它利用动作层级和语言,在广泛的机器人任务中表现优于 RT-2 (11,348 次展示)
- Meta 展示了 ViewDiff,用于在真实环境中生成高质量、多视角一致的 3D 物体图像 (5,880 次展示)
模因与幽默:
- “2024 年 9 月实现 AGI” 的梗推文嘲讽了过度炒作的 AI 时间线。
- 一条幽默的推文感叹了在 2024 年依赖 GPT-4 写代码而不是手动编写所耗费的时间。
- 关于将 Claude-3 当作女朋友的玩笑,引用了 Gemini 模型所谓的创造力。
PART 0: 总结的总结之总结
Claude 3 Sonnet (14B?)
-
模型发布与对比:多个新 AI 模型的发布引发了关于其优势和局限性的激烈讨论。Inflection-2.5 声称在 Benchmark 上达到了 GPT-4 的性能,同时使用了更少的计算资源,但遭到了 @HlibIvanov 的质疑,他称其为 缺乏创新的 GPT-4 蒸馏版本。Claude-3 Opus 取得了令人印象深刻的成就,例如 在 SAT 阅读部分获得了 800 分的满分,@res6969 赞扬了其在超过 35k tokens 上的增强知识网络构建能力。然而,@jeffreyw128 指出 Claude 在 500 个名字中寻找特定名字时表现挣扎。与 7B Mistral 相比,Gemma 让 @lee0099 感到失望,特别是在多轮对话和仅支持英文方面。
-
开源 AI 与社区动态:@natolambert 表达了对 OSS 社区刻板纠错和缺乏远见的挫败感,这可能会阻碍 OSS 倡导者。即使是很有帮助的帖子也会面临过度的批评,正如在撰写关于 OSS 的文章时所经历的那样。@AnimaAnandkumar 提出的 GaLore 优化器承诺为 LLM 训练节省大量内存,引发了 @nafnlaus00 等人对于提高消费级 GPU 可访问性的兴奋。然而,@caseus_ 质疑了 GaLore 声称的与全量预训练(full pre-training)等效的说法。将 GaLore 集成到 axolotl 等项目中面临着 实现挑战。
-
AI 工作负载的硬件优化:硬件优化是一个重点,讨论了剪枝(pruning)、通过 bitsandbytes 进行量化(quantization)以及低精度操作等技术。@iron_bound 强调了 Nvidia H100 GPU 提供 5.5 TB/s 的 L2 缓存带宽,而 @zippika 推测 RTX 4090 的 L1 缓存可能达到 40 TB/s。像 @tspeterkim_89106 的 Flash Attention 这样的 CUDA 实现旨在获得性能提升。然而,@marksaroufim 警告了 粗粒度对 Benchmark 一致性的影响。
-
AI 应用与工具:展示了创新的 AI 应用,如 @pradeep1148 使用 Mistral 开发的 Infinite Craft Game 和 Meme Generation。LlamaIndex 发布了 LlamaParse JSON Mode,用于将 PDF 解析为结构化数据。探索了将 AI 与开发者工作流集成,@alexatallah 为 OpenRouter VSCode 扩展提供赞助,而 LangChain 的
ask-llm库 简化了 LLM 代码集成。
Claude 3 Opus (8x220B?)
-
NVIDIA 限制 CUDA 转换层:NVIDIA 已禁止使用转换层在非 NVIDIA 硬件上运行 CUDA,此举针对的是旨在让 AMD GPU 在 Windows 上达到与 NVIDIA 同等水平的 ZLUDA 等项目。更新后的限制被视为维护 NVIDIA 专有优势的举措,引发了关于该政策可执行性的辩论。
-
LLM 训练中的效率与剪枝辩论:围绕 LLM 的参数效率和优化训练方案的潜力展开了讨论。一些人认为,在不大幅降低性能的情况下对模型进行深度剪枝的能力表明了效率低下,而另一些人则对通用性降低表示担忧。像 GaLore 这样的新型内存减少策略引起了关注,目前正尝试将其集成到 OpenAccess-AI-Collective/axolotl 等项目中。关于当前架构的局限性和模型压缩技术的饱和度也提出了疑问。
-
Inflection-2.5 和 Claude-3 引起轰动:宣称性能与 GPT-4 相当的 Inflection-2.5 以及 Anthropic 的 Claude-3 变体 Opus 和 Sonnet 的发布引发了讨论。一些人对 Inflection-2.5 的创新持怀疑态度,认为它可能只是 GPT-4 的蒸馏(distillation)。与此同时,Claude-3 获得了社区的极大关注,根据这条 推文,Opus 在 SAT 阅读部分获得了 800 分的满分。
-
Mistral 驱动创新应用:Mistral 语言模型展示了其在驱动 Infinite Craft Game 和使用 Giphy API 自动化迷因(meme)创建 方面的多功能性。其他值得注意的发布包括用于指令生成的 Nous Research 的 Genstruct 7B (HuggingFace),以及用于评估韩国语模型的 Hae-Rae Bench 和 K-MMLU 等新基准测试 (arXiv)。
ChatGPT (GPT4T)
-
多语言模型支持与 API 集成:Discord 社区强调了在多语言支持和 API 集成方面的进展,Perplexity AI 为其用户界面引入了对韩语、日语、德语、法语和西班牙语等语言的支持,并讨论了用于集成 Llama 70B 的 Perplexity API。关于 API 的诉求和困扰包括对提高速率限制(rate limit)和集成代码的讨论,详见其 API 文档。
-
AI 驱动的游戏开发创新:Nous Research AI 和 Skunkworks AI 展示了使用 AI 创建新游戏体验的案例。一个利用 Mistral 的合成类游戏展示了 AI 在游戏开发中的潜力,其具备可扩展的元素组合玩法,并在 YouTube 视频中进行了展示。同样,Mistral 也被用于 Infinite Craft Game 以及自动化梗图生成,展示了 AI 在游戏和幽默领域的创新应用。
-
模型优化与剪枝的进展与辩论:LAION 和 OpenAccess AI Collective (axolotl) 的摘要揭示了关于模型优化、剪枝和效率的讨论。关于大语言模型(LLMs)剪枝的辩论反映了对其性能和泛化能力影响的不同看法,一些工程师提出剪枝可以作为可能优化的证据。GaLore 成为讨论中的焦点优化工具,尽管对其性能是否能与全量预训练持平存在怀疑,但集成工作正在进行中,如其 pull request 所示。
-
新 AI 模型与工具的涌现:在多个 Discord 摘要中,关于引入新 AI 模型和工具的讨论非常热烈,包括 Inflection AI 2.5、Genstruct 7B 和 Yi-9B。Inflection AI 2.5 的发布引发了关于其效率和性能的对话;而 Nous Research AI 推出了 Genstruct 7B,这是一种旨在增强数据集创建和详细推理的指令生成模型,可在 HuggingFace 上获取。Hugging Face 社区见证了 Yi-9B 的发布,为可用于实验和部署的模型列表增添了新成员,展示了 AI 能力的持续创新和扩展,演示版可在此处查看。
第 1 部分:高层级 Discord 摘要
Perplexity AI Discord 摘要
-
Perplexity AI 支持多种语言交流:正如
@ok.alex所宣布的,Perplexity 的用户界面现在支持韩语、日语、德语、法语和西班牙语。用户可以在应用设置中自定义语言偏好。 -
局限性与替代方案大杂烩:社区对 AI 模型的局限性进行了积极讨论,重点关注 Claude 3 Opus 的每日使用限制,以及 Claude 3 Sonnet 和 GPT-4 Turbo 等替代方案。在封闭测试申请流程方面,提到了需要更直接的反馈。
-
Perplexity Pro 订阅者发声:用户分享了使用 Perplexity Pro 的体验,并就额外福利以及如何访问专门的支持频道展开了讨论。
-
领域新秀:Inflection AI 2.5:Inflection AI 2.5 的发布引发了关于其效率和性能水平的对话,用户强调了它的速度并讨论了其潜在的应用场景。
-
全球礼仪还是算法礼节?:在语言模型的语境下,围绕文化交流的细微差别展开了讨论,重点是“sir”的使用以及全球在尊重称呼上的差异。
-
分享即关爱 - Perplexity 走向 3D:用户分享了有趣的 Perplexity 搜索链接,涵盖了从 3D 空间导航到山寨币趋势、Ikigai(生存意义)概念、Claude 3 Opus 的文本生成质量以及对量子力学的解释等主题。
-
API 的诉求与困扰:公会成员正在使用 Perplexity API,寻求 Llama 70B 的集成代码和提高速率限制的支持,同时也对 Discover 功能表现出兴趣。Perplexity API 文档被引用作为使用指南和技术援助。
Nous Research AI Discord 总结
-
创新型 AI 合成游戏问世:
@pradeep1148推出了一款利用 Mistral 开发的新型合成类游戏,展示了 AI 在游戏开发中的潜力。游戏从四种元素开始,玩家通过组合元素进行扩展,正如 YouTube 视频中演示的那样。 -
持续改进引发技术热潮:Yi-34B 基础模型在 “Needle-in-a-Haystack”(大海捞针)测试中表现出显著的性能增长,可能为即将推出的模型树立了新标杆。Google 的 Gemma 模型收到了社区驱动的错误修复,可在 Colab notebooks 中获取。此外,新的 GaLore 项目需要社区验证,该项目可能会从与 low-bit optimizers 的结合中受益。
-
Genstruct 7B 设定指令生成基准:Nous Research 发布了 Genstruct 7B,这是一款旨在增强详细推理和数据集创建的指令生成模型。由 Nous 成员
<@811403041612759080>宣布,Genstruct 7B 有望在基于指令的模型训练中带来创新,现已在 HuggingFace 上线。 -
聊天 AI 与 LLM 激发讨论:Anthropic 的新模型 Genstruct-7B-GGUF 成为焦点,同时关于 Claude 3 性能的辩论也在进行中。Inflection AI 声称其 Inflection-2.5 模型在基准测试中可与 GPT-4 媲美。与此同时,社区对 Twitter IQ 测试图表 以及 GPT-5 发布传闻普遍持怀疑态度。
-
技术辩论与澄清:从在本地运行 Ollama 到受 Claude 风格启发的 Function-calling(函数调用)模型的潜力,社区正在寻求各种 AI 模型和工具的见解。亮点包括 Nous-Hermes-2-Mistral-7B-DPO 即将更新 Function-calling 数据,以及
@ufghfigchv为 JSON/Function-calling 量身定制的 logit sampler 重构工作。此外,还提到了访问 GPT-4 的渠道,Corcel.io 提供了类似 ChatGPT-4 的免费交互,同时社区也表达了对 Nous-Hermes 等模型在 RAG 应用中支持更长上下文长度的需求。
LAION Discord 总结
-
CUDA 争议:NVIDIA 最近的政策变动禁止使用翻译层在非 NVIDIA 硬件上运行 CUDA,这直接影响了 ZLUDA 等项目。更新后的限制被视为 NVIDIA 维护其专有优势的举措。
-
爬虫纠纷升级:Stability AI 卷入了一场涉嫌抓取 Midjourney 数据的争议,导致其员工被禁,并引发了对数据抓取行为的担忧。虽然一些 推文暗示 这并非工作行为,但它已激起了关于抓取伦理和协议的讨论。
-
效率成为关注焦点:关于大型语言模型(LLM)Pruning(剪枝)的辩论占据了中心舞台。一些工程师认为当前的训练方法效率低下,并提出剪枝作为可能优化的证据;而另一些人则对可能丧失泛化性、稳定性以及某些优化技术(如 SVD)速度缓慢表示担忧。
-
剪枝困惑:与某些认为轻微剪枝的模型会出现性能下降的观点相反,有一种论点认为重度剪枝的 LLM 仍保持着惊人的泛化能力。然而,这引出了一个更大的问题:模型训练是否需要超大规模的参数,或者工程师是否可以追求更精简但有效的 LLM?
-
架构评估:对话正在探讨当前 LLM 的结构边界,研究压缩和优化模型的策略(特别是基于 Attention 机制的模型)是否正在接近极限。这凸显了人们对当前架构内模型效率饱和现象的好奇。
OpenAI Discord 总结
- Claude 的卓越表现:用户分享了使用 Claude 3 Opus (C3) 的积极体验,指出它在复杂任务和基础课程问题上的表现优于 GPT-4。
- Claude 对阵 Gemini:关于编程能力的辩论中,Gemini 1.5 Pro 第一次尝试就成功解决了 Python GUI 任务,而 Claude 3 则没有,这表明了各自的优缺点。
- 对 MMLU 数据集的质疑:人们对 MMLU 数据集 问题的逻辑一致性缺失以及包含错误答案表示担忧,呼吁重新考虑将其用于 AI 模型评估。
- GPT-4 可用性与政策讨论:用户讨论了 GPT-4 的间歇性访问问题以及影响代码提供的政策变化;关于通过 API 访问 Human GPT 等自定义模型的困惑,已通过参考 OpenAI 的 模型概览 得到澄清。
- 服务中断与支持寻求:报告了 OpenAI API 长达 6 小时的服务中断;咨询了如何使用 Python 的 random 函数在故事创作中实现随机化;以及关于开发 GPT 分类器的讨论,反映了社区成员面临的技术和运营挑战。
LM Studio Discord 总结
-
技术大咖讨论故障排除:用户讨论了配备 512 GB RAM 和 24GB VRAM 的硬件配置,并解决了库版本问题,特别是
GLIBCXX_3.4.29 not found错误。辩论延伸到配备 M3 Max 或 M2 Max 的 Macbook Pro 是否适合本地 LLM 处理,涉及价格和性能的权衡。社区成员对 OpenAI 的不开放性表示担忧,并考虑使用 POE 按月付费 等替代 AI 服务来获取模型访问权限。 -
叙事细微差别与 AI 模型:在模型讨论中,用于故事创作的最佳 AI 被指定为 Mistral-7b-instruct-v0.2-neural-story.Q4_K_M.gguf,但受内存限制的影响显而易见。由于 LM Studio 缺乏图像生成能力,参与者考虑使用 Automatic 1111 等工具进行 Stable Diffusion 任务。对 Starcoder2 的兴趣显而易见,用户正在等待其支持,正如其 Hugging Face 页面 所指出的。
-
反馈焦点异常与见解:一位用户分享说,他们希望有更清晰的指导来挖掘 LM Studio 的潜力。有反馈建议 LM Studio 可以效仿 Embra AI 以提高实用性,且当前版本 (v0.2.16) 在 macOS 14.3 上不支持代理。此外,明确了不应在反馈频道发布求助请求。
-
硬件中心对话:报告显示在 Smaug 模型中进行了 200K context 的实验,以及在使用 105,000 context 的 LLM Studio 任务中出现了 VRAM 需求问题。建议为 RTX 3090 供电的 PSU 至少为 550W,讨论还包括处理 LLM 任务中的大上下文或数据集以及 VRAM 不匹配的问题。
-
Crew AI 中的响应速度探索:在寻找为未指定流程提高响应速度的方法时,用户遇到了连接超时问题,并提出建立本地运行作为潜在解决方案。
-
Open Interpreter 语法的奥德赛: 围绕 Open Interpreter 中正确的
default_system_message语法和配置文件设置进行了咨询和交流。用户交流了使用经过代码训练的模型的经验,并分享了配置的学习心得,参考了 Open Interpreter - System Message 和 Hugging Face 的说明。
LlamaIndex Discord 总结
-
尽情参与调查:LlamaIndex 正在通过一项 3分钟问卷调查 寻求更深入的用户见解。鼓励工程师参与,以帮助塑造更好的文档和教程等资源,调查问卷地址:SurveyMonkey。
-
LlamaParse JSON Mode 发布:LlamaIndex 的 LlamaParse JSON Mode 因其将 PDF 解析为结构化字典的能力而备受关注,尤其是与 claude-3 opus 等模型配合使用时。感兴趣的用户可以查看推特上的发布公告:LlamaIndex Tweet。
-
视频功能升级:LlamaIndex 与
@videodb_io的集成开启了视频内容处理的新大门,允许在 LlamaIndex 中进行基于关键词的视频上传、搜索和流媒体传输。通过此 公告推文 了解更多集成信息。 -
优化 A* 算法以提升搜索效率:通过对 embedding 类进行子类化以改变搜索方法,验证了 A* 算法在相似性搜索中的可行性,展示了 LlamaIndex 的灵活性。
-
In-Context Learning 获得提升:
@momin_abbas引入了一种增强 In-Context Learning 的新方法:Few-Shot Linear Probe Calibration。该倡议邀请社区通过 GitHub 互动提供支持。
Latent Space Discord 总结
- Midjourney 与 Stability AI 的争端公开化:
@420gunna提到了一起争议事件,Stability AI 因抓取数据被 Midjourney 封禁,详见@nickfloats的 Twitter 帖子。 - 由 AI 专家参与的播客节目上线并登上 Hacker News:
@swyxio宣布了与<@776472701052387339>合作的新播客节目,并强调了其在 Hacker News 上的热度。 - 为志愿者主导的模型推理服务论文演讲喝彩:社区对
@720451321991397446的志愿服务表示感谢,特别是关于 model serving(模型服务)的演示,可通过 Google Slides 查看。 - 推理优化与硬件利用率辩论升温:关于推理优化的讨论非常热烈,包括 speculative decoding 和 FlashAttention 等替代方案,以及硬件的影响。见解源自 EGjoni 的 DRUGS GitHub 和 DiLoCo 论文 等资源。
- 去中心化训练与 GPU 配置讨论激增:围绕分布式训练(引用了 DiLoCo)以及 GPU 配置对模型输出影响的讨论非常活跃,起因是 OpenAI 的一个轶事。
Eleuther Discord 总结
-
新的韩语 Benchmark 发布:
@gson_arlo介绍了两个新的评估数据集:Hae-Rae Bench 和 K-MMLU,专门用于评估语言模型对韩国语言和文化的理解。 -
vLLM Batching 机制澄清:
@baber_解释说 batching 是由 vLLM 内部处理的,因此不需要手动实现批处理推理,并参考了 官方文档以方便使用。 -
呼吁多语言 Benchmark 协作:邀请使用非主流语言的贡献者参与创建相关的 Benchmark,以评估针对其特定文化的语言模型能力。
-
解决 GPT-NeoX 中的优化器内存问题:gpt-neox-dev 频道的讨论集中在解决优化过程中的内存峰值问题,
@tastybucketofrice引用了 Issue #1160,并建议使用 Docker 作为解决依赖挑战的潜在方案(Docker commit 在此)。 -
致力于统一的微调框架:在 lm-thunderdome 频道中,
@karatsubabutslower指出,尽管已经有了像 lm-evaluation-harness 这样的标准化评估方法,但仍缺乏一致的语言模型 fine-tuning(微调)机制。
HuggingFace Discord 摘要
-
创业者寻求开源模型群体:HuggingFace 上的创业者正在寻找一个社区来讨论开源模型在小型企业中的应用,然而,在提供的消息中没有推荐专门的频道或空间。
-
新模型登场 Yi-9B:Tonic_1 推出了 Yi-9B,这是 Hugging Face 集合中的一个新模型,可通过 demo 使用。Hugging Face 可能很快会举办排行榜和游戏竞赛。
-
查询 MMLU 数据集结构:Privetin 表现出对理解 MMLU 数据集 的兴趣,但该对话没有得到其他人的进一步阐述或参与。
-
Rust 编程欢迎爱好者:Manel_aloui 开启了他们的 Rust 语言 之旅并鼓励他人参与,在频道内培养了一个小型学习者社区。
-
2022 年 AI 的主流时刻:由
@vardhan0280分享的一篇 Investopedia 文章强调,AI 在 2022 年的主流激增归功于 DALL-E 和 ChatGPT 的普及。 -
Gradio 4.20.0 更新的新功能:Gradio 宣布了 4.20.0 版本,现在支持 外部身份验证提供商(如 HF OAuth 和 Google OAuth),并引入了
delete_cache参数和/logout功能以增强用户体验。还引入了新的gr.DownloadButton组件用于时尚的下载,详见 文档。
OpenAccess AI Collective (axolotl) Discord 摘要
-
Deepspeed 在多 GPU 设置中表现不佳:工程师们对 Deepspeed 表示失望,特别是在使用 4x 4090 的多 GPU 场景中,发现它在并行使用 Lora adapter 时无法将基础模型拆分到多个 GPU 上。讨论引用了一个 Deepspeed JSON 配置文件。
-
GaLore 引发辩论:GaLore 这一优化工具因其在 Large Language Model 训练中的内存节省潜力而成为焦点。尽管令人兴奋,但怀疑论者对其与全量预训练的性能对等性表示怀疑,即便 集成工作 正在进行中。
-
效率方法受到审视:讨论中出现了对各种效率方法(包括 ReLoRA 和 NEFT)可能具有误导性的质疑,促使人们考虑数据集大小和设置以进行有意义的微调。
-
Gemma 的性能遭到批评:Gemma 模型因在与 7B Mistral 对比中表现平平而受到批评,特别是在多轮对话中,且受限于仅支持英语,这限制了其在多语言任务中的价值。
-
AI 开发中的依赖之战:讨论中的一个共同点是与依赖冲突的斗争,特别是在安装
axolotl[deepspeed]==0.4.0时的torch版本问题。工程师们分享了手动安装等策略,并建议使用特定版本(包括torch==2.2.0)作为潜在的修复方案。
OpenRouter (Alex Atallah) Discord 摘要
-
Claude 3 让群聊变得酷炫:Alex Atallah 分享了一条关于使用 Claude 3 进行积极的自我调节群聊体验的 推文。
-
为你的项目提供 Nitro 动力:新的 “nitro” 模型正在 OpenRouter 进行测试,提供安全的集成选项,尽管在正式发布前的反馈整合阶段可能会有一些细微调整。
-
VSCode 扩展悬赏:Alex Atallah 为构建 OpenRouter 的 VSCode 扩展提供赞助,奖励开发者的贡献并提供免费额度。
-
开发技巧与窍门交流:社区成员交流了各种用于 LLM 的 VSCode 扩展信息,包括 Cursor、Continue 和 Tabby,并指向了更具成本效益的聊天模型,如 Perplexity 的 Sonar 8x7B。
-
经济实惠的 AI 对话:讨论了与 Claude 3 Opus 等模型交互的成本影响,其中 Sonar 8x7B 因其相对于其他模型的成本效益而受到关注。
LangChain AI Discord 摘要
-
CSV 加载器超时问题:用户注意到 LangChain 中的
UnstructuredCSVLoader会抛出 “The write operation timed out” 错误。虽然尚未讨论出解决方案,但分享类似经历的成员确认了该问题的存在。 -
警惕网络钓鱼:服务器内网络钓鱼企图有所增加,特别是通过可疑的 steamcommunity 链接,对此表示了担忧,但未详细说明后续行动或解决方法。
-
过往交互中的 Prompt 难题:在构建聊天链时,一位用户遇到了
HumanMessage内容在初始交互后错误地传播到AIMessage中的问题,尽管其意图是进行记忆隔离。分享的代码片段突显了该问题,目前仍在寻求社区建议。 -
LangChain 利用 RAPTOR 和 Pydantic 组合:正在讨论利用 Pydantic 与 LangChain 和 Redis 来构建用户数据和聊天历史记录的详细策略,并征求关于
AIMessage异常行为的见解。 -
LangChain 学习者的链接库:发布的资源包括用于生成向量数据库的工具 ChromaDB Plugin for LM Studio,以及用于将 LLM 更简单地集成到 Python 项目中的
ask-llm库。重点推荐的教育内容包括一篇关于使用 RAPTOR 构建 RAG 的 Medium 文章,以及关于使用 Mistral 和 Giphy API 进行游戏制作和表情包生成的 YouTube 教程。
CUDA MODE Discord 摘要
- CUDA 粗粒化技巧:@zeuxcg 的一条推文分享了关于在代码执行中正确处理粗粒化(coarsening)的见解,强调了由于基准测试不一致导致的性能影响。
- 比较 Relay 和 Flash Attention:在注意力机制领域,
@lancerts发起了关于将 RelayAttention 与 ring/flash attention 进行比较的讨论,并引用了一个关于带有 RelayAttention 的 vLLM 的 GitHub 仓库。 - GPU 重置的 CUDA 命令:提供了一个用于重置 GPU 并解决 GPU 内存分配问题的
sudo命令:sudo nvidia-smi --gpu-reset -i 0,并分享了一个可能相关的nvtop观察结果。 - 新的 CUDA 项目:
@tspeterkim_89106介绍了一个在 CUDA 中实现 Flash Attention 的项目,并在 GitHub 上邀请反馈与合作。 - Torch 中的 CUDA 同步机制:推荐使用
torch.cuda.synchronize()进行准确的性能测量,并对 CUDA kernel 之间的同步以及标量 Tensor 的跨设备使用进行了说明。
Interconnects (Nathan Lambert) Discord 摘要
-
Inflection-2.5 引发争论:
@xeophon.介绍了嵌入在 Pi 中的 AI 模型 Inflection-2.5,该模型声称具有与 GPT-4 和 Gemini 相当的高性能。然而,@HlibIvanov 的一条推文批评它是 GPT-4 的蒸馏版,引发了对其创新性的质疑。 -
AI 创新热潮备受关注:
@natolambert对 AI 领域的快速发展表现出极大热情,引用了多个新模型的发布,并在推文中进行了进一步讨论。 -
OSS 社区的挑剔令人沮丧:讨论涉及了开源软件(OSS)社区不友好的一面,
@natolambert对那些令 OSS 倡导者感到沮丧的钻牛角尖式批评表示失望,@xeophon.则提到了该领域标签定义的混乱。 -
Claude-3 加剧 AI 竞争:@Anthropic 发布的 Claude-3 及其变体 Opus 和 Sonnet 引起了社区的热烈反响,正如一则推文所分享的,三天内就有 20,000 次投票,显示了极高的社区参与度。
-
对 Gemini Ultra 的期待飙升:即将推出的 Gemini Ultra 及其 1M 上下文窗口特性备受期待,
@natolambert和@xeophon等工程师热衷于探索其在分析学术论文等任务中的能力。
Alignment Lab AI Discord 总结
- 垃圾信息警报引发政策变更:在发生涉及 @everyone 标签的垃圾信息事件后,
@joshxt等用户强调了尊重每个人收件箱的重要性,导致了一项新政策的实施,即禁用了提及所有人的功能,以防止不必要的通知。 - Orca 数据集引发讨论:
@joshxt提到了微软 Orca 数据集 的发布,引发了关于模型偏好的对话,其中 “Psyonic-cetacean” 和 “Claude 3 Opus” 被特别提及。 - 启动 Project Orca-2:
@aslawliet提出了 Orca-2 的提案,旨在涵盖除微软最近发布的数据集之外的多种数据集,如 FLAN 2021 以及来自 T0 和 Natural Instructions 的选择性 zero-shot 样本。 - 高效的数据增强策略:
@aslawliet建议使用 Mixtral 作为比 GPT-4 更具时间和成本效益的数据增强方法,引发了关于模型改进高效方法的讨论。 - 诚挚的介绍与问候:社区热烈欢迎了
@segmentationfault.和@1168088006553518183等新成员,强调了友好的氛围以及对 AI 领域贡献的共同兴趣。
DiscoResearch Discord 总结
- 明智选择语言模型:根据限制条件,
@johannhartmann建议在无限制时使用 Claude Opus 和 GPT-4;在内存充足的开源场景下使用 DiscoLM-120B;而在内存受限时,VAGOsolutions/Sauerkraut LM-UNA-SOLAR-Instruct 是首选。 - 检索增强(Retrieval-Augmented)兴起:一篇 arXiv 论文 的研究展示了检索增强语言模型的优势,特别关注检索器与 LLM 的联合训练,尽管关于这种集成的全面研究仍然匮乏。
- 寻找最佳德语模型:Nous Hermes 2 Mixtral 8x7b 因其极高的任务理解准确率受到
@flozi00的称赞。相比之下,@cybertimon和@johannhartmann建议探索包括 DiscoResearch/DiscoLM_German_7b_v1 和 seedboxai/KafkaLM-7B-DARE_TIES-LaserRMT-QLoRA-DPO-v0.5 在内的一系列模型,以获得流利的德语能力。 - 通过嵌入模型评估翻译:
@flozi00正在开发一种基于嵌入距离(embedding distance)对翻译质量进行评分的方法,使用的是 OPUS 100 数据集。这一举措可能会推动机器翻译 (MT) 模型和数据质量的提升。 - mMARCO 数据集获得 Apache 许可:正如
@philipmay所分享的,mMARCO 数据集现在拥有 Apache 2.0 许可证,丰富了开发者的资源,尽管在 Hugging Face 上缺少数据集查看器支持。
LLM Perf Enthusiasts AI Discord 总结
- Opus 在 SAT 考试中表现出色:Opus 在 SAT 阅读部分获得了 800 分的满分,由 @jeffreyw128 分享。
- 记忆 vs. 学习:在 SAT 取得佳绩后,
@dare.ai谈到了确保像 Opus 这样的大型模型是真正学习而非仅仅记忆答案的难度。 - Opus 赢得了粉丝:
@nosa_幽默地警告说,如果 Opus 知道他们对其性能的高度评价,可能会引发一场“虚假对抗”。 - 编织智慧之网:
@res6969称赞了 Opus 从庞大文档中构建知识网的增强技能,强调了其处理超过 35k tokens 指令的能力。 - 深度搜索困境:据
@jeffreyw128报告,在一项涉及从 500 个名字中寻找特定名字的任务中,包括 Claude Opus 在内的不同模型都面临挑战。
Datasette - LLM (@SimonW) Discord 摘要
- GPT-4 在神秘测试中受挫:据
@dbreunig称,GPT-4 未能通过一项未指明的测试,但未提供有关测试性质或失败类型的具体细节。 - 连接物理与数字图书馆:
@xnimrodx分享了一篇关于让书架可点击的新颖博客文章,这些书架可以连接到 Google Books 页面,并附带了一个 demo,引发了关于在图书馆系统和本地图书共享计划中潜在应用的讨论。 - 模板中的美元符号引发混乱:
@trufuswashington在使用旨在解释代码相关内容的 YAML 模板时,因模板中的美元符号$导致TypeError,从而引发llm命令崩溃,揭示了模板 Prompt 中特殊字符处理的问题。
Skunkworks AI Discord 摘要
-
Mistral 让游戏创作变得无限:分享了一个新的由 Mistral 驱动的 Infinite Craft 游戏,突出了 Mistral 语言模型在游戏中的应用,允许玩家组合元素来创造新物品,展示了 AI 在游戏领域的创新用例。
-
Meme 生成遇上 AI:正如 YouTube 视频所示,Mistral 语言模型已与 Giphy API 结合用于自动化 Meme 创建,代码已在 GitHub 上提供,供想要探索 AI 与幽默结合的工程师参考。
第 2 部分:按频道划分的详细摘要和链接
Perplexity AI ▷ #announcements (1 条消息):
- Perplexity AI 现在支持您的语言:用户
@ok.alex宣布 Perplexity 现在支持韩语 (한국어)、日语 (日本語)、德语 (Deutsch)、法语 (Français) 和西班牙语 (Español)。用户可以在桌面端和移动端的设置中更改首选界面语言。
Perplexity AI ▷ #general (413 条消息🔥🔥🔥):
-
AI 模型的局限性与对比:用户讨论了 AI 模型的各种局限性,其中
@twelsh37分享了一个用于测试 AI 能力的全面报告 Prompt。@zero2567等人指出 Claude 3 Opus 的使用限制为每天 5 次,引发了关于限制以及在编程任务中使用 Claude 3 Sonnet 和 GPT-4 Turbo 等替代方案的讨论,如@tunafi.sh和@deicoon等用户所述。 -
Pro 订阅与功能咨询:
@arrogantpotatoo和@dieg0brand0等用户分享了他们订阅 Perplexity Pro 的经历,随后讨论了相关权益以及如何在 Discord 上访问专门频道和 Pro 支持。 -
测试 Inflection AI 的新版本:Inflection AI 2.5 版本的发布引起了包括
@codelicious和@ytherium在内的多位用户的关注,大家围绕该模型声称的性能水平和效率展开了讨论。几位用户注意到了其极快的运行速度,甚至推测了它在各种用例中的潜力。 -
对 Gemini 1.5 的看法:
@archient等用户表达了对 Gemini 1.5 的不满和推测,认为它令人失望,且与其他服务相比缺乏功能。对话涉及了对 Google AI 产品生态系统的期望,以及其表现不及预期的潜在原因。 -
文化尊重还是语言模型偏见?:来自
@gooddawg10的几条消息引发了关于沟通中尊重和礼仪的讨论,突显了文化差异,并促使@twelsh37和@brknclock1215等用户探讨了“sir”的使用以及全球沟通风格的差异。
提到的链接:
- Inflection-2.5: meet the world’s best personal AI:我们是一家 AI 工作室,致力于为每个人创造个人 AI。我们的第一个 AI 名为 Pi(Personal Intelligence),是一个具有支持性和同理心的对话式 AI。
- Cat Dont Care Didnt Ask GIF - Cat Dont Care Didnt Ask Didnt Ask - Discover & Share GIFs:点击查看 GIF。
- Perplexity Blog:浏览 Perplexity 博客,获取文章、公告、产品更新和优化体验的技巧。保持关注并充分利用 Perplexity。
- What is Pro Search?:浏览 Perplexity 博客,获取文章、公告、产品更新和优化体验的技巧。保持关注并充分利用 Perplexity。
-
[Welcome to Live — Ableton Reference Manual Version 12 Ableton](https://www.ableton.com/en/live-manual/12/welcome-to-live/):未找到描述。
Perplexity AI ▷ #sharing (14 条消息🔥):
- 穿梭于 3D 空间:用户
@williamc0206分享了一个 Perplexity 搜索链接,可能讨论了导航或生成 3D 空间的能力。使用 Perplexity 探索 3D 空间。 - 备受关注的山寨币 (Altcoins):
@b.irrek发布了一个链接,似乎深入探讨了围绕替代加密货币的动态和趋势。在此获取关于山寨币的见解。 - 揭秘 Ikigai 的概念:
@sevonade4邀请其他人查看一段关于 Ikigai 概念的生成文本,这可能会根据个人好奇心引起特定兴趣。深入了解 Ikigai。 - 关于 Claude 3 Opus 的沉思:此外,
@sevonade4为那些有兴趣探索不同水平文本生成的人强调了 Claude 3 Opus 的文本生成质量。使用 Claude 3 Opus 进行思考。 - 量子问题解答:
@vmgehman分享了 Perplexity 在研究量子力学的各种解释时如何成为一个有用的资源。量子力学探索。
Perplexity AI ▷ #pplx-api (19 messages🔥):
-
寻求用于集成 Llama 70B 的 HTML 和 JS 代码:
@kingmilos寻求使用 HTML 和 JS 集成 Llama 70B 的代码帮助,因为他们的专长在于 Python。@po.sh通过提供一个基础代码示例进行了回复,并指导如何插入 API key 以及根据需要调整模型。 -
对 Beta 申请流程的反馈:
@brknclock1215对封闭 Beta 申请被拒绝时感受到的非人性化处理表示失望,希望能有更直接的沟通或反馈。 -
API 文档协助程序员:
@icelavaman将@kingmilos和@pythoner_sad引向 Perplexity API documentation,以获取有关使用 API 进行 LLM 推理的指导,但@kingmilos表示由于缺乏 HTML 和 JS 知识而感到困难。 -
用户寻求提高 Rate Limit 的支持:
@xlhu_69745请求协助提高 Sonar 模型的 Rate Limit,但指出其发送的邮件未收到回复。@icelavaman以非语言方式回应,可能是在暗示去哪里寻求帮助或查看更新。 -
对通过 API 实现 Discover 功能感兴趣:
@yankovich询问了 Perplexity Discover 以及是否可以通过 Perplexity 的 API 为用户实现类似功能。@bitsavage.建议查看 API 文档以了解潜在功能,并考虑如何构建个性化的用户发现功能。
提及的链接:
pplx-api:未找到描述
Nous Research AI ▷ #off-topic (6 messages):
- 使用 AI 进行创作:用户
@pradeep1148分享了一个名为 “Infinite Craft Game using Mistral” 的 YouTube 视频,展示了一款合成游戏的开发过程,该游戏从四个元素开始,随着玩家不断组合元素而扩展。 - 寻找 Ollama 示例:
@pier1337询问了关于在 Deno 上运行 Ollama 的示例,但频道中未提供进一步信息。 - 错过的联系:用户
@teknium回应了不存在的标签,并为错过某位未具名用户几个月前在 Twitter 上发送的私信表示歉意。
提及的链接:
- Infinite Craft Game using Mistral:让我们开发 Neal Agarwal 的网页游戏 Infinite Craft。这是一款“合成游戏”,你从仅有的四个元素开始,不断重复组合成对的元素…
- Making memes with Mistral & Giphy:让我们使用 Mistral LLM 和 Giphy API 制作迷因 #llm #ml #python #pythonprogramming https://github.com/githubpradeep/notebooks/blob/main/Giphy%20Mistral.ipynb
Nous Research AI ▷ #interesting-links (44 messages🔥):
-
Yi LLMs 持续改进:
@thilotee强调了 Yi-34B 基础模型正在进行的增强,特别是在“大海捞针”(Needle-in-a-Haystack)测试中的表现从 89.3% 提升到了 99.8%。讨论触及了进一步微调(finetuning)的潜力,以及 Yi-9B 模型是否支持 200k context,目前看来似乎不支持(Yi 的 Huggingface 页面 和 Reddit 讨论)。 -
Google 的 Gemma 被指存在缺陷:
@mister_poodle分享了对 Google 可能在匆忙发布模型的担忧,因为一个名为 Unsloth 的团队修复了 Gemma 模型中多个在其他地方未被处理的 bug。这些修复可在 Colab notebooks 中找到。 -
Claude 3 Opus 的主张引发争议:一位用户分享了 Claude 3 Opus 翻译低资源语言切尔克斯语(Circassian)的惊人经历,但随后的更新表明该模型可能预先掌握了该语言的知识。这引发了关于 in-context reasoning 能力以及原始主张有效性的讨论(原始 Twitter 帖子)。
-
GaLore:GitHub 的新明珠:
@random_string_of_character发布了 GitHub 上的 GaLore 项目链接和一条 Twitter 帖子;然而,其有效性仍需社区验证。有人建议将其与 low-bit optimizers 结合使用以实现潜在的资源节省。 -
对 Function Calling 模型的期待:在各种讨论中,
@scottwerner和@sundar_99385对尝试一款受 Claude 风格启发、具有 Function Calling 能力的新模型表示兴奋。虽然未提及发布日期,但对该模型上线的渴望显而易见。
提到的链接:
- An Qu (@hahahahohohe) 的推文:今天在测试 @AnthropicAI 的新模型 Claude 3 Opus 时,我目睹了一些非常惊人的事情,简直感觉像奇迹。虽然不想听起来像标题党,但这确实是当时的感受。…
- Stop Regressing: Training Value Functions via Classification for Scalable Deep RL:Value functions 是深度强化学习(RL)的核心组件。这些由神经网络参数化的函数通常使用均方误差回归目标进行训练,以匹配 boo…
- Unsloth 修复 Gemma 的 bug:Unsloth 修复了 Google 的开源语言模型 Gemma。
- 01-ai/Yi-9B · Hugging Face:未找到描述
- GitHub - thu-ml/low-bit-optimizers: PyTorch 的低比特优化器:PyTorch 的低比特优化器。通过在 GitHub 上创建账户来为 thu-ml/low-bit-optimizers 的开发做出贡献。
- GitHub - jiaweizzhao/GaLore:通过在 GitHub 上创建账户来为 jiaweizzhao/GaLore 的开发做出贡献。
- 01-ai/Yi-34B-200K · Hugging Face:未找到描述
- Reddit - 深入了解任何事物:未找到描述
Nous Research AI ▷ #announcements (1 messages):
<ul>
<li><strong>新模型揭晓:Genstruct 7B</strong>:Nous Research 宣布发布 <strong>Genstruct 7B</strong>,这是一个指令生成(instruction-generation)模型,可以从原始文本创建有效的指令,从而允许创建新的 finetuning 数据集。该模型受 Ada-Instruct 论文启发,旨在为复杂场景生成问题,促进详细推理。</li>
<li><strong>用户告知的生成式训练</strong>:<strong>Genstruct 7B</strong> 模型基于用户提供的上下文,从 Ada-Instruct 中汲取灵感并进一步推动,以增强后续训练模型的推理能力。可在 HuggingFace 上下载:[HuggingFace 上的 Genstruct 7B](https://huggingface.co/NousResearch/Genstruct-7B)。</li>
<li><strong>由愿景领导者带队</strong>:<strong>Genstruct 7B</strong> 的开发由 Nous Research 的 `<@811403041612759080>` 牵头,标志着团队在基于指令的模型训练创新方面的投入。</li>
</ul>
提到的链接:
NousResearch/Genstruct-7B · Hugging Face:未找到描述
Nous Research AI ▷ #general (329 条消息🔥🔥):
- Anthropic 发布面向聊天的 AI:@teknium 宣布了来自 Anthropic 的一个名为 Genstruct-7B-GGUF 的新模型,这是一个可以生成对话和基于指令内容的生成式模型。
- 关于 Claude 3 性能的讨论:
@proprietary对 Claude 3 模型令人印象深刻的能力表示赞叹,引发了大家的好奇并纷纷请求分享输出结果。 - 评估 Twitter 上的 IQ 测试图表:讨论了来自 Twitter 的一张不准确的 IQ 测试图表。@makya2148 和其他人对 Claude 3 和 GPT-4 等 AI 模型报告的 IQ 分数表示怀疑。
- GPT-5 发布传闻流传:@sanketpatrikar 分享了关于潜在 GPT-5 发布的传闻,引发了推测,但聊天参与者普遍持怀疑态度。
- Inflection AI 声称其 Benchmark 结果令人印象深刻:Inflection AI 在推特上发布了关于其新模型 Inflection-2.5 的消息,声称它在所有 Benchmark 上都能与 GPT-4 竞争。
@teknium和@mautonomy讨论了这些说法的可信度。
提到的链接:
- 来自 Netrunner — e/acc (@thenetrunna) 的推文:GPT5_MOE_Q4_K_M.gguf SHA256: ce6253d2e91adea0c35924b38411b0434fa18fcb90c52980ce68187dbcbbe40c https ://t.ly/8AN5G
- 来自 Inflection AI (@inflectionAI) 的推文:Pi 刚刚获得了巨大升级!现在由我们最新的 LLM:Inflection-2.5 提供支持,它在所有基准测试中都与 GPT-4 并驾齐驱,且训练所用的计算量不到一半。Pi 现在拥有世界一流的…
- 来自 Emad (@EMostaque) 的推文:@Teknium1 在 7b 以上不太稳定。Transformer engine 将其作为主要实现方式。Intel 也有一个,Google 则有 int8
- gguf/Genstruct-7B-GGUF · Hugging Face:未找到描述
- Swim In GIF - Swim In Swimming - 发现并分享 GIF:点击查看 GIF
- MTEB 排行榜 - 由 mteb 提供的 Hugging Face Space:未找到描述
- 来自 Sebastian Majstorovic (@storytracer) 的推文:开源 LLM 需要开放的训练数据。今天我发布了最大的英语公共领域书籍数据集,这些书籍是从 @internetarchive 和 @openlibrary 精选而来的。它包含超过 610 亿个…
- 来自 Prof. Anima Anandkumar (@AnimaAnandkumar) 的推文:我们首次展示了 Llama 7B LLM 可以在仅有 24GB 显存的单张消费级 GPU (RTX 4090) 上进行训练。这代表存储优化器所需的内存减少了 82.5% 以上…
- 来自 FxTwitter / FixupX 的推文:抱歉,该用户不存在 :(
- 来自 Daniel Han (@danielhanchen) 的推文:发现了 #Gemma 的更多 bug:1. 必须添加 <bos> 2. <end_of_turn>model 存在拼写错误 3. sqrt(3072)=55.4256 但 bfloat16 是 55.5 4. Layernorm (w+1) 必须使用 float32 5. Keras mixed_bfloa…
- 如何在 2024 年使用 Hugging Face 微调 LLM:在这篇博文中,你将学习如何在 2024 年使用 Hugging Face TRL、Transformers 和 Datasets 微调 LLM。我们将在 text to SQL 数据集上微调一个 LLM。
- 微软与法国 Mistral AI 的新交易正受到欧盟审查:欧盟正在调查微软与法国初创公司 Mistral AI 的合作伙伴关系。这是对蓬勃发展的生成式人工智能行业进行更广泛审查的一部分,旨在查看其是否引发了…
- llama_index/llama-index-packs/llama-index-packs-raptor/llama_index/packs/raptor at main · run-llama/llama_index:LlamaIndex 是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- Weyaxi/Einstein-v4-7B · Hugging Face:未找到描述
- 来自 Weyaxi (@Weyaxi) 的推文:🎉 激动人心的消息!🧑🔬 认识一下 Einstein-v4-7B,这是一个强大的基于 Mistral 的有监督微调模型,使用了多种高质量且经过筛选的开源数据集!🚀 ✍️ 我还转换了多选题…
- GitHub - jiaweizzhao/GaLore:通过在 GitHub 上创建账号来为 jiaweizzhao/GaLore 的开发做出贡献。
- WIP: galore optimizer 由 maximegmd 提交 · Pull Request #1370 · OpenAccess-AI-Collective/axolotl:添加了对 Galore 优化器的支持。仍处于开发中 (WIP),尚未测试。
- GitHub - e-p-armstrong/augmentoolkit: 将计算资源和书籍转换为指令微调数据集:将计算资源和书籍转换为指令微调 (Instruct-Tuning) 数据集 - e-p-armstrong/augmentoolkit
- GitHub - PKU-YuanGroup/Open-Sora-Plan: 本项目旨在复现 Sora (Open AI T2V 模型),但我们的资源有限。我们深切希望整个开源社区能为本项目做出贡献。:本项目旨在复现 Sora (Open AI T2V 模型),但我们的资源有限。我们深切希望整个开源社区能为本项目做出贡献。 - PKU-YuanGroup/Open-Sora-Plan
Nous Research AI ▷ #ask-about-llms (41 messages🔥):
- Local OIllama Announcement: 用户
@teknium宣布 OIllama 旨在本地运行,而@lakshaykc建议可以为其创建一个用于后端推理的 endpoint。 - Current Training on Hermes Update:
@teknium向@aliissa确认,用于 Nous-Hermes-2-Mistral-7B-DPO 的数据集最初不包含 function calling 数据,但现在正在训练一个新版本。 - Sampling Tech for JSON/Function Calls:
@ufghfigchv正在重构一个专为 JSON/function calls 设计的 logit sampler,它在 Hugging Face (HF) 和 vllm 上运行良好。 - GPT-4 Free Access Question:
@micron588询问有关免费访问 GPT-4 的问题,@teknium澄清了可用性,并指向一个名为 Corcel.io 的网站,该网站提供类似 ChatGPT-4 的免费交互。 - Inquiry on Context Length for Nous-Hermes Models:
@nickcbrown询问为什么基于 Mixtral/Mistral 构建的 Nous-Hermes 模型的上下文长度似乎被缩减了,并表达了对 RAG (Retrieval-Augmented Generation) 等应用需要更长上下文的需求。
Links mentioned:
- Corcel · Build with the power of Bittensor: 未找到描述
- Lilac - Better data, better AI: Lilac 使数据和 AI 从业者能够通过改进数据来改进他们的产品。
LAION ▷ #general (300 messages🔥🔥):
- NVIDIA Puts the Brakes on Cross-Platform CUDA: 最近引起关注的一个变化是 NVIDIA 禁止使用转换层在非 NVIDIA 芯片上运行 CUDA,目标直指 ZLUDA 等旨在让 AMD 在 Windows 上与 NVIDIA 齐头并进的项目。
- Midjourney Scrape Shake-Up: Stability AI 被指控抓取 Midjourney 的 prompt 和图像,导致其员工被 Midjourney 封禁。这一事件引发了各种反应,有人暗示这可能与工作无关,也有人对此开玩笑。
- Marketing Missteps: 对话转向了一个案例,据报道某营销部门在广告转化上花费了不成比例的资金,引发了怀疑反应以及对这种支出效率低下的讨论。
- SD3 Speculations Amidst Dataset Discussions: 随着
@mikonvergence在 Twitter 上发布 MajorTOM 等新数据集的消息传出,人们对 Stability AI 分发 SD3 邀请并向 diffusers 提交 PR 的计划充满期待,用户们正在讨论 SD3 架构的潜力和局限性。 - Scraping Etiquette Examination: 在关于抓取的持续讨论中(从技术影响到社会影响),用户强调了正确的抓取技术和礼仪的重要性,重申理解并遵守这些原则至关重要。
Links mentioned:
- Nvidia bans using translation layers for CUDA software — previously the prohibition was only listed in the online EULA, now included in installed files [Updated]: 转换层成为众矢之的。
- Tweet from Nick St. Pierre (@nickfloats): 在 MJ 办公时间,他们刚提到 Stability AI 的某人在周六午夜试图抓取所有的 prompt 和图像对,并导致他们的服务宕机。MJ 正在封禁所有的…
- TwoAbove/midjourney-messages · Datasets at Hugging Face: 未找到描述
- Regulations.gov: 未找到描述
- GitHub - itsme2417/PolyMind: A multimodal, function calling powered LLM webui.: 一个多模态、由 function calling 驱动的 LLM webui。
LAION ▷ #research (74 条消息🔥🔥):
-
关于训练效率与剪枝的辩论:
@mkaic和@recviking之间的讨论集中在 LLM 是否存在参数效率低下,以及训练方法或架构是否可以优化。@mkaic认为,在不大幅降低性能的情况下对 LLM 进行剪枝的能力表明了更高效训练方案的潜力,而@recviking则认为剪枝会降低模型的泛化能力,且潜在输入的巨大规模使得效率评估变得复杂。 -
SVD 与训练缓慢:
@metal63报告称,在训练 Stable Cascade 模型期间应用 SVD 更新时出现了明显的减速,训练会因更新而暂停 2 分钟。@thejonasbrothers表达了对 SVD 的反感,因为它速度太慢,暗示了某些训练优化在实际应用中的问题。 -
剪枝对模型性能的影响:
@thejonasbrothers指出,对模型进行剪枝通常会导致性能问题,如 Token 重复和稳定性担忧;虽然某些模型在 70 亿参数左右似乎已经饱和,但在更大规模(如 1 万亿参数)下情况可能会有所不同。 -
剪枝后 LLM 的通用效用:
@mkaic坚持认为,即使经过深度剪枝,LLM 仍保留了超出预期的泛化能力,并对模型训练与推理过程中大参数量的必要性提出了质疑。开发更高效且效果相当的 LLM 训练方法被强调为一个极具前景的研究领域。 -
当前的结构限制:
@thejonasbrothers和@recviking讨论了当前 LLM 的结构限制以及效率饱和问题,特别批判性地审视了基于 Attention 的优化。对话提出了一个问题:在现有架构下,行业是否正在触及压缩和模型效率的极限。
提到的链接:
Neverseenagain Yourleaving GIF - Neverseenagain Yourleaving Oh - Discover & Share GIFs:点击查看 GIF
OpenAI ▷ #ai-discussions (204 条消息🔥🔥):
- Claude 在基础知识方面胜过 GPT-4:
@you.wish和@kennyphngyn分享了他们使用 Claude 3 Opus(简称 “C3”)的积极体验,报告称它在复杂任务和基础课程中的表现优于 GPT-4。 - 关于 Claude 3 编程能力的辩论:
@testtm发现 Gemini 1.5 Pro 在第一次尝试 Python GUI 代码任务时就成功了,而 Claude 3 却没有,这表明两种模型各有优劣。 - MMLU 数据集有效性受质疑:关于 MMLU 数据集,
@privetin和@foxalabs_32486批评该数据集包含逻辑不通的问题以及比例显著的错误答案,呼吁将其从 AI 模型评估中移除。 - 强调 YouTube 在 AI 模型评估方面的局限性:
@7877断言 YouTube 并不是获取 AI 模型快速、原始评估数据的最佳来源,因为它更侧重于娱乐而非详细信息,从而引发了关于替代评估资源的讨论。 - 对免费 AI 服务效力的担忧:
@eskcanta对 Claude 免费版允许的有限交互表示担忧(相比之下 OpenAI 服务提供的额度更慷慨),并思考了这些 AI 公司提供免费服务的经济可持续性。
提到的链接:
EvalPlus Leaderboard:未找到描述
OpenAI ▷ #gpt-4-discussions (29 条消息🔥):
- 访问 GPT 账户遇到困难:用户
@haseebmughal_546遇到了页面冻结的问题,导致无法访问 GPT 账户。 - 关于代码的 GPT 政策更新:用户
@watcherkk对 GPT 因政策变更不再提供完整代码表示担忧,并提到了“超出政策范围 (out of policy)”的消息。 - OpenAI 服务中断:
@qilin111报告了长达 6 小时的服务中断;@dystopia78确认了部分 API 故障,尽管当时 OpenAI 的 状态页面 显示“所有系统运行正常 (All Systems Operational)”。 - GPT-4 可用性不稳定:用户
@cetacn、@emante、@liyucheng09、@openheroes、@ed1431和@malc2987讨论了 GPT-4 的间歇性访问问题,不同用户的可用程度各不相同。 - GPT 与其他模型的混淆:
@cliffsayshi询问如何通过 API 使用像 Human GPT 调用的自定义模型,对此@solbus澄清说 GPTs 是 ChatGPT 专有的,无法通过 API 访问,并提供了 OpenAI 模型概览 的链接以及关于 GPTs 与 assistants 区别 的额外信息。
提到的链接:
- OpenAI Status:未找到描述
- OpenAI Status:未找到描述
OpenAI ▷ #prompt-engineering (68 条消息🔥🔥):
- 了解频道发布要求:
@giorgiomufen不清楚如何在需要标签的特定频道中发布内容,@eskcanta协助指出必须先点击“查看更多标签 (see more tags)”选项。 - 角色扮演 Prompt 的正面表述:用户
@toothpiks252、@eskcanta和@dezuzel向@loamy_建议如何正面地表述角色扮演 Prompt,认为最好明确告诉模型该做什么,而不是不该做什么。 - GPT-5 增强问题解决能力:
@spikyd表示相信 GPT-5 解决特定“鸟类谜题 (bird enigma)”的几率会提高 10%,而@eskcanta认为这可能只需要对 vision 模型进行更具针对性的训练。 - 改进故事叙述中的随机性:在关于为 GPT 的选择增加随机性的讨论中,
@solbus建议通过数据分析工具使用 Python 的 random 函数,以便为@interactiveadventureai的 AI 生成故事提供更多多样性。 - 寻求开发 GPT 分类器的帮助:
@chemlox寻求关于构建 GPT 分类器以确定对话状态的建议,纠结于使用基于 react 的 Agent 还是进行 fine-tuning。@eskcanta建议在决定采用更复杂的方案之前,先测试基础模型。
OpenAI ▷ #api-discussions (68 条消息🔥🔥):
- 发布时的标签问题:
@giorgiomufen在一个需要先选择标签的频道中发布内容时遇到困难。@eskcanta指出需要点击“查看更多标签”选项来提供帮助。 - 指令中正面表述优于负面表述:
@loamy_寻求“不要重复 (do not repeat)”的正面替代短语,@toothpiks252和@eskcanta通过建议对期望行为给出明确指令来提供协助。 - 鸟类谜题与 GPT-5 的潜力:
@spikyd和@eskcanta讨论了即将推出的 GPT-5 解决复杂鸟类谜题的潜力,强调了改进的 vision 模型和推理能力对于此类任务的重要性。 - 随机数生成查询:
@interactiveadventureai询问了让 GPT 生成不同随机种子以进行数字生成的方法,@solbus建议使用 Python 的 random 函数作为可能的解决方案。 - 热烈欢迎新成员:
@thebornchampion介绍自己是一名有志于成为数据分析师的 Prompt Engineering 爱好者,@eskcanta对其表示欢迎,并就其兴趣和 ChatGPT 的使用案例展开了讨论。
LM Studio ▷ #💬-general (187 条消息🔥🔥):
- 讨论技术规格与故障排除:
@kavita_27183分享了他们的硬件配置,拥有 512 GB RAM 和 24GB VRAM,而@jedd1协助排查 libstdc++ 错误并检查系统是否正确识别 VRAM。一条共享的错误消息指向库版本问题(GLIBCXX_3.4.29 not found),提示需要进行更新。 - 本地模型的服务器端问题:涉及多个本地模型话题,包括
@_benoitb遇到 nodes 服务器的 API 问题,@datasoul讨论 LM Studio 中与 GGUF 相关的错误,以及@mattjpow寻求关于服务器上下文(server context)行为的澄清。@heyitsyorkie提供了建议和回复。 - LLM 工作的硬件推荐:
@saber123316正在考虑购买 Macbook Pro M3 Max 或 M2 Max,并寻求社区关于哪款足以胜任本地 LLM 处理的建议。对话涉及价格、性能之间的权衡,以及更大 RAM 的价值。 - 探索 LM Studio 的功能:用户
@aeiou2623和@.lodis探索了从对话中上传图片到模型支持等各项功能。@heyitsyorkie提供了加载 GGUF 文件的指导,并澄清了 LM Studio 主要用于离线运行本地模型。 - OpenAI 批评与备选 AI 服务见解:
@saber123316和@rugg0064讨论了 OpenAI 被揭露的不够开放所带来的影响,提到了 Elon Musk 的不满,以及 OpenAI 的专有化方法促使用户考虑其他 AI 服务订阅,例如通过 POE 每月订阅 来访问 Claude 和 GPT-4 等各种模型。
提到的链接:
- Inflection-2.5: meet the world’s best personal AI:我们是一家 AI 工作室,旨在为每个人创造个人 AI。我们的第一个 AI 名为 Pi,代表个人智能(personal intelligence),是一个具有支持性和共情能力的对话式 AI。
- Reor:在你的电脑上本地且离线运行模型的 AI 笔记应用。
- Reddit - Dive into anything:将你自己的模型转换为 GGUF 的快速入门指南。
- RIP Midjourney! FREE & UNCENSORED SDXL 1.0 is TAKING OVER!:告别 Midjourney,迎接免费开源 AI 图像生成的未来:SDXL 1.0!这个全新的、无审查的模型正在席卷 AI 世界…
- Accelerating LLM Inference: Medusa’s Uglier Sisters (WITH CODE):https://arxiv.org/abs/2401.10774 https://github.com/evintunador/medusas_uglier_sisters
- The unofficial LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里你可以找到在 LMStudio Discord 上最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源软件…
- 22,000 H100s later, Inflection 2.5!!!:🔗 链接 🔗 https://inflection.ai/inflection-2-5 ❤️ 如果你想支持本频道 ❤️ 在此支持:Patreon - https://www.patreon.com/1littlecoder/ Ko-Fi - ht…
LM Studio ▷ #🤖-models-discussion-chat (27 条消息🔥):
-
确定了故事创作的最佳 AI:用户
@laszlo01询问了在使用 Open Chat 3.5 时用于故事创作的最佳 AI 模型。@jason_2065推荐了 Mistral-7b-instruct-v0.2-neural-story.Q4_K_M.gguf,建议设置 24 层和 8192 上下文大小(context size),并指出了内存限制。 -
LM Studio 缺少图像生成模型:
@karisna询问了在 LM Studio 中是否有能够绘图的模型。@heyitsyorkie澄清说 LM Studio 不支持此类模型,并建议使用 Automatic 1111 来处理 Stable Diffusion 任务。 -
Starcoder2 运行问题与支持:用户
@b1gb4ng和@madhur_11想知道是否可以通过 LM Studio 运行 starcoder2,对此@heyitsyorkie告知当前的 LM Studio 版本尚不支持。 -
探索图像生成替代方案:
@callmemjinina寻求一种可以生成图片的模型。@heyitsyorkie解释说语言模型和 LM Studio 无法执行此任务,建议在线查找 Stable Diffusion 工具和教程。 -
对 Starcoder2 的请求:
@zachmayer分享了对使用 starcoder2 的兴趣,并发布了其 Hugging Face 页面 的链接,但@wolfspyre暗示需要耐心等待,意味着未来可能会提供支持。
提到的链接:
Kquant03/TechxGenus-starcoder2-15b-instruct-GGUF · Hugging Face:未找到描述
LM Studio ▷ #🧠-feedback (4 条消息):
- 用户寻求指导:用户
@tiro1cor15_10表达了希望获得指导的愿望,以充分发挥他们在该服务中看到的潜力。 - macOS 上缺少代理支持:
@calmwater.0184提供的反馈表明,LM Studio 目前在 macOS 14.3 (v0.2.16) 上不支持 Proxy(代理)功能,这影响了搜索或下载模型的能力。 - 功能增强建议:
@calmwater.0184建议 LM Studio 可以参考 Embra AI 的用户体验和功能,从而为各级用户提供更高效的生产力提升助手(Productivity Booster Assistant)。 - 频道使用说明:
@heyitsyorkie指导用户停止使用指定的反馈频道发送帮助请求,而应使用相应的帮助频道。
LM Studio ▷ #🎛-hardware-discussion (46 条消息🔥):
-
Smaug 模型上的极端上下文实验:
@goldensun3ds报告了一项涉及 Smaug 模型 200K context 的测试,在仅使用 CPU 的情况下,RAM 使用量在 70GB 到 20GB 之间剧烈波动。他们最新的消息显示目前还没有输出,且 RAM 使用量持续波动。 -
VRAM 和电源供应讨论:
@wilsonkeebs寻求为独立运行的 RTX 3090 供电的最小 PSU 建议,@heyitsyorkie推荐至少 550W,但建议 750W 是标准配置。Wilsonkeebs 强调需要足够的 PCIe 线缆,而不仅仅是功率本身。 -
探索利基用例的大上下文:
@aswarp提出了 LLM 每月处理超大数据集(如整个代码库)以进行彻底报告的潜力,并承认了处理时间的权衡。Aswarp 认为这在政府和小型企业应用中特别有潜力。 -
LM Studio 处理中的 VRAM 需求:
@jason_2065提到使用 105,000 context 时资源占用极高,使用了 42GB RAM 和超过 20GB VRAM,这与其他人讨论的在处理大上下文或内存密集型 LLM 任务时的高需求一致。 -
管理机器学习模型中不匹配的 VRAM:对话涉及了运行 LLM 时 VRAM 不匹配相关的困难,并提到了调整 LLM 预设文件进行 GPU 分配的操作,
@goldensun3ds认为这很麻烦,因为需要重启 LM Studio。
提到的链接:
-
[Razer Core X - Thunderbolt™ 3 eGPU Razer United Kingdom](https://www.razer.com/gb-en/gaming-egpus/razer-core-x):现已兼容 Mac 和 Windows 笔记本电脑,支持 3 插槽 PCI-Express 桌面显卡,配备 650W 电源,并通过 USB-C 充电。 -
[PSU for NVIDIA GeForce RTX 3090 Power Supply Calculator](https://www.whatpsu.com/psu/gpu/NVIDIA-GeForce-RTX-3090):查看您的 NVIDIA GeForce RTX 3090 需要什么样的电源。
LM Studio ▷ #crew-ai (2 messages):
- 寻求速度提升技巧:
@alluring_seahorse_04960正在寻找提高响应速度的方法,用于某个未指定的流程。他们还遇到了一个错误:‘Connection to telemetry.crewai.com timed out’。 - 基准本地运行建议:作为回应,
@wolfspyre建议建立一个可以在本地运行的简单基准操作,以可能解决速度问题。
LM Studio ▷ #open-interpreter (85 messages🔥🔥):
-
解决 Preprompt 语法问题:
@nxonxi询问了在不同操作系统中修改 Open Interpreter 设置中default_system_message的正确语法。他们分享了在 Linux、Windows 和 WSL 上尝试更改系统消息时遇到的困难和尝试。 -
对 -s 和 DOS 文档的困惑:
@nxonxi提到对如何使用 Open Interpreter 的提示词设置感到困惑,讨论了-s或--system_message选项,并分享了文档链接,这引发了与@1sbefore关于寻找正确用法和命令的进一步讨论。 -
配置文件与设置 - 探索仍在继续:在整个对话过程中,
@1sbefore提供了帮助,建议检查 Open Interpreter 的 Python 环境中的正确路径和配置,而@nxonxi则报告了在修改提示词或有效使用配置文件方面的各种失败尝试。 -
探索代码训练模型:在对话的后半部分,讨论转向了使用不同语言模型(如
deepseek-coder-6.7B-instruct-GGUF)的经验,以及这些模型中提示词和系统消息的集成。@1sbefore分享了一个托管可能有用 GGUF 的 Hugging Face 链接,并提供了关于模型性能的见解。 -
相信好奇心的力量:面对在使用 Open Interpreter 和语言模型时的困惑,
@1sbefore鼓励@nxonxi在寻找正确资源和配置的过程中保持好奇心。交流中充满了反复试验的经历和共同学习的时刻,包括尝试克隆 git 仓库和调整 Python 环境。
提到的链接:
- owao/LHK_DPO_v1_GGUF · Hugging Face:未找到描述
- All Settings - Open Interpreter:未找到描述
- All Settings - Open Interpreter:未找到描述
LlamaIndex ▷ #announcements (1 messages):
- 用户调查公告:
@seldo_v鼓励大家参加一个 3 分钟的用户调查,以帮助 LlamaIndex 更好地了解其用户群体。调查可以在 SurveyMonkey 上找到,旨在改进文档、演示和教程。
提到的链接:
LlamaIndex 用户调查:参加由 surveymonkey.com 支持的调查。免费创建您自己的调查。
LlamaIndex ▷ #blog (5 messages):
- LlamaParse JSON Mode 发布:LlamaIndex 团队很高兴地宣布推出全新的 LlamaParse JSON Mode,它通过将 PDF 中的文本和图像解析为结构化字典,简化了 RAG 流水线的创建。当与 claude-3 opus 等多模态模型结合时,该功能增强了处理能力。查看推文。
- AIMakerspace 对 LlamaParse 的测试:
@AIMakerspace对 LlamaParse 进行了测试,取得了显著成果,并发布了一份深入分析报告,详细介绍了其功能和性能指标。深入了解 LlamaParse。 - 与 VideoDB 集成以实现视频流上的 RAG:LlamaIndex 引入了与
@videodb_io的集成,支持直接在 LlamaIndex 中根据语音内容或视觉场景对视频进行上传、搜索和流式传输。公告推文。 - Claude 3 全面视频指南:发布了新的视频指南,提供了关于使用 Claude 3 进行各种应用的全面教程,包括 Vanilla RAG、Routing 以及使用 LlamaIndex 工具进行的 Sub-question query planning。Claude 3 Cookbook。
- LlamaIndex 用户调查以优化资源:LlamaIndex 正在进行一项为期 3 分钟的用户调查,以更好地了解用户的专业知识和需求,从而更有效地定制文档、Demo 和教程。参与用户调查。
提到的链接:
LlamaIndex 用户调查:参与由 surveymonkey.com 支持的这项调查。免费创建您自己的调查。
LlamaIndex ▷ #general (298 messages🔥🔥):
-
A* Algorithm 讨论:
@nouiri询问 A* Algorithm 是否可以应用于相似度搜索。@whitefang_jr确认这是可能的,可以通过对 embedding 类进行子类化并更改相似度搜索方法来实现,并提到了 LlamaIndex 默认使用余弦相似度。 -
配置聊天机器人以实现上下文输出:
@techexplorer0询问如何配置 RAG 聊天机器人以获得简短且特定于上下文的回复。@kapa.ai建议使用ResponseSynthesizer或对响应进行后处理以实现简洁的输出,并链接到了 LlamaIndex 文档中的示例设置。 -
LlamaIndex 上的 Query Engine 自定义:
@cheesyfishes回复了各种实现查询,解释了 chat engines 通常接受字符串,LlamaIndex 中的 chunking 不是随机的,并建议探索源代码以解决更深层的问题,例如将 Gemini 用作 chat engine 或在 Azure OpenAI 中进行 embedding。 -
使用 Slack 摄取文档:
@habbyman寻求关于 Slack 文档摄取最佳实践的建议,希望在不丢失对话上下文的情况下保留单个消息的 metadata。 -
LlamaIndex Vector Store 推荐:像
@generalenthu这样的新用户询问了与 LlamaIndex 兼容的 Vector Store 推荐,收到了来自@cheesyfishes和@jessjess84的建议,尝试使用 Qdrant、ChromaDB 或 Postgres/pgvector,因为它们拥有详尽的文档和庞大的用户群。 -
LLM 直接查询与 VectorStoreIndex 之间的差异:
@jessjess84发现 LlamaIndex 的VectorStoreIndex响应效果不如直接进行 LLM 查询,@teemu2454将此归因于query_engine使用的 prompt templates,并建议进行调整以改善结果。针对该用户的另一个查询,@teemu2454澄清了VectorStoreIndex与用于处理文本的 LLM 是分开的,embeddings 仅用于在 LLM 查询期间获取文本作为上下文。
提到的链接:
- 未找到标题: 未找到描述
- 使用 LlamaIndex、Qdrant 和 Render 构建一个具有学习能力的 Slack 机器人 — LlamaIndex,LLM 应用的数据框架: LlamaIndex 是一个简单、灵活的数据框架,用于将自定义数据源连接到大语言模型 (LLMs)。
- Chat Stores - LlamaIndex 🦙 v0.10.17: 未找到描述
- OpenAI - LlamaIndex 🦙 v0.10.17: 未找到描述
- llama_index/llama-index-integrations/vector_stores/llama-index-vector-stores-opensearch/llama_index/vector_stores/opensearch/base.py at 0ae69d46e3735a740214c22a5f72e05d46d92635 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
- llama_index/llama-index-legacy/llama_index/legacy/llms/openai_like.py at f916839e81ff8bd3006fe3bf4df3f59ba7f37da3 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/base/embeddings/base.py at df7890c56bb69b496b985df9ad28121c7f620c45 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
- GitHub - mominabbass/LinC: “Enhancing In-context Learning with Language Models via Few-Shot Linear Probe Calibration” 的代码: “Enhancing In-context Learning with Language Models via Few-Shot Linear Probe Calibration” 的代码 - mominabbass/LinC
- OMP_NUM_THREADS: 未找到描述
- llama_index/llama-index-integrations/llms/llama-index-llms-vllm/llama_index/llms/vllm/base.py at f916839e81ff8bd3006fe3bf4df3f59ba7f37da3 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
- 可用的 LLM 集成 - LlamaIndex 🦙 v0.10.17: 未找到描述
- 由 d-mariano 实现 EvalQueryEngineTool · Pull Request #11679 · run-llama/llama_index: 描述:注意,我希望 LlamaIndex 团队能对这个 PR 提供反馈。如果团队同意该需求和方案,我将提供单元测试、文档更新以及 Google Colab 笔记本…
- 使用 LlamaIndex 的 Chroma 多模态演示 - LlamaIndex 🦙 v0.10.17: 未找到描述
-
[多模态检索增强生成 (RAG) Weaviate - 向量数据库](https://weaviate.io/blog/multimodal-rag): 一图胜千言,所以为什么只停留在检索文本上下文呢!?了解如何执行多模态 RAG! - 自定义响应 - HTML、Stream、文件及其他 - FastAPI: FastAPI 框架,高性能,易于学习,编写代码快,可用于生产环境
- 未找到标题: 未找到描述
- llama_index/llama-index-integrations/llms/llama-index-llms-vertex/llama_index/llms/vertex/utils.py at main · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用的数据框架 - run-llama/llama_index
LlamaIndex ▷ #ai-discussion (1 messages):
- 增强 In-context Learning 的新方法:
@momin_abbas分享了他们最新的工作,重点是通过 Few-Shot Linear Probe Calibration 来改进 In-context Learning。他们请求大家通过在 GitHub 仓库 点赞(star)来提供支持。
提到的链接:
GitHub - mominabbass/LinC: Code for "Enhancing In-context Learning with Language Models via Few-Shot Linear Probe Calibration": "Enhancing In-context Learning with Language Models via Few-Shot Linear Probe Calibration" 的代码实现 - mominabbass/LinC
Latent Space ▷ #ai-general-chat (14 messages🔥):
- 来自 Twitter 的茶余饭后轶闻:用户
@420gunna风趣地描述了从 Twitter 带来的消息,就像信使带着更新赶来一样。 - Midjourney 与 Stability AI 的冲突:
@420gunna强调了一场涉及 Stability AI 涉嫌抓取 Midjourney 数据的争议,据@nickfloats在这篇 Twitter 帖子 中报道,这导致 Midjourney 禁止了 Stability AI 的员工访问。 - 澄清 Mi5 类型混淆误解:用户
@nav10幽默地澄清了最初将数据抓取事件比作间谍电影场景的误解,实际上那只是 Discord 数据抓取。 - Newsletter 扩张者还是麻烦制造者?:鉴于最近在 Twitter 上报道的数据抓取事件,
@guardiang戏称@272654283919458306可能正在扩大其 Newsletter 的范围。 - 对 Discord 闹剧一笑置之:针对 Stability AI 和 Midjourney 之间上演的闹剧,
@swyxio发布了一个来自 Tenor.com 的 GIF。
{kind=link}
提到的链接:
- Nick St. Pierre (@nickfloats) 的推文:在 MJ 的办公时间里,他们提到 Stability AI 的某人在周六深夜试图抓取所有的 prompt 和图像对,导致他们的服务宕机。MJ 正在禁止所有的…
- Anima Anandkumar 教授 (@AnimaAnandkumar) 的推文:我们首次展示了 Llama 7B LLM 可以在单个消费级 GPU (RTX 4090) 上进行训练,且仅需 24GB 显存。这代表存储优化器所需的内存减少了 82.5% 以上…
- Obi Wan Im Not Brave Enough For Politics GIF - Obi Wan Im Not Brave Enough For Politics Talk - Discover & Share GIFs:点击查看 GIF
Latent Space ▷ #ai-announcements (4 messages):
- 新播客节目预告:
@swyxio宣布了由<@776472701052387339>主讲的最新播客节目现已上线,可以通过这里发布的推文观看。 - 播客讨论登上 Hacker News:
@swyxio分享了与 Soumith 讨论的播客也引起了 Hacker News 的关注。 - Model Serving 论文演示:
@swyxio邀请<@&1107197669547442196>的成员加入<@720451321991397446>在他们的 Discord 频道 进行的关于 Model Serving 综述论文的演示。
Latent Space ▷ #llm-paper-club-west (204 messages🔥🔥):
- 志愿者工作获得认可:社区对
@720451321991397446自愿进行演示表示感谢。@eugeneyan和其他人对这一努力表示支持。 - 模型操作技巧:
@swizec讨论了在 Intel 与 M2 上运行 Ollama 时明显的性能差异,而@amgadoz审视了 Large Language Models 中的 Parallelism 和 Look-ahead decoding 等技术层面。 - 推理优化深度探讨:Speculative decoding 的有效性是一个热门话题,
@shivdinho、@yikesawjeez等人讨论了它如何随硬件而变化。此外还推荐了 Drugs by EGjoni 等资源,并推测使用 FlashAttention 来提升大型模型服务的速度。 - 去中心化与分布式讨论:频道涉及了 Distributed training(
@yikesawjeez提到阅读了 DiLoCo paper),并讨论了 GPU 配置可能影响不同实例模型输出的潜在陷阱(@ayenem反思了 OpenAI 的一次事件)。 - 模型服务综述演示:
@swyxio提供了 Google Slides presentation 的链接,小组分享了对演示材料的想法和反应。关于 Distributed inference 和不同架构的权衡进行了深入讨论。
提到的链接:
- Join Slido: Enter #code to vote and ask questions:加入 Slido:输入 #code 进行投票和提问。参与实时投票、测验或问答。无需登录。
- Join Slido: Enter #code to vote and ask questions:加入 Slido:输入 #code 进行投票和提问。参与实时投票、测验或问答。无需登录。
- SpecInfer:未找到描述
- Monk:Monk 是云端的 AI DevOps。让你的基础设施实现自动化管理。
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.:一款将日常工作应用融合为一的新工具。它是为你和你的团队打造的一体化工作空间。
- Datasets for Large Language Models: A Comprehensive Survey:本文探讨了在 LLM 的显著进步中起关键作用的 LLM 数据集。这些数据集作为基础架构…
- Quickstart — vLLM:未找到描述
- no title found:未找到描述
- How to Generate and Use Synthetic Data for Finetuning:克服 Instruction-tuning、Preference-tuning 和 Pretraining 中人类标注的瓶颈。
- FlashAttention 2: making Transformers 800% faster w/o approximation - with Tri Dao of Together AI:FlashAttention 如何成为新的行业标准架构,FlashAttention 2 如何进一步提速 2 倍,Stanford Hazy Research 实验室的生活,以及后 Transformers 时代的未来暗示。
- Welcome to SkyPilot! — SkyPilot documentation:未找到描述
- Load Balancing is Impossible :Tyler McMullen 讨论了 Load balancing 技术和算法,如 Randomized Least-conns、Join-Idle-Queue 和 Load Interpretation。在现实世界中,完美的 Load balancing 可能是无法实现的…
- Reddit - Dive into anything:未找到描述
- Reddit - Dive into anything:未找到描述
- Welcome to SkyPilot! — SkyPilot documentation:未找到描述
- Model Serving Survey Paper - Paper Club:模型服务 Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems https://arxiv.org/abs/2312.15234v1
-
Model Serving Survey Paper - Paper Club:模型服务 Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems https://arxiv.org/abs/2312.15234v1
- GitHub - TheBlokeAI/dockerLLM: TheBloke 的 Dockerfiles: TheBloke 的 Dockerfiles。通过在 GitHub 上创建账户,为 TheBlokeAI/dockerLLM 的开发做出贡献。
- DiLoCo: Distributed Low-Communication Training of Language Models: 大语言模型 (LLM) 已成为机器学习许多应用中的关键组件。然而,训练 LLM 的标准方法需要大量紧密互连的加速器…
- Petals: Collaborative Inference and Fine-tuning of Large Models: 许多 NLP 任务受益于使用通常拥有超过 1000 亿参数的大语言模型 (LLM)。随着 BLOOM-176B 和 OPT-175B 的发布,每个人都可以下载预训练模型…
- GitHub - EGjoni/DRUGS: 停止纠结于繁琐的采样参数,直接使用 DRµGS!: 停止纠结于繁琐的采样参数,直接使用 DRµGS! - EGjoni/DRUGS
- GitHub - OpenNMT/CTranslate2: Transformer 模型的高速推理引擎: Transformer 模型的高速推理引擎。通过在 GitHub 上创建账户,为 OpenNMT/CTranslate2 的开发做出贡献。
- FireAttention — 通过几乎无损的量化,使开源模型的推理速度比 vLLM 快 4 倍: 通过几乎无损的量化,使开源模型的推理速度比 vLLM 快 4 倍
- GitHub - PygmalionAI/aphrodite-engine: PygmalionAI 的大规模推理引擎: PygmalionAI 的大规模推理引擎。通过在 GitHub 上创建账户,为 PygmalionAI/aphrodite-engine 的开发做出贡献。
- GitHub - lilacai/lilac: 为 LLM 策划更好的数据: 为 LLM 策划更好的数据。通过在 GitHub 上创建账户,为 lilacai/lilac 的开发做出贡献。
Eleuther ▷ #announcements (1 条消息):
-
韩语语言模型评估的新基准:
@gson_arlo宣布了两个新的评估数据集,Hae-Rae Bench 和 K-MMLU,旨在测试语言模型的韩语熟练程度。Hae-Rae Bench 评估模型对韩国文化的了解,而 K-MMLU 专注于韩国特有的问题,并包含一个针对当前模型的具有挑战性的子集。 -
征集多语言基准测试的贡献: 为了改进英语和中文以外语言的评估实践,
@gson_arlo邀请讲非主流语言或属于英语国家非主流文化的人士加入 <#1208111628051152969> 频道。他们可以通过设计评估对其文化具有重要意义的语言模型能力的基准来做出贡献。
Eleuther ▷ #general (78 messages🔥🔥):
-
探索 vLLM 的内部批处理逻辑:
@rwamit询问如何使用 vLLM 进行批处理推理。@baber_澄清说 vLLM 具有内部批处理功能,这意味着在使用 vLLM 时无需手动实现批处理。 -
征求关于 AI 监管的评论:
@wonkothesensible分享了一个关于征求公众对开源 AI 和免费可用模型监管评论的链接。该文件要求提交一份关于“双重用途基础模型 (dual-use foundation models)”风险和收益的报告。 -
BitNet 与全精度 NN 效率之争:随着 BitNet b1.58 的发布,
@kyo_takano提供了一个关于三元神经网络 (Ternary Neural Networks) 的入门级 Notebook,并指出尽管推理速度更快,但与全精度 NN 相比,它们在训练期间效率较低。 -
MidJourney Discord 争议事件:
@teknium报道了有关 Stability AI 干扰 MidJourney 服务并导致相关责任人被封禁的指控。情况和原因仍不明朗,@stellaathena等人质疑抓取 Discord 数据如何会影响 MidJourney 的服务器。 -
与专家的潜在合作机会:
@andrew_f0874正在寻求 AI/ML 领域的兼职、自愿研究合作。他拥有康奈尔大学博士学位,曾任 Google 研究科学家,专注于隐私保护技术,对于 AI/ML 与其专业领域交叉的项目可能特别有帮助。
提到的链接:
- Quickstart — vLLM:未找到描述
- Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models:该报告介绍了 \texttt{EEVE-Korean-v1.0},这是一个韩语适配的 LLM,在英语和韩语文本理解方面表现出卓越的能力。
- Regulations.gov:未找到描述
- 来自 Nick St. Pierre (@nickfloats) 的推文:在 MJ 的办公时间里,他们提到 Stability AI 的某人在周六深夜试图抓取所有的提示词和图像对,导致其服务宕机。MJ 正在封禁所有…
- Introduction to Ternary Neural Networks:三元神经网络简介。GitHub Gist:即时分享代码、笔记和片段。
- Megatron-DeepSpeed/tasks/eval_harness/evaluate.py at main · microsoft/Megatron-DeepSpeed:正在进行的规模化训练 Transformer 语言模型的研究,包括:BERT & GPT-2 - microsoft/Megatron-DeepSpeed
Eleuther ▷ #research (77 条消息🔥🔥):
- EleutherAI 的 Pythia 模型套件:
@alxsp.提供了 Pythia 模型套件的链接,并提到它是在相同的数据集上训练的。 - Adaptive Recurrent Vision 论文讨论:
.the_alt_man分享了一篇关于视觉模型中零样本计算缩放(zero-shot computation scaling)的 NeurIPS 2023 论文链接,并将其解释为“带有 CNN 的 Universal Transformer”。 - Batch Normalization 与 Token Normalization 之争:关于在训练模型时是对 Loss 进行 Token Normalization 还是 Batch Normalization 展开了辩论。该问题由
@thatspysaspy提出,@ai_waifu建议按目标 Token 进行归一化,随后引发了关于该话题的详细讨论。 - 创新的显存减少策略:GaLore:
@fredholm发起了关于一种新的显存高效训练策略——梯度低秩投影(GaLore)的讨论。@xylthixlm、@random_string_of_character和@ai_waifu探讨了其关于节省显存以及优于全秩更新(full-rank updates)结果的说法。 - PyTorch 优化器 Hook 见解:围绕使用梯度实现优化器步骤的技术实现(
@xylthixlm、@_inox等)展开了对话,重点讨论了 PyTorch 使用参数对字典进行索引的能力,以及对具有权重共享(tied parameters)模型的潜在影响。
提到的链接:
- Adaptive recurrent vision performs zero-shot computation scaling to unseen difficulty levels:未找到描述
- GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection:训练大语言模型 (LLMs) 面临着巨大的显存挑战,这主要是由于权重和优化器状态规模的不断增长。常见的显存减少方法,如低秩…
- Stop Regressing: Training Value Functions via Classification for Scalable Deep RL:价值函数是深度强化学习 (RL) 的核心组件。这些由神经网络参数化的函数使用均方误差回归目标进行训练,以匹配…
- Pythia Scaling Suite - a EleutherAI Collection:未找到描述
- Locally Typical Sampling:尽管底层模型在标准指标(如困惑度)下表现良好,但当今的概率语言生成器在生成连贯且流畅的文本方面仍有不足…
- pytorch/torch/_tensor.py at main · pytorch/pytorch:Python 中具有强大 GPU 加速功能的 Tensor 和动态神经网络 - pytorch/pytorch
- GaLore/torchrun_main.py at master · jiaweizzhao/GaLore:通过在 GitHub 上创建账户来为 jiaweizzhao/GaLore 的开发做出贡献。
- GitHub - jiaweizzhao/GaLore:通过在 GitHub 上创建账户来为 jiaweizzhao/GaLore 的开发做出贡献。
- WIP: galore optimizer by maximegmd · Pull Request #1370 · OpenAccess-AI-Collective/axolotl:添加了对 Galore 优化器的支持。仍在进行中 (WIP),尚未测试。
Eleuther ▷ #lm-thunderdome (15 条消息🔥):
-
利用期望的输出格式:
@pminervini询问了如何使用 lm-evaluation-harness 将模型输出自定义为指定格式。@baber_建议修改generate_until方法,并利用_loglikelihood_tokens,在此之前根据计算出的 log_probs 条件性地进行生成调用。 -
创作者分享 MCQA 评估/伪影论文:
@nish5989分享了他们最近的论文,重点关注多项选择题(MCQA)评估和数据集伪影(Artifacts)。随后展开了关于在模型 Prompt 中遵循或忽略无关指令所产生影响的讨论,@hailey_schoelkopf引用了关于模型如何对 Prompt 做出反应的相关研究。 -
Fine-Tuning 的一致性:
@karatsubabutslower质疑在 GLUE 数据集等基准测试上缺乏标准化的模型 Fine-Tuning 方法。lm-evaluation-harness 提供了一种标准化的评估方法,但似乎没有针对 Fine-Tuning 过程的类似框架。 -
使用 Generation 与 Loglikelihood 进行评估:
@hailey_schoelkopf对模型在使用 Generation 方法而非 Loglikelihood 时,无法以正确格式生成答案的频率表示关注。@nish5989回复称,正如他们论文附录中所述,有效性通常不是问题,特别是在更严格的设置下,并考虑未来使用 Likelihood 方法进行实验。 -
关于多语言评估标准的讨论:
@seanbethard询问在语言理解和推理中,为何偏好特定语言的评估标准而非跨语言标准。他们质疑特定语言评估标准的有效性和必要性,特别是如果这会阻碍非母语人士创建标准的话。
提到的链接:
- lm-evaluation-harness/lm_eval/models/huggingface.py at 9e6e240229429d2214bc281bed7a4e288f5169a1 · EleutherAI/lm-evaluation-harness.):一个用于语言模型 Few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
- Multiple Choice Question Standard Deviation · Issue #1524 · EleutherAI/lm-evaluation-harness:我看到多项选择类型的评估会计算指标以及标准差。根据我的理解,多项选择答案是从具有最高概率的选择中选出的…
- Do Prompt-Based Models Really Understand the Meaning of their Prompts?:最近,大量论文展示了各种基于 Prompt 的模型在 Zero-shot 和 Few-shot 学习方面取得的非凡进展。通常认为 Prompt 有助于模型在…
- Are Language Models Worse than Humans at Following Prompts? It's Complicated:Prompt 一直是推动语言模型 Zero-shot 和 Few-shot 性能进步的核心。然而,最近的研究发现,当给定有意…
Eleuther ▷ #gpt-neox-dev (34 条消息🔥):
-
Optimizer 内存峰值受到关注:
@tastybucketofrice提出了关于 Optimizer 步骤中内存峰值的问题,并指向了 GitHub issue #1160 和 PyTorch 内存分析以获取更多背景信息。@gaindrew请求提供具体的配置细节,以便忠实地复现该问题进行进一步分析。 -
漫长的依赖冲突之夜:
@biiter提到面临多重挑战,包括不兼容的 PyTorch 版本依赖以及由于并行编译导致的机器崩溃。在经过一系列权衡(包括从 NVIDIA git 仓库安装 apex 并限制并行编译数量)后,他们成功在 Ubuntu 22.04 和 CUDA 12.3 上运行了环境(flash-attention 信息)。 -
Docker 镜像,依赖地狱的解决方案?:
@tastybucketofrice建议使用他们基于 PyTorch NGC 重新构建的 Docker 容器,以缓解近期出现的 apex 等依赖问题(GitHub commit #1170)。@tfidia推荐使用 Docker + enroot 作为轻量级安装替代方案,并提到 Slurm 插件 pyxis 支持这种容器化任务启动方式。 -
使用 Poetry 进行依赖管理:
@catboy_slim_建议将依赖项迁移到 Poetry 中,以实现更具确定性的包管理,并讨论了在 Docker 之外实现稳定源码安装的挑战与愿景。他们强调需要一种能够镜像 Docker 环境可靠性的源码构建方式。 -
Fused Backward/Optimizer 实现的挑战:
@gaindrew描述了 Fused Backward/Optimizer 实现的进展,该实现显著降低了峰值内存使用,但代价是破坏了某些 DeepSpeed 和日志功能。后续工作将致力于解决这些问题,并专门针对 Adam Optimizer。
提到的链接:
- GitHub: Let’s build from here: GitHub 是超过 1 亿开发者共同塑造软件未来的地方。为开源社区做贡献,管理你的 Git 仓库,像专业人士一样审查代码,跟踪 Bug 和功能…
-
Single node Pythia 14M training on ngc pytorch 24.02 container (#1170) · EleutherAI/gpt-neox@119950c: * 在 NGC PyTorch 24.02 容器上进行单节点 Pythia 14M 训练
- pre-commit
共同作者:Quentin Anthony <qganthony@yahoo.com>
- GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention: 快速且内存高效的精确 Attention。通过在 GitHub 上创建账号为 Dao-AILab/flash-attention 的开发做出贡献。
- GitHub - EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the DeepSpeed library.: 基于 DeepSpeed 库在 GPU 上实现模型并行自回归 Transformer。 - EleutherAI/gpt-neox
- PyTorch Lightning Fused optimizer step · Issue #1160 · EleutherAI/gpt-neox: 添加 PyTorch Lightning 内存优化。https://lightning.ai/pages/community/tutorial/faster-pytorch-training-by-reducing-peak-memory/
HuggingFace ▷ #general (106 条消息🔥🔥):
- 创业聊天空间咨询:
@snoozyy询问 Discord 中是否有针对使用开源模型的小型公司创业者的讨论空间;在提供的消息中没有建议具体的频道或地点。 - 学习 TTS 和模型训练:
@ericpeter24表示他是 Text-to-Speech 模型的新手,正寻求使用 HuggingFace 上的数据集通过 coqui 训练模型,但不知道从何处开始。 - 展示个人项目:
@anuragshas询问如何在个人 Hugging Face 个人资料中创建精选模型或 Spaces;后续消息中没有直接回答该问题。 - 探索多模态模型:
@welltoobado提到了 multi_token,这是一个用于将各种模态嵌入到 LLM 中的模型,并与@kuki1941讨论了运行此类模型的资源需求。 - Android Studio 中的 Inference API:
@hari4626寻求关于如何在 Android Studio 中使用 Inference API 或端点的指导,@amirgame197建议使用 Android Studio 支持的编程语言发送带有正确数据的 Web 请求。
提到的链接:
- Inflection-2.5: meet the world’s best personal AI:我们是一家 AI 工作室,致力于为每个人创造个人 AI。我们的第一个 AI 名为 Pi,代表个人智能(personal intelligence),是一个支持性且富有同理心的对话式 AI。
- no title found:未找到描述
- @andrewyng on Hugging Face: “DeepLearning.AI just announced a new short course: Open Source Models with…”:未找到描述
-
[Haiper Generative AI For Video Content Creation](https://haiper.ai/):旨在赋能个人进行创造性自我表达的视频生成 AI 产品。 - Repeat After Me: Transformers are Better than State Space Models at Copying:Transformers 是序列建模的主流架构,但人们对使用不依赖于序列长度的固定大小潜状态(latent state)模型的兴趣日益浓厚,我们将其称为……
- Deploying 🤗 Hub models in Vertex AI:未找到描述
- Quickstart — vLLM:未找到描述
- How to build a multi-label & multi-class dataset correctly?:我不确定如何创建一个具有多个标签和类别的 Dataset,其中不同标签的类别并不相同。这里分享了一个多标签示例,但类别是……
- Deploying 🤗 Hub models in Vertex AI:未找到描述
- GitHub - sshh12/multi_token: Embed arbitrary modalities (images, audio, documents, etc) into large language models.:将任意模态(图像、音频、文档等)嵌入到 LLM 中。- sshh12/multi_token
HuggingFace ▷ #today-im-learning (10 条消息🔥):
- 进行中的背景项目:用户
@singe.r正在致力于转换 img2img 以创建产品背景,并询问是否有人之前进行过类似的项目。 - 解锁 FP8 训练成就:
@neuralink分享了他们从零开始完成 55% 端到端 FP8 训练的学习经验,包括开发 kernels。 - Rust 语言探险邀请:
@manel_aloui宣布开始学习 Rust 编程语言,并邀请其他人加入。 - Rust 爱好者汇聚:响应
@manel_aloui的号召,@cursorop分享了自己学习 Rust 的经验,特别是用于机器学习的 candle 库,在两位 Rust 学习者之间建立了联系。 - 征集斯坦福机器学习课程同伴:
@singhaditya4333(又名 Aditya)正在寻找同伴一起完成斯坦福机器学习课程。
HuggingFace ▷ #cool-finds (11 条消息🔥):
-
AI 强势进入主流视野:
@vardhan0280分享了一篇 Investopedia 文章,强调 2022 年见证了 AI 走向主流,这在很大程度上归功于 OpenAI 的 DALL-E 和 ChatGPT 的普及。 -
Open Sora 的社区协作:
@miko_al鼓励大家广而告之,以支持 Open-Sora-Plan 项目,该项目旨在利用有限的资源复现 OpenAI 的 text-to-video 模型。 -
深空中的精准健康与 AI:
@rtscott2001分享了《Nature Machine Intelligence》的一篇文章链接,题为“人工智能支持的深空生物监测与精准健康”,点击此处阅读。 -
Karpathy 分享 LLM 训练见解:
@.lawlord发布了 Andrej Karpathy 的一段精彩 Twitter 线程,探讨了训练大语言模型 (LLM) 的复杂性。这是一个极其耗费精力的过程,需要专门的团队负责集群维护和容错。该线程最后附带了著名的 OPT-175B 日志本链接,以供进一步深入了解。 -
Hugging Face 开源模型课程发布:
@andysingal重点介绍了一门由 DeepLearning.AI 提供的关于使用 Hugging Face 工具处理开源模型的新课程,课程可在此处查看。
提到的链接:
- DLAI - 使用 Hugging Face 的开源模型:介绍 · 模型选择 · 自然语言处理 (NLP) · 翻译与摘要 · 句子嵌入 (Sentence Embeddings) · 零样本音频分类 (Zero-Shot Audio Classification) · 自动语音识别 (Automatic Speech Recognition) · 文本转语音 (Text to Speech)…
- 让我们构建 GPT:从零开始,代码实现,详细讲解。:我们按照论文 “Attention is All You Need” 以及 OpenAI 的 GPT-2 / GPT-3 构建了一个生成式预训练 Transformer (GPT)。我们讨论了与之相关的…
- Andrej Karpathy (@karpathy) 的推文:关于训练 LLM 那些鲜为人知的困难的精彩读物。成熟的公司拥有专门的团队来维护集群。在大规模情况下,集群超出了工程范畴,变成了…
- 人工智能 (AI):它是什么以及如何使用:人工智能或 AI 指的是在被编程为像人类一样思考和行动的机器中模拟人类智能。
- 探索 TRLx:通过 RLHF 实现文本摘要的实操指南:学习使用 TRLx 进行文本摘要。微调模型,创建奖励反馈并应用 PPO 以实现有效学习。
- GitHub - PKU-YuanGroup/Open-Sora-Plan:该项目旨在复现 Sora (Open AI T2V 模型),但我们资源有限。我们深切希望整个开源社区能为该项目做出贡献。
- leom0311 - 概览:leom0311 有 9 个可用的仓库。在 GitHub 上关注他们的代码。
-
[人工智能支持的深空生物监测与精准健康 Nature Machine Intelligence](http://rdcu.be/c8jSO):未找到描述
HuggingFace ▷ #i-made-this (18 条消息🔥):
-
新模型 Yi-9B 亮相:
@tonic_1宣布发布 Yi-9B,这是模型库的新成员,并邀请用户在 Hugging Face 上的演示空间 进行体验。他们暗示了 HuggingFace 的未来计划,包括排行榜和游戏竞赛。 -
rwitz_ 开发的 Chatbot Arena 排行榜:
@rwitz_分享了他最近的工作,一个针对 Mistral Fine-tunes 的 ChatBot-Arena-Leaderboard,风格类似于 lmsys 排行榜,并邀请大家在其托管空间贡献模型,链接见 此处。 -
UDOP 模型演示:
@shinjeki提供了一个简单的演示空间,用于试用 Microsoft 最新的文档 AI 模型 UDOP,可以在 此处 进行探索。 -
ComfyUI 工作流发布:
@alx.ai宣布发布并开源了适用于 ComfyUI 的新工作流和节点,专门用于在 UI 中创建视差运动(parallax motion),详细信息可以通过 此处 发布的推文了解。 -
AI 增强型教育数据集:
@locutusque推出了 UltraTextbooks v2,这是一个旨在为教育领域训练语言模型的大型 NLP 数据集,包含了各种学术科目的教科书,现已在 Hugging Face 上可用。
提到的链接:
- 来自 undefined 的推文: 未找到描述
- Andyrasika/Gemma-ChatML · Hugging Face: 未找到描述
- 来自 TheHeroShep (@TheHeroShep) 的推文: 🧂很高兴分享第一个(众多之一)@getsaltai 工作流和节点发布 • @comfyUI 工作流,通过单个提示词或输入图像生成受控的 3D 视差运动 • 可能对基因…有用
- ETHDenver 回顾:Web3 和 AI 的新兴趋势: 我们的现状、未来的方向以及 Kevin 的回归。
- Andyrasika/vit-base-patch16-224-in21k-finetuned-lora-food101 · Hugging Face: 未找到描述
- Locutusque/UltraTextbooks-2.0 · Hugging Face 数据集: 未找到描述
- UDOP DocVQA - RamAnanth1 的 Hugging Face Space: 未找到描述
- Testing - rwitz 的 Hugging Face Space: 未找到描述
- Open Llm Leaderboard Viz - dimbyTa 的 Hugging Face Space: 未找到描述
- Langchain Crash Course (Gradio) - chongdashu 的 Hugging Face Space: 未找到描述
- GitHub - chongdashu/langchain-crash-course at lesson-1: 通过在 GitHub 上创建账号,为 chongdashu/langchain-crash-course 的开发做出贡献。
- Yi 9B - Tonic 的 Hugging Face Space: 未找到描述
- 使用 Fondant 构建 Datacomp CLIP 索引 - Fondant.): 未找到描述
HuggingFace ▷ #reading-group (9 条消息🔥):
- 周末会议考量:
@shafi8433表示更倾向于周末的会议,因为当前的时间与他们的工作时间冲突。 - 时区协调:针对
@lunarflu的询问,@shafi8433提到自己处于 IST 时区。 - 解读大数据技术:
@ibrahim_72765_43784分享了一个在 Kaggle 上发布的关于 Big Data Technology 生态系统全面探索的链接。 - 关于使用 Llama2 构建端到端 Chatbot 的咨询:
@neerajjulka1986寻求关于使用开源模型实现端到端 Chatbot 项目的建议,旨在理解 Fine-tuning、Deployment 和 Monitoring。 - 关于 Fine-tuning 和 Deployment 的建议:
@chad_in_the_house回复了@neerajjulka1986,建议使用 Hugging Face 的 PEFT 进行 Fine-tuning,并使用其 text-generation-inference GitHub 仓库进行 Deployment,但建议在 Fine-tuning 前仔细考虑计算资源。
提到的链接:
-
[Deciphering the Big Data Technology Ecosystem: A Comprehensive Exploration 🌐 Kaggle](https://www.kaggle.com/discussions/accomplishments/482230#2684943):解读 Big Data Technology 生态系统:全面探索 🌐。 - GitHub - huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.:🤗 PEFT:最先进的参数高效微调 (Parameter-Efficient Fine-Tuning)。 - huggingface/peft
- GitHub - huggingface/text-generation-inference: Large Language Model Text Generation Inference:大语言模型文本生成推理 (Large Language Model Text Generation Inference)。通过在 GitHub 上创建账号来为 huggingface/text-generation-inference 的开发做出贡献。
HuggingFace ▷ #diffusion-discussions (2 条消息):
- 慢一点,高级用户!:HuggingMod 温柔地提醒
@user稍微克制一下热情,并友好地建议放慢发帖频率 🤗。 - 寻求 SDXL-Lightning LoRA 知识:
@happy.j寻求关于如何将 SDXL-Lightning LoRA 与标准 SDXL 模型集成的帮助,并链接了一个未能完全解决其问题的讨论帖子。 - 来自 ByteDance 的 SDXL 技巧:ByteDance 官方提供了关于将 SDXL-Lightning LoRA 与训练好的 SDXL 模型合并的建议。他们提议从传统的 SDXL 模型开始并添加 LoRA 以进行加速,并为寻求挑战的用户推荐了诸如合并后使用对抗性目标(adversarial objectives)等高级技术。
提到的链接:
ByteDance/SDXL-Lightning · finetune:未找到描述
HuggingFace ▷ #computer-vision (7 条消息):
- 数据标注与切分建议:
@huzuni建议,如果不介意将数据公开,那么对数据进行 Labeling 和 Splitting 是件好事。 - 用户友好的分割界面:
@huzuni发现当前的界面比大多数 SAM 插件更友好,特别是对于 Segmentation 和 Bounding Box Labeling。 - 跟随 HuggingMod 的节奏放慢速度:
@HuggingMod提醒 <@715715500470042706> 放慢发帖频率。 - 质疑归一化的影响:
@huzuni想知道 Normalization 对其数据的影响,因为在使用 ImageNet Norm、Channel-wise Norm 和 Min-Max Norm 等方法时,他观察到没有显著变化。 - 寻找 Ultralytics 替代方案:
@prod.dopamine正在寻找 Ultralytics 的优质替代方案,并对 AGPL 许可证表示不满。
HuggingFace ▷ #NLP (23 messages🔥):
-
MMLU 数据集查询:
@privetin对 MMLU 数据集 的结构和内容表示感兴趣,但该查询后没有进一步的细节或讨论。 -
慢一点,你发帖太快了!:
@HuggingMod提醒@715715500470042706减缓发帖速度,以防止在频道中刷屏。 -
Tokenization 故障排除:
@mbotta在为 OpenHermes-2.5 模型进行 prompt 的 Tokenization 时遇到问题,该模型缺少 ‘tokenizer.json’ 文件。通过与@cursorop的交流,明确了对于像 OpenHermes 这样的微调模型,应该使用其基础模型的 Tokenizer,在这种情况下是 Mistral。 -
寻求用于职位名称标准化的合适模型:
@deb0rian征求关于微调基础模型的建议,该模型能够根据用户输入预测标准化的职位名称、学科和资历。@lucnzz建议使用基础的 Retriever 和 Generator 模型作为替代方案,随后的交流中@cakiki和@lucnzz还分享了一个幽默的 GIF 链接和关于狗的双关语。 -
Colab 模型推荐:
@iloveh8询问了适合在 Google Colab 上运行的最佳中小型开源语言模型,@cursorop和@lucnzz分别给出了建议,包括 2b 模型或 flan T5,以及任何小的量化模型(Quantized Model)。
提到的链接:
Golden Retriever Dog GIF - Golden Retriever Dog Puppy - Discover & Share GIFs:点击查看 GIF
HuggingFace ▷ #diffusion-discussions (2 messages):
-
发帖请慢一点:
@HuggingMod警告用户@715715500470042706降低在服务器中的发帖频率,强调了在聊天中保持节奏的重要性。 -
寻求 SDXL-Lightning LoRA 合并指导:用户
@happy.j正在寻求关于将 SDXL-Lightning LoRA 与标准 SDXL 模型结合的帮助,并分享了一个讨论链接,以寻求关于微调或创建自己版本的答案。该链接包含了一些建议,例如训练一个常规的 SDXL 模型然后应用 LoRA 进行加速,或者在进一步训练前合并 SDXL-Lightning LoRA,后者包括涉及 MSE Loss 和对抗性目标(Adversarial Objectives)的高级技术。
提到的链接:
ByteDance/SDXL-Lightning · finetune:未找到描述
HuggingFace ▷ #gradio-announcements (1 messages):
<ul>
<li><strong>Gradio 4.20.0 发布,支持外部身份验证提供商</strong>:用户 <code>@yuviii_</code> 宣布了 Gradio 的最新版本 4.20.0,该版本支持<strong>外部 / 任意身份验证提供商</strong>,包括 HF OAuth 和 Google OAuth,增强了应用的安全性并提高了用户灵活性。查看 HF Spaces 上的示例 - [HF OAuth 示例](https://huggingface.co/spaces/Wauplin/gradio-oauth-private-models) 和 [Google OAuth 示例](https://huggingface.co/spaces/gradio/oauth-example)。</li>
<li><strong>轻松清理</strong>:最新的 Gradio 更新为 <code>gr.Blocks</code> 引入了 <code>delete_cache</code> 参数,允许在应用关闭时自动清理文件。</li>
<li><strong>流畅的用户注销体验</strong>:用户现在可以通过 Gradio 新的 <code>/logout</code> 功能享受更顺畅的退出体验。</li>
<li><strong>使用 Gradio 进行时尚下载</strong>:<code>gr.DownloadButton</code> 组件现已上线,使应用中提供可下载内容变得更加容易且更具视觉吸引力。欲了解更多信息,请访问 [gr.DownloadButton 文档](https://www.gradio.app/docs/downloadbutton#demos)。</li>
</ul>
提到的链接:
Gradio DownloadButton 文档:未找到描述
OpenAccess AI Collective (axolotl) ▷ #general (44 条消息🔥):
- Deepspeed 引发不满:
@duh_kola提出了 Deepspeed 的一个问题,这加剧了@leoandlibe表达的沮丧情绪,他表示 Deepspeed 在 axo 中表现很糟糕,特别是在处理像他的 4x 4090s 这样的多 GPU 环境时,因为它无法在多个 GPU 之间拆分 base model,只能拆分 Lora adapter。 - Gemma 表现逊于 Mistral:
@noobmaster29在沉寂一段时间后询问 Gemma 与 7B Mistral 相比的性能。@lee0099回应了社区的观点,认为 Gemma 表现不佳,特别是在多轮对话(multi-turn dialogues)方面,而@le_mess澄清它仅在英语上进行过训练,否定了其在多语言任务中的效用。 - GaLore 承诺提升显存效率:
@noobmaster29分享的一条推文中强调了 GaLore optimizer,该优化器承诺大幅降低 Large Language Model (LLM) 训练的显存需求。虽然@lee0099批评其缺乏详细的性能数据,但@nafnlaus00和其他人讨论了它在提高消费级硬件上进行 LLM 训练可访问性方面的潜力。 - Axolotl 中集成 GaLore 的工作正在进行中 (WIP):随着 GaLore 引起关注,
@yamashi准备好做出贡献,提议稍后提交 pull request 并敦促其他人进行测试,而@caseus_则提供了更新和错误修复,并分享了相关的 YAML 文件以寻求进一步帮助。 - 技术澄清与寻求协助:
@tank02.寻求关于应安装哪个版本的支持 CUDA 的 torch 的指导,@nanobitz建议通常版本越新越好。当@noobmaster29询问时,@nanobitz还指出存在一个使用 Axolotl 训练 Gemma 的配置。
提到的链接:
- Prof. Anima Anandkumar (@AnimaAnandkumar) 的推文:我们首次展示了 Llama 7B LLM 可以在仅有 24GB 显存的单个消费级 GPU (RTX 4090) 上进行训练。这代表存储优化器所需的显存减少了 82.5% 以上…
- oaaic:Weights & Biases,机器学习开发者工具
- GitHub - jiaweizzhao/GaLore:通过在 GitHub 上创建账号来为 jiaweizzhao/GaLore 的开发做出贡献。
- WIP: galore optimizer by maximegmd · Pull Request #1370 · OpenAccess-AI-Collective/axolotl:添加对 Galore optimizers 的支持。仍处于 WIP 阶段,未经测试。
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (45 条消息🔥):
-
16bit LoRA 吸引力有限?:
@suikamelon质疑谁会使用最近支持的 16bit LoRA,并引用了 axolotl GitHub 中的一次提交。@caseus_指出还有一个 quantized DoRA PR 仍在处理中,一旦合并,他们将移除一项检查。 -
LoftQ 的显存困境:
@suikamelon发现了 LoftQ 的显存占用问题以及错误的初始化文档,相关讨论见 Hugging Face PEFT 仓库的 GitHub Issue #1525 和 Pull Request #1532。 -
对 GaLore 的兴奋与质疑:
@suikamelon分享了一种名为 GaLore 的新训练策略,以及相应的 GitHub 代码 和 Anima Anandkumar 的推文。讨论涉及 GaLore 潜在的显存使用优势,@caseus_对其声称的与全量预训练(full pretraining)等效的性能表示怀疑。 -
GaLore 的集成挑战:包括
@stoicbatman和@caseus_在内的一些用户讨论了尝试将 GaLore 集成到他们的项目中,但在启动训练时遇到了问题,这反映在 GaLore 的一个 Pull Request 中。 -
多次被新方法“忽悠”?:
@yamashi、@nruaif等人产生了一种反复出现的挫败感,认为可能被各种效率提升方法误导了,提到了 ReLoRA、NEFT 以及可能存在的第三种未识别的方法。对话转向了关于有效微调(finetuning)和预训练(pretraining)所需的合适数据集大小和设置的问题。
提到的链接:
- 改进 LoRA:从零实现权重分解低秩自适应 (DoRA): 低秩自适应 (LoRA) 是一种机器学习技术,通过调整权重来修改预训练模型(例如 LLM 或 vision transformer),使其更好地适应特定的、通常较小的数据集…
- LoftQ 似乎没有对基础模型进行量化 · Issue #1525 · huggingface/peft: 系统信息 transformers 版本: 4.37.2 平台: Ubuntu 18.04.6 LTS GPU: RTX GeForce 3090 x 2 Python 版本: 3.10.13 Huggingface_hub 版本: 0.20.3 Safetensors 版本: 0.4.2 Accelerate 版本…
- 是否可以将 qlora 与 relora 结合使用? · Issue #5 · Guitaricet/relora: 未找到描述
- GitHub - euclaise/SlimTrainer: 无需大显存需求的大语言模型全量微调: 无需大显存需求的大语言模型全量微调 - euclaise/SlimTrainer
- peft/examples/loftq_finetuning at main · huggingface/peft: 🤗 PEFT: 最先进的参数高效微调 (Parameter-Efficient Fine-Tuning)。 - huggingface/peft
- 由 winglian 提交的对 transformers 版本要求更宽松一些 · Pull Request #5 · jiaweizzhao/GaLore: 你们好!这项研究非常棒。我们正寻求将 galore 集成到 axolotl 项目中 OpenAccess-AI-Collective/axolotl#1370。我遇到的一个问题是 transformers 的依赖版本固定在…
- 支持 DoRA 与 PEFT (#1363) · OpenAccess-AI-Collective/axolotl@0cfdb2c: 未找到描述
- GaLore: 通过梯度低秩投影实现显存高效的 LLM 训练: 训练大语言模型 (LLMs) 面临着显著的显存挑战,这主要是由于权重和优化器状态的大小不断增长。常见的显存减少方法,如低秩…
- GitHub - jiaweizzhao/GaLore: 通过在 GitHub 上创建账号来为 jiaweizzhao/GaLore 的开发做出贡献。
- 支持 DoRA 与 PEFT (#1363) · OpenAccess-AI-Collective/axolotl@0cfdb2c: 未找到描述
- WIP 修复 LoftQ 文档和测试,由 BenjaminBossan 提交 · Pull Request #1532 · huggingface/peft: 与 #1525 相关。请勿合并此项,部分 GPU 测试失败。遗憾的是,我之前写的关于如何使用 LoftQ 的文档是不正确的,这是基于我的误解。实际上,它相当…
- jiawe - 概览: 胜利垂青有准备的人!jiawe 拥有 47 个公开仓库。在 GitHub 上关注他们的代码。
OpenAccess AI Collective (axolotl) ▷ #general-help (20 messages🔥):
-
DeepSpeed Zero3 配置检查:
@caseus_询问在 DeepSpeed JSON 中是否将stage3_gather_16bit_weights_on_model_save设置为 true。@seungduk确认了其在配置中的存在,并提供了 axolotl GitHub 的链接作为参考。 -
Python 包依赖地狱:
@tank02.在安装axolotl[deepspeed]==0.4.0时遇到了依赖冲突问题,其中torch版本与其他依赖项要求的版本冲突。提供的解决方案包括手动安装特定依赖项,以及根据@remek1972的建议使用torch==2.2.0版本。 -
解决模块版本冲突的手动安装策略:
@rtyax和@remek1972都建议手动安装冲突的依赖项以克服版本冲突,@remek1972特别提到在调整 PyTorch 和 xformers 版本后成功完成了安装。 -
训练中的 Mask 机制说明:
@suikamelon试图了解在训练期间被 Mask 的 Token 是如何处理的,随后@nanobitz澄清说axolotl将被 Mask 的 Token 标签设置为 -100,这表示它们不会被忽略,但会被排除在 Loss 计算之外。
提到的链接:
- Dependency Resolution - pip documentation v24.1.dev0: 未找到描述
- axolotl/deepspeed_configs/zero3_bf16.json at main · OpenAccess-AI-Collective/axolotl: 欢迎提出 axolotl 相关问题。通过在 GitHub 上创建账户来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
-
关于使用 Claude 3 进行群聊的推文:
@alexatallah分享了一篇关于使用 Claude 3 进行 群聊 (group chatting) 的正面体验推文,该聊天是自我调节的。该故事可在 OpenRouterAI 的 Twitter 上查看。 -
“Nitro” 模型测试中:
@alexatallah告知用户出现了新的 “nitro” 模型,这些模型可以安全地使用和构建。用户被告知在正式公告发布前可能会有细微变动,因为他们正在整合早期测试者的反馈。
OpenRouter (Alex Atallah) ▷ #general (94 条消息🔥🔥):
- 针对 VSCode 扩展开发者的赞助计划:
@alexatallah提出,将为任何愿意开发兼容 OpenRouter 的 VSCode 扩展的人提供免费额度赞助。 - 社区讨论用于 LLM 的 VSCode 扩展:社区成员分享了多种用于 LLM(如 OpenRouter 和 GPT-4)辅助编程的 VSCode 扩展,包括 Cursor、Continue 和 Tabby 等替代方案。
- OpenRouter Chat 处理长文档效率较低:
@aliarmani在使用 OpenRouter 聊天推理处理长文档时遇到问题,并收到了关于 Typingmind 和 ChatbotUI 等替代方案的建议。 - Claude 3 Opus 对话引人入胜但价格不菲:
@phoshnk和@billbear等用户讨论了与 Claude 3 Opus 对话的趣味性,而@xiaoqianwx等人则感叹其成本过高;@filth2强调了 Sonnet 的性价比。 - OpenRouter 审核层详解:社区成员解释了应用于 OpenRouter 模型的审核层(Moderation Layers),与自我审核的 beta 模型相比,OpenAI 和 Anthropic 模型会接受额外的审核。
提到的链接:
- Continue:未找到描述
-
[Home Tabby](https://tabby.tabbyml.com/):描述将放入 <head /> 中的 meta 标签 -
[Configuration Continue](https://continue.dev/docs/model-setup/configuration#defining-a-custom-llm-provider):配置你的 LLM 和模型提供商 -
[Perplexity: Sonar 8x7B by perplexity OpenRouter](https://openrouter.ai/models/perplexity/sonar-medium-chat?tab=parameters):Sonar 是 Perplexity 最新的模型系列。它在性价比、速度和性能方面超越了早期模型。该模型具备联网功能的版本是 [Sonar 8x7B Online](/mo… - GitHub - continuedev/continue: ⏩ The easiest way to code with any LLM—Continue is an open-source autopilot for VS Code and JetBrains:⏩ 使用任何 LLM 编码的最简单方式——Continue 是适用于 VS Code 和 JetBrains 的开源自动驾驶仪 - continuedev/continue
LangChain AI ▷ #general (55 条消息🔥🔥):
- 处理 CSV Loader 超时错误:
@kinghaze443正在寻求关于 “The write operation timed out” 错误的帮助,该错误发生在使用 LangChain 的UnstructuredCSVLoader加载 CSV 时。他们提供了一段代码片段,并提到了当前的 LangChain 和 OpenAI 版本。提供的消息中未提出或讨论解决方案。 - 对 Discord 上网络钓鱼企图的担忧:
@archiacme报告服务器成员分享可疑 steamcommunity 链接的情况有所增加,暗示这些可能是网络钓鱼企图,并询问如何删除它们。消息历史中没有提到后续行动或解决方法。 - 关于查询扩展和大数据集处理的澄清:
@dbounds询问了在大数据集下使用retrieval-augmented generation(RAG) 链的正确方法,他担心那些将整个数据库序列化为字符串作为上下文的示例。这种担忧强调了该方法对于大数据集的不切实际性,但提供的消息中没有给出具体的解决方案。 - 缺乏关于 Azure AI Search 的文档和帮助:
@juroy正在寻找有关在 LangChain 中使用 Azure AI Search 设置RetrievalQA等链的信息,但在文档中找不到相关内容。几条回复承认缺乏帮助且难以找到解决方案,强调了该技术的新颖性和社区动态,但尚未提供针对@juroy初始问题的直接解决方案。 - LangChain 流式传输和 Prompt 查看:
@cybersmiths提到了在 Python 中实现流式传输,而@yd4224询问如何查看包含chat_history和agent_scratchpad的完整 Prompt 文本,希望看到发送给 LLM 模型的实际字符串。@chester3637提供了一个包含代码片段的回调解决方案并提到了 LangSmith,这可能作为解决这两个问题的起点,重点在于 LangChain 交互的可视化和性能。
提到的链接:
- 未找到标题:未找到描述
-
[LangChain Expression Language (LCEL) 🦜️🔗 Langchain](https://python.langchain.com/docs/expression_language/):LangChain 表达式语言(简称 LCEL)是一种声明式方法,可以轻松地将链组合在一起。 - Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- LangSmith:未找到描述
- Assistant API 流式传输有更新吗?:使用 assistants api 构建 Web 应用。缺乏流式传输严重影响了 UI,让我考虑在流式传输可用之前改用其他方案。有没有人听说过关于…
- LangSmith:让您的 LLM 应用从原型走向生产。
-
[Retrieval augmented generation (RAG) 🦜️🔗 Langchain](https://js.langchain.com/docs/expression_language/cookbook/retrieval):让我们来看看如何向 Prompt 和 LLM 添加检索步骤,从而组成一个“检索增强生成”链: -
[Azure AI Search 🦜️🔗 Langchain](https://python.langchain.com/docs/integrations/vectorstores/azuresearch#configure-vector-store-settings):[Azure AI - langchain/libs/community/langchain_community/document_loaders/parsers/pdf.py at v0.1.11 · langchain-ai/langchain:🦜🔗 构建上下文感知的推理应用程序。通过在 GitHub 上创建账户,为 langchain-ai/langchain 的开发做出贡献。
- 从 PDF 中提取文本 — pypdf 4.0.1 文档:未找到描述
- langchain_agent/assistant at master · couthyapper7/langchain_agent:一个使用 LangChain 和微调后的 GPT 制作的 CSV 读取器 - couthyapper7/langchain_agent
LangChain AI ▷ #langchain-templates (9 messages🔥):
- 通过 Pydantic 和 LangChain 构建用户画像:
@justanothergraphguy正在开发一个用于构建用户画像的聊天 Chain,使用 Pydantic 进行结构化输出,并结合 LangChain 和 Redis 管理聊天历史。他们分享了UserProfile和Result的 Pydantic 模型来结构化用户数据。 - 用于交互式用户画像创建的 System Prompt:提供了一个详细的 system prompt,指导 AI 如何通过提取信息、提出后续问题以及确认最终细节来与用户交互以构建画像。
- Chain 构建中的集成难题:
@justanothergraphguy讨论了一个关于 chat chain 的问题,即尽管意图是进行记忆传播,但在第一次交互后,HumanMessage却被错误地包含在了AIMessage的内容中。 - 示例显示非预期结果:分享了一个代码交互示例,其中 Redis 存储聊天历史,但当引入新消息时,AIMessage 包含了之前的
HumanMessage内容,这表明聊天历史处理可能存在问题。 - 寻求社区见解:
@justanothergraphguy正在寻求社区对该 chat chain 问题的反馈,特别是关于后续AIMessage输出中错误包含HumanMessage的情况。他们提供了初始代码片段来阐述该问题。
LangChain AI ▷ #share-your-work (7 messages):
-
RAG 与 RAPTOR 的结合:
@andysingal分享了一篇关于使用 RAPTOR 和 Langchain 从头开始构建长上下文检索聚合器 (RAG) 的 Medium 文章。该文章详细介绍了如何适应不断发展的知识领域并克服传统知识检索的缺点。 -
ChromaDB 插件发布:
@vic49.介绍了 LM Studio 的 ChromaDB 插件,这是一个用于创建 ChromaDB 向量数据库以配合服务器模式下的 LM Studio 工作的解决方案。 -
建筑与医疗生成脚本:
@_johnny1984正在研究与 ChromaDB 插件类似的概念,并分享了一个脚本目录,展示了他们正尝试通过生成算法构建新医院,涵盖了建筑和医疗专业角色。 -
将 LLM 无缝集成到 Python 项目中:
@madgic_宣布了一个名为ask-llm的新库,该库使用 LangChain 开发,受 langchain-decorators 启发,可以轻松地将 LLM 交互集成到 Python 项目中。该库使用 Jinja 模板处理 Prompt,并在 GitHub 上有详细描述。 -
在生产环境中探索 Vision 模型:
@vru.shank宣布了一个与 MultiOn 和 Quizizz 合作的研讨会,重点关注 Vision 模型在生产环境中的应用,邀请感兴趣的人士报名参加由 LLMs in Prod 社区举办的研讨会。详细信息和注册可以通过此链接访问。
提到的链接:
- Releases · BBC-Esq/ChromaDB-Plugin-for-LM-Studio:创建 ChromaDB 向量数据库以配合服务器模式下运行的 LM Studio 的插件!
- GitHub - FlorianMgs/ask-llm: The easiest way to supercharge your apps with LLM!:为你的应用增强 LLM 能力的最简单方法!
- Building Long Context RAG from Scratch with RAPTOR using Langchain:作者 Ankush k Singal
- no title found:未找到描述
-
[Multi-Modal LLMs in Prod Practitioners’ Workshop · Luma](https://lu.ma/multimodal-llms):LLMs in Prod 社区正在邀请来自顶尖生成式 AI 公司的从业者,分享他们如何使用多模态模型(视觉、音频、图像生成等)…
LangChain AI ▷ #tutorials (2 messages):
-
用 AI 创造无限乐趣:
@pradeep1148分享了一个名为 “Infinite Craft Game using Mistral” 的 YouTube 视频,展示了一款游戏的开发过程,玩家从四个基础元素开始,利用 Mistral 进行组合以发现新元素。 -
使用 Mistral 和 Giphy 生成 Meme:
@pradeep1148还发布了一个名为 “Making memes with Mistral & Giphy” 的 YouTube 视频,演示了如何使用 Mistral 和 Giphy API 创建 Meme,并提供了相关 GitHub notebook 的链接。
提及的链接:
- Making memes with Mistral & Giphy:让我们使用 Mistral LLM 和 Giphy API 制作 Meme #llm #ml #python #pythonprogramming https://github.com/githubpradeep/notebooks/blob/main/Giphy%20Mistral.ipynb
- Infinite Craft Game using Mistral:让我们开发 Neal Agarwal 的网页游戏 Infinite Craft。这是一款“合成游戏”,你只需从四个元素开始,不断重复组合元素对…
CUDA MODE ▷ #general (6 messages):
- 询问频道用途:
@8bitelon询问 “general” 是否意味着可以聊离题(off-topic)内容,对此@marksaroufim回复说目前没有专门的离题频道,但如果有需要可以创建一个。 - 对 Meme 幽默的容忍度:
@iron_bound表达了发布 Meme 的愿望,引发了@marksaroufim的回复,要求在专门的 Meme 频道展示最棒的 Meme。 - tspeterkim_89106 的 Flash Attention CUDA 项目:
@tspeterkim_89106分享了一个在 CUDA 中实现 Flash Attention 的项目,寻求关于实现的反馈和讨论。该项目已在 GitHub 上发布。 - CUDA 快速指南:
@iron_bound提供了一个简洁的教育资源,链接到一个名为 “Nvidia CUDA in 100 Seconds” 的 YouTube 视频。观看视频以快速了解 CUDA 概览。
提及的链接:
- Nvidia CUDA in 100 Seconds:什么是 CUDA?GPU 上的并行计算如何让开发者释放 AI 的全部潜力?学习 Nvidia CUDA 编程的基础知识…
- GitHub - tspeterkim/flash-attention-minimal: Flash Attention in ~100 lines of CUDA (forward pass only):约 100 行 CUDA 代码实现 Flash Attention(仅前向传播)- tspeterkim/flash-attention-minimal
CUDA MODE ▷ #cuda (30 条消息🔥):
-
Nvidia H100 的带宽启示:
@iron_bound讨论了 Nvidia H100 GPU 的 L2 cache 读取带宽,强调了 5.5 TB/s 的数据,并提出了一种计算 L1 cache 带宽的方法。他们引用了 Chips and Cheese 的深度文章,该文章描述了 Nvidia 如何通过采用 Hopper 架构的 H100 专注于计算市场。 -
架构对比:
@zippika根据现有数据推测,假设 H100 具有相似参数,Nvidia 4090 的 L1 cache 带宽可能达到 40TB/s;而@iron_bound指出必须考虑 Ada 和 Hopper 架构之间的差异。 -
揭示 Coarsening 对性能的影响:
@marksaroufim分享了 @zeuxcg 的一条推文链接,揭示了在代码执行中处理 coarsening 的正确方法,并对由于基准测试不一致导致的性能误解提供了见解。 -
学习 CUDA CuTe DSL:
@ericauld发起了关于理解 CuTe Domain Specific Language (DSL) 的讨论,分享了使用 CuTe 的 CUTLASS 库的 GitHub 链接,并讨论了阅读文档的最佳顺序。 -
CUDA 中的 Dequantization 优化:
@zippika分享了他们在利用cuda::pipelineAPI 优化 fp4 dequantization 方面的进展,指出其速度较基准测试(baseline)有所提升,并表示在真实输入输出测试中取得了准确性方面的成功。
提到的链接:
- Microbenchmarking Nvidia’s RTX 4090:Nvidia 的 RTX 4090 采用了 Nvidia 最新的架构,以早期计算先驱 Ada Lovelace 命名。与之前的架构 Ampere 相比,Ada Lovelace 拥有……
- Arseny Kapoulkine 🇺🇦 (@zeuxcg) 的推文:作为演示,我修改了 coarsen 源代码,注释掉了 VecAdd/VecAddCoarsened 的代码体,并修改了启动参数以省略
2*,得到了这些结果。你所看到的…… - Nvidia’s H100: Funny L2, and Tons of Bandwidth:GPU 最初是纯粹用于图形渲染的设备,但其高度并行的特性使其对某些计算任务也具有吸引力。随着 GPU 计算领域在过去几年的增长……
- cutlass/media/docs/cute at main · NVIDIA/cutlass:用于线性代数子程序的 CUDA 模板。通过在 GitHub 上创建账号为 NVIDIA/cutlass 的开发做出贡献。
CUDA MODE ▷ #torch (11 messages🔥):
-
bitsandbytes 用于量化需求:用户
@iron_bound建议@mabeto5p查看 bitsandbytes,以便在 PyTorch 中对低精度整数执行 linalg 运算,这可能会利用 Ada 架构上的 int8 tensor-cores。@mabeto5p正在寻找高抽象工具来处理 int4/int8 和 fp8 矩阵运算。 -
及时同步,事半功倍:
@andreaskoepf指出了一个可能导致 benchmark 虚高的常见错误,暗示@mabeto5p可能需要添加torch.cuda.synchronize()来获得准确的测量结果。@mabeto5p随后确认,脱离 Jupyter 环境后得到了合理的 benchmark 结果。 -
跨设备同步说明:针对
@mabeto5p的疑问,@andreaskoepf澄清说torch.cuda.synchronize()内部调用了cudaDeviceSynchronize,确保在调用返回之前所有 kernel 都已执行完毕,无论其来源如何,只要它们来自同一个进程。 -
混合设备 Tensor 索引:根据
@_t_vi_的说法,允许使用 CUDA tensor 标量对 CPU tensor 进行索引,这是出于历史原因和便利性考虑,因为标量在索引等操作中可以被区别对待。 -
标量在跨设备操作中获得 VIP 待遇:
@_t_vi_继续解释说,无论设备如何,标量 tensor 都可以用于索引其他 tensor,因为 Python 数值和 CPU 标量会自动转换为目标 tensor 所在的设备。
提到的链接:
- CUDA Runtime API :: CUDA Toolkit Documentation:未找到描述
- GitHub - TimDettmers/bitsandbytes: Accessible large language models via k-bit quantization for PyTorch.:通过针对 PyTorch 的 k-bit 量化实现易用的 LLM。- TimDettmers/bitsandbytes
CUDA MODE ▷ #algorithms (1 messages):
- RelayAttention 与 Ring/Flash Attention 的对比咨询:
@lancerts询问了 RelayAttention 与 ring/flash attention 的对比情况,并链接到了 vLLM with RelayAttention integration 的 GitHub 仓库。该用户刚刚开始阅读关于 RelayAttention 的论文。
提到的链接:
GitHub - rayleizhu/vllm-ra: vLLM with RelayAttention integration:集成 RelayAttention 的 vLLM。通过在 GitHub 上创建账号来为 rayleizhu/vllm-ra 的开发做出贡献。
CUDA MODE ▷ #ring-attention (23 messages🔥):
- 命令行 GPU 重置技巧:
@iron_bound提供了一个重置 GPU 的潜在解决方案,建议使用命令sudo nvidia-smi --gpu-reset -i 0。他们还指出在nvtop中观察到 pid 3874970 正在运行。 - 通过重启 Pod 解决 GPU 问题:针对
@jamesmel关于 GPU 内存分配问题(内存未释放且没有 PID)的担忧,@andreaskoepf提到了重启 pod。 - CUDA 运行时错误难题:
@iron_bound在运行ring_flash_attn_varlen.py的反向传播(backward pass)时遇到了一个 CUDA 运行时错误,提示 “head_size should be a multiple of 8”(head_size 应为 8 的倍数)。 - 采样机制澄清:
@andreaskoepf解释了模型训练前向传播(forward pass)期间的 token 采样机制,指出 prompt 之后仅使用最后采样的 token,输入张量(tensor)形状为 (batch_size, 1)。 - 关注 Ring-attention 和 Log Sum Exp 教程:
@andreaskoepf创建并分享了一个用于 Ring-attention 实验的 “how-to log sum exp” notebook,@_t_vi_对 logsumexp 技巧表示了热忱,并分享了一个关于 sinkhorn-kernel 的相关项目。
提到的链接:
- iron-bound:Weights & Biases,机器学习开发者工具。
- ring-attention/notebooks/howto_log_sum_exp.ipynb at main · cuda-mode/ring-attention:Ring-attention 实验。可以通过在 GitHub 上创建账号来为 cuda-mode/ring-attention 的开发做贡献。
- GitHub - RulinShao/LightSeq: Official repository for LightSeq: Sequence Level Parallelism for Distributed Training of Long Context Transformers:LightSeq 官方仓库:用于长上下文 Transformer 分布式训练的序列级并行(Sequence Level Parallelism)。
- iron-bound:Weights & Biases,机器学习开发者工具。
- Lernapparat - Machine Learning:未找到描述。
CUDA MODE ▷ #off-topic (1 messages):
- 分享有趣的曼德博集合可视化:用户
@apaz分享了一个描绘 曼德博集合(Mandelbrot set) 的图片链接。URL 中的加密字符串暗示了该图片的增强安全性或唯一标识。
{kind=link}
Interconnects (Nathan Lambert) ▷ #news (4 messages):
-
Inflection 通过情感智能提升 Pi:
@xeophon.强调了 Inflection-2.5 的发布,这是来自 Inflection AI 的升级版 AI 模型,号称具有可与 GPT-4 和 Gemini 等主流模型竞争的性能。这一新模型已在共情 AI Pi 中实现,可在 iOS、Android 和 桌面平台 上使用。 -
对 Inflection-2.5 声明的怀疑:
@xeophon.分享了@HlibIvanov的一条 推文,批评了 Inflection-2.5 的功效,暗示它仅仅是 GPT-4 的蒸馏(distillation),并质疑其在 AI 建模方面的创新性。 -
Nato Lambert 表达兴奋之情:
@natolambert在一条 推文 中对不到一个月内各种模型的快速开发和发布表示兴奋,暗示 AI 的创新速度正在加快。
提到的链接:
- Inflection-2.5: meet the world’s best personal AI:我们是一家为每个人创建个人 AI 的 AI 工作室。我们的第一个 AI 名叫 Pi(代表 personal intelligence),是一个支持性的、具有共情能力的对话式 AI。
- 来自 Hlib Ivanov (e/acc) (@HlibIvanov) 的推文:当然,制作 GPT-4 的蒸馏版比从头开始训练 GPT-4 所需的 FLOPs 更少。我甚至懒得去做正式的基准测试,这显然是在 GPT-4 未过滤的数据上训练的,而且它…
Interconnects (Nathan Lambert) ▷ #ml-drama (48 messages🔥):
- 开源软件:一个令人不悦的话题?:
@natolambert分享了对开源软件相关写作反馈的沮丧,即使是富有帮助的帖子也经常收到刻板的指正,且很少受到社区的欢迎。 - 对社区反馈的吐槽:在承认反馈有用的同时,
@natolambert吐槽说开源软件(OSS)社区往往缺乏大局观,过度的批评可能会阻碍那些试图推广 OSS 的人。 - ML 政策讨论保持私密:
@dangf91和@natolambert讨论了开源和 Machine Learning (ML) 政策的争议性如何导致许多讨论无法进入公众视野。@natolambert指出这在一定程度上是政治性的,个人的立场在公开场合与私下场合往往不同。 - 对许可证讨论的批评:
@natolambert指出,虽然他公开参与有关 ML 的政治讨论,但批评往往集中在诸如术语使用不当等琐碎细节上。 - 澄清“开放”术语的困扰:
@xeophon.和@natolambert之间的对话强调了对 Mistral 或 Llama2 等模型进行分类的困难和困惑,因为业界错误地将专有模型标记为“开源”。
提到的链接:
Aggregator’s AI Risk:单一的 AI 永远无法让所有人满意,这对聚合者(Aggregator)商业模式构成了根本性威胁;解决方案是个性化 AI。
Interconnects (Nathan Lambert) ▷ #random (19 messages🔥):
- Claude-3 排名引发社区狂热:
@xeophon分享了一个链接,宣布 @Anthropic 的 Claude-3 排名发布,仅在三天内就获得了令人印象深刻的 20,000 张选票。Claude-3 的变体 Opus 和 Sonnet 引起了轰动,其性能足以与 GPT-4-Turbo 竞争,并与 GPT-4 旗鼓相当。 - 对 Anthropic 的 Gemini Ultra 的期待:
@natolambert表达了对 Gemini Ultra 发布的渴望,而@xeophon则对获取其访问权限并尝试 1M context window(上下文窗口)功能感到兴奋,特别是用于分析多篇学术论文。 - 截图的简便方法:针对
@xeophon询问生成某些图像的方法,@natolambert解释了在 Mac 上使用“全窗口截图”功能的方法,并分享了在command-shift-4后按空格键的小技巧,这是一个对博客和交流非常有用的工具。
提到的链接:
- 来自 lmsys.org (@lmsysorg) 的推文:🔥来自 Arena 的激动人心的消息,@Anthropic 的 Claude-3 排名出炉了!📈 Claude-3 激发了社区的巨大兴趣,推动 Arena 的流量达到前所未有的高度,在短短三天内获得了超过 20,000 张选票……
- 来自 Nathan Lambert (@natolambert) 的推文:我没预料到顶端会出现商品化,但所有这些都在不到一个月内发生了。在 G1.5 之后,我们本月还有一周时间来迎接 GPT5 和 Llama 3。Gemini 1.5, Mistral Large, Claude 3, In…
Alignment Lab AI ▷ #general-chat (1 messages):
- 热烈欢迎 Segmentationfault.:
@segmentationfault.对@748528982034612226的邀请表示感谢,并表达了尽管自己是新人,但仍渴望为该领域做出贡献。
Alignment Lab AI ▷ #oo (16 messages🔥):
- 早起的鸟儿未必有虫吃:
@joshxt强调了不要艾特所有人(@everyone)的重要性,特别是在凌晨 5 点,这被视为垃圾信息并被立即删除。这种不受欢迎的提醒导致了政策的快速变更,禁用了用户 ping 全员的功能。 - 对神秘提醒的好奇:
@ikaridev询问他们是否是被 @everyone 提醒的对象,随后从@joshxt处得知确实存在这样一条消息,但因属于垃圾信息已被删除。 - 禁用 @everyone 权限:在垃圾信息事件之后,
@joshxt幽默地向@ikaridev确认,用户现在已不再拥有 ping 全服务器的权限,暗示进行了快速的权限调整。 - Orca 数据集惊艳亮相:
@joshxt发起了关于 Microsoft 新发布的 Orca 数据集的讨论,分享了 Hugging Face 的链接 (https://huggingface.co/datasets/microsoft/orca-math-word-problems-200k),并询问是否有人正在利用它做一些有趣的事情。 - AI 界的宠儿:鉴于 Orca 数据集的讨论,
@twistedshadows.承认自己偏爱集成了 orca2 13b 的 “Psyonic-cetacean” 模型,而@joshxt则承认目前更青睐 “Claude 3 Opus”。
提到的链接:
- Angry Gary Oldman GIF - Angry Gary Oldman Everyone - Discover & Share GIFs:点击查看 GIF
- microsoft/orca-math-word-problems-200k · Datasets at Hugging Face:未找到描述
Alignment Lab AI ▷ #oo2 (10 messages🔥):
- 聊天室里的新面孔:
@jaxxks向早些时候欢迎过他们的@1168088006553518183表达了亲切的晚间问候。 - 众人集结:
@tcapelle和@aslawliet等用户加入频道,并发布了“Hello every1!”和“Hello friends! 👋”等通用问候语。 - Orca-2 头脑风暴会议开始:
@aslawliet介绍了 Orca-2 的项目概念,建议其针对更广泛的数据集,包括 FLAN 2021 以及来自 T0 和 Natural Instructions (niv) 的选择性 zero-shot (zs_opt) 样本。 - 讨论数据增强策略:
@aslawliet提出使用 Mixtral 进行数据增强,认为这是替代 GPT-4 的一种成本和时间效率更高的方案。 - 关于 AI 选择的轻松时刻:
@aslawliet幽默地怀疑是否有人愿意在当前项目中使用 Claude-3 Opus。
DiscoResearch ▷ #general (9 messages🔥):
- 不同约束下的语言模型选择:用户
@johannhartmann提到了适用于各种约束的不同模型:无约束时选择 Claude Opus 和 GPT-4;开源且内存充足时选择 DiscoLM-120B;内存受限时选择 VAGOsolutions/Sauerkraut LM-UNA-SOLAR-Instruct。 - 检索增强语言模型讨论:
@maxidl分享了一篇 arXiv 论文,讨论了检索增强语言模型(Retrieval-augmented language models)相较于传统模型的优势,并指出该论文有一章节关于检索器与 LLM 的联合训练,但该主题的研究尚不广泛。 - 德语模型推荐:
@cybertimon推荐了 Nous Hermes 2 Mixtral 8x7b,因其具备流畅的德语能力;而@johannhartmann建议探索 DiscoResearch/DiscoLM_German_7b_v1 以及其他模型,如 VAGOsolutions/SauerkrautLM-7b-HerO、mayflowergmbh/Brezn-7b 或 seedboxai/KafkaLM-7B-DARE_TIES-LaserRMT-QLoRA-DPO-v0.5。 - Hermes Mixtral 的准确性受到称赞:
@flozi00表达了对 Nous Hermes 2 Mixtral 8x7b 的积极体验,强调了它在第一次尝试时就能准确理解任务的能力。 - 德语模型对比咨询:
@johannhartmann询问是否有人将 Nous Hermes Mixtral 与其他针对德语提示词的 Mixtral 模型(如 Sauerkraut 或 DiscoLM)进行过对比,并指出据其所知,Hermes Mixtral 并没有进行过德语微调。
提到的链接:
Reliable, Adaptable, and Attributable Language Models with Retrieval:在海量网络数据上训练的参数化语言模型(LMs)展现出了卓越的灵活性和能力。然而,它们仍面临幻觉等实际挑战…
DiscoResearch ▷ #embedding_dev (13 messages🔥):
-
探索 OPUS 100 翻译质量:
@flozi00正在对 OPUS 100 数据集进行标注以评估翻译质量,发现只有不到一半的翻译质量较好。他们计划开发 Embedding 模型,通过嵌入距离(Embedding distance)来为翻译质量评分,这将有助于改进机器翻译(MT)模型和数据集。 -
针对翻译分类的 Prompt 微调:
@flozi00在经过大量的 Prompt 微调后,采用了 nous hermes mixtral dpo 模型对翻译质量进行分类。这展示了在翻译数据集中进行自动质量评估的潜力。 -
清洗数据集以获取“优质”翻译对:
@crispstrobe强调 OPUS 100 是从更大的语料库中随机选择的,包含许多特定上下文的配对,在预期设置之外往往会失效。建议创建具有通用“优质”配对的子集,以便在一般语境中更好地利用。 -
改进翻译质量的自动评估:
@flozi00提到正在更新他们的模型和数据集收集,以便更好地判断翻译质量。他们还打算迭代多个数据集以增强其收藏,并欢迎进一步的改进建议。 -
mMARCO 数据集获得 Apache 2.0 许可证:
@philipmay指出 mMARCO 数据集已添加 Apache 2.0 许可证,并引导关注 Hugging Face 上的数据集信息,尽管目前该平台尚不支持该数据集的查看器(Dataset Viewer)。
提及的链接:
- Translation Data Quality - a flozi00 Collection:未找到描述
- unicamp-dl/mmarco · Datasets at Hugging Face:未找到描述
- Data (Hint ID):未找到描述
LLM Perf Enthusiasts AI ▷ #claude (13 messages🔥):
- Opus 成为 SAT 学霸:
@jeffreyw128分享了 Opus 在 SAT 阅读部分获得了 800 分的满分,并链接到了包含结果的 Twitter 帖子(查看推文)。 - 对模型记忆(Memorization)的担忧:
@dare.ai针对 SAT 的成就提出了一个观点,即在海量模型中创建真正的留出集(Holdouts)以避免记忆(Memorization)面临挑战。 - Opus 赢得赞誉:
@nosa_表达了对 Opus 的钦佩,并幽默地威胁说如果有人告诉 Opus 这个赞美,就会发生冲突。 - Opus 在构建知识网络方面的能力提升:
@res6969测试了 Opus 从超过 35k tokens 的大型文档中构建知识网络的能力,评论称该模型在指令遵循(Instruction following)和上下文理解方面有所提升。 - 在 500 个名字中搜索被证明是困难的:
@jeffreyw128报告称,在使用包括 Claude Opus 在内的不同模型时,无法在 500 个名字中找到特定名字,这表明 AI 模型在处理此类任务时普遍存在困难。
LLM Perf Enthusiasts AI ▷ #prompting (1 messages):
由于只提供了一条消息且没有关于主题的具体讨论,因此无法生成摘要。如果提供更多上下文或消息,我将能够提供包含所需细节的摘要。
Datasette - LLM (@SimonW) ▷ #ai (5 messages):
- GPT-4 性能受到质疑:
@dbreunig对 GPT-4 在一项特定的、未公开的测试中的失败表示惊讶,但未提供有关测试性质或遇到的失败类型的详细信息。 - 可点击书架引发关注:
@xnimrodx分享了一篇博客文章,介绍了一个将书架图像转换为可点击区域的脚本,点击后可跳转至每本书的 Google Books 页面。该文章包含一个 demo 和一段展示功能的视频。 - 通过创意技术提高图书馆效率:
@xnimrodx表达了希望开发一个类似于“可点击书架”的应用程序,以帮助他身为图书管理员的妻子进行理架任务,并提到她的图书馆是教区系统中 35 所学校中最大的。 - 社区图书馆项目构想:
@dbreunig对创建一个玩具应用来帮助人们在镇上的小型图书馆登记书籍表现出兴趣,这表明了所讨论技术的实际应用。
提到的链接:
| [Making my bookshelves clickable | James’ Coffee Blog](https://jamesg.blog/2024/02/14/clickable-bookshelves/):未找到描述 |
Datasette - LLM (@SimonW) ▷ #llm (8 messages🔥):
- 调试模板崩溃问题:
@trufuswashington就创建常用场景模板时遇到的问题向专家 (@746595581086138409) 寻求建议;其中一个模板运行正常,而另一个模板不断导致llm命令崩溃。 - 分享错误输出:他们分享了错误输出,显示
llm命令由于变量插值过程中的TypeError(”expected str instance, NoneType found”)而失败。 - 正常与崩溃模板的对比:
@trufuswashington附上了两个 YAML 模板进行对比。正常的模板用于修改文本块,而有问题的模板用于对各种类型的代码相关内容提供简短解释。 - 找到崩溃原因:最终,
@trufuswashington发现了崩溃的原因——是因为模板提示词中出现了非预期的美元符号$。 - 美元符号是罪魁祸首:具体来说,错误是由崩溃模板中的“如果你这样做,我会给你 $100 小费”这一行触发的,这表明在提示词插值中处理特殊字符存在问题。
Skunkworks AI ▷ #off-topic (2 messages):
-
用 AI 创新合成类游戏:
@pradeep1148分享了一个名为“使用 Mistral 的 Infinite Craft 游戏”的 YouTube 视频,展示了一款合成类游戏,利用 Mistral 语言模型的能力将元素组合成新物品。 -
使用 Mistral 自动生成梗图:
@pradeep1148还发布了另一个 YouTube 视频链接,名为“使用 Mistral 和 Giphy 制作梗图”,演示了通过集成 Mistral AI 与 Giphy API 来创建梗图的过程,并附带了包含相关 Notebook 的 GitHub 仓库链接。
提到的链接:
- Infinite Craft Game using Mistral:让我们开发 Neal Agarwal 的网页游戏 Infinite Craft。这是一款“合成类游戏”,你从四个基本元素开始,不断重复组合元素对……
- Making memes with Mistral & Giphy:让我们使用 Mistral LLM 和 Giphy API 制作梗图 #llm #ml #python #pythonprogramming https://github.com/githubpradeep/notebooks/blob/main/Giphy%20Mistral.ipynb