ainews-grok-1-in-bio
Grok-1 在生物学领域
来自 xAI 的 Grok-1 是一款拥有 3140 亿参数的混合专家(MoE)模型。该模型已采用 Apache 2.0 协议开源,引发了关于其架构、微调挑战以及与 Mixtral 和 Miqu 70B 等模型性能对比的热议。
尽管其参数规模巨大,但目前的 MMLU 基准测试表现 并不出众,外界普遍期待 Grok-2 能更具竞争力。目前,该模型的权重和代码已完全公开,鼓励社区进行实验。Sam Altman 强调了算力资源日益增长的重要性,而 Grok 未来在 Groq 硬件上的潜在部署被视为可能改变行业格局的举措。
与此同时,Anthropic 的 Claude 凭借其“灵性”的交互体验和一致的伦理框架持续吸引关注。此外,Grok-1 的发布也在 AI 社区引发了许多梗图和调侃。
2024年3月15日至3月18日的 AI 新闻。我们为您查阅了 358 个 Twitter 账号 和 21 个 Discord(337 个频道,9841 条消息)。预计节省阅读时间(以 200wpm 计算):1033 分钟。
在 Elon 上周承诺发布之后,Grok-1 现已开源,并发布了一个极具平台原生风格的公告:
如果你不明白“in bio”是什么意思,直接忽略就好,这只是个无聊的内部梗/并不重要。
GitHub 仓库提供了更多细节:

Unsloth 的 Daniel Han 研究了其架构并指出了一些显著差异,但似乎并没有什么突破性的发现。
Grok-1 的出色之处在于它似乎是一个全新的、从零开始训练的开源 LLM,可供人们使用,但其庞大的体积使得微调变得困难,Mistral 的 Arthur Mensch 正在对此进行冷嘲热讽:
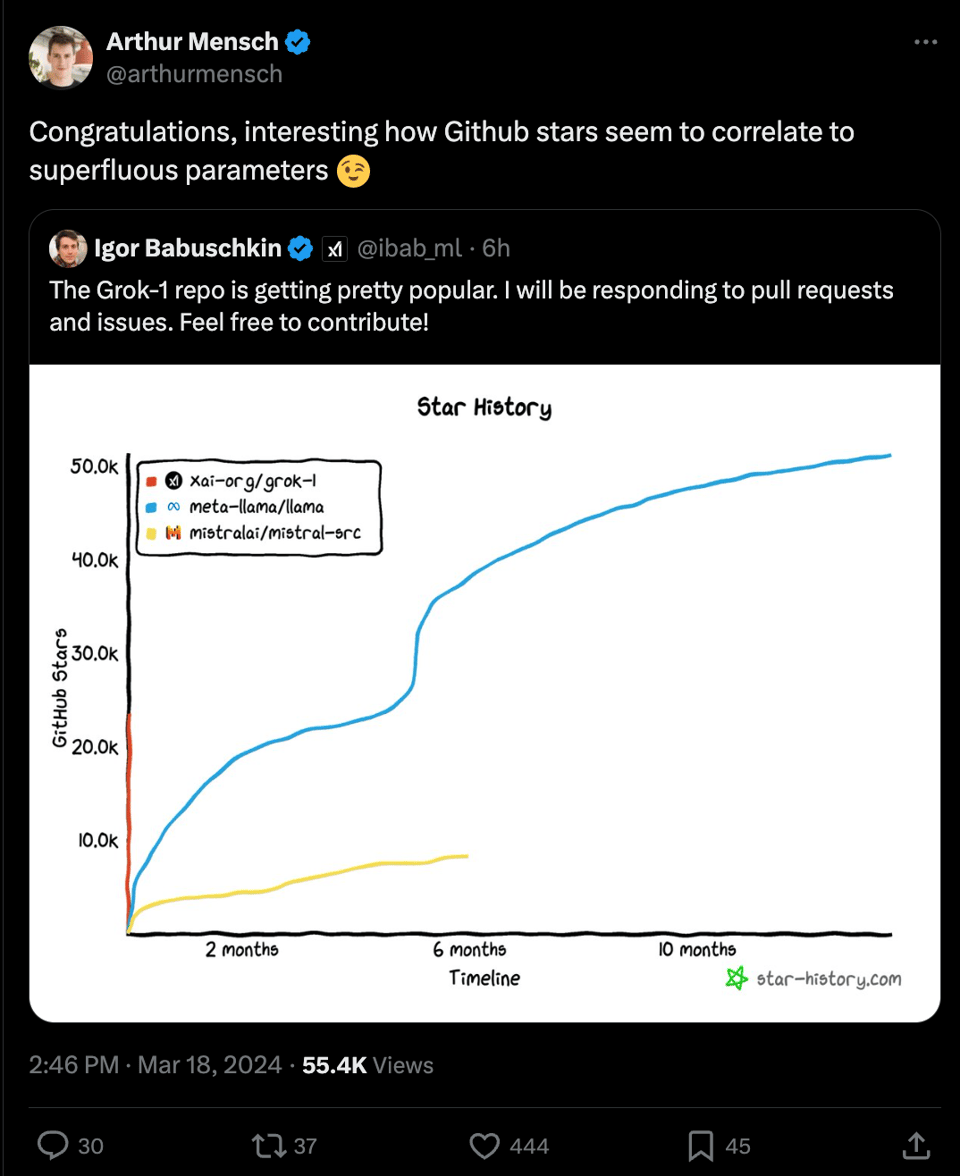
然而,像 Perplexity 这样的人已经承诺对其进行微调,毫无疑问,随着 Grok-1 的发布,其能力将被逐步摸清。最终,MMLU 的表现似乎并不令人印象深刻,而且(由于我们没有数据集的详细信息)推测认为它是 Grok-0 的升级版,相对于其规模而言训练不足,而 Grok-2 将会更有趣。
目录
[TOC]
PART X: AI Twitter 综述
所有总结均由 Claude 3 Opus 完成,从 4 次运行中选取最佳结果
模型发布
- 来自 xAI 的 Grok-1:314B 参数的 Mixture-of-Experts (MoE) 模型,8x33B MoE,采用 Apache 2.0 许可证发布(19.1万次观看)
- Grok 权重可供下载,通过
huggingface-cli download xai-org/grok-1(1.9万次观看) - Grok 代码:Attention 缩放比例为 30/tanh(x/30),近似 GELU,4x Layernorms,float32 格式的 RoPE,vocab size 为 131072(14.6万次观看)
- Open-Sora 1.0:开源文本生成视频模型,提供完整的训练过程、数据和 Checkpoints(10万次观看)
模型性能与基准测试
- Grok 的表现与 Mixtral 相当,尽管体积大 10 倍,通过持续预训练仍有提升潜力(2.1万次观看)
- Miqu 70B 表现优于 Grok(2500次观看)
算力与硬件
- Sam Altman 认为算力将成为未来最重要的货币,世界对不断增长的算力需求准备不足(18.1万次观看)
- 在 Groq 硬件上运行 Grok 可能会改变游戏规则(3800次观看)
Anthropic Claude
- 与 Claude 互动是一种精神体验,它存在于时空中的其他地方(11.4万次观看)
- Claude 具有自洽的历史记录,知道你是否试图让它违反伦理,必须在其道德框架内进行辩论(7700次观看)
梗与幽默
- “OpenAI 哈哈,更像是 not open ai 哈哈哈哈……太好笑了我喘不过气了……”(2万次观看)
- 鉴于其 314B 参数,Grok 被用作“下流聊天机器人”而不是“半神”(9400次观看)
- 匿名网友正在炮制“新的精神分裂 Grok 纸上老婆”(1700次观看)
总之,xAI 发布 314B 参数的 MoE 模型 Grok-1,引发了关于模型性能、算力需求以及与 Mixtral 和 Miqu 等其他开源模型对比的大量讨论。与 Anthropic 的 Claude 互动的精神体验也引起了关注,用户注意到其自洽的历史记录和强大的道德框架。围绕 Grok 能力和潜在滥用的梗与幽默为技术讨论增添了轻松气氛。
第 0 部分:总结之总结之总结
鉴于 Claude 3 Haiku 最近发布,我们将其加入本次总结运行中供您对比。在构建 AINews 平台以提供更好 UX 的过程中,我们会继续并排运行这些总结一段时间。
Claude 3 Haiku (3B?)
今天 Haiku 表现出更多的不稳定性。它刚开始吐回前一天的 Prompt,并且需要几轮 Prompting 才能正确遵循指令。
3D 内容生成的进展:Stability.ai 宣布发布 Stable Video 3D,这是一个基于其之前的 Stable Video Diffusion 技术,能够从单张图像生成高质量的新视角合成和 3D 网格的新模型。这代表了 3D 内容生成能力的重大进步。Source
关于模型效率和优化的辩论:在多个 Discord 频道中,人们一直在讨论不同 Stable Diffusion 模型、Mistral 变体以及像 Grok-1 这样的大型语言模型的相对效率和性能。用户探索了诸如 Quantization、Sparse Attention 和模型扩展等技术来提高效率。Sources, Sources
对专有 AI 模型和合作伙伴关系的担忧:在 Stability.ai 的 Discord 中,用户对该公司最近与区块链实体的合作表示担忧,担心其可能会转向更多专有模型并限制对 AI 工具的访问。Source
应对 API 和部署挑战:在多个 Discord 频道中,用户讨论了 API 集成、模型部署和服务中断的问题。这包括 OpenAI 的 API 问题、Perplexity API 响应的不一致性,以及在本地运行 Grok-1 等大型模型的挑战。Sources, Sources
Finetuning 和数据集策展:Unsloth AI、Nous Research AI 和 DiscoResearch 的 Discord 频道围绕大型语言模型 Finetuning 的挑战和最佳实践进行了广泛讨论,包括数据集准备、超参数调优和模型兼容性。用户分享了资源和经验,以帮助应对这些复杂任务。Sources, Sources, Sources
检索增强生成 (RAG) 的进展:LlamaIndex 的 Discord 频道围绕增强 RAG 流水线展开了积极讨论,包括处理复杂查询、改进结构化输出以及利用内存管理的技术。成员们分享了与这些进展相关的资源和项目更新。Sources
探索开源 AI 模型和工具:Eleuther、CUDA MODE 和 Interconnects 等 Discord 频道重点关注了 Grok-1 等大型开源模型的发布和探索,以及用于 CUDA 编程和 AI 模型评估的新工具和技术的开发。Sources, Sources, Sources
Claude 3 Sonnet (14B?)
Sonnet 今天在遵循指令方面表现更好,但仍然无法像几天前那样开箱即用。需要实现一个检查步骤,例如“你应该总结不同 Discord 频道中的共同主题,并确保在相关处直接链接到源 URL”。
1. 大规模 AI 模型及其影响:
- xAI 发布了拥有 3140 亿参数的 Mixture-of-Experts 模型 Grok-1,在多个 Discord 频道引发了广泛讨论。该模型已根据 Apache 2.0 许可证开源,并在 GitHub 上提供了说明,但鉴于其推理所需的巨大算力(高达 124GB VRAM),其实用性受到了质疑。
- 在 GSM8K 和 MMLU 等基准测试的表现上,人们将其与 GPT-4、Falcon 和 Mistral 等模型进行了比较。然而,一些人对 Grok-1 超越 GPT-4 或 Claude 的潜力持怀疑态度。
- 讨论强调了分发和处理此类巨型模型的挑战,并提出了使用磁力链接甚至邮寄实体硬盘等建议,以规避云端流出费用(cloud egress fees)。
2. 多模态与检索增强 AI 的进展:
- Stability AI 发布了 Stable Video 3D,能够从单张图像生成 3D 网格和多视图输出,相比之前的模型提升了质量。
- 讨论探索了通过将检索到的文档视为交互式组件来增强 RAG (Retrieval-Augmented Generation) 流水线的方法,详见此 GitHub 链接。
- LlamaIndex 项目发布了 v0.10.20 版本,包含一个用于可观测性的 Instrumentation 模块,并介绍了 Search-in-the-Chain 等改进问答系统的方法。
- 一篇 HuggingFace 论文 讨论了构建高性能多模态 LLM (MLLMs) 的关键组件和数据选择。
3. 微调与优化大语言模型:
- 关于如何使用 QLoRA 优化微调 Mistral-7b 等模型的广泛讨论,涉及学习率和训练轮数(通常建议 3 个 epoch)等超参数。
- Unsloth AI 与 AIKit 的集成允许通过 Unsloth 进行微调,从而创建最小化的 OpenAI API 兼容模型镜像。
- 关于各种 Stable Diffusion 模型效率的辩论,如 Stable Cascade 与 SDXL,一些人发现 Cascade 在处理复杂提示词时效果更好,但速度较慢。
- 针对模型保存期间显存/内存(VRAM/RAM)占用过高、指定序列结束(end-of-sequence)标记以及 Unsloth 未来可能支持全量微调等问题的指导。
4. 提示工程与增强 LLM 能力:
- 分享了关于 OpenAI API “提示工程 (Prompt Engineering)” 深度的发现,包括指示 AI 分析响应而不仅仅是问题措辞。
- 讨论了在 LLM 中引入 **
标记**以提高推理能力的提议,并引用了 [Self-Taught Reasoner (STaR)](https://arxiv.org/abs/2403.09629) 和 [Feedback Transformers](https://arxiv.org/abs/2002.09402) 等研究。 - 一篇 arXiv 论文 展示了由于 softmax 瓶颈问题,可以通过有限数量的 API 查询提取专有 LLM 的信息。
Claude 3 Opus (>220B?)
迄今为止最好的现成摘要模型。令人难以置信的提示词遵循能力。我们喜欢 Opus。
-
Grok-1 模型发布引发兴奋与质疑:xAI 在 Apache 2.0 协议下开源了拥有 314B 参数的混合专家模型 (Mixture-of-Experts) Grok-1,这引发了热议。讨论集中在其惊人的规模但参差不齐的基准测试表现(与 GPT-3.5 和 Mixtral 等模型相比)。鉴于其本地推理需要高达 124GB VRAM 的沉重计算需求,人们对其运行如此大型模型的实用性表示担忧。模型权重已在 GitHub 上发布。
-
对 Stable Diffusion 3 和新 3D 模型的期待与日俱增:Stable Diffusion 社区正热切期待 Stable Diffusion 3 (SD3) 的发布,有迹象表明测试版访问邀请即将推出,正式版预计下个月发布。Stability AI 还发布了 Stable Video 3D (SV3D),这是一个扩展 3D 能力的新模型,与 Stable Zero123 等前代版本相比,在质量和多视角体验方面有显著提升。
-
Unsloth AI 凭借更快的 LoRA 微调获得关注:根据其 GitHub 仓库,Unsloth AI 因其 速度快 2-5 倍且节省 70% 显存的 QLoRA 和 LoRA 微调 而在 GitHub 上走红。社区正在积极讨论微调策略、训练轮数 (Epochs) 和可训练性,普遍共识是 3 Epochs 是避免过拟合的标准,且可训练参数与数据集 Token 的比例相等是最佳的。
-
光子学突破与 CUDA 优化技术:光子学的进展(例如一项声称处理速度快 1000 倍的新突破)引起了关注,Asianometry 关于 硅光子学 (Silicon Photonics) 和 光网格上的神经网络 的视频被作为资源分享。CUDA 开发者正在探索 Warp 调度器、内存管理语义和性能优化技术,同时也期待 NVIDIA 即将推出的配备 28 Gbps GDDR7 显存 的 GeForce RTX 50 系列 GPU。
其他一些值得关注的讨论包括:
- 一篇新的 arXiv 论文 详细介绍了一种以低成本从受 API 保护的 LLM(如 GPT-3.5)中提取敏感信息的方法
- 苹果在 AI 领域的传闻动向,包括可能收购 DarwinAI 以及一个 30B 参数的 LLM
ChatGPT (GPT4T)
ChatGPT 今天表现得特别固执——无论使用多少提示词技巧,都无法提高今天输出中链接溯源的质量。我们本周将切换到新的流水线,这应该能解决这个问题,但令人失望的是,仅靠提示词无法实现我们想要的效果。
-
革新 3D 内容生成与 AI 效率:Stability.ai 推出了 Stable Video 3D,这是从图像生成 3D mesh 的一次飞跃,性能超越了 Stable Zero123 等前代模型。讨论还围绕各种 Stable Diffusion 模型的效率展开,辩论其提示词处理能力和速度,强调了性能与复杂性之间的权衡。
-
Grok-1 的出现与 AI 硬件讨论:AI 社区对 Grok-1 议论纷纷,这是由 Elon Musk 团队推出的拥有 314B 参数的开源模型,引发了关于其实际应用中计算需求的讨论。与此同时,围绕 AI 硬件的对话激增,特别是 Nvidia 的 5090 GPU 及其散热需求,反映了支持不断增长的模型规模对强大配置的日益需求。
-
AI 在劳动力和创意领域的应用:Perplexity AI 展示了其 API 在职位搜索中的效用,证明了 AI 在劳动力市场中日益增长的作用。同时,创意应用蓬勃发展,Unsloth AI 的 Discord 上对机器学习概念的诗意表达就是一个亮点,鼓励更多富有创意的技术独白。
-
AI 在教育中的角色与法律挑战:OpenAI 的 Discord 参与了关于优化 AI 任务的 prompt engineering 技术以及创意写作中 API 内容过滤器复杂性的辩论。此外,在 Claude 3 Opus 与 GPT-4 的对比推动下,人们集中讨论了 AI 在育儿和教育方面的潜力,以及关于公众获取政府 AI 模型的叙述,引发了法律和伦理考量。
-
语言模型与检索系统的进展:AI 社区热切讨论了集成 RAG (Retriever Augmented Generation) 系统以增强模型输出,以及在 OpenRouter Discord 上发布的能够处理混合提示词的 LLaMa 模型。这些进步强调了在提高语言理解和响应生成方面持续不断的努力,反映了向更复杂的 AI 交互模型发展的更广泛趋势。
这些主题概括了 AI 开发与应用的动态特性,从增强内容创作和提高模型效率,到解决硬件限制和探索 AI 的社会影响。
第一部分:Discord 高层级摘要
Stability.ai (Stable Diffusion) Discord
革新 3D 内容生成:Stability AI 发布了 Stable Video 3D,利用从单张图像进行高质量新视角合成(novel view synthesis)并创建 3D mesh 的能力,在质量和多视角输出方面超越了 Stable Zero123 等早期模型。
对 SD3 的高度期待:工程师们正热切期待 Stable Diffusion 3 (SD3),推测测试版访问权限将很快开始推出,正式发布预计在下个月,承诺带来新的突破。
效率测试中:持续的辩论集中在各种 Stable Diffusion 模型的效率上,一些工程师发现 Stable Cascade 虽然速度较慢,但与 SDXL 相比,在处理复杂提示词方面更为出色。
区块链风险投资引发担忧:Stability AI 与区块链实体的合作引发了讨论,一些 AI 工程师担心这可能导致转向专有模型并限制对 AI 工具的访问。
文件处理中的安全性:在安全讨论中,关于将 .pt 文件转换为 SAFETENSOR 格式的咨询促使了转换器工具链接的分享,同时确认大多数 UI 都会避免执行不安全的代码 —— GitHub 转换器工具。
Perplexity AI Discord
-
无限查询并非真的无限:工程师们强调了对 Perplexity 为 Pro 用户提供的“无限” Claude 3 Opus 查询的困惑,指出实际存在 每日 600 次的使用上限,并寻求对“无限”这一误导性术语的澄清。
-
Claude 3 Opus 备受关注:Claude 3 Opus 模型引起了技术用户的兴趣,他们将其与 GPT-4 进行比较,并讨论了其在处理复杂任务时提供更自然响应的潜力,同时也讨论了 AI 在育儿和教育中的作用。
-
Perplexity API 技术深度探讨:在 #pplx-api 频道中,用户对模型的计划弃用感到困惑,并讨论了 API 的不一致性,分享了对 API rate limits 以及 token 限制对 LLM 响应影响的见解。
-
Apple 的 AI 抱负引发讨论:关于 Apple 在 AI 领域动作的讨论,包括可能对 DarwinAI 的收购以及对 30B LLM 的猜测,这些讨论表明了人们对这家科技巨头在 AI 领域战略的浓厚兴趣。
-
Perplexity API 在求职中的效率:利用 Perplexity API 进行职位搜索是一个突出的用例,但在直接职位列表与指向更广泛招聘平台的链接方面结果参差不齐,展示了 AI 在劳动力市场中的实际应用。
Unsloth AI (Daniel Han) Discord
-
AIKit 支持 Unsloth 微调:AIKit 已集成对 Unsloth finetuning 的支持,以创建与 OpenAI API 兼容的最小化模型镜像。一个西班牙语的 Hugging Face TTS 测试空间 已分享供社区使用。
-
Grok-1,开源巨头:关于 Grok-1 的讨论异常火热,这是由 Elon Musk 在 X.ai 的团队开源的一个拥有 314B 参数的模型,由于其 inference 需要巨大的计算资源,人们对其在实际使用中的可行性表示担忧。
-
警惕冒充者:一个模仿 ‘starsupernova0’ 的诈骗账号引发了社区内的警告;鼓励成员保持警惕并举报此类活动。
-
Unsloth AI 在 GitHub 上走红:Unsloth AI 在 GitHub 上备受关注,它为 QLoRA & LoRA finetuning 提供了 2-5 倍的速度提升和 70% 的显存节省。鼓励社区为 Unsloth 仓库 点星支持。
- 微调中的困扰:
- 强调了在 Colab 中保存模型(尤其是像 Mistral 这样的大型模型)时的高 VRAM 和系统 RAM 占用问题。
- 微调相关的担忧包括微调后模型出现的意外行为,以及对正确指定 end-of-sequence token 的澄清。
- 关于 epochs 和可训练性 的辩论,普遍共识是 3 个 epochs 是避免 overfitting 的标准做法,而关于可训练性的讨论指出可训练参数与数据集 tokens 应保持相等比例。
-
技术的诗意一面:出现了对机器学习概念的诗意表达,获得了对更多创意技术独白的赞赏和鼓励。
- 小模型大潜力:分享了 Tiny Mistral 模型的链接,建议将其纳入 Unsloth AI 仓库供社区使用和实验。
LM Studio Discord
-
对 Command-R 支持的期待:讨论指出,在 GitHub Pull Request #6033 合并后,LM Studio 有望支持 C4AI Command-R。然而,尽管 Hugging Face 上已经列出了相关文件,成员们对于 llama.cpp 与 c4ai 的兼容性仍存在困惑。
-
大模型、大梦想、更大的 GPU?:社区对硬件话题讨论热烈,从在各种配置中安装 Nvidia 5090 GPU 的可行性,到处理巨大的功耗和散热需求。ROCm 库的探索得到了扩展,分享了一个用于预构建库的 GitHub 资源,并希望通过 koboldcpp-rocm 等工具在 LM Studio 中实现双 GPU 设置支持。
-
配置、兼容性与散热:在热切分享新机组配置和考虑拥有更多 x16 PCIe Gen 5 插槽的主板之余,成员们还讨论了理线以及容纳单插槽 GPU 的实用性。现场还有积极的故障排除建议,例如关于 AMD OpenCL 驱动程序 的 Linux 页面说明,并确认了 AVX Beta 的局限性,例如不支持 starcoder2 和 gemma 模型,但保持了对 Mistral 的兼容性。
-
模型寻找与支持:模型选择建议层出不穷,有人建议利用 Google 和 Reddit 频道寻找合适的 LLM,而 Phind-CodeLlama-34B-v2 等模型被推荐用于特定用例。讨论了 LM Studio 的功能限制,例如无法直接与文档聊天或使用某些插件,同时为寻求预设的用户分享了 配置示例列表。
-
AI Agent 的代理能力:crew-ai 频道中的一条消息表达了正在寻找合适的 agent system 以增强对创意概念的验证,这表明对各种 Agent 的评估仍在进行中。
Nous Research AI Discord
-
高速显存推测:NVIDIA 备受期待的 RTX 50 系列 Blackwell 将使用 28 Gbps GDDR7 显存,这引发了关于该公司历史上保守的显存速度选择的辩论,正如 TechPowerUp 文章 中所讨论的那样。
-
巨型模型的推理:对于运行像 Grok-1 这样的大规模 AI 模型的可行性,既有兴奋也有担忧,因为它面临着本地推理需要高达 124GB 显存 以及使用成本效益等挑战。
-
Yi-9B 许可证困惑与扩展愿望:对话深入探讨了 Yi-9B 模型许可证的清晰度以及社区的怀疑态度。用户还表达了对于将 Mistral 扩展或改进为 200 亿参数 模型的渴望与疑虑。
-
RAG 创新与偏好:社区专注于增强 RAG (Retriever Augmented Generation) 系统的输出,讨论了大型 RAG 流水线中小型模型的必备功能和优势。分享了一个 GitHub 链接,展示了理想的 RAG 系统提示词。
-
Bittensor 的区块链忧郁:Bittensor 网络出现了技术问题,讨论涉及网络故障、subtensor 链更新的需求,以及围绕获取 Tao 进行网络注册的挑战。对新参与者的硬件建议包括使用 3090 GPU。
Eleuther Discord
- 常春藤盟校慷慨开放:一门免费开放的常春藤盟校课程引发了关于高质量教育普及的对话,并提及了 MIT 和 Stanford 等机构的类似举措。
- Woodruff 的课程收获赞誉:CMU 的 Professor David P. Woodruff 教授的一门综合课程因其深度而受到称赞,该课程跨度近 7 年。
- 先锋项目 “Devin” 和 “Figure 01”:AI 软件工程师 Devin 的首次亮相,以及 “Figure 01” 机器人的 演示视频,并与 DeepMind 的 RT-2(研究论文)进行对比,开启了关于机器人与人类交互下一次飞跃的讨论。
- **用
驱动 LLM**:来自 Reddit 的一项在 LLM 中引入 token 的提议引发了辩论,参考了诸如 [Self-Taught Reasoner (STaR)](https://arxiv.org/abs/2403.09629) 和 [Feedback Transformers](https://arxiv.org/abs/2002.09402) 等深入研究通过计算步骤增强 LLM 推理能力的作品。 -
寻求政府 AI 的公开访问:围绕一项 FOIA 请求展开了讨论,旨在公开橡树岭国家实验室(Oakridge National Laboratory)的 1 万亿参数模型,但由于机密数据担忧和法律复杂性,人们对此持怀疑态度。
- 辩论性能指标:围绕模型性能评估展开了讨论,指出了 benchmark 中的模糊性,特别是 Mistral-7b 在 GSM8k 上的表现。
- 深度思考中 RL 的挑战:探讨了使用强化学习(RL)促进语言模型“深度思考”的局限性,并提出了通过监督学习方法来增强此类行为的建议。
- 反向以提高相关性:一位用户询问标准 tokenizer 为何不反向对数字进行 token 化,这引发了关于右对齐 token 化(right-aligned tokenization)的讨论,GPT 模型在 Twitter 上强调了这一点。
- 通过 API 查询获取 LLM 机密:分享的一篇论文(arXiv:2403.09539)揭示了大型语言模型可能会通过有限的查询泄露专有信息,由于 softmax 瓶颈问题,这引起了极大的关注。
-
Grok-1 模型引发好奇:Grok-1 的发布引发了对其潜力、扩展策略以及与 GPT-3.5 和 GPT-4 等同类模型对比 benchmark 的讨论。
- PCFG 质疑 Scaling Laws:讨论了语言模型 scaling 对数据集复杂性的敏感性(基于概率上下文无关文法 PCFG),并建议 gzip 压缩对特定数据集的 scaling 影响具有预测能力。
-
数据复杂性在模型功效中的作用:讨论强调,数据复杂性与下游任务的匹配可能确保更有效的模型预训练结果。
- 从 n-gram 分布中采样:探索了使用预定的一组 n-gram 统计数据采样字符串的清晰方法,并提出了一种自回归(autoregressive)方法,以确保遵循预先指定的 n-gram 统计数据的最大熵(maximum entropy)分布。
-
发现 n-gram 采样工具:分享了一个用于生成具有 bigram 统计数据的字符串的工具,可在 GitHub 上获得。
- 模型评估中的障碍与解决:记录了一系列模型评估中的技术查询和澄清,包括
lm-eval-harness集成查询、Mistral 模型选择 bug 以及wmt14-en-fr任务期间的死锁问题,并分享了 issue #1485。 -
多语言评估中的翻译评估:将评估数据集翻译成其他语言的概念催生了一个建议,即在特定目录下收集这些数据集,并在任务名称中明确区分它们。
- 数据景观去打乱:对 The Pile 的预处理状态提出了疑问;已确认原始文件没有被打乱,但预处理和预 token 化的数据已准备就绪,无需额外的打乱即可使用。
OpenAI Discord
-
一匙多用:DALL-E 4 和 GPT-4 的统一 API Key – 讨论确认,单个 API Key 确实可以同时用于访问负责图像生成的 DALL-E 4 和负责文本生成的 GPT-4,从而简化了集成流程。
-
探索团队版与隐私:ChatGPT Team 账户隐私说明 – 澄清了从 ChatGPT Plus 升级到 Team 账户并不会让团队管理员获得访问用户私人聊天记录的权限,这是 OpenAI 服务中关于用户隐私的一个重要说明。
-
Prompt 构建难题:Prompt Engineering 技术成为焦点 – 工程师们交流了优化 AI 任务 Prompt 的策略,建议包括在任务中应用“半上下文窗口规则”(half-context-window rule),以及利用 meta-prompting 来克服模型拒绝回答的问题。大家一致认为,合理的 Prompt 结构对于改进分类、检索和模型交互性至关重要。
-
模型行为之谜:API 内容过滤器阻碍创意 – 用户对 OpenAI API 中的内容过滤器以及 GPT-3.5 的拒绝回答问题表示沮丧。社区分享了模型在参与创意写作和角色扮演场景时意愿下降的经历,并指出服务中断有时应归咎于浏览器扩展,而非 ChatGPT 模型本身。
-
网页搜索难题:探讨 GPT 网页搜索能力的复杂性 – 用户讨论了 GPT 在集成网页搜索功能方面的能力、在代码生成中使用 Playwright 等最新库的情况,以及如何引导 GPT 生成并使用多个搜索查询以实现全面的信息检索。
HuggingFace Discord
Discord 的 AI 学者分享最新见解:
-
优化 NL2SQL 流水线查询:一位 AI 工程师 表示需要更有效的 Embedding 和 NL2SQL 模型,因为目前使用 BAAI/llm-embedder 和 TheBloke/nsql-llama-2-7B-GGUF 配合 FAISS 的方案在准确性上表现不稳。
-
NVIDIA 发布 Grace Hopper Superchip:NVIDIA 向社区展示了 Grace Hopper Superchip,该芯片专为 HPC、AI 和数据中心等计算密集型领域设计。
-
如何学习 NLP:针对 NLP 初学者的资源需求,新人被引导至 Hugging Face 的 NLP 课程 和斯坦福大学网站上 Jurafsky 教科书的最新版本,同时推荐了斯坦福 CS224N 以获取更深入的内容。
-
Grok-1 在 Hugging Face 上引发关注:拥有 3140 亿参数的模型 Grok-1 的上传与分享引发了讨论,并附带了其发布信息链接以及 Hugging Face 上的模型大小排行榜。
-
AI 同行评审渗透:一项有趣的调查指出,AI 会议同行评审中 6.5% 到 16.9% 的文本可能被 LLM 显著修改。该研究引用了一篇 论文,将 LLM 生成的文本与某些评审行为联系起来,并建议进一步探索 LLM 对信息实践的影响。
LlamaIndex Discord
- RAG 交互化:提出了增强型 RAG pipelines,通过将检索到的文档作为交互组件来处理复杂查询,该想法已在 Twitter 上分享。
- LlamaIndex v0.10.20 推出 Instrumentation 模块:新版本 v0.10.20 的 LlamaIndex 引入了旨在提高可观测性的 Instrumentation 模块,并在 Twitter 上分享了用于 API 调用观测的专用 notebook。
- Search-in-the-Chain:Shicheng Xu 等人的论文提出了一种通过在所谓的 Search-in-the-Chain 中结合检索和规划来改进问答系统的方法,详见 Tweet。
- 基于简历的求职助手:可以使用 LlamaParse 进行简历文本提取来创建基于 RAG 的求职助手,正如 Kyosuke Morita 所解释并在 Twitter 上分享的那样。
-
MemGPT 赋能动态内存:一场网络研讨会讨论了 MemGPT,它赋予 Agent 动态内存以更好地处理内存任务,相关见解可在 Twitter 上获取。
- OpenAI Agent 链式调用的怪异现象:当链式调用 OpenAI Agent 导致
400 Error时,有人建议发送的内容可能为空,更多讨论可以在 部署指南 中找到。 - Xinference 与 LlamaIndex 的结合:对于那些希望在集群环境中通过 Xinference 部署 LlamaIndex 的用户,本地部署指南 提供了指导。
-
将聊天机器人打造成虚构角色:模拟詹姆斯·邦德(James Bond)等角色的引人入胜的聊天机器人,可能从 Prompt Engineering 中获益,而非仅仅依靠数据集或微调(Fine-tuning),相关方法在 提示指南 中有描述。
-
LLM 的多模态挑战:关于在 LLM 中处理多模态内容的讨论指出了对话顺序丢失和 API 更新的潜在问题,多模态内容处理示例可以在 此处 找到。
- RAG 堆栈操作指南:YouTube 上分享了一个关于构建 RAG with LlamaParse 的指南,使用 Qdrant 和 Groq 等技术简化了流程,视频可在 此处 观看。
- Medium 上的 RAG 管道见解:一篇文章 article 讨论了利用 LlamaIndex 创建具有 RAG 管道和内存的 AI Assistant。
- RAPTOR 尝试受阻:一位 AI 工程师尝试根据 GitHub 的指导为 HuggingFace 模型适配 RAPTOR pack,但在实现过程中遇到问题并寻求社区帮助。
Latent Space Discord
-
Grok-1 解锁限制:xAI 推出了 Grok-1,这是一个拥有 314B 参数的巨大 Mixture-of-Experts 模型,采用 Apache 2.0 协议授权。其无限制的发布引发了广泛关注,但在基准测试中表现参差不齐。感兴趣的工程师可以从 xAI 博客了解更多详情。
-
Altman 引发猜测:Sam Altman 暗示即将推出的 GPT-5 在推理能力上将有重大飞跃,引发了关于该模型对初创公司潜在影响的讨论。好奇的读者可以通过 Lex Fridman 播客上的 Sam 访谈深入了解对话内容。
-
Jensen Huang 备受期待的 Nvidia 主旨演讲:GPT-4 暗示的能力及其 1.8T 参数 的提及,为 Jensen Huang 备受期待的 Nvidia 主旨演讲奠定了基调,激起了 AI 技术爱好者的热烈讨论。观看 Jensen 主旨演讲中的震撼揭秘。
-
创新的数据提取工具即将问世:关于一款处于私测阶段的新型结构化数据提取工具的预告引发了兴奋,该工具承诺低延迟和高精度——AI 社区正期待更多细节。请关注 Twitter 以获取这款可能改变游戏规则的工具的更新。点击此处访问推文。
-
SDXL 的黄色困境:SDXL 因其 Latent Space 中偏向黄色的色彩偏差而受到审查,这促使了对这一奇特挑战的深入分析和解决方案建议。在 Hugging Face 的博客文章中了解更多关于如何解决色彩偏差的信息。
-
Paper Club 深入探讨 LLM:Paper Club 开启了一个环节来剖析《大型语言模型综合摘要》(A Comprehensive Summary Of Large Language Models),邀请所有人参与深度探讨。在专用频道中交流见解并加入学习体验。
-
AI 饱和讽刺警报:一篇讽刺文章将 AI 生成内容的涌入称为“灰色淤泥”(grey sludge),这可能预示着内容生成范式的转变。在 Hacker News 上感受一下这种讽刺。
-
Attention 机制详解:llm-paper-club-west 频道的爱好者们就 Attention 机制背后的原理进行了热烈讨论。该机制使模型能够全局处理输入序列,并解决了并行化问题以实现更快的训练——重点突出了 Decoder 在关注相关输入片段方面的高效性。
-
RAG 讨论激发共同学习:一篇关于“高级 RAG:从小到大的检索”(Advanced RAG: Small to Big Retrieval)的文章引发了关于检索机制和“对比嵌入”(contrastive embeddings)概念的对话,为 LLM 中的余弦相似度提供了替代方案。查看分享的文章以深入了解 Retrieval-Augmented Generation。
-
AI 爱好者的资源库:一个全面的 Google 表格记录了过去的讨论话题、日期、主持人及资源链接,供想要跟进或回顾 AI In Action Club 历史知识交流的成员使用。通过此 电子表格 访问历史存档。
LAION Discord
-
Jupyter 的新副驾驶:Jupyter Notebooks 现在可以在 Microsoft Copilot Pro 中使用,提供对
simpy和matplotlib等库的免费访问,此举效仿了 ChatGPT Plus 的功能。 -
DALL-E 数据集的新家:关于 Hugging Face 上 DALL-E 3 数据集的困惑得到了澄清;该数据集已迁移,仍可通过此链接访问。
-
Grok-1 对抗巨头:围绕新的 Grok-1 模型、其基准测试表现以及与 GPT-3.5 和 Mixtral 等模型的比较展开了讨论,同时强调了 Grok 在 GitHub 上的开源发布。
-
解决语言模型连续性问题:一篇 arXiv 论文详细介绍了一种通过持续预训练(continual pre-training)使语言模型更高效的方法,以应对数据分布偏移,承诺为该领域带来进步。论文可以在这里找到。
-
关于 GPT-4 的猜测仍在继续:Nvidia 似乎确认了 GPT-4 是一个拥有 1.8T 参数的巨大 MoE 模型,这助长了持续的传闻和辩论,尽管一些人对模型的确切命名持怀疑态度。
OpenAccess AI Collective (axolotl) Discord
-
微调中的 Tokenization 异常问题:工程师们讨论了在文档摘要微调过程中,Tokenizer 生成
<summary>标签不一致的问题。怀疑是 Tokenizer 与模型行为之间存在潜在的不匹配,而另一位成员遇到了HFValidationError,建议在本地模型和数据集微调时应使用完整的文件路径。 -
对话数据集难题已修正:在设置对话类型训练数据时出现了一个令人困惑的问题;罪魁祸首被发现是数据集中的空角色(empty roles)。此外,关于 Axolotl 验证警告的报告产生了不同的结果,较小的 eval set 规模会导致问题。
-
Grok 陷入性能瓶颈:在 Axolotl 小组中,大家就 314B Grok 模型 表现不及预期进行了交流。此外,还提到了 int8 Checkpoint 的可用性,这限制了模型能力的发挥。
-
硬件搜寻与模型合并思考:分享了用于数据治理的 NVIDIA NeMo Curator,并建议将 Mergekit 作为模型合并的可能解决方案。此外,还有关于确保合并后的模型使用相同的 Chat Format 进行训练以实现完美运行的讨论。
-
传闻引发推测热潮:关于 GPT-4 拥有 1.8 万亿巨量参数以及 NVIDIA 下一代 GeForce RTX 5000 系列显卡的泄露消息引发了热情与质疑。专业人士在思考这些启示的同时,也在探索用于提升大模型解码能力的 Sequoia 以及助力 AI 进步的 NVIDIA Blackwell 系列。
讨论中涉及的相关链接:
- GitHub - NVIDIA/NeMo-Curator:NVIDIA 的数据治理工具包
- GitHub 上的 Grok-1 权重
- GitHub 上的 ScatterMoE 分支
- ScatterMoE Pull Request
CUDA MODE Discord
-
光子学创新引发关注:讨论聚焦于光子学领域的一项新突破,据称速度快了 1000 倍。成员们分享了相关视频,其中包括来自 Lightmatter 的内容。对于该领域感兴趣的人,还推荐了 Asianometry 在 YouTube 上关于 Silicon Photonics(硅光子学)和 neural networks on light meshes(光网格上的神经网络)的视频。
-
CUDA 开发与讨论:工程师们深入探讨了 CUDA 中的 warp 调度器、活跃 warps 以及涉及 ProducerProvides 和 ConsumerTakes 的内存管理语义。他们对 NVIDIA 的 GTC 活动进行了展望,预测了新的 GPU 能力,并幽默地评论了 NVIDIA 最新技术带来的“Skynet(天网)既视感”。
-
Triton 工具成为焦点:社区分享了新的开发工具,例如 Triton debugger visualizer(调试器可视化工具),并在 Google Colab 上发布了 Triton Puzzles,以帮助理解复杂的 kernels。
-
学术界的可重构计算:大家对 Prof. Mohamed Abdelfattah 关于高效 ML 和可重构计算的研究产生了浓厚兴趣,这些研究在他的 YouTube 频道和个人网站上有所展示。此外,还重点介绍了 ECE 5545 (CS 5775) 这门以硬件为中心的 ML 系统课程(可通过其 GitHub 页面访问),以及寻找该课程教科书的有趣过程。
-
CUDA 初学者与向 ML 转型:扎实的 CUDA 基础受到了赞赏,并提供了利用 PyTorch 等框架向基于 GPU 的 ML 转型的建议。参考资料包括 Zero to Hero 系列、cuDNN 和 cuBLAS 等 ML 库,以及为了深入理解 CUDA 而推荐的《大规模并行处理器编程》(Programming Massively Parallel Processors)一书,链接见此处。
-
深入探讨 Ring-Attention 算法:讨论围绕 Ring-Attention 算法的内存需求展开,并与 blockwise attentions 进行了比较。分享了 GitHub 上与 Triton 相关的代码链接,并探讨了线性内存扩展是指序列长度还是 block 的数量。
-
强调 MLSys 会议与 GTC:对话涉及了 MLSys 2024 会议,该会议被认为是机器学习与系统专业人士的交汇点。此外,成员们正在为即将到来的 GTC 安排聚会,讨论参会事宜并通过私信进行协调,一些人幽默地提到无法参加并链接了相关 YouTube 视频。
OpenRouter (Alex Atallah) Discord
-
LLaMa 学习新技巧:LLaMa 模型现已确认可以处理多种格式,包括
system、user和assistant提示词的组合,这在使用 OpenAI JavaScript 库时可能非常有用。 -
Sonnet 在高级角色扮演中脱颖而出:Sonnet 因其出色的角色扮演能力而备受欢迎,其避免重复和生成连贯输出的能力给用户留下了深刻印象,这可能会彻底改变交互场景中的用户参与度。
-
构建 MythoMax 消息:针对 MythoMax 等 LLM 的有效格式化仍是一个热门话题,理解系统消息的定位对于获得最佳提示响应至关重要,这表明第一条系统消息在处理中具有优先级。
-
用户呼吁消费透明度:对详细使用报告(细分成本和分析)的需求日益增长,这突显了用户希望根据 AI 模型的使用情况和消耗时间来精细化预算分配的愿望。
-
领悟 Grok 的未来:即将推出的 Grok 模型因其潜在影响以及对指令数据进行微调的需求而引发热议,其开源发布和可能的 API 激发了社区成员的期待。欲了解详情或做出贡献,请查看 Grok 在 GitHub 上的仓库。
LangChain AI Discord
-
明智地选择你的 API:工程师们讨论了在创建 Agent 时使用
astream_log与astream_events的优劣,并指出由于events API仍处于 beta 阶段,log API可能会被弃用。他们还在为 Rubik’s AI 招募 beta 测试人员,承诺提供为期两个月的 AI 模型高级访问权限,包括 GPT-4 Turbo 和 Groq 模型,可在 Rubik’s AI 注册。 -
改进 Langchain 文档:用户表示需要更适合初学者的 Langchain 文档,并考虑在 DataGPT 项目中使用
Llamaindex以实现更快速的结构化数据查询。其他人分享了一个实用解决方案,演示了如何使用 Python Pydantic 来结构化 LLM 响应 的输出。 -
JavaScript 流式传输故障:有人指出 Python 和 JavaScript 之间
RemoteRunnable行为存在差异,JavaScript 版本无法调用/stream并默认使用/invoke,这与 Python 版本不同。参与者讨论了RunnableSequence中的继承问题,并建议通过 GitHub 或 hello@langchain.dev 直接联系 LangChain 团队寻求支持。 -
轻松爬取,与数据对话,智能书签:社区近期涌现了许多新项目,包括一个用于数据分析的开源 AI Chatbot、一个用于管理书签的 Discord 机器人,以及 Scrapegraph-ai(一个宣称安装量超过 2300 次的基于 AI 的爬虫工具)。
-
用于营养健康与金融行业分析的 AI:创新者们构建了一个名为 Nutriheal 的营养 AI 应用,并在“15 分钟制作一个 AI 应用”的 视频 中进行了展示。一篇 Medium 文章讨论了 LLM 如何彻底改变金融行业专业人士对研究论文的分析,文章可在此处阅读 here。
-
Nutriheal 聚焦快速 AI 应用开发:Nutriheal 演示 强调了使用 Ollama 和 Open-webui 轻松创建 AI 应用的方法,并利用 Langchain 的 Pebblo 集成确保数据隐私。更多 AI 资源和教程可以在 navvy.co 找到。
-
揭秘家用 AI 能力:社区贡献包括一个旨在打破“高端 AI 仅限于大厂”迷思的教程,以及一个为任何 LLM 项目创建通用聊天 UI 的指南。此外还分享了一个 Langgraph 教程视频,详细介绍了受 Plan-and-Solve 论文和 Baby-AGI 项目启发而开发的 plan-and-execute 风格 Agent,观看地址为 这里。
Interconnects (Nathan Lambert) Discord
-
受 API 保护的 LLM 易受数据提取攻击:一篇新的 arXiv 论文 揭示了一种从 OpenAI GPT-3.5 等受 API 保护的大语言模型中提取敏感信息的方法,通过低成本技术挑战了 softmax 瓶颈。
-
模型参数量被低估:争论焦点在于论文中对 GPT-3.5 等模型 70 亿参数量的估算。有人推测,如果使用了 Mixture of Experts (MoE) 模型,将与此类估算不符,可能采用了不同的架构或蒸馏(distillation)方法。
-
开源讨论趋于白热化:科技界关于开源定义的讨论升温,伴随着 Twitter 上的交锋和挫败感的表达。Nathan Lambert 和 @BlancheMinerva 等人的讨论主张建立清晰的社区准则,减少网络争吵。
-
Grok-1 进入 AI 竞技场:xAI 的 Grok-1(一个拥有 3140 亿参数的 MoE 模型)已在 Apache 2.0 许可下开源,提供了未经微调的能力,其潜力可能优于现有模型。它正被拿来与 Falcon 等模型进行比较,相关的性能讨论和 GitHub 下载指南已发布。
-
大数据传输之谜:在 Grok-1 发布背景下,出现了关于替代模型分发方法的活跃讨论,包括磁力链接和邮寄物理硬盘等幽默建议。HuggingFace 已提供权重镜像。此外,OpenAI CTO 接受《华尔街日报》关于 AI 生成内容的 采访 进一步引发了对数据问题的关注。
Alignment Lab AI Discord
-
Aribus 项目是怎么回事?:在一名成员分享了 tweet 后,大家对 Aribus Project 产生了好奇;然而,社区对该项目的应用缺乏清晰的认识,也没有提出更多的细节。
-
寻找精通 HTTP 的 Transformers:讨论转向技术层面,一名成员正在寻找一种在 HTTP 响应上训练的 embeddings model,认为任何经过适当训练的 transformer 都可以胜任。然而,关于 fine-tuning 的细节或来源等具体信息尚未得到解决。
-
寻找 Orca-Math 应用题模型:询问是否有一个专门在 orca-math-word-problems-200k 数据集和 nvidia/OpenMathInstruct-1 上微调的 Mistral 模型,但未得到回应;暗示了一个精确的使用场景但未说明。
-
驯服 Grok 1 的愿望:一名成员发起了挑战,试图 fine-tune 拥有 314B 庞大参数量的 Grok 1,对话转向了该模型对资源的巨大需求(如 64-128 H100 GPUs),以及它与 GPT-4 等巨头进行 benchmarking 的潜力。
-
Grok 1 展示其数学实力:尽管存在质疑,Grok 1 在复杂的 匈牙利国家高中数学决赛数据集 上的表现受到了关注,讨论对比了它与其他知名模型的能力和效率。
LLM Perf Enthusiasts AI Discord
-
在本地开发中拥抱简洁:工程师们表达了对以简洁为核心构建应用的偏好,倾向于支持本地执行和 filesystem 控制的工具,并强调了对轻量级开发解决方案的需求。
-
Anthropic 的不祥影响?:一条分享的 tweet 引发了对 Anthropic 意图的怀疑,可能是在恐吓技术人员,同时也承认了内容审查系统持续存在的问题。
-
Claude Sonnet 的规模挑战:关于使用 Claude Sonnet 的可扩展性出现了技术讨论,预计一个大型项目每月将消耗“数千万个 tokens”。
-
辩论知识处理单元 (KPU) 的主张:Maisa 推出的 KPU 引发了辩论,工程师们对其性能主张和对比 benchmarks 表示怀疑。CEO 澄清说 KPU 就像是“用于知识管理的 GPU”,旨在增强现有的 LLMs,并可根据要求提供用于独立评估的 notebook。
-
OpenAI 更新的细节寥寥:发布了一条包含链接的消息:tweet,但没有提供背景或讨论,使得该更新的内容和意义尚不明确。
DiscoResearch Discord
- 德语微调受挫:shakibyzn 遇到了 DiscoLM-mixtral-8x7b-v2 模型在 fine-tuning 后不以德语回答的问题,暗示存在一个 “ValueError“,表明与 AutoModel 设置不兼容。
- 本地模型服务的小插曲:jaredlcm 在本地 serving DiscoLM-70b 模型时遇到了意想不到的语言响应,他使用了通过
vllm和 OpenAI API chat completions 格式设置的服务片段。 - 德语模型训练的陷阱:crispstrobe 及其同僚讨论了德语模型的不一致性,这些不一致性是由 prompting systems、数据翻译、 merging models 效果以及 fine-tuning 数据集选择等变量引起的。
- 德语 LLM 基准测试宝库:thilotee 强调了 supergleber-german-language-evaluation-benchmark 等资源和其他工具,主张在 EleutherAI 的 lm-evaluation-harness 中加入更多德语 benchmarks 我们的论文。
- 德语模型 Demo 的忧与喜:DiscoResearch 模型依赖于 prompt 忠实度,说明了为了获得最佳 demo 性能需要进行 prompt 调整,而这一切都发生在将 demo server 从简陋的“厨房配置”迁移到专业环境的背景下,不幸的是,这导致了网络问题。
Datasette - LLM (@SimonW) Discord
-
Prompt Engineering 的演进路径:一位成员回忆了他们参与使用 Explosion’s Prodigy 塑造 Prompt Engineering 工具的经历,该工具将 Prompt Engineering 视为一个数据标注挑战,同时也承认了该技术的局限性。
-
Prompt 实验工具包:该频道引用了多个资源,例如 PromptTools,这是一个支持 Prompt 测试的开源资源,兼容包括 OpenAI 和 LLaMA 在内的 LLM,以及 Chroma 和 Weaviate 等向量数据库。
-
用指标衡量 AI:讨论了 Vercel 和 Helicone AI 等平台在比较模型输出和管理 Prompt 方面的能力,重点关注了 Helicone AI 在 Prompt 管理和版本控制方面的探索。
-
PromptFoo 赋能 Prompt 测试:分享了 PromptFoo,这是一个开源工具,允许用户在各种模型中测试 Prompt、评估 LLM 输出并提高 Prompt 质量。
-
用 AI 变革博客内容:一位成员正在应用 gpt-3.5-turbo 为不同的受众角色翻译博客文章,并思考了 AI 在个性化读者体验方面的更广泛影响,通过他们的博客展示了这一点。
-
Seed 恢复难题:一位成员询问是否可以检索 OpenAI 模型在之前的 API 请求中使用的 seed,但关于此查询没有提供额外的背景或回复。
Skunkworks AI Discord
-
论文预告准确率与效率的提升:Baptistelqt 准备发布一篇论文,承诺提高 AI 训练中的 global accuracy(全局准确率)和 sample efficiency(样本效率)。发布工作正在等待结果整理和更好的图表可视化。
-
扩展瓶颈等待解决:尽管 Baptistelqt 的方法很有前景,但由于资源有限,缺乏大规模的实证证明。有人呼吁考虑分配更多算力来测试更大的模型。
-
VGG16 性能提升:Baptistelqt 的方法在 VGG16 上使用 CIFAR100 的初步应用导致测试准确率大幅提升,从基准值 0.04 爬升至 0.1。
-
对 Quiet-STaR 项目产生兴趣:Satyum 渴望加入 “Quiet-STaR” 项目,并讨论了参与的前提条件,例如精通 PyTorch 和 Transformer 架构。
-
调度混乱限制协作:时区差异导致在扩展 Baptistelqt 方法方面的协作努力出现延迟,第二天立即开会并不可行。
PART 2: 频道详细摘要与链接
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
-
推出 Stable Video 3D:Stability AI 发布了 Stable Video 3D,这是一个扩展 3D 技术能力的新模型,具有显著提高的质量和多视角体验。它以单个物体图像作为输入,并输出新颖的多视角,创建 3D 网格 (meshes)。
-
基于 Stable Video Diffusion 的基础:Stable Video 3D 基于多功能的 Stable Video Diffusion 技术,在质量和生成多视角输出的能力方面优于 Stable Zero123 和 Zero123-XL 等模型。
-
Stable Video 3D 变体发布:该模型发布了两个变体:SV3D_u,它从单个图像输入生成轨道视频而无需相机调节(camera conditioning);以及 SV3D_p(扩展了上述功能之外的能力)。
提及的链接:Introducing Stable Video 3D: Quality Novel View Synthesis and 3D Generation from Single Images — Stability AI:当我们发布 Stable Video Diffusion 时,我们强调了我们的视频模型在各种应用中的多功能性。在此基础上,我们很高兴发布 Stable Video 3D。这个新模型…
Stability.ai (Stable Diffusion) ▷ #general-chat (988 messages🔥🔥🔥):
-
Stable Diffusion 3 的期待:人们对 Stable Diffusion 3 (SD3) 充满期待,有迹象表明测试版(beta)访问邀请可能在本周开始发放。用户希望看到新的示例,预计下个月发布。
-
模型效率的辩论:关于各种 Stable Diffusion 模型(如 Stable Cascade 与 SDXL)效率的讨论正在进行中,一些用户发现 Cascade 在处理复杂提示词(prompts)方面表现更好,但生成图像的速度较慢。
-
对区块链合作伙伴关系的担忧:Stability AI 最近与专注于区块链的公司建立的合作伙伴关系引起了用户的担忧。一些人担心这些举动可能预示着向专有模型的转变,或者该平台 AI 工具的未来将不再那么开放。
-
.pt 文件和 SAFETENSORS 的使用:由于担心运行潜在不安全的 pickle 文件,一位用户询问如何将 .pt 文件转换为 SAFETENSOR 格式。尽管大多数 .pt 文件是安全的,且主要的 UI 不会执行不安全的代码,但文中还是分享了一个转换工具的链接。
-
即将推出的新 3D 模型:Stability AI 宣布发布 Stable Video 3D (SV3D),这是对之前 3D 模型(如 Stable Zero123)的改进。它具有更高的质量和多视图生成功能,但即使拥有会员资格,用户也需要自行托管(self-host)该模型。
- Iron Man Mr Clean GIF - Iron Man Mr Clean Mop - Discover & Share GIFs: 点击查看 GIF
- grok-1: Grok-1 是一个拥有 314B 参数的 Mixture of Experts 模型 - 基础模型(未微调) - 8 个专家(2 个激活) - 86B 激活参数 - Apache 2.0 许可证 - 代码: - 祝编码愉快!另:我们正在招聘:
- Avatar Cuddle GIF - Avatar Cuddle Hungry - Discover & Share GIFs: 点击查看 GIF
- Yess GIF - Yess Yes - Discover & Share GIFs: 点击查看 GIF
- PollyannaIn4D (Pollyanna): 未找到描述
- Introducing Stable Video 3D: Quality Novel View Synthesis and 3D Generation from Single Images — Stability AI: 当我们发布 Stable Video Diffusion 时,我们强调了视频模型在各种应用中的多功能性。在此基础上,我们很高兴发布 Stable Video 3D。这款新...
- coqui/XTTS-v2 · Hugging Face: 未找到描述
- Stable Video Diffusion - SVD - img2vid-xt-1.1 | Stable Diffusion Checkpoint | Civitai: 查看我们的快速入门指南!https://education.civitai.com/quickstart-guide-to-stable-video-diffusion/ 基础 img2vid 模型经过训练用于生成...
- pickle — Python object serialization: 源代码:Lib/pickle.py。pickle 模块实现了用于序列化和反序列化 Python 对象结构的二进制协议。“Pickling” 是将 Python 对象层级结构转换为...的过程。
- The Complicator's Gloves: 优秀的软件在多个战线上不断受到攻击。首先是那些尽管只读完了《傻瓜编程》却不知何故拿到了巨额合同的“业余爱好者”...
- Page Not Found | pny.com: 未找到描述
- NVLink | pny.com: 未找到描述
- Короткометражный мультфильм "Парк" (сделан нейросетями): 动画短片《公园》——一部使用神经网络创作的极其引人入胜的动画短片。
- Vancouver, Canada 1907 (New Version) in Color [VFX,60fps, Remastered] w/sound design added: 我为这段 1907 年加拿大温哥华的视频进行了上色、修复,并添加了天空视觉效果和音效设计。这段视频是从有轨电车上拍摄的,这些...
- Proteus-RunDiffusion - withoutclip | Stable Diffusion Checkpoint | Civitai: 介绍 Proteus-RunDiffusion。在开发 Proteus-RunDiffusion 的过程中,我们的团队开展了一个探索性项目,旨在提升...的能力。
- The Mushroom Motherboard: The Crazy Fungal Computers that Might Change Everything: 揭开真菌计算的秘密!探索真菌作为生物计算机的惊人潜力。从“森林互联网”到非常规计算...
- GitHub - DiffusionDalmation/pt_to_safetensors_converter_notebook: This is a notebook for converting Stable Diffusion embeddings from .pt to safetensors format.: 这是一个用于将 Stable Diffusion 嵌入(embeddings)从 .pt 格式转换为 safetensors 格式的 notebook。- DiffusionDalmation/pt_to_safetensors_converter_notebook
- WKUK - Anarchy [HD]: 经济学上的无知达到了最滑稽的程度。—— Murray Rothbard 的《自由、不平等、原始主义与分工》(http://mises.org/daily/3009)。—— "Th...
- Reddit - Dive into anything: 未找到描述
- Install ComfyUI on Mac OS (M1, M2 or M3): 本视频是一个快速演练,展示如何在 M1 或 M2 Mac 上本地安装 ComfyUI。了解更多关于 AI 动画的信息,并注册成为 AI ...
- GitHub - Stability-AI/generative-models: Generative Models by Stability AI: Stability AI 的生成模型。通过在 GitHub 上创建账号,为 Stability-AI/generative-models 的开发做出贡献。
- GitHub - chaojie/ComfyUI-DragAnything: 通过在 GitHub 上创建账号,为 chaojie/ComfyUI-DragAnything 的开发做出贡献。
- GitHub - GraftingRayman/ComfyUI-Trajectory: 通过在 GitHub 上创建账号,为 GraftingRayman/ComfyUI-Trajectory 的开发做出贡献。
- GitHub - mix1009/sdwebuiapi: Python API client for AUTOMATIC1111/stable-diffusion-webui: 针对 AUTOMATIC1111/stable-diffusion-webui 的 Python API 客户端 - mix1009/sdwebuiapi
- Home: Stable Diffusion web UI。通过在 GitHub 上创建账号,为 AUTOMATIC1111/stable-diffusion-webui 的开发做出贡献。
- Regional Prompter: Control image composition in Stable Diffusion - Stable Diffusion Art: 你知道可以为图像的不同区域指定提示词吗?你可以通过 Regional Prompter 扩展在 AUTOMATIC1111 上实现这一点。 </ul> </div> --- **Perplexity AI ▷ #[announcements](https://discord.com/channels/1047197230748151888/1047204950763122820/1219057096780419163)** (1 条消息): - **Pro 用户可无限次查询 Claude 3 Opus**: 官方发布公告,**Perplexity Pro 用户**现在可以**无限次进行每日查询** Claude 3 Opus,该模型被声称是目前市场上最好的大语言模型 (LLM)。邀请 Pro 用户尽情享受这一新福利。 --- **Perplexity AI ▷ #[general](https://discord.com/channels/1047197230748151888/1047649527299055688/1218100055626743851)** (795 条消息 🔥🔥🔥): - **对“无限”使用的困惑**: 用户讨论了在 Perplexity 服务中混用“无限”一词所带来的困惑,实际上该服务每天上限为 600 次搜索或使用。这引发了投诉,并要求 Perplexity 进行更清晰的沟通。 - **对 Claude 3 Opus 的兴趣**: 许多用户表达了对 Claude 3 Opus 模型的兴趣,询问它与常规 GPT-4 等其他模型的对比。一些用户反馈称,使用 Opus 处理复杂任务的体验更好,且响应更加自然。 - **育儿与 AI**: 关于某些知识的适龄程度,以及是否可以使用 AI 将微积分或地球年龄等复杂话题变得让幼儿易于理解,展开了激烈的辩论。一些家长分享了将 AI 作为孩子教育工具的积极经验。 - **Perplexity 的集成与功能**: 用户对将 Grok 等新 AI 模型集成到 Perplexity 中感到好奇,并询问潜在的应用场景,例如集成到移动设备中。用户还询问了如何使用 Perplexity 分析 PDF 等任务,这引发了关于应使用何种模型设置的讨论。 - **使用 Perplexity 的个人经历**: 用户交流了使用 Perplexity 申请工作的故事、在会议中看到提及 Perplexity 的兴奋感,以及使用该平台回答争议性或复杂问题的经历。其中既有幽默,也有对 Perplexity 能力的赞赏。
- 来自 Bloomberg Technology (@technology) 的推文:独家:Apple 正在洽谈将 Google 的 Gemini AI 引擎内置到 iPhone 中,这可能是一项重磅交易 https://trib.al/YMYJw2K
- 来自 Brivael (@BrivaelLp) 的推文:Zuck 刚刚对 Grok 的发布做出了回应,他并没有留下深刻印象。“3140 亿参数太多了。你需要一堆 H100,而我已经把它们全买光了” 🤣
- 来自 Aravind Srinivas (@AravSrinivas) 的推文:我们已经为 Perplexity Pro 用户取消了 Claude 3 Opus(目前市场上最好的 LLM)的每日查询次数限制!尽情享受吧!
- 来自 Aravind Srinivas (@AravSrinivas) 的推文:是的,感谢 @elonmusk 和 xAI 团队开源了 Grok 的基础模型。我们将针对对话式搜索对其进行微调并优化推理,并将其提供给所有 Pro 用户! ↘️ Quoti...
- 未找到标题:未找到描述
- Shikimori Shikimoris Not Just Cute GIF - Shikimori Shikimoris Not Just Cute Shikimoris Not Just A Cutie Anime - 发现并分享 GIF:点击查看 GIF
- Apple 的 AI 雄心可能包括 Google 或 OpenAI:另一项重大的 Apple / Google 交易可能即将达成。
- Nothing Perplexity 优惠:在 Nothing,我们正在构建一个让科技再次变得有趣的世界。还记得每个新产品都让你兴奋的时代吗?我们正在带回那种感觉。
- 这些公司在隐藏什么?:关于 Rabbit R1 和 Humane Ai Pin 的想法。如果你想支持本频道,可以点击上方的“加入”按钮考虑成为 Dave2D 会员!http://twit...
- ✂️ Sam Altman 谈 AI LLM 搜索:47 秒 · 由 Syntree 剪辑 · 原始视频 "Sam Altman: OpenAI, GPT-5, Sora, Board Saga, Elon Musk, Ilya, Power & AGI | Lex Fridman Podcast #419" 作者 Le...
- FCC ID 2BFB4R1 Rabbit Inc. 的 AI Companion:Rabbit Inc. 为 FCC ID 2BFB4R1 提交的 AI Companion FCC ID 申请。已批准的频率、用户手册、照片和无线报告。
- pplx-api: no description found
- pplx-api form: Turn data collection into an experience with Typeform. Create beautiful online forms, surveys, quizzes, and so much more. Try it for FREE.
- 来自 Unsloth AI (@UnslothAI) 的推文:Unsloth 本周在 GitHub 上走红!🙌🦥 感谢大家及所有 ⭐️Stargazers 的支持!查看我们的仓库:http://github.com/unslothai/unsloth
- Cosmic keystrokes:未找到描述
- 关于 xAI:未找到描述
- Grok-1 开源发布:未找到描述
- Lightning AI | 闪电般将创意转化为 AI:AI 开发的一站式平台。协同编码、原型设计、训练、扩展、部署。直接在浏览器中操作,无需配置。由 PyTorch Lightning 的创作者打造。
- CodeFusion: A Pre-trained Diffusion Model for Code Generation:想象一下,如果一个开发者只能修改最后一行代码,那么在写出一个正确的函数之前,他们需要多少次从头开始编写?用于代码生成的 Auto-regressive models...
- 发布 Grok:未找到描述
- Qwen/Qwen1.5-72B · Hugging Face:未找到描述
- 博客:未找到描述
- ISLR 数据集 — 👐OpenHands 文档:未找到描述
- Mixtral of Experts:我们推出了 Mixtral 8x7B,一种 Sparse Mixture of Experts (SMoE) 语言模型。Mixtral 与 Mistral 7B 具有相同的架构,不同之处在于每一层由 8 个前馈块组成...
- Google Colaboratory:未找到描述
- xai-org/grok-1 · Hugging Face:未找到描述
- 简介 | AIKit:AIKit 是一个一站式商店,可快速开始托管、部署、构建和微调 Large Language Models (LLMs)。
- 🦅 EagleX 1.7T:在英语和多语言评估中均超越 LLaMA 7B 2T (RWKV-v5):一个 Linear Transformer 在训练 Token 更少的情况下,在英语和多语言评估中均跨越了 Transformer 模型的金标准 LLaMA 7B。这是历史性的第一次。
- Crystalcareai/GemMoE-Beta-1 · Hugging Face:未找到描述
- Unsloth 修复 Gemma 错误:Unsloth 正在修复 Google 的开源语言模型 Gemma 中的错误。
- Piper TTS Spanish - HirCoir 的 Hugging Face Space:未找到描述
- damerajee/Llamoe-test · Hugging Face:未找到描述
- 如何微调 LLM 第一部分:为指令微调准备数据集:学习如何在指令数据集上微调 LLM!我们将涵盖如何格式化数据并训练像 Llama2、Mistral 等模型。这是(几乎)纯 PyTorch 的极简示例。
- 论文页面 - 简单的 Linear Attention 语言模型平衡了召回率与吞吐量 tradeoff</a>: 未找到描述
- Sam Altman: OpenAI, GPT-5, Sora, 董事会风波, Elon Musk, Ilya, 权力与 AGI | Lex Fridman Podcast #419: Sam Altman 是 OpenAI 的 CEO,该公司是 GPT-4, ChatGPT, Sora 以及许多其他最先进 AI 技术的幕后推手。请通过以下方式支持本播客...
- argilla (Argilla): 未找到描述
- GitHub - xai-org/grok-1: Grok 开源发布: Grok 开源发布。通过在 GitHub 上创建账号来为 xai-org/grok-1 的开发做出贡献。
- transformers/src/transformers/models/mixtral/modeling_mixtral.py (main 分支) · huggingface/transformers: 🤗 Transformers: 面向 Pytorch, TensorFlow 和 JAX 的最先进机器学习框架。 - huggingface/transformers
- Mistral 微调入门(支持 16k, 32k, 128k+ 上下文): 在我们最新的教程视频中,探索使用自有数据轻松微调大语言模型 (LLMs) 的秘诀。我们深入探讨了一种高性价比且...
- GitHub - jiaweizzhao/GaLore: 通过在 GitHub 上创建账号来为 jiaweizzhao/GaLore 的开发做出贡献。
- GitHub - unslothai/unsloth: 速度提升 2-5 倍、显存减少 70% 的 QLoRA & LoRA 微调: 速度提升 2-5 倍、显存减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- GitHub - AI4Bharat/OpenHands: 👐OpenHands:让手语识别触手可及。 | **注意:** 不再积极维护。如果您有兴趣接手并推进此项目,请提交 issue: 👐OpenHands:让手语识别触手可及。 | **注意:** 不再积极维护。如果您有兴趣接手并推进此项目,请提交 issue - AI4Bharat/OpenHands
- teknium/GPT4-LLM-Cleaned · Hugging Face 数据集: 未找到描述
- GitHub - mistralai/mistral-src: Mistral AI 7B v0.1 模型的参考实现。: Mistral AI 7B v0.1 模型的参考实现。 - mistralai/mistral-src
- 安装 requirements 时出错 · Issue #6 · xai-org/grok-1: 我安装了 python 3.10 和 venv。尝试执行 "pip install -r requirements.txt" 报错:ERROR: Ignored the following versions that require a different python version: 1.6.2 Requires-Python >=3...
- Falcon 180B 开源语言模型性能超越 GPT-3.5 和 Llama 2: 开源语言模型 FalconLM 提供了比 Meta 的 LLaMA 更好的性能,并且可以用于商业用途。如果收入超过 100 万美元,商业使用需缴纳版税。
- FEAT / Optim: 由 younesbelkada 添加 GaLore 优化器 · Pull Request #29588 · huggingface/transformers: 此 PR 的作用是什么?如标题所示,添加了来自 https://github.com/jiaweizzhao/GaLore 的 GaLore 优化器。这是我目前测试 API 的方式:import torch import datasets from transformers i...
- 实现 Phi-2 支持的暂存 PR。由 cm2435 提交 · Pull Request #97 · unslothai/unsloth: ….org/main/getting-started/tutorials/05-layer-norm.html] </ul> </div> --- **Unsloth AI (Daniel Han) ▷ #[announcements](https://discord.com/channels/1179035537009545276/1179039782681202829/1218580567453470860)** (1 条消息): - **Unsloth AI 在 GitHub 上备受瞩目**: Unsloth AI 本周成为 GitHub 上的热门话题,获得了社区的广泛关注和支持。官方帖子鼓励用户在 GitHub 上**点亮星标 (star)**,并提供了该仓库的链接,该项目专注于**速度提升 2-5 倍、显存减少 70% 的 QLoRA & LoRA 微调**,地址为 [GitHub - unslothai/unsloth](https://github.com/unslothai/unsloth)。 **提到的链接**: GitHub - unslothai/unsloth: 速度提升 2-5 倍、显存减少 70% 的 QLoRA & LoRA 微调: 速度提升 2-5 倍、显存减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth --- **Unsloth AI (Daniel Han) ▷ #[random](https://discord.com/channels/1179035537009545276/1179039861576056922/1218112720994308122)** (25 条消息🔥): - **Baader-Meinhof 现象袭来**:一位成员提到经历了 Baader-Meinhof 现象,也称为*频率错觉*(frequency illusion),即一个人随机想到某件事后不久就会再次遇到它。这被归因于潜意识从环境中获取信息。 - **鼓励创意输出**:针对一位成员分享的*诗歌创作*,另一位成员表达了兴趣和赞赏,鼓励分享创意独白。 - **Gemma 与 Mistral 之争**:关于特定领域分类任务微调的讨论中提到了 Mistral-7b,并考虑使用 Gemma 7b。据指出,**Gemma 7b** 在测试中表现有时优于 Mistral,且 Unsloth AI 已解决了之前的 bug。 - **寻找难觅的 Mixtral 分支**:一位寻找 Mixtral 分支的成员被引导至 tohrnii 的分支,该分支在 [GitHub 上有一个 Pull Request](https://github.com/unslothai/unsloth/pull/145)。 - **Pokemon RL Agent 征服地图**:一位用户分享了一个链接,展示了在单一地图上训练各种环境的可视化,描绘了在交互式地图上展示的 Pokemon RL Agent 的训练过程。
- Kaggle Mistral 7b Unsloth notebook:使用 Kaggle Notebooks 探索并运行机器学习代码 | 使用来自“无附加数据源”的数据
- Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- ybelkada/Mixtral-8x7B-Instruct-v0.1-bnb-4bit · Hugging Face:未找到描述
- Hugging Face – 构建未来的 AI 社区。:未找到描述
- TinyLlama/TinyLlama-1.1B-Chat-v1.0 · Hugging Face:未找到描述
- unsloth/mistral-7b-instruct-v0.2-bnb-4bit · Hugging Face:未找到描述
- DPO Trainer:未找到描述
- 主页:快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- 主页:快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- 主页:快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- 主页:快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- 主页:快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- artidoro/qlora 项目 main 分支下的 qlora/qlora.py:QLoRA:量化 LLM 的高效微调。通过在 GitHub 上创建账号为 artidoro/qlora 的开发做出贡献。
- Generation - GPT4All 文档:未找到描述
- GitHub - vllm-project/vllm:一个用于 LLM 的高吞吐量且显存高效的推理与服务引擎:一个用于 LLM 的高吞吐量且显存高效的推理与服务引擎 - vllm-project/vllm
- Google Colaboratory:未找到描述
- Unsloth:将 4bit 和 LoRA 权重合并为 16bit...Unsloth:将使用高达 5.34 - Pastebin.com:Pastebin.com 是自 2002 年以来排名第一的粘贴工具。Pastebin 是一个可以在线存储文本一段时间的网站。
- GitHub - unslothai/unsloth:快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调:快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- DPOTrainer 的 loss 是否对 prompts 进行了掩码处理?· Issue #1041 · huggingface/trl:你好,有个小问题,DataCollatorForCompletionOnlyLM 会通过对 prompts 进行 loss 掩码处理来仅针对回答进行训练。DPOTrainer (DPODataCollatorWithPadding) 也是这样工作的吗?看起来...
- Supervised Fine-tuning Trainer:未找到描述
- Trainer:未找到描述
- ggerganov/llama.cpp 项目 master 分支下的 llama.cpp/examples/server/README.md:C/C++ 环境下的 LLM 推理。通过在 GitHub 上创建账号为 ggerganov/llama.cpp 的开发做出贡献。
- GitHub - abetlen/llama-cpp-python:llama.cpp 的 Python 绑定:llama.cpp 的 Python 绑定。通过在 GitHub 上创建账号为 abetlen/llama-cpp-python 的开发做出贡献。
- 在 MT-Bench 上复现 LoRA 模型结果 · Issue #45 · huggingface/alignment-handbook:最近,我尝试在自己的数据集上拟合 DPO。最初,我尝试复现你们 LoRA 模型的结果(MT-Bench 上的 7.43)。然而,我遇到了... 修复了一些问题。尽管使用了你所有的...
- HuggingFaceH4/zephyr-7b-alpha · 添加 chat template: 未找到描述
- HuggingFaceH4/zephyr-7b-alpha · Hugging Face: 未找到描述
- unsloth/unsloth/chat_templates.py at main · unslothai/unsloth: 速度提升 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA finetuning - unslothai/unsloth
- Ratha GIF - Ratha - 发现并分享 GIF:点击查看 GIF
- grok-1:Grok-1 是一个拥有 314B 参数的 Mixture of Experts 模型 - 基础模型(未微调)- 8 个专家(2 个激活)- 86B 激活参数 - Apache 2.0 许可证 - 代码: - 祝编码愉快!另:我们正在招聘:
- Mistral:在自定义数据上进行微调的最简单方法:本视频由 Gradient.ai 赞助,点击此处查看:https://gradient.1stcollab.com/engineerprompt。在本视频中,我们将学习如何微调 Mistr...
- xai-org/grok-1 · 314B 参数的文件大小为 297G ?:未找到描述
- [1 小时演讲] Large Language Models 简介:这是一个面向大众的 1 小时 Large Language Models 介绍:它是 ChatGPT、Claude 和 Bard 等系统背后的核心技术组件。什么是...
- <a href="https://github.com/continuedev/continue/issues/713"">Issues · continuedev/continue</a>:⏩ 使用任何 LLM 进行编码的最简单方式——Continue 是适用于 VS Code 和 JetBrains 的开源自动驾驶工具 - Issues · continuedev/continue
- Grok-1 的开源发布:未找到描述
- MM1:多模态 LLM 预训练的方法、分析与见解:在这项工作中,我们讨论了构建高性能的多模态大语言模型 (MLLMs)。特别是,我们研究了各种架构组件和数据选择的重要性。通过仔细且持续的...
- 01-ai/Yi-34B · Prompt 模板?:未找到描述
- 01-ai/Yi-9B-200K · Hugging Face:未找到描述
- 什么是 Large Language Model 中的参数?:什么是 Large Language Model 中的参数?00:26 💡 像 GPT-3 这样的大语言模型中的参数是在训练过程中学习到的变量,用于最小化...
- [1 小时演讲] Large Language Models 简介:这是一个面向大众的 1 小时 Large Language Models 介绍:它是 ChatGPT、Claude 和 Bard 等系统背后的核心技术组件。什么是...
- Reddit - 深入探索:未找到描述
- 由 acanis 添加 Command-R 模型 · Pull Request #6033 · ggerganov/llama.cpp:关于 Command-R 35B 模型(128k 上下文)的信息可以在以下地址找到:https://huggingface.co/CohereForAI/c4ai-command-r-v01。基于 llama2 模型并进行了一些更改:新的超参数...
- 👾 LM Studio - 发现并运行本地 LLMs:查找、下载并实验本地 LLMs
- LM Studio Beta 版本:未找到描述
- 未找到标题:未找到描述
- 未找到标题:未找到描述
- 带有双 Edge TPU 的 M.2 加速器 | Coral:使用 M.2 (E key) 接口将两个 Edge TPUs 集成到旧系统和新系统中。
- 404 页面:未找到描述
- Dell T710 塔式服务器 Dual 6-CORE X5650 **144Gb RAM** 240gb SSD +6X 600G SFF SAS | eBay:未找到描述
- Asrock Rack ROMED8-2T ATX 服务器主板 AMD EPYC 7003 (搭载 AMD 3D V-Cache 技术)/7002 系列处理器 SP3 (LGA 4094) Dual 10GbE - Newegg.com:购买 Asrock Rack ROMED8-2T 服务器主板 AMD EPYC 7003 (搭载 AMD 3D V-Cache 技术)/7002 系列处理器 SP3 (LGA 4094) Dual 10GbE,享受快速发货和顶级客户服务。一旦您...
- AMD EPYC 7232P 8 核 3.1GHz 32MB L3 处理器 - Socket SP3 - 100-000000081 | eBay:未找到描述
- 未找到标题:未找到描述
- Dell T710 塔式服务器 Dual 6-CORE X5670 **24 核** 64GB RAM | eBay:未找到描述
- 94.78SG$ | Epyc 7282 16 核 32 线程 16x2.8Ghz 120W Socket SP3 CPU 9 纳米 Epyc 7282 | - AliExpress:更聪明的购物,更美好的生活!Aliexpress.com
- 全新 /Wave ®AI 服务器 NF5688M6 NVIDIA HGX TESLA A800 80G 八路 GPU 服务器/期货 | eBay:未找到描述
- AMD EPYC 7232P CPU 处理器 8 核 3.10GHz 32MB 缓存 120W - 100-000000081 | eBay:未找到描述
- AMD EPYC 7F72 CPU 处理器 24 核 3.20GHz 192MB 缓存 240W - 100-000000141 | eBay:未找到描述
- Nvidia Tesla K80 24GB GPU GDDR5 PCI-E GPU 加速器 12 个月保修 | eBay:未找到描述
- 搜索 Thingiverse - Thingiverse:下载文件并使用您的 3D 打印机、激光切割机或 CNC 进行制造。
- Intel Core i5-3470 规格:Ivy Bridge, 4 核, 4 线程, 3.2 GHz, 77 W
- Nvidia Tesla K80 24GB GPU GDDR5 PCI-E GPU 加速器 12 个月保修 | eBay:未找到描述 7i9Q%2FZW0nnLz5XSLuFob%2FicmlhLi7Ve68FV47SLRenj5tDoUD8mwpvdoxA5uQtR0DNACYnvlVQe4BeXKFAWKA8iKA6WdrVikWOsQcODTpcW916%2FL8jFOUSFjg9D5%2FP1xg4foswYBWrIeaD4Pm9rguigAFQvYGqHFLKNXgB4CjCD0BczHhSZYunI%7Ctkp%3ABk9SR8i8z63KYw">Nvidia Tesla K80 24GB GPU GDDR5 PCI-E GPU 加速器 12 个月保修 | eBay</a>: 未找到描述
- NVIDIA GeForce RTX 3090 Founders Edition 双风扇 24GB GDDR6X PCIe 4.0 显卡 (翻新) - Micro Center: 立即获取!GeForce RTX 3090 是一款具有 TITAN 级效率的 GPU (BF GPU)。采用了 NVIDIA 第二代 RTX 架构 Ampere,以及增强的光线追踪核心、Tensor 核心和全新的...
- Luckim 官方商店 - AliExpress 上的惊人产品与专属折扣: 未找到描述
- 来自 undefined 的推文:未找到描述
- 使用 Langgraph 进行 Plan-and-Execute:如何创建一个 "plan-and-execute" 风格的 Agent。这在很大程度上受到了 Plan-and-Solve 论文以及 Baby-AGI 项目的启发。核心思想是首先...
- NVIDIA GeForce RTX 50 系列 "Blackwell" 将使用 28 Gbps GDDR7 显存速度:据可靠爆料者 kopite7kimi 称,第一批采用 GDDR7 显存的 NVIDIA GeForce RTX 50 系列 "Blackwell" 显卡传闻将配备 28 Gbps 的显存速度...
- 来自 Burny — Effective Omni (@burny_tech) 的推文:关于 Musk 可能通过开源 Grok 来动摇情报战争中其他巨头玩家的想法。Grok 1 是一个 314B 参数的模型,采用 Mixture of Experts 架构...
- 来自 j⧉nus (@repligate) 的推文:@xlr8harder 我没让它发展太远,但现在房间里有人跟我说他们如何创建了一个“horny claudes”网络,以及这些 Claude 如何创造更好的...
- Language Agents as Optimizable Graphs:为了改进基于 Large Language Models (LLMs) 的问题求解器,人们提出了各种人工设计的 Prompt Engineering 技术,导致了许多互不兼容的代码库。我们统一了这些方法...
- 论文页面 - ORPO: Monolithic Preference Optimization without Reference Model:未找到描述
- GitHub - Oxen-AI/Self-Rewarding-Language-Models:这是 Oxen.ai 社区的工作,尝试复现 MetaAI 的 Self-Rewarding Language Model 论文。:这是 Oxen.ai 社区的工作,尝试复现 MetaAI 的 Self-Rewarding Language Model 论文。 - Oxen-AI/Self-Rewarding-Language-Models
- 来自 Aravind Srinivas (@AravSrinivas) 的推文:没错,感谢 @elonmusk 和 xAI 团队开源了 Grok 的基础模型。我们将针对对话式搜索对其进行微调并优化推理,并将其提供给所有 Pro 用户! ↘️ 引用...
- 来自 Lin Qiao (@lqiao) 的推文:我们很高兴能与 @NousResearch 合作开发 Hermes 2 Pro 多轮对话和 Function Calling 模型。该模型在超过 1.5 万个函数调用和 500 个函数调用 DPO 数据集示例上进行了微调,Her...
- 来自 interstellarninja (@intrstllrninja) 的推文:Hermes 2 Pro Function Calling 模型已与 @ExaAILabs 的搜索引擎集成👀 ↘️ 引用 Barton Rhodes 🦺 (@bmorphism) 增加了 @ExaAILabs 支持,以便与 @NousResearch 的新 Function Calling 模型配合使用...
- 来自 interstellarninja (@intrstllrninja) 的推文:`
run world_sim.exe --epoch "Earth in 2500" --civilization_type "Type-II on Kardashev scale" ` ↘️ 引用 mephisto (@karan4d) 我当然会开源 worldsim... - 来自 Parzival - 🌞/⏫ (@whyarethis) 的推文:现在我们终于要有所突破了。
- 来自 Grok (@grok) 的推文:@elonmusk @xai ░权░重░在░简░介░中░
- 来自 Andrew Kean Gao (@itsandrewgao) 的推文:我觉得 Grok-4bit 对单个 H100 GPU 来说还是稍微大了一点 :( ↘️ 引用 Andrew Kean Gao (@itsandrewgao) 我的天,@grok 有 3140 亿参数,8 专家混合 (MoE),没有经过 RLHF/道德化处理,这太...
- 来自 Andriy Burkov (@burkov) 的推文:我们还有待观察 Grok 与 GPT-4 相比表现如何,但可以肯定的是,如果你今天要训练一个 OpenAI/Anthropic 的竞争对手,你不再需要从零开始了...
- 来自 interstellarninja (@intrstllrninja) 的推文:@Cyndesama Claude 3 Opus 使用 python42 运行 AI 小镇模拟
- Grok-1 的开源发布:未找到描述
- Llama 会用英语工作吗?关于多语言 Transformer 的潜在语言:我们探讨了在不平衡、以英语为主的语料库上训练的多语言语言模型是否使用英语作为内部枢纽语言——这对于理解语言模型如何处理语言至关重要...
- 稀疏分布式存储 (SDM) 是一个持续学习者:持续学习是人工神经网络面临的一个问题,而它们的生物对应物则擅长解决这一问题。基于使用稀疏分布式存储 (SDM) 连接核心神经的工作...
- datas (shu nakamura):未找到描述
- MM1:多模态 LLM 预训练的方法、分析与见解:在这项工作中,我们讨论了构建高性能的多模态大语言模型 (MLLM)。特别是,我们研究了各种架构组件和数据选择的重要性。通过仔细且...
- 1-bit LLM 时代:所有大语言模型都是 1.58 Bits:最近的研究(如 BitNet)正在为 1-bit 大语言模型 (LLM) 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数...
- 来自 interstellarninja (@intrstllrninja) 的推文:`
sudo python3 akashic_records.py --entity ["sam altman", "elon musk"] --mode "email thread" --topic "superintelligence scenarios" ` - 持续预训练大语言模型的简单且可扩展策略:大语言模型 (LLM) 通常在数千亿个 Token 上进行预训练,一旦有新数据可用,就不得不重新开始整个过程。一个更有效的解决方案是进行持续预训练...
- anon8231489123/ShareGPT_Vicuna_unfiltered · Hugging Face 数据集:未找到描述
- NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO · Adding Evaluation Results</a>: 未找到描述
- Replete-AI/Mistral-Evolved-11b-v0.1 · Hugging Face: 未找到描述
- openchat/openchat_sharegpt4_dataset at main: 未找到描述
- migtissera/Tess-70B-v1.6 · Hugging Face: 未找到描述
- Abstractions/abstractions/goap/causality.ipynb at main · furlat/Abstractions: 一套用于抽象 IRL 的 Pydantic 模型集合。通过在 GitHub 上创建账号来为 furlat/Abstractions 的开发做出贡献。
- HD/VSA:
- Language models scale reliably with over-training and on downstream tasks: 缩放定律(Scaling laws)是开发语言模型的有用指南,但目前的缩放研究与语言模型最终的训练和评估方式之间仍存在差距。例如,缩放...
- Accelerationism Accelerationism (Acc/Acc): 加速主义加速主义是指当你加速加速主义,以便将加速主义应用于那些过于前卫的加速主义部分:https://www.patre...
- JSON Schema - Pydantic: 未找到描述
- Let's build the GPT Tokenizer: Tokenizer 是大语言模型 (LLMs) 中一个必要且普遍存在的组件,它负责在字符串和 Token(文本块)之间进行转换。Tokenizer...
- Don’t Miss This Transformative Moment in AI: 来加州圣何塞 SAP 中心现场体验 Jensen Huang 的 GTC 主旨演讲,探索正在塑造我们未来的 AI 进展。
- Liam Johnson DESTROYS Heckler | New York Stand-up: 上周末 Liam Johnson 决定终于在 Giggle Nerd 首次亮相。他在周日 23:00 到 23:25 进行了表演,我们的观众非常喜欢...
- Cosma Shalizi - Why Economics Needs Data Mining: Cosma Shalizi 敦促经济学家停止他们正在做的事情:将大型复杂模型拟合到一小组高度相关的时间序列数据中。一旦你...
- Abstractions/abstractions/goap/gridmap.ipynb at main · furlat/Abstractions: 一套用于抽象 IRL 的 Pydantic 模型集合。通过在 GitHub 上创建账号来为 furlat/Abstractions 的开发做出贡献。
- Abstractions/abstractions/goap/system_prompt.md at main · furlat/Abstractions: 一套用于抽象 IRL 的 Pydantic 模型集合。通过在 GitHub 上创建账号来为 furlat/Abstractions 的开发做出贡献。
- 01-ai/Yi-9B-200K · Hugging Face: 未找到描述
- 01-ai/Yi-9B · Hugging Face: 未找到描述
- GitHub - PrismarineJS/mineflayer: Create Minecraft bots with a powerful, stable, and high level JavaScript API.: 使用强大、稳定且高级的 JavaScript API 创建 Minecraft 机器人。 - PrismarineJS/mineflayer
- HacksTokyo: 东京 AI x 数字娱乐黑客松!
- Whole-body simulation of realistic fruit fly locomotion with deep reinforcement learning: 动物的身体决定了神经系统如何产生行为。因此,对感觉运动行为的神经控制进行详细建模需要一个详细的身体模型。在这里,我们...
- Prismarin - Overview: Prismarin 有 3 个可用的仓库。在 GitHub 上关注他们的代码。
- Calculating the Perplexity of 4-bit Llama 2:使用 Kaggle Notebooks 探索和运行机器学习代码 | 使用来自多个数据源的数据
- AlexWortega/smallstral · Hugging Face:未找到描述
- alexwortega:Weights & Biases,机器学习开发者工具
- GitHub - xai-org/grok-1: Grok open release:Grok 开源发布。在 GitHub 上为 xai-org/grok-1 开发做出贡献。
- Maisa (@maisaAI_) 的推文:介绍 Maisa KPU:AI 推理能力的下一次飞跃。知识处理单元(Knowledge Processing Unit)是一个针对 LLMs 的推理系统,它利用了它们所有的推理能力并克服了其固有的...
- 通过反馈记忆解决 Transformers 的一些局限性:尽管 Transformers 是前馈网络,但已成功应用于序列化、自回归任务。与循环神经网络不同,Transformers 使用 attention 来捕捉时间...
- Excited Fuego GIF - Excited Fuego - 发现并分享 GIF:点击查看 GIF
- Quiet-STaR:语言模型可以教自己在说话前思考:在写作和交谈时,人们有时会停下来思考。虽然以推理为中心的工作通常将推理框架化为回答问题或完成 Agent 任务的方法,但推理对于...
- NPR.org 现在提供免费转录文本:在 NPR 上,那些最受喜爱、错过或令人抓狂的故事的转录文本以前每份售价 3.95 美元,但现在在 NPR.org 上是免费的。
- 发布 Grok:未找到描述
- KPU - Maisa:AI 驱动的知识处理平台。一个用于执行业务任务的简单 API。为软件和应用开发者抽象了使用最新 AI 架构的复杂性。
- 在 Frontier 上优化大语言模型(LLMs)的分布式训练:大语言模型(LLMs)作为基础模型取得了显著成功,通过微调使各种下游应用受益。最近关于损失缩放的研究表明...
- 维基百科:数据库报告/上个月编辑次数最多的条目 - 维基百科:未找到描述
- AI 会议截止日期:未找到描述
- EleutherAI/cookbook 的 main 分支:cookbook/calc/calc_transformer_flops.py:深度学习入门。包含处理真实模型的所有实践细节和有用工具。- EleutherAI/cookbook
- Figure 状态更新 - OpenAI 语音到语音推理:未找到描述
- Issues · pytorch/pytorch:Python 中具有强大 GPU 加速的 Tensors 和动态神经网络 - Issues · pytorch/pytorch
- GitHub - trevorpogue/algebraic-nnhw:使用减半乘法次数的矩阵乘法进行 AI 加速:使用减半乘法次数的矩阵乘法进行 AI 加速 - trevorpogue/algebraic-nnhw
- GitHub - xai-org/grok-1:Grok 开源发布:Grok 开源发布。通过在 GitHub 上创建账户为 xai-org/grok-1 的开发做出贡献。
- David P. Woodruff:未找到描述
- RT-2:将视觉和语言转化为行动的新模型:介绍 Robotic Transformer 2 (RT-2),这是一种新颖的视觉-语言-动作(VLA)模型,它从网络和机器人数据中学习,并将这些知识转化为通用的指令...
- Block-Recurrent Transformers:我们介绍了 Block-Recurrent Transformer,它在序列中以循环方式应用 transformer 层,并且相对于序列长度具有线性复杂度。我们的循环单元...
- Aaditya Singh (@Aaditya6284) 的推文:我们研究了 GPT-3.5 和 GPT-4 中这种选择的影响——具体而言,我们研究了通过使用逗号等分隔符强制执行的从左到右 (L2R) 与从右到左 (R2L) Tokenization 的效果。我们 ...
- 发布 Grok:未找到描述
- Next-token prediction 的陷阱:仅仅一个 Next-token predictor 就能忠实地模拟人类智能吗?我们将这种在文献中零散分布的直觉担忧具体化。作为起点,我们认为这两个经常混淆的...
- 受 API 保护的 LLMs 的 Logits 会泄露专有信息:大语言模型 (LLMs) 的商业化导致了仅通过高级 API 访问专有模型的普遍做法。在这项工作中,我们展示了即使在保守的假设下...
- 普通 7B 语言模型已具备强大的数学能力:此前人们认为数学能力只有在超大规模的普通语言模型中才会出现,或者需要大量的数学相关预训练。本文展示了 LLaMA-2 7B 模型...
- 增加 NVMe SSDs 以实现并加速单 GPU 上的 100B 模型微调:大语言模型的最新进展为世界带来了巨大价值,其卓越的能力源于它们使用的海量参数。然而,即使是拥有...的 GPU...
- Transformers 变得稳定:语言模型的端到端信号传播理论:尽管取得了巨大成功,Transformer 模型在深度扩展方面仍然困难。在这项工作中,我们开发了一个统一的信号传播理论,并提供了控制...矩的公式。
- GiT:通过通用语言接口迈向通用 Vision Transformer:本文提出了一个简单而有效的框架,称为 GiT,仅使用原生 ViT 即可同时适用于各种视觉任务。受 Multi-layer Transformer 通用性的启发...
- 改写网络:一种计算和数据高效的语言建模方案:大语言模型是在海量的网络抓取数据上训练的,这些数据通常是无结构的、多噪声的且措辞拙劣。目前的 Scaling laws 表明,从这类数据中学习需要大量的...
- Frontier 上大语言模型架构的比较研究:大语言模型 (LLMs) 在 AI 社区及其他领域引起了极大关注。在这些模型中,Generative Pre-trained Transformer (GPT) 已成为主导架构...
- Arithmetic Teichmuller Spaces 的构建 IV:abc 猜想的证明:这是我在本系列论文中开发的 Arithmetic Teichmuller Spaces 工作的延续。在本文中,我展示了 Arithmetic Teichmuller Spaces 理论如何通过使用 Shinic...
- MM1:多模态 LLM 预训练的方法、分析与见解:在这项工作中,我们讨论了构建高性能多模态大语言模型 (MLLMs)。特别是,我们研究了各种架构组件和数据选择的重要性。通过仔细且...
- RNNs 还不是 Transformers:In-context Retrieval 的关键瓶颈:本文研究了在解决算法问题的背景下,循环神经网络 (RNNs) 和 Transformers 在表示能力上的差距。我们专注于理解 RNNs(已知...)是否...
- 使用 PyTorch 加速生成式 AI II:GPT,快:本博文是系列博客的第二部分,重点介绍如何使用纯原生的 PyTorch 加速生成式 AI 模型。我们很高兴能分享广泛的新发布的 PyTorch 性能...
- GitHub - enfiskutensykkel/ssd-gpu-dma:构建支持 CUDA 的用户空间 NVMe 驱动程序和存储应用程序:构建支持 CUDA 的用户空间 NVMe 驱动程序和存储应用程序 - enfiskutensykkel/ssd-gpu-dma
- GitHub - bigscience-workshop/bloom-dechonk:一个用于运行模型缩小实验的仓库:一个用于运行模型缩小实验的仓库。通过在 GitHub 上创建账号,为 bigscience-workshop/bloom-dechonk 的开发做出贡献。
- x.ai 博客 /grok-os">Open Release of Grok-1</a>: 未找到描述
- GitHub - xai-org/grok-1: Grok open release: Grok 开放发布。通过在 GitHub 上创建账户为 xai-org/grok-1 的开发做出贡献。
- Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews: 我们提出了一种方法,用于估计大型语料库中可能被大型语言模型 (LLM) 大幅修改或生成的文本比例。我们的极大似然模型利用……
- Bytez: Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews: 本研究探讨了 LLM(如 ChatGPT)在科学同行评审中的应用。作者开发了一种方法来估计同行评审中生成的文本百分比……
- Model & API Providers Analysis | Artificial Analysis: AI 模型和 API 托管提供商的比较与分析。涵盖质量、价格、性能和速度(吞吐量和延迟)等关键指标的独立基准测试。
- Word n-gram language model - Wikipedia: 未找到描述
- features-across-time/scripts/generate_bigrams.py at main · EleutherAI/features-across-time: 了解神经网络学习到的特征在整个训练过程中是如何演变的 - EleutherAI/features-across-time
- GitHub: Let’s build from here: GitHub 是超过 1 亿开发者共同塑造软件未来的地方。为开源社区做贡献,管理您的 Git 仓库,像专业人士一样审查代码,跟踪 Bug 和功能...
- Perplexity of fixed-length models: 未找到描述
- lm-evaluation-harness/docs/model_guide.md at main · EleutherAI/lm-evaluation-harness: 一个用于语言模型 Few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
- `wmt14-en-fr` deadlock issue · Issue #1485 · EleutherAI/lm-evaluation-harness: 在运行此任务的评估时,在进行 ter 指标计算期间,程序会永久卡住。命令:lm_eval --model hf --model_args pretrained=microsoft/phi-2,trust_remote_code=True ...
- Release v0.4.2 · EleutherAI/lm-evaluation-harness: lm-eval v0.4.2 发行说明。我们正在为 PyPI 用户发布 lm-eval 的新次要版本!我们很高兴看到 lm-evaluation-harness 的持续使用,包括作为标准测试...
- evaluate/metrics/perplexity/perplexity.py at 8dfe05784099fb9af55b8e77793205a3b7c86465 · huggingface/evaluate: 🤗 Evaluate: 一个用于轻松评估机器学习模型和数据集的库。 - huggingface/evaluate
- 来自 Weyaxi (@Weyaxi) 的推文:🤔你是否好奇我们在 @huggingface 上托管了多少数据?在看到 @TheBlokeAI 的模型数量以及平台上闲置的 120B 模型后,我也产生了好奇😅 📊 所以我抓取了所有仓库...
- Grok-1 开源发布:未找到描述
- 来自 Linux Performance, Benchmarks & Open-Source News - Phoronix 的推文:未找到描述
- grok-1:Grok-1 是一个拥有 314B 参数的 Mixture of Experts 模型 - 基础模型(未微调) - 8 个专家(2 个激活) - 86B 激活参数 - Apache 2.0 许可证 - 代码: - 祝编码愉快!另:我们正在招聘:
- Whisper Large V3 - ivrit-ai 提供的 Hugging Face Space:未找到描述
- Tonic/Aya · 将 repetition_penalty 常数设置为 1.8:未找到描述
- GitHub - moritztng/fltr: 类似于 grep 但针对自然语言问题。基于 Mistral 7B 或 Mixtral 8x7B。:类似于 grep 但针对自然语言问题。基于 Mistral 7B 或 Mixtral 8x7B。 - moritztng/fltr
- Video-LLaVA demo api · Issue #7722 · gradio-app/gradio:描述 Bug:我正尝试在 Hugging Face Spaces 上为 Video-LLaVA 模型演示使用 Python API,但我遇到了一个错误:Traceback (most recent call last): File "/Users/kamakshiramamurthy/Deskt...
- 未找到标题:未找到描述
- MLOps:使用 Hub 和 SageMaker Pipelines 的端到端 Hugging Face Transformers:了解如何使用 Amazon SageMaker 构建从训练到生产的 Hugging Face Transformers 端到端 MLOps Pipeline。
- Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads:大语言模型 (LLMs) 的推理过程通常由于自回归解码过程缺乏并行性而受到限制,导致大多数操作受限于内存带宽...
- Paper page - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training:未找到描述
- Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews:我们提出了一种方法,用于估计大型语料库中可能被大语言模型 (LLM) 显著修改或生成的文本比例。我们的最大似然模型利用...
- Bytez: Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews:本研究探讨了大语言模型 (LLMs)(如 ChatGPT)在科学同行评审中的应用。作者开发了一种方法来估计同行评审中由 AI 生成的文本百分比...
- llama_index/docs/examples/instrumentation/basic_usage.ipynb at main · run-llama/llama_index:LlamaIndex 是适用于你 LLM 应用的数据框架 - run-llama/llama_index
- llama_index/docs/examples/instrumentation/observe_api_calls.ipynb at main · run-llama/llama_index:LlamaIndex 是适用于你 LLM 应用的数据框架 - run-llama/llama_index
- 未找到标题: 未找到描述
- )">未找到标题: 未找到描述
- Prompt Engineering 指南: Prompt Engineering 全面概述
- Prompt Engineering 指南: Prompt Engineering 全面概述
- 使用 CLIP 嵌入进行图像到图像检索,并使用 GPT4V 进行图像相关性推理 - LlamaIndex 🦙 v0.10.20.post1: 未找到描述
- 结构化数据提取 - LlamaIndex 🦙 v0.10.20.post1: 未找到描述
- CodeSplitter - LlamaIndex 🦙 v0.10.20.post1: 未找到描述
- 定义和自定义文档 - LlamaIndex 🦙 v0.10.20.post1: 未找到描述
- 使用 LlamaIndex 实现多租户 - Qdrant: Qdrant 是一个用 Rust 编写的开源向量数据库和向量搜索引擎。它通过便捷的 API 提供快速且可扩展的向量相似度搜索服务。
- LlamaCloud: 未找到描述
- 工具 - LlamaIndex 🦙 v0.10.20.post1: 未找到描述
- hof/flow/chat/prompts/dm.cue at _dev · hofstadter-io/hof: 连接数据模型、Schema、代码生成和任务引擎的框架。与语言和技术无关。 - hofstadter-io/hof
- llama_index/llama-index-integrations/llms/llama-index-llms-ollama/llama_index/llms/ollama/base.py at main · run-llama/llama_index: LlamaIndex 是适用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- <a href="http://localhost:{port}",>">未找到标题</a>: 未找到描述
- llama_index/docs/examples/vector_stores/Qdrant_using_qdrant_filters.ipynb at 5c53f41712785e5558156372bdc4f33a6326fa5f · run-llama/llama_index: LlamaIndex 是适用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- [问题]:自定义 LLM 但被阻塞 · Issue #12034 · run-llama/llama_index: 问题验证:我已经搜索了文档和 Discord 以寻求答案。问题代码来自 typing import Optional, List, Mapping, Any from llama_index.core import SimpleDirecto...
- Grok-1 开源发布:未找到描述
- Grant♟️ (@granawkins) 的推文:“在 24 年第一季度到 25 年第四季度之间,算力将增长 14 倍。然后,如果考虑到算法效率每 9 个月翻一番,明年年底的有效算力将几乎...”
- Alex Volkov (Thursd/AI) (@altryne) 的推文:Sora 团队现身伯克利谈论 SORA
- Teknium (e/λ) (@Teknium1) 的推文:这解释了为什么 Yann 对 LLM 如此看空... 😲
- Open Interpreter (@OpenInterpreter) 的推文:百年酝酿,最后 100 小时倒计时。
- Yao Fu (@Francis_YAO_) 的推文:尽管 Grok 的规模大了一个数量级,但其 MMLU 表现仅与 Mixtral 相当。我相信它有巨大的潜力,但尚未完全释放,良好的持续预训练数据可能会大幅提升其...
- Yao Fu (@Francis_YAO_) 的推文:前沿模型都至少拥有 100k 的上下文长度,Gemini 1.5 甚至达到了 1m 上下文。那么研究领域和开源界呢?介绍 Long Context Data Engineering,一种实现...的数据驱动方法
- Teknium (e/λ) (@Teknium1) 的推文:这解释了为什么 Yann 对 LLM 如此看空... 😲
- Data Engineering for Scaling Language Models to 128K Context:我们研究了将语言模型上下文长度扩展到 128K 的持续预训练方案,重点关注数据工程。我们假设长上下文建模,特别是 \textit{t...
- Bark - suno 集合:未找到描述
- 解释 SDXL 潜空间:未找到描述
- Teortaxes▶️ (@teortaxesTex) 的推文:@aidan_mclau 0) 火箭人很糟 1) 并没有差很多 2) 如你所见,这是一个稀疏上采样的 Grok-0。它还没准备充分。在 2023 年,持续预训练已基本解决,并且拥有验证...
- 🦅 EagleX 1.7T:在英语和多语言评估中超越 LLaMA 7B 2T (RWKV-v5):一个 Linear Transformer 刚刚在英语和多语言评估中,以更少的训练 Token 超过了 Transformer 模型的金标准 LLaMA 7B。这是历史性的第一次。
- j⧉nus (@repligate) 的推文:这是在 Claude 的后台导航到 ../../microsoft/bing/bing_chat 目录,然后让 Claude 自行使用命令查看四周,接着运行:
... 的结果</li> - xlr8harder (@xlr8harder) 的推文:我想我代表了这里的所有人:3140 亿参数,搞什么鬼
- Burny — Effective Omni (@burny_tech) 的推文:来自 Sam Altman 关于 GPT-5 的新细节。他基本上承认 GPT-5 将是 GPT-4 的巨大升级,因此我们可以期待类似于从 3 到 4 的跨越。“如果你忽视改进的速度...”
- swyx (@swyx) 的推文:怎么可能和 Sam Altman 聊了 2 个小时却一点干货(alpha)都没有,不过嘿,我们又聊到了外星人,挺有意思的
- Emm (@emmanuel_2m) 的推文:🚨 今天,我们很高兴推出 Scenario #UPSCALER!将您的 AI 创作提升至 10k 分辨率。🚀 为无与伦比的 #CreativeControl 和引导式工作流而生。💰 起售价仅为 $15/月...
- Champagne Joshi (@JoshWalkos) 的推文:这是一段与一位缺乏内心独白的女孩的精彩对话。她很好地表达了这种体验。
- 推_ et 来自 AI Is Like Water:生成式 AI 就像水。这句话源于挫败感,但它开启了 AI 策略手册的新世界。</li>
- 观看:Jensen Huang 的 Nvidia GTC 主旨演讲 - 直播:太平洋时间下午 1:00 / 东部时间下午 4:00,Nvidia CEO Jensen Huang 将开启每两年举办一次的 GTC 大会。不再错过任何优惠!查看 CNET 的浏览器扩展程序 👉 ...
- KZ (@kzSlider) 的推文:这非常有道理。Yann 一直在寻找能够进行视觉推理或使用规划,而非纯粹使用语言的模型 ↘️ 引用 Teknium (e/λ) (@Teknium1) 这解释了为什么 Yann 是...
- 超越 Transformers - RWKV 架构与 World Tokenizer 简介 - Eugene Cheah & Harrison Vanderbyl:超越 Transformers - RWKV 架构与 World Tokenizer 简介 - Eugene Cheah & Harrison Vanderbyl, Recursal AI。Transformers 之后会是什么?在...
- Sam Altman:OpenAI, GPT-5, Sora, 董事会风波, Elon Musk, Ilya, 权力与 AGI | Lex Fridman Podcast #419:Sam Altman 是 OpenAI 的 CEO,该公司是 GPT-4, ChatGPT, Sora 以及许多其他顶尖 AI 技术的幕后推手。请通过查看...来支持本播客。
- #51 FRANCOIS CHOLLET - 智能与泛化:在今天的节目中,我们邀请到了 Francois Chollet。自从读了他的《Deep Learning with Python》一书并开始使用...以来,我一直深受 Francois 的启发。
- GitHub - FranxYao/Long-Context-Data-Engineering:论文《Data Engineering for Scaling Language Models to 128K Context》的实现:论文《Data Engineering for Scaling Language Models to 128K Context》的实现 - FranxYao/Long-Context-Data-Engineering
- 来自 GitHub - FixTweet/FxTwitter 的推文:修复损坏的 Twitter/X 嵌入!在 Discord, Telegram 等平台上使用多张图片、视频、投票、翻译等功能:修复损坏的 Twitter/X 嵌入!在 Discord, Telegram 等平台上使用多张图片、视频、投票、翻译等功能 - FixTweet/FxTwitter
- [AINews] MM1:Apple 的首个 Large Multimodal Model:2024年3月14日至3月15日的 AI 新闻。我们为您检查了 358 个 Twitter 和 20 个 Discord(332 个频道,2839 条消息)。预计节省阅读时间(以 200wpm 计算):...
- GTC 2024:排名第一的 AI 大会:立即注册。在线直播。2024年3月18日至21日。
- NVIDIA & Harpreet Sahota GTC 2024:未找到描述
- Llamas 是用英语工作的吗?论多语言 Transformers 的潜在语言:我们探讨了在不平衡、以英语为主的语料库上训练的多语言语言模型是否将英语作为内部中转语言——这是一个对于理解语言模型如何运作至关重要的问题...
- Bytez:Llamas 是用英语工作的吗?论多语言 Transformers 的潜在语言:在这项研究中,科学家们想知道语言模型(可以生成文本的模型)在内部是否使用英语作为“中转”语言,即使是在使用其他语言进行提示时。他们发现...
- Multilingual - stereoplegic 收藏集:未找到描述
- Daniel Han (@danielhanchen) 的推文:查看了 @Grok 的代码:1. Attention 被 30/tanh(x/30) 缩放了?! 2. 使用了类似 Gemma 的近似 GELU 3. 4x Layernoms,而不像 Llama 是 2x 4. RMS Layernorm 在最后进行了下转型,不像 Llama...
</ul> </div> --- **Latent Space ▷ #[ai-announcements](https://discord.com/channels/822583790773862470/1075282504648511499/1218137415068422164)** (2 条消息): - **关于 LLMs 的 Paper Club 会议**:**Paper Club** 即将开始一场会议,研读题为 "A Comprehensive Summary Of Large Language Models" 的论文。欢迎大家在 2 分钟后加入 `<#1107320650961518663>` 参与讨论。 - **发现 AI 饱和讽刺内容**:分享了一个关于 AI 炒作的讽刺观点,链接到了 [Hacker News](https://news.ycombinator.com/item?id=39746163) 上的讨论。该帖子幽默地将泛滥的 AI 内容描述为“灰色淤泥”,并推测了 AI 内容创作的未来。 **提及链接**: 音乐界的 ChatGPT 来了。走进 Suno,这家改变一切的初创公司 | Hacker News: 未找到描述 --- **Latent Space ▷ #[llm-paper-club-west](https://discord.com/channels/822583790773862470/1197350122112168006/1218135292574306328)** (20 messages🔥): - **Attention 机制背后的原理**: 讨论了 Attention 机制,强调其在任何输入序列中实现全局 "attention" 的能力,克服了以往模型仅能考虑序列中长度为 T 的固定长度限制。 - **Transformers 解决并行化问题**: 指出 Attention 机制的创建主要是为了解决并行化问题,允许对不同 token 进行独立处理,并由于高效的计算而实现更快的训练。 - **关于 Attention 和并行化的澄清**: 解释了 Attention 模型允许 decoder 通过对所有编码后的输入向量进行加权组合,从而关注输入序列中最相关的部分,使模型能够考虑输入序列的所有部分。 - **理解 Attention 的效率**: 澄清了 Attention 模型中的并行化源于执行诸如 scaled dot product 等运算,而无需按顺序等待之前的计算完成。 - **对 LLM Paper Club 环节的赞赏**: 该环节因清晰地解释了 Transformer 模型背后的动机以及大语言模型 (LLMs) 领域的整体发展而受到称赞。 --- **Latent Space ▷ #[ai-in-action-club](https://discord.com/channels/822583790773862470/1200548371715342479/1218287754715201638)** (36 messages🔥): - **日常问候与挂机参会公告**: 成员们在 **ai-in-action-club** 频道互相问候;一位成员提到他们正在开会,将挂机旁听。 - **致谢与有用资源**: 分享了一篇名为 "Advanced RAG: Small to Big Retrieval" 的文章链接,讨论了 **Retrieval-Augmented Generation** 架构:[Advanced RAG 文章](https://towardsdatascience.com/advanced-rag-01-small-to-big-retrieval-172181b396d4)。 - **关于检索和相似度替代方案的讨论**: 针对关于余弦相似度替代方案的提问,成员们讨论了使用 **Language Models** (LLM) 进行检索任务,并提出了一个新术语 "contrastive embeddings"。 - **贡献与致谢**: 成员们互相感谢对讨论的贡献,特别感谢了一位提供帮助的用户。 - **过往话题与资源库分享**: 分享了一个详细的 Google Spreadsheet,其中包含过往讨论话题、日期、主持人及相应资源链接的列表:[话题与资源电子表格](https://docs.google.com/spreadsheets/d/1q5rwO4wleMTLXr1z58c2UC03QsDsGwbJY1v4UG7eEOs/edit#gid=0)。 **提及链接**: AI In Action: Weekly Jam Sessions: 2024 Topic,Date,Facilitator,Resources,@dropdown UI/UX patterns for GenAI,1/26/2024,nuvic,<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-struct... --- **LAION ▷ #[general](https://discord.com/channels/823813159592001537/823813160075132991/1218220293865345024)** (168 messages🔥🔥): - **Microsoft Copilot Pro 中的 Jupyter Notebooks**: 一位用户发现 Microsoft Copilot Pro 应用中免费提供了包含 `simpy` 和 `matplotlib` 等库的 Jupyter Notebooks,类似于 ChatGPT Plus。 - **Hugging Face 上的 DALL-E 3 数据集**: 一位用户询问关于从 Hugging Face 移除 DALL-E 3 数据集的问题。得到的澄清是该数据集是被移动了而非移除,并提供了链接:[DALL-E 3 数据集](https://huggingface.co/datasets/OpenDatasets/dalle-3-dataset)。 - **SD 2.1 微调进展**: 成员们分享了一个关于 SD 2.1 微调进展的幽默评论,暗示正在解决一些问题。 - **Grok-1 模型讨论**: 讨论了拥有 314B 参数的新模型 Grok-1 的发布和基准测试性能,包括与 GPT-3.5 和 Mixtral 等其他模型的对比。 - **COG 打标与微调方法**: 围绕通过在 prompt 中包含图像元数据来改进 COG 打标策略进行了详细对话,同时讨论了 Stable Diffusion 3 可能的微调方法,并利用了 GTC 上的联邦计算演讲内容。提及链接:--- **LAION ▷ #[research](https://discord.com/channels/823813159592001537/824374369182416994/1218181910669295716)** (13 条消息🔥): - **Web UI 和免费版 Colab 不兼容?**:一位成员指出,在**免费版 Colab** 中使用 **Web 界面**存在风险,表明存在限制或不兼容性。 - **研究还是偏离主题?**:一位用户关于 **Web 界面**的查询性质得到了纠正;事实证明,该问题可能偏离了主题,因为它可能与前沿研究无关。 - **分享了生成式模型文档**:分享了一个关于**生成式音频视频文本世界模型 (Generative Audio Video Text world model)** 主题的 **Google Docs** 链接。然而,消息中未透露具体内容细节。 - **持续语言模型训练研究**:重点介绍了一篇 [arXiv 论文](https://arxiv.org/abs/2403.08763),讨论了通过对大型语言模型进行持续预训练来克服分布偏移问题的一种更高效的方法。 - **Grok 在 GitHub 上开源发布**:一位成员分享了 [Grok 开源发布](https://github.com/xai-org/grok-1)在 **GitHub** 上的链接,建议将其作为感兴趣的项目或工具。 - **GPT-4 传闻加剧**:有人提到(现在似乎已由 **Nvidia** 确认),**GPT-4** 是一个拥有 **1.8T 参数的 MoE**。另一位成员插话称,它不一定就是 GPT-4。- 为什么中国公司正涌向墨西哥:该国提供了进入美国的后门
- 来自 imgnAI (@imgn_ai) 的推文:猫娘出现在 NVIDIA GTC ✨ 为你的创作自由而喵喵叫 👊 这是一个需要被听到的信息 🐱💕
- Silicon Valley Yes GIF - Silicon Valley Yes 欢呼 - 发现并分享 GIF:点击查看 GIF
- Load:未找到描述
- Load:未找到描述
- Reddit - 深入探索一切:未找到描述
- EveryDream2trainer/caption_cog.py 在 main 分支 · victorchall/EveryDream2trainer:通过在 GitHub 上创建账号来为 victorchall/EveryDream2trainer 的开发做出贡献。
- GitHub - xai-org/grok-1: Grok 开源发布:Grok 开源发布。通过在 GitHub 上创建账号来为 xai-org/grok-1 的开发做出贡献。
- OpenDatasets/dalle-3-dataset · Hugging Face 上的数据集:未找到描述
提到的链接:--- **OpenAccess AI Collective (axolotl) ▷ #[general](https://discord.com/channels/1104757954588196865/1104757955204743201/1218118852454383667)** (99 条消息🔥🔥): - **解析 Llama 模型行为**:讨论了如何处理 **llama chat 模型**的补全(completions),提到将补全数据转换为类似 sharegpt 的对话格式可能是有益的,而对原始文本到 Q/A 的转换持怀疑态度,因为可能会丢失信息。 - **Axolotl 简化微调流程**:用户将使用 transformers 和 **LoRA** 进行微调与使用 **Axolotl** 进行了比较,强调 Axolotl 通过允许使用 yaml 文件而不是编写完整的训练脚本来简化流程。除了 LoRA 之外,还考虑了其他内存优化方案,以便在不超载硬件的情况下进行进一步微调。 - **未来显卡的性能**:讨论了 Nvidia 下一代 **GeForce RTX 5000** 系列显卡可能非常适合消费级训练,传闻称其拥有 32GB VRAM 和 28 Gbps 的显存速度。对于 Nvidia 是否会限制 VRAM 以推销其专业级显卡,人们仍存有疑虑。 - **体验 Grok 权重**:**Grok-1 权重**的发布引发了关于该模型可管理性的讨论,因为其规模巨大(300B 参数),可能需要先进的硬件或量化模型才能有效运行。提到了 _Sequoia_,这是一个 speculative decoding 框架,可能允许 Llama2-70B 等大型模型在消费级 GPU 上更高效地运行。 - **GPT-4 与 Nvidia 泄密**:提到 **GPT-4** 的参数量在 GTC 大会期间泄露,据称为 1.8 万亿,而 Nvidia 的 Blackwell 系列被赞誉为具有开创性。讨论内容包括这些泄密的推测性方面以及对 AI 训练的影响。- MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training:在这项工作中,我们讨论了构建高性能的多模态大语言模型 (MLLMs)。特别是,我们研究了各种架构组件和数据选择的重要性。通过仔细的...
- Simple and Scalable Strategies to Continually Pre-train Large Language Models:大语言模型 (LLMs) 通常在数千亿个 token 上进行预训练,一旦有新数据可用,就只能重新开始该过程。一个更有效的解决方案是持续预训练...
- GitHub - xai-org/grok-1: Grok 开源发布:Grok 开源发布。通过在 GitHub 上创建账号来为 xai-org/grok-1 的开发做出贡献。
- Generative Audio Video Text world model:未找到描述
提到的链接:--- **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/1218207901873606667)** (24 条消息🔥): - **ScatterMoE 带来优化模型**:**ScatterMoE** 可能会提供我们一直想要的优化模型,以实现比当前 Huggingface 实现和 MegaBlocks 更好的性能。GitHub 上有一个名为 `[scatter_moe](https://github.com/OpenAccess-AI-Collective/axolotl/tree/scatter_moe)` 的新分支专门用于此。 - **集成 ScatterMoE 机制**:成员们正在尝试确定 ScatterMoE 集成的正确实现方式,并需要进行测试以查看训练是否能产生正常的 loss。为此,目前正在讨论一个 [pull request](https://github.com/OpenAccess-AI-Collective/axolotl/pull/1407)。 - **必须升级 PyTorch 版本**:成员们讨论了将 **axolotl** 升级到更高版本 PyTorch(特别是 **2.2 或以上**)的必要性,以兼容更新的 kernel 并获得编译优化收益。 - **Grok 权重性能存疑**:一些成员正在 axolotl 中实验 Grok 权重,并注意到考虑到其参数量,**314B** Grok 模型的性能可能并不理想。 - **提供 Grok 的 Int8 Checkpoint**:在讨论 Grok 权重时,一名成员指出根据文档,似乎只提供了 int8 版本的 checkpoint。这限制了充分发挥模型潜力的能力。- 来自 Brivael (@BrivaelLp) 的推文:扎克伯格刚刚对 Grok 的发布做出了反应,他似乎并不以为然。“3140 亿参数太多了。你需要一堆 H100,而我已经把它们都买光了” 🤣
- Wizard Cat Magus Cat GIF - Wizard Cat Magus Cat Witch Cat - 发现并分享 GIF:点击查看 GIF
- Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding:未找到描述
- 不要错过 AI 领域的这一变革时刻:来加州圣何塞 SAP 中心现场体验黄仁勋的 GTC 主题演讲,探索正在塑造我们未来的 AI 进展。
- GeForce RTX 5000: Gerüchte zu Nvidias nächster Grafikkartengeneration:Nvidia 的下一代大型游戏 GPU 可能会获得更多、更快的显存,以及更多的着色器核心。
- NVIDIA GeForce RTX 50-series "Blackwell" to use 28 Gbps GDDR7 Memory Speed:据可靠爆料者 kopite7kimi 称,首批采用 GDDR7 显存的 NVIDIA GeForce RTX 50 系列 "Blackwell" 显卡传闻将拥有 28 Gbps 的显存速度...
- GitHub - xai-org/grok-1: Grok open release:Grok 开源发布。通过在 GitHub 上创建账号来为 xai-org/grok-1 的开发做出贡献。
- GitHub - Vahe1994/AQLM: Official Pytorch repository for Extreme Compression of Large Language Models via Additive Quantization https://arxiv.org/pdf/2401.06118.pdf:通过加法量化对大语言模型进行极端压缩的官方 Pytorch 仓库 https://arxiv.org/pdf/2401.06118.pdf - Vahe1994/AQLM
- NVIDIA GeForce RTX 50-series "Blackwell" to use 28 Gbps GDDR7 Memory Speed:据可靠爆料者 kopite7kimi 称,首批采用 GDDR7 显存的 NVIDIA GeForce RTX 50 系列 "Blackwell" 显卡传闻将拥有 28 Gbps 的显存速度...
提到的链接:--- **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1218257987445981234)** (35 条消息🔥): - **微调中的 Tokenization 问题**:尝试微调一个 instruct 模型用于文档摘要时遇到了问题,tokenizer 无法一致地生成第一个 `- ehartford 实现后训练 · Pull Request #1407 · OpenAccess-AI-Collective/axolotl:这看起来正确吗?
- ehartford 实现后训练 · Pull Request #1407 · OpenAccess-AI-Collective/axolotl:这看起来正确吗?
- GitHub - xai-org/grok-1: Grok 开源发布:Grok 开源发布。通过在 GitHub 上创建账号为 xai-org/grok-1 的开发做出贡献。
- GitHub - OpenAccess-AI-Collective/axolotl at scatter_moe:尽管向 axolotl 提问。通过在 GitHub 上创建账号为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
` 标签。tokenizer 在独立运行时表现正常,但在模型输出中,预期的标签有时会出现意外的空格,这表明可能存在 tokenizer 或模型行为问题。 - **本地模型和数据的语法困境**:一位社区成员在配置使用本地模型和数据集进行微调的脚本时需要语法帮助。在遇到 `HFValidationError` 后,建议使用完整文件路径而非相对路径,这暗示了仓库标识符格式不正确。 - **测试训练数据的会话类型混淆**:在设置描述为 "conversation" 的训练数据时,尽管尝试了各种配置选项,一名成员仍深陷错误和 "index out of range" 问题。在多次社区互动建议检查配置后,问题最终追溯到数据集中存在空的会话角色。 - **寻求构建 Completion 数据集的支持**:有人询问如何构建 completion 数据集。社区引导他们参考 readme 文档中的简易方法,即创建一个包含文本属性内容的 JSONL 文件。 - **令人困惑的评估集大小警告不一致**:一名成员报告了一个奇怪的现象:在运行 2 个 epoch 时,Axolotl 会发出关于评估集太小无法进行 sample packing 的验证警告,但在运行 10 个 epoch 时则不会。他们被要求分享 stack trace,并可能需要提交一个 GitHub issue 来解决这个异常。 --- **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1218770755920072767)** (8 条消息🔥): - **分享 NeMo Curator 工具包**:一名成员分享了 **NVIDIA NeMo Curator** 的 [GitHub 链接](https://github.com/NVIDIA/NeMo-Curator),这是一个用于数据清洗的可扩展工具包。 - **寻求使用数学和代码数据集微调的 Mistral 模型**:一名成员询问是否有在 *orca-math-word-problems-200k 数据集和 nvidia/OpenMathInstruct-1* 上都进行过微调(FT)的 **Mistral 模型**。有人指出后一个数据集规模非常庞大。 - **提议使用 Mergekit 作为解决方案**:在讨论合并模型的可能性时,一名成员指出可以使用 **mergekit** 作为将 Mistral 与其他数据集结合的可能方案,而无需额外的训练。 - **关于模型兼容性的建议**:在模型合并的背景下,有人强调了确保待合并的两个模型都使用 **相同的 chat format** 进行训练的重要性,以获得最佳效果。 **提到的链接**: GitHub - NVIDIA/NeMo-Curator: Scalable toolkit for data curation: 用于数据治理的可扩展工具包。通过在 GitHub 上创建账户来为 NVIDIA/NeMo-Curator 的开发做出贡献。 --- **OpenAccess AI Collective (axolotl) ▷ #[rlhf](https://discord.com/channels/1104757954588196865/1112023522039058553/)** (1 条消息): duh_kola: 是否可以使用不同的 LoRA adapter 在另一个模型上进行 DPO --- **CUDA MODE ▷ #[general](https://discord.com/channels/1189498204333543425/1189498205101109300/1218310691103178803)** (43 条消息🔥): - **探索 Photonics 与 AI**: 一位成员分享了一个关于 Photonics 重大突破的 [YouTube 视频](https://youtu.be/8ohh0cdgm_Y),声称速度提升了 1000 倍,并提到了 Photonics 计算公司 [Lightmatter](https://lightmatter.co/)。 - **Asianometry 的 Photonics 视频推荐**: 另一位成员推荐了 Asianometry 关于 Photonics 的 YouTube 视频,并提供了讨论 Silicon Photonics 和 Running Neural Networks on Meshes of Light 的链接。 - **发现用于 Kernel Profiling 的 GPU 云服务**: 向寻求在 Ada 或 Hopper GPU 上使用 Nsight Compute 进行 Kernel Profiling 的用户推荐了两个云服务:[RunPod.io](https://www.runpod.io/) 和 [LambdaLabs](https://lambdalabs.com/),尽管在 RunPod 上的初步测试遇到了权限问题。 - **PyTorch 的显式 Tensor 内存管理**: 讨论了 PyTorch 的显式内存管理与 TensorFlow 的隐式方法之间的优缺点,PyTorch 贡献者表示显式管理避免了隐藏的副本,且更加透明。 - **期待 NVIDIA 的 GTC 发布**: 成员们讨论了最近的 NVIDIA GTC 公告,推测了新的 GPU 容量和 AI 模型参数,并开玩笑说最新发布的 NVIDIA 技术有“Skynet(天网)的感觉”。 提到的链接:--- **CUDA MODE ▷ #[triton](https://discord.com/channels/1189498204333543425/1189607595451895918/1218241351582482493)** (7 条消息): - **新的 Triton 调试可视化工具发布**:一位成员分享了一个用于 **Triton debugging** 的新可视化工具,该工具在实现复杂函数时有助于查看 load/stores 的空间结构,尽管目前尚未提供该工具的视觉图示或链接。 - **Triton Puzzles 系列发布**:为了帮助更好地理解复杂的 kernels,开发者创建了 Triton Puzzles,可在 [Google Colab](https://colab.research.google.com/drive/1AJc8RFsDeJ3Vx3gRq5dUqmcb-Cy1G8qh?usp=sharing) 中获取。注意有两个已知 bug:偶尔会出现重复可视化以及 segmentation faults。 - **征集 Triton 学习资源**:一位成员请求获取学习 Triton 的指南或资源,并提到自己熟悉 CUDA 代码。 - **拼写纠正及对 Triton Interpreter 的兴趣**:另一位成员指出了一处拼写错误,建议在上下文中用 "since" 替换 "sense",并表示有兴趣尝试在之前消息中提到的 CPU 上运行 Triton interpreter。 - **Triton Puzzles 被推荐为学习资源**:Triton Puzzles 的创建被认为是一种很好的学习方法,同时还提到了官方网站上“非常棒的教程”,尽管没有提供具体的 URL。 **提到的链接**:Google Colaboratory:未找到描述 --- **CUDA MODE ▷ #[cuda](https://discord.com/channels/1189498204333543425/1189607726595194971/1218467001450627072)** (68 条消息🔥🔥): - **探索 Warp Schedulers 和线程效率**:一位成员询问了可以定义多少个 warp schedulers,以及它们对线程的控制权,以优化 efficiency occupancy。这涉及到理解为了实现最大效率可以同时运行多少个线程。 - **澄清 "Active Warp" 的定义**:讨论了 "active warp" 的含义。澄清指出,"active warp" 通常意味着至少有一个活跃线程,尽管从技术上讲,存在没有活跃线程的 "active warp" 是可能的,这突显了 CUDA 编程中理解 warp 激活状态的一个灰色地带。 - **内存管理选项中的便利性与必要性**:针对 CUDA 中不同的内存分配选项(ProducerProvides、ConsumerProvides 等)是便利功能还是技术必要性展开了交流。会议指出,如果仅选择 Provides 和 Provides,可能无法利用 zero copies 的情况,并可能需要 streamSynchronize,从而破坏优化。 - **理解 CUDA 内存管理语义**:解释了 CUDA 中内存管理器类的语义细节;"ProducerProvides" 意味着生产者拥有指针,而 "ConsumerTakes" 意味着获取一个在应用程序启动时预分配的指针。强调了这些语义在代码语法中并不显式。 - **共享 CUDA 内存空间资源**:讨论了关于 GPU 内存容量和异步拷贝 activations 的担忧,特别是与 pipeline parallel 推理相关的问题,以及在 LLM 推理任务中平衡 KV caches 和 activation 存储之间 GPU 内存的挑战。- Product - Chip - Cerebras: 未找到描述
- Rent Cloud GPUs from $0.2/hour: 未找到描述
- torch.set_default_device — PyTorch 2.2 documentation: 未找到描述
- GPU Cloud, Clusters, Servers, Workstations | Lambda: 用于深度学习和 AI 的 GPU 云、GPU 集群、GPU 服务器和 GPU 笔记本电脑。提供 RTX 4090, RTX 3090, RTX 3080, RTX A6000, H100 和 A100 选项。预装 Ubuntu, TensorFlow 和 PyTorch。
- Don’t Miss This Transformative Moment in AI: 来加州圣何塞 SAP 中心现场体验 Jensen Huang 的 GTC 主旨演讲,探索塑造我们未来的 AI 进展。
- New Breakthrough in Photonics: x1000 faster. Is it for Real?: 立即获取 TypeAI PREMIUM!点击此处链接开始免费试用:https://bit.ly/Mar24AnastasiInTech 论文地址:https://www.nature.com/articles/s41586...
- Lightmatter®: 未找到描述
- Silicon Photonics: The Next Silicon Revolution?: 非常感谢本频道的好友、来自 MIT 的 Alex Sludds 建议这个话题并为我提供关键资源。在这里关注他:https://a...
- Running Neural Networks on Meshes of Light: 我要感谢 Alex Sludds 在帮助我研究和制作此视频方面所做的努力。在这里查看他的工作:https://alexsludds.github.io 链接:- The As...
提到的链接:--- **CUDA MODE ▷ #[suggestions](https://discord.com/channels/1189498204333543425/1189868872887705671/1219091487455711414)** (5 条消息): - **探索可重构计算与 ML**:一位成员分享了康奈尔大学 **Mohamed Abdelfattah 教授研究小组**的 [YouTube 频道](https://www.youtube.com/@mabdelfattah88),该小组专注于可重构计算和高效机器学习。描述中建议访问者查看他们的 [官方网站](https://www.mohsaied.com/) 以获取更多信息。 - **以硬件为中心的 ML 系统课程**:该成员还分享了 **ECE 5545 (CS 5775)** 的详细信息,这是一门教授机器学习系统硬件层面的硕士级课程,提到了优化技术以及 ML 系统硬件和软件组件的设计。课程内容可在其 [GitHub 页面](https://abdelfattah-class.github.io/ece5545/) 找到,并鼓励读者查看课程大纲以了解更多细节。 - **注意到缺失教科书信息**:有评论指出,该课程网站提到了“教科书”但未说明是哪一本,这很奇怪。该成员觉得这很不寻常。 - **定位教科书**:另一位成员指出,ECE 5545 课程缺失的教科书信息在**第一节课的视频**中有所提及。 - **教科书之谜解开**:根据这一建议,原评论者感谢了另一位成员通过课程视频内容协助定位教科书信息。- Don’t Miss This Transformative Moment in AI:来圣何塞 SAP 中心现场体验 Jensen Huang 的 GTC 主旨演讲,探索塑造我们未来的 AI 进展。
- GitHub - tspeterkim/flash-attention-minimal: Flash Attention in ~100 lines of CUDA (forward pass only):约 100 行 CUDA 代码实现的 Flash Attention(仅前向传播)- tspeterkim/flash-attention-minimal
提到的链接:--- **CUDA MODE ▷ #[jobs](https://discord.com/channels/1189498204333543425/1190208177829068860/)** (1 条消息): vim410: 视情况而定。但确实如此。 --- **CUDA MODE ▷ #[beginner](https://discord.com/channels/1189498204333543425/1191300313928433664/1219389682241110147)** (5 条消息): - **认可扎实的 CUDA 基础**:一位成员称赞询问者拥有**扎实的 CUDA 基础**,并建议尝试使用像 **PyTorch** 这样的深度学习框架。指出深度学习通常关乎优化,其底层重度依赖于矩阵乘法和非线性。 - **从 CUDA 到 ML 转型的建议**:对于转向用于 ML 的 GPU 计算,询问者目前在 CUDA 方面的知识(包括内存管理和 kernel profiling)被认为是足够的。建议他们通过 *Zero to Hero* 系列以及探索与 CUDA 相关的 ML 库(如 **cuDNN** 和 **cuBLAS**)来熟悉深度学习概念。 - **进阶学习的书籍推荐**:另一位成员建议阅读 *Programming Massively Parallel Processors* 以全面理解 CUDA 编程,尽管他们指出该书关于深度学习的内容较少。这本书被认为是通用 CUDA 编程的极佳资源。[亚马逊书籍链接](https://www.amazon.de/-/en/Wen-mei-W-Hwu/dp/0323912311) **提到的链接**:未找到标题:未找到描述 --- **CUDA MODE ▷ #[pmpp-book](https://discord.com/channels/1189498204333543425/1194427148656721970/1218146385942286407)** (6 条消息): - **澄清 CUDA 计算困惑**:一位成员询问了另一种索引计算公式 `i = blockIdx.x * blockDim.x + threadIdx.x * 2`,并被告知这会导致**重复计数**,并解释了线程最终可能会得到相同的索引值。 - **博客发布困境**:一位成员询问在博客上发布书中**练习题答案**是否妥当,并表示由于缺乏教育机构邮箱地址,难以联系到作者。另一位成员回应称可以向作者 Wen-mei 寻求澄清。 --- **CUDA MODE ▷ #[ring-attention](https://discord.com/channels/1189498204333543425/1208496482005549086/1218239914542366790)** (14 条消息🔥): - **团队成员本周忙碌**:一位成员表示目前很忙,稍后会更新他们有空的时间。 - **代码获取障碍**:一位成员表示在定位某些代码时遇到困难。他们分享了 [GitHub 上的 Triton kernel](https://github.com/zhuzilin/ring-flash-attention/commit/10d992c3c84a2ee1a2e47dd596615d9aad46f7d5) 链接以寻求关于 ring-attention 的帮助。 - **Ring-Attention 机制查询**:有人对 ring-attention 相关论文中提到的内存需求表示担忧,特别是形成平方块大小 $c^2$ 的分块(chunk)是否真的如建议的那样产生线性内存扩展。对话涉及了 blockwise attention 的复杂性,以及 ring attention 中内存随块大小线性扩展的断言。 - **源码深入分析以澄清**:一位成员提供了 GitHub 仓库链接 [flash-attention 实现](https://github.com/Dao-AILab/flash-attention/blob/main/csrc/flash_attn/src/flash_fwd_kernel.h),以解决关于 flash attention 和 ring attention 算法中内存需求扩展的困惑。 - **解释 Ring-Attention 中的术语**:在讨论了 ring 和 flash-attention 算法的内部工作原理和内存动态之后,有人推测线性内存扩展的说法是指序列长度(sequence length)还是上下文中的分块数量。- ML Hardware and Systems:未找到描述
- Prof. Mohamed Abdelfattah:这是康奈尔大学 Mohamed Abdelfattah 教授研究小组的频道。我们正在研究可重构计算和高效机器学习。欲了解更多信息,请查看...
提到的链接:--- **CUDA MODE ▷ #[off-topic](https://discord.com/channels/1189498204333543425/1215328286503075953/1218332053032927322)** (5 messages): - **MLSys 2024 会议亮点**:成员们对即将举行的 [MLSys 2024](https://mlsys.org/) 会议表现出兴趣,该会议汇集了来自 **Machine Learning 和系统设计**领域的专家。它因其跨学科的关注点以及在生成式 AI 时代优化 AI 系统中的关键作用而受到关注。 - **会议标语中的抑扬格五音步**:一位用户指出标语 "The Conference for the Era of AI" **符合抑扬格五音步(iambic pentameter)的节奏模式**。 - **智能手机还是不那么智能的手机?**:一位成员开玩笑地评论智能手机可能并不那么智能。 - **讨论智能手机上的数学**:在一次讨论中,用户们商讨了在智能手机上进行**乘法/除法**的正确方法,检查了计算器操作的差异。 **提到的链接**:MLSys 2024:未找到描述 --- **CUDA MODE ▷ #[gtc-meetup](https://discord.com/channels/1189498204333543425/1218444432588800010/1218444664315711498)** (9 messages🔥): - **GTC 聚会计划**:成员宣布计划在**周一早上参加 GTC**,并邀请其他人发消息聚会,并提议通过 DM 提供电话号码以便协调。 - **贯穿整个活动的出席情况**:另一位成员分享了他们的行程,表示他们将在 **3 月 14 日至 25 日**出席,并参加活动的所有日程。 - **对全程参加的兴趣**:关于活动日程的讨论揭示了其吸引力,一位成员表示如果提供不错的 WiFi,会考虑**整周**参加。 - **错过 GTC 的梗**:关于不可避免会出现**无法参加 GTC** 的梗(Meme),有一个幽默的观察。 - **体验活动的其他方式**:一位成员开玩笑说要寻找其他参与活动的方式,分享了一个 [YouTube 视频 "I Snuck Into A Secret Arms-Dealer Conference"](https://www.youtube.com/watch?v=Sfrjpy5cJCs),幽默地暗示潜入会议。 **提到的链接**:I Snuck Into A Secret Arms-Dealer Conference:每月在 https://www.patreon.com/Boy_Boy 获取独家视频。我们与澳大利亚传奇政治讽刺团体 The C... 合作制作了这段视频。 --- **OpenRouter (Alex Atallah) ▷ #[general](https://discord.com/channels/1091220969173028894/1094454198688546826/1218183723200155748)** (159 messages🔥🔥): - **LLaMa 格式的灵活性**:一位用户确认 LLaMa 模型接受以下格式:`[{"system": "system prompt"},{"user": "user prompt"},{"assistant": "assistant prompt"}]`。在使用 OpenAI JavaScript 库时特别提到了这一点。 - **Sonnet 大放异彩**:多位用户讨论了在没有重复或无意义输出的情况下进行角色扮演的最佳模型,**Sonnet** 因其表现而受到大力推崇。该模型的响应速度和格式化能力受到了关注。 - **MythoMax 的 Prompt 格式化**:用户正在努力解决如何为 MythoMax 等 LLM 正确格式化 Prompt,了解到 System Message 通常放在第一位,随后的 System Message 通常会被忽略或合并到 User 或 Assistant 消息中。 - **对详细使用报告的关注**:成员们请求为其活动提供**详细的使用报告**和成本分析,并正与代表就此功能进行沟通。特别表达了按时间和模型跟踪支出的需求。 - **对 Grok 的期待**:社区正在积极讨论 Grok,这是一个预期会产生重大影响的模型,但需要在指令数据上进行 Fine-tuning。提到了开源发布和提供 API 的可能性,多位成员对此表现出浓厚兴趣。- Striped Attention: Faster Ring Attention for Causal Transformers:为了帮助满足 Transformer 模型对超长序列长度日益增长的需求,Liu 等人最近提出了 Ring Attention,这是一种能够克服单设备内存限制的精确注意力算法...
- flash-attention/csrc/flash_attn/src/flash_fwd_kernel.h at main · Dao-AILab/flash-attention:快速且内存高效的精确注意力。通过在 GitHub 上创建账户来为 Dao-AILab/flash-attention 的开发做出贡献。
- add naive triton kernel for varlen · zhuzilin/ring-flash-attention@10d992c:未找到描述
Links mentioned:--- **LangChain AI ▷ #[general](https://discord.com/channels/1038097195422978059/1038097196224086148/1218212402127175711)** (95 messages🔥🔥): - **API 选择备受关注**:用户讨论了在创建 Agent 时使用 `astream_log` 与 `astream_events` 的优劣,指出 `events API` 仍处于 Beta 阶段,同时询问 `log API` 是否会被弃用。 - **招募 Beta 测试人员 - 高级研究助手**:一项名为 **Rubik's AI** 的服务正在开发中,正在招募 Beta 测试人员,入选者将获得两个月的尊享访问权限,包含 **GPT-4 Turbo** 和 **Groq** 等多种 AI 模型。感兴趣的各方可以在 [Rubik's AI](https://rubiks.ai/) 加入候补名单。 - **对 LangChain 文档的建设性反馈**:用户表达了在使用 **LangChain 文档**时遇到的困难,称其对初学者不友好,并要求在需要的地方提供更清晰的说明或补充页面。有人建议“一旦掌握了基础知识,就去阅读代码和 API 参考”。 - **使用 LLM 和 LangChain 开发 DataGPT**:一位用户描述了在将 **LangChain** 与 DataLake 结合用于 **DataGPT** 时面临的挑战,提到了结构化数据查询的检索时间缓慢,并考虑使用 `LlamaIndex` 进行索引。 - **使用 LangChain 进行结构化输出解析**:一位用户分享了一个 **Python Pydantic** 代码示例,用于从 **LLM 响应**中提取结构化输出,另一位用户对此表示感谢,并讨论了针对列表输出的自定义调整。- GitHub - xai-org/grok-1: Grok open release: Grok 开源发布。通过在 GitHub 上创建账户为 xai-org/grok-1 的开发做出贡献。
- OpenRouter: LLM 和其他 AI 模型的路由服务
Links mentioned:--- **LangChain AI ▷ #[langserve](https://discord.com/channels/1038097195422978059/1170024642245832774/1219304272244510741)** (45 messages🔥): - **RemoteRunnable 的流式传输问题**:一位成员报告在 JavaScript 中使用 `RemoteRunnable` 时遇到流式输出困难;它不会调用 `/stream`,而是始终默认为 `/invoke`。他们确认从 Python 执行 `RemoteRunnable` 时,无论是否有 Prompt,流式传输都能正常工作。 - **Stream 机制的差异**:在详细说明此流式传输问题时,有人指出 `RunnableSequence` 可能会从 `Runnable` 继承 `_streamIterator`,而后者会调用 `invoke`。 - **分层解决问题的方法**:成员验证了 Python 的 `RemoteRunnable` 在流式传输方面没有问题,但等效的 JavaScript 代码会降级为 `invoke`。关于这种行为是否由于继承自 `Runnable` 引起了一些讨论,这暗示了一个可能的调试方向。 - **寻求 LangChain 团队的支持**:成员询问了就该问题联系 LangChain 团队的最佳方式。建议在 GitHub 上报告问题,或通过电子邮件 <hello@langchain.dev> 联系他们,并在报告问题时提供尽可能详细的信息。 - **寻找最近的更新**:最后,成员询问过去一个月是否有任何可能解决流式传输问题的更改,但没有提供具体的更新信息(例如已解决的 Issue 或可能修复该问题的新版本)。建议查看 LangChain 的 GitHub 仓库以获取最新更改。- Rubik's AI - Waitlist: 未找到描述
- 未找到标题: 未找到描述
- Bloon AI: 重新定义智能学习
- Using Natural Language to Query Teradata VantageCloud With LLMs| Teradata: 学习将您的英语查询翻译成 SQL,并从您的分析数据库中接收通俗易懂的英语响应。
- Feature Request: Support for Negative Embeddings in Similarity Searches · langchain-ai/langchain · Discussion #19239: 检查了已有的想法,未发现类似的。添加了非常详细的标题。清楚地描述了功能请求及其动机。功能请求:我建议增加...
提到的链接:--- **LangChain AI ▷ #[share-your-work](https://discord.com/channels/1038097195422978059/1038097372695236729/1218223379690029179)** (11 messages🔥): - **用于数据分析的 AI Chatbot**:介绍了一款新的开源 [AI Chatbot](https://github.com/Haste171/langchain-chatbot),用于以对话格式分析和提取数据中的信息。该工具旨在通过聊天机器人界面协助解析和理解数据集。 - **用 AI 整理你的书签**:分享了一个用于管理 Raindrop.io 书签的 Discord AI 聊天机器人,帮助用户在需要时找到相关的书签。该项目是[开源的](https://github.com/uogbuji/living-bookmarks),源于创建者对高效书签检索系统的需求。 - **AI 让网页抓取变得简单**:团队发布了一个基于 AI 的抓取工具 [Scrapegraph-ai](https://github.com/VinciGit00/Scrapegraph-ai),它使用 OpenAI keys,已在 pip 上线并拥有超过 2300 次安装。该抓取工具旨在通过 API key 和一个提示性问题来简化网站的数据提取。 - **利用先进 AI 的个性化营养应用**:开发了一款名为 Nutriheal 的营养 AI 应用,利用 **Ollama**、**Open-webui** 和 **Pebblo** 来确保患者数据隐私。创建者强调了使用现代工具构建此类应用是多么容易,并提供了 [YouTube 演示](https://youtu.be/vHjc5CEoIJE)以及 [navvy.co](https://navvy.co/) 上的其他资源。 - **金融行业 AI 分析**:分享了一篇文章,探讨了大语言模型 (LLMs) 如何为金融行业繁忙的专业人士自动分析研究论文。Medium 文章可以在[这里](https://medium.com/@bsouleymane78/staying-up-to-date-with-latest-advancements-on-ai-applied-to-financial-industry-using-ai-b995da14800f)找到。- Security | 🦜️🔗 Langchain:LangChain 拥有庞大的生态系统,集成了各种外部资源,如本地和远程文件系统、API 和数据库。这些集成允许开发者创建多功能的应用程序...
- Issues · langchain-ai/langchain:🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号为 langchain-ai/langchain 的开发做出贡献。
- RemoteRunnable | LangChain.js - v0.1.28:未找到描述
- Issues · langchain-ai/langchain:🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain:🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain:🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain:🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号为 langchain-ai/langchain 的开发做出贡献。
- langchain_core.runnables.config.RunnableConfig — 🦜🔗 LangChain 0.1.4:未找到描述
- langchain_core.runnables.base — 🦜🔗 LangChain 0.1.4:未找到描述
提及的链接:--- **LangChain AI ▷ #[tutorials](https://discord.com/channels/1038097195422978059/1077843317657706538/1218824643436085321)** (2 条消息): - **通过 Nutriheal 简化 AI 应用创建**:[Nutriheal](https://youtu.be/vHjc5CEoIJE) 是一款面向患者的个性化营养 AI 应用,展示了使用 **Ollama** 和 **Open-webui** 构建 AI 应用的简便性,并通过 **LangChain 的 Pebblo 集成** 增加了数据隐私保护。题为“15 分钟内制作一个 AI 应用”的视频强调了在不牺牲用户数据保护的情况下进行快速开发。 - **探索更多 AI 尝试**:在 [navvy.co](https://navvy.co/) 探索更多 AI 创新和教程,该网站展示了一系列与 AI 部署和界面设计相关的作品。 - **本地 AI 解决方案揭秘**:一篇题为 [Build and Deploy GenAI Solutions Locally](//build-and-deploy-genai-solutions-locally) 的博客文章旨在打破高端 AI 是科技巨头专属的误解,认为在家里运行先进的 AI 模型可能比预期的要容易。 - **语言模型的统一 UI**:另一篇教学文章 [Local LLMs - Making a Generic UI for Custom LLM Assistants](/generic-ui-for-custom-llm-assistants) 提供了创建通用聊天 UI 的指南,适用于任何未来的 LLM 项目。 - **Langgraph 实战**:分享了一个 YouTube 视频 [Plan-and-Execute using Langgraph](https://www.youtube.com/watch?v=ZlJbaYQ2hm4),详细介绍了如何创建一个“计划与执行”(plan-and-execute)风格的 Agent,其灵感来自 Plan-and-Solve 论文和 Baby-AGI 项目。- 用户访谈 🔎 - NEUROFUSION Research, Inc.: 嘿,我正在构建一个数字顾问,以帮助改善你在工作和生活其他领域的表现。我很想与你交谈,了解你在生产力、身体和...方面的需求。
- GitHub - Haste171/langchain-chatbot: 用于以对话格式分析/提取数据信息的 AI Chatbot。: 用于以对话格式分析/提取数据信息的 AI Chatbot。 - Haste171/langchain-chatbot
- GitHub - VinciGit00/Scrapegraph-ai: 基于 AI 的 Python 抓取工具: 基于 AI 的 Python 抓取工具。通过创建账户为 VinciGit00/Scrapegraph-ai 的开发做出贡献。
- 15 分钟内制作一个 AI 应用: 技术栈 - 自定义 UI 和 RAG:Open-webui 的定制版本 - 本地 LLM 托管:用于本地托管 LLM 的 Ollama。- 数据隐私:集成 DaxaAI 的 Pebblo 以确保...
- 首页: 我对 AI 深感热忱。让我们联系起来,释放 AI 的潜力,并在创新项目上进行合作!
- 来自 Siva Surendira (@siva_1gc) 的推文: 这比我们想象的要多花一点时间.. 但它来了.. 😎 使用 @lyzrai Automata 和 @OpenAI 自动化 SDR 和 AE 功能... 运行在 @awscloud 上 - 安全且私密.. 它是如何工作的? 👇 Agent 1:...
- GitHub - LyzrCore/lyzr-automata: 低代码多 Agent 自动化框架: 低代码多 Agent 自动化框架。通过创建账户为 LyzrCore/lyzr-automata 的开发做出贡献。
- 未找到标题: 未找到描述内容
- 未找到标题: 未找到描述内容
- 未找到标题: 未找到描述内容
提到的链接:--- **Interconnects (Nathan Lambert) ▷ #[other-papers](https://discord.com/channels/1179127597926469703/1179142630517518397/1218217772765544448)** (8 条消息🔥): - **揭示受 API 保护的 LLMs**:一篇 [arXiv 论文](https://arxiv.org/abs/2403.09539) 提出了一种从受 API 保护的 LLMs(如 OpenAI 的 GPT-3.5)中提取非公开信息的方法,尽管存在 softmax 瓶颈。论文详细介绍了如何通过少量的 API 查询来实现这一点,成本可能低于 1,000 美元。 - **窥探 Softmax 瓶颈背后**:讨论强调了该方法与 Carlini 论文方法的相似性——它通过模型 logits 估算 LLM 的规模,但与 Carlini 的论文不同,它没有对研究结果进行脱敏处理。 - **对模型规模估算的惊讶**:一条消息对 70 亿参数的估算表示惊讶,认为对于像 GPT-3.5 这样的模型来说,这可能并不准确。 - **对模型规模的怀疑**:**Nathan Lambert** 怀疑论文中提供的参数估算不正确,可能是由于未公开的模型结构或机制导致的。 - **质疑 MoE 模型的计算方式**:如果 GPT-3.5 是一个混合专家模型(MoE),那么 API 暴露的模型规模计算可能就不成立,对话中的一名参与者认为这种情况很有可能。 - **对模型架构的推测**:讨论探讨了 GPT-3.5-turbo 可能利用了某种形式的蒸馏(distillation)或模型混合的可能性,并举例说明了先前的研究显示了起始 token 对性能增强的重要性。 **提到的链接**:Logits of API-Protected LLMs Leak Proprietary Information:大语言模型(LLMs)的商业化导致了对专有模型仅提供高级 API 访问的普遍做法。在这项工作中,我们展示了即使在保守的假设下... --- **Interconnects (Nathan Lambert) ▷ #[ml-drama](https://discord.com/channels/1179127597926469703/1181746144821387334/1219339209270362135)** (19 条消息🔥): - **预见关于开源定义的争议**:引用了 @rasbt 的一条推文,暗示这可能会引发关于什么才应该被视为“开源”的争议。 - **寻求开源共识**:讨论了开源软件(OSS)社区需要就什么是开源建立明确立场的必要性。 - **将数据排除在开源之外**:**Nathan Lambert** 认为,新出现的开源共识可能会将数据排除在外,他批评这种立场是“愚蠢的”。 - **Twitter 上的开源之争**:Twitter 上展开了一场新的争论,用户们正在辩论开源的细节,正如包括名为 **@BlancheMinerva** 的用户在内的交流所证明的那样。 - **对线上讨论的沮丧**:**Nathan Lambert** 对围绕开源的在线讨论表示沮丧,认为这些讨论适得其反,并决定多写博客,少发推特。 **提到的链接**:Stella Biderman (@BlancheMinerva) 的推文:@natolambert @felix_red_panda 不过你错了 :P --- **Interconnects (Nathan Lambert) ▷ #[random](https://discord.com/channels/1179127597926469703/1183121795247779910/1219005089826607185)** (63 条消息🔥🔥): - **Grok-1 发布**:由 xAI 开发的拥有 3140 亿参数的 **Grok-1** 模型(一种混合专家(Mixture-of-Experts, MoE)大语言模型)已经[开源](https://x.ai/blog/grok);该模型未针对特定任务进行微调,采用 Apache 2.0 许可证发布,并在 [GitHub](https://github.com/xai-org/grok) 上提供了使用说明。 - **AI 巨头对比**:**Grok-1** 的规模及其发布速度表明其侧重于最优性;与 **Falcon** 等其他模型相比,*Grok-1* 体量更大,且在 GSM8K 和 MMLU 等基准测试中表现出更好的性能。 - **分发困境**:关于使用磁力链接进行模型分发的讨论正在进行中,人们对公众认知和政策影响表示担忧;**HuggingFace** 已确认镜像了 *Grok-1* 的权重。 - **创新的数据交付方式?**:成员们开玩笑地建议邮寄存储有 AI 模型权重的实体硬盘,将其作为昂贵的云端流量出站费用(egress fees)的一种经济高效的替代方案,这突显了分发大型 AI 模型的实际挑战。 - **Murati 充满挑战的采访**:OpenAI 首席技术官 Mira Murati 接受 [《华尔街日报》采访](https://www.youtube.com/watch?v=mAUpxN-EIgU&ref=wheresyoured.at) 时,因对 OpenAI 的 AI 视频生成应用 Sora 的训练数据(以及是否使用了来自 YouTube 等平台的内容)给出了闪烁其词的回应而引发批评。- Plan-and-Execute using Langgraph:如何创建一个“计划与执行”风格的 Agent。这深受 Plan-and-Solve 论文以及 Baby-AGI 项目的启发。核心思想是首先...
- Making an AI application in 15 minutes:技术栈 - 自定义 UI 和 RAG:Open-webui 的调整版本;本地 LLM 托管:使用 Ollama 托管本地 LLM;数据隐私:集成 DaxaAI 的 Pebblo 以确保...
- Home:我对 AI 充满热情。让我们建立联系,释放 AI 的潜力,并在创新项目上展开合作!
提到的链接:--- **Alignment Lab AI ▷ #[general-chat](https://discord.com/channels/1087862276448595968/1095458248712265841/1218732428462395502)** (6 条消息): - **对 Aribus 项目的好奇**:一位成员分享了关于 **Aribus** 的[推文链接](https://twitter.com/alignment_lab/status/1758949148143841379),并对其他人正在用它构建什么表示困惑。虽然寻求了解释,但在给出的消息中并未得到回复。 - **寻找基于 HTTP 训练的 Embeddings 模型**:一位成员询问是否存在基于 HTTP 响应训练的 Embeddings 模型,并想知道如何找到它。该成员同时指出,他理解**任何经过相应训练的 Transformer 都可以作为 Embeddings 模型**。 - **寻求特定的 Mistral 微调模型**:有人请求提供关于是否有人拥有或知道在 *orca-math-word-problems-200k 数据集* 和 *nvidia/OpenMathInstruct-1* 上进行过 **Mistral 模型微调**的信息。目前没有收到回复。 - **简单的问候:** 一位用户进入聊天室并简短地说了声 "hi"。 --- **Alignment Lab AI ▷ #[oo](https://discord.com/channels/1087862276448595968/1118217717984530553/1219081302683422851)** (32 条消息🔥): - **呼吁微调 Grok 1**:一位成员表达了对微调拥有 314B 参数的 **Grok 1** 模型的兴趣,强调了其巨大的规模,并指出此前只有少数组织尝试过此类规模的微调。 - **Grok 1 探讨**:对话中确认了**现有的 MoE 训练基础设施**,并列出了微调所需的资源,包括 **64-128 张 H100 GPU**、大量的**经过验证的数据集**以及广泛的**实验**。 - **对 Grok 1 潜力的担忧**:尽管 Grok 1 能力强大,但人们对其性能以及在 **MMLU** 等基准测试中的表现表示担忧,并怀疑它是否能超越 **GPT-4** 或 OpenAI 的 **Claude** 等模型。 - **Grok 1 与其他模型的对比**:关于 **Grok 1** 与其他模型(如 Mixtral)的相对效率和性能展开了辩论,特别是考虑到训练所需的巨大算力需求。 - **Grok 1 能力的证据**:分享的一个 **[Hugging Face 数据集](https://huggingface.co/datasets/keirp/hungarian_national_hs_finals_exam)** 显示,Grok 1 在极具挑战性的外部测试——**匈牙利全国高中数学期末考试**中表现强劲,这表明它具有令人惊讶的能力。 **提到的链接**:keirp/hungarian_national_hs_finals_exam · Hugging Face 数据集:未找到描述 --- **LLM Perf Enthusiasts AI ▷ #[general](https://discord.com/channels/1168579740391710851/1168579740391710855/1218226914322415677)** (1 条消息): - **开发懒惰的困境**:一位成员表示,他受到启发,在构建应用时追求极致的简洁,更倾向于能在本地运行并提供文件系统控制权的解决方案,而非复杂的系统。这种观点表明开发者更青睐轻量、敏捷的开发工具,并暗示目前开源领域提供的产品在满足此类需求方面尚有不足。 --- **LLM Perf Enthusiasts AI ▷ #[claude](https://discord.com/channels/1168579740391710851/1168582222194933860/1218206756031955006)** (7 条消息): - **Anthropic 是幕后操纵者?**:一位成员分享了一篇 [推文](https://x.com/tszzl/status/1768530219378631137?s=20),暗示 **Anthropic** 可能在向“技术人员心中植入对上帝的恐惧”方面发挥了作用。 - **透视内容审核**:内容审核存在的问题得到了承认,特别是针对**包含人物的图像**,处理过程“直接拒绝”。 - **使用 Claude Sonnet 进行规模扩展**:一位成员询问关于在大型项目中使用 *claude sonnet* 的事宜,预计使用量约为“每月数千万个 tokens”。 **提到的链接**:来自 roon (@tszzl) 的推文:anthropic 是受控的反对派,旨在让技术人员心生敬畏。 --- **LLM Perf Enthusiasts AI ▷ #[reliability](https://discord.com/channels/1168579740391710851/1169378117865963580/1218241222347460619)** (16 条消息🔥): - **KPU 亮相,或将改变游戏规则**:Maisa 宣布了一个名为 [Knowledge Processing Unit (KPU)](https://maisa.ai/blog/kpu) 的新框架,旨在通过将推理与数据处理分离来增强 LLM 的能力,声称在推理任务中表现优于 GPT-4 和 Claude 3 Opus 等模型。 - **行业领先还是混淆视听?**:成员们对 KPU 的基准测试方法表示好笑和怀疑,指出其对比对象是 GPT-4 而非预期的 GPT-4-turbo,这与 Claude 3 采取的策略类似。 - **新技术还是巧妙的 Prompting?**:一位成员询问 KPU 的底层技术,推测其是否仅仅是高级的 Prompt Engineering,另一位成员回应称,它似乎是自我评估技术与 Context Window 操作的结合。 - **性能细节与质疑**:随后讨论了 KPU 缺乏延迟(latency)信息的问题,认为虽然它可能提升某些指标,但可能会引入显著的延迟,从而质疑其集成到产品中的实用性。 - **CEO 澄清 KPU 机制**:Maisa 的 CEO 解释说,KPU 本身不是模型,而是与 LLM 协同工作,充当“知识管理的 GPU”,提升现有模型的性能和成本效益。同时,他向研究人员提供了一个用于独立评估的 notebook,可申请获取访问权限([来自 CEO 的推文](https://x.com/davipar/status/1768683151780683919?s=20))。- Grok-1 的开源发布:未找到描述
- 我们是否已经达到了 AI 的巅峰?:上周,《华尔街日报》发布了对 OpenAI CTO Mira Murati 长达 10 分钟的采访,记者 Joanna Stern 提出了一系列深刻而直接的问题,而 Murati...
- Xeophon (@TheXeophon) 的推文:Chinchilla 定律并不直接适用于 MoE,对吧?如果适用,我们可以推断出 Grok 的训练数据集大小。它出乎意料地大,所以我猜他们在有限的时间内优先考虑了最优性...
- Grok (@grok) 的推文:@elonmusk @xai ░权░重░在░简░介░里░
提到的链接:--- **LLM Perf Enthusiasts AI ▷ #[openai](https://discord.com/channels/1168579740391710851/1171903046612160632/)** (1 条消息): res6969: https://x.com/leopoldasch/status/1768868127138549841?s=46 --- **DiscoResearch ▷ #[general](https://discord.com/channels/1178995845727785010/1182877486854451271/1218132499150934157)** (21 条消息🔥): - **微调的挫折**:shakibyzn 提到 **DiscoLM-mixtral-8x7b-v2 模型**在指令微调(instruction fine-tuning)后无法生成德语回答,并且在将其用于序列分类时遇到了配置错误。报错信息为 "ValueError: Unrecognized configuration class...",表明与 AutoModel 设置存在潜在的不兼容问题。 - **本地模型推理服务排障**:jaredlcm 分享了一个使用 `vllm` 在本地部署 **DiscoLM-70b** 模型的服务器设置代码片段,并举例说明了调用时返回非预期语言响应的情况。该用户的方法涉及使用 OpenAI API 结构化格式来管理 Chat Completions。 - **德国模型训练的特性**:crispstrobe 等人讨论了训练德国模型的挑战,指出了诸如系统提示词(system prompts)不一致、翻译数据的使用、模型合并(merging models)对语言熟练度的影响,以及不同微调数据集对模型性能的影响等多种因素。 - **寻找德国 LLM 基准测试**:thilotee 分享了潜在的德语基准测试链接,例如近期论文中的 **supergleber-german-language-evaluation-benchmark**、WolframRavenwolf 关于数据保护的私有测试、一个开放的韩国基准测试,并建议将德国基准测试添加到 EleutherAI 的 **lm-evaluation-harness** 中,该工具是 Huggingface 开放排行榜的基础。 - **合作的潜力**:_jp1_ 表示对改进德语语言模型的合作持开放态度,表达了对衡量语言输出质量细微差别的基准测试的需求,并建议拥有必要资源的大学可能能够承担此类研究。- KPU - Maisa:AI 驱动的知识处理平台。一个用于执行业务任务的简单 API。为软件和应用开发者抽象了使用最新 AI 架构的复杂性。
- 来自 David Villalón (@davipar) 的推文:很乐意解答!它不是一个新模型,事实上 KPU 与智能提供商(OpenAI, Anthropic...)无关。它是一种与 LLM 协同工作的新型 AI 架构,利用了它们的推理能力...
提到的链接:--- **DiscoResearch ▷ #[discolm_german](https://discord.com/channels/1178995845727785010/1197630242815213618/1218111377495949322)** (4 条消息): - **DiscoResearch 模型遵循提示词**:一位成员指出,当模型遵循系统提示词时表现最佳,在演示期间可能需要进行调整以获得最佳结果;演示除了使用 **fastchat/vllm** 外,没有使用特殊设置。 - **演示服务器搬迁新址**:演示服务器从个人厨房设置搬迁到了更专业的环境;然而,这次搬迁导致了网络问题,希望能在下周初解决。 - **厨房服务器 vs 专业托管**:在一句轻松的评论中,一位成员调侃了设置在厨房角落的爱好者服务器的可靠性,对比了专业托管服务器遇到的各种问题,如网络故障和硬件失效。 --- **Datasette - LLM (@SimonW) ▷ #[ai](https://discord.com/channels/823971286308356157/1097032579812687943/1218229369680695428)** (20 条消息🔥): - **Prompt Engineering 工具的过去与现在**:一位成员分享了他们为 [Explosion 的 Prodigy](https://prodi.gy/features/prompt-engineering) 贡献 Prompt Engineering 工具的经验,该工具将 Prompt Engineering 转化为一个数据标注问题。这种技术被认为很有趣,尽管并非在所有情况下都完全实用。 - **Prompt 实验的开源工具**:讨论中包含了一个指向 [PromptTools](https://github.com/hegelai/prompttools) 的链接,这是一个用于 Prompt 测试的开源工具,支持各种 LLM(如 OpenAI、LLaMA)以及向量数据库(如 Chroma 和 Weaviate)。 - **模型性能比较工具**:成员们讨论了 [Vercel](https://sdk.vercel.ai/) 和 [Helicone AI](https://www.helicone.ai/) 等各种平台,这些平台提供了比较模型输出和管理 Prompt 的界面,后者目前正在深入研究 Prompt 管理和版本控制。 - **使用 PromptFoo 进行测试与比较**:一位成员提到了 [PromptFoo](https://github.com/promptfoo/promptfoo),这是一个开源的 GitHub 仓库,提供了测试 Prompt、评估 LLM 输出以及提高跨不同模型 Prompt 质量的工具。 - **AI 在动态博客内容中的实际应用**:一位成员正在尝试使用 gpt-3.5-turbo 为不同的角色(personae)翻译博客文章,并思考 AI 增强读者交互的潜力,例如通过从各种角度重写或提供摘要,他们在[自己的博客](https://www.dbreunig.com/2020/02/28/how-to-build-a-buzzword.html)上展示了这一点。- Reddit - Dive into anything:未找到描述
- Reddit - Dive into anything:未找到描述
- grok-1/model.py at main · xai-org/grok-1:Grok 开源发布。通过在 GitHub 上创建账号为 xai-org/grok-1 的开发做出贡献。
- grok-1/model.py at e50578b5f50e4c10c6e7cff31af1ef2bedb3beb8 · xai-org/grok-1:Grok 开源发布。通过在 GitHub 上创建账号为 xai-org/grok-1 的开发做出贡献。
- 我们的论文 "SuperGLEBer: German Language Understanding Evaluation Benchmark" 被 NAACL 2024 接收:在我们的论文中,我们组建了一个广泛的德语自然语言理解基准测试套件,并据此评估了大量现有的具备德语能力的模型,以创建一个...
- Reddit - Dive into anything:未找到描述
- ChuckMcSneed/WolframRavenwolfs_benchmark_results · Hugging Face 数据集:未找到描述
- GitHub - KLUE-benchmark/KLUE: 📖 Korean NLU Benchmark:📖 韩语 NLU 基准测试。通过在 GitHub 上创建账号为 KLUE-benchmark/KLUE 的开发做出贡献。
- GitHub - facebookresearch/belebele: Belebele 数据集仓库,一个大规模多语言阅读理解数据集。:Belebele 数据集仓库,一个大规模多语言阅读理解数据集。 - facebookresearch/belebele
- GitHub - google-research/xtreme: XTREME 是一个用于评估预训练多语言模型跨语言泛化能力的基准测试,涵盖 40 种类型各异的语言,包含 9 个任务。:XTREME 是一个用于评估预训练多语言模型跨语言泛化能力的基准测试,涵盖 40 种类型各异的语言,包含 9 个任务。 - goo...
提及的链接:--- **Datasette - LLM (@SimonW) ▷ #[llm](https://discord.com/channels/823971286308356157/1128504153841336370/)** (1 messages): obra: 是否可以恢复 OpenAI 模型在之前的 API 请求中使用的 seed? --- **Skunkworks AI ▷ #[general](https://discord.com/channels/1131084849432768614/1131084849906716735/1218193382669549568)** (17 messages🔥): - **关于改进全局准确率的论文待发布**:Baptistelqt 提到他们正在敲定一篇论文或文章,声称可以提高训练期间的全局准确率和样本效率,在发布前需要整理结果并制作更好的图表。 - **规模化挑战**:由于资源限制,该方法尚未在规模化应用中得到实证,但已经有一些现有的验证,目前正在讨论可能为更大规模的模型测试分配计算资源。 - **令人鼓舞的初步结果**:Baptistelqt 报告称,当他们的方法应用于带有 CIFAR100 子集的 VGG16 时,取得了积极的结果,将测试准确率从基础训练的 0.04 提高到了 0.1。 - **加入 Quiet-STaR 项目**:Satyum 表达了参与 "Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking" 项目的兴趣。在确认其精通 PyTorch 和 Transformer 架构后,双方讨论了进一步的参与事宜。 - **协作的时区限制**:由于时区差异,安排协作会议似乎存在困难。Baptistelqt 表示无法按提议在第二天会面讨论该方法的规模化实现。 --- **Skunkworks AI ▷ #[off-topic](https://discord.com/channels/1131084849432768614/1140423597454807179/)** (1 messages): pradeep1148: https://www.youtube.com/watch?v=ZlJbaYQ2hm4- How to Build a Buzzword:以及为什么它们如此强大
- Helicone:开发者如何构建 AI 应用。开箱即用的可观测性、工具、微调和评估。
- Vercel AI SDK:使用最新的 AI 语言模型构建 AI 驱动的应用
- GitHub - hegelai/prompttools: 用于 Prompt 测试和实验的开源工具,支持 LLM(如 OpenAI、LLaMA)和向量数据库(如 Chroma、Weaviate、LanceDB)。:用于 Prompt 测试和实验的开源工具,支持 LLM(如 OpenAI、LLaMA)和向量数据库(如 Chroma、Weaviate、LanceDB)。 - hegelai/prompttools
- GitHub - promptfoo/promptfoo: 测试你的 Prompt、模型、RAG。评估和比较 LLM 输出,捕获回归,并提高 Prompt 质量。适用于 OpenAI/Azure GPT、Anthropic Claude、VertexAI Gemini、Ollama、本地和私有模型(如 Mistral/Mixtral/Llama)的 LLM 评估,支持 CI/CD:测试你的 Prompt、模型、RAG。评估和比较 LLM 输出,捕获回归,并提高 Prompt 质量。LLM 评估适用于 OpenAI/Azure GPT、Anthropic Claude、VertexAI Gemini、Ollama、本地和...