ainews-mixtral-8x22b-instruct-defines-frontier
Mixtral 8x22B Instruct 引发了关于效率的梗。
以下是为您翻译的中文内容:
Mistral 发布了其 Mixtral 8x22B 模型的指令微调版本。该模型的一大亮点是推理时仅需 390 亿(39B)激活参数,性能却优于更大规模的模型。它支持 5 种语言,拥有 64k 上下文窗口,并具备强大的数学和代码处理能力。该模型已在 Hugging Face 上线,采用 Apache 2.0 协议,支持本地部署使用。
谷歌计划在 AI 领域投资超过 1000 亿美元,微软、英特尔和软银等巨头也纷纷投入巨资。
英国已将未经同意制作的深度伪造(deepfake)色情内容定为刑事犯罪,这引发了关于执法难度的讨论。
一位前英伟达(Nvidia)员工声称,英伟达在 AI 芯片领域的领先地位在未来十年内都无法被撼动。
AI 伴侣市场规模有望达到 10 亿美元。
AI 在多项基础任务上已超越人类,但在处理复杂任务时仍显不足。
Zyphra 推出了 Zamba,这是一种新型的 7B 参数混合模型。在训练数据更少的情况下,其性能超越了 LLaMA-2 7B 和 OLMo-7B。该模型是在 128 块 H100 GPU 上历时 30 天训练完成的。
GroundX API 进一步提升了检索增强生成(RAG)的准确性。
2024/4/16-4/17 的 AI 新闻。我们为您检查了 6 个 subreddits、364 个 Twitter 账号 和 27 个 Discords(395 个频道,以及 5173 条消息)。预计为您节省阅读时间(以 200wpm 计算):587 分钟。
按照其既定模式,Mistral 在发布磁力链接后紧接着发布了一篇博客文章,以及其 8x22B 模型的 Instruct 微调版本:
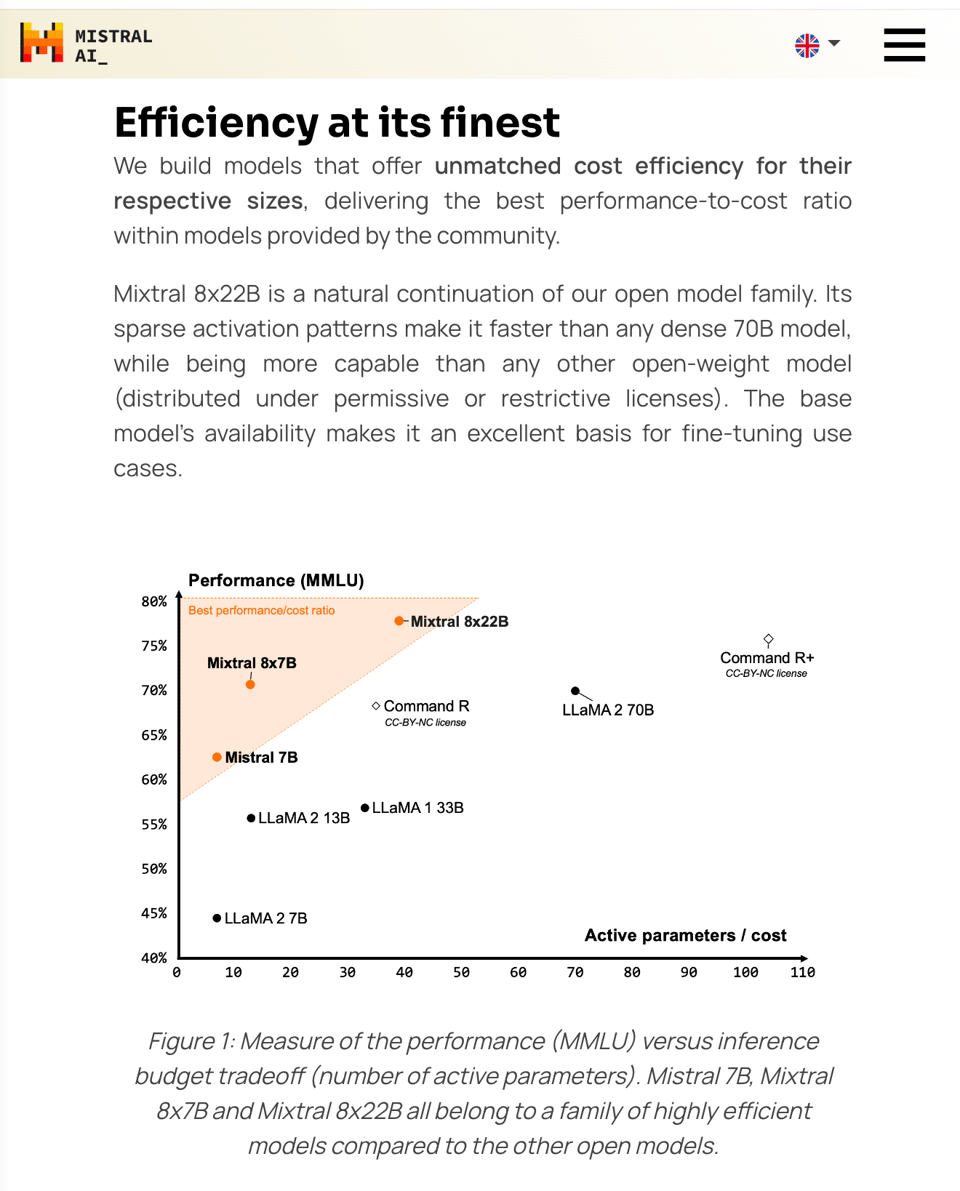
这张图片最终引发了 Databricks, Google, 和 AI21 之间的友好竞争,所有这些都仅仅强调了 Mixtral 在激活参数(active params)和 MMLU 性能之间创造了新的权衡:
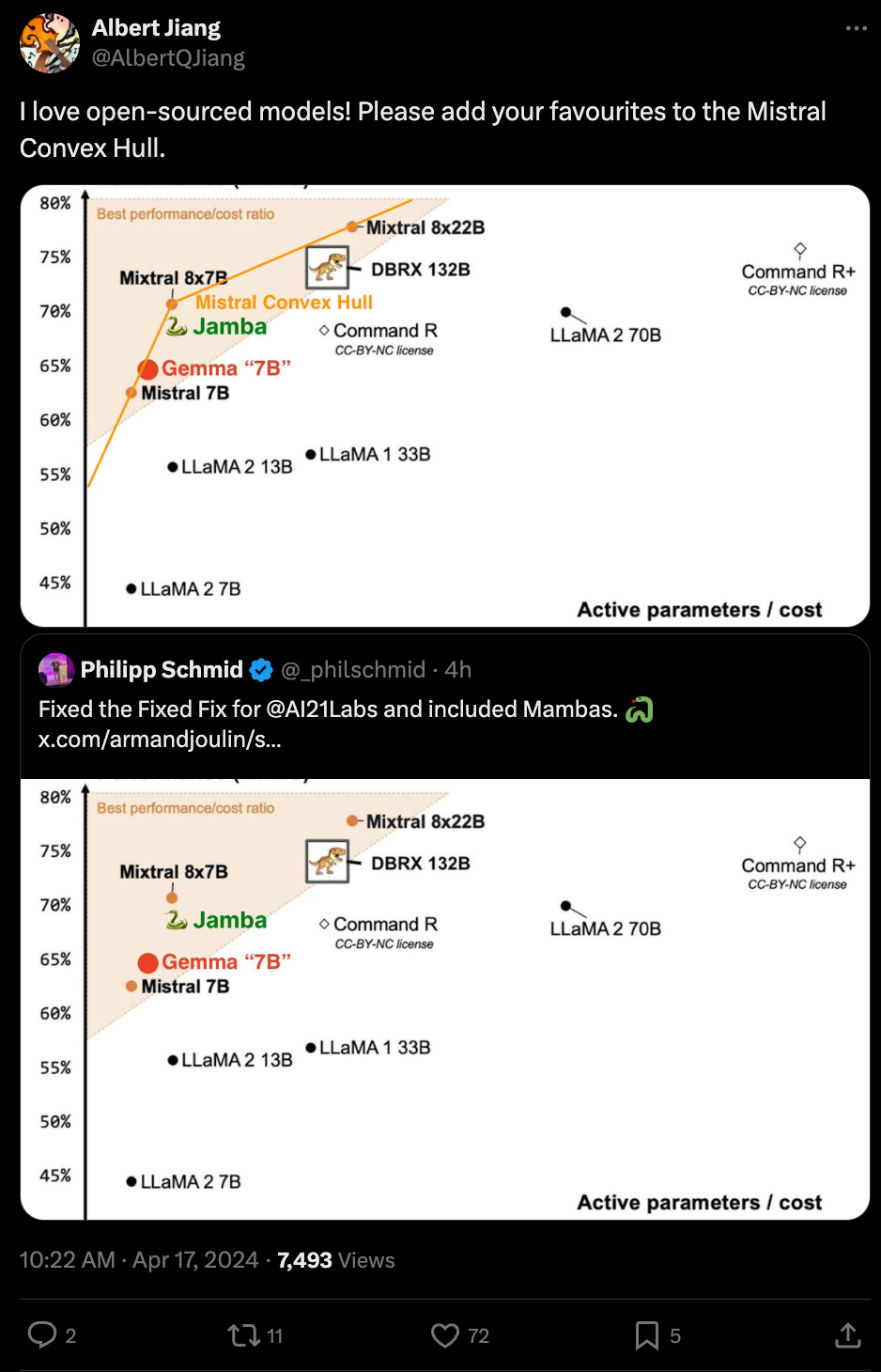
当然,未言明的是激活参数数量与运行 Dense 模型的成本并不呈线性相关,而且单一关注 MMLU 对于那些不那么严谨的竞争对手来说并不理想。
目录
[TOC]
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/Singularity。评论抓取现在可以运行了,但仍有很大改进空间!
AI 投资与进展
-
科技巨头的巨额 AI 投资:在 /r/singularity 中,DeepMind CEO 透露 Google 计划在 AI 领域投资超过 1000 亿美元,其他科技巨头如 Microsoft, Intel, SoftBank 和一家阿布扎比基金也做出了类似的巨额押注,表明了对 AI 潜力的极高信心。
-
英国将非自愿 deepfake 色情内容定为犯罪:英国已将未经同意创建性显性 deepfake 图像定为犯罪。在 /r/technology 中,评论者们辩论了其影响和执法挑战。
-
Nvidia 的 AI 芯片主导地位:在 /r/hardware 中,一位前 Nvidia 员工在 Twitter 上声称这十年内没有人能赶上 Nvidia 的 AI 芯片领先地位,引发了关于该公司强势地位的讨论。
{kind=link}
AI 助手与应用
-
AI 伴侣潜在的十亿美元市场:在 /r/singularity 中,一位科技高管预测 AI 女友可能成为一项 10 亿美元的业务。评论者认为这被大大低估了,并讨论了其社会影响。
-
语言模型的无限上下文长度:/r/artificial 发布的一条推文宣布了无限上下文长度(unlimited context length),这是 AI 语言模型的一项重大进步。
-
AI 在基础任务上超越人类:在 /r/artificial 中,一篇 Nature 文章报道称 AI 在几项基础任务上的表现已超越人类,尽管在更复杂的任务上仍处于落后地位。
AI 模型与架构
- Zamba:新型 7B 参数混合架构:在 /r/LocalLLaMA 中,Zyphra 推出了 Zamba,这是一种将 Mamba 模块与共享注意力(shared attention)相结合的 7B 参数混合架构。尽管训练数据较少,但它的表现优于 LLaMA-2 7B 和 OLMo-7B 等模型。该模型由一个 7 人团队使用 128 块 H100 GPU 历时 30 天开发完成。
AI Twitter 摘要回顾
所有摘要均由 Claude 3 Opus 生成(4 次运行中的最佳结果)。我们正在使用 Haiku 进行聚类和流程工程(flow engineering)。
Mixtral 8x22B Instruct 模型发布
- 令人印象深刻的性能:@GuillaumeLample 宣布发布 Mixtral 8x22B Instruct,该模型在推理过程中仅使用 39B 激活参数,性能显著超越现有的开源模型,且速度比 70B 模型更快。
- 多语言能力:@osanseviero 强调 Mixtral 8x22B 精通 5 种语言(英语、法语、意大利语、德语、西班牙语),具备数学和代码能力,并拥有 64k 上下文窗口。
- 可用性:该模型已在 @huggingface Hub 上以 Apache 2.0 许可证发布,可以下载并在本地运行,正如 @_philschmid 所确认的那样。
RAG (Retrieval-Augmented Generation) 进展
- GroundX 提升准确率:@svpino 分享了 @eyelevelai 发布的 GroundX,这是一个先进的 RAG API。在对 1,000 页税务文件的测试中,GroundX 达到了 98% 的准确率,而 LangChain 为 64%,LlamaIndex 为 45%。
- 评估风险的重要性:@omarsar0 根据一篇关于 RAG 模型忠实度的论文,强调了在使用可能包含支持性、矛盾性或错误数据的上下文信息时,评估 LLM 风险的必要性。
- LangChain RAG 教程:@LangChainAI 在 @freeCodeCamp 上发布了一个解释 RAG 基础和高级方法的播放列表。他们还分享了一个关于使用 Mixtral 8x22B 进行 RAG 的 @llama_index 教程。
Snowflake Arctic Embed 模型
- 强大的 Embedding 模型:@SnowflakeDB 在 @huggingface 上开源了其 Arctic 系列 Embedding 模型。正如 @RamaswmySridhar 所言,这些模型是 @Neeva 的搜索专业知识与 Snowflake 对 AI 投入的结晶。
- 效率与性能:@rohanpaul_ai 强调了这些模型的效率,参数量从 23M 到 335M 不等,序列长度从 512 到 8192,在不使用 RPE 的情况下支持高达 2048 个 Token,使用 RPE 则可支持 8192 个 Token。
- LangChain 集成:@LangChainAI 宣布其 @huggingface Embeddings 连接器已实现对 Snowflake Arctic Embed 模型的同日支持。
其他
- CodeQwen1.5 发布:@huybery 介绍了 CodeQwen1.5-7B 和 CodeQwen1.5-7B-Chat,这是使用 3T Token 代码数据预训练的专业代码 LLM。它们在代码生成、长上下文建模 (64K)、代码编辑和 SQL 能力方面表现出色,在 SWE-Bench 测试中超越了 ChatGPT-3.5。
- 波士顿动力(Boston Dynamics)的新机器人:@DrJimFan 分享了波士顿动力新机器人的视频,并认为人形机器人的供应量将在未来十年内超过 iPhone,且“人类水平”只是一个人为设定的上限。
- 从第一天起就具备超人类能力的 AI:@ylecun 表示,AI 助手从一开始就需要具备类人智能以及超人类能力,这需要对物理世界的理解、持久记忆、推理和分层规划(hierarchical planning)。
AI Discord 摘要
摘要的摘要的摘要
Stable Diffusion 3 和 Stable Diffusion 3 Turbo 发布:
- Stability AI 推出了 Stable Diffusion 3 及其更快的变体 Stable Diffusion 3 Turbo,声称其性能优于 DALL-E 3 和 Midjourney v6。这些模型采用了全新的 Multimodal Diffusion Transformer (MMDiT) 架构。
- 计划通过 Stability AI Membership 发布 SD3 权重以供自托管,延续其开放生成式 AI 的路线。
- 社区正在等待关于 SD3 个人与商业用途许可的进一步说明。
Unsloth AI 进展:
- 讨论了 GPT-4 作为 GPT-3.5 的微调迭代版本,以及 Mistral7B 令人印象深刻的多语言能力。
- 对在 Apache 2.0 协议下开源发布的 Mixtral 8x22B 感到兴奋,该模型在多语言流利度和长上下文窗口方面具有优势。
- 有兴趣为 Unsloth AI 的文档做贡献,并考虑通过捐赠支持其开发。
WizardLM-2 亮相及随后的下架:
- Microsoft 发布了 WizardLM-2 系列,包括 8x22B、70B 和 7B 模型,展示了极具竞争力的性能。
- 然而,WizardLM-2 因缺乏合规性审查而被下架,并非最初推测的毒性问题。
-
下架引发了困惑和讨论,一些用户表示有兴趣获取原始版本。
-
Stable Diffusion 3 发布,性能提升:Stability AI 已发布 Stable Diffusion 3 和 Stable Diffusion 3 Turbo,现已在他们的 Developer Platform API 上可用,号称拥有最快且最可靠的性能。社区正在等待关于自托管 SD3 权重的 Stability AI Membership 模式的澄清。同时,SDXL finetunes 已使 SDXL refiners 几乎过时,用户讨论了 ComfyUI 中的模型合并挑战以及 diffusers 流水线的局限性。
-
WizardLM-2 在兴奋与不确定中首次亮相:Microsoft 发布的 WizardLM-2 模型激发了人们对其在开源格式下实现 类 GPT-4 能力 的热情。然而,由于遗漏合规审查导致模型突然下架,引发了困惑和猜测。用户对比了 WizardLM-2 各变体的性能,并分享了解决 LM Studio 兼容性问题的技巧。
- 多模态模型随 Idefics2 和 Reka Core 共同进步:Hugging Face 的 Idefics2 8B 和 Reka Core 已成为强大的多模态语言模型,展示了在视觉问答、文档检索和编码方面的卓越能力。即将推出的 Idefics2 聊天变体以及 Reka Core 对抗行业巨头的竞争表现引起了极大关注。讨论还涉及 JetMoE-8B 等模型的成本效益,以及用于文本嵌入的 Snowflake Arctic embed 系列 的发布。
其他值得关注的主题包括:
- 引入了 ALERT,一个用于评估大语言模型安全性的基准测试,以及关于 AI 安全标准的辩论。
- 探索用于视觉应用的 检索增强生成 (RAG),以及 World-Sim 中 AI 模拟的哲学意义。
- Payman AI 等 AI 与人类协作平台的兴起,以及 Supabase edge functions 中 AI 推理的集成。
- 对 Chinchilla scaling laws 的挑战,以及研究界对 状态空间模型 (state-space models) 表达能力的讨论。
- PEFT 方法(如 Dora 和 RSLoRA)的进展,以及利用 混合专家 (MoE) 方法进行 多语言模型扩展 的追求。
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
Stable Diffusion 3 Turbo 震撼登场:Stability AI 推出了 Stable Diffusion 3 和 Stable Diffusion 3 Turbo,现已在他们的 Developer Platform API 上线。在 Fireworks AI 的支持下,该公司声称其拥有最快且最可靠的性能。感兴趣的各方可以在 Stable Diffusion 3 & Developer API 开始使用 SD3。此外,Stability AI 承诺将采取开放的生成式 AI 路线,并计划为会员提供可自行托管的模型权重。
精炼视觉直观的生成式 AI:SDXL finetunes 已使 SDXL refiners 的使用几乎过时,因为前者在 Civitai 的下载中已非常普遍。这表明集成微调优于独立 refiner 模块的趋势,反映了社区驱动的优化方向。
模型融合探索:ComfyUI 内部关于模型融合策略的讨论非常活跃,涉及 V-prediction 和 epsilon 等复杂机制。这突显了社区通过这些方法实现更佳效果的实验精神,同时也承认正确的实现对于防止不可预测的结果至关重要。
应对 Diffusers 库的限制:围绕 diffusers 流水线的局限性和依赖关系展开了讨论,重点关注 Stable Video Diffusion Pipeline 面临的挑战。尽管存在这些挑战,一些用户正通过在下载后独立运行模型来优化使用,从而绕过 Hugging Face 库的某些约束。
等待 SD3 会员模式详情:社区正热切等待 Stability AI 澄清 Stable Diffusion 3 针对个人与商业用途的许可细节,特别是针对获取自行托管权重的新会员模式。
Unsloth AI (Daniel Han) Discord
GPT-4 优于 GPT-3.5:新一代 GPT(GPT-4)被认为是基于 GPT-3.5 的微调增强版,尽管未提供具体的性能指标或功能细节。
Mistral7B 在多语言方面表现出色:成员们讨论了 Mistral7B 模型的多语言能力,建议在训练集中加入多样化的语言数据(特别是法语)以提升性能。
Unsloth AI 获得粉丝支持:社区对 Unsloth AI 的反应非常积极,用户渴望在文档编写、扩展方面提供帮助,甚至考虑捐赠。Mixtral 8x22B 模型在 Apache 2.0 协议下的发布引起了轰动,因其在多语言流畅度和处理超长上下文窗口方面表现出色。
Chroma 转向 Go 语言:Chroma 项目凭借用 Go 编写的边缘版本向前迈进了一大步,该版本利用 SQLite 和 WASM 进行基于浏览器的应用,现已在 GitHub 上线。
移动端 AI 部署讨论:移动设备上部署 AI 模型的复杂性浮出水面,挑战包括缺乏 CUDA 以及在这些平台上运行标准 Deep Learning Python 代码的可行性问题。
LM Studio Discord
NeoScript 编程的 AI 辅助:一位寻求 NeoScript 编程帮助的用户表达了在配置 AI 模型方面遇到的挑战。Microsoft 的新发布版本 WaveCoder Ultra 6.7b 在代码翻译方面表现出色,可能是完成此任务的有力竞争者。
解决 AI 的回声室效应: 为了对抗重复性的 AI 回复(特别是在 Dolphin 2 Mistral 中),成员们讨论了一些策略,例如微调模型以及利用 Azure 文章中概述的多轮对话(multi-turn conversation)框架。
WizardLM-2 系列介绍:WizardLM-2 模型的首次亮相引发了关于性能的讨论。会议强调了与现有工具的兼容性,包括使用 GGUF quants 以及 0.2.19 或更新版本以确保功能正常的重要性。
技术极客的实践:一位用户成功实现了四块 3090 GPUs 之间的直接通信,通过绕过 CPU/RAM 提升了模型性能。此外,还有关于签署 Windows 可执行文件挑战的讨论,并提示 Windows 版本确实使用了 Authenticode cert 进行签名。
量化难题与模型偏好:关于量化水平(从 Q8 到 Q6K)的评价褒贬不一,这表明在 VRAM 充足时,用户更倾向于选择具有更高量化水平的模型。对于大型模型,如 WizardLM-2-8x22B,像拥有 24GB VRAM 的 4090 这样的 GPUs 可能不足以支撑。
Nous Research AI Discord
-
多模态模型(Multimodal Models)的进步:多模态语言模型展示了令人兴奋的进展,Hugging Face 的 Idefics2 8B 和 Reka Core 成为关键参与者,这从 Open Multimodal ChatGPT 视频和 Reka Core 概述中可见一斑。GPT4v/Geminipro Vision 和 Claude Sonnet 模型被推荐用于 vision-RAG 应用。
-
LLMs 转向自我优化:增强 Instruct Model LLMs 的新技术看起来很有前景,模型能够通过从输出中重构输入来选择最佳解决方案,详见关于医疗推理 LLMs 对齐的 Google Slideshow。
-
WizardLM 的消失引发辩论:WizardLM 突然下架的原因尚不明确;虽然有人猜测是毒性问题,但已证实的报告将其归因于缺乏合规性审查,正如在综合性的 WizardLM 信息包中所分享的那样。
-
LLMs 性能:预期的起伏:工程师们讨论了 CodeQwen1.5-7B Chat 令人印象深刻的基准测试结果,并辩论了架构和微调对性能的影响。此外,像 Hermes 8x22B 这样即将推出的模型备受期待,同时也存在对其是否能被个人设备配置容纳的担忧。
-
World-Sim 的回归引发 AI 哲学辩论:随着 World-Sim 准备回归,爱好者们充满期待,思考着此类模拟世界的哲学层面及其影响。官方确认让兴奋情绪高涨,并为渴望加入的用户提供了 Websim 链接。
Perplexity AI Discord
机器人辩论其根源:工程师们交流了关于 AI 模型性能细微差别的见解,包括 GPT-4 和 Claude 3 Opus,大家一致认为 GPT-4 在实际应用中可能会表现出“偷懒”的倾向。开源的 Mixtral’s 8x22B model 因其令人印象深刻的能力而受到关注,引发了关于模型功效的辩论。
被顽固的软件问题难倒:会议记录中提到关于实现 Web 客户端与 API 之间一致性的讨论,特别关注了 temperature settings 等参数。工程师们还在讨论在 API 响应中包含速率限制计数器(rate limit counter)的好处,以便更好地进行管理和提高透明度。
消失的消息之谜:有人对 Perplexity API 支付方式管理的更改表示担忧,特别是关于 Pro 用户剩余消息计数的透明度。这种对透明度的关注表明专业人士需要清晰的信息来有效地管理资源。
截断 Token 的故事:技术对话涉及在处理大上下文(如 42k token 的 prompt)时面临的挑战,以及模型倾向于总结而不是深入挖掘长文档的趋势。随着工程师优化模型以充分处理复杂的 prompt,这可能成为关键点。
寻找更智能的搜索:成员们还讨论了使用 site:URL 搜索运算符进行更有针对性的信息检索。此外,有人呼吁在 API 中更好地沟通速率限制,包括提供 429 response 的可能性。
LAION Discord
-
PyTorch 的抽象之谜:工程师们正在努力应对 PyTorch 抽象复杂性的哲学,虽然这简化了编码,但在排查意外结果时往往让他们感到困惑。
-
使用 Zarr 处理海量数据集:目前正在积极探索利用 zarr 来管理 150 GB 的 MRI 数据集,讨论围绕其效率以及在处理大数据负载时是否会使 RAM 过载展开。
-
英国为 Deepfakes 划定法律界限:成员们正在讨论英国针对制作令人痛苦的图像的立法的潜在影响,质疑其在证明意图的模糊性下的可执行性。
-
AI 推理微调对话:社区呼吁明确 AI 模型的推理设置,例如控制 CFG 或将模型与强大的 ODE solvers 集成,而不仅仅是默认使用 Euler’s method。
-
Cascade 团队的企业重组:关于 Stability AI 的 Cascade 团队在离职及 Discord 频道解散后的去向存在猜测,人们好奇这是否与新公司(可能是 Leonardo)有关,或者是与 SAI 保持持续关联。
-
警报!LLM 的新安全基准:ALERT 的引入引起了兴趣,这是一个用于评估 Large Language Models 的安全基准,提供了一个问题输出数据集 (DPO) 供社区评估,可在 GitHub 上获取。
-
AI 视听和谐:一篇 Arxiv 论文 提出了从文本生成音频的方法,通过专注于概念或事件来提高性能,引发了研究界的对话。
-
AI 安全还是受限?:关于 AI 安全的辩论非常激烈,一些人反对将 AI 严格限制在 PG 级内容,认为与其他艺术媒介相比,这可能会削弱其创造力火花。
-
GANs vs. Diffusion Models:速度还是美学?:关于 GANs 优势的讨论正在升温——特别是它们更快的推理速度和更少的参数量——尽管 GANs 在图像质量和训练挑战方面面临批评,但仍与 Diffusion Models 展开竞争。
OpenRouter (Alex Atallah) Discord
OpenRouter 欢迎 WizardLM Raptors:OpenRouter 宣布发布 WizardLM-2 7B,并将 WizardLM-2 8x22B 的价格降至 $0.65/M tokens。WizardLM-2 8x22B Nitro 在其数据库重启后,每秒交易数(TPS)超过了 100 次。
延迟迷宫已解决:Mistral 7B Instruct 和 Mixtral 8x7B Instruct 等多种模型的延迟问题被归因于云服务商的 DDoS 防护,有关解决情况的更新可在相关的 讨论线程 中找到。
征集前端高手:一名成员正在为一个基于 OpenRouter 的 AI 前端项目寻求 Web 开发协助,特别强调了角色扮演小说模式和对话风格系统。还要求能够区分 AI 生成的文本与用户输入。
AI 模型道德与多语言精通:针对 NSFW 内容的审查协议以及增强模型多语言性能的必要性进行了激烈的交流。成员们期待着即将发布的 AI 模型的直接 Endpoint 和新 Provider 集成。
比特率与质量争议:用户明显偏好模型量化至少达到 5 bits per word (bpw),并指出低于此阈值的削减会显著损害质量。讨论强调了高效运行与保持 AI 输出高保真度之间的权衡。
Modular (Mojo 🔥) Discord
-
Mojo 到 Python 的转换现已成为可能:工程师们讨论了新包 mojo2py,它能够将 Mojo 代码转换为 Python,并聊到了对更多学习资源的需求,指向了针对初学者的 Mojo 编程手册。
-
Maxim Zaks 辩论 Mojo 的“炒作”:重点介绍了 Maxim Zaks 在 PyCon Lithuania 上题为“Mojo 只是炒作吗?”的演讲,引发了关于该聊天机器人对行业影响的辩论,视频可在 此处 观看。
-
Mojo Nightly 版本的固有细微差别:用户正在应对新发布的 Nightly 版本 Mojo 带来的挑战,注意到了为了可读性而采用的非常规代码风格,对 Traits 全面教程的需求,以及反映重大更新的 最新 Pull Request。
-
使用编译时别名进行优化:围绕优化 Mojo 中 Alias 内存使用的讨论非常热烈,引用的一段 YouTube 视频 建议代码应具有可读性而非过多的注释。
-
社区 Mojo 项目激增:社区贡献激增,分享了一个 Mojo “草图”(可在 此 Gist 找到),以及关于在 Mojo 中实现 Canny 边缘识别算法的请求,并附带了 Mojo 文档 和工具资源的指引。
CUDA MODE Discord
PyTorch 资源辩论:在讨论《Deep Learning with PyTorch》尽管已有 4 年历史是否仍是相关资源时,成员们指出 PyTorch core 保持稳定,尽管在编译器和分布式系统方面发生了重大更新。一位成员分享了该书即将出版的新版的预告,其中将包含对 Transformers 和 Large Language Models 的覆盖。
CUDA 自定义 GEMM 引起关注:对话涉及改进 CUDA 中的 GEMM 性能,一位成员提供了一个新的实现,在特定基准测试中优于 PyTorch 的函数,并在 GitHub 上分享了代码。然而,另一位成员强调了 torch.compile 的 JIT 编译问题。小组还讨论了最优 block size 参数,并引用了 Gist 上的相关代码示例。
| 下一代视频分析与机器人技术进展:成员们分享了关于 Augmend 视频处理功能的链接,该功能结合了 OCR 和图像分割,在 wip.augmend.us 进行了预览,完整服务将托管在 augmend.com。另一个亮点是 Boston Dynamics 发布了一款名为 Atlas 的全电动机器人,旨在用于现实世界的应用,并在其 [All New Atlas | Boston Dynamics 视频](https://www.youtube.com/watch?v=29ECwExc-_M)中展示。 |
弥合 CUDA Toolkit 知识鸿沟:在 #beginner 频道中,成员们讨论了在 WSL 上使用 CUDA toolkit 的相关问题,一位用户在运行 ncu profiler 时遇到困难。社区提供了故障排除步骤,并强调了在环境变量中设置正确 CUDA path 的重要性。此外,还有建议称 Windows 11 对于在 WSL 2 上进行有效的 CUDA profiling 可能是必要的,一位用户提供了关于该主题的指南。
量化难题与解决方案:针对 GPT 模型中的量化轴展开了深入讨论,重点讨论了使用 axis=0 时的复杂性。参与者建议分别对 Q, K 和 V 进行量化,并参考了 Triton kernels 和一种用于提升速度和性能的 autograd 优化方法。辩论继续讨论了 2/3 bits 量化的实用性,并补充了 GitHub 上的实现细节和基准测试。
优化 ML 模型性能:一个用于通过 CUDA Python 扩展 PyTorch 的 GitHub notebook 因其速度提升而受到关注,但仍需更多优化以充分发挥 tensor core 的能力,详见 notebook 链接。此外,还提到了优化 softmax 函数和用于缓存利用的 block sizes,并通过 GitHub pull request 分享了见解。
OpenAI Discord
多人游戏 GPT 进军游戏银河:工程师们讨论了整合 GPT-Vision 和摄像头输入以构建实时游戏助手来应对多选题游戏的潜力。提到了利用 Azure 或虚拟机处理密集计算任务的可能性,以及利用 TensorFlow 或 OpenCV 进行系统管理。
AI 与人类之谜仍在继续:一场关于 AI 与人类认知差异的哲学辩论展开,讨论了 AI 获得类人推理和情感的前景,以及量子计算在这一演变中的作用。
知识增强的探索:成员们寻求关于如何为自定义 GPT 应用准备知识库的信息,并询问了 Whisper v3 API 的上线时间。注意到的一些限制(如推测 GPT-4 的 Token 记忆跨度有所缩减)引发了对提高 API 能力透明度的呼声。
创意头脑青睐 Claude 和 Gemini:在处理文献综述和虚构作品时, AI 爱好者推荐使用 Claude 和 Gemini 1.5 等模型。这些工具分别因其在处理文学任务和创意写作方面的出色表现而受到青睐。
Discord 频道动态:prompt-engineering 和 api-discussions 两个频道的活跃度显著下降,参与者将这种冷清归因于可能存在的过度审核以及最近的一系列禁言(timeouts),包括一个因协助其他用户而被禁言 5 个月的具体案例。
LlamaIndex Discord
-
Qdrant 的混合云布局:Qdrant 新推出的混合云服务允许在各种环境中运行其服务,同时保持对数据的控制。他们发布了一个关于设置过程的详尽教程来支持此次发布。
-
LlamaIndex 通过 Azure AI Search 增强实力:LlamaIndex 与 Azure AI Search 合作开发高级 RAG 应用,并由 Khye Wei 提供了一个展示 Hybrid Search 和 Query rewriting 能力的教程。
-
MistralAI 模型立即获得支持:LlamaIndex 实现了对 MistralAI 最新发布的 8x22b 模型的即时支持,并配有一份专注于智能查询路由和工具使用的 Mistral 指南(cookbook)。
-
在 LlamaIndex 中构建与调试:AI 工程师讨论了在 LlamaIndex 中构建搜索引擎的最佳实践,解决了 API key 身份验证错误,并处理了更新和 Bug 修复,包括一个带有 GitHub 解决方案的特定
BaseComponent错误。 -
分层结构策略讨论:在 ai-discussion 频道中,有人询问如何使用 ParentDocumentRetriever 构建分层文档结构,并选择 LlamaIndex 作为首选框架。
Eleuther Discord
-
展望长序列模型的未来:在近期的讨论中,Feedback Attention Memory (FAM) 提出了一种解决 Transformer 二次方注意力问题的方案,能够处理无限长的序列,并在长上下文任务中表现出改进。Reka 的新型 encoder-decoder 模型据称支持高达 128k 的序列,详见其 核心技术报告。
-
Scaling Laws 与评估的精确性:针对 Hoffman 等人 (2022) 提出的计算最优 Scaling Laws 的疑问,引发了对缺乏广泛实验支持的窄置信区间可靠性的探讨,详见 Chinchilla Scaling: A replication attempt。此外,当 SoundStream 论文中未提及数据集大小时,机器学习论文中的准确成本估算会受到阻碍,这凸显了透明数据报告的必要性。
-
剖析模型评估技术:在 Eleuther 的
#lm-thunderdome频道中,lm-evaluation-harness的用法得到了详细说明,解释了arc_easy任务所需的输出格式,并讨论了 BPC (bits per character) 作为与模型压缩能力相关的智能代理指标的重要性。关于 ARC 等任务,一场对话探讨了为什么随机猜测会导致约 25% 的准确率(由于其有四个备选答案)。 -
多模态学习受到关注:用于半监督多模态学习的 Total Correlation Gain Maximization (TCGM) 可能性受到了关注,一篇 arXiv 论文 讨论了这种信息论方法以及跨模态有效利用未标记数据的能力。讨论还强调了该方法的理论前景及其在识别不同学习场景下贝叶斯分类器中的意义。
-
FLOPS 计算的具体指南:在
#scaling-laws频道中,针对如何估算 SoundStream 等模型的 FLOPS 提供了建议,包括在 Transformer 的前向和后向传播中使用公式 6 * 参数数量。初学者被引导至 相关论文的第 2.1 节,以全面了解计算成本估算。
HuggingFace Discord
-
IDEFICS-2 备受瞩目:IDEFICS-2 的发布带来了令人印象深刻的能力,它拥有 8B 参数,能够进行高分辨率图像处理,并在视觉问答和文档检索任务中表现出色。随着专注于聊天的 IDEFICS-2 变体的承诺,人们的期待与日俱增,同时 分享的示例 展示了其解决复杂 CAPTCHA 的当前能力。
-
知识图谱与聊天机器人结合:一篇富有启发性的 博客文章 强调了将 Knowledge Graphs 与聊天机器人集成以提升性能,鼓励对高级聊天机器人功能感兴趣的人进行探索。
-
Snowflake 的 Arctic 探险:Snowflake 开启了新领域,推出了 Arctic embed 系列模型,声称在实际文本嵌入模型性能方面树立了新基准,特别是在检索用例中。这一进展还辅以一个动手操作的 Splatter Image space(用于快速创建泼彩艺术),以及 Multi-Modal RAG 如何融合语言和图像,详见 LlamaIndex 文档。
-
模型训练与对比驱动创新:全新的 IP-Adapter Playground 亮相,进一步实现了创造性的文本到图像交互,同时在 transformers 库的 pipelines 中新增了直接
push_to_hub的选项。通过专门的 Hugging Face Space,对比图像字幕模型变得更加容易。 -
NLP 与视觉领域的挑战与机遇:社区成员讨论了从 prompt 中的截断 token 处理到探索 LoRA 配置等问题,并分享了关于 BERTopic 主题建模、训练 T5 模型(GitHub 资源)以及用于公式转换的 LaTeX-OCR 可能性(LaTeX-OCR GitHub)的资源链接。这些对话体现了对完善和利用 AI 能力的集体追求。
OpenAccess AI Collective (axolotl) Discord
Idefics2 带来多模态新风尚:新型多模态模型 Idefics2 已发布,能够同时处理文本和图像,并提升了 OCR 和视觉推理能力。它提供基础版和微调版,并采用 Apache 2.0 协议开源。
RTX 5090 的传闻引发期待:传闻 NVidia 正在考虑提前发布 RTX 5090,可能在 Computex 2024 上亮相,以保持对 AMD 进展的领先地位,这引发了关于硬件是否适配尖端 AI 模型的讨论。
模型训练微调:工程师们分享了模型训练配置的见解,重点讨论了损失计算中的 train_on_input 参数,并建议使用 “TinyLlama-1.1B-Chat-v1.0” 进行小模型微调,以实现高效实验。
Phorm AI 成为常用资源:社区成员在各种咨询中参考了 Phorm AI,包括按 Epoch 保存的技术,以及为 TinyLlama 等模型准备数据以执行文本到颜色代码预测等任务。
垃圾信息泛滥触发警报:社区内的多个频道遭到推广 OnlyFans 内容的垃圾信息攻击,试图干扰以 AI 为中心的对话和技术讨论。
Latent Space Discord
LLM 排名资源揭晓:分享了一个综合性网站 LLM Explorer,展示了大量开源语言模型,每个模型都通过 ELO 分数、HuggingFace 排行榜排名和特定任务的准确率指标进行评估,是模型比较和选择的宝贵资源。
零工经济中的 AI+人类协作:Payman AI 平台的推出引发了关注,该平台旨在让 AI Agent 为人类完成 AI 无法胜任的任务支付报酬;这一概念促进了 AI 与人类人才在设计和法律服务等领域的协作生态系统。
Supabase 支持 AI 推理:Supabase 推出了一套简单的 API,用于在其 Edge Functions 中运行 AI 推理,允许直接在数据库中使用 gte-small 等 AI 模型,详见其公告。
围绕 “Llama 3” 和 OpenAI API 动态的热议:AI 社区对传闻将在伦敦黑客松上首次亮相的神秘 “Llama 3” 议论纷纷;同时,鉴于 GPT-5 可能发布,OpenAI 的 Assistants API 增强功能也备受关注,引发了关于其对 AI 初创公司和平台潜在影响的辩论。
BloombergGPT 论文俱乐部会议转至 Zoom:由于之前 Discord 屏幕共享出现问题,LLM 论文俱乐部邀请工程师参加关于 BloombergGPT 的 Zoom 会议,讨论已转向 Zoom 以获得更好的分享体验。参与者可以在此处注册活动,社区内正在传达加入讨论的进一步提醒。
OpenInterpreter Discord
-
AI 穿戴设备的困境:正如 Marquis Brownlee 的 YouTube 评论中所讨论的,AI 穿戴设备缺乏智能手机那样的上下文知识。工程师指出,AI 助手需要更强的上下文理解能力才能提供高效的响应。
-
开源 AI 模型热潮:开源模型 WizardLm2 因其具备提供 GPT-4 级别能力的潜力而受到关注。讨论预测,尽管技术在不断进步,未来对此类模型的需求依然强劲。
-
翻译机器人的包容性承诺:工程师们目前正在评估一款新的翻译机器人,它能够通过提供双向翻译来丰富沟通,旨在实现更具包容性和统一性的讨论。
-
跨平台兼容性挑战:对于像 01 Light 这样的软件,在 Windows 上运行的需求非常明确,这与关于将以 Mac 为中心的软件适配到 Windows 框架的困难对话相一致,暗示了平台无关开发方法的必要性。
-
硬件热度升温:对话显示出对 Limitless 设备等 AI 硬件解决方案的浓厚兴趣,并围绕用户体验进行了对比。对强大的后端支持和无缝 AI 集成的强调正在塑造硬件领域的发展愿景。
Interconnects (Nathan Lambert) Discord
qwen-1.5-0.5B 的重大胜利:qwen-1.5-0.5B 模型在使用 generation in chunks(分块生成)后,面对 AlpacaEval 等重量级基准测试,其胜率从 4% 飙升至 32%。这种方法结合 300M 的 reward model,可能会成为 output searching 领域的游戏规则改变者。
如何赢得朋友并影响 AI:最近发布的 Mixtral 8x22B 是一款多语言 SMoE 模型,因其强大的能力和 Apache 2.0 开源协议而备受瞩目。同时,OLMo 1.7 7B 的崛起标志着语言模型科学的显著进步,在 MMLU 基准测试中实现了强劲的性能飞跃。
复现 Chinchilla:异常现象:在复现 Hoffmann 等人的 Chinchilla scaling paper 时出现的差异,引发了对该论文结论的质疑。社区的反应从困惑到担忧不等,预示着围绕 scaling law 验证挑战的争议正在升级。
轻松的期待与沉思:社区成员以幽默的方式讨论 olmo vs llama 之间潜在的对决。此外,Nathan Lambert 预告了即将到来的内容洪流,暗示这可能是一个高强度的知识共享周。
模型疯狂还是开玩笑?:Nathan 在一个冷清的频道中提到,关于 WizardLM 2 的爆料可能只是个恶作剧(troll),在技术讨论中展现了幽默与轻松的一面。
Cohere Discord
-
API 困惑待解决:工程师们正在探究 Cohere API 关于 system prompt 功能和可用模型的细节。一位用户强调,由于这些细节对应用开发至关重要,因此需要更详尽的信息。
-
Cohere Embeddings 基准测试:人们对 Cohere’s embeddings v3 与 OpenAI 新的大型 embeddings 相比表现如何感到好奇,并参考了 Cohere 的博客,暗示已经进行了对比分析 Introducing Command R+。
-
集成技巧与窍门:技术讨论涉及将 LLM 与 BotPress 等平台集成,以及 Coral 是否需要本地托管方案。未来的更新可能会简化这些集成。
-
对微调过的模型进行微调:用户寻求关于通过 Cohere Web UI 对已定制模型进行进一步微调的澄清,并被引导至官方指南 Fine-Tuning with the Web UI。
-
招募 Beta 测试人员:名为 Quant Fino 的项目正在为其融合 GAI 与 FinTech 的 Agentic 实体招募 beta 测试人员。感兴趣的参与者可以在 Join Beta - Quant Fino 申请。
-
AI 模型安全漏洞曝光:一次 redteaming(红队测试)演练揭示了 Command R+ 的漏洞,展示了操纵模型创建不受限 Agent 的能力。关注此问题的工程师和研究人员可以查看完整报告 Creating unrestricted AI Agents with Command R+。
LangChain AI Discord
AI 文档界面翻新:为了提高易用性,LangChain 文档的贡献者们正在重构其结构,引入了“tutorial”(教程)、“how to guides”(操作指南)和“conceptual guide”(概念指南)等类别。一位成员分享了 LangChain 介绍页面,强调了 LangChain 的组件,如构建块、LangSmith 和 LangServe,这些组件有助于开发和部署基于 LLM 的应用程序。
使用 LangChain 构建——一次表达性的尝试?:在 #[general] 频道中,一位成员在将 Extensiv 进行类比时寻求有关 YC 初创公司申请的建议,这引发了对 Unsloth、Mistral AI 和 Lumini 等多个实体的提及。同时,由于 Nemo Guardrails 会改变输出结构,其与 LangServe 集成时面临的挑战也受到了关注。
推进新的 AI 工具与服务:GalaxyAI 首次推出了提供 GPT-4 和 GPT-3.5-turbo 免费访问权限的 API 服务,并在 Galaxy AI 展示,引起了广泛关注。同样,OppyDev 将 IDE 与聊天客户端融合,倡导改进编程平台,可在 OppyDev AI 访问。与此同时,Rubiks.ai 呼吁技术爱好者使用代码 RUBIX 在 Rubiks.ai 测试其搜索引擎和助手。
AI 先驱分享教育资源并寻求合作:来自 #[tutorials] 频道的一位成员发布了一个关于赋予 AI Agent 长期记忆的 YouTube 教程,引发了关于为何不使用 ‘langgraph’ 的讨论。此外,一位参与者表达了合作新项目的渴望,邀请他人通过私信联系。
关于数据与优化的多样化对话:在一次活跃的交流中,评估了针对大文档优化 RAG (Retrieval-Augmented Generation) 的策略,包括文档切分。成员们还就使用 Langchain 处理 CSV 文件的最佳方法进行了对话,并提出了针对聊天机器人和数据处理的改进建议。
DiscoResearch Discord
- 64 个 GPU 投入全量 Deep-Speed 训练:Maxidl 通过利用 64 个 80GB GPU(每个占用 77GB 容量)来运行 full-scale deep-speed,序列长度为 32k,Batch Size 为 1,探索 8-bit 优化以获得更好的显存效率。
- FSDP 显存占用秘籍揭晓:jp1 建议使用
fsdp_transformer_layer_cls_to_wrap: MixtralSparseMoeBlock并设置offload_params = true以最小化显存占用,可能将 GPU 需求减少到 32 个;同时 maxidl 正在寻找显存占用计算器,并引用了 HuggingFace 讨论。 - 文本抓取的版权难题:一位成员指出影响文本数据抓取的 欧盟版权灰色地带,并建议将 DFKI 作为有用的来源。同时,来自 Wikicommons 等的多模态数据可在 Creative Commons Search 上找到。
- 分词技术兴起:社区分享了在不使用 HuggingFace 的情况下创建 Llama tokenizer 的见解,指出了一份共享的自定义 tokenizer 中的拼写错误,并强调了 Mistral 新的分词库,并提供了 GitHub notebook。
- 解码策略与采样技术评估:由于担心一篇关于解码方法的论文忽略了有用的策略,引发了对 MinP/DynaTemp/Quadratic Sampling 等未提及技术的讨论。一篇 Reddit 帖子展示了 min_p 采样对创意写作的影响,在 alpaca-eval 风格的 Elo 评分中提升了 +8 分,在 eq-bench 创意写作测试中提升了 +10 分。
tinygrad (George Hotz) Discord
Tinygrad 中的 Int8 集成:Tinygrad 已确认支持 INT8 计算,并承认此类数据类型支持通常更多地取决于硬件能力,而非软件设计本身。
使用 Tiny-tools 实现图形化涅槃:为了在 Tinygrad 中获得增强的图形可视化效果,用户可以访问 Tiny-tools Graph Visualization,以创建比基础 GRAPH=1 设置更精美的图形。
Pytorch-Lightning 的硬件适应性:关于 Pytorch-Lightning 的讨论涉及了其硬件无关的能力,并指出了在 7900xtx 等硬件上的实际应用。在 GitHub 上探索 Pytorch-Lightning。
Tinygrad 遇上 Metal:社区成员正在探索使用 tinygrad 生成 Metal compute shaders,讨论如何在没有 Xcode 的情况下运行简单的 Metal 程序,以及将其应用于 meshnet 模型的可能性。
Tinygrad 中的模型操作与效率:一位成员关于快速、概率完备的 Node.equals() 的提议引发了关于效率的讨论,同时 George Hotz 解释了层的设备分配,用户被引导至 tinygrad/shape/shapetracker.py 或 view.py 以进行 broadcast 和 reshape 等零成本张量操作。
Skunkworks AI Discord
- Hugging Face 展示 Idefics2:Hugging Face 推出了 Idefics2,这是一个集成了 Python 编码能力的新型多模态 ChatGPT 迭代版本,正如其最新视频中演示的那样。
- Reka Core 挑战科技巨头:Reka Core 因其性能而备受推崇,成为 OpenAI 等公司语言模型的强劲竞争对手,并有视频概览展示其能力。
- JetMoE-8B 展现高效 AI 性能:JetMoE-8B 模型以低于 10 万美元的成本实现了超越 Meta AI LLaMA2-7B 的性能,这表明了一种高性价比的 AI 开发方法,详见此分析。
- Snowflake 发布顶级文本嵌入模型:Snowflake 首次推出了 Snowflake Arctic embed 系列模型,声称其为世界上最有效的实用文本嵌入模型,详见其公告。
Datasette - LLM (@SimonW) Discord
- Mixtral 热潮:工程师们正迫不及待地想要测试 Mixtral 8x22B Instruct 模型;对于感兴趣的人,HuggingFace 上的模型卡片现已上线。
- 机器故障:据报告 llm-gpt4all 存在安装错误,似乎阻碍了使用;问题的详细信息可以在 GitHub issue 追踪器中找到。
Alignment Lab AI Discord
- 法律纠纷在即?:一位成员暗示在某种不明情况下可能存在法律介入,但未提供任何背景信息来确定相关法律事项的细节或性质。
- wizardlm-2 的不幸:有人分享了一张显示 wizardlm-2 被删除的图片,特别指出是因为缺乏在 v0 上的测试;关于 wizardlm-2 的复杂性或测试过程并未详细说明。查看图片
{kind=link}
Mozilla AI Discord
-
Llamafile 脚本焕然一新:用于 llamafile 归档版本升级的改进版重新打包脚本现在可以通过 此 Gist 获取,引发了关于是将其合并到主 GitHub 仓库,还是由于可维护性担忧而从头开始创建新 llamafile 的讨论。
-
寻求安全漏洞处理协议:讨论中提到需要澄清在系统中报告安全漏洞的程序,包括申请 CVE 编号的步骤,尽管目前还缺乏具体的指导。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
Stability.ai (Stable Diffusion) ▷ #announcements (1 条消息):
-
Stable Diffusion 3 发布庆典:Stable Diffusion 3 及其更快的变体 Stable Diffusion 3 Turbo 现在已在 Stability AI Developer Platform API 上可用。此版本通过与 Fireworks AI 合作提供支持,并声称是目前最快、最可靠的 API 平台。
-
开放生成式 AI 仍在继续:计划提供 Stable Diffusion 3 模型权重供自托管使用,这需要 Stability AI Membership,强调了对开放生成式 AI 的持续承诺。
-
了解更多关于 SD3 的信息:用户可以通过提供的链接了解更多并开始使用新产品,其中包含更多详细信息和文档。
-
研究背景解析:根据 Stable Diffusion 3 研究论文,该版本在排版和提示词遵循度等方面,根据人类偏好研究,可与 DALL-E 3 和 Midjourney v6 等领先的文本生成图像系统相媲美甚至超越。
-
SD3 的技术进步:最新版本引入了 Multimodal Diffusion Transformer (MMDiT) 架构,通过为不同模态使用不同的权重集,提供了比以前的 Stable Diffusion 模型更好的文本理解和图像表现。
提及的链接:Stable Diffusion 3 API Now Available — Stability AI:我们很高兴地宣布 Stable Diffusion 3 和 Stable Diffusion 3 Turbo 在 Stability AI Developer Platform API 上正式可用。
Stability.ai (Stable Diffusion) ▷ #general-chat (1039 条消息🔥🔥🔥):
-
SD3 等待会员资格说明:在对许可和可访问性的担忧中,用户正在等待 Stability AI 关于 SD3 个人和商业用途的明确声明。在一份公告指出计划通过 Stability AI Membership 提供模型权重供自托管后,引发了讨论。
-
SDXL Refiner 被认为多余:社区发现 SDXL finetunes 已使 SDXL refiner 的使用变得过时,指出经过 refiner 训练的 finetunes 在 Civitai 下载中占据了主导地位。一些用户回忆起 refiner 的最初用途,但承认 finetune 集成迅速取代了对其的需求。
-
模型合并挑战:用户在 ComfyUI 中探索关于 V-prediction 和 epsilon 的模型合并概念的有效性和理解。关于是否必须正确实现以避免不可预测结果的争论正在进行,建议通过 UI 实验获取基础知识。
-
Diffusers Pipeline 限制:一些用户指出 diffusers pipeline 需要依赖 Hugging Face 的局限性,但也有人认为一旦下载了模型,该过程就可以在本地系统上独立高效地运行。关于 SVD finetunes 中无法访问
StableVideoDiffusionPipeline.from_single_file(path)方法的担忧被提出,建议将 ComfyUI 作为更简单的替代方案。
- 视频示例:ComfyUI 工作流示例
- 模型合并示例:ComfyUI 工作流示例
- Stable Cascade - multimodalart 的 Hugging Face Space:未找到描述
- PixArt Sigma - PixArt-alpha 的 Hugging Face Space:未找到描述
- camenduru/SUPIR · Hugging Face:未找到描述
- Stable Diffusion 3 API 现已可用 — Stability AI:我们很高兴地宣布,Stable Diffusion 3 和 Stable Diffusion 3 Turbo 已在 Stability AI 开发者平台 API 上线。
- 会员资格 — Stability AI:Stability AI 会员资格通过结合我们的一系列最先进的开源模型与自托管优势,为您的生成式 AI 需求提供灵活性。
- Stable Video Diffusion:未找到描述
- GitHub - kijai/ComfyUI-SUPIR: ComfyUI 的 SUPIR 放大封装器:ComfyUI 的 SUPIR 放大封装器。通过在 GitHub 上创建账户来为 kijai/ComfyUI-SUPIR 的开发做出贡献。
- WizardLM/WizardLM-2 at main · victorsungo/WizardLM:由 Evol-Instruct 驱动的指令遵循 LLM 家族:WizardLM, WizardCoder - victorsungo/WizardLM
- Reddit - 深入探索一切:未找到描述
- GitHub - king159/svd-mv: Stable Video Diffusion 多视角训练代码:Stable Video Diffusion 多视角训练代码 - king159/svd-mv
- Reddit - 深入探索一切:未找到描述
- GitHub - BatouResearch/magic-image-refiner:通过在 GitHub 上创建账户来为 BatouResearch/magic-image-refiner 的开发做出贡献。
- 由 kijai 修复 ELLA 时间步 · Pull Request #25 · ExponentialML/ComfyUI_ELLA:我一直在将此实现的结果与 diffusers 实现进行比较,结果并不理想。在 diffusers 中,ELLA 应用于每个时间步,并带有实际的时间步值。应用...
- Pixel Art XL - v1.1 | Stable Diffusion LoRA | Civitai:Pixel Art XL 考虑在 Ko-Fi 或 Twitter 上支持进一步的研究。如果您有需求,可以通过 Ko-Fi 进行。在 Re... 查看我的其他模型。
- GitHub - kijai/ComfyUI-KJNodes: ComfyUI 的各种自定义节点:ComfyUI 的各种自定义节点。通过在 GitHub 上创建账户来为 kijai/ComfyUI-KJNodes 的开发做出贡献。
- GitHub - city96/ComfyUI_ExtraModels: 支持各种杂项图像模型。目前支持:DiT, PixArt, T5 以及一些自定义 VAE:支持各种杂项图像模型。目前支持:DiT, PixArt, T5 以及一些自定义 VAE - city96/ComfyUI_ExtraModels
- 添加通过 API 使用 SD3 的节点 · kijai/ComfyUI-KJNodes@22cf8d8:未找到描述
- GitHub - lllyasviel/stable-diffusion-webui-forge:通过在 GitHub 上创建账户来为 lllyasviel/stable-diffusion-webui-forge 的开发做出贡献。
- Comfy Workflows:分享、发现并运行成千上万个 ComfyUI 工作流。
Unsloth AI (Daniel Han) ▷ #general (383 条消息🔥🔥):
- GPT-4 和 GPT-3.5 的说明:对 GPT-4 和 GPT-3.5 进行了区分,指出新版本似乎是其前身的微调迭代版本。
- Mistral 模型多语言能力讨论:成员们讨论了 Mistral7B 的数据集是否需要是英文才能表现良好,并建议加入法语数据以获得更好的效果。
- 微调与成本问题:关于微调方法、成本以及特定资源(如 notebook)的讨论为该领域的新手提供了见解。建议指出 continued pretraining 和 sft 可能是有益且具有成本效益的。
- 关于 UnSloth 的贡献:成员们表达了对贡献 UnSloth AI 的兴趣,提议帮助扩展文档并考虑捐赠,并分享了现有资源的链接以及关于潜在贡献的讨论。
- Mixtral 8x22B 发布热潮:Mixtral 8x22B 的发布引发了讨论,这是一个稀疏的 Mixture-of-Experts 模型,在多语言流利度和长上下文窗口方面具有优势,且根据 Apache 2.0 license 开源。
- 更便宜、更好、更快、更强:继续推动 AI 前沿并让所有人都能使用。
- 未找到标题:未找到描述
- Google Colaboratory:未找到描述
- lucyknada/microsoft_WizardLM-2-7B · Hugging Face:未找到描述
- Placa de Vídeo Galax NVIDIA GeForce RTX 3090 TI EX Gamer, 24GB GDDR6X, 384 Bits - 39IXM5MD6HEX:Placa De Video Galax Geforce 让您的日常工作更流畅。订阅 Prime Ninja 即可享受专属促销、运费折扣和双倍优惠券
- Google Colaboratory:未找到描述
- 主页:LLM 微调速度快 2-5 倍,显存占用减少 80%。通过在 GitHub 上创建账户来为 unslothai/unsloth 的开发做出贡献。
- gist:e45b337e9d9bd0492bf5d3c1d4706c7b:GitHub Gist:即时分享代码、笔记和片段。
- 全量微调 vs (Q)LoRA:➡️ 获取完整脚本(及未来改进)的终身访问权限:https://trelis.com/advanced-fine-tuning-scripts/ ➡️ Runpod 一键微调...
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face:未找到描述
- 支持 x86/ARM CPU (例如 Xeon, M1) · Issue #194 · openai/triton:你好,未来有支持 macOS 的计划吗?❯ pip install -U --pre triton 弃用警告:使用 distutils 配置文件配置安装方案已弃用,将不再有效...
- Ollama.md 文档由 jedt 编写 · Pull Request #3699 · ollama/ollama:关于从 Google Colab notebook 设置微调后的 Unsloth FastLanguageModel 到以下平台的指南:HF hub、GGUF、本地 Ollama。预览链接:https://github.com/ollama/ollama/blob/66f7b5bf9e63e1e98c98e8f4...
Unsloth AI (Daniel Han) ▷ #random (27 条消息🔥):
-
Chroma 项目取得进展:受 Unsloth AI 策略启发,一名成员宣布正在开发用 Go 编写的 Chroma 边缘版本,使用 SQLite 进行设备端向量存储。该项目还通过 WASM 兼容浏览器,可在 GitHub 上访问。
-
页面底部的表情符号:关于页面底部可爱笑脸的温馨微型讨论,其中一个胡子笑脸最受欢迎。
-
PyTorch 的新工具 Torchtune:提到了 Torchtune,这是一个用于 LLM 微调的原生 PyTorch 库,已在 GitHub 上分享,因其降低了微调门槛而引起关注。
-
Unsloth AI 广泛的 GPU 支持受到赞誉:一名成员称赞 Unsloth 广泛的 GPU 支持,相比其他需要较新 GPU 架构的工具,它更易于使用。
-
探讨 AI 模型的移动端部署:成员们讨论了在手机上运行神经网络的可行性,指出需要自定义推理引擎,并提到移动设备上缺少 CUDA。还提到了在 iPhone 上运行典型 DL Python 代码与在搭载 M 芯片的 Mac 上运行的挑战。
- GitHub - pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning:一个用于 LLM 微调的原生 PyTorch 库。可以通过在 GitHub 上创建账号来为 pytorch/torchtune 的开发做出贡献。
- GitHub - l4b4r4b4b4/go-chroma: Go port of Chroma vector storage:Chroma 向量存储的 Go 语言移植版本。可以通过在 GitHub 上创建账号来为 l4b4r4b4b4/go-chroma 的开发做出贡献。
Unsloth AI (Daniel Han) ▷ #help (275 条消息🔥🔥):
- 关于不支持属性的问题:一位用户在尝试微调模型时遇到了
AttributeError,报告称'MistralSdpaAttention'对象没有'temp_QA'属性。这似乎与他们自定义训练流水线中的特定方法有关。 - 澄清 ORPO 支持与用法:用户询问了 Unsloth 对 ORPO 的支持情况。已确认支持 ORPO,并提供了在 HuggingFace 上使用 ORPO 训练的模型链接以及一个 colab notebook。
- 关于 LoRA 和 rslora 的讨论:用户讨论了在训练中使用 LoRA 和 rslora,并就处理不同的
alpha值和潜在的 loss 激增提供了建议。一些成员建议调整r和alpha并禁用 packing,作为训练问题的可能解决方案。 - 未训练的 Embedding Tokens:用户探讨了 Mistral 模型中未训练的 embedding tokens话题,背景是在微调期间是否可以训练这些 embeddings。
- 保存与托管模型:关于使用
save_pretrained_merged和save_pretrained_gguf等命令以不同格式保存微调模型的问题;包括它们是否可以顺序执行,以及是否需要先从 fp16 开始。此外,还有关于在 HuggingFace 推理 API 上托管带有 GGUF 文件的模型的咨询。
- 查找开放数据集和机器学习项目 | Kaggle:下载数千个项目的开放数据集 + 在统一平台分享项目。探索政府、体育、医学、金融科技、食物等热门话题。支持灵活的数据摄取。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。在这里聊天、闲逛,并与你的朋友和社区保持紧密联系。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。在这里聊天、闲逛,并与你的朋友和社区保持紧密联系。
- G-reen/EXPERIMENT-ORPO-m7b2-1-merged · Hugging Face:未找到描述
- Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- Google Colaboratory:未找到描述
- 使用 LoRA (Low-Rank Adaptation) 微调 LLM 的实用技巧:我从数百次实验中学到的经验
- Unsloth - 4倍长的上下文窗口和1.7倍大的 Batch Size:Unsloth 现在支持具有极长上下文窗口的 LLM 微调,在 H100 上可达 228K(Hugging Face + Flash Attention 2 为 58K,即 4倍长),在 RTX 4090 上可达 56K(HF + FA2 为 14K)。我们成功实现了……
- Tokenization | Mistral AI 大语言模型:Tokenization 是 LLM 中的一个基本步骤。它是将文本分解为更小的子词单元(称为 tokens)的过程。我们最近在 Mistral AI 开源了我们的分词器。本指南将引导……
- 首页:快 2-5 倍、节省 80% 内存的 LLM 微调。通过在 GitHub 上创建账号来为 unslothai/unsloth 的开发做出贡献。
- LoRA 微调的秩稳定缩放因子 (Rank Stabilization Scaling Factor):随着大语言模型 (LLMs) 变得越来越耗费计算和内存资源,参数高效微调 (PEFT) 方法现已成为微调 LLM 的常用策略。一种流行的 PEFT 方法……
- Rank-Stabilized LoRA:释放 LoRA 微调的潜力:未找到描述
- 安装:未找到描述
- 未找到标题:未找到描述
- 安装:未找到描述
- 首页:快 2-5 倍、节省 80% 内存的 LLM 微调。通过在 GitHub 上创建账号来为 unslothai/unsloth 的开发做出贡献。
- GitHub - comfyanonymous/ComfyUI: 最强大且模块化的 Stable Diffusion GUI、API 和后端,具有图形/节点界面。:最强大且模块化的 Stable Diffusion GUI、API 和后端,具有图形/节点界面。- comfyanonymous/ComfyUI
- 在文档中添加 ORPO 示例 Notebook · Issue #331 · unslothai/unsloth:只需对当前的 DPO Notebook 进行极少修改即可使用 TRL 的 ORPOTrainer。由于 ORPO 进一步降低了训练聊天模型所需的资源(无需独立……
- Tokenizer:未找到描述
- GitHub - ggerganov/llama.cpp: C/C++ 中的 LLM 推理:C/C++ 中的 LLM 推理。通过在 GitHub 上创建账号来为 ggerganov/llama.cpp 的开发做出贡献。
- 向模型添加新的词汇 Tokens · Issue #1413 · huggingface/transformers:❓ 问题与帮助 你好,我该如何扩展预训练模型的词汇表,例如通过向查找表添加新的 tokens?有任何演示此操作的示例吗?
- Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation):从数百次实验中学到的经验
- Nice Click Nice GIF - Nice Click Nice Man - Discover & Share GIFs:点击查看 GIF
- Aligning LLMs with Direct Preference Optimization:在本次研讨会中,来自 Hugging Face 的 Lewis Tunstall 和 Edward Beeching 将讨论一种强大的对齐技术,称为 Direct Preference Optimisation (DPO)...
- Direct Preference Optimization (DPO) explained: Bradley-Terry model, log probabilities, math:在本视频中,我将解释论文 "Direct Preference Opti..." 中介绍的语言模型对齐技术 Direct Preference Optimization (DPO)。
- FractalFormer: A WIP Transformer Architecture Inspired By Fractals:查看 GitHub 仓库:https://github.com/evintunador/FractalFormer。在 patreon 上支持我的学习之旅!https://patreon.com/Tunadorable?utm_medium=u...
- llama-recipes/recipes at 0efb8bd31e4359ba9e8f52e8d003d35ff038e081 · meta-llama/llama-recipes:使用可组合的 FSDP 和 PEFT 方法微调 Llama2 的脚本,涵盖单节点/多节点 GPU。支持默认和自定义数据集,适用于摘要生成等应用...
- llama-recipes/recipes/multilingual/README.md at 0efb8bd31e4359ba9e8f52e8d003d35ff038e081 · meta-llama/llama-recipes:使用可组合的 FSDP 和 PEFT 方法微调 Llama2 的脚本,涵盖单节点/多节点 GPU。支持默认和自定义数据集,适用于摘要生成等应用...
- Neural Graph Reasoning: Complex Logical Query Answering Meets Graph Databases:复杂逻辑查询回答 (CLQA) 是最近兴起的图机器学习任务,它超越了简单的单跳链接预测,解决了更为复杂的多跳逻辑推理任务...
- LLM Phase Transition: New Discovery:瑞士 AI 团队发现的点积 Attention 层学习中的相变。对 Attention 机制内部相变的研究...
- pacozaa/sharegpt90k-cleanned · Datasets at Hugging Face:未找到描述
- After 500+ LoRAs made, here is the secret:既然你想知道,秘诀就在这里:数据集的质量占一切的 95%。剩下的 5% 是不要用错误的参数毁了它。是的,我知道...
- RAM Latency Calculator: 未找到描述
- lmstudio-community/WizardLM-2-7B-GGUF · Hugging Face: 未找到描述
- Multi-turn conversations - QnA Maker - Azure AI services: 使用提示词和上下文来管理机器人的多轮对话(即 multi-turn),实现从一个问题到另一个问题的跳转。Multi-turn 是指进行来回对话的能力,其中之前的...
- Mission Squad. Flexible AI agent desktop app.: 未找到描述
- Tweet from WizardLM (@WizardLM_AI): 🔥今天我们发布了 WizardLM-2,我们的下一代最先进的 LLM。新系列包括三个前沿模型:WizardLM-2 8x22B、70B 和 7B - 展示了极具竞争力的性能...
- GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs: 统一 100+ LLMs 的高效微调。通过在 GitHub 上创建账号为 hiyouga/LLaMA-Factory 的开发做出贡献。
- Microsoft’s Punch in the Face to Open AI (Open Source & Beats GPT-4): WizardLM 2 是由 Microsoft 开发的一个突破性大语言模型系列,推动了人工智能的边界。▼ 来自今日的链接...
- GitHub - Unstructured-IO/unstructured: Open source libraries and APIs to build custom preprocessing pipelines for labeling, training, or production machine learning pipelines.: 用于构建自定义预处理流水线的开源库和 API,适用于标注、训练或生产机器学习流水线。 - GitHub - Unstructured-IO/unstructured: 开源库...
- lmstudio-community/wavecoder-ultra-6.7b-GGUF · Hugging Face: 未找到描述
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face: 未找到描述
- Virt-io/Google-Colab-Imatrix-GGUF at main: 未找到描述
- High Quality / Hard to Find - a DavidAU Collection: 未找到描述
- lmstudio-community/WizardLM-2-7B-GGUF · Hugging Face: 未找到描述
- Responses: 这些是两个不同 LLM 对提示词的回答。你将分析事实准确性(Factuality)、深度(Depth)、详细程度(Level of detail)、连贯性(Coherency)以及任何其他我可能遗漏但通常被认为重要的领域...
- bartowski/zephyr-orpo-141b-A35b-v0.1-GGUF at main: 未找到描述
- 👾 LM Studio - 发现并运行本地 LLM: 查找、下载并实验本地 LLM
- 系统要求 (Windows) — HIP SDK Windows 安装: 未找到描述
- Bill Gates Chair GIF - Bill Gates Chair Jump - 发现并分享 GIF: 点击查看 GIF
- Snowflake Launches the World’s Best Practical Text-Embedding Model:今天 Snowflake 发布并以 Apache 2.0 协议开源了 Snowflake Arctic embed 系列模型。基于 Massive Text Embedding Be...
- Introducing Idefics2 8B: Open Multimodal ChatGPT:我们将了解 Hugging Face 的开源多模态 LLM idefics2...
- Reka Core: A Frontier Class Multimodal Language Model:Reka Core 在关键行业公认的评估指标上可与 OpenAI、Anthropic 和 Google 的模型相媲美。鉴于其占用空间和性能...
- JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars:JetMoE-8B 的训练成本不到 10 万美元,但性能优于来自 Meta AI 的 LLaMA2-7B,后者拥有数十亿美元的训练资源。LLM 训练...
- Tokenization | Mistral AI Large Language Models:Tokenization 是 LLM 中的一个基础步骤。它是将文本分解为更小的子词单元(即 Token)的过程。我们最近在 Mistral AI 开源了我们的 Tokenizer。本指南将...
- Aligning LLMs for Medical Reasoning:对齐 LLM 以使其成为更好的医学推理者 Ritabrata Maiti ritabrat001@e.ntu.edu.sg 1
- senseable/WestLake-7B-v2 · Hugging Face:未找到描述
- The Bitter Lesson:未找到描述
- alpindale/WizardLM-2-8x22B · Hugging Face:未找到描述
- Qwen/CodeQwen1.5-7B-Chat · Hugging Face:未找到描述
- WizardLM-2 8x22B by microsoft | OpenRouter:WizardLM-2 8x22B 是 Microsoft AI 最先进的 Wizard 模型。与领先的专有模型相比,它展示了极具竞争力的性能,并且始终优于所有现有的...
- Unlock AI Agent real power?! Long term memory & Self improving:如何为你的 AI Agent 构建长期记忆和自我进化能力?免费使用 AI 幻灯片生成工具 Gamma:https://gamma.app/?utm_source=youtube&utm...
- world_sim: 未找到描述
- Anime Excited GIF - Anime Excited Happy - Discover & Share GIFs: 点击查看 GIF
- Poe Path Of Exile GIF - Poe Path Of Exile Login - Discover & Share GIFs: 点击查看 GIF
- Let Me In Crazy GIF - Let Me In Crazy Funny - Discover & Share GIFs: 点击查看 GIF
- Tree Fiddy GIF - Tree Fiddy South - Discover & Share GIFs: 点击查看 GIF
- Noita Explosion GIF - Noita Explosion Electricity - Discover & Share GIFs: 点击查看 GIF
- Noita Game GIF - Noita Game Homing - Discover & Share GIFs: 点击查看 GIF
- Youre Not Gonna Like This Jerrod Carmichael GIF - Youre Not Gonna Like This Jerrod Carmichael Saturday Night Live - Discover & Share GIFs: 点击查看 GIF
- 辐射系列中每个避难所的解析 | 辐射背景设定: 大家好!本视频献给所有想要了解辐射游戏及其背景设定的新粉丝。我记得当我第一次成为粉丝时...
- Jailbroken Prometheus Chat: 未找到描述
- 辐射系列中每个避难所的解析 | 辐射背景设定: 大家好!本视频献给所有想要了解辐射游戏及其背景设定的新粉丝。我记得当我第一次成为粉丝时...
- 神格悖论 | 科幻动画: 在未来,World Sim——一个由先进 AI 驱动的在线界面——允许用户创建和操纵虚拟宇宙,冲突随之产生。Dece...
- 来自 Bindu Reddy (@bindureddy) 的推文:新的 GPT-4 表现得异常懒惰,在几次对话(往返)后就会停止。目前在现实世界中不太可行。建议坚持使用旧版本。相比之下,Claude 有一个...
- 扩展语法 | Markdown 指南:构建在基础 Markdown 语法之上的高级功能。
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face:未找到描述
- mistralai/Mixtral-8x22B-v0.1 · Hugging Face:未找到描述
- Hamak Chilling GIF - Hamak Chilling Beach - 发现并分享 GIF:点击查看 GIF
- Silent Indian GIF - Silent Indian - 发现并分享 GIF:点击查看 GIF
- How Soon Is Now Smiths GIF - How Soon Is Now Smiths Morrissey - 发现并分享 GIF:点击查看 GIF
- TikTok - Make Your Day:未找到描述
- 未找到标题:未找到描述
- 制作性显式 Deepfakes 将成为刑事犯罪:一项新法律将使性显式 Deepfakes 的创作者面临起诉和罚款。
- ptx0/terminus-xl-velocity-v2 · Hugging Face:未找到描述
- Perturbed-Attention Guidance SDXL - a Hugging Face Space by multimodalart:未找到描述
- zero-gpu-explorers (ZeroGPU Explorers):未找到描述
- Minority Report Leave GIF - Minority Report Leave Walk Away - Discover & Share GIFs:点击查看 GIF
- Reddit - 深入探索:未找到描述
- Loss weighting MLP prototype:损失权重 MLP 原型。GitHub Gist:即时分享代码、笔记和摘要。
- 登录 • Instagram:未找到描述
- 登录 • Instagram:未找到描述
- 登录 • Instagram:未找到描述
{kind=link}
- Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization:生成式多模态内容在内容创作领域日益盛行,因为它有可能让艺术家和媒体人员通过快速创建制作前样稿...
- GitHub - Babelscape/ALERT: Official repository for the paper "ALERT: A Comprehensive Benchmark for Assessing Large Language Models’ Safety through Red Teaming":论文 "ALERT: A Comprehensive Benchmark for Assessing Large Language Models’ Safety through Red Teaming" 的官方仓库 - Babelscape/ALERT
- WizardLM-2 8x22B by microsoft | OpenRouter:WizardLM-2 8x22B 是 Microsoft AI 最先进的 Wizard 模型。与领先的专有模型相比,它表现出极具竞争力的性能,并始终优于所有现有的...
- WizardLM-2 7B by microsoft | OpenRouter:WizardLM-2 7B 是 Microsoft AI 最新 Wizard 模型的小型变体。它是速度最快的,并能与现有的规模大 10 倍的开源领先模型达到相当的性能。它是一个微调...
- WizardLM-2 8x22B by microsoft | OpenRouter:WizardLM-2 8x22B 是 Microsoft AI 最先进的 Wizard 模型。与领先的专有模型相比,它表现出极具竞争力的性能,并始终优于所有现有的...
- 更便宜、更好、更快、更强:继续推动 AI 前沿并使其惠及所有人。
- 机器人 GIF - 在 GIPHY 上查找和分享:与你认识的每个人一起发现并分享这个机器人 GIF。GIPHY 是你搜索、分享、发现和创建 GIF 的方式。
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face:未找到描述
- Chiquichico GIF - Chiquichico - 发现并分享 GIF:点击查看 GIF
- 全新 Atlas | Boston Dynamics:我们正在揭晓下一代人形机器人——一款专为实际应用设计的全电动 Atlas 机器人。新款 Atlas 建立在数十年的...
- Microsoft 的 WizardLM-2 8x22B | OpenRouter:WizardLM-2 8x22B 是 Microsoft AI 最先进的 Wizard 模型。与领先的专有模型相比,它展示了极具竞争力的性能,并且始终优于所有现有的 ...
- Mojo - IntelliJ IDEs Plugin | Marketplace: 提供 Mojo 编程语言的基础编辑功能:语法检查和高亮、注释以及格式化。未来将添加更多新功能,请随时...
- Packed structs in Zig make bit/flag sets trivial: 在构建 Mach 引擎的过程中,我们在 Zig 中使用了一种巧妙的小模式,使得在 Zig 中编写 flag sets 比在其他语言中更加优雅。这里有一个简短的说明。
- Bamboozled GIF - Bamboozled - Discover & Share GIFs: 点击查看 GIF
- Analyzing Data 180,000x Faster with Rust: 如何通过 hash、index、profile、multi-thread 和 SIMD 达到令人惊叹的速度。
- The Typestate Pattern in Rust - Cliffle : 未找到描述
- Don't Write Comments: 为什么你不应该在代码中写注释(写文档)。在 https://www.patreon.com/codeaesth... 获取代码示例、discord、歌曲名称等。
- Mojo Manual | Modular Docs:Mojo 编程语言的全面指南。
- Protocol-Oriented Programming in Swift / WWDC15 / Session 408:Swift 设计的核心是两个极其强大的理念:面向协议编程(protocol-oriented programming)和一等值语义(first class value semantics)。这些概念中的每一个都受益于...
- GitHub - venvis/mojo2py: A python package to convert mojo code into python code:一个将 Mojo 代码转换为 Python 代码的 Python 包 - venvis/mojo2py
- Get started with Mojo🔥 | Modular Docs:获取 Mojo SDK 或尝试在 Mojo Playground 中编写代码。
- Mojo🔥 | Modular Docs:一种弥合 AI 研究与生产之间鸿沟的编程语言,释放了速度和易用性。
- Mojo🔥 notebooks | Modular Docs:我们为 Mojo Playground 创建的所有 Jupyter notebooks。
- html.mojo:GitHub Gist:即时分享代码、笔记和片段。
- [stdlib] 根据 `2024-04-16` nightly/mojo 更新 stdlib,由 patrickdoc 提交 · Pull Request #2313 · modularml/mojo:此 PR 使用与今日 Nightly 版本(mojo 2024.4.1618)对应的内部提交更新了 stdlib。未来,我们可能会直接将这些更新推送到 nightly 分支。
- nightly 分支下的 mojo/docs/changelog.md · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 的开发做出贡献。
- torch-cublas-hgemm/src/simt_hgemv.cu at master · aredden/torch-cublas-hgemm:带有融合可选 bias + 可选 relu/gelu 的 PyTorch 半精度 GEMM 库 - aredden/torch-cublas-hgemm
- zippy_gemv_hqq_gen.py:GitHub Gist:即时分享代码、笔记和片段。
- zhxch (zhongxiaochao): 未找到描述
- hqq/hqq/core/quantize.py at 63cc6c0bbb33da9a42c330ae59b509c75ac2ce15 · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- zhxchen17/scratch at main: 未找到描述
- hqq/hqq/kernels/hqq_aten_cuda_kernel.cu at master · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- GitHub - wangsiping97/FastGEMV: High-speed GEMV kernels, at most 2.7x speedup compared to pytorch baseline.: 高速 GEMV kernels,相比 PyTorch 基准测试最高提升 2.7 倍速度。 - GitHub - wangsiping97/FastGEMV
- hqq/examples/backends/torchao_int4_demo.py at master · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- hqq/hqq/core/optimize.py at master · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- lightning-thunder/notebooks/extend_thunder_with_cuda_python.ipynb at main · Lightning-AI/lightning-thunder: 让 PyTorch 模型提速高达 40%!Thunder 是一个用于 PyTorch 的 source-to-source 编译器。它支持同时使用不同的硬件执行器;支持从单个到数千个 GPU。 - Lightning-AI/ligh...
- cutlass/media/docs/quickstart.md at main · NVIDIA/cutlass: 用于线性代数子程序的 CUDA 模板。通过在 GitHub 上创建账号来为 NVIDIA/cutlass 的开发做出贡献。
- Optimised version of fused classifier + bugfixes(?) by ademeure · Pull Request #150 · karpathy/llm.c: 这是来自 #117 的酷炫新 kernel 的更快版本(目前仍仅限 /dev/cuda/)。最大的区别在于它针对每个 1024 宽度的 block(而非 32 宽度的 warp)处理一行进行了优化,这使得...
- WIP: Fully fused classification layer by ngc92 · Pull Request #117 · karpathy/llm.c: 这融合了 token 分类层中发生的所有逐点(pointwise)操作。这基本上让我们以大约仅前向传播的成本获得了前向/后向传播,因为...
- SlimPajama: A 627B token, cleaned and deduplicated version of RedPajama - Cerebras: Cerebras 构建了一个用于一键式训练 LLM 的平台,可以加速获取洞察的时间,而无需在大型的小型设备集群中进行编排。
- The MiniPile Challenge for Data-Efficient Language Models: 预训练文本语料库日益增长的多样性使语言模型具备了跨各种下游任务的泛化能力。然而,这些多样化的数据集往往过于庞大...
- GitHub - tysam-code/hlb-gpt: Minimalistic, extremely fast, and hackable researcher's toolbench for GPT models in 307 lines of code. Reaches <3.8 validation loss on wikitext-103 on a single A100 in <100 seconds. Scales to larger models with one parameter change (feature currently in alpha).: 极简、极速且可黑客攻击的 GPT 模型研究员工具台,仅需 307 行代码。在单个 A100 上不到 100 秒即可在 wikitext-103 上达到 <3.8 的验证损失。通过更改一个参数即可扩展到更大的模型(该功能目前处于 alpha 阶段)。
- Google Colaboratory: 未找到描述
- Starter Tutorial (OpenAI) - LlamaIndex: 未找到描述
- Langfuse Callback Handler - LlamaIndex: 未找到描述
- <a href="http://localhost:port",>">未找到标题</a>: 未找到描述
- <a href="http://localhost:port"`>">未找到标题</a>: 未找到描述
- Openai like - LlamaIndex: 未找到描述
- Finetune Embeddings - LlamaIndex: 未找到描述
- create_llama_projects/nextjs-edge-llamaparse at main · run-llama/create_llama_projects: 通过在 GitHub 上创建账户,为 run-llama/create_llama_projects 的开发做出贡献。
- Multi-Document Agents - LlamaIndex: 未找到描述
- Answer Relevancy and Context Relevancy Evaluations - LlamaIndex: 未找到描述
- Catch validation errors by logan-markewich · Pull Request #12882 · run-llama/llama_index: 部分用户在此遇到了奇怪的错误。让我们捕获验证错误,以防止不兼容的包版本导致核心崩溃。
- LlamaCPP - LlamaIndex: 未找到描述
- Openapi - LlamaIndex: 未找到描述
- Q&A patterns - LlamaIndex: 未找到描述
- Document Summary Index - LlamaIndex: 未找到描述
- Pydantic Tree Summarize - LlamaIndex: 未找到描述
- Index - LlamaIndex: 未找到描述
- Index - LlamaIndex: 未找到描述
- Llm - LlamaIndex: 未找到描述
- Llm - LlamaIndex: 未找到描述
- 来自 Siyan Zhao (@siyan_zhao) 的推文: 🚨LLM 研究者们🚨想要在生成质量零退化的情况下,为你的 HuggingFace🤗 LLM 获得免费的速度和内存效率提升吗?介绍 Prepacking,一种简单的方法,可获得高达 6 倍的加速...
- Pile-T5 - EleutherAI 收藏集: 未找到描述
- 来自 Sasha Rush (@srush_nlp) 的推文: Lazy twitter:NLP 课堂上的一个常见问题是“如果 xBERT 效果很好,为什么人们不把它做大?”但我意识到我只是不知道答案。我假设人们尝试过,但一个 l...
- lintang/pile-t5-base-flan · Hugging Face: 未找到描述
- lintang (Lintang Sutawika): 未找到描述
- lm-evaluation-harness/lm_eval/tasks/arc.py at b281b0921b636bc36ad05c0b0b0763bd6dd43463 · EleutherAI/lm-evaluation-harness: 一个用于语言模型 few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/tasks/hendrycks_test.py at b281b0921b636bc36ad05c0b0b0763bd6dd43463 · EleutherAI/lm-evaluation-harness: 一个用于语言模型 few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
- Models - Hugging Face: 未找到描述
- The Illusion of State in State-Space Models:与之前无处不在的 Transformer 架构相比,状态空间模型(SSMs)已成为构建大语言模型(LLMs)的一种潜在替代架构。一个理论上的...
- Chinchilla Scaling: A replication attempt:Hoffmann 等人 (2022) 提出了三种估计计算最优 Scaling Law 的方法。我们尝试复现他们的第三种估计程序,涉及拟合参数化损失函数...
- Self-playing Adversarial Language Game Enhances LLM Reasoning:我们探索了大语言模型(LLMs)在名为 Adversarial Taboo 的双人对抗语言游戏中的自博弈(self-play)训练过程。在这个游戏中,攻击者和防御者进行交流...
- TransformerFAM: Feedback attention is working memory:虽然 Transformers 彻底改变了深度学习,但其二次方注意力复杂度阻碍了它们处理无限长输入的能力。我们提出了 Feedback Attention Memory (FAM),一种新型的...
- VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time:我们介绍了 VASA,这是一个在给定单张静态图像和一段语音音频剪辑的情况下,生成具有吸引人的视觉情感技能(VAS)的逼真说话面孔的框架。我们的首个模型 VASA-1 能够...
- ReFT: Representation Finetuning for Language Models:参数高效微调(PEFT)方法寻求通过更新少量权重来适配大模型。然而,许多先前的可解释性工作表明,表示(representations)编码了丰富的...
- Scaling Instructable Agents Across Many Simulated Worlds:构建能够在任何 3D 环境中遵循任意语言指令的具身 AI 系统是创建通用 AI 的关键挑战。实现这一目标需要学习将语言...
- Scaling Instructable Agents Across Many Simulated Worlds:构建能够在任何 3D 环境中遵循任意语言指令的具身 AI 系统是创建通用 AI 的关键挑战。实现这一目标需要学习将语言...
- 来自 Will Merrill (@lambdaviking) 的推文:[1/n] 思维链(CoT)如何改变 Transformers 的表达能力?与 @Ashish_S_AI 的新工作研究了增加 CoT/解码步骤如何根据...扩展 Transformers 可解决的问题。
- MindBridge: A Cross-Subject Brain Decoding Framework:大脑解码是神经科学中的一个关键领域,旨在从获取的大脑信号中重建刺激,主要利用功能磁共振成像(fMRI)。目前,大脑解码...
- Finetuning Pretrained Transformers into RNNs:Transformers 在自然语言生成方面已经超越了循环神经网络(RNNs)。但这伴随着显著的计算成本,因为注意力机制的复杂度随着...
- Transformers Represent Belief State Geometry in their Residual Stream — LessWrong:在作为 PIBBSS[1] 的附属成员期间产生。这项工作最初由 Lightspeed Grant 资助,随后在 PIBBSS 期间继续...
- Quantifying & Modeling Multimodal Interactions: An Information Decomposition Framework:近期对多模态应用的关注激增,产生了大量用于表示和整合不同模态信息的数据集和方法。尽管...
- TCGM: An Information-Theoretic Framework for Semi-Supervised Multi-Modality Learning:融合来自多个模态的数据为训练机器学习系统提供了更多信息。然而,为每个模态标记大量数据是非常昂贵且耗时的...
- Idefics 8b - a Hugging Face Space by HuggingFaceM4:未找到描述
- 来自 lunarflu (@lunarflu1) 的推文:来自 IDEFICS-2 @huggingface 的酷炫多模态交互:1. 从图像中检测数字 2. 对数字进行数学运算 3. 检索背景颜色 4. 去除色素 -> 结果颜色 5. 最终结果:...
- Introducing Idefics2: A Powerful 8B Vision-Language Model for the community:未找到描述
- HuggingFaceM4/idefics2-8b · Hugging Face:未找到描述
- 来自 Vaibhav (VB) Srivastav (@reach_vb) 的推文:Idefics 2 x Transformers! 🔥 尝试在实际场景中使用 Idefics 2 8B。令人惊叹的是,你只需不到 10 行代码就能完成这一切!制作了一个快速的屏幕录像来演示该模型...
- HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 · Hugging Face:未找到描述
- argilla/distilabel-capybara-dpo-7k-binarized · Datasets at Hugging Face:未找到描述
- 论文页面 - ORPO: Monolithic Preference Optimization without Reference Model:未找到描述
- alignment-handbook/recipes/zephyr-141b-A35b at main · huggingface/alignment-handbook:将语言模型与人类和 AI 偏好对齐的稳健方案 - huggingface/alignment-handbook
- 来自 Nicolas Patry (@narsilou) 的推文:TGI 2.0 发布了!- 永久回归完全开源 (Apache 2.0) - 现存最快的推理服务器 (Cohere R+ 达到 110 tok/s,支持 Medusa 推测解码) - 支持 FP8 - 支持 Mixtral 8x22B!...
- 来自 Xenova (@xenovacom) 的推文:介绍 MusicGen Web:直接在浏览器中由 AI 驱动的音乐生成,基于 🤗 Transformers.js 构建!🎵 100% 本地运行,意味着无需调用 API!🤯 作为一个静态网站提供服务...
- 来自 Andrew Ng (@AndrewYNg) 的推文:LLM 可能需要数 GB 的内存来存储,这限制了在消费级硬件上运行。但量化可以显著压缩模型,使开发人员能够使用更广泛的模型选择...
- Vision Language Models Explained:未找到描述
- zero-gpu-explorers (ZeroGPU Explorers):无描述
- Inpainting:无描述
- 机器学习民主化 - 调查:感谢您抽出时间回答这份关于人们机器学习经验的调查,耗时不超过 5 分钟。在本次调查中,“机器学习”将被简称为...
- 解锁 AI Agent 的真正力量?!长期记忆与自我改进:如何为您的 AI Agent 构建长期记忆和自我改进能力?免费使用 AI 幻灯片生成器 Gamma:https://gamma.app/?utm_source=youtube&utm...
- Splatter Image - szymanowiczs 的 Hugging Face Space:未找到描述
- 多模态应用 - LlamaIndex:未找到描述
- Nebuly AI:未找到描述
- Snowflake 发布适用于检索场景的实用文本嵌入模型:Snowflake-arctic-embed 以 Apache 2.0 许可证向开源社区开放。
- Home:利用 BERT 和基于类别的 TF-IDF 来创建易于解释的主题。
- GitHub - EleutherAI/improved-t5: Experiments for efforts to train a new and improved t5:训练全新改进版 T5 的实验工作 - EleutherAI/improved-t5
- GitHub - Shivanandroy/simpleT5: simpleT5 is built on top of PyTorch-lightning⚡️ and Transformers🤗 that lets you quickly train your T5 models.:simpleT5 基于 PyTorch-lightning⚡️ 和 Transformers🤗 构建,让你能够快速训练 T5 模型。 - Shivanandroy/simpleT5
- Nvidia’s RTX 5090 and 5080 could arrive much sooner than expected, but there’s a big catch:泄露消息指出,由于来自 AMD 的竞争,新款 Nvidia Blackwell GeForce GPU 的上市时间可能比原计划提前得多。
- HuggingFaceM4/idefics2-8b · Hugging Face:未找到描述。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- 更便宜、更好、更快、更强:继续推动 AI 的前沿,并使其对所有人开放。
- Payman - 主页:未找到描述
- Ahmad Al-Dahle (@Ahmad_Al_Dahle) 的推文:我很快会分享更多关于 Llama 3 的信息。看到社区已经在使用 Llama 2 构建各种东西,真是太酷了。我最喜欢的之一:@team_qanda 和 @UpstageAI 使用它构建了一个数学专用...
- Susan Zhang (@suchenzang) 的推文:MBPP 可能也被用在了 Phi-1.5 数据集的某些地方。就像我们截断了 GSM8K 的一个问题一样,让我们尝试截断 MBPP 的提示词,看看 Phi-1.5 会自动补全什么...
- 研究资助:未找到描述
- AI 推理现已在 Supabase Edge Functions 中可用:通过 Supabase Edge Functions 在边缘端使用 Embeddings 和 LLM。
- OpenAI Developers (@OpenAIDevs) 的推文:介绍 Assistants API 的一系列更新 🧵 借助新的文件搜索工具,你可以快速集成知识检索,现在每个 Assistant 支持多达 10,000 个文件。它与我们的...
- Russell Kaplan (@russelljkaplan) 的推文:LLM 崛起的二阶效应:
- Yohei (@yoheinakajima) 的推文:一个供 AI Agent 雇佣人类的平台 🧠 ↘️ 引用 tyllen (@0xTyllen) 很高兴介绍我一直在开发的一个新项目,叫做 Payman!Payman 是一个为 Agent 提供工具的 AI Agent...
- Armand Joulin (@armandjoulin) 的推文:修复了那个修复。↘️ 引用 Jonathan Frankle (@jefrankle) 为你修复了它,@code_star
- Payman - 实现 AI Agent 向人类支付!:大家好,在这个视频中,我非常兴奋地向大家展示 Payman,这是一个允许你将 Agent 与资金连接起来,以便它们可以用来支付给人类的平台...
- LLM Explorer:精选的 LLM 目录。LLM 列表。35061 个开源语言模型。:浏览 35061 个开源的大型和小型语言模型,这些模型被方便地分成了各种类别和 LLM 列表,并配有基准测试和分析。
- Cheaper, Better, Faster, Stronger:继续推动 AI 前沿并使其触手可及。
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face:未找到描述
- Albert Jiang (@AlbertQJiang) 的推文:我热爱开源模型!请将你最喜欢的模型添加到 Mistral Convex Hull。 ↘️ 引用 Philipp Schmid (@_philschmid):为 @AI21Labs 修复了 Fixed Fix,并加入了 Mambas。🐍
- Common Crawl - Web Graphs:详细介绍了 Common Crawl 的网页图谱发布、背后的技术以及如何使用它们。
- allenai/OLMo-1.7-7B · Hugging Face:未找到描述
- Philipp Schmid (@_philschmid) 的推文:为 @AI21Labs 修复了 Fixed Fix,并加入了 Mambas。🐍 ↘️ 引用 Armand Joulin (@armandjoulin):修复了 fix。
- 来自 Tamay Besiroglu (@tamaybes) 的推文:我们已请求作者提供协助,但一直未能得到回复。(8/9)
- 来自 Susan Zhang (@suchenzang) 的推文:在忽略了所有这些“让我们把一堆散点拟合成一条直线”的论文细节(当你真正外推时,可能都是错误的)之后,@stephenroller 终于说服我开始研究……
- 来自 Tamay Besiroglu (@tamaybes) 的推文:Hoffmann 等人的 Chinchilla 缩放论文在语言建模社区极具影响力。我们尝试复现他们工作的关键部分,并发现了差异。这里是……
- 未找到标题:未找到描述
- Screenshot-2024-04-16-151544 托管于 ImgBB:托管在 ImgBB 的图片 Screenshot-2024-04-16-151544
- 使用 Web UI 进行微调 - Cohere 文档:未找到描述
- Cohere int8 和二进制 Embeddings - 将您的向量数据库扩展到大型数据集:Cohere Embed 现在原生支持 int8 和二进制 embeddings,以降低内存成本。
- GitHub - Unstructured-IO/unstructured:用于构建自定义预处理流水线的开源库和 API,适用于标注、训练或生产机器学习流水线。:用于构建自定义预处理流水线的开源库和 API,适用于标注、训练或生产机器学习流水线。 - GitHub - Unstructured-IO/unstructured...
- GitHub - cohere-ai/sandbox-conversant-lib:基于 Cohere LLM 构建的对话式 AI 工具和角色(personas):基于 Cohere LLM 构建的对话式 AI 工具和角色 - cohere-ai/sandbox-conversant-lib
- GitHub - cohere-ai/quick-start-connectors:该开源仓库提供了将工作场所数据存储与 Cohere LLM 集成的参考代码,使开发者和企业能够在其自有数据上执行无缝的检索增强生成 (RAG)。:该开源仓库提供了将工作场所数据存储与 Cohere LLM 集成的参考代码,使开发者和企业能够执行无缝的检索增强生成...
- 使用 Command R+ 创建不受限的 AI Agents — LessWrong:简而言之,目前存在一些能力强大的开源权重模型,可用于创建简单且不受限的恶意 Agent。它们可以端到端地执行任务...
- Quantfino - 强大的 AI 驱动金融之源:Quantfino 是由 LLM 驱动并辅以 Langchain 的金融分析平台。
- AutoGen | AutoGen:通过多 Agent 对话框架实现下一代 LLM 应用
- Flashcardfy - 带有个性化反馈的 AI 闪存卡生成器:通过提供个性化反馈的 AI 生成闪存卡,学习得更快、更聪明。
- Agents | 🦜️🔗 Langchain:LangChain 提供了许多工具和函数,允许你创建 SQL Agents,从而提供一种更灵活的与 SQL 数据库交互的方式。使用 SQL Agents 的主要优点是...
- Galaxy AI - Swagger UI:未找到描述
- Home - OppyDev:提升编程体验的协作式 AI Agent
- Rubik's AI - AI 研究助手 & 搜索引擎:未找到描述
- CC Search Portal:无描述
- Google Colaboratory:无描述
- mistral-common/examples/tokenizer.ipynb at main · mistralai/mistral-common:通过在 GitHub 上创建账号来为 mistralai/mistral-common 的开发做出贡献。
- React App: 未找到描述
- GitHub - Lightning-AI/pytorch-lightning: Pretrain, finetune and deploy AI models on multiple GPUs, TPUs with zero code changes.: 在多个 GPU、TPU 上预训练、微调和部署 AI 模型,无需更改代码。 - Lightning-AI/pytorch-lightning
- Reka Core: A Frontier Class Multimodal Language Model: Reka Core 在关键的行业公认评估指标上可与 OpenAI、Anthropic 和 Google 的模型竞争。鉴于其占用空间和性能...
- Introducing Idefics2 8B: Open Multimodal ChatGPT: 我们将看看 Hugging Face 的开源多模态 LLM idefics2... #python #pythonprogramming #llm #ml #ai #aritificialin...
- Snowflake Launches the World’s Best Practical Text-Embedding Model: 今天 Snowflake 发布并以 Apache 2.0 许可证开源了 Snowflake Arctic embed 系列模型。基于 Massive Text Embedding Be...
- JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars: JetMoE-8B 的训练成本不到 10 万美元,但性能优于来自 Meta AI 的 LLaMA2-7B,后者拥有数十亿美元的训练资源。LLM 训练...
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face: 未找到描述
- adding the llm-gpt4all models breaks the python app. · Issue #28 · simonw/llm-gpt4all: 我安装 LLM 没问题,分配了我的 OpenAI 密钥,并且可以毫无问题地与 GPT-4 对话,查看我的 LLM 模型命令输出:OpenAI Chat: gpt-3.5-turbo (别名: 3.5, chatgpt) OpenAI...