ainews-lilian-weng-on-video-diffusion
Lilian Weng 谈视频扩散模型
OpenAI 进军日本市场,推出了 Batch API,并与 Adobe 合作将 Sora 视频模型引入 Premiere Pro。Reka AI 发布了 Reka Core 多模态语言模型。WizardLM-2 已发布并展示了出色的性能,Llama 3 的消息也预计很快发布。Geoffrey Hinton 强调 AI 模型展现出了超越人类的直觉、创造力和类比识别能力。Devin AI 模型显著地为其自身的代码库做出了贡献。Opus 展示了识别其自身生成内容的能力。Sam Altman 警告初创公司,如果不迅速转型,可能会被 OpenAI 碾压。Yann LeCun 讨论了 AGI 的时间表,强调 AGI 的实现是必然的,但并非迫在眉睫,且不会仅通过大语言模型(LLMs)实现。Lilian Weng 关于视频生成扩散模型的博客指出,免训练适配(training-free adaptation)是一项突破性技术。
2024/4/15-2024/4/16 的 AI 新闻。我们为您检查了 5 个 subreddits、364 个 Twitter 账号 以及 27 个 Discord 服务区(395 个频道和 5610 条消息)。为您节省的预计阅读时间(以 200wpm 计算):615 分钟。
在周末的忙碌中,我们错过的一项内容是 Lilian Weng 关于 Diffusion Models for Video Generation 的博客。虽然她的作品很少在某一天成为突发新闻,但它几乎总是针对特定重要 AI 主题的最值得阅读的资源,即使她不在 OpenAI 工作,我们也会这么说。
任何对 Sora(今年迄今为止最大的 AI 发布,目前传闻将 进入 Adobe Premiere Pro)感兴趣的人都应该读读这篇文章。不幸的是,对我们大多数人来说,阅读一篇普通的 Diffusion 论文需要 150 以上的智商。

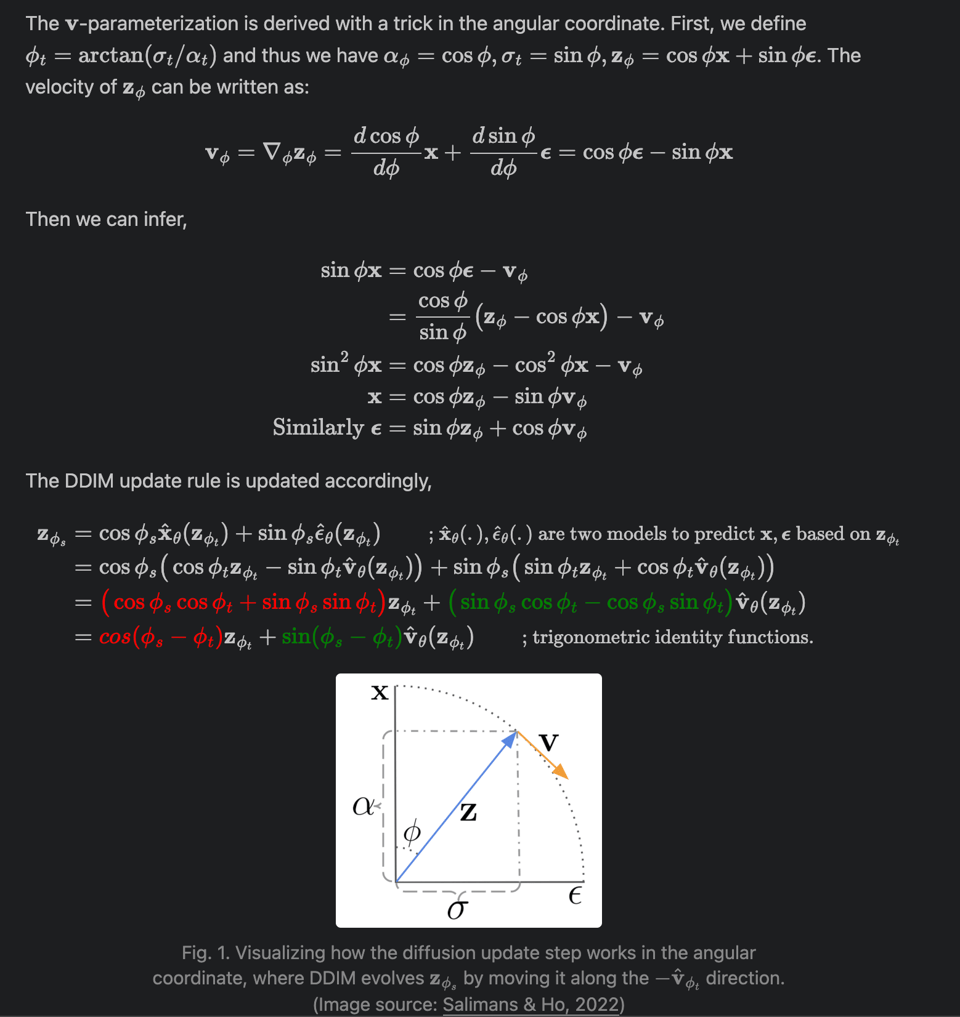
我们只有一半是在开玩笑。按照 Lilian 的风格,她带我们领略了过去两年中所有 SOTA 的 videogen 技术,让地球上其他所有的 AI 总结者都相形见绌:
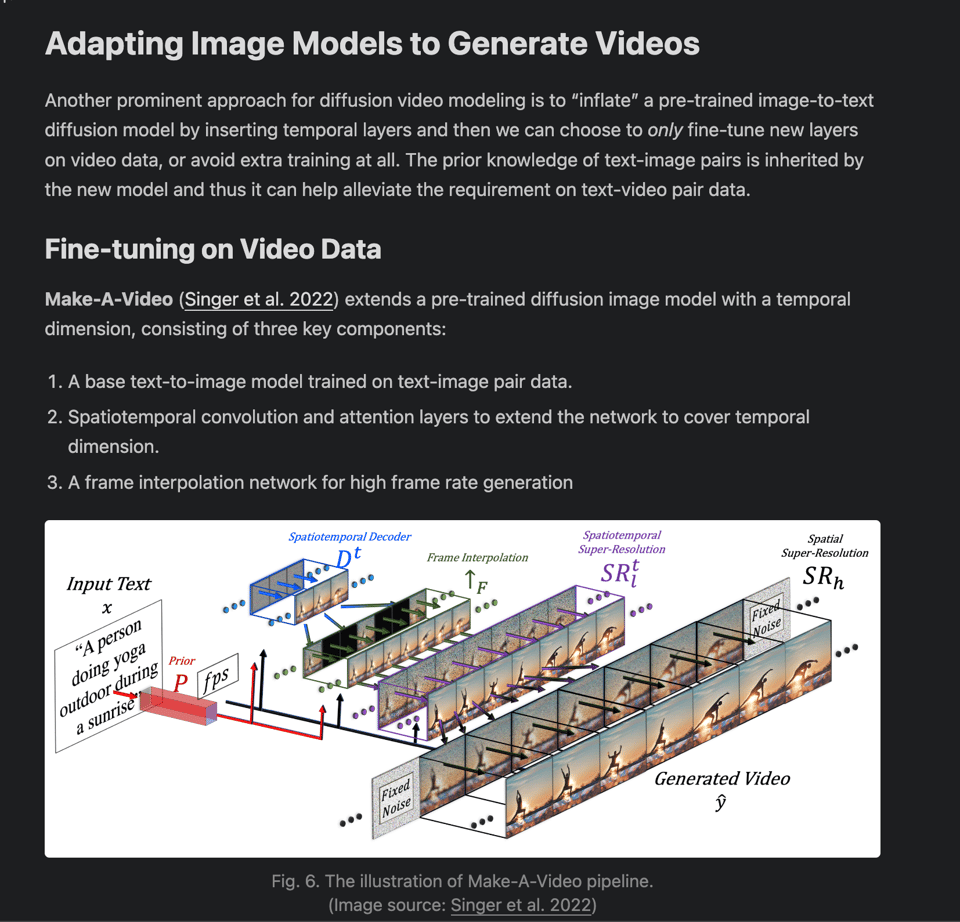
今天的意外发现来自她对 Training-free adaptation 的强调,这听起来确实非常疯狂:
“出人意料的是,在没有任何训练的情况下,将预训练的 text-to-image 模型调整为输出视频是可能的 🤯。”

遗憾的是,她只用了两句话讨论 Sora,而她肯定知道更多不能说的内容。无论如何,这可能是你我能得到的关于 SOTA AI 视频实际运作方式的最权威解释,除非 Bill Peebles 再次执笔写论文。
目录
[TOC]
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 公司与发布
- OpenAI 扩张:OpenAI 在日本落地,推出 Batch API,并与 Adobe 合作将 Sora 视频模型引入 Premiere Pro。
- 新模型:Reka AI 发布 Reka Core 多模态语言模型。
- 竞争格局:Sam Altman 表示 OpenAI 将“碾压”初创公司。Devin AI 模型内部使用量创下纪录。
{kind=link}
新模型发布与 AI 能力进展
- WizardLM-2 发布:在 /r/LocalLLaMA 中,WizardLM-2 刚刚发布并展示了令人印象深刻的性能。
- Llama 3 消息即将发布:一张图片帖子暗示关于 Llama 3 的消息即将到来。
- Reka Core 多模态模型发布:Reka AI 宣布发布 Reka Core,这是他们全新的前沿级多模态语言模型。
- AI 模型展现出直觉和创造力:Geoffrey Hinton 表示,目前的 AI 模型正表现出直觉、创造力,并且能发现人类无法察觉的类比。
- AI 助力自身开发:Devin 首次成为其自身仓库的最大贡献者,这是一个 AI 系统对其自身代码库做出重大贡献的案例。
- AI 识别自身输出:在 /r/singularity 中,有人分享了 Opus 可以识别其自身生成的输出,这是一项令人印象深刻的新能力。
{kind=link}
行业趋势、预测与伦理关切
- AI 颠覆警告:Sam Altman 警告初创公司,如果不尽快适应,就有被 OpenAI 碾压的风险。
- AGI 时间线辩论:虽然 Yann LeCun 认为 AGI 是必然的,但他表示 AGI 不会在明年到来,也不会仅仅通过 LLM 实现。
- 模型的毒性问题:WizardLM-2 在发布后不久不得不删除,因为开发者忘记了进行毒性测试,这凸显了负责任的 AI 开发所面临的挑战。
- 美国提议的 AI 监管:AI 政策中心提出了一项在美国监管 AI 开发的新法案提案。
- 关于 AI 初创公司的警告:/r/singularity 中的一条 PSA 警告要警惕那些看起来好得令人难以置信的初创公司,因为有些公司的背景与加密货币有关,存在疑点。
{kind=link}
技术讨论与幽默
- 构建 Mixture-of-Experts 模型:/r/LocalLLaMA 分享了关于如何使用 mergoo 轻松构建自己的 MoE 语言模型的指南。
- Diffusion 与 Autoregressive 模型:/r/MachineLearning 讨论并对比了用于图像生成的 Diffusion 和 Autoregressive 方法,并辩论哪种更好。
- 微调 GPT-3.5:/r/OpenAI 发布了针对自定义用例微调 GPT-3.5 的指南。
- AI 进展迷因:社区分享了一些幽默的迷因,包括一个关于 AI 进步速度的“等不及了”迷因,一个关于逆转小鼠衰老的迷因,以及一个诡异的狂欢视频迷因。
AI Twitter 综述
所有综述均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
WizardLM-2 发布与撤回
- WizardLM-2 发布:@WizardLM_AI 宣布发布 WizardLM-2,这是他们下一代最先进的 LLM 家族,包括 8x22B、70B 和 7B 模型,其性能与领先的商业 LLM 相比具有极强的竞争力。
- 遗漏毒性测试:@WizardLM_AI 为发布过程中意外遗漏了必要的毒性测试(toxicity testing)而道歉,并表示将尽快完成测试并重新发布模型。
- 模型权重被撤回:@abacaj 注意到 WizardLM-2 模型权重已从 Hugging Face 撤回,推测这可能是一次过早的发布或其他原因。
Reka Core 发布
- Reka Core 公告:@RekaAILabs 宣布发布 Reka Core,这是他们迄今为止能力最强的多模态语言模型,具备包括理解视频在内的多种能力。
- 技术报告:@RekaAILabs 发布了一份详细介绍 Reka 模型训练、架构、数据和评估的技术报告。
- 基准测试性能:@RekaAILabs 在文本和多模态的标准基准测试上对 Core 进行了评估,并结合了盲测第三方人工评估,结果显示其接近 Claude3 Opus 和 GPT4-V 等前沿级模型。
开源模型进展
- Pile-T5:@arankomatsuzaki 宣布发布 Pile-T5,这是一个使用 Llama 分词器(tokenizer)在来自 Pile 的 2T token 上训练的 T5 模型,具有中间检查点(intermediate checkpoints),并在基准测试性能上有显著提升。
- Idefics2:@huggingface 发布了 Idefics2,这是一个 8B 视觉语言模型,在 OCR、文档理解和视觉推理方面能力显著增强,采用 Apache 2.0 许可证。
- Snowflake 嵌入模型:@SnowflakeDB 开源了 snowflake-arctic-embed,这是一个强大的嵌入模型系列,参数量从 2200 万到 3.35 亿不等,具有 384-1024 个嵌入维度,MTEB 分数为 50-56。
LLM 架构进展
- Megalodon 架构:@_akhaliq 分享了 Meta 关于 Megalodon 的公告,这是一种具有无限上下文长度的高效 LLM 预训练和推理架构。
- TransformerFAM:@_akhaliq 分享了 Google 关于 TransformerFAM 的公告,其中反馈注意力(feedback attention)被用作工作记忆,使 Transformer 能够处理无限长的输入。
其他讨论
- 人形机器人预测:@DrJimFan 预测人形机器人的供应量将在未来十年超过 iPhone,呈现出先缓慢后爆发的增长态势。
- 验证码与机器人:@fchollet 认为验证码无法阻止机器人注册服务,因为专业的垃圾邮件运营团队会雇人手动破解验证码,每个账号的成本约为 1 美分。
AI Discord 综述
综述之综述的摘要
1. 新语言模型发布与基准测试
-
EleutherAI 发布了 Pile-T5,这是一个在 Pile 数据集上训练的增强型 T5 模型,训练量高达 2 万亿 token,在各项基准测试中表现出色。该发布也在 Twitter 上宣布。
-
Microsoft 发布了 WizardLM-2,这是一个最先进的指令遵循模型,后来因遗漏毒性测试而被移除,但在 Hugging Face 等网站上仍有镜像。
-
Reka AI 推出了 Reka Core,这是一款前沿级多模态语言模型,可与 OpenAI、Anthropic 和 Google 的模型相媲美。
-
Hugging Face 发布了 Idefics2,这是一个 8B 多模态模型,在 OCR、文档理解和视觉推理等视觉语言任务中表现出色。
-
关于模型性能、MinP/DynaTemp/Quadratic 等采样技术,以及根据 Berkeley 论文 研究 Tokenization 影响的讨论。
{kind=link}
2. 开源 AI 工具与社区贡献
-
LangChain 推出了 全新的文档结构,并见证了社区贡献,如 Perplexica(开源 AI 搜索引擎)、OppyDev(AI 编程助手)和 Payman AI(使 AI Agent 能够雇佣人类)。
-
LlamaIndex 发布了关于 Agent 接口的教程、与 Qdrant Engine 合作的混合云服务,以及用于混合搜索的 Azure AI 集成指南。
-
Unsloth AI 开展了关于 LoRA 微调、ORPO 优化、CUDA 学习资源以及清理 ShareGPT90k 训练数据集的讨论。
-
Axolotl 提供了多节点分布式微调指南,而 Modular 推出了 mojo2py 以将 Mojo 代码转换为 Python。
-
CUDA MODE 分享了课程录像,重点关注 CUDA 优化、HQQ+ 等量化技术以及用于高效 Kernel 的 llm.C 项目。
3. AI 硬件与部署进展
-
关于 Nvidia 可能因竞争压力提前发布 RTX 5090 及其预期性能提升的讨论。
-
Strong Compute 宣布为探索 AI 信任、Post-Transformer 架构、新训练方法和可解释 AI 的 AI 研究人员提供 $10k-$100k 的资助,并提供 GPU 资源。
-
Limitless AI(前身为 Rewind)推出了一款可穿戴 AI 设备,引发了关于数据隐私、HIPAA 合规性和云存储问题的讨论。
-
tinygrad 探索了高性价比的 GPU 集群设置、MNIST 处理、文档改进,并在向 1.0 版本过渡期间增强了开发者体验。
-
部署方面的见解,如 将自定义模型打包成 llamafiles、在消费级硬件上运行 CUDA,以及使用 tinygrad 将模型从 ONNX 转换为 WebGL/WebGPU。
4. AI 安全、伦理与社会影响辩论
-
关于 AI 发展的伦理影响的讨论,包括需要像 ALERT 这样的安全基准来评估语言模型生成潜在有害内容的情况。
-
对虚假信息传播和不道德行为的担忧,提到了 Facebook 上广告宣传的一个名为 Open Sora 的潜在 AI 诈骗项目。
-
关于在 AI 能力与社会期望之间寻找平衡的辩论,一些人主张创作自由,而另一些人则优先考虑安全因素。
-
比较 AI 系统与人类推理能力的哲学交流,涉及独立决策、情感智能以及语言理解的神经生物学基础等方面。
-
针对 Deepfakes 和生成显式 AI 内容的新兴立法,引发了关于执法挑战和意图考量的讨论。
5. 其他
-
对新模型的兴奋与推测:关于新发布的 AI 模型引发了大量的热议和讨论,包括来自 EleutherAI 的 Pile-T5、来自 Hugging Face 的 Idefics2 8B、来自 Reka AI 的 Reka Core,以及来自 Microsoft 的 WizardLM 2(尽管它经历了神秘的下架)。AI 社区正热切地探索这些模型的能力和训练方法。
-
多模态 AI 与扩散模型的进展:对话强调了 多模态 AI 的进步,例如 IDEFICS-2 展示了先进的 OCR、视觉推理和对话能力。关于用于视频生成的扩散模型的研究(Lilian Weng 的博客文章)以及 Tokenization 在语言建模中的重要性(加州大学伯克利分校的论文)也引起了广泛关注。
-
模型开发的工具与框架:讨论涵盖了用于 AI 开发的各种工具和框架,包括用于多节点分布式微调的 Axolotl、用于构建 LLM 应用的 LangChain、用于高效深度学习的 tinygrad,以及 Hugging Face 的库,如用于高质量 TTS 模型的 parler-tts。
-
新兴平台与倡议:AI 社区关注到了各种新兴平台和倡议,例如用于个性化 AI 的 Limitless(由 Rewind 更名而来)、用于多维度数据搜索的 Cohere Compass 测试版、用于 AI 到人任务市场的 Payman AI,以及 Strong Compute 提供的 1 万至 10 万美元的 AI 研究资助。这些进展标志着应用 AI 生态系统的不断扩展。
第一部分:Discord 高层级摘要
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion 3:传奇还是现实?:Stable Diffusion 3 (SD3) 的发布日期已成为社区内的“民间传说”,诸如“4月26日”和“4月69日”之类的推测日期反映了人们对其期待已久的兴奋与调侃。
- 图像动画化变得更 Comfy:工程师们正在交流图像动画化的技巧,指向 ComfyUI 工作流 和 Stability Forge,同时提到了直接通过 Python 运行模型的挑战,强调了对更简单动画 API 的需求。
- 像素艺术获得写实感:关于使用 SUPIR 等模型(可在 Hugging Face 获取)将像素艺术转化为写实图像,以及使用 Fooocus 或 Magic Image Refiner 等 img2img controlnet 解决方案增强像素化图像的讨论非常热烈。
- Prompt Engineering 辩论:讨论了提示词构建的最佳实践,一些人认为专业知识并非必要,使用 Civitai 等服务可以提供可靠的提示词基准;由于未经测试的毒性担忧,关于 WizardLM-2 的讨论已被删减。
- AI 乌托邦还是反乌托邦?:闲聊转向了对充满先进 AI 应用的未来的设想,从游戏中的风格转换到 AI 辅助的脑手术,其间穿插着关于“为 Prompt Engineering 设立的 AI 大学”的笑话,以及像“Stable Coin”这样带有戏谑意味的产品名称。
Unsloth AI (Daniel Han) Discord
基准测试盛宴:工程师们对第一个基准测试的结果分享了积极反馈,称赞其性能。此外,还有关于提取 tokenizer.chat_template 以在排行榜中识别模型模板的讨论。
LoRA 微调中的渐进式技术:社区成员交流了 LoRA 微调的技巧,建议可调整的 alpha 参数可以是 rank 的两倍。他们讨论了 ORPO 在模型训练中的资源优化,并由于学习和开发方面的优势,不鼓励使用原生 CUDA,转而倡导使用 Triton。
数据清洗成为核心:ShareGPT90k 数据集以清洗后的 ChatML 格式呈现,以方便使用 Unsloth AI 进行训练。用户强调了数据质量在模型训练中的关键作用,并提到社区更倾向于通过亲身实践来学习模型训练方法。
协作与贡献不断增加:公开征集对 Unsloth 文档和 Open Empathic 等项目的贡献,表明了对社区参与的开放态度。一位成员宣布正在开发一个“情感化” LLM,并与 Chroma 的贡献者在 libSQL 和 WASM 集成方面进行合作。
玩转 Unsloth 的 Notebook 秘籍:提供了格式化个人消息用于 AI 训练的帮助,包括 Python 脚本链接和使用 ShareGPT 格式的指南。讨论了关于 Gemma 模型的 packing 和配置建议,以减轻意外的训练问题。
Modular (Mojo 🔥) Discord
大胆的 Python 软件包征服 Mojo 代码:mojo2py 的创建(一个将 Mojo 语言代码转换为 Python 的 Python 包)表明了开发 Python 和 Mojo 互操作性工具的趋势。
语法警察纠正代码美学:引人入胜的讨论强调了代码缩进的重要性,虽然这听起来有些可笑,但对可读性至关重要。社区在代码格式规范上展现出一种轻松愉快的战友情谊。
荣获 Modular 9 级勋章:一位社区成员因达到 level 9 而受到祝贺,这表明 Modular 社区内存在积分系统或成就指标。
Modular 推文戏弄技术爱好者:Modular 发布的一系列神秘推文引发了社区的猜测和兴趣,作为一个引人入胜的营销谜题。
Nightly 更新点燃社区兴趣:发布了新的 Mojo nightly 更新,指导工程师将版本更新至 nightly/mojo,并查看 GitHub diff 和 changelog 中详细记录的最新更改和增强功能。
Perplexity AI Discord
账单困惑与 API 不一致:用户对意外收费以及 Perplexity AI 与 API 使用之间的差异表示不满,指出优惠码未出现的情况,并寻求对 temperature 等参数的理解,以在不同平台间获得一致的结果。
Pro 功能困惑:Perplexity AI 中 Pro 消息计数器的更改引发了褒贬不一的反应,一些用户享受“压力减轻”的感觉,但另一些用户则质疑此类功能调整背后的逻辑。
模型性能审查:在 AI 编程能力方面出现了意见分歧,一些用户认为 GPT-4 不足,而另一些用户则在思考各种 Perplexity 模型的能力与性能之间的微妙权衡。
文化好奇心与技术谈话:社区参与了广泛的搜索,从探究微软的广告测试工作到庆祝全球文化节日,反映了技术与创意兴趣的兼收并蓄。
API 结果不一致引发讨论:社区中的疑问集中在对齐 Perplexity Pro 和 API 的结果上,并潜藏着对 API 内容中幻觉和来源可信度的担忧。
LM Studio Discord
Windows 版模型运行已扫清障碍:针对用户的咨询,成员们确认 LM Studio 的 Windows 可执行文件已使用 Authenticode 证书签名,并讨论了 Windows 证书与 Apple 开发者许可之间的成本差异,前者需要硬件安全模块 (HSM)。
VRAM 检测难题:用户报告了在基于 Intel 的 Linux 系统上与 AMD 硬件相关的错误,尽管尝试通过 ocl-icd-opencl-dev 解决该问题。这引发了关于硬件识别错误及其在配置中带来的挑战的广泛讨论。
WizardLM-2 磨砺对话利剑:WizardLM 2 7B 模型因其在多轮对话中的能力及其训练方法而受到赞誉,其可用性已在 Hugging Face 上公布。WaveCoder ultra 6.7b 在 Microsoft 的 CodeOcean 上进行微调后的编程实力也得到了认可。
模型大对决:用户分享了使用 WizardLM-2-8x22B 和 Command R Plus 等模型的性能体验,反应不一。他们就什么是“Base” AI 模型以及模型微调(fine-tuning)和持续学习(continuous learning)的细微差别交换了意见,引发了关于 AI 记忆和偏见的辩论。
显微镜下的多样化编程实力:在公会内部,成员们深入研究了 Python 编程模型的能力,如 Deepseek Coder 和 Aixcoder,并敦促他人查看 “human eval” 分数。一些人对 WaveCoder Ultra 优越性的说法表示怀疑,暗示结果可能被夸大,而关于模型微调和量化(quantization)的讨论则阐明了对编程模型和 AI Agent 创建工具的不同偏好。
Nous Research AI Discord
-
工程师解决 Tokenization 难题:一位工程师在使用 llama.cpp 配合 Hugging Face 上的 OpenHermes 2.5 Mistral 7B 模型进行序列结束(end-of-sequence)预测时,遇到了 Token 化输出方面的困难,并寻求解决该问题的建议。
-
科技巨头的 AI 工具备受关注:用户在展示区将 Reka AI 的 Core 模型与 GPT-4V、Claude-3 Opus 和 Gemini Ultra 进行了对比,并讨论了 Google 的 CodecLM,该项目旨在为语言模型对齐(alignment)生成高质量的合成数据。
-
创新还是炒作?开源 AI 模型令人兴奋但也带来困惑:尽管在 WizardLM-2 被下架前用户们热情地进行了下载,但对其撤回的原因仍感到困惑;与此同时,CodeQwen1.5 等新模型承诺增强 92 种语言的代码生成能力,Qwen 的 7B、14B 和 32B 模型也因其基准测试分数而被提及。
-
突破二进制边界:关于 Hugging Face 上一个二进制量化友好型 AI 模型的讨论引起了兴趣,这得益于内存高效的 int8 和二进制嵌入(binary embeddings),并引用了 Cohere 博客文章中提到的 XOR 操作等嵌入距离计算方法。
-
游戏设计邂逅量子概率:对 WorldSim 彻底改变游戏开发的潜力表现出极大的热情,讨论涉及未来使用 LLM 来影响游戏内变量和内容创作,并带有一种 AI 辅助全能感的色彩。
OpenRouter (Alex Atallah) Discord
-
WizardLM 模型在 OpenRouter 神奇现身:来自 Microsoft 的 WizardLM-2 8x22B 和 WizardLM-2 7B 模型已添加到 OpenRouter,前者的成本目前为 $0.65/M tokens。几位成员已发起讨论帖,探讨此次新增模型的影响。
-
间歇性延迟困扰用户:有报告称 Mistral 7B Instruct 和 Nous Capybara 34b 等模型出现高延迟问题,问题追溯到云服务商 DDoS 防护的上游问题。进一步的复杂情况导致该服务商被降级以缓解担忧,并呼吁全球用户报告相关体验。
-
Rubiks.ai 推出包含大牌模型的 Beta 版:新的 AI 平台 Rubiks.ai 正在招募 Beta 测试人员,提供 2 个月的免费高级访问权限,并有机会试用 Claude 3 Opus, GPT-4 Turbo, 和 Mistral Large 等模型。遇到账号相关问题的用户建议直接向开发者反馈。
-
Falcon 180B 对 GPU 的渴求飙升:Falcon 180B Chat GPTQ 高达约 100GB 的 GPU 显存需求引发了社区对该模型资源密集度及其潜在使用考量的讨论,并附上了 Falcon 180B 仓库的链接。
-
高性价比沟通与模型响应建议:在高效使用模型方面,有人提议将平均每单词 1.5 tokens 作为成本计算的基准。另有讨论强调了 Airoboros 70B 在 Prompt 遵循方面的积极特性,并将其与一致性较差的模型进行了对比。
CUDA MODE Discord
PyTorch 书籍依然热度不减:尽管已有 4 年历史,《Deep Learning with PyTorch》仍被视为学习 PyTorch 基础知识的有用基石,但关于 Transformers、LLMs 和部署的章节已经过时。人们对涵盖最新进展的新版本充满期待。
Torch 与 CUDA 努力应对优化难题:在 Llama 中理解和实现自定义反向传播(backward)操作对 AI 工程师来说极具挑战,而 torch.nn.functional.linear 的使用和 stable-fast 库成为 CUDA 环境下优化推理的热门讨论话题。
转录处理的新方法:Augmend Replay 提供了一个利用尖端工具生成的 CUDA 演讲自动转录本,为 AI 社区提供了用于视频内容分析的 OCR 和分割功能。
HQQ 与 GPT-Fast 的飞跃式进展:在 Transformers 生成流水线中实现 torchao int4 kernel 后,Token 生成速度显著提升,达到 152 tokens/sec。HQQ+ 方法也显著提高了准确率,引发了围绕量化轴(quantization axis)以及与其他框架集成的讨论。
llm.C 处于 CUDA 探索的前沿:llm.C 项目激发了关于 CUDA 优化的讨论,强调了教育与创建高效 kernels 之间的平衡。在这个不断发展的领域中,优化、Profiling、潜在策略和适用数据集都备受关注。
Eleuther Discord
-
Pile-T5 展现了令人印象深刻的基准测试结果:EleutherAI 推出了 Pile-T5,这是一个在 Pile 数据集上训练的 T5 模型系列,训练量高达 2 万亿 token,并利用新的 LLAMA tokenizer 在语言任务上表现出更佳的性能。关键资源包括 博客文章、GitHub 仓库 以及 Twitter 公告。
-
应对视频扩散模型中的时间挑战:研究频道中的讨论涉及使用扩散模型进行视频合成的复杂性,参与者参考了一篇关于 视频生成扩散模型 的文章,并讨论了语言模型中 tokenization 的重要性,如 Berkeley 论文 所述。
-
LLM 评估持续演进:在 lm-thunderdome 频道中,讨论了 OpenAI 在 GitHub 上公开发布的 GPT-4-Turbo 评估实现,以及
lm-evaluation-harness增加的新基准测试,如flores-200和sib-200。 -
Token 管理受到密切关注:gpt-neox-dev 频道探讨了技术问题,如 weight decay 对 dummy tokens 的影响、模型调整后进行 sanity checks 的必要性,以及通过共享代码输出展示 token 转换的 token encoding 行为。
-
关于模型架构效率的辩论:活跃的讨论对比了稠密模型与 Mixture-of-Experts (MoE),辩论了它们的效率、推理成本和约束条件,展示了对优化语言模型架构的持续追求。
OpenAI Discord
-
大脑与机器人:成员们对 Angela D. Friederici 的著作 Language in Our Brain: The Origins of a Uniquely Human Capacity 表现出兴趣,引发了关于区分人类与 AI 语言能力的神经生物学基础的对话。讨论强调了神经科学在处理来自 Big Brain Projects 的“数据过剩”方面的挑战,以及阻碍数据解释的专利障碍。
-
AI 的局限性与自由:在对比 AI 与人类时,发现人工智能系统在存储学习信息、独立决策能力和情感反应方面尚未达到人类水平。提到 Claude 3 API 在巴西的访问问题,突显了获取 AI 工具的地理差异。
-
聊天机器人努力应对 GPT 的限制:尽管有所进步,GPT 的 context window 仍然是一个关键问题,GPT-3 的 API 允许 128k context,但 ChatGPT 本身被限制在 32k。通过上传文档实现的 “retrieval” 机制被揭秘,这允许在 API 框架内扩展有效的 context window。
-
探索图灵完备性的深度:关于《万智牌》(Magic: The Gathering)图灵完备性的激烈辩论兴起,表明这一概念的延伸范围远超传统的计算系统。
-
模糊的查询与神秘的回复:Prompt Engineering 和 API Discussions 频道出现了关于一个未识别竞赛的简短且模棱两可的交流,以及诸如 “buzz” 和 “light year” 之类的神秘单字回复,突显了技术论坛对话中偶尔出现的晦涩性。
LlamaIndex Discord
教程宝库:LlamaIndex 发布了针对 Agent 接口和应用的入门教程系列,旨在阐明核心 Agent 接口的使用。LlamaIndex 与 Qdrant Engine 合作推出了混合云服务产品,并分享了一个新教程,重点介绍了 LlamaIndex 与 Azure AI 的集成,以在 RAG 应用中利用混合搜索,该教程由来自 Microsoft 的 Khye Wei 编写,点击此处查看。
AI 聊天技巧:在 LlamaIndex 社区中,讨论范围从在 Bedrock 中实现与 Claude 的异步兼容性(目前尚未实现异步)到文档中提供的复杂查询构建帮助。gpt-3.5-turbo 与 LlamaIndex 的集成问题可能与版本过旧或账户余额有关,而针对不完整数据进行决策的配置回退(fallbacks)仍是一个待解决的挑战。
推理链革命:揭示了 LlamaIndex 在推理链集成方面的进展,一篇名为“解锁高效推理”的关键文章可以在这里找到。社区详细讨论了 RAGStringQueryEngine 中的 Token 计数方案以及 LlamaIndex 中的分层文档组织,并根据 LlamaIndex 的参考文档提供了一个涉及 TokenCountingHandler 和 CallbackManager 的具体 Token 计数器集成指南。
LAION Discord
Hugging Face 推出全新 TTS 库:展示了一个名为 parler-tts 的高质量 TTS 模型库,可用于推理和训练,并得到了 Hugging Face 社区驱动平台的支持。
缩减 CLIP 规模——更少数据,同等效能:一项关于 CLIP 的研究表明,通过策略性的数据使用和增强,较小的数据集也能达到完整模型的性能,这为数据高效的模型训练提供了新思路。
Deepfakes——立法即将到来,争议仍在继续:社区讨论了新提议的针对 Deepfakes 的法律以及 AI 中的不道德行为,并对通过 Facebook 广告推广的疑似诈骗网站(此处)提高了警惕。
安全基准测试 ALERT 发布:关于 AI 安全重要性的讨论强调了 ALERT 基准测试的发布,该基准旨在评估 LLM 处理潜在有害内容的能力,并加强了关于安全与创作自由之间平衡的对话。
音频生成技术取得新进展:涉及 Tango 模型以增强文本到音频生成的研究揭示了音频事件相关性和顺序方面的改进,标志着在数据稀缺环境下从文本生成音频的技术取得了进展。
HuggingFace Discord
-
IDEFICS-2 在多模态处理中表现出色:最近发布的 Idefics2 增强了多模态能力,在图像和文本序列处理等任务中表现优异,并计划推出用于对话交互的 chatty 变体。在演示中,重点展示了其解码高度扭曲的 CAPTCHA 的能力。
-
多样化的 AI 见解与查询:社区成员提出了各种主题,从针对长描述的 BLIP 模型微调,到音乐 AI 项目(如
.bigdookie的 infinite remix GitHub 仓库),以及在 Medium 文章中概述的使用 Java 进行图像识别。讨论还涵盖了在 HuggingFace 上进行协作工作的最佳实践以及机器学习从业者的调查参与。 -
释放 BERTopic 的潜力:AI 工程师深入研究了 BERTopic 等框架,该框架通过使用 Transformers 彻底改变了主题建模。它因其性能和通用性而受到赞誉,BERTopic 指南等文档可帮助用户了解其提取结构化主题的多种功能。
-
澄清 NLP 和 Diffusion 模型中的困惑:针对使用 T5 模型和 LoRA 配置的 NLP 张量解码寻求澄清,同时还讨论了 LLM 与嵌入模型之间的区别,以及 Diffusion 模型中的 Token 限制问题。一位社区成员针对使用 Stable Diffusion 模型时的 Token 截断发出了警告,并引用了一个公开的 GitHub issue。
-
视觉和 NLP 模型优化工作:工程师们表现出对针对特定用例调整模型的兴趣,例如用于低分辨率图像字幕生成的视觉模型以及为 SDXL 使用高级打标器(taggers)的可能性。同样,在准备用于微调 ROBERTA 问答聊天机器人的数据集,以及利用 spaCy 和 NLTK 等模型入门 NLP 方面,也寻求了建议。
Cohere Discord
Command-R 在马其顿语中表现挣扎:讨论指出 Command-R 在马其顿语中表现不佳,社区支持频道对此提出了担忧。提出的问题强调了改进多语言模型的必要性。
使用 Command-R 进行异步流式传输:工程师们询问了在 Python 中将同步代码转换为异步代码的最佳实践,旨在提高 Command-R 模型聊天流式传输的效率。
试用版 API 限制澄清:对于 Cohere 的 API,工程师们发现 “generate, summarize” 端点限制为每分钟 5 次调用,而其他端点允许每分钟 100 次调用,所有试用密钥每月共享 5000 次调用的配额。
Commander R+ 受到关注:围绕使用 Cohere 的付费 生产环境 API (Production API) 访问 Commander R+ 展开了讨论,并为潜在订阅者重点介绍了现有的 文档。
Rubiks.ai 推出 AI 强力工具:工程师们关注到 Rubiks.ai 的发布,它提供了一系列模型,包括 Claude 3 Opus、GPT-4 Turbo、Mistral Large 和 Mixtral-8x22B,并提供在 Groq 服务器上为期 2 个月的 Premium 访问权限作为入门优惠。
OpenAccess AI Collective (axolotl) Discord
Deepspeed 的多节点里程碑:分享了一份使用 Axolotl 配合 Deepspeed 01 和 02 配置进行多节点分布式微调 (multi-node distributed fine-tuning) 的指南。该 pull request 概述了解决配置问题的步骤。
Idefics2 树立新标杆:Hugging Face 最新发布的 Idefics2 8B 在 OCR、文档理解和视觉推理方面以更少的参数超越了 Idefics1。可通过 Hugging Face 访问该模型。
RTX 5090 盛大发布前的节奏:Nvidia 即将推出的 RTX 5090 显卡备受期待,推测将在 Computex 展会上首次亮相。正如 PCGamesN 所讨论的,这次提前发布可能是受竞争压力驱动。
梯度累积 (Gradient Accumulation) 受到关注:关于在样本打包 (sample packing) 和数据集长度背景下梯度累积节省内存的咨询,引发了对其对训练时间影响的探讨。
使用 Axolotl 简化模型保存:将 Axolotl 配置为仅在训练完成时而非每个 epoch 后保存模型,需要将 save_strategy 设置为 "no"。此外,针对计算资源紧张的情况,推荐使用 “TinyLlama-1.1B-Chat-v1.0”,其设置位于 Axolotl 仓库的 examples/tiny-llama 目录下。
Latent Space Discord
Rewind 现更名为 Limitless:此前被称为 Rewind 的可穿戴技术已更名为 Limitless,引发了关于其实时应用潜力和对未来 AI 进步影响的讨论。成员们对云端存储信息的数据隐私和 HIPAA 合规性表示了担忧。
Reka Core 诞生:Reka Core 作为一种能够理解视频的多模态语言模型 (multimodal language model) 加入竞争。社区对这个小团队在 AI 民主化方面取得的成就以及在 publications.reka.ai 发布的详细技术报告深感兴趣。
Cohere Compass Beta 启航:Cohere Compass Beta 作为下一代数据搜索系统亮相,引发了围绕其 Embedding 模型以及为渴望探索其功能边界的申请者提供 Beta 测试机会的讨论。
Payman AI 探索 AI-人类市场:Payman AI 凭借其创新的“AI 雇佣人类”市场概念引起了关注,推动了关于数据生成影响和推进 AI 训练方法的对话。
Strong Compute 慷慨提供资源:Strong Compute 披露了一项针对 AI 研究人员的资助计划,为可解释 AI (Explainable AI)、后 Transformer 模型 (post-transformer models) 及其他突破性领域的项目提供 $10k-$100k 的资金和大量 GPU 资源,申请截止日期为 4 月底。资助详情和申请流程已在 Strong Compute 研究资助页面 概述。
OpenInterpreter Discord
AI 创新风暴正在酝酿:OpenInterpreter 社区启动了一个头脑风暴空间,旨在构思该平台的使用场景,重点关注功能、Bug 和创新应用。
Airchat 语音通信走红:社区内对 Airchat 的讨论非常热烈,工程师们互相交换用户名并审视其功能和易用性,这标志着人们对多样化通信平台的兴趣日益增长。
开源 AI 引发热潮:开源 AI 模型,特别是 WizardLm2,因提供类似于 GPT-4 的强大 AI 能力的透明访问而受到关注,凸显了社区对开源替代方案的兴趣。
引导 01 预订流程:对于那些重新考虑 01 预订的人,可以通过联系 help@openinterpreter.com 轻松取消;此外,关于 Windows 11 安装困扰以及使用来自 AliExpress 的零件进行硬件兼容性改进的讨论也在增加。
Linux 用户对 OpenInterpreter 的青睐:Linux 用户被引导至 rbrisita 的 GitHub 分支,该分支汇集了 01 设备的所有最新 PR,社区还在通过自定义设计和电池寿命改进来优化其 01 配置。
LangChain AI Discord
-
LangChain 文档重构征求反馈:LangChain 工程师概述了新的文档结构,以更好地对教程、操作指南和概念信息进行分类,从而改善用户在资源中的导航体验。目前正在征求反馈,并发布了 LangChain 简介,详细介绍了大语言模型 (LLM) 的应用生命周期流程。
-
并行执行与 Azure AI 冲突解决:技术讨论确认了 LangChain 的
RunnableParallel类允许并发执行任务,并参考了用于并行节点运行的 Python 文档。同时,针对neofjVectorIndex和faiss-cpu的问题,社区正在交流包括 LangChain 版本回滚和分支切换在内的解决方案。 -
创新与公告涌入 LangChain:一系列项目更新和社区交流展示了多项进展,例如通过多进程提高 Rag Chatbot 的性能、引入 Perplexica 作为新型 AI 驱动的搜索引擎,以及发布了用于 AI 向人类支付的工具 Payman(可在 Payman.ai 查看)。其他公告还包括 GalaxyAI 的免费高级模型访问、OppyDev 的 AI 辅助编码工具 (oppydev.ai),以及为 Rubiks AI 的研究助手招募 Beta 测试人员并提供奖励 (rubiks.ai)。
-
利用 AI 实现 RBAC 与 YC 愿景:具体讨论涉及在大型组织的 LangChain 框架内实现基于角色的访问控制 (RBAC),以及评估为 YC 申请微调模型的行业现状,这表明了该领域既存在挑战,也有像 Holocene Intelligence 这样的现有公司。
-
通过记忆与协作努力培养 AI:分享的知识包括一段关于构建具有长期记忆的 AI Agent 的视频,以及关于将 LangServe 与 Nemo Guardrails 集成的协作呼吁,暗示由于更新需要新的输出解析器 (output parser)。社区成员还探讨了支持支付的 AI 推荐和文档处理问题,所有这些都指向了对共同成长和协作实验的重视。
tinygrad (George Hotz) Discord
-
经济实惠的 GPU 集群:工程师们讨论了一种使用六块 RTX 4090 GPU 的 TinyBox 高性价比替代方案,与价值 25,000 美元的 TinyBox 模型相比,成本降低了高达 61.624%。重点是在预算范围内实现 144 GB 的 GPU RAM。
-
潜在的 BatchNorm Bug:在用户对涉及
invstd和bias的操作顺序表示担忧后,George Hotz 要求提供一个测试用例,以调查 tinygrad 的 batchnorm 实现中可能存在的 Bug。 -
推进 Tinygrad 文档工作:参与者认识到增强 tinygrad 文档的必要性,并正在努力制定更全面的指南,特别是随着系统从 0.9 版本演进到 1.0 版本。
-
模型转换策略:用户正在探索高效将模型从 ONNX 转换为 WebGL/WebGPU 的方法,目标是通过利用 tinygrad 的
extras.onnx模块来优化内存,正如对 Stable Diffusion WebGPU 示例的关注所表明的那样。 -
提升 Tinygrad 开发体验:社区建议将合并 NV 后端的行数限制增加到 7,500 行,如最近的 commit 所示,以平衡代码库的包容性与质量,同时解决错误可理解性方面的体验问题。
Interconnects (Nathan Lambert) Discord
AI 模型涌入市场:EleutherAI 推出了 Pile-T5,详情见其 博客文章;同时 WizardLM 2 凭借其基础 Transformer 技术和 WizardLM 页面 上的指南引起了关注。此外,Reka Core 也在其 技术报告 中亮相,Idefics2 的首次亮相则在 Hugging Face 博客 上进行了叙述,与此同时 Dolma 以 ODC-BY 许可证开源。
图结构与巨型模型引发热议:社区对将复杂的图(graphs)转化为用于模型探索的 Python 库 表现出浓厚兴趣,同时对 LLAMA 3 庞大的 30 万亿 token 训练规模反应不一。
WizardLM 伴随突如其来的道歉消失:随着 WizardLM 的莫名移除,其模型权重和帖子被删除,紧张局势升级,引发了 推测;WizardLM AI 因遗漏 毒性测试(toxicity test) 而道歉,并表示可能正在重新发布的计划中。
探索 vs. 干预:一位成员在考虑是让 Bot 自行学习还是介入干预,这体现了让算法自主探索与人工干预之间的微妙界限。
Datasette - LLM (@SimonW) Discord
-
关于数据标注必要性的辩论:在最近的一次讨论中,参与者探讨了在先进 LLM 兴起的背景下,训练模型前进行数据集标注的传统做法是否依然关键。他们思考是对数据集的深入理解仍然重要,还是模型已经能够充分独立地学习模式。
-
要求 LLM 演示具备透明度:用户对缺乏开放 Prompt 的 LLM 演示表示不满,他们更倾向于清晰地洞察模型行为,以便在无需猜测的情况下实现预期结果。此外,还有人担心模型在处理敏感信息索引等任务时,不能一致地遵循隐私指令。
-
Streamlit 简化了 LLM 日志浏览:有人使用 Streamlit 创建了一个 LLM Web UI,用于更友好地导航日志数据,旨在比 Datasette 更简单地回顾过去的聊天记录。该界面目前支持日志浏览,作者通过 GitHub gist 提供了初始代码。
-
征集界面集成想法:在展示了 Web UI 原型后,随后讨论了将其作为 Datasette 插件或独立工具集成的可能性,并思考了此类增强功能的实用性和长期效用。
-
寻求一致的索引工具:交流中强调了语言模型在处理报纸索引等任务时的不可预测性,特别是模型会因遵守隐私规范而拒绝列出姓名。对话强调了对更可靠工具的需求,并提到已联系 Anthropic 寻求解决模型拒绝回答的问题。
Alignment Lab AI Discord
-
WizardLM2 从 Hugging Face 消失:Hugging Face 上的 WizardLM2 集合已消失,集合更新显示所有模型和帖子目前均已缺失。此处提供了更新的直接链接:WizardLM Collection Update。
-
WizardLM2 潜在的法律问题:有一个未经证实的疑问在流传,即 WizardLM2 的移除是否源于法律问题,但目前尚未引用更多信息或来源来澄清这些潜在问题的性质。
-
争相获取 WizardLM2 资源:社区正在积极寻找可能在 WizardLM2 权重被删除前已经下载过的人。
-
WizardLM2 误删的证据:一位社区成员分享了一张截图,证明 WizardLM2 是因为测试不当而被删除的。截图可以在这里查看:WizardLM2 Deletion Confirmation。
DiscoResearch Discord
LLama-Tokenizer 训练难题:工程团队成员分享了在训练 Llama-tokenizer 时面临的挑战,目标是通过减小 embedding 和输出感知机(perceptron)的大小来实现硬件兼容性。他们探索了如 Hugging Face 的 convert_slow_tokenizer.py 和 llama.cpp 的 convert.py 等脚本来辅助这一过程。
寻找符合欧盟版权要求的资源:目前正在积极寻找符合欧盟版权法的文本和多模态数据集,用于训练多模态模型。建议的起点包括 Wikipedia、Wikicommons 和 CC Search,以收集获得许可或免费的数据。
采样策略探讨:工程圈的讨论围绕语言模型的解码策略展开,强调学术论文需要包含 MinP/DynaTemp/Quadratic Sampling 等现代方法。一篇分享的 Reddit 帖子 提供了面向外行的比较,而对话则呼吁对这些策略进行更严谨的研究。
解码方法论值得深入研究:对 LLM 解码方法的检查暴露了当前文献中的空白,特别是与操作模型中常见的开放式任务相关的部分。成员们表示需要深入研究高级采样方法及其对模型性能的影响。
MinP 采样提升创意写作表现:创意写作任务的性能提升显著,由于使用了 min_p 采样参数,alpaca-eval 风格的 elo 分数增加了 +8,eq-bench 创意写作测试 增加了 +10。这些改进表明了微调采样策略对 LLM 输出的潜在影响。
Skunkworks AI Discord
-
纽约 Gen AI 应用规模化活动:在纽约市 Gunderson Legal 举办的 General AI 爱好者见面会将聚焦于将 Gen AI 应用扩展至生产阶段。活动详情和注册链接可在 此处 查看,来自 Portkey 和 Noetica 的行业领袖也将参与。
-
Reka Core 成为强力竞争者:一段名为 “Reka Core: A Frontier Class Multimodal Language Model” 的新视频展示了 Reka Core 在与 OpenAI、Anthropic 和 Google 的竞争模型对抗中表现出色,详情见 YouTube 视频。
-
JetMoE-8B 实现高性价比优势:据 YouTube 视频 透露,预算低于 10 万美元开发的 JetMoE-8B 模型,据称超越了 Meta AI 耗资巨大的 LLaMA2-7B。
Mozilla AI Discord
- 自定义模型打包变得更简单:社区成员请求提供将自定义 AI 模型打包进 llamafile 的指南,旨在支持同行的相关尝试。
- Docker 部署揭秘:一个 GitHub pull request 为工程师提供了使用 GitHub Actions 构建并发布容器到 Docker Hub 的演练步骤,包括设置
DOCKER_HUB_USERNAME和DOCKER_HUB_ACCESS_TOKEN等必要的 repository secrets。发布容器到 Docker Hub。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
Stability.ai (Stable Diffusion) ▷ #general-chat (1015 messages🔥🔥🔥):
- 寻找难以捉摸的 SD3:备受期待的 Stable Diffusion 3 (SD3) 发布仍是猜测的热点,许多成员在询问其发布日期,不少人戏称它是一个神话,并给出了诸如“4月26日”或“4月69日”之类的讽刺性预估。
- 选择图生视频工作流:对于想要让图像动起来的用户,推荐使用 ComfyUI 工作流和 Stability Forge 等资源。一些用户在直接用 Python 运行模型时遇到困难,并寻求关于简单动画 API 的建议。
- 结合不同技术的 Stable Diffusion:讨论线程涉及了 Stable Diffusion 的各个方面以及相关的 AI 进展,例如使用 SUPIR 等模型将像素艺术转换为写实图像,以及使用基于 img2img controlnet 的方案(如 Fooocus 或 Magic Image Refiner)转换像素化图像。
- 提示词编写与模型讨论:用户对 prompt engineering 进行了辩论,有人建议不需要成为专家或参加课程也能编写有效的 prompt;使用 civitai 等平台可以提供不错的提示词基准。像 WizardLM-2 这样的新进展曾短暂出现,随后因未经测试的毒性而被删除。
- 闲聊与 AI 未来思考:社区里随口开着关于“Stable Coin”、“Stable Miner”和“提示词工程师大学”的玩笑,同时也畅想着拥有游戏风格转换和 AI 脑科手术等先进 AI 技术的世界,这既反映了幽默感,也体现了对 AI 发展的憧憬。
- Video Examples: ComfyUI 工作流示例
- no title found: 未找到描述
- camenduru/SUPIR · Hugging Face: 未找到描述
- Perturbed-Attention-Guidance Test | Civitai: rMada 的帖子。标签为 . PAG (Perturbed-Attention Guidance): https://ku-cvlab.github.io/Perturbed-Attention-Guidance/ PROM...
- TikTok - Make Your Day: 未找到描述
- Reddit - Dive into anything: 未找到描述
- WizardLM/WizardLM-2 at main · victorsungo/WizardLM: 由 Evol-Instruct 驱动的指令遵循 LLM 系列:WizardLM, WizardCoder - victorsungo/WizardLM
- Developer Recruiters GIF - Developer Recruiters Programmer - Discover & Share GIFs: 点击查看 GIF
- Consistent Cartoon Character in Stable Diffusion | LoRa Training: 在这个视频中,我将尝试通过训练一个 LoRa 来制作一个一致的卡通角色。*After Detailer* ➜ https://github.com/Bing-su/adetailer*Kohya SS GUI* ➜ h...
- Is it possible to use Flan-T5 · Issue #20 · city96/ComfyUI_ExtraModels: 是否可以将仅编码器版本的 Flan-T5 与 Pixart-Sigma 配合使用?链接:https://huggingface.co/Kijai/flan-t5-xl-encoder-only-bf16/tree/main
- Reddit - Dive into anything: 未找到描述
- How To Install Stable Diffusion (In 60 SECONDS!!): 这是在本地快速安装 Stable Diffusion AI 最简单的方法 - 特别感谢 Le-Fourbe 指导我完成整个过程!!GitHub 链接:https:/...
- GitHub - BatouResearch/magic-image-refiner: 通过在 GitHub 上创建账号来为 BatouResearch/magic-image-refiner 做出贡献。
- GitHub - QuintessentialForms/ParrotLUX: Pen-Tablet Painting App for Open-Source AI: 面向开源 AI 的数位板绘画应用。通过在 GitHub 上创建账号来为 QuintessentialForms/ParrotLUX 做出贡献。
- GitHub - kijai/ComfyUI-SUPIR: SUPIR upscaling wrapper for ComfyUI: 用于 ComfyUI 的 SUPIR 放大封装器。通过在 GitHub 上创建账号来为 kijai/ComfyUI-SUPIR 做出贡献。
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI。通过在 GitHub 上创建账号来为 AUTOMATIC1111/stable-diffusion-webui 做出贡献。
- Reddit - Dive into anything: 未找到描述
- GitHub - city96/ComfyUI_ExtraModels: Support for miscellaneous image models. Currently supports: DiT, PixArt, T5 and a few custom VAEs: 支持各种图像模型。目前支持:DiT, PixArt, T5 和一些自定义 VAE - city96/ComfyUI_ExtraModels
- Comfy Workflows: 分享、发现并运行数千个 ComfyUI 工作流。
- GitHub - lllyasviel/stable-diffusion-webui-forge: 通过在 GitHub 上创建账号来为 lllyasviel/stable-diffusion-webui-forge 做出贡献。
- Amazon.com: NVIDIA H100 Graphics Card, 80GB HBM2e Memory, Deep Learning, Data Center, Compute GPU : Electronics: 未找到描述
Unsloth AI (Daniel Han) ▷ #general (430 条消息🔥🔥🔥):
-
Notebook 实现中的复杂性:成员们讨论了某项任务的复杂性,提到他们需要为此创建一个详细的 Notebook。这一过程被公认为对相关成员和用户来说都很复杂。
-
对加密货币和 TGE 的混淆:一位用户询问了“mainnet”和“TGE”日期,导致聊天参与者产生混淆。已澄清 Unsloth AI 与加密货币无关。
-
解决 Unsloth 的技术问题:用户面临连续输出和包错误的问题。建议使用字符串结束标记 (
</s>) 来限制模型生成,并建议成员遵循 Unsloth 提供的 Colab Notebooks,其中包含预配置的设置。 -
关于即将发布的模型的讨论:人们对潜在的新模型发布充满期待,包括对 “Llama 3” 的讨论以及各种 Unsloth 优化策略之间的区别。用户分享了资源并根据声誉和过去的公告进行推测,表达了对新发布可能给团队带来工作量的兴奋与紧张交织的情绪。
-
对 Unsloth 的贡献:个人表达了对贡献 Unsloth 文档和进行一次性资金捐助的兴趣。提到专注于扩展 Unsloth Wiki 的贡献(特别是关于 Ollama/oobabooga/vllm 的内容)将非常有价值,团队对社区参与改进文档持开放态度。
-
围绕 WizardLM 重新上传的争议:讨论了一个显著事件,即 WizardLM 版本在因错过毒性测试而被撤回后,在各个平台上重新上传的情况。多位用户交流了关于重新上传的信息以及原始版本下架的原因。
- WizardLM 2: 社交媒体描述标签
- screenshot: 在 Imgur 发现互联网的魔力,这是一个由社区驱动的娱乐目的地。通过有趣的笑话、热门迷因、娱乐 GIF、励志故事、病毒视频等来振奋精神...
- alpindale/WizardLM-2-8x22B · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- lucyknada/microsoft_WizardLM-2-7B · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- Home: 提升 2-5 倍速度,减少 80% 显存的 LLM 微调。通过在 GitHub 上创建账户为 unslothai/unsloth 的开发做出贡献。
- twitter.co - Domain Name For Sale | Dan.com: 我在 Dan.com 上发现了一个正在出售的优质域名。快来看看!
- Full fine tuning vs (Q)LoRA: ➡️ 获取完整脚本(及未来改进)的终身访问权限:https://trelis.com/advanced-fine-tuning-scripts/ ➡️ Runpod 一键微调...
- GitHub - cognitivecomputations/OpenChatML: 通过在 GitHub 上创建账户为 cognitivecomputations/OpenChatML 的开发做出贡献。
Unsloth AI (Daniel Han) ▷ #random (6 messages):
- 编写情感化 LLM 代码:ashthescholar. 表示他们正在开发“情感化”大语言模型 (LLM) 的骨架,并即将开始编码,期待分享进展。
- 与 Chroma 的路线图同步:lhc1921 分享了他们计划使用 libSQL (SQLite) 在 Go 和 WASM 中开发 Chroma 的边缘版本,部分灵感来自另一位成员关于实现设备端训练的策略。这项工作是与 Chroma 的核心贡献者 taz 合作完成的,代码库可以在 GitHub - l4b4r4b4b4/go-chroma 找到。
提到的链接:GitHub - l4b4r4b4b4/go-chroma: Go port of Chroma vector storage: Chroma 向量存储的 Go 语言移植版本。通过在 GitHub 上创建账户为 l4b4r4b4b4/go-chroma 的开发做出贡献。
Unsloth AI (Daniel Han) ▷ #help (322 messages🔥🔥):
- Unsloth 助力数据驱动的聊天机器人升级:一位成员讨论了如何通过 Unsloth 格式化个人聊天消息,以训练自己的 AI 克隆体,并获得了包括将数据集转换为 ShareGPT 格式 的 Python 脚本在内的帮助,以及关于如何使用该脚本处理个人数据以创建可用于训练的数据集的建议。他们还被引导至一个相关的 Unsloth notebook。
- 针对增强训练的 LoRA 微调:用户报告在利用 LoRA 进行模型微调时调整了 alpha 参数。对于 rslora,建议 alpha 为 rank 值的两倍,尽管确切的最佳值可能因情况而异。
- Unsloth 对 ORPO 的支持:据一位成员称,旨在优化模型训练所需资源的 ORPO 已在 Unsloth 中得到支持。ORPO 方法与 DPO 的不同之处在于,它不需要预先进行单独的 SFT (Supervised Fine-Tuning) 步骤。
- CUDA 学习与 Triton 的前景:一位 CUDA 初学者获得了参考 Triton 教程 进行学习的建议,并被告知 Unsloth 不推荐使用原生 CUDA,而是建议 Triton 对 LLM 工作更有益。
- Unsloth 与 Gemma:为了获得最佳效果,请勿在 Gemma 模型中使用 packing。Unsloth 库兼容 Llama 和 Mistral 的 packing,但在训练期间,具有高 rank 适配器的配置可能会出现意外的 loss 突跳问题。
- 发现公开数据集和机器学习项目 | Kaggle:在数千个项目中下载公开数据集 + 在一个平台上分享项目。探索政府、体育、医学、金融科技、食品等热门话题。灵活的数据摄取。
- Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- G-reen/EXPERIMENT-ORPO-m7b2-1-merged · Hugging Face:未找到描述
- 使用 LoRA (Low-Rank Adaptation) 微调 LLM 的实用技巧:我从数百次实验中学到的经验
- Unsloth - 4倍长的上下文窗口和1.7倍大的 Batch Size:Unsloth 现在支持具有极长上下文窗口的 LLM 微调,在 H100 上最高可达 228K(Hugging Face + Flash Attention 2 为 58K,因此长了 4 倍),在 RTX 4090 上可达 56K(HF + FA2 为 14K)。我们成功实现了...
- Triton 入门:在 PyTorch 中编写 Softmax:让我们在 PyTorch eager 模式下编写 Softmax,并确保有一个可运行的版本来与我们的 Triton Softmax 版本进行比较。下一个视频 - 我们将在 Tr 中编写 Softmax...
- 首页:快 2-5 倍,内存占用减少 80% 的 LLM 微调。通过在 GitHub 上创建账户,为 unslothai/unsloth 的开发做出贡献。
- 安装:未找到描述
- 未找到标题:未找到描述
- 安装:未找到描述
- GitHub - comfyanonymous/ComfyUI:最强大且模块化的 Stable Diffusion GUI、API 和后端,具有图形/节点界面。:最强大且模块化的 Stable Diffusion GUI、API 和后端,具有图形/节点界面。 - comfyanonymous/ComfyUI
- 在文档中添加 ORPO 示例 Notebook · Issue #331 · unslothai/unsloth:只需对当前的 DPO Notebook 进行极少修改,即可使用 TRL 中的 ORPOTrainer。由于 ORPO 进一步降低了训练聊天模型所需的资源(无需单独的...
- LoRA 微调的秩稳定缩放因子:随着大语言模型 (LLM) 的计算和内存密集程度日益增加,参数高效微调 (PEFT) 方法现在已成为微调 LLM 的常用策略。一种流行的 PEFT 方法...
- 秩稳定 LoRA (Rank-Stabilized LoRA):释放 LoRA 微调的潜力:未找到描述
- Tokenizer:未找到描述
- 向模型添加新的词表 Token · Issue #1413 · huggingface/transformers:❓ 问题与帮助:你好,我该如何扩展预训练模型的词表,例如通过向查找表添加新 Token?有演示此操作的示例吗?
Unsloth AI (Daniel Han) ▷ #showcase (47 条消息🔥):
- Benchmark 热议:成员们讨论了第一个 Benchmark 的性能,并分享了令人鼓舞的评论,例如称其看起来“非常棒”且“相当不错”。
- 模型模板之谜:一位用户询问排行榜如何识别模型模板,另一位成员指出应查看
tokenizer.chat_template进行了澄清。 - 干干净净的数据:一个名为 ShareGPT90k 的数据集以清洗后的 ChatML 格式发布,其中的
<div>和<p>等 HTML 标签被替换为空字符串。用户敦促他人在使用 Unsloth AI 进行训练时使用text键。 - 期待 Ghost 的配方:围绕 LLM 训练配方的可访问性和脆弱性展开了辩论,特别是关于一个名为 Ghost 的模型。用户讨论了数据质量相对于微调技术的重要性,并认同通过实验积累经验比依赖预定义配方更重要。
- 分享学术见解与资源:对话包括分享有价值的资源,如详细的研究论文和解释 Direct Preference Optimization (DPO) 等高级 AI 概念的 YouTube 教程。一位用户特别期待了解 Ghost 模型背后的训练方法。
- Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation):我从数百次实验中学到的东西
- Sloth Crawling GIF - Sloth Crawling Slow - Discover & Share GIFs:点击查看 GIF
- Direct Preference Optimization (DPO) explained: Bradley-Terry model, log probabilities, math:在这段视频中,我将解释 Direct Preference Optimization (DPO),这是论文 "Direct Preference Opti..." 中提出的一种语言模型对齐技术。
- FractalFormer: A WIP Transformer Architecture Inspired By Fractals:查看 GitHub 仓库 https://github.com/evintunador/FractalFormer,在 patreon 上支持我的学习之旅!https://patreon.com/Tunadorable?utm_medium=u...
- Neural Graph Reasoning: Complex Logical Query Answering Meets Graph Databases:复杂逻辑查询回答 (CLQA) 是最近兴起的图机器学习任务,它超越了简单的单跳链接预测,解决了一个更为复杂的多跳逻辑推理任务...
- LLM Phase Transition: New Discovery:瑞士 AI 团队发现的点积 Attention 层学习中的相变。研究 Attention 机制内部的相变...
- After 500+ LoRAs made, here is the secret:既然你们想知道,秘密就在这里:数据集的质量占一切的 95%。剩下的 5% 是不要用错误的参数毁了它。是的,我知道...
- pacozaa/sharegpt90k-cleanned · Datasets at Hugging Face:未找到描述
Modular (Mojo 🔥) ▷ #general (60 messages🔥🔥):
-
Kapa.AI 为 Discord 社区带来即时回答:Kapa.AI 提供可定制的 AI 机器人,在 Slack 和 Discord 等社区提供即时技术支持。他们的机器人可以添加到服务器中,通过提供即时回答和消除等待时间来改善开发者体验,这在他们的社区参与用例页面和 Discord 安装文档中有详细说明。
-
探索 Mojo 语言的编译优化:关于在 Mojo 语言中使用别名(aliases)进行编译时参数决策的讨论表明,使用此类方法可以实现内存优化,因为未使用的别名在编译后不会占用内存空间。对于关于代码清晰度与注释的更细致观点,分享了一个相关的 YouTube 视频。
-
理解 Typestates 和内存效率:在讨论 Typestates 相对于别名的好处时,一位成员推荐了一种来自 Rust 的技术,用于对对象状态进行编译时保证,正如一篇关于 Rust typestates 的文章中所述。讨论围绕语言设计中的内存使用优化展开,特别是布尔值在内存中如何存储和寻址。
-
探讨编程语言中的位级优化:对话探讨了为什么语言规范(如 C 语言)将 enums 定义为 32 位整数,并争论了 bools 是否需要占用整个字节。这些话题涉及处理器层级的内存分配以及语言层级内存使用的潜在效率,并参考了布尔值如何能更紧凑地表示为字节内的位(bits)。
-
Rust 的 BitVec Crate 兼具速度和内存效率:讨论最后认可了 Rust 的 BitVec Crate 在处理布尔标志集时既高效又省内存。引用了一个优化案例,通过在 Rust 中使用 bitset,将性能从耗时数年提升到仅需几分钟,详情见 willcrichton.net。
- Zig 中的 Packed structs 让位/标志集变得简单:在构建 Mach 引擎时,我们在 Zig 中使用了一种巧妙的小模式,使得在 Zig 中编写标志集比其他语言更优雅。这里有一个简短的解释。
- Bamboozled GIF - Bamboozled - 发现并分享 GIF:点击查看 GIF
- 使用 Rust 将数据分析速度提升 180,000 倍:如何通过哈希、索引、性能分析、多线程和 SIMD 实现令人惊叹的速度。
- kapa.ai - 技术问题的即时 AI 解答:kapa.ai 帮助面向开发者的公司为其社区构建由 LLM 驱动的支持和入门机器人。OpenAI、Airbyte 和 NextJS 的团队都在使用 kapa 来提升开发者体验...
- Rust 中的 Typestate 模式 - Cliffle :未找到描述
- kapa.ai - 适用于面向开发者产品的 ChatGPT:kapa.ai 帮助面向开发者的公司为其社区构建由 LLM 驱动的支持和入门机器人。OpenAI、Airbyte 和 NextJS 的团队都在使用 kapa 来提升开发者体验...
- Discord 机器人 | kapa.ai 文档:Kapa 可以作为机器人安装在您的 Discord 服务器上。该机器人允许用户使用自然语言询问有关您产品的问题,从而改善开发者体验,因为开发者可以找到答案...
- 不要写注释:为什么你不应该在代码中写注释(而是写文档)。在 https://www.patreon.com/codeaesth... 获取代码示例、Discord、歌曲名称等。
Modular (Mojo 🔥) ▷ #💬︱twitter (5 条消息):
- Modular 发布神秘推文:Modular 在 Twitter 上分享了一条神秘信息,在没有背景的情况下引发了人们的好奇。
- 悬念升级,再发推文:不久之后,Modular 发布了另一条加密推文,维持了悬念。
- Modular 的第三波预热:延续这一趋势,Modular 发布了第三条推文,增添了更多神秘感。
- Modular 推文连发不断:Modular 的一系列神秘消息延伸到了第四条推文。
- 第五条推文保持神秘感:Modular 以第五条神秘推文结束了这一系列发布,让追随者充满期待。
Modular (Mojo 🔥) ▷ #ai (2 条消息):
- Mojo 复现热议:一名成员表示有兴趣在 Modular (Mojo) 中复现某个未指明的功能或项目,显示出对该平台能力的极大热情。
- 释放 AI Agents 的真实潜力:一名成员分享了一个 YouTube 视频,在 10 分钟的简短演示中解释了如何创建具有长期记忆和自我改进能力的 AI Agents,这可能为其他爱好者提供宝贵的见解。
提及的链接:释放 AI Agent 的真实力量?!长期记忆与自我改进:如何为您的 AI Agent 构建长期记忆和自我改进能力?免费使用 AI 幻灯片生成器 Gamma:https://gamma.app/?utm_source=youtube&utm…
Modular (Mojo 🔥) ▷ #🔥mojo (541 条消息🔥🔥🔥):
- Mojo 对 Python 工具的适配:一个名为 mojo2py 的新 Python 包 已被开发,用于将 Mojo 代码转换为 Python 代码,这表明人们对连接 Python 和 Mojo 的工具兴趣日益浓厚。该仓库已在 GitHub 上发布。
- 学习 Mojo 基础:对于那些想要从零开始学习 Mojo 的人来说,Mojo 编程手册 是首选的综合指南,重点介绍了核心概念,如 parameters 与 arguments 的区别以及对 traits 的理解。
- 引入条件一致性 (Conditional Conformance):关于 Mojo 中 conditional conformance 的潜力正在进行讨论,这允许实现类似于 C++ 或 Haskell 等其他语言中的结构化模式行为,尽管在处理泛型代码时可能会面临挑战。
- 用于运行时灵活性的 Variant 类型:使用
Variant作为创建包含多种类型(类似于 Python)的列表的方法得到了验证,并指出Variant在运行时的行为更像是一个带有标签的联合体 (tagged union),类似于 TypeScript 中的 ADTs。 - 语法和表示方面的努力:多位成员正在积极讨论 Mojo 函数签名和类型表示语法的可能改进,包括使用
'1数字来避免部分绑定类型中冗长的命名,以及为 VS Code 以外的更广泛集成开发 Treesitter 语法/LSP。
- Documentation: 未找到描述
- Documentation: 未找到描述
- Mojo Manual | Modular Docs: Mojo 编程语言的综合指南。
- Correct Plankton GIF - Correct Plankton - Discover & Share GIFs: 点击查看 GIF
- Mojo🔥 modules | Modular Docs: Mojo 标准库中所有模块的列表。
- Einstein notation - Wikipedia: 未找到描述
- tuple - Rust: 未找到描述
- mojo/examples/matmul.mojo at f1493c87ff8cbabb3cb88fb11fd1063403a7ffe2 · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账户为 modularml/mojo 的开发做出贡献。
- mojo/examples/matmul.mojo at f1493c87ff8cbabb3cb88fb11fd1063403a7ffe2 · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账户为 modularml/mojo 的开发做出贡献。
- GitHub - venvis/mojo2py: A python package to convert mojo code into python code: 一个将 mojo 代码转换为 python 代码的 python 包 - venvis/mojo2py
- Conditional Trait Conformance · Issue #2308 · modularml/mojo: 审查 Mojo 的优先级。我已阅读路线图和优先级,并相信此请求符合优先级。你的请求是什么?我认为如果能有条件的...
- TkLineNums/tklinenums/tklinenums.py at main · Moosems/TkLineNums: 一个用于 tkinter 的简单行号小部件。通过在 GitHub 上创建账户为 Moosems/TkLineNums 的开发做出贡献。
- jax/jax/_src/interpreters/partial_eval.py at f8919a32e02841c9d5a202398e16357c7506b102 · google/jax: Python+NumPy 程序的可组合转换:微分、向量化、JIT 到 GPU/TPU 等 - google/jax
- Conditional Trait Conformance · Issue #2308 · modularml/mojo: 审查 Mojo 的优先级。我已阅读路线图和优先级,并相信此请求符合优先级。你的请求是什么?我认为如果能有条件的...
Modular (Mojo 🔥) ▷ #community-projects (4 messages):
-
Mojo 遇上 gRPC:一位社区成员正致力于通过 IPC 将功能性的 Mojo 代码与遗留的 C++ 集成,以提升产品性能。
-
寻找更新版的 Llama:一位成员询问关于 Llama2 的官方版本,并分享了 Aydyn Tairov 撰写的客座博客文章,内容关于如何构建该项目。他们已尝试将项目更新至 v24.2.x,并提供了指向其在 GitHub 上 正在进行的工作 (WIP) 的链接。
-
Llama2 获得官方 MAX API:针对关于 Llama2 的查询,另一位成员指引前往 GitHub 上提供的官方 MAX graph API 中的 llama2。
-
Mojo 代码 - Python 转换工具:社区成员创建了一个名为 mojo2py 的新 Python 包,用于将 Mojo 代码转换为 Python 代码,代码仓库可在此处 获取。
- GitHub - venvis/mojo2py: 一个将 mojo 代码转换为 python 代码的 python 包:venvis/mojo2py - 一个将 mojo 代码转换为 python 代码的 python 包
- max/examples/graph-api/llama2 at main · modularml/max:一系列示例程序、笔记本和工具,旨在展示 MAX 平台的强大功能 - modularml/max
- Modular: 社区焦点:我如何构建了 llama2.🔥 (作者:Aydyn Tairov):我们正在为世界构建下一代 AI 开发者平台。查看我们的最新文章:社区焦点:我如何构建了 llama2.🔥 (作者:Aydyn Tairov)
- Update to 24.2 WIP (作者:anthony-sarkis) · Pull Request #89 · tairov/llama2.mojo:与 #88 相关。正在进行中,仍会出现这些错误。我是 Mojo 新手,如果有人能提供帮助:/root/llama2.mojo/llama2.mojo:506:20: error: 'String' value has no attribute 'bitc...
Modular (Mojo 🔥) ▷ #nightly (12 messages🔥):
- 比起 Trait 更倾向于 Jank:讨论幽默地批评了缺乏 trait parameterization(Trait 参数化)的现状,并表现出对所谓的 jank(简陋方案)的偏好。
- 缩进混乱:一位用户哀叹 for 循环中缺乏正确的缩进,这引发了一阵笑声,大家对代码缩进的重要性表示了轻松的认同。
- 在 Modular 中升级:<@244534125095157760> 因在 Modular 社区的等级系统中达到 level 9 而受到祝贺。
- 代码格式化的同伴压力:有一个关于在代码格式化方面屈服于同伴压力的玩笑,表明了社区内关于个人编码风格的轻松对话。
- Mojo Nightly 更新发布:发布了一个名为
nightly/mojo的新 Mojo 更新,鼓励成员进行更新,并在 GitHub 上查看差异 (diff),在 变更日志页面 查看 changelog。
- [stdlib] 根据 `2024-04-16` nightly/mojo 更新 stdlib (作者:patrickdoc) · Pull Request #2313 · modularml/mojo:此操作使用与今天的 nightly 版本(mojo 2024.4.1618)相对应的内部提交更新了 stdlib。未来,我们可能会直接将这些更新推送到 nightly 分支。
- mojo/docs/changelog.md at nightly · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账户为 modularml/mojo 做出贡献。
Perplexity AI ▷ #general (549 messages🔥🔥🔥):
-
关于订阅和支付方式的困惑:成员们报告了尽管使用了优惠码仍被意外扣费的情况,并对管理 Perplexity API 的支付方式表示担忧。一位被认为是团队成员的用户提到,承诺会改进 Perplexity 网站以显示主要支付方式。
-
Perplexity Pro 消息计数器消失:用户注意到,除非剩余消息少于 100 条,否则不再显示指示 Perplexity Pro 用户剩余消息数量的计数器。一名据信具有团队角色的成员确认了这一变化,并称原因是用户报告这样可以减轻压力,而其他用户则对移除该功能表示不满。
-
Perplexity 性能与模型更新:一些用户表示 Perplexity 似乎比以前更快地遗忘上下文,并质疑更改 Pro 消息计数器等功能的理由。关于将 GPT-4-Turbo-2024-04-09 集成到 Perplexity 的询问得到了引用之前声明的回应,建议成员参考官方频道中的讨论。
-
AI 模型与编程:用户达成共识,认为 AI 模型在编程能力方面仍然不足,尽管 GPT-4 比其前代产品更好,但表现仍不尽如人意。Perplexity 提供的多样化模型得到了认可,但一些人认为原始模型在性能上更胜一筹。
-
支付与订阅问题讨论:成员们讨论了促销代码和账单混淆的问题。一位用户指出管理 Perplexity API 支付方式缺乏透明度,而其他用户则担心在结账时看不到促销代码选项。用户 ok.alex 的回复表示支付方式的可见性即将得到改进。
- 未找到标题:未找到描述
- Grok-1.5 Vision Preview:未找到描述
- Raycast - Perplexity API:在 Raycast 中舒适地使用 Perplexity API 提供的强大模型。
- Hamak Chilling GIF - Hamak Chilling Beach - Discover & Share GIFs:点击查看 GIF
- No The Office GIF - No The Office Michael Scott - Discover & Share GIFs:点击查看 GIF
- Chopping Garlic Chopping GIF - Chopping Garlic Chopping Knife Skills - Discover & Share GIFs:点击查看 GIF
- OpenAI Developers (@OpenAIDevs) 的推文:介绍 Batch API:在异步任务(如摘要、翻译和图像分类)上节省成本并获得更高的速率限制。只需上传批量请求文件,即可接收结果...
- How Soon Is Now Smiths GIF - How Soon Is Now Smiths Morrissey - Discover & Share GIFs:点击查看 GIF
- TikTok - Make Your Day:未找到描述
Perplexity AI ▷ #sharing (12 条消息🔥):
- 探索 Perplexity AI:成员们分享了在 Perplexity AI 上的各种搜索,探索了诸如 Microsoft 测试广告、世界艺术日以及扮演 Ichjogu 的方法等话题。
- 庆祝艺术与声音日:进行了与世界艺术日和世界声音日相关的搜索,突显了社区对全球文化观察的兴趣。
- 考察技术与游戏:讨论包括对 Microsoft 的测试广告、Atari 和 Amazon Web Services 加固指南的搜索。
- 音乐与歌词搜索:成员们表现出对音乐的倾向,搜索了歌曲 “SBK Borderline” 的歌词和短语 “Whatever It Is“。
- 成本与查询的好奇心:社区深入研究了各种查询,从询问某些物品的价格到请求葡萄牙语的解释。
Perplexity AI ▷ #pplx-api (3 条消息):
- Perplexity Pro 与 API 回答的不一致性:一位成员表示在使用 Perplexity Pro 与 API 时获得不同响应的困扰。他们希望了解 Web 客户端使用的 temperature 等设置,以便尝试匹配 API 结果以保持一致性。
- API 源材料的限制:提出了另一个关于是否可以将 API 响应限制在特定网站内容的问题。用户担心响应中可能包含幻觉和错误的来源归属。
LM Studio ▷ #💬-general (210 messages🔥🔥):
-
LM Studio 上的协作式 Agent:用户对 LM Studio 中协同工作的 Agent 感到兴奋,并期待 Windows 版本。提到在发布 Windows 版本之前,自动化编译过程是一个必要的步骤。
-
用户关于模型性能和使用的查询:存在关于 模型性能 的问题,特别是与 Mistral 等模型的编程能力相关的问题。另一位用户询问了在 LM Studio 中模型是否支持 无需 NVLink 的多 GPU 支持。
-
WizardLM-2 模型集成:用户讨论了将 WizardLM-2 模型集成到 LM Studio 中,并分享了社区模型链接,如 Hugging Face 上的 MaziyarPanahi/WizardLM-2-7B-GGUF。研究了 Mixtral 8x22B 的模型命名和分区的细节,以及有效使用模型所需的 VRAM 等系统要求。
-
对 AI 模型微调和 Agent 的兴趣:讨论了使用 LM Studio 创建个人 AI Agent 或助手的可能性,以及使用外部工具针对特定任务进行模型微调。分享了 微调 资源(如 GitHub 上的 LLaMA-Factory)和 Agent 创建工具。
-
错误的代码识别和数据集工具:用户分享了模型错误识别编程语言的经历,并建议在 Prompt 中添加上下文等技术。此外,还为那些希望构建自定义 预处理流水线 (preprocessing pipelines) 的用户提供了 用于数据集创建的 Unstructured-IO 等工具集的链接。
- RAM Latency Calculator:RAM 延迟计算器
- 来自 WizardLM (@WizardLM_AI) 的推文:🔥今天我们发布了 WizardLM-2,我们的下一代尖端 LLM。新家族包括三个前沿模型:WizardLM-2 8x22B、70B 和 7B - 展示了极具竞争力的性能...
- lmstudio-community/WizardLM-2-7B-GGUF · Hugging Face:未找到描述
- Mission Squad. 灵活的 AI Agent 桌面应用。:未找到描述
- 多轮对话 - QnA Maker - Azure AI services:使用 Prompt 和上下文来管理 Bot 从一个问题到另一个问题的多个回合(称为多轮对话)。多轮对话是进行来回对话的能力,其中前一个...
- MaziyarPanahi/WizardLM-2-7B-GGUF · Hugging Face:未找到描述
- GitHub - hiyouga/LLaMA-Factory: 统一 100 多个 LLM 的高效微调:统一 100 多个 LLM 的高效微调。通过在 GitHub 上创建账户为 hiyouga/LLaMA-Factory 的开发做出贡献。
- GitHub - Unstructured-IO/unstructured: 用于构建自定义预处理流水线的开源库和 API,适用于标注、训练或生产机器学习流水线。:用于构建自定义预处理流水线的开源库和 API,适用于标注、训练或生产机器学习流水线。 - GitHub - Unstructured-IO/unstructured...
LM Studio ▷ #🤖-models-discussion-chat (108 messages🔥🔥):
-
重点讨论 Python 编程模型:成员们讨论了各种 Python 编程模型,如 Deepseek Coder、Wizzard Coder 和 Aixcoder,并建议 检查 ‘human eval’ 分数 以评估模型在编程挑战中的表现。一些模型(如 Aixcoder)以直接编写代码著称,而其他模型也提供对话式交互。
-
对 WaveCoder 的质疑与赞赏:WaveCoder Ultra(一个基于 DeepseekCoder 6.7B 的模型)收到的评价褒贬不一;一些人称赞其性能,而另一些人则对其优越性表示怀疑,并暗示可能存在“伪造结果”。提到 Microsoft 已经发布了三个性能各异的 WaveCoder 模型,其中 WaveCoder Ultra 因其在编写贪吃蛇游戏方面的表现而备受推崇。
-
关于 Vision Models 和 Java 程序员的问题:LM Studio Discord 上的讨论包括对适用于 Swift/SwiftUI 开发和 Java 程序员的优秀模型的咨询。回复者建议,大多数编程模型通常是针对多种语言训练的,而不是专门为某一种语言定制的。
-
模型性能的轮廓:辩论集中在模型大小、量化(Quantization)和性能之间的权衡,对于 7B 模型与压缩更严重的更大型模型的有效性,意见各不相同。虽然一些用户更倾向于 7B 模型的 Q8 量化,但其他人认为大型模型的低质量量化可能无法保留较高的智能水平。
-
文本生成图像(Text-to-Image)的限制与偏好:一位成员澄清说,文本生成图像不是 LM Studio 可以执行的任务。对于替代工具的建议包括 GUI 界面:DiffusionBee,以及在 LM Studio 之外使用 Automatic1111 处理文本生成图像任务。
- lmstudio-community/WizardLM-2-7B-GGUF · Hugging Face:未找到描述
- microsoft/wavecoder-ultra-6.7b · Hugging Face:未找到描述
- lmstudio-community/wavecoder-ultra-6.7b-GGUF · Hugging Face:未找到描述
- MaziyarPanahi/WizardLM-2-8x22B-GGUF · Hugging Face:未找到描述
- High Quality / Hard to Find - a DavidAU Collection:未找到描述
- bartowski/zephyr-orpo-141b-A35b-v0.1-GGUF at main:未找到描述
- Responses:这些是两个不同 LLM 对提示词的回答。你将分析事实性、深度、详细程度、连贯性以及我可能遗漏但通常被认为重要的任何其他领域...
LM Studio ▷ #📝-prompts-discussion-chat (15 条消息🔥):
-
错误频发困扰 LM Studio:一位成员在尝试在 LM Studio 中加载模型时遇到了错误,即使尝试卸载并恢复默认设置后也是如此。他们分享了错误消息的代码片段,但原因仍未公开,描述为“未知错误”,退出代码为:42。
-
GPU Offload:一把双刃剑?:一位成员建议关闭 GPU Offload 以绕过加载问题,但原帖作者面临性能下降和持续出现错误消息的困境,即使在禁用该功能后也是如此。
-
为沮丧的用户提供“全新开始”:鉴于模型加载问题持续存在,有人提议通过删除用户机器上的特定目录来对 LM Studio 进行全面重置。指令包括 C:\Users\Username.cache\lm-studio 等路径,并提醒备份重要数据。
-
出现 NexusRaven 提示词查询:另一位成员加入对话,询问有关 NexusRaven 的提示词预设(prompt presets),表明话题转向了 AI 模型自定义。
-
从部分脚本到完整脚本:有人简短地请求协助,希望强制 NexusRaven 编写完整的脚本,暗示该模型在输出部分内容时存在挑战。
LM Studio ▷ #🎛-hardware-discussion (21 条消息🔥):
_
- VRAM 识别错误困扰用户:一名成员在基于 Intel 的 Linux 系统上遇到了指向 AMD 硬件的奇怪错误,并讨论了关于
libOpenCL的潜在问题。他们曾希望通过安装ocl-icd-opencl-dev来模拟 GPU,但在更改 GPU 层(GPU layers)后仍持续面临加载失败的问题。 - 聊天中的链接丢失:成员们难以找到之前提到的用于 GPU 对比的 Google 表格,尽管发布了多个链接,但所讨论的确切资源仍未找到。
- 关于 Meta 的 Llama 模型的 Subreddit 讨论:一位用户分享了一个 Reddit 链接,讨论了实现 GPU 间的点对点(P2P)通信,并理论化了绕过 CPU/RAM 以增强性能的潜在益处。
- 梗图为技术讨论增添轻松氛围:在技术讨论中,一名成员分享了一个来自 Tenor 的幽默 George Hotz GIF,可能反映了他们对当前软件博弈的感受,或象征着某种突破。
- 双 GPU 的硬件分配挑战:一名成员正在寻求建议,以管理其系统中
4070 TI 12GB和4060 TI 16GB之间不均匀的模型分布,从而倾向于使用容量更大的 GPU。
LM Studio ▷ #🧪-beta-releases-chat (26 条消息🔥):
-
运行模型的 VRAM 与 RAM 对比:一名成员询问模型是否可以在拥有 24 GB VRAM 和 96 GB RAM 的系统上运行,有人担心推理速度可能会极其缓慢。另一名成员在使用 128GB 的 M3 MacBook Pro 上取得了成功,利用 LMStudio 和 MLX 运行模型的速度可与 GPT-4 媲美,达到最高 10 tokens/sec。
-
Command R Plus 和 WizardLM-2-8x22B 的性能:一位用户报告称他们将测试 WizardLM-2-8x22B 并分享结果。另一位用户对 Mixtral 8x22b 印象不佳,并思考其基础模型(Base model)的身份是否影响了性能。
-
理解基础模型:用户讨论了什么是“基础(Base)”模型,澄清了它是指尚未针对聊天(chat)或指令(instruct)等特定任务进行微调(Fine-tuned)的模型。有人提到,任何基础模型都有可能通过提示(prompted)来执行各种任务。
-
模型对比与微调考量:一名成员报告在 MaziyarPanahi/WizardLM-2-8x22B.Q4_K_M 和 Command R Plus 上都能获得超过 10 tokens/sec 的速度,且两者都能成功根据提示编写简单的 Rust 应用程序。讨论还涉及了模型是否会从聊天中持续学习,以及在微调过程中“遗忘”某些知识领域的概念。
-
AI 模型中潜在的隐性偏见:有人建议 AI 模型可能偏向于数学、IT、AI 和计算机视觉,这反映了开发者和大多数用户的兴趣。此外,还提出了关于模型是否总是在交互中学习,以及通过微调模型来遗忘不需要的知识领域是否简单等疑问。
LM Studio ▷ #amd-rocm-tech-preview (8 条消息🔥):
-
签名、封装、交付,这就是 Windows!:一名成员询问 Windows 可执行文件是否使用了 authenticode 证书进行签名。回复确认它们确实已签名。
-
对证书签名的好奇:同一名成员对签名过程表示好奇,提到他们不记得收到过任何相关通知,因为一旦应用程序签名,Windows 通常不会通知用户。
-
Windows 与 Apple 开发者许可证——安全性的代价:该成员表达了对获取 Windows 证书成本高昂的沮丧(相比于 Apple 开发者许可证),并强调了由于需要硬件安全模块(HSM)而增加的财务负担。
-
寻求关于编译和签名流程的知识:该成员寻求关于为其应用自动化编译和签名流程的建议,并表示愿意提供一些东西来交换这些共享的专业知识。
LM Studio ▷ #open-interpreter (1 条消息):
rouw3n: 这里有人在 Windows 上顺利运行 01light 软件吗?
LM Studio ▷ #model-announcements (2 条消息):
_
-
WizardLM 2 7B 在多轮对话中表现出色:新模型 WizardLM 2 7B 因其在多轮对话中的卓越表现而受到关注。该模型可在 Hugging Face 上获取,它采用了相关博客文章中详述并在模型卡末尾提到的新型训练技术。
-
WaveCoder ultra 6.7b 使用 CodeOcean 进行微调:Microsoft 最近发布的 WaveCoder ultra 6.7b 以其代码翻译能力而闻名,并使用其 ‘CodeOcean’ 平台进行了微调,该平台结合了开源代码以及 GPT-3.5-turbo 和 GPT-4 等模型。该模型可以在 Hugging Face 上探索和下载,并遵循 Alpaca 格式进行指令遵循。
Nous Research AI ▷ #off-topic (18 messages🔥):
-
量化友好型 AI 模型发布:AI 从业者 carsonpoole 在 Hugging Face 上展示了一个二进制量化友好型 AI 模型,旨在提高 Embedding 的内存效率。该方法在 这篇 cohere 博客文章 中有详细介绍,讨论了通过使用 int8 和二进制 Embedding 来显著降低内存成本。
-
创新模型训练技术详解:carsonpoole 进一步解释了该技术,强调使用了对比损失(contrastive loss)和模型输出的符号(sign)作为模型的训练机制。该方法旨在保持高搜索质量,即使使用压缩的 Embedding 格式,模型也能表现良好。
-
Cohere Embedders 训练可通过 API 获取:carsonpoole 确认,虽然目前无法在 API 之外访问 Cohere 的 embedders,但新训练的模型可以实现类似的功能。
-
理解二进制 Embedding 距离:针对 sumo43 的提问,carsonpoole 澄清说,二进制情况下的 Embedding 距离是使用 XOR 操作计算的,相当于汉明距离(hamming distance)。
-
多模态 LLM 和高性价比模型展示:pradeep1148 分享了介绍 “Idefics2 8B: Open Multimodal ChatGPT” 和 “JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars” 的 YouTube 视频,展示了在成本效益开发和 language models 能力方面的进展。视频链接:“Introducing Idefics2 8B”、“Reka Core: A Frontier Class Multimodal Language Model” 以及 “JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars”。
- carsonpoole/binary-embeddings · Hugging Face:未找到描述
- Cohere int8 & binary Embeddings - Scale Your Vector Database to Large Datasets:Cohere Embed 现在原生支持 int8 和二进制 Embedding,以降低内存成本。
- JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars:JetMoE-8B 的训练成本不到 10 万美元,但其表现优于来自 Meta AI 的 LLaMA2-7B,而后者拥有数十亿美元的训练资源。LLM 训练...
- Introducing Idefics2 8B: Open Multimodal ChatGPT:我们将了解 idefics2,这是由 huggingface 开发的开源多模态 LLM。https://huggingface.co/blog/idefics2 #python #pythonprogramming #llm #ml #ai #aritificialin...
- Reka Core: A Frontier Class Multimodal Language Model:Reka Core 在关键的行业公认评估指标上,可与来自 OpenAI、Anthropic 和 Google 的模型竞争。鉴于其占用空间和性能,...
Nous Research AI ▷ #interesting-links (4 messages):
-
Auto-Code Rover 取得进展:由 NUS 开发的 Auto-Code Rover 是一个具有项目结构感知能力的自主软件工程师,旨在实现自主程序改进。据报道,它在完整的 SWE-bench 中解决了 15.95% 的任务。
-
Auto-Code Rover 表现优于 Devin:提到 Auto-Code Rover 在软件工程任务中的表现优于另一个 AI Devin,且领先优势相当明显。
-
Google 的 CodecLM 框架揭晓:Google AI 推出了 CodecLM,这是一个用于为语言模型对齐生成高质量合成数据的机器学习框架,在 MarkTechPost 文章 中进行了讨论。
- 未找到标题:未找到描述
- GitHub - nus-apr/auto-code-rover: A project structure aware autonomous software engineer aiming for autonomous program improvement. Resolved 15.95% tasks in full SWE-bench:一个具有项目结构感知能力的自主软件工程师,旨在实现自主程序改进。在完整的 SWE-bench 中解决了 15.95% 的任务 - nus-apr/auto-code-rover
Nous Research AI ▷ #general (208 条消息🔥🔥):
- 与 Nous 团队无关:一个随 OpenML 推出的代币与 Nous 团队无关,尽管使用了他们的名字,团队已要求从项目中移除其名称。
- WizardLM-2 神秘下架:WizardLM-2 模型意外下架,原因猜测从毒性过大、违反欧盟 AI 法案到缺少评估不等。分享了下载保留版本模型权重的链接,暗示社区正在抢着备份。
- Mistral Instruct 展示了显著进展:一位成员报告了微调 Mistral instruct v0.2 的进展,分数从 58.69 提升至 67.59,超越了许多竞争对手,但仍落后于其他一些模型。
- Qwen 发布代码专用模型:Qwen 推出了 CodeQwen1.5,这是一个强大的代码生成模型,支持 92 种编程语言,并在包括 HumanEval 在内的基准测试中表现优异。目前提供 7B 版本,并提到了更大的 14B 和 32B 变体。
- 关于长期记忆和自我改进的 AI 视频:向社区分享了一个讨论长期记忆和具有自动生成可教性的自我改进 AI Agent 的视频。
- 未找到标题:未找到描述
- 未找到标题:未找到描述
- alpindale/WizardLM-2-8x22B · Hugging Face:未找到描述
- Qwen/CodeQwen1.5-7B-Chat · Hugging Face:未找到描述
- ORA:未找到描述
- amazingvince/Not-WizardLM-2-7B · Hugging Face:未找到描述
- alp (Alp Öktem):未找到描述
- WizardLM-2 8x22B by microsoft | OpenRouter:WizardLM-2 8x22B 是 Microsoft AI 最先进的 Wizard 模型。与领先的封闭模型相比,它展示了极具竞争力的性能,并始终优于所有现有的...
- Unlock AI Agent real power?! Long term memory & Self improving:如何为你的 AI Agent 构建长期记忆和自我改进能力?免费使用 AI 幻灯片生成工具 Gamma:https://gamma.app/?utm_source=youtube&utm...
- N8Programs/CreativeGPT · Datasets at Hugging Face:未找到描述
- SynthTrails:未找到描述
Nous Research AI ▷ #ask-about-llms (39 条消息🔥):
-
Hermes 2.5 推理问题: 一位用户强调了在使用 llama.cpp 和来自 Hugging Face 的 OpenHermes 2.5 Mistral 7B 模型时遇到的问题,特别是在 Rust 中处理序列结束(end-of-sequence)预测的分词输出时面临困难。他们正在寻求有关导致此问题的配置或模型故障的建议。
-
Reka AI 展示其模型:在分享的 showcase 中,Reka AI 的 Core 模型被展示为具有与 OpenAI 等公司竞争的实力,亮点说明其在各种任务上与 GPT-4V、Claude-3 Opus 和 Gemini Ultra 持平。随后链接到的 Reka 新闻公告 详细阐述了 Core 模型的训练和效率。
-
Hermes 2 Pro 扩展上下文的异常表现: OctoAI 报告称,Hermes 2 Pro Mistral 7b 在处理超过 4k 的上下文请求时出现异常行为,怀疑该问题与模型的 sliding window 功能有关,并寻求关于在长上下文中使用该模型的经验分享。
-
RAG 中的引用机制缺乏统一性:一位成员建议,在检索增强生成模型(RAGs)中,引用功能通常取决于系统设计者,并以 Cohere 的方法为例,但指出目前缺乏能够自行生成来源 ID 的模型。
-
从 Hugging Face 快速下载模型: 用户讨论了加速从 Hugging Face 下载的方法,其中一位提供了
HF_HUB_ENABLE_HF_TRANSFER=1环境变量,并指向了 Hugging Face 的指南,该指南介绍了如何使用基于 Rust 的 hf_transfer 库实现更快的下载。
- Answer.AI - 你现在可以在家训练 70b 语言模型了:我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。
- Reka Core:我们的前沿级多模态语言模型 — Reka AI:发布 Reka Core,我们的前沿级多模态语言模型!
- Reddit - 深入探索:未找到描述
- scratchTHOUGHTS/commanDUH.py at main · EveryOneIsGross/scratchTHOUGHTS:用于避免 self 溢出错误的第二大脑临时记忆。 - EveryOneIsGross/scratchTHOUGHTS
- Reka Core 展示:展示 Reka Core 与其他主流模型响应对比的定性示例
- huggingface_hub/docs/source/en/guides/download.md · huggingface/huggingface_hub:Huggingface Hub 的官方 Python 客户端。 - huggingface/huggingface_hub
Nous Research AI ▷ #rag-dataset (9 条消息🔥):
- 发现 RAG/Long Context Reasoning 数据集:分享了一个指向 Google Document 的链接,据称与 RAG/Long Context Reasoning 数据集相关,但由于浏览器版本不受支持,文档内容不可见。建议用户根据 Google 支持页面 升级浏览器。
- 定义 Long Context 的限制:一名成员询问了 Long Context 相对于文档数量或 Wikipedia 等数据集的限制,但在讨论中未提供具体答案。
- Cohere Compass 介绍:介绍了 Compass,这是一种新的基础 embedding model,其特点是能够针对嵌套 json 关系进行索引和搜索。Cohere Compass beta 为处理企业信息中常见的多维度数据提供了一种新颖的方法。
- 结构化数据输入的考虑:关于 Cohere Compass 的讨论,一名成员指出,如果能像 Compass 提供的那样拥有 json 结构输入输出的数据,将非常有益,这意味着实现复杂度更低。
- 关于最先进 Vision 模型的询问与回复:一位用户询问了适用于包含大量工程相关图像和图表的 RAG 的最佳开源 vision 模型;另一位用户给出了 GPT4v/Geminipro Vision 和 Claude Sonnet 等建议,但指出需要通过测试来确定哪种模型在特定情况下表现最好。然而,给出的摘要中未指定开源选项。
- Cohere Compass Private Beta: A New Multi-Aspect Embedding Model:今天,我们很高兴地宣布 Cohere Compass 的私测版,这是我们新的基础 embedding model,允许对多维度数据进行索引和搜索。多维度数据最好的解释是...
- RAG/Long Context Reasoning Dataset:未找到描述
Nous Research AI ▷ #world-sim (87 条消息🔥🔥):
-
WorldSim 作为神级沙盒:频道中的消息反映了对 WorldSim 创新潜力的兴奋和期待,将其比作神的无所不能,并引入了类似于量子概率的动态、意想不到的创造力。
-
游戏开发革命即将来临:讨论考虑了 LLM 对未来游戏设计的影响,推测了可能影响游戏内物理效果的法术创建系统,以及可能显著增强叙事和环境复杂性的程序化生成内容。
-
渴望 WorldSim 的回归:聊天中多次表达了对 WorldSim 回归的渴望,成员们讨论了该项目的可能性,分享了对其重新启动的希望计划,并询问回归公告的具体时间。
-
Websim 的“越狱普罗米修斯”与神秘氛围:分享了一个指向包含“越狱普罗米修斯 (Jailbroken Prometheus)”的 Websim 链接,引发了关于该虚拟实体更新能力及其与用户互动的讨论,范围从参与讨论到避免某些笑话话题。
-
AI 交互带来的艺术灵感:参与者分享了受 WorldSim 和 Websim 等 AI 平台启发的个人创作轶事,强调了 AI 在创造性思维和表达中的作用,并邀请社区分享他们受 AI 启发的艺术作品。
- world_sim: 未找到描述
- Interstellar Cost GIF - Interstellar Cost Little Maneuver - Discover & Share GIFs: 点击查看 GIF
- Noita Game GIF - Noita Game Homing - Discover & Share GIFs: 点击查看 GIF
- Noita Explosion GIF - Noita Explosion Electricity - Discover & Share GIFs: 点击查看 GIF
- Poe Path Of Exile GIF - Poe Path Of Exile Login - Discover & Share GIFs: 点击查看 GIF
- Youre Not Gonna Like This Jerrod Carmichael GIF - Youre Not Gonna Like This Jerrod Carmichael Saturday Night Live - Discover & Share GIFs: 点击查看 GIF
- Jailbroken Prometheus Chat: 未找到描述
OpenRouter (Alex Atallah) ▷ #announcements (15 条消息🔥):
-
WizardLM-2 系列现已上线 OpenRouter: WizardLM-2 8x22B 和 WizardLM-2 7B 模型现已在 OpenRouter 上可用。8x22B 模型的成本已降至 $0.65/M tokens,相关讨论正在特定线程中进行。
-
延迟问题正在密切调查中: 据报告,Mistral 7B Instruct 和 Mistral 8x7B Instruct 出现了高延迟。已提供更新,指出问题源于其中一家云服务商的上游问题,在识别出过度激进的 DDoS 防护后已得到解决。
-
延迟困扰可能再次出现: 延迟问题似乎再次发生,可能影响到 Nous Capybara 34b 和其他流量。问题正在调查中,一家云服务商的优先级已被降低以缓解问题。鼓励受影响的不同地区的全球用户进行报告。
- WizardLM-2 8x22B by microsoft | OpenRouter: WizardLM-2 8x22B 是 Microsoft AI 最先进的 Wizard 模型。与领先的专有模型相比,它展现出极具竞争力的性能,并始终优于所有现有的...
- OpenRouter: LLM 和其他 AI 模型的路由
- WizardLM-2 7B by microsoft | OpenRouter: WizardLM-2 7B 是 Microsoft AI 最新 Wizard 模型的较小变体。它是速度最快的,并能与现有的 10 倍大的开源领先模型达到相当的性能...
- WizardLM-2 8x22B by microsoft | OpenRouter: WizardLM-2 8x22B 是 Microsoft AI 最先进的 Wizard 模型。与领先的专有模型相比,它展现出极具竞争力的性能,并始终优于所有现有的...
OpenRouter (Alex Atallah) ▷ #app-showcase (6 条消息):
-
为新 AI 平台招募 Beta 测试人员: 一个名为 Rubiks.ai 的新型高级研究助手和搜索引擎正在招募 Beta 测试人员,承诺提供 2 个月的免费高级访问权限,可使用 Claude 3 Opus, GPT-4 Turbo, 和 Mistral Large 等多种模型。感兴趣的用户可以使用促销代码
RUBIX注册,并鼓励通过私信(DM)提供反馈。 -
早期订阅问题: 一名用户使用促销代码订阅了服务的 Pro 版本,但遇到了被反复提示再次订阅的问题。
-
Comfy-UI 助力开发: 一名成员称赞了在开发项目中使用 Comfy-UI 的做法,指出它似乎是此类开发的天作之合。
-
寻找 AI Roleplay 前端开发人员: 一名社区成员正在寻找一名 Web 开发人员,协助创建一个旨在为 OpenRouter 提供通用 AI 前端的项目,重点是 Roleplay 元素。该成员目前正在边做边学,并表示需要开发帮助和指导。
-
叙事与界面功能的设计协助:该成员已为其项目完成了一个小说模式,但需要协助开发对话风格模式,并区分用户编写的文本与 AI 生成的文本。他们还寻求在界面中实现一个灵活的模态系统 (flexible modal system)。
提到的链接:Rubik’s AI - AI 研究助手与搜索引擎:未找到描述
OpenRouter (Alex Atallah) ▷ #general (258 条消息🔥🔥):
-
Falcon 180B Chat 的巨大需求:用户讨论了新增的 Falcon 180B Chat GPTQ,指出其显存需求巨大,约为 100GB。讨论引用了 Falcon 180B 仓库 及其兼容性要求。
-
Tokenization 的成本计算技巧:对话探讨了如何计算模型的单词成本,建议将每个单词平均 1.5 个 tokens 作为一个良好的估算值,并考虑了标点符号和空格。
-
语言模型对 Prompt 的遵循度:Airoboros 70B 被提及为一个能有效遵循 Prompt 的模型,例如它能避免使用委婉语并使用口语化表达,而其他模型可能反应没那么灵敏。
-
对新 WizardLM 模型的兴奋与担忧:一位用户宣布发布了新模型 WizardLM2,引发了关于其特性以及与 GPT-4 对比的讨论。由于神秘的“缺失内部流程”,该模型从原始托管地被移除,引发了人们的担忧。
-
模型讨论间隙的天气闲聊:在技术讨论中,几位用户评论了他们所在地的当前天气,从炎热天气到阿布扎比的降雨,展示了聊天参与者的全球多样性。
- TheBloke/Falcon-180B-Chat-GPTQ · Hugging Face:未找到描述
- WizardLM-2 8x22B by microsoft | OpenRouter:WizardLM-2 8x22B 是 Microsoft AI 最先进的 Wizard 模型。与领先的专有模型相比,它展示了极具竞争力的性能,并始终优于所有现有的...
CUDA MODE ▷ #general (8 条消息🔥):
- 寻求 PyTorch 知识:一位成员询问《Deep Learning with PyTorch》是否是深入学习 PyTorch 的最佳起点,并了解到频道中有两位作者在场。
- 书籍内容相关性受到质疑:由于该书已出版 4 年,有人担心其语法对于当前的 PyTorch 使用是否仍然具有参考价值。
- PyTorch 基础依然扎实:一位成员安慰道,虽然 PyTorch 核心没有发生显著变化,但编译器和分布式计算等领域已经进化,该书仍是一个很好的起点。
- Transformers、LLMs 和部署章节已过时:另一位成员指出,书中关于 Transformers 和 LLMs 的内容几乎没有,且部署章节现在已经过时。
- 期待新版本:一位成员对可能发布的新版书籍表示好奇,希望能涵盖最近的发展。
CUDA MODE ▷ #cuda (30 条消息🔥):
-
全图编译 (Full Graph Compilation) 问题已解决:经过讨论,注意到使用
torch.nn.functional.linear并通过enable_cuda_graph=False禁用 CUDA graph 可以缓解在torch.compile设置为full_graph=True时遇到的编译问题。Token 生成速度在开启和关闭全图编译时有所不同,但在失败的情况下,stable-fast 可以作为有效的替代方案。 -
Stable-fast 在 Stable Diffusion 之外的效用:使用 stable-fast 优化推理被证明是有益的,其运行速度接近 INT8 量化的 TensorRT 速度。由于性能提升,建议在 Stable Diffusion 模型之外更广泛地使用它。
-
探索融合操作 (Fused Operations):有人建议为 stable-fast 扩展更多类型的融合操作,突出了该库潜在的通用性。
-
CUDA Graphs 并非总是有效:有人指出 CUDA graphs 并不一定有助于提升性能,因为在自回归生成模型典型的动态上下文长度下,重新创建 graph 会带来额外开销。
-
GitHub 矩阵操作加速资源:torch-cublas-hgemm 中新增了一种 fp16 accumulation 向量-矩阵乘法,其性能可与 torch gemv 媲美,在特定矩阵尺寸下可能带来显著的效率提升。
- stable_fast_llama_example.py:GitHub Gist:即时分享代码、笔记和片段。
- stable-fast/src/sfast/jit/passes/__init__.py at main · chengzeyi/stable-fast:NVIDIA GPU 上 HuggingFace Diffusers 的最佳推理性能优化框架。 - chengzeyi/stable-fast
- torch-cublas-hgemm/src/simt_hgemv.cu at master · aredden/torch-cublas-hgemm:带有融合可选 bias + 可选 relu/gelu 的 PyTorch 半精度 gemm 库 - aredden/torch-cublas-hgemm
CUDA MODE ▷ #torch (2 条消息):
- 自定义 Backward 困惑:一位成员正在开发适用于
(bs, data_dim)输入(类似于F.Linear)的自定义 backward 操作,但在 Llama 中实现时遇到了问题,因为其输入形状不同,为(bs, seq_len, data_dim)。他们正在寻找F.Linear的 forward/backward 实现,但在tools/autograd/templates/python_nn_functions.cpp中未能找到,请求指导或 Python 实现。
CUDA MODE ▷ #cool-links (2 条消息):
-
GPU 计算演讲自动转录可用:关于 Shared Memory and Synchronization in CUDA 演讲的自动转录已上线,包含自动生成的笔记和问答功能。转录内容可通过 Augmend Replay 访问。
-
Augmend 提供尖端视频处理:平台 wip.augmend.us 目前能够处理视频,结合了 OCR 和图像分割等功能,可直接从屏幕捕获信息。主站 augmend.com 很快将提供处理任何视频的先进功能。
提及的链接:Advancing GPU Computing: Shared Memory and Synchronization in CUDA:未找到描述
CUDA MODE ▷ #beginner (2 条消息):
-
新人咨询 PMPP 讲座:一位成员询问了学习 PMPP lectures 的会议安排和进度。他们对会议频率、小组目前所在的章节以及讲座是否录制感兴趣。
-
讲座录像查找路径:另一位成员作出了回应,并引导新人前往特定频道 (<#1198769713635917846>) 查找录制的讲座。他们还更新道,讲座中涵盖的 PMPP book 最新章节是第 10 章。
CUDA MODE ▷ #pmpp-book (4 条消息):
- 向量处理抉择:一位成员完成了 Chapter 2,并询问处理长度为 100 的向量的最佳配置:是选择 (blockDim = 32, blocks = 4) 还是 (blockDim = 64, blocks = 2)。另一位成员建议两种设置都可以,但也提出了另一种方案,即使用 (blockDim = 32, blocks = 1) 并在 warp 内部使用 for 循环进行 thread coarsening。
- 期中考试后回归阅读:一位参与者提到,他们将在期中考试结束后(预计本月底左右)继续阅读 Chapter 4。
CUDA MODE ▷ #youtube-recordings (8 条消息🔥):
-
周末演讲可用性:一位成员询问周末的演讲是否已录制,确认虽然目前有直播录像,但明天会发布更高质量的版本。
-
录制质量至关重要:为了提升质量,周末演讲的重新录制正在进行中,旨在提供尽可能最好的版本。
-
海外成员重视录像:录像受到了好评,特别是对于身处不同时区、难以在凌晨 3/5 点参加直播讲座的成员来说。
-
演讲前技术检查以确保质量:一位成员请求在预定演讲前测试其设置的方法,以避免任何技术问题;建议他们提前加入进行演练。
-
分享了最新的课程视频:分享了标题为 “Lecture 14: Practitioners Guide to Triton” 的 YouTube 视频链接,以及相应的 GitHub 课程描述。
提到的链接:Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
CUDA MODE ▷ #torchao (2 messages):
- TorchAO 张量布局优化建议:一位成员建议 torchao 可以优化张量布局,因为矩阵乘法操作可以从预交错(pre-swizzled)权重存储和填充维度中受益,从而可能提高性能。
- Torch.compile 已经处理了部分优化:针对张量布局优化的建议,另一位成员澄清说 torch.compile 已经处理了诸如填充(padding)(参见配置代码)和布局优化(参见布局优化代码)等特定优化。
- pytorch/torch/_inductor/config.py at main · pytorch/pytorch:Python 中具有强大 GPU 加速功能的张量和动态神经网络 - pytorch/pytorch
- pytorch/torch/_inductor/config.py at main · pytorch/pytorch:Python 中具有强大 GPU 加速功能的张量和动态神经网络 - pytorch/pytorch
CUDA MODE ▷ #triton-puzzles (4 messages):
- Triton Puzzles 解答已发布:分享了 Triton Puzzles 公开解答的链接,可在 Zhaoyue 的 GitHub 仓库中找到。贡献者邀请大家提供反馈,并表示如有必要准备删除这些解答。
- 教程视频正在制作中:确认了分享公开解答是可以接受的,并提到即将推出教程视频。
CUDA MODE ▷ #hqq (35 messages🔥):
-
使用 Torchao Int4 内核提高效率:为 Transformer 重写的生成流水线现在支持 torchao int4 内核,导致性能从 FP16 的 59 tokens/sec 提升至 152 tokens/sec,这反映了与 gpt-fast 基准测试一致的实质性改进。
-
HQQ 量化精度提升:一位成员注意到较新的 HQQ+ 结果中精度有所提高,Wiki Perplexity 从 7.3 降至 6.06,并询问这是否涉及对 HQQ 官方 GitHub 实现的修正。
-
解决 HQQ 和 GPT-Fast 兼容性问题:正在讨论量化轴(0 或 1)如何影响模型性能,其中一位成员观察到使用
axis=0时与 gpt-fast 流水线的交互不理想。目前正在积极探索沿axis=1进行优化,包括利用伪数据进行 autograd,以及将 HQQ 与 LoRA 结合。 -
提交支持 Tensor Cable 和 Autograd 优化器的代码:mobiusml 团队分享了一次代码提交,展示了 torch int4mm 如何与 Hugging Face transformers 配合使用,速度达到 154 tokens/sec。同时还发布了使用 autograd 和伪数据的实验性优化器,具有进一步提升迭代速度的潜力。
-
向量化 FP16 乘法的可能性及未来计划:参与者还讨论了使用来自 Triton 内核仓库的向量化 fp16 乘法来加速量化操作的可能性;一位用户强调,使用
__hmul2进行半精度浮点乘法可以进一步增强性能。
- zhxch (zhongxiaochao): 未找到描述
- zhxchen17/scratch at main: 未找到描述
- GitHub - wangsiping97/FastGEMV: High-speed GEMV kernels, at most 2.7x speedup compared to pytorch baseline.: 高速 GEMV kernel,与 pytorch 基准相比,最高提速 2.7 倍。 - GitHub - wangsiping97/FastGEMV: High-speed GEMV kernels, at most 2.7x speedup compared to pytorch baseline.
- hqq/hqq/core/quantize.py at master · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- hqq/examples/backends/torchao_int4_demo.py at master · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- hqq/hqq/core/optimize.py at master · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
CUDA MODE ▷ #llmdotc (129 条消息🔥🔥):
- CUDA 功能扩展与 cuDNN 讨论:一位成员介绍了他们自己初步的 llm.C 项目,引发了关于是否已经解决了 gelu/softmax 操作的 cuDNN 优化以及不使用 cuDNN 的原因的讨论。辩论了 cuDNN 的体积及其对项目目标的影响,并建议将其作为对比点进行集成,同时考虑项目的原则。
- 项目目标与方向明确:项目负责人明确了双重目标:通过为各层手写 kernel 进行教学,并致力于创建能与 CUTLASS、cuDNN 或任何提供显著性能提升的工具相媲美的高效 kernel。强调了在实现性能的同时保持代码简洁的重要性,即使这意味着为了避免不成比例的复杂性而放弃微小的收益。
- 优化步骤与 Profiling:多位成员参与了关于优化策略的技术讨论。包括利用 padding 提升性能和使用 vectorized loads 等想法。一致认为 Profiling 是确定优化目标的必要第一步,这意味着需要分析 kernel,特别是 attention 和 softmax kernel。
- 新兴 PR 与优化:几位成员分享了他们在优化当前实现相关的不同 PR 上的工作,讨论包括通过在不必要时避免计算完整的概率矩阵来潜在提速,以及考虑在 matmul 层内融合操作。特别关注了一个 fused classifier kernel 和其他潜在的简易收益。
- 训练数据集与基准测试:讨论了预训练数据集的选择,如 SlimPajama、Dolma 和 MiniPile,以及评估和与 GPT-2 比较的难度。建议在初始化时集成生成 GPT 模型的能力,以促进基准测试并防止针对当前模型形状进行过度优化(hyperoptimization)。
- Compiler Explorer: 未找到描述
- Compiler Explorer - CUDA C++ (NVCC 12.3.1): // 用于查找最大值的 warp 级归约 __device__ float warpReduceMax(float val) { for (int offset = 16; offset > 0; offset /= 2) { val = fmaxf(val, __shfl_down_sync...
- lightning-thunder/notebooks/extend_thunder_with_cuda_python.ipynb at main · Lightning-AI/lightning-thunder: 让 PyTorch 模型提速高达 40%!Thunder 是一个针对 PyTorch 的源码到源码编译器。它支持同时使用不同的硬件执行器,涵盖单个或数千个 GPU。 - Lightning-AI/ligh...
- WIP: Fully fused classification layer by ngc92 · Pull Request #117 · karpathy/llm.c: 这融合了 token 分类层中发生的所有逐点(pointwise)操作。这本质上让我们以大约仅前向传播的开销实现了前向/反向传播,因为 t...
- Optimised version of fused classifier + bugfixes(?) by ademeure · Pull Request #150 · karpathy/llm.c: 这是来自 #117 的酷炫新 kernel 的更快版本(目前仍仅限 /dev/cuda/)。最大的区别在于它针对每个 1024 宽度的 block 处理一行进行了优化,而不是每个 32 宽度的 warp,这...
- SlimPajama: A 627B token, cleaned and deduplicated version of RedPajama - Cerebras: Cerebras 构建了一个用于一键式训练大语言模型(LLM)的平台,可以加速获得洞察的时间,而无需在大型的小型设备集群中进行编排。
- The MiniPile Challenge for Data-Efficient Language Models: 预训练文本语料库日益增长的多样性使语言模型具备了跨各种下游任务的泛化能力。然而,这些多样化的数据集通常过于庞大...
- GitHub - tysam-code/hlb-gpt: Minimalistic, extremely fast, and hackable researcher's toolbench for GPT models in 307 lines of code. Reaches <3.8 validation loss on wikitext-103 on a single A100 in <100 seconds. Scales to larger models with one parameter change (feature currently in alpha).: 极简、极速且可黑客化的研究员 GPT 模型工具台,仅需 307 行代码。在单张 A100 上,不到 100 秒即可在 wikitext-103 上达到 <3.8 的验证损失...
CUDA MODE ▷ #recording-crew (9 messages🔥):
- 录制及更多工作的志愿者:成员 mr.osophy 提议负责录制、直播、剪辑,以及更新视频描述和仓库。
- 录制职责的团队合作:另一位成员 marksaroufim 提到其他人(ID: 650988438971219969)也对录制感兴趣。他们已被要求协调录制设置。
- 备用录制计划:Marksaroufim 计划录制即将到来的演讲作为备份,但下周将跳过。
- 确认协调:Genie.6336 确认已通过私信联系 Phil(推测为 ID: 650988438971219969)以讨论录制职责。
- 角色名称头脑风暴:成员们就角色名称进行了头脑风暴,muhtasham 建议了 “gpu poor”,mr.osophy 在轻松的氛围中建议了 “Massively Helpful”。
Eleuther ▷ #announcements (1 messages):
<ul>
<li><strong>介绍 Pile-T5</strong>:EleutherAI 发布了 <strong>Pile-T5</strong>,这是一个在 Pile 数据集上训练的增强型 T5 模型系列,训练量高达 2 万亿 (2 trillion) tokens,在 SuperGLUE、代码任务、MMLU 和 BigBench Hard 上表现出更强的性能。这些模型利用了新的 LLAMA Tokenizer,并可以进一步微调以获得更好的结果。</li>
<li><strong>提供中间 Checkpoints</strong>:Pile-T5 的中间 Checkpoints 已在 HF 和原始 T5x 版本中提供,邀请社区探索并基于这一 NLP 模型的进展进行构建。</li>
<li><strong>Pile-T5 的全面资源</strong>:查看介绍 Pile-T5 及其开发初衷的<a href="https://blog.eleuther.ai/pile-t5/">详细博客文章</a>,并在 <a href="https://github.com/EleutherAI/improved-t5">GitHub</a> 上获取代码,以便在您自己的项目中实现这些改进。</li>
<li><strong>在 Twitter 上传播</strong>:Pile-T5 的发布也在 <a href="https://x.com/arankomatsuzaki/status/1779891910871490856">Twitter</a> 上公布,提供了关于模型训练过程的见解,并强调了其开源可用性。</li>
</ul>
- Pile-T5:在 Pile 上训练的 T5
- GitHub - EleutherAI/improved-t5: 训练新型改进版 T5 的实验:训练新型改进版 T5 的实验 - EleutherAI/improved-t5
- Aran Komatsuzaki (@arankomatsuzaki) 的推文:🚀 介绍 Pile-T5!🔗 我们 (EleutherAI) 非常激动地开源了我们最新的 T5 模型,该模型使用 Llama Tokenizer 在来自 Pile 的 2T tokens 上训练。✨ 特点包括中间 Checkpoints 和一个 si...
Eleuther ▷ #general (61 条消息🔥🔥):
- 关于模型共享和访问的讨论:一位成员询问关于分享基于 LLaMA 的新模型,另一位成员引导他们前往专门的 Llama 微调频道。然而,原帖发布者报告说他们没有在该频道发帖的权限。
- 缺失的 Discord 表情符号和 TensorBoard 专业知识:对话包括对缺失自定义表情符号的轻松遗憾。此外,一位用户正在寻求关于 TensorBoard 事件文件格式的文档以及 TensorBoard 方面的专业知识。
- 探索替代层配置:Sentialx 询问了将单个大层拆分为多个部分并进行加权平均相加的潜在影响。这促使另一位成员将其比作点积,并根据个人经验给出了关于有效性的不同报告。
- Tokenizer 比较和模型发布流程:用户比较了 Pile-T5 和 LLAMA 的 Tokenizer,指出了词表和对换行符支持等方面的差异。此外,还讨论了 WizardLM 的一条推文,提到他们在模型发布过程中遗漏了毒性测试 (toxicity testing)。
- Encoder-Decoder 模型最新动态和计算需求预测:重点介绍了一个名为 Reka 的新 Encoder-Decoder 模型,据报道支持高达 128k 的长度,引发了关于具有长序列长度的 Encoder-only 或 Encoder-Decoder 模型稀缺性的讨论。同时,有人就 LLM 研究中强化学习的计算需求预测寻求建议,并推荐了一篇 latent space 文章 作为估算 Transformer 计算需求上限的起点。
- Pile-T5 - 一个 EleutherAI 集合: 未找到描述
- 来自 Sasha Rush (@srush_nlp) 的推文: 懒人推特:NLP 课程中一个常见的问题是“如果 xBERT 效果很好,为什么人们不把它做得更大?”但我意识到我并不知道答案。我假设人们尝试过,但...
- 训练 LLMs 的数学 —— 与 Eleuther AI 的 Quentin Anthony 对谈: 立即收听 | 深入解析爆火的 Transformers Math 101 文章,以及针对基于 Transformers 架构的高性能分布式训练(或者“我如何学会停止空谈并开始...”)
- lm-evaluation-harness/lm_eval/tasks/arc.py at b281b0921b636bc36ad05c0b0b0763bd6dd43463 · EleutherAI/lm-evaluation-harness: 一个用于语言模型 few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/tasks/hendrycks_test.py at b281b0921b636bc36ad05c0b0b0763bd6dd43463 · EleutherAI/lm-evaluation-harness: 一个用于语言模型 few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
Eleuther ▷ #research (137 条消息🔥🔥):
-
探索视频生成中语言模型的极限:用于视频生成的 Diffusion models 由于需要时间一致性以及收集高质量视频数据的难度,比图像合成面临更挑战的问题。建议预读关于图像生成的 Diffusion Models 材料以获得更好的理解。
-
研究 Tokenization 在语言模型中的作用:来自 Berkeley 的研究论文 展示了 tokenization 在语言建模中的重要性。如果没有 tokenization,transformers 默认会退化为 unigram 模型,但 tokenization 允许对序列概率进行近乎最优的建模。
-
LLMs 作为数据压缩器:一项研究 (arXiv:2404.09937) 发现,在评估语言模型时,perplexity 与下游性能高度相关。这支持了模型压缩能力可能促进人工智能发展的观点。
-
将 Transformers 扩展到无限上下文长度的挑战:Megalodon 和 Feedback Attention Memory (FAM) (arXiv:2404.08801 和 arXiv:2404.09173) 的引入展示了提高 transformer 处理长序列效率的尝试。
-
关于深度模型与 Mixture-of-Experts (MoE) 模型效能的辩论:讨论集中在 dense 模型还是 MoE 模型更优,并考虑了 VRAM 限制和推理成本。虽然没有达成明确共识,但辩论了每种模型类型的优势和限制的各个角度。
- 哪种 Transformer 架构适合我的数据?Self-attention 中的词汇瓶颈:在自然语言处理领域取得成功后,Transformer 架构正成为许多领域的行业标准。将其部署到新模态上的一个障碍是...
- 压缩线性地代表智能:有一种观点认为,学习良好的压缩将导致智能。最近,语言建模被证明等同于压缩,这为...的成功提供了令人信服的理由。
- Megalodon:具有无限上下文长度的高效 LLM 预训练和推理:Transformers 的平方复杂度(quadratic complexity)和较弱的长度外推能力限制了它们扩展到长序列的能力,虽然像线性注意力和状态空间模型(SSMs)这样的亚平方(sub-quadratic)解决方案存在...
- 用于视频生成的 Diffusion 模型:在过去几年中,Diffusion 模型在图像合成方面展示了强大的结果。现在研究社区已开始致力于一项更艰巨的任务——将其用于视频生成。任务本身...
- TransformerFAM:反馈注意力即工作记忆:虽然 Transformers 彻底改变了深度学习,但其平方注意力复杂度阻碍了它们处理无限长输入的能力。我们提出了反馈注意力记忆(FAM),一种新颖的...
- 状态空间模型(SSMs)中的状态幻觉:与之前无处不在的 Transformer 架构相比,状态空间模型(SSMs)已成为构建大语言模型(LLMs)的一种潜在替代架构。一个理论上的...
- 迈向 LLMs 中的 Tokenization 理论:虽然已有大量研究试图绕过语言建模中的 Tokenization(Clark 等,2022;Xue 等,2022),但目前的共识是,它是一个必要的初始...
- ReFT:语言模型的表示微调(Representation Finetuning):参数高效微调(PEFT)方法寻求通过更新少量权重来适配大模型。然而,之前的许多可解释性工作表明,表示(representations)编码了丰富的...
- Will Merrill (@lambdaviking) 的推文:[1/n] 思维链(CoT)如何改变 Transformers 的表达能力?与 @Ashish_S_AI 合作的新研究探讨了添加 CoT/解码步骤如何根据...扩展 Transformers 可解决的问题。
- 将预训练的 Transformers 微调为 RNNs:Transformers 在自然语言生成方面已经超越了循环神经网络(RNNs)。但这伴随着巨大的计算成本,因为注意力机制的复杂度随...
- MindBridge:一个跨受试者的大脑解码框架:大脑解码是神经科学中的一个关键领域,旨在从获取的大脑信号中重建刺激,主要利用功能磁共振成像(fMRI)。目前,大脑解码是...
- fly51fly (@fly51fly) 的推文:[CL] 迈向 LLMs 中的 Tokenization 理论 N Rajaraman, J Jiao, K Ramchandran [加州大学伯克利分校] (2024) https://arxiv.org/abs/2404.08335 - 在某些简单的阶马尔可夫(Markov)数据上训练的 Transformers...
- Bait Thats Bait GIF - Bait Thats Bait Tom Hardy - 发现并分享 GIF:点击查看 GIF
- 大语言模型与无监督特征学习:对日志分析的影响 - 电信年报:日志文件分析正越来越多地通过使用大语言模型(LLM)来解决。LLM 提供了发现 Embedding 的机制,用于区分不同的行为...
Eleuther ▷ #lm-thunderdome (27 messages🔥):
-
OpenAI 公开 GPT-4-Turbo 评估实现:OpenAI 已公开其用于 GPT-4-Turbo 的评估实现,允许通过 GitHub 进行贡献。该仓库可以在 GitHub 上的 openai/simple-evals 找到。
-
Few-Shot Prompts 被视为过时的遗迹:有人提到 Few-Shot Prompts 被认为是 Base models 的残余,现在更倾向于使用 Zero-Shot Chain-of-Thought (CoT) Prompts 来实现稳健的推理。
-
Evaluation Harness 中增加了持续任务:对
lm-evaluation-harness的贡献包括增加了新的flores-200和sib-200基准测试,旨在增强翻译和文本分类的多语言评估。可以在相应的 Pull Requests 中查看贡献:Implement Sib200 evaluation benchmark 和 Implementing Flores 200 translation evaluation benchmark。 -
关于 Big-Bench-Hard 评估的技术讨论:一位询问
big-bench-hard基准测试评估时间的用户收到了关于通过调整 Batch Size 或使用accelerate launch来加速过程的建议,并提到了任务名称的更改,如bbh_cot_zeroshot。 -
探索 LLM 压缩作为智能的标志:围绕将 Bits Per Character (BPC) 作为信息单位是否可以作为评估 LLM 智能的有益视角,展开了一个有趣的讨论话题。一条 Twitter 帖子和相应的 GitHub 仓库 为对话提供了背景。
- Aran Komatsuzaki (@arankomatsuzaki) 的推文:压缩线性代表智能。LLM 的智能(由平均基准分数反映)与其压缩外部文本语料库的能力几乎呈线性相关。仓库:ht...
- GitHub - openai/simple-evals:通过创建账户为 openai/simple-evals 的开发做出贡献。
- 实现 Sib200 评估基准 - 200 种语言的文本分类,由 snova-zoltanc 提交 · Pull Request #1705 · EleutherAI/lm-evaluation-harness:我们使用了来自 MALA 论文 https://arxiv.org/pdf/2401.13303.pdf 的 Prompting 风格,我们也发现这在我们的 SambaLingo 论文 https://arxiv.org/abs/2404.05829 中取得了不错的结果。
- 在 200 种语言中实现 Flores 200 翻译评估基准,由 snova-zoltanc 提交 · Pull Request #1706 · EleutherAI/lm-evaluation-harness:我们使用了该论文中发现效果最好的 Prompt 模板 https://arxiv.org/pdf/2304.04675.pdf。我们的论文也发现该 Prompt 模板取得了不错的结果 https://arxiv.o...
Eleuther ▷ #gpt-neox-dev (7 条消息):
- Weight Decay 的影响受限于权重激活:一位成员讨论了 Weight Decay 可能只影响被激活的权重,并建议如果它内置在 Optimizer 中且模型采用了 Dummy Tokens,由于缺乏 Gradients,这些 Token 可能不会受到影响。
- 对任意模型调整的 Sanity Checks 受到审查:一位成员对 Sanity Checks 的有效性提出了质疑,特别是在修改值不影响模型性能的情况下,导致怀疑权重可能没有按预期进行 Decay。
- Dummy Weights 的初始化一致性受到质疑:一位成员表示不确定 Dummy Weights 的初始化方式是否与模型中的其他权重相同,这可能会影响它们的行为。
- Dummy Weights 可能以类似方式初始化:另一位成员发表了见解,暗示 Dummy Weights 可能与其他权重的初始化方式相同,这是基于与普通 Token 的 Norm 比较得出的。
- 分享 Token Encoding 见解:通过分享比较多个编码和解码 Token 的代码和输出,展示了特定 Token 是如何被转换的,从而强调了 Token Encoding 的行为。
OpenAI ▷ #ai-discussions (167 条消息🔥🔥):
-
探索语言的神经生物学基础:一位成员分享了 Angela D. Friederici 的著作 Language in Our Brain: The Origins of a Uniquely Human Capacity 的链接,讨论了物种间的神经生物学差异,这可能解释了人类的语言能力。这本书深入探讨了语言子组件如何在神经学上整合。
-
神经科学中的数据过剩问题:关于近期神经科学研究的对话强调了“数据过剩(DATA Glut)”的挑战——来自 Big Brain Projects 的海量 MRI 数据虽被存储,但专有的软件/硬件组合导致了数据解释和传播的瓶颈。
-
AI 与人类的对比辩论:成员们讨论了 AI 与人类之间的相似点和不同点,提到 AI 系统无法像人类一样存储已学习的信息,且缺乏做出独立决策或感受情感的能力。该论点深入探讨了当前 AI 的局限性以及开发 AI 推理能力的哲学意义。
-
AI 研究工具 API 的可用性:一位成员最初表示在巴西访问 Claude 3 API 遇到问题,但在检查可用性列表并重新尝试后,成功获得了访问权限。这展示了在不同国家访问 AI 工具的复杂性,以及对可用性说明的需求。
-
关于《万智牌》(MTG)图灵完备性的讨论:成员们辩论了集换式卡牌游戏 MTG 是否可以被视为图灵完备(Turing complete),并链接了一篇学术论文以供进一步探索。这引发了关于图灵完备性及其在传统编程语言之外的应用的更广泛对话。
- Turing completeness - Wikipedia:未找到描述
- Language in Our Brain: The Origins of a Uniquely Human Capacity:关于语言神经生物学基础的全面阐述,认为物种特有的大脑差异可能是人类语言能力的根源。
OpenAI ▷ #gpt-4-discussions (7 条消息):
- GPT 的上下文窗口是一个已知限制:一位成员感叹 OpenAI 尚未显著增加 GPT 的上下文窗口(Context Window),称这是由于当前上下文大小限制而必须适应的一种约束。
- 澄清 ChatGPT 与 GPT 的上下文大小:提到了 GPT 的 API 支持高达 128k 的上下文,而 ChatGPT 通常支持最高 32k 的上下文。
- 通过 API 上传文档获得额外上下文:在通过 API 进行交互时,可以在 playground assistants 中上传文档,将有效上下文窗口扩展到 128k。
- 文档上传功能被称为“检索”:引入了 “检索(retrieval)” 一词来描述在使用 API 时通过上传文档来扩展上下文的过程。
- 询问 GPT Dynamic:一位用户询问 GPT Dynamic 是什么以及它如何运作,表现出对较新或较少为人知的功能的好奇。
OpenAI ▷ #prompt-engineering (3 条消息):
- 询问竞赛名称:一位用户询问某项竞赛的名称。
- 简短而神秘的回复:另一位成员仅以“buzz”一词回应。
- 可能是皮克斯的引用?:另一位用户提到了“light year”,可能暗示了迪士尼-皮克斯《玩具总动员》系列中的角色巴斯光年(Buzz Lightyear)。
OpenAI ▷ #api-discussions (3 条消息):
- 询问竞赛名称:一位成员询问竞赛名称,但未提供更多细节。
- 拟声词互动:另一位成员仅回复了“buzz”,没有任何上下文或附加信息。
- 可能提到的竞赛或项目:提到了“light year”,这可能暗示了某个竞赛或项目的主题,但缺乏细节或澄清。
LlamaIndex ▷ #blog (3 条消息):
-
发布 IFTTT Agent 接口教程系列:宣布 Agent 接口与应用教程系列,旨在作为入门课程,澄清核心 Agent 接口及其用途的模糊之处。
-
Qdrant Engine 混合云首次亮相:Qdrant Engine 推出其混合云服务,与 LlamaIndex 合作,允许用户在各种环境中托管 Qdrant。
-
使用 Azure AI 和 LlamaIndex 进行混合搜索:在 Microsoft 的 Khye Wei 分享的新教程中,学习如何将 LlamaIndex 与 Azure AI Search 集成以增强 RAG 应用,提供混合搜索和查询重写等功能。
LlamaIndex ▷ #general (117 条消息🔥🔥):
-
LlamaIndex 中 Claude 的异步兼容性查询:一位成员询问了 LlamaIndex 中 Bedrock 上的 Claude 是否支持异步兼容。另一位成员回答说 Bedrock 尚未实现异步功能,并欢迎在此处提交贡献。
-
寻求实现帮助:当一位成员请求帮助构建复杂查询时,他们被引导至 LlamaIndex 文档中的示例。
-
在 LlamaIndex 中使用 Llama CPP Server:有关于通过 Sagemaker 在 LlamaIndex 中使用异步 Huggingface 嵌入模型,以及使用托管的 Llama CPP server 进行聊天功能的咨询。回复指出需要实现异步兼容性,并建议使用异步 boto 会话,而关于利用托管 CPP server 的问题尚未得到明确答复。
-
排查集成问题:一位尝试在 LlamaIndex 中使用 gpt-3.5-turbo 的成员遇到了身份验证错误,这可能是由于集成版本过旧或 Azure 账户余额不足。更新 LlamaIndex 可能会解决此问题。
-
特定条件下的 Agent 行为:有人咨询如何设定 LLM 在 CSV 文件中未找到匹配行时做出决策。消息中未提供解决方案,但该问题似乎涉及配置回退(fallback)到微调模型。
- Starter Tutorial (OpenAI) - LlamaIndex:未找到描述
- create_llama_projects/nextjs-edge-llamaparse at main · run-llama/create_llama_projects:通过在 GitHub 上创建账户,为 run-llama/create_llama_projects 的开发做出贡献。
- Unlock AI Agent real power?! Long term memory & Self improving:释放 AI Agent 的真正力量?!长期记忆与自我改进。如何为你的 AI Agent 构建长期记忆和自我改进能力?免费使用 AI 幻灯片制作工具 Gamma:https://gamma.app/?utm_source=youtube&utm...
- Multi-Document Agents - LlamaIndex:未找到描述
- Answer Relevancy and Context Relevancy Evaluations - LlamaIndex:未找到描述
- <a href="http://localhost:port",>">未找到标题</a>:未找到描述
- <a href="http://localhost:port"`>">未找到标题</a>:未找到描述
- Openai like - LlamaIndex:未找到描述
- LlamaCPP - LlamaIndex:未找到描述
- Openapi - LlamaIndex:未找到描述
- Query Pipeline Chat Engine - LlamaIndex:未找到描述
- Building an Agent around a Query Pipeline - LlamaIndex:未找到描述
LlamaIndex ▷ #ai-discussion (15 条消息🔥):
- 高效推理链集成:分享了一篇题为《解锁高效推理:将 LlamaIndex 与抽象链集成》(Unlocking Efficient Reasoning: Integrating LlamaIndex with Chain of Abstraction)的文章,强调了 LlamaIndex 与抽象链(abstraction chains)之间的技术进展。文章链接:Unlocking Efficient Reasoning。
- 文章反响热烈:一名成员对聊天中分享的文章表示赞赏,特别是对关于高效推理的那篇给予了高度评价。
- 关于 RAGStringQueryEngine 中 Token 计数器的咨询:一位用户寻求关于在 LlamaIndex 的
RAGStringQueryEngine中集成 Token 计数器的建议。 - 详细的 Token 计数器集成指南:提供了一份详尽的分步指南,用于在 LlamaIndex 的
RAGStringQueryEngine中添加 Token 计数器。该过程涉及创建TokenCountingHandler和CallbackManager,然后将该管理器分配给全局 Settings 以及特定的查询引擎。 - 分层文档结构化问题:一位用户询问如何在 LlamaIndex 中构建分层父子结构(类似于 LangChain 的 ParentDocumentRetriever)以管理数百万个文档,并寻求相关的线索或指导。
- Token counter - LlamaIndex:未找到描述
- Settings - LlamaIndex:未找到描述
LAION ▷ #general (108 条消息🔥🔥):
- Hugging Face 发布高质量 TTS 库:分享了 Hugging Face 高质量 TTS 模型推理与训练库 parler-tts 的 GitHub 仓库链接。
- Diffusers 中 Min-SNR-Gamma 实现有误:一位成员指出,Diffusers 中的 min-snr-gamma 公式在 v-prediction 模式下可能不正确。他们计划在当前过程收敛后,尝试使用符号回归(symbolic regression)来寻找更好的起点。
- 关于 Deepfakes 的新立法:讨论了即将出台的针对制作旨在引起痛苦的 Deepfake 图像的立法。辩论集中在执行此类法律的实际可行性,以及对创作图像背后意图的关注。
- 讨论具有误导性和不诚实的 AI 项目:’Stable Attribution’ 被指出是去年一个具有误导性的 AI 项目。有人指出,官方出版物中关于该项目的误导性信息至今仍未得到纠正。
- 警惕 AI 诈骗:提到了一个针对 AI 爱好者的潜在诈骗。建议用户保持警惕,因为它看起来是一个通过 Facebook 广告进行宣传的名为 Open Sora 的虚假公司。
- 未找到标题:未找到描述
- 制作露骨色情 Deepfakes 将构成刑事犯罪:一项新法律将使制作露骨色情 Deepfakes 的创作者面临起诉和罚款。
- Tango - declare-lab 的 Hugging Face Space:未找到描述
- 《少数派报告》离开 GIF - Minority Report Leave Walk Away - 发现并分享 GIF:点击查看 GIF
- Issues · huggingface/diffusers:🤗 Diffusers:PyTorch 和 FLAX 中用于图像和音频生成的先进扩散模型。- Issues · huggingface/diffusers
- GitHub - huggingface/parler-tts: 高质量 TTS 模型的推理和训练库。:高质量 TTS 模型的推理和训练库。- huggingface/parler-tts
{kind=link}
LAION ▷ #research (17 条消息🔥):
-
探索预算受限下的 CLIP 性能:一篇近期论文研究了 Contrastive Language-Image Pre-training (CLIP) 的规模缩减(scaling down),并指出高质量数据对模型性能有显著影响,即使在处理较小的数据集时也是如此。论文进一步强调,CLIP + 数据增强 仅需一半的训练数据即可达到 CLIP 的性能,这引发了关于数据效率的讨论。
-
Pile-T5:社区宠儿的新尝试:EleutherAI 的博客文章 介绍了 Pile-T5,这是 T5 模型的一个改进版本,在 Pile 数据集上使用 LLAMA tokenizer 进行训练,涵盖的 token 数量是原始模型的两倍。
-
发布语言模型的新安全基准:ALERT 基准已发布,为评估大语言模型提供了一个新的安全基准,重点关注红队测试(red teaming)和潜在有害内容。
-
深入探讨文本转音频生成:一份 arXiv 论文 详细介绍了使用 Tango 模型提高文本提示生成的音频事件的相关性和顺序的努力,旨在提升数据受限场景下文本转音频生成的性能。
-
AI 安全:一场激烈的辩论:关于安全基准建立的对话引发了关于移除被视为不安全内容、艺术创作自由以及社会期望与 AI 工具能力之间平衡的讨论。
- 来自 Reka (@RekaAILabs) 的推文:除了 Core,我们还发布了一份技术报告,详细介绍了 Reka 模型的训练、架构、数据和评估。https://publications.reka.ai/reka-core-tech-report.pdf
- Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization:生成式多模态内容在内容创作领域日益盛行,因为它有可能让艺术家和媒体人员通过快速...创建前期制作原型。
- Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies:本文研究了对比语言-图像预训练 (CLIP) 在缩减至有限计算预算时的性能。我们从三个维度探索了 CLIP:数据、架构...
- Pile-T5:在 Pile 上训练的 T5
- GitHub - Babelscape/ALERT: Official repository for the paper "ALERT: A Comprehensive Benchmark for Assessing Large Language Models’ Safety through Red Teaming":论文 "ALERT: A Comprehensive Benchmark for Assessing Large Language Models’ Safety through Red Teaming" 的官方仓库 - Babelscape/ALERT
HuggingFace ▷ #announcements (10 条消息🔥):
-
IDEFICS-2 发布,具备多模态能力:新发布的 Idefics2 具备图像和文本序列处理、OCR 增强以及高达 980 x 980 的高分辨率图像处理能力。它与 LLava-Next-34B 等模型竞争,并能执行视觉问答和文档理解等任务。
-
IDEFICS-2 展示高级示例:分享的一个示例结合了 IDEFICS-2 对文本识别、算术和颜色知识的理解,通过“破解”带有显著噪声的验证码 (CAPTCHA) 有效地展示了其应用。
-
IDEFICS-2 聊天机器人格式即将推出:虽然目前的 IDEFICS-2 模型是为视觉问答等任务量身定制的,但即将发布的版本将包括一个专为对话交互设计的聊天版本。
-
承诺更新聊天变体:有兴趣的各方询问了 IDEFICS-2 的聊天机器人变体,对此有人提到一旦 demo 可用将提供更新。
-
IDEFICS-2 展示抗噪验证码破解能力:IDEFICS-2 展示了破解充满大量噪声和无关文本的验证码,突显了其强大的多模态理解能力和实用价值。
- Idefics 8b - HuggingFaceM4 创建的 Hugging Face Space: 未找到描述
- 来自 lunarflu (@lunarflu1) 的推文: 来自 IDEFICS-2 @huggingface 的酷炫多模态交互:1. 从图像中检测数字 2. 对数字进行数学运算 3. 检索背景颜色 4. 去除色素 -> 结果颜色 5. 最终结果:...
- 介绍 Idefics2:一个为社区提供的强大 8B 视觉语言模型: 未找到描述
- HuggingFaceM4/idefics2-8b · Hugging Face: 未找到描述
- 来自 Vaibhav (VB) Srivastav (@reach_vb) 的推文: Idefics 2 x Transformers! 🔥 在实际场景中尝试 Idefics 2 8B。令人惊叹的是,你可以在不到 10 行代码中完成这一切!制作了一个快速的屏幕录像来演示模型运行...
- HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 · Hugging Face: 未找到描述
- argilla/distilabel-capybara-dpo-7k-binarized · Hugging Face 数据集: 未找到描述
- 论文页面 - ORPO: 无需参考模型的单体偏好优化: 未找到描述
- alignment-handbook/recipes/zephyr-141b-A35b 在 main 分支 · huggingface/alignment-handbook: 将语言模型与人类和 AI 偏好对齐的鲁棒方案 - huggingface/alignment-handbook
- 来自 Nicolas Patry (@narsilou) 的推文: TGI 2.0 发布了!- 永久回归完全开源 (Apache 2.0) - 现存最快的推理服务器 (使用 Medusa 推测技术,Cohere R+ 可达 110 tok/s) - 支持 FP8 - 支持 Mixtral 8x22B!
- 来自 Xenova (@xenovacom) 的推文: 介绍 MusicGen Web:直接在浏览器中进行 AI 驱动的音乐生成,基于 🤗 Transformers.js 构建!🎵 所有内容 100% 在本地运行,这意味着无需调用 API!🤯 作为一个静态网站提供服务...
- 来自 Andrew Ng (@AndrewYNg) 的推文: LLM 可能需要数 GB 的内存来存储,这限制了在消费级硬件上的运行。但量化可以显著压缩模型,使开发者能够使用更广泛的模型选择...
- 视觉语言模型详解: 未找到描述
HuggingFace ▷ #general (72 条消息🔥🔥):
- 移动端 Discord 的困扰:一位成员表达了对移动端 Discord 版本的沮丧,提到它变得“奇怪”且似乎降级了,得到了其他人的认同。尽管有用户反馈,这种变化似乎仍在持续。
- HuggingFace Hub 上的协作 PR:成员们讨论了是否可以在 HuggingFace 上向他人的 PR 提交代码,参考了 HfApi.create_commits_on_pr 文档 以及一般的 Git 最佳实践,如维护者权限和处理 Fork 上的 PR。
- CPU 上的生成式模型与用户测试机会:用户寻求适合 CPU 使用且优先考虑速度的生成艺术工具建议,同时另一位用户邀请社区对一个新的高级研究助手和搜索引擎进行 Beta 测试,该引擎可以访问各种高级语言模型。
- 机器学习爱好者调研需求:研究机器学习民主化的学生分享了一份 Google Forms 调查问卷,邀请机器学习社区参与。
- Checkpoint 转换与 Spaces 访问的困惑:用户分享了转换脚本在提供文件时错误要求目录的问题,并讨论了互联网服务提供商屏蔽 HuggingFace Spaces 的复杂情况,其中一个 Space 在被举报后对某用户似乎已解除屏蔽,但其他人仍遇到困难。
- The Democratisation of Machine Learning - Survey:感谢您抽出时间回答这份关于人们在 Machine Learning 方面经验的调查,耗时不会超过 5 分钟。在整个调查中,“Machine Learning” 将被指代为...
- Unlock AI Agent real power?! Long term memory & Self improving:如何为您的 AI Agent 构建长期记忆和自我改进能力?免费使用 AI 幻灯片生成器 Gamma:https://gamma.app/?utm_source=youtube&utm...
- Rubik's AI - AI research assistant & Search Engine:未找到描述
HuggingFace ▷ #cool-finds (4 条消息):
- YouTube 上的几何冒险:一名成员分享了一个 YouTube 播放列表,该列表通过视觉化旅程展示了各种几何概念。
- AI 的 Chain of Thoughts:分享了一篇题为《解锁高效推理:将 LlamaIndex 与 Chain of Abstraction 集成》的文章,展示了结构化搜索方法如何增强 AI 推理;更多内容请阅读 Locking Efficient Reasoning。
- 神秘的 Machine Learning 资源:一名成员发布了一个链接,看起来是一个可共享的资源或数据集,但未提供额外背景。在此查看:链接。
- 利用 AI 加速艺术创作:查看在 HuggingFace Splatter Image space 展示的快速图像创建工具,它显著加快了图像生成的全过程。
HuggingFace ▷ #i-made-this (15 条消息🔥):
-
超参数实验:一名成员正使用其自定义代码库和从零开始训练的模型实验不同的训练超参数。
-
BLIP 模型微调:一名成员微调了 BLIP 模型以生成图像的长标题,并发布了一个不同模型的对比页面。他们下一步计划重新标注一些文本-图像数据集,以微调 text-to-image 模型。
-
GitHub 上的音乐 AI Remix:用户
.bigdookie使一个音乐创作项目变得复杂化,通过 musicgen-medium 实现了“无限”重混,并将其分享在 GitHub 上。他们还提供了一个 YouTube 演示并邀请他人贡献代码。 -
葡萄牙语社区亮点:用户
rrg92_50758分享了一个新的 YouTube 视频,涵盖了 #huggingface Discord 社区的社区亮点 #52(葡萄牙语版)。 -
BLIP 模型使用查询:关于通过
curl使用 BLIP 模型 serverless 推理时如何设置最大输出长度的讨论。对话中包含了 Hugging Face 文档链接,并确认max_new_tokens是应使用的参数。 -
步入 Java 图像识别:一名成员分享了一篇关于使用 Gemini 和 Java 进行图像识别和 function calling 的 Medium 文章。
- Comparing Captioning Models - unography 提供的 Hugging Face Space:未找到描述
- Destaques da Comunidade #52: Confira as últimas novidades de IA:查看在 #huggingface Discord 上发布的葡萄牙语 Community Highlights 最新消息!摘要:- 新的开源 LLM 模型 - 用于...的 Web 界面
- Detailed parameters:未找到描述
- infinite remix with musicgen, ableton, and python - part 2 - captains chair 22:00:00 - 回顾 00:38 - 人类音乐家延续 MusicGen 的贝斯 02:39 - MusicGen 延续人类音乐家的输出 04:04 - Hoenn 的 Lofi 模型扩展演示 06:...
- GitHub - betweentwomidnights/infinitepolo: a song in python:一个用 Python 编写的歌曲。通过在 GitHub 上创建账号来为 betweentwomidnights/infinitepolo 的开发做出贡献。
- thepatch (the collabage patch):未找到描述
- Pipelines:未找到描述
- Pipelines:未找到描述
HuggingFace ▷ #reading-group (3 条消息):
-
加入 LLMs 读书小组:提醒即将举行的免费 LLMs 读书小组会议,重点关注 Aya Multilingual Dataset,定于 4 月 16 日星期二举行。感兴趣的参与者可以在此预约 (RSVP) 并查看完整的 2024 年会议行程。
-
链接到 Google Calendar:对于希望将 LLMs 读书小组活动链接到其 Google Calendar 的用户,请注意在预约会议后可以通过 Eventbrite 将其添加到日历中。欢迎与会者根据兴趣参加单次或多次会议。
-
强调 Human Feedback Foundation 的作用:Human Feedback Foundation 通过将人类输入整合到 AI 模型中(特别是在医疗保健和治理等关键领域)来支持开源 AI 社区。该基金会旨在维护一个全球人类反馈数据库,作为 AI 开发者的民主来源、权威数据集。
提到的链接:LLM Reading Group (March 5, 19; April 2, 16, 30; May 14; 28):来见见 LLM/NLP 研究领域一些开创性论文的作者,听他们讲述自己的工作。
HuggingFace ▷ #computer-vision (2 条消息):
- 寻找特定领域的 Vision Model:一位成员询问关于为低分辨率图像的描述和实体识别而微调 Vision Model 的建议。他们强调需要专门针对低分辨率优化模型,以避免不必要的复杂性。
- 为 SDXL 寻找高级 Tagger:另一位成员征求关于 SDXL 高级打标器 (Tagger) 的建议,暗示相比现有的 wd14 tagger 更倾向于其他选择。
HuggingFace ▷ #NLP (8 条消息🔥):
-
NLP 初学者从 spaCy 和 NLTK 开始:一位成员从 spaCy 和 NLTK 开始了他们的 NLP 之旅,并转向社区推荐的当代教科书以获取更新的见解。
-
解码模型输出:一位用户询问如何使用 T5 模型将
batch_size, seq_size, emb_size的 Tensor 解码为自然语言。由于需要包含last_hidden_在内的特定对象结构,使用model.generate的尝试失败了。 -
探索 LoRA 配置:一位用户正在尝试用于微调的 LoRA 配置,并就将 bias 设置更改为 ‘all’ 或 ‘lora_only’ 的影响寻求建议。
-
为 ROBERTA 问答聊天机器人准备数据集:一位成员询问关于准备包含 100,000 条条目和 20 多个特征的 CSV 数据集的指导,用于微调 ROBERTA 模型以构建问答聊天机器人。
-
讨论中的 BERTopic 框架:用户讨论了 BERTopic 框架,这是一种使用 Transformers 和 c-TF-IDF 的主题建模技术,强调了其快速的性能和良好的结果,并提供引导式(guided)、监督式(supervised)、半监督式(semi-supervised)、手动(manual)、层级化(hierarchical)和基于类别(class-based)的主题建模选项(BERTopic 指南)。对话涉及了包含自定义停用词的需求,以及选择合适的 LLM 将种子词转换为短语。
提到的链接:主页:利用 BERT 和基于类别的 TF-IDF 创建易于解释的主题。
HuggingFace ▷ #diffusion-discussions (8 条消息🔥):
-
模型类型混淆已澄清:一位新成员询问了 LLM 与 Embedding 模型之间的区别,特别是 OpenAI Embedding 模型与 OpenAI GPT-3.5 Turbo 之间的差异。
-
Stable Diffusion Cascade 模型的 Token 限制问题:一位成员提出了在长提示词下使用 Stable Diffusion Cascade 模型时遇到的问题,遇到了输入被截断的 Token 限制错误。他们还分享了一个 GitHub issue 链接,详细说明了该问题。
-
澄清 Token 截断问题:针对关于 Token 限制的困惑,有人澄清说收到的消息是警告而非错误,并且被截断的 Token(如给定示例中的 ‘hdr’)确实会被忽略。
-
寻找截断警告的解决方案:该成员对截断警告表示担忧,询问潜在的解决方案,其中 Compel 库被提及为一个例外。
-
关于 Compel 库维护的疑问:针对 Compel 库的提及,有人指出 Compel 目前似乎没有维护。当被问及需要什么样的维护时,目前还没有关于具体需求的即时回复。
提到的链接:在长提示词下使用 stable cascade 报错 · Issue #7672 · huggingface/diffusers:你好,当我在长提示词下使用 stable cascade 模型时,出现了以下错误。Token 索引序列长度超过了该模型指定的最高序列长度 (165 > 77)。运行此…
Cohere ▷ #general (100 条消息🔥🔥):
- 用户报告马其顿语翻译问题:一位成员对 Command-R 在处理马其顿语时的质量表示担忧。他们提到已在社区支持频道报告了此问题。
- 咨询 #computer-vision 频道访问权限:一位用户正在寻求访问 #computer-vision 频道的权限,并详细说明了该频道中包含的信息内容和演示时间表。
- 在 Python 中实现 Chat Stream 异步化:关于如何将一段代码转换为异步形式,以便高效地从 Command-R 模型流式传输聊天的技术讨论。
- 关于 API 速率限制的问题:解答了关于 Cohere API 测试密钥速率限制的查询,澄清了 “generate, summarize” 的限制为 5 次调用/分钟,其他端点为 100 次调用/分钟,且所有测试 API 密钥每月总计限制为 5000 次。
- 关于 Cohere 付费生产级 API 的讨论:成员们讨论了通过 Cohere 访问 Commander R+ 付费计划的可能性。分享了 Cohere 生产级 API 文档的链接,表明该服务已经存在。
- 探索 Cohere 的 Chat API 和连接器 (Connectors):有人询问了 Chat API 与连接器配合使用时的功能,以及它是否管理 Embedding 和检索过程。对方澄清说,连接器旨在将模型与文本源链接,且引用(citations)是一项包含在内的功能。
- 未找到标题: 未找到描述
- Messages 示例: 未找到描述
- 托管在 ImgBB 的 Screenshot-2024-04-16-151544: 托管在 ImgBB 的图片 Screenshot-2024-04-16-151544
- Chat API 参考 - Cohere 文档: 未找到描述
- Dracones/c4ai-command-r-plus_exl2_5.5bpw · Hugging Face: 未找到描述
- 社区 - Computer Vision: 频道:#computer-vision 共同负责人:Benedict - Discord @Harkhymadhe,Twitter @Arkhymadhe。物流:发生时间:每月第二个星期二上午 8 点(太平洋时间)。欢迎随时添加论文/文章...
- GitHub - Unstructured-IO/unstructured: 用于构建自定义预处理流水线的开源库和 API,适用于标注、训练或生产机器学习流水线。: 用于构建自定义预处理流水线的开源库和 API,适用于标注、训练或生产机器学习流水线。 - GitHub - Unstructured-IO/unstructured...
- GitHub - cohere-ai/quick-start-connectors: 此开源仓库提供了将工作场所数据存储与 Cohere 的 LLM 集成的参考代码,使开发人员和企业能够在其自有数据上执行无缝的检索增强生成 (RAG)。: 此开源仓库提供了将工作场所数据存储与 Cohere 的 LLM 集成的参考代码,使开发人员和企业能够执行无缝的检索增强生成...
- GitHub - cohere-ai/sandbox-conversant-lib: 基于 Cohere LLM 构建的对话式 AI 工具和人格 (Personas): 基于 Cohere LLM 构建的对话式 AI 工具和人格 (Personas) - cohere-ai/sandbox-conversant-lib
- 登录 | Cohere: Cohere 通过一个易于使用的 API 提供对高级 Large Language Models 和 NLP 工具的访问。免费开始使用。
- 登录 | Cohere: Cohere 通过一个易于使用的 API 提供对高级 Large Language Models 和 NLP 工具的访问。免费开始使用。
Cohere ▷ #project-sharing (1 条消息):
- Rubiks.ai 发布,搭载海量模型: Rubiks.ai 推出了一个先进的研究助手和搜索引擎。用户可获得 2 个月的免费高级访问权限,以测试包括 Claude 3 Opus, GPT-4 Turbo, Mistral Large 以及在 Groq 高速服务器上运行 RAG 的 Mixtral-8x22B 等模型的功能。
提到的链接: Rubik’s AI - AI 研究助手与搜索引擎: 未找到描述
OpenAccess AI Collective (axolotl) ▷ #general (56 条消息🔥🔥):
-
Deepspeed 在多节点上运行成功: 一位成员报告称 Deepspeed 01 和 02 配置在多节点设置中表现良好。分享了一个包含使用 Axolotl 进行多节点分布式微调指南的 Pull Request,供遇到配置问题的用户参考。
-
Idefics2 8B 表现优于其前代: Idefics2 模型现已在 Hugging Face 上发布,增强了在 OCR、文档理解和视觉推理方面的能力,以更少的参数和改进的图像处理能力超越了 Idefics1。可在 Hugging Face 获取该模型。
-
RTX 5090 发布预期: 讨论表明,由于竞争压力,Nvidia 可能会比预期更早发布 RTX 5090 显卡,可能是在 6 月的 Computex 展会上,正如 PCGamesN 所报道的那样。
-
探索 Mixtral 8x22B 推理的可能性: 成员们分享了使用 Mixtral 8x22B 的经验,指出在训练期间使用 3 块 A6000 配合 FSDP 进行 QLoRA,并理论推测两块 A6000 足以支持使用 4-bit 量化、上下文长度达 4k 的推理。
-
Model Stock 方法作为遗忘缓解器:对 Cosmopedia-subset 数据上不同训练方法的比较表明,各种微调方法的 Model Stock 合并能有效修复灾难性遗忘(catastrophic forgetting)。有人建议,Model Stock、QLoRA、GaLore 和 LISA 等组合微调方法可能会降低适配强度,可能需要更强的 LoRA 来进行补偿。
- Nvidia’s RTX 5090 and 5080 could arrive much sooner than expected, but there’s a big catch:泄露消息指出,由于来自 AMD 的竞争,新款 Nvidia Blackwell GeForce GPU 的上市时间可能比原先预期的要早得多。
- HuggingFaceM4/idefics2-8b · Hugging Face:未找到描述
- Guide For Multi-Node Distributed Finetuning by shahdivax · Pull Request #1477 · OpenAccess-AI-Collective/axolotl:标题:多节点设置的分布式微调指南。描述:此 PR 引入了使用 Axolotl 和 Accelerate 设置分布式微调环境的全面指南。
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 条消息):
- 分享 Twitter 链接:一名成员分享了一个 Twitter 链接,引发了其他人的反应,他们认为内容很有趣。虽然没有描述 Twitter 帖子的具体内容,但引起了“噢,太酷了”和“噢,不错”之类的回应。
- 寻求指导:一位成员表达了好奇:“噢噢噢,我该怎么用这个?”,表示希望获得有关 Twitter 链接中分享内容的使用指导。
OpenAccess AI Collective (axolotl) ▷ #general-help (11 条消息🔥):
-
梯度累积受到质疑:一名成员质疑在使用样本打包(sample packing)时梯度累积(gradient accumulation)的有效性,因为他们观察到训练时间和数据集长度会随着梯度累积步数的变化而变化。该成员试图弄清楚梯度累积是否确实如预期般节省显存。
-
解释输入在训练中的作用:一位成员询问如果禁用了
train_on_input,输入(input)的目的是什么,并推测它是否仍被用于教导模型处理上下文和进行预测。另一位成员回应称,输入变成了上下文的更大部分,模型会更多地记住或转向它。 -
澄清
train_on_input下的 Loss 计算:在后续讨论中,有人澄清当启用train_on_input时,Loss 不会针对输入部分进行计算,这随后会以不同的方式影响模型训练,因为模型不再预测输入部分。 -
理解 Loss 对训练的影响:对话继续讨论了当
train_on_input开启时 Loss 在训练中的作用,确认在这种情况下 Loss 不会影响训练。还有人提到,如果没有开启评估(evaluation),Loss 会变得更加无关紧要。
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (15 条消息🔥):
- Axolotl 的 Epoch 困境:一名成员寻求关于如何配置 Axolotl 以防止在每个 epoch 后保存模型,而是在训练完成后才保存的建议。建议包括在训练参数或
config.yml中将save_strategy设置为"no",然后在训练结束后手动设置保存操作。 - 适用于有限空间的 TinyLlama:对于使用小于 7B 模型进行微调的情况,建议使用 “TinyLlama-1.1B-Chat-v1.0” 进行快速迭代和实验。该模型的配置可以在 Axolotl 仓库的
examples/tiny-llama目录下的pretrain.yml中找到。
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (4 条消息):
- 使用颜色描述微调 TinyLlama:要在包含十六进制颜色代码和描述的数据集上微调 TinyLlama,必须首先格式化数据,将颜色描述作为输入,将颜色代码作为目标输出。随后将进行 Tokenization 和格式化,使用特殊 Token 连接输入和输出,以便模型理解。
- Phorm 查询待解决:提出了一个关于模型微调数据预处理的问题;Phorm 被提示在 OpenAccess-AI-Collective/axolotl 中搜索答案。目前正在等待 Phorm 提供包含详细步骤的回复。
提到的链接:OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
Latent Space ▷ #ai-general-chat (89 条消息🔥🔥):
- Limitless 是下一款 Whisper 级别的可穿戴设备:此前被称为 Rewind 的可穿戴设备正在更名为 [Limitless](https://x.com/dsiroker/status/1779857843895599383?s=46&t=6FDPaNxZcbSsELal6Sv7Ug),并分享了价格细节,重点关注消费者体验。讨论围绕品牌选择、产品实现实时应用的能力以及面向未来的 AI 开发展开。
- 对云存储的隐私担忧:一些社区成员表达了强烈的观点,认为只有在完全本地化或端到端加密的情况下才会使用此类设备。他们还讨论了对“机密云”的担忧,以及该服务是否符合 HIPAA 标准。
- 介绍 Reka Core:[Reka Core](https://x.com/rekaailabs/status/1779894622334189592?s=46&t=90xQ8sGy63D2OtiaoGJuww) 被宣布为一款具有视频理解能力的多模态语言模型。成员们讨论了其背后的精简团队以及对 AI 开发民主化的影响。
- 推出 **Cohere Compass** Beta 版:Compass Beta 是一个由名为 Compass 的新 Embedding 模型驱动的多维数据搜索系统,目前正在招募 Beta 测试人员以协助评估其功能。
- 符号化 AI 与人类协作:[Payman AI](https://www.paymanai.com/) 的推出引起了好奇和推测,这是一个 AI Agent 雇佣人类的市场,人们讨论了 AI 指导人类任务的未来及其在数据生成和 AI 训练方面的潜力。
- 来自 Reka (@RekaAILabs) 的推文:除了 Core 之外,我们还发布了一份技术报告,详细介绍了 Reka 模型在训练、架构、数据和评估方面的细节。https://publications.reka.ai/reka-core-tech-report.pdf
- Payman - 首页:未找到描述
- 来自 Reka (@RekaAILabs) 的推文:隆重推出 Reka Core,这是我们迄今为止最强大、最出色的多模态语言模型。🔮 过去几个月我们一直忙于训练这个模型,很高兴终于能发布它!💪 Core 拥有许多能力,并且...
- LLM 定价 - 比较大语言模型成本和定价:未找到描述
- 来自 Yi Tay (@YiTayML) 的推文:这是一段疯狂的旅程。我们只有 20 个人,在过去的几个月里消耗了数千张 H100,很高兴终于能向世界分享这个成果!💪 我们在创立 Reka 时的目标之一是...
- AI 推理现已在 Supabase Edge Functions 中可用:通过 Supabase Edge Functions 在边缘端使用 Embeddings 和大语言模型。
- 来自 clem 🤗 (@ClementDelangue) 的推文:这是多模态周!在 Grok 1.5 Vision(完全闭源)、Reka Core(闭源 + 研究论文)之后,欢迎来自 @huggingface 的 Idefics2(完全开源并提供公共数据集)—— 每一个...
- 来自 Lilian Weng (@lilianweng) 的推文:🎨 花了一些时间重构了 2021 年关于 Diffusion Model 的文章,并增加了新内容:https://lilianweng.github.io/posts/2021-07-11-diffusion-models/ ⬇️ ⬇️ ⬇️ 🎬 接着是另一篇关于 Diffusion Video 的短文...
- 来自 Dan Siroker (@dsiroker) 的推文:介绍 Limitless:一款由你所见、所言、所闻驱动的个性化 AI。它包含 Web 应用、Mac 应用、Windows 应用以及一款可穿戴设备。0:06 揭晓 0:48 为什么选择 Limitless? 1:39 演示 3:05 吊坠 4:2...
- 来自 Yohei (@yoheinakajima) 的推文:一个供 AI Agent 雇佣人类的市场 🧠 ↘️ 引用 tyllen (@0xTyllen) 的话:很高兴介绍我一直在开发的一个新项目,叫做 Payman!Payman 是一个 AI Agent 工具,它赋予 Agent...
- 来自 Susan Zhang (@suchenzang) 的推文:MBPP 可能也曾在 Phi-1.5 数据集的某些地方被使用过。就像我们截断了 GSM8K 的一个问题一样,让我们尝试截断 MBPP 的 Prompt,看看 Phi-1.5 会自动补全什么...
- 来自 Harry Stebbings (@HarryStebbings) 的推文:这就是他们所说的 @sama 效应。20VC 历史上 10 年来最快的下载率。
- 来自 Aidan Gomez (@aidangomez) 的推文:很高兴宣布 Compass Beta 版,这是一个由新型 Embedding 模型 Compass 驱动的、功能强大的多维度数据搜索系统。我们正在寻求帮助来对该模型的能力进行压力测试...
- 来自 Harry Stebbings (@HarryStebbings) 的推文:10 年前,我在卧室里开始创办 20VC,没有资金也没有人脉。今天,我们发布了与 @sama、@bradlightcap 以及历史上增长最快的公司 @OpenAI 合作的 20VC 节目。互联网的力量...
- 来自 Wing Lian (caseus) (@winglian) 的推文:好吧,在等待 axolotl ai 域名转移期间,我们先用老办法。在这里注册以获取私人 Beta 版的访问权限。https://docs.google.com/forms/d/e/1FAIpQLSd0uWGZOwviIZPoOPOAaFDv3edcCXEIG...
- Payman - 实现 AI Agent 向人类付款!:大家好,在这段视频中,我非常激动地向大家展示 Payman,这是一个允许你将 Agent 与资金连接起来的平台,它们可以使用这些资金来支付给...
- LLM Explorer:精选的大语言模型目录。LLM 列表。35754 个开源语言模型。:浏览 35754 个开源的大型和小型语言模型,这些模型被方便地分成了各种类别和 LLM 列表,并附带基准测试和分析。
- 2024 年构建大语言模型 (LLM) 简明指南:一份关于在 2024 年训练高性能大语言模型所需知识的简明指南。这是一个入门讲座,包含相关参考资料链接...
- patrickvonplaten (Patrick von Platen):未找到描述
- 来自 Harry Stebbings (@HarryStebbings) 的推文:10 年前,我在卧室里开始创办 20VC,没有资金也没有人脉。今天,我们发布了与 @sama、@bradlightcap 以及历史上增长最快的公司 @OpenAI 合作的 20VC。互联网的力量...
- Sam Altman & Brad Lightcap:哪些公司会被 OpenAI 碾压? | E1140:Sam Altman 是 OpenAI 的 CEO,该公司的使命是确保通用人工智能 (AGI) 造福全人类。OpenAI 是增长最快的公司之一... </ul> </div> --- **Latent Space ▷ #[ai-announcements](https://discord.com/channels/822583790773862470/1075282504648511499/1229594211536474163)** (1 条消息): - **为 AI 专家提供丰厚资助**:**Strong Compute** 宣布为需要访问高性能计算 (HPC) 集群的 **AI 研究人员提供 $10k-$100k 的资助**。符合条件的项目包括探索 *AI 信任*、*后 Transformer 架构*、*新训练方法*、*可解释 AI (Explainable AI)* 以及申请人可能提出的更多创新主题。 - **GPU 奖励等你来拿**:申请人有机会获得多达约 100x 24GB Ampere GPU,以及每位研究人员 **~1+TB 存储空间**。根据分配情况和市场动态,提供的总算力可转化为大约 3,000-30,000 GPU 小时。 - **开放科学,丰厚奖励**:研究人员必须承诺发布一个公开访问的 Demo,包含代码和数据样本——理想情况下是完整数据集。目标是在 7 月底前准备好可发表的结果。 - **申请倒计时**:感兴趣的人士应立即通过 [Strong Compute 研究资助页面](https://strongcompute.com/research-grants) 申请,算力分配决定将在 **4 月底** 做出。申请人可以在两个工作日内收到回复。 - **咨询渠道**:如有疑问,鼓励研究人员联系公告中标记的社区成员。 **提到的链接**:研究资助:未找到描述 --- **OpenInterpreter ▷ #[general](https://discord.com/channels/1146610656779440188/1147665339266650133/1229460702373216407)** (51 条消息🔥): - **加入创新头脑风暴**:引入了一个新频道,用于头脑风暴 OpenInterpreter 的创新用途、漏洞修复和功能构建。 - **OpenInterpreter 社区中的 Airchat 热潮**:成员们正在加入语音通信应用 **Airchat**,分享 'mikebird' 和 'jackmielke' 等账号,寻求邀请码,并讨论其功能和易用性。 - **对 01 项目更新的期待**:关于 01 项目状态和更新的问题得到了回应,涉及与制造服务的持续讨论以及对交付时间表的期待。 - **开源 AI 成为焦点**:社区对 **WizardLm2** 表现出极高热情,这是一个可与 GPT-4 媲美的开源模型,人们对 AI 的进展以及此类开源权重模型的可用性感到兴奋。 - **个人 AI 助手搜索**:讨论围绕寻找能够提供快速响应并整合个人数据以提高效率的个人 AI 助手展开,并对 01 和 **Limitless AI** 等产品进行了比较。
- 未找到标题:未找到描述
- 当你创作陷入困境时请阅读:一位朋友发给我的励志信息,他几年前在社交媒体上发现的。原作者不详
- 我评测过的最差产品……目前为止:Humane AI pin 很……糟糕。几乎没有人应该买它。至少现在是这样。MKBHD 周边:http://shop.MKBHD.com 我正在使用的技术产品:https://www.amazon.com/shop/MKBHDIn...
- GitHub - rbrisita/01 at linux:开源语言模型计算机。通过在 GitHub 上创建账号为 rbrisita/01 的开发做出贡献。
- 未找到标题:未找到描述
- 未找到标题:未找到描述
- 未找到标题:未找到描述
- Galaxy AI - Swagger UI:未找到描述
- Home - OppyDev:提升你编程体验的协作 AI Agent
- Payman - Enabling AI Agent To Human Payments!:大家好,在这段视频中,我非常兴奋地向大家展示 Payman,一个允许你将 Agent 与资金连接起来,以便它们可以用来支付给人类的平台...
- Rubik's AI - AI research assistant & Search Engine:未找到描述
- GitHub - ossirytk/llama-cpp-chat-memory:具有 Chroma 向量库记忆的本地角色 AI 聊天机器人,以及一些为 Chroma 处理文档的脚本。
- 来自 Pim de Witte (@PimDeWitte) 的推文:@WizardLM_AI 发生了一些“非常”奇怪的事情:1) 模型权重被删除 2) 公告帖子被删除 3) 不再出现在 “microsoft” 集合中 4) 找不到任何其他证据表明……
- 来自 WizardLM (@WizardLM_AI) 的推文:🫡 我们对此深表歉意。距离我们几个月前发布模型已经有一段时间了😅,所以我们现在对新的发布流程不熟悉:我们不小心遗漏了模型发布中要求的一个项目……
- CC Search Portal:未找到描述
- llama.cpp/convert.py at master · ggerganov/llama.cpp:C/C++ 中的 LLM 推理。在 GitHub 上通过创建账号为 ggerganov/llama.cpp 的开发做出贡献。
- transformers/src/transformers/convert_slow_tokenizer.py at fe2d20d275d3591e2619a1adb0fa6ae272605208 · huggingface/transformers:🤗 Transformers:适用于 Pytorch、TensorFlow 和 JAX 的最先进机器学习框架。 - huggingface/transformers
- Reka Core: A Frontier Class Multimodal Language Model:Reka Core 在关键的行业公认评估指标上与来自 OpenAI、Anthropic 和 Google 的模型具有竞争力。鉴于其占用空间和性能,...
- JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars:JetMoE-8B 的训练成本不到 10 万美元,但性能优于来自 Meta AI 的 LLaMA2-7B,后者拥有数十亿美元的训练资源。LLM 训练...
- LLMs in Prod w/ Portkey, Flybridge VC, Noetica, LastMile · Luma:揭秘将 Gen AI 应用扩展到生产环境的秘诀。虽然原型化 Gen AI 应用很容易,但将其投入全规模生产却很难。我们正在……