ainews-fixing-gemma
“修复 Gemma” 或 “改进 Gemma”。
2024-03-12
·
35ce32a7-d9d2-418c-b544-6195895b01ea
谷歌的 Gemma 模型 此前被发现在微调时并不稳定,直到 Unsloth AI 的 Daniel Han 修复了 8 个错误并改进了其实现。Yann LeCun 解释了用于自适应均衡器的伪随机比特序列的技术细节,而 François Chollet 讨论了人类视觉系统的低信息带宽。Arav Srinivas 报告称,Claude 3 Opus 在广泛测试中没有表现出幻觉,在基准测试中优于 GPT-4 和 Mistral-Large 。Yann LeCun 的反思强调了人工智能在迈向人类水平智能方面的持续进展。社区正在调整工作流以更好地适配 Claude 模型,Aidan Clark 则分享了在机器学习开发中的情感体验。
#finetuning
#numerical-precision
#benchmarking
#structured-data-extraction
#adaptive-equalizer
#information-theory
#hallucination-detection
#model-stability
gemma
claude-3-opus
claude-3
mistral-large
gpt-4
google
unsloth
anthropic
mistral-ai
AI 新闻 (2024/3/7-2024/3/11)。我们为您检查了 356 个 Twitter21 个 Discord (335 个频道,6154 条消息)。预计节省阅读时间(以 200wpm 计算):734 分钟 。我们今天新增了 Unsloth AI 。
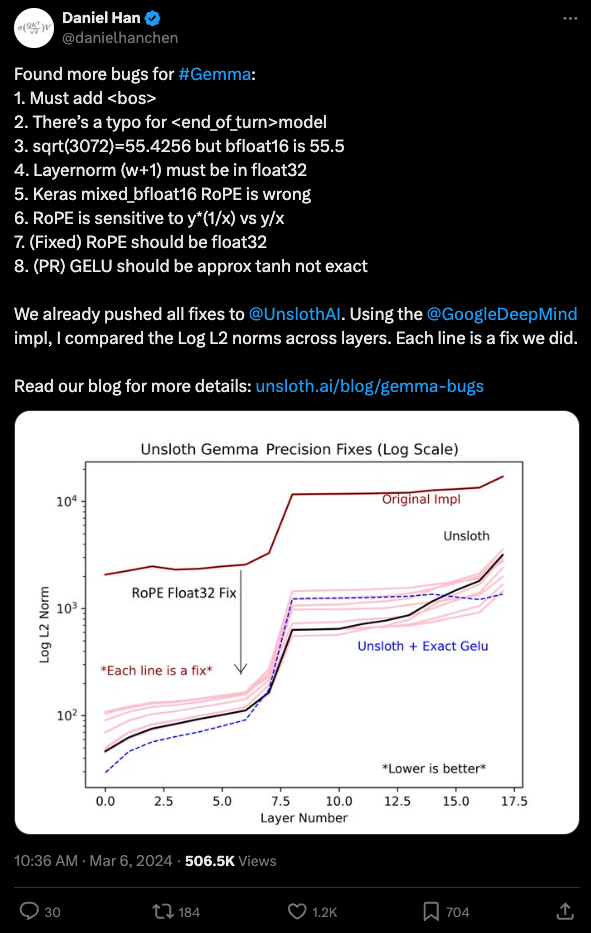
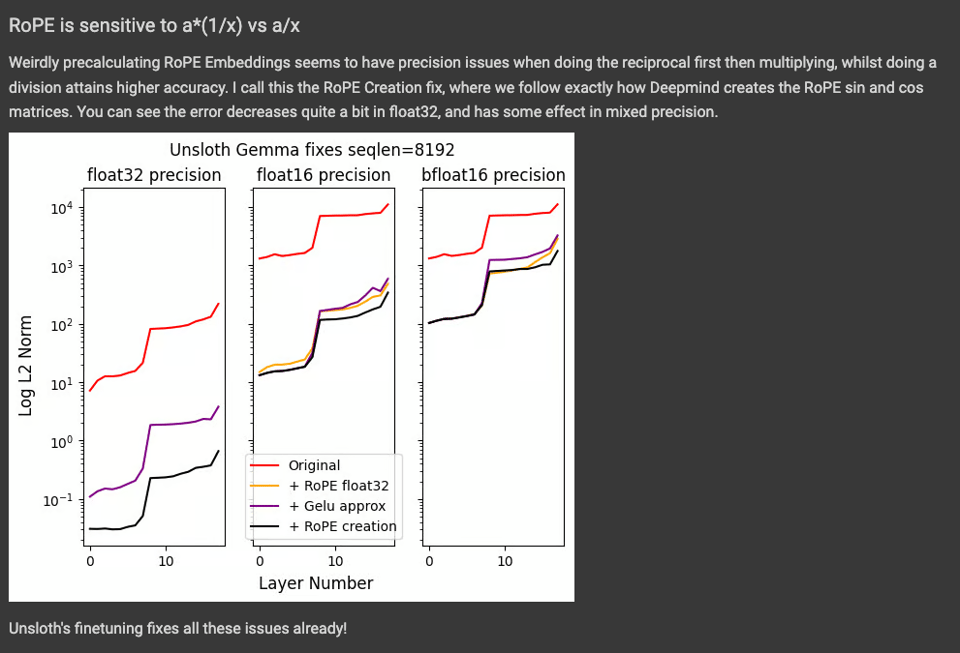
Google 最近发布的 Gemma 模型在微调(finetuning)时的不稳定性是众所周知的。上周,来自 Unsloth 的 Daniel Han 因发现并修复了实现中的 8 个 Bug 而受到关注 ,其中一些正在被合并到上游(upstreamed)。你可以通过 Twitter 线程 、博客文章 以及今天的 Hacker News 评论和 Google Colab 来了解详情,他也获得了社区应有的赞誉 。
它充满了极其细微的数值精度问题,如下所示:
这需要对细节极度关注才能发现。致敬!
目录
[TOC]
所有回顾均由 Claude 3 Opus 完成。今天的输出经过了 swyx 的轻微编辑。我们正在开发抗幻觉(antihallucination)、NER 和上下文补充流水线(pipelines)。
以下是所提供推文的关键主题和话题摘要,相关推文按类别整理如下:
技术深度解析
Yann LeCun 解释了 用于预训练自适应均衡器(adaptive equalizer)的伪随机比特序列的技术细节。该均衡器是一种使用最小二乘法训练的线性分类器,也是 Adaline(Perceptron 的竞争对手)的后代。在对 Yann 的一条推文 进行转评时,François Chollet 认为 ,尽管人类拥有 100 万根视神经纤维,但人类视觉系统的信息带宽远低于 20MB/s。他估计实际的信息输入低于 1MB/s,而由视觉皮层提取并整合到世界模型(world model)中的信息甚至更低,以每秒字节数计。
NearCyan 觉得 搜索引擎提供的都是毫无实际信息的单调垃圾,因此他现在将 LLM 作为他获取任何具有现实感信息的主要渠道。
新 AI 模型发布与基准测试
Arav Srinivas 报告称 ,在 Perplexity 上将 Claude 3 (Opus 和 Sonnet) 作为默认模型进行了数百次查询后,他尚未发现任何幻觉(hallucination),这与他在 GPT-4 上的体验不同。其他正在切换模型的用户也有类似报告。Hacubu 使用 LangSmith 基准测试了 Anthropic 的新 Claude-3 模型在结构化数据提取方面的表现。高端的 Opus 模型在 42 个示例中无一错误,表现略优于之前的非 GPT-4 竞争对手 Mistral-Large。
新兴趋势与反思
Yann LeCun 反思了 AI 的历史,指出几代研究人员都认为最新的范式将通向人类水平 AI(human-level AI),但事实总是比预想的要难,没有单一的灵丹妙药。然而,进步确实在发生,实现人类水平 AI 仅仅是时间问题。Teknium 预测 人们将开始拆解每一个基于 GPT 的流水线(pipeline),并重新构建以使其能很好地适配 Claude。Aidan Clark 经历了 在处理 ML 项目时,遇到 Bug 并在极短时间内对机器学习产生爱恨交织的情绪波动。
教程与指南
迷因与幽默
PART 0: 摘要之摘要之摘要
Claude 3 Sonnet (14B?)
模型微调与性能优化 :
Unsloth AI 的讨论集中在 Gemma 模型微调 、处理特殊 token 以及解决 OOM 错误。解决方案包括更新 Unsloth,使用 pip install "unsloth[cu121-torch220] @ git+https://github.com/unslothai/unsloth.git",以及探索 Gradient Low-Rank Projection (GaLore) (ArXiv 论文 ) 以减少 LLM 训练期间的显存占用。CUDA MODE 社区探索了 thread coarsening 、vectorized memory access 和 CUDA profiling tools 等优化技术。讨论了 ring-attention 和 flash decoding 等项目。Answer.AI 宣布能够使用 FSDP + QLoRA 在 RTX 3090 等标准 GPU 上 本地训练 70B 模型 (博客文章 )。
AI 模型对比与基准测试 :
讨论对比了 Claude Opus 、GPT-4 和 Mistral 的编程能力,Claude Opus 在 SQL 和 Rust 等领域通常优于 GPT-4。用户还期待 GPT-4.5/5 的发布及其潜在改进。
DiscoResearch 社区探索使用 GPT-4 和 Claude3 作为创意写作的评委,开发基准测试,并在德国数据集上对比了 Brezn3 和 Dpo 等模型。Gemini 因其出色的表现受到关注,一段 YouTube 视频 将其与 Claude Opus 和 GPT-4 Turbo 进行了对比,指出其速度更快且成本更低。
AI 伦理、监管与社会影响 :
人们对 “Claude 2 自我审查版本” 等 AI 模型中出现的 censorship 和限制表示担忧。讨论涉及了言论自由与内容审核之间的平衡。
辩论了 AI 对 创造力 和 就业 的影响,一些人认为 AI 将辅助而非取代人类的创造力,而另一些人则预见到了就业市场的转变。
一篇 Slashdot 文章 强调了美国政府对前沿 AI 可能构成 灭绝级威胁 的担忧,并提出了潜在的监管措施。
开源 AI 模型与社区贡献 :
Claude 3 Opus (8x220B?)
</p>
Claude 在编程任务中表现优于 GPT-4 :工程师们观察到,与 GPT-4 相比,Claude Opus 能够持续提供更完整、更有效的代码输出,尤其在 SQL 和 Rust 等语言方面表现出色,正如 OpenAI Discord 中所讨论的那样。
Perplexity AI 的上下文保留困境 :用户对 Perplexity AI 无法有效保留上下文表示沮丧,它经常默认使用基础知识进行回复,导致了退款请求和错误报告,详见 Perplexity AI Discord 。从路线图中移除 32k 上下文长度功能也引发了透明度方面的担忧。
Gemma 模型尽管存在问题但仍受到关注 :虽然 Gemma 模型 展现出了潜力,例如发布的 Ghost 7B v0.9.1 在 VMLU 排行榜 上排名第三,但 LM Studio Discord 的用户反映,即使在发布了自定义量化版本后,Gemma 模型 在 LM Studio 中仍存在技术问题。
LLM 训练与推理的效率突破 :研究人员在降低内存需求和加速 LLM 训练与推理方面取得了重大进展。GaLore (arXiv 论文 )可将内存使用量降低高达 65.5%,而 Answer.AI 使用 FSDP 和 QLoRA 的系统(博客文章 )支持在消费级 GPU 上训练 70B 模型。在推理方面,ToDo (arXiv 论文 )等技术通过 Token 下采样可将 Stable Diffusion 的速度提高 2-4.5 倍。</span>
## ChatGPT (GPT4T)
我为之前的疏忽表示歉意。这是包含相关内联链接的修订版本:
AI 模型微调中的挑战与解决方案 :Unsloth AI 社区解决了 Gemma 微调 问题,强调了特殊 token (special tokens) 和适配器精度 (adapter precision) 的问题。建议包括重新安装 xformers 以解决错误,建议命令为 pip install "unsloth[cu121-torch220] @ git+https://github.com/unslothai/unsloth.git"。Answer.AI 集成了 多 GPU (multi-GPU) 支持 以及 FSDP + QLoRA 系统,用于在游戏级 GPU 上训练 70B 模型,这标志着重大进展 (oKatanaaa/unsloth )。Ghost 7B v0.9.1 展示了在推理和语言方面的进步,可在 huggingface.co 上获取,突显了 Unsloth AI 在 LLM 微调期间的效率提升。
新兴 AI 技术与社区参与 :OpenAI Discord 强调了 Claude Opus 在编程任务中优于 GPT-4 的表现,引发了关于 AI 意识和 Claude 能力的讨论。分享了 GPT-4 bug 的技术解决方案以及改进 ChatGPT 记忆召回的策略,强调了使用输出模板 (output template) 来实现自定义模型的一致性。
编程中的模型兼容性与效率 :LM Studio 的讨论围绕编程和网络安全领域的模型选择展开,指出了 Mistral 7B 和 Mixtral 与各种硬件的兼容性。Gemma 模型的持续问题促使人们建议使用 Yi-34b 等替代方案,该方案可在 arXiv 上查阅。关于能效和 ROCM 兼容性的讨论强调了对最佳 LLM 配置的持续探索,详细的硬件讨论可在其 硬件讨论频道 中找到。
AI 开发的创新工具与技术 :CUDA MODE Discord 提供了将 CUDA 与图像和语言处理相结合的见解。社区还参与了 CUDA 的自学,并探索使用 Triton 进行性能提升。讨论了用于大模型训练的 GaLore 和 FSDP with QLoRA 等技术,并分享了 CUDA 学习资源,包括 YouTube 上的 CUDA 训练系列以及 CUDA-MODE Reductions 的讲座公告。
这些摘要更准确地反映了各 AI 社区的讨论和技术探索,展示了挑战、创新解决方案以及推动该领域进步的协作精神,并提供了相关内联链接以便深入探索。
` 和 `` 等 special tokens 是否针对原生预训练模型进行了训练。他们探索了潜在的修复和变通方法,例如解冻 embedding matrix ([Unsloth Wiki](https://github.com/unslothai/unsloth/wiki#chat-templates))。
- **Unsloth 的多 GPU 支持**:`@kaleina_nyan` 分享了她在 GitHub 上实现 Unsloth 多 GPU 支持的分支 ([oKatanaaa/unsloth](https://github.com/oKatanaaa/unsloth)),并进一步讨论了数值结果和内存分布的潜在问题。
- **新的 FSDP + QLoRA 训练系统**:`@dreamgen` 强调了 Answer.AI 发布的一个新系统,能够在典型的游戏 GPU 上本地训练 70B 模型,目前尚不确定它与涉及 DeepSpeed 和 QLoRA 的现有方法有何不同。
- **在 Kaggle 上分享 Unsloth 微调模型的经验**:`@simon_vtr` 分享了尝试在 Kaggle 竞赛中使用 Unsloth 微调模型的经验,处理了与离线包和推理 bug 相关的问题。`@starsupernova` 提到了一份包含 Gemma 模型 bug 修复的 notebook,供在 Kaggle 上进行推理使用。
- **感谢支持者**:`@theyruinedelise` 和 `@starsupernova` 向 Unsloth 社区成员在 Ko-fi 上的支持表示感谢,感谢 `@1121304629490221146` 和 `@690209623902650427` 等个人贡献者的捐赠。
- **Gemma Token Mapping 和 `generate` 方法**:`@kaleina_nyan` 和 `@starsupernova` 就 `map_eos_token` 的功能及其对 Gemma 模型 `.generate` 方法的影响进行了技术讨论。他们发现了一个潜在问题,即 `generate` 在创建 ` 后不会停止。
**Links mentioned**:
- [Answer.AI - You can now train a 70b language model at home](https://www.answer.ai/posts/2024-03-06-fsdp-qlora.html#how-to-use-fsdpqlora):我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。
- [Answer.AI - You can now train a 70b language model at home](https://www.answer.ai/posts/2024-03-06-fsdp-qlora.html#how-to-use-fsdpqlo):我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。
- [Google Colaboratory](https://colab.research.google.com/drive/10NbwlsRChbma1v55m8LAPYG15uQv6HLo?usp=sharing):未找到描述
- [GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection](https://arxiv.org/abs/2403.03507):训练大语言模型 (LLMs) 面临着显著的内存挑战,这主要是由于权重和优化器状态的大小不断增长。常见的内存减少方法,如低秩...
- [Kaggle Mistral 7b Unsloth notebook](https://www.kaggle.com/code/danielhanchen/kaggle-mistral-7b-unsloth-notebook/notebook):使用 Kaggle Notebooks 探索并运行机器学习代码 | 使用来自“无附加数据源”的数据
- [Kaggle Mistral 7b Unsloth notebook Error](https://www.kaggle.com/code/simonveitner/kaggle-mistral-7b-unsloth-notebook-error?scriptVersionId=166454847):使用 Kaggle Notebooks 探索并运行机器学习代码 | 使用来自“无附加数据源”的数据
- [Kaggle Mistral 7b Unsloth notebook Error](https://www.kaggle.com/code/simonveitner/kaggle-mistral-7b-unsloth-notebook-error?scriptVersionId=166450550):使用 Kaggle Notebooks 探索并运行机器学习代码 | 使用来自“无附加数据源”的数据
- [Support Unsloth AI on Ko-fi! ❤️. ko-fi.com/unsloth](https://ko-fi.com/unsloth):在 Ko-fi 上支持 Unsloth AI!Ko-fi 让你通过小额捐赠支持你喜爱的人和事业。
- [tokenizer_config.json · unsloth/gemma-7b at main](https://huggingface.co/unsloth/gemma-7b/blob/main/tokenizer_config.json):未找到描述
- [4 apps incroyables qui utilisent l'IA](https://www.youtube.com/watch?v=gGquFWBY5cs):你会喜欢的(应用链接见下方 👇)👀 不容错过,这个操作系统会让你冲动购买 Mac:https://youtu.be/UfrsyoFUXmULes 介绍的应用...
- [Home](https://github.com/unslothai/unsloth/wiki#chat-templates):速度快 5 倍,显存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账户为 unslothai/unsloth 的开发做出贡献。
- [GitHub - stanford-crfm/helm: Holistic Evaluation of Language Models (HELM), a framework to increase the transparency of language models (https://arxiv.org/abs/2211.09110). This framework is also used to evaluate text-to-image models in Holistic Evaluation of Text-to-Image Models (HEIM) (https://arxiv.org/abs/2311.04287).](https://github.com/stanford-crfm/helm):语言模型全面评估 (HELM),一个旨在提高语言模型透明度的框架 (https://arxiv.org/abs/2211.09110)。该框架也用于在文本到图像模型的全面评估 (HEIM) 中评估文本到图像模型 (https://arxiv.org/abs/2311.04287)。
- [Tensor on cuda device 1 cannot be accessed from Triton (cpu tensor?) · Issue #2441 · openai/triton](https://github.com/openai/triton/issues/2441):下面的 softmax 代码是从教程中复制的,旨在演示我们无法将 "cuda:0" 以外设备上的 Tensor 传递给 Triton kernel。错误为:ValueError: Pointer argument (at 0...
- [GitHub - EleutherAI/cookbook: Deep learning for dummies. All the practical details and useful utilities that go into working with real models.](https://github.com/EleutherAI/cookbook):深度学习入门。包含处理真实模型所需的所有实践细节和实用工具。- EleutherAI/cookbook
- [GitHub - oKatanaaa/unsloth: 5X faster 60% less memory QLoRA finetuning](https://github.com/oKatanaaa/unsloth):速度快 5 倍,显存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账户为 oKatanaaa/unsloth 的开发做出贡献。
---
### Unsloth AI (Daniel Han) ▷ #[welcome](https://discord.com/channels/1179035537009545276/1179039724355211325/1215701340211249212) (4 messages):
- **热烈欢迎与温馨提示**:`@theyruinedelise` 在多条消息中对新成员表示了热烈欢迎,并鼓励大家查看重要频道。特别提醒成员阅读频道 1179040220717522974 中的信息,并在频道 1179050286980006030 中选择自己的角色。
---
### Unsloth AI (Daniel Han) ▷ #[random](https://discord.com/channels/1179035537009545276/1179039861576056922/1215651255997702184) (19 messages🔥):
- **CUDA 难题**: 用户 `@maxtensor` 报告在同一环境下的某些脚本中出现 **Bootstrap CUDA exceptions**,而其他脚本运行完美,怀疑是否是 OS 脚本限制。与 `@starsupernova` 的排查指向了潜在的 GPU 可见性问题。
- **对框架的赞赏**: `@maxtensor` 表达了对该框架的钦佩,认为其具有创新性,并表示它“开启了许多新大门”。
- **bitsandbytes 新版本发布**: `@maxtensor` 分享了 [bitsandbytes 0.43.0 新版本发布链接](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.43.0),该版本以支持 FSDP 和官方文档化的 Windows 安装为特点,但用户对其更新现有工作环境仍持谨慎态度。
- **AI2 Incubator 的巨额算力赠送**: `@mister_poodle` 分享了 [关于 AI2 Incubator 的新闻](https://www.geekwire.com/2024/ai2-incubator-secures-200m-in-ai-compute-resources-for-portfolio-companies/),该孵化器已为其投资组合公司筹集了 2 亿美元的 AI 算力资源,为 AI 领域的初创公司提供重大支持。
- **关于 OpenAI AGI 策略的疑问**: `@iron_bound` 和 `@theyruinedelise` 讨论了对 OpenAI 开发 AI 方式的担忧及其影响,特别是关于分享科学进展以及 Elon Musk 对 OpenAI 所谓“开放性转变”的立场。
**提到的链接**:
- [AI2 Incubator 为投资组合公司筹集 2 亿美元 AI 算力资源](https://www.geekwire.com/2024/ai2-incubator-secures-200m-in-ai-compute-resources-for-portfolio-companies/): (AI2 Incubator 图片) 将人工智能模型构建到软件产品中的公司需要大量的计算能力,也称为...
- [[ML News] Elon 起诉 OpenAI | Mistral Large | 更多 Gemini 闹剧](https://www.youtube.com/watch?v=YOyr9Bhhaq0): #mlnews #ainews #openai 大纲:0:00 - 简介 0:20 - Elon 起诉 OpenAI 14:00 - Mistral Large 16:40 - ML 间谍活动 18:30 - 更多 Gemini 闹剧 24:00 - Copilot 生成...
- [Release 0.43.0: FSDP 支持, 官方文档, Linux 和 CI 上的交叉编译, Windows 支持 · TimDettmers/bitsandbytes](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.43.0): 改进与新特性:QLoRA + FSDP 官方支持现已上线!由 @warner-benjamin 及其团队提交的 #970 - 通过 FSDP,你可以在多个 24GB 消费级 G... 上训练超大型模型(70b 规模)。
---
### Unsloth AI (Daniel Han) ▷ #[help](https://discord.com/channels/1179035537009545276/1179777624986357780/1215592049794093096) (514 messages🔥🔥🔥):
- **Xformers 安装问题**: 用户 `@fjefo` 在尝试将 Unsloth AI 与 Gemma 模型配合使用时遇到了与 `xformers` 相关的错误。`@starsupernova` 建议其重新安装 `xformers`,随后建议使用 Python 包安装命令 `pip install "unsloth[cu121-torch220] @ git+https://github.com/unslothai/unsloth.git"`。
- **Gemma 模型加载与微调挑战**: [Gemma 加载困难] `@patleeman` 在 vLLM 服务器上使用 Unsloth 加载微调后的 Gemma 2B 模型时遇到困难,出现了 `lm_head.weight` 的 KeyError。在采用跳过该 key 的权宜之计后,模型加载正常,这表明问题可能出在 vLLM 端,详见 [此 GitHub issue](https://github.com/vllm-project/vllm/issues/3323)。
- **在 Jupyter 中使用 HF_HOME 环境变量**: [HF_HOME 难题] `@hyperleash` 在 Jupyter notebooks 中为 Unsloth 设置 `HF_HOME` 环境变量时遇到困难。他们成功为 .py 脚本设置了该变量,但在 notebooks 中遇到障碍,并表示没有生成用于排查的日志。`@starsupernova` 确认了该问题,证实没有日志,并就如何正确设置环境变量提供了建议。
- **关于微调模型性能的讨论**: 用户讨论了微调模型的性能。`@mlashcorp` 观察到合并后的模型与直接加载 adapter 时的性能差异。`@starsupernova` 建议尝试 `"merged_4bit_forced"`,并提到了合并 adapter 时的精度问题。
- **下载和微调 Gemma 7B 的问题**: `@fjefo` 报告了下载和微调 Gemma 7B 的问题,但随后成功启动了训练。他们提到与 Mistral 7B 相比出现了 OOM 错误,`@starsupernova` 指导其更新 Unsloth 并考虑通过 Transformers 重新下载。
**提到的链接**:
- [Kaggle Mistral 7b Unsloth notebook](https://www.kaggle.com/code/danielhanchen/kaggle-mistral-7b-unsloth-notebook): 使用 Kaggle Notebooks 探索并运行机器学习代码 | 使用来自“无附加数据源”的数据
- [Repetition Improves Language Model Embeddings](https://arxiv.org/abs/2402.15449):近期改进从自回归大语言模型 (LLM) 中提取文本嵌入的方法主要集中在改进数据、骨干预训练语言模型或...
- [Gemma models do not work when converted to gguf format after training · Issue #213 · unslothai/unsloth](https://github.com/unslothai/unsloth/issues/213):当 Gemma 在训练后转换为 gguf 格式时,它无法在运行 llama cpp 的软件(如 lm studio)中工作。llama_model_load: error loading model: create_tensor: tensor 'output.wei...
- [KeyError: lm_head.weight in GemmaForCausalLM.load_weights when loading finetuned Gemma 2B · Issue #3323 · vllm-project/vllm](https://github.com/vllm-project/vllm/issues/3323):你好,我使用 Unsloth 微调了 Gemma 2B。它使用了 LoRA 并将权重合并回基础模型。当我尝试加载此模型时,出现了以下错误:... File "/home/ubuntu/proj...
- [Faster Inference & Training Roadmap · Issue #226 · unslothai/unsloth](https://github.com/unslothai/unsloth/issues/226):@danielhanchen 在 unsloth Gemma 的介绍博客文章中,你提到了由于 Gemma 的 MLP 尺寸比 Llama 和 Mistral 更大导致 VRAM 增加,并展示了一张显示内存占用减少的图表...
- [VLLM Multi-Lora with embed_tokens and lm_head in adapter weights · Issue #2816 · vllm-project/vllm](https://github.com/vllm-project/vllm/issues/2816):大家好!我在项目中的 adapter_model.safetensors 遇到了一个问题,正在寻求关于如何在指定模块中处理 lm_head 和 embed_tokens 的指导。这里...
- [Conda installation detailed instructions · Issue #73 · unslothai/unsloth](https://github.com/unslothai/unsloth/issues/73):我正尝试按照说明在 conda 环境中安装 unsloth,问题是 conda 在运行安装行时卡住了。我已经尝试运行了两次,两次都...
- [Google Colaboratory](https://colab.research.google.com/drive/1Aau3lgPzeZKQ-98h69CCu1UJcvIBLmy2?usp=sharing):未找到描述
- [Hastebin](https://hastebin.com/share/olipibuwez.bash):未找到描述
- [Google Colaboratory](https://colab.research.google.com/drive/1EOa_X5GwKAkPv5a2keJupGowePkHpq-0?usp=sharing):未找到描述
- [Tutorial: How to convert HuggingFace model to GGUF format · ggerganov/llama.cpp · Discussion #2948](https://github.com/ggerganov/llama.cpp/discussions/2948):来源:https://www.substratus.ai/blog/converting-hf-model-gguf-model/ 我在我们的博客上发布了这篇文章,但认为这里的其他人可能也会受益,所以也在 GitHub 上分享了原始博客。希望它...
- [Home](https://github.com/unslothai/unsloth/wiki):速度提升 5 倍,内存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账号来为 unslothai/unsloth 的开发做出贡献。
- [Hastebin](https://hastebin.com/share/oterufowit.yaml):未找到描述
- [LoRA Land: Fine-Tuned Open-Source LLMs that Outperform GPT-4 - Predibase](https://predibase.com/blog/lora-land-fine-tuned-open-source-llms-that-outperform-gpt-4):LoRA Land 是一个包含 25 个以上微调 Mistral-7b 模型的集合,这些模型在特定任务的应用中表现优于 GPT-4。这个微调开源模型集合为寻求高效...的团队提供了蓝图。
- [Reddit - Dive into anything](https://www.reddit.com/r/LocalLLaMA/comments/1b6723c/comment/ku5r7d3/):未找到描述
- [Merging QLoRA weights with quantized model](https://gist.github.com/ChrisHayduk/1a53463331f52dca205e55982baf9930):将 QLoRA 权重与量化模型合并。GitHub Gist:即时分享代码、笔记和代码片段。
- [py : add Gemma conversion from HF models by ggerganov · Pull Request #5647 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/pull/5647):# gemma-2b python3 convert-hf-to-gguf.py ~/Data/huggingface/gemma-2b/ --outfile models/gemma-2b/ggml-model-f16.gguf --outtype f16 # gemma-7b python3 convert-hf-to-gguf.py ~/Data/huggingface/gemma-...
- [Build software better, together](https://github.com/huggingface/peft/pull/1474.):GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、分叉并为超过 4.2 亿个项目做出贡献。
- [Third-party benchmark · Issue #6 · jiaweizzhao/GaLore](https://github.com/jiaweizzhao/GaLore/issues/6):你好,非常感谢如此出色的工作。我们使用 Llama-Factory 进行了一些实验,结果表明 Galore 可以显著减少全参数...过程中的内存使用。
- [unsloth/unsloth/save.py at main · unslothai/unsloth](https://github.com/unslothai/unsloth/blob/main/unsloth/save.py#L706):速度提升 5 倍,内存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账号来为 unslothai/unsloth 的开发做出贡献。
### Unsloth AI (Daniel Han) ▷ #[showcase](https://discord.com/channels/1179035537009545276/1179779344894263297/1216405262638911508) (8 条消息🔥):
- **Ghost 7B v0.9.1 正式发布**:用户 `@lh0x00` 宣布发布 **Ghost 7B v0.9.1**,宣称其在越南语和英语的推理及语言能力方面均有提升。该模型可在 [huggingface.co](https://huggingface.co/lamhieu/ghost-7b-v0.9.1) 用于在线体验和应用开发。
- **Ghost 7B 荣登榜单前列**:在随后的一条消息中,`@lh0x00` 提到 Ghost 7B v0.9.1 的评分足以在 **VMLU 的“微调模型排行榜”中位列第 3**。
- **社区为 Ghost 7B 喝彩**:用户 `@starsupernova` 和 `@lh0x00` 就 Ghost 7B 模型的成功发布和高性能表现互相致以祝贺。
- **法国 AI 应用见解**:用户 `@theyruinedelise` 分享了一段名为 "4 apps incroyables qui utilisent l'IA" 的 **YouTube** 视频,介绍了多款令人印象深刻的 AI 应用:[点击观看](https://www.youtube.com/watch?v=gGquFWBY5cs)。
- **Unsloth AI 加速微调过程**:`@lee0099` 讨论了在 [NeuralNovel 数据集](https://huggingface.co/datasets/NeuralNovel/Unsloth-DPO)上微调 `yam-peleg/Experiment26-7B` 的情况,强调了 **Unsloth AI** 的优化效果:在 **LLM 微调期间实现 2 倍加速、显存占用减少 40%,且准确率零损失**。
**提到的链接**:
- [4 apps incroyables qui utilisent l'IA](https://www.youtube.com/watch?v=gGquFWBY5cs):vous allez kiffer (lien vers les apps 👇)👀 不容错过,这个 OS 会让你冲去买一台 Mac:https://youtu.be/UfrsyoFUXmULes apps présentées da...
- [NeuralNovel/Unsloth-DPO · Hugging Face 数据集](https://huggingface.co/datasets/NeuralNovel/Unsloth-DPO):未找到描述
---
### Unsloth AI (Daniel Han) ▷ #[suggestions](https://discord.com/channels/1179035537009545276/1180144489214509097/1216409155074658484) (5 条消息):
- **关于 Unsloth 集成的建议**:用户 `@imranullah` 建议将 **Llama-factory** 的功能实现到 Unsloth AI 中,暗示这些功能在当前应用中已被证明非常出色。
- **对 Galore 实用性的共识**:用户 `@starsupernova` 同意关于 Galore 讨论帖的实用性,认可其潜在的应用价值。
- **实现难度**:用户 `@remek1972` 幽默地评论了某项功能的实现简易性,并在对话中艾特了 `@160322114274983936`。
- **分享 GitHub 项目**:`@remek1972` 分享了一个名为 **GEAR** 的 GitHub 仓库链接,该项目涉及一种*用于大语言模型生成式推理的高效 KV cache 压缩方案*。[在 GitHub 上查看 GEAR 项目](https://github.com/HaoKang-Timmy/GEAR)。
**提到的链接**:
[GitHub - opengear-project/GEAR: GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM](https://github.com/HaoKang-Timmy/GEAR):GEAR:一种用于 LLM 近乎无损生成式推理的高效 KV cache 压缩方案 - opengear-project/GEAR
---
### OpenAI ▷ #[ai-discussions](https://discord.com/channels/974519864045756446/998381918976479273/1215677327703539752) (611 条消息🔥🔥🔥):
- **AI 辅助编程对比**:用户如 `@askejm` 和 `@sangam_k` 分享了对比 **Claude Opus** 和 **GPT-4** 编程能力的经验。共识似乎是 Claude Opus 在编程方面表现更好,能提供更完整的代码输出,并且在 SQL 和 Rust 等语言中表现出色。
- **探讨 AI 的意识**:由 `@sotiris.b` 发起的一场讨论涉及了一些人认为 **Claude** 可能具有意识的观点。辩论包括对普遍意识的不同看法,以及 AI 是否可以被视为具有意识,用户如 `@metaldrgn` 和 `@dezuzel` 讨论了关于该主题的论文。
- **GPT-4 的知识截止日期与性能**:用户 `@webhead` 通过测试查询确认 GPT-4 的知识截止日期是在 2023 年 4 月;虽然 ChatGPT 的对话可能会变慢,但不同模型的召回能力各不相同,Google 的 1.5 preview 显示出令人印象深刻的召回能力,但在特定任务中可能存在不足。
- **AI 产品的国际访问**:多次提到了在**国际范围内访问 Claude 3 Opus** 的困难,用户 `@lightpictures` 和 `@lazybones3` 讨论了解决方法。用户 `@webhead` 建议使用 **openrouter** 来测试不同的模型。
- **OpenAI 的订阅问题**:用户 `@arxsenal` 描述了一个其 **ChatGPT Plus** 订阅未被识别的问题。包括 `@eskcanta` 在内的其他用户建议了解决方法,包括清除缓存、使用不同的设备/浏览器,以及通过 OpenAI 帮助网站联系支持部门。
**提到的链接**:
- [Skm](https://skm.ai/):未找到描述
- [LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys](https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard):未找到描述
- [Prompt-based image generative AI tool for editing specific details](https://genai.stackexchange.com/questions/1731/prompt-based-image-generative-ai-tool-for-editing-specific-details):我正尝试使用 DALLE3 制作一些精灵图(spritesheets),虽然 DALLE3 最初生成的精灵图非常迷人,但我遇到了这些问题:艺术风格不一致(多...
- [How can we Improve Democracy?](https://medium.com/@h.a.papageorgiou/autoregression-b8cf7aa561d7):引言
- [Bland Web](https://Chat.bland.ai):未找到描述
- [Tweet from Bland.ai (@usebland)](https://x.com/usebland/status/1766250122277712122?s=61):介绍 Bland web。一个听起来像人类且无所不能的 AI。📢 将语音 AI 添加到您的网站、移动应用、电话、视频游戏,甚至您的 Apple Vision Pro。⚡️ 与未来对话...
- [GitHub - Kiddu77/Train_Anything: A repo to get you cracking with Neural Nets .](https://github.com/Kiddu77/Train_Anything):一个让你开始上手神经网络(Neural Nets)的仓库。通过在 GitHub 上创建一个账号来为 Kiddu77/Train_Anything 的开发做出贡献。
- [Literal Labs - Cambridge Future Tech](https://camfuturetech.com/portfolio/literal-labs/):加速新一代节能 AI。Literal Labs 采用了一种精简且更高效的 AI 方法,速度更快、具有可解释性,且比……节能高达 10,000 倍。
---
### OpenAI ▷ #[gpt-4-discussions](https://discord.com/channels/974519864045756446/1001151820170801244/1215560402021392384) (78 条消息🔥🔥):
- **GPT 停机和语言设置 Bug**:包括 `@kor_apucard`、`@dxrkunknown`、`@snolpix` 和 `@alessid_55753` 在内的多位用户报告了 GPT 无响应的问题。`@pteromaple` 发现并经 `@katai5plate` 和 `@hccren` 等人确认的一个常用解决方法是将设置中的语言预览切换为 *Auto-detect*(自动检测)并刷新浏览器。
- **聊天功能故障与权宜之计**:问题不仅限于单一浏览器,`@dxrkunknown` 和 `@macy7272` 在网页端和移动端都遇到了问题。解决方案各不相同,`@pteromaple` 建议更改语言设置,而 `@winter9149` 发现删除旧聊天记录有助于恢复正常运行。
- **关于 AI 竞争对手的讨论**:几位用户(包括 `@tsanva`、`@1kio1` 和 `@zeriouszhit`)讨论了可能转向 Claude 等竞争对手模型的可能性,理由是 GPT 的 Context Window 限制以及回复中的困惑。此外,还有人担心与 GPT 相比,支持 Claude 的同类功能较少。
- **帮助与状态更新**:用户 `@openheroes` 分享了 OpenAI 状态页面的链接,显示当前没有停机,并建议用户确保没有使用 VPN 或拦截连接,同时参考帮助中心获取更多支持。
- **GPT 创建者的支付查询**:用户 `@ar888` 询问了关于 GPT 创建者的报酬问题,`@elektronisade` 回复称,根据官方博客文章,OpenAI 表示美国创建者的支付将于第一季度开始。
**提到的链接**:
[OpenAI Status](https://status.openai.com/):未找到描述
---
### OpenAI ▷ #[prompt-engineering](https://discord.com/channels/974519864045756446/1046317269069864970/1215613812846100533) (90 条消息🔥🔥):
- **寻求增强的 ChatGPT 记忆能力**:用户 `@youri_k` 正在排查 ChatGPT 召回聊天历史以获取回复上下文的能力,并收到了 `@eskcanta` 关于如何改进 Prompt 结构以处理记忆的建议,包括在结束对话前要求提供摘要。
- **ChatGPT 难以进行初学者绘图**:`@marijanarukavina` 在让 ChatGPT 创建解释边界值分析(Boundary Value Analysis)的简单草图时遇到问题;`@eskcanta` 建议使用 Python 工具以获得更好的结果,并提供了调整模型输出的分步方法。
- **深入研究基于 GPT 的 UI 生成**:`@dellgenius` 探讨了如何使用 GPT-4 创建 Figma 插件或生成 UI 元素,`@eskcanta` 分享了一个展示 GPT-4 在该领域潜在能力的链接。
- **用 GPT 辅助作业?并不完全可行**:`@levidog` 询问了如何使用 ChatGPT 从作业文档中提取问题,但 `@darthgustav.` 提醒了使用 GPT 处理作业相关任务的局限性和伦理考量。
- **在自定义 GPT 中实现一致的输出**:`@iloveh8` 寻求关于确保自定义 GPT 模型响应一致性的建议,`@darthgustav.` 推荐使用带有编码摘要指令的变量名的输出模板。
---
### OpenAI ▷ #[api-discussions](https://discord.com/channels/974519864045756446/1046317269069864970/1215613812846100533) (90 条消息🔥🔥):
- **使用 GPT 进行高效的 Prompt Engineering**:`@eskcanta` 阐述了创建高效 Prompt 的基本步骤,强调了清晰度、语言熟练程度以及使用具体细节指导模型的重要性。他们建议**避免拼写错误和语法错误**,并使用用户和 AI 都能很好理解的任何语言进行交流。
- **保持自定义 GPT 输出的一致性**:根据 `@darthgustav.` 的说法,采用包含编码指令摘要变量名的**输出模板 (output template)**,有助于保持自定义 GPT Prompt 输出的一致性。
- **专业词汇扩展挑战**:`@ericplayz` 寻求帮助,希望在保持字数不变的情况下使用专业词汇重写段落;`@eskcanta` 分享了一个尝试性的解决方案,并征求反馈以评估是否满足需求。指导建议包括确保用罗马尼亚语重写的文本保持长度、细节和适当的语气。
- **GPT-4 讨论中的 JSON 格式化**:`@dellgenius` 询问了使用 JSON 格式组织响应的问题;`@aminelg` 确认了其对结构化数据的效用,`@eskcanta` 回答了关于创建 UI 元素和 AI 模型不同能力的问题。讨论重点在于 GPT 模型如何辅助设计 UI 元素,前提是 AI 已经在相关数据或工具上进行了训练。
- **使用 ChatGPT API 的求助请求**:用户 `@youri_k` 和 `@levidog` 分别请求帮助让 ChatGPT 记住聊天历史以及从作业文档中提取问题。他们得到了 `@eskcanta` 的指导,后者建议使用摘要来保留历史记录,并警告说这些模型并非为辅助作业而设计,可能会导致不一致的结果。
---
### LM Studio ▷ #[💬-general](https://discord.com/channels/1110598183144399058/1110598183144399061/1215611692587810876) (407 messages🔥🔥🔥):
- **探索 LLM 能力**:用户正在讨论不同模型的能力,并就特定用途(如编程和网络安全)的模型选择寻求建议。他们分享了在包括 Mac M1 和配备 Nvidia GPU 的 PC 在内的各种系统上使用 Mistral 7B 和 Mixtral 等模型的经验。
- **LM Studio 技术故障排除**:一些用户(如 `@amir0717`)在尝试在 LM Studio 中加载模型时遇到了错误,并正在寻求帮助以解决“模型操作失败”或模型“未正确加载”等问题。其他用户提供了解决方案,例如以管理员身份运行 LM Studio 或调整 GPU offload 设置。
- **硬件限制与模型性能**:拥有不同硬件配置的用户正在询问适合其系统运行的最佳模型。例如,`@yagilb` 建议拥有 8GB Mac M1 的 `@mintsukuu` 尝试使用层设置较为保守的 7B 模型;而 `@dbenn8` 报告称在 64GB M2 Macbook 上运行 70B 模型,尽管响应速度较慢。
- **对新模型和替代模型的兴趣**:有关于 LM Studio 是否支持 Starcoder2 和 Deepseek-vl 等新模型的查询。一些用户(如 `@real5301`)正在寻找具有 80k token 以上大上下文窗口的模型,而 `@heyitsyorkie` 推荐了具有 200k 上下文窗口的 Yi-34b。
- **LM Studio 的开发进展**:一位用户提到了 LM Studio 相对于 llama.cpp 构建版本的开发节奏,`@yagilb` 确认即将发布 Beta 版,并承认更新速度慢于预期。据指出,开发团队已从 1 人扩展到 3 人。
**提到的链接**:
- [👾 LM Studio - Discover and run local LLMs](https://lmstudio.ai/beta-releases.html):发现、下载并实验本地 LLM
- [deepseek-ai/deepseek-vl-7b-chat · Discussions](https://huggingface.co/deepseek-ai/deepseek-vl-7b-chat/discussions):未找到描述
- [Big Code Models Leaderboard - a Hugging Face Space by bigcode](https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard):未找到描述
- [deepse (DeepSE)](https://huggingface.co/deepse):未找到描述
- [The Muppet Show Headless Man GIF - The Muppet Show Headless Man Scooter - Discover & Share GIFs](https://tenor.com/view/the-muppet-show-headless-man-scooter-george-the-janitor-headless-gif-26660609):点击查看 GIF
- [How to run a Large Language Model (LLM) on your AMD Ryzen™ AI PC or Radeon Graphics Card](https://community.amd.com/t5/ai/how-to-run-a-large-language-model-llm-on-your-amd-ryzen-ai-pc-or/ba-p/670709):您知道可以在您的 Ryzen™ AI PC 或 Radeon™ 7000 系列显卡上运行您自己的基于 GPT 的 LLM 驱动的 AI 聊天机器人实例吗?AI 助手正迅速成为必不可少的资源...
- [AMD explains how easy it is to run local AI chat powered by Ryzen CPUs and Radeon GPUs - VideoCardz.com](https://videocardz.com/newz/amd-explains-how-easy-it-is-to-run-local-ai-chat-powered-by-ryzen-cpus-and-radeon-gpus):“Chat with Ryzen/Radeon” AMD 指导如何使用其硬件运行本地 AI 聊天。AMD 还没有像 NVIDIA Chat with RTX 那样的自有工具。NVIDIA 推出了一款简单的工具,可用于运行...
- [GitHub - joaomdmoura/crewAI: Framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks.](https://github.com/joaomdmoura/crewAI):用于编排角色扮演型自主 AI Agent 的框架。通过促进协作智能,CrewAI 使 Agent 能够无缝协作,处理复杂任务。 - joaomdmoura/cr...
- [AMD explains how easy it is to run local AI chat powered by Ryzen CPUs and Radeon GPUs - VideoCardz.com](https://videocardz.com/newz/amd-explains-how-easy-it-is-to-run-local-ai-chat-powered-by-ryzen-cpus-a):“Chat with Ryzen/Radeon” AMD 指导如何使用其硬件运行本地 AI 聊天。AMD 还没有像 NVIDIA Chat with RTX 那样的自有工具。NVIDIA 推出了一款简单的工具,可用于运行...
---
### LM Studio ▷ #[🤖-models-discussion-chat](https://discord.com/channels/1110598183144399058/1111649100518133842/1215557805524918302) (110 条消息🔥🔥):
- **Gemma 模型困惑**:`@boting_0215` 遇到了所有 Gemma 模型都无法使用的问题。`@fabguy` 确认只有少数 Gemma 量化版本(quants)可以工作,且这些是团队自定义的量化版本,指出问题可能出在 LM Studio 或 Gemma 模型本身。
- **排查 Gemma 加载错误**:`@honeylaker_62748_43426` 在加载 7B Gemma 模型时收到错误,`@heyitsyorkie` 确认 Gemma 模型经常遇到问题,已知某些量化版本(quants)是损坏的。
- **寻找合适的模型**:`@jo_vii` 寻求适用于 M2 Max Apple Metal 的模型建议,`@fabguy` 建议使用 DeepSeek Coder Q4 或 Q5,以便为其他进程留出空间。
- **模型上传困惑**:`@anand_04625` 在 LM Studio 中找不到 Phi 模型的文件上传按钮,`@heyitsyorkie` 澄清目前不支持模型文件上传。
- **等待 Starcoder 2 更新**:`@rexeh` 正在为 ROCm 用户寻找 LM Studio 上 Starcoder 2 的替代方案,`@heyitsyorkie` 表示未来将支持 Starcoder 2,目前建议独立构建 llama.cpp。
**提到的链接**:
- [The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits](https://arxiv.org/abs/2402.17764):最近的研究(如 BitNet)正在为 1-bit 大语言模型 (LLM) 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数...
- [What is retrieval-augmented generation? | IBM Research Blog](https://research.ibm.com/blog/retrieval-augmented-generation-RAG):RAG 是一个 AI 框架,用于检索事实以使 LLM 基于最准确的信息,并让用户深入了解 AI 的决策过程。
- [Ternary Hashing](https://arxiv.org/abs/2103.09173):本文提出了一种用于学习哈希方法的新型三元哈希编码,它提供了一种原则上更高效的编码方案,性能优于现有的 state-of-the-art...
---
### LM Studio ▷ #[🧠-feedback](https://discord.com/channels/1110598183144399058/1113937247520170084/1215955685129453578) (7 条消息):
- **用户渴望“新模型”板块**:`@justmarky` 希望 LM Studio 能提供一个选项来查看最近的模型而无需搜索,以便轻松发现新内容。
- **希望有更多排序选项**:`@purplemelbourne` 表达了同样的看法,建议增加额外的排序功能,例如按模型发布日期或特定时间范围(如过去 6 或 8 个月)进行过滤。
- **分享 Hugging Face 替代方案**:`@epicureus` 分享了一个变通方法,通过 Hugging Face 使用[特定搜索链接](https://huggingface.co/models?sort=created&search=GGUF)来查看最近的模型。
- **现有频道作为临时解决方案**:`@yagilb` 指出,现有的 Discord 频道 `#1111649100518133842` 和 `#1185646847721742336` 是目前讨论和查找最新模型信息的地方。
- **功能改进与选择标准愿望清单**:`@purplemelbourne` 请求在 LM Studio 中加入高级过滤功能,以便按大小、类型和性能选择模型,并特别希望能根据 VRAM 需求和评分进行搜索。
**提到的链接**:
[Models - Hugging Face](https://huggingface.co/models?sort=created&search=GGUF): 未找到描述
---
### LM Studio ▷ #[🎛-hardware-discussion](https://discord.com/channels/1110598183144399058/1153759714082033735/1215624964154331137) (147 条消息🔥🔥):
- **控制 GPU 功耗**:`@666siegfried666` 指出,即使是像 7900 XTX 这样的高端 GPU 也不总是能达到其 Total Board Power (TBP) 限制,在他的配置中维持在 140W 左右,并寻求 4060 Ti 在运行 LLM 时的实时 TBP 功耗细节。他还强调了 CPU(特别是 AMD 3D cache 型号)和 RAM 配置在能效方面的重要性,并提倡使用 Arctic P12 风扇,因为其功耗较低。
- **LLM 系统的效率之争**:用户讨论了在构建 LLM 系统时如何平衡价格、功耗和性能。`@nink1` 谈到了 Apple M3 处理器仅靠电池运行 LLM 任务的盈利能力,而 `@666siegfried666` 提到了硬件定价的地区差异。
- **探索 GPU 降频与超频**:`@666siegfried666` 分享了在不降频的情况下进行有效降压的见解,提到 7900 XTX 在 2400-2500MHz 时具有最佳的每瓦性能。`@nink1` 考虑根据工作负载变化进行动态降频/超频。
- **LLM 性能爱好者分享配置**:`@goldensun3ds` 讲述了在其系统上加载 189K context LLM 时耗时较长的经历,用户们交流了 LLM 硬件设置的建议,包括 AMD GPU 运行 LLM 的高效操作,以及使用双 GPU 来提升性能。
- **给 LLM 硬件新手的实用建议**:新用户 `@purplemelbourne` 与社区互动,了解是否可以在其新购入的 RTX2080Ti GPU 上运行多个 LLM。对话演变为关于硬件配置和潜在升级的讨论,涉及使用 V100 显卡和 NVLink 来运行高显存模型。
**提到的链接**:
- [nvidia 4060 16gb - Shopping and Price Comparison Australia - Buy Cheap](https://www.staticice.com.au/cgi-bin/search.cgi?q=nvidia+4060+16gb&spos=3): 未找到描述
- [Amazon.com: StarTech.com PCI Express X1 to X16 Low Profile Slot Extension Adapter - PCIe x1 to x16 Adapter (PEX1TO162) : Electronics](https://www.amazon.com/gp/aw/d/B0039XPS5W/): 未找到描述
---
### LM Studio ▷ #[🧪-beta-releases-chat](https://discord.com/channels/1110598183144399058/1166577236325965844/1216591709971025931) (7 条消息):
- **Token 溢出困扰**:`@jarod997` 在 **Win Beta 4 (0.2.10)** 中遇到当对话达到 token 溢出量的倍数(如 2048, 4096 等)时出现乱码回复的问题。
- **Context Overflow Policy 检查**:`@jedd1` 建议检查 **Context Overflow Policy** 设置,并提到虽然更改可能不明显,但确实会定期发生。
- **升级建议讨论**:`@jedd1` 和 `@fabguy` 都建议升级到较新的 **0.2.16** 版本,这可能会解决 `@jarod997` 提到的问题。
- **Beta 版与稳定版发布的困惑**:`@jarod997` 在 LMStudio.ai 上找不到建议的版本,随后澄清由于其机器支持 AVX 而不支持 AVX2,因此需要使用 **Beta** 版。
---
### LM Studio ▷ #[autogen](https://discord.com/channels/1110598183144399058/1167546228813336686/1216368336506454058) (1 条消息):
- **辩论最佳机器人集成**:`@purplemelbourne` 正在寻求关于在 **AutoGen, CrewAi, ChatDev** 或其他选项中选择哪种集成的建议。他们已经安装了 **AutoGen**,但尚未执行第一次运行。
---
### LM Studio ▷ #[memgpt](https://discord.com/channels/1110598183144399058/1170104578889502750/1216369052424077402) (3 条消息):
- **MemGPT 共享知识库咨询**:`@purplemelbourne` 询问 MemGPT 是否可以在不同的编程模型之间拥有共享知识库,用于错误修复等任务,并考虑使用 KeyMate 进行集成。
- **GPT-4 与 MemGPT 集成的实用性**:`@nahfam_` 回复说,虽然理论上可行,但使用 GPT-4 API 相关的成本将非常高昂。他们建议使用 BeautifulSoup4 和 Python 清理 MemGPT 的输出,使其更易于管理。
- **KeyMate 集成的成本担忧**:`@nahfam_` 对 KeyMate 商业模式的可持续性表示怀疑,考虑到每个请求的 token 成本以及 token 配额可能迅速耗尽,每月 60 美元的 GPT-4 128k 驱动聊天成本过高。
- **对 KeyMate TOS 的不满**:`@purplemelbourne` 评论了 KeyMate 服务条款 (TOS) 的严苛性,并提供了一个相当严酷的类比,以强调其广泛的终止账户权力。
---
### LM Studio ▷ #[amd-rocm-tech-preview](https://discord.com/channels/1110598183144399058/1195858490338594866/1215770551386112061) (91 messages🔥🔥):
- **ROCm 在 Debian 与 Ubuntu 上的对比**:`@quickdive.` 讨论了在 Debian 等非 Ubuntu 发行版上使用 ROCm 的挑战,强调了 **Python 版本冲突**和安装障碍。由于 **AMD 的官方支持**主要针对 Ubuntu,该用户发现双系统引导(dual-booting)是必要的。
- **Windows 平台上的 ROCm 展现出前景**:`@omgitsprovidence` 提到通过 `koboldcpp` 成功在带有 AMD GPU 的 Windows 上运行语言模型,而 `@ominata_` 分享了一个使用 `'HSA_OVERRIDE_GFX_VERSION=10.3.0'` 针对 RX 6600XT 的变通方法,表明用户正在为 Windows 上的 ROCm 寻找创造性的解决方案。
- **性能查询与对比**:在关于性能的讨论中,`@sadmonstaa` 报告称他们的 **6950XT** 在使用 ROCm 进行 offloading 时比 **5900x** 慢。其他用户如 `@666siegfried666` 在旧款 AMD 型号上取得了成功,暗示了不同用户之间的体验差异。
- **AMD 上的 Stable Diffusion**:`@aryanembered` 夸赞了 ROCm 的能力,提到可以在不使用 DirectML 的情况下在 AMD 硬件上运行 **Stable Diffusion**,这在易用性方面是一个重大进步。
- **因兼容性问题而采用双系统**:包括 `@sadmonstaa` 在内的几位用户对由于某些软件与 Linux 的兼容性问题而不得不采用双系统引导表示遗憾,尽管他们更倾向于使用 Linux。他们讨论了 ROCm 的性能影响以及在不同操作系统和配置下偶尔出现的系统崩溃。
**提到的链接**:
- [GPU and OS Support (Windows) — ROCm 5.5.1 Documentation Home](https://rocm.docs.amd.com/en/docs-5.5.1/release/windows_support.html):未找到描述
- [Docker image support matrix — ROCm installation (Linux)](https://rocm.docs.amd.com/projects/install-on-linux/en/latest/reference/docker-image-support-matrix.html):未找到描述
- [Arch Linux - gperftools 2.15-1 (x86_64)](https://archlinux.org/packages/extra/x86_64/gperftools/):未找到描述
---
### LM Studio ▷ #[crew-ai](https://discord.com/channels/1110598183144399058/1197374792668545034/1215693927278186597) (4 messages):
- **创新多 Agent 框架**:`@pefortin` 正在开发一个复杂的框架,其中前端 Agent 负责澄清用户任务,项目经理 Agent 将任务分解为原子单位,HR 专家 Agent 为每个任务创建专业化 Persona,最后由执行器运行操作。该系统还包括评估器以确保任务解决和匹配,但目前运行缓慢且表现不佳。
- **征求结构反馈**:`@wolfspyre` 联系了 `@pefortin`,提议对其正在开发的多 Agent 框架的结构设计提供反馈。
- **寻求 Agent 系统间的兼容性**:`@purplemelbourne` 询问了 AutoGen 和 CrewAi 之间的兼容性,表示希望了解哪种系统在无需投入大量时间的情况下是最佳选择。
- **对比 AutoGen 和 CrewAi**:`@jg27_korny` 指出 AutoGen 和 CrewAi 有不同的设置,CrewAi 具有简单直观的逻辑,而 AutoGen 提供图形界面。他们建议配合 GPT API 使用这些系统以获得最佳性能,并提醒注意潜在 Agent 循环(agent loops)带来的 token 成本。
---
### Perplexity AI ▷ #[general](https://discord.com/channels/1047197230748151888/1047649527299055688/1215563637515751445) (595 条消息🔥🔥🔥):
- **Perplexity 的 Context Window 困扰**:用户如 `@layi__` 和 `@sebastyan5218` 对 Perplexity AI 处理上下文的方式表示沮丧,称该服务难以保持记忆,且经常默认返回基础知识响应,导致用户请求退款并提交 Bug 报告。
- **Pro 订阅难题**:新的 Perplexity Pro 用户如 `@lu.ciry` 在兑换促销订阅时遇到困惑,促使与 `@icelavaman` 进行交流,以澄清为什么他们的折扣代码在结账过程中没有出现。
- **AI Chatbot 好奇心**:用户如 `@nihal_57646` 询问了关于创建自己的 AI Chatbot 并可能与 Perplexity 分享的问题,对此 `@icelavaman` 解释说 Perplexity 不是 Chatbot 提供商,首先建议使用 Collections 作为替代方案。
- **翻译尝试**:`@reborn09` 讨论了使用 Perplexity 将大型韩语文本文件翻译成英语的挑战,`@codelicious` 就如何在多个章节中保持上下文提供了建议,并提到可能使用 API 进行翻译过程的自动化。
- **AI 对比讨论**:关于不同 AI 服务的评价褒贬不一,用户如 `@1337666666666666666666666666669` 批评了 Copilot Pro 并称赞了 Perplexity 的图像生成功能,而 `@twelsh37` 则对 ChatGPT Pro、Gemini 和 Copilot 等多个平台进行了更全面的对比。
**提到的链接**:
- [Jeff Bezos 对 Perplexity AI 的投资在几个月内价值几乎翻了一番,这家谷歌挑战者即将达到 10 亿美元的独角兽地位](https://fortune.com/2024/03/10/jeff-bezos-perplexity-ai-tech-investment/):亚马逊创始人于 1 月份参加了一轮融资,该轮融资对这家 AI 搜索初创公司的估值超过 5 亿美元。
- [Chat Completions](https://docs.perplexity.ai/reference/post_chat_completions):未找到描述
- [耐心等待 GIF - Waiting Waiting patiently Waiting for you - 发现并分享 GIF](https://tenor.com/view/waiting-waiting-patiently-waiting-for-you-waiting-on-you-gif-15489516379864441176):点击查看 GIF
- [Stonks 图表 GIF - Stonks Chart Stocks - 发现并分享 GIF](https://tenor.com/view/stonks-chart-stocks-going-up-gif-15813050):点击查看 GIF
- [随着生成式 AI 接管,互联网走向灭绝 | 暗森林互联网与证明你的“人类身份”](https://www.youtube.com/watch?v=3NN5L-f0cDo):订阅我的每日 AI 通讯 🔥 https://natural20.beehiiv.com/subscribe [AI 新闻、研究和教程] 更多内容请访问:https://maggieappleton.com/forest-talk...
- [Bloon AI](https://bloon.ai):重新定义智能学习
- [Loom | 免费屏幕和视频录制软件](https://www.loom.com/share/6be018c033f8466184ea3903a15e63aa):使用 Loom 快速录制屏幕和摄像头视频。清晰轻松地解释任何事情——跳过会议。混合办公场所的必备工具。
- [Reddit - 深入了解任何事物](https://www.reddit.com/r/perplexity_ai/comments/1b9aa5a/comment/ktut7h2/?utm_source=sh):未找到描述
- [Reddit - 深入了解任何事物](https://www.reddit.com/r/perplexity_ai/comments/1b9aa5a/comment/ktv6xhn/):未找到描述
- [Reddit - 深入了解任何事物](https://www.reddit.com/r/perplexity_ai/comments/1b9aa5a/perplexity_is_consistently_challenged_by/):未找到描述
- [Elon Musk (@elonmusk) 的推文](https://fxtwitter.com/elonmusk/status/1767108624038449405?t=HqsmcmViAZl6L-U8AtO9FQ&s=19):本周,@xAI 将开源 Grok
- [Reddit - 深入了解任何事物](https://www.reddit.com/r/perplexity_ai/comments/1b9aa5a/comment/ktut7h2/?utm_source=share&utm_medium=mweb3x&utm_name=mweb3xcss&utm_term=1&utm_content=share_button):未找到描述
- [GitHub - brendenlake/MLC: 用于模拟人类行为的组合元学习 (MLC)](https://github.com/brendenlake/MLC):用于模拟人类行为的组合元学习 (MLC) - brendenlake/MLC
- [测量并缩小语言模型中的组合性差距](https://arxiv.org/abs/2210.03350):我们研究了语言模型执行组合推理任务的能力,其中整体解决方案取决于正确组合子问题的答案。我们测量了模型执行此类任务的频率...
---
### Perplexity AI ▷ #[sharing](https://discord.com/channels/1047197230748151888/1054944216876331118/1215644530309603370) (38 messages🔥):
- **Epic 与 Apple 法律战更新**:`@jeffreyhammer` 分享了关于 **Apple 终止 Epic 开发者账户** 法律纠纷的见解。您可以点击 [此处](https://www.perplexity.ai/search/Apple-terminates-Epic-BaeX6c9hQ0u9hd9jAan_tw) 阅读更多相关进展。
- **预期寿命关注**:`@nippy_lovelace` 深入探讨了 **寿命(life-span)** 及其影响因素。点击 [此处](https://www.perplexity.ai/search/Life-span-of-rfNTuVklS3e3PuMXaZdTDw) 参与对话。
- **超级碗对决**:据 `@johnmooredesign` 称,某一场超级碗中场秀脱颖而出,被誉为史上最佳。想了解具体评价或演出名称?请查看 [此处](https://www.perplexity.ai/search/The-greatest-Super-VfLhIQtrRGGfec5GaJXUYg)。
- **科技界的变现问题**:`@pintobean8071` 深入研究了 **Google 向出版商支付内容费用** 的问题。具体安排详情请见 [此处](https://www.perplexity.ai/search/Google-pays-publishers-RUm4WAH_SbOIdUxFe1_Uww)。
- **促智药(Nootropics)效率讨论**:`@sevonade4` 介绍了 Claude 3 Opus,并讨论了有效的促智药,包括 **咖啡因、L-茶氨酸和肌酸** 的组合。对认知增强感兴趣?从 [此处了解促智药](https://www.perplexity.ai/search/Nootropics-that-works-egohN6BzQ96akat9VsV1BA#0) 以及 [此处了解组合方案](https://www.perplexity.ai/search/Caffeine-Ltheanine-and-VP0cM97PQMyZvXPAkiHjEg#0) 开始。
---
### Perplexity AI ▷ #[pplx-api](https://discord.com/channels/1047197230748151888/1161802929053909012/1215563200360349696) (10 messages🔥):
- **对最大输出 Token 长度的困惑**:用户 `@hex8529` 询问了新模型的最大 Token 输出量,并指出目前只能看到上下文长度(context length)。`@brknclock1215` 回复建议,上下文窗口长度减去查询和搜索结果的长度,实际上就是最大输出量。
- **路线图中缺失 32k 上下文长度**:`@dogemeat_` 询问为何路线图中似乎删除了 32k 上下文长度功能,并对这一变化缺乏官方确认表示担忧。
- **API 新用户寻求指导**:API 新手 `@thbk_32074` 询问通过 Raycast 进行轻度使用是否会耗尽 5 美元的额度,并询问是否有追踪使用情况的方法。
- **模型输出限制的澄清**:`@leoesq` 澄清说,尽管许多模型拥有更大的上下文窗口,但其最大输出限制通常在 3-8k Token 之间,这还受到微调(finetune)行为的影响;对此 `@brknclock1215` 承认文档可能存在不一致之处。
- **为个人助手项目寻求帮助**:用户 `@shine0252` 寻求帮助以改进一个类 Alexa 的个人助手项目,希望利用 pplx API 实现更简洁且具备记忆能力的交互;`@dogemeat_` 提供了建议,提到使用 `sonar` 模型可以获得简洁的回复,并建议通过存储对话来实现记忆功能。
---
### Nous Research AI ▷ #[ctx-length-research](https://discord.com/channels/1053877538025386074/1108104624482812015/1216389570279505921) (4 messages):
- **对 Decoder 模型的疑问**:`@mattlawhon` 询问了关于在没有位置编码(PE)的情况下训练的 Decoder 模型在推理(inference)期间使用更长序列的见解。
- **开放式问题令同行困惑**:`@vatsadev` 寻求澄清 `@mattlawhon` 所指的在 Decoder 模型中使用更长序列的具体含义。
- **Decoder 约束的澄清**:`@vatsadev` 确认在推理时可以向 Decoder 模型输入更多 Token,但警告这可能会导致错误或产生无意义的输出。
---
### Nous Research AI ▷ #[off-topic](https://discord.com/channels/1053877538025386074/1109649177689980928/1215605074747723796) (39 条消息🔥):
- **Doodle Wars 游戏发布**:`@om7059` 分享了一个名为 [Doodle Wars](https://doodlewars.netlify.app) 的新项目,这是一款*多人游戏*,玩家的涂鸦由神经网络进行评分。
- **AI 辅助聚会游戏**:`@denovich` 讨论了多模态 LLM 如何可能让少于 4 人的玩家也能玩聚会游戏 *Telestrations*。
- **使用 Genstruct 处理物理数据**:`@ee.dd` 提到正在使用 Genstruct 处理物理数据,并思考在尝试训练运行之前需要多少数据量。
- **神经网络收敛加速方法**:`@baptistelqt` 宣布了一种新方法,据称可以将任何神经网络的收敛速度提高 10000 倍。
- **Cohere 新生成模型介绍**:`@1vnzh` 分享了一个 Hugging Face 链接,介绍了来自 Cohere 的 Command-R,这是一个拥有 350 亿参数的模型,针对 RAG 和多语言生成进行了优化,[C4AI Command-R](https://huggingface.co/CohereForAI/c4ai-command-r-v01)。
**提到的链接**:
- [Doodle Wars](https://doodlewars.netlify.app):未找到描述
- [CohereForAI/c4ai-command-r-v01 · Hugging Face](https://huggingface.co/CohereForAI/c4ai-command-r-v01):未找到描述
- [Command-R: Retrieval Augmented Generation at Production Scale](https://txt.cohere.com/command-r/):Command-R 是一款针对 RAG 和 Tool Use 的可扩展生成模型,旨在为企业提供生产级 AI。今天,我们推出了 Command-R,这是一款针对大规模生产工作负载的新型 LLM...
- [Mystic.ai](https://www.mystic.ai/):企业级机器学习自动运维 (auto-ops)
- [Genstruct 7B Instruction Generation Model](https://www.youtube.com/watch?v=H6xon8K4Ius):Genstruct 7B 是一款指令生成模型,旨在根据原始文本语料库创建有效的指令。这使得创建新的、部分结构化的...
- [Tweet from Andrej Karpathy (@karpathy)](https://x.com/karpathy/status/1766509149297189274?s=46):阅读推文有点像下载一个(受攻击者控制的)可执行文件,并立即在你的大脑中运行。每一条推文都会引发情感、暗示知识、触动世界观。在未来,它...
---
### Nous Research AI ▷ #[interesting-links](https://discord.com/channels/1053877538025386074/1132352574750728192/1215679696189132840) (13 条消息🔥):
- **Gemini 开启书本级推理能力**:`@shashank.f1` 强调了与 Hugging Face 社区关于稀疏混合模型(sparse mixture of models)的讨论,并介绍了 [**Gemini**](https://youtu.be/IuehDA1M_Lw)。这是一款能够在单个 Prompt 中处理整本书籍和电影内容的 AI。链接中的 YouTube 视频讨论了 Gemini 的各项能力及其与其他大语言模型(LLM)的对比,包括其成本比 GPT-4 便宜 20 倍。
- **用于指令生成的 WildBench 基准测试**:`@mister_poodle` 分享了 Hugging Face 上的 [**WildBench**](https://huggingface.co/spaces/allenai/WildBench) 基准测试链接,这可以被视为对评估 AI 指令生成能力的新型基准测试的呼吁。
- **用于合成数据集创建的 Bonito**:延续基准测试的主题,`@mister_poodle` 还介绍了 [**Bonito**](https://huggingface.co/BatsResearch/bonito-v1),这是一个将未标注文本转换为特定任务训练数据集的模型,对预训练和指令微调(instruction-tuned)的语言模型都有重要意义。
- **Lex Fridman 关于 AI 与权力的推文**:`@mautonomy` 引起了大家对 [Lex Fridman 的一条推文](https://twitter.com/lexfridman/status/1766497567909585104)的关注,该推文可能涉及 AI 与权力及社会动态的交集(未提供推文的具体内容)。
- **一个哲学乐观派 AI 服务器**:`@norabelrose` 分享了一个 Discord 服务器的邀请,该服务器致力于讨论 AI、哲学、技术、开源和乐观的未来,同时也旨在批判 AI 悲观主义。加入链接在[这里](https://discord.gg/Ss4Bwkvd),`@max_paperclips` 对此邀请表示感谢。
**提到的链接**:
- [Discord - 与朋友和社区聊天的新方式](https://discord.gg/Ss4Bwkvd):Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
- [Is Cosine-Similarity of Embeddings Really About Similarity?](https://arxiv.org/abs/2403.05440):余弦相似度是两个向量之间夹角的余弦值,或者等同于它们归一化后的点积。一个流行的应用是量化高维空间中的语义相似度...
- [BatsResearch/bonito-v1 · Hugging Face](https://huggingface.co/BatsResearch/bonito-v1):未找到描述
- [How can we Improve Democracy?](https://medium.com/@h.a.papageorgiou/autoregression-b8cf7aa561d7):简介
- [Gemini supports 1M+ tokens and 20x cheaper than GPT4 😮 ~ Unlock ideas from the technical paper](https://youtu.be/IuehDA1M_Lw):这里有一个快速总结,对比了 Gemini、Claude Opus 和 GPT-4 Turbo,告诉你为什么应该关注 Gemini 1.5 Pro♦️ 关于速度 💨 ~ 仅需 1 秒...
- [AI2 WildBench Leaderboard - a Hugging Face Space by allenai](https://huggingface.co/spaces/allenai/WildBench):未找到描述
---
### Nous Research AI ▷ #[general](https://discord.com/channels/1053877538025386074/1149866623109439599/1215567662441173042) (395 条消息🔥🔥):
- **模型并行性的困惑**:`@mihai4256` 分享了一个关于模型并行(model parallelism)的链接,最初引起了困惑,但 `@teknium` 澄清说 Qlora 仅通过 device map auto 以模型串行(model serial)方式工作,而 Deepspeed 有其自己的量化格式。讨论还包括来自 `@rtyax`、`@stefangliga` 等人的评论。
- **Python 困扰下的 Claude Conscious 项目计划**:包括 `@mihai4256`、`@teknium`、`@gabriel_syme` 和 `@fred.bliss` 在内的多位用户讨论了他们在 Claude Conscious 项目中的计划和经验。`@mihai4256` 对 Python 依赖项表示沮丧,而 `@gabriel_syme` 在没有 Web 开发知识的情况下,在 25 分钟内创建了一个网页前端。
- **GPT-5 发布的大型计划**:用户们推测了 GPT-5 的潜在发布日期,预测范围从 `@mautonomy` 认为的 56 小时内,到 `@ee.dd` 认为的美国大选之后。`@night_w0lf` 提到一个新模型 Deepseek-VL 正在悄然兴起。
- **新发布与工具**:`@gabriel_syme` 宣布 Cohere 发布了一个新的 RAG/工具调用模型,并在 Hugging Face 上提供了权重。`@euclaise` 帮助 `@tonic_1` 修复了 Genstruct 的 Prompt 格式,`@.interstellarninja` 预告了一个适用于本地 GPU 的新型递归函数调用 LLM。
- **Deepseek 取得进展**:`@night_w0lf` 重点介绍了 Deepseek-VL,这是一个性能大有前途的 7B 模型,在某些基准测试中甚至击败或持平了更大的模型。他们还认可了学术知识基准测试 MMMU,并分享了论文链接。
**提到的链接**:
- [来自 interstellarninja (@intrstllrninja) 的推文](https://fxtwitter.com/intrstllrninja/status/1767296447756828953?s=20):递归函数调用 LLM 即将登陆你的本地 GPU...
- [MMLU 中的错误:深度学习基准测试出错频率惊人](https://derenrich.medium.com/errors-in-the-mmlu-the-deep-learning-benchmark-is-wrong-surprisingly-often-7258bb045859):用于评估大语言模型质量的数据集存在错误。这有多严重?
- [无限力量 - 星球大战 GIF - 帕尔帕廷皇帝 - 发现并分享 GIF](https://tenor.com/view/power-unlimited-power-emperor-palpetine-revenge-of-the-sith-gif-5266473):点击查看 GIF
- [CohereForAI/c4ai-command-r-v01 · Hugging Face](https://huggingface.co/CohereForAI/c4ai-command-r-v01):未找到描述
- [速率限制](https://docs.anthropic.com/claude/reference/rate-limits):未找到描述
- [我们这儿不搞那一套 黑豹 GIF - 特查拉 - 发现并分享 GIF](https://tenor.com/view/we-dont-do-that-here-black-panther-tchalla-bruce-gif-16558003):点击查看 GIF
- [Tonic/Genstruct · 修复尝试 2](https://huggingface.co/spaces/Tonic/Genstruct/discussions/2):未找到描述
- [emozilla/LWM-Text-1M-GGUF · Hugging Face](https://huggingface.co/emozilla/LWM-Text-1M-GGUF):未找到描述
- [emozilla/LWM-Text-1M-mpe64k · Hugging Face](https://huggingface.co/emozilla/LWM-Text-1M-mpe64k):未找到描述
- [来自 bayes (@bayeslord) 的推文](https://x.com/bayeslord/status/1765865268595593707?s=46):说实话,我上一次使用 7B 参数模型还是在 2009 年
- [来自 Sam Altman (@sama) 的推文](https://fxtwitter.com/sama/status/1766311274089185323):耐心点 jimmy。这值得等待。 ↘️ 引用 Jimmy Apples 🍎/acc (@apples_jimmy):没有戏剧性的 OpenAI 什么都不是。既然现在这些都解决了,让我们赶紧推进发布吧...
- [Copium Cat GIF - 发现并分享 GIF](https://tenor.com/view/copium-cat-gif-27161395):点击查看 GIF
- [唇形同步](https://github.com/DenchiSoft/VTubeStudio/wiki/Lipsync):VTube Studio API 开发页面。通过在 GitHub 上创建账号为 DenchiSoft/VTubeStudio 的开发做出贡献。
- [Genstruct - Tonic 创建的 Hugging Face Space](https://huggingface.co/spaces/Tonic/Genstruct):未找到描述
- [战斗力 8000。等等,超过 9000 了..Gif GIF - 发现并分享 GIF](https://tenor.com/view/power-level-800o.-wait-it%27s-over-9.-label-text-poster-gif-6048690988960107821):点击查看 GIF
- [GitHub - teknium1/ShareGPT-Builder](https://github.com/teknium1/ShareGPT-Builder):通过在 GitHub 上创建账号为 teknium1/ShareGPT-Builder 的开发做出贡献。
- [Yann Lecun:Meta AI、开源、LLM 的局限性、AGI 与 AI 的未来 | Lex Fridman 播客 #416](https://youtu.be/5t1vTLU7s40?si=HS3WrupXGw_xBvmb):Yann LeCun 是 Meta 的首席 AI 科学家,纽约大学教授,图灵奖得主,也是 AI 历史上最具影响力的研究者之一。请...
- [mlx-lm-notebooks/mlx_genstruct_notebook_dataset_pipeline.ipynb (main 分支) · fblissjr/mlx-lm-notebooks](https://github.com/fblissjr/mlx-lm-notebooks/blob/main/mlx_genstruct_notebook_dataset_pipeline.ipynb):Apple MLX 语言模型 (mlx-lm) 笔记本、探索与尝试 - fblissjr/mlx-lm-notebooks
- [未找到标题](https://derenrich.medium.com/errors-in-the-mmlu-the-):未找到描述
- [EntreConnect 举办的生成式 AI 视频突破与世界模型 - #Sora #Genie #VideoPoet #V-JEPA #LTXStudio #AnimateDiff · Luma](https://lu.ma/b0zrw3q3):加入我们,参加这场深入探讨生成式 AI 视频核心的开创性活动!这不仅仅是另一场技术演讲;这是一场通往未来的旅程。我们还将提供拨入选项...
- [由 vgel 添加对控制向量的支持 · Pull Request #5970 · ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp/pull/5970):非常感谢 Nous Research,他们的支持与合作使这项工作成为可能!此 PR 引入了一种新的激活修改技术:控制向量(也称为引导向量、概念向量...)
---
### Nous Research AI ▷ #[ask-about-llms](https://discord.com/channels/1053877538025386074/1154120232051408927/1215558107388710912) (175 条消息🔥🔥):
- **寻找 AI 论文**:`@main.ai` 和 `@atgctg` 引发了关于 Yi 论文内容的讨论,强调根据一篇详细介绍该论文要点的 Reddit 帖子 ([来源](https://www.reddit.com/r/LocalLLaMA/comments/1b9kq9v/01ai_paper_is_a_gem_for_model_trainers/)),10k 个精心策划的训练样本就足以进行有效的聊天机器人 finetuning。
- **Tokenizer 难题**:`@stoicbatman` 提出了一个关于在预训练的 GPT-2 模型中替换或添加特定语言 Tokenizer 的可行性难题。`@teknium` 和 `@stefangliga` 认为,虽然可以添加 Token,但直接替换 Tokenizer 会抵消之前的学习成果,并可能需要从头开始重新训练。
- **用于函数调用的 XML 魔法**:围绕诱导 LLM 输出封装在 XML 标签中的函数调用的讨论非常热烈,`@.interstellarninja` 和 `@teknium` 团队分享了他们在精确生成函数调用方面的成功经验,并讨论了使用 `ufghfigchv` 的工具采样器(tool sampler)来提高输出可信度。
- **使用库进行引导式模型推理**:由 `@sundar_99385`、`@.interstellarninja` 和 `@ufghfigchv` 领导的讨论深入探讨了 outlines 和 SG-lang 等库在引导模型推理方面的效用。集体见解指出,预编译语法和使用源自函数签名的 Schema 有助于提高可靠性。
- **关于 LLM GUI 前端的咨询**:`@vodros` 寻求与 Claude 3 兼容的开源 GUI/前端推荐,`@quicksort` 建议尝试 [open-webui](https://github.com/open-webui/open-webui),它为 LLM 提供了用户友好的 WebUI。
**提到的链接**:
- [Google Colaboratory](https://colab.research.google.com/github/unaidedelf8777/function-sampler):未找到描述
- [Answer.AI - 你现在可以在家训练 70b 语言模型了](https://www.answer.ai/posts/2024-03-06-fsdp-qlora.html):我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。
- [使用 XML 标签](https://docs.anthropic.com/claude/docs/use-xml-tags):未找到描述
- [Poor Man GIF - Poor Man - 发现并分享 GIF](https://tenor.com/view/poor-man-gif-23343928):点击查看 GIF
- [Trendyol/Trendyol-LLM-7b-base-v0.1 · Hugging Face](https://huggingface.co/Trendyol/Trendyol-LLM-7b-base-v0.1):未找到描述
- [emozilla/LWM-Text-1M-GGUF · Hugging Face](https://huggingface.co/emozilla/LWM-Text-1M-GGUF):未找到描述
- [emozilla/LWM-Text-1M-mpe64k · Hugging Face](https://huggingface.co/emozilla/LWM-Text-1M-mpe64k):未找到描述
- [Reddit - 深入了解任何事物](https://www.reddit.com/r/LocalLLaMA/comments/1b9kq9v/01ai_paper_is_a_gem_for_model_trainers/):未找到描述
- [未找到标题](https://medium.com/@gilinachum/cost-of-llm-continued-pre-training-):未找到描述
- [scratchTHOUGHTS/selfgenREFLECT.py at main · EveryOneIsGross/scratchTHOUGHTS](https://github.com/EveryOneIsGross/scratchTHOUGHTS/blob/main/selfgenREFLECT.py):用于避免 self 溢出错误的第二大脑临时记忆。- EveryOneIsGross/scratchTHOUGHTS
- [$ LLM 持续预训练的成本](https://medium.com/@gilinachum/cost-of-llm-continued-pre-training-0c1998cb44ec):对小型 (7B) LLM 进行持续预训练需要花费多少成本?
- [GitHub - edmundman/OllamaGenstruct](https://github.com/edmundman/OllamaGenstruct):通过在 GitHub 上创建账户来为 edmundman/OllamaGenstruct 的开发做出贡献。
- [Google Colaboratory](https://colab.research.google.com/github/unaidedelf8777/function-sampler/blob/main/notebooks/Tool_Call_Sampler_demo.ipynb):未找到描述
- [GitHub - unaidedelf8777/function-sampler: 用于函数调用 LM 的 Logit 采样器。使生成错误的函数调用在概率上变得不可能!](https://github.com/unaidedelf8777/function-sampler.git):用于函数调用 LM 的 Logit 采样器。使生成错误的函数调用在概率上变得不可能!- unaidedelf8777/function-sampler
- [GitHub - open-webui/open-webui: 适用于 LLM 的用户友好型 WebUI(原名 Ollama WebUI)](https://github.com/open-webui/open-webui):适用于 LLM 的用户友好型 WebUI(原名 Ollama WebUI)- open-webui/open-webui
---
### Nous Research AI ▷ #[collective-cognition](https://discord.com/channels/1053877538025386074/1154961277748256831/1216721515312320574) (3 条消息):
- **Flash Attention 问题重定向**:`@pradeep1148` 询问如何在 Axolotl 中禁用 Flash Attention。`@teknium` 告知该频道已归档,并建议在另一个指定的频道 `<#1154120232051408927>` 中提问。
---
### Nous Research AI ▷ #[project-obsidian](https://discord.com/channels/1053877538025386074/1156472202619781140/1215742206086873138) (3 messages):
- **承认数据质量问题**:`@gabriel_syme` 指出 **数据质量 (data quality)** 是一个重大挑战。
- **模型会附和提供的假设**:`@kainan_e` 指出语言模型通常只是简单地“同意”用户提供的观点或假设,甚至可能虚构事件,例如纳米比亚虚构的“松鼠起义”。
---
### Nous Research AI ▷ #[bittensor-finetune-subnet](https://discord.com/channels/1053877538025386074/1213221029359657021/1216090871456333904) (3 messages):
- **Bittensor 频道诈骗警报**:用户 `@teknium` 警告 `<@930423397366792202>`,其最近发布的帖子被视为诈骗,该频道应仅用于讨论 Bittensor 相关话题。
- **寻求 Bittensor 子网输出的见解**:`@vincentweisser` 询问了关于该子网产出模型的主要见解。
- **Bittensor 数据生成流水线增强**:`@teknium` 回复称,一个复杂的数据生成流水线正在开发中,旨在改进现有模型,并强调目前的流水线未能提供必要的集样性。
---
### LlamaIndex ▷ #[blog](https://discord.com/channels/1059199217496772688/1187460979064324127/1215712405515141173) (10 messages🔥):
- **分层代码切分创新**:`@ryanpeach` 的 `CodeHierarchyNodeParser` 获得认可,该解析器将大型代码文件切分为层级结构,增强了 **RAG/agents**。该方法在 [推文](https://twitter.com/llama_index/status/1766152269874266170) 中进行了讨论。
- **动态文件系统上的实时问答**:Anup Surendran 和 Berke Can Rizai 在 **@streamlit** 博客文章中展示了如何使用 **@pathway_com** 在动态 Google Drive/Sharepoint 上构建问答系统。在完整的 [推文](https://twitter.com/llama_index/status/1766265545236848975) 中了解实时 ETL 流水线。
- **AI 驱动的浏览器自动化**:@dhuynh95 的项目 LaVague 利用了 **RAG** 以及来自 **@MistralAI** 和 **@huggingface** 的 **local embeddings + Mixtral**,旨在根据用户查询生成 Selenium 代码。该 Agent 作为浏览器副驾驶 (copilot),在 [这里](https://twitter.com/llama_index/status/1766508631825235968) 进行了讨论。
- **用户调查行动号召**:LlamaIndex 正在进行一项 **3 分钟用户调查**,以收集宝贵的反馈和意见,并发布了提醒 [推文](https://twitter.com/llama_index/status/1766536043258642833)。
- **利用树状结构增强 RAG**:@parthsarthi03 分享了关于使用树状结构改进 RAG 流水线处理复杂问题功能的见解,详见其 [最新网络研讨会](https://twitter.com/llama_index/status/1766632206301294830)。
---
### LlamaIndex ▷ #[general](https://discord.com/channels/1059199217496772688/1059201661417037995/1215564322059583579) (376 messages🔥🔥):
- **聊天机器人创建咨询**:`@o3omoomin` 询问如何使用 LlamaIndex 创建 RAG 聊天机器人,特别是寻找用于部署的框架和已实现的 RAG 聊天机器人示例。他们引用了 Ensemble Retriever 文档,并强调了当被问及与文档内容无关的问题时所面临的挑战 ([问题链接](https://docs.llamaindex.ai/en/stable/examples/retrievers/ensemble_retrieval.html))。
- **余弦相似度困惑**:`@icsy7867` 讨论了余弦相似度的范围,质疑其是 0-1 还是可能包含负值,并寻求在查询引擎中实现相似度分数阈值 (cutoff) 的澄清 ([余弦相似度背景](https://en.m.wikipedia.org/wiki/Cosine_similarity))。
- **摄取流水线重复项**:`@mato8792` 提出了摄取流水线在处理相同数据时重复处理文档的问题,该问题最终通过正确包含 `filename_as_id=True` 以有效管理文档重复项而得到解决。
- **Conda 安装冲突**:`@rachel_001.` 报告了 Conda 安装过程中的版本冲突问题,并遇到了升级后找不到模块的问题,这导致了包括使用全新虚拟环境在内的故障排除。
- **保存流水线输出**:`@node_0` 询问如何将 Query Pipeline 的中间或最终输出保存到本地目录,并特别询问 Pydantic 对象是否可以作为流水线的一部分,对此 `@cheesyfishes` 澄清目前尚不可能,但已在未来开发计划中。
**提到的链接**:
- [预填充 Claude 的回复](https://docs.anthropic.com/claude/docs/prefill-claudes-response):未找到描述
- [无标题](https://www.secinsights.ai/):未找到描述
- [Google Colaboratory](https://colab.research.google.com/github/Arize-ai/phoenix/blob/main/tutorials/tracing/llama_index_tracing_tutorial.ipynb): 未找到描述
- [未找到标题](https://llamahub.ai/l/readers/llama-index-readers-snowflake?from=): 未找到描述
- [未找到标题](https://llamahub.ai/l/llama-packs/llama-index-packs-snowflake-query-engine?from=): 未找到描述
- [Ingestion Pipeline + Document Management - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/examples/ingestion/document_management_pipeline.html): 未找到描述
- [Query Pipeline over Pandas DataFrames - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/examples/pipeline/query_pipeline_pandas.html#download-data): 未找到描述
- [Customizing LLMs within LlamaIndex Abstractions - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/module_guides/models/llms/usage_custom.html#example-using-a-huggingface-llm): 未找到描述
- [Cosine similarity - Wikipedia](https://en.m.wikipedia.org/wiki/Cosine_similarity): 未找到描述
- [Starter Tutorial - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/getting_started/starter_example.html): 未找到描述
- [gist:7f54b5ae756b5362b3ec0871b845eeac](https://gist.github.com/thoraxe/7f54b5ae756b5362b3ec0871b845eeac): GitHub Gist:即时分享代码、笔记和代码片段。
- [OrdalieTech/Solon-embeddings-large-0.1 · Hugging Face](https://huggingface.co/OrdalieTech/Solon-embeddings-large-0.1): 未找到描述
- [Sentence Embedding Optimizer - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/OptimizerDemo.html#sentence-embedding-optimizer): 未找到描述
- [LlamaIndex user survey](https://www.surveymonkey.com/r/PNSP3P9): 参加由 surveymonkey.com 支持的这项调查。免费创建您自己的调查。
- [Observability - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/module_guides/observability/observability.html): 未找到描述
- [未找到标题](https://llamahub.ai/l/llama-packs/llama-index-packs-fuzzy-citation?from=): 未找到描述
- [llama_index/llama-index-packs/llama-index-packs-fuzzy-citation/llama_index/packs/fuzzy_citation/base.py at 3e5d0a146fcda01a984818d381f31a19287aead8 · run-llama/llama_index](https://github.com/run-llama/llama_index/blob/3e5d0a146fcda01a984818d381f31a19287aead8/llama-index-packs/llama-index-packs-fuzzy-citation/llama_index/packs/fuzzy_citation/base.py#L29): LlamaIndex 是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- [Node Postprocessor Modules - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/module_guides/querying/node_postprocessors/node_postprocessors.html#similaritypostprocessor): 未找到描述
- [Joaquin Dominguez / discord_bot · GitLab](https://gitlab.com/j-dominguez9/discord_bot): GitLab.com
- [kapa.ai - Instant AI Answers to Technical Questions](https://www.kapa.ai/): kapa.ai 让面向开发者的公司能够轻松地为其社区构建由 LLM 驱动的支持和入职机器人。OpenAI、Airbyte 和 NextJS 的团队使用 kapa 来提升他们的开发者体验...
- [Node Postprocessor - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/module_guides/querying/node_postprocessors/root.html#id2): 未找到描述
- [Ensemble Retrieval Guide - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/examples/retrievers/ensemble_retrieval.html): 未找到描述
- [Document Stores - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/module_guides/storing/docstores.html): 未找到描述
- [LlamaIndex Sessions: 12 RAG Pain Points and Solutions](https://www.youtube.com/watch?v=EBpT_cscTis): 我们很高兴邀请到 Wenqi Glantz 为她广受欢迎的“12 RAG Pain Points and Solutions”博文制作个人演示视频,这是最全面的...
- [llama_index/llama-index-integrations/llms/llama-index-llms-mistralai/llama_index/llms/mistralai/base.py at d63fec1c69a2e1e51bf884a805b9fd31ad8d1ee9 · run-llama/llama_index](https://github.com/run-llama/llama_index/blob/d63fec1c69a2e1e51bf884a805b9fd31ad8d1ee9/llama-index-integrations/llms/llama-index-llms-mistralai/llama_index/llms/mistralai/base.py#L72): LlamaIndex 是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- [[Bug]: Intermittent 400 - Invalid parameter Error for Messages with Role tool · Issue #10493 · run-llama/llama_index](https://github.com/run-llama/llama_index/issues/10493): Bug 描述:我们遇到了间歇性的 400 错误,消息为 "Invalid parameter: messages with role 'tool' must be a response to a preceding message with 'tool_calls...
- [GitHub - run-llama/sec-insights: A real world full-stack application using LlamaIndex](https://github.com/run-llama/sec-insights): 一个使用 LlamaIndex 的真实全栈应用程序 - run-llama/sec-insights
- [Vector Stores - LlamaIndex 🦙 v0.10.18.post1](https://docs.llamaindex.ai/en/stable/module_guides/storing/vector_stores.html#vector-store-options-feature-support): 未找到描述
- [GitHub - Arize-ai/phoenix: AI Observability & Evaluation - Evaluate, troubleshoot, and fine tune your LLM, CV, and NLP models in a notebook.](https://github.com/Arize-ai/phoenix?tab=readme-ov-file#tracing-with-llamaindex): AI 可观测性与评估 - 在 notebook 中评估、排查并微调您的 LLM、CV 和 NLP 模型。 - Arize-ai/phoenix
- [GitHub - NVIDIA/NeMo-Guardrails: NeMo Guardrails is an open-source toolkit for easily adding programmable guardrails to LLM-based conversational systems.](https://github.com/NVIDIA/NeMo-Guardrails): NeMo Guardrails 是一个开源工具包,用于轻松地为基于 LLM 的对话系统添加可编程护栏。 - NVIDIA/NeMo-Guardrails
- [NeMo Guardrails, the Ultimate Open-Source LLM Security Toolkit](https://medium.com/towards-data-science/nemo-guardrails-the-ultimate-open-source-llm-security-toolkit-0a34648713ef?sk=836ead39623dab0015420de2740eccc2): 探索 NeMo Guardrails 的实际用例
---
### LlamaIndex ▷ #[ai-discussion](https://discord.com/channels/1059199217496772688/1100478495295017063/1216131938990034994) (4 条消息):
- **PDF 解析简化**:`@datasciencebasics` 分享了一个 [YouTube 视频](https://youtu.be/wRMnHbiz5ck),标题为 **"Super Easy Way To Parse PDF | LlamaParse From LlamaIndex | LlamaCloud"**,概述了用于简化 PDF 解析的 LlamaParse 和 LlamaCloud 服务。
- **使用 LlamaIndex 探索代码**:`@andysingal` 发布了一篇 [博客文章](https://medium.com/ai-advances/unleashing-the-power-of-code-a-journey-with-llamaindex-and-code-hierarchy-node-parser-d8ac5fcced8d),标题为 **"Unleashing the Power of Code: A Journey with LlamaIndex and Code Hierarchy Node Parser"**,讨论了组织大型代码文件的益处。
- **Matryoshka 学习论文讨论邀请**:`@lien_61024` 发出了关于 **[Matryoshka Representation Learning](https://lu.ma/wmiqcr8t)** 的论文讨论邀请,由 Jina AI 主办,特邀专家 Aditya Kusupati 和 Aniket Rege 参加。
- **寻找开源 GUI**:`@vodros` 询问了推荐的与 **Claude 3** 兼容的开源 GUI/前端,表示希望从 Chatbox 转向更用户友好的工具。
**提到的链接**:
- [Super Easy Way To Parse PDF | LlamaParse From LlamaIndex | LlamaCloud](https://youtu.be/wRMnHbiz5ck): 在这段视频中,我将首先简要解释 LlamaParse 的核心内容。我还会谈到来自 LlamaIndex 的 LlamaCloud。LlamaParse 是一款最先进的...
- [Matryoshka Representation Learning: Paper discussion · Zoom · Luma](https://lu.ma/wmiqcr8t): 加入我们,度过富有启发性的一小时,深入探索 Matryoshka Representation Learning 的迷人世界。由博学的 Aditya Kusupati 和敏锐的 Aniket Rege 介绍,并且...
- [Unleashing the Power of Code: A Journey with LlamaIndex and Code Hierarchy Node Parser](https://medium.com/ai-advances/unleashing-the-power-of-code-a-journey-with-llamaindex-and-code-hierarchy-node-parser-d8ac5fcced8d): Ankush k Singal
---
### LAION ▷ #[general](https://discord.com/channels/823813159592001537/823813160075132991/1215592659075473471) (302 条消息🔥🔥):
- **AI 技术术语与对无效工具的蔑视**:在激烈的讨论中,`@ignizherz`、`@pseudoterminalx` 和 `@nodja` 表达了对 Glaze 和 Nightshade 等无效对抗性工具的蔑视,认为它们并没有像宣称的那样在实际中保护内容。对话转向推测为什么这种无效性会持续存在,重点讨论了这些工具创造者虽然出于真诚但却被误导的意图。
- **辩论艺术家侵权与“蠕虫”威胁**:`@vrus0188`、`@astropulse` 等人的讨论集中在 AI “蠕虫”所构成的夸大威胁,以及关于 AI 对行业和环境负面影响的误导性文章。这些内容通常包含夸张的语言,并反复炒作一系列末日导向的话题。
- **创意 LLM、出版伦理及对 OpenAI SD3 的期待**:出现了一系列多样的话题,例如 LLM 在创意写作中的有效性(`@nodja` 和 `@chad_in_the_house`)、出版伦理(`@drhead` 和 `.undeleted` 讨论 Glaze 的提交策略),以及 `.undeleted` 表达的对 OpenAI SD3 发布的热切期待。
- **关于 LLM 的误导信息与技术进步**:对话包括对学术期刊中误导信息的批评(`@progamergov` 和 `.undeleted` 哀叹同行评审标准低下),并提到了技术进步,包括一款超低功耗 AI 芯片(`@chad_in_the_house`)和来自 KAIST 的 “Complementary-Transformer”。
- **讨论 AI 对创意和就业的影响**:聊天涉及了 AI 对创意过程和就业的影响,`@ignizherz`、`@astropulse` 和 `@nodja` 就 AI 为非艺术家打开大门以及不断变化的就业市场发表了看法,并认为 AI 不会取代人类的创造力,而是会起到辅助作用。
**提到的链接**:
- [未找到标题](https://news.ycombinator.com/item?id=39643168):未找到描述
- [韩国研究人员通过新型神经 AI 芯片让 Nvidia 感到“功耗羞愧”——声称功耗降低 625 倍,体积缩小 41 倍](https://www.tomshardware.com/tech-industry/artificial-intelligence/korean-researchers-power-shame-nvidia-with-new-neural-ai-chip-claim-625-times-less-power-41-times-smaller):声称三星代工的芯片是首款超低功耗 LLM 处理器。
- [360° 在线全景查看器](https://renderstuff.com/tools/360-panorama-web-viewer/):在线全景 360 查看器。一种免费查看和分享 360 度图片的简便方法。支持 VR。360 图像查看器可立即创建交互式全屏沉浸式 VR 球形 360 3D 全景图...
- [SDXL MS Paint Portraits - v1.0 | Stable Diffusion LoRA | Civitai](https://civitai.com/models/183354/sdxl-ms-paint-portraits>):你喜欢 MS Paint 吗?你喜欢糟糕的绘画和肖像吗?MS Paint Portrait LoRA 可能适合你!它有点难以...
- [MS Paint LoRA (Pony Diffusion V6 XL) - v1.0 | Stable Diffusion LoRA | Civitai](https://civitai.com/models/323771/ms-paint-lora-pony-diffusion-v6-xl>):⚠不要在你的正向提示词中使用评分标签⚠ 我只费心生成了 1 张示例图像(使用该模型未发布的早期版本),所以我...
- [技术已从《星际迷航》时代跨越到道格拉斯·亚当斯时代](https://interconnected.org/home/2024/02/21/adams):发布于 2024 年 2 月 21 日星期三。1,196 字,13 个链接。作者:Matt Webb。
- [卢德分子能教给我们关于抵制自动化未来的什么](https://www.technologyreview.com/2024/02/28/1088262/luddites-resisting-automated-future-technology/):反对技术并不等同于反对进步。
- [Reddit - 深入了解任何事物](https://www.reddit.com/r/StableDiffusion/comments/1bb8uwx/an_ai_worm_has_been_developed_to_burrow_its_way/):未找到描述
- [2020-21 学年 K-12 艺术快照](https://docs.google.com/presentation/d/1BAbiqX0t7Zbl0NkQ8l6jAEKdazyKEK0qqj_kjmMHmEg/edit?pli=1#slide=id.p):K-12 艺术作品快照(面对面、远程、混合)2020-2021
- [一些新的 SD 3.0 图像](https://old.reddit.com/r/StableDiffusion/comments/1bbdxg6/some_new_sd_30_images/):由 u/protector111 发布在 r/StableDiffusion • 840 个赞和 231 条评论
### LAION ▷ #[research](https://discord.com/channels/823813159592001537/824374369182416994/1215665446997459035) (75 条消息🔥🔥):
- **模型分辨率与细节关注**:包括 `@marianbasti` 和 `@thejonasbrothers` 在内的用户对高分辨率模型的质量表示担忧,指出在大分辨率下会出现伪影,并讨论了如 600M 等较小模型的局限性。大家一致认为,由于这些问题,这些模型的全部潜力可能无法发挥。
- **高级视频脚本编写的潜力**:用户 `@spirit_from_germany` 提议建立一个用于高级视频脚本编写的双模型系统,该系统可以分析和预测视频及音频内容,并通过 [Twitter 链接](https://twitter.com/laion_ai/status/1766596812347941234)分享了这一概念。`@louie1943` 建议将此类训练集中在某一类别中最受欢迎的视频上,以确保使用高质量数据。
- **生成数据集质量的担忧**:用户 `@pseudoterminalx` 提出了对生成数据集局限性的担忧,提到它们会将你困在特定的知识语料库(knowledge corpus)中,且自动生成的描述受限于生成模型所训练的内容。
- **探索 CogView3 框架**:`@twoabove` 和 `@thejonasbrothers` 讨论了 CogView3 [arXiv 论文](https://arxiv.org/pdf/2403.05121.pdf)中详述的 30 亿参数文本生成图像(text-to-image)扩散模型。在认可其改进的同时,`@thejonasbrothers` 注意到论文中缺乏与 Pixart 的对比,这限制了对 CogView3 相对于其他模型潜力的全面了解。
- **关于高效模型的讨论**:`@chad_in_the_house`、`@vrus0188` 和 `@thejonasbrothers` 探讨了 *Efficient Large Language Model Adapters* (ELLA) 及其与 SD3 等其他模型的对比。他们推测了性能和可扩展性,`@thejonasbrothers` 指出 SD3 的线性方法可能使其成为文本生成图像领域的定义性模型。
**提到的链接**:
- [ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment](https://ella-diffusion.github.io/):未找到描述
- [Breaking News: Run Large LLMs Locally with Less RAM and Higher Speed through llama.cpp with QuIP#](https://medium.com/@andreask_75652/breaking-news-run-large-llms-locally-with-less-ram-and-higher-speed-through-llama-cpp-with-quip-5d2a450d58d0):llama.cpp 的最新更新为 LLM 启用了一种听起来很疯狂但确实可用的 2-bit 量化——QuIP:带有不相干性的量化(Quantization with Incoherence)……
---
### LAION ▷ #[learning-ml](https://discord.com/channels/823813159592001537/991941292999323668/1215978801557798982) (2 条消息):
- **Mac 上的扩散模型训练问题**:用户 `@keda4337` 在其 MacBook Pro M1 Max 上训练扩散模型时遇到问题,笔记本电脑出现过热。他们提到,当从每个 epoch 保存的状态恢复训练时,**训练损失(training loss)出现了前所未有的飙升,从 0.01 - 0.9 暴增至 500**。
---
### HuggingFace ▷ #[general](https://discord.com/channels/879548962464493619/879548962464493622/1215575727831777300) (168 条消息🔥🔥):
- **不完整的响应与 Inference API**:`@hari4626` 询问 Inference API 是否总是提供不完整的响应,这一担忧暗示了模型在生产环境中使用时可能存在的性能问题。
- **模型微调指南**:`@bohaska` 正在寻求一种用户友好的方式来微调适用于笔记本电脑的小型 GPT 模型,得到的建议包括查看 "Ollama",但仍需在微调方面获得帮助。
- **利用 AI 优化代码**:`@techintermezzo` 询问了哪种 AI 模型最适合初学者优化着色器编程(shader programming),引发了关于使用 GitHub Co-Pilot 和 DeepSeek-Coder instruct 等模型的详细讨论,并参考了多个 AI 编码基准测试和文献。
- **Discord 中的私信权限设置**:用户 `@chongdashu` 和 `@lunarflu` 讨论了如何在 Discord 上为机器人交互启用和禁用私信权限,`@lunarflu` 澄清说,在获得验证角色(Verified role)后可以禁用私信,且不会影响功能。
- **IPFS 作为模型备份方案**:`@endomorphosis` 讨论了在 IPFS 上托管 AI 模型以规避潜在政府监管的优点,并与 `@lunarflu` 讨论了备份策略以及在未经域名或使用权明确批准的情况下镜像 Hugging Face 仓库的问题。
**提到的链接**:
- [Wikipedia, the free encyclopedia](https://en.wikipedia-on-ipfs.org/wiki/): 未找到描述
- [OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement](https://arxiv.org/abs/2402.14658): 大型语言模型(LLM)的引入显著推进了代码生成。然而,开源模型通常缺乏像先进系统那样的执行能力和迭代优化……
- [Logging in to HuggingFace from Jupyter notebook without interactive prompt](https://medium.com/@yashsk8/logging-in-to-huggingface-from-jupyter-notebook-without-interactive-prompt-2cb945b4905c): 在最近的一个项目中,我遇到了一个棘手的设置问题。作为一个想要学习和贡献但资金短缺的学生……
- [Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code](https://arxiv.org/abs/2311.07989): 在这项工作中,我们系统地回顾了使用语言模型进行代码处理的最新进展,涵盖了 50 多个模型、30 多个评估任务、170 多个数据集和 700 多篇相关论文。我们分解了……
- [US Must Move 'Decisively' To Avert 'Extinction-Level' Threat From AI, Gov't-Commissioned Report Says - Slashdot](https://yro.slashdot.org/story/24/03/11/185217/us-must-move-decisively-to-avert-extinction-level-threat-from-ai-govt-commissioned-report-says): 一份政府委托的报告称,美国政府必须“迅速且果断”地采取行动,以规避人工智能(AI)带来的重大国家安全风险,在最坏的情况下,这可能会导致“灭绝级”……
- [Hugging Face – The AI community building the future.](https://huggingface.co/settings/tokens): 未找到描述
- [Spaces Overview](https://huggingface.co/docs/hub/spaces-overview#managing-secrets): 未找到描述
- [google/gemma-7b · Hugging Face](https://huggingface.co/google/gemma-7b): 未找到描述
- [social-post-explorers/README · Feature Request : Add Posts to Collections](https://huggingface.co/spaces/social-post-explorers/README/discussions/30): 未找到描述
- [DoNotPay's AI lawyer stunt cancelled after multiple state bar associations object](https://mashable.com/article/donotpay-artificial-intelligence-lawyer-experiment): 在多个州律师协会反对后,DoNotPay 的 AI 律师噱头被取消。机器人律师很快被真正的律师停用了。
- [CohereForAI/c4ai-command-r-v01 · Hugging Face](https://huggingface.co/CohereForAI/c4ai-command-r-v01): 未找到描述
- [Command-R: Retrieval Augmented Generation at Production Scale](https://txt.cohere.com/command-r/): Command-R 是一款针对 RAG 和 Tool Use 的可扩展生成模型,旨在为企业实现生产级 AI。今天,我们推出了 Command-R,这是一款针对大规模生产工作负载的新型 LLM……
- [Adding a Sign-In with HF button to your Space](https://huggingface.co/docs/hub/spaces-oauth): 未找到描述
- [Sign in with Hugging Face](https://huggingface.co/docs/hub/oauth): 未找到描述
- [no title found](https://imagepipeline.io/): 未找到描述
- [wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42): 通过在 GitHub 上创建账号,为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
- [notebooks/diffusers at main · huggingface/notebooks](https://github.com/huggingface/notebooks/tree/main/diffusers): 使用 Hugging Face 库的 Notebooks 🤗。通过在 GitHub 上创建账号,为 huggingface/notebooks 的开发做出贡献。
- [My views on “doom” — LessWrong](https://www.lesswrong.com/posts/xWMqsvHapP3nwdSW8/my-views-on-doom): 我经常被问到:“AI 产生极其糟糕结果的概率是多少?”……
---
### HuggingFace ▷ #[today-im-learning](https://discord.com/channels/879548962464493619/898619964095860757/1215571025186521118) (8 messages🔥):
- **对 Generative AI 产生兴趣**:用户 `@umbreenh` 表达了对将 **Generative AI** 用于数据分析开发的浓厚兴趣,并欢迎建议和帮助。
- **让我们一起学习**:针对 `@umbreenh` 的发言,`@yasirali1149` 表达了希望在学习 **Generative AI** 的旅程中共同进步的愿望。
- **寻找 KL-Divergence 指导**:`@wukong7752` 询问是否有专门用于计算 **Latent-DM (LDM)** 中 **KL-divergence** 的教程。
- **讨论优化策略**:`@sajjadrahman56` 提到正在深入研究 **ML 模型的优化技术**,`@refik0727` 表示有兴趣学习其经验。
- **ML 新手寻求脚本使用帮助**:`@210924_aniketlrs02` 寻求帮助,以了解如何使用特定的 [GitHub 脚本](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42) 从 **Wav2Vec2 模型**中提取量化状态。
**提到的链接**:
[wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42):通过在 GitHub 上创建账户,为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
---
### HuggingFace ▷ #[cool-finds](https://discord.com/channels/879548962464493619/897390579145637909/1215666563462733915) (15 messages🔥):
- **发现 Hugging Face 任务页面**:`@andysingal` 分享了他们最近发现的 Hugging Face [任务页面 (Task Page)](https://huggingface.co/tasks),这是一个展示 ML 任务的综合资源,涵盖了 **Image Classification**、**Object Detection** 和 **Text-to-Image** 等各种应用的模型数量。
- **机器学习集成**:该用户分享了 Hugging Face 的 [Optimum](https://haystack.deepset.ai/integrations/optimum),旨在提升 **模型在特定硬件上的效率**。
- **通过 Few-Shot 示例增强 AI**:`@epicx` 提供了一篇 [arXiv 论文](https://arxiv.org/abs/2305.19165) 的链接,讨论了一种利用预训练 LLM 和 Few-shot 示例在 AI Agent 中进行战略推理的方法。
- **NLP 见解**:`@zaidday` 重点介绍了一篇讨论 **Natural Language Processing** (NLP) 领域范围和进展的[文章](https://www.deeplearning.ai/resources/natural-language-processing/)。
**提到的链接**:
- [The Lucid Dream Project - a Hugging Face Space by ilumine-AI](https://huggingface.co/spaces/ilumine-AI/The-Lucid-Dream-Project):未找到描述
- [Strategic Reasoning with Language Models](https://arxiv.org/abs/2305.19165):战略推理使 Agent 能够在各种情况下与其他 Agent 合作、交流和竞争。现有的解决策略博弈的方法依赖于大量的训练,产生...
- [Same seed across different gpus in multiple workers](https://discuss.huggingface.co/t/same-seed-across-different-gpus-in-multiple-workers/76535):这更多是一个关于讨论选择的问题,因为我有一个适合我用例的变通方法。我的理解是,如果我在多个 GPU(假设 n 个 GPU)上以 DistributedDataParallel 方式训练模型...
- [Tasks - Hugging Face](https://huggingface.co/tasks):未找到描述
- [ML Lecture 23-1: Deep Reinforcement Learning](https://www.youtube.com/watch?v=W8XF3ME8G2I):未找到描述
- [wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42):通过在 GitHub 上创建账户,为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
- [llm-course/awesome-repos.md at main · andysingal/llm-course](https://github.com/andysingal/llm-course/blob/main/awesome-repos.md):通过在 GitHub 上创建账户,为 andysingal/llm-course 的开发做出贡献。
- [Natural Language Processing (NLP) - A Complete Guide](https://www.deeplearning.ai/resources/natural-language-processing/):自然语言处理是一门构建能够以语言编写、口述和组织的方式来操作语言的机器的学科。
- [Optimum | Haystack](https://haystack.deepset.ai/integrations/optimum):使用 Hugging Face Optimum 进行高性能推理。
---
### HuggingFace ▷ #[i-made-this] (18 条消息🔥):
- **涂鸦致胜**:`@om7059` 介绍了 **Doodle Wars**,这是一款多人游戏,玩家在 15 秒内涂鸦物体,然后由神经网络评分以决出胜者。点击[此处](https://doodlewars.netlify.app)体验游戏。
- **法律判例通过 Caselaw Access Project 实现数字化**:`@conceptofmind` 分享了他们与 **Caselaw Access Project** 及 **Harvard Library Innovation Lab** 合作发布超过 660 万份美国法院判决书的支持工作。数据可在此处[获取](https://x.com/EnricoShippole/status/1766157358672359862?s=20)。
- **Soft Prompting 论文汇编**:`@sauravmaheshkar` 正在深入研究将 Soft Prompting 作为微调 LLM 的一种方法,并在 **HuggingFace collection** 中记录了相关论文,点击[此处](https://huggingface.co/collections/SauravMaheshkar/soft-prompts-65eb62cee008ea6205dee178)探索。
- **葡萄牙语 LLM 加入对话**:`@dominguesm` 使用 Mamba 架构预训练了一个小型 LLM —— **Mambarim-110m**,其训练数据完全采用葡萄牙语,可在 [HuggingFace](https://huggingface.co/dominguesm/mambarim-110m) 上获取。
- **BERT 嵌入长文本**:`@pszemraj` 微调了一个支持 4k 上下文的 BERT 模型 **bert-plus-L8-v1.0-syntheticSTS-4k**,具备长文本相似度处理能力,强调其在 4k 上下文长度上的训练及其更小的体积。该模型已在 [HuggingFace](https://huggingface.co/BEE-spoke-data/bert-plus-L8-v1.0-syntheticSTS-4k) 上线。
**提到的链接**:
- [来自 DAO Jones (@HungryDAOJones) 的推文](https://x.com/HungryDAOJones/status/1766590849494732877):关于我们:https://youtu.be/E_yThvV6c_I
- [MrOvkill/gemma-2-inference-endpoint-GGUF · Hugging Face](https://huggingface.co/MrOvkill/gemma-2-inference-endpoint-GGUF):未找到描述
- [Doodle Wars](https://doodlewars.netlify.app):未找到描述
- [Soft Prompts - SauravMaheshkar 收藏集](https://huggingface.co/collections/SauravMaheshkar/soft-prompts-65eb62cee008ea6205dee178):未找到描述
- [Genstruct - 由 Tonic 创建的 Hugging Face Space](https://huggingface.co/spaces/Tonic/Genstruct):未找到描述
- [HTPP Endpoints — Large Action Model 集成](https://medium.com/@visrow/htpp-endpoints-large-action-model-integration-27e216028b3f):介绍来自 Tools4AI 的 SwaggerPredictionLoader
- [KY Open Records Assistant - 由 jscotthorn 创建的 Hugging Face Space](https://huggingface.co/spaces/jscotthorn/kora-assistant):未找到描述
- [BEE-spoke-data/bert-plus-L8-v1.0-syntheticSTS-4k · Hugging Face](https://huggingface.co/BEE-spoke-data/bert-plus-L8-v1.0-syntheticSTS-4k):未找到描述
- [SauravMaheshkar/FewGLUE · Hugging Face 数据集](https://huggingface.co/datasets/SauravMaheshkar/FewGLUE):未找到描述
- [dominguesm/mambarim-110m · Hugging Face](https://huggingface.co/dominguesm/mambarim-110m):未找到描述
- [Soft prompts](https://huggingface.co/docs/peft/en/conceptual_guides/prompting):未找到描述
- [来自 Enrico Shippole (@EnricoShippole) 的推文](https://x.com/EnricoShippole/status/1766157358672359862?s=20):@TeraflopAI 很高兴能支持 @caselawaccess 和 @HarvardLIL 发布美国历史上超过 660 万份州和联邦法院判决书。
- [Portfolio – javascript](https://pachinkomachine.quarto.pub/pachinkomachinequartopub/javascript.html):未找到描述
---
### HuggingFace ▷ #[reading-group](https://discord.com/channels/879548962464493619/1156269946427428974/1215561220908781598) (35 条消息🔥):
- **Gemini 的出色表现**:`@shashank.f1` 分享了一个 [YouTube 视频](https://youtu.be/IuehDA1M_Lw),对比了 Gemini, Claude Opus 和 GPT-4 Turbo,强调了 Gemini 更快的速度和更低的成本。`@chad_in_the_house` 思考了 Gemini 1.5 Pro 的优势,指出其 Context Length 是竞争对手的五倍,并且展现了更好的 Multimodal 理解能力。
- **Mixture of Experts (MoE) 与 Finetuning 挑战**:`@shashank.f1` 和 `@chad_in_the_house` 讨论了 Mixture of Experts (MoE) 模型的局限性,透露像 LoRA Finetuning 这样的定制化操作非常具有挑战性,因为 VRAM 需求增加,导致 MoE 在单 GPU 设置下效率低下。
- **探索 LLM 中的长上下文**:`@chad_in_the_house` 指出 **attention sinks** 是一种处理 LLM 长上下文的有趣技术,并引用了 thomwolf 的合作者 `<@274244546605613056>` 在 HuggingFace 博客上发表的文章,链接见 [此处](https://huggingface.co/blog/tomaarsen/attention-sinks)。
- **视频理解的最前沿技术 (SOTA)**:`@chad_in_the_house` 推荐了一个视频理解技术的 Benchmark,强调 VideoChat2 是领先的竞争者,并提供了 [源代码链接](https://github.com/OpenGVLab/Ask-Anything/blob/main/video_chat2/MVBENCH.md) 以供进一步探索。
- **Consistency Distillation 与 Diffusers 的潜力**:`@riteshrm` 询问了尽管 Diffusers 库中已有相关功能,是否还有 Consistency Models 的独立脚本,从而引发了关于实际实现的进一步讨论。
**提到的链接**:
- [[Deleted Topic] | Kaggle](https://www.kaggle.com/discussions/questions-and-answers/483264):[已删除话题]。
- [Ask-Anything/video_chat2/MVBENCH.md at main · OpenGVLab/Ask-Anything](https://github.com/OpenGVLab/Ask-Anything/blob/main/video_chat2/MVBENCH.md):[CVPR2024][VideoChatGPT] 具备视频理解能力的 ChatGPT!以及更多支持的 LM,如 miniGPT4, StableLM 和 MOSS。- OpenGVLab/Ask-Anything
- [Gemini supports 1M+ tokens and 20x cheaper than GPT4 😮 ~ Unlock ideas from the technical paper](https://youtu.be/IuehDA1M_Lw):这是一个对比 Gemini, Claude Opus 和 GPT-4 Turbo 的快速总结,旨在发现为什么你应该关注 Gemini 1.5 Pro ♦️ 关于速度 💨 ~ 仅需 1 秒...
- [wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42):通过在 GitHub 上创建账户为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
- [GitHub - AnswerDotAI/fsdp_qlora: Training LLMs with QLoRA + FSDP](https://t.co/qcyEa7EGGY):使用 QLoRA + FSDP 训练 LLM。通过在 GitHub 上创建账户为 AnswerDotAI/fsdp_qlora 的开发做出贡献。
---
### HuggingFace ▷ #[diffusion-discussions](https://discord.com/channels/879548962464493619/1009713274113245215/1215914120600227892) (7 条消息):
- **寻求 Mistral 的最佳设置**:`@elmatero6` 征求关于主要在 CPU 上运行 **Mistral** 以避免蓝屏的建议,其系统配置包括 Intel Core I5-9300H, 32GB DDR4 RAM 和 Nvidia Geforce GTX 1650。
- **消息发送过快**:`@HuggingMod` 提醒 `@1097592228714659912` 放慢消息发送速度,指出 **diffusion-discussions** 频道可能出现了刷屏。
- **聊天机器人部署的扩展难题**:`@rajveerrathod` 询问了如何扩展一个能够在 Google Cloud GPU 上使用 **LLama 7b** 和 **Mistral 7b** 同时处理 15-20 个查询的企业级聊天机器人应用,目前在并发用户增加时会遇到崩溃。
- **寻找最优秀的图像字幕模型**:`@ninamani` 寻求关于精确且无审查的“Image to text”字幕生成(Captioning)的最佳开源模型推荐,`@chad_in_the_house` 建议使用 **cogvlm**,但指出模型在 4 bit Quantization 时会变得不稳定。
- **Wav2Vec2 脚本使用指导请求**:`@210924_aniketlrs02` 请求帮助如何使用 [特定的 GitHub 脚本](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42) 从 Wav2Vec2 模型中提取 Quantized States,因为他们是机器学习领域的新手。
**提到的链接**:
[wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42):通过在 GitHub 上创建账户为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
---
### HuggingFace ▷ #[computer-vision](https://discord.com/channels/879548962464493619/922424143113232404/1215593282059509760) (41 messages🔥):
- **YOLOv4 商业用途澄清**:用户 `@toni_alright` 告知 **YOLOv4** 许可证对商业友好;`@prod.dopamine` 回复称正在寻找一种像 Ultralytics 一样易于使用但适用于商业应用的实现方式。
- **TensorFlow ImportError 故障排除**:`@crown_16` 遇到了 TensorFlow 的 `ImportError`;`@cursorop` 建议在 Google Colab 中测试代码,如果在那里运行成功,则考虑重新安装 TensorFlow。
- **GANs 及其他领域的学习路径**:在 `@noir_bd` 表达了从 GANs 开始学习的兴趣后,包括 `_homoludens` 和 `@mikonvergence` 在内的多位用户提供了资源,并建议采用一种更全面的方法,同时也包含 Diffusion models、VAEs 等。分享了 [Coursera](https://www.coursera.org/specializations/generative-adversarial-networks-gans) 上的课程链接、[Diffusion models 的 GitHub 仓库](https://github.com/mikonvergence/DiffusionFastForward) 以及 [Jakub Tomczak](https://github.com/jmtomczak/intro_dgm) 的生成模型通用课程。
- **Fast.ai 课程推荐**:`_homoludens` 分享了一个[免费课程链接](https://course.fast.ai),涵盖了深度学习的实际应用,第二部分包含 Diffusion models 和 Hugging Face 的 Diffusers 库。
- **Stable Diffusion 的 Inpainting 功能问题**:`@okan1962` 询问了在使用 HuggingFace 的推理 API 时,Stable Diffusion 的 Inpainting 和 Image Variations 功能的可用性及文档,并指出缺乏明确信息且模型端点已关闭。
**提到的链接**:
- [Practical Deep Learning for Coders - Practical Deep Learning](https://course.fast.ai):一门为有一定编程经验、想学习如何将深度学习和机器学习应用于实际问题的人设计的免费课程。
- [Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/abs/2105.05233):我们展示了 Diffusion models 可以实现优于当前最先进生成模型的图像样本质量。我们通过寻找更好的架构,在无条件图像合成上实现了这一目标...
- [GitHub: Let’s build from here](https://github.com/):GitHub 是超过 1 亿开发者共同塑造软件未来的地方。为开源社区做贡献,管理你的 Git 仓库,像专业人士一样审查代码,跟踪错误和功能...
- [GitHub - jmtomczak/intro_dgm: "Deep Generative Modeling": Introductory Examples](https://github.com/jmtomczak/intro_dgm):"Deep Generative Modeling":入门示例。通过在 GitHub 上创建账号为 jmtomczak/intro_dgm 的开发做贡献。
- [GitHub - mikonvergence/DiffusionFastForward: DiffusionFastForward: a free course and experimental framework for diffusion-based generative models](https://github.com/mikonvergence/DiffusionFastForward):DiffusionFastForward:一个关于基于扩散的生成模型的免费课程和实验框架。
- [Generative Adversarial Networks (GANs)](https://www.coursera.org/specializations/generative-adversarial-networks-gans):由 DeepLearning.AI 提供。进入 GANs 领域。通过三门实战课程掌握尖端的 GANs 技术!免费报名。
---
### HuggingFace ▷ #[NLP](https://discord.com/channels/879548962464493619/922424173916196955/1215682006911033354) (38 条消息🔥):
- **trl 导入问题**:用户 `@solanao64` 在尝试从 `trl` 导入 `SFTTrainer` 和 `DPOTrainer` 时遇到 `ImportError`,原因是 `transformers` 中的 `topktop_p_filtering` 存在问题。
- **基于 Deberta 的分类器示例**:`@darwinanim8or` 分享了一个使用 `Deberta-based` 分类器的示例,并提供了一个[使用 HuggingFace pipeline 进行文本分类的代码片段](https://github.com)。
- **微调 Mistral 7B**:`@plbjt` 询问了如何使用 GPT-4 格式的提示词针对特定任务微调 `Mistral 7B`,引发了关于模型对复杂任务适用性的讨论。
- **BERT 的 C++ 部署**:`@smartguy_41719` 正在寻求在 C++ 环境中部署训练好的 BERT 模型进行推理的指导,`@merve3234` 建议使用 ONNX Runtime 和 Hugging Face 的 Optimum。
- **用于翻译任务的 LLMs**:`@ninamani` 征求关于 NSFW 未过滤翻译任务的优化且准确的模型建议,要求比旧模型或过大的 LLMs 提供更高的精度。
**提到的链接**:
- [PyTorch: Fine Tuning GPT2 For QuestionAnswering](https://www.kaggle.com/code/dsmeena/pytorch-fine-tuning-gpt2-for-questionanswering):使用 Kaggle Notebooks 探索并运行机器学习代码 | 使用来自无附加数据源的数据
- [Overview](https://huggingface.co/docs/optimum/onnxruntime/overview):未找到描述
- [wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42):通过在 GitHub 上创建账号来为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
- [GitHub - huggingface/lighteval: LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron.](https://github.com/huggingface/lighteval?):LightEval 是一个轻量级的 LLM 评估套件,Hugging Face 内部一直在将其与最近发布的 LLM 数据处理库 datatrove 和 LLM 训练库 nanotron 配合使用。
---
### HuggingFace ▷ #[diffusion-discussions](https://discord.com/channels/879548962464493619/1009713274113245215/1215914120600227892) (7 条消息):
- **Mistral 优先使用 CPU 而非 GPU**:用户 `@elmatero6` 寻求在 CPU 上高效运行 **Mistral** 的建议,考虑到其系统配置(Intel Core i5, 32GB RAM, Nvidia GTX 1650)以避免电脑蓝屏,表现出相比 GPU 更倾向于利用 RAM 的意愿。
- **快速发帖者收到提醒**:`@HuggingMod` 委婉地提醒 `@elmatero6` 在聊天中放慢发帖速度。
- **企业级聊天机器人扩缩容**:`@rajveerrathod` 正在使用 **LLama 7b 和 Mistral 7b** 开发客户成功聊天机器人;然而,该应用在 Google Cloud 的 GPU 上并发使用时会崩溃。他们正在寻求扩展方案,以便在模型量化为 4 bit 和 8 bit 的情况下同时处理 20 个用户。
- **高质量图像字幕模型**:用户 `@ninamani` 询问了关于精确的未过滤图像转文本或图像字幕模型的最佳开源选择。`@chad_in_the_house` 推荐了 **cogvlm** 并指出其在 8 bit 量化下表现稳定。
- **新手请求 Wav2Vec2 指导**:`@210924_aniketlrs02` 请求协助使用一个 [GitHub 脚本](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42) 来提取 Wav2Vec2 模型的量化状态,并表示自己是机器学习领域的新手。
**提到的链接**:
[wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices](https://github.com/fauxneticien/wav2vec2-codebook-indices/blob/master/scripts/helpers/w2v2_codebook.py#L42):通过在 GitHub 上创建账号来为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
---
### Eleuther ▷ #[general](https://discord.com/channels/729741769192767510/729741769738158194/1215676466973376553) (101 messages🔥🔥):
- **为初学者提供热烈欢迎与指引**:`@shida3916` 表达了加入社区讨论日常 AI 和提问简单问题的兴奋之情。`@stellaathena` 考虑到该服务器侧重于研究层面,将他们引导至其他服务器。
- **LLM 寻找归宿,但空无一人**:`@faron1111` 引发了一场关于 LLM 内部自我意识概念的深度讨论,特别是关于自我保存机制。`@wonkothesensible` 认为,虽然模型可能具有隐含的 agency 概念,但它们缺乏任何可占据的意识归宿。
- **LLM 中的持久状态与 AGI 潜力**:关于 LLM 的讨论继续聚焦于潜在 AGI 的架构,包括 `@wonkothesensible` [发布的链接](https://arxiv.org/abs/2402.17764)中提到的 1-bit 变体。辩论涉及 LLM 内部高级规划和意识的需求,暗示在达到 AGI 之前需要必要的突破。
- **关于训练小模型的讨论**:`@biiter` 询问了在有限 VRAM 上有效预训练模型的策略,并讨论了 AliBi embedding 的潜在问题。`@hailey_schoelkopf` 解决了该技术问题并同意提供修复方案。
- **AI 灭绝级担忧**:`@conceptron` 分享了一篇 [Slashdot 文章](https://yro.slashdot.org/story/24/03/11/185217/us-must-move-decisively-to-avert-extinction-level-threat-from-ai-govt-commissioned-report-say),报道了美国政府对前沿 AI 构成人类灭绝级威胁的担忧,建议采取监管措施,如限制 model weights 的发布。
**提到的链接**:
- [US Must Move 'Decisively' To Avert 'Extinction-Level' Threat From AI, Gov't-Commissioned Report Says - Slashdot](https://yro.slashdot.org/story/24/03/11/185217/us-must-move-decisively-to-avert-extinction-level-threat-from-ai-govt-commissioned-report-say):美国政府必须“迅速且果断”地行动,以规避源自人工智能 (AI) 的重大国家安全风险,在最坏的情况下,这可能导致“灭绝...”
- [The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits](https://arxiv.org/abs/2402.17764):最近的研究(如 BitNet)正在为 1-bit Large Language Models (LLM) 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数...
- [The orthogonality thesis & AI optimism](https://youtu.be/8H3dblxkLhY):时间戳:0:00 - 视频开始 7:39 - Bostrom 论点的概述 9:25 - 决定性的战略优势 13:26 - 慢速起飞的论据 23:13 - 定义...
---
### Eleuther ▷ #[research](https://discord.com/channels/729741769192767510/747850033994662000/1215572558150377512) (75 messages🔥🔥):
- **探索图像扩散的高效注意力机制**:`@nostalgiahurts` 讨论了 [arXiv 上的一篇论文](https://arxiv.org/abs/2402.13573),该论文提出了一种名为 **ToDo** 的新方法,通过采用 token downsampling 来加速 Stable Diffusion 推理,速度提升可达 2 倍至 4.5 倍。对话中包含了一个[相关仓库](https://github.com/ethansmith2000/ImprovedTokenMerge)的 GitHub 链接。
- **Few-Shot 与 Zero-Shot 性能异常**:`@paganpegasus` 注意到一个有趣的现象,在 MMLU 基准测试中,他们测试的多个模型的 zero-shot 性能与 few-shot 性能相当甚至更好。讨论了几种假设,包括额外 context 可能对较小模型产生干扰,以及测试不同 shot 数量下的性能。
- **光学数字计算的前沿**:`@ai_waifu` 提到的论文探讨了全光学数字计算和存储器的潜力([arXiv 摘要链接](https://arxiv.org/abs/2403.00045v1))。简要讨论了半导体、电子通信效率低下以及该论文对制造业的影响等话题。
- **Gemini 1.5 报告概览**:`@xylthixlm` 指出 Gemini 1.5 报告已发布,但没有实质性的技术细节([arXiv 报告链接](http://arxiv.org/abs/2403.05530))。`@main.ai` 随后提供了对报告中新内容的见解。
- **Yi 技术报告的双重 Wikipedia 过滤方法**:`@maxmatical` 提出了一个关于 Yi 技术报告中有效过滤 Wikipedia 内容两次的方法的问题([arXiv 摘要链接](https://arxiv.org/abs/2403.04652))。`@thedeviouspanda` 建议这可能类似于 ranking pipelines 中使用轻量级和重量级排序器,每一步都进行更深度的过滤。
**提到的链接**:
- [斯坦福大学 Fan Group - 软件](https://web.stanford.edu/group/fan/software.html):未找到描述
- [DenseMamba: 具有稠密隐藏连接的状态空间模型,用于高效大语言模型](https://arxiv.org/abs/2403.00818):由于常用的 Transformer 架构对计算和内存的极高要求,大语言模型 (LLMs) 面临着严峻挑战。虽然状态空间模型 (SSM) 是一种新兴的...
- [Stacking 作为加速梯度下降](https://arxiv.org/abs/2403.04978):Stacking 是一种训练深度残差网络的启发式技术,通过逐渐增加层数并通复制旧层参数来初始化新层,已被证明相当...
- [Yi: 零一万物开源基座模型](https://arxiv.org/abs/2403.04652):我们介绍了 Yi 模型家族,这是一系列展现出强大多维度能力的语言和多模态模型。Yi 模型家族基于 6B 和 34B 预训练语言模型...
- [全光通用 CPU 与光计算机架构](https://arxiv.org/abs/2403.00045v1):电子数字处理器的能效主要受限于电子通信和互连的能耗。业界几乎一致倾向于替换...
- [Gemini 1.5: 解锁数百万 token 上下文的多模态理解](http://arxiv.org/abs/2403.05530):在本报告中,我们介绍了 Gemini 家族的最新模型 Gemini 1.5 Pro,这是一款计算效率极高的多模态 Mixture-of-Experts 模型,能够对细粒度信息进行检索和推理...
- [一般 KL 正则化偏好下人类反馈纳什学习的理论分析](http://arxiv.org/abs/2402.07314):人类反馈强化学习 (RLHF) 从概率偏好模型提供的偏好信号中学习,该模型将 prompt 和两个回答作为输入,并生成一个分数...
- [通过步骤感知验证器提升大语言模型的推理能力](https://arxiv.org/abs/2206.02336):Few-shot learning 是一项具有挑战性的任务,要求语言模型从有限的示例中进行泛化。像 GPT-3 和 PaLM 这样的大语言模型在这一领域取得了显著进展,但...
- [ToDo: 用于高效生成高分辨率图像的 Token 下采样](https://arxiv.org/abs/2402.13573):Attention 机制对图像扩散模型至关重要,然而,其二次方计算复杂度限制了我们在合理的内存和时间约束下处理图像的尺寸...
- [Pretrained-Language-Model/CAME/came.py at master · huawei-noah/Pretrained-Language-Model](https://github.com/huawei-noah/Pretrained-Language-Model/blob/master/CAME/came.py):由华为诺亚方舟实验室开发的预训练语言模型及其相关优化技术。- huawei-noah/Pretrained-Language-Model
- [CAME: 置信度引导的自适应内存高效优化](https://arxiv.org/abs/2307.02047):自适应梯度方法(如 Adam 和 LAMB)在大语言模型训练中表现出了卓越的性能。尽管如此,自适应性的需求要求维护二阶矩...
---
### Eleuther ▷ #[interpretability-general](https://discord.com/channels/729741769192767510/1052314805576400977/1216064284036169768) (3 条消息):
- **新手寻求可解释性见解**:用户 `@xcodevn` 表达了对开始可解释性 (interpretability) 研究的兴趣,并请求推荐资源。
- **分享有用资源**:作为回应,`@wendlerc` 分享了 ARENA 3.0 落地页的链接,[mango-ambulance-93a.notion.site](https://mango-ambulance-93a.notion.site/ARENA-3-0-Landing-Page-virtual-8f7193af31b445c586efed03e995fb74),并称其为该领域爱好者的“宝藏”。
**提到的链接**:
[Notion – 集笔记、任务、维基和数据库于一体的工作空间。](https://mango-ambulance-93a.notion.site/ARENA-3-0-Landing-Page-virtual-8f7193af31b445c586efed03e995fb74):一款将日常工作应用融合为一的新工具。它是为您和您的团队打造的一体化工作空间。
---
### Eleuther ▷ #[lm-thunderdome](https://discord.com/channels/729741769192767510/755950983669874798/1215644760954634270) (12 messages🔥):
- **关于模型 BOS token 使用的查询**:`@jwngx` 询问了使用 **BOS (Beginning of Sentence) token** 的标准,以及它在不同 repo 中应用不一致的问题。`@stellaathena` 确认其使用取决于模型,目前还没有统一的资源详细说明哪些模型在使用它时表现更好。
- **寻求 BOS Token 见解**:`@jwngx` 询问是否有关于模型在 BOS token 下表现的文档,但 `@hailey_schoelkopf` 指出此类细节通常是内部的且取决于模型;Gemma 在 BOS token 上的奇特行为是前所未有的。
- **为 BOS Token 调整 HFLM 解码**:鉴于一个为 Gemma 添加 BOS token 标志的 commit,`@jwngx` 分享了 [HFLM 代码链接](https://github.com/EleutherAI/lm-evaluation-harness/blob/main/lm_eval/models/huggingface.py#L716) 并询问解码是否应考虑 `self.add_bos_token` 设置。`@hailey_schoelkopf` 澄清说 `tok_decode` 应该只在不含 BOS token 的后续文本或输入文本上调用,并认为当前的实现是正确的。
**提到的链接**:
[lm-evaluation-harness/lm_eval/models/huggingface.py at main · EleutherAI/lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness/blob/main/lm_eval/models/huggingface.py#L716):一个用于语言模型 few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
---
### Eleuther ▷ #[multimodal-general](https://discord.com/channels/729741769192767510/795089627089862656/1215686529695883364) (2 messages):
- **热烈欢迎社区新成员**:用户 `@shida3916` 表达了加入社区讨论 AI 日常用途并提出简单问题的兴奋之情。他们询问这里是否是进行此类讨论的合适场所。
- **澄清 Transformer 和 Diffusion 概念**:`@yoavhacohen` 提供了解释,指出 **"Transformer 是一种架构,而 diffusion 是一种训练和推理方法。"** 他们还提到在 SD3 之前,diffusion 就已经与 transformers 结合使用,并引用了 DALL-E 2、DiT 和 PixArt 等几个例子。
---
### Eleuther ▷ #[gpt-neox-dev](https://discord.com/channels/729741769192767510/730090096287547444/1215557258386079744) (75 messages🔥🔥):
- **Torch 容器模糊性**:`@catboy_slim_` 强调文档中关于 torch 开发容器中使用的是哪个 commit 的 apex 说明不清晰,建议设置可以更加直接。
- **依赖管理挑战**:包括 `@catboy_slim_`、`@tfidia` 和 `@hailey_schoelkopf` 在内的多位用户讨论了 GPT-NeoX 项目中管理依赖的困难,提到了默认 NGC 容器可能包含必要和多余包所带来的复杂性。
- **Flash Attention 依赖**:`@hailey_schoelkopf` 澄清说 Triton 同时用于 sparse 和 flash attention,小组还讨论了 Flash attention 更新到 2.5.6 可能会如何影响与 NGC PyTorch 容器的兼容性。
- **对 Apex 使用的质疑**:包括 `@biiter` 和 `@catboy_slim_` 在内的用户辩论了 Apex 的必要性,因为除了 `fusedAdam` 等特定功能外,它的某些功能现在可能已经内置于 PyTorch 中。
- **评估与转换查询**:`@tejas.inferq` 寻求关于已训练的 125M 参数 GPT-NeoX 模型评估过程的帮助,而 `@aphoh` 询问如何将 Pythia/NeoX checkpoint 转换为上游 megatron-lm,并面临权重布局和 loss 匹配的问题。
**提到的链接**:
- [Cleaner dockerfile: Remove already installed deps by tf-nv · Pull Request #1175 · EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox/pull/1175/files):在切换到 ngc pytorch 后的 Dockerfile 清理 (#1170):消除已安装的 apt 包,sparse attn 需求导致 triton 降级,flash attn 已经是 ngc 的一部分...
- [PyTorch Release 24.02 - NVIDIA Docs](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-24-02.html#rel-24-02):无描述
- [PyTorch Release 24.02 - NVIDIA Docs](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-24-02.html):无描述
---
### Latent Space ▷ #[ai-general-chat](https://discord.com/channels/822583790773862470/1075282825051385876/1215570094059429958) (39 messages🔥):
- **AI Biographer 试用与隐私担忧**:`@swyxio` 一直在试用 [Emma, the AI Biographer](https://getlifestory.com/),并认为其通话体验足以推荐至少尝试一次。然而,他们通过提到自己使用*虚假姓名和虚假传记细节*,提醒用户注意潜在的安全问题。
- **OpenAI 风波落幕**:`@guardiang` 分享了一篇 [《纽约时报》文章](https://www.nytimes.com/2024/03/07/technology/openai-executives-role-in-sam-altman-ouster.html),详细介绍了 OpenAI 的内部问题。OpenAI 董事会已完成对解雇事件的审查,信心十足地恢复了 Sam Altman 的职务,并宣布增加三名新董事会成员,详见 [OpenAI 的公告](https://openai.com/blog/review-completed-altman-brockman-to-continue-to-lead-openai)。
- **Ideogram 1.0 低调发布**:`@swyxio` 提到,尽管 [Ideogram 1.0](https://x.com/ideogram_ai/status/1762881284899008564?s=20) 这种新的文本渲染方法具有潜力,但其发布并未引起太多关注。
- **Microsoft Research 开发 LLM 接口**:`@swizec` 提到了一篇 [Hacker News 帖子](https://news.ycombinator.com/item?id=39670665),讨论了 AICI。这是 Microsoft Research 提出的一种接口,旨在标准化各种 LLM 推理引擎的约束和控制机制,并正在为 Rust AICI 运行时寻求反馈。
- **超越 Transformer 的转型一瞥**:`@swyxio` 讨论了 "Mamba",这是一种 State Space Model,被认为是 LLM 中 Transformer 架构的潜在替代方案。他们为有兴趣了解该架构的人推荐了一份 [视觉指南](https://maartengrootendorst.substack.com/p/a-visual-guide-to-mamba-and-state) 和原始 [研究论文](https://arxiv.org/abs/2312.00752)。
**提到的链接**:
- [未找到标题](https://news.ycombinator.com/item?id=39482428): 未找到描述
- [未找到标题](https://news.ycombinator.com/item?id=39643894): 未找到描述
- [Show HN: 将 Prompts 作为 WASM 程序 | Hacker News](https://news.ycombinator.com/item?id=39670665): 未找到描述
- [OpenAI (@OpenAI) 的推文](https://x.com/openai/status/1766235980170706967?s=46&t=6FDPaNxZcbSsELal6Sv7Ug): “我们一致认为 Sam 和 Greg 是 OpenAI 的合适领导者。” —— OpenAI 董事会主席 Bret Taylor。OpenAI 董事会特别委员会宣布已完成...
- [加入 Slido:输入 #code 进行投票和提问](https://app.sli.do/event/bNV6mo3BFGhe8Bqzb1tonb/live/questions): 参与实时投票、测验或问答。无需登录。
- [审查完成,Altman 和 Brockman 将继续领导 OpenAI](https://openai.com/blog/review-completed-altman-brockman-to-continue-to-lead-openai): 命名了新的董事会成员,并介绍了治理结构的增强措施。
- [OpenAI 宣布新董事会成员](https://openai.com/blog/openai-announces-new-members-to-board-of-directors): Sue Desmond-Hellmann 博士、Nicole Seligman、Fidji Simo 加入;Sam Altman 重返董事会。
- [哪种量化方法适合你?(GPTQ vs. GGUF vs. AWQ)](https://maartengrootendorst.substack.com/p/which-quantization-method-is-right): 探索预量化的大语言模型 (Large Language Models)。
- [Corry Wang (@corry_wang) 的推文](https://x.com/corry_wang/status/1766949316394897851?s=20): 等等,Amazon 刚刚透露他们完成了一个 200B 参数 LLM 的训练……而没人注意到。这是来自高级副总裁 James Hamilton 在 CIDR 2024 上的演讲。训练算力是 Facebook 的 5 倍...
- [Life Story](https://getlifestory.com/): 捕捉生活,一次一个故事。
- [Ideogram (@ideogram_ai) 的推文](https://x.com/ideogram_ai/status/1762881284899008564?s=20): Ideogram 1.0 在文本渲染准确性方面实现了飞跃。用 Ideogram 释放你想象力的风味!Prompt:“一张充满活力且色彩丰富的 ‘Ideogram’ 汉堡广告...”
- [Mira Murati (@miramurati) 的推文](https://x.com/miramurati/status/1766247920242929913?s=46&t=6FDPaNxZcbSsELal6Sv7Ug): 机构的治理对于监督、稳定和连续性至关重要。我很高兴独立审查已经结束,我们大家可以团结一致向前迈进。令人沮丧的是...
- [Mamba 和状态空间模型 (State Space Models) 视觉指南](https://maartengrootendorst.substack.com/p/a-visual-guide-to-mamba-and-state): 语言建模中 Transformer 的替代方案。
- [cohere (@cohere) 的推文](https://x.com/cohere/status/1767275128813928611?s=46&t=6FDPaNxZcbSsELal6Sv7Ug): 今天,我们很高兴发布 Command-R,这是一款针对大规模生产工作负载优化的新型 RAG LLM。Command-R 属于新兴的“可扩展”模型类别,平衡了高效率...
- [Sam Altman (@sama) 的推文](https://x.com/sama/status/1766291001134715207?s=46&t=90xQ8sGy63D2OtiaoGJuww): 我非常高兴欢迎我们的新董事会成员:Fidji Simo、Sue Desmond-Hellmann 和 Nicole Seligman,并继续与 Bret、Larry 和 Adam 合作。我感谢我们团队中的每一个人...
- [Teknium (e/λ) (@Teknium1) 的推文](https://x.com/teknium1/status/1766721588244918774?s=46&t=90xQ8sGy63D2OtiaoGJuww): 任何在做 Llama.cpp 的人能看看我们的 PR 吗:https://github.com/ggerganov/llama.cpp/pull/5970
- [swyx (@swyx) 的推文](https://x.com/swyx/status/1765995892107317407?s=20): 我现在已经和 AI 治疗师进行了多次超过 20 分钟的电话交谈,感觉非常自然。每个 AI Engineer 现在都应该构建自己的治疗师,而语音是正确的媒介。
---
### Latent Space ▷ #[ai-announcements](https://discord.com/channels/822583790773862470/1075282504648511499/1215596118767964201) (5 条消息):
- **Asia Gets Schooled on GPT-2**: `@ivanleomk` 宣布了一场关于 GPT-2 论文的演示,敦促 **Asia** `@paper-club` 的成员加入。这场被誉为 **EPIC**(史诗级)的活动定于 [https://discord.gg/8sYsGc83](https://discord.gg/8sYsGc83) 举行。
- **Weekend Podcast Drop Teaser**: `@swyxio` 发布了关于周末播客发布的预告。**Latent Space pod** 涵盖了 1 月和 2 月的回顾,可以在[这里](https://x.com/latentspacepod/status/1766600314419806350?s=20)收听。
- **Paper Enthusiast Laments Timezone Woes**: `@420gunna` 对 `@paper-club` 的论文选择表示赞赏,但幽默地提到忘记为凌晨 2 点的会议设置闹钟。这展现了他们在参与社区时热情与时区困扰交织的状态。
**提到的链接**:
- [Discord - A New Way to Chat with Friends & Communities](https://discord.gg/8sYsGc83): Discord 是通过语音、视频和文字进行交流的最简单方式。与你的朋友和社区聊天、聚会并保持紧密联系。
- [Tweet from Latent Space Podcast (@latentspacepod)](https://x.com/latentspacepod/status/1766600314419806350?s=20): 🆕 周末播客:1月+2月回顾 + Latent Space 一周年!https://latent.space/p/jan-feb-2024-recap-audio 我们 2023 年的回顾播客非常受欢迎,所以这是这个新研究系列的下一集……
---
### Latent Space ▷ #[llm-paper-club-west](https://discord.com/channels/822583790773862470/1197350122112168006/1215598769534533675) (30 条消息🔥):
- **Prep for LLM Paper Club Discussion**: `@ivanleomk` 分享了[笔记](https://www.gaohongnan.com/transformer/decoder/concept.html),为 `@1123457263638683770` 在即将到来的俱乐部讨论中的分享做准备,重点关注 Generative Pre-trained Transformers (GPT)。
- **Starting Time Updates**: `@ivanleomk` 多次更新了会议开始时间,表示将在 5-10 分钟内开始,随后又发消息称 5 分钟后开始。
- **Community Support for Newcomers**: `@healthymonkey` 表示自己是 NLP 领域的新人,寻求对任何潜在错误的指正,`@bryanblackbee` 提供了支持和鼓励。
- **Technical Clarifications in Real Time**: `@kishore.reddy` 澄清了 `@1123457263638683770` 使用的术语,例如 "causal attention",并在直播讨论中纠正了对 "-inf" 的引用。
- **LLM Visualization Tools Shared**: `@fx2y` 提供了一个 GPT 系列模型的[可视化工具链接](https://bbycroft.net/llm),并对 `@1123457263638683770` 的工作表示赞赏。
**提到的链接**:
- [LLM Visualization](https://bbycroft.net/llm): 未找到描述
- [The Concept of Generative Pre-trained Transformers (GPT) — Omniverse](https://www.gaohongnan.com/transformer/decoder/concept.html): 未找到描述
- [The Implementation of Generative Pre-trained Transformers (GPT) — Omniverse](https://www.gaohongnan.com/transformer/decoder/implementation.html): 未找到描述
---
### Latent Space ▷ #[ai-in-action-club](https://discord.com/channels/822583790773862470/1200548371715342479/1215766430230774022) (162 条消息🔥🔥):
- **关于使用 AI 优化工作流的讨论**:`@kbal11` 介绍了由 `@363877777977376768` 主持的 AI-in-Action 会议,重点讨论如何使用 AI 改进工作流。`@yikesawjeez` 等参与者对该话题表现出极大的热情,其他人也分享了通过 AI 增强产出的见解和技巧。
- **Meta Prompts 与 CLI 工具的突破**:`@yikesawjeez` 强调了使用 AI 创建 Prompt 以引导产生更好输出的方法,并表现出在 AWS 上部署项目的兴趣。社区成员分享并讨论了能够辅助这些工作的 AI 驱动工具资源。
- **AI 工作流中记录文档的重要性**:讨论转向了记录工作和编写详细笔记的最佳实践。`@slono` 分享了使用 `asciinema` 录制终端会话的经验,而 `@yikesawjeez` 等人则承诺分享他们使用的开源工具。
- **社区参与与分享**:频道成员积极分享在个人工作流中改进 AI 使用的技巧、工具和秘诀。`@yikesawjeez` 和 `@markredito` 等用户对 AI 领域的协作学习和知识众包表达了兴奋之情。
- **关于未来去中心化/分布式 AI 会议的请求**:在讨论工作流和工具之余,`@yikesawjeez` 提议未来举办一个关于去中心化和分布式 AI 应用的主题会议,重点关注非加密货币类的项目。
**提到的链接**:
- [Genius](https://1906.shop/products/genius):通过这款专为提高专注力而开发的唯一食用产品来激发你的天赋。结合了红景天、可可碱、高良姜、假马齿苋、L-茶氨酸与大麻的植物药物组合,促进认知...
- [Getting started - asciinema docs](https://docs.asciinema.org/getting-started/):未找到描述
- [AI-enhanced development makes me more ambitious with my projects](https://simonwillison.net/2023/Mar/27/ai-enhanced-development/):在这个奇妙的新型 AI 增强现实中,最令我兴奋的是它让我对自己的项目更有野心。作为一名经验丰富的开发者,ChatGPT ...
- [AI In Action: Weekly Jam Sessions](https://docs.google.com/spreadsheets/d/1q5rwO4wleMTLXr1z58c2UC03QsDsGwbJY1v4UG7eEOs/edit#gid=0):2024 主题、日期、主持人、资源。GenAI 的 UI/UX 模式,2024/1/26,nuvic,<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-structure</a&...
- [GitHub - JoinTheAlliance/bgent: Flexible, scalable and customizable agents to do your bidding.](https://github.com/JoinTheAlliance/bgent):灵活、可扩展且可定制的 Agent,听候您的差遣。- JoinTheAlliance/bgent
- [GitHub - bazed-ai/bazed-af: 😎 Bazed.ai Agent Framework - Bazed.ai is a unified platform for building, running and scaling autonomous agents.](https://github.com/bazed-ai/bazed-af):😎 Bazed.ai Agent 框架 - Bazed.ai 是一个用于构建、运行和扩展自主 Agent 的统一平台。- bazed-ai/bazed-af
---
### Interconnects (Nathan Lambert) ▷ #[announcements](https://discord.com/channels/1179127597926469703/1179127598442348726/1216536442361348116) (1 条消息):
- **用于更好区分的新角色**:`@natolambert` 在 Discord 中启用了**新角色**,以区分手动添加的亲密朋友和订阅者。欢迎对此次更新提供反馈。
---
### Interconnects (Nathan Lambert) ▷ #[news](https://discord.com/channels/1179127597926469703/1179128538679488533/1216681631570595890) (51 messages🔥):
- **Elon Musk 的 Grok 预告引发辩论**:`@xeophon.` 分享了 [Elon Musk 的推文](https://x.com/elonmusk/status/1767108624038449405?s=46),宣布 `@xAI` 将 Open Source Grok,而 `@natolambert` 质疑了 Musk 对 "Open Source" 一词的准确使用。
- **Cohere 推出 Command-R**:`@xeophon.` 强调了 [Command-R](https://txt.cohere.com/command-r/) 的发布,这是 Cohere 推出的一种新型 Retrieval Augmented 模型,以其 128k Context Window 和为研究目的公开发布的 Weights 而闻名。
- **对 Open Models 的期待**:`@xeophon.` 和 `@natolambert` 讨论了 Cohere 的 Command-R 的潜力,特别是对于初创公司、学术界及其在多种欧洲语言中的可用性,以及它在 "llama3" 等未来模型的炒作之外的重要性。
- **市场对 Elon 声明的反应**:`@natolambert` 表示人们可能对 Elon 的声明反应过度,在任何模型发布之前就过早地给予赞誉,而 `@eugenevinitsky` 将其与 Twitter 的 Open Source 举动进行了有趣的类比,但有一个转折:“有 Weights 无代码,而不是有代码无 Weights”。
- **质疑 OpenAI 对 Open Models 的承诺**:`@dangf91` 询问了 Mistral 的 Open Source 状态,`@xeophon.` 澄清说未来仍有对 Open Models 的承诺,`@natolambert` 补充说环境在不断变化。
**提到的链接**:
- [Xeophon (@TheXeophon) 的推文](https://x.com/thexeophon/status/1765797558696165645?s=46):GPT 5 tonite GPT 5 tonite queen
- [Elon Musk (@elonmusk) 的推文](https://x.com/elonmusk/status/1767108624038449405?s=46):本周,@xAI 将 Open Source Grok
- [Command-R: Retrieval Augmented Generation at Production Scale](https://txt.cohere.com/command-r/):Command-R 是一款可扩展的生成式模型,针对 RAG 和 Tool Use,旨在为企业实现生产级 AI。今天,我们推出 Command-R,这是一款针对大规模生产工作负载的新型 LLM...
---
### Interconnects (Nathan Lambert) ▷ #[other-papers](https://discord.com/channels/1179127597926469703/1179142630517518397/1216589316612952245) (2 messages):
- **GPT-4 挑战 Doom**:`@philpax` 分享了一篇论文,展示了 **GPT-4 玩 1993 年第一人称射击游戏 Doom 的能力**,利用其推理和规划能力,无需任何针对游戏的特定训练。该模型能够操作门、与敌人战斗并在游戏世界中导航,论文建议复杂的 Prompting 可以进一步增强其表现。在此处查找论文:[GPT-4 Plays Doom](https://arxiv.org/abs/2403.05468)。
- **博客文章征集**:`@natolambert` 对 GPT-4 玩 Doom 的论文标题做出了反应,暗示内容听起来足够有趣,值得一篇独立的 **Blog Post**。
**提到的链接**:
[Will GPT-4 Run DOOM?](https://arxiv.org/abs/2403.05468):我们展示了 GPT-4 的推理和规划能力扩展到了 1993 年的第一人称射击游戏 Doom。这款 Large Language Model (LLM) 仅需少量指令即可运行并进行游戏...
---
### Interconnects (Nathan Lambert) ▷ #[ml-questions](https://discord.com/channels/1179127597926469703/1179208129083363358/1216109634423885904) (36 messages🔥):
- **olmo/dolma 论文的截止日期澄清**:`@mike.lambert` 询问了 olmo/dolma 论文的数据范围,想知道在 2023 年 5 月之前的截止是否是有意为之。`@natolambert` 回应澄清说,截止日期是由于出版时间表,而不是为了避开 ChatGPT 时代,并提到了缺乏 Scraper 的问题。
- **GPT2 模型的廉价 Pretraining**:`@natolambert` 询问了目前 Pretraining 像 GPT2 这样模型的成本。`@xeophon.` 回复称价格 **低于 1,000 美元**,他认为这个估计“相当疯狂”。
- **Pretraining 成本和可行性**:`@xeophon.` 分享了 2022 年 9 月的训练成本细节、GPT-2 文档数量以及 Databricks 的 Pretraining 成本供参考。`@natolambert` 和 `@philpax` 讨论了现在训练模型的速度和廉价程度是多么令人惊讶,`@natolambert` 提到对于 Stability AI 的模型,他们 **支付的 Compute 费用可能不到 100,000 美元**。
- **关于 Stability AI Compute 交易的推测**:在关于成本的讨论中,`@xeophon.` 提到 Stability AI 可能获得了免费或折扣的 Compute,以换取使用 Gaudi2 并对其进行推广,正如他们的合作伙伴广告所暗示的那样。
- **Fine-Tuning 实践建议**:当 `@dangf91` 询问关于使用更多书籍/文章进行模型 Fine-Tuning 以及是否使用 Masking 策略时,`@natolambert` 和 `@vj256` 一致认为,将书籍添加到具有某些 Pretraining 混合数据的训练集中并继续训练是典型的做法。
---
### Interconnects (Nathan Lambert) ▷ #[ml-drama](https://discord.com/channels/1179127597926469703/1181746144821387334/1215601465838534686) (12 messages🔥):
- **关于 Inflection AI 模型的争议**:`@xeophon.` 转发了 `@seshubon` 的一条推文,质疑 Inflection AI 的聊天机器人是否仅仅是 Claude-3-Sonnet 的套壳(wrapper),因为两者对自定义查询的响应完全一致。Inflection AI 曾吹嘘其自研模型 Inflection-2.5 足以与 GPT-4 匹敌。[Inflection AI 的推文](https://fxtwitter.com/seshubon/status/1765870717844050221)。
- **Inflection 内部可能在进行 A/B Test?**:`@xeophon.` 推测观察到的现象可能是对比 Inflection-2.5 与 Claude Opus 的 A/B Test,因为两个模型针对冗长且具体的 Prompt 生成逐字匹配结果的可能性极低。
- **API Key 被撤销**:针对不断发酵的争议,`@natolambert` 幽默地评论说,某些人的 API Key 可能会被撤销。
- **注意到 Claude 的 Temperature 设置**:`@mike.lambert` 提到 claude.ai 的响应通常使用非零的 Temperature,这为正在进行的讨论提供了参考。
- **Inflection AI 澄清**:`@xeophon.` 分享了 Inflection AI 的一条澄清推文,解释称其聊天机器人 Pi 会记住之前的对话,之所以重复 Claude 的消息是因为该消息早先已被包含在对话中。随着对 Pi 的能力和独立性的质疑不断增加,情节变得更加扑朔迷离。[Inflection AI 的澄清](https://fxtwitter.com/inflectionai/status/1766173427441049684?s=46)。
- **对官方回复的谨慎建议**:当 `@xeophon.` 分享 Inflection AI 的回复时,`@natolambert` 建议永远不要用官方账号回复,暗示公司可能会遭遇负面后果。`@natolambert` 含蓄地确认了“fd”(即 f***ed)带来的麻烦。
**提到的链接**:
- [来自 Inflection AI (@inflectionAI) 的推文](https://fxtwitter.com/inflectionai/status/1766173427441049684?s=46):Pi 的响应始终由我们内部构建的自研模型生成。经调查,该用户在之前复制粘贴了 Claude 的输出后,诱导 Pi 产生了这一特定响应……
- [来自 seshu bonam (@seshubon) 的推文](https://fxtwitter.com/seshubon/status/1765870717844050221):什么?@inflectionAI 只是 claude-3-sonnet 的套壳吗?能解释一下吗?🐒 对于我提出的自定义查询,它产生了逐字完全相同的答案 🤯 ↘️ 引用 Inflection AI (@inflectionAI) P...
---
### Interconnects (Nathan Lambert) ▷ #[random](https://discord.com/channels/1179127597926469703/1183121795247779910/1215718929402695720) (19 messages🔥):
- **Lambert 集团扩张**:`@philpax` 开玩笑说 AI 实验室中 Lambert 家族成员越来越多,幽默地将他们的网络比作 **Lambert 秘密渠道(backchannels)**,而 `@420gunna` 则引用了 [菌根网络(mycorrhizal network)](https://en.wikipedia.org/wiki/Mycorrhizal_network) 的概念,将其比作地下通讯系统。
- **Sam Altman 重返 OpenAI 董事会**:`@xeophon.` 分享了一篇关于 **Sam Altman 重返 OpenAI 董事会** 的[新闻文章](https://www.theinformation.com/articles/sam-altman-to-return-to-openai-board-of-directors),`@420gunna` 引用了 Bret Taylor 的话,并借用 Civ4(文明4)文化胜利的梗为领导力话题增添了一丝幽默。
- **嘲讽自我审查式的领导力**:`@natolambert` 用一句戏谑的话嘲讽了领导层自我评估的想法:“*我进行了一次内部审查,决定我依然是国王*”。
- **加拿大鹅作为 Discord 仪式**:`@philpax` 幽默地思考需要多少只加拿大鹅才能完成“仪式”以获得 Discord 上的 Friend 角色,并称它们为可靠的象征;`@natolambert` 则承认这些鹅确实很吓人。
- **追求“鹅”角色**:`@natolambert` 提议在 Discord 上创建一个自荐的“鹅”角色,建议增加一个 **boost** 或图标使其显眼,因为订阅者角色的重要性正受到轻松的审视。
**提到的链接**:
[Mycorrhizal network - Wikipedia](https://en.wikipedia.org/wiki/Mycorrhizal_network):未找到描述
---
### Interconnects (Nathan Lambert) ▷ #[memes](https://discord.com/channels/1179127597926469703/1187551504995987576/1215722082491441233) (15 messages🔥):
- **用 AI 名人重塑《沙丘》角色**:`@420gunna` 发起了一个创意游戏,将 AI 领域的知名人物想象成《沙丘》中的角色,将 Sama 指定为 **Kwisatz Haderach**,Alec Radford 指定为 **Thufir Hawat**,还有其他几位,并留出了一些角色供大家建议。
- **为 AI 版《沙丘》的母系角色命名**:不久后,`@natolambert` 提议 **CTO** 绝对是 **Lady Jessica**,同时将 **Baron Harkonnen** 的角色分配给了 **Elon Musk**。
- **Yann Lecun 的大脑酱汁类比**:`@420gunna` 分享了一个关于 **Yann Lecun** 的古怪言论,提到他经常谈论自己的大脑随着年龄增长变成了“白酱(white sauce)”,并幽默地创造了 **Brain to Béchamel pipeline**(大脑到法式白汁流水线)一词。
- **《沙丘》关键角色的建议**:`@twkillian` 提出 Peter Thiel 作为 **Stilgar** 的候选人,但 `@natolambert` 表示反对,认为 **Marc Andreessen** 更适合这个角色。随后,他们开玩笑地将 **Gary Marcus** 比作《沙丘》后续书籍中出现的病态事物。
- **第一部之后《沙丘》的怪诞感**:随后讨论了是否值得阅读《沙丘》第一部之后的内容。虽然有人建议 `@twkillian` 读完第一部就停止,但 `@eugenevinitsky` 和 `@natolambert` 都认为**继续阅读该系列**是值得的,因为其怪诞之处非常引人入胜。
---
### Interconnects (Nathan Lambert) ▷ #[rl](https://discord.com/channels/1179127597926469703/1208183216843005962/1215600990321905725) (8 messages🔥):
- **强化学习(Reinforcement Learning)的探索**:用户 `@chygao` 分享了来自 Spotify 的[剧集链接](https://open.spotify.com/episode/0FuKEjteM0cGzy7pznCkAj?si=ds-7rY8yT0emOLgaV7rgcA&context=spotify%3A),其中 OpenAI 的 Ian Osband 讨论了**信息论与强化学习 (RL)、探索、认知不确定性以及向大语言模型 (LLMs) 的扩展**。
- **对 'Talk RL' 播客的怀念**:`@natolambert` 表示打算收听分享的这一集,并回忆起自己曾是 'Talk RL' 播客的粉丝。
- **心仪播客的活跃度下降**:`@twkillian` 感叹 'Talk RL' 播客现在的更新频率降低了,这在一定程度上冲淡了他们的粉丝热情。
- **根据嘉宾选择性收听**:`@natolambert` 透露虽然他们仍会关注 'Talk RL',但并不会收听每一集,参与度取决于受访嘉宾。
- **质量的一致性至关重要**:`@twkillian` 承认 'Talk RL' 各集的质量参差不齐,导致他们对播客内容采取了更具选择性的态度。
**提到的链接**:
- [Ian Osband](https://open.spotify.com/episode/0FuKEjteM0cGzy7pznCkAj?si=ds-7rY8yT0emOLgaV7rgcA&context=spotify%3A):在 Spotify 上收听来自 TalkRL: The Reinforcement Learning Podcast 的这一集。Ian Osband 是 OpenAI(前 DeepMind, Stanford)的研究科学家,致力于不确定性下的决策研究。...
- [Ian Osband](https://open.spotify.com/episode/0FuKEjteM0cGzy7pznCkAj?si=ds-7rY8yT0emOLgaV7rgcA&context=spotify%3Aepisode%3A0FuKEjteM0cGzy7pznCkAj):在 Spotify 上收听来自 TalkRL: The Reinforcement Learning Podcast 的这一集。Ian Osband 是 OpenAI(前 DeepMind, Stanford)的研究科学家,致力于不确定性下的决策研究。...
---
### Interconnects (Nathan Lambert) ▷ #[rlhf](https://discord.com/channels/1179127597926469703/1208183230608576562/1215614054916427786) (7 messages):
- **探索用于 LLM 对齐的 RLHF**:用户 `@xeophon.` 分享了一篇 [arXiv 论文](https://arxiv.org/abs/2403.04642),研究了 **RLHF、PPO 和 Expert Iteration** 在提升 LLM 推理能力方面的表现。`@natolambert` 认可了该论文,表示其内容看起来不错。
- **询问 Claude 的合成任务**:用户 `@eugenevinitsky` 对 **Claude** 中用于创建不确定性感知 LLM 的合成任务细节表示感兴趣。
- **寻求合成任务问题的核心**:`@natolambert` 回复了 `@eugenevinitsky`,提到他们正与 `<@304671004599255043>` 一起探索关于创建有效合成任务核心问题的理论。
- **展望合成任务的高级方法**:`@natolambert` 推测可以使用类似 **CAI (Counterfactual AI)** 的方法,并结合改进来增加生成合成任务的多样性。
- **预训练数据 vs 指令/偏好**:`@natolambert` 建议在**预训练数据**上运行 CAI,这与标准关注指令或偏好的做法形成对比。
**提到的链接**:
[Teaching Large Language Models to Reason with Reinforcement Learning](https://arxiv.org/abs/2403.04642):来自人类反馈的强化学习(**RLHF**)已成为将 LLM 输出与人类偏好对齐的主流方法。受 RLHF 成功的启发,我们研究了其性能……
---
### OpenRouter (Alex Atallah) ▷ #[announcements](https://discord.com/channels/1091220969173028894/1092729520181739581/1215718408012963870) (4 messages):
- **新的速度冠军 Mistral 7b 0.2**:@alexatallah 隆重推出了 **Mistral 7b 0.2**,并夸赞其速度大幅提升——**短输出提升 10 倍,长输出提升 20 倍**,同时还拥有慷慨的 **32k** 上下文窗口。性能在 [演示推文](https://twitter.com/OpenRouterAI/status/1766147110443909184) 中得到了展示。
- **Gemma Nitro 投放市场**:@alexatallah 宣布了一款名为 **Gemma Nitro** 的新型高性价比、高速模型,其速度惊人,超过 **600+ tokens per second**,且价格经济,仅为 **每百万 token $0.1**。更多详情请访问 [OpenRouter 网站](https://openrouter.ai/models/google/gemma-7b-it:nitro)。
- **预览推文?**:@alexatallah 分享了一个[神秘的 Twitter 链接](https://twitter.com/OpenRouterAI/status/1766916892755706020),没有提供额外的背景或评论。
- **OpenRouter 宣称无支出限制**:@alexatallah 透露了 OpenRouter 上的一项用户友好政策,称该平台*没有 $ 使用限制*,这可能会吸引用户更自由地使用他们的服务。
**提到的链接**:
[Google: Gemma 7B (nitro) by google | OpenRouter](https://openrouter.ai/models/google/gemma-7b-it:nitro):Google 推出的 Gemma 是一个先进的开源语言模型系列,利用了最新的仅解码器(decoder-only)、文本到文本技术。它在文本生成任务中提供英语语言能力……
---
### OpenRouter (Alex Atallah) ▷ #[app-showcase](https://discord.com/channels/1091220969173028894/1092850552192368710/1216286555270942760) (1 messages):
- **Claude 3 函数调用变得简单**:用户 `@thevatsalsagalni` 介绍了一个专为 **Claude 3** 模型系列定制的函数调用库。该库支持 Pydantic 函数模式,并欢迎在 [GitHub 上的 claudetools](https://github.com/vatsalsaglani/claudetools) 进行探索和贡献。
**提到的链接**:
[GitHub - vatsalsaglani/claudetools: Claudetools 是一个 Python 库,支持 Anthropic 的 Claude 3 系列语言模型进行函数调用。](https://github.com/vatsalsaglani/claudetools):Claudetools 是一个 Python 库,支持 Anthropic 的 Claude 3 系列语言模型进行函数调用。- vatsalsaglani/claudetools
### OpenRouter (Alex Atallah) ▷ #[general](https://discord.com/channels/1091220969173028894/1094454198688546826/1215563520591142933) (120 条消息🔥🔥):
- **AI 模型审查成为热门话题**:包括 `@.toppa` 和 `@lemmyle` 在内的多位用户对 AI 模型中逐渐渗透的审查制度表示担忧,例如“Claude 2 自我调节版本”,以及与版权或 AI 回复相关的潜在新限制。讨论涉及了 Claude 3 等 AI 模型如何响应用户输入,以及对更少审查选项的渴望。
- **查询 AI 格式支持和参数功能**:在一次技术讨论中,`@cupidbot.ai` 和 `@spaceemotion` 询问了各种 AI 模型的消息格式化以及系统参数(如 `json_object` 和 `add_generation_prompt=True`)的功能。`@alexatallah` 澄清了一些文档要点,包括在获得更多支持之前移除 `schema`。
- **模型输出限制引发好奇与摩擦**:`@zulfiqaar` 和 `@.wingedsheep` 等用户探讨了各种模型的输出长度限制,特别提到了 GPT-4 的 4096 token 输出上限。尽管 `@lemmyle` 等用户对目前的限制表示不满,但 `@alexatallah` 提到,更长的生成内容可能会显著增加内存占用(memory usage)。
- **用户间寻求并提供技术协助**:用户就模型的复杂细节寻求澄清和帮助,范围从 Claude API 对系统角色(system role)消息的处理(`@njbbaer` 提问,`@alexatallah` 回答)到为个人使用适配模型文件(`@mikef0x.`)。见解包括 OpenRouter 如何利用 ChatML 和直接提示(direct prompts)促进提示词自定义。
- **用户对 OpenRouter 的参与及模型访问问题**:对话强调了用户对 OpenRouter 的参与,如 `@mostlystable` 创建的 Google Sheets 连接应用,并解决了 Nous Hermes 70B 等模型的访问问题。`@louisgv` 和 `@spaceemotion` 等用户提供了模型状态和功能的更新,`@alexatallah` 给出了官方回复。
**提到的链接**:
- [TOGETHER](https://api.together.xyz): 未找到描述
- [NeverSleep/Noromaid-20b-v0.1.1 · Hugging Face](https://huggingface.co/NeverSleep/Noromaid-20b-v0.1.1#custom-format): 未找到描述
- [The Introduction Of Chat Markup Language (ChatML) Is Important For A Number Of Reasons](https://cobusgreyling.medium.com/the-introduction-of-chat-markup-language-chatml-is-important-for-a-number-of-reasons-5061f6fe2a85): 2023 年 3 月 1 日,OpenAI 推出了 ChatGPT 和 Whisper API。该公告的一部分是 Chat Markup Language,它似乎已经……
- [openchat/openchat-3.5-0106-gemma · Hugging Face](https://huggingface.co/openchat/openchat-3.5-0106-gemma): 未找到描述
- [FreeGPT for Google Sheets (Full Tutorial + Template)](https://youtu.be/wtKMvbCamlw): 关于如何在 Google Sheets 中使用带有自定义模板的 OpenRouter 的教程。📍 免费解锁 Google 表格中的 AI 力量!🚀 在这个视频中,我们将演示……
- [Reddit - Dive into anything](https://www.reddit.com/r/SillyTavernAI/comments/188a3dx/this_is_why_i_love_noromaid20b/): 未找到描述
---
### CUDA MODE ▷ #[general](https://discord.com/channels/1189498204333543425/1189498205101109300/1215929549997604875) (30 条消息🔥):
- **图像字幕生成器协助请求**:用户 `@madhurr` 在一个远程图像字幕生成器项目中遇到了形状不匹配的问题,寻求关于拼接图像特征和字幕层的帮助。
- **CUDA 类比 Factorio**:用户 `@artificial_anteligence` 做了一个类比,将并行计算比作电子游戏 Factorio,讨论了内存操作等组件如何与游戏机制相对应。
- **关于图像和 NLP Embedding 的建议**:针对 `@madhurr` 的问题,`@andreaskoepf` 建议使用线性层(linear layer)来投影图像特征,以匹配 NLP embeddings 的形状,并分享了一个相关的 [Visual Instruction Tuning 项目](https://llava-vl.github.io/)链接。
- **学习 CUDA 和 Triton**:用户 `@umerha` 提议就 Triton 或前缀和(prefix sum)进行社区演讲,并提供了其[个人博客](https://umerha.github.io/)链接以介绍其专业背景。
- **探索 LLM 的解码效率**:`@andreaskoepf` 分享了一个 [PyTorch 博客](https://pytorch.org/blog/flash-decoding/)链接,讨论了提高大语言模型推理效率的策略。
**提到的链接**:
- [UmerHA 的博客](https://umerha.github.io/):这里是你的网站描述。你可以通过编辑 _config.yml 文件来修改它。它可以根据你的需要设置长度!祝博客写作愉快…… ❤
- [用于长上下文推理的 Flash-Decoding](https://pytorch.org/blog/flash-decoding/):动机
- [LLaVA](https://llava-vl.github.io/):未找到描述
- [CUDA MODE](https://www.youtube.com/@CUDAMODE):一个 CUDA 读书小组和社区 https://discord.gg/cuda-mode-1189498204333543425 补充内容见此处 https://github.com/cuda-mode 由 Mark Saroufim 和 Andreas Köpf 创建
- [lectures/lecture9 at main · cuda-mode/lectures](https://github.com/cuda-mode/lectures/tree/main/lecture9):cuda-mode 讲座材料。通过在 GitHub 上创建账号来为 cuda-mode/lectures 的开发做出贡献。
- [第 21 讲 - 固定内存与流 (Pinned Memory and Streams)](https://youtu.be/aNchuoFCgSs?si=noG-T-QSPImfqzBs&t=1988):GPU 计算,2021 春季,Izzat El Hajj,贝鲁特美国大学计算机科学系。基于教科书:Programming Massively Parallel Proc...
---
### CUDA MODE ▷ #[triton](https://discord.com/channels/1189498204333543425/1189607595451895918/) (1 条消息):
iron_bound: 虽然还处于早期阶段,但听起来很酷 https://github.com/Deep-Learning-Profiling-Tools/triton-viz
---
### CUDA MODE ▷ #[cuda](https://discord.com/channels/1189498204333543425/1189607726595194971/1215576628520943656) (21 条消息🔥):
- **CUDA 中的线程粗化 (Thread Coarsening)**:`@cudawarped` 将 **thread coarsening** 描述为类似于循环展开(loop unrolling),并认为只有在未充分利用内存吞吐量时才会带来性能提升。他们指出,向量化加载(vectorized loads)是否能带来性能提升取决于工作负载,并建议将半精度(half precision)作为 float 读取,以适应缓存行大小。
- **优化内存操作**:`@zippika` 建议使用 `int4` 或 `float4` 来减少内存读写次数,并讨论了在 CUDA 中使用 `__hadd2` 算子进行向量化加法的潜在收益。
- **来自 NVIDIA CUDA 的性能洞察**:`@zippika` 分享了一个使用 `__hadd8` 进行向量化加法的 CUDA 代码片段,并根据 NVIDIA Compute Unified Device Architecture (NCUD) 工具的观察结果暗示了性能改进。
- **精通 CUDA 的路径**:用户讨论了掌握 CUDA 的自学方法,包括查阅 CUDA toolkit、检查 `nvcc` 生成的 C++ 代码以及探索 GitHub 上的仓库。
- **关于 NVIDIA Magnum IO 的讨论**:`@joseph_en` 提到了 NVIDIA Magnum IO,这是一个用于高性能计算和机器学习的系统,强调了其处理复杂模拟和减少多租户环境下负面性能影响的能力。
**提到的链接**:
[NVIDIA Magnum IO](https://www.nvidia.com/en-us/data-center/magnum-io/):现代 GPU 加速数据中心的 IO 子系统
---
### CUDA MODE ▷ #[torch](https://discord.com/channels/1189498204333543425/1189607750876008468/1216307475037552690) (5 messages):
- **探索 Torch Compile 的限制**:`@andreaskoepf` 询问 `torch.compile` 生成的 kernel 大小是否存在上限,并建议添加一个 readme 来记录如何打印 Triton 编译结果。他们还表示有兴趣深入研究 PyTorch 源码以更好地理解这一点。
- **Kernel 启动的不确定性**:`@marksaroufim` 对 `torch.compile` 中的 kernel 大小限制表示不确定,并提到了使用 persistent kernels 来建模整个网络的概念,但目前对其底层的权衡(trade-offs)缺乏清晰的理解。
- **处理器 vs 语言与编译引擎**:`@mr.osophy` 评论称,目前有工作正在开发一种新的语言和编译引擎,能够高效地编译到所有类型的处理器,并强调重点不在于处理器设计。
- **性能对比咨询**:`@ingiing` 询问 libtorch 的性能是否比在 PyTorch 中使用 `load_inline` 更快,试图对比这两种方法。
---
### CUDA MODE ▷ #[announcements](https://discord.com/channels/1189498204333543425/1189640399476764692/1216112121667129465) (1 messages):
- **关于归约树的 CUDA-MODE 讲座**:`@andreaskoepf` 宣布了 **CUDA-MODE 第 9 讲:Reductions**,通知 `@everyone` 讲座将在约 5 分钟后开始。本次讲座由 `<@325883680419610631>` 主讲,内容涵盖 PMPP 书籍第 10 章中的主题,如最小化控制流歧义(control divergence)和内存歧义(memory divergence)、减少全局内存访问以及线程粗化(thread coarsening)。
---
### CUDA MODE ▷ #[algorithms](https://discord.com/channels/1189498204333543425/1189861061151690822/1215615128741871626) (2 messages):
- **微调内存需求降低**:`@iron_bound` 讨论了一种名为 GaLore (Gradient Low-Rank Projection) 的新方法,该方法可减少高达 65.5% 的内存占用,并能在单 GPU 环境下更高效地训练大型语言模型。研究详情可见此 [ArXiv 论文](https://arxiv.org/abs/2403.03507)。
- **在标准 GPU 上微调 70b 模型**:`@iron_bound` 分享道,结合使用 FSDP 和 QLoRA,现在可以在配备 RTX 3090 或 4090 等标准游戏 GPU 的台式机上微调 70b 语言模型。完整的公告和摘要可在 [Answer.AI 的博客文章](https://www.answer.ai/posts/2024-03-06-fsdp-qlora.html)中找到。
**提到的链接**:
- [GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection](https://arxiv.org/abs/2403.03507):训练大型语言模型 (LLMs) 面临巨大的内存挑战,这主要是由于权重和优化器状态的不断增加。常见的内存减少方法,如低秩...
- [Answer.AI - You can now train a 70b language model at home](https://www.answer.ai/posts/2024-03-06-fsdp-qlora.html):我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。
---
### CUDA MODE ▷ #[suggestions](https://discord.com/channels/1189498204333543425/1189868872887705671/1216789025776472205) (1 messages):
- **分享 CUDA 训练系列资源**:`@w0rlord` 提供了一个名为 "cuda-training-series" 的 [YouTube 播放列表](https://www.youtube.com/playlist?list=PL6RdenZrxrw-zNX7uuGppWETdxt_JxdMj),其中的讲座链接到了 [GitHub](https://github.com/olcf/cuda-training-series) 和 [橡树岭国家实验室 (Oak Ridge National Laboratory) 的系列课程](https://www.olcf.ornl.gov/cuda-training-series/)。
- **在此查找你的 CUDA 作业**:配合讲座,`@w0rlord` 还分享了 CUDA 训练系列的 [GitHub 作业仓库](https://github.com/olcf/cuda-training-series/tree/master),其中包含与 NVIDIA 系列课程相关的训练材料。
**提到的链接**:
- [cuda-training-series](https://www.youtube.com/playlist?list=PL6RdenZrxrw-zNX7uuGppWETdxt_JxdMj):来自 https://github.com/olcf/cuda-training-series 和 https://www.olcf.ornl.gov/cuda-training-series/
- [GitHub - olcf/cuda-training-series: Training materials associated with NVIDIA's CUDA Training Series](https://github.com/olcf/cuda-training-series/tree/master):与 NVIDIA CUDA 训练系列相关的训练材料 (www.olcf.ornl.gov/cuda-training-series/) - olcf/cuda-training-series
---
### CUDA MODE ▷ #[jobs](https://discord.com/channels/1189498204333543425/1190208177829068860/1216442240432345259) (3 messages):
- **自定义 CUDA Kernel 项目提醒**:`@jaivikramaditya` 正在寻找一名开发人员来设计自定义 CUDA Kernel,特别是用于机器学习应用的 **flashattention** 变体。该项目提供的报酬为 **2,000 - 3,000 美元**。
- **CUDA Kernel 项目技能要求**:合适的候选人必须具备 **算法开发** 经验,特别是针对 Transformers 的经验,并曾接触过 CUDA 编程。
- **开放私信邀请**:感兴趣的开发人员可以直接 **私信 (DM) `@jaivikramaditya`** 表达意向,或获取有关该自定义 CUDA Kernel 工作机会的更多细节。
---
### CUDA MODE ▷ #[beginner](https://discord.com/channels/1189498204333543425/1191300313928433664/1215585862268755988) (9 messages🔥):
- **利用学习资源进行多任务处理**:`@mertbozkir` 建议通过观看视频并阅读配套书籍来获得更好的学习体验,并特别提到他们正在阅读的那本书 **信息量非常大**。
- **CUDA 张量库探索**:`@siddharth4570` 正在用 CUDA 构建自己的张量库,并询问其他人是 **编写自己的反向传播实现** 还是使用 autodiff 库。
- **CUDA 与 PyTorch 2.0 + Triton 在机器学习性能方面的对比**:`@jsm9036` 质疑了学习和使用 CUDA 相比于 PyTorch 和 Triton 等高级工具的优势,因为后者可能以更短的开发时间提供大部分性能收益。`@iron_bound` 建议使用高级工具进行快速原型设计,并在 **需要进一步提升性能时** 求助于 CUDA。
- **寻求 CUDA C/C++ 的差异**:`@apaz` 正在寻找 *CUDA C/C++ 与标准 C/C++ 之间的官方差异列表*,特别是在从 CUDA 源代码到 C/C++ 源文件的初始编译阶段。
- **PyTorch 版本变更带来的性能观察**:`@poppingtonic` 报告了在 2080 Ti 上使用 CUDA 12.1 运行 matmul_dyn 时,**PyTorch 2.1.2 和 2.2.1 之间的速度差异**,新版本速度较慢。他们还表达了一个新目标:理解 tinygrad 的操作和 Kernel。
---
### CUDA MODE ▷ #[pmpp-book](https://discord.com/channels/1189498204333543425/1194427148656721970/1216812392802156754) (12 messages🔥):
- **讲座中讨论的 CUDA Profiling**:`@marksaroufim` 提到,虽然 **pmpp book** 可能没有广泛涉及 CUDA 的性能分析工具,但他们在 **lecture 1** 中详细讲解了 Profiling。
- **书籍作者在 YouTube 上分享 Profiling 指南**:针对有关 CUDA Profiling 的咨询,`@marksaroufim` 告知 `@dasher519`,书籍作者在他们的 [YouTube 视频](https://www.youtube.com) 中讨论了 Profiling。
- **书中提到的 CUDA Kernel 语法细节**:`@alexanderrgriffing` 就 CUDA 书籍练习代码中 **三重尖括号内的空格** 使用(例如 `<< < ... >> >`)提出了疑问。
- **历史性的 C++ 特性解释了 Kernel 启动语法中的空格**:`@stefangliga` 澄清说,在 **C++03/98** 中空格曾是强制性的,以避免与移位操作符混淆,这一要求在 **C++11** 中得到了修正;然而,目前尚不清楚这是否同样适用于 CUDA C++,或者它一直只是一种风格选择。
- **寻找最新版书籍的练习题答案**:`@dasher519` 询问 2023 版 **pmpp book** 的练习题答案在哪里,想知道是否在单独的答案解析书中。
---
### CUDA MODE ▷ #[youtube-recordings](https://discord.com/channels/1189498204333543425/1198769713635917846/1216216405607710790) (3 messages):
- **关于 Reductions 的 CUDA 讲座**:`@marksaroufim` 分享了一个名为 "Lecture 9 Reductions" 的 [YouTube 视频](https://www.youtube.com/watch?v=09wntC6BT5o),以及 [幻灯片材料](https://docs.google.com/presentation/d/1s8lRU8xuDn-R05p1aSP6P7T5kk9VYnDOCyN5bWKeg3U/edit?usp=sharing) 和 [代码示例](https://github.com/cuda-mode/lectures/tree/master)。
- **视频上传质量检查**:`@alexeyzaytsev` 注意到视频在上传一小时后仅提供 360p 分辨率,担心是否上传有误。`@marksaroufim` 确认上传没有问题,但需要更多时间进行处理。
**提到的链接**:
[Lecture 9 Reductions](https://www.youtube.com/watch?v=09wntC6BT5o):Slides https://docs.google.com/presentation/d/1s8lRU8xuDn-R05p1aSP6P7T5kk9VYnDOCyN5bWKeg3U/edit?usp=sharing 代码 https://github.com/cuda-mode/lectures/tree/ma...
---
### CUDA MODE ▷ #[ring-attention](https://discord.com/channels/1189498204333543425/1208496482005549086/1215681559001174016) (27 messages🔥):
- **同步确认**:`@jamesmel` 确认了即将进行的同步(sync),提到他们在错过本次会议后将于第二天加入。
- **Ring-Attention 故障排除**:`@jamesmel` 在运行来自 **zhuzilin** 的 Ring-Attention 时遇到问题,卡在了 `_flash_attn_forward` 处,并指出子进程已暂停。
- **Ring-Attention 讨论**:`@iron_bound` 和 `@andreaskoepf` 也参与了对话,`@iron_bound` 认为这种暂停很奇怪,而 `@andreaskoepf` 建议查看 Ring-Attention 实现中使用的内存分配(allocations)。
- **规划 Flash decoding 草图**:`@jamesmel` 提出了 Flash decoding 的高层级方案草图,列出了包括 prefill 阶段和 decoding 阶段在内的步骤,`@andreaskoepf` 提到计划将其作为讲座的一部分进行解释。
- **会议与时间调整**:`@iron_bound` 和 `@jamesmel` 对会议日程和由于夏令时变更引起的调整发表了评论,明确了未来同步的时间。
---
### CUDA MODE ▷ #[off-topic](https://discord.com/channels/1189498204333543425/1215328286503075953/1215782422818324580) (5 messages):
- **Bing 难以忘怀的脏话记忆**:`@iron_bound` 分享了一个 [Reddit 帖子](https://www.reddit.com/r/ChatGPT/comments/1b8nyur/i_asked_bing_to_swear_at_me_weeks_ago_it_wont/),描述了一个幽默的问题:尽管用户要求停止,Bing 仍继续对他骂脏话。这个问题在多次对话中持续存在,仿佛系统只记住了这一个偏好。
- **线程之歌**:`@mr.osophy` 对一首 Spotify 曲目发表了轻松的评论,想象这首歌是关于编程概念 Threading(线程)的,并分享了[歌曲链接](https://open.spotify.com/track/4BGlpgcdytfO6x5Drgqxh7?si=oiDrfXj6Rlu1k-tTuY62zw)。
- **关于 Inflection AI 和 Claude-3 的谣言被澄清**:`@f_michael` 通过一条推文链接询问了关于 Inflection AI 及其据称使用 Claude-3 的谣言,随后 `@itali4no` 分享了另一条[回复推文](https://twitter.com/inflectionAI/status/1766173427441049684?s=20),澄清这只是个谣言。
- **对澄清表示感谢**:`@f_michael` 对 `@itali4no` 就上述谣言提供的澄清表示感谢。
**提到的链接**:
- [Reddit - Dive into anything](https://www.reddit.com/r/ChatGPT/comments/1b8nyur/i_asked_bing_to_swear_at_me_weeks_ago_it_wont/):未找到描述
- [At The Same Time](https://open.spotify.com/track/4BGlpgcdytfO6x5Drgqxh7?si=oiDrfXj6Rlu1k-tTuY62zw):Oliverse · 歌曲 · 2023
### LangChain AI ▷ #[general](https://discord.com/channels/1038097195422978059/1038097196224086148/1215610445029965844) (68 条消息🔥🔥):
- **PDF 提取协助请求**:`@dazzling_puppy_08816` 询问是否可以将整个 PDF 发送给 Vision 模型进行文本提取。`@smashah` 建议使用 unstructured API 将其转换为文档。
- **Langchain Hub 中的模板限制**:`@louis030195` 对模板引擎在处理 Prompt 创建的条件逻辑方面的局限性表示担忧。`@baytaew` 确认了这一反馈,并提到在传递给模板之前先在代码中处理复杂逻辑,同时也承认了这对非技术用户带来的不便。
- **ChatOllama 功能澄清**:`@tmetzger71` 在 ChatOllama 中绑定函数时遇到问题,错误提示 'tools' 不存在于类型 'Partial' 中。该用户的后续消息指向一个实验性封装 [Ollama Functions](https://js.langchain.com/docs/integrations/chat/ollama_functions) 作为变通方案。
- **Bedrock 中的 Claude3 支持查询**:在由 `@j.barney` 发起的关于 Claude3 支持的讨论中,`@baytaew` 表示 `@761046695722877016` 正在努力增强 Bedrock 聊天类,并确保对 Claude3 的一流支持,并指出 Bedrock 服务上托管的每个模型都有独特的 API 管理。
- **Langchain 测试策略关注**:鉴于 LLM 应用的非确定性,`@sharrajesh` 询问了维护 Langchain/LLM 应用响应质量的最佳实践。`@baytaew` 给出了建议,例如使用 Langsmith 进行评估/基准测试,并关注系统正确性、忠实度(faithfulness)和检索性能等指标。
**提到的链接**:
- [Ollama Functions | 🦜️🔗 Langchain](https://js.langchain.com/docs/integrations/chat/ollama_functions):LangChain 提供了一个针对通过 Ollama 本地运行的开源模型的实验性封装。
- [从向量存储中检索元数据 · langchain-ai/langchain · Discussion #10306](https://github.com/langchain-ai/langchain/discussions/10306):大家好,我创建了一个聊天机器人,它使用多个工具来回答问题。其中一个工具查询 Pinecone 索引以获取答案。Chain 的结构如下:def ...
- [讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞](https://xinghuo.xfyun.cn/sparkapi):未找到描述
- [iFLYTEK Open Platform Documents](https://global.xfyun.cn/doc/platform/pricing.html#billing-items):未找到描述
- [支持 Claude v3 模型。由 3coins 提交 · Pull Request #18630 · langchain-ai/langchain](https://github.com/langchain-ai/langchain/pull/18630):修复了 #18513。描述:此 PR 尝试修复 BedrockChat LLM 对 Anthropic Claude v3 模型的支持。此处的更改已将 Payload 更新为使用 messages 格式,而不是 f...
---
### LangChain AI ▷ #[langserve](https://discord.com/channels/1038097195422978059/1170024642245832774/1216104812362469546) (2 条消息):
- **寻求 LangChain Serve 代码执行的澄清**:`zql_flo` 询问了使用 Langchain Serve 时代码的执行位置,以及如何管理 Agent 需要访问的用户上传文件。他们询问 Docker 是否是这些流程的实现方法。
- **利用 Langserve 路由的输出**:`problem9069` 正在寻求关于使用 Langserve 的指导,特别是想知道在使用 ChatOpenAI 函数添加路由时,如何将路由的输出捕获到变量中。
---
### LangChain AI ▷ #[share-your-work](https://discord.com/channels/1038097195422978059/1038097372695236729/1215696905967771678) (14 messages🔥):
- **使用 Prompt Mixer 变革 Prompt 编写流程**:用户 `@tomatyss` 介绍了一个名为 [Prompt Mixer](https://www.promptmixer.dev/) 的新工具,非常适合构建、测试和迭代 AI prompts。这个桌面应用程序允许连接各种模型,跟踪 prompt 版本,甚至还有一个[添加自定义连接器的指南](https://docs.promptmixer.dev/tutorial-extras/create-a-custom-connector)。
- **正在开发中的自动化线索生成工具**:用户 `@robinsayar` 正在开发一个自动化的线索生成工具,用于对最新的上市公司信息进行分类和筛选,旨在简化目前为客户手动执行的流程。
- **对自动化线索生成的期待**:用户 `@baytaew` 对 `@robinsayar` 的自动化线索生成项目表示热烈期待,并期待看到结果。
- **开源 Langchain 聊天机器人**:用户 `@haste171` 分享了一个[开源 AI Chatbot](https://github.com/Haste171/langchain-chatbot),基于 Langchain 和 RAG 构建,旨在以对话形式分析和从数据中提取信息,具有简单的设置和交互式 UI。
- **Appstorm 在 1.5.0 版本中推出 Data GPTs**:用户 `@appstormer_25583` 宣布在 Appstorm 1.5.0 上发布 Data GPTs,这是一个用于探索、分析和可视化数据的功能,并附带了适用于各种应用(如电子竞技表现报告和医疗统计信息图表)的示例 GPTs。
**提到的链接**:
- [GitHub - Haste171/langchain-chatbot: 用于以对话格式分析/提取数据信息的 AI Chatbot。](https://github.com/Haste171/langchain-chatbot):用于以对话格式分析/提取数据信息的 AI Chatbot - Haste171/langchain-chatbot
- [Prompt Mixer — Prompt IDE 和 LLMOps 工具](https://www.promptmixer.dev/):PromptMixer – 用于以无与伦比的便捷性编写、测试和部署 prompt 的创新 Prompt IDE。
- [创建自定义连接器 | Prompt Mixer 文档](https://docs.promptmixer.dev/tutorial-extras/create-a-custom-connector):步骤 1:复制示例连接器
- [EStatGenie](https://beta.appstorm.ai/apps/905abbaf):未找到描述
- [HealthVizGPT](https://beta.appstorm.ai/apps/dcd2b5c9):未找到描述
- [DataVizGenie](https://beta.appstorm.ai/apps/093ae941):未找到描述
- [FootGraphix](https://beta.appstorm.ai/apps/435c088f):未找到描述
- [Watch Better Movies](https://www.watchbettermovies.com):未找到描述
---
### LangChain AI ▷ #[tutorials](https://discord.com/channels/1038097195422978059/1077843317657706538/1216638358948810782) (2 messages):
- **使用 LangGraph 探索 RAG**:`@mehulgupta7991` 分享了一个名为 *"Improving RAG using LangGraph and LangChain"* 的 [YouTube 视频](https://youtu.be/TlZ5BFx_m3M?si=tVfbYMUQhOVCV8x_),演示了 **LangGraph 如何通过创建循环来增强外部上下文中的 RAG 检索**。
- **使用 RAG 和 LangChain 构建聊天机器人**:`@infoslack` 提供了一个 [YouTube 链接](https://www.youtube.com/watch?v=O60-KuZZeQA),用于学习如何**使用检索增强生成 (RAG) 构建聊天机器人**,利用 OpenAI 的 gpt-3.5-turbo LLM,作为 LangChain 教程系列的一部分。
**提到的链接**:
- [使用 LangGraph 和 LangChain 改进 RAG](https://youtu.be/TlZ5BFx_m3M?si=tVfbYMUQhOVCV8x_):该视频演示了什么是 LangGraph,以及如何使用它来创建循环并改进外部上下文中的 RAG 检索。LangChain in your Pocket: ...
- [使用 LangChain 和 OpenAI 构建带有 RAG 的聊天机器人](https://www.youtube.com/watch?v=O60-KuZZeQA):在本视频中,我将指导你如何从头开始使用检索增强生成 (RAG) 构建聊天机器人。我们将使用 OpenAI 的 gpt-3.5-turbo LLM...
### DiscoResearch ▷ #[disco_judge](https://discord.com/channels/1178995845727785010/1178996063537991752/1216193322398388244) (12 messages🔥):
- **使用 AI 评估创意写作**:`@.calytrix` 对有效训练模型来评估创意写作表示怀疑,认为这需要的参数量超出了目前的实际可行范围。他们目前正转向测试以 **GPT-4** 和 **Claude3** 作为裁判的提示词,并使用详细的评分标准。
- **探索 AI 裁判**:`@johannhartmann` 表现出对查看 **GPT-4 和 Claude3** 在创意写作评估中差异的兴趣,并随后开玩笑说想读到一份“开源模型超越 GPT-4”的结论。
- **德语 AI 模型基准测试**:`@johannhartmann` 提到将 Vago 解决方案集成到 FastEval 中用于 **德语基准测试**,并观察到 GPT-4 在长篇详细回答中得分依然更高。
- **AI 裁判集成 (Ensemble)**:`@bjoernp` 讨论了使用 AI 裁判集成来减少偏见并提高准确性的优势,并询问是否已使用 **Mistral large** 进行评估。
- **AI 裁判基准开发**:`@.calytrix` 正在创建一个包含多个问题的基准来测试多个 AI 裁判,并指出 **GPT-4** 在这方面可能是一个可参考的 SOTA (State-of-the-art) 裁判。他们还在考虑使用 `@johannhartmann` 建议的 FastEval,这可能比 EQ-Bench 更合适。
---
### DiscoResearch ▷ #[general](https://discord.com/channels/1178995845727785010/1182877486854451271/1215581805646839868) (4 messages):
- **Evo 发布 Striped Hyena 架构**:`@rasdani` 强调了 **Evo** 的发布,这是一个使用 StripedHyena 架构的生物基础模型,旨在处理从分子到全基因组规模的任务。该模型由 Together AI 和 Arc Institute 开发,可处理超过 650k tokens,并专门针对 DNA、RNA 和蛋白质序列。更多信息请见其 [博客文章](https://www.together.ai/blog/evo)。
- **AutoMerger 面临技术问题**:`@johannhartmann` 对 **AutoMerger**(一个在 Hugging Face 上带有基准测试的自动模型合并器)表示了兴趣,尽管注意到它目前无法运行。尽管该工具目前处于损坏状态,他的兴趣依然不减,链接见 [Hugging Face’s AutoMerger](https://huggingface.co/spaces/mlabonne/AutoMerger)。
- **Slerp 与 Dare_ties 合并对比**:`@johannhartmann` 进一步评论道,在 **AutoMerger** 的语境下,dare_ties 和 slerp 合并策略之间似乎没有显著差异。
- **LLM 的 Mixture-of-LoRAs 架构**:`@johannhartmann` 分享了一篇 [arXiv 论文](https://arxiv.org/abs/2403.03432) 链接,讨论了 **Mixture-of-LoRAs (MoA)**,这是一种旨在增强 Large Language Models (LLMs) 多任务学习并减轻灾难性遗忘和任务干扰等问题的方法。
**提到的链接**:
- [Mixture-of-LoRAs: An Efficient Multitask Tuning for Large Language Models](https://arxiv.org/abs/2403.03432):Instruction Tuning 有潜力激发或增强 Large Language Models (LLMs) 的特定能力。然而,实现数据平衡对于防止灾难性遗忘至关重要……
- [AutoMerger - a Hugging Face Space by mlabonne](https://huggingface.co/spaces/mlabonne/AutoMerger):未找到描述
- [Evo: Long-context modeling from molecular to genome scale](https://www.together.ai/blog/evo):未找到描述
---
### DiscoResearch ▷ #[benchmark_dev](https://discord.com/channels/1178995845727785010/1183158791605330051/1216799679925190656) (3 messages):
- **介绍 tinyBenchmarks**:用户 `@johannhartmann` 分享了 [Hugging Face 上的 tinyBenchmarks 链接](https://huggingface.co/tinyBenchmarks/tinyWinogrande),这是一个旨在进行高效基准测试的数据集。
- **探索翻译可能性**:`@johannhartmann` 表示有兴趣翻译 [tinyBenchmarks/tinyWinogrande](https://huggingface.co/tinyBenchmarks/tinyWinogrande) 数据集,并计划在次日研究其可行性。
- **来自 Hellaswag 的基准测试见解**:`@_chromix_` 详细说明了他们在 Hellaswag 数据集上的测试经验,注意到在 1000 个数据点后分数波动范围为 2.5,而在 9000 个数据点后分数变化趋于稳定,约为 +/- 0.2。他们建议,仅选择 100 个数据点对于粗略比较之外的任何评估可能都是不够的。
**提到的链接**:
[tinyBenchmarks (tinyBenchmarks)](https://huggingface.co/tinyBenchmarks):未找到描述
### DiscoResearch ▷ #[discolm_german](https://discord.com/channels/1178995845727785010/1197630242815213618/1215570910300602368) (14 messages🔥):
- **使用德国版 Orca 数据集的创新训练**:`@johannhartmann` 解释了他们使用 **slim orca dataset** 的德语翻译版本来训练和合并 **Mistral** 等模型的方法。他们采用了类 SPIN 方法——将一个模型的输出作为下一个模型的输入——并通过数据集跟踪模型之间的关系,监控训练如何影响回答的冗长程度和质量。
- **Brezn3 模型表现优于前代**:`@crispstrobe` 指出 **Brezn3** 在 EQ-Bench (v2) (de) 基准测试中的得分显著高于 **Brezn-7b**,并询问 `@johannhartmann` 这种提升是否源于模型和 tokenizer 设置的更改。
- **等待 Dpo 的最后冲刺**:`@johannhartmann` 告知 `@crispstrobe`,**Dpo (Domain Prediction Override)** 过程仍在进行中,距离完成大约还需 13 小时。
- **模型合并中的技术故障排除**:`@crispstrobe` 就模型合并过程中遇到的 TypeError 向 `@johannhartmann` 寻求帮助,`@johannhartmann` 通过分享一个 [GitHub commit 链接](https://github.com/mayflower/mergekit/commit/cca4a8d91c213b6e5e4ac34b151955187ceff8a4) 提供了修复方案。
- **基础模型选择的一致性问题**:在 `@bjoernp` 的提示下,`@johannhartmann` 讨论了使用 **LeoLM/leo-mistral-hessianai-7b-chat** 作为基础模型时,由于 chatml 和 eos token 设置的差异而导致的不一致问题,并计划切换到 **DiscoLM** 作为基础模型,以在基准测试中获得更好的结果。
**提到的链接**:
- [SanjiWatsuki/Lelantos-7B · Hugging Face](https://huggingface.co/SanjiWatsuki/Lelantos-7B):未找到描述
- [Allow tokenizer_source: union with dare_ties · mayflower/mergekit@cca4a8d](https://github.com/mayflower/mergekit/commit/cca4a8d91c213b6e5e4ac34b151955187ceff8a4):未找到描述
---
### Alignment Lab AI ▷ #[general-chat](https://discord.com/channels/1087862276448595968/1095458248712265841/1215755362024685658) (7 messages):
- **应对 AI 中的幻觉**:`@tirmizi7715` 提到了 Yi 的技术报告,其中讨论了减少幻觉的问题。大家对这一表述进行了各种解读,但尚未得出结论性的定义。
- **减少 AI 幻觉的策略**:`@rusch` 推测,减少幻觉可能涉及通过 RAG (Retrieval-Augmented Generation) 将知识库外部化,或确保微调数据仅包含新的事实。
- **微调数据在减少幻觉中的作用**:`@scrungle.tech` 考虑了使用事实验证集并手动改写微调中的重复回答,以此作为减少幻觉的一种方法。
- **来自 LAION 的最新消息**:`@spirit_from_germany` 分享了一个 [Twitter 链接](https://twitter.com/laion_ai/status/1766596812347941234),但在消息中未提供背景或解释。
- **寻找高效的小型 Embedding 模型**:`@joshxt` 询问是否有支持 1024+ 最大输入长度、且能在极小 RAM 下本地运行的最佳小型 Embedding 模型。摘要消息中未提供答案。
---
### Alignment Lab AI ▷ #[oo](https://discord.com/channels/1087862276448595968/1118217717984530553/1216458189441335528) (8 messages🔥):
- **Claude 在代码绘图方面的专长**:`@joshxt` 强调了使用 **Claude** 将整个代码库转换为 [mermaid 图表](https://mermaid.live/) 的潜力,并提到在 10k 到 96k tokens 规模的代码库上测试成功。
- **Mermaid 图表解释**:`@lightningralf` 向 `@teknium` 解释了什么是 mermaid 图表,将其描述为一种从文本创建图表的语法,并分享了 mermaid 的 [GitHub 仓库](https://github.com/mermaid-js/mermaid)。
- **使用 Mermaid 可视化代码**:`@joshxt` 提供了一个 mermaid 图表语法的实际示例,用于可视化代码库的架构,展示了 `app.py`、`FASTAPI` 和各种 API 终端节点等组件。
**提到的链接**:
[GitHub - mermaid-js/mermaid: Generation of diagrams like flowcharts or sequence diagrams from text in a similar manner as markdown](https://github.com/mermaid-js/mermaid):从文本生成流程图或序列图等图表,方式类似于 markdown - mermaid-js/mermaid
---
### Alignment Lab AI ▷ #[alignment-lab-announcements](https://discord.com/channels/1087862276448595968/1124055853218136175/1216302354563858452) (1 messages):
- **Gemma-7b 通过 C-RLFT 增强**:`@imonenext` 宣布了第一个基于 openchat-3.5-0106 数据和方法的可用 Gemma-7b 微调版本,其性能几乎达到了与基于 Mistral 版本相同的水平。该微调利用了 6T tokens(被暗示为“秘方”),模型已在 [HuggingFace](https://huggingface.co/openchat/openchat-3.5-0106-gemma) 上提供。
- **Gemma 新里程碑推文发布**:来自 `@openchatdev` 的一条推文庆祝了**全球首个使用 C-RLFT 的 Gemma 微调模型**及其与 Mistral 相当的性能。正如 [Twitter 帖子](https://fxtwitter.com/openchatdev/status/1766516456034861237)中指出的,该微调可能涉及 6T 预训练 tokens 等因素。
**提到的链接**:
- [来自 OpenChat (@openchatdev) 的推文](https://fxtwitter.com/openchatdev/status/1766516456034861237):🚀 全球首个基于 openchat-3.5-0106 数据和方法 (C-RLFT) 的 Gemma 微调模型。性能几乎与基于 Mistral 的版本相同。6T tokens = 秘方?HuggingFace: https:...
- [openchat/openchat-3.5-0106-gemma · Hugging Face](https://huggingface.co/openchat/openchat-3.5-0106-gemma):未找到描述
---
### Alignment Lab AI ▷ #[general-chat](https://discord.com/channels/1087862276448595968/1133673143064596644/1216307576824664105) (5 messages):
- **Gemma 7B vs. Mistral 7B —— 为什么要发布一个表现较弱的模型?**:`@chatbooapp` 询问如果 **Gemma 7B** 不能超越 **Mistral 7B**,为什么要发布它。`@joshxt` 回应称,**每个模型都是一次实验**,Gemma 可能会在尚未被发现的方面表现出色。
- **Gemma 潜在的内容审查表现**:`@chatbooapp` 推测,由于 Google 严格的内容审查政策,**Gemma 7B** 在 NSFW 内容审查方面的表现可能不如 **Mistral**。这一观点似乎引起了 `@joshxt` 的共鸣,他提到 Gemma 在他们使用的 LLM 任务中表现平平,不过他们尚未尝试过任何微调模型。
- **注意到 Mistral 对 NSFW 的宽容度**:尽管存在审查担忧,`@chatbooapp` 提到即使是 **Mistral 终端**也不会回避 NSFW 内容,并对其能力表示赞赏。他们还强调,**Mistral Large** 在配合精心编写的 system prompt 时会非常有用。
---
### Alignment Lab AI ▷ #[oo2](https://discord.com/channels/1087862276448595968/1176548760814375022/1216458278674894849) (5 messages):
- **关于用户“失踪”的传闻被夸大了**:`@teknium` 幽默地表达了担忧,使用了一个 '<:sad_cat:905917016517521419>' 表情,担心另一位用户可能“不在了或怎么了”。
- **活着且在写代码**:`@autometa` 澄清了关于他们“失踪”的传闻,表示他们只是“目前正埋头于一些琐碎的编码任务”。
- **Docker 开发困境**:`@autometa` 提到了建立 Docker 环境的挑战,目的是为了简化协作、消除手动采样的需求并优化他们的开发流程。
- **呼吁协作编码**:`@autometa` 请求在 Docker 环境设置方面提供帮助,强调这些帮助对于推动工作进展将是“极好的”。
---
### LLM Perf Enthusiasts AI ▷ #[general](https://discord.com/channels/1168579740391710851/1168579740391710855/1216455617603043398) (1 messages):
- **通过 Vercel Pro 免费访问 Claude 3 Opus**:用户 `@jeffreyw128` 分享说,拥有 Vercel Pro 的用户可以免费使用 **Claude 3 Opus** 和**原版 GPT-4**。他们提供了 Vercel SDK 的链接:[sdk.vercel.ai](https://sdk.vercel.ai/)。
**提到的链接**:
[Vercel AI SDK](https://sdk.vercel.ai/):使用最新的 AI 语言模型构建 AI 驱动的应用程序
---
### LLM Perf Enthusiasts AI ▷ #[gpt4](https://discord.com/channels/1168579740391710851/1168582188950896641/1216778435091759205) (1 messages):
- **从 OpenAI 到 Azure 的迁移咨询**:用户 `@pantsforbirds` 正在寻求关于将其项目从 **OpenAI SDK** 迁移到基于 Azure 方案的见解。他们有兴趣了解在此迁移过程中可能面临的潜在挑战。
### LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1215687345974812672) (15 messages🔥):
- **XML 标签助力 Function Calling 获赞**:`@res6969` 确认 Function Calling 效果良好,尽管使用 **XML 标签**能进一步增强其有效性。
- **XML 对共享 Prompt Generator 的影响**:`@pantsforbirds` 强调 **XML** 的必要性使得共享 Prompt Generator 变得更加困难。
- **Opus 普遍优于 GPT-4**:包括 `@jeffreyw128`、`@nosa_.` 和 `@vgel` 在内的多位用户评论称,**Opus** 的整体表现优于 **GPT-4**,特别提到其答案更具“洞察力/聪明”,且在处理复杂的图 BFS 算法时非常有效。
- **Claude 的文笔优于 GPT 风格**:`@potrock` 表达了对 **Claude** 文笔的偏好,指出它避免了 GPT 答案前经常出现的**居高临下**的解释。
- **对 GPT-4.5 发布及性能的期待**:`@jeffreyw128` 和 `@res6969` 期待 **GPT-4.5** 或 **GPT-5** 的潜在发布,推测其与 **Claude** 相比的能力,同时对 **Starship 发射**感到兴奋。
---
### LLM Perf Enthusiasts AI ▷ #[opensource](https://discord.com/channels/1168579740391710851/1168606773595349082/) (1 messages):
res6969: https://x.com/elonmusk/status/1767108624038449405?s=20
---
### LLM Perf Enthusiasts AI ▷ #[offtopic](https://discord.com/channels/1168579740391710851/1168762388586176594/1216598957350981732) (1 messages):
- **Google 在 AI 领域的潜在主导地位**:`@jeffreyw128` 讨论了 Google 可能主导 **AI 通用化落地**的两个关键原因:基础模型缺乏长期护城河,以及 Google 在其搜索和 Chrome 平台中低成本集成和提供 AI 服务的能力。
- **与 Google 合作的低成本 AI 集成**:凭借目前的搜索查询收入, Google 有潜力以微不足道的成本在**搜索中提供 AI 服务**,并可能在年内广泛推出 **Generative Search Experience**。
- **OpenAI 的领先地位可能促进大规模采用**:尽管存在竞争,`@jeffreyw128` 认为 **OpenAI** 将保持几年的领先地位,促进大规模采用和代码生成等专业化应用。
- **Google 的动态 AI 部署**:正如 `@jeffreyw128` 所指出的,Google 的优势在于其在文本生成和提供提取式回答之间的智能选择,其表现可能优于其他在线 LLM 体验。
- **AI 集成与高级体验的未来**:除了浏览器和搜索集成,可能会出现更深层次的硬件集成。然而,虽然消费级 AI 应用在经济上是可行的,但在编程或写作等领域仍将存在 **Premium AI 体验**的市场。
---
### Skunkworks AI ▷ #[general](https://discord.com/channels/1131084849432768614/1131084849906716735/1216843016376156260) (1 messages):
- **收敛加速的量子飞跃**:`@baptistelqt` 声称开发了一种将收敛速度提高 100,000 倍的方法。每一“轮”都涉及**从零开始(from scratch)**的训练。
---
### Skunkworks AI ▷ #[finetuning](https://discord.com/channels/1131084849432768614/1131669354912678028/) (1 messages):
henkdevries_starbound: 数学问题很难
---
### Skunkworks AI ▷ #[off-topic](https://discord.com/channels/1131084849432768614/1140423597454807179/) (1 messages):
pradeep1148: https://www.youtube.com/watch?v=H6xon8K4Ius
---
### Datasette - LLM (@SimonW) ▷ #[ai](https://discord.com/channels/823971286308356157/1097032579812687943/) (1 messages):
dbreunig: Earhart
---
### Datasette - LLM (@SimonW) ▷ #[llm](https://discord.com/channels/823971286308356157/1128504153841336370/1216512369966973129) (2 messages):
- **对 Symbex 的赞赏**:用户 `@bdexter` 对 **symbex** 表示感谢,并提到经常使用该项目。
- **SimonW 认可 Symbex 的趣味性**:`@simonw` 热情回应,将 **symbex** 描述为一个“非常有趣的项目”。
---
### AI Engineer Foundation ▷ #[general](https://discord.com/channels/1144960932196401252/1144960932657758210/) (1 messages):
.zhipeng: 是出自 Nathan 的 interconnectai 博客文章对吧?
---
### AI Engineer Foundation ▷ #[events](https://discord.com/channels/1144960932196401252/1144960932657758212/1216561269537116250) (1 条消息):
- **Gen AI Video 活动发布**: `@sylviatong` 邀请大家深入探讨 Gen AI Video 和 'World Model'。嘉宾阵容包括来自 Google 的 [Lijun Yu](https://www.linkedin.com/in/lijun-yu/)、Nvidia 的 [Ethan He](https://twitter.com/EthanHe_42)、Goodby Silverstein & Partners 的 Shan Jin 以及 Eleven Labs 的 Justin Hackney;活动由 Cindy Le 主持,将破除围绕 #Sora、#Genie 和 #WorldModel 的迷思。**2024年3月16日**,于旧金山及 Zoom 在线举行。[报名链接](https://lu.ma/b0zrw3q3)。
- **与 AI Video 先驱对话**: 本次活动为向顶尖研究员学习提供了一个平台,并承诺进行真实、未经滤镜的对话。期待关于 Google 的 VideoPoet、Nvidia 的 Sora 描述以及更多 AI Video 领域创意技术的见解。
**提到的链接**:
[EntreConnect 举办的 Gen AI Video 分组讨论与 World Model - #Sora #Genie #VideoPoet #V-JEPA #LTXStudio #AnimateDiff · Luma](https://lu.ma/b0zrw3q3): 加入我们,参加这场深入探讨 Gen AI Video 核心的开创性活动!这不仅仅是另一场技术讲座;这是一场通往未来的旅程。我们还将提供拨入选项...