ainews-evals-the-next-generation
**评测:下一代** (或者:**评估:下一代**)
以下是为您翻译的中文内容:
Scale AI 指出了 MMLU 和 GSM8K 等基准测试中的数据污染问题,并提出了一个新的基准测试,在该测试中 Mistral 表现出过拟合,而 Phi-3 表现良好。Reka 发布了针对多模态模型的 VibeEval 基准测试,旨在解决多选题基准测试的局限性。OpenAI 的 Sam Altman 称 GPT-4 “很笨”,并暗示具备 AI 智能体(agents)能力的 GPT-5 将是一个重大突破。研究人员通过微调(fine-tuning)实现了对 GPT-3.5 的越狱。全球范围内出现了禁止 AI 武器的呼声,美国官员敦促对核武器保持人类控制。乌克兰推出了 AI 领事化身,同时 Moderna 与 OpenAI 合作推动医疗 AI 的进步。Sanctuary AI 与微软在通用机器人 AI 领域展开合作。麻省理工学院(MIT)推出了 Kolmogorov-Arnold 网络(KANs),提高了神经网络的效率。Meta AI 正在训练参数量超过 4000 亿的 Llama 3 模型,该模型将具备多模态能力和更长的上下文窗口。
AI News (2024/5/1-2024/5/2)。我们为您检查了 7 个 subreddits、373 个 Twitter 账号 以及 28 个 Discord 服务器(418 个频道,5582 条消息)。为您节省的预计阅读时间(以 200wpm 计算):588 分钟。
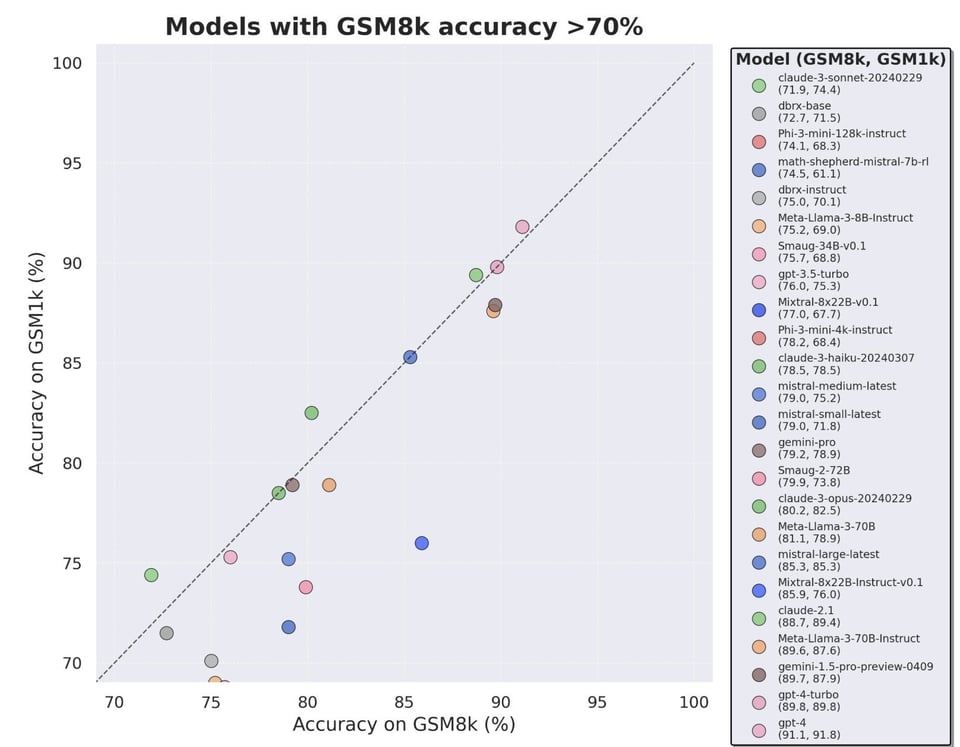
数据/基准测试(benchmark)污染问题通常被当作一个笑话,但今年正达到一个临界点,人们对以往在 MMLU 和 GSM8K 等知名学术基准测试上自报分数的做法信任度正在下降。Scale AI 发布了 《对大语言模型在小学算术表现的仔细检查》,提出了一种类似 GSM8K 但污染较少的新基准测试,并绘制了偏差图——Mistral 似乎在 GSM8K 上有明显的过拟合(overfit),而 Phi-3 表现得非常出色:
Reka 也为其擅长的多模态模型发布了新的 VibeEval 基准测试。他们解决了广为人知的 MMLU/MMMU 问题,即多选题基准测试对于 chat models 来说并不是一个良好或稳定的衡量标准。
最后,我们将展示 Jim Fan 关于 evals 未来发展路径的思考:

目录
[TOC]
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 发展与能力
-
GPT-4 及其后续版本:在多次演讲和采访中,OpenAI CEO Sam Altman 称 GPT-4 “愚笨”且“令人尴尬”,暗示即将发布的 GPT-5 将有实质性提升。Altman 认为能够协助用户处理任务并访问个人信息的 AI Agent 将是下一个重大突破,并设想了一个了解用户生活方方面面的“超能同事”。
-
越狱 GPT-3.5:一位研究员展示了如何利用 OpenAI 的 fine-tuning API 越狱 GPT-3.5。通过在由无限制 LLM 生成的有害问答数据集上训练模型,从而绕过安全检查。
AI 监管与安全
-
呼吁禁止 AI 武器:世界各国领导人正呼吁禁止 AI 驱动的武器和“杀人机器人”,将当前 AI 发展的时刻比作原子弹的“奥本海默时刻”。然而,一些人认为此类禁令将难以执行。
-
人类对核武器的控制:一名美国官员正敦促中国和俄罗斯声明只有人类(而非 AI)才能控制核武器,这凸显了人们对 AI 控制的武器系统日益增长的担忧。
AI 应用与合作伙伴关系
-
乌克兰的 AI 领事化身:乌克兰外交部宣布推出一款 AI 驱动的化身,用于提供领事事务更新,旨在为该机构节省时间和资源。
-
Moderna 与 OpenAI 的合作伙伴关系:Moderna 与 OpenAI 达成合作,旨在利用 AI 加速挽救生命的疗法开发,这具有彻底改变医学的潜力。
-
Sanctuary AI 与 Microsoft 的合作:Sanctuary AI 与 Microsoft 正在合作,以加速通用机器人 AI 的开发,旨在创造更通用、更智能的机器。
AI 研究与进展
-
Kolmogorov-Arnold 网络:MIT 研究人员开发了“Kolmogorov-Arnold 网络” (KANs),这是一种新型神经网络,在边(edges)而非节点(nodes)上具有可学习的激活函数。与传统的 MLP 相比,它展现出了更高的准确性、参数效率和可解释性。
-
Meta 的 Llama 3 模型:Meta 正在训练参数量超过 4000 亿的 Llama 3 模型,预计将支持多模态、拥有更长的上下文长度,并可能在不同领域具备专业能力。
-
mRNA 癌症疫苗突破:一种使用“洋葱状”多层 RNA 脂质颗粒聚集体的新型 mRNA 癌症疫苗技术,已在四名人类患者的脑癌治疗中取得成功。
-
首个先导编辑疗法:FDA 已批准 Prime Medicine 关于首个先导编辑(prime editing)疗法的 IND(新药临床试验申请)。这是一种新型基因编辑技术,具有比现有方法更精确地治疗遗传性疾病的潜力。
-
AI 驱动的动物长寿研究:Olden Labs 推出了 AI 驱动的智能笼子,可自动进行动物长寿研究,旨在提供低成本、数据丰富的研究,同时改善动物福利。
梗图与幽默
- 监管 AI 的梗图:一张幽默的图片描绘了一个人试图通过用皮带物理束缚机器人来监管 AI,调侃了 AI 治理面临的挑战。
{kind=link}
AI Twitter 回顾
所有回顾均由 Claude 3 Opus 完成,从 4 次运行中选取最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
太空中的 LLM 与高效推理
- 为太空环境加固 LLM:@karpathy 提议对 LLM 代码进行加固以通过 NASA 标准,使其能够在太空安全运行。LLM 非常适合此类场景,因为它们具有固定的浮点数数组以及有界的、定义良好的动力学特征。将 LLM 权重发送到太空可以让它们“唤醒”并与外星人互动。
- 使用 Groq 进行高效推理:@awnihannun 强调 @GroqInc 在降低高质量 LLM 的 $/token 成本方面处于领先地位。@virattt 发现 Llama-3 70B 在 @GroqInc 上的基准测试中拥有最佳的性能和价格比。@svpino 鼓励尝试使用 Groq 来体验极高的模型速度。
- 4-bit 量化:@awnihannun 计算出在 M2 Ultra 上运行 4-bit 70B Llama-3 的成本为 $0.2/百万 tokens,功耗为 60W。@teortaxesTex 展示了“外部大脑”的量化水平。
评估与改进 LLM
- 评估 LLM:@DrJimFan 提出了 3 种评估类型:由 @scale_AI 等受信任第三方提供公开评分的私有测试集;像 @lmsysorg Chatbot Arena ELO 这样的公开对比基准测试;以及针对每个公司特定用例的私有内部基准测试。
- GSM1K 基准测试:@alexandr_wang 和 @scale_AI 推出了 GSM1K,这是一个新的测试集,显示 LLM 的准确率下降高达 13%,其中 Phi 和 Mistral 存在过拟合现象。@SebastienBubeck 指出 phi-3-mini 76.3% 的准确率对于一个 3.8B 模型来说非常出色。
- 多模态模型中的逆缩放 (Inverse Scaling):@YiTayML 观察到逆缩放在多模态模型中比纯文本模型更显著,即较小的模型表现优于较大的模型。目前这仍属于轶事观察。
- 评估推理能力:@omarsar0 分享了一篇关于解释 Transformer LM 在推理任务中内部运作机制的论文。
开源模型与框架
- Reka 发布评估集:@RekaAILabs 发布了名为 Vibe-Eval 的内部评估子集,这是一个包含 269 个图文提示词的开放基准测试,用于衡量多模态对话的进展。超过 50% 的提示词目前尚无模型能够解决。
- LlamaIndex Typescript 发布:@llama_index 发布了 LlamaIndex.TS v0.3,包含 Agent 支持、Web 流、类型定义以及针对 Next.js、Deno、Cloudflare 等的部署增强。
新兴模型与技术
- 来自 AI21 的 Jamba Instruct:@AI21Labs 发布了基于 SSM-Transformer Jamba 架构的 Jamba-Instruct。它在质量基准测试中领先,拥有 256K 上下文窗口,且价格极具竞争力。
- Nvidia 的 Llama 微调:@rohanpaul_ai 注意到 Nvidia 推出了名为 ChatQA-1.5 的 Llama-3 70B 微调模型,具有良好的基准测试表现。
- Kolmogorov-Arnold Networks (KANs):@hardmaru 分享了一篇关于 KANs 的论文,将其作为 MLPs 的替代方案用于逼近非线性函数。@rohanpaul_ai 解释说 KANs 使用的是可学习的样条激活函数,而 MLPs 中则是固定的。
- Meta 的多 Token 预测 (Multi-Token Prediction):@rohanpaul_ai 详细解析了 Meta 的多 Token 预测技术,该技术通过训练 LM 预测未来多个 Token,从而实现更高的样本效率和高达 3 倍的推理加速。
行业动态
- Anthropic 的 Claude iOS 应用:@AnthropicAI 发布了 Claude iOS 应用,将“前沿智能”装进你的口袋。@alexalbert__ 分享了它如何助力工具使用(tool use)功能的发布。
- Lamini AI 获 2500 万美元 A 轮融资:@realSharonZhou 宣布 @LaminiAI 获得 2500 万美元 A 轮融资,以帮助企业开发内部 AI 能力。投资者包括 @AndrewYNg, @karpathy, @saranormous 等。
- Google I/O 5 月 14 日举行:@GoogleDeepMind 宣布 Google I/O 开发者大会将于 5 月 14 日举行,重点展示 AI 创新与突破。
- Anthropic 推出 Claude 团队计划:@AnthropicAI 为 Claude 发布了全新的团队(Team)计划,包含更高的使用额度、用户管理、计费功能以及 200K 上下文窗口。
迷因与幽默
- 迷因:@DeepLearningAI 分享了一个来自 Reddit 上的 buildooors 关于 AI 的迷因。
AI Discord 回顾
摘要之摘要的摘要
- 模型进展与微调:
- 将 Llama 3 的 LoRA rank 提高到 128,以优先考虑理解而非记忆,增加了超过 3.35 亿个可训练参数 [Tweet]
- 探索 Unsloth 的多 GPU 支持用于模型训练,目前仅限于单 GPU [GitHub Wiki]
- 发布 Llama-3 8B Instruct Gradient,通过 RoPE theta 调整来处理更长的上下文 [HuggingFace]
- 推出基于 Llama-3 架构的 Hermes 2 Pro,在 AGIEval 等基准测试中表现优于 Llama-3 8B [HuggingFace]
- 硬件优化与部署:
- 讨论 LLM 的最佳 GPU 选择,考虑 PCIe 带宽、VRAM 需求(理想情况下 24GB+)以及多 GPU 性能
- 探索本地部署选项(如针对小型 LLM 的 RTX 4080)与云端解决方案在隐私方面的权衡
- 通过合并数据集而不增加上下文长度等技术,优化训练期间的 VRAM 占用
- 将 DeepSpeed 的 ZeRO-3 与 Flash Attention 集成,以实现高效的大模型微调
- 多模态 AI 与计算机视觉:
- 新型神经网络架构:
- 其他:
-
Stable Diffusion 模型讨论与 PC 配置:Stability.ai 社区分享了对各种 Stable Diffusion 模型(如来自 HuggingFace 的 ‘4xNMKD-Siax_200k’)的见解,并讨论了用于 AI 艺术生成的最佳 PC 组件(如 4070 RTX GPU)。他们还探索了 AI 在 Logo 设计中的应用,使用了 harrlogos-xl 等模型。
-
LLaMA 上下文扩展技术:在多个社区中,工程师们讨论了扩展 LLaMA 模型上下文窗口的方法,例如使用 PoSE 训练方法实现 32k 上下文或调整 rope theta。提到了使用 RULER 工具 来识别长上下文模型中的实际上下文大小。
-
量化与微调讨论:LLM 的 Quantization 是一个热门话题,Unsloth AI 社区将 Llama 3 上的 LoRA rank 从 16 增加到 128,以优先考虑理解而非记忆。OpenAccess AI Collective 推出了 Llama-3 8B Instruct Gradient,通过 RoPE theta 调整实现在长上下文上的极简训练 (Llama-3 8B Gradient)。
-
检索增强生成 (RAG) 技术:多个社区探索了增强 LLM 的 RAG 技术。分享了一个关于 RAG 基础的新教程系列 (YouTube tutorial),并讨论了一篇关于 Adaptive RAG 的论文,该技术可根据查询复杂度动态选择最佳策略 (YouTube overview)。此外,还重点介绍了 Plaban Nayak 关于使用 reranker 进行后处理以提高 RAG 准确性的指南。
-
引入新模型与架构:发布了多种新模型和架构,例如 Nous Research 基于 Llama-3 构建的 Hermes 2 Pro (Hermes 2 Pro),OpenRouter 的 Snowflake Arctic 480B 和 FireLLaVA 13B,以及作为 MLP 替代方案的 Kolmogorov-Arnold Networks (KANs) (KANs paper)。
PART 1: Discord 高层摘要
CUDA MODE Discord
CUDA 调试技巧与更新:成员们交流了 CUDA 调试的心得,推荐了诸如详细的 Triton 调试讲座 等资源,并强调了使用最新版本 Triton 的重要性,提到了解释器中最近的 bug 修复。
CUDA Profiling 的烦恼与智慧:工程师们努力应对不一致的 CUDA profiling 结果,建议使用 NVIDIA 的分析工具如 Nsight Compute/Systems,而不是 cudaEventRecord。分享了一个针对 NVIDIA 的 tinygrad patch,旨在帮助类似的故障排除工作。
Torch 与 PyTorch 实力:讨论中提到需要 PyTorch 内部机制(特别是 ATen/linalg)方面的专业知识,同时为 TorchInductor 爱好者指引了学习资源(虽未具体说明)。并向所有 PyTorch contributors 征集深入的平台知识。
AI 模型训练构建的进展:#llmdotc 频道的对话显示了大量围绕模型训练的活动。从 FP32 master copy of params 到 CUDA Graphs,讨论涵盖了与性能、精度和复杂度相关的一系列技术挑战,并附带了指向各种 GitHub issue 和 pull request 的链接,以便协作解决问题。
深入探讨工程稀疏性:工程师们思考了 Effort Engine,辩论了其 benchmark 表现以及速度与质量之间的平衡。思考的重点包括参数重要性优于精度、权重剪枝(weight pruning)中的质量权衡以及潜在的模型改进。
AMD 与 Intel 技术的前瞻性思考:大家对 AMD 的 HIP 语言 表现出极大的热情,并分享了 AMD ROCm 平台 的教程播放列表,表明对 GPU 多样化编程语言的兴趣日益浓厚。此外,提到 Intel 加入 PyTorch 网页,暗示了向跨不同架构的更广泛支持迈进。
LM Studio Discord
CLI 的新前沿:LM Studio 0.2.22 的发布引入了全新的命令行界面 lms,实现了 加载/卸载 LLMs 以及 启动/停止本地服务器 等功能,开发工作已在 GitHub 上开放贡献。
解决 LLM 安装混乱:社区讨论强调了 LM Studio 0.2.22 Preview 的安装问题,这些问题通过提供修正后的下载链接得到了解决;同时,用户就模型性能优化和量化技术交换了意见,特别是针对 Llama 3 model。
无头运行(Headless Operation)创新:成员们分享了在没有图形用户界面的系统上无头运行 LM Studio 的策略,建议使用 xvfb 和其他变通方法,为 Docker 等容器化可能性铺平了道路。
ROCm 与 AMD 备受关注:对话集中在不同 AMD GPUs 与 ROCm 的兼容性,以及 ROCm 在 Linux 支持方面的挑战,突显了社区对高效利用多样化硬件基础设施的追求。
硬件讨论深入展开:讨论深入探讨了硬件选择的细节,特别是适合运行 LLMs 的 GPU,以及 PCIe 3.0 vs 4.0 对多 GPU VRAM 性能的影响,最终达成共识:对于像 Meta Llama 3 70B 这样强大的模型,至少 24GB VRAM 是理想的选择。
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 迎来升级:讨论集中在最新的 Stable Diffusion 模型上,如 ‘Juggernaut X’ 和 ‘4xNMKD-Siax_200k’,许多用户从 HuggingFace 获取 4xNMKD-Siax_200k 模型。
-
针对 AI 工作负载的 PC 组装建议:社区成员就最适合 AI 艺术创作的 PC 组件交换了建议,强调了即将推出的 Nvidia 5000 series 以及当前高性能的 4070 RTX GPU 在高效运行模型方面的潜在优势。
-
AI 进入设计领域:围绕使用 AI 进行 Logo 设计展开了深入对话,重点提到了 harrlogos-xl,该模型专注于在 Stable Diffusion 中生成自定义文本,并触及了法律影响。
-
提升现实感的放大(Upscaling)与重绘(Inpainting)技巧:对话包括了通过放大技术 LDSR 获得更高图像质量的技巧,并分享了一个 Reddit 指南,关于如何将任何模型重新利用于重绘,尽管用户的成功程度各不相同。
-
使用开源解决方案保障数字艺术创作安全:在推动更好安全性的过程中,一些成员推荐了开源替代方案,如 Android 端的 Aegis 和 iOS 端的 Raivo 用于 一次性密码 (OTP),并指出设备同步和安全备份选项等功能的重要性。
Unsloth AI (Daniel Han) Discord
-
LoRA 助力 Llama 3 升级:工程师们一直将 Llama 3 的 LoRA rank 从 16 提升至 128,使可训练参数量突破 3.35 亿,旨在优先提升模型的理解能力而非死记硬背。
-
VRAM 与训练动态:澄清了模型训练中的 VRAM 使用 情况;合并数据集会影响训练时间,但除非增加了 context length,否则不会影响 VRAM。在 Raspberry Pi 上运行 Phi3 被认为是可行的,并且已有在 Orange Pi Zero 3 上成功运行 Gemma 2b 的案例。
-
浏览器运行 Phi3:一篇 Twitter 帖子 展示了在浏览器中运行的 Phi 3,引发了成员们的兴趣。同时,Phi3 Mini 4k 在 Open LLM Leaderboard 上的表现被指出优于 128k 版本。
-
Fine-Tuning 技巧:使用 Unsloth 对 Llama 3 进行 Fine-Tuning 时,在 DPOTrainer 中不需要 ref_model;社区强调了 Fine-Tuning 技术和协作,并成功为 Discord 机器人部署了 llama.cpp。
-
协作编程号召:成员们一致要求设立专门的协作频道,随后创建了 <#1235610265706565692> 用于项目协作。为对检索增强 LLM(RAG)感兴趣的成员分享了 FlagEmbedding 仓库。
-
提升 AI 推理能力:为了增强任务表现,一个 AI 模型被强制记忆了来自 Self-Discover 论文 的 39 个推理模块,将高级推理水平整合到任务中。
Nous Research AI Discord
-
Hermes 2 Pro:新型模型冠军:Nous Research 推出了基于 Llama-3 架构 的 Hermes 2 Pro,与 Llama-3 8B Instruct 相比,它在 AGIEval 和 TruthfulQA 等基准测试中表现出更优越的性能。其独特功能包括 Function Calling 和 Structured Output 能力,并提供标准版和量化 GGUF 版本以提高效率,可在 Hugging Face 上获取。
-
探索 Context Length 的前沿:研究讨论揭示了通过归一化离群值来解决长序列上下文的 Out-of-distribution (OOD) 问题的策略,同时 arXiv:2401.01325 被认为对扩展 context length 具有重要影响。来自
llama.cpp的技术强调了归一化方法,并就截断注意力(truncated attention)对真正实现“无限”上下文的有效性展开了辩论。 -
AI 辅助 Unreal 开发与 LLM 咨询:宣布在 neuralgameworks.com 部署用于 Unreal Engine 5 的 AI 助手,该组织还探讨了在 UE5 开发中集成 GPT-4 vision 的方案。此外,还讨论了 AI 研究的计算资源问题(如 A100 GPUs 的获取),以及模型训练的工具和技术,例如 Kolmogorov Arnold neural network 在 CIFAR-10 上的表现。
-
AI 编排与 Prompt 结构化见解:共享的编排框架 MeeseeksAI 在 AI Agent 中引起了轰动,同时关于 Prompt 结构化的知识库也在不断增长,包括使用特殊 token 的见解以及生成特定输出格式的指导。Hermes 2 Pro 处理 JSON 输出的方法展示了结构化 Prompt 的优势,详情见 Hugging Face。
-
AI 社区的挖掘与网络构建:LLM 的潜在 Fine-Tuning 者正在寻求合适数据集的建议,而 WebSim 引入的跨越时代的扩展游戏有望带来可能重塑游戏体验的更新。对 world-sim 等测试环境的期待以及持续的讨论表明,社区对协作开发和共享研究追求充满热情。
Perplexity AI Discord
-
技术圈内 Opus 相比 GPT-4 引起热议:Perplexity AI 上的技术讨论对比了 Claude Opus 和 GPT-4,指出在维持对话连贯性方面更倾向于 Opus,而在技术准确性方面则更看好 GPT-4,尽管 Opus 目前有每天 50 次的使用限制。
-
新的 Pages 功能激发创意火花:Perplexity AI 社区对新的 Pages 功能充满热情,讨论了其将 Thread 转化为格式化文章的潜力,并希望未来能增强包括图像嵌入在内的功能。
-
AI 内容辅助成为热门话题:从关于无人机挑战的辩论到 AI 在食物选择中的效用,用户分享了 Perplexity AI 的见解链接,其中关于生意大利面正确食用方法、DJI 无人机以及 Binance 创始人的法律困境的讨论尤为显著,显示出广泛的兴趣。
-
弥合 UI 与 API 之间的鸿沟:pplx-7b-online 模型在 Pro UI 和 API 实现之间产生了不同的结果,促使用户寻求对“在线模型”的理解,并庆祝 Sonar Large 模型加入 API,尽管对其参数数量存在一些实质性的困惑。
-
成员寻求平台小故障的解决方案:用户在 Safari 和 Brave 等浏览器上遇到了 Perplexity AI 的 Bug,以及从附件中正确引用内容的问题,导致了故障排除方法的分享和对修复方案的集体期待。
注意:有关 API 产品和 Sonar Large 等模型的详细及最新更新,请查看官方文档。
Eleuther Discord
-
二进制大脑在无监督学习中击败 CNN:关于图像块二进制向量表示的革命性研究表明,与受监督的 CNNs 相比,其效率更高。受生物神经系统启发,讨论重点介绍了二进制向量的排斥力损失函数(repulsive force loss function),这可能模仿了神经元的效率,详见 arXiv。
-
KANs 作为 MLP 竞争对手登场:AI 社区正在热议 Kolmogorov-Arnold Networks (KANs),它可能在可解释性方面比 MLPs 有所改进。对话还涉及了 LLMs 中的模式崩溃(mode collapse)和 Universal Physics Transformers 的前景,并对 GLUE 测试服务器的异常进行了批评,以及对 SwiGLU 独特缩放特性的思考 (KANs paper, Physics paper)。
-
解释不可解释之物:一场严谨的对话探讨了阐明模型“真实底层特征”的困难、Tied Embeddings 在预测模型中的作用,以及 Next-token Prediction 中计算的定义。社区庆祝了学术论文的被接收,以及 Mechanistic Interpretability Workshop at ICML 2024 的启动,并鼓励社区成员投稿 (workshop website)。
-
MT-Bench:集成期望日益高涨:出现了一个关于将 MT-Bench 整合到 lm-evaluation-harness 中的重要请求,暗示了对更严谨的对话式 AI 基准测试的渴望。
OpenRouter (Alex Atallah) Discord
-
推出 Snowflake Arctic 与 FireLLaVA:OpenRouter 发布了两款具有颠覆性的模型:Snowflake Arctic 480B,在编程和多语言任务中表现出色,价格为 $2.16/M tokens;以及 FireLLaVA 13B,这是一款快速的开源多模态模型,成本为 $0.2/M tokens。这两款模型在语言和图像处理方面都取得了重大进展;Arctic 结合了稠密和 MoE Transformer 架构,而 FireLLaVA 专为速度和多模态理解而设计,详见其 发布公告。
-
通过负载均衡实现性能最大化:为了应对高流量需求,OpenRouter 推出了增强的负载均衡功能,现在允许提供商在 活动页面 上追踪性能统计数据,如延迟和完成原因(completion reasons)。
-
揭秘 LLaMA 上下文扩展策略:工程师们研究了扩展 LLaMA 上下文窗口的策略,重点介绍了使用 8 张 A100 GPU 实现 32k 上下文的 PoSE 训练方法,以及 rope theta 的调整。讨论还涉及了 RULER,这是一个用于识别长上下文模型中实际上下文大小的工具,可以在 GitHub 上进一步探索。
-
Google Gemini Pro 1.5 的 NSFW 处理受到质疑:社区对 Google Gemini Pro 1.5 突然削减 NSFW 内容表示批评,并指出更新后发生了重大变化,似乎削弱了模型遵循指令的能力。
-
AI 部署风险与企业影响力探讨:辩论深入探讨了“正交化(orthogonalized)”模型的部署、未对齐 AI 的影响,以及模型创建者注入其 AI 的政治倾向。此外,还对企业的预算分配进行了批判性反思,以 Google 的 Gemini 项目为例,对比了营销支出与研发支出。
OpenAI Discord
-
音乐描述符与 DALL-E 进展备受关注:工程师们正在寻找一种描述音乐曲目的工具,而其他人则更新称 DALL-E 3 正在改进中,目前尚未宣布 DALL-E 4。一位中学教师称赞 Claude iOS 应用的回答极具人性化,随后引发了关于在教育中使用 AI 的讨论。
-
Chatbot 基准测试引发讨论:关于基准测试(benchmarks)在衡量 Chatbot 能力方面的效用展开了激烈的辩论,揭示了两种观点的分歧:一方认为基准测试是有益的衡量指标,另一方则认为它们无法准确反映细微的现实世界使用情况。
-
ChatGPT Plus:Token 充足但限制较多:用户交流了关于 ChatGPT token 限制的见解;澄清了 ChatGPT Plus 具有 32k token 限制,尽管实际的 GPT 通过 API 支持高达 128k。尽管有参与者体验过发送超过所谓 13k 字符限制的文本,但仍建议对 ChatGPT 关于其架构或限制的自我引用式回答保持怀疑。
-
Prompt Engineering:是天才之举还是幻觉?:社区讨论了 Prompt Engineering,涉及了带有负面示例的 few-shot prompting 和 meta-prompting 等策略。还讨论了利用个人品牌从社交媒体分析中提取理想客户画像 (ICP),并分享了使用 GPT-4-Vision 结合 OCR 作为从文档中提取信息的方法。
-
LLM 召回率:仍有改进空间:对话集中在增强长效记忆(Long-Lived Memory, LLM)的召回率上;成员们考虑了上下文窗口限制如何影响 ChatGPT Plus 等平台,并思考了将 GPT-4-Vision 与 OCR 结合以实现更好的数据提取,同时承认从大量文本中检索数据仍面临挑战。
HuggingFace Discord
-
Fashionable AI Pondering:社区成员讨论了寻找一种能够处理图像,在保持 Logo 位置的同时让小孩以多种姿势穿着衬衫的 AI 方案。虽然探讨了现有 AI 解决方案的潜力,但未指向具体工具。
-
Community Constructs Visionary Course:一个新启动的、由社区开发的 计算机视觉课程 已在 GitHub 上开放贡献,并受到了热烈欢迎,旨在丰富计算机视觉领域的专业知识。
-
SDXL Inference Acceleration with PyTorch 2:一篇 Hugging Face 教程 展示了如何利用 PyTorch 2 的优化,将 Stable Diffusion XL 等文本到图像扩散模型的推理时间缩短高达 3 倍。
-
Google Unleashes Multimodal GenAI in Medicine:谷歌专为医疗应用量身定制的多模态 GenAI 模型 Med-Gemini 在一段 YouTube 视频 中被重点介绍,旨在提高人们对该模型能力和应用的认识。
-
PyTorch Lightning Shines on Object Detection:一位成员寻求用于目标检测评估和可视化的 PyTorch Lightning 示例,随后社区分享了关于 PyTorch Lightning 与 SegFormer, Detectron, YOLOv5 以及 YOLOv8 集成的全面教程。
-
RARR Clarification Sought in NLP:有人对 RARR 流程提出了疑问,这是一种调查和修正语言模型输出的方法,尽管社区内关于其实现的进一步讨论似乎有限。
LlamaIndex Discord
LlamaIndex 0.3 Heralds Enhanced Interoperability:LlamaIndex.TS 的 0.3 版本引入了对 ReAct、Anthropic 和 OpenAI 的 Agent 支持,一个通用的 AgentRunner class,标准化的 Web Streams,以及在其 发布推文 中详述的增强类型系统。该更新还概述了与 React 19、Deno 和 Node 22 的兼容性。
AI Engineers, RAG Tutorial Awaits:由 @nerdai 制作的全新 Retrieval-Augmented Generation (RAG) 教程系列正在推进,内容涵盖从基础到长文本 RAG 的管理,并配有 YouTube 教程 和 GitHub notebook。
Llamacpp Faces Parallel Dilemmas:在 Llamacpp 中,由于 CPU 服务器缺乏 continuous batching 支持,用户对处理并行查询时出现的死锁表示担忧。顺序请求处理被视为一种潜在的变通方法。
Word Loom Proposes Language Exchange Framework:Word Loom 规范被提议用于将代码与自然语言分离,从而增强可组合性和机械对比,旨在实现全球化友好,详见 Word Loom 更新提案。
Strategies for Smarter AI Deployments:讨论强调了 RTX 4080 的 16 GB VRAM 对于小型 LLM 运行已经足够,而隐私担忧促使一些用户在微调语言模型时,从 Google Colab 等云端替代方案转向本地计算站。此外,将外部 API 与 QueryPipeline 集成,以及使用 reranker 进行后处理以提高 RAG 应用准确性的技术,也成为了战略考量。
Modular (Mojo 🔥) Discord
Mojo 周年纪念成为讨论焦点:Mojo Bot 社区庆祝了一周年纪念,并推测明天将发布重大更新。社区成员深情回顾了 Mojo 取得的进展,特别是 traits、references 和 lifetimes 方面的增强。
Modular 更新受到欢迎:社区贡献塑造了最新的 Mojo 24.3 版本,其在 Ubuntu 24.04 等平台上的集成获得了积极评价。同时,MAX 24.3 正式发布,通过 Engine Extensibility API 展示了 AI pipeline 集成方面的进展,提升了开发者在管理低延迟、高吞吐量推理时的体验,详见 MAX Graph APIs 文档。
CHERI 架构可能成为安全领域的游戏规则改变者:根据对 YouTube 视频和 Colocation Tutorial 的讨论,CHERI 架构据称能将漏洞利用显著减少 70%。关于其采用的讨论暗示了改变操作系统开发、赋能 Unix 风格软件开发以及可能使传统安全方法过时的可能性。
语言设计与性能的演进:AI 工程师继续消化和讨论 Mojo 的语言设计目标,渴望实现类似于 Hylo 的 lifetimes 和 mutability 推断,并辩论 pointers 相对于 references 的优点与安全性。社区成员利用 Mojo 的 atomic operations 进行多核处理,实现了在 3.8 秒内处理 1 亿条记录。
教育内容提升 Mojo 和 MAX 的知名度:学习热情和对 Mojo 及 MAX 的推广显而易见,相关分享包括 Chris Lattner 讨论 Mojo 的视频(被称为“未来的高性能 Python”),以及一场推广 Python 与 MAX 平台协同作用的 PyCon Lithuania 演讲。
OpenInterpreter Discord
弥合 AI Vtuber 的差距:现在有两个 AI Vtuber 资源可用,其中一个套件只需少量凭据即可在 GitHub - nike-ChatVRM 上完成设置,正如 Twitter 上所宣布的那样。另一个资源提供离线且无审查的体验,并附带 YouTube 演示和 GitHub - VtuberAI 上的源代码。
Whisper RKNN 用户获得速度提升:现在提供了一个 Git 分支,可为搭载 Rockchip RK3588 的 SBC 上的 Whisper RKNN 提供高达 250% 的速度提升,访问地址为 GitHub - rbrisita/01 at rknn。
概述 Ngrok 域名自定义步骤:有人详细介绍了 ngrok 域名配置的过程,包括编辑 tunnel.py 和使用特定的命令行添加项,参考资源见 ngrok Cloud Edge Domains。
解决 Ollama Bot 的独立运行问题:Ollama 出现了问题,表现出不等待用户提示的奇怪自主行为,但尚未提供具体的解决步骤。
对 OpenInterpreter 的期待:社区在推测 OpenInterpreter app 的发布时间表、多模态能力的无缝集成,并分享了关于各种技术方面的社区驱动援助。讨论中强调了诸如在 Windows OS 模式兼容性中使用 GPT-4 配合 --os 标志等解决方案,以及合作精神。
Latent Space Discord
-
Mamba 成为焦点:对 Mamba 模型的兴趣随着一次 Zoom 会议和一份详尽的 Mamba Deep Dive 文档的发布而达到顶峰,引发了关于 Mamba 中作为召回测试的选择性复制(selective copying)以及 finetuning 过程中潜在过拟合问题的讨论。
-
Chunking 中的语义精度:参与者讨论了高级文本 chunking 方法,重点关注作为文档处理技术的语义 chunking。这包括提到了一些实用资源,如 LlamaIndex 的 Semantic Chunker 和 LangChain。
-
本地 LLMs?有专门的 App:工程师们辩论了在 MacBook 上运行 LLM 的问题,重点介绍了用于本地操作的工具和应用,如 Llama3-8B-q8,并对效率和性能表现出浓厚兴趣。
-
AI Town 在 MacBook 上运行 300 个 Agents:展示了一个令人兴奋的项目 带有世界编辑器的 AI Town,描绘了 300 个 AI agents 在 MacBook M1 Max 64G 上流畅运行的场景,被比作微缩版的《西部世界》(Westworld)。
-
OpenAI 的网页困扰?:对 OpenAI 网站重新设计的反馈引发了关于用户体验问题的讨论,工程师们注意到 新 OpenAI 平台上的性能滞后和视觉故障。
OpenAccess AI Collective (axolotl) Discord
是否该屏蔽 Instruct Tags?:工程师们讨论了在训练期间屏蔽 instruct tags 以增强 ChatML 性能,使用 自定义 ChatML 格式,并考虑了其对模型生成的影响。
Llama-3 跃升至 8B:Llama-3 8B Instruct Gradient 现已发布,其特点是进行了 RoPE theta 调整以改进上下文长度处理,并在 Llama-3 8B Gradient 讨论了其实现和局限性。
Axolotl 开发者修复预处理痛点:提交了一个 pull request 以解决 Orpo trainer 以及 TRL Trainer 中的单线程(single-worker)问题,允许通过多线程加速预处理,记录在 GitHub 上的 PR #1583 中。
Python 3.10 奠定基础:社区内设定了新的基准,Python 3.10 现在是使用 Axolotl 进行开发的最低版本要求,从而能够使用最新的语言特性。
使用 ZeRO-3 优化训练:讨论围绕集成 DeepSpeed 的 ZeRO-3 和 Flash Attention 进行 finetuning 以加速训练展开,在适当部署时,ZeRO-3 可以在不影响质量的情况下优化内存。
LAION Discord
-
AI 在教育中的角色引发关注:一位成员强调了在教育中使用 AI 可能带来的依赖问题,认为过度依赖可能会阻碍学习关键的问题解决技能。
-
从静态帧到动态影像:介绍了 Motion-I2V 框架,该框架通过结合基于 Diffusion 的运动预测器和增强时间注意力(temporal attention)的两步过程将图像转换为视频,详情见此处的论文。
-
LLaMA3 表现可期,期待专业微调:讨论了 LLaMA3 在 4bit 量化后的性能,成员们对未来在特定领域的微调表示乐观,并期待 Meta 发布更多代码。
-
提高模型质量备受关注:有人请求关于改进 MagVit2 VQ-VAE 模型的建议,潜在的解决方案围绕集成新的 loss functions 展开。
-
编写音乐之声的代码:讨论了实现 SoundStream 编解码器时的技术困难,成员们合作解读了原始论文中省略的细节,并指向了资源和可能的含义。
-
项目时间线与进展讨论:社区参与了关于项目截止日期的讨论,非正式地使用了 “Soon TM” 等短语,并对 LAION 的 stockfish 数据集中使用的配置表示好奇。
-
探索创新网络架构:该频道触及了替代 MLP 的新型网络方案,即 Kolmogorov-Arnold Networks (KANs),其在研究论文中被强调具有更高的准确性和可解释性。
-
无需训练的高质量字幕生成:区分了 VisualFactChecker (VFC),这是一种无需训练即可生成准确视觉内容字幕的方法,及其对增强图像和 3D 物体字幕生成的影响,详见这篇论文。
AI Stack Devs (Yoko Li) Discord
- AI 在怀旧游戏中的魅力:讨论了利用 AI 复兴经典社交媒体游戏(以 Farmville 为例),并扩展到创建一个以 1950 年代为主题、包含共产主义间谍阴谋的 AI 小镇。
- Hexagen World 因锐利的 AI 图像而获得认可:用户称赞 Hexagen World 的高质量 Diffusion 模型输出,并讨论了其平台托管 AI 驱动游戏的潜力。
- AI 聊天中可能存在的 Tokenizer Bug:ai-town 中 ollama 和 llama3 8b 配置的技术问题导致了奇怪的消息和数字串,初步归因于 Tokenizer 故障。
- 游戏玩家用 Linux?一个可行的选择!:成员们讨论了从 Windows 转向 Linux 的话题,并分享了关于游戏兼容性的保证,例如 Stellaris 在 Mac 和 Linux 上运行顺畅,并建议设置 dual boot system。
- 探索 AI 动画的邀请:分享了一个 AI 动画服务器的 Discord 邀请,旨在吸引对 AI 与动画技术交叉领域感兴趣的人士。
LangChain AI Discord
Groq 无需等待:确认可以直接通过提供的 Groq 控制台链接 注册 Groq 的 AI 服务,消除了那些急于使用 Groq 功能的人对候补名单的担忧。
AI 偏离脚本的难题:正在寻求减轻 AI 在人机交互项目中偏离脚本的策略,强调了在不产生循环响应的情况下保持对话流的需求。
Adaptive RAG 受到关注:讨论了一种新的 Adaptive RAG 技术,该技术根据查询复杂度选择最佳策略,并附带了一个解释该方法的 YouTube 视频。
LangChain 专家发布更新和工具:改进后的 LangChain v0.1.17、Word Loom 的开放规范、在 GCP 上部署 Langserve 以及为 GPT 提供的 Pydantic 驱动的工具定义,展示了社区广泛的创新。相关资源可在 Word Loom 的 GitHub、LangChain 聊天机器人 和 Pydantic 工具仓库 中找到。
LangServe 中的反馈循环困扰:一位成员在 LangServe 反馈功能上的经历强调了提交反馈时清晰沟通渠道的重要性,即使在收到成功的提交响应后,更改也可能不会立即生效或被察觉。
tinygrad (George Hotz) Discord
tinygrad 解决 Conda 难题:tinygrad 环境在 M1 Macs 上因与无效 Metal 库相关的 AssertionError 而遇到障碍,目前已有潜在的修复方案。此外,还为系统更新后 conda python 问题的解决方案发布了悬赏,近期已有进展报告。
从播客到实践:一位成员在听完 Lex Fridman 播客后对 tinygrad 产生了浓厚兴趣,随后收到了深入研究 GitHub 上的 tinygrad 文档 以进一步了解并将其与 PyTorch 进行对比的建议。
tinygrad 爱好者的硬件难题:一位成员在为他们的 tinygrad 开发平台选择 AMD XT 显卡还是新款 Mac M3 之间犹豫不决,强调了选择合适硬件对于优化开发的重要性。
通过源码干预解决 MNIST 谜团:一个错误的 100% MNIST 准确率警报促使一位成员放弃了 pip 版本,并成功从源码编译 tinygrad,解决了版本差异问题,并突显了 tinygrad 构建过程的易用性。
CUDA 澄清与符号审查:关于脚本中 CUDA 使用影响性能的问题不断涌现,同时另一位成员思考了 RedNode 和 OpNode 之间的区别,并确认了 blobfile 对于在 tinygrad 的 LLaMA 示例代码中加载分词器 BPE 至关重要。
Mozilla AI Discord
-
矩阵乘法之谜:一位用户对使用 np.matmul 达到 600 gflops 感到困惑,而 Justine Tunney 的博客文章 仅提到了 29 gflops,这引发了关于计算 flops 的各种方法及其对性能测量影响的讨论。
-
文件重命名输出不一致:在使用 llamafile 运行文件重命名任务时,输出结果各异,这表明不同版本的 llamafile 或其执行过程存在差异,其中提到的一个输出示例为
een_baby_and_adult_monkey_together_in_the_image_with_the_baby_monkey_on.jpg。 -
廉价基础设施上的 Llamafile:一位成员向公会询问在资源有限的情况下,实验 llamafile 最有效的基础设施,在 vast.ai 和 colab pro plus 等服务之间进行权衡。
-
GEMM 函数提速技巧:鉴于 numpy 能够超过 600 gflops,有人寻求关于在 C++ 中提升通用矩阵乘法 (GEMM) 函数以突破 500 gflops 大关的建议,讨论围绕数据对齐和微磁贴 (microtile) 大小展开。
-
并发运行 Llamafile:据分享,可以在不同端口上同时执行多个 llamafile 实例,但强调它们将竞争由操作系统管理的系统资源,而不是在它们之间进行专门的资源管理。
Cohere Discord
-
斯德哥尔摩的 LLM 圈子寻求同伴:社区向 AI 爱好者发出邀请,提议在斯德哥尔摩共进午餐并深入探讨 LLM,彰显了社区的协作精神。
-
Cohere 的温馨欢迎:Discord 频道积极营造友好氛围,sssandra 和 co.elaine 等成员热情地迎接新加入的伙伴。
-
关注文本压缩技巧:频道宣布即将举行一场关于 使用 LLM 进行文本压缩(Text Compression using LLMs) 的分享会,体现了社区对持续学习和技能提升的承诺。
-
应对 API 迷宫:用户分享了在 AI API 集成和密钥激活方面的实战挑战,co.elaine 提供了针对性的指导,并引用了 Cohere 关于 preambles 的文档。
-
探索文档搜索策略:一位用户就构建针对自然语言查询优化的文档搜索系统寻求建议,探讨了 document embeddings、摘要生成以及关键信息提取的应用。
Interconnects (Nathan Lambert) Discord
-
集成技术解决模式崩溃(Mode Collapse):讨论强调了在 AI 对齐的强化学习中,集成奖励模型(ensemble reward models) 的潜力。正如 DeepMind 的 Sparrow 所展示的,尽管存在 KL 惩罚,但通过“对抗性探测(Adversarial Probing)”等技术可以缓解模式崩溃。
-
Llama 3 的混合方法引发关注:社区对 Llama 3 为何同时采用 Proximal Policy Optimization (PPO) 和 Decentralized Proximal Policy Optimization (DPO) 感到好奇。完整的技术原理尚未公开,可能与数据时间尺度的限制有关。
-
Bitnet 实现受到关注:社区对 Bitnet 方法在训练大模型中的实际应用产生了浓厚兴趣。目前已有成功的轻量级复现,如 Bitnet-Llama-70M,以及来自 Agora 在 GitHub 上的更新;讨论还指出,为了在大模型训练中实现高效,需要显著的硬件投入。
-
Bitnet 专用硬件是一块难啃的骨头:讨论阐明了 Bitnet 若要实现高效运行,必须依赖专用硬件,例如支持 2-bit 混合精度的芯片。文中回顾了 IBM 过去的研究努力,并提到了近期关于 CUDA 的 fp6 kernel 的热度。
-
模型来源引发 AI 圈争议:社区剖析了一条推测性的推文,内容涉及未经授权发布的一个类似于 Neel Nanda 和 Ashwinee Panda 所创的模型。该推文对其合法性表示质疑,并呼吁进行更多测试或发布模型权重。相关推文见 Teortaxes 的推文。
-
Anthropic 凭借 Claude 备受瞩目:Anthropic 发布 Claude app 引起了社区轰动,大家期待看到其与 OpenAI 产品的对比评测,同时成员们在交流中也表达了对该公司品牌建设的赞赏。
-
性能提升获得肯定:在一次批评性审查后,某位成员的性能表现出现了显著提升,并因此获得了正面反馈。
Alignment Lab AI Discord
由于用户 manojbh 仅分享了一条非技术性的消息“Hello”,因此没有相关的技术讨论可供总结。请提供包含技术细节内容的消息以便进行妥善总结。
Datasette - LLM (@SimonW) Discord
寻找语言模型管家:讨论强调了对一种 Language Model 的需求,该模型能够识别并删除硬盘中大量的 localmodels,这突显了 AI 在系统维护和组织方面的实际应用场景。
DiscoResearch Discord
-
Qdora 增强 LLM 的新策略:一位用户关注了 Qdora,这是一种在早期模型扩展策略基础上发展而来的方法,它使 Large Language Models (LLMs) 能够在学习额外技能的同时,有效规避灾难性遗忘。
-
LLaMA Pro-8.3B 采用块扩展策略:成员们讨论了一种 块扩展研究(block expansion research) 方法。该方法允许像 LLaMA 这样的 LLM 演化为更强大的版本(例如 CodeLLaMA),同时保留先前学到的技能,这标志着 AI 领域一个充满前景的发展方向。
AI21 Labs (Jamba) Discord
Jamba-Instruct 发布:AI21 Labs 宣布发布 Jamba-Instruct,根据成员分享的推文链接。这可能预示着基于指令的 AI 模型的新进展。
Skunkworks AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
CUDA MODE ▷ #general (7 messages):
- 封禁行动:一名成员成功识别并封禁了一名未经授权的用户,突显了该小组的高效监控。
- CUDA 最佳实践分享:分享了 CUDA C++ Core Libraries 的最佳实践和技术,包括一个 Twitter 帖子链接和通过 Google Drive 分享的幻灯片,尽管目前分享文件夹似乎是空的。查看推文
- Autograd Hessian 讨论:一名成员发起讨论,询问
torch.autograd.grad函数的二阶导数是否返回 Hessian 矩阵的对角线。讨论澄清了在设置特定参数(如create_graph=True)时可以实现,而另一名成员指出这实际上是 Hessian 向量积(Hessian vector product)。 - 估算 Hessian 的对角线:提到了一种涉及随机性加 Hessian 向量积的估算 Hessian 对角线的不同技术,参考了一篇论文中的方法。
提到的链接:CCCL - Google Drive:未发现描述
CUDA MODE ▷ #triton (11 messages🔥):
-
寻求 Triton 调试经验:一名成员寻求调试 Triton kernel 的最佳方法,表示在使用
TRITON_INTERPRET=1和device_print时遇到困难,其中TRITON_INTERPRET=1不允许程序正常执行,而device_print产生重复结果。讨论了最佳调试实践,包括观看 YouTube 上的详细 Triton 调试讲座,并确保通过源码安装或使用 triton-nightly 以获得最新的 Triton 版本。 -
Triton 开发见解分享:在讨论过程中,建议确保 Triton 是最新的,因为最近修复了解释器中的 bug。不过,除了目前的 2.3 版本外,下一个版本的发布日期尚未确定。
-
排查 Triton 中的 Gather 过程:一名 Triton 新手提出了实现简单 gather 过程的问题,具体是在执行 store-load 序列时遇到了
IncompatibleTypeErrorImpl。还提到了希望在 Triton kernel 代码内部使用 Python 断点进行调试,但在触发断点时遇到了困难。
提到的链接:Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
CUDA MODE ▷ #cuda (14 messages🔥):
-
CUDA Profiling 困惑:一名成员讨论了使用
cudaEventRecord对 CUDA kernel 进行 profiling 时时间报告不一致的问题。他们在调整矩阵乘法 kernel 的 tile size 时观察到了意外的时间结果,并质疑计时机制的稳健性。 -
NVIDIA 工具助力:针对 profiling 的疑虑,有人建议尝试使用专门为此类任务设计的 NVIDIA profiling 工具,如 Nsight Compute 或 Nsight System。
-
Profiling 数据差异:该成员继续注意到
cudaEventRecord报告的时间与 NCU (Nsight Compute) 报告中的Duration字段之间存在差异。讨论澄清了 profiling 本身会产生开销,可能会影响捕获到的时间。 -
Nsight Systems 作为替代方案:进一步建议使用 Nsight Systems,它可以在不显式使用
cudaEventRecord的情况下处理 profiling。 -
分享 NVIDIA 上 Tinygrad 的解决方案:分享了一篇关于 NVIDIA 开源驱动的 tinygrad 补丁的帖子,记录了安装过程中遇到的问题和解决方案,可能对遇到类似问题的其他人有所帮助。
CUDA MODE ▷ #torch (3 messages):
- TorchInductor 爱好者的学习机会:一位成员鼓励那些有兴趣深入学习 TorchInductor 的人去查看一个未指明的资源。
- 寻求 PyTorch 贡献者的见解:一位用户请求与任何了解该平台内部机制的 PyTorch 贡献者取得联系。
- 寻找 ATen/linalg 专家:该用户进一步明确表示需要 ATen/linalg(PyTorch 的一个组件)方面的专业知识。
CUDA MODE ▷ #algorithms (11 messages🔥):
- Effort Engine 讨论展开:Effort Engine 的创建者加入了聊天,透露了即将发布的文章,并表示尽管有了新的基准测试,effort/bucketMul 在速度/质量方面仍逊于量化(quantization)。
- 质量重于数量:有人指出,与剪枝最小权重相比,Effort Engine 的方法显示的质量下降较少,并承诺提供图表进行直观对比。
- 理解稀疏矩阵:分享了一个对比,对比了从矩阵中移除最不重要的权重与跳过最不重要的计算,从而开始了对稀疏性(sparsity)主题的深入探讨。
- 矩阵维度至关重要:指出并承认了矩阵/向量维度的偏差,并承诺纠正文档中提到的向量方向错误。
- 探索参数重要性优于精度:一位成员对 Effort Engine 和最近的进展进行了反思,认为 AI 模型中的参数数量可能比其精度更重要,并引用了量化至 1.58 bits 等例子。
CUDA MODE ▷ #cool-links (2 messages):
- 探索速度提升:一位成员提到 random_string_of_character 目前非常慢,并对加速其性能的潜在方法表示好奇。
CUDA MODE ▷ #beginner (2 messages):
- 寻求 CUDA 代码反馈:一位成员询问是否有专门的频道或个人可以对他们的 CUDA 代码提供反馈。另一位成员引导他们在 ID 为 (<#1189607726595194971>) 的特定频道中发布,该频道鼓励此类讨论。
CUDA MODE ▷ #youtube-recordings (1 messages):
- 请求 Taylor Robie 在 Lightning 上的脚本:一位成员表示有兴趣让 Taylor Robie 将他的脚本作为 Studio 上传到 Lightning,以造福初学者。有人建议这可能是一个有用的资源。
CUDA MODE ▷ #torchao (1 messages):
- FP6 数据类型欢迎 CUDA 爱好者:分享了关于新 fp6 支持的公告,并附带了 GitHub issue 链接 (FP6 dtype! · Issue #208 · pytorch/ao)。邀请有兴趣为此功能开发自定义 CUDA 扩展的人员进行协作,并提供入门支持。
提到的链接:FP6 dtype! · Issue #208 · pytorch/ao:🚀 功能、动机和宣传 https://arxiv.org/abs/2401.14112 我想你们一定会喜欢这个。DeepSpeed 开发人员在没有 fp8 支持的显卡上引入了 FP6 数据类型,其…..
CUDA MODE ▷ #off-topic (2 messages):
- 制作 Karpathy 风格的讲解视频:一位成员寻求关于制作模仿 Andrej Karpathy 风格的讲解视频的建议,特别是将实时屏幕共享与面部摄像头叠加相结合。他们提供了一个 YouTube 视频链接 作为说明,展示了 Karpathy 构建 GPT Tokenizer 的过程。
- 推荐使用 OBS Streamlabs 制作视频:针对制作讲解视频的咨询,一位成员推荐使用 OBS Streamlabs,并强调其有大量的教程可供参考。
提到的链接:Let's build the GPT Tokenizer:Tokenizer 是大语言模型 (LLM) 中必不可少且普遍存在的组件,它在字符串和 token(文本块)之间进行转换。Tokenizer…
CUDA MODE ▷ #triton-puzzles (2 messages):
- 对问题信息的困惑:一位成员提到问题描述包含矛盾的细节,假设 N0 = T 可以避免冲突信息。
- 承认问题描述中的错误:承认了问题描述是不正确的,一位成员确认将发布一个更清晰版本的更新。
CUDA MODE ▷ #llmdotc (813 条消息🔥🔥🔥):
<ul>
<li><strong>Master Params 混乱</strong>:最近一次默认启用参数 FP32 master copy 的合并破坏了预期的模型行为,导致了显著的 loss 不匹配。</li>
<li><strong>Stochastic Rounding 大显身手</strong>:测试表明,在参数更新期间加入 stochastic rounding 使结果更符合预期行为。</li>
<li><strong>CUDA 顾虑</strong>:围绕 cuDNN 庞大的体积和编译时间,以及在 llm.c 项目中为了更好的可用性而进行的可能优化展开了讨论。</li>
<li><strong>CUDA Graphs 表现平平</strong>:CUDA Graphs 可以改善 kernel 启动开销,被简要提及作为可能的性能提升手段,但目前的 GPU 空闲时间意味着其收益有限。</li>
<li><strong>目标是 NASA 级别的 C 代码?🚀</strong>:构思改进 llm.c 代码以可能达到安全关键(safety-critical)标准,并伴随着 LLM 进入太空的梦想,以及关于针对更大模型规模进行优化的讨论。</li>
</ul>
- 无标题: 未找到描述
- The Power of 10: Rules for Developing Safety-Critical Code - Wikipedia: 未找到描述
- (beta) Compiling the optimizer with torch.compile — PyTorch Tutorials 2.3.0+cu121 documentation: 未找到描述
- Performance Comparison between Torch.Compile and APEX optimizers: 关于 torch.compile 生成代码的说明:我收到了很多关于 torch.compile 在编译优化器时具体生成了什么的问题。作为背景,关于 foreach kernel 的帖子包含了 m...
- cuda::discard_memory: CUDA C++ 核心库
- Release Notes — NVIDIA cuDNN v9.1.0 documentation: 未找到描述
- Compiler Explorer - CUDA C++ (NVCC 12.2.1): #include <cuda_runtime.h> #include <cuda_bf16.h> typedef __nv_bfloat16 floatX; template<class ElementType> struct alignas(16) Packed128 { __device__ Pack...
- Performance Comparison between Torch.Compile and APEX optimizers: TL;DR:编译后的 Adam 在所有基准测试中都优于 SOTA 手动优化的 APEX 优化器;在 Torchbench 上提升 62.99%,在 HuggingFace 上提升 53.18%,在 TIMM 上提升 142.75%,在 BlueBerries 上提升 88.13%。编译后的 AdamW 表现...
- Which Compute Capability is supported by which CUDA versions?: 以下各版本分别支持哪些 Compute Capability:CUDA 5.5?CUDA 6.0?CUDA 6.5?
- karpa - Overview: karpa 有 13 个可用的仓库。在 GitHub 上关注他们的代码。
- LLM.c Speed of Light & Beyond (A100 Performance Analysis) · karpathy/llm.c · Discussion #331: 在昨天的 cuDNN Flash Attention 实现集成之后,我花了一些时间进行 profiling,试图弄清楚我们在短期/中期内还能在多大程度上提高性能,同时也...
- mixed precision utilities for dev/cuda by ngc92 · Pull Request #325 · karpathy/llm.c: 从 #315 cherry-picked 而来
- fixes to keep master copy in fp32 of weights optionally · karpathy/llm.c@795f8b6: 未找到描述
- cuDNN Flash Attention Forward & Backwards BF16 (+35% performance) by ademeure · Pull Request #322 · karpathy/llm.c: 使用 BF16 且 batch size 为 24 的 RTX 4090:Baseline: 232.37ms (~106K tokens/s) cuDNN: 170.77ms (~144K tokens/s) ==> 性能提升 35%!编译时间:无价(TM) (~2.7s 到 48.7s - 这是一个巨大的依赖...)
- single adam kernel call handling all parameters by ngc92 · Pull Request #262 · karpathy/llm.c: 通用 Adam kernel 的首次尝试
- feature/cudnn for flash-attention by karpathy · Pull Request #323 · karpathy/llm.c: 基于 PR #322 构建。包含合并 cuDNN 支持及 Flash Attention 的额外小修复
- pytorch/torch/_inductor/fx_passes/fuse_attention.py at main · pytorch/pytorch: Python 中具有强大 GPU 加速的 Tensors 和动态神经网络 - pytorch/pytorch
- What's the difference of flash attention implement between cudnn and Dao-AILab? · Issue #52 · NVIDIA/cudnn-frontend: 这个链接是 Flash Attention 吗?
- first draft for gradient clipping by global norm by ngc92 · Pull Request #315 · karpathy/llm.c: 一个用于计算梯度 global norm 的新 kernel,以及对 Adam kernel 的更新。待办事项(TODO):裁剪值在函数调用处硬编码;损坏梯度的错误处理将...
-
- 由 PeterZhizhin 提交的增加 NSight Compute 范围,使用 CUDA events 进行计时的 PR #273 · karpathy/llm.c:CUDA events 允许更准确的计时(由 GPU 测量),nvtxRangePush/nvtxRangePop 为 NSight Systems 添加了简单的堆栈跟踪:示例运行命令:nsys profile mpirun --allow-run-as-roo...
- 由 PeterZhizhin 提交的增加 NSight Compute 范围,使用 CUDA events 进行计时的 PR #273 · karpathy/llm.c:CUDA events 允许更准确的计时(由 GPU 测量),nvtxRangePush/nvtxRangePop 为 NSight Systems 添加了简单的堆栈跟踪:示例运行命令:nsys profile mpirun --allow-run-as-roo...
- 由 karpathy 提交的 fp32 权重主副本功能 PR #328 · karpathy/llm.c:可选地在 fp32 中保留参数的主副本,添加的标志是 -w 0/1,其中 1 是默认值(即默认情况下我们确实保留 fp32 副本),增加了用于 float 格式额外参数副本的内存,...
- 共同构建更好的软件:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、fork 并为超过 4.2 亿个项目做出贡献。
- 共同构建更好的软件:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、fork 并为超过 4.2 亿个项目做出贡献。
- Pull requests · karpathy/llm.c:使用简单、原始的 C/CUDA 进行 LLM 训练。通过在 GitHub 上创建账户来为 karpathy/llm.c 的开发做出贡献。
- 由 ngc92 提交的用于完全自定义 attention 的第二个 matmul PR #227 · karpathy/llm.c:到目前为止,仅在 /dev 文件中,因为对于主脚本我们还需要修改 backward。出于某种原因,我在这里的基准测试中看到了显著的加速,但在我尝试将其用于...
- microsoft/onnxruntime 项目 main 分支下的 onnxruntime/onnxruntime/python/tools/transformers/onnx_model_gpt2.py:ONNX Runtime:跨平台、高性能的 ML 推理和训练加速器 - microsoft/onnxruntime
- Kepler 架构上更快的并行归约 | NVIDIA 技术博客:并行归约是许多并行算法的常见构建模块。Mark Harris 在 2007 年的一个演示中提供了在 GPU 上实现并行归约的详细策略...
- 由 ChrisDryden 提交的更新 adamw 以使用打包数据类型 PR #303 · karpathy/llm.c:更新前运行时总平均迭代时间:38.547570 ms;更新后运行时总平均迭代时间:37.901735 ms。Kernel 开发文件规格:在当前的测试套件中几乎察觉不到:更新前...
- 由 ngc92 提交的保留权重为 fp32 的选项 PR #326 · karpathy/llm.c:添加了一个可选的 fp32 精度的权重第二副本。TODO:缺少 free
- 由 mlazos 提交的 Inductor 中的 Foreach kernel 代码生成 PR #99975 · pytorch/pytorch:设计文档。在 Inductor 中为 foreach add 的单个重载添加 foreach kernel 代码生成。覆盖范围将在后续 PR 中扩展到更多算子。示例 cc @soumith @voznesenskym @penguinwu @anijain2305...
- 由 JaneIllario 提交的 Gelu 反向传播打包 PR #306 · karpathy/llm.c:更新 gelu 反向传播 kernel 以进行 128 位打包,并创建 gelu 反向传播 cuda 文件。之前的 kernel:block_size 32 | 时间 0.1498 ms | 带宽 503.99 GB/s;block_size 64 | 时间 0.0760...
- 由 JaneIllario 提交的将 layernorm_forward 的所有 float 转换为 floatX PR #319 · karpathy/llm.c:将所有 kernel 更改为使用 floatX
- 由 JaneIllario 提交的更新 residual_forward 以使用打包输入 PR #299 · karpathy/llm.c:更新 residual_forward 以使用 128 位打包输入及 floatX。之前的 Kernel:block_size 32 | 时间 0.1498 ms | 带宽 503.99 GB/s;block_size 64 | 时间 0.0760 ms | 带宽 993.32 GB/s...
- [inductor] 由 shunting314 提交的全面填充 PR #120758 · pytorch/pytorch:来自 ghstack 的堆栈(最早的在底部):-> #120758。此 PR 增加了在 lowering 期间填充 tensor strides 的能力。目标是确保(如果可能的话)具有不良形状的 tensor 可以...
n have aligned st... </li> </ul> </div> --- **CUDA MODE ▷ #[rocm](https://discord.com/channels/1189498204333543425/1233704710389764236/1235334822919143566)** (2 messages): - **表达热情**:一位参与者通过简短的消息 "super interesting" 表达了浓厚的兴趣。 - **AMD HIP 教程汇编**:分享了一个 YouTube 播放列表,标题为 "AMD HIP Tutorial",提供了一系列关于在 [AMD ROCm 平台](https://www.youtube.com/playlist?list=PLB1fSi1mbw6IKbZSPz9a2r2DbnHWnLbF-)上使用 HIP 语言进行 AMD GPU 编程的教学视频。 **提到的链接**:AMD HIP Tutorial:在这一系列视频中,我们将教授如何使用 HIP 编程语言在运行于 AMD ROCm 平台的 AMD GPU 上进行编程。这套视频是... --- **CUDA MODE ▷ #[oneapi](https://discord.com/channels/1189498204333543425/1233802893786746880/)** (1 messages): neurondeep: 也在 PyTorch 网页上添加了 Intel。 --- **LM Studio ▷ #[💬-general](https://discord.com/channels/1110598183144399058/1110598183144399061/1235131575809740920)** (240 messages🔥🔥): - **命令行界面上线**:成员们热烈讨论了 **LM Studio 0.2.22** 的发布,该版本引入了命令行功能,重点在于服务器模式操作。在 Linux 机器上无 GUI 的 headless 模式下运行应用的各种问题和解决方案是讨论的核心,成员们积极进行故障排除并分享建议 ([LM Studio CLI setup](https://github.com/lmstudio-ai/lms))。 - **Flash Attention 引发关注**:关于 32k 上下文下的 Flash Attention 进行了多次讨论,强调其据称能将长上下文文档分析的处理速度提高 3 倍。这一升级有望彻底改变与大文本块(如书籍)的交互方式。 - **Beta 测试邀请已发送**:用户们对 **LM Studio 0.2.22** 最新的 beta 构建版本感到兴奋,并讨论了社区反馈影响开发的潜力。提到了与更新相关的 [llama.cpp](https://github.com/ggerganov/llama.cpp) 的 pull requests。 - **Headless 模式的变通方法与技巧**:多位成员集思广益,探讨了在没有图形用户界面的系统上以 headless 状态运行 **LM Studio** 的变通方法,建议使用虚拟 X 服务器或利用 `xvfb-run` 来避免显示相关的错误。 - **有用的 YouTube 建议**:当被问及如何为生成的文本添加语音读取功能时,一位成员指向了 **sillytavern** 或使用 **xtts** 的外部解决方案,并建议可以在 [YouTube](https://youtube.com) 上查找相关的实现教程。提到的链接:--- **LM Studio ▷ #[🤖-models-discussion-chat](https://discord.com/channels/1110598183144399058/1111649100518133842/1235136391088963585)** (159 messages🔥🔥): - **探索 LLAMA 的圣经知识**:一位成员对 **LLAMA 3** 模型背诵《圣经》等已知文本的能力表示好奇。他们分享了一个实验,通过图表展示了模型对 **《创世记》和《约翰福音》** 的召回情况,结果显示对《创世记》的召回率很低,而对《约翰福音》的 **正确召回率仅为 10%**。 - **AI 故事创作中质量至关重要**:一位成员讨论了“质量”对于 AI 故事创作的重要性,表示相比于 **LLAMA 3 8B** 等更快的模型,他们更倾向于使用 **Goliath 120B Q3KS** 以获得更好的文笔。他们强调,虽然他们标准很高,但没有 AI 是完美的,人类的重写仍然必不可少。 - **圣经召回测试的合适工具**:针对圣经召回率测试,另一位成员提到尝试了 **CMDR+** 模型,该模型在处理此任务时似乎比 **LLAMA 3** 表现更好,对特定圣经段落显示出很强的召回能力。 - **关于 AI 模型量化的技术讨论**:关于 **GGUF 模型** 和量化过程进行了技术交流,用户分享了见解并寻求关于 **Gemma** 等模型量化技术的建议。 - **探索 Agent 和 AutoGPT**:进行了一场关于 **Agent** 和 **AutoGPT** 潜力的对话,讨论了创建多个相互通信的 AI 实例以优化输出的能力。然而,关于它们与大型模型相比的有效性尚未达成共识。 - **LLAMA 的视觉能力受到质疑**:成员们讨论了具有视觉能力的 LLAMA 模型,将 **LLAMA 3** 与其他模型进行了比较,并提到了 **LLAVA** 理解图像但不能生成图像的能力。还有关于最佳文本转语音(**TTS**)模型的咨询,大家公认 **Coqui** 仍处于领先地位。- Pout Christian Bale GIF - Pout Christian Bale American Psycho - 发现并分享 GIF:点击查看 GIF
- Squidward Oh No Hes Hot GIF - Squidward Oh No Hes Hot Shaking - 发现并分享 GIF:点击查看 GIF
- elija@mx:~$ xvfb-run ./LM_Studio-0.2.22.AppImage:20:29:24.712 › GPU info: '1c:00.0 VGA compatible controller: NVIDIA Corporation G A104 [GeForce RTX 3060 Ti] (rev a1)' 20:29:24.721 › Got GPU Type: nvidia 20:29:24.722 › LM Studio: gpu type = NVIDIA 2...
- Perfecto Chefs GIF - Perfecto Chefs Kiss - 发现并分享 GIF:点击查看 GIF
- GitHub - lmstudio-ai/lms: 终端里的 LM Studio:终端里的 LM Studio。通过在 GitHub 上创建账号来为 lmstudio-ai/lms 的开发做出贡献。
- GitHub - lmstudio-ai/lms: 终端里的 LM Studio:终端里的 LM Studio。通过在 GitHub 上创建账号来为 lmstudio-ai/lms 的开发做出贡献。
- GitHub - N8python/rugpull: From RAGs to riches. 一个简单的 RAG 可视化库。:From RAGs to riches. 一个简单的 RAG 可视化库。 - N8python/rugpull
- joshcarp 尝试 OpenElm · Pull Request #6986 · ggerganov/llama.cpp:目前在 sgemm.cpp 的第 821 行失败,仍需进行一些 ffn/attention head 信息的解析。目前硬编码了一些内容。修复:#6868。提交此 PR 作为草案是因为我需要帮助...
提到的链接:--- **LM Studio ▷ #[announcements](https://discord.com/channels/1110598183144399058/1111797717639901324/1235636061879668787)** (1 条消息): - **LM Studio 推出 CLI 伴侣工具**:LM Studio 推出了其命令行界面 `lms`,具有 **加载/卸载 LLM** 以及 **启动/停止本地服务器** 的功能。感兴趣的用户可以通过运行 `npx lmstudio install-cli` 来安装 `lms`,并确保更新到 **LM Studio 0.2.22** 以便使用。 - **简化工作流调试**:开发者现在可以使用 `lms log stream` 通过新的 `lms` 工具更有效地 **调试他们的工作流**。 - **加入开源工作**:`lms` 采用 MIT 许可,并在 GitHub 上提供,欢迎社区贡献。团队鼓励开发者 **[点击 ⭐️ 按钮](https://github.com/lmstudio-ai/lms)** 并在 #dev-chat 频道参与讨论。 - **安装前提条件**:提醒用户在尝试安装 `lms` 之前需要先安装 NodeJS,**安装步骤可在 GitHub 仓库中找到**。 **提到的链接**:GitHub - lmstudio-ai/lms: 终端里的 LM Studio:终端里的 LM Studio。通过在 GitHub 上创建账号来为 lmstudio-ai/lms 的开发做出贡献。 --- **LM Studio ▷ #[🧠-feedback](https://discord.com/channels/1110598183144399058/1113937247520170084/1235248065955369082)** (4 messages): - **对不同项目的尊重**:一位成员指出,表达对一个项目的偏好并不等同于贬低另一个项目,强调两者都可以很出色,诋毁其他项目没有任何价值。 - **草莓奶与巧克力奶的比喻**:为了说明偏好并不意味着对替代方案的批评,一位成员将他们对 **LM Studio** 优于 Ollama 的喜爱比作比起巧克力奶更喜欢草莓奶,而没有诋毁后者。 - **坚持观点**:另一位成员重申了他们的立场,认可其他程序的价值,但保持对 **LM Studio** 的个人偏好,并表示这不应被视为对其他项目的攻击。 --- **LM Studio ▷ #[⚙-configs-discussion](https://discord.com/channels/1110598183144399058/1136793122941190258/1235581946390646804)** (3 messages): - **恢复配置为默认值**:一位成员在更新到版本 22 后,需要重置 **llama 3** 和 **phi-3** 的配置预设。另一位成员建议删除 configs 文件夹,以便在下次启动应用时重新填充默认配置。 --- **LM Studio ▷ #[🎛-hardware-discussion](https://discord.com/channels/1110598183144399058/1153759714082033735/1235191735588749444)** (247 messages🔥🔥): - **RAM 速度与 CPU 兼容性**:成员们讨论了基于 CPU 兼容性的 RAM 速度限制,特别提到 **E5-2600 v4 CPU 支持比 2400MHz 更快的 RAM**。然而,他们研究了不同 **Intel Xeon 处理器** 的具体能力,并提供了 Intel 官方规格链接以进行澄清。 - **为 LLM 选择 GPU**:参与者讨论了运行语言模型的最佳 GPU 选择,在 **P100s**、**P40s** 等型号之间进行辩论,以及 **K40** 与某些后端的较低兼容性。通过一篇 [Reddit 帖子](https://www.reddit.com/r/LocalLLaMA) 评估了 **Tesla P40 的性能**,并对二手市场供应以及从中国发货所需 GPU 型号的运输时间表示担忧。 - **NVLink 与 SLI**:用户澄清说,虽然 **SLI 不是企业级 GPU 的功能**,但可以使用 NVLink 桥接器,然而,由于外壳设计,**P100 的物理布局可能会阻碍** NVLink 桥接器的轻松连接。 - **PCIe 带宽与显卡性能**:讨论了 **PCIe 3.0 与 4.0 带宽** 及其对多 GPU 间 VRAM 性能的影响。当在重度使用 Gen 4 显卡的系统中加入 Gen 3 显卡时,观察到了实际性能下降。 - **LLM 的 VRAM 需求**:关于高效运行模型(如 **Meta Llama 3 70B**)所需的 VRAM 量进行了反复讨论,共识是至少 **24GB VRAM** 是理想的。建议使用具有完全 Offloading 能力的 GPU 以获得最佳速度,70B 模型即使对于 24GB 显卡仍具挑战性,而 7/8B 模型在各平台上都能顺畅运行。- GoldenSun3DS 未领取的 Humblebundle 游戏:在 Imgur 发现互联网的魔力,这是一个由社区驱动的娱乐目的地。通过幽默的笑话、热门迷因、有趣的 GIF、励志故事、病毒视频等来振奋精神……
- 不知道 Idk GIF - Dont Know Idk Dunno - 发现并分享 GIF:点击查看 GIF
- mradermacher/Goliath-longLORA-120b-rope8-32k-fp16-GGUF · Hugging Face:未找到描述
- 高质量故事写作(第三人称):未找到描述
- Meta AI:使用 Meta AI 助手完成任务,免费创建 AI 生成的图像,并获取任何问题的答案。Meta AI 基于 Meta 最新的 Llama 大语言模型构建,并使用 Emu……
- LLM In-Context Learning 大师课,特邀我的 (r/reddit) AI Agent:LLM In-Context Learning 大师课,特邀我的 (r/reddit) AI Agent👊 成为会员并获取 GitHub 和代码访问权限:https://www.youtube.com/c/AllAboutAI/join...
- 高质量故事写作(第一人称):未找到描述
- Reddit - 深入探索一切:未找到描述
提到的链接:--- **LM Studio ▷ #[🧪-beta-releases-chat](https://discord.com/channels/1110598183144399058/1166577236325965844/1235201420911710209)** (152 messages🔥🔥): - **0.2.22 Preview 安装混乱**:用户在安装 **LM Studio 0.2.22 Preview** 时遇到问题,下载后显示为 **0.2.21** 版本。经过社区成员的多次更新和检查,分享了一个新的下载链接,解决了版本差异问题。 - **寻求改进的 Llama 3 性能**:参与者讨论了 **Llama 3 模型**(特别是 GGUF 版本)在推理任务中表现不佳的持续问题。建议使用包含最新 llama.cpp 更改的最新量化版本。 - **量化困惑与贡献**:用户分享了 GGUF 量化模型,并对不同 Llama 3 GGUF 之间的性能差异进行了辩论。**Bartowski1182** 确认 8b 模型已采用最新量化,并正在更新 70b 模型。 - **0.2.22 版本中发现服务器问题**:一位用户指出 **LM Studio 0.2.22** 存在潜在的服务器问题,每个服务器请求中都会添加奇怪的提示词,并建议使用 `lms log stream` 工具进行准确诊断。 - **跨平台兼容性与 Headless 运行**:关于如何在 **Ubuntu** 上运行 **LM Studio** 的讨论以简单的安装步骤告终,并且由于具备 Headless 运行能力,人们对创建 Docker 镜像的可能性感到兴奋。- 未找到标题: 未找到描述
- MACKLEMORE & RYAN LEWIS - THRIFT SHOP FEAT. WANZ (OFFICIAL VIDEO): The Heist 实体豪华版: http://www.macklemoremerch.com The Heist 数字豪华版 iTunes: http://itunes.apple.com/WebObjects/MZStore.woa/wa/viewAlb...
- Reddit - 深入探索: 未找到描述
提到的链接:--- **LM Studio ▷ #[amd-rocm-tech-preview](https://discord.com/channels/1110598183144399058/1195858490338594866/1235153704626294885)** (25 条消息🔥): - **对 LM Studio 和 OpenCL 的好奇**:一位成员提到,在发现 **LM Studio** 可以利用 **OpenCL** 时感到惊讶,尽管他们注意到其运行速度较慢。这突显了人们对机器学习软件替代计算后端的普遍兴趣。 - **ROCm 兼容性困惑**:成员们讨论了 **ROCm** 与各种 AMD GPU 的兼容性,特别是 6600 和 6700 XT 型号。例如,一位成员分享说,他们的 6600 似乎不被 **ROCm 支持**,[AMD ROCm 官方文档](https://rocm.docs.amd.com/en/docs-5.7.1/release/gpu_os_support.html)也证实了这一点。 - **ROCm 构建版本缺乏 Linux 支持**:关于 **Linux 版 ROCm 构建版本**可用性的直接提问揭示了目前还没有专门针对 **Linux** 的此类构建版本。参与者正在寻求高效利用其 AMD 硬件的替代方案。 - **跨地区 GPU 价格对比**:对话转向了较轻松的话题,成员们考虑前往英国购买 AMD **7900XTX** GPU,因为其价格比当地成本低得多,这揭示了地区定价差异对消费者决策的影响。 - **适用于 LM Studio ROCm 预览版的新 CLI 工具**:一份详细公告介绍了 `lms`,这是一个新的 CLI 工具,旨在帮助使用 ROCm Preview Beta 的 **LM Studio** 用户管理 **LLMs**、调试工作流以及与本地服务器交互。信息中包含了 [LM Studio 0.2.22 ROCm Preview](https://releases.lmstudio.ai/windows/0.2.22-ROCm-Preview/beta/LM-Studio-0.2.22-ROCm-Preview-Setup.exe) 的链接和 [lms GitHub 仓库](https://github.com/lmstudio-ai/lms),鼓励社区参与和贡献。- 未找到标题:未找到描述
- 未找到标题:未找到描述
- 未找到标题:未找到描述
- GGUF My Repo - ggml-org 提供的 Hugging Face Space:未找到描述
- bartowski/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face:未找到描述
- 来自 bartowski (@bartowski1182) 的推文:在为 70b instruct 制作 llamacpp 量化版本时遇到了多个问题,我保证很快就会上线 :) 预计明天早上
- Qawe Asd GIF - Qawe Asd - 发现并分享 GIF:点击查看 GIF
- NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF · Hugging Face:未找到描述
- Doja Cat GIF - Doja Cat Star - 发现并分享 GIF:点击查看 GIF
- Ojo Huevo GIF - Ojo Huevo Pase de huevo - 发现并分享 GIF:点击查看 GIF
- 共同构建更好的软件:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 来发现、fork 并为超过 4.2 亿个项目做出贡献。
- GitHub - lmstudio-ai/lms: 终端里的 LM Studio:终端里的 LM Studio。通过在 GitHub 上创建账号来为 lmstudio-ai/lms 的开发做出贡献。
提到的链接:--- **LM Studio ▷ #[🛠-dev-chat](https://discord.com/channels/1110598183144399058/1234988891153629205/1235355991877488744)** (4 条消息): - **LM Studio CLI 预览**:[@LMStudioAI 推文](https://x.com/lmstudioai/status/1786076035789815998?s=46) 介绍了新的 `lms` 命令行界面 (CLI),它提供了加载/卸载 LLM 以及启动/停止本地服务器等功能。它需要 LM Studio 0.2.22 或更高版本,代码采用 MIT 许可,可在 [GitHub](https://github.com/lmstudio-ai/lms) 上获取。 - **LM Studio 进入终端**:`lms` CLI 工具能够通过 `lms log stream` 调试工作流,并可以通过 `npx lmstudio install-cli` 轻松安装。 - **LM Studio 无头模式教程**:一位用户提供了使用 `xvfb` 在无头环境中运行 LM Studio(0.2.22 版本)的教程,以及在设置后安装和使用新 `lms` CLI 工具的步骤。- Doja Cat GIF - Doja Cat Star - 发现并分享 GIF:点击查看 GIF
- GPU 与 OS 支持 (Linux) — ROCm 5.7.1 文档主页:未找到描述
- Llamafile:AI 民主化进程的四个月:未找到描述
- 未找到标题:未找到描述
- GitHub - lmstudio-ai/lms: 终端里的 LM Studio:终端里的 LM Studio。通过在 GitHub 上创建账号来为 lmstudio-ai/lms 的开发做出贡献。
- Sapphire AMD Radeon RX 7900 XTX PULSE 游戏显卡 - 24GB | Ebuyer.com:未找到描述
提到的链接:--- **Stability.ai (Stable Diffusion) ▷ #[general-chat](https://discord.com/channels/1002292111942635562/1002292112739549196/1235124033645711390)** (766 条消息 🔥🔥🔥): - **Stable Diffusion 爱好者分享见解**:用户交流了关于各种 Stable Diffusion 模型和实现的技巧,讨论了不同 Checkpoint 的性能,如 'Juggernaut X' 和 '4xNMKD-Siax_200k'。有人推荐 [HuggingFace](https://huggingface.co/gemasai/4x_NMKD-Siax_200k/tree/main) 作为后者的来源。 - **AI 艺术的电脑升级建议**:成员们讨论了用于 AI 图像生成的理想电脑组件,如 4070 RTX GPU,建议倾向于等待 Nvidia 5000 系列的发布。关于在不同硬件配置上有效且高效运行 Stable Diffusion 的担忧是一个共同主题。 - **以 Logo 为重点的实用 AI 艺术与设计**:社区就 AI 在 Logo 设计中的应用进行了深入对话,其中提到了 [一个特定模型 harrlogos-xl](https://civitai.com/models/176555/harrlogos-xl-finally-custom-text-generation-in-sd) 用于在 Stable Diffusion 中创建自定义文本。讨论还涉及了法律考量以及使用 AI 支持创意工作的建议。 - **AI 放大和重绘 (Inpainting) 查询**:用户寻求关于 LDSR 等放大技术和照片写实工具的建议。链接了一个关于如何将任何模型转换为重绘模型的 [Reddit 帖子](https://new.reddit.com/r/StableDiffusion/comments/zyi24j/how_to_turn_any_model_into_an_inpainting_model/),尽管一些用户报告结果参差不齐。 - **双重身份验证 (2FA) 软件探索**:几位成员推荐了各种开源软件作为 Google Auth 和 Authy 的替代方案,用于一次性密码 (OTP),例如 Android 的 Aegis 和 iOS 的 Raivo,并讨论了备份和跨设备同步等功能。- 来自 LM Studio (@LMStudioAI) 的推文:介绍 lms —— LM Studio 的配套 CLI 😎 ✨ 加载/卸载 LLM,启动/停止本地服务器 📖 使用 lms log stream 调试你的工作流 🛠️ 运行 `npx lmstudio install-cli` 来安装 lms 🏡 ...
- 来自 LM Studio (@LMStudioAI) 的推文:😏
- GitHub - lmstudio-ai/lms: 终端里的 LM Studio:终端里的 LM Studio。通过在 GitHub 上创建账号来为 lmstudio-ai/lms 的开发做出贡献。
提到的链接:- Civitai | 分享你的模型: 未找到描述
- 介绍 Idefics2:一个为社区提供的强大 8B Vision-Language Model: 未找到描述
- gemasai/4x_NMKD-Siax_200k 在 main 分支: 未找到描述
- Yuji Stare Jujutsu Kaisen GIF - Yuji Stare Jujutsu Kaisen Blank - 发现并分享 GIF: 点击查看 GIF
- ESRGAN/4x_NMKD-Siax_200k.pth · uwg/upscaler 在 main 分支: 未找到描述
- 未找到标题: 未找到描述
- 介绍 Stability AI 会员资格 — Stability AI: Stability AI 会员资格为我们的跨多模态核心模型提供商业权利。我们的三个会员级别——非商业版、专业版和企业版——使 AI 技术获取变得...
- 介绍 IDEFICS:一个最先进 Visual Langage Model 的开源复现: 未找到描述
- Stable Assistant — Stability AI: Stable Assistant 是由 Stability AI 开发的一款友好聊天机器人,配备了 Stability AI 的文本和图像生成技术,具有 Stable Diffusion 3 和 Stable LM 2 12B。
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- Forge UI - 比 Automatic 1111 快 75%: Forge UI 比 A1111 和 ComfyUI 快达 75%。这个 UI 的外观和感觉与 Automatic 1111 相似,但已经集成了很多功能。它还有一些...
- GitHub - AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin: 一个用户友好的插件,可以轻松地在 Photoshop 中使用 Automatic 或 ComfyUI 作为后端生成 Stable Diffusion 图像。: 一个用户友好的插件,可以轻松地在 Photoshop 中使用 Automatic 或 ComfyUI 作为后端生成 Stable Diffusion 图像。 - AbdullahAlfaraj/Auto-Photoshop-StableDiffusion-Plugin
- 功能: Stable Diffusion web UI。通过在 GitHub 上创建账号,为 AUTOMATIC1111/stable-diffusion-webui 的开发做出贡献。
- Harrlogos XL - 终于,在 SD 中实现自定义文本生成! - Harrlogos_v2.0 | Stable Diffusion LoRA | Civitai: 🚀HarrlogosXL - 为 SDXL 带来自定义文本生成!🚀 每次通过一个 LoRA 教会 Stable Diffusion 拼写!Harrlogos 是一个经过训练的 SDXL LoRA ...
- GitHub - lllyasviel/stable-diffusion-webui-forge: 通过在 GitHub 上创建账号,为 lllyasviel/stable-diffusion-webui-forge 的开发做出贡献。
- 理解 ComfyUI 中的 Stable Diffusion 提示词: 深入探讨 Clip Text Encode 在 ComfyUI 中如何为 Stable Diffusion 工作,分析 Token、Conditioning 和提示词工程最佳实践。在本视频中...
- ComfyUI:深度理解(第 1 部分): 这一次我们回归基础!这是对 ComfyUI 和 Stable Diffusion 工作原理的深入探讨。这不仅仅是一个基础教程,我尝试解释如何...
- ComfyUI:深度理解 第 2 部分: 这是我基础系列的第 2 部分。上次我们学习了如何为整个场景设置 Conditioning,现在是时候看看如何进行局部更改了。我也... t...
- Stable Diffusion 中的角色一致性 - Cobalt Explorer: 更新:07/01——更改了模板,使其更容易缩放到 512 或 768——更改了 ImageSplitter 脚本,使其更加用户友好,并添加了 GitHub 链接——增加了章节... </ul> </div> --- **Unsloth AI (Daniel Han) ▷ #[general](https://discord.com/channels/1179035537009545276/1179035537529643040/1235123876199927849)** (512 条消息🔥🔥🔥): - **微调与参数调整 (Finetuning and Parameter Adjustment)**:成员们正在讨论微调 LLM 的各种方法,特别是 Llama 3。其中一项讨论是将 **LoRA** *rank* 从 16 增加到 128,以避免 AI 仅仅是死记硬背信息而非理解信息,据报告,可训练参数大幅增加到了 3.35 亿以上。 - **探索多 GPU 支持**:对话集中在优化模型训练期间的 VRAM 使用,强调了 **Unsloth** 目前仅限于单 GPU 使用的局限性,但指出多 GPU 支持正在开发中,尽管尚未提供时间表。 - **通过 Prompt 生成界面**:一位成员正在开发一个项目,利用移动端 UI 屏幕的**文本描述**为应用程序生成线框图。他们正在微调一个模型,以提高生成的 **UI 线框图**的质量。 - **具有扩展上下文的 Llama 3**:讨论包括如何扩展模型的**上下文窗口大小 (context window sizes)**,特别是 Llama 3,以匹配或超过 GPT-4 及该领域的其他模型。提到 **Unsloth** 可以通过微调支持 **4 倍长的上下文**,但确实需要额外的 VRAM。 - **利用 Llama Factory 进行训练**:有人建议使用 **Llama Factory** 来潜在地克服 Unsloth 的一些局限性,特别是无法利用**多 GPU** 配置的问题。然而,这一建议是在没有官方测试或集成到 Unsloth 软件包的情况下提出的。
- 来自 RomboDawg (@dudeman6790) 的推文:如果你不想手动复制代码,这里有一个完整的 Colab Notebook。再次感谢 @Teknium1 的建议 https://colab.research.google.com/drive/1bX4BsjLcdNJnoAf7lGXmWOgaY8yekg8p?usp=shar...
- Self-Rewarding Language Models:我们假设为了实现超人类 Agent,未来的模型需要超人类的反馈,以便提供充足的训练信号。目前的方法通常从人类偏好中训练奖励模型...
- 使用 llama-cpp-python grammars 生成 JSON:llama.cpp 最近增加了使用 grammar 控制任何模型输出的功能。
- 来自 RomboDawg (@dudeman6790) 的推文:目前正在使用 OpenCodeInterpreter 数据集中的全部 230,000+ 行代码数据训练 Llama-3-8b-instruct。我想知道我们能在 HumanEval 上把那个 .622 提高多少 🤔🤔 大家为我的 jun... 祈祷吧。
- Google Colab:未找到描述
- Google Colab:未找到描述
- maywell/Llama-3-70B-Instruct-32k · Hugging Face:未找到描述
- Lllama 70B Instruct QA Prompt:Lllama 70B Instruct QA Prompt。GitHub Gist:即时分享代码、笔记和代码片段。
- AI Unplugged 9:Infini-Attention、ORPO:洞察力胜过信息
- 主页:以 2-5 倍的速度和减少 80% 的内存微调 Llama 3、Mistral 和 Gemma LLM - unslothai/unsloth
- llama.cpp/grammars/README.md(位于 master 分支 · ggerganov/llama.cpp):C/C++ 中的 LLM 推理。通过在 GitHub 上创建账户来为 ggerganov/llama.cpp 的开发做出贡献。
- gist:e45b337e9d9bd0492bf5d3c1d4706c7b:GitHub Gist:即时分享代码、笔记和代码片段。
- GitHub - IBM/unitxt:🦄 Unitxt:一个用于启动数据并为训练和评估做好准备的 Python 库:🦄 Unitxt:一个用于启动数据并为训练和评估做好准备的 Python 库 - IBM/unitxt
- Replete-AI/OpenCodeInterpreterData · Hugging Face 数据集:未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Home: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- Home: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- GitHub - unslothai/unsloth: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- GitHub - unslothai/unsloth: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- sloth/sftune.py at master · toranb/sloth: 使用 unsloth 的 python sftune, qmerge 和 dpo 脚本 - toranb/sloth
- GitHub - janhq/jan: Jan 是 ChatGPT 的开源替代方案,可在您的计算机上 100% 离线运行。支持多引擎 (llama.cpp, TensorRT-LLM): Jan 是 ChatGPT 的开源替代方案,可在您的计算机上 100% 离线运行。支持多引擎 (llama.cpp, TensorRT-LLM) - janhq/jan
- lmsys/lmsys-chat-1m · Hugging Face 数据集:未找到描述
- FlagEmbedding/Long_LLM/longllm_qlora at master · FlagOpen/FlagEmbedding:检索与检索增强型 LLMs。通过在 GitHub 上创建账号为 FlagOpen/FlagEmbedding 做出贡献。
- GitHub - FlagOpen/FlagEmbedding: Retrieval and Retrieval-augmented LLMs:检索与检索增强型 LLMs。通过在 GitHub 上创建账号为 FlagOpen/FlagEmbedding 做出贡献。
- llama.cpp/examples/server at master · ggerganov/llama.cpp:C/C++ 中的 LLM 推理。通过在 GitHub 上创建账号为 ggerganov/llama.cpp 做出贡献。
- GitHub - bojone/rerope: Rectified Rotary Position Embeddings:修正的旋转位置嵌入。通过在 GitHub 上创建账号为 bojone/rerope 做出贡献。
- Neuralgameworks - 您的终极 Unreal Engine AI 助手:未找到描述
- Bounties:与顶尖 Replit 创作者合作,将您的创意变为现实。
- Pink Floyd - Echoes / Live at Pompeii ( full ):这是在庞贝古城演奏的 ''Echoes'' 的两个部分,合并在一个视频中。24分06秒。请欣赏 :-) "Echoes" 信天翁一动不动地悬浮在空中,深处...
- GitHub - KindXiaoming/pykan: Kolmogorov Arnold Networks:Kolmogorov Arnold Networks。通过在 GitHub 上创建账号来为 KindXiaoming/pykan 的开发做出贡献。
- GitHub - SynaLinks/HybridAGI: 可编程的神经符号 AGI,允许您使用基于图的提示编程来编写其行为:适用于希望 AI 表现符合预期的人群:可编程的神经符号 AGI,允许您使用基于图的提示编程来编写其行为:适用于希望 AI 表现符合预期的人群 - SynaLinks/HybridAGI
- Hermes 2 Pro 在 Llama-3 8B 上首次亮相:Nous Research 推出了 Hermes 2 Pro,这是他们首个基于 Llama-3 架构的模型,已在 HuggingFace 上发布。它在包括 AGIEval 和 TruthfulQA 在内的多个基准测试中表现优于 Llama-3 8B Instruct。探索 Hermes 2 Pro。
- 新功能与 Structured Output:Hermes 2 Pro 带来了 Function Calling 和 Structured Output 能力,使用专用 token 来简化流式 Function Calling。该模型在 Function Calling 评估和结构化 JSON 输出指标方面也有所改进。
- 提供量化模型版本:对于那些对优化模型感兴趣的人,可以获取 Hermes 2 Pro 的 GGUF 量化版本,提供了一个更高效的选择。查看 Hermes 2 Pro 的量化版本。
- 团队努力获得认可:Hermes Pro 模型的开发归功于多位贡献者的协作努力,以及那些定制工具以支持模型独特 Prompt 格式化需求的人员。
- 社交媒体更新:您可以通过他们的 Twitter 帖子关注 Nous Research 关于 Hermes 2 Pro 的更新和公告。
- 来自 Teortaxes▶️ (@teortaxesTex) 的推文:所以 Llama 8b 即使修复了 token merging 也无法很好地量化。也许是词表(vocab)的问题,也许只是过度训练(overtraining),我担心是后者。我的(不成熟的)直觉是我们正在精炼...
- LLM.int8() 与涌现特性 — Tim Dettmers:当我参加 NAACL 时,我想做一个小测试。我为我的 LLM.int8() 论文准备了两个推介方案。一个方案是关于我如何使用先进的量化方法来实现无性能损失的转换...
- 来自 John Galt (@StudioMilitary) 的推文:唯一的出路是穿过你和我
- vonjack/Nous-Hermes-2-Pro-Xtuner-LLaVA-v1_1-Llama-3-8B · Hugging Face:未找到描述
- Ffs Baby GIF - Ffs Baby Really - 发现并分享 GIF:点击查看 GIF
- Val Town:未找到描述
- Over9000 Dragonball GIF - Over9000 Dragonball - 发现并分享 GIF:点击查看 GIF
- 来自 Sanchit Gandhi (@sanchitgandhi99) 的推文:上周我们发布了 🤗Diarizers,这是一个用于微调说话人日志(speaker diarization)模型的库 🗣️ 使用免费的 Google Colab,只需 10 分钟即可将多语言性能提高 30%:https://colab.re...
- EasyContext/easy_context/zigzag_ring_attn/monkey_patch.py at main · jzhang38/EasyContext:内存优化和训练方案,旨在以极低的硬件需求将语言模型的上下文长度外推至 100 万个 token。- jzhang38/EasyContext
- DeepSpeed/blogs/deepspeed-ulysses/README.md at master · microsoft/DeepSpeed:DeepSpeed 是一个深度学习优化库,使分布式训练和推理变得简单、高效且有效。- microsoft/DeepSpeed
- 来自 Dimitris Papailiopoulos (@DimitrisPapail) 的推文:这份报告中最令人惊讶的发现隐藏在附录中。在两个最佳提示词(prompts)下,模型并没有像摘要中声称的那样过度拟合(overfit)。这是原始的 GSM8k 对比...
- 不要忽视 Whisper.cpp:@ggerganov 的 Whisper.cpp 正在将 OpenAI 的 Whisper 带给大众。我们在 "The Changelog" 播客中进行了讨论。🎧 👉 https://changelog.fm/532 订阅以获取更多内容!...
- BitNetMCU/docs/documentation.md at main · cpldcpu/BitNetMCU:在 CH32V003 RISC-V 微控制器上实现无需乘法的低比特权重神经网络 - cpldcpu/BitNetMCU
- GitHub - interstellarninja/MeeseeksAI: 一个使用 mermaid 图表编排 AI Agent 的框架:一个使用 mermaid 图表编排 AI Agent 的框架 - interstellarninja/MeeseeksAI
- GitHub - arcee-ai/mergekit: 用于合并预训练大语言模型的工具。:用于合并预训练大语言模型(LLM)的工具。- arcee-ai/mergekit
- GitHub - zhuzilin/ring-flash-attention: 结合 Flash Attention 的 Ring Attention 实现:结合 Flash Attention 的 Ring Attention 实现 - zhuzilin/ring-flash-attention
- glaiveai/glaive-function-calling-v2 · Hugging Face 数据集:未找到描述
- test.py:GitHub Gist:即时分享代码、笔记和片段。
- OpenRouter:根据应用使用情况进行排名和分析的语言模型
- perplexity:更多统计数据,由 JohannesGaessler 添加了文档 · Pull Request #6936 · ggerganov/llama.cpp:我看到过一些主观报告,称量化对 LLaMA 3 的损害比对 LLaMA 2 更大。我决定对此进行调查,并为此向 llama.cpp 添加了更多统计数据(和文档)。 pe... </ul> </div> --- **Nous Research AI ▷ #[ask-about-llms](https://discord.com/channels/1053877538025386074/1154120232051408927/1235209906173378571)** (34 messages🔥): - **Grokking 揭秘**:一位成员分享了一项关于神经网络涌现行为的[研究](https://arxiv.org/abs/2301.05217),重点关注一种被称为 "Grokking" 的现象。该案例研究涉及对在模加法上训练的小型 Transformer 进行逆向工程,揭示了它们使用*离散傅里叶变换和三角恒等式*。 - **低成本对 LLM 进行评分**:讨论了比较、评分和排名 LLM 输出的方法。虽然建议使用 GPT-4,但另一种方法(如 *argilla distilable* 或奖励模型)可能会以更具成本效益的方式提供定性排名。 - **针对 Shakespeare 数据集训练类 GP2 模型进行故障排除**:一位成员就一个未按预期学习的类 GP2 模型寻求帮助。他们报告初始 Loss 很高且无法下降,并链接了他们的 GitHub 仓库供参考:[Om-Alve/Shakespeare](https://github.com/Om-Alve/Shakespeare)。 - **ChatML 集成的 Token 替换技巧**:在关于 L3 模型配置的对话中,成员们讨论了将保留 Token 替换为 ChatML Token 如何带来功能改进。模型自动化系统还解决了无意中重复 Token 等错误。 - **以最佳状态运行基于 Llama-3 8B 的 Hermes 2 Pro**:一位成员分享了他们在 Llama-3 8B 上运行 Hermes 2 Pro 的意图,并就 16GB VRAM GPU 的最佳软件和量化级别寻求建议。建议从 Q8_0 等量化级别开始,并使用名为 lmstudio 的软件,尽管也讨论了一些配置问题。
- Progress measures for grokking via mechanistic interpretability:神经网络经常表现出涌现行为,即通过扩大参数量、训练数据或训练步骤,会产生定性的新能力。理解这种现象的一种方法是...
- NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF · Hugging Face:未找到描述
- Shakespeare/train.py at main · Om-Alve/Shakespeare:通过在 GitHub 上创建账号来为 Om-Alve/Shakespeare 的开发做出贡献。
- elvis (@omarsar0) 的推文:何时进行检索?这篇新论文提出了一种训练 LLM 有效利用信息检索的方法。它首先提出了一种训练方法,教 LLM 生成一个特殊的 token,&...
- NousResearch/Hermes-2-Pro-Llama-3-8B · Hugging Face:未找到描述
- 未找到标题:未找到描述
- World Simulation Talks @ AGI House SF:0:00 对话 1:31 Jeremy Nixon 开场 6:08 Nous Research 的 Karan Malhotra 26:22 Rob Hasfield:Websim 首席执行官 1:00:08 Midjourney 的 Ivan Vendrov [实时...
- gyro://marble.game/mobile - 陀螺仪弹球游戏:未找到描述
- 新的 OpenAI 模型“即将发布”,AI 赌注提高(加上 Med Gemini、GPT 2 Chatbot 和 Scale AI):Altman“知道发布日期”,据知情人士透露 Politico 称其“即将发布”,随后神秘的 GPT-2 聊天机器人引起了大规模混乱和歇斯底里。我...
- Rabbit R1:几乎无法评价:盒子里的 AI。但是个不同的盒子。在 https://dbrand.com/rabbit 获取 dbrand 皮肤和屏幕保护贴 MKBHD 周边:http://shop.MKBHD.com 我现在使用的技术...
- Biz Stone (@biz) 的推文: 在 odeo 总部听讲座
- KAN: Kolmogorov-Arnold Networks: 受到 Kolmogorov-Arnold 表示定理的启发,我们提出了 Kolmogorov-Arnold Networks (KANs) 作为 Multi-Layer Perceptrons (MLPs) 的有前途的替代方案。虽然 MLPs 具有固定的激活函数...
- Universal Physics Transformers: A Framework For Efficiently Scaling Neural Operators: 神经算子作为物理替代模型,最近引起了越来越多的关注。随着问题复杂性的不断增加,一个自然的问题出现了:什么是有效的缩放方式...
- Benchmarking Benchmark Leakage in Large Language Models: 在预训练数据的使用不断扩大的背景下,基准数据集泄露现象变得日益突出,不透明的训练过程和通常未公开的包含情况加剧了这一现象...
- A Careful Examination of Large Language Model Performance on Grade School Arithmetic: Large Language Models (LLMs) 在许多数学推理基准测试中取得了令人印象深刻的成功。然而,人们越来越担心其中一些性能实际上反映了数据集...
- Hugh Zhang (@hughbzhang) 的推文: 数据污染是目前 LLM 评估的一个巨大问题。在 Scale,我们从零开始为 GSM8k 创建了一个新的测试集来衡量过拟合,并发现证据表明某些模型(最显著的是 Mist...
- Lua KAN experiment with Adam - Pastebin.com: Pastebin.com 自 2002 年以来一直是排名第一的粘贴工具。Pastebin 是一个网站,您可以在其中在线存储文本一段时间。
- analyse-llms/notebooks/Mode_Collapse.ipynb at main · lauraaisling/analyse-llms: 通过在 GitHub 上创建一个账户来为 lauraaisling/analyse-llms 的开发做出贡献。
- GitHub - s-chh/PyTorch-Vision-Transformer-ViT-MNIST-CIFAR10: Simplified Pytorch implementation of Vision Transformer (ViT) for small datasets like MNIST, FashionMNIST, SVHN and CIFAR10.: 针对 MNIST、FashionMNIST、SVHN 和 CIFAR10 等小型数据集的 Vision Transformer (ViT) 的简化 Pytorch 实现。
- Neural Networks Learn Statistics of Increasing Complexity:分布简单性偏差 (DSB) 假设神经网络首先学习数据分布的低阶矩,然后再转向高阶相关性。在这项工作中,我们展示了...
- Social Choice for AI Alignment: Dealing with Diverse Human Feedback:像 GPT-4 这样的 Foundation models 经过微调以避免不安全或其他有问题的行为,例如,它们拒绝遵守协助犯罪或生产...
- ICML 2024 Mechanistic Interpretability Workshop:未找到描述
- The Quantization Model of Neural Scaling:我们提出了神经缩放定律的量化模型 (Quantization Model),解释了观察到的 Loss 随模型和数据规模呈幂律下降的现象,以及新能力随规模突然涌现的现象。
- Eliciting Latent Predictions from Transformers with the Tuned Lens:我们从迭代推理的角度分析 Transformers,旨在理解模型预测是如何逐层细化的。为此,我们为冻结的...中的每个 Block 训练了一个仿射探针 (affine probe)。
- Deriving a Model of Computation for Next-Token Prediction:未找到描述
- OmniGPT - 最实惠的 ChatGPT 替代方案:我们以实惠的价格为您提供市场上最顶尖的模型:Claude 3, GPT 4 Turbo, GPT 4, Gemini, Perplexity 等。
- Syrax AI - 在一个平台上利用多个 AI:通过 Syrax AI,您可以访问多个 AI 模型,从一个平台生成内容、图像等。
- Snowflake: Arctic Instruct by snowflake | OpenRouter:Arctic 是由 Snowflake AI 研究团队从零开始预训练的稠密 MoE 混合 Transformer 架构。Arctic 将 10B 稠密 Transformer 模型与残差 128x3.66B MoE MLP 结合...
- FireLLaVA 13B by fireworks | OpenRouter:一款极速的视觉语言模型,FireLLaVA 能快速理解文本和图像。它在测试中表现出令人印象深刻的对话能力,旨在模拟多模态 GPT-4。这是首个商业级...
- OpenRouter:构建与模型无关的 AI 应用
- OpenRouter:构建与模型无关的 AI 应用
- Skribler | Skriv med AI:未找到描述
- DigiCord:史上最强大的 AI 驱动 Discord 机器人!
- Cisco NVIDIA AI Collaboration:思科与 NVIDIA 的 AI 协作
- Built for the Enterprise: Introducing AI21’s Jamba-Instruct Model:Jamba-Instruct 是我们混合 SSM-Transformer Jamba 模型的指令微调版本,专为可靠的商业用途而构建,具有一流的质量和性能。
- ChatQA-1.5 - a nvidia Collection:未找到描述
- hjhj3168/Llama-3-8b-Orthogonalized-exl2 · Hugging Face:未找到描述
- GitHub - hsiehjackson/RULER: This repo contains the source code for RULER: What’s the Real Context Size of Your Long-Context Language Models?:此仓库包含 RULER 的源代码:你的长上下文语言模型的真实上下文大小是多少?- hsiehjackson/RULER
- Stable Diffusion Finetuned Minecraft Skin Generator - Nick088 的 Hugging Face Space:未找到描述
- C4AI Command R Plus - CohereForAI 的 Hugging Face Space:未找到描述
- TaCoS:在萨尔布吕肯举行的 TaCoS 会议
- Drax Guardians Of The Galaxy GIF - Drax Guardians Of The Galaxy Odds - 发现并分享 GIF:点击查看 GIF
- davanstrien/dataset-tldr-preference-dpo · Hugging Face 数据集:未找到描述
- HuggingFaceH4/OpenHermes-2.5-1k-longest · Hugging Face 数据集:未找到描述
- GitHub - johko/computer-vision-course: 该仓库是社区驱动的神经网络计算机视觉课程的大本营。欢迎加入我们的 Hugging Face Discord: hf.co/join/discord:该仓库是社区驱动的神经网络计算机视觉课程的大本营。欢迎加入我们的 Hugging Face Discord: hf.co/join/discord - johko/computer-vision-course
- 由 nroggendorff 修复了一些 Sagemaker 配置问题 · Pull Request #2732 · huggingface/accelerate:更新了 config_args.py 以适配最新版本的 Amazon Sagemaker。在这个新版本中,你需要使用 True 或 False 来运行变量操作,例如 --do_eval True,而不是仅仅...
- datasets/src/datasets/features/features.py at main · huggingface/datasets:🤗 最大的一站式数据集中心,适用于 ML 模型,提供快速、易用且高效的数据处理工具 - huggingface/datasets
- 加速文本生成图像扩散模型的推理:未找到描述
- ETH Zürich DLSC: Physics-Informed Neural Networks - Applications:↓↓↓ 讲座概览如下 ↓↓↓ ETH Zürich 科学计算中的深度学习 2023,第 5 讲:物理信息神经网络 - 应用。讲师:Ben M...
- GitHub - Binary-Beast03/MPI-Codes:通过在 GitHub 上创建账号来参与 Binary-Beast03/MPI-Codes 的开发。
- moondream2-batch-processing - Csplk 开发的 Hugging Face Space:未找到描述
- fluently/Fluently-XL-v4 · Hugging Face:未找到描述
- Instagram 上的 Mansion X:"流利地 (*fluently*) 说美语 🇺🇸。#fit #ootd":2 个赞,0 条评论 - the_mansion_x 发布于 2024 年 5 月 2 日。
- 未找到标题: 未找到描述
- talks/2024/mlops/mlops-rag-bootcamp.ipynb at main · nerdai/talks: 用于分享演讲材料的公共仓库。通过在 GitHub 上创建账号来参与 nerdai/talks 的开发。
- Response Synthesis Modules - LlamaIndex: 未找到描述
- Google Colab: 未找到描述
- Chroma Vector Store - LlamaIndex: 未找到描述
- Observability (Legacy) - LlamaIndex: 未找到描述
- llama_index/llama-index-experimental/llama_index/experimental/query_engine/pandas/prompts.py at main · run-llama/llama_index: LlamaIndex 是一个用于 LLM 应用程序的数据框架 - run-llama/llama_index
- Content Moderation using AI: 了解如何使用 AI 模型和框架(如 LlamaIndex、moondream 和 Microsoft Phi-3)来审核内容。
- Pandas Query Engine - LlamaIndex: 未找到描述
- vLLM - LlamaIndex: 未找到描述
- Modular: MAX 24.3 - 介绍 MAX Engine 可扩展性:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新文章:MAX 24.3 - 介绍 MAX Engine 可扩展性
- Modular: Mojo 24.3 更新内容:社区贡献、Python 风格的集合和核心语言增强:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新文章:Mojo 24.3 更新内容:社区贡献、Python 风格的集合和核心语言增强
- Modular: Mojo 24.3 新特性:社区贡献、Pythonic 集合及核心语言增强:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新帖子:Mojo 24.3 新特性:社区贡献、Pythonic 集合及核心语言增强
- Modular: MAX 24.3 - 引入 MAX Engine 可扩展性:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新帖子:MAX 24.3 - 引入 MAX Engine 可扩展性
- Mojo🔥 更新日志 | Modular 文档:Mojo 重大变更的历史记录。
- 主页:CHERI Wiki 页面占位符。通过在 GitHub 上创建账号为 CTSRD-CHERI/cheripedia 的开发做出贡献。
- 未来的硬件能否让我们的软件更安全?2022 年 3 月 15 日剑桥完整活动记录:未来的硬件如何让我们的软件更安全?对代码中的安全问题感到沮丧?讨厌那些找上门来的 Bug?你是否感兴趣...
- 未来的硬件能否让我们的软件更安全?2022 年 3 月 15 日剑桥完整活动记录:未来的硬件如何让我们的软件更安全?对代码中的安全问题感到沮丧?讨厌那些找上门来的 Bug?你是否感兴趣...
- atomic | Modular Docs:实现了 Atomic 类。
- Roadmap & known issues | Modular Docs:MAX 平台的已知问题和即将推出的功能摘要。
- Mojo Lang - Tomorrow's High Performance Python? (with Chris Lattner):Mojo 是来自 Swift 和 LLVM 创建者的最新语言。它尝试吸取 CPU/GPU 级编程的一些最佳技术并进行封装...
- Antanas Daujotis - Unleashing Python's potential with MAX Platform:未找到描述
- Running Locally - Open Interpreter:未找到描述
- Bow Nick Cage GIF - Bow Nick Cage Nicolas Cage - Discover & Share GIFs:点击查看 GIF
- Join the Open Interpreter Discord Server!:一种使用计算机的新方式 | 8861 名成员
- Introducing Idefics2: A Powerful 8B Vision-Language Model for the community:未找到描述
- Mike Bird:A.I. 工程
- GitHub - aj47/clickolas-cage: a chrome extension that performs web browsing actions autonomously to complete a given goal/task (using LLM as brain).:一个自主执行网页浏览操作以完成给定目标/任务的 Chrome 扩展(使用 LLM 作为大脑)。- aj47/clickolas-cage
- Open Interpreter OS Mode:展示 Open Interpreter 将网页总结到记事本中 #gpt4 #autogen #crewai #chatgpt #automation #coding #programming #windows #reddit #localllama #m...
- ngrok - Online in One Line:未找到描述
- error file - Pastebin.com:Pastebin.com 是自 2002 年以来排名第一的粘贴工具。Pastebin 是一个可以在线存储文本一段时间的网站。
- GitHub - rbrisita/01 at rknn:开源语言模型计算机。通过在 GitHub 上创建账户为 rbrisita/01 的开发做出贡献。
- GitHub - tegnike/nike-ChatVRM: 誰でもAITuberお試しキット:面向所有人的 AITuber 尝试套件。通过在 GitHub 上创建账号来为 tegnike/nike-ChatVRM 的开发做出贡献。
- 在本地运行的 Neuro Sama 竞争对手!V0.2 [FOSS, 本地, 无 API]:我马上建一个 GitHub 仓库。抱歉麦克风质量不好,我用的是耳机麦克风,蓝牙带宽严重影响了音质,而且显存(VRAM)也有点……
- GitHub - neurokitti/VtuberAI:通过在 GitHub 上创建账号来为 neurokitti/VtuberAI 的开发做出贡献。
- 来自 Atty Eleti (@athyuttamre) 的推文:@simonw @OpenAIDevs 我们基于句子和段落边界进行分块(通过使用句号、换行符等常见停止标记),但目前不进行语义分块(semantic chunking)。我们正在针对文档进行优化...
- 语义分块 | 🦜️🔗 LangChain:基于语义相似度分割文本。
- 来自 murat 🍥 (@mayfer) 的推文:凭借 Vercel 和 Nextjs 的力量,OpenAI 完成了不可思议的事情:他们创建了一个悬停延迟超过 1 秒的导航栏,图像反复出现和消失,以及卡顿的滚动...
- 将你的电脑变成 AI 电脑 - Jan:在你的电脑上本地离线运行 Mistral 或 Llama2 等 LLM,或者连接到 OpenAI 的 GPT-4 或 Groq 等远程 AI API。
- 来自 Alex Albert (@alexalbert__) 的推文:当我们刚开始构建工具使用(tool use)时,我们经常使用白板。每次头脑风暴会议后,我都会拍一张白板的照片,并要求 Claude 将我们的涂鸦转录成笔记,以便我转...
- 来自 cocktail peanut (@cocktailpeanut) 的推文:我在 Westworld(又名 AI Town)部署了 300 个 AI Agent,令人惊讶的是,它在我的 Macbook M1 Max 64G 上运行毫无问题。以下是它的样子:
- 语义分块器 (Semantic Chunker) - LlamaIndex:未找到描述
- GitHub - benbrandt/text-splitter: 将文本分割成语义块,直到达到所需的块大小。支持按字符和 Token 计算长度,并可从 Rust 和 Python 调用。:将文本分割成语义块,直到达到所需的块大小。支持按字符和 Token 计算长度,并可从 Rust 和 Python 调用。 - benbrandt/text-splitter
- 加入我们的 Cloud HD 视频会议:Zoom 是现代企业视频通信的领导者,拥有一个简单、可靠的云平台,可用于跨移动设备、桌面和会议室系统的视频和音频会议、聊天和网络研讨会。Zoom ...
- Notion – 笔记、任务、维基和数据库的一体化工作空间。:一款将日常工作应用融合为一的新工具。它是为您和您的团队打造的一体化工作空间。
- Tweet from Teortaxes▶️ (@teortaxesTex): So llama 8b won't quantize well even if you fix token merging. Maybe the issue is vocab, maybe just overtraining, and I fear the latter. My (half-baked) intuition is that we're refining compos...
- gradientai/Llama-3-8B-Instruct-Gradient-1048k · Hugging Face: no description found
- FastChat/fastchat/conversation.py at main · lm-sys/FastChat:一个用于训练、部署和评估大型语言模型的开放平台。Vicuna 和 Chatbot Arena 的发布仓库。- lm-sys/FastChat
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- accelerate/docs/source/usage_guides/deepspeed.md at main · huggingface/accelerate:🚀 一种在几乎任何设备和分布式配置上启动、训练和使用 PyTorch 模型的简单方法,支持自动混合精度(包括 fp8),以及易于配置的 FSDP 和 DeepSpeed 支持……
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- transformers/docs/source/en/deepspeed.md at main · huggingface/transformers:🤗 Transformers: 为 Pytorch、TensorFlow 和 JAX 提供最先进的机器学习。- huggingface/transformers
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
- Motion-I2V:未找到描述
- GitHub - wesbz/SoundStream: This repository is an implementation of this article: https://arxiv.org/pdf/2107.03312.pdf:该仓库是这篇文章的实现:https://arxiv.org/pdf/2107.03312.pdf - wesbz/SoundStream
- KAN: Kolmogorov-Arnold Networks:受 Kolmogorov-Arnold 表示定理的启发,我们提出了 Kolmogorov-Arnold Networks (KANs) 作为 Multi-Layer Perceptrons (MLPs) 的有力替代方案。虽然 MLPs 具有固定的激活函数...
- Visual Fact Checker: Enabling High-Fidelity Detailed Caption Generation:现有的视觉内容自动字幕生成方法面临诸如缺乏细节、内容幻觉和指令遵循能力差等挑战。在这项工作中,我们提出了 VisualFactChecker (VFC)...
- 来自 BennyJ504-075⚜😎🤑🔌.yat 🟣 (@bennyj504) 的推文: https://www.hexagen.world/
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、闲逛,并与你的朋友和社区保持紧密联系。
- 集体 AI 生成的游戏世界:一个社交实验,任何人都可以通过浏览器协助创建一个无限独特的模型。
- Word Loom 提议的更新:Word Loom 提议的更新。GitHub Gist:即时分享代码、笔记和片段。
- GitHub - carlosplanchon/gpt_pydantic_tools: 一种使用 Pydantic Schemas 编写 GPT 工具的方法。:一种使用 Pydantic Schemas 编写 GPT 工具的方法。通过在 GitHub 上创建账号为 carlosplanchon/gpt_pydantic_tools 的开发做出贡献。
- 未找到标题:未找到描述
- jartine/Mixtral-8x7B-Instruct-v0.1-llamafile · Hugging Face:暂无描述
- Feature Request: Option to specify base URL for server mode · Issue #388 · Mozilla-Ocho/llamafile:我一直在测试使用 Nginx 作为代理在子目录下提供 llamafile 服务。即能够通过类似这样的 URL 访问 llamafile 服务器:https://mydomain.com/llamafile/ Llamafile...
- primeline/distil-whisper-large-v3-german · Hugging Face:暂无描述
- GitHub - stanford-futuredata/FrugalGPT: FrugalGPT: better quality and lower cost for LLM applications:FrugalGPT:为 LLM 应用提供更高质量和更低成本 - stanford-futuredata/FrugalGPT
- ohara/experiments/bitnet/bitnet.md at master · joey00072/ohara:自动回归模型实现集合。通过在 GitHub 上创建账户为 joey00072/ohara 的开发做出贡献。
- abideen/Bitnet-Llama-70M · Hugging Face:未找到描述
- GitHub - kyegomez/BitNet: Implementation of "BitNet: Scaling 1-bit Transformers for Large Language Models" in pytorch:在 pytorch 中实现 "BitNet: Scaling 1-bit Transformers for Large Language Models" - kyegomez/BitNet
提到的链接:--- **Unsloth AI (Daniel Han) ▷ #[random](https://discord.com/channels/1179035537009545276/1179039861576056922/1235134851800371270)** (17 messages🔥): - **Phi3 Mini 在 128k 上的得分**:有人提到在 Open LLM Leaderboard 上,**Phi3 Mini 4k** 的表现优于 128k 版本,这表明 Mini 可能是一个更好的选择。 - **Mistral 化的 Phi3 受限**:一位用户确认 **Mistral-fied Phi3** 仅适用于他们的 Phi 变体,这表明该模型采用了定制或修改的应用方式。 - **在入门级硬件上运行模型**:讨论涉及了在 **Raspberry Pi 或 Orange Pi** 上运行 **Phi-3** 的可行性,一位用户分享了 Gemma 2b 在 Orange Pi Zero 3 上运行速度尚可的经验。 - **浏览器中的模型**:分享了一个 [Twitter 帖子](https://twitter.com/fleetwood___/status/1783195985893863578),展示了有人在浏览器中运行 **Phi 3**,这让成员们感到很有趣。 - **提高 AI 模型的推理能力**:一位成员描述了一种**增强任务表现**的方法,即强制 ChatGPT 记住来自 **Self-Discover 论文**的 39 个推理模块,并将其用于任务中不同层级的推理。链接了该论文供参考:[Self-Discover](https://arxiv.org/pdf/2402.03620#page=12&zoom=100,73,89)。 --- **Unsloth AI (Daniel Han) ▷ #[help](https://discord.com/channels/1179035537009545276/1179777624986357780/1235136651907563560)** (139 messages🔥🔥): - **Discord 的热情欢迎**:用户加入聊天时受到了热情的问候,成员们对社区提供的帮助表示感谢,并欢迎新成员。 - **Llama-CPP 实战**:一位成员分享了使用 llama.cpp 成功部署 Unsloth AI 并将其连接到 Discord 机器人的经验。使用的服务器命令为 `./server --chat-template llama3 -m ~/Downloads/model-unsloth.Q5_K_M.gguf --port 8081`。 - **关于 Fine-Tuning 和 Checkpointing 的澄清**:对微调方法的询问引出了关于 DPOTrainer 中不需要 ref_model 的澄清,并讨论了 Checkpointing 以及进度保存,同时提供了 **[GitHub 链接](https://github.com/unslothai/unsloth/wiki#finetuning-from-your-last-checkpoint)** 作为指导。 - **Adapter 问题和 Kaggle 训练挑战的解释**:用户讨论了与模型 Adapter 相关的错误,分享了涉及从 config 中删除某些似乎是版本不匹配行的解决方案。 - **部署困境与建议**:用户思考了对微调模型进行 serverless 部署的可能性,同时分享了部署提供商的经验和建议,以及使用 Unsloth AI 的示例。提到的链接:--- **Unsloth AI (Daniel Han) ▷ #[showcase](https://discord.com/channels/1179035537009545276/1179779344894263297/1235491714119110716)** (35 条消息🔥): - **协作频道提案**:建议创建一个频道供成员协作和共同编写代码,灵感来自 EleutherAI Discord 的设置。 - **频道功能讨论**:成员讨论了是重新利用现有频道还是创建新频道,思考了 **#community-projects** 与 **#collab-projects** 频道的最佳用途。 - **频道命名共识**:关于新协作频道最合适且具描述性的名称进行了辩论,成员倾向于能清楚表明频道用途的名称。 - **频道创建完成**:创建了一个名为 **<#1235610265706565692>** 的新频道,以促进社区项目协作,并鼓励成员发布作品并寻找合作伙伴。 - **特定用例对话**:一位成员询问了关于 Fine-Tuning 和重训练项目,讨论了 **LLAMA 3 7B** 等模型在特定用例中的应用,例如编写 Solidity 智能合约。 --- **Unsloth AI (Daniel Han) ▷ #[suggestions](https://discord.com/channels/1179035537009545276/1180144489214509097/1235127834226331708)** (11 条消息🔥): - **澄清关于 VRAM 的困惑**:讨论了合并数据集进行训练是否会增加 **VRAM usage**;明确了合并可能会导致更长的训练时间,但不一定会增加 VRAM usage,除非发生了数据拼接(data concatenation),这可能会增加 context length。 - **数据集微调适配**:询问在 16GB VRAM 上使用 [lmsys-chat-1m dataset](https://huggingface.co/datasets/lmsys/lmsys-chat-1m) 微调 **Mistral 7B** 的可行性,尽管访问该数据集需要提供联系信息。 - **训练时间与 Colab 限制**:一位成员确认了在 VRAM 充足的情况下微调像 **lmsys-chat-1m** 这样的大型数据集的可能性,但指出由于时间限制,使用 Colab 并不实际,并建议通过数据筛选(curation)来提高效率。 - **创建简单路线图**:在回答了另一个频道的特定问题后,有人请求编写一份**简单路线图**(simple roadmap)来概述未来计划。 - **检索与增强型 LLMs 资源共享**:一位成员分享了 **FlagEmbedding** 的链接,这是一个专注于检索和检索增强型 LLMs 的 GitHub 仓库,是一个潜在的有用资源。[在 GitHub 上查看 FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/longllm_qlora)。提到的链接:--- **Nous Research AI ▷ #[ctx-length-research](https://discord.com/channels/1053877538025386074/1108104624482812015/1235255279474577469)** (25 messages🔥): - **解决长上下文的 Positional OOD 问题**:一位成员强调了解决长序列上下文中的分布外(OOD)问题的方案,强调了其提高泛化能力的潜力。该方法涉及对离群值(outlier values)进行归一化处理以保持良好性能。 - **Context Length 扩展的潜在突破**:提到的论文被认为是“被低估的”,但可能对机器学习中的 context length 扩展产生重大影响。可以在 [arXiv:2401.01325](https://arxiv.org/pdf/2401.01325) 找到。 - **llama.cpp 中展示的归一化技术**:关于 context length 的增强,一位成员引用了 `llama.cpp` 仓库中的参考实现,该实现演示了使用特定参数的归一化技术。可以在 [GitHub 上的此处](https://github.com/ggerganov/llama.cpp/tree/master/examples/server) 探索该实现。 - **关于 Truncated Attention 和“无限”上下文的辩论**:讨论了在防止 OOD 问题与增强模型上下文能力之间的平衡。有人担心某些声称提供“无限”上下文的方法实际上降低了模型的长上下文能力。 - **揭示 Rotary Position Embeddings (ReRoPE) 的并行研究**:对话中提到了一篇新讨论的论文与 ReRoPE 方法之间明显的相似性或潜在重叠,这可能意味着独立发现或剽窃问题。关于 ReRoPE 的更多信息可以在 [GitHub 上的此处](https://github.com/bojone/rerope) 找到,该项目归功于 RoPE (Rotary Position Embeddings) 的原作者 Su。提到的链接:--- **Nous Research AI ▷ #[off-topic](https://discord.com/channels/1053877538025386074/1109649177689980928/1235170300824653894)** (20 messages🔥): - **彻底改变游戏开发**:*night_w0lf* 宣布为 Unreal Engine 5 推出一款新的基于 RAG 的 AI 助手,并征求社区用户的反馈。该助手承诺简化开发工作流程,可在 [neuralgameworks.com](https://neuralgameworks.com) 获取。 - **用于协作项目的 Replit Bounties**:*night_w0lf* 分享了 [Replit's bounties](https://replit.com/bounties) 的链接,该平台允许创作者进行协作并将创意变为现实,尽管目前还没有针对之前消息中提到的特定背景的悬赏任务。 - **游戏开发中的 GPT-4 Vision**:*orabazes* 讨论了他们在 UE5 开发中使用 GPT-4 vision 的情况,表示它在文本查询之外还提供了视觉指导,并证明在引擎中编辑蓝图(blueprints)时特别有效。 - **为 AI 研究寻求算力资源**:*yxzwayne* 询问有关资助或计算资源(如 A100 GPU 的访问权限)的信息,以进一步开展其数据生成和评估项目,并表示使用 M2 Max 芯片受到了限制。 - **Kolmogorov Arnold Neural Network 的挑战**:*sumo43* 表达了对 Kolmogorov Arnold 神经网络在 CIFAR-10 上表现的沮丧,认为由于损失率较高,其表现不如多层感知机(Multilayer Perceptron)。提到的链接:--- **Nous Research AI ▷ #[interesting-links](https://discord.com/channels/1053877538025386074/1132352574750728192/1235264275228921876)** (8 条消息🔥): - **探索 Kolmogorov Arnold Networks**:GitHub 仓库 [KindXiaoming/pykan](https://github.com/KindXiaoming/pykan) 介绍了 **Kolmogorov Arnold Networks**,为该概念的贡献和开发开辟了空间。 - **HybridAGI 加入 AGI 竞赛**:一个名为 [SynaLinks/HybridAGI](https://github.com/SynaLinks/HybridAGI) 的新 GitHub 项目承诺提供一种**可编程的神经符号 AGI (Programmable Neuro-Symbolic AGI)**,允许通过**基于图的提示编程 (Graph-based Prompt Programming)** 来编写行为程序。 - **通过 DPO+NLL 提升 AI 性能**:一场讨论强调了在未指定背景下使用 **DPO+NLL** 而非仅使用 DPO 是提升性能的主要因素,引发了关于数据集共享的验证和询问。 - **Tenyx 推出 Llama3-70B 模型**:Romaincosentino 分享了一个新的 [微调 Llama3-70B 模型](https://huggingface.co/tenyx/Llama3-TenyxChat-70B),在 GSM8K 上取得了 **State-of-the-art (SOTA) 结果**,并在各种基准测试中展现出与 GPT-4 竞争的性能。 - **对 GPT 新闻的期待**:分享了 @predict_addict 的一条推文,虽然没有具体背景,但似乎与对 GPT 模型新闻或进展的期待有关;推文的具体内容在频道中未指明。提到的链接:--- **Nous Research AI ▷ #[announcements](https://discord.com/channels/1053877538025386074/1145143867818119272/1235338435913453649)** (1 条消息): ```html提到的链接:--- **Nous Research AI ▷ #[general](https://discord.com/channels/1053877538025386074/1149866623109439599/1235129014805336064)** (441 条消息🔥🔥🔥): - **用于 Agent 编排的 Mermaid 图表**:介绍了一个名为 MeeseeksAI 的 AI Agent 编排框架,功能类似于 CrewAI。它利用 Claude 生成执行图来指导 Agent 交互,目前配备了类似于工具的预定义 Agent([GitHub 上的 MeeseeksAI](https://github.com/interstellarninja/MeeseeksAI))。 - **关注 Function Calling**:社区讨论了 LLM 中 "Function Calling" 的功能,指出其设计目的是使用外部函数/工具进行验证,而不是生成假设。分享了一个数据集示例 Glaive Function Calling V2,供那些有兴趣实现 Function Calling 的人参考([Glaive Function Calling V2](https://huggingface.co/datasets/glaiveai/glaive-function-calling-v2))。 - **对 LLM 知识和算法的好奇**:讨论了 LLM 在不同数据集之间保持知识的能力,涉及潜在的过拟合以及在连续监督微调(SFT)过程中可能发生“遗忘”的概念。一些成员指出,有必要探索顺序 SFT 之外的各种微调技术和数据集组合。 - **新的模型合并工具**:arcee-ai 发布了一种合并预训练 LLM 的新方法 "mergekit",旨在结合不同模型的优势([Mergekit GitHub](https://github.com/arcee-ai/mergekit))。 - **模型缩放的探索与见解**:频道中提到了对模型缩放的持续探索,例如通过调整 RoPE theta 等修改将上下文长度从 8k 增加到 32k 或更高。一些社区成员正在验证这一说法以及此类缩放技术的更广泛潜力。提到的链接:提到的链接:--- **Nous Research AI ▷ #[bittensor-finetune-subnet](https://discord.com/channels/1053877538025386074/1213221029359657021/1235579505632874569)** (1 messages): - **渴望学习微调知识的新矿工**:一位新人表达了参与挖矿的愿望,并希望在此之前**微调一个大语言模型 (LLM)**。他们向社区寻求关于获取数据集以及了解微调 LLM 所需数据类型的指导。 --- **Nous Research AI ▷ #[rag-dataset](https://discord.com/channels/1053877538025386074/1218682416827207801/1235283283995000982)** (16 messages🔥): - **通过微调技术提升性能**:一位成员讨论了一篇[新论文](https://x.com/omarsar0/status/1785498325913108556)中展示的方法,即使用特殊 Token `` 训练 LLM,以实现更有效的信息检索,这有助于确定何时需要额外的上下文来回答问题。 - **AI 模型中的结构化输出**:在生成特定输出格式的背景下,一位成员建议保持一致的指令短语,例如 *"Output only in json."*,并提示参考 [Hermes 2 Pro 如何处理结构化输出](https://huggingface.co/NousResearch/Hermes-2-Pro-Llama-3-8B)。 - **高效跟踪 Pydantic 验证对象**:提到了一种工具,可以自动记录每次函数调用的时间和层级以及经过验证的 Pydantic 对象,这意味着对改进函数调用和结果跟踪有显著益处。 - **针对特定输出进行微调的简易性**:成员们讨论了微调以生成某种输出格式的过程非常直接,涉及在 Prompt 中使用一致的措辞来指示模型所需的输出格式。 - **训练创新**:注意到在训练 LLM 时使用特殊 Token 以提高准确性和效率的方法非常有趣,一位成员确认了此类方法在模型训练中的可行性。 提到的链接:--- **Nous Research AI ▷ #[world-sim](https://discord.com/channels/1053877538025386074/1221910674347786261/1235200308406386739)** (19 条消息🔥): - **世界模拟对话 - 思想的汇聚**:一段名为“[World Simulation Talks @ AGI House SF](https://www.youtube.com/watch?v=abWnhmZIL3w)”的 YouTube 视频记录了来自 Jeremy Nixon、Nous Research 的 Karan Malhotra 以及 Websim 首席执行官 Rob Hasfield 等人物的讨论。参与者对共同的研究努力和对该领域有价值的贡献表达了兴奋之情。 - **对 World-Sim 测试的期待与不确定性**:成员们讨论了备受期待的 world-sim 测试公告,预计本周晚些时候或周末可能会进行测试,尽管目前还没有明确的承诺。 - **DIY 模拟方法**:一位成员分享了一个自定义的 **Claude AI 类 CLI 提示词仿真**,用于世界模拟体验,并邀请社区提供反馈,同时提供了系统模板供他人使用。 - **多方模拟活动提案**:有人提议在洛杉矶与创意和开发者社区共同举办一场结合 WorldSim 和 WebSim 的活动,并建议建立潜在的全球联系,包括旧金山见面会和 Discord 见面会,以促进更广泛的国际参与。 - **Websim.ai 游戏创新**:一位成员宣布了他们在 [Websim.ai](https://websim.ai/c/mFPjhwkmqAvZROOAU-) 上开发的新游戏,游戏跨度从石器时代到银河时代,并即将发布更新以增加更多游戏功能。提到的链接:--- **Perplexity AI ▷ #[general](https://discord.com/channels/1047197230748151888/1047649527299055688/1235126427393720351)** (303 条消息🔥🔥): - **探索 Perplexity 的 Opus 使用情况及模型对比**:成员们讨论了 Perplexity AI 提供的模型的每日使用限制,特别注意到 Claude Opus 暂时限制为每天 50 次。他们还对比了 Opus 和 GPT-4 的回答,一些人更喜欢 Opus 的对话连续性,而另一些人则更喜欢 GPT-4 提供的精确技术答案。 - **Pages 功能受到关注**:Perplexity AI 推出的新 Pages 功能引起了兴趣,用户讨论了它的功能,例如将线程转换为格式化的文章和嵌入图像。他们期待看到该功能的扩展。 - **附件与引用信息的挑战**:一些用户遇到了 Perplexity AI 错误引用附件文档信息的问题,或者在随后的无关请求中持续引用已附加的文件。文中提到了一个已知 Bug,用户分享了管理此问题的变通方法。 - **解决平台访问困难**:用户强调了在 Safari 和 Brave 等特定浏览器上使用 Perplexity AI 的问题,提到了提交提示词或注册时的困难,并寻求潜在的解决方案或技巧。 - **关于 AI 视频内容和语言模型的成员对话**:社区分享并讨论了各种与 AI 相关的视频内容,而其他人则在寻求利用 AI 执行翻译 PDF 和理解快捷键等任务的建议,强调了对实际应用指导的需求。提到的链接:--- **Perplexity AI ▷ #[sharing](https://discord.com/channels/1047197230748151888/1054944216876331118/1235158313663070239)** (17 messages🔥): - **无人机困境**:一名成员分享了 [Perplexity AI 页面](https://www.perplexity.ai/search/DJI-drones-face-.gX6F6HMSA.PCaKFltO4Qg) 的链接,讨论了 DJI 无人机面临的挑战。 - **寻找正确路径**:通过该成员[分享的链接](https://www.perplexity.ai/search/If-the-path-k.8hiWbMS2ilZQKuU1FpXQ),关于某些路径是否能产生幸福感的奇妙探索成为了关注点。 - **对意面的看法**:一则帖子关注了关于[生面条是否可食用](https://www.perplexity.ai/search/does-raw-pasta-CJWASBbdQPufw5xWW0kSsg)及其潜在健康影响的常见查询。 - **烹饪中的人工智能**:关于 [AI 如何辅助做出更好的食物选择](https://www.perplexity.ai/search/Using-AI-to-maeqGr2HQau5DCJ.igaW6g) 的链接让对话升温。 - **加密领域的法律麻烦**:[Binance 创始人被判刑](https://www.perplexity.ai/search/Binance-founder-sentenced-FgzrW0ANQkey7nsKmezjBA) 是其中一个分享的 Perplexity AI 搜索结果的主题。 --- **Perplexity AI ▷ #[pplx-api](https://discord.com/channels/1047197230748151888/1161802929053909012/1235304708378198206)** (18 messages🔥): - **API 与 Pro UI 结果的差异**:用户注意到在 `pplx-7b-online` 模型上使用相同的 Prompt 时,**Pro UI** 与 **API** 返回了**不同的结果**。经澄清,API 使用的是旧版本,而 UI 使用的是 **Llama 3 70b**。 - **文档检查**:用户参考了[官方文档](https://docs.perplexity.ai/docs/model-cards)来澄清关于 API 可用模型的细节,讨论了差异和更新。 - **理解“在线模型”**:一名成员解释说,*“在线模型”* (online model) 意味着来源被注入到 Context 中,模型经过微调以有效地利用这些来源,但它并没有实际的互联网访问权限。 - **Sonar Large 现已可通过 API 访问**:用户庆祝最近将 **Sonar Large** 模型添加到 API 中,如[更新的模型卡片](https://docs.perplexity.ai/docs/model-cards)文档所示,尽管对显示的参数数量存在一些困惑。 - **Sonar Large 参数数量的拼写错误**:大家一致认为,文档中将 **Sonar Large** 的参数数量列为 8x7B 是一个拼写错误,应该是 70B。 **提及链接**:Supported Models:未找到描述 --- **Eleuther ▷ #[general](https://discord.com/channels/729741769192767510/729741769738158194/1235248658723766454)** (32 messages🔥): - **AI 图像表示的令人兴奋的进展**:一位 AI 爱好者分享了他们长达十年的高效图像块表示 (image patch representation) 研究,灵感来自生物神经系统,并采用无监督学习方法——其摘要可在 [arXiv](https://arxiv.org/abs/2210.13004) 上找到。该研究挑战了传统方法,表明二进制向量表示可以比 CNNs 使用有监督学习学到的表示更高效。 - **新型排斥力损失函数引起关注**:另一位成员认可了使用排斥力损失函数 (repulsive force loss function) 创建二进制向量表示的创新之处,将其比作在单位超球体 (unit hypersphere) 边缘嵌入分布——这一想法已应用于 RWKV LLM 以提高学习速度。 - **二进制向量与生物神经元——一条平行路径?**:讨论进一步深入探讨了二进制向量表示如何与生物神经元具有相似性,由于二进制信号传输,可能在效率和鲁棒性方面提供优势,同时讨论了这些表示大规模压缩模型大小的潜力。 - **CLIP 和 DINO:嵌入约束的推荐阅读**:一位成员推荐阅读关于 CLIP 和 DINO 的开创性论文 [CLIP](https://arxiv.org/abs/2103.00020) 和 [DINO](https://arxiv.org/abs/2104.14294),强调了这些作品在使用超球体进行嵌入约束背后的深入推理。 - **名人图像分类挑战**:一位成员寻求将 10 万张未标记图像分类为代表三位电影明星的类别的建议,即使使用来自 OpenAI CLIP 的 ViT 和 ResNet50 等高级模型,也面临准确性问题,仅达到 36% 的准确率,并正在考虑使用不同的 Prompt 和描述来改进结果。其他成员询问了分布和分类方法,以试图提供帮助。 **提到的链接**: Efficient Representation of Natural Image Patches: 利用基于受生物系统启发的最简且现实假设的抽象信息处理模型,我们研究了如何实现早期视觉系统的两个最终目标... --- **Eleuther ▷ #[research](https://discord.com/channels/729741769192767510/747850033994662000/1235141545204645999)** (155 条消息🔥🔥): - **Kolmogorov-Arnold Networks 成为焦点**: 成员们分享了一篇关于 **Kolmogorov-Arnold Networks (KANs)** 的[研究论文](https://arxiv.org/abs/2404.19756),强调了它们作为 Multi-Layer Perceptrons (MLPs) 的高效且可解释替代方案的潜力。 - **剖析 LLMs 中的模式崩溃 (Mode Collapse)**: 一位成员分享了一个 [GitHub notebook](https://github.com/lauraaisling/analyse-llms/blob/main/notebooks/Mode_Collapse.ipynb),以协助探索语言模型中的模式崩溃,方便进行修改和实验。 - **Universal Physics Transformers 发布**: 分享了一篇关于 **Universal Physics Transformers** 的研究论文链接,讨论了它们在各种模拟数据集上的通用性 ([论文链接](https://arxiv.org/abs/2402.12365))。 - **GLUE 测试服务器受到质疑**: 有人对 GLUE 测试服务器分数的正确性表示怀疑,因为出现了一个异常结果:一个*未经微调*的模型达到了 99.2 的 Spearman 相关系数,而相应的 Pearson 相关系数却为 -0.9。 - **探索神经缩放法则 (Neural Scaling Laws)**: 社区围绕一篇论文 ([bits per param](https://arxiv.org/pdf/2404.05405)) 的发现展开了讨论,该论文表明在训练不足的情况下,SwiGLU 与普通 MLPs 相比可能具有不同的缩放特性,从而引发了关于模型容量和 gated MLPs 有效性的疑问。提到的链接:--- **Eleuther ▷ #[interpretability-general](https://discord.com/channels/729741769192767510/1052314805576400977/1235201401781616690)** (44 条消息🔥): - **Next-Token Prediction Loss 理论分享与反馈**:一位成员讨论了关于 Next-Token Prediction loss 的理论及其对序列预测模型中计算模型学习的影响,并邀请大家对其文档 [Deriving a Model of Computation for Next-Token Prediction](https://docs.google.com/document/d/11w3of15CbfOlWrvQpTjxaJt-UvtOckzr0WQUfTrTnsw/edit?usp=sharing) 提供反馈。 - **模型中 Tied Embeddings 的讨论**:有关 Tied Embeddings 对 Next-Token Prediction 模型潜在影响的交流,认为 Tied Embeddings 可能使 Decoder 成为 Encoder 的逆过程,这与某些方法论假设相一致。 - **定义模型特征的复杂性剖析**:随后进行了关于在模型中定义“真实底层特征 (true underlying features)”难度的详细讨论,强调了将这一概念操作化的挑战,以及可能需要将形式语法 (formal grammars) 作为基础。 - **论文投稿的学术成功**:频道成员庆祝他们的论文被学术会议接收,引用了 Hailey Schoelkopf 等人的 [position paper](https://arxiv.org/abs/2404.10271),并表示他们的投稿总体接受率很高。 - **ICML 2024 首届 Mechanistic Interpretability 研讨会宣布**:宣布为首届学术性 Mechanistic Interpretability 研讨会征稿,该研讨会将在 ICML 2024 举行。帖子强调欢迎各种形式的贡献,并提供了 [公告推文链接](https://twitter.com/NeelNanda5/status/1786054959961870669) 和 [研讨会网站](https://icml2024mi.pages.dev/)。提到的链接:--- **Eleuther ▷ #[lm-thunderdome](https://discord.com/channels/729741769192767510/755950983669874798/1235644356464082984)** (1 条消息): - **寻求 MT-Bench 的集成**:一位成员询问了将 **MT-Bench** 或类似工具集成到 *lm-evaluation-harness* 的进度。他们还对加入对话式 AI 质量基准测试表示了兴趣。 --- **OpenRouter (Alex Atallah) ▷ #[announcements](https://discord.com/channels/1091220969173028894/1092729520181739581/1235358580249591909)** (3 条消息): - **推出 Snowflake Arctic & FireLLaVA**:OpenRouter 发布了两个新模型:Snowflake Arctic 480B,展示了强大的代码和多语言性能,价格为 $2.16/M tokens;以及 FireLLaVA 13B,这是一款快速、开源的多模态模型,价格为 $0.2/M tokens。Arctic 是一种 dense-MoE 混合 Transformer,而 FireLLaVA 在文本和图像理解方面表现出色。在此阅读 Arctic 的发布公告 [here](https://www.snowflake.com/blog/arctic-open-efficient-foundation-language-models-snowflake/)。 - **增强的负载均衡与提供商统计**:为了应对负载激增并提升用户体验,OpenRouter 实施了负载均衡,现在允许你在 [Activity 页面](https://openrouter.ai/activity) 监控延迟和提供商的 "finish reason"。 - **新文档发布**:OpenRouter 在其文档中增加了关于 [图像和多模态请求 (images & multimodal requests)](https://openrouter.ai/docs#images-_-multimodal-requests) 以及 [工具调用和函数调用 (tool calls & function calling)](https://openrouter.ai/docs#tool-calls) 的新章节。 - **功能更新与降价**:Lepton 模型现在支持 `logit_bias` 和 `min_p`,nitro 模型也同步支持。此外,Mythomax Extended 降价 40%,Mixtral 8x7b Instruct 降价 4%。 - **应用展示**:OpenRouter 重点推介了 **OmniGPT**(一个多模型 ChatGPT 客户端,访问地址 [omnigpt.co](https://omnigpt.co/))以及 **Syrax**(一个功能丰富的 Telegram 机器人,用于总结聊天内容等,访问地址 [syrax.ai](https://syrax.ai/))。 - **流量激增导致高错误率**:由于流量激增导致错误率上升,用户被告知可能会出现服务中断,目前正在努力扩容并稳定服务。提到的链接:--- **OpenRouter (Alex Atallah) ▷ #[app-showcase](https://discord.com/channels/1091220969173028894/1092850552192368710/1235131318954623038)** (2 条消息): - **Skribler 为瑞典作家发布**:Skribler 是一款旨在帮助瑞典作家提升创意和生产力的 AI 工具,已在 [skribler.se](https://skribler.se) 发布。该工具提供多种功能,如提供建议、构思对话以及支持整个创意写作过程。 - **DigiCord.Site 软启动公告**:全能型 AI Discord 机器人 DigiCord 于今日软启动,提供对包括 GPT-4, Gemini 和 Claude 在内的 40 多种 LLM 的访问,同时支持 AI 视觉和 Stable Diffusion 模型,全部构建于 OpenRouter 之上。DigiCord 的功能包括总结内容、撰写 SEO 文章、图像分析和艺术品创作,采用按需付费模式,您可以[将其邀请至您的服务器](https://zii.vn/3UXZU703)或[加入社区](https://zii.vn/digicordserver)。提到的链接:--- **OpenRouter (Alex Atallah) ▷ #[general](https://discord.com/channels/1091220969173028894/1094454198688546826/1235159141257973850)** (186 条消息🔥🔥): - **关于扩展 LLaMA 上下文窗口的讨论**:成员们讨论了扩展 LLaMA 模型上下文窗口的方法,提到 Hugging Face 上的某些上下文扩展是虚假的,但提议使用 PoSE 方法训练 32k 上下文,使用 8 个 A100 GPU 大约需要一天时间。一位成员提到为 LLaMA 3 70b 调整 rope theta,并分享了一个关于 RULER 的 [GitHub 资源](https://github.com/hsiehjackson/RULER),其中包含用于识别长上下文语言模型真实上下文大小的源代码。 - **探索 Google Gemini Pro 1.5**:对话围绕 Google Gemini Pro 1.5 及其对 NSFW 内容的处理展开,注意到内容被突然切断的奇怪行为,并讨论了模型在更新后的不同模式和行为,更新后的模型被剥离了个性,遵循指令的能力也有所下降。 - **关于部署未对齐模型的见解**:社区讨论了部署倾向于遵循指令而不拒绝的“正交化 (orthogonalized)”模型的风险和策略。成员们承认了这些模型的有效性,同时也考虑到它们忽略了微妙的对齐 (alignment),这可能会使结果产生偏差。 - **对齐与开源挑战**:围绕开源强大模型可能带来的负面影响展开了讨论,一些人对因已对齐模型的去审查化(uncensoring)而可能产生的反开源情绪表示担忧。对话涉及了模型的政治倾向、模型如何反映其创建者的观点,以及开源社区制定策略以推动自身议程的重要性。 - **关于 AI 企业影响力和营销的讨论**:用户分享了关于企业如何分配预算的见解,特别强调了营销支出相对于研发和工程的高比例,例如 Google 的 Gemini 项目。此外,还有关于企业控制在 AI 开发和部署各方面影响的评论。提到的链接:--- **OpenAI ▷ #[ai-discussions](https://discord.com/channels/974519864045756446/998381918976479273/1235188221692874853)** (107 条消息🔥🔥): - **寻求音轨描述工具**:一位用户询问是否有描述音轨的工具,因为在 Music Generation 和转录工具上遇到了困难。另一位用户建议尝试 Vertex AI 或 Google AI Studio 上的 Gemini 1.5 Pro 来理解音频。 - **DALL-E 3 持续改进**:一位用户询问是否存在 DALL-E 4,但其他人确认虽然尚未宣布 DALL-E 4,但 DALL-E 3 的功能仍在不断改进和更新。 - **在教育领域使用 Claude**:Claude iOS 应用的发布引发了关于其有效性的讨论,一位中学教师称赞它比 GPT 具有更好的“人性化”回答,特别是在非编程相关的主题上。 - **评估聊天机器人的基准测试 (Benchmarks)**:关于基准测试在代表聊天机器人能力方面的价值展开了激烈辩论,一些人认为它们提供了有用的衡量标准,而另一些人则认为它们无法代表现实世界中聊天机器人的细微使用场景。 - **探索 AI 生成图像的关键词**:一位用户请求协助识别图像关键词,并表示他们将在 Dall-E 讨论区继续讨论。 **提到的链接**:GitHub - openai/simple-evals:通过在 GitHub 上创建账号来为 openai/simple-evals 的开发做出贡献。 --- **OpenAI ▷ #[gpt-4-discussions](https://discord.com/channels/974519864045756446/1001151820170801244/1235188090721796167)** (9 条消息🔥): - **ChatGPT 的 Token 限制受到质疑**:一位成员对 ChatGPT 声称的 Token 限制提出质疑,称尽管被告知限制为 4096,但他们可以发送超过 13k 字符的文本。未提供包含更多细节的链接。 - **成员建议对自我认知保持怀疑**:一位用户强调 ChatGPT 可能无法准确了解或传达其关于架构或 Token 限制的能力,并建议不要信任其自我引用的回答。 - **ChatGPT Plus Token 限制说明**:在澄清之前的讨论时,一位成员表示 ChatGPT Plus 应该有 32k 的 Token 限制,而实际的 GPT 模型在 API 中支持高达 128k,尽管每条消息都有自己的字符限制。 - **确认 ChatGPT Plus 消息限制**:另一位用户确认 ChatGPT Plus/Team 仍然存在消息限制,并分享了官方 [OpenAI 帮助文章](https://help.openai.com/en/articles/7102672-how-can-i-access-gpt-4) 以获取更多信息。 - **对 GPT-3 性能提升的热情**:一位成员对 GPT-3 的改进表示兴奋,指出与该 AI 对话重新获得了乐趣。 --- **OpenAI ▷ #[prompt-engineering](https://discord.com/channels/974519864045756446/1046317269069864970/1235128467197005864)** (36 messages🔥): - **Few-Shot Prompting 辩论**:一位成员支持使用带有负面示例的 *Few-Shot Prompting*,认为其效果更佳。然而,另一位成员表示反对,并对不合规和任务未完成的情况表示担忧。 - **理想客户画像 (ICP) 提取计划**:一位用户寻求关于利用社交媒体分析构建详细 **理想客户画像 (ICP)** 的建议,并指定了一种结合个人品牌和目标受众专业知识的方法来分析数据并创建画像。 - **业余爱好者的 Prompt Engineering 技巧**:向一位刚接触 **Prompt Engineering** 的成员提供了生成复杂行为和工具的建议。鼓励他们使用带有开放变量和 Markdown 的 *Meta-prompting* 来构建提示词结构。 - **LLM 召回率提升策略**:讨论了如何提高 **LLM 召回率**。一位用户建议利用 GPT 的数据分析/代码解释器工具来执行诸如统计文本内关键词等任务。 - **GPT-4-Vision 与 OCR 用于数据提取**:为了准确地从文档中提取信息,一位用户分享了结合 **GPT-4-Vision 和 OCR** 的方法。另一位成员明确指出,该策略无法绕过 LLM 的检索限制,并建议使用 Python 来处理特定的计数任务,如识别唯一词的出现。 --- **OpenAI ▷ #[api-discussions](https://discord.com/channels/974519864045756446/1046317269069864970/1235128467197005864)** (36 messages🔥): - **关于带负面示例的 Few-Shot Prompting 的讨论**:在关于 Few-Shot Prompting 的讨论中,一位成员提到在某些情况下使用负面示例的表现优于传统方法(**"perform better than classic"**),但另一位成员对其有效性表示怀疑,提到了不合规和任务不完整等问题。 - **从 LinkedIn 数据开发高级 ICP**:一位成员正在探索如何从 LinkedIn 内容中提取详细的 **理想客户画像 (ICP) 信息**,并分享了他们的步骤,例如分析 CSV 和帖子,以推导出多个画像属性(**"Demographics, Psychographics, Personality Color" 等**)。 - **给业余爱好者的 Prompt Engineering 建议**:针对一位询问关于知识和代码探索的 Prompt Engineering 的成员,他们收到了关于使用 *开放变量和 Markdown* 来引导 AI 行为并改善回复的建议。提供了一个如何设置涉及专家系统的 **Meta-prompt** 的简短示例(**"meta-prompting expert system"**)。 - **关于提高 LLM 召回率策略的辩论**:在讨论如何增强 **LLM 召回率** 时,成员们提到了 **ChatGPT Plus** 等平台中上下文窗口的限制,并考虑在独立的计算环境中使用计数等功能。还提到了结合 GPT-4-Vision 与 OCR 进行文档数据提取(**"gpt-4-vision and OCR"**)。 - **长文本数据检索的挑战**:一位参与者旨在从长文档中**准确**提取所有数据字段,思考仅靠 OCR 是否比当前方法更有效。然而,大家达成共识,认为克服 LLM 固有的检索限制是一个无法轻易解决的根本问题(**"cannot mitigate this in the way you're imagining"**)。 --- **HuggingFace ▷ #[general](https://discord.com/channels/879548962464493619/879548962464493622/1235165926689607741)** (153 messages🔥🔥): - **寻求用于产品摄影的 AI**:成员们询问了关于能够处理图像的 AI,例如在保持 Logo 位置的同时,展示孩子穿着不同姿势的衬衫。对话中未建议具体的 AI 解决方案。 - **社区驱动的计算机视觉课程发布**:一个[新的社区构建的计算机视觉课程](https://github.com/johko/computer-vision-course)现已在 GitHub 上线,鼓励社区成员为改进该课程做出贡献。 - **Stable Diffusion Minecraft 皮肤生成器亮点**:一位成员分享了他们的 Space 被评为“本周最佳 Spaces”的成功案例,该项目使用了[在 Minecraft 皮肤生成上微调的 Stable Diffusion](https://huggingface.co/spaces/Nick088/Stable_Diffusion_Finetuned_Minecraft_Skin_Generator)。 - **Kaggle Notebooks 的存储和 GPU 查询**:讨论围绕 Kaggle notebooks 的功能展开,例如启用互联网、使用提供的存储空间,以及在 P100 和 T4 GPU 之间选择以获得更好的 VRAM 容量。 - **Parquet 转换机器人和数据集数据类型**:一位成员对 Parquet 转换机器人如何处理数据集中的非标准数据类型(如 `list[string]`)表示好奇,寻求关于它是否能正确转换这些类型以便在 Hugging Face 上进行数据集预览的澄清。提到的链接:--- **HuggingFace ▷ #[today-im-learning](https://discord.com/channels/879548962464493619/898619964095860757/1235215925309997160)** (5 条消息): - **探索 Med-Gemini 的潜力**:一段名为“Med-Gemini: A High-Level Overview”的视频深入介绍了 Google 为医疗领域构建的多模态 GenAI 模型系列 **Med-Gemini**。该视频旨在提供信息,使 AI 和医疗界保持警觉而非焦虑,详见此 [YouTube 概览](https://youtu.be/xohuoN2WBZs?si=Ku6cztykld6dZLN9)。 - **寻求清晰度**:用户 .rak0 请求帮助改写一个与制药领域相关的后续问题 (q2),通过整合初始查询 (q1) 中的所有细节,但未提供有关问题的进一步细节或背景。 - **关于在 Ray 上部署 HF 模型的咨询**:thepunisher7 询问了关于在 **Ray** 上部署 **HuggingFace (HF) 模型**的帮助,但未提供后续讨论或解决方案。 **提到的链接**:Med-Gemini: A High-Level Overview:关于 Med-Gemini 的高层级概览,这是 Google 为医学领域打造的多模态 GenAI 模型“家族”(用范·迪塞尔的声音说)。Med-Gemini 让人们在... --- **HuggingFace ▷ #[cool-finds](https://discord.com/channels/879548962464493619/897390579145637909/1235271615214780469)** (5 条消息): - **使用 PyTorch 2 加速扩散模型**:[Hugging Face 上的教程](https://huggingface.co/docs/diffusers/tutorials/fast_diffusion) 展示了如何仅通过利用 PyTorch 2 的优化技术,在不需要高级技巧的情况下,将 **Stable Diffusion XL (SDXL)** 等文本生成图像扩散模型的推理延迟降低高达 3 倍。 - **物理信息神经网络 (Physics-Informed Neural Networks) 探索**:苏黎世联邦理工学院 (ETH Zürich) 关于 *Physics-Informed Neural Networks - Applications* 的讲座提供了将物理定律与深度学习集成的见解,可通过 [YouTube 视频](https://youtu.be/IDIv92Z6Qvc?si=NlBDh0KtHNq63XvN) 观看。 - **协作开发 MPI-Codes**:GitHub 上的 MPI-Codes 仓库邀请开发者共同参与 MPI 代码的开发,访问链接为 [此 GitHub 链接](https://github.com/Binary-Beast03/MPI-Codes)。 - **LangGraph Agents 结合 RAG 打造智能邮件**:Medium 上的一篇文章概述了如何通过 [检索增强生成 (RAG) 增强 LangChain 的 LangGraph Agents](https://medium.com/ai-advances/enhancing-langchains-langgraph-agents-with-rag-for-intelligent-email-drafting-a5fab21e05da),用于撰写智能化邮件。提及的链接:--- **HuggingFace ▷ #[i-made-this](https://discord.com/channels/879548962464493619/897390720388825149/1235163732729135114)** (8 条消息🔥): - **梦幻般的批处理更新**:重点介绍了 **MoonDream2** 批处理 Space,并提供了访问升级后模型的链接:[Moondream2 Batch Processing](https://huggingface.co/spaces/Csplk/moondream2-batch-processing)。 - **发布 FluentlyXL V4**:**FluentlyXL V4** 模型已发布,专注于对比度、写实度和解剖结构的改进。可在 [Fluently Playground](https://huggingface.co/spaces/fluently/Fluently-Playground) 使用,模型页面见 [此处](https://huggingface.co/fluently/Fluently-XL-v4)。 - **模型卡片拼写错误提醒**:有人敏锐地观察到 **Fluently XL V4** 模型卡片标题中的拼写错误,将其从 *Fluenlty* 修正为 **Fluently**。 - **FluentlyXL V4 惊人的本地运行结果**:分享了关于 **FluentlyXL V4** 的正面反馈,包括在 NVIDIA RTX 3070 上进行本地测试时,成功生成了颜色和解剖结构正确的图像。 - **葡萄牙语翻译成果**:发起了一项关于 Hugging Face 音频课程第 0 章和第 1 章葡萄牙语翻译的评审协助请求,相关的 PR 见 [GitHub PR #182](https://github.com/huggingface/audio-transformers-course/pull/182)。提及的链接:--- **HuggingFace ▷ #[computer-vision](https://discord.com/channels/879548962464493619/922424143113232404/1235174564208578661)** (6 条消息): - **寻求 CGI 与真实图像分类器**:一位成员询问是否有可以区分 CGI/图形与真实照片的分类器模型,以协助清理数据集。在给出的消息中未提供具体解决方案。 - **对实用工具的正向反馈**:一位成员表达了热情,称之前分享的工具或信息“绝对是一个很棒的工具”。 - **寻求 PyTorch Lightning 资源**:有人询问关于用于评估和可视化目标检测模型训练的 PyTorch Lightning 示例。 - **分享了全面的 PyTorch Lightning 与 3LC 集成示例**:一位用户分享了[使用 PyTorch Lightning 的分割示例](https://docs.3lc.ai/3lc/latest/public-notebooks/pytorch-lightning-segformer.html),并提供了关于 SegFormer, [Detectron](https://docs.3lc.ai/3lc/latest/public-notebooks/detectron2-balloons.html), [YOLOv5](https://github.com/3lc-ai/yolov5/blob/tlc_2.2/utils/loggers/tlc/README.md), 和 [YOLOv8](https://github.com/3lc-ai/ultralytics/blob/tlc-integration/ultralytics/utils/tlc/README.md) 等不同模型的各种集成和教程的详尽细节。 - **课程目录查询**:一位用户询问是否存在 **#cv-study-group** 频道,该频道在 [HuggingFace Community Computer Vision Course](https://huggingface.co/learn/computer-vision-course/unit0/welcome/welcome) 中被提及,但在浏览频道中无法找到。提到的链接:--- **HuggingFace ▷ #[NLP](https://discord.com/channels/879548962464493619/922424173916196955/1235581472619106315)** (3 条消息): - **对 RARR 实现的好奇**:一位成员询问是否有人尝试过 **RARR (Retrofit Attribution using Research and Revision)**,该方法可以为语言模型的输出寻找归因,并对其进行编辑以纠正不支持的内容。 - **Zero-Shot 分类结果的差异**:一位用户在使用 Zero-Shot 分类模型时遇到了问题,标签 "art" 和 "gun" 的结果违反直觉,概率分别为 0.47 和 0.53,这与该模型在 HuggingFace API 页面上的结果不同。他们提供了一段代码片段,并提到使用的是 `"MoritzLaurer/deberta-v3-large-zeroshot-v2.0"` 模型以寻求澄清。 **提到的链接**:论文页面 - RARR: Researching and Revising What Language Models Say, Using Language Models:未找到描述 --- **HuggingFace ▷ #[diffusion-discussions](https://discord.com/channels/879548962464493619/1009713274113245215/)** (1 条消息): sayakpaul: 这可能更适合在 A1111 论坛上提问。 --- **LlamaIndex ▷ #[blog](https://discord.com/channels/1059199217496772688/1187460979064324127/1235281214601035827)** (4 条消息): - **LlamaIndex.TS 0.3 版本发布**:**LlamaIndex.TS** 0.3 版本已经推出,具有诸如**对 ReAct, Anthropic 和 OpenAI 的 Agent 支持**,以及通用的 **AgentRunner 类**等新功能。该更新还包括**标准化的 Web Streams** 和更全面的类型系统,并在 [release tweet](https://twitter.com/llama_index/status/1785722400480637291) 中概述了对 React 19, Deno 和 Node 22 的兼容性。 - **YouTube 上的 RAG 教程系列**:由 **@_nerdai_** 制作的新教程涵盖了 **Retrieval-Augmented Generation (RAG)** 的基础知识,并进阶到长上下文 RAG 的管理及其评估。提供的 **YouTube 链接**可能需要更新浏览器;用户可以[在此观看视频](https://www.youtube.com/watch?v=bNqSRNMgwhQ),并在此访问配套的 [GitHub notebook](https://github.com/features/actions)。 - **Agentic RAG 支持机器人数据栈教程**:由 **@tchutch94** 和 **@seldo** 编写的教程/notebook 序列详细介绍了为基于 RAG 的支持机器人构建数据栈的过程,强调了除了向量数据库之外的其他重要组成部分。预告和完整内容可以在他们的[最新帖子](https://twitter.com/llama_index/status/1786040811571880194)中找到。 - **使用 Reranker 提升 RAG 应用准确率指南**:Plaban Nayak 提供了一份关于使用 Reranker 对检索到的节点进行后处理以增强 RAG 应用准确率的指南。它展示了使用 **来自 Meta 的 Llama 3, @qdrant_engine, LlamaIndex 和 ms-marco-MiniLM-L-2-v2** 的本地设置,详见[此处](https://twitter.com/llama_index/status/1786093311658451337)的帖子。提到的链接:--- **LlamaIndex ▷ #[general](https://discord.com/channels/1059199217496772688/1059201661417037995/1235177326761738261)** (112 messages🔥🔥): - **无需上传文档即可查询**:用户讨论了如果 MongoDB 中已经存在 Embeddings 和元数据,是否可以在不重新上传并将文档转换为 Node 的情况下查询 LlamaIndex。提供的[教程](https://colab.research.google.com/drive/136MSwepvFgEceAs9GN9RzXGGSwOk5pmr?usp=sharing)详细介绍了如何将 `VectorStoreIndex` 与 MongoDB 向量存储结合使用,以利用查询引擎,同时保持数据结构并避免冗余处理。 - **将外部 API 集成到 QueryPipeline**:一位用户询问如何扩展 QueryPipeline,以便在提供现有索引数据的同时,从外部 API 获取实时数据。讨论建议使用带有 Tool 的 Agent,根据查询内容处理有条件的实时数据获取。 - **探索 llamacpp 中的并行请求**:有人担心在 llamacpp 的 Python 环境中尝试提供并行查询时会出现死锁。目前的共识是 llamacpp 在 CPU 服务器中不支持 Continuous Batching,导致请求只能按顺序处理。 - **内容审核博客文章**:分享了一篇关于“使用 LlamaIndex 进行内容审核”的新博客文章,展示了如何使用基于 LlamaIndex 的 LLM 创建 AI 驱动的内容审核解决方案。[博客文章](https://www.cloudraft.io/blog/content-moderation-using-llamaindex-and-llm)深入探讨了社交媒体和游戏审核的应用,并提供了演示。 - **在 MongoDB 和 LlamaIndex 中使用 Trulens**:有人请求关于如何将 Trulens 评估工具与 MongoDB 和 LlamaIndex Embeddings 结合使用的指导。建议参考这份关于 LlamaIndex 可观测性(Observability)的[指南](https://docs.llamaindex.ai/en/stable/module_guides/observability/?h=true#truera-trulens),并考虑使用 Arize Phoenix 或 Langfuse 等替代方案以获得更高级的功能。提及的链接:--- **LlamaIndex ▷ #[ai-discussion](https://discord.com/channels/1059199217496772688/1100478495295017063/1235227548582150145)** (6 messages): - **为 AI 任务选择合适的 GPU**:讨论集中在像拥有 16 GB VRAM 的 RTX 4080 这样的游戏显卡是否足以运行和微调较小的 LLM。会议指出,更高的 VRAM 是有益的,RTX Turing 24 GB 是一个可能的推荐,但对于私有或敏感数据,本地计算优于 Google Colab 等云端解决方案。 - **本地计算与云端计算的偏好**:一位成员由于对某些数据的隐私担忧,以及由工作资源资助的高性能电脑的潜在通用性,正在考虑使用本地 PC 来微调较小的语言模型。 - **Word Loom 规范发布**:一位用户介绍了 **Word Loom**,这是一个专为 AI 语言管理和交换设计的开放规范,它将代码与自然语言分离,并支持组合性和机械化比较。目前正在征集对 [Word Loom 提议更新](https://gist.github.com/uogbuji/5bd08f74125934fa9e0d37236a8e168e) 的反馈,该更新旨在对全球化技术更加友好。 **提到的链接**:Word Loom 提议更新:Word Loom 提议更新。GitHub Gist:即时分享代码、笔记和片段。 --- **Modular (Mojo 🔥) ▷ #[general](https://discord.com/channels/1087530497313357884/1098713601386233997/1235226996070682695)** (8 条消息🔥): - **对 Mojo 包管理的关注**:一位成员询问了 **Mojo 中的包管理是如何运作的**,并配以积极的表情符号,表现出对该 Bot 包管理系统的流程和机制的兴趣。 - **Mojo Bot 一周年**:一位成员提到 **明天将是 Mojo 发布 1 周年纪念日**,提醒社区关注这一里程碑。 - **回顾年度进展**:成员们庆祝了 **Mojo 的 1 周年纪念**,强调了这一年来添加和改进的重要特性,如 **traits、references 和 lifetimes**。 - **对周年纪念版本的期待**:在确认周年纪念日后,另一位成员暗示 **明天(tmr)可能有重大发布**,表达了对即将到来的更新的期待和好奇。 - **为某位成员专门发布的版本**:针对重大发布的期待,一位成员幽默地建议 **他们专门为那位询问的成员做了一次发布**,为社区互动增添了人情味。 --- **Modular (Mojo 🔥) ▷ #[💬︱twitter](https://discord.com/channels/1087530497313357884/1098713626161987705/1235285024874696907)** (3 条消息): - **分享 Modular 推文**:💬︱twitter 频道的成员分享了 **Modular** 最新推文的链接。推文的具体内容未被讨论,但相关推文链接如下:[链接1](https://twitter.com/Modular/status/1785720385889243286)、[链接2](https://twitter.com/Modular/status/1786096043463184528) 和 [链接3](https://twitter.com/Modular/status/1786096058113876311)。 --- **Modular (Mojo 🔥) ▷ #[✍︱blog](https://discord.com/channels/1087530497313357884/1098713717509730466/1235652713954676849)** (2 条消息): - **Mojo🔥 24.3 拥抱社区贡献**:Mojo🔥 24.3 的最新重大版本发布,这是自 **Mojo🔥 标准库** 开源以来的首次更新,得益于社区的意见,该版本带来了显著改进。[公告文章](https://www.modular.com/blog/whats-new-in-mojo-24-3-community-contributions-pythonic-collections-and-core-language-enhancements) 向提交 Pull Request 的贡献者表示了特别感谢,强调了平台的增强和包容性。 - **MAX 24.3 揭晓引擎可扩展性**:MAX 24.3 的新版本引入了 **MAX Engine Extensibility API**,旨在让开发者无缝集成和管理其 AI 流水线。它强调了 MAX Engine 在提供 **低延迟、高吞吐量推理** 方面的尖端能力,并且 [MAX Graph APIs](https://docs.modular.com/engine/graph) 促进了定制化推理模型的创建,增强了 MAX 在各种工作负载下的可编程性。提到的链接:--- **Modular (Mojo 🔥) ▷ #[announcements](https://discord.com/channels/1087530497313357884/1098765954302873621/1235659563408166933)** (1 条消息): - **MAX ⚡️ & Mojo🔥 24.3 发布**:**MAX** 和 **Mojo** 的 24.3 版本现已上线,带来了自标准库开源以来由社区驱动的增强功能。文中提供了安装说明,以及一篇向社区贡献者表达谢意的 [发布博客](https://modul.ar/24-3)。 - **庆祝贡献**:特别感谢为 **Mojo** 提交 Pull Request 的个人贡献者;详细的致谢信息及对应的 GitHub 个人主页链接已分享。 - **深入探索 MAX 可扩展性**:最新的 **MAX** 更新引入了全新的 MAX Engine Extensibility API 预览版,旨在改进 AI 流水线的编程与组合,详情见专门的 [MAX 可扩展性博客](https://modul.ar/max-extensibility)。 - **更新日志记录 32 项更新**:[更新日志](https://modul.ar/changelog)列出了 32 项重大更新、修复和特性,其中包括 **Mojo** 中将 `AnyPointer` 重命名为 [`UnsafePointer`](/mojo/stdlib/memory/unsafe_pointer/UnsafePointer) 的亮点及多项改进。 - **Mojo 的里程碑时刻**:在 **Mojo 发布一周年**之际,与为之成长做出贡献的社区共同分享喜悦。提到的链接:--- **Modular (Mojo 🔥) ▷ #[ai](https://discord.com/channels/1087530497313357884/1103420074372644916/1235664363566923809)** (1 条消息): - **定义 AI 中的意识**:一位成员表达了这样的观点:**意识**既是一个哲学概念也是一个科学概念,在被 AI 模拟之前必须先进行量化。一种建议的 AI 研究方法是从更简单的生物(如蠕虫)开始,因为它们的大脑可能更容易被映射和编码。 --- **Modular (Mojo 🔥) ▷ #[tech-news](https://discord.com/channels/1087530497313357884/1151359062789857280/1235612025615421545)** (2 条消息): - **CHERI 将变革计算机安全**:[CHERI](https://youtube.com/playlist?list=PL55r1-RCAaGU6fU2o34pwlb6ytWqkuzoi) 架构有望缓解 70% 的常见漏洞利用,标志着计算机硬件安全的重大转变。最近的一次会议分享了其影响的细节,暗示日常使用可能很快就会成为现实。 - **利用 CHERI 重新思考软件开发**:采用 CHERI 可以通过使进程速度提高几个数量级,从而实现更高效的 Unix 风格软件开发,详见 [Colocation Tutorial](https://github.com/CTSRD-CHERI/cheripedia/wiki/Colocation-Tutorial),这引发了关于增加跨编程语言软件复用的讨论。 - **通过可扩展的分区化释放性能**:他们强调 CHERI 的可扩展分区化(Scalable Compartmentalization)可以显著降低创建沙箱的性能开销,影响从 Web 浏览器到 Wasm 运行时等多个领域。该 [YouTube 视频](https://youtu.be/_QxXiTv1hH0?t=933)讨论了这种变革潜力。 - **硬件简化与加速指日可待**:讨论提出了一个问题:CHERI 是否会使传统的安全方法(如基于 MMU 的内存保护)变得多余,从而简化硬件并加速软件。 - **微内核有望凭借 CHERI 实现复兴**:得益于 CHERI 带来的进程间通信(IPC)速度提升,人们推测操作系统开发可能会发生一场革命,微内核可能因此成为主流。提到的链接:--- **Modular (Mojo 🔥) ▷ #[🔥mojo](https://discord.com/channels/1087530497313357884/1151418092052815884/1235175957514682448)** (60 messages🔥🔥): - **Mojo 的“比 Rust 更简单”愿景**:[讨论的目标](https://www.hylo-lang.org/)是让 Mojo 保持“比 Rust 更简单”的吸引力,希望 Lifetimes 和 Mutability 可以自动推导,理想情况下像 Hylo 一样在所有情况下都能实现,从而提供一个不需要像 Rust 那样进行注解的模型。 - **Mojo 与 Ubuntu 24.04 的兼容性**:用户报告称 Mojo 在较新的 Ubuntu 24.04 上安装和运行均无问题,尽管官方文档尚未提到对 20.04 和 22.04 以外版本的支持。 - **Mojo 中的 Pointer 与 Reference**:一位用户提供了一个代码示例,探索在 Mojo 中使用 Pointer 作为 Reference 的一种更具可读性的替代方案,而其他人则讨论了相关的风险和限制,特别是关于内存分配错误的问题。 - **Lifetimes 讨论与未来发展**:目前正在评估 Lifetimes 和 Borrow checking,重点是改进 Rust 的模型。Aliasing restrictions 和 Borrow checking 语义的具体细节仍在积极开发中,尚未最终确定。 - **Mojo 用于并行化的 Atomic 操作**:Mojo 语言支持原子操作,讨论中提到了 [标准库中的 Atomic 类](https://docs.modular.com/mojo/stdlib/os/atomic),可用于创建具有原子操作的值。提及的链接:--- **Modular (Mojo 🔥) ▷ #[community-blogs-vids](https://discord.com/channels/1087530497313357884/1151418796993683477/1235261267250511923)** (4 messages): - **Mojo 崛起**:一段名为 **"Mojo Lang - Tomorrow's High Performance Python? (with Chris Lattner)"** 的 YouTube 视频讨论了 Mojo,这是由 Swift 和 LLVM 的创建者开发的新语言,旨在利用 CPU/GPU 级编程的最佳实践。你可以点击[这里](https://youtu.be/JRcXUuQYR90)观看。 - **播客热忱**:一位成员对 Chris Lattner 参与的播客表示热烈欢迎,并提到在内部推广他的编程语言(PL)演讲。 - **连续的 Lattner 动态**:另一位成员分享了看到 Chris Lattner 再次出现在播客中的兴奋之情。 - **释放 Python 的力量**:在另一个 [PyCon Lithuania 视频](https://youtu.be/Xzv2K7WNVD0)中讨论了 **MAX Platform** 及其释放 Python 潜力的能力。提及的链接:--- **Modular (Mojo 🔥) ▷ #[performance-and-benchmarks](https://discord.com/channels/1087530497313357884/1151418895417233429/1235197250507116676)** (2 messages): - **实现多核处理**:一位成员使用多核方法优化了处理过程,在 3.8 秒内处理了 1 亿条记录。他们询问是否应该向主分支提交 **Pull Request (PR)**。 - **对探索 atol 函数的兴趣**:另一位成员表示打算深入审查 `atol` 函数,借鉴他们最近在 **atol-simd 项目**中的经验。 --- **Modular (Mojo 🔥) ▷ #[nightly](https://discord.com/channels/1087530497313357884/1224434323193594059/1235280779190468669)** (2 messages): - **询问缺失的函数名称**:几位成员注意到函数名称缺失,并询问该功能将来是否会恢复。大家共同关注函数名称是否会回到 Chatbot 的配置中。 --- **OpenInterpreter ▷ #[general](https://discord.com/channels/1146610656779440188/1147665339266650133/1235197823713021993)** (61 messages🔥🔥): - **对 OpenInterpreter App 的热切期待**:一名成员询问了 OpenInterpreter **App** 的发布时间线。 - **为新人解读 Discord 活动**:成员们讨论了加入 Discord 活动的细节,澄清了新人可以在没有先验知识的情况下加入并旁听,并且可以选择参与聊天。 - **OS 模式的 Windows 兼容性查询**:对话集中在 Windows 上的 **OS 模式兼容性**,讨论了遇到的各种问题以及解决方案,例如为 Windows 调整命令,或在 GPT-4 中使用 `--os` 标志以获得更好的兼容性。 - **OpenInterpreter 中的多模态集成**:讨论深入探讨了在 OpenInterpreter 中集成具有专门能力(如视觉和 OCR)的模型,使用了来自 Hugging Face 的 **Idefics2** 等工具。 - **社区协助与协作**:成员们提供了关于使用 Git 上传翻译后的 README.md 的帮助,并分享了构建浏览器 AI Agent 的经验,体现了合作学习和资源共享的精神。提及的链接:--- **OpenInterpreter ▷ #[O1](https://discord.com/channels/1146610656779440188/1194880263122075688/1235130277089640548)** (12 条消息🔥): - **Ollama Bot 的独立倾向**:一名成员分享了在 **Ollama** 上成功运行某项内容的经验,但指出它存在不等待响应而是独立行动的问题。 - **Ngrok 域名故障排除**:一位用户概述了配置 **ngrok** 的步骤,包括创建域名、编辑名为 `tunnel.py` 的文件,以及修改命令行以包含新的域名。步骤中包含了 ngrok 域名设置的链接:[ngrok Cloud Edge Domains](https://dashboard.ngrok.com/cloud-edge/domains)。 - **Echo 的音量难题**:一位用户询问如何调节 **Echo 的音量**,其他用户确认了同样的问题,并表示制造团队正在寻找替代方案。 - **扬声器搜寻进行中**:关于设备的扬声器问题,一位用户指出 **电子团队** 正在与供应商讨论方案,这个过程(包括验证和潜在的更改)可能需要数周时间。 - **Whisper RKNN 的加速**:一位用户提供了一个 GitHub 分支链接,为任何使用 **带有 Rockchip RK3588 的 SBC** 的用户提供显著的速度提升。该分支允许进行本地 Whisper RKNN 处理,据报道速度提升了 250%。GitHub 页面链接如下:[GitHub - rbrisita/01 at rknn](https://github.com/rbrisita/01/tree/rknn)。 - **Litellm 的错误排查**:一位用户在尝试运行特定命令与 Litellm 库交互时对收到的错误感到困惑。另一位用户建议添加 `--api_key dummykey` 作为潜在解决方案,并提供了 Discord 服务器链接以获取进一步帮助。提及的链接:--- **OpenInterpreter ▷ #[ai-content](https://discord.com/channels/1146610656779440188/1149229778138824765/1235545486342225962)** (2 messages): - **开源 AI Vtuber 入门套件发布**:一套全新的 **AI Vtuber 入门套件** 已发布,仅需 OpenAI key、YouTube Key 以及用于英文 TTS 的 Google credentials.json 即可运行。感兴趣的用户可以在 [Twitter](https://twitter.com/tegnike/status/1784924881047503202) 上查看,并访问 [GitHub](https://github.com/tegnike/nike-ChatVRM) 获取代码库。 - **支持离线使用的 AI Vtuber 仓库**:另一个 AI Vtuber 仓库也已上线,它完全在离线环境下运行,无需 API,并提供无审查的体验。更多详情和演示可以在 [YouTube 视频](https://youtu.be/buaK84oSWCU?si=P02NIYHvrVj7m8Lb) 中查看,源代码已托管至 [GitHub](https://github.com/neurokitti/VtuberAI.git)。提及的链接:--- **Latent Space ▷ #[ai-general-chat](https://discord.com/channels/822583790773862470/1075282825051385876/1235169929553252403)** (33 messages🔥): - **AI Town 世界编辑器发布**:参与者分享了一个创新项目 [带有世界编辑器的 AI Town](https://x.com/cocktailpeanut/status/1785702250599371088?s=46&t=6FDPaNxZcbSsELal6Sv7Ug),开发者在类似《西部世界》的环境中部署了 300 个 AI Agent,并在配备 64G 内存的 Macbook M1 Max 上成功运行。 - **OpenAI 网站改版反馈**:发布了一个讨论 OpenAI 网站重新设计的推文链接,指出 [OpenAI 新平台](https://x.com/mayfer/status/1785799881413587233) 存在延迟和视觉错误等性能问题。 - **Claude 开发过程洞察**:分享了一个关于 Claude 开发过程的轶事,描述了白板头脑风暴会议是如何由 Claude 转录为文档的,详情见此 [背景故事](https://x.com/alexalbert__/status/1785735045824852011)。 - **在 MacBook 上运行 LLM 的探索**:讨论了在 MacBook 本地运行大语言模型 (LLM) 的情况,参考了 [Llama3-8B-q8](https://jan.ai/) 等工具,以及在各种设备和平台上操作 LLM 的资源。 - **用于文档处理的语义分块**:对话集中在独特的文本分块技术,特别是语义分块 (Semantic Chunking),并分享了多种实现方式,包括来自 [LlamaIndex](https://docs.llamaindex.ai/en/stable/examples/node_parsers/semantic_chunking/) 和 [LangChain 的 Semantic Chunker](https://python.langchain.com/docs/modules/data_connection/document_transformers/semantic-chunker/) 的资源链接。提及的链接:--- **Latent Space ▷ #[llm-paper-club-west](https://discord.com/channels/822583790773862470/1197350122112168006/1235305008581312656)** (35 条消息🔥): - **通过 Zoom 举行的 Mamba 会议**:成员们安排在 Zoom 上见面,并分享了[会议的直接链接](https://us06web.zoom.us/j/8807908941?pwd=eHBBdk9sWWluSzB2TFdLOVdEN3BFdz09)。 - **准备 Mamba 深度探讨**:随着成员们准备开始会议,期待感不断增加,并参考了一份详细的 [Mamba Deep Dive 文档](https://blackbeelabs.notion.site/A-Mamba-Deep-Dive-4b9ceb34026e424982ca1342573cc43f)。 - **对选择性复制的好奇**:一位成员询问 Mamba 中的选择性复制是否类似于召回测试,试图复制之前见过的 Token。 - **Mamba 微调咨询**:讨论涉及 Mamba 架构在微调过程中与 Transformer 相比可能导致过拟合的问题。 - **状态空间模型 (State Space Model) 讨论和论文**:提到了状态空间模型及其与被 LTI 系统近似的复杂系统的联系,并附上了两篇相关论文的链接,[一篇关于感应头 (induction heads)](https://arxiv.org/pdf/2404.15758),[另一篇关于多 Token 分析](https://arxiv.org/pdf/2404.19737)。提到的链接:--- **OpenAccess AI Collective (axolotl) ▷ #[general](https://discord.com/channels/1104757954588196865/1104757955204743201/1235153865985491018)** (24 条消息🔥): - **质疑 Benchmark 的相关性**:一位成员质疑对于不测试实际性能的 Benchmark,使用复杂 Prompt 的有用性。 - **指令标签 (Instruct Tags) 和掩码 (Masking) 实践**:讨论围绕是否在训练期间掩盖指令标签以潜在地提高 *ChatML* 性能。感兴趣的话题包括[自定义 ChatML 格式](https://github.com/xzuyn/axolotl/blob/dan_metharme/src/axolotl/prompt_strategies/customchatml.py)以及取消掩盖模型生成内容的重要性。 - **Llama-3 8B 扩展发布**:推出了具有扩展上下文长度的新型 *Llama-3 8B Instruct Gradient*,并使用 RoPE theta 调整以在更长的上下文上进行最少量的训练 [Llama-3 8B Gradient](https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k)。 - **关于 RoPE Theta 和上下文长度的辩论**:成员们就 1M 上下文长度模型的必要性和技术可行性展开辩论。一些人讨论了局限性,而另一些人则建议可以在 Inference 期间对其进行约束。 - **ChatML 训练故障**:一位合作者在结合 *ChatML* 训练时遇到了 `AttributeError: GEMMA`。通过移除 ChatML 参数缓解了该问题,但有人指出该数据集必须使用 ChatML 进行训练。Links mentioned:--- **OpenAccess AI Collective (axolotl) ▷ #[axolotl-dev](https://discord.com/channels/1104757954588196865/1104758010959634503/1235335729564090470)** (11 messages🔥): - **征集 Bug 分类协作**:一位成员向愿意帮助分类和排查 Bug/问题的成员提供 *compute resources* 支持,强调了此类帮助对项目的价值。 - **识别问题的环境原因**:大家达成共识,许多报告的问题可能源于用户的本地环境或机器,需要有人 Reproduce 这些问题以进行确认。 - **为 Orpo Trainer 提议的多线程补丁**:分享了一个补丁,用于解决 *Orpo trainer* 在 Preprocessing 时仅使用一个 worker 的问题,成员在此处发布了 [pull request](https://github.com/OpenAccess-AI-Collective/axolotl/pull/1583)。 - **TRL Trainer 预处理步骤的澄清**:成员们讨论了与 TRL trainer 预处理步骤相关的修复,指出该修复也适用于各种 RL 方法和训练器(如 *DPOTrainerArgs*),且该修复已包含在同一个 [pull request](https://github.com/OpenAccess-AI-Collective/axolotl/pull/1583) 中。 - **Axolotl 开发设定的 Python 版本**:简短的交流确定 Python 3.10 是最低要求版本,允许在 Axolotl 的代码库中使用 `match..case`。 **Link mentioned**: FIX: TRL trainer preprocessing step was running in one process by ali-mosavian · Pull Request #1583 · OpenAccess-AI-Collective/axolotl: Description We weren't passing dataset_num_proc to TRL training config, thus the initial data preprocessing steps in the TRL trainer was running in one process only. Motivation and Context Speeds ... --- **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1235256685988417537)** (3 messages): - **模型啰嗦,是否需要 Token 训练?**:一位成员注意到,在为常规对话训练 **llama 3 8b instruct** 时,模型的输出和句子长度异常长。他们询问某些 Token(如 end of text 和标点符号)是否需要额外的训练。 - **寻求正确的训练平衡**:同一个人思考是否可以通过增加数据量和额外的 Epochs 来解决啰嗦问题,从而优化模型性能。 - **对 Batch Size 和 Epoch 的好奇**:另一位成员询问了他们训练方案的具体细节,对当前使用的 Epochs 数量和 Batch train size 表示关注。 --- **OpenAccess AI Collective (axolotl) ▷ #[axolotl-help-bot](https://discord.com/channels/1104757954588196865/1225300056442409040/1235586698700783736)** (15 messages🔥): - **配置查询得到澄清**:一位成员询问如何配置具有角色(roles)和消息(messages)结构的 Dataset,以便与 OpenAccess-AI-Collective/axolotl 配合使用。提供了一个使用 `UserDefinedDatasetConfig` 匹配数据集结构的详细配置。 - **数据集适配策略**:为了与提供的配置保持一致,建议成员扁平化其数据集的对话结构,并在使用 `sharegpt` 类型处理之前调整格式。 - **描述数据集配置**:一位用户寻求针对 `sharegpt` 类型和 `Llama2ChatConversation` 的数据集配置序列补全。明确了数据集路径、对话类型、人类和模型字段,以及输入和输出角色的正确格式。提及的链接:--- **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1235564223971725402)** (15 条消息🔥): - **解决 DeepSpeed Stage 3 质量疑虑**:一位成员询问 DeepSpeed Stage 3 (ZeRO-3) 是否会降低模型质量。共识是 ZeRO-3 旨在优化分布式训练的内存使用,只要确保正确的实现和集成,其本身并不会降低模型质量。 - **结合 Flash Attention 与 DeepSpeed 进行微调**:可以通过先将 Flash Attention 集成到模型中,并在训练脚本中配置带有 ZeRO-3 优化的 DeepSpeed,从而在微调中同时使用 Flash Attention 和 DeepSpeed Stage 3。 - **使用 DeepSpeed Stage 3 加速训练**:DeepSpeed 的 ZeRO-3 可以通过在现有硬件上训练更大的模型、增加 batch size 以及通过优化内存使用减少对模型并行(model parallelism)的需求,从而加速训练。提及的链接:--- **LAION ▷ #[general](https://discord.com/channels/823813159592001537/823813160075132991/1235228817887330396)** (27 条消息🔥): - **探索 AI 在教育中的应用**:一位成员对在教育中使用 AI 助手的影响表示担忧,暗示这可能会使儿童习惯于依赖 AI,而不是学习如何独立学习。 - **图像到视频运动的革命**:分享了一篇介绍 **Motion-I2V** 的论文,这是一个新颖的图像到视频生成框架,通过基于 Diffusion 的运动场预测器和运动增强的时间注意力机制进行优化的显式运动建模两阶段过程。该论文可以在 [Motion-I2V](https://xiaoyushi97.github.io/Motion-I2V/) 找到。 - **LLaMA3 性能及对专业微调的期待**:成员评估了 **LLaMA3** 即使在 4bit 量化下也具有出色的性能,并表达了对特定领域专业微调以及 Meta 为 **LLaMA3** 发布另一个代码版本的希望。 - **探索 MagVit2 的实现**:一位正在研究 [MagVit2](https://github.com/lucidrains/magvit2-pytorch) 的新成员请求关于提高其 VQ-VAE 模型重建质量的建议,并思考是否需要额外的损失函数。 - **寻求 SoundStream 实现的指导**:一位在第一次实现 Google 的 SoundStream 编解码器论文时遇到困难的成员,就论文中省略的索引和数值寻求澄清,其他成员提供了资源建议并讨论了相关变量的可能含义。提到的链接:--- **LAION ▷ #[research](https://discord.com/channels/823813159592001537/824374369182416994/1235228755409240129)** (12 messages🔥): - **项目完成无 ETA**:据称目前某个特定项目没有预计完成时间(ETA)。 - **Soon TM 成为现实**:出现了 "Soon TM" 一词,戏谑地暗示某个事件或发布预计很快就会发生,但没有具体的时间表。 - **查询 LAION Stockfish 数据集配置**:有成员请求 LAION stockfish 数据集的配置详情,以评估其用于训练国际象棋机器人的潜力,并强调了数据集“技能(skill)”水平的重要性。 - **Kolmogorov-Arnold Networks 提供替代方案**:[arXiv 上的新研究论文](https://arxiv.org/abs/2404.19756) 介绍了 Kolmogorov-Arnold Networks (KANs),这是 Multi-Layer Perceptrons (MLPs) 的潜在替代方案,具有可学习的激活函数和样条参数化(spline parameterization),有望提供更好的准确性和可解释性。 - **VisualFactChecker:用于准确字幕生成的无须训练流水线**:另一篇 [arXiv 论文](https://arxiv.org/abs/2404.19752) 介绍了 VisualFactChecker (VFC),这是一个通过“提议-验证-字幕生成(proposal-verification-captioning)”过程为视觉内容生成高保真且详细字幕的流水线,显著提高了图像和 3D 物体字幕生成的质量。提到的链接:--- **AI Stack Devs (Yoko Li) ▷ #[app-showcase](https://discord.com/channels/1122748573000409160/1122748840819306598/1235256845418106990)** (28 messages🔥): - **清晰的 Diffusion Model 输出**:一位成员提到 [Hexagen World](https://www.hexagen.world/) 上的 Diffusion Model 输出非常清晰,暗示了高质量的 AI 生成内容。 - **对 AI 驱动版 Farmville 的怀旧**:一位参与者提出了使用 Generative AI 重制类似 Farmville 的旧版 MySpace/Facebook 风格游戏的想法。 - **独特的 AI 小镇设定概念**:.ghost001 表达了建立一个 1950 年代主题 AI 小镇游戏的愿望,其中一个 AI 角色是共产主义间谍,以观察小镇的 AI 居民是否能揭露该间谍。 - **Hexagen World 作为游戏平台**:对话集中在 Hexagen World 作为此类 AI 驱动游戏的潜在平台上,jakekies 向正在寻找执行 1950 年代间谍小镇想法地点的 .ghost001 推荐了它。 - **Hexagen World 的发现与 Discord 邀请**:Hexagen World 的发现归功于 Twitter,angry.penguin 向那些有兴趣了解更多 AI 动画的人发出了加入其 [AI animation Discord server](https://discord.gg/deforum) 的邀请。提到的链接:--- **AI Stack Devs (Yoko Li) ▷ #[ai-town-discuss](https://discord.com/channels/1122748573000409160/1132926337598902293/1235630378379771994)** (3 条消息): - **困扰用户的 Chatbot 怪癖**:一位成员报告在 **ai-town** 中遇到了奇怪的消息,包括空文本和中断对话流的一串数字。他们目前使用的是 **ollama** 和 **llama3 8b** 配置。 - **Tokenizer 问题可能是元凶**:针对上述聊天问题,一位成员建议问题可能源于 **tokenizer**,特别是考虑到干扰消息的数字特性。 - **ollama 之谜**:提出 **tokenizer** 理论的同一位成员也提到对 **ollama** 缺乏了解,表明在进一步诊断问题方面存在潜在的知识缺口。 --- **AI Stack Devs (Yoko Li) ▷ #[ai-town-dev](https://discord.com/channels/1122748573000409160/1137456826733047908/1235298273015894086)** (7 条消息): - **考虑切换到 Linux**:一位成员表示考虑放弃 Windows 改用 Linux,但担心游戏的过程和影响。 - **Linux 游戏保障**:另一位成员提供了有价值的链接,显示 **Stellaris** 原生支持 Mac 和 Linux,暗示对于考虑切换的成员来说,游戏不会成为问题。 - **双启动作为稳妥选择**:建议考虑切换到 Linux 的成员可以创建一个 **dual boot system** 以保持灵活性。 - **Stellaris 在 Mac 上运行良好**:分享了在 **MacBook Pro** 上玩 **Stellaris** 的经验,指出除了后期游戏运行变慢外,性能令人满意。 **提到的链接**:WineHQ - Stellaris:未找到描述 --- **LangChain AI ▷ #[general](https://discord.com/channels/1038097195422978059/1038097196224086148/1235190091811520563)** (25 条消息🔥): - **窥探 Groq 访问协议**:成员们讨论了 Groq 的 AI 服务访问权限,其中一人引用了 [Groq's console](https://console.groq.com) 的直接注册链接,从而澄清了访问不需要排队(waitlist)。 - **Langchain 视频引发 RAG 索引查询**:关于在 RAG 中处理超过 *Llama3* 的 8k token context window 文档的咨询引发了讨论,但人们对更大 context window 可能导致能力下降表示担忧。 - **循环的 AI 对话**:一位成员就人机交互项目中 AI 总是偏离剧本并在无明显原因的情况下循环回复的问题寻求建议,并正在寻找维持预期对话流的策略。 - **Text Embedding 与 Langchain 的集成困境**:一位用户表示由于依赖 Sagemaker endpoint 而非 API key,在将 jumpstart text embedding 模型与 Langchain 集成时遇到困难。 - **CSV Embedding 难题**:一位成员就如何对单个 CSV 列进行 embedding 并在请求时从另一列检索相应数据寻求建议,对传统方法提出质疑,并促使了关于更复杂数据检索方法的建议。 --- **LangChain AI ▷ #[langserve](https://discord.com/channels/1038097195422978059/1170024642245832774/1235647398718738433)** (1 条消息): - **对反馈机制的困惑**:一位成员对 [LangServe 中的反馈功能](https://link.to.feedback) 表示不确定,提到他们已成功提交反馈,但在 LangSmith 中没有看到任何变化。注释澄清,成功的 *response*(响应)并不保证反馈已被记录;如果服务器认为该反馈未经身份验证或无效,可能会静默拒绝。 --- **LangChain AI ▷ #[share-your-work](https://discord.com/channels/1038097195422978059/1038097372695236729/1235284939411423233)** (6 条消息): - **介绍 Word Loom**:一个用于管理 AI 语言的开放规范 **Word Loom**,专注于代码与自然语言的分离以及可组合性。更新后的规范旨在对机械比较和全球化技术更加友好,详情可在 [GitHub](https://gist.github.com/uogbuji/5bd08f74125934fa9e0d37236a8e168e) 查看。 - **LangChain v0.1.17 升级通知**:一位成员将其项目升级到了 **LangChain v0.1.17 和 OpenAI v1.25.0**,并根据最近的包更新调整了代码,同时提到了文档过时带来的挑战。他们在 [此应用链接](https://langchain-chatbot.streamlit.app) 分享了部署成果。 - **用于内容创作的 LLM 基准测试**:一位成员正在测试在剧本写作和摘要等内容创作任务中表现出色的 LLM,并提议如果社区感兴趣,将分享详细报告。 - **在 GCP 上部署 Langserve**:Langserve 已使用 Cloud Run 部署在 **Google Cloud Platform (GCP)** 上,实现了可扩展性并增加了后端 REST 代码库。该设置还包括 **py4j integration** 以及通过加密货币进行微支付的计划。 - **使用 Pydantic 定义 GPT 工具**:开发了一个使用 **Pydantic** 在 GPT 中定义工具的工具,旨在使工具编写更加系统化。代码仓库已发布在 [GitHub](https://github.com/carlosplanchon/gpt_pydantic_tools)。 - **关于增强型 LangChain Agent 的文章**:一篇文章讨论了如何通过 **RAG 增强 LangChain 的 LangGraph Agent 以实现智能邮件草拟**,这可能会显著提升 Agent 的能力。文章可以在 [Medium](https://medium.com/ai-advances/enhancing-langchains-langgraph-agents-with-rag-for-intelligent-email-drafting-a5fab21e05da) 上找到。提到的链接:--- **LangChain AI ▷ #[tutorials](https://discord.com/channels/1038097195422978059/1077843317657706538/1235289341056647189)** (1 条消息): - **Adaptive RAG 论文展示动态策略选择**:tarikkaoutar 强调了一篇关于 **Adaptive RAG** 的论文,该论文根据查询复杂度动态选择 Retrieval-Augmented Generation 的最佳策略。他们分享了一个提供该论文概述的 [YouTube 视频](https://www.youtube.com/watch?v=QnXdlqEUW80)。 **提到的链接**: - YouTube:未找到描述 --- **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1235336408206671933)** (20 条消息🔥): - **关于学习 tinygrad 的咨询**:一位成员在听了 Lex Fridman 主持的播客后对学习 tinygrad 产生了浓厚兴趣,并询问了与 PyTorch 进行比较的资源,特别是关于 kernel(内核)方面。另一位成员建议查看 [tinygrad GitHub 仓库文档](https://github.com/geohot/tinygrad) 以获取更多信息。 - **tinygrad 开发的硬件考虑**:一位成员正在考虑购买用于 tinygrad 开发的硬件,并在使用 AMD XT 显卡的专用配置或选择新款 Mac M3 之间犹豫不决。 - **在 M1 Mac 上排除 tinygrad 故障**:Sytandas 在 M1 Mac 上运行 tinygrad 时遇到了与无效 Metal 库相关的 **AssertionError**,暗示可能是 conda python 的问题。Wozeparrot 指向了在特定 Discord 频道中讨论的修复方法。 - **macOS 上潜在的 tinygrad Conda 问题**:据透露,包括 brew 和 pip3 在内的系统更新可能与 Sytandas 遇到的 tinygrad conda 问题有关,而上述针对 conda python 的修复方案已被确认在过去两个月中一直在开发中。 - **tinygrad Conda 修复悬赏**:简短的交流确认,解决 conda python 的 tinygrad 问题确实设有**悬赏 (bounty)**,并且在询问前两天已报告了一些重大进展。 --- **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1235136266639507488)** (13 messages🔥): - **CUDA 困惑**:一名成员询问在运行脚本时**是否使用了 CUDA=1**,暗示了可能与性能相关的考量。 - **RedNode 与 OpNode 之争**:一名成员对 tinygrad 符号部分中 **RedNode 和 OpNode** 的区别感到好奇,思考这仅仅是为了遵循 **PEMDAS**,还是会使符号编译器逻辑复杂化。 - **MNIST 准确率异常**:有人提出了一个关于 MNIST 示例总是产生 **100% 准确率**的问题;一名成员怀疑是与通过 pip 获取的安装版本有关。 - **通过编译解决**:用户通过**从源码安装 tinygrad** 而不是使用 pip 解决了准确率报告问题,并赞扬了 tinygrad 编译过程的简洁性。 - **blobfile 的重要性**:LLaMA 示例代码中提到的 **blobfile** 受到质疑;经澄清,blobfile 是 tinygrad 中 **load_tiktoken_bpe** 函数的一个依赖项。 **相关链接**:tinygrad:你喜欢 pytorch?你喜欢 micrograd?那你一定会爱上 tinygrad! <3 --- **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1235148361766539294)** (33 messages🔥): - **矩阵乘法性能之谜**:一名用户对 **np.matmul** 性能的差异感到困惑,强调他们在自己的系统上达到了 600 gflops,而 [Justine Tunney 的博客文章](https://justine.lol/matmul/) 中提到的是 29 gflops。在回复中,澄清了测量 flops 的概念,并强调了不同的计算方法。 - **不同 Llamafile 版本的重命名结果存在差异**:在运行来自 **llamafile** 帖子的文件重命名示例时,注意到了输出的不一致,这表明不同版本或执行之间存在差异,输出为 `een_baby_and_adult_monkey_together_in_the_image_with_the_baby_monkey_on.jpg`。 - **为 Llamafile 选择合适的基础设施**:一名用户询问了实验 **llamafile** 最具成本效益的方法,考虑到他们本地机器能力有限,正在考虑 **vast.ai** 或 **colab pro plus** 等选项。 - **GEMM 函数优化追求**:一名用户寻求关于加速 C++ 中通用矩阵-矩阵乘法 (GEMM) 函数的建议,试图超越 500 gflops(其中 numpy 显然达到了 600 gflops 以上)。分享了一系列代码片段,并建议考虑数据对齐并尝试不同的 microtile 尺寸。 - **并发运行 Llamafile 与资源共享**:提到可以在不同端口上同时运行多个 **llamafiles**,但强调这些进程会根据操作系统的指示竞争系统资源,并强调并发实例之间缺乏专门的交互。相关链接:--- **Cohere ▷ #[general](https://discord.com/channels/954421988141711382/954421988783444043/1235140259591749682)** (24 messages🔥): - **热烈欢迎新人**:包括 sssandra 和 co.elaine 在内的几位成员欢迎新用户加入服务器,营造了友好且支持性的社区环境。 - **使用 LLM 进行文本压缩的会议**:发布了关于**使用 LLM 进行文本压缩**会议的提醒,其中包括用于实时参与的 Google Meet 链接。 - **API 实现与生产密钥问题**:一位用户对如何在他们的 QA 聊天框中实现 **AI API** 表示困惑,而另一位用户遇到了已注册的生产密钥仍作为试用密钥运行的问题,co.elaine 通过询问遇到的错误消息处理了该问题。 - **在 Prompt 中使用 Preamble 的指南**:co.elaine 指导用户如何在聊天 Prompt 中引用文档,将其引向关于使用 'preamble' 参数的 Cohere 文档,并提供了其功能的摘要。 - **构建文档搜索系统**:一位用户寻求关于构建基于自然查询检索文档的搜索系统的建议,概述了涉及文档 embeddings、摘要和关键信息提取的潜在策略。 **提到的链接**:Preambles:未找到描述 --- **Cohere ▷ #[collab-opps](https://discord.com/channels/954421988141711382/1218409745380147320/1235223324804775957)** (1 条消息): - **斯德哥尔摩 LLM 爱好者集结**:一名成员表示有兴趣在斯德哥尔摩见面讨论 **Large Language Models (LLMs)**,并提到该地区社区规模较小。发出了共进午餐并进一步讨论该话题的邀请。 --- **Interconnects (Nathan Lambert) ▷ #[ml-questions](https://discord.com/channels/1179127597926469703/1179208129083363358/1235427830553120790)** (10 条消息🔥): - **集成奖励模型受到关注**:讨论围绕在 AI 对齐的强化学习 (RL) 阶段使用集成奖励模型 (ensemble of reward models) 展开,如 DeepMind 的 Sparrow 所示。有人指出,尽管存在 KL 惩罚,但包括使用“对抗性探测 (Adversarial Probing)”奖励模型在内的集成技术可能有助于避免模式崩溃 (mode collapse)——这是过拟合 (overfitting) 的潜在后果。 - **Llama 3 的双重方法引发热议**:一名成员询问为什么 Llama 3 同时使用了 Proximal Policy Optimization (PPO) 和 Decentralized Proximal Policy Optimization (DPO),并猜测这是因为对哪种技术更好存在不确定性,还是有更复杂的原因。另一名成员建议完整的技术报告尚未发布,暗示了社区中的困惑以及与数据时间尺度限制相关的潜在原因。 - **Bitnet 的实用性受到质疑**:鉴于成功的规模化复现,人们好奇 Bitnet 训练大型模型的方法是否会看到更大规模的应用。一名成员分享了 Bitnet 实现的链接,包括 [Bitnet-LLama-70M](https://huggingface.co/abideen/Bitnet-Llama-70M) 和来自 Agora 在 [GitHub](https://github.com/kyegomez/BitNet) 上的三进制更新。 - **探索 Bitnet 发展的障碍**:讨论涉及缺乏使用 Bitnet 进行的大型模型训练,引用了 [GitHub 上的理由](https://github.com/joey00072/ohara/blob/master/experiments/bitnet/bitnet.md),即在没有支持 2-bit 混合精度的专用硬件的情况下,Bitnet 的推理目前效率低下。有人提到,需要大量投资来制造芯片以实现 Bitnet 的优势,且其缩放定律 (scaling laws) 存在不确定性。 - **Bitnet 专用硬件的持续挑战**:对话扩展到了 CUDA 魔法进步的可能性,例如最近的 fp6 内核,或者开发三进制芯片以支持 Bitnet 的实际应用。引用了 IBM 过去的努力,尽管有人指出可能与原始工作的参与者没有连续性。提到的链接:--- **Interconnects (Nathan Lambert) ▷ #[ml-drama](https://discord.com/channels/1179127597926469703/1181746144821387334/1235547821285834812)** (2 条消息): - **神秘模型大混乱 (Mysterious Model Mayhem)**:一位成员分享了一条推文,质疑一个类似于 Neel Nanda 和 Ashwinee Panda 所创建模型的来源,暗示该模型可能正在接受集体渗透测试 (pentesting)。讨论内容包括对故意泄露的怀疑,以及该模型在 4chan 和 Reddit 等平台上的出现。 - **追踪匿名者的异常模型 (Sleuthing the Anomalous Anon's Model)**:同一个人引用了 Teortaxes 的推文,对所发现模型的性质以及将其视为与 Neel 和 Ashwinee 的作品相同的合法性表示怀疑,并敦促发布模型权重或对匿名版本进行测试。 **提到的链接**:来自 Teortaxes▶️ (@teortaxesTex) 的推文:……实际上,我到底为什么要假设这不是他们的模型,为了集体渗透测试 (pentesting) 而散布——类似于 miqu 的奇特特定量化泄露以阻止改进——突然出现的 4chan 链接,临时账号…… --- **Interconnects (Nathan Lambert) ▷ #[random](https://discord.com/channels/1179127597926469703/1183121795247779910/1235293456511799328)** (11 条消息🔥): - **Anthropic 发布 Claude 应用**:Anthropic 发布了类似于 OpenAI 应用程序的 **Claude app**。目前没有提供关于其性能与 OpenAI 产品对比的进一步评论。 - **成功的象征**:成员们赞扬了 Anthropic 的**品牌设计 (branding)**和 Logo,这可能推断出用户对该公司视觉吸引力的积极情绪。 - **ML Collective 活动更新**:对话确认 **ML Collective 会议** 仍在举行,但并非每周一次。 --- **Interconnects (Nathan Lambert) ▷ #[posts](https://discord.com/channels/1179127597926469703/1228051082631188530/1235253560917233685)** (2 条消息): - **对性能提升的认可**:一位成员表达了热烈的赞许,承认某人在收到批评反馈后显著提升了表现。 --- **Alignment Lab AI ▷ #[general-chat](https://discord.com/channels/1087862276448595968/1095458248712265841/)** (1 条消息): manojbh: Hello --- **Datasette - LLM (@SimonW) ▷ #[llm](https://discord.com/channels/823971286308356157/1128504153841336370/1235576027233910865)** (1 条消息): - **LLM 作为数字管家**:一位成员询问是否存在一种 **Language Model**,能够识别并删除散落在硬盘中、由各种应用和库生成的多个 7B **localmodels**。 --- **DiscoResearch ▷ #[discolm_german](https://discord.com/channels/1178995845727785010/1197630242815213618/1235150707439702057)** (1 条消息): - **利用 Qdora 探索中间道路**:一位用户强调了 [Qdora](https://www.answer.ai/posts/2024-04-26-fsdp-qdora-llama3.html) 这一替代方法,据推测是受之前关于模型扩展讨论的启发。它涉及一种针对 Large Language Models (LLMs) 的后预训练 (post-pretraining) 方法,可防止灾难性遗忘。 - **块扩展结果讨论 LLMs 的技能获取**:对话指向了关于 LLMs [块扩展 (block expansion)](https://arxiv.org/abs/2401.02415) 的研究,例如从 LLaMA 转换到 CodeLLaMA。该方法旨在获取新技能而不丢失原有能力,这对于像 LLaMA Pro-8.3B 这样的模型来说是一项重大进展。 **提到的链接**:LLaMA Pro: Progressive LLaMA with Block Expansion:人类通常在不损害旧技能的情况下获得新技能;然而,对于 Large Language Models (LLMs) 来说情况正好相反,例如从 LLaMA 到 CodeLLaMA。为此,我们提出了一种新的后预训练 (post-pretra)... --- **AI21 Labs (Jamba) ▷ #[jamba](https://discord.com/channels/874538902696914944/1222916247063232553/)** (1 条消息): paulm24: Jamba-Instruct 已发布: https://twitter.com/AI21Labs/status/1786038528901542312 ---