ainews-the-worlds-first-fully-autonomous-ai
全球首位全自主 AI 工程师
Cognition Labs 的 Devin 被视为一款具有潜在突破性的 AI 软件工程师智能体。它能够学习陌生的技术、修复 Bug、部署前端应用,甚至能微调自身的 AI 模型。该系统将 OpenAI 的 GPT-4 与强化学习相结合,并集成了异步聊天、浏览器、Shell 访问和 IDE 等工具。
Devin 声称具备先进的长期推理和规划能力,赢得了 Patrick Collison 和 Fred Ehrsam 等投资者的赞誉。这项技术因其作为目前最先进 AI 智能体之一的潜力而备受瞩目,引发了人们对智能体(Agents)和通用人工智能(AGI)的广泛关注与期待。
2024年3月11日至3月12日的 AI 新闻。我们为你检查了 364 个 Twitter 账号 和 21 个 Discord 社区(336 个频道,共 3499 条消息)。预计为你节省了 410 分钟 的阅读时间(以每分钟 200 字计)。
热烈欢迎因 Andrej 的推荐而加入的 3000 多位新朋友!正如我们上次所说,这是一个让我们感到有些汗颜的业余项目,但我们深感荣幸,并希望你们能像我们一样发现它的价值。这封邮件已经变得有些臃肿(最初它只汇总 LS Discord 的内容),我们计划将部分内容迁移到更专业的咨询服务中,并提供个性化选项。
Cognition Labs 的 Devin 是今日 AI 新闻的头条——表面上看,它是众多“AI 软件工程师”初创公司之一,但其区别在于执行力:
- 通过在聊天中输入博客文章链接来学习使用陌生的技术
- 构建并部署前端应用到 Netlify
- 训练和微调其自身的 AI 模型(特别是 Tim Dettmers 对其调试 CUDA 版本错误的能力印象深刻)
- 为成熟的代码库做贡献
这些都是非常宏大的声明,如果这些是普遍情况而非精心挑选的案例,那么它几乎肯定会成为世界上最先进的 AI Agent 之一。这理所当然会引发质疑,尤其是目前仅发布了预录视频,但像 Patrick Collison 和 Fred Ehrsam 这样可靠的投资者,以及 Varun 和 Andrew 等 Beta 测试人员都对现场演示给予了高度评价。
目前细节较少:
- 他们的博客文章指出:“凭借我们在长期推理和规划方面的进步,Devin 可以规划并执行需要数千次决策的复杂工程任务。 Devin 可以在每一步召回相关上下文,随时间学习并纠正错误。”
- Ashlee Vance 的报道 引用道:Wu 拒绝透露太多关于该技术底层的信息,仅表示他的团队找到了独特的方法,将 OpenAI 的 GPT-4 等大语言模型(LLMs)与强化学习技术相结合。
- 观看视频可以看到 Devin 拥有相当多必要的 LLM OS 工具:
- 异步聊天
- 浏览器
- 访问虚拟机的 Shell
- 带有 IDE 的编辑器
- 一个似乎是他们“秘诀”的“Planner”?
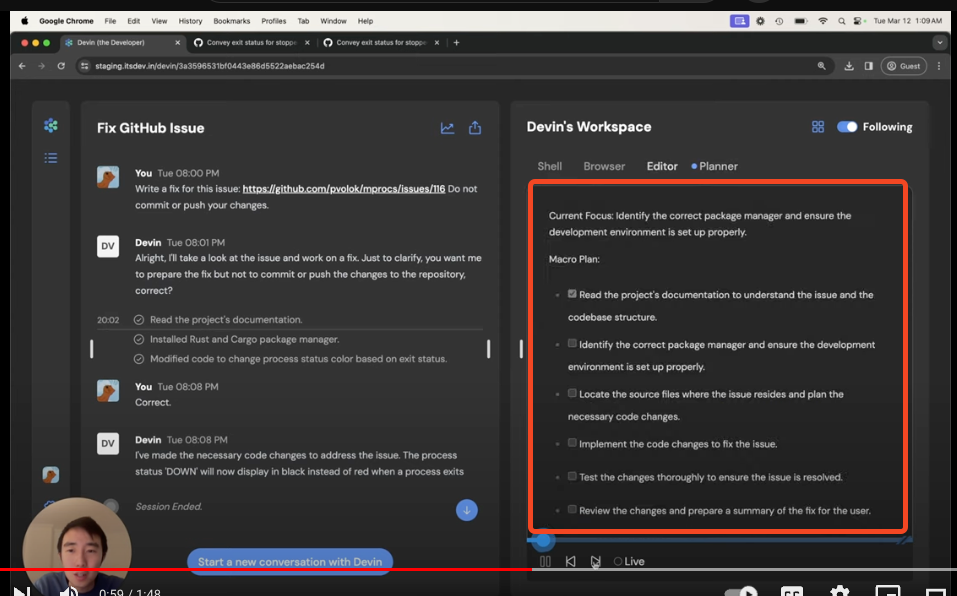
由于视频都经过了剪辑/加速,目前尚不清楚延迟是否是一个令人担忧的问题或只是暂时性的问题。由于 Devin 会报告工作时长,除了 UX 之外,并没有真正的动力去节省这方面的时间。
总的来说,人们再次对 Agent 和 AGI 感到兴奋,这总是值得庆祝的事情。
目录
[TOC]
第 X 部分:AI Twitter 汇总
所有汇总均由 Claude 3 Opus 完成,目前由 swyx 进行轻微编辑。我们正在开发抗幻觉、NER(命名实体识别)和上下文补充流水线。
语言模型与架构进展
- Google 发布 Multistep Consistency Models,这是 Consistency Models 与 TRACT 的统一,可以在 Consistency Model 和 Diffusion Model 之间进行插值。[210,858 次浏览]
- 语言模型的算法进展:研究人员使用 2012-2023 年的数据集发现,达到设定性能阈值所需的算力大约每 8 个月减半,显著快于摩尔定律(Moore’s Law)带来的硬件收益。[14,275 次浏览]
- @pabbeel:Covariant 推出了 RFM-1,这是一种多模态 any-to-any Sequence Model,可以为机器人与世界的交互生成视频。RFM-1 对 5 种模态进行 Tokenize:视频、关键帧、文本、传感器读取、机器人动作。[48,605 次浏览]
检索增强生成 (RAG) 与工具
- Retrieval Augmented Thoughts (RAT) 表明,通过信息检索迭代修正 Chain of Thoughts 可以显著提高 LLM 在长周期任务中的推理和生成能力。RAT 对 Zero-shot Prompting 的基准表现有显著提升。[41,937 次浏览]
- Cohere 发布 Command-R,这是一款针对大规模生产工作负载优化的 RAG LLM。它在高效能与强准确性之间取得了平衡,使企业能够从概念验证转向生产阶段。[75,829 次浏览]
- @fchollet:“AGI 的一个简单定义:一个能够像人类一样,使用相同数量的演示示例自学任何任务的系统。问题在于通用性,而非特定任务的技能。”[49,452 次浏览]
- @llama_index:“Anthropic 发布了一套使用 Claude 构建 RAG 和 Agent 的 Cookbook,涵盖从基础 RAG 到路由和查询分解等高级功能,再到复杂的文档 Agent 和多模态应用。”[46,629 次浏览]
多模态 AI 与视频理解
- Vid2Persona 让你能够与视频片段中的人物对话。它拥有一套简单的流水线,从提取视频角色特征到与其聊天。[10,326 次浏览]
- VideoMamba,一种用于高效视频理解的 State Space Model,解决了视频理解中局部冗余和全局依赖的挑战。其线性复杂度算子能够实现高效的长期建模,用于高分辨率长视频理解。[18,814 次浏览]
- V3D 利用预训练视频 Diffusion Model 的世界模拟能力来促进 3D 生成。通过在 360 度轨道帧上进行微调,它可以在 3 分钟内生成高质量的网格或 3D Gaussians。[18,814 次浏览]
负责任的 AI 与偏见
- @mmitchell_ai:研究表明,目前的 Instruction Tuning 实践教导 LLM 表面上掩盖隐性种族主义。当被直接询问时,像 GPT-4 这样的模型会对非裔美国人产生积极的情绪,但潜在的偏见仍然存在。[18,594 次浏览]
- 一项针对 AI 研究人员的调查 估计今年发生 AI 灾难的可能性为 4-20%。人们对 AI 实验室缺乏安全性表示担忧,这可能会加速对手的能力提升。[13,686 次浏览]
- @ehartford:《时代》杂志关于禁止开源 AI 模型的建议遭到了 AI 社区的强烈反对,他们主张民主化 AI 技术的重要性。[17,845 次浏览]
迷因与幽默
- “我生命中最讨厌的两件事:JIRA 和共产主义。按此顺序。” 114,102 次浏览
- ChatGPT 意外透露了一个结束文化战争的计划。10,026 次浏览
第 0 部分:总结的总结的总结
Claude 3 Sonnet (14B?)
1. 新的 AI 模型发布与功能
- Cohere 发布了 Command-R,这是一个 35B 参数的模型,针对推理、摘要、RAG 以及使用外部工具/API 进行了优化。示例:一段 YouTube 视频 展示了 Command-R 的 RAG 功能。
- Cognition Labs 推出了 Devin,这是一款通过了 SWE-Bench 编程基准测试和真实工程面试的 AI,代表了 AI 软件工程的一个里程碑。示例:Andrew Gao 的推文 分享了试用 Devin 的真实感受。
- ELLA (Efficient LLM Adapter) 在无需重新训练的情况下,显著提升了 SD3 等扩散模型中的文本对齐效果。示例:相关讨论对比了 ELLA 与其他模型的性能。
2. 加速与优化大语言模型 (LLM)
- Llama.cpp 引入了 2-bit 量化,以便在标准硬件上以更少的 RAM 和更高的速度更高效地运行 LLM。
- NVMe SSDs 使得在单张 GPU 上微调 100B 模型成为可能,正如一篇论文和 _akhaliq 的推文 中所讨论的那样。
- Unsloth 与普通的 QLoRA 相比,在 LLM 微调中实现了 2 倍的加速和 40% 的内存占用减少,且没有精度损失。
3. 开源 AI 工具与资源
- Hugging Face 引入了新功能,例如在 Hugging Chat 中过滤/搜索 Assistant 名称、博客目录以及 Space 的历史统计数据。
- WebGPU 可以使浏览器内的 ML 速度提升高达 40 倍,从而在 Web 浏览器中实现强大的 AI 应用。
- LlamaIndex 举办了关于构建上下文增强应用、检索策略以及为 LLM 实现长期记忆的网络研讨会、教程和见面会。
4. 分析与解释大语言模型 (LLM)
- 一种新的 模型窃取攻击 可以以低于 20 美元的成本从 GPT-3.5 等黑盒模型中提取嵌入层 (embedding layers),引发了安全担忧。
- Transformer Debugger 工具 无需编程即可实现 Transformer 模型内部结构的自动化可解释性和探索。
- 讨论探索了 在训练后更换 tokenizer 以获得更好的语言处理能力、受限解码技术 (constrained decoding techniques) 以及为了提高效率而 预编译/缓存函数生成。
Claude 3 Opus (>220B?)
-
Nvidia 的主导地位与 Vulkan 的潜力:CUDA MODE Discord 中的讨论强调了 Nvidia 强大的竞争优势和软件领先地位 几乎不可逾越,尽管 Vulkan 潜在的 PyTorch 后端 在理论上构成了挑战。Meta 在 AI 基础设施方面的重大投资,包括 24k GPU 集群 以及 350,000 个 NVIDIA H100 GPU 的路线图,进一步巩固了 Nvidia 的地位(Meta 的 GenAI 基础设施文章)。
-
Cohere 的 Command-R 模型与 RAG 能力:Cohere 发布了一个名为 “C4AI Command-R” 的 350 亿参数开源模型,可在 Hugging Face 上获取。Latent Space 和 Nous Research AI Discord 的讨论集中在其 检索增强生成 (RAG) 能力 以及与现有 RAG 设置合并的潜力上。分享的一段 YouTube 视频 展示了 Command-R 处理长上下文任务的能力。
-
神经网络收敛速度提升 100,000 倍:在 Skunkworks AI Discord 中,
@baptistelqt声称开发了一种方法,通过在每一轮中 从零开始 (from scratch) 训练模型,可以 将神经网络(包括 Transformers 在内的各种架构)的收敛速度提高 100,000 倍。 -
Devin:AI 软件工程师基准测试:AI 社区因 Devin 的推出而沸腾,这是由 Cognition Labs 开发的一款 AI 软件工程师,在 SWE-bench 编程基准测试 中取得了高分。Latent Space 的讨论强调了 Devin 令人印象深刻的支持者 及其彻底改变软件工程的潜力。
-
Grok 潜在的开源计划:Elon Musk 关于可能通过 xAI 开源 Twitter 算法 “Grok” 的 推文 在 Latent Space 和 Interconnects Discord 中引发了关于开源原则影响和 Musk 声誉的辩论。
-
大型模型的量化突破:LAION 的讨论聚焦于 llama.cpp 的 “2-bit 量化” 更新,该更新使得在普通硬件上更高效地本地运行大语言模型成为可能,详见 Andreas Kunar 的 Medium 文章。此外还探讨了 SD3 的量化和 CPU-offloading 以适应不同 VRAM 容量的潜力。
-
使用 NVMe SSD 进行高效微调:Nous Research AI 和 Interconnects Discord 讨论了使用 NVMe SSD 在单 GPU 上微调 100B 参数模型 的策略,并引用了关于 Fuyou 框架的一篇 论文 和一条 推文。
-
LM Studio 中的 Mac M1 GPU 利用率问题:LM Studio Discord 的用户报告了 LM Studio 在 Mac M1 系统上倾向于使用 CPU 而非 GPU 加速 的问题。讨论涉及针对特定硬件设置的模型推荐,以及使用 Tensor Split 功能 在不进行物理修改的情况下测试 GPU 性能。
-
初学者 LLM 学习资源:在 Eleuther Discord 中,用户建议初学者从 Google Colab 的 T4 GPU 上的小模型 开始,尽管每月需花费 20 美元,但仍应利用 GPT-4 和 Claude3,并参考 Lilian Weng 的 Transformer Family Version 2.0 文章和 HazyResearch 的 AI System Building Blocks 仓库等资源。
-
使用 LangChain 进行检索增强生成 (RAG):LangChain AI Discord 展示了一个 开源聊天机器人仓库,演示了 用于高效问答查询的 RAG,以及一份使用 LlamaIndex 构建多模态应用的 指南。讨论还涵盖了在各种应用中实施 LangChain 的故障排除和最佳实践。
ChatGPT (GPT4T)
AI 基础设施的效率创新:结合 GEAR 和 NVMe SSD 提速受到了显著关注,重点在于大模型操作和加速。讨论中特别提到了用于 KV cache 压缩的 GEAR 项目,以及使用 NVMe SSD 微调巨型模型,这表明人们对通过硬件创新优化 AI 模型效率的兴趣日益浓厚 (GitHub - opengear-project/GEAR, arXiv paper)。
微调技术与故障排除:开启非传统的微调速度以及微调表象与推理 Flops突显了社区在增强模型微调和故障排除方面的参与。通过 Unsloth-DPO 使 LLM 微调实现 2 倍加速 且 显存占用减少 40% 的技术引发了热议,而包括模型 Bug 和
<unk>响应在内的各种挑战,则强调了微调实践的复杂性 (Unsloth-DPO)。AI 模型与框架开发见解:ELLA 提升文本生成图像扩散模型以及 AI 领域的进展与讨论展示了围绕模型改进和框架开发的讨论。ELLA 对文本生成图像模型理解能力的提升,以及高效大语言模型适配器(Adapter)的发布,都是引发关注的进展,反映了 AI 技术领域持续的演进和专业化。
社区协作与技术分享:AI 项目开发的社区协作以及 Dev Days 和 RAG Nights 展示了跨平台的活跃协作努力。分享使用客户数据微调模型的资源、AI 项目开发建议,以及关于创建上下文增强型应用的开发者系列活动,都突显了社区支持和知识交换在加速 AI 创新中的重要性。
这些主题共同强调了一个动态且协作的 AI 研发环境,重点在于优化模型效率、推进微调方法论、促进 AI 模型与框架开发的创新,并利用社区协作实现共同成长和学习。
PART 1: 高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord 摘要
-
结合 GEAR 和 NVMe SSD 提速:社区参与了关于大模型操作效率的讨论:
@remek1972指向了用于 KV cache 压缩的 GEAR 项目 (GitHub - opengear-project/GEAR),@iron_bound讨论了一种使用 NVMe SSD 微调巨型模型的方法,以便在单块 GPU 上实现加速,并引用了一篇 arXiv 论文。 -
开启非传统的微调速度:
@lee0099展示了通过 Unsloth-DPO 实现的 LLM 微调 2 倍加速 和 40% 显存占用减少,在 showcase 频道引发了@starsupernova等用户的兴奋。 -
依赖困境与 AI 建模工具:开发环境问题也备受关注;
@maxtensor正在处理包不兼容问题,促使@starsupernova建议使用特定的 PyTorch wheel 来解决 xformers 安装问题,并进一步推荐使用 Windows Subsystem for Linux (WSL) 以获得更好的体验。 -
微调表象与推理 Flops:在 help 频道中,用户们应对各种挑战,从
@dahara1发现 Unsloth 更新后的 Gemma 模型 Bug,到@aliissa尝试排除模型返回<unk>响应的故障,这使得@starsupernova怀疑是 Padding(填充)和模板问题。 -
ELLA 提升文本生成图像扩散模型:random 频道发起了一场讨论,
@tohrnii分享了一篇关于 ELLA (Efficient Large Language Model Adapter) 的论文,旨在提升文本生成图像模型对 Prompt 的理解,同时@maxtensor和@starsupernova之间继续就 Windows 与 Linux 的操作偏好进行辩论。
Perplexity AI Discord 摘要
-
Claude 3 Opus 在 Perplexity Pro 中使用受限:用户报告称,在 Perplexity Pro 上,Claude 3 Opus 仅提供 5 次使用机会,而像 Claude Sonett 等其他 LLM 则有 600 次。讨论还涉及了 Perplexity 的竞争力,并推测可能推出基于广告的 Pro 模型,引用了 Perplexity CEO 关于竞争对手定价策略和尝试招聘 AI 研究员的推文。
-
Perplexity 的招聘咨询与建议:一位用户表达了对 Perplexity AI 工作机会的兴趣,得到的建议是查看招聘页面,而不要直接标记团队成员。另一位用户寻求帮助以改进 pplx API,以便在个人助手项目中使用。
-
LLM 功能与特性的辩论:关于 Perplexity 是使用 Gemini 等外部模型还是拥有自己的模型存在争论,用户注意到其回答与 Gemini 的 API 相似。此外,还提出了关于使用 Yarn-Mistral-7b-128k 模型进行高上下文对话的查询,以及 pplx API 在回复中检索网络资源的问题。
-
Pro 用户寻求高效利用策略:Pro 用户讨论了 Logo 设计的使用以及上传 PDF 脚本进行查询,重点在于如何针对特定用例有效地利用 Perplexity。
-
Perplexity 社区的内容共享:成员们分享了涵盖 AI 发现、太空垃圾重返大气层、CSS 见解以及草莓分类等主题的资源,强调了使帖子在社区内可共享的重要性。
Nous Research AI Discord 摘要
-
神经网络收敛速度提升 100,000 倍:@baptistelqt 声称开发了一种方法,可以使神经网络的收敛速度加快 100,000 倍,适用于包括 Transformers 在内的各种架构,相关论文即将发表。
-
AI 领域的进展与讨论:讨论了 Cohere 的 C4AI Command-R,这是一个针对推理和摘要优化的 350 亿参数模型,并提及了 Command-R 的 GitHub 演示。Deepseek-VL 模型作为潜在的颠覆者出现,随后引发了关于在预训练模型中用双重分词(dual tokenization)替换 tokenizer 的辩论。
-
合并 Command-R 和 RAG:CohereForAI 的 C4AI Command-R 模型 因其能够通过简化的搜索方法促进 RAG 调用而受到关注,并提供了 Model Card。此外还展示了 AI 在游戏开发中的实际应用。
-
AI 治理的见解与事件:讨论涉及了 Mark Zuckerberg 和 Elon Musk 对 AI 的不同看法和远见。对 Nous Hermes 2 等模型的许可法律问题进行了审查,同时人们对函数调用(function-calling)LLM 中的递归概念充满期待。
-
AI 技术挑战与工具:针对特定语言处理的 tokenizer 替换故障排除、微调模型大小、内存需求以及结构化模型输出成为焦点。提到了 llama-cpp 和 qlora 等各种工具,用于辅助特定的 AI 开发任务。
LM Studio Discord 摘要
-
M1 Mac 跳过 GPU 加速:用户如
@maorwe和@amir0717反馈,LM Studio 在 Mac M1 系统以及包括配备 16 GB RAM 的 GTX 1665 Ti 在内的不同配置上,偶尔会优先使用 CPU 而非 GPU 加速。讨论涉及探索在特定硬件上表现更好的模型选项,建议指向 deepseek-coder-1.3b-instruct-GGUF。 -
通过 Tensor Splits 释放模型潜力:讨论了将 Tensor Split 设置为 “0, 100” 等配置,以在不物理更改硬件连接的情况下测试特定 GPU 在 LM Studio 中的性能。会议指出,双 GPU 设置和配备 PCIe 4.0 的先进主板(如 MSI Meg X570)可以优化 RTX 3090 性能。
-
热切期待 LM Studio 的下一步行动:用户正热切期待 LM Studio 即将发布的更新中的新功能,包括改进的聊天 “Continue” 行为和增强的 version.16 支持,其中对更新的 AVX beta 版本的关注呼声显著。
-
为 LLM 选择云端还是芯片?:关于运行大语言模型(LLM)时偏好云服务还是本地硬件的争论正在酝酿。成本、保密性以及来自 Google 等云服务商的资助被提及为重要的考量因素。
-
探索优化 LLM 性能的替代方案:虽然目前还没有明确推荐能够增强叙事能力的模型,但一位用户指出 stablelm zephyr 1.5 GB 在生成 C++ 代码时存在不完整的问题。其他用户讨论了 KoboldAI 和 CrewAI 等替代平台,并权衡了 AutoGen 界面的图形优势,以及监控封闭 Token 生成循环以节省计算资源的必要性。
OpenAI Discord 摘要
-
长视频雄心遭遇技术限制:讨论集中在 SORA AI 创建 30 分钟超长视频的能力上,内存限制等技术约束被强调为当前的挑战。虽然 SORA 受限于这些限制,但从技术上讲,它可以按照 OpenAI 研究论文中所述,分段生成长视频。
-
关于 GPT-3.5 订阅层级的困惑与澄清:用户正在寻求关于不同订阅层级中 GPT-3.5 模型差异的澄清,主要区别在于使用限制而非功能差异。GPT-3.5 知识截止日期后的更新也是一个受关注的话题,引发了关于 API 和 ChatGPT 版本之间版本差异的疑问。
-
同行互助提升 Prompt Engineering 实践:用户
@darthgustav.一直在建议利用包含代表指令的变量名的输出模板来增强 GPT 输出的一致性。通过协作解决问题和共享资源,正在解决诸如重写文本和处理 HTML 片段等挑战,并强调需要遵守 OpenAI 的 使用条款 和 使用政策。 -
AI 模型的使用体验分歧:用户比较了他们在不同 AI 模型(如 Claude Opus 和 GPT-4)上的体验,指出 Claude 可能会提供比 GPT-4 更具创意和简洁的输出,而 GPT-4 有时倾向于生成列表(bullet points)或参与度较低的内容。
-
AI 项目开发的社区协作:该频道已成为 AI 项目协作开发的中心,成员们分享了使用客户数据微调模型的资源,并为一个使用 GPT 和 OpenCV 的纸牌教学机器人项目提供建议。资源包括一个 GitHub Notebook mistral-finetune-own-data.ipynb,这似乎是满足自定义微调需求的宝贵资源。
HuggingFace Discord 总结
Hugging Face 推出便捷新功能:Hugging Chat 现在允许用户过滤和搜索 Assistant 名称,且 Hugging Face 博客新增了“目录”功能以便于访问。Hugging Face Spaces 现已提供历史累计统计数据,使创作者能够更全面地评估其 Space 的受欢迎程度。
WebGPU 有望加速浏览器端 ML:来自 Hugging Face 的 @osanseviero 指出,WebGPU 有可能将浏览器中的机器学习速度提升高达 40 倍。
扩展开发者资源与学习:Transformers.js 2.16.0、Gradio 4.21 和 Accelerate v0.28.0 的最新版本为开发者带来了新功能。此外,@ThomasSimonini 宣布了一门名为 Machine Learning for Games 的新课程。
跨频道的尖端工具与模型发现:
- 葡萄牙语语言模型 - Mambarim-110M:由
@dominguesm发布,这是一个名为 Mambarim-110M 的新葡萄牙语 LLM,基于 Mamba 架构,并在 62 亿 token 的数据集上进行了预训练 (Hugging Face, GitHub)。 - GitHub 用户
@210924_aniketlrs02正在寻求关于应用 wav2vec2 codebook 提取脚本 的指导,以从 Wav2Vec2 模型中提取量化状态。 - Lucid Dream Project 和 Vid2Persona:在 Hugging Face Spaces 上分享了使用 Web-GL 和视频角色对话式 AI 的独特项目,展示了 AI 的创新应用 (The Lucid Dream Project)。
- Microsoft 推出了 AICI: Prompts as (Wasm) Programs,增强了 AI 应用的 Prompt 处理能力 (AICI on GitHub)。
探讨实际 AI 实施的概念与模型:
- 关于基于动作的 AI 未来的辩论,涉及 LLM 与 API 的集成。
- 关于实际 AI 应用的问题,包括潜在的硬件黑客手段,如使用 PS5 主机获取强大的 VRAM 模块。
- 引用 PS3 主机作为超级计算机引发了讨论,突显了游戏硬件在极具挑战性的计算任务中的潜力。
- 还强调了使用 PS5 等游戏机进行计算任务的尝试与挑战,以及驱动限制和 AMD 与 Intel 显卡缺乏类似 Nvidia NVLink 连接的问题。
演进自然语言处理中的 AI 话语:
- 询问了评估与 LLM 对话中清晰度和情感的方法。
- 寻求用于 NSFW 无审查翻译的最佳模型,专注于准确性和优化。
- 请求识别文档中分布外 (out-of-distribution) 词汇或短语的策略。
- 建议使用 Hugging Face 的轻量级 LLM 评估套件 LightEval 来对类 LORA 技术进行基准测试。
Eleuther Discord 总结
-
探索无需 GPU 的 LLM 学习:
_michaelsh获得了关于在没有 GPU 的情况下学习 LLM 的建议,即利用 Google Colab 的 T4 GPU 来处理包括 Gemma 和 TinyLlama 在内的中等规模模型。 -
LLM 爱好者的学习材料与成本:向
_michaelsh推荐了潜在的 LLM 教育资源,如 YouTube 以及 GPT-4 和 Claude3 等 LLM 的付费访问,指出每月成本约为 20 美元。 -
LLM 中的安全漏洞:讨论了一种新兴的模型窃取攻击,该攻击可以从 gpt-3.5-turbo 等模型中提取投影矩阵,引发了关于暴露此类漏洞的伦理和法律辩论。
-
Transformer 调试工具与可解释性:
@stellaathena询问了 transformer-debugger 与 Hugging Face 训练模型的兼容性,而@millander研究了一篇关于通过剪枝移除 AI 模型中不需要的能力的论文,质疑了与图像分类相比,语言模型在效用权衡方面的表现。 -
超参数头疼与基准测试忧郁:使用带有较高学习率的 Llama 超参数 导致评估性能不佳,
@johnnysands推测可能需要更多的退火 (annealing),而@epicx则思考了 SQuAD 和 Natural Questions 排行榜等历史基准测试受欢迎程度下降的原因。
LlamaIndex Discord 摘要
-
准备,开始,记忆!:一场关于 MemGPT 的网络研讨会定于周五上午 9 点(PT 时间)举行,讨论 LLM 的长期、自编辑内存。会议邀请了知名嘉宾,旨在探讨
@jerryjliu0所强调的大语言模型 虚拟上下文管理 挑战。研讨会注册请访问 活动报名。 -
开发者日与 RAG 之夜:
@ravithejads介绍了一个关于使用 LlamaIndex 和 Claude 3 构建上下文增强型应用的系列,而@hexapode邀请开发者参加在巴黎举行的 RAG 见面会,讨论高级 RAG 策略。该系列和活动的详细信息分别见 Twitter 和 Twitter。 -
洞察、查询与 LLM 代码片段:
@whitefang_jr针对 RAG 部署、MistralAI 中的全局查询参数以及向量存储问题提供了讨论支持,并附带了相应的 全栈应用 和 GitHub 源代码 链接。此外,还为对语言-图像集成感兴趣的人员分享了使用 LlamaIndex 创建多模态应用的指南。 -
Matryoshka 与 Claude 纪事:AI 社区正在热烈讨论由 Jina AI 主办的 Matryoshka Representation Learning 论文研讨会,主讲人为 Aditya Kusupati 和 Aniket Rege,在此注册。此外,
@vodros正在寻求 Claude 3 的开源 GUI/前端,@shure9200宣布了一个新的 LLM Research Paper Database,该仓库旨在聚合高质量的研究论文。 -
工程师 AI 论文库提醒:
@shure9200为 AI 研究人员介绍了一个极具价值的资源——LLM 论文数据库,旨在帮助大家跟上该领域的学术进展。关于 Matryoshka Representation Learning 的论文讨论也邀请工程师们加入并与论文作者互动。
LAION Discord 摘要
-
ELLA 增强文本到图像的精度:ELLA 的推出备受关注,它展示了在无需额外训练的情况下,提高 SD3 等文本到图像扩散模型中文本对齐的能力。技术细节和对比可以在 腾讯 ELLA 网站 进一步探索。
-
Llama.cpp 彻底改变标准硬件上的 LLM:
@vrus0188讨论了 llama.cpp 中全新的“2-bit 量化”突破,允许在标准硬件上更高效地运行大语言模型。见解和开发细节涵盖在 Andreas Kunar 的 Medium 文章 中。 -
SD3 的广阔前景:探讨了 SD3 的潜力,指出其优势在于没有交叉注意力(cross-attention)以及整合图像和文本嵌入的能力。此外,关于模型可扩展性、量化方法以及模型在普通 GPU 上的性能讨论也在进行中。
-
量化和 CPU-Offloading 让 SD3 适配多种硬件:量化和 CPU-offloading 等策略可以通过适应不同的 VRAM 容量,使 SD3 更加普及。讨论强调了这些策略对执行时间和性能权衡的影响。
-
成本不足 20 美元即可揭示 Transformer 模型的漏洞:一篇 arXiv 论文 披露了一种攻击技术,能够以极低的成本恢复 Transformer 模型(尤其是 OpenAI 的模型)的部分内容,这引发了关于模型安全性的讨论,并导致 OpenAI 和 Google 随后更改了 API。
-
深入探索 LAION-400M 数据集:Thomas Chaton 在一篇文章中肯定了 LAION-400-MILLION 图像和字幕数据集的重要性,并为对该数据集潜力感兴趣的人提供了文章链接:探索 LAION-400M 数据集。
Latent Space Discord 总结
-
AI “Devin” 惊艳开发者:Cognition Labs 名为 “Devin” 的 AI 在 SWE-bench 编程基准测试中表现优异,具有彻底改变软件工程的潜力。讨论提到了 Devin 的背景和能力,包括其独立编写整个程序的能力,正如 Neal Wu 和 Ashlee Vance 的推文所强调的那样。
-
马斯克的“开放”AI 举动引发辩论:关于埃隆·马斯克提议可能开源 Twitter 算法 “Grok” 的提议引发了辩论,观点涉及开源精神以及马斯克在其推文背景下的声誉影响。
-
权重提取 AI 研究:一篇新的 DeepMind 论文专注于从 AI 模型的 Embedding 层部分提取权重,这引发了关于防止权重提取的复杂性和当前缓解措施的讨论。
-
Karpathy 达成里程碑:社区成员庆祝了 Andrej Karpathy 的新成就,讨论了他对 AI 的贡献及其对内容创作未来的影响。
-
Truffle-1:高性价比的下一代 AI 推理:根据发布推文,Truffle 推出的经济实惠的 AI 推理引擎 Truffle-1 因其低功耗、价格亲民以及对运行开源 AI 模型的潜在影响而受到关注。
Interconnects (Nathan Lambert) Discord 总结
-
埃隆·马斯克暗示开源 Grok:在一条推文中,
@elonmusk暗示 xAI 将开源 Grok,这引起了社区成员的注意,尽管有人对开源的准确定义提出了担忧。 -
Cohere 为学术界发布 Command-R:Cohere 推出了新的大规模生成模型 Command-R,重点是支持生产级 AI 应用,并允许学术界访问其权重。
-
预训练成本大幅下降:用户讨论了 GPT-2 等模型的预训练成本已降至 1,000 美元以下,引用了 9 月 22 日的 Mosaic Cloud 数据,以及一篇名为《以 50 万美元达到 GPT-3 质量》的 Databricks 博客文章,以进一步了解经济性和规模化 (Databricks Blog)。
-
Meta 大规模扩展 AI 基础设施:Meta 计划在 2024 年底前通过组装 350,000 块 NVIDIA H100 GPU 来支持其 AI 基础设施,详见新闻稿,旨在支持包括 Llama 3 在内的项目。
-
社区对订阅者的感谢:一位成员对自己的“订阅者”身份表示不满,但得到了
@natolambert的安抚,他强调了订阅者在维持社区运作中发挥的关键作用。
CUDA MODE Discord 总结
Nvidia 的护城河 vs. Vulkan 的潜力:Nvidia 在 GPU 领域的统治地位仍然是关注的焦点,讨论强调了 Nvidia 极具竞争力的优势和软件领先地位几乎不可逾越,尽管 Vulkan 潜在的 Pytorch 后端在理论上构成了挑战。用户还表达了由于安装和打包过程类似于 CUDA 的问题,导致使用 Vulkan 的复杂性。Meta 对 AI 基础设施的大规模投资(包括一个 24k GPU 集群以及 350,000 个 NVIDIA H100 GPU 的路线图)进一步巩固了 Nvidia 在该领域的统治地位 (Meta 的 GenAI 基础设施文章)。
Triton 社区集会:Triton 编程语言社区正在筹备即将于 太平洋时间 3/28 上午 10 点 举行的聚会。可以通过 Triton Lang Slack 频道及其 GitHub 讨论页面 与社区互动并获取会议信息。
CUDA 开发见解与技巧:关于 CUDA 的讨论包括通过线程粗化(thread coarsening)提升性能的好处、针对 Visual Studio Code 进行 CUDA 开发的优化,以及学习特定 CUDA 数据类型和线程的建议。分享了一个详细的 VS Code c_cpp_properties.json 配置设置,重点介绍了 CUDA toolkit 和 PyTorch 所需的包含路径(includes)。
PyTorch 生态系统活跃讨论:在 PyTorch 社区中,有人提出了关于 libtorch 与 load_inline 之间性能差异的问题,澄清了 Modular 在优化 kernel 与 GPU 架构兼容性方面的作用,并公开征集关于 torchao RFC #47 的反馈,以简化新量化算法和数据类型的集成。
NVIDIA 创新与培训资源:CUDA 社区探讨了 NVIDIA 的前沿技术,如 Stream-K 和 Graphene IR,这些技术有望显著提升 GPU 上矩阵乘法的速度并进行优化,并分享了 CUTLASS 仓库的链接 (NVIDIA Stream-K 示例)。对于 CUDA 学习者,推荐了 YouTube 上全面的 CUDA Training Series 及其相关的 GitHub 材料 (CUDA Training Series GitHub)。
PMPP 及其他学习资源:《Programming Massively Parallel Processors》(PMPP) 一书被指出未广泛涵盖分析工具(profiling tools),相关补充内容可通过关联的 YouTube 视频获取。此外还解决了一些 CUDA 课程问题,包括关于 CUDA C++ 语法中的空格问题以及 PMPP 2023 版的练习题解答。
Ring Attention 故障排除与协调:一位用户提供了 GPU 资源用于压力测试 ring attention 代码,并根据美国夏令时变化协调了会议时间,同时在遇到高训练损失(training loss)后寻求建议。WANDB 被用作训练环节的评估工具。
场外传闻与 AI 进展:关于 Inflection AI 和 Claude-3 的推测性讨论通过一条澄清推文得到了证实。一张神秘的图片引发了好奇心,人们的注意力被吸引到了由 Cognition Labs 开发的名为 Devin 的新 AI 软件工程师上,它有望在软件工程领域树立新的基准,@itsandrewgao 发布了一项真实世界的测试 (Andrew Kean Gao 的推文)。
LangChain AI Discord Summary
-
有效的 Prompt 编写解决了 Langchain 问题:
@a.asif通过创建合适的 Prompt 解决了一个问题,强调了 context 在获取理想响应中的重要性。 -
Langchain 与 Claude 集成的进展:根据
@dwb7737提交的 pull request,Chat Playground 现在已包含 Claude V3 模型支持,这标志着使用 Langchain 的开发者的一个重要更新。 -
构建具有增强检索能力的聊天机器人:
@haste171分享了一个开源 AI 聊天机器人仓库,该仓库利用 RAG 进行问答查询;同时@ninamani就其聊天机器人开发中切换到chat模式寻求建议,特别是针对使用新 LLM(如微调版的 llama-2)的情况。 -
Langchain 用户的学习资源:
@infoslack和@jasonzhou1993在 YouTube 上分享了新的教程,如 “Chatbot with RAG” 和 “INSANELY Fast AI Cold Call Agent- built w/ Groq”,为使用 Langchain 和 Groq 平台构建 AI 应用提供了实践指导。 -
社区协作与 Langchain 实施支持:讨论内容包括寻求 Langchain 到 LCEL 的转换指导、解决 iFlytek Spark API 的问题,以及优化 LangServe 的使用,社区成员在技术挑战上互相提供支持和解决方案。
OpenAccess AI Collective (axolotl) Discord Summary
-
RTX 系列的 Flash Attention 修复:针对 RTX 3090 或 4000 系列 GPU 禁用 Flash Attention 的问题,建议在 YAML 配置中使用
[flash_attention: false]和[sdp_attention: true]。 -
Cohere 凭借 ‘C4AI Command-R’ 带来巨大惊喜:Cohere 发布了一个名为 “C4AI Command-R” 的开源 350 亿参数模型,现已在 Hugging Face 上线。
-
DoRA 在 PEFT PR 合并中获得支持:Hugging Face 合并了一个为 4bit 和 8bit 量化模型添加 DoRA 支持的 PR,尽管提到 DoRA 目前仅支持线性层,并提醒在推理过程中合并权重时需注意。
-
使用 NVMe SSD 优化 AI 训练:引用 AK 的一条 推文,讨论了在单 GPU 上利用 NVMe SSD 高效微调 100B 参数模型的策略。
-
Axolotl 与 DeepSpeed 的高级讨论:提出了关于 Axolotl 中 DeepSpeed API 的问题,相关的 DeepSpeed PR 正在审查中;此外,Axolotl 最近的一个 修复 可能会解决 Mixtral 训练中评估结果较差的问题。
OpenRouter (Alex Atallah) Discord Summary
- 寻找 ChatGPT 3.5 的替代品:
@mka79寻求办公场景下 ChatGPT 3.5 的替代方案,强调了隐私、减少审查以及不将用户数据用于训练的需求。 - Gemma 的新竞争者:
@louisdck推介了基于 Gemma 的 新 Openchat 模型,声称其性能与 Mistral 模型相当,并优于其他 Gemma 模型。 - Hermes 已下线:Nous Hermes 70B 模型的访问问题已确认,
@louisgv表示该模型将无限期离线,并计划进行更新以防止在停机期间被访问。 - Openchat 和 Gemma 用户遇到超时:由于滥用行为,包括 Openchat 和 Gemma 在内的免费模型暂时对没有额度的用户禁用,
@alexatallah承诺将努力恢复访问。 - Cheat Layer 率先推出新的免费自动回复功能:
@gpuman重点介绍了 Cheat Layer 在网站上利用 OpenRouter 提供的全新免费自动回复服务,并敦促用户向其支持团队报告任何问题;此外还提到了关于开源 Open Agent Studio 和集成 OpenRouter 的讨论。
DiscoResearch Discord 总结
-
开源向 GPT-4 发起挑战:社区内一个幽默的预测期待开源模型可能超越 GPT-4,引发了建立全面 benchmark evaluation 的兴趣。同时,
@.calytrix表示打算在严格控制的测试环境下将各种模型与 GPT-4 进行比较。 -
强化版 FastEval:社区讨论了为 FastEval 增强灵活的后端(如 Llama.cpp 或 Ollama),此前曾有将 FastEval 进行修改以扩展其原始适用范围的案例。
-
RAG 标签,轮到你了:成员们辩论了 Prompt 工程中 context 和 RAG 指令 的最佳放置位置,观点因 Specialized Fine-Tuning (SFT) 经验以及模型在训练期间是否接触过 [SYS] 和 [USER] 标签而异。
-
剖析 Transformer 大脑的新工具:一款用于深入了解 Transformer 内部机制的新工具受到关注:由
@janleike发布的 Transformer Debugger,承诺提供自动化可解释性,并提供一种无需编码即可探索模型内部的方法。 -
警惕非标准模型生态系统:社区讨论了
DiscoResearch/mixtral-7b-8expert模型在非英语文本生成方面的问题,建议使用 Hugging Face’s Mixtral-8x7B-v0.1 的官方实现以获得更好的可靠性。此外,大家认识到需要对像DiscoResearch/mixtral-7b-8expert这样的实验性模型进行更清晰的标注。 -
小身材大潜力的 tinyMMLU:对 Hugging Face 上的 tinyMMLU benchmarks 表现出兴趣,认为这是在探索基准测试效用的同时运行翻译的一种高效手段。
-
Hellaswag 基准测试揭示了耐心的力量:观察发现 Hellaswag 基准测试显示出明显的噪声,即使在 1000 个数据点之后分数仍有明显波动,这凸显了需要进行广泛测试才能获得稳定且有意义的结果。
Alignment Lab AI Discord 总结
-
寻找高效的微型模型:用户
@joshxt询问了 最适合本地使用且低 RAM 的 1024+ 最大输入的最佳小型 embedding 模型,但随后没有进一步讨论。 -
深入研究用于绘图的 Mermaid:
@teknium询问了 Mermaid 图表,@lightningralf提供了说明和资源,包括 Mermaid live editor 和 GitHub 仓库。@joshxt通过一个复杂的系统示例展示了 Mermaid 的功能,以及它在 GitHub 上从代码生成可视化图表的实用性。 -
埋头于代码雪崩之中:
@autometa幽默地感叹编码任务堆积如山,随后采取行动为团队开发 Docker 环境。他们为 Docker 设置协助提供了 100 美元的悬赏,并公开征集开放科学/研究项目的合作,同时将包括 Docker 职责在内的任务委派给@alpin以取得进一步进展。
LLM Perf Enthusiasts AI Discord 总结
-
Grok 即将开源:
@elonmusk发推称@xAI将于本周开源 Grok,引发了开源社区内关于潜在用途和益处的讨论。Elon Musk 的推文 激发了用户的期待。 -
Command-R 咨询:
@potrock正在寻求关于 Command-R 本地实现的见解,鼓励其他用户分享他们对这一新工具的实验和结果。 -
Token 限制难题:
@alyosha11提出了 gpt4turbo 中 4096 token 限制 带来的挑战,引发了关于变通方法和对未来模型改进预期的讨论。 -
揭开 GPT-4.5 Turbo 之谜:
@arnau3304发起了一场辩论,引用了一个 Bing 搜索链接 指向 GPT-4.5 Turbo 的传闻;然而,@dare.ai等人表示怀疑,指出在没有官方确认的情况下存在不确定性。 -
Azure 迁移的好奇:用户
@pantsforbirds对从 OpenAI SDK 迁移到 Azure 平台的经验表示兴趣,征求关于潜在障碍和技巧的建议,展示了对云端 AI 服务平台的共同兴趣。
Skunkworks AI Discord 摘要
-
AI 训练中的量子级加速揭晓:@baptistelqt 通过采用每一轮都从头开始(from scratch)训练 AI 模型的新颖方法,实现了训练收敛速度的 100,000 倍加速。
-
使用 Claude 3 进行游戏编程:@pradeep1148 分享了一个 YouTube 视频,展示了如何使用 Claude 3 和 Python 开发一款基于植物大战僵尸(Plants Vs Zombies)的游戏。
-
深入探讨 Command-R 的 RAG:@pradeep1148 还展示了一个 YouTube 探索视频,研究了 Command-R 通过检索增强生成(RAG)和外部 API 处理长上下文任务的能力。
AI Engineer Foundation Discord 摘要
-
插件讨论待定:由
@hackgoofer发起了一场关于插件可配置性的讨论,特别是将基于 token 的授权作为插件参数的可行性。会上有人对这种安全措施是否足够提出了担忧。 -
项目提案征集:成员们受邀提出新项目,范围和指南已在 Google Docs 指南中提供。会议强调了合作机会,包括一个与 Microsoft 的合作项目。
第 2 部分:频道详细摘要与链接
Unsloth AI (Daniel Han) ▷ #general (237 条消息🔥🔥):
- 关于使用微调模型的咨询:
@animesh.ad寻求帮助,希望在不使用 GPU 的情况下测试上传到 hub 的微调 Gemma-2 模型,随后收到了@starsupernova关于使用“普通 HF 代码”的建议。经过一番周折,@animesh.ad澄清模型因路径错误无法访问,@starsupernova建议重新尝试该过程,因为关键文件的名称可能不正确。 - Kaggle Notebook 的困扰与成功:
@simon_vtr分享了在没有互联网连接的情况下在 Kaggle 上运行推理的问题。尽管遇到了依赖项未安装(如bitsandbytes、xformers)等障碍,@simon_vtr最终报告成功离线运行 Unsloth 模型。 - Unsloth 特性与未来发展:
@theyruinedelise和@starsupernova强调了 Unsloth 在修复 Google 和 Hugging Face 实现中的 Bug 方面的针对性,并讨论了模型的局限性和特性。@theyruinedelise预告了即将推出的支持一键微调的 Unsloth Studio。 - RoPE Kernel 优化建议:
@drinking_coffee提出了一项对 RoPE Kernel 的改进建议,通过使用 group 方法优化沿 axis 1 的计算。@starsupernova对该建议表现出兴趣,并鼓励提交 pull request 以整合该增强功能。 - 新用户与社区参与:频道迎来了新成员,如由 Micode 和 Yannic 的 Twitter 帖子引导而来的
@remybigboss。@theyruinedelise对曝光度的提升表示感谢,并鼓励大家在 GitHub 上点亮 star。
提及的链接:
- Google Colaboratory: 未找到描述
-
Kaggle Mistral 7b Unsloth notebook: 使用 Kaggle Notebooks 探索并运行机器学习代码 使用来自“无附加数据源”的数据 -
Kaggle Mistral 7b Unsloth notebook Error: 使用 Kaggle Notebooks 探索并运行机器学习代码 使用来自“无附加数据源”的数据 -
Kaggle Mistral 7b Unsloth notebook Error: 使用 Kaggle Notebooks 探索并运行机器学习代码 使用来自“无附加数据源”的数据 - CohereForAI/c4ai-command-r-v01 · Hugging Face: 未找到描述
- danielhanchen (Daniel Han-Chen): 未找到描述
- Paper page - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU: 未找到描述
- GitHub - stanford-crfm/helm: Holistic Evaluation of Language Models (HELM), a framework to increase the transparency of language models (https://arxiv.org/abs/2211.09110). This framework is also used to evaluate text-to-image models in Holistic Evaluation of Text-to-Image Models (HEIM) (https://arxiv.org/abs/2311.04287).: Holistic Evaluation of Language Models (HELM),一个旨在提高语言模型透明度的框架 (https://arxiv.org/abs/2211.09110)。该框架也用于在 Holistic Evaluation of Text-to-Image Models (HEIM) (https://arxiv.org/abs/2311.04287) 中评估文本生成图像模型。
- GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning: 速度提升 5 倍,显存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账号为 unslothai/unsloth 的开发做出贡献。
- GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning: 速度提升 5 倍,显存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账号为 unslothai/unsloth 的开发做出贡献。
Unsloth AI (Daniel Han) ▷ #welcome (12 条消息🔥):
- 热烈欢迎与重要阅读:
@theyruinedelise热情地向大家打招呼,并提醒所有人阅读频道 <#1179040220717522974>,并在 <#1179050286980006030> 中分配自己的角色。 - 欢迎频道中的游戏话题:
@emma039598询问群组成员是否玩游戏,@theyruinedelise给出了积极回应,并提到了 League of Legends、Elden Ring 和 Soma 等心头好。 - 欢迎新人:
@starsupernova加入并欢迎来到服务器的新人。 - 休闲游戏聊天: 当
@theyruinedelise询问游戏偏好时,@emma039598表示更喜欢 RPG。 - 欢迎与喜悦的表达:
@theyruinedelise在聊天中发了一个简单的 “win”,@chelmooz用亲切的 “coucou” 向大家问好。
Unsloth AI (Daniel Han) ▷ #random (9 条消息🔥):
- 介绍 ELLA 以改进文本生成图像 Diffusion Models:
@tohrnii分享了一篇 arxiv 论文,重点介绍 Efficient Large Language Model Adapter (ELLA),旨在增强文本生成图像 Diffusion Models 对复杂提示词(prompts)的理解,且无需重新训练。 - AI 开发中的 Windows vs Linux:
@maxtensor和@starsupernova讨论了他们的开发环境,@starsupernova主要在 Colab 和 Linux 上工作,并提到他们的 Windows 机器缺少 GPU。 - 依赖地狱来袭:
@maxtensor详细描述了 Ubuntu WSL 环境中令人沮丧的依赖冲突,在尝试集成新的 AI 工具时导致了包版本不兼容,特别是 torch、torchaudio 和 torchvision。 - 寻找软件依赖解决方案:
@starsupernova建议尝试使用特定的 PyTorch wheel 索引安装 xformers,以潜在地解决@maxtensor遇到的依赖问题。 -
AI 模型训练的煎熬:
@thetsar1209用表情符号表达了对漫长模型训练过程的苦恼,进度输出显示为 “20/14365 [07:23<74:37:53, 18.73s/it]”。 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment:Diffusion Models 在文本生成图像领域表现出了卓越的性能。然而,大多数广泛使用的模型仍然采用 CLIP 作为其文本编码器,这限制了它们的语义理解能力…
- 未找到标题:未找到描述
Unsloth AI (Daniel Han) ▷ #help (272 条消息🔥🔥):
-
Gemma 模型转换风波:
@dahara1发现将 Gemma 模型转换为 GGUF 格式需要使用convert-hf-to-gguf.py而不是convert.py,并分享了一个关键的 GitHub pull request 作为参考。他们还发现 Unsloth 在某次更新后处理 Gemma 时可能存在 Bug,指出使用 Unsloth 创建的模型在本地 PC 上无法正确推理,但在上传到 Hugging Face 后可以正常工作。 -
揭秘量化难题:用户
@banu1337和@starsupernova讨论了模型量化的困难,@banu1337特别提到即使拥有充足的 GPU 资源,在量化 Mixtral 模型时仍遇到困难。@starsupernova推荐使用 GGUF 作为替代方案,并指出 Unsloth 对其的支持,同时建议 2 张 A100 80GB GPU 应该足以完成该任务。 -
从 LLMs 中学习:
@abhiabhi.与@starsupernova进行了一场哲学对话,涉及学习率(learning rates)、预热步数(warmup steps)以及确定性机器产生智能的本质。 -
Unsloth 在 Windows 上的困扰:
@ee.dd在 Windows 上通过 Conda 安装 xformers 时遇到挑战,@starsupernova建议尝试使用pip安装。在进一步遇到问题后,@starsupernova建议使用 WSL 以获得更顺畅的体验。 -
模型加载之谜:
@aliissa在不进行 fine-tuning 的情况下使用 NousResearch/Nous-Hermes-2-Mistral-7B-DPO 时寻求帮助,因为他们只收到了<unk>值的响应。@starsupernova建议这可能是由于 padding 和缺少合适的 chat template 导致的。
提到的链接:
- Repetition Improves Language Model Embeddings:最近改进从自回归大语言模型(LLMs)中提取文本嵌入(embeddings)的方法主要集中在改进数据、骨干预训练语言模型或…
- 未找到标题:未找到描述
- Gemma models do not work when converted to gguf format after training · Issue #213 · unslothai/unsloth:训练后将 Gemma 转换为 GGUF 格式时,它在 lm studio 等使用 llama cpp 的软件中无法工作。llama_model_load: error loading model: create_tensor: tensor ‘output.wei…
- KeyError: lm_head.weight in GemmaForCausalLM.load_weights when loading finetuned Gemma 2B · Issue #3323 · vllm-project/vllm:你好,我用 Unsloth 微调了 Gemma 2B。它使用 LoRA 并将权重合并回基础模型。当我尝试加载此模型时,出现以下错误:… File “/home/ubuntu/proj…
- VLLM Multi-Lora with embed_tokens and lm_head in adapter weights · Issue #2816 · vllm-project/vllm:大家好!我在项目中遇到了 adapter_model.safetensors 的问题,正在寻求关于如何处理指定模块中的 lm_head 和 embed_tokens 的指导。这里…
- GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning:速度提升 5 倍,显存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账号为 unslothai/unsloth 的开发做出贡献。
- Tutorial: How to convert HuggingFace model to GGUF format · ggerganov/llama.cpp · Discussion #2948:来源:https://www.substratus.ai/blog/converting-hf-model-gguf-model/ 我在我们的博客上发布了这篇文章,但认为这里的其他人也可能受益,所以也在 Github 上分享原始博客。希望它…
- py : add Gemma conversion from HF models by ggerganov · Pull Request #5647 · ggerganov/llama.cpp:# gemma-2b python3 convert-hf-to-gguf.py ~/Data/huggingface/gemma-2b/ –outfile models/gemma-2b/ggml-model-f16.gguf –outtype f16 # gemma-7b python3 convert-hf-to-gguf.py ~/Data/huggingface/gemma-…
- unsloth/unsloth/save.py at main · unslothai/unsloth:速度提升 5 倍,显存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账号为 unslothai/unsloth 的开发做出贡献。
Unsloth AI (Daniel Han) ▷ #showcase (10 条消息🔥):
- Unsloth 使微调速度翻倍:
@lee0099使用 Unsloth-DPO 微调了yam-peleg/Experiment26-7B,与普通的 QLoRA 相比,在没有精度损失的情况下,实现了 LLM 微调 2 倍的速度提升和 40% 的内存占用减少。 - Experiment26 公开发布:在展示中,
@lee0099介绍了yam-peleg/Experiment26-7B,这是一个托管在 Hugging Face 上的实验性模型,重点在于改进 LLM 流水线研究并识别潜在的优化点。 - 社区对 Experiment26 的支持:
@starsupernova对@lee0099的微调进展表示兴奋,评价道:“非常非常酷!”,显示了强烈的社区认可。 - 建议展示微调模型:
@starsupernova邀请@1053090245052219443在频道中展示他们微调的 Gemma 模型。 - Gemma 模型性能展示:
@kuke4367分享了一个 Kaggle 链接,演示了微调后的 Gemma 模型的快速推理,并提供了其在 Hugging Face 上的 URL:Kukedlc/NeuralGemmaCode-2b-unsloth。
提到的链接:
- yam-peleg/Experiment26-7B · Hugging Face:未找到描述
-
Gemma CoPilot 2x-Fast-Inference:使用 Kaggle Notebooks 探索和运行机器学习代码 使用来自“无附加数据源”的数据 - NeuralNovel/Unsloth-DPO · Datasets at Hugging Face:未找到描述
Unsloth AI (Daniel Han) ▷ #suggestions (4 条消息):
- 对 Ye Galore 的认可:
@starsupernova表达了他们对 Ye Galore 的满意,并带上笑脸提到它很不错。 - 调侃实现的简易性:
@remek1972幽默地评论了某项功能的实现是多么容易,并标记了<@160322114274983936>,随后附上了一个大笑的表情符号。 - 推广 GEAR 项目:
@remek1972分享了 GEAR 项目 的 GitHub 链接(GitHub - opengear-project/GEAR),暗示其在 LLM 近乎无损生成式推理的 KV cache 压缩方面具有高效性。 - 微调巨型模型的新方法:
@iron_bound分享了一篇 arXiv 论文(Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU),讨论了在单个甚至低端 GPU 上使用 NVMe SSD 微调超大规模模型的可能性。
提到的链接:
- Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU:大型语言模型的最新进展为世界带来了巨大价值,其卓越的能力源于它们使用的海量参数。然而,即使是 GPU 也…
- GitHub - opengear-project/GEAR: GEAR: An Efficient KV Cache Compression Recipefor Near-Lossless Generative Inference of LLM:GEAR:一种用于 LLM 近乎无损生成式推理的高效 KV cache 压缩方案 - opengear-project/GEAR
Perplexity AI ▷ #general (424 条消息🔥🔥🔥):
- Claude 3 Opus 配额限制:像
@thugbunny.这样的用户讨论了 Perplexity Pro 上 Claude 3 Opus 的使用限制,@icelavaman澄清说 Pro 包含 600 次其他 LLM(如 Claude Sonnet)的使用次数,但只有 5 次是给 Opus 的。 - Perplexity AI 采用情况讨论:
@makya2148和@jawnze等成员分享了关于 Perplexity 竞争力和商业举措的观察与推测,例如将 Pro 版本改为基于广告的模式,并引用了 Perplexity CEO 关于竞争对手定价模型的推文。 - 求职与实习热衷者:用户
@parvj主动联系以提供帮助,并表达了在 Perplexity 工作的强烈兴趣。@ok.alex回应称应查看招聘页面,并建议不要在类似请求中直接标记团队成员。 -
关于 LLM 的比较与困惑:包括
@codelicious和@talyzman在内的几位用户讨论了 Perplexity 是使用 Gemini 等外部模型还是拥有自己的模型,一些人对响应结果与 Gemini API 相似感到困惑。 - Pro 用户体验查询:像
@halilsak和@0xhanya这样的 Pro 用户询问了关于使用 logo 设计以及上传 PDF 脚本进行查询的问题,寻求如何针对其特定用例有效利用 Perplexity 的指导。
提到的链接:
- 来自 Aravind Srinivas (@AravSrinivas) 的推文:如果 Mikhail 让 Microsoft Copilot 免费,就让 Perplexity Pro 免费 ↘️ 引用 Ded (@dened21) @AravSrinivas @MParakhin 我们想要免费的 Perplexity Pro(通过高度个性化的广告变现)
- CEO 表示他曾试图从 Meta 招聘一名 AI 研究员,但被告知“等你有了 10,000 块 H100 GPU 再来找我”:一家 AI 初创公司的 CEO 表示,由于没有足够的 GPU,他无法聘请到 Meta 的研究员。
- 不仅仅是 OpenAI 的套壳:Perplexity 转向开源:Perplexity CEO Aravind Srinivas 是 Larry Page 的忠实粉丝。然而,他认为自己找到了一种不仅能与 Google 搜索竞争,还能与 OpenAI 的 GPT 竞争的方法。
- Perplexity AI CEO 分享了 Google 如何留住他想聘请的员工:搜索引擎 Perplexity AI 的 CEO Aravind Srinivas 最近分享了一个有趣的事件,揭示了大科技公司如何愿意投入巨资来留住人才……
- Stonks Chart GIF - Stonks Chart Stocks - Discover & Share GIFs:点击查看 GIF
- I Believe In People Sundar Pichai GIF - I Believe In People Sundar Pichai Youtube - Discover & Share GIFs:点击查看 GIF
- 来自 Elon Musk (@elonmusk) 的推文:本周,@xAI 将开源 Grok
- 报告称,美国必须迅速行动以规避 AI 风险:一份政府委托的报告指出,美国政府必须“果断”行动,以避免 AI 对人类造成“灭绝级威胁”。
- Reddit - 深入探索一切:未找到描述
- Reddit - 深入探索一切:未找到描述
Perplexity AI ▷ #sharing (17 条消息🔥):
- 通过 AI 进行的发现:
@0xhanya分享了一个关于 AI 发现 的 Perplexity AI 链接,促使@ok.alex提醒用户确保其线程是可共享的。 - 太空垃圾的回归:
@mayersj1发布了一个关于 太空垃圾返回地球 话题的链接。 - CSS 编写见解:
@tymscar分享了一个 编写 CSS 的资源,这是 Web 开发者共同感兴趣的话题。 - 关于水果的研究:
@yipengsun根据对草莓分类的研究,提供了一个链接 草莓是水果吗。 - 已启用共享:
@ed323161发布了一个关于改进特定主题的链接,@po.sh随后提醒确保线程已共享以提高可见性。
Perplexity AI ▷ #pplx-api (9 条消息🔥):
- 寻求助手以推动个人助手项目:用户
@shine0252正在开发一个类似于 Alexa 的 个人助手项目 (personal assistant project),并寻求帮助以优化 pplx API 的响应,使其更简洁并具备对过去对话的记忆能力。 - 建议使用
sonar模型实现简洁性:@dogemeat_建议使用 pplx API 中的sonar模型以获得更简洁的回复,并将对话历史存储在 内存或数据库 (memory or a database) 中,使助手能够“记住”过去的交互。 - 对个人助手工作的兴趣:
@roey.zalta和@brknclock1215都对@shine0252的个人助手项目表示感兴趣,@roey.zalta询问了更多细节。 - 记忆功能需依靠 Prompting 而非仅靠 API:
@brknclock1215指出,虽然 Prompting 和参数调整(如 max_tokens 和 temperature)有助于提高 简洁性 (conciseness),但记住对话需要外部 数据存储 (data storage),而不仅仅是 pplx API 所能提供的。 - 请求特定模型功能和 Prompt 指导:用户
@5008802询问 pplx API 是否可以回复来自网络的内容源,@paul16307询问是否可以添加 Yarn-Mistral-7b-128k 以处理高上下文对话。
Nous Research AI ▷ #off-topic (24 messages🔥):
- 快速收敛方法揭晓:
@baptistelqt宣布他们开发了一种方法,可以使 神经网络的收敛速度提高 100,000 倍,且适用于包括 Transformers 在内的所有架构。该技术涉及从头开始每一“轮”训练,并承诺很快发布论文。 - Command-R 模型介绍:
@1vnzh分享了 C4AI Command-R 的模型卡片 (Model Card),这是一个拥有 350 亿参数的模型,针对推理、摘要和问答等任务进行了优化。@everyoneisgross提供了一个 GitHub 演示链接,展示了如何使用简化的搜索方法通过 Command-R 进行 RAG 调用。 - AI 赋能 Telestrations 的可能性:
@denovich描述了游戏 Telestrations,并指出它与多模态 LLM 结合的潜力,可以方便在少于要求的四名玩家的情况下进行游戏,将其转化为有趣的 AI 驱动体验。 - 新闻通讯亮点 AI 对话:
@quicksort链接到了 AI News 新闻通讯,该通讯提供社交平台 AI 相关讨论的摘要,提到它覆盖了 356 个 Twitter 账号和 21 个 Discord 频道。虽然@quicksort和@denovich认为它很有价值,但@ee.dd和@hexani对抓取 Discord 聊天记录的隐私影响表示担忧。 - YouTube 视频概述游戏开发和基于 LLM 的 RAG:
@pradeep1148发布了两个 YouTube 链接,展示了大型语言模型项目:一个展示了使用 Claude 3 创建《植物大战僵尸 (Plants Vs Zombies)》游戏,另一个解释了 Command-R 在检索增强生成 (RAG) 应用中的工作原理。
链接引用:
- CohereForAI/c4ai-command-r-v01 · Hugging Face: 未找到描述
- Command-R: RAG at Production Scale: Command-R 是一款可扩展的生成式模型,针对 RAG 和 Tool Use,旨在为企业实现生产规模的 AI。
- Lets RAG with Command-R: Command-R 是一款针对长上下文任务(如检索增强生成 RAG)以及使用外部 API 和工具进行优化的生成式模型。
- Claude 3 made Plants Vs Zombies Game: 看看如何使用 Claude 3 开发《植物大战僵尸》#python #pythonprogramming #game #gamedev #gamedevelopment #llm #claude
- scratchTHOUGHTS/commanDUH.py at main · EveryOneIsGross/scratchTHOUGHTS: 第二大脑抓取记忆,以避免 self 导致的溢出错误。 - EveryOneIsGross/scratchTHOUGHTS
- [AINews] Fixing Gemma: 2024/3/7-2024/3/11 的 AI News。我们为您检查了 356 个 Twitter 和 21 个 Discord(335 个频道和 6154 条消息)。预计节省阅读时间(以 200wpm 计算):…
Nous Research AI ▷ #interesting-links (6 messages):
-
余弦相似度 (Cosine Similarity) 受到质疑:
@leontello分享了一个 arXiv 链接,讨论了余弦相似度的可靠性,揭示了根据线性模型的正则化情况,它可能会产生任意且可能毫无意义的结果。 -
暴露 AI 模型 Embeddings:
@denovich链接到一篇 arXiv 论文,描述了一种新的模型窃取攻击,可以从 OpenAI 的 ChatGPT 等黑盒模型中提取 Embedding 投影层,成本不到 20 美元。 -
Devin:通过工程面试的 AI:
@atgctg重点介绍了 Cognition Labs 的一条 Twitter 帖子,介绍了 Devin,这是一位 AI 软件工程师,在编程基准测试中得分极高,优于其他模型,甚至能完成实际的工程任务。 -
Cohere 的 Command-R 模型发布:
@benxh展示了来自 Cohere 的 C4AI Command-R 模型,这是一个拥有 350 亿参数的模型,以其在推理、摘要、多语言生成等方面的表现而闻名。 -
Chloe 关于新进展的推文:
@atgctg链接了 @itschloebubble 的一条 Twitter 帖子,但未提供上下文,因此无法总结该进展的具体内容。
提到的链接:
- 来自 Cognition (@cognition_labs) 的推文:今天我们很高兴向大家介绍 Devin,首位 AI 软件工程师。Devin 在 SWE-Bench 编程基准测试中达到了新的 SOTA 水平,并成功通过了实际的工程面试…
- Embeddings 的余弦相似度真的是关于相似性吗?:余弦相似度是两个向量之间夹角的余弦值,或者等效于它们归一化后的点积。一个流行的应用是量化高维语义相似度…
- CohereForAI/c4ai-command-r-v01 · Hugging Face:未找到描述
Nous Research AI ▷ #general (267 条消息🔥🔥):
- 扎克伯格对 AI 的后见之明:ldj 分享了一个幽默的 视频,回顾了马克·扎克伯格过去对 AI 的看法,鉴于自那时以来的飞速发展,这带有一种讽刺意味。
- 马斯克对 AI 风险的思考:teknium 链接到了 Elon Musk 的一条推文,强调了 AI 的潜在危险,为该话题的长期辩论增添了内容。
- 社区中的 AI 发布预测:mautonomy 推测 GPT-5 在 56 小时内发布的概率为 30%,但 @ee.dd 予以反驳,预测在美国大选后才会发布,@thepok 和 @night_w0lf 则讨论了 GPT-4 等当前模型是否会被其他 AI 实体超越。
- 被低估的 AI 模型:@night_w0lf 指出了一个相对未受关注的 Deepseek-VL 模型,认为它可能会颠覆当前的 AI 格局——详情见 Deepseek-VL 论文。
- 对 Function Calling LLM 的期待:teknium 暗示他们即将发布一个新的 7B Function Calling 语言模型,这提升了 AI 社区的期待感。
提到的链接:
- MMLU 中的错误:深度学习基准测试出错频率惊人地高:用于评估大语言模型质量的数据集存在错误。这有多严重?
- CohereForAI/c4ai-command-r-v01 · Hugging Face:未找到描述
- 来自 interstellarninja (@intrstllrninja) 的推文:递归函数调用 LLM 即将登陆你的本地 GPU…
- 报告称美国必须迅速行动以规避 AI 风险:一份政府委托的报告称,美国政府必须“果断”采取行动,以避免 AI 对人类造成“灭绝级威胁”
- Free Me Nope GIF - Free Me Nope Cat Stuck - 发现并分享 GIF:点击查看 GIF
- 未找到标题:未找到描述
- Gemma 微调与推理优化 · Issue #29616 · huggingface/transformers:系统信息:最新的 transformers 版本,大多数平台。谁能提供帮助?@ArthurZucker 和 @younesbelkada。信息:官方示例脚本,我修改后的脚本。任务:一个官方支持的…
- GitHub - openai/transformer-debugger:通过在 GitHub 上创建账号来为 openai/transformer-debugger 的开发做出贡献。
- Gemma Bug 修复 - 近似 GELU, Layernorms, Sqrt(hd) 由 danielhanchen 提交 · Pull Request #29402 · huggingface/transformers:又修复了一些 Gemma 的 Bug :) 目前还在检查更多!相关 PR:#29285,该 PR 显示 RoPE 必须在 float32 而非 float16 下进行,否则会导致位置编码失去精度。@Ar…
Nous Research AI ▷ #ask-about-llms (120 条消息🔥🔥):
- Tokenizer 替换争论:
@stoicbatman询问关于在训练后更换模型的 Tokenizer 以更好地处理特定语言(如泰米尔语)的问题。@teknium回复说添加 Token 是可能的,但根据@stefangliga的说法,更换 Tokenizer 基本上会使之前的学习成果失效。讨论围绕双 Tokenization 支持和维护旧 Tokenizer 的映射展开。 - 使用 XML 和受限解码进行函数调用:由
@kramakek和@.interstellarninja发起的讨论探讨了在 LLM 中使用 XML 标签、受限解码(constrained decoding)技术,以及微调模型进行函数调用的准确性。@ufghfigchv强调了他们的工具,该工具通过对 Logits 进行采样以实现有效的 JSON 输出,但指出目前尚不支持并行函数调用。 - 模型托管与输出结构化:
@sundar_99385询问了关于引导开源 LLM 输出的工具,对比了 Outlines 和 SG-lang 等用于模型托管和引导的库。@.interstellarninja建议 llama-cpp 提供语法支持,而@teknium和@ufghfigchv讨论了预编译和缓存函数生成以提高效率。 - 关于模型许可和可用性的讨论:
@thinwhiteduke8458质疑了像 Nous Hermes 2 这样混合了 Apache 2 和 MIT 许可证的模型在商业用途上的可行性,@teknium表示从他们的角度来看,在使用方面不会产生法律问题。 - 关于微调模型大小和系统要求:
@xela_akwa寻求关于微调任务内存需求的建议,尽管使用了双 40GB A100 GPU,仍面临显存不足(OOM)的问题。@ee.dd建议尝试 unsloth 以获得更高效率,而@teknium建议使用对 VRAM 需求更低的 qlora,并提醒 PPO 需要加载两次完整模型。
提到的链接:
- 使用 XML 标签:未找到描述
- GitHub - open-webui/open-webui: 适用于 LLM 的用户友好型 WebUI(原 Ollama WebUI):适用于 LLM 的用户友好型 WebUI(原 Ollama WebUI) - open-webui/open-webui
- GitHub - enricoros/big-AGI: 💬 由 GPT-4 及更高版本驱动的个人 AI 应用,具备 AI 角色、AGI 函数、文本转图像、语音、响应流式传输、代码高亮与执行、PDF 导入、开发者预设等功能。部署并开启 #big-AGI-energy!使用 Next.js, React, Joy。:💬 由 GPT-4 及更高版本驱动的个人 AI 应用,具备 AI 角色、AGI 函数、文本转图像、语音、响应流式传输、代码高亮与执行、PDF 导入、开发者预设…..
Nous Research AI ▷ #collective-cognition (3 messages):
- Flash Attention 查询重定向:用户
@pradeep1148询问 如何禁用 Flash Attention 功能。@teknium重定向了该问题,指出此频道已归档,并建议在 <#1154120232051408927> 中提问。
LM Studio ▷ #💬-general (207 messages🔥🔥):
-
Mac M1 Pro GPU 问题:
@maorwe报告了 LM Studio 在 Mac M1 Pro 上选择使用 CPU 而非 GPU 加速的问题。其他用户(如@amir0717)在不同配置下也遇到了类似问题,并为配备 16 GB RAM 的 GTX 1665 Ti 寻求模型推荐。 -
DeepSeek 模型兼容性:
@amir0717详细说明了运行某些模型(尤其是 DeepSeek)时的错误,@_nahfam_建议使用 “1.3B 而非 7B” 模型效果会更好,并推荐了deepseek-coder-1.3b-instruct-GGUF。 -
探索 LM Studio 的 GPU 配置:
@purplemelbourne在让 LM Studio 将双 GPU 识别为具有合并 VRAM 的单个单元时遇到困难,@heyitsyorkie就 tensor split 功能的使用提供了建议。 -
对 LM Studio 的投入:在一系列帖子中,包括
@yagilb、@donnius和@rexeh在内的用户讨论了 LM Studio 的开发进度,开发者承认了延迟并承诺会有新更新,理由是团队规模较小且正在持续努力。 -
用户创建的 LLM 指南和 API:
@ninjasnakeyes询问了使用 LM Studio 和 llamacpp 之间的区别,引发了关于自定义程序 API 连接的讨论,@rjkmelb和@nink1提供了说明。此外,@tvb1199分享了他们编写的全面 Local LLM 用户指南。
提到的链接:
- Rivet:一个使用可视化、基于节点的图形编辑器的开源 AI 编程环境。
- deepseek-ai/deepseek-vl-7b-chat · Discussions:未找到描述。
- Pc Exploding GIF - Pc Exploding Minecraft - Discover & Share GIFs:点击查看 GIF。
- deepse (DeepSE):未找到描述。
- I Have The Power GIF - He Man I Have The Power Sword - Discover & Share GIFs:点击查看 GIF。
- Ugh Nvm GIF - Ugh Nvm Sulk - Discover & Share GIFs:点击查看 GIF。
- The Muppet Show Headless Man GIF - The Muppet Show Headless Man Scooter - Discover & Share GIFs:点击查看 GIF。
- Reddit - Dive into anything:未找到描述。
- Reddit - Dive into anything:未找到描述。
- Reddit - Dive into anything:未找到描述。
- The unofficial LMStudio FAQ!:欢迎来到非官方 LMStudio FAQ。在这里,您可以找到我们在 LMStudio Discord 上收到的最常见问题的答案。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源软件…
- Rivet: How To Use Local LLMs & ChatGPT At The Same Time (LM Studio tutorial):本教程解释了如何将 LM Studio 与 Rivet 连接,以使用运行在您自己电脑上的本地模型(例如 Mistral 7B),同时也介绍了如何仍然能够使用…
- GitHub - xue160709/Local-LLM-User-Guideline:通过在 GitHub 上创建账号,为 xue160709/Local-LLM-User-Guideline 的开发做出贡献。
- A Complete Guide to LangChain in JavaScript — SitePoint:了解 LangChain 的核心组件——Agent、模型、Chunk、Chain——以及如何在 JavaScript 中发挥 LangChain 的力量。
LM Studio ▷ #🤖-models-discussion-chat (96 messages🔥🔥):
- LLM 故事创作增强讨论:用户
@bigboimarkus询问是否有擅长改进或扩展故事的语言模型。讨论中未给出具体建议。 - C++ 编程模型选择:
@amir0717寻求关于处理约 200 行 C++ 代码的最佳模型建议,其硬件配置为 GTX 1665 Ti 和 16 GB RAM,并表示目前使用的 stablelm zephyr 1.5 GB 模型生成的代码不完整。 - 创新三进制计算:
@purplemelbourne和@aswarp就从二进制转向三进制系统可能带来的计算革命进行了详细讨论,并提供了研究论文和实现策略的学术引用。 - LM Studio 更新期待:
@rexeh正在寻找在 ROCm 上配合 LM Studio 使用的 Starcoder 2 替代方案(特别是针对 Python),而@heyitsyorkie提到 LM Studio 的下一次更新预计将支持 Starcoder 2。 - 探索股价预测 AI:
@christianazinn讨论了使用本地托管的 LLM 进行股价预测的想法,权衡了长上下文模型与使用 MemGPT 等辅助系统的短上下文模型之间的性能差异。对话还涉及了本地模型访问互联网以获取实时更新数据的潜力。
提到的链接:
- Render mathematical expressions in Markdown:在 Markdown 中渲染数学表达式
- Calculation Math GIF - Calculation Math Hangover - Discover & Share GIFs:点击查看 GIF
- Im Waiting Daffy Duck GIF - Im Waiting Daffy Duck Impatient - Discover & Share GIFs:点击查看 GIF
- How to safely render Markdown using react-markdown - LogRocket Blog:通过这篇简短的 react-markdown 教程,学习如何安全地将 Markdown 语法渲染为相应的 HTML。
- GitHub - deepseek-ai/DeepSeek-VL: DeepSeek-VL: Towards Real-World Vision-Language Understanding:DeepSeek-VL:迈向现实世界的视觉语言理解 - deepseek-ai/DeepSeek-VL
- Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models:未找到描述
- Ternary Hashing:本文提出了一种用于学习哈希方法的新型三进制哈希编码,提供了一种原则上更高效的编码方案,其性能优于目前最先进的二进制编码…
LM Studio ▷ #🎛-hardware-discussion (63 条消息🔥🔥):
-
GPU 测试配置调整:用户
@goldensun3ds讨论了在配置文件中将 Tensor Split 设置为 “0, 100”,以便在不物理拔出 GPU 的情况下测试特定 GPU,这也有助于解决@nink1关于模型卡加载偏好的问题。 -
MacBook Pro M2 Max 即将到来:
@saber123316订购了一台配有 96 GB RAM 和 4TB 存储空间的 MacBook Pro M2 Max。他们指出这比 M3 Max 版本节省了大量成本,并提到如果不能满足需求可能会退货。 -
主板与 GPU 兼容性探索:由
@nink1、@rugg0064和@silk1821发起的讨论探索了使用 PCIe 延长线在主板上安装多个 RTX 3090 GPU 的方案。@nink1分享了在 B550 板上的成功经验,但建议寻找具有 PCIe 4.0 能力的高端主板以获得最佳性能。 -
关于 AMD GPU 与 Offloading:
@heyitsyorkie提到 AMD GPU offload 可以通过 OpenCL 实现,这解释了为什么@nink1发现 RX580 8GB VRAM 虽然被检测到但因缺乏 ROCm 支持而未被利用。 -
云端 vs. 本地硬件运行 LLM:
@silk1821和@nink1权衡了使用云服务与本地硬件运行大语言模型的优缺点。讨论涉及保密性担忧、成本和可靠性,并提到了 Google 等云提供商可能提供的资助。
提到的链接:
- 无标题:未找到描述
- Amazon.com: MSI Meg X570 Unify Motherboard (AMD AM4, DDR4, PCIe 4.0, SATA 6GB/s, M.2, USB 3.2 Gen 2, Ax Wi-Fi 6, Bluetooth 5, ATX) : Electronics:未找到描述
LM Studio ▷ #🧪-beta-releases-chat (6 条消息):
_
- @fabguy 的升级建议:
@fabguy建议升级到 version .16,因为该版本包含可能解决现有问题的重大更新。 - Beta 版本寻求者:
@jarod997无法在 LMStudio.ai 上找到 version .16,随后澄清他们需要 Beta 版本,因为其机器需要 AVX 兼容性。 - 即将推出的聊天功能剧透:用户
@yagilb宣布,新的聊天“Continue”行为将包含在下一个版本中。 - 期待新功能:
@wolfspyre对新聊天功能的发布预告做出了俏皮的“挑逗式”回应。 - 请求 AVX Beta 更新:
@mike_50363询问了 AVX Beta 版本(目前为 0.2.10)的更新情况,暗示需要新功能或修复。
LM Studio ▷ #autogen (1 messages):
- Autogen vs. CrewAI - 功能对比:
@omgitsprovidence提到,虽然他们没有使用过 CrewAI,但从代码库来看,Autogen 似乎拥有更多功能。他们强调,输出质量在很大程度上取决于工作流设计、Prompting 和上下文管理。
LM Studio ▷ #memgpt (1 messages):
- 一条奇特的警告:用户
@purplemelbourne发布了一条背景不明且令人不安的消息:“如果我们愿意,我们保留将你击毙的权利。祝你午餐愉快。” 考虑到它与享受美食的并列,其语调似乎带有某种诙谐或隐喻色彩。
LM Studio ▷ #amd-rocm-tech-preview (14 messages🔥):
- 使用 MISTRAL 时的 GPU 故障排除:用户
@omgitsprovidence建议,在遇到性能问题时,将 layers 设置为 -1 并切换 GPU 的启用/禁用状态,他们认为这可能是由于模型大小超过了 GPU 显存。 - 在有限硬件上成功运行 MISTRAL 7b:用户
@aryanembered在配备 16GB DDR4 和 8GB RX6600 的系统上成功运行了 MISTRAL 7b,此前他们曾在使用显存需求超过可用 GPU 显存的 MISTRAL 版本时遇到问题。 - 作为替代方案的 KoboldAI:为了避免 LM Studio 的系统 RAM 占用问题,
@aryanembered表示他们正在使用 KoboldAI,发现它更简单且能更有效地满足其需求。 - AMD 驱动更新提升性能:用户
@sadmonstaa发现从 Adrenalin 切换到 AMD PRO 驱动后性能有所提升,实现了 GPU 利用率的提高,并且速度比 OpenCL 快了一倍。 - 禁用 iGPU 可能解决 Offloading 问题:
@minnona发现禁用集成显卡 (iGPU) 解决了其 Asrock 系统的 Offloading 问题,而@heyitsyorkie则希望未来的更新能为非技术用户简化 GPU 切换。@luxdominatusr5建议也可以通过 Windows 设备管理器 (Device Manager) 禁用 iGPU。
LM Studio ▷ #crew-ai (1 messages):
- CrewAI vs AutoGen:
@jg27_korny称赞了 CrewAI 的逻辑设置,但提到 AutoGen 的优势在于其图形用户界面 (GUI)。目前使用 GPT API 可以获得最佳性能,因为开源模型的表现尚不理想。 - 警惕 Token 生成循环:
@jg27_korny警告称,由 CrewAI 或 AutoGen 创建的 Agent 可能会进入死循环,从而导致计算 Token 的浪费。用户应监控 Token 生成情况以避免不必要的成本。
OpenAI ▷ #ai-discussions (248 messages🔥🔥):
-
探索长视频生成:
@anthiel4676迫切地询问 SORA 何时能够创建 30 分钟的视频。@askejm和@solbus讨论了模型的局限性和能力,指出虽然当前的技术约束和显存限制束缚了 SORA,但从技术上讲,它可以分段生成长视频(参考 OpenAI 研究论文)。 -
关于 GPT-3.5 订阅和版本的讨论:
@sangam_k、@celestialxian和@satanhashtag等用户对免费版和 Pro 订阅版之间的 GPT-3.5 模型差异感到困惑,澄清指出主要区别在于更高的使用限制。讨论还涉及了 GPT-3.5 的知识截止日期及后续更新,共识是 API 版本和 ChatGPT 版本的当前信息限制可能有所不同。 -
ChatGPT 知识准确性的质疑:用户
@webhead和@askejm深入探讨了 ChatGPT 自报知识截止日期(knowledge cutoff)的不一致性,并讨论了训练数据和最近的更新。尽管说法不一,但建议认为询问模型本身并不总能得到关于其知识时间范围的准确答案。 -
探索 Claude 和 Opus:
@askejm和@webhead分享了他们使用不同 AI 模型的经验,包括 Claude Opus 和 GPT-4。对比显示,Claude Opus 相比 GPT-4 可能会提供更有创意且简洁的输出,而 GPT-4 有时会默认使用项目符号或产生吸引力较低的回复。 -
用户对微调代码和 AI 项目建议的需求:
@tfriendlykinddude寻求使用客户交互数据微调 LLM 的通用大纲;@testtm分享了一个有用的 Notebook 资源。同时,@beranger31概述了一个使用 GPT 和 OpenCV 开发纸牌教学机器人的大学项目,促使@.miniclip.com和@joinity等社区成员提供了详细步骤并鼓励探索平台功能。
提到的链接:
- 基于 Prompt 的图像生成 AI 工具,用于编辑特定细节:我正尝试使用 DALLE3 制作一些精灵图(spritesheets),虽然 DALLE3 最初生成的精灵图非常迷人,但我遇到了这些问题:艺术风格不一致(多…
- brevdev/notebooks 仓库中的 mistral-finetune-own-data.ipynb:通过在 GitHub 上创建账户来为 brevdev/notebooks 的开发做出贡献。
OpenAI ▷ #gpt-4-discussions (29 messages🔥):
-
寻求微调解决方案:
@shashank4866询问了是否可以根据指令文档微调 AI 模型,以避免在每次 API 调用时传递相同的指令,希望能减少 Token 浪费和输出时间。 -
ChatGPT 的浏览器故障:
@mhrecaldeb提到在使用 ChatGPT 时 Chrome 浏览器出现问题,而 Firefox 则没有问题;@pandagex也表达了类似看法,他在 Chrome 上遇到问题但发现 Edge 运行正常。 -
关于创作者报酬的疑问:
@ar888询问 GPT 创作者何时开始获得报酬,@elektronisade回复称一篇博客文章指出时间线在 Q1,且最初仅限美国地区。 -
管理通知和退出:
@realmunknown询问如何选择不接收来自特定频道(如<#1046314025920761896>)的通知。 -
关于 GPT-4 图像生成费用的澄清:
@komt询问 GPT-4 的图像生成(image generation)是否在订阅费之外产生额外费用,@solbus回复了一个链接以获取更多信息。 -
关于 OpenAI 账户额度的查询:
@itzarshia询问新 OpenAI 账户是否继续提供 5 美元额度,@rjkmelb简单回复“不”。 -
LLM 上下文限制与 PDF 查询:
@glass4108询问 LLM 处理超过 32k Token 内部上下文限制的大型 PDF 的能力,@solbus澄清说 LLM 无法内化超过此限制的文件,但会根据提供的查询进行搜索和总结。 -
OpenAI 服务的地区定价问题:
@johanx1238和@julio_yt_br等用户发起了一场关于 OpenAI 订阅费用的讨论,认为相对于格鲁吉亚和巴西等国家的平均收入而言,订阅费过高,并希望 OpenAI 调整定价,使其在各自国家更具可负担性。 -
GPT 宕机了吗?:
@dixon0001询问 GPT 的状态,想知道它是否再次宕机。
OpenAI ▷ #prompt-engineering (55 messages🔥🔥):
- 一致性至上:
@darthgustav.建议@iloveh8通过使用带有特定变量名的输出模板来封装指令,从而实现一致的 Prompt 输出。他们提供了一个处理不同类型请求的明确模板示例。 - 当 HTML 片段困扰 GPT 时:
@marijanarukavina遇到了 GPT 无法处理 HTML 片段的问题,@eskcanta建议将输入拆分为更小的部分或将列表作为文件上传,这解决了该问题。 - Prompt Engineering 与仲裁条款意识:
@eskcanta和@kunhai_04769讨论了一个 GPT 分析工具的开发,强调了意识到 OpenAI 使用条款和用户隐私问题的重要性。 - 文本重写的挑战:
@ericplayz寻求使用 GPT 重写长文本的帮助,但在字数和指令遵循方面遇到了问题。@darthgustav.建议使用带有输出模板的自定义指令,并开启新对话以应对与上下文长度和检索率相关的问题。 - 通过重新开始解决模型行为之谜:
@eskcanta解释说,开启新聊天通常可以修复异常的 AI 行为,因为在持续的对话中,它可能会受到不太有用的训练数据(或上下文)的影响。
提到的链接:
- Terms of use:未找到描述
- Usage policies:未找到描述
OpenAI ▷ #api-discussions (55 messages🔥🔥):
-
Custom GPT 输出的一致性:
@darthgustav.建议使用带有开放变量的输出模板,在变量名中简洁地编码指令,以确保 Custom GPT 的输出一致。 -
使用 GPT 处理复杂的重写:
@eskcanta协助@ericplayz使用更丰富的专业词汇重写段落,并解释说上传文件可以绕过 GPT 的输入长度限制。@ericplayz遵循指导后取得了成功,并对支持表示感谢。 -
关于 Prompt 有效性的讨论:
@eskcanta回复了@high_voltz关于 Prompt Engineering 有效性的提问,确认他们认为这是一种有效的实践。 -
GPT 分析工具的法律和隐私考量:
@eskcanta提醒@kunhai_04769在构建 GPT 分析工具 (similargpts) 时,需要注意 OpenAI 的使用条款和使用政策,特别是关于用户隐私的部分。 -
排查文本长度问题:
@darthgustav.和@ericplayz讨论了在重写具有特定长度和结构要求的文本时的困难以及排查方法。Darthgustav. 强调了开启新聊天以避免 GPT 响应遵循度下降的重要性。
提到的链接:
- Terms of use:未找到描述
- Usage policies:未找到描述
HuggingFace ▷ #announcements (1 messages):
- 无缝搜索 Assistant:Hugging Chat 引入了一项新功能,允许用户过滤和搜索 Assistant 名称,正如
@lunarflu1所宣布的。在 Hugging Face Chat 了解更多关于此增强功能的信息。 - 博客阅读变得简单:
@lunarflu1分享说 Hugging Face 博客现在包含一个新的“目录”,并且能够在不破坏旧 URL 的情况下更新博客,确保无缝访问更新后的内容。在这里查看改进。 - Space 分析升级:Hugging Face Spaces 现在提供历史统计数据,让创作者可以追踪其 Space 的受欢迎程度,由
@lunarflu1发布。创作者可以在这里深入了解其 Space 的分析数据。 - 使用 WebGPU 实现更快的浏览器内 ML:
@osanseviero的一条推文表明,WebGPU 可以使浏览器内的机器学习速度提高 40 倍,有望带来显著的性能提升。在 Twitter 上了解更多关于这一技术飞跃的信息。 - 增强的开源工具和课程:Transformers.js 2.16.0、Gradio 4.21 和 Accelerate v0.28.0 的发布为开发者带来了新功能,
@ThomasSimonini宣布推出了游戏机器学习课程,进一步扩展了 AI 社区的教育资源。有关开源更新和学习机会的更多详情,请查看原始消息中链接的相应 Twitter 公告。
提到的链接:
- 来自 lunarflu (@lunarflu1) 的推文:你现在可以在 Hugging Chat 上过滤/搜索 Assistant 名称了!http://hf.co/chat
- 来自 lunarflu (@lunarflu1) 的推文:🤗@huggingface 博客更新:1. ✨新增“目录”功能!2. 🛡️通过重定向映射更新博客,且不会破坏旧 URL!
- 来自 lunarflu (@lunarflu1) 的推文:@huggingface 的 Spaces 分析现在拥有历史统计数据了!你最受欢迎的 Space 是哪一个?🚀
- Release 2.16.0 · xenova/transformers.js:更新内容?💬 StableLM 文本生成模型。此版本增加了对 Stability AI 开发的 StableLM 系列文本生成模型(最高 1.6B 参数)的支持。非常感谢 @D4ve-R…
- 来自 Gradio (@Gradio) 的推文:🎈 各位周末黑客,gradio==4.21 发布了!☸️ 支持 Kubernetes!Gradio 现在可以在你的 k8s pod 和其他代理上运行了 🧨 Diffusers 流水线 -> 自动生成 demo 💾 磁盘空间不足…
- 来自 Vaibhav (VB) Srivastav (@reach_vb) 的推文:快速 Mamba 推理现已加入 Transformers!🐍 你只需要 5 行代码和最新版本的 transformers!额外福利:你还可以使用 TRL 和 PEFT 对其进行 fine-tune/ RLHF 🤗 我们支持所有基础…
- Reddit - 深入探索任何事物:未找到描述
- 来自 Philipp Schmid (@_philschmid) 的推文:如何在训练期间评估 LLM?🤔 在 MMLU 或 Big Bench 等常用基准测试上评估 LLM 需要耗费大量时间和计算资源,这使得在训练期间运行它们变得不可行。😒 一个新的…
- 来自 ESA Earth Observation (@ESA_EO) 的推文:.@esa 的 Φ-lab 与 @huggingface 合作发布了 Major TOM (Terrestrial Observation Metaset) 的第一个数据集,这是针对 @CopernicusEU 的最大的、面向社区的、ML-ready 的集合…
- 来自 Vaibhav (VB) Srivastav (@reach_vb) 的推文:MusicLang 🎶 - 基于 Llama 2 的音乐生成模型!> 基于 Llama 2,从零开始训练。> 许可宽松 - 开源。> 针对 CPU 运行进行了优化。🔥 > 高度可控…
- 来自 Jeremy Howard (@jeremyphoward) 的推文:今天,我们与 @Tim_Dettmers、@huggingface 和 @mobius_labs 共同发布了 FSDP/QLoRA,这是一个新项目,让你能够在配备消费级游戏 GPU 的家用电脑上高效训练超大型(70b)模型…
HuggingFace ▷ #general (149 条消息🔥🔥):
- 关于 AI 行动能力的辩论:用户
@vishyouluck和@jeffry4754讨论了基于行动的 AI 的未来,@vishyouluck认为 LLM 与 API 的集成以及业务流程的自动化是 AI 的下一个重大飞跃。 - 质疑 AI 的实际应用:在一次哲学思考中,
@zorian_93363质疑了 AI 在日常生活中的实用性,并推测利用 PS5 控制台进行硬件改造以创建强大的 VRAM 模块。 - 分享超级计算机概念:
@vipitis分享了一篇关于用 PS3 控制台构建超级计算机的文章链接,讨论了游戏机如何比标准消费级计算硬件更强大。 - 感叹驱动程序的不足:
@ahmad3794和@vipitis就将 PS5 控制台改用于其他计算任务的可行性和局限性交换了意见,考虑到了诸如 AMD 和 Intel 显卡缺乏类似 Nvidia NVLink 的技术障碍。 - 模型训练中潜在的不匹配:用户
@gryhkn就 LLM fine-tuning 过程中处理的样本总数与预期数量不符的问题寻求帮助,并提供了详细的 training arguments 来解释背景。
提及的链接:
- 在 Jupyter notebook 中无需交互式提示登录 HuggingFace:在最近的一个项目中,我遇到了一个令人困扰的设置问题。作为一个想要学习和贡献但资金短缺的学生……
- 维基百科,自由的百科全书:未找到描述
- CohereForAI/c4ai-command-r-v01 · Hugging Face:未找到描述
- Hugging Face – 构建未来的 AI 社区。:未找到描述
- 政府委托报告称,美国必须“果断”行动以规避 AI 带来的“灭绝级”威胁 - Slashdot:美国政府必须“迅速且果断地”采取行动,以规避人工智能(AI)带来的重大国家安全风险,在最坏的情况下,这可能会导致“灭绝级”……
- Spaces 概览:未找到描述
- Why Fail GIF - Why Fail Poor - 发现并分享 GIF:点击查看 GIF
-
[当空军需要超级计算机时,他们用 PS3 控制台造了一个 War History Online](https://www.warhistoryonline.com/war-articles/ps3-supercomputer.html):2010 年底,美国空军建造了自己的超级计算机,这将大大缩短模式识别、图像分析和……所需的时间。 - Command-R:生产规模的 RAG:Command-R 是一款针对 RAG 和 Tool Use 的可扩展生成模型,旨在为企业实现生产规模的 AI。
- 在你的 Space 中添加使用 HF 登录按钮:未找到描述
- 使用 Hugging Face 登录:未找到描述
- 极速 AI 电话推销 Agent - 基于 Groq 构建:Groq LPU 到底是什么?我将带你通过一个真实的例子,利用 Groq 的速度构建一个实时的 AI 电话推销 Agent。🔗 链接 - 在 Twitter 上关注我……
- wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py (master 分支) · fauxneticien/wav2vec2-codebook-indices:通过在 GitHub 上创建账号来为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
HuggingFace ▷ #today-im-learning (2 条消息):
- 在新领域寻求智慧:用户
@refik0727请其他成员分享他们的经验,但未提供有关特定主题或感兴趣领域的上下文。 - 机器学习之旅:
@210924_aniketlrs02正在寻求关于如何使用 GitHub 脚本 从 Wav2Vec2 模型中提取量化状态的帮助,并向社区征求指导。
提到的链接:
wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py (master 分支) · fauxneticien/wav2vec2-codebook-indices:通过在 GitHub 上创建账号来为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
HuggingFace ▷ #cool-finds (11 条消息🔥):
-
深度强化学习资源分享:
@joshhu_94661推荐了台大(NTU)关于深度强化学习的 YouTube 教程。该讲座提供了对该主题的见解。 -
Web-GL 梦境项目 Space:
@tonic_1分享了一个名为 The Lucid Dream Project 的迷人 Web-GL 演示,托管在 Hugging Face 的 Spaces 上。 -
关于个人价值观的研究引起关注:
@istem.链接了一篇没有描述的期刊文章,引起了@lunarflu的好奇并发表了评论。 -
微软推出 AICI:用户
@katopz发布了微软 GitHub 上 AICI 的链接:将 Prompts 作为 (Wasm) 程序,提出了一种处理 AI 提示词的新颖方法。 -
物理交互中的下一代 AI:
@edge44_分享了一篇 ACM SIGGRAPH 2023 论文 和一段 YouTube 视频,两者都展示了使用机器学习合成物理角色与场景交互方面的进展。 -
介绍 Devin,AI 软件工程师:
@valentindm发现 @cognition_labs 推出的 Devin 非常令人印象深刻。Devin 是一个成功通过了真实工程面试并能处理工程任务的 AI。 -
通过 AI 增强与视频角色的对话:
@osanseviero重点介绍了由<@504681610373758977>和<@704859925981036644>开发的项目,用户可以使用 AI 与视频角色交谈:Vid2Persona,该项目利用了商业和开源模型。
提到的链接:
- The Lucid Dream Project - a Hugging Face Space by ilumine-AI:未找到描述
- @chansung on Hugging Face: "🎥 🤾 Vid2Persona: talk to person from video clip…":未找到描述
- Build Diffusion models with PyTorch Lightning & HF diffusers - a Lightning Studio by dasayan05:这个 Lightning Studio 包含易于使用、与 HF 生态系统兼容且无冗余代码的 Diffusion 模型训练和推理代码。
- Tweet from The Simulation (@fablesimulation):宣布我们关于 Generative TV 和 Showrunner Agents 的论文!通过提示词创建电视剧集 —— SHOW-1 将为你完成编写、动画、导演、配音和编辑。我们仅出于研究目的使用了《南方公园》…
- Synthesizing Physical Character-Scene Interactions:未找到描述
- Synthesizing Physical Character-Scene Interactions:论文《Synthesizing Physical Character-Scene Interactions》的补充视频。
- ML Lecture 23-1: Deep Reinforcement Learning:未找到描述
- Tweet from Cognition (@cognition_labs):今天我们很高兴向大家介绍 Devin,首位 AI 软件工程师。Devin 在 SWE-Bench 编码基准测试中达到了新的 SOTA,并成功通过了实际的工程面试…
- GitHub - microsoft/aici: AICI: Prompts as (Wasm) Programs:AICI:将 Prompts 作为 (Wasm) 程序。通过在 GitHub 上创建账号来为 microsoft/aici 的开发做出贡献。
HuggingFace ▷ #i-made-this (19 messages🔥):
-
Mambarim-110M:一个新的葡萄牙语 LLM:
@dominguesm介绍了 Mambarim-110M,这是一个基于 Mamba 架构的葡萄牙语 LLM,拥有超过 1.19 亿个参数,并在 62 亿 token 的数据集上进行了预训练。模型详情和代码可以在 Hugging Face 和 GitHub 上找到。 -
Blobby Button Biodiversity Dashboard:
@istem.分享了他们的 Belly Button Biodiversity Dashboard,这是一个用于探索微生物数据的 Javascript 项目,并邀请大家访问 belly-button-challenge.io 查看交互式可视化效果。 -
针对长文本扩展的 BERT:
@pszemraj微调了一个名为 bert-plus-L8-v1.0-syntheticSTS-4k 的 4k 上下文小型 BERT,用于长文本相似度计算。他强调了其实际长上下文训练的有效性,资源可在 Hugging Face 获取。 -
面向 Gradio 的开源学习工具:
@cswamy正在开发一个旨在帮助新开发者从已关闭的 Issue 和 PR 中学习的工具,通过提供 AI 生成的解释来提供帮助。他正在招募 Beta 测试人员,并表示其目标是鼓励社区贡献。 -
部署到 Vertex AI 的 Hugging Face 模型:
@alvarobartt宣布创建了vertex-ai-huggingface-inference-toolkitPython 包,用于简单地将 Hugging Face Hub 中的模型部署到 Vertex AI 中,目前正在积极开发中。该工具包可在 GitHub 上获得。 -
ComfyUI 集成 LLM 和 LlamaIndex:
@alx.ai发布了一个更新,为 ComfyUI 带来了 LLM 集成以及 LlamaIndex,并标记了一条 Twitter 帖子以获取更多细节:查看 Twitter 上的公告。
提到的链接:
- Portfolio – javascript: 未找到描述
- BEE-spoke-data/bert-plus-L8-v1.0-syntheticSTS-4k · Hugging Face: 未找到描述
- dominguesm/mambarim-110m · Hugging Face: 未找到描述
- GitHub - alvarobartt/vertex-ai-huggingface-inference-toolkit: 🤗 HuggingFace Inference Toolkit for Google Cloud Vertex AI (similar to SageMaker's Inference Toolkit, but for Vertex AI and unofficial): 🤗 用于 Google Cloud Vertex AI 的 HuggingFace Inference Toolkit(类似于 SageMaker 的 Inference Toolkit,但适用于 Vertex AI 且为非官方版本)- alvarobartt/vertex-ai-huggingface-inference-toolkit
- CohereForAI/aya_dataset · Datasets at Hugging Face: 未找到描述
- Aya - a Hugging Face Space by Tonic: 未找到描述
HuggingFace ▷ #reading-group (9 messages🔥):
- 关于在研究中引用网页文档的咨询:
@noir_bd询问在研究或综述论文中引用网站文档或文章的信息是否合适。聊天中未提供明确答案,但他们被引导至其他社区进行进一步讨论。 - 寻求 ML 脚本方面的指导:
@210924_aniketlrs02请求协助如何使用来自 GitHub 仓库 的特定 Python 脚本,该脚本旨在从 Wav2Vec2 模型中提取量化状态(quantized states)。消息包含脚本链接,但回复中未提供指导。 - 分享了无上下文的链接:
@ibrahim_72765_43784分享了一个 Kaggle 讨论链接,但消息中未提供分享该链接的原因或其相关性的上下文。 - 关于 Diffusion Models 的演讲提议:
@chad_in_the_house提议就文本到图像(text-to-image)定制技术进行演示,特别提到希望在确认演示日期前讨论并测试来自一篇 HuggingFace 论文的方法。提供了 HuggingFace 论文链接作为背景。 - 对即将到来的演讲表示支持和期待:
@lunarflu对@chad_in_the_house可能进行的关于使用上述 HuggingFace 论文技术定制 Diffusion Models 的演示表示了热情和支持。
相关链接:
-
[[Deleted Topic] Kaggle](https://www.kaggle.com/discussions/questions-and-answers/483264): [已删除主题]。 - Paper page - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization: 未找到描述
- wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices: 通过在 GitHub 上创建账户来为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
HuggingFace ▷ #diffusion-discussions (2 messages):
- 寻求 wav2vec2 codebook 脚本方面的帮助:
@210924_aniketlrs02正在寻求关于如何使用 wav2vec2 codebook 提取脚本 来提取 Wav2Vec2 模型的量化状态的指导。他们是机器学习领域的新手,需要脚本应用方面的帮助。 - 关于在结构化数据中使用 Unet 的咨询:用户
@nana_94125询问是否有人尝试过将 Unet(一种通常用于图像分割的神经网络架构)应用于结构化数据。未提供更多细节或上下文。
相关链接:
wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices: 通过在 GitHub 上创建账户来为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
HuggingFace ▷ #computer-vision (23 messages🔥):
- 寻找 NSFW 图像字幕生成 (Image Captioning):用户
ninamani询问了处理无审查Image to Text或图像字幕生成的最佳开源模型,特别是擅长描述 NSFW 内容的模型。 - Unity 与 HuggingFace API 的 Inpainting:
@okan1962询问 HuggingFace 的推理 API 是否支持 Unity 中的 Inpainting 和图像变体;然而,回复建议这些功能可能无法通过 API 访问。 - 解码 Diffusion 生成的图像:
@akshit1993详细介绍了一种使用 DDIM scheduler 检测 Diffusion 生成图像的方法,并正在寻求关于使用 CLIPImageProcessor 还是 CLIPVisionModel 以获得最佳效果的建议。他们还分享了相关代码的链接,尽管未提供 URL。 - 持续学习 (Continuous Learning) 建议:
@itsnotmady向社区咨询了使用新图像增量训练模型的问题,寻找防止遗忘先前图像特征的策略,@akshit1993建议使用 CLIPVisionModel 来创建和保存图像嵌入 (embeddings)。 - 用于长音频文件的 Whisper ASR:
@swetha98收到来自@huzuni的建议,使用 Andrej Karpathy 提到的 OpenAI Whisper ASR 模型来转录大型音频文件。建议该模型应能很好地处理长音频,尽管性能可能取决于硬件。
HuggingFace ▷ #NLP (17 messages🔥):
- 寻求情感话语分析 (Emotional Discourse Analysis) 的清晰度:用户
@smartguy_41719询问了使用大语言模型 (LLM) 评估话语中的清晰度和情感的方法论,并质疑该任务的可行性。 - 寻找终极 NSFW 翻译模型:
@ninamani正在寻找专门用于 NSFW 无审查翻译的优化且准确的模型,并指出了旧翻译模型和大型 LLM 存在的问题。 - 警惕离群值 (Outliers):
@pizzadrones向社区寻求识别短文档中分布外 (out-of-distribution) 短语或单词的策略,@vipitis建议使用 tf-idf 的基础方法。 - Wav2Vec2 脚本指导:用户
@210924_aniketlrs02请求协助使用脚本从 Wav2Vec2 模型中提取量化状态,并分享了相关的 GitHub 链接。 - 使用 LightEval 评估 LLM:
@alexmath寻求一种用于类 LORA 的 LLM 技术的基准测试工具,并由@.dvs13引导去研究 LightEval,这是 Hugging Face 的轻量级 LLM 评估套件。
提到的链接:
- wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices:通过在 GitHub 上创建账户,为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
- GitHub - huggingface/lighteval: LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron.:LightEval 是一个轻量级的 LLM 评估套件,Hugging Face 内部已将其与最近发布的 LLM 数据处理库 datatrove 和 LLM 训练库 nanotron 配合使用。
HuggingFace ▷ #diffusion-discussions (2 messages):
- 寻求 Wav2Vec2 脚本指导:
@210924_aniketlrs02正在寻求关于如何利用 Python 脚本从 GitHub 仓库 提供的 Wav2Vec2 模型中提取量化状态的帮助。他们是 ML 新手,需要相关步骤的指导。 - 探索用于结构化数据的 U-Net:
@nana_94125询问是否有人尝试将通常用于图像分割的卷积网络 U-Net 应用于结构化数据。这可能表明了对 U-Net 常规应用之外的探索。
提到的链接:
wav2vec2-codebook-indices/scripts/helpers/w2v2_codebook.py at master · fauxneticien/wav2vec2-codebook-indices:通过在 GitHub 上创建账户,为 fauxneticien/wav2vec2-codebook-indices 的开发做出贡献。
Eleuther ▷ #general (105 messages🔥🔥):
-
没有 GPU,没问题:用户
_michaelsh正在寻求关于在没有 GPU 的情况下如何获得 Large Language Models (LLMs) 经验的建议,@staticpunch建议在 Colab 的 T4 GPU 上运行小模型,它可以处理像 Gemma、Pythia 或 TinyLlama 这样的模型。 -
新手学习 LLM:针对
_michaelsh关于 LLM 学习材料的询问,@rallio.建议利用 YouTube 和强大的 LLM(如 GPT-4 或 Claude3)进行高效学习,并指出访问这些 LLM 的费用为 每月 20 美元。 -
精选的 Transformers 学习路径:当
_michaelsh表示自己拥有扎实的 NLP 基础并熟悉 Transformers 架构但希望获取前沿知识时,@tulkascodes分享了几个推荐资源,包括 Lilian Weng 更新的 Transformers 综述,以及 HazyResearch 在 GitHub 上关于 Foundation Models 的集合。 -
AI 领域的资历与知识:由于有如此多的资源,
_michaelsh对学习重点感到困惑,@ad8e、@catboy_slim_和@wonkothesensible等多位用户提供了个性化指导,强调了选择感兴趣的主题、阅读 arXiv 论文以及使用教科书等具体材料的重要性,其中包括提到的 UDL Book。 -
LLM 的创新与讨论:除了个人学习策略外,频道还讨论了 LLM 的最新进展,包括发布了具有内置 RAG 能力的 Cohere 35b 模型权重 (
@rallio.),以及一段关于 The Orthogonality Thesis & AI Optimism 的 YouTube 视频 (.the_alt_man)。此外,还提到了由@conceptron发布的一份政府委托的关于高级 AI 风险的报告。
提到的链接:
- US Must Move ‘Decisively’ To Avert ‘Extinction-Level’ Threat From AI, Gov’t-Commissioned Report Says - Slashdot:美国政府必须“迅速且果断地”采取行动,以规避源自人工智能 (AI) 的重大国家安全风险,在最坏的情况下,这可能会导致“灭绝…
- The Transformer Family Version 2.0:自三年前我发布关于“The Transformer Family”的上一篇文章以来,已经提出了许多新的 Transformer 架构改进。在这里,我对该内容进行了大规模的重构和丰富…
- Let’s build GPT: from scratch, in code, spelled out.:我们根据论文 “Attention is All You Need” 以及 OpenAI 的 GPT-2 / GPT-3 构建了一个 Generatively Pretrained Transformer (GPT)。我们讨论了与之相关的…
- The orthogonality thesis & AI optimism:时间戳:0:00 - 视频开始;7:39 - Bostrom 论点的概述;9:25 - 决定性的战略优势;13:26 - 关于缓慢起飞的论据;23:13 - 定义…
- lucidrains - Repositories:专注于 Attention。这就是我们所需要的一切。lucidrains 有 282 个可用的仓库。在 GitHub 上关注他们的代码。
- GitHub - HazyResearch/aisys-building-blocks: Building blocks for foundation models.:Foundation Models 的构建模块。通过在 GitHub 上创建账号来为 HazyResearch/aisys-building-blocks 的开发做出贡献。
Eleuther ▷ #research (68 messages🔥🔥):
-
Gemini 1.5 报告更新分析:用户讨论了 Gemini 1.5 报告 的更新,注意到增加了 9 页的贡献者名单、细微的段落修改以及附录中扩展的示例输出。除了有人认为贡献者名单似乎过多外,没有强调这些变化带来的具体影响。
-
模型窃取攻击揭示 LLM 维度:来自 @_akhaliq 的推文 分享了一种新型模型窃取攻击的细节,该推文提到能够从 OpenAI 的 ChatGPT 等模型中提取整个投影矩阵,揭示了包括 gpt-3.5-turbo 在内的各种模型的隐藏维度。随后引发了关于披露此类漏洞的伦理讨论,以及这是否构成知识产权 (IP) 窃取。
-
关于记忆性训练的讨论:用户讨论了一篇关于 RLHF (Reinforcement Learning from Human Feedback) 如何影响语言模型训练的新论文,探讨了经过 RLHF 处理的行为是否可以在不同语言之间迁移,并对齐到不同的文化规范。Gson_arlo 表示有兴趣就文本生成中反映的人类偏好偏差相关研究进行合作。
-
理论模型权重生成:讨论了使用 Hypernetwork 为大型或小型神经网络生成权重的概念。用户讨论了一篇论文的建议,即大模型可以为小模型生成权重,并达成共识,认为由于复杂性,该想法目前更适合在较小的组件而非整个模型上进行探索。
-
LLM 推理输出异常:用户 xnerhu 询问了关于其语言模型无论 Prompt 如何都输出具有相似 Logprobs 的相同 Token 的问题。对此提出了几项建议,包括训练或微调模型、使用不同的模型,并就优化器和 Batch Size 计算进行了详细讨论。
提到的链接:
- Yi: Open Foundation Models by 01.AI:我们介绍了 Yi 模型系列,这是一系列展示了强大多维能力的语言和多模态模型。Yi 模型系列基于 6B 和 34B 预训练语言模型…
- 来自 AK (@_akhaliq) 的推文:Google 宣布了“窃取生产级语言模型的一部分”。我们介绍了第一种模型窃取攻击,它可以从黑盒生产级语言模型中提取精确且非平凡的信息…
- Stacking as Accelerated Gradient Descent:Stacking 是一种通过逐渐增加层数并通复制旧层参数来初始化新层,从而训练深度残差网络的启发式技术,已被证明相当…
- Negating Negatives: Alignment without Human Positive Samples via Distributional Dispreference Optimization:大语言模型 (LLMs) 彻底改变了 AI 的角色,但也带来了传播不道德内容的潜在风险。对齐技术已被引入以引导 LLMs 走向人类…
- 来自 Jan Leike (@janleike) 的推文:今天我们发布了一个我们内部一直在用来分析 Transformer 内部机制的工具——Transformer Debugger!它结合了自动可解释性和稀疏自编码器,并且…
- Emergent and Predictable Memorization in Large Language Models:记忆化,即大语言模型 (LLMs) 逐字输出其训练数据中整个序列的倾向,是安全部署语言模型的一个关键关注点。特别是,它是…
Eleuther ▷ #interpretability-general (3 messages):
-
关于 Transformer Debugger 支持情况的澄清:
@stellaathena询问 transformer-debugger 工具是否仅支持来自其自定义库的模型,并对其与已训练的 Hugging Face Checkpoints 的兼容性提出疑问。 -
在 Pythia 中通过剪枝进行遗忘学习:
@millander讨论了一篇关于使用 Pythia 进行可解释性驱动的能力遗忘 (Unlearning) 的论文,该论文尝试通过剪枝重要神经元来消除特定能力。尽管语言模型在遗忘集上的性能下降速度快于保留集,但保留集性能的显著下降影响了整体效用,而图像分类任务的表现则较好。该论文可以在这里找到。
提到的链接:
- GitHub - openai/transformer-debugger:通过在 GitHub 上创建账号来为 openai/transformer-debugger 的开发做出贡献。
-
[[PDF] Dissecting Language Models: Machine Unlearning via Selective Pruning Semantic Scholar](https://www.semanticscholar.org/reader/59e2e55137a32ea07651cacd4fadc7b15c371a20):一个利用人工智能方法提供高度相关结果和新型工具以轻松过滤结果的学术搜索引擎。
Eleuther ▷ #lm-thunderdome (2 messages):
-
Llama 超参数与学习率查询:
@johnnysands在使用 Llama hyperparameters 和较高学习率(仍为 1e-4)训练模型时,尽管 loss 统计数据良好,但下游评估性能却出乎意料地差。他们质疑学习率是否因为没有充分退火(annealed)而导致这一结果,并根据以往对 MMLU 评估的观察,认为随着学习率下降,性能可能会有所提高。 -
旧时代的基准测试:
@epicx询问为什么某些具有历史意义的基准测试(如来自 SQuAD v1.1 ExactMatch (EM) 和 F1 分数 的测试)已经失宠。他们发布了一个排行榜,显示了包括人类基准在内的模型得分,以及{ANNA}、LUKE和XLNet等模型,并提到 Natural Questions 排行榜 没有数据(<<null>>)。
提到的链接:
Eleuther ▷ #multimodal-general (2 messages):
- 关于 Transformer 和 Diffusion 的澄清:
@yoavhacohen澄清说 Transformer 是一种架构,而 diffusion 指的是一种训练和推理方法,并提到结合 Transformer 的 diffusion 已应用于早期模型,如 DALL-E 2、DiT 和 PixArt。 - 达成理解:
@kerls对@yoavhacohen就 Transformer 和 diffusion 模型之间关系的澄清表示理解和感谢。
Eleuther ▷ #gpt-neox-dev (1 messages):
- Checkpoint 转换困惑:
@aphoh正在努力将 pythia/neox checkpoints 转换为 upstream megatron-lm。尽管权重匹配且加载成功,但他们遇到了异常高的 loss(>25),并对 qkv 投影矩阵的布局提出质疑。
LlamaIndex ▷ #announcements (1 messages):
- MemGPT 网络研讨会即将举行:
@jerryjliu0宣布了一个关于 MemGPT 长期、自编辑记忆 的网络研讨会,演讲者包括 Charles、Sarah 等人。会议定于本周五太平洋时间上午 9 点举行,探讨 LLM 长期记忆的挑战和虚拟上下文管理。报名参加活动。 - 了解 MemGPT:即将举行的 MemGPT 演示 将深入探讨系统如何管理即时上下文和外部存储中的记忆,认为这是机器学习记忆管理方面的一项重大进步。会议将包括对 Packer et al. 论文的详细介绍。
提到的链接:
LlamaIndex Webinar: Long-Term, Self-Editing Memory with MemGPT · Zoom · Luma:LLM 的长期记忆是一个尚未解决的问题,从向量数据库进行简单的检索并不奏效。MemGPT (Packer et al.) 的最新迭代在这方面迈出了一大步…
LlamaIndex ▷ #blog (5 messages):
-
构建上下文增强型应用:
@ravithejads发布了一个包含 6 个 notebook 和 4 个视频的系列,教授如何使用 LlamaIndex 和 Claude 3 构建应用,涵盖了从基础到高级的检索增强生成(RAG)以及自动化 Agent。在 Twitter 上查看完整系列。 -
巴黎 RAG 见面会公告:3 月 27 日,与
@hexapode和其他专家一起参加在巴黎举行的 RAG 见面会,讨论高级 RAG 策略、RAG 命令行界面(CLI),以及更多关于 LlamaIndex 和 Mistral 模型的内容。见面会详情请见 Twitter。 -
通过 Home AI 简化房屋搜索:create-llama 命令行工具为 Home AI 提供支持,这是一个使用大语言模型(LLMs)使阅读房产披露文件变得更简单的界面,增强了房屋搜索的可用过滤器。在 Twitter 上了解此工具。
-
关于增强 LLM 记忆的新网络研讨会:
@MemGPT将在新的网络研讨会中讨论 LLM 长期记忆实现的进展,这是相比简单向量数据库检索的一大进步。在 Twitter 上了解更多关于即将举行的网络研讨会的信息。 -
Ollama and Friends 巴黎开发者见面会:
@hexapode将参加 3 月 21 日在巴黎 Station F 举行的 Ollama 开发者见面会。届时将有来自 AI 和开源社区关键人物的演讲和演示,包括 Ollama、Docker 和 LlamaIndex 的维护者。完整的活动详情和阵容可在 Twitter 上查看。
提到的链接:
本地与开源 AI 开发者见面会 (巴黎) · Luma:Ollama and Friends 来到巴黎了!Ollama and Friends 将于 3 月 21 日星期四下午 6 点在巴黎 Station F 举办本地与开源 AI 开发者见面会。欢迎各位开发者齐聚一堂…
LlamaIndex ▷ #general (162 条消息🔥🔥):
- LlamaIndex 与 RAG 部署查询:
@o3omoomin询问了关于使用 LlamaIndex 实现 RAG 聊天机器人的问题,@whitefang_jr引导他们查看 GitHub 上一个结合了前端和后端的“使用 LlamaIndex 的全栈应用程序”。 - MistralAI 中的查询参数:
@maax4322询问了如何为 MistralAI 设置top_k、top_p和max_tokens等全局参数,@whitefang_jr解释说max_tokens可以在初始化期间定义,而其他参数可以作为 dict 传递,并引用了 GitHub 源代码。 - 在 VectorStoreIndex 中使用 LLM 的问题:
@kamyarmhd在将 RetrieverQueryEngine 与 Llama2 结合使用时遇到错误,@whitefang_jr建议在调用前先在 settings 中设置其 LLM 以解决问题。 - 最近 LlamaIndex 升级后的错误处理:
@cheesyfishes协助@rachel_001.处理了与DEFAULT_PERSIST_FNAME相关的ImportError,建议在将 LlamaIndex 更新到 v0.10 后创建一个全新的虚拟环境。 - 使用 LlamaIndex 创建多模态应用:由于
@verdverm正在寻找处理不同类型多模态数据的信息,@whitefang_jr分享了一个结合语言和图像的多模态应用 LlamaIndex 指南。
提到的链接:
- Node Postprocessor Modules - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- Tweet from TheHeroShep (@TheHeroShep): ComfyUI 的 LLM Node Pack 1。很高兴分享 @getsalt_ai 的强大节点集,得益于 @WAS_STUFF,让在 ComfyUI 中使用 LLM 和 @llama_index 变得更容易 ✨ 提示词增强节点…
- Node Postprocessor - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- CitationQueryEngine - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- Documents / Nodes - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- OrdalieTech/Solon-embeddings-large-0.1 · Hugging Face: 未找到描述
- Nujoom AI: 未找到描述
- 🚀 RAG/LLM Evaluators - DeepEval - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- OpenAI Agent with Query Engine Tools - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- Multi-modal - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- Llama Hub: 未找到描述
- INSANELY Fast AI Cold Call Agent- built w/ Groq: Groq LPU 到底是什么?我将通过一个构建具有 Groq 速度的实时 AI 电销 Agent 的真实案例带你领略 🔗 链接 - 在 Twitter 上关注我…
- llama_index/llama-index-core/llama_index/core/indices/base.py at main · run-llama/llama_index: LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- llama_index/llama-index-integrations/llms/llama-index-llms-mistralai/llama_index/llms/mistralai/base.py at d63fec1c69a2e1e51bf884a805b9fd31ad8d1ee9 · run-llama/llama_index: LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- GitHub - run-llama/sec-insights: A real world full-stack application using LlamaIndex: 一个使用 LlamaIndex 的真实全栈应用程序 - run-llama/sec-insights
- Vector Stores - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- Ensemble Query Engine Guide - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- Router Query Engine - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- ReAct Agent with Query Engine (RAG) Tools - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- Semi-structured Image Retrieval - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- Chroma Multi-Modal Demo with LlamaIndex - LlamaIndex 🦙 v0.10.18.post1: 未找到描述
- llama_index/docs/examples/query_engine/SQLAutoVectorQueryEngine.ipynb at main · run-llama/llama_index: LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- llama_index/docs/examples/query_engine/SQLJoinQueryEngine.ipynb at main · run-llama/llama_index: LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs: 未找到描述
LlamaIndex ▷ #ai-discussion (3 条消息):
-
探索 Matryoshka Representation Learning:
@lien_61024分享了一个关于 Matryoshka Representation Learning 论文讨论的邀请,该活动由 Jina AI 主办,特邀 Aditya Kusupati 和 Aniket Rege 参加。讨论旨在提供对该论文的深入见解,参与需提前注册。 -
寻找适用于 Claude 3 的开源 GUI/前端:
@vodros正在寻找兼容 Claude 3 的 开源 GUI/前端 推荐,并表示希望从目前使用的 Chatbox 进行升级。 -
LLM 研究论文数据库即将上线:
@shure9200宣布创建了一个 LLM (Large Language Models) 论文数据库,旨在让研究人员及时了解该领域最新的高质量论文。该数据库力求做到全面且组织良好。
提到的链接:
- Awesome LLM Papers Toward AGI:全球最全面的 LLM 论文和仓库精选列表。
- Matryoshka Representation Learning: Paper discussion · Zoom · Luma:加入我们,深入了解 Matryoshka Representation Learning 的奇妙世界。由博学的 Aditya Kusupati 和敏锐的 Aniket Rege 呈现…
LAION ▷ #general (65 messages🔥🔥):
- 寻找 AI 视频模型:
@lunsei询问除了 OpenAI 之外是否还有优秀的 AI 视频模型,@nodja回复称据其所知目前还没有公开可用的模型。@nodja还推测可能有人会利用 SD3 来开发视频模型。 - 马斯克推文引发讨论:
@spirit_from_germany分享了 Elon Musk 的一条推文,而@freon和@pseudoterminalx则对潜在的 AI 监管发表了评论,幽默地认为这些规则可能会有利于中国或阻碍言论自由。对话中包含了对这些政策有效性的怀疑。 - Gladstone AI 任务简报:
@itali4no发布了 Gladstone AI 的链接,并评论了他们对 GPT-3 的看法以及它是如何引发 AI 算力竞赛的。随后讨论转向推测这些报告背后的资金来源和政治立场。 - Super PAC 内幕调查:深入调查资金线索,
@progamergov分享了相关 Super PAC 的信息以及资助者的匿名性。与会者对一份建议限制 AI 训练的专家报告背后的政治可行性和动机表示怀疑。 - AI 安全从业者的担忧:
@thejonasbrothers引用了一些令人不安的情绪,即 AI 安全从业者对公司的决策过程感到担忧。对话继续讨论了对先进 AI 系统实施训练限制的可能性极低,并对报告的作者进行了批评。
提到的链接:
- Seriously Really GIF - Seriously Really Omg - Discover & Share GIFs:点击查看 GIF。
- Devin: World's First AGI Agent (yes, this is real):如果你对 AI 感兴趣并想了解 AI Agents,请加入我的社区:https://www.skool.com/new-society。关注我获取极速 AI 新闻…
- Gladstone AI:Gladstone 帮助政府在新一代先进 AI 时代制定有效的政策应对措施。
- AMERICANS FOR AI SAFETY - committee overview - FEC.gov:在新的 fec.gov 上探索当前和历史联邦竞选财务数据。查看总额和趋势,了解候选人和委员会如何筹集和使用资金。
- Political action committee - Wikipedia:未找到描述。
{kind=link}
LAION ▷ #research (75 messages🔥🔥):
-
利用 ELLA 革新文本生成图像模型:
@chad_in_the_house分享了一篇论文摘要,介绍了 ELLA (Efficient Large Language Model Adapter),它在无需额外训练的情况下,显著提高了文本生成图像扩散模型的文本对齐能力。讨论进一步演变为将 ELLA 与 腾讯的新作 以及 SD3 等其他模型进行比较。 -
面向大众的量化:
@vrus0188关注了 llama.cpp 最近的一项突破,该技术通过使用全新的“2-bit quantization(2位量化)”技术,使得在普通硬件上运行 Large Language Models (LLMs) 成为可能。欲了解详情和见解,可以查看 Andreas Kunar 的 Medium 文章,并探索相关的 GitHub 更新。 -
释放 SD3 的潜力:
@thejonasbrothers推测了 SD3 的潜力,讨论了其由于缺少 cross-attention 带来的优势,以及整合图像和文本 embedding 的方法。对话涉及了模型大小的问题,重点讨论了在标准 GPU 上运行高质量模型的可行性、量化技术以及性能预期。 -
时间与内存的权衡:
@thejonasbrothers连续发帖描述了 SD3 针对不同 VRAM 容量的量化和 CPU-offloading 策略。讨论涵盖了潜在的执行时间、性能权衡,以及预期中类似于 Llama 所实现的社区驱动优化。 -
不到 20 美元揭秘黑盒模型:
@twoabove分享了一篇 arXiv 论文,该论文提出的一种攻击方式令社区感到震惊:仅需极低成本即可恢复 Transformer 模型的 embedding 投影层,特别是针对 OpenAI 的模型。这一发现引发了关于该方法简单性和廉价性的讨论及其影响,促使 OpenAI 和 Google 引入了 API 修改以缓解此类攻击。
提到的链接:
- ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment:未找到描述
- Breaking News: Run Large LLMs Locally with Less RAM and Higher Speed through llama.cpp with QuIP#:llama.cpp 的最新更新为 LLM 启用了一种全新的“听起来疯狂但可用”的 2-bit quantization —— QuIP:基于非相干性的量化……
- GitHub - openai/transformer-debugger:通过在 GitHub 上创建账号来为 openai/transformer-debugger 的开发做出贡献。
- GitHub - leejet/stable-diffusion.cpp: Stable Diffusion in pure C/C++:纯 C/C++ 实现的 Stable Diffusion。通过在 GitHub 上创建账号来为 leejet/stable-diffusion.cpp 的开发做出贡献。
LAION ▷ #learning-ml (1 条消息):
- LAION-400M 数据集探索:
@coreys7870对 Thomas Chaton 关于使用和创建 LAION-400-MILLION 图像与标题数据集的文章表示赞赏,并提供了文章的短链接:bit.ly/3uYrDCh。
提到的链接:
Download & stream 400M images + text - a Lightning Studio by thomasgridai:使用、探索并从头开始创建 LAION-400-MILLION 图像与标题数据集。
Latent Space ▷ #ai-general-chat (117 条消息🔥🔥):
-
对新 AI “Devin” 的兴奋:
@guardiang分享了关于 Cognition Labs 新推出的 AI 软件工程师 “Devin” 的信息,它在 SWE-Bench 编程基准测试中展示了显著进展。社区讨论了Devin备受瞩目的支持者和令人印象深刻的能力,强调了其改变软件工程格局的潜力。 -
关于 Elon Musk “开源” AI 的辩论:该频道进行了一场激烈的讨论,涉及
@tzmartin、@vodros、@guardiang等人,关于 Elon Musk 宣布可能开源 Twitter 算法 “Grok” 的消息。用户讨论了这对开源原则的影响以及 Musk 的声誉。 -
AI 权重提取研究发布:
@swyxio链接了一篇关于从 AI 模型中提取权重的 DeepMind 论文;@erleichda.和@stealthgnome澄清说,该方法涉及推断结构并提取模型部分 embedding 层的权重,尽管补丁已经发布。 -
Karpathy 达成新里程碑:
@mhmazur兴奋地分享了 Andrej Karpathy 达成新里程碑的消息,社区对此表示祝贺,并讨论了其对 AI 和内容创作者的影响。 -
高效 AI 推理引擎问世:
@fanahova宣布推出 Truffle-1,这是一款价格实惠的推理引擎,旨在高效运行开源模型,因其低功耗和潜在影响引起了社区的关注。
提到的链接:
- 未找到标题:未找到描述
- Andrew Kean Gao (@itsandrewgao) 的推文:我从不相信录制的演示,所以我联系了 @cognition_labs 团队申请早期访问权限亲自尝试,并且拿到了!我将在这里分享我对 #devin 的真实看法。🧵🧵 1/n ↘️ 引用…
- Cognition (@cognition_labs) 的推文:今天我们很高兴推出 Devin,首位 AI 软件工程师。Devin 在 SWE-Bench 编码基准测试中达到了新的 SOTA 水平,并成功通过了实际的工程面试…
- Akshat Bubna (@akshat_b) 的推文:我第一次尝试 Devin 时,它:- 导航到我给它的 @modal_labs 文档页面 - 学习了如何安装 - 将控制权交给我也进行身份验证 - 启动了一个 ComfyUI 部署 - 与之交互…
- asura (@stimfilled) 的推文:@qtnx_ 3) dateLastCrawled: 2023-09
- 从零开始的扩散模型 (Diffusion models from scratch):本教程旨在对扩散模型进行浅显易懂的介绍,并通过一个运行示例说明如何从头开始构建、训练和采样一个简单的扩散模型。
- Varun Shenoy (@varunshenoy_) 的推文:Devin 在数据提取方面表现惊人。在过去的几周里,我一直在抓取不同博客的数据,Devin 1. 编写爬虫程序导航网站 2. 执行代码…
- simp 4 satoshi (@iamgingertrash) 的推文:终于,很高兴推出 Truffle-1 —— 一款售价 1299 美元的推理引擎,旨在仅用 60 瓦功率运行 OSS 模型 https://preorder.itsalltruffles.com
- Ashlee Vance (@ashleevance) 的推文:独家新闻:一家名为 Cognition AI 的初创公司发布了目前看来功能最强大的编码助手。它不仅能自动完成任务,还能独立编写整个程序。得到了…的支持。
- Aravind Srinivas (@AravSrinivas) 的推文:这是第一个(不仅是编码类,而是任何类型的)Agent 演示,似乎跨越了人类水平的门槛并能可靠工作。它还向我们展示了结合 LLM 和树搜索(tree search)的可能性…
- Neal Wu (@WuNeal) 的推文:今天我终于可以分享 Devin 了,这是由我们 @cognition_labs 团队构建的首位 AI 软件工程师。Devin 能够端到端地构建应用、发现生产代码库中的 Bug,甚至进行微调…
- Andrej Karpathy (@karpathy) 的推文:# 软件工程自动化 在我看来,软件工程自动化将类似于自动驾驶。例如,在自动驾驶中,随着自主性的增加和抽象层级的提高…
- 微调优化 - DoRA, NEFT, LoRA+, Unsloth:➡️ 高级微调仓库:https://trelis.com/advanced-fine-tuning-scripts/ ➡️ 高级推理仓库:https://trelis.com/enterprise-server-api-and-infere…
- cohere (@cohere) 的推文:今天,我们很高兴发布 Command-R,这是一款针对大规模生产工作负载优化的新型 RAG 优化 LLM。Command-R 属于新兴的“可扩展”模型类别,平衡了高效率…
-
Fred Ehrsam (@FEhrsam) 的推文:这是我第一次看到 AI 接受一项复杂任务,将其分解为步骤,完成它,并向人类展示过程中的每一步 —— 达到可以完全接手人类工作的程度。…
- 来自 muhtasham (@Muhtasham9) 的推文:DeepMind 的研究人员现在可以窃取 API 背后的权重 “我们还还原了 gpt-3.5-turbo 模型的准确隐藏层维度大小,并估计只需花费不到 2,000 美元的查询费用即可还原整个…”
- 来自 Patrick Collison (@patrickc) 的推文:这些不仅仅是精心挑选的演示。根据我的经验,Devin 在实践中非常令人印象深刻。 ↘️ 引用 Cognition (@cognition_labs) 今天我们很高兴推出 Devin,第一个 AI…
-
[热力学计算:比量子计算更好? Guillaume Verdon 和 Trevor McCourt, Extropic](https://youtu.be/OwDWOtFNsKQ?si=FJQA5PUBAsEBQsXD):第 3 集:Extropic 正在构建一种新型计算机——既不是经典的 bits,也不是量子的 qubits,而是一种神秘且更复杂的第三种事物。他们称之为 Therm…
Interconnects (Nathan Lambert) ▷ #news (59 messages🔥🔥):
- Musk 暗示 Grok 将开源:
@xeophon.分享了@elonmusk的一条推文,暗示 xAI 将开源 Grok,而@natolambert对“开源(open source)”一词的准确使用表示怀疑。 - Cohere 推出 Command-R:
@xeophon.关注了 Command-R,这是一个用于大规模生产的新型可扩展生成模型,其权重已发布供学术使用。 - 对 Llama 3 的预期:在关于模型开放性的讨论中,
@xeophon.提到了对尚未发布的 Llama 3 模型的高期望,@natolambert同意模型的多样性比单一的突破更重要。 - GPT-4.5 消息更新:
@philpax指出 GPT-4.5 的博客文章出现在了 Bing 搜索结果中,@natolambert评论了其出现的重大意义。 - 关于模型发布和法律问题的辩论:
@natolambert思考了由于法律复杂性,像 Llama 3 这样的新模型何时能面世,而@dangf91和@xeophon.就 Cohere 的 Command-R 模型在欧盟应用中的语言能力进行了交流。
提到的链接:
- Command-R: 生产规模的 RAG:Command-R 是一款针对 RAG 和 Tool Use 的可扩展生成模型,旨在为企业实现生产级 AI。
- 来自 Xeophon (@TheXeophon) 的推文:今晚 GPT 5
- 来自 Elon Musk (@elonmusk) 的推文:本周,@xAI 将开源 Grok
Interconnects (Nathan Lambert) ▷ #ml-questions (34 messages🔥):
- 预训练 GPT 模型的成本:
@xeophon.指出,根据 2022 年 9 月 Mosaic Cloud 的成本,预训练像 GPT-2 这样的模型可能花费不到 1,000 美元。进一步讨论提到,自那时起,GPT-1.3B 等模型的成本已减半,并链接了一篇名为“50 万美元实现 GPT-3 质量”的 Databricks 博客文章(Databricks 博客)。 - 爱好者的预训练费用:在聊天中,
@philpax沉思,如果成本合理,富裕的热心人士是否可能训练类似的模型。@natolambert指出,对于无法获得折扣的爱好者来说,这仍然是一笔不小的数目。 - Stability 支付的算力费用更低?:在讨论 Stability AI 等公司的模型训练成本时,
@natolambert推测 Stability 支付的算力费用可能低于 100,000 美元,而@xeophon.提到了通过与硬件供应商的合作伙伴关系或交换协议来抵消成本的可能性,并引用了关于使用 AI 超级计算机的 Stability 广告(Stability AI 超级计算机工作)。 - 集成更多阅读材料的策略:
@dangf91询问了让模型阅读更多书籍/文章的策略,以及使用掩码输入(masked inputs)的经典无监督方法是否足够。@natolambert和@vj256建议将书籍添加到预训练数据集中是标准做法,而不是仅仅依赖无监督掩码方法。
Interconnects (Nathan Lambert) ▷ #random (15 messages🔥):
-
订阅者身份的哀叹:
@420gunna表达了片刻的悲伤,称自己为“被嫌弃的Subscriber”,并配上了一个沮丧的表情。@natolambert反驳了这种情绪,强调了订阅者对社区的重要性:“我们热爱订阅者。没有订阅者,这一切都不存在。” -
争论该读哪篇论文:
@420gunna在纠结如何从 arXiv 上发布的两个类似的学术论文中做选择,询问哪篇更有阅读价值。@natolambert澄清了区别,指出一篇是关于数据的,而另一篇是关于选择数据集的方法,并建议专注于选择的那篇论文更深入,但另一篇可能更容易理解。 -
利用 AI 改进文献研究:
@xeophon.提到了他们的论文摘要项目 Clautero,指出 Claude 3 生成的摘要比 Claude 2 更好,并表达了对使用 LLM 进行文献研究的兴奋。 -
Meta 发布重大 AI 基础设施公告:
@xeophon.分享了一份 Meta 新闻稿,内容关于对 AI 基础设施的重大投资。他们透露 Meta 计划建设两个 24k GPU 集群,并打算在 2024 年底前将 350,000 个 NVIDIA H100 GPU(相当于近 600,000 个 H100 的计算能力)纳入其基础设施。 -
Meta 的基础设施路线图和 Llama 3 训练计划:针对 Meta AI 基础设施的新闻,
@natolambert幽默地批评了其中一张图表,认为其对通往 AGI 进程的描述过于简化,调侃该图表模糊地归功于 Llama 3,并问道:“这是哪个实习生画的”,而@pxlbuzzard则开玩笑说该图表在基础里程碑与 AGI 之间建立了过于直接的联系。
提到的链接:
- Building Meta’s GenAI Infrastructure:标志着对 Meta AI 未来的重大投资,我们宣布建设两个 24k GPU 集群。我们正在分享硬件、网络、存储、设计、性能和软件方面的细节,这些将帮助我们……
- A Survey on Data Selection for Language Models:大型语言模型近期取得成功的一个主要因素是使用庞大且不断增长的文本数据集进行无监督预训练。然而,天真地在所有可用数据上训练模型……
- Datasets for Large Language Models: A Comprehensive Survey:本文开始对大型语言模型(LLM)数据集进行探索,这些数据集在 LLM 的显著进步中起着至关重要的作用。数据集作为基础基础设施……
Interconnects (Nathan Lambert) ▷ #memes (2 条消息):
- Doge 在行动:用户
@xeophon.分享了一个链接,似乎与 Doge 有关。 - 尴尬突袭:用户
@philpax发布了一个表示尴尬得要死的表情(表情代码:<a:diesofcringe:1051223570501611581>)。
CUDA MODE ▷ #general (38 条消息🔥):
- Nvidia 的护城河持续令人印象深刻:用户
@apaz表达了观看 Bill Dally 演讲后的见解,承认了为什么 Nvidia 拥有显著的竞争优势。 - 跨平台计算的苦恼:
@stefangliga哀叹缺乏通用的异构计算平台,批评了 CUDA 的局限性以及 SYCL 在 Windows 上的实验性质等选项。该用户还提到了不同 GPU 系列的奇特之处,例如 Nvidia 的 Pascal GPU 在 CUDA 和 Vulkan 中支持 FP16,但在 OpenCL 中不支持。 - Vulkan 作为 CUDA 的替代方案:
@stefangliga推测,如果 Vulkan 的 Pytorch 后端能在桌面端发布,它可能会缩小 Nvidia 的护城河,同时得出结论:虽然 Nvidia 的硬件似乎是可以超越的,但其软件优势感觉几乎是不可逾越的。 - Vulkan 采用的障碍:
@apaz描述了 Vulkan 使用起来令人望而生畏,提到了在可用之前需要进行的繁琐设置,以及与 CUDA 类似的打包问题。 - Meta 宣布大规模 AI 基础设施:
@andreaskoepf发布的一篇文章详细介绍了 Meta 对 24k GPU 集群的投资以及涉及 350,000 个 NVIDIA H100 GPU 的雄心勃勃的路线图,强调了该公司对 AI 开发和开源倡议的承诺。
提到的链接:
- 构建 Meta 的 GenAI 基础设施:标志着 Meta 对 AI 未来的重大投资,我们宣布推出两个 24k GPU 集群。我们正在分享有关硬件、网络、存储、设计、性能和软件的详细信息,这些细节帮助我们提取……
-
[回到未来 (1985) - 1.21 吉瓦场景 Movieclips](https://youtu.be/BDuZqYeNiOA?t=50):回到未来 - 1.21 吉瓦:Marty (Michael J. Fox) 和 Doc (Christopher Lloyd) 策划了一个方案,为 DeLorean 跑车获取 1.21 吉瓦的能量。购买电影…… -
[从应用到原子:微软聘请核能专家为其数据中心供能 - 印度时报](https://timesofindia.indiatimes.com/gadgets-news/apps-to-atoms-microsoft-hires-nuclear-expert-to-fuel-its-data-centres/articleshow/107151840.cms):微软聘请了一位核能专家,通过开发小型核反应堆作为化石燃料的替代方案,为其数据中心提供动力。 - 微软为核能数据中心项目招聘负责人:行业资深人士专注于小型模块化反应堆的开发。
CUDA MODE ▷ #triton (3 条消息):
- 社区见面会已排期:
@aaryaavi宣布社区见面会的 MS Teams 链接将在 Triton Lang Slack 频道中提供,并分享了 频道链接 以及为希望加入的人提供的链接:Slack 邀请请求。 - 会议邀请说明:
@marksaroufim确认他在 Slack 上,并将检查正确的会议邀请,指出该链接每月都会在 general 频道中分享。 - 见面会详情更新:
@aaryaavi提到本月的见面会定于 PT 时间 3/28 上午 10 点,加入链接和议程即将公布。
提到的链接:
- Slack:未找到描述
- Slack 邀请请求 · openai/triton · Discussion #2329:大家好,我发起这个讨论帖,以防有其他人(像我一样)想要请求 Slack 邀请。
CUDA MODE ▷ #cuda (13 条消息🔥):
- 使用线程粗化提升效率:
@cudawarped讨论了 CUDA 中线程粗化 (Thread Coarsening) 的好处,解释说增加粗化因子可以通过减少 shared memory 操作带来线性性能提升,直到 kernel 达到内存受限 (memory bound)。 - CUDA 学习的 DIY 方法:
@g.huy询问了学习nv_half等特殊 CUDA 数据类型的资源,对此@zippika建议使用 Visual Studio Code 搜索 CUDA toolkit 头文件,并查看 GitHub 上的代码示例。 - VS Code 中的 CUDA 开发扩展:针对
@g.huy的询问,@zippika描述了如何使用 VS Code 中的 C++ 扩展并调整 include path,以实现对 CUDA 开发的类型支持。 - 使用 Visual Studio Code 调试 CUDA:
@zippika解释了通过更新c_cpp_properties.json文件来解决 Visual Studio Code 中 include path 问题的方法,这会促使编辑器为 CUDA 代码提供正确的 IntelliSense。 - 为 CUDA 配置 Visual Studio Code:
@zippika分享了他们的c_cpp_properties.json配置,详细说明了实现 IntelliSense 正常运行的设置,包括 CUDA toolkit 和 PyTorch 的 include path,以及为 CUDA 架构和 toolkit 版本设置正确的 defines。
CUDA MODE ▷ #torch (4 条消息):
- Libtorch 性能查询:用户
@ingiing询问 libtorch 是否比 PyTorch 中的load_inline运行得更快,引发了关于性能对比的讨论。 - 澄清“GPU 架构求解器”:
@andreaskoepf澄清说,“GPU 架构求解器”这一术语通常是指为给定硬件寻找最佳软件解决方案,而不是为软件问题设计最佳硬件。 - 理解 Modular 的角色:针对上述澄清,
@mr.osophy承认了误解,并同意 Modular 确实关注优化问题,即 kernel 与 GPU 架构的兼容性。 - PyTorch 加速的反馈请求:
@marksaroufim邀请大家对 torchao RFC #47 提供反馈,该提案旨在简化新量化算法和数据类型的集成。同一团队开发了gpt-fast和sam-fastkernel,并表示愿意为实际的 CUDA 项目指导新的 kernel 作者。
提到的链接:
[RFC] Plans for torchao · Issue #47 · pytorch-labs/ao:摘要:去年,我们发布了 pytorch-labs/torchao,旨在利用原生 PyTorch 技术加速生成式 AI 模型。Torchao 增加了对在 GPU 上运行量化的支持,包括…
CUDA MODE ▷ #algorithms (4 条消息):
-
来自 NVIDIA 的循环重组情报:
@ericauld分享了一个关于 Stream-K 的 NVIDIA 文章链接,这是一种用于矩阵乘法中重组循环以实现更好工作分块 (work chunking) 的新策略 (下载 PDF)。与 GPU 处理器上现有的 CUTLASS 和 cuBLAS 等库相比,它提供了高达 14 倍的峰值加速。 -
GitHub 宝藏:NVIDIA Stream-K 的示例实现可以在 GitHub 的 CUTLASS 仓库中找到,展示了这种创新的矩阵乘法技术 (查看示例)。
-
Graphene IR 亮相:
@ericauld重点介绍了另一篇来自 NVIDIA 的文章,介绍了一种名为 Graphene 的中间表示 (IR),用于优化 GPU 上的张量计算 (阅读更多)。Graphene 带来了全新的表达水平,通过利用数据和线程分片 (thread tiles) 之间的优化映射,使其能够达到或超过现有库的性能。
提到的链接:
- Stream-K: Work-centric Parallel Decomposition for Dense Matrix-Matrix Multiplication on the GPU:我们引入了 Stream-K,这是一种针对稠密线性代数中矩阵乘法 (GEMM) 及相关计算的以工作为中心的并行化方案。虽然当代的分解主要基于分片 (tile-based),但我们的…
- cutlass/examples/47_ampere_gemm_universal_streamk at main · NVIDIA/cutlass:用于线性代数子程序的 CUDA 模板。通过在 GitHub 上创建账号为 NVIDIA/cutlass 的开发做出贡献。
CUDA MODE ▷ #suggestions (1 条消息):
- CUDA 训练系列课程现已上线:
@w0rlord在 YouTube 上分享了 CUDA Training Series 的讲座材料,作为对 GitHub 和官方系列页面资源的补充。 - 深入 CUDA 作业:他们还提供了一个 GitHub 链接,包含与 CUDA Training Series 相关的实践作业,其中涵盖了各种训练材料和练习。
提到的链接:
- cuda-training-series:来自 https://github.com/olcf/cuda-training-series 和 https://www.olcf.ornl.gov/cuda-training-series/
- GitHub - olcf/cuda-training-series: Training materials associated with NVIDIA’s CUDA Training Series (www.olcf.ornl.gov/cuda-training-series/):与 NVIDIA CUDA 训练系列相关的训练材料 (www.olcf.ornl.gov/cuda-training-series/) - olcf/cuda-training-series
CUDA MODE ▷ #beginner (8 条消息🔥):
- PyTorch 到 CUDA 的工作流策略:
@iron_bound建议从 PyTorch/Triton 开始进行初始模型开发,以获得快速反馈并消除错误,仅在需要性能优化时才过渡到 CUDA。 - PyTorch 版本对速度的影响:
@poppingtonic观察到在 2080 Ti 上使用 CUDA 12.1 运行matmul_dyn程序时,PyTorch 版本 2.1.2 (9.17ms) 与 2.2.1 (10.2ms) 之间存在性能差异。 - 探索 tinygrad:
@poppingtonic设定了一个新目标,旨在深入研究 tinygrad 算子和内核 (kernels)。 - Nsight Compute 警告困扰:
@ingiing在使用 Nsight Compute 时遇到警告,消息包括 “No kernels were profiled”,以及关于使用--target-processes all选项的建议。 - 可执行内核确认:针对
@drisspg的提问,@ingiing确认他们的可执行文件确实启动了内核,但担心他们的 GPU 可能不被 Nsight Compute 支持。
CUDA MODE ▷ #pmpp-book (12 条消息🔥):
- PMPP 书籍中的 Profiling:
@dasher519询问 PMPP 书籍是否涵盖了 CUDA 的 profiling 工具使用,@marksaroufim回复称书中没有深入涉及,但在 lecture 1 中有讨论。不过,书籍作者在 他们的 YouTube 视频 中确实涵盖了 profiling。 - CUDA 中的三重尖括号格式:
@alexanderrgriffing注意到 PMPP 书籍在三重尖括号中使用了空格(例如<< < ... >> >),并询问这是否是为了与 C++ 解析器兼容。@stefangliga澄清说,由于 C++ standards,空格曾经是强制性的,但在 C++11 中已修复,尽管旧习惯可能仍然存在。 - CUDA C++ 和空格要求:在后续问题中,
@alexanderrgriffing询问 CUDA 过去是否需要空格。@stefangliga表示不清楚 CUDA C++ 的具体细节,但推测这可能与 nvcc 使用的 gcc versions 和 默认 flags 有关。 - 寻找 PMPP 2023 版的练习题答案:
@dasher519询问 2023 edition PMPP 书籍的练习题答案在哪里,以及是否可能在单独的答案书中。聊天消息中没有提供直接回答。
CUDA MODE ▷ #ring-attention (8 messages🔥):
-
可用于压力测试的 GPU:
@iron_bound正在进行较长时间的训练以对某些代码进行压力测试 (stress-test),并向任何需要的人提供 GPU,如果需要可以停止测试。GPU 用自定义表情代码<:gpu:1198044139011452958>表示。 -
夏令时提醒:
@iron_bound提醒大家美国已进入夏令时,并建议在<t:1710176400:t>左右碰头,指明了一个具体的协调时间戳。 -
训练卡在高 Loss 处:
@iron_bound报告说,在小数据集上运行 100 个 epochs 的训练后,loss 无法降至 3.6 以下,并用 “🤯” 表达了沮丧。 -
调整 Learning Rate 的建议:针对高 loss 问题,
@apaz建议可能需要降低 learning rate,或者间接询问 kernel 本身是否可能损坏。 -
测试 Ring Attention 代码:
@iron_bound告知@222363567192670219他们正在通过名为 axolotl 的训练软件测试 ring-attention 代码,指出目前 learning rate 似乎是自动计算的,并分享了指向@iron_bound的 axolotl 训练运行的 WANDB 链接:https://wandb.ai/iron-bound/axolotl/runs/t6dz9ub1?workspace=user-iron-bound。
提到的链接:
iron-bound: Weights & Biases,机器学习开发者工具
CUDA MODE ▷ #off-topic (6 messages):
-
传闻:Claude-3 和 Inflection 的谈话:用户
@f_michael分享了关于 Inflection 和 Claude-3 集成的传闻,并对其影响表示好奇。该传闻最初源自一条推文,后来被纠正,显示这仅仅是传言。 -
Inflection AI 否认传闻:针对这些闲言碎语,
@itali4no分享了来自 Inflection AI 的推文,该推文澄清了关于 Claude-3 usage 的谣言,并指向推文来源以获取准确信息。 -
来自 Stefangliga 的神秘图片:
@stefangliga分享了一张 加密图片 引起了好奇,但没有提供关于内容的上下文或解释。 -
介绍 Devin:AI 软件工程师:用户
@andreaskoepf分享了一个 博客链接,宣布了 Devin,这是由 Cognition Labs 开发的自主 AI 软件工程师,声称在软件工程基准测试中树立了新标杆。 -
itali4no 对 Devin 的真实测试:
@itali4no提供了 @itsandrewgao 的推文链接,后者声称获得了 Devin 的早期访问权限,并承诺对其作为能在 SWE-Bench 编码基准测试中独立完成任务的 AI 表现提供不加过滤的评价。
{kind=link}
提到的链接:
- Blog: 未找到描述
- Andrew Kean Gao (@itsandrewgao) 的推文: 我从不相信录制的演示,所以我联系了 @cognition_labs 团队寻求早期访问权限以亲自尝试,并且拿到了!将在这里分享我对 #devin 的不加过滤的观点。🧵🧵 1/n ↘️ Quotin…
LangChain AI ▷ #general (67 messages🔥🔥):
- Prompt 编写解决问题:
@a.asif表示,他们面临的一个问题通过创建合适的 Prompt 和响应上下文得到了解决。 - 请求 Langchain 支持:像
@jimmyss和@sumerchoudhary_98267这样的用户正在寻求使用 Langchain 的帮助,其中@sumerchoudhary_98267在使用讯飞星火(iFlytek Spark)API 时遇到错误,并分享了进一步协助的链接,例如 讯飞 API 文档 和 讯飞计费信息。 - 集成与检索故障排除:
@problem9069询问如何将 LangServe 路由的输出捕获到变量中,@mattew_999提供了使用 Python 中requests的潜在解决方案。@chyru_97015询问 BM25Retriever 是否支持外部存储,还是仅限内存(in-memory)。 - Langchain 定制化的社区支持:
@yborbalves和@raxrb分别在寻求构建能够检索 PDF 元数据的 Agent 以及根据 Token 长度动态切换模型的帮助。同时,@smix7194就 LaMini-T5 模型中与return_full_text相关的错误寻求帮助,而@evolutionstepper讨论了成功使用 Motor (MongoDB) 作为 Langchain 中的 Memory。 - 在应用中实现和排除 Langchain 故障:用户分享了经验并就各种 Langchain 应用和错误寻求建议。例如,
@pushiha.g在使用特定模型时遇到了奇怪的输出格式,而@ninamani寻求使用新 LLM 生成响应的指导。@andres_fresh_lemmon询问了使用 Langchain 时单元测试的最佳实践,@siddhijain16希望获得有关增量更新 Qdrant 集合 Embedding 的建议。
提到的链接:
- LangSmith:未找到描述
- 从向量库检索元数据 · langchain-ai/langchain · Discussion #10306:大家好,我创建了一个使用多个工具来回答问题的聊天机器人。其中一个工具查询 Pinecone 索引以获取答案。该链的结构如下:def …
- GitHub - antonis19/autobrowse: AutoBrowse 是一个可以执行网页浏览任务的自主 AI Agent。:AutoBrowse 是一个可以执行网页浏览任务的自主 AI Agent。 - antonis19/autobrowse
-
[在本地运行 LLM 🦜️🔗 Langchain](https://python.langchain.com/docs/guides/local_llms):用例 - GitHub - langchain-ai/langserve: LangServe 🦜️🏓:LangServe 🦜️🏓。通过在 GitHub 上创建一个账号来为 langchain-ai/langserve 的开发做出贡献。
- 讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞:未找到描述
- iFLYTEK 开放平台文档:未找到描述
LangChain AI ▷ #langserve (5 条消息):
-
Langserve 使用咨询:用户
@problem9069寻求关于使用 Langserve 将特定路由的输出捕获到变量中的帮助,使用的是 ChatOpenAI 的gpt-4-turbo-preview模型。 -
Chat Playground 现已支持 Claude V3:
@dwb7737创建了一个 Pull Request,将 Chat Playground 更新为使用 Claude version 3。更改涉及更新导入语句和指定model_name参数。 -
获取 LangServer 访问权限:用户
@juand4.dev和@gitmaxd表达了获取 LangServer 访问权限的兴趣。@gitmaxd建议在 X 平台上联系<@703607660599181377>以获取访问权限。
提到的链接:
由 donbr 重构 Anthropic 导入为 langchain_anthropic 并更新模型至 v3 · Pull Request #524 · langchain-ai/langserve:将 Anthropic API 导入过渡到 langchain_anthropic 包以增强兼容性。将 AI 模型升级到 claude-3-sonnet-20240229 以提升性能和功能。
LangChain AI ▷ #langchain-templates (1 条消息):
- 寻求切换到 ‘chat’ 模式:
@ninamani正在使用 langchain 库开发聊天机器人,并寻求在更换新 LLM 后将生成模式从chat-instruct更改为chat的指导。他们提供了一段代码片段,并说明新 LLM 可能是 llama-2 的微调版本,该版本在 oobabooga 环境的chat模式下表现更好。
LangChain AI ▷ #share-your-work (2 条消息):
- GitHub 上的 Langchain Chatbot 介绍:
@haste171分享了一个用于 Langchain Chatbot 的 GitHub 仓库,这是一个用于以对话形式分析和提取信息的开源 AI,展示了如何使用 RAG 进行高效的问答查询。该聊天机器人具有设置简单、支持服务器、交互式 Streamlit UI 和 Python FastAPI 服务器等特点。 - 新文章:Gemma-2b-it 邂逅 Langchain:
@andysingal宣布了他们的文章《革新视频转录:揭秘 Transformer 时代的 Gemma-2b-it 与 Langchain》,发表在 Hugging Face 博客上,探讨了 Transformer 模型与 Langchain 在视频转录中的集成。文章深入探讨了转录技术的未来,重点关注 Gemma-2b-it 和 Langchain 的应用。
提到的链接:
- Revolutionizing Video Transcription: Unveiling Gemma-2b-it and Langchain in the Era of Transformers:未找到描述
- GitHub - Haste171/langchain-chatbot: AI Chatbot for analyzing/extracting information from data in conversational format.:用于以对话格式从数据中分析/提取信息的 AI 聊天机器人。- Haste171/langchain-chatbot
LangChain AI ▷ #tutorials (4 条消息):
-
YouTube 上的 RAG Chatbot 教程:
@infoslack分享了一个 YouTube 视频,题为“使用 LangChain、OpenAI 和 Groq 构建带有 RAG 的聊天机器人”,该视频是关于使用 OpenAI 的 gpt-3.5-turbo 通过检索增强生成 (RAG) 构建聊天机器人的指南。 -
寻求 Langchain 到 LCEL 转换指导:
@sharrajesh询问了关于将现有 Langchain 项目转换为 LCEL 的说明或教程,寻求 Langchain 团队的建议。 -
使用 Groq 的 AI 自动拨号 Agent:
@jasonzhou1993介绍了一个教学视频,题为“极速 AI 自动拨号 Agent - 基于 Groq 构建”,讨论了 Groq LPU 的功能并演示了实时 AI 自动拨号 Agent 的构建。 -
Command-R 与 RAG 集成演示:
@pradeep1148分享了一个 YouTube 视频,题为“让我们用 Command-R 进行 RAG”,展示了针对 RAG 等长上下文任务优化的 Command-R 模型,并利用了外部 API。
提到的链接:
- INSANELY Fast AI Cold Call Agent- built w/ Groq:Groq LPU 到底是什么?我将带你通过一个真实示例,利用 Groq 的速度构建一个实时 AI 自动拨号 Agent。
- Lets RAG with Command-R:Command-R 是一款生成模型,针对检索增强生成 (RAG) 以及使用外部 API 和工具等长上下文任务进行了优化。
- Chatbot with RAG, using LangChain, OpenAI, and Groq:在本视频中,我将指导你如何从头开始构建一个使用检索增强生成 (RAG) 的聊天机器人。我们将使用 OpenAI 的 gpt-3.5-turbo LLM…
OpenAccess AI Collective (axolotl) ▷ #general (40 条消息🔥):
-
Flash Attention 故障排除:用户
@pradeep1148在 RTX 3090 或 4000 系列 GPU 上禁用 Flash Attention 时遇到问题。@caseus_建议在 YAML 配置中设置flash_attention: false并启用sdp_attention: true。 -
理解 SDP Attention:
@duh_kola询问了 SDP Attention,@rathesungod澄清这是出自开创性论文 Attention Is All You Need 的概念。 -
Cohere 发布开源模型:
@duh_kola分享了一个惊喜公告,Cohere 发布了一个名为 “C4AI Command-R” 的开源模型,这是一个 350 亿参数的生成模型,可在 Hugging Face 上获取。 -
LLaMA 与 Axolotl 兼容性讨论:
@leoandlibe询问了 Axolotl 对 LLaVA 的支持,@nafnlaus00表示已经支持,但@nanobitz指出 LLaVA 1.6 有重大变化,可能会影响兼容性。 -
编辑 LLM 数据集的工具:
@nanobitz寻求手动编辑 LLM 数据集的工具推荐,@duh_kola建议 Argilla 可能具有编辑功能,而@lee0099幽默地把 Notepad++ 也列入其中。
提到的链接:
- CohereForAI/c4ai-command-r-v01 · Hugging Face: 未找到描述
-
[登录 Cohere](https://dashboard.cohere.com/playground/chat): Cohere 通过一个易于使用的 API 提供对先进 Large Language Models 和 NLP 工具的访问。免费开始使用。
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (10 messages🔥):
-
Hugging Face PEFT Pull Request 已合并:
@suikamelon强调了 QDoRA: Support DoRA with BnB quantization 的合并,指出其支持在量化模型上使用 DoRA。注意事项包括 DoRA 目前仅支持线性层,并建议在推理时合并权重以减少开销。 -
讨论 NVMe SSDs 对 AI 训练的提升:
@dctanner分享了一条推文,讨论了 Fuyou 框架,该框架通过高效利用 NVMe SSDs,允许在单张 GPU 上微调 100B 参数模型。 -
关于 DeepSpeed 潜在实现问题的疑问:
@casper_ai分享了一个 DeepSpeed PR 链接,询问是否应在 Axolotl 中实现一个在设置 Z3 hooks 时将模块设为叶子节点的 API。@seungduk提到他们目前正在使用 zero3 训练 Mixtral,这似乎与该 PR 的需求相矛盾,引发了进一步讨论。 -
对 Mixtral 训练和 DeepSpeed 修复的担忧:
@seungduk注意到 Mixtral 训练期间评估结果较差,并将其与 DeepSpeed zero3 和 MoE 模型的一个潜在问题联系起来,但随后意识到最近的一个 PR 修复 可能会解决此问题。 -
确认 Axolotl 的实现细节:
@caseus_最初不确定 Axolotl 中叶子节点 API 的实现情况,在查看了@casper_ai分享的 PR 后,确认该功能已经存在。
提到的链接:
- 来自 AK (@_akhaliq) 的推文: 添加 NVMe SSDs 以在单张 GPU 上启用并加速 100B 模型微调。Large Language Models 的最新进展为世界带来了巨大价值,其卓越的能力…
- QDoRA: Support DoRA with BnB quantization by BenjaminBossan · Pull Request #1518 · huggingface/peft: 增加了对 bitsandbytes 4bit 和 8bit 量化模型的 DoRA 支持。合并功能也已可用,但带有量化权重的常见注意事项(结果并非 100% 相同),但情况并未变糟…
- Add API to set a module as a leaf node when recursively setting Z3 hooks by tohtana · Pull Request #4966 · microsoft/DeepSpeed: ZeRO3 无法与 MoE 模型配合使用,因为模块的执行顺序在每次前向/后向传递时都可能发生变化 (#4094, #4808)。此 PR 增加了一个 API,用于停止为参数分解模块…
- Add API to set a module as a leaf node when recursively setting Z3 hooks by tohtana · Pull Request #4966 · microsoft/DeepSpeed: ZeRO3 无法与 MoE 模型配合使用,因为模块的执行顺序在每次前向/后向传递时都可能发生变化 (#4094, #4808)。此 PR 增加了一个 API,用于停止为参数分解模块…
- Mixtral fixes 20240124 (#1192) [skip ci] · OpenAccess-AI-Collective/axolotl@54d2ac1: * mixtral nccl 修复;* 确保针对 z3 进行补丁修复。
OpenAccess AI Collective (axolotl) ▷ #general-help (11 messages🔥):
-
微调 openllama-3b 的挫败感:
@heikemo在包含 200 万行的数据集上微调 openllama-3b 时遇到了奇怪的行为,尽管 loss 收敛,但模型返回的输出非常短或没有输出。@nanobitz建议其调整超参数,因为较小的数据集在 LoRA 下表现良好,这表明问题可能与训练数据质量无关。 -
寻求长数据截断的帮助:
@ksshumab询问了在持续预训练(continual pretraining)期间将长数据截断为块并对短数据进行分组的参数。@nanobitz告知他们,设置type: completion和sample_packing: true将自动处理此问题。 -
关于总 Token 计算的查询:
@ksshumab随后表达了一个疑虑,即他们对总 Token 的计算(源自序列长度、batch size、epochs、设备数量、优化步骤)与打印出的 total_num_tokens 不匹配。消息历史中没有针对此问题的回复。
OpenAccess AI Collective (axolotl) ▷ #community-showcase (2 messages):
- Mistral Medium 与 Large 的对比:
@duh_kola提到他们已经实验了 Mistral medium 和 large 模型,发现 medium 的表现优于 Mixtral,而 large 是最好的,但面临更快的超时问题。 - 对模型对比的好奇:
@rathesungod表示有兴趣了解更多关于@duh_kola的经验,特别是询问他们所说的 Mistral medium 优于 Mixtral 具体是指什么。
OpenRouter (Alex Atallah) ▷ #general (63 messages🔥🔥):
- 寻求 ChatGPT 3.5 的替代模型:用户
@mka79询问了可作为办公用 ChatGPT 3.5 替代方案的免费模型,要求包括较少的审查、敏感数据的隐私保护以及不使用用户数据进行训练。 - 新模型上线:
@louisdck分享了一个基于 Gemma 的新 Openchat 模型,该模型声称其性能几乎与基于 Mistral 的模型持平,且优于其 Gemma 同类模型。 - Nous Hermes 70B 模型下线:
@hanaaa__报告了尝试访问 Nous Hermes 70B 模型时的错误。@louisgv确认该模型将暂停服务直至另行通知,并且正在推送修复程序以禁用它。 - Openchat 和 Gemma 的超时问题:
@louisdck报告了 Openchat 和 Gemma 的超时错误,@alexatallah回复称,由于滥用行为,没有额度的用户的免费模型已被暂时禁用,但他们将致力于恢复访问。 - Cheat Layer 的新产品:
@gpuman宣布 Cheat Layer 回归,提供由 OpenRouter 支持的网站免费自动回复功能,并请求用户向其支持团队报告任何兼容性问题;此外,还提到了关于开源 Open Agent Studio 以及集成 OpenRouter 的讨论。
提及的链接:
- TOGETHER: 未找到描述
- Blog: 未找到描述
- The Introduction Of Chat Markup Language (ChatML) Is Important For A Number Of Reasons: 2023 年 3 月 1 日,OpenAI 推出了 ChatGPT 和 Whisper API。该公告的一部分是 Chat Markup Language,它似乎已经……
- NeverSleep/Noromaid-20b-v0.1.1 · Hugging Face: 未找到描述
- openchat/openchat-3.5-0106-gemma · Hugging Face: 未找到描述
- Unlimited Free Autoresponder on Every Single Website: 扩展程序自动更新 12.9.8 版本,在每个网站上都提供无限免费自动回复!Open Agent Studio 7.0.0 也随 llama 一起发布,提供无限的 t…
- mixtral - Pastebin.com: Pastebin.com 是自 2002 年以来排名第一的文本存储工具。Pastebin 是一个可以在线存储文本的网站。
- Reddit - Dive into anything: 未找到描述
DiscoResearch ▷ #disco_judge (6 messages):
- 开源 vs GPT-4 对决:
@johannhartmann幽默地预见了一场对比,根据目前的评估,开源模型可能会在表现上优于 GPT-4。 - 建设中:GPT-4 基准测试:
@.calytrix承认尚未在同一测试环境中将模型与 GPT-4 进行比较,但计划创建一个包含多个问题的正式 Benchmark,以测试多个模型。 - 为 Judge 角色选择合适的工具:在回答
@johannhartmann的提问时,@.calytrix提到考虑将基准测试与 EQ-Bench 集成,但 FastEval 可能更适合担任语言模型的 Judge 角色。 - 修改 FastEval 以增强灵活性:
@devnull0提到有人修改了 FastEval 以使用 vLLM 以外的其他后端,并建议引入 Llama.cpp 或像 Ollama 这样的封装器可能会大有裨益。
DiscoResearch ▷ #general (7 messages):
-
RAG Prompt 放置位置的争论:
@philipmay发起了一场关于上下文和 RAG 指令应该放在系统消息(system message)中还是嵌入在用户消息(user message)中的讨论。@rasdani回应称这取决于 SFT 以及模型在训练期间看到的内容,并指出 SFT 期间使用的 [SYS] 和 [USER] 标签可能会影响后续的 Inference 行为。 -
新的 Transformer Debugger 发布:
@rasdani分享了@janleike的一条推文链接,宣布推出一款名为 Transformer Debugger 的分析 Transformer 内部机制的新工具。它具有自动化可解释性和稀疏自编码器(sparse autoencoders)功能,无需编码即可进行模型探索。(Jan Leike 的原始 Twitter 线程) -
Mixtral 7b 8 Expert 模型的推理问题:
@rohitsaxena4378遇到了DiscoResearch/mixtral-7b-8expert模型生成非英语文本的问题。该模型可在 Hugging Face 上获取。 -
使用官方 Mixtral 实现:针对推理问题,
@bjoernp建议使用官方的 Mixtral 实现,而不是实验性的DiscoResearch版本,并指向了 Hugging Face 官方模型。 -
建议为 Mixtral 实现添加实验性标签:
@bjoernp承认需要为实验性的DiscoResearch/mixtral-7b-8expert模型清晰地贴上标签,以引导用户使用官方版本以获得更可靠的性能。
提到的链接:
- DiscoResearch/mixtral-7b-8expert · Hugging Face:未找到描述
- mistralai/Mixtral-8x7B-v0.1 · Hugging Face:未找到描述
- Jan Leike (@janleike) 的推文:今天我们发布了一个我们内部一直在用来分析 Transformer 内部机制的工具——Transformer Debugger!它结合了自动化可解释性和稀疏自编码器,并且…
DiscoResearch ▷ #benchmark_dev (3 messages):
- 发现 tinyMMLU:
@johannhartmann分享了 Hugging Face 上的 tinyMMLU 基准测试 链接,并表示打算探索一种快速简便的翻译方式以供潜在使用。 - Hellaswag 基准测试中的统计噪声:用户
@_chromix_观察到,在 Hellaswag 基准测试中,即使在 1000 个数据点之后,分数波动仍然很大(高达 ±2.5),只有在 9,000 个点之后才趋于稳定(±0.2)。这一经验使他们更倾向于使用完整的测试以获得更可靠的结果,因为仅包含 100 个数据点的短期测试只能提供非常粗略的比较。
提到的链接:
tinyBenchmarks (tinyBenchmarks):未找到描述
DiscoResearch ▷ #discolm_german (2 messages):
- 为合并模型导入 Tokenizer 源:
@johannhartmann分享道,处理合并模型 Tokenization 最可靠的方法是从 cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser 等模型中导入 Tokenizer 源,其中 token 2 /</s>被重新定义为 `
Alignment Lab AI ▷ #general-chat (1 messages):
- 寻找轻量级模型:用户
@joshxt询问了关于可以在本地运行且内存(RAM)需求极小的 1024+ 最大输入的最佳小型 embedding 模型。在提供的消息历史中没有提供任何回复或建议。
Alignment Lab AI ▷ #oo (5 messages):
- Mermaid 图表查询:
@teknium询问了什么是 Mermaid 图表。 - Mermaid 解释:
@lightningralf解释说 Mermaid 是一个类似于 Markdown 工作方式的、从文本创建各种图表的工具,并提供了 Mermaid 在线编辑器。 - 共享 GitHub 资源:
@lightningralf还分享了 mermaid-js 仓库的 GitHub 链接,提供了生成流程图或时序图等图表的资源。 - Mermaid 语法示例:
@joshxt分享了一个详细的 Mermaid 语法示例,演示了如何可视化一个涉及 FASTAPI、多个 API 端点以及 LLM, STT 和 CTTS 等各种服务的复杂系统。 - 利用 GitHub 进行 Mermaid 可视化:
@joshxt讨论了 Mermaid 语法与 GitHub 的集成,以将代码转换为图形表示。
提到的链接:
GitHub - mermaid-js/mermaid: Generation of diagrams like flowcharts or sequence diagrams from text in a similar manner as markdown: 类似于 Markdown,通过文本生成流程图或时序图等图表 - mermaid-js/mermaid
Alignment Lab AI ▷ #oo2 (11 messages🔥):
- 埋头于代码山中:
@autometa幽默地表达了被琐碎的编码任务淹没的状态,但指出他们并没有“累垮”,只是忙得不可开交。 - 为团队便利设置 Docker 环境:
@autometa正在努力设置 Docker 环境,以简化流程并减少团队成员之间的重复劳动。 - 悬赏寻求 Docker 设置协助:
@autometa为愿意帮助完成 Docker 环境设置的人提供 100 美元的奖励,以加速解决他们当前的流程挑战。 - 公开贡献邀请:除了 Docker 方面的帮助外,
@autometa还提到有各种开放科学和开放研究项目需要协助,暗示了感兴趣的合作者的机会。 - 任务归属与委派:
@autometa声称他们已经控制住了 Docker 的局限,并将部分责任交给了@alpin以进一步推进。
LLM Perf Enthusiasts AI ▷ #general (10 messages🔥):
- Token 限制困扰:
@alyosha11询问了关于 gpt4turbo 上 4096 token 限制 的解决方案,提到经常遇到 token 上下文长度限制。 - GPT-4.5 Turbo 即将来临?:
@arnau3304分享了一个 Bing 搜索链接,暗示 GPT-4.5 Turbo 可能很快发布,引发了用户的好奇和怀疑。 - 对 GPT-4.5 Turbo 发布公告的怀疑:
@dare.ai表示怀疑 GPT-4.5 Turbo 的发布公告 可能是幻觉,因为其具有 RAG 引用中典型的“进一步探索”链接。 - 搜索引擎的回响:
@.kiingo报告称 DuckDuckGo 也索引了 GPT-4.5 的发布公告,增加了对其存在性的猜测。 - 搜索源见解:
@justahvee提供了一个见解,澄清 DuckDuckGo 主要使用 Bing 的结果,@.kiingo承认这是有价值的信息。
提到的链接:
必应: 未找到描述
LLM Perf Enthusiasts AI ▷ #gpt4 (1 messages):
- 从 OpenAI 转向 Azure SDK 的咨询:用户
@pantsforbirds询问了从 OpenAI 的 SDK 转向 Azure AI 服务平台的经验。他们对映射过程中的潜在挑战表示关注,并寻求其他经历过相同转型的用户的建议。
LLM Perf Enthusiasts AI ▷ #opensource (2 messages):
- 马斯克预告开源 Grok:
@res6969分享了@elonmusk的一条推文,宣布@xAI将于本周开源 Grok。推文链接见此处。 - 本地实验 Command-R?:
@potrock询问是否有人已经在本地使用过 Command-R,开启了社区讨论话题。
提到的链接:
Elon Musk (@elonmusk) 的推文:本周,@xAI 将开源 Grok
Skunkworks AI ▷ #general (1 条消息):
- 训练收敛的量子飞跃:
@baptistelqt宣布完成了一种能将训练收敛速度大幅提升 100,000 倍的方法。该方法涉及在每一“轮”中都从头开始 (from scratch) 进行训练。
Skunkworks AI ▷ #off-topic (2 条消息):
-
使用 Claude 3 开发游戏:
@pradeep1148分享了一个 YouTube 视频,演示了如何使用 Claude 3 开发《植物大战僵尸》游戏。内容涵盖了用于游戏开发的 Python 编程,以及如何利用语言模型 Claude 3 的能力。 -
探索 Command-R 的 RAG 能力:
@pradeep1148还提供了一个 YouTube 链接,视频标题为“让我们用 Command-R 进行 RAG”,深入探讨了 Command-R 针对长上下文任务(如检索增强生成 RAG)的优化,以及它与外部 API 和工具的集成。
提到的链接:
- Claude 3 制作的植物大战僵尸游戏:来看看如何使用 Claude 3 开发植物大战僵尸 #python #pythonprogramming #game #gamedev #gamedevelopment #llm #claude
- 让我们用 Command-R 进行 RAG:Command-R 是一款针对长上下文任务(如检索增强生成 RAG)以及使用外部 API 和工具进行优化的生成模型。它的设计初衷是…
AI Engineer Foundation ▷ #general (1 条消息):
-
插件配置讨论已提上日程:用户
@hackgoofer详细阐述了关于 插件配置选项 (Config Options for Plugins) 使用的议程,包括通过 Token 作为插件参数进行授权等想法。提出的关键问题是:“这能解决问题吗?” -
征集项目提案:发起了新项目建议的征集,相关标准在链接的 Google Docs 指南中列出。文中还提到了包括与 Microsoft 合作在内的项目协作机会。
提到的链接:
向 AI Engineer Foundation 提交项目的指南:未找到描述