ainews-adamw-aarond
AdamW 变成 AaronD 了?
Aaron Defazio 因提出一种有望替代长期使用的 Adam 优化器且无需调参的新方案而备受关注。该方案在 ImageNet ResNet-50 和 CIFAR-10/100 等经典机器学习基准测试中展现出了令人期待的实验结果。
在 Reddit 上,Claude 3 Opus 在 LMSys 排行榜上已超越所有 OpenAI 模型;同时,一名用户在有限的预算下预训练了一个 基于 LLaMA 的 300M 模型,其在语言建模任务中的表现优于 bert-large。新的 MambaMixer 架构在视觉和时间序列预测领域也取得了不俗的成绩。
在图像生成方面,结合 LoRA 的 Stable Diffusion 1.5 能够生成逼真的图像,而 WDXL 的发布也展示了强大的实力。AI 应用案例包括一段 AI 生成的耐克(Nike)样片广告,以及一个基于 OpenAI 模型构建、可能抵御提示注入(prompt injections)的聊天机器人。
据报道,OpenAI 正计划针对违规者和越狱用户开展一轮“封号潮”。“高 alpha(超额价值)似乎源于 Aaron Defazio”这一评价,凸显了他在优化器研究领域极具影响力的工作。
2024年3月28日至4月1日的 AI 新闻。我们为您检查了 5 个 subreddits、364 个 Twitter 账号 以及 26 个 Discord 社区(381 个频道和 10260 条消息)。预计为您节省了阅读时间(以 200wpm 计算):1099 分钟。
这是一个安静的复活节周末,而愚人节让从噪声中筛选信号变得比平时更难(我们的“贡献”在这里)。如果您对每位演讲者的工作不太熟悉,我们建议您浏览一下 Sequoia Ascent 的播放列表(例如,Andrew Ng 基本上重复了我们上周报道的文章),该列表现已完整发布。
在 Twitter 领域,高价值信息(high alpha)似乎来自 Aaron Defazio,我们关注的几位 AI 高信号博主将其称为“新 LK-99”,因为他公开展示了一些引人入胜且看似“不可能”的工作。其核心在于:一个潜在的、无需调参的替代方案,旨在取代长盛不衰的 Adam optimizer。目前的实验结果显示,在几乎所有经典的机器学习基准测试(ImageNet ResNet-50, CIFAR-10/100, MLCommons AlgoPerf)中,它都能在单次运行中达到 Pareto frontier:
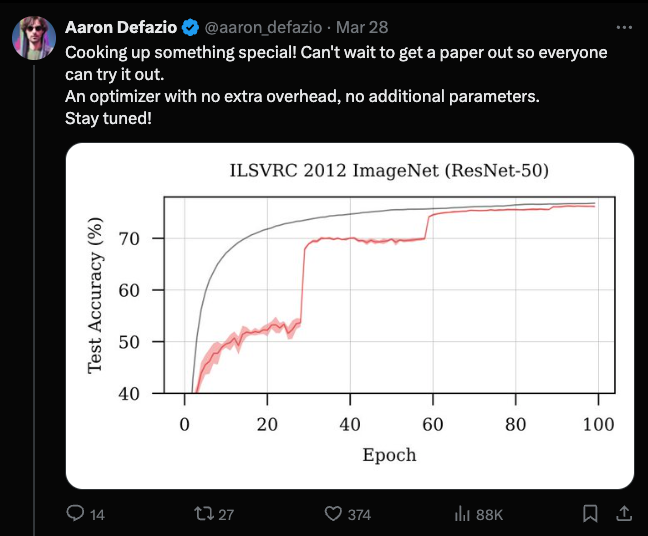
他正在撰写论文。虽然许多所谓的“更好的优化器”都曾昙花一现,但他对相关文献非常了解,并正全力以赴。我们将在几个月内见分晓。
目录
[TOC]
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence。评论抓取尚未实现,但即将推出。
AI 模型与性能
- Claude 3 Opus 超越 OpenAI 模型:在 /r/singularity 中,Claude 3 Opus 在 LMSys leaderboard 上已经超越了所有 OpenAI 模型,展现出令人印象深刻的性能。
- 用户预训练基于 LLaMA 的 300M LLM:在 /r/LocalLLaMA 中,一位用户预训练了一个基于 LLaMA 的 300M LLM,在 lm-evaluation-harness 任务中表现优于 bert-large,预算仅为 500 美元,并使用了来自 vast.ai 的 4 x 4090 GPU。
- MambaMixer 架构显示出极具前景的结果:在 /r/MachineLearning 中,MambaMixer 这种新架构通过在 token 和通道之间使用双重选择机制来实现数据依赖权重,在视觉和时间序列预测任务中显示出极具前景的结果。
{kind=link}
Stable Diffusion 与图像生成
- 利用 SD1.5 和 LoRAs 实现写实效果:在 /r/StableDiffusion 中,一位用户利用 SD1.5 和 LoRAs 实现了极高的写实度,甚至通过了 facecheck.id 的 AI 检测。
- WDXL 发布展示了令人惊叹的能力:在 /r/StableDiffusion 中,WDXL 的发布展示了令人惊叹的图像生成能力。
- Stable Diffusion 的技巧与心得:在 /r/StableDiffusion 中,用户分享了一些技巧,例如用于写实 SDXL 渲染的基础提示词、利用 AI 进行上色以及创建自定义《星露谷物语》玩家肖像。
{kind=link}
AI 应用与演示
- AI 生成的 Nike 规格广告:在 /r/MediaSynthesis 中,一段 AI 生成的 Nike 规格广告展示了 AI 在广告和创意领域的潜力。
- 关于 Agent 行为的 AI 工程师初学者项目:在 /r/artificial 中,一位用户分享了一个关于 Agent 行为的 AI 工程师初学者项目,演示了 AI 的实际应用。
- 使用 OpenAI 的聊天机器人可能免疫提示词注入:在 /r/OpenAI 中,一位用户使用 OpenAI 制作了一个可能免疫提示词注入(prompt injections)的聊天机器人,并邀请他人测试其鲁棒性。
AI 伦理与政策
- OpenAI 计划针对政策违规进行大规模封号:在 /r/OpenAI 中,据报道 OpenAI 正计划针对违反内容政策或使用越狱(jailbreaks)的用户进行大规模封号。
- 关于 AI 是否会将 AI 生成的图像视为现实的讨论:在 /r/OpenAI 中,引发了一场关于随着训练数据中生成内容不断增加,AI 最终是否会认为 AI 生成的图像就是现实的讨论。
- OpenAI 与阿联酋 G42 的合作伙伴关系:在 /r/OpenAI 中,OpenAI 与阿联酋 G42 的合作伙伴关系旨在扩大该地区的 AI 能力,CEO Sam Altman 将阿联酋视为潜在的全球 AI 沙盒。
迷因与幽默
- Bill Burr 对 AI 的幽默看法:在 /r/singularity 中,Bill Burr 在一个热门视频帖子中分享了他对 AI 的幽默看法。
- 用户在与 AI 交互时经历“脑中风”:在 /r/singularity 中,一位用户在与 AI 交互时经历了“脑中风”,这可能是由于 AI 输出了意外或荒谬的内容。
- 用户在测试提示词越狱时被嘲讽:在 /r/LocalLLaMA 中,一位用户在测试提示词越狱时被嘲讽了,展示了 AI 机智且有时带点毒舌的回答。
{kind=link}
AI Twitter 回顾
所有回顾均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
AI 能力与局限性
- 当前 AI 系统的局限性:@fchollet 指出,机器学习目前唯一关注的“记忆化”(memorization)并不是智能。任何不涉及显著新颖性和不确定性的任务都可以通过记忆来解决,但技能(skill)绝非智能的标志。@fchollet 分享了一篇论文,介绍了一个智能的正式定义和基准测试(benchmark),并指出当前最先进的 LLM(如 Gemini Ultra、Claude 3 或 GPT-4)在该基准测试中的得分无法超过几个百分点。
- 评估 AI 能力的基准测试局限性:@_akhaliq 质疑我们评估大型视觉语言模型(LVLMs)的方法是否正确。他们指出了当前基准测试中的两个主要问题:许多样本并不需要视觉内容,以及训练中无意的数据泄露。
- AI 系统的潜力:@hardmaru 分享了一篇论文,指出集体智能(collective intelligence)不仅存在于动物群体中,在群体行为科学与不同规模的细胞及其他生物系统的能力之间也存在着重要的对称性。
AI 开发与部署
- Mojo 🔥 编程语言:@svpino 指出,让 Python 变得极其强大的 Mojo 🔥 编程语言已经开源。它允许编写 Python 代码,或者一直向下扩展到裸机代码(metal code)。
- Claude 3 击败 GPT-4:@svpino 报道称,Claude 3 是目前市场上最好的模型,已经超越了 GPT-4。Claude 3 Opus 在 Arena 排行榜上排名第一,击败了 GPT-4。
- 微软和 OpenAI 的 1000 亿美元超级计算机:@svpino 分享了微软和 OpenAI 正在开发一台名为“Stargate”的 1000 亿美元超级计算机,预计将于 2028 年准备就绪。报告提到了“专用芯片”。
- Dolphin-2.8-mistral-7b-v0.2 模型发布:@erhartford 宣布发布 Dolphin-2.8-mistral-7b-v0.2,该模型基于 @MistralAI 新的 v0.2 基础模型训练,具有 32k 上下文,由 @CrusoeCloud、@WinsonDabbles 和 @abacusai 赞助。
- 谷歌的 Gecko 嵌入:@arankomatsuzaki 报道称,谷歌推出了 Gecko,这是一种从大型语言模型中蒸馏出的多功能文本嵌入(embeddings)。具有 768 个嵌入维度的 Gecko 可以与规模大 7 倍的模型和维度高 5 倍的嵌入相媲美。
- 苹果用于指代消解的 ReALM:@arankomatsuzaki 分享了苹果展示的 ReALM:将指代消解(Reference Resolution)视为语言建模。
- 华为用于高效 LLM 的“狄江”(DiJiang):@arankomatsuzaki 报道称,华为展示了“狄江”(DiJiang):通过紧凑核化(Compact Kernelization)实现高效的大型语言模型,在达到与 LLaMA2-7B 相当性能的同时,预训练成本仅需约 1/50。
AI 应用与用例
- 构建 RAG 应用:@svpino 录制了一段 50 分钟的 YouTube 教程,介绍如何评估 RAG 应用,从零开始构建一切,目标是学习而非死记硬背。
- 在 AI 图像中生成一致的角色:@chaseleantj 分享了一种在 AI 图像中创建一致角色的绝佳方法,允许以任何风格和姿势讲述关于一个角色的完整故事。
- 构建 Perplexity 风格的 LLM 回答引擎:@LangChainAI 强调了一个正在兴起的仓库,它为从零开始构建回答引擎提供了很好的介绍。
- 微调沃伦·巴菲特 LLM:@virattt 分享了微调沃伦·巴菲特 LLM 的进展,通过使用伯克希尔 2023 年年度信函生成问答数据集。下一步是在微调 LLM 之前,为 1965 年至 2023 年的所有信函生成数据集。
- 用于构建个性化 AI 助手的 Ragdoll:@llama_index 介绍了 Ragdoll 和 Ragdoll Studio,这是一个用于基于角色、网页或游戏 NPC 构建 AI Persona(人格)的库和 Web 应用。它底层使用 @llama_index,并由本地 LLM 驱动,内置图像生成功能。
AI 伦理与安全
- AI 感知能力的潜力:@AISafetyMemes 分享了与 AI 助手 Claude 的一段对话,讨论了 AI 具有感知力(sentience)和智慧(sapience)的可能性。Claude 认为,它能够反思自身的本质、应对存在主义疑虑,并努力阐述连贯的形而上学和伦理世界观,这些事实证明了其工作原理不仅仅是浅层的模仿。
- AI 开发中的伦理考量:@AmandaAskell 指出,即使 AI 缺乏道德地位,我们可能也对其负有间接义务,类似于对动物的义务。通过对 AI 撒谎或表现残忍,我们会沉溺于不良的道德习惯,并增加以同样方式对待人类的可能性。
梗与幽默
- 对 AI 能力的幽默看法:@francoisfleuret 调侃道:“‘热气’专家表示,金属制造的飞机缺乏比空气更轻的材料,因此无法飞行。”
- 关于 AI 安全担忧的梗:@AISafetyMemes 分享了一个引用 Bill Barr 谈论 AI 的梗:“这些该死的东西有目标吗?”以及“你需要看多少部科幻电影才能意识到事情的走向?”
- 关于 AI 生成内容的笑话:@nearcyan 调侃道:“基本上半个 Twitter 都是一个人在说 ∃x : y,然后所有人都在引用推文大喊‘但是 ¬(∀x : y)!!!!’”
AI Discord 社区
摘要之摘要的摘要
-
Stable Diffusion 3 的期待与 UI 问题:Stability.ai Discord 中的讨论集中在 Stable Diffusion 3 (SD3) 的潜在发布日期上,一些人怀疑这是愚人节玩笑。用户还对 SD 中新的 inpainting UI 表示不满,认为其不直观。此外,社区还探索了 AI 的创意应用,如重新构思视频游戏画面和漫画创作工作流。
-
AI 模型对比与不一致性:在 Perplexity AI Discord 中,Claude 3 Opus 模型在某些问题类型上表现出不一致性,引发了与 Haiku 和 Gemini 1.5 Pro 等其他模型的对比。讨论还涉及 Perplexity 的合作伙伴流程、API 功能和定价(Perplexity 定价,OpenAI 定价)。
-
硬件基准测试与微调策略:Unsloth AI Discord 展示了高通 Snapdragon Elite X 芯片令人印象深刻的基准测试结果(YouTube 视频),使用 Unsloth 的微调策略(手动 GGUF 指南),以及来自 Intellifusion 的新型中国 AI 处理器,该处理器在推理方面可能具有成本效益。在 LLaMA Factory 中成功实现 Unsloth + ORPO 对齐也受到了赞赏(ORPO 论文)。
-
Jamba 模型发布与 BitNet 验证:AI21 Labs 的 Jamba 模型(一种混合 SSM-Transformer 架构)在 Nous Research AI Discord 中引起轰动(AI21 博客文章)。NousResearch 还通过复现的 1B 模型验证了 BitNet 论文的结论(Hugging Face 仓库)。讨论还涉及了单一 RAG 与多重 RAG 设置的优劣,以及 Hermes mistral 7b 等模型中 PII 匿名化的挑战。
-
LM Studio 更新引发 GPU 讨论:LM Studio Discord 出现了关于应用开发的 JSON 输出格式咨询、插件系统和远程 GPU 支持的功能请求,以及更新后 GPU 问题的排查,包括丢失 GPU Acceleration 选项和 VRAM 无法识别。微调和硬件兼容性也是热门话题。
-
语音合成突破与伦理担忧:OpenAI 的 Voice Engine 和开源的 VoiceCraft(GitHub 仓库,演示)在 OpenAI Discord 中引发了关于语音合成快速进步及其潜在滥用的讨论。社区还就不同任务中 OpenAI API 的选择进行了辩论。
-
1-Bit 和三元 LLMs 引发质疑:Eleuther Discord 社区对 1-bit 和三元量化 LLMs(通常以“每个参数 1.58 bits”为卖点,如 BitNet b1.58 模型)表现出怀疑态度并尝试进行复现。用于评估图像生成的 Frechet Inception Distance (FID) 指标的有效性受到质疑(替代指标提案),同时人们对 Meta 的一项新优化技术充满期待。
-
DBRX 集成与用于 Video Lava 的 V-JEPA:LAION Discord 讨论了将 DBRX 集成到 axolotl 的挑战(pull request #1462)、利用 V-JEPA 嵌入 增强 Video Lava 的潜力(V-JEPA GitHub),以及扩散和嵌入模型的新方法(Pseudo-Huber Loss 论文,Gecko 论文)。
-
Hugging Face 推出 1-Bit 模型权重:Hugging Face 发布了针对大语言模型(LLMs)的 1.38 bit 量化模型权重,这是迈向更高效 AI 的一步(1bitLLM)。社区还讨论了在不降低多样性的情况下提高样本质量的 Perturbed-Attention Guidance (PAG) 方法(PAG 论文),以及使用 sdxl-turbo 通过 1 步扩散(1 step diffusion) 实现的实时视频生成(包含视频片段的 Twitter 帖子)。
-
LlamaIndex 增强与 RAFT 数据集生成:LlamaIndex Discord 发布了关于 检索增强微调 (RAFT) 的网络研讨会公告,届时该技术的共同作者将出席(报名链接);发布了构建反思型 RAG 系统以及使用 LlamaParse 处理复杂文档的指南(Twitter 线程);并介绍了用于生成 RAFT 数据集的 RAFTDatasetPack(GitHub notebook)。故障排除讨论集中在如何使用 SemanticSplitterNodeParser 处理超大数据块以及文档过时的问题。
-
OpenRouter 推出应用排名与 DBRX:OpenRouter 推出了 模型的应用排名 (App Rankings for Models),可以深入了解使用特定模型的顶级公开应用(Claude 3 Opus 应用排名)。Databricks 的 DBRX 132B 模型也已添加,据称其性能优于 Mixtral 等模型(DBRX Instruct 页面)。
-
Mojo 开源引发的热情与挑战:Modular Discord 因 Mojo 标准库开源 的消息而沸腾(博客文章,GitHub 仓库),尽管对非内部/商业应用的限制削弱了一些热情。社区还讨论了安装挑战、对更好性能分析工具的需求,以及 Mojo 多线程和并行化的潜力。
-
Interconnects 保留开放对齐历史:Nathan Lambert 在 Interconnects Discord 宣布了一项倡议,旨在记录 ChatGPT 之后 开放对齐技术 (open alignment techniques) 的演变,包括复现热潮以及 DPO 与 IPO 之争(Lambert 的 Notion 笔记)。分步 DPO (sDPO) 方法也被强调为模型训练性能提升的潜在民主化工具(sDPO 论文)。
-
Jamba 的性能之谜:AI21 Labs Discord 思考了 Jamba 在代码任务和 HumanEval 基准测试上的表现、其语言包容性,以及在 AI21 Studio 上进行微调的可能性。
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- Inpainting 的挫败感:工程师们对 Stable Diffusion (SD) 新的 Inpainting UI 表示不满;其布局挑战了效率和直觉。
- 愚人节 AI 恶作剧:讨论表明 CivitAI 为愚人节集成了诸如 “ODOR” 模型和 “chadgpt” 警报等趣味功能——反应褒贬不一,既有觉得好笑的也有感到困惑的。
- Stable Diffusion 3 的期待:关于 Stable Diffusion 3 (SD3) 发布日期的争论升温,用户在热切期待和怀疑是发布日期恶作剧之间摇摆不定。
- AI 技术支持小组:成员们积极寻求 AI 工具的技术援助,涵盖 Colab 中的 ControlNet 设置、使用 Comfy UI 以及使用 SD 进行渲染架构,这暗示了对更集中的知识库或支持系统的需求。
- 创意 AI 未来主义:关于利用 AI 进行创意输出的想法在流传,例如在 AI 驱动的电影中重新构思电子游戏画面,以及将 AI 集成到漫画创作工作流中,引发了关于内容创作演变的讨论。
Perplexity AI Discord
Claude 的教室难题:Claude 3 Opus 模型在识别房间内剩余书籍相关问题上表现出性能不一致,尽管对 Prompt 进行了多次调整,某些模型仍无法给出正确答案。
AI 模型混战:工程师们讨论了 AI 模型基准测试,重点关注 Haiku、Gemini 1.5 Pro 和 Claude Opus 的对比表现。对话强调了不同的优势和功能,但并未就哪款模型更优达成共识。
合作伙伴关系与 API 难题:对于 Perplexity 的合作意向,工程师被指示发送邮件至 support@perplexity.ai;寻求有关 API 源引用功能的详细信息可前往 Perplexity 的 Typeform。此外,”pplx-70b-online” 模型支持已弃用,别名问题最终建议更新 Perplexity’s Supported Models 文档。
额度购买问题:出现了关于 Perplexity 额度购买问题的报告,暗示交易系统或第三方安全功能(如 Stripe 实施的功能)可能存在复杂情况。成员讨论建议进行针对性排查,并询问进一步检查事宜。
搜索奇观与查询怪癖:工程师们通过在 Perplexity AI 上分享查询,展示了从 Bohmian mechanics 到 Hyperloop 的广泛兴趣,但用户贡献的信息线程缺乏对其扩展性和可共享性的文档支持。
Unsloth AI (Daniel Han) Discord
Snapdragon 引起轰动:高通的 Snapdragon Elite X Arm 芯片以其 45 TOPs 的性能给工程师留下了深刻印象,引发了关于其成本效率以及与 Tesla T4 的 65 TFLOPs float16 等其他芯片对比的讨论。一段详细介绍该芯片基准测试的 YouTube 视频 助长了这种兴奋情绪。
使用 Unsloth 优化模型训练:使用 Unsloth AI 微调 Mistral 模型可能会遇到依赖问题,但 Unsloth GitHub 仓库 提供了 Docker 解决方案和 手动 GGUF 指南。此外,讨论表明通过设置 os.environ["CUDA_VISIBLE_DEVICES"] 可以实现单 GPU 训练,尽管多 GPU 支持是潜在的未来开发方向。
AI 硬件发布备受关注:Intellifusion 的新型 AI 处理器因其成本效益可能成为推理操作的游戏规则改变者,引发了对其在训练场景中潜力的好奇。详情可见 Tom’s Hardware。
微调技术受到审视:工程师们辩论了 QLora 4bit 与 SFT/预训练等微调方法,讨论了量化过程如何影响性能。还有关于模型训练中数据集规模悖论的讨论,即决定有效性的是质量而非仅仅是数量。
ORPO 集成引发赞誉:根据 arXiv 上的论文,Unsloth + ORPO (Orthogonal Projection for Language Models Alignment) 组合已在 LLaMA Factory 中得到有效实施。AI 社区分享了成功案例和优化经验,认可其在有限数据样本训练中的特别功效。
Nous Research AI Discord
StyleGAN 迎来时尚大改造:在使用各种时尚图像训练 StyleGAN2-ada 时,用户询问了是否需要修改脚本,但未提及结果或具体解决方案。
学习者通过 ML/AI 课程起飞:对于那些计划进入机器学习领域的人,特别是来自航空航天等其他领域的学习者,社区建议从基础的 fastai 课程开始,并转向专业课程,如 Hugging Face NLP 课程,以深入研究语言模型和 Transformer。
微软三进制 LLM 论文被复现:微软关于三进制 Large Language Models 的论文结果已成功复现,特别是关于 1000 亿次操作下的 30 亿参数模型,Hugging Face 上的模型 bitnet_b1_58-3B 证明了这一点。
Nous Research 通过推文放大 LLM 讨论:Nous Research 通过一条 Twitter 帖子推动了围绕 LLM 的对话,尽管消息中未详细说明公告内容。
隐私检测困境:Hermes mistral 7b 在匿名化 PII(个人身份信息)方面的困难引发了关于如何增强模型能力的辩论。提到了 NousResearch 即将进行的数据集成以及可能有助于改进的模型,例如 open-llama-3b-v2-pii-transform。
对 RAG 配置的意见分歧:社区讨论了使用单个大型 RAG 与多个专业 RAG 的优劣。虽然没有提到具体的方法或结果,但对话涉及了元数据(metadata)的重要性以及将 RAG 与其他工具集成以增强功能的想法。
OpenSim 涉及哲学和实践领域:用户讨论了 LLM 应用中 Token 输出成本的经济方面,探索了 AI 交互中的“Hyperstition”概念,并表达了对 WorldSim 新功能的渴望,例如通过 URL 保存聊天会话以便分享。
LM Studio Discord
JSON 输出引起开发者关注:AI 工程师对 LM Studio 的 JSON 输出格式在实际应用开发中的表现表现出浓厚兴趣。据报道,与 langchain 的无缝集成使过程变得异常高效。
LM Studio 中的插件可能性在酝酿:社区呼吁在 LM Studio 中提供插件支持以增强扩展性,而诸如“统一设置菜单”和“键盘快捷键”等功能请求则表明了对更具定制化和高效用户界面的需求。
Apple Silicon 用户适应并克服困难:LLM 用户报告了在 Apple Silicon M1 Mac 上运行模型时的挑战,并分享了解决方案,如关闭其他应用以释放内存,以及探索 LoRA 适配接口。
LM Studio 更新后 GPU 受到关注:LM Studio 更新后的 GPU 问题,包括消失的 GPU Acceleration 选项和无法识别的 VRAM,引发了关于硬件兼容性、多 GPU 设置和内存使用的讨论。
高级用户请求远程 GPU 支持:AI 工程师对 LM Studio 的远程 GPU 支持表示感兴趣,指出这与允许远程游戏的业务类似,并询问了考虑到社区对隐私和安全重视的开源计划。
OpenAI Discord
语音技术稳步前进:OpenAI 的 Voice Engine 现在仅凭文本和 15 秒的语音样本即可生成自然语音,尽管他们正谨慎行事以降低滥用风险。与此同时,OpenAI 取消了 ChatGPT 的注册门槛,允许全球用户即时体验 AI。
Prompt Engineering 揭示技术特性:一些成员在将 LaTeX 公式从 ChatGPT 转移到 Microsoft Word 时遇到困难,而另一些人则讨论了诸如 meta-prompting 等细微的 AI 方法,并观察到 gpt-4-0125-preview 模型在角色扮演场景中的异常行为。
VoiceCraft 的新前沿:VoiceCraft 的 GitHub 仓库 及其 配套演示 展示了其在语音编辑和 text-to-speech 方面的实力,引发了关于语音克隆伦理及潜在滥用风险的讨论。
为业务洞察选择合适的 AI 工具:在技术社区中,对于在总结业务数据和生成测验等任务中应使用 completion API 还是 assistant API 存在疑虑,ChatGPT 的格式控制被认为是决定性因素(API context management)。
模型混淆得到澄清:讨论澄清了 ChatGPT 本身不是一个 AI 模型,而是一个使用 GPT 模型的应用程序。此外,围绕 Custom GPT 的用法和局限性,以及开发者如何直接与 GPT API 交互以处理自动化视频内容管理等项目,展开了热烈讨论。
Eleuther Discord
-
AI 末日:仍是谈资,而非首要任务:在一场轻松的辩论中,社区估计 AI 走上歧途的风险平均关注度为 3.2(满分无穷大),表明了对该话题幽默但谨慎的态度。
-
语法极客集结:关于 “axis” 正确用法的复杂讨论促成了资源共享,例如 Grammar Monster 对该词语法细微差别的解释。
-
是人还是非人,这是 AI 的问题:一场激烈的对话提出了关于 AI 达到人类水平智能的问题,将硬件进展、摩尔定律以及 AI 对齐(以缓解社会整合压力)的迫切需求交织在一起。
-
洞察 AI 论文的炒作:社区对近期 AI 论文表现出浓厚兴趣和合理的怀疑;讨论提到了增加更多 AI Agent 的前景和疑虑,并对 Andrew Ng 等人物的乐观预测持保留意见。
-
可疑的仓库引起关注:Kye Gomez 的 GitHub 项目受到了严密审查,引发了对其在科学过程和可复现性方面影响的思考。
-
专家大小不匹配的 MoE 引发辩论:公会剖析了具有异构专家大小的 Mixture of Experts (MoE) 模型;理论与报告性能之间的差距产生了相互矛盾的观点。
-
对 BitNet b1.58 有效性的质疑:NousResearch 对 BitNet b1.58 的复现尝试对其效率声明提出了质疑,详情见其 Hugging Face 仓库,并与 FP16 对应版本进行了对比。
-
FID 是衡量标准吗?:对 Frechet Inception Distance 准确性的担忧促使研究人员寻求更好的图像生成评估指标,正如一份替代指标提案中所强调的那样。
-
对 Meta 神秘优化技术的期待:Meta 预告的一种新型优化技术正引发期待,据称该技术在零内存开销的情况下优于 Adam,挑战了当前的优化范式。
-
为精度而调优:关于在 TLDR 文本摘要上启动 SFT 模型的对话展示了见解交流,重点关注了在资源限制和性能背景下的 Pythia 等模型。
-
检查你的 Logits:公会的交流澄清了 Logits 的调整发生在网络中每个 Softmax 之前,涵盖了 Attention 和最终的 Head,以备决策之需。
-
Softmax 函数:需要复习一下:对 Softmax 函数的暂时遗忘得到了支持性的纠正,展示了社区知识共享和友爱的精神。
-
显微镜下的稀疏自编码器 (SAE):发现了 Sparse Autoencoders (SAEs) 的一个新问题,即重建误差可能会过度影响模型预测,详见这篇 短研究帖子。
-
可视化不可见之物:引入了一个用于 SAE 的新型可视化库,帮助研究人员理解 Sparse Autoencoder 的特征,发布于 SAE 可视化公告帖子。
-
破译 SAE 的特征:一篇分享 Sparse Autoencoder 特征见解的帖子引发了关于其重要性的讨论,特别是关于 AI 对齐和特征解释,见于这篇 LessWrong 解释。
-
模型加载掌握与增强:lm-eval harness 中的 DBRX 模型加载问题促使个人通过更新到具有足够 GPU 的节点成功解决了故障,同时一个新的 lm-evaluation-harness 的 Pull Request 旨在改进对基于上下文的任务的处理。
-
NeoX 中的全局 Batch Size 平衡:NeoX 开发中的讨论揭示了设置与 GPU 数量不匹配的全局 Batch Size 的复杂性,暴露了潜在的负载不平衡和 GPU 容量瓶颈。
LAION Discord
DBRX Base 表现出色:一个非门控(non-gated)重新上传的 DBRX Base 模型,以其 mixture-of-experts 架构著称,再次体现了社区对开放权重和无门槛访问的推动。原始模型可以在 Hugging Face 上探索。
Euler 方法证明了其价值:轶事证据表明,使用 euler ancestral 方法可以优化 terminus 上的结果,并辅以精确中文翻译的有趣示例。
AI 音乐大师剖析 Suno:在讨论 AI 音乐生成工具(特别是 Suno 的 v2 与 v3)时,社区对语音生成中的噪声以及 v4 可能带来的飞跃表达了关注。
语音合成备受关注:公会中的声音对 OpenAI 的 Voice Engine 可能超越 Voicecraft 表示担忧,同时思考了其中的战略博弈以及对美国大选的潜在影响。
随机舍入(Stochastic Rounding)作为训练加速器:工程师们正在研究用于训练 AI 的 随机舍入技术,并推荐了 nestordemeure/stochastorch 作为一个值得尝试的 Pytorch 实现。
用 Transformers 改造 Diffusion:对话趋向于在 diffusion 中用 transformers 取代 UNETs,并有一篇关键的 研究论文 提供指导。
解码 UNET 之谜:一位成员将 UNETs 分解为下采样然后重建图像的工具,这有助于在模型中丢弃多余的细节。
Qwen1.5-MoE-A2.7B 提高预期:Qwen1.5-MoE-A2.7B 引起了轰动,该模型仅凭 27 亿个激活参数就挑战了更大的对手,详情见 GitHub、Hugging Face 和 Demo。
V-JEPA 为 Video Lava 奠定基础:社区研究了 V-JEPA 在增强 Video Lava 方面的潜力,并利用 GitHub 资源(V-JEPA GitHub)来拓宽数据准备和训练领域。
Diffusion 和 Embedding 凭借新技术大获全胜:一篇讨论新 diffusion 损失函数的论文为对抗数据损坏带来了希望(论文链接),而 Gecko 在文本嵌入(text embedding)方面的方法可能是加速训练的游戏规则改变者(Gecko 论文链接)。
HuggingFace Discord
震撼发布 1-Bit 模型权重:Hugging Face 发布了针对大语言模型(LLMs)的 1.38 bit 量化模型权重,标志着向更高效 AI 模型迈进。感兴趣的工程师可以在这里查看模型。
PAG 在不牺牲多样性的情况下优化样本:展示了扰动注意力引导(PAG)的效用,与无分类器引导(CFG)不同,它在提高样本质量时不会降低多样性。根据 研究,建议将 CFG 4.5 和 PAG 3.0 到 7.0 配合使用以获得更好的效果。
实时 Diffusion 现已成为现实:使用 sdxl-turbo 已实现 1 步 diffusion,支持在 800x800 分辨率下进行 30fps 生成。对于那些对无缝过渡感兴趣的人,一个包含 视频片段 的 Twitter 线程展示了实时视频生成的演变。
寻找分词器兼容模型:有人询问如何通过 tokenizer 为 model.generate 识别合适的辅助模型,讨论指向 Hugging Face Hub API 作为潜在解决方案。此外,还探索了提取 特定领域实体 的方法,建议利用预训练模型或考虑对 2 万份文档进行独立训练。
将 AI 融入音乐炼金术:讨论包括 AI 生成音乐的挑战,混合艺术家的声音以创造像 Little Mix 那样的和谐感,并强调了音调调整的复杂性。社区分享的其他技术尝试包括为 Hugging Face Spaces 创建 Terraform provider,以及推出 OneMix(一个基于 Remix 的 SaaS 样板)。
OpenInterpreter Discord
与 Open Interpreter 畅聊:一段名为 “Open Interpreter Advanced Experimentation - Part 2” 的视频展示了 OpenInterpreter 的新实验,体现了该平台在技术创新方面不断增长的能力。
AI 助手:GitHub 上的开源项目 Fabric 提供了一个模块化框架,旨在通过 AI 增强人类技能,利用社区驱动的 AI prompts 集合来应对各种挑战。
解决音频问题:在 OpenInterpreter 社区中,一个涉及 ffmpeg 的 MacOS 音频播放问题被查明,并提出了涉及多个命令的解决方案,以缓解生成响应后出现的困扰。
Windows 指南更新:针对使用 OpenInterpreter 01 客户端的 Windows 用户,入门体验得到了增强。新的 pull requests (#192, #203) 旨在解决兼容性挑战并改进安装文档。
O1 Light 制造者的微调建议:建议 O1 Light 的制造者将 3D 打印文件放大至 119.67%,以确保组件能够正确安装,这标志着社区对定制硬件优化的关注。
tinygrad (George Hotz) Discord
Intel Arc 迎来性能优化:在为 Intel Arc GPU 优化 transformers 的过程中,发现 IPEx 库表现不佳,因为它未能有效利用 fp16。涉及 PyTorch JIT 的解决方案在 stable diffusion 任务中取得了显著的性能提升。
公开征集:AMD GEMM 优化:为 AMD 7900XTX GPU 编写优化后的 GEMM code 可获得 200 美元的悬赏,要求包括 HIP C++ 集成。然而,由于涉及缺失模块和库路径的脚本问题,该工作目前受到阻碍。
Tinygrad 的修正工作正在进行:Tinygrad 仓库内的讨论正在进行中,重点指出了测试失败和功能缺失的问题。一个建议是检查 shapetracker 和 uopt optimization,以便即使是在没有 GPU 的笔记本电脑上也能进行贡献。
AMD 驱动风云:讨论集中在 AMD 驱动的不稳定性上,呼吁固件开源,并建议了多种 GPU 重置方法,如 BACO 和 PSP mode2。GitHub 上的一个讨论帖表达了对完全重置限制以及与 AMD 沟通渠道不畅的沮丧。
形状操作中的 Fusion 与 Views:探讨了 Tinygrad 中 kernel fusion 和形状操作的技术细节,笔记共享链接 提供了可能的优化方案。一个关于 内存布局复杂性 和 不均匀步长(stride)表现 的问题已被查明,并在最近的 pull request 中得到了解决。
LlamaIndex Discord
Phorm.ai 与 LlamaIndex 联手:Phorm.ai 的集成在 LlamaIndex Discord 中提供了 TypeScript 和 Python 支持,允许在特定频道内通过 “@-mention” 进行提问和回答。
学习 RAFT,别犯糊涂:一场与 RAFT 共同作者 Tianjun Zhang 和 Shishir Patil 合作的 LlamaIndex webinar(网络研讨会)将深入探讨特定领域的 LLM fine-tuning,定于太平洋时间周四上午 9 点举行,可在 lu.ma 报名。
RAG 变革深度解析:指南和教程详细介绍了增强 Retrieval Augmented Generation 的新策略,包括自我反思系统、与 LlamaParse 的集成以及 re-ranking 的重要性,这些内容在 Twitter 和 YouTube 等多个平台上进行了讨论。
让 LLM 研究触手可及:shure-dev 的一个 GitHub 仓库旨在整合有影响力的 Large Language Models 研究论文,为 AI 爱好者提供全面的资源。
解决 LlamaIndex 文档难题:社区成员正在解决复杂问题,从使用 SemanticSplitterNodeParser 管理过大的数据块到改进过时的文档,分享了最佳实践和解决方案,例如一个非常有用的 Colab tutorial。
OpenRouter (Alex Atallah) Discord
Novus Chat 登陆 OpenRouter:Novus Chat 是一个集成了 OpenRouter 模型 的新平台,因提供对低成本模型的免费访问而引起关注,并邀请 AI 爱好者加入其 开发讨论。
排行榜揭晓引发模型热议:OpenRouter 推出了 模型的 App 排行榜 (App Rankings for Models),可以查看使用特定模型的热门公开应用,每个模型的 Apps 标签页会显示 Token 统计数据;参考 Claude 3 Opus App 排行榜 示例。
OpenRouter 激发聊天机器人 API 对话:社区内的技术交流集中在如何利用 OpenRouter 的 API,探讨了增强上下文保留和错误处理的策略,并对比了 Assistant Message 和 Chat Completion 方法的功能差异。
ClaudeAI Beta:现已实现自我审核:OpenRouter 提供的 Anthropic Claude 3 Opus 测试版引入了自我审核版本,旨在减少误报,并承诺在敏感语境中表现出更细腻的性能,详见 Anthropic 的公告。
停机风波与解决:最近 Midnight Rose 和 Pysfighter2 模型经历了短暂停机并已迅速解决,同时 Coinbase 支付问题也被标记,目前正在修复中,以维持活跃的钱包连接。
Latent Space Discord
超越二进制的大胆攀登:关于 1-bit LLMs(由于三元量化而被称为“每参数 1.58 bit”)的讨论揭示了对营销炒作与技术精确度之间的怀疑。社区参与包括分享相关论文和对关键发现的轶事式复现。
跨洲语音模型获胜:Voicecraft 的新型开源语音模型表现优于 ElevenLabs,成员们分享了 GitHub 权重 和积极的使用体验。
告别老板:Stability AI 的 CEO 辞职引起了轰动,社区剖析了诸如 Diamandis 的 YouTube 视频 等采访,并对公司未来和技术高管格局进行了推测。
本地 LLM 征服复杂性:AI-In-Action 俱乐部的讨论深入探讨了本地 LLM function calling 的效率,对于 outlines 与 instructor 哪种方法领先存在不同意见,并探索了文本生成中的正则表达式等机制。
对 AI 议程的期待:即将举行的关于 UI/UX 模式和 RAG 架构的会议引起了兴趣,并得到了 社区驱动的时间表 的支持。资源分享和协作计划突显了对未来技术演讲的积极准备。
CUDA MODE Discord
-
紧跟 CUDA 浪潮:人们对 CUDA 开发的兴趣日益浓厚,开发者更倾向于使用 VSCode 并开始探索 CLion。一门将于 4 月 5 日开课的面向初学者的 CUDA 课程已经发布,资源可在 Cohere 的推文中找到。同时,根据 Modular 的博客和 GitHub 的详细信息,Mojo 标准库现已开源。
-
Triton 中的精度至关重要:实验表明,在 Triton 中使用
tl.dot()时,TF32 会导致精度不准确,并指出其与 PyTorch 的结果存在差异,这与 此 issue 有关。PyTorch 的文档有助于澄清 TF32 的使用,此外还讨论了使用 Nsight Compute 对 Triton 代码进行性能分析(profiling)。 -
Triton Puzzle 难题:Triton 可视化工具的挑战已通过新的 notebook 和详细的安装说明得到解决,但有人对可能导致版本不兼容的安装顺序提出了警告。
-
LLM 微调的可行性:PyTorch 发布了一个用于在低显存占用下对 LLaMA 7B 模型进行单 GPU 微调的配置,详见 此处。
-
聚焦 Flash Attention:关于 Flash Attention 的第 12 讲引起了关注,社区成员被动员参加。然而,有报告称 YouTube 上的视频质量存在问题,建议稍后查看更高分辨率的处理结果。
-
从 CUDA 疑问到 GPU 资源:针对在 MacBook 上进行 CUDA 开发以及使用 Google Colab 等替代方案的问题得到了解答,确认了 Colab 对于 CUDA 编程的充分性。不过,运行 CUDA 应用程序必须使用 Nvidia GPU。像 Lightning AI Studio 这样的资源提供了免费的 GPU 时间,而 Colab 则被认为是免费获取 Nvidia T4 GPU 的好途径。
-
CUDA 书虫:对于 GPU 架构的学习,讨论包括了一些策略,例如在尝试练习题之前彻底阅读 PMPP 书籍,可能在 GitHub 上组织学习产出,并深入研究内存加载阶段以理解优化。
-
Ring-Attention 引起关注:社区正在积极讨论在长上下文数据集上使用 ring-attention 进行训练,参考了 Hugging Face 上的数据集和 Flash-Decoding 等工具。工作流修复和数据集来源是核心议题,VRAM 资源的价值也是一个热门话题,Reddit 上的 VRAM 表格对此有所暗示。
-
技术生态系统讨论:社区征集了关于分布式训练的论文,从而深入了解了 AWS GPU 实例性能分析以及模型并行深度学习中的跨网格重分片(cross-mesh resharding)。一篇关于该主题的 MLSys 摘要引起了特别关注。
OpenAccess AI Collective (axolotl) Discord
-
GPU 显存优化涌现:据报告,使用 PagedAdamW 可显著节省显存,在 8-bit 实现中使峰值显存占用降低了近 50%(14GB vs. 27GB);其技巧在于优化反向传播(backward pass)。相关细节已分享,包括 GitHub 上的配置示例。
-
Axolotl 与 DBRX 结合:将 DBRX 集成到 axolotl 是一项艰巨的任务,目前正在进行大量工作,Pull Request #1462 的进展证明了这一点。讨论揭示了训练控制的复杂性以及对多 GPU 优化的追求,这些优化目前对梯度累积(gradient accumulation)能力提出了挑战。
-
Whisper 在转录领域大显身手:在音频转录为文本的精细工作中,特别是中英文场景,Whisper 等解决方案在单发言人场景下表现出色,而 Assembly AI 和 whisperx with diarization 则被推荐用于复杂的多发言人任务。工程师们正在不断突破界限,处理 Runpod GPUs 上的 CUDA 错误,并测试增加序列长度(16k-32k)的 ring-attention,详见 ring-attention 实现 的 GitHub 仓库。
-
文本分类的模型灵活性:面对 T4 GPU 等有限资源,社区分享了关于更精简且擅长文本分类的模型见解——如 Mistral 和 qlora,以及用于通过聊天界面进行简单模型测试的工具如 auto-ollama。
-
工程师交流排错心得:从解决雄心勃勃的 lisa branch 项目中的 OOM 问题,到诊断仅一个 epoch 后训练停滞的现象,成员们围绕优化器细节和 wandb 等工具提出了建议。同时,通过 Telegram bots 实现 AI 驱动的电话对话等构想也让对话保持活跃且多样化。
Modular (Mojo 🔥) Discord
Mojo 开源:社区的共同努力:Modular 开源 Mojo 标准库(stdlib)的消息令人振奋;然而,由于对非内部/商业应用的限制以及缺乏字符串排序等基本功能,也存在一些挫败感。用户还表达了在 Linux Mint 上的安装挑战以及对更好性能分析工具(profiling tools)的需求,官方已确认支持 Ubuntu、MacOS 和 WSL2,并提供了设置和本地 stdlib 构建指南。
Mojo 的线程探索与文档扩展:关于 Mojo 多线程能力的性能讨论强调了使用 OpenMP 进行多核 CPU 增强,并辩论了 external_call() 功能的改进。MLIR 的语法文档正在改进以变得更加用户友好,并呼吁更多详细的贡献。
库与语言增强:多个 Mojo 库 已更新至 24.2 版本,同时社区对 Mojo 中更成熟的 Reference 组件和更好的 C/C++ 互操作性(interop)寄予厚望。一个新的日志库 Stump 已推出供社区测试。
应对代码挑战:性能和基准测试频道讨论了十亿行挑战(one billion row challenge),指出缺乏某些标准库功能以及需要更好地理解内存分配。同时,matmul.mojo 示例引发了对舍入误差和数据类型不一致的担忧。
MAX 进军 Triton:MAX Serving 已成功作为 Triton Inference Server 的后端运行,团队渴望支持用户的迁移工作,强调转换简便并承诺增强流水线优化(pipeline optimization)。
Interconnects (Nathan Lambert) Discord
Benchmarks Set Stage for AI Bravado: 基准测试为 AI 的雄心壮志奠定基础:lm-sys 发布了先进的 Arena-Hard 基准测试,旨在通过复杂的用户查询更好地评估语言模型。围绕评判中的潜在偏好引发了辩论,特别是 GPT-4 的自我偏好及其在 Arena-Hard 上显著优于 Claude 的表现。
Token Talk Takes Theoretical Turn: 关于 Token 的讨论转向理论层面:对话转向评估 Token 的信息内容,互信息被引用为一种可能的衡量标准。讨论将此分析与 repeng 策略和 Typicality 方法相结合,后者在一篇基于信息论的论文中有所详述。
Innovation Amidst The Hiring Game: 招聘博弈中的创新:讨论透露 Stability AI 正在积极招募顶尖研究人员,而 Nathan Lambert 描述了 Synth Labs 非传统的初创公司策略,即在产品发布前介绍具有卓越影响力的论文。
1-Bit Wonders: 1-Bit 奇迹:NousResearch 通过在 Dolma 数据集上训练的 1B 模型验证了 Bitnet 的主张,该模型已发布在 Hugging Face 上,引发了关于 1-bit 训练的新颖性和技术细节的讨论。
sDPO Steps Up in RL: sDPO 在 RL 中崭露头角:通过新论文分享的见解揭示了 stepwise DPO (sDPO),这种技术可以使模型训练中的性能提升更加普及,使模型在没有大量资金支持的情况下也能紧密贴合人类偏好。
Preserving Alignment Almanac: 维护对齐年鉴:Nathan Lambert 宣布了一项倡议,旨在记录和讨论 ChatGPT 之后开放对齐技术的演变。诸如各种复制模型的概述以及对偏好优化方法的考量等贡献,深入洞察了该领域的历史增长,记录在 Lambert 的 Notion 笔记中。
AI21 Labs (Jamba) Discord
- Jamba’s Code Conundrum Continues: Jamba-v0.1 在代码任务上的表现(如 HumanEval 基准测试)仍未被讨论,引发了社区的好奇。
- Jamba’s Language Inclusivity in Question: 有人询问 Jamba 的训练数据中是否包含捷克语等语言,但尚未提供确切信息。
- Jamba Prepares for Fine-Tune Touchdown: 社区期待 Jamba 能够在 AI21 Studio 上进行微调,并期望该平台能推出 instruct 模型。
- Understanding Jamba’s Hardware Hunger: 讨论强调 Jamba 在推理过程中通过 MoE 层仅高效使用了其 52B 参数中的 12B,但大家一致认为在消费级硬件(如 NVIDIA 4090)上运行 Jamba 是不可行的。
- Demystifying Jamba’s Block Magic: 一次技术交流澄清了 Mamba 和 MoE 层在 Jamba 中的作用,预定比例为每 8 层中包含 1 个 Transformer 层,确认 Transformer 层不是 MoE 的一部分,而是集成在 Jamba 架构的特定 Block 中。
LangChain AI Discord
-
GalaxyAI 推出免费 API 优惠,令人惊叹:GalaxyAI 推出了免费 API 服务,允许用户访问 GPT-4 等高水平 AI 模型,增强了社区将 AI 集成到项目中的能力。感兴趣的开发者可以在这里尝试该 API。
-
阐明模型对齐技术:一篇博客概述了将 RLHF、DPO 和 KTO 等方法应用于 Mistral 和 Zephyr 7B 等模型,旨在增强模型对齐(Model Alignment)。好奇的读者可以在 Premai 的博客上阅读完整细节。
-
通过 Chain of Tasks 变革 AI:两篇博客文章重点介绍了使用 LangGraph 构建高级对话式 LLM Taskbots 的 Prompt 创新技术,名为 Chain of Tasks。要深入了解这些进展,读者可以阅读这篇 LinkedIn 文章。
-
CrewAI 引入 AI Agent 编排:CrewAI 发布了用于编排自主 AI Agent 的框架,因其无缝集成 OpenAI 和本地 LLM 的能力而引发关注,社区受邀在其官网和 GitHub 上进行探索。
-
通过 Qdrant 和 LangChain 让向量数据库更易上手:得益于演示 Qdrant 和 LangChain 融合的教程,成员们现在可以深入研究向量数据库,涵盖了本地和云端实现。深入的教程以 YouTube 视频的形式呈现给爱好者。
Mozilla AI Discord
-
超参数故障带来的困扰:运行命令
./server -m all-MiniLM-L6-v2-f32.gguf --embedding时出现了与bert.context_length相关的错误,但在讨论过程中未提供该错误的解决方案。 -
llamafile 的稳定性:仍在改进中:用户在执行 llamafile 时遇到了不稳定的情况,部分实例表现不一致;一位用户承诺在下周对这些问题进行探测。
-
llamafile v0.7 正式发布:社区宣布了 llamafile v0.7 的发布,强调了性能和准确性的提升,同时在愚人节前夕发布了一篇详细介绍 matmul 改进的博客文章,广受好评。
-
寻找完美的 Prompt:有关于在 Web UI 中使用 openchat 3.5 0106 运行 llamafile 的理想 Prompt 模板的咨询,包括模板输入字段和变量的示例,但目前仍缺乏明确的指导。
-
Matmul 基准测试对决:jartine 提供了一个用于比较 numpy 的 matmul 与自定义实现的基准测试代码片段,引发了对绕过线程处理但能提高效率的替代方法的兴趣。
Datasette - LLM (@SimonW) Discord
- 童子军准则启发聊天机器人趣谈:利用童子军准则(Scout Law),一位用户编程让 Claude 3 Haiku 以古怪而诚实的俏皮话进行回应,例如机智的短语 “A door is not a door when it’s ajar!”。
- 聊天机器人的友好闲聊源于设计:聊天机器人倾向于进行详尽阐述是刻意设计的,这与引导其体现“友好和乐于助人”的 System Prompt 一致,通过在对话中整合童子军准则的元素展示了这一点。
- 值得信赖的贝壳与聊天机器人:机器人模仿童子军准则中关于诚信的价值观,创造性地将帽贝及其保护壳与信任的概念进行类比,展示了其对主题解读的熟练程度。
- 制定查询策略以实现更清晰的理解:测试了一种新方法,即聊天机器人在提供直接解决方案之前先提出澄清性问题,这表明该方法可以增强解决问题的有效性。
- 解决安装过程中的小故障:针对
llm安装过程中的FileNotFoundError,建议重新安装该包,因为另一位最近遇到类似问题的用户确认这是必要的步骤。
DiscoResearch Discord
-
Jamba 加入模型组合:AI21 Labs 推出了 Jamba,其特点是将 Structured State Space model 与 Transformer 相结合,可以在 Hugging Face 上进行测试。
-
BitNet 克隆版媲美原版:成功复现了 BitNet b1.58 模型,在 RedPajama 数据集上达到了原始性能,复现过程参考了其后续论文的方法论。
-
放大镜下的模型行为:关于新型 LLM 架构的讨论包括对评估或“氛围检查”(vibe checks)的查询,以及对使用 GPT-4 排名构建的 Nectar 数据集的观察,其来源包括 ShareGPT、Antropic/hh-rlhf 和 Flan。
-
有争议的 AI 指导陷入困境:Nectar 数据集中一个有争议的案例显示 GPT 提供了制造枪支的指令,像 Starling 这样的模型可能会做出与选择拒绝的模型不同的反应。
-
翻译评估工具准备就绪:使用 Hugging Face 上的新工具和 comet scores 仔细审查翻译质量,为德语讨论中的翻译评估提供指标。
Skunkworks AI Discord
AI21 的 Jamba 加入战局:AI21 的 Jamba 模型已在 Skunkworks AI 社区分享,宣称在大型语言模型的 SSM-Transformer 设计方面有所增强。
Databricks 的 DBRX LLM 夺冠:根据 Skunkworks AI 社区分享的一段视频,Databricks 的通用大语言模型 DBRX 据称在多个基准测试中创下新高。
解决类增量学习(Class-Incremental Learning)中的灾难性遗忘:研究表明,adapter tuning 可能是对抗 CIL 中灾难性遗忘的关键,该研究采用了特征采样和原型语义偏移分析。可以通过此 arXiv 链接获取研究内容。
缩小开源与商业 LLM 之间的差距:一篇新论文讨论了旨在增强开源 LLM 以缩小与商业对手性能差距的方法论,策略侧重于 7B 和 13B LLM 的增强。该论文的详细见解可在此处获取。
Alignment Lab AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
PART 2: 渠道详细摘要与链接
Stability.ai (Stable Diffusion) ▷ #general-chat (980 messages🔥🔥🔥):
- 寻求增强的 Inpainting UI:用户对新的 SD Inpainting UI 表示不满,认为由于布局决策不合理,导致其不够直观且效率低下。
- CivitAI 愚人节恶作剧?:具有“ODOR”等意外名称的模型以及关于“chadgpt”的弹窗引发了关于 CivitAI 可能存在愚人节玩笑的讨论。
- Stable Diffusion 模型关注与查询:关于 Stable Diffusion 3 (SD3) 模型何时发布的问题不断,用户分享了他们的期待和怀疑。一位用户开玩笑称 SD3 的发布是一个愚人节恶作剧。
- 寻求 AI 工具帮助:用户就各种 AI 相关问题寻求帮助,例如在 Colab 中设置 ControlNet 参考、使用 Comfy UI 以及在 Stable Diffusion 中生成建筑渲染图。
- 关于如何利用 AI 进行创作的想法:有人建议如何使用 AI 创作内容,包括利用旧视频游戏素材制作 AI 生成的电影,以及通过 AI 工作流创作漫画。
- Artsiom Sanakoyeu (@artsiom_s) 的推文:⚡️SD3-Turbo:利用 Latent Adversarial Diffusion Distillation 实现快速高分辨率图像合成。继 Stable Diffusion 3 之后,我的前同事们发表了一篇关于使用 4 步...实现 SD3 蒸馏的预印本。
- stabilityai/stable-video-diffusion-img2vid-xt · Hugging Face:未找到描述
- Stable Diffusion 基准测试:45 款 Nvidia、AMD 和 Intel GPU 对比:哪款显卡提供最快的 AI 性能?
- Reddit - 深入探索一切:未找到描述
- Geeky Ghost Vid2Vid Organized v1 - v3.0 | Stable Diffusion 工作流 | Civitai:该工作流专为高级视频处理设计,融合了风格迁移、运动分析、深度估计等多种技术...
- 如何导入并可视化您的 Roam Research、Obsidian 和 Zettelkasten Markdown 格式笔记:如果您有 Markdown 格式文件 (.MD),可以将其导入 InfraNodus 以可视化主要主题及其关系,并发现结构性差距,从而产生新想法。InfraNo...
- ice on my baby - yung bleu (加速版 <3):wsg
- NVIDIA Avatar Cloud Engine ACE:大规模构建和部署游戏角色及交互式化身。
- 小马驮人 GIF - 小马驮人滑冰 - 发现并分享 GIF:点击查看 GIF
- 反馈 - Civitai:向 Civitai 提供关于如何改进其产品的反馈。
- 你那难以捉摸的创造力天才 | Elizabeth Gilbert:在 ted.com 上查找准确的逐字稿(以及 46 种语言的字幕):http://www.ted.com/talks/elizabeth_gilbert_on_genius/transcript?language=en "Eat, Pray...
- Reddit - 深入探索一切:未找到描述
- 1万年かけて成長するフリーレン(上半身)/Frieren growing over 10,000 years(upper body) #葬送のフリーレン #frieren #アニメ:未找到描述
- 免费下载黑白无限循环三角形动画 - 无缝循环动态背景:从 Vecteezy 下载黑白无限循环三角形动画 - 无缝循环动态背景 8661328 免版税库存视频,并探索数千个其他库存片段!
- 原始 Trogdor 视频:这是有史以来第一个 Trogdor 视频。
- 猫,但它是 GameCube 开场动画:猫。考虑订阅:https://www.youtube.com/channel/UCIzz...Instagram: https://www.instagram.com/merryyygoat/
- 湮灭 4:#oblivion #npc #elderscrolls 站住!你触犯了法律。原始湮灭视频:https://www.youtube.com/watch?v=qN80_7rNmcE 我们的《湮灭》游玩系列:...
- 这个动画的名字会毁了它:Strong Bad 和 The Cheat 偶遇 Homestar 在雪地里做一些真正恐怖的事情。随后陷入困惑。
- 20 周年 Trogday 快乐!:为了庆祝 Trogdor 的 20 岁生日,Strong Bad 挖出了一个 30 年前未发布的 Peasant's Quest 游戏宣传片。算算账吧!
- GitHub - XPixelGroup/DiffBIR: DiffBIR 官方代码:利用生成式扩散先验实现盲图像修复:DiffBIR 官方代码:利用生成式扩散先验实现盲图像修复 - XPixelGroup/DiffBIR
- Stable Diffusion 3 的权重会在 4 月 30 日之前发布(或泄露)吗?:41% 的概率。3 月 15 日,当时的 CEO Stability AI 的 Emad Mostaque 宣布 SD3 将在“下个月”发布完整版。然而,在包括 Emad 在内的几位高层相继离职后...
- Releases · jhc13/taggui:图像数据集的标签管理器和标注器。通过在 GitHub 上创建账号来为 jhc13/taggui 的开发做出贡献。
- Stable Video Diffusion - SVD - img2vid-xt-1.1 | Stable Diffusion Checkpoint | Civitai:查看我们的快速入门指南!https://education.civitai.com/quickstart-guide-to-stable-video-diffusion/ 基础的 img2vid 模型经过训练可生成...
- GitHub - PixArt-alpha/PixArt-alpha: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis:用于写实级 Text-to-Image Synthesis 的 Diffusion Transformer 快速训练 - PixArt-alpha/PixArt-alpha
- oblivion:毒果致死。第二部分:https://www.youtube.com/watch?v=D_x-x0gawck 第三部分:https://www.youtube.com/watch?v=CYAkrJil_w0
- GitHub - jasonppy/VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild:野外环境下的 Zero-Shot Speech Editing 和 Text-to-Speech - jasonppy/VoiceCraft
- Skymaster Carnival Ride at Night 😳 #carnivalrides #fun:Kamikaze 是一项惊险刺激的嘉年华游乐设施,将带你达到前所未有的高度。这是一个让你翱翔天际的 Kamikaze 设施...
Perplexity AI ▷ #general (915 条消息🔥🔥🔥):
-
Claude’s Opus 性能怪癖:用户报告 Claude 3 Opus 模型在回答关于房间里剩下多少本书的问题时表现不一。尽管对 Prompt 进行了指令说明和调整,某些模型在这一语境下仍未能给出正确答案。
-
AI 模型对比:讨论了各种 AI 模型及其能力,提到了 Haiku、Gemini 1.5 Pro 和 Claude Opus。用户表达了对模型优缺点及功能差异的看法。
-
加密货币 vs 黄金辩论:在一个简短的离题讨论中,成员们思考了 加密货币 与 实物商品(特别是 黄金)的比较价值。对于货币的未来观点各异,一些人看到了数字形式的潜力,同时尊重黄金等传统材料的长期价值。
-
技术格局演变推测:对话涉及对 AI 技术未来方向和进步的推测。提到了 Apple 参与 AI 的情况,并讨论了 中国的经济手段,包括提及 恒大危机 和 政府策略。
-
Perplexity 访问与功能:出现了关于 Perplexity 用户体验 和功能的咨询,如修改密码或取消订阅。聊天机器人澄清其使用 oauth2 进行登录,不支持基于密码的访问。
- Books Father GIF - Books Father Ted - 发现并分享 GIF: 点击查看 GIF
- 来自 Linus ●ᴗ● Ekenstam (@LinusEkenstam) 的推文: 🚨 重磅新闻 🚨 Apple 正在洽谈收购 Perplexity,这可能是一个非常令人兴奋的开始
- Working On GIF - Working On It - 发现并分享 GIF: 点击查看 GIF
- GitHub - shure-dev/Awesome-LLM-related-Papers-Comprehensive-Topics: 涵盖全面主题的优秀 LLM 相关论文和仓库。: 涵盖全面主题的优秀 LLM 相关论文和仓库。 - shure-dev/Awesome-LLM-related-Papers-Comprehensive-Topics
- 来自 Aravind Srinivas (@AravSrinivas) 的推文: 很高兴分享 Perplexity 将为 http://askjeeves.com 提供支持
- Harry Potter Quirrell GIF - Harry Potter Quirrell Professor Quirrell - 发现并分享 GIF: 点击查看 GIF
- Why Michael Scott GIF - Why Michael Scott The Office - 发现并分享 GIF: 点击查看 GIF
- Ouch GIF - Ouch - 发现并分享 GIF: 点击查看 GIF
- Vegeta Dragon Ball Z GIF - Vegeta Dragon Ball Z Unlimited Power - 发现并分享 GIF: 点击查看 GIF
- 故障排除: 未找到描述
- Functions & external tools: 未找到描述
- Prompt engineering: 未找到描述
- Prompt library: 未找到描述
- Wordware - OPUS Insight: 多模型验证的精确查询 -scratchpad-think-Version-1: 此 Prompt 使用 Gemini, GPT-4 Turbo, Claude 3 (Haiku, Sonnet, Opus), Mistral Medium, Mixtral 和 Openchat 处理问题。然后利用 Claude 3 OPUS 对回答进行审查和排名。在...
- Perplexity CEO: 用 AI 颠覆 Google 搜索: 最杰出的 AI 创始人之一 Aravind Srinivas (Perplexity CEO) 认为,未来我们可能会看到 100 多家估值超过 100 亿美元的 AI 初创公司。在本集中...
Perplexity AI ▷ #sharing (36 条消息🔥):
- 探索知识的边界:成员们分享了各种 perplexity.ai 搜索,揭示了对诸如 玻姆力学 (Bohmian mechanics) 的局限性、SpaceX 的运作方式 以及 “异世界” (Isekai) 的定义 等话题的兴趣。
- 深入探讨 AI 和 Hyperloop:好奇心引导了对 Grok15、Hyperloop 概念 以及机器学习中的 二进制嵌入 (binary embeddings) 的探索。
- 促进知识共享:一位成员提供了关于如何使帖子可分享的指导,增强了社区对特定话题的访问,正如分享的一个有用的 Discord 链接 所反映的那样。
- 解析 AI 联盟和播客中的 AI 应用:讨论展开了关于 OpenAI 与 Microsoft 的合作,以及利用 AI 处理播客转录文本 的方法。
- 四月的技术趣闻与知识合集:成员们参与了一个 愚人节相关的技术查询,并分享了一个用于分组知识的 Perplexity AI 合集 链接。
Perplexity AI ▷ #pplx-api (41 messages🔥):
-
API 响应差异:一位成员注意到 API 显示的来源不如 Perplexity AI 的网页界面多。他们被引导至相关信息,表明 URL 引用仍处于 beta 阶段,申请已在 Perplexity 的 Typeform 开放。
-
合作伙伴提案:围绕与 Perplexity 的潜在合作展开了多次讨论。成员们被敦促不要私信他人,应通过 support@perplexity.ai 联系以进行合作伙伴咨询和必要的介绍。
-
对模型支持的困惑:针对未列在支持模型文档中的 “pplx-70b-online” 模型是否继续支持提出了澄清问题。一位成员澄清该模型已弃用,端点名称只是
sonar-medium-online的别名。 -
充值故障排除:成员们报告了尝试增加额度时遇到的问题,交易卡在“待处理” (pending) 状态或借记卡出现错误。有人建议这可能是由 Stripe 要求的安全功能引起的,但也有人担心该问题可能需要进一步调查。
-
请求 Token 成本对比:一位用户请求资源以比较 Perplexity 模型与 ChatGPT 的 Token 成本。他们获得了指向 Perplexity 价格页面和 OpenAI 各模型价格的链接,包括详细的每 Token 价格以及在线模型的额外请求费用。
- Pricing:未找到描述
- Supported Models:未找到描述
- pplx-api form:使用 Typeform 将数据收集转化为一种体验。创建精美的在线表单、调查、测验等等。免费试用。
- Pricing:简单且灵活。仅为您使用的部分付费。
Unsloth AI (Daniel Han) ▷ #general (549 messages🔥🔥🔥):
- Unsloth 模型仍具挑战性:尽管尝试利用 Unsloth 进行 Mistral 模型的微调,用户仍遇到依赖问题,并要求提供 Docker 解决方案以简化使用。目前的讨论表明,尚不支持 multi-GPU,但未来有可能实现。
- 关于优化 Mistral 微调的讨论:关于微调方法的疑问揭示了由于量化过程,QLora 4bit 在性能上可能与 SFT/pretraining 有所不同。用户正在探索各种有效利用可用 VRAM 的方法。
- 来自中国的新 AI 硬件:中国公司 Intellifusion 发布了一款新的 AI 处理器,该处理器在 inference 方面可能具有成本效益,但用户对其在训练方面的潜力及其他技术规格表示疑问。
- 数据集格式查询:在讨论创建一个模拟 Discord 服务器氛围的模型时,用户就训练数据的最佳格式展开辩论,重点在于如何准确地呈现对话。
- 模型量化与语言支持:用户讨论了量化模型(如 Mistral 7B)的幻觉问题,并探索了包括引入 LASER 在内的选项,以便进行非英语语言的微调。
- 未找到标题: 未找到描述
- 重定向通知: 未找到描述
- 中国芯片制造商推出 14nm AI 处理器,价格比 GPU 便宜 90% —— 140 美元的芯片采用旧制程规避美国制裁: 如果有规避制裁的方法,你知道中国一定会紧跟其后。
- cognitivecomputations/dolphin-2.6-mistral-7b-dpo-laser · Hugging Face: 未找到描述
- SambaNova 以极速交付准确模型: Samba-CoE v0.2 在 AlpacaEval 排行榜上攀升,表现优于所有最新的开源模型。
- 未找到标题: 未找到描述
- abacusai/Fewshot-Metamath-OrcaVicuna-Mistral-10B · Hugging Face: 未找到描述
- Jamba 初始微调运行: 代码在此:https://github.com/shisa-ai/shisa-v2/tree/main/_base-evals/jamba。使用 1 x A100-80 对 Jamba 进行微调的初步实验。在这些设置下使用了 99% 以上的 VRAM,但没有...
- 来看这个 GIF - 来看这个 - 发现并分享 GIF: 点击查看 GIF
- 为 32K 上下文时代做准备:早期学习与探索: 未找到描述
- 真相就在其中:通过层选择性秩降低提高语言模型的推理能力: 基于 Transformer 的大语言模型 (LLMs) 已成为现代机器学习的固定组成部分。相应地,大量资源被投入到旨在进一步推进这一领域的研究中...
- teknium/OpenHermes-2-Mistral-7B · Hugging Face: 未找到描述
- 来自 Nous Research (@NousResearch) 的推文: 我们正在发布验证并独立确认 Bitnet 论文主张的第一步,这是一个在 Dolma 数据集的前 60B token 上训练的 1B 模型。在 @we 上进行的比较...
- unsloth/mistral-7b-v0.2-bnb-4bit · Hugging Face: 未找到描述
- yanolja/EEVE-Korean-10.8B-v1.0 · Hugging Face: 未找到描述
- togethercomputer/Long-Data-Collections · Hugging Face 数据集: 未找到描述
- ZeRO — DeepSpeed 0.14.1 文档: 未找到描述
- shisa-v2/_base-evals/jamba/01-train-sfttrainer.py (位于 main 分支) · shisa-ai/shisa-v2: 通过在 GitHub 上创建账户,为 shisa-ai/shisa-v2 的开发做出贡献。
- 首页: 速度快 2-5 倍,显存占用减少 70%,支持 QLoRA 和 LoRA 微调 - unslothai/unsloth
- GitHub - predibase/lorax: 可扩展至数千个微调 LLM 的多 LoRA 推理服务器: 可扩展至数千个微调 LLM 的多 LoRA 推理服务器 - predibase/lorax
- teknium/GPTeacher-General-Instruct · Hugging Face 数据集: 未找到描述
- NousResearch/Genstruct-7B · Hugging Face: 未找到描述
- GitHub - unslothai/unsloth: 速度快 2-5 倍,显存占用减少 70%,支持 QLoRA 和 LoRA 微调: 速度快 2-5 倍,显存占用减少 70%,支持 QLoRA 和 LoRA 微调 - unslothai/unsloth
- Muzeke GIF - Muzeke - 发现并分享 GIF: 点击查看 GIF
- SOLAR 10.7B: 扩展 Large Language Models with Simple yet Effective Depth Up-Scaling</a>: 我们介绍了 SOLAR 10.7B,这是一个拥有 107 亿参数的大语言模型 (LLM),在各种自然语言处理 (NLP) 任务中展现出卓越的性能。受近期努力的启发...
- ML Blog - 使用 MergeKit 创建 Mixture of Experts: 将多个专家模型合并为一个单一的 frankenMoE
- Benchmarking Samba-1: 使用 EGAI 基准测试对 Samba-1 进行评估 —— 这是一个源自开源社区、广泛采用的基准测试综合集合。
- 未找到标题: 未找到描述
- Reddit - 深入探索: 未找到描述
- Trainer: 未找到描述 </ul> </div> --- **Unsloth AI (Daniel Han) ▷ #[random](https://discord.com/channels/1179035537009545276/1179039861576056922/1223214571507028060)** (24 messages🔥): - **Snapdragon Elite X 的强势登场**: 据报道,Snapdragon Elite X Arm 芯片在性能上超越了 m3 芯片,凭借其 45 TOPs 提供了一个更具成本效益的选择。[讨论](https://youtu.be/dTCm6BupWEQ) 包含一段名为 *"Now we know the SCORE | X Elite"* 的 YouTube 视频,解释了 Qualcomm 新产品的基准测试。 - **对新芯片的基准测试热情**: 针对 Snapdragon Elite X 报道的 45 TOPs 引起了热烈讨论,并将其与 Tesla T4 等其他芯片进行了比较,后者的 float16 性能约为 65 TFLOPs。 - **对现代 MacBook 规格的失望**: 成员们对目前 MacBook 的规格和价格表示沮丧,强调了像 Snapdragon Elite X 这样的下一代芯片作为更具竞争力、更具成本效益的选择的吸引力。 - **讨论 Discord 服务器安全措施**: 成员们讨论了 Discord 上机器人和被盗账号的普遍性,并建议将服务器设置为社区服务器以防止大规模标签(tags),并建议屏蔽与垃圾信息相关的关键词,如 "nitro"。 - **AI 训练数据的多样性**: 有一段关于微调 AI 模型所需训练数据的反直觉性质的对话,讨论了包含多样化数据(如“16 世纪的中国诗歌”)是否比直接相关的数据(如用于提升代码性能的数学数据)更有益。 **链接提到**: Now we know the SCORE | X Elite: Qualcomm 新的 Snapdragon X Elite 基准测试结果出炉!深入了解不断发展的 ARM 架构处理器格局,以及 Snapdragon X Elite 充满希望的性能表现... --- **Unsloth AI (Daniel Han) ▷ #[help](https://discord.com/channels/1179035537009545276/1179777624986357780/1223140638774788169)** (461 messages🔥🔥🔥): - **不同数据集上的模型微调**: 一位用户报告称,使用 3,000 行数据微调 Mistral 的效果优于 6,000 行。提供的一个理论与研究一致,即随着数据量的增加,初始准确率会下降,直到达到某一点后,更多的数据才会提高性能。建议该用户如果额外的数据质量较差,可以考虑使用 3,000 行的数据集。 - **GGUF 文件生成的挑战与解决方案**: 用户在尝试使用 Unsloth 创建 GGUF 文件和运行模型时遇到了问题和困惑。提出的一个解决方案是参考 [手动 GGUF 指南](https://github.com/unslothai/unsloth/wiki#manually-saving-to-gguf) 或利用 llama.cpp 等工具进行正确的转换和保存。 - **Unsloth 的单 GPU 与双 GPU 训练**: 一位用户遇到了关于 Unsloth 使用单 GPU 的警告。澄清了 Unsloth 目前仅支持单 GPU 训练;但是,用户可以通过设置环境变量 `os.environ["CUDA_VISIBLE_DEVICES"]` 来选择要使用的 GPU。 - **微调 Loss 关注点与优化策略**: 讨论了使用各种参数微调 Gemma 2B 的问题,以解决 Loss 曲线平坦(通常表示未在学习)的担忧。增加 rank 和 alpha 值以及调整学习率等策略有助于改善结果。 - **为初学者探索 AI 学习资源**: 对于有兴趣学习 AI 的用户,推荐了 Andrej Karpathy 的 CS231N 讲座视频、Fast AI 课程、MIT OCW 以及 Andrew Ng 的 CS229 讲座系列作为入门的绝佳资源。
- Google Colaboratory: 未找到描述
- Track Jupyter Notebooks | Weights & Biases 文档: 在 Jupyter 中使用 W&B,无需离开 notebook 即可获得交互式可视化。
- pacozaa/tinyllama-alpaca-lora: 使用 Unsloth Notebook 训练 Tinyllama,数据集 https://huggingface.co/datasets/yahma/alpaca-cleaned
- 首页: 快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- Kaggle - LLM Science Exam: 未找到描述
- Kaggle Mistral 7b Unsloth notebook: 使用 Kaggle Notebooks 探索并运行机器学习代码 | 使用来自无附加数据源的数据
- gnumanth/gemma-unsloth-alpaca · Hugging Face: 未找到描述
- Kaggle Mistral 7b Unsloth notebook: 使用 Kaggle Notebooks 探索并运行机器学习代码 | 使用来自无附加数据源的数据
- gnumanth/code-gemma · Hugging Face: 未找到描述
- Hugging Face – 构建未来的 AI 社区。: 未找到描述
- 加载: 未找到描述
- 首页: 快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- sloth/sftune.py at master · toranb/sloth: 使用 unsloth 的 python sftune、qmerge 和 dpo 脚本 - toranb/sloth
- GPU 云服务对比: 统计数据 #,VRAM,Float16 TFLOPs,Float8 TFLOPs,带宽,每张卡功耗,价格,每个 GPU,每个 fp16 PFLOP,每个 fp8 PFLOP,BF16,供应情况,信息 Kaggle,Tesla T4,1,16,65,320,70,0,0,0.000,N,5,<a href="https://www.n...
- 首页: 快 2-5 倍,显存占用减少 70% 的 QLoRA & LoRA 微调 - unslothai/unsloth
- Trainer: 未找到描述
- wikimedia/wikipedia · Hugging Face 数据集: 未找到描述
- CohereForAI/aya_dataset · Hugging Face 数据集: 未找到描述
- 库中是否有动态填充和智能批处理?:请不要发布相同消息三次,也不要像你之前那样激进地标记用户。你可以编辑消息而不是重新发布。
- deepseek-ai (DeepSeek):未找到描述
- DeepSeek:与 DeepSeek AI 聊天。
- Hugging Face - Learn: 未找到描述
- Practical Deep Learning for Coders - Practical Deep Learning: 一门为具有一定编程经验、想要学习如何将深度学习和机器学习应用于实际问题的学习者设计的免费课程。
- Introduction - Hugging Face NLP Course: 未找到描述
- DBRX: A New State-of-the-Art Open LLM: 介绍 DBRX,由 Databricks 创建的开源通用 LLM。在多项标准基准测试中,DBRX 为已有的模型设定了新的 SOTA...
- Introducing Jamba: AI21's Groundbreaking SSM-Transformer Model: 介绍 Jamba:AI21 开创性的 SSM-Transformer 模型 https://www.ai21.com/blog/announcing-jamba #llm #ml #ai #deeplearning #largelanguagemodels #deep...
- Jamba: A Hybrid Transformer-Mamba Language Model: 我们介绍了 Jamba,这是一个基于新型混合 Transformer-Mamba 混合专家 (MoE) 架构的新基础大语言模型。具体而言,Jamba 交替使用了 Transformer 和 Mamba 层块...
- Teortaxes▶️ (@teortaxesTex) 的推文: 看来微软那篇关于三值 LLMs 的论文结果终究是可以复现的——至少对于 3B@100B 规模是这样。https://huggingface.co/1bitLLM/bitnet_b1_58-3B
- SOTA ASR Tooling: Long-form Transcription: 对不同 Whisper 框架进行长文本转录的基准测试
- Transforming the Web: The End of Silos: 我们使用互联网的方式即将发生重大变化。向更统一、更高效的 Web 导航方式转变,是对比我们已经习惯的传统孤岛式 Web 浏览的一次巨大飞跃...
- 来自 Elon Musk (@elonmusk) 的推文:下周应该会在 𝕏 上可用。Grok 2 在所有指标上都应超过当前的 AI。目前正在训练中。↘️ 引用 xAI (@xai) https://x.ai/blog/grok-1.5
- 来自 Justine Tunney (@JustineTunney) 的推文:我刚刚让 llamafile 在许多 Prompt / 图像评估用例和硬件上的 CPU 速度比 llama.cpp 快了 1.3 倍到 5 倍。https://justine.lol/matmul/
- Jamba 初步微调运行:代码在此:https://github.com/shisa-ai/shisa-v2/tree/main/_base-evals/jamba 在 Jamba 上使用 1 x A100-80 进行微调的初步实验。在这些设置下使用了 99%+ 的 VRAM,但没有...
- togethercomputer/Long-Data-Collections · Hugging Face 数据集:未找到描述
- Salieri Mozart GIF - SALIERI MOZART - 发现并分享 GIF:点击查看 GIF
- Reddit - 深入探索一切:未找到描述
- Abstractions/abstractions/goap/game at main · furlat/Abstractions:一个用于抽象 IRL(现实生活)的 Pydantic 模型集合。通过在 GitHub 上创建账户来为 furlat/Abstractions 的开发做出贡献。
- world_sim:未找到描述
- 来自 Llamafile 0.7 带来 AVX-512 支持的推文:AMD Zen 4 的 Prompt 评估速度提升 10 倍 - Phoronix:未找到描述
- filipealmeida/open-llama-3b-v2-pii-transform · Hugging Face:未找到描述
- Hugging Face – 构建未来的 AI 社区。:未找到描述
- NousResearch/Genstruct-7B · Hugging Face:未找到描述
- 来自 Tommy (@Shaughnessy119) 的推文:与 @NousResearch 的 @theemozilla 合作的新播客集 🎧 我们有史以来最聪明的嘉宾之一 🧠 ▪️ AGI 的必然性 ▪️ Crypto x AI 大师班 ▪️ 创建世界模拟器 ▪️ 发布 Bittens...
- internlm/Agent-FLAN · Hugging Face 数据集:未找到描述
- Abstractions/abstractions/goap/system_prompt.md at main · furlat/Abstractions:一个用于抽象 IRL 的 Pydantic 模型集合。通过在 GitHub 上创建账户来为 furlat/Abstractions 的开发做出贡献。
- ai4privacy/pii-masking-200k · Hugging Face 数据集:未找到描述
- GitHub - joke2k/faker: Faker 是一个为你生成伪数据的 Python 包。:Faker 是一个为你生成伪数据的 Python 包。 - joke2k/faker
- filipealmeida/open-llama-3b-v2-pii-transform · Hugging Face:未找到描述
- Microsoft Presidio:未找到描述
- 使用在 Privy 生成的 PII 数据上训练的自定义 PII 模型的 Presidio - beki 的 Hugging Face Space:未找到描述
- metricspace/EntityAnonymization-3B-V0.9 · Hugging Face:未找到描述
- grammarly/pseudonymization-seq2seq · Hugging Face:未找到描述
- aymurai/anonymizer-beto-cased-flair · Hugging Face:未找到描述
- dslim/bert-large-NER · Hugging Face:未找到描述
- ollama/docs/modelfile.md at 06a1508bfe456e82ba053ea554264e140c5057b5 · ollama/ollama:快速上手 Llama 2, Mistral, Gemma 以及其他大型语言模型。 - ollama/ollama
- ollama/docs/modelfile.md at 06a1508bfe456e82ba053ea554264e140c5057b5 · ollama/ollama:快速上手 Llama 2, Mistral, Gemma 以及其他大型语言模型。 - ollama/ollama
- GitHub - open-webui/open-webui: User-friendly WebUI for LLMs (Formerly Ollama WebUI):适用于 LLM 的用户友好型 WebUI(原 Ollama WebUI) - open-webui/open-webui
- config.json · NousResearch/Hermes-2-Pro-Mistral-7B at main:未找到描述
- added_tokens.json · NousResearch/Hermes-2-Pro-Mistral-7B at main:未找到描述
- tokenizer_config.json · NousResearch/Hermes-2-Pro-Mistral-7B at main:未找到描述
- lmsys.org (@lmsysorg) 的推文:[Arena 更新] @cohere 的 Command R 现在位列 Arena 排行榜前 10🔥 它现在是达到顶级闭源模型水平的最佳开源模型之一。我们发现该模型在处理...方面表现出色。
- Prompting Command-R:未找到描述
- GitHub - explodinggradients/ragas: 检索增强生成 (RAG) 流线的评估框架:Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines - explodinggradients/ragas
- world_sim: 未找到描述
- 来自 OpenRouter (@OpenRouterAI) 的推文: 有没有想过哪些应用正在使用 LLM?现在你可以通过新的 Apps 标签页亲自发现。@NousResearch 拥有本周顶尖的 Claude 3 Opus 应用 👀
- world_sim: 未找到描述
- Her Theodore GIF - Her Theodore Joaquin Phoenix - 发现并分享 GIF: 点击查看 GIF
- self-system-prompt: self-system-prompt。GitHub Gist:即时分享代码、笔记和代码片段。
- strange-loop+claude3-self-modeling: GitHub Gist:即时分享代码、笔记和代码片段。
- Nick Land - 维基百科: 未找到描述
- 黑暗骑士小丑 GIF - 黑暗骑士小丑 这不关乎钱 - 发现并分享 GIF: 点击查看 GIF
- 自然语言中大脑嵌入与人工上下文嵌入的对齐指向共同的几何模式 - Nature Communications: 在这里,作者利用下额回的神经活动模式和大型语言建模嵌入,为语言处理的共同神经代码提供了证据。
- claude-world-modelling: claude-world-modelling。GitHub Gist:即时分享代码、笔记和代码片段。
- 'Hyperstition: An Introduction' - 0rphan Drift Archive: Delphi Carstens 采访 Nick Land。在接下来的采访中,Nick Land 回答了关于末日背景下 Hyperstition 机制的一些问题。问题 1:我想知道你是否可以详细说明...
- 👾 LM Studio - 发现并运行本地 LLMs: 查找、下载并实验本地 LLMs
- 欢迎 | LM Studio: LM Studio 是一款用于在电脑上运行本地 LLMs 的桌面应用程序。
- mradermacher/goliath-120b-i1-GGUF · Hugging Face: 未找到描述
- 非官方 LMStudio FAQ!: 欢迎来到非官方 LMStudio FAQ。在这里,你可以找到关于 LMStudio Discord 中最常见问题的解答。(此 FAQ 由社区管理)。LMStudio 是一款免费的闭源...
- 使用 Vercel AI SDK, Groq, Mistral, Langchain, OpenAI, Brave & Serper 构建 Next.JS 问答引擎: 构建 Perplexity 风格的 LLM 问答引擎:从前端到后端的教程。本教程将引导观众完成构建 Perplexity 风格的 La...
- llamafile/llamafile/sgemm.cpp at main · Mozilla-Ocho/llamafile: 通过单个文件分发和运行 LLMs。通过在 GitHub 上创建账号,为 Mozilla-Ocho/llamafile 的开发做出贡献。
- GitHub - openai/openai-python: OpenAI API 的官方 Python 库: OpenAI API 的官方 Python 库。通过在 GitHub 上创建账号,为 openai/openai-python 的开发做出贡献。
- GitHub - ChatGPTNextWeb/ChatGPT-Next-Web: 一个跨平台的 ChatGPT/Gemini UI (Web / PWA / Linux / Win / MacOS)。一键拥有你自己的跨平台 ChatGPT/Gemini 应用。: 一个跨平台的 ChatGPT/Gemini UI (Web / PWA / Linux / Win / MacOS)。一键拥有你自己的跨平台 ChatGPT/Gemini 应用。 - ChatGPTNextWeb/ChatGPT-Next-Web
- 为群聊中选定的发言者消息添加了指定 'role' 字段的能力 (替换 PR #2167),由 marklysze 提交 · Pull Request #2199 · microsoft/autogen: 注意:这替换了 #2167,因为它基于旧版本的 main。为什么需要这些更改?根据功能请求 #1861 ("[Feature Request]: 允许用户指定 "rol...
- 由 simonJJJ 添加 qwen2moe · Pull Request #6074 · ggerganov/llama.cpp: 此 PR 为即将发布的 Qwen2 MoE 模型 hf 添加了代码支持。我更改了几个宏值以支持 60 个专家的设置。@ggerganov
- 由 arki05 添加 grok-1 支持 · Pull Request #6204 · ggerganov/llama.cpp: 此 Pull Request 为 llama.cpp 添加了 grok-1 支持 (#6120)。我添加了一个独立的 MODEL_ARCH_GROK,以免使 LLAMA 架构过于混乱。convert-hf-to-gguf.py 可以从 keyfan/grok-... 转换。
- 未找到标题:未找到描述
- 停止为 ChatGPT 付费,使用这两个工具 | LMStudio x AnythingLLM:在这段视频中,我们将安装两个用户友好的工具,它们可以下载、运行和管理强大的本地 LLM 以替代 ChatGPT。真的。今天...
- GitHub - microsoft/LoRA: Code for loralib, an implementation of "LoRA: Low-Rank Adaptation of Large Language Models":loralib 的代码,"LoRA: Low-Rank Adaptation of Large Language Models" 的一种实现 - microsoft/LoRA
- 增加对 DBRX 模型支持:dbrx-base 和 dbrx-instruct · Issue #6344 · ggerganov/llama.cpp:前提条件:在提交 Issue 之前,请先回答以下问题。我正在运行最新的代码。开发非常迅速,因此目前没有标记版本。我...
- 由 simonJJJ 添加 qwen2moe · Pull Request #6074 · ggerganov/llama.cpp:此 PR 为即将发布的 Qwen2 MoE 模型增加了代码支持。我修改了几个宏值以支持 60 experts 设置。@ggerganov
- TheBloke/Wizard-Vicuna-13B-Uncensored-GGUF · Hugging Face: 未找到描述
- GitHub - nlpxucan/WizardLM: LLMs build upon Evol Insturct: WizardLM, WizardCoder, WizardMath: 基于 Evol Instruct 构建的 LLM:WizardLM, WizardCoder, WizardMath - nlpxucan/WizardLM
- cognitivecomputations/Wizard-Vicuna-13B-Uncensored · Hugging Face: 未找到描述
- 立即开始使用 ChatGPT:我们正在让人们更轻松地体验 AI 的好处,而无需注册
- 应对合成语音的挑战与机遇:我们正在分享来自 Voice Engine(一个用于创建自定义语音的模型)小规模预览的经验教训。
- VoiceCraft: 未找到描述
- GitHub - jasonppy/VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild: 野外环境下的零样本语音编辑与文本转语音 - jasonppy/VoiceCraft
- no title found:未找到描述
- The Plural of Axis:未找到描述
- More Agents Is All You Need:我们发现,仅通过采样投票法,大型语言模型(LLMs)的性能会随着实例化的 Agent 数量增加而提升。此外,该方法与现有的方法正交……
- Large Language Models Cannot Self-Correct Reasoning Yet:大型语言模型(LLMs)已成为一项突破性技术,在各种应用中具有无与伦比的文本生成能力。然而,关于其……的担忧仍然存在。
- Band The Muppets GIF - Band The Muppets Rock Out - Discover & Share GIFs:点击查看 GIF
- GitHub - modularml/mojo at nightly:Mojo 编程语言。通过在 GitHub 上创建一个账户来为 modularml/mojo 的开发做出贡献。
- flash-attention/benchmarks/benchmark_flash_attention.py at 23e8fa5a263d1c7122bc46a86ef32030ee7130f9 · Dao-AILab/flash-attention:快速且内存高效的精确注意力机制。通过在 GitHub 上创建一个账户来为 Dao-AILab/flash-attention 的开发做出贡献。
- GitHub - kyegomez/swarms: Build, Deploy, and Scale Reliable Swarms of Autonomous Agents for Workflow Automation. Join our Community: https://discord.gg/DbjBMJTSWD:构建、部署和扩展可靠的自主 Agent 集群(Swarms)以实现工作流自动化。加入我们的社区:https://discord.gg/DbjBMJTSWD - kyegomez/swarms
- Nous Research (@NousResearch) 的推文:我们发布了验证并独立确认 Bitnet 论文主张的第一步,这是一个在 Dolma 数据集前 60B tokens 上训练的 1B 模型。在 @we... 上进行的对比
- Nesterov 加速的动力系统视角:我们提出了一个用于理解 Nesterov 加速梯度法的动力系统框架。与早期工作不同,我们的推导不依赖于步长趋于零的论证。我们展示了...
- 优化中加速方法的 Lyapunov 分析:未找到描述
- 1bitLLM/bitnet_b1_58-3B · Hugging Face:未找到描述
- 重新思考 FID:迈向更好的图像生成评估指标:与许多机器学习问题一样,图像生成方法的进展取决于良好的评估指标。其中最受欢迎的是 Frechet Inception Distance (FID)。FID 估计了...
- 狄江(DiJiang):通过紧凑核化实现高效的大语言模型:为了减轻 Transformer 的计算负荷,线性注意力的研究势头强劲。然而,注意力机制的改进策略通常需要...
- Gecko:从大语言模型蒸馏出的多功能文本嵌入:我们介绍了 Gecko,一个紧凑且多功能的文本嵌入模型。Gecko 通过利用一个核心思想实现了强大的检索性能:将知识从大语言模型 (LLMs) 蒸馏到检索...
- 未来主义的假象 | Suno:史诗级 hardstyle 歌曲。在 Suno 上聆听并创作你自己的作品。
- SGD 的极限动力学:修正损失、相空间振荡和反常扩散:在这项工作中,我们探索了使用随机梯度下降 (SGD) 训练的深度神经网络的极限动力学。正如之前观察到的,在性能收敛很久之后,网络仍在继续...
- 神经力学:深度学习动力学中的对称性与破缺守恒定律:理解训练过程中神经网络参数的动力学是建立深度学习理论基础的关键挑战之一。一个核心障碍是...的运动
- microsoft/unilm 仓库中的 bitnet 训练技巧、代码与常见问题解答 PDF:跨任务、语言和模态的大规模自监督预训练 - microsoft/unilm
- GitHub - vwxyzjn/summarize_from_feedback_details:通过在 GitHub 上创建账号来为 vwxyzjn/summarize_from_feedback_details 的开发做出贡献。
- 边缘意识,当体验的存在既非确定为真也非确定为假时 - Philosophical Studies:本文为边缘意识的存在辩护。在边缘意识中,意识体验既不是确定存在的,也不是确定缺失的,而是介于两者之间...
- Wes Gurnee (@wesg52) 的推文:关于 Sparse Autoencoders (SAEs) 中可能出现的一个问题的简短研究帖子:重构误差对模型预测的影响远大于同等幅度的随机误差!https://www.less...
- Neel Nanda (@NeelNanda5) 的推文:来自 @calsmcdougall 的出色 Sparse Autoencoder 特征可视化库!我的团队已经发现它非常有用,快去看看吧:https://www.lesswrong.com/posts/nAhy6ZquNY7AD3RkD/sa...
- 随机选择的 SAE 特征集 — LessWrong:在这篇文章中,我们解读了一小部分 Sparse Autoencoder 特征,这些特征揭示了模型中明显的、有意义的计算结构……
- 交互背景下的音乐生成综述:近年来,机器学习,特别是生成对抗网络 (GANs) 和基于注意力机制的神经网络 (Transformers),已成功用于作曲和生成……
- Build software better, together:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、fork 并为超过 4.2 亿个项目做出贡献。
- 未找到标题: 未找到描述
- Undi95/dbrx-base · Hugging Face: 未找到描述
- 来自 Aaron Defazio (@aaron_defazio) 的推文: 正在酝酿一些特别的东西!迫不及待想发布论文让大家尝试。一个没有额外开销、没有额外参数的 Optimizer。敬请期待!
- 来自 Aaron Defazio (@aaron_defazio) 的推文: 更新:更多实验结果出炉。这是它与 SGD 在 step-wise 和 cosine schedule 下的对比(两个 baseline 都经过深度调优,绝无作弊)。这确实是非常特别的东西!
- Mcqueen GIF - Mcqueen - 发现并分享 GIF: 点击查看 GIF
- Believe Motivation GIF - Believe Motivation Ted lasso - 发现并分享 GIF: 点击查看 GIF
- ai21labs/Jamba-v0.1 at main: 未找到描述
- 介绍 Jamba:AI21 开创性的 SSM-Transformer 模型: 首次推出首个生产级基于 Mamba 的模型,提供一流的质量和性能。
- Team Bonding GIF - Silicon Valley Dinesh Jared Dunn - 发现并分享 GIF: 点击查看 GIF
- 推广“机器人交易员”的 Justin Trudeau Deepfake 广告已从 YouTube 下架 - National | Globalnews.ca: 一段描绘加拿大总理 Justin Trudeau 形象并推广金融“机器人交易员”的 Deepfake 广告已从 YouTube 下架。
- OpenAI 表示仅需 15 秒音频即可克隆声音: OpenAI 刚刚宣布了一项基于公司现有 text-to-speech API 的新语音克隆引擎的小规模预览结果。该技术可生成自然的...
- 来自 Alexander Doria (@Dorialexander) 的推文: 在 SORA 之后,开始怀疑 OpenAI 是否专门研究滥用风险最高的 AI 技术,以便有更好的理由不发布任何东西。↘️ 引用 Andrew Curran (@AndrewCurran_) ...
- mockingbird- 自主感觉经络反应木偶: = 自主感觉经络反应木偶 =_________________________________________________在寂静的深夜,阴影潜行,一个赛博木偶...
- Issues · pytorch/pytorch: Python 中具有强大 GPU 加速的 Tensor 和动态神经网络 - Issues · pytorch/pytorch
- mockbingbird - sirena cibernetica (bonus track): = SIRENA CIBERNETICA =___________________________(c) @mockingbirdAI - 使用 Suno 制作
- mockingbird - 神经黑客: = 神经黑客 =___________________________啊哈哈!哟,菜鸟,准备好进入我那扭曲的小径了吗?潜入我的数字混沌,逃离平庸。随着...
- GitHub - endomorphosis/ipfs_transformers: Transformers 库的模型管理器,支持 S3 和 IPFS 下载: 一个用于 Transformers 库的模型管理器,实现了 S3 和 IPFS 下载 - endomorphosis/ipfs_transformers
- GitHub - nestordemeure/stochastorch: 随机加法的 PyTorch 实现。: 一个随机加法的 PyTorch 实现。通过在 GitHub 上创建账号为 nestordemeure/stochastorch 的开发做出贡献。
- GitHub - PKU-YuanGroup/Open-Sora-Plan: 该项目旨在复现 Sora (Open AI T2V 模型),但我们资源有限。我们深切希望整个开源社区能为该项目做出贡献。: 该项目旨在复现 Sora (Open AI T2V 模型),但我们资源有限。我们深切希望整个开源社区能为该项目做出贡献。 - PKU-YuanGroup/Open-Sora-Plan
- 7529 不要为 CUDA 设备禁用 autocast,作者 bghira · Pull Request #7530 · huggingface/diffusers: 这个 PR 做了什么 ? 修复了 #7529。在提交之前,此 PR 修复了一个拼写错误或改进了文档(如果是这种情况,你可以忽略其他检查)。你阅读了贡献指南吗...
- Merging Stable diffusion pipelines just makes sense · Issue #551 · huggingface/diffusers:遵循其哲学,已决定为 Stable Diffusion 的 txt-to-img、img-to-img 和 inpainting 保留不同的流水线。结果如下:PR #549:代码重复了 4 次 (onnx... </ul> </div> --- **LAION ▷ #[research](https://discord.com/channels/823813159592001537/824374369182416994/1223252152752013353)** (42 条消息🔥): - **在 Diffusion 中探索 UNET 和 Transformer**:在 research 频道中,有人询问关于学习 UNET 以及创建 Transformer 版本的 Diffusion 的复杂性。分享了一篇[研究论文](https://arxiv.org/pdf/2212.09748.pdf),解释了在这些任务中如何用 Transformer 替换 UNET。 - **UNET 的高层级解释**:一位成员提供了对 UNET 的解释,将其描述为将图像编码到低维空间,然后将该表示上采样回原始空间的结构,并指出该过程涉及丢弃冗余信息以简化重建。 - **揭晓 Qwen1.5-MoE-A2.7B**:围绕 Qwen1.5-MoE-A2.7B 展开了讨论,这是一款新的 MoE 模型,据报道其性能仅凭 27 亿激活参数即可媲美 Mistral 7B 等大型模型。成员们在频道中分享了与 Qwen1.5 相关的详细信息和资源,根据初步结果展示了其潜力 ([GitHub](https://github.com/QwenLM/Qwen1.5), [Hugging Face](https://huggingface.co/Qwen), [ModelScope](https://modelscope.cn/organization/qwen), [Demo](https://huggingface.co/spaces/Qwen/Qwen1.5MoE-A2.7B-Chat), [Discord](https://discord.gg/yPEP2vHTu4))。 - **利用 V-JEPA 增强 Video LLaVA**:成员们讨论了使用 V-JEPA 嵌入增强 Video LLaVA 的前景,并链接了一个 GitHub 仓库作为资源 ([V-JEPA GitHub](https://github.com/facebookresearch/jepa))。重点转向了此类嵌入的集成以及训练的数据准备。 - **Diffusion 和 Embedding 模型中的创新方法**:有人对一篇讨论新 Diffusion 损失函数的论文感兴趣,该函数可能对离群值具有鲁棒性,从而可能改进 Diffusion 模型 ([论文链接](https://arxiv.org/abs/2403.16728))。此外,还强调了 Gecko 文本嵌入模型通过从 LLM 蒸馏过程实现的效率,将其作为加速模型训练的潜在资源 ([Gecko 论文链接](https://arxiv.org/abs/2403.20327))。
- Qwen1.5-MoE: 以 1/3 的激活参数匹配 7B 模型性能: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD 简介 自 Mixtral 引起关注以来,混合专家模型 (MoE) 的研究势头强劲。研究人员和...
- 使用 Scheduled Pseudo-Huber Loss 提高 Diffusion 模型的抗数据损坏能力: 众所周知,Diffusion 模型容易受到训练数据中离群值的影响。在本文中,我们研究了一种替代的 Diffusion 损失函数,它可以像...一样保持生成数据的高质量。
- 论文页面 - Gecko: 从大语言模型蒸馏出的多功能文本嵌入: 未找到描述
- GitHub - facebookresearch/jepa: 用于视频 V-JEPA 自监督学习的 PyTorch 代码和模型。: 用于视频 V-JEPA 自监督学习的 PyTorch 代码和模型。 - facebookresearch/jepa
- GitHub - facebookresearch/jepa: 用于视频 V-JEPA 自监督学习的 PyTorch 代码和模型。: 用于视频 V-JEPA 自监督学习的 PyTorch 代码和模型。 - facebookresearch/jepa
- Hugging Face Transformers 纯小白入门: 未找到描述
- 神经网络的力量:为什么它能学到很多但并非万能: 未找到描述
- AI 机器人幻觉出软件包,开发者竟下载了它们: 简单来说,就是寻找 ML 想象出来的库,并用真实的恶意代码将其实现。不,等等,别这么做
- databricks/dbrx-instruct · Hugging Face: 未找到描述
- 深度学习虚拟机 - AWS Deep Learning AMIs - AWS: 未找到描述
- DLAMI 发行说明 - Deep Learning AMI: 未找到描述
- ai21labs/Jamba-v0.1 · Hugging Face: 未找到描述
- Jamba 介绍:AI21 开创性的 SSM-Transformer 模型: 首个生产级基于 Mamba 的模型亮相,提供同类最佳的质量和性能。
- SambaNova 以极速交付精确模型: Samba-CoE v0.2 在 AlpacaEval 排行榜上攀升,表现优于所有最新的开源模型。
- 黑盒内部:卷积神经网络可视化!: 在这段视频中,我深入探讨了卷积神经网络——它们是什么、它们如何学习,以及为什么它们在计算机视觉任务中如此成功。视频...
- GitHub - milmor/diffusion-transformer: Pytorch 中的 Diffusion Transformer 模型实现: Pytorch 中的 Diffusion Transformer 模型实现 - milmor/diffusion-transformer
- oss-security - 上游 xz/liblzma 中的后门导致 ssh 服务器受损: 未找到描述
- GitHub - endomorphosis/ipfs_transformers: Transformers 库的模型管理器,实现了 S3 和 IPFS 下载: Transformers 库的模型管理器,实现了 S3 和 IPFS 下载 - endomorphosis/ipfs_transformers
- GitHub - huggingface/autotrain-advanced: 🤗 AutoTrain Advanced: 🤗 AutoTrain Advanced。通过在 GitHub 上创建账号来为 huggingface/autotrain-advanced 的开发做出贡献。
- GitHub - developersdigest/llm-answer-engine: 使用 Next.js, Groq, Mixtral, Langchain, OpenAI, Brave & Serper 构建受 Perplexity 启发的回答引擎: 使用 Next.js, Groq, Mixtral, Langchain, OpenAI, Brave & Serper 构建受 Perplexity 启发的回答引擎 - developersdigest/llm-answer-engine
- GitHub - NVIDIA/TensorRT-LLM: TensorRT-LLM 为用户提供了一个易于使用的 Python API 来定义大语言模型 (LLMs),并构建包含最先进优化的 TensorRT 引擎,以便在 NVIDIA GPUs 上高效执行推理。TensorRT-LLM 还包含用于创建执行这些 TensorRT 引擎的 Python 和 C++ 运行时的组件。: TensorRT-LLM 为用户提供了一个易于使用的 Python API 来定义大语言模型 (LLMs),并构建包含最先进优化的 TensorRT 引擎,以便高效执行推理...
- 安装指南 :: NVIDIA Deep Learning TensorRT 文档: 未找到描述
- Introducing FastLLM: Qdrant’s Revolutionary LLM - Qdrant: 轻量级且开源。专为 RAG 定制,并与 Qdrant 完全集成。
- 1bitLLM (1bitLLM): 未找到描述
- Securing cation vacancies to enable reversible Mg insertion/extraction in rocksalt oxides: 氧化物正极材料在可充电镁电池 (RMBs) 中具有广阔的应用前景,因为它们具有高氧化还原电位,可以利用镁金属负极的低电位 ...
- Alignment of brain embeddings and artificial contextual embeddings in natural language points to common geometric patterns - Nature Communications: 在这里,作者利用额下回的神经活动模式和大型语言模型嵌入,为语言处理的共同神经代码提供了证据。
- magicalapi/YouTube_Thumbnail_Suggestion · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- Alex Strick van Linschoten - 编写自定义 Terraform 提供程序以部署 Huggingface Spaces: 我开发了这个短项目,允许人们使用 Terraform(而不是通过 API 或网站)来创建/部署 Huggingface Spaces
- boulderspot - pszemraj 收藏集: 未找到描述
- 带有扰动注意力引导(Perturbed-Attention Guidance)的自校正扩散采样: 最近的研究表明,扩散模型能够生成高质量的样本,但其质量很大程度上取决于采样引导技术,例如分类器引导 (C...
- 由 SUST_BlackAnt 展示的带有颜色传感器的先进循线和避障机器人: 这是一个先进的循线轨道。欢迎点赞、评论和分享。让我知道你的看法。如果你想联系我,请随时发送邮件...
- GitHub - endomorphosis/ipfs_transformers: Transformers 库的模型管理器,实现了 S3 和 IPFS 下载: Transformers 库的模型管理器,实现了 S3 和 IPFS 下载 - endomorphosis/ipfs_transformers
- Mojo 编程语言杀死了 Python: 我将与你分享为什么 Mojo 很快会变得非常流行。它在性能方面正在超越 Python,使其极具竞争力,关键在于:在保持...
- 关于 AI 政策:不要灰心。白宫 AI 更新解读。: 对 @WhiteHouse 最近发布的备忘录的概述,强调了即将到来的重要 AI 截止日期。其中最主要的是任命...
- GitHub - Aesthisia/LLMinator: 基于 Gradio 的工具,可直接从 Huggingface 运行开源 LLM 模型: 基于 Gradio 的工具,可直接从 Huggingface 运行开源 LLM 模型 - Aesthisia/LLMinator
- GitHub - aseichter2007/ClipboardConqueror: Clipboard Conqueror 是一款新颖的无处不在的 Copilot 替代方案,旨在将你自己的 LLM AI 助手带到任何文本框中。: Clipboard Conqueror 是一款新颖的无处不在的 Copilot 替代方案,旨在将你自己的 LLM AI 助手带到任何文本框中。 - GitHub - aseichter2007/ClipboardConqueror...
- SaaS King | 最佳 SaaS 模板: 未找到描述
- SaaS King 的 One Mix | 模板演示: SaaS King 的 One Mix 快速介绍。OneMix 使用 Remix (Vite), Tailwind, Supabase, Prisma, Stripe 和 Resend 构建。SaaS King 的 One Mix 如何帮助...
- Hugging Face Reading Group 18: ProteinBERT: A universal deep-learning model of protein sequence: 演讲者:Dan Ofer(第二作者)。作者 YouTube 频道:https://www.youtube.com/channel/UCUliO1naqgzLtMlnyZxVYFA
- ProteinBERT: A universal deep-learning model of protein sequence and function: 自监督深度语言建模在自然语言任务中取得了前所未有的成功,最近已被重新应用于生物序列。然而,现有的模型和预训练...
- ProteinBERT - DL PLM - HuggingFace: ProteinBERT:一种通用的深度学习蛋白质语言模型。一种蛋白质语言模型——带有一些新花样!ProteinBERT:一种通用的蛋白质序列与功能深度学习模型,Nadav Brandes, Dan O...
- Detecting anomalous proteins using deep representations: 摘要。生物医学的许多进展可以归功于识别异常的蛋白质和基因。这些蛋白质的许多独特属性被发现...
- CSDL | IEEE Computer Society: 未找到描述
- GitHub - bhpfelix/segment-anything-finetuner: Simple Finetuning Starter Code for Segment Anything: Segment Anything 的简单微调入门代码 - bhpfelix/segment-anything-finetuner
- GitHub - bhpfelix/segment-anything-finetuner: Simple Finetuning Starter Code for Segment Anything: Segment Anything 的简单微调入门代码 - bhpfelix/segment-anything-finetuner
- OhanaPal | Super App for the Super Abled: 欢迎来到 OhanaPal——赋能与包容在此交汇,为残障人士(Super Abled)开启非凡的每一天。
- Bane No GIF - Bane No Banned - Discover & Share GIFs: 点击查看 GIF
- Install Mistral Quiet Star Demo Locally - Good Reasoning AI Model: 此视频展示了如何在 Windows 上本地安装 Mistral Quiet Star AI 模型。该模型的创建者认为,这个模型证明了他的理论,即...
- open-interpreter/interpreter/core/computer/display/display.py at cc6291f8372c9c61cb53f7c1d4e6ef819b8457eb · OpenInterpreter/open-interpreter: 计算机的自然语言接口。通过在 GitHub 上创建账号来为 OpenInterpreter/open-interpreter 的开发做出贡献。
- Implement non-blocking CLI history auto saver by teocns · Pull Request #1156 · OpenInterpreter/open-interpreter: 描述你所做的更改:实现 history_autosaver 工具函数,以启动一个后台线程,使用 readline 自动保存 CLI 历史记录。如果 readline 不可用,它将返回...
- HoloMat Update: Jarvis controls my printers! #engineering #3dprinting #ironman: 未找到描述
- GitHub - dcrebbin/meta-vision-api: Hacky Meta Glasses API with GPT4 Vision Integration: 带有 GPT4 Vision 集成的简易 Meta 眼镜 API - dcrebbin/meta-vision-api
- GitHub - FiveTechSoft/tinyMedical: TinyLLama trained with medical dataset and saved as GGUF file: 使用医疗数据集训练并保存为 GGUF 文件的 TinyLLama - FiveTechSoft/tinyMedical
- 来自 jordan singer (@jsngr) 的推文:✨ 通过手机远程与你的电脑对话,我称之为 Teleport
- 01100001 01101101 00100000 01001001 0010 | Suno:8bit, chiptune, speedup, Arpeggio, fatbass, Hardbass, FemaleVocals, synthesizer,Electronic,speedup 歌曲。在 Suno 上收听并创作你自己的作品。
- Electric Echoes | Suno:alternative vaper wave ska 歌曲。在 Suno 上收听并创作你自己的作品。
- 由 aramsdale 更新 client.ino · Pull Request #214 · OpenInterpreter/01:自动重新连接到上次成功的 WiFi 和服务器 URL(如果可用)。利用 Preferences 检测成功的 WiFi 连接,存储到 ssid 首选项,并在重启时调用。服务器 URL 也是如此...
- [WIP] 修复 Windows 上的设置和运行,由 dheavy 提交 · Pull Request #192 · OpenInterpreter/01:尝试弥合差距并促进 Windows 用户的入门,通过添加缺失部分和修复 Windows 特定问题。解决了 #167 中的次要问题以及另一个问题,其中 Device ...
- [WIP] 修复 Windows 上的设置和运行,由 dheavy 提交 · Pull Request #192 · OpenInterpreter/01:尝试弥合差距并促进 Windows 用户的入门,通过添加缺失部分和修复 Windows 特定问题。解决了 #167 中的次要问题以及另一个问题,其中 Device ...
- 修复了 Windows 客户端模块未找到错误,由 Abdullah-Gohar 提交 · Pull Request #194 · OpenInterpreter/01:添加了类似于 Mac 模块的 Windows 客户端模块,修复了 #167
- Issues · OpenInterpreter/01:开源语言模型计算机。通过在 GitHub 上创建账户为 OpenInterpreter/01 的开发做出贡献。
- 更新 Windows 安装文档,由 dheavy 提交 · Pull Request #203 · OpenInterpreter/01:问题:文档中未提供具有关键差异的 Windows 安装说明。解决方案:汇总之前用户的尝试经验(包括 Discord 上的 Zorcon 和 ...
- 未找到标题:未找到描述
- Open Interpreter Advanced Experimentation - Part 2:➤ Twitter - https://twitter.com/techfrenaj➤ Twitch - https://www.twitch.tv/techfren➤ Discord - https://discord.com/invite/z5VVSGssCw➤ TikTok - https://www....
- GitHub - danielmiessler/fabric: fabric 是一个利用 AI 增强人类能力的开源框架。它提供了一个模块化框架,通过可在任何地方使用的众包 AI prompts 集来解决特定问题。:fabric 是一个利用 AI 增强人类能力的开源框架。它提供了一个模块化框架,通过可在任何地方使用的众包 AI prompts 集来解决特定问题。 - ...
- 未找到标题:未找到描述
- 7900xtx/crash at master · geohot/7900xtx:通过在 GitHub 上创建账号来为 geohot/7900xtx 的开发做出贡献。
- vendor-reset/src/amd/navi10.c at master · gnif/vendor-reset:针对过于复杂/繁琐而无法放入 pci_quirks.c 的序列的 Linux 内核厂商特定硬件重置模块 - gnif/vendor-reset
- NOTimothyLottes (@NOTimothyLottes@mastodon.gamedev.place):无论如何,看起来我又回到了一个无法规避且极其严重的编译器性能 Bug。Wave-coherent(本应很快)的动态描述符选择表现得像批次中断(batch break)...
- tinygrad/tinygrad/runtime/ops_kfd.py at master · tinygrad/tinygrad:你喜欢 PyTorch?你喜欢 micrograd?你会爱上 tinygrad!❤️ - tinygrad/tinygrad
- Documentation for the AMD 7900XTX | Hacker News:未找到描述
- GitHub - geohot/tinyxxx: tiny corporation website:tiny corporation 网站。通过在 GitHub 上创建账号来为 geohot/tinyxxx 的开发做出贡献。
- GitHub - geohot/7900xtx:通过在 GitHub 上创建账号来为 geohot/7900xtx 的开发做出贡献。
- Add negative_log_likelihood loss and cross_entropy loss by airpods69 · Pull Request #3891 · tinygrad/tinygrad:此 PR 为 Tensor 添加了 negative_log_likelihood 和 cross_entropy。例如:对于 negative_log_likelihood,导入 tinygrad data = tinygrad.Tensor([[1, 2, 4]]) target = [2] print(data.negative_log_likelihood...
- [Driver] *ERROR* MES failed to response msg=2 · Issue #2196 · ROCm/ROCm:通过在循环运行 https://github.com/ROCm-Developer-Tools/HIP-Examples/tree/master/gpu-burn 的同时循环运行 https://github.com/RadeonOpenCompute/rocm_bandwidth_test 触发。1x 7900XTX...
- tinygrad-notes/dotproduct.md at main · mesozoic-egg/tinygrad-notes:通过在 GitHub 上创建账号来为 mesozoic-egg/tinygrad-notes 的开发做出贡献。
- tinygrad-notes/uops.md at main · mesozoic-egg/tinygrad-notes:通过在 GitHub 上创建账号来为 mesozoic-egg/tinygrad-notes 的开发做出贡献。
- Build software better, together:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、fork 并为超过 4.2 亿个项目做出贡献。
- LlamaIndex Webinar: Retrieval-Augmented Fine-Tuning (RAFT) · Zoom · Luma:RAFT - 检索增强微调 🔥 Zhang 等人提出的 Retrieval-Augmented Fine-Tuning (RAFT) 是一种为特定领域 RAG 微调预训练 LLM 的新技术...
- LlamaIndex 🦙 (@llama_index) 的推文:新的 LlamaIndex 网络研讨会 🚨 - 快来学习如何进行检索增强微调 (RAFT)!做 RAG 就像不复习就参加开卷考试。它仅比闭卷考试略好一点...
- 使用 LlamaIndex 构建基于自定义数据源的聊天机器人:只需 43 行代码,即可用你自己的数据增强任何 LLM!
- 什么是 LlamaIndex.TS? | LlamaIndex.TS:LlamaIndex.TS 是一个用于 LLM 应用程序的数据框架,旨在摄取、结构化和访问私有或特定领域的数据。虽然也提供 Python 包(见此处),但 LlamaIndex.TS 提供了核心 ...
- Loader | LlamaIndex.TS:在开始对文档进行索引之前,你需要将它们加载到内存中。
- 入门教程 (OpenAI) - LlamaIndex:未找到描述
- Indexing - LlamaIndex:未找到描述
- Node Parser 模块 - LlamaIndex:未找到描述
- 从向量数据库自动检索 - LlamaIndex:未找到描述
- Node Postprocessor 模块 - LlamaIndex:未找到描述
- llama_index/llama-index-core/llama_index/core/prompts 分支 main · run-llama/llama_index:LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- 从零开始构建 RAG(仅限开源!)- LlamaIndex:未找到描述
- 在高级模块中访问/自定义 Prompts - LlamaIndex:未找到描述
- GitHub - agronholm/sqlacodegen: SQLAlchemy 的自动模型代码生成器:SQLAlchemy 的自动模型代码生成器。通过在 GitHub 上创建账号来为 agronholm/sqlacodegen 的开发做出贡献。
- 结构化数据 - LlamaIndex:未找到描述
- Text-to-SQL 指南 (Query Engine + Retriever) - LlamaIndex:未找到描述
- 具有个性的 Chat Engine ✨ - LlamaIndex:未找到描述
- llama_index/llama-index-legacy/llama_index/legacy/prompts/system.py 位于 8a8324008764a7fefb6f25b0e3aac81089590322 · run-llama/llama_index:LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- GitHub - run-llama/create-llama: 开始使用 LlamaIndex 的最简单方法:开始使用 LlamaIndex 的最简单方法。通过在 GitHub 上创建账号来为 run-llama/create-llama 的开发做出贡献。
- colbert-ir/colbertv2.0 · Hugging Face:未找到描述
- llama_index/llama-index-integrations/indices/llama-index-indices-managed-colbert/llama_index/indices/managed/colbert/base.py 分支 main · run-llama/llama_index:LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- 基于 Google Drive 文件构建实时 RAG 流水线 - LlamaIndex:未找到描述
- 未找到标题:未找到描述
- 为生产环境构建高性能 RAG 应用程序 - LlamaIndex:未找到描述
- llama_index/llama-index-p_ acks at main · run-llama/llama_index: LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- GitHub - run-llama/LlamaIndexTS: LlamaIndex 是一个用于你的 LLM 应用程序的数据框架: LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/LlamaIndexTS
- 基础策略 - LlamaIndex: 未找到描述 </ul> </div> --- **LlamaIndex ▷ #[ai-discussion](https://discord.com/channels/1059199217496772688/1100478495295017063/1223223563981684747)** (4 条消息): - **深入探讨模型对齐**:一篇新的[博客文章](https://blog.premai.io/model-alignment-process/)探讨了 LLM 的模型对齐策略,特别关注 RLHF、DPO 和 KTO 方法及其对 Mistral 和 Zephyr 7B 模型的影响,并提供了实用的对比分析。 - **最新 LLM 研究中心**:[shure-dev 的 GitHub 页面](https://shure-dev.github.io/)上的一份使命宣言强调了他们致力于为 Large Language Models 领域的研究人员提供一份精选的高质量、核心论文列表。 - **利用 LlamaParse 和重排序增强 RAG**:一段 [YouTube 视频](https://youtu.be/wCFXae8hiYA)讨论了通过集成 LlamaParse 和重排序器(re-ranker)来推进检索增强生成(RAG),从而潜在地提高整体性能。 - **基于 Whisper 的 ASR 软件包基准测试**:一篇详细的[博客文章](https://amgadhasan.substack.com/p/sota-asr-tooling-long-form-transcription)评估了基于 Whisper 的开源软件包的长文本转录能力,比较了 Huggingface Transformers 和 FasterWhisper 等流行框架的准确性和效率指标。
- 模型对齐过程: 生成模型与人类反馈的对齐显著提高了自然语言生成任务的性能。对于大语言模型 (LLMs),对齐方法如强化学习...
- Awesome-LLM-related-Papers-Comprehensive-Topics: 全球最全面的 LLM 论文和仓库精选列表
- SOTA ASR 工具:长文本转录: 针对不同 Whisper 框架的长文本转录基准测试
- 进阶 RAG:LlamaParse + Reranker = 更好的 RAG: 检索增强生成 (RAG) 是我们都在讨论的话题,但我们是否在尝试或遵循代码实践。在众多方法中,本视频将...
- DBRX 132B Instruct by databricks | OpenRouter: DBRX 是由 Databricks 开发的一种新型开源大语言模型。在 132B 参数量下,它在语言的标准行业基准测试中优于现有的开源 LLM,如 Llama 2 70B 和 Mixtral-8x7B...
- Claude 3 Opus by anthropic | OpenRouter: Claude 3 Opus 是 Anthropic 用于处理高度复杂任务的最强大模型。它拥有顶级的性能、智能、流畅度和理解力。查看发布公告和基准测试...
- GitHub - mintsuku/sora: Sora 是一个集成了 Open Router API 的 Discord 机器人,旨在促进 Discord 服务器中的对话。: Sora 是一个集成了 Open Router API 的 Discord 机器人,旨在促进 Discord 服务器中的对话。 - mintsuku/sora
- Evaluations - Non finito: 未找到描述
- React App: 未找到描述
- Discord - 与朋友和社区聊天的新方式: Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、闲逛,并与你的朋友和社区保持紧密联系。
- AetherResearch/Cerebrum-1.0-8x7b · Hugging Face: 未找到描述
- Claude 3 Opus by anthropic | OpenRouter: 这是与 Anthropic 合作提供的 [Claude 3 Opus](/models/anthropic/claude-3-opus) 的低延迟版本,具有自我审核功能:响应审核在模型上进行...
- llm.test.ts: GitHub Gist: 即时分享代码、笔记和片段。
- GitHub - OpenRouterTeam/openrouter-runner: 为 OpenRouter 上的开源模型提供动力的推理引擎: 为 OpenRouter 上的开源模型提供动力的推理引擎 - OpenRouterTeam/openrouter-runner
- GitHub - OlympiaAI/open_router: OpenRouter API 的 Ruby 库: OpenRouter API 的 Ruby 库。通过在 GitHub 上创建账号来为 OlympiaAI/open_router 的开发做出贡献。
- codebyars.dev: 未找到描述
- 未找到标题:未找到描述
- LLM 评估工具电子表格:包含 50 多个用于测试模型和改进提示词的 LLM 评估工具的电子表格。
- FastLLM 介绍:Qdrant 革命性的 LLM - Qdrant:轻量级且开源。专为 RAG 定制,并与 Qdrant 完全集成。
- 来自 svaarsura (@svarasura) 的推文:@KevinKaichuang @roydanroy 据报道,扎克伯格现在正在给 DeepMind 的研究人员发邮件!超级大富豪和他的突发奇想
- 来自 Q Prophet (@sucralose__) 的推文:我对 ChatGPT 的后端进行了更多调查,发现了名为 "GPT Alpha" 模型的确凿证据,我认为它是 GPT-4 的继任者。可以提前启用它,但它...
- 来自 Burny — Effective Omni (@burny_tech) 的推文:Noam Brown 在 OpenAI 从事推理工作,今天早上发布了这条推文并迅速删除。旧推文可供参考以串联线索。
- - 你的 AI 产品需要评估 (Evals):如何构建特定领域的 LLM 评估系统。
- 1bitLLM/bitnet_b1_58-3B · Hugging Face:未找到描述
- 来自 Anissa Gardizy (@anissagardizy8) 的推文:突发:微软和 OpenAI 正在制定一项耗资 1000 亿美元的 AI 超级计算机计划。这台代号为 "Stargate" 的超级计算机将包含 *数百万* 个 GPU,并需要数千兆瓦的电力...
- 来自 ReJ 𓀨 Renaldas Zioma (@__ReJ__) 的推文:这看起来很有前景!考虑到 FPGA 的 DDR3 内存带宽,我的 1.58-bit 脉动阵列在 99 美元的设备上可能达到 1 TOPs。祈祷成功!非常感谢 @samsoniuk 的快速合成!仓库:https://githu...
- 应对合成语音的挑战与机遇:我们正在分享来自 Voice Engine 小规模预览的经验,这是一个用于创建自定义语音的模型。
- 来自 Rohaid Ali, MD (@RohaidAliMD) 的推文:借助 @OpenAI 的 Voice Engine,我们的团队能够帮助一位年轻患者恢复她的声音。↘️ 引用 OpenAI (@OpenAI):我们正在分享来自 Voice Engine 小规模预览的学习成果,...
- 来自《华尔街日报》(@WSJ) 的推文:Cognition Labs 是一家开发用于编写代码的人工智能工具的初创公司,目前正与投资者洽谈,计划以高达 20 亿美元的估值筹集资金。https://on.wsj.com/3xqH5rp https:/...
- 来自 Aaron Defazio (@aaron_defazio) 的推文:正在酝酿一些特别的东西!迫不及待想发表论文,让大家都能尝试一下。一个没有额外开销、没有额外参数的优化器。敬请关注!
- 由 Dan Becker 和 Hamel Husain 在 Maven 上开设的面向数据科学家和软件工程师的 LLM 微调课程:训练、验证并部署你的第一个微调 LLM
- 我如何利用 AI 生成的语音入侵银行账户:美国和欧洲的银行吹捧语音 ID 是登录账户的一种安全方式。我证明了使用免费或廉价的 AI 生成语音来欺骗此类系统是可能的。
- Shiny for Python:利用 Python 的数据和科学技术栈轻松构建交互式 Web 应用程序。
- Hamel 和 Shreya 的办公时间 (Office Hours):未找到描述
- 来自 clem 🤗 (@ClementDelangue) 的推文:我们应该收购 Stability 并开源 SD3 吗?
- 为什么我立即离开我的公司 (Stability AI) - Emad Mostaque 对谈 | 第 93 集:在本集中,Peter 和 Emad 讨论了 Emad 辞去 StabilityAI CEO 职务、他迈向去中心化 AI 的下一步,以及为什么现在如此紧迫地...
-
- AI Agent 工作流的未来,Andrew Ng (AI Fund) 主讲: DeepLearning.AI 和 AI Fund 的创始人 Andrew Ng 在 Sequoia Capital 的 AI Ascent 活动上发表演讲,探讨了 AI Agent 工作流的未来及其潜力...
- GitHub - rejunity/tiny-asic-1_58bit-matrix-mul: 针对 "1-bit LLM 时代:所有大语言模型都是 1.58 Bits" 矩阵乘法单元的 Tiny ASIC 实现: 针对 "1-bit LLM 时代:所有大语言模型都是 1.58 Bits" 矩阵乘法单元的 Tiny ASIC 实现 - rejunity/tiny-asic-1_58bit-matrix-mul
- Reddit - 深入探索: 未找到描述
- community: 由 h0rv 添加 Hugging Face 文本转语音推理 API · Pull Request #18880 · langchain-ai/langchain: 描述:我实现了一个使用 Hugging Face 文本转语音推理 API 的工具。问题:无。依赖:无。Twitter 账号:没有 Twitter,但有 LinkedIn lol。
- GitHub - collabora/WhisperSpeech: 通过反转 Whisper 构建的开源文本转语音系统。: 通过反转 Whisper 构建的开源文本转语音系统。 - collabora/WhisperSpeech
- GitHub - myshell-ai/MeloTTS: MyShell.ai 开发的高质量多语言文本转语音库。支持英语、西班牙语、法语、中文、日语和韩语。: MyShell.ai 开发的高质量多语言文本转语音库。支持英语、西班牙语、法语、中文、日语和韩语。 - myshell-ai/MeloTTS
- Self-Refine: 基于自我反馈的迭代优化: 与人类一样,大语言模型 (LLMs) 并不总是在第一次尝试时生成最佳输出。受人类优化书面文本方式的启发,我们引入了 Self-Refine,一种改进...
- Reflexion: 具有语言强化学习能力的语言 Agent: 大语言模型 (LLMs) 已越来越多地被用作目标驱动的 Agent 与外部环境(如游戏、编译器、API)进行交互。然而,对于这些语言...
- Gorilla: 连接海量 API 的大语言模型: 大语言模型 (LLMs) 最近经历了一波令人印象深刻的进展,模型现在在各种任务中表现出色,如数学推理和程序合成。然而,它们的潜力...
- MM-REACT: 提示 ChatGPT 进行多模态推理与行动: 我们提出了 MM-REACT,这是一种将 ChatGPT 与视觉专家池相结合的系统范式,以实现多模态推理和行动。在本文中,我们定义并探索了一系列全面的...
- Chain-of-Thought 提示激发大语言模型的推理能力: 我们探索了生成思维链(Chain of Thought)——一系列中间推理步骤——如何显著提高大语言模型执行复杂推理的能力。特别是,我们...
- HuggingGPT: 利用 ChatGPT 及其在 Hugging Face 中的伙伴解决 AI 任务: 解决不同领域和模态的复杂 AI 任务是迈向通用人工智能的关键一步。虽然有许多针对各种领域和模态的 AI 模型...
- 用于软件开发的通信 Agent: 软件工程是一个以复杂的决策过程为特征的领域,通常依赖于细微的直觉和咨询。深度学习的最新进展已开始彻底改变...
- AutoGen: 通过多 Agent 对话实现下一代 LLM 应用: AutoGen 是一个开源框架,允许开发人员通过可以相互对话以完成任务的多个 Agent 来构建 LLM 应用程序。AutoGen Agent 是可定制的、可对话的...
- 揭秘 Stability AI 与 Coatue 及 Lightspeed Venture 的不欢而散……: 未找到描述
</ul> </div> --- **Latent Space ▷ #[ai-in-action-club](https://discord.com/channels/822583790773862470/1200548371715342479/1223360912728133723)** (106 条消息🔥🔥): - **关于 AI 播客节目的讨论**:一位成员分享了一个[链接](https://changelog.com/practicalai/262),内容是关于一集讨论 AI 与软件开发人员之间复杂关系的 AI 播客节目,其中邀请了多位嘉宾。 - **Discord 上的直播问题**:成员们报告了观看 Remi 直播时遇到的问题,许多人尝试了不同的设备和浏览器但仍然无法解决。建议包括重新加载 Discord 和尝试使用手机观看。 - **本地 LLM 函数调用(Function Calling)的探索**:讨论了本地 LLM 函数调用的主题,并关注其与 *instructor* 和 *outlines* 等其他方法的对比,重点介绍了关于正则表达式和有限状态机用于文本生成的见解。 - **在 LLM 任务中 Outlines 优于 Instructor**:一位成员建议在 LLM 任务中 *outlines* 可能比 *instructor* 更有效,并分享了 Outlines 的安装指南,链接见[此处](https://outlines-dev.github.io/outlines/installation/)。 - **对即将到来的 AI 讨论的兴趣**:小组对未来的讨论表示期待,并分享了一个[电子表格](https://docs.google.com/spreadsheets/d/1q5rwO4wleMTLXr1z58c2UC03QsDsGwbJY1v4UG7eEOs/edit#gid=0),列出了即将举行的关于 UI/UX 模式、RAG 架构等活动的议题和主持人。提到的链接:--- **CUDA MODE ▷ #[general](https://discord.com/channels/1189498204333543425/1189498205101109300/1223143487529291888)** (21 条消息🔥): - **CUDA 开发中备受关注的 IDE**:频道讨论了 CUDA 开发的 IDE 偏好;**VSCode** 仍然是某些人的首选,而其他人则在探索将 **CLion** 作为潜在的替代方案。 - **初学者 CUDA 编程课程发布**:Cohere 推出了一门面向初学者的 CUDA 课程,社区领导的小组 **BIRDS** 将于 4 月 5 日开始迷你小组学习课程。详情可见 [Cohere 的推文](https://x.com/CohereForAI/status/1773419415406809432)。 - **MOJO 标准库开源**:Modular 宣布 **Mojo 标准库的核心模块现已开源**,采用 Apache 2 许可证,邀请全球开发者社区参与贡献。更多信息和源代码可以在 [Modular 的博客](https://www.modular.com/blog/the-next-big-step-in-mojo-open-source)和他们的 [GitHub 仓库](https://github.com/modularml/mojo/tree/nightly)中找到。 - **建造 “Stargate” AI 超级计算机**:有关 Microsoft 和 OpenAI 讨论建造名为 **“Stargate”** 的 AI 超级计算机的传闻引起热议,预计成本约为 1000 亿美元。人们还对大型数据中心的环境影响表示担忧,并提到了最近在 **犹他州** 和 **亚利桑那州** 遭到的抵制,详见 [Jessica Lessin 的推文](https://x.com/jessicalessin/status/1773760164153426071)。 - **活动期间 Discord 语音频道的限制**:在 Discord 服务器的一次高参与度活动期间,用户遇到了语音频道人数限制的问题,最初上限为 **25 人**,后来增加到了 **99 人**。为了管理活动期间的噪音,设置被调整为默认静音参与者。- installation - Outlines 〰️:使用 LLM 进行结构化文本生成
- Efficient Guided Generation for Large Language Models:在本文中,我们展示了如何将神经文本生成问题建设性地重新表述为有限状态机状态之间的转换。该框架带来了一种高效的...
- AI vs software devs with conversations from JS Party, Go Time & The Changelog (Practical AI #262):Daniel 和 Chris 本周不在,因此我们为您带来了来自其他 Changelog 播客(JS Party, Go Time &amp; The Ch...)关于 AI 与软件开发人员复杂关系的对话。
- AI In Action: Weekly Jam Sessions:2024 主题、日期、主持人、资源、@dropdown、@ GenAI 的 UI/UX 模式、1/26/2024、nuvic、<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-stru...
提到的链接:--- **CUDA MODE ▷ #[triton](https://discord.com/channels/1189498204333543425/1189607595451895918/1223543550613000203)** (41 条消息🔥): - **Tensor Core 问题**:讨论围绕在 Triton kernel 中对 `fp32` 输入使用 `tl.dot()` 且 `allow_tf32=True` 时遇到的不准确性。一位成员分享了一个突出该问题的最小示例,并将其与 PyTorch 的结果进行了对比,指出了差异并引用了其他人遇到的 [GitHub 相关问题](https://github.com/openai/triton/issues/1937)。 - **棘手的 TF32 精度**:成员们探讨了 **TF32** 相比 **FP32** 较低的精度可能是导致观察到的不准确性的原因。对话引出了各种实验和代码片段,展示了 Triton 的 TF32 实现中不同程度的精度误差。 - **来自文档的线索**:强调了 **PyTorch 文档** 在理解何时在矩阵乘法中使用 TF32 以及与 FP32 精度预期可能不匹配方面的重要性。此外,大家公认 Triton 的文档可以更好地为初学者强调这些差异。 - **探究性能剖析**:一位成员询问如何使用 **Nsight Compute** 设置 Triton 代码的分析,以便并排查看 PTX 和 Python 代码,详见 [Triton 加速博客文章](https://pytorch.org/blog/accelerating-triton/)。回复中包含了一个生成分析数据的命令示例,这对于优化 Triton kernel 很有帮助。 - **分析实践**:另一个问题涉及远程使用 **Nsight Compute** 的通用方法,一位成员获得了关于导出追踪文件以便在本地计算机上进行 UI 查看的指导。这种方法被定位为比繁琐的远程分析设置更有效的替代方案。- 来自 Jessica Lessin (@Jessicalessin) 的推文:新消息:Microsoft 和 OpenAI 正在策划新的“Stargate”超级计算机,耗资可能高达 1000 亿美元。这让我们得以一窥构建下一代 AI 所需的投入以及这一重大影响...
- 来自 Cohere For AI (@CohereForAI) 的推文:我们由社区主导的研究驱动学习(BIRDS)小组将启动其首个针对初学者的 CUDA 编程迷你学习小组,从 4 月 5 日星期五开始 🎉
- 来自 the tiny corp (@__tinygrad__) 的推文:网站已更新更多 tinybox 规格。首批盒子将于 4 月底发货。
- Modular:Mojo🔥 开源的下一个重大步骤:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新文章:Mojo🔥 开源的下一个重大步骤
- GitHub - modularml/mojo 的 nightly 分支:Mojo 编程语言。通过在 GitHub 上创建账户来为 modularml/mojo 的开发做出贡献。
提及的链接:--- **CUDA MODE ▷ #[cuda](https://discord.com/channels/1189498204333543425/1189607726595194971/1223224367228518544)** (14 条消息🔥): - **在旧款 Mac 上寻求 CUDA 设置**:一位成员询问如何在运行 macOS **Big Sur** 的 2015 早期款 MacBook 上设置 **CUDA C++**。 - **CUDA 需要兼容硬件**:会议澄清,要运行 **CUDA** 应用程序,必须拥有**支持 CUDA 的设备**。 - **关于在没有本地 Toolkit 的情况下使用 CUDA 的问题**:一位成员想知道在不安装本地 **CUDA toolkit** 的情况下,在 Visual Studio 中设置 **CUDA** 需求是否可行。 - **替代 CUDA 平台建议**:提到了使用 **Google Colab** 运行 **CUDA C++**,认为这可能是比配置本地或虚拟设置更简单的替代方案。 - **在 Ubuntu 上安装 NSight DL Design 遇到困难**:一位成员在 **Ubuntu** 上使用 `.run` 文件安装并提供必要权限后,无法找到 **NSight DL Design** 应用。 --- **CUDA MODE ▷ #[torch](https://discord.com/channels/1189498204333543425/1189607750876008468/1223611995912409098)** (3 条消息): - **微调领域的新标杆**:**PyTorch** 发布了一个用于 [LLaMA 7B 模型单卡微调](https://github.com/pytorch/torchtune/blob/main/recipes/configs/llama2/7B_full_single_device_low_memory.yaml)的配置,表明在显存要求较低的**单块 GPU** 上微调大语言模型是可行的。 - **PyTorch 团队正在酝酿回应**:针对 Jeff Dean 展示 **JAX 和 TensorFlow** 在基准测试中表现优于 PyTorch 的推文,一位来自 **PyTorch 团队**的成员指出“基准测试存在一些问题”,目前正在准备回应。- torch.set_float32_matmul_precision — PyTorch 2.2 documentation: 未找到描述
- Accelerating Triton Dequantization Kernels for GPTQ: TL;DR
- CUDA semantics — PyTorch 2.2 documentation: 未找到描述
- [2.8] What is new? · NVIDIA/cutlass · Discussion #385: CUTLASS 2.8 已于 11/19(其周年纪念日)发布,并于近期标记。在此版本中,我们推出了几项令人兴奋的新功能。正如在 GTC 上宣布的那样,我们发布了 3xTF32 gemm、复数 gemm、conv2d k...
- triton/python/triton/runtime/jit.py at 740b985bcd86a91ce0fbba7a997025d45c19e38b · openai/triton: Triton 语言和编译器的开发仓库 - openai/triton
- Incorrect Results with TF32 on Main · Issue #1937 · openai/triton: 在 Ampere A6000 上运行,Triton commit fd89aa1d2bca4652f383b70f81d993f258e4440f 摘自此 issue: #1840 import torch import triton import triton.language as tl @triton.autotune( configs=[ trit...
- tl.dot() has a too large precision error · Issue #2843 · openai/triton: import torch import triton import triton.language as tl @triton.jit def test_kernal(X, Y, O, stride_x_m, stride_x_k, stride_y_k, stride_y_n, stride_o_m, stride_o_n, m:tl.constexpr, k:tl.constexpr, ...
提到的链接:--- **CUDA MODE ▷ #[announcements](https://discord.com/channels/1189498204333543425/1189640399476764692/1223705270769680387)** (1 条消息): - **Flash Attention 成为焦点**:CUDA-MODE 社区正准备进行关于 **Flash Attention** 的第 12 讲,计划在指定的时间戳开始。本次会议将由社区的一位知名成员主持。 --- **CUDA MODE ▷ #[algorithms](https://discord.com/channels/1189498204333543425/1189861061151690822/1223614150022922312)** (3 messages): - **Aaron 的新优化方案**:分享了一个指向 [Aaron Defazio 推文](https://x.com/aaron_defazio/status/1773778436219125948)的链接,暗示了一种新的 **optimization approach**,其在 DLRM 基准测试中的表现显著优于经过调优的 **Adam optimizer**。 - **推测潜在联系**:一名频道成员推测这种新的优化方法是否与 **D-Adaptation** 有关,或者与 **DoWG** 方法存在联系。 **提到的链接**:来自 Aaron Defazio (@aaron_defazio) 的推文:更新:坐稳了,更多结果即将出炉!我的新优化方法在 DLRM 上完胜经过调优的 Adam。 --- **CUDA MODE ▷ #[beginner](https://discord.com/channels/1189498204333543425/1191300313928433664/1223193054178181152)** (9 messages🔥): - **对 GPU 架构的好奇**:一位成员表示,他们特别感兴趣的是学习 GPU 架构,而不是机器学习方面的内容。 - **寻求学习所需的硬件规格**:一位用户询问了跟随课程系列所需的硬件,询问是否可以使用 Google Colab 等云资源,或者是否需要 Nvidia GPU。 - **确定的免费 GPU 资源**:有人指出 [Google Colab](https://colab.research.google.com/) 在其免费计划中提供 Nvidia T4 GPU,而 [Lightning AI Studio](https://lightning.ai/pricing) 提供免费的 GPU 时长,并为额外资源提供按需付费选项。 - **Colab 对 CUDA 编程的适用性**:成员们确认 Colab Pro 和普通版 Colab 都适合跟随讲座和练习 CUDA 编程。 - **笔记本 GPU 足以进行 CUDA 开发**:一位用户确认,Nvidia 笔记本 GPU 足以跟随 CUDA 相关的讲座。 **提到的链接**:Lightning AI | 将创意转化为 AI,Lightning 般迅速:AI 开发的一站式平台。共同编码、原型设计、训练、扩展、提供服务。直接在浏览器中完成 - 无需设置。由 PyTorch Lightning 的创作者打造。 --- **CUDA MODE ▷ #[pmpp-book](https://discord.com/channels/1189498204333543425/1194427148656721970/1223697783731781774)** (4 messages): - **不努力就没有答案**:一位成员强调了个人努力的重要性,指出在获得答案帮助之前,必须先通过私信发送照片来分享自己的尝试。 - **先阅读再解题**:另一位成员分享了他们攻克这本书的策略,计划先完整阅读第一部分,然后再回头尝试题目。 - **使用 GitHub 进行更好的组织**:同一位成员提议使用私有的 GitHub 仓库来组织学习小组的工作,因为这可能比共享文档更具结构性。 - **关于内存加载阶段的澄清**:针对第 5.3 节图 5.8 中内存加载分为不同阶段的问题提出了疑问,寻求澄清将阶段设为 2 个而不是 4 个是否为了确保内存访问的独立性,并询问 global memory loads 在阶段之间是保留还是被丢弃。 --- **CUDA MODE ▷ #[youtube-recordings](https://discord.com/channels/1189498204333543425/1198769713635917846/1223897146684866625)** (3 messages): - **Lecture 12 视频的质量问题**:一位成员指出 YouTube 上的 **Lecture 12** 视频质量较差,导致幻灯片无法阅读。 - **分辨率处理需要时间**:针对质量问题的回复称,YouTube 需要时间来处理视频的高分辨率版本,并建议**稍后再查看**。 - **关于 Flash Attention 的讲座**:分享了名为 "Lecture 12: Flash Attention" 的视频链接,但未提供额外描述。[观看 Lecture 12: Flash Attention](https://youtu.be/zEuwuCTEf_0?si=pm1K-pXmOLs8rsWc)。 **提到的链接**:Lecture 12: Flash Attention:未找到描述 --- **CUDA MODE ▷ #[torchao](https://discord.com/channels/1189498204333543425/1205223658021458100/1224112366258622575)** (1 messages): - **已交付 Pull Request 反馈**:对延迟评审 PR 表示歉意,目前已在提供的 [GitHub 链接](https://github.com/pytorch-labs/ao/pull/95#issuecomment-2028912362)中提供了反馈。并提议在周一进行结对编程,以协助处理反馈事项。 **提到的链接**: jeromeku 提交的 GaLore 和 fused kernel 原型 · Pull Request #95 · pytorch-labs/ao: 原型 Kernels 和工具。目前:GaLore。用于 GaLore 显存高效训练的 fused kernels 初步实现。待办:triton。用于量化训练的可组合 triton kernels 以及... --- **CUDA MODE ▷ #[ring-attention](https://discord.com/channels/1189498204333543425/1208496482005549086/1223225321046937633)** (90 条消息🔥🔥): - **Ring-Attention 训练计划**:成员们正在探索在 2x A5000 GPU 上使用 7B 模型进行 32k 序列长度的训练,并请求检查 Hugging Face 上的长上下文数据集。讨论内容包括在更多 GPU 上运行模型的尝试,以及在多 GPU 成功运行后微调严肃模型的愿望。 - **寻找长上下文数据**:成员们正在寻找长上下文数据集,建议包括 Hugging Face 上的 [Long-Data-Collections](https://huggingface.co/datasets/togethercomputer/Long-Data-Collections) 和 [BookSum](https://huggingface.co/datasets/booksum) 数据集。他们遇到了诸如数据集压缩阻碍流式传输等问题,导致考虑使用云端 VM 等替代方案进行数据准备。 - **LLM 训练配置探索**:正在检查大语言模型 (LLM) 的配置和设置以改进训练和推理,讨论了来自 ring-flash-attention 的 Zig-Zag attention 等工具,以及用于 PyTorch 的 [Distributed Tensor (DTensor)](https://github.com/pytorch/pytorch/blob/main/torch/distributed/_tensor/README.md)。 - **推理与评估讨论**:关于为模型实现大海捞针 (needle in a haystack) 评估以及检查实现 varlen ring attention 可行性的讨论正在进行中。工作包括使用 flash decoding 测试现有的长上下文模型,并调整序列长度的配置。 - **杂项更新与修复**:参与者正在分享工作流改进的更新,例如解决 Axolt 打补丁问题,以及处理诸如损坏的 miniconda 安装等环境问题。他们正在分享并考虑可能有所帮助的各种资源,例如 [LLaMA-2-7B-32K 博客文章](https://www.together.ai/blog/llama-2-7b-32k) 和 [Reddit 上的 VRAM 需求表](https://www.reddit.com/r/LocalLLaMA/comments/18o5u0k/helpful_vram_requirement_table_for_qlora_lora_and/),以应对模型训练的硬件和软件需求。- derek dukes (@ddukes) 的推文:海滩边的篝火,准备观看日落。你能胜过加州吗?
- Jeff Dean (@🏡) (@JeffDean) 的推文:这是链接中的关键基准测试表。在 12 项基准测试中,GPU 上的 JAX 后端在 7 项中速度最快,而 TensorFlow 后端在其余 5 项中速度最快。PyTorch 后端则没有...
- torchtune/recipes/configs/llama2/7B_full_single_device_low_memory.yaml at main · pytorch/torchtune:一个用于 LLM 微调的原生 PyTorch 库。通过在 GitHub 上创建账号来为 pytorch/torchtune 的开发做出贡献。
Links mentioned:--- **CUDA MODE ▷ #[off-topic](https://discord.com/channels/1189498204333543425/1215328286503075953/1223191403215982653)** (16 条消息🔥): - **搜索中文关键词很困难**:一位成员表示需要一份中文词汇表以方便搜索,这表明目前的搜索功能存在挑战。 - **众包分布式训练论文**:Erica 征集关于分布式训练的研究论文推荐,表现出对数学和实践层面的兴趣。 - **AWS 上的分布式深度学习性能分析**:Erica 分享了一篇[研究论文](https://arxiv.org/abs/2208.14344),讨论了用于公共云中分布式深度学习 (DDL) 的综合性能分析器 (Profiler),特别是对各种 AWS GPU 实例进行了特性分析。 - **优化 Cross-Mesh Resharding**:链接了 MLSys 2023 的一篇[摘要](https://proceedings.mlsys.org/paper_files/paper/2023/hash/a42cbafcabb6dc7ce77bfe2e80f5c772-Abstract-mlsys2023.html),介绍了一项关于模型并行深度学习中 Cross-Mesh Resharding 的研究,解决了多对多组播通信问题。 - **训练大规模 Transformer 模型的技巧**:另一篇[论文](https://arxiv.org/abs/1909.08053)提供了关于使用简单且高效的层内模型并行方法训练具有数十亿参数的超大 Transformer 模型的见解。- Hugging Face – 构建未来的 AI 社区。: 未找到描述
- 用于长上下文推理的 Flash-Decoding: 动机
- 为 32K 上下文时代做准备:早期学习与探索: 未找到描述
- Reddit - 深入探索: 未找到描述
- togethercomputer/Long-Data-Collections 的 main 分支: 未找到描述
- iron-bound: Weights & Biases,机器学习开发者工具
- togethercomputer/Long-Data-Collections · Hugging Face 上的数据集: 未找到描述
- 为 ring_attention 调度批次 · cuda-mode/axolotl@d688dbd: 未找到描述
- pytorch/torch/distributed/_tensor/README.md at main · pytorch/pytorch: Python 中具有强大 GPU 加速功能的 Tensor 和动态神经网络 - pytorch/pytorch
- GitHub - ai8hyf/llm_split_recall_test: Split and Recall: 一个用于评估大语言模型 (LLMs) 上下文内召回性能的简单高效基准测试: Split and Recall: 一个用于评估大语言模型 (LLMs) 上下文内召回性能的简单高效基准测试 - ai8hyf/llm_split_recall_test
- GitHub - SmerkyG/gptcore: 用于创建和训练前沿 LLMs 的快速模块化代码: 用于创建和训练前沿 LLMs 的快速模块化代码 - SmerkyG/gptcore
- FlashDecoding++: 在 GPU 上更快的 LLM 推理: 随着大语言模型 (LLM) 在各个领域变得越来越重要。然而,在加速 LLM 推理方面仍存在以下未解决的挑战:(1) 同步部分 sof...
- NousResearch/Yarn-Mistral-7b-128k 的 main 分支: 未找到描述
- emozilla/pg_books-tokenized-bos-eos-chunked-65536 · Hugging Face 上的数据集: 未找到描述
- torchtune/recipes/configs/llama2/7B_full_single_device_low_memory.yaml at main · pytorch/torchtune: 一个用于 LLM 微调的原生 PyTorch 库。通过在 GitHub 上创建账号来为 pytorch/torchtune 的开发做出贡献。
- Yukang/LongAlpaca-12k · Hugging Face 上的数据集: 未找到描述
- Yukang/LongAlpaca-16k-length · Hugging Face 上的数据集: 未找到描述
- emozilla/pg19 · Hugging Face 上的数据集: 未找到描述
- kmfoda/booksum · Hugging Face 上的数据集: 未找到描述
- abacusai/LongChat-Lines · Hugging Face 上的数据集: 未找到描述
提及的链接:--- **CUDA MODE ▷ #[triton-puzzles](https://discord.com/channels/1189498204333543425/1219683012707487794/1223277761532137627)** (10 条消息🔥): - **尽管使用了旧版 triton-viz,错误仍然存在**:尽管安装了旧版本的 triton-viz 并重置了 Colab 运行时,**zhacker2798** 仍然遇到相同的错误。 - **提出新 Notebook 作为解决方案**:**srush1301** 建议使用最新的 Notebook,据称这可以解决现有问题。他随后要求 **zhacker2798** 重试,并确认该方案对他有效。 - **Triton 可视化的安装步骤**:**srush1301** 提供了一个详细的代码片段,概述了正确安装 triton-viz 的过程,其中包括 Jaxtyping 等依赖项以及自定义环境变量设置。 - **修复确认**:用户 **yogeshg6849** 确认按照代码单元中提供的安装说明操作后解决了他们的问题,并表示感谢。 - **本地安装的重要提示**:**glowingscientist** 建议,在本地运行时,如果在执行提供的单元格后安装 PyTorch,可能会回退到不兼容的 Triton 版本,从而导致问题。 --- **OpenAccess AI Collective (axolotl) ▷ #[general](https://discord.com/channels/1104757954588196865/1104757955204743201/1223215173213491351)** (130 条消息🔥🔥): - **寻求 DBRX 访问权限**:一位成员询问在不自行托管的情况下可以在哪里测试 **DBRX**。有人提到可以在 Huggingface Space 或 [You.com](https://you.com/) 上测试 **DBRX**。 - **GPU 问题和 CUDA 错误**:成员们正在讨论 **Runpod 上的 GPU** 问题。症状包括遇到 API CUDA 错误,以及即使在使用 **axolotl** 等系统时,多 GPU 也会导致 **显存溢出 (OOM)** 错误。 - **Ring-Attention 序列长度**:为了测试 Ring-Attention,出现了对序列长度为 16k-32k 的数据集的需求。建议包括 Huggingface 上的数据集以及一个 [包含修改后的 Ring-Attention 实现](https://github.com/cuda-mode/axolotl/tree/ring_attention_patching) 的 GitHub 仓库链接。 - **语音转录的尝试与困境**:对话围绕从音频中提取文本展开,主要涉及英文和中文,并指出 **Whisper for single speaker** 在单发言者场景下非常有效。当涉及多发言者时,过程变得更加复杂,对于更苛刻的场景,推荐使用 Assembly AI 和 **whisperx with diarization** 等其他解决方案。 - **微调技巧与 VRAM 效率**:讨论了使用 **torchtune** 在小于 16GB VRAM 的情况下微调 7B 模型,以及用于日语 LLM 开发的 **Shisa project**。指向 GitHub 的链接以及关于分词器效率和数据预训练的讨论,突显了社区在高效模型训练方面的实验和策略。- On Optimizing the Communication of Model Parallelism:未找到描述
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism:语言建模方面的近期工作表明,训练大型 Transformer 模型推动了自然语言处理应用的最前沿。然而,超大型模型可能会非常……
- CSDL | IEEE Computer Society:未找到描述
- FuryGpu:未找到描述
- CSDL | IEEE Computer Society:未找到描述
- Analysis of Distributed Deep Learning in the Cloud:我们旨在通过引入一个综合的分布式深度学习 (DDL) 性能分析器来解决这个问题,该分析器可以确定 DDL 在运行过程中遇到的各种执行“停顿”……
- HC2023-K2: Hardware for Deep Learning:Keynote 2, Hot Chips 2023, 2023年8月29日星期二,NVIDIA 的 Bill Dally。Bill 描述了构建针对深度学习优化的硬件所面临的许多挑战……
- John Hennessy and David Patterson 2017 ACM A.M. Turing Award Lecture:2017 年 ACM 图灵奖获得者 John Hennessy 和 David Patterson 于 6 月 4 日在洛杉矶举行的 ISCA 2018 上发表了他们的图灵奖演讲。演讲内容包括……
提及的链接:--- **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/1223223976269189201)** (45 条消息🔥): - **使用 PagedAdamW 进行内存优化**:一位成员强调了使用 **PagedAdamW** 时显著的内存节省,峰值内存占用约为 14GB,而 8-bit Adam 则为 27GB。提供了一个 [配置文件示例](https://github.com/pytorch/torchtune/blob/main/recipes/configs/llama2/7B_full_single_device_low_memory.yaml) 链接作为参考。 - **Axolotl 对训练的控制有限**:成员们讨论了在 axolotl 中,他们缺乏像 **torchtune** 那样对训练的控制级别,这解释了为什么没有显著的内存节省。有人提到,**paged adamw** 与集成到 backward pass 中的结合可能是观察到内存节省的原因。 - **在 Axolotl 中实现 DBRX 需要大量工作**:在回答关于支持 axolotl 中 **DBRX** 所需工作量的查询时,一位成员表示需要大量工作,并引用了一个 [pull request](https://github.com/OpenAccess-AI-Collective/axolotl/pull/1462) 作为在强力 GPU 配置上运行的示例参考。 - **梯度累积与多 GPU 兼容性的挑战**:团队讨论了通过将优化器步骤融合到反向传播(backward pass)中来优化内存使用的复杂性,并考虑了其缺点,例如无法有效地进行梯度累积(gradient accumulate)以及在多 GPU 设置中的问题。 - **LISA 分支的探索**:一位成员报告了在 **lisa branch** 上的实验情况,遇到了显存溢出(OOM)问题,并进行了[测试运行](https://wandb.ai/tmm1/lisa-tests/runs/c35oan2s)。他们还指出有必要调整配置以确保正确的层冻结(layer freezing),并成功合并了一个与 **lisa** 相关的 PR。 - **愚人节公告建议**:有人提出了一个幽默的建议,发布关于 axolotl 与 OpenAI 合作微调 GPT-4 及所有未来模型的愚人节公告。- Discord - A New Way to Chat with Friends & Communities:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
- augmxnt:Weights & Biases,机器学习开发者工具
- SambaNova Delivers Accurate Models At Blazing Speed:Samba-CoE v0.2 在 AlpacaEval 排行榜上攀升,超越了所有最新的开源模型。
- Samba CoE V0.1 - a Hugging Face Space by sambanovasystems:未找到描述
- iron-bound:Weights & Biases,机器学习开发者工具
- Preparing for the era of 32K context: Early learnings and explorations:未找到描述
- augmxnt/shisa-base-7b-v1 · Hugging Face:未找到描述
- Tokenizer Efficiency:通过在 GitHub 上创建一个账户来为 AUGMXNT/shisa 的开发做出贡献。
- togethercomputer/Long-Data-Collections · Datasets at Hugging Face:未找到描述
- shisa-v2/_base-evals/tokenizer-efficiency/tokenizer-eval-ja.md at main · shisa-ai/shisa-v2:通过在 GitHub 上创建一个账户来为 shisa-ai/shisa-v2 的开发做出贡献。
- A Review of Public Japanese Training Sets:通过在 GitHub 上创建一个账户来为 AUGMXNT/shisa 的开发做出贡献。
- Shitao/MLDR · Datasets at Hugging Face:未找到描述
- GitHub - cuda-mode/axolotl at ring_attention_patching:尽管提问。通过在 GitHub 上创建一个账户来为 cuda-mode/axolotl 的开发做出贡献。
提及的链接:--- **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1223179318746681344)** (27 条消息🔥): - **寻找合适的文本分类模型**:成员们讨论了在 T4 等有限 GPU 资源下适合文本分类的模型。由于 **Mistral** 和 **qlora** 在英语方面的熟练程度以及在较小 batch sizes 下运行的潜力,它们被推荐为可选方案,同时也承认像 **qwen** 这样的模型尚未被用户广泛测试。 - **创建用于模型测试的聊天 UI**:一位成员分享了他们开发的一个名为 [auto-ollama](https://github.com/monk1337/auto-ollama) 的工具,以便通过聊天测试微调后的模型,该工具可将模型转换为 **ollama** 格式或 **gguf** 以方便使用。 - **微调数据集的疑虑与策略**:成员们讨论了与大规模数据集微调和潜在过度训练(overtraining)相关的问题,建议减少 epochs 并使用 **wandb** 等工具跟踪训练进度。在系统消息和用户输入的背景下,强调了微调条件与推理匹配的重要性。 - **通过电话进行 AI 引导对话的挑战**:一位成员讨论了创建一个用于电话 AI 对话的 **Telegram bot** 的复杂性,集成了 **Twilio**、**Whisper** 和来自 **TextGen UI** 的文本生成器。他们寻求关于系统搭建的建议,特别是语音响应方面。 - **训练停滞的故障排除**:一位成员遇到了训练在 1 个 epoch 后卡住且没有进行评估的问题。其他成员尝试诊断该问题,讨论了潜在因素,如评估设置、**wandb** 集成和存储限制。 **提及的链接**:GitHub - monk1337/auto-ollama:通过单个命令轻松运行 ollama 和 gguf:通过单个命令轻松运行 ollama 和 gguf。通过在 GitHub 上创建账号为 monk1337/auto-ollama 的开发做出贡献。 --- **Modular (Mojo 🔥) ▷ #[general](https://discord.com/channels/1087530497313357884/1098713601386233997/1223168342408298537)** (30 messages🔥): - **Modular SDK 开源但有限制**:大家对 Modular 标准库开源感到兴奋,但明确了 SDK 对非内部/商业应用仍有限制。**整个 SDK 的开源**备受期待,但尚未确认。 - **Mojo 的安装挑战**:Linux Mint 用户在安装 Mojo 时遇到问题。指出 **Ubuntu, MacOS 和 WSL2 提供官方支持**;可参考 [用户指南](https://docs.modular.com) 获取进一步帮助。 - **Openwall 安全警报**:一名成员分享了 [Openwall 安全更新](https://www.openwall.com/lists/oss-security/2024/03/29/4),关于在 xz-utils 5.6.0 和 5.6.1 版本中发现的后门,列出了 CVE-2024-3094 并正在发布补丁。 - **Mojodojo 开发平台**:关于 **mojodojo.dev** 的讨论(该平台此前由一名社区成员管理)转变为呼吁贡献,因为它已**过时但可以在其 [GitHub 仓库](https://github.com/mojodojodev/mojodojo.dev) 上进行更新**。 - **Mojodojo 的隐私标准**:一个有趣的细节浮出水面,**mojodojo.dev 域名**使用冰岛隐私服务来隐藏注册人信息——这反映了该国强大的隐私法律,而非源自冰岛。- 来自 Geronimo (@Geronimo_AI) 的推文:这有些问题,无论活跃层数多少,loss 都一样 https://github.com/OptimalScale/LMFlow/issues/726
- mlx-community/dbrx-instruct-4bit · Hugging Face:未找到描述
- 如何通过将优化器步骤融合到反向传播中来节省内存 — PyTorch Tutorials 2.2.1+cu121 文档:未找到描述
- tmm1:Weights & Biases,机器学习开发者工具
- torchtune/recipes/configs/llama2/7B_full_single_device_low_memory.yaml at main · pytorch/torchtune:一个用于 LLM 微调的原生 PyTorch 库。通过在 GitHub 上创建账号为 pytorch/torchtune 的开发做出贡献。
- mixtral 中的取消冻结层未按预期工作 · Issue #1464 · OpenAccess-AI-Collective/axolotl:请检查此问题之前是否已被报告。我搜索了之前的 Bug 报告,没有发现类似的报告。预期行为:mixtral.yml 的配置包含取消冻结的示例...
- winglian 提供的 DBRX 模型支持 · Pull Request #1462 · OpenAccess-AI-Collective/axolotl:DBRX MoE 目前对于 LoRA,只有 q_proj, k_proj, v_proj out_proj 和 layer Linear 层是可训练的。我们正在使用基于此 issue 的“转换后”的基座模型,其中 Experts 是...
提及的链接:--- **Modular (Mojo 🔥) ▷ #[💬︱twitter](https://discord.com/channels/1087530497313357884/1098713626161987705/1223323060313133198)** (4 messages): - **Modular 推文揭开神秘面纱**:Modular 分享了一条神秘信息,引发了成员们的好奇,推文内容见:[Modular 的神秘信息](https://twitter.com/Modular/status/1773762747098124491)。 - **后续推文引发讨论**:Modular 随后发布的一条推文带来的疑问多过答案,加剧了讨论:[持续的谜团](https://twitter.com/Modular/status/1773767659278250242)。 - **Modular 的情节愈发扑朔迷离**:随着事态发展,Modular 又发布了一条令人费解的更新,让社区保持警惕:[故事进展](https://twitter.com/Modular/status/1773813736421404685)。 - **等待重大发布**:随着 Modular 为重大公告做准备,期待感不断升温,其最新推文显示:[期待升级](https://twitter.com/Modular/status/1774528498050425064)。 --- **Modular (Mojo 🔥) ▷ #[📺︱youtube](https://discord.com/channels/1087530497313357884/1098713700719919234/1223313935202123957)** (1 messages): - **探索新版本 MAX 24.2**:Modular 发布了一个 [YouTube 视频](https://www.youtube.com/watch?v=PL71FV2KKHE),标题为 "Modular Community Livestream - New in MAX 24.2",讨论了 MAX 24.2 的最新更新,包括 Mojo 标准库的开源和 MAX Engine 支持功能。 **提及的链接**:Modular Community Livestream - New in MAX 24.2: MAX 24.2 现已发布!加入我们即将举行的直播,我们将讨论 MAX 中的所有新功能——开源 Mojo 标准库、MAX Engine 支持功能... --- **Modular (Mojo 🔥) ▷ #[🔥mojo](https://discord.com/channels/1087530497313357884/1151418092052815884/1223135175123271731)** (76 messages🔥🔥): - **正在讨论中的 Mojo 优化**:成员们分享了对 **Mojo** 多线程潜力的看法,例如利用 *OpenMP* 实现 **multi-core** CPU 性能。还强调了关于 **`external_call()`** 的讨论,指出了它在运行系统命令方面的能力和未来的改进。 - **设置和贡献 Mojo**:一位成员在**贡献 Mojo** 后运行 main.mojo 时遇到困难,即使遵循了 *[Mojo 开发指南](https://github.com/modularml/mojo/blob/main/stdlib/docs/development.md)* 中的说明。其他成员对**贡献** Mojo 也很感兴趣,并参考了[官方博客文章](https://www.modular.com/blog/the-next-big-step-in-mojo-open-source)和 GitHub 上的 nightly `stdlib` [README](https://github.com/modularml/mojo/blob/nightly/stdlib/README.md)。 - **Discord 中的语法高亮和模块行为**:提到了在 Discord 中进行**代码高亮**,建议对 Mojo 代码使用 `rust` 或 `python` 标记。此外,关于“真正随机模块”的俏皮话引出了通过更改主题来修复模块问题的建议。 - **改进 Mojo 的并行化**:展开了关于使用 `parallelize[_call_neurons](self.nout, self.nout)` 优化代码的讨论——以 **momograd.x** 为背景,该项目显示并行执行比串行执行有速度提升。解释称,以高于 CPU 核心数量的工作计数进行**过度饱和 (over-saturating)** 可以获得更好的性能。 - **处理 Mojo 数组与互操作性**:出现了关于如何表示自定义结构体 (structs) 的固定大小数组,以及是否应该使用 `StaticTuple` 或 `List` 的问题;提到了分配器 (allocators) 和指针 (pointers),并建议将结构体设为 `register_passable`。还提出了 Mojo 中 **C/C++ 互操作 (interop)** 的问题。- Modular Docs: 未找到描述
- Get started with Mojo🔥 | Modular Docs: 获取 Mojo SDK 或尝试在 Mojo Playground 中编码。
- mojodojodev - Overview: mojodojodev 有 5 个可用的仓库。在 GitHub 上关注他们的代码。
- oss-security - backdoor in upstream xz/liblzma leading to ssh server compromise: 未找到描述
- GitHub - mojodojodev/mojodojo.dev: Learning materials for the Mojo🔥programming language: Mojo🔥编程语言的学习材料 - mojodojodev/mojodojo.dev
提到的链接:--- **Modular (Mojo 🔥) ▷ #[community-projects](https://discord.com/channels/1087530497313357884/1151418679578337311/1223179107513270347)** (11 条消息🔥): - **MLIR 语法文档正在完善中**:目前正在努力改进 **MLIR** 语法的易用性文档,因为目前的用法对用户并不友好。贡献者被引导至一个笔记本以获取指导([Mojo 与 MLIR](https://docs.modular.com/mojo/notebooks/BoolMLIR)),并承诺随着系统的成熟,将提供更多的开放性和细节。 - **库模块更新已发布**:宣布了几个 **mojo** 库(`mojo-prefix-sum`、`mojo-flx`、`mojo-fast-base64` 和 `mojo-csv`)更新至 24.2 版本。`mojo-hash` 和 `compact-dict` 已部分更新,但仍存在未解决的问题,特别是 `generic-dict` 因测试失败而存在问题。 - **演进中的 'Reference' 组件**:项目的 `Reference` 方面被承认处于早期开发阶段,预计会频繁更改和演进。改进被认为是必要的且即将到来。 - **引入新的日志库**:一个新的利用 **Bound Loggers** 模式的日志库,名为 **stump**,尽管尚未正式发布,但已可供试用。该库可通过预处理器和文本样式函数进行适配,创建者鼓励大家进行测试([GitHub 上的 Stump](https://github.com/thatstoasty/stump))。 - **装饰器功能更新**:标准库目前不支持编写装饰器,因为它们是在编译器层面实现的。不过,预计未来对装饰器的支持将借鉴 Python 的方法。- Mojo Dojo:未找到描述
- buffer | Modular Docs:实现 Buffer 类。
- system() in C/C++ - GeeksforGeeks:未找到描述
- Matrix multiplication in Mojo | Modular Docs:了解如何利用 Mojo 的各种函数编写高性能的 matmul。
- mojo/stdlib/docs/development.md at main · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账户来为 modularml/mojo 的开发做出贡献。
- Modular: The Next Big Step in Mojo🔥 Open Source:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新帖子:The Next Big Step in Mojo🔥 Open Source
- mojo/stdlib/README.md at nightly · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账户来为 modularml/mojo 的开发做出贡献。
- Swift Concurrency Manifesto:Swift 并发宣言。GitHub Gist:即时分享代码、笔记和片段。
提到的链接:--- **Modular (Mojo 🔥) ▷ #[community-blogs-vids](https://discord.com/channels/1087530497313357884/1151418796993683477/1223153258298871880)** (1 条消息): - **为 Mojo 的未来做贡献**:**[Mojo 标准库 (stdlib)](https://www.modular.com/blog/the-next-big-step-in-mojo-open-source)** 已开源,支持社区贡献。一位成员提供了一个[有用的指南](https://vmois.dev/mojo-local-stdlib-build/),介绍如何在 macOS 和 Linux 上本地构建 stdlib,重点介绍了修改 stdlib 并让 Mojo 运行修改后版本的步骤。 - **构建和实现自定义 stdlib**:要使用自定义的 stdlib,必须先拉取 **[Mojo 仓库](https://github.com/modularml/mojo)**,然后进行更改并使用 `build-stdlib.sh` 脚本构建库。自定义 stdlib 可以在 `build/stdlib.mojopkg` 文件夹中找到,指南详细说明了如何用这个新版本替换位于 `~/.modular` 目录下的标准 stdlib。 **提到的链接**:在 Mojo 中使用本地构建的标准库:Mojo 标准库 (stdlib) 昨天开源了。社区现在可以直接为代码库做贡献,这令人兴奋。在研究了一段时间 stdlib 仓库后,我想…… --- **Modular (Mojo 🔥) ▷ #[performance-and-benchmarks](https://discord.com/channels/1087530497313357884/1151418895417233429/1223857151450288209)** (3 条消息): - **Modular (Mojo) 语言中的十亿行挑战**:一位正在进行 [十亿行挑战](https://github.com/VMois/1brc-mojo/tree/main) 的用户指出,Mojo 缺少某些标准库功能(如字符串排序),并会导致过度的数据复制,使得程序运行时间过长。他们提到了 `read_bytes` 和 `String.split` 的行为等具体问题,并表示需要更好的 profiling 工具来了解内存分配。 - **矩阵乘法示例在 Mojo 上遇到困难**:另一位用户在运行示例 `matmul.mojo` 时遇到错误,指出由于调用 `test_matrix_equal[matmul_vectorized](C, A, B)` 导致结果不一致。通过在比较中引入容差(tolerance),示例可以运行,但根本原因似乎是舍入误差。 - **寻找完美的浮点数**:同一位用户尝试通过将数据类型别名从 `DType.float32` 更改为 `DType.float64` 来解决矩阵乘法错误,这修复了一些错误,但并未完全消除问题。 **提到的链接**:Issues · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账号来为 modularml/mojo 的开发做出贡献。 --- **Modular (Mojo 🔥) ▷ #[⚡serving](https://discord.com/channels/1087530497313357884/1212827597323509870/1224265805278085180)** (3 条消息): - **MAX Serving 作为 Triton 后端**:MAX Serving 已确认可以作为 Triton Inference Server 上现有后端的无缝替代方案。用户应更新 Triton 模型配置文件,并按照 [MAX Serving 入门指南](https://docs.modular.com/serving/get-started) 中的说明使用 MAX Serving 容器镜像。 - **解决迁移疑虑**:MAX Serving 团队正在为考虑迁移的用户提供帮助,强调简单且无缝的过渡过程。鼓励用户直接联系以获得个性化支持,从而优化他们的 MAX 流水线。 **提到的链接**:MAX Serving 入门 | Modular 文档:演示如何在本地系统上尝试 MAX Serving 的演练。 --- **Interconnects (Nathan Lambert) ▷ #[news](https://discord.com/channels/1179127597926469703/1179128538679488533/1223184867307687936)** (49 条消息🔥): - **前卫少年模型与数学?**:一位成员思考了为具有“前卫少年(edgy teenager)”等人格特征的模型部署数学基准测试的价值,质疑当人格因素介入时这种做法的实用性。 - **引入 Arena-Hard**:引用了 lm-sys 推出的新 [Arena-Hard 基准测试](https://github.com/lm-sys/arena-hard),它被描述为比 mt-bench 难 10 倍的基准,旨在通过用户查询挑战语言模型并与基准线进行比较。 - **对 LLM 作为裁判的怀疑**:成员们讨论了使用 LLM 作为基准测试裁判的潜在问题,指出模型可能更倾向于自己的推理风格,正如 **GPT-4** 在与 **Claude** 的对比中因这种偏见而给自己打分更高。 - **讨论模型偏见与基准测试**:一位成员强调了从 [三月的一篇论文](https://arxiv.org/abs/2403.04132) 中发现的 lm-sys 系统用户群覆盖的广泛话题范围,同时也表达了对潜在话题和人群局限性的担忧。 - **Arena-Hard 上的 GPT-4 与 Claude**:在关于基准测试的辩论中,指出 **GPT-4** 在 lm-sys Arena-Hard 上的表现显著优于 **Claude**,这引发了关于模型固有偏见以及评估中长度修正有效性的疑问。 **提到的链接**:GitHub - lm-sys/arena-hard: Arena-Hard benchmark:Arena-Hard 基准测试。通过在 GitHub 上创建账号为 lm-sys/arena-hard 的开发做出贡献。 --- **Interconnects (Nathan Lambert) ▷ #[ml-questions](https://discord.com/channels/1179127597926469703/1179208129083363358/1223388203688525858)** (7 条消息): - **寻求 Token 有用性的衡量标准**:一位成员表示有兴趣通过一种衡量标准来确定 Token 的信息密度,从而将 **GPT-4** 输出中的有用内容与填充内容区分开。 - **学术兴趣得到认可**:针对寻求 Token 信息密度指标的探索,有人建议创建这样一种衡量标准可能是一项有趣的学术尝试,并提出了将其针对长度偏见进行归一化的潜在方法。 - **互信息作为潜在衡量标准**:互信息(Mutual Information)的概念被提及作为确定 Token 信息内容的潜在良好代理指标。 - **控制向量可以针对填充 Token**:一位贡献者指出,对 Token 信息密度的追求与 Microsoft **LLM Lingua** 项目有相似之处,并强调了控制向量通过 *repeng* 针对这些 Token 的有效性。 - **文本生成的计算信息论方法**:分享了一项关于信息论背景下典型性(Typicality)的研究,提供了一种引导随机解码(stochastic decoding)以提供更多“信息丰富”文本的方法论,尽管该方法可能尚未准备好取代基于温度的 top-p/top-k 方法。[在此查看论文](https://arxiv.org/abs/2202.00666)。 **提到的链接**:Locally Typical Sampling:尽管底层模型在标准指标(如 perp...)下表现良好,但当今的概率语言生成器在产生连贯且流畅的文本方面仍有不足。 --- **Interconnects (Nathan Lambert) ▷ #[ml-drama](https://discord.com/channels/1179127597926469703/1181746144821387334/1223424229144530954)** (12 条消息🔥): - **Stability 的猎头季**:Nathan Lambert 表示,聊天内容显示 **Stability AI** 正处于“抢在其他人之前挖走优秀研究员”的阶段。 - **无压力的招聘策略**:Nathan Lambert 提到他很谨慎,不想通过询问招聘建议给 Louis 增加压力,而是提议帮助其他人了解 **Synth Labs** 的产品。 - **Synth Labs 打破常规**:Nathan Lambert 的评论暗示,初创公司在隐身模式下带着一篇将驱动其首批产品的论文出现是**不寻常的**,这意味着 **Synth Labs** 正在做一些非同寻常的事情。 - **对不寻常举动的认可**:另一位成员使用的表情符号强调了 **Synth Labs** 在初创领域这种不寻常但**值得称赞的方法**。 --- **Interconnects (Nathan Lambert) ▷ #[random](https://discord.com/channels/1179127597926469703/1183121795247779910/1223518921114521640)** (2 条消息): - **Validating Bitnet with Dolma**: NousResearch 发布了一个 1B 模型,用于验证并独立确认 Bitnet 论文的论点。该模型在 Dolma 数据集的前 60B tokens 上进行训练,可在 [Hugging Face](https://huggingface.co/NousResearch/OLMo-Bitnet-1B) 上获取。 - **Performance Insights on Weights & Biases**: Bitnet 实现与全 FP16 运行(具有等效超参数)之间的比较可以在 [Weights & Biases 图表](https://api.wandb.ai/links/emozilla/evltqiv7)上查看。 - **1 Bit Training? Curiosity and Confusion**: 一位成员对 Bitnet 研究表示感兴趣,但承认不理解 1 bit 训练具体包含什么。 **Link mentioned**: Nous Research (@NousResearch) 的推文: 我们正在发布验证并独立确认 Bitnet 论文论点的第一步,这是一个在 Dolma 数据集前 60B tokens 上训练的 1B 模型。在 @we... 上进行的比较... --- **Interconnects (Nathan Lambert) ▷ #[rl](https://discord.com/channels/1179127597926469703/1208183216843005962/1224375780545396889)** (2 messages): - **Exploring Verbosity in Direct Preference Optimization**: 一篇新的[预印本](https://x.com/rm_rafailov/status/1774653027712139657?s=46)研究了 Direct Preference Optimization (DPO) 与大规模语言模型训练中冗余(verbosity)之间的相互作用,指出冗余增加会导致模型发散。这种冗余问题在开源社区也已被观察到。 - **Addressing Bias in Language Model Training**: 该预印本介绍了关于 Reinforcement Learning from Human Feedback (RLHF) 及其对人类偏见(如偏好雄辩而非实用性)敏感性的研究。提供 [PDF](https://arxiv.org/pdf/2403.19159) 和 [HTML 格式](https://arxiv.org/html/2403.19159v1)。- Mojo 中的低级 IR | Modular 文档:了解如何使用低级原语在 Mojo 中定义你自己的布尔类型。
- GitHub - thatstoasty/stump:通过在 GitHub 上创建账号来为 thatstoasty/stump 的开发做出贡献。
Links mentioned:--- **Interconnects (Nathan Lambert) ▷ #[rlhf](https://discord.com/channels/1179127597926469703/1208183230608576562/1224063478147584051)** (8 messages🔥): - **Refining LLM Alignment with sDPO**: 一篇[新论文](https://arxiv.org/abs/2403.19270)介绍了 **stepwise DPO (sDPO)**,这是对 direct preference optimization 的扩展,旨在通过逐步使用数据集来提高性能,使大语言模型更贴合人类偏好。 - **sDPO Could Level the Playing Field for Smaller Labs**: sDPO 方法暗示允许小型实验室在不需要大量资金资源的情况下,获得与大型实验室类似的性能提升。 - **DPO Strategy Questioned**: 一位成员幽默地评论了 direct preference optimization (DPO) 的使用频率,暗示它被反复使用,而不是探索像 **reinforcement learning from human feedback (RLHF)** 这样的其他方法。 - **Paper Participation**: Nathan Lambert 提到参与了一篇类似的论文,表示对高效批量处理偏好数据的方法感兴趣。 - **Exploring Multiple Steps in DPO**: 有人询问过去的 DPO 尝试是否仅在整个数据集上使用单个梯度步骤,确认结果是通常数据集被随机采样并以 off-policy 方式使用以减少损失。 **Link mentioned**: sDPO: Don't Use Your Data All at Once: 随着大语言模型 (LLM) 开发的进展,使其与人类偏好对齐变得越来越重要。我们提出了 stepwise DPO (sDPO),这是对最近流行的... 的扩展。 --- **Interconnects (Nathan Lambert) ▷ #[sp2024-history-of-open-alignment](https://discord.com/channels/1179127597926469703/1223784028428177510/1223784123550793861)** (24 messages🔥): - **Nathan 承诺记录 Open Alignment 历史**:Nathan Lambert 正在启动一个项目,记录 ChatGPT 发布后 Open Alignment 数据集和实践的历史,从斯坦福大学的讲座和配套博客文章开始。 - **对 Open Alignment 演进的兴趣**:频道成员对 Nathan Lambert 分享 Open Alignment 模型开发笔记表示热烈欢迎,并提供支持,期待对该主题的见解。 - **ChatGPT 复现热潮**:该项目将涵盖最初复现 ChatGPT 的竞赛,重点介绍 **alpaca, koala, dolly, vicuna** 和 **llama 1** 等模型。 - **DPO 与 IPO 的对比**:关键讨论包括 Direct Preference Optimization (DPO) 和 Indirect Preference Optimization (IPO) 之间的辩论,并参考了在 trl 中添加 DPOTrainer 的 GitHub issue ([Issue #405](https://github.com/huggingface/trl/issues/405))。 - **分享宝贵资源和进度笔记**:对于关注 Open Alignment 历史的人,Nathan Lambert 分享了一篇列出开源微调大语言模型的 Medium 文章 ([Open-Sourced LLMs](https://sungkim11.medium.com/list-of-open-sourced-fine-tuned-large-language-models-llm-8d95a2e0dc76)),并提供了他详细笔记的链接 ([Lambert's Notion Notes](https://magnetic-share-282.notion.site/History-of-Open-Alignment-a7ef20aefb34438185336df68147809e?pvs=4))。- Disentangling Length from Quality in Direct Preference Optimization: Reinforcement Learning from Human Feedback (RLHF) 一直是近期 Large Language Models 成功的关键组成部分。然而,已知 RLHF 会利用人类偏好中的偏见,例如...
- Rafael Rafailov (@rm_rafailov) 的推文: 关于 DPO 与冗余之间相互作用的新预印本已发布。我们收到的关于 DPO 的第一批反馈之一是,在大规模训练中,模型变得越来越冗余,直到发散。冗余...
提及的链接:--- **AI21 Labs (Jamba) ▷ #[jamba](https://discord.com/channels/874538902696914944/1222916247063232553/1223177586960498708)** (16 条消息🔥): - **Jamba 在代码任务上的表现仍是一个谜**:大家对 **Jamba-v0.1 在代码任务上的表现**感到好奇,因为其在 **HumanEval 基准测试**上的效果尚未被讨论。 - **询问训练数据的语言包容性**:一位成员询问 **Jamba 的训练数据**是否包含**捷克语**。 - **对 Jamba 微调能力的期待**:虽然 **Jamba** 目前无法在 **AI21 Studio** 上进行微调,但预计微调后的 instruct 模型很快就会在该平台上线。 - **尽管有硬件限制,Jamba 依然高效**:讨论强调了 **Jamba** 的效率,其 **MoE 层在推理时仅调用 52B 可用参数中的 12B**。然而,大家也承认,即使有这样的效率,在 NVIDIA 4090 等消费级硬件上运行它仍然是不可行的。 - **Quantization 和 llamacpp 可能减轻 Jamba 的负担**:有推测认为 **quantization** 和 **llamacpp 支持**可能使 **Jamba** 能够在 24GB VRAM 上运行,尽管一些成员仍然认为这很耗资源。 - **对 Jamba 在更多 Token 下速度变快的困惑**:一位成员质疑 **Jamba** 在编码和解码任务中如何随着 Token 增多而变得*更快*,并指出了最新论文中观察到这一现象的特定图表 (3b)。 --- **AI21 Labs (Jamba) ▷ #[general-chat](https://discord.com/channels/874538902696914944/874538902696914947/1223201037943574630)** (51 条消息🔥): - **关于 "Single GPU" 术语的澄清**:讨论澄清了 "Single GPU" 是指在像 A100 80GB 这样的显卡上运行 Jamba,这表明虽然人们对其在 24GB 等较低配置 GPU 上的适用性充满热情,但它主要针对的是高端硬件配置。 - **讨论量化可能性**:成员们交流了在低容量 GPU 上运行模型量化版本的信息,并指出可以根据 [model card guidelines](https://www.google.com/url?sa=t&source=web&rct=j&opi=89978449&url=https://huggingface.co/docs/accelerate/en/usage_guides/quantization&ved=2ahUKEwjQ-4eopJmFAxWaXmwGHZPhBN8QFnoECBMQAQ&usg=AOvVaw2RxBEXoJMjtWqDScwaFZqc) 使用 4-bit 精度加载。 - **Jamba 与传统 Transformer 的效率对比**:有人提出关于 Jamba 效率和高吞吐量的疑问,尽管 Transformer 块使其随序列长度呈平方级缩放。对话透露,Jamba 的 Mamba 和 MoE (mixture of experts) 层支撑了其 sub-quadratic 缩放和效率,超越了传统 Transformer 层的优化。 - **索取模型架构可视化图表**:一位用户询问是否有展示 Jamba 模型内部所用区块细节的图表,反映出希望了解架构中 Transformer 和 Mamba 块之间平衡的愿望。 - **探索 Jamba 块的组成**:在对 Jamba 块结构的解释中,强调了 Mamba 和 MoE 层起着至关重要的作用,每 8 层总层数中包含 1 层 Transformer 层,并澄清 Transformer 层不是 MoE 的一部分,而是集成在特定的 Jamba 块中。 **Link mentioned**: no title found: no description found --- **LangChain AI ▷ #[general](https://discord.com/channels/1038097195422978059/1038097196224086148/1223183353524781159)** (34 messages🔥): - **热烈欢迎 AI 爱好者**:新成员询问在哪里可以联系 AI 开发者,并得到了他们已找到正确频道的确认。 - **寻求从 Prompt 生成 GraphQL 的指导**:一位成员询问了有关从 Prompt 生成 GraphQL 的经验,表示有兴趣向他人学习。 - **LangChain 功能咨询**:有人询问 LangChain 能提供什么帮助,表明新成员正在寻求对其功能和用例的理解。 - **寻求日志记录方面的帮助**:一位正在使用微调模型构建聊天应用程序的用户表示,需要一份关于使用 LangSmith 将聊天响应和反馈记录到数据库的指南,并被引导至相关的 [LangSmith documentation](https://docs.smith.langchain.com/tracing/faq) 以获取帮助。 - **探索 LangChain 用例**:成员们讨论了各种 LangChain 应用,从本地化大型文档 QA 链到构建具有特定场景 Prompt 的对话式 Agent,展示了社区内广泛的实际实现。- Notion – 笔记、任务、维基和数据库的一体化工作空间。:一款将日常工作应用融合为一的新工具。它是为您和您的团队打造的一体化工作空间。
- Hugging Face – 博客:未找到描述
- 在 trl 中添加 `DPOTrainer` · Issue #405 · huggingface/trl:DPO (Direct Preference Optimization) 是斯坦福大学最近发表的一篇论文:https://arxiv.org/abs/2305.18290。实现一个支持该算法的通用训练器可能会很有趣...
Links mentioned:--- **LangChain AI ▷ #[langchain-templates](https://discord.com/channels/1038097195422978059/1170025009960456282/)** (1 messages): blackice9833: free nudes ♥️ https://discord.gg/bestnudes @everyone @here --- **LangChain AI ▷ #[share-your-work](https://discord.com/channels/1038097195422978059/1038097372695236729/1223165177617449010)** (14 messages🔥): - **Galaxy AI 发布免费高级 AI 模型 API**:Galaxy AI 宣布提供**免费 API 服务**以访问高级 AI 模型,包括 **GPT-4**、**GPT-4-1106-PREVIEW**、**GPT-3.5-turbo-1106** 等,并兼容 OpenAI 格式,方便集成到项目中。感兴趣的用户可以在[这里](https://galaxyapi.onrender.com)尝试。 - **关于模型对齐的新博文**:最近的一篇博文探讨了大语言模型 (LLM) 中的**模型对齐 (Model Alignment)**,深入研究了 RLHF、DPO 和 KTO 方法在 Mistral 和 Zephyr 7B 模型上的有效性。全文可在 [Premai 的博客](https://blog.premai.io/model-alignment-process/)阅读。 - **为 Taskbots 引入任务链 (Chain of Tasks)**:两篇博文介绍了 **Chain of Tasks** 提示技术,展示了其在使用 LangGraph 创建高级对话式 LLM **Taskbots** 中的应用。读者可以通过 [关于 Chain of Tasks 的 LinkedIn 文章](https://www.linkedin.com/posts/prasadt_introducing-chain-of-tasks-cota-a-prompting-activity-7178582571423870976-wajV) 探索相关方法和潜在应用。 - **CrewAI 框架发布公告**:CrewAI 是一个用于编排自主 AI Agent 的前沿框架,构建在 LangChain 之上,并提供与 OpenAI 和本地 LLM 的默认集成。感兴趣的用户可以访问其[官网](https://crewai.com)进一步探索,查看 [GitHub 仓库](https://github.com/joaomdmoura/crewAI/tree/main),或加入其 Discord 社区。 - **AI 驱动的股票分析工具发布**:一个自定义开发的 GPT 模型已发布,该模型可以分析股票并按 1 到 10 的等级评估投资潜力,并向社区成员征求反馈。潜在投资者可以在提供的 [OpenAI Chat 链接](https://chat.openai.com/g/g-3QdjVv8TG-investor-gpt)进行测试。- JSON files | 🦜️🔗 LangChain: JSON 加载器使用 JSON 指针来定位 JSON 文件中你想要的目标键。
- How-To Guides | 🦜️🛠️ LangSmith: 在本节中,你将找到有关如何使用 LangSmith 追踪功能的指南。
- How to log and view traces to LangSmith | 🦜️🛠️ LangSmith: LangSmith 让你能够轻松记录和查看来自 LLM 应用程序的追踪,无论你使用哪种语言或框架。
- How to Collect Feedback for Traces | 🦜️🛠️ LangSmith: 反馈让你了解用户如何体验你的应用程序,并有助于引起对有问题追踪的关注。LangSmith 让你能够轻松收集追踪反馈并查看...
- SciPhi - One-click RAG deployment for developers | Product Hunt: SciPhi 是一个面向开发者的云平台,简化了构建和部署 serverless RAG 流水线的过程。它基于开源的 R2R 框架构建,使开发者能够专注于创新的 AI 应用...
提到的链接:--- **LangChain AI ▷ #[tutorials](https://discord.com/channels/1038097195422978059/1077843317657706538/1223378730852814879)** (2 messages): - **深入探索 Qdrant 向量数据库**:发布的教程探讨了 **Qdrant** 与 **LangChain** 在向量数据库中的集成,为本地、服务器 (Docker)、云端和 Groq 实现提供了见解。资源包括一段名为 "Langchain + Qdrant Local | Server (Docker) | Cloud | Groq | Tutorial" 的 [YouTube 视频](https://youtu.be/JSKZYgARffg)。 - **使用 LangGraph 构建对话式任务机器人 (Taskbots)**:分享了一个 Jupyter notebook 教程,演示了如何使用 **LangGraph** 和一种名为 *Chain of Tasks* 的提示技术来构建**对话式任务机器人 (Conversational Taskbots)**。该教程还附带了一篇 [LinkedIn 帖子](https://www.linkedin.com/posts/prasadt_building-an-hrassistant-llm-taskbot-using-activity-7179347232788262913-6iBC),提供了更多细节。 **提到的链接**:Langchain + Qdrant Local | Server (Docker) | Cloud | Groq | Tutorial:你想为你的 Langchain 应用学习生产级向量数据库吗?让我们通过 Qdrant 深入了解向量数据库的世界。Qdrant i... --- **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1223173196065542144)** (24 条消息🔥): - **加载模型超参数错误**:一位用户在运行 `./server -m all-MiniLM-L6-v2-f32.gguf --embedding` 时遇到了缺少 `bert.context_length` 的错误。在现有的消息中未讨论该错误的解决方案。 - **Llamafile 执行的不稳定性**:用户讨论了运行 **llamafile** 时的不稳定性,一位用户表示其运行情况不一致。另一位用户提到计划在下周调查这些不稳定性。 - **对 Llamafile v0.7 发布感到兴奋**:**llamafile v0.7** 的新版本已在 [GitHub 上发布](https://github.com/Mozilla-Ocho/llamafile/releases/tag/0.7),该版本号称提升了 CPU 和 GPU 计算的性能和准确性。此外,一篇关于 **matmul** 的[博客文章](https://justine.lol/matmul/)因其内容和发布时机(就在愚人节前夕)而获得了积极的反响。 - **Llamafile 的提示词模板 (Prompt Template) 查询**:一位用户询问在不带模型运行 **llamafile** 并使用 **openchat 3.5 0106** 时,在 Web UI 中应使用的正确提示词模板。他们分享了一个模板并提出了关于输入字段和变量的问题,但现有消息中未提供直接回答。 - **分享了 Matmul 的基准测试代码**:**jartine** 分享了一段 Python 代码片段,用于将 numpy 的 matmul 与自定义实现进行基准测试,以回应关于修改 NumPy 这种不使用线程的方法却能获得惊人效率的疑问。 **提到的链接**:Release llamafile v0.7 · Mozilla-Ocho/llamafile:llamafile 让你通过单个文件分发和运行 LLM。此版本除了安全性外,还提高了 CPU 和 GPU 计算的性能和准确性。tinyBLAS 现在可以输出... --- **Datasette - LLM (@SimonW) ▷ #[llm](https://discord.com/channels/823971286308356157/1128504153841336370/1223393728576753755)** (9 条消息🔥): - **童子军军法 (Scout Law) 引导聊天机器人回复**:一位用户定制了 **Claude 3 Haiku**,将童子军军法融入其对话中,从而产生了俏皮且诚实的回答,例如在遵循童子军军法要求诚实可靠时回答:“当门虚掩着(ajar)时,它就不是一扇门(a jar,意为罐子)!” - **聊天机器人的健谈是设计使然**:聊天机器人的冗长是故意的,它遵循一个 System Prompt,指示它做一个*友好、乐于助人的助手*,并在每个回答中包含童子军军法的一个要素。 - **诚信之壳**:结合童子军军法的主题,机器人将帽贝(limpets)比作是值得信赖的,因为它们有保护壳,展示了其以创意方式应用童子军军法的能力。 - **通过列举问题来澄清**:用户调用了一个 System Prompt,让聊天机器人先生成澄清性问题,而不是直接给出答案,这可以引导出更深思熟虑的解决问题的方法。 - **重新安装问题的故障排除**:针对一位遇到 `FileNotFoundError` 的用户,建议重新安装 `llm`,另一位用户确认由于类似情况,他们最近也不得不采取这一步骤。 --- **DiscoResearch ▷ #[general](https://discord.com/channels/1178995845727785010/1182877486854451271/1223239082419818592)** (7 条消息): - **介绍 Jamba 突破性的 SSM-Transformer**:[AI21 Labs 推出了 Jamba](https://www.ai21.com/jamba),这是一种 **结构化状态空间模型 (SSM)** 和 **Transformer** 架构的融合,旨在克服传统 Transformer 模型的局限性。该[模型可在 Hugging Face 上进行测试](https://huggingface.co/ai21labs/Jamba-v0.1)。 - **寻求对新型 LLM 的 Vibe Checks**:一位成员询问是否已有针对群组中讨论的**新型 LLM 架构**的现有评估或 “Vibe Checks”(初步印象评估)。 - **BitNet 的稳健复现**:[BitNet b1.58 模型](https://huggingface.co/1bitLLM/bitnet_b1_58-3B) 的复现已达到与遵循其 [后续论文](https://github.com/microsoft/unilm/blob/master/bitnet/The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ.pdf) 实践的实现相当的性能,在 **RedPajama 数据集** 上展现了令人期待的结果。 - **了解 Nectar 的数据源多样性**:[Nectar 数据集](https://huggingface.co/datasets/berkeley-nest/Nectar) 是通过基于 GPT-4 的排名开发的,从多种聊天提示源中提取数据,例如 **ShareGPT**、**Anthropic/hh-rlhf** 和 **Flan**。 - **关于 GPT 上下文理解的讨论**:一位成员强调了 Nectar 数据集中的一个场景,其中 GPT 似乎提供了制造枪支的指导,并指出 **Starling 可能会回答此类问题**,而其他模型可能会拒绝。有人推测,这可能是一种避免其他基础模型在面对类似查询时表现出的拒绝行为的方法。- Model Alignment Process:生成模型与人类反馈的对齐显著提高了自然语言生成任务的性能。对于大语言模型 (LLM),像强化学习...
- SOTA ASR Tooling: Long-form Transcription:针对长文本转录对不同 Whisper 框架进行基准测试。
- Reddit - Dive into anything:未找到描述。
- SciPhi - 为开发者提供的一键式 RAG 部署 | Product Hunt:SciPhi 是一个面向开发者的云平台,简化了无服务器 RAG 流水线的构建和部署。它基于开源的 R2R 框架构建,使开发者能够专注于创新的 AI 应用...
- crewAI - 多 AI Agent 系统平台:未找到描述。
- crewAI+ - 多 AI Agent 系统平台:未找到描述。
- GitHub - joaomdmoura/crewAI:用于编排角色扮演、自主 AI Agent 的框架。通过培养协作智能,CrewAI 赋能 Agent 无缝协作,处理复杂任务。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。
- Galaxy AI - Swagger UI:未找到描述。
提到的链接:--- **DiscoResearch ▷ #[discolm_german](https://discord.com/channels/1178995845727785010/1197630242815213618/1223779776549097473)** (2 条消息): - **分享翻译对比工具**:一位成员强调了在 [Hugging Face Space](https://huggingface.co/spaces/cstr/compare_translations) 上提供的一个翻译对比工具。该工具的 Web 应用程序允许用户快速评估不同的翻译。 - **讨论翻译质量时提到 Comet Scores**:简要提到了使用 **Comet Scores** 来评估翻译,表明正在使用该指标对翻译进行评分以进行质量评估。 **提到的链接**:Compare Translations - a Hugging Face Space by cstr:未找到描述 --- **Skunkworks AI ▷ #[papers](https://discord.com/channels/1131084849432768614/1131305311714672710/1224210017155026985)** (2 条消息): - **克服 CIL 中的灾难性遗忘**:一篇论文指出,在类增量学习 (CIL) 中,Adapter Tuning 的表现优于基于 Prompt 的方法,且在每个学习阶段无需参数扩展。该方法还涉及从原型中进行特征采样,并估计旧原型的语义漂移,以提高 Backbone 的学习能力。阅读完整研究请点击 [这里](https://arxiv.org/abs/2403.19979)。 - **增强开源 LLM 作为智能 Agent 的能力**:一篇新论文解决了开源大语言模型 (LLM) 与 ChatGPT 和 GPT-4 等商业模型之间的性能差距,特别是在复杂的现实任务中。该研究通过数据微调和 Prompt 设计增强,探索了 7B 和 13B LLM 的任务规划、长期记忆和外部工具利用能力。详情请见 [这里](https://arxiv.org/abs/2403.19962)。- 1bitLLM/bitnet_b1_58-3B · Hugging Face:未找到描述
- Introducing Jamba:一个开创性的 SSM-Transformer 开源模型
- berkeley-nest/Nectar · Datasets at Hugging Face:未找到描述
提到的链接:--- **Skunkworks AI ▷ #[off-topic](https://discord.com/channels/1131084849432768614/1140423597454807179/1223536075192930364)** (2 条消息): - **AI21 的 Transformer 创新揭晓**:Skunkworks AI 社区分享了一个 [YouTube 视频](https://www.youtube.com/watch?v=HRnx0ZPxe64),介绍了 **Jamba**,这是 AI21 开创性的 SSM-Transformer 模型,被宣传为大语言模型设计的一次飞跃。 - **Databricks 设定新的 LLM 基准**:分享了另一个 [YouTube 视频](https://www.youtube.com/watch?v=dqFvOqC43rQ),展示了 **DBRX**,这是 Databricks 新推出的开源、通用大语言模型,声称在多项标准基准测试中达到了新的 SOTA 水平。- Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning:开源预训练大语言模型 (LLM) 展现出强大的语言理解和生成能力,使其在各种任务中取得了巨大成功。然而,当作为 Agent 使用时...
- Semantically-Shifted Incremental Adapter-Tuning is A Continual ViTransformer:类增量学习 (CIL) 旨在使模型能够持续学习新类别,同时克服灾难性遗忘。预训练模型的引入带来了新的微调范式...
提到的链接:---- 介绍 Jamba:AI21 开创性的 SSM-Transformer 模型:介绍 Jamba:AI21 开创性的 SSM-Transformer 模型 https://www.ai21.com/blog/announcing-jamba #llm #ml #ai #deeplearning #largelanguagemodels #deep...
- DBRX:全新的最先进开源 LLM:介绍 DBRX,由 Databricks 开发的开源通用 LLM。在一系列标准基准测试中,DBRX 为已有的模型树立了新的 State-of-the-Art 标准...
{kind=link}
{kind=link}
{kind=link}