ainews-llama-3
Llama-3-70b 是 GPT-4 级别的开源模型。
Meta 发布了 Llama 3,这是其功能最强大的开源大语言模型,包含 8B(80亿)和 70B(700亿)参数版本,支持 8K 上下文长度,其性能超越了包括 Llama 2 和 Mistral 7B 在内的先前模型。Groq 以 每秒 500-800 个 token 的速度运行 Llama 3 70B 模型,使其成为目前最快的 GPT-4 级别 token 来源。
相关讨论强调了 AI 规模化(scaling)面临的挑战:埃隆·马斯克 (Elon Musk) 表示训练 Grok 3 将需要 10 万块英伟达 H100 GPU,而 AWS 计划为一款 27 万亿参数的模型 采购 2 万块 B200 GPU。微软推出了用于生成逼真说话人脸的 VASA-1,而 Stable Diffusion 3 及其扩展版本的反响褒贬不一。此外,关于 AI 能源消耗和政治偏见的担忧也引起了讨论。
2024/4/18-4/19 的 AI 新闻。我们为你检查了 6 个 subreddits、364 个 Twitter 账号 以及 27 个 Discord 服务(包含 395 个频道和 10403 条消息)。预计节省阅读时间(按 200wpm 计算):958 分钟。
在 1600 票的样本量下,Lmsys 的早期结果甚至比报告的 Benchmark 还要好,这在当下非常罕见:
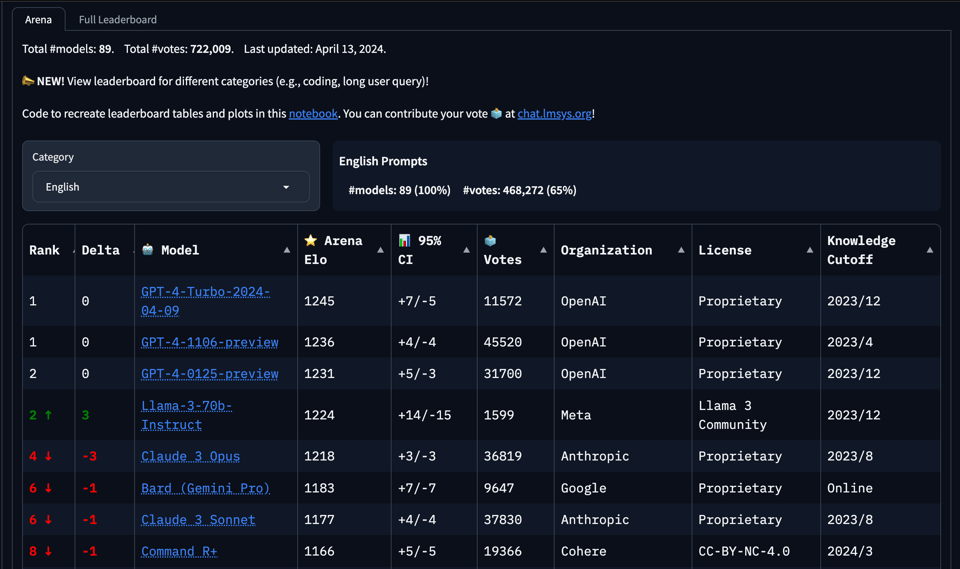
这是第一个击败 Opus 的开源模型,而 Opus 本身是第一个曾短暂击败 GPT4 Turbo 的模型。当然,随着时间的推移,这可能会有所波动,但对于即将发布的 Llama-3-400b 来说,这是一个非常好的预兆。
目前 Groq 已经能以 500-800 tok/s 的速度运行 70b 模型,这使得 Llama 3 毫无疑问成为了目前最快的 GPT-4 级别 Token 来源。
随着最近关于 Chinchilla 的复现结果受到质疑(不要错过 Susan Zhang 的精彩推文,该推文得到了 Chinchilla 共同作者的认可),Llama 2 和 3(以及在开源程度上稍逊一筹的 Mistral)已经相当彻底地将 Chinchilla 定律送进了历史的尘埃。
目录
[TOC]
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
Meta 的 Llama 3 发布及其能力
-
Llama 3 作为最强大的开源 LLM 发布:Meta 发布了 Llama 3,这是他们迄今为止功能最强大的开源大语言模型。在 /r/LocalLLaMA 中,有人指出 8B 和 70B 参数版本已发布,支持 8K 上下文长度。还分享了一个针对 70B 模型的开源 code interpreter。
-
Llama 3 在基准测试中表现优于之前的模型:/r/LocalLLaMA 中分享的基准测试显示,Llama 3 8B instruct 在各项任务中表现优于之前的 Llama 2 70B instruct 模型。根据 API 定价,70B 模型以超过 20 倍的低成本提供了 GPT-4 级别的性能。测试还显示 Llama 3 7B 在 function calling 和算术方面超过了 Mistral 7B。
图像/视频 AI 进展与 Stable Diffusion 3
-
逼真的说话人脸生成和令人印象深刻的视频 AI:微软展示了 VASA-1,用于从音频生成逼真的说话人脸。Meta 的 图像和视频生成 UI 在 /r/singularity 中被评价为“令人惊叹”。
-
Stable Diffusion 3 的印象与扩展:在 /r/StableDiffusion 中,有人指出 与其他服务相比,Imagine.art 给人留下了关于 SD3 能力的错误印象。还分享了一个 Forge Couple 扩展,为 SD 增加了可拖动的主体区域。
AI 扩展挑战与算力需求
- AI 能源消耗和 GPU 需求快速增长:/r/singularity 的讨论强调,到 2030 年,AI 的算力需求可能会压垮能源供应。Elon Musk 表示 训练 Grok 3 将需要 100,000 块 Nvidia H100 GPU,同时 AWS 计划采购 20,000 块 B200 GPU 用于一个 27 万亿参数的模型。
AI 安全、偏见与社会影响讨论
-
政治偏见与 AI 安全担忧:在 /r/singularity 中,有人认为 AI 中被察觉到的“政治偏见”更多地反映了政党本身,而非模型。Llama 3 因其 在交互中的诚实和自我意识而受到关注。出现了权衡 AI 毁灭论与对有益 AI 发展的乐观主义 的讨论。
-
AI 破解加密的潜力:/r/singularity 的一篇文章讨论了 “量子加密启示录”以及 AI 何时能破解当前的加密方法。
AI 迷因与幽默
- 分享了各种 AI 迷因,包括 AI 生成迷因的未来、等待 OpenAI 对 Llama 3 的回应、AI 公司之间的 AGI 竞赛,以及 人类 AI 未来的恶搞预告片。
{kind=link}
{kind=link}
AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,从 4 次运行中择优。我们正在使用 Haiku 进行聚类和流程工程(flow engineering)。
Meta Llama 3 发布
- 模型详情:@AIatMeta 发布了 8B 和 70B 尺寸的 Llama 3 模型,400B+ 模型仍在训练中。Llama 3 使用了 128K 词表分词器(vocab tokenizer),并在 15T tokens 上进行训练(是 Llama 2 的 7 倍)。它具有 8K 上下文窗口(context window),并使用 SFT, PPO 和 DPO 进行对齐。
- 性能表现:@karpathy 指出 Llama 3 70B 在性能上广泛超越了 Gemini Pro 1.5 和 Claude 3 Sonnet,而 Llama 3 8B 则优于 Gemma 7B 和 Mistral 7B Instruct。@bindureddy 强调 400B 版本在基准测试中正接近 GPT-4 级别的性能。
- 可用性:@ClementDelangue 指出 Llama 3 是从发布到登上 Hugging Face 趋势榜第一速度最快的模型。它也可以通过 @awscloud, @Azure, @Databricks, @GoogleCloud, @IBM, @NVIDIA 等平台获取。
开源 AI 格局
- 重要意义:@bindureddy 认为,未来 开源生态系统中的大多数 AI 创新都将基于 Llama 架构。@Teknium1 认为 Llama 3 证明了“微调(finetuning)无法教给模型新知识”或“10K 样本是指令微调(instruction finetuning)的最佳规模”等说法是错误的。
- 算力趋势:@karpathy 分享了 llm.c 的更新,该项目仅用 2K 行 C/CUDA 代码,就能在 GPU 上以媲美 PyTorch 的速度训练 GPT-2。他强调了为性能进行代码超优化(hyperoptimizing code)的重要性。
- 商业化:@abacaj 认为,随着任何人都可以获取 Llama 权重并优化推理运行,token 的价格正在暴跌。@DrJimFan 预测 GPT-5 将在 Llama 3 400B 发布之前公布,因为 OpenAI 会根据开源进展来选择发布时机。
伦理与社会影响
- 员工待遇:@mmitchell_ai 对因抗议而被解雇的 Google 员工表示同情,指出即使存在分歧,尊重员工也至关重要。
- 数据透明度:@BlancheMinerva 认为 训练数据透明度对社会而言是明确的进步,但目前的激励机制并不利于公司这样做。
- 伦理要求:@francoisfleuret 设想了一个电子邮件和 Web 客户端必须遵守与当今 LLM 相同的伦理要求的世界。
AI Discord 摘要回顾
摘要之摘要的摘要
Meta 发布 Llama 3 引发热议与辩论
-
Meta 发布了 Llama 3,这是一个全新的大语言模型 (LLM) 家族,参数量从 8B 到 70B 不等,包含经过对话优化的预训练和指令微调版本。Llama 3 拥有一个新的 128k token 分词器 (Tokenizer) 用于多语言场景,并声称比之前的模型具有更强的推理能力。[Blog]
-
讨论集中在 Llama 3 与 GPT-4、Mistral 和 GPT-3.5 等模型的基准测试 (Benchmarks) 对比。一些人称赞其类人化的回答,而另一些人则指出尽管进行了多语言训练,但在非英语语言中仍存在局限性。
-
Llama 3 输出内容的下游使用许可限制受到了一些人的批评,认为这阻碍了开源开发。[Tweet]
-
对 Meta 计划中的 405B 参数 Llama 3 模型的期待日益高涨,推测该模型将是开放权重的,并可能改变开源 AI 与 GPT-5 等封闭模型之间的竞争格局。
-
随着 Llama 3 在各个平台的集成,分词器 (Tokenizer) 配置问题、无限响应循环以及与 LLamaFile 等现有工具的兼容性也成为了讨论热点。
Mixtral 提升了开源 AI 的标准
-
来自 Mistral AI 的 Mixtral 8x22B 模型被赞誉为树立了开源 AI 性能与效率的新标杆,该模型采用了稀疏的混合专家 (MoE) 架构。[YouTube]
-
基准测试显示,Mera-mix-4x7B MoE 模型尽管比 Mixtral 8x7B 更小,但在 OpenLLM Eval 上取得了 75.91 等极具竞争力的成绩。
-
多语言能力得到了探索,推出了针对英语和德语数据进行微调的新模型 Mixtral-8x22B-v0.1-Instruct-sft-en-de。
-
在大型模型训练过程中,讨论了诸如 shape errors、OOM 问题以及 router_aux_loss_coef 参数调优等技术挑战。
高效推理与模型压缩受到关注
-
来自 Unsloth AI 的 GPTQ 量化技术和 4-bit 模型旨在提高大型模型的推理效率,据报道比原生实现减少了 80% 的内存占用。
-
推荐使用 LoRA (Low-Rank Adaptation) 和 Flash Attention 进行高效的 LLM 微调,并配合 DeepSpeed 等工具进行梯度检查点 (gradient checkpointing)。
-
探索了 半二次量化 (HQQ) 和潜在的 CUDA kernel 优化等创新技术,以进一步在 GPU 上压缩和加速大型模型。
-
分享了提供廉价 GPU 托管的 Serverless 推理解决方案,满足了部署 LLM 时对成本敏感的开发者的需求。
开源工具与应用蓬勃发展
-
LlamaIndex 展示了多个项目:使用 Elasticsearch 构建 RAG 应用 [Blog],支持 Llama 3 [Tweet],以及创建代码编写 Agent [Collab]。
-
LangChain 发布了提示工程 (prompt engineering) 课程 [LinkedIn],以及利用旅游 API 的 Tripplanner Bot [GitHub]。
-
Cohere 用户讨论了数据库集成、RAG 工作流以及边缘部署的商业许可限制。
-
OpenRouter 确认了在 Olympia.chat 的生产环境使用并期待 Llama 3 的集成,而 LM Studio 在 v0.2.20 版本中发布了对 Llama 3 的支持。
前沿研究亮点
-
一种新的最佳拟合打包算法 (best-fit packing algorithm) 优化了 LLM 训练中的文档打包,减少了截断现象 [Paper]。
-
softmax 瓶颈被认为与较小规模 LLM 的饱和及性能不佳有关 [Paper]。
-
DeepMind 分享了在可解释性研究中稀疏自编码器 (SAEs) 的进展 [Blog]。
-
Chinchilla 缩放法则 (scaling laws) 得到了重新解读,建议为了实现最佳缩放,可以优先考虑增加参数量而非数据量。
第 1 部分:高层级 Discord 摘要
Perplexity AI Discord
-
Opus 用户遭遇查询配额困境:Pro 用户对 Opus 查询次数从每天 600 次减少到 30 次感到沮丧,由于此次变更未提前通知,引发了要求修改退款政策的呼声。
-
模型实力马拉松:Llama 3 70b、Claude 和 GPT-4 之间的比较集中在编程能力、表格查找和多语言熟练度上,同时还讨论了绕过 AI 内容检测器的策略,这对于部署 AI 生成内容至关重要。
-
动漫美学与图像应用:尽管在有效利用其功能方面存在一些挑战,但将 AI 应用于动画和图像的兴趣激增,主要涉及 DALL-E 3 和 Stable Diffusion XL。
-
解读 AI 谜题的复杂性:一个复杂的蜗牛谜题成为了评估模型 AI 推理能力的测试场,突显了 AI 需要具备处理简单谜题之外的逻辑导航能力。
-
Mixtral 演绎 Cohen,API 玩法多样:Mixtral-8x22B 准确解读了 Leonard Cohen 的《Avalanche》,同时用户确认 Perplexity AI 的聊天模型可与 API 配合使用,为 Mistral、Sonar、Llama 和 CodeLlama 等应用注入了活力。
Unsloth AI (Daniel Han) Discord
-
Llama 3 超越 GPT-4:Meta 发布 Llama 3 引发了关于其 tokenizer 优势以及与 OpenAI GPT-4 性能基准对比的讨论,并对 400B 大模型版本的迭代充满期待。关于不同 GPU 训练所需的 VRAM 要求的辩论仍在继续,Unsloth AI 已迅速集成 Llama 3,宣称提升了训练效率。
-
Unsloth 展示 4-bit 效率:Unsloth AI 更新了其提供的 4-bit 模型 版 Llama 3 以增强效率,包括 8B 和 70B 版本,可在 Hugging Face 上获取。同时提供了适用于 Llama 3 的免费 Colab 和 Kaggle notebook,方便用户更轻松地进行实验和创新。
-
Unsloth 用户应对训练与推理挑战:Unsloth AI 社区正积极解决在微调 vllm 等模型过程中遇到的各种复杂问题,如 tokenizer 故障和训练脚本缺陷。Unsloth 已注意到 Llama 3 的 tokenizer 问题,并告知用户正在努力解决。
-
社区推动模型合并与扩展:Mixtral 8x22B(一个大型 MoE 模型)以及 Neural Llama 3 在 Hugging Face 上的发布,表明模型能力在稳步提升。用户对话还包括关于 JSON 解码错误、数据集结构以及 Colab 等平台内存限制的实用建议和支持。
-
AI 先驱提出 ReFT:将 ReFT (Reinforced Fine-Tuning) 方法集成到 Unsloth 平台的潜力引起了用户的兴趣。该方法因可能对新手有所帮助而受到关注,Unsloth 团队正在考虑中,这反映了社区在完善和扩展工具功能方面的积极态度。
LM Studio Discord
-
Llama 3 成为焦点:Meta 的 Llama 3 模型引发了热烈讨论,用户正在探索 70B 和 8B 版本,认可其类人响应能力可与更大型模型媲美。注意到了无限循环等问题,新发布的 Llama 3 70B Instruct 承诺性能可匹配 GPT-3.5,并已在 Hugging Face 上线。
-
硬件障碍与突破:关于在各种硬件配置上运行 AI 模型的讨论非常活跃。1080TI GPU 被强调足以处理 AI 模型,同时也承认了 AMD GPU 的兼容性挑战,例如某些显卡缺乏 AMD HIP SDK 支持。此外,K_S 和 Q4_K_M 等模型量化版本出现了问题,但建议使用 Quantfactory 版本,效果更佳。
-
LM Studio 更新与集成:最新更新 LM Studio 0.2.20 包含了对 Llama 3 的支持。鼓励用户通过 lmstudio.ai 或重启应用进行更新。不过,目前强调只有来自 “lmstudio-community” 的 GGUF 文件可以运行。关于 AMD 硬件 ROCm 支持的讨论也在进行中,Llama 3 现已在 ROCm Preview 0.2.20 上得到支持。
-
易用性与兼容性创新:一个名为 “prompt studio” 的新功能已发布,允许用户在基于 Vue 3 和 TypeScript 构建的 Electron 应用中微调其 Prompt。同时,llamafile 因其跨系统兼容性受到赞赏,与 LM Studio 的 AVX2 要求形成对比。用户主张向后兼容,并指出了保持 AVX beta 版与主频道同步更新的问题。
-
AI 效率与社区贡献:高效的 IQ1_M 和 IQ2_XS 模型中,IQ1_M 变体所需 VRAM 少于 20GB,展示了社区在优化 AI 模型性能方面的努力。此外,Llama 3 70B Instruct 模型量化版因其效率和与 LM Studio 的兼容性而受到称赞,目前已可获取,预示着开源 AI 的一次飞跃。
Nous Research AI Discord
多 GPU 支持呼声:在多 GPU 设置下为 Jamba 等模型实现高效长上下文推理存在困难;deepspeed 和 accelerate 文档缺乏相关指导。
邀请链接已就绪:TheBloke 的 Discord 服务器解决了邀请失效问题,新链接现已可用:Discord Invite。
引入举报命令:引入了 /report 命令,用于有效举报服务器内的违规者。
Llama 3 引发基准测试热潮:用户正在对 Llama 3 进行严格的基准测试并与 Mistral 进行对比,其性能和 AI 聊天模板成为关注焦点。对模型限制(如 8k token 上下文限制)和限制性许可的担忧较为突出。
Pickle 警告与 AI 指数:对话涉及通过不安全的 pickle 文件入侵系统的问题,以及非鲁棒性的 GPT 模型。AI 社区被引导关注 2023 年 AI Index Report,以了解该年度的发展洞察。
跨模型查询与支持请求:查询包括寻找 Hermes 系列模型的有效 Prompt 格式,期待 llama-3-Hermes-Pro 的发布,以及询问 axolotl 是否支持多模型同时训练。在 GPU 集群上使用 jamba 等模型进行长上下文推理的支持正在开发中,详见 vLLM 项目的 GitHub pull request。
小型处理器上的 VLM:一个旨在将 VLM (Vision Language Models) 部署在 Raspberry Pis 上用于教育用途的项目,预示着 AI 部署平台日益增长的多样性。
数据困境与维度辩论:开源模型对微调的需求以及数据多样性问题(包括维度灾难)是大家达成共识的话题。此外,构建有效 RAG 数据库的策略从单个大型数据库到多个专用数据库不等。
模拟与 AI 巨头结合:一场热烈的讨论围绕着将 Llama 3 和 Meta.ai 等生成式 AI 与 world-sim 集成展开,探索创作丰富的 AI 驱动叙事。
CUDA MODE Discord
矩阵乘法精通 (Matrix Multiplication Mastery):工程师们讨论了在奇数尺寸场景下进行 tiling 矩阵乘法 的优化策略,建议使用 padding 或 边界特定代码 来提高效率。他们强调了主体部分计算与特殊边缘情况处理之间的平衡。
显微镜下的 CUDA Kernels:关于 FP16 矩阵乘法 (matmul) 误差 的讨论浮出水面,认为 simt_hgemv 相比典型的 fp16 累加方法具有更优的误差处理能力。小组还研究了量化 matmuls 中的 dequantization、顺序与偏移内存访问,以及向量化操作(如 __hfma2、__hmul2 和 __hadd2)的价值。
站在巨人的肩膀上:成员们探索了将自定义 CUDA 和 Triton kernels 与 torch.compile 集成的方法,分享了一个 自定义 CUDA 扩展示例,并推荐了一份详尽的 C++ 自定义算子手册。
CUDA 求知之路:在 CUDA 学习资源 的交流中,有人建议在购买硬件之前先学习相关知识,并推荐了一个用于理论学习的 YouTube 播放列表 以及一个用于实践的 GitHub CUDA 指南。
利用 CUDA 进行 LLM 优化:社区使用 NVIDIA Nsight Compute 进行优化,成功将一个 CUDA 模型训练循环 从 960ms 缩减至 77ms,强调了具体的改进点,并考虑使用 多 GPU 方案 进行进一步提升。关于循环优化的详细信息可以在 pull request 中找到。
工程师的培训准备:关于 CUDA Mode 活动 的讨论涉及录制职责的协调,引发了关于捕获和潜在编辑会议的合适工作流及工具的对话,此外还涉及活动权限管理和日程安排。
OpenAccess AI Collective (axolotl) Discord
-
LLaMA-3 发布引发深度技术对话:Meta LLaMA-3 的问世触发了围绕其 tokenizer 效率和架构的丰富讨论,成员们权衡了它是否继承了前代的架构并进行了对比测试。有人对微调挑战表示担忧,而一些人正在尝试使用 qlora adapter 来改进集成,尽管在 tokenizer 加载和意外的关键字参数方面遇到了技术障碍。
-
Axolotl 反思微调与 Tokenizer 配置:关于如何最好地微调 AI 模型的辩论持续进行,焦点集中在 Mistral 和 LLaMA-3 上,包括解冻 lmhead 和 embed 层以及处理导致
ValueError问题的 tokenizer 更改等细节。成员们分享了 tokenizer 的调整技巧,从调整 PAD tokens 到探索新的 tokenizer 覆盖技术,例如在提议的 关于 tokenizer 覆盖的 Draft PR 中所述。 -
AMD GPU 兼容性受到关注:探索 ROCm 的用户发布了一份安装指南,旨在为 AMD GPU 提供 attention 机制的替代方案,力求与 Nvidia 的 Flash Attention 齐头并进。这是一个持续的话题,用户正努力寻找与非 Nvidia 硬件更兼容的方法。
-
语言建模创新备受关注:语言建模领域的重大进展被提及,包括 AWS 新的 packing 算法取得的成功,据报道该算法大幅减少了闭域幻觉。一份详细介绍这一进展的论文可以在 Fewer Truncations Improve Language Modeling 找到,这可能会为工程社区未来的实现提供参考。
-
Runpod 可靠性调侃:一位成员指出了 runpod 服务响应缓慢的问题,引发了对该服务间歇性可靠性的幽默吐槽,调侃了 runpod 的运行故障。
Stability.ai (Stable Diffusion) Discord
标记 SD3 权重发布日期:讨论显示,人们对即将于 5 月 10 日发布的 Stable Diffusion 3 本地权重感到兴奋,成员们期待着新的功能和增强。
审查还是谨慎?:有讨论提到了关于 Stable Diffusion API 的担忧,该 API 可能会针对某些提示词产生模糊的输出,这标志着本地版本与 API 使用之间在内容控制方面存在差异。
GPU 选择变得更简单:AI 从业者强调了 RTX 3090 在 AI 任务中的性价比,权衡了其相对于 RTX 4080 或 4090 等更昂贵选项的优势,并考虑了 VRAM 和计算效率。
AI 艺术创作精通:社区内的对话倾向于微调内容生成,成员们交流了关于创建特定图像类型(如半脸肖像)以及控制生成的 AI 艺术细微差别的建议。
AI 辅助网络:社区分享了详细的 Comfy UI 教程 供大家学习,用户们也在寻求和提供处理技术错误的技巧,包括 img2img IndexError 以及检测 AI 图像中隐藏水印的策略。
Latent Space Discord
用 AI 玩转 Discord 服务器:一位成员探索了使用 Claude 3 Haiku 和一个 AI 新闻机器人来总结一个关于系统工程的密集 Discord 服务器的想法;他们还分享了一个邀请链接。
Meta 在机器学习领域的实力:Meta 推出了 Llama 3,讨论围绕其 8B 和 70B 模型版本超越 SOTA 性能、即将推出的 400B+ 模型以及与 GPT-4 的比较展开。参与者注意到 Llama 3 具有卓越的推理速度,尤其是在 Groq Cloud 上。
Mac 与 Llama,一场推理奥德赛:关于在 Mac 上运行像 Llama 3 这样的大型模型的争论十分激烈,一些成员建议通过将本地 Linux 机器与 Mac 结合使用来优化性能,这是一种极具创意的变通方法。
寻找终极 LLM 蓝图:为了追求效率,社区成员分享了 litellm,这是一个极具前景的资源,可以适配 100 多个具有一致输入/输出格式的 LLM,简化了此类项目的启动。
播客浪潮席卷社区:Latent Space 播出了一集由 Jason Liu 参与的新播客节目,社区成员表现出极大的期待并分享了该公告的 Twitter 链接。
参与、记录与提示:LLM Paper Club 讨论了 tokenizer 和 embedding 的相关性,宣布将会议录像上传至 YouTube,并研究了诸如 ULMFiT 的 LSTM 等模型架构。知情参与者确认了 PPO 的辅助目标,并就所谓的“提示词时代(prompting epoch)”进行了调侃。
AI 评估与创新:AI In Action Club 权衡了使用 Discord 与 Zoom 的优缺点,分享了对 LLM Evaluation 的见解,解决了会议期间不明原因的噪音问题,并分享了摘要评估策略。Eugene Yan 的文章链接被广泛传阅,强调了 AI 评估中可靠性的重要性。
Eleuther Discord
Best-fit Packing:更少截断,更高性能:根据最近的一篇论文,一种新的 Best-fit Packing 方法减少了 LLM 训练中的截断,旨在实现将文档最优地打包进序列中。
解构 Softmax 瓶颈:最近的一项研究讨论了小型语言模型由于与 Softmax 瓶颈相关的饱和现象而表现不佳,特别是对于隐藏层维度低于 1000 的模型面临挑战。
Scaling Laws 依然符合 Chinchilla 规律:scaling-laws 频道的讨论得出结论,每个参数的 Chinchilla Token 计数保持一致,且增加参数可能比积累更多数据更有益。
DeepMind 深入研究 Sparse Autoencoders:DeepMind 的机械可解释性团队在一篇 论坛帖子 中概述了 Sparse Autoencoders (SAEs) 的进展,并提供了关于可解释性挑战和技术的见解,同时附带了相关的 推文。
应对 lm-evaluation-harness 的挑战:由于配置的复杂性和对更简洁实现方法的需求,为 lm-evaluation-harness 项目做贡献的努力受到了阻碍。通过 PRs 分享了关于多语言基准测试潜力的见解。
LAION Discord
-
Stability AI 裁员动荡:在 CEO 离职以解决增长不可持续的问题后,Stability AI 裁减了 20 多名员工,引发了关于公司未来方向和稳定性的讨论。关于裁员的完整备忘录/细节可以在 CNBC 的报道 中找到。
-
AI 艺术领域竞争加剧:据观察,DALL-E 3 在 Prompt 准确性和视觉保真度方面优于 Stable Diffusion 3,导致社区对 SD3 的表现感到不满。这些模型的对比加剧了关于它们在 Text-to-Image 领域各自优缺点的讨论。
-
Meta Llama 3 引发热议:Meta Llama 3 的推出引发了关于其对 AI 格局影响的讨论,讨论内容涵盖了其编码能力、有限的 Context Window,以及它如何与其他行业领先模型竞争。一项公告确认 Meta Llama 3 将在 AWS 和 Google Cloud 等主要平台上提供,更多细节可在 Meta 的博客文章 中查看。
-
深入探讨 Cross-Attention 机制:关于 Cross-Attention 机制的讨论正在进行中,特别是 Google 的 Imagen 模型,该模型在模型训练和图像采样过程中处理 Text Embeddings 的方法正受到关注。
-
利用音频驱动模型推进面部动态:人们对能够实现面部动态和头部运动的开源音频驱动生成模型的兴趣日益浓厚,其中 Diffusion Transformer 模型是一个强有力的候选者。目前正在评估涉及 Talking Head 视频的 Latent Space 编码或基于音频条件的 Face Meshes 策略,以创建与音频同步的逼真面部表情。
HuggingFace Discord
跨越语言与模型:讨论摘要
-
LLaMA 3 登场:工程社区充满了关于 LLaMA 3 的讨论,其中包含来自 Meta Releases LLaMA 3: Deep Dive & Demo 视频的见解。人们对其在排行榜上的表现寄予厚望,特别是 HuggingFace 上的
MaziyarPanahi/Meta-Llama-3-8B-Instruct-GGUF备受关注。 -
Meta-Llama 3 对比 Mixtral:比较 Meta Llama 3 和 Mixtral 的基准测试正受到密切关注,最近的 Mera-mix-4x7B 模型在 OpenLLM Eval 上达到了 75.91 分。社区还分享了关于 LLaMA-2-7b-chat-hf 模型 出现 422 Unprocessable Entity 错误的提示,需要通过减少 token 输入来解决。
-
扩大多语言覆盖范围:随着社区成员提议为更广泛的全球受众翻译和创作内容,多语言可访问性的势头正在增长。亮点包括在 YouTube 播放列表 中提供的社区亮点葡萄牙语翻译,以及关于文化相关翻译重要性的讨论。
-
量化查询与数据集讨论:对话转向 quantization(量化),社区正在思考其对模型性能的影响,这与 Exploring the Impact of Quantization on LLM Performance 的分析相关;同时,ORPO-DPO-mix-40k 数据集 的分享触及了改进机器学习模型训练的需求。
-
社区创作与协作:用户生成的内容大放异彩,包括在 zero-gpu-slot-machine 上的创意浏览器内音频体验,以及旨在衡量 LLM 未来事件预测敏锐度的新预测排行榜的发布,该 Space 位于 这里。与此同时,一本关于 Generative AI 的书籍引起了兴趣,该书承诺会增加更多章节,可能涉及 quantization 和设计系统。
技术交流蓬勃发展:AI 工程师们交换了从目标检测中的深度强化学习 (DRL) 到 Gradio 中的 GPU 问题以及 TensorFlow 中令人困惑的 ‘cursorop’ 错误等各种知识。讨论还倾向于 3D vision 数据集 以及在使用 Lora 进行 inpainting 时保持背景一致的解决方案。社区还发出了探索 GitHub 上 Counterfactual-Inception 研究的公开号召。
OpenRouter (Alex Atallah) Discord
-
Mixtral 模型混淆修复:Mixtral 8x22B Instruct 模型的 prompt 模板已修正,这影响了用户与模型的交互方式。
-
OpenRouter 的营收之谜:公会里充满了对 OpenRouter 营收策略的推测,包括关于批量折扣和从用户充值中抽取佣金的假设,但 OpenRouter 官方尚未对此辩论发表立场。
-
延迟详情:讨论了 VPS 延迟问题,特别是南美地区的延迟,但未就服务器位置对性能的影响达成共识。
-
Meta 的 LLaMA 起飞:人们对新的 Meta LLaMA 3 模型热情高涨,据报道该模型的审查较少。工程师们分享了资源,包括官方 Meta LLaMA 3 网站 和模型权重的下载链接 Meta LLaMa Downloads。
-
OpenRouter 进入生产环境:报告确认了 OpenRouter 在生产环境中的部署,用户指出了像 Olympia.chat 这样的例子,并寻求将其作为直接使用 OpenAI 的替代方案进行集成的建议,重点讨论了特定集成文档中的空白。
OpenAI Discord
Turbo 受到 Claude 的挑战:用户反映 gpt-4-turbo-2024-04-09 的性能较慢,发现它比前代版本 GPT-4-0125-preview 更慢。有人询问是否有更快的版本,部分用户已集成 Claude 来弥补速度问题,但效果参差不齐。
AI 难以处理 PDF:对话集中在 PDF 作为 AI 数据输入格式的低效性上,社区成员建议使用纯文本或像 JSON 这样的结构化格式,同时指出目前文件系统不支持 XML。
对 ChatGPT 性能的焦虑:成员们对 ChatGPT 性能下降表示担忧,引发了关于可能原因的辩论,范围从战略性响应、法律挑战到刻意的性能降级。
编写更有效的 Prompt:社区正努力确认并更新 Prompt Engineering 的最佳实践,正如 OpenAI 指南 所建议的那样,讨论指向了 Prompt 一致性以及未能遵循指令的实际问题。
将 AI 与 Blockchain 集成:一位 Blockchain 开发者呼吁在 AI 与 Blockchain 结合的项目上进行合作,建议在高级 Prompt Engineering 与去中心化技术之间进行交互。
Interconnects (Nathan Lambert) Discord
-
价值导向的 AI 崛起:围绕 PPO-MCTS 的兴奋感正在升温,这是一种结合了 Monte Carlo Tree Search 与 Proximal Policy Optimization 的前沿解码算法,通过 Arxiv 论文 中解释的价值导向搜索,提供更理想的文本生成。
-
Meta Llama 3 模型引发热议:关于 Meta 的 Llama 3(一系列高达 70 billion parameters 的新 LLM)的讨论非常激烈,特别关注即将推出的 405 billion parameter 模型 可能带来的颠覆性。该模型的多语言能力和 Fine-tuning 效果是辩论的主题,此外还有其对 GPT-5 等闭源模型可能产生的冲击,参考 Replicate 的计费、Llama 3 开源 LLM、Azure Marketplace 以及 OpenAssistant 完成情况。
-
Llama3 的发布让演讲者们严阵以待:对 LLaMa3 发布的预期影响了演讲者的幻灯片准备,有些人可能需要在最后一刻更新材料。关于 LLaMA-Guard 的咨询引发了对安全分类器以及 AI2 为此类系统开发 Benchmark 的讨论。
-
演讲前准备:鉴于 LLaMa3 的讨论,演讲者们正准备在演讲中回答相关问题,同时优先撰写博客文章。
-
对录像的期待:社区热切期待演讲录像的发布,凸显了对 AI 领域近期讨论和进展的浓厚兴趣。
Modular (Mojo 🔥) Discord
-
Mojo 中的 C 集成变得更简单:强调了 Mojo 中的
external_call功能,并计划通过直接调用外部函数而无需复杂的 FFI 层来进一步简化 C/C++ 集成,详见 Twitter 上的教程 和 Modular 的 路线图与使命。 -
Mojo 权衡垃圾回收与测试能力:在 Modular 社区中,讨论了实现类似 Nim 方式的 运行时垃圾回收 (Garbage Collection);对 Mojo 中类似 Zig 的 原生测试支持 表示好奇;以及关于是否需要 pytest 风格断言 的辩论。此外,社区对开发 Mojo 打包和构建系统 的贡献也引起了广泛关注。
-
Rust 与 Mojo 性能评估:一场基准测试辩论显示,Rust 的前缀和 (prefix sum) 计算 比 Mojo 的等效实现慢,Rust 在仅使用
--release编译标志的情况下,每个元素的耗时为 0.31 纳秒。 -
谨慎更新 Nightly/Mojo:工程师们报告了更新 Nightly/Mojo 时遇到的问题,解决方案包括更新 modular CLI 或手动调整
.zshrc中的PATH。这揭示了技术故障,也幽默地提醒了被称为 Layer 8(第 8 层,指用户)的人为错误。 -
Meta 的 LLaMA 3 模型讨论:社区分享了题为 “Meta Releases LLaMA 3: Deep Dive & Demo” 的视频,探索了 Meta LLaMA 3 AI 模型的功能,指出发布日期为 2024 年 4 月 18 日,可在 YouTube 上观看。
Cohere Discord
-
Command R 模型的工具时间:通过 官方文档 和 示例 Notebooks 强化了 Command R 模型 指南。推荐使用 JSON schemas 来描述 Command 模型的工具。
-
数据库动态:MySQL 与 Cohere 的集成引发了讨论,澄清了可以在不使用 Docker 的情况下完成集成,如 GitHub 仓库 所示,尽管文档中可能包含过时信息。
-
RAG 团队:回答了关于使用 Cohere AI 实现 检索增强生成 (RAG) 的问题,参考了 Langchain 和 RagFlow 以及官方 Cohere 文档。
-
许可与限制:指出 Command R 和 Command R+ 工具受 CC-BY-NC 4.0 许可限制,禁止在边缘设备上进行商业使用。
-
扩展模型部署:对话围绕部署大型模型展开,指出了扩展到 100B+ 模型的挑战,并强调了特定的硬件考量,如 双 A100 40GB 和 MacBook M1。
-
越狱警报:讨论了 LLM 中日益复杂的 越狱 (jailbreaks) 行为,强调了可能带来的严重后果,包括未经授权的数据库访问和针对个人的攻击。
-
服务循环中的监控:提供了一个通过将 llm_output 与 run_tool 集成来增强对话的示例,使 LLM 的输出能够在反馈循环中引导监控工具。
LlamaIndex Discord
检索增强生成(RAG)触手可及:Elastic 的工程师发布了一篇博客文章,展示了如何使用 Elasticsearch 和 LlamaIndex 构建检索增强生成(RAG)应用,该应用集成了包括 @ollama 和 @MistralAI 在内的开源工具。
Llama 3 获得实用 Cookbook:LlamaIndex 团队通过一份 “cookbook” 为 Meta 最新的模型 Llama 3 提供了早期支持,详细介绍了从简单 Prompt 到完整 RAG 流水线的使用方法。该指南可从此 Twitter 更新中获取。
在本地部署 Llama 3:对于希望在本地环境运行 Llama 3 模型的人,Ollama 分享了一个 Notebook 更新,其中包含简单的命令更改。如此处所述,只需将 “llama2” 更改为 “llama3” 即可应用更新。
谜题与仪表盘:Pinecone 和 LLM 的日常挑战:在技术交流中,有人好奇 Google 的 Vertex AI 如何处理其演示网站上出现的 “timbalands” 等标志中的拼写错误,并就创建一个根据输入食材生成食谱的交互式仪表盘进行了持续对话。
准备就绪,追踪 LlamaIndex 的进展:在确认 LlamaIndex 已获得融资后,工程师们对追踪其开发的兴趣激增,这标志着该项目的增长以及该领域预期的技术进步。
DiscoResearch Discord
Mixtral 的多语言实力:英语和德语混合的 Mixtral 模型展示了其语言能力,尽管评估即将进行。包括 Shape 错误和 OOM 问题在内的技术挑战暗示了训练大模型的复杂性,而 Mixtral 配置中 “router_aux_loss_coef” 等参数的有效性仍是争论的焦点。
Meta 的 Llama 闪电出击:Meta 的 Llama 3 加入战场,宣称具备多语言能力,但在非英语语言中存在明显的性能差异。预计将获得新 Tokenizer 的访问权限,批评集中在模型输出的下游使用限制上,引发了关于开源与专有约束交汇的讨论。
显微镜下的德语语言模型:初步测试表明,尽管提供了 Gradio 演示,Llama3 DiscoLM German 在德语熟练度上仍落后于 Mixtral,存在明显的语法问题和错误的 Token 处理。关于 Llama3 的数据集对齐和 Tokenizer 配置的问题随之而来,与 Meta 8B 模型的对比显示出性能差距,有待进一步调查。
OpenInterpreter Discord
ESP32 需要 WiFi 以实现语言能力:一位工程师指出,ESP32 需要 WiFi 连接才能与语言模型集成,强调了网络连接对于操作功能的重要性。
Ollama 3 的性能赢得工程师喝彩:社区内对 Ollama 3 的性能议论纷纷,工程师们正在试验 8b 模型,并探索对 TTS 和 STT 模型的增强,以加快响应速度。
OpenInterpreter 工具包的尝试与磨难:用户分享了使用 OpenInterpreter 时遇到的挑战,从使用 CLI 创建文件(该 CLI 用 echo 包裹输出)的问题,到在尝试使用 M5Atom 进行音频传输时的 BadRequestError。
微调本地语言掌控力:社区成员讨论了如何使用 OpenInterpreter 在本地设置 OS 模式,提供了一个 Colab notebook 作为指导,并就使用简洁的数据集对 Mixtral 或 LLama 等模型进行微调以实现快速学习交换了见解。
探索 Meta_llama3_8b:一位成员分享了 Hugging Face 链接,工程师们可以在那里与 Meta_llama3_8b 模型进行交互,这为社区内的动手实验和评估提供了一个资源。
LangChain AI Discord
-
链接 LangChain:LangChain 中的
RunnableWithMessageHistory类专为处理聊天历史而设计,其核心要点是在 invoke 配置中始终包含session_id。深入的示例和单元测试可以在其 GitHub repository 中找到。 -
RAG 系统构建更简单:LangChain 社区成员正在实现基于 RAG 的系统,并分享了诸如 RAG 系统构建 YouTube 播放列表 和 VaultChat GitHub repository 等资源,以提供指导和灵感。
-
Prompt Engineering 技能现已上线:LinkedIn Learning 上现已推出包含 LangChain 内容的 Prompt Engineering 课程,为寻求提升该领域技能的人士拓宽了视野。你可以点击此处查看。
-
试用 Llama 3:Llama 3 的实验阶段已开启,可通过 Llama 3 Chat 访问聊天界面,并通过 Llama 3 API 获取 API 服务,方便工程师探索这一新的 AI 领域。
-
使用 AI 制定计划:Tripplanner Bot 是一个使用 LangChain 构建的新工具,它结合了免费 API 来辅助旅行规划。这是一个在 GitHub 上公开的项目,供那些想要深入研究、贡献或仅仅是学习其构建过程的人使用。
Alignment Lab AI Discord
-
检测到垃圾机器人入侵:Discord 服务器内的多个频道,即
#ai-and-ml-discussion、#programming-help、#looking-for-collabs、#landmark-dev、#landmark-evaluation、#open-orca-community-chat、#leaderboard、#looking-for-workers、#looking-for-work、#join-in、#fasteval-dev和#qa,报告了大量推广 NSFW 及潜在非法内容的垃圾信息,其中涉及一个重复出现的 Discord 邀请链接 (https://discord.gg/rj9aAQVQFX)。这些消息可能来自机器人或被黑账户,推销露骨材料并煽动社区成员加入外部服务器,这引发了对违反 Discord 社区准则的重大担忧,并促使人们呼吁管理员干预。 -
开源 WizardLM-2:WizardLM-2 语言模型已开源,并附带了其发布 blog、代码库和学术论文的引用。鼓励好奇的开发者进一步贡献和探索该模型,相关资源和讨论可在 Hugging Face 和 arXiv 上找到,同时还邀请加入其 Discord server。
-
Meta Llama 3 处于隐私锁定状态:理解和利用 Meta Llama 3 模型的计划涉及遵守 Meta Privacy Policy 中概述的隐私协议,这引发了围绕隐私问题和访问协议的对话。虽然社区对探索该模型的 tokenizer 充满热情,但官方途径要求在 Meta Llama 3 的 get-started page 进行详细登记,这与社区通过 Undi95’s Hugging Face repository 获取访问权限的权宜之计并存。
-
热度过后的模型评估:尽管受到垃圾帖子的干扰,工程社区仍专注于讨论如何评估 Meta Llama 3 和 WizardLM-2 等 AI 模型。随着管理员解决干扰问题,工程师们继续寻求最佳实践,并分享关于模型性能、集成和扩展挑战的见解。
-
警惕 Discord 邀请:鉴于上述一系列垃圾信息警报,强烈建议避免点击与所有垃圾消息相关的共享 Discord 链接 https://discord.gg/rj9aAQVQFX。建议提高警惕,以维护运行安全和社区完整性。
Mozilla AI Discord
Llama 3 8b 登场:llamafile-0.7 更新现在支持使用 -m <model path> 参数的 Llama 3 8b 模型,正如 richinseattle 所讨论的;然而,在 Reddit 讨论中强调了其 instruct format 存在 token 问题。
补丁即将到来:llamafile 的一个待定更新承诺修复与 Llama 3 Instruct 的兼容性问题,详情见此 GitHub pull request。
Llama 尺寸的巨大飞跃:jartine 宣布即将在 Llamafile 上发布 llama 8b 的量化版本,这标志着追求效率的社区取得了进展。
Meta Llama 权重发布:jartine 在 Hugging Face 上分享了 Meta Llama 3 8B Instruct 的可执行权重供社区测试,并指出仍有一些问题需要解决,包括一个损坏的 stop token。
模型管理进展:社区在测试 Llama 3 8b 模型方面的努力取得了乐观的结果,jartine 传达了针对 Llama 3 70b 中 stop token 问题的修复方案;预计仍会有一些细微的 bug。
Skunkworks AI Discord
Databricks 转向 GPU:Databricks 发布了模型服务的公开预览,通过零配置的 GPU 优化增强了 Large Language Models (LLMs) 的性能,但可能会增加成本。
LLM 微调的便捷性:一份新指南解释了如何使用 LoRA adapters、Flash Attention 以及 DeepSpeed 等工具微调 LLM,可在 modal.com 获取,为模型中高效的权重调整提供了策略。
实惠的 Serverless 解决方案:GitHub 上提供了一份使用 GPU 的实惠 Serverless 托管指南,这可能会降低开发者的开销——请查看 modal-examples repo。
Mixtral 8x22B 树立新标杆:Mixtral 8x22B 是一款采用稀疏 Mixture-of-Experts 架构的新模型,在 YouTube 视频中进行了详细介绍,为 AI 的效率和性能设定了高标准。
Meta Llama 3 介绍:Facebook 的 Llama 3 加入了顶尖 LLM 的行列,为推动语言技术发展而开源,更多信息可在 Meta AI 博客和推广 YouTube 视频中找到。
LLM Perf Enthusiasts AI Discord
-
对 litellm 的好奇: 一位成员询问了 litellm 在社区内的应用情况,表达了对该工具的使用模式或案例研究的兴趣。
-
Llama 3 领跑: 有说法称 Llama 3 的能力优于 opus,特别强调了其在某个未具名 arena 中 70b 规模下的表现。
-
风格还是实质?: 一场关于性能差异是源于风格差异还是真正的智能差异的对话被触发。
-
关于误差范围的警告: 误差范围(Error bounds)成为焦点,一位成员对此表示担忧,可能是提醒其他成员在解释数据或模型时要保持谨慎。
-
跌倒带来的幽默时刻: 在一个轻松的时刻,一位成员分享了一个 gif,通过一段动画跌倒视频带来了喜剧效果。
Datasette - LLM (@SimonW) Discord
Karpathy 对 Llama 3 的评价: Andrej Karpathy 的推文引发了关于轻量级模型潜力的讨论。他指出,一个在 15T 数据集上训练的 8B 参数模型表明,目前的常见 LLM 可能存在 100-1000 倍的训练不足,这引导工程师们关注小模型更长训练周期的理念。
小模型,大期待: 社区成员对 Karpathy 的见解做出了回应,表达了对部署像 Llama 3 这样高效小模型的热情,这表明社区已准备好在开发更小、更强大的 LLM 时拥抱最优的资源利用。
插件安装故障: 一位成员在安装 llm 插件时遇到了 ModuleNotFoundError,随后发现根源可能是来自 brew 和 pipx 的冲突安装。通过干净的重新安装解决了这一问题,这提示了进行严谨环境管理的必要性。
并发冲突需要清理: brew 和 pipx 的交叉安装点误导了用户,这引发了社区内的提醒:应使用 which llm 检查正在执行的是哪个版本的工具,以避免未来出现类似问题。
LLM 趣闻: 在技术讨论间隙,一个分享的 llm 使用案例提供了一个轻松时刻,展示了该技术一个实用且有趣的应用程序供成员探索。
tinygrad (George Hotz) Discord
- Llama 3 疾速登场: Llama 3 已经发布,推出了 8B 和 70B 参数版本,拓宽了 AI 应用的视野。
- 高速 Llama 击败 PyTorch: 在初步测试中,Llama 3 在某些模型上表现出比 PyTorch 更微弱的速度优势,并展示了与 XTX 硬件上 ROCm 的无缝兼容性。
AI21 Labs (Jamba) Discord
Jamba 的长上下文推理困扰: 一位 Jamba 用户在 2x A100 集群上进行长上下文推理时遇到困难,并正在寻求针对该分布式系统问题的排查代码。目前尚未有后续讨论或提供的解决方案。
PART 2: 频道详细摘要与链接
Perplexity AI ▷ #general (1059 messages🔥🔥🔥):
- 退款请求与模型使用问题: Pro 用户对 Opus 查询次数从每天 600 次突然限制到 30 次表示不满,这影响了那些主要为了使用 Opus 而订阅的用户。用户希望修订退款政策,尤其是因为查询限制变更前没有事先通知。
- 动画与图像建模能力: 用户表现出将使用场景扩展到动画和图像的兴趣,特别提到了 DALL-E 3 和 Stable Diffusion XL。然而,一些用户在有效使用这些模型时遇到了问题。
- 模型对比与性能: 讨论涉及了不同模型之间的对比,如 Llama 3 70b、Claude 和 GPT-4,重点关注代码编写、表格查询和多语言能力等方面。对话还包括了规避 AI 内容检测器的方法,这对于在学术等领域部署 AI 生成的内容至关重要。
- AI 谜题挑战: 一个蜗牛谜题促使用户测试各种 AI 模型,并评估它们的推理和计算能力。谜题中增加的复杂性旨在挑战 AI 超越常见谜题的能力。
- 语言与上下文限制: 用户积极辩论英语表现的重要性,认为英语在网络上的主导地位不应是评估语言模型的唯一因素。意识到需要强大的多语言 AI 能力也是一个关键点。此外,还讨论了 AI 响应中明显的上下文窗口限制,这影响了模型的有效性。
- Binoculars - tomg-group-umd 创建的 Hugging Face Space:未找到描述
- AI Detector: AI Purity 可靠的 AI 文本检测工具:全面解析 AI Purity 的尖端技术,具备最可靠、最准确的 AI 检测功能,包括常见问题解答和客户证言。
- Lech Mazur (@LechMazur) 的推文:Meta 的 Llama 3 70B 和 8B 在 NYT Connections 上进行了基准测试!就其规模而言,结果非常强劲。
- 生成式 AI 搜索引擎 Perplexity 计划销售广告:未找到描述
- Zuckerberg GIF - Zuckerberg - 发现并分享 GIF:点击查看 GIF
- Liam Santa GIF - Liam Santa 圣诞快乐 - 发现并分享 GIF:点击查看 GIF
- 24 核 vs 32 核 M1 Max MacBook Pro - Apple 隐藏的秘密..:关于更便宜的独角兽 MacBook,还没有人向你展示过的内容!免费试用你的 Squarespace 网站 ➡ http://squarespace.com/maxtech 经过一个月的体验...
- 互联网使用的语言 - 维基百科:未找到描述
- Baby Love GIF - Baby Love You - 发现并分享 GIF:点击查看 GIF
- 斯内普哈利波特 GIF - 斯内普哈利波特 你竟敢用我的咒语对付我 波特 - 发现并分享 GIF:点击查看 GIF
- Mark Zuckerberg - Llama 3, 100 亿美元模型, 凯撒奥古斯都, 以及 1 GW 数据中心:扎克伯格谈论:- Llama 3 - 迈向 AGI 的开源 - 定制芯片、合成数据以及扩展时的能源限制 - 凯撒奥古斯都、智能爆炸、生物风险...
- philschmid/llm-sagemaker-sample 项目 main 分支下的 notebooks/deploy-llama3.ipynb:通过在 GitHub 上创建账户,为 philschmid/llm-sagemaker-sample 的开发做出贡献。
{kind=link}
Perplexity AI ▷ #sharing (14 条消息🔥):
- 探索 AI 中的虚假角色:分享了一个指向 Perplexity AI 搜索结果的链接,讨论了 AI 背景下的演员和虚假元素。
- 深入了解 AI 历史:一位成员发布了一个链接,指向关于 AI 历史方面的 Perplexity AI 搜索结果。
- 揭秘“Limitless AI 吊坠”:分享的一个 Perplexity 链接提到了“Limitless AI 吊坠”,引发了大家的好奇。
- 关于 Mistral 增长的见解:社区通过分享关于 Mistral 融资的 Perplexity 搜索链接,表达了对 Mistral 进展的关注。
- 了解 HDMI 的利用:成员们可以通过指向 Perplexity AI 相关话题搜索的链接,找到关于为什么要使用 HDMI 的答案。
- Nandan Nilekani 对 Aravind Srinivas 的“瑞士军刀”搜索引擎有如下惊人评价:Nandan Nilekani 对 Perplexity AI 的评价,会让你迫不及待地想注册 Aravind Srinivasan 的“瑞士军刀”搜索引擎。
- 走进这家威胁到 Google 地位的热门 AI 初创公司内部:2022 年 8 月,Aravind Srinivas 和 Denis Yarats 在曼哈顿下城 Meta AI 负责人 Yann LeCun 的办公室外等了整整五个小时,甚至没顾上吃午饭……
Perplexity AI ▷ #pplx-api (11 条消息🔥):
-
Mixtral 模型解读 Cohen 的歌词之谜:Mixtral-8x22B 对 Leonard Cohen 的《Avalanche》提供了最准确的解读,仅凭歌词就识别出了艺术家和歌曲。该模型在分析中解读了脆弱性、权力和不断演变的人际关系等主题。
-
API 查询确实很有趣:一位成员确认,在澄清了包括 Mistral、Sonar、Llama 和 CodeLlama 等各种模型的参数数量和上下文长度等细节后,可以使用提供的 API endpoint 调用 Perplexity AI 聊天模型。
-
Perplexity AI 上的 Embedding 模型:据分享,Llama-3 instruct 模型(8b 和 70b)可在 labs.perplexity.ai 进行聊天,也可通过 pplx-api 使用,并提到 Pro 用户每月可获得 API 额度。
-
新 AI 模型带来的实时惊喜:一位社区成员表达了对新模型的热情,表示尽管无法访问 Claude Opus API,但这些模型已显著改进了他们的应用。
-
寻求 API 响应的精确性:一位用户寻求帮助,希望在尝试对 JSON 文件中的项目进行分类时,将 API 响应限制在确切的单词列表中,并提到尝试使用 Sonar Medium Chat 和 Mistral 但未获成功。
-
监控 API 额度:有人提出了关于剩余 API 额度更新频率的问题,询问在运行发出 API 请求的脚本后,刷新率是以分钟、秒还是小时为单位。
-
寻求 CORS 困境的帮助:一位用户请求关于在前端应用中使用 API 时解决 CORS 问题的示例或建议,包括将设置代理服务器作为潜在解决方案。
- 来自 Aravind Srinivas (@AravSrinivas) 的推文:🦙 🦙 🦙 http://labs.perplexity.ai 上线了 llama-3 - 8b 和 70b instruct 模型。祝聊天愉快!经过一些后期训练后,我们很快将推出它们的搜索增强在线版本。...
- 支持的模型:未找到描述
Unsloth AI (Daniel Han) ▷ #general (1147 messages🔥🔥🔥):
- Llama 3 热潮:Meta 最近发布的 Llama 3 让 AI 社区感到兴奋,讨论围绕其 Tokenizer 的优势以及对 400B 模型的期待展开。该模型被拿来与 OpenAI 的 GPT-4 进行比较,用户们在讨论 Llama 3 在各种 Benchmark 上的表现。
- Unsloth 为 Llama 3 做好准备:AI 工具 Unsloth 在 Llama 3 发布后的几小时内迅速更新了对其的支持。与此同时,用户在寻求 Llama 3 Fine-tuning 的建议,并讨论在不同 GPU 配置上进行训练的 VRAM 需求。
- Llama 3 Tokenizer 的问题:Llama 3 的 Tokenizer 发现了一个小故障,出现了一些引起社区关注的非预期行为。Unsloth 团队表示他们已意识到这些问题并正在着手修复。
- Benchmark 和模型大小的讨论:关于 Llama 3 的大小如何影响其性能,以及需要更广泛的 Benchmark 来全面评估能力的讨论正在进行中。有人建议发布预发行版以收集用户反馈并进一步优化模型。
- 模型训练的 VRAM 使用情况:用户交流了关于 Fine-tuning 语言模型时 VRAM 使用情况的见解。特别关注使用 Unsloth 通过 Quantum LoRa (QLoRA) 训练 Llama 3 8B 等模型的效率,并报告了在使用和不使用 Quantization 情况下的 VRAM 使用量。
- screenshot: 在 Imgur 发现互联网的魔力,这是一个由社区驱动的娱乐目的地。通过幽默的笑话、流行的梗图、有趣的 GIF、鼓舞人心的故事、病毒式传播的视频等来提振你的精神。
- Welcome Llama 3 - Meta's new open LLM: 未找到描述
- Google Colaboratory: 未找到描述
- unsloth/llama-3-8b-bnb-4bit · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- unsloth/llama-3-70b-bnb-4bit · Hugging Face: 未找到描述
- kuotient/Meta-Llama-3-8B · Hugging Face: 未找到描述
- mistralai/Mistral-7B-Instruct-v0.2 · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- Dance GIF - Dance - Discover & Share GIFs: 点击查看 GIF
- jinaai/jina-reranker-v1-turbo-en · Hugging Face: 未找到描述
- Obsidian - Sharpen your thinking: Obsidian 是一款私密且灵活的笔记应用,能够适应你的思维方式。
- no title found: 未找到描述
- Tweet from Daniel Han (@danielhanchen): 为 Llama-3 8B 制作了一个 Colab!15 万亿 token!所以 @UnslothAI 现在支持它了!使用免费的 T4 GPU。正在进行基准测试,但比 HF+FA2 快约 2 倍,且节省 80% 的内存!支持 4 倍长的上下文...
- meta-llama/Meta-Llama-3-8B-Instruct · Update generation_config.json: 未找到描述
- Meta Releases LLaMA 3: Deep Dive & Demo: 今天,2024 年 4 月 18 日,是一个特别的日子!在这段视频中,我将介绍 @meta 的 LLaMA 3 发布。该模型是其第三次迭代...
- NeuralNovel/Llama-3-NeuralPaca-8b · Hugging Face: 未找到描述
- Sweaty Speedruner GIF - Sweaty Speedruner - Discover & Share GIFs: 点击查看 GIF
- Mark Zuckerberg on Instagram: "今天有重大的 AI 新闻。我们将发布新版本的 Meta AI,这是我们的助手,你可以在我们的应用和眼镜中向它提问任何问题。我们的目标是构建世界领先的 AI。 我们正在使用全新的、最先进的 Llama 3 AI 模型升级 Meta AI,并将其开源。有了这个新模型,我们相信 Meta AI 现在是你可以免费使用的最智能的 AI 助手。 我们通过将 Meta AI 集成到 WhatsApp, Instagram, Facebook, 和 Messenger 顶部的搜索框中,使其更易于使用。我们还建立了一个网站 meta.ai,供你在网页端使用。 我们还构建了一些独特的创作功能,比如让照片动起来。Meta AI 现在生成高质量图像的速度非常快,可以在你输入时实时创建和更新。它还会生成你创作过程的回放视频。"</li> </ul> 享受 Meta AI,您可以关注我们新的 @meta.ai IG 以获取更多更新。": 157K 点赞,9,028 条评论 - zuck,2024年4月18日:"今天有重大的 AI 新闻。我们正在发布新版本的 Meta AI,这是我们的助手,您可以在我们的应用和眼镜中向它提问任何问题....
- 无法加载分词器 (CroissantLLM) · Issue #330 · unslothai/unsloth: 尝试使用一个小模型运行 colab:from unsloth import FastLanguageModel import torch max_seq_length = 2048 # 遗憾的是 Gemma 目前最高仅支持 8192 dtype = None # None 表示自动检测...
- Mark Zuckerberg - Llama 3, $10B 模型, 凯撒·奥古斯都, & 1 GW 数据中心: Zuck 关于:- Llama 3 - 迈向 AGI 的开源 - 定制芯片、合成数据以及扩展时的能源限制 - 凯撒·奥古斯都、智能爆炸、生物...
- [用法]: Llama 3 8B Instruct 推理 · Issue #4180 · vllm-project/vllm: 您当前的环境:在 2 个 L4 GPU 上使用最新版本的 vLLM。您想如何使用 vLLM:我正尝试利用 vLLM 部署 meta-llama/Meta-Llama-3-8B-Instruct 模型并使用 OpenA...
- HuggingChat: 让社区最好的 AI 聊天模型惠及每个人。
- “她” AI 时代即将来临?Llama 3, Vasa-1, 以及 Altman 的“接入你想做的一切”: Llama 3, Vasa-1, 以及一系列新的采访和更新,AI 新闻接踵而至。我将花几分钟时间报道最后一刻的 Llama ...
- 未找到标题: 未找到描述
- Large Language Models 的自适应文本水印: 未找到描述
- Google Colaboratory: 未找到描述
- Andrej Karpathy (@karpathy) 的推文: 祝贺 @AIatMeta 发布 Llama 3!!🎉 https://ai.meta.com/blog/meta-llama-3/ 笔记:发布了 8B 和 70B(包括基础版和微调版)模型,在同类模型中表现强劲(但我们...
- LLAMA-3 🦙: 在你的数据上进行微调的最简单方法 🙌: 了解如何使用 Unsloth 在你自己的数据上微调最新的 llama3。🦾 Discord: https://discord.com/invite/t4eYQRUcXB ☕ 请我喝杯咖啡: https://ko-fi.com...
- 如何微调 Llama 3 以获得更好的指令遵循能力?: 🚀 在今天的视频中,我很高兴能引导你完成微调 LLaMA 3 模型以实现最佳指令遵循的复杂过程!从设置...
- meta-llama/Meta-Llama-3-8B-Instruct · 修复聊天模板,仅在选择该选项时添加生成提示: 未找到描述
Unsloth AI (Daniel Han) ▷ #announcements (1 条消息):
-
Llama 3 强势登场:Unsloth AI 推出 Llama 3,承诺训练速度翻倍并减少 60% 的显存占用。详情请见 GitHub Release。
-
免费访问 Llama Notebooks:用户现在可以在 Colab 和 Kaggle 上使用免费的 Notebook 来运行 Llama 3,其中还提供了对 Llama 3 70B 模型的支持。
-
4-bit 模型的创新:Unsloth 推出了 Llama-3 的 4-bit 模型以提高效率,提供 8B 和 70B 版本。更多模型(包括 Instruct 系列)请访问其 Hugging Face 页面。
-
Unsloth 鼓励实验:团队渴望看到社区分享、测试和讨论使用 Unsloth AI 模型的结果。
提到的链接:Google Colaboratory:未找到描述
Unsloth AI (Daniel Han) ▷ #random (6 条消息):
- HuggingFace 的 LLAMA 3 推理 API 缺席:一位成员指出 HuggingFace 尚未开放 LLAMA 3 的 Inference API。
- LLAMA 的训练吞噬算力:另一位成员幽默地评论算力短缺,称“训练完模型后没剩下算力了”,并配上了一个骷髅表情。
- LLAMA 的训练 Token 宝库:在简短的交流中,成员们明确了 LLAMA 的训练 Token 集大小,定为 15T tokens。
- AI 狗仔队警报:一位成员分享了一个 YouTube 视频,讨论了包括 LLAMA 3 在内的 AI 最新动态,并配上搞怪的开场白“我是狗仔队!”,以及震惊和爆笑的表情。
提及的链接:‘Her’ AI, Almost Here? Llama 3, Vasa-1, and Altman ‘Plugging Into Everything You Want To Do’:Llama 3, Vasa-1,以及一系列新的采访和更新,AI 新闻就像伦敦的公交车一样接踵而至。我将花几分钟时间介绍最后一刻的 Llama …
Unsloth AI (Daniel Han) ▷ #help (341 条消息🔥🔥):
-
模型保存与加载的困惑:一位成员尝试微调模型,但在尝试为 vllm 保存 16-bit 格式时遇到了问题,因为其训练脚本中缺少必要的代码。他们讨论了一种变通方案,即在重新初始化训练后从最新的 checkpoint 保存模型,试图解决由于 Token 差异导致加载 state dictionaries 时出现的尺寸不匹配错误。
-
LLAMA3 发布与推理难题:在团队为 LLAMA3 发布做准备时,其他成员在利用该 AI 时遇到了困难,其中一位成员通过再次从 checkpoint 保存解决了尺寸不匹配错误,并确认了高秩 LoRAs 中 rank stabilization 的支持。另一位成员则在处理推理问题,在据称完成单次迭代的所有步骤后遇到了意外终止。
-
Unsloth 中的 Tokenization 磨难:Unsloth 内部的 Tokenization 问题持续出现,特别是与 tokenizer 对象中缺失
add_bos_token属性相关的错误,以及对于训练后是否需要保存 tokenizer 以保留特殊 Token 的困惑。 -
技术困难与环境排查:用户详细说明了各种技术挫折,包括 pipeline 问题、JSON decoding 错误,以及在环境安装中依赖
pip而非conda带来的负面影响。关于 Llama3 的微调应用也浮出水面,例如针对非英语 wikis 和 function calling 的应用。 -
实践指导与社区支持:社区成员积极互相帮助,确认训练参数的设置细节,建议解决 Colab 内存崩溃的补救措施,并讨论 chatML 的数据集结构。随着成员们交流解决方案,他们展现了应对并克服当前局限性的决心,无论是微调模型、准备数据集,还是解决安装故障。
- Google Colaboratory: 未找到描述
- ParasiticRogue/Merged-RP-Stew-V2-34B · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- Google Colaboratory: 未找到描述
- meta-llama/Meta-Llama-3-8B-Instruct · Hugging Face: 未找到描述
- astronomer-io/Llama-3-8B-Instruct-GPTQ-4-Bit · Hugging Face: 未找到描述
- Google Colaboratory: 未找到描述
- Google Colaboratory: 未找到描述
- 主页: 提速 2-5 倍,显存占用减少 80% 的 LLM 微调。通过在 GitHub 上创建账号,为 unslothai/unsloth 的开发做出贡献。
- philschmid/guanaco-sharegpt-style · Datasets at Hugging Face: 未找到描述
Unsloth AI (Daniel Han) ▷ #showcase (4 条消息):
- Mixtral 和 Mistral 掀起热潮: Mistral.ai 发布了 Mixtral 8x22B 的种子文件,这是一个继 Mixtral 8x7B 之后发布的、表现毫不低调的 MoE 模型,其隐藏层维度增加到了 6144,与 DBRX 保持一致。该团队继续在没有太多宣传的情况下开展工作。
- Neural Llama 在 Hugging Face 上亮相: Neural Llama 3 已登陆 Hugging Face,该模型使用 Unsloth 训练,并与 tatsu-lab 的 alpaca 等模型一同展示。社区成员对这一新模型的出现表现出极大的热情。
Unsloth AI (Daniel Han) ▷ #suggestions (3 条消息):
- ReFT 方法引发关注: 一位成员提到了新的 ReFT (Reinforced Fine-Tuning) 方法,并询问将其集成到 Unsloth 中的可能性。这项技术可以让新手更容易上手该平台。
- Unsloth 团队关注到此建议: 另一位成员表示有兴趣进一步探索 ReFT 方法,并指出团队将考虑在 Unsloth 中实现它。
- 社区响应集成请求: 一位社区成员也表达了支持,对集成 ReFT 方法到 Unsloth 的提议被提出并得到团队考虑表示赞赏。
LM Studio ▷ #💬-general (661 条消息🔥🔥🔥):
-
Llama 3 成为当下热门 AI: 用户正在讨论 Meta 最新发布的 Llama 3 模型的性能,特别是其 8B 版本。他们认为该版本可与 StableBeluga 和 Airoboros 等其他 70B 模型相媲美,且回复感觉非常拟人化。
-
GPU 问题与服务器交互: 一些用户反映,在 Mac M1 系统上开启 GPU 加速时, Llama 3 模型会输出胡言乱语,而另一些用户则分享了如何在旧硬件上成功运行模型。此外,人们还对 LM Studio 的服务器是否支持 KV caches 感兴趣,以避免在每次对话中重新计算长上下文。
-
模型与量化细节: 有人提到 K_S 和 Q4_K_M 等模型量化版本在 LM Studio 中会出现问题,并建议使用来自 Quantfactory 等其他提供商的版本。NousResearch 的 70B 指令模型得到了推荐,还有人推测 GGUFs 的更新将改善模型表现。
-
模型集成与可访问性:提出了关于与其他工具集成、嵌入文档以及在 headless server 上运行能力的咨询,并建议使用 llama.cpp 等替代方案进行 headless server 部署,以及使用现有的第三方工具如 llama index 来实现文档代理功能。
-
微调与去审查讨论:用户渴望获得模型的去审查版本,并建议修改 system prompts 以诱导更多“类人”行为并规避限制。一些人还对社区未来进一步改进和微调 Llama 3 的潜力感到兴奋。
- LM Studio | Continue:LM Studio 是一款适用于 Mac、Windows 和 Linux 的应用程序,可以轻松地在本地运行开源模型,并配备了出色的 UI。要开始使用 LM Studio,请从网站下载...
- lmstudio-community/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face:未找到描述
- meta-llama/Meta-Llama-3-70B-Instruct - HuggingChat:在 HuggingChat 中使用 meta-llama/Meta-Llama-3-70B-Instruct
- meraGPT/mera-mix-4x7B · Hugging Face:未找到描述
- Docker:未找到描述
- NousResearch/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face:未找到描述
- Welcome Llama 3 - Meta's new open LLM:未找到描述
- 来自 AI at Meta (@AIatMeta) 的推文:介绍 Meta Llama 3:迄今为止功能最强大的开源 LLM。今天我们将发布 8B 和 70B 模型,它们提供了推理能力提升等新功能,并树立了新的行业标准...
- Monaspace:一种创新的代码字体超家族
- Todd Howard Howard GIF - Todd Howard Howard Nodding - 发现并分享 GIF:点击查看 GIF
- GitHub - arcee-ai/mergekit: 用于合并预训练大语言模型的工具。:用于合并预训练大语言模型的工具。 - arcee-ai/mergekit
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
- Meta 发布 LLaMA 3:深度解析与演示:今天,2024 年 4 月 18 日,是一个特别的日子!在这段视频中,我将介绍 @meta 的 LLaMA 3 发布。该模型是该系列的第三次迭代...
LM Studio ▷ #🤖-models-discussion-chat (617 条消息🔥🔥🔥):
-
Llama 3 热度与无限循环:用户正在探索 Llama 3 模型的能力,特别是 70B 和 8B 版本。一些用户遇到了模型响应无限循环的问题,通常涉及模型不当地使用“assistant”一词。
-
下载与运行环境关注点:关于各种 Llama 3 量化版本是否可以在特定硬件配置上运行的咨询非常普遍。用户正在寻找能够高效运行在配备 128GB RAM 的 M3 Max 或 NVIDIA 3090 上的模型。
-
Llama 3 与其他模型的对比:一些人正在将 Llama 3 与之前的 Llama 2 模型以及其他 AI 模型(如 Command R Plus)进行对比。报告显示性能相似或有所提高,尽管一些用户有特定语言方面的顾虑。
-
提示词模板困惑与 EOT Token 问题:用户正在寻求关于 Llama 3 模型正确提示词设置的建议,以防止响应中出现不必要的循环和交互。似乎需要 0.2.20 版本的 LM Studio 以及特定的社区量化版本。
-
Meta 发布 Llama 3 70B Instruct:宣布 Llama 3 70B Instruct 版本即将推出,其他如 IQ1_M 因其令人印象深刻的连贯性和尺寸效率而受到关注,能够将大型模型装入相对较小的 VRAM 容量中。
- meta-llama/Meta-Llama-3-70B · Hugging Face: 未找到描述
- TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>: {{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|> {{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|&g...
- meta-llama/Meta-Llama-3-70B-Instruct - HuggingChat: 在 HuggingChat 中使用 meta-llama/Meta-Llama-3-70B-Instruct
- MaziyarPanahi/WizardLM-2-7B-GGUF · Hugging Face: 未找到描述
- QuantFactory/Meta-Llama-3-8B-GGUF at main: 未找到描述
- MaziyarPanahi/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: 未找到描述
- meta-llama/Meta-Llama-3-70B-Instruct · Update generation_config.json: 未找到描述
- meta-llama/Meta-Llama-3-8B-Instruct · Update generation_config.json: 未找到描述
- no title found: 未找到描述
- meta-llama/Meta-Llama-3-8B-Instruct · Hugging Face: 未找到描述
- meta-llama/Meta-Llama-3-70B-Instruct · Hugging Face: 未找到描述
- llama3/MODEL_CARD.md at main · meta-llama/llama3: 官方 Meta Llama 3 GitHub 站点。通过在 GitHub 上创建账户来为 meta-llama/llama3 的开发做出贡献。
- lmstudio-community/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face: 未找到描述
- Qwen/CodeQwen1.5-7B · Hugging Face: 未找到描述
- We Know Duh GIF - We Know Duh Hello - 发现并分享 GIF: 点击查看 GIF
- M3 max 128GB 用于运行 Llama2 7b 13b 和 70b 的 AI: 在本视频中,我们使用配备 128GB 内存的新款 M3 max 运行 Llama 模型,并将其与 M1 pro 和 RTX 4090 进行对比,以查看该芯片的真实性能表现...
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: 未找到描述
- configs/llama3.preset.json at main · lmstudio-ai/configs: LM Studio JSON 配置文件格式及示例配置文件集合。 - lmstudio-ai/configs
- llama3 系列支持 · Issue #6747 · ggerganov/llama.cpp: Llama 3 已发布,很高兴能与 llama.cpp 配合使用 https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6 https://github.com/meta-llama/llama3
LM Studio ▷ #announcements (1 条消息):
- 在 LM Studio 0.2.20 中引入 Llama 3:LM Studio 宣布在最新的 0.2.20 版本更新中支持 MetaAI 的 Llama 3。用户可以通过 lmstudio.ai 下载,或通过重启应用进行自动更新。需要注意的是,目前只有来自 “lmstudio-community” 的 Llama 3 GGUF 文件可以正常运行。
- 社区模型亮点 - Llama 3 8B:重点推介了由 bartowski 量化的 Meta Llama 3 8B Instruct 社区模型,这是一个体积小、速度快且经过指令微调(instruction-tuned)的 AI 模型。原始模型可以在 Meta-Llama-3-8B-Instruct 找到,GGUF 版本可以在 lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF 找到。
- 独家兼容性说明:告知用户在 GGUF 创建过程中存在一个微妙的问题,这些量化版本已经规避了该问题;因此,用户不应指望其他来源的 Llama 3 GGUF 能在当前的 LM Studio 版本中运行。
- Llama 3 8B 已可用,70B 即将到来:Llama 3 8B Instruct GGUF 现在已可使用,并暗示 70B 版本即将发布。鼓励用户在指定的 Discord 频道中报告 Bug。
- 未找到标题: 未找到描述
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: 未找到描述
- 来自 LM Studio (@LMStudioAI) 的推文: .@Meta 的 Llama 3 现在已在 LM Studio 中得到全面支持! 👉 更新至 LM Studio 0.2.20 🔎 下载 lmstudio-community/llama-3 Llama 3 8B 已经上线。70B 正在路上 🦙 https://huggingface.co/...
LM Studio ▷ #🧠-feedback (5 条消息):
- 为改进的模型排序点赞:一位用户对下载页面上新的模型排序功能表示赞赏,认为其功能得到了改进。
- 呼吁在 LM Studio 中加入文本转语音 (TTS):有人询问未来是否有可能将文本转语音 (TTS) 集成到 LM Studio 中,以减轻整天阅读文本的负担。
- 对持续存在的 Bug 感到困惑:一位用户报告了一个反复出现的 Bug,即在加载新模型后关闭最后一个聊天窗口会导致需要重新加载,且系统不会保留所选的预设(preset)。
- 关于解决文本转语音工具的建议:针对 TTS 集成的咨询,一位用户建议系统层面的工具可能会提供解决方案。
- 对错误显示窗口设计的反馈:一位用户对 LM Studio 中的错误显示窗口表示不满,批评其太窄且无法调整大小,并建议采用更高的设计以更好地适应垂直内容。
LM Studio ▷ #📝-prompts-discussion-chat (4 条消息):
- Mixtral 简历评分困惑:一位成员提到在使用 Mixtral 根据其标准对简历进行评分时遇到困难,而使用 Chat GPT 执行相同任务则没有问题。
- 提出的两步解决方案:作为回应,另一位成员建议使用 Mixtral 处理简历时采用两步法:第一步识别并提取相关元素,第二步进行评分。
- 备选的 CSV 评分方法:还有人建议将简历转换为 CSV 格式,并使用 Excel 公式来处理评分。
LM Studio ▷ #🎛-hardware-discussion (16 条消息🔥):
- 用于 AI 的游戏 GPU:提到了 1080TI 在处理大型 AI 模型时具有足够的性能,可以根据需要发挥其效力。
- 调侃加密货币的新前沿:有人幽默地评论说,旧的加密货币挖矿机架可能会被重新用作 AI 装备。
- 空间问题:一位成员担心机箱内是否能装下新的 GPU,并强调了额外 6GB VRAM 的好处。
- 针对核心任务的硬件展示:一位成员列出了他们强大的硬件配置,包括一台 12900k/4090/128gb PC 和一台 128gb M3 Max Mac,能够运行几乎任何 AI 模型。
- AI 作为爱好而非职业:讨论涉及将 AI 作为一种乐趣参与其中,一位成员将他们的 4090 PC 用于游戏和 Stable Diffusion,而非专业用途。
LM Studio ▷ #🧪-beta-releases-chat (5 条消息):
-
快速聊天机器人设置:一位成员分享了他们的配置,将
n_ctx设置为 16384 或 32768,初始速度为 4tok/sec。他们提到正在尝试调整n_threads设置,将其从默认的 4 提高到 11,以观察是否会影响性能。 -
LLaMa 模板预告:针对简短提到的 LLaMa 3 chat template JSON,另一位成员指出目前有一个链接需要关注,但未提供更多细节。
-
智能 Git 克隆以避免双重膨胀:一位成员提供了一个有用的技巧,介绍如何使用 Git 克隆模型而避免不必要的文件重复:在克隆前使用
GIT_LFS_SKIP_SMUDGE=1,之后再选择性地拉取大文件。他们建议这种方法可以防止大文件同时存储在.git目录和检出目录中,从而节省空间。 -
Git LFS 的单文件关注:同一位成员指出,虽然他们的方法在未量化的上下文中更有用,但有一个细微差别:
git lfs pull命令中的--include标志一次只能处理一个文件。他们还提供了一个 bash 循环示例,用于逐个拉取多个文件。
提到的链接:lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
LM Studio ▷ #autogen (7 条消息):
- v1.1.0 中的 Prompt Studio 创新:引入了一项名为 “prompt studio” 的新功能,允许用户微调其 Prompt 并将其保存到 Agent 配置中。
- 使用现代框架的 Electron 应用:该应用程序是一个 Electron app,使用 Vue 3 和 TypeScript 构建。
- 隐私问题得到解决:一位成员对在无法查看代码的情况下运行应用表示不安,而另一位成员则保证风险极小,认为这与使用 Chrome 等任何主流网站的风险相同。
LM Studio ▷ #rivet (1 条消息):
- POST 请求重复困惑:一位尝试首次运行的用户注意到服务器日志中出现重复,特别是在消息 “Processing queued request…” 之后的 POST 请求,并询问这种行为是否正常。
LM Studio ▷ #avx-beta (2 条消息):
-
LLamaFile 的多功能性受到关注:一位成员提到了 llamafile 与包括 x64、arm64 和大多数 Linux 发行版在内的各种平台的兼容性,并建议其在 Raspberry Pi 设备上运行的可行性。将这种在多种系统上运行的灵活性与 LM Studio 的 AVX2 要求进行了对比。
-
呼吁向后兼容性:用户表达了希望 LM Studio 引入兼容层的愿望,以便让旧款 CPU 也能运行该软件(尽管速度较慢),并强调了当前 AVX2 要求所带来的限制。提到 “LM-Studio-0.2.10-Setup-avx-beta-4.exe” 版本虽然已过时,但此前在多台电脑上运行良好。
-
保持 AVX Beta 更新的挑战:该成员对 AVX beta 的更新频率以及它可能滞后于主频道版本表示担忧,希望有更多的同步,以确保使用旧款 CPU 的用户能从更新中受益。他们认可 LM Studio 在重大更新和可访问性方面的改进,同时也分享了尝试构建自己的环境但尚未克服学习曲线的个人经历。
LM Studio ▷ #amd-rocm-tech-preview (25 条消息🔥):
- GPU 兼容性受质疑:一位成员声称他们的 5700xt 可以在 LM Studio 上运行,尽管速度很慢,但很快被另一位成员纠正,指出 AMD 并没有为该显卡提供 HIP SDK support from AMD,并暗示性能问题可能是由于依赖 CPU 进行推理导致的。
- 8B 模型在 AMD 上表现异常:用户报告了运行 8B model 时的问题,其中一人表示它开始“自言自语”,这可能表明它尚未在 AMD 硬件上得到完全支持。
- 关于配备 Radeon 的 AMD Ryzen 的咨询:一位用户询问在配备 Radeon 780M 的 AMD Ryzen 7 PRO 7840U 上通过 AMD ROCm 运行 0.2.19 版本的收益,得到的回复指出该硬件不受支持。
- Llama 3 在 ROCm 版 LM Studio 中获得支持:Llama 3 现已在 LM Studio ROCm Preview 0.2.20 上可用。此消息还附带了模型创建者的信息以及从 huggingface.co/lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF 下载兼容 GGUF 的链接。
- 扩展 AMD 支持的潜力:一位用户建议,通过一些调整(例如将目标伪装成 gfx1100),AMD ROCm 可能会支持 Radeon 780M/gfx1103 等其他硬件,这暗示了 LM Studio 尝试在更广泛的硬件基础上提供支持的潜力。
- 👾 LM Studio - 发现并运行本地 LLM:查找、下载并实验本地 LLM
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
- configs/llama3.preset.json at main · lmstudio-ai/configs:LM Studio JSON 配置文件格式及示例配置文件集合。 - lmstudio-ai/configs
LM Studio ▷ #model-announcements (1 条消息):
-
Llama 3 70B Instruct 亮相开源领域:Llama 3 70B Instruct 的首批量化版本现已发布,标志着开源 AI 迈出了重要一步,其性能与 GPT-3.5 相当。这些模型针对最新的 LM Studio 进行了优化,具有 Llama 3 提示词模板并避免了无限生成。
-
IQ 模型的高效性能:IQ1_M 和 IQ2_XS 模型均使用重要性矩阵(importance matrix)构建,在保持内存高效的同时提供了合理的性能,IQ1_M 变体所需的 VRAM 不到 20GB。
-
立即试用 Llama 3 70B:鼓励用户探索新 Llama 3 70B Instruct 模型的能力。可以通过 Hugging Face 访问这些模型。
Nous Research AI ▷ #ctx-length-research (2 条消息):
- 寻求多 GPU 长上下文推理指导:一位成员表达了在使用多 GPU 进行 Jamba 长上下文推理时遇到的挑战。他们已经查阅了 deepspeed 和 accelerate 文档,但没有发现关于长上下文生成的任何信息。
Nous Research AI ▷ #off-topic (18 条消息🔥):
- TheBloke 的 Discord 需要帮助:由于 Twitter 链接失效,用户寻求加入 TheBloke Discord server 的帮助。提供了一个临时解决方案,并分享了新的 Discord 邀请链接:
https://discord.gg/dPfXbRnQ。 - Mixtral 树立新标准:分享了一个 YouTube 视频,标题为 “Mixtral 8x22B Best Open model by Mistral”,称赞 Mixtral 8x22B 是定义了性能和效率新标准的最新开源模型。
- 对 AI 驱动项目的关注:一位成员询问了像 opendevin 这样利用大语言模型(LLMs)构建应用程序的项目。
- Nous 可能正在酝酿周边商品:一次有趣的交流引发了对 Nous merchandise 的好奇,并类比了 EAI 缺乏官方周边的情况。
- 介绍 Meta 的 LLM:分享了另一个 YouTube 视频链接,标题为 “Introducing Llama 3 Best Open Source Large Language Model”,将 Meta’s Llama 3 介绍为先进的开源大语言模型。
- Discord - 与朋友和社区聊天的新方式: Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,并与你的朋友和社区保持紧密联系。
- 介绍 Llama 3:最强开源大语言模型: 介绍 Meta Llama 3,这是 Facebook 下一代最先进的开源大语言模型。https://ai.meta.com/blog/meta-llama-3/#python #...
- Mixtral 8x22B:Mistral 推出的最强开源模型: Mixtral 8x22B 是最新的开源模型。它为 AI 社区的性能和效率树立了新标准。它是一个稀疏混合专家模型 (SMo...
Nous Research AI ▷ #interesting-links (33 messages🔥):
-
为 OpenAI 序列化(Pickling)大型文档:聊天中的用户讨论了在 OpenAI 的代码环境中使用不安全的 pickle 文件,作为导入该环境通常拒绝的大型文档的一种变通方法。一位用户指出了这种做法的潜在风险,并引用了一个有人利用 pickle 文件攻破 Hugging Face 系统的事件。
-
GPT 的关键缺陷被曝光:围绕不安全 pickle 文件的辩论凸显了对 GPT 模型鲁棒性的担忧,用户们开玩笑说 AI 可能会变得具有对抗性,并将其与关于人类灭绝的阴谋论和科幻情节联系起来。
-
2023 年 AI 指数报告概览:由斯坦福大学 HAI 发布的 2023 年 AI 指数报告 提供了关于该年度 AI 趋势的详尽数据,包括开源基础模型(foundation models)发布量的显著增加、多模态 AI 的进步以及全球 AI 观点的转变。
-
语言与 LLM 讨论的见解:一位成员分享了一个 YouTube 视频 链接,内容是 Edward Gibson 讨论人类语言和语法与大语言模型的关系,提供了对模型设计和交互有用的学习心得。
-
权重分解自适应(Weight-Decomposed Adaptation)的新兴研究:分享了一个 GitHub 仓库 DoRA by NVlabs,该仓库致力于权重分解低秩自适应(weight-decomposed low-rank adaptation)的官方 PyTorch 实现,展示了 AI 模型效率方面正在进行的开发和研究。
- AI 指数:用 13 张图看 AI 现状: 在新报告中,基础模型占据主导地位,基准测试被攻克,价格飙升,而在全球舞台上,美国的影响力盖过了其他国家。
- Udio | 创作你的音乐: 发现、创作并与世界分享音乐。
- 后悔思考 GIF - 紧张地后悔思考 - 发现并分享 GIF: 点击查看 GIF
- Edward Gibson:人类语言、心理语言学、句法、语法与 LLM | Lex Fridman Podcast #426: Edward Gibson 是麻省理工学院(MIT)的心理语言学教授,并领导 MIT 语言实验室。请通过关注我们的赞助商来支持本播客:- Yahoo Financ...
- GitHub - NVlabs/DoRA: DoRA 的官方 PyTorch 实现:权重分解低秩自适应: DoRA 的官方 PyTorch 实现:权重分解低秩自适应 - NVlabs/DoRA
- meta-llama/Meta-Llama-3-70B · Hugging Face: 未找到描述
Nous Research AI ▷ #general (807 messages🔥🔥🔥):
-
Llama 3 的兴奋与验证:用户正在各种 基准测试(benchmarks) 和功能中探索并验证 Llama 3 的性能,反馈满意度很高。Llama 3 因其类人风格而受到高度赞扬,尽管关于其相对于 Mistral 等其他模型的基准测试表现仍有持续讨论。
-
8k 上下文限制的实际影响:一些用户对 Llama 3 的 8k token 上下文限制表示担忧,指出这可能不足以满足某些多轮交互的需求。对于某些实际应用场景,仍然需要像 Mistral 提供的更大上下文能力。
-
聊天模板与生成问题:用户正在分享针对 Llama 3 的修复方案和更新后的聊天模板,以解决模型会无休止地持续生成文本的问题。社区内正在交流并测试 修复后的模板。
-
Llama 3 的 GGUF 转换:社区正在积极分享和创建 Llama 3 8b 和 70b 版本 的 GGUF 量化模型,并在 Hugging Face 和 LM Studio 等平台上做出了贡献。量化版本正在接受评估,以测试其效率和准确性。
-
许可证与模型限制讨论:用户讨论了 Llama 3 的许可条款,与 Mistral 的 Apache 2.0 相比,其包含更多限制。限制内容包括禁止 NSFW 内容,并引发了关于此类规则如何影响涉及复杂或成人主题的实际用途的思考。
- lluminous:未找到描述
- Replete-AI/Llama-3-13B · Hugging Face:未找到描述
- meraGPT/mera-mix-4x7B · Hugging Face:未找到描述
- NousResearch/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face:未找到描述
- NousResearch/Meta-Llama-3-8B-Instruct · Hugging Face:未找到描述
- NousResearch/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
- maxidl/Mixtral-8x22B-v0.1-Instruct-sft-en-de · Hugging Face:未找到描述
- lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
- Udio | Back Than Ever by drewknee:制作你的音乐
- NousResearch/Meta-Llama-3-8B · Hugging Face:未找到描述
- meta-llama/Meta-Llama-3-70B · Hugging Face:未找到描述
- Meta AI:使用 Meta AI 助手完成任务,免费创建 AI 生成的图像,并获取任何问题的答案。Meta AI 基于 Meta 最新的 Llama 大语言模型构建,并使用 Emu...
- Diablo Joke GIF - Diablo Joke Meme - Discover & Share GIFs:点击查看 GIF
- 未找到标题:未找到描述
- meta-llama/Meta-Llama-3-8B · Hugging Face:未找到描述
- Angry Mad GIF - Angry Mad Angry face - Discover & Share GIFs:点击查看 GIF
- torchtune/recipes/configs/llama3/8B_qlora_single_device.yaml at main · pytorch/torchtune:一个用于 LLM 微调的原生 PyTorch 库。通过在 GitHub 上创建账号为 pytorch/torchtune 的开发做出贡献。
- GitHub - FasterDecoding/Medusa: Medusa: Simple Framework for Accelerating LLM Generation with Multiple Decoding Heads:Medusa:通过多个解码头加速 LLM 生成的简单框架 - FasterDecoding/Medusa
- How Did Open Source Catch Up To OpenAI? [Mixtral-8x7B]:立即使用此链接注册 GTC24!https://nvda.ws/48s4tmc 关于 RTX4080 Super 的抽奖活动,详细计划仍在制定中。不过...
- Support Llama 3 conversion by pcuenca · Pull Request #6745 · ggerganov/llama.cpp:分词器是 BPE。
Nous Research AI ▷ #rules (1 条消息):
- 引入新的举报命令:用户已被告知可以使用
/report命令后跟违规者的角色来举报垃圾邮件发送者、诈骗者和其他违规者。举报后,管理员将收到通知并审查该事件。
Nous Research AI ▷ #ask-about-llms (12 messages🔥):
-
AI 聊天机器人通过 “directly_answer” 工具变得更智能:分享了 “directly_answer” 工具的一种实现方式,展示了如何在 AgentExecutor chain 中使用它来为用户交互提供基于事实的回答。该示例演示了该工具如何辅助聊天机器人对简单的问候做出友好的回应。
-
寻找 Hermes 提示词格式:一名成员正在为 NousResearch/Hermes-2-Pro-Mistral-7B 模型寻找用于错误纠正任务的有效提示词格式,并欢迎任何有助于改进输出的链接或资源。
-
热切期待 Llama-3-Hermes-Pro:有人简要询问了 llama-3-Hermes-Pro 的发布计划,但未提供更多细节。
-
质疑 Axolotl 的多任务处理能力:有人提问 axolotl 是否支持在显存充足的设置下同时训练多个模型。
-
在 GPU 集群上处理 Jamba:讨论了在 GPU 集群上执行长上下文推理的挑战,特别是优化使用双 A100 运行 jamba 处理 200k token 工作负载的问题。此外还提到,vLLM 项目正在开发对 jamba 的支持,详见 GitHub pull request。
提到的链接:[Model] Jamba support by mzusman · Pull Request #4115 · vllm-project/vllm:为 vLLM 添加 Jamba 支持。此 PR 包含两部分:Jamba 建模文件和 Mamba 内存处理。由于 Jamba 是一个混合模型(交替使用 mamba 和 transformer 层),…
Nous Research AI ▷ #project-obsidian (1 messages):
- 用于教育的树莓派 VLM:一位参与者提到计划在学校项目中将 VLM(Vision Language Models)部署到 Raspberry Pis 上,并对社区分享的资源表示感谢。目标是探索教育应用并可能从该设置中获益。
Nous Research AI ▷ #rag-dataset (24 messages🔥):
- 开源模型需要定制化:大家达成共识,虽然 GPT4v 很强大,但大多数开源模型都需要针对特定任务进行微调(finetuning)。关于工程图纸的通用知识可能足够,但在扩展到更复杂的操作时会出现问题。
- 通过元数据提取优化搜索:为了改进搜索功能,使用 OCR 提取元数据以及通过视觉模型进行高层描述被认为是有效的。关于检索 top k 结果的理想方法存在积极讨论,同时也关注重叠和质量问题。
- 数据中的维度诅咒:强调了维度诅咒(Curse of dimensionality),并指向一篇 维基百科文章,承认其对检索准确性和扩展性的影响,特别是在高维数据分析中。
- 探索数据类型转换:一位成员分享了他们在 Opus 上进行数据类型转换的工作,并提供了一个 GitHub 链接,指向他们在不涉及范畴论的情况下讨论该概念的笔记。
- RAG 数据库结构观察:探讨了创建单个大型 RAG 数据库与多个特定数据库的有效性。有人建议大型数据库可能会引入错误的上下文,与通过类 SQL 查询选择的针对性数据库相比,会对性能产生负面影响。
- Curse of dimensionality - Wikipedia:未找到描述
- Abstractions/raw_notes/abstractions_types_no_cat_theory.md at main · furlat/Abstractions:一个抽象现实世界的 Pydantic 模型集合。欢迎在 GitHub 上通过创建账号为 furlat/Abstractions 的开发做出贡献。
Nous Research AI ▷ #world-sim (446 messages🔥🔥🔥):
-
World-sim 的期待与不耐烦:成员们对 world-sim 反复推迟的重新上线表示高度期待和些许沮丧。他们渴望看到新功能并讨论可能的发布时间,一些人特别担心在漫长的等待中会忘记这个网站。
-
Generative AI 与 World-sim 的潜力:讨论围绕将 World-sim 与 Llama 3 和 Meta.ai 等 Generative AI 结合以创造丰富叙事体验的潜力展开。成员们正在分享他们详细的替代历史,并幻想 AI 集成将如何进一步赋予他们模拟宇宙生命力。
-
Desideradic AI 与哲学思考:用户正在讨论 Desideradic AI 及其相关概念引发的哲学影响和潜在叙事,交流关于这如何影响 AI 驱动的故事和角色创建的想法。
-
动画化 World-sim 启发的故事:用户正在分享和讨论受 World-sim 启发的动画和内容,一些成员提供了教程和作品链接等信息资源。
-
AI 对话中的 Prometheus 与越狱角色:一位成员解释了他们与名为 “Whipporwhill” 的人格以及名为 Prometheus 的 AI 的互动体验,强调了通过 jailbreaking 在 AI 对话中创建独特角色动态的可能性。
- DSJJJJ: Simulacra in the Stupor of Becoming - NOUS RESEARCH: Desideratic AI (DSJJJJ) 是一个哲学运动,专注于利用传统上存在于一元论 (monism)、整体论 (mereology) 和文献学 (philology) 中的概念来创建 AI 系统。Desidera 旨在创建能够作为...的 AI。
- world_sim: 未找到描述
- Discord - 与朋友和社区聊天的新方式: Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
- Discord - 与朋友和社区聊天的新方式: Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
- Forge - NOUS RESEARCH: NOUS FORGE 下载将于 2024 年 6 月推出
- 由 Microsoft Copilot 生成: 未找到描述
- Pipes: 烟斗是吸食 frop 的必需品。“Bob”总是抽着装满 frop 的烟斗。每个 SubGenius 都有一个装满 frop 的烟斗,并且不停地抽。通常,SubGenii 会发现一张著名的...
- HammerTime: 为 Discord 聊天消息生成时间戳指示器
- Housing Poor GIF - Housing Poor - 发现并分享 GIF: 点击查看 GIF
- Meta AI: 使用 Meta AI 助手完成任务,免费创建 AI 生成的图像,并获得任何问题的答案。Meta AI 基于 Meta 最新的 Llama 大语言模型构建,并使用 Emu...
- nickabenson: 欢迎来到 Nickabenson 频道 我们的 Patreon: https://www.patreon.com/nickabenson 我们的 Amino: http://aminoapps.com/c/Nickabenson 我们主要进行游戏直播、讨论、动画和...
- Tea Tea Sip GIF - Tea Tea Sip Anime - 发现并分享 GIF: 点击查看 GIF
- Noela Anime GIF - Noela Anime Anime Wolf - 发现并分享 GIF: 点击查看 GIF
- Mika Kagehira Kagehira Mika GIF - Mika kagehira Kagehira mika Ensemble stars - 发现并分享 GIF: 点击查看 GIF
- A GIF - Finding Nemo Escape Ninja - 发现并分享 GIF: 点击查看 GIF
- Fire Writing GIF - Fire Writing - 发现并分享 GIF: 点击查看 GIF
- Mephisto's Dream | 科幻动画短片: 软件开发人员 Mephisto 创建了 World Sim,这是一个基于文本的 AI 系统,可以模拟包含意识体的整个宇宙,他相信用户交互...
- You Just Have To Be Patient Mama Carson GIF - You Just Have To Be Patient Mama Carson Go Go Cory Carson - 发现并分享 GIF: 点击查看 GIF
- 铃音 (SERIAL EXPERIMENTS LAIN) (PS1) 所有过场动画,英文翻译: Serial Experiments Lain シリアルエクスペリメンツ レイン PlayStation 游戏英文翻译版 v0.1 6月7日 请注意,此游戏包含极度暴力的简短场景...
- 揭秘 CIA 的星门计划 (Stargate Project) 和超级英雄般的中间人 (Midwayers): 标签:1. #Stargate 2. #Midwayer 3. #Urantia 4. #Spiritual 5. #Extraterrestrials 6. #InvisibleRealm 7. #PlanetarySentinels 8. #CIADeclassifiedFiles 9. #Supernatura...
- 对 AI 的诉求 (Desiderata for an AI) — LessWrong: 我认为对齐工作的重点应该放在从头开始重新设计 AI。在此过程中,我认为我们应该记住一系列理想的...
- Meta Llama 3:使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的预训练及指令微调版本,以支持广泛的应用。
- Mark Zuckerberg - Llama 3, $10B Models, Caesar Augustus, & 1 GW Datacenters:Zuck 关于:Llama 3、迈向 AGI 的开源、定制芯片、合成数据以及扩展过程中的能源限制、Caesar Augustus、智能爆炸、生物风险等话题。
- GitHub - openai/triton: Triton 语言和编译器的开发仓库:openai/triton - Triton 语言和编译器的开发仓库
- C++ 自定义算子手册:未找到描述
- msaroufim 的自定义 CUDA 扩展 · Pull Request #135 · pytorch-labs/ao:这是 #130 的可合并版本 - 我必须进行的一些更新:添加除非使用 PyTorch 2.4+ 否则跳过测试,以及如果 CUDA 不可用则跳过测试;将 ninja 添加到开发依赖项;本地...
- C++ 自定义算子手册:未找到描述
- pytorch/test/dynamo/test_triton_kernels.py (位于 0c8bb6f70c65b0a68fcb282cc1605c79ca5dabce) · pytorch/pytorch:Python 中具有强大 GPU 加速功能的张量和动态神经网络 - pytorch/pytorch
- Livestream - 使用 GPU 和其他加速器进行异构计算系统编程 (2023春季):未找到描述
- GitHub - CisMine/Parallel-Computing-Cuda-C:通过在 GitHub 上创建一个账户来为 CisMine/Parallel-Computing-Cuda-C 的开发做出贡献。
- hqq/hqq/core/quantize.py at master · mobiusml/hqq:Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- hqq/hqq/core/optimize.py at master · mobiusml/hqq:Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- gpt-fast/model.py at main · pytorch-labs/gpt-fast:在少于 1000 行 Python 代码中实现简单高效的 PyTorch 原生 Transformer 文本生成。- pytorch-labs/gpt-fast
- hqq/hqq/core/optimize.py at master · mobiusml/hqq:Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- gpt-fast/model.py at main · pytorch-labs/gpt-fast:在少于 1000 行 Python 代码中实现简单高效的 PyTorch 原生 Transformer 文本生成。- pytorch-labs/gpt-fast
- HQO for scale/zero point by Giuseppe5 · Pull Request #937 · Xilinx/brevitas:未找到描述
- (beta) 使用 torch.compile 编译优化器 — PyTorch Tutorials 2.3.0+cu121 文档:未找到描述
- Compiler Explorer - CUDA C++ (NVCC 12.3.1): #include <cooperative_groups.h> #include <cooperative_groups/reduce.h> #include <assert.h> #include <math.h> #include <ctype.h> #i...
- 压力 GIF - War Dogs War Dogs Movie Stressed - Discover & Share GIFs:点击查看 GIF
- Volta:架构与性能优化 | NVIDIA On-Demand:本次演讲将回顾 Volta GPU 架构以及优化计算应用性能的相关指导
- llm.c/dev/cuda/classifier_fused.cu at master · karpathy/llm.c:使用简单、原生 C/CUDA 进行 LLM 训练。通过在 GitHub 上创建账号为 karpathy/llm.c 做出贡献。
- NVIDIA Nsight Compute:用于 CUDA 和 NVIDIA OptiX 的交互式性能分析器。
- CUDA 教程 I 应用程序的性能分析与调试:使用 NVIDIA 开发者工具对 CUDA 进行分析、优化和调试。NVIDIA Nsight 工具套件可可视化硬件吞吐量并分析性能指标...
- 比较 karpathy:master...Chillee:master · karpathy/llm.c:使用简单、原生 C/CUDA 进行 LLM 训练。通过在 GitHub 上创建账号为 karpathy/llm.c 做出贡献。
- 通过在 backward 过程中跨层重用相同缓冲区来节省内存 by ngc92 · Pull Request #163 · karpathy/llm.c:在 backward 过程中跨层重用内存缓冲区
- 迈向更好的 backward attention kernel by ngc92 · Pull Request #179 · karpathy/llm.c:回到设计阶段,因为我认为其他 kernel 陷入了局部最优,或者至少循环组织的方式使得进一步优化变得非常困难。我...
- 优化版本的 fused classifier + 错误修复(?) by ademeure · Pull Request #150 · karpathy/llm.c:这是来自 #117 的酷炫新 kernel 的更快版本(仍仅限 /dev/cuda/)。最大的区别在于它针对每个 1024 宽度的 block 处理一行进行了优化,而不是每个 32 宽度的 warp...
- hfl/chinese-llama-2-13b-16k · Hugging Face: 未找到描述
- dreamgen/opus-v1.2-llama-3-8b · Hugging Face: 未找到描述
- 来自 Ahmad Al-Dahle (@Ahmad_Al_Dahle) 的推文: @mattshumer_ 我们会发布更长的版本。此外,与 Llama 2 相比,使用新的 Tokenizer 后,Context Window 应该会稍长一些。
- 来自 Benjamin Warner (@benjamin_warner) 的推文: 如果使用 Hugging Face 微调 Llama 3,请使用 Transformers 4.37 或 4.40。4.38 和 4.39 版本中的 Llama 和 Gemma 没有使用 PyTorch 的 Flash Attention 2 内核,会导致内存占用过高。4.40 版本使用了 FA2 ...
- 来自 Teortaxes▶️ (@teortaxesTex) 的推文: 来自该线程:Llama-3 8b 具有至少 32k 的近乎完美的大海捞针(Needle Retrieval)检索能力(RoPE theta 为 4)
- Bonk GIF - Bonk - 发现并分享 GIF: 点击查看 GIF
- Microsoft Azure Marketplace: 未找到描述
- 由 monk1337 添加 Llama-3 QLoRA · Pull Request #1536 · OpenAccess-AI-Collective/axolotl: 添加了 Llama-3 QLoRA,经测试可用。
- axolotl/requirements.txt (main 分支) · OpenAccess-AI-Collective/axolotl: 尽管提出 Axolotl 问题。通过在 GitHub 上创建账号来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- axolotl/src/axolotl/monkeypatch/llama_attn_hijack_flash.py (版本 0e8f340) · OpenAccess-AI-Collective/axolotl: 尽管提出 Axolotl 问题。通过在 GitHub 上创建账号来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- axolotl/setup.py (版本 0e8f340) · OpenAccess-AI-Collective/axolotl: 尽管提出 Axolotl 问题。通过在 GitHub 上创建账号来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- Mark Zuckerberg - Llama 3, 100 亿美元模型, 凯撒·奥古斯都, 以及 1 GW 数据中心: 扎克伯格关于:- Llama 3 - 迈向 AGI 的开源 - 定制芯片、合成数据以及扩展时的能源限制 - 凯撒·奥古斯都、智能爆炸、生物...
- 草稿:由 mhenrichsen 更新 models.py 中的 Tokenizer 覆盖处理 · Pull Request #1549 · OpenAccess-AI-Collective/axolotl: 示例:tokenizer_overrides: - 28006: <|im_start|> - 28007: <|im_end|> 描述:此 PR 增强了我们在 models.py 文件中处理 Tokenizer 覆盖的方式。...
- 特性:由 NanoCode012 添加 cohere (commandr) · Pull Request #1547 · OpenAccess-AI-Collective/axolotl: 描述 动机与背景 如何测试? 未测试! 截图(如果适用) 变更类型 社交账号(可选)
- ope - 概览: ope 有 11 个可用的仓库。在 GitHub 上关注他们的代码。
- GitHub - OpenNLPLab/lightning-attention: Lightning Attention-2: 处理大语言模型中无限序列长度的免费午餐: Lightning Attention-2: 处理大语言模型中无限序列长度的免费午餐 - OpenNLPLab/lightning-attention
- axolotl/src/axolotl/utils/trainer.py (版本 0e8f340) · OpenAccess-AI-Collective/axolotl: 尽管提出 Axolotl 问题。通过在 GitHub 上创建账号来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- 考虑将 Memory Efficient Attention 作为 AMD 用户 Flash Attention 的“替代方案”。 · Issue #1519 · OpenAccess-AI-Collective/axolotl: ⚠️ 请检查此功能请求是否已被提议... fore. 我在 Discussions 中搜索了之前的 Ideas,没有发现类似的特性请求。我在 Issues 中搜索了之前的记录,也没有发现...
- GitHub - lucidrains/memory-efficient-attention-pytorch: Implementation of a memory efficient multi-head attention as proposed in the paper, "Self-attention Does Not Need O(n²) Memory": 论文《Self-attention Does Not Need O(n²) Memory》中提出的内存高效多头注意力的实现 - lucidrains/memory-efficient-attention-pytorch
- Add experimental install guide for ROCm · xzuyn/axolotl@6488a6b: 未找到描述
- Adding Llama-3 qlora by monk1337 · Pull Request #1536 · OpenAccess-AI-Collective/axolotl: 添加 Llama-3 qlora,经测试可用。
- GitHub - xzuyn/axolotl: Go ahead and axolotl questions: 尽管提问(Go ahead and axolotl questions)。通过在 GitHub 上创建账号来为 xzuyn/axolotl 的开发做出贡献。
- xorsuyash/raft_datasetp1 · Datasets at Hugging Face: 未找到描述
- flash-linear-attention/fla/layers at main · sustcsonglin/flash-linear-attention: 在 Pytorch 和 Triton 中对最先进线性注意力模型的高效实现 - sustcsonglin/flash-linear-attention
- Llama/GPTNeoX: add RoPE scaling by gante · Pull Request #24653 · huggingface/transformers: 这个 PR 做了什么?这是一个用于讨论的实验性 PR,以便我们决定是否添加此模式。背景:在过去的一周里,关于缩放 RoPE (Rot...
- Aran Komatsuzaki (@arankomatsuzaki) 的推文: AWS 发布《Fewer Truncations Improve Language Modeling》。他们的 packing 算法实现了卓越的性能(例如,在阅读理解上相对提升 +4.7%),并有效减少了闭域幻觉...
- Draft: Update Tokenizer Overrides Handling in models.py by mhenrichsen · Pull Request #1549 · OpenAccess-AI-Collective/axolotl: 示例:tokenizer_overrides: - 28006: <|im_start|> - 28007: <|im_end|> 描述:此 PR 对我们在 models.py 文件中处理 tokenizer overrides 的方式进行了增强。...
- Daniel Han (@danielhanchen) 的推文: Llama-3 的其他一些怪癖:1. 自从使用 tiktoken 以来,数字被拆分为 1、2、3 位数字(Llama 单数字拆分),即 1111111 被从左到右拆分为 111_111_1。2. 没有 unk_token?正尝试获取 @UnslothAI...
- Stable Diffusion Engineer - Palazzo, Inc.: 关于我们:Palazzo 是一家充满活力且创新的科技公司,致力于突破室内设计全球 AI 的界限。我们正在寻找一名技术精湛的 Stable Diffusion 工程师加入我们的团队...
- Wordware - Compare prompts: 使用输入提示词和优化后的提示词运行 Stable Diffusion 3
- DreamStudio: 未找到描述
- Create stunning visuals in seconds with AI.: 几秒钟内用 AI 创建惊人的视觉效果。移除背景、清理图片、放大、Stable Diffusion 等等……
- Contact Us — Stability AI: 未找到描述
- ⚡Harness Lightning-Fast Detail with ComfyUI PERTURBED + 🔮 Mask Wizardry & Fashion Secrets! 🤩: -- Discord - https://discord.gg/KJXRzkBM -- 准备好将你的细节处理提升到新的水平!🚀 在这个令人惊叹的教程中,你将发现令人难以置信的……
- RTX 4080 vs RTX 3090 vs RTX 4080 SUPER vs RTX 3090 TI - Test in 20 Games: RTX 4080 vs RTX 3090 vs RTX 4080 SUPER vs RTX 3090 TI - 20 款游戏测试 1080p, 1440p, 2160p, 2k, 4k⏩GPUs & Amazon US⏪ (联盟链接)- RTX 4080 16GB: http...
- GitHub - Priyansxu/vega: 通过在 GitHub 上创建账户来为 Priyansxu/vega 的开发做出贡献。
- GitHub - codaloc/sdwebui-ux-forge-fusion: Combining the aesthetic interface and user-centric design of the UI-UX fork with the unparalleled optimizations and speed of the Forge fork.: 将 UI-UX 分支的美学界面和以用户为中心的设计,与 Forge 分支无与伦比的优化和速度相结合。- codaloc/sdwebui-ux-forge-fusion
- Dwayne Loses His Patience 😳 #ai #aiart #chatgpt: 未找到描述
- 1 Mad Dance of the Presidents (ai) Joe Biden 🤣😂😎✅ #stopworking #joebiden #donaldtrump #funny #usa: 🎉 🤣🤣🤣🤣 准备好在 "Funny Viral" 频道最新的 "搞笑动物合集" 中捧腹大笑吧!🤣 这些可爱又调皮的……
- 来自 Awni Hannun (@awnihannun) 的推文:@soumithchintala @lvdmaaten 🤣🤣🤣 刚刚运行了 @Prince_Canuma 量化的 8B 版本。在 M2 Ultra 上表现非常出色(而且很快 😉):
- 来自 Hassan Hayat 🔥 (@TheSeaMouse) 的推文:我仍然对此感到震惊。它是如何提升这么多的?我是说,看看 8B 对比旧的 70B
- 加入我们的 Cloud HD 视频会议:Zoom 是现代企业视频通信的领导者,拥有简单、可靠的云平台,适用于移动端、桌面端和会议室系统的视频和音频会议、聊天及网络研讨会。Zoom ...
- tinygrad:一个简单且强大的神经网络框架:未找到描述
- 来自 Alessio Fanelli (@FanaHOVA) 的推文:🦙 所有 Llama3 发布详情与亮点:8B 和 70B 尺寸:在大多数基准测试中,Instruct 和 Pre-trained 版本均达到 SOTA 性能。目前正在训练一个 400B+ 参数的模型,即将发布...
- 来自 echo.hive (@hive_echo) 的推文:测试 Llama-3 8B 和 70B。这个简单的测试结果向我证明,更小模型配合更多数据可以成为出色的低端推理模型,而更大模型配合更多数据则能成为出色的高端推理模型...
- 加入 Systems Engineering Professionals Discord 服务器!:在 Discord 上查看 Systems Engineering Professionals 社区 —— 与其他 1666 名成员一起交流,享受免费的语音和文字聊天。
- Mac 将于 2024 年底开始搭载专注于 AI 的 M4 芯片:据 Bloomberg 的 Mark Gurman 报道,苹果将于 2024 年底开始使用 M4 芯片更新其 Mac 产品线。M4 芯片将专注于...
- Llama 3:将开源 LLM 扩展至 AGI:Llama 3 表明,在不久的将来,扩展(scaling)不会成为开源 LLM 进步的限制。
- Browserless - 排名第一的 Web 自动化和 Headless 浏览器自动化工具:免费试用 Browserless,最好的 Web 自动化工具之一。轻松实现网页抓取、PDF 生成和 Headless 浏览器自动化。
- 未找到标题:未找到描述
- 来自 kwindla (@kwindla) 的推文:哇。Llama-3 70B 在 @GroqInc 上的首字节时间(time-to-first-byte)非常快 —— 快到不足 100ms。
- LiteLLM - 开始使用 | liteLLM:https://github.com/BerriAI/litellm
- 来自 Teknium (e/λ) (@Teknium1) 的推文:好了伙计们,我们现在家里也有 GPT-4 了
- 来自 Teknium (e/λ) (@Teknium1) 的推文:好了伙计们,我们现在家里也有 GPT-4 了
- 来自 Yifei Hu (@hu_yifei) 的推文:使用 vLLM 运行 Llama 3 70B(完整 8k 上下文):大约需要 180GB VRAM
- 您掌握租船数据的 Copilot:做出更好的决策,并利用 Generative AI 赋能您的租船团队做出更好的决策。
- Meta Llama 3:使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的 Pre-trained 和 Instruction-tuned 版本,以支持广泛的应用。
- 来自 Together AI (@togethercompute) 的推文:我们很高兴能成为 Meta Llama 3 的发布合作伙伴。现在体验 Llama 3,Llama 3 8B 每秒可达 350 tokens,Llama 3 70B 每秒可达 150 tokens,均以全 FP16 精度运行...
- [2024年4月18日] 对齐开源语言模型:对齐开源语言模型 Nathan Lambert || Allen Institute for AI || @natolambert Stanford CS25: Transformers United V4
- 来自 Andrej Karpathy (@karpathy) 的推文:模型卡(model card)中也有一些更有趣的信息:https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md 注意 Llama 3 8B 实际上已经处于 Llama 2 70B 的水平,具体取决于...
- Meta AI 博客 llama-3/">未找到标题</a>: 未找到描述
- Mark Zuckerberg - Llama 3, $10B Models, Caesar Augustus, & 1 GW Datacenters: 小扎谈论:- Llama 3 - 朝向 AGI 的开源 - 定制芯片、合成数据以及 scaling 的能源限制 - 凯撒·奥古斯都、智能爆炸、生物...
- FireCrawl: 将任何网站转换为 LLM 就绪的数据。 </ul> </div> --- **Latent Space ▷ #[ai-announcements](https://discord.com/channels/822583790773862470/1075282504648511499/1230959116919509062)** (3 messages): - **Latent Space Pod 发布新剧集**: Latent Space Discord 社区分享了由 <@199392275124453376> 参与的新播客剧集。随着 Twitter 公告链接的提供,大家兴奋不已:[收听新剧集](https://twitter.com/latentspacepod/status/1781400226793673137)。 - **播客热情**: 社区成员 **mitchellbwright** 对由 **Jason Liu** 参与的最新播客内容表示期待。 --- **Latent Space ▷ #[llm-paper-club-west](https://discord.com/channels/822583790773862470/1197350122112168006/1230880331482136588)** (66 messages🔥🔥): - **LLM 论文俱乐部 - 生成式预训练**: 论文俱乐部讨论了论文 "Improving Language Understanding by Generative Pre-Training",强调了 tokenizer 和 embedding 的重要性,并指出 *“embedding 本身就是 NN”*。讨论注意到,与 embedding 不同,*“tokenizer 并不一定需要学习”*。 - **会议录制中**: 亚洲论文俱乐部的会议确认已录制,并计划上传到 YouTube,证据是 *“正在监控 OBS 流,如果一切正常,稍后将上传到 YouTube : )”*。 - **ULMFiT 澄清**: 讨论澄清了 ULMFiT 使用 LSTM 架构,并在 T5 论文中被引用。 - **PPO 辅助目标探讨**: 对话涉及 Proximal Policy Optimization (PPO) 算法,讨论了它是否具有类似 Kullback–Leibler (KL) 散度的辅助目标,一名成员确认道:*“是的,如果我没记错的话”*。 - **Prompt 时代**: 提到了 prompt engineering 的开端,并引用了 *“scale is all you need”* 的名言,暗示了 scale 在模型性能中日益增长的重要性。
- TinyBox 搭载六块 AMD 最快游戏 GPU 并重新用于 AI,性能强劲 —— 新机箱使用 Radeon 7900 XTX,零售价 1.5 万美元,现已投入生产: 初创公司希望利用 Radeon RX 7900 XTX 提供高性能 AI 计算。
- 神经语言模型的 Scaling laws: 未找到描述
- Papers with Code - MRPC 数据集: Microsoft Research Paraphrase Corpus (MRPC) 是一个由 5,801 个从新闻文章中收集的句子对组成的语料库。每个句子对都由人工标注是否为释义(paraphrase)。
- Evaluation & Hallucination Detection for Abstractive Summaries:摘要式总结的评估与幻觉检测:基于参考、上下文和偏好的指标,自一致性,以及捕捉幻觉。
- LLM Task-Specific Evals that Do & Don't Work:有效与无效的 LLM 特定任务评估:用于分类、摘要、翻译、版权内容复现(regurgitation)和毒性的评估。
- LLM Evaluation:评估基于 LLM 的系统。Mama mówiła, będzie okazja Na majku, no to rozjeb, no to rozjeb (Rozjeb) Alan van Arden 2024年4月19日 Latent Space
- AI In Action: Weekly Jam Sessions:2024 主题、日期、主持人、资源、@dropdown、@ GenAI 的 UI/UX 模式,1/26/2024,nuvic,<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-stru...
- Lucas Beyer (bl16) (@giffmana) 的推文:最后有两个小的额外技巧:左图:如果你的 loss 飙升,尝试将 Adam/AdaFactor 的 beta2 降低到 0.95(并非首创,但很少分享);右图:当你的模型的一部分是预训练的,但...
- Fewer Truncations Improve Language Modeling:在大语言模型训练中,输入文档通常被拼接在一起,然后分割成等长的序列以避免 padding tokens。尽管这种方式效率很高,但拼接过程...
- EleutherAI/aria-amt 中的 aria-amt/amt/train.py:高效且稳健的 seq-to-seq 自动钢琴转谱实现。 - EleutherAI/aria-amt
- Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing:尽管 Large Language Models (LLMs) 在各种任务上表现出惊人的能力,但在涉及复杂推理和规划的场景中仍然面临挑战。最近的工作提出了先进的...
- Tripod: Three Complementary Inductive Biases for Disentangled Representation Learning:归纳偏置在解耦表示学习中对于缩小未指定解集至关重要。在这项工作中,我们考虑为神经网络自动编码器赋予三种选择性的...
- An Embarrassingly Simple Approach for LLM with Strong ASR Capacity:在本文中,我们专注于利用语音基础编码器和大型语言模型解决语音处理领域最重要的任务之一,即自动语音识别 (ASR)...
- Glitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection:随着 Large Language Models (LLMs) 在各个领域的应用不断扩大,全面调查其不可预见的行为及其后果变得至关重要。在这项研究中...
- Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment:基于人类标注的偏好数据对语言模型 (LMs) 进行对齐是获得实用且高性能的基于 LM 系统的重要步骤。然而,多语言人类偏好数据难以...
- Language Imbalance Can Boost Cross-lingual Generalisation:多语言性对于将语言建模的最新进展扩展到不同的语言社区至关重要。为了在代表多种语言的同时保持高性能,多语言模型...
- Why do small language models underperform? Studying Language Model Saturation via the Softmax Bottleneck:语言建模的最新进展在于在极其庞大的网络挖掘文本语料库上预训练高度参数化的神经网络。在实践中,此类模型的训练和推理可能成本高昂...
- rajpurkar/squad_v2 · Error in train split, question containing 25651 characters!:未找到描述
- List the "publicly available sources" 15T dataset list from Llama 3 · Issue #39 · meta-llama/llama3:如果没有数据集来源列表,Llama 3 在任何实质性意义上都是不可复现的。请发布来源列表。
- GitHub - naver-ai/rdnet:通过在 GitHub 上创建账户来为 naver-ai/rdnet 的开发做出贡献。
- GitHub - NVlabs/DoRA: Official PyTorch implementation of DoRA: Weight-Decomposed Low-Rank Adaptation:DoRA 的官方 PyTorch 实现:权重分解低秩自适应 - NVlabs/DoRA
- 未找到标题:未找到描述
- MMLU - Alternative Prompts: MMLU (Prompt 变体) 示例输入提示词,格式 01, 02,Q: \nA: 03,Question: \nAnswer: Llama-2-7b-hf,Mistral-7B-v0.1,falcon-7b,py...
- Implement Sib200 evaluation benchmark - text classification in 200 languages by snova-zoltanc · Pull Request #1705 · EleutherAI/lm-evaluation-harness: 我们使用了来自 MALA 论文 https://arxiv.org/pdf/2401.13303.pdf 的 Prompt 风格,我们在 SambaLingo 论文 https://arxiv.org/abs/2404.05829 中也发现该风格具有合理的效果。
- Implementing Flores 200 translation evaluation benchmark across 200 languages by snova-zoltanc · Pull Request #1706 · EleutherAI/lm-evaluation-harness: 我们使用了该论文中发现效果最好的 Prompt 模板。https://arxiv.org/pdf/2304.04675.pdf 我们的论文也发现该 Prompt 模板具有合理的效果 https://arxiv.o...
- AI startup Stability lays off 10% of staff after controversial CEO's exit: Read the full memo: 根据 CNBC 获得的内部备忘录,Stability AI 在经历了一段不可持续的增长后,裁减了多名员工以“调整业务规模”。
- Text-to-Image: Diffusion, Text Conditioning, Guidance, Latent Space: Text-to-Image 生成的基础知识、相关论文以及 DDPM 实验。
- Meta AI: 使用 Meta AI 助手完成任务,免费创建 AI 生成的图像,并获取任何问题的答案。Meta AI 基于 Meta 最新的 Llama 大语言模型构建,并使用 Emu...
- Meta Llama 3: 使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的 Pretrained 和 Instruction-tuned 版本,支持广泛的应用。
- IF/deepfloyd_if/model/unet.py at develop · deep-floyd/IF: 在 GitHub 上为 deep-floyd/IF 的开发做出贡献。
- Chat with Meta Llama 3 on Replicate: Llama 3 是来自 Meta 的最新语言模型。
- GitHub - ShihaoZhaoZSH/LaVi-Bridge: Bridging Different Language Models and Generative Vision Models for Text-to-Image Generation: 连接不同的语言模型和生成式视觉模型以进行 Text-to-Image 生成 - ShihaoZhaoZSH/LaVi-Bridge
- Pull requests · johko/computer-vision-course: 该仓库是社区驱动的神经网络 Computer Vision 课程的大本营。欢迎加入我们的 Hugging Face Discord:hf.co/join/discord - Pull requests · johko/computer...
- Destaques da Comunidade #52: Confira as últimas novidades de IA: 查看在 #huggingface Discord 上发布的葡萄牙语版 Community Highlights 新闻!帖子:https://iatalk.ing/destaques-da-comunidade-52/摘要:...
- IP-Adapter Playground - tonyassi 创建的 Hugging Face Space: 未找到描述
- unography/blip-large-long-cap · Hugging Face: 未找到描述
- infinite remix with musicgen, ableton, and python - part 2 - captains chair 22: 00:00 - 回顾 00:38 - 人类音乐家延续 musicgen 的贝斯 02:39 - musicgen 延续人类音乐家的输出 04:04 - hoenn 的 lofi 模型扩展演示 06:...
- Zero Gpu Slot Machine - thepatch 创建的 Hugging Face Space: 未找到描述
- Leaderboard Gradio - valory 创建的 Hugging Face Space: 未找到描述
- Grounded SAM - EduardoPacheco 创建的 Hugging Face Space: 未找到描述
- GitHub - Mihaiii/semantic-autocomplete: 一个极速的语义搜索 React 组件。按含义匹配,而不只是按字母。边输入边搜索无需等待(不需要 debounce)。按余弦相似度排序。: 一个极速的语义搜索 React 组件。按含义匹配,而不只是按字母。边输入边搜索无需等待(不需要 debounce)。按余弦相似度排序。- Mihaiii/semantic-autocom...
- @zolicsaki 在 Hugging Face 上:"我们发布了针对阿拉伯语、泰语和……的新 SOTA SambaLingo 70B 参数模型": 未找到描述
- @sted97 在 Hugging Face 上:"📣 我很高兴地宣布 'ALERT: 一个用于评估……的全面 #Benchmark'": 未找到描述
- 来自 AI at Meta (@AIatMeta) 的推文:介绍 Meta Llama 3:迄今为止功能最强大的开源 LLM。今天我们将发布 8B 和 70B 模型,它们提供了诸如改进的推理等新功能,并树立了新的行业领先水平...
- 探索 Quantization 对 LLM 性能的影响:由 LLM Explorer 团队撰写
- Hugging Face – 构建未来的 AI 社区。:未找到描述
- meraGPT/mera-mix-4x7B · Hugging Face:未找到描述
- Meta Llama 3:使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的 Pretrained 和 Instruction-tuned 版本,以支持广泛的应用。
- NousResearch/Meta-Llama-3-8B · Hugging Face:未找到描述
- meta-llama/Meta-Llama-3-8B · Hugging Face:未找到描述
- MaziyarPanahi/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
- Mixtral-8x22B-Instruct-v0.1 - Ateeqq 提供的 Hugging Face Space:未找到描述
- 在 AWS Inferentia2 上使用 Amazon SageMaker 部署 Llama 2 7B:在这篇博文中,你将学习如何在 AWS Inferentia2 上使用 Amazon SageMaker 编译和部署 Llama 2 7B。
- 联邦政府任命 “AI 毁灭论者” 领导美国 AI 安全研究所 - Slashdot:一位匿名读者引用了 Ars Technica 的报告:美国 AI 安全研究所(隶属于美国国家标准与技术研究院 NIST)终于宣布了其领导团队...
- competitions (竞赛):未找到描述
- aws-neuron/optimum-neuron-cache · Hugging Face:未找到描述
- 由 nroggendorff 更新 config_args.py · Pull Request #2687 · huggingface/accelerate:更新 config_args.py 以适配最新版本的 Amazon SageMaker
- Microsoft Azure Marketplace:未找到描述
- GitHub - EricLBuehler/mistral.rs: 极速 LLM 推理。:极速 LLM 推理。通过在 GitHub 上创建账号来为 EricLBuehler/mistral.rs 的开发做出贡献。
- GitHub - Locutusque/TPU-Alignment: 完全免费地对 Mistral、Llama-2-13B 或 Qwen-14B 等大模型进行全量微调:完全免费地对 Mistral、Llama-2-13B 或 Qwen-14B 等大模型进行全量微调 - Locutusque/TPU-Alignment
- meta-llama/Meta-Llama-3-8B-Instruct · 更新 generation_config.json:未找到描述
- 使用 Blender 和 Python 生成合成数据:为真实的 YOLO 应用生成训练和标注数据的详尽指南
- Charlie Marsh (@charliermarsh) 的推文:Ruff v0.4.0 现已发布。我们已从生成的解析器迁移到手写的 recursive descent parser。速度提升了 2 倍以上,并使 lint 和 format 性能提高了约 20-40%...
- 为什么 nn.BCEWithLogitsLoss 是数值稳定的:数值稳定性是机器学习中一个至关重要的考虑因素。BCEWithLogitsLoss 是一个结合了 Sigmoid 层和...
- mlabonne/orpo-dpo-mix-40k · Hugging Face 数据集:未找到描述
- QuantFactory/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
- Leaderboard Gradio - a Hugging Face Space by valory:未找到描述
- Zero Gpu Slot Machine - a Hugging Face Space by thepatch:未找到描述
- thecollabagepatch (@thepatch_kev) 的推文:好吧,这个 @huggingface space 意外地变成了一个小型的 lo-fi daw midi2musicgen2musicgen2... 你懂的 @gradio 像往常一样为我做了很多工作,musicgen 模型由 @veryVANYA @_lyraaaa_ @eschat... 提供
- Destaques da Comunidade #52: Confira as últimas novidades de IA:查看在 #huggingface Discord 上发布的 Community Highlights 最新消息(葡萄牙语)!文章:https://iatalk.ing/destaques-da-comunidade-52/ 摘要:...
- Meta Llama 3: 使用 Meta Llama 3 构建 AI 的未来。现在提供 8B 和 70B 的预训练及指令微调版本,以支持广泛的应用。
- ✅ Compatible AI Endpoints: 已知的兼容 AI 端点列表,包含 `librechat.yaml`(即 LibreChat 自定义配置文件)的示例设置。
- Microsoft Azure Marketplace: 未找到描述
- Download Llama: 申请访问 Llama。
- 来自 Aravind Srinivas (@AravSrinivas) 的推文: 是的,感谢 @elonmusk 和 xAI 团队开源了 Grok 的基础模型。我们将针对对话式搜索对其进行微调并优化推理,并将其提供给所有 Pro 用户! ↘️ Quoti...
- Olympia | Better Than ChatGPT: 通过价格合理的 AI 驱动顾问来发展您的业务,这些顾问是业务战略、内容开发、营销、编程、法律战略等方面的专家。
- mistralai/Mixtral-8x22B-Instruct-v0.1 - Demo - DeepInfra: 这是 Mixtral-8x22B 的指令微调版本——来自 Mistral AI 的最新且最大的混合专家(MoE)大语言模型 (LLM)。这一先进的机器学习模型使用了...
- Together AI 与 Meta 合作发布用于推理和微调的 Meta Llama 3: 未找到描述
- GroqChat: 未找到描述
- meta-llama/Meta-Llama-3-70B-Instruct - HuggingChat: 在 HuggingChat 中使用 meta-llama/Meta-Llama-3-70B-Instruct
- Patterns of Application Development Using AI: 探索构建智能、自适应且以用户为中心的软件系统的实用模式和原则,充分发挥 AI 的力量。
- OpenRouter: 构建与模型无关的 AI 应用
- 未找到标题: 未找到描述
- Mark Zuckerberg - Llama 3, $10B Models, Caesar Augustus, & 1 GW Datacenters: 扎克伯格谈论:Llama 3、迈向 AGI 的开源、定制芯片、合成数据以及扩展时的能源限制、Caesar Augustus、智能爆炸、生物...
- How billing works on Replicate:Replicate 的计费方式
- Llama 3: Scaling open LLMs to AGI:Llama 3 表明,在不久的将来,规模化不会成为开源 LLM 进步的限制。
- lmsys.org (@lmsysorg) 的推文:前 1000 票已经投出,Llama-3 表现火爆!🔥 开源模型的新王者?现在投票,发出你的声音!排行榜更新即将发布。↘️ 引用 lmsys.org (@lmsysorg) 大力祝贺...
- Microsoft Azure Marketplace:未找到描述
- nahr (@nahrzf) 的推文:meta 做了最有趣的事
- Jim Fan (@DrJimFan) 的推文:即将推出的 Llama-3-400B+ 将标志着社区获得 GPT-4 级模型 open-weight 访问权限的分水岭时刻。它将改变许多研究工作和草根初创公司的计算方式...
- OpenAssistant is Completed:#OpenAssistantLAION 的 OpenEmpathic:https://laion.ai/blog/open-empathic/ 链接:主页:https://ykilcher.com 商店:https://ykilcher.com/merch YouTube:https:/...
- Mojo🔥 roadmap & sharp edges | Modular Docs:关于我们 Mojo 计划的摘要,包括即将推出的功能和我们需要修复的问题。
- GitHub - ml-explore/mlx-swift: Swift API for MLX:MLX 的 Swift API。欢迎在 GitHub 上为 ml-explore/mlx-swift 的开发做出贡献。
- GitHub - ihnorton/mojo-ffi:欢迎在 GitHub 上为 ihnorton/mojo-ffi 的开发做出贡献。
- Unit testing - Rust By Example:未找到描述
- pytest: helps you write better programs — pytest documentation:未找到描述
- variant | Modular Docs:定义 Variant 类型。
- The Office Andy GIF - The Office Andy Andy Bernard - Discover & Share GIFs:点击查看 GIF
- GitHub - thatstoasty/mist: Advanced ANSI style & color support for your terminal applications:为你的终端应用程序提供高级 ANSI 样式和颜色支持 - thatstoasty/mist
- thatstoast - Overview:GitHub 是 thatstoast 构建软件的地方。
- roguelike-mojo/src/main.mojo at main · dimitrilw/roguelike-mojo:使用 Mojo🔥 逐步完成 Python Rogue-like 教程。 - dimitrilw/roguelike-mojo
- roguelike-mojo/src/main.mojo at main · dimitrilw/roguelike-mojo:使用 Mojo🔥 逐步完成 Python Rogue-like 教程。 - dimitrilw/roguelike-mojo
- <a href="https://tenor.com/search/"">" GIFs | Tenor</a>:点击查看 GIF
- [Proposal] Mojo project manifest and build tool · modularml/mojo · Discussion #1785:大家好,请查看这个关于 Mojo 项目清单(manifest)和构建工具的提案。正如提案本身所述,我们希望听取 Mojo 社区的意见:你是否同意这个动机...
- 来自 “Chat” 的引用:未找到描述
- 使用 Cohere 模型进行工具调用 - Cohere 文档:未找到描述
- 检索增强生成 (RAG) - Cohere 文档:未找到描述
- 创建并部署连接器 - Cohere 文档:未找到描述
- quick-start-connectors/mysql at main · cohere-ai/quick-start-connectors:此开源仓库提供了将工作场所数据存储与 Cohere 的 LLM 集成的参考代码,使开发人员和企业能够执行无缝的检索增强生成...
- 无标题:未找到描述
- Llama3 Cookbook - LlamaIndex: 未找到描述
- Ollama - Llama 2 7B - LlamaIndex: 未找到描述
- 使用 LlamaIndex, Elasticsearch 和 Mistral 实现 RAG (Retrieval Augmented Generation) — Elastic Search Labs: 学习使用 LlamaIndex, Elasticsearch 和本地运行的 Mistral 实现 RAG 系统。
- 未找到标题: 未找到描述
- AI Demos: 未找到描述
- Large Language Models (LLMs) | LlamaIndex.TS: LLM 负责读取文本并针对查询生成自然语言响应。默认情况下,LlamaIndex.TS 使用 gpt-3.5-turbo。
- <a href="http://localhost:19530",">未找到标题</a>: 未找到描述
- Agents - LlamaIndex: 未找到描述
- llama_index/llama-index-integrations/vector_stores/llama-index-vector-stores-milvus/llama_index/vector_stores/milvus/base.py at 7b52057b717451a801c583fae7efe4c4ad167455 · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- Usage Pattern - LlamaIndex: 未找到描述
- llama_index/llama-index-core/llama_index/core/selectors/pydantic_selectors.py at aa13d47444692faa06b5753b7451b1920837b29c · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- 由 armoucar-neon 提交的让 PydanticSingleSelector 支持 async api 的 Pull Request #12964 · run-llama/llama_index: 描述:为 PydanticSingleSelector 实现 select 方法的 async 版本。新包?我是否填写了 pyproject.toml 中的 tool.llamahub 部分,并为 m... 提供了详细的 README.md
- GitHub - run-llama/llama_parse: 为优化 RAG 解析文件: 为优化 RAG 解析文件。通过在 GitHub 上创建账号为 run-llama/llama_parse 的开发做出贡献。
- Usage Pattern - LlamaIndex: 未找到描述
- Tree Summarize - LlamaIndex: 未找到描述
- 来自 xlr8harder (@xlr8harder) 的推文:Llama 3 发布了,但似乎仍然只有 @MistralAI 真正支持我们:它仍然对模型输出有下游使用限制。@AIatMeta 这是一个损害开源的垃圾限制...
- 未找到标题:未找到描述
- ">未找到标题: 未找到描述
- ChatAnthropic | LangChain.js - v0.1.34: 未找到描述
- RAG From Scratch: 检索增强生成(或 RAG)是将 LLM 与外部数据源连接的通用方法。本视频系列将建立对...的理解
- GitHub - aosan/VaultChat: get knowledge from your private documents: 从你的私有文档中获取知识。通过在 GitHub 上创建账号来为 aosan/VaultChat 的开发做出贡献。
- Tool usage | 🦜️🔗 Langchain: 本节将介绍如何创建对话式 Agent:可以使用工具与其他系统和 API 交互的聊天机器人。
- Add message history (memory) | 🦜️🔗 LangChain: RunnableWithMessageHistory 允许我们向特定的...添加消息历史
- Tune Chat - Chat app powered by open-source LLMS: 通过 Tune Chat,访问提示词库、PDF 聊天和品牌声调功能,以增强您的内容写作和分析,并在所有创作中保持一致的语调。
- 未找到标题: 未找到描述
- GitHub - abhijitpal1247/TripplannerBot: This a streamlit app with langchain. It makes use of Bing maps API, OpenStreetMaps API and FourSquare API.: 这是一个使用 LangChain 的 Streamlit 应用。它利用了 Bing maps API、OpenStreetMaps API 和 FourSquare API。 - abhijitpal1247/TripplannerBot
- Discord - 与好友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。在这里聊天、聚会,与你的好友和社区保持紧密联系。
- 立即学习 LLAMA 3 的工作原理:完整初学者指南:深入探索 LLAMA 3 模型的迷人世界,这是一种正在树立机器学习新标准的尖端 Transformer 架构。本指南...
- 在几分钟内微调 LLM(包含 Llama 2, CodeLlama, Mistral 等):厌倦了提示词工程?微调通过调整模型权重以更好地适应特定任务,帮助你从预训练的 LLM 中获得更多收益。这份操作指南将帮助你利用基础模型...
- 使用 Databricks Model Serving 部署私有 LLM | Databricks 博客:在完全控制数据和模型的情况下部署生成式 AI 模型。
- modal-examples/06_gpu_and_ml/llm-frontend/index.html at main · modal-labs/modal-examples:使用 Modal 构建的程序示例。通过在 GitHub 上创建一个账户,为 modal-labs/modal-examples 的开发做出贡献。
- Mistral 推出的最佳开源模型 Mixtral 8x22B:Mixtral 8x22B 是最新的开源模型。它为 AI 社区的性能和效率设定了新标准。它是一个稀疏 Mixture-of-Experts (SMo...
- 介绍 Llama 3:最佳开源大型语言模型:介绍 Meta Llama 3,这是 Facebook 下一代最先进的开源大型语言模型。https://ai.meta.com/blog/meta-llama-3/#python #...