ainews-to-be-named-5820
Meta Llama 3 (8B, 70B) *(注:8B 和 70B 分别代表 80 亿和 700 亿参数)*
Meta 发布了 Llama 3 模型的部分版本,包括 8B 和 70B 变体,而 400B 变体仍在训练中,被誉为首个达到 GPT-4 级别的开源模型。Stability AI 推出了 Stable Diffusion 3 API,模型权重即将发布,其真实感可与 Midjourney V6 媲美。波士顿动力 (Boston Dynamics) 展示了全电动人形机器人 Atlas,微软 则推出了 VASA-1 模型,能在 RTX 4090 上以 40fps 的速度生成逼真的说话人脸。
作为 OpenAI 的欧洲竞争对手,Mistral AI 正在寻求 50 亿美元的融资,其 Mixtral-8x22B-Instruct-v0.1 模型在 64K 上下文基准测试中达到了 100% 的准确率。在 AI 安全讨论方面,前 OpenAI 董事会成员 Helen Toner 呼吁对顶级 AI 公司进行审计,摩门教会也发布了 AI 使用原则。
新的 AI 开发工具包括:用于扩散模型的 Ctrl-Adapter、用于合成数据集流水线的 Distilabel 1.0.0、利用大语言模型进行数据清洗的 Data Bonsai,以及使用行为树构建大语言模型智能体的 Dendron。此外,网络梗图(Memes)也展现了 AI 发展中的幽默与文化参考。此次发布的 Llama 3 模型具有更强的推理能力、12.8 万个 token 的词汇表、8K token 的序列长度,并采用了分组查询注意力(GQA)机制。
2024年4月17日至4月18日的 AI 新闻。我们为您检查了 6 个 subreddits、364 个 Twitter 账号以及 27 个 Discord 社区(包含 395 个频道和 9849 条消息)。预计节省阅读时间(按 200wpm 计算):918 分钟。
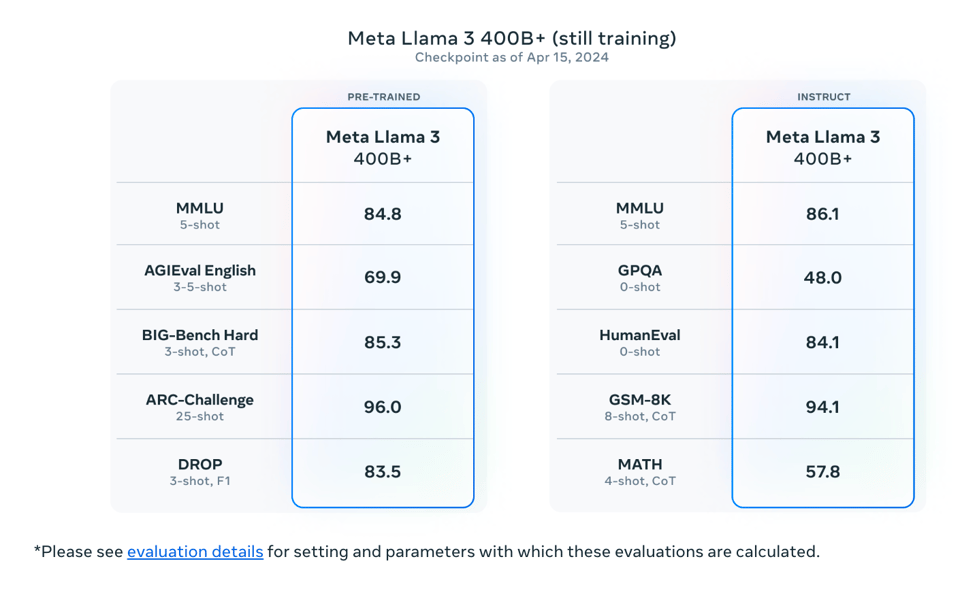
正如广泛预告的那样,Meta 今天部分发布了 Llama 3,包括 8B 和 70B 版本,但全场焦点是 400B 版本(仍在训练中),它被广泛誉为第一个 GPT-4 级别的 OSS 模型。
我们今天大部分时间都在旅途中,所以明天会补全剩余的所有评论,但可以前往 HN 查看最佳的实时报道。
目录
[TOC]
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
近期 AI 发展的关键主题
-
Stable Diffusion 3 发布与对比:Stability AI 发布了 Stable Diffusion 3 API,模型权重即将推出。SD3 与 Midjourney V6 的对比结果褒贬不一,而写实性测试展示了 SD3 的实力。Emad Mostaque 确认 SD3 权重将发布在 Hugging Face 上,并附带 ComfyUI 工作流。
-
机器人与 AI Agent 的进展:Boston Dynamics 展示了其人形机器人 Atlas 的电动版本,具有令人印象深刻的灵活性。Menteebot 是一款真人大小的 AI 机器人,可通过自然语言控制。Microsoft 的 VASA-1 模型可生成栩栩如生的说话面孔,在 RTX 4090 上可实现 40fps 的实时音频驱动。
-
新语言模型与基准测试:Mistral,这家欧洲的 OpenAI 竞争对手,正寻求 50 亿美元的融资。他们的 Mixtral-8x22B-Instruct-v0.1 在 64K 上下文下以 100% 的准确率超越了开源模型。新的 7B merge 模型结合了不同基础模型的优势。Coxcomb,一个 7B 的创意写作模型,在基准测试中表现良好。
-
AI 安全与监管讨论:前 OpenAI 董事会成员 Helen Toner 呼吁对顶尖 AI 公司进行审计,以共享有关能力和风险的信息。摩门教会发布了 AI 使用原则,指出了其益处和风险。
-
AI 开发工具与框架:Ctrl-Adapter 框架将控制适配到 diffusion 模型。Distilabel 1.0.0 支持使用 LLM 构建合成数据集流水线。Data Bonsai 使用 LLM 清理数据,并集成了 ML 库。Dendron 使用行为树构建 LLM Agent。
-
梗图与幽默:一个“理想 vs 现实”的梗图嘲讽了 AI 发展与未来愿景。PS2 风格 LORA 中的 Snoop Dogg 展示了 AI 梗图的潜力。AI 版 Sans vs Frisk 用 AI 艺术重新构思了《传说之下》(Undertale)。一个幽默的观点建议 AI 目前还没那么先进。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
AI Twitter 回顾
所有回顾均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在与 Haiku 合作进行聚类和流程工程。
以下是按要求格式提供的摘要:
Meta Llama 3 发布
- Llama 3 模型发布:@AIatMeta 宣布发布 Llama 3 8B 和 70B 模型,提供了改进的推理能力,并为同尺寸模型设定了新的 SOTA。未来几个月预计将发布更多模型、功能和研究论文。
- 模型详情:@omarsar0 指出 Llama 3 使用了标准的 decoder-only transformer、128K token 词表、8K token 序列、grouped query attention、15T 预训练 token,以及 SFT、rejection sampling、PPO 和 DPO 等对齐技术。
- 性能:@DrJimFan 将 Llama 3 70B 的性能与 Claude 3 Opus、GPT-4 和 Gemini 进行了对比,显示其正接近 GPT-4 水平。@ylecun 也强调了 8B 和 70B 模型强劲的 benchmark 结果。
开源 LLM 进展
- Mixtral 8x22B 发布:@GuillaumeLample 发布了 Mixtral 8x22B,这是一个拥有 141B 参数(39B 激活)、多语言能力、原生 function calling 和 64K 上下文窗口的开源模型。它为开源模型设定了新标准。
- Mixtral 性能:@bindureddy 指出 Mixtral 8x22B 具有最佳性价比,拥有强劲的 MMLU 性能,且具备通过微调超越 GPT-4 的潜力。@rohanpaul_ai 强调了它的数学能力。
- 开源模型排行榜:@bindureddy 和 @osanseviero 分享了开源模型排行榜,展示了开源模型的快速进步和普及。Llama 3 有望进一步推动这一进程。
AI Agent 与 RAG (Retrieval-Augmented Generation)
- RAG 基础:@LangChainAI 与 @RLanceMartin 和 @freeCodeCamp 合作发布了一系列解释 RAG 基础和高级方法的视频播放列表。
- Mistral RAG Agent:@llama_index 和 @LangChainAI 分享了关于使用 @MistralAI 新的 8x22B 模型构建 RAG Agent 的教程,展示了文档路由、相关性检查和工具使用。
- RAG 的忠实度:@omarsar0 分享了一篇论文,量化了 RAG 设置中 LLM 内部知识与检索信息之间的张力,强调了在信息敏感领域部署 LLM 的影响。
AI 课程与教育
- Google ML 课程:@svpino 分享了 300 小时的免费 Google ML 工程课程,涵盖从入门到高级的各个级别。
- Hugging Face 课程:@DeepLearningAI 宣布了一个关于 Hugging Face 量化基础的新免费课程,旨在让开源模型更易获得且更高效。
- 斯坦福 CS224N 人口统计:@stanfordnlp 分享了本季度 CS224N 615 名学生的人口统计数据,显示了跨专业和跨级别的广泛代表性。
其他
- Zerve 作为 Jupyter 的替代方案:@svpino 建议 Zerve(一个与 Jupyter 理念不同的基于 Web 的 IDE)在许多用例中可能取代 Jupyter notebook。它具有针对 ML/DS 工作流的独特功能。
- 资本利得与通货膨胀:@scottastevenson 解释了通货膨胀期间的资本利得税如何导致人们在没有实际收益的情况下被征税,从而通过退休基金、住房和企业等资产影响中产阶级。
AI Discord 回顾
摘要之摘要的摘要
Llama 3 发布引发热潮:Meta 发布了 Llama 3(一个 8B 和 70B 参数的指令微调模型),在 AI 社区引起了极大关注。关键细节:
- 承诺提供更强的推理能力,并在各项任务中树立了“新的行业基准”。
- 可通过 Together AI’s API 等合作伙伴进行推理和微调,提供高达 350 tokens/sec 的速度。
- 对即将推出的 400B+ 参数版本充满期待。
- 一些人对输出限制表示担忧,认为这阻碍了开源开发。
Mixtral 8x22B 重新定义效率:新发布的 Mixtral 8x22B 因其性能、成本效益以及在数学、编程和多语言任务中的专业化而备受赞誉。亮点包括:
- 通过稀疏 Mixture-of-Experts (MoE) 架构,在 141B 总参数中利用了 39B 激活参数。
- 支持 64K token 上下文窗口,实现精确的信息召回。
- 采用 Apache 2.0 开源许可证发布,并附带 Mistral 的自定义 tokenizer。
分词器(Tokenizers)与多语言能力受到关注:随着 Llama 3 和 Mixtral 等强大模型的出现,它们的分词器和多语言性能成为关注焦点:
- Llama 3 的 128K 词汇量分词器涵盖了 30 多种语言,但在非英语任务中可能表现不佳。
- Mistral 开源了其支持 tool calls 和结构化输出的分词器,以标准化微调过程。
- 关于更大的分词器词汇量有利于多语言 LLM 的讨论。
缩放法则(Scaling Laws)与复现挑战:AI 研究社区围绕缩放法则和具有影响力论文的可复现性展开了激烈辩论:
- Chinchilla scaling paper 的研究结果受到质疑,作者承认存在错误并开源了数据。
- 对于结果是证实还是反驳了scaling laws 的存在,各方持有不同观点。
- 呼吁在从有限数据进行推断时,应采用更符合实际的实验次数和更窄的置信区间。
其他
-
Llama 3 发布引发热潮与审视:Meta 发布的 Llama 3(包含 8B 和 70B 参数模型)引发了 AI 社区的广泛兴趣和测试。工程师们对其性能媲美前代 Llama 2 和 GPT-4 印象深刻,但也注意到了 128k token 上下文窗口等局限性。Axolotl 和 Unsloth 等框架正在进行集成,量化版本也已出现在 Hugging Face 上。然而,一些人对 Llama 3 在下游使用上的许可限制表示担忧。
-
Mixtral 和 WizardLM 突破开源边界:Mistral AI 的 Mixtral 8x22B 和 Microsoft 的 WizardLM-2 作为强大的开源模型引起了轰动。Mixtral 8x22B 拥有 39B 激活参数,擅长数学、编程和多语言任务。WizardLM-2 提供了一个 8x22B 的旗舰版本和一个快速的 7B 变体。两者都展示了开源模型的飞速进步,支持范围已扩展到 OpenRouter 和 LlamaIndex 等平台。
-
Stable Diffusion 3 发布,评价褒贬不一:Stability AI 在 API 上发布了 Stable Diffusion 3,但初步印象褒贬不一。虽然它在排版和提示词遵循方面有所进步,但一些人报告了性能问题和大幅涨价。该模型无法在本地使用也招致了批评,尽管 Stability AI 承诺很快将向会员提供权重。
-
CUDA 难题与优化:CUDA 工程师们应对了各种挑战,从分块矩阵乘法(tiled matrix multiplication) 到 自定义 kernel 与 torch.compile 的兼容性。讨论深入探讨了内存访问模式、warp 分配以及 Half-Quadratic Quantization (HQQ) 等技术。llm.c 项目 进行了多项优化,减少了内存占用并加速了 attention 机制。
-
AI 生态系统随着新平台和资金投入而扩张:AI 初创领域活动频繁,theaiplugs.com 作为 AI 插件和助手的市场首次亮相,SpeedLegal 在 Product Hunt 上线。一份涵盖 550 轮融资、总额达 300 亿美元的 AI 初创公司融资数据集 被汇编并分享。Cohere 和 Replicate 等平台推出了新模型和定价结构,标志着生态系统正趋于成熟。
第 1 部分:Discord 高层摘要
Perplexity AI Discord
-
Opus 限额缩减对话次数:工程师们对意料之外的 Opus 模型使用限制感到不满,该限制突然从每天 600 条消息降至 30 条,打乱了原有计划,并促使一些人寻求退款或寻找替代方案,如 Tune Chat。
-
Llama 3 热度超出预期:关于 Meta 的开源 Llama 3 模型讨论热烈,工程师们分享了相关链接并讨论其潜力,同时密切关注 Twitter 上发布的最新 Benchmark(基准测试)以及像 llama3 这样提供深入探索的链接。
-
API 生态系统在波折中成长:在关于 API 不一致性的讨论中,mixtral-8x22b-instruct 加入了 Perplexity Labs 的产品阵容(位于 labs.pplx.ai),并且 Perplexity Pro 用户现在每月可获得 5 美元的 API Credit。
-
对排版变革的共同热情:工程师们对排版技术的发展表现出兴奋,传阅了关于 新 Tubi 字体 的链接及相关讨论。
-
模型执行诗意分析:mixtral-8x22b-instruct 因其对歌词(如 Leonard Cohen 的作品)的细致理解而受到赞誉,这表明在内容解读方面为其他模型树立了新标杆。
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion 3 强势登陆 API:Stability AI 已在开发者平台 API 上推出了 Stable Diffusion 3 及其 Turbo 版本,声称在排版和 Prompt(提示词)遵循度方面有显著改进。
- 面向大众的模型权重:Stability AI 承诺向会员发布模型权重,鼓励 Self-hosting(自托管)并支持更广泛的开源生成式 AI 运动。
- GPU 辩论升温:关于是投资即将发布但尚未上市的 GPU(如 5090),还是选择当前的高性能显卡(如二手 3090)来处理 AI 任务的讨论非常激烈,重点考量了 VRAM 容量和 NVLink 能力。
- AI Influencer(AI 网红)—— 一门有争议的技艺:对话涉及 AI Influencer 的创建,揭示了从单纯的好奇到盈利目的等多种动机,同时也伴随着对其社会贡献的质疑。
- 微调修复与求职:工程师们交流了微调新模型以获得更好性能的见解,同时关注 AI 领域的职位空缺和合作伙伴关系,并分享了 Palazzo, Inc. 的 Stable Diffusion 工程师 招聘帖。
Nous Research AI Discord
-
Snowflake 的 Embedding 引发讨论:新推出的 Snowflake text-embedding 模型 成为关注焦点,引发了关于语言向量空间和符号语言形式的讨论。针对文中提到的 256 维 Embedding(相较于常见的 1500 维),成员们对其效率和意义表示关注,并计划自行测试其检索准确率。
-
模型安全漏洞曝光:讨论揭示了 Hugging Face 发生的一起涉及恶意 .pickle 文件的安全事件,并思考了 OpenAI 系统中类似的漏洞。这突显了 AI 系统安全中持续存在的风险和挑战,强调了工程师设计强大防御措施的必要性。
-
Llama 3 增强了基准测试的热度:尽管有人担心 Meta 的 Llama 3 与 Mixtral 8x22B 等模型相比在 Context Length 方面存在限制,但其性能表现仍引起了轰动。社区正在积极讨论使用 MLX 进行 Finetuning,但 Mistral 模型突然设置访问限制(gating)暗示了监管挑战或滥用预防措施。
-
Prompt 困惑与 GPU 思考:用户针对 Hermes 2 Pro 模型的 Prompt 行为以及对 “directly_answer” 工具的需求进行了问答交流。此外,在 GPU 集群上进行 Long Context Inference 的技术挑战,以及使用双 A100 GPU 配合 Jamba 处理 200k Tokens 的案例是讨论的重点,这对于从事类似高容量部署方案的工程师具有参考价值。
-
WorldSim 传闻:社区成员正满怀期待且俏皮地等待 WorldSim 的重新发布。用户的见解建议实施使用限制和收费,以防止导致关停的操纵性输入。该平台在用户生成 AI 文明方面的潜力,成为了期待和哲学探讨的重要话题。
LM Studio Discord
Llama 3 正在炒热 LM Studio:新的 Meta Llama 3,特别是 8B Instruct 版本,随着其在 Hugging Face 上的发布和可用性引发了热潮,但用户报告了意外的输出重复和 Prompt 循环问题。爱好者们讨论了在本地运行 WizardLM-2-8x22B 等大模型的可行性,普遍认为在 24GB 的 Nvidia 4090 显卡上运行可能并不实际。
技术故障与成功:AI 工程师分享了在从 Ryzen 5 3600 到 Mac M1 和 M3 Max 等不同硬件配置上优化 Llama 3 性能的方法,一位用户通过调整主板设置以降低运行温度,解决了 Thermal Throttling(热节流)问题。双 P100 GPU 对某些人来说比较棘手,存在利用率不当的问题,同时用户也讨论了不同 NVIDIA GPU 根据需要贡献 VRAM 的能力。
AI 应用参与与咨询:基于 Electron 的应用 MissionSquad 在最近的 V1.1.0 版本中提供了 Prompt Studio,引起了广泛关注。然而,一些倾向于查看源代码的用户对透明度提出了要求,这与隐私权衡之间存在讨论。将 Text-to-Speech (TTS) 功能整合进 LM Studio 的建议反映了用户对增强交互性的渴望。
AMD 历险记:使用 AMD 配置的用户在运行 LM Studio 时遇到了 GPU 选择挑战。虽然最新的 ROCm preview (0.2.19) 应该能解决 iGPU 选择难题,但有关推理异常的报告表明,对于 8B 模型 等大模型的支持仍存在问题。社区分享了一个禁用 iGPU 的变通方法,并建议针对持续存在的问题提交更新或 Bug 报告。
Prompt 创作征集:LM Studio 的讨论延伸到了实际事务,如策划联盟营销活动,用户要求 AI 模型提供超越通用输出的特异性。一位成员强调,在寻求开发者参与时,需要的是事务性安排而非投机性伙伴关系。
Unsloth AI (Daniel Han) Discord
Llama 3 发布吸引工程师:技术 Discord 社区成员积极参与了 Llama 3 的讨论和测试,评估其基准测试结果。结果显示,尽管参数较少(8B 对比 70B),其性能与前代 Llama 2 相当。他们尝试将其集成到 Unsloth AI 框架中,引用了针对 8B 模型的 Google Colab notebook,并探索了 70B 模型的 4-bit 量化版本。
应对移动端缺失 CUDA 的挑战:参与者指出,由于缺乏 CUDA 兼容性,在移动设备上部署神经网络面临挑战,引发了关于使用自定义推理引擎作为替代方案的讨论。这些对话涉及了为 iPhone 硬件部署而编译神经网络模型的复杂性。
TorchTune 放弃旧硬件支持:TorchTune 停止支持旧版 GPU,引发了关于其对使用前代硬件用户影响的讨论。用户提到了利用 Obsidian 等笔记工具进行知识管理的变通方法。
许可物流与命名游戏:遵守 Llama 3 新许可条款的重要性成为讨论话题,特别是任何衍生模型名称中必须包含 “Llama 3” 前缀的要求。这种对细节的关注强调了开源 AI 领域中法律考量的重要性。
双语头脑风暴:社区思考了创建双语模型的策略,权衡了潜在解决方案的成本和复杂性,例如用于翻译层的三次 LLM 调用。此外,Distributed Negotiation Optimization (DNO) 引起了关注,人们意识到虽然它尚未在库中实现,但可以作为 Direct Preference Optimization (DPO) 的有效迭代。
CUDA MODE Discord
分块变换:在讨论分块矩阵乘法 (tiled matrix multiplication) 时,工程师指出,尽管为分块而对大矩阵进行填充 (padding) 会增加计算量,但可以节省内存带宽。
Meta 的 Llama 缺少 MOE:Meta 最新发布的 Llama 3 是一个 405B 参数的稠密模型 (dense model),没有采用 MOE (Mixture of Experts) 架构,这与其它的 SOTA 架构形成对比。Meta Llama 3 详情
CUDA 远征者交谈:CUDA 讨论范围广泛,从加载大型数据集的最佳实践和优化 kernel 设置,到调试结果差异以及剖析内存访问模式及其对性能的影响。
Triton 与自定义操作的难题:AI 工程师交流了使自定义函数与 torch.compile 兼容的技术,并参考了处理 torch.jit.ignore 的方法以及自定义 Triton kernel 的演示。针对 torch.compile 的自定义 CUDA GitHub PR 引用 和 自定义 Triton kernel 的组合 是对话的一部分。
量化困境:深入讨论了 半二次量化 (Half-Quadratic Quantization, HQQ) 方法,特别是关注 axis=0 与 axis=1 量化的对比,并解决 Transformer 权重矩阵拼接的挑战。分享的链接包括对当前实践的评估、创新的优化技术,以及未来将 HQQ 集成到 torchao 的可能增强方案。HQQ 实现详情
CUDA 活动的协作协调:Massively Parallel Crew 计划重叠的小组讨论和 CUDA MODE 活动,展示了在安排录制、克服调度冲突和后期制作工作方面的团队合作。
LAION Discord
SD3 仅通过 API 首次亮相,评价褒贬不一:Stability AI 发布了 通过 API 提供的 SD3,反响不一。人们承认其存在一些性能问题,特别是在文本渲染方面,同时也关注到其迈向货币化的战略举措。
数据集困境:随着 LAION 数据集从 Huggingface 下架,成员们开始寻找替代方案,如 coyo-700m 和 datacomp-1b 来训练新模型。同时,PAG 在 SDXL 上的应用也引起了关注,虽然它提供了比以往更好的视觉效果,但仍未超过 DALLE-3 的能力。
Stability AI 的动荡局面:Stability AI 高层的离职引发了关于公司未来以及对开源 AI 模型潜在影响的讨论,管理不善的担忧阴云笼罩。更广泛的 AI 社区开始测试并对 Meta 的 LLaMA 3 做出反应,尽管其上下文窗口较小,但其在各种任务中的表现赢得了赞赏。
GANs 在效率上保持微弱领先:GANs 因其推理速度和参数效率而受到关注,但它们难以训练,且视觉效果往往不尽如人意。与此同时,微软发布的 VASA-1 将利用音频线索,彻底改变实时逼真的谈话面部生成。
数据集与模型不断演进:HQ-Edit 现已开放,这是一个包含约 200,000 次编辑的大型指令引导图像编辑数据集,有望增强未来的 AI 图像编辑工具。此外,Meta 宣布推出强大的开源 Llama 3 语言模型,展示了其对 AI 普及和进步的承诺。
OpenAccess AI Collective (axolotl) Discord
Llama 的提升:新发布的 Llama 3 凭借基于 Tiktoken 的分词器和 8k 上下文长度实现了性能飞跃。
Axolotl 提升表现:已提交 PR 将 Llama 3 Qlora 集成到 Axolotl 中,并讨论了在 80GB GPU 配置下的 CUDA 错误。此外,微调后的 Adapter 出现了挑战,通过将分词器设置更改为 legacy=False 和 use_fast=True 得到了解决。
微调技巧:深入探讨微调技术,成员们努力使用 rope_theta 等参数扩展上下文长度,并分享了在模型微调过程中通过取消冻结特定层来防止训练崩溃的经验。
配置难题:Axolotl 不解析 YAML 文件中的注释,而用户对在 YAML 配置中设置 PAD tokens 的可行性表示了兴趣,这表明需要更清晰的配置文档。
Token 调整技术:交流中重点介绍了使用 add_tokens 和手动调整词汇表来替换 token 的方法,引发了关于 Llama-3 等模型最佳分词器调整的技术探讨。
OpenRouter (Alex Atallah) Discord
-
Atlas 走向全电动化:Boston Dynamics 展示了 Atlas 机器人的全新全电动版本,强调了相比之前版本的进步,该展示在视频中引发了大量讨论。
-
Mixtral 和 WizardLM 重新定义 LLMs:Mistral AI 的 Mixtral 8x22B Instruct 拥有 39B 激活参数,专注于数学、代码和多语言任务;而 Microsoft AI 的 WizardLM-2 展示了其自身的 8x22B 模型以及更快的 7B 变体。这些模型拥有令人印象深刻的基准测试结果,并使用微调技术来增强其指令遵循能力。
-
Llama 3 随 Meta 进入 AI 舞台:Together AI 与 Meta 合作,推出了用于微调的 Meta Llama 3,提供 8B 和 70B 参数模型,并在 API 基准测试中实现了高达每秒 350 个 token 的吞吐量。
-
通过 OpenRouter 重新定义 AI 访问:OpenRouter 的讨论集中在利用 WizardLM 和 Claude 等模型进行限制更少的应用,并提到 Together AI 正在使用 Mixtral,以及为扩展上下文应用而自行托管 Llama 3。
-
订阅系统故障与初创公司推荐:有报告称 OpenRouter 的订阅系统出现问题,同时社区邀请大家关注成员的初创公司 Product Hunt 上的 SpeedLegal,这是一个用于合同谈判的 AI 工具。
OpenAI Discord
Claude 对全球舞台的渴望:有讨论指出 Claude 在文学相关任务中表现出色,但在某些地理区域仍无法访问,这凸显了对其更广泛可用性的渴望。
Whisper v3 的传闻:人们对 Whisper v3 API 的发布充满期待,考虑到距离最初发布已有一年,这是一个重要的后续版本,但官方细节仍然寥寥无几。
GPT-4 遗忘了过去?:社区观察表明 GPT-4 的记忆能力有所下降,成员们注意到该 AI 的 Token 容量似乎有所减少,尽管目前还缺乏确凿证据。
检测到 GPT-4 速度下降:用户报告称 GPT-4-0125-preview 等版本出现了延迟,影响了对响应时间敏感的应用;尽管 gpt-4-turbo-2024-04-09 被作为解决方案提出,但用户感觉其速度也变慢了。
AI 与区块链的新前沿:一位成员指出了 AI 与区块链的交汇点,并邀请大家在 Prompt 开发方面进行协作,以推动这一新颖集成的进步。
Eleuther Discord
为 SoundStream 的 FLOPs 操心:社区指导帮助一位新手估算了 SoundStream 的训练 FLOPs,并根据一篇 Transformer 论文 提供了关于每 Token 操作数和数据集大小乘积的详细建议。
Scaling Laws 的审查加强:一篇 复现尝试论文 挑战了 Hoffmann et al. 提出的 Scaling Laws,引发了关于置信区间以及此类大型语言模型(LLM)所需实验实际数量的讨论。
解读 Tokenizer 对 LLM 的影响:工程专家们辩论了更大 Tokenizer 词汇量的益处,特别是针对多语言 LLM,并考虑了在 Tokenizer 不同时使用 bits per byte 等方法来理解模型困惑度(Perplexity)。
整合 LLM 中的新兴技术:社区讨论涉及了 Untied Embeddings 和新型 Attention 机制对 LLM 的有效性,并探讨了将 蒙特卡洛树搜索(MCTS) 与 LLM 结合以获得更好的推理能力,正如腾讯的 AlphaLLM 所探索的那样。
资源共享与协作评审呼吁:分享了如 lintang/pile-t5-base-flan 等经过 Flan 微调的模型链接,并请求评审 flores-200 和 sib-200 基准测试的 PR,这对于推进多语言评估至关重要。
Modular (Mojo 🔥) Discord
将 C 与 Mojo 集成:为那些有兴趣在 Mojo 中使用 C 的用户指出了 mojo-ffi 项目 和一个 使用 external_call 的教程。该教程特别讲解了如何在 Mojo 中调用 libc 函数。
Modular 的精彩推文:Modular 最近的推文引起了关注,并提供了直接链接,指向 第一条推文 和 第二条推文。
Mojo 的兼容性查询:讨论涉及了 Mojo 插件与 Windows 和 WSL 的兼容性,Mojo Playground 可能推出的支持低内存占用的 Nightly Build 特性 GitHub 讨论,以及 Variant 尚不支持 Movable Trait 这一待处理问题。
社区项目促进增长:围绕 Mojo 的社区活动包括:解决 Mojo 24.2 的编译问题,一名学生寻求在 Mojo 中实现算法的指导,以及社区通过指向 Mojo 入门 页面等资源提供的支持性响应。
LLaMa 的崛起:一段 YouTube 视频 报道了 Meta LLaMa 3 的发布并探索了该模型的新特性,表明社区对前沿 AI 研究持续关注。
Interconnects (Nathan Lambert) Discord
-
MCTS 与 PPO 结合助力 AI 突破:探索 蒙特卡洛树搜索 (MCTS) 与 近端策略优化 (PPO) 的融合可能是 AI 决策领域的游戏规则改变者,从而产生一种新型的 PPO-MCTS 价值引导解码算法,旨在改进自然语言生成。这里有一篇关于该主题的创新研究论文。
-
语言模型领域的新秀:AI 社区正因 Mixtral 8x22B 和 OLMo 1.7 7B 等令人印象深刻的模型推出而沸腾,这些模型在多语言流利度和 MMLU 分数上都树立了新标杆。Mixtral Instruct 在聊天机器人应用方面的进步前景,以及对 Meta Llama 3 规模的好奇,凸显了 AI 领域正处于显著扩张和普及的时期。相关细节和资源链接:Mixtral 8x22B Apache 2.0,Hugging Face 上的 OLMo,以及 Mixtral-Instruct 模型卡片。
-
Chinchilla 缩放定律争议:Chinchilla 论文中备受争议的缩放定律引发了 AI 社区的热烈讨论,研究人员 @tamaybes、@suchenzang 和 @drjwrae 发表了看法,作者 @borgeaud_s 也承认了一个错误。这场激烈的辩论强调了数据验证和透明度的必要性。参考推文证实了辩论的激烈程度:tamaybes 的推文,suchenzang 的担忧,以及 borgeaud_s 的承认。
-
AI 喜剧时刻:Nathan Lambert 被一段 《周六夜现场》(Saturday Night Live) 的短剧 逗乐了,该短剧扰乱了一场 AI 新闻直播活动,精准捕捉到了 AI 对文化的影响力已跨入幽默领域。
-
AI 奇闻与沉思:讨论在即将到来的 OLMO vs. LLaMa 3 模型对决,以及《三体》、播客专题、数字命理学和博客文章预测之间的深奥联系中摇摆。与此同时,Jeremy Howard 关于“实验性”方面的推文引发了猜测。Jeremy 的推文引起了关注。
-
SnailBot 缓慢而稳步的进展:SnailBot 或许赢不了速度竞赛,但它在 WIP(进行中)帖子上的功能性正冲向终点线,讽刺地反映了技术领域经常面临的速度难题。
Cohere Discord
-
Web UI 微调 - 简单开始,其余交给 API:在 Cohere 通过 Web UI 启动模型微调非常用户友好,但使用新数据集进行进一步微调则需要使用 API,详细说明可在 官方文档 中找到。
-
Cohere 的最新奇才:Command R+:Cohere 推出的 Command R+ 因其显著的进步而受到认可。可以在 Cohere 网站上探索广泛的功能对比和模型能力。
-
伦理 AI:应对 Command R+ 的潜在风险:针对 Command R+ 提出的担忧涉及可能被操纵用于不道德目的的漏洞,正如链接到 LessWrong 的红队演练所强调的那样。
-
LLMs 越狱 - 从语言到代理:对话围绕 AI 越狱的概念展开,指出重点已从提取不当语言转向诱导 大语言模型 (LLMs) 产生复杂的自主行为——这是在敏感环境中使用 AI 的组织必须考虑的关键因素。
-
Cohere Command 与 Llama – 性能笔记:用户对 Llama 3 模型的能力印象深刻,讨论了在评估 AI 时实际应用的重要性。70b 和 400b 等大型变体模型的性能是根据它们对数学方程和 SVG 标记等复杂提示词的响应来评估的。
Latent Space Discord
- 创业玩笑掩盖真实对话:成员们幽默地提议成立一家初创公司来创建更优越的聊天库,暗示可能超越 OpenAI 等巨头。
- 本地模型:小即是新的大趋势:公会讨论了向具有用户友好界面的小型、高性能 AI 模型转变的潜力,强调权宜之计优于复杂性。
- 延迟:每一毫秒都至关重要:工程师们强调,延迟对用户体验和 AI 应用的成功采用是有害的,突出了快速响应的重要性。
- AI 性能下降之谜:分享了关于 AWS 托管的 Claude 3 性能急剧下降的观察,临床概念提取任务的准确率从 95% 以上降至接近于零。
- 会议移至 Zoom:llm-paper-club-west 通过将会议移至 Zoom 并提供提醒以确保平稳过渡,促进了关于论文的讨论,Zoom 会议链接。
OpenInterpreter Discord
Windows 上的 PowerShell 难题:工程师们报告了在 Windows 上实现 OpenInterpreter 的挑战,特别是 PowerShell 无法识别 OPENAI_API_KEY 等环境变量。还讨论了安装 poetry 所需的时间以及在各种 Windows 环境中运行 OpenInterpreter 的复杂性。
ESP32 的连接困扰:用户分享了连接 ESP32 设备的困难,建议指向不同的 IDE 和使用 curl 命令。与消息数组相关的错误消息强调了设备连接的持续问题。
使用本地服务器和 WebSockets 进行调试:围绕为 OpenInterpreter 设置本地服务器以及排除 WebSockets 和 Python 版本不兼容问题出现了挑战。努力包括通过 curl 手动配置服务器地址,以及尝试解决音频缓冲问题。
探索跨设备兼容性:关于 OpenInterpreter 的讨论涉及在 Windows 上使用 LM Studio,同时在 Mac 上运行软件,强调了跨操作系统兼容性的必要性。用户报告称切换到 MacBook 以潜在地规避现有障碍。
Hugging Face 亮点:一条消息引用了一个 Hugging Face space,用户可以在其中与 Meta LLM3_8b 聊天,表明了社区对实验替代语言模型的兴趣。
LlamaIndex Discord
-
MistralAI 的 8x22b 登场:MistralAI 发布了 8x22b 模型,LlamaIndex 自发布之初就已支持该模型,具有 RAG、查询路由和工具使用等高级功能,详见 Twitter 帖子。
-
使用 Elasticsearch 构建免费 RAG 的教程:博客文章详细介绍了 LlamaIndex 和 Elasticsearch 在创建免费检索增强生成 (RAG) 应用指南中的应用。
-
高效 RAG 系统的实现技巧:AI 工程师讨论了优化 RAG 实现和提供多语言支持的方法,重点介绍了微调指南和 RAG 内的摘要技术资源,包括 Q&A Summarization。
-
Google 的无限上下文预示 LLM 的未来:正在讨论 Google 开发的一种允许大语言模型处理无限上下文的方法,这对面临潜在范式转移的 RAG 等现有框架具有影响。技术方法及其影响在 VentureBeat 的文章中进行了探讨。
-
揭秘数据驱动的 AI 融资洞察:manhattanproject2023 为 AI 社区提供了访问与 AI 融资相关的详细数据集的机会,其中包含公司发展各个阶段的 300 亿美元投资,可在 AI Hype Train - Airtable 进行分析。
LangChain AI Discord
SQL Skirmish to Chatbot Progress: 工程师们正在应对 LangChain 的 SQL agent 限制以及聊天机器人实现的 prompt engineering 挑战,参考资料包括 createOpenAIToolsAgent 和 SqlToolkit,旨在将 SQL 数据库集成到对话式 AI 中。
Memory Management Mentorship: 重点关注利用 RunnableWithMessageHistory 来管理聊天历史,并参考了 LangChain 代码库中记录的动手建议和代码示例,以增强消息检索和聊天机器人的 memory 能力。
Marketplace for AI Plugs Emerges: theaiplugs.com 已上线,为销售 AI 插件、工具和助手提供解决方案,并处理 API、营销和计费,以简化创作者的工作流程。
Product Hunt Seeks AI Speedsters: SpeedLegal 在 Product Hunt 上亮相,寻求社区支持,同时一门新的 prompt engineering 课程已在 LinkedIn Learning 上线,供那些渴望提升技能的人学习。
Llama 3 Thunders into Public Domain: 开发者公开了 Llama 3 的访问权限,邀请用户通过 聊天界面 和 API 探索其功能,这是将先进 AI 工具传播给更广泛受众努力的一部分。
Alignment Lab AI Discord
-
Alert for Inappropriate Content Across Channels: Discord 公会内的多个频道遭到推广成人内容的垃圾信息攻击,具体涉及 “Hot Teen & Onlyfans Leaks” 以及 Discord 邀请链接 (邀请链接)。鉴于这些事件,公会成员被敦促加强审核。
-
Spam Infiltrates Technical Discussions: 困扰公会的垃圾信息问题在 #programming-help 和 #alignment-lab-ai 等技术讨论频道,以及 #general-chat 和 #join-in 等社区频道中都很普遍,这表明公会面临着全范围的审核挑战。
-
Wizards of the Code Unveil WizardLM-2: WizardLM-2 模型已取得进展,现已在 Hugging Face 上公开访问,并通过 WizardLM-2 发布博客、GitHub 仓库、相关的 Twitter 账号 以及 arXiv 上的学术论文提供了额外资源。
-
Seek and You Shall Find Meta Llama 3 Tokenizer: 在一名公会成员请求 Meta Llama 3-8B tokenizer 后,用户 Undi95 提供了该资源,现在可以在 Hugging Face 上找到,从而规避了遵守特定隐私政策的需要。
-
Community Calls for Action: #open-orca-community-chat 等频道的讨论强调了采取立即审核行动(包括可能的封禁)的必要性,以维护以工程为核心的公会环境的完整性。
DiscoResearch Discord
VRAM 饥渴:贪多嚼不烂?:根据讨论,使用 Adam 优化器训练 Mixtral-8x22B 模型需要惊人的 3673 GB VRAM。即使是 64 个 80GB 的 GPU 也不足以避免在训练 32k 序列长度时出现显存溢出(OOM)错误。此外,成员们正在权衡使用 8-bit 优化来管理巨大显存需求的潜力。
模型训练的成就与挫折:一个专注于英语和德语指令的全新 Mixtral-8x22B 模型已训练完成,并在 Hugging Face 上共享。然而,在实现 fsdp_transformer_layer_cls_to_wrap: MixtralSparseMoeBlock 时遇到了形状错误(shape errors),这表明参数状态可能未充分利用混合精度,从而使 FSDP 配置复杂化。
Tokenizer 统一工作:Mistral 公布了其专为跨模型兼容性设计的 Tokenizer 库,具有 Tool Calls 和结构化输出功能,示例可在该 Jupyter Notebook 中找到。
Meta 的 Llama 3 带着雄心勃勃的支持亮相:Meta 发布了 Llama 3,因其增强的多语言能力和与云平台的直接集成而备受关注。尽管训练集中存在多语言数据,但其 128K token 的 tokenizer 因非英语表现可能欠佳而受到审查。更多详情请见 Meta AI Blog。
模型开放性的双刃剑:随着 Llama 3 的出现,人们对 Llama 3 输出的限制感到担忧,这可能会阻碍开源开发,也反映出社区更偏向于像 MistralAI 这样限制较少的平台。社区的保留意见在这条批判性的 推文 中得到了体现。
Datasette - LLM (@SimonW) Discord
-
创业公司在 Product Hunt 上崭露头角:一位成员在 Product Hunt 上发布了他们的创业项目 SpeedLegal,这是一款 AI 工具,旨在通过识别风险和简化法律术语来辅助合同谈判。
-
Karpathy 提倡精心打磨小模型:Andrej Karpathy 最近的推文 暗示社区对小模型的训练普遍不足,并指出一个经过 15T token 数据集精心磨练的 8B 参数模型可以与更大的模型相媲美。
-
小模型赢得社区青睐:小巧且经过勤奋训练的 AI 模型这一概念引起了社区的共鸣,这可能是受到 Karpathy 倡导的挖掘小架构潜力的启发。
-
密切关注 Mixtral:社区成员热衷于测试 Mixtral 8x22B Instruct,Hugging Face 上的模型卡片 已被分享,详细介绍了使用案例和实现方法。
-
插件混乱挑战 LLM 开发:llm-gpt4all 插件安装中出现的问题导致 Python 应用程序崩溃,这在 GitHub issue #28 中被强调,并引发了对 LLM 插件韧性和依赖管理的担忧。
tinygrad (George Hotz) Discord
- PyTorch Lightning 以硬件中立性出击:对话强调了 PyTorch-Lightning 的能力,即无需修改代码即可在包括 GPU 和 TPU 在内的各种平台上训练、微调和部署 AI 模型。
- AMD Radeon GPU 的成功案例:一块 AMD Radeon 7900XTX GPU 已成功用于运行 PyTorch-Lightning,展示了其与多样化硬件选项的兼容性。
- ROCm 为 PyTorch 带来速度提升:在 7900XTX GPU 上测试时,利用 ROCm 的优化,PyTorch-Lightning 在某些模型上的表现比常规 PyTorch 更快。
- 领域内的新 AI 模型:新 AI 模型 LLaMa3 已经发布,提供了适用于不同规模 AI 应用的预训练版本,详见其 官方页面。
- Tinygrad 迈向高效 Tensor 操作:在 tinygrad 中,正在追求 broadcast、reshape、permute 等零成本 Tensor 操作,并建议探索 tinygrad/shape/shapetracker.py 或 view.py 以获取战略指导。
Skunkworks AI Discord
-
AI 社区对新模型发布反响热烈:讨论重点关注了 Snowflake Arctic embed 模型系列、Mixtral 8x22B 以及 Meta 的 Llama 3 的发布,称赞它们是文本 embedding 和大型语言模型 (LLM) 领域的里程碑。通过 YouTube 链接 分享了这些模型的详细见解和介绍。
-
对 Serverless Fine-tuning 的好奇:一场对话引发了对开源 AI 模型 no-code fine-tuning 和 serverless 推理平台 可能性的兴趣,类似于某些平台为 GPT-3.5 提供的便捷性。
-
非正式闲聊缺乏实质内容:频道中出现了一个充满活力的问候 “HELLLLOOOOOOOO!!!!!!!!”,但缺乏与工程讨论相关的实质性内容。
-
大量模型介绍视频:社区分享了来自 YouTube 的宝贵视频资源,为对 AI 模型开发前沿感兴趣的人提供了 Snowflake Arctic embed 模型、Mixtral 8x22B 和 Llama 3 的概览。
-
无代码 AI 工具——是梦想还是即将到来?:有人提出了关于是否存在(或正在开发)支持 GPT-3.5 以外模型的 no-code AI 平台 的问题,暗示了对更易用的 AI fine-tuning 技术潜藏的需求。
Mozilla AI Discord
Llamafile 脚本现已更加简洁:一个升级且简洁版本的 llamafile 归档版本升级重包脚本 已在 Gist 中分享,并考虑将其添加到 llamafile GitHub repo。该成员提醒,从头开始创建新的 llamafile 比重新打包旧版本更好。
漏洞报告步骤受到询问:有人询问如何报告 安全漏洞 以及获取 CVEs 的流程,该问题已转至线下进行更详细的讨论。
警惕暴露 LLM APIs:发布了一个关于公开暴露 LLM API 端点 的通用警告,强调这并非第一次在 LLM 基础设施代码 中发现 bug。重点强调了以往在此类系统中遇到漏洞的经验。
LLM Perf Enthusiasts AI Discord
- 关于 LITELLM 使用情况的咨询:一位名为 jeffreyw128 的成员询问社区是否有人正在使用 litellm,寻求与该工具有关的见解或经验。
AI21 Labs (Jamba) Discord
- 征集分布式推理实现的示例代码:一位在使用 2x A100 GPU 配置对 AI21 Labs 的 Jamba 进行 长上下文推理 时遇到挑战的成员,正在寻求示例代码以应对分布式系统的复杂性。特别请求针对多 GPU 集群上分布式推理场景的示例。
PART 2: 各频道详细摘要与链接
Perplexity AI ▷ #general (910 条消息🔥🔥🔥):
- Opus 使用限制引发不满:用户对最近 Opus 模型的使用限制表示不满,指出其在未事先通知的情况下从每天 600 条减少到 30 条消息,影响了新老订阅用户。
- 关于退单和退款的争论:针对意外的服务变更,用户就退单和退款的可能性展开了长时间讨论,不同用户权衡了法律和伦理考量,部分用户向 Perplexity 支持团队寻求退款。
- 对 Llama 3 的期待:对来自 Meta 的开源模型 Llama 3 的期待很高,用户讨论了其潜力,并分享了关于其 benchmark 和能力的外部链接。
- 取消订阅与替代服务:由于 Opus 限制的降低,几位用户报告取消了试用或正式订阅,而其他用户则考虑迁移到不同的服务或等待 Perplexity 解决问题。
- 技术问题与侧边讨论:用户报告了不相关的技术问题,例如在 Android 上使用 App 时遇到困难,一些侧边对话包括分享与 AI 发展相关的 YouTube 视频或推文等外部内容。
- 来自 Perplexity (@perplexity_ai) 的推文:了解更多关于 Llama 3 的信息 👇https://www.perplexity.ai/search/Llama-3-Overview-Mz3Cw09KTdq9gavmibDBeA
- Tune Chat - 由开源 LLM 驱动的聊天应用:通过 Tune Chat,访问 Prompts 库、Chat with PDF 和 Brand Voice 功能,以增强您的内容写作和分析,并在所有创作中保持一致的语调。
- llama3:Meta Llama 3:迄今为止功能最强大的开源 LLM
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face:未找到描述
- 未找到标题:未找到描述
- 来自 Lech Mazur (@LechMazur) 的推文:Meta 的 Llama 3 70B 和 8B 在 NYT Connections 上进行了基准测试!就其规模而言,结果非常强劲。
- https://i.redd.it/w5wsw2ecq9vc1.png:未找到描述
- Wack Whack GIF - Wack Whack - 发现并分享 GIF:点击查看 GIF
- Klatschen Clapping GIF - Klatschen Clapping - 发现并分享 GIF:点击查看 GIF
- Microsoft Azure Marketplace:未找到描述
- Ladies And Gentlemen Mikey Day GIF - Ladies And Gentlemen Mikey Day Saturday Night Live - 发现并分享 GIF:点击查看 GIF
- Zuckerberg GIF - Zuckerberg - 发现并分享 GIF:点击查看 GIF
- Laptop Smoking GIF - Laptop Smoking Fire - 发现并分享 GIF:点击查看 GIF
- Snape Harry Potter GIF - Snape Harry Potter You Dare Use My Own Spells Against Me Potter - 发现并分享 GIF:点击查看 GIF
- Movie One Eternity Later GIF - Movie One Eternity Later - 发现并分享 GIF:点击查看 GIF
- PictoChat Online,由 ayunami2000 开发。:使用 Java 编写服务器的 PictoChat Web 应用!源码:https://github.com/ayunami2000/ayunpictojava
- Nintendo DS PictoChat 回来了!:Nintendo DS 的 PictoChat 并没有消失,现在有一个网站可以让你重温那些给朋友发送恶搞画作的光辉岁月,而且是线上的!Pi...
- 24 核 vs 32 核 M1 Max MacBook Pro - Apple 隐藏的秘密..:关于这款更便宜的独角兽 MacBook,还没有人向你展示过的内容!获取您的 Squarespace 网站免费试用 ➡ http://squarespace.com/maxtech 经过一个月的体验...
- Mark Zuckerberg - Llama 3、100 亿美元模型、凯撒·奥古斯都以及 1 GW 数据中心:小扎谈论:- Llama 3 - 朝向 AGI 的开源 - 定制芯片、合成数据以及扩展时的能源限制 - 凯撒·奥古斯都、智能爆炸、生物...
- GitHub - meta-llama/llama3: Meta Llama 3 官方 GitHub 站点:Meta Llama 3 官方 GitHub 站点。通过在 GitHub 上创建账号来为 meta-llama/llama3 的开发做出贡献。
- Rick Astley - Never Gonna Give You Up (官方音乐视频):Rick Astley 的 “Never Gonna Give You Up” 官方视频。新专辑《Are We There Yet?》现已发行:在此下载:https://RickAstley.lnk.to/AreWe...
- Meta AI:使用 Meta AI 助手处理事务、免费创建 AI 生成的图像,并获取任何问题的答案。Meta AI 基于 Meta 最新的 Llama 大语言模型构建,并使用 Emu...
{kind=link}
</div>
Perplexity AI ▷ #sharing (12 条消息🔥):
- 排版变换 (Typographic Transformation):一位成员发现讨论 新的 Tubi 字体 很有价值,表达了对排版话题的热情。
- 真实性的幻象 (Illusion of Authenticity):两位不同的成员指向了一个链接,讨论 演员如何在行业中运行虚假 场景。
- 探索过去 (Exploring the Past):“m” 的历史 引起了一位成员的兴趣,并为对这一特定历史见解感兴趣的人分享了链接。
- 无限的雄心 (Boundless Ambitions):Limitless AI 吊坠 引起了关注,一位成员引导其他人参与相关讨论。
- 创作与策展 (Creation & Curation):成员们分享了对一系列话题的兴趣,从制作 特定事物,到数据可视化技术,甚至是 Adobe 对其 Firefly AI 的训练。
Perplexity AI ▷ #pplx-api (12 messages🔥):
-
API 摘要请求与差异:一位用户询问是否可以通过 API 获取引用或摘要,并注意到
sonar-medium-online的响应与浏览器应用中的响应有所不同。分享了一个指向 Discord 频道的链接以获取更多信息,尽管根据消息显示,分享的链接是无效的。 -
Perplexity API 与 OpenAI 的集成:一位成员分享了在尝试将 Perplexity 的 API 与 OpenAI GPTs 的 actions 集成时请求停滞的经历,暗示在创建功能性 OpenAPI schema 方面存在困难。
-
Mixtral-8x22b 现已可用:社区获悉 Perplexity Labs 和 API 新增了
mixtral-8x22b-instruct,并提供了在 labs.pplx.ai 上进行尝试的链接。 -
深入探讨 Leonard Cohen 的 “Avalanche”:一位用户强调了
mixtral-8x22b-instruct的出色表现,分享了关于该模型对 Leonard Cohen 歌曲 “Avalanche” 诠释的详细反馈,以及它在仅凭歌词识别艺术家和歌曲方面如何超越其他模型。 -
新 AI 模型丰富用户体验:讨论了各种新模型的可用性更新,如
llama-3-8b-instruct和llama-3-70b-instruct,透露它们已添加到 Perplexity Labs 和 API 中,并提到拥有 Perplexity Pro 的用户每月可获得 5 美元的 API 额度。此外,一位成员对这些新模型为他们的应用程序带来的性能提升表示满意。
- 来自 Perplexity (@perplexity_ai) 的推文:🚨 更新:我们已将 mixtral-8x22b-instruct 添加到 Perplexity Labs 和我们的 API! ↘️ 引用 Perplexity (@perplexity_ai) Mixtral-8X22B 现已在 Perplexity Labs 上可用!快去 http://... 体验一下吧
- 来自 Aravind Srinivas (@AravSrinivas) 的推文:🦙 🦙 🦙 http://labs.perplexity.ai 上线了 llama-3 - 8b 和 70b instruct 模型。祝聊天愉快!经过一些后期训练后,我们很快将推出它们的联网搜索版本。...
- 支持的模型:未找到描述
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
-
Stable Diffusion 3 在 API 上线:Stability AI 激动地宣布,与 Fireworks AI 合作,在 Stability AI 开发者平台 API 上正式推出 Stable Diffusion 3 和 Stable Diffusion 3 Turbo。详细信息和访问说明请见 此处。
-
文生图魔力超越竞争对手:Stable Diffusion 3 在排版和提示词遵循方面 超越了 DALL-E 3 和 Midjourney v6 等竞争对手,它采用了先进的 Multimodal Diffusion Transformer (MMDiT) 架构以增强文本和图像处理能力,正如 研究论文 中所强调的那样。
-
开源生成式 AI 的新篇章:官方承诺很快将向拥有 Stability AI 会员资格的用户 提供用于自托管的模型权重,强调了 Stability AI 对开源生成式 AI 的奉献精神。
提到的链接:Stable Diffusion 3 API 现已可用 — Stability AI:我们很高兴地宣布,Stable Diffusion 3 和 Stable Diffusion 3 Turbo 已在 Stability AI 开发者平台 API 上提供。
Stability.ai (Stable Diffusion) ▷ #general-chat (947 条消息🔥🔥🔥):
- API 优先于本地使用:SD3 目前仅可通过 API 访问,每张图像的成本约为 0.065 美元;人们期待该模型在不久的将来能开放本地使用。
- 关于硬件需求的讨论:用户正在权衡是等待 5090 等新型 GPU,还是购买二手 3090 等现有选项进行 AI 工作,并考虑了 VRAM、速度、功耗和 NVLink 支持等因素。
- 微调与生成挑战:大家承认,虽然新模型在某些领域(如解剖结构生成)可能显得乏善可陈,但 Fine-tuning 有可能弥补这些不足。
- 创建 AI 网红?:关于 AI Influencers 的讨论指出了从好奇心到盈利的各种动机,同时也有部分用户对这类尝试的社会价值持怀疑态度。
- AI 模型考量与工作机会:讨论内容包括对 API 积分定价结构(与 Ideogram 等替代方案相比)的担忧、不同模型版本输出质量的差异,以及对 AI 相关项目的工作机会或合作伙伴关系的请求。
- 模型合并示例: ComfyUI 工作流示例
- Stable Diffusion 工程师 - Palazzo, Inc.: 关于我们:Palazzo 是一家充满活力且创新的科技公司,致力于突破室内设计领域 Global AI 的界限。我们正在寻找一名熟练的 Stable Diffusion 工程师加入我们的团队...
- 来自 Stability AI (@StabilityAI) 的推文: 今天,我们很高兴地宣布 Stable Diffusion 3 和 Stable Diffusion 3 Turbo 已在 Stability AI Developer Platform API 上可用。我们与 @FireworksAI_HQ 合作,这是最快的...
- 耗电巨大的 AI 正在损害全球电力供应: 数据中心正成为 AI 发展的瓶颈。
- 卡牌游戏开发商称其支付给一位“AI 艺术家” 90,000 美元来生成卡牌艺术,因为“没有人能达到他交付的质量”: 未找到描述
- Stable Video Diffusion: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- TikTok - 记录美好生活: 未找到描述
- 联系我们 — Stability AI: 未找到描述
- 会员资格 — Stability AI: Stability AI 会员资格通过结合我们的一系列最先进的开放模型与自托管优势,为您的生成式 AI 需求提供灵活性。
- 联邦政府任命“AI 末日论者”负责美国机构的 AI 安全: 前 OpenAI 研究员曾预测 AI 有 50% 的几率杀死我们所有人。
- 过度依赖 AI 的影响:平衡技术与批判性思维: 我是一个 27 岁、积极、开明且热爱技术的发烧友。我是一个有点懒的人,这帮助我让事情变得更……
- 解码 Stable Diffusion:LoRA、Checkpoints 和关键词简化版!: 🌟 通过我们清晰简洁的指南解开 Stable Diffusion 的奥秘!🌟 加入我们,我们将分解复杂的 AI 术语,如 'LoRA'、'Checkpoint' 和 'Con...
- 未找到标题: 未找到描述
- GitHub - kijai/ComfyUI-KJNodes: ComfyUI 的各种自定义节点: ComfyUI 的各种自定义节点。通过在 GitHub 上创建账户,为 kijai/ComfyUI-KJNodes 的开发做出贡献。
- 风云!风云城堡 | 官方预告片 | Amazon Prime: 让我们动起来!80 年代标志性的日本游戏节目《风云城堡》现在正在热播 🏯 订阅:http://bit.ly/PrimeVideoSG 开始您的 30 天免费试用:...
- RTX 4080 vs RTX 3090 vs RTX 4080 SUPER vs RTX 3090 TI - 20 款游戏测试: RTX 4080 vs RTX 3090 vs RTX 4080 SUPER vs RTX 3090 TI - 20 款游戏测试 1080p, 1440p, 2160p, 2k, 4k ⏩GPU & Amazon 美国⏪ (联盟链接)- RTX 4080 16GB: http...
- GitHub - ShineChen1024/MagicClothing: Magic Clothing 的官方实现:可控的服装驱动图像合成: Magic Clothing 的官方实现:可控的服装驱动图像合成 - ShineChen1024/MagicClothing
- GitHub - PierrunoYT/stable-diffusion-3-web-ui: 这是一个基于 Web 的用户界面,用于使用 Stability AI API 生成图像。它允许用户输入文本提示词,选择输出格式和纵横比,并根据提供的参数生成图像。: 这是一个基于 Web 的用户界面,用于使用 Stability AI API 生成图像。它允许用户输入文本提示词,选择输出格式和纵横比,并根据提供的参数生成图像...
- GitHub - Priyansxu/vega: 通过在 GitHub 上创建账户,为 Priyansxu/vega 的开发做出贡献。
- <a href=" Comfy Workflows 视频页面:运行并探索并非针对单一任务的工作流,而是展示 ComfyUI 动画和视频有多么出色。例如:酷炫的人物动画、实时 LCM 艺术等。
- GitHub - TencentQQGYLab/ELLA: ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment:ELLA:为 Diffusion Models 配备 LLM 以增强语义对齐 - TencentQQGYLab/ELLA
- GitHub - codaloc/sdwebui-ux-forge-fusion: Combining the aesthetic interface and user-centric design of the UI-UX fork with the unparalleled optimizations and speed of the Forge fork.:将 UI-UX 分支的美观界面和以用户为中心的设计,与 Forge 分支无与伦比的优化和速度相结合。- codaloc/sdwebui-ux-forge-fusion
- April | 2024 | Ars Technica:未找到描述
- Dwayne Loses His Patience 😳 #ai #aiart #chatgpt:未找到描述
- 1 Mad Dance of the Presidents (ai) Joe Biden 🤣😂😎✅ #stopworking #joebiden #donaldtrump #funny #usa:🎉 🤣🤣🤣🤣 准备好在 "Funny Viral" 频道最新的 "搞笑动物合集" 中大笑不止吧!🤣 这些可爱的以及各种...
- DreamStudio:未找到描述
- 利用 AI 在几秒钟内创建令人惊叹的视觉效果。:移除背景、清理图片、放大、Stable Diffusion 等等……
- Wordware - 比较提示词:使用输入提示词和优化后的提示词运行 Stable Diffusion 3。 </ul> </div> --- **Nous Research AI ▷ #[off-topic](https://discord.com/channels/1053877538025386074/1109649177689980928/1230135613546565773)** (46 条消息🔥): - **Snowflake 发布突破性嵌入模型**:Snowflake 推出并开源了一个全新的 [文本嵌入模型 (text-embedding model)](https://www.youtube.com/watch?v=p9T7ZgtM5Mo),标志着文本分析能力的进步。 - **破译语言的向量空间**:成员们思考了高维向量空间内意义表示的概念框架,讨论了“意义向量空间内的包络 (envelopes)”的可能性,暗示了基于尺度的形成以及新符号语言形式的潜力。 - **讨论加密通信类比**:对话探讨了加密与各种科学现象(如引力动力学)之间的类比,并思考了由于“对无穷大做功 (performing Work on Infinity)”而导致的发散性语言和理解的需求。 - **初创公司在 Product Hunt 寻求支持**:一位用户为其最近在 [Product Hunt](https://www.producthunt.com/posts/speedlegal) 上推出的初创公司 *SpeedLegal* 请求反馈和支持,随后的讨论涉及了该产品的市场契合度和潜在的商业策略。 - **寻求并分享 Bloke Discord 邀请链接**:在发现 Twitter 上的链接失效后,社区成员协助分享了 Bloke Discord 服务器的有效链接,并就解除临时机器人限制以方便发布邀请进行了交流。
- 加入 TheBloke AI Discord 服务器!:用于讨论和支持 AI Large Language Models 以及通用 AI。 | 24155 名成员
- 介绍 Llama 3:最强开源 Large Language Model:介绍 Meta Llama 3,这是 Facebook 下一代最先进的开源 Large Language Model。https://ai.meta.com/blog/meta-llama-3/#python #...
- Snowflake 发布全球最佳实用 Text-Embedding 模型:今天 Snowflake 发布并以 Apache 2.0 协议开源了 Snowflake Arctic embed 系列模型。基于 Massive Text Embedding Be...
- Mixtral 8x22B:Mistral 最好的开源模型:Mixtral 8x22B 是最新的开源模型。它为 AI 社区的性能和效率树立了新标准。它是一个稀疏的 Mixture-of-Experts (SMo...
- SpeedLegal - 你的个人 AI 合同谈判专家 | Product Hunt:SpeedLegal 是一款 AI 工具,可帮助你更好地理解和谈判合同。它可以快速识别潜在风险,并用简单的语言解释复杂的法律术语。SpeedLegal 还提供...
- AI Index: 13 张图表揭示 AI 现状:在新报告中,基础模型占据主导地位,基准测试(benchmarks)失效,价格飙升,而在全球舞台上,美国遥遥领先。
- Tokenization | Mistral AI 大语言模型:Tokenization 是 LLM 中的一个基础步骤。它是将文本分解为更小的子词单元(称为 tokens)的过程。我们最近在 Mistral AI 开源了我们的分词器。本指南将...
- meta-llama/Meta-Llama-3-70B · Hugging Face:未找到描述
- Udio | 创作你的音乐:向世界发现、创作并分享音乐。
- SpeedLegal - 你的个人 AI 合同谈判专家 | Product Hunt:SpeedLegal 是一款 AI 工具,可帮助你更好地理解和谈判合同。它可以快速识别潜在风险,并用简单的语言解释复杂的法律条款。SpeedLegal 还提供...
- Edward Gibson:人类语言、心理语言学、句法、语法与 LLMs | Lex Fridman Podcast #426:Edward Gibson 是麻省理工学院(MIT)的心理语言学教授,并领导 MIT 语言实验室。请通过查看我们的赞助商来支持本播客:- Yahoo Financ...
- Hugging Face 被黑了:链接:主页:https://ykilcher.com 商店:https://ykilcher.com/merch YouTube:https://www.youtube.com/c/yannickilcher Twitter:https://twitter.com/ykilcher Dis...
- GitHub - NVlabs/DoRA: DoRA 的官方 PyTorch 实现:权重分解低秩自适应(Weight-Decomposed Low-Rank Adaptation):DoRA 的官方 PyTorch 实现:权重分解低秩自适应 - NVlabs/DoRA
- 后悔思考 GIF - 后悔思考 紧张 - 发现并分享 GIF:点击查看 GIF
- lluminous: 未找到描述
- NousResearch/Meta-Llama-3-8B-Instruct · Hugging Face: 未找到描述
- N8Programs/Coxcomb-GGUF · Hugging Face: 未找到描述
- meraGPT/mera-mix-4x7B · Hugging Face: 未找到描述
- NousResearch/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: 未找到描述
- Meta AI: 使用 Meta AI 助手完成任务,免费创建 AI 生成的图像,并获取任何问题的答案。Meta AI 基于 Meta 最新的 Llama 大语言模型构建,并使用了 Emu,...
- N8Programs/Coxcomb · Hugging Face: 未找到描述
- maxidl/Mixtral-8x22B-v0.1-Instruct-sft-en-de · Hugging Face: 未找到描述
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: 未找到描述
- Udio | Back Than Ever by drewknee: 制作你的音乐
- NousResearch/Meta-Llama-3-8B · Hugging Face: 未找到描述
- meta-llama/Meta-Llama-3-8B · Hugging Face: 未找到描述
- no title found: 未找到描述
- meta-llama/Meta-Llama-3-70B · Hugging Face: 未找到描述
- NousResearch/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: 未找到描述
- LLM running on Roland MT-32: LLM 在 Roland MT-32 上运行。演示来自 N8 的新型故事讲述模型 "https://huggingface.co/N8Programs/Coxcomb"。
- Angry Mad GIF - Angry Mad Angry face - Discover & Share GIFs: 点击查看 GIF
- Reddit - Dive into anything: 未找到描述
- Diablo Joke GIF - Diablo Joke Meme - Discover & Share GIFs: 点击查看 GIF
- torchtune/recipes/configs/llama3/8B_qlora_single_device.yaml at main · pytorch/torchtune: 一个用于 LLM 微调的原生 PyTorch 库。通过在 GitHub 上创建账号来为 pytorch/torchtune 的开发做出贡献。
- How Did Open Source Catch Up To OpenAI? [Mixtral-8x7B]: 现在就使用此链接报名参加 GTC24!https://nvda.ws/48s4tmc。关于 RTX4080 Super 的抽奖活动,详细计划仍在制定中。然而...
- OLMo 1.7–7B: A 24 point improvement on MMLU: 今天,我们发布了 70 亿参数开源语言模型 OLMo 1.7–7B 的更新版本。该模型在 MMLU 上得分为 52,位列...
- GitHub - asg017/sqlite-vss: A SQLite extension for efficient vector search, based on Faiss!: 一个基于 Faiss 的高效向量搜索 SQLite 扩展!- asg017/sqlite-vss
- Rubik's AI - AI research assistant & Search Engine: 未找到描述
- Support Llama 3 conversion by pcuenca · Pull Request #6745 · ggerganov/llama.cpp: 分词器(Tokenizer)是 BPE。
- MTEB Leaderboard - a Hugging Face Space by mteb: no description found
- Curse of dimensionality - Wikipedia: no description found
- Abstractions/raw_notes/abstractions_types_no_cat_theory.md at main · furlat/Abstractions: A Collection of Pydantic Models to Abstract IRL. Contribute to furlat/Abstractions development by creating an account on GitHub.
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
- world_sim:未找到描述
- Let Me In Crazy GIF - Let Me In Crazy Funny - 发现并分享 GIF:点击查看 GIF
- Pipes:Pipes 是吸食 frop 的必需品。"Bob" 总是抽着装满 frop 的烟斗。每个 SubGenius 都有一个装满 frop 的烟斗,并且不停地抽。通常,SubGenii 会发现一张名人的照片...
- Fire Writing GIF - 火焰文字 - 发现并分享 GIF:点击查看 GIF
- Anime Excited GIF - 动漫兴奋快乐 - 发现并分享 GIF:点击查看 GIF
- A GIF - 海底总动员逃脱忍者 - 发现并分享 GIF:点击查看 GIF
- Mika Kagehira Kagehira Mika GIF - Mika kagehira Kagehira mika Ensemble stars - 发现并分享 GIF:点击查看 GIF
- Tree Fiddy GIF - Tree Fiddy South - 发现并分享 GIF:点击查看 GIF
- Tea Tea Sip GIF - 动漫品茶 - 发现并分享 GIF:点击查看 GIF
- Forge - NOUS RESEARCH:NOUS FORGE 下载将于 2024 年 6 月推出
- DSJJJJ: Simulacra in the Stupor of Becoming - NOUS RESEARCH:Desideratic AI (DSJJJJ) 是一项哲学运动,专注于利用传统上存在于一元论、分体论和语言学中的概念来创建 AI 系统。Desidera 旨在创建能够作为更好...
- DSJJJJ: Simulacra in the Stupor of Becoming - NOUS RESEARCH:Desideratic AI (DSJJJJ) 是一项哲学运动,专注于利用传统上存在于一元论、分体论和语言学中的概念来创建 AI 系统。Desidera 旨在创建能够作为更好...
- meraGPT/mera-mix-4x7B · Hugging Face:未找到描述
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
- LM Studio | Continue:LM Studio 是一款适用于 Mac、Windows 和 Linux 的应用程序,可以轻松地在本地运行开源模型,并配有出色的 UI。要开始使用 LM Studio,请从网站下载...
- meta-llama/Meta-Llama-3-70B-Instruct - HuggingChat:在 HuggingChat 中使用 meta-llama/Meta-Llama-3-70B-Instruct
- Mission Squad. Flexible AI agent desktop app.:未找到描述
- Monaspace:一个创新的代码字体超家族
- 来自 AI at Meta (@AIatMeta) 的推文:介绍 Meta Llama 3:迄今为止功能最强大的开源 LLM。今天我们将发布 8B 和 70B 模型,它们提供了诸如改进推理等新功能,并树立了新的行业领先水平...
- Welcome Llama 3 - Meta's new open LLM:未找到描述
- Puss In Boots Math GIF - Puss In Boots Math I Never Counted - Discover & Share GIFs:点击查看 GIF
- Johnny English Agent GIF - Johnny English Agent Yawn - Discover & Share GIFs:点击查看 GIF
- Meta Releases LLaMA 3: Deep Dive & Demo:今天,2024 年 4 月 18 日,是一个特别的日子!在这段视频中,我将介绍 @meta 的 LLaMA 3 发布。该模型是该系列的第三个迭代版本...
- GitHub - arcee-ai/mergekit: Tools for merging pretrained large language models.:用于合并预训练大语言模型的工具。- arcee-ai/mergekit
- Improve cpu prompt eval speed by jart · Pull Request #6414 · ggerganov/llama.cpp:此更改上游化了 llamafile 的 CPU 矩阵乘法内核,从而提高了图像和 Prompt 评估速度。首先,Q4_0 和 Q8_0 权重在 CPU 上的运行速度应提高约 40%。最大的收益...
- Qwen/CodeQwen1.5-7B · Hugging Face: 未找到描述
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face: 未找到描述
- meta-llama/Meta-Llama-3-70B-Instruct - HuggingChat: 在 HuggingChat 中使用 meta-llama/Meta-Llama-3-70B-Instruct
- LLM Benchmarks: 未找到描述
- meta-llama/Meta-Llama-3-70B · Hugging Face: 未找到描述
- QuantFactory/Meta-Llama-3-8B-Instruct-GGUF 在 main 分支: 未找到描述
- meta-llama/Meta-Llama-3-70B-Instruct · Hugging Face: 未找到描述
- MaziyarPanahi/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: 未找到描述
- MaziyarPanahi/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: 未找到描述
- Meta Llama 3: 使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的预训练及指令微调版本,支持广泛的应用场景。
- meta-llama/Meta-Llama-3-8B-Instruct · Hugging Face: 未找到描述
- The Same Thing We Do Every Night Take Over The World GIF - The Same Thing We Do Every Night Take Over The World Mad - 发现并分享 GIF: 点击查看 GIF
- AnythingLLM | 终极 AI 商业智能工具: AnythingLLM 是为您的组织打造的终极企业级商业智能工具。拥有对 LLM 的无限控制、多用户支持、内外向工具支持以及...
- Dog Angry GIF - Dog Angry Rabid - 发现并分享 GIF: 点击查看 GIF
- meta-llama/Meta-Llama-3-70B-Instruct · 更新 generation_config.json: 未找到描述
- QuantFactory/Meta-Llama-3-8B-GGUF 在 main 分支: 未找到描述
- meta-llama/Meta-Llama-3-8B-Instruct · 更新 generation_config.json: 未找到描述
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: 未找到描述
- 未找到标题: 未找到描述
- configs/llama3.preset.json 在 main 分支 · lmstudio-ai/configs: LM Studio JSON 配置文件格式及示例配置文件集合。 - lmstudio-ai/configs
- llama3/MODEL_CARD.md 在 main 分支 · meta-llama/llama3: Meta Llama 3 官方 GitHub 站点。通过在 GitHub 上创建账号来为 meta-llama/llama3 的开发做出贡献。
- We Know Duh GIF - We Know Duh Hello - 发现并分享 GIF: 点击查看 GIF
- meta-llama/Meta-Llama-3-8B · Hugging Face: 未找到描述
- TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>: {{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|> {{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|&g...
- llama3 系列支持 · Issue #6747 · ggerganov/llama.cpp: llama3 已发布,很高兴能在 llama.cpp 中使用 https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6 https://github.com/meta-llama/llama3
- 未找到标题:未找到描述
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
- 来自 LM Studio (@LMStudioAI) 的推文:.@Meta 的 Llama 3 现已在 LM Studio 中获得全面支持!👉 更新至 LM Studio 0.2.20 🔎 下载 lmstudio-community/llama-3。Llama 3 8B 已经上线,70B 即将推出 🦙 https://huggingface.co/...
- 👾 LM Studio - 发现并运行本地 LLM:查找、下载并实验本地 LLM
- 👾 LM Studio - 发现并运行本地 LLM:查找、下载并实验本地 LLM
- unsloth/llama-3-70b-bnb-4bit · Hugging Face: 未找到描述
- Effort Engine: 一种可能的新型 LLM 推理算法。平滑且实时地调整推理过程中想要进行的计算量。
- Daniel Han (@danielhanchen) 的推文: 为 Llama-3 8B 制作了一个 Colab!15 万亿 tokens!现在 @UnslothAI 已支持它!使用免费的 T4 GPU。正在进行基准测试,但比 HF+FA2 快约 2 倍,且节省 80% 内存!支持 4 倍长的上下文...
- 更便宜、更好、更快、更强: 继续推动 AI 前沿,让所有人都能使用。
- meraGPT/mera-mix-4x7B · Hugging Face: 未找到描述
- 定价 – Replicate: 未找到描述
- HuggingChat: 让社区最好的 AI 聊天模型惠及每一个人。
- unsloth/llama-3-8b-bnb-4bit · Hugging Face: 未找到描述
- kuotient/Meta-Llama-3-8B · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- mistralai/Mistral-7B-Instruct-v0.2 · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- 欢迎 Llama 3 - Meta 的新型开源 LLM: 未找到描述
- Meta Llama 3: 使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的预训练及指令微调版本,以支持广泛的应用。
- “Her” AI 即将来临?Llama 3、Vasa-1 以及 Altman 的“接入你想做的一切”: Llama 3、Vasa-1 以及一系列新的采访和更新,AI 新闻就像伦敦的公交车一样接踵而至。我将花几分钟时间介绍最后一刻的 Llama...
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face: 未找到描述
- jinaai/jina-reranker-v1-turbo-en · Hugging Face: 未找到描述
- meta-llama/Meta-Llama-3-8B · Hugging Face: 未找到描述
- Microsoft Azure Marketplace: 未找到描述
- 满头大汗的 Speedruner GIF - 发现并分享 GIF: 点击查看 GIF
- NeuralNovel/Llama-3-NeuralPaca-8b · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- 未找到标题: 未找到描述
- Mark Zuckerberg 在 Instagram 上表示: “今天有重大的 AI 消息。我们正在发布新版本的 Meta AI,这是我们的助手,你可以在我们的应用和眼镜中向它提出任何问题。我们的目标是打造全球领先的 AI。 我们正在使用全新的、最先进的 Llama 3 AI 模型升级 Meta AI,并将其开源。有了这个新模型,我们相信 Meta AI 现在是你可以免费使用的最智能的 AI 助手。 通过将其集成到 WhatsApp、Instagram、Facebook 和 Messenger 顶部的搜索框中,我们让 Meta AI 变得更易于使用。我们还建立了一个网站 meta.ai,供你在网页端使用。 我们还开发了一些独特的创作功能,比如让照片动起来。Meta AI 现在生成高质量图像的速度非常快,甚至可以在你输入时实时创建和更新。它还会生成你创作过程的回放视频。” 享受 Meta AI,您可以关注我们新的 @meta.ai IG 以获取更多更新。"</a>: 103K 点赞, 6,182 条评论 - zuck 2024年4月18日:"今天有重大的 AI 新闻。我们正在发布新版本的 Meta AI,这是我们的助手,您可以在我们的应用和眼镜中向它提问任何问题....
- 未找到标题: 未找到描述
- Dance GIF - Dance - 发现并分享 GIF: 点击查看 GIF
- Obsidian - 磨砺你的思维: Obsidian 是一款私密且灵活的笔记应用,能够适应你的思维方式。
- Meta 发布 LLaMA 3:深度解析与演示: 今天,2024年4月18日,是一个特别的日子!在这段视频中,我将介绍 @meta 的 LLaMA 3 发布。该模型是其第三次迭代...
- gist:e45b337e9d9bd0492bf5d3c1d4706c7b: GitHub Gist:即时分享代码、笔记和片段。
- Mark Zuckerberg - Llama 3, $10B 模型, Caesar Augustus, & 1 GW 数据中心: Zuck 关于:- Llama 3 - 迈向 AGI 的开源 - 定制芯片、合成数据以及扩展中的能源限制 - Caesar Augustus、智能爆炸、生物...
- Ollama.md 文档,由 jedt 提交 · Pull Request #3699 · ollama/ollama: 关于从 Google Colab 笔记本设置微调后的 Unsloth FastLanguageModel 到:HF hub、GGUF、本地 Ollama 的指南。预览链接:https://github.com/ollama/ollama/blob/66f7b5bf9e63e1e98c98e8f4...
- 无法加载分词器 (CroissantLLM) · Issue #330 · unslothai/unsloth: 尝试使用小型模型运行 colab:from unsloth import FastLanguageModel import torch max_seq_length = 2048 # 遗憾的是 Gemma 目前仅支持最高 8192 dtype = None # None 用于自动检测...
- Adaptive Text Watermark for Large Language Models: 未找到描述
- 支持 x86/ARM CPU (例如 Xeon, M1) · Issue #194 · openai/triton: 你好,未来有支持 macOS 的计划吗? ❯ pip install -U --pre triton 弃用提示:使用 distutils 配置文件配置安装方案已弃用,将不再起作用...
- 官方 Llama 3 META 页面: [https://llama.meta.com/llama3/](https://llama.meta.com/llama3/)
- ParasiticRogue/Merged-RP-Stew-V2-34B · Hugging Face:未找到描述
- Tokenization | Mistral AI Large Language Models:Tokenization 是 LLM 的一个基本步骤。它是将文本分解为更小的子词单元(称为 tokens)的过程。我们最近在 Mistral AI 开源了我们的分词器。本指南将...
- Google Colaboratory:未找到描述
- Home:速度快 2-5 倍,内存减少 80% 的 LLM 微调。通过在 GitHub 上创建账号为 unslothai/unsloth 的开发做出贡献。
- Meta Llama 3: 使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的预训练及指令微调版本,以支持广泛的应用。
- Mark Zuckerberg - Llama 3, $10B Models, Caesar Augustus, & 1 GW Datacenters: Zuck 关于:- Llama 3 - 朝向 AGI 的开源 - 定制芯片、合成数据以及扩展时的能源限制 - Caesar Augustus、智能爆炸、生物...
- C++ 自定义算子手册:无描述
- msaroufim 的自定义 CUDA 扩展 · Pull Request #135 · pytorch-labs/ao:这是 #130 的可合并版本 - 我必须进行一些更新:添加除非使用 PyTorch 2.4+ 否则跳过测试的逻辑,以及如果 CUDA 不可用则跳过测试;将 ninja 添加到开发依赖项...
- C++ 自定义算子手册:无描述
- pytorch/test/dynamo/test_triton_kernels.py:Python 中的 Tensor 和动态神经网络,具有强大的 GPU 加速 - pytorch/pytorch
- Environment Variables:未找到描述
- Profiling CUDA programs on WSL 2:未找到描述
- Livestream - Programming Heterogeneous Computing Systems with GPUs and other Accelerators (Spring 2023):未找到描述
- GitHub - CisMine/Parallel-Computing-Cuda-C:通过在 GitHub 上创建账号来为 CisMine/Parallel-Computing-Cuda-C 的开发做出贡献。
- hqq/hqq/core/quantize.py at master · mobiusml/hqq:Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- hqq/hqq/core/optimize.py at master · mobiusml/hqq:Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- hqq/hqq/kernels/hqq_aten_cuda_kernel.cu at master · mobiusml/hqq:Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- gpt-fast/model.py at main · pytorch-labs/gpt-fast:少于 1000 行 Python 代码实现的简单高效的 PyTorch 原生 Transformer 文本生成。- pytorch-labs/gpt-fast
- hqq/hqq/core/optimize.py at master · mobiusml/hqq:Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- gpt-fast/model.py at main · pytorch-labs/gpt-fast:少于 1000 行 Python 代码实现的简单高效的 PyTorch 原生 Transformer 文本生成。- pytorch-labs/gpt-fast
- hqq/hqq/core/quantize.py at 63cc6c0bbb33da9a42c330ae59b509c75ac2ce15 · mobiusml/hqq:Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- HQO for scale/zero point by Giuseppe5 · Pull Request #937 · Xilinx/brevitas:无描述
- Stress GIF - War Dogs 电影 Stressed - 发现并分享 GIF:点击查看 GIF
- NVIDIA Nsight Compute:用于 CUDA 和 NVIDIA OptiX 的交互式分析器。
- 共同构建更好的软件:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 发现、fork 并为超过 4.2 亿个项目做出贡献。
- karpathy/llm.c 项目中的 llm.c/dev/cuda/classifier_fused.cu:使用简单、原始的 C/CUDA 进行 LLM 训练。通过在 GitHub 上创建账号为 karpathy/llm.c 的开发做出贡献。
- CUDA 教程 I 分析和调试应用程序:使用 NVIDIA 开发者工具对 CUDA 进行分析、优化和调试。NVIDIA Nsight 系列工具可可视化硬件吞吐量并分析性能...
- NVIDIA/cutlass 项目中的 cutlass/media/docs/quickstart.md:线性代数子程序的 CUDA 模板。通过在 GitHub 上创建账号为 NVIDIA/cutlass 的开发做出贡献。
- Volta:架构与性能优化 | NVIDIA On-Demand:本次演讲将回顾 Volta GPU 架构以及优化计算应用程序性能的相关指导。
- ngc92 对 attention backward 的进一步改进 · Pull Request #170 · karpathy/llm.c:线程复用寄存器中的数据以减少内存传输的 Backward kernel。此 PR 基于我之前的 PR,应先合并之前的。完成后,我将进行 rebase 并移除...
- ngc92 通过在 backward 过程中跨层复用相同缓冲区来节省内存 · Pull Request #163 · karpathy/llm.c:在 backward pass 期间跨层复用内存缓冲区。
- ademeure 提供的 Fused Classifier 优化版本 + Bug 修复(?) · Pull Request #150 · karpathy/llm.c:这是来自 #117 的酷炫新 kernel 的更快版本(仍仅限 /dev/cuda/)。最大的区别在于它针对每个 1024 宽度的 block 处理一行进行了优化,而不是每个 32 宽度的 warp...
- 使用 NVIDIA CUDA 11.2 C++ 编译器提升生产力和性能 | NVIDIA 技术博客:11.2 CUDA C++ 编译器包含旨在提高开发者生产力和 GPU 加速应用程序性能的功能与增强。编译器工具链获得了 LLV...
- 在 Kepler 上实现更快的 Parallel Reductions | NVIDIA 技术博客:Parallel reduction 是许多并行算法的常见构建模块。Mark Harris 在 2007 年的一次演讲中提供了在 GPU 上实现 Parallel reductions 的详细策略...
- 在 Replicate 上与 Meta Llama 3 对话:Llama 3 是来自 Meta 的最新语言模型。
- Perturbed-Attention Guidance SDXL - multimodalart 创建的 Hugging Face Space:未找到描述
- AI 初创公司 Stability 在争议性 CEO 离职后裁员 10%:阅读完整备忘录:根据 CNBC 获得的内部备忘录,Stability AI 在经历了一段不可持续的增长后,裁减了数名员工以“调整业务规模”。
- 联邦政府任命“AI 末日论者”负责美国研究所的 AI 安全:前 OpenAI 研究员曾预测 AI 有 50% 的概率杀死全人类。
- ptx0/terminus-xl-velocity-v2 · Hugging Face:未找到描述
- Meta Llama 3:使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的预训练及指令微调版本,以支持广泛的应用。
- Meta AI:使用 Meta AI 助手处理事务、免费创建 AI 生成的图像,并获取任何问题的答案。Meta AI 基于 Meta 最新的 Llama 大语言模型构建,并使用了 Emu...
- zero-gpu-explorers (ZeroGPU Explorers):未找到描述
- Reddit - 深入探索一切:未找到描述
- Jump Dive GIF - 跳跃 潜水 游泳 - 发现并分享 GIF:点击查看 GIF
- GitHub - ShihaoZhaoZSH/LaVi-Bridge: 连接不同语言模型与生成式视觉模型以实现文本到图像生成:连接不同语言模型与生成式视觉模型以实现文本到图像生成 - ShihaoZhaoZSH/LaVi-Bridge
- 登录 • Instagram:未找到描述
- 登录 • Instagram:未找到描述
- 登录 • Instagram:未找到描述
- HQ-Edit: 一个用于基于指令的图像编辑的高质量数据集:未找到描述
- 未找到标题:未找到描述
- VASA-1 - 微软研究院:在新标签页中打开
- Adding Llama-3 qlora by monk1337 · Pull Request #1536 · OpenAccess-AI-Collective/axolotl:添加 Llama-3 QLoRA,经测试可用。
- Teortaxes▶️ (@teortaxesTex) 的推文:来自线程:Llama-3 8b 具有至少 32k 的近乎完美的大海捞针检索能力(RoPE theta 为 4)
- hfl/chinese-llama-2-13b-16k · Hugging Face:未找到描述
- Microsoft Azure Marketplace:未找到描述
- Bonk GIF - Bonk - 发现并分享 GIF:点击查看 GIF
- Mark Zuckerberg - Llama 3, $10B Models, Caesar Augustus, & 1 GW Datacenters:扎克伯格谈论:Llama 3、迈向 AGI 的开源、定制芯片、合成数据、扩展的能源限制、Caesar Augustus、智能爆炸、生物风险等...
- Adding Llama-3 qlora by monk1337 · Pull Request #1536 · OpenAccess-AI-Collective/axolotl:添加 Llama-3 QLoRA,经测试可用。
- xorsuyash/raft_datasetp1 · Hugging Face 数据集:未找到描述
- Llama/GPTNeoX: add RoPE scaling by gante · Pull Request #24653 · huggingface/transformers:此 PR 的作用?这是一个用于讨论的实验性 PR,以便我们决定是否添加此模式。背景:在过去的一周里,关于缩放 RoPE 的进展有几项...
- Aran Komatsuzaki (@arankomatsuzaki) 的推文:AWS 展示了“减少截断可改进语言建模”。他们的打包算法实现了卓越的性能(例如,阅读理解相对提升 +4.7%),并减少了闭域幻觉...
- Daniel Han (@danielhanchen) 的推文:Llama-3 的其他一些奇特之处:1. 由于使用了 tiktoken,数字被拆分为 1、2、3 位数字(Llama 是单数字拆分),即 1111111 从左到右拆分为 111_111_1;2. 没有 unk_token?正尝试让 @UnslothAI...
- axolotl/src/axolotl/cli/__init__.py (main 分支) · OpenAccess-AI-Collective/axolotl:尽管提问。通过在 GitHub 上创建账户,为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- OpenAccess-AI-Collective/axolotl | Phorm AI 代码搜索:更快地理解代码。
- Mixtral 8x22B by mistralai | OpenRouter: Mixtral 8x22B 是来自 Mistral AI 的大规模语言模型。它包含 8 个专家,每个专家 220 亿参数,每个 token 同时使用 2 个专家。它通过 [X](https://twitter...
- Mixtral 8x22B Instruct by mistralai | OpenRouter: Mistral 官方对 [Mixtral 8x22B](/models/mistralai/mixtral-8x22b) 进行指令微调(instruct fine-tuned)的版本。在 141B 总参数中使用了 39B 激活参数,为其规模提供了无与伦比的成本效率。...
- WizardLM-2 8x22B by microsoft | OpenRouter: WizardLM-2 8x22B 是 Microsoft AI 最先进的 Wizard 模型。与领先的专有模型相比,它展示了极具竞争力的性能,并持续超越所有现有的...
- Zephyr 141B-A35B by huggingfaceh4 | OpenRouter: Zephyr 141B-A35B 是一个混合专家(MoE)模型,拥有 141B 总参数和 35B 激活参数。在公开可用的合成数据集混合物上进行了微调。它是...的指令微调版本。
- WizardLM-2 7B by microsoft | OpenRouter: WizardLM-2 7B 是 Microsoft AI 最新 Wizard 模型的较小变体。它是速度最快的,并能与现有的 10 倍大的开源领先模型达到相当的性能。它是一个微调...
- MythoMax 13B by gryphe | OpenRouter: Llama 2 13B 性能最高且最受欢迎的微调版本之一,具有丰富的描述和角色扮演能力。#merge 注意:这是 [此模型](/models/gryphe/mythomax... 的扩展上下文版本。
- MythoMax 13B by gryphe | OpenRouter: Llama 2 13B 性能最高且最受欢迎的微调版本之一,具有丰富的描述和角色扮演能力。#merge
- Mixtral 8x7B Instruct by mistralai | OpenRouter: 由 Mistral AI 开发的预训练生成式稀疏混合专家模型(Sparse Mixture of Experts),用于聊天和指令用途。包含 8 个专家(前馈网络),总计 470 亿参数。指令模型微调...
- Mistral 7B Instruct by mistralai | OpenRouter: 一个 7.3B 参数的模型,在所有基准测试中均优于 Llama 2 13B,并针对速度和上下文长度进行了优化。这是 Mistral 7B Instruct 的 v0.1 版本。对于 v0.2,请使用 [此模型](/models/mistral...
- Toppy M 7B by undi95 | OpenRouter: 一个狂野的 7B 参数模型,使用来自 mergekit 的新 task_arithmetic 合并方法合并了多个模型。合并模型列表:- NousResearch/Nous-Capybara-7B-V1.9 - [HuggingFaceH4/zephyr-7b-be...
- 使用 CodeQwen1.5 编写代码: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD 简介 利用大语言模型 (LLM) 力量的高级编程工具的出现,显著提升了程序员的生产力...
- 更便宜、更好、更快、更强: 继续推动 AI 的前沿,并让所有人都能使用。
- Together AI 与 Meta 合作发布用于推理和微调的 Meta Llama 3: 未找到描述
- 来自 Aravind Srinivas (@AravSrinivas) 的推文: 是的,感谢 @elonmusk 和 xAI 团队开源了 Grok 的基础模型。我们将针对对话式搜索对其进行微调并优化推理,并将其提供给所有 Pro 用户! ↘️ 引用...
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face: 未找到描述
- meta-llama/Meta-Llama-3-70B-Instruct - HuggingChat: 在 HuggingChat 中使用 meta-llama/Meta-Llama-3-70B-Instruct
- 机器人 GIF - 在 GIPHY 上查找和分享: 发现并与你认识的每个人分享这个机器人 GIF。GIPHY 是你搜索、分享、发现和创建 GIF 的方式。
- 下载 Llama: 申请访问 Llama。
- 全新 Atlas | Boston Dynamics: 我们正在揭晓下一代人形机器人——一款专为现实世界应用设计的全电动 Atlas 机器人。新款 Atlas 建立在数十年的...
- Meta Llama 3: 使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的预训练及指令微调版本,以支持广泛的应用。
- ✅ 兼容的 AI Endpoints: 已知的兼容 AI Endpoints 列表,包含 `librechat.yaml`(即 LibreChat 自定义配置文件)的示例设置。
- Microsoft Azure Marketplace: 未找到描述
- openai 的 GPT-3.5 Turbo | OpenRouter: GPT-3.5 Turbo 是 OpenAI 最快的模型。它可以理解并生成自然语言或代码,并针对聊天和传统的补全任务进行了优化。由 OpenAI 更新以指向 [l...
- Olympia | 优于 ChatGPT: 通过价格合理的 AI 驱动顾问来发展您的业务,这些顾问是业务战略、内容开发、营销、编程、法律战略等方面的专家。
- Chiquichico GIF - Chiquichico - 发现并分享 GIF: 点击查看 GIF
- mistralai/Mixtral-8x22B-Instruct-v0.1 - Demo - DeepInfra: 这是 Mixtral-8x22B 的指令微调版本——来自 Mistral AI 的最新且最大的混合专家 (MoE) 大语言模型 (LLM)。这款最先进的机器学习模型使用了一个...
- 使用 AI 的应用开发模式: 探索构建智能、自适应且以用户为中心的软件系统的实用模式和原则,充分利用 AI 的力量。
- OpenRouter: 构建与模型无关的 AI 应用
- 未找到标题:未找到描述
- Mark Zuckerberg - Llama 3, $10B Models, Caesar Augustus, & 1 GW Datacenters:扎克伯格谈论:- Llama 3 - 迈向 AGI 的开源 - 定制芯片、合成数据以及扩展时的能源限制 - Caesar Augustus、智能爆炸、生物风险...
- Siyan Zhao (@siyan_zhao) 的推文: 🚨LLM 研究者们🚨想要在生成质量零退化的前提下,为你的 HuggingFace🤗 LLM 免费提升速度和内存效率吗?介绍 Prepacking,一种简单的方法,可获得高达 6 倍的速...
- Fewer Truncations Improve Language Modeling: 在 LLM 训练中,输入文档通常被拼接在一起,然后分割成等长的序列以避免 Padding Token。尽管这种拼接方式效率很高,但...
- OpenHathi 系列:一种低成本构建双语 LLM 的方法: 暂无描述
- lintang/pile-t5-base-flan · Hugging Face: 暂无描述
- lintang (Lintang Sutawika): 暂无描述
- Chinchilla Scaling: A replication attempt:Hoffmann 等人 (2022) 提出了三种估算计算优化 Scaling Law 的方法。我们尝试复现他们的第三种估算程序,该程序涉及拟合参数化损失函数...
- rajpurkar/squad_v2 · Error in train split, question containing 25651 characters!:未找到描述
- An Embarrassingly Simple Approach for LLM with Strong ASR Capacity:在本文中,我们专注于解决语音处理领域最重要的任务之一,即自动语音识别 (ASR),利用语音基础编码器和大型语言模型...
- Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing:尽管大型语言模型 (LLM) 在各种任务上具有令人印象深刻的能力,但它们在涉及复杂推理和规划的场景中仍然面临困难。最近的工作提出了先进的...
- Tripod: Three Complementary Inductive Biases for Disentangled Representation Learning:归纳偏置对于解耦表示学习中缩小未指定解集至关重要。在这项工作中,我们考虑为神经网络自动编码器赋予三种选择性的...
- Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment:基于人类标注的偏好数据对语言模型 (LM) 进行对齐是获得实用且高性能的基于 LM 系统的重要步骤。然而,多语言人类偏好数据难以...
- Scaling Instructable Agents Across Many Simulated Worlds:构建能够在任何 3D 环境中遵循任意语言指令的具身 AI 系统是创建通用 AI 的关键挑战。实现这一目标需要学习将语言...
- Glitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection:随着大型语言模型 (LLM) 在各个领域的应用不断扩大,全面调查其不可预见的行为及随之而来的结果变得至关重要。在这项研究中...
- 未找到标题:未找到描述
- GitHub - NVlabs/DoRA: Official PyTorch implementation of DoRA: Weight-Decomposed Low-Rank Adaptation:DoRA 的官方 PyTorch 实现:权重分解低秩自适应 - NVlabs/DoRA
- Implement Sib200 evaluation benchmark - text classification in 200 languages by snova-zoltanc · Pull Request #1705 · EleutherAI/lm-evaluation-harness:我们使用了来自 MALA 论文 https://arxiv.org/pdf/2401.13303.pdf 的 Prompt 风格,我们也发现该风格在我们的 SambaLingo 论文 https://arxiv.org/abs/2404.05829 中取得了不错的结果。
- Implementing Flores 200 translation evaluation benchmark across 200 languages by snova-zoltanc · Pull Request #1706 · EleutherAI/lm-evaluation-harness:我们使用了该论文中发现效果最好的 Prompt 模板 https://arxiv.org/pdf/2304.04675.pdf。我们的论文也发现该 Prompt 模板效果不错 https://arxiv.o...
- Mojo - IntelliJ IDEs Plugin | Marketplace:为 Mojo 编程语言提供基础编辑功能:语法检查与高亮、注释和格式化。未来将添加更多新功能...
- 允许在在线 Playground 使用 `nightly` · modularml/mojo · Discussion #2321:我没有足够的 RAM 来运行虚拟机或 Docker 并同时打开文档,因此依赖在线 Playground 运行 Mojo 代码。如果有一个小的下拉菜单允许我切换到 nightly 版本...
- GitHub - ihnorton/mojo-ffi:参与 GitHub 上 ihnorton/mojo-ffi 的开发。
- No More GIF - No More Go T Sam - Discover & Share GIFs:点击查看 GIF
- roguelike-mojo/src/main.mojo at main · dimitrilw/roguelike-mojo:使用 Mojo🔥 逐步完成 Python Rogue-like 教程。 - dimitrilw/roguelike-mojo
- roguelike-mojo/src/main.mojo at main · dimitrilw/roguelike-mojo:使用 Mojo🔥 逐步完成 Python Rogue-like 教程。 - dimitrilw/roguelike-mojo
- <a href="https://tenor.com/search/"">" GIFs | Tenor</a>:点击查看 GIF
- Get started with Mojo🔥 | Modular Docs:获取 Mojo SDK 或尝试在 Mojo Playground 中编写代码。
- Mojo🔥 | Modular Docs:一种弥合 AI 研究与生产之间鸿沟的编程语言,兼顾速度与易用性。
- Mojo🔥 notebooks | Modular Docs:我们为 Mojo Playground 创建的所有 Jupyter notebooks。
- 更便宜、更好、更快、更强:继续推动 AI 前沿,让所有人都能使用。
- nahr (@nahrzf) 的推文:Meta 做了最有趣的事
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face:未找到描述
- Philipp Schmid (@_philschmid) 的推文:修复了为 @AI21Labs 做的修复,并包含了 Mambas。🐍 ↘️ 引用 Armand Joulin (@armandjoulin) 的话:修复了那个修复。
- Common Crawl - Web Graphs:详细介绍了 Common Crawl 的网页图谱发布、背后的技术以及如何使用它们。
- Replicate 的计费方式:Replicate 的计费方式
- Llama 3:将开源 LLM 扩展至 AGI:Llama 3 表明,在不久的将来,Scaling 不会成为开源 LLM 进步的限制。
- Albert Jiang (@AlbertQJiang) 的推文:我热爱开源模型!请将你最喜欢的模型添加到 Mistral Convex Hull。 ↘️ 引用 Philipp Schmid (@_philschmid) 的话:修复了为 @AI21Labs 做的修复,并包含了 Mambas。🐍
- Microsoft Azure Marketplace:未找到描述
- allenai/OLMo-1.7-7B · Hugging Face:未找到描述
- Jim Fan (@DrJimFan) 的推文:即将推出的 Llama-3-400B+ 将成为一个分水岭时刻,社区将获得对 GPT-4 级模型的权重开放访问(open-weight access)。它将改变许多研究工作和草根初创公司的考量……
- OLMo 1.7–7B:在 MMLU 上提升了 24 分:今天,我们发布了 70 亿参数开源语言模型 OLMo 1.7–7B 的更新版本。该模型在 MMLU 上得分为 52,位列……
- OpenAssistant 已完成:#OpenAssistantLAION 的 OpenEmpathic:https://laion.ai/blog/open-empathic/ 链接:主页:https://ykilcher.com 衍生品:https://ykilcher.com/merch YouTube:https:/...
- 来自 Tamay Besiroglu (@tamaybes) 的推文:Hoffmann 等人发表的 Chinchilla scaling 论文在语言建模社区极具影响力。我们尝试复现其工作的核心部分,并发现了差异。这里是...
- 来自 Susan Zhang (@suchenzang) 的推文:在忽略了所有这些“让我们把一团点拟合成一条线”的论文中的细节后(当你真正外推时,这些可能都是错的),@stephenroller 终于说服了我去深入研究...
- 来自 Jack Rae (@drjwrae) 的推文:很好的分析。我认为这解释了为什么方法 3 与方法 1 和 2 不匹配。此外,我看到人们在分享这篇论文,并暗示这证明了 scaling laws 并不存在。我对他们发现的看法是...
- 来自 Tamay Besiroglu (@tamaybes) 的推文:我们已向作者寻求帮助,但尚未得到回复。(8/9)
- 来自 Sebastian Borgeaud (@borgeaud_s) 的推文:伟大的分析,方法 3 终于达成一致了!我们论文中的 loss scale 太低,导致 L-BFGS 过早终止,从而导致拟合效果不佳。修复此问题后,我们可以复现 ...
- 引用自 “Chat”: 未找到描述
- 未找到标题: 未找到描述
- 检索增强生成 (RAG) - Cohere Docs: 未找到描述
- HuggingChat: 让每个人都能使用社区最好的 AI 聊天模型。
- 使用 Web UI 进行微调 - Cohere Docs: 未找到描述
- Cohere int8 & 二进制 Embeddings - 将您的向量数据库扩展到大型数据集: Cohere Embed 现在原生支持 int8 和二进制 embeddings,以降低内存成本。
- 使用 Cohere 模型的工具调用 - Cohere Docs: 未找到描述
- 来自 Russell Kaplan (@russelljkaplan) 的推文:大语言模型(LLM)崛起的二阶效应:
- 更便宜、更好、更快、更强:继续推动 AI 的前沿,并让所有人都能使用。
- 加入 Systems Engineering Professionals Discord 服务器!:查看 Discord 上的 Systems Engineering Professionals 社区——与 1664 名其他成员一起交流,享受免费的语音和文字聊天。
- 来自 OpenAI Developers (@OpenAIDevs) 的推文:介绍 Assistants API 的一系列更新 🧵 借助新的文件搜索工具,你可以快速集成知识检索,现在每个助手最多允许 10,000 个文件。它适用于我们的...
- 加入我们的云高清视频会议:Zoom 是现代企业视频通信领域的领导者,拥有简单、可靠的云平台,可跨移动设备、桌面和会议室系统进行视频和音频会议、聊天和网络研讨会。Zoom ...
- 来自 fofr (@fofrAI) 的推文:每张 SD3 图像消耗 6.5 个积分。10 美元 = 1,000 积分。所以每张图像是 0.065 美元。或者是通过相同 API 生成 SDXL 成本的 10 倍。 ↘️ 引用 Stability AI (@StabilityAI) 今天,我们很高兴 ...
- Meta Llama 3:使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的预训练及指令微调版本,以支持广泛的应用。
- 未找到标题:未找到描述
- 来自 Awni Hannun (@awnihannun) 的推文:@soumithchintala @lvdmaaten 🤣🤣🤣 刚刚运行了 @Prince_Canuma 量化的 8B 版本。在 M2 Ultra 上表现非常好(而且很快 😉):
- 来自 Amir Efrati (@amir) 的推文:最新消息:Mistral 在获得 20 亿美元融资仅几个月后,正寻求 50 亿美元的估值。LLM 竞赛前端的融资行动依然势头不减。 https://www.theinformation.com/articles/mistral-an-openai-rival...
- GGUF,绕远路:什么是 ML artifact?
- 来自 Matt Shumer (@mattshumer_) 的推文:Claude 3 Opus 变得糟糕多了... :(
- 来自 OpenAI Developers (@OpenAIDevs) 的推文:介绍 Assistants API 的一系列更新 🧵 借助新的文件搜索工具,你可以快速集成知识检索,现在每个助手最多允许 10,000 个文件。它适用于我们的...
- 来自 Alessio Fanelli (@FanaHOVA) 的推文:🦙 所有 Llama 3 发布详情和亮点:8B 和 70B 尺寸:Instruct 和预训练版本在大多数基准测试中均达到 SOTA 性能。目前正在训练一个 400B+ 参数的模型,稍后将发布...
- 来自 Together AI (@togethercompute) 的推文:我们很高兴能成为 Meta Llama 3 的发布合作伙伴。现在即可体验 Llama 3,Llama 3 8B 每秒高达 350 个 token,Llama 3 70B 每秒高达 150 个 token,以全 FP16 精度运行...
- 来自 Andrej Karpathy (@karpathy) 的推文:模型卡片中也有一些更有趣的信息:https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md 注意 Llama 3 8B 实际上处于 Llama 2 70B 的水平,这取决于...
- 来自 Mistral AI Labs (@MistralAILabs) 的推文:在发布 Mixtral 8x22B 的同时,我们还发布了我们的 tokenizer,它超越了通常的文本 <-> token 转换,增加了对工具和结构化对话的解析。仓库:https://github.com/mis...
- 掌握租船数据的副驾驶:利用生成式 AI 做出更好的决策,并赋能你的租船团队做出更好的决策。
- 研究资助:未找到描述
- 马克·扎克伯格 - Llama 3、100 亿美元模型、凯撒·奥古斯都和 1 GW Datacenters: Zuck 谈 Llama 3 - 迈向 AGI 的开源 - 定制芯片、合成数据以及扩展时的能源限制 - 凯撒·奥古斯都、智能爆炸、生物...
- Armand Joulin (@armandjoulin) 的推文: 修复了那个修复。 ↘️ 引用 Jonathan Frankle (@jefrankle) 为你修复了它,@code_star
- 未找到标题: 未找到描述
- 从单张图像进行 3D 重建!Few-Shot Neural Radiance Fields | NeRF #12: 使用元学习从单张图像进行新视角合成、3D 重建和神经辐射场(Neural Radiance Fields)。论文 "Learned Initializat..." 的实现。 </ul> </div> --- **Latent Space ▷ #[llm-paper-club-west](https://discord.com/channels/822583790773862470/1197350122112168006/1230231139893903394)** (19 messages🔥): - **Paper Club West 开始**: 成员们以问候开启了 **llm-paper-club-west** 会议,并确认了屏幕共享等功能已正常运行。 - **转移到 Zoom**: 几条消息提供了 [Zoom 会议链接](https://us06web.zoom.us/j/8807908941?pwd=eHBBdk9sWWluSzB2TFdLOVdEN3BFdz09),引导成员将会议从 Discord 转移到 Zoom。发布了多次提醒以确保所有参会成员都收到了信息。 - **因承诺克服对 Zoom 的抵触**: 尽管表达了对 Zoom 的厌恶,一位成员还是加入了会议,保持了社区参与度。 - **Zoom 接入协调**: 一位成员进行实时协调,确保等待加入 Zoom 会议的人员获得准入。 **提到的链接**: 加入我们的 Cloud HD 视频会议: Zoom 是现代企业视频通信的领导者,拥有一个简单、可靠的云平台,可用于移动设备、桌面和会议室系统的视频和音频会议、聊天和网络研讨会。Zoom ... --- **OpenInterpreter ▷ #[general](https://discord.com/channels/1146610656779440188/1147665339266650133/1230174214560944140)** (49 messages🔥): - **Windows 上的 OpenInterpreter 使用困扰**: 用户在 Windows 上设置 OpenInterpreter 时遇到困难,问题范围从软件过度偏向 Mac 到系统执行 OS 控制任务时的挑战。 - **对 OpenInterpreter 潜力的乐观态度**: 尽管设置过程受挫,用户仍对 OpenInterpreter 的能力充满热情,例如编写和运行用于文本转摩尔斯电码的 Arduino 代码,并在 Raspberry Pi 搭配 Ubuntu 等不同设置上展示了进展。 - **日本的投影仪机器人手机引起关注**: 一位用户展示了来自日本的[带投影仪的机器人手机](https://twitter.com/CashTHLo/status/1780518436713762889),思考其 3D 扫描能力与 GPT-4-vision 协同的潜力,并寻求该想法的合作。 - **为 OpenInterpreter 探索本地 LLM**: 出现了关于使用本地语言模型处理 OpenInterpreter 任务的查询,以及关于使用 **Ollama 3** 等模型进行本地 OS 模式使用的能力和设置的讨论。 - **利用强大硬件挑战 OI 极限**: 一位用户提到购买了四块 Tesla P40 用于 OpenInterpreter,寻求关于尝试哪些模型以增强性能的建议,并对潜在能力表示兴奋。
- 简介 - Open Interpreter: 未找到描述
- Google Colaboratory: 未找到描述
- GitHub - botgram/shell-bot: :robot: 执行命令并发送实时输出的 Telegram 机器人: :robot: 执行命令并发送实时输出的 Telegram 机器人 - botgram/shell-bot
- RAG (Retrieval Augmented Generation) with LlamaIndex, Elasticsearch and Mistral — Elastic Search Labs:学习使用 LlamaIndex、Elasticsearch 和本地运行的 Mistral 实现 RAG 系统。
- Ollama - Llama 2 7B - LlamaIndex:未找到描述
- MistralAI Cookbook - LlamaIndex:未找到描述
- Llama3 Cookbook - LlamaIndex:未找到描述
- AI Demos:未找到描述
- 未找到标题:未找到描述
- llama_index/llama-index-integrations/readers/llama-index-readers-google/llama_index/readers/google/drive/base.py:LlamaIndex 是适用于 LLM 应用程序的数据框架
- Usage Pattern - LlamaIndex:未找到描述
- Usage Pattern - LlamaIndex:未找到描述
- Finetune Embeddings - LlamaIndex:未找到描述
- Q&A patterns - LlamaIndex:未找到描述
- Document Summary Index - LlamaIndex:未找到描述
- Pydantic Tree Summarize - LlamaIndex:未找到描述
- ">未找到标题:未找到描述
- AutoGen | AutoGen:通过多智能体对话框架赋能下一代 LLM 应用
- Flashcardfy - 带有个性化反馈的 AI 抽认卡生成器:使用提供个性化反馈的 AI 生成抽认卡,学习得更快、更聪明。
- Agents | 🦜️🔗 Langchain:LangChain 提供了许多工具和函数,允许你创建 SQL Agents,从而提供一种更灵活的与 SQL 数据库交互的方式。使用 SQL Agents 的主要优点是...
- Tool usage | 🦜️🔗 Langchain:本节将介绍如何创建对话式 Agents:可以使用工具与其他系统和 API 交互的聊天机器人。
- Add message history (memory) | 🦜️🔗 LangChain:RunnableWithMessageHistory 让我们能够为某些内容添加消息历史
- RAG From Scratch:Retrieval augmented generation (或 RAG) 是一种将 LLM 与外部数据源连接的通用方法。本视频系列将建立起对...的理解。
- GitHub - aosan/VaultChat: 从你的私有文档中获取知识:从你的私有文档中获取知识。通过在 GitHub 上创建一个账户来为 aosan/VaultChat 的开发做出贡献。
- SpeedLegal - Your personal AI contract negotiator | Product Hunt: SpeedLegal is an AI tool that helps you understand and negotiate contracts better. It can quickly identify potential risks and explain complicated legal terms in simple language. SpeedLegal also gives...
- Tune Chat - Chat app powered by open-source LLMS: With Tune Chat, access Prompts library, Chat with PDF, and Brand Voice features to enhance your content writing and analysis and maintain a consistent tone across all your creations.
- no title found: no description found
- Unlocking Efficiency: The Power of Multi-Step Tools with Langchain and Cohere: Ankush k Singal
- mistral-common/examples/tokenizer.ipynb at main · mistralai/mistral-common: 通过在 GitHub 上创建账户来为 mistralai/mistral-common 的开发做出贡献。
- no title found: 未找到描述
- 来自 xlr8harder (@xlr8harder) 的推文: Llama 3 发布了,但似乎仍然只有 @MistralAI 真正支持我们:它仍然对模型输出有下游使用限制。@AIatMeta 这是一个损害开源的垃圾限制...
- mistralai/Mixtral-8x22B-Instruct-v0.1 · Hugging Face:未找到描述
- adding the llm-gpt4all models breaks the python app. · Issue #28 · simonw/llm-gpt4all:我顺利安装了 llm,分配了 OpenAI 密钥,并且可以毫无问题地与 gpt4 对话,查看我的 llm models 命令输出:OpenAI Chat: gpt-3.5-turbo (aliases: 3.5, chatgpt) OpenAI...
- Meta Llama 3:使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的预训练及指令微调版本,以支持广泛的应用。
- GitHub - Lightning-AI/pytorch-lightning: Pretrain, finetune and deploy AI models on multiple GPUs, TPUs with zero code changes.:在无需更改代码的情况下,在多个 GPU、TPU 上预训练、微调和部署 AI 模型。 - Lightning-AI/pytorch-lightning
- Mixtral 8x22B Mistral 最佳开源模型:Mixtral 8x22B 是最新的开源模型。它为 AI 社区的性能和效率设定了新标准。它是一个稀疏混合专家模型(SMo...
- 介绍 Llama 3 最佳开源大语言模型:介绍 Meta Llama 3,Facebook 下一代最先进的开源大语言模型。https://ai.meta.com/blog/meta-llama-3/#python #...
- Snowflake 发布世界上最好的实用文本嵌入模型:今天 Snowflake 发布并以 Apache 2.0 许可证开源了 Snowflake Arctic embed 系列模型。基于 Massive Text Embedding Be...