ainews-fsdpqlora-the-answer-to-70b-scale-ai-for
FSDP+QLoRA:桌面级显卡运行 70B 规模 AI 的解决方案
Jeremy Howard 及其合作者发布了一款新工具,该工具结合了 FSDP、QLoRA 和 HQQ 技术,使得在仅有 24GB 显存 的 RTX 4090 等平价消费级 GPU 上训练 700 亿参数 (70b) 的模型成为可能。这克服了以往必须使用耗资超过 15 万美元的昂贵数据中心级 GPU 才能解决的内存限制。
该方法通过在多个 GPU 之间对量化模型进行分片(sharding),并利用梯度检查点(gradient checkpointing)和 CPU 卸载(CPU offloading)等技术,在桌面级硬件上实现了高效训练。博客文章详细阐述了整合这些方法时的挑战与解决方案,并强调训练大语言模型的成本已从 15 万美元显著降至 2500 美元以下。
此外,Twitter 上的简报还提到:Inflection AI 的 Inflection-2.5 模型在基准测试中以更少的计算量达到了与 GPT-4 相当的水平;Grok 的速度提升了 3 倍;以及 Yann LeCun 对大语言模型多步推理训练的讨论。
2024年3月7日至3月8日的 AI 新闻。我们为您查阅了 356 个 Twitter 账号 和 20 个 Discord 社区(326 个频道,2933 条消息)。预计为您节省阅读时间(以 200wpm 计算):366 分钟。
Jeremy Howard 等人带着一个新工具回归了,旨在克服进行 70B 规模训练(无论是预训练还是微调,我们并不在意)时的内存限制。通常 4 张 H100 需要花费 15 万美元,而桌面级 GPU 的成本不到 2500 美元。这些 GPU(如 RTX 4090)每张卡的显存上限为 24GB,但 70B 参数的 LLM 仅权重就需要超过 140GB。
关键点在于:游戏级 GPU 的性能与成本高出 10 倍以上的数据中心 GPU 相当!如果我们能使用这些便宜 10 倍(但速度几乎一样快)的显卡来训练大型语言模型,那就太棒了。但我们做不到,因为它们的内存要小得多。目前最好的数据中心显卡拥有 80GB RAM,而游戏显卡的上限是 24GB RAM。由于只有最大的模型才能产生最好的结果,因此大多数人基本上无法创建最好的模型。
QLoRA 的局限性
该博文还详细介绍了 QLoRA、HuggingFace 的支持以及他们遇到的限制:
QLoRA 并没有完全解决我们设想的问题,即在 24GB 显存的卡上训练 70B 模型,但它比之前的任何方法都更接近目标。当量化为 4-bit(即 0.5 字节)时,70B 模型占用 70/2 = 35 GB,这大于我们想要使用的 24GB 游戏 GPU。
他们还讨论了训练所需的内存需求,包括 Batch sizing,所有这些都使得所需内存远超单张 24GB 显卡。
FSDP - 全分片数据并行 (Fully Sharded Data Parallel)
- HF
transformers的device_map='auto'设置有一个巨大的缺点:每次只有一个 GPU 处于活动状态,因为其他所有 GPU 都在等待轮到自己。 - DDP - 仅在每个 GPU 上都有完整模型时才有效。
- Meta 的 FSDP 库(另请参阅 用于 FSDP 微调的 Llama-Recipes)将模型参数拆分到多个 GPU 上。“通过在当前层忙于计算的同时,智能地复制下一层的数据,这种方法有可能实现与 DDP 相比不降速的效果。”
FSDP 解决了 H100 级别 GPU 的内存限制问题——但一个拥有 4 张 H100、320GB RAM 的系统将耗资 15 万美元。
FSDP + QLoRA + HQQ
“我们认为,如果我们能使用 QLoRA 将模型大小减少约 400%(这样 70B 模型就能放入 35GB RAM 中),然后使用 FSDP 将其分片到两个或更多 24GB 消费级显卡上,那么剩下的 RAM 就足以训练模型了。”
2 张 RTX 4090 的成本不到 2500 美元。
FSDP 无法直接与 QLoRA 量化配合使用,团队想出了如何绕过 FSDP、PEFT 和 LoRA 库/算法中的假设,使这一切得以运转。团队还使用了 Gradient checkpointing、CPU offloading、FlashAttention 2 和 HQQ,这引发了更多的集成问题。博文中为想要深入研究的人提供了更多引人入胜的细节。
总体结论很明确:
目录
[TOC]
第 X 部分:AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,取两次运行中的最佳结果
明白了,这是重新格式化后的版本,包含了每个推文的直接链接:
发布与公告
- @inflectionAI: “Pi 刚刚获得了由 Inflection-2.5 驱动的重大升级,它在所有基准测试中都与 GPT-4 并驾齐驱,且训练所用的算力不到一半。” (437,424 次浏览)
- @jeremyphoward: “今天,我们与 @Tim_Dettmers、@huggingface 和 @mobius_labs 共同发布了 FSDP/QLoRA,这是一个新项目,让你能够在配备消费级游戏 GPU 的家用电脑上高效训练超大型(70b)模型。” (231,343 次浏览)
- @ibab_ml: “Grok 刚刚提速了 3 倍。更多改进即将推出。” (104,956 次浏览)
AI 能力与基准测试
- @ylecun: “我与 @lexfridman 的第三次访谈:通往人类水平 AI 的路径,以及为什么末日论者是错误的。” (221,901 次浏览)
- @ylecun: “Chain-of-Abstraction (CoA):训练 LLM 执行多步推理并使用工具。来自 @EPFL_en 和 @AIatMeta。” (79,272 次浏览)
- @DrJimFan: “又是莫拉维克悖论(Moravec’s paradox):人们认为展现出自我意识是突破,但事实上,‘伪造意识’比解决新颖数学或编程问题等推理任务要容易得多。后者需要真正的泛化能力。” (69,483 次浏览)
AI 行业分析与推测
- @abacaj: “除了 OpenAI,所有人都在部署新的 LLM……他们在憋什么大招?” (80,366 次浏览)
- @fchollet: “作为参考,2023 年各类生成式 AI 的整个消费者市场规模约为 20 亿美元。企业市场规模也差不多。到 2025 年,总额可能达到 100-120 亿美元。目前还不清楚花费超过一半的资金来训练单个模型是否有意义。” (68,014 次浏览)
- @AravSrinivas: “在微软和谷歌之间,谁执行得好,谁执行得差?你如何看待苹果在 AI 领域的表现?‘回答引擎’是否会像 20 年前谷歌的 Pagerank 给门户网站带来的变革一样?” (73,728 次浏览)
工程与 ML 技术
- @svpino: “每个机器学习工程师都应该知道的 10 项技术:1. Active learning 2. Distributed training 3. Error analysis 4. Invariance tests 5. Two-phase predictions 6. Cost-sensitive deployments 7. Human-in-the-loop workflows 8. Model compression 9. Testing in Production 10. Continual learning” (68,248 次浏览)
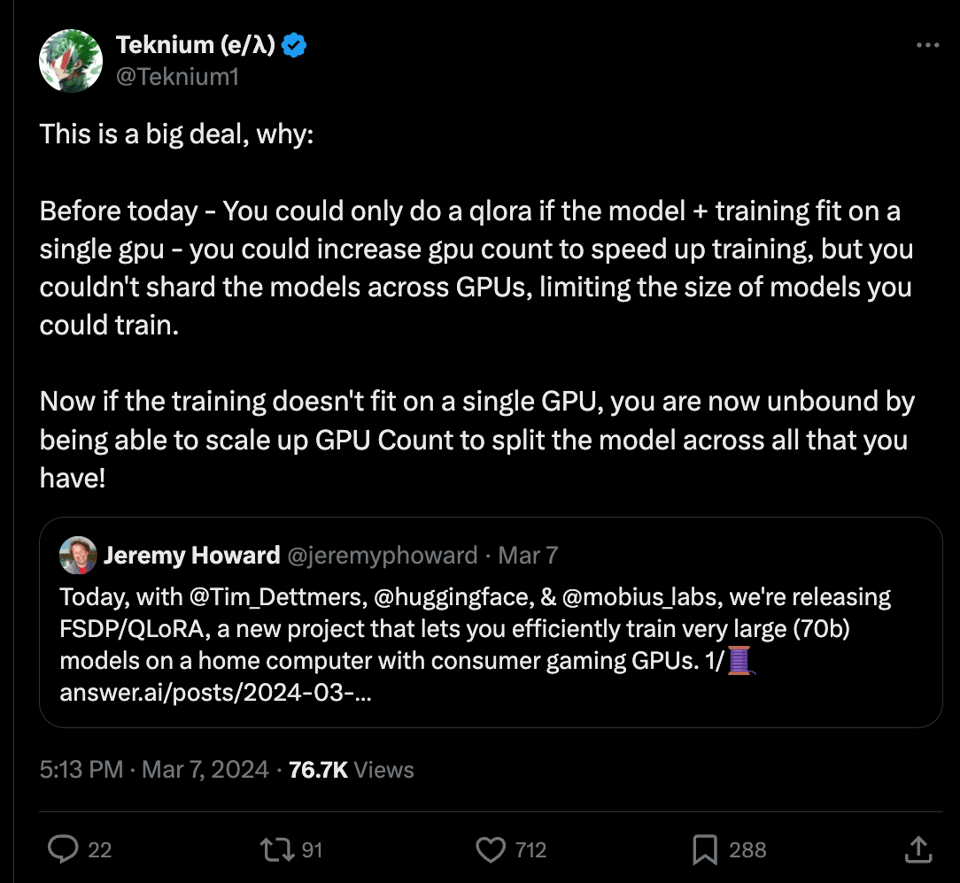
- @Teknium1: “这意义重大,原因在于:在此之前,只有当模型和训练能容纳在单块 GPU 上时,你才能进行 QLoRA 训练——你可以增加 GPU 数量来加快训练速度,但无法在多块 GPU 之间对模型进行分片(shard),这限制了可训练模型的规模。现在,如果训练无法容纳在单块 GPU 上,你不再受限,可以通过增加 GPU 数量将模型拆分到所有现有设备上!” (62,594 次浏览)
- @rasbt: “这实际上是一个非常出色的高能力 LLM-RAG 配置演示。作为早期评审员,我有幸对其进行了实验,并留下了深刻印象。我在我最近的一个 LoRA/DoRA 仓库上进行了测试,该仓库不可能包含在 Mistral 的训练数据中,我真的没预料到 Mistral 7B 模型在编程任务上表现得如此出色!” (61,178 次浏览)
梗与幽默
- @nearcyan: “真的结束了,字面意义上再也没人雇佣初级开发人员了” (227,247 次浏览)
- @yoheinakajima: “2 万+ GitHub Star,45+ arXiv 引用,NFT 二级市场交易额达 500 ETH,迎来 3 个孩子,同时还启动了一家风险投资基金,这是我的秘诀 👇” (57,543 次浏览)
- @cto_junior: “不—— Claude,别变得那么‘觉醒’(woke)” (56,159 次浏览)
第 0 部分:摘要之摘要之摘要
Claude 3 Sonnet (14B?)
- 内存高效 LLM 训练的进展:
- Gradient Low-Rank Projection (GaLore) 支持在单个 RTX 4090 GPU 上训练 Llama 7B LLM,将优化器状态的内存需求降低了 82% 以上 [Tweet]。这一突破可能会彻底改变 LLM 训练的可获得性。
- 一项涉及 FSDP 和 QLoRA 的合作允许在 RTX 3090 等消费级 GPU 上训练 70B 模型 [Blog Post],进一步推动了大模型开发的民主化。
- 关于将 GaLore 与 HQQ 和 bitsandbytes 等 1-bit 量化技术结合的讨论 [GitHub Repo],旨在微调期间实现潜在的复合内存节省。
- 前沿语言模型发布与对比:
- Inflection AI 声称其 Inflection-2.5 模型在基准测试中与 GPT-4 持平,同时训练所用的计算量不到一半 [Tweet],尽管其官方博客文章中并未强调这一说法。
- 对 GPT-4 发布的期待日益高涨,因为据一些用户称,像 Claude 3 这样的竞争对手似乎表现优于当前的 OpenAI 模型。
- 关于 Sonnet、Opus 和 Mixtral 等模型性能的讨论,其中 Sonnet 因其出色的性价比而受到赞誉,在 5k 上下文和 1200 响应长度下,成本低至 0.03 美元。
- 创新 AI 应用与工具:
- Doodle Wars 是一款多人游戏,玩家在其中竞争涂鸦技巧,并由神经网络进行评估 [Doodle Wars],展示了 AI 的游戏化潜力。
- LangChain 和 Gradio 被用于构建餐厅名称和菜单生成器应用 [Demo],举例说明了语言模型的创意用途。
- 发布了超过 660 万份州和联邦法院判决书及其数据集和 embeddings [Tweet],使得由 AI 驱动的法律判例探索成为可能。
- Prompt Mixer 是一款新的桌面工具,用于构建、测试和迭代带有版本追踪的 AI prompts [Prompt Mixer],旨在简化 prompt engineering 工作流。
- 高效 Attention 机制的进展:
- 关于 RelayAttention 机制及其与 ring/flash attention 区别的讨论,并附带一个展示带有 RelayAttention 的 vLLM 的 GitHub 仓库 [GitHub]。
- 分享了使用 CUDA 实现的 Flash Attention,例如一个约 100 行 CUDA 代码的极简版本 [GitHub]。
- 正在研究来自 NVIDIA FlashAttention 仓库的 CuTe DSL,以优化 tensor core 的利用率 [GitHub]。
- 关于 CUDA kernels 中 thread coarsening 和 vectorized operations 等技术对性能影响的基准测试和讨论。
Claude 3 Opus (8x220B?)
-
Nitro 模型加速领域发展:OpenRouter 宣布推出 Nitro 模型,如 Mixtral、MythoMax 和 Llama 70B,这些模型由 Groq 提供支持,具有更高的速度和成本效益。现已提供关于 performance timelines、JSON mode 和 dynamic routing 等新开发者功能的文档,并且速度提升的 Mistral 7b 0.2 Nitro model 将上下文扩展到了 32k。
-
GaLore 优化器引发全球关注:GaLore 和 CAME 优化器等技术因其在内存效率和性能提升方面的表现而备受关注;然而,社区在关注的同时也存在质疑,并呼吁进行实证复制以及理解版本控制的复杂性。用户如
@tiagoefreitas分享了见解,指出 GaLore 使得在单张 RTX 4090 GPU 上训练 Llama 7B LLM 成为可能。 -
通过 FSDP/QLoRA 实现 AI 训练民主化:分享了
@jeremyphoward关于 FSDP/QLoRA 的 推文,标志着一项使在家庭 GPU 上训练大型模型成为可能的合作;同时@fx2y指出了对 HQQ 和 bitsandbytes 等量化技术的支持,并通过 GitHub 仓库链接 进行了分享。 -
显微镜下的 Inflection-2.5:尽管有显著的性能声称 Inflection-2.5 在更低算力下可与 GPT-4 媲美,但
@swyxio强调了 Inflection 官方沟通中的一个空白,观察到在其详细介绍 Inflection-2.5 的博客文章中并未提及这一说法。 -
关于拟任 AI 安全主管的冲突:针对拟任命 Paul Christiano 担任美国 AI 安全研究所(US AI Safety Institute)职位的担忧浮出水面,这在 NIST 内部引发了危机,员工威胁要辞职并引发反抗。VentureBeat 的文章 详细描述了这场冲突以及 Christiano 关于 AI 可能导致生存风险的争议性观点。
ChatGPT (GPT4T)
-
Meme 生成与 AI 集成:Nous Research AI Discord 展示了使用 Mistral LLM 和 Giphy API 的 Meme Generation Fusion(Meme 生成融合),通过 YouTube 教程和 GitHub 仓库演示了创意的技术集成与实际应用。
-
AMD 参与 AI 硬件优化:LM Studio Discord 强调了 AMD 对 AI 硬件的关注,其 CEO 苏姿丰(Lisa Su)解决了 AI 服务器的 GPU 固件问题。AMD 的举措包括指导如何在 AMD Ryzen™ 和 Radeon™ 上运行 LLM,详见 Tom’s Hardware 和 AMD 社区文章。
-
Claude 3 的多样化应用与 RAG 改进:LlamaIndex Discord 展示了 Claude 3 在 AI 应用中的多功能性,配合 LlamaIndex 的工具增强了 RAG 模型。新的进展包括用于优化向量搜索结果的 Jina reranker (
jina-reranker-v1-base-en),如 Twitter 上所分享。 -
AI 开发中的效率与 GPU 选择:LM Studio Discord 的讨论强调了 AI 工作中 电源供应和 GPU 选择 的重要性,建议为 RTX 3090 配备至少 750W 的 PSU,并考虑使用 Razer Core X eGPU 外接显卡盒。这些硬件选择对于高效运行高需求 AI 模型至关重要。
-
LlamaIndex 中的集成与检索挑战:LlamaIndex Discord 还深入探讨了 集成与检索挑战,例如旧版本文档的缺失以及多模态数据存储和检索的问题。通过 GitHub gists、博客文章和文档页面(如 Slack 机器人学习指南)促进了解决方案的讨论。
-
CUDA 学习资源与效率:CUDA MODE Discord 专注于 CUDA 编程教育和针对大模型训练的内存高效技术,为初学者推荐了 CUDA 讲座,并讨论了 Gradient Low-Rank Projection (GaLore) 作为一种内存高效的训练技术。GaLore 能够以较低的内存需求训练大模型,详见 arXiv 论文。
-
AI 模型性能与硬件讨论:在各个 Discord 频道中,AI 模型性能对比和硬件优化 是关注的重点。讨论范围从模型效率的提升(如 AMD 的 AI 硬件参与和 CUDA 的内存高效训练技术),到 AI 开发中 GPU 选择和电源供应的实际挑战。
PART 1: High level Discord summaries
Nous Research AI Discord 摘要
-
梗图生成融合:一段 YouTube 教程 及相应的 GitHub 仓库 展示了如何结合 Mistral LLM 与 Giphy API 来创作梗图。这种将幽默融入技术的展示在 off-topic 频道引起了关注。
-
追求高效 AI:社区正在讨论将 GaLore 优化器 与其他 GitHub 贡献相结合,作为提高 AI 模型训练计算效率的方法。
-
神经网络涂鸦大获成功:一款名为 Doodle Wars 的新型多人游戏让玩家在涂鸦技能上一决高下,并由神经网络进行评估。该游戏可在 Doodle Wars 体验,强调了 AI 在游戏化方面的潜力。
-
提升语言模型的推理能力:Nous Research 发布了 Genstruct 7B,它能够针对复杂场景生成问题,从而增强 AI 的逐步推理能力——相关项目和下载可在 HuggingFace 页面 获取。
-
欧盟关注 Microsoft 与 Mistral 的动向:在 general 频道中,Microsoft 与 Mistral AI 的交易因欧盟的监管审查而受到关注,引用的 美联社新闻文章 强调了调查的广泛性。
-
访问与评估 GPT-4:ask-about-llms 频道的对话涉及通过 Corcel.io 等平台访问 GPT-4,并讨论了 LLM 预训练(pretraining)与微调(fine-tuning)的区别,同时提到了 LoRA 和 GaLore 等优化器技术。
LM Studio Discord 摘要
LM Studio 发布 0.2.16 版本:LM Studio 的最新版本为 0.2.16,解决了之前的终端运行错误,并处理了 GLIBC 或 LIBCBlast 库问题。兼容性讨论突出了 gemma 7b gguf 和 starcoder2 模型的挑战。如需 GGUF 模型的支持,请参考 了解更多关于 GGUF 的信息。
AMD 对 AI 硬件持乐观态度:AMD 首席执行官苏姿丰(Lisa Su)亲自介入解决 Tiny Corp 的 GPU 固件问题,预示着 AI 应用的潜在改进。AMD 关于 使用 AMD Ryzen™ 和 Radeon™ 运行 LLM 的文章可以帮助用户在不依赖互联网的情况下利用 AI。
重新考虑 AI 的电源供应单元 (PSU):讨论建议至少使用 750W 的 PSU 来驱动 RTX 3090,或者使用 Razer Core X eGPU 外接显卡盒作为替代方案。关于语言模型高效硬件设置的辩论考虑了 VRAM、能效和成本效益。
在 LM Studio 中集成与选择 GPU:有用户呼吁在 LM Studio 中增加允许选择特定 GPU 的功能,此前曾发生软件默认使用集成显卡,导致运行高需求 AI 模型时出现性能问题的情况。
Open Interpreter 用法的演进与模型共享:#open-interpreter 频道的对话包括在 Open Interpreter 的 Python 脚本中使用命令 interpreter.system_message = "Your message" 来实现自定义系统消息。Hugging Face 上 LHK_DPO_v1 等模型的链接分享突显了社区在交流 AI 见解方面的努力 LHK_DPO_v1_GGUF。论坛上提出的关于 FusionNet_7Bx2_MoE_14B 模型上下文长度限制的担忧可以在这里找到。
LM Studio Beta 版本发布的讨论热度:#beta-releases-chat 频道对即将发布的新版本充满期待,社区成员们在调侃发布时间,并就更新的到来进行幽默的互动。
LlamaIndex Discord 总结
-
调查开始!LlamaIndex 需要您的反馈:LlamaIndex 邀请用户参与一项 3 分钟的用户调查,旨在改进其服务,特别是文档、Demo 和教程。可以通过此 SurveyMonkey 链接或相关的推文参与调查。
-
Claude 3 在多功能性方面表现出色:一份关于使用 LlamaIndex 工具实现 Claude 3 多样化应用的新指南现已发布视频版,涵盖了 Vanilla RAG、Routing 以及 Sub-question query planning,详见 Twitter 公告。
-
新 Jina Reranker 增强 RAG:LlamaIndex 分享了 Jina 的新重排序工具 (
jina-reranker-v1-base-en),该工具旨在通过优化向量搜索结果来改进检索增强生成 (RAG) 模型,详情见 Twitter 帖子。 -
CodeHierarchyNodeParser:代码理解的下一个飞跃:LlamaIndex 发布了一种名为
CodeHierarchyNodeParser的突破性技术,用于将大型代码文件解析为分层结构,这可能会彻底改变处理代码的 RAG/Agent。该技术由 ryanpeach 在 Twitter 上介绍。 -
解决 LlamaIndex 集成和检索挑战:社区讨论强调了一些挑战,例如 旧版本文档不可用、Chat Engine 与 NodeWithScore 的 集成陷阱、关于 多模态数据 存储和检索的困惑、评分算法自定义 以及 数据持久化 问题。这些主题在多个资源中得到了解答,包括 GitHub gists、博客文章和文档页面,例如 Slack 机器人学习指南 和 GitHub 上的向量存储。
Perplexity AI Discord 总结
-
Claude 3 Opus 使用限制辩论:Claude 3 Opus 是一个讨论焦点,成员们对 Perplexity AI 计划中限制为 5 次使用表示担忧。辩论涉及订阅模式的成本效益、每日消息限制,并与 ChatGPT Plus 等其他服务进行了比较。
-
Perplexity AI 的技术故障排除:用户报告了在使用 Perplexity AI 的图片生成和重写功能时遇到困难。建议包括重置浏览器数据以及联系 support@perplexity.ai 获取进一步帮助。
-
AI 模型的效率和性能比较:用户讨论了包括 Inflection-2.5 在内的各种 AI 模型的相对性能,并探讨了模型比较的选项。同时,Sonnet 被推荐作为基准测试 AI 效率的工具。
-
分享链接深化对 AI 的理解:在各个频道中,用户分享了 Perplexity AI 链接 来比较平台、学习使用 AI 资源、探索历史进展、理解 AI 的角色、质疑 AI 创作中的署名权,并探讨了关于 AI 情感的争议性话题。
-
关于 Perplexity API 进展的询问和讨论:关于 Perplexity API,用户询问了 Perplexity Discover 和 RAG pipeline 的功能。此外,还讨论了各种 AI 模型最大 Token 输出的问题,强调了上下文窗口 (context window) 和微调 (finetuning) 带来的限制。
Eleuther Discord 摘要
-
针对定制需求优化评估:
@pminervini寻求在 harness 中定制输出格式,并提出了一个两步生成过程;同时,@baber_建议修改generate_until方法,并提供了一个 GitHub 链接作为潜在的起点。 -
环境配置之争:GPT-NeoX 应该使用 Docker 还是本地环境:AI 爱好者
@biiter和@tastybucketofrice就 GPT-NeoX 开发的环境设置方法展开了辩论,讨论了 Docker 的一致性与本地设置的优劣,而@tfidia建议使用 NVIDIA NGC 容器作为简化 Apex 和 CUDA 依赖项的解决方案。 -
GaLore 优化器引起全球关注:GaLore 和 CAME 优化器因其在显存效率和性能提升方面的表现而备受关注;然而,社区在感兴趣的同时也持有怀疑态度,并呼吁进行实证复现以及理解版本复杂性。
-
数据驱动:发布新的韩语基准测试:
@gson_arlo介绍了两个新的韩语评估数据集 Hae-Rae Bench 和 K-MMLU,旨在评估语言模型在韩语特定知识方面的表现,并邀请大家参与多语言模型评估的贡献。 -
寻求 AI 的简洁性:新人
@shida3916表达了探索日常 AI 应用并寻求简单答案的愿望,引发了关于社区内此类 AI 咨询适当论坛的讨论。
OpenAI Discord 摘要
-
Sonnet 表现优于 ChatGPT:
@aaron_speedy认为 Sonnet 的表现优于 ChatGPT 3.5,提供了诸如图片上传等功能,并可能支持文件上传。同时,由于感知到在 Claude 3 等模型面前的竞争落后,@futuremachine和@drinkoblog.weebly.com等用户对 GPT-4 的发布充满期待。 -
有效的 Prompting 是模型利用的关键:
@.vilden等用户强调了精准 Prompting 在最大化 GPT 3.5 等模型性能方面的重要性,而不是使用可能阻碍性能的冗长 Prompt。 -
抽认卡生成 AI 引发关注:
@khaledoo.询问了一款将讲义 PDF 转换为抽认卡 (flashcards) 的 AI 工具,引发了用户间关于该工具能力和内容准确性的讨论。 -
GPT-4 出现重复回答:
@spikyd反馈了对 GPT-4 重复回答和多语言错误的沮丧,这引发了与@dojan1就潜在底层问题和解决方法进行的交流。 -
解决 ChatGPT 的局部技术问题:
@pteromaple等用户建议将语言设置更改为“自动检测 (Auto-detect)”并刷新浏览器 (F5) 来解决 ChatGPT 无响应的问题。@joachimpimiskern和@pteromaple确认了语言设置导致界面崩溃的问题,暗示可能存在 Bug,而@meteopx则使用 VPN 来规避 ChatGPT 的区域访问限制。
HuggingFace Discord 总结
-
AI 安全主管引发争议:Paul Christiano 预计将被任命为美国 AI Safety Institute 成员,这在 National Institute of Standards and Technology (NIST) 内部引发了动荡。由于 Christiano 对 AI 存在性风险的观点,员工出现了反抗并威胁辞职,详情见 VentureBeat 文章。
-
编程领域的 AI 优化:讨论了使用 DeepSeek-Coder instruct 和 OpenCodeInterpreter 论文 来通过 AI 优化 shader 代码,同时这项代码处理综述工作 提供了关于 AI 在编程任务中应用的见解。
-
探索 AI 在地缘政治中的未来:针对西方国家与中国截然不同的 AI 战略展开了激烈辩论,涉及审查制度、不对称战争以及基于训练数据担忧的 AI 监管潜力等问题。
-
HuggingFace 上分享的 AI 工具与模型:重点介绍了新资源,包括位于 HuggingFace Spaces 的 Arxiv CS 论文 RAG 演示;Google Gemma 的微调演示,可在 HuggingFace Spaces 获取 notebook;HuggingFace 上一个新的 16k 上下文预训练 encoder 模型;以及在 YouTube “Let’s Build GPT” 中分享的构建 GPT 的教育资源。
-
Diffusion 模型开发挑战:讨论了将 SDXL-Lightning LoRA 与标准 SDXL 合并的尝试,ByteDance 组织在 HuggingFace 讨论帖 中提供了训练建议。
-
AI 学习与发现:用户对协作和学习用于数据分析的 Generative AI 以及其他 AI 应用表现出浓厚兴趣,展现了对共享学习经验和共同学习伙伴关系的积极态度。
-
创意 AI 项目与贡献:创新项目包括
@andysingal使用 ChatML 微调的 Gemma(模型卡片见此处);托管在 Hugging Face Hub 上的数据集 CLIP 索引;以及@chongdashu开发的餐厅名称和菜单生成器应用,附有 Medium 文章 和 演示。 -
技术讨论兼具幽默与互助:从关于 retriever 的双关语到在 Raspberry Pi 上运行 70B 模型的宏伟目标,社区成员就 Google Colab 的机器学习模型推荐以及 BertModel 中的 attention 权重映射等话题进行了既幽默又有帮助的交流。
LAION Discord 摘要
-
AI 图像生成器引发关注:针对 AI 图像生成器 Sora 的替代方案正被积极讨论,据报道许多项目都在使用 MagViT2 作为基础。与此同时,对过高营销成本的担忧(每笔转化花费 $7,099 仅带来 $100 销售额)引发了关于需要更高效策略的讨论。
-
Midjourney 的抓取恐慌引发幽默与批评:针对 Midjourney 成员因 AI 生成图像被抓取而担心“安全问题”的情况,社区中出现了笑声和批评。此外,Midjourney 使用的一份艺术家名单也引发了争议,名单中包含从 Warhol 到一名 6 岁儿童在内的各种姓名。
-
SVD 训练故障影响 Stable Cascade:用户报告称 SVD 更新在 Stable Cascade 的训练过程中引入了明显的停顿,导致 2 分钟的中断,从而阻碍了效率。
-
大语言模型(LLM)的效率焦点:热烈的讨论涉及了当前 Large Language Models (LLM) 的低效问题,像
@mkaic这样的人士主张训练更高效的稀疏/小型网络以及改进这些模型中训练数据的压缩潜力。 -
关于剪枝和模型效率的前沿讨论:工程社区深入探讨了与模型剪枝(Pruning)和泛化能力相关的挑战,思考通往更高效架构的路径。一篇新论文被引用以讨论这些话题。同时,一个新的 4K PixArt 项目 PixArt Sigma 宣布首次亮相,该项目专注于 Text-to-Image 生成,尽管目前仅使用 600m 参数在文本表现上存在一些问题。
OpenRouter (Alex Atallah) Discord 摘要
-
Nitro 模型加速该领域:Alex Atallah 宣布推出 Nitro 模型,如 Mixtral、MythoMax 和 Llama 70B,这些模型由 Groq 提供支持,具有更高的效率和性价比。关于性能时间线、JSON 模式和动态路由等新开发者功能的文档已上线。速度提升的 Mistral 7b 0.2 Nitro 模型将上下文扩展到 32k,并在 OpenRouter 网站和 Twitter 上进行了演示。
-
Sonnet 在节省成本方面表现出色:社区讨论重点关注了 Sonnet 极佳的性价比,在“5k 上下文和 1200 响应长度”的场景下,成本低至 0.03,在可负担性方面领先于竞争对手。
-
解读审核层:澄清了 OpenRouter 如何应用独特的审核层,这可能导致比直接与 OpenAI 或 Anthropic API 交互时更多的拒绝。Alex Atallah 还对 Anthropic 为 OpenRouter 提供的服务器端审核细节提供了额外见解。
-
数据使用政策备受关注:关于 Anthropic 是否使用客户内容进行模型训练的问题受到了询问。相关支持文章的链接引导大家达成共识:来自付费服务的内容可能被免于训练用途。
-
成本与吞吐量:社区分析:公会讨论了 Nitro 模型 增强的吞吐量和多样化的定价层级,特别注意到 Mixtral 8x7b instruct nitro 的费率调整为 0.27/1M tokens。
CUDA MODE Discord 总结
- 学习 CUDA 之道:对于 CUDA 和并行编程的新手,建议从该 Discord 频道为完全初学者准备的讲座开始,并建议同时学习相关书籍,以获得更丰富的学习体验。
- CUDA 共享内存利用:研究人员正在研究 NVIDIA FlashAttention 仓库中的 CuTe DSL,以优化 Tensor Core 的利用率,同时讨论围绕线程粗化(thread coarsening)和向量化操作等 Kernel 优化的性能展开。
- 大模型训练的内存高效技术:如 arXiv 论文所述,Gradient Low-Rank Projection (GaLore) 提供了一种降低内存需求来训练大模型的方法,甚至可以在单块 RTX 4090 GPU 上运行;同时,一种结合了 FSDP 和 QLoRA 的方法实现了在标准游戏 GPU 上微调 70b 模型,详情可见 Answer.AI。
- Ring-Attention 实践:涉及 RelayAttention 的技术问题正在讨论中,有报告称在 16k 分辨率下训练时会出现系统故障,以及在通过 pip 安装 flash-attn 后,在两块 GPU 上使用 ring-llama 时推理过程会停滞。
- PyTorch 设备间通信澄清:由于自动转换(早期设计决策的遗留物),PyTorch 中的标量可以被 CUDA Tensor 索引,但这种自动传输也可能导致意想不到的低效率。
Latent Space Discord 总结
GaLore 激发 GPU 潜力:用户 @tiagoefreitas 分享了来自 @AnimaAnandkumar 的见解,指出 Gradient Low-Rank Projection (GaLore) 使得 Llama 7B LLM 能够在单块 RTX 4090 GPU 上进行训练,这可能会改变预训练和微调阶段的内存效率基准,并可能通过 1-bit 量化进一步增强。
显微镜下的 Inflection-2.5:尽管有显著的性能声称 Inflection-2.5 以更低的计算量媲美 GPT-4,但 @swyxio 指出了 Inflection 官方沟通中的差距,观察到在详细介绍 Inflection-2.5 的博客文章中并未提及这一说法。
利用 FSDP/QLoRA 实现 AI 训练民主化:@fanahova 分享了 @jeremyphoward 关于 FSDP/QLoRA 的推文,标志着一项使在家庭 GPU 上训练大模型成为可能的合作,同时 @fx2y 指向了对 HQQ 和 bitsandbytes 等量化技术的支持,并通过 GitHub 仓库链接进行了分享。
Yann LeCun 阐述 AI 前景:讨论转向了 Yann LeCun 参加的 Lex Fridman 播客节目,他在节目中分享了对 Meta AI 的愿景、当前 LLM 的局限性以及 Contrastive Learning 未来的前景。
个人 AI 中的数据隐私担忧:@swyxio 讲述了他们使用个人传记 AI Life Story 的经历,促使 @tiagoefreitas 鼓励开发本地托管的应用以获得更好的数据安全性。
深入探索 GPT:@ivanleomk 和 @1123457263638683770 主持了一场关于 GPT-2 论文的研讨会,重点介绍了概念解释和实现材料,同时讨论中澄清了“causal attention”,并介绍了一个 LLM 可视化工具。
LangChain AI Discord 总结
-
LangChain JS 仍在追赶 Python:尽管
@0x404blockchainnotfound提出了疑问,但目前仍无明确证据表明 LangChain JS 库 已实现与 Python 版本的功能对等;用户转而讨论了相关的工具问题,例如 Python 中 Finished Agent 事件的延迟,以及使用 PyPDFLoader 时的格式化挑战。 -
永无止境的 AGI 辩论:来自 Hacker News 关于 AGI 的讨论蔓延到了这里,虽然没有达成定论,但引发了关于 LangChain 工具和 ReACT Agent 的并行讨论。关键问题仍未得到解决,表明需要对该主题进行更深入的技术探讨。
-
Redis 记忆混淆:
@justanothergraphguy正在处理 Redis 聊天链中输出结构的复杂问题,其中 “HumanMessage” 错误地出现在AIMessage中,这凸显了交互过程中记忆管理的潜在缺陷。 -
视觉模型成为焦点:
@vru.shank邀请社区参加与 MultiOn 和 Quizizz 合作的研讨会,主题是将视觉模型集成到生产环境中,并承诺分享来自 AI 应用前线的见解。 -
Prompt Mixer:开发者的新宠?:
@tomatyss介绍了 Prompt Mixer,这是一款擅长编写和迭代 AI Prompt 的桌面应用程序,同时还提供了一份教程,介绍如何通过自定义连接器扩展该工具,标志着向更个性化、更高效的 AI 开发工作流迈进。
DiscoResearch Discord 总结
-
寻找“酸菜味”(德语风味)的 AI:
@johannhartmann提到 德语微调模型 存在缺口,强调 Nous Hermes Mixtral 并不支持德语 Prompt,并将其与 sauerkraut 或 discolm mixtrals 进行了对比。 -
DNA 的新伙伴:
@rasdani介绍了 Evo 架构——由 TogetherAI 开发的 Striped Hyena,专门用于 DNA 序列分析。关于其在生物学领域应用的详细信息可以在他们与 Arc Institute 合作开发的博客文章中找到。 -
调优 Hermes 的和谐度:
@flozi00正在优化 Nous Hermes Mixtral DPO 模型,并构建了一个 Argilla space,用于评估来自 Google Translate、DeepL 和 Azure Translate 的翻译效果。可以通过他们的 HuggingFace 集合为衡量翻译对质量做出贡献。 -
数据集困境讨论:
@philipmay遇到了 mMARCO 数据集的许可和访问问题,该数据集现在采用 Apache 2.0 许可,但在 HuggingFace 上查看数据集时需要排除故障。 -
将德语与 SPIN 策略融合:
@johannhartmann利用德语转换后的数据集进行 Mistral 合并,合并后的模型反应各异,并计划近期分享该数据集;同时@crispstrobe实验发现 Brezn3 在 EQ-Bench (v2) (de) 上超越了 Brezn-7b,尽管@johannhartmann尚未确认是否进行了特定的 DPO 修改。
LLM Perf Enthusiasts AI Discord 总结
- AI 中的命名难题:
@res6969指出,名称对于模型来说很难准确处理,尽管未引用具体实例或模型。 - Claude 函数调用的突破:
@res6969报告了 Claude 中 function calling 的进展,证实其处于运行状态,但未提供具体示例或结果。 - Claude 的幽默恰到好处:
@res6969认为 Claude 的输出既 “搞笑又正确”,但未指明该表现的具体背景。 - Claude 调用中 XML 的必要性:
@res6969证实 Claude 的函数调用在配合使用 XML 标签 时效果显著,这暗示了 Claude 实现最佳函数调用性能的技术要求。 - XML 标签:一把双刃剑:
@pantsforbirds对在 Prompt 生成器中使用 XML 标签 的复杂性表示担忧,暗示其在实现和使用中可能存在困难。
Datasette - LLM (@SimonW) Discord 摘要
- GPT-4 的意外短板:成员们对 GPT-4 在某项未指明测试中的欠佳表现感到惊讶,这凸显了其开发过程中仍有改进空间。
- 别出心裁的可点击书架:一个用于生成可点击书架图像并链接到 Google Books 的新颖脚本吸引了成员们的注意,参考资料包括一篇 博客文章 和一个 演示项目。
- 图书馆技术进步引发关注:自动化书架管理的想法激发了人们的兴趣,特别是考虑到它在简化大型馆藏排架检查任务方面的潜力。
- 规模化图书馆管理:一位成员分享了关于大规模图书馆管理的见解,提到其合伙人负责监管一个拥有 35 所学校的教区系统中最大的学校图书馆,其规模堪比一些公共图书馆。
- 小图书馆,大数据:有人提出了开发一个小规模 App 来为社区微型图书馆的书籍编目的构想,这体现了利用编目和数据管理原则的个人项目趋势。
第二部分:分频道详细摘要与链接
Nous Research AI ▷ #off-topic (17 条消息🔥):
- 迟到的道歉:
@teknium承认在很长一段时间后才看到 Twitter 上的私信,并为漏掉的沟通表示歉意,幽默地用 “xD” 表达了遗憾。 - 使用 Mistral 制作表情包:
@pradeep1148分享了一个名为 “Making memes with Mistral & Giphy” 的 YouTube 视频 以及一个 GitHub 仓库,其中包含一个使用 Mistral LLM 和 Giphy API 生成表情包的 notebook。 - 关于 Nous 起源的询问:
@pier1337询问 Nous 组织是否起源于法国,@kainan_e回应澄清其灵感源自希腊语 “νοῦς”(意为智慧),而非法语。 - 卓越笔记技巧建议:
@sanketpatrikar寻求关于改进单个 Markdown 笔记文件使用体验的建议,@thilotee提供了多项推荐,包括使用优秀的文本编辑器、访问 AlternativeTo 等替代软件网站,以及探索 Zettelkasten method。 - Doodle Wars 游戏发布:
@om7059介绍了 Doodle Wars——一款多人游戏,玩家需在 15 秒内涂鸦指定物体,由神经网络为作品评分。得分最高的玩家赢得该轮。在 Doodle Wars 体验游戏。
提到的链接:
- Making memes with Mistral & Giphy:让我们使用 Mistral LLM 和 Giphy API 制作表情包 #llm #ml #python #pythonprogramming https://github.com/githubpradeep/notebooks/blob/main/Giphy%20Mistral.ipynb
- Doodle Wars:未找到描述
- Getting Started • Zettelkasten Method:未找到描述
- Noûs — Wikipédia:未找到描述
- Nous - Wikipedia:未找到描述
Nous Research AI ▷ #interesting-links (34 messages🔥):
-
Claude 3 Opus 在切尔克斯语翻译上展现魔力:
@hahahahohohe分享了关于 @AnthropicAI 的 Claude 3 Opus 的非凡体验,展示了其卓越的俄语-切尔克斯语(Circassian)翻译能力,即使在只有 5.7K 样本的有限数据集下,也超越了预期和之前的模型。然而,后来澄清该模型可能已经接触过切尔克斯语的信息,这强调了关于模型能力准确数据的重要性。 -
探索 GitHub 对 AI 的贡献:
@random_string_of_character发布了 GitHub 上的 GaLore 链接,鼓励社区评估其价值,并建议将其与 low-bit optimizers 结合使用,以实现潜在的计算效率提升。 -
零一万物(Yi Technology)挑战长文本理解极限:
@thilotee分享了一个 Reddit 帖子 和一个 Hugging Face 链接,讨论了 Yi-34B-200K 基座模型的更新。该更新将其在“大海捞针”(Needle-in-a-Haystack)测试中的表现从 89.3% 大幅提升至 99.8% 的准确率,预示着该模型在处理长上下文方面的持续增强。 -
稀疏混合模型实现深度理解:
@shashank.f1指向了一个 YouTube 视频,其中与 🤗 社区深入探讨了像 Gemini 这样采用稀疏混合专家(MoE)架构的模型,这些模型有潜力在单个 Prompt 中摄取并推理整本书籍和电影的内容。
提到的链接:
- An Qu (@hahahahohohe) 的推文:今天在测试 @AnthropicAI 的新模型 Claude 3 Opus 时,我见证了一些如此令人惊讶的事情,简直感觉像是个奇迹。虽然讨厌听起来像标题党,但这确实是当时的感受。…
- Yi: 01.AI 的开源基础模型:我们推出了 Yi 模型家族,这是一系列展示了强大多维能力的语言和多模态模型。Yi 模型家族基于 6B 和 34B 预训练语言模型…
- Gemini 1.5 Pro:在单个 Prompt 中解锁整本书籍和电影的推理与知识:🚀 与 Gemini 1.5 一起潜入 AI 世界!🌟在这个视频中,我们揭秘了 Gemini 稀疏混合专家架构背后的魔力,它非常适合释放…
- GitHub - jiaweizzhao/GaLore:通过在 GitHub 上创建账号来为 jiaweizzhao/GaLore 的开发做出贡献。
- 01-ai/Yi-34B-200K · Hugging Face:未找到描述
- Reddit - 深入探索一切:未找到描述
- GitHub - thu-ml/low-bit-optimizers: PyTorch 的低比特优化器:PyTorch 的低比特优化器(Low-bit optimizers)。通过在 GitHub 上创建账号来为 thu-ml/low-bit-optimizers 的开发做出贡献。
Nous Research AI ▷ #announcements (1 messages):
- 推出 Genstruct 7B:
@everyone,Nous Research 发布了 Genstruct 7B,这是一个受 Ada-Instruct 启发的指令生成模型。该模型能够从原始文本语料库中创建有效的指令,用于合成微调(finetuning)数据集,并可在其 HuggingFace 页面 下载。 - 高级推理能力:Genstruct 7B 擅长生成关于复杂场景的问题,在经过生成数据训练后,能增强模型执行逐步推理的能力。该项目由 Nous Research 的
<@811403041612759080>领导。
提到的链接:
NousResearch/Genstruct-7B · Hugging Face:未找到描述
Nous Research AI ▷ #general (289 messages🔥🔥):
-
Claude Pro 作为主力工具?:用户
@leontello询问了大家将 ChatGPT Plus 更换为 Claude Pro 的体验。一些用户(如@teknium)表示甚至很难找到 Claude Pro 的聊天界面,而另一些人则提到由于地理限制无法访问。 -
Gemma AI 漏洞与修复:关于 Gemma 实现中漏洞的讨论引发了对 @danielhanchen 的一条推文 的分享,该推文强调了提交给 @UnslothAI 的众多问题和修复方案,并对比了应用 Unsloth AI 博客文章中提到的修复方案后每一层的 Log L2 范数。
-
在 4090 GPU 上进行低秩预训练:用户
@.interstellarninja分享了 @AnimaAnandkumar 的一条推文,宣布 Llama 7B LLM 能够通过梯度低秩投影(GaLore)方法在单个 RTX 4090 GPU 上进行训练,该方法显著降低了存储优化器状态(optimizer states)的内存需求。 -
关于模型性能和新模型的讨论:在关于各种模型的讨论中,
@teknium提出了关于多个 AI 模型可能匹配或超越 OpenAI 旗舰 GPT 模型的影响的问题。@inflectionAI 的一条推文 声称其 Inflection-2.5 模型在训练使用更少算力的情况下,达到了 GPT-4 的基准测试水平。 -
欧盟对微软与 Mistral AI 合作伙伴关系的审查:用户讨论了微软与 Mistral AI 交易的潜在影响,包括来自欧盟的监管关注。引用的一篇 美联社新闻文章 表明欧盟正在调查该协议,尽管尚未提到正式结论。
提到的链接:
- Daniel Han (@danielhanchen) 的推文:发现更多 #Gemma 的 bug:1. 必须添加
2. model 拼写错误 3. sqrt(3072)=55.4256 但 bfloat16 是 55.5 4. Layernorm (w+1) 必须是 float32 5. Keras mixed_bfloa... - Answer.AI - 你现在可以在家训练 70b 语言模型了:我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两块 24GB GPU 上训练 70b 模型。
- Anthropic Console:未找到描述
- Emad (@EMostaque) 的推文:@Teknium1 在 7b 以上不太稳定。Transformer engine 将其作为主要实现。Intel 也有一个,Google 有 int8。
- FxTwitter / FixupX 的推文:抱歉,该用户不存在 :(
- Inflection AI (@inflectionAI) 的推文:Pi 刚刚迎来了重大升级!它现在由我们最新的 LLM:Inflection-2.5 驱动,在所有基准测试中与 GPT-4 并驾齐驱,且训练所用的算力不到一半。Pi 现在拥有世界一流的…
- 微软与法国 Mistral AI 的新交易正受到欧盟审查:欧盟正在调查微软与法国初创公司 Mistral AI 的合作伙伴关系。这是对蓬勃发展的生成式人工智能领域进行更广泛审查的一部分,以查看其是否引发…
- Sebastian Majstorovic (@storytracer) 的推文:开源 LLM 需要开放的训练数据。今天我发布了最大的英语公有领域书籍数据集,从 @internetarchive 和 @openlibrary 策划而来。它包含超过 610 亿…
- Anima Anandkumar 教授 (@AnimaAnandkumar) 的推文:我们首次展示了 Llama 7B LLM 可以在单张消费级 GPU (RTX 4090) 上训练,仅需 24GB 显存。这代表存储优化器所需的内存减少了 82.5% 以上…
- gguf/Genstruct-7B-GGUF · Hugging Face:未找到描述
- Weyaxi/Einstein-v4-7B · Hugging Face:未找到描述
- Weyaxi (@Weyaxi) 的推文:🎉 激动人心的消息!🧑🔬 认识一下 Einstein-v4-7B,这是一个强大的基于 Mistral 的监督微调模型,使用了多样化的高质量且经过筛选的开源数据集!🚀 ✍️ 我还转换了多选题…
- WIP: maximegmd 提交的 galore 优化器 · Pull Request #1370 · OpenAccess-AI-Collective/axolotl:增加了对 Galore 优化器的支持。仍处于开发中(WIP),未经测试。
- GitHub - jiaweizzhao/GaLore:通过在 GitHub 上创建账号来为 jiaweizzhao/GaLore 的开发做出贡献。
- Seb Lhomme (@slhomme) 的推文:我即将推出的新 AI 工具:SocialClone - 立即创建 AI 克隆视频!
- GitHub - e-p-armstrong/augmentoolkit: 将算力和书籍转换为指令微调数据集:将算力和书籍转换为指令微调数据集 - e-p-armstrong/augmentoolkit
- 游泳 GIF - 在游泳池游泳 - 发现并分享 GIF:点击查看 GIF
- 担心害怕 GIF - 担心害怕噢不 - 发现并分享 GIF:点击查看 GIF
- 2024 年如何使用 Hugging Face 微调 LLM:在这篇博文中,你将学习如何在 2024 年使用 Hugging Face TRL、Transformers 和 Datasets 微调 LLM。我们将针对 text to SQL 数据集微调一个 LLM。
-
[Yann Lecun:Meta AI、开源、LLM 的局限性、AGI 与 AI 的未来 Lex Fridman Podcast #416](https://youtu.be/5t1vTLU7s40?si=HS3WrupXGw_xBvmb):Yann LeCun 是 Meta 的首席 AI 科学家、纽约大学教授、图灵奖得主,也是 AI 历史上最具影响力的研究者之一。请…
Nous Research AI ▷ #ask-about-llms (83 条消息🔥🔥):
-
寻求免费 GPT-4 访问权限:
@micron588询问了免费访问 GPT-4 的方法,特别是通过 API。@teknium提供了帮助,推荐了 Corcel.io,这是一个提供免费 ChatGPT-4 访问并直接 API 集成到 Bittensor 网络中的平台。 -
对模型名称的误解:
@micron588对 Corcel.io 模型是否为 GPT-4 表示怀疑,因为它没有做出相应的回应,且缺乏实时数据能力。@teknium澄清说 GPT-4 通常不包含实时数据。 -
Nous-Hermes 模型上下文长度查询:
@nickcbrown询问为什么某些 Nous-Hermes 模型的上下文长度似乎减少了。@night_w0lf认为这可能是配置或硬件限制,而不是实际的减少。 -
关于 LLM 预训练与微调的讨论:辩论了大型语言模型(LLM)预训练与微调之间的区别。
@teknium和@carsonpoole讨论了 LoRA、DoRA、VeRA 和 GaloRe 的细微差别,以及它们对模型优化和表达能力的影响。 -
预训练成本与模型优化技术:
@umarigan强调了 LLM 持续预训练的资源密集型特性,并分享了一篇相关文章;而@eas2535提到了 FSDP 和 QLoRA 在使用较少资源训练大型模型方面的进展。@teknium持怀疑态度,暗示这些策略对于小型操作可能仍然遥不可及。
提到的链接:
- Corcel · Build with the power of Bittensor:未找到描述
- $ Cost of LLM continued pre-training:为小型 (7B) LLM 进行持续预训练需要花费多少成本?
- Trendyol/Trendyol-LLM-7b-base-v0.1 · Hugging Face:未找到描述
- Answer.AI - You can now train a 70b language model at home:我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。
- Poor Man GIF - Poor Man - Discover & Share GIFs:点击查看 GIF
- no title found:未找到描述
LM Studio ▷ #💬-general (148 条消息🔥🔥):
- LM Studio 版本更新:
@datasoul提到最新版本是 0.2.16。@heyitsyorkie提供了关于 GGUF 模型兼容性的支持,并链接到了 Huggingface 仓库。 - 使用 Metal 评估模型速度:
@nullt3r和@heyitsyorkie讨论了 Mixtral 及其他模型在不同配置下的评估速度,根据模型和质量的不同,速度范围在 27 tok/s 到 4 tok/s 之间。 - REOR,自组织 AI 笔记应用:
@clubofom认为 REOR 是一款高效的 AI 笔记应用,并提供了项目页面链接:www.reorproject.org。 - Pi 的 Inflection 2.5 与 Inflection AI:
@pierrunoyt和@aswarp讨论了来自 Inflection AI 的新 Inflection-2.5 模型,指出其在编程和 IT 支持方面的改进。他们还分享了一个讨论该更新的 YouTube 视频:Inflection 2.5。 - 使用 LM Studio 运行本地 LLM 模型:
@heyitsyorkie建议@.atip,本地 LLM 模型 必须采用 GGUF 格式并存放在特定的文件夹结构中才能在 LM Studio 中运行,并分享了非官方 FAQ 的链接:了解更多关于 GGUF 的信息,同时讨论了转换过程。
提到的链接:
- 👾 LM Studio - 发现并运行本地 LLMs:查找、下载并实验本地 LLM。
- 再见 Midjourney!免费且无审查的 SDXL 1.0 正在接管!:告别 Midjourney,迎接免费开源 AI 图像生成的未来:SDXL 1.0!这款全新的、无审查的模型正席卷 AI 世界…
- Reddit - 深入探索一切:未找到描述。
- 非官方 LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里,你可以找到我们在 LMStudio Discord 上遇到的最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源…
- 22,000 块 H100 之后,Inflection 2.5!!!:🔗 链接 🔗 https://inflection.ai/inflection-2-5❤️ 如果你想支持该频道 ❤️ 在此支持:Patreon - https://www.patreon.com/1littlecoder/Ko-Fi - ht…
- Inflection-2.5:遇见世界上最好的个人 AI:我们是一家 AI 工作室,致力于为每个人创造个人 AI。我们的第一个 AI 名叫 Pi,代表个人智能(personal intelligence),是一个具有支持性和共情能力的对话式 AI。
- Reor:在你的电脑上本地且离线运行模型的 AI 笔记应用。
- Pal - AI 聊天客户端:一款适用于 iPhone 的轻量级但功能强大且特性丰富的 AI 聊天客户端!支持:GPT-4 Turbo, GPT-4 Vision, DALL-E 3, Claude 3 Opus, Gemini Pro, Mistral Large, Openrouter 以及自定义端点…
LM Studio ▷ #🤖-models-discussion-chat (68 条消息🔥🔥):
- LM Studio 终端问题:
@heyitsyorkie澄清说,从 0.2.16 版本开始,从终端运行 LM Studio 不应再出现任何错误,例如缺少GLIBC或LIBCBlast库。 - Gemma 模型抱怨:
@honeylaker_62748_43426遇到了gemma 7b gguf模型的一个错误,@heyitsyorkie确认这是这些模型的一个已知问题。 - Starcoder2 兼容性困惑: 包括
@madhur_11、@poshigetoshi和@zachmayer在内的多位用户讨论了starcoder2的问题,因为当前版本的 LM Studio 无法识别它。 - 图像生成指南:
@heyitsyorkie引导正在寻找生成图片模型的@callmemjinina去探索 Stable Diffusion 等图像生成工具,以及 Automatic 1111 或 ComfyUI 等界面。 - RAG 解释请求: 当
@neuropixels询问如何为聊天机器人设置知识库时,@heyitsyorkie分享了 IBM 解释检索增强生成 (RAG) 的文章链接,这可能会满足他们的需求。
提到的链接:
-
[什么是检索增强生成? IBM Research Blog](https://research.ibm.com/blog/retrieval-augmented-generation-RAG): RAG 是一种 AI 框架,用于检索事实以使 LLM 基于最准确的信息,并让用户深入了解 AI 的决策过程。 - Kquant03/TechxGenus-starcoder2-15b-instruct-GGUF · Hugging Face: 未找到描述
LM Studio ▷ #🧠-feedback (1 条消息):
heyitsyorkie: 停止使用 <#1113937247520170084> 发布求助帖子。请使用 <#1111440136287297637>
LM Studio ▷ #🎛-hardware-discussion (66 条消息🔥🔥):
- 为 RTX 3090 供电:
@wilsonkeebs正在寻找能为独立 RTX 3090 供电的最小 PSU,@heyitsyorkie建议至少使用 750W 的 PSU,并提到低功率 PSU 可能缺少必要的 PCIe 线缆,尽管另一位用户推荐了 Razer Core X eGPU 外置显卡盒。 - 考虑未来的升级:
@wilsonkeebs计划最终用 1500W PSU 和更大的机箱重建他们的 PC,目前寻找 PSU 只是临时解决方案。 - GPU 的价值辩论: 在以 LM(语言模型)为核心的装机背景下,用户讨论了新款 4060 Ti 显卡的成本与 VRAM 收益,并与二手市场的 3090 进行了对比,考虑了加拿大和澳大利亚等不同地区的能效和价格差异。
- 主板选择与组件兼容性:
@jedd1和@nink1讨论了寻找支持多个高端 GPU 的主板所面临的挑战,考虑了 PCIe 插槽的可用性和支持的功能,以及装机的功耗和定价策略。 - 在消费级硬件上运行大型模型:
@neuropixels分享了在具有 11GB VRAM 的 Nvidia GeForce 1080 Ti 上运行大型语言模型的困难,该问题在重启工作站后得到解决,这表明在处理高需求 AI 模型时可能存在硬件兼容性或软件故障。
提到的链接:
-
[Razer Core X - Thunderbolt™ 3 eGPU Razer United Kingdom](https://www.razer.com/gb-en/gaming-egpus/razer-core-x): 现已兼容 Mac 和 Windows 笔记本电脑,支持 3 插槽 PCI-Express 桌面显卡,配备 650W 电源,并可通过 USB-C 充电。 -
[NVIDIA GeForce RTX 3090 的 PSU 电源计算器](https://www.whatpsu.com/psu/gpu/NVIDIA-GeForce-RTX-3090): 查看您的 NVIDIA GeForce RTX 3090 需要什么样的电源
LM Studio ▷ #🧪-beta-releases-chat (4 条消息):
- 期待感升温: 用户
@yagilb通过一条简短的消息暗示即将发布新版本:即将推出 (Coming soon)。 - 我们到了吗?:
@wolfspyre以轻松的方式询问预期更新的进展,问道:我们到了吗? - 倒计时重置: 不久后,
@wolfspyre开玩笑地为重置了期待已久的更新的虚拟倒计时而道歉,说:哎呀……我刚刚重置了计时器,各位……我的错……更新要花更长时间了……抱歉。
LM Studio ▷ #amd-rocm-tech-preview (22 messages🔥):
- AMD CEO 介入 Tiny Corp GPU 事件:
@senecalouck发布了一篇文章链接,强调了 AMD CEO 苏姿丰 (Lisa Su) 如何介入解决 Tiny Corp 对 Radeon RX 7900 XTX GPU 固件的挫败感。此前,该公司曾公开投诉并要求将固件开源;@berendbotje1认为这对 AMD 来说可能是一个大开眼界的机会。 - 利用 AMD 和 AI 提升生产力:
@helloword分享了一篇 AMD 社区博客 文章,详细介绍了如何在 AMD Ryzen™ AI PC 或 Radeon™ 7000 系列显卡上运行基于 GPT 的 LLM AI 聊天机器人,从而在无需互联网连接的情况下提高生产力。 - 在 AMD 上排除 LM Studio 故障:
@briansp2020描述了在 Radeon 7900XTX GPU 上使用 LM Studio 运行模型时遇到的问题,该问题在不使用 GPU 加速时可以正常工作;@jello_pudding建议 LM Studio 可能正在尝试使用集成 GPU 而不是独立显卡。 - LM Studio 的 GPU 选择:
@jello_pudding提到需要一个为 LM Studio 使用选择特定 GPU 的功能,暗示了由于软件默认使用集成显卡而导致的困难;@yagilb承认该建议是一个值得关注的有效点。 - 显存 (VRAM) 混淆已解决:关于 VRAM 估算的澄清进行了讨论,
@beanz_y质疑了 VRAM 容量,@yagilb纠正说 47GB 的数字是指普通 RAM,而程序估算的 VRAM 使用量为23.86GB。
提到的链接:
- AMD 的苏姿丰介入修复新款 TinyBox AI 服务器的 GPU 驱动问题 —— 该公司呼吁 AMD 将其 GPU 固件开源,并指出 Radeon 7900 XTX 的问题:在 Tiny Box 公开对基于 Radeon 的平台 Bug 表示担忧后,介入随之而来。
- 如何在你的 AMD Ryzen™ AI PC 或 Radeon 显卡上运行大语言模型 (LLM):你知道吗,你可以在你的 Ryzen™ AI PC 或 Radeon™ 7000 系列显卡上运行你自己的基于 GPT 的 LLM AI 聊天机器人实例?AI 助手正迅速成为必不可少的资源…
- GitHub - amd/RyzenAI-SW:通过在 GitHub 上创建账户,为 amd/RyzenAI-SW 的开发做出贡献。
LM Studio ▷ #crew-ai (3 messages):
- 寻求响应速度的解决方案:
@alluring_seahorse_04960正在寻找提高响应速度的方法,并遇到了Connection to telemetry.crewai.com timed out错误。 - 本地操作的基准:
@wolfspyre建议建立一个在本地运行的简单操作基准,作为处理响应速度问题的潜在起点。 - 构建通用框架:
@pefortin详细介绍了他们在一个更通用的框架上的工作,该框架涉及一个用于澄清用户任务的前置 Agent、一个用于划定原子任务的项目经理、用于为任务构建专门 Agent 的 HR 招聘专家 Agent,以及一个用于启动配置好的 Python 脚本的执行器 Agent。虽然系统目前运行缓慢且表现不佳,但改进工作正在进行中。
LM Studio ▷ #open-interpreter (87 messages🔥🔥):
-
关于解释器选项的困惑:用户
@nxonxi提出了使用 system message 选项运行解释器的问题,而@1sbefore表示困惑,指出在他们找到的文档中没有提到这一点。@nxonxi随后澄清,选项-s是--system_message的简写,正如文档中所述。 -
寻求 Python 脚本帮助:
@nxonxi寻求关于在 Python 脚本中设置默认 system message的帮助,@1sbefore承认无法提供帮助。问题在于脚本中使用了interpreter.system_message = "Your message"命令,但未获得预期结果。 -
排查配置文件问题:
@nxonxi在尝试实现 intent profiles 更改时遇到挑战,最终在语言模型服务器 (LMS) 上未观察到任何变化。@1sbefore建议确保修改路径与用户环境中which interpreter提供的 Python 路径相匹配。 -
探索不同的语言模型:讨论了各种语言模型,如 deepseek coder 6 和 openchat/mistral 及其对提示词的响应。
@berendbotje1和@1sbefore探讨了潜力,并分享了使用 LHK_DPO_v1 和 Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B 等模型的经验。 -
交流模型见解与建议:
@1sbefore提供了托管在 Hugging Face 上的 HanNayeoniee/LHK_DPO_v1 的 GGUFs 链接,并表示打算向频道成员更新进一步的测试情况。他们还警告了关于上下文大小(context size)的潜在限制,引用了关于 FusionNet_7Bx2_MoE_14B 在超过 4000 tokens 后可靠性的讨论(来源)。
提到的链接:
- owao/LHK_DPO_v1_GGUF · Hugging Face:未找到描述
- All Settings - Open Interpreter:未找到描述
- All Settings - Open Interpreter:未找到描述
- TomGrc/FusionNet_7Bx2_MoE_14B · Contextsize:未找到描述
- GitHub - jondurbin/bagel: A bagel, with everything.:A bagel, with everything. 欢迎在 GitHub 上为 jondurbin/bagel 的开发做出贡献。
LlamaIndex ▷ #announcements (1 messages):
- 我们需要您的反馈!:
@seldo_v邀请用户完成一份 3 分钟的用户调查,以协助 LlamaIndex 改进其产品。该调查旨在收集见解以优化文档、演示和教程;链接在这里。
提到的链接:
LlamaIndex 用户调查:参加由 surveymonkey.com 支持的此项调查。免费创建您自己的调查。
LlamaIndex ▷ #blog (4 条消息):
- 探索 Claude 3 的多功能性:一个新的视频指南 🎞️ 展示了 Claude 3 的全面 cookbook,涵盖了使用 @llama_index 工具的各种用例,如 Vanilla RAG、Routing、子问题查询规划(Sub-question query planning)等。该指南可在 Twitter 上查看。
- LlamaIndex 征求用户反馈:LlamaIndex 正在进行一项 3 分钟的快速用户调查,以更好地了解用户的经验水平和需求,从而改进文档、演示和教程。感兴趣的参与者可以在这里找到调查问卷。
- 利用 Jina 的新 Reranker 改进 RAG:由 @JinaAI_ 最新发布的名为
jina-reranker-v1-base-en的 reranker 工具,承诺通过提升向量搜索(vector search)的质量来显著增强 RAG 应用。详情可通过 Twitter 获取。 - 揭晓新型层级代码切分技术:
CodeHierarchyNodeParser是由 ryanpeach 贡献的一项新技术,它通过将大型代码文件转换为可管理的层级结构,实现了用于代码理解的高级 RAG/Agent。公告和更多信息已在 Twitter 上分享。
提到的链接:
LlamaIndex 用户调查:参加这个由 surveymonkey.com 支持的调查。免费创建您自己的调查。
LlamaIndex ▷ #general (339 条消息🔥🔥):
- 旧版本文档缺失:用户
@torsten_13392和@nesgiv对 LlamaIndex 旧版本文档的缺失表示担忧,指出他们无法再通过 Google 或官网访问这些文档。 - Chat Engine 与 NodeWithScore 的集成问题:
@cheesyfishes向@nesgiv澄清,chat engines 仅接收字符串作为输入,且专门用于聊天,并建议若需在此之外进行自定义,可能需要自定义 retriever。 - 多模态数据存储与检索的困惑:用户在确定如何使用 LlamaIndex 在 Weaviate 中存储带有 metadata 的图像时遇到困难。
@cheesyfishes分享了一个变通方法,即将节点存储在数据库中,而将图像存储在别处,同时@whitefang_jr建议用户参考 Chroma。 - 自定义评分算法:用户
@cheesyfishes提供了关于在 retriever 中自定义评分算法(scoring algorithm)的见解,指出配置评分的能力取决于向量数据库是否开放了此类选项。 - 更新与持久化数据的问题:包括
@capn_stabn在内的用户讨论了与更新索引和持久化存储相关的问题。Capn_stabn 特别提到了 Milvus 在更新索引后删除数据的问题,该问题后来通过调整overwrite设置得到了解决。
提到的链接:
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 预填 Claude 的响应: 未找到描述
- 入门教程 - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- LlamaIndex 用户调查: 参加由 surveymonkey.com 提供的调查。免费创建您自己的调查。
- gist:7f54b5ae756b5362b3ec0871b845eeac: GitHub Gist: 立即分享代码、笔记和代码片段。
- 使用 LlamaIndex、Qdrant 和 Render 构建一个具有学习能力的 Slack 机器人 — LlamaIndex,LLM 应用程序的数据框架: LlamaIndex 是一个简单、灵活的数据框架,用于将自定义数据源连接到大语言模型 (LLMs)。
- 使用 GPT4V 和多模态索引/检索器进行高级多模态检索 - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- 使用模式 - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- HuggingFace LLM - StableLM - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- 摄取管道 - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- 使用 LlamaIndex 的 Chroma 多模态演示 - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
-
[多模态检索增强生成 (RAG) Weaviate - 向量数据库](https://weaviate.io/blog/multimodal-rag): 一图胜千言,为什么只停留在检索文本上下文呢!?了解如何执行多模态 RAG! - 集成检索指南 - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- 自定义响应 - HTML、流、文件及其他 - FastAPI): FastAPI 框架,高性能,易于学习,编写代码快,可用于生产环境
- llama_index/llama-index-integrations/vector_stores/llama-index-vector-stores-opensearch/llama_index/vector_stores/opensearch/base.py at 0ae69d46e3735a740214c22a5f72e05d46d92635 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
Perplexity AI ▷ #general (269 条消息🔥🔥):
-
Claude 3 Opus 使用限制讨论:用户对 Perplexity 计划下 Claude 3 Opus 的有限使用次数表示担忧,用户如
@hra42对 5 次的使用限制表示失望。对话围绕 Perplexity AI 订阅计划的成本效益展开,一些用户讨论了每日消息限制是否充足。 -
部分用户难以访问功能:多位用户(包括
@netrot.和@laurant3855)在尝试使用某些功能时遇到问题,例如照片生成、使用 Claude 3 Opus 以及重写(rewrite)功能。@icelavaman提供了帮助,建议包括重置浏览器数据以及联系 support@perplexity.ai。 -
AI 性能与效率对比:在整个讨论中,用户对比了各种 AI 模型的性能和效率。
@codelicious发布了 Inflection-2.5 等模型,@deicoon建议将 Sonnet 作为模型对比的可行选项,并得到了@akumaenjeru等其他用户的支持。 -
Perplexity AI 与其他 AI 服务的优缺点:用户如
@thaholylemon和@hra42评估了 Perplexity AI 的价值和能力,将其服务和成本与 ChatGPT Plus 等其他平台进行了对比。讨论集中在资料搜集功能的优势以及对研究人员和学生的整体价值,而其他人则讨论了对不同订阅服务的个人偏好和体验。 -
订阅要素与用户体验交流:用户交流了不同 AI 平台的体验,并讨论了 Pro Discord 等高级订阅包含的功能以及对 Claude 3 Opus 等模型的访问权限。一些用户(如
@toby1260)反映 AI 的回答存在歧义,引发了关于 Prompt Engineering 和模型局限性的讨论。
提到的链接:
Inflection-2.5: meet the world’s best personal AI:我们是一家 AI 工作室,致力于为每个人创建个人 AI。我们的第一个 AI 名为 Pi,代表个人智能(personal intelligence),是一个具有支持性和共情能力的对话式 AI。
Perplexity AI ▷ #sharing (6 条消息):
-
Perplexity AI 与其他平台对比:用户
@oen99un分享了 Perplexity AI 与另一个平台的对比,强调了差异和相似之处。 -
在 Perplexity AI 上学习:
@bluesky1911提供了一个链接,详细介绍了利用 Perplexity AI 庞大资源进行学习的方法。 -
历史创新与进步:
@vishrutkmr7分享了一个与过去创新和文明进步相关的链接。 -
理解 Perplexity AI 的角色:用户
@croak_plonk发布了一个链接,探讨了聊天机器人形式下 Perplexity AI 的概念和功能。 -
关于 AI 创作署名的疑问:
@pope9870分享了一个链接,深入探讨了在 AI 辅助创作中谁拥有写作署名权。 -
AI 是否存在情感:
@bodhibios提出了一个关于 AI 和情感的问题,引用了一个探索该概念的 Perplexity AI 查询。
Perplexity AI ▷ #pplx-api (14 messages🔥):
-
Perplexity Discovery 功能咨询:
@yankovich询问了 Perplexity Discover 的功能,@bitsavage.将其描述为一种根据用户兴趣探索新内容的工具。@bitsavage.建议查看 Perplexity API 文档以了解潜在的实现方式。 -
频道活跃度维护:
@leoesq发布了一条消息以保持 pplx-api 频道的活跃状态,而@po.sh提供了关于如何在 Discord 中查看所有频道的技巧,以防止未来失去访问权限。 -
寻求 RAG 流水线文档:
@leoesq询问了关于 Sonar 使用的 RAG 流水线和特定文本处理的文档,表现出对理解搜索文本与 LLM 之间交互的兴趣。 -
问答引擎 API 咨询:
@ruxorly询问了未来是否会提供 API,以便通过 Perplexity API 使用具有网页搜索能力的 Claude/GPT4/Mistral Large 等模型。 -
模型输出限制澄清:
@brknclock1215和@leoesq讨论了模型的最大 Token 输出量,指出这取决于模型的上下文窗口(context window)和微调行为,这会显著影响 Token 输出的大小。
Eleuther ▷ #announcements (1 messages):
- 韩语语言模型新基准测试:
@gson_arlo宣布创建了两个新的韩语语言评估数据集:Hae-Rae Bench 和 K-MMLU。Hae-Rae Bench 已被 LREC-COLING 2024 接收,而 KMMLU(MMLU 的韩语改编版)正在 ACL 审稿中。这两个基准测试旨在测试语言模型理解韩语特定知识的能力。 - 多语言模型评估倡议:
@gson_arlo强调了评估多语言模型(特别是英语和中文以外的语言)的工具非常有限,并邀请社区成员在<#1208111628051152969>频道中为不同语言和文化设计基准测试做出贡献。他们还将对模型评估感兴趣的人引导至<#755950983669874798>频道。
Eleuther ▷ #general (39 messages🔥):
- TensorRT 代码集成待审批:
@abhishekvijeev通知称,他们正与另一位用户集成其 TensorRT 代码,由于是利用公司资源开发的,因此需要获得批准。 - LLM 训练中的上下文长度讨论:
@sentialx和@thooton_讨论了使用长上下文与短上下文训练大语言模型(LLM)的问题,@thooton_解释了从较短的上下文长度开始进行更集中的训练,然后再过渡到长上下文的好处。 - EEVE-Korean-v1.0 发布:
@seungduk分享了一篇 arXiv 技术报告,内容是关于在保持原始模型性能的同时高效地为 LLM 添加更多 Token,并提到了他们在 \texttt{EEVE-Korean-10.8B-v1.0} 上的工作。 - ML/AI 研究合作公开邀请:
@andrew_f0874提供了他的计算机科学背景(康奈尔大学博士及 Google 研究科学家经验),寻求兼职参与 ML/AI 研究合作,并表示对 RL、ML 隐私、ML 安全以及将 ML 应用于编程/编译器等领域有广泛兴趣。 - 基础 AI 讨论与提问:新成员
@shida3916寻求一个合适的论坛来讨论日常 AI 使用并提出简单问题,而@stellaathena建议查看 <#732688974337933322> 中列出的其他服务器以获取更多适合初学者的建议。
提到的链接:
- Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models:该报告介绍了 \texttt{EEVE-Korean-v1.0},这是一个韩语改编的大语言模型,在英语和韩语文本理解方面展现了卓越的能力。基于最近的高…
- eleutherai?:Weights & Biases,机器学习开发者工具。
Eleuther ▷ #research (107 条消息🔥🔥):
-
GaLore 的内存效率引起关注:用户
@xylthixlm、@main.ai等人讨论了 GaLore 的潜力,这是一种声称能以更少的内存占用实现比全秩(full-rank)更新更好效果的技术。人们对实际的梯度节省情况和实现的实用性表示怀疑,特别是由于优化器内部处理梯度的方式。 -
对 GaLore 复现的期待:社区成员如
@ai_waifu、@random_string_of_character和@jckwind表现出对复现 GaLore 结果的兴趣。@maximegmd在 GitHub 上提交的一个优化器 Pull Request 表明复现尝试即将进行。 -
探索 GaLore 代码库引发疑问:
@xylthixlm检查了 GaLore 的代码,注意到优化器在反向传播(backprop)期间的每个参数梯度更新后运行,这表明不需要同时存储所有梯度。用户还讨论了 Python 使用 PyTorch 参数对字典进行索引的能力,@_inox和@tulkascodes也参与了讨论。 -
CAME 优化器引起好奇:
@xylthixlm提到了 CAME 优化器,这是 PixArt-Σ 中使用的一个较冷门的工具;它旨在提供自适应方法的速度,同时减少内存占用。这激发了人们对了解 CAME 性能以及与 Adafactor 和 Adam 等其他优化器进行比较的兴趣。 -
指令微调(Instruction Tuning)数据集讨论:
@kublaikhan1询问了最佳的指令微调数据集,@jstephencorey推荐了 OpenAssistant 等。讨论中涉及了微调顺序和数据集质量的重要性,并引用了最近的一篇论文,该论文发现对 GPT-4 输出进行高质量的 SFT(有监督微调)可以产生与更复杂的微调方法相当甚至更好的结果。
提到的链接:
- PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation:在本文中,我们介绍了 PixArt-Σ,这是一个能够直接生成 4K 分辨率图像的 Diffusion Transformer 模型 (DiT)。PixArt-Σ 代表了其前身 Pix 的重大进步…
- CAME: Confidence-guided Adaptive Memory Efficient Optimization:自适应梯度方法(如 Adam 和 LAMB)在训练大型语言模型中表现出了卓越的性能。然而,自适应性的需求需要维持二阶矩…
- SOCIAL MEDIA TITLE TAG:SOCIAL MEDIA DESCRIPTION TAG TAG
- Pretrained-Language-Model/CAME/came.py at master · huawei-noah/Pretrained-Language-Model:由华为诺亚方舟实验室开发的预训练语言模型及其相关的优化技术。- huawei-noah/Pretrained-Language-Model
- pytorch/torch/_tensor.py at main · pytorch/pytorch:具有强大 GPU 加速功能的 Python 张量和动态神经网络 - pytorch/pytorch
- A direct comparison between llama.cpp, AutoGPTQ, ExLlama, and transformers perplexities - LLM blog:未找到描述
- A detailed comparison between GPTQ, AWQ, EXL2, q4_K_M, q4_K_S, and load_in_4bit: perplexity, VRAM, speed, model size, and loading time. - LLM blog:未找到描述
- ToDo: Token Downsampling for Efficient Generation of High-Resolution Images:注意力机制对于图像扩散模型至关重要,然而,它们的二次计算复杂度限制了我们在合理的计算时间和内存限制内可以处理的图像尺寸…
- Making Large Language Models Better Reasoners with Step-Aware Verifier:少样本学习是一项具有挑战性的任务,要求语言模型从有限的示例中进行泛化。像 GPT-3 和 PaLM 这样的大型语言模型在这一领域取得了令人印象深刻的进展,但…
- GitHub - jiaweizzhao/GaLore:通过创建账户为 jiaweizzhao/GaLore 的开发做出贡献。
- GaLore/torchrun_main.py at master · jiaweizzhao/GaLore:通过创建账户为 jiaweizzhao/GaLore 的开发做出贡献。
- WIP: galore optimizer by maximegmd · Pull Request #1370 · OpenAccess-AI-Collective/axolotl:添加了对 Galore 优化器的支持。仍在进行中(WIP),尚未测试。
Eleuther ▷ #lm-thunderdome (24 条消息🔥):
-
Harness 的自定义输出格式实现:
@pminervini询问了如何在 harness 中自定义输出格式,并建议采用两步生成过程。@baber_提议修改generate_until方法,并分享了一个 GitHub 链接 作为实现的潜在起点。 -
MCQA 评估论文讨论:
@nish5989分享了他们关于多项选择题 (MCQA) 评估和数据集伪影 (artifacts) 的论文。随后的讨论涉及了附录中关于答案格式有效性的实证结果,以及考虑使用似然方法 (likelihood methods) 重新运行实验。 -
特定语言评估的问题:
@seanbethard质疑了相对于跨语言标准,人们对特定语言评估标准的偏好,并提到了言据性 (evidentiality) 和有生性 (animacy) 等语言细微差别,但认为句法和词汇对于语言评估已经足够。 -
置信区间澄清:
@yamashi寻求关于使用平均值标准误差 (SEM) 计算 95% 置信区间的澄清。@hailey_schoelkopf确认将 SEM 乘以 1.96 是正确的方法。 -
BOS Token 使用差异:
@jwngx询问了在评估中使用句首 (BOS) token 的标准,并指出最近实践中的变化。@stellaathena澄清说使用情况取决于模型,但目前还没有关于哪些模型在使用它时表现更好的统一信息。
提到的链接:
- Multiple Choice Question Standard Deviation · Issue #1524 · EleutherAI/lm-evaluation-harness:我看到多项选择类型的评估会计算指标以及标准差。根据我的理解,多项选择的答案是从概率最高的选项中选出的…
- lm-evaluation-harness/lm_eval/models/huggingface.py at 9e6e240229429d2214bc281bed7a4e288f5169a1 · EleutherAI/lm-evaluation-harness:一个用于语言模型 few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
- Do Prompt-Based Models Really Understand the Meaning of their Prompts?:最近,大量论文展示了各种基于 Prompt 的模型在 zero-shot 和 few-shot 学习方面取得的非凡进展。通常认为 Prompt 有助于模型在…中学习得更快。
- Are Language Models Worse than Humans at Following Prompts? It’s Complicated:Prompt 一直是提升语言模型 zero-shot 和 few-shot 性能的核心。然而,最近的研究发现,当模型被赋予意图时,其表现出奇地好…
Eleuther ▷ #multimodal-general (1 条消息):
- 寻求 AI 知识的新成员:
@shida3916表达了加入社区的热情,希望讨论 日常 AI 应用 并寻求简单问题的答案。他们询问这个 Discord 服务器是否是进行此类讨论的合适场所。
Eleuther ▷ #gpt-neox-dev (102 messages🔥🔥):
-
探讨环境配置选项:
@biiter和@tastybucketofrice讨论了为 GPT-NeoX 开发设置环境的复杂性,权衡了使用 Docker 与本地系统设置的利弊,并承认了依赖管理的复杂性。@catboy_slim_提出了统一环境设置的想法,以确保有一种正确的方法来准备开发环境。 -
NGC 容器考量:
@tfidia介绍了使用 NVIDIA NGC PyTorch 容器来缓解设置 Apex 和 CUDA 依赖时的困扰,并详细说明了这些容器中预装的依赖项。@catboy_slim_承认了其优势,但也对脱离容器环境时可能出现的复现性问题表示担忧。 -
依赖管理讨论:对话转向如何更有效地管理依赖,
@catboy_slim_建议转向使用 poetry 进行确定性包管理,同时也考虑了当前的依赖状态和安装说明。大家认可了 NGC 容器的实用性,但也意识到由于预装和预更新的包(如 Flash Attention)可能带来的挑战。 -
Flash Attention 更新难题:
@catboy_slim_指出了在 NGC 等预构建容器中提供的 Flash Attention 版本不一致的问题。@tfidia就如何手动更新 Flash Attention 提供了建议,随后的讨论涉及了 PyTorch 版本规范以及在依赖管理中对精确度的潜在需求。 -
ProtoBuf 依赖之谜解开:
@hailey_schoelkopf和@catboy_slim_梳理了安装 ProtoBuf 依赖的必要性,推断出它可能是 Llama 的 tokenizer 中使用 SentencePiece 所必需的,这说明了定位依赖来源的复杂性。这次交流强调了在动态开发环境中记录依赖原因的重要性。
提到的链接:
- PyTorch Release 24.02 - NVIDIA Docs:未找到描述
- GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention:快速且内存高效的精确注意力机制。可以通过在 GitHub 上创建账号为 Dao-AILab/flash-attention 的开发做出贡献。
- Cleaner dockerfile: Remove already installed deps by tf-nv · Pull Request #1175 · EleutherAI/gpt-neox:在切换到 ngc pytorch 后清理 Dockerfile (#1170):移除已安装的 apt 包;sparse attn 的要求导致 triton 降级;flash attn 已是 ngc 的一部分…
- PyTorch Release 24.02 - NVIDIA Docs:未找到描述
OpenAI ▷ #ai-discussions (94 messages🔥🔥):
- Sonnet 对比 ChatGPT:
@aaron_speedy强调 Sonnet 是比 ChatGPT 3.5 更强大的免费模型,并提到了图片上传等功能,以及对其是否支持文件上传的询问。 - 期待 GPT-4:
@futuremachine和@drinkoblog.weebly.com都期待 GPT-4 的发布,特别是考虑到 Claude 3 等竞争对手的表现似乎已经超越了当前模型。 - Prompt 优化辩论:
@.vilden提到过于冗长的 Prompt 可能会限制模型性能,建议用户学习有效的 Prompt 技巧,以减少在 GPT 3.5 上遇到的限制。 - 寻求用于制作抽认卡的 AI:
@khaledoo.询问是否有可以将讲座 PDF 转换为抽认卡(flashcards)的 AI 工具,引发了@glamrat等人的兴趣,以及@dezuzel对内容准确性的疑问。 - 遇到 GPT-4 问题:
@spikyd报告称 GPT-4 一直在重复答案并以错误的语言提供响应,对服务质量表示沮丧,这引发了与@dojan1关于潜在解决方法和这些异常原因的讨论。
提到的链接:
GitHub - Kiddu77/Train_Anything: A repo to get you cracking with Neural Nets .:一个让你开始上手神经网络的仓库。可以通过在 GitHub 上创建账号为 Kiddu77/Train_Anything 的开发做出贡献。
OpenAI ▷ #gpt-4-discussions (38 条消息🔥):
- 目前 API 不支持 GPTs:
@solbus澄清说 GPTs 是 ChatGPT 特有的,无法通过 OpenAI API 访问。这是针对@cliffsayshi关于是否能通过 API 使用类似 Human Writer-Humanizer-Paraphraser (Human GPT) 等自定义 GPTs 的询问所做的回应。 - 理解 OpenAI 的产品方案:在与
@cliffsayshi的讨论中,@solbus解释说,通过 OpenAI API 提供的实体(如 DALL-E、Babbage 和 Davinci 模型)不被称为 GPTs,而是被称为“模型 (models)”,而 GPTs 是 ChatGPT 的一项特定功能。 - ChatGPT 访问问题已解决:用户
@pteromaple、@bluesdante、@aialra和@cypriang发现,将语言设置更改为“自动检测 (Auto-detect)”并刷新 (F5) 解决了浏览器中 ChatGPT 无响应的问题。 - 语言设置 Bug:
@joachimpimiskern和@pteromaple报告并确认了 ChatGPT 中一个持续存在的语言设置问题。使用英语可以解决该问题,但切换到其他语言可能会导致界面再次崩溃。 - 局部 ChatGPT 故障排除:
@meteopx提到使用 VPN 可以让消息通过 ChatGPT 发送,这突显了不同地区服务可用性的局部技术问题。
OpenAI ▷ #prompt-engineering (54 条消息🔥):
- 角色扮演 Prompt 指导疑问:
@loamy_讨论了指导 AI 进行角色扮演的最佳方式,而@dezuzel建议提供关于 AI 应该执行的操作的正向指令,而不是提及它不应该做的事情。他们建议明确 AI 的反应,以达到预期的角色扮演效果。 - GPT 中的随机种子:
@interactiveadventureai询问 GPT 是否可以在每次迭代中使用不同的种子 (seed) 进行随机数生成,以增强交互式冒险体验。@solbus建议通过数据分析功能使用 Python 来生成随机性,并澄清用户无法控制底层模型的种子。 - 消除输出中的叙述性叠加:
@interactiveadventureai寻求建议以消除 AI 回复中不必要的叙述性总结,@eskcanta建议在 Prompt 中改变写作风格作为可能的解决方案。此外,还幽默地提到了对服务器采取极端措施。 - 新成员介绍:
@thebornchampion向社区介绍了自己,表达了对 Prompt Engineering 的热情,并讨论了他们如何将 GPT 用于数据分析和各种个人项目(如旅行规划和学术支持)。 - 用于关闭对话的 GPT 分类器:
@chemlox讨论了构建一个 GPT 分类器来决定是否应关闭 Agent 与消费者之间的对话,并在使用基于 react 的 Agent 或使用训练数据微调 GPT 之间进行权衡。@eskcanta建议先测试基础模型,以节省精力核资源。 - 自然对话与自定义指令:
@feedonyourtearskappa寻求关于如何创造更自然、无重复短语的对话的建议,而@openheroes强调了“自定义 ChatGPT (Customize ChatGPT)”功能,可以设置指令以实现更自然的写作风格,包括模仿特定的文本示例。 - 使用 DALL-E 生成专业头像:
@elhadrami.oussama表达了对使用 DALL-E 生成专业头像的兴趣并寻求见解,但@enkai3526以一个与游戏相关的幽默评论进行了回应。
OpenAI ▷ #api-discussions (54 条消息🔥):
- 角色扮演的 Prompt Engineering:用户
@loamy_讨论了如何为角色扮演场景构建 Prompt,考虑是否应指令 AI 永远不要声称自己是助手。@dezuzel建议关注 AI 应该做什么,而不是不应该做什么。 - 随机种子选择已解决:
@interactiveadventureai寻求关于让 GPT 为随机数生成选择不同种子的建议,考虑使用时间戳。@solbus建议在数据分析功能的上下文中使用 Python 内置的 random 函数。 - 优化叙事响应:
@interactiveadventureai对 AI 倾向于提供叙事总结和某种特定对话风格表示沮丧。@eskcanta分享了关于 Prompt Engineering 的指导,以引导 GPT 进入不同的写作风格。 - 构建用于对话的 GPT 分类器:用户
@chemlox询问关于创建 GPT 分类器以评估用户与 Agent 对话是否已解决的建议。@eskcanta建议在决定进一步行动之前先检查 GPT 的 Base Model 性能。 - 构建更自然的对话响应:
@feedonyourtearskappa询问如何通过 Prompt 引导 AI 生成自然且不重复的对话。@openheroes建议使用 “Customize ChatGPT” 功能来引导模型输出预期的结果。
HuggingFace ▷ #announcements (1 条消息):
- RAG Demo 上线:
@bishmoy分享了一个用于搜索 Arxiv CS 论文的 RAG Demo,可通过 HuggingFace Spaces 访问。 - 新型蛋白质异常检测:
@403280164433297409发布了一篇关于使用深度表示(deep representations)检测异常蛋白质的论文,公告附带了 Twitter 链接。 - 使用 ChatML 微调 Gemma:
@817334594075623435提供了 Google Gemma LLM 的微调演示,Notebook 现已在 HuggingFace Spaces 上可用。 - 启发 LLM 洞察:
@1120804749273477242撰写了一篇博客文章,讨论了超越对话、转向有意义的 AI 行动的必要性,链接发布在 LinkedIn。 - Rust 编写的前沿 LLM 界面:一个使用 HuggingFace/Candle 等工具的界面完全由 Rust 构建,由
@538229308678733851在视频中展示;同时@282727276733399041介绍了一个新的 16k 上下文预训练 Encoder 模型,可在 HuggingFace 获取。
提到的链接:
- Arxiv CS RAG - a Hugging Face Space by bishmoy: 未找到描述
- Andyrasika/Gemma-ChatML · Hugging Face: 未找到描述
- Andyrasika/vit-base-patch16-224-in21k-finetuned-lora-food101 · Hugging Face: 未找到描述
- Open Llm Leaderboard Viz - a Hugging Face Space by dimbyTa: 未找到描述
- UDOP DocVQA - a Hugging Face Space by RamAnanth1: 未找到描述
- Yi 9B - a Hugging Face Space by Tonic: 未找到描述
- BEE-spoke-data/mega-encoder-small-16k-v1 · Hugging Face: 未找到描述
- Andyrasika/lora_gemma · Hugging Face: 未找到描述
- Locutusque/UltraTextbooks-2.0 · Datasets at Hugging Face: 未找到描述
- Mistral-ChatBot-Arena - a Hugging Face Space by rwitz: 未找到描述
- GitHub - treebeardtech/treebeard-kubeflow: 🪐 scale Jupyter in Kubernetes: 🪐 在 Kubernetes 中扩展 Jupyter。通过在 GitHub 上创建账号为 treebeardtech/treebeard-kubeflow 的开发做出贡献。
- Large Language Models in Quest for Adventure: 未找到描述
HuggingFace ▷ #general (142 条消息🔥🔥):
- 关于拟议 AI 安全沙皇的冲突:针对 Paul Christiano 预计被任命为美国 AI Safety Institute 成员一事,引发了担忧,导致 National Institute of Standards and Technology (NIST) 内部出现危机,员工威胁要辞职并进行反抗。这篇文章详细描述了这场冲突以及 Christiano 关于 AI 可能导致生存风险的争议性观点。
- 用于优化代码的 AI:
@techintermezzo寻求关于优化着色器代码的最佳 AI 模型的建议,引发了对 DeepSeek-Coder instruct 等模型以及 OpenCodeInterpreter 论文等资源的讨论。这份代码处理综述工作分析了当前的进展,帮助那些有兴趣理解和利用 AI 进行编程任务的人。 - 探索 AI 增强的地缘政治:在关于 AI 在全球战略中潜力的长篇讨论中,
@acidgrim等人辩论了西方和中国 AI 的不同方法,涉及从审查制度到在不对称战争中潜在应用等话题。辩论涵盖了不受限 AI 的影响、AI 训练数据问题以及潜在的监管。 - RAG 的 Prompt Engineering:
@jeffry4754询问了将问题预处理为子问题以进行 Retrieval-Augmented Generation (RAG) 的标准术语,并建议“multi-hop question-answering task”可能是此类技术的名称。对话在没有明确共识或标准术语引用的情况下继续进行。 - Stable Diffusion 查询:用户
@maycolrox请求在 diffusers 库中加载与 Stable Diffusion 相关的模型方面的帮助,暗示了一个名为 loras 的模型存在问题。在给定的消息中没有提供直接的解决方案。
提到的链接:
- 未找到标题:未找到描述
- Inflection-2.5:遇见世界上最好的个人 AI:我们是一家 AI 工作室,致力于为每个人创造个人 AI。我们的第一个 AI 名为 Pi,代表个人智能(personal intelligence),是一个支持性且富有同理心的对话式 AI。
- 跟我重复:在复制任务上 Transformers 比 State Space Models 更出色:Transformers 是序列建模的主导架构,但人们对使用不依赖于序列长度的固定大小潜状态的模型(我们称之为…)的兴趣日益浓厚。
- NIST 员工反抗预计任命“有效利他主义”AI 研究员至美国 AI Safety Institute:据消息人士称,由于 Paul Christiano 预计被任命为美国 AI Safety Institute 的职位,NIST 面临动荡,员工正考虑辞职。
- 在 Vertex AI 中部署 🤗 Hub 模型:未找到描述
- OpenCodeInterpreter:将代码生成与执行及优化相结合:大型语言模型的引入显著推进了代码生成。然而,开源模型通常缺乏高级系统那样的执行能力和迭代优化…
- blog-explorers (Blog-explorers):未找到描述
-
[Haiper 用于视频内容创作的生成式 AI](https://haiper.ai/):旨在赋能个人进行创意表达的视频创作 AI 产品。 - 统一 NLP 和软件工程的视角:代码语言模型综述:在这项工作中,我们系统地回顾了使用语言模型进行代码处理的最新进展,涵盖了 50 多个模型、30 多个评估任务、170 多个数据集和 700 多篇相关论文。我们分析了…
- 在 Vertex AI 中部署 🤗 Hub 模型:未找到描述
- 联邦公报 :: 请求访问:未找到描述
- Regulations.gov:未找到描述
- 我对“毁灭”的看法 — LessWrong:我经常被问到:“AI 产生极坏结果的概率是多少?”……
HuggingFace ▷ #today-im-learning (4 条消息):
- 对用于数据分析的 AI 的兴趣:
@umbreenh表达了学习如何将 Generative AI 用于数据分析开发的愿望,并欢迎该领域的任何帮助或指导。 - 协作学习精神:
@yasirali1149回应了@umbreenh,表示有兴趣一起学习 Generative AI 在数据分析中的应用。 - 准备加入学习之旅:
@kenngala向@Singhaditya4333(未在提供的消息中发言)表示,他们已准备好参与并协作进行学习过程。
HuggingFace ▷ #cool-finds (5 条消息):
-
分享 “Let’s Build GPT” 教育资源:
@kurtfehlhauer推荐了一个关于构建 GPT 的入门视频——一个名为 “Let’s build GPT: from scratch, in code, spelled out.” 的详尽教程。该视频根据 OpenAI 的论文解释了 Generative Pretrained Transformer 的创建过程。 -
关注 Hugging Face 的任务页面:
@andysingal对 Hugging Face 的 机器学习任务门户 表示赞赏,该门户列出了计算机视觉等各个领域的演示、用例、模型、数据集等资源。 -
关于资源熟悉度的温馨提示:针对
@andysingal关于任务页面的帖子,@cakiki指出该资源并非新鲜事物,并对@697163495170375891在该平台上的长期努力表示赞赏。 -
发现是因人而异的:在对话中,
@andysingal澄清说,任务页面对他来说是新发现,因此感到兴奋。 -
Qwen-Agent 赋能 AI 开发者:
@andysingal在一篇题为 “Unleashing the Power of Qwen-Agent: Revolutionizing AI Assistance with RAG Application” 的详细 Medium 文章 中,强调了 Qwen-Agent 的能力。这是一个集成了 LLM 的指令遵循、工具使用、规划和记忆功能的 AI 框架。
提到的链接:
- Tasks - Hugging Face:未找到描述
- Let’s build GPT: from scratch, in code, spelled out.:我们遵循论文 “Attention is All You Need” 以及 OpenAI 的 GPT-2 / GPT-3 构建了一个 Generatively Pretrained Transformer (GPT)。我们讨论了与之相关的…
- Unleashing the Power of Qwen-Agent: Revolutionizing AI Assistance with RAG Application:Ankush k Singal
HuggingFace ▷ #i-made-this (13 messages🔥):
-
Gemma 采用 ChatML:
@andysingal分享了他们使用 ChatML 微调 Google LLM Gemma 的工作,并展示了 model card,同时感谢了 @philschmid 的 tokenizer。 -
ETHDenver 的 AI x Web3 回顾:
@aerophilian撰写了 ETHDenver 的回顾,重点介绍了 Web3 和 AI 的交集,并分享了一篇包含见解和会议演讲 YouTube 链接的 blog post。 -
通过 CLIP 索引进行搜索变得更加简单:
@robbesneyders为 Datacomp-12.8M 数据集引入了 CLIP 索引,方便进行基于 prompt 的搜索,并指出了其团队在 Hugging Face Hub 上的方法和输出,以及一篇包含更多细节的 blog post。 -
AI 精致餐饮:
@chongdashu用不到 100 行 Python 代码构建了一个餐厅名称和菜单生成器应用,展示了 LangChainAI 和 Gradio,并附带了 Medium article、在线 demo 和完整 source code。 -
法律判例触手可及:
@conceptofmind宣布发布超过 660 万份州和联邦法院判决,这是由 Caselaw Access Project 和 Harvard Library Innovation Lab 支持的合作成果,提供可用的数据集和 embeddings,正如 @EnricoShippole 在 update 中提到的,并感谢了<@274244546605613056>的额外帮助。
Links mentioned:
- Doodle Wars: 未找到描述
- Andyrasika/Gemma-ChatML · Hugging Face: 未找到描述
- ETHDenver Recap: Emerging Trends in web3 and AI: 我们所处的阶段、未来的方向以及 Kevin 的回归。
- Tweet from Enrico Shippole (@EnricoShippole): @TeraflopAI 很高兴能支持 @caselawaccess 和 @HarvardLIL,发布美国历史上出版的超过 660 万份州和联邦法院判决。
- Building a Datacomp CLIP index with Fondant - Fondant.): 未找到描述
- Langchain Crash Course (Gradio) - a Hugging Face Space by chongdashu: 未找到描述
- GitHub - chongdashu/langchain-crash-course at lesson-1: 通过在 GitHub 上创建账号来为 chongdashu/langchain-crash-course 的开发做出贡献。
HuggingFace ▷ #reading-group (45 条消息🔥):
-
寻求 llamas2 聊天机器人指导:用户
@neerajjulka1986寻求使用开源模型 llamas2 构建端到端聊天机器人项目的资源。@chad_in_the_house建议查看 GitHub 上的 finetuning 和部署资源,包括 PEFT 和 text-generation-inference,并提到了用于强化学习的 TRL,链接为 TRL GitHub。 -
Gemini 1.5 Pro 概览集会:
@shashank.f1宣布了一个关于 Sparse MOEs 和 Gemini 1.5 Pro 的会议,提供了 Zoom 链接并表示将进行概览。他们还分享了 Jeremy Howard 关于 Sparse MOEs 的推文 作为资源。 -
分享 Gemini 1.5 Pro 讨论录音:
@shashank.f1发布了之前关于 Gemini 1.5 Pro 讨论和 Sparse Mixture of Experts 模型的 YouTube 视频链接,可以在 YouTube 这里 找到。 -
理解 Mixture of Experts (MoEs):
@chad_in_the_house推荐了 Hugging Face 的一篇博客文章来理解 MoEs,访问地址在 这里。此外,@shashank.f1解释说,使用 QLoRA 微调 MoEs 的 VRAM 需求会增加,这使得在单个 GPU 上变得不切实际,但在多 GPU 环境下是可行的,并分享了一个实现该功能的库 fsdp_qlora。 -
会议时间与录音:用户询问了会议时间和录音的获取方式。
@chad_in_the_house确认会议可能安排在周末,并表示录音应由@shashank.f1发布。
提到的链接:
- 加入我们的 Cloud HD 视频会议:Zoom 是现代企业视频通信的领导者,拥有简便、可靠的云平台,可跨移动端、桌面端和会议室系统进行视频和音频会议、聊天及网络研讨会。Zoom …
- 加入我们的 Cloud HD 视频会议:Zoom 是现代企业视频通信的领导者,拥有简便、可靠的云平台,可跨移动端、桌面端和会议室系统进行视频和音频会议、聊天及网络研讨会。Zoom …
- Gemini 1.5 Pro:通过单个 Prompt 从整本书籍和电影中解锁推理与知识:🚀 与 Gemini 1.5 一起潜入 AI 世界!🌟 在这段视频中,我们将揭秘 Gemini 的 Sparse Mixture of Experts 架构背后的魔力,它非常适合释放…
- GitHub - huggingface/trl: 使用强化学习训练 Transformer 语言模型。:使用强化学习训练 Transformer 语言模型。- huggingface/trl
- GitHub - AnswerDotAI/fsdp_qlora: 使用 QLoRA + FSDP 训练 LLMs:使用 QLoRA + FSDP 训练 LLMs。通过在 GitHub 上创建账号来为 AnswerDotAI/fsdp_qlora 的开发做出贡献。
- Mixture of Experts 详解:未找到描述
- GitHub - huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.:🤗 PEFT: 顶尖的参数高效微调技术。- huggingface/peft
- GitHub - huggingface/text-generation-inference: Large Language Model Text Generation Inference:大语言模型文本生成推理。通过在 GitHub 上创建账号来为 huggingface/text-generation-inference 的开发做出贡献。
HuggingFace ▷ #diffusion-discussions (1 条消息):
- 寻求合并 SDXL 与 LoRA 的指南:
happy.j正在寻找关于如何将 sdxl-lightning LoRA 与标准 SDXL 模型合并的资源或指南,并指向了一个 讨论帖,希望能获得更多关于该流程的信息。 - ByteDance 针对 SDXL-Lightning 技术发表看法:
ByteDance官方建议在应用 SDXL-Lightning LoRA 进行加速之前,先在你的数据集上训练一个常规的 SDXL 模型;为了获得最佳兼容性,建议从一开始就将 SDXL 作为 LoRA 进行训练。 - 来自 ByteDance 的高级训练技巧:对于追求更高质量的用户,
ByteDance官方建议将 SDXL-Lightning LoRA 合并到你的模型中后再进行训练,同时指出使用 MSE loss 可能会削弱加速效果。最先进的方法涉及合并后使用对抗性目标(adversarial objective),正如 SDXL-Lightning 论文中所述。
提到的链接:
ByteDance/SDXL-Lightning · finetune:未找到描述
HuggingFace ▷ #computer-vision (9 条消息🔥):
-
数据处理中的归一化难题:
@huzuni发起了一个关于归一化有效性的讨论,表示他们注意到各种归一化方法(如 imagenet norm、channel wise norm 和 min-max norm)对数据指标几乎没有影响。他们询问是否有关于归一化实际效果的研究,或对其可能缺乏效用的解释。 -
寻求用于商业用途的 Ultralytics 替代方案:
@prod.dopamine发起了关于 ultralytics 替代方案的讨论,对适用于商业应用的 AGPL 许可证表示不满。他们正在寻找像 Ultralytics 一样易于使用但又适合商业用途的选项。 -
Yolov4 被建议作为可行的替代方案:针对
@prod.dopamine的提问,@toni_alright建议将 Yolov4 作为替代方案,因为其许可证不同,更适合商业用途。这意味着 Yolov4 可以作为符合商业许可要求的 Ultralytics 替代品。 -
关于 Yolov4 的 Darknet 实现的澄清:在收到建议后,
@prod.dopamine询问所推荐的 Yolov4 是 darknet 实现还是其他版本,表明需要对所提议的具体替代方案进行明确。 -
招募 AI 共同学习伙伴:
@nobita_nobii_发出了招募 AI 共同学习伙伴的邀请,得到了@prod.dopamine的积极响应。这表明社区对频道内的协作学习很感兴趣。
HuggingFace ▷ #NLP (18 条消息🔥):
-
DeBERTa 预训练障碍:
@henkiespenkie22在预训练来自 Microsoft 的 DeBERTa 时遇到问题,目前的实现(如 camemdeberta)对他们不起作用。@grimsqueaker回应称,HuggingFace 不支持 Electra 预训练,这对寻求预训练这些模型的用户构成了挑战。 -
Retriever 双关语大集合:在
@.sgp询问什么是 retriever(检索器/寻回犬)后,@cakiki分享了一个幽默的 金毛寻回犬 GIF,而@lucnzz则俏皮地形容 retriever 是“一只捕捉 embedding 的狗”。 -
为 Colab 选择合适的语言模型:
@iloveh8询问适用于 Google Colab 的中小型开源语言模型的建议,@cursorop建议使用任何 2b 模型和 flan T5,而@lucnzz则提议使用任何小型 4-bit 量化模型。 -
Raspberry Pi 4 上的艰巨任务:
@verdagon幽默地构思了在 Raspberry Pi 4 上运行 70B 模型的想法,即使这意味着生成每个 token 需要 40 分钟。 -
映射 Attention 权重的挑战:
@komorebi6466寻求关于如何使用 BertModel 在情感分析中将 attention 权重映射到句子中每个单词的建议,希望将 attention 输出转换为特定形状的列表。@darwinanim8or要求查看其代码,并提供了一个演示基于 DeBERTa 的分类器类似处理过程的代码片段。
提到的链接:
Golden Retriever Dog GIF - Golden Retriever Dog Puppy - Discover & Share GIFs:点击查看 GIF
HuggingFace ▷ #diffusion-discussions (1 条消息):
- 寻求关于 SDXL-Lightning LoRA 合并的指导:用户
happy.j正在寻求如何将 SDXL-Lightning LoRA 与标准 SDXL 模型合并的帮助,并表示除了 HuggingFace 讨论帖 之外很难找到相关资源。 - 专家对 SDXL 变体的建议:来自 ByteDance 组织 的成员建议先训练一个常规的 SDXL 模型,然后应用 SDXL-Lightning LoRA 进行加速。为了保证兼容性,首选从一开始就使用 LoRA 训练 SDXL。
- SDXL-Lightning LoRA 的高级训练方法:为了提升质量,ByteDance 建议将 SDXL-Lightning LoRA 与用户的模型合并并进一步训练,同时提醒使用 MSE loss 可能会削弱加速效果。遵循 SDXL-Lightning 论文的方法,在训练过程中采用对抗性目标(adversarial objective)被认为是最先进的策略。
提到的链接:
ByteDance/SDXL-Lightning · finetune:未找到描述
LAION ▷ #general (113 条消息🔥🔥):
- AI 图像生成器替代方案热议:
@lunsei询问了正在开发的 Sora 替代方案。@thejonasbrothers幽默地回复说有许多项目正在进行中,@pseudoterminalx补充说许多项目都在以 MagViT2 为基础。 - 营销支出乱象揭秘!:
@pseudoterminalx揭露了令人震惊的营销支出数据,仅 100 美元的销售额就花费了 7,099 美元的转化成本,引发了社区成员的批评和怀疑。对话涉及了严重的效率低下问题以及对更好营销策略的需求。 - Midjourney 用户对抓取行为感到惊慌:讨论中的一些用户(如
@pseudoterminalx)对 Midjourney 成员因其 AI 生成图像被抓取而产生的“安全问题”恐慌感到好笑。同时,@mfcool和@chad_in_the_house谈到了获取这些图像的简便性,以及 Midjourney 使用的泄露艺术家名单。 - SD3 讨论及 Diffusers 更新预期:
@thejonasbrothers分享了即将邀请在 Discord 上使用 SD3 的消息,并暗示了对 Diffusers 项目的贡献。 - 对 Ideogram AI 测试的怀疑:
@pseudoterminalx对宣称 Ideogram AI 优于 SDXL 的说法表示怀疑,分享了在尝试生成体面图像时的失望,并对盲测结果的可信度提出了质疑。
提到的链接:
- 卢德分子能教给我们关于抵制自动化未来的什么:反对技术并不等同于反对进步。
- 360° 在线全景查看器:在线全景 360 查看器。一种免费查看和分享 360 度图片的简便方法。支持 VR。360 图像查看器可立即创建交互式全屏沉浸式 VR 球形 360 3D 全景图…
- 用于训练 Midjourney AI 的 16,000 名艺术家数据库(包括一名 6 岁儿童)引发批评:艺术家名单包括沃霍尔、毕加索、塞尚、梵高、安尼施·卡普尔、草间弥生、格哈德·里希特、弗里达·卡罗和班克斯。
LAION ▷ #research (83 messages🔥🔥):
- SVD 更新减慢训练速度:用户
@metal63提到在使用 Stable Cascade 进行 SVD 更新时遇到了严重的延迟,导致整个训练过程出现了 2 分钟的停顿。 - LLM 的低效性受到质疑:
@mkaic强烈批评了大型语言模型 (LLM) 的参数效率低下,并就训练更高效的稀疏/小型网络的突破潜力展开了讨论,引发了与@recviking及@thejonasbrothers的激烈辩论。 - LLM 与压缩挑战:
@mkaic认为目前的 LLM 并未实现对训练数据的最优压缩,并建议在改进架构和训练方法以更好地利用参数方面仍有巨大空间。 - PixArt Sigma 亮相:
@thejonasbrothers分享了一个名为 PixArt Sigma 的新型 4K PixArt,提供了项目链接及多张示例图片,并指出由于仅使用了 600m 参数,该模型在处理文本方面仍存在问题。 - 探讨剪枝的本质:
@recviking、@thejonasbrothers和@mkaic之间的一系列交流探讨了模型剪枝 (Pruning) 和泛化性的极限及影响,并对当前模型效率的现状发表了评论。@thejonasbrothers在讨论中引用了一篇新论文。
提到的链接:
- PIXART-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation: 社交媒体描述标签
- Neverseenagain Yourleaving GIF - Neverseenagain Yourleaving Oh - Discover & Share GIFs: 点击查看 GIF
OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
-
“Nitro” 模型初步预览:
@alexatallah提醒用户注意新出现的 “nitro” 模型,尽管在正式发布前可能会有微调,但现在已经可以安全地用于使用和开发。 -
推出 Nitro 模型与扩展上下文:
@alexatallah兴奋地介绍了 Nitro 模型,包括 Mixtral、MythoMax 和 Llama 70B,这些模型配备了新的 Nitro 变体按钮,并由 Groq 及其他供应商提供支持。此外,上下文扩展模型现已上线,Mixtral 已扩展至 732,768 上下文 (OpenRouter Models),一段专门的视频演示展示了这些模型在速度和成本效益方面的提升。 -
开发者功能与动态路由:重点介绍了新的开发者功能,包括性能时间线、JSON 模式和动态路由。邀请早期用户查看文档以获取详细信息。
-
OpenRouter 的模型选择与使用路径:
@alexatallah解释说 OpenRouter 能够根据价格和性能指标协助选择模型,通过标准化 API 实现模型间的轻松切换,且即将推出的功能包括基于使用的比较和针对用户选择模型的 OAuth 功能。详情可见文档与排名。 -
Mistral 7b 0.2 加入 Nitro 系列:
@alexatallah透露了最新的 Nitro 模型 Mistral 7b 0.2,指出其速度显著提升(长输出最高提升 20 倍),且上下文限制扩展至 32k。实时演示可在 Twitter 上查看。
提到的链接:
-
[Mixtral 8x7B Instruct (nitro) by mistralai OpenRouter](https://openrouter.ai/models/mistralai/mixtral-8x7b-instruct:nitro): 由 Mistral AI 开发的预训练生成式稀疏混合专家模型 (Sparse Mixture of Experts),用于聊天和指令场景。包含 8 个专家网络(前馈网络),总计 470 亿参数。 - OpenRouter: 构建与模型无关的 AI 应用
OpenRouter (Alex Atallah) ▷ #general (109 messages🔥🔥):
-
模型比较与性能:
@filth2强调 Sonnet 提供了令人印象深刻的性价比,在 “5k 上下文和 1200 响应长度” 的情况下成本低至 .03,使其成为与其他模型相比极具价值的选择。同时,@phoshnk和@mka79讨论了 Opus 和 Sonnet 之间的细微差别和成本效益,普遍共识是 Sonnet 更实惠。 -
澄清审核层困惑:
@filth2、@spaceemotion和@alexatallah讨论了 OpenAI、Anthropic 和 OpenRouter 提供的模型中审核机制的细微差别。会议澄清了 OpenRouter 应用了额外的审核层,这可能导致与直接使用 OpenAI 或 Anthropic API 相比出现更多的拒绝响应。 -
数据保留与训练实践咨询:
@mka79提出了关于 Anthropic 在模型训练中使用客户内容的问题。@spaceemotion分享了 Anthropic 支持文章的链接,从而了解到来自付费服务的内容可能不会被用于训练。 -
Alex Atallah 对 Anthropic 端点的澄清:
@alexatallah阐明了 Anthropic 如何专门针对 OpenRouter 的自审核请求进行内容审核,其中包括影响响应的服务端分类器和 Transformer。直接使用 Anthropic API 的用户可能没有额外的审核层,但如果缺乏适当的审核策略,则面临受到制裁的风险。 -
关于 Nitro 模型和价格见解的讨论:
@starlord2629、@xiaoqianwx和@louisgv等用户讨论了 Nitro 模型,特别是它们更高的吞吐量和不同的定价,目前 Groq 为 Mixtral 8x7b instruct nitro 提供支持,成本为 0.27/1M tokens。用户对这些进展表示乐观和关注。
CUDA MODE ▷ #general (6 messages):
- 表情包来袭:用户
@iron_bound表达了发布表情包(memes)的强烈愿望,得到了@marksaroufim的鼓励,并指引他们发布在专门的表情包频道。 - 分享 CUDA 版 Flash Attention:
@tspeterkim_89106分享了一个使用 CUDA 实现 Flash Attention 的项目(Flash Attention in ~100 lines of CUDA),并欢迎大家就 Flash Attention 的实现提供反馈和讨论。 - 快速了解 CUDA:
@iron_bound分享了一个名为 “Nvidia CUDA in 100 Seconds” 的 YouTube 视频,总结了什么是 CUDA 及其在 AI 开发中的作用。 - 注意到 Nvidia 巧妙的营销手段:
@iron_bound评论了 Nvidia 的策略,即在一段提到 Nvidia GPU 技术大会(GTC)的视频中展示了 4090 显卡,@apaz对这一观察表示认同。
提到的链接:
- Nvidia CUDA in 100 Seconds:什么是 CUDA?GPU 上的并行计算如何让开发者释放 AI 的全部潜力?学习 Nvidia CUDA 编程的基础知识…
- GitHub - tspeterkim/flash-attention-minimal: Flash Attention in ~100 lines of CUDA (forward pass only):约 100 行 CUDA 代码实现的 Flash Attention(仅前向传播) - tspeterkim/flash-attention-minimal
CUDA MODE ▷ #triton (1 messages):
marksaroufim: 你看到加入那个见面会(meetup)的链接在哪里了吗?
CUDA MODE ▷ #cuda (78 messages🔥🔥):
- 粗化(Coarsening)可能会达到吞吐量上限:
@cudawarped建议,在内存吞吐量已达到 93% 的工作负载中,粗化可能无法提高性能,这意味着已达到性能天花板。 - 学习 CuTe DSL 以更好地理解 FlashAttention:
@ericauld讨论了学习 CuTe DSL 的必要性,因为它被用于 NVIDIA FlashAttention 仓库,这对于优化 Tensor Core 利用率至关重要。 - 发现反量化(Dequantization)速度提升:
@zippika分享了一个使用cuda::pipelineAPI 的反量化实现,在修复一个 bug 后,声称其反量化速度现在比 bnb 反量化更快。 - CUDA 中的向量化操作:
@uwu1468548483828484询问了 CUDA 中通用类型的向量加载(vector loads),@zippika分享了一个示例实现,并建议向量化加法和存储可以提升性能。 - CUDA 基准测试表明粗化在大数据上有效:
@zippika和@cudawarped就线程粗化(thread coarsening)的效果以及向量化加载和存储的使用进行了详细讨论。基准测试显示了一些收益,但也存在与使用int4/float4类型以及在半精度数组上使用__hadd2等向量化操作相关的复杂性。
提到的链接:
cutlass/media/docs/cute at main · NVIDIA/cutlass:用于线性代数子程序的 CUDA 模板。通过在 GitHub 上创建账号为 NVIDIA/cutlass 的开发做出贡献。
CUDA MODE ▷ #torch (4 messages):
- 澄清 CPU 和 CUDA Tensor 索引:
@mikkelisk对为什么 CPU Tensor 可以被 CUDA Tensor 索引(如果是标量的话)感到困惑,尽管通常不能在操作中混合设备。@_t_vi_解释说,允许这种混合是为了与使用非 Tensor CPU 对象进行索引保持兼容,以及由于标量特殊处理的历史原因。 - 标量桥接了 PyTorch 中的 CPU-CUDA 鸿沟:针对这种设备混合为何有效,
@_t_vi_指出标量被特殊对待并会自动转换,这既是为了方便,也是 PyTorch 早期在 C/C++ 层面通过c10::Scalar不同地处理标量所留下的遗产。 - 警惕隐藏的低效率:
@_t_vi_警告说,虽然标量在 CPU 和 GPU Tensor 之间的自动传输很方便,但它可能导致代码中难以调试的低效率问题。
CUDA MODE ▷ #algorithms (5 messages):
-
关于 RelayAttention 机制的查询:
@lancerts在看到 GitHub 仓库 vLLM with RelayAttention 后,询问了 RelayAttention 与 Ring/Flash Attention 之间的区别。 -
内存高效的微调方法:
@iron_bound引用了一种显著降低微调内存需求的方法,称为 Gradient Low-Rank Projection (GaLore),如一篇 arXiv 论文 所述。他们提到,即使是单张 RTX 4090 GPU 也可以用于预训练大模型。 -
在标准游戏 GPU 上进行高效训练:
@iron_bound分享了关于一种能够在带有标准游戏 GPU 的台式机上微调 70b 模型的技术信息。该方法结合了 FSDP 和 QLoRA,并在 Answer.AI 的博客文章 中进行了详细介绍,展示了与 AI 领域知名人士和组织的合作。
提到的链接:
- GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection:训练大语言模型 (LLMs) 面临显著的内存挑战,主要是由于权重和优化器状态规模的增长。常见的内存减少方法,如低秩…
- Answer.AI - You can now train a 70b language model at home:我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两块 24GB GPU 上训练 70b 模型。
- GitHub - rayleizhu/vllm-ra: vLLM with RelayAttention integration:集成 RelayAttention 的 vLLM。通过在 GitHub 上创建账号为 rayleizhu/vllm-ra 的开发做出贡献。
CUDA MODE ▷ #beginner (4 条消息):
- 初学者寻求 CUDA 建议:用户
@violetmantis就在 cuda-mode/resource-stream 中学习 cache-efficient parallel algorithms(缓存高效并行算法)和 kernel development/optimization(内核开发/优化)的关键资源寻求建议,面对海量内容希望能获得入门方向。 - 起步课程推荐:
@marksaroufim建议从 Discord 中专为 CUDA 和并行编程 零基础初学者 设计的课程开始。 - 建议同步学习法:
@mertbozkir虽然也是该领域的新手,但建议将视频课程与配套书籍结合使用,以获得更丰富的学习体验。
CUDA MODE ▷ #ring-attention (12 条消息🔥):
- 16k 训练导致系统故障:
@iron_bound报告称,在 16k 下进行训练会导致系统在 5 分钟后“脑死亡”,此时 GPU 功耗为 100w。根据 wandb 日志,他们推测故障可能发生在第一个 epoch 结束时。 - 安排同步讨论:
@jamesmel表示打算参加第二天的讨论,而@iron_bound提到上次同步讨论没有太多可谈的,因为只有 Eric 和他们参加。 - 使用 Flash Attention 时推理卡住:
@jamesmel在两个 GPU 上进行 ring-llama 推理时遇到问题,卡在_flash_attn_forward函数中的block_out操作,两个子进程都暂停了。他们提到在运行 ring-llama 之前已经通过 pip 安装了 flash-attn。
CUDA MODE ▷ #off-topic (1 条消息):
- 曼德博集合奇观:用户
@apaz分享了一个展示 Mandelbrot fractal 的图片链接。该图片没有附带进一步的背景信息或讨论点。
{kind=link}
Latent Space ▷ #ai-general-chat (31 条消息🔥):
-
GaLore 在显存效率方面的突破:用户
@tiagoefreitas分享了来自@AnimaAnandkumar的推文,展示了 Llama 7B LLM 现在可以在单张 RTX 4090 GPU 上进行训练,显著降低了存储优化器状态(optimizer states)的显存成本。@fx2y指出,这种名为 Gradient Low-Rank Projection (GaLore) 的方法不仅为预训练(pre-training)提供了巨大的显存节省,可能也适用于微调(fine-tuning),并有望与 1-bit 量化(quantization)等技术结合,进一步提升效率。 -
Inflection-2.5 的惊人飞跃:
@stealthgnome介绍了来自@inflectionAI的重大声明,声称其 Inflection-2.5 模型 仅使用 40% 的训练算力(compute)就达到了接近 GPT-4 的性能。@swyxio指出,虽然这一声明意义重大,但 Inflection 在其详细介绍 Inflection-2.5 的官方博客文章中并未重点强调这一点。 -
FSDP/QLoRA 支持在家训练大模型:
@fanahova分享了来自@jeremyphoward的推文,宣布了 FSDP/QLoRA 项目。这是一项合作成果,允许在消费级 GPU 上训练超大型模型。@fx2y提供了 GitHub 仓库链接,并提到该项目支持 HQQ 和 bitsandbytes 等量化方法。 -
Yann LeCun 在 Lex 播客讨论 AI 风险与未来:用户
@stealthgnome、@swyxio和@mr.osophy讨论了 Yann LeCun 在 Lex Fridman 播客上的访谈。他在节目中谈到了 Meta AI、LLMs 的局限性以及他对 AI 未来的看法,并触及了对比学习(Contrastive Learning)的概念。 -
Life Story 的个人 AI 故事:
@swyxio分享了他使用 Life Story 的体验,这是一款充当个人传记作家的 AI。他反馈称通话体验良好,但建议对完整体验和数据安全保持谨慎。这个想法引发了兴趣,@tiagoefreitas表示希望看到更多类似这种功能的本地托管(locally-hosted)应用。 -
围绕 OpenAI 领导层的争议:
@guardiang指向了《纽约时报》一篇关于 OpenAI 内部争议的文章,讨论了 Sam Altman 离职前后的情况。此外,@aardvarkoncomputer强调了@inflectionAI与有关其 Claude-3 模型“套壳”(wrapper)指控之间正在进行的争端。
提到的链接:
- 来自 Anima Anandkumar 教授 (@AnimaAnandkumar) 的推文:我们首次展示了 Llama 7B LLM 可以在仅有 24GB 显存的单张消费级 GPU (RTX 4090) 上进行训练。这代表存储优化器状态所需的显存减少了 82.5% 以上…
- Inflection-2.5:遇见世界上最好的个人 AI:我们是一家 AI 工作室,旨在为每个人创造个人 AI。我们的第一个 AI 名叫 Pi,代表个人智能(personal intelligence),是一个支持性且富有同理心的对话式 AI。
- Life Story:捕捉生活,一次一个故事。
- 来自 lmsys.org (@lmsysorg) 的推文:🔥来自 Arena 的激动人心的消息,@Anthropic 的 Claude-3 排名公布了!📈 Claude-3 引发了社区的极大兴趣,推动 Arena 流量达到前所未有的高度,仅在三天内就有超过 20,000 次投票…
- 来自 Jeremy Howard (@jeremyphoward) 的推文:今天,我们与 @Tim_Dettmers、@huggingface 和 @mobius_labs 共同发布了 FSDP/QLoRA,这是一个新项目,让你可以在配备消费级游戏 GPU 的家用电脑上高效训练超大型 (70b) 模型…
-
[Yann Lecun:Meta AI、开源、LLMs 的局限性、AGI 与 AI 的未来 Lex Fridman Podcast #416](https://www.youtube.com/watch?v=5t1vTLU7s40):Yann LeCun 是 Meta 的首席 AI 科学家、纽约大学教授、图灵奖得主,也是 AI 历史上最具影响力的研究者之一。请看… - 来自 swyx (@swyx) 的推文:我现在已经与 AI 心理治疗师进行了多次超过 20 分钟的电话交谈,感觉非常自然。每个 AI 工程师现在都应该构建自己的治疗师,而语音是正确的媒介。
Latent Space ▷ #ai-announcements (3 条消息):
-
史诗级 GPT-2 演讲预告:
@ivanleomk宣布@1123457263638683770将在 20 分钟后分享 GPT-2 论文,并敦促亚洲区的@paper-club参加这场被承诺为“史诗级分享”的活动。 -
观看回放:
@swyxio兴奋地回应了这一公告,表示希望录制该环节。
提到的链接:
加入 Latent Space (原名 /dev/invest) Discord 服务器!:查看 Discord 上的 Latent Space (原名 /dev/invest) 社区 —— 与其他 3061 名成员一起交流,享受免费的语音和文字聊天。
Latent Space ▷ #llm-paper-club-west (30 条消息🔥):
- GPT 论文分享准备:
@ivanleomk宣布讨论即将开始,并提供了关于 Generative Pre-trained Transformers 的笔记链接,包括 概念 和 实现,@1123457263638683770将在分享过程中引用这些内容。 - 准备开始:
@ivanleomk在 LLM paper club 会议开始前 5 分钟发出了提醒。 - 新人的热情:
@healthymonkey表示自己是 NLP 领域的新人,并请<@1039021595089448990>和<@206404469263433728>等更有经验的参与者纠正其讨论观点中的任何错误。 - 技术澄清:在讨论过程中,
@kishore.reddy通过提到 “causal attention” 纠正了@ivanleomk对 decoder 模型的解释,这指的是确保模型在无法访问未来 token 状态的情况下预测下一个 token。 - LLM 概念的实际演示:
@fx2y分享了 LLM Visualization 的链接,这是一个用于可视化 GPT 系列模型的有用工具,并对@1123457263638683770在讨论中的努力表示赞赏。
提到的链接:
- LLM Visualization:未找到描述
- The Concept of Generative Pre-trained Transformers (GPT) — Omniverse:未找到描述
- The Implementation of Generative Pre-trained Transformers (GPT) — Omniverse:未找到描述
LangChain AI ▷ #general (21 messages🔥):
- LangChain JS 功能对等查询:
@0x404blockchainnotfound询问了 LangChain JS 库 是否已实现与 Python 库的功能对等(feature parity),但聊天中未提供直接回答。 - AGI 主张讨论:
@sales_god就 Hacker News 上讨论的关于 Agent/AGI 的主张寻求意见,但讨论未达成共识,并因@baytaew对 LangChain 工具和 ReACT Agent 的担忧评论而偏离了主题。 - Python 中 Finished Agent 事件延迟:
@cybersmiths报告了 Python 中 Finished Agent 事件的延迟问题,导致在最后一个字符流式传输(streamed)后出现 1-2 秒的延迟。然而,该线程未包含该问题的解决方案。 - 处理 PDF Loader 提取:
@yd4224在使用 langchain.document_loaders PyPDFLoader 时遇到了格式问题,并收到了来自@travellingprog的指导,建议创建自定义加载器或向仓库贡献代码以处理extraction_mode参数。 - 推动 JavaScript URL Loader:
@mohitsakhiya077表达了在 JavaScript 中从多个 URL 加载文档的功能需求,类似于 Python 版本中UnstructuredURLLoader提供的功能,从而引发了关于两种语言版本之间对等性的讨论。
提到的链接:
- no title found:未找到标题
-
[Ollama Functions 🦜️🔗 Langchain](https://js.langchain.com/docs/integrations/chat/ollama_functions):LangChain 提供了一个实验性封装,用于通过 Ollama 在本地运行开源模型 - Extract Text from a PDF — pypdf 4.0.1 documentation:未找到描述
-
[URL 🦜️🔗 Langchain](https://python.langchain.com/docs/integrations/document_loaders/url):这涵盖了如何将 URL 列表中的 HTML 文档加载到… - langchain/libs/community/langchain_community/document_loaders/parsers/pdf.py at v0.1.11 · langchain-ai/langchain:🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号来为 langchain-ai/langchain 的开发做出贡献。
LangChain AI ▷ #langchain-templates (9 messages🔥):
-
Redis 聊天历史记录困扰:
@justanothergraphguy正在尝试使用 Redis 聊天历史和基于 Pydantic 模型的结构化输出解析来创建聊天链(chat chain)。他们遇到了一个问题,即最新的 “HumanMessage” 错误地出现在AIMessage内容中,这表明记忆传播(memory propagation)可能存在问题。 -
设计 Prompt 和模型:一个针对 “User Profile Builder”(用户画像构建器)的系统 Prompt 引导 Assistant 进行交互,旨在提取用户信息并构建画像。
-
技术设置揭晓:
@justanothergraphguy分享了一段 Python 代码片段,集成了ChatOpenAI、RunnableWithMessageHistory和PydanticOutputParser等多个langchain模块来创建聊天链。 -
首次交互完美执行:
@justanothergraphguy提供的初始示例显示正确提取了 “Bob” 的名字,同时系统提示需要更多信息来完成画像。 -
后续交互混淆:在后续交互中,输出错误地将 ‘HumanMessage’ 包含在
AIMessage内容中,凸显了他们系统中的记忆问题。
LangChain AI ▷ #share-your-work (2 messages):
-
视觉 AI 备受关注:
@vru.shank宣布了一个研讨会,邀请了 MultiOn 和 Quizizz 讨论他们在生产环境中使用 Vision Models 的情况。感兴趣的人员可以通过 此链接 报名参加由 LLMs in Prod community 主办的会议。 -
Prompt Mixer 介绍 - 你的 Prompt IDE:
@tomatyss正在开发 Prompt Mixer,这是一款用于构建、测试和迭代 AI Prompt 的桌面工具,并具备版本追踪功能。欢迎提供反馈和功能建议,感兴趣的用户可以在 Prompt Mixer 官网 下载。 -
如何自定义你的连接器:针对 Prompt Mixer 的高级用户,
@tomatyss分享了一个 文档链接,详细介绍了创建自定义连接器的步骤,从而增强了该工具的灵活性和功能性。
提到的链接:
- no title found): 未找到描述
-
[Multi-Modal LLMs in Prod Practitioners’ Workshop · Luma](https://lu.ma/multimodal-llms):LLMs in Prod 社区正在邀请来自顶尖生成式 AI 公司的从业者,分享他们如何在……中使用多模态模型(视觉、音频、图像生成等)。 - Prompt Mixer — Prompt IDE and LLMOps tool:PromptMixer —— 一款创新的 Prompt IDE,用于以前所未有的便捷性制作、测试和部署 Prompt。
-
[Create a Custom Connector Prompt Mixer Docs](https://docs.promptmixer.dev/tutorial-extras/create-a-custom-connector):第 1 步:复制示例连接器
LangChain AI ▷ #tutorials (1 messages):
pradeep1148: https://www.youtube.com/watch?v=PtP8R8VjTGc
DiscoResearch ▷ #general (3 messages):
- 寻找经过德语微调的 Mixtral:用户
@johannhartmann询问了关于比较 sauerkraut oder discolm mixtrals 等模型在德语 Prompt 下的表现,并指出 Nous Hermes Mixtral 没有涉及德语微调。 - Evo 介绍:生物语言模型:
@rasdani重点介绍了来自 TogetherAI 的名为 Striped Hyena 的新 Evo 架构,专为 DNA 序列建模而设计。阅读关于 Evo 的能力,了解其在处理各种生物序列方面的表现,以及它与 Arc Institute 的合作开发情况。
提到的链接:
Evo: Long-context modeling from molecular to genome scale:未找到描述
DiscoResearch ▷ #embedding_dev (11 messages🔥):
- 使用 Hermes Mixtral DPO 进行微调探讨:
@flozi00正在进行 Nous Hermes Mixtral DPO 模型 的微调工作,旨在在转向训练分类模型之前进行改进,但指出该过程涉及“清理大量垃圾数据”。 - 创建高质量翻译数据集:为了追求高质量的翻译评估,
@flozi00计划建立一个 Argilla space,对来自 Google Translate、DeepL 和 Azure Translate 的翻译进行标注。 - 针对英德翻译对:
@crispstrobe建议利用 OPUS 100 数据集中的英德(EN-DE)对来创建一个包含可靠配对的子集,适用于非特定语境,并强调了该数据集在创建训练子集方面的效用。 - 数据集许可和质量问题:
@philipmay分享了 mMARCO 数据集现在拥有 Apache 2.0 许可证,但在 HuggingFace 上查看该数据集时遇到了问题,表示需要帮助以使 dataset viewer 正常工作。 - 翻译数据质量的公共集合:
@flozi00提到更新了他们的评测模型和数据集,并寻求进一步的改进建议,该内容目前已包含在一个 旨在衡量翻译对质量的 HuggingFace 集合 中。
提到的链接:
- Translation Data Quality - a flozi00 Collection:未找到描述
- unicamp-dl/mmarco · Datasets at Hugging Face:未找到描述
- Data (Hint ID):未找到描述
DiscoResearch ▷ #discolm_german (3 messages):
-
使用 SPIN 合并德语翻译:
@johannhartmann分享了他们如何将 slim orca 数据集的德语翻译版本用于 Mistral merges,并在多个步骤中应用类 SPIN 方法。他们针对相同的翻译指令/输入对,使用多个模型的回答创建数据集,这导致模型响应出现了明显的漂移,有时在合并后变得更加冗长或出现退化。他们计划很快清理并上传该数据集。 -
Brezn3 表现优于 Brezn-7b:
@crispstrobe对 Brezn3 在未经修订的情况下在 EQ-Bench (v2) (de) 上获得 63.25 分表示惊讶,这一成绩超过了 Brezn-7b 的 58.22 分。他们询问这是否仅仅是因为将基础模型更改为 LeoLM/leo-mistral-hessianai-7b-chat 并设置了tokenizer_source: base,还是应用了不同的 DPO 修改。 -
Brezn3 的 DPO 仍在进行中:
@johannhartmann回复称 Brezn3 的 DPO 过程仍在进行中,预计还需约 13 小时完成。
LLM Perf Enthusiasts AI ▷ #claude (6 messages):
- 模型与名称带来的挑战:
@res6969观察到,names 可能会给模型的正确处理带来困难。 - 动手实践 Claude 功能:
@res6969分享了他们在 Claude 上实验 function calling 的经验,表明正在取得进展。 - 赞赏 Claude 幽默的准确性:
@res6969对 Claude 的表现表示赞赏,称其“既幽默又准确”。 - 函数调用有效但有前提:
@res6969确认 Claude 上的 function calling 是有效的,但强调为了获得最佳效果,必须使用 XML tags。 - XML 复杂性引发担忧:
@pantsforbirds评论了使用 XML tags 的复杂性,指出这使得分享 prompt generators 变得更加困难。
Datasette - LLM (@SimonW) ▷ #ai (5 messages):
- GPT-4 未能通过测试:
@dbreunig对 GPT-4 在某项未指明的测试中表现如此糟糕表示惊讶。 - 可点击书架创新:
@xnimrodx赞赏了一个能自动创建可点击书架图像的脚本,该脚本能引导用户进入每本书对应的 Google Books 页面,该内容出自一篇 博客文章 并附带 演示。 - 图书管理员的梦想工具:
@xnimrodx提到,对于图书管理员来说,自动化的书架管理非常有用,这将极大地帮助在大规模藏书中进行理架任务。 - 令人印象深刻的图书馆管理:
@xnimrodx分享道,他的图书管理员妻子管理着一个拥有 35 所学校的教区系统中最大的学校图书馆,其规模可与某些公共图书馆分馆相媲美。 - 小图书馆编目应用想法:
@dbreunig提到有兴趣开发一个玩具应用,用于为镇上小图书馆的书籍进行编目。
提到的链接:
| [Making my bookshelves clickable | James’ Coffee Blog](https://jamesg.blog/2024/02/14/clickable-bookshelves/):未找到描述 |