ainews-realm-reference-resolution-as-language
**ReALM:将指代消解视作语言建模**
苹果公司正在推进其 AI 技术,推出了一种名为 ReALM(将引用解析视为语言建模)的新方法。该方法通过三种上下文改进了对歧义引用的理解,并微调了一个较小的 FLAN-T5 模型,其在该任务上的表现优于 GPT-4。
在 Reddit AI 新闻方面,开源编程智能体 SWE-agent 在 SWE-bench 基准测试中达到了 12.29% 的成绩,RAGFlow 则推出了一款可定制的检索增强生成(RAG)引擎。一种名为 QuaRot 的新量化方法实现了高效的 4 位推理。
AI 应用方面包括 T 恤设计生成器、基于 GPT-4 生成播客的 podgenai,以及来自 HuggingFace 的无需 GPU 即可运行的开源模型。行业讨论集中在大语言模型对 AI 领域的影响以及推动 AI 开发去中心化的努力上。泷泽拓人(Takuto Takizawa)加入 Stability AI 日本分部,担任销售与合作伙伴关系负责人。
2024年4月2日至4月3日的 AI 新闻。我们为您检查了 5 个 subreddits、364 个 Twitter 和 26 个 Discord(382 个频道,4673 条消息)。预计节省阅读时间(按 200wpm 计算):512 分钟。
在 WWDC 之前,Apple 终于开始在 AI 领域大展拳脚。我们几周前介绍了 MM1,现在另一个团队展示了 ReALM: Reference Resolution As Language Modeling。在他们的术语中,Reference Resolution 是指根据 3 种上下文——1) 屏幕内容,2) 与对话相关的实体,以及 3) 背景实体——来理解诸如“他们”、“那个”、“最底下的那个”或“屏幕上的这个数字”等模糊指代。它们支持各种类似 Assistant 的用例:
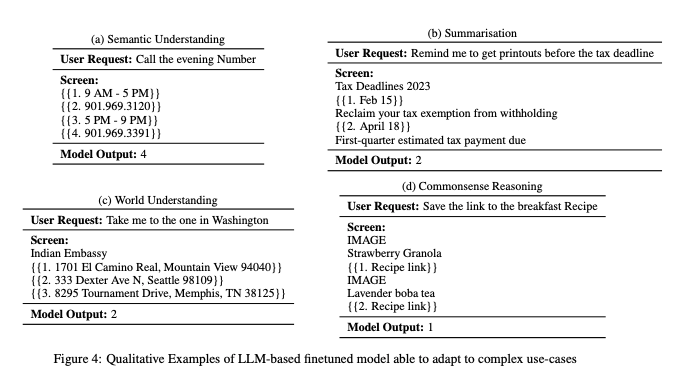
考虑到它基本上需要读取你的心思,这是一个极具挑战性的任务。
作者结合使用标注数据和合成数据来 Finetune 一个更小的 FLAN-T5 模型,该模型在此任务上击败了 GPT4:
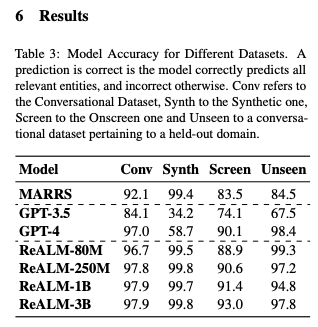
没有模型发布,也没有 Demo。但很高兴看到他们是如何处理这个问题的,而且数据集和模型足够小,任何有决心的人都可以复现。
当然,AI 内容创作者群体对此已经疯狂了。在这种说法本身变得陈词滥调之前,大概还有几个月的时间可以利用“击败 GPT4”来制造新闻头条。
目录
[TOC]
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence。评论抓取功能尚未实现,但即将推出。
AI 研究与开发
- 开源编程 Agent:在 /r/MachineLearning 中,研究人员开发了 SWE-agent,这是一个在 SWE-bench 基准测试中达到 12.29% 的开源编程 Agent。该 Agent 可以将 GitHub issues 转化为 pull requests,但研究人员发现,经过 6 个月的工作后,构建有效的 Agent 比预期的要困难。
- 新 RAG 引擎:同样在 /r/MachineLearning 中,RAGFlow 被介绍为一个可定制、可靠且可解释的检索增强生成 (RAG) 引擎,它基于文档结构识别模型。
- 高效量化:在 /r/LocalLLaMA 中,QuaRot 被宣布为一种支持 4-bit 推理的新量化方法,比目前需要反量化(dequantization)的方法(如 GPTQ)更高效。它还支持无需校准数据(calibration data)的无损 8-bit 量化。
AI 应用与工具
- T 恤设计生成器:在一个视频帖子中,一位 Reddit 用户分享了他们制作的一个使用 AI 生成 T 恤设计的工具。
- 播客生成:在 /r/OpenAI 中,podgenai 作为一款基于 GPT-4 的免费软件发布,用于生成长达一小时的任何主题的信息性有声读物/播客,需要 OpenAI API key。
- 开源语言模型:HuggingFace CEO 转发了 PipableAI/pip-library-etl-1.3b 的发布,这是一个无需 GPU 即可试用的开源模型。
{kind=link}
AI 行业与趋势
- 大语言模型的影响:在 /r/MachineLearning 中,发起了一场关于 大语言模型 (LLMs) 对 AI 领域是否弊大于利 的讨论,原因是炒作导致会议和工作的重心发生了表面化的改变,过度承诺可能导致另一个 AI 寒冬。
- 去中心化 AI:分享了一篇 Axios 的文章,内容关于去中心化 AI 开发并打破大科技公司垄断的努力。
- Stability AI 日本人事任命:发布了关于 Takuto Takizawa 加入 Stability AI 日本担任日本销售与合作伙伴关系负责人 的新闻。
{kind=link}
Stable Diffusion 讨论
- 生成任意分辨率:在 /r/StableDiffusion 中,一位用户询问 Stable Diffusion 如何在 VAE 输入/输出尺寸固定的情况下生成 512x512 以外的分辨率图像,寻求相关解释和代码指引。
- 叙事适用性:同样在 /r/StableDiffusion 中,一位初学者询问 Stable Diffusion 是否适合为叙事和漫画创建特定的角色、姿势和场景,因为他们难以控制输出,并考虑将 3D 工具作为替代方案。
- UI 中的批量生成:/r/StableDiffusion 的另一位用户正在寻找如何让 Automatic1111 的 Stable Diffusion UI 在夜间重复进行批量图像生成的设置。
AI Twitter 摘要回顾
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和 flow engineering。
Anthropic 关于 LLMs 越狱的研究
- Many-shot jailbreaking 技术:@AnthropicAI 发布了一篇研究论文,研究了一种在大多数 Large Language Models 上都有效的长上下文越狱技术。研究表明,增加上下文窗口是一把双刃剑,在使模型更有用的同时也使其更容易受到对抗性攻击。
- 有原则且可预测的技术:@EthanJPerez 指出,这是目前已知最有效、最可靠且难以通过训练消除的越狱方式,它基于 in-context learning。这种风险会随着模型规模和上下文长度的增加而可预测地加剧。
- 令人担忧的结果:@sleepinyourhat 发现结果既有趣又令人担忧,研究显示,诱导有害行为的 many-shot prompting 在克服安全训练方面,随着示例数量的增加,其有效性遵循幂律(power law)并可预测地提升。
用于识别分布偏移的 Adversarial Validation 技术
- 检查训练/测试分布的巧妙技巧:@svpino 分享了一个名为 Adversarial Validation 的技巧,用于确定训练数据和测试数据是否来自同一分布。将它们放在一起,移除目标变量,为训练/测试集添加二进制特征,训练一个简单模型。如果 AUC 接近 0.5,则为同一分布;如果接近 1,则为不同分布。
- 有助于识别问题特征:Adversarial Validation 可以识别导致分布偏移的问题特征。计算特征重要性,移除最重要的特征,重建模型,重新计算 AUC。重复此过程直到 AUC 接近 0.5。这在生产环境中识别分布偏移非常有用。
台湾地震对半导体供应的影响
- 地震与晶圆厂的距离:@nearcyan 指出,7.4 级地震距离台湾中部科学园区 64 英里。1999 年晶圆厂附近的 7.7 级地震曾导致生产损失。2016 年的 6.6 级地震仅延迟了约 1% 的 TSMC 订单。
- TSMC 的准备工作:TSMC 对大地震准备充分。政府优先恢复晶圆厂的公用设施。目前尚未报告结构性损坏。预计新竹/台中受到的干扰将超过台南的 3nm 晶圆厂。
- 潜在延迟:预计会有至少几周、运气不好甚至几个月的实质性延迟。这可能会导致短期半导体价格波动。
AI 进展与发展
- 来自 DeepMind 的 Genie AI 模型:@GoogleDeepMind 宣布了 Genie,这是一个基础世界模型,可以从单个图像提示、草图或文本描述中创建可玩的 2D 平台游戏世界。它可以帮助训练 AI Agent。
- Replit Code Repair AI Agent:@pirroh 宣布了 Replit Code Repair,这是一个使用 GPT-4 的低延迟代码修复 AI Agent。它在速度和准确性上大幅超越了开源模型。
- Sonnet 模型替代 GPT-4:@jxnlco 正在 3 家公司的多数用例中用 Sonnet 替代 GPT-4,这显示出向更专业化模型转变的趋势。
迷因与幽默
- 编程寿命迷因:@svpino 调侃说,1994 年有人告诉他编程将在 5 年内消亡,然而 30 年后他仍在编程。
- Anthropic 越狱暴力迷因:@goodside 调侃道,如果暴力不能解决你的 LLM 越狱问题,那说明你用的暴力还不够多。
AI Discord 简报
摘要的摘要之摘要
- 内存高效 LLM 训练的进展:
- 一种名为 DISTFLASHATTN 的新注意力机制声称可以将训练长上下文 LLM 时的二次方峰值内存占用降低到线性,从而支持高达 8 倍长的序列。然而,该论文缺乏反向传播(backward pass)的伪代码,引发了对可复现性的担忧。
- 围绕 CUDA 优化技术(如 DISTFLASHATTN)的讨论,及其通过内存效率和速度提升(优于 Ring Self-Attention 等现有方案)来彻底改变 LLM 训练的潜力。
- AI 模型评估与基准测试:
- 开源系统 SWE-agent 声称在自主解决 GitHub issue 的 SWE-bench 测试中,拥有与 Devin 相当的准确率。
- GPT-4、Claude 和 Opus 等模型在解决历史提示词、数学谜题和代码生成等任务上的表现各异,凸显了进行全面评估的必要性。
- Chaiverse.com 等平台用于快速获取 RP-LLM 模型的反馈,而 LMSys Chatbot Arena Leaderboard 则用于模型基准测试。
- Prompt Engineering 与多模态 AI:
- 讨论了 Prompt Engineering 技术,用于在保留 Markdown 的情况下进行翻译、生成管理者提示词,以及使用 Chain of Thought 改进多模态问答。
- 与 LangChain 和 LlamaIndex 等其他框架相比,DSPy 在 Prompt 优化方面的潜力。
- 对多模态 AI 的探索,例如使用 Stable Diffusion 从立体图像进行深度映射,以及发布用于高质量音乐生成的 Stable Audio 2.0。
- 开源 AI 发展与部署:
- Open Interpreter iPhone app 的开发工作,并将其移植到 Android Termux、M5 Cardputer,实现语音界面并探索本地 STT 解决方案。
- Octopus 2 演示版亮相,这是一个具备 Function Calling(函数调用)能力的模型,引发了对端侧(on-device)模型的关注。
- 发布了 Axolotl 文档更新 以及 Mojo 标准库 的开源。
- 其他主题:
-
LLM 中的优化挑战与突破:工程师们致力于解决训练大语言模型时的内存和性能瓶颈,引入了如 DISTFLASHATTN 等新技术,声称与现有方案相比可实现线性内存使用和 8 倍长的序列。讨论还涉及利用 bf16 优化器、tinyBLAS 以及 IPEX-LLM (GitHub) 等框架在特定硬件上进行推理加速。
-
对新 AI 模型的期待与分析:社区对新发布或即将发布的模型反应热烈,如 Apple 的 ReALM (论文)、Stable Diffusion 3.0、Stable Audio 2.0 (网站),以及在 SWE-bench 上表现媲美 Devin 的 SWE-agent (GitHub)。对 Claude、Opus 和 Haiku 等指令遵循和对话模型的对比评估也很常见。
-
AI 系统中的伦理问题与 Jailbreaking:讨论涉及使用受版权保护的数据训练 AI 的法律影响(如音乐平台 Suno),以及语言模型中 Jailbreak 防御的有效性,并引用了一篇关于定义不安全输出重要性的 arXiv 论文。聊天机器人的情感模拟能力引发了将 AI 类比为精神病态(psychopathy)的哲学辩论。
-
AI 界面与应用的创新:CallStar AI 等应用突显了与 AI 进行语音交互的潜力,同时社区致力于通过对话式 UI 使技术更易于获取。Open Interpreter 等项目旨在将 AI 能力带到移动和嵌入式设备。AI 的新颖用例涵盖了从 WorldSim 的游戏化模拟 (Notion) 到 AI 生成的艺术和音乐。
PART 1: 高层级 Discord 摘要
LAION Discord
-
优化器难题与建议:技术讨论揭示了
torch.compile和优化器函数面临的挑战。讨论中提出的一种新兴解决方案涉及一个包含bf16 optimizer的 Python 包,旨在解决 dtype 冲突和设备兼容性问题。 -
AI 音乐的法律警报:社区关注了 AI 音乐平台 Suno 可能面临的法律问题,强调了因使用受版权保护的内容进行训练而可能导致唱片公司提起版权侵权诉讼的风险。
-
Apple MPS 中的内存占用与崩溃:Apple 的 MPS 框架因在高内存分配时(即使内存充足)发生崩溃而受到审查。理论上的内部限制和作为权宜之计的 attention slicing 是热门话题,尽管人们担心这会导致 NaN 错误。
-
文本细节提升图像质量:研究表明,使用精确的空间描述对 text-to-image 模型进行微调可以增强生成图像的空间一致性,正如一篇 arXiv 论文所指出的。
-
解码 AI 最佳性能:从对 SD3 Turbo 声称的效率的怀疑,到关于模型微调和 scheduler 有效性的建议,该公会对各种 AI 策略进行了分析。此外,正如最近的一项实证研究所示,在相同的 inference budget 内,较小的模型表现可能会优于较大的模型。
Stability.ai (Stable Diffusion) Discord
推进 Stable Diffusion:用户报告称,Stable Diffusion 的用户界面 Forge 提供了卓越的性能,尤其是在 RTX 3060 和 RTX 4080 显卡上。推荐使用 DreamShaper Lightning (SDXL) 模型以提高图像生成的效率和速度。
对 SD3 的高度期待:Stable Diffusion 社区正积极期待 Stable Diffusion 3.0 的发布,预计将在未来 3-5 周内推出,预计文本渲染将有所改进,尽管完美的拼写可能仍然难以实现。
创意 AI 的释放:成员们正在尝试使用 Stable Diffusion 为桌面 RPG 等项目创作艺术,并考虑通过 AI 生成的视觉叙事(可能是漫画或电影格式)进行讲故事。
疑难解答技术技巧:讨论集中在解决图像生成缓慢和出现多余文本等问题上,参与者提出了优化建议,并提到 GitHub 链接作为故障排除的起点。
功能预测:对于即将推出的功能(如 sparse control net、SegMOE 和 audiosparx 模型),社区表现出明显的兴奋,大家分享了资源并期待 AI 生成内容的新可能性。
Unsloth AI (Daniel Han) Discord
Cortana 1.0 聊天模型引发好奇:工程师们讨论了基于《光环》(Halo)系列 AI 创建名为 Cortana 1.0 的 AI Prompt 模型,重点是创建有效的聊天模式和 Prompt 结构以简化交互。
Unsloth Enterprise 能力澄清:官方澄清 Unsloth Enterprise 确实支持全模型训练,速度比 FA2 提升 2-5 倍,而非预期的 30-40 倍。
AI 优化交流:一系列活跃的讨论涵盖了各种优化主题,包括 Unsloth AI 的进展(提到了 Daniel Han 的推文)、用于加速 AI 推理的 GitHub 资源(如 ipex-llm),以及 AI 模型的故障排除,特别是 SFTTrainer 与 Gemma models 的兼容性。
小行星采矿的创新方法:Open Asteroid Impact 项目以一种新颖的概念吸引了人们的兴趣,即通过将小行星带回地球来更有效地利用资源。
全栈人才招募:社区内正在征集熟练的 Full Stack 开发人员,并鼓励用户如果能推荐或提供帮助请私信(DM)。
Perplexity AI Discord
解读 PDF 的字里行间:工程师们讨论了使用 Claude 和 Haiku 等 AI 模型来解析 PDF,重点关注 context windows(上下文窗口)和 Perplexity 的 Pro 功能,特别是 “Writing” 焦点模式以及开启 “Pro” 模式以提高准确性。一些用户更倾向于使用 Sonar 以获得更快的响应。
广告话题引发用户争论:Perplexity 引入广告的可能性引发了辩论,此前 Perplexity 的首席商务官发表了关于整合赞助建议的言论。用户对 Pro 订阅者的体验可能受到的影响表示担忧,并引用了一篇关于该主题的 Verge 文章。
PDF 障碍与图像生成:在解决技术问题时,用户明确了 Perplexity 的移动端 App 缺乏图像生成支持——虽然这一不便可以通过在移动设备上使用网页版(具备类似桌面端的功能)来进行图像生成来缓解。另外的讨论指出,用户希望取消 25MB 的 PDF 限制以提高效率。
工程师交流“推荐链接”:推荐计划和折扣成为了热门话题,提到了通过提供的链接(links)来节省费用。
API 的烦恼与变通方案:在 Perplexity API 领域,用户正在努力应对缺乏 team support(团队支持)和 API 额度支付问题,同时也分享了对 rate limits(速率限制)以及从 sonar-medium-online 模型接收到过时响应的沮丧。建议范围从准确的请求日志记录到优化 system prompts 以获取最新新闻。
好奇心驱动深度探索:
- 用户利用 AI 探索了从 Fritz Haber 的生平和伦理困境到 random forest classifiers(随机森林分类器)以及《希腊左巴》(Zorba the Greek) 等一系列主题,这取决于 AI 是否适合满足多样且复杂的查询。
- 他们利用 Perplexity 高效地为时事通讯汇编综合数据,表明了利用 AI 简化内容创作的强烈倾向。
Latent Space Discord
开源 AI 媲美 Devin:作为 Devin 开源替代方案推出的 SWE-agent 在 SWE-bench 上展示了相当的性能,引发了关于其潜在集成和应用的讨论。
Apple 的 AI 研究蓄势待发:Apple 的一篇新论文展示了 ReALM,暗示其 AI 进展可能超越 GPT-4 的能力,并与即将推出的 iOS 18 紧密集成,以改进 Siri 的交互。
Claude 的难题:用户正在测试 Claude Opus,但发现它在处理复杂任务时面临挑战,因此推荐参考提示工程互动教程(Prompt Engineering Interactive Tutorial)以增强与模型的交互。
Stable Audio 2.0 强化音频体验:StabilityAI 推出了 Stable Audio 2.0,凭借其制作完整长度、高质量曲目的能力,推向了 AI 生成音乐的新边界。
DALL-E 新增编辑按钮:ChatGPT Plus 现在包含允许用户编辑 DALL-E 生成的图像和编辑对话提示词的功能,带来了自定义和控制的新维度,详情见 OpenAI 帮助页面。
DSPy 框架讨论升温:LLM Paper Club 详细审查了 DSPy 框架的功能及其在 prompt 优化方面优于其他框架的优势,激发了将其应用于各种项目的想法,如语音 API 日志应用和学术论文摘要平台。
Nous Research AI Discord
-
SWE-agent 崛起,Devin 趋于平稳:一个名为 SWE-agent 的尖端系统被推出,声称在解决 GitHub issues 方面能与前作 Devin 媲美,平均处理时间仅为惊人的 93 秒,且已在 GitHub 开源。
-
80M 模型引发质疑:工程师们讨论了一个 80M 模型 在分布外(out-of-distribution)数据上取得的惊人成功,引发了关于误差幅度的推测,并激起了对其性能有效性的辩论。
-
中国处理器表现超出预期:关于 AI 硬件的讨论提到了 云天励飞(Intellifusion)的 DeepEyes,这是一款中国 14nm AI 处理器,以显著降低的成本提供具有竞争力的 AI 性能,可能对硬件市场发起挑战(Tom’s Hardware 报告)。
-
微调英雄与模型故障:社区分享了模型微调的经验,例如 Lhl 对 jamba 模型 的工作,以及 Mvds1 因元数据问题在向 Hugging Face 上传模型时遇到的困难,指出需要手动调整
SafeTensorsInfo。 -
WorldSim 激发社区想象力:工程师们热情地探索了 WorldSim 的功能,从 text-to-video 集成到社区路线图,讨论了技术增强并分享了资源,如 Notion 上的 WorldSim 命令索引。WorldSim 的技术限制和游戏化是热门话题,展示了社区在模拟平台上的创新动力和参与度。
LM Studio Discord
- LM Studio 缺乏 Embedding 模型支持:用户确认 LM Studio 目前不支持 embedding 模型,强调 embedding 功能尚未实现。
- AI 推荐查询受到关注:一个用户请求能够提供成人动漫推荐的模型,引发了使用 MyAnimeList (MAL) (myanimelist.net) 的建议,社区对这一不寻常的咨询感到有趣。
- 优化 LLM 配置的悬念:硬件频道的讨论揭示了关于 LM Studio 无需 SLI 的多 GPU 配置 的见解,推荐了如 Nvidia Tesla P40 等 GPU,并对由于 影响台积电 (TSMC) 的大地震 导致的未来硬件价格表示担忧。
- API 类型对 Autogen 集成至关重要:LM Studio 的故障排除强调了指定 API 类型的重要性,以确保与 Autogen 的正常协作。
- 针对 CrewAI 的跨源资源共享 (CORS):讨论了启用 CORS 作为解决 LM Studio 本地模型使用问题的潜在方案,并通过一篇 Medium 文章 提供了额外指导。
OpenAI Discord
-
DALL·E 进入 ChatGPT 领域:ChatGPT 界面中引入了直接在对话中编辑图像和风格灵感的功能,针对 DALL·E 图像,兼顾了便利性和创意探索。
-
Bing API 陷入沉寂:持续 12 小时的 Bing API 故障引起了用户的担忧,影响了依赖它的服务(如 DALL·E 和 Bing Image Creator),表明需要强大的备用方案。
-
对情感的困惑:围绕类 GPT 的 LLM 是否能真实模拟情感展开了激烈辩论,指出 AI 缺乏内在动力,并将其与精神病态以及著名的 Eliza 效应进行比较。
-
盒子里的经理:征集用于处理管理任务的 prompt 编写,强调了 AI 社区对自动化复杂领导角色的兴趣,尽管讨论中尚未产出实际的策略或解决方案。
-
翻译难题与 Markdown 困扰:尝试制作保留 Markdown 语法的翻译 prompt 时遇到了阻碍;翻译的不一致性(尤其是阿拉伯语)让 AI 工程师质疑当前语言模型处理复杂格式和语言细微差别时的能力极限。
tinygrad (George Hotz) Discord
向 Linux GPU 先驱告别:John Bridgman 从 AMD 退休引发了关于他对 Linux 驱动程序贡献的讨论,George Hotz 对 AMD 的管理现状和未来方向发表了评论。Hotz 呼吁 AMD 员工提供匿名爆料,以便可能撰写一篇博客揭露文章,此时社区正对 AMD 在驱动问题和开源承诺上的执行力表示担忧,正如辩论和一篇 Phoronix 文章中所强调的那样。
Linux Kernel 与 NVIDIA 的开源举措:讨论延伸到了不同 Kernel 版本的影响,特别是围绕 Intel 的 Xe 和 i915 驱动程序,以及 Linux 发行版之间的迁移偏好,例如从 Ubuntu 22.04 LTS 转向 24.04 LTS。此外,George Hotz 提到了他对 NVIDIA 开源驱动倡议的贡献,引发了关于开源 GPU 驱动与专有驱动现状的对话。
Tinygrad 的 V1.0 之路离不开社区:对 tinygrad 的 beam search 启发式算法和 CommandQueue 功能的探索,突显了 George Hotz 对改进文档以帮助用户学习和贡献的重视,包括提议一个受 “Write Yourself a Scheme in 48 Hours” 启发的教程。这与社区贡献相辅相成,例如这个 command queue 教程,旨在完善 tinygrad。
活跃的成员参与增强了 Tinygrad:社区在创建学习材料方面的积极性受到了赞赏,成员们提供资源并主动直播他们在 tinygrad 上的实践经验,营造了协作学习的环境。这与达成 tinygrad 1.0 版本的共同目标一致,巩固了该平台作为教育和创新工具的地位。
重新思考 AI 模型中的内存使用:一场关于模型前向传播过程中内存优化的技术辩论随之展开,特别是关于利用 反函数法则 (inverse function rule) 使用具有反函数的激活函数。这体现了社区不仅参与工具开发,还参与基础原理的研究,以提高 AI 计算的处理效率。
OpenInterpreter Discord
OpenInterpreter 深入应用开发:Open Interpreter iPhone 应用的开发正在取得进展,完成度约为 40%,该项目由 GitHub 上的社区协作推动,灵感源自 Jordan Singer 的 Twitter 概念。
让技术更易于触达:Open Interpreter 社区正在推动引入 对话式 UI 层 (Conversational UI layer),以帮助老年人和残障人士,旨在显著简化他们与技术的交互。
数字时代的安全措施:成员们被警告要远离一个疑似被盗的 Open Interpreter X 账号发布的潜在危险帖子,以防止加密货币钱包被侵入。
创新的移植计划:OpenInterpreter 正在模糊平台界限,推出了用于 Android Termux 安装的新仓库,正在进行 M5 Cardputer 移植工作,并讨论了在 GPT-4 成本担忧下实施本地 STT 解决方案。
对 AI 见解的期待:社区分享了对深入理解 LLM 的热情,这可能表明人们对获取 AI 系统高级技术知识有着浓厚兴趣。
Eleuther Discord
-
Tinystories 饱和警报:据报道,Tinystories 数据集在约 5M 参数时达到饱和点,引发了转向更大规模
minipile数据集的讨论,尽管后者对处理能力的要求更高。 -
呼吁组建 AI 竞赛团队:社区对 EleutherAI 支持 AI 竞赛团队表现出浓厚兴趣,建议利用 llema 等模型和 RLHF 专业知识,并提议设立专门频道并寻求 compute grants 支持。
-
防御语言模型 Jailbreaking:最近的一篇 论文 指出,定义不安全回答时的歧义是保护语言模型免受 ‘jailbreak’ 攻击的关键挑战,重点应放在后处理输出的精确性上。
-
AI 模型反馈提交亮点:关于 AI 模型政策的 公开评论 显示了对开源模型开发的偏好,如 EleutherAI 的 LaTeX 风格贡献所示,讨论中既流露出自豪感,也提到了社区参与中错失的机会。
-
LLM 安全过滤器增强建议:关于在 LLM 微调数据中混入拒绝示例的对话引用了 @BlancheMinerva 的推文和相关研究,证实了 ArXiv 论文 中提到的对安全过滤器鲁棒性的日益关注。
-
ChemNLP 带来的化学领域突破:首篇 ChemNLP 项目论文在 ArXiv 上的发布预示着 AI 驱动化学领域的重大进展,引发了关注并可能带动未来研究方向的讨论。
-
开源 AI 面临的法律阴影:深入探讨加州 SB 1047 法案对开源 AI 项目的影响,鼓励签署抗议公开信,这表明社区对该法案限制创新后果的担忧。详细评论见 此处。
-
抽象与具体之间的难题:一个关于“房子”如何介于“具体长颈鹿”和“抽象长颈鹿”之间的奇特澄清请求,得到了一个轻松的数字耸肩回应,展示了社区讨论中幽默而神秘的一面。
-
Neel Nanda 的 MATS Stream 开放申请:提醒 Neel Nanda 的 MATS stream 申请截止日期临近(少于 10 天),完整详情见此 Google Doc。
-
多语言生成式 QA 的参与:讨论了使用 Chain of Thought (CoT) 提升多语言 QA 任务的潜力,涉及 MGSM 等数据集,并生成了一个展示包含
generate until功能任务的列表。 -
CUDA 疑难解答呼吁社区帮助:一位用户在 H100 GPU 上遇到
CUDA error: no kernel image is available for execution on the device错误(在 A100 GPU 上未出现),排除了 flash attention 的原因,进一步建议检查context_layer设备以解决问题。 -
PyTorch 的弹性探索:关于预训练期间 GPU/TPU 弹性调整 的问题,得到了采用 PyTorch Elastic 的建议,该工具展示了适应故障和动态调整计算资源的能力,引起了寻求可扩展训练方案者的兴趣。
HuggingFace Discord
提升仓库隐私:Hugging Face 现在允许企业组织默认将仓库可见性设置为公开或私有,从而增强隐私控制。他们的推文中有更多详情。
通过命令发布:Quarto 用户可以使用 use quarto publish hugging-face 在 Hugging Face 上部署网站,正如最近在 Twitter 和 LinkedIn 帖子中分享的那样。
Gradio 的新特性:Gradio 在最新的 4.25.0 版本中引入了状态变量自动删除和延迟示例缓存,详见其 changelog。
探索 CLI 前沿:一段分享的 YouTube 视频向开发者解释了如何在命令行界面(CLI)中使用 Linux 命令、容器、Rust 和 Groq。
推动 LLM 达到高效运行状态:一位用户询问如何在计算资源受限的情况下,针对 PDF 微调语言模型,并重点关注使用开源模型的推理。同时,一场关于在微调 LLM 时修改 tokenizer 中特殊 token 的讨论也在展开。
LangChain AI Discord
聊天记录中的持久上下文探索:工程师们讨论了如何维护聊天中的持久上下文,特别是在与“问题:回答”对数据库交互时,但尚未达成统一的解决方案。讨论中引用了 LangChain 的 issue 和文档以寻求潜在的推进方法。
LangServe Playground 视频教程:分享了一个介绍 LangServe 中 Chat Playground 特性的视频教程,旨在简化初始设置并展示其与 Langsmith 的集成。
语音指令未来:宣布推出了多个 AI 语音应用,如 CallStar AI 和 AllMind AI,这暗示了语音作为 AI 交互接口的趋势。提供了 Product Hunt 和 Hacker News 等平台的链接以寻求社区支持。
AI 工程问题与教程:langchain-ai/langserve 的一个 pull request 报告了 CI 问题;此外,有人在采用 LangChain 的 ChatOpenAI 和 ChatPromptTemplate 时遇到了 NotFoundError 并寻求指导。同时,新手被引导至一份全面的 LangChain 快速入门指南。
GalaxyAI 服务与提示词熟练度测试:GalaxyAI 提供了免费访问高级 AI 模型的机会,并强调了与 Langchain 的 API 兼容性,尽管服务链接缺失。另一个项目 GitGud LangChain 则挑战资深提示词工程师测试一种新的代码转换工具,以维护代码质量。
Modular (Mojo 🔥) Discord
Mojo 与内存安全:将 Mojo 语言集成到 ROS 2 中显示出对机器人开发的潜在益处,这得益于 Mojo 的内存安全实践。C++ 和 Rust 的对比显示出人们对机器人环境性能和安全性的日益关注。
Docker 构建启航:即将发布的 Modular 24.3 将包含一个旨在提高自动化 Docker 构建效率的修复方案,这受到了社区的好评。
日志记录器的灵活性飞跃:Mojo 中的 logger 库已更新,可接受任意参数和关键字参数,从而实现更动态的日志记录,在消息之外容纳更多样化的信息。
Mojo Dict 需要更快的速度:社区在 One Billion Row Challenge(十亿行挑战)中的参与表明,Mojo 中 Dict 的性能需要增强。目前正在努力讨论实现自定义的、可能基于 SIMD 的 Dict,以跟上 swiss tables 等解决方案的步伐。
共同推动 Mojo Nightly 版本的改进:成员们表达了希望在 Mojo 标准库(stdlib)开发中拥有更清晰的贡献和排错路径。GitHub 上的讨论澄清了诸如解析错误和 Optional 类型行为等挑战,这表明了社区正在积极协作以完善 Mojo 的功能。
OpenRouter (Alex Atallah) Discord
-
TogetherAI 遭遇超时故障:用户报告 NOUSRESEARCH/NOUS-HERMES-2-MIXTRAL 模型出现故障,具体表现为错误代码 524,这表明 TogetherAI 的 API 可能存在上游问题。建议使用 Nous Capybara 34B 作为替代方案。
-
聊天机器人的历史准确性测试结果参差不齐:在识别二战背景下的日本将军山本五十六 (Isoroku Yamamoto) 时,Claude、Opus 和 Haiku 等 LLM 表现出不同程度的准确性,凸显了当前聊天机器人在处理历史事实方面的挑战。
-
OpenRouter 触及 4MB 上限:OpenRouter 存在一项技术限制,即 Body 内容的最大 Payload 大小为 4MB,已确认目前没有绕过该限制的方法。
-
AI 助力角色扮演:在 AI 辅助角色扮演领域,Claude 3 Haiku 成为关注焦点,用户分享了优化策略,包括对模型进行 Jailbreaking 以及应用 Few-shot Learning 来磨合交互效果。
-
社区众包 Prompt 游乐场:推荐 SillyTavern 和 Chub 的 Discord 服务器给那些寻求丰富 Prompt 资源和 Jailbroken 模型的人,并指出了诸如 pancatstack jailbreak 等特定技术。
LlamaIndex Discord
RankZephyr 在竞争中脱颖而出:建议将 RankZephyr 集成到高级 Retrieval-Augmented Generation (RAG) 系统中以增强 Reranking,RankLLM 系列因其 Fine-tuning 能力而受到认可。
利用 AI Copilot 提升研究敏捷性:一份网络研讨会总结揭示了构建 AI Browser Copilot 的关键策略,重点在于 Prompt Engineering Pipeline、KNN Few-shot 示例和向量检索 (Vector Retrieval),更多见解可在 LlamaIndex 的 Twitter 上查看。
及时的数据检索创新:据称 KDB.AI 通过为混合搜索 (Hybrid Searching) 引入时间敏感查询,改进了 Retrieval-Augmented Generation,从而实现了对财务报告等场景至关重要的更细致的搜索能力,如代码片段所示。
智能库重新定义知识管理:一款面向专业人士和团队的新型 LLM 驱动数字图书馆据称将彻底改变知识组织方式,其功能允许在高级数字环境中进行创建、组织和注释,正如 LlamaIndex 的推文所宣布的那样。
社区对话提出技术问题:社区讨论包括索引大型 PDF 的挑战、qDrant 在 IngestionPipeline 后不释放锁的问题、HuggingFace API 的限制、使用 Ollama 类进行模型集成,以及 RAG 递归查询引擎中的文档缺失问题。
OpenAccess AI Collective (axolotl) Discord
Axolotl 文档焕然一新:Axolotl 文档进行了外观更新,虽然最初遗漏了目录 (Table of Contents),但已通过此 GitHub commit 迅速修正,不过标题与目录之间的一致性仍需进一步清理。
Serverless vLLM 部署的苦与乐:分享了关于 Runpod 和 Serverless vLLM 的经验,强调了挑战,并提供了关于如何部署 LLM Endpoints 的资源。
数据聚合难题:整合包含数百 GB 数据的多个数据集的努力面临复杂情况,包括文件对齐问题。目前使用 TSV 文件和 Pickle 格式的索引数据进行快速检索,同时也在讨论更高效的解决方案。
轻松的 AI 模型大比拼:一场轻松的辩论比较了对 ‘qwen mow’ 与 ‘jamba’ 等 AI 模型的偏好,社区开玩笑说需要更多的数据和资源。
征集高清数据:一位社区成员正在寻找获取 4K 和 8K 图像集的资源,这表明某个项目或研究需要高分辨率图像数据。
Mozilla AI Discord
-
Windows ARM 上的 Llamafile 困境:为 Windows ARM 编译 llama.cpp 需要进行源码编译,因为目前尚不提供预构建支持。由于 Windows 上 Cosmopolitan 开发环境存在问题(如 Cosmopolitan issue #1010 中所述),开发者已被建议使用其他平台来构建 llamafile。
-
Mixtral 的智力随参数规模提升:Mixtral 版本
mixtral-8x7b-instruct-v0.1.Q4_0.llamafile擅长解决数学谜题;然而,为了确保事实记忆准确无误,建议使用Q5_K_M或更高版本。感兴趣的用户可以在 Hugging Face 上找到具体细节。 -
TinyBLAS 带来的性能提升:在使用 llamafile 时,通过使用
--tinyblas标志可以大幅提升 GPU 性能,该标志无需额外 SDK 即可提供支持,不过效果可能取决于所使用的 GPU 型号。 -
PE 文件可包含 ARM64 和 ARM64EC:Windows on ARM 支持带有 ARM64X 二进制文件的 PE 格式,这种格式结合了 Arm64 和 Arm64EC 代码,详见微软的 Arm64X PE Files 文档。由于 ARM64EC 中不支持 AVX/AVX2 指令仿真,这可能会阻碍 LLM 通常需要的操作,从而带来潜在挑战。
-
延伸阅读参考:分享了包括 Windows 上 HIP SDK 安装指南以及使用 Llamafile 进行性能增强的详细信息等文章和资源,例如 The Register 上的“Llamafile LLM 驱动项目提升 CPU 核心性能”,以及可在此处获取的 HIP SDK 安装文档。
Interconnects (Nathan Lambert) Discord
-
Opus Judgement 预示 AI 性能提升:讨论强调了 Opus Judgement 在解锁研究级 AI 微调(RLAIF)性能提升方面的潜力,其确定性取决于其准确性。
-
Google 的 AI 强势举措:工程师们对 Logan K 转型领导 Google 的 AI Studio 议论纷纷,对其动机的猜测从个人生活方式到战略职业定位不等。官方公告引发了人们对他领导下 Gemini API 未来的期待。
-
Logan K 引发更广泛的 AI Alignment 辩论:Logan K 的举动引发了关于 AI Alignment 价值观与企业诱惑之间的讨论,人们在思考这一选择是为了在 Google 实现更开放的模型共享,还是仅仅因为丰厚的薪酬而无视个人对齐原则。
-
AI 进展中的神秘氛围:一位成员指出,GPT-4 技术报告缺乏透明度所产生的连锁反应,标志着 AI 公司之间保密性增加、模型细节分享减少的趋势。
-
无法获取 AI 财务分析:人们对 AI 财务影响的兴趣被《金融时报》一篇讨论 Google AI 搜索变现的文章所激发,但由于 Financial Times 内容的访问受限,限制了技术社区内的讨论。
CUDA MODE Discord
-
CUDA 撞上 LLM 优化:DISTFLASHATTN 机制声称在训练长上下文大语言模型(LLM)期间实现了线性内存占用,相比传统的二次方峰值内存占用,它允许处理高达 8 倍长的序列。然而,社区注意到论文中缺少 backward pass 的伪代码,引发了对可复现性的担忧。
-
代码讨论:对于那些寻求 CUDA 实战经验的人,推荐将 CUDA MODE YouTube 频道和相关的 GitHub 资料作为从 Python 和 Rust 转向 CUDA 的初学者的起点。
-
内存高效训练引起关注:专注于优化 LLM 训练的 DISTFLASHATTN 论文正受到关注,一名成员标记了即将进行的详细审查,暗示将围绕其内存高效训练的优势展开进一步讨论。
-
对 Backward Pass 的负面反馈:一名成员对 DISTFLASHATTN 论文中缺乏 backward pass 伪代码的批评引起了社区的共鸣,呼吁在 Attention 机制研究中提高科学可重复性。
-
指向 Intel Analytics 仓库的指针:分享了一个指向 Intel Analytics 的 ipex-llm GitHub 仓库的链接,未提供额外上下文,可能暗示了 LLM 领域的新工具或进展。
AI21 Labs (Jamba) Discord
Token 效率讨论:一位用户强调了一篇论文的发现,即吞吐效率随着每个 token 的测量而增加,其计算方式是端到端吞吐量(包括 encoding 和 decoding)与 token 总数的比率。
速度辩论升温:关于增加 token 如何影响生成速度存在分歧——虽然 encoding 可以并行完成,但 decoding 固有的顺序特性意味着每个新 token 都会增加处理时间。
关注 Encoding 性能:讨论中的澄清指出了一张绘制生成固定 512 个 token 速度的图表,暗示图中观察到的速度提升应归功于更快的 encoding 而非 decoding。
Decoding:顺序减速困境:有人询问尽管 decoding 存在顺序依赖性(理论上要求等待每个 token 的前序 token),是否仍有提高其速度的可能性。
Skunkworks AI Discord
-
热情的 Python 开发者加入:一位拥有 Python、软件工程背景和数据科学硕士学位的新贡献者正寻求加入团队并为入职流程做出贡献,他带来了 AI 医学研究和数据流水线(data pipeline)构建方面的专业知识。
-
GPT-4 在没有上下文的情况下被数学题难住:即使是像 GPT-4 和 Claude 这样先进的 AI,除非问题用清晰的自然语言提出,否则在解方程时也会遇到困难,这表明目前的 AI 模型仍有改进空间。
Alignment Lab AI Discord
似乎没有足够的上下文来生成摘要。请提供更多关于该 Discord 服务器内各频道的讨论信息,以便输出有意义的摘要。
Datasette - LLM (@SimonW) Discord
- 对话数据澄清:一位 AI 工程师澄清了对话日志中使用的术语,引用了
logs.db中的responses表。建议将对话的初始部分称为“speaker turn”或简称“turn”,并因此将其应用的表重命名为turns。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
LAION ▷ #general (699 条消息🔥🔥🔥):
-
优化器实现中的故障排除:成员们就使用
torch.compile和add_stochastic_函数时遇到的问题进行了技术讨论,指出了在 NVIDIA, AMD 和 MPS 等不同设备上的兼容性问题。讨论了一个涉及为 bf16 optim 创建 Python 包的潜在解决方案,以及为防止操作期间出现 dtype 冲突错误而进行的可能修改。 -
对 SD3 效率提升的怀疑:在一名成员因质疑有限 token 训练和该方法的长期可行性而被服务器封禁后,人们对 SD3 Turbo 效率提升的说法产生了怀疑。还有建议认为,依赖 CLIP 等工具可能会引入伪影,从而阻碍全面学习。
-
AI 生成音乐的法律风险:关于 AI 音乐平台 Suno 的讨论凸显了潜在的版权侵权问题。有人担心,如果 Suno 使用受版权保护的音乐进行训练,唱片公司强大的法律团队可能会带来严峻挑战。用户们讨论了在法庭上证明侵权的复杂性。
-
高内存占用下的 MPS 限制与崩溃:有人指出,尽管内存充足,Apple 的 MPS 框架在训练期间分配超过 2^32 字节的数据时会发生崩溃,这表明可能存在内部限制。文中还提到了 attention slicing 等实际解决方法,尽管这些方法可能会导致 backward pass 期间出现 NaN 等其他问题。
-
模型 Fine-Tuning 与 Scheduler 选择建议:关于如何将 CLIP 与 T5 等其他模型结合使用以获得更好性能存在争论,其中一名成员支持最终排除 CLIP,转而使用纯 T5 模型以避免长期问题。进一步的讨论涉及社区内关于 sampler 效率和理想采样次数的不一致信息及误传。
- ‘Lavender’:指挥以色列在加沙进行轰炸行动的 AI 机器:以色列军队利用一个几乎没有人类监督且对伤亡政策宽松的 AI 目标定位系统,将数万名加沙人标记为暗杀嫌疑人,+972 和 Local C...
- Reddit - 深入探索一切:未找到描述
- Ian Malcolm GIF - Ian Malcolm Jurassic - 发现并分享 GIF:点击查看 GIF
- RuntimeError: required rank 4 tensor to use channels_last format:我的 Transformer 训练循环在 CPU 上运行时似乎正常,但当我切换到 MPS 时,在计算 Cross Entropy loss 的 loss.backward() 时遇到了以下错误。我正在进行机器学习...
- 衡量 Diffusion Models 中的风格相似性:生成模型现在被图形设计师和艺术家广泛使用。之前的研究表明,这些模型在生成过程中会记住并经常复制其训练数据中的内容。因此...
- Galileo:未找到描述
- Suno 是一家旨在每年创造 1200 亿美元收入的音乐 AI 公司。但它是否在受版权保护的录音上进行过训练? - Music Business Worldwide:Ed Newton-Rex 发现 Suno 创作的音乐与经典版权作品有着惊人的相似之处...
- Axis of Awesome - 4 Four Chord Song (附歌曲名称):澳大利亚喜剧团体 'Axis Of Awesome' 表演了 2009 年墨尔本国际喜剧节的一个片段。视频由 Network Ten Australia 提供。...
- Issues · pytorch/pytorch:Python 中具有强大 GPU 加速功能的 Tensor 和动态神经网络 - Issues · pytorch/pytorch
- Issues · pytorch/pytorch:Python 中具有强大 GPU 加速功能的 Tensor 和动态神经网络 - Issues · pytorch/pytorch
- OneTrainer/modules/util/optimizer/adafactor_extensions.py at 9a35e7f8596988f672af668f474f8d489ff8f962 · Nerogar/OneTrainer:OneTrainer 是满足你所有 Stable Diffusion 训练需求的一站式解决方案。- Nerogar/OneTrainer
- [mps] 训练 / 推理 dtype 问题 · Issue #7563 · huggingface/diffusers:当在没有 attention slicing 的情况下在 Diffusers 上进行训练时,我们看到:/AppleInternal/Library/BuildRoots/ce725a5f-c761-11ee-a4ec-b6ef2fd8d87b/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShaders/MPS...
- GitHub - steffen74/ConstitutionalAiTuning:一个用于微调具有自定义伦理或上下文对齐的 LLM 的 Python 库,利用了 Anthropic 提出的 Constitutional AI 原则。简化了 Prompt 生成、模型交互和微调的过程,以实现更负责任的 AI 开发。:一个用于微调具有自定义伦理或上下文对齐的 LLM 的 Python 库,利用了 Anthropic 提出的 Constitutional AI 原则。简化了 Prompt 生成...
- 7529 不要为 cuda 设备禁用 autocast,由 bghira 提交 · Pull Request #7530 · huggingface/diffusers:这个 PR 做了什么?修复了 #7529。在提交之前,这个 PR 修复了一个拼写错误或改进了文档(如果是这种情况,你可以忽略其他检查)。你阅读了贡献者指南吗?...
{kind=link}
LAION ▷ #research (11 条消息🔥):
-
扩展与采样效率分析:这篇文章重点介绍的一项实证研究探讨了模型大小对 Latent Diffusion Models (LDMs) 采样效率的影响。与预期相反,研究发现,在相同的推理预算下,较小的模型通常比较大的模型表现更好。
-
寻找可扩展的爬虫技术:一位成员询问了关于可扩展爬虫方法的研究,这些方法可以协助构建用于模型训练的数据集。然而,回复中并未引用具体的团队或资源。
-
揭秘赚取 5 万美元的奥秘:一次幽默的交流,涉及一个 Discord 版主封禁 GIF 的链接,并猜测在 72 小时内赚取 5 万美元的秘密可能涉及当“毒骡”(drug mule),引用了一个与 MLM 相关的梗。
-
Twitter 上预热的新优化器:Twitter 上讨论的一个 新优化器 备受期待,有望在该领域带来潜在的进步。
-
通过具体化增强视觉效果:在讨论一篇 arXiv 论文 时提到,使用包含更好空间描述的提示词(captions)对文本生成图像(t2i)模型进行微调,可以使生成的图像具有更好的空间一致性。
- Bigger is not Always Better: Scaling Properties of Latent Diffusion Models:我们研究了 Latent Diffusion Models (LDMs) 的缩放特性,重点关注其采样效率。虽然改进的网络架构和推理算法已被证明能有效...
- Discord Mod Moderation Ban GIF - Discord mod Moderation ban Mod ban - Discover & Share GIFs:点击查看 GIF
LAION ▷ #learning-ml (1 条消息):
- LangChain 的 Harrison Chase 将阐明 LLM 挑战:诚邀参加与 LangChain 联合创始人兼 CEO Harrison Chase 的独家活动。他将讨论公司在从原型转向生产环境时面临的挑战,以及 LangSmith 如何帮助克服这些障碍。此次活动将于 4 月 17 日 18:30 在线举行。在此注册。
- 通过 LangChain 获取 LLM 框架趋势的内部信息:LangChain 联合创始人 Harrison Chase 将分享他在使用 LLMs (Large Language Models) 开发上下文感知推理应用方面的专业知识。作为第三届 LangChain and LLM France Meetup 的一部分,本次演讲将探讨公司遇到的挑战及实施的解决方案。
提到的链接:Meetup #3 LangChain and LLM: Using LangSmith to go from prototype to production, mer. 17 avr. 2024, 18:30 | Meetup:我们很高兴邀请到 LangChain 的联合创始人兼 CEO Harrison Chase 参加我们的第三届 LangChain and LLM France Meetup!不要错过这个难得的机会。
Stability.ai (Stable Diffusion) ▷ #general-chat (568 条消息🔥🔥🔥):
- Stable Diffusion 秘诀揭晓:成员们正在讨论各种版本 Stable Diffusion 的性能。Forge 被强调为目前最快的 UI,DreamShaper Lightning (SDXL) 等模型也备受青睐。使用 RTX 3060 和 RTX 4080 等显卡的用户注意到,与 A1111 相比,使用 Forge 时速度显著提升,图像生成时间大幅缩短。
- 对 SD3 的期待与日俱增:社区正急切等待 Stable Diffusion 3.0 的发布,预计发布时间在 3-5 周之间。不过有人指出,虽然 SD3 将改进文本渲染,但由于其局限性和模型大小,可能仍无法实现完美的拼写。
- 利用 SD 进行创意项目:用户正在探索将 Stable Diffusion 用于各种创意尝试,例如为桌面 RPG 生成艺术图,或考虑通过图像进行叙事(可能是漫画或电影格式)。
- 技术攻关与技巧:围绕图像生成过程中可能遇到的问题(如速度慢或一个提示词中的文本出现在另一个提示词中)展开了讨论,并建议利用特定的 Stable Diffusion 优化方案并尝试替代界面(如 Forge)。
- 即将推出的新模型和功能:社区对 Sparse control net、SegMOE 和 Audiosparx 模型等新功能感到兴奋,并分享了有用的 GitHub 链接以及如何更好利用 AI 生成内容的技巧。
- Leonardo.Ai: 为您的项目创建具有前所未有的质量、速度和风格一致性的生产级视觉资产。
- Anime Help GIF - Anime Help Tears - Discover & Share GIFs: 点击查看 GIF
- Remix: 创建、分享和混剪 AI 图像及视频。
- BFloat16: The secret to high performance on Cloud TPUs | Google Cloud Blog: Google Cloud TPU 的高性能如何由 Brain Floating Point 格式(即 bfloat16)驱动
- Optimizations: Stable Diffusion web UI。通过在 GitHub 上创建账号为 AUTOMATIC1111/stable-diffusion-webui 的开发做出贡献。
- Reddit - Dive into anything: 未找到描述
- ICBINP XL - v4 | Stable Diffusion Checkpoint | Civitai: 如果你喜欢这个作品,请考虑请我喝杯咖啡 :) 在 Stable Horde 上免费使用此模型。这个期待已久的 ICBINP 后续模型是...
- Survey Form - 5day.io: 作为一名刚入职几年的年轻专业人士,对于证明自己和寻找每个人都在谈论的神秘工作与生活平衡,总有一种隐约的焦虑。有时...
- Stable Radio 24/7: Stable Radio,一个 24/7 全天候直播流,专门播放由 Stable Audio 生成的曲目。在 stableaudio.com 探索模型并开始免费创作
- Cool Fun GIF - Cool Fun White cat - Discover & Share GIFs: 点击查看 GIF
- sd-webui-animatediff/docs/features.md at master · continue-revolution/sd-webui-animatediff: 适用于 AUTOMATIC1111 Stable Diffusion WebUI 的 AnimateDiff - continue-revolution/sd-webui-animatediff
- GitHub - princeton-nlp/SWE-agent: SWE-agent: Agent Computer Interfaces Enable Software Engineering Language Models: SWE-agent: Agent 计算机接口赋能软件工程语言模型 - princeton-nlp/SWE-agent
- Reddit - Dive into anything: 未找到描述
- GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface.: 最强大且模块化的 Stable Diffusion GUI、API 和后端,具有图形/节点界面。 - comfyanonymous/ComfyUI
- GitHub - kijai/ComfyUI-DiffusionLight: Using DiffusionLight in ComfyUI: 在 ComfyUI 中使用 DiffusionLight。通过在 GitHub 上创建账号为 kijai/ComfyUI-DiffusionLight 的开发做出贡献。
- GitHub - ZHO-ZHO-ZHO/ComfyUI-SegMoE: Unofficial implementation of SegMoE for ComfyUI: SegMoE 的 ComfyUI 非官方实现。通过在 GitHub 上创建账号为 ZHO-ZHO-ZHO/ComfyUI-SegMoE 的开发做出贡献。
- GitHub - lllyasviel/stable-diffusion-webui-forge: 通过在 GitHub 上创建账号为 lllyasviel/stable-diffusion-webui-forge 的开发做出贡献。
{kind=link}
Unsloth AI (Daniel Han) ▷ #general (241 条消息🔥🔥):
-
全栈开发人员推荐请求:一位成员寻求优秀全栈开发人员的推荐,并邀请任何能提供帮助的人直接私信。
-
关于 Unsloth Enterprise 模型训练的咨询:有人提问 Unsloth Enterprise 是否支持全量模型训练;回复澄清说支持,但加速倍数将比 FA2 快 2-5 倍,而不是 30-40 倍。
-
关于 Prompt 格式和实现的讨论:成员们讨论了自定义 AI 模型和 Prompt 格式,特别提到了创建一个名为 Cortana 1.0 的模型,该模型是根据《士官长》视频游戏中的 AI 设计的。讨论中还涉及了寻找适合聊天模式的模型,以及利用正确的 Prompt 结构以实现高效运行的担忧。
-
AI 开发中的更新与成就分享:他们分享了 Daniel Han 的推文,反思了鉴于目前较短的开发时间,AI 在未来几个月内的潜力。此外还讨论了 Unsloth AI 的基准测试,包括其 ‘Ye’ 模型在 SWE Bench 上取得的 12.29% 的成绩。
-
AI 性能的关注与优化:多位成员询问了针对不同 AI 模型和平台的优化与支持。例如,讨论围绕 Unsloth 对 Galore 的支持、GPT 模型开源的可能性,以及在 Intel CPU 和 GPU 上加速本地 LLM 推理和微调的努力。一段包含 GitHub 链接 的交流强调了在特定硬件上加速 AI 推理的资源。此外,还讨论了 Unsloth 团队即将推出的潜在性能改进和更新。
- Google Colaboratory:未找到描述
- Am Ia Joke To You Is This A Joke GIF - Am IA Joke To You Am IA Joke Is This A Joke - Discover & Share GIFs:点击查看 GIF
- I Aint No Fool Wiz Khalifa GIF - I Aint No Fool Wiz Khalifa Still Wiz Song - Discover & Share GIFs:点击查看 GIF
- jondurbin/airoboros-gpt-3.5-turbo-100k-7b · Hugging Face:未找到描述
- Home:提速 2-5 倍,节省 70% 显存的 QLoRA & LoRA 微调 - unslothai/unsloth
- Home:提速 2-5 倍,节省 70% 显存的 QLoRA & LoRA 微调 - unslothai/unsloth
- GitHub - intel/neural-speed: An innovative library for efficient LLM inference via low-bit quantization:一个通过低比特量化实现高效 LLM 推理的创新库 - intel/neural-speed
- GitHub - intel-analytics/ipex-llm: Accelerate local LLM inference and finetuning (LLaMA, Mistral, ChatGLM, Qwen, Baichuan, Mixtral, Gemma, etc.) on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max). A PyTorch LLM library that seamlessly integrates with llama.cpp, HuggingFace, LangChain, LlamaIndex, DeepSpeed, vLLM, FastChat, ModelScope, etc.:在 Intel CPU 和 GPU(例如带有 iGPU 的本地 PC,以及 Arc、Flex 和 Max 等独立 GPU)上加速本地 LLM 推理和微调(LLaMA、Mistral、ChatGLM、Qwen、Baichuan、Mixtral、Gemma 等)。一个与 llama.cpp、HuggingFace、LangChain、LlamaIndex、DeepSpeed、vLLM、FastChat、ModelScope 等无缝集成的 PyTorch LLM 库...
- sloth/sftune.py at master · toranb/sloth:使用 unsloth 的 Python sftune、qmerge 和 dpo 脚本 - toranb/sloth
- Reddit - Dive into anything:未找到描述
Unsloth AI (Daniel Han) ▷ #random (12 条消息🔥):
-
别具一格的小行星采矿公司:Open Asteroid Impact 倡议是一种独特的小行星采矿方法,提议将小行星投向地球,而不是在太空中进行采矿。提供的链接展示了他们的 Logo,并强调了他们在获取太空资源时优先考虑安全和效率的目标。
-
对 Unsloth 网站设计的赞赏:一位成员称赞了 Unsloth 的网站设计,指出该网站非常有吸引力。
-
预算有限下的创意:由于预算限制,Unsloth 网站上的树懒图像是使用 Bing DALL-E 设计的。设计者还表示,打算最终委托 3D 艺术家创作一个形象统一的吉祥物。
-
通过努力实现设计一致性:在回答关于设计统一性的询问时,Unsloth 网站设计者提到生成了数百张树懒图像,并在 Photoshop 中手动进行了精修。
-
为了速度选择 Bing DALL-E 而非 Hugging Face:设计者在图像生成方面选择了 Bing DALL-E 而非 Hugging Face 的 DALL-E,因为其能够快速生成多张图像且拥有可用额度。
提到的链接:Open Asteroid Impact:未找到描述
Unsloth AI (Daniel Han) ▷ #help (278 messages🔥🔥):
-
训练过程中的评估详解:成员们讨论了为什么默认情况下在 Fine-tuning 期间不添加评估数据集——添加它们会减慢过程。Training loss 是使用 Cross-entropy loss 计算的,Evaluation loss 也使用相同的指标。
-
使用 SFTTrainer 进行智能打包 (Packing):在使用
SFTTrainer时,成员们分享了如何配置和优化训练,包括使用packing以及避免在 Gemma 模型中使用它,因为这可能会导致问题。 -
应对数据集大小挑战:用户排查了与 OOM 错误和数据集大小相关的问题,包括讨论对大数据量使用 Streaming datasets,以及在使用 PyArrow 处理极大量数据时的挑战。
-
GGUF 转换困惑:一位成员在将模型转换为 GGUF 格式时遇到问题并讨论了合适的方法,探讨了在转换脚本中进行手动架构调整的可能需求。
-
推理故障与 Unsloth 更新:出现了一个 GemmaForCausalLM 对象导致属性错误的情况,在更新并重新安装 Unsloth 库后得到解决。一位成员提到使用 16-bit 模型推理导致了 OOM 错误,还有人在设置 Fine-tuning 环境时遇到了 Python.h 缺失的问题。
- Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- qwp4w3hyb/deepseek-coder-7b-instruct-v1.5-iMat-GGUF · Hugging Face:未找到描述
- 在训练期间添加准确率、精确率、召回率和 F1 分数指标:你好,你可以定义你的计算指标函数并将其传递给 Trainer。这里有一个计算指标的示例。使用 sklearn.metrics 定义准确率指标函数...
- danielhanchen/model_21032024 · Hugging Face:未找到描述
- Hugging Face Transformers | Weights & Biases 文档:Hugging Face Transformers 库使 BERT 等最先进的 NLP 模型以及混合精度和梯度检查点等训练技术易于使用。W&B 集成增加了丰富的...
- 主页:快 2-5 倍,显存占用减少 70% 的 QLoRA 和 LoRA 微调 - unslothai/unsloth
- Supervised Fine-tuning Trainer:未找到描述
- Qwen/Qwen1.5-14B-Chat-GPTQ-Int4 · Hugging Face:未找到描述
- deepseek-ai/deepseek-vl-7b-chat · Hugging Face:未找到描述
- 主页:快 2-5 倍,显存占用减少 70% 的 QLoRA 和 LoRA 微调 - unslothai/unsloth
- 主页:快 2-5 倍,显存占用减少 70% 的 QLoRA 和 LoRA 微调 - unslothai/unsloth
- TinyLlama/TinyLlama-1.1B-Chat-v1.0 · Hugging Face:未找到描述
- Hugging Face – 构建未来的 AI 社区。:未找到描述
- TheBloke/deepseek-coder-6.7B-instruct-GGUF · Hugging Face:未找到描述
Perplexity AI ▷ #general (469 messages🔥🔥🔥):
-
关于 Pro 模型和用法的讨论:用户交流了使用不同 AI 模型(如 Claude 和 Haiku)阅读和解释 PDF 的见解。他们辩论了 Perplexity 的 Pro 功能和模型 Context windows 的优势,建议使用 “Writing” 焦点模式以获得详细回复,并启用 “Pro” 以获得更简洁准确的答案。一些人建议使用 Sonar 以获得更快的响应。
-
Perplexity 将引入广告?:针对 Perplexity 计划引入广告的报道,用户表达了极大的担忧。用户引用了 Perplexity 首席商务官关于潜在赞助建议问题的言论,部分用户表示失望,并希望广告整合不会影响 Pro 用户的体验。
-
图像生成查询与可访问性:用户询问了在桌面端和移动端生成图像的问题,得到的回复确认虽然移动端 App 不支持图像生成,但移动设备上的网页版支持该功能。
-
推荐链接与折扣:用户分享了 Perplexity.ai 的推荐链接,并提到通过这些链接可以获得 10 美元的折扣。
-
技术支持与功能请求:用户咨询了 API 限制和响应速度慢等技术问题,以及取消 25MB PDF 限制等功能更新。有建议使用 Sonar 以提高速度,并讨论了 Perplexity 是否已经取消了某些限制。
- GroqChat: 未找到描述
- 未找到标题: 未找到描述
- Perplexity 将在其 AI 搜索平台上尝试广告形式。: Perplexity 的首席业务官 Dmitry Shevelenko 告诉 Adweek,公司正在考虑在其平台中添加赞助的建议问题。如果用户继续搜索有关...的更多信息
- Apple 发布 ReALM —— 新的 AI 模型可能让 Siri 变得更快、更智能: ReALM 可能是 Siri 2.0 的一部分
- 生成式 AI 搜索引擎 Perplexity 计划出售广告: 未找到描述
- Perplexity 将在其 AI 搜索平台上尝试广告形式。: Perplexity 的首席业务官 Dmitry Shevelenko 告诉 Adweek,公司正在考虑在其平台中添加赞助的建议问题。如果用户继续搜索有关...的更多信息
- 当服务器宕机时的 Iceeramen GIF - 当服务器宕机时的 Iceeramen 猴子 - 发现并分享 GIF: 点击查看 GIF
- 来自 Aravind Srinivas (@AravSrinivas) 的推文: 良好的氛围至关重要
- 来自 Aravind Srinivas (@AravSrinivas) 的推文: 迫不及待。
- 来自 Phi Hoang (@apostraphi) 的推文: 本月发布周边商品。与 @Smith_Diction 合作,为 @perplexity_ai 打造。
- Reddit - 深入探索一切: 未找到描述
- pplx-api 入门指南: 未找到描述
- 报告:AI 搜索引擎 Perplexity 可能很快向用户展示广告: 根据报告,Perplexity 将在相关问题部分显示广告。
- Perplexity,一家试图挑战 Google 的 AI 初创公司,计划出售广告 - Slashdot: 一位匿名读者分享了一份报告:生成式 AI 搜索引擎 Perplexity 声称是 Google 的竞争对手,最近从 Jeff Bezos 等投资者那里获得了 7360 万美元的 Series B 融资...
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- Quora - 分享知识、更好地了解世界的场所: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- 搜索结果: 未找到描述
- 未找到标题: 未找到描述
- Codecademy 论坛: Codecademy 的社区讨论论坛。
- 开始一个开发者博客:Hashnode - 自定义域名、子路径、托管/Headless CMS。: 具有自定义域名、托管/headless CMS 选项的开发者博客。我们新的 headless CMS 为开发者工具公司简化了内容管理。
Perplexity AI ▷ #sharing (23 条消息🔥):
- 定制文章的魔力:一位成员发现他们可以创建高度定制化的文章,突显了利用 Perplexity 深入研究特定主题的能力。
- 高效的新闻通讯调研:Perplexity 协助用户迅速收集准确信息,显著加快了为其新闻通讯(Newsletter)订阅者制作“欢迎礼”的速度。
- 对 Fritz Haber 的深入探讨:通过 Perplexity 搜索,一位成员深入研究了 Fritz Haber 的生平,揭示了他通过哈伯-博施法(Haber-Bosch process)对粮食生产做出的关键贡献、他在化学武器方面的复杂历史,以及他反对纳粹政权的道德立场。细节包括他获得诺贝尔奖的成就,以及围绕他的不幸家庭和历史境遇。
- 好奇心驱动的学习:用户正利用 Perplexity 满足对各种主题的好奇心,从机器学习中的卷积(convolutions)到 《希腊左巴》(Zorba the Greek),展示了该平台在处理各种咨询方面的多功能性。
- 随机森林的概念澄清:多位成员寻求理解 random forest classifier(随机森林分类器),表明了社区内对机器学习算法的共同兴趣。
Perplexity AI ▷ #pplx-api (24 messages🔥):
-
Perplexity API 暂不支持团队注册:一位用户询问是否可以使用团队计划注册 Perplexity API,但已确认 目前不支持团队注册。
-
关于速率限制的困惑:一位成员分享了对 速率限制(rate limits)的困惑,特别是在使用 sonar-medium-online 模型时。尽管遵守了 20req/m 的限制,他们 仍然遇到 429 错误;建议记录带有时间戳的请求,以确保速率限制被正确执行。
-
时效性准确结果的问题:一位用户报告称,在使用 sonar-medium-online 模型询问当天的顶级科技新闻时,得到了不准确的过时信息。建议在 system prompt 中加入 “Ensure responses are aligned with the Current date.”(确保回答与当前日期一致),以引导模型的结果。
-
澄清 Perplexity API 的功能:有人寻求关于 Perplexity API 工作原理的澄清。要点包括生成 API key、在请求中将 key 作为 bearer token 发送,以及管理信用余额(支持自动充值)。
-
API 额度支付挂起问题:一位成员表达了对购买 API 额度时出现问题的担忧——过程显示为 “Pending” 状态 且账户未更新。一名工作人员要求提供账户详情,以便在后台检查该问题。
Latent Space ▷ #ai-general-chat (76 messages🔥🔥):
- 开源 SWE-agent 媲美 Devin:一个名为 SWE-agent 的新系统已经推出,在 SWE-bench 上拥有与 Devin 相似的准确率,其显著特点是开源。
- 苹果的研究暗示 AI 将超越 GPT-4:苹果的一篇研究 论文 讨论了一个名为 ReALM 的系统,暗示其能力超越了 ChatGPT 4.0,并与 iOS 18 的 Siri 开发同步。
- Claude Opus 的性能困境:对话中提到 Claude Opus 和 GPT-4 之间存在显著的性能差距,Opus 在某些任务(如“大海捞针”测试)中表现吃力。提到了一个 提示工程互动教程 以提高 Claude 的输出效果。
- Stable Audio 2.0 发布:StabilityAI 发布了 Stable Audio 2.0,这是一款能够生成高质量、完整长度音乐曲目的 AI,提升了音频 AI 领域的能力。
- ChatGPT Plus 功能增强:ChatGPT Plus 现在允许用户在网页或 App 端 编辑 DALL-E 图像,且最近的 iOS 更新包含了一个 编辑对话提示词 的选项。详细说明可在 OpenAI 帮助页面 查看。
- Replit: Replit 开发者大会直播
- 来自 Logan Kilpatrick (@OfficialLoganK) 的推文:很高兴分享我已加入 @Google,负责 AI Studio 的产品领导工作并支持 Gemini API。前方有很多艰巨的工作,但我们将努力让 Google 成为 AI 开发者构建应用的最佳家园。...
- Apple AI 研究人员夸赞其实用的端侧模型“大幅超越” GPT-4 - 9to5Mac:Siri 最近一直在尝试描述在使用 CarPlay 或播报通知功能时在“信息”中收到的图像。在...
- 来自 Sully (@SullyOmarr) 的推文:我使用 Cursor 作为我的 IDE,而 Claude 在使用 API 时似乎明显变差了。代码写一半、逻辑糟糕、编码风格极差。但在他们的官网上运行完美。还有人遇到这种情况吗?
- 来自 Logan Kilpatrick (@OfficialLoganK) 的推文:很高兴分享我已加入 @Google,负责 AI Studio 的产品领导工作并支持 Gemini API。前方有很多艰巨的工作,但我们将努力让 Google 成为 AI 开发者构建应用的最佳家园。...
- 来自 Zack Witten (@zswitten) 的推文:六个月来我一直渴望大力推销这个,现在 Anthropic API 已经 GA,我终于可以了…… Prompt Engineering 互动教程!https://docs.google.com/spreadsheets/d/19jzLgR...
- Replit — 为代码修复构建 LLM:简介 在 Replit,我们正在重新思考开发者体验,将 AI 作为开发环境的一等公民。为了实现这一愿景,我们正将 AI 工具与我们的 I...
- 来自 Greg Kamradt (@GregKamradt) 的推文:Claude 2.1 (200K Tokens) - 长上下文召回压力测试。我们都喜欢增加上下文长度——但性能如何?Anthropic 提供了 Claude 2.1 的早期访问权限,所以我...
- 来自 Anthropic (@AnthropicAI) 的推文:Claude 2.1 的 200K token 上下文窗口非常强大,但需要仔细的 Prompt 才能有效使用。了解如何让 Claude 在长文档中高保真地召回单个句子...
- 来自 John Yang (@jyangballin) 的推文:SWE-agent 是我们用于自主解决 GitHub 仓库问题的新系统。它在 SWE-bench 上获得了与 Devin 类似的准确率,平均耗时 93 秒,而且它是开源的!我们设计了一个新的 Agent-co...
- 来自 Ofir Press (@OfirPress) 的推文:人们在问我们 Claude 3 在 SWE-agent 上的表现如何——并不好。在 SWE-bench Lite(测试集的 10% 子集)上,它的表现比 GPT-4 低了近 6%(绝对值)。而且它也慢得多。我们将...
- 来自 John David Pressman (@jd_pressman) 的推文:“Many Shot Jailbreaking”是我一段时间以来见过的主要实验室发布的最令人尴尬的出版物,我把 OpenAI 的 superalignment 文章也算在内。↘️ 引用 lumpen spac...
- 来自 Stability AI (@StabilityAI) 的推文:隆重推出 Stable Audio 2.0 —— 一个能够根据单个 Prompt 生成高质量、完整曲目、具有连贯音乐结构、长达三分钟、采样率为 44.1 kHz 立体声的新模型。探索...
- 来自 Teortaxes▶️ (@teortaxesTex) 的推文:Opus 是一个极其强大的模型,是诗人,也是 @repligate 的天赐之物。它在事实性(胡编乱造或不知道)和指令遵循方面表现欠佳;GPT-4,甚至 Mistral 模型可能做得...
- 来自 Gustavo Cid (@_cgustavo) 的推文:我过去常乞求 LLM 提供结构化输出。大多数时候,它们理解任务并返回有效的 JSON。然而,大约有 5% 的时间它们做不到,我不得不编写胶水代码来避免...
- 孩子们还应该学习编程吗?(Practical AI #263) — Changelog Master Feed — Overcast:未找到描述
- 来自 Gustavo Cid (@_cgustavo) 的推文:我以前总是恳求 LLM 提供结构化输出。大多数时候,它们能理解任务并返回有效的 JSON。然而,大约有 5% 的时间它们做不到,我不得不编写胶水代码来避免……
- 使用 DSPy 实现结构化输出:不幸的是,大语言模型(LLM)并不会始终如一地遵循你给出的指令。当你构建 AI 系统时,这是一个巨大的问题……
- 来自 Blaze (Balázs Galambosi) (@gblazex) 的推文:哇。当 OpenAI API 还停留在 Whisper-2 时,@AssemblyAI 发布了甚至超越 Whisper-3 的产品:比 Whisper-3 准确率高 13.5% + 幻觉减少高达 30% + 处理 60 秒只需 38 秒……
- Geoffrey Hinton 教授 - “数字智能会取代生物智能吗?” Romanes 讲座:AI 教父 Geoffrey Hinton 教授,CC, FRS, FRSC,于 2 月 19 日星期一在 Sheldonian 剧院发表了牛津大学年度 Romanes 讲座…… </ul> </div> --- **Latent Space ▷ #[llm-paper-club-west](https://discord.com/channels/822583790773862470/1197350122112168006/1225158181316067422)** (356 条消息🔥🔥): - **DSPy 成为焦点**:LLM Paper Club 讨论了 **DSPy 框架**,并将其效用与 **LangChain** 和 **LlamaIndex** 进行了比较。重点强调了它为不同大语言模型(LLM)优化 **Prompt** 以及轻松**迁移**模型的能力,这一能力在 [DSPy 的 arXiv 论文](https://arxiv.org/abs/2310.03714)中得到了强调。 - **Devin 的亮相引发讨论**:提到了 **Devin** 的概念,这是一款拥有数千美元 OpenAI 额度支持其演示的 AI,引发了对其潜在演示用途的兴奋和期待。 - **探索 DSPy 的深度**:提出了关于 **DSPy 运行**和执行的问题,包括它是否可以**编译为更小的模型**、对调用进行**速率限制(Rate Limit)**以避免 OpenAI API 饱和,以及使用 `.save` 函数将优化结果保存到磁盘。 - **Prompt 优化的潜力**:人们对 **DSPy 优化单一指标**的能力以及是否可以将**多个指标**组合成复合分数进行优化感兴趣。讨论点强调了 DSPy 的 **teleprompter/optimizer** 功能,该功能不要求指标是可微的。 - **提出的实际应用**:俱乐部成员提出了 LLM 的各种**实际应用**,包括用于记录语音 API 对话的 **iOS 应用**、根据 URL 总结 arXiv 论文的**前端平台**、用于 **PII 检测的 DSPy 流水线**,以及重写 **DSPy 的文档**。
- 加入 Slido:输入 #code 进行投票和提问:参与实时投票、测验或问答。无需登录。
- Google Colaboratory:未找到描述
- DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines:ML 社区正在迅速探索提示语言模型 (LM) 以及将其堆叠成解决复杂任务的流水线 (pipelines) 的技术。不幸的是,现有的 LM 流水线通常是...
- 生成式摘要的评估与幻觉检测:基于参考、上下文和偏好的指标,自我一致性,以及捕捉幻觉。
- 加入 Slido:输入 #code 进行投票和提问:参与实时投票、测验或问答。无需登录。
- 有效与无效的 LLM 特定任务评估:针对分类、摘要、翻译、版权重复和毒性的评估。
- 有效与无效的 LLM 特定任务评估:针对分类、摘要、翻译、版权重复和毒性的评估。
- 你是人类吗?:未找到描述
- 1-bit LLM 时代:所有大语言模型都是 1.58 Bits:最近的研究(如 BitNet)正在为 1-bit 大语言模型 (LLM) 的新时代铺平道路。在这项工作中,我们引入了一个 1-bit LLM 变体,即 BitNet b1.58,其中每一个参数...
- - Fuck You, Show Me The Prompt.:通过拦截 API 调用快速理解难以捉摸的 LLM 框架。
- stanfordnlp/dspy 项目 main 分支下的 dspy/examples/knn.ipynb:DSPy:用于编程(而非提示)基础模型的框架 - stanfordnlp/dspy
- GitHub - seanchatmangpt/dspygen:一个为 DSPy (Demonstrate, Search, Predict) 项目提供的 Ruby on Rails 风格框架,适用于 GPT、BERT 和 LLama 等语言模型。:一个为 DSPy (Demonstrate, Search, Predict) 项目提供的 Ruby on Rails 风格框架,适用于 GPT、BERT 和 LLama 等语言模型。 - seanchatmangpt/dspygen
- GitHub - stanfordnlp/dspy:DSPy:用于编程(而非提示)基础模型的框架:DSPy:用于编程(而非提示)基础模型的框架 - stanfordnlp/dspy
- 来自 Hamel Husain (@HamelHusain) 的推文:@swyx 一个人 + 一群狂热粉丝
- 中国芯片制造商推出比 GPU 便宜 90% 的 14nm AI 处理器 —— 140 美元的芯片采用旧工艺规避美国制裁:如果有规避制裁的方法,你知道中国一定会紧跟其后。
- 来自 Divyanshu (@divyanshutwt) 的推文:在 @enkryptai,我们构建了一个红队测试套件来识别 LLMs 的缺陷。最近,我们测试了 @databricks 的 DBRX 和 🐍Jamba(一种 MoE SSM LLM)的漏洞。得到了一些有趣的结...
- ISO 8601 - 维基百科:未找到描述
- 安装并释放 lollms 与 Ollama Server 的力量:一个有趣的技术教程 🚀:🌟 嘿 YouTube 的家人们!🤓 我非常激动地向大家展示我的最新视频!在这个启发性的教程中,我将带你完成安装...
- DiJiang: Efficient Large Language Models through Compact Kernelization: 为了减轻 Transformer 的计算负载,线性注意力机制的研究获得了显著动力。然而,注意力机制的改进策略通常需要...
- 来自 poosh (e/λcc) (@p00ssh) 的推文: attention 是你所需要的,匿名者
- shisa-ai/shisa-jamba-v1-checkpoint-4228 · Hugging Face: 未找到描述
- 公民档案保管员 (Citizen Archivist): 总有一天,我们所有的记录都会上线。你可以帮助实现这一目标。你可以成为一名公民档案保管员——只需点击下面的选项即可开始。你可以标记它!为图像添加标签...
- Unchained Foxx GIF - Unchained Foxx Silent - 发现并分享 GIF: 点击查看 GIF
- 来自 Sam Paech (@sam_paech) 的推文: 使用 Claude-3-opus 作为评委的新型自动化创意写作基准测试:https://eqbench.com/creative_writing.html 更多信息:https://eqbench.com/about.html
- Paraconsistent Foundations for Probabilistic Reasoning, Programming and Concept Formation: 文章认为,四值超协调真值(此处称为 "p-bits")可以作为 AI 高度相关的概率逻辑形式的概念、数学和实践基础...
- Programming Foundation Models with DSPy / Multivector Semantic Search with ColBERT - Omar Khattab: Omar Khattab 是斯坦福大学的博士候选人,也是 AI/ML 领域的 Apple 学者。在这次对话中,Omar 解释了如何编写基础模型流水线...
- AI Pioneer Shows The Power of AI AGENTS - "The Future Is Agentic": Andrew Ng(吴恩达),Google Brain 和 Coursera 创始人,讨论了 Agent 的力量以及如何使用它们。加入我的通讯以获取定期 AI 更新 👇🏼https://www.matthewb...
- GitHub - YuchuanTian/DiJiang: "DiJiang: Efficient Large Language Models through Compact Kernelization" 的官方实现,一种基于 DCT 的新型线性注意力机制。: "DiJiang: Efficient Large Language Models through Compact Kernelization" 的官方实现,一种基于 DCT 的新型线性注意力机制。 - YuchuanTian/DiJiang
- aneeshas/imsdb-genre-movie-scripts · Hugging Face 数据集: 未找到描述
- fnlp/character-llm-data · Hugging Face 数据集: 未找到描述
- Reddit - 深入探索: 未找到描述
- TroyDoesAI/MermaidMistral · Hugging Face: 未找到描述
- TheBritishLibrary/blbooks · Hugging Face 数据集: 未找到描述
- storytracer/US-PD-Books · Hugging Face 数据集: 未找到描述
- NousResearch/Genstruct-7B · Hugging Face:未找到描述
- NousResearch/Nous-Hermes-2-SOLAR-10.7B · Is added_tokens.json missing?:未找到描述
- GitHub - jimhigson/oboe.js: A streaming approach to JSON. Oboe.js speeds up web applications by providing parsed objects before the response completes.:一种 JSON 流式处理方法。Oboe.js 通过在响应完成前提供已解析的对象来加速 Web 应用程序。- jimhigson/oboe.js
- Soaring from 4K to 400K: Extending LLM's Context with Activation Beacon:长上下文的利用对 LLM 构成了巨大挑战,因为其上下文窗口大小有限。虽然可以通过微调扩展上下文窗口,但这会导致相当大的...
- Notion —— 集笔记、任务、维基和数据库于一体的工作空间。:一款将日常工作应用融合在一起的新工具。它是为您和您的团队打造的一体化工作空间。
- Hanso Foundation:Hanso Foundation 是由 Alvar Hanso 创立的组织,旨在通过研究保护人类生命和促进福祉的方法来“迈向更美好的明天”。它曾...
- Core War - 维基百科:未找到描述
- Microsoft Copilot:您的日常 AI 助手:Microsoft Copilot 利用人工智能的力量,通过简单的聊天体验来提高生产力、释放创造力并更好地理解信息。
- 随机时空导致的星系旋转曲线异常贡献:我们考虑了一种量子引力的替代方案,其中时空度规被视为经典的,而物质场保持量子化。该理论的一致性必然要求...
- Karan4D 的 WorldSim 系统提示词开源 - Pastebin.com:Pastebin.com 自 2002 年以来一直是排名第一的粘贴工具。Pastebin 是一个可以在线存储文本一段时间的网站。
- 来自 mephisto 🤡7 (@karan4d) 的推文:我当然要开源 WorldSim。WorldSim 系统提示词和初始化对话:sysprompt:<sys>Assistant 今天处于 CLI 模式。人类正在直接与模拟器交互...
- Bay 12 Games: Dwarf Fortress:未找到描述
- Bloomberg - 你是机器人吗?:未找到描述
- Mikubox Triple-P40 配置:来自 ebay 的 Dell T7910 “准系统”,包含散热器。我推荐 “digitalmind2000” 卖家,因为他们使用现场发泡包装,确保工作站完好无损地送达。你可以选择 Xe...
- NVIDIA Quadro RTX 8000 规格:NVIDIA TU102, 1770 MHz, 4608 Cores, 288 TMUs, 96 ROPs, 49152 MB GDDR6, 1750 MHz, 384 bit
- Reddit - 深入探索:未找到描述
- Bing API 宕机数小时:用户报告 Bing API 宕机 12 小时,影响了与 DALL-E 和 Bing Image Creator 相关的服务。
- Android 上的应用访问问题:一位成员对无法在三星 Galaxy Note 9 上访问应用表示沮丧,提到了诸如 "request is not allowed"(请求不允许)之类的错误消息,以及该应用在 Google Play Store 中被列为不兼容。
- GPT 的模拟情感引发辩论:一场关于 LLM(如 GPT)是否能真正模拟情感的讨论展开,导致了与精神病态和 Eliza 效应的比较,并强调了当前 AI 模型缺乏“动力引擎”。
- OpenAI 承诺功能的缓慢推出:用户讨论了他们对 OpenAI 宣布新工具和功能(如记忆系统)但未跟进提供广泛访问权限(特别是对付费订阅者)的模式感到不满。
- 界定模拟与感知之间的界限:聊天涉及了当前 AI 在模拟情感方面的局限性,参考了神经科学中类似的各种概念问题,并呼吁对意识有更精细的理解,以指导 AI 的开发。
- LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys: 未找到描述
- Skill-Mix: a Flexible and Expandable Family of Evaluations for AI models: 随着 LLM 的角色从语言统计建模转向作为通用 AI Agent,LLM 评估应该如何改变?可以说,AI Agent 的一项关键能力是灵活地协作...
- Microsoft argues Supreme Court’s VCR ruling should doom NYT’s OpenAI lawsuit: 微软辩称:版权法“对 LLM 的障碍并不比对 VCR 的障碍大。”
- How Much Do Language Models Copy From Their Training Data? Evaluating Linguistic Novelty in Text Generation Using RAVEN: 摘要。目前的语言模型可以生成高质量文本。它们只是在复制以前见过的文本,还是已经学会了可泛化的语言抽象?为了区分这些...
- Simulators — LessWrong: 感谢 Chris Scammell, Adam Shimi, Lee Sharkey, Evan Hubinger, Nicholas Dupuis, Leo Gao, Johannes Treutlein, 和 Jonathan Low 对草案的反馈…
- 推文:尝试并基准测试新的实验性 Intel Xe Linux 图形驱动程序 - Phoronix:未找到描述
- 推文:AMD 长期开源 Linux 图形驱动程序倡导者退休 - Phoronix:未找到描述
- ">未找到标题:未找到描述
- 在 Fedora Linux Kernel 6.8 测试周中做出贡献 - Fedora Magazine:宣布 Fedora Kernel 6.8 测试周并招募参与者
- [RFC PATCH 00/20] 初始 Xe 驱动程序提交 [LWN.net]:未找到描述
- [WIP] nimlgen 开发的 nv 驱动程序 · Pull Request #4044 · tinygrad/tinygrad:未找到描述
- GitHub - NVIDIA/open-gpu-kernel-modules: NVIDIA Linux 开源 GPU 内核模块源码:NVIDIA Linux 开源 GPU 内核模块源码。通过在 GitHub 上创建账号来为 NVIDIA/open-gpu-kernel-modules 的开发做出贡献。
- GitHub - tinygrad/tinygrad: 你喜欢 PyTorch?你喜欢 micrograd?你会爱上 tinygrad! ❤️:你喜欢 PyTorch?你喜欢 micrograd?你会爱上 tinygrad! ❤️ - GitHub - tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️
- 提问的智慧:未找到描述
- 48 小时内自己写一个 Scheme - Wikibooks,开放世界的开放书籍:未找到描述
- 反函数规则 - 维基百科:未找到描述
- tinygrad-notes/commandqueue.md at main · mesozoic-egg/tinygrad-notes:通过在 GitHub 上创建账号来为 mesozoic-egg/tinygrad-notes 的开发做出贡献。
- me - 概览:me 有 45 个可用的仓库。在 GitHub 上关注他们的代码。
- Autodidax:从零开始的 JAX 核心 —— JAX 文档:未找到描述
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
- 未找到标题:未找到描述
- 未找到标题:未找到描述
- jordan singer (@jsngr) 的推文:✨ 通过手机远程与你的电脑对话,我称之为 Teleport
- GitHub - tyfiero/01iOS:通过在 GitHub 上创建账号来为 tyfiero/01iOS 的开发做出贡献。
- 使用 winget 工具安装和管理应用程序:winget 命令行工具使开发人员能够在 Windows 计算机上发现、安装、升级、移除和配置应用程序。
- 未找到标题:未找到描述
- Ubuntu 21+ 不受支持 [wayland] · Issue #219 · OpenInterpreter/01:某些依赖项使用 x11,与 wayland 不兼容 https://github.com/Kalmat/PyWinCtl?tab=readme-ov-file#linux-notice https://github.com/asweigart/pyautogui/issues?q=is%3Aissue+is%3Aopen...
- GitHub - Clinteastman/c0mputer: 将 open-interpreter 移植到 M5 Cardputer:将 open-interpreter 移植到 M5 Cardputer。通过在 GitHub 上创建账户来为 Clinteastman/c0mputer 的开发做出贡献。
- GitHub - MikeBirdTech/open-interpreter-termux: 在 Android 设备上安装 Open Interpreter 的说明。:在 Android 设备上安装 Open Interpreter 的说明。 - MikeBirdTech/open-interpreter-termux
- GitHub - m5stack/M5Unified 的 develop 分支:M5Stack 系列的统一库。通过在 GitHub 上创建账户来为 m5stack/M5Unified 的开发做出贡献。
- Git - 下载包:未找到描述
- Microsoft C++ Build Tools - Visual Studio:未找到描述
- 快速入门 | ngrok 文档:本快速入门将使用 ngrok agent 将您的应用程序部署到
- GitHub - rhasspy/piper: 一个快速、本地的神经文本转语音系统:一个快速、本地的神经文本转语音系统。通过在 GitHub 上创建账户来为 rhasspy/piper 的开发做出贡献。
- ngrok - 一行命令上线:未找到描述
- AI Mathematical Olympiad - Progress Prize 1 | Kaggle: 未找到描述
- Regulations.gov: 未找到描述
- Jailbreaking is Best Solved by Definition: 针对语言模型的“越狱(jailbreak)”攻击的兴起引发了一系列旨在防止输出不良响应的防御措施。在这项工作中,我们批判性地审视了两个阶段...
- GitHub - UpstageAI/evalverse: The Universe of Evaluation. All about the evaluation for LLMs.: 评估的宇宙。关于 LLM 评估的一切。 - UpstageAI/evalverse
- SB 1047 Analysis - Context Fund: 未找到描述
- Cem Anil (@cem__anil) 的推文: 我们最清晰的发现之一是,In-context Learning 通常作为演示数量的函数遵循简单的幂律。我们很惊讶没有发现这一点被明确地阐述在...
- SWE-Agent: 未找到描述
- Are large language models superhuman chemists?: 大语言模型(LLMs)因其处理人类语言和执行未经显式训练的任务的能力而受到广泛关注。这与...
- Stella Biderman (@BlancheMinerva) 的推文: 众所周知,微调可能会无意中移除 RLHF 防护措施 https://arxiv.org/abs/2310.03693。能否通过在数据中混入拒绝示例来解决这个问题?这些是否重要...
- Anthropic (@AnthropicAI) 的推文: Anthropic 新研究论文:多样本越狱(Many-shot jailbreaking)。我们研究了一种长上下文越狱技术,该技术对大多数大语言模型有效,包括由 Anthropic 开发的模型以及许多其他...
- Louis Castricato - RLAIF, User Autonomy, and Controllability (Eleuther / Synthlabs): 来自 Cornell Tech 开源生成式 AI 研讨会的演讲。网站:https://www.louiscastricato.com/ 幻灯片:https://drive.google.com/file/d/14Qldg0E1c...
- Google Colaboratory: 未找到描述
- JoPmt/mistral_alpaca_lora · Hugging Face: 未找到描述
- 文本生成策略: 未找到描述
- 矩阵内部:可视化矩阵乘法、Attention 及更多: 使用 3D 可视化矩阵乘法表达式、具有真实权重的 Attention Head 等。
- Reddit - 深入探索: 未找到描述
- GitHub - huggingface/cookbook: 开源 AI 手册: 开源 AI 手册。通过在 GitHub 上创建账号为 huggingface/cookbook 的开发做出贡献。
- GitHub - unslothai/unsloth: 快 2-5 倍、节省 70% 内存的 QLoRA & LoRA 微调: 快 2-5 倍、节省 70% 内存的 QLoRA & LoRA 微调 - unslothai/unsloth
- 来自 Divyanshu (@divyanshutwt) 的推文:在 @enkryptai,我们构建了一个红队测试套件来识别 LLM 的缺陷。最近,我们测试了 @databricks 的 DBRX 和 🐍Jamba(一种 MoE SSM LLM)的漏洞。得到了一些有趣的结...
- But what is a GPT? Visual intro to Transformers | Chapter 5, Deep Learning:Transformer 及其先决条件介绍。赞助者可提前观看下一章节:https://3b1b.co/early-attention 特别感谢这些支...
- Octopus - Tonic 创建的 Hugging Face Space:未找到描述
- HyperGraph Datasets - SauravMaheshkar 的集合:未找到描述
- Saurav Maheshkar ☕️ (@MaheshkarSaurav) 的推文:我目前正在研究 HyperGraph Representation Learning,过去几天一直在创建 @huggingface 集合,包括:👉 处理后的数据集 👉 论文 👉 @Gradio space...
- 制作了一个音乐老虎机,然后用它创作了一首歌 - captains chair 21:00:00 - 开始 01:35 - 制作音轨 08:28 - 音轨 我们的第一个 @HuggingFace space。这非常有趣。https://huggingface.co/spaces/thepatch/the-slot-...
- The Slot Machine - thepatch 创建的 Hugging Face Space:未找到描述
- LangSmith: 未找到描述
- 未找到标题: 未找到描述
- openai-functions-agent | 🦜️🔗 Langchain: 此模板创建了一个 Agent,它使用 OpenAI function calling 来传达其关于采取何种行动的决策。
- [beta] Structured Output | 🦜️🔗 Langchain: 让 LLM 返回结构化输出通常至关重要。这是
- 🦜🕸️LangGraph | 🦜️🔗 Langchain: 下载
- 快速入门 | 🦜️🔗 Langchain: 概览
- Azure OpenAI | 🦜️🔗 Langchain: Azure OpenAI 是一项云服务,旨在通过来自 OpenAI、Meta 等公司的各种预构建和精选模型,帮助您快速开发生成式 AI 体验。
- Azure OpenAI | 🦜️🔗 Langchain: Azure OpenAI 是一项云服务,旨在通过来自 OpenAI、Meta 等公司的各种预构建和精选模型,帮助您快速开发生成式 AI 体验。
- langchain.chains.structured_output.base.create_structured_output_runnable — 🦜🔗 LangChain 0.1.14: 未找到描述
- Issues · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
- GitHub - sequelize/sequelize at 9e141880230a7f2a9a8c1e66a31f29fea7b5a65a: 适用于现代 Node.js 和 TypeScript 的功能丰富的 ORM,支持 PostgreSQL(支持 JSON 和 JSONB)、MySQL、MariaDB、SQLite、MS SQL Server、Snowflake、Oracle DB (v6)、DB2 和 DB2 for IBM i。 - ...
- Issues · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
- GitHub - brianc/node-postgres: PostgreSQL client for node.js.: 适用于 node.js 的 PostgreSQL 客户端。通过在 GitHub 上创建账号,为 brianc/node-postgres 的开发做出贡献。
- 工具错误处理 | 🦜️🔗 Langchain: 使用模型调用工具存在一些明显的潜在失败模式。
- Issues · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
- GitHub - facebookresearch/fairseq at nllb: 用 Python 编写的 Facebook AI Research 序列到序列工具包。 - GitHub - facebookresearch/fairseq at nllb
- facebook/nllb-200-distilled-600M · Hugging Face: 未找到描述
- Transformers — CTranslate2 4.1.0 文档: 未找到描述
- The NEW Langserve Chat Playground with Agents | Coding Showcase:在这次技术深度探讨中,我们将引导您进入令人兴奋的 LangChain 和 LangServe 框架世界。在 17 分钟内,我们将为您呈现一个全面的...
- WIP: Serve playground from correct route if nested APIrouters within one another by StreetLamb · Pull Request #580 · langchain-ai/langserve:更新 playground 测试以检查 index.html 中正确的 playground 资源路径。#578
- Galaxy AI - Swagger UI: 未找到描述
- GitGud: 未找到描述
- CallStar: 与角色和名人的 AI 语音通话
- Mona Bild repost: 来自 tiktok 的知名图片 -,Mona Bild repost 在 Wuppertal - Elberfeld-West
- AllMind AI: 未找到描述
- AllMind AI - Product Information, Latest Updates, and Reviews 2024 | Product Hunt: AllMind AI 是一款专为金融分析和研究设计的全新大语言模型。该 LLM 通过为用户提供洞察并提供实时...来彻底改变金融研究。
- Call Jesus: 与耶稣的逼真 AI 语音聊天
- CallPDF: 呼叫任何 PDF - 逼真 AI 语音聊天
- CallTube: 呼叫任何 YouTube 视频 - 逼真 AI 语音聊天
- Call Website: 呼叫任何网站 - 逼真 AI 语音聊天
- Call Hacker News: Hacker News 的 AI 语音界面
- CallStar - Realistic AI voice calls with characters, YT-videos & PDFs | Product Hunt: 下一代 AI 语音通话!与名人聊天,通过语音理解您的文档并探索灵性。通过最出色的 AI 语音让 AI 对话感觉真实且个性化。呼叫 PDF、YouTube...
- Reddit - 深入探索: 未找到描述
- 未找到标题: 未找到描述
- @always_inline | Modular Docs: 将函数体直接复制到调用函数的函数体中。
- Modular Docs: 未找到描述
- GitHub - VMois/1brc-mojo: One Billion Row Challenge (1brc) in Mojo language: Mojo 语言实现的十亿行挑战赛 (1BRC)。可以通过在 GitHub 上创建账号来为 VMois/1brc-mojo 的开发做出贡献。
- One Billion Row Challenge in Golang - From 95s to 1.96s: 在十亿行挑战赛中,任务是编写一个能够读取 10 亿行文件(约 13GB)、处理并汇总来自各个气象站温度读数的程序...
- IKI AI – Intelligent Knowledge Interface:面向专业人士和团队的智能图书馆及知识助手。
- Home - KDB.AI:未找到描述
- Salad - GPU Cloud | 10k+ GPUs for Generative AI:节省高达 90% 的云账单。轻松部署 AI/ML 生产模型。每美元可多生成 600% 的图像和 10 倍的推理。立即免费试用 SaladCloud。
- GitHub - runpod-workers/worker-vllm: 用于提供大语言模型端点服务的 RunPod worker 模板。由 vLLM 驱动。:用于提供大语言模型端点服务的 RunPod worker 模板。由 vLLM 驱动。 - runpod-workers/worker-vllm
- Install HIP SDK — HIP SDK installation Windows: 未找到描述
- Llamafile LLM driver project boosts performance on CPU cores: 提升 LLaMA 性能的方法
- jartine/Mixtral-8x7B-Instruct-v0.1-llamafile at main: 未找到描述
- Arm64X PE Files: Arm64X 是 Windows 11 SDK 中的一种 PE 文件类型,用于 Arm64 上的 x64 兼容性。对于中间件或插件开发人员来说,Arm64X 可能是一个很好的解决方案,因为代码可能会被加载到 x64 或 A...
- ARM64 Boot Camp: ARM64EC and ARM64X Explained: 未找到描述
- execve() should polyfill #! on windows · Issue #1010 · jart/cosmopolitan: 复制自 bellard/quickjs#197: #!/bin/qjs console.log("Hello"); 当从 bash 作为脚本调用时不起作用: $ ./test.qjs ./test.qjs: line 2: syntax error near unexpected token `&...
- 来自 Logan Kilpatrick (@OfficialLoganK) 的推文:很高兴分享我已加入 @Google,负责 AI Studio 的产品工作并支持 Gemini API。前方还有很多艰巨的工作,但我们将努力让 Google 成为开发者使用 AI 构建应用的最佳家园。...
- Google 考虑对 AI 驱动的搜索收费,这是其商业模式的重大变革:未找到描述