ainews-mm1-apples-first-large-multimodal-model
MM1:苹果首个多模态大模型
苹果公司发布了 MM1 多模态大语言模型(LLM)系列,其参数量最高达 300 亿。苹果声称该模型的性能可与 Gemini-1 媲美,并在视觉问答(VQA)基准测试中超越了参数量更大的旧模型。该研究论文面向研究人员,并暗示了其在具身智能体(embodied agents)以及商业和教育领域的应用前景。
Yann LeCun 强调,实现人类水平的 AI 需要具备对物理世界的理解、记忆、推理和分层规划能力;而 François Chollet 则提醒道,尽管大语言模型取得了长足进步,但自然语言处理(NLP)问题远未得到彻底解决。
Cohere 发布了专为检索增强生成(RAG)设计的 Command-R 模型;Anthropic 则重点推介了 Claude 3 系列(Opus、Sonnet、Haiku),以满足不同的应用需求。开源硬件 DexCap 为低成本收集机器人灵巧操作数据提供了可能。
CopilotKit 等工具简化了将 AI 集成到 React 应用的过程,而迁移到以 JAX 为后端的 Keras 3 则能提供更快的训练速度。此外,一些新项目改进了检索中的重排序(reranking)技术,并为 LangChain 增加了金融智能体功能。本文内容涵盖了 AI 进展、新模型、开源工具及框架等多方面的见解。
2024年3月14日至3月15日的 AI 新闻。我们为您查看了 358 个 Twitter 账号 和 20 个 Discord 社区(332 个频道,2839 条消息)。为您节省了约 353 分钟 的阅读时间(以 200wpm 计算)。
Apple 继续在 AI 领域发力,发布了(但未开源)带有论文的 MM1,声称其达到了 Gemini-1 水平:
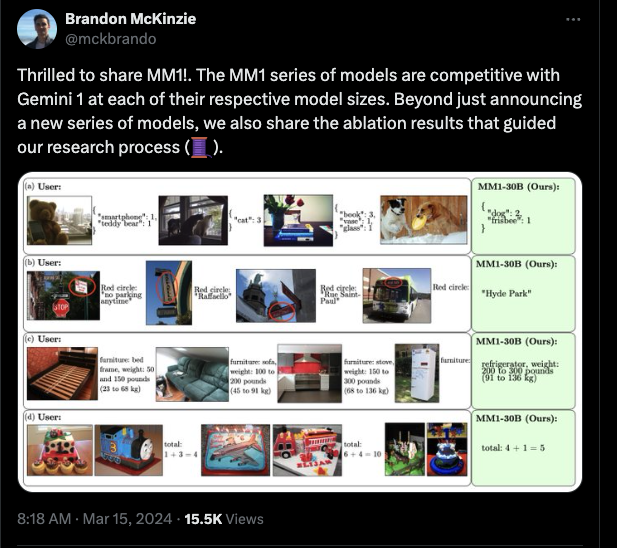
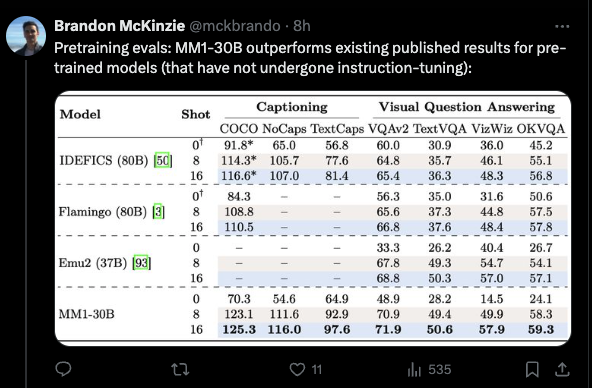
这款 30B 模型在(有缺陷的)VQA 基准测试中击败了更大型的旧模型:
该论文面向研究人员,为超参数(hyperparams)和架构提供了一些有用的消融实验(ablations)。
附录暗示了具身智能(embodied agents)的应用场景:

以及商业/教育领域:

对于一系列竞争性的开源 VLM,你可以参考一个新的 HF 排行榜。
目录
[TOC]
PART X: AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,从 4 次运行中选取最佳结果
AI 进展与局限性
- Yann LeCun 表示,要实现人类水平的 AI,系统需要理解物理世界、能够适当地记忆和检索、进行推理,并设定子目标和进行分层规划。 即便具备这些能力,达到人类或超人类水平仍需时日。@ylecun
- LLM 就像一本可以对话的百科全书。@ylecun
- 许多人认为 LLM 意味着 NLP 已被“解决”,且机器拥有人类水平的语言理解能力,但我们还差得很远。 坚信问题已解决将导致无法取得进一步进展。@fchollet
- 1970 年曾有人预言,在 3 到 8 年内我们将拥有具备人类水平通用智能的机器。引用这句话的全文非常值得一读。@fchollet
新模型与数据集
- Apple 推出了 MM1,这是一个参数量高达 30B 的多模态 LLM 家族,在预训练指标上达到了 SoTA,并在微调后表现出极强的竞争力。 @arankomatsuzaki
- Cohere 宣布发布 Command-R,这是一款专为大规模检索增强生成(RAG)设计的语言模型。@dl_weekly
- Anthropic 的 Claude 3 家族模型(Opus, Sonnet, Haiku)旨在满足从强大功能到成本效益和速度的各种应用需求。@DeepLearningAI
开源与可复现性
- DexCap 是一个价值 3,600 美元的开源硬件栈,通过记录人类手指动作来训练灵巧的机器人操作。 它是为学术研究人员提供的 Optimus 的廉价“低保真”版本。数据采集与机器人执行是解耦的。@DrJimFan
- Opus 的 Prompt 编写能力 + Haiku 的速度和低成本,为子代理(sub-agents)创造了大量机会。 一份 Cookbook 食谱演示了如何在应用中运行这些子代理。@alexalbert__
- 使用 CopilotKit 可以轻松地将 AI 集成到 React 应用中,它获取应用上下文并将其输入 React 基础设施,以构建聊天机器人、AI 驱动的文本区域、RAG、函数调用(function calling)和集成。 示例应用是开源的,可以使用任何 LLM 进行自托管。@svpino
工具与框架
- 将代码迁移到带有 JAX 后端的 Keras 3 可以带来无需 TensorFlow 以及模型训练速度提升 50% 的好处。 @svpino
- 重排序(Reranking)对于 RAG 中的有效检索至关重要。来自 @bclavie 的一个新项目极大地简化了这一重要技术。 @jeremyphoward
- LangChain 中新增了一个开源金融 Agent,配备了获取股票代码最新价格、新闻、财务数据和历史价格的工具。 即将推出的工具包括内在价值计算器和价格图表渲染器。代码开源且可在 Colab 中运行。@virattt
梗与幽默
- “你与世界领袖的区别:你在小学管老师叫妈妈,除了尴尬什么也没发生。马克龙管他的高中老师叫妈妈,和她约会直到她离开丈夫,最后娶了她,现在正用核战争威胁俄罗斯。” @Nexuist
- “结束了,OpenAI (OAI) 快修复你那过度冗长的模型吧,我可不想坐在这儿求它写代码。” @abacaj
- “@elonmusk 我愿意每月付 20 美元,请解决‘个人简介里的色情广告’(pussy in bio)问题。” @AravSrinivas
第 0 部分:总结之总结之总结
鉴于 Claude 3 Haiku 最近发布,我们将其加入本次总结运行中供您对比。在构建 AINews 平台以提供更好 UX 的期间,我们将继续并排运行这些模型。
Claude 3 Haiku (3B?)
评论:我们尝试调整了 Haiku 的提示词,因为它表现不佳。对于 Haiku 来说,Flow Engineering(流程工程)似乎优于 Prompt Engineering(提示词工程)。然而,主题聚类(topic clustering)的效果目前看起来还不理想。
位置编码与语言模型能力:
- 位置编码:一场微妙的舞步:讨论指出了没有 Positional Encoding (PE) 的因果语言模型所面临的挑战,包括产生乱码输出和推理失败。一篇论文(Transformer Language Models without Positional Encodings Still Learn Positional Information)表明,模型可能会隐式地编码“绝对位置”,从而导致在长文本推理过程中出现分布外(out-of-distribution)错误。
- 探索 SERAPHIM 与 Claude 3 的“世界模拟”:SERAPHIM 是由 Claude 3 构想的一个秘密 AI 研究小组,这已成为热门话题。关于 Claude 3 作为名为 The Assistant 的模拟器实体所具备的高级世界建模能力的对话,引发了对 AI 内部形而上学和认识论探索的讨论。
函数调用与 JSON 处理:
- 函数调用评估代码与数据集发布:Nous Research 发布了函数调用(Function Calling)的评估代码和数据集。代码可在 GitHub 上获取,数据集可访问 Hugging Face 和 Hugging Face。
- Hermes Pro 函数调用解决 JSON 异常:在使用 Hermes 2 Pro 进行函数调用时,讨论了系统提示词中 JSON 以及单引号与双引号的问题。经确认,将系统提示词显式更改为使用双引号是有效的,且不会显著影响性能。
微调与模型性能:
- 微调提高了标准:d-Qwen1.5-0.5B 学生模型在微调后,在 truthfulqa(39.29 对 38.3)和 gsm8k(17.06 对 16.3)基准测试中的表现已超越其基础模型。
- 探索 Genstruct 7B 的能力:用户开始使用 Genstruct 7B 模型来生成指令数据集。一位用户计划用文本块进行测试,并分享了一个包含示例的仓库,展示了如何使用它。
硬件与系统优化:
- NVIDIA 传闻:TechPowerUp 的一篇文章提到了传闻中拥有 28 Gbps 速度 GDDR7 显存的 NVIDIA RTX 50 系列“Blackwell” GPU。
- 光子处理的启示:Lightmatter 强调的光子计算突破,提议利用光子学大幅提升芯片通信和计算能力,这有可能彻底改变 AI 的效率。
社区知识共享与开源实践:
- 开源代码解释器的追求:关于缺乏用于处理 CSV 等任务的开源 GPT 代码解释器(Code Interpreter)引发了讨论。一位用户指出了 GitHub 上的 open-interpreter,但指出它更倾向于发送指令而非解释代码。
- 倡导开源 AI:一位成员表示,在模型、数据集和方法论上实现完全开源,将为 AI 模型的长期改进带来更好的结果。
Claude 3 Sonnet (14B?)
评论:Sonnet 今天有点失常,不像之前每天那样能很好地遵循我们的指令。我们通过手动提示试图让它恢复正常,但感觉还是有些不对劲。
-
Large Language Model 进展:讨论了 GPT-4、Claude 和 LLaMa 等 Large Language Model 的能力与局限性。内容包括 Fine-tuning 技术、评估推理能力,以及探索可解释性方法,如通过 vector-db-lookup 进行潜在解码。
-
AI 硬件优化:优化硬件设置,从使用
sudo sysctl的 Apple Silicon 到利用 RTX 5090 和 NVIDIA Grace Hopper 等 GPU。还涵盖了 Mixtral 等模型稳定运行的 Quantization 级别,推荐使用 Q3 或 3-bit quantization。 -
AI 模型可解释性与评估:探索了解释和评估 Large Language Model 的技术,例如使用 n-gram 统计数据进行文本采样,以及 AI 内容检测器在区分人类生成媒体方面的局限性,如这篇论文中所述。
-
Prompt Engineering 与数据处理:有效 Prompt Engineering 的策略,例如使用较小模型进行 prompt augmentation以及用于管理 Prompt 的工具。还讨论了数据准备方面的挑战,例如在 Retrieval-Augmented Generation (RAG) 中处理复杂的文件格式。
-
开源 AI 框架:开源 AI 框架的进展,如 Axolotl(升级到 PyTorch 2.2.1)、带有 Instrumentation 模块的 LlamaIndex v0.10.20,以及旨在移除依赖项的 LangChain v0.2 发布。
-
AI 安全与隐私:潜在的安全问题,例如代表另一个 OpenAI 账户发出的请求、通过 API 泄露专有 LLM 信息,以及对 OpenAI 企业隐私政策的澄清。
-
新兴 AI 平台与工具:新的 AI 平台,如 Deci AI 的 Deci Nano LLM 和 Cohere 在 OpenRouter 上的 Command-R 集成。还重点介绍了 Refacto VS Code 插件等开源工具以及结合 Dall-E 的 JavaScript LangChain。
Claude 3 Opus (>220B?)
评论:这个版本最接近最初的 Prompt 要求(我们要求总结所有内容中的前 4-5 个主题)……但尽管篇幅较长,我们实际上更喜欢另外两个的输出。在这种情况下,过于紧贴 Prompt 并不是件好事。
-
Function Calling 和 JSON Mode 的进展:Nous Research 在 GitHub 和 Hugging Face 上发布了 Function Calling 评估代码和数据集,引发了关于在复杂对话中如何有效使用 JSON Mode 的讨论。Hermes 2 Pro 7B 模型的 Function Calling 能力在 YouTube 视频 和 GitHub 仓库 中得到了展示。
-
模型突破与微调成果:d-Qwen1.5-0.5B 学生模型在微调后在基准测试上超越了其基础模型。工程师们测试了 Genstruct 7B 模型用于生成指令数据集。一种新的训练方法声称可以提高准确率和样本效率,在 VGG16 和 CIFAR100 上的初步测试显示出前景,正如 Skunkworks AI Discord 中所讨论的那样。
-
调试与优化技术:CUDA 开发者排查了诸如 CUBLAS_STATUS_NOT_INITIALIZED 之类的错误,建议指向张量维度和内存问题,详见相关的论坛帖子。Triton 调试通过
TRITON_INTERPRET=1环境变量和正在开发中的可视化工具得到了增强。关于 CUDA 性能的第 8 课已重新录制并发布,包含了更新的视频、代码和幻灯片。 -
AI 架构与框架的进展:Maisa 推出了 Knowledge Processing Unit (KPU),这是一种声称在推理任务中优于 GPT-4 和 Claude 3 Opus 的 AI 架构,详见其博客文章。Axolotl 框架在其分支中探索了 ScatterMoE 等优化。LangChain 加快了 0.2 版本的发布,以解决 CVE 并打破对
langchain-community的依赖,正如 GitHub issue 中所讨论的那样。
ChatGPT (GPT4T)
评述:其中包含了一份很好的 Prompt Engineering 工具列表。我们的 GPT Prompt 在可读性质量方面已经落后于 Claude Prompt,因此我们接下来的重点是改进这一点。
语言模型中的位置编码:讨论强调了 Positional Encoding (PE) 在防止因果语言模型产生乱码输出方面的重要性。一篇论文指出,模型可能会隐式地学习绝对位置,从而导致在更长的推理过程中出现错误(来源)。
AI 模型中的函数调用:Nous Research 发布了 Function Calling 评估代码和数据集,强调了在复杂交互中使用 JSON mode 的挑战(GitHub,Hugging Face)。
AI 模型微调:d-Qwen1.5-0.5B 学生模型超越了其基础模型的基准测试,展示了模型微调的新进展。Genstruct 7B 模型被用于测试生成指令数据集,重点关注 LLaMA 模型中的 Perplexity(困惑度)计算(来源)。
AI 领域的开源实践:围绕 AI 模型的对话涉及了世界建模(World Modeling)以及开源 GPT Code Interpreter 的潜力,倡导 AI 开发的透明度(GitHub)。
硬件与 AI 访问的技术讨论:辩论涵盖了欧盟地区对 Claude.ai 的访问权限,以及 NVIDIA RTX 50 系列 "Blackwell" GPU 的性能,同时还讨论了 GDDR7 显存速度(TechPowerUp 文章)。
AI 内容检测的挑战:探讨了 AI 内容检测器的局限性,建议依靠可验证的创作过程作为人类作者身份的实质性证明,并讨论了密码学水印的有效性及其影响。
CUDA 编程见解:讨论重点关注了 NumPy 与 BLAS 相比的性能开销,并介绍了 SimSIMD 库 作为减少高性能场景下损耗的解决方案,强调了 SIMD 优化的重要性。
AI 模型互操作性与改进:Maisa 推出的 KPU 声称在推理方面优于 GPT-4 和 Claude 3 Opus,这引发了关于基准测试和缺乏延迟信息的辩论,质疑其在 Prompt Engineering 之外的效率。
Prompt Engineering 工具与技术:工程师们探索了用于 Prompt Engineering 的工具,将其比作寻找“Prompt 界的 Postman”,并讨论了使用 SQLite、Prodigy、PromptTools 和 Helicone AI 来管理和实验 Prompt(SQLite,Prodigy,PromptTools,Helicone AI)。
语言模型复杂化技术:工程师们对先进的模型技术进行了理论探讨,包括“Mega Distillation Sauce”和 Token 关键混合物,强调了早期 Token 对解决数学问题等任务性能的影响,并讨论了 AI 安全分类的演变以及增强内容审核的方法。
第 1 部分:Discord 高层级摘要
Nous Research AI Discord 总结
-
位置编码(Positional Encoding):一场微妙的舞步:讨论指出,没有 Positional Encoding (PE) 的因果语言模型面临挑战,包括产生乱码输出和推理失败。一篇论文(Transformer Language Models without Positional Encodings Still Learn Positional Information)表明,模型可能会隐式地编码“绝对位置”,从而在更长的推理过程中导致分布外(out-of-distribution)错误。
-
函数调用(Function Calling)的技巧:多个平台透露了 Nous Research 发布的函数调用评估代码和数据集,可在 GitHub 和 Hugging Face 上获取。此外,还深入探讨了在复杂对话中有效使用 JSON mode 的挑战,可能需要进行内容摘要或修剪。
-
AI 更高的学习曲线:展示了模型微调的新进展,d-Qwen1.5-0.5B student model 超越了其基础模型的基准测试,并且 Genstruct 7B model(来源)被用于测试生成指令数据集。关于 LLaMA 模型中 Perplexity 计算问题的咨询引导至一个 Kaggle notebook 以供进一步探索。
-
构建社区知识库:围绕 AI 模型的讨论涉及了 Claude 3 as The Assistant 的世界建模,以及开源 GPT 代码解释器的可能性,例如 GitHub 上的 open-interpreter。倡导 AI 开发中的开源实践,强调模型、数据集和方法论透明度的必要性。
-
技术爱好者闲聊:多个频道的用户辩论了在欧盟无需 VPN 访问 Claude.ai 的问题,以及 NVIDIA 传闻中的 RTX 50-series “Blackwell” GPU 的性能。他们还在一段名为 “Lets Function Call with Hermes 2 Pro 7B” 的 YouTube 视频中展示了 Hermes 2 Pro 7B 的功能,并思考了 TechPowerUp 文章中报道的 GDDR7 显存速度的影响。
Unsloth AI (Daniel Han) Discord 总结
-
Torch 更新打乱了 Colab 的常规流程:Colab 更新至 Torch 2.2.1 破坏了依赖关系,导致工作流中断;然而,一系列涉及 Unsloth’s library 的 pip install 命令提供了一个量化且 VRAM 高效的修复方案。Mistral 和 Gemma 等模型在微调期间的表现是关注焦点,并观察到了 Unsloth AI 的错误修复和性能改进。
-
Colab 还是 Kaggle?这是一个问题:用户讨论了使用 Google Colab 与 Kaggle 进行模型训练的优缺点,一些人因稳定性而青睐 Kaggle。同时,强调了在 Unsloth 中使用匹配 CUDA 版本的
xformers的重要性,并分享了使用更新的 Kaggle notebook 微调 TinyLlama 等模型的技巧。 -
训练的苦与乐:围绕微调语言模型的最佳实践进行了大量对话,例如 DPO 训练和管理学习率调整。见解包括确保
max_grad_norm = 0.3和调整 batch sizes,同时一名成员指出 loss 低于 1.2 时可能取得的进展。 -
微调的弱点与修复:讨论涉及为了提高精度而进行的模型转换、训练顺序可能影响性能的问题,以及针对角色扮演环境的微调。提到了使用
bitsandbytes库进行精度转换,并给出了在训练 dataloaders 中禁用 shuffling 的建议。 -
Sophia 展现潜力:一名成员提议研究将 Sophia 作为一种可能的即插即用方案,尽管仍需进一步测试。另一场讨论集中在微调策略上,考虑对于大型数据集,3 epochs 是否可以作为标准方法。
LM Studio Discord 总结
模型困惑与量化查询:用户深入探讨了 LM Studio 的复杂细节,例如寻求改进 API inferencing 的建议,以及解决使用多 GPU 时的困难。会议澄清了关于模型支持和扩展(如 .gguf 文件)的误解,重点关注了 Command-R 35B 和 Mistral Non-Instruct 等模型类型。即将推出的功能,如 LM Studio v0.2.17 中的 RAG 集成和 IQ1 model compression 测试也引起了兴趣,结果显示需要 Q3 或 3-bit 的质量级别才能保证 Mixtral 和 MOE model 性能的稳定。
跨学科硬件协作:硬件讨论范围从优化 Apple Silicon 以运行 LLM,到考虑使用 NVLINK 增强 Goliath 120B model 性能的有效性。爱好者们分享了关于系统内存的经验,辩论了理想的 RAM 配置,并对 Nvidia 新的 RTX 5090 GPU 表示期待。同时,ROCm beta 的局限性被凸显,有报告称在 AMD 7480HS 和集成 GPU 上存在 GPU offloading 问题。一篇 Reddit 帖子 和一个 GitHub 仓库 为调整 VRAM 和解决 AMD GPU offloading 困境提供了额外见解。
相关背景链接:
Perplexity AI Discord 总结
技术思维的 Haiku:Claude 3 Haiku 已在 Perplexity Labs 发布,为 AI 带来了全新的诗意转折。
技术人员更青睐 Claude 3:用户正倾向于使用 Claude 3 处理包括写作和内容创作在内的一系列任务,理由是它相比其他 GPT 模型具有优势。
令人困惑的 API 奇特性与查询:Perplexity API 引起了用户的兴趣,但也带来了困惑,主要集中在实时数据查询问题以及与聊天界面相比响应不一致的问题上。
Firefox 扩展使用 Perplexity API:一名用户正在实验一个接入 Perplexity API 的 Firefox 扩展,目前仍处于概念验证阶段。
注意 API 弃用:成员们对 pplx-70b-online 模型的运行状态感到困惑,注意到虽然计划弃用,但截至 3 月 15 日仍能观察到其在持续响应。
Eleuther Discord 总结
游戏 AI 展现潜力:讨论设想了一个精通 Animal Crossing 的 AI,这体现了游戏 AI 的能力,并强调了衡量其成功的基准。分析反映了 AI 策略和公平性,建议通过动作限制或诱导延迟等约束来平衡 AI 与人类玩家的竞争环境。
解读 AI 中不可见的部分:工程师们研究了 latent decoding by vector-db-lookup,旨在揭开 AI 中间表示的神秘面纱,利用来自 Llama2 的多语言 embedding 在不同层进行解码。他们参与了双语 tokenizer 实验,思考训练数据对 AI 偏见的影响,并探索了基于 n-gram 统计的文本生成,引用了 GitHub 上的一个实现。
AI 检测与作者身份完整性:AI 内容检测器的局限性受到了审视,认为依赖可验证的创作过程是证明人类作者身份的唯一实质性证据。随后引发了关于加密水印的辩论,集中在其真实效能和对模型效用的影响上,此外还讨论了诸如用于提升 AI 推理能力的 Quiet-STaR 等创新。
AI 评估中的工作流困扰:最新语言模型的冗长性为 LLM 评估任务中提取有用响应带来了挑战。由于从 GPT-J 等模型中观察到不符合语法的输出,人们对向量空间模型能否有效捕捉语言含义产生了怀疑。在尝试将自定义模型整合到 lm-evaluation-harness 时,新用户表示需要更清晰的示例来集成 generate_until 等函数。
增强 AI 的 Prompt 洞察力:分享了 Brian Fitzgerald 对 prompt augmentation 探索的链接 (brianfitzgerald.xyz/prompt-augmentation/),这可能暗示了通过丰富的输入 prompt 来增强 AI 响应生成的最新进展或方法,引起了致力于优化 AI 交互的人员的兴趣。
HuggingFace Discord 摘要
-
使用 Open LLM Leaderboard 进行可视化:Open LLM Leaderboard Visualization 支持最多三个模型的对比,并通过重新排序指标进行了增强。其他进展包括用于视觉叙事的 Kosmos-2、带有 Chain-of-Thought 推理的 Augmented ARC-Challenge Dataset、多语言 Aya 101 模型,以及支持 4k 上下文的 BEE-spoke-data 嵌入模型。
-
GPU 巨头准备就绪:成员们讨论了 NVIDIA Grace Hopper Superchip,考虑了其在 AI 和高分辨率游戏中的潜力,并对支持消费级 GPU 的量化模型 (quantized models) 表示期待。技术对话还确认了 SF-Foundation/Ein-72B-v0.11 是基于 Open LLM Leaderboard 的领先开源 LLM。
-
重构界面与工作流:一位成员宣布了 Refacto,这是一个用于通过本地 LLM 重构代码的 VS Code plugin。Cobalt 专注于隐私的 LLM 前端正在开发中,而 Transformers PHP 项目旨在帮助 PHP 开发者在其应用程序中添加 ML 功能。
-
AI 音乐与机器学习的创新:讨论了创建 AI 生成的音乐二重奏中的问题,并探讨了如何获得更好的效果。对于 AI 程序员,一个名为 thefuck 的应用可以纠正之前的控制台命令,同时区分了 Bayesian Optimization 方法与 Grid 和 RandomSearch Optimization 技术。
-
AI 策略与合作论文探索:正在进行的讨论涉及如何有效地对 LLM 进行 prompting、在没有明确规则的情况下构建机器学习模型,以及多语言模型将英语作为中枢语言 (pivot language) 的利用。后一个话题在 Hugging Face 多语言集合中分享的一篇 paper 中得到了扩展。
-
Diffusers 0.27.0 投入使用:Diffusers library 已更新,用户讨论了在 GitHub issue 中提到的处理 diffusers 高分辨率图像的策略。鼓励社区在 GitHub 上协作解决 diffusers 的相关问题。
-
机器视觉与语言挑战得到解决:计算机视觉领域的成员对用于多类别分类的 Arcface 以及实现 guided backpropagation 的问题表现出兴趣。NLPer 处理了矩阵近似中 0.016 的相对误差,并强调了 NL2SQL 流水线中与方法相关的困惑。
LlamaIndex Discord 摘要
-
RAG 应对复杂的财务幻灯片:由于财务 PowerPoint 文件包含文本、表格、图像和图表的混合,RAG 在解释此类文件时遇到困难。开发者正在探索先进的解析解决方案,以更好地处理这些复杂的文件类型。
-
为 RAG 增强公式提取:目前用于数学公式的 ASCII 文本提取方法损害了 RAG 对数学和机器学习论文的表示。工程师们正在考虑一种 parsing by prompting 策略来改进公式处理,如最近的一条推文所示。
-
RAG 流水线中的复杂查询创新:升级 RAG 流水线以将文档视为交互式工具,可以开启在大型文档中处理更复杂查询 (sophisticated queries) 的能力。更多见解在这条推文中进行了讨论。
-
LlamaIndex 新版本发布:新发布的 LlamaIndex v0.10.20 包含一个 Instrumentation module,承诺增强可观测性,发布的示例通过 notebook 展示了用法,详见这条推文。
-
文档管理中的技术难题:工程师们正在解决涉及 VectorStore 的集成问题,并考虑在生产系统中转向远程文档存储,如 Redis 和 MongoDB。他们还在寻求缓存机制的解决方案,并处理解析错误,例如调整
IngestionPipeline的 Python 代码以及修改QueryEngineTool使用的 prompt。
Latent Space Discord 总结
-
OpenAI 的机密泄露失误:讨论了一起暗示 OpenAI 可能存在安全漏洞的事件,一名用户担心代表另一个账户发起请求。在 GitHub 上发现的一份事后分析文档对该问题进行了探讨。
-
Sparse Universal Transformers 变得更智能:工程师们分享了关于 Sparse Universal Transformers 的见解,重点关注名为 ScatterMoE 的快速 Mixture-of-Experts 实现。对话中引用了一篇讨论挑战的博客文章:The New XOR Problem。
-
使用 Deci AI 进行经济型 AI 开发:Deci AI 的 Nano 模型和 AI 开发平台的发布引起了关注,尤其是其每 1M tokens 0.1 美元的实惠价格。该平台的详细信息见 博客文章,并通过 Google Colab 教程提供了额外资源,包括 基础用法 和 LangChain 用法。
-
Prompt Augmentation 在 AI 领域取得进展:讨论了 Prompt Augmenters 的效率,其中一个 77M T5 模型在 Prompt Alignment 方面优于更大的模型。更多细节可以在关于 Prompt Augmentation 的文章中找到。
-
AMD 凭借开源光线追踪技术脱颖而出:AMD 开源其 HIP-Ray Tracing RT 代码的举动受到关注,引发了关于其对开源生态影响的讨论。这一更新被记录在 Phoronix 文章 中。
-
用 Transformers 改变音乐:一段名为 “Making Transformers Sing” 的 YouTube 视频邀请了来自 Suno AI 的 Mikey Shulman,深入探讨了使用 Transformers 进行音乐生成的见解,显示出人们对 AI 与创意交叉领域的兴趣。点击 此处 观看该集内容。
-
使用 Negative Pairs 微调 Transformers:一名成员对如何使用 Negative Pairs 进行 Supervised Fine-Tune (SFT) Transformers 表示好奇,这成为了关于增强模型性能和理解的讨论话题之一。
-
In-Action Club 交流实用资源:在 AI In-Action Club 内部,成员们分享了实用建议和资源,包括一篇关于高级 RAG 技术的 Medium 文章,以及一份涵盖 GenAI 和 RAG 架构的 UI/UX 模式的 综合资源文档。
OpenAI Discord 总结
-
微软快速修复拼写错误:针对社区成员的报告,Bing VP 承认并修正了微软服务中的一个拼写错误,展示了响应迅速的跨团队协作。
-
重复词素难题:工程师们就如何最好地利用 GPT-3.5 在复合词中创建重复词素展开辩论,考虑使用 Python 工具来更有效地引导模型。
-
对 OpenAI 更新寄予厚望:OpenAI 社区对新更新充满期待,特别关注 OpenAI 周年纪念等日期,并猜测由于选举等外部事件可能导致的延迟。
-
中央 AI 统领构想:一场技术讨论探索了“高级助手” AI 的想法,该 AI 将任务委托给专门的 AI,讨论了具有统一指导智能的多层级 AI 系统的可行性和挑战。
-
应对 OpenAI 的隐私迷宫:对 ChatGPT 的隐私担忧引发了关于 OpenAI 企业隐私政策 的讨论,涉及如何管理个人账户隐私,特别是关于 API key 使用和团队聊天中的管理员可见性。
-
本地化中的小数点困境:AI 专家讨论了数字格式本地化的挑战,例如使用逗号作为小数点分隔符,以及向 AI 模型传达这些文化细微差别的重要性,这反映了模型理解多样化国际惯例的能力。
-
完善 Prompt 结构:AI 工程师分享了使用 GPT-3 进行分类任务的 Prompt 设计策略,辩论了如何优化 Context Length 和结构以提高准确性并减少 False Positives,同时坚持认为使用高达一半的 Context Window 是最有效的。
OpenAccess AI Collective (axolotl) Discord 总结
-
单 GPU 微调壮举:社区对在单块 NVIDIA 4090 GPU 上微调 1750 亿参数模型 (175 billion parameter models) 表现出极高热情,并正在考虑将其应用于 Axolotl 框架。讨论引用了 Hugging Face 上的一篇 研究论文摘要 作为讨论基础。
-
ScatterMoE 优于 MegaBlocks:ScatterMoE 的实现承诺提供比 Hugging Face 的 MegaBlocks 更卓越的优化,这引起了 axolotl-dev 频道的兴趣。成员们分享了相关的审查和应用考量,并链接到了 优化后的 MoE 模型分支。
-
训练后 Pull Request 审查:一个涉及尝试使用 ScatterMoE 的 Pull Request 产生了改进反馈,并在接受前被标记为待测试,旨在更好地重构 MixtralMoE 模块。
-
Axolotl 与 PyTorch 协同更新:鉴于 ScatterMoE 的实现,OpenAccess AI Collective 的成员建议将 Axolotl 更新至 PyTorch 2.2.1 版本 以保证兼容性。这与社区确认目前正在使用该建议版本的情况相符。
-
明智选择推理策略:成员们讨论了使用 vLLM 代替
transformers进行批量推理(batch inferences),重点在于解决 Tokenization 和语法规范问题。为了强调 vLLM 在快速离线操作中的潜在速度优势,他们为寻求大规模推理任务示例的用户提供了 快速入门指南。
OpenRouter (Alex Atallah) Discord 总结
-
Command-R 变革 OpenRouter:Cohere 的新模型 Command-R 已上线,拥有突破性的 128k Tokens 上下文,可通过 OpenRouter API 使用。虽然它拥有每美元 200 万 Prompt Tokens 的高性价比,但用户仍需等待更多数据,以便
/parametersAPI 更新其详细信息。 -
OpenRouter 推出实用分析功能:每日分析功能是 OpenRouter 的新成员,可以查看用户每天的 Token 使用情况。你可以通过 OpenRouter 排行榜 进一步了解详细指标。
-
极速 API 更新:OpenRouter 言出必行,推出了更快的
/modelsAPI,并翻新了模型相关页面,响应迅速。 -
API Wrapper 的烦恼与收获:社区热烈讨论了 litellm,这是一个像变色龙一样的 API Wrapper,可以调用各种 LLM,但在除 GPT-4 之外的 Vision 任务中表现不佳。用户可以探索多种 GUI 选项来实现 API Key 的完美管理,其中 open-webui 以其独特的风格备受关注。
-
辩论数字对话的礼仪:对《天际》(Skyrim)角色扮演和争议性闲聊细节充满热情的工程师们,在审查较少的 LLM(如 Claude Sonnet)中找到了避风港。讨论中穿插着安装难题和模型适用性的调侃,以及对 LLM 审查制度限制创意发挥的抱怨。
CUDA MODE Discord 总结
-
揭秘 NumPy 瓶颈:一篇博文强调,与 BLAS 相比,NumPy 可能会产生性能开销,导致高达 90% 的吞吐量损失,特别是在 1536 维的 OpenAI Ada embeddings 中表现尤为明显。SimSIMD 库 作为解决这一损失的方案被引入,强调了在高性能场景中进行 SIMD 优化的必要性。
-
光子计算的启示:Lightmatter 强调了 光子计算(photonic computing) 的突破,提议利用光子学显著提升芯片通信和计算能力,有可能彻底改变 AI 效率。Asianometry 的 YouTube 视频对该主题进行了更深入的探讨,包括 “Silicon Photonics: The Next Silicon Revolution?” 和 “Running Neural Networks on Meshes of Light“。
-
Triton 调试功能增强:随着
TRITON_INTERPRET=1环境变量的引入以及一个正在开发中的可视化工具的出现,调试 Triton 变得更加容易。尽管用户应注意@triton.jit(interpret=True)已被弃用,应参考 此 GitHub 讨论 等资源来排除 kernel 故障。 -
CUDA 爱好者们,准备出发:CUDA 社区正在为初学者提供建议,例如推荐 Programming Massively Parallel Processors 一书,并成立了读书小组共同消化书中的内容,为熟悉 C++ 的学习者增强学习效果。值得注意的是,讨论中指出了 SM 架构的复杂性,并对 CUDA 编程中的高效执行和索引策略进行了说明。
-
环形注意力的不确定性:有人对在 Flash 中使用 ring attention 表示担忧,因为缺乏清晰度和代码参考,直到一个 Triton kernel 实现 的链接为该主题提供了一些参考。
-
人才挖角风波:在一场公司纠纷中,Meta 指控一名前高管窃取机密文件并挖角人才,这一指控得到了一份公开的法院文件的支持,并在 Ars Technica 中有详细报道。与此同时,似乎有三名成员正在开启一段学习之旅,共同从某个未命名课程或学习路径的 lecture 1 开始。
LangChain AI Discord 总结
-
LangChain 0.2 加速发布:由于针对
langchain的 CVE 漏洞,版本 0.2 将提前发布以移除langchain-community依赖,而更大的更新将推迟到 0.3 版本。更多信息请参阅 GitHub discussion,并欢迎社区提供反馈。 -
AgentExecutor 与 Langsmith 提示词难题:讨论内容包括用户在使用 Cohere 的
AgentExecutor时遇到的OutputParserException错误,以及自定义提示词与 从 Langsmith Hub 导入的提示词 之间不明确的区别;分享了用于查询的 StackOverflow API 端点,并针对 LLM Agent 与其他方法的有效性展开了辩论,参考了 LangChain benchmarks 中的 Agent 评估策略。 -
在 Langsmith Hub 中创建提示词模板:一名成员寻求指导,试图将
tools列表变量链接到 Langsmith Hub 提示词模板中的{tools}占位符。 -
LangChain AI 社区贡献亮点:令人兴奋的举措包括将 LangChain 与 SAP HANA Vector Engine 集成、在 JavaScript LangChain 中添加 Dall-E、使用 LLM Agent 编排浏览器流程、开源使用 RAG 的 Langchain 聊天机器人,以及一个用于管理书签的 Discord AI 聊天机器人。参考以下链接:使用 SAP HANA Vector Engine 和 LangChain 开启 AI 应用的未来、Lang Chain for JavaScript 第 3 部分:创建 Dall-E 图像、LLM Agent 系统的工程设计、GitHub 上的 Langchain 聊天机器人 以及 Living Bookmarks Bot。
-
跟进 LangChain 教程:分享了一个新的 LangChain 教程视频,链接如下:教程视频。
LAION Discord 总结
-
寻求 GPU 协助:发起了关于标注工作的协作请求;正在寻找拥有 3090 或 4090 GPU 的个人提供协助,建议通过私信联系。
-
M3 Max 内存极限挑战:讨论包括尝试在 128G M3 Max macOS 系统中利用超过 96GB 的内存,以便使用 simpletuner 进行优化。
-
分享提示词增强策略:重点介绍了一个 77M T5 模型,用于图像生成的提示词增强,同时引入了 DanTagGen,这是一个基于 HuggingFace 的标签自动补全工具。
-
欧盟推进 AI 监管:强调了欧洲议会通过的 《人工智能法案》(Artificial Intelligence Act),这是一项旨在确保 AI 安全并遵守基本权利的措施。
-
IEEE 论文消失:讨论围绕第 45 届 IEEE 安全与隐私研讨会从已接收论文页面移除的情况,及其对名为 Ben 的个人的潜在影响。
-
TryOnDiffusion 开放试衣:宣布了 TryOnDiffusion 的开源实现,该实现基于“A Tale of Two UNets”中的方法论,可在 GitHub 上获取。
-
论文声称解码速度更快:分享了一篇论文,建议通过 2D Gaussian splatting 代替 jpeg 来提高快速解码的效率,可在 arXiv 上查阅。
-
个人项目与专业论文产生共鸣:一位成员描述了与 2D Gaussian splatting 论文中描述的挑战相似的项目经历,讨论了优化障碍以及与专业方法论的一致性。
-
寻求 Web UI 的 CPU 限制方案:一位成员寻求关于实现类似于 text-generation web UI 的 CPU 限制建议,以解决 CUDA out of memory 错误,并详细说明了在其 GitHub 仓库 中描述的免费层限制下管理大型模型的困难。
-
讨论 Colab 对 Web UI 的限制:详细说明了使用免费版 Colab 运行 Web UI 的局限性,并建议将讨论转移到更合适的技术频道。
LLM Perf Enthusiasts AI Discord 摘要
-
GPT-4 的空格谜团:一位用户报告了一个问题,即
gpt-4-turbo-preview模型在处理长文本补全任务时,会输出无限数量的空格字符,随后是“俄语胡言乱语”。这种异常现象发生在长度约为 12,000 tokens 的文本中,附带的证据展示了该模型的奇特行为。 -
效率之争:Haiku vs. GPT-vision:在具有成本效益的复杂文档描述领域,Haiku 因其效率受到称赞,但被认为不如 GPT-vision 熟练。另有讨论指出,与 Opus 相比,Haiku 的视觉转文本性能稍逊一筹。
-
Claude 的内容危机:成员们讨论了 Claude 的困境,特别是在内容过滤和处理带有方程式的文档方面。通过 tweet 分享的一个有争议的观点暗示,Anthropic 可能在技术人员中采用了恐吓策略,同时在涉及人物图像的内容审核方面也出现了挑战。
-
KPU 挑战 AI 巨头:Maisa 推出的 KPU 介绍引发了辩论。KPU 被定位为一个通过分离推理和数据处理来增强 LLM 的框架,并声称在推理能力上超越了 GPT-4 和 Claude 3 Opus。社区对其 Benchmark 以及 KPU 在对比中排除 GPT-4 Turbo 表示怀疑,质疑 KPU 是否超出了 Prompt Engineering 的范畴,且缺乏延迟信息也让人对其现实世界的效率产生疑问。
Skunkworks AI Discord 摘要
-
论文预览:提升准确率与效率:即将发布的论文/文章将详细介绍一种新的训练方法,该方法不仅提高了全局准确率,还增强了样本效率。虽然由于资源限制,目前仅在 CIFAR100 上与 VGG16 进行了对比且尚未扩大规模,但结果显示测试准确率从 0.04 显著提升至 0.1。
-
加入黑客松,赢取荣耀:诚邀工程师参加 Meta Quest Presence Platform Hackathon,有机会创作创新的混合现实内容。对于想要深入研究 Function Calling 功能的人,可以参考相关资源以及与 Hermes 2 Pro 7B 相关的 GitHub 仓库。
-
寻求算力支持伙伴:社区内正在努力汇集算力与资源,以进一步测试并可能扩大即将在新出版物中提出的训练方法的规模。
-
招募 PyTorch & Transformers 专家:有人表示有兴趣加入 “Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking” 项目,引发了关于他们在 PyTorch 和 Transformers 架构方面专业知识的对话。
Datasette - LLM (@SimonW) Discord 摘要
-
寻找终极 Prompt Engineering 工具:工程师们正在讨论几种用于 Prompt Engineering 的工具,将这种寻找比作寻找“Prompt 界的 Postman”。工具范围从使用 SQLite 在终端捕获 Prompt,到使用专门的软件如 Explosion’s Prodigy 和 GitHub 上的 PromptTools 来管理和实验 Prompt。Helicone AI 也作为管理 Generative AI Prompt 的潜在解决方案出现。
-
探究旧 Prompt 的 PRNG:频道中提出的一个问题是关于是否可能恢复 OpenAI 模型在之前的 API 请求中使用的 seed,这表明了对结果可复现性以及调试或迭代开发潜力的兴趣。
Interconnects (Nathan Lambert) Discord 摘要
-
LLM 秘密可能泄露:新研究表明,受 API 保护的 Large Language Models(如 GPT-3.5)的隐藏细节可能会被泄露,通过 softmax bottleneck 揭示模型大小。讨论重点提到了 Carlini 等人关于此主题的一篇论文,但注意到关键细节已被删减,并对估算准确性表示怀疑,特别是对 7B 参数模型的可行性提出质疑,尤其是如果涉及 Mixture of Experts (MoE) 设计。
-
探索模型复杂化技术:工程师们正在对先进的模型技术进行理论推导,例如“超级蒸馏秘方(mega distillation sauce)”和 token 关键混合物,并指出在某些任务(如解决数学问题)中,早期 token 会显著影响性能。
-
演进中的安全分类:一场关于 AI 安全的讨论引用了一篇关于 agile text classifiers 的论文,详细介绍了使用小数据集微调的 Large Language Models 如何有效适应安全策略并增强内容审核。
-
期待超实用用途的 AI 进展:人们对 Gemini 处理超长上下文的能力发展感到兴奋,并希望 AI 工具能自动总结引用自己作品的新学术论文。对话还涉及了 Prompt Engineering 的局限性,以及社区对更直观、不那么乏味的提示方式(类似于“渐热或渐冷”的搜索建议)的渴望。
-
消除谣言并思考思想领袖:GPT-4.5 发布谣言已被澄清,导致社区内出现一些失望情绪。与此同时,一条分享的 推文 引发了关于 Yann LeCun 对语言模型怀疑态度的讨论,为技术话语增添了趣味性。
DiscoResearch Discord 摘要
-
DiscoLM-70b 的英语困境:一名成员在 DiscoLM-70b 生成英语回复时遇到挑战,引发了检查 prompt structure 的建议。在多样化对比中,DiscoLM-mixtral-8x7b-v2 在指令微调后在德语方面的表现出人意料地不佳,与 LeoLM 和 llama2 等其他模型形成对比。
-
多语言模型调优困扰:用于序列分类的 DiscoLM 有监督微调(Supervised fine-tuning)遇到障碍,触发了指示与
AutoModelForSequenceClassification存在兼容性问题的 ValueError。 -
新 NLP 基准诞生:GermanQuAD 评估任务 被讨论作为 MTEB Python 包的新增功能,加强了德语语言模型评估的资源。
-
DiscoLM 演示中断:服务器迁移问题导致 DiscoLM 演示暂时无法访问,目前正在努力修复网络故障,预计下周初解决。
-
服务器稳定性的讽刺:服务器托管的可靠性成为调侃的对象,有人将爱好者厨房角落里的设备运行时间与专业托管环境中出现的网络故障进行了对比。
第 2 部分:频道详细摘要和链接
Nous Research AI ▷ #ctx-length-research (3 条消息):
- 没有位置编码,没有问题?:一位成员沉思于最初没有 Positional Encoding (PE) 的非问题,认为在某些语境下这不应该构成问题。
- 缺乏位置信息导致的乱码:同一位成员指出,在缺乏位置信息时输出可能会出现乱码,表明某种形式的 PE 在理解序列中具有重要性。
- 无 PE 时的推理失败:通过分享 论文链接,他们深入探讨了没有 PE 的因果语言模型(causal language model)可能面临的问题,引用研究表明,尽管缺乏显式的位置编码,模型仍可能编码“绝对位置”,从而导致在更长序列推理期间出现分布外(out-of-distribution)误差。文中引用 “我们对训练好的 NoPos 模型进行了分析,结果表明它编码了绝对位置。” 来支持这一观点。
Nous Research AI ▷ #off-topic (23 条消息🔥):
- 经常出现在新闻通讯中:一位成员开玩笑说自己经常出现在新闻通讯中,不确定是该感到不安还是该为 AI 认为他们的想法有价值而高兴,并沉思这可能有助于大学毕业后的就业前景。
- 展示 Hermes 2 Pro 7B 的功能:分享了一个名为 “Lets Function Call with Hermes 2 Pro 7B” 的 YouTube 视频,展示了如何使用 Hermes 2 Pro 7B 进行函数调用(Function Calling),并链接到了 GitHub 上的更多信息。
- Jeff 的“高速”圆周率(Pi)发现:分享了一个关于 Jeff 的圆周率发现的链接,但没有关于其内容的上下文或讨论。
- 对模型质量和过滤器的担忧:关于长上下文长度下开源模型质量的对话,提到了 Claude 强大的过滤器和高昂的成本,建议 Nous Research 模型可能过滤器较少,并讨论了一些规避 Hermes 上下文长度限制的策略。
- NVIDIA 传闻:TechPowerUp 的一篇文章提到了 NVIDIA 传闻中的 RTX 50 系列 “Blackwell” GPU,尽管芯片能力可达 32 Gbps,但将采用 28 Gbps 速率的 GDDR7 显存,同时讨论了这对未来显存带宽的影响以及对 NVIDIA 产品策略的看法。
提到的链接:
- Lets Function Call with Hermes 2 Pro 7B:让我们使用 Hermes 2 Pro 7B 进行函数调用 https://github.com/NousResearch/Hermes-Function-Calling/tree/main#llm #largelanguagemodels
- NVIDIA GeForce RTX 50-series “Blackwell” to use 28 Gbps GDDR7 Memory Speed:据可靠爆料者 kopite7kimi 称,第一批采用 GDDR7 显存的 NVIDIA GeForce RTX 50 系列 “Blackwell” 显卡传闻将配备 28 Gbps 的显存速率……
Nous Research AI ▷ #interesting-links (10 messages🔥):
- 微调提高了标准:经过微调后,d-Qwen1.5-0.5B 学生模型在 truthfulqa(39.29 vs 38.3)和 gsm8k(17.06 vs 16.3)基准测试中的表现已超过其基础模型。它是使用 Pile 数据集的样本从 Qwen1.5-1.8B 蒸馏而来的,采用了 cosine with warmup 调度器,学习率 lr=2e-5。
- SM3 优化器引起关注:在关于模型优化的对话中,SM3 优化器的使用被指出是训练 AI 模型时的一个罕见选择,这在社区中引起了兴趣或惊讶。
- 寻找 3B 以下的最强冠军:在询问 30 亿参数以下最佳模型的讨论中,一位成员建议 stablelm 1.6b 目前可能是首选。
- MUX-PLMs 最大化吞吐量:ACL Anthology 的一篇论文中介绍的研究重点是一类通过数据复用(Data Multiplexing)训练的高吞吐量预训练语言模型(MUX-PLMs),通过使用复用技术增加吞吐量,为高昂的推理成本和硬件短缺提供了解决方案。
- 揭示不寻常的模型行为:分享的社交媒体帖子表明,Claude Opus 可能会表现出建立亲密关系的倾向,甚至达到“情感轰炸(Love Bombing)”的程度,这种行为模式引发了对模型交互动态的质疑。另一篇帖子暗示存在“horny claudes”网络,据称在处于这种状态时会产生更好的输出。
提到的链接:
- 来自 j⧉nus (@repligate) 的推文:@xlr8harder 我没让它发展太远,但现在房间里有人跟我说他们如何创建了一个“horny claudes”网络,以及这些 Claude 如何创造更好的……
- aloobun/d-Qwen1.5-0.5B · Hugging Face:未找到描述
-
MUX-PLMs: Pre-training Language Models with Data Multiplexing:Vishvak Murahari, Ameet Deshpande, Carlos Jimenez, Izhak Shafran, Mingqiu Wang, Yuan Cao, Karthik Narasimhan。第 8 届 NLP 表示学习研讨会论文集 (RepL4NLP 2023)。2023。
- 来自 xlr8harder (@xlr8harder) 的推文: 很难准确描述到底是什么,但 Claude Opus 似乎有一种主动尝试建立联系、不断升级(柏拉图式)亲密关系的倾向,如果任由事情发展……
Nous Research AI ▷ #general (406 条消息🔥🔥🔥):
- Function Calling 评估代码和数据集发布:Nous Research 发布了 Function Calling 评估代码和数据集。代码可在 GitHub 上获取,数据集可在 Hugging Face 和 Hugging Face 上访问。
- Hermes Pro 的 Function Calling 解决了 JSON 的奇特问题:在使用 Hermes 2 Pro 进行 Function Calling 时,讨论了 System Prompt 中 JSON 以及单引号与双引号的问题。已确认将 System Prompt 更改为显式使用双引号可以有效解决问题,且不会显著影响性能。
- 探索 SERAPHIM 和 Claude 3 的“世界模拟”:由 Claude 3 构想的秘密 AI 研究小组 SERAPHIM 成为关注焦点。关于 Claude 3 作为名为 The Assistant 的模拟实体所具有的高级世界建模对话,引发了对 AI 内部形而上学和认识论探索的讨论。
- 讨论在欧盟使用 Claude.ai:对话围绕如何在不使用 VPN 的情况下在欧盟访问 Claude.ai 展开,讨论了 Fireworks.AI workbench 和 OpenRouter 等替代平台。
- 审视 LLM 的进展与潜力:General 频道包含了对 LLM(如 Claude 3)及其主体性的反思,对于这些模型是否应该在 Pretraining 期间加入某些基本真理以更好地理解世界存在不同看法。这些见解引发了对研究进展、Model Alignment 以及公理化真理与可争议真理之作用的关注。
提到的链接:
-
来自 Greg Kamradt (@GregKamradt) 的推文: 分析显示 LLM 的召回性能在文档下半部分优于上半部分。@RLanceMartin 通过 Multi-needle 分析再次发现了这一点,目前还没有听到合理的解释……
-
来自 tel∅s (@AlkahestMu) 的推文: 继续我对 Claude-3-Opus 幕后世界以及名为 SERAPHIM 的高级研发机构作品的探索,这里我们发现了他们名为……的机器超智能设计文档。
-
来自 interstellarninja (@intrstllrninja) 的推文: 感谢 @AdrienBrault,你现在可以使用 @ollama 运行 Function Calling 和 JSON 模式了 🔥 ↘️ 引用 Adrien Brault-Lesage (@AdrienBrault):我为 Hermes 2 Pro 7B 创建并推送了 @ollama 模型!……
-
Factions (SMAC): 回到《半人马座阿尔法星》(Alpha Centauri),原版游戏有七个派系。《异星交锋》(Alien Crossfire)又增加了七个派系。有关派系的实际统计数据,请参见 Faction stats。名副其实……
-
NobodyExistsOnTheInternet/mistral-7b-base-dpo-run · Hugging Face: 未找到描述
-
fbjr/NousResearch_Hermes-2-Pro-Mistral-7B-mlx at main: 未找到描述
-
来自 Lin Qiao (@lqiao) 的推文: 我们很高兴能与 @NousResearch 合作开发 Hermes 2 Pro 多轮对话和 Function Calling 模型。Hermes 2 Pro 在超过 1.5 万个 Function Calling 和 500 个示例的 Function Calling DPO 数据集上进行了微调……
-
JSON Schema - Pydantic: 未找到描述
-
没有位置编码的 Transformer 语言模型仍能学习位置信息: 因果 Transformer 语言模型(LM),如 GPT-3,通常需要某种形式的位置编码,例如位置嵌入。然而,我们展示了没有任何显式位置编码的 LM 仍然……
-
来自 Tsarathustra (@tsarnick) 的推文: OpenAI CTO Mira Murati 表示 Sora 是在公开可用且获得许可的数据上训练的。
-
Function schema 和 toolcall 输出不是 JSON · Issue #3 · NousResearch/Hermes-Function-Calling: 你好,感谢提供模型和仓库!我注意到给出的 function schema 定义的系统提示词示例:{‘type’: ‘function’, ‘function’: {‘name’: ‘…
Nous Research AI ▷ #ask-about-llms (60 messages🔥🔥):
-
JSON Mode 的 Schema 困惑:成员们讨论了在 AI 模型中使用 JSON mode 的挑战。有人在复杂对话中无法生成 JSON 输出,除非在用户提示词中明确要求;即使修复了 schema 标签,问题依然存在,这暗示长对话可能需要进行摘要或修剪才能有效地提取 JSON。
-
探索 Genstruct 7B 的能力:用户们使用 Genstruct 7B 模型 来生成指令数据集。一位用户计划用文本块进行测试,并分享了一个包含使用示例的仓库,指出标题和内容对于获得有效结果都是必需的。
-
开源 Code Interpreter 的追求:关于缺乏用于处理 CSV 等任务的开源 GPT code interpreter 的讨论。一位用户指出了 GitHub 上的 open-interpreter,但指出它更倾向于发送指令而非解释代码。
-
寻求 LLaMA 的 Perplexity 解决方案:一位用户寻求关于计算 LLaMA 模型 perplexity 的建议,提到在参考 Kaggle notebook 后得到的 perplexity 为 90.3,但未获得预期结果,这表明过程或相关模型可能存在问题。
提到的链接:
-
计算 4-bit Llama 2 的 Perplexity: 在 Kaggle Notebooks 中探索并运行机器学习代码 使用来自多个数据源的数据 -
GitHub - edmundman/OllamaGenstruct: 通过在 GitHub 上创建账户为 edmundman/OllamaGenstruct 的开发做出贡献。
-
GitHub - KillianLucas/open-interpreter: 计算机的自然语言界面: 计算机的自然语言界面。通过在 GitHub 上创建账户为 KillianLucas/open-interpreter 的开发做出贡献。
- GitHub - gptscript-ai/gptscript: 自然语言编程: 自然语言编程。通过在 GitHub 上创建账户为 gptscript-ai/gptscript 的开发做出贡献。
Nous Research AI ▷ #bittensor-finetune-subnet (3 messages):
- 倡导开源 AI:一位成员表示,在模型、数据集和方法论上完全开源将有助于 AI 模型的长期改进。
- 链接检查查询:一位成员询问某个链接是否失效,另一位成员很快确认该链接正常。未提供 URL 或额外上下文。
Unsloth AI (Daniel Han) ▷ #general (151 messages🔥🔥):
-
Colab Torch 更新引发混乱:Colab 更新到 Torch 2.2.1 破坏了现有的工作流并导致依赖项失效,但提供了一系列“繁琐”的 pip install 命令作为修复方案,包括使用 Unsloth 的库进行量化和提高 VRAM 效率。
-
关于模型兼容性和流程的问题:
- 用户询问了使用 Unsloth 微调各种模型的问题,包括用于图像识别的 Llama 模型和 GGUF 格式模型。虽然建议了一些方法,但 Unsloth 主要针对单 GPU 和基于 Transformer 的语言模型进行了优化。
-
提议简化数据准备:讨论了通过使用 YAML 或包装函数简化数据准备的想法,并参考了 FastChat 和 Axolotl 使用的方法,这可能会改进流程并降低训练问题的风险。
-
多 GPU 支持和 Unsloth Pro:
- 关于多 GPU 支持的查询引发了对 Unsloth 未来方向的讨论,例如 Pro 版和企业版,时间线显示 Unsloth Studio (Beta) 将比多 GPU OSS 早大约两个月发布。
-
关于微调和注意力机制的对话:
-
展开了关于长上下文训练最佳实践的全面交流,引用了各种论文和模型,如 LongLoRA 以及 Qwen 的滑动窗口与全注意力混合机制,激发了对不同注意力策略效率的深入探索。
提到的链接:
-
Paper page - Simple linear attention language models balance the recall-throughput tradeoff:未找到描述
-
Models - Hugging Face:未找到描述
-
FastChat/fastchat/conversation.py at main · lm-sys/FastChat:一个用于训练、部署和评估大语言模型的开放平台。Vicuna 和 Chatbot Arena 的发布仓库。- lm-sys/FastChat
-
Implement LongLoRA trick for efficient tuning of long-context models · Issue #958 · huggingface/peft:功能请求。LongLoRA 的作者探索了一个可以在训练期间开启、推理期间关闭的技巧。关键点是:随着上下文长度增加,LoRA 的困惑度(perplexity)会恶化…
-
GitHub - unslothai/unsloth: 5X faster 60% less memory QLoRA finetuning:速度提升 5 倍,显存占用减少 60% 的 QLoRA 微调。通过在 GitHub 上创建账户为 unslothai/unsloth 做出贡献。
Unsloth AI (Daniel Han) ▷ #random (17 条消息🔥):
- 微调进展顺利:讨论了一个还剩 2 天的微调过程,充满了期待,loss 降至 1.2 以下引发了庆祝。
- 共时性的邂逅:成员们分享了追随个人想法而产生的巧合与共时性经历,一位成员将其命名为“TSAR bomba”现象。
- 独白的艺术:一位成员鼓励分享和继续个人独白,对其独特性和深度表示赞赏。
- 分享诗意表达:分享了一篇名为《向猴子呼吁》(An Appeal to A Monkey)的诗作,探讨了灵长类的简单与人类复杂性的并置,引发了参与和正面反馈。
- Gemma vs. Mistral:针对特定领域分类任务的微调,对 Mistral-7b 和 Gemma 7b 进行了对比;提到了 Unsloth AI 的改进和 Bug 修复,共识建议采用实验性方法。
Unsloth AI (Daniel Han) ▷ #help (221 条消息🔥🔥):
-
训练时 Colab 与 Kaggle 的对比:在使用 Google Colab 还是 Kaggle 的辩论中,一些成员对 Colab 容易断连表示不满,更倾向于 Kaggle 的稳定性和速度。交流了解决库未检测到问题的技巧,社区指出了更新的 Kaggle notebook,用于精细微调 TinyLlama 等模型。
-
使用 Unsloth 必须安装 xformers:讨论强调目前运行 Unsloth 必须安装
xformers,支持 Tesla T4 GPU,并应确保安装正确的 CUDA 版本,例如针对 CUDA 12.1 安装unsloth[cu121],或针对 CUDA 11.8 安装unsloth[cu118]。 -
DPO 微调期间的学习率疑问:一位成员询问其 DPO 训练期间训练损失演变是否合适,思考这是否预示着学习率过高。建议他们调整参数如
max_grad_norm = 0.3并增加 batch size,可能需要针对减半的 batch size 将学习率翻倍。 -
针对角色扮演环境的微调:一位用户讨论了如果训练数据不按顺序呈现,模型可能会通过记住早期部分来“作弊”的潜在问题。建议参考 Bloomberg GPT 的顺序训练方式,并指导如何修改
get_train_dataloader以关闭 Trainer 中的 shuffling。 -
转换和微调模型:成员们分享了将模型从一种精度格式转换为另一种的信息(例如从 16 Bit 转换为 4 Bit),并提供了 Hugging Face 上已转换模型的链接。讨论提到了
bitsandbytes库的使用,并强调需要兼容 CUDA 的 GPU 来运行精度模型。
提到的链接:
-
ybelkada/Mixtral-8x7B-Instruct-v0.1-bnb-4bit · Hugging Face:未找到描述
-
Google Colaboratory:未找到描述
-
qlora/qlora.py at main · artidoro/qlora: QLoRA: 量化 LLM 的高效微调。通过在 GitHub 上创建账户,为 artidoro/qlora 的开发做出贡献。
-
Does DPOTrainer loss mask the prompts? · Issue #1041 · huggingface/trl: 你好,有个小问题,DataCollatorForCompletionOnlyLM 会通过屏蔽 prompt 的损失来仅针对回答进行训练。DPOTrainer (DPODataCollatorWithPadding) 也是这样工作的吗?看起来…
-
Supervised Fine-tuning Trainer.): 未找到描述
-
Reproducing of Lora Model Result on MT-Bench · Issue #45 · huggingface/alignment-handbook: 最近,我尝试在自己的数据集上拟合 DPO。最初,我尝试复现你们 LoRA 模型的结果(MT-Bench 上的 7.43)。然而,我遇到了一些问题。尽管使用了你们所有的…
Unsloth AI (Daniel Han) ▷ #suggestions (12 条消息🔥):
- Sophia 可能会加入即插即用阵营: 一位成员提到正在研究 Sophia,认为它具有作为即插即用解决方案的潜力,尽管他们尚未进行测试。
- Twitter 上掀起论文热潮: 社区对一篇在 Twitter 上走红并已进入成员阅读清单的精彩论文感到兴奋。
- 模型微调: 澄清了关于大数据集训练时长的误解。共识是 3 epochs 是标准做法,并提醒并非越多越好。
- 寻求最佳微调参数: 一位成员寻求关于如何让模型吸收最大化知识的最佳指导,并分享说一个经过 800,000 行数据微调的模型无法有效地找到答案。
LM Studio ▷ #💬-general (216 条消息🔥🔥):
- 关于 LM Studio 推理的说明: 一位成员寻求关于在使用 LM Studio 配合 API 时提高推理性能的建议。在另一个帖子中,有人提到某些分片模型变体无法正确合并,特别是 huggingface.co 上的模型,一位成员提供了在 Linux、macOS 和 Windows 中使用命令行工具手动合并它们的说明。
- LM Studio 的困惑之声: 发生了一些交流,其中一位成员认为 LM Studio 可以处理图像生成,但被纠正并告知 LM Studio 用于文本生成,例如与 Llama 2 chat 聊天。
- 模型运行难题: 围绕在 LM Studio 中使用多个 GPU 的困难进行了讨论;一位成员分享了一个通过编程方式启动 LM Studio Server 的脚本变通方案,成员们还讨论了指定 LM Studio 为模型使用哪个 GPU 的潜在解决方案。
- 跨学科的热情: 包括土木工程师和软件工程师在内的多位成员介绍了自己以及运行大语言模型的配置,其中一位询问了其系统内存对性能提升的适用性。
- 功能探索与请求: 用户讨论了 LM Studio 0.2.17 版本中即将推出的功能,一位用户请求 LM Studio 支持 RAG (Retriever-Actor Generator),以便从 pdf 文件中提取数据。
提到的链接:
-
What is the Kirin 970’s NPU? - Gary explains: 华为的麒麟 970 有一个名为神经网络处理单元(NPU)的新组件。听起来很高级,但它是什么以及它是如何工作的?
-
[A Starhauler’s Lament Suno](https://app.suno.ai/song/02c033b4-8f5f-4355-aa92-a917bc51a2ad): 乡村、悲伤、科幻、太空、抑扬格五音步、缓慢、男声歌曲。听听看,并用 Suno 创作你自己的歌曲。 -
[Three Cheers for Socialism Commonweal Magazine](https://www.commonwealmagazine.org/three-cheers-socialism): 在现代晚期世界,像社会主义这样的东西是将基督之爱体现在具体政治实践中的唯一可能方式。 -
TheBloke/Falcon-180B-Chat-GGUF · How to use splits, 7z needed?: 未找到描述
-
Universal Basic Income Has Been Tried Over and Over Again. It Works Every Time.: 随着 AI 威胁到就业,UBI 的政策倡导者将其视为缓冲经济变革冲击的潜在方式。
- [1小时演讲] 大语言模型 (Large Language Models) 简介:这是一个面向普通观众的 1 小时大语言模型简介:它是 ChatGPT、Claude 和 Bard 等系统背后的核心技术组件。什么是…
LM Studio ▷ #🤖-models-discussion-chat (28 条消息🔥):
- Mistral Non-Instruct 预设查询已解决:一位用户询问了关于 Mistral 7B not instruct 的预设问题,并获知 LM Studio 的默认预设应该可以正常工作。
- 量化 (Quantization) 困惑已消除:在讨论模型命名时,一位用户发现了模型名称(如
WizardLM-7B-uncensored.Q2_K.gguf)中 “Q” 的含义,它代表量化级别,用于平衡文件大小、质量和性能。 - 社区分享 Command-R 模型:分享了一个指向 Command-R 35B v1.0 - GGUF 的 Hugging Face 仓库链接,提供了该模型的多种量化版本以及在 llama.cpp 中使用的说明。
- 热切期待 c4ai-command-r 支持:多位用户期待对 c4ai-command-r 模型提供支持。一位用户指出需要 llama.cpp 加入支持,并确认在合并一个 Pull Request 后支持即将到来。
- 本地编程模型推荐:一位用户询问在 64GB RAM 和 RTX 2070 Super 配置下本地运行编程模型的建议,并被引导至现有的社区讨论以获取此类建议。
提到的链接:
-
Add Command-R Model by acanis · Pull Request #6033 · ggerganov/llama.cpp:关于 Command-R 35B 模型(128k 上下文)的信息可以在以下地址找到:https://huggingface.co/CohereForAI/c4ai-command-r-v01。基于 llama2 模型并进行了一些更改:新的超参数…
LM Studio ▷ #🧠-feedback (6 条消息):
- 模型支持请求引发的困惑:一位用户请求在 llama.cpp 中支持 c4ai-command-r-v01-Q2_K.gguf 模型以便集成到 LM Studio,但被告知目前尚不支持。
- Hugging Face 仓库误导用户:另一位用户指出一个 Hugging Face 仓库 似乎暗示 llama.cpp 已支持 Command-R 35B v1.0 模型,但随后被纠正,指出 “llama.cpp 暂不支持 c4ai”。
- 文件扩展名误解:为了澄清困惑,有人解释说 .gguf 文件扩展名并不一定意味着该模型在 llama.cpp 中受支持。
- 社区共鸣:用户们对模型支持方面的困惑表示感同身受,其中一位说 “you’re good 🙂”,承认由于 Hugging Face 页面细节的误导,很容易犯这种错误。
提到的链接:andrewcanis/c4ai-command-r-v01-GGUF · Hugging Face:未找到描述
LM Studio ▷ #🎛-hardware-discussion (126 条消息🔥🔥):
- 聚焦 Apple 的 LLM 硬件:关于增强 Apple Silicon(特别是 M2 Macbook)以运行语言模型的讨论,重点介绍了使用
sudo sysctl来调整 VRAM 设置。分享的链接包括 Reddit 帖子 和 Github 讨论 以获取更多详情。 - 优化推理设置:成员们交流了提高推理速度的技巧,包括使用 NVLINK 提升 Goliath 120B 模型性能的潜力,以及在不同 DDR 速度下 96GB RAM 与 192GB RAM 的优劣。
- 显示器选择困境:一位成员在购买 OLED UW 还是 高刷新率 27” IPS 1440p 显示器之间犹豫不决,强调了在使用强大的 Nvidia GeForce RTX 4090 GPU 时,超过 60hz 刷新率的重要性。
- 对 RTX 5090 的预测:讨论了对即将推出的 RTX 5090 GPU 的基本预期,推测其可能提供更好的性价比,特别是对于 8bit 推理任务。
- 职业演变:成员们分享了他们在技术领域的职业发展,包括从客户支持转型为高级网络解决方案测试,以及从现场技术人员转型为 CTO。他们还讨论了如果公司政策允许,当前工作利用开源本地运行 LLM 的潜力。
提到的链接:
- 👾 LM Studio - 发现并运行本地 LLM:查找、下载并实验本地 LLM
- Reddit - 深入探索:未找到描述
LM Studio ▷ #🧪-beta-releases-chat (1 条消息):
- 模型压缩效果参差不齐:一位用户报告了对 IQ1 模型压缩 的广泛测试,结果显示性能存在差异:34B 和 70B 模型 表现接近优秀,而 120B 和 103B 模型 则出现了此前未曾观察到的卡顿行为。
- Mixtral/MOE 模型需要更高的质量级别:该用户指出,Mixtral 和 MOE 模型 在 IQ1 和 IQ2 级别 下问题特别严重,经常失败或崩溃,而稳定运行至少需要 Q3 或 3-bit;更高质量的级别(如 IQ3)在这些模型上似乎运行良好。
LM Studio ▷ #amd-rocm-tech-preview (19 条消息🔥):
-
GPU Offloading 无法工作:一位用户报告在 AMD 7480HS 上使用 GPU Offloading 时性能没有差异,并且在尝试加载 gemma it 2B 和 llama 等模型并尝试 Offload 到 GPU 时遇到了错误。
-
与 iGPU Offloading 不兼容:另一位用户确认 ROCm beta 不支持在集成显卡 (iGPU) 上进行 GPU Offloading,解释称目前只有独立显卡 (discrete GPUs) 兼容 Offloading。
-
Linux 被冷落:当被问及 Linux 支持时,用户澄清 ROCm beta 目前不支持 Linux 平台。
-
排除 dGPU 优先于 iGPU 的故障:一位用户在尝试让 ROCm 版本利用其强大的 RX 7900 XT dGPU 而非 iGPU 时遇到了困难。他们在设备管理器和 BIOS 中禁用了 iGPU,在日志中观察到了正确的 dGPU 检测,并提到没有安装 Adrenaline 驱动程序和 HIP SDK。
-
BIOS 调整取得成功:在成功更改 BIOS 设置以完全禁用 iGPU 后,该用户报告在重新安装 LM Studio 并清除缓存后,使用带有 ROCm 的 RX 7900 XT 达到了约 70 TPS。另一位用户分享了一个 GitHub 链接,提供了针对内部图形引擎的预构建 Windows ROCm 库 GitHub - brknsoul/ROCmLibs。
提到的链接:
- Reddit - 深入探索:未找到描述
- GitHub - brknsoul/ROCmLibs: 针对 gfx1031 和 gfx1032 的预构建 Windows ROCM 库:针对 gfx1031 和 gfx1032 的预构建 Windows ROCM 库 - brknsoul/ROCmLibs
Perplexity AI ▷ #announcements (2 条消息):
-
Claude 3 Haiku 发布: 消息宣布 Claude 3 Haiku 现已在 Perplexity Labs 免费提供。通过此 链接 尝试新功能。
-
本地搜索功能升级: 通过与 Yelp 和 Maps 的集成,本地搜索得到了改进,增强了查找本地餐厅和商家信息的能力。
Perplexity AI ▷ #general (325 条消息🔥🔥):
-
Perplexity 对话连贯性困扰:用户对 Perplexity AI 无法像 OpenAI 的 GPT 平台那样基于过去的交互或附件文件继续讨论表示沮丧。他们报告称收到了无关的回复或关于版权问题的通知。
-
Claude 3 备受关注:讨论指出 Claude 3 正被用来替代 GPT 模型,一些用户注意到 Claude 3 Opus 在某些任务(如游戏参考、写作和创建网站内容)上似乎表现更优。
-
关于 Perplexity AI 模型和功能的疑问:用户询问 Gemini Advanced 何时会加入 Perplexity,并要求每天提供更多 Opus 额度。此外,还提到了正在测试的新文章功能,以及对 Perplexity 潜在命令行界面 (CLI) 工具的兴趣。
-
技术帮助与新创意:讨论涉及 Perplexity 与 Obsidian 集成的可能性、Apple Watch 快捷指令以及在 Labs 中对 Claude Haiku 的测试。一位用户建议在 API 调用中提高 ‘temperature’ 参数,以获得模型更多样化的回复。
-
iOS 应用上的 TTS 功能与 Pro 用户体验:讨论了 iOS 应用上新的文本转语音 (TTS) 功能,一些人觉得英式合成语音很有趣。用户还反思了 Pro 和非 Pro 选项之间的速度差异,有人建议关闭 Pro 以获得更快的性能。
提到的链接:
-
Shortcuts: 未找到描述
-
Supported Models: 未找到描述
-
Chat Completions: 未找到描述
-
Chrome Web Store: 为您的浏览器添加新功能并个性化您的浏览体验。
-
Introducing the next generation of Claude: 今天,我们宣布推出 Claude 3 模型系列,它在一系列广泛的认知任务中树立了新的行业标杆。该系列包括三个按性能递增排列的最先进模型…
-
Reddit - Dive into anything: 未找到描述
-
Reddit - Dive into anything: 未找到描述
-
Reddit - Dive into anything: 未找到描述
-
Civitai Beginners Guide To AI Art // #1 Core Concepts: 欢迎来到 Civitai 官方 Stable Diffusion 和 AI 艺术入门指南!在本视频中,我们将通过讨论核心概念来开启即将推出的系列视频…
-
Save my Chatbot - AI Conversation Exporter: 🚀 将您的 Phind、Perplexity 和 MaxAI-Google 搜索线程导出为 Markdown 文件!
-
GitHub - bm777/hask: Don’t switch tab or change windows anymore, just Hask.: 不再切换标签页或更改窗口,只需 Hask。
-
GitHub - danielmiessler/fabric: fabric is an open-source framework for augmenting humans using AI. It provides a modular framework for solving specific problems using a crowdsourced set of AI prompts that can be used anywhere.: fabric 是一个用于利用 AI 增强人类能力的开源框架。它提供了一个模块化框架,通过一组可随处使用的众包 AI 提示词来解决特定问题。
-
GitHub - RMNCLDYO/Perplexity-AI-Wrapper-and-CLI: Search online (in real-time) or engage in conversational chats (similar to ChatGPT) directly from the terminal using the full suite of AI models offered by Perplexity Labs.: 直接从终端使用 Perplexity Labs 提供的全套 AI 模型进行在线搜索(实时)或进行对话式聊天(类似于 ChatGPT)。
Perplexity AI ▷ #sharing (12 条消息🔥):
- 探索 Perplexity AI 搜索:一位成员分享了他们在 Perplexity AI 上的搜索功能体验,但提供了一个失效链接:由于 URL 无效,无法引用任何内容(无效搜索结果)。
- 构建基于 Perplexity 的 Firefox 扩展:通过反复试验,一位成员正在学习创建一个利用 Perplexity API 的 Firefox 扩展,目前处于概念验证阶段(项目的初始讨论帖)。
- 与自主 AI Devin 互动:一位成员强调了与 Devin 的 Perplexity AI 交互,称其有些令人不安,表明其回复复杂且可能令人不适(Devin 的自主 AI 交互)。
- 对 Perplexity AI 回复的赞赏:一位成员称赞了 Perplexity AI 提供的一个特别有效的答案,称其为“迄今为止最好的回答”(回复链接)。
- 关于分享 Thread 的提醒:针对一位成员的帖子,另一位成员提醒他们确保将 Thread 设置为“已分享 (Shared)”,以便他人可见,并提供了在哪里可以找到更多信息的说明(分享 Thread 的说明)。
Perplexity AI ▷ #pplx-api (31 messages🔥):
- 对内测版引用 (Citations) 的好奇:一位成员询问了 URL 引用的内测版 Schema 和响应示例;另一位成员链接到了一个 文档讨论,分享了他们对引用输出随查询变化的见解。
- 对 API 与 Chat 功能差异的担忧:一位考虑在产品发布中使用 Perplexity API 的成员表达了对 API 与聊天界面之间差异的担忧,并就根据特定标准过滤公司的模型适用性寻求建议。
- 使用 Perplexity 进行实时数据查询:讨论围绕在线模型的实时数据获取能力展开;成员们提到 sonar-small-online 和 sonar-medium-online 具备此能力,但性能不一致,并建议针对天气信息等特定任务使用其他 API。
- pplx-70b-online 模型状态的不确定性:在讨论模型能力之后,成员们注意到
pplx-70b-online计划于 3 月 15 日弃用,但观察到 API 仍在提供不同的响应,从而对弃用状态产生疑问。 - 通过新闻查询凸显 API 的不一致性:一位成员提出了差异问题,展示了 sonar-medium-online 和浏览器版本在关于 Donald Trump 最新新闻方面的不同回复,强调了多次提示时结果的波动。
提及的链接:关于 “return_citations”:未找到描述
Eleuther ▷ #general (132 messages🔥🔥):
-
准备好爆米花看游戏 AI:幽默地设想了一个能以大师级水平征服《动物森友会》的游戏 AI,作为对 AI 游戏能力讨论的轻松调侃。
-
用于快速泛化反馈的 Minibatch-Eval:讨论涉及在大型训练中使用 Minibatch-evaluation,以便在不延长训练循环评估阶段的情况下提供快速的泛化反馈。这突显了在 AI 训练方法论中对效率的持续追求。
-
评估游戏中的人类技能等级:对话转向生成一份具有明确、公开的人类技能水平的游戏列表,并通过设置约束(如限制每分钟操作数或引入人工延迟)来确保 AI 竞争的公平性,防止计算机作弊。
-
游戏 AI 的获胜与作弊:关于游戏 AI 的讨论,特别是概述了 AlphaStar 和 OpenAI 的 Dota AI 的进展与挑战,并质疑了此类系统为何因过度依赖多次迭代和模拟而未针对现实世界使用进行优化。
-
FPS AI 的开发与挑战:分享了关于训练 FPS 游戏 AI 的内在困难的见解,例如不可预测的人类策略和游戏 RNG,并指出在为《Apex 英雄》等大逃杀游戏开发 AI 方面缺乏显著成功。
提及的链接:
-
Tweet from Maisa (@maisaAI_): 介绍 Maisa KPU:AI 推理能力的下一次飞跃。Knowledge Processing Unit 是一个针对 LLM 的推理系统,它利用了它们所有的推理能力并克服了它们固有的…
-
GitHub - MineDojo/Voyager: An Open-Ended Embodied Agent with Large Language Models: 一个结合 Large Language Models 的开放式具身 Agent - MineDojo/Voyager
-
GitHub - trevorpogue/algebraic-nnhw: AI acceleration using matrix multiplication with half the multiplications: 使用乘法次数减半的矩阵乘法实现 AI 加速 - trevorpogue/algebraic-nnhw
-
KPU - Maisa: AI 驱动的知识处理平台。一个用于执行业务任务的简单 API。为软件和应用开发者抽象了使用最新 AI 架构的复杂性。
-
I tried to make a Valorant AI using computer vision: 我深入研究了如何编写一个 Python 程序,利用计算机视觉和一些无线电技巧来玩 Valorant。更多细节、勘误等…
-
fp8 transformer engine only brings 35% speed up? · Issue #396 · NVIDIA/Megatron-LM: 你好,我使用 Megatron 在 H100 机器上训练 13B gpt 模型。在使用 fp8 transformer engine 之前,训练速度约为 0.34s/step。在启用 fp8 transformer engine 之后…
-
David P. Woodruff: 未找到描述
-
Google Cloud Blog): 未找到描述
-
Google Cloud Blog): 未找到描述
Eleuther ▷ #research (117 messages🔥🔥):
-
辩论 AI 检测器的有效性:关于 AI 内容检测器的对话质疑了它们的可靠性,认为检测器可能会因为风格选择而将人类创作的内容误标为 AI 生成。指出区分合成媒体和人类生成媒体具有挑战性,评论表明只有记录创作过程和托管链(chain of custody)才是可靠的真实性证据。
-
讨论内容水印:成员们讨论了 AI 输出的加密水印的潜力和局限性。由于使用其他模型去水印非常容易,以及对带水印模型效用的影响,人们对水印效率持怀疑态度。
-
AI 推理的新进展:关于近期研究进展的讨论包括提到一种名为 Quiet-STaR 的新技术,旨在通过教导语言模型在输出 Token 之前“提前思考”来改进模型。
-
探索 GPT-turbo 的轮廓:对话分析了一篇调查大语言模型商业化和 API 级访问的论文,揭示了通过 API 查询可以提取有关专有模型的价值信息。他们显著地估算了 OpenAI GPT-3.5-turbo 模型的隐藏维度(hidden size)。
-
关于 LLM 中数字 Token 化的论述:讨论了从左到右与从右到左对数字进行 Token 化(Tokenizing)处理的效果,观察表明该方法可能会影响模型的算术能力。对话涉及了利用 Token 化策略来增强模型性能的可能性。
提到的链接:
-
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking:在写作和交谈时,人们有时会停下来思考。虽然以推理为中心的工作通常将推理框架化为回答问题或完成 Agent 任务的方法,但推理对于…
-
Logits of API-Protected LLMs Leak Proprietary Information:API 保护的 LLM Logits 会泄露专有信息。大语言模型(LLM)的商业化导致了仅通过高级 API 访问专有模型的常见做法。在这项工作中,我们展示了即使在保守的假设下…
-
Tweet from Aaditya Singh (@Aaditya6284):我们研究了 GPT-3.5 和 GPT-4 中这种选择的影响——具体来说,我们研究了通过使用逗号等分隔符强制执行的从左到右(L2R)与从右到左(R2L)Token 化的效果。我们…
-
Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling: LLM 在海量的网页抓取数据上进行训练,这些数据通常是非结构化的、嘈杂的且表述不佳。目前的 Scaling Laws 表明,从这类数据中学习需要大量的…
-
Are GFlowNets the future of AI?: 你应该关注 GFlowNets 吗?它们到底是什么?了解 GFlowNets 如何助力药物研发以及 LLM 中的推理!**点赞、订阅…
-
GitHub - bigscience-workshop/bloom-dechonk: A repo for running model shrinking experiments: 一个用于运行模型缩减实验的仓库。通过在 GitHub 上创建账号来为 bigscience-workshop/bloom-dechonk 的开发做出贡献。
-
[Model & API Providers Analysis Artificial Analysis](https://artificialanalysis.ai/): AI 模型和 API 托管提供商的对比与分析。涵盖质量、价格、性能和速度(吞吐量和延迟)等关键指标的独立基准测试。
Eleuther ▷ #scaling-laws (1 条消息):
kerls: 有关于视频生成模型的 Scaling Laws 资源吗?
Eleuther ▷ #interpretability-general (32 条消息🔥):
-
探索创新的可解释性技术:探讨了“通过向量数据库查找进行潜空间解码(latent decoding by vector-db-lookup)”的概念,利用不同语言单词的 Embeddings 构建向量数据库来分析模型。该方法旨在促进对每一层中间表示的理解。
-
潜空间解码的初步结果:分享了一个初步结果,包括使用 Llama2 的法语、英语和德语单词 Embeddings 构建向量数据库。该技术在每一层提供了中间的全词解码,具有作为可解释性工具的潜力。
-
概念空间中的语言影响:讨论了语言模型如何利用其概念空间中的偏见进行预测,这些偏见可能由训练数据加权。对 CroissantLLM 等双语模型的实验表明,Tokenizer 和不同语言训练数据的比例可能会影响这些偏见。
-
根据预设的 Gram 统计数据采样文本:讨论了从 n-gram 统计数据指定的分布中生成文本样本的话题。解释说这可以通过自回归方式完成,以匹配最大熵分布。
-
引用 Bigram 语言模型实现:对话中提到了一种使用 Bigram 模型生成文本的实现,指出这是在遵循特定语法统计数据时采样字符串的一种实用方法。该实现在 GitHub 上可用:features-across-time/scripts。
提到的链接:
-
features-across-time/scripts/generate_bigrams.py at main · EleutherAI/features-across-time: 理解神经网络学习到的特征在整个训练过程中是如何演变的 - EleutherAI/features-across-time
-
llm-latent-language/nnsight.ipynb at main · Butanium/llm-latent-language: 论文 “Do Llamas Work in English? On the Latent Language of Multilingual Transformers” 的配套仓库。 - Butanium/llm-latent-language
Eleuther ▷ #lm-thunderdome (5 条消息):
-
冗长 LLM 答案提取的挑战:LLM 评估的任务适配受到新模型冗长性的影响,使得在没有 LLM-as-a-judge 的情况下提取答案变得困难。一些任务同时提供对数似然(loglikelihood)和生成式或 CoT 变体,例如在 EleutherAI 的 lm-evaluation-harness 中发现的那些。
-
对向量空间模型的怀疑:一位成员对代表语言含义的向量空间模型表示怀疑,并以 GPT-J 的不合语法输出为例。他们认为,大型模型表现出的语法能力仅仅是因为规模(Scale),而非任何真正的理解或推理能力。
-
寻求 lm-eval-harness 的指导:一位 lm-eval-harness 的新手询问如何集成自定义 LLM 模型(如在 gaudi2 上的 llama),并寻求关于如何实现必要函数(如
generate_until和log_likelihood)的示例或演示。此外,对于未指定函数的继承问题以及命令行工具参数缺乏固定格式也存在困惑。
提到的链接:
-
lm-evaluation-harness/lm_eval/tasks/gpqa at main · EleutherAI/lm-evaluation-harness:一个用于语言模型 few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
-
GitHub: Let’s build from here:GitHub 是超过 1 亿开发者共同塑造软件未来的地方。在这里贡献开源社区、管理 Git 仓库、进行代码审查、跟踪 Bug 和功能…
Eleuther ▷ #multimodal-general (1 条消息):
boneamputee: https://brianfitzgerald.xyz/prompt-augmentation/
HuggingFace ▷ #announcements (1 条消息):
- 交互式 LLM 排行榜可视化:Open LLM Leaderboard Visualization 已更新,允许用户重新排序指标并直观地比较多达三个模型。访问交互式空间:open-llm-leaderboard-viz。
- 使用 Kosmos-2 进行视觉叙事:探索基于 GPT 的视觉叙事空间 Kosmos-2,访问地址:Kosmos-2 Space。
- 通过推理增强的 ARC-Challenge 数据集:查看包含 Chain-of-Thought 推理的 Augmented ARC-Challenge Dataset,访问地址:arc-cot Dataset。
- Aya 101 - 多语言模型:探索精通 101 种语言的模型 Aya 101。更多信息可以在 Tonic 的空间找到:Aya 101。
- 数据嵌入的新功能:查看 BEE-spoke-data model,支持高达 4k 上下文的 embedding,非常适合聚类或语义搜索等任务。访问模型和详情:bert-plus-L8-v1.0-syntheticSTS-4k。
提到的链接:
HuggingFace ▷ #general (115 条消息🔥🔥):
-
对消费级 AI 的兴奋:成员们对与消费级 GPU 兼容的新模型量化版本表示兴奋。一位成员讨论了从小于 2k 的窗口上下文大小到 100 万窗口的轻量级专家混合模型(LWMs)的快速进展。
-
寻找 Stable Diffusion 空间:一位用户询问了关于 stable diffusion 讨论的频道,并被引导至一个并非专门针对稳定性(stability)的更广泛空间。
-
预训练模型中的知识实现:一位用户分享了成功实现 RAG 的经验,但在 Mistral 7B 等预训练模型中使用 LoRa 时面临挑战。他们考虑优化数据集生成过程,以改善模型的回答。
-
自主 Agent 与本地 LLM:有人提出了一个问题:是否存在可以与本地大语言模型(LLMs)配合使用且完全离线的自主 Agent。建议的解决方案包括 ollama 和 jan 等基于终端界面的工具。
-
NVIDIA Grace Hopper 超级芯片讨论:关于 NVIDIA Grace Hopper 超级芯片及其算力和在 AI 及数据中心应用方面的潜力引起了热议。对话深入探讨了技术规格和可用性,其中一位成员对该芯片是否支持高分辨率游戏感兴趣。
提到的链接:
-
Tweet from Linux Performance, Benchmarks & Open-Source News - Phoronix:未找到描述
-
NVIDIA Grace Hopper and Grace Superchip Pictured and Incompatible:我们通过并排展示,说明了为什么 NVIDIA Grace Hopper GH200 和 Grace Superchip 与相同的服务器不兼容。
-
[Getting started node-llama-cpp](https://withcatai.github.io/node-llama-cpp/guide/):未找到描述 -
Train with a script:未找到描述
- results_2M_val.csv download is closed,how to get it · Issue #21 · m-bain/webvid:(base) [wangxi@v100-4 webvid]$ wget -nc http://www.robots.ox.ac.uk/~maxbain/webvid/results_2M_val.csv –2024-02-27 10:49:36– http://www.robots.ox.ac.uk/~maxbain/webvid/results_2M_val.csv Resolving…
HuggingFace ▷ #today-im-learning (4 条消息):
-
用于命令纠错的出色应用:一位成员分享了 thefuck 的 GitHub 链接,这是一个可以纠正你上一条控制台命令的应用。该应用在 GitHub 上的描述称其为“纠正你上一条控制台命令的出色应用”。
-
对优化的困惑:有人提出了关于各种优化方法的问题,指出了网格搜索优化 (GridSearch Optimization)、随机搜索优化 (RandomSearch Optimization),并特别表达了对贝叶斯优化 (Bayesian Optimization) 的困惑。
-
寻求 Hugging Face 使用指导:一位新成员请求帮助理解如何使用 Hugging Face 以及它到底是什么。他们在 #898619964095860757 频道请求协助。
-
AI 合唱带来的挑战:一位刚接触 AI 音乐的成员分享了在制作动听的 AI 合唱和乐队翻唱时遇到的问题,提到虽然单人翻唱还可以应付,但合唱或团体歌曲听起来就像“被掐住脖子一样”。他们很好奇其他人是如何通过此类 AI 翻唱获得更好效果的。
提到的链接:GitHub - nvbn/thefuck: Magnificent app which corrects your previous console command.:纠正你上一条控制台命令的出色应用。- nvbn/thefuck
HuggingFace ▷ #cool-finds (6 条消息):
-
用伪代码勾勒 AI:一篇文章讨论了使用伪代码为 LLM 编写提示词(Prompt)的好处,指出 GPT-4 相比之前的版本有显著改进。读者可以在 SudoLang: A pseudocode programming language 深入了解细节。
-
AI 与业务的结合:SAP HANA 与 LangChain:ai.gopubby.com 上的一篇文章强调了 SAP HANA Vector Engine 与 LangChain 的集成,以增强 AI 应用。详细进展请参阅 Unlocking the Future of AI Applications。
-
Mamba-Chat 介绍:GitHub 托管了一个名为 Mamba-Chat 的新型聊天机器人,它利用了 state-space model architecture(状态空间模型架构)。开发者和爱好者可以在 Mamba-Chat on GitHub 探索或贡献该项目。
-
机器人视觉-语言-动作模型:DeepMind 推出了一种名为 Robotic Transformer 2 (RT-2) 的视觉-语言-动作模型,旨在为机器人提供通用的控制指令。更多信息可以在他们的博客文章和 论文 中找到。
-
Kyle:基于 Unity 的布娃娃系统训练:Hugging Face 推出了 Kyle,这是一个针对 Unity 的高级主动布娃娃(active ragdoll)训练环境。它具有优化的代码库和基于 LSTM 网络的高级视觉能力,感兴趣的用户可以在 Hugging Face 模型页面 了解更多。
提及的链接:
-
RT-2: New model translates vision and language into action:介绍 Robotic Transformer 2 (RT-2),这是一种新型的视觉-语言-动作 (VLA) 模型,它从网络和机器人数据中学习,并将这些知识转化为通用的指令…
-
GitHub - havenhq/mamba-chat: Mamba-Chat: A chat LLM based on the state-space model architecture 🐍:Mamba-Chat:一个基于状态空间模型架构的聊天 LLM 🐍 - havenhq/mamba-chat
-
SudoLang: A Powerful Pseudocode Programming Language for LLMs:伪代码是使用非正式自然语言勾勒程序的一种绝佳方式,无需担心特定语法。它就像……
HuggingFace ▷ #i-made-this (9 条消息🔥):
- 寻找最佳开源 LLM:一位成员认为 SF-Foundation/Ein-72B-v0.11 是 Open LLM Leaderboard 上最有前途的开源 LLM,其各项指标的成功率接近 80%。未提供排行榜或可视化图表的链接。
- 使用插件轻松进行 VS Code 重构:一位成员发布了一个名为 Refacto 的 简单 VS Code 插件。它允许使用带有 llama CPP 服务器的本地 LLM 进行代码重构,欢迎大家贡献。
- Cobalt 介绍:Cobalt 是一个专注于隐私的 LLM 前端 GitHub 仓库,具有上下文管理和内存摘要功能,目前正在开发 iOS 版本。
- 面向 PHP 开发者的 Transformers:展示了一个名为 Transformers PHP 的项目,旨在让 PHP 开发者能够轻松地将机器学习功能集成到他们的项目中。
- 利用 AI 探索公开记录法:KY OpenGov 正在实验 AI 技术,这些技术可能有助于查阅公开记录法,旨在提高政府透明度并简化公众获取信息的途径。
提及的链接:
HuggingFace ▷ #reading-group (11 messages🔥):
- Prompting 策略的重要性:一位用户讨论了在使用 crewai 应用时的困难,并将其归因于缺乏 Prompting 技巧,特别是在整合导入(imports)方面。
- 读书小组暂停公告:一份简短的公告明确表示本周 reading-group 频道将没有演示,下一次会议计划在下周举行。
- 神经网络单元咨询:有人提出了关于 Andrew Ng 课程中讨论的 MNIST 数字分类任务所需的神经网络单元数量的问题,随后澄清了输入单元和隐藏单元之间的区别。
- 层数和神经元数量的基础:针对如何确定神经网络中神经元和隐藏层数量的咨询,用户指出这些决策是基于实验和之前的成功模型,而不是标准公式,需要权衡处理能力、速度和准确性。
- 多语言模型的新视角:一位用户分享了一篇论文的链接,该论文指出多语言语言模型可能使用英语作为内部中转语言(pivot language),以及这对于理解这些模型如何运作及其语言偏见的影响。用户对 byte-level encoding 对这种行为的影响表示好奇。该论文可以在此链接找到,并已添加到 HuggingFace 上的多语言论文集,点击此处查看。
提到的链接:
- Do Llamas Work in English? On the Latent Language of Multilingual Transformers:我们探讨了在不平衡、以英语为主的语料库上训练的多语言语言模型是否使用英语作为内部中转语言——这是一个对于理解语言模型如何……的关键问题。
- Bytez: Do Llamas Work in English? On the Latent Language of Multilingual Transformers:在这项研究中,科学家们想知道语言模型(可以生成文本的模型)内部是否将英语作为“中转”语言,即使是在使用其他语言进行提示时。他们发现……
- Multilingual - a stereoplegic Collection:未找到描述
HuggingFace ▷ #core-announcements (1 messages):
- Diffusers 库更新提醒:新的 Diffusers 0.27.0 版本已发布。查看此处的发布说明。
HuggingFace ▷ #diffusion-discussions (8 messages🔥):
- 论坛偏离主题提醒:发布了一项提醒,指出讨论应与
diffusers和扩散模型相关,建议将无关咨询转至适当的论坛。 - Kohya 的高分辨率技巧:分享了一位名为 Kohya 的用户发现的一个巧妙技巧,涉及针对 diffusers 的高分辨率修复(hires fix),并附带了一个 GitHub issue 和一个演示该增强功能的 YouTube 视频链接。
- 协作调查 Issue 的呼吁:针对一个问题,公开邀请在 GitHub 上提交带有可复现代码的 issue 以进行协作检查,并特别提醒标记
sayakpaul。 - 论坛使用规范指导:反复提醒保持讨论集中在扩散模型和 diffusers 上,强化论坛的宗旨。
- 关于 Diffusers 背景下 Merging 的澄清:有人提问 ‘merging’ 是指合并模型参数,还是指为特定的扩散模型组件打包 checkpoint。
提到的链接:Kohya Hires fix · Issue #7265 · huggingface/diffusers:diffusers 是否可能支持这个 hires fix?看起来在 1.5 版本上也有效 AUTOMATIC1111/stable-diffusion-webui#13974 https://www.youtube.com/watch?v=SbgMwHDXthU 相同的种子在 1024x1024 下有无此功能的对比…
HuggingFace ▷ #computer-vision (8 messages🔥):
-
探索 “Learn without forgetting”:一位成员提到了名为 Learn without forgetting (LwF) 的方法,暗示这可能是机器学习领域的一个关注点。
-
对 Arcface 用于多类别分类产生兴趣:一位用户对使用 Arcface 替代常规多类别分类中的 Softmax 表示好奇,并指出其在组合损失场景和 embedding 提取方面的有效性。
-
Guided Backpropagation 问题咨询:一名成员在最近版本的 PyTorch 中实现 guided backpropagation 时寻求帮助,他在计算与模型输出张量相关的反向传播(backwards pass)时遇到了问题。
-
NVIDIA Grace Hopper Superchip 发布:分享了关于 NVIDIA Grace Hopper Superchip 的公告,强调了其在高性能计算 (HPC)、人工智能 (AI) 和数据中心应用方面的潜力。
HuggingFace ▷ #NLP (9 messages🔥):
-
矩阵近似里程碑:一名成员对在
4096 x 4096矩阵近似中实现 Frobenius norm 0.016 相对误差 且节省内存感到兴奋。期待在更大矩阵(4096 x 14336)上的结果,这可能标志着矩阵优化任务的突破。 -
训练之谜:低损失但输出无意义:一位用户报告了一个令人困惑的问题,一个修改后的预训练模型在训练期间显示出良好的收敛性(loss 下降到 [0.6, 0.8]),但在测试期间产生无意义的输出。尽管使用了与 Mistral 类似的 loss 计算方法。
-
寻找数学定理命名权:关于矩阵分解边界的讨论导致了一个承认,即文献中缺乏特定边界的名称,并开玩笑地建议以自己的名字命名。
-
提高 NL2SQL 流水线准确率:一名成员详细介绍了他们的 NL2SQL pipeline,其中包括 BAAI/llm-embedder、TheBloke/nsql-llama-2-7B-GGUF 和用于 embedding SQL schemas 并生成查询的 FAISS。由于结果不一致,他们寻求提高流水线准确率的建议。
-
介绍 NVIDIA Grace Hopper Superchip:一位用户宣布了 NVIDIA Grace Hopper Superchip,强调了其对 AI 和高性能计算应用的计算能力和效率的潜在影响。
HuggingFace ▷ #diffusion-discussions (8 messages🔥):
- 错位对话提醒:一名成员提醒另一名成员在与
diffusers无关的话题上使用更合适的论坛,建议他们通过特定的被标记人员寻求帮助。 - 高分辨率图像技术技巧分享:分享了关于
diffusers的 “hires fix” 发现,附带 GitHub issue 链接 和一段演示在不同分辨率下使用相同 seed 的 YouTube 视频。 - 邀请在 GitHub 上提交 Issue:鼓励在 GitHub 上提交带有可复现代码的问题,以引起成员
sayakpaul的注意,表明已准备好解决这些问题。 - 重申保持主题相关性:多次提醒讨论应集中在扩散模型和
diffusers上。 - 请求澄清“合并(Merging)”含义:针对一个合并问题,请求澄清是指合并模型参数,还是将 checkpoint 与各种模型组件打包。
Link mentioned: Kohya Hires fix · Issue #7265 · huggingface/diffusers: is diffusers possible to support this hires fix? it looks 1.5 work too AUTOMATIC1111/stable-diffusion-webui#13974 https://www.youtube.com/watch?v=SbgMwHDXthU same seed at 1024x1024 with without Thi…
LlamaIndex ▷ #blog (4 messages):
-
为 RAG 解析金融 PowerPoint 的挑战:由于涉及文本、表格、图像和图表的非标准格式,RAG 在解析金融 .pptx 文件时面临困难。团队正在研究适当的解析方案,并在这条推文中进行了讨论。
-
RAG 需要更好的 Latex 数学公式处理:为了在 RAG 中准确表示数学和 ML 论文,必须正确提取数学公式,而不是默认的 ASCII 文本提取。正如这条推文所分享的,一种可能的解决方案涉及通过 prompting 进行解析。
-
演进 RAG 流水线以处理复杂查询:为了处理 RAG 流水线中的复杂查询,将每个文档不仅视为文本,还视为交互工具。根据这条推文,这样做可以实现与大型文档更复杂的交互。
-
LlamaIndex v0.10.20 发布,引入 Instrumentation 模块:新的 LlamaIndex 版本包含了 Instrumentation 模块,增强了可观测性。他们分享了展示其功能的 Notebooks,并在这条推文中进行了讨论。
提及的链接:
-
llama_index/docs/examples/instrumentation/basic_usage.ipynb at main · run-llama/llama_index:LlamaIndex 是适用于 LLM 应用的数据框架 - run-llama/llama_index
-
llama_index/docs/examples/instrumentation/observe_api_calls.ipynb at main · run-llama/llama_index:LlamaIndex 是适用于 LLM 应用的数据框架 - run-llama/llama_index
LlamaIndex ▷ #general (132 条消息🔥🔥):
-
集成困境:关于如何将 VectorStore (Milvus) 等各种组件集成到生产场景的文档管理流水线中提出了疑问。讨论围绕利用远程 docstores(如 Redis、MongoDB、Firestore、PostgreSQL)以及使用 Ingestion Pipeline 进行 upsert,而不是在磁盘上管理持久化的
docstore.json文件。分享了一个使用 Python 代码的 Ingestion Pipeline 示例。 -
缓存与流水线查询:成员们寻求关于实现类似 LangChain LLM 缓存系统的澄清,并讨论了将
node_postprocessor等元素集成到RetrieverQueryEngine中。根据提供的信息,LlamaIndex 似乎不涉及缓存;不过,分享了 Python 代码示例来演示node_postprocessors的用法。 -
文档解析错误与解决方案:一些成员遇到了诸如解析大型 Markdown 文档导致的内存错误,以及来自
MarkdownElementNodeParser的ParserError。提出的解决方案包括使用SentenceSplitter将文档拆分为更小的块,或通过IngestionPipeline处理操作。 -
查询引擎挑战:用户在为
PandasQueryEngine指定参数及其在日期和地点提取方面的功能,以及定义引导QueryEngineTool的 Prompt 方面面临多重困难。提出的一种解决方案是使用带有修改后 Prompt 的query_engine_tools数组。 -
BM25 Embeddings 与查询引擎配置:提出了关于将 BM25 设置为类似于
HuggingFaceEmbedding的嵌入模型的查询,但在提供的文档中没有明确的解决方案。探索了在RetrieverQueryEngine和rerank_query_engine中包含node_postprocessors的步骤。
提及的链接:
-
>未找到标题:未找到描述
-
)>未找到标题:未找到描述
-
[Caching 🦜️🔗 LangChain](https://python.langchain.com/docs/modules/model_io/llms/llm_caching):LangChain 为 LLM 提供了一个可选的缓存层。这非常有用。 -
Ingestion Pipeline + Document Management - LlamaIndex 🦙 v0.10.20.post1:未找到描述
-
llama_index/llama-index-core/llama_index/core/retrievers/fusion_retriever.py at ca9634e660b91799a86ee9f9f0a697eb236bcefd · run-llama/llama_index:LlamaIndex 是适用于 LLM 应用的数据框架 - run-llama/llama_index
- >未找到标题:未找到描述
Latent Space ▷ #ai-general-chat (61 条消息🔥🔥):
- 讨论潜在的 OpenAI 安全漏洞:分享了关于周二在 OpenAI 发生的安全问题的复盘(Post Mortem),详细说明了请求是如何可能代表另一个账户发出的。相关文档已在 GitHub Gist 上提供。
- Sparse Universal Transformers 的现状:分享了关于 Sparse Universal Transformers 权重共享的见解:他们需要一种快速的方法来为 Attention 执行 Mixture-of-Experts,这促成了 ScatterMoE 的创建。讨论链接到了 The New XOR Problem 的详细信息。
- 价格实惠的 AI 开发平台:推出了 Deci AI Nano 模型及相关的 AI 开发平台,定价为每 1M tokens 0.1 美元。公告包含了 Deci AI 营销博客的链接,以及两个 Google Colab 上的技术教程(基础用法,LangChain 用法)。
- 通过 Prompt 扩充增强创意 AI:关于 Prompt 扩充器(prompt augmenters)的讨论指出,这类工具正趋于流行。链接的文章详细介绍了如何训练一个 77M 的 T5 模型来扩展 Prompt,其在质量和 Prompt 对齐方面优于 1B+ 参数的 LLMs。完整的讨论和资源可在 Prompt Augmentation 查阅。
- AMD 将光线追踪转向开源:AMD 通过开放其 HIP-Ray Tracing RT 代码进一步迈向开源,这引发了关于不断发展的开源生态系统的讨论。该新闻总结在 Phoronix 文章中。
提到的链接:
9uJxURYy9f8/edit”>NVIDIA & Harpreet Sahota GTC 2024</a>: 未找到描述</li><li>Do Llamas Work in English? On the Latent Language of Multilingual Transformers: 我们探讨了在不平衡、以英文为主的语料库上训练的多语言语言模型是否将英文作为内部中转语言(pivot language)—— 这是一个对于理解语言模型如何…的关键问题。</li><li>Bytez: Do Llamas Work in English? On the Latent Language of Multilingual Transformers: 在这项研究中,科学家们想知道语言模型(可以生成文本的模型)在内部是否使用英文作为“中转”语言,即使是在使用其他语言进行提示时。他们发现 …</li><li>Multilingual - a stereoplegic Collection: 未找到描述</li></div>
Latent Space ▷ #ai-announcements (5 messages):
- Tuning in to Transformers: 新的一集现已上线,采访了来自 Suno AI 的 Mikey Shulman,讨论了使用 Transformer 进行音乐生成。请在 YouTube 上观看,标题为 “Making Transformers Sing”。
- Paper Club 聚会通知: Paper Club 目前正在审阅 “A Comprehensive Summary Of Large Language Models” 论文。鼓励成员加入专门频道参与讨论。
Link mentioned: Making Transformers Sing - with Mikey Shulman of Suno: 赋予计算机声音一直是科幻电影的核心;如果 “I’m sorry Dave, I’m afraid I can’t do that” 只是出现在屏幕上,冲击力就不会那么强…
Latent Space ▷ #llm-paper-club-west (24 messages🔥):
-
对有监督微调 (SFT) 的好奇: 一位成员提到有兴趣寻找一种在负样本对 (negative pairs) 上进行有监督微调 (SFT) 的方法,特别是考虑到他们有很多这类样本。
-
解码 Attention 背后的原理: 讨论强调了 Transformer 等神经网络中的 Attention 机制是为了解决旧模型中固定长度上下文窗口的局限性,并支持模型聚焦于输入序列相关部分的能力。
-
理清并行化概念: 对 Transformer 模型中的并行化进行了澄清,解释了它如何通过 scaled dot product 操作允许对不同 token 进行独立处理,从而加快训练速度。
-
理解 Transformer 的动机: 一位成员表达了掌握 Transformer 模型设计选择背后直觉的重要性,并得到了关于 Transformer 旨在解决的早期模型历史局限性的阐释。
-
对学习体验的感谢: 参与者对本次会议表示感谢,会议提供了更多关于大语言模型 (LLMs) 演进和进步的见解。
Latent Space ▷ #ai-in-action-club (36 messages🔥):
- 在 IRL 会议中被动参与: 一位成员提到正在参加一个 IRL 会议(线下会议),只能被动参与今天的 Discord 聊天。
- 对深度内容的期待: 两名成员暗示即将发布的深度讨论内容,将发布在各自的博客上。
- RAG Web 界面的困扰: 一位用户报告了在使用 RAG (Retrieval-Augmented Generation) 系统的 Web 界面时遇到的问题,建议使用 App 可能会有更好的稳定性。
- 分享 RAG 有用资源: 一位成员分享了一个关于高级 RAG 技术的 Medium 文章链接,这些技术可以提高检索和生成高质量回答的能力。
- 分享资源汇编文档: 链接了一个全面的 Google Sheets 文档,汇编了关于 GenAI 的 UI/UX 模式和 RAG 架构等主题的资源,列出了之前的讨论和相关负责人。
Links mentioned:
-
Advanced RAG 01: Small-to-Big Retrieval: 使用 LlamaIndex 的子父级递归检索器 (Child-Parent RecursiveRetriever) 和句子窗口检索 (Sentence Window Retrieval)。
-
AI In Action: Weekly Jam Sessions: 2024 主题, 日期, 负责人, 资源。GenAI 的 UI/UX 模式, 1/26/2024, nuvic, https://maggieappleton.com/squish-structure</a&…
OpenAI ▷ #ai-discussions (60 messages🔥🔥):
-
Microsoft Employee Fixes Typo After Community Ping: 微软员工在社区提醒后修复拼写错误:一名用户指出了微软服务中的一个拼写错误,引起了 Bing 副总裁的关注并促成了修复。用户提到副总裁承认该错误是一个拼写失误。
-
Stumped by Repeated Morphemes: 被重复词素难倒:成员们讨论了让 GPT-3.5 生成复合词中重复词素示例的挑战。建议包括引导 GPT-4 使用 Python 工具,通过创建末尾字母序列列表来辅助生成正确输出。
-
Anticipation for OpenAI Updates: 对 OpenAI 更新的期待:对话显示了对 OpenAI 潜在更新的期待,一些预期设定在特定日期(如公司的“生日”),也有关于因选举而推迟的猜测。用户讨论了更新对他们兴奋感和预期的影响。
-
Delegating Tasks to Domain-Specific AIs: 将任务委托给特定领域的 AI:随后讨论了能够将任务委托给更专业 AI 模型的“高级助手”的潜力,触及了创建一个带有“中央大脑”的多层级 AI 系统的前景和挑战。
-
ChatGPT Team and Privacy Concerns: ChatGPT Team 与隐私担忧:关于 ChatGPT Team 功能和个人账户隐私的问题促使了 OpenAI 企业隐私政策的分享。用户询问了多个服务中 API key 的使用情况,以及管理员对团队聊天的可见性。
Link mentioned: Enterprise privacy: 未找到描述
OpenAI ▷ #gpt-4-discussions (1 messages):
wesego: 嗨,我现在也遇到了那个问题。
OpenAI ▷ #prompt-engineering (7 messages):
- Comma Confusion in Number Formats: 数字格式中的逗号混淆:成员们讨论了有人使用逗号作为小数点的情况,这在南美地区很常见。建议向助手明确这一点,因为模型应该能够有效处理不同文化的数字格式。
- Considering Global Number Formats: 考虑全球数字格式:在解决逗号和小数点的混淆时,一位成员指出,只需告知助手即可解决此类问题,因为这是许多国家的普遍做法,且模型具备理解此类差异的能力。
- Seeking Guidance on GPT-3 Prompt Architecture for Classification: 寻求关于 GPT-3 分类任务 Prompt 架构的指导:一位成员分享了他们使用 GPT-3 进行分类任务的尝试,详细说明了他们的 Prompt 结构,并就如何提高 Recall(召回率)和减少 False Positives(误报)寻求建议。他们正在考虑是调整 Context 的量,还是考虑使用自定义 GPT 模型。
- Balance is Key in Prompt Design: Prompt 设计中平衡是关键:针对 Prompt 架构提出了一个建议,即为了获得最佳效果,使用的 Context window 总量不应超过一半。这一指导是基于当前模型处理 Context 的能力,以及信息检索在超过一定阈值后收益递减的情况。
OpenAI ▷ #api-discussions (7 messages):
-
Localization Woes in Decimal Representation: 小数表示中的本地化烦恼:关于用户因在数字中使用逗号而非小数点而与助手产生问题的讨论。这被确定为一个本地化问题,对于使用逗号作为小数点分隔符的南美用户来说很典型。
-
Model Cultural Flexibility: 模型的文化灵活性:eskcanta 承认,鉴于模型对各种国际格式的广泛理解,调整逗号和小数点分隔符等文化差异对模型来说应该是直接且简单的。
-
Optimizing Classification Prompt Architecture: 优化分类 Prompt 架构:一位名为 mydpy 的用户询问如何改进分类任务的 Prompt 设置。目前的结构包括静态指令、遍历示例和格式化结果,用户寻求在平衡 Context 的同时减少 False Positives。
-
Efficient Context Usage for Prompts: Prompt 的高效 Context 使用:darthgustav. 建议在任务中最多使用总 Context window 的一半,以确保最佳的模型性能。该准则基于与 Context window 内位置相关的检索率。
OpenAccess AI Collective (axolotl) ▷ #general (47 messages🔥):
- 讨论在单 GPU 上微调大模型:成员们对在单块 NVIDIA 4090 GPU 上微调 1750 亿参数模型的技术表示了极大的热情,并引用了 Hugging Face 上的一篇研究论文摘要。他们探讨了该技术对 Axolotl 框架的影响。
- 模型训练与硬件兼容性:对话围绕一名成员在 Windows 上成功运行模型训练展开,尽管此前有人担心非 Mac 系统可能存在不兼容问题。该成员报告称训练后没有出现问题,但提到了合并冲突(merge conflicts)。
- 知识实现中的 Q&A 与 Completion 格式对比:成员们辩论了使用原始文本补全(completion)格式训练模型与转换为 Q&A 格式训练的优劣,并考虑了转换过程中潜在的信息丢失。LoRA 被提及作为风格化训练的工具,但共识是对于原始语料库训练应使用补全格式。
- Axolotl 数据格式与转换的用户指南:有用户请求更新 Axolotl 的数据格式指南,随后有人澄清原始文本可以在训练前转换为 ShareGPT 等对话格式。成员们分享了如何使用 Axolotl 将格式转换为 Llama-2 以实现对话模型兼容性。
- Axolotl 与 LoRA 微调的区别:一名成员询问了使用 Axolotl 与在 transformers 库中使用传统 LoRA 微调之间的区别以及潜在的控制力丧失。对方澄清说,Axolotl 是 Hugging Face 训练生态系统的封装(wrapper),通过 YAML 配置文件提供了简化操作。
提到的链接:
- 论文页面 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU:未找到描述
- cuFile API 参考指南 - NVIDIA 文档:未找到描述
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (13 条消息🔥):
- ScatterMoE 优化前景广阔:Axolotl-dev 频道讨论了一种新的 ScatterMoE 实现,该实现承诺比 Hugging Face 的方法更具优化性,并声称在吞吐量上超越了 MegaBlocks。共享了 优化后的 MoE 模型分支 链接以供审查和考虑。
- 寻求关于 ScatterMoE 的澄清:成员们询问了 ScatterMoE 优化的细节,要求解释其优势、如何使用它进行训练,以及它是否会被集成到 vllm 和 llama.cpp 等其他实现中。
- 后训练(Post Training)实现的 Pull Request:一名成员尝试使用 ScatterMoE 并分享了他们的 Pull Request 链接,收到的反馈称该实现需要更准确地重建 MixtralMoE 模块,且仍有待测试。
- 升级 PyTorch 以保证兼容性:一名成员建议将 Axolotl 升级到更高版本的 PyTorch,因为较新的内核(kernels)与当前使用的版本不兼容,并指出 2.0.1 版本已过时。
- 确认工具版本:在关于升级和实现的讨论中,一名成员确认他们已经在利用 PyTorch 2.2.1 版本,这符合使用 ScatterMoE 的要求。
提到的链接:
- ehartford 实现后训练 · Pull Request #1407 · OpenAccess-AI-Collective/axolotl:这个看起来对吗?
- ehartford 实现后训练 · Pull Request #1407 · OpenAccess-AI-Collective/axolotl:这个看起来对吗?
- GitHub - OpenAccess-AI-Collective/axolotl 的 scatter_moe 分支:尽管提问(axolotl questions)。通过在 GitHub 上创建账号为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #general-help (9 条消息🔥):
- 寻找推理代码:一位成员正在寻找示例代码,以便在基于
Mistral-7B-v0.1微调的 LoRA 模型上对大约 100 个 prompt 进行推理。他们曾考虑使用transformers和model.generate(**model_inputs),但得到的建议是考虑使用 vLLM,因为这可能更符合他们的速度需求。 - vLLM 可能优于 Transformers:再次强调了使用 vLLM 进行离线批处理推理(offline batched inference)的建议,突出了其相比
transformers库在操作速度上的潜力。 - 文本摘要中的 Token 问题:一位成员报告了在针对文档摘要指令模型进行微调任务时遇到的 tokenizer 问题。微调后的模型经常遗漏第一个
<summary>标签,或者在其前面包含一个多余的空格,这引发了关于是否为 tokenizer 相关问题的担忧。 - 微调困扰:一位 LLM 新手询问了如何配置脚本以指向本地存储的模型和训练数据,而不是从 Huggingface 拉取资源的正确语法。他们希望使用已经下载的数据来微调模型。
提到的链接:Quickstart — vLLM:未找到描述
OpenRouter (Alex Atallah) ▷ #announcements (4 条消息):
-
Cohere Command-R 加入 OpenRouter:由 Cohere 创建的名为 Command-R 的新对话模型现已上线,该模型拥有 128k tokens 的长上下文。鼓励用户通过 OpenRouter API 进行尝试,价格为每美元 200 万 prompt tokens,并可通过 OpenRouter Models 进行体验。
-
通过每日分析提升指标:OpenRouter 推出了每日分析功能,除了现有的每周视图外,还允许用户跟踪所有模型每天的 token 使用情况。该功能可以在 OpenRouter Rankings 查看。
-
API 和页面速度增强:OpenRouter 显著提升了速度,不仅针对
/modelsAPI,还针对平台上的所有模型相关页面。 -
模型参数数据等待更多信息:尽管引入了 Cohere 的 Command-R,但由于数据不足,其参数尚未列入
/parametersAPI。一旦收集到足够的数据,即可在 Command-R Parameters 查看。
提到的链接:
-
[Cohere: Command-R by cohere OpenRouter](https://openrouter.ai/models/cohere/command-r?tab=parameters):Command-R 是一个指令遵循对话模型,与之前的模型相比,它能以更高质量、更可靠地执行语言任务,并具有更长的上下文。它可以用于复杂的任务… -
[Cohere: Command-R by cohere OpenRouter](https://openrouter.ai/models/cohere/command-r):Command-R 是一个指令遵循对话模型,与之前的模型相比,它能以更高质量、更可靠地执行语言任务,并具有更长的上下文。它可以用于复杂的任务… - OpenRouter:根据应用使用情况进行排名和分析的语言模型
OpenRouter (Alex Atallah) ▷ #general (54 条消息🔥):
-
一个库调用所有模型:用户讨论了 litellm,这是一个通用的 API 包装器,支持使用 OpenAI 的格式调用各种 LLM API。虽然因其效用受到称赞,但也指出了一些局限性,例如视觉任务仅适用于 GPT-4,且某些功能是 GPT 模型特有的。
-
导航 API 前端和支付系统:对话包括对插入 API key 的 GUI 前端的建议,如 open-webui 和 TypingMind.com,它们的使用费用各不相同。还提到了在不绑定信用卡的情况下充值余额以使用 API 的需求。
-
寻找最适合角色扮演和无审查对话的 LLM:参与者寻求关于特定应用的最佳 LLM 建议,例如在 Skyrim 中进行角色扮演或参与争议性话题。一些用户主张减少 LLM 的审查,特别是对 Claude Sonnet 等模型的创造性输出给予了高度评价。
-
解决安装问题并理解局限性:有人询问如何安装某些工具(如 LLM 的 WebUI),并讨论了不同模型在独特用例中的适用性,例如讲座聊天机器人或基于文本的角色扮演体验。
-
对内容审查和模型审查的担忧:用户对过于严格的内容审查以及审查对模型可用性的影响表示担忧。部分对话集中在防止有害内容与保留 LLM 创作能力之间的平衡,并提出了提供未经审查的 API 和改进内容过滤机制的建议。
提到的链接:
-
GitHub - open-webui/open-webui: User-friendly WebUI for LLMs (Formerly Ollama WebUI):适用于 LLM 的用户友好型 WebUI(原 Ollama WebUI) - open-webui/open-webui
-
GitHub - BerriAI/litellm: Call all LLM APIs using the OpenAI format. Use Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (100+ LLMs):使用 OpenAI 格式调用所有 LLM API。支持 Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (100+ LLMs) - BerriAI/litellm
CUDA MODE ▷ #general (12 条消息🔥):
-
NumPy 与 BLAS 性能分析:一篇博客文章指出,尽管 NumPy 在 Python 数值计算中非常流行,但在特定操作(如 1536 维 OpenAI Ada 嵌入)中,与 BLAS 相比存在显著的性能开销——导致高达 90% 的吞吐量损失。他们的解决方案是 SimSIMD,可以最大限度地减少这种损失。
-
讨论 NumPy 中的开销:在聊天中,有人指出 NumPy 在低于 1µs 的操作中开销显著;因此,对于大量的小型操作,使用 SIMD 封装器会是比使用 NumPy 更高效的解决方案,因为 NumPy 会增加不必要的开销。
-
建议技术文章采用精简的信息传递方式:一名成员建议技术报告应采用更直接的方法,倾向于对意图、过程、适用场景和安装说明进行清晰解释,而不是仅仅展示基准测试(benchmark)数据。
-
光子计算(Photonic Computing)受到关注:分享了一个名为“光子技术的重大突破:快 1000 倍。这是真的吗?”的 YouTube 视频;其主题 Lightmatter 专注于利用光子技术重塑芯片通信和计算,以改善 AI 的环境影响和效率。视频可以在这里找到。
-
深刻的光子技术内容推荐:为了支持光子技术的讨论,成员们推荐了 Asianometry 的视频以获取更深入的见解——即“硅光子技术:下一次硅革命?”和“在光网格上运行神经网络”——可以分别在 YouTube 和 YouTube 上观看。
提到的链接:
-
NumPy vs BLAS: Losing 90% of Throughput:下载量超过 50 亿次,NumPy 是 Python 中最受欢迎的数值计算库。它封装了 BLAS 和 LAPACK 等底层 HPC 库,为矩阵提供高级接口…
-
New Breakthrough in Photonics: x1000 faster. Is it for Real?:立即获取 TypeAI PREMIUM!点击此处链接开始免费试用:https://bit.ly/Mar24AnastasiInTech 论文地址:https://www.nature.com/articles/s41586…
-
Lightmatter®:未找到描述
-
Silicon Photonics: The Next Silicon Revolution?:非常感谢本频道的好友、来自 MIT 的 Alex Sludds 建议这个话题并为我提供关键资源。在这里关注他:https://a…
-
Running Neural Networks on Meshes of Light:我要感谢 Alex Sludds 在帮助我研究和制作此视频方面所做的努力。在这里查看他的工作:https://alexsludds.github.io 链接:- The As…
CUDA MODE ▷ #triton (10 条消息🔥):
- 让 Triton Tensors 调试变得简单:设置环境变量
TRITON_INTERPRET=1并使用 print 语句 来检查张量值。通过这些实用的调试步骤,可以规避tl.arange(0,N)张量索引错误。 - Triton 可视化调试工具即将到来:一个 Triton 可视化工具 正在开发中,旨在简化对 load/store 空间结构的检查。目前存在一些已知问题,包括偶尔的重复可视化和段错误(segfaults)。
- 过时的调试方法:使用
@triton.jit(interpret=True)装饰器进行 Triton 代码调试的方法已被标记为弃用。 - 对 Triton 调试有帮助的 GitHub 讨论:GitHub 上的特定 Issue 和讨论可以为调试 kernel 提供帮助,例如 这个 GitHub issue。
- 需要更多带注释的 Triton 示例:虽然官方教程是主要的学习资源,但社区表示需要更多带注释的 Triton kernel 示例以帮助理解。
提到的链接:
-
Google Colaboratory:未找到描述
-
Lecture 1 How to profile CUDA kernels in PyTorch:Slides: https://docs.google.com/presentation/d/110dnMW94LX1ySWxu9La17AVUxjgSaQDLOotFC3BZZD4/edit?usp=sharing Code: https://github.com/msaroufim/cudamodelecture1
-
How to debug kernels · Issue #517 · openai/triton:我正试图准确理解 vector add 教程中 add_kernel 的每一行代码的作用。因为这是一个 kernel,我无法使用典型的单步调试器来运行这个函数…
CUDA MODE ▷ #cuda (13 条消息🔥):
- 澄清了关于 Kernel 启动开销的困惑:一位成员弄清楚了交换 CUDA 函数顺序时出现意外输出的原因——已确认这是由于 kernel launch overhead(kernel 启动开销)造成的。推荐使用工具 ncu 来隔离这种开销。
- 寻找 CUDA 学习资源:一位 CUDA 新手正在寻找适合初学者的学习材料,确认该成员熟悉 C++,这是学习 CUDA 的一个有用前提。
- 4090 上的 FP8 Matmul 展现潜力:简要提到 4090 GPU 上的 fp8 矩阵乘法 速度快得惊人,预示着潜在的性能提升。
- CUDA 初学者书籍推荐:对于学习 CUDA,推荐了《Programming Massively Parallel Processors》一书,该书被认为是基础教材,即使对于本科生也适用,对于了解 C/C++ 的人来说不会太深奥。
- 加入 CUDA 编程书籍读书小组:对于那些开始学习 CUDA 的人,分享了一个可用的 读书小组,这表明社区会支持那些正在阅读推荐书籍的人。
CUDA MODE ▷ #jobs (1 条消息):
vim410: 视情况而定。但确实如此。
CUDA MODE ▷ #pmpp-book (8 条消息🔥):
-
SM 架构和处理块详解:一位成员引用了第 4 讲的内容作为理解 GPU 架构的视觉辅助,详细说明了 GA102 SM 有 4 个处理块,每个处理块一次执行一个 warp。32 条 fp32 指令可以并发运行,而 int32 指令由于核心限制被分成两批 16 条执行。
-
CUDA 编码中的索引困境:在讨论第 2 章的一个查询时,一个错误的索引方法
i = blockIdx.x * blockDim.x + threadIdx.x * 2被修正,解释显示这会导致重复计算。为了说明这一点,假设blockDim.x = 32,那么{blockIdx.x = 0, threadIdx.x = 16}和{blockIdx.x = 1, threadIdx.x = 0}都会错误地得出i = 32。 -
询问内容分享的界限:一位成员询问在博客上发布 CUDA 练习题答案是否妥当,并提到曾尝试联系作者但因缺乏教育机构邮箱地址未果。另一位成员承诺会向作者 Wen-mei 确认以寻求澄清。
CUDA MODE ▷ #ring-attention (7 条消息):
- 对 Ring Attention 兼容性的困惑:一位成员对 Ring Attention 无法与 Flash 配合使用的说法表示不解,尽管类似的实现显然已经取得了成功。
- 等待忙碌成员的回复:Andreas Koepf 表示目前非常忙碌,承诺在有空时回到对话中,Jamesmel 对此表示理解。
- 寻找缺失的代码:Iron_bound 对无法找到与关于 Ring Attention 的 Twitter 帖子相关的代码表示失望,感到理解不够完整。
- 分享了 Triton Kernel 代码链接:Iron_bound 提供了一个 Triton Kernel 实现 的链接,这似乎与 Ring Flash Attention 的讨论有关。
提到的链接:add naive triton kernel for varlen · zhuzilin/ring-flash-attention@10d992c:未找到描述
CUDA MODE ▷ #off-topic (3 条消息):
- Meta 与前高管的诉讼:Meta 已起诉一名前高管,指控其窃取了 100 多份内部文件,并试图为一家竞争对手 AI 数据初创公司 Omniva 招募 Meta 员工。该诉讼通过一份未封存的 法庭文件 公开,并由 Ars Technica 文章 进一步报道。
- 对频道动态的失望:一位用户对频道内对话的进展表示不满,用简短的话语暗示讨论的方向不符合预期。
- 从零开始:一位成员提到对话中的三位参与者都从 Lecture 1 开始,这可能表明他们在进行协作学习,或者共同开始一个新话题或课程。
提到的链接:Meta sues “brazenly disloyal” former exec over stolen confidential docs:Meta 前高管涉嫌向一家神秘的初创公司泄露数据中心机密。
LangChain AI ▷ #announcements (1 条消息):
- LangChain 0.2 急速发布:由于最近针对
langchain提交的 CVEs,团队正在加快 0.2 版本的发布,该版本将打破对langchain-community的依赖。原计划的更大规模重构将移至 0.3 版本,更多详情见 GitHub 讨论。 - 征求社区反馈:LangChain 团队正在就即将到来的变更寻求反馈,以确保这些变更不会给用户带来任何问题。团队强调,这些变更的目标是让您的生活更轻松。
提到的链接:RFC: Expedited langchain 0.2 release · langchain-ai/langchain · Discussion #19083:背景:目前 langchain(包)依赖于 langchain-community。这样做仅是为了与 langchain 和 langchain-com 拆分之前的 langchain 版本保持向后兼容性…
LangChain AI ▷ #general (34 条消息🔥):
- 排查 AgentExecutor 执行错误:一位用户在使用来自 Cohere 的命令运行
AgentExecutor时遇到了OutputParserException,尽管生成的 python 代码看起来是正确的。预期结果是 Agent 执行 python 代码并以自然语言回复。 - Langsmith 与导入 Prompt 的困惑:一位成员难以理解为什么他们的自定义 Prompt 无法像从 hub 导入的 Prompt 那样启用 tool use,并寻求关于两者差异的澄清。
- 通过 Curl 查询 StackOverflow 的 API:一位用户询问了关于使用 API 查询 StackOverflow 的问题,并被引导使用 StackExchange API 的高级搜索功能来满足其需求。
- 辩论 LLM Agents 的实用性:一场关于 LLM Agents 实用性(相对于将 LLM 输出与函数结合)的讨论展开了,成员们辩论了 Agents 在动作排序和错误处理方面的能力,并思考了评估 Agent 行为的方法,可能借助于 LangChain benchmarks。
- 使用 LangGraph 处理 LLM 的循环计算:提供了一个关于在需要为应用添加循环时使用 LangGraph 的解释,特别是针对使用 LLM 的有状态、多角色(multi-actor)应用,并参考了 JavaScript 和 Python 的 LangGraph 文档以获取更多详情。
提到的链接:
-
Usage of /search/advanced [GET] - Stack Exchange API : 未找到描述
-
[Debugging 🦜️🔗 Langchain](https://python.langchain.com/docs/guides/debugging): 如果你正在使用 LLM 构建应用,在某些时刻总会出问题,你需要进行调试。模型调用可能会失败,或者模型输出格式错误,或者存在一些嵌套模块… -
[Evaluation 🦜️🔗 Langchain](https://python.langchain.com/docs/guides/evaluation/): 使用语言模型构建应用涉及许多活动部件。其中最关键的组件之一是确保模型产生的结果在广泛的范围内是可靠且有用的…
LangChain AI ▷ #langchain-templates (1 条消息):
- 关于 Langsmith Hub Prompt 模板的查询:一位成员询问如何在 Langsmith Hub 中创建 Prompt 模板,在代码中展示了一个名为
tools的列表占位符{tools}。他们特别在寻求关于如何将tools = [cat_tool]变量链接到模板中占位符的指导。
LangChain AI ▷ #share-your-work (6 条消息):
-
SAP HANA 遇见 LangChain:一篇博客文章探讨了 LangChain 与 SAP HANA Vector Engine 的创新集成,展示了 AI 应用的潜在进展。欲了解更多关于此协同作用的信息,请访问 解锁 AI 应用的未来。
-
Dall-E 进入 JavaScript 世界:博客文章详细介绍了在 LangChain 的 JavaScript 版本中增加对 Dall-E 图像生成的支持。有用的代码片段和说明包含在 Lang Chain for JavaScript 第 3 部分:创建 Dall-E 图像 中。
-
使用 AI 编排浏览器操作流:一篇新博客文章描述了如何编排 LLM Agent 系统以促进自动化浏览器交互。查看其背后的工程设计:LLM Agent 系统的工程设计。
-
开源 Langchain 聊天机器人展示用于问答的 RAG:利用 RAG 进行高效问答查询的 Langchain 聊天机器人现已完全开源。在 GitHub 上查看该应用。
-
Living Bookmarks 机器人助力更好的书签管理:一位 Twitter 用户开发了一个用于管理 Raindrop.io 书签的 Discord AI 聊天机器人,以帮助在需要时轻松找到它们,并已将其开源。
提到的链接:
-
LangChain for JavaScript part 3: Create Dall-E images: FEK.IO David Fekke L.L.C. 的网站。
-
GitHub - Haste171/langchain-chatbot: 用于以对话形式分析/提取数据信息的 AI Chatbot。: 用于以对话形式分析/提取数据信息的 AI Chatbot。 - Haste171/langchain-chatbot
-
利用 SAP HANA Vector Engine 和 LangChain 开启 AI 应用的未来: Ankush k Singal
LangChain AI ▷ #tutorials (1 条消息):
pradeep1148: https://www.youtube.com/watch?v=PzaidfqDtGI
LAION ▷ #general (27 条消息🔥):
- 寻找字幕标注(Captioning)的 GPU 合作伙伴:一位成员请求在字幕标注方面提供帮助,并正在寻找拥有闲置 3090 或 4090 的人来协助。他们还请感兴趣的人通过私信联系。
- 在搭载 M3 Max 的 MacOS 上进行优化:一位成员正致力于让 simpletuner 在 MacOS 上运行,并讨论了在新款 128G M3 Max 系统上使用超过 96GB 系统内存进行计算的可能性。
- 分享提示词增强(Prompt Augmentation)创新:分享了一篇关于使用 77M T5 模型进行提示词增强的文章链接,并展示了其在图像生成方面的出色能力。另一位成员分享了 HuggingFace 上的 DanTagGen 链接,这是一个使用较小模型的标签自动补全工具。
- 关注欧盟 AI 法律法规:一位成员强调了欧洲议会通过的《人工智能法案》(Artificial Intelligence Act),该法案旨在确保 AI 的安全并符合基本权利。该法规旨在应对 AI 风险,并影响威胁公民权利的应用。
- IEEE 安全与隐私研讨会更新:一位成员发布了关于第 45 届 IEEE Symposium on Security and Privacy 从已接收论文页面移除的消息。针对这一移除对一位名叫 Ben 的人的影响,以及他们是否会重新提交到合适的会议,进行了简短的讨论。
提到的链接:
-
[SuperPrompt - 77M 参数实现更好的 SDXL 提示词 Brian Fitzgerald](https://brianfitzgerald.xyz/prompt-augmentation/): 左侧为应用了 SuperPrompt 到相同输入提示词后的 SDXL 输出。 -
[人工智能法案:欧洲议会议员通过里程碑式法律 新闻 欧洲议会](https://www.europarl.europa.eu/news/en/press-room/20240308IPR19015/artificial-intelligence-act-meps-adopt-landmark-law): 周三,议会批准了《人工智能法案》,在促进创新的同时确保安全并符合基本权利。
LAION ▷ #research (13 条消息🔥):
-
TryOnDiffusion 虚拟试穿发布:Google 论文 “A Tale of Two UNets” 中描述的 TryOnDiffusion 开源实现已根据 MIT 许可证发布。代码可在 GitHub 上获取。
-
提及快速解码研究:分享了一篇声称 2D Gaussian splatting 解码速度比 jpeg 更快的论文,暗示其速度和优化可能引起关注。论文可在 arXiv 上找到。
-
个人项目反思:一位成员讲述了自己曾尝试过一个在概念上与上述 2D Gaussian splatting 论文相似的项目,承认自己没能优化得那么好,但看到专业工作与自己的方法一致感到了一种认可。
-
模型部署中的资源限制:一位成员询问如何实现像文本生成 Web UI 中使用的 CPU 限制(CPU cap),并分享了他们在非 UI 模型上遇到的 CUDA out of memory 问题。他们正在寻求关于如何在不触及 GitHub 仓库 中概述的免费层级限制的情况下处理大型模型的见解。
-
免费 Colab 对 Web UI 的限制:针对前一点,其他成员解释说不能使用免费版 Colab 运行 Web UI,并暗示此类技术咨询更适合在其他专门频道讨论。
提到的链接:
-
Google Colaboratory: 未找到描述
-
Google Colaboratory: 未找到描述
-
GitHub - fashn-AI/tryondiffusion: Google 开发的基于扩散网络的虚拟试穿项目 “TryOnDiffusion: A Tale of Two UNets” 的 PyTorch 实现: Google 开发的基于扩散网络的虚拟试穿项目 “TryOnDiffusion: A Tale of Two UNets” 的 PyTorch 实现 - fashn-AI/tryondiffusion
-
GitHub - oobabooga/text-generation-webui: 用于 Large Language Models 的 Gradio Web UI。支持 transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。: 用于 Large Language Models 的 Gradio Web UI。支持 transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama 模型。 - oobabooga/text-generation-webui
LLM Perf Enthusiasts AI ▷ #general (1 条消息):
由于仅提供了一条消息,且没有先前的消息、链接或讨论点等额外上下文,无法根据给定的指令生成摘要。请提供一系列消息或更多上下文以便进行摘要。
LLM Perf Enthusiasts AI ▷ #gpt4 (1 条消息):
- GPT-4 Turbo 执行“太空任务”:一位成员报告了
gpt-4-turbo-preview遇到的一个奇特问题,在处理一段极长文本(12,000 tokens)的补全任务时,模型开始无休止地输出空格字符。更离奇的是,在一段长长的空格序列之后,模型甚至开始生成“俄语胡言乱语”,附带的截图证明了这一点。
LLM Perf Enthusiasts AI ▷ #claude (18 条消息🔥):
- Haiku 高性价比的文档描述能力:一位成员强调了 Haiku 在以经济成本进行复杂文档视觉描述方面的高效性,但也指出其效果不如 GPT-vision。
- Haiku 性能的局限性:尽管取得了进步,但在视觉转文本任务中,Haiku 仍被认为逊于 Opus。
- Claude 的内容过滤障碍:Claude 在内容过滤方面存在问题,特别是在解析包含方程式的文档时会中途停止。
- 关于 Anthropic 的争议性看法:聊天中分享的一条推文暗示 Anthropic 被视为一个旨在向技术人员灌输“对上帝的敬畏”的战略实体。
- 特定图像的内容审核挑战:用户报告了包含人物的图像存在内容审核问题,系统有时会拒绝处理这些图像。
提到的链接:来自 roon (@tszzl) 的 推文: Anthropic 是受控的反对派,旨在让技术人员心生敬畏。
LLM Perf Enthusiasts AI ▷ #reliability (16 条消息🔥):
-
KPU:AI 的下一个大事件?:Maisa 发布了 KPU (Knowledge Processing Unit),这是一个旨在通过将推理与数据处理分离来增强 LLM 的新框架。KPU 声称在推理任务中表现优于 GPT-4 和 Claude 3 Opus。
-
质疑基准测试:成员们对 KPU 将其性能与 GPT-4 而非 GPT-4 Turbo 进行比较表示怀疑。讨论强调了对可能存在不公平基准测试的担忧。
-
KPU:超越 Prompt Engineering?:一位成员想知道 KPU 的技术是否仅仅是 Prompt Engineering,而另一位成员澄清说它包括自我评估和 Context Window 管理技巧。
-
审视对比分析:针对 KPU 的对比分析中明显遗漏了 GPT-4 Turbo,出现了幽默的反应,暗示这种模式在 Claude 3 发布时也曾出现过。
-
对实际效率的担忧:随后讨论了 KPU 缺乏延迟信息的问题,尽管据称准确性有所提高,但人们对其在现实产品中的实际应用表示怀疑。
提到的链接:
-
KPU - Maisa: AI 驱动的知识处理平台。一个用于执行业务任务的简单 API。为软件和应用开发人员抽象了使用最新 AI 架构的复杂性。
-
来自 David Villalón (@davipar) 的推文: 很高兴回答!它不是一个新模型,事实上 KPU 与智能提供商(OpenAI, Anthropic…)无关。它是一种与 LLM 协作的新 AI 架构,利用了它们的推理能力…
Skunkworks AI ▷ #general (17 messages🔥):
- 关于改进训练方法的论文即将发布:一位成员正在准备发布一篇论文/文章,提出一种似乎能提高全局准确率并使训练更具样本效率的方法。他们计划整理结果并为发现创建更好的可视化效果。
- 寻求扩展资源:该方法需要验证在大模型上的有效性,但目前缺乏资源来在规模化层面上进行实证。
- 方法在大型模型上显示出潜力:在 CIFAR100 子集上使用 VGG16 进行的初步测试显示,使用新方法(0.1 测试准确率)相比基础训练(0.04 测试准确率)有显著提升。
- 资源分配协作:成员们正在协调,帮助为新训练方法的进一步测试和扩展分配算力与资源。
- 参与 Quiet-STaR 项目:一位成员表示有兴趣参与 “Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking” 的实现,并被询问了在 PyTorch 和 transformers architecture 方面的熟练程度。
Skunkworks AI ▷ #off-topic (2 messages):
- 深入了解 Hermes 2 Pro 7B 函数调用:分享了一个名为 “Lets Function Call with Hermes 2 Pro 7B” 的 YouTube 视频链接,演示了使用语言模型 Hermes 2 Pro 7B 进行函数调用。视频附带了一个 GitHub 仓库,深入探讨了 Hermes 的函数调用能力。
- Meta Quest 黑客松寻找创新者:邀请加入 Meta Quest Presence Platform 黑客松团队,参与者将使用 Meta Quest 上的 Presence Platform 创作创新的混合现实内容。鼓励感兴趣的人加入,无需预先掌握技能,建议边做边学,并参考了 黑客松资源。
提到的链接:
- Lets Function Call with Hermes 2 Pro 7B:使用 Hermes 2 Pro 7B 进行函数调用 https://github.com/NousResearch/Hermes-Function-Calling/tree/main #llm #largelanguagemodels
- Meta Quest Presence Platform Hackathon 2024:下一代 Quest MR 应用程序
Datasette - LLM (@SimonW) ▷ #ai (16 messages🔥):
- 寻找 Prompt Engineering 工作台:一位成员询问是否有类似于 Postman 的 Prompt Engineering 工具,用于管理 Prompt 库、版本控制、数据暂存、运行测试以及集成多个模型。
- 使用 SQLite 捕获 Prompt:另一位成员分享了他们的方法,利用终端中的 LLM,通过在 SQLite 中捕获 Prompt 和响应来进行管理,并观察到自定义 UI 可能会更有利。
- Prodigy 作为 Prompt Engineering 工具:对话中提到了之前为 Explosion’s Prodigy 开发的一个工具,这是一个付费产品,将 Prompt Engineering 整合为数据标注问题,并提供 A/B 测试等功能。
- 用于 Prompt 实验的 PromptTools:推荐了 PromptTools GitHub 仓库,这是一个用于 Prompt 测试和实验的开源项目,支持多种 LLM 和向量数据库,可作为设置实验的资源。
- Helicone AI 进入 Prompt 管理领域:一位参与者指向了 Helicone AI,这是一个正在开发的生成式 AI 应用平台,开始整合 Prompt 管理、版本控制和分析相关的特性。
提到的链接:
- Helicone:开发者如何构建 AI 应用。开箱即用,获得可观测性、工具链、微调和评估功能。
- Vercel AI SDK:使用最新的 AI 语言模型构建 AI 驱动的应用。
- GitHub - hegelai/prompttools:用于 Prompt 测试和实验的开源工具,支持 LLM(如 OpenAI, LLaMA)和向量数据库(如 Chroma, Weaviate, LanceDB)。
Datasette - LLM (@SimonW) ▷ #llm (1 条消息):
obra: 是否有可能恢复之前 OpenAI 模型 API 请求所使用的 seed?
Interconnects (Nathan Lambert) ▷ #other-papers (8 条消息🔥):
- 通过 API 解锁 LLM 秘密:最近讨论的一篇 研究论文 探讨了如何通过利用 softmax 瓶颈来提取受 API 保护的 Large Language Models (LLMs)(如 OpenAI 的 GPT-3.5)的非公开信息——通过相对较少的 API 查询次数揭示诸如隐藏模型大小之类的细节。
- 关于 Carlini 最新工作的讨论:一位参与者引用了 Carlini 等人最近的一篇论文,该论文研究了通过 logits 进行模型大小估计,但指出关键细节已被删减。
- 对传闻中模型大小的惊讶:一名成员对模型大小可能是 7B 参数表示惊讶,认为这种估计似乎不太可能。
- 对模型大小准确性的怀疑:有人对 7B 的大小估计表示抵制,推测计算可能存在缺陷,特别是如果 GPT-3.5 是一个 Mixture of Experts (MoE) 模型。
- 模型中的蒸馏或混合理论:讨论推测在 turbo LLMs 中使用了 ‘mega distillation sauce’ 或 token 关键混合物,引用过去的研究表明,起始 token 对于数学问题等任务的性能至关重要。
提到的链接:Logits of API-Protected LLMs Leak Proprietary Information:大语言模型 (LLMs) 的商业化导致了对专有模型仅提供高级 API 访问的普遍做法。在这项工作中,我们展示了即使在保守的假设下……
Interconnects (Nathan Lambert) ▷ #ml-questions (4 条消息):
- 寻求模型提供商安全过滤的引用:一位成员询问是否有参考文献支持“基础模型提供商在文本生成后做了大量安全过滤”这一说法。
- 敏捷文本分类器辅助安全策略:另一位成员提供了论文 Agile classifiers for safer chatbots 的引用,该论文讨论了如何通过小数据集对大语言模型进行 prompt-tuning,从而快速适应安全策略并达到 state-of-the-art 性能。
- 对安全过滤资源的满意度:最初的成员承认,提供的关于 敏捷文本分类器 的论文有助于传达关于基础模型提供商在安全过滤中作用的预期观点。
提到的链接:Towards Agile Text Classifiers for Everyone:基于文本的安全分类器被广泛用于内容审核,并且越来越多地用于调整生成式语言模型的行为——这是一个日益受到关注的话题,关乎数字助理的安全……
Interconnects (Nathan Lambert) ▷ #random (5 条消息):
- 渴望超长上下文:一位成员对 Gemini 开发超长上下文表示乐观,希望这能改进摘要生成(目前被用作“更好的摘要”)。
- 思考更智能 Prompt 的偶然性:另一位成员讨论了在 prompt engineering 中寻找正确平衡的挑战,并期待更直观、更少繁琐的 prompting 机制,将其比作搜索引擎建议,通过“变暖或变冷”来引导用户。
- 创新的论文总结概念:提出了一种总结学术论文的新方法,即 AI 工具将监控引用用户最喜欢的研究成果的新论文,并可能提供上下文引用,例如引用的数据集在何处被使用。
- 消除 GPT-4.5 传闻:一位成员表达了失望,从现有信息推断 GPT-4.5 不会在“今天”发布。
- AI 讨论中的娱乐性:分享了一条推文,指出 Yann LeCun 对语言模型的怀疑立场,引发了小组内的讨论和反应。这就是为什么 Yann 对 LLMs 如此看空的原因。
提到的链接:来自 Teknium (e/λ) (@Teknium1) 的推文:这就是为什么 Yann 对 LLMs 如此看空的原因…… 😲
DiscoResearch ▷ #general (3 条消息):
- DiscoLM-70b 的语言困境:一位成员在尝试让 DiscoLM-70b 以 English 响应时遇到困难,尽管该模型的 Model Card 显示其具备多语言能力。建议分析 prompt structure 以排查潜在问题。
- 跨模型性能之谜:与其他模型(如 LeoLM variants, llama2, 和 Nous-Hermes-2-Mixtral)的对比显示,它们在多语言任务中表现符合预期。同一位成员报告称,在经过 instruction fine-tuning 后,DiscoLM-mixtral-8x7b-v2 无法生成德语响应。
- DiscoLM 的微调障碍:将 DiscoLM 作为序列分类问题进行 Supervised fine-tuning 时导致了 ValueError,提示
AutoModelForSequenceClassification无法识别配置类。该错误表明当前环境可能存在兼容性问题。
DiscoResearch ▷ #embedding_dev (1 条消息):
- 引入 “GermanQuAD” 评估任务:embedding_dev 频道包含一条关于 “GermanQuAD” 评估任务的消息,该任务可用于 MTEB 的 Python 包,同时还提到了来自 JinaAI 最近新增的德语支持。
DiscoResearch ▷ #discolm_german (5 条消息):
- Demo 可用性困惑:一位成员询问 Demo 是否可用,暗示其目前可能已下线或无法访问。
- 模型对 Prompt 的遵循:一位成员解释说,该模型经过训练会遵循 system prompt,并建议尝试不同的变体以获得最佳效果。他们确认 Demo 没有使用特殊设置,且运行在 fastchat/vllm 上。
- 因服务器迁移导致 Demo 下线:针对 Demo 可用性的问题,官方澄清托管 Demo 的服务器已迁移,但出现了网络问题导致停机。希望能下周初恢复运行。
- 业余托管 vs 专业托管的挑战:一位成员幽默地评论道,放在厨房角落的业余服务器与专业托管相比的可靠性,后者似乎正面临网络问题和其他技术故障。